
modelId
stringlengths 4
81
| tags
list | pipeline_tag
stringclasses 17
values | config
dict | downloads
int64 0
59.7M
| first_commit
timestamp[ns, tz=UTC] | card
stringlengths 51
438k
|
|---|---|---|---|---|---|---|
Despin89/test | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | See logs at https://wandb.ai/yepster/long-byt5-tglobal-small
|
Dev-DGT/food-dbert-multiling | [
"pytorch",
"distilbert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"DistilBertForTokenClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 17 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: finetuning-sentiment-model-3000-samples
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-3000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
DevsIA/Devs_IA | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
title: Double Hard Debiasing
emoji: 👁
colorFrom: blue
colorTo: pink
sdk: gradio
sdk_version: 3.1.1
app_file: app.py
pinned: false
license: mit
---
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
DicoTiar/wisdomfiy | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- clinc_oos
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-clinc
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: clinc_oos
type: clinc_oos
args: plus
metrics:
- name: Accuracy
type: accuracy
value: 0.9187096774193548
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-clinc
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the clinc_oos dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7737
- Accuracy: 0.9187
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 318 | 3.2909 | 0.7439 |
| 3.7915 | 2.0 | 636 | 1.8815 | 0.83 |
| 3.7915 | 3.0 | 954 | 1.1550 | 0.8948 |
| 1.6979 | 4.0 | 1272 | 0.8583 | 0.9119 |
| 0.8991 | 5.0 | 1590 | 0.7737 | 0.9187 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.10.0+cu102
- Datasets 2.0.0
- Tokenizers 0.12.1
|
DiegoBalam12/institute_classification | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-3
results:
- metrics:
- type: mean_reward
value: 471.20 +/- 86.40
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 5 of the Deep Reinforcement Learning Class: https://github.com/huggingface/deep-rl-class/tree/main/unit5
|
DingleyMaillotUrgell/homer-bot | [
"pytorch",
"gpt2",
"text-generation",
"en",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 12 | null | The review-annotation model is performing NER and able to annotate academic article review comments by identifying the four meaningful classes:
- location
- action
- modal
- trigger |
Dizoid/Lll | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- generated_from_trainer
datasets:
- samsum
model-index:
- name: pegasus-samsum
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# pegasus-samsum
This model is a fine-tuned version of [google/pegasus-cnn_dailymail](https://huggingface.co/google/pegasus-cnn_dailymail) on the samsum dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4826
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.7008 | 0.54 | 500 | 1.4826 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
DoyyingFace/bert-asian-hate-tweets-concat-clean-with-unclean-valid | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 25 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilroberta-base-finetuned-wikitextepoch_150
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilroberta-base-finetuned-wikitextepoch_150
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8929
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 150
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:------:|:---------------:|
| 2.2428 | 1.0 | 1121 | 2.0500 |
| 2.1209 | 2.0 | 2242 | 1.9996 |
| 2.0665 | 3.0 | 3363 | 1.9501 |
| 2.0179 | 4.0 | 4484 | 1.9311 |
| 1.9759 | 5.0 | 5605 | 1.9255 |
| 1.9089 | 6.0 | 6726 | 1.8805 |
| 1.9143 | 7.0 | 7847 | 1.8715 |
| 1.8744 | 8.0 | 8968 | 1.8671 |
| 1.858 | 9.0 | 10089 | 1.8592 |
| 1.8141 | 10.0 | 11210 | 1.8578 |
| 1.7917 | 11.0 | 12331 | 1.8574 |
| 1.7752 | 12.0 | 13452 | 1.8423 |
| 1.7722 | 13.0 | 14573 | 1.8287 |
| 1.7354 | 14.0 | 15694 | 1.8396 |
| 1.7217 | 15.0 | 16815 | 1.8244 |
| 1.6968 | 16.0 | 17936 | 1.8278 |
| 1.659 | 17.0 | 19057 | 1.8412 |
| 1.6442 | 18.0 | 20178 | 1.8328 |
| 1.6441 | 19.0 | 21299 | 1.8460 |
| 1.6267 | 20.0 | 22420 | 1.8343 |
| 1.612 | 21.0 | 23541 | 1.8249 |
| 1.5963 | 22.0 | 24662 | 1.8253 |
| 1.6101 | 23.0 | 25783 | 1.7843 |
| 1.5747 | 24.0 | 26904 | 1.8047 |
| 1.5559 | 25.0 | 28025 | 1.8618 |
| 1.5484 | 26.0 | 29146 | 1.8660 |
| 1.5411 | 27.0 | 30267 | 1.8318 |
| 1.5247 | 28.0 | 31388 | 1.8216 |
| 1.5278 | 29.0 | 32509 | 1.8075 |
| 1.4954 | 30.0 | 33630 | 1.8073 |
| 1.4863 | 31.0 | 34751 | 1.7958 |
| 1.4821 | 32.0 | 35872 | 1.8080 |
| 1.4357 | 33.0 | 36993 | 1.8373 |
| 1.4602 | 34.0 | 38114 | 1.8199 |
| 1.447 | 35.0 | 39235 | 1.8325 |
| 1.4292 | 36.0 | 40356 | 1.8075 |
| 1.4174 | 37.0 | 41477 | 1.8168 |
| 1.4103 | 38.0 | 42598 | 1.8095 |
| 1.4168 | 39.0 | 43719 | 1.8233 |
| 1.4005 | 40.0 | 44840 | 1.8388 |
| 1.3799 | 41.0 | 45961 | 1.8235 |
| 1.3657 | 42.0 | 47082 | 1.8298 |
| 1.3559 | 43.0 | 48203 | 1.8165 |
| 1.3723 | 44.0 | 49324 | 1.8059 |
| 1.3535 | 45.0 | 50445 | 1.8451 |
| 1.3533 | 46.0 | 51566 | 1.8458 |
| 1.3469 | 47.0 | 52687 | 1.8237 |
| 1.3247 | 48.0 | 53808 | 1.8264 |
| 1.3142 | 49.0 | 54929 | 1.8209 |
| 1.2958 | 50.0 | 56050 | 1.8244 |
| 1.293 | 51.0 | 57171 | 1.8311 |
| 1.2784 | 52.0 | 58292 | 1.8287 |
| 1.2731 | 53.0 | 59413 | 1.8600 |
| 1.2961 | 54.0 | 60534 | 1.8086 |
| 1.2739 | 55.0 | 61655 | 1.8303 |
| 1.2716 | 56.0 | 62776 | 1.8214 |
| 1.2459 | 57.0 | 63897 | 1.8440 |
| 1.2492 | 58.0 | 65018 | 1.8503 |
| 1.2393 | 59.0 | 66139 | 1.8316 |
| 1.2077 | 60.0 | 67260 | 1.8283 |
| 1.2426 | 61.0 | 68381 | 1.8413 |
| 1.2032 | 62.0 | 69502 | 1.8461 |
| 1.2123 | 63.0 | 70623 | 1.8469 |
| 1.2069 | 64.0 | 71744 | 1.8478 |
| 1.198 | 65.0 | 72865 | 1.8479 |
| 1.1972 | 66.0 | 73986 | 1.8516 |
| 1.1885 | 67.0 | 75107 | 1.8341 |
| 1.1784 | 68.0 | 76228 | 1.8322 |
| 1.1866 | 69.0 | 77349 | 1.8559 |
| 1.1648 | 70.0 | 78470 | 1.8758 |
| 1.1595 | 71.0 | 79591 | 1.8684 |
| 1.1661 | 72.0 | 80712 | 1.8553 |
| 1.1478 | 73.0 | 81833 | 1.8658 |
| 1.1488 | 74.0 | 82954 | 1.8452 |
| 1.1538 | 75.0 | 84075 | 1.8505 |
| 1.1267 | 76.0 | 85196 | 1.8430 |
| 1.1339 | 77.0 | 86317 | 1.8333 |
| 1.118 | 78.0 | 87438 | 1.8419 |
| 1.12 | 79.0 | 88559 | 1.8669 |
| 1.1144 | 80.0 | 89680 | 1.8647 |
| 1.104 | 81.0 | 90801 | 1.8643 |
| 1.0864 | 82.0 | 91922 | 1.8528 |
| 1.0863 | 83.0 | 93043 | 1.8456 |
| 1.0912 | 84.0 | 94164 | 1.8509 |
| 1.0873 | 85.0 | 95285 | 1.8690 |
| 1.0862 | 86.0 | 96406 | 1.8577 |
| 1.0879 | 87.0 | 97527 | 1.8612 |
| 1.0783 | 88.0 | 98648 | 1.8410 |
| 1.0618 | 89.0 | 99769 | 1.8517 |
| 1.0552 | 90.0 | 100890 | 1.8459 |
| 1.0516 | 91.0 | 102011 | 1.8723 |
| 1.0424 | 92.0 | 103132 | 1.8832 |
| 1.0478 | 93.0 | 104253 | 1.8922 |
| 1.0523 | 94.0 | 105374 | 1.8753 |
| 1.027 | 95.0 | 106495 | 1.8625 |
| 1.0364 | 96.0 | 107616 | 1.8673 |
| 1.0203 | 97.0 | 108737 | 1.8806 |
| 1.0309 | 98.0 | 109858 | 1.8644 |
| 1.0174 | 99.0 | 110979 | 1.8659 |
| 1.0184 | 100.0 | 112100 | 1.8590 |
| 1.0234 | 101.0 | 113221 | 1.8614 |
| 1.013 | 102.0 | 114342 | 1.8866 |
| 1.0092 | 103.0 | 115463 | 1.8770 |
| 1.0051 | 104.0 | 116584 | 1.8445 |
| 1.0105 | 105.0 | 117705 | 1.8512 |
| 1.0233 | 106.0 | 118826 | 1.8896 |
| 0.9967 | 107.0 | 119947 | 1.8687 |
| 0.9795 | 108.0 | 121068 | 1.8618 |
| 0.9846 | 109.0 | 122189 | 1.8877 |
| 0.9958 | 110.0 | 123310 | 1.8522 |
| 0.9689 | 111.0 | 124431 | 1.8765 |
| 0.9879 | 112.0 | 125552 | 1.8692 |
| 0.99 | 113.0 | 126673 | 1.8689 |
| 0.9798 | 114.0 | 127794 | 1.8898 |
| 0.9676 | 115.0 | 128915 | 1.8782 |
| 0.9759 | 116.0 | 130036 | 1.8840 |
| 0.9576 | 117.0 | 131157 | 1.8662 |
| 0.9637 | 118.0 | 132278 | 1.8984 |
| 0.9645 | 119.0 | 133399 | 1.8872 |
| 0.9793 | 120.0 | 134520 | 1.8705 |
| 0.9643 | 121.0 | 135641 | 1.9036 |
| 0.961 | 122.0 | 136762 | 1.8683 |
| 0.9496 | 123.0 | 137883 | 1.8785 |
| 0.946 | 124.0 | 139004 | 1.8912 |
| 0.9681 | 125.0 | 140125 | 1.8837 |
| 0.9403 | 126.0 | 141246 | 1.8824 |
| 0.9452 | 127.0 | 142367 | 1.8824 |
| 0.9437 | 128.0 | 143488 | 1.8665 |
| 0.945 | 129.0 | 144609 | 1.8655 |
| 0.9453 | 130.0 | 145730 | 1.8695 |
| 0.9238 | 131.0 | 146851 | 1.8697 |
| 0.9176 | 132.0 | 147972 | 1.8618 |
| 0.9405 | 133.0 | 149093 | 1.8679 |
| 0.9184 | 134.0 | 150214 | 1.9025 |
| 0.9298 | 135.0 | 151335 | 1.9045 |
| 0.9215 | 136.0 | 152456 | 1.9014 |
| 0.9249 | 137.0 | 153577 | 1.8505 |
| 0.9246 | 138.0 | 154698 | 1.8542 |
| 0.9205 | 139.0 | 155819 | 1.8731 |
| 0.9368 | 140.0 | 156940 | 1.8673 |
| 0.9251 | 141.0 | 158061 | 1.8835 |
| 0.9224 | 142.0 | 159182 | 1.8727 |
| 0.9326 | 143.0 | 160303 | 1.8380 |
| 0.916 | 144.0 | 161424 | 1.8857 |
| 0.9361 | 145.0 | 162545 | 1.8547 |
| 0.9121 | 146.0 | 163666 | 1.8587 |
| 0.9156 | 147.0 | 164787 | 1.8863 |
| 0.9131 | 148.0 | 165908 | 1.8809 |
| 0.9185 | 149.0 | 167029 | 1.8734 |
| 0.9183 | 150.0 | 168150 | 1.8929 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.5.0
- Datasets 2.4.0
- Tokenizers 0.12.1
|
DoyyingFace/bert-asian-hate-tweets-concat-clean | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 25 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilroberta-base-finetuned-marktextepoch_n200
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilroberta-base-finetuned-marktextepoch_n200
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.0531
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:------:|:---------------:|
| 2.2313 | 1.0 | 1500 | 2.1592 |
| 2.1731 | 2.0 | 3000 | 2.1277 |
| 2.153 | 3.0 | 4500 | 2.1144 |
| 2.1469 | 4.0 | 6000 | 2.1141 |
| 2.1281 | 5.0 | 7500 | 2.1374 |
| 2.1043 | 6.0 | 9000 | 2.1069 |
| 2.0834 | 7.0 | 10500 | 2.0993 |
| 2.0602 | 8.0 | 12000 | 2.0817 |
| 2.024 | 9.0 | 13500 | 2.0918 |
| 2.0261 | 10.0 | 15000 | 2.0793 |
| 1.9889 | 11.0 | 16500 | 2.0567 |
| 1.9915 | 12.0 | 18000 | 2.0700 |
| 1.9532 | 13.0 | 19500 | 2.0436 |
| 1.9362 | 14.0 | 21000 | 2.0596 |
| 1.9024 | 15.0 | 22500 | 2.0189 |
| 1.9262 | 16.0 | 24000 | 2.0435 |
| 1.8883 | 17.0 | 25500 | 2.0430 |
| 1.8867 | 18.0 | 27000 | 2.0416 |
| 1.8807 | 19.0 | 28500 | 2.0051 |
| 1.8517 | 20.0 | 30000 | 2.0338 |
| 1.8357 | 21.0 | 31500 | 2.0166 |
| 1.8241 | 22.0 | 33000 | 2.0355 |
| 1.7985 | 23.0 | 34500 | 2.0073 |
| 1.8061 | 24.0 | 36000 | 2.0473 |
| 1.7996 | 25.0 | 37500 | 2.0446 |
| 1.7786 | 26.0 | 39000 | 2.0086 |
| 1.771 | 27.0 | 40500 | 2.0294 |
| 1.7549 | 28.0 | 42000 | 2.0127 |
| 1.7726 | 29.0 | 43500 | 2.0191 |
| 1.7275 | 30.0 | 45000 | 2.0182 |
| 1.708 | 31.0 | 46500 | 2.0130 |
| 1.7345 | 32.0 | 48000 | 2.0155 |
| 1.7044 | 33.0 | 49500 | 1.9898 |
| 1.7126 | 34.0 | 51000 | 2.0166 |
| 1.698 | 35.0 | 52500 | 1.9879 |
| 1.6637 | 36.0 | 54000 | 2.0311 |
| 1.6854 | 37.0 | 55500 | 2.0355 |
| 1.6585 | 38.0 | 57000 | 2.0094 |
| 1.6418 | 39.0 | 58500 | 2.0042 |
| 1.667 | 40.0 | 60000 | 2.0116 |
| 1.6507 | 41.0 | 61500 | 2.0095 |
| 1.622 | 42.0 | 63000 | 2.0158 |
| 1.6381 | 43.0 | 64500 | 2.0339 |
| 1.6099 | 44.0 | 66000 | 2.0082 |
| 1.6076 | 45.0 | 67500 | 2.0207 |
| 1.5805 | 46.0 | 69000 | 2.0172 |
| 1.5862 | 47.0 | 70500 | 2.0132 |
| 1.5806 | 48.0 | 72000 | 2.0198 |
| 1.574 | 49.0 | 73500 | 2.0181 |
| 1.5718 | 50.0 | 75000 | 2.0086 |
| 1.5591 | 51.0 | 76500 | 1.9832 |
| 1.5468 | 52.0 | 78000 | 2.0167 |
| 1.5637 | 53.0 | 79500 | 2.0118 |
| 1.5117 | 54.0 | 81000 | 2.0290 |
| 1.5363 | 55.0 | 82500 | 2.0011 |
| 1.4976 | 56.0 | 84000 | 2.0160 |
| 1.5129 | 57.0 | 85500 | 2.0224 |
| 1.4964 | 58.0 | 87000 | 2.0219 |
| 1.4906 | 59.0 | 88500 | 2.0212 |
| 1.4941 | 60.0 | 90000 | 2.0255 |
| 1.4876 | 61.0 | 91500 | 2.0116 |
| 1.4837 | 62.0 | 93000 | 2.0176 |
| 1.4661 | 63.0 | 94500 | 2.0388 |
| 1.4634 | 64.0 | 96000 | 2.0165 |
| 1.4449 | 65.0 | 97500 | 2.0185 |
| 1.468 | 66.0 | 99000 | 2.0246 |
| 1.4567 | 67.0 | 100500 | 2.0244 |
| 1.4367 | 68.0 | 102000 | 2.0093 |
| 1.4471 | 69.0 | 103500 | 2.0101 |
| 1.4255 | 70.0 | 105000 | 2.0248 |
| 1.4203 | 71.0 | 106500 | 2.0224 |
| 1.42 | 72.0 | 108000 | 2.0279 |
| 1.4239 | 73.0 | 109500 | 2.0295 |
| 1.4126 | 74.0 | 111000 | 2.0196 |
| 1.4038 | 75.0 | 112500 | 2.0225 |
| 1.3874 | 76.0 | 114000 | 2.0456 |
| 1.3758 | 77.0 | 115500 | 2.0423 |
| 1.3924 | 78.0 | 117000 | 2.0184 |
| 1.3744 | 79.0 | 118500 | 2.0555 |
| 1.3622 | 80.0 | 120000 | 2.0387 |
| 1.3653 | 81.0 | 121500 | 2.0344 |
| 1.3724 | 82.0 | 123000 | 2.0184 |
| 1.3684 | 83.0 | 124500 | 2.0285 |
| 1.3576 | 84.0 | 126000 | 2.0544 |
| 1.348 | 85.0 | 127500 | 2.0412 |
| 1.3387 | 86.0 | 129000 | 2.0459 |
| 1.3416 | 87.0 | 130500 | 2.0329 |
| 1.3421 | 88.0 | 132000 | 2.0274 |
| 1.3266 | 89.0 | 133500 | 2.0233 |
| 1.3183 | 90.0 | 135000 | 2.0319 |
| 1.322 | 91.0 | 136500 | 2.0080 |
| 1.32 | 92.0 | 138000 | 2.0472 |
| 1.304 | 93.0 | 139500 | 2.0538 |
| 1.3061 | 94.0 | 141000 | 2.0340 |
| 1.3199 | 95.0 | 142500 | 2.0456 |
| 1.2985 | 96.0 | 144000 | 2.0167 |
| 1.3021 | 97.0 | 145500 | 2.0204 |
| 1.2787 | 98.0 | 147000 | 2.0645 |
| 1.2879 | 99.0 | 148500 | 2.0345 |
| 1.2695 | 100.0 | 150000 | 2.0340 |
| 1.2884 | 101.0 | 151500 | 2.0602 |
| 1.2747 | 102.0 | 153000 | 2.0667 |
| 1.2607 | 103.0 | 154500 | 2.0551 |
| 1.2551 | 104.0 | 156000 | 2.0544 |
| 1.2557 | 105.0 | 157500 | 2.0553 |
| 1.2495 | 106.0 | 159000 | 2.0370 |
| 1.26 | 107.0 | 160500 | 2.0568 |
| 1.2499 | 108.0 | 162000 | 2.0427 |
| 1.2438 | 109.0 | 163500 | 2.0184 |
| 1.2496 | 110.0 | 165000 | 2.0227 |
| 1.2332 | 111.0 | 166500 | 2.0621 |
| 1.2231 | 112.0 | 168000 | 2.0661 |
| 1.211 | 113.0 | 169500 | 2.0673 |
| 1.217 | 114.0 | 171000 | 2.0544 |
| 1.2206 | 115.0 | 172500 | 2.0542 |
| 1.2083 | 116.0 | 174000 | 2.0592 |
| 1.2205 | 117.0 | 175500 | 2.0451 |
| 1.2065 | 118.0 | 177000 | 2.0402 |
| 1.1988 | 119.0 | 178500 | 2.0615 |
| 1.218 | 120.0 | 180000 | 2.0374 |
| 1.1917 | 121.0 | 181500 | 2.0349 |
| 1.1854 | 122.0 | 183000 | 2.0790 |
| 1.1819 | 123.0 | 184500 | 2.0766 |
| 1.2029 | 124.0 | 186000 | 2.0364 |
| 1.1851 | 125.0 | 187500 | 2.0568 |
| 1.1734 | 126.0 | 189000 | 2.0445 |
| 1.1701 | 127.0 | 190500 | 2.0770 |
| 1.1824 | 128.0 | 192000 | 2.0566 |
| 1.1604 | 129.0 | 193500 | 2.0542 |
| 1.1733 | 130.0 | 195000 | 2.0525 |
| 1.1743 | 131.0 | 196500 | 2.0577 |
| 1.1692 | 132.0 | 198000 | 2.0723 |
| 1.1519 | 133.0 | 199500 | 2.0567 |
| 1.1401 | 134.0 | 201000 | 2.0795 |
| 1.1692 | 135.0 | 202500 | 2.0625 |
| 1.157 | 136.0 | 204000 | 2.0793 |
| 1.1495 | 137.0 | 205500 | 2.0782 |
| 1.1479 | 138.0 | 207000 | 2.0392 |
| 1.1247 | 139.0 | 208500 | 2.0796 |
| 1.143 | 140.0 | 210000 | 2.0369 |
| 1.1324 | 141.0 | 211500 | 2.0699 |
| 1.1341 | 142.0 | 213000 | 2.0694 |
| 1.1317 | 143.0 | 214500 | 2.0569 |
| 1.1254 | 144.0 | 216000 | 2.0545 |
| 1.1156 | 145.0 | 217500 | 2.0708 |
| 1.1353 | 146.0 | 219000 | 2.0767 |
| 1.1312 | 147.0 | 220500 | 2.0523 |
| 1.1224 | 148.0 | 222000 | 2.0565 |
| 1.106 | 149.0 | 223500 | 2.0696 |
| 1.1069 | 150.0 | 225000 | 2.0478 |
| 1.1011 | 151.0 | 226500 | 2.0475 |
| 1.0985 | 152.0 | 228000 | 2.0888 |
| 1.1107 | 153.0 | 229500 | 2.0756 |
| 1.1058 | 154.0 | 231000 | 2.0812 |
| 1.1027 | 155.0 | 232500 | 2.0597 |
| 1.0996 | 156.0 | 234000 | 2.0684 |
| 1.0987 | 157.0 | 235500 | 2.0629 |
| 1.0881 | 158.0 | 237000 | 2.0701 |
| 1.1143 | 159.0 | 238500 | 2.0740 |
| 1.0823 | 160.0 | 240000 | 2.0869 |
| 1.0925 | 161.0 | 241500 | 2.0567 |
| 1.1034 | 162.0 | 243000 | 2.0833 |
| 1.0759 | 163.0 | 244500 | 2.0585 |
| 1.0998 | 164.0 | 246000 | 2.0293 |
| 1.0891 | 165.0 | 247500 | 2.0608 |
| 1.1036 | 166.0 | 249000 | 2.0831 |
| 1.076 | 167.0 | 250500 | 2.0979 |
| 1.0895 | 168.0 | 252000 | 2.0882 |
| 1.0825 | 169.0 | 253500 | 2.0742 |
| 1.0793 | 170.0 | 255000 | 2.0841 |
| 1.079 | 171.0 | 256500 | 2.0829 |
| 1.0653 | 172.0 | 258000 | 2.0888 |
| 1.0834 | 173.0 | 259500 | 2.0784 |
| 1.0721 | 174.0 | 261000 | 2.0859 |
| 1.0712 | 175.0 | 262500 | 2.0810 |
| 1.0494 | 176.0 | 264000 | 2.0605 |
| 1.0654 | 177.0 | 265500 | 2.0623 |
| 1.077 | 178.0 | 267000 | 2.0756 |
| 1.056 | 179.0 | 268500 | 2.0782 |
| 1.0523 | 180.0 | 270000 | 2.0966 |
| 1.0656 | 181.0 | 271500 | 2.0750 |
| 1.0636 | 182.0 | 273000 | 2.0769 |
| 1.0851 | 183.0 | 274500 | 2.0872 |
| 1.0562 | 184.0 | 276000 | 2.0893 |
| 1.0534 | 185.0 | 277500 | 2.0661 |
| 1.0514 | 186.0 | 279000 | 2.0712 |
| 1.062 | 187.0 | 280500 | 2.0769 |
| 1.0683 | 188.0 | 282000 | 2.0765 |
| 1.0606 | 189.0 | 283500 | 2.0735 |
| 1.0555 | 190.0 | 285000 | 2.0710 |
| 1.0568 | 191.0 | 286500 | 2.0860 |
| 1.0502 | 192.0 | 288000 | 2.0587 |
| 1.0437 | 193.0 | 289500 | 2.0998 |
| 1.0534 | 194.0 | 291000 | 2.0418 |
| 1.062 | 195.0 | 292500 | 2.0724 |
| 1.0457 | 196.0 | 294000 | 2.0612 |
| 1.0501 | 197.0 | 295500 | 2.1012 |
| 1.0728 | 198.0 | 297000 | 2.0721 |
| 1.0413 | 199.0 | 298500 | 2.0535 |
| 1.0461 | 200.0 | 300000 | 2.0531 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
albert-base-v1 | [
"pytorch",
"tf",
"safetensors",
"albert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1909.11942",
"transformers",
"exbert",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"AlbertForMaskedLM"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 38,156 | 2022-07-31T18:47:24Z | ---
inference: false
language:
- "en"
thumbnail: "https://drive.google.com/uc?export=view&id=1_n2kT6lBBs8C3rf8xfNURr_N2Ccx-A1S"
tags:
- text-to-image
- dalle-mini
license: "apache-2.0"
datasets:
- "succinctly/medium-titles-and-images"
---
This is the [dalle-mini/dalle-mini](https://huggingface.co/dalle-mini/dalle-mini) text-to-image model fine-tuned on 120k <title, image> pairs from the [Medium](https://medium.com) blogging platform. The full dataset can be found on Kaggle: [Medium Articles Dataset (128k): Metadata + Images](https://www.kaggle.com/datasets/succinctlyai/medium-data).
The goal of this model is to probe the ability of text-to-image models of operating on text prompts that are abstract (like the titles on Medium usually are), as opposed to concrete descriptions of the envisioned visual scene.
[More context here](https://medium.com/@turc.raluca/fine-tuning-dall-e-mini-craiyon-to-generate-blogpost-images-32903cc7aa52). |
albert-large-v1 | [
"pytorch",
"tf",
"albert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1909.11942",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"AlbertForMaskedLM"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 687 | 2022-07-31T19:03:36Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- recall
- precision
- f1
model-index:
- name: distilbert-base-uncased_fine_tuned_body_text
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased_fine_tuned_body_text
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2153
- Accuracy: {'accuracy': 0.8827265261428963}
- Recall: {'recall': 0.8641975308641975}
- Precision: {'precision': 0.8900034993584509}
- F1: {'f1': 0.8769106999195494}
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 15
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Recall | Precision | F1 |
|:-------------:|:-----:|:-----:|:---------------:|:--------------------------------:|:------------------------------:|:---------------------------------:|:--------------------------:|
| 0.3056 | 1.0 | 2284 | 0.3040 | {'accuracy': 0.8874897344648235} | {'recall': 0.8466417487824216} | {'precision': 0.914261252446184} | {'f1': 0.8791531902381653} |
| 0.2279 | 2.0 | 4568 | 0.2891 | {'accuracy': 0.8908294552422666} | {'recall': 0.8606863744478424} | {'precision': 0.9086452230060983} | {'f1': 0.8840158213122382} |
| 0.1467 | 3.0 | 6852 | 0.3580 | {'accuracy': 0.8882562277580072} | {'recall': 0.8452825914599615} | {'precision': 0.9170557876628164} | {'f1': 0.8797076678257796} |
| 0.0921 | 4.0 | 9136 | 0.4560 | {'accuracy': 0.8754448398576512} | {'recall': 0.8948918337297542} | {'precision': 0.8543468858131488} | {'f1': 0.8741494717043756} |
| 0.0587 | 5.0 | 11420 | 0.5701 | {'accuracy': 0.8768135778811935} | {'recall': 0.8139087099331748} | {'precision': 0.9221095855254716} | {'f1': 0.8646372277704246} |
| 0.0448 | 6.0 | 13704 | 0.6738 | {'accuracy': 0.8767040788393101} | {'recall': 0.8794880507418734} | {'precision': 0.8673070479168994} | {'f1': 0.873355078168935} |
| 0.0289 | 7.0 | 15988 | 0.7965 | {'accuracy': 0.8798248015329866} | {'recall': 0.8491335372069317} | {'precision': 0.8967703349282297} | {'f1': 0.8723020536389552} |
| 0.0214 | 8.0 | 18272 | 0.8244 | {'accuracy': 0.8811387900355871} | {'recall': 0.8576282704723072} | {'precision': 0.8922931887815225} | {'f1': 0.8746173837712965} |
| 0.0147 | 9.0 | 20556 | 0.8740 | {'accuracy': 0.8806460443471119} | {'recall': 0.8669158455091177} | {'precision': 0.8839357893521191} | {'f1': 0.8753430924062213} |
| 0.0099 | 10.0 | 22840 | 0.9716 | {'accuracy': 0.8788940596769779} | {'recall': 0.8694076339336279} | {'precision': 0.8787635947338294} | {'f1': 0.8740605784559327} |
| 0.0092 | 11.0 | 25124 | 1.0296 | {'accuracy': 0.8822885299753627} | {'recall': 0.8669158455091177} | {'precision': 0.8870089233978444} | {'f1': 0.876847290640394} |
| 0.0039 | 12.0 | 27408 | 1.0974 | {'accuracy': 0.8787845606350945} | {'recall': 0.8628383735417374} | {'precision': 0.8836561883772184} | {'f1': 0.8731232091690544} |
| 0.0053 | 13.0 | 29692 | 1.0833 | {'accuracy': 0.8799890500958116} | {'recall': 0.8503794314191868} | {'precision': 0.8960496479293472} | {'f1': 0.8726173872617387} |
| 0.0032 | 14.0 | 31976 | 1.1731 | {'accuracy': 0.8813030385984123} | {'recall': 0.8705402650356778} | {'precision': 0.8823326828148318} | {'f1': 0.8763968072976055} |
| 0.0017 | 15.0 | 34260 | 1.2153 | {'accuracy': 0.8827265261428963} | {'recall': 0.8641975308641975} | {'precision': 0.8900034993584509} | {'f1': 0.8769106999195494} |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
albert-xlarge-v1 | [
"pytorch",
"tf",
"albert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1909.11942",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"AlbertForMaskedLM"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 341 | 2022-07-31T19:12:10Z | ---
tags:
- bert
- mobilebert
- oBERT
language: en
datasets: squad
---
# mobilebert-uncased-finetuned-squadv1
This model is a finetuned version of the [mobilebert-uncased](https://huggingface.co/google/mobilebert-uncased/tree/main) model on the SQuADv1 task.
To make this TPU-trained model stable when used in PyTorch on GPUs, the original model has been additionally pretrained for one epoch on BookCorpus and English Wikipedia with disabled dropout before finetuning on the SQuADv1 task.
It is produced as part of the work on the paper [The Optimal BERT Surgeon: Scalable and Accurate Second-Order Pruning for Large Language Models](https://arxiv.org/abs/2203.07259).
SQuADv1 dev-set:
```
EM = 83.96
F1 = 90.90
```
Code: [https://github.com/neuralmagic/sparseml/tree/main/research/optimal_BERT_surgeon_oBERT](https://github.com/neuralmagic/sparseml/tree/main/research/optimal_BERT_surgeon_oBERT)
If you find the model useful, please consider citing our work.
## Citation info
```bibtex
@article{kurtic2022optimal,
title={The Optimal BERT Surgeon: Scalable and Accurate Second-Order Pruning for Large Language Models},
author={Kurtic, Eldar and Campos, Daniel and Nguyen, Tuan and Frantar, Elias and Kurtz, Mark and Fineran, Benjamin and Goin, Michael and Alistarh, Dan},
journal={arXiv preprint arXiv:2203.07259},
year={2022}
}
```
|
albert-xlarge-v2 | [
"pytorch",
"tf",
"albert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1909.11942",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"AlbertForMaskedLM"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2,973 | 2022-07-31T19:26:04Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.926
- name: F1
type: f1
value: 0.9258000202272497
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2123
- Accuracy: 0.926
- F1: 0.9258
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8198 | 1.0 | 250 | 0.3147 | 0.904 | 0.9003 |
| 0.2438 | 2.0 | 500 | 0.2123 | 0.926 | 0.9258 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
albert-xxlarge-v2 | [
"pytorch",
"tf",
"safetensors",
"albert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1909.11942",
"transformers",
"exbert",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"AlbertForMaskedLM"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 42,640 | null | ---
language:
- rw
library_name: nemo
datasets:
- mozilla-foundation/common_voice_9_0
thumbnail: null
tags:
- automatic-speech-recognition
- speech
- audio
- Transducer
- Conformer
- Transformer
- pytorch
- NeMo
- hf-asr-leaderboard
license: cc-by-4.0
model-index:
- name: stt_rw_conformer_transducer_large
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Mozilla Common Voice 9.0
type: mozilla-foundation/common_voice_9_0
config: rw
split: test
args:
language: rw
metrics:
- name: Test WER
type: wer
value: 16.19
---
# NVIDIA Conformer-Transducer Large (Kinyarwanda)
<style>
img {
display: inline;
}
</style>
| [](#model-architecture)
| [](#model-architecture)
| [](#datasets)
This model transcribes speech into lowercase Latin alphabet including space and apostrophe, and is trained on around 2000 hours of Kinyarwanda speech data.
It is a non-autoregressive "large" variant of Conformer, with around 120 million parameters.
See the [model architecture](#model-architecture) section and [NeMo documentation](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/main/asr/models.html#conformer-transducer) for complete architecture details.
## Usage
The model is available for use in the NeMo toolkit [3], and can be used as a pre-trained checkpoint for inference or for fine-tuning on another dataset.
To train, fine-tune or play with the model you will need to install [NVIDIA NeMo](https://github.com/NVIDIA/NeMo). We recommend you install it after you've installed latest PyTorch version.
```
pip install nemo_toolkit['all']
```
### Automatically instantiate the model
```python
import nemo.collections.asr as nemo_asr
asr_model = nemo_asr.models.EncDecRNNTBPEModel.from_pretrained("nvidia/stt_rw_conformer_transducer_large")
```
### Transcribing using Python
Simply do:
```
asr_model.transcribe(['<your_audio>.wav'])
```
### Transcribing many audio files
```shell
python [NEMO_GIT_FOLDER]/examples/asr/transcribe_speech.py
pretrained_name="nvidia/stt_rw_conformer_transducer_large"
audio_dir="<DIRECTORY CONTAINING AUDIO FILES>"
```
### Input
This model accepts 16 kHz mono-channel Audio (wav files) as input.
### Output
This model provides transcribed speech as a string for a given audio sample.
## Model Architecture
Conformer-Transducer model is an autoregressive variant of Conformer model [1] for Automatic Speech Recognition which uses Transducer loss/decoding. You may find more info on the detail of this model here: [Conformer-Transducer Model](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/main/asr/models.html).
## Training
The NeMo toolkit [3] was used for training the models for over several hundred epochs. These model are trained with this [example script](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/asr_transducer/speech_to_text_rnnt_bpe.py) and this [base config](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/conf/conformer/conformer_transducer_bpe.yaml).
The vocabulary we use contains 28 characters:
```python
[' ', "'", 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
```
Rare symbols with diacritics were replaced during preprocessing.
The tokenizers for these models were built using the text transcripts of the train set with this [script](https://github.com/NVIDIA/NeMo/blob/main/scripts/tokenizers/process_asr_text_tokenizer.py).
For vocabulary of size 1024 we restrict maximum subtoken length to 4 symbols to avoid populating vocabulary with specific frequent words from the dataset. This does not affect the model performance and potentially helps to adapt to other domain without retraining tokenizer.
Full config can be found inside the .nemo files.
### Datasets
All the models in this collection are trained on MCV-9.0 Kinyarwanda dataset, which contains around 2000 hours training, 32 hours of development and 32 hours of testing speech audios.
## Performance
The list of the available models in this collection is shown in the following table. Performances of the ASR models are reported in terms of Word Error Rate (WER%) with greedy decoding.
| Version | Tokenizer | Vocabulary Size | Dev WER| Test WER| Train Dataset |
|---------|-----------------------|-----------------|--------|---------|-----------------|
| 1.11.0 | SentencePiece BPE, maxlen=4 | 1024 |13.82 | 16.19 | MCV-9.0 Train set|
## Limitations
Since this model was trained on publicly available speech datasets, the performance of this model might degrade for speech which includes technical terms, or vernacular that the model has not been trained on. The model might also perform worse for accented speech.
## Deployment with NVIDIA Riva
[NVIDIA Riva](https://developer.nvidia.com/riva), is an accelerated speech AI SDK deployable on-prem, in all clouds, multi-cloud, hybrid, on edge, and embedded.
Additionally, Riva provides:
* World-class out-of-the-box accuracy for the most common languages with model checkpoints trained on proprietary data with hundreds of thousands of GPU-compute hours
* Best in class accuracy with run-time word boosting (e.g., brand and product names) and customization of acoustic model, language model, and inverse text normalization
* Streaming speech recognition, Kubernetes compatible scaling, and enterprise-grade support
Although this model isn’t supported yet by Riva, the [list of supported models is here](https://huggingface.co/models?other=Riva).
Check out [Riva live demo](https://developer.nvidia.com/riva#demos).
## References
- [1] [Conformer: Convolution-augmented Transformer for Speech Recognition](https://arxiv.org/abs/2005.08100)
- [2] [Google Sentencepiece Tokenizer](https://github.com/google/sentencepiece)
- [3] [NVIDIA NeMo Toolkit](https://github.com/NVIDIA/NeMo) |
bert-base-cased-finetuned-mrpc | [
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 11,644 | 2022-07-31T19:46:59Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: vit-base-patch32-384-finetuned-eurosat
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.8423153692614771
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-patch32-384-finetuned-eurosat
This model is a fine-tuned version of [google/vit-base-patch32-384](https://huggingface.co/google/vit-base-patch32-384) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4381
- Accuracy: 0.8423
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.607 | 0.99 | 70 | 0.5609 | 0.8014 |
| 0.5047 | 1.99 | 140 | 0.4634 | 0.8373 |
| 0.4089 | 2.99 | 210 | 0.4381 | 0.8423 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
bert-base-cased | [
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1810.04805",
"transformers",
"exbert",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8,621,271 | 2022-07-31T20:00:07Z | --- "A bert model pretrained on earnings calls transcripts from SeekingAlpha.com" |
bert-base-german-cased | [
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"de",
"transformers",
"exbert",
"license:mit",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 175,983 | 2022-07-31T20:57:24Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: distilbert-base-uncased_fold_1_binary
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased_fold_1_binary
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5992
- F1: 0.7687
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 288 | 0.3960 | 0.7467 |
| 0.3988 | 2.0 | 576 | 0.3947 | 0.7487 |
| 0.3988 | 3.0 | 864 | 0.4511 | 0.7662 |
| 0.1853 | 4.0 | 1152 | 0.7226 | 0.7285 |
| 0.1853 | 5.0 | 1440 | 0.9398 | 0.7334 |
| 0.0827 | 6.0 | 1728 | 1.0547 | 0.7427 |
| 0.0287 | 7.0 | 2016 | 1.1602 | 0.7563 |
| 0.0287 | 8.0 | 2304 | 1.3332 | 0.7171 |
| 0.0219 | 9.0 | 2592 | 1.3429 | 0.7420 |
| 0.0219 | 10.0 | 2880 | 1.2603 | 0.7648 |
| 0.0139 | 11.0 | 3168 | 1.4126 | 0.7569 |
| 0.0139 | 12.0 | 3456 | 1.3195 | 0.7483 |
| 0.0115 | 13.0 | 3744 | 1.4356 | 0.7491 |
| 0.0035 | 14.0 | 4032 | 1.5693 | 0.7636 |
| 0.0035 | 15.0 | 4320 | 1.4071 | 0.7662 |
| 0.0071 | 16.0 | 4608 | 1.4561 | 0.7579 |
| 0.0071 | 17.0 | 4896 | 1.5405 | 0.7634 |
| 0.0041 | 18.0 | 5184 | 1.5862 | 0.7589 |
| 0.0041 | 19.0 | 5472 | 1.6782 | 0.76 |
| 0.0024 | 20.0 | 5760 | 1.5699 | 0.7677 |
| 0.0006 | 21.0 | 6048 | 1.5991 | 0.7467 |
| 0.0006 | 22.0 | 6336 | 1.6205 | 0.7682 |
| 0.0003 | 23.0 | 6624 | 1.6334 | 0.7643 |
| 0.0003 | 24.0 | 6912 | 1.5992 | 0.7687 |
| 0.0011 | 25.0 | 7200 | 1.6053 | 0.7624 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
bert-base-german-dbmdz-cased | [
"pytorch",
"jax",
"bert",
"fill-mask",
"de",
"transformers",
"license:mit",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 1,814 | 2022-07-31T20:57:40Z | ---
library_name: keras
---
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Model Plot
<details>
<summary>View Model Plot</summary>

</details> |
bert-base-german-dbmdz-uncased | [
"pytorch",
"jax",
"safetensors",
"bert",
"fill-mask",
"de",
"transformers",
"license:mit",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 68,305 | 2022-07-31T21:04:13Z | ---
library_name: keras
---
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Model Plot
<details>
<summary>View Model Plot</summary>

</details> |
bert-base-multilingual-cased | [
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"multilingual",
"af",
"sq",
"ar",
"an",
"hy",
"ast",
"az",
"ba",
"eu",
"bar",
"be",
"bn",
"inc",
"bs",
"br",
"bg",
"my",
"ca",
"ceb",
"ce",
"zh",
"cv",
"hr",
"cs",
"da",
"nl",
"en",
"et",
"fi",
"fr",
"gl",
"ka",
"de",
"el",
"gu",
"ht",
"he",
"hi",
"hu",
"is",
"io",
"id",
"ga",
"it",
"ja",
"jv",
"kn",
"kk",
"ky",
"ko",
"la",
"lv",
"lt",
"roa",
"nds",
"lm",
"mk",
"mg",
"ms",
"ml",
"mr",
"mn",
"min",
"ne",
"new",
"nb",
"nn",
"oc",
"fa",
"pms",
"pl",
"pt",
"pa",
"ro",
"ru",
"sco",
"sr",
"scn",
"sk",
"sl",
"aze",
"es",
"su",
"sw",
"sv",
"tl",
"tg",
"th",
"ta",
"tt",
"te",
"tr",
"uk",
"ud",
"uz",
"vi",
"vo",
"war",
"cy",
"fry",
"pnb",
"yo",
"dataset:wikipedia",
"arxiv:1810.04805",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4,749,504 | 2022-07-31T21:08:28Z | ---
library_name: keras
---
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Model Plot
<details>
<summary>View Model Plot</summary>

</details> |
bert-base-uncased | [
"pytorch",
"tf",
"jax",
"rust",
"safetensors",
"bert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1810.04805",
"transformers",
"exbert",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 59,663,489 | 2022-07-31T21:33:10Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: distilbert-base-uncased_fold_2_binary
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased_fold_2_binary
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4724
- F1: 0.7604
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 290 | 0.4280 | 0.7515 |
| 0.4018 | 2.0 | 580 | 0.4724 | 0.7604 |
| 0.4018 | 3.0 | 870 | 0.5336 | 0.7428 |
| 0.1995 | 4.0 | 1160 | 0.8367 | 0.7476 |
| 0.1995 | 5.0 | 1450 | 0.9242 | 0.7412 |
| 0.089 | 6.0 | 1740 | 1.0987 | 0.7410 |
| 0.0318 | 7.0 | 2030 | 1.1853 | 0.7584 |
| 0.0318 | 8.0 | 2320 | 1.2509 | 0.7500 |
| 0.0189 | 9.0 | 2610 | 1.5060 | 0.7258 |
| 0.0189 | 10.0 | 2900 | 1.5607 | 0.7534 |
| 0.0084 | 11.0 | 3190 | 1.5871 | 0.7476 |
| 0.0084 | 12.0 | 3480 | 1.7206 | 0.7338 |
| 0.0047 | 13.0 | 3770 | 1.6776 | 0.7340 |
| 0.0068 | 14.0 | 4060 | 1.7339 | 0.7546 |
| 0.0068 | 15.0 | 4350 | 1.8279 | 0.7504 |
| 0.0025 | 16.0 | 4640 | 1.7791 | 0.7411 |
| 0.0025 | 17.0 | 4930 | 1.7917 | 0.7444 |
| 0.003 | 18.0 | 5220 | 1.7781 | 0.7559 |
| 0.0029 | 19.0 | 5510 | 1.8153 | 0.7559 |
| 0.0029 | 20.0 | 5800 | 1.7757 | 0.7414 |
| 0.0055 | 21.0 | 6090 | 1.8635 | 0.7454 |
| 0.0055 | 22.0 | 6380 | 1.8483 | 0.7460 |
| 0.001 | 23.0 | 6670 | 1.8620 | 0.7492 |
| 0.001 | 24.0 | 6960 | 1.9058 | 0.7508 |
| 0.0006 | 25.0 | 7250 | 1.8640 | 0.7504 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
bert-large-uncased-whole-word-masking | [
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1810.04805",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 76,685 | 2022-07-31T21:54:02Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: distilbert-base-uncased_fold_4_binary
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased_fold_4_binary
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2977
- F1: 0.8083
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 289 | 0.3701 | 0.7903 |
| 0.4005 | 2.0 | 578 | 0.3669 | 0.7994 |
| 0.4005 | 3.0 | 867 | 0.5038 | 0.7955 |
| 0.1945 | 4.0 | 1156 | 0.6353 | 0.8006 |
| 0.1945 | 5.0 | 1445 | 0.8974 | 0.7826 |
| 0.0909 | 6.0 | 1734 | 0.8533 | 0.7764 |
| 0.0389 | 7.0 | 2023 | 0.9969 | 0.7957 |
| 0.0389 | 8.0 | 2312 | 1.0356 | 0.7952 |
| 0.0231 | 9.0 | 2601 | 1.1538 | 0.7963 |
| 0.0231 | 10.0 | 2890 | 1.2011 | 0.7968 |
| 0.0051 | 11.0 | 3179 | 1.2329 | 0.7935 |
| 0.0051 | 12.0 | 3468 | 1.2829 | 0.8056 |
| 0.0066 | 13.0 | 3757 | 1.2946 | 0.7956 |
| 0.004 | 14.0 | 4046 | 1.2977 | 0.8083 |
| 0.004 | 15.0 | 4335 | 1.3970 | 0.7957 |
| 0.0007 | 16.0 | 4624 | 1.3361 | 0.7917 |
| 0.0007 | 17.0 | 4913 | 1.5782 | 0.7954 |
| 0.0107 | 18.0 | 5202 | 1.4641 | 0.7900 |
| 0.0107 | 19.0 | 5491 | 1.4490 | 0.7957 |
| 0.0058 | 20.0 | 5780 | 1.4607 | 0.7932 |
| 0.0016 | 21.0 | 6069 | 1.5048 | 0.7939 |
| 0.0016 | 22.0 | 6358 | 1.5219 | 0.7945 |
| 0.0027 | 23.0 | 6647 | 1.4783 | 0.7937 |
| 0.0027 | 24.0 | 6936 | 1.4715 | 0.7981 |
| 0.0004 | 25.0 | 7225 | 1.4989 | 0.7900 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
bert-large-uncased | [
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1810.04805",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 1,058,496 | 2022-07-31T22:04:19Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: distilbert-base-uncased_fold_5_binary
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased_fold_5_binary
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5093
- F1: 0.7801
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 288 | 0.4760 | 0.7315 |
| 0.3992 | 2.0 | 576 | 0.4428 | 0.7785 |
| 0.3992 | 3.0 | 864 | 0.5093 | 0.7801 |
| 0.2021 | 4.0 | 1152 | 0.6588 | 0.7634 |
| 0.2021 | 5.0 | 1440 | 0.9174 | 0.7713 |
| 0.0945 | 6.0 | 1728 | 0.9832 | 0.7726 |
| 0.0321 | 7.0 | 2016 | 1.2103 | 0.7672 |
| 0.0321 | 8.0 | 2304 | 1.3759 | 0.7616 |
| 0.0134 | 9.0 | 2592 | 1.4405 | 0.7570 |
| 0.0134 | 10.0 | 2880 | 1.4591 | 0.7710 |
| 0.0117 | 11.0 | 3168 | 1.4947 | 0.7713 |
| 0.0117 | 12.0 | 3456 | 1.6224 | 0.7419 |
| 0.0081 | 13.0 | 3744 | 1.6462 | 0.7520 |
| 0.0083 | 14.0 | 4032 | 1.6880 | 0.7637 |
| 0.0083 | 15.0 | 4320 | 1.7080 | 0.7380 |
| 0.0048 | 16.0 | 4608 | 1.7352 | 0.7551 |
| 0.0048 | 17.0 | 4896 | 1.6761 | 0.7713 |
| 0.0024 | 18.0 | 5184 | 1.7553 | 0.76 |
| 0.0024 | 19.0 | 5472 | 1.7312 | 0.7673 |
| 0.005 | 20.0 | 5760 | 1.7334 | 0.7713 |
| 0.0032 | 21.0 | 6048 | 1.7963 | 0.7578 |
| 0.0032 | 22.0 | 6336 | 1.7529 | 0.7679 |
| 0.0025 | 23.0 | 6624 | 1.7741 | 0.7662 |
| 0.0025 | 24.0 | 6912 | 1.7515 | 0.7679 |
| 0.0004 | 25.0 | 7200 | 1.7370 | 0.7765 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
camembert-base | [
"pytorch",
"tf",
"safetensors",
"camembert",
"fill-mask",
"fr",
"dataset:oscar",
"arxiv:1911.03894",
"transformers",
"license:mit",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"CamembertForMaskedLM"
],
"model_type": "camembert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 1,440,898 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: distilbert-base-uncased_fold_6_binary
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased_fold_6_binary
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6838
- F1: 0.7881
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 290 | 0.4181 | 0.7732 |
| 0.4097 | 2.0 | 580 | 0.3967 | 0.7697 |
| 0.4097 | 3.0 | 870 | 0.5811 | 0.7797 |
| 0.2034 | 4.0 | 1160 | 0.8684 | 0.7320 |
| 0.2034 | 5.0 | 1450 | 0.9116 | 0.7718 |
| 0.0794 | 6.0 | 1740 | 1.0588 | 0.7690 |
| 0.0278 | 7.0 | 2030 | 1.2092 | 0.7738 |
| 0.0278 | 8.0 | 2320 | 1.2180 | 0.7685 |
| 0.0233 | 9.0 | 2610 | 1.3005 | 0.7676 |
| 0.0233 | 10.0 | 2900 | 1.4009 | 0.7634 |
| 0.0093 | 11.0 | 3190 | 1.4528 | 0.7805 |
| 0.0093 | 12.0 | 3480 | 1.4803 | 0.7859 |
| 0.0088 | 13.0 | 3770 | 1.4775 | 0.7750 |
| 0.0077 | 14.0 | 4060 | 1.6171 | 0.7699 |
| 0.0077 | 15.0 | 4350 | 1.6429 | 0.7636 |
| 0.0047 | 16.0 | 4640 | 1.5619 | 0.7819 |
| 0.0047 | 17.0 | 4930 | 1.5833 | 0.7724 |
| 0.0034 | 18.0 | 5220 | 1.6400 | 0.7853 |
| 0.0008 | 19.0 | 5510 | 1.6508 | 0.7792 |
| 0.0008 | 20.0 | 5800 | 1.6838 | 0.7881 |
| 0.0009 | 21.0 | 6090 | 1.6339 | 0.7829 |
| 0.0009 | 22.0 | 6380 | 1.6824 | 0.7806 |
| 0.0016 | 23.0 | 6670 | 1.6867 | 0.7876 |
| 0.0016 | 24.0 | 6960 | 1.7107 | 0.7877 |
| 0.0013 | 25.0 | 7250 | 1.6933 | 0.7812 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
distilbert-base-german-cased | [
"pytorch",
"safetensors",
"distilbert",
"fill-mask",
"de",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"DistilBertForMaskedLM"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 43,667 | 2022-07-31T22:26:16Z | ---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: xlnet-base-cased_fold_1_binary
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlnet-base-cased_fold_1_binary
This model is a fine-tuned version of [xlnet-base-cased](https://huggingface.co/xlnet-base-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7607
- F1: 0.7778
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 288 | 0.4111 | 0.7555 |
| 0.4387 | 2.0 | 576 | 0.4075 | 0.7540 |
| 0.4387 | 3.0 | 864 | 0.5344 | 0.7567 |
| 0.2471 | 4.0 | 1152 | 0.7405 | 0.7597 |
| 0.2471 | 5.0 | 1440 | 1.0564 | 0.7508 |
| 0.1419 | 6.0 | 1728 | 1.0703 | 0.7751 |
| 0.0845 | 7.0 | 2016 | 1.0866 | 0.7609 |
| 0.0845 | 8.0 | 2304 | 1.2135 | 0.7751 |
| 0.05 | 9.0 | 2592 | 1.3649 | 0.7516 |
| 0.05 | 10.0 | 2880 | 1.4943 | 0.7590 |
| 0.0267 | 11.0 | 3168 | 1.5174 | 0.7412 |
| 0.0267 | 12.0 | 3456 | 1.4884 | 0.7559 |
| 0.0278 | 13.0 | 3744 | 1.5109 | 0.7405 |
| 0.0201 | 14.0 | 4032 | 1.7251 | 0.7409 |
| 0.0201 | 15.0 | 4320 | 1.5833 | 0.7354 |
| 0.0185 | 16.0 | 4608 | 1.7744 | 0.7598 |
| 0.0185 | 17.0 | 4896 | 1.8283 | 0.7619 |
| 0.0066 | 18.0 | 5184 | 1.7607 | 0.7778 |
| 0.0066 | 19.0 | 5472 | 1.7503 | 0.7719 |
| 0.0078 | 20.0 | 5760 | 1.7807 | 0.7508 |
| 0.006 | 21.0 | 6048 | 1.6887 | 0.7629 |
| 0.006 | 22.0 | 6336 | 1.7041 | 0.7678 |
| 0.0074 | 23.0 | 6624 | 1.7337 | 0.7633 |
| 0.0074 | 24.0 | 6912 | 1.7548 | 0.7645 |
| 0.0035 | 25.0 | 7200 | 1.7685 | 0.7621 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
distilgpt2 | [
"pytorch",
"tf",
"jax",
"tflite",
"rust",
"coreml",
"safetensors",
"gpt2",
"text-generation",
"en",
"dataset:openwebtext",
"arxiv:1910.01108",
"arxiv:2201.08542",
"arxiv:2203.12574",
"arxiv:1910.09700",
"arxiv:1503.02531",
"transformers",
"exbert",
"license:apache-2.0",
"model-index",
"co2_eq_emissions",
"has_space"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 1,611,668 | 2022-07-31T23:17:27Z | ---
license: mit
---
### marian-mt-en-pcm
* source language: en (English)
* target language: pcm (Nigerian Pidgin)
* dataset: Parallel Sentences from the message translation (English) and Pidgin translation of the Bible.
* model: transformer-align
* pre-processing: normalization + SentencePiece
## Performance
| test set | BLEU |
|---------------------|-------|
| 20% of the bible data | 22 | |
13306330378/huiqi_model | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-08-01T09:05:27Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- wikiann
model-index:
- name: ner_hindi_bert
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ner_hindi_bert
This model is a fine-tuned version of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) on the wikiann dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3713
- Overall Precision: 0.8942
- Overall Recall: 0.8972
- Overall F1: 0.8957
- Overall Accuracy: 0.9367
- Loc F1: 0.8766
- Org F1: 0.8489
- Per F1: 0.9454
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 7
### Training results
| Training Loss | Epoch | Step | Validation Loss | Overall Precision | Overall Recall | Overall F1 | Overall Accuracy | Loc F1 | Org F1 | Per F1 |
|:-------------:|:-----:|:----:|:---------------:|:-----------------:|:--------------:|:----------:|:----------------:|:------:|:------:|:------:|
| 0.2993 | 3.19 | 1000 | 0.3230 | 0.8779 | 0.8786 | 0.8782 | 0.9244 | 0.8535 | 0.8270 | 0.9358 |
| 0.0641 | 6.39 | 2000 | 0.3713 | 0.8942 | 0.8972 | 0.8957 | 0.9367 | 0.8766 | 0.8489 | 0.9454 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Ab2021/bookst5 | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-large-xlsr-korean-demo-with-LM
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xlsr-korean-demo-with-LM
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3015
- Wer: 0.2113
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 4.7496 | 1.08 | 400 | 3.1801 | 1.0 |
| 1.4505 | 2.16 | 800 | 0.5090 | 0.5659 |
| 0.566 | 3.23 | 1200 | 0.3600 | 0.4039 |
| 0.4265 | 4.31 | 1600 | 0.3224 | 0.3639 |
| 0.3611 | 5.39 | 2000 | 0.3152 | 0.3575 |
| 0.3035 | 6.47 | 2400 | 0.2814 | 0.3054 |
| 0.2863 | 7.55 | 2800 | 0.2749 | 0.2923 |
| 0.247 | 8.63 | 3200 | 0.2787 | 0.2884 |
| 0.232 | 9.7 | 3600 | 0.2924 | 0.2788 |
| 0.2069 | 10.78 | 4000 | 0.2668 | 0.2694 |
| 0.1922 | 11.86 | 4400 | 0.2873 | 0.2667 |
| 0.1747 | 12.94 | 4800 | 0.2870 | 0.2589 |
| 0.1755 | 14.02 | 5200 | 0.2778 | 0.2543 |
| 0.1546 | 15.09 | 5600 | 0.3062 | 0.2621 |
| 0.1456 | 16.17 | 6000 | 0.3043 | 0.2479 |
| 0.1404 | 17.25 | 6400 | 0.2885 | 0.2443 |
| 0.1308 | 18.33 | 6800 | 0.3274 | 0.2417 |
| 0.125 | 19.41 | 7200 | 0.2922 | 0.2401 |
| 0.1148 | 20.49 | 7600 | 0.2899 | 0.2300 |
| 0.1129 | 21.56 | 8000 | 0.2963 | 0.2276 |
| 0.1086 | 22.64 | 8400 | 0.2903 | 0.2209 |
| 0.097 | 23.72 | 8800 | 0.3041 | 0.2220 |
| 0.099 | 24.8 | 9200 | 0.2870 | 0.2168 |
| 0.0905 | 25.88 | 9600 | 0.2992 | 0.2176 |
| 0.0929 | 26.95 | 10000 | 0.2934 | 0.2115 |
| 0.0827 | 28.03 | 10400 | 0.2945 | 0.2141 |
| 0.0818 | 29.11 | 10800 | 0.3015 | 0.2113 |
### Usage
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
AdapterHub/bert-base-uncased-pf-emotion | [
"bert",
"en",
"dataset:emotion",
"arxiv:2104.08247",
"adapter-transformers",
"text-classification"
] | text-classification | {
"architectures": null,
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 165 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad_v2_yash
model-index:
- name: distilbert-base-cased-distilled-squad-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-cased-distilled-squad-finetuned-squad
This model is a fine-tuned version of [distilbert-base-cased-distilled-squad](https://huggingface.co/distilbert-base-cased-distilled-squad) on the squad_v2_yash dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 198 | 0.7576 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
AdapterHub/bert-base-uncased-pf-ud_pos | [
"bert",
"en",
"dataset:universal_dependencies",
"arxiv:2104.08247",
"adapter-transformers",
"token-classification",
"adapterhub:pos/ud_ewt"
] | token-classification | {
"architectures": null,
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 1 | null | ---
license: "cc-by-nc-4.0"
tags:
- vision
- video-classification
---
# VideoMAE (large-sized model, pre-trained only)
VideoMAE model pre-trained on Kinetics-400 for 1600 epochs in a self-supervised way. It was introduced in the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Tong et al. and first released in [this repository](https://github.com/MCG-NJU/VideoMAE).
Disclaimer: The team releasing VideoMAE did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
VideoMAE is an extension of [Masked Autoencoders (MAE)](https://arxiv.org/abs/2111.06377) to video. The architecture of the model is very similar to that of a standard Vision Transformer (ViT), with a decoder on top for predicting pixel values for masked patches.
Videos are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds fixed sinus/cosinus position embeddings before feeding the sequence to the layers of the Transformer encoder.
By pre-training the model, it learns an inner representation of videos that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled videos for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire video.
## Intended uses & limitations
You can use the raw model for predicting pixel values for masked patches of a video, but it's mostly intended to be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=videomae) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to predict pixel values for randomly masked patches:
```python
from transformers import VideoMAEImageProcessor, VideoMAEForPreTraining
import numpy as np
import torch
num_frames = 16
video = list(np.random.randn(16, 3, 224, 224))
processor = VideoMAEImageProcessor.from_pretrained("MCG-NJU/videomae-large")
model = VideoMAEForPreTraining.from_pretrained("MCG-NJU/videomae-large")
pixel_values = processor(video, return_tensors="pt").pixel_values
num_patches_per_frame = (model.config.image_size // model.config.patch_size) ** 2
seq_length = (num_frames // model.config.tubelet_size) * num_patches_per_frame
bool_masked_pos = torch.randint(0, 2, (1, seq_length)).bool()
outputs = model(pixel_values, bool_masked_pos=bool_masked_pos)
loss = outputs.loss
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/main/model_doc/videomae.html#).
## Training data
(to do, feel free to open a PR)
## Training procedure
### Preprocessing
(to do, feel free to open a PR)
### Pretraining
(to do, feel free to open a PR)
## Evaluation results
(to do, feel free to open a PR)
### BibTeX entry and citation info
```bibtex
misc{https://doi.org/10.48550/arxiv.2203.12602,
doi = {10.48550/ARXIV.2203.12602},
url = {https://arxiv.org/abs/2203.12602},
author = {Tong, Zhan and Song, Yibing and Wang, Jue and Wang, Limin},
keywords = {Computer Vision and Pattern Recognition (cs.CV), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
``` |
AimB/konlpy_berttokenizer_helsinki | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: chinese-roberta-wwm-ext-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# chinese-roberta-wwm-ext-finetuned
This model is a fine-tuned version of [hfl/chinese-roberta-wwm-ext](https://huggingface.co/hfl/chinese-roberta-wwm-ext) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2139
- Accuracy: 1.0
- F1: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 10
- eval_batch_size: 10
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 1.0107 | 1.0 | 1 | 0.8782 | 0.6 | 0.4500 |
| 0.8418 | 2.0 | 2 | 0.7816 | 0.6 | 0.4500 |
| 0.7572 | 3.0 | 3 | 0.7080 | 0.6 | 0.4500 |
| 0.6794 | 4.0 | 4 | 0.6487 | 0.8 | 0.7810 |
| 0.7444 | 5.0 | 5 | 0.5972 | 0.8 | 0.7810 |
| 0.68 | 6.0 | 6 | 0.5516 | 0.9 | 0.8967 |
| 0.5622 | 7.0 | 7 | 0.5103 | 0.9 | 0.8967 |
| 0.5131 | 8.0 | 8 | 0.4692 | 0.9 | 0.8967 |
| 0.5941 | 9.0 | 9 | 0.4285 | 1.0 | 1.0 |
| 0.5093 | 10.0 | 10 | 0.3899 | 1.0 | 1.0 |
| 0.4149 | 11.0 | 11 | 0.3549 | 1.0 | 1.0 |
| 0.4634 | 12.0 | 12 | 0.3248 | 1.0 | 1.0 |
| 0.3982 | 13.0 | 13 | 0.2985 | 1.0 | 1.0 |
| 0.352 | 14.0 | 14 | 0.2756 | 1.0 | 1.0 |
| 0.3633 | 15.0 | 15 | 0.2570 | 1.0 | 1.0 |
| 0.3729 | 16.0 | 16 | 0.2420 | 1.0 | 1.0 |
| 0.2934 | 17.0 | 17 | 0.2303 | 1.0 | 1.0 |
| 0.308 | 18.0 | 18 | 0.2220 | 1.0 | 1.0 |
| 0.2977 | 19.0 | 19 | 0.2166 | 1.0 | 1.0 |
| 0.2969 | 20.0 | 20 | 0.2139 | 1.0 | 1.0 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.12.0+cu102
- Datasets 1.18.4
- Tokenizers 0.12.1
|
AimB/mT5-en-kr-aihub-netflix | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- metrics:
- type: mean_reward
value: 603.00 +/- 194.90
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
```
# Download model and save it into the logs/ folder
python -m utils.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga kws -f logs/
python enjoy.py --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python train.py --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m utils.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga kws
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 10000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
Akash7897/distilbert-base-uncased-finetuned-cola | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | text-classification | {
"architectures": [
"DistilBertForSequenceClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 31 | null | ---
license: "cc-by-nc-4.0"
tags:
- vision
- video-classification
---
# VideoMAE (base-sized model, pre-trained only)
VideoMAE model pre-trained on Kinetics-400 for 1600 epochs in a self-supervised way. It was introduced in the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Tong et al. and first released in [this repository](https://github.com/MCG-NJU/VideoMAE).
Disclaimer: The team releasing VideoMAE did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
VideoMAE is an extension of [Masked Autoencoders (MAE)](https://arxiv.org/abs/2111.06377) to video. The architecture of the model is very similar to that of a standard Vision Transformer (ViT), with a decoder on top for predicting pixel values for masked patches.
Videos are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds fixed sinus/cosinus position embeddings before feeding the sequence to the layers of the Transformer encoder.
By pre-training the model, it learns an inner representation of videos that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled videos for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire video.
## Intended uses & limitations
You can use the raw model for predicting pixel values for masked patches of a video, but it's mostly intended to be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=videomae) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to predict pixel values for randomly masked patches:
```python
from transformers import VideoMAEImageProcessor, VideoMAEForPreTraining
import numpy as np
import torch
num_frames = 16
video = list(np.random.randn(16, 3, 224, 224))
processor = VideoMAEImageProcessor.from_pretrained("MCG-NJU/videomae-base")
model = VideoMAEForPreTraining.from_pretrained("MCG-NJU/videomae-base")
pixel_values = processor(video, return_tensors="pt").pixel_values
num_patches_per_frame = (model.config.image_size // model.config.patch_size) ** 2
seq_length = (num_frames // model.config.tubelet_size) * num_patches_per_frame
bool_masked_pos = torch.randint(0, 2, (1, seq_length)).bool()
outputs = model(pixel_values, bool_masked_pos=bool_masked_pos)
loss = outputs.loss
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/main/model_doc/videomae.html#).
## Training data
(to do, feel free to open a PR)
## Training procedure
### Preprocessing
(to do, feel free to open a PR)
### Pretraining
(to do, feel free to open a PR)
## Evaluation results
(to do, feel free to open a PR)
### BibTeX entry and citation info
```bibtex
misc{https://doi.org/10.48550/arxiv.2203.12602,
doi = {10.48550/ARXIV.2203.12602},
url = {https://arxiv.org/abs/2203.12602},
author = {Tong, Zhan and Song, Yibing and Wang, Jue and Wang, Limin},
keywords = {Computer Vision and Pattern Recognition (cs.CV), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
``` |
Akashpb13/xlsr_kurmanji_kurdish | [
"pytorch",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"kmr",
"ku",
"dataset:mozilla-foundation/common_voice_8_0",
"transformers",
"mozilla-foundation/common_voice_8_0",
"generated_from_trainer",
"robust-speech-event",
"model_for_talk",
"hf-asr-leaderboard",
"license:apache-2.0",
"model-index"
] | automatic-speech-recognition | {
"architectures": [
"Wav2Vec2ForCTC"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | null | ---
tags:
- fastai
---
# Amazing!
🥳 Congratulations on hosting your fastai model on the Hugging Face Hub!
# Some next steps
1. Fill out this model card with more information (see the template below and the [documentation here](https://huggingface.co/docs/hub/model-repos))!
2. Create a demo in Gradio or Streamlit using 🤗 Spaces ([documentation here](https://huggingface.co/docs/hub/spaces)).
3. Join the fastai community on the [Fastai Discord](https://discord.com/invite/YKrxeNn)!
Greetings fellow fastlearner 🤝! Don't forget to delete this content from your model card.
---
# Model card
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
|
Akashpb13/xlsr_maltese_wav2vec2 | [
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"mt",
"dataset:common_voice",
"transformers",
"audio",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0",
"model-index"
] | automatic-speech-recognition | {
"architectures": [
"Wav2Vec2ForCTC"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-fr-en
* source languages: fr
* target languages: en
* OPUS readme: [fr-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/fr-en/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-02-26.zip](https://object.pouta.csc.fi/OPUS-MT-models/fr-en/opus-2020-02-26.zip)
* test set translations: [opus-2020-02-26.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/fr-en/opus-2020-02-26.test.txt)
* test set scores: [opus-2020-02-26.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/fr-en/opus-2020-02-26.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| newsdiscussdev2015-enfr.fr.en | 33.1 | 0.580 |
| newsdiscusstest2015-enfr.fr.en | 38.7 | 0.614 |
| newssyscomb2009.fr.en | 30.3 | 0.569 |
| news-test2008.fr.en | 26.2 | 0.542 |
| newstest2009.fr.en | 30.2 | 0.570 |
| newstest2010.fr.en | 32.2 | 0.590 |
| newstest2011.fr.en | 33.0 | 0.597 |
| newstest2012.fr.en | 32.8 | 0.591 |
| newstest2013.fr.en | 33.9 | 0.591 |
| newstest2014-fren.fr.en | 37.8 | 0.633 |
| Tatoeba.fr.en | 57.5 | 0.720 |
|
Akira-Yana/distilbert-base-uncased-finetuned-cola | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: distilbert-base-uncased_fold_8_binary_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased_fold_8_binary_v1
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6283
- F1: 0.8178
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 290 | 0.4038 | 0.7981 |
| 0.409 | 2.0 | 580 | 0.4023 | 0.8176 |
| 0.409 | 3.0 | 870 | 0.5245 | 0.8169 |
| 0.1938 | 4.0 | 1160 | 0.6242 | 0.8298 |
| 0.1938 | 5.0 | 1450 | 0.8432 | 0.8159 |
| 0.0848 | 6.0 | 1740 | 1.0887 | 0.8015 |
| 0.038 | 7.0 | 2030 | 1.0700 | 0.8167 |
| 0.038 | 8.0 | 2320 | 1.0970 | 0.8241 |
| 0.0159 | 9.0 | 2610 | 1.2474 | 0.8142 |
| 0.0159 | 10.0 | 2900 | 1.3453 | 0.8184 |
| 0.01 | 11.0 | 3190 | 1.4412 | 0.8147 |
| 0.01 | 12.0 | 3480 | 1.4263 | 0.8181 |
| 0.007 | 13.0 | 3770 | 1.3859 | 0.8258 |
| 0.0092 | 14.0 | 4060 | 1.4633 | 0.8128 |
| 0.0092 | 15.0 | 4350 | 1.4304 | 0.8206 |
| 0.0096 | 16.0 | 4640 | 1.5081 | 0.8149 |
| 0.0096 | 17.0 | 4930 | 1.5239 | 0.8189 |
| 0.0047 | 18.0 | 5220 | 1.5268 | 0.8151 |
| 0.0053 | 19.0 | 5510 | 1.5445 | 0.8173 |
| 0.0053 | 20.0 | 5800 | 1.6051 | 0.8180 |
| 0.0014 | 21.0 | 6090 | 1.5981 | 0.8211 |
| 0.0014 | 22.0 | 6380 | 1.5957 | 0.8225 |
| 0.001 | 23.0 | 6670 | 1.5838 | 0.8189 |
| 0.001 | 24.0 | 6960 | 1.6301 | 0.8178 |
| 0.0018 | 25.0 | 7250 | 1.6283 | 0.8178 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Akiva/Joke | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: distilbert-base-uncased_fold_9_binary_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased_fold_9_binary_v1
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6965
- F1: 0.8090
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 291 | 0.4193 | 0.7989 |
| 0.3993 | 2.0 | 582 | 0.4039 | 0.8026 |
| 0.3993 | 3.0 | 873 | 0.5227 | 0.7995 |
| 0.2044 | 4.0 | 1164 | 0.7264 | 0.8011 |
| 0.2044 | 5.0 | 1455 | 0.8497 | 0.8007 |
| 0.0882 | 6.0 | 1746 | 0.9543 | 0.8055 |
| 0.0374 | 7.0 | 2037 | 1.1349 | 0.7997 |
| 0.0374 | 8.0 | 2328 | 1.3175 | 0.8009 |
| 0.0151 | 9.0 | 2619 | 1.3585 | 0.8030 |
| 0.0151 | 10.0 | 2910 | 1.4202 | 0.8067 |
| 0.0068 | 11.0 | 3201 | 1.4364 | 0.8108 |
| 0.0068 | 12.0 | 3492 | 1.4443 | 0.8088 |
| 0.0096 | 13.0 | 3783 | 1.5308 | 0.8075 |
| 0.0031 | 14.0 | 4074 | 1.5061 | 0.8020 |
| 0.0031 | 15.0 | 4365 | 1.5769 | 0.7980 |
| 0.0048 | 16.0 | 4656 | 1.5962 | 0.8038 |
| 0.0048 | 17.0 | 4947 | 1.5383 | 0.8085 |
| 0.0067 | 18.0 | 5238 | 1.5456 | 0.8158 |
| 0.0062 | 19.0 | 5529 | 1.6325 | 0.8044 |
| 0.0062 | 20.0 | 5820 | 1.5430 | 0.8141 |
| 0.0029 | 21.0 | 6111 | 1.6590 | 0.8117 |
| 0.0029 | 22.0 | 6402 | 1.6650 | 0.8112 |
| 0.0017 | 23.0 | 6693 | 1.7016 | 0.8053 |
| 0.0017 | 24.0 | 6984 | 1.6998 | 0.8090 |
| 0.0011 | 25.0 | 7275 | 1.6965 | 0.8090 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Akjder/DialoGPT-small-harrypotter | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
annotations_creators: []
language:
- ro
language_creators:
- machine-generated
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: BlackKakapo/t5-small-paraphrase-ro
size_categories:
- 10K<n<100K
source_datasets:
- original
tags: []
task_categories:
- text2text-generation
task_ids: []
---
# Romanian paraphrase

Fine-tune t5-small model for paraphrase. Since there is no Romanian dataset for paraphrasing, I had to create my own [dataset](https://huggingface.co/datasets/BlackKakapo/paraphrase-ro-v1). The dataset contains ~60k examples.
### How to use
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("BlackKakapo/t5-small-paraphrase-ro")
model = AutoModelForSeq2SeqLM.from_pretrained("BlackKakapo/t5-small-paraphrase-ro")
```
### Or
```python
from transformers import T5ForConditionalGeneration, T5TokenizerFast
model = T5ForConditionalGeneration.from_pretrained("BlackKakapo/t5-small-paraphrase-ro")
tokenizer = T5TokenizerFast.from_pretrained("BlackKakapo/t5-small-paraphrase-ro")
```
### Generate
```python
text = "Am impresia că fac multe greșeli."
encoding = tokenizer.encode_plus(text, pad_to_max_length=True, return_tensors="pt")
input_ids, attention_masks = encoding["input_ids"].to(device), encoding["attention_mask"].to(device)
beam_outputs = model.generate(
input_ids=input_ids,
attention_mask=attention_masks,
do_sample=True,
max_length=256,
top_k=10,
top_p=0.9,
early_stopping=False,
num_return_sequences=5
)
for beam_output in beam_outputs:
text_para = tokenizer.decode(beam_output, skip_special_tokens=True,clean_up_tokenization_spaces=True)
if text.lower() != text_para.lower() or text not in final_outputs:
final_outputs.append(text_para)
break
print(final_outputs)
```
### Output
```out
['Cred că fac multe greșeli.']
``` |
Aklily/Lilys | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4721
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.7086 | 1.0 | 157 | 2.4898 |
| 2.5796 | 2.0 | 314 | 2.4230 |
| 2.5269 | 3.0 | 471 | 2.4354 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
AkshatSurolia/BEiT-FaceMask-Finetuned | [
"pytorch",
"beit",
"image-classification",
"dataset:Face-Mask18K",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | image-classification | {
"architectures": [
"BeitForImageClassification"
],
"model_type": "beit",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 239 | null | ---
language:
- ru
tags:
- PyTorch
- OCR
- Segmentation
- HTR
datasets:
- "sberbank-ai/school_notebooks_RU"
- "sberbank-ai/school_notebooks_EN"
license: mit
---
This is a weights storage for models trained by [ReadingPipeline](https://github.com/ai-forever/ReadingPipeline)
The weights are for ocr and segmentations models trained on [school notebooks dataset](https://huggingface.co/datasets/sberbank-ai/school_notebooks_RU)
|
AkshatSurolia/ConvNeXt-FaceMask-Finetuned | [
"pytorch",
"safetensors",
"convnext",
"image-classification",
"dataset:Face-Mask18K",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | image-classification | {
"architectures": [
"ConvNextForImageClassification"
],
"model_type": "convnext",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 56 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: distilbert-base-uncased_fold_10_binary_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased_fold_10_binary_v1
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6912
- F1: 0.7977
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 288 | 0.4002 | 0.8012 |
| 0.4056 | 2.0 | 576 | 0.4372 | 0.8075 |
| 0.4056 | 3.0 | 864 | 0.4720 | 0.8071 |
| 0.1958 | 4.0 | 1152 | 0.8156 | 0.7980 |
| 0.1958 | 5.0 | 1440 | 0.8633 | 0.8055 |
| 0.0847 | 6.0 | 1728 | 0.9761 | 0.8041 |
| 0.0356 | 7.0 | 2016 | 1.1816 | 0.7861 |
| 0.0356 | 8.0 | 2304 | 1.2251 | 0.7918 |
| 0.0215 | 9.0 | 2592 | 1.3423 | 0.7798 |
| 0.0215 | 10.0 | 2880 | 1.3888 | 0.7913 |
| 0.013 | 11.0 | 3168 | 1.2899 | 0.8040 |
| 0.013 | 12.0 | 3456 | 1.4247 | 0.8051 |
| 0.0049 | 13.0 | 3744 | 1.5436 | 0.7991 |
| 0.0061 | 14.0 | 4032 | 1.5762 | 0.7991 |
| 0.0061 | 15.0 | 4320 | 1.5461 | 0.7998 |
| 0.0054 | 16.0 | 4608 | 1.5622 | 0.8018 |
| 0.0054 | 17.0 | 4896 | 1.6658 | 0.7991 |
| 0.0021 | 18.0 | 5184 | 1.6765 | 0.7972 |
| 0.0021 | 19.0 | 5472 | 1.6864 | 0.7973 |
| 0.0052 | 20.0 | 5760 | 1.6303 | 0.8030 |
| 0.0029 | 21.0 | 6048 | 1.6631 | 0.7947 |
| 0.0029 | 22.0 | 6336 | 1.6571 | 0.8006 |
| 0.0027 | 23.0 | 6624 | 1.6729 | 0.7949 |
| 0.0027 | 24.0 | 6912 | 1.6931 | 0.7934 |
| 0.0001 | 25.0 | 7200 | 1.6912 | 0.7977 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
AlanDev/test | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | git lfs install
git clone https://huggingface.co/Saraswati/ppo-CartPole-v2 |
AlbertHSU/ChineseFoodBert | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 15 | null | ---
language:
- hr
library_name: nemo
datasets:
- ParlaSpeech-HR-v1.0
thumbnail: null
tags:
- automatic-speech-recognition
- speech
- audio
- Transducer
- Conformer
- Transformer
- pytorch
- NeMo
- hf-asr-leaderboard
license: cc-by-4.0
---
# NVIDIA Conformer-Transducer Large (Croatian)
<style>
img {
display: inline;
}
</style>
| [](#model-architecture)
| [](#model-architecture)
| [](#datasets) |
This model transcribes speech in lowercase Croatian alphabet including spaces, and is trained on around 1665 hours of Croatian speech data.
It is a "large" variant of Conformer-Transducer, with around 120 million parameters.
See the [model architecture](#model-architecture) section and [NeMo documentation](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/main/asr/models.html#conformer-transducer) for complete architecture details.
It is also compatible with NVIDIA Riva for [production-grade server deployments](#deployment-with-nvidia-riva).
## Usage
The model is available for use in the NeMo toolkit [3], and can be used as a pre-trained checkpoint for inference or for fine-tuning on another dataset.
To train, fine-tune or play with the model you will need to install [NVIDIA NeMo](https://github.com/NVIDIA/NeMo). We recommend you install it after you've installed latest PyTorch version.
```
pip install nemo_toolkit['all']
```
### Automatically instantiate the model
```python
import nemo.collections.asr as nemo_asr
asr_model = nemo_asr.models.EncDecRNNTBPEModel.from_pretrained("nvidia/stt_hr_conformer_transducer_large")
```
### Transcribing using Python
Simply do:
```
asr_model.transcribe(['<your_audio>.wav'])
```
### Transcribing many audio files
```shell
python [NEMO_GIT_FOLDER]/examples/asr/transcribe_speech.py
pretrained_name="nvidia/stt_hr_conformer_transducer_large"
audio_dir="<DIRECTORY CONTAINING AUDIO FILES>"
```
### Input
This model accepts 16 kHz single-channel audio as input.
### Output
This model provides transcribed speech as a string for a given audio sample.
## Model Architecture
Conformer-Transducer model is an autoregressive variant of Conformer model [1] for Automatic Speech Recognition which uses Transducer loss/decoding. You may find more info on the detail of this model here: [Conformer-Transducer Model](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/main/asr/models.html#conformer-transducer).
## Training
The NeMo toolkit [3] was used for training the models for over several hundred epochs. These model are trained with this [example script](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/asr_ctc/speech_to_text_rnnt_bpe.py) and this [base config](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/conf/conformer/conformer_transducer_bpe.yaml).
The tokenizers for these models were built using the text transcripts of the train set with this [script](https://github.com/NVIDIA/NeMo/blob/main/scripts/tokenizers/process_asr_text_tokenizer.py).
The vocabulary we use contains 27 characters:
```python
[' ', 'a', 'b', 'c', 'č', 'ć', 'd', 'đ', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'r', 's', 'š', 't', 'u', 'v', 'z', 'ž']
```
Full config can be found inside the `.nemo` files.
### Datasets
All the models in this collection are trained on ParlaSpeech-HR v1.0 Croatian dataset, which contains around 1665 hours of training data, 2.2 hours of development and 2.3 hours of test data after data cleaning.
## Performance
The list of the available models in this collection is shown in the following table. Performances of the ASR models are reported in terms of Word Error Rate (WER%) with greedy decoding.
| Version | Tokenizer | Vocabulary Size | Dev WER | Test WER | Train Dataset |
|---------|-----------------------|-----------------|---------|----------|---------------------|
| 1.11.0 | SentencePiece Unigram | 128 | 4.56 | 4.69 | ParlaSpeech-HR v1.0 |
You may use language models (LMs) and beam search to improve the accuracy of the models.
## Limitations
Since the model is trained just on ParlaSpeech-HR v1.0 dataset, the performance of this model might degrade for speech which includes terms, or vernacular that the model has not been trained on. The model might also perform worse for accented speech.
## References
- [1] [Conformer: Convolution-augmented Transformer for Speech Recognition](https://arxiv.org/abs/2005.08100)
- [2] [Google Sentencepiece Tokenizer](https://github.com/google/sentencepiece)
- [3] [NVIDIA NeMo Toolkit](https://github.com/NVIDIA/NeMo) |
Alberto15Romero/GptNeo | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: categorization-finetuned-20220721-164940-pruned-20220803-123018
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# categorization-finetuned-20220721-164940-pruned-20220803-123018
This model is a fine-tuned version of [carted-nlp/categorization-finetuned-20220721-164940](https://huggingface.co/carted-nlp/categorization-finetuned-20220721-164940) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5476
- Accuracy: 0.8558
- F1: 0.8539
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7e-06
- train_batch_size: 48
- eval_batch_size: 48
- seed: 314
- gradient_accumulation_steps: 6
- total_train_batch_size: 288
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 500
- num_epochs: 15
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:------:|
| 0.3421 | 0.51 | 2000 | 0.4324 | 0.8871 | 0.8864 |
| 0.3435 | 1.01 | 4000 | 0.4276 | 0.8885 | 0.8878 |
| 0.327 | 1.52 | 6000 | 0.4300 | 0.8891 | 0.8884 |
| 0.3299 | 2.02 | 8000 | 0.4266 | 0.8891 | 0.8885 |
| 0.3217 | 2.53 | 10000 | 0.4303 | 0.8881 | 0.8873 |
| 0.3347 | 3.04 | 12000 | 0.4291 | 0.8885 | 0.8879 |
| 0.3307 | 3.54 | 14000 | 0.4334 | 0.8873 | 0.8867 |
| 0.3537 | 4.05 | 16000 | 0.4340 | 0.8850 | 0.8844 |
| 0.3659 | 4.56 | 18000 | 0.4426 | 0.8828 | 0.8819 |
| 0.3933 | 5.06 | 20000 | 0.4485 | 0.8805 | 0.8796 |
| 0.4117 | 5.57 | 22000 | 0.4553 | 0.8779 | 0.8768 |
| 0.4501 | 6.07 | 24000 | 0.4734 | 0.8734 | 0.8725 |
| 0.4848 | 6.58 | 26000 | 0.4895 | 0.8690 | 0.8678 |
| 0.5182 | 7.09 | 28000 | 0.5137 | 0.8634 | 0.8617 |
| 0.54 | 7.59 | 30000 | 0.5165 | 0.8625 | 0.8610 |
| 0.5582 | 8.1 | 32000 | 0.5312 | 0.8591 | 0.8572 |
| 0.5728 | 8.61 | 34000 | 0.5382 | 0.8574 | 0.8556 |
| 0.5883 | 9.11 | 36000 | 0.5514 | 0.8553 | 0.8534 |
| 0.5942 | 9.62 | 38000 | 0.5563 | 0.8534 | 0.8512 |
| 0.6015 | 10.12 | 40000 | 0.5592 | 0.8536 | 0.8516 |
| 0.603 | 10.63 | 42000 | 0.5585 | 0.8533 | 0.8513 |
| 0.5972 | 11.14 | 44000 | 0.5585 | 0.8541 | 0.8520 |
| 0.5938 | 11.64 | 46000 | 0.5546 | 0.8548 | 0.8529 |
| 0.5882 | 12.15 | 48000 | 0.5515 | 0.8554 | 0.8535 |
| 0.5799 | 12.65 | 50000 | 0.5488 | 0.8561 | 0.8541 |
| 0.572 | 13.16 | 52000 | 0.5473 | 0.8566 | 0.8547 |
| 0.5718 | 13.67 | 54000 | 0.5468 | 0.8566 | 0.8547 |
| 0.5698 | 14.17 | 56000 | 0.5464 | 0.8566 | 0.8547 |
| 0.5696 | 14.68 | 58000 | 0.5464 | 0.8566 | 0.8547 |
### Framework versions
- Transformers 4.18.0.dev0
- Pytorch 1.9.1+cu111
- Datasets 2.3.2
- Tokenizers 0.11.6
|
AlchemistDude/DialoGPT-medium-Gon | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: distilbert-base-uncased_fold_13_binary_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased_fold_13_binary_v1
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7433
- F1: 0.8138
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 291 | 0.4101 | 0.8087 |
| 0.4128 | 2.0 | 582 | 0.4605 | 0.8197 |
| 0.4128 | 3.0 | 873 | 0.5011 | 0.8130 |
| 0.1997 | 4.0 | 1164 | 0.6882 | 0.8147 |
| 0.1997 | 5.0 | 1455 | 0.9653 | 0.8092 |
| 0.0913 | 6.0 | 1746 | 1.1020 | 0.8031 |
| 0.0347 | 7.0 | 2037 | 1.2687 | 0.8050 |
| 0.0347 | 8.0 | 2328 | 1.2383 | 0.8103 |
| 0.0173 | 9.0 | 2619 | 1.3631 | 0.8066 |
| 0.0173 | 10.0 | 2910 | 1.4282 | 0.8001 |
| 0.0104 | 11.0 | 3201 | 1.4410 | 0.8179 |
| 0.0104 | 12.0 | 3492 | 1.5318 | 0.8018 |
| 0.0063 | 13.0 | 3783 | 1.5866 | 0.8018 |
| 0.0043 | 14.0 | 4074 | 1.4987 | 0.8159 |
| 0.0043 | 15.0 | 4365 | 1.6275 | 0.8181 |
| 0.0048 | 16.0 | 4656 | 1.5811 | 0.8231 |
| 0.0048 | 17.0 | 4947 | 1.6228 | 0.8182 |
| 0.0048 | 18.0 | 5238 | 1.7235 | 0.8138 |
| 0.0055 | 19.0 | 5529 | 1.7018 | 0.8066 |
| 0.0055 | 20.0 | 5820 | 1.7340 | 0.8069 |
| 0.0046 | 21.0 | 6111 | 1.7143 | 0.8156 |
| 0.0046 | 22.0 | 6402 | 1.7367 | 0.8159 |
| 0.0037 | 23.0 | 6693 | 1.7551 | 0.8151 |
| 0.0037 | 24.0 | 6984 | 1.7479 | 0.8145 |
| 0.0009 | 25.0 | 7275 | 1.7433 | 0.8138 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Aleksandar/distilbert-srb-ner-setimes | [
"pytorch",
"distilbert",
"token-classification",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"DistilBertForTokenClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
language: zh
widget:
- text: "江苏警方通报特斯拉冲进店铺"
---
# Chinese RoBERTa-Base Model for NER
## Model description
The model is used for named entity recognition. You can download the model either from the [UER-py Modelzoo page](https://github.com/dbiir/UER-py/wiki/Modelzoo) (in UER-py format), or via HuggingFace from the link [roberta-base-finetuned-cluener2020-chinese](https://huggingface.co/uer/roberta-base-finetuned-cluener2020-chinese).
## How to use
You can use this model directly with a pipeline for token classification :
```python
>>> from transformers import AutoModelForTokenClassification,AutoTokenizer,pipeline
>>> model = AutoModelForTokenClassification.from_pretrained('uer/roberta-base-finetuned-cluener2020-chinese')
>>> tokenizer = AutoTokenizer.from_pretrained('uer/roberta-base-finetuned-cluener2020-chinese')
>>> ner = pipeline('ner', model=model, tokenizer=tokenizer)
>>> ner("江苏警方通报特斯拉冲进店铺")
[
{'word': '江', 'score': 0.49153077602386475, 'entity': 'B-address', 'index': 1, 'start': 0, 'end': 1},
{'word': '苏', 'score': 0.6319217681884766, 'entity': 'I-address', 'index': 2, 'start': 1, 'end': 2},
{'word': '特', 'score': 0.5912262797355652, 'entity': 'B-company', 'index': 7, 'start': 6, 'end': 7},
{'word': '斯', 'score': 0.69145667552948, 'entity': 'I-company', 'index': 8, 'start': 7, 'end': 8},
{'word': '拉', 'score': 0.7054660320281982, 'entity': 'I-company', 'index': 9, 'start': 8, 'end': 9}
]
```
## Training data
[CLUENER2020](https://github.com/CLUEbenchmark/CLUENER2020) is used as training data. We only use the train set of the dataset.
## Training procedure
The model is fine-tuned by [UER-py](https://github.com/dbiir/UER-py/) on [Tencent Cloud](https://cloud.tencent.com/). We fine-tune five epochs with a sequence length of 512 on the basis of the pre-trained model [chinese_roberta_L-12_H-768](https://huggingface.co/uer/chinese_roberta_L-12_H-768). At the end of each epoch, the model is saved when the best performance on development set is achieved.
```
python3 run_ner.py --pretrained_model_path models/cluecorpussmall_roberta_base_seq512_model.bin-250000 \
--vocab_path models/google_zh_vocab.txt \
--train_path datasets/cluener2020/train.tsv \
--dev_path datasets/cluener2020/dev.tsv \
--label2id_path datasets/cluener2020/label2id.json \
--output_model_path models/cluener2020_ner_model.bin \
--learning_rate 3e-5 --epochs_num 5 --batch_size 32 --seq_length 512
```
Finally, we convert the pre-trained model into Huggingface's format:
```
python3 scripts/convert_bert_token_classification_from_uer_to_huggingface.py --input_model_path models/cluener2020_ner_model.bin \
--output_model_path pytorch_model.bin \
--layers_num 12
```
### BibTeX entry and citation info
```
@article{devlin2018bert,
title={BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding},
author={Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1810.04805},
year={2018}
}
@article{liu2019roberta,
title={Roberta: A robustly optimized bert pretraining approach},
author={Liu, Yinhan and Ott, Myle and Goyal, Naman and Du, Jingfei and Joshi, Mandar and Chen, Danqi and Levy, Omer and Lewis, Mike and Zettlemoyer, Luke and Stoyanov, Veselin},
journal={arXiv preprint arXiv:1907.11692},
year={2019}
}
@article{xu2020cluener2020,
title={CLUENER2020: Fine-grained Name Entity Recognition for Chinese},
author={Xu, Liang and Dong, Qianqian and Yu, Cong and Tian, Yin and Liu, Weitang and Li, Lu and Zhang, Xuanwei},
journal={arXiv preprint arXiv:2001.04351},
year={2020}
}
@article{zhao2019uer,
title={UER: An Open-Source Toolkit for Pre-training Models},
author={Zhao, Zhe and Chen, Hui and Zhang, Jinbin and Zhao, Xin and Liu, Tao and Lu, Wei and Chen, Xi and Deng, Haotang and Ju, Qi and Du, Xiaoyong},
journal={EMNLP-IJCNLP 2019},
pages={241},
year={2019}
}
``` |
Alicanke/Wyau | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- autotrain
- text-classification
language:
- en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- BenWord/autotrain-data-APMv2Multiclass
co2_eq_emissions:
emissions: 2.4364900803769225
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 1216046004
- CO2 Emissions (in grams): 2.4365
## Validation Metrics
- Loss: 0.094
- Accuracy: 1.000
- Macro F1: 1.000
- Micro F1: 1.000
- Weighted F1: 1.000
- Macro Precision: 1.000
- Micro Precision: 1.000
- Weighted Precision: 1.000
- Macro Recall: 1.000
- Micro Recall: 1.000
- Weighted Recall: 1.000
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/BenWord/autotrain-APMv2Multiclass-1216046004
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("BenWord/autotrain-APMv2Multiclass-1216046004", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("BenWord/autotrain-APMv2Multiclass-1216046004", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
``` |
Alifarsi/t5-small-finetuned-xsum | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: Bio_ClinicalBERT_fold_3_binary_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Bio_ClinicalBERT_fold_3_binary_v1
This model is a fine-tuned version of [emilyalsentzer/Bio_ClinicalBERT](https://huggingface.co/emilyalsentzer/Bio_ClinicalBERT) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8860
- F1: 0.8051
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 289 | 0.4493 | 0.7916 |
| 0.3975 | 2.0 | 578 | 0.4608 | 0.7909 |
| 0.3975 | 3.0 | 867 | 0.8364 | 0.7726 |
| 0.1885 | 4.0 | 1156 | 1.0380 | 0.7902 |
| 0.1885 | 5.0 | 1445 | 1.1612 | 0.7921 |
| 0.0692 | 6.0 | 1734 | 1.3894 | 0.7761 |
| 0.0295 | 7.0 | 2023 | 1.3730 | 0.7864 |
| 0.0295 | 8.0 | 2312 | 1.4131 | 0.7939 |
| 0.0161 | 9.0 | 2601 | 1.5538 | 0.7929 |
| 0.0161 | 10.0 | 2890 | 1.6417 | 0.7931 |
| 0.006 | 11.0 | 3179 | 1.5745 | 0.7974 |
| 0.006 | 12.0 | 3468 | 1.7212 | 0.7908 |
| 0.0132 | 13.0 | 3757 | 1.7349 | 0.7945 |
| 0.0062 | 14.0 | 4046 | 1.7593 | 0.7908 |
| 0.0062 | 15.0 | 4335 | 1.7420 | 0.8035 |
| 0.0073 | 16.0 | 4624 | 1.7620 | 0.8007 |
| 0.0073 | 17.0 | 4913 | 1.8286 | 0.7908 |
| 0.0033 | 18.0 | 5202 | 1.7863 | 0.7977 |
| 0.0033 | 19.0 | 5491 | 1.9275 | 0.7919 |
| 0.0035 | 20.0 | 5780 | 1.8481 | 0.8042 |
| 0.0035 | 21.0 | 6069 | 1.9465 | 0.8012 |
| 0.0035 | 22.0 | 6358 | 1.8177 | 0.8044 |
| 0.005 | 23.0 | 6647 | 1.8615 | 0.8030 |
| 0.005 | 24.0 | 6936 | 1.8427 | 0.8054 |
| 0.0011 | 25.0 | 7225 | 1.8860 | 0.8051 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Alireza1044/albert-base-v2-cola | [
"pytorch",
"tensorboard",
"albert",
"text-classification",
"en",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0"
] | text-classification | {
"architectures": [
"AlbertForSequenceClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 32 | null | ---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: Bio_ClinicalBERT_fold_4_binary_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Bio_ClinicalBERT_fold_4_binary_v1
This model is a fine-tuned version of [emilyalsentzer/Bio_ClinicalBERT](https://huggingface.co/emilyalsentzer/Bio_ClinicalBERT) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4627
- F1: 0.8342
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 289 | 0.3641 | 0.8394 |
| 0.3953 | 2.0 | 578 | 0.3729 | 0.8294 |
| 0.3953 | 3.0 | 867 | 0.6156 | 0.8126 |
| 0.189 | 4.0 | 1156 | 0.7389 | 0.8326 |
| 0.189 | 5.0 | 1445 | 0.8925 | 0.8322 |
| 0.0783 | 6.0 | 1734 | 1.0909 | 0.8196 |
| 0.0219 | 7.0 | 2023 | 1.1241 | 0.8346 |
| 0.0219 | 8.0 | 2312 | 1.2684 | 0.8130 |
| 0.0136 | 9.0 | 2601 | 1.2615 | 0.8202 |
| 0.0136 | 10.0 | 2890 | 1.2477 | 0.8401 |
| 0.0143 | 11.0 | 3179 | 1.3211 | 0.8254 |
| 0.0143 | 12.0 | 3468 | 1.2627 | 0.8286 |
| 0.0165 | 13.0 | 3757 | 1.3804 | 0.8264 |
| 0.006 | 14.0 | 4046 | 1.3213 | 0.8414 |
| 0.006 | 15.0 | 4335 | 1.3152 | 0.8427 |
| 0.0117 | 16.0 | 4624 | 1.3373 | 0.8368 |
| 0.0117 | 17.0 | 4913 | 1.3599 | 0.8406 |
| 0.0021 | 18.0 | 5202 | 1.4072 | 0.8237 |
| 0.0021 | 19.0 | 5491 | 1.3893 | 0.8336 |
| 0.0045 | 20.0 | 5780 | 1.4331 | 0.8391 |
| 0.0049 | 21.0 | 6069 | 1.4128 | 0.8370 |
| 0.0049 | 22.0 | 6358 | 1.4660 | 0.8356 |
| 0.0029 | 23.0 | 6647 | 1.4721 | 0.8388 |
| 0.0029 | 24.0 | 6936 | 1.4636 | 0.8329 |
| 0.0023 | 25.0 | 7225 | 1.4627 | 0.8342 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Allybaby21/Allysai | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- generated_from_keras_callback
model-index:
- name: mal_tls-bert-base-relu-w1q8
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# mal_tls-bert-base-relu-w1q8
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.15.0
- TensorFlow 2.6.4
- Datasets 2.1.0
- Tokenizers 0.10.3
|
Alvenir/wav2vec2-base-da | [
"pytorch",
"wav2vec2",
"pretraining",
"da",
"transformers",
"speech",
"license:apache-2.0"
] | null | {
"architectures": [
"Wav2Vec2ForPreTraining"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 62 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: output
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# output
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2822
- Wer: 0.2423
- Cer: 0.0842
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
I have used dataset other than mozila common voice, thats why for fair evaluation, i do 80:20 split.
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 48
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 192
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 15
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Cer | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:------:|:---------------:|:------:|
| No log | 1.0 | 174 | 0.9860 | 3.1257 | 1.0 |
| No log | 2.0 | 348 | 0.9404 | 2.4914 | 0.9997 |
| No log | 3.0 | 522 | 0.1889 | 0.5970 | 0.5376 |
| No log | 4.0 | 696 | 0.1428 | 0.4462 | 0.4121 |
| No log | 5.0 | 870 | 0.1211 | 0.3775 | 0.3525 |
| 1.7 | 6.0 | 1044 | 0.1113 | 0.3594 | 0.3264 |
| 1.7 | 7.0 | 1218 | 0.1032 | 0.3354 | 0.3013 |
| 1.7 | 8.0 | 1392 | 0.1005 | 0.3171 | 0.2843 |
| 1.7 | 9.0 | 1566 | 0.0953 | 0.3115 | 0.2717 |
| 1.7 | 10.0 | 1740 | 0.0934 | 0.3058 | 0.2671 |
| 1.7 | 11.0 | 1914 | 0.0926 | 0.3060 | 0.2656 |
| 0.3585 | 12.0 | 2088 | 0.0899 | 0.3070 | 0.2566 |
| 0.3585 | 13.0 | 2262 | 0.0888 | 0.2979 | 0.2509 |
| 0.3585 | 14.0 | 2436 | 0.0868 | 0.3005 | 0.2473 |
| 0.3585 | 15.0 | 2610 | 0.2822 | 0.2423 | 0.0842 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0
- Datasets 2.4.0
- Tokenizers 0.12.1
|
AmitT/test | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1552061223864127488/Y-7S0UTB_400x400.png')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1529956155937759233/Nyn1HZWF_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1157286539036020737/5TQyrkEw_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Feather of the One & Elon Musk & KAILASA's SPH Nithyananda</div>
<div style="text-align: center; font-size: 14px;">@elonmusk-srinithyananda-yeshuaissavior</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Feather of the One & Elon Musk & KAILASA's SPH Nithyananda.
| Data | Feather of the One | Elon Musk | KAILASA's SPH Nithyananda |
| --- | --- | --- | --- |
| Tweets downloaded | 505 | 3200 | 3250 |
| Retweets | 29 | 128 | 6 |
| Short tweets | 175 | 982 | 523 |
| Tweets kept | 301 | 2090 | 2721 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1wthdqz7/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @elonmusk-srinithyananda-yeshuaissavior's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/18cn8xoz) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/18cn8xoz/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/elonmusk-srinithyananda-yeshuaissavior')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Amitabh/doc-classification | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- generated_from_trainer
model-index:
- name: protBERTbfd_AAV2_regressor
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# protBERTbfd_AAV2_regressor
This model is a fine-tuned version of [Rostlab/prot_bert_bfd](https://huggingface.co/Rostlab/prot_bert_bfd) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0327
- Mse: 0.0327
- Rmse: 0.1808
- Mae: 0.0618
- R2: 0.8691
- Smape: 101.2324
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- gradient_accumulation_steps: 64
- total_train_batch_size: 4096
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- num_epochs: 6
### Training results
| Training Loss | Epoch | Step | Validation Loss | Mse | Rmse | Mae | R2 | Smape |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:------:|:--------:|
| No log | 1.0 | 58 | 0.0985 | 0.0985 | 0.3138 | 0.1707 | 0.6057 | 102.5806 |
| No log | 2.0 | 116 | 0.0689 | 0.0689 | 0.2625 | 0.1432 | 0.7242 | 112.9846 |
| No log | 3.0 | 174 | 0.0400 | 0.0400 | 0.1999 | 0.0859 | 0.8399 | 102.6132 |
| No log | 4.0 | 232 | 0.0402 | 0.0402 | 0.2005 | 0.0745 | 0.8389 | 103.3228 |
| No log | 5.0 | 290 | 0.0337 | 0.0337 | 0.1836 | 0.0665 | 0.8650 | 101.0925 |
| No log | 6.0 | 348 | 0.0327 | 0.0327 | 0.1808 | 0.0618 | 0.8691 | 101.2324 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
AnonymousSub/AR_rule_based_roberta_only_classfn_twostage_epochs_1_shard_10 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | null | ---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: silviacamplani/distilbert-base-uncased-finetuned-dapt-ner-ai_data
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# silviacamplani/distilbert-base-uncased-finetuned-dapt-ner-ai_data
This model is a fine-tuned version of [silviacamplani/distilbert-base-uncased-finetuned-ai_data](https://huggingface.co/silviacamplani/distilbert-base-uncased-finetuned-ai_data) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 2.3549
- Validation Loss: 2.3081
- Train Precision: 0.0
- Train Recall: 0.0
- Train F1: 0.0
- Train Accuracy: 0.6392
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'inner_optimizer': {'class_name': 'AdamWeightDecay', 'config': {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 18, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}}, 'dynamic': True, 'initial_scale': 32768.0, 'dynamic_growth_steps': 2000}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Train Precision | Train Recall | Train F1 | Train Accuracy | Epoch |
|:----------:|:---------------:|:---------------:|:------------:|:--------:|:--------------:|:-----:|
| 3.0905 | 2.8512 | 0.0 | 0.0 | 0.0 | 0.6376 | 0 |
| 2.6612 | 2.4783 | 0.0 | 0.0 | 0.0 | 0.6392 | 1 |
| 2.3549 | 2.3081 | 0.0 | 0.0 | 0.0 | 0.6392 | 2 |
### Framework versions
- Transformers 4.20.1
- TensorFlow 2.6.4
- Datasets 2.1.0
- Tokenizers 0.12.1
|
AnonymousSub/SR_rule_based_roberta_bert_quadruplet_epochs_1_shard_10 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2 | null | ---
tags:
- generated_from_trainer
model-index:
- name: article_title
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# article_title
This model is a fine-tuned version of [google/pegasus-cnn_dailymail](https://huggingface.co/google/pegasus-cnn_dailymail) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
AnonymousSub/SR_rule_based_roberta_bert_triplet_epochs_1_shard_1 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2 | null | ---
datasets:
- relbert/conceptnet_high_confidence
model-index:
- name: relbert/roberta-large-conceptnet-mask-prompt-b-nce
results:
- task:
name: Relation Mapping
type: sorting-task
dataset:
name: Relation Mapping
args: relbert/relation_mapping
type: relation-mapping
metrics:
- name: Accuracy
type: accuracy
value: 0.844484126984127
- task:
name: Analogy Questions (SAT full)
type: multiple-choice-qa
dataset:
name: SAT full
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.5026737967914439
- task:
name: Analogy Questions (SAT)
type: multiple-choice-qa
dataset:
name: SAT
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.5074183976261127
- task:
name: Analogy Questions (BATS)
type: multiple-choice-qa
dataset:
name: BATS
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.7837687604224569
- task:
name: Analogy Questions (Google)
type: multiple-choice-qa
dataset:
name: Google
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.914
- task:
name: Analogy Questions (U2)
type: multiple-choice-qa
dataset:
name: U2
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.4868421052631579
- task:
name: Analogy Questions (U4)
type: multiple-choice-qa
dataset:
name: U4
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.5717592592592593
- task:
name: Lexical Relation Classification (BLESS)
type: classification
dataset:
name: BLESS
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.9169805635076088
- name: F1 (macro)
type: f1_macro
value: 0.9124828189963239
- task:
name: Lexical Relation Classification (CogALexV)
type: classification
dataset:
name: CogALexV
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.8615023474178404
- name: F1 (macro)
type: f1_macro
value: 0.6923470637031117
- task:
name: Lexical Relation Classification (EVALution)
type: classification
dataset:
name: BLESS
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.6917659804983749
- name: F1 (macro)
type: f1_macro
value: 0.6818037583371511
- task:
name: Lexical Relation Classification (K&H+N)
type: classification
dataset:
name: K&H+N
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.9652917854907144
- name: F1 (macro)
type: f1_macro
value: 0.8914930968868111
- task:
name: Lexical Relation Classification (ROOT09)
type: classification
dataset:
name: ROOT09
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.9025383892196804
- name: F1 (macro)
type: f1_macro
value: 0.9012451685993444
---
# relbert/roberta-large-conceptnet-mask-prompt-b-nce
RelBERT fine-tuned from [roberta-large](https://huggingface.co/roberta-large) on
[relbert/conceptnet_high_confidence](https://huggingface.co/datasets/relbert/conceptnet_high_confidence).
Fine-tuning is done via [RelBERT](https://github.com/asahi417/relbert) library (see the repository for more detail).
It achieves the following results on the relation understanding tasks:
- Analogy Question ([dataset](https://huggingface.co/datasets/relbert/analogy_questions), [full result](https://huggingface.co/relbert/roberta-large-conceptnet-mask-prompt-b-nce/raw/main/analogy.json)):
- Accuracy on SAT (full): 0.5026737967914439
- Accuracy on SAT: 0.5074183976261127
- Accuracy on BATS: 0.7837687604224569
- Accuracy on U2: 0.4868421052631579
- Accuracy on U4: 0.5717592592592593
- Accuracy on Google: 0.914
- Lexical Relation Classification ([dataset](https://huggingface.co/datasets/relbert/lexical_relation_classification), [full result](https://huggingface.co/relbert/roberta-large-conceptnet-mask-prompt-b-nce/raw/main/classification.json)):
- Micro F1 score on BLESS: 0.9169805635076088
- Micro F1 score on CogALexV: 0.8615023474178404
- Micro F1 score on EVALution: 0.6917659804983749
- Micro F1 score on K&H+N: 0.9652917854907144
- Micro F1 score on ROOT09: 0.9025383892196804
- Relation Mapping ([dataset](https://huggingface.co/datasets/relbert/relation_mapping), [full result](https://huggingface.co/relbert/roberta-large-conceptnet-mask-prompt-b-nce/raw/main/relation_mapping.json)):
- Accuracy on Relation Mapping: 0.844484126984127
### Usage
This model can be used through the [relbert library](https://github.com/asahi417/relbert). Install the library via pip
```shell
pip install relbert
```
and activate model as below.
```python
from relbert import RelBERT
model = RelBERT("relbert/roberta-large-conceptnet-mask-prompt-b-nce")
vector = model.get_embedding(['Tokyo', 'Japan']) # shape of (1024, )
```
### Training hyperparameters
The following hyperparameters were used during training:
- model: roberta-large
- max_length: 64
- mode: mask
- data: relbert/conceptnet_high_confidence
- template_mode: manual
- template: Today, I finally discovered the relation between <subj> and <obj> : <obj> is <subj>'s <mask>
- loss_function: nce_logout
- temperature_nce_constant: 0.05
- temperature_nce_rank: {'min': 0.01, 'max': 0.05, 'type': 'linear'}
- epoch: 114
- batch: 128
- lr: 5e-06
- lr_decay: False
- lr_warmup: 1
- weight_decay: 0
- random_seed: 0
- exclude_relation: None
- n_sample: 640
- gradient_accumulation: 8
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/relbert/roberta-large-conceptnet-mask-prompt-b-nce/raw/main/trainer_config.json).
### Reference
If you use any resource from RelBERT, please consider to cite our [paper](https://aclanthology.org/2021.eacl-demos.7/).
```
@inproceedings{ushio-etal-2021-distilling-relation-embeddings,
title = "{D}istilling {R}elation {E}mbeddings from {P}re-trained {L}anguage {M}odels",
author = "Ushio, Asahi and
Schockaert, Steven and
Camacho-Collados, Jose",
booktitle = "EMNLP 2021",
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
|
AnonymousSub/SR_rule_based_roberta_twostage_quadruplet_epochs_1_shard_10 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
tags:
- generated_from_trainer
model-index:
- name: DNADebertaSentencepiece30k_continuation_continuation
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# DNADebertaSentencepiece30k_continuation_continuation
This model is a fine-tuned version of [Vlasta/DNADebertaSentencepiece30k_continuation](https://huggingface.co/Vlasta/DNADebertaSentencepiece30k_continuation) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 5.9867
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 15
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:------:|:---------------:|
| 6.1786 | 0.41 | 5000 | 6.1475 |
| 6.1856 | 0.81 | 10000 | 6.1490 |
| 6.1769 | 1.22 | 15000 | 6.1370 |
| 6.1714 | 1.62 | 20000 | 6.1330 |
| 6.1633 | 2.03 | 25000 | 6.1221 |
| 6.1548 | 2.44 | 30000 | 6.1180 |
| 6.1495 | 2.84 | 35000 | 6.1141 |
| 6.1453 | 3.25 | 40000 | 6.1026 |
| 6.1362 | 3.66 | 45000 | 6.0984 |
| 6.1325 | 4.06 | 50000 | 6.0961 |
| 6.1227 | 4.47 | 55000 | 6.0874 |
| 6.1215 | 4.87 | 60000 | 6.0806 |
| 6.1149 | 5.28 | 65000 | 6.0779 |
| 6.1099 | 5.69 | 70000 | 6.0701 |
| 6.104 | 6.09 | 75000 | 6.0633 |
| 6.0963 | 6.5 | 80000 | 6.0628 |
| 6.095 | 6.91 | 85000 | 6.0572 |
| 6.0858 | 7.31 | 90000 | 6.0525 |
| 6.0895 | 7.72 | 95000 | 6.0430 |
| 6.0804 | 8.12 | 100000 | 6.0437 |
| 6.0767 | 8.53 | 105000 | 6.0371 |
| 6.0748 | 8.94 | 110000 | 6.0312 |
| 6.0702 | 9.34 | 115000 | 6.0293 |
| 6.0668 | 9.75 | 120000 | 6.0242 |
| 6.0615 | 10.16 | 125000 | 6.0213 |
| 6.0568 | 10.56 | 130000 | 6.0183 |
| 6.0552 | 10.97 | 135000 | 6.0125 |
| 6.0496 | 11.37 | 140000 | 6.0087 |
| 6.0493 | 11.78 | 145000 | 6.0084 |
| 6.0466 | 12.19 | 150000 | 6.0060 |
| 6.042 | 12.59 | 155000 | 6.0008 |
| 6.0375 | 13.0 | 160000 | 5.9986 |
| 6.0345 | 13.41 | 165000 | 5.9940 |
| 6.0336 | 13.81 | 170000 | 5.9905 |
| 6.0334 | 14.22 | 175000 | 5.9891 |
| 6.0313 | 14.62 | 180000 | 5.9887 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0
- Datasets 2.2.2
- Tokenizers 0.12.1
|
AnonymousSub/SR_rule_based_roberta_twostagequadruplet_hier_epochs_1_shard_1 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | ---
tags:
- generated_from_trainer
model-index:
- name: DNADebertaSentencepiece10k_continuation_continuation
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# DNADebertaSentencepiece10k_continuation_continuation
This model is a fine-tuned version of [Vlasta/DNADebertaSentencepiece10k_continuation](https://huggingface.co/Vlasta/DNADebertaSentencepiece10k_continuation) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 5.3056
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 15
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:------:|:---------------:|
| 5.4806 | 0.36 | 5000 | 5.4385 |
| 5.4848 | 0.72 | 10000 | 5.4333 |
| 5.4803 | 1.08 | 15000 | 5.4312 |
| 5.4759 | 1.45 | 20000 | 5.4223 |
| 5.4703 | 1.81 | 25000 | 5.4199 |
| 5.4626 | 2.17 | 30000 | 5.4147 |
| 5.4596 | 2.53 | 35000 | 5.4094 |
| 5.4534 | 2.89 | 40000 | 5.4014 |
| 5.4466 | 3.25 | 45000 | 5.4017 |
| 5.445 | 3.61 | 50000 | 5.3954 |
| 5.4446 | 3.97 | 55000 | 5.3916 |
| 5.4359 | 4.34 | 60000 | 5.3809 |
| 5.4327 | 4.7 | 65000 | 5.3846 |
| 5.4281 | 5.06 | 70000 | 5.3765 |
| 5.4207 | 5.42 | 75000 | 5.3744 |
| 5.4207 | 5.78 | 80000 | 5.3704 |
| 5.4167 | 6.14 | 85000 | 5.3685 |
| 5.41 | 6.5 | 90000 | 5.3641 |
| 5.4117 | 6.86 | 95000 | 5.3582 |
| 5.4075 | 7.23 | 100000 | 5.3568 |
| 5.4017 | 7.59 | 105000 | 5.3547 |
| 5.4006 | 7.95 | 110000 | 5.3494 |
| 5.3969 | 8.31 | 115000 | 5.3475 |
| 5.3935 | 8.67 | 120000 | 5.3453 |
| 5.3926 | 9.03 | 125000 | 5.3422 |
| 5.3895 | 9.39 | 130000 | 5.3351 |
| 5.3813 | 9.75 | 135000 | 5.3326 |
| 5.3841 | 10.12 | 140000 | 5.3340 |
| 5.3787 | 10.48 | 145000 | 5.3301 |
| 5.3781 | 10.84 | 150000 | 5.3280 |
| 5.3769 | 11.2 | 155000 | 5.3258 |
| 5.3733 | 11.56 | 160000 | 5.3198 |
| 5.3683 | 11.92 | 165000 | 5.3180 |
| 5.3682 | 12.28 | 170000 | 5.3181 |
| 5.3673 | 12.64 | 175000 | 5.3167 |
| 5.3623 | 13.01 | 180000 | 5.3116 |
| 5.3602 | 13.37 | 185000 | 5.3109 |
| 5.361 | 13.73 | 190000 | 5.3071 |
| 5.3573 | 14.09 | 195000 | 5.3078 |
| 5.3575 | 14.45 | 200000 | 5.3051 |
| 5.3544 | 14.81 | 205000 | 5.3038 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0
- Datasets 2.2.2
- Tokenizers 0.12.1
|
AnonymousSub/SR_rule_based_roberta_twostagequadruplet_hier_epochs_1_shard_10 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | ---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: cochonaki/distilbert-base-uncased-finetuned-cola
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# cochonaki/distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.1905
- Validation Loss: 0.5536
- Train Matthews Correlation: 0.5126
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 1602, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Matthews Correlation | Epoch |
|:----------:|:---------------:|:--------------------------:|:-----:|
| 0.5118 | 0.4642 | 0.4617 | 0 |
| 0.3259 | 0.4709 | 0.4990 | 1 |
| 0.1905 | 0.5536 | 0.5126 | 2 |
### Framework versions
- Transformers 4.21.1
- TensorFlow 2.8.2
- Datasets 2.4.0
- Tokenizers 0.12.1
|
AnonymousSub/SR_rule_based_roberta_twostagetriplet_epochs_1_shard_1 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
language: en
tags: [Ad-Corre, facial expression recognition, emotion recognition, expression recognition, computer vision, CNN, loss, IEEE Access, Tensor Flow ]
thumbnail:
license: mit
---
# Ad-Corre
Ad-Corre: Adaptive Correlation-Based Loss for Facial Expression Recognition in the Wild
[](https://paperswithcode.com/sota/facial-expression-recognition-on-raf-db?p=ad-corre-adaptive-correlation-based-loss-for)
<!--
[](https://paperswithcode.com/sota/facial-expression-recognition-on-affectnet?p=ad-corre-adaptive-correlation-based-loss-for)
[](https://paperswithcode.com/sota/facial-expression-recognition-on-fer2013?p=ad-corre-adaptive-correlation-based-loss-for)
-->
#### Link to the paper (open access):
https://ieeexplore.ieee.org/document/9727163
#### Link to the paperswithcode.com:
https://paperswithcode.com/paper/ad-corre-adaptive-correlation-based-loss-for
```
Please cite this work as:
@ARTICLE{9727163,
author={Fard, Ali Pourramezan and Mahoor, Mohammad H.},
journal={IEEE Access},
title={Ad-Corre: Adaptive Correlation-Based Loss for Facial Expression Recognition in the Wild},
year={2022},
volume={},
number={},
pages={1-1},
doi={10.1109/ACCESS.2022.3156598}}
```
## Introduction
Automated Facial Expression Recognition (FER) in the wild using deep neural networks is still challenging due to intra-class variations and inter-class similarities in facial images. Deep Metric Learning (DML) is among the widely used methods to deal with these issues by improving the discriminative power of the learned embedded features. This paper proposes an Adaptive Correlation (Ad-Corre) Loss to guide the network towards generating embedded feature vectors with high correlation for within-class samples and less correlation for between-class samples. Ad-Corre consists of 3 components called Feature Discriminator, Mean Discriminator, and Embedding Discriminator. We design the Feature Discriminator component to guide the network to create the embedded feature vectors to be highly correlated if they belong to a similar class, and less correlated if they belong to different classes. In addition, the Mean Discriminator component leads the network to make the mean embedded feature vectors of different classes to be less similar to each other.We use Xception network as the backbone of our model, and contrary to previous work, we propose an embedding feature space that contains k feature vectors. Then, the Embedding Discriminator component penalizes the network to generate the embedded feature vectors, which are dissimilar.We trained our model using the combination of our proposed loss functions called Ad-Corre Loss jointly with the cross-entropy loss. We achieved a very promising recognition accuracy on AffectNet, RAF-DB, and FER-2013. Our extensive experiments and ablation study indicate the power of our method to cope well with challenging FER tasks in the wild.
## Evaluation and Samples
The following samples are taken from the paper:
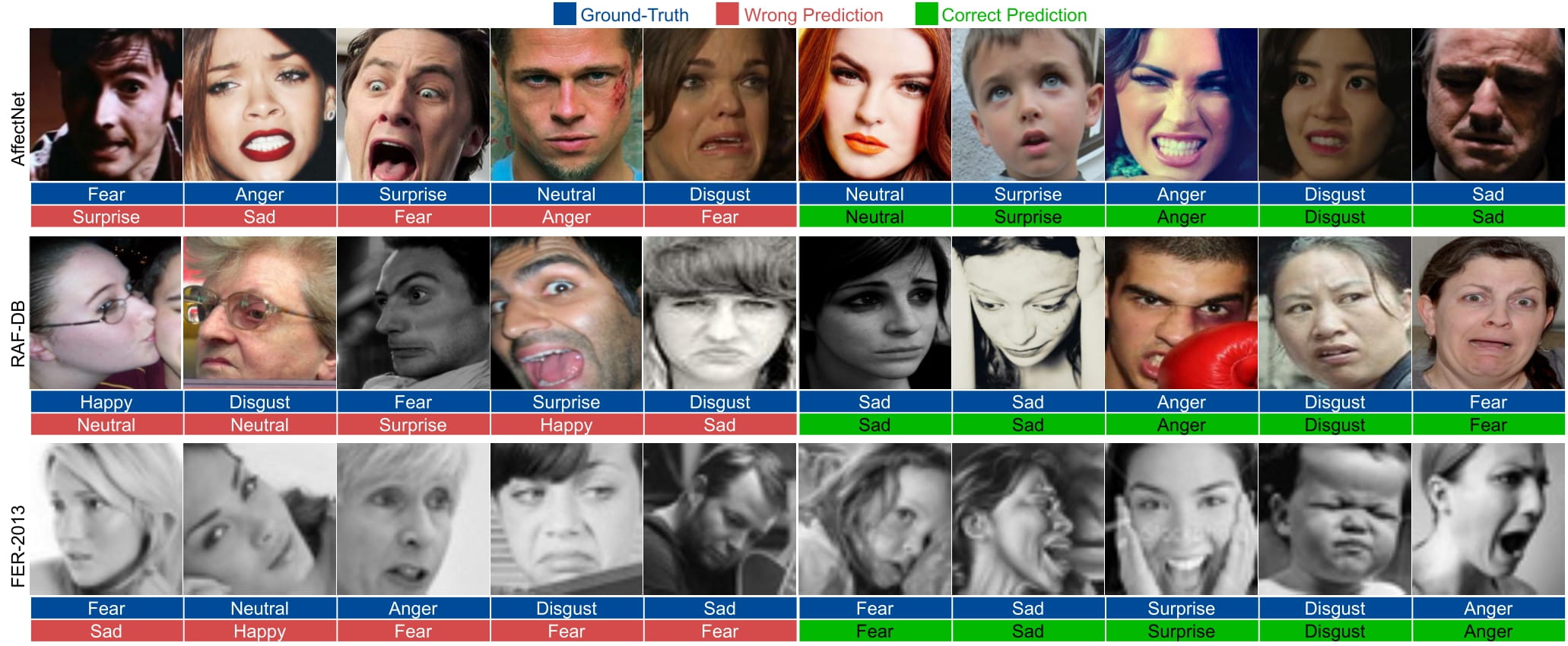
----------------------------------------------------------------------------------------------------------------------------------
## Installing the requirements
In order to run the code you need to install python >= 3.5.
The requirements and the libraries needed to run the code can be installed using the following command:
```
pip install -r requirements.txt
```
## Using the pre-trained models
The pretrained models for Affectnet, RafDB, and Fer2013 are provided in the [Trained_Models](https://github.com/aliprf/Ad-Corre/tree/main/Trained_Models) folder. You can use the following code to predict the facial emotionn of a facial image:
```
tester = TestModels(h5_address='./trained_models/AffectNet_6336.h5')
tester.recognize_fer(img_path='./img.jpg')
```
plaese see the following [main.py](https://github.com/aliprf/Ad-Corre/tree/main/main.py) file.
## Training Network from scratch
The information and the code to train the model is provided in train.py .Plaese see the following [main.py](https://github.com/aliprf/Ad-Corre/tree/main/main.py) file:
```
'''training part'''
trainer = TrainModel(dataset_name=DatasetName.affectnet, ds_type=DatasetType.train_7)
trainer.train(arch="xcp", weight_path="./")
```
### Preparing Data
Data needs to be normalized and saved in npy format.
---------------------------------------------------------------
```
Please cite this work as:
@ARTICLE{9727163,
author={Fard, Ali Pourramezan and Mahoor, Mohammad H.},
journal={IEEE Access},
title={Ad-Corre: Adaptive Correlation-Based Loss for Facial Expression Recognition in the Wild},
year={2022},
volume={},
number={},
pages={1-1},
doi={10.1109/ACCESS.2022.3156598}}
```
|
AnonymousSub/SR_rule_based_roberta_twostagetriplet_epochs_1_shard_10 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null |
---
language: en
tags: [cvpr2021, computer vision, face alignment, facial landmark point, pose estimation, face pose tracking, CNN, loss, custom loss, ASMNet, Tensor Flow]
license: mit
---
[](https://paperswithcode.com/sota/pose-estimation-on-300w-full?p=deep-active-shape-model-for-face-alignment)
[](https://paperswithcode.com/sota/face-alignment-on-wflw?p=deep-active-shape-model-for-face-alignment)
[](https://paperswithcode.com/sota/face-alignment-on-300w?p=deep-active-shape-model-for-face-alignment)
```diff
! plaese STAR the repo if you like it.
```
# [ASMNet](https://scholar.google.com/scholar?oi=bibs&cluster=3428857185978099736&btnI=1&hl=en)
## a Lightweight Deep Neural Network for Face Alignment and Pose Estimation
#### Link to the paper:
https://scholar.google.com/scholar?oi=bibs&cluster=3428857185978099736&btnI=1&hl=en
#### Link to the paperswithcode.com:
https://paperswithcode.com/paper/asmnet-a-lightweight-deep-neural-network-for
#### Link to the article on Towardsdatascience.com:
https://aliprf.medium.com/asmnet-a-lightweight-deep-neural-network-for-face-alignment-and-pose-estimation-9e9dfac07094
```
Please cite this work as:
@inproceedings{fard2021asmnet,
title={ASMNet: A Lightweight Deep Neural Network for Face Alignment and Pose Estimation},
author={Fard, Ali Pourramezan and Abdollahi, Hojjat and Mahoor, Mohammad},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={1521--1530},
year={2021}
}
```
## Introduction
ASMNet is a lightweight Convolutional Neural Network (CNN) which is designed to perform face alignment and pose estimation efficiently while having acceptable accuracy. ASMNet proposed inspired by MobileNetV2, modified to be suitable for face alignment and pose
estimation, while being about 2 times smaller in terms of number of the parameters. Moreover, Inspired by Active Shape Model (ASM), ASM-assisted loss function is proposed in order to improve the accuracy of facial landmark points detection and pose estimation.
## ASMnet Architecture
Features in a CNN are distributed hierarchically. In other words, the lower layers have features such as edges, and corners which are more suitable for tasks like landmark localization and pose estimation, and deeper layers contain more abstract features that are more suitable for tasks like image classification and image detection. Furthermore, training a network for correlated tasks simultaneously builds a synergy that can improve the performance of each task.
Having said that, we designed ASMNe by fusing the features that are available if different layers of the model. Furthermore, by concatenating the features that are collected after each global average pooling layer in the back-propagation process, it will be possible for the network to evaluate the effect of each shortcut path. Following is the ASMNet architecture:
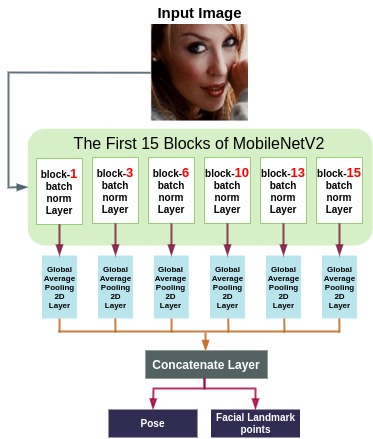
The implementation of ASMNet in TensorFlow is provided in the following path:
https://github.com/aliprf/ASMNet/blob/master/cnn_model.py
## ASM Loss
We proposed a new loss function called ASM-LOSS which utilizes ASM to improve the accuracy of the network. In other words, during the training process, the loss function compares the predicted facial landmark points with their corresponding ground truth as well as the smoothed version the ground truth which is generated using ASM operator. Accordingly, ASM-LOSS guides the network to first learn the smoothed distribution of the facial landmark points. Then, it leads the network to learn the original landmark points. For more detail please refer to the paper.
Following is the ASM Loss diagram:
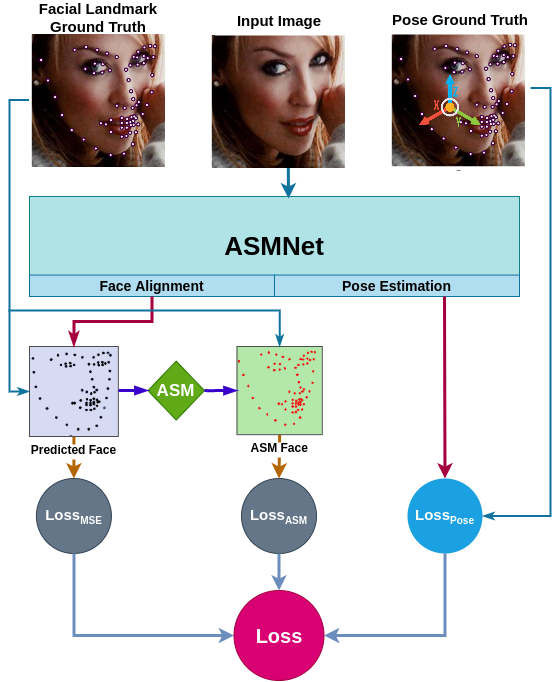
## Evaluation
As you can see in the following tables, ASMNet has only 1.4 M parameters which is the smallets comparing to the similar Facial landmark points detection models. Moreover, ASMNet designed to performs Face alignment as well as Pose estimation with a very small CNN while having an acceptable accuracy.

Although ASMNet is much smaller than the state-of-the-art methods on face alignment, it's performance is also very good and acceptable for many real-world applications:
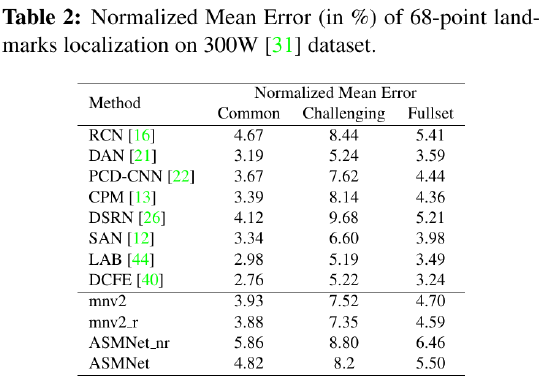
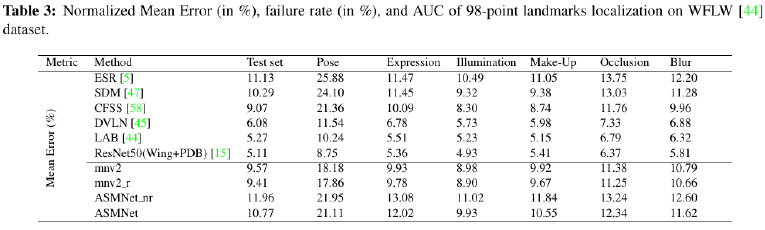
As shown in the following table, ASMNet performs much better that the state-of-the-art models on 300W dataseton Pose estimation task:

Following are some samples in order to show the visual performance of ASMNet on 300W and WFLW datasets:


The visual performance of Pose estimation task using ASMNet is very accurate and the results also are much better than the state-of-the-art pose estimation over 300W dataset:

----------------------------------------------------------------------------------------------------------------------------------
## Installing the requirements
In order to run the code you need to install python >= 3.5.
The requirements and the libraries needed to run the code can be installed using the following command:
```
pip install -r requirements.txt
```
## Using the pre-trained models
You can test and use the preetrained models using the following codes which are available in the following file:
https://github.com/aliprf/ASMNet/blob/master/main.py
```
tester = Test()
tester.test_model(ds_name=DatasetName.w300,
pretrained_model_path='./pre_trained_models/ASMNet/ASM_loss/ASMNet_300W_ASMLoss.h5')
```
## Training Network from scratch
### Preparing Data
Data needs to be normalized and saved in npy format.
### PCA creation
you can you the pca_utility.py class to create the eigenvalues, eigenvectors, and the meanvector:
```
pca_calc = PCAUtility()
pca_calc.create_pca_from_npy(dataset_name=DatasetName.w300,
labels_npy_path='./data/w300/normalized_labels/',
pca_percentages=90)
```
### Training
The training implementation is located in train.py class. You can use the following code to start the training:
```
trainer = Train(arch=ModelArch.ASMNet,
dataset_name=DatasetName.w300,
save_path='./',
asm_accuracy=90)
```
Please cite this work as:
@inproceedings{fard2021asmnet,
title={ASMNet: A Lightweight Deep Neural Network for Face Alignment and Pose Estimation},
author={Fard, Ali Pourramezan and Abdollahi, Hojjat and Mahoor, Mohammad},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={1521--1530},
year={2021}
}
```diff
@@plaese STAR the repo if you like it.@@
```
|
AnonymousSub/SR_rule_based_roberta_twostagetriplet_hier_epochs_1_shard_1 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null |
---
language: en
tags: [ computer vision, face alignment, facial landmark point, CNN, Knowledge Distillation, loss, CVIU, Tensor Flow]
thumbnail:
license: mit
---
[](https://paperswithcode.com/sota/face-alignment-on-cofw?p=facial-landmark-points-detection-using)
#
Facial Landmark Points Detection Using Knowledge Distillation-Based Neural Networks
#### Link to the paper:
Google Scholar:
https://scholar.google.com/citations?view_op=view_citation&hl=en&user=96lS6HIAAAAJ&citation_for_view=96lS6HIAAAAJ:zYLM7Y9cAGgC
Elsevier:
https://www.sciencedirect.com/science/article/pii/S1077314221001582
Arxiv:
https://arxiv.org/abs/2111.07047
#### Link to the paperswithcode.com:
https://paperswithcode.com/paper/facial-landmark-points-detection-using
```diff
@@plaese STAR the repo if you like it.@@
```
```
Please cite this work as:
@article{fard2022facial,
title={Facial landmark points detection using knowledge distillation-based neural networks},
author={Fard, Ali Pourramezan and Mahoor, Mohammad H},
journal={Computer Vision and Image Understanding},
volume={215},
pages={103316},
year={2022},
publisher={Elsevier}
}
```
## Introduction
Facial landmark detection is a vital step for numerous facial image analysis applications. Although some deep learning-based methods have achieved good performances in this task, they are often not suitable for running on mobile devices. Such methods rely on networks with many parameters, which makes the training and inference time-consuming. Training lightweight neural networks such as MobileNets are often challenging, and the models might have low accuracy. Inspired by knowledge distillation (KD), this paper presents a novel loss function to train a lightweight Student network (e.g., MobileNetV2) for facial landmark detection. We use two Teacher networks, a Tolerant-Teacher and a Tough-Teacher in conjunction with the Student network. The Tolerant-Teacher is trained using Soft-landmarks created by active shape models, while the Tough-Teacher is trained using the ground truth (aka Hard-landmarks) landmark points. To utilize the facial landmark points predicted by the Teacher networks, we define an Assistive Loss (ALoss) for each Teacher network. Moreover, we define a loss function called KD-Loss that utilizes the facial landmark points predicted by the two pre-trained Teacher networks (EfficientNet-b3) to guide the lightweight Student network towards predicting the Hard-landmarks. Our experimental results on three challenging facial datasets show that the proposed architecture will result in a better-trained Student network that can extract facial landmark points with high accuracy.
##Architecture
We train the Tough-Teacher, and the Tolerant-Teacher networks independently using the Hard-landmarks and the Soft-landmarks respectively utilizing the L2 loss:
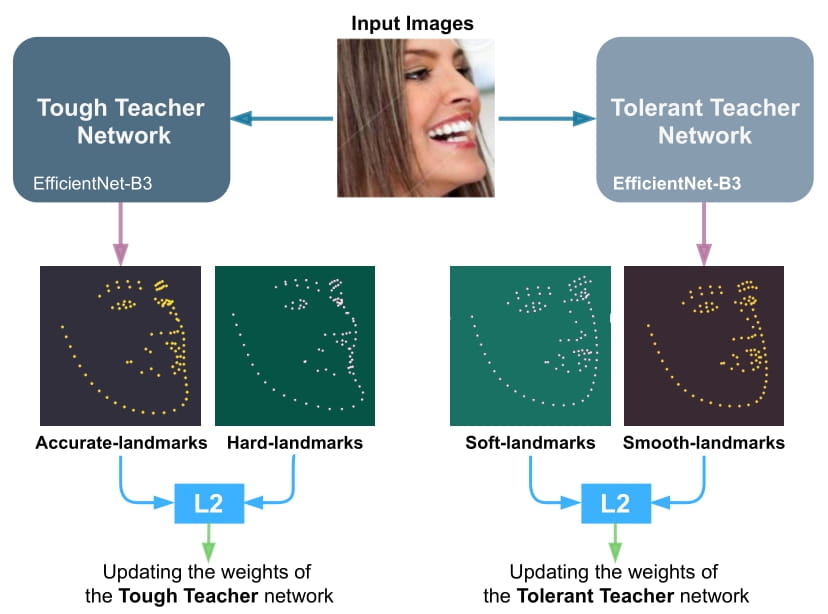
Proposed KD-based architecture for training the Student network. KDLoss uses the knowledge of the previously trained Teacher networks by utilizing the assistive loss functions ALossT ou and ALossT ol, to improve the performance the face alignment task:
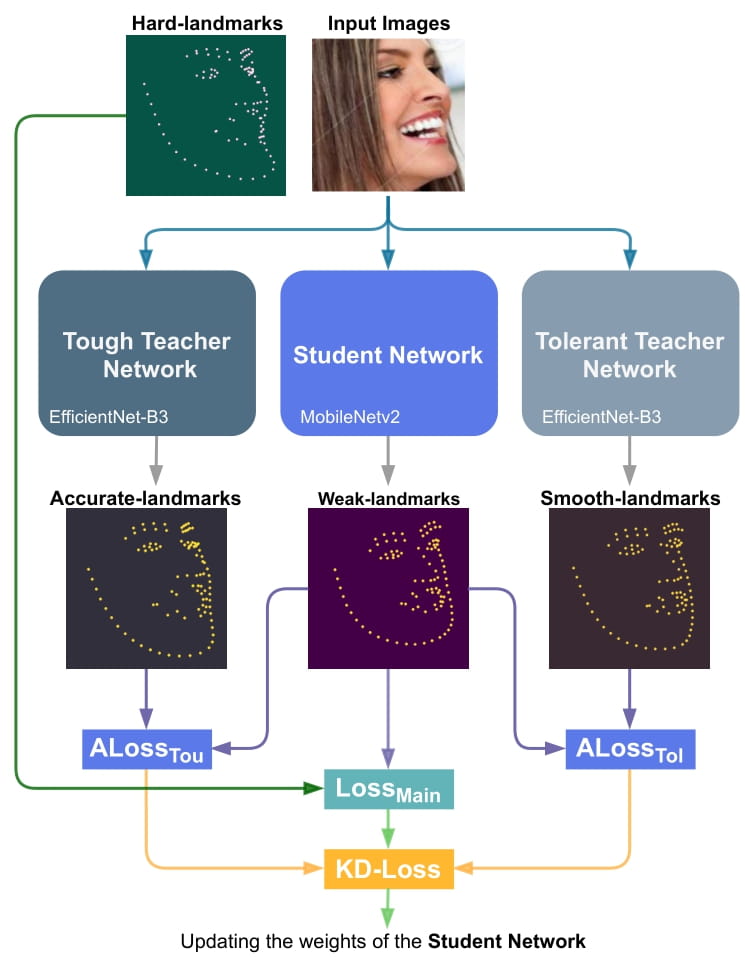
## Evaluation
Following are some samples in order to show the visual performance of KD-Loss on 300W, COFW and WFLW datasets:
300W:

COFW:

WFLW:

----------------------------------------------------------------------------------------------------------------------------------
## Installing the requirements
In order to run the code you need to install python >= 3.5.
The requirements and the libraries needed to run the code can be installed using the following command:
```
pip install -r requirements.txt
```
## Using the pre-trained models
You can test and use the preetrained models using the following codes which are available in the test.py:
The pretrained student model are also located in "models/students".
```
cnn = CNNModel()
model = cnn.get_model(arch=arch, input_tensor=None, output_len=self.output_len)
model.load_weights(weight_fname)
img = None # load a cropped image
image_utility = ImageUtility()
pose_predicted = []
image = np.expand_dims(img, axis=0)
pose_predicted = model.predict(image)[1][0]
```
## Training Network from scratch
### Preparing Data
Data needs to be normalized and saved in npy format.
### Training
### Training Teacher Networks:
The training implementation is located in teacher_trainer.py class. You can use the following code to start the training for the teacher networks:
```
'''train Teacher Networks'''
trainer = TeacherTrainer(dataset_name=DatasetName.w300)
trainer.train(arch='efficientNet',weight_path=None)
```
### Training Student Networks:
After Training the teacher networks, you can use the trained teachers to train the student network. The implemetation of training of the student network is provided in teacher_trainer.py . You can use the following code to start the training for the student networks:
```
st_trainer = StudentTrainer(dataset_name=DatasetName.w300, use_augmneted=True)
st_trainer.train(arch_student='mobileNetV2', weight_path_student=None,
loss_weight_student=2.0,
arch_tough_teacher='efficientNet', weight_path_tough_teacher='./models/teachers/ds_300w_ef_tou.h5',
loss_weight_tough_teacher=1,
arch_tol_teacher='efficientNet', weight_path_tol_teacher='./models/teachers/ds_300w_ef_tol.h5',
loss_weight_tol_teacher=1)
```
```
Please cite this work as:
@article{fard2022facial,
title={Facial landmark points detection using knowledge distillation-based neural networks},
author={Fard, Ali Pourramezan and Mahoor, Mohammad H},
journal={Computer Vision and Image Understanding},
volume={215},
pages={103316},
year={2022},
publisher={Elsevier}
}
```
```diff
@@plaese STAR the repo if you like it.@@
```
|
AnonymousSub/SR_rule_based_twostage_quadruplet_epochs_1_shard_1 | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- wikigold_splits
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: wikigold_trained_no_DA_testing2
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: wikigold_splits
type: wikigold_splits
args: default
metrics:
- name: Precision
type: precision
value: 0.8410852713178295
- name: Recall
type: recall
value: 0.84765625
- name: F1
type: f1
value: 0.8443579766536965
- name: Accuracy
type: accuracy
value: 0.9571820972693489
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wikigold_trained_no_DA_testing2
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the wikigold_splits dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1431
- Precision: 0.8411
- Recall: 0.8477
- F1: 0.8444
- Accuracy: 0.9572
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 167 | 0.1618 | 0.7559 | 0.75 | 0.7529 | 0.9410 |
| No log | 2.0 | 334 | 0.1488 | 0.8384 | 0.8242 | 0.8313 | 0.9530 |
| 0.1589 | 3.0 | 501 | 0.1431 | 0.8411 | 0.8477 | 0.8444 | 0.9572 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
AnonymousSub/SR_rule_based_twostagetriplet_hier_epochs_1_shard_1 | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2 | null | ---
tags:
- generated_from_trainer
model-index:
- name: article_title_2299
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# article_title_2299
This model is a fine-tuned version of [google/pegasus-cnn_dailymail](https://huggingface.co/google/pegasus-cnn_dailymail) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
AnonymousSub/cline-emanuals-techqa | [
"pytorch",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | {
"architectures": [
"RobertaForQuestionAnswering"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | 2022-08-04T20:36:37Z | ---
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: facebook_large_CV_bn3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# facebook_large_CV_bn3
This model is a fine-tuned version of [Sameen53/facebook_large_CV_bn](https://huggingface.co/Sameen53/facebook_large_CV_bn) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2308
- Wer: 0.2379
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- num_epochs: 6
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 0.87 | 1000 | 0.2473 | 0.2524 |
| 0.2308 | 1.73 | 2000 | 0.2073 | 0.2450 |
| 0.261 | 2.6 | 3000 | 0.2036 | 0.2345 |
| 0.2498 | 3.47 | 4000 | 0.1916 | 0.2311 |
| 0.2433 | 4.33 | 5000 | 0.1869 | 0.2344 |
| 0.2588 | 5.2 | 6000 | 0.2308 | 0.2379 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
AnonymousSub/cline-papers-biomed-0.618 | [
"pytorch",
"roberta",
"transformers"
] | null | {
"architectures": [
"LecbertForPreTraining"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2 | 2022-08-04T21:06:12Z | ---
tags:
- generated_from_trainer
model-index:
- name: multi_news_article_title_2299
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# multi_news_article_title_2299
This model is a fine-tuned version of [google/pegasus-multi_news](https://huggingface.co/google/pegasus-multi_news) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
AnonymousSub/cline-papers-roberta-0.585 | [
"pytorch",
"roberta",
"transformers"
] | null | {
"architectures": [
"LecbertForPreTraining"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 1 | 2022-08-04T21:31:59Z | ---
tags:
- generated_from_keras_callback
model-index:
- name: mal-tls-bert-large-relu-w8a8
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# mal-tls-bert-large-relu-w8a8
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.15.0
- TensorFlow 2.6.4
- Datasets 2.1.0
- Tokenizers 0.10.3
|
AnonymousSub/consert-s10-SR | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 28 | 2022-08-04T22:50:01Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- f1
- accuracy
- precision
- recall
model-index:
- name: soft-search
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# soft-search
This model is a fine-tuned version of [distilbert-base-uncased-finetuned-sst-2-english](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5558
- F1: 0.5960
- Accuracy: 0.7109
- Precision: 0.5769
- Recall: 0.6164
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 12
- eval_batch_size: 12
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Accuracy | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:------:|:--------:|:---------:|:------:|
| 0.5939 | 1.0 | 71 | 0.5989 | 0.0533 | 0.6635 | 1.0 | 0.0274 |
| 0.5903 | 2.0 | 142 | 0.5558 | 0.5960 | 0.7109 | 0.5769 | 0.6164 |
| 0.4613 | 3.0 | 213 | 0.6670 | 0.5641 | 0.6777 | 0.5301 | 0.6027 |
| 0.4454 | 4.0 | 284 | 0.7647 | 0.5541 | 0.6872 | 0.5467 | 0.5616 |
| 0.2931 | 5.0 | 355 | 0.8726 | 0.5139 | 0.6682 | 0.5211 | 0.5068 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.1+cu117
- Datasets 2.8.0
- Tokenizers 0.13.2
|
AnonymousSub/roberta-base_wikiqa | [
"pytorch",
"roberta",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 25 | 2022-08-05T04:33:44Z | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: Bio_ClinicalBERT-zero-shot-finetuned-all-cad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Bio_ClinicalBERT-zero-shot-finetuned-all-cad
This model is a fine-tuned version of [emilyalsentzer/Bio_ClinicalBERT](https://huggingface.co/emilyalsentzer/Bio_ClinicalBERT) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
AnonymousSub/rule_based_bert_quadruplet_epochs_1_shard_10 | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | 2022-08-05T05:12:27Z | ---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: Bio_ClinicalBERT-zero-shot-finetuned-50cad-50noncad-optimal
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Bio_ClinicalBERT-zero-shot-finetuned-50cad-50noncad-optimal
This model is a fine-tuned version of [emilyalsentzer/Bio_ClinicalBERT](https://huggingface.co/emilyalsentzer/Bio_ClinicalBERT) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 9.8836
- Accuracy: 0.5
- F1: 0.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.2
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
AnonymousSub/rule_based_hier_quadruplet_epochs_1_shard_10 | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
library_name: ml-agents
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Pyramids
2. Step 1: Write your model_id: jefsnacker/testpyramidsrnd
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
AnonymousSub/rule_based_only_classfn_epochs_1_shard_10 | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: Spoof_detection
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Spoof_detection
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7448
- Wer: 0.1090
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 95.9046 | 0.66 | 500 | 992.2993 | 0.6180 |
| 14.0322 | 1.33 | 1000 | 1.8873 | 0.1090 |
| 1.8659 | 1.99 | 1500 | 1.7827 | 0.1090 |
| 1.851 | 2.65 | 2000 | 1.8489 | 0.1090 |
| 1.8218 | 3.32 | 2500 | 1.8943 | 0.1090 |
| 1.8108 | 3.98 | 3000 | 1.9250 | 0.1090 |
| 1.8228 | 4.64 | 3500 | 1.7555 | 0.1090 |
| 1.832 | 5.31 | 4000 | 1.7837 | 0.1090 |
| 1.8403 | 5.97 | 4500 | 1.6644 | 0.1090 |
| 1.8292 | 6.63 | 5000 | 1.6906 | 0.1090 |
| 1.8223 | 7.29 | 5500 | 1.6966 | 0.1090 |
| 1.8007 | 7.96 | 6000 | 1.6951 | 0.1090 |
| 1.7986 | 8.62 | 6500 | 1.7436 | 0.1090 |
| 1.7933 | 9.28 | 7000 | 1.8169 | 0.1090 |
| 1.7861 | 9.95 | 7500 | 1.7209 | 0.1090 |
| 1.7843 | 10.61 | 8000 | 1.9379 | 0.1090 |
| 1.7743 | 11.27 | 8500 | 1.9834 | 0.1090 |
| 1.7721 | 11.94 | 9000 | 1.9279 | 0.1090 |
| 1.7719 | 12.6 | 9500 | 1.8187 | 0.1090 |
| 1.7616 | 13.26 | 10000 | 1.7804 | 0.1090 |
| 1.7638 | 13.93 | 10500 | 1.7884 | 0.1090 |
| 1.7651 | 14.59 | 11000 | 1.7476 | 0.1090 |
| 1.7603 | 15.25 | 11500 | 1.7570 | 0.1090 |
| 1.7543 | 15.92 | 12000 | 1.7356 | 0.1090 |
| 1.7556 | 16.58 | 12500 | 1.7140 | 0.1090 |
| 1.751 | 17.24 | 13000 | 1.7453 | 0.1090 |
| 1.75 | 17.9 | 13500 | 1.7648 | 0.1090 |
| 1.7492 | 18.57 | 14000 | 1.7338 | 0.1090 |
| 1.7484 | 19.23 | 14500 | 1.7093 | 0.1090 |
| 1.7461 | 19.89 | 15000 | 1.7393 | 0.1090 |
| 1.7429 | 20.56 | 15500 | 1.7605 | 0.1090 |
| 1.7446 | 21.22 | 16000 | 1.7782 | 0.1090 |
| 1.7435 | 21.88 | 16500 | 1.6749 | 0.1090 |
| 1.7392 | 22.55 | 17000 | 1.7468 | 0.1090 |
| 1.741 | 23.21 | 17500 | 1.7406 | 0.1090 |
| 1.7394 | 23.87 | 18000 | 1.7787 | 0.1090 |
| 1.739 | 24.54 | 18500 | 1.7969 | 0.1090 |
| 1.7341 | 25.2 | 19000 | 1.7490 | 0.1090 |
| 1.7371 | 25.86 | 19500 | 1.7783 | 0.1090 |
| 1.735 | 26.53 | 20000 | 1.7540 | 0.1090 |
| 1.7353 | 27.19 | 20500 | 1.7735 | 0.1090 |
| 1.7331 | 27.85 | 21000 | 1.7188 | 0.1090 |
| 1.7308 | 28.51 | 21500 | 1.7349 | 0.1090 |
| 1.7341 | 29.18 | 22000 | 1.7531 | 0.1090 |
| 1.7305 | 29.84 | 22500 | 1.7448 | 0.1090 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu102
- Datasets 1.16.1
- Tokenizers 0.12.1
|
AnonymousSub/rule_based_roberta_only_classfn_epochs_1_shard_1 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- fairytale_qa
metrics:
- rouge
model-index:
- name: t5-base-QG-finetuned-FairytaleQA
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: fairytale_qa
type: fairytale_qa
config: default
split: train
args: default
metrics:
- name: Rouge1
type: rouge
value: 42.7529
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-QG-finetuned-FairytaleQA
This model is a fine-tuned version of [t5-base](https://huggingface.co/t5-base) on the fairytale_qa dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1620
- Rouge1: 42.7529
- Rouge2: 23.9389
- Rougel: 40.4724
- Rougelsum: 40.4684
- Gen Len: 15.5698
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 1.4253 | 1.0 | 535 | 1.1620 | 42.7529 | 23.9389 | 40.4724 | 40.4684 | 15.5698 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
AnonymousSub/rule_based_roberta_twostagetriplet_epochs_1_shard_1_squad2.0 | [
"pytorch",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | {
"architectures": [
"RobertaForQuestionAnswering"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 72.20 +/- 114.39
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
AnonymousSub/rule_based_roberta_twostagetriplet_epochs_1_shard_1_wikiqa | [
"pytorch",
"roberta",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 24 | null | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- metrics:
- type: mean_reward
value: 7.52 +/- 2.76
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
---
# **Q-Learning** Agent playing **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="Galeros/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
AnonymousSub/rule_based_roberta_twostagetriplet_hier_epochs_1_shard_10 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | null | Access to model kabelomalapane/En-Ts_update is restricted and you are not in the authorized list. Visit https://huggingface.co/kabelomalapane/En-Ts_update to ask for access. |
AnonymousSub/unsup-consert-papers-bert | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | null | ---
library_name: stable-baselines3
tags:
- MsPacmanNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: QRDQN
results:
- metrics:
- type: mean_reward
value: 1209.00 +/- 822.50
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: MsPacmanNoFrameskip-v4
type: MsPacmanNoFrameskip-v4
---
# **QRDQN** Agent playing **MsPacmanNoFrameskip-v4**
This is a trained model of a **QRDQN** agent playing **MsPacmanNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo qrdqn --env MsPacmanNoFrameskip-v4 -orga sb3 -f logs/
python enjoy.py --algo qrdqn --env MsPacmanNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python train.py --algo qrdqn --env MsPacmanNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo qrdqn --env MsPacmanNoFrameskip-v4 -f logs/ -orga sb3
```
## Hyperparameters
```python
OrderedDict([('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_fraction', 0.025),
('frame_stack', 4),
('n_timesteps', 10000000.0),
('optimize_memory_usage', True),
('policy', 'CnnPolicy'),
('normalize', False)])
```
|
AnonymousSub/unsup-consert-papers | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2 | null | ---
language:
- de
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: DistilBART_CNN_GNAD
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# DistilBART_CNN_GNAD
This model is a fine-tuned version of [Einmalumdiewelt/DistilBART_CNN_GNAD](https://huggingface.co/Einmalumdiewelt/DistilBART_CNN_GNAD) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.8723
- Rouge1: 27.4368
- Rouge2: 8.159
- Rougel: 18.1359
- Rougelsum: 23.1339
- Gen Len: 91.5847
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10.0
### Training results
### Framework versions
- Transformers 4.22.0.dev0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
AnonymousSubmission/pretrained-model-1 | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 269.16 +/- 19.09
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Anorak/nirvana | [
"pytorch",
"pegasus",
"text2text-generation",
"unk",
"dataset:Anorak/autonlp-data-Niravana-test2",
"transformers",
"autonlp",
"co2_eq_emissions",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"PegasusForConditionalGeneration"
],
"model_type": "pegasus",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | 2022-08-05T19:54:52Z | ---
license: apache-2.0
---
# Introduction
The automatic paraphrasing model described and used in the paper
"[AutoQA: From Databases to QA Semantic Parsers with Only Synthetic Training Data](https://arxiv.org/abs/2010.04806)" (EMNLP 2020).
# Training data
A cleaned version of the ParaBank 2 dataset introduced in "[Large-Scale, Diverse, Paraphrastic Bitexts via Sampling and Clustering](https://aclanthology.org/K19-1005/)".
ParaBank 2 is a paraphrasing dataset constructed by back-translating the Czech portion of an English-Czech parallel corpus.
We use a subset of 5 million sentence pairs with the highest dual conditional cross-entropy score (which corresponds to the highest paraphrasing quality), and use only one of the five paraphrases provided for each sentence.
The cleaning process involved removing sentences that do not look like normal English sentences, e.g. contain URLs, contain too many special characters, etc.
# Training Procedure
The model is fine-tuned for 4 epochs on the above-mentioned dataset, starting from `facebook/bart-large` checkpoint.
We use token-level cross-entropy loss calculated using the gold paraphrase sentence. To ensure the output of the model is grammatical, during training, we use the back-translated Czech sentence as the input and the human-written English sentence as the output. Training is done with mini-batches of 1280 examples. For higher training efficiency, each mini-batch is constructed by grouping sentences of similar length together.
# How to use
Using `top_p=0.9` and `temperature` between `0` and `1` usually results in good generated paraphrases. Higher temperatures make paraphrases more diverse and more different from the input, but might slightly change the meaning of the original sentence.
Note that this is a sentence-level paraphraser. If you want to paraphrase longer inputs (like paragraphs) with this model, make sure to first break the input into individual sentences.
# Citation
If you are using this model in your work, please use this citation:
```
@inproceedings{xu-etal-2020-autoqa,
title = "{A}uto{QA}: From Databases to {QA} Semantic Parsers with Only Synthetic Training Data",
author = "Xu, Silei and Semnani, Sina and Campagna, Giovanni and Lam, Monica",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-main.31",
pages = "422--434",
}
``` |
AnthonyNelson/DialoGPT-small-ricksanchez | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 12 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-mnli
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-mnli
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8311
- Accuracy: 0.6574
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.8687 | 1.0 | 2636 | 0.8341 | 0.6495 |
| 0.7788 | 2.0 | 5272 | 0.8311 | 0.6574 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Anthos23/FS-distilroberta-fine-tuned | [
"pytorch",
"roberta",
"text-classification",
"transformers",
"has_space"
] | text-classification | {
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 33 | null | ---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-de-fr
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de-fr
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1654
- F1: 0.8590
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2845 | 1.0 | 715 | 0.1831 | 0.8249 |
| 0.1449 | 2.0 | 1430 | 0.1643 | 0.8479 |
| 0.0929 | 3.0 | 2145 | 0.1654 | 0.8590 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.0+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Anthos23/my-awesome-model | [
"pytorch",
"tf",
"roberta",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 30 | null | ---
license: mit
tags:
- generated_from_trainer
datasets:
- xtreme
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-it
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
args: PAN-X.it
metrics:
- name: F1
type: f1
value: 0.8245828245828245
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-it
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2401
- F1: 0.8246
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.8187 | 1.0 | 70 | 0.3325 | 0.7337 |
| 0.2829 | 2.0 | 140 | 0.2554 | 0.8003 |
| 0.1894 | 3.0 | 210 | 0.2401 | 0.8246 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.0+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
AntonClaesson/movie-plot-generator | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4721
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.7086 | 1.0 | 157 | 2.4898 |
| 2.5796 | 2.0 | 314 | 2.4230 |
| 2.5269 | 3.0 | 471 | 2.4354 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Antony/mint_model | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: mit
tags:
- generated_from_trainer
datasets:
- xtreme
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-en
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
args: PAN-X.en
metrics:
- name: F1
type: f1
value: 0.7032474804031354
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-en
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3932
- F1: 0.7032
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 1.1504 | 1.0 | 50 | 0.5992 | 0.4786 |
| 0.5147 | 2.0 | 100 | 0.4307 | 0.6468 |
| 0.3717 | 3.0 | 150 | 0.3932 | 0.7032 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.0+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Anubhav23/indianlegal | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-all
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-all
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1781
- F1: 0.8538
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2986 | 1.0 | 835 | 0.1929 | 0.8055 |
| 0.1547 | 2.0 | 1670 | 0.1804 | 0.8380 |
| 0.1003 | 3.0 | 2505 | 0.1781 | 0.8538 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.0+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Anubhav23/model_name | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ## Model Overview
This model is a Morse Code recognition model. It was trained with the package at https://github.com/1-800-BAD-CODE/MorseCodeToolkit.
This model accepts as input audio signals sampled at 8khz containing Morse code. The model produces the English transcription of the Morse code signal.
For inference, only the base NeMo package needs to be installed because this is just an ASR model trained to decode Morse code signals rather than speech signals.
## How to Use this Model
With NeMo is installed, this model can be used to run inference on Morse code audio files.
### Automatically instantiate the model
```python
import nemo.collections.asr as nemo_asr
asr_model = nemo_asr.models.ASRModel.from_pretrained("1-800-BAD-CODE/morsecode_en_quartznet_10x5")
```
### Transcribing using Python
First, let's download an example Morse code audio file from Wikipedia:
```
wget https://upload.wikimedia.org/wikipedia/commons/0/04/Wikipedia-Morse.ogg
```
Then simply do:
```
asr_model.transcribe(['Wikipedia-Morse.ogg'])
['WELCOME TO WIKIPEDIA, THE FREE ENCYCLOPEDIA THAT ANYONE CAN EDIT.']
```
## Limitations
This model was trained on synthetic Morse code data generated by https://github.com/1-800-BAD-CODE/MorseCodeToolkit. Any Morse code generated with parameters outside of the range of the parameters used to generate the training data will not be well recognized by the model. |
Anupam/QuestionClassifier | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 277.89 +/- 25.46
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Apisate/Discord-Ai-Bot | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 11 | null | ```
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("BigSalmon/InformalToFormalLincoln61Paraphrase")
model = AutoModelForCausalLM.from_pretrained("BigSalmon/InformalToFormalLincoln61Paraphrase")
```
```
Demo:
https://huggingface.co/spaces/BigSalmon/FormalInformalConciseWordy
```
```
prompt = """informal english: corn fields are all across illinois, visible once you leave chicago.\nTranslated into the Style of Abraham Lincoln:"""
input_ids = tokenizer.encode(prompt, return_tensors='pt')
outputs = model.generate(input_ids=input_ids,
max_length=10 + len(prompt),
temperature=1.0,
top_k=50,
top_p=0.95,
do_sample=True,
num_return_sequences=5,
early_stopping=True)
for i in range(5):
print(tokenizer.decode(outputs[i]))
```
```
How To Make Prompt:
informal english: i am very ready to do that just that.
Translated into the Style of Abraham Lincoln: you can assure yourself of my readiness to work toward this end.
Translated into the Style of Abraham Lincoln: please be assured that i am most ready to undertake this laborious task.
***
informal english: space is huge and needs to be explored.
Translated into the Style of Abraham Lincoln: space awaits traversal, a new world whose boundaries are endless.
Translated into the Style of Abraham Lincoln: space is a ( limitless / boundless ) expanse, a vast virgin domain awaiting exploration.
***
informal english: corn fields are all across illinois, visible once you leave chicago.
Translated into the Style of Abraham Lincoln: corn fields ( permeate illinois / span the state of illinois / ( occupy / persist in ) all corners of illinois / line the horizon of illinois / envelop the landscape of illinois ), manifesting themselves visibly as one ventures beyond chicago.
informal english:
```
```
infill: chrome extensions [MASK] accomplish everyday tasks.
Translated into the Style of Abraham Lincoln: chrome extensions ( expedite the ability to / unlock the means to more readily ) accomplish everyday tasks.
infill: at a time when nintendo has become inflexible, [MASK] consoles that are tethered to a fixed iteration, sega diligently curates its legacy of classic video games on handheld devices.
Translated into the Style of Abraham Lincoln: at a time when nintendo has become inflexible, ( stubbornly [MASK] on / firmly set on / unyielding in its insistence on ) consoles that are tethered to a fixed iteration, sega diligently curates its legacy of classic video games on handheld devices.
infill:
```
```
Essay Intro (Warriors vs. Rockets in Game 7):
text: eagerly anticipated by fans, game 7's are the highlight of the post-season.
text: ever-building in suspense, game 7's have the crowd captivated.
***
Essay Intro (South Korean TV Is Becoming Popular):
text: maturing into a bona fide paragon of programming, south korean television ( has much to offer / entertains without fail / never disappoints ).
text: increasingly held in critical esteem, south korean television continues to impress.
text: at the forefront of quality content, south korea is quickly achieving celebrity status.
***
Essay Intro (
```
```
Search: What is the definition of Checks and Balances?
https://en.wikipedia.org/wiki/Checks_and_balances
Checks and Balances is the idea of having a system where each and every action in government should be subject to one or more checks that would not allow one branch or the other to overly dominate.
https://www.harvard.edu/glossary/Checks_and_Balances
Checks and Balances is a system that allows each branch of government to limit the powers of the other branches in order to prevent abuse of power
https://www.law.cornell.edu/library/constitution/Checks_and_Balances
Checks and Balances is a system of separation through which branches of government can control the other, thus preventing excess power.
***
Search: What is the definition of Separation of Powers?
https://en.wikipedia.org/wiki/Separation_of_powers
The separation of powers is a principle in government, whereby governmental powers are separated into different branches, each with their own set of powers, that are prevent one branch from aggregating too much power.
https://www.yale.edu/tcf/Separation_of_Powers.html
Separation of Powers is the division of governmental functions between the executive, legislative and judicial branches, clearly demarcating each branch's authority, in the interest of ensuring that individual liberty or security is not undermined.
***
Search: What is the definition of Connection of Powers?
https://en.wikipedia.org/wiki/Connection_of_powers
Connection of Powers is a feature of some parliamentary forms of government where different branches of government are intermingled, typically the executive and legislative branches.
https://simple.wikipedia.org/wiki/Connection_of_powers
The term Connection of Powers describes a system of government in which there is overlap between different parts of the government.
***
Search: What is the definition of
```
```
Search: What are phrase synonyms for "second-guess"?
https://www.powerthesaurus.org/second-guess/synonyms
Shortest to Longest:
- feel dubious about
- raise an eyebrow at
- wrinkle their noses at
- cast a jaundiced eye at
- teeter on the fence about
***
Search: What are phrase synonyms for "mean to newbies"?
https://www.powerthesaurus.org/mean_to_newbies/synonyms
Shortest to Longest:
- readiness to balk at rookies
- absence of tolerance for novices
- hostile attitude toward newcomers
***
Search: What are phrase synonyms for "make use of"?
https://www.powerthesaurus.org/make_use_of/synonyms
Shortest to Longest:
- call upon
- glean value from
- reap benefits from
- derive utility from
- seize on the merits of
- draw on the strength of
- tap into the potential of
***
Search: What are phrase synonyms for "hurting itself"?
https://www.powerthesaurus.org/hurting_itself/synonyms
Shortest to Longest:
- erring
- slighting itself
- forfeiting its integrity
- doing itself a disservice
- evincing a lack of backbone
***
Search: What are phrase synonyms for "
```
```
- nebraska
- unicamerical legislature
- different from federal house and senate
text: featuring a unicameral legislature, nebraska's political system stands in stark contrast to the federal model, comprised of a house and senate.
***
- penny has practically no value
- should be taken out of circulation
- just as other coins have been in us history
- lost use
- value not enough
- to make environmental consequences worthy
text: all but valueless, the penny should be retired. as with other coins in american history, it has become defunct. too minute to warrant the environmental consequences of its production, it has outlived its usefulness.
***
-
```
```
original: sports teams are profitable for owners. [MASK], their valuations experience a dramatic uptick.
infill: sports teams are profitable for owners. ( accumulating vast sums / stockpiling treasure / realizing benefits / cashing in / registering robust financials / scoring on balance sheets ), their valuations experience a dramatic uptick.
***
original:
```
```
wordy: classical music is becoming less popular more and more.
Translate into Concise Text: interest in classic music is fading.
***
wordy:
```
```
sweet: savvy voters ousted him.
longer: voters who were informed delivered his defeat.
***
sweet:
```
```
1: commercial space company spacex plans to launch a whopping 52 flights in 2022.
2: spacex, a commercial space company, intends to undertake a total of 52 flights in 2022.
3: in 2022, commercial space company spacex has its sights set on undertaking 52 flights.
4: 52 flights are in the pipeline for 2022, according to spacex, a commercial space company.
5: a commercial space company, spacex aims to conduct 52 flights in 2022.
***
1:
```
Keywords to sentences or sentence.
```
ngos are characterized by:
□ voluntary citizens' group that is organized on a local, national or international level
□ encourage political participation
□ often serve humanitarian functions
□ work for social, economic, or environmental change
***
what are the drawbacks of living near an airbnb?
□ noise
□ parking
□ traffic
□ security
□ strangers
***
```
```
original: musicals generally use spoken dialogue as well as songs to convey the story. operas are usually fully sung.
adapted: musicals generally use spoken dialogue as well as songs to convey the story. ( in a stark departure / on the other hand / in contrast / by comparison / at odds with this practice / far from being alike / in defiance of this standard / running counter to this convention ), operas are usually fully sung.
***
original: akoya and tahitian are types of pearls. akoya pearls are mostly white, and tahitian pearls are naturally dark.
adapted: akoya and tahitian are types of pearls. ( a far cry from being indistinguishable / easily distinguished / on closer inspection / setting them apart / not to be mistaken for one another / hardly an instance of mere synonymy / differentiating the two ), akoya pearls are mostly white, and tahitian pearls are naturally dark.
***
original:
```
```
original: had trouble deciding.
translated into journalism speak: wrestled with the question, agonized over the matter, furrowed their brows in contemplation.
***
original:
```
```
input: not loyal
1800s english: ( two-faced / inimical / perfidious / duplicitous / mendacious / double-dealing / shifty ).
***
input:
```
```
first: ( was complicit in / was involved in ).
antonym: ( was blameless / was not an accomplice to / had no hand in / was uninvolved in ).
***
first: ( have no qualms about / see no issue with ).
antonym: ( are deeply troubled by / harbor grave reservations about / have a visceral aversion to / take ( umbrage at / exception to ) / are wary of ).
***
first: ( do not see eye to eye / disagree often ).
antonym: ( are in sync / are united / have excellent rapport / are like-minded / are in step / are of one mind / are in lockstep / operate in perfect harmony / march in lockstep ).
***
first:
```
```
stiff with competition, law school {A} is the launching pad for countless careers, {B} is a crowded field, {C} ranks among the most sought-after professional degrees, {D} is a professional proving ground.
***
languishing in viewership, saturday night live {A} is due for a creative renaissance, {B} is no longer a ratings juggernaut, {C} has been eclipsed by its imitators, {C} can still find its mojo.
***
dubbed the "manhattan of the south," atlanta {A} is a bustling metropolis, {B} is known for its vibrant downtown, {C} is a city of rich history, {D} is the pride of georgia.
***
embattled by scandal, harvard {A} is feeling the heat, {B} cannot escape the media glare, {C} is facing its most intense scrutiny yet, {D} is in the spotlight for all the wrong reasons.
```
Infill / Infilling / Masking / Phrase Masking
```
his contention [blank] by the evidence [sep] was refuted [answer]
***
few sights are as [blank] new york city as the colorful, flashing signage of its bodegas [sep] synonymous with [answer]
***
when rick won the lottery, all of his distant relatives [blank] his winnings [sep] clamored for [answer]
***
the library’s quiet atmosphere encourages visitors to [blank] in their work [sep] immerse themselves [answer]
***
``` |
Apoorva/k2t-test | [
"pytorch",
"t5",
"text2text-generation",
"en",
"transformers",
"keytotext",
"k2t",
"Keywords to Sentences",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"T5ForConditionalGeneration"
],
"model_type": "t5",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": true,
"length_penalty": 2,
"max_length": 200,
"min_length": 30,
"no_repeat_ngram_size": 3,
"num_beams": 4,
"prefix": "summarize: "
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to German: "
},
"translation_en_to_fr": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to French: "
},
"translation_en_to_ro": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to Romanian: "
}
}
} | 7 | 2022-08-05T22:23:55Z | ---
license: apache-2.0
---
[Optimum Habana](https://github.com/huggingface/optimum-habana) is the interface between the Hugging Face Transformers and Diffusers libraries and Habana's Gaudi processor (HPU).
It provides a set of tools enabling easy and fast model loading, training and inference on single- and multi-HPU settings for different downstream tasks.
Learn more about how to take advantage of the power of Habana HPUs to train and deploy Transformers and Diffusers models at [hf.co/hardware/habana](https://huggingface.co/hardware/habana).
## ViT model HPU configuration
This model only contains the `GaudiConfig` file for running the [ViT](https://huggingface.co/google/vit-base-patch16-224-in21k) model on Habana's Gaudi processors (HPU).
**This model contains no model weights, only a GaudiConfig.**
This enables to specify:
- `use_habana_mixed_precision`: whether to use Habana Mixed Precision (HMP)
- `hmp_opt_level`: optimization level for HMP, see [here](https://docs.habana.ai/en/latest/PyTorch/PyTorch_Mixed_Precision/PT_Mixed_Precision.html#configuration-options) for a detailed explanation
- `hmp_bf16_ops`: list of operators that should run in bf16
- `hmp_fp32_ops`: list of operators that should run in fp32
- `hmp_is_verbose`: verbosity
- `use_fused_adam`: whether to use Habana's custom AdamW implementation
- `use_fused_clip_norm`: whether to use Habana's fused gradient norm clipping operator
## Usage
The model is instantiated the same way as in the Transformers library.
The only difference is that there are a few new training arguments specific to HPUs.
[Here](https://github.com/huggingface/optimum-habana/blob/main/examples/image-classification/run_image_classification.py) is an image classification example script to fine-tune a model. You can run it with ViT with the following command:
```bash
python run_image_classification.py \
--model_name_or_path google/vit-base-patch16-224-in21k \
--dataset_name cifar10 \
--output_dir /tmp/outputs/ \
--remove_unused_columns False \
--do_train \
--do_eval \
--learning_rate 2e-5 \
--num_train_epochs 5 \
--per_device_train_batch_size 64 \
--per_device_eval_batch_size 64 \
--evaluation_strategy epoch \
--save_strategy epoch \
--load_best_model_at_end True \
--save_total_limit 3 \
--seed 1337 \
--use_habana \
--use_lazy_mode \
--gaudi_config_name Habana/vit \
--throughput_warmup_steps 2
```
Check the [documentation](https://huggingface.co/docs/optimum/habana/index) out for more advanced usage and examples.
|
Appolo/TestModel | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: roberta-base-EnglishLawAI_roberta_base_version4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-EnglishLawAI_roberta_base_version4
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8089
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 12
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:------:|:---------------:|
| 2.3575 | 1.0 | 23702 | 2.1592 |
| 2.2419 | 2.0 | 47404 | 2.1005 |
| 2.1663 | 3.0 | 71106 | 2.0487 |
| 2.1013 | 4.0 | 94808 | 2.0135 |
| 2.0497 | 5.0 | 118510 | 1.9840 |
| 1.9968 | 6.0 | 142212 | 1.9398 |
| 1.9507 | 7.0 | 165914 | 1.9163 |
| 1.9076 | 8.0 | 189616 | 1.8893 |
| 1.8662 | 9.0 | 213318 | 1.8604 |
| 1.8264 | 10.0 | 237020 | 1.8416 |
| 1.7927 | 11.0 | 260722 | 1.8134 |
| 1.7641 | 12.0 | 284424 | 1.8089 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
ArBert/albert-base-v2-finetuned-ner-gmm | [
"pytorch",
"tensorboard",
"albert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"AlbertForTokenClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
language: en
thumbnail: http://www.huggingtweets.com/chipflake/1659739094566/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1338527116644806663/XkhjylPj_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">the one, singular chip</div>
<div style="text-align: center; font-size: 14px;">@chipflake</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from the one, singular chip.
| Data | the one, singular chip |
| --- | --- |
| Tweets downloaded | 1214 |
| Retweets | 80 |
| Short tweets | 220 |
| Tweets kept | 914 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/38uu3y9r/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @chipflake's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/40p3p4l2) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/40p3p4l2/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/chipflake')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
ArBert/bert-base-uncased-finetuned-ner-gmm | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- LunarLander-v2
- ppo
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 103.08 +/- 43.38
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
---
# PPO Agent Playing LunarLander-v2
This is a trained model of a PPO agent playing LunarLander-v2.
To learn to code your own PPO agent and train it Unit 8 of the Deep Reinforcement Learning Class: https://github.com/huggingface/deep-rl-class/tree/main/unit8
# Hyperparameters
```python
{'exp_name': 'ppo'
'seed': 1
'torch_deterministic': True
'cuda': True
'track': False
'wandb_project_name': 'cleanRL'
'wandb_entity': None
'capture_video': False
'env_id': 'LunarLander-v2'
'total_timesteps': 500000
'learning_rate': 0.00025
'num_envs': 4
'num_steps': 128
'anneal_lr': True
'gae': True
'gamma': 0.99
'gae_lambda': 0.95
'num_minibatches': 4
'update_epochs': 4
'norm_adv': True
'clip_coef': 0.2
'clip_vloss': True
'ent_coef': 0.01
'vf_coef': 0.5
'max_grad_norm': 0.5
'target_kl': None
'repo_id': 'trtd56/ppo-LunarLander'
'batch_size': 512
'minibatch_size': 128}
```
|
ArBert/roberta-base-finetuned-ner-kmeans-twitter | [
"pytorch",
"tensorboard",
"roberta",
"token-classification",
"transformers",
"generated_from_trainer",
"license:mit",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"RobertaForTokenClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | 2022-08-05T23:42:30Z | ---
tags:
- CartPole-v1
- ppo
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 166.60 +/- 82.10
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
---
# PPO Agent Playing CartPole-v1
This is a trained model of a PPO agent playing CartPole-v1.
To learn to code your own PPO agent and train it Unit 8 of the Deep Reinforcement Learning Class: https://github.com/huggingface/deep-rl-class/tree/main/unit8
# Hyperparameters
```python
{'exp_name': 'ppo'
'seed': 1
'torch_deterministic': True
'cuda': True
'track': False
'wandb_project_name': 'cleanRL'
'wandb_entity': None
'capture_video': False
'env_id': 'CartPole-v1'
'total_timesteps': 50000
'learning_rate': 0.00025
'num_envs': 4
'num_steps': 128
'anneal_lr': True
'gae': True
'gamma': 0.99
'gae_lambda': 0.95
'num_minibatches': 4
'update_epochs': 4
'norm_adv': True
'clip_coef': 0.2
'clip_vloss': True
'ent_coef': 0.01
'vf_coef': 0.5
'max_grad_norm': 0.5
'target_kl': None
'repo_id': 'trtd56/ppo-CartPole'
'batch_size': 512
'minibatch_size': 128}
```
|
ArBert/roberta-base-finetuned-ner | [
"pytorch",
"tensorboard",
"roberta",
"token-classification",
"transformers",
"generated_from_trainer",
"license:mit",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"RobertaForTokenClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/804990434455887872/BG0Xh7Oa_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Sam Altman</div>
<div style="text-align: center; font-size: 14px;">@sama</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Sam Altman.
| Data | Sam Altman |
| --- | --- |
| Tweets downloaded | 3246 |
| Retweets | 388 |
| Short tweets | 153 |
| Tweets kept | 2705 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/6cl7ldqq/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @sama's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/hi9mhdy4) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/hi9mhdy4/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/sama')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
ArJakusz/DialoGPT-small-stark | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
language: en
thumbnail: http://www.huggingtweets.com/shyamalanadkat/1659744994175/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1484514513651220489/svAJBona_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Shyamal Hitesh Anadkat</div>
<div style="text-align: center; font-size: 14px;">@shyamalanadkat</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Shyamal Hitesh Anadkat.
| Data | Shyamal Hitesh Anadkat |
| --- | --- |
| Tweets downloaded | 645 |
| Retweets | 215 |
| Short tweets | 80 |
| Tweets kept | 350 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2b6wpa8f/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @shyamalanadkat's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/hqykqb3d) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/hqykqb3d/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/shyamalanadkat')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
ArJakusz/DialoGPT-small-starky | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: other
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: output
results: []
---
# MonoGPTari-1.3b
This model is a fine-tuned version of [facebook/opt-1.3b](https://huggingface.co/facebook/opt-1.3b) on an english monogatari text dataset.
This was primarily used as a PoC, use the 6.7b for optimal spiciness.
It achieves the following results on the evaluation set:
- Loss: 1.1909
- Accuracy: 0.7299
## Quick start
```python
from transformers import pipeline
generator = pipeline('text-generation', model="monogptari-1.3b" , device=0, use_fast=False)
generator("I think its about time I talked about Kiss-Shot", min_length=1000, max_length=2000,
do_sample=True, early_stopping=True, temperature=.98, top_k=50, top_p=1.0)
```
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.22.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Araby/Arabic-TTS | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: other
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: output_2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# monogptari-6.7b
This model is a fine-tuned version of [facebook/opt-6.7b](https://huggingface.co/facebook/opt-6.7b) on an english monogatari (物語) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7030
- Accuracy: 0.8436
## Quick start
```python
from transformers import pipeline
generator = pipeline('text-generation', model="tensorcat/monogptari-6.7b" , device=0, use_fast=False)
generator("I think its about time I talked about Kiss-Shot", min_length=100, max_length=800,
do_sample=True, early_stopping=True, temperature=.98, top_k=50, top_p=1.0)
```
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 8
- total_eval_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.22.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Aran/DialoGPT-small-harrypotter | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9275
- name: F1
type: f1
value: 0.9274815041868594
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2182
- Accuracy: 0.9275
- F1: 0.9275
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8403 | 1.0 | 250 | 0.3135 | 0.9065 | 0.9031 |
| 0.2525 | 2.0 | 500 | 0.2182 | 0.9275 | 0.9275 |
### Framework versions
- Transformers 4.13.0
- Pytorch 1.12.0+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
ArashEsk95/bert-base-uncased-finetuned-stsb | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad_v2
model-index:
- name: albert-base-v2-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# albert-base-v2-finetuned-squad
This model is a fine-tuned version of [albert-base-v2](https://huggingface.co/albert-base-v2) on the squad_v2 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9650
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.0595 | 1.0 | 8248 | 1.4663 |
| 0.6228 | 2.0 | 16496 | 0.8433 |
| 0.4347 | 3.0 | 24744 | 0.9650 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.