
modelId
stringlengths 4
81
| tags
sequence | pipeline_tag
stringclasses 17
values | config
dict | downloads
int64 0
59.7M
| first_commit
timestamp[ns, tz=UTC] | card
stringlengths 51
438k
|
|---|---|---|---|---|---|---|
Bakkes/BakkesModWiki | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | # paddle paddle版本的RoFormer
# 需要安装最新的paddlenlp
`pip install git+https://github.com/PaddlePaddle/PaddleNLP.git`
## 预训练模型转换
预训练模型可以从 huggingface/transformers 转换而来,方法如下(适用于roformer模型,其他模型按情况调整):
1. 从huggingface.co获取roformer模型权重
2. 设置参数运行convert.py代码
3. 例子:
假设我想转换https://huggingface.co/junnyu/roformer_chinese_base 权重
- (1)首先下载 https://huggingface.co/junnyu/roformer_chinese_base/tree/main 中的pytorch_model.bin文件,假设我们存入了`./roformer_chinese_base/pytorch_model.bin`
- (2)运行convert.py
```bash
python convert.py \
--pytorch_checkpoint_path ./roformer_chinese_base/pytorch_model.bin \
--paddle_dump_path ./roformer_chinese_base/model_state.pdparams
```
- (3)最终我们得到了转化好的权重`./roformer_chinese_base/model_state.pdparams`
## 预训练MLM测试
### test_mlm.py
```python
import paddle
import argparse
from paddlenlp.transformers import RoFormerForPretraining, RoFormerTokenizer
def test_mlm(text, model_name):
model = RoFormerForPretraining.from_pretrained(model_name)
model.eval()
tokenizer = RoFormerTokenizer.from_pretrained(model_name)
tokens = ["[CLS]"]
text_list = text.split("[MASK]")
for i,t in enumerate(text_list):
tokens.extend(tokenizer.tokenize(t))
if i==len(text_list)-1:
tokens.extend(["[SEP]"])
else:
tokens.extend(["[MASK]"])
input_ids_list = tokenizer.convert_tokens_to_ids(tokens)
input_ids = paddle.to_tensor([input_ids_list])
with paddle.no_grad():
pd_outputs = model(input_ids)[0][0]
pd_outputs_sentence = "paddle: "
for i, id in enumerate(input_ids_list):
if id == tokenizer.convert_tokens_to_ids(["[MASK]"])[0]:
tokens = tokenizer.convert_ids_to_tokens(pd_outputs[i].topk(5)[1].tolist())
pd_outputs_sentence += "[" + "||".join(tokens) + "]"
else:
pd_outputs_sentence += "".join(
tokenizer.convert_ids_to_tokens([id], skip_special_tokens=True)
)
print(pd_outputs_sentence)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--model_name", default="roformer-chinese-base", type=str, help="Pretrained roformer name or path."
)
parser.add_argument(
"--text", default="今天[MASK]很好,我想去公园玩!", type=str, help="MLM text."
)
args = parser.parse_args()
test_mlm(text=args.text, model_name=args.model_name)
```
### 输出
```bash
python test_mlm.py --model_name roformer-chinese-base --text 今天[MASK]很好,我想去公园玩!
# paddle: 今天[天气||天||阳光||太阳||空气]很好,我想去公园玩!
python test_mlm.py --model_name roformer-chinese-base --text 北京是[MASK]的首都!
# paddle: 北京是[中国||谁||中华人民共和国||我们||中华民族]的首都!
python test_mlm.py --model_name roformer-chinese-char-base --text 今天[MASK]很好,我想去公园玩!
# paddle: 今天[天||气||都||风||人]很好,我想去公园玩!
python test_mlm.py --model_name roformer-chinese-char-base --text 北京是[MASK]的首都!
# paddle: 北京是[谁||我||你||他||国]的首都!
``` |
Bala/model_name | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: en
thumbnail: https://github.com/junnyu
tags:
- pytorch
- electra
- roformer
- rotary position embedding
license: mit
datasets:
- openwebtext
---
# 一、 个人在openwebtext数据集上添加rotary-position-embedding,训练得到的electra-small模型
# 二、 复现结果(dev dataset)
|Model|CoLA|SST|MRPC|STS|QQP|MNLI|QNLI|RTE|Avg.|
|---|---|---|---|---|---|---|---|---|---|
|ELECTRA-Small-OWT(original)|56.8|88.3|87.4|86.8|88.3|78.9|87.9|68.5|80.36|
|**ELECTRA-RoFormer-Small-OWT (this)**|55.76|90.45|87.3|86.64|89.61|81.17|88.85|62.71|80.31|
# 三、 训练细节
- 数据集 openwebtext
- 训练batch_size 256
- 学习率lr 5e-4
- 最大句子长度max_seqlen 128
- 训练total step 50W
- GPU RTX3090
- 训练时间总共耗费55h
# 四、wandb日志
- [**预训练日志**](https://wandb.ai/junyu/electra_rotary_small_pretrain?workspace=user-junyu)
- [**GLUE微调日志**](https://wandb.ai/junyu/electra_rotary_glue_100?workspace=user-junyu)
# 五、 使用
```python
import torch
from transformers import ElectraTokenizer,RoFormerModel
tokenizer = ElectraTokenizer.from_pretrained("junnyu/roformer_small_discriminator")
model = RoFormerModel.from_pretrained("junnyu/roformer_small_discriminator")
inputs = tokenizer("Beijing is the capital of China.", return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
print(outputs[0].shape)
``` |
Balgow/prod_desc | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: zh
tags:
- bert
- pytorch
widget:
- text: "巴黎是[MASK]国的首都。"
---
https://github.com/dbiir/UER-py/wiki/Modelzoo 中的
MixedCorpus+BertEncoder(large)+MlmTarget
https://share.weiyun.com/5G90sMJ
Pre-trained on mixed large Chinese corpus. The configuration file is bert_large_config.json
## 引用
```tex
@article{zhao2019uer,
title={UER: An Open-Source Toolkit for Pre-training Models},
author={Zhao, Zhe and Chen, Hui and Zhang, Jinbin and Zhao, Xin and Liu, Tao and Lu, Wei and Chen, Xi and Deng, Haotang and Ju, Qi and Du, Xiaoyong},
journal={EMNLP-IJCNLP 2019},
pages={241},
year={2019}
}
```
|
Banshee/dialoGPT-luke-small | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: zh
tags:
- wobert
inference: False
---
## 介绍
### tf版本
https://github.com/ZhuiyiTechnology/WoBERT
### pytorch版本
https://github.com/JunnYu/WoBERT_pytorch
## 安装(主要为了安装WoBertTokenizer)
```bash
pip install git+https://github.com/JunnYu/WoBERT_pytorch.git
```
## 使用
```python
import torch
from transformers import BertForMaskedLM as WoBertForMaskedLM
from wobert import WoBertTokenizer
pretrained_model_or_path_list = [
"junnyu/wobert_chinese_plus_base", "junnyu/wobert_chinese_base"
]
for path in pretrained_model_or_path_list:
text = "今天[MASK]很好,我[MASK]去公园玩。"
tokenizer = WoBertTokenizer.from_pretrained(path)
model = WoBertForMaskedLM.from_pretrained(path)
inputs = tokenizer(text, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs).logits[0]
outputs_sentence = ""
for i, id in enumerate(tokenizer.encode(text)):
if id == tokenizer.mask_token_id:
tokens = tokenizer.convert_ids_to_tokens(outputs[i].topk(k=5)[1])
outputs_sentence += "[" + "||".join(tokens) + "]"
else:
outputs_sentence += "".join(
tokenizer.convert_ids_to_tokens([id],
skip_special_tokens=True))
print(outputs_sentence)
# RoFormer 今天[天气||天||心情||阳光||空气]很好,我[想||要||打算||准备||喜欢]去公园玩。
# PLUS WoBERT 今天[天气||阳光||天||心情||空气]很好,我[想||要||打算||准备||就]去公园玩。
# WoBERT 今天[天气||阳光||天||心情||空气]很好,我[想||要||就||准备||也]去公园玩。
```
## 引用
Bibtex:
```tex
@techreport{zhuiyiwobert,
title={WoBERT: Word-based Chinese BERT model - ZhuiyiAI},
author={Jianlin Su},
year={2020},
url="https://github.com/ZhuiyiTechnology/WoBERT",
}
``` |
Batsy24/DialoGPT-small-Twilight_EdBot | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | null | ---
language:
- en
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
- f1
model-index:
- name: bert_finetuning_test
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: GLUE MRPC
type: glue
args: mrpc
metrics:
- name: Accuracy
type: accuracy
value: 0.8284313725490197
- name: F1
type: f1
value: 0.8817567567567567
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert_finetuning_test
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the GLUE MRPC dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4023
- Accuracy: 0.8284
- F1: 0.8818
- Combined Score: 0.8551
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1.0
### Training results
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.1+cu102
- Datasets 1.17.0
- Tokenizers 0.11.0
|
Battlehooks/distilbert-base-uncased-finetuned-squad | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language:
- en
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
- f1
model-index:
- name: bert_finetuning_test
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: GLUE MRPC
type: glue
args: mrpc
metrics:
- name: Accuracy
type: accuracy
value: 0.8284313725490197
- name: F1
type: f1
value: 0.8817567567567567
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert_finetuning_test
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the GLUE MRPC dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4023
- Accuracy: 0.8284
- F1: 0.8818
- Combined Score: 0.8551
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1.0
### Training results
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.1+cu102
- Datasets 1.17.0
- Tokenizers 0.11.0
|
BatuhanYilmaz/bert-finetuned-mrpc | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: en
tags:
- go-emotion
- text-classification
- pytorch
datasets:
- go_emotions
metrics:
- f1
widget:
- text: "Thanks for giving advice to the people who need it! 👌🙏"
license: mit
---
## Model Description
1. Based on the uncased BERT pretrained model with a linear output layer.
2. Added several commonly-used emoji and tokens to the special token list of the tokenizer.
3. Did label smoothing while training.
4. Used weighted loss and focal loss to help the cases which trained badly.
|
BatuhanYilmaz/distilbert-base-uncased-finetuned-squad-d5716d28 | [
"pytorch",
"distilbert",
"fill-mask",
"en",
"dataset:squad",
"arxiv:1910.01108",
"transformers",
"question-answering",
"license:apache-2.0",
"autotrain_compatible"
] | question-answering | {
"architectures": [
"DistilBertForMaskedLM"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 18 | null | ---
language: en
tags:
- go-emotion
- text-classification
- pytorch
datasets:
- go_emotions
metrics:
- f1
widget:
- text: "Thanks for giving advice to the people who need it! 👌🙏"
license: mit
---
## Model Description
1. Based on the uncased BERT pretrained model with a linear output layer.
2. Added several commonly-used emoji and tokens to the special token list of the tokenizer.
3. Did label smoothing while training.
4. Used weighted loss and focal loss to help the cases which trained badly.
## Results
Best Result of `Macro F1` - 53%
## Tutorial Link
- [GitHub](https://github.com/justin871030/GoEmotions) |
BatuhanYilmaz/dummy | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
model-index:
- name: bertweet-covid--vaccine-tweets-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bertweet-covid19-base-uncased-pretraining-covid-vaccine-tweets
This model is a fine-tuned version of [justinqbui/bertweet-covid19-base-uncased-pretraining-covid-vaccine-tweets](https://huggingface.co/justinqbui/bertweet-covid19-base-uncased-pretraining-covid-vaccine-tweets) which was finetuned by using [this google fact check](https://huggingface.co/datasets/justinqbui/covid_fact_checked_google_api) ~3k dataset size and webscraped data from [polifact covid info](https://huggingface.co/datasets/justinqbui/covid_fact_checked_polifact) ~ 1200 dataset size and ~1200 tweets pulled from the CDC with tweets containing the words covid or vaccine.
It achieves the following results on the evaluation set (20% from the dataset randomly shuffled and selected to serve as a test set):
- Validation Loss: 0.267367
- Accuracy: 91.1370%
To use the model, use the inference API.
Alternatively, to run locally
```
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("justinqbui/bertweet-covid-vaccine-tweets-finetuned")
model = AutoModelForSequenceClassification.from_pretrained("justinqbui/bertweet-covid-vaccine-tweets-finetuned")
```
## Model description
This model is a fine-tuned version of pretrained version [justinqbui/bertweet-covid19-base-uncased-pretraining-covid-vaccine-tweets](https://huggingface.co/justinqbui/bertweet-covid19-base-uncased-pretraining-covid-vaccine-tweets). Click on [this](https://huggingface.co/justinqbui/bertweet-covid19-base-uncased-pretraining-covid-vaccine-tweets) to see how the pre-training was done.
This model was fine-tuned with a dataset of ~5500. A web scraper was used to scrape polifact and a script was used to pull from the google fact check API. Because ~80% of both these datasets were either false or misleading, I pulled about ~1200 tweets from the CDC related to covid and labelled them as true. ~30% of this dataset is considered true and the rest false or misleading. Please see the published datasets above for more detailed information.
The tokenizer requires the emoji library to be installed.
```
!pip install nltk emoji
```
## Intended uses & limitations
The intended use of this model is to detect if the contents of a covid tweet is potentially false or misleading. This model is not an end all be all. It has many limitations. For example, if someone makes a post containing an image, but has attached a satirical image, this model would not be able to distinguish this. If a user links a website, the tokenizer allocates a special token for links, meaning the contents of the linked website is completely lost. If someone tweets a reply, this model can't look at the parent tweets, and will lack context.
This model's dataset relies on the crowd-sourcing annotations being accurate. This data is only accurate of up until early December 2021. For example, it probably wouldn't do very ell with tweets regarded the new omicron variant.
Example true inputs:
```
Covid vaccines are safe and effective. -> 97% true
Vaccinations are safe and help prevent covid. -> 97% true
```
Example false inputs:
```
Covid vaccines will kill you. -> 97% false
covid vaccines make you infertile. -> 97% false
```
## Training and evaluation data
This model was finetuned by using [this google fact check](https://huggingface.co/datasets/justinqbui/covid_fact_checked_google_api) ~3k dataset size and webscraped data from [polifact covid info](https://huggingface.co/datasets/justinqbui/covid_fact_checked_polifact) ~ 1200 dataset size and ~1200 tweets pulled from the CDC with tweets containing the words covid or vaccine.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-5
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
-
### Training results
| Training Loss | Epoch | Validation Loss | Accuracy |
|:-------------:|:-----:|:---------------:|:--------:|
| 0.435500 | 1.0 | 0.401900 | 0.906893 |
| 0.309700 | 2.0 | 0.265500 | 0.907789 |
| 0.266200 | 3.0 | 0.216500 | 0.911370 |
### Framework versions
- Transformers 4.13.0
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
BeIR/query-gen-msmarco-t5-base-v1 | [
"pytorch",
"jax",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"T5ForConditionalGeneration"
],
"model_type": "t5",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": true,
"length_penalty": 2,
"max_length": 200,
"min_length": 30,
"no_repeat_ngram_size": 3,
"num_beams": 4,
"prefix": "summarize: "
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to German: "
},
"translation_en_to_fr": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to French: "
},
"translation_en_to_ro": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to Romanian: "
}
}
} | 1,816 | null | ---
tags: autonlp
language: unk
widget:
- text: "I love AutoNLP 🤗"
datasets:
- jwuthri/autonlp-data-shipping_status_2
co2_eq_emissions: 32.912881644048
---
# Model Trained Using AutoNLP
- Problem type: Binary Classification
- Model ID: 27366103
- CO2 Emissions (in grams): 32.912881644048
## Validation Metrics
- Loss: 0.18175844848155975
- Accuracy: 0.9437683592110785
- Precision: 0.9416809605488851
- Recall: 0.8459167950693375
- AUC: 0.9815242330050846
- F1: 0.8912337662337663
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/jwuthri/autonlp-shipping_status_2-27366103
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("jwuthri/autonlp-shipping_status_2-27366103", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("jwuthri/autonlp-shipping_status_2-27366103", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
``` |
Bee-Garbs/DialoGPT-real-cartman-small | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | null | Rates Twitter biographies on decision-making preference: Thinking or Feeling. Roughly corresponds to [agreeableness.](https://en.wikipedia.org/wiki/Agreeableness)
Go to your Twitter profile, copy your biography and paste in the inference widget, remove any URLs and press hit!
Trained on self-described personality labels. Interpret as a continuous score, not as a discrete label. Remember that models employ pure statistical reasoning (and may consequently make no sense sometimes.)
Have fun!
Note: Performance on inputs other than Twitter biographies [the training data source] is not verified.
For further details and expected performance, read the [paper](https://arxiv.org/abs/2109.06402). |
Beelow/wav2vec2-ukrainian-model-large | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | Classifies Twitter biographies as either introverts or extroverts.
Go to your Twitter profile, copy your biography and paste in the inference widget, remove any URLs and press hit!
Trained on self-described personality labels. Interpret as a continuous score, not as a discrete label. Have fun!
Barack Obama: Extrovert; Ellen DeGeneres: Extrovert; Naomi Osaka: Introvert
Note: Performance on inputs other than Twitter biographies [the training data source] is not verified.
For further details and expected performance, read the [paper](https://arxiv.org/abs/2109.06402). |
Belin/T5-Terms-and-Conditions | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | >tr|Q8ZR27|Q8ZR27_SALTY Putative glycerol dehydrogenase OS=Salmonella typhimurium (strain LT2 / SGSC1412 / ATCC 700720) OX=99287 GN=ybdH PE=3 SV=1
MNHTEIRVVTGPANYFSHAGSLERLTDFFTPEQLSHAVWVYGERAIAAARPYLPEAFERA
GAKHLPFTGHCSERHVAQLAHACNDDRQVVIGVGGGALLDTAKALARRLALPFVAIPTIA
ATCAAWTPLSVWYNDAGQALQFEIFDDANFLVLVEPRIILQAPDDYLLAGIGDTLAKWYE
AVVLAPQPETLPLTVRLGINSACAIRDLLLDSSEQALADKQQRRLTQAFCDVVDAIIAGG
GMVGGLGERYTRVAAAHAVHNGLTVLPQTEKFLHGTKVAYGILVQSALLGQDDVLAQLIT
AYRRFHLPARLSELDVDIHNTAEIDRVIAHTLRPVESIHYLPVTLTPDTLRAAFEKVEFF
RI
|
BenDavis71/GPT-2-Finetuning-AIRaid | [
"pytorch",
"jax",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | null | ---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
datasets:
- kSaluja/autonlp-data-tele_new_5k
co2_eq_emissions: 2.96638567287195
---
# Model Trained Using AutoNLP
- Problem type: Entity Extraction
- Model ID: 557515810
- CO2 Emissions (in grams): 2.96638567287195
## Validation Metrics
- Loss: 0.12897901237010956
- Accuracy: 0.9713212700580403
- Precision: 0.9475614228089475
- Recall: 0.96274217585693
- F1: 0.9550914803178709
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/kSaluja/autonlp-tele_new_5k-557515810
```
Or Python API:
```
from transformers import AutoModelForTokenClassification, AutoTokenizer
model = AutoModelForTokenClassification.from_pretrained("kSaluja/autonlp-tele_new_5k-557515810", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("kSaluja/autonlp-tele_new_5k-557515810", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
``` |
BenQLange/HF_bot | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2021-10-18T16:13:48Z | ---
tags:
- conversational
---
#wanda bot go reeeeeeeeeeeeeeeeeeeeee |
Bharathdamu/wav2vec2-large-xls-r-300m-hindi | [
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"dataset:common_voice",
"transformers",
"generated_from_trainer",
"license:apache-2.0"
] | automatic-speech-recognition | {
"architectures": [
"Wav2Vec2ForCTC"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | null | # Reference extraction in patents
This repository contains a finetuned BERT model that can extract references to scientific literature from patents.
See https://github.com/kaesve/patent-citation-extraction and https://arxiv.org/abs/2101.01039 for more information. |
Bharathdamu/wav2vec2-large-xls-r-300m-hindi3-colab | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | # Reference extraction in patents
This repository contains a finetuned SciBERT model that can extract references to scientific literature from patents.
See https://github.com/kaesve/patent-citation-extraction and https://arxiv.org/abs/2101.01039 for more information.
|
Bharathdamu/wav2vec2-model-hindi-stt | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- conversational
---
#Radion DialoGPT Model |
Bharathdamu/wav2vec2-model-hindibhasha | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1639
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.2291 | 1.0 | 5533 | 1.1581 |
| 0.9553 | 2.0 | 11066 | 1.1249 |
| 0.7767 | 3.0 | 16599 | 1.1639 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.10.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
|
Bhumika/roberta-base-finetuned-sst2 | [
"pytorch",
"tensorboard",
"roberta",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"model-index"
] | text-classification | {
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 85 | null | ---
language:
- "Python"
thumbnail: "url to a thumbnail used in social sharing"
tags:
- "sentiment analysis"
- "STEM"
- "text classification"
---
Welcome! This is the model built for the sentiment analysis on the STEM course reviews at UCLA.
- Author: Kaixin Wang
- Email: [email protected]
- Time Updated: March 2022 |
Bhuvana/t5-base-spellchecker | [
"pytorch",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"T5ForConditionalGeneration"
],
"model_type": "t5",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": true,
"length_penalty": 2,
"max_length": 200,
"min_length": 30,
"no_repeat_ngram_size": 3,
"num_beams": 4,
"prefix": "summarize: "
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to German: "
},
"translation_en_to_fr": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to French: "
},
"translation_en_to_ro": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to Romanian: "
}
}
} | 93 | null | ---
language: ko
tags:
- KakaoBrain
- KoGPT
- GPT
- GPT3
license: cc-by-nc-4.0
---
# KoGPT
KakaoBrain's Pre-Trained Language Models.
* KoGPT (Korean Generative Pre-trained Transformer)
* [https://github.com/kakaobrain/kogpt](https://github.com/kakaobrain/kogpt)
* [https://huggingface.co/kakaobrain/kogpt](https://huggingface.co/kakaobrain/kogpt)
## Model Descriptions
### KoGPT6B-ryan1.5b
* [\[huggingface\]\[kakaobrain/kogpt\]\[KoGPT6B-ryan1.5b\]](https://huggingface.co/kakaobrain/kogpt/tree/KoGPT6B-ryan1.5b)
* [\[huggingface\]\[kakaobrain/kogpt\]\[KoGPT6B-ryan1.5b-float16\]](https://huggingface.co/kakaobrain/kogpt/tree/KoGPT6B-ryan1.5b-float16)
| Hyperparameter | Value |
|:---------------------|--------------:|
| \\(n_{parameters}\\) | 6,166,502,400 |
| \\(n_{layers}\\) | 28 |
| \\(d_{model}\\) | 4,096 |
| \\(d_{ff}\\) | 16,384 |
| \\(n_{heads}\\) | 16 |
| \\(d_{head}\\) | 256 |
| \\(n_{ctx}\\) | 2,048 |
| \\(n_{vocab}\\) | 64,512 |
| Positional Encoding | [Rotary Position Embedding (RoPE)](https://arxiv.org/abs/2104.09864) |
| RoPE Dimensions | 64 |
## Hardware requirements
### KoGPT6B-ryan1.5b
#### GPU
The following is the recommended minimum GPU hardware guidance for a handful of example KoGPT.
* `32GB GPU RAM` in the required minimum memory size
### KoGPT6B-ryan1.5b-float16
#### GPU
The following is the recommended minimum GPU hardware guidance for a handful of example KoGPT.
* half-precision requires NVIDIA GPUS based on Volta, Turing or Ampere
* `16GB GPU RAM` in the required minimum memory size
## Usage
### prompt
```bash
python -m kogpt --help
usage: KoGPT inference [-h] [--model MODEL] [--revision {KoGPT6B-ryan1.5b}]
[--device {cpu,cuda}] [-d]
KakaoBrain Korean(hangul) Generative Pre-Training Model
optional arguments:
-h, --help show this help message and exit
--model MODEL huggingface repo (default:kakaobrain/kogpt)
--revision {KoGPT6B-ryan1.5b}
--device {cpu,cuda} (default:cuda)
-d, --debug
```
```bash
python -m kogpt
prompt> 인간처럼 생각하고, 행동하는 '지능'을 통해 인류가 이제까지 풀지 못했던
temperature(0.8)>
max_length(128)> 64
인간처럼 생각하고, 행동하는 '지능'을 통해 인류가 이제까지 풀지 못했던 문제의 해답을 찾을 수 있을 것이다. 과학기술이 고도로 발달한 21세기를 살아갈 우리 아이들에게 가장 필요한 것은 사고력 훈련이다. 사고력 훈련을 통해, 세상
prompt>
...
```
### python
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained(
'kakaobrain/kogpt', revision='KoGPT6B-ryan1.5b-float16', # or float32 version: revision=KoGPT6B-ryan1.5b
bos_token='[BOS]', eos_token='[EOS]', unk_token='[UNK]', pad_token='[PAD]', mask_token='[MASK]'
)
model = AutoModelForCausalLM.from_pretrained(
'kakaobrain/kogpt', revision='KoGPT6B-ryan1.5b-float16', # or float32 version: revision=KoGPT6B-ryan1.5b
pad_token_id=tokenizer.eos_token_id,
torch_dtype='auto', low_cpu_mem_usage=True
).to(device='cuda', non_blocking=True)
_ = model.eval()
prompt = '인간처럼 생각하고, 행동하는 \'지능\'을 통해 인류가 이제까지 풀지 못했던'
with torch.no_grad():
tokens = tokenizer.encode(prompt, return_tensors='pt').to(device='cuda', non_blocking=True)
gen_tokens = model.generate(tokens, do_sample=True, temperature=0.8, max_length=64)
generated = tokenizer.batch_decode(gen_tokens)[0]
print(generated) # print: 인간처럼 생각하고, 행동하는 '지능'을 통해 인류가 이제까지 풀지 못했던 문제의 해답을 찾을 수 있을 것이다. 과학기술이 고도로 발달한 21세기를 살아갈 우리 아이들에게 가장 필요한 것은 사고력 훈련이다. 사고력 훈련을 통해, 세상
```
## Experiments
### In-context Few-Shots
| Models | #params | NSMC (Acc.) | YNAT (F1) | KLUE-STS (F1) |
|:--------------|--------:|------------:|----------:|--------------:|
| HyperCLOVA[1] | 1.3B | 83.9 | 58.7 | 60.9 |
| HyperCLOVA[1] | 6.9B | 83.8 | 67.5 | 59.3 |
| HyperCLOVA[1] | 13.0B | 87.9 | 67.9 | 60.0 |
| HyperCLOVA[1] | 39.0B | 88.0 | 71.4 | 61.6 |
| HyperCLOVA[1] | 82.0B | **88.2** | 72.7 | **65.1** |
| **Ours** | 6.0B | 87.8 | **78.0** | 64.3 |
### Finetuning / P-Tuning
We have been reported to have issues(https://github.com/kakaobrain/kogpt/issues/17) with our downstream evaluation.
The previously published performance evaluation table was deleted because it was difficult to see it as a fair comparison because the comparison target algorithm was different and the performance measurement method could not be confirmed.
You can refer to the above issue link for the existing performance evaluation table and troubleshooting results.
## Limitations
KakaoBrain `KoGPT` was trained on `ryan dataset`, a dataset known to contain profanity, lewd, political changed, and other harsh language.
Therefore, `KoGPT` can generate socially unacceptable texts. As with all language models, It is difficult to predict in advance how `KoGPT` will response to particular prompts and offensive content without warning.
Primarily Korean: `KoGPT` is primarily trained on Korean texts, and is best for classifying, searching, summarizing or generating such texts.
`KoGPT` by default perform worse on inputs that are different from the data distribution it is trained on, including non-Korean as well as specific dialects of Korean that are not well represented in the training data.
[comment]: <> (If abnormal or socially unacceptable text is generated during testing, please send a "prompt" and the "generated text" to [[email protected]](mailto:[email protected]). )
카카오브레인 `KoGPT`는 욕설, 음란, 정치적 내용 및 기타 거친 언어에 대한 처리를 하지 않은 `ryan dataset`으로 학습하였습니다.
따라서 `KoGPT`는 사회적으로 용인되지 않은 텍스트를 생성할 수 있습니다. 다른 언어 모델과 마찬가지로 특정 프롬프트와 공격적인 콘텐츠에 어떠한 결과를 생성할지 사전에 파악하기 어렵습니다.
`KoGPT`는 주로 한국어 텍스트로 학습을 하였으며 이러한 텍스트를 분류, 검색, 요약 또는 생성하는데 가장 적합합니다.
기본적으로 `KoGPT`는 학습 데이터에 잘 나타나지 않는 방언뿐만아니라 한국어가 아닌 경우와 같이 학습 데이터에서 발견하기 어려운 입력에서 좋지 않은 성능을 보입니다.
[comment]: <> (테스트중에 발생한 비정상적인 혹은 사회적으로 용인되지 않는 텍스트가 생성된 경우 [[email protected]](mailto:[email protected])로 "prompt"와 "생성된 문장"을 함께 보내주시기 바랍니다.)
## Citation
If you apply this library or model to any project and research, please cite our code:
```
@misc{kakaobrain2021kogpt,
title = {KoGPT: KakaoBrain Korean(hangul) Generative Pre-trained Transformer},
author = {Ildoo Kim and Gunsoo Han and Jiyeon Ham and Woonhyuk Baek},
year = {2021},
howpublished = {\url{https://github.com/kakaobrain/kogpt}},
}
```
## Contact
This is released as an open source in the hope that it will be helpful to many research institutes and startups for research purposes. We look forward to contacting us from various places who wish to cooperate with us.
[[email protected]](mailto:[email protected])
## License
The `source code` of KakaoBrain `KoGPT` are licensed under [Apache 2.0](LICENSE.apache-2.0) License.
The `pretrained wieghts` of KakaoBrain `KoGPT` are licensed under [CC-BY-NC-ND 4.0 License](https://creativecommons.org/licenses/by-nc-nd/4.0/) License.
카카오브레인 `KoGPT`의 `소스코드(source code)`는 [Apache 2.0](LICENSE.apache-2.0) 라이선스 하에 공개되어 있습니다.
카카오브레인 `KoGPT`의 `사전학습된 가중치(pretrained weights)`는 [CC-BY-NC-ND 4.0 라이선스](https://creativecommons.org/licenses/by-nc-nd/4.0/) 라이선스 하에 공개되어 있습니다.
모델 및 코드, 사전학습된 가중치를 사용할 경우 라이선스 내용을 준수해 주십시오. 라이선스 전문은 [Apache 2.0](LICENSE.apache-2.0), [LICENSE.cc-by-nc-nd-4.0](LICENSE.cc-by-nc-nd-4.0) 파일에서 확인하실 수 있습니다.
## References
[1] [HyperCLOVA](https://arxiv.org/abs/2109.04650): Kim, Boseop, et al. "What changes can large-scale language models bring? intensive study on hyperclova: Billions-scale korean generative pretrained transformers." arXiv preprint arXiv:2109.04650 (2021).
|
BigSalmon/DaBlank | [
"pytorch",
"jax",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"T5ForConditionalGeneration"
],
"model_type": "t5",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": true,
"length_penalty": 2,
"max_length": 200,
"min_length": 30,
"no_repeat_ngram_size": 3,
"num_beams": 4,
"prefix": "summarize: "
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to German: "
},
"translation_en_to_fr": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to French: "
},
"translation_en_to_ro": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to Romanian: "
}
}
} | 4 | null | ## BioELECTRA:Pretrained Biomedical text Encoder using Discriminators
Recent advancements in pretraining strategies in NLP have shown a significant improvement in the performance of models on various text mining tasks. In this paper, we introduce BioELECTRA, a biomedical domain-specific language encoder model that adapts ELECTRA (Clark et al., 2020) for the Biomedical domain. BioELECTRA outperforms the previous models and achieves state of the art (SOTA) on all the 13 datasets in BLURB benchmark and on all the 4 Clinical datasets from BLUE Benchmark across 7 NLP tasks. BioELECTRA pretrained on PubMed and PMC full text articles performs very well on Clinical datasets as well. BioELECTRA achieves new SOTA 86.34%(1.39% accuracy improvement) on MedNLI and 64% (2.98% accuracy improvement) on PubMedQA dataset.
For a detailed description and experimental results, please refer to our paper [BioELECTRA:Pretrained Biomedical text Encoder using Discriminators](https://www.aclweb.org/anthology/2021.bionlp-1.16/).
## How to use the discriminator in `transformers`
```python
from transformers import ElectraForPreTraining, ElectraTokenizerFast
import torch
discriminator = ElectraForPreTraining.from_pretrained("kamalkraj/bioelectra-base-discriminator-pubmed")
tokenizer = ElectraTokenizerFast.from_pretrained("kamalkraj/bioelectra-base-discriminator-pubmed")
sentence = "The quick brown fox jumps over the lazy dog"
fake_sentence = "The quick brown fox fake over the lazy dog"
fake_tokens = tokenizer.tokenize(fake_sentence)
fake_inputs = tokenizer.encode(fake_sentence, return_tensors="pt")
discriminator_outputs = discriminator(fake_inputs)
predictions = torch.round((torch.sign(discriminator_outputs[0]) + 1) / 2)
[print("%7s" % token, end="") for token in fake_tokens]
[print("%7s" % int(prediction), end="") for prediction in predictions[0].tolist()]
``` |
BigSalmon/Flowberta | [
"pytorch",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"RobertaForMaskedLM"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 13 | null | ## BioELECTRA:Pretrained Biomedical text Encoder using Discriminators
Recent advancements in pretraining strategies in NLP have shown a significant improvement in the performance of models on various text mining tasks. In this paper, we introduce BioELECTRA, a biomedical domain-specific language encoder model that adapts ELECTRA (Clark et al., 2020) for the Biomedical domain. BioELECTRA outperforms the previous models and achieves state of the art (SOTA) on all the 13 datasets in BLURB benchmark and on all the 4 Clinical datasets from BLUE Benchmark across 7 NLP tasks. BioELECTRA pretrained on PubMed and PMC full text articles performs very well on Clinical datasets as well. BioELECTRA achieves new SOTA 86.34%(1.39% accuracy improvement) on MedNLI and 64% (2.98% accuracy improvement) on PubMedQA dataset.
For a detailed description and experimental results, please refer to our paper [BioELECTRA:Pretrained Biomedical text Encoder using Discriminators](https://www.aclweb.org/anthology/2021.bionlp-1.16/).
## How to use the discriminator in `transformers`
```python
from transformers import ElectraForPreTraining, ElectraTokenizerFast
import torch
discriminator = ElectraForPreTraining.from_pretrained("kamalkraj/bioelectra-base-discriminator-pubmed")
tokenizer = ElectraTokenizerFast.from_pretrained("kamalkraj/bioelectra-base-discriminator-pubmed")
sentence = "The quick brown fox jumps over the lazy dog"
fake_sentence = "The quick brown fox fake over the lazy dog"
fake_tokens = tokenizer.tokenize(fake_sentence)
fake_inputs = tokenizer.encode(fake_sentence, return_tensors="pt")
discriminator_outputs = discriminator(fake_inputs)
predictions = torch.round((torch.sign(discriminator_outputs[0]) + 1) / 2)
[print("%7s" % token, end="") for token in fake_tokens]
[print("%7s" % int(prediction), end="") for prediction in predictions[0].tolist()]
``` |
BigSalmon/InformalToFormalLincoln16 | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
language: en
tags:
- glossbert
license: mit
datasets:
- SemCor3.0
---
## GlossBERT
A BERT-based model fine-tuned on SemCor 3.0 to perform word-sense-disambiguation by leveraging gloss information. This model is the research output of the paper titled: '[GlossBERT: BERT for Word Sense Disambiguation with Gloss Knowledge](https://arxiv.org/pdf/1908.07245.pdf)'
Disclaimer: This model was built and trained by a group of researchers different than the repository's author. The original model code can be found on github: https://github.com/HSLCY/GlossBERT
## Usage
The following code loads GlossBERT:
```py
from transformers import AutoTokenizer, BertForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained('kanishka/GlossBERT')
model = BertForSequenceClassification.from_pretrained('kanishka/GlossBERT')
```
## Citation
If you use this model in any of your projects, please cite the original authors using the following bibtex:
```
@inproceedings{huang-etal-2019-glossbert,
title = "{G}loss{BERT}: {BERT} for Word Sense Disambiguation with Gloss Knowledge",
author = "Huang, Luyao and
Sun, Chi and
Qiu, Xipeng and
Huang, Xuanjing",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP)",
month = nov,
year = "2019",
address = "Hong Kong, China",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/D19-1355",
doi = "10.18653/v1/D19-1355",
pages = "3507--3512"
}
``` |
BigSalmon/InformalToFormalLincoln18 | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: distilbert-base-uncased-CoLA-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.5689051637185746
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-CoLA-finetuned-cola
This model is a fine-tuned version of [textattack/distilbert-base-uncased-CoLA](https://huggingface.co/textattack/distilbert-base-uncased-CoLA) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6996
- Matthews Correlation: 0.5689
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| No log | 1.0 | 134 | 0.6061 | 0.5074 |
| No log | 2.0 | 268 | 0.5808 | 0.5652 |
| No log | 3.0 | 402 | 0.6996 | 0.5689 |
| 0.0952 | 4.0 | 536 | 0.8249 | 0.5385 |
| 0.0952 | 5.0 | 670 | 0.8714 | 0.5567 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
|
BigSalmon/InformalToFormalLincoln23 | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 5 | null | ---
language:
- hi
license: apache-2.0
tags:
- automatic-speech-recognition
- generated_from_trainer
- hf-asr-leaderboard
- mozilla-foundation/common_voice_7_0
- robust-speech-event
datasets:
- mozilla-foundation/common_voice_7_0
model-index:
- name: ''
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 7.0
type: mozilla-foundation/common_voice_7_0
args: hi
metrics:
- name: Test WER
type: wer
value: 39.21
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
#
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the MOZILLA-FOUNDATION/COMMON_VOICE_7_0 - HI dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7805
- Wer: 0.4340
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 8000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.36 | 400 | 1.9130 | 0.9244 |
| 5.0013 | 2.71 | 800 | 0.7789 | 0.5944 |
| 0.6544 | 4.07 | 1200 | 0.7298 | 0.5852 |
| 0.4021 | 5.42 | 1600 | 0.6978 | 0.5667 |
| 0.3003 | 6.78 | 2000 | 0.6764 | 0.5382 |
| 0.3003 | 8.14 | 2400 | 0.7249 | 0.5463 |
| 0.2345 | 9.49 | 2800 | 0.7280 | 0.5124 |
| 0.1993 | 10.85 | 3200 | 0.7289 | 0.4690 |
| 0.1617 | 12.2 | 3600 | 0.7431 | 0.4733 |
| 0.1432 | 13.56 | 4000 | 0.7448 | 0.4733 |
| 0.1432 | 14.92 | 4400 | 0.7746 | 0.4485 |
| 0.1172 | 16.27 | 4800 | 0.7589 | 0.4742 |
| 0.1035 | 17.63 | 5200 | 0.7539 | 0.4353 |
| 0.0956 | 18.98 | 5600 | 0.7648 | 0.4495 |
| 0.0845 | 20.34 | 6000 | 0.7877 | 0.4719 |
| 0.0845 | 21.69 | 6400 | 0.7884 | 0.4434 |
| 0.0761 | 23.05 | 6800 | 0.7796 | 0.4386 |
| 0.0634 | 24.41 | 7200 | 0.7729 | 0.4306 |
| 0.0571 | 25.76 | 7600 | 0.7826 | 0.4298 |
| 0.0508 | 27.12 | 8000 | 0.7805 | 0.4340 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.1+cu102
- Datasets 1.18.3
- Tokenizers 0.11.0
|
BigSalmon/Points | [
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"transformers",
"has_space"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 13 | null | https://www.geogebra.org/m/cwcveget
https://www.geogebra.org/m/b8dzxk6z
https://www.geogebra.org/m/nqanttum
https://www.geogebra.org/m/pd3g8a4u
https://www.geogebra.org/m/jw8324jz
https://www.geogebra.org/m/wjbpvz5q
https://www.geogebra.org/m/qm3g3ma6
https://www.geogebra.org/m/sdajgph8
https://www.geogebra.org/m/e3ghhcbf
https://www.geogebra.org/m/msne4bfm
https://www.geogebra.org/m/nmcv2te5
https://www.geogebra.org/m/hguqx6cn
https://www.geogebra.org/m/jnyvpgqu
https://www.geogebra.org/m/syctd97g
https://www.geogebra.org/m/nq9erdby
https://www.geogebra.org/m/au4har8c |
BigSalmon/T5Salmon | [
"pytorch",
"jax",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"T5ForConditionalGeneration"
],
"model_type": "t5",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": true,
"length_penalty": 2,
"max_length": 200,
"min_length": 30,
"no_repeat_ngram_size": 3,
"num_beams": 4,
"prefix": "summarize: "
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to German: "
},
"translation_en_to_fr": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to French: "
},
"translation_en_to_ro": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to Romanian: "
}
}
} | 6 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: opus-mt-en-ru-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# opus-mt-en-ru-finetuned
This model is a fine-tuned version of [kazandaev/opus-mt-en-ru-finetuned](https://huggingface.co/kazandaev/opus-mt-en-ru-finetuned) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7763
- Bleu: 41.0065
- Gen Len: 29.7548
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-06
- train_batch_size: 49
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:------:|:---------------:|:-------:|:-------:|
| 0.6903 | 1.0 | 35147 | 0.7779 | 40.9223 | 29.7846 |
| 0.6999 | 2.0 | 70294 | 0.7776 | 40.8267 | 29.8421 |
| 0.7257 | 3.0 | 105441 | 0.7769 | 40.8549 | 29.8765 |
| 0.7238 | 4.0 | 140588 | 0.7763 | 41.0225 | 29.7129 |
| 0.7313 | 5.0 | 175735 | 0.7763 | 41.0065 | 29.7548 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
|
BigSalmon/T5Salmon2 | [
"pytorch",
"jax",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"T5ForConditionalGeneration"
],
"model_type": "t5",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": true,
"length_penalty": 2,
"max_length": 200,
"min_length": 30,
"no_repeat_ngram_size": 3,
"num_beams": 4,
"prefix": "summarize: "
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to German: "
},
"translation_en_to_fr": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to French: "
},
"translation_en_to_ro": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to Romanian: "
}
}
} | 13 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: opus-mt-en-ru-finetuned_v2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# opus-mt-en-ru-finetuned_v2
This model is a fine-tuned version of [kazandaev/opus-mt-en-ru-finetuned_v2](https://huggingface.co/kazandaev/opus-mt-en-ru-finetuned_v2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8471
- Bleu: 37.5148
- Gen Len: 29.8495
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-06
- train_batch_size: 49
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:------:|:---------------:|:-------:|:-------:|
| 0.7688 | 1.0 | 50906 | 0.8533 | 37.1941 | 29.8644 |
| 0.764 | 2.0 | 101812 | 0.8504 | 37.1506 | 29.8481 |
| 0.7637 | 3.0 | 152718 | 0.8485 | 37.3499 | 29.7743 |
| 0.7593 | 4.0 | 203624 | 0.8477 | 37.4428 | 29.8165 |
| 0.7579 | 5.0 | 254530 | 0.8471 | 37.5148 | 29.8495 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.6
|
BigSalmon/prepositions | [
"pytorch",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"RobertaForMaskedLM"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: opus-mt-ru-en-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# opus-mt-ru-en-finetuned
This model is a fine-tuned version of [kazandaev/opus-mt-ru-en-finetuned](https://huggingface.co/kazandaev/opus-mt-ru-en-finetuned) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0399
- Bleu: 43.5078
- Gen Len: 26.1256
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-06
- train_batch_size: 49
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:------:|:---------------:|:-------:|:-------:|
| 0.7462 | 1.0 | 35147 | 1.0422 | 43.3884 | 26.1742 |
| 0.7501 | 2.0 | 70294 | 1.0407 | 43.5296 | 26.1671 |
| 0.7471 | 3.0 | 105441 | 1.0402 | 43.5133 | 26.1118 |
| 0.7514 | 4.0 | 140588 | 1.0401 | 43.492 | 26.1529 |
| 0.7565 | 5.0 | 175735 | 1.0399 | 43.5078 | 26.1256 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
|
BigeS/DialoGPT-small-Rick | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | null | ---
tags: autonlp
language: unk
widget:
- text: "I love AutoNLP 🤗"
datasets:
- kbhugging/autonlp-data-text2sql
co2_eq_emissions: 1.4091714704861447
---
# Model Trained Using AutoNLP
- Problem type: Summarization
- Model ID: 18413376
- CO2 Emissions (in grams): 1.4091714704861447
## Validation Metrics
- Loss: 0.26672711968421936
- Rouge1: 61.765
- Rouge2: 52.5778
- RougeL: 61.3222
- RougeLsum: 61.1905
- Gen Len: 18.7805
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_HUGGINGFACE_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/kbhugging/autonlp-text2sql-18413376
``` |
BobBraico/distilbert-base-uncased-finetuned-imdb-accelerate | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2021-11-09T10:17:25Z | This is an example of how a kenLM model can be downloaded with [PyCTCDecode](https://github.com/kensho-technologies/pyctcdecode) .
Simply run the following code:
```python
from pyctcdecode import LanguageModel
language_model = LanguageModel.load_from_hf_hub("kensho/5gram-spanish-kenLM")
```
The model was trained by [Patrick von Platen](https://huggingface.co/patrickvonplaten) for demonstration purposes. |
BobBraico/distilbert-base-uncased-finetuned-imdb | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | This is an example of how a kenLM model can be downloaded with [PyCTCDecode](https://github.com/kensho-technologies/pyctcdecode) .
Simply run the following code:
```python
from pyctcdecode import BeamSearchDecoderCTC
decoder = BeamSearchDecoderCTC.load_from_hf_hub("kensho/beamsearch_decoder_dummy")
```
The model was created by [Patrick von Platen](https://huggingface.co/patrickvonplaten) for demonstration purposes. |
BogdanKuloren/continual-learning-paper-embeddings-model | [
"pytorch",
"mpnet",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"MPNetModel"
],
"model_type": "mpnet",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 11 | 2021-11-19T15:28:25Z | This is an example of how a kenLM model can be downloaded with [PyCTCDecode](https://github.com/kensho-technologies/pyctcdecode) .
Simply run the following code:
```python
from pyctcdecode import LanguageModel
language_model = LanguageModel.load_from_hf_hub("kensho/dummy_full_language_model")
```
The model was created by [Patrick von Platen](https://huggingface.co/patrickvonplaten) for demonstration purposes. |
Bosio/full-sentence-distillroberta3-finetuned-wikitext2 | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- gan
- computer vision
- horse to zebra
license:
- cc0-1.0
---
## Keras Implementation of CycleGAN model using [Horse to Zebra dataset](https://www.tensorflow.org/datasets/catalog/cycle_gan#cycle_ganhorse2zebra) 🐴 -> 🦓
This repo contains the model and the notebook [to this Keras example on CycleGAN](https://keras.io/examples/generative/cyclegan/).
Full credits to: [Aakash Kumar Nain](https://twitter.com/A_K_Nain)
## Background Information
CycleGAN is a model that aims to solve the image-to-image translation problem. The goal of the image-to-image translation problem is to learn the mapping between an input image and an output image using a training set of aligned image pairs. However, obtaining paired examples isn't always feasible. CycleGAN tries to learn this mapping without requiring paired input-output images, using cycle-consistent adversarial networks.
 |
BossLee/t5-gec | [
"pytorch",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"T5ForConditionalGeneration"
],
"model_type": "t5",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": true,
"length_penalty": 2,
"max_length": 200,
"min_length": 30,
"no_repeat_ngram_size": 3,
"num_beams": 4,
"prefix": "summarize: "
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to German: "
},
"translation_en_to_fr": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to French: "
},
"translation_en_to_ro": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to Romanian: "
}
}
} | 6 | 2022-02-21T05:35:07Z | ---
language:
- en
thumbnail:
tags:
- keras
- tensorflow
- image-classification
library_name: generic
libraries: TensorBoard
license: apache-2.0
metrics:
- accuracy
model-index:
- name: Image-Classification-using-EANet
results:
- task:
type: Image-Classification-using-EANet
dataset:
type: Image
name: CIFAR100
metrics:
- type: accuracy
value: []
- type: validation loss
value: []
---
## Image-Classification-using-EANet with Keras
This repo contains the model and the notebook on [Image Classification using EANet with Keras](https://keras.io/examples/vision/eanet/).
Credits: [ZhiYong Chang](https://github.com/czy00000) - Original Author
HF Contribution: [Drishti Sharma](https://huggingface.co/spaces/DrishtiSharma)
### Introduction
This example implements the EANet model for image classification, and demonstrates it on the [CIFAR-100](https://huggingface.co/datasets/cifar100) dataset. EANet introduces a novel attention mechanism named external attention, based on two external, small, learnable, and shared memories, which can be implemented easily by simply using two cascaded linear layers and two normalization layers. It conveniently replaces self-attention as used in existing architectures. External attention has linear complexity, as it only implicitly considers the correlations between all samples.
### Implemention of the EANet model
The EANet model leverages external attention. The computational complexity of traditional self attention is O(d * N ** 2), where d is the embedding size, and N is the number of patch. The authors find that most pixels are closely related to just a few other pixels, and an N-to-N attention matrix may be redundant. So, they propose as an alternative an external attention module where the computational complexity of external attention is O(d * S * N). As d and S are hyper-parameters, the proposed algorithm is linear in the number of pixels. In fact, this is equivalent to a drop patch operation, because a lot of information contained in a patch in an image is redundant and unimportant. |
Botslity/Bot | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2021-12-13T18:12:33Z | ---
language:
- en
datasets:
- imdb
tags:
- text-classification
widget:
- text: "I like that movie, but I'm not sure if it's my favorite."
---
## Keras Implementation of Bidirectional LSTMs for Sentiment Analysis on IMDB 🍿🎥
This repo contains the model and the notebook [on Bidirectional LSTMs for Sentiment Analysis on IMDB](https://keras.io/examples/nlp/bidirectional_lstm_imdb/).
Full credits to: [François Chollet](https://github.com/fchollet)
HF Contribution: [Drishti Sharma](https://huggingface.co/DrishtiSharma)
### Metrics after 10 epochs:
- train_loss: 0.2085
- train_acc: 0.9194
- val_loss: 0.3019
- val_acc: 0.8778
|
BotterHax/DialoGPT-small-harrypotter | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
language:
- en
- fr
tags:
- seq2seq
- translation
license:
- cc0-1.0
---
## Keras Implementation of Character-level recurrent sequence-to-sequence model
This repo contains the model and the notebook [to this Keras example on Character-level recurrent sequence-to-sequence model](https://keras.io/examples/nlp/lstm_seq2seq/).
Full credits to: [fchollet](https://twitter.com/fchollet)
## Background Information
This example demonstrates how to implement a basic character-level recurrent sequence-to-sequence model. We apply it to translating short English sentences into short French sentences, character-by-character. Note that it is fairly unusual to do character-level machine translation, as word-level models are more common in this domain.
## Limitations
It works on text of length <= 15 characters
## Parameters needed for using the model
```python
latent_dim = 256
num_encoder_tokens = 71
max_encoder_seq_length = 15
num_decoder_tokens = 92
max_decoder_seq_length = 59
``` |
Branex/gpt-neo-2.7B | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-02-07T07:17:24Z | ---
library_name: keras
tags:
- image-to-image
---
# Conditional Generative Adversarial Network
This repo contains the model and the notebook to [this Keras example on Conditional GAN](https://keras.io/examples/generative/conditional_gan/).
Full credits to: [Sayak Paul](https://twitter.com/RisingSayak)
# Background Information
Training a GAN conditioned on class labels to generate handwritten digits.
Generative Adversarial Networks (GANs) let us generate novel image data, video data, or audio data from a random input. Typically, the random input is sampled from a normal distribution, before going through a series of transformations that turn it into something plausible (image, video, audio, etc.).
However, a simple DCGAN doesn't let us control the appearance (e.g. class) of the samples we're generating. For instance, with a GAN that generates MNIST handwritten digits, a simple DCGAN wouldn't let us choose the class of digits we're generating. To be able to control what we generate, we need to condition the GAN output on a semantic input, such as the class of an image.
In this example, we'll build a Conditional GAN that can generate MNIST handwritten digits conditioned on a given class. Such a model can have various useful applications:
let's say you are dealing with an imbalanced image dataset, and you'd like to gather more examples for the skewed class to balance the dataset. Data collection can be a costly process on its own. You could instead train a Conditional GAN and use it to generate novel images for the class that needs balancing.
Since the generator learns to associate the generated samples with the class labels, its representations can also be used for other downstream tasks. |
Brendan/cse244b-hw2-roberta | [
"pytorch",
"roberta",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 28 | 2022-02-14T20:18:45Z | ---
tags:
- video-prediction
- moving-mnist
- video-to-video
license: cc0-1.0
---
## Tensorflow Keras Implementation of Next-Frame Video Prediction with Convolutional LSTMs 📽️
This repo contains the models and the notebook [on How to build and train a convolutional LSTM model for next-frame video prediction](https://keras.io/examples/vision/conv_lstm/).
Full credits to [Amogh Joshi](https://github.com/amogh7joshi)
## Background Information
The [Convolutional LSTM](https://papers.nips.cc/paper/2015/file/07563a3fe3bbe7e3ba84431ad9d055af-Paper.pdf) architectures bring together time series processing and computer vision by introducing a convolutional recurrent cell in a LSTM layer. This model uses the Convolutional LSTMs in an application to next-frame prediction, the process of predicting what video frames come next given a series of past frames.

## Training Dataset
This model was trained on the [Moving MNIST dataset](http://www.cs.toronto.edu/~nitish/unsupervised_video/).
For next-frame prediction, our model will be using a previous frame, which we'll call `f_n`, to predict a new frame, called `f_(n + 1)`. To allow the model to create these predictions, we'll need to process the data such that we have "shifted" inputs and outputs, where the input data is frame `x_n`, being used to predict frame `y_(n + 1)`.

|
BrianTin/MTBERT | [
"pytorch",
"jax",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 11 | null | ---
language: en
tags:
- ConvMixer
- keras-io
license: apache-2.0
datasets:
- cifar10
---
# ConvMixer model
The ConvMixer model is trained on Cifar10 dataset and is based on [the paper](https://arxiv.org/abs/2201.09792v1), [github](https://github.com/locuslab/convmixer).
Disclaimer : This is a demo model for Sayak Paul's keras [example](https://keras.io/examples/vision/convmixer/). Please refrain from using this model for any other purpose.
## Description
The paper uses 'patches' (square group of pixels) extracted from the image, which has been done in other Vision Transformers like [ViT](https://arxiv.org/abs/2010.11929v2). One notable dawback of such architectures is the quadratic runtime of self-attention layers which takes a lot of time and resources to train for usable output. The ConvMixer model, instead uses Convolutions along with the MLP-mixer to obtain similar results to that of transformers at a fraction of cost.
### Intended Use
This model is intended to be used as a demo model for keras-io.
|
Brinah/1 | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-02-05T17:44:15Z | ---
tags:
- speech recognition
- ctc
dataset:
- LJSpeech dataset
license: cc0-1.0
---
## Automatic Speech Recognition using CTC model on the 🤗Hub!
Full credits go to [Mohamed Reda Bouadjenek]() and [Ngoc Dung Huynh]().
This repository contains the model from [this notebook on Automatic Speech Recognition using CTC](https://keras.io/examples/audio/ctc_asr/).
|
Broadus20/DialoGPT-small-harrypotter | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | 2021-12-14T11:52:03Z | ---
tags:
- reinforcement learning
- cartpole
- deep deterministic policy gradient
license:
- cc0-1.0
---
## Keras Implementation of Deep Deterministic Policy Gradient ⏱🤖
This repo contains the model and the notebook [to this Keras example on Deep Deterministic Policy Gradient on pendulum](https://keras.io/examples/rl/ddpg_pendulum/).
Full credits to: [Hemant Singh](https://github.com/amifunny)

## Background Information
Deep Deterministic Policy Gradient (DDPG) is a model-free off-policy algorithm for learning continous actions.
It combines ideas from DPG (Deterministic Policy Gradient) and DQN (Deep Q-Network). It uses Experience Replay and slow-learning target networks from DQN, and it is based on DPG, which can operate over continuous action spaces.
This tutorial closely follow this paper - Continuous control with deep reinforcement learning
We are trying to solve the classic Inverted Pendulum control problem. In this setting, we can take only two actions: swing left or swing right.
What make this problem challenging for Q-Learning Algorithms is that actions are continuous instead of being discrete. That is, instead of using two discrete actions like -1 or +1, we have to select from infinite actions ranging from -2 to +2.
Just like the Actor-Critic method, we have two networks:
Actor - It proposes an action given a state.
Critic - It predicts if the action is good (positive value) or bad (negative value) given a state and an action.
DDPG uses two more techniques not present in the original DQN:
First, it uses two Target networks.
Why? Because it add stability to training. In short, we are learning from estimated targets and Target networks are updated slowly, hence keeping our estimated targets stable.
Conceptually, this is like saying, "I have an idea of how to play this well, I'm going to try it out for a bit until I find something better", as opposed to saying "I'm going to re-learn how to play this entire game after every move". See this StackOverflow answer.
Second, it uses Experience Replay.
We store list of tuples (state, action, reward, next_state), and instead of learning only from recent experience, we learn from sampling all of our experience accumulated so far.
|
Brokette/projetCS | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"transformers"
] | automatic-speech-recognition | {
"architectures": [
"Wav2Vec2ForCTC"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | 2022-02-10T17:15:47Z | ---
tags:
- computer-vision
- image-segmentation
license:
- cc0-1.0
library_name: keras
---
## Multiclass semantic segmentation using DeepLabV3+
This repo contains the model and the notebook [to this Keras example on Multiclass semantic segmentation using DeepLabV3+](https://keras.io/examples/vision/deeplabv3_plus/).
Full credits to: [Soumik Rakshit](http://github.com/soumik12345)
The model is trained for demonstrative purposes and does not guarantee the best results in production. For better results, follow & optimize the [Keras example]((https://keras.io/examples/vision/deeplabv3_plus/) as per your need.
## Background Information
Semantic segmentation, with the goal to assign semantic labels to every pixel in an image, is an essential computer vision task. In this example, we implement the DeepLabV3+ model for multi-class semantic segmentation, a fully-convolutional architecture that performs well on semantic segmentation benchmarks.
## Training Data
The model is trained on a subset (10,000 images) of [Crowd Instance-level Human Parsing Dataset](https://arxiv.org/abs/1811.12596). The Crowd Instance-level Human Parsing (CIHP) dataset has 38,280 diverse human images. Each image in CIHP is labeled with pixel-wise annotations for 20 categories, as well as instance-level identification. This dataset can be used for the "human part segmentation" task.
## Model
The model uses ResNet50 pretrained on ImageNet as the backbone model.
References:
1. [Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation](https://arxiv.org/pdf/1802.02611.pdf)
2. [Rethinking Atrous Convolution for Semantic Image Segmentation](https://arxiv.org/abs/1706.05587)
3. [DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs](https://arxiv.org/abs/1606.00915) |
Brona/poc_de | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2021-12-03T14:36:01Z | ---
tags:
- image-to-text
- generic
library_name: generic
pipeline_tag: image-to-text
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-1.jpg
example_title: Kedis
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-2.jpg
example_title: Cat in a Crate
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-3.jpg
example_title: Two Cats Chilling
license: cc0-1.0
---
## Tensorflow Keras Implementation of an Image Captioning Model with encoder-decoder network. 🌃🌅🎑
This repo contains the models and the notebook [on Image captioning with visual attention](https://www.tensorflow.org/tutorials/text/image_captioning?hl=en).
Full credits to TensorFlow Team
## Background Information
This notebook implements TensorFlow Keras implementation on Image captioning with visual attention.
Given an image like the example below, your goal is to generate a caption such as "a surfer riding on a wave".

To accomplish this, you'll use an attention-based model, which enables us to see what parts of the image the model focuses on as it generates a caption.
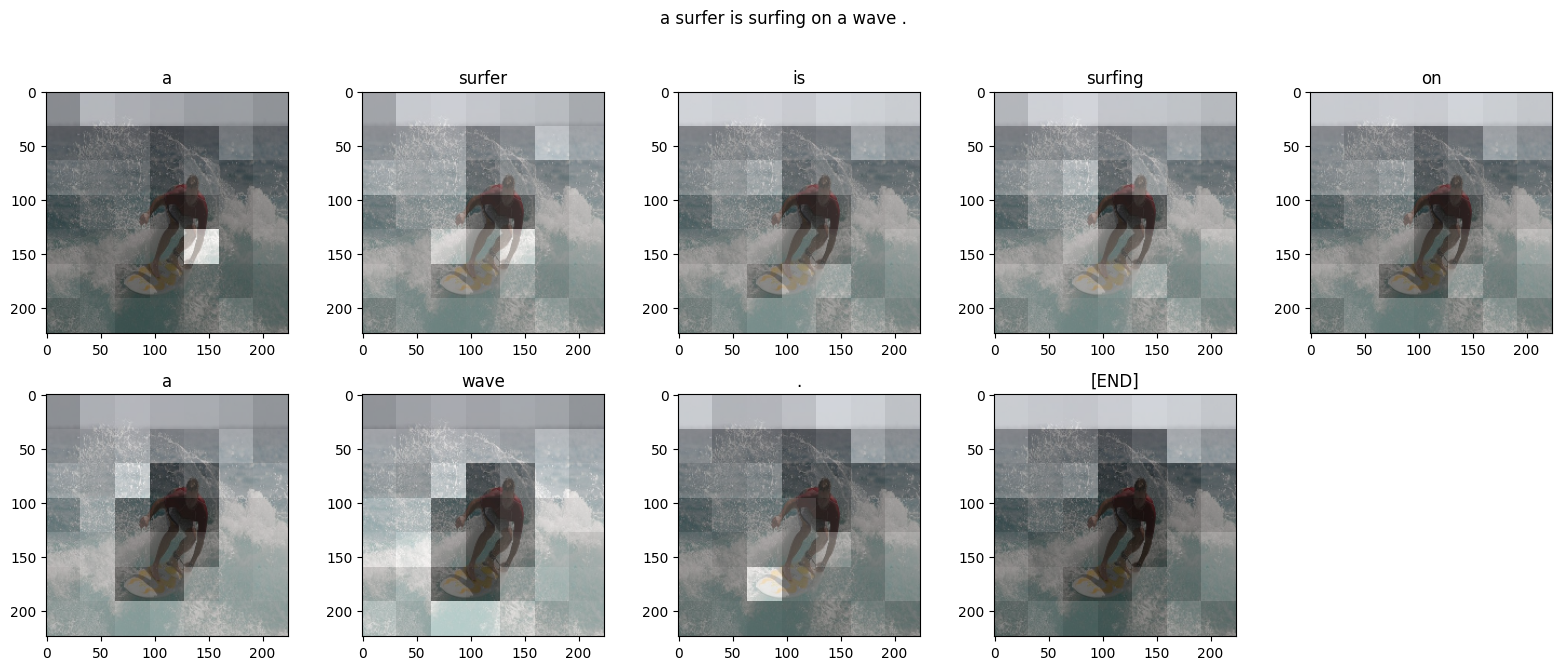
The model architecture is similar to [Show, Attend and Tell: Neural Image Caption Generation with Visual Attention](https://arxiv.org/abs/1502.03044).
This notebook is an end-to-end example. When you run the notebook, it downloads the [MS-COCO](https://cocodataset.org/#home) dataset, preprocesses and caches a subset of images using Inception V3, trains an encoder-decoder model, and generates captions on new images using the trained model.
|
Brunomezenga/NN | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-02-17T05:50:02Z | ---
license: apache-2.0
library_name: keras
tags:
- image-to-image
---
## Zero-DCE for low-light image enhancement
**Original Author**: [Soumik Rakshit](https://github.com/soumik12345) <br>
**Date created**: 2021/09/18 <br>
**HF Contribution**: [Harveen Singh Chadha](https://github.com/harveenchadha)<br>
**Dataset**: [LOL Dataset](https://huggingface.co/Harveenchadha/low-light-image-enhancement/blob/main/lol_dataset.zip)
## [Spaces Demo](https://huggingface.co/spaces/Harveenchadha/low-light-image-enhancement)
## Description: Implementing Zero-Reference Deep Curve Estimation for low-light image enhancement.
Zero-Reference Deep Curve Estimation or Zero-DCE formulates low-light image enhancement as the task of estimating an image-specific tonal curve with a deep neural network. In this example, we train a lightweight deep network, DCE-Net, to estimate pixel-wise and high-order tonal curves for dynamic range adjustment of a given image.
Zero-DCE takes a low-light image as input and produces high-order tonal curves as its output. These curves are then used for pixel-wise adjustment on the dynamic range of the input to obtain an enhanced image. The curve estimation process is done in such a way that it maintains the range of the enhanced image and preserves the contrast of neighboring pixels. This curve estimation is inspired by curves adjustment used in photo editing software such as Adobe Photoshop where users can adjust points throughout an image’s tonal range.
Zero-DCE is appealing because of its relaxed assumptions with regard to reference images: it does not require any input/output image pairs during training. This is achieved through a set of carefully formulated non-reference loss functions, which implicitly measure the enhancement quality and guide the training of the network.
Sample Images:
<img src="https://keras.io/img/examples/vision/zero_dce/zero_dce_25_0.png" >
<img src="https://keras.io/img/examples/vision/zero_dce/zero_dce_25_1.png" >
<img src="https://keras.io/img/examples/vision/zero_dce/zero_dce_25_2.png" >
<img src="https://keras.io/img/examples/vision/zero_dce/zero_dce_25_3.png" >
<img src="https://keras.io/img/examples/vision/zero_dce/zero_dce_25_4.png" >
<img src="https://keras.io/img/examples/vision/zero_dce/zero_dce_25_5.png" >
<img src="https://keras.io/img/examples/vision/zero_dce/zero_dce_25_6.png" >
<img src="https://keras.io/img/examples/vision/zero_dce/zero_dce_25_7.png" >
|
Bryanwong/wangchanberta-ner | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-02-18T11:27:07Z | ---
tags:
- computer-vision
- image-classification
license:
- cc0-1.0
library_name: keras
---
## Image Classification using MobileViT
This repo contains the model and the notebook [to this Keras example on MobileViT](https://keras.io/examples/vision/mobilevit/).
Full credits to: [Sayak Paul](https://twitter.com/RisingSayak)
## Background Information
MobileViT architecture (Mehta et al.), combines the benefits of Transformers (Vaswani et al.) and convolutions. With Transformers, we can capture long-range dependencies that result in global representations. With convolutions, we can capture spatial relationships that model locality.
Besides combining the properties of Transformers and convolutions, the authors introduce MobileViT as a general-purpose mobile-friendly backbone for different image recognition tasks. Their findings suggest that, performance-wise, MobileViT is better than other models with the same or higher complexity (MobileNetV3, for example), while being efficient on mobile devices.
## Training Data
The model is trained on a [tf_flowers dataset](https://www.tensorflow.org/datasets/catalog/tf_flowers) |
Brykee/BrykeeBot | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- image-segmentation
library_name: keras
---
## Model description
The original idea from Keras examples [Monocular depth estimation](https://keras.io/examples/vision/depth_estimation/) of author [Victor Basu](https://www.linkedin.com/in/victor-basu-520958147/)
Full credits go to [Vu Minh Chien](https://www.linkedin.com/in/vumichien/)
Depth estimation is a crucial step towards inferring scene geometry from 2D images. The goal in monocular depth estimation is to predict the depth value of each pixel or infer depth information, given only a single RGB image as input.
## Dataset
[NYU Depth Dataset V2](https://cs.nyu.edu/~silberman/datasets/nyu_depth_v2.html) is comprised of video sequences from a variety of indoor scenes as recorded by both the RGB and Depth cameras from the Microsoft Kinect.
## Training procedure
### Training hyperparameters
**Model architecture**:
- UNet with a pretrained DenseNet 201 backbone.
The following hyperparameters were used during training:
- learning_rate: 1e-04
- train_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: ReduceLROnPlateau
- num_epochs: 10
### Training results
| Epoch | Training loss | Validation Loss | Learning rate |
|:------:|:-------------:|:---------------:|:-------------:|
| 1 | 0.1333 | 0.1315 | 1e-04 |
| 2 | 0.0948 | 0.1232 | 1e-04 |
| 3 | 0.0834 | 0.1220 | 1e-04 |
| 4 | 0.0775 | 0.1213 | 1e-04 |
| 5 | 0.0736 | 0.1196 | 1e-04 |
| 6 | 0.0707 | 0.1205 | 1e-04 |
| 7 | 0.0687 | 0.1190 | 1e-04 |
| 8 | 0.0667 | 0.1177 | 1e-04 |
| 9 | 0.0654 | 0.1177 | 1e-04 |
| 10 | 0.0635 | 0.1182 | 9e-05 |
### View Model Demo

<details>
<summary> View Model Plot </summary>

</details>
|
Brykee/DialoGPT-medium-Morty | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | 2022-02-12T04:21:49Z | ---
tags:
- multimodal-entailment
- generic
---
## Tensorflow Keras Implementation of Multimodal entailment.
This repo contains the models [Multimodal Entailment](https://keras.io/examples/nlp/multimodal_entailment/#dataset-visualization).
Credits: [Sayak Paul](https://twitter.com/RisingSayak) - Original Author
HF Contribution: [Rishav Chandra Varma](https://huggingface.co/reichenbach)
## Background Information
### Introduction
In this example, we will build and train a model for predicting multimodal entailment. We will be using the [multimodal entailment dataset](https://github.com/google-research-datasets/recognizing-multimodal-entailment) recently introduced by Google Research.
### What is multimodal entailment?
On social media platforms, to audit and moderate content we may want to find answers to the following questions in near real-time:
Does a given piece of information contradict the other?
Does a given piece of information imply the other?
In NLP, this task is called analyzing textual entailment. However, that's only when the information comes from text content. In practice, it's often the case the information available comes not just from text content, but from a multimodal combination of text, images, audio, video, etc. Multimodal entailment is simply the extension of textual entailment to a variety of new input modalities.
|
Bryson575x/riceboi | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- multimodal-entailment
- generic
---
## Tensorflow Keras Implementation of Named Entity Recognition using Transformers.
This repo contains code using the model. [Named Entity Recognition using Transformers](https://keras.io/examples/nlp/ner_transformers/).
Credits: [Varun Singh](https://www.linkedin.com/in/varunsingh2/) - Original Author
HF Contribution: [Rishav Chandra Varma](https://huggingface.co/reichenbach)
## Background Information
### Introduction
Named Entity Recognition (NER) is the process of identifying named entities in text. Example of named entities are: "Person", "Location", "Organization", "Dates" etc. NER is essentially a token classification task where every token is classified into one or more predetermined categories.
We will train a simple Transformer based model to perform NER. We will be using the data from CoNLL 2003 shared task. For more information about the dataset, please visit the [dataset website](https://www.clips.uantwerpen.be/conll2003/ner/). However, since obtaining this data requires an additional step of getting a free license, we will be using HuggingFace's datasets library which contains a processed version of this [dataset](https://huggingface.co/datasets/conll2003).
|
Bubb-les/DisloGPT-medium-HarryPotter | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | 2021-12-13T17:44:30Z | ---
tags:
- ocr
- computer vision
- object detection
- image-to-text
license:
- cc0-1.0
---
## Keras Implementation of OCR model for reading captcha 🤖🦹🏻
This repo contains the model and the notebook [to this Keras example on OCR model for reading captcha](https://keras.io/examples/vision/captcha_ocr/).
Full credits to: [Aakash Kumar Nain](https://twitter.com/A_K_Nain)
## Background Information
This example demonstrates a simple OCR model built with the Functional API. Apart from combining CNN and RNN, it also illustrates how you can instantiate a new layer and use it as an "Endpoint layer" for implementing CTC loss.
This model uses subclassing, learn more about subclassing from [this guide](https://keras.io/guides/making_new_layers_and_models_via_subclassing/).

|
BumBelDumBel/TRUMP | [
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"transformers",
"generated_from_trainer",
"license:mit"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 5 | null | ---
tags:
- convnet
- mnist
- generative
license:
- cc0-1.0
---
## Keras Implementation of PixelCNN on MNIST 🔢
This repo contains the model [PixelCNN](https://keras.io/examples/generative/pixelcnn/).
Sample images generated:
<img src="https://i.ibb.co/RDWbJBM/image.png" width="120" height='120'> <img src="https://i.ibb.co/kGPTDDb/104c083f-68e4-4d10-8b37-a242a7f10dd6.png" width="120" height='120'> <img src="https://i.ibb.co/9Wqqhyc/indir-5.png" width="120" height='120'> <img src="https://i.ibb.co/x7yh5py/indir-6.png" width="120" height='120'>
Full credits to author: [ADMoreau](https://github.com/ADMoreau)
|
BumBelDumBel/ZORK-AI-TEST | [
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"transformers",
"generated_from_trainer",
"license:mit"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | 2022-02-21T17:10:52Z | ---
tags:
- pointnet
- segmentation
- 3d
- image
license: cc0-1.0
---
## Point cloud segmentation with PointNet
This repo contains [an Implementation of a PointNet-based model for segmenting point clouds.](https://keras.io/examples/vision/pointnet_segmentation/).
Full credits to [Soumik Rakshit](https://github.com/soumik12345), [Sayak Paul](https://github.com/sayakpaul)
## Background Information
A "point cloud" is an important type of data structure for storing geometric shape data. Due to its irregular format, it's often transformed into regular 3D voxel grids or collections of images before being used in deep learning applications, a step which makes the data unnecessarily large. The PointNet family of models solves this problem by directly consuming point clouds, respecting the permutation-invariance property of the point data. The PointNet family of models provides a simple, unified architecture for applications ranging from object classification, part segmentation, to scene semantic parsing.
In this example, we demonstrate the implementation of the PointNet architecture for shape segmentation.
**References**
* [PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation](https://arxiv.org/abs/1612.00593)
* [Point cloud classification with PointNet](https://keras.io/examples/vision/pointnet/)
* [Spatial Transformer Networks](https://arxiv.org/abs/1506.02025)

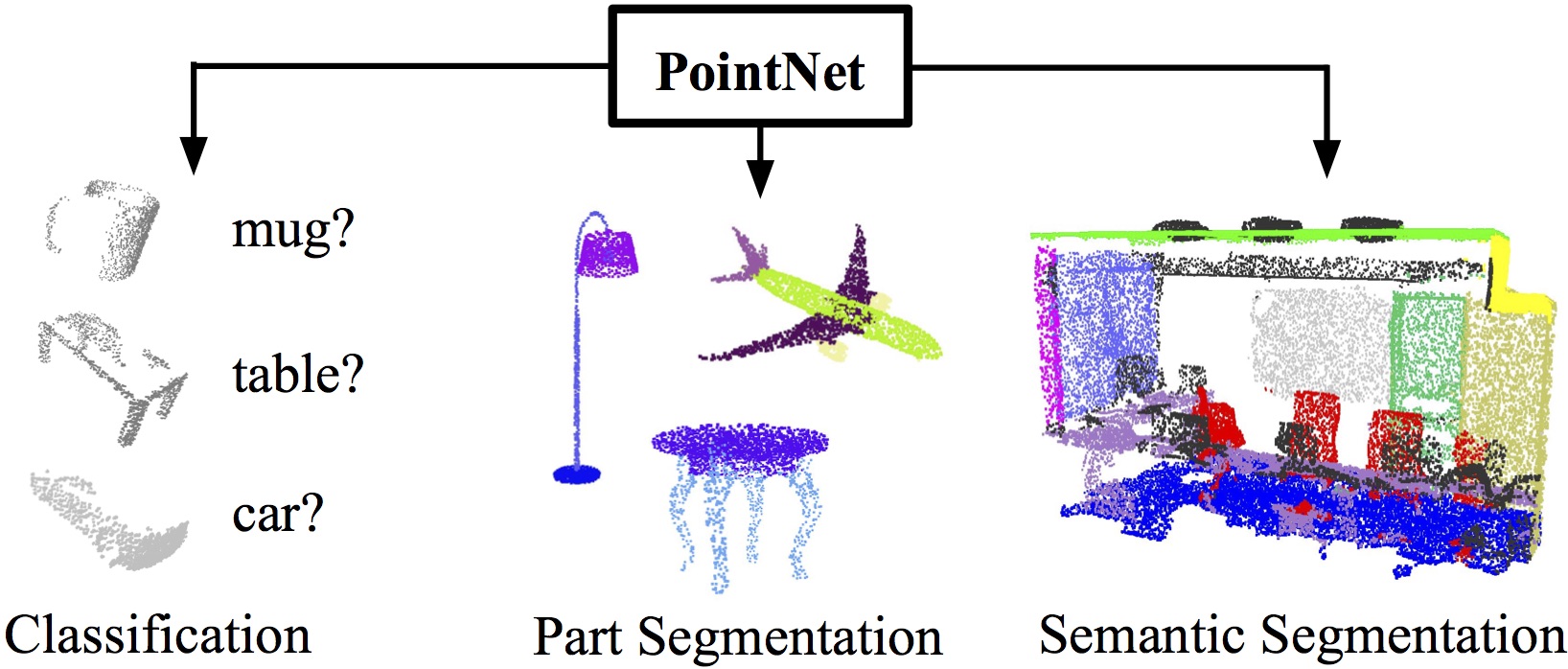
## Training Dataset
This model was trained on the [ShapeNet dataset](https://shapenet.org/).
The ShapeNet dataset is an ongoing effort to establish a richly-annotated, large-scale dataset of 3D shapes. ShapeNetCore is a subset of the full ShapeNet dataset with clean single 3D models and manually verified category and alignment annotations. It covers 55 common object categories, with about 51,300 unique 3D models.
**Prediction example**
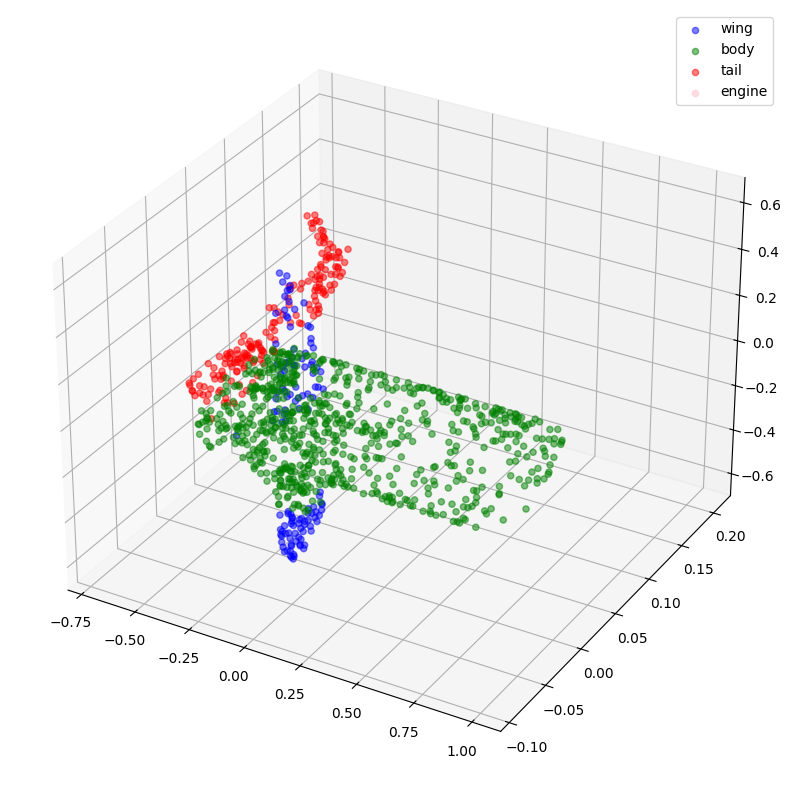
|
BumBelDumBel/ZORK_AI_FANTASY | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- reinforcement learning
- proximal policy optimization
license:
- cc0-1.0
---
## Keras Implementation of Proximal Policy Optimization on Cartpole Environment 🔨🤖
This repo contains the model and the notebook [to this Keras example on PPO for Cartpole](https://keras.io/examples/rl/ppo_cartpole/).
Full credits to: Ilias Chrysovergis

## Background Information
### CartPole-v0
A pole is attached by an un-actuated joint to a cart, which moves along a frictionless track. The system is controlled by applying a force of +1 or -1 to the cart. The pendulum starts upright, and the goal is to prevent it from falling over. A reward of +1 is provided for every timestep that the pole remains upright. The episode ends when the pole is more than 15 degrees from vertical, or the cart moves more than 2.4 units from the center. After 200 steps the episode ends. Thus, the highest return we can get is equal to 200.
### Proximal Policy Optimization
PPO is a policy gradient method and can be used for environments with either discrete or continuous action spaces. It trains a stochastic policy in an on-policy way. Also, it utilizes the actor critic method. The actor maps the observation to an action and the critic gives an expectation of the rewards of the agent for the observation given. Firstly, it collects a set of trajectories for each epoch by sampling from the latest version of the stochastic policy. Then, the rewards-to-go and the advantage estimates are computed in order to update the policy and fit the value function. The policy is updated via a stochastic gradient ascent optimizer, while the value function is fitted via some gradient descent algorithm. This procedure is applied for many epochs until the environment is solved.
|
BumBelDumBel/ZORK_AI_SCIFI | [
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"transformers",
"generated_from_trainer"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 14 | 2022-02-16T13:28:15Z | ---
tags:
- RandAugment
- Image Classification
license: apache-2.0
datasets:
- cifar10
metrics:
- Accuracy
---
## RandAugment for Image Classification for Improved Robustness on the 🤗Hub!
[Paper](https://arxiv.org/abs/1909.13719) | [Keras Tutorial](https://keras.io/examples/vision/randaugment/)
Keras Tutorial Credit goes to : [Sayak Paul](https://twitter.com/RisingSayak)
**Excerpt from the Tutorial:**
Data augmentation is a very useful technique that can help to improve the translational invariance of convolutional neural networks (CNN). RandAugment is a stochastic vision data augmentation routine composed of strong augmentation transforms like color jitters, Gaussian blurs, saturations, etc. along with more traditional augmentation transforms such as random crops.
Recently, it has been a key component of works like [Noisy Student Training](https://arxiv.org/abs/1911.04252) and [Unsupervised Data Augmentation for Consistency Training](https://arxiv.org/abs/1904.12848). It has been also central to the success of EfficientNets.
## About The dataset
The model was trained on [**CIFAR-10**](https://huggingface.co/datasets/cifar10), consisting of 60000 32x32 color images in 10 classes, with 6000 images per class. There are 50000 training images and 10000 test images.
|
Buntan/BuntanAI | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2021-11-04T12:28:15Z | ---
tags:
- image-segmentation
- generic
library_name: generic
dataset:
- oxfort-iit pets
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-1.jpg
example_title: Kedis
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-2.jpg
example_title: Cat in a Crate
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-3.jpg
example_title: Two Cats Chilling
license: cc0-1.0
---
## Keras semantic segmentation models on the 🤗Hub! 🐶 🐕 🐩
Full credits go to [François Chollet](https://twitter.com/fchollet).
This repository contains the model from [this notebook on segmenting pets using U-net-like architecture](https://keras.io/examples/vision/oxford_pets_image_segmentation/). We've changed the inference part to enable segmentation widget on the Hub. (see ```pipeline.py```)
## Background Information
Image classification task tells us about a class assigned to an image, and object detection task creates a boundary box on an object in an image. But what if we want to know about the shape of the image? Segmentation models helps us segment images and reveal their shapes. It has many variants, including, panoptic segmentation, instance segmentation and semantic segmentation.This post is on hosting your Keras semantic segmentation models on Hub.
Semantic segmentation models classify pixels, meaning, they assign a class (can be cat or dog) to each pixel. The output of a model looks like following.

We need to get the best prediction for every pixel.

This is still not readable. We have to convert this into different binary masks for each class and convert to a readable format by converting each mask into base64. We will return a list of dicts, and for each dictionary, we have the label itself, the base64 code and a score (semantic segmentation models don't return a score, so we have to return 1.0 for this case). You can find the full implementation in ```pipeline.py```.

Now that you know the expected output by the model, you can host your Keras segmentation models (and other semantic segmentation models) in the similar fashion. Try it yourself and host your segmentation models!
 |
Buntan/bert-finetuned-ner | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"dataset:conll2003",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
library_name: keras
tags:
- image-classification
datasets:
- STL-10
license: apache-2.0
---
# Semi-supervised image classification using contrastive pretraining with SimCLR
## Description
This is a simple image classification model trained with **Semi-supervised image classification using contrastive pretraining with SimCLR**
The training procedure was done as seen in the example on <a href='https://keras.io/examples/vision/semisupervised_simclr/' target='_blank'>**keras.io**</a> by András Béres.
The model was **trained on STL-10**, which includes ten classes: airplane, bird, car, cat, deer, dog, horse, monkey, ship, truck.
## Metrics
There is a public W&B dashboard available <a href='https://wandb.ai/johko-cel/semi-supervised-contrastive-learning-simclr'>here</a> which illustrates the difference in different metrics such as accuracy of a baseline supervised trained model, a purely unsupervised model (pretrain) and the supervised finetuned model based on the unsupervised.
## Background
(by András Béres on <a href='https://keras.io/examples/vision/semisupervised_simclr/' target='_blank'>**keras.io**</a> )
Semi-supervised learning is a machine learning paradigm that deals with partially labeled datasets. When applying deep learning in the real world, one usually has to gather a large dataset to make it work well. However, while the cost of labeling scales linearly with the dataset size (labeling each example takes a constant time), model performance only scales sublinearly with it. This means that labeling more and more samples becomes less and less cost-efficient, while gathering unlabeled data is generally cheap, as it is usually readily available in large quantities.
Semi-supervised learning offers to solve this problem by only requiring a partially labeled dataset, and by being label-efficient by utilizing the unlabeled examples for learning as well.
In this example, I pretrained an encoder with contrastive learning on the STL-10 semi-supervised dataset using no labels at all, and then fine-tuned it using only its labeled subset. |
Buntan/xlm-roberta-base-finetuned-marc-en | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-01-29T20:52:06Z | ---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: keras-io/sentiment-analysis
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# keras-io/sentiment-analysis
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.6865
- Validation Loss: 0.7002
- Train Accuracy: 0.4908
- Epoch: 4
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': 1e-04, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Accuracy | Epoch |
|:----------:|:---------------:|:--------------:|:-----:|
| 0.6865 | 0.6975 | 0.4908 | 0 |
| 0.6865 | 0.6973 | 0.4908 | 1 |
| 0.6865 | 0.6976 | 0.4908 | 2 |
| 0.6865 | 0.6975 | 0.4908 | 3 |
| 0.6865 | 0.7002 | 0.4908 | 4 |
### Framework versions
- Transformers 4.16.2
- TensorFlow 2.7.0
- Datasets 1.18.2
- Tokenizers 0.11.0
|
Bwehfuk/Ron | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- lstm
license:
- cc0-1.0
---
## Keras Implementation of Convolutional Neural Networks for MNIST 1️⃣2️⃣3️⃣
This repo contains the model and the notebook [on Simple MNIST convnet](https://keras.io/examples/vision/mnist_convnet/).
Full credits to: [François Chollet](https://github.com/fchollet)
|
CALM/CALM | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-02-03T19:23:42Z | ---
license: mit
tags:
- image-to-image
---
## Notes
* This model is a trained version of the Keras Tutorial [Image Super Resolution](https://keras.io/examples/vision/super_resolution_sub_pixel/)
* The model has been trained on inputs of dimension 100x100 and outputs images of 300x300.
[Link to a pyimagesearch](https://www.pyimagesearch.com/2021/09/27/pixel-shuffle-super-resolution-with-tensorflow-keras-and-deep-learning/) tutorial I worked on, where we have used Residual blocks along with the Efficient sub pixel net. |
CALM/backup | [
"lean_albert",
"transformers"
] | null | {
"architectures": [
"LeanAlbertForPretraining",
"LeanAlbertForTokenClassification",
"LeanAlbertForSequenceClassification"
],
"model_type": "lean_albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | ---
library_name: keras
tags:
- image-classification
datasets:
- cifar10
license: apache-2.0
---
A classification model trained with <a href='https://arxiv.org/abs/2004.11362' target='_blank'>**Supervised Contrastive Learning**</a> (Prannay Khosla et al.).
The training procedure was done as seen in the example on <a href='https://keras.io/examples/vision/supervised-contrastive-learning/' target='_blank'>**keras.io**</a> by Khalid Salama.
The model was **trained on cifar10**, which includes ten classes: airplane, automobile, bird, cat, deer, dog, frog, horse, ship, truck.
The **test accuracy after 50 epochs** of the model with contrastive learning was **81.06%** (opposed to 79.88% without contrastive learning). |
CAMeL-Lab/bert-base-arabic-camelbert-ca-ner | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 85 | 2022-02-04T11:30:43Z | ---
tags:
- transformers
- swin-transformers
- Keras
- image-classification
dataset:
- CIFAR-100
license: cc0-1.0
---
## Image classification with Swin Transformers on the 🤗Hub!
Author: [Kelvin Idanwekhai](https://twitter.com/KelvinIdan).
[Paper](https://arxiv.org/abs/2103.14030) | [Keras Tutorial](https://keras.io/examples/vision/swin_transformers/)
Excerpt from the Tutorial:
Swin Transformer (Shifted Window Transformer) can serve as a general-purpose backbone for computer vision. Swin Transformer is a hierarchical Transformer whose representations are computed with shifted windows. The shifted window scheme brings greater efficiency by limiting self-attention computation to non-overlapping local windows while also allowing for cross-window connections. This architecture has the flexibility to model information at various scales and has a linear computational complexity with respect to image size.
## About The dataset
The dataset we are using here is called [CIFAR-100](https://www.cs.toronto.edu/~kriz/cifar.html). The CIFAR-10 dataset consists of 60000 32x32 color images in 10 classes, with 6000 images per class. There are 50000 training images and 10000 test images.
The dataset is divided into five training batches and one test batch, each with 10000 images. The test batch contains exactly 1000 randomly-selected images from each class. The training batches contain the remaining images in random order, but some training batches may contain more images from one class than another. Between them, the training batches contain exactly 5000 images from each class.
|
CAMeL-Lab/bert-base-arabic-camelbert-ca-pos-egy | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 16,451 | 2021-12-14T09:02:11Z | ---
tags:
- autoencoder
- time series
- anomaly detection
license:
- cc0-1.0
---
## Keras Implementation of time series anomaly detection using an Autoencoder ⌛
This repo contains the model and the notebook [for this time series anomaly detection implementation of Keras](https://keras.io/examples/timeseries/timeseries_anomaly_detection/).
Full credits to: [Pavithra Vijay](https://github.com/pavithrasv)
## Background Information
This notebook demonstrates how you can use a reconstruction convolutional autoencoder model to detect anomalies in timeseries data. |
CAMeL-Lab/bert-base-arabic-camelbert-ca-pos-glf | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 18 | 2022-02-02T17:37:00Z | ---
tags:
- time-series
- transformers
dataset:
- FordA
license: cc0-1.0
---
## Timeseries classification with a Transformer model on the 🤗Hub!
Full credits go to [Theodoros Ntakouris](https://github.com/ntakouris).
This repository contains the model from [this notebook on time-series classification using the attention mechanism](https://keras.io/examples/timeseries/timeseries_classification_transformer/).
The dataset we are using here is called [FordA](http://www.j-wichard.de/publications/FordPaper.pdf). The data comes from the UCR archive. The dataset contains 3601 training instances and another 1320 testing instances. Each timeseries corresponds to a measurement of engine noise captured by a motor sensor. For this task, the goal is to automatically detect the presence of a specific issue with the engine. The problem is a balanced binary classification task. |
CAMeL-Lab/bert-base-arabic-camelbert-ca-pos-msa | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 71 | 2022-01-12T08:59:41Z | ---
datasets:
- squad
license: apache-2.0
tags:
- generated_from_keras_callback
metrics:
- f1
model-index:
- name: transformers-qa
results:
- task:
name: "Question Answering"
type: question-answering
dataset:
type: squad
name: SQuAD
args: en
metrics:
[]
widget:
- context: "Keras is an API designed for human beings, not machines. Keras follows best practices for reducing cognitive load: it offers consistent & simple APIs, it minimizes the number of user actions required for common use cases, and it provides clear and actionable feedback upon user error."
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Question Answering with Hugging Face Transformers and Keras 🤗❤️
This model is a fine-tuned version of [distilbert-base-cased](https://huggingface.co/distilbert-base-cased) on SQuAD dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.9300
- Validation Loss: 1.1437
- Epoch: 1
## Model description
Question answering model based on distilbert-base-cased, trained with 🤗Transformers + ❤️Keras.
## Intended uses & limitations
This model is trained for Question Answering tutorial for Keras.io.
## Training and evaluation data
It is trained on [SQuAD](https://huggingface.co/datasets/squad) question answering dataset. ⁉️
## Training procedure
Find the notebook in Keras Examples [here](https://keras.io/examples/nlp/question_answering/). ❤️
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': 5e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 1.5145 | 1.1500 | 0 |
| 0.9300 | 1.1437 | 1 |
### Framework versions
- Transformers 4.16.0.dev0
- TensorFlow 2.6.0
- Datasets 1.16.2.dev0
- Tokenizers 0.10.3
|
CAMeL-Lab/bert-base-arabic-camelbert-ca | [
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 580 | 2022-02-17T08:00:12Z | ---
title: Video Vision Transformer on medmnist
emoji: 🧑⚕️
colorFrom: red
colorTo: green
sdk: gradio
app_file: app.py
pinned: false
license: apache-2.0
library_name: keras
---
## Keras Implementation of Video Vision Transformer on medmnist
This repo contains the model [to this Keras example on Video Vision Transformer](https://keras.io/examples/vision/vivit/).
## Background Information
This example implements [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Arnab et al., a pure Transformer-based model for video classification. The authors propose a novel embedding scheme and a number of Transformer variants to model video clips.
## Datasets
We use the [MedMNIST v2: A Large-Scale Lightweight Benchmark for 2D and 3D Biomedical Image Classification](https://medmnist.com/) dataset.
## Training Parameters
```
# DATA
DATASET_NAME = "organmnist3d"
BATCH_SIZE = 32
AUTO = tf.data.AUTOTUNE
INPUT_SHAPE = (28, 28, 28, 1)
NUM_CLASSES = 11
# OPTIMIZER
LEARNING_RATE = 1e-4
WEIGHT_DECAY = 1e-5
# TRAINING
EPOCHS = 80
# TUBELET EMBEDDING
PATCH_SIZE = (8, 8, 8)
NUM_PATCHES = (INPUT_SHAPE[0] // PATCH_SIZE[0]) ** 2
# ViViT ARCHITECTURE
LAYER_NORM_EPS = 1e-6
PROJECTION_DIM = 128
NUM_HEADS = 8
NUM_LAYERS = 8
``` |
CAMeL-Lab/bert-base-arabic-camelbert-da-ner | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 42 | null | ---
tags:
- image-classification
- keras
license: apache-2.0
---
# Train a Vision Transformer on small datasets
Author: [Aritra Roy Gosthipaty](https://twitter.com/ariG23498)
[Keras Blog](https://keras.io/examples/vision/vit_small_ds/) | [Colab Notebook](https://colab.research.google.com/github/keras-team/keras-io/blob/master/examples/vision/ipynb/vit_small_ds.ipynb)
In the academic paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929), the authors mention that Vision Transformers (ViT) are data-hungry. Therefore, pretraining a ViT on a large-sized dataset like JFT300M and fine-tuning it on medium-sized datasets (like ImageNet) is the only way to beat state-of-the-art Convolutional Neural Network models.
The self-attention layer of ViT lacks locality inductive bias (the notion that image pixels are locally correlated and that their correlation maps are translation-invariant). This is the reason why ViTs need more data. On the other hand, CNNs look at images through spatial sliding windows, which helps them get better results with smaller datasets.
In the academic paper [Vision Transformer for Small-Size Datasets](https://arxiv.org/abs/2112.13492v1), the authors set out to tackle the problem of locality inductive bias in ViTs.
The main ideas are:
- Shifted Patch Tokenization
- Locality Self Attention
# Use the pre-trained model
The model is pre-trained on the CIFAR100 dataset with the following hyperparameters:
```python
# DATA
NUM_CLASSES = 100
INPUT_SHAPE = (32, 32, 3)
BUFFER_SIZE = 512
BATCH_SIZE = 256
# AUGMENTATION
IMAGE_SIZE = 72
PATCH_SIZE = 6
NUM_PATCHES = (IMAGE_SIZE // PATCH_SIZE) ** 2
# OPTIMIZER
LEARNING_RATE = 0.001
WEIGHT_DECAY = 0.0001
# TRAINING
EPOCHS = 50
# ARCHITECTURE
LAYER_NORM_EPS = 1e-6
TRANSFORMER_LAYERS = 8
PROJECTION_DIM = 64
NUM_HEADS = 4
TRANSFORMER_UNITS = [
PROJECTION_DIM * 2,
PROJECTION_DIM,
]
MLP_HEAD_UNITS = [
2048,
1024
]
```
I have used the `AdamW` optimizer with cosine decay learning schedule. You can find the entire implementation in the keras blog post.
To use the pretrained model:
```python
loaded_model = from_pretrained_keras("keras-io/vit-small-ds")
_, accuracy, top_5_accuracy = loaded_model.evaluate(test_ds)
print(f"Test accuracy: {round(accuracy * 100, 2)}%")
print(f"Test top 5 accuracy: {round(top_5_accuracy * 100, 2)}%")
```
For an indepth understanding of the model uploading and downloading process one can refer to this [colab notebook](https://colab.research.google.com/drive/1nCMhefqySzG2p8wyXhmeAX5urddQXt49?usp=sharing).
Important: The data augmentation pipeline is excluded from the model. TensorFlow `2.7` has a weird issue of serializaiton with augmentation pipeline. You can follow [this GitHub issue](https://github.com/huggingface/huggingface_hub/issues/593) for more updates. To send images through the model, one needs to make use of the `tf.data` and `map` API to map the augmentation. |
CAMeL-Lab/bert-base-arabic-camelbert-da-poetry | [
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:1905.05700",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 37 | 2022-02-04T07:21:24Z | ---
tags:
- image-classification
- keras
license: apache-2.0
---
# Train a Vision Transformer on small datasets
Author: [Jónathan Heras](https://twitter.com/_Jonathan_Heras)
[Keras Blog](https://keras.io/examples/vision/vit_small_ds/) | [Colab Notebook](https://colab.research.google.com/github/keras-team/keras-io/blob/master/examples/vision/ipynb/vit_small_ds.ipynb)
In the academic paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929), the authors mention that Vision Transformers (ViT) are data-hungry. Therefore, pretraining a ViT on a large-sized dataset like JFT300M and fine-tuning it on medium-sized datasets (like ImageNet) is the only way to beat state-of-the-art Convolutional Neural Network models.
The self-attention layer of ViT lacks locality inductive bias (the notion that image pixels are locally correlated and that their correlation maps are translation-invariant). This is the reason why ViTs need more data. On the other hand, CNNs look at images through spatial sliding windows, which helps them get better results with smaller datasets.
In the academic paper [Vision Transformer for Small-Size Datasets](https://arxiv.org/abs/2112.13492v1), the authors set out to tackle the problem of locality inductive bias in ViTs.
The main ideas are:
- Shifted Patch Tokenization
- Locality Self Attention
# Use the pre-trained model
The model is pre-trained on the CIFAR100 dataset with the following hyperparameters:
```python
# DATA
NUM_CLASSES = 100
INPUT_SHAPE = (32, 32, 3)
BUFFER_SIZE = 512
BATCH_SIZE = 256
# AUGMENTATION
IMAGE_SIZE = 72
PATCH_SIZE = 6
NUM_PATCHES = (IMAGE_SIZE // PATCH_SIZE) ** 2
# OPTIMIZER
LEARNING_RATE = 0.001
WEIGHT_DECAY = 0.0001
# TRAINING
EPOCHS = 50
# ARCHITECTURE
LAYER_NORM_EPS = 1e-6
TRANSFORMER_LAYERS = 8
PROJECTION_DIM = 64
NUM_HEADS = 4
TRANSFORMER_UNITS = [
PROJECTION_DIM * 2,
PROJECTION_DIM,
]
MLP_HEAD_UNITS = [
2048,
1024
]
```
I have used the `AdamW` optimizer with cosine decay learning schedule. You can find the entire implementation in the keras blog post.
To use the pretrained model:
```python
loaded_model = from_pretrained_keras("keras-io/vit_small_ds_v2")
```
|
CAMeL-Lab/bert-base-arabic-camelbert-da-pos-glf | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 54 | 2021-07-11T16:33:46Z | ---
language: si
tags:
- sinhala
- gpt2
pipeline_tag: text-generation
widget:
- text: "මම"
---
This is a finetunes version of keshan/sinhala-gpt2 with newswire articles. This was finetuned on ~12MB of data
- Num examples=8395
- Batch size =8
It got a Perplexity of 3.15 |
CAMeL-Lab/bert-base-arabic-camelbert-da-pos-msa | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 27 | null | ---
language: si
tags:
- Sinhala
- text-generation
- gpt2
datasets:
- mc4
---
### Overview
This is a smaller GPT2 model trained on [MC4](https://github.com/allenai/allennlp/discussions/5056) Sinhala dataset. As Sinhala is one of those low resource languages, there are only a handful of models been trained. So, this would be a great place to start training for more downstream tasks.
## Model Specification
The model chosen for training is GPT2 with the following specifications:
1. vocab_size=50257
2. n_embd=768
3. n_head=12
4. n_layer=12
5. n_positions=1024
## How to Use
You can use this model directly with a pipeline for casual language modeling:
```py
from transformers import pipeline
generator = pipeline('text-generation', model='keshan/sinhala-gpt2')
generator("මම", max_length=50, num_return_sequences=5)
```
|
CAMeL-Lab/bert-base-arabic-camelbert-da-sentiment | [
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"has_space"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 19,850 | 2021-07-12T19:45:07Z | ---
language: si
license: cc-by-4.0
tags:
- sinhala
- roberta
pipeline_tag: fill-mask
widget:
- text: මම සිංහල භාෂාව <mask>
---
# Sinhala roberta on mc4 dataset
|
CAMeL-Lab/bert-base-arabic-camelbert-mix-pos-glf | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 132 | 2020-10-13T16:18:37Z | # kevinrobinson/perturbations_table_quickstart model card
This is just for UI smoke testing, and shouldn't be used for anything else.
It's built from https://github.com/PAIR-code/lit/blob/main/lit_nlp/examples/quickstart_sst_demo.py.
|
CAMeL-Lab/bert-base-arabic-camelbert-msa-did-madar-twitter5 | [
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 75 | 2021-11-17T04:17:43Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- matthews_correlation
model-index:
- name: chinese-bert-wwm-ext-finetuned-cola
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# chinese-bert-wwm-ext-finetuned-cola
This model is a fine-tuned version of [hfl/chinese-bert-wwm-ext](https://huggingface.co/hfl/chinese-bert-wwm-ext) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5747
- Matthews Correlation: 0.4085
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:-----:|:---------------:|:--------------------:|
| 0.5824 | 1.0 | 66375 | 0.5746 | 0.4083 |
| 0.5824 | 2.0 | 66376 | 0.5747 | 0.4085 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.7.1
- Datasets 1.15.1
- Tokenizers 0.10.3
|
CLAck/en-vi | [
"pytorch",
"marian",
"text2text-generation",
"en",
"vi",
"dataset:ALT",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] | translation | {
"architectures": [
"MarianMTModel"
],
"model_type": "marian",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | 2021-07-17T00:09:14Z | ---
language: bn
tags:
- text generation
- bengali
- gpt2
- bangla
- causal-lm
widget:
- text: "জীবনের মানে "
pipeline_tag: text-generation
---
<!--
---
tags:
- generated_from_trainer
datasets:
- null
model_index:
- name: bengali-lyricist-gpt2
results:
- task:
name: Causal Language Modeling
type: text-generation
---
-->
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bengali-lyricist-gpt2
This model is a fine-tuned version of [flax-community/gpt2-bengali](https://huggingface.co/flax-community/gpt2-bengali) on the [Bengali Song Lyrics](https://www.kaggle.com/shakirulhasan/bangla-song-lyrics) dataset from Kaggle.
It achieves the following results on the evaluation set:
- Loss: 2.1199
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 284 | 2.0302 |
| 1.9991 | 2.0 | 568 | 2.0079 |
| 1.9991 | 3.0 | 852 | 1.9956 |
| 1.9135 | 4.0 | 1136 | 1.9885 |
| 1.9135 | 5.0 | 1420 | 1.9840 |
| 1.8561 | 6.0 | 1704 | 1.9831 |
| 1.8561 | 7.0 | 1988 | 1.9828 |
| 1.8094 | 8.0 | 2272 | 1.9827 |
| 1.7663 | 9.0 | 2556 | 1.9868 |
| 1.7663 | 10.0 | 2840 | 1.9902 |
| 1.7279 | 11.0 | 3124 | 1.9961 |
| 1.7279 | 12.0 | 3408 | 2.0023 |
| 1.6887 | 13.0 | 3692 | 2.0092 |
| 1.6887 | 14.0 | 3976 | 2.0162 |
| 1.6546 | 15.0 | 4260 | 2.0225 |
| 1.6217 | 16.0 | 4544 | 2.0315 |
| 1.6217 | 17.0 | 4828 | 2.0410 |
| 1.5953 | 18.0 | 5112 | 2.0474 |
| 1.5953 | 19.0 | 5396 | 2.0587 |
| 1.5648 | 20.0 | 5680 | 2.0679 |
| 1.5648 | 21.0 | 5964 | 2.0745 |
| 1.5413 | 22.0 | 6248 | 2.0836 |
| 1.5238 | 23.0 | 6532 | 2.0890 |
| 1.5238 | 24.0 | 6816 | 2.0969 |
| 1.5043 | 25.0 | 7100 | 2.1035 |
| 1.5043 | 26.0 | 7384 | 2.1091 |
| 1.4936 | 27.0 | 7668 | 2.1135 |
| 1.4936 | 28.0 | 7952 | 2.1172 |
| 1.4822 | 29.0 | 8236 | 2.1186 |
| 1.4783 | 30.0 | 8520 | 2.1199 |
### Framework versions
- Transformers 4.9.0.dev0
- Pytorch 1.9.0+cu102
- Datasets 1.9.1.dev0
- Tokenizers 0.10.3
|
CLAck/vi-en | [
"pytorch",
"marian",
"text2text-generation",
"en",
"vi",
"dataset:ALT",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] | translation | {
"architectures": [
"MarianMTModel"
],
"model_type": "marian",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | null | ---
language: en
thumbnail: Keywords to Sentences
tags:
- keytotext
- k2t
- Keywords to Sentences
license: mit
datasets:
- WebNLG
- Dart
metrics:
- NLG
---
# keytotext

Idea is to build a model which will take keywords as inputs and generate sentences as outputs.
### Keytotext is powered by Huggingface 🤗
[](https://pypi.org/project/keytotext/)
[](https://pepy.tech/project/keytotext)
[](https://colab.research.google.com/github/gagan3012/keytotext/blob/master/Examples/K2T.ipynb)
[](https://share.streamlit.io/gagan3012/keytotext/UI/app.py)
## Model:
Keytotext is based on the Amazing T5 Model:
- `k2t`: [Model](https://huggingface.co/gagan3012/k2t)
- `k2t-tiny`: [Model](https://huggingface.co/gagan3012/k2t-tiny)
- `k2t-base`: [Model](https://huggingface.co/gagan3012/k2t-base)
Training Notebooks can be found in the [`Training Notebooks`](https://github.com/gagan3012/keytotext/tree/master/Training%20Notebooks) Folder
## Usage:
Example usage: [](https://colab.research.google.com/github/gagan3012/keytotext/blob/master/Examples/K2T.ipynb)
Example Notebooks can be found in the [`Notebooks`](https://github.com/gagan3012/keytotext/tree/master/Examples) Folder
```
pip install keytotext
```

## UI:
UI: [](https://share.streamlit.io/gagan3012/keytotext/UI/app.py)
```
pip install streamlit-tags
```
This uses a custom streamlit component built by me: [GitHub](https://github.com/gagan3012/streamlit-tags)
 |
CLTL/gm-ner-xlmrbase | [
"pytorch",
"tf",
"xlm-roberta",
"token-classification",
"nl",
"transformers",
"dighum",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"XLMRobertaForTokenClassification"
],
"model_type": "xlm-roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2 | null | ---
language: id
tags:
- indogpt
- indobenchmark
- indonlg
license: mit
inference: false
datasets:
- Indo4B+
---
# IndoBART-v2 Model fine-tuned version
Fine-tuned version of IndoBART-v2 with machine translation id->su using default hyperparameter from indoBART paper.
by Ryan Abdurohman
# IndoBART-v2 Model
[IndoBART-v2](https://arxiv.org/abs/2104.08200) is a state-of-the-art language model for Indonesian based on the BART model. The pretrained model is trained using the BART training objective.
## All Pre-trained Models
| Model | #params | Training data |
|--------------------------------|--------------------------------|-----------------------------------|
| `indobenchmark/indobart-v2` | 132M | Indo4B-Plus (26 GB of text) |
## Authors
<b>IndoBART</b> was trained and evaluated by Samuel Cahyawijaya*, Genta Indra Winata*, Bryan Wilie*, Karissa Vincentio*, Xiaohong Li*, Adhiguna Kuncoro*, Sebastian Ruder, Zhi Yuan Lim, Syafri Bahar, Masayu Leylia Khodra, Ayu Purwarianti, Pascale Fung
## Citation
If you use our work, please cite:
```bibtex
@article{cahyawijaya2021indonlg,
title={IndoNLG: Benchmark and Resources for Evaluating Indonesian Natural Language Generation},
author={Cahyawijaya, Samuel and Winata, Genta Indra and Wilie, Bryan and Vincentio, Karissa and Li, Xiaohong and Kuncoro, Adhiguna and Ruder, Sebastian and Lim, Zhi Yuan and Bahar, Syafri and Khodra, Masayu Leylia and others},
journal={arXiv preprint arXiv:2104.08200},
year={2021}
}
```
|
CLTL/icf-levels-adm | [
"pytorch",
"roberta",
"text-classification",
"nl",
"transformers",
"license:mit"
] | text-classification | {
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 33 | null | # Unreliable News Classifier (English)
Trained, validate, and tested using a subset of the NELA-GT-2018 dataset. The dataset is split such that there was no overlap in of news sources between the three sets.
This model used the pre-trained weights of `bert-base-cased` as starting point and was able to achieve 84% accuracy on the test set.
For more details: [Github](https://github.com/khizon/CS284_final_project) |
CLTL/icf-levels-att | [
"pytorch",
"roberta",
"text-classification",
"nl",
"transformers",
"license:mit"
] | text-classification | {
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 32 | 2022-01-14T00:02:21Z | # Unreliable News Classifier (English)
Trained, validate, and tested using a subset of the NELA-GT-2018 dataset. The dataset is split such that there was no overlap in of news sources between the three sets.
This model used the pre-trained weights of `distilbert-base-cased` as starting point (only 4 layers) and was able to achieve 84% accuracy on the test set. It has less than 1% difference in performance compared to the BERT based model while having **2.0x** the speed.
For more details: [Github](https://github.com/khizon/CS284_final_project) |
CSResearcher/TestModel | [
"license:mit"
] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-01-26T19:43:59Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xls-r-300m-kika4_my-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-kika4_my-colab
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 70
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
Cameron/BERT-rtgender-opgender-annotations | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 33 | null | ---
language:
- id
license: apache-2.0
tags:
- automatic-speech-recognition
- hf-asr-leaderboard
- robust-speech-event
datasets:
- mozilla-foundation/common_voice_7_0
metrics:
- wer
- cer
model-index:
- name: wav2vec2-large-xls-r-300m-Indonesian
results:
- task:
type: automatic-speech-recognition
name: Speech Recognition
dataset:
type: mozilla-foundation/common_voice_7_0
name: Common Voice id
args: id
metrics:
- type: wer
value: 25.06
name: Test WER With LM
- type: cer
value: 6.5
name: Test CER With LM
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Dev Data
type: speech-recognition-community-v2/dev_data
args: id
metrics:
- name: Test WER
type: wer
value: 99.61
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Test Data
type: speech-recognition-community-v2/eval_data
args: id
metrics:
- name: Test WER
type: wer
value: 106.39
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-Indonesian
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4087
- Wer: 0.2461
- Cer: 0.0666
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 400
- num_epochs: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Cer |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|
| 5.0788 | 4.26 | 200 | 2.9389 | 1.0 | 1.0 |
| 2.8288 | 8.51 | 400 | 2.2535 | 1.0 | 0.8004 |
| 0.907 | 12.77 | 600 | 0.4558 | 0.4243 | 0.1095 |
| 0.4071 | 17.02 | 800 | 0.4013 | 0.3468 | 0.0913 |
| 0.3 | 21.28 | 1000 | 0.4167 | 0.3075 | 0.0816 |
| 0.2544 | 25.53 | 1200 | 0.4132 | 0.2835 | 0.0762 |
| 0.2145 | 29.79 | 1400 | 0.3878 | 0.2693 | 0.0729 |
| 0.1923 | 34.04 | 1600 | 0.4023 | 0.2623 | 0.0702 |
| 0.1681 | 38.3 | 1800 | 0.3984 | 0.2581 | 0.0686 |
| 0.1598 | 42.55 | 2000 | 0.3982 | 0.2493 | 0.0663 |
| 0.1464 | 46.81 | 2200 | 0.4087 | 0.2461 | 0.0666 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.18.2.dev0
- Tokenizers 0.11.0
|
Camzure/MaamiBot-test | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | null | ---
language:
- sv-SE
license: apache-2.0
tags:
- automatic-speech-recognition
- robust-speech-event
- hf-asr-leaderboard
datasets:
- mozilla-foundation/common_voice_8_0
metrics:
- wer
- cer
model-index:
- name: wav2vec2-xls-r-300m-swedish
results:
- task:
type: automatic-speech-recognition
name: Speech Recognition
dataset:
type: mozilla-foundation/common_voice_8_0
name: Common Voice sv-SE
args: sv-SE
metrics:
- type: wer
value: 24.73
name: Test WER
args:
- learning_rate: 7.5e-05
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 50
- mixed_precision_training: Native AMP
- type: cer
value: 7.58
name: Test CER
args:
- learning_rate: 7.5e-05
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 50
- mixed_precision_training: Native AMP
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-Swedish
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3641
- Wer: 0.2473
- Cer: 0.0758
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7.5e-05
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Cer |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|
| 6.1097 | 5.49 | 500 | 3.1422 | 1.0 | 1.0 |
| 2.985 | 10.98 | 1000 | 1.7357 | 0.9876 | 0.4125 |
| 1.0363 | 16.48 | 1500 | 0.4773 | 0.3510 | 0.1047 |
| 0.6111 | 21.97 | 2000 | 0.3937 | 0.2998 | 0.0910 |
| 0.4942 | 27.47 | 2500 | 0.3779 | 0.2776 | 0.0844 |
| 0.4421 | 32.96 | 3000 | 0.3745 | 0.2630 | 0.0807 |
| 0.4018 | 38.46 | 3500 | 0.3685 | 0.2553 | 0.0781 |
| 0.3759 | 43.95 | 4000 | 0.3618 | 0.2488 | 0.0761 |
| 0.3646 | 49.45 | 4500 | 0.3641 | 0.2473 | 0.0758 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.18.2.dev0
- Tokenizers 0.11.0
|
dccuchile/albert-large-spanish-finetuned-pawsx | [
"pytorch",
"albert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"AlbertForSequenceClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 25 | null | ---
language: en
tags:
- exbert
license: mit
datasets:
- bookcorpus
- wikipedia
---
# RoBERTa base model
Pretrained model on English language using a masked language modeling (MLM) objective. It was introduced in
[this paper](https://arxiv.org/abs/1907.11692) and first released in
[this repository](https://github.com/pytorch/fairseq/tree/master/examples/roberta). This model is case-sensitive: it
makes a difference between english and English.
Disclaimer: The team releasing RoBERTa did not write a model card for this model so this model card has been written by
the Hugging Face team.
|
dccuchile/albert-tiny-spanish-finetuned-mldoc | [
"pytorch",
"albert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"AlbertForSequenceClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 32 | null | ---
language:
- en
tags:
- pytorch
- token-classification
- nominalizations
datasets:
- kleinay/qanom
---
# Nominalization Detector
This model identifies "predicative nominalizations", that is, nominalizations that carry an eventive (or "verbal") meaning in context. It is a `bert-base-cased` pretrained model, fine-tuned for token classification on top of the "nominalization detection" task as defined and annotated by the QANom project [(Klein et. al., COLING 2020)](https://www.aclweb.org/anthology/2020.coling-main.274/).
## Task Description
The model is trained as a binary classifier, classifying candidate nominalizations.
The candidates are extracted using a POS tagger (filtering common nouns) and additionally lexical resources (e.g. WordNet and CatVar), filtering nouns that have (at least one) derivationally-related verb. In the QANom annotation project, these candidates are given to annotators to decide whether they carry a "verbal" meaning in the context of the sentence. The current model reproduces this binary classification.
## Demo
Check out our cool [demo](https://huggingface.co/spaces/kleinay/nominalization-detection-demo)!
## Usage
The candidate extraction algorithm is implemented inside the `qanom` package - see the README in the [QANom github repo](https://github.com/kleinay/QANom) for full documentation. The `qanom` package is also available via `pip install qanom`.
For ease of use, we encapsulated the full nominalization detection pipeline (i.e. candidate extraction + predicate classification) in the `qanom.nominalization_detector.NominalizationDetector` class, which internally utilize this `nominalization-candidate-classifier`:
```python
from qanom.nominalization_detector import NominalizationDetector
detector = NominalizationDetector()
raw_sentences = ["The construction of the officer 's building finished right after the beginning of the destruction of the previous construction ."]
print(detector(raw_sentences, return_all_candidates=True))
print(detector(raw_sentences, threshold=0.75, return_probability=False))
```
Outputs:
```json
[[{'predicate_idx': 1,
'predicate': 'construction',
'predicate_detector_prediction': True,
'predicate_detector_probability': 0.7626778483390808,
'verb_form': 'construct'},
{'predicate_idx': 4,
'predicate': 'officer',
'predicate_detector_prediction': False,
'predicate_detector_probability': 0.19832570850849152,
'verb_form': 'officer'},
{'predicate_idx': 6,
'predicate': 'building',
'predicate_detector_prediction': True,
'predicate_detector_probability': 0.5794129371643066,
'verb_form': 'build'},
{'predicate_idx': 11,
'predicate': 'beginning',
'predicate_detector_prediction': True,
'predicate_detector_probability': 0.8937646150588989,
'verb_form': 'begin'},
{'predicate_idx': 14,
'predicate': 'destruction',
'predicate_detector_prediction': True,
'predicate_detector_probability': 0.8501205444335938,
'verb_form': 'destruct'},
{'predicate_idx': 18,
'predicate': 'construction',
'predicate_detector_prediction': True,
'predicate_detector_probability': 0.7022264003753662,
'verb_form': 'construct'}]]
```
```json
[[{'predicate_idx': 1, 'predicate': 'construction', 'verb_form': 'construct'},
{'predicate_idx': 11, 'predicate': 'beginning', 'verb_form': 'begin'},
{'predicate_idx': 14, 'predicate': 'destruction', 'verb_form': 'destruct'}]]
```
## Cite
```latex
@inproceedings{klein2020qanom,
title={QANom: Question-Answer driven SRL for Nominalizations},
author={Klein, Ayal and Mamou, Jonathan and Pyatkin, Valentina and Stepanov, Daniela and He, Hangfeng and Roth, Dan and Zettlemoyer, Luke and Dagan, Ido},
booktitle={Proceedings of the 28th International Conference on Computational Linguistics},
pages={3069--3083},
year={2020}
}
```
|
dccuchile/albert-xxlarge-spanish-finetuned-xnli | [
"pytorch",
"albert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"AlbertForSequenceClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 68 | null | ---
language: ar
datasets:
- common_voice
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Arabic by Othmane Rifki
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice ar
type: common_voice
args: ar
metrics:
- name: Test WER
type: wer
value: 46.77
---
# Wav2Vec2-Large-XLSR-53-Arabic
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Arabic using the [Common Voice](https://huggingface.co/datasets/common_voice).
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import librosa
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "ar", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("kmfoda/wav2vec2-large-xlsr-arabic")
model = Wav2Vec2ForCTC.from_pretrained("kmfoda/wav2vec2-large-xlsr-arabic")
resamplers = { # all three sampling rates exist in test split
48000: torchaudio.transforms.Resample(48000, 16000),
44100: torchaudio.transforms.Resample(44100, 16000),
32000: torchaudio.transforms.Resample(32000, 16000),
}
def prepare_example(example):
speech, sampling_rate = torchaudio.load(example["path"])
example["speech"] = resamplers[sampling_rate](speech).squeeze().numpy()
return example
test_dataset = test_dataset.map(prepare_example)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Arabic test data of Common Voice.
```python
import librosa
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "ar", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("kmfoda/wav2vec2-large-xlsr-arabic")
model = Wav2Vec2ForCTC.from_pretrained("kmfoda/wav2vec2-large-xlsr-arabic")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\؟\_\؛\ـ\—]'
resamplers = { # all three sampling rates exist in test split
48000: torchaudio.transforms.Resample(48000, 16000),
44100: torchaudio.transforms.Resample(44100, 16000),
32000: torchaudio.transforms.Resample(32000, 16000),
}
def prepare_example(example):
speech, sampling_rate = torchaudio.load(example["path"])
example["speech"] = resamplers[sampling_rate](speech).squeeze().numpy()
return example
test_dataset = test_dataset.map(prepare_example)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 52.53
## Training
The Common Voice `train`, `validation` datasets were used for training.
The script used for training can be found [here](https://huggingface.co/kmfoda/wav2vec2-large-xlsr-arabic/tree/main) |
dccuchile/albert-large-spanish | [
"pytorch",
"tf",
"albert",
"pretraining",
"es",
"dataset:large_spanish_corpus",
"transformers",
"spanish",
"OpenCENIA"
] | null | {
"architectures": [
"AlbertForPreTraining"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 75 | null | ---
tags:
- conversational
---
#Harry Potter model |
dccuchile/bert-base-spanish-wwm-cased-finetuned-ner | [
"pytorch",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 81 | 2021-09-15T14:19:15Z | ---
language: en
tags:
- bart
- seq2seq
- summarization
license: apache-2.0
datasets:
- samsum
widget:
- text: "Hannah: Hey, do you have Betty's number?\nAmanda: Lemme check\nAmanda: Sorry,\
\ can't find it.\nAmanda: Ask Larry\nAmanda: He called her last time we were at\
\ the park together\nHannah: I don't know him well\nAmanda: Don't be shy, he's\
\ very nice\nHannah: If you say so..\nHannah: I'd rather you texted him\nAmanda:\
\ Just text him \U0001F642\nHannah: Urgh.. Alright\nHannah: Bye\nAmanda: Bye bye\n"
model-index:
- name: bart-large-xsum-samsum
results:
- task:
name: Abstractive Text Summarization
type: abstractive-text-summarization
dataset:
name: 'SAMSum Corpus: A Human-annotated Dialogue Dataset for Abstractive Summarization'
type: samsum
metrics:
- name: Validation ROUGE-1
type: rouge-1
value: 54.3921
- name: Validation ROUGE-2
type: rouge-2
value: 29.8078
- name: Validation ROUGE-L
type: rouge-l
value: 45.1543
- name: Test ROUGE-1
type: rouge-1
value: 53.3059
- name: Test ROUGE-2
type: rouge-2
value: 28.355
- name: Test ROUGE-L
type: rouge-l
value: 44.0953
- task:
type: summarization
name: Summarization
dataset:
name: samsum
type: samsum
config: samsum
split: train
metrics:
- name: ROUGE-1
type: rouge
value: 46.2492
verified: true
- name: ROUGE-2
type: rouge
value: 21.346
verified: true
- name: ROUGE-L
type: rouge
value: 37.2787
verified: true
- name: ROUGE-LSUM
type: rouge
value: 42.1317
verified: true
- name: loss
type: loss
value: 1.6859958171844482
verified: true
- name: gen_len
type: gen_len
value: 23.7103
verified: true
---
## `bart-large-xsum-samsum`
This model was obtained by fine-tuning `facebook/bart-large-xsum` on [Samsum](https://huggingface.co/datasets/samsum) dataset.
## Usage
```python
from transformers import pipeline
summarizer = pipeline("summarization", model="knkarthick/bart-large-xsum-samsum")
conversation = '''Hannah: Hey, do you have Betty's number?
Amanda: Lemme check
Amanda: Sorry, can't find it.
Amanda: Ask Larry
Amanda: He called her last time we were at the park together
Hannah: I don't know him well
Amanda: Don't be shy, he's very nice
Hannah: If you say so..
Hannah: I'd rather you texted him
Amanda: Just text him 🙂
Hannah: Urgh.. Alright
Hannah: Bye
Amanda: Bye bye
'''
summarizer(conversation)
``` |
CheonggyeMountain-Sherpa/kogpt-trinity-poem | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 15 | null | ---
tags:
- spacy
- token-classification
language:
- en
license: mit
model-index:
- name: en_core_med7_lg
results:
- task:
name: NER
type: token-classification
metrics:
- name: NER Precision
type: precision
value: 0.8649613325
- name: NER Recall
type: recall
value: 0.8892966361
- name: NER F Score
type: f_score
value: 0.876960193
---
| Feature | Description |
| --- | --- |
| **Name** | `en_core_med7_lg` |
| **Version** | `3.4.2.1` |
| **spaCy** | `>=3.4.2,<3.5.0` |
| **Default Pipeline** | `tok2vec`, `ner` |
| **Components** | `tok2vec`, `ner` |
| **Vectors** | 514157 keys, 514157 unique vectors (300 dimensions) |
| **Sources** | n/a |
| **License** | `MIT` |
| **Author** | [Andrey Kormilitzin](https://www.kormilitzin.com/) |
### Label Scheme
<details>
<summary>View label scheme (7 labels for 1 components)</summary>
| Component | Labels |
| --- | --- |
| **`ner`** | `DOSAGE`, `DRUG`, `DURATION`, `FORM`, `FREQUENCY`, `ROUTE`, `STRENGTH` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `ENTS_F` | 87.70 |
| `ENTS_P` | 86.50 |
| `ENTS_R` | 88.93 |
| `TOK2VEC_LOSS` | 226109.53 |
| `NER_LOSS` | 302222.55 |
### BibTeX entry and citation info
```bibtex
@article{kormilitzin2021med7,
title={Med7: A transferable clinical natural language processing model for electronic health records},
author={Kormilitzin, Andrey and Vaci, Nemanja and Liu, Qiang and Nevado-Holgado, Alejo},
journal={Artificial Intelligence in Medicine},
volume={118},
pages={102086},
year={2021},
publisher={Elsevier}
}
``` |
CheonggyeMountain-Sherpa/kogpt-trinity-punct-wrapper | [
"ko",
"gpt2",
"license:cc-by-nc-sa-4.0"
] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- spacy
- token-classification
language:
- en
license: mit
model-index:
- name: en_core_med7_trf
results:
- task:
name: NER
type: token-classification
metrics:
- name: NER Precision
type: precision
value: 0.8822157434
- name: NER Recall
type: recall
value: 0.925382263
- name: NER F Score
type: f_score
value: 0.9032835821
---
| Feature | Description |
| --- | --- |
| **Name** | `en_core_med7_trf` |
| **Version** | `3.4.2.1` |
| **spaCy** | `>=3.4.2,<3.5.0` |
| **Default Pipeline** | `transformer`, `ner` |
| **Components** | `transformer`, `ner` |
| **Vectors** | 514157 keys, 514157 unique vectors (300 dimensions) |
| **Sources** | n/a |
| **License** | `MIT` |
| **Author** | [Andrey Kormilitzin](https://www.kormilitzin.com/) |
### Label Scheme
<details>
<summary>View label scheme (7 labels for 1 components)</summary>
| Component | Labels |
| --- | --- |
| **`ner`** | `DOSAGE`, `DRUG`, `DURATION`, `FORM`, `FREQUENCY`, `ROUTE`, `STRENGTH` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `ENTS_F` | 90.33 |
| `ENTS_P` | 88.22 |
| `ENTS_R` | 92.54 |
| `TRANSFORMER_LOSS` | 2502627.06 |
| `NER_LOSS` | 114576.77 |
### BibTeX entry and citation info
```bibtex
@article{kormilitzin2021med7,
title={Med7: A transferable clinical natural language processing model for electronic health records},
author={Kormilitzin, Andrey and Vaci, Nemanja and Liu, Qiang and Nevado-Holgado, Alejo},
journal={Artificial Intelligence in Medicine},
volume={118},
pages={102086},
year={2021},
publisher={Elsevier}
}
``` |
Chertilasus/main | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | Converted for Tensorflow
```
!pip install transformers sentencepiece
from transformers import TFAutoModel, AutoTokenizer
name = "ai4bharat/indic-bert"
model = TFAutoModel.from_pretrained(name, from_pt=True)
tokenizer = AutoTokenizer.from_pretrained(name)
model.save_pretrained("local-indic-bert")
tokenizer.save_pretrained("local-indic-bert")
```
|
Chinmay/mlindia | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | Converted for Tensorflow
```
!pip install transformers sentencepiece
from transformers import TFAutoModel, AutoTokenizer
name = "xlm-roberta-base"
model = TFAutoModel.from_pretrained(name, from_pt=True)
tokenizer = AutoTokenizer.from_pretrained(name)
model.save_pretrained("local-xlm-roberta-base")
tokenizer.save_pretrained("local-xlm-roberta-base")
``` |
Chiuchiyin/DialoGPT-small-Donald | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | Converted for Tensorflow
```
name = "xlm-roberta-large"
!rm -rf local
!git clone https://huggingface.co/kornesh/"$name" local
model = TFAutoModel.from_pretrained(name, from_pt=True)
tokenizer = AutoTokenizer.from_pretrained(name)
model.save_pretrained("local")
tokenizer.save_pretrained("local")
!cd local/ && git lfs install && git add . && git commit -m "Initial commit" && git push
``` |
Chiuchiyin/Donald | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2021-04-15T00:54:47Z | ---
language: "en"
tags:
- twitter
- stance-detection
- election2020
- politics
license: "gpl-3.0"
---
# Pre-trained BERT on Twitter US Election 2020 for Stance Detection towards Joe Biden (KE-MLM)
Pre-trained weights for **KE-MLM model** in [Knowledge Enhance Masked Language Model for Stance Detection](https://www.aclweb.org/anthology/2021.naacl-main.376), NAACL 2021.
# Training Data
This model is pre-trained on over 5 million English tweets about the 2020 US Presidential Election. Then fine-tuned using our [stance-labeled data](https://github.com/GU-DataLab/stance-detection-KE-MLM) for stance detection towards Joe Biden.
# Training Objective
This model is initialized with BERT-base and trained with normal MLM objective with classification layer fine-tuned for stance detection towards Joe Biden.
# Usage
This pre-trained language model is fine-tuned to the stance detection task specifically for Joe Biden.
Please see the [official repository](https://github.com/GU-DataLab/stance-detection-KE-MLM) for more detail.
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
import numpy as np
# choose GPU if available
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# select mode path here
pretrained_LM_path = "kornosk/bert-election2020-twitter-stance-biden-KE-MLM"
# load model
tokenizer = AutoTokenizer.from_pretrained(pretrained_LM_path)
model = AutoModelForSequenceClassification.from_pretrained(pretrained_LM_path)
id2label = {
0: "AGAINST",
1: "FAVOR",
2: "NONE"
}
##### Prediction Neutral #####
sentence = "Hello World."
inputs = tokenizer(sentence.lower(), return_tensors="pt")
outputs = model(**inputs)
predicted_probability = torch.softmax(outputs[0], dim=1)[0].tolist()
print("Sentence:", sentence)
print("Prediction:", id2label[np.argmax(predicted_probability)])
print("Against:", predicted_probability[0])
print("Favor:", predicted_probability[1])
print("Neutral:", predicted_probability[2])
##### Prediction Favor #####
sentence = "Go Go Biden!!!"
inputs = tokenizer(sentence.lower(), return_tensors="pt")
outputs = model(**inputs)
predicted_probability = torch.softmax(outputs[0], dim=1)[0].tolist()
print("Sentence:", sentence)
print("Prediction:", id2label[np.argmax(predicted_probability)])
print("Against:", predicted_probability[0])
print("Favor:", predicted_probability[1])
print("Neutral:", predicted_probability[2])
##### Prediction Against #####
sentence = "Biden is the worst."
inputs = tokenizer(sentence.lower(), return_tensors="pt")
outputs = model(**inputs)
predicted_probability = torch.softmax(outputs[0], dim=1)[0].tolist()
print("Sentence:", sentence)
print("Prediction:", id2label[np.argmax(predicted_probability)])
print("Against:", predicted_probability[0])
print("Favor:", predicted_probability[1])
print("Neutral:", predicted_probability[2])
# please consider citing our paper if you feel this is useful :)
```
# Reference
- [Knowledge Enhance Masked Language Model for Stance Detection](https://www.aclweb.org/anthology/2021.naacl-main.376), NAACL 2021.
# Citation
```bibtex
@inproceedings{kawintiranon2021knowledge,
title={Knowledge Enhanced Masked Language Model for Stance Detection},
author={Kawintiranon, Kornraphop and Singh, Lisa},
booktitle={Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies},
year={2021},
publisher={Association for Computational Linguistics},
url={https://www.aclweb.org/anthology/2021.naacl-main.376}
}
``` |
ChoboAvenger/DialoGPT-small-DocBot | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: "en"
tags:
- twitter
- stance-detection
- election2020
- politics
license: "gpl-3.0"
---
# Pre-trained BERT on Twitter US Election 2020 for Stance Detection towards Joe Biden (f-BERT)
Pre-trained weights for **f-BERT** in [Knowledge Enhance Masked Language Model for Stance Detection](https://www.aclweb.org/anthology/2021.naacl-main.376), NAACL 2021.
# Training Data
This model is pre-trained on over 5 million English tweets about the 2020 US Presidential Election. Then fine-tuned using our [stance-labeled data](https://github.com/GU-DataLab/stance-detection-KE-MLM) for stance detection towards Joe Biden.
# Training Objective
This model is initialized with BERT-base and trained with normal MLM objective with classification layer fine-tuned for stance detection towards Joe Biden.
# Usage
This pre-trained language model is fine-tuned to the stance detection task specifically for Joe Biden.
Please see the [official repository](https://github.com/GU-DataLab/stance-detection-KE-MLM) for more detail.
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
import numpy as np
# choose GPU if available
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# select mode path here
pretrained_LM_path = "kornosk/bert-election2020-twitter-stance-biden"
# load model
tokenizer = AutoTokenizer.from_pretrained(pretrained_LM_path)
model = AutoModelForSequenceClassification.from_pretrained(pretrained_LM_path)
id2label = {
0: "AGAINST",
1: "FAVOR",
2: "NONE"
}
##### Prediction Neutral #####
sentence = "Hello World."
inputs = tokenizer(sentence.lower(), return_tensors="pt")
outputs = model(**inputs)
predicted_probability = torch.softmax(outputs[0], dim=1)[0].tolist()
print("Sentence:", sentence)
print("Prediction:", id2label[np.argmax(predicted_probability)])
print("Against:", predicted_probability[0])
print("Favor:", predicted_probability[1])
print("Neutral:", predicted_probability[2])
##### Prediction Favor #####
sentence = "Go Go Biden!!!"
inputs = tokenizer(sentence.lower(), return_tensors="pt")
outputs = model(**inputs)
predicted_probability = torch.softmax(outputs[0], dim=1)[0].tolist()
print("Sentence:", sentence)
print("Prediction:", id2label[np.argmax(predicted_probability)])
print("Against:", predicted_probability[0])
print("Favor:", predicted_probability[1])
print("Neutral:", predicted_probability[2])
##### Prediction Against #####
sentence = "Biden is the worst."
inputs = tokenizer(sentence.lower(), return_tensors="pt")
outputs = model(**inputs)
predicted_probability = torch.softmax(outputs[0], dim=1)[0].tolist()
print("Sentence:", sentence)
print("Prediction:", id2label[np.argmax(predicted_probability)])
print("Against:", predicted_probability[0])
print("Favor:", predicted_probability[1])
print("Neutral:", predicted_probability[2])
# please consider citing our paper if you feel this is useful :)
```
# Reference
- [Knowledge Enhance Masked Language Model for Stance Detection](https://www.aclweb.org/anthology/2021.naacl-main.376), NAACL 2021.
# Citation
```bibtex
@inproceedings{kawintiranon2021knowledge,
title={Knowledge Enhanced Masked Language Model for Stance Detection},
author={Kawintiranon, Kornraphop and Singh, Lisa},
booktitle={Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies},
year={2021},
publisher={Association for Computational Linguistics},
url={https://www.aclweb.org/anthology/2021.naacl-main.376}
}
``` |
ChoboAvenger/DialoGPT-small-joshua | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: "en"
tags:
- twitter
- stance-detection
- election2020
- politics
license: "gpl-3.0"
---
# Pre-trained BERT on Twitter US Election 2020 for Stance Detection towards Donald Trump (KE-MLM)
Pre-trained weights for **KE-MLM model** in [Knowledge Enhance Masked Language Model for Stance Detection](https://www.aclweb.org/anthology/2021.naacl-main.376), NAACL 2021.
# Training Data
This model is pre-trained on over 5 million English tweets about the 2020 US Presidential Election. Then fine-tuned using our [stance-labeled data](https://github.com/GU-DataLab/stance-detection-KE-MLM) for stance detection towards Donald Trump.
# Training Objective
This model is initialized with BERT-base and trained with normal MLM objective with classification layer fine-tuned for stance detection towards Donald Trump.
# Usage
This pre-trained language model is fine-tuned to the stance detection task specifically for Donald Trump.
Please see the [official repository](https://github.com/GU-DataLab/stance-detection-KE-MLM) for more detail.
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
import numpy as np
# choose GPU if available
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# select mode path here
pretrained_LM_path = "kornosk/bert-election2020-twitter-stance-trump-KE-MLM"
# load model
tokenizer = AutoTokenizer.from_pretrained(pretrained_LM_path)
model = AutoModelForSequenceClassification.from_pretrained(pretrained_LM_path)
id2label = {
0: "AGAINST",
1: "FAVOR",
2: "NONE"
}
##### Prediction Neutral #####
sentence = "Hello World."
inputs = tokenizer(sentence.lower(), return_tensors="pt")
outputs = model(**inputs)
predicted_probability = torch.softmax(outputs[0], dim=1)[0].tolist()
print("Sentence:", sentence)
print("Prediction:", id2label[np.argmax(predicted_probability)])
print("Against:", predicted_probability[0])
print("Favor:", predicted_probability[1])
print("Neutral:", predicted_probability[2])
##### Prediction Favor #####
sentence = "Go Go Trump!!!"
inputs = tokenizer(sentence.lower(), return_tensors="pt")
outputs = model(**inputs)
predicted_probability = torch.softmax(outputs[0], dim=1)[0].tolist()
print("Sentence:", sentence)
print("Prediction:", id2label[np.argmax(predicted_probability)])
print("Against:", predicted_probability[0])
print("Favor:", predicted_probability[1])
print("Neutral:", predicted_probability[2])
##### Prediction Against #####
sentence = "Trump is the worst."
inputs = tokenizer(sentence.lower(), return_tensors="pt")
outputs = model(**inputs)
predicted_probability = torch.softmax(outputs[0], dim=1)[0].tolist()
print("Sentence:", sentence)
print("Prediction:", id2label[np.argmax(predicted_probability)])
print("Against:", predicted_probability[0])
print("Favor:", predicted_probability[1])
print("Neutral:", predicted_probability[2])
# please consider citing our paper if you feel this is useful :)
```
# Reference
- [Knowledge Enhance Masked Language Model for Stance Detection](https://www.aclweb.org/anthology/2021.naacl-main.376), NAACL 2021.
# Citation
```bibtex
@inproceedings{kawintiranon2021knowledge,
title={Knowledge Enhanced Masked Language Model for Stance Detection},
author={Kawintiranon, Kornraphop and Singh, Lisa},
booktitle={Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies},
year={2021},
publisher={Association for Computational Linguistics},
url={https://www.aclweb.org/anthology/2021.naacl-main.376}
}
``` |
ChrisP/xlm-roberta-base-finetuned-marc-en | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: "en"
tags:
- twitter
- stance-detection
- election2020
- politics
license: "gpl-3.0"
---
# Pre-trained BERT on Twitter US Election 2020 for Stance Detection towards Donald Trump (f-BERT)
Pre-trained weights for **f-BERT** in [Knowledge Enhance Masked Language Model for Stance Detection](https://www.aclweb.org/anthology/2021.naacl-main.376), NAACL 2021.
# Training Data
This model is pre-trained on over 5 million English tweets about the 2020 US Presidential Election. Then fine-tuned using our [stance-labeled data](https://github.com/GU-DataLab/stance-detection-KE-MLM) for stance detection towards Donald Trump.
# Training Objective
This model is initialized with BERT-base and trained with normal MLM objective with classification layer fine-tuned for stance detection towards Donald Trump.
# Usage
This pre-trained language model is fine-tuned to the stance detection task specifically for Donald Trump.
Please see the [official repository](https://github.com/GU-DataLab/stance-detection-KE-MLM) for more detail.
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
import numpy as np
# choose GPU if available
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# select mode path here
pretrained_LM_path = "kornosk/bert-election2020-twitter-stance-trump"
# load model
tokenizer = AutoTokenizer.from_pretrained(pretrained_LM_path)
model = AutoModelForSequenceClassification.from_pretrained(pretrained_LM_path)
id2label = {
0: "AGAINST",
1: "FAVOR",
2: "NONE"
}
##### Prediction Neutral #####
sentence = "Hello World."
inputs = tokenizer(sentence.lower(), return_tensors="pt")
outputs = model(**inputs)
predicted_probability = torch.softmax(outputs[0], dim=1)[0].tolist()
print("Sentence:", sentence)
print("Prediction:", id2label[np.argmax(predicted_probability)])
print("Against:", predicted_probability[0])
print("Favor:", predicted_probability[1])
print("Neutral:", predicted_probability[2])
##### Prediction Favor #####
sentence = "Go Go Trump!!!"
inputs = tokenizer(sentence.lower(), return_tensors="pt")
outputs = model(**inputs)
predicted_probability = torch.softmax(outputs[0], dim=1)[0].tolist()
print("Sentence:", sentence)
print("Prediction:", id2label[np.argmax(predicted_probability)])
print("Against:", predicted_probability[0])
print("Favor:", predicted_probability[1])
print("Neutral:", predicted_probability[2])
##### Prediction Against #####
sentence = "Trump is the worst."
inputs = tokenizer(sentence.lower(), return_tensors="pt")
outputs = model(**inputs)
predicted_probability = torch.softmax(outputs[0], dim=1)[0].tolist()
print("Sentence:", sentence)
print("Prediction:", id2label[np.argmax(predicted_probability)])
print("Against:", predicted_probability[0])
print("Favor:", predicted_probability[1])
print("Neutral:", predicted_probability[2])
# please consider citing our paper if you feel this is useful :)
```
# Reference
- [Knowledge Enhance Masked Language Model for Stance Detection](https://www.aclweb.org/anthology/2021.naacl-main.376), NAACL 2021.
# Citation
```bibtex
@inproceedings{kawintiranon2021knowledge,
title={Knowledge Enhanced Masked Language Model for Stance Detection},
author={Kawintiranon, Kornraphop and Singh, Lisa},
booktitle={Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies},
year={2021},
publisher={Association for Computational Linguistics},
url={https://www.aclweb.org/anthology/2021.naacl-main.376}
}
``` |
ChrisVCB/DialoGPT-medium-cmjs | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
language: "en"
tags:
- twitter
- masked-token-prediction
- election2020
- politics
license: "gpl-3.0"
---
# Pre-trained BERT on Twitter US Political Election 2020
Pre-trained weights for [Knowledge Enhance Masked Language Model for Stance Detection](https://www.aclweb.org/anthology/2021.naacl-main.376), NAACL 2021.
We use the initialized weights from BERT-base (uncased) or `bert-base-uncased`.
# Training Data
This model is pre-trained on over 5 million English tweets about the 2020 US Presidential Election.
# Training Objective
This model is initialized with BERT-base and trained with normal MLM objective.
# Usage
This pre-trained language model **can be fine-tunned to any downstream task (e.g. classification)**.
Please see the [official repository](https://github.com/GU-DataLab/stance-detection-KE-MLM) for more detail.
```python
from transformers import BertTokenizer, BertForMaskedLM, pipeline
import torch
# Choose GPU if available
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Select mode path here
pretrained_LM_path = "kornosk/bert-political-election2020-twitter-mlm"
# Load model
tokenizer = BertTokenizer.from_pretrained(pretrained_LM_path)
model = BertForMaskedLM.from_pretrained(pretrained_LM_path)
# Fill mask
example = "Trump is the [MASK] of USA"
fill_mask = pipeline('fill-mask', model=model, tokenizer=tokenizer)
# Use following line instead of the above one does not work.
# Huggingface have been updated, newer version accepts a string of model name instead.
fill_mask = pipeline('fill-mask', model=pretrained_LM_path, tokenizer=tokenizer)
outputs = fill_mask(example)
print(outputs)
# See embeddings
inputs = tokenizer(example, return_tensors="pt")
outputs = model(**inputs)
print(outputs)
# OR you can use this model to train on your downstream task!
# Please consider citing our paper if you feel this is useful :)
```
# Reference
- [Knowledge Enhance Masked Language Model for Stance Detection](https://www.aclweb.org/anthology/2021.naacl-main.376), NAACL 2021.
# Citation
```bibtex
@inproceedings{kawintiranon2021knowledge,
title={Knowledge Enhanced Masked Language Model for Stance Detection},
author={Kawintiranon, Kornraphop and Singh, Lisa},
booktitle={Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies},
year={2021},
publisher={Association for Computational Linguistics},
url={https://www.aclweb.org/anthology/2021.naacl-main.376}
}
``` |
Chun/w-en2zh-hsk | [
"pytorch",
"marian",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"MarianMTModel"
],
"model_type": "marian",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 1 | 2021-08-27T05:59:33Z | ---
tags:
- Conversational
---
# Tony Stark DialoGPT Model |
Chun/w-en2zh-otm | [
"pytorch",
"mbart",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"MBartForConditionalGeneration"
],
"model_type": "mbart",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | 2022-02-19T07:59:10Z | # SaShiMi

> **It's Raw! Audio Generation with State-Space Models**\
> Karan Goel, Albert Gu, Chris Donahue, Christopher Ré\
> Paper: https://arxiv.org/pdf/2202.09729.pdf
This repository contains a release of the artifacts for the SaShiMi paper. To use our code and artifacts in your research, please refer to the instructions at [https://github.com/HazyResearch/state-spaces/tree/main/sashimi](https://github.com/HazyResearch/state-spaces/tree/main/sashimi). |
Chun/w-zh2en-mtm | [
"pytorch",
"mbart",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"MBartForConditionalGeneration"
],
"model_type": "mbart",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | 2022-01-20T10:41:07Z | ---
language: ko
datasets:
- kresnik/zeroth_korean
tags:
- speech
- audio
- automatic-speech-recognition
license: apache-2.0
model-index:
- name: 'Wav2Vec2 XLSR Korean'
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Zeroth Korean
type: kresnik/zeroth_korean
args: clean
metrics:
- name: Test WER
type: wer
value: 4.74
- name: Test CER
type: cer
value: 1.78
---
## Evaluation on Zeroth-Korean ASR corpus
[Google colab notebook(Korean)](https://colab.research.google.com/github/indra622/tutorials/blob/master/wav2vec2_korean_tutorial.ipynb)
```
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
from datasets import load_dataset
import soundfile as sf
import torch
from jiwer import wer
processor = Wav2Vec2Processor.from_pretrained("kresnik/wav2vec2-large-xlsr-korean")
model = Wav2Vec2ForCTC.from_pretrained("kresnik/wav2vec2-large-xlsr-korean").to('cuda')
ds = load_dataset("kresnik/zeroth_korean", "clean")
test_ds = ds['test']
def map_to_array(batch):
speech, _ = sf.read(batch["file"])
batch["speech"] = speech
return batch
test_ds = test_ds.map(map_to_array)
def map_to_pred(batch):
inputs = processor(batch["speech"], sampling_rate=16000, return_tensors="pt", padding="longest")
input_values = inputs.input_values.to("cuda")
with torch.no_grad():
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
batch["transcription"] = transcription
return batch
result = test_ds.map(map_to_pred, batched=True, batch_size=16, remove_columns=["speech"])
print("WER:", wer(result["text"], result["transcription"]))
```
### Expected WER: 4.74%
### Expected CER: 1.78% |
Chungu424/qazwsx | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2020-05-21T16:09:24Z | ---
language: ko
---
# 📈 Financial Korean ELECTRA model
Pretrained ELECTRA Language Model for Korean (`finance-koelectra-base-discriminator`)
> ELECTRA is a new method for self-supervised language representation learning. It can be used to
> pre-train transformer networks using relatively little compute. ELECTRA models are trained to
> distinguish "real" input tokens vs "fake" input tokens generated by another neural network, similar to
> the discriminator of a GAN.
More details about ELECTRA can be found in the [ICLR paper](https://openreview.net/forum?id=r1xMH1BtvB)
or in the [official ELECTRA repository](https://github.com/google-research/electra) on GitHub.
## Stats
The current version of the model is trained on a financial news data of Naver news.
The final training corpus has a size of 25GB and 2.3B tokens.
This model was trained a cased model on a TITAN RTX for 500k steps.
## Usage
```python
from transformers import ElectraForPreTraining, ElectraTokenizer
import torch
discriminator = ElectraForPreTraining.from_pretrained("krevas/finance-koelectra-base-discriminator")
tokenizer = ElectraTokenizer.from_pretrained("krevas/finance-koelectra-base-discriminator")
sentence = "내일 해당 종목이 대폭 상승할 것이다"
fake_sentence = "내일 해당 종목이 맛있게 상승할 것이다"
fake_tokens = tokenizer.tokenize(fake_sentence)
fake_inputs = tokenizer.encode(fake_sentence, return_tensors="pt")
discriminator_outputs = discriminator(fake_inputs)
predictions = torch.round((torch.sign(discriminator_outputs[0]) + 1) / 2)
[print("%7s" % token, end="") for token in fake_tokens]
[print("%7s" % int(prediction), end="") for prediction in predictions.tolist()[1:-1]]
print("fake token : %s" % fake_tokens[predictions.tolist()[1:-1].index(1)])
```
# Huggingface model hub
All models are available on the [Huggingface model hub](https://huggingface.co/krevas).
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.