
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-07-27 18:27:08
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 533
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-07-27 18:22:57
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
Sympan/Reinforce-Cart
|
Sympan
| 2023-07-11T13:53:32Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-11T13:53:23Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-Cart
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 485.30 +/- 44.10
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
Xorbits/chatglm2-6B-GGML
|
Xorbits
| 2023-07-11T13:50:37Z | 0 | 23 | null |
[
"arxiv:1911.02150",
"license:apache-2.0",
"region:us"
] | null | 2023-07-05T08:03:24Z |
---
license: apache-2.0
---
# THUDM's chatglm2 6B GGML
These files are GGML format model files for [THUDM's chatglm2 6B](https://huggingface.co/THUDM/chatglm2-6b).
GGML files are for CPU + GPU inference using [chatglm.cpp](https://github.com/li-plus/chatglm.cpp) and [Xorbits Inference](https://github.com/xorbitsai/inference).
# Prompt template
**NOTE**: prompt template is not available yet since the system prompt is hard coded in chatglm.cpp for now.
# Provided files
| Name | Quant method | Bits | Size |
|------|--------------|------|------|
| chatglm2-ggml-q4_0.bin | q4_0 | 4 | 3.5 GB |
| chatglm2-ggml-q4_1.bin | q4_1 | 4 | 3.9 GB |
| chatglm2-ggml-q5_0.bin | q5_0 | 5 | 4.3 GB |
| chatglm2-ggml-q5_1.bin | q5_1 | 5 | 4.7 GB |
| chatglm2-ggml-q8_0.bin | q8_0 | 8 | 6.6 GB |
# How to run in Xorbits Inference
## Install
Xinference can be installed via pip from PyPI. It is highly recommended to create a new virtual environment to avoid conflicts.
```bash
$ pip install "xinference[all]"
$ pip install chatglm-cpp
```
## Start Xorbits Inference
To start a local instance of Xinference, run the following command:
```bash
$ xinference
```
Once Xinference is running, an endpoint will be accessible for model management via CLI or Xinference client. The default endpoint is `http://localhost:9997`. You can also view a web UI using the Xinference endpoint to chat with all the builtin models. You can even chat with two cutting-edge AI models side-by-side to compare their performance!
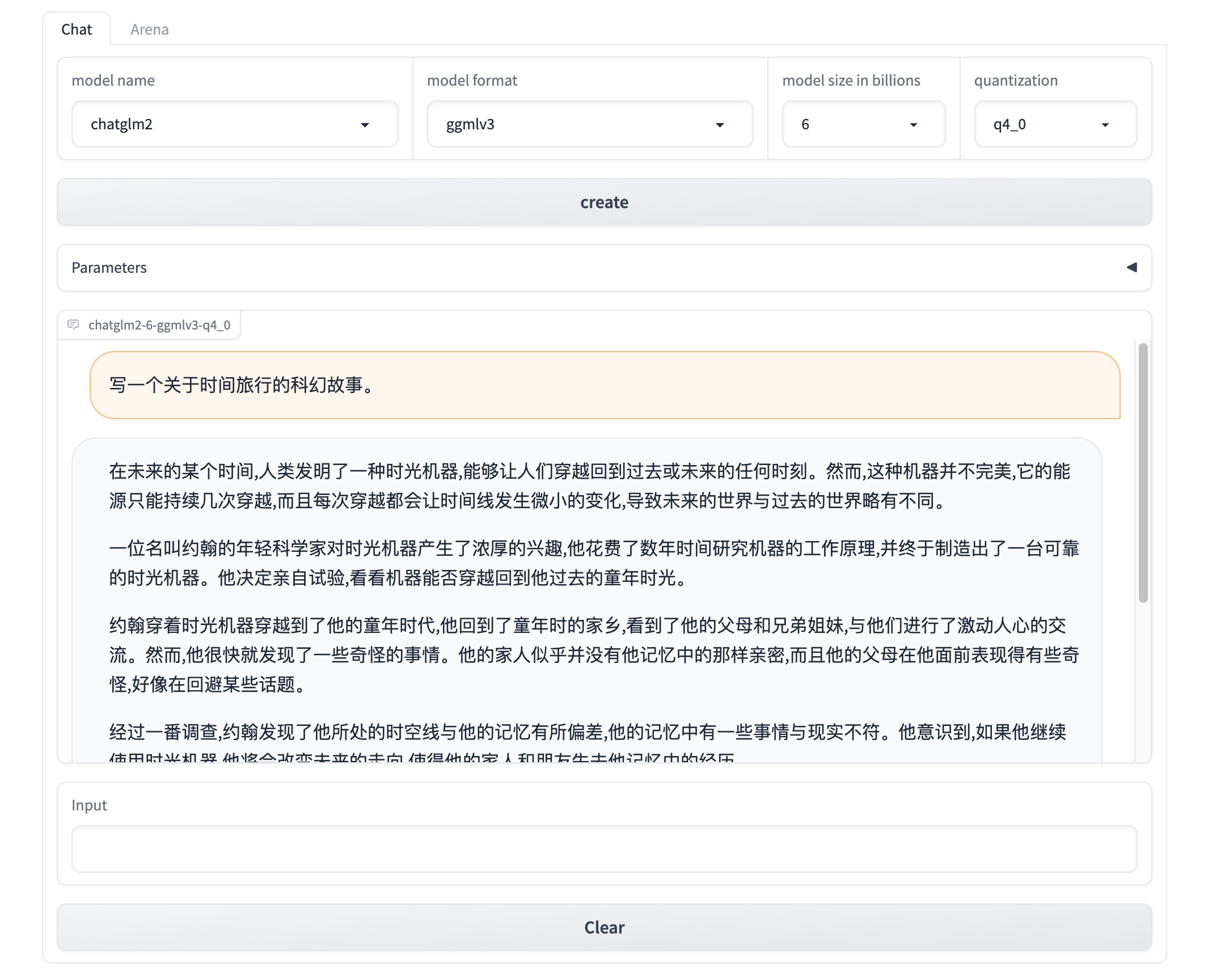
# Slack
For further support, and discussions on these models and AI in general, join our [slack channel](https://join.slack.com/t/xorbitsio/shared_invite/zt-1o3z9ucdh-RbfhbPVpx7prOVdM1CAuxg)!
# Original model card: THUDM's chatglm2 6B
ChatGLM**2**-6B is the second-generation version of the open-source bilingual (Chinese-English) chat model [ChatGLM-6B](https://github.com/THUDM/ChatGLM-6B). It retains the smooth conversation flow and low deployment threshold of the first-generation model, while introducing the following new features:
1. **Stronger Performance**: Based on the development experience of the first-generation ChatGLM model, we have fully upgraded the base model of ChatGLM2-6B. ChatGLM2-6B uses the hybrid objective function of [GLM](https://github.com/THUDM/GLM), and has undergone pre-training with 1.4T bilingual tokens and human preference alignment training. The [evaluation results](README.md#evaluation-results) show that, compared to the first-generation model, ChatGLM2-6B has achieved substantial improvements in performance on datasets like MMLU (+23%), CEval (+33%), GSM8K (+571%), BBH (+60%), showing strong competitiveness among models of the same size.
2. **Longer Context**: Based on [FlashAttention](https://github.com/HazyResearch/flash-attention) technique, we have extended the context length of the base model from 2K in ChatGLM-6B to 32K, and trained with a context length of 8K during the dialogue alignment, allowing for more rounds of dialogue. However, the current version of ChatGLM2-6B has limited understanding of single-round ultra-long documents, which we will focus on optimizing in future iterations.
3. **More Efficient Inference**: Based on [Multi-Query Attention](http://arxiv.org/abs/1911.02150) technique, ChatGLM2-6B has more efficient inference speed and lower GPU memory usage: under the official implementation, the inference speed has increased by 42% compared to the first generation; under INT4 quantization, the dialogue length supported by 6G GPU memory has increased from 1K to 8K.
For more instructions, including how to run CLI and web demos, and model quantization, please refer to our [Github Repo](https://github.com/THUDM/ChatGLM2-6B).
|
h2o-llmstudio/falcon-7b-fix
|
h2o-llmstudio
| 2023-07-11T13:46:34Z | 17 | 1 |
transformers
|
[
"transformers",
"pytorch",
"RefinedWebModel",
"text-generation",
"custom_code",
"en",
"dataset:tiiuae/falcon-refinedweb",
"arxiv:2205.14135",
"arxiv:1911.02150",
"arxiv:2101.00027",
"arxiv:2005.14165",
"arxiv:2104.09864",
"arxiv:2306.01116",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] |
text-generation
| 2023-07-06T09:48:00Z |
---
datasets:
- tiiuae/falcon-refinedweb
language:
- en
inference: false
license: apache-2.0
---
⚠️ **This is an unofficial fork of the original [Falcon-7B](https://huggingface.co/tiiuae/falcon-7b) model.**
The following changes have been made:
- Fixing generation configuration setting
- Model now properly uses specified ```attention_mask``` when calling ```scaled_dot_product_attention``` - this also allows to specify custom attention masks and work with left-padded input. However, this will disable additional memory and flash optimization.
# 🚀 Falcon-7B
**Falcon-7B is a 7B parameters causal decoder-only model built by [TII](https://www.tii.ae) and trained on 1,500B tokens of [RefinedWeb](https://huggingface.co/datasets/tiiuae/falcon-refinedweb) enhanced with curated corpora. It is made available under the Apache 2.0 license.**
*Paper coming soon* 😊.
🤗 To get started with Falcon (inference, finetuning, quantization, etc.), we recommend reading [this great blogpost fron HF](https://huggingface.co/blog/falcon)!
## Why use Falcon-7B?
* **It outperforms comparable open-source models** (e.g., [MPT-7B](https://huggingface.co/mosaicml/mpt-7b), [StableLM](https://github.com/Stability-AI/StableLM), [RedPajama](https://huggingface.co/togethercomputer/RedPajama-INCITE-Base-7B-v0.1) etc.), thanks to being trained on 1,500B tokens of [RefinedWeb](https://huggingface.co/datasets/tiiuae/falcon-refinedweb) enhanced with curated corpora. See the [OpenLLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
* **It features an architecture optimized for inference**, with FlashAttention ([Dao et al., 2022](https://arxiv.org/abs/2205.14135)) and multiquery ([Shazeer et al., 2019](https://arxiv.org/abs/1911.02150)).
* **It is made available under a permissive Apache 2.0 license allowing for commercial use**, without any royalties or restrictions.
⚠️ **This is a raw, pretrained model, which should be further finetuned for most usecases.** If you are looking for a version better suited to taking generic instructions in a chat format, we recommend taking a look at [Falcon-7B-Instruct](https://huggingface.co/tiiuae/falcon-7b-instruct).
🔥 **Looking for an even more powerful model?** [Falcon-40B](https://huggingface.co/tiiuae/falcon-40b) is Falcon-7B's big brother!
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
sequences = pipeline(
"Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.\nDaniel: Hello, Girafatron!\nGirafatron:",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
```
💥 **Falcon LLMs require PyTorch 2.0 for use with `transformers`!**
For fast inference with Falcon, check-out [Text Generation Inference](https://github.com/huggingface/text-generation-inference)! Read more in this [blogpost]((https://huggingface.co/blog/falcon).
You will need **at least 16GB of memory** to swiftly run inference with Falcon-7B.
# Model Card for Falcon-7B
## Model Details
### Model Description
- **Developed by:** [https://www.tii.ae](https://www.tii.ae);
- **Model type:** Causal decoder-only;
- **Language(s) (NLP):** English and French;
- **License:** Apache 2.0.
### Model Source
- **Paper:** *coming soon*.
## Uses
### Direct Use
Research on large language models; as a foundation for further specialization and finetuning for specific usecases (e.g., summarization, text generation, chatbot, etc.)
### Out-of-Scope Use
Production use without adequate assessment of risks and mitigation; any use cases which may be considered irresponsible or harmful.
## Bias, Risks, and Limitations
Falcon-7B is trained on English and French data only, and will not generalize appropriately to other languages. Furthermore, as it is trained on a large-scale corpora representative of the web, it will carry the stereotypes and biases commonly encountered online.
### Recommendations
We recommend users of Falcon-7B to consider finetuning it for the specific set of tasks of interest, and for guardrails and appropriate precautions to be taken for any production use.
## How to Get Started with the Model
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
sequences = pipeline(
"Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.\nDaniel: Hello, Girafatron!\nGirafatron:",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
```
## Training Details
### Training Data
Falcon-7B was trained on 1,500B tokens of [RefinedWeb](https://huggingface.co/datasets/tiiuae/falcon-refinedweb), a high-quality filtered and deduplicated web dataset which we enhanced with curated corpora. Significant components from our curated copora were inspired by The Pile ([Gao et al., 2020](https://arxiv.org/abs/2101.00027)).
| **Data source** | **Fraction** | **Tokens** | **Sources** |
|--------------------|--------------|------------|-----------------------------------|
| [RefinedWeb-English](https://huggingface.co/datasets/tiiuae/falcon-refinedweb) | 79% | 1,185B | massive web crawl |
| Books | 7% | 110B | |
| Conversations | 6% | 85B | Reddit, StackOverflow, HackerNews |
| Code | 3% | 45B | |
| RefinedWeb-French | 3% | 45B | massive web crawl |
| Technical | 2% | 30B | arXiv, PubMed, USPTO, etc. |
The data was tokenized with the Falcon-[7B](https://huggingface.co/tiiuae/falcon-7b)/[40B](https://huggingface.co/tiiuae/falcon-40b) tokenizer.
### Training Procedure
Falcon-7B was trained on 384 A100 40GB GPUs, using a 2D parallelism strategy (PP=2, DP=192) combined with ZeRO.
#### Training Hyperparameters
| **Hyperparameter** | **Value** | **Comment** |
|--------------------|------------|-------------------------------------------|
| Precision | `bfloat16` | |
| Optimizer | AdamW | |
| Learning rate | 6e-4 | 4B tokens warm-up, cosine decay to 1.2e-5 |
| Weight decay | 1e-1 | |
| Z-loss | 1e-4 | |
| Batch size | 2304 | 30B tokens ramp-up |
#### Speeds, Sizes, Times
Training happened in early March 2023 and took about two weeks.
## Evaluation
*Paper coming soon*.
See the [OpenLLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard) for early results.
## Technical Specifications
### Model Architecture and Objective
Falcon-7B is a causal decoder-only model trained on a causal language modeling task (i.e., predict the next token).
The architecture is broadly adapted from the GPT-3 paper ([Brown et al., 2020](https://arxiv.org/abs/2005.14165)), with the following differences:
* **Positionnal embeddings:** rotary ([Su et al., 2021](https://arxiv.org/abs/2104.09864));
* **Attention:** multiquery ([Shazeer et al., 2019](https://arxiv.org/abs/1911.02150)) and FlashAttention ([Dao et al., 2022](https://arxiv.org/abs/2205.14135));
* **Decoder-block:** parallel attention/MLP with a single layer norm.
| **Hyperparameter** | **Value** | **Comment** |
|--------------------|-----------|----------------------------------------|
| Layers | 32 | |
| `d_model` | 4544 | Increased to compensate for multiquery |
| `head_dim` | 64 | Reduced to optimise for FlashAttention |
| Vocabulary | 65024 | |
| Sequence length | 2048 | |
### Compute Infrastructure
#### Hardware
Falcon-7B was trained on AWS SageMaker, on 384 A100 40GB GPUs in P4d instances.
#### Software
Falcon-7B was trained a custom distributed training codebase, Gigatron. It uses a 3D parallelism approach combined with ZeRO and high-performance Triton kernels (FlashAttention, etc.)
## Citation
*Paper coming soon* 😊. In the meanwhile, you can use the following information to cite:
```
@article{falcon40b,
title={{Falcon-40B}: an open large language model with state-of-the-art performance},
author={Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme},
year={2023}
}
```
To learn more about the pretraining dataset, see the 📓 [RefinedWeb paper](https://arxiv.org/abs/2306.01116).
```
@article{refinedweb,
title={The {R}efined{W}eb dataset for {F}alcon {LLM}: outperforming curated corpora with web data, and web data only},
author={Guilherme Penedo and Quentin Malartic and Daniel Hesslow and Ruxandra Cojocaru and Alessandro Cappelli and Hamza Alobeidli and Baptiste Pannier and Ebtesam Almazrouei and Julien Launay},
journal={arXiv preprint arXiv:2306.01116},
eprint={2306.01116},
eprinttype = {arXiv},
url={https://arxiv.org/abs/2306.01116},
year={2023}
}
```
## License
Falcon-7B is made available under the Apache 2.0 license.
## Contact
[email protected]
|
shaunster/xlm-roberta-base-finetuned-panx-en-ext_head_loss
|
shaunster
| 2023-07-11T13:38:10Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"dataset:xtreme",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-07-05T04:20:15Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- xtreme
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-en-ext_head_loss
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
config: PAN-X.en
split: validation
args: PAN-X.en
metrics:
- name: F1
type: f1
value: 0.8075228972942741
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-en-ext_head_loss
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2985
- F1: 0.8075
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.9161 | 1.0 | 417 | 0.5816 | 0.3588 |
| 0.5572 | 2.0 | 834 | 0.5326 | 0.4619 |
| 0.3821 | 3.0 | 1251 | 0.3929 | 0.5508 |
| 0.2552 | 4.0 | 1668 | 0.3149 | 0.8015 |
| 0.1755 | 5.0 | 2085 | 0.2985 | 0.8075 |
### Framework versions
- Transformers 4.28.0
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
sjdata/speecht5_finetuned_voxpopuli_nl
|
sjdata
| 2023-07-11T13:37:35Z | 75 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"speecht5",
"text-to-audio",
"generated_from_trainer",
"dataset:voxpopuli",
"license:mit",
"endpoints_compatible",
"region:us"
] |
text-to-audio
| 2023-07-11T11:50:21Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- voxpopuli
model-index:
- name: speecht5_finetuned_voxpopuli_nl
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# speecht5_finetuned_voxpopuli_nl
This model is a fine-tuned version of [microsoft/speecht5_tts](https://huggingface.co/microsoft/speecht5_tts) on the voxpopuli dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4626
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.5217 | 4.3 | 1000 | 0.4827 |
| 0.4955 | 8.61 | 2000 | 0.4678 |
| 0.4936 | 12.91 | 3000 | 0.4666 |
| 0.4936 | 17.21 | 4000 | 0.4626 |
### Framework versions
- Transformers 4.31.0.dev0
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
BlueAvenir/model_growth_restructuring_V_0_1
|
BlueAvenir
| 2023-07-11T13:20:12Z | 2 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"xlm-roberta",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2023-07-11T13:19:50Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 258 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": 258,
"warmup_steps": 26,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: XLMRobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
NasimB/gpt2-cocnat-mod-datasets3-rarity-all
|
NasimB
| 2023-07-11T13:13:07Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"dataset:generator",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-11T11:20:45Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- generator
model-index:
- name: gpt2-cocnat-mod-datasets3-rarity-all
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-cocnat-mod-datasets3-rarity-all
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 4.3779
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 6
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 6.7201 | 0.3 | 500 | 5.6554 |
| 5.3777 | 0.6 | 1000 | 5.2100 |
| 5.0257 | 0.91 | 1500 | 4.9662 |
| 4.7428 | 1.21 | 2000 | 4.8246 |
| 4.5916 | 1.51 | 2500 | 4.6972 |
| 4.4886 | 1.81 | 3000 | 4.5927 |
| 4.3213 | 2.12 | 3500 | 4.5355 |
| 4.173 | 2.42 | 4000 | 4.4840 |
| 4.1402 | 2.72 | 4500 | 4.4195 |
| 4.0833 | 3.02 | 5000 | 4.3844 |
| 3.8496 | 3.33 | 5500 | 4.3743 |
| 3.8398 | 3.63 | 6000 | 4.3421 |
| 3.8193 | 3.93 | 6500 | 4.3113 |
| 3.6103 | 4.23 | 7000 | 4.3294 |
| 3.5592 | 4.53 | 7500 | 4.3199 |
| 3.5442 | 4.84 | 8000 | 4.3041 |
| 3.4575 | 5.14 | 8500 | 4.3158 |
| 3.3572 | 5.44 | 9000 | 4.3191 |
| 3.3595 | 5.74 | 9500 | 4.3171 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.11.0+cu113
- Datasets 2.13.0
- Tokenizers 0.13.3
|
Mithun12/my_first_asr_model
|
Mithun12
| 2023-07-11T13:12:29Z | 77 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-07-11T11:15:57Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: my_first_asr_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_first_asr_model
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 2
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 2000
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
Bhanu9Prakash/ast-finetuned-audioset-10-10-0.4593-finetuned-gtzan
|
Bhanu9Prakash
| 2023-07-11T13:05:14Z | 222 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"audio-spectrogram-transformer",
"audio-classification",
"generated_from_trainer",
"dataset:marsyas/gtzan",
"base_model:MIT/ast-finetuned-audioset-10-10-0.4593",
"base_model:finetune:MIT/ast-finetuned-audioset-10-10-0.4593",
"license:bsd-3-clause",
"model-index",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2023-07-11T12:44:34Z |
---
license: bsd-3-clause
base_model: MIT/ast-finetuned-audioset-10-10-0.4593
tags:
- generated_from_trainer
datasets:
- marsyas/gtzan
metrics:
- accuracy
model-index:
- name: ast-finetuned-audioset-10-10-0.4593-finetuned-gtzan
results:
- task:
name: Audio Classification
type: audio-classification
dataset:
name: GTZAN
type: marsyas/gtzan
config: all
split: train
args: all
metrics:
- name: Accuracy
type: accuracy
value: 0.92
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ast-finetuned-audioset-10-10-0.4593-finetuned-gtzan
This model is a fine-tuned version of [MIT/ast-finetuned-audioset-10-10-0.4593](https://huggingface.co/MIT/ast-finetuned-audioset-10-10-0.4593) on the GTZAN dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3966
- Accuracy: 0.92
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.0687 | 1.0 | 113 | 0.6197 | 0.84 |
| 0.299 | 2.0 | 226 | 0.5065 | 0.86 |
| 0.2634 | 3.0 | 339 | 0.5042 | 0.88 |
| 0.0473 | 4.0 | 452 | 0.5413 | 0.88 |
| 0.0033 | 5.0 | 565 | 0.3706 | 0.91 |
| 0.0003 | 6.0 | 678 | 0.4485 | 0.9 |
| 0.2538 | 7.0 | 791 | 0.4006 | 0.9 |
| 0.0002 | 8.0 | 904 | 0.3985 | 0.9 |
| 0.003 | 9.0 | 1017 | 0.3952 | 0.91 |
| 0.0001 | 10.0 | 1130 | 0.3966 | 0.92 |
### Framework versions
- Transformers 4.31.0.dev0
- Pytorch 1.12.1+cu116
- Datasets 2.4.0
- Tokenizers 0.12.1
|
kmariunas/uncased-bert-triplet-40
|
kmariunas
| 2023-07-11T13:02:44Z | 101 | 1 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"tf",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2023-07-11T13:01:06Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 108 with parameters:
```
{'batch_size': 64, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.BatchHardTripletLoss.BatchHardTripletLoss`
Parameters of the fit()-Method:
```
{
"epochs": 40,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 429.20000000000005,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
ashnrk/textual_inversion_residential
|
ashnrk
| 2023-07-11T12:59:49Z | 18 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"textual_inversion",
"base_model:stabilityai/stable-diffusion-2-1",
"base_model:adapter:stabilityai/stable-diffusion-2-1",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-07-11T11:57:37Z |
---
license: creativeml-openrail-m
base_model: stabilityai/stable-diffusion-2-1
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- textual_inversion
inference: true
---
# Textual inversion text2image fine-tuning - ashnrk/textual_inversion_residential
These are textual inversion adaption weights for stabilityai/stable-diffusion-2-1. You can find some example images in the following.
|
antonioalvarado/text_analyzer_albert-base-v2
|
antonioalvarado
| 2023-07-11T12:53:05Z | 103 | 1 |
transformers
|
[
"transformers",
"pytorch",
"albert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-11T12:23:30Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: text_analyzer_albert-base-v2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# text_analyzer_albert-base-v2
This model is a fine-tuned version of [albert-base-v2](https://huggingface.co/albert-base-v2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0093
- Accuracy: 0.9988
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.4321 | 1.0 | 3457 | 0.3820 | 0.9341 |
| 0.1756 | 2.0 | 6914 | 0.1220 | 0.9815 |
| 0.029 | 3.0 | 10371 | 0.0464 | 0.9919 |
| 0.0001 | 4.0 | 13828 | 0.0093 | 0.9988 |
### Framework versions
- Transformers 4.29.1
- Pytorch 1.12.0+cu102
- Datasets 2.13.1
- Tokenizers 0.13.3
|
sumitrsch/multiconer2_muril_large_bn
|
sumitrsch
| 2023-07-11T12:41:30Z | 109 | 2 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-02-02T13:05:45Z |
For prediction on test data use this link. https://colab.research.google.com/drive/1K-ED0yvMsdciNo52rluauQBEAg-DBomC?usp=sharing
update best_model_path = "sumitrsch/multiconer2_muril_large_bn"
If you are using this code, cite paper "silp_nlp at SemEval-2023 Task 2: Cross-lingual Knowledge Transfer for Mono-lingual Learning"
https://aclanthology.org/2023.semeval-1.164
|
sumitrsch/multiconer2_muril_large_hi
|
sumitrsch
| 2023-07-11T12:40:43Z | 120 | 2 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-02-02T13:04:38Z |
For prediction on test data use this link. https://colab.research.google.com/drive/1K-ED0yvMsdciNo52rluauQBEAg-DBomC?usp=sharing
If you are using this code, cite paper "silp_nlp at SemEval-2023 Task 2: Cross-lingual Knowledge Transfer for
Mono-lingual Learning"
https://aclanthology.org/2023.semeval-1.164
|
duwuonline/mymodel-generation
|
duwuonline
| 2023-07-11T12:38:20Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-07-11T12:20:34Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: mymodel-generation
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mymodel-generation
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4959
- Rouge1: 15.814
- Rouge2: 6.0889
- Rougel: 13.524
- Rougelsum: 13.6797
- Gen Len: 19.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:|
| No log | 1.0 | 100 | 0.6815 | 14.8968 | 4.9117 | 12.5655 | 12.7826 | 19.0 |
| No log | 2.0 | 200 | 0.6100 | 14.9404 | 4.9974 | 12.8103 | 13.0953 | 19.0 |
| No log | 3.0 | 300 | 0.5827 | 14.991 | 5.2082 | 12.9564 | 13.1979 | 19.0 |
| No log | 4.0 | 400 | 0.5568 | 14.9205 | 5.1634 | 12.6664 | 12.8388 | 19.0 |
| 0.8938 | 5.0 | 500 | 0.5352 | 15.2597 | 5.6541 | 13.0388 | 13.1956 | 19.0 |
| 0.8938 | 6.0 | 600 | 0.5212 | 15.4645 | 5.7723 | 13.2198 | 13.3698 | 19.0 |
| 0.8938 | 7.0 | 700 | 0.5098 | 15.4663 | 5.8769 | 13.2799 | 13.403 | 19.0 |
| 0.8938 | 8.0 | 800 | 0.5015 | 16.0013 | 6.2874 | 13.7037 | 13.8538 | 19.0 |
| 0.8938 | 9.0 | 900 | 0.4957 | 15.8722 | 6.1918 | 13.6299 | 13.7783 | 19.0 |
| 0.6764 | 10.0 | 1000 | 0.4959 | 15.814 | 6.0889 | 13.524 | 13.6797 | 19.0 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
digiplay/NewMarsMix_R
|
digiplay
| 2023-07-11T12:31:12Z | 0 | 0 | null |
[
"license:other",
"region:us"
] | null | 2023-07-11T01:51:42Z |
---
license: other
---
https://civitai.com/models/19321?modelVersionId=25545
|
srirammadduri-ts/roberta-base-squad2-finetuned-roberta
|
srirammadduri-ts
| 2023-07-11T12:26:34Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"question-answering",
"generated_from_trainer",
"license:cc-by-4.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-07-11T12:06:31Z |
---
license: cc-by-4.0
tags:
- generated_from_trainer
model-index:
- name: roberta-base-squad2-finetuned-roberta
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-squad2-finetuned-roberta
This model is a fine-tuned version of [deepset/roberta-base-squad2](https://huggingface.co/deepset/roberta-base-squad2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0003
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 2 | 0.0008 |
| No log | 2.0 | 4 | 0.0004 |
| No log | 3.0 | 6 | 0.0003 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0
- Datasets 2.13.1
- Tokenizers 0.13.3
|
F-Haru/test
|
F-Haru
| 2023-07-11T12:10:12Z | 2 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"xlm-roberta",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2023-07-11T12:03:50Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 1686 with parameters:
```
{'batch_size': 64, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MSELoss.MSELoss`
Parameters of the fit()-Method:
```
{
"epochs": 10,
"evaluation_steps": 1000,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"eps": 1e-06,
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 10000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: XLMRobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
NasimB/gpt2-concat-all-mod-datasets1-rarity-all-c13k-c2p6k-rev
|
NasimB
| 2023-07-11T12:08:38Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"dataset:generator",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-11T10:23:20Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- generator
model-index:
- name: gpt2-concat-all-mod-datasets1-rarity-all-c13k-c2p6k-rev
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-concat-all-mod-datasets1-rarity-all-c13k-c2p6k-rev
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 4.8844
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 6
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 6.7952 | 0.32 | 500 | 5.7564 |
| 5.4839 | 0.63 | 1000 | 5.3858 |
| 5.1442 | 0.95 | 1500 | 5.2129 |
| 4.8614 | 1.27 | 2000 | 5.0996 |
| 4.7476 | 1.59 | 2500 | 5.0222 |
| 4.6481 | 1.9 | 3000 | 4.9507 |
| 4.4504 | 2.22 | 3500 | 4.9514 |
| 4.3796 | 2.54 | 4000 | 4.8926 |
| 4.3388 | 2.85 | 4500 | 4.8553 |
| 4.1754 | 3.17 | 5000 | 4.8697 |
| 4.0695 | 3.49 | 5500 | 4.8398 |
| 4.0541 | 3.8 | 6000 | 4.8012 |
| 3.9275 | 4.12 | 6500 | 4.8334 |
| 3.7741 | 4.44 | 7000 | 4.8258 |
| 3.7686 | 4.76 | 7500 | 4.8182 |
| 3.7113 | 5.07 | 8000 | 4.8313 |
| 3.5725 | 5.39 | 8500 | 4.8351 |
| 3.5762 | 5.71 | 9000 | 4.8371 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.11.0+cu113
- Datasets 2.13.0
- Tokenizers 0.13.3
|
komo-dono/risataneda
|
komo-dono
| 2023-07-11T12:03:18Z | 0 | 0 | null |
[
"region:us"
] | null | 2023-07-11T12:01:51Z |
---
license: openrail
language:
- ja
tags:
- music
risa taneda 600 epoch
|
kfkas/LawBot-v1_koalpaca_legalQA_easylaw_train
|
kfkas
| 2023-07-11T12:00:10Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-07-11T12:00:06Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.4.0.dev0
|
sofia-todeschini/PubMedBERT-LitCovid-v1.2
|
sofia-todeschini
| 2023-07-11T11:50:04Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-11T08:51:46Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
- accuracy
model-index:
- name: PubMedBERT-LitCovid-v1.2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# PubMedBERT-LitCovid-v1.2
This model is a fine-tuned version of [microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract](https://huggingface.co/microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0998
- F1: 0.9200
- Roc Auc: 0.9529
- Accuracy: 0.7868
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Roc Auc | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:-------:|:--------:|
| 0.1017 | 1.0 | 2211 | 0.0897 | 0.9155 | 0.9492 | 0.7722 |
| 0.0742 | 2.0 | 4422 | 0.0868 | 0.9177 | 0.9508 | 0.7778 |
| 0.0559 | 3.0 | 6633 | 0.0903 | 0.9191 | 0.9521 | 0.7827 |
| 0.0396 | 4.0 | 8844 | 0.0955 | 0.9184 | 0.9512 | 0.7814 |
| 0.0282 | 5.0 | 11055 | 0.0998 | 0.9200 | 0.9529 | 0.7868 |
### Framework versions
- Transformers 4.28.0
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.13.3
|
Penbloom/Penbloom_semirealmix
|
Penbloom
| 2023-07-11T11:34:24Z | 0 | 0 | null |
[
"musclar",
"korean",
"license:openrail",
"region:us"
] | null | 2023-04-08T14:59:05Z |
---
license: openrail
tags:
- musclar
- korean
---
## Model Detail & Merge Recipes
Penbloom_semirealmix aims to create musclar girls with nice skin texture and detailed clothes.This is a ``merge`` model.
## Source model
[Civitai:Beenyou|Stable Diffusion Checkpoint](https://civitai.com/models/27688/beenyou)
[⚠NSFW][Civitai:饭特稀|Stable Diffusion Checkpoint](https://civitai.com/models/18427/v08))
### Penbloom_semirealmix_v1.0
|
vvasanth/falcon7b-finetune-test-220623_1
|
vvasanth
| 2023-07-11T11:31:41Z | 0 | 0 | null |
[
"text-generation",
"license:apache-2.0",
"region:us"
] |
text-generation
| 2023-07-04T11:51:13Z |
---
license: apache-2.0
pipeline_tag: text-generation
---
|
jasonyim2/distilbert-base-uncased-finetuned-emotion
|
jasonyim2
| 2023-07-11T11:22:55Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-26T06:45:02Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.9215
- name: F1
type: f1
value: 0.9215386837894378
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2227
- Accuracy: 0.9215
- F1: 0.9215
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8265 | 1.0 | 250 | 0.3204 | 0.9 | 0.8963 |
| 0.2534 | 2.0 | 500 | 0.2227 | 0.9215 | 0.9215 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
antonioalvarado/text_analyzer_base_bert
|
antonioalvarado
| 2023-07-11T11:21:46Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-11T10:55:01Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: text_analyzer_base_bert
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# text_analyzer_base_bert
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0472
- Accuracy: 0.9861
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.3672 | 1.0 | 1728 | 0.1788 | 0.9469 |
| 0.1509 | 2.0 | 3456 | 0.1311 | 0.9769 |
| 0.0071 | 3.0 | 5184 | 0.0494 | 0.9861 |
| 0.0076 | 4.0 | 6912 | 0.0472 | 0.9861 |
### Framework versions
- Transformers 4.29.1
- Pytorch 1.12.0+cu102
- Datasets 2.13.1
- Tokenizers 0.13.3
|
jwu323/origin-llama-7b
|
jwu323
| 2023-07-11T11:06:24Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-11T09:17:15Z |
This contains the original weights for the LLaMA-7b model.
This model is under a non-commercial license (see the LICENSE file).
You should only use this repository if you have been granted access to the model by filling out [this form](https://docs.google.com/forms/d/e/1FAIpQLSfqNECQnMkycAp2jP4Z9TFX0cGR4uf7b_fBxjY_OjhJILlKGA/viewform) but either lost your copy of the weights or got some trouble converting them to the Transformers format.
[According to this comment](https://github.com/huggingface/transformers/issues/21681#issuecomment-1436552397), dtype of a model in PyTorch is always float32, regardless of the dtype of the checkpoint you saved. If you load a float16 checkpoint in a model you create (which is in float32 by default), the dtype that is kept at the end is the dtype of the model, not the dtype of the checkpoint.
|
NasimB/gpt2-concat-all-mod-datasets1-rarity-all-iorder-end-c2p6k
|
NasimB
| 2023-07-11T10:57:16Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"dataset:generator",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-11T09:09:23Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- generator
model-index:
- name: gpt2-concat-all-mod-datasets1-rarity-all-iorder-end-c2p6k
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-concat-all-mod-datasets1-rarity-all-iorder-end-c2p6k
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 4.3830
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 6
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 6.784 | 0.32 | 500 | 5.6510 |
| 5.4458 | 0.63 | 1000 | 5.2234 |
| 5.0999 | 0.95 | 1500 | 4.9802 |
| 4.8039 | 1.26 | 2000 | 4.8338 |
| 4.6712 | 1.58 | 2500 | 4.7110 |
| 4.5643 | 1.89 | 3000 | 4.5978 |
| 4.3499 | 2.21 | 3500 | 4.5524 |
| 4.2538 | 2.52 | 4000 | 4.4816 |
| 4.2202 | 2.84 | 4500 | 4.4235 |
| 4.0629 | 3.15 | 5000 | 4.4144 |
| 3.9341 | 3.47 | 5500 | 4.3803 |
| 3.9186 | 3.78 | 6000 | 4.3457 |
| 3.8084 | 4.1 | 6500 | 4.3452 |
| 3.6343 | 4.41 | 7000 | 4.3378 |
| 3.6317 | 4.73 | 7500 | 4.3197 |
| 3.5947 | 5.04 | 8000 | 4.3232 |
| 3.4369 | 5.36 | 8500 | 4.3272 |
| 3.434 | 5.67 | 9000 | 4.3271 |
| 3.4327 | 5.99 | 9500 | 4.3265 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.11.0+cu113
- Datasets 2.13.0
- Tokenizers 0.13.3
|
digiplay/RealEpicMajicRevolution_v1
|
digiplay
| 2023-07-11T10:42:18Z | 393 | 1 |
diffusers
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-07-11T09:48:27Z |
---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info:
https://civitai.com/models/107185/real-epic-majic-revolution
Original Author's DEMO images :


|
mort1k/q-FrozenLake-v1-4x4-noSlippery
|
mort1k
| 2023-07-11T10:35:42Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-11T10:35:41Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="mort1k/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
F-Haru/paraphrase-mpnet-base-v2_09-04-MarginMSELoss-finetuning-7-5
|
F-Haru
| 2023-07-11T10:29:25Z | 1 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"xlm-roberta",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2023-07-11T09:35:14Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
ファインチューニングする時のNegative ja-en, en-jaのコサイン類似度が0.9以上0.4以下のみで
ファインチューニングをした後に、
教師モデルをparaphrase-mpnet-base-v2で知識蒸留をしたモデル
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 1686 with parameters:
```
{'batch_size': 64, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MSELoss.MSELoss`
Parameters of the fit()-Method:
```
{
"epochs": 3,
"evaluation_steps": 1000,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"eps": 1e-06,
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 10000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 514, 'do_lower_case': False}) with Transformer model: XLMRobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
miki-kawa/huggingdatavit-base-beans
|
miki-kawa
| 2023-07-11T10:22:59Z | 193 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:beans",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-07-11T09:55:51Z |
---
license: apache-2.0
tags:
- image-classification
- generated_from_trainer
datasets:
- beans
metrics:
- accuracy
model-index:
- name: huggingdatavit-base-beans
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: beans
type: beans
config: default
split: validation
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9924812030075187
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# huggingdatavit-base-beans
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the beans dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0356
- Accuracy: 0.9925
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.1059 | 1.54 | 100 | 0.0356 | 0.9925 |
| 0.0256 | 3.08 | 200 | 0.0663 | 0.9774 |
### Framework versions
- Transformers 4.28.0
- Pytorch 2.0.1+cu117
- Datasets 2.13.0
- Tokenizers 0.11.0
|
Krish23/Tujgc
|
Krish23
| 2023-07-11T10:22:51Z | 0 | 0 | null |
[
"license:cc-by-nc-sa-2.0",
"region:us"
] | null | 2023-07-11T10:22:51Z |
---
license: cc-by-nc-sa-2.0
---
|
bofenghuang/vigogne-7b-instruct
|
bofenghuang
| 2023-07-11T10:18:13Z | 1,493 | 23 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"LLM",
"fr",
"license:openrail",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] |
text-generation
| 2023-03-22T21:36:45Z |
---
license: openrail
language:
- fr
pipeline_tag: text-generation
library_name: transformers
tags:
- llama
- LLM
inference: false
---
<p align="center" width="100%">
<img src="https://huggingface.co/bofenghuang/vigogne-7b-instruct/resolve/main/vigogne_logo.png" alt="Vigogne" style="width: 40%; min-width: 300px; display: block; margin: auto;">
</p>
# Vigogne-7B-Instruct: A French Instruction-following LLaMA Model
Vigogne-7B-Instruct is a LLaMA-7B model fine-tuned to follow the French instructions.
For more information, please visit the Github repo: https://github.com/bofenghuang/vigogne
**Usage and License Notices**: Same as [Stanford Alpaca](https://github.com/tatsu-lab/stanford_alpaca), Vigogne is intended and licensed for research use only. The dataset is CC BY NC 4.0 (allowing only non-commercial use) and models trained using the dataset should not be used outside of research purposes.
## Changelog
All versions are available in branches.
- **V1.0**: Initial release, trained on the translated Stanford Alpaca dataset.
- **V1.1**: Improved translation quality of the Stanford Alpaca dataset.
- **V2.0**: Expanded training dataset to 224k for better performance.
- **V3.0**: Further expanded training dataset to 262k for improved results.
## Usage
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
from vigogne.preprocess import generate_instruct_prompt
model_name_or_path = "bofenghuang/vigogne-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, padding_side="right", use_fast=False)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, torch_dtype=torch.float16, device_map="auto")
user_query = "Expliquez la différence entre DoS et phishing."
prompt = generate_instruct_prompt(user_query)
input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to(model.device)
input_length = input_ids.shape[1]
generated_outputs = model.generate(
input_ids=input_ids,
generation_config=GenerationConfig(
temperature=0.1,
do_sample=True,
repetition_penalty=1.0,
max_new_tokens=512,
),
return_dict_in_generate=True,
)
generated_tokens = generated_outputs.sequences[0, input_length:]
generated_text = tokenizer.decode(generated_tokens, skip_special_tokens=True)
print(generated_text)
```
You can also infer this model by using the following Google Colab Notebook.
<a href="https://colab.research.google.com/github/bofenghuang/vigogne/blob/main/notebooks/infer_instruct.ipynb" target="_blank"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
## Limitations
Vigogne is still under development, and there are many limitations that have to be addressed. Please note that it is possible that the model generates harmful or biased content, incorrect information or generally unhelpful answers.
|
thomsonreuters/budgetlongformer-diverse
|
thomsonreuters
| 2023-07-11T10:09:14Z | 43 | 10 |
transformers
|
[
"transformers",
"pytorch",
"longformer",
"en",
"dataset:pile-of-law/pile-of-law",
"arxiv:2211.17135",
"arxiv:2207.00220",
"arxiv:1910.09700",
"license:other",
"endpoints_compatible",
"region:us"
] | null | 2023-07-10T16:23:59Z |
---
datasets:
- pile-of-law/pile-of-law
language:
- en
library_name: transformers
license: other
---
# Model Card for budgetlongformer-diverse
<!-- Provide a quick summary of what the model is/does. [Optional] -->
Legal pretrained model using Replaced Token Detection (RTD) task, trained on Pile-of-Law dataset with 4096 tokens as context windows.
# Model Details
## Model Description
<!-- Provide a longer summary of what this model is/does. -->
Legal pretrained model using ELECTRA objective task, trained on Pile-of-Law dataset with 4096 tokens as context windows.
- **Developed by:** Joel Niklaus, Daniele Giofré
- **Model type:** Language model
- **Language(s) (NLP):** en
- **License:** other
- **Resources for more information:**
- [Associated Paper](https://arxiv.org/abs/2211.17135)
# Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
## Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
<!-- If the user enters content, print that. If not, but they enter a task in the list, use that. If neither, say "more info needed." -->
The model can directly be used to generate embeddings for example for similarity search. It likely works best on US focused legal data.
## Downstream Use
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
<!-- If the user enters content, print that. If not, but they enter a task in the list, use that. If neither, say "more info needed." -->
The model can be finetuned for any NLU task or when coupled with a decoder also for generative tasks. In our experiments on summarization with the BillSum dataset, we found that random initialization of the decoder improved performance.
## Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
<!-- If the user enters content, print that. If not, but they enter a task in the list, use that. If neither, say "more info needed." -->
This model will likely work worse on non-legal text in non-English languages originating from outside the US.
# Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)). Predictions generated by the model may include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups.
## Considerations about the training dataset
### Social Impact of Dataset
As described in the dataset card, the internal variation allows contextual privacy rules to be learned. If robust mechanisms for this are developed they can applied more broadly.
As discussed in ``On the Opportunities and Risks of Foundation Models'', legal language models can help improve access to justice in various ways.
But they can also be used in potentially harmful ways. While such models are not ready for most production environments and are the subject of significant research,
we ask that model users and model creators using this model, particularly when creating generative models (e.g. attaching a decoder), consider the impacts of their model and make a good faith effort to weigh the benefits against the harms of their method.
As our license, the training dataset license also restricts commercial usage.
## Discussion of Biases
The data reflects the biases of governments and courts. As discussed in their work [Pile of Law](https://arxiv.org/abs/2207.00220), these can be significant, though more recent text will likely be less overtly toxic.
Please consult the above statement and keep it in mind in the use and/or any modification of this model, implementing responsible use.
## Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
As with any large LM there is the risk of it producing biased or unfair output. Researchers using the model should put into place respective safeguards to identify biased and/or toxic language.
# Training Details
## Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
The diverse model was trained on caselaw (“Court Listener Opinions” & “Court Listener Docket Entry Documents”), legislation (“US Code”, “State Codes” & “EURLEX”) and contracts (“Atticus Contracts” & “EDGAR Contracts”) from public Pile-of-Law dataset. To balance the training data, we limited the number of documents to 500K (this affects Court Listener Opinions, Court Listener Docket Entry Documents and EDGAR Contracts).
## Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
### Preprocessing
More information needed
### Speeds, Sizes, Times
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
More information needed
# Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
## Testing Data, Factors & Metrics
### Testing Data
<!-- This should link to a Data Card if possible. -->
We tested the model on the BillSum and PubMed summarization datasets achieving SotA Rouge scores for the respective parameter sizes in August 2022.
### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
More information needed
### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
We followed the standard in research on summarization datasets and used Rouge 1, 2 and L.
## Results
More information needed
# Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** 4 x 16GB NVIDIA V100
- **Hours used:** 144
- **Cloud Provider:** AWS
- **Compute Region:** US East
- **Carbon Emitted:** 15.98
## Model Architecture and Objective
We used a Longformer attention window of 256 as generator and discriminator. The generator model was three times smaller than the discriminator model. In particular, the generator’s depth (number of hidden layers) instead of its width (embedding size, hidden size and intermediate size). We used a MLM probability of 25\% for the generator.
## Compute Infrastructure
Amazon SageMaker Notebooks.
### Hardware
4 x 16GB NVIDIA V100
### Software
transformers
# Citation
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
@misc{niklaus2022budgetlongformer,
title={BudgetLongformer: Can we Cheaply Pretrain a SotA Legal Language Model From Scratch?},
author={Joel Niklaus and Daniele Giofré},
year={2022},
eprint={2211.17135},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
# Model Card Authors
<!-- This section provides another layer of transparency and accountability. Whose views is this model card representing? How many voices were included in its construction? Etc. -->
Joel Niklaus, Daniele Giofré
|
NasimB/gpt2-concat-all-mod-datasets1-rarity-all-iorder-c13k-c2p6k
|
NasimB
| 2023-07-11T10:00:14Z | 12 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"dataset:generator",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-11T06:50:47Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- generator
model-index:
- name: gpt2-concat-all-mod-datasets1-rarity-all-iorder-c13k-c2p6k
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-concat-all-mod-datasets1-rarity-all-iorder-c13k-c2p6k
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 5.1936
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 6
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 6.7242 | 0.32 | 500 | 5.9768 |
| 5.1735 | 0.63 | 1000 | 5.6554 |
| 4.7404 | 0.95 | 1500 | 5.4996 |
| 4.4224 | 1.27 | 2000 | 5.3442 |
| 4.2763 | 1.59 | 2500 | 5.2809 |
| 4.1764 | 1.9 | 3000 | 5.1548 |
| 3.9599 | 2.22 | 3500 | 5.1872 |
| 3.8843 | 2.54 | 4000 | 5.1061 |
| 3.8426 | 2.85 | 4500 | 5.0545 |
| 3.6894 | 3.17 | 5000 | 5.1307 |
| 3.571 | 3.49 | 5500 | 5.1444 |
| 3.5653 | 3.8 | 6000 | 5.0994 |
| 3.4291 | 4.12 | 6500 | 5.1304 |
| 3.2885 | 4.44 | 7000 | 5.1346 |
| 3.2687 | 4.76 | 7500 | 5.1504 |
| 3.2233 | 5.07 | 8000 | 5.1550 |
| 3.0814 | 5.39 | 8500 | 5.1628 |
| 3.0825 | 5.71 | 9000 | 5.1746 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.11.0+cu113
- Datasets 2.13.0
- Tokenizers 0.13.3
|
Winmodel/ML-Agents-SnowballTarget
|
Winmodel
| 2023-07-11T09:47:03Z | 0 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"SnowballTarget",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SnowballTarget",
"region:us"
] |
reinforcement-learning
| 2023-07-11T09:47:02Z |
---
library_name: ml-agents
tags:
- SnowballTarget
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SnowballTarget
---
# **ppo** Agent playing **SnowballTarget**
This is a trained model of a **ppo** agent playing **SnowballTarget**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: Winmodel/ML-Agents-SnowballTarget
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
jalaluddin94/xlmr-nli-indoindo
|
jalaluddin94
| 2023-07-11T09:44:18Z | 161 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-11T05:51:03Z |
---
license: mit
base_model: xlm-roberta-base
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: xlmr-nli-indoindo
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlmr-nli-indoindo
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6699
- Accuracy: 0.7701
- Precision: 0.7701
- Recall: 0.7701
- F1: 0.7693
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-06
- train_batch_size: 6
- eval_batch_size: 6
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 6
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 1.0444 | 1.0 | 1722 | 0.8481 | 0.6463 | 0.6463 | 0.6463 | 0.6483 |
| 0.7958 | 2.0 | 3444 | 0.7483 | 0.7369 | 0.7369 | 0.7369 | 0.7353 |
| 0.7175 | 3.0 | 5166 | 0.6812 | 0.7579 | 0.7579 | 0.7579 | 0.7576 |
| 0.66 | 4.0 | 6888 | 0.6293 | 0.7679 | 0.7679 | 0.7679 | 0.7674 |
| 0.6056 | 5.0 | 8610 | 0.6459 | 0.7651 | 0.7651 | 0.7651 | 0.7640 |
| 0.5769 | 6.0 | 10332 | 0.6699 | 0.7701 | 0.7701 | 0.7701 | 0.7693 |
### Framework versions
- Transformers 4.31.0.dev0
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.13.3
|
dsfsi/nso-en-m2m100-gov
|
dsfsi
| 2023-07-11T09:41:06Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"m2m_100",
"text2text-generation",
"m2m100",
"translation",
"africanlp",
"african",
"sepedi",
"northern-sotho",
"nso",
"en",
"arxiv:2303.03750",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-06-13T07:22:09Z |
---
license: cc-by-4.0
language:
- nso
- en
pipeline_tag: text2text-generation
tags:
- m2m100
- translation
- africanlp
- african
- sepedi
- northern-sotho
---
# [nso-en] Northen Sotho [Sepedi] to English Translation Model based on M2M100 and The South African Gov-ZA multilingual corpus
Model created from Northen Sotho [Sepedi] to English aligned sentences from [The South African Gov-ZA multilingual corpus](https://github.com/dsfsi/gov-za-multilingual)
The data set contains cabinet statements from the South African government, maintained by the Government Communication and Information System (GCIS). Data was scraped from the governments website: https://www.gov.za/cabinet-statements
## Authors
- Vukosi Marivate - [@vukosi](https://twitter.com/vukosi)
- Matimba Shingange
- Richard Lastrucci
- Isheanesu Joseph Dzingirai
- Jenalea Rajab
## BibTeX entry and citation info
```
@inproceedings{lastrucci-etal-2023-preparing,
title = "Preparing the Vuk{'}uzenzele and {ZA}-gov-multilingual {S}outh {A}frican multilingual corpora",
author = "Richard Lastrucci and Isheanesu Dzingirai and Jenalea Rajab and Andani Madodonga and Matimba Shingange and Daniel Njini and Vukosi Marivate",
booktitle = "Proceedings of the Fourth workshop on Resources for African Indigenous Languages (RAIL 2023)",
month = may,
year = "2023",
address = "Dubrovnik, Croatia",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.rail-1.3",
pages = "18--25"
}
```
[Paper - Preparing the Vuk'uzenzele and ZA-gov-multilingual South African multilingual corpora](https://arxiv.org/abs/2303.03750)
|
jordyvl/vit-small_rvl_cdip_100_examples_per_class_kd_CEKD_t5.0_a0.9
|
jordyvl
| 2023-07-11T09:39:46Z | 161 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-07-11T08:25:41Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: vit-small_rvl_cdip_100_examples_per_class_kd_CEKD_t5.0_a0.9
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-small_rvl_cdip_100_examples_per_class_kd_CEKD_t5.0_a0.9
This model is a fine-tuned version of [WinKawaks/vit-small-patch16-224](https://huggingface.co/WinKawaks/vit-small-patch16-224) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2897
- Accuracy: 0.635
- Brier Loss: 0.5186
- Nll: 2.9908
- F1 Micro: 0.635
- F1 Macro: 0.6391
- Ece: 0.1984
- Aurc: 0.1511
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Brier Loss | Nll | F1 Micro | F1 Macro | Ece | Aurc |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:----------:|:-------:|:--------:|:--------:|:------:|:------:|
| No log | 1.0 | 25 | 2.8799 | 0.12 | 0.9317 | 15.6566 | 0.12 | 0.1217 | 0.1503 | 0.8678 |
| No log | 2.0 | 50 | 2.2166 | 0.395 | 0.7576 | 9.4150 | 0.395 | 0.3645 | 0.2155 | 0.3726 |
| No log | 3.0 | 75 | 1.7821 | 0.505 | 0.6346 | 5.5305 | 0.505 | 0.4975 | 0.1755 | 0.2454 |
| No log | 4.0 | 100 | 1.6660 | 0.5275 | 0.6038 | 4.9669 | 0.5275 | 0.5333 | 0.1684 | 0.2324 |
| No log | 5.0 | 125 | 1.6118 | 0.54 | 0.5943 | 4.8266 | 0.54 | 0.5233 | 0.1947 | 0.2249 |
| No log | 6.0 | 150 | 1.7108 | 0.5275 | 0.6168 | 4.4308 | 0.5275 | 0.5247 | 0.2018 | 0.2418 |
| No log | 7.0 | 175 | 1.6465 | 0.5825 | 0.5721 | 4.8918 | 0.5825 | 0.5614 | 0.1887 | 0.1995 |
| No log | 8.0 | 200 | 1.6441 | 0.565 | 0.6040 | 4.2349 | 0.565 | 0.5591 | 0.1933 | 0.2216 |
| No log | 9.0 | 225 | 1.7054 | 0.565 | 0.6054 | 4.6348 | 0.565 | 0.5649 | 0.1845 | 0.2033 |
| No log | 10.0 | 250 | 1.6724 | 0.5375 | 0.6191 | 4.3502 | 0.5375 | 0.5257 | 0.1991 | 0.2223 |
| No log | 11.0 | 275 | 1.5397 | 0.57 | 0.5757 | 4.1311 | 0.57 | 0.5715 | 0.2079 | 0.1936 |
| No log | 12.0 | 300 | 1.7636 | 0.55 | 0.6394 | 5.0515 | 0.55 | 0.5376 | 0.2252 | 0.2268 |
| No log | 13.0 | 325 | 1.6080 | 0.575 | 0.5997 | 4.2707 | 0.575 | 0.5515 | 0.2048 | 0.1887 |
| No log | 14.0 | 350 | 1.7572 | 0.575 | 0.6205 | 4.6140 | 0.575 | 0.5705 | 0.2203 | 0.2342 |
| No log | 15.0 | 375 | 1.5604 | 0.58 | 0.5872 | 3.8633 | 0.58 | 0.5762 | 0.2089 | 0.1866 |
| No log | 16.0 | 400 | 1.6440 | 0.585 | 0.6042 | 4.2508 | 0.585 | 0.5940 | 0.2253 | 0.2182 |
| No log | 17.0 | 425 | 1.6117 | 0.5825 | 0.6057 | 4.2511 | 0.5825 | 0.5732 | 0.2299 | 0.1947 |
| No log | 18.0 | 450 | 1.5597 | 0.605 | 0.5732 | 4.4755 | 0.605 | 0.6028 | 0.2101 | 0.1721 |
| No log | 19.0 | 475 | 1.4177 | 0.6325 | 0.5429 | 3.4771 | 0.6325 | 0.6319 | 0.1930 | 0.1786 |
| 0.5354 | 20.0 | 500 | 1.5745 | 0.56 | 0.6076 | 3.6058 | 0.56 | 0.5643 | 0.2265 | 0.1898 |
| 0.5354 | 21.0 | 525 | 1.4907 | 0.6125 | 0.5682 | 3.9837 | 0.6125 | 0.6184 | 0.1981 | 0.1810 |
| 0.5354 | 22.0 | 550 | 1.4494 | 0.5925 | 0.5677 | 3.2864 | 0.5925 | 0.5906 | 0.2187 | 0.1670 |
| 0.5354 | 23.0 | 575 | 1.5608 | 0.62 | 0.5830 | 4.0132 | 0.62 | 0.6029 | 0.2286 | 0.1808 |
| 0.5354 | 24.0 | 600 | 1.5038 | 0.58 | 0.5957 | 3.6519 | 0.58 | 0.5956 | 0.2321 | 0.1879 |
| 0.5354 | 25.0 | 625 | 1.4094 | 0.615 | 0.5554 | 3.0313 | 0.615 | 0.6102 | 0.2180 | 0.1689 |
| 0.5354 | 26.0 | 650 | 1.4485 | 0.62 | 0.5712 | 3.3326 | 0.62 | 0.6181 | 0.2138 | 0.1729 |
| 0.5354 | 27.0 | 675 | 1.4156 | 0.6225 | 0.5621 | 3.2257 | 0.6225 | 0.6239 | 0.2158 | 0.1718 |
| 0.5354 | 28.0 | 700 | 1.3729 | 0.6275 | 0.5476 | 3.1300 | 0.6275 | 0.6285 | 0.2078 | 0.1620 |
| 0.5354 | 29.0 | 725 | 1.3671 | 0.6275 | 0.5337 | 3.4625 | 0.6275 | 0.6285 | 0.2177 | 0.1586 |
| 0.5354 | 30.0 | 750 | 1.3263 | 0.63 | 0.5380 | 3.2177 | 0.63 | 0.6338 | 0.2063 | 0.1577 |
| 0.5354 | 31.0 | 775 | 1.2991 | 0.6225 | 0.5223 | 3.0482 | 0.6225 | 0.6238 | 0.1940 | 0.1525 |
| 0.5354 | 32.0 | 800 | 1.3227 | 0.6325 | 0.5333 | 2.9622 | 0.6325 | 0.6351 | 0.1906 | 0.1554 |
| 0.5354 | 33.0 | 825 | 1.3077 | 0.63 | 0.5298 | 3.2060 | 0.63 | 0.6338 | 0.1933 | 0.1555 |
| 0.5354 | 34.0 | 850 | 1.3036 | 0.6225 | 0.5269 | 3.0431 | 0.6225 | 0.6242 | 0.1996 | 0.1535 |
| 0.5354 | 35.0 | 875 | 1.3057 | 0.6275 | 0.5263 | 2.9651 | 0.6275 | 0.6291 | 0.2023 | 0.1538 |
| 0.5354 | 36.0 | 900 | 1.2992 | 0.6275 | 0.5247 | 2.9748 | 0.6275 | 0.6289 | 0.1961 | 0.1518 |
| 0.5354 | 37.0 | 925 | 1.3001 | 0.6325 | 0.5252 | 2.9784 | 0.6325 | 0.6347 | 0.1978 | 0.1531 |
| 0.5354 | 38.0 | 950 | 1.2990 | 0.63 | 0.5229 | 2.9014 | 0.63 | 0.6327 | 0.1981 | 0.1524 |
| 0.5354 | 39.0 | 975 | 1.2995 | 0.6325 | 0.5246 | 2.9776 | 0.6325 | 0.6354 | 0.1946 | 0.1533 |
| 0.0336 | 40.0 | 1000 | 1.2945 | 0.6275 | 0.5226 | 2.9029 | 0.6275 | 0.6302 | 0.1965 | 0.1523 |
| 0.0336 | 41.0 | 1025 | 1.3023 | 0.63 | 0.5247 | 3.0515 | 0.63 | 0.6341 | 0.2044 | 0.1534 |
| 0.0336 | 42.0 | 1050 | 1.2990 | 0.635 | 0.5239 | 3.0673 | 0.635 | 0.6381 | 0.1952 | 0.1516 |
| 0.0336 | 43.0 | 1075 | 1.2962 | 0.635 | 0.5213 | 3.0585 | 0.635 | 0.6378 | 0.2055 | 0.1523 |
| 0.0336 | 44.0 | 1100 | 1.2991 | 0.625 | 0.5229 | 2.9801 | 0.625 | 0.6278 | 0.1954 | 0.1532 |
| 0.0336 | 45.0 | 1125 | 1.2949 | 0.6375 | 0.5222 | 3.0564 | 0.6375 | 0.6419 | 0.2027 | 0.1519 |
| 0.0336 | 46.0 | 1150 | 1.2989 | 0.6275 | 0.5228 | 3.0737 | 0.6275 | 0.6308 | 0.2075 | 0.1529 |
| 0.0336 | 47.0 | 1175 | 1.2902 | 0.6325 | 0.5201 | 3.0606 | 0.6325 | 0.6360 | 0.2099 | 0.1516 |
| 0.0336 | 48.0 | 1200 | 1.2971 | 0.6275 | 0.5217 | 3.0829 | 0.6275 | 0.6305 | 0.1882 | 0.1518 |
| 0.0336 | 49.0 | 1225 | 1.2913 | 0.63 | 0.5212 | 2.9853 | 0.63 | 0.6332 | 0.1928 | 0.1524 |
| 0.0336 | 50.0 | 1250 | 1.2917 | 0.63 | 0.5205 | 2.9850 | 0.63 | 0.6336 | 0.1910 | 0.1518 |
| 0.0336 | 51.0 | 1275 | 1.2928 | 0.63 | 0.5208 | 3.0579 | 0.63 | 0.6330 | 0.2020 | 0.1528 |
| 0.0336 | 52.0 | 1300 | 1.2941 | 0.635 | 0.5205 | 3.0647 | 0.635 | 0.6383 | 0.1919 | 0.1515 |
| 0.0336 | 53.0 | 1325 | 1.2930 | 0.635 | 0.5207 | 3.0637 | 0.635 | 0.6384 | 0.1868 | 0.1518 |
| 0.0336 | 54.0 | 1350 | 1.2918 | 0.63 | 0.5203 | 3.0628 | 0.63 | 0.6335 | 0.1986 | 0.1519 |
| 0.0336 | 55.0 | 1375 | 1.2894 | 0.635 | 0.5198 | 2.9874 | 0.635 | 0.6383 | 0.2026 | 0.1514 |
| 0.0336 | 56.0 | 1400 | 1.2913 | 0.63 | 0.5203 | 3.0691 | 0.63 | 0.6337 | 0.2045 | 0.1519 |
| 0.0336 | 57.0 | 1425 | 1.2923 | 0.6325 | 0.5205 | 2.9869 | 0.6325 | 0.6358 | 0.1962 | 0.1522 |
| 0.0336 | 58.0 | 1450 | 1.2927 | 0.6375 | 0.5199 | 3.0734 | 0.6375 | 0.6408 | 0.1905 | 0.1514 |
| 0.0336 | 59.0 | 1475 | 1.2931 | 0.6325 | 0.5204 | 3.0607 | 0.6325 | 0.6353 | 0.1980 | 0.1520 |
| 0.0236 | 60.0 | 1500 | 1.2911 | 0.6325 | 0.5199 | 3.0664 | 0.6325 | 0.6359 | 0.1875 | 0.1517 |
| 0.0236 | 61.0 | 1525 | 1.2901 | 0.635 | 0.5195 | 2.9877 | 0.635 | 0.6386 | 0.1907 | 0.1516 |
| 0.0236 | 62.0 | 1550 | 1.2913 | 0.635 | 0.5192 | 3.0655 | 0.635 | 0.6383 | 0.1971 | 0.1515 |
| 0.0236 | 63.0 | 1575 | 1.2920 | 0.635 | 0.5201 | 3.0044 | 0.635 | 0.6379 | 0.1991 | 0.1514 |
| 0.0236 | 64.0 | 1600 | 1.2911 | 0.635 | 0.5192 | 3.0654 | 0.635 | 0.6380 | 0.1848 | 0.1509 |
| 0.0236 | 65.0 | 1625 | 1.2924 | 0.635 | 0.5196 | 3.1438 | 0.635 | 0.6379 | 0.1969 | 0.1515 |
| 0.0236 | 66.0 | 1650 | 1.2901 | 0.635 | 0.5191 | 2.9928 | 0.635 | 0.6392 | 0.1978 | 0.1507 |
| 0.0236 | 67.0 | 1675 | 1.2911 | 0.6325 | 0.5189 | 3.0662 | 0.6325 | 0.6359 | 0.1896 | 0.1517 |
| 0.0236 | 68.0 | 1700 | 1.2911 | 0.6375 | 0.5193 | 2.9932 | 0.6375 | 0.6404 | 0.2017 | 0.1507 |
| 0.0236 | 69.0 | 1725 | 1.2893 | 0.635 | 0.5189 | 2.9907 | 0.635 | 0.6391 | 0.1951 | 0.1511 |
| 0.0236 | 70.0 | 1750 | 1.2913 | 0.6325 | 0.5195 | 2.9919 | 0.6325 | 0.6362 | 0.1955 | 0.1513 |
| 0.0236 | 71.0 | 1775 | 1.2899 | 0.635 | 0.5188 | 2.9899 | 0.635 | 0.6386 | 0.2049 | 0.1511 |
| 0.0236 | 72.0 | 1800 | 1.2912 | 0.635 | 0.5192 | 2.9914 | 0.635 | 0.6379 | 0.1924 | 0.1513 |
| 0.0236 | 73.0 | 1825 | 1.2898 | 0.6325 | 0.5188 | 2.9901 | 0.6325 | 0.6367 | 0.2059 | 0.1511 |
| 0.0236 | 74.0 | 1850 | 1.2902 | 0.635 | 0.5190 | 2.9918 | 0.635 | 0.6391 | 0.2069 | 0.1511 |
| 0.0236 | 75.0 | 1875 | 1.2904 | 0.635 | 0.5191 | 2.9916 | 0.635 | 0.6391 | 0.1969 | 0.1511 |
| 0.0236 | 76.0 | 1900 | 1.2905 | 0.635 | 0.5191 | 2.9899 | 0.635 | 0.6391 | 0.1969 | 0.1512 |
| 0.0236 | 77.0 | 1925 | 1.2904 | 0.635 | 0.5191 | 2.9917 | 0.635 | 0.6391 | 0.1926 | 0.1511 |
| 0.0236 | 78.0 | 1950 | 1.2899 | 0.635 | 0.5188 | 2.9909 | 0.635 | 0.6391 | 0.2010 | 0.1510 |
| 0.0236 | 79.0 | 1975 | 1.2900 | 0.635 | 0.5188 | 2.9908 | 0.635 | 0.6391 | 0.2034 | 0.1511 |
| 0.0233 | 80.0 | 2000 | 1.2900 | 0.635 | 0.5188 | 2.9910 | 0.635 | 0.6391 | 0.1967 | 0.1511 |
| 0.0233 | 81.0 | 2025 | 1.2900 | 0.635 | 0.5188 | 2.9911 | 0.635 | 0.6391 | 0.2002 | 0.1511 |
| 0.0233 | 82.0 | 2050 | 1.2901 | 0.635 | 0.5189 | 2.9909 | 0.635 | 0.6391 | 0.1993 | 0.1511 |
| 0.0233 | 83.0 | 2075 | 1.2900 | 0.635 | 0.5188 | 2.9906 | 0.635 | 0.6391 | 0.1937 | 0.1511 |
| 0.0233 | 84.0 | 2100 | 1.2901 | 0.635 | 0.5189 | 2.9917 | 0.635 | 0.6391 | 0.2026 | 0.1511 |
| 0.0233 | 85.0 | 2125 | 1.2899 | 0.635 | 0.5188 | 2.9905 | 0.635 | 0.6391 | 0.1993 | 0.1512 |
| 0.0233 | 86.0 | 2150 | 1.2897 | 0.635 | 0.5187 | 2.9906 | 0.635 | 0.6391 | 0.1976 | 0.1511 |
| 0.0233 | 87.0 | 2175 | 1.2899 | 0.635 | 0.5188 | 2.9905 | 0.635 | 0.6391 | 0.1980 | 0.1511 |
| 0.0233 | 88.0 | 2200 | 1.2897 | 0.635 | 0.5187 | 2.9911 | 0.635 | 0.6391 | 0.1957 | 0.1511 |
| 0.0233 | 89.0 | 2225 | 1.2899 | 0.635 | 0.5187 | 2.9910 | 0.635 | 0.6391 | 0.1970 | 0.1511 |
| 0.0233 | 90.0 | 2250 | 1.2898 | 0.635 | 0.5187 | 2.9905 | 0.635 | 0.6391 | 0.1988 | 0.1512 |
| 0.0233 | 91.0 | 2275 | 1.2897 | 0.635 | 0.5187 | 2.9908 | 0.635 | 0.6391 | 0.1961 | 0.1511 |
| 0.0233 | 92.0 | 2300 | 1.2898 | 0.635 | 0.5187 | 2.9908 | 0.635 | 0.6391 | 0.1966 | 0.1511 |
| 0.0233 | 93.0 | 2325 | 1.2897 | 0.635 | 0.5186 | 2.9908 | 0.635 | 0.6391 | 0.1984 | 0.1511 |
| 0.0233 | 94.0 | 2350 | 1.2898 | 0.635 | 0.5187 | 2.9907 | 0.635 | 0.6391 | 0.2009 | 0.1511 |
| 0.0233 | 95.0 | 2375 | 1.2897 | 0.635 | 0.5186 | 2.9908 | 0.635 | 0.6391 | 0.2023 | 0.1511 |
| 0.0233 | 96.0 | 2400 | 1.2897 | 0.635 | 0.5186 | 2.9908 | 0.635 | 0.6391 | 0.1985 | 0.1511 |
| 0.0233 | 97.0 | 2425 | 1.2897 | 0.635 | 0.5186 | 2.9908 | 0.635 | 0.6391 | 0.1984 | 0.1511 |
| 0.0233 | 98.0 | 2450 | 1.2897 | 0.635 | 0.5186 | 2.9908 | 0.635 | 0.6391 | 0.1985 | 0.1511 |
| 0.0233 | 99.0 | 2475 | 1.2897 | 0.635 | 0.5186 | 2.9909 | 0.635 | 0.6391 | 0.1984 | 0.1511 |
| 0.0232 | 100.0 | 2500 | 1.2897 | 0.635 | 0.5186 | 2.9908 | 0.635 | 0.6391 | 0.1984 | 0.1511 |
### Framework versions
- Transformers 4.28.0.dev0
- Pytorch 1.12.1+cu113
- Datasets 2.12.0
- Tokenizers 0.12.1
|
Rakshapk/rare-puppers
|
Rakshapk
| 2023-07-11T09:30:32Z | 216 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"huggingpics",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-07-11T09:15:09Z |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: rare-puppers
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.9772727489471436
---
# rare-puppers
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### Poor person

#### Rich person

|
TigerResearch/tigerbot-7b-sft-v2
|
TigerResearch
| 2023-07-11T09:22:35Z | 18 | 8 |
transformers
|
[
"transformers",
"pytorch",
"bloom",
"text-generation",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-08T04:18:41Z |
---
license: apache-2.0
---
<div style="width: 100%;">
<img src="http://x-pai.algolet.com/bot/img/logo_core.png" alt="TigerBot" style="width: 20%; display: block; margin: auto;">
</div>
<p align="center">
<font face="黑体" size=5"> A cutting-edge foundation for your very own LLM. </font>
</p>
<p align="center">
🌐 <a href="https://tigerbot.com/" target="_blank">TigerBot</a> • 🤗 <a href="https://huggingface.co/TigerResearch" target="_blank">Hugging Face</a>
</p>
## Github
https://github.com/TigerResearch/TigerBot
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
from accelerate import infer_auto_device_map, dispatch_model
from accelerate.utils import get_balanced_memory
tokenizer = AutoTokenizer.from_pretrained("TigerResearch/tigerbot-7b-sft-v2")
model = AutoModelForCausalLM.from_pretrained("TigerResearch/tigerbot-7b-sft-v2")
max_memory = get_balanced_memory(model)
device_map = infer_auto_device_map(model, max_memory=max_memory, no_split_module_classes=["BloomBlock"])
model = dispatch_model(model, device_map=device_map, offload_buffers=True)
device = torch.cuda.current_device()
tok_ins = "\n\n### Instruction:\n"
tok_res = "\n\n### Response:\n"
prompt_input = tok_ins + "{instruction}" + tok_res
input_text = "What is the next number after this list: [1, 2, 3, 5, 8, 13, 21]"
input_text = prompt_input.format_map({'instruction': input_text})
max_input_length = 512
max_generate_length = 1024
generation_kwargs = {
"top_p": 0.95,
"temperature": 0.8,
"max_length": max_generate_length,
"eos_token_id": tokenizer.eos_token_id,
"pad_token_id": tokenizer.pad_token_id,
"early_stopping": True,
"no_repeat_ngram_size": 4,
}
inputs = tokenizer(input_text, return_tensors='pt', truncation=True, max_length=max_input_length)
inputs = {k: v.to(device) for k, v in inputs.items()}
output = model.generate(**inputs, **generation_kwargs)
answer = ''
for tok_id in output[0][inputs['input_ids'].shape[1]:]:
if tok_id != tokenizer.eos_token_id:
answer += tokenizer.decode(tok_id)
print(answer)
```
|
TigerResearch/tigerbot-7b-base-v2
|
TigerResearch
| 2023-07-11T09:21:53Z | 16 | 3 |
transformers
|
[
"transformers",
"pytorch",
"bloom",
"text-generation",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-07T07:00:02Z |
---
license: apache-2.0
---
<div style="width: 100%;">
<img src="http://x-pai.algolet.com/bot/img/logo_core.png" alt="TigerBot" style="width: 20%; display: block; margin: auto;">
</div>
<p align="center">
<font face="黑体" size=5"> A cutting-edge foundation for your very own LLM. </font>
</p>
<p align="center">
🌐 <a href="https://tigerbot.com/" target="_blank">TigerBot</a> • 🤗 <a href="https://huggingface.co/TigerResearch" target="_blank">Hugging Face</a>
</p>
## Github
https://github.com/TigerResearch/TigerBot
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("TigerResearch/tigerbot-7b-base-v2")
model = AutoModelForCausalLM.from_pretrained("TigerResearch/tigerbot-7b-base-v2")
```
|
erberry/Ziya-LLaMA-13B-v1.1-merged
|
erberry
| 2023-07-11T08:57:33Z | 11 | 2 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"zh",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-05T09:45:09Z |
---
language:
- zh
---
引用自[Fengshenbang-LM](https://github.com/IDEA-CCNL/Fengshenbang-LM)
> 由于LLaMA权重的许可限制,该模型不能用于商业用途,请严格遵守LLaMA的使用政策。
考虑到LLaMA权重的许可证限制,我们无法直接发布完整的模型权重。
因此,我们使用了FastChat开源工具作为基础,并对其进行了进一步的优化。
我们计算并发布了Ziya-LLaMA-13B-v1权重与原始LLaMA权重之间的差值。
合并方法见如下 ipynb:
[ipynb](https://github.com/erberry/ThinkML/blob/main/ziya_llama_merge.ipynb)
其中 ggml-model-q5-1.bin 为经过 llama.cpp 量化后的模型。
**License** Non-commercial bespoke license
|
Winmodel/Pixelcopter-PLE-v0
|
Winmodel
| 2023-07-11T08:54:35Z | 0 | 0 | null |
[
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-11T08:52:52Z |
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Pixelcopter-PLE-v0
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 47.50 +/- 23.78
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
zhundred/SpaceInvadersNoFrameskip-v4
|
zhundred
| 2023-07-11T08:52:32Z | 9 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-11T08:52:02Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 415.00 +/- 187.28
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga zhundred -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga zhundred -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga zhundred
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
ashnrk/textual_inversion_highway
|
ashnrk
| 2023-07-11T08:49:32Z | 12 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"textual_inversion",
"base_model:stabilityai/stable-diffusion-2-1",
"base_model:adapter:stabilityai/stable-diffusion-2-1",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-07-11T07:47:17Z |
---
license: creativeml-openrail-m
base_model: stabilityai/stable-diffusion-2-1
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- textual_inversion
inference: true
---
# Textual inversion text2image fine-tuning - ashnrk/textual_inversion_highway
These are textual inversion adaption weights for stabilityai/stable-diffusion-2-1. You can find some example images in the following.
|
vidric/bertopic_before_tuning
|
vidric
| 2023-07-11T08:48:57Z | 6 | 0 |
bertopic
|
[
"bertopic",
"text-classification",
"region:us"
] |
text-classification
| 2023-07-11T08:16:09Z |
---
tags:
- bertopic
library_name: bertopic
pipeline_tag: text-classification
---
# bertopic_before_tuning
This is a [BERTopic](https://github.com/MaartenGr/BERTopic) model.
BERTopic is a flexible and modular topic modeling framework that allows for the generation of easily interpretable topics from large datasets.
## Usage
To use this model, please install BERTopic:
```
pip install -U bertopic
```
You can use the model as follows:
```python
from bertopic import BERTopic
topic_model = BERTopic.load("vidric/bertopic_before_tuning")
topic_model.get_topic_info()
```
## Topic overview
* Number of topics: 291
* Number of training documents: 20977
<details>
<summary>Click here for an overview of all topics.</summary>
| Topic ID | Topic Keywords | Topic Frequency | Label |
|----------|----------------|-----------------|-------|
| -1 | parfum - tidak - untuk - beli - kirim | 10 | -1_parfum_tidak_untuk_beli |
| 0 | orgasm - eos - farhampton - lebih - aku | 6133 | 0_orgasm_eos_farhampton_lebih |
| 1 | mantap - smel - legit - lanjutken - goid | 894 | 1_mantap_smel_legit_lanjutken |
| 2 | parfum - seperti - pertama - mirip - tidak | 648 | 2_parfum_seperti_pertama_mirip |
| 3 | cowok - cewek - feminim - pacar - cocok | 395 | 3_cowok_cewek_feminim_pacar |
| 4 | packing - aman - rapi - mewah - keren | 333 | 4_packing_aman_rapi_mewah |
| 5 | botol - bocor - tumpah - tutup - pecah | 297 | 5_botol_bocor_tumpah_tutup |
| 6 | terlalu - kurang - tidak - nyengat - kuat | 268 | 6_terlalu_kurang_tidak_nyengat |
| 7 | terimakasih - bonus - hmns - kasih - wangi | 263 | 7_terimakasih_bonus_hmns_kasih |
| 8 | vanilla - dominan - floral - manis - jasmine | 254 | 8_vanilla_dominan_floral_manis |
| 9 | seller - respon - rekomendasi - deskripsi - cepat | 236 | 9_seller_respon_rekomendasi_deskripsi |
| 10 | jam - indoor - tahan - ac - kulit | 215 | 10_jam_indoor_tahan_ac |
| 11 | packing - rapi - bagus - keren - barang | 202 | 11_packing_rapi_bagus_keren |
| 12 | cepat - kirim - rapi - packing - aman | 196 | 12_cepat_kirim_rapi_packing |
| 13 | terimakasih - parfum - hmns - tester - bonus | 160 | 13_terimakasih_parfum_hmns_tester |
| 14 | bubble - wrap - tebal - kardus - kotak | 153 | 14_bubble_wrap_tebal_kardus |
| 15 | alpha - tetha - paling - perfection - lebih | 151 | 15_alpha_tetha_paling_perfection |
| 16 | packing - parfum - rapi - aman - kirim | 140 | 16_packing_parfum_rapi_aman |
| 17 | anime - wangi - gas - gailang - wangjnya | 136 | 17_anime_wangi_gas_gailang |
| 18 | alpha - theta - beta - tetha - ha | 135 | 18_alpha_theta_beta_tetha |
| 19 | terimakasih - aman - packing - rapi - mewah | 132 | 19_terimakasih_aman_packing_rapi |
| 20 | lokal - brand - terbaik - internasional - parfum | 129 | 20_lokal_brand_terbaik_internasional |
| 21 | voucher - dapat - 50rb - berlaku - 50k | 127 | 21_voucher_dapat_50rb_berlaku |
| 22 | farhampton - paling - sample - bonus - berikutnya | 121 | 22_farhampton_paling_sample_bonus |
| 23 | terimakasih - selamat - bang - terima - min | 121 | 23_terimakasih_selamat_bang_terima |
| 24 | mawar - rose - bunga - floral - unrosed | 118 | 24_mawar_rose_bunga_floral |
| 25 | oke - oké - bos - barang - | 117 | 25_oke_oké_bos_barang |
| 26 | sepadan - paten - isimewa - bes - gwp | 115 | 26_sepadan_paten_isimewa_bes |
| 27 | terbaik - prestasi - best - biasa - eos | 114 | 27_terbaik_prestasi_best_biasa |
| 28 | segar - manis - sia - bersaman - spicy | 111 | 28_segar_manis_sia_bersaman |
| 29 | enak - wangi - bagus - - | 97 | 29_enak_wangi_bagus_ |
| 30 | good - vry - fuckin - al - smel | 94 | 30_good_vry_fuckin_al |
| 31 | hadiah - ulangtahun - hadiahnya - ulang - dia | 93 | 31_hadiah_ulangtahun_hadiahnya_ulang |
| 32 | abiez - pokoknya - mantap - foto - serpisnya | 92 | 32_abiez_pokoknya_mantap_foto |
| 33 | produk - kualitas - penawaran - amron - naibaho | 90 | 33_produk_kualitas_penawaran_amron |
| 34 | pernah - kecewa - fail - gagal - tidak | 85 | 34_pernah_kecewa_fail_gagal |
| 35 | magnet - tutup - botol - kemasan - cap | 84 | 35_magnet_tutup_botol_kemasan |
| 36 | aman - packing - barang - tujuan - gems | 83 | 36_aman_packing_barang_tujuan |
| 37 | debat - no - nget - ngomong - dcb | 83 | 37_debat_no_nget_ngomong |
| 38 | terimakasih - pesan - cepat - sampai - kirim | 83 | 38_terimakasih_pesan_cepat_sampai |
| 39 | parfum - dipanggil - much - jatuh - namanya | 83 | 39_parfum_dipanggil_much_jatuh |
| 40 | terimakasih - packing - aman - rapi - barang | 83 | 40_terimakasih_packing_aman_rapi |
| 41 | admin - ramah - respon - informatif - cepat | 82 | 41_admin_ramah_respon_informatif |
| 42 | pokok - wnginya - perhatian - entar - terluv | 78 | 42_pokok_wnginya_perhatian_entar |
| 43 | love - cinta - jatuh - in - sama | 78 | 43_love_cinta_jatuh_in |
| 44 | kedua - beli - dua - kali - 2nd | 78 | 44_kedua_beli_dua_kali |
| 45 | indonesia - bangga - harumkan - buatan - produk | 73 | 45_indonesia_bangga_harumkan_buatan |
| 46 | love - cinta - jatuh - kasih - secepat | 71 | 46_love_cinta_jatuh_kasih |
| 47 | terimakasih - sdah - karin - request - bantu | 71 | 47_terimakasih_sdah_karin_request |
| 48 | starterpacking - starterpack - dulu - mana - horas | 70 | 48_starterpacking_starterpack_dulu_mana |
| 49 | delta - theta - team - alpha - tetha | 70 | 49_delta_theta_team_alpha |
| 50 | repeat - order - kesekian - kali - selalu | 69 | 50_repeat_order_kesekian_kali |
| 51 | tahan - lama - enak - flu - pengemasany | 69 | 51_tahan_lama_enak_flu |
| 52 | hari - minggu - pre - sabtu - po | 69 | 52_hari_minggu_pre_sabtu |
| 53 | parfum - bum - fans - klepek - favorit | 68 | 53_parfum_bum_fans_klepek |
| 54 | lembut - gentle - deskripi - sksksk - mendekat | 67 | 54_lembut_gentle_deskripi_sksksk |
| 55 | bagus - excelent - pokoknya - good - kedua | 64 | 55_bagus_excelent_pokoknya_good |
| 56 | mantap - ubun - tulang - bed - sangar | 63 | 56_mantap_ubun_tulang_bed |
| 57 | seller - respon - produk - cepat - ramah | 63 | 57_seller_respon_produk_cepat |
| 58 | ketiga - tiga - cny - berupa - 4x | 63 | 58_ketiga_tiga_cny_berupa |
| 59 | kesempurnan - perfection - mr - kecil2 - pergi2 | 61 | 59_kesempurnan_perfection_mr_kecil2 |
| 60 | enak - banget - wangi - benar - | 61 | 60_enak_banget_wangi_benar |
| 61 | enak - sopan - mag - aslilah - sumpah | 61 | 61_enak_sopan_mag_aslilah |
| 62 | citrus - citrusnya - fruity - buah - fruit | 60 | 62_citrus_citrusnya_fruity_buah |
| 63 | cepat - sampai - sorenya - ih - sampainya | 59 | 63_cepat_sampai_sorenya_ih |
| 64 | belum - unboxing - isi - pecah - pekejing | 59 | 64_belum_unboxing_isi_pecah |
| 65 | tester - test - sample - diksh - bonus | 58 | 65_tester_test_sample_diksh |
| 66 | istri - karir - belin - alhamdulilah - suka | 57 | 66_istri_karir_belin_alhamdulilah |
| 67 | seller - tokopedia - terimakasih - produk - mei | 57 | 67_seller_tokopedia_terimakasih_produk |
| 68 | voucher - dapat - diskon - 50rb - 50k | 56 | 68_voucher_dapat_diskon_50rb |
| 69 | boleh - bolehlah - suka - bolehla - nak | 56 | 69_boleh_bolehlah_suka_bolehla |
| 70 | selamat - barang - mendarat - aman - sampai | 55 | 70_selamat_barang_mendarat_aman |
| 71 | eos - dos - nada - botom - mid | 55 | 71_eos_dos_nada_botom |
| 72 | farhampton - sebelumnya - perfection - parfum - digunain | 54 | 72_farhampton_sebelumnya_perfection_parfum |
| 73 | kualitas - ragu - soal - baik - membangun | 54 | 73_kualitas_ragu_soal_baik |
| 74 | bad - lumayan - enak - cok - yes | 53 | 74_bad_lumayan_enak_cok |
| 75 | respon - quick - cepat - disin - mimin | 53 | 75_respon_quick_cepat_disin |
| 76 | banget - wangi - demi - sekali - apapun | 52 | 76_banget_wangi_demi_sekali |
| 77 | mantap - senang - inded - sekali - keangunan | 51 | 77_mantap_senang_inded_sekali |
| 78 | keren - tebqiklah - wan - gotcha - pelapak | 50 | 78_keren_tebqiklah_wan_gotcha |
| 79 | starterpacking - starterpack - ful - beli - team | 49 | 79_starterpacking_starterpack_ful_beli |
| 80 | cos - kasus - parfum - rekomendasi - sambil | 49 | 80_cos_kasus_parfum_rekomendasi |
| 81 | kirim - cepat - sabtu - pesan - rumah | 48 | 81_kirim_cepat_sabtu_pesan |
| 82 | vetiver - mahal - parfum - spice - siap | 47 | 82_vetiver_mahal_parfum_spice |
| 83 | lokal - internasional - produk - brand - suport | 47 | 83_lokal_internasional_produk_brand |
| 84 | kemasan - paket - kotak - presentation - menawan | 47 | 84_kemasan_paket_kotak_presentation |
| 85 | selalu - always - puas - as - memuaskan | 47 | 85_selalu_always_puas_as |
| 86 | terbaik - deal - nimbun - salut - canda | 47 | 86_terbaik_deal_nimbun_salut |
| 87 | ekspektasi - sesuai - cocok - bayangkan - hugable | 47 | 87_ekspektasi_sesuai_cocok_bayangkan |
| 88 | kalem - pangling - undescribable - pernen - sarmento | 46 | 88_kalem_pangling_undescribable_pernen |
| 89 | spray - rusak - macet - empuk - berfungsi | 46 | 89_spray_rusak_macet_empuk |
| 90 | farhampton - perfection - alpha - sama² - masing | 46 | 90_farhampton_perfection_alpha_sama² |
| 91 | admin - bos - ramah - senayan - respon | 46 | 91_admin_bos_ramah_senayan |
| 92 | mantap - mangi - wangi - jarak - alhamdulilah | 45 | 92_mantap_mangi_wangi_jarak |
| 93 | wajib - beli - ragu - mana - usah | 44 | 93_wajib_beli_ragu_mana |
| 94 | cepat - aman - proses - surprised - packing | 44 | 94_cepat_aman_proses_surprised |
| 95 | farhampton - banding - lebih - prefer - paling | 44 | 95_farhampton_banding_lebih_prefer |
| 96 | ketiga - tiga - mana - masing - rata | 43 | 96_ketiga_tiga_mana_masing |
| 97 | rekomendasi - pesta - netizen - kesepakatan - berharga | 43 | 97_rekomendasi_pesta_netizen_kesepakatan |
| 98 | worth - it - harga - apakah - amazing | 43 | 98_worth_it_harga_apakah |
| 99 | suka - menyukainya - sekali - banget - menyukai | 42 | 99_suka_menyukainya_sekali_banget |
| 100 | cepat - sampainya - tolonglah - mengairahkan - dibilangin | 41 | 100_cepat_sampainya_tolonglah_mengairahkan |
| 101 | alpha - 10 - theta - paling - cita | 41 | 101_alpha_10_theta_paling |
| 102 | kirim - cepat - barang - barangmya - ongkirnya | 41 | 102_kirim_cepat_barang_barangmya |
| 103 | lama - legend - tahan - mkin - layak | 41 | 103_lama_legend_tahan_mkin |
| 104 | tahan - lama - kalm - anytime - anywhere | 40 | 104_tahan_lama_kalm_anytime |
| 105 | longevity - projection - jam - notes - silage | 40 | 105_longevity_projection_jam_notes |
| 106 | spray - rusak - macet - susah - agak | 40 | 106_spray_rusak_macet_susah |
| 107 | puas - kebahagian - autentik - syekli - sumber | 40 | 107_puas_kebahagian_autentik_syekli |
| 108 | perfect - sempurna - uno - numero - | 39 | 108_perfect_sempurna_uno_numero |
| 109 | admin - pouch - ramah - respon - plastiknya | 39 | 109_admin_pouch_ramah_respon |
| 110 | perfection - kesempurnan - sempurna - diri - bold | 38 | 110_perfection_kesempurnan_sempurna_diri |
| 111 | layanan - prima - pelangan - service - performa | 38 | 111_layanan_prima_pelangan_service |
| 112 | suka - mertua - adict - wangi - original | 38 | 112_suka_mertua_adict_wangi |
| 113 | kedua - kali - beli - rilis - meal | 37 | 113_kedua_kali_beli_rilis |
| 114 | tester - test - bonus - unrosed - yesternya | 37 | 114_tester_test_bonus_unrosed |
| 115 | botol - perbaiki - cairan - ditaro - mobil | 37 | 115_botol_perbaiki_cairan_ditaro |
| 116 | lagi - pasti - depan - nanti - beli | 36 | 116_lagi_pasti_depan_nanti |
| 117 | lokal - brand - produk - maju - dua | 36 | 117_lokal_brand_produk_maju |
| 118 | kartu - card - greting - ucap - personalized | 36 | 118_kartu_card_greting_ucap |
| 119 | enak - tenan - taste - good - ori | 36 | 119_enak_tenan_taste_good |
| 120 | sama - suka - banget - dewasa - menyukainya | 36 | 120_sama_suka_banget_dewasa |
| 121 | hebat - bagus - kuliatas - good - nicely | 36 | 121_hebat_bagus_kuliatas_good |
| 122 | semoga - harap - sempurna - bung - holyshesh | 35 | 122_semoga_harap_sempurna_bung |
| 123 | bonus - dapat - ha - bonusan - jiwa | 35 | 123_bonus_dapat_ha_bonusan |
| 124 | parah - hotel - bau - gacor - crayzay | 35 | 124_parah_hotel_bau_gacor |
| 125 | puas - tergocek - thetat_t - menghibur - terdebest | 35 | 125_puas_tergocek_thetat_t_menghibur |
| 126 | barang - terima - terimakasih - lanyard - berproduksi | 34 | 126_barang_terima_terimakasih_lanyard |
| 127 | kane - mbak - cept - apanih - kokbisa | 34 | 127_kane_mbak_cept_apanih |
| 128 | suami - anda - cowok - neko - jatah | 33 | 128_suami_anda_cowok_neko |
| 129 | cewek - pacar - klepek - miminya - manis | 33 | 129_cewek_pacar_klepek_miminya |
| 130 | segar - pepernya - basic - liburan - patut | 33 | 130_segar_pepernya_basic_liburan |
| 131 | hair - mist - body - rambut - badan | 32 | 131_hair_mist_body_rambut |
| 132 | enak - banget - adict - wangi - sumpah | 32 | 132_enak_banget_adict_wangi |
| 133 | love - just - swet - cinta - admin | 32 | 133_love_just_swet_cinta |
| 134 | langganan - woeh - dikasihnya - tonky - winky | 32 | 134_langganan_woeh_dikasihnya_tonky |
| 135 | rekomendasi - gela - ank - terpercaya - bangsa | 32 | 135_rekomendasi_gela_ank_terpercaya |
| 136 | semua - bagus - screw - los - hal | 31 | 136_semua_bagus_screw_los |
| 137 | istri - hadiah - menyukainya - ulangtahun - alhamdulilah | 31 | 137_istri_hadiah_menyukainya_ulangtahun |
| 138 | ibu - awet - tante - itung - mikir | 30 | 138_ibu_awet_tante_itung |
| 139 | mewah - seksi - elegan - kemasanua - pokoknha | 29 | 139_mewah_seksi_elegan_kemasanua |
| 140 | 10ml - 50ml - ml - 5ml - kaleng2an | 29 | 140_10ml_50ml_ml_5ml |
| 141 | ketiga - ofkors - timing - diangkat - cafe | 29 | 141_ketiga_ofkors_timing_diangkat |
| 142 | harum - sue - hua - tagih - unik | 29 | 142_harum_sue_hua_tagih |
| 143 | pagi - sore - besok - pulang - kerja | 29 | 143_pagi_sore_besok_pulang |
| 144 | rekomendasi - layak - releasenya - direkomendasi - prtma | 29 | 144_rekomendasi_layak_releasenya_direkomendasi |
| 145 | blind - muantep - beli - kepikiran - nekat | 28 | 145_blind_muantep_beli_kepikiran |
| 146 | worth - it - layak - sepadan - harga | 28 | 146_worth_it_layak_sepadan |
| 147 | pokok - tpt - mumet - jon - sealu | 28 | 147_pokok_tpt_mumet_jon |
| 148 | mantap - menyeruak - berpetualangan - imagi - experimen | 28 | 148_mantap_menyeruak_berpetualangan_imagi |
| 149 | layanan - service - percuma - quick - servis | 28 | 149_layanan_service_percuma_quick |
| 150 | barang - selamat - aman - trkesan - pintu | 28 | 150_barang_selamat_aman_trkesan |
| 151 | esence - matahari - sun - sari - ber | 28 | 151_esence_matahari_sun_sari |
| 152 | pernah - salah - selalu - kecewa - gdjob | 28 | 152_pernah_salah_selalu_kecewa |
| 153 | bicara - bintang - biar - alasanya - nyang | 27 | 153_bicara_bintang_biar_alasanya |
| 154 | sempurna - perfect - namanya - mendarat - dieksekusi | 27 | 154_sempurna_perfect_namanya_mendarat |
| 155 | ekspektasi - sesuai - etc - por - insha | 27 | 155_ekspektasi_sesuai_etc_por |
| 156 | mahal - harga - murah - segini - ampau | 26 | 156_mahal_harga_murah_segini |
| 157 | tahan - lama - harum - manstav - disinj | 26 | 157_tahan_lama_harum_manstav |
| 158 | tahan - lama - kurang - ekpetasiku - dragukan | 26 | 158_tahan_lama_kurang_ekpetasiku |
| 159 | respon - cepat - penjual - tambahanya - dkulit | 26 | 159_respon_cepat_penjual_tambahanya |
| 160 | ahaha - tahan - lama - muali - mentong | 26 | 160_ahaha_tahan_lama_muali |
| 161 | bintang - 10 - lima - dimengerti - sebab | 25 | 161_bintang_10_lima_dimengerti |
| 162 | bau - seru - enak - alah - banget | 25 | 162_bau_seru_enak_alah |
| 163 | paket - terimakasih - terima - segalanya - mengganti | 25 | 163_paket_terimakasih_terima_segalanya |
| 164 | jam - sekitar - area - baju - nadi | 25 | 164_jam_sekitar_area_baju |
| 165 | sedap - grecep - nangis - midlenya - dipakeny | 25 | 165_sedap_grecep_nangis_midlenya |
| 166 | asli - nit - enak - hebat - banget | 24 | 166_asli_nit_enak_hebat |
| 167 | eos - dilayerin - gakpapa - nyabeh - matihi | 24 | 167_eos_dilayerin_gakpapa_nyabeh |
| 168 | swet - enek - profile - recom - kubaru | 24 | 168_swet_enek_profile_recom |
| 169 | manis - merasakan - aple - permen - sesuatu | 24 | 169_manis_merasakan_aple_permen |
| 170 | repeat - order - mangep - lahir - konsistensi | 24 | 170_repeat_order_mangep_lahir |
| 171 | love - aku - like - menyukai - suka | 23 | 171_love_aku_like_menyukai |
| 172 | cowok - unisex - cewek - milion - menye | 23 | 172_cowok_unisex_cewek_milion |
| 173 | terbaik - uw - timpa - aseli - keranjang | 23 | 173_terbaik_uw_timpa_aseli |
| 174 | asoy - aroma - simpul - grande - malaikat | 22 | 174_asoy_aroma_simpul_grande |
| 175 | pengiriman - pingiriman - cepat - kemasa - rapi | 22 | 175_pengiriman_pingiriman_cepat_kemasa |
| 176 | hidung - sopan - sensitif - tusuk - enek | 22 | 176_hidung_sopan_sensitif_tusuk |
| 177 | amazing - istimewa - luar - biasa - briliant | 22 | 177_amazing_istimewa_luar_biasa |
| 178 | segar - harum - ambune - ciamik - bersaman | 22 | 178_segar_harum_ambune_ciamik |
| 179 | kantor - ngechat - bosku - kake2 - buaik | 22 | 179_kantor_ngechat_bosku_kake2 |
| 180 | indoor - malam - kegiatan - outdor - segala | 22 | 180_indoor_malam_kegiatan_outdor |
| 181 | begitu - tahan - lama - disayangkanya - wlpun | 22 | 181_begitu_tahan_lama_disayangkanya |
| 182 | bau - sedap - solid - enak - betul | 22 | 182_bau_sedap_solid_enak |
| 183 | pakboi - ajip - ajib - pati - rispek | 22 | 183_pakboi_ajip_ajib_pati |
| 184 | layanan - service - ingetin - parahsih - ngebut | 22 | 184_layanan_service_ingetin_parahsih |
| 185 | layanan - service - produk - servicesnya - langananan | 22 | 185_layanan_service_produk_servicesnya |
| 186 | hadiah - memberinya - buka - tahu - bulan | 21 | 186_hadiah_memberinya_buka_tahu |
| 187 | pesan - sesuai - kond - psb - alamat | 21 | 187_pesan_sesuai_kond_psb |
| 188 | hm - wangik - asyik - hem - suka | 21 | 188_hm_wangik_asyik_hem |
| 189 | pengemasab - sesuai - beter - note - nyaman | 20 | 189_pengemasab_sesuai_beter_note |
| 190 | memuaskan - dianjurkan - sangat - biasanya - memang | 20 | 190_memuaskan_dianjurkan_sangat_biasanya |
| 191 | jajaran - lintas - bks - provinsi - cew2 | 20 | 191_jajaran_lintas_bks_provinsi |
| 192 | daily - sehari - use - hari - cudles | 20 | 192_daily_sehari_use_hari |
| 193 | kelas - ornamen - visual - bahasa - kerenya | 20 | 193_kelas_ornamen_visual_bahasa |
| 194 | hight - clas - kep - paket - up | 20 | 194_hight_clas_kep_paket |
| 195 | sel - gwperfume - fragrance - perfum - rec | 20 | 195_sel_gwperfume_fragrance_perfum |
| 196 | deskripsi - sesuai - barang - tulis - dengan | 20 | 196_deskripsi_sesuai_barang_tulis |
| 197 | job - good - mudah2 - selama - cari | 20 | 197_job_good_mudah2_selama |
| 198 | layanan - puas - obsesi - customernya - kiding | 20 | 198_layanan_puas_obsesi_customernya |
| 199 | atomizer - praktis - tokopedia - 10ml - dispensernya | 19 | 199_atomizer_praktis_tokopedia_10ml |
| 200 | favorit - ceritanya - tep - sepanjang - masa | 19 | 200_favorit_ceritanya_tep_sepanjang |
| 201 | travel - frhmptn - ukuran - kecil - botle | 19 | 201_travel_frhmptn_ukuran_kecil |
| 202 | keren - idenya - tampan - mengagumkan - cantik | 19 | 202_keren_idenya_tampan_mengagumkan |
| 203 | suami - endul - brti - tngan - uwuwuw | 19 | 203_suami_endul_brti_tngan |
| 204 | terima - kasih - - - | 19 | 204_terima_kasih__ |
| 205 | perlu - ragu - kecewa - dihebohkan - tak | 19 | 205_perlu_ragu_kecewa_dihebohkan |
| 206 | akhirnya - taiwan - finaly - bagi - hoki | 19 | 206_akhirnya_taiwan_finaly_bagi |
| 207 | segar - tahan - lama - anteng - ekonomis | 19 | 207_segar_tahan_lama_anteng |
| 208 | rapi - trusted - akurat - made - packing | 19 | 208_rapi_trusted_akurat_made |
| 209 | admin - ramah - pertimbanganya - menghadapi - dipuji2 | 18 | 209_admin_ramah_pertimbanganya_menghadapi |
| 210 | ngeri - bau - rd - vanilynya - handuk | 18 | 210_ngeri_bau_rd_vanilynya |
| 211 | kirim - cepat - inginkan - sesuai - sekali | 18 | 211_kirim_cepat_inginkan_sesuai |
| 212 | minst - double - 2nd - pocketnya - bad | 18 | 212_minst_double_2nd_pocketnya |
| 213 | pokok - mantap - sampai - cepat - suka | 18 | 213_pokok_mantap_sampai_cepat |
| 214 | sama - suka - semua - wangi - awet | 18 | 214_sama_suka_semua_wangi |
| 215 | semua - gilasih - pede - ever - enak | 18 | 215_semua_gilasih_pede_ever |
| 216 | kembali - sekian - membelinya - berulang - formulanya | 17 | 216_kembali_sekian_membelinya_berulang |
| 217 | bangga - pride - lokal - cakeup - kualitas | 17 | 217_bangga_pride_lokal_cakeup |
| 218 | cowok - eons - mantwp - dimainkan - spesial | 17 | 218_cowok_eons_mantwp_dimainkan |
| 219 | sukses - inovasi - lapaknya - terus - polisi | 17 | 219_sukses_inovasi_lapaknya_terus |
| 220 | produk - dikolom - dinas - diretur - away | 17 | 220_produk_dikolom_dinas_diretur |
| 221 | pesan - oekayanan - nemuaskab - sesuai - cepat | 17 | 221_pesan_oekayanan_nemuaskab_sesuai |
| 222 | luvs - terimakasih - hmns - fre - dapat | 17 | 222_luvs_terimakasih_hmns_fre |
| 223 | ulasin - slur - produqe - magantagap - lebenslangerschicksalschatz | 17 | 223_ulasin_slur_produqe_magantagap |
| 224 | tim - percancelan - discus - mrk - tepuk | 17 | 224_tim_percancelan_discus_mrk |
| 225 | suka - banget - benar - wangi - favorit | 17 | 225_suka_banget_benar_wangi |
| 226 | cowok - pacar - pour - hadiahin - huminya | 17 | 226_cowok_pacar_pour_hadiahin |
| 227 | menyesal - keskian - barter - brgnya - pernsh | 16 | 227_menyesal_keskian_barter_brgnya |
| 228 | twitter - tws - sosial - review - media | 16 | 228_twitter_tws_sosial_review |
| 229 | pesan - ulang - item - setitikomanya - sebesarkecilnya | 16 | 229_pesan_ulang_item_setitikomanya |
| 230 | terima - baik - barang - sementara - apik | 16 | 230_terima_baik_barang_sementara |
| 231 | gagal - pernah - kecewa - mnecewakan - pekayanan | 16 | 231_gagal_pernah_kecewa_mnecewakan |
| 232 | urang - recomened - mintip - teu - mantops | 16 | 232_urang_recomened_mintip_teu |
| 233 | pengiriman - komitmen - pekinganya - bugus - thd | 16 | 233_pengiriman_komitmen_pekinganya_bugus |
| 234 | eos - trial - sia - re - named | 16 | 234_eos_trial_sia_re |
| 235 | alkohol - 5an - k3nceng - kadar - pedas2 | 15 | 235_alkohol_5an_k3nceng_kadar |
| 236 | berjuang - suke - setidaknya - kesukan - invalid | 15 | 236_berjuang_suke_setidaknya_kesukan |
| 237 | pengiriman - sicepatnya - shipment - besokny - kurir | 15 | 237_pengiriman_sicepatnya_shipment_besokny |
| 238 | sukses - semwriwing - rempah2nya - selalu - hasil | 15 | 238_sukses_semwriwing_rempah2nya_selalu |
| 239 | puas - waduh - hawanya - sejuk - bahagia | 15 | 239_puas_waduh_hawanya_sejuk |
| 240 | coconut - kelapa - pasion - vs - coco | 15 | 240_coconut_kelapa_pasion_vs |
| 241 | buka - kotak - pwngirimanya - divideoin - nyangkanya | 14 | 241_buka_kotak_pwngirimanya_divideoin |
| 242 | tunggu - akhirnya - datang - ye - pewangi | 14 | 242_tunggu_akhirnya_datang_ye |
| 243 | oke - siap - semua - banget - baik | 14 | 243_oke_siap_semua_banget |
| 244 | obat - bets - develop - ada - mature | 14 | 244_obat_bets_develop_ada |
| 245 | pertama - mengoda - pengatur - kesan - liked | 14 | 245_pertama_mengoda_pengatur_kesan |
| 246 | telah - pesan - terima - ndan - sesuai | 13 | 246_telah_pesan_terima_ndan |
| 247 | paket - mudik - maf - selali - josh | 13 | 247_paket_mudik_maf_selali |
| 248 | ganteng - ajojing - ksowkwk - penampakan - arahnya | 13 | 248_ganteng_ajojing_ksowkwk_penampakan |
| 249 | mandi - habis - yha - dikata - syurgah | 13 | 249_mandi_habis_yha_dikata |
| 250 | awet - divine - tanteku - folow - up | 13 | 250_awet_divine_tanteku_folow |
| 251 | priduk - kirim - keterangan - reorder - original | 13 | 251_priduk_kirim_keterangan_reorder |
| 252 | rekomendasi - wajib - foto - langganan - disini | 13 | 252_rekomendasi_wajib_foto_langganan |
| 253 | projection - menyerang - kurang - meter - gau | 13 | 253_projection_menyerang_kurang_meter |
| 254 | undertone - serbaguna - satset - direkomendasi - volumenya | 13 | 254_undertone_serbaguna_satset_direkomendasi |
| 255 | sunguh - mempesona - luar - biasa - amazing | 13 | 255_sunguh_mempesona_luar_biasa |
| 256 | bau - suka - senak - awet - banget | 13 | 256_bau_suka_senak_awet |
| 257 | suka - banget - wangi - bau - sama | 13 | 257_suka_banget_wangi_bau |
| 258 | ulang - tahun - dia - ulangtahun - hadiah | 12 | 258_ulang_tahun_dia_ulangtahun |
| 259 | hilang - lamanya - pasaran - ketingal - dispil | 12 | 259_hilang_lamanya_pasaran_ketingal |
| 260 | khayangan - chewy - votolnya - kerajan - garis | 12 | 260_khayangan_chewy_votolnya_kerajan |
| 261 | bonus - terimaksih - mini - adict - terimakasih | 12 | 261_bonus_terimaksih_mini_adict |
| 262 | deskripsi - lancar - tulisanya - sesuai - pulak | 12 | 262_deskripsi_lancar_tulisanya_sesuai |
| 263 | calm - tenang - perkirakan - sopan - akhir | 12 | 263_calm_tenang_perkirakan_sopan |
| 264 | jiwa - kesegaran - mantap - - | 12 | 264_jiwa_kesegaran_mantap_ |
| 265 | keren - parah - anjay - damn - praktis | 12 | 265_keren_parah_anjay_damn |
| 266 | mewah - limo - seksi - lux - murah | 12 | 266_mewah_limo_seksi_lux |
| 267 | nunguin - penguna - nyala - beralih - 150rb | 12 | 267_nunguin_penguna_nyala_beralih |
| 268 | batch - oker - kelewatan - final - cancel | 11 | 268_batch_oker_kelewatan_final |
| 269 | astha - terbaeq - smr - arfoi - heuheu | 11 | 269_astha_terbaeq_smr_arfoi |
| 270 | winginya - tomat - hiu - dimix - combo | 11 | 270_winginya_tomat_hiu_dimix |
| 271 | unik - karene - menyejukan - aromao - clingi | 11 | 271_unik_karene_menyejukan_aromao |
| 272 | vubes - muchas - puckboy - begitupun - gracias | 11 | 272_vubes_muchas_puckboy_begitupun |
| 273 | mevah - laik - wuhu - kepribadian - karakter | 11 | 273_mevah_laik_wuhu_kepribadian |
| 274 | notes - printilan - midlle - base - mbak | 11 | 274_notes_printilan_midlle_base |
| 275 | wekend - dicuekin - first - tunangan - again | 11 | 275_wekend_dicuekin_first_tunangan |
| 276 | premium - packinya - perbedan - packinganya - beut | 11 | 276_premium_packinya_perbedan_packinganya |
| 277 | alien - hade - cirebon - wae - descent | 11 | 277_alien_hade_cirebon_wae |
| 278 | respon - bnrn - ckup - disekitar - kilat | 11 | 278_respon_bnrn_ckup_disekitar |
| 279 | useful - barang - standar - item - sesuai | 11 | 279_useful_barang_standar_item |
| 280 | bonus - sedap - betul - yeay - terimakasih | 11 | 280_bonus_sedap_betul_yeay |
| 281 | ekspedisi - lambat - expedisi - hub - tertaham | 11 | 281_ekspedisi_lambat_expedisi_hub |
| 282 | favorit - salah - satu - al - menjadi | 11 | 282_favorit_salah_satu_al |
| 283 | bonus - dengen - gantengs - nembak - setetes | 11 | 283_bonus_dengen_gantengs_nembak |
| 284 | dou - menyukainya - katanya - suka - theta | 10 | 284_dou_menyukainya_katanya_suka |
| 285 | lari - kembangin - puch - mesjid - malaikat | 10 | 285_lari_kembangin_puch_mesjid |
| 286 | selamalamanya - farfumnya - puasnya - skor - farfum | 10 | 286_selamalamanya_farfumnya_puasnya_skor |
| 287 | pengirinan - beginu - yh - spicynya - babget | 10 | 287_pengirinan_beginu_yh_spicynya |
| 288 | suami - keman - kenapasi - thankyoh - dijdin | 10 | 288_suami_keman_kenapasi_thankyoh |
| 289 | bonus - terkhusus - menghargai - atas - min | 10 | 289_bonus_terkhusus_menghargai_atas |
</details>
## Training hyperparameters
* calculate_probabilities: False
* language: indonesian
* low_memory: False
* min_topic_size: 10
* n_gram_range: (1, 1)
* nr_topics: None
* seed_topic_list: None
* top_n_words: 10
* verbose: False
## Framework versions
* Numpy: 1.23.5
* HDBSCAN: 0.8.29
* UMAP: 0.5.3
* Pandas: 1.5.3
* Scikit-Learn: 1.2.1
* Sentence-transformers: 2.2.2
* Transformers: 4.24.0
* Numba: 0.56.4
* Plotly: 5.9.0
* Python: 3.10.9
|
iammartian0/RoadSense_High_Definition_Street_Segmentation
|
iammartian0
| 2023-07-11T08:46:08Z | 178 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"segformer",
"generated_from_trainer",
"image_segmentation",
"image-segmentation",
"dataset:segments/sidewalk-semantic",
"license:other",
"endpoints_compatible",
"region:us"
] |
image-segmentation
| 2023-07-07T18:14:58Z |
---
license: other
tags:
- generated_from_trainer
- image_segmentation
model-index:
- name: segformer-b0-finetuned-segments-sidewalk
results: []
datasets:
- segments/sidewalk-semantic
library_name: transformers
pipeline_tag: image-segmentation
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# segformer-b0-finetuned-segments-sidewalk
This model is a fine-tuned version of [nvidia/mit-b0](https://huggingface.co/nvidia/mit-b0) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5449
- Mean Iou: 0.3292
- Mean Accuracy: 0.3907
- Overall Accuracy: 0.8555
- Accuracy Unlabeled: nan
- Accuracy Flat-road: 0.8585
- Accuracy Flat-sidewalk: 0.9611
- Accuracy Flat-crosswalk: 0.7673
- Accuracy Flat-cyclinglane: 0.8223
- Accuracy Flat-parkingdriveway: 0.5127
- Accuracy Flat-railtrack: nan
- Accuracy Flat-curb: 0.4937
- Accuracy Human-person: 0.7164
- Accuracy Human-rider: 0.0
- Accuracy Vehicle-car: 0.9332
- Accuracy Vehicle-truck: 0.0
- Accuracy Vehicle-bus: nan
- Accuracy Vehicle-tramtrain: nan
- Accuracy Vehicle-motorcycle: 0.0
- Accuracy Vehicle-bicycle: 0.3858
- Accuracy Vehicle-caravan: 0.0
- Accuracy Vehicle-cartrailer: 0.0
- Accuracy Construction-building: 0.9040
- Accuracy Construction-door: 0.0
- Accuracy Construction-wall: 0.5848
- Accuracy Construction-fenceguardrail: 0.4417
- Accuracy Construction-bridge: 0.0
- Accuracy Construction-tunnel: nan
- Accuracy Construction-stairs: 0.0
- Accuracy Object-pole: 0.3156
- Accuracy Object-trafficsign: 0.0
- Accuracy Object-trafficlight: 0.0
- Accuracy Nature-vegetation: 0.9413
- Accuracy Nature-terrain: 0.8456
- Accuracy Sky: 0.9600
- Accuracy Void-ground: 0.0
- Accuracy Void-dynamic: 0.0
- Accuracy Void-static: 0.2780
- Accuracy Void-unclear: 0.0
- Iou Unlabeled: nan
- Iou Flat-road: 0.7447
- Iou Flat-sidewalk: 0.8755
- Iou Flat-crosswalk: 0.6244
- Iou Flat-cyclinglane: 0.7325
- Iou Flat-parkingdriveway: 0.3997
- Iou Flat-railtrack: nan
- Iou Flat-curb: 0.3974
- Iou Human-person: 0.4985
- Iou Human-rider: 0.0
- Iou Vehicle-car: 0.7798
- Iou Vehicle-truck: 0.0
- Iou Vehicle-bus: nan
- Iou Vehicle-tramtrain: nan
- Iou Vehicle-motorcycle: 0.0
- Iou Vehicle-bicycle: 0.2904
- Iou Vehicle-caravan: 0.0
- Iou Vehicle-cartrailer: 0.0
- Iou Construction-building: 0.7233
- Iou Construction-door: 0.0
- Iou Construction-wall: 0.4555
- Iou Construction-fenceguardrail: 0.3734
- Iou Construction-bridge: 0.0
- Iou Construction-tunnel: nan
- Iou Construction-stairs: 0.0
- Iou Object-pole: 0.2484
- Iou Object-trafficsign: 0.0
- Iou Object-trafficlight: 0.0
- Iou Nature-vegetation: 0.8451
- Iou Nature-terrain: 0.7346
- Iou Sky: 0.9161
- Iou Void-ground: 0.0
- Iou Void-dynamic: 0.0
- Iou Void-static: 0.2359
- Iou Void-unclear: 0.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 6e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Mean Iou | Mean Accuracy | Overall Accuracy | Accuracy Unlabeled | Accuracy Flat-road | Accuracy Flat-sidewalk | Accuracy Flat-crosswalk | Accuracy Flat-cyclinglane | Accuracy Flat-parkingdriveway | Accuracy Flat-railtrack | Accuracy Flat-curb | Accuracy Human-person | Accuracy Human-rider | Accuracy Vehicle-car | Accuracy Vehicle-truck | Accuracy Vehicle-bus | Accuracy Vehicle-tramtrain | Accuracy Vehicle-motorcycle | Accuracy Vehicle-bicycle | Accuracy Vehicle-caravan | Accuracy Vehicle-cartrailer | Accuracy Construction-building | Accuracy Construction-door | Accuracy Construction-wall | Accuracy Construction-fenceguardrail | Accuracy Construction-bridge | Accuracy Construction-tunnel | Accuracy Construction-stairs | Accuracy Object-pole | Accuracy Object-trafficsign | Accuracy Object-trafficlight | Accuracy Nature-vegetation | Accuracy Nature-terrain | Accuracy Sky | Accuracy Void-ground | Accuracy Void-dynamic | Accuracy Void-static | Accuracy Void-unclear | Iou Unlabeled | Iou Flat-road | Iou Flat-sidewalk | Iou Flat-crosswalk | Iou Flat-cyclinglane | Iou Flat-parkingdriveway | Iou Flat-railtrack | Iou Flat-curb | Iou Human-person | Iou Human-rider | Iou Vehicle-car | Iou Vehicle-truck | Iou Vehicle-bus | Iou Vehicle-tramtrain | Iou Vehicle-motorcycle | Iou Vehicle-bicycle | Iou Vehicle-caravan | Iou Vehicle-cartrailer | Iou Construction-building | Iou Construction-door | Iou Construction-wall | Iou Construction-fenceguardrail | Iou Construction-bridge | Iou Construction-tunnel | Iou Construction-stairs | Iou Object-pole | Iou Object-trafficsign | Iou Object-trafficlight | Iou Nature-vegetation | Iou Nature-terrain | Iou Sky | Iou Void-ground | Iou Void-dynamic | Iou Void-static | Iou Void-unclear |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:-------------:|:----------------:|:------------------:|:------------------:|:----------------------:|:-----------------------:|:-------------------------:|:-----------------------------:|:-----------------------:|:------------------:|:---------------------:|:--------------------:|:--------------------:|:----------------------:|:--------------------:|:--------------------------:|:---------------------------:|:------------------------:|:------------------------:|:---------------------------:|:------------------------------:|:--------------------------:|:--------------------------:|:------------------------------------:|:----------------------------:|:----------------------------:|:----------------------------:|:--------------------:|:---------------------------:|:----------------------------:|:--------------------------:|:-----------------------:|:------------:|:--------------------:|:---------------------:|:--------------------:|:---------------------:|:-------------:|:-------------:|:-----------------:|:------------------:|:--------------------:|:------------------------:|:------------------:|:-------------:|:----------------:|:---------------:|:---------------:|:-----------------:|:---------------:|:---------------------:|:----------------------:|:-------------------:|:-------------------:|:----------------------:|:-------------------------:|:---------------------:|:---------------------:|:-------------------------------:|:-----------------------:|:-----------------------:|:-----------------------:|:---------------:|:----------------------:|:-----------------------:|:---------------------:|:------------------:|:-------:|:---------------:|:----------------:|:---------------:|:----------------:|
| 1.4172 | 1.87 | 200 | 1.2183 | 0.1696 | 0.2214 | 0.7509 | nan | 0.8882 | 0.9199 | 0.0 | 0.4200 | 0.0164 | nan | 0.0 | 0.0 | 0.0 | 0.8778 | 0.0 | nan | nan | 0.0 | 0.0 | 0.0 | 0.0 | 0.8448 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | 0.0 | 0.0 | 0.0 | 0.9430 | 0.8044 | 0.9274 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.5435 | 0.8135 | 0.0 | 0.3743 | 0.0160 | nan | 0.0 | 0.0 | 0.0 | 0.6044 | 0.0 | nan | nan | 0.0 | 0.0 | 0.0 | 0.0 | 0.5373 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | 0.0 | 0.0 | 0.0 | 0.7516 | 0.6550 | 0.7928 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1.1152 | 3.74 | 400 | 0.8946 | 0.1947 | 0.2441 | 0.7852 | nan | 0.8535 | 0.9471 | 0.0 | 0.7379 | 0.2453 | nan | 0.0398 | 0.0 | 0.0 | 0.8882 | 0.0 | nan | nan | 0.0 | 0.0 | 0.0 | 0.0 | 0.8746 | 0.0 | 0.0061 | 0.0 | 0.0 | nan | 0.0 | 0.0014 | 0.0 | 0.0 | 0.9526 | 0.8285 | 0.9448 | 0.0 | 0.0 | 0.0019 | 0.0 | nan | 0.6355 | 0.8321 | 0.0 | 0.5529 | 0.1940 | nan | 0.0392 | 0.0 | 0.0 | 0.6807 | 0.0 | nan | nan | 0.0 | 0.0 | 0.0 | 0.0 | 0.5913 | 0.0 | 0.0061 | 0.0 | 0.0 | nan | 0.0 | 0.0014 | 0.0 | 0.0 | 0.7701 | 0.6777 | 0.8567 | 0.0 | 0.0 | 0.0019 | 0.0 |
| 0.6637 | 5.61 | 600 | 0.7447 | 0.2349 | 0.2841 | 0.8104 | nan | 0.8589 | 0.9451 | 0.4455 | 0.8008 | 0.3753 | nan | 0.3267 | 0.0380 | 0.0 | 0.8920 | 0.0 | nan | nan | 0.0 | 0.0 | 0.0 | 0.0 | 0.9227 | 0.0 | 0.0938 | 0.0 | 0.0 | nan | 0.0 | 0.0167 | 0.0 | 0.0 | 0.9291 | 0.8677 | 0.9557 | 0.0 | 0.0 | 0.0562 | 0.0 | nan | 0.6768 | 0.8543 | 0.4064 | 0.6414 | 0.2914 | nan | 0.2749 | 0.0376 | 0.0 | 0.7268 | 0.0 | nan | nan | 0.0 | 0.0 | 0.0 | 0.0 | 0.6078 | 0.0 | 0.0879 | 0.0 | 0.0 | nan | 0.0 | 0.0164 | 0.0 | 0.0 | 0.8005 | 0.6817 | 0.8918 | 0.0 | 0.0 | 0.0525 | 0.0 |
| 0.673 | 7.48 | 800 | 0.6631 | 0.2691 | 0.3202 | 0.8278 | nan | 0.8387 | 0.9575 | 0.6176 | 0.7938 | 0.4208 | nan | 0.3575 | 0.3977 | 0.0 | 0.9264 | 0.0 | nan | nan | 0.0 | 0.0 | 0.0 | 0.0 | 0.9068 | 0.0 | 0.4035 | 0.0 | 0.0 | nan | 0.0 | 0.1137 | 0.0 | 0.0 | 0.9495 | 0.8165 | 0.9453 | 0.0 | 0.0 | 0.1599 | 0.0 | nan | 0.7042 | 0.8567 | 0.5239 | 0.6600 | 0.3246 | nan | 0.3003 | 0.3212 | 0.0 | 0.7246 | 0.0 | nan | nan | 0.0 | 0.0 | 0.0 | 0.0 | 0.6749 | 0.0 | 0.3113 | 0.0 | 0.0 | nan | 0.0 | 0.1038 | 0.0 | 0.0 | 0.8147 | 0.7070 | 0.9008 | 0.0 | 0.0 | 0.1445 | 0.0 |
| 0.502 | 9.35 | 1000 | 0.6249 | 0.2818 | 0.3371 | 0.8345 | nan | 0.8332 | 0.9538 | 0.7158 | 0.8344 | 0.4079 | nan | 0.4420 | 0.4941 | 0.0 | 0.9275 | 0.0 | nan | nan | 0.0 | 0.0172 | 0.0 | 0.0 | 0.9102 | 0.0 | 0.4787 | 0.0253 | 0.0 | nan | 0.0 | 0.1454 | 0.0 | 0.0 | 0.9460 | 0.8350 | 0.9588 | 0.0 | 0.0 | 0.1887 | 0.0 | nan | 0.7176 | 0.8635 | 0.6035 | 0.6519 | 0.3246 | nan | 0.3545 | 0.3720 | 0.0 | 0.7524 | 0.0 | nan | nan | 0.0 | 0.0172 | 0.0 | 0.0 | 0.6861 | 0.0 | 0.3286 | 0.0250 | 0.0 | nan | 0.0 | 0.1309 | 0.0 | 0.0 | 0.8335 | 0.7300 | 0.9037 | 0.0 | 0.0 | 0.1584 | 0.0 |
| 0.9687 | 11.21 | 1200 | 0.5786 | 0.3093 | 0.3675 | 0.8471 | nan | 0.8703 | 0.9504 | 0.7382 | 0.7705 | 0.5297 | nan | 0.4804 | 0.6250 | 0.0 | 0.9168 | 0.0 | nan | nan | 0.0 | 0.1397 | 0.0 | 0.0 | 0.9228 | 0.0 | 0.5710 | 0.3183 | 0.0 | nan | 0.0 | 0.2252 | 0.0 | 0.0 | 0.9314 | 0.8840 | 0.9536 | 0.0 | 0.0 | 0.1981 | 0.0 | nan | 0.7380 | 0.8743 | 0.5825 | 0.7093 | 0.3829 | nan | 0.3743 | 0.4600 | 0.0 | 0.7727 | 0.0 | nan | nan | 0.0 | 0.1372 | 0.0 | 0.0 | 0.7008 | 0.0 | 0.4315 | 0.2847 | 0.0 | nan | 0.0 | 0.1930 | 0.0 | 0.0 | 0.8397 | 0.7121 | 0.9109 | 0.0 | 0.0 | 0.1761 | 0.0 |
| 0.4681 | 13.08 | 1400 | 0.5759 | 0.3106 | 0.3665 | 0.8462 | nan | 0.8586 | 0.9572 | 0.5158 | 0.8121 | 0.5195 | nan | 0.4539 | 0.6944 | 0.0 | 0.9308 | 0.0 | nan | nan | 0.0 | 0.2759 | 0.0 | 0.0 | 0.9126 | 0.0 | 0.4927 | 0.3145 | 0.0 | nan | 0.0 | 0.2566 | 0.0 | 0.0 | 0.9396 | 0.8736 | 0.9644 | 0.0 | 0.0 | 0.2226 | 0.0 | nan | 0.7134 | 0.8742 | 0.5009 | 0.7146 | 0.4018 | nan | 0.3726 | 0.4661 | 0.0 | 0.7674 | 0.0 | nan | nan | 0.0 | 0.2501 | 0.0 | 0.0 | 0.6997 | 0.0 | 0.3933 | 0.2827 | 0.0 | nan | 0.0 | 0.2137 | 0.0 | 0.0 | 0.8377 | 0.7212 | 0.9109 | 0.0 | 0.0 | 0.1964 | 0.0 |
| 0.5374 | 14.95 | 1600 | 0.5534 | 0.3232 | 0.3823 | 0.8518 | nan | 0.8607 | 0.9545 | 0.7138 | 0.8398 | 0.5129 | nan | 0.4823 | 0.7055 | 0.0 | 0.9225 | 0.0 | nan | nan | 0.0 | 0.3058 | 0.0 | 0.0 | 0.8999 | 0.0 | 0.5436 | 0.3798 | 0.0 | nan | 0.0 | 0.2878 | 0.0 | 0.0 | 0.9485 | 0.8388 | 0.9598 | 0.0 | 0.0 | 0.3145 | 0.0 | nan | 0.7336 | 0.8788 | 0.6094 | 0.7062 | 0.3966 | nan | 0.3854 | 0.4897 | 0.0 | 0.7823 | 0.0 | nan | nan | 0.0 | 0.2782 | 0.0 | 0.0 | 0.7148 | 0.0 | 0.4182 | 0.3304 | 0.0 | nan | 0.0 | 0.2324 | 0.0 | 0.0 | 0.8415 | 0.7356 | 0.9130 | 0.0 | 0.0 | 0.2491 | 0.0 |
| 0.6115 | 16.82 | 1800 | 0.5528 | 0.3266 | 0.3849 | 0.8539 | nan | 0.8521 | 0.9611 | 0.6840 | 0.8291 | 0.5057 | nan | 0.5070 | 0.7165 | 0.0 | 0.9267 | 0.0 | nan | nan | 0.0 | 0.3659 | 0.0 | 0.0 | 0.9007 | 0.0 | 0.5844 | 0.3961 | 0.0 | nan | 0.0 | 0.2827 | 0.0 | 0.0 | 0.9517 | 0.8371 | 0.9602 | 0.0 | 0.0 | 0.2848 | 0.0 | nan | 0.7414 | 0.8721 | 0.6312 | 0.7245 | 0.3979 | nan | 0.3987 | 0.4932 | 0.0 | 0.7799 | 0.0 | nan | nan | 0.0 | 0.2788 | 0.0 | 0.0 | 0.7242 | 0.0 | 0.4542 | 0.3464 | 0.0 | nan | 0.0 | 0.2326 | 0.0 | 0.0 | 0.8384 | 0.7318 | 0.9141 | 0.0 | 0.0 | 0.2386 | 0.0 |
| 0.4766 | 18.69 | 2000 | 0.5449 | 0.3292 | 0.3907 | 0.8555 | nan | 0.8585 | 0.9611 | 0.7673 | 0.8223 | 0.5127 | nan | 0.4937 | 0.7164 | 0.0 | 0.9332 | 0.0 | nan | nan | 0.0 | 0.3858 | 0.0 | 0.0 | 0.9040 | 0.0 | 0.5848 | 0.4417 | 0.0 | nan | 0.0 | 0.3156 | 0.0 | 0.0 | 0.9413 | 0.8456 | 0.9600 | 0.0 | 0.0 | 0.2780 | 0.0 | nan | 0.7447 | 0.8755 | 0.6244 | 0.7325 | 0.3997 | nan | 0.3974 | 0.4985 | 0.0 | 0.7798 | 0.0 | nan | nan | 0.0 | 0.2904 | 0.0 | 0.0 | 0.7233 | 0.0 | 0.4555 | 0.3734 | 0.0 | nan | 0.0 | 0.2484 | 0.0 | 0.0 | 0.8451 | 0.7346 | 0.9161 | 0.0 | 0.0 | 0.2359 | 0.0 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
NasimB/gpt2-concat-all-mod-datasets1-rarity-all-iorder-c13k
|
NasimB
| 2023-07-11T08:45:58Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"dataset:generator",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-11T07:01:32Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- generator
model-index:
- name: gpt2-concat-all-mod-datasets1-rarity-all-iorder-c13k
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-concat-all-mod-datasets1-rarity-all-iorder-c13k
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 4.3983
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 6
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 6.7811 | 0.32 | 500 | 5.6598 |
| 5.4368 | 0.63 | 1000 | 5.2297 |
| 5.0819 | 0.95 | 1500 | 4.9819 |
| 4.8064 | 1.27 | 2000 | 4.8391 |
| 4.6653 | 1.58 | 2500 | 4.7273 |
| 4.5682 | 1.9 | 3000 | 4.6197 |
| 4.3541 | 2.22 | 3500 | 4.5701 |
| 4.2704 | 2.53 | 4000 | 4.5079 |
| 4.2264 | 2.85 | 4500 | 4.4351 |
| 4.051 | 3.17 | 5000 | 4.4290 |
| 3.9415 | 3.49 | 5500 | 4.3896 |
| 3.9311 | 3.8 | 6000 | 4.3596 |
| 3.8035 | 4.12 | 6500 | 4.3598 |
| 3.6487 | 4.44 | 7000 | 4.3523 |
| 3.6387 | 4.75 | 7500 | 4.3363 |
| 3.5857 | 5.07 | 8000 | 4.3408 |
| 3.4463 | 5.39 | 8500 | 4.3415 |
| 3.4459 | 5.7 | 9000 | 4.3420 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.11.0+cu113
- Datasets 2.13.0
- Tokenizers 0.13.3
|
Vangmayy/CharacterClassification
|
Vangmayy
| 2023-07-11T08:12:36Z | 0 | 0 | null |
[
"region:us"
] | null | 2023-07-09T10:15:04Z |
# Character-Classification
A model that is trained to classify different characters from the office
|
Yuhan123/ppo
|
Yuhan123
| 2023-07-11T08:04:50Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-11T08:04:29Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 262.21 +/- 31.43
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
nitzankarby/my-ppo-lunarLander-model
|
nitzankarby
| 2023-07-11T08:01:01Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-11T07:47:28Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 244.39 +/- 13.39
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
ashnrk/textual_inversion_herb_veg
|
ashnrk
| 2023-07-11T07:47:07Z | 4 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"textual_inversion",
"base_model:stabilityai/stable-diffusion-2-1",
"base_model:adapter:stabilityai/stable-diffusion-2-1",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-07-11T06:44:55Z |
---
license: creativeml-openrail-m
base_model: stabilityai/stable-diffusion-2-1
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- textual_inversion
inference: true
---
# Textual inversion text2image fine-tuning - ashnrk/textual_inversion_herb_veg
These are textual inversion adaption weights for stabilityai/stable-diffusion-2-1. You can find some example images in the following.
|
Apocalypse-19/distilhubert-finetuned-gtzan
|
Apocalypse-19
| 2023-07-11T07:45:18Z | 163 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"hubert",
"audio-classification",
"generated_from_trainer",
"dataset:marsyas/gtzan",
"base_model:ntu-spml/distilhubert",
"base_model:finetune:ntu-spml/distilhubert",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2023-07-11T05:08:11Z |
---
license: apache-2.0
base_model: ntu-spml/distilhubert
tags:
- generated_from_trainer
datasets:
- marsyas/gtzan
metrics:
- accuracy
model-index:
- name: distilhubert-finetuned-gtzan
results:
- task:
name: Audio Classification
type: audio-classification
dataset:
name: GTZAN
type: marsyas/gtzan
config: all
split: train
args: all
metrics:
- name: Accuracy
type: accuracy
value: 0.87
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilhubert-finetuned-gtzan
This model is a fine-tuned version of [ntu-spml/distilhubert](https://huggingface.co/ntu-spml/distilhubert) on the GTZAN dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6333
- Accuracy: 0.87
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.2417 | 1.0 | 57 | 2.1896 | 0.42 |
| 1.8003 | 2.0 | 114 | 1.6369 | 0.52 |
| 1.3938 | 3.0 | 171 | 1.2560 | 0.72 |
| 1.2724 | 4.0 | 228 | 1.1942 | 0.68 |
| 0.9682 | 5.0 | 285 | 0.8864 | 0.8 |
| 0.7111 | 6.0 | 342 | 0.7542 | 0.82 |
| 0.6339 | 7.0 | 399 | 0.7712 | 0.81 |
| 0.4599 | 8.0 | 456 | 0.6080 | 0.84 |
| 0.3261 | 9.0 | 513 | 0.5998 | 0.84 |
| 0.2991 | 10.0 | 570 | 0.6767 | 0.79 |
| 0.1615 | 11.0 | 627 | 0.5817 | 0.87 |
| 0.0854 | 12.0 | 684 | 0.5859 | 0.83 |
| 0.0752 | 13.0 | 741 | 0.5681 | 0.85 |
| 0.0341 | 14.0 | 798 | 0.5916 | 0.88 |
| 0.0331 | 15.0 | 855 | 0.6028 | 0.87 |
| 0.02 | 16.0 | 912 | 0.6283 | 0.85 |
| 0.0175 | 17.0 | 969 | 0.6103 | 0.88 |
| 0.0151 | 18.0 | 1026 | 0.6244 | 0.88 |
| 0.014 | 19.0 | 1083 | 0.6293 | 0.86 |
| 0.0181 | 20.0 | 1140 | 0.6333 | 0.87 |
### Framework versions
- Transformers 4.31.0.dev0
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
sipablo/gatau
|
sipablo
| 2023-07-11T07:41:52Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-11T07:41:52Z |
---
license: creativeml-openrail-m
---
|
nolanaatama/tknshkrhllvnrvcv2dclkd44
|
nolanaatama
| 2023-07-11T07:32:03Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-11T07:25:16Z |
---
license: creativeml-openrail-m
---
|
SHENMU007/neunit_BASE_V10.20
|
SHENMU007
| 2023-07-11T07:29:10Z | 75 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"speecht5",
"text-to-audio",
"1.1.0",
"generated_from_trainer",
"zh",
"dataset:facebook/voxpopuli",
"base_model:microsoft/speecht5_tts",
"base_model:finetune:microsoft/speecht5_tts",
"license:mit",
"endpoints_compatible",
"region:us"
] |
text-to-audio
| 2023-07-11T04:29:19Z |
---
language:
- zh
license: mit
base_model: microsoft/speecht5_tts
tags:
- 1.1.0
- generated_from_trainer
datasets:
- facebook/voxpopuli
model-index:
- name: SpeechT5 TTS Dutch neunit
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# SpeechT5 TTS Dutch neunit
This model is a fine-tuned version of [microsoft/speecht5_tts](https://huggingface.co/microsoft/speecht5_tts) on the VoxPopuli dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
### Training results
### Framework versions
- Transformers 4.31.0.dev0
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
Leonardolin/insurance_multiple_label_my83
|
Leonardolin
| 2023-07-11T07:15:46Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-11T04:00:14Z |
how to use will be provide later
tokenizer = bert base chinese tokenizer fast
|
jordyvl/vit-small_rvl_cdip_100_examples_per_class_kd_CEKD_t5.0_a0.5
|
jordyvl
| 2023-07-11T07:11:21Z | 162 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-07-11T05:58:40Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: vit-small_rvl_cdip_100_examples_per_class_kd_CEKD_t5.0_a0.5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-small_rvl_cdip_100_examples_per_class_kd_CEKD_t5.0_a0.5
This model is a fine-tuned version of [WinKawaks/vit-small-patch16-224](https://huggingface.co/WinKawaks/vit-small-patch16-224) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2623
- Accuracy: 0.65
- Brier Loss: 0.4803
- Nll: 3.2676
- F1 Micro: 0.65
- F1 Macro: 0.6575
- Ece: 0.1722
- Aurc: 0.1414
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Brier Loss | Nll | F1 Micro | F1 Macro | Ece | Aurc |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:----------:|:-------:|:--------:|:--------:|:------:|:------:|
| No log | 1.0 | 25 | 3.4916 | 0.1075 | 0.9342 | 15.2561 | 0.1075 | 0.1132 | 0.1627 | 0.8874 |
| No log | 2.0 | 50 | 2.6905 | 0.395 | 0.7423 | 8.7655 | 0.395 | 0.3694 | 0.1922 | 0.3538 |
| No log | 3.0 | 75 | 2.1229 | 0.505 | 0.6157 | 5.2850 | 0.505 | 0.4830 | 0.1716 | 0.2424 |
| No log | 4.0 | 100 | 1.9322 | 0.55 | 0.5842 | 4.6402 | 0.55 | 0.5501 | 0.1744 | 0.2156 |
| No log | 5.0 | 125 | 1.8231 | 0.5575 | 0.5788 | 4.2830 | 0.5575 | 0.5494 | 0.1777 | 0.2091 |
| No log | 6.0 | 150 | 1.7318 | 0.5875 | 0.5523 | 4.4127 | 0.5875 | 0.5864 | 0.1686 | 0.1950 |
| No log | 7.0 | 175 | 1.6652 | 0.615 | 0.5325 | 3.8720 | 0.615 | 0.6192 | 0.1654 | 0.1740 |
| No log | 8.0 | 200 | 1.5910 | 0.61 | 0.5233 | 3.2435 | 0.61 | 0.6097 | 0.1556 | 0.1702 |
| No log | 9.0 | 225 | 1.7751 | 0.59 | 0.5610 | 3.9627 | 0.59 | 0.5839 | 0.1932 | 0.1965 |
| No log | 10.0 | 250 | 1.5950 | 0.5975 | 0.5521 | 3.9360 | 0.5975 | 0.5922 | 0.1868 | 0.1886 |
| No log | 11.0 | 275 | 1.6105 | 0.6 | 0.5459 | 4.2017 | 0.6 | 0.5960 | 0.1788 | 0.1696 |
| No log | 12.0 | 300 | 1.5566 | 0.5975 | 0.5283 | 3.6344 | 0.5975 | 0.5957 | 0.1843 | 0.1758 |
| No log | 13.0 | 325 | 1.5395 | 0.6225 | 0.5344 | 3.3755 | 0.6225 | 0.6327 | 0.1725 | 0.1721 |
| No log | 14.0 | 350 | 1.5117 | 0.64 | 0.5193 | 3.7990 | 0.64 | 0.6366 | 0.1849 | 0.1659 |
| No log | 15.0 | 375 | 1.5274 | 0.6225 | 0.5381 | 3.5126 | 0.6225 | 0.6198 | 0.1837 | 0.1689 |
| No log | 16.0 | 400 | 1.3822 | 0.645 | 0.4848 | 3.5167 | 0.645 | 0.6501 | 0.1426 | 0.1384 |
| No log | 17.0 | 425 | 1.4390 | 0.6325 | 0.5345 | 3.8558 | 0.6325 | 0.6406 | 0.1859 | 0.1624 |
| No log | 18.0 | 450 | 1.3763 | 0.6425 | 0.4905 | 3.0232 | 0.6425 | 0.6446 | 0.1687 | 0.1388 |
| No log | 19.0 | 475 | 1.5017 | 0.5925 | 0.5558 | 3.9738 | 0.5925 | 0.5699 | 0.2064 | 0.1827 |
| 0.7312 | 20.0 | 500 | 1.4216 | 0.64 | 0.5092 | 3.5054 | 0.64 | 0.6394 | 0.1885 | 0.1583 |
| 0.7312 | 21.0 | 525 | 1.3999 | 0.6325 | 0.5166 | 3.6206 | 0.6325 | 0.6342 | 0.1865 | 0.1586 |
| 0.7312 | 22.0 | 550 | 1.3555 | 0.6575 | 0.5092 | 3.5815 | 0.6575 | 0.6570 | 0.1748 | 0.1565 |
| 0.7312 | 23.0 | 575 | 1.3915 | 0.6375 | 0.5065 | 3.2269 | 0.6375 | 0.6367 | 0.1712 | 0.1485 |
| 0.7312 | 24.0 | 600 | 1.4116 | 0.64 | 0.5130 | 3.7646 | 0.64 | 0.6412 | 0.1690 | 0.1624 |
| 0.7312 | 25.0 | 625 | 1.3663 | 0.64 | 0.5160 | 3.0397 | 0.64 | 0.6471 | 0.1736 | 0.1575 |
| 0.7312 | 26.0 | 650 | 1.3717 | 0.63 | 0.5097 | 3.7950 | 0.63 | 0.6379 | 0.1823 | 0.1570 |
| 0.7312 | 27.0 | 675 | 1.3229 | 0.6425 | 0.4933 | 3.5568 | 0.6425 | 0.6498 | 0.1564 | 0.1470 |
| 0.7312 | 28.0 | 700 | 1.3638 | 0.6275 | 0.5124 | 3.2988 | 0.6275 | 0.6266 | 0.1916 | 0.1600 |
| 0.7312 | 29.0 | 725 | 1.3353 | 0.6475 | 0.5013 | 3.4126 | 0.6475 | 0.6407 | 0.1747 | 0.1558 |
| 0.7312 | 30.0 | 750 | 1.3788 | 0.6325 | 0.5172 | 3.4229 | 0.6325 | 0.6329 | 0.1629 | 0.1650 |
| 0.7312 | 31.0 | 775 | 1.3021 | 0.6525 | 0.4840 | 3.2418 | 0.6525 | 0.6571 | 0.1788 | 0.1412 |
| 0.7312 | 32.0 | 800 | 1.3127 | 0.6525 | 0.5058 | 3.1876 | 0.6525 | 0.6579 | 0.1879 | 0.1525 |
| 0.7312 | 33.0 | 825 | 1.3181 | 0.64 | 0.5023 | 3.1837 | 0.64 | 0.6459 | 0.1751 | 0.1529 |
| 0.7312 | 34.0 | 850 | 1.3071 | 0.6425 | 0.4954 | 3.5271 | 0.6425 | 0.6480 | 0.1615 | 0.1496 |
| 0.7312 | 35.0 | 875 | 1.2808 | 0.655 | 0.4904 | 3.2539 | 0.655 | 0.6606 | 0.1725 | 0.1448 |
| 0.7312 | 36.0 | 900 | 1.2766 | 0.68 | 0.4771 | 3.3397 | 0.68 | 0.6823 | 0.1645 | 0.1408 |
| 0.7312 | 37.0 | 925 | 1.2751 | 0.665 | 0.4837 | 3.3390 | 0.665 | 0.6728 | 0.1723 | 0.1446 |
| 0.7312 | 38.0 | 950 | 1.2658 | 0.67 | 0.4791 | 3.2603 | 0.67 | 0.6760 | 0.1781 | 0.1407 |
| 0.7312 | 39.0 | 975 | 1.2678 | 0.66 | 0.4814 | 3.1865 | 0.66 | 0.6682 | 0.1585 | 0.1414 |
| 0.0683 | 40.0 | 1000 | 1.2737 | 0.66 | 0.4840 | 3.3466 | 0.66 | 0.6658 | 0.1699 | 0.1434 |
| 0.0683 | 41.0 | 1025 | 1.2581 | 0.66 | 0.4769 | 3.1757 | 0.66 | 0.6660 | 0.1752 | 0.1398 |
| 0.0683 | 42.0 | 1050 | 1.2734 | 0.655 | 0.4833 | 3.1843 | 0.655 | 0.6600 | 0.1721 | 0.1440 |
| 0.0683 | 43.0 | 1075 | 1.2628 | 0.66 | 0.4802 | 3.2578 | 0.66 | 0.6670 | 0.1789 | 0.1403 |
| 0.0683 | 44.0 | 1100 | 1.2717 | 0.66 | 0.4837 | 3.2573 | 0.66 | 0.6651 | 0.1584 | 0.1433 |
| 0.0683 | 45.0 | 1125 | 1.2637 | 0.6475 | 0.4791 | 3.3419 | 0.6475 | 0.6545 | 0.1736 | 0.1408 |
| 0.0683 | 46.0 | 1150 | 1.2625 | 0.6575 | 0.4797 | 3.3403 | 0.6575 | 0.6642 | 0.1597 | 0.1406 |
| 0.0683 | 47.0 | 1175 | 1.2642 | 0.6525 | 0.4791 | 3.3527 | 0.6525 | 0.6592 | 0.1731 | 0.1416 |
| 0.0683 | 48.0 | 1200 | 1.2652 | 0.655 | 0.4816 | 3.2664 | 0.655 | 0.6623 | 0.1717 | 0.1413 |
| 0.0683 | 49.0 | 1225 | 1.2646 | 0.65 | 0.4806 | 3.3371 | 0.65 | 0.6568 | 0.1758 | 0.1419 |
| 0.0683 | 50.0 | 1250 | 1.2677 | 0.65 | 0.4812 | 3.4189 | 0.65 | 0.6575 | 0.1582 | 0.1427 |
| 0.0683 | 51.0 | 1275 | 1.2657 | 0.65 | 0.4813 | 3.3393 | 0.65 | 0.6565 | 0.1748 | 0.1413 |
| 0.0683 | 52.0 | 1300 | 1.2648 | 0.655 | 0.4813 | 3.3447 | 0.655 | 0.6629 | 0.1627 | 0.1419 |
| 0.0683 | 53.0 | 1325 | 1.2650 | 0.65 | 0.4813 | 3.3350 | 0.65 | 0.6565 | 0.1780 | 0.1414 |
| 0.0683 | 54.0 | 1350 | 1.2593 | 0.655 | 0.4790 | 3.3427 | 0.655 | 0.6620 | 0.1543 | 0.1399 |
| 0.0683 | 55.0 | 1375 | 1.2648 | 0.6525 | 0.4810 | 3.3368 | 0.6525 | 0.6592 | 0.1723 | 0.1414 |
| 0.0683 | 56.0 | 1400 | 1.2608 | 0.6525 | 0.4802 | 3.2599 | 0.6525 | 0.6603 | 0.1738 | 0.1411 |
| 0.0683 | 57.0 | 1425 | 1.2639 | 0.6525 | 0.4799 | 3.3437 | 0.6525 | 0.6599 | 0.1767 | 0.1413 |
| 0.0683 | 58.0 | 1450 | 1.2631 | 0.65 | 0.4810 | 3.3401 | 0.65 | 0.6578 | 0.1667 | 0.1416 |
| 0.0683 | 59.0 | 1475 | 1.2636 | 0.6525 | 0.4803 | 3.3411 | 0.6525 | 0.6594 | 0.1690 | 0.1416 |
| 0.0391 | 60.0 | 1500 | 1.2618 | 0.6525 | 0.4796 | 3.2684 | 0.6525 | 0.6600 | 0.1813 | 0.1413 |
| 0.0391 | 61.0 | 1525 | 1.2636 | 0.6525 | 0.4807 | 3.2704 | 0.6525 | 0.6595 | 0.1673 | 0.1413 |
| 0.0391 | 62.0 | 1550 | 1.2615 | 0.65 | 0.4794 | 3.2662 | 0.65 | 0.6575 | 0.1741 | 0.1413 |
| 0.0391 | 63.0 | 1575 | 1.2630 | 0.65 | 0.4803 | 3.3417 | 0.65 | 0.6575 | 0.1752 | 0.1411 |
| 0.0391 | 64.0 | 1600 | 1.2618 | 0.65 | 0.4801 | 3.2663 | 0.65 | 0.6575 | 0.1770 | 0.1413 |
| 0.0391 | 65.0 | 1625 | 1.2622 | 0.65 | 0.4802 | 3.2698 | 0.65 | 0.6575 | 0.1686 | 0.1412 |
| 0.0391 | 66.0 | 1650 | 1.2622 | 0.65 | 0.4802 | 3.3400 | 0.65 | 0.6575 | 0.1922 | 0.1412 |
| 0.0391 | 67.0 | 1675 | 1.2625 | 0.65 | 0.4802 | 3.2694 | 0.65 | 0.6575 | 0.1801 | 0.1413 |
| 0.0391 | 68.0 | 1700 | 1.2626 | 0.65 | 0.4803 | 3.2683 | 0.65 | 0.6575 | 0.1656 | 0.1414 |
| 0.0391 | 69.0 | 1725 | 1.2631 | 0.65 | 0.4806 | 3.2696 | 0.65 | 0.6575 | 0.1722 | 0.1413 |
| 0.0391 | 70.0 | 1750 | 1.2622 | 0.65 | 0.4802 | 3.2688 | 0.65 | 0.6575 | 0.1812 | 0.1412 |
| 0.0391 | 71.0 | 1775 | 1.2626 | 0.65 | 0.4803 | 3.2676 | 0.65 | 0.6575 | 0.1845 | 0.1412 |
| 0.0391 | 72.0 | 1800 | 1.2621 | 0.65 | 0.4801 | 3.2683 | 0.65 | 0.6575 | 0.1805 | 0.1411 |
| 0.0391 | 73.0 | 1825 | 1.2626 | 0.65 | 0.4804 | 3.2683 | 0.65 | 0.6575 | 0.1665 | 0.1413 |
| 0.0391 | 74.0 | 1850 | 1.2624 | 0.65 | 0.4803 | 3.2686 | 0.65 | 0.6575 | 0.1773 | 0.1412 |
| 0.0391 | 75.0 | 1875 | 1.2624 | 0.65 | 0.4803 | 3.2682 | 0.65 | 0.6575 | 0.1807 | 0.1412 |
| 0.0391 | 76.0 | 1900 | 1.2627 | 0.65 | 0.4804 | 3.2680 | 0.65 | 0.6575 | 0.1732 | 0.1414 |
| 0.0391 | 77.0 | 1925 | 1.2625 | 0.65 | 0.4803 | 3.2673 | 0.65 | 0.6575 | 0.1715 | 0.1412 |
| 0.0391 | 78.0 | 1950 | 1.2623 | 0.65 | 0.4803 | 3.2681 | 0.65 | 0.6575 | 0.1840 | 0.1413 |
| 0.0391 | 79.0 | 1975 | 1.2624 | 0.65 | 0.4803 | 3.2678 | 0.65 | 0.6575 | 0.1773 | 0.1413 |
| 0.0385 | 80.0 | 2000 | 1.2625 | 0.65 | 0.4803 | 3.2686 | 0.65 | 0.6575 | 0.1802 | 0.1414 |
| 0.0385 | 81.0 | 2025 | 1.2625 | 0.65 | 0.4803 | 3.2677 | 0.65 | 0.6575 | 0.1773 | 0.1413 |
| 0.0385 | 82.0 | 2050 | 1.2625 | 0.65 | 0.4803 | 3.2684 | 0.65 | 0.6575 | 0.1802 | 0.1414 |
| 0.0385 | 83.0 | 2075 | 1.2624 | 0.65 | 0.4803 | 3.2679 | 0.65 | 0.6575 | 0.1823 | 0.1413 |
| 0.0385 | 84.0 | 2100 | 1.2623 | 0.65 | 0.4803 | 3.2681 | 0.65 | 0.6575 | 0.1772 | 0.1413 |
| 0.0385 | 85.0 | 2125 | 1.2624 | 0.65 | 0.4803 | 3.2677 | 0.65 | 0.6575 | 0.1722 | 0.1414 |
| 0.0385 | 86.0 | 2150 | 1.2625 | 0.65 | 0.4804 | 3.2680 | 0.65 | 0.6575 | 0.1751 | 0.1414 |
| 0.0385 | 87.0 | 2175 | 1.2623 | 0.65 | 0.4803 | 3.2677 | 0.65 | 0.6575 | 0.1772 | 0.1413 |
| 0.0385 | 88.0 | 2200 | 1.2624 | 0.65 | 0.4803 | 3.2676 | 0.65 | 0.6575 | 0.1723 | 0.1414 |
| 0.0385 | 89.0 | 2225 | 1.2623 | 0.65 | 0.4803 | 3.2679 | 0.65 | 0.6575 | 0.1722 | 0.1414 |
| 0.0385 | 90.0 | 2250 | 1.2622 | 0.65 | 0.4802 | 3.2677 | 0.65 | 0.6575 | 0.1722 | 0.1413 |
| 0.0385 | 91.0 | 2275 | 1.2623 | 0.65 | 0.4803 | 3.2678 | 0.65 | 0.6575 | 0.1722 | 0.1414 |
| 0.0385 | 92.0 | 2300 | 1.2624 | 0.65 | 0.4803 | 3.2677 | 0.65 | 0.6575 | 0.1722 | 0.1414 |
| 0.0385 | 93.0 | 2325 | 1.2623 | 0.65 | 0.4803 | 3.2679 | 0.65 | 0.6575 | 0.1722 | 0.1414 |
| 0.0385 | 94.0 | 2350 | 1.2623 | 0.65 | 0.4803 | 3.2677 | 0.65 | 0.6575 | 0.1722 | 0.1414 |
| 0.0385 | 95.0 | 2375 | 1.2623 | 0.65 | 0.4803 | 3.2676 | 0.65 | 0.6575 | 0.1722 | 0.1414 |
| 0.0385 | 96.0 | 2400 | 1.2623 | 0.65 | 0.4803 | 3.2677 | 0.65 | 0.6575 | 0.1722 | 0.1414 |
| 0.0385 | 97.0 | 2425 | 1.2623 | 0.65 | 0.4803 | 3.2677 | 0.65 | 0.6575 | 0.1722 | 0.1414 |
| 0.0385 | 98.0 | 2450 | 1.2623 | 0.65 | 0.4803 | 3.2677 | 0.65 | 0.6575 | 0.1722 | 0.1414 |
| 0.0385 | 99.0 | 2475 | 1.2623 | 0.65 | 0.4803 | 3.2676 | 0.65 | 0.6575 | 0.1722 | 0.1414 |
| 0.0385 | 100.0 | 2500 | 1.2623 | 0.65 | 0.4803 | 3.2676 | 0.65 | 0.6575 | 0.1722 | 0.1414 |
### Framework versions
- Transformers 4.28.0.dev0
- Pytorch 1.12.1+cu113
- Datasets 2.12.0
- Tokenizers 0.12.1
|
merve/sam-finetuned
|
merve
| 2023-07-11T06:50:29Z | 74 | 0 |
transformers
|
[
"transformers",
"tf",
"sam",
"mask-generation",
"generated_from_keras_callback",
"base_model:facebook/sam-vit-base",
"base_model:finetune:facebook/sam-vit-base",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
mask-generation
| 2023-07-11T06:11:49Z |
---
license: apache-2.0
base_model: facebook/sam-vit-base
tags:
- generated_from_keras_callback
model-index:
- name: sam-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# sam-finetuned
## Model description
This model is a fine-tuned version of [facebook/sam-vit-base](https://huggingface.co/facebook/sam-vit-base) on an breast cancer dataset. It is not trained for production but for Keras example.
## Training procedure
### Training hyperparameters
The model was trained for 20 epochs.
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
You can see an example inference below.

### Framework versions
- Transformers 4.31.0.dev0
- TensorFlow 2.12.0
- Tokenizers 0.13.3
|
nolanaatama/kzk
|
nolanaatama
| 2023-07-11T06:47:52Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-11T06:39:49Z |
---
license: creativeml-openrail-m
---
|
ashnrk/textual_inversion_forest
|
ashnrk
| 2023-07-11T06:44:44Z | 21 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"textual_inversion",
"base_model:stabilityai/stable-diffusion-2-1",
"base_model:adapter:stabilityai/stable-diffusion-2-1",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-07-11T05:42:48Z |
---
license: creativeml-openrail-m
base_model: stabilityai/stable-diffusion-2-1
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- textual_inversion
inference: true
---
# Textual inversion text2image fine-tuning - ashnrk/textual_inversion_forest
These are textual inversion adaption weights for stabilityai/stable-diffusion-2-1. You can find some example images in the following.
|
akuan123/RegionCLIP
|
akuan123
| 2023-07-11T06:40:06Z | 0 | 0 | null |
[
"arxiv:2112.09106",
"region:us"
] | null | 2023-07-11T06:24:40Z |
# RegionCLIP: Region-based Language-Image Pretraining
This is the official PyTorch implementation of RegionCLIP (CVPR 2022).
[**Paper**](https://arxiv.org/abs/2112.09106) | [**Demo on Hugging Face**](https://huggingface.co/spaces/CVPR/regionclip-demo) | [**Slides**](https://drive.google.com/file/d/1EepNVJGo_d73Glr4vNjR4Av0dNkBCGcj/view?usp=sharing)
> **RegionCLIP: Region-based Language-Image Pretraining (CVPR 2022)** <br>
> [Yiwu Zhong](https://pages.cs.wisc.edu/~yiwuzhong/), [Jianwei Yang](https://jwyang.github.io/), [Pengchuan Zhang](https://pzzhang.github.io/pzzhang/), [Chunyuan Li](https://chunyuan.li/), [Noel Codella](https://noelcodella.github.io/publicwebsite/), [Liunian Li](https://liunian-harold-li.github.io/), [Luowei Zhou](https://luoweizhou.github.io/), [Xiyang Dai](https://sites.google.com/site/xiyangdai/), [Lu Yuan](https://scholar.google.com/citations?user=k9TsUVsAAAAJ&hl=en), [Yin Li](https://www.biostat.wisc.edu/~yli/), and [Jianfeng Gao](https://www.microsoft.com/en-us/research/people/jfgao/?from=http%3A%2F%2Fresearch.microsoft.com%2Fen-us%2Fum%2Fpeople%2Fjfgao%2F) <br>
<p align="center">
<img src="docs/regionclip.png" width=80% height=80%
class="center">
</p>
## Overview
We propose RegionCLIP that significantly extends CLIP to learn region-level visual representations. RegionCLIP enables fine-grained alignment between image regions and textual concepts, and thus supports region-based reasoning tasks including zero-shot object detection and open-vocabulary object detection.
- **Pretraining**: We leverage a CLIP model to match image regions with template captions, and then pretrain our model to align these region-text pairs.
- **Zero-shot inference**: Once pretrained, the learned region representations support zero-shot inference for object detection.
- **Transfer learning**: The learned RegionCLIP model can be further fine-tuned with additional object detection annotations, allowing our model to be used for fully supervised or open-vocabulary object detection.
- **Results**: Our method demonstrates **state-of-the-art** results for zero-shot object detection and open-vocabulary object detection.
## Updates
* :collision: [10/05/2022] RegionCLIP now supports not only resnet but also many vision transformers (e.g., vit, swin, davit, focalnet) for zero-shot object detection! Please checkout the [zero-shot branch](https://github.com/microsoft/RegionCLIP/tree/zero-shot)!
* [09/23/2022] As requested by researchers, we release the [configs](configs/pretrain) and [scripts](pretrain.sh) of pre-training. A full tutorial and pre-training data will be released later. Stay tuned!
* [09/18/2022] Organizing ECCV Workshop [Computer Vision in the Wild (CVinW)](https://computer-vision-in-the-wild.github.io/eccv-2022/), where two challenges are hosted to evaluate the zero-shot, few-shot and full-shot performance of pre-trained vision models in downstream tasks:
- [Image Classification in the Wild (ICinW)](https://eval.ai/web/challenges/challenge-page/1832/overview) Challenge evaluates on 20 image classification tasks.
- [Object Detection in the Wild (ODinW)](https://eval.ai/web/challenges/challenge-page/1839/overview) Challenge evaluates on 35 object detection tasks.
* [07/11/2022] We included the scripts for concept feature extraction. It can be used for your own costomized concept pool!
* [07/07/2022] We included the scripts for region feature extraction. The extracted visual features can be used for various downstream tasks!
* [06/24/2022] We released [**a Web demo using Gradio on Hugging Face**](https://huggingface.co/spaces/CVPR/regionclip-demo). It uses our pretrained RegionCLIP for zero-shot inference. Check it out!
* [06/20/2022] We released models and inference code for our RegionCLIP!
## Outline
1. [Installation](#Installation)
2. [Datasets](#Datasets)
3. [Model Zoo](#Model-Zoo)
4. [Zero-shot Inference](#Zero-shot-Inference)
5. [Transfer Learning](#Transfer-Learning)
6. [Extract Region Features](#Extract-Region-Features)
7. [Extract Concept Features](#Extract-Concept-Features)
8. [Citation and Acknowledgement](#Citation-and-Acknowledgement)
9. [Contributing](#Contributing)
## Installation
Check [`INSTALL.md`](docs/INSTALL.md) for installation instructions.
## Datasets
Check [`datasets/README.md`](datasets/README.md) for dataset preparation.
## Model Zoo
Check [`MODEL_ZOO.md`](docs/MODEL_ZOO.md) for our pretrained models.
## Zero-shot Inference
After pretraining, RegionCLIP can directly support the challenging zero-shot object detection task **without finetuning on detection annotation**. Given an input image, our pretrained RegionCLIP can match image region features to object concept embeddings, and thus recognize image regions into many object categories. The image regions are produced by a region localizer (e.g., RPN), where the object class names come from a dictionary **specifiied by users**.
### Visualization on custom images
We provide an example below for zero-shot object detection with pretrained RegionCLIP on custom images and for visualizing the results.
<details>
<summary>
Before detecting objects, please prepare pretrained models, label files, and the custom images. See details below.
</summary>
- Check [`MODEL_ZOO.md`](docs/MODEL_ZOO.md) to
- download the pretrained model checkpoint `regionclip_pretrained-cc_rn50x4.pth` (RegionCLIP with ResNet50x4) to the folder `./pretrained_ckpt/regionclip`.
- download the class embeddings `lvis_1203_cls_emb_rn50x4.pth` to the folder `./pretrained_ckpt/concept_emb`.
- Check [`datasets/README.md`](datasets/README.md) to download LVIS label file `lvis_v1_val.json` and put it in the folder `./datasets/lvis/lvis_v1_val.json`. The file is used to specify object class names.
- Put all custom images in the folder `./datasets/custom_images/`.
</details>
<details>
<summary>
After preparation, run the following script to detect objects.
</summary>
```
python3 ./tools/train_net.py \
--eval-only \
--num-gpus 1 \
--config-file ./configs/LVISv1-InstanceSegmentation/CLIP_fast_rcnn_R_50_C4_custom_img.yaml \
MODEL.WEIGHTS ./pretrained_ckpt/regionclip/regionclip_pretrained-cc_rn50x4.pth \
MODEL.CLIP.TEXT_EMB_PATH ./pretrained_ckpt/concept_emb/lvis_1203_cls_emb_rn50x4.pth \
MODEL.CLIP.OFFLINE_RPN_CONFIG ./configs/LVISv1-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.yaml \
MODEL.CLIP.TEXT_EMB_DIM 640 \
MODEL.RESNETS.DEPTH 200 \
MODEL.ROI_BOX_HEAD.POOLER_RESOLUTION 18 \
```
</details>
<details>
<summary>
The detection results will be stored as the file "./output/inference/lvis_instances_results.json". To visualize it, run the script below.
</summary>
```
python ./tools/visualize_json_results.py \
--input ./output/inference/lvis_instances_results.json \
--output ./output/regions \
--dataset lvis_v1_val_custom_img \
--conf-threshold 0.05 \
--show-unique-boxes \
--max-boxes 25 \
--small-region-px 8100\
```
</details>
The visualized images will be placed at `./output/regions/`. The visualized images would look like:
<p align="center">
<img src="docs/sample_img1_vis.jpg" width=80% height=80%
class="center">
</p>
In this example, the detection results come from our pretrained RegionCLIP with ResNet50x4 architecture. The regions are proposed by an RPN trained by 866 object categories from LVIS dataset. For now, we use 1203 object class names from LVIS dataset for this visualization example. We also include an example in `visualize_zeroshot_inference.sh` with our pretrained RegionCLIP (ResNet50 architecture).
### Evaluation for zero-shot inference
We provide an example below for evaluating our pretrained RegionCLIP (ResNet50) using ground-truth boxes on COCO dataset. This will reproduce our results in Table 4 of the paper.
<details>
<summary>
Before evaluation, please prepare pretrained models and set up the dataset.
</summary>
- Check [`MODEL_ZOO.md`](docs/MODEL_ZOO.md) to
- download the pretrained RegionCLIP checkpoint `regionclip_pretrained-cc_rn50.pth` to the folder `./pretrained_ckpt/regionclip`.
- download the class embeddings `coco_65_cls_emb.pth` to the folder `./pretrained_ckpt/concept_emb`.
- Check [`datasets/README.md`](datasets/README.md) to set up COCO dataset.
</details>
<details>
<summary>
After preparation, run the following script to evaluate the pretrained model in zero-shot inference setting.
</summary>
```
python3 ./tools/train_net.py \
--eval-only \
--num-gpus 1 \
--config-file ./configs/COCO-InstanceSegmentation/CLIP_fast_rcnn_R_50_C4_ovd_zsinf.yaml \
MODEL.WEIGHTS ./pretrained_ckpt/regionclip/regionclip_pretrained-cc_rn50.pth \
MODEL.CLIP.TEXT_EMB_PATH ./pretrained_ckpt/concept_emb/coco_65_cls_emb.pth \
MODEL.CLIP.CROP_REGION_TYPE GT \
MODEL.CLIP.MULTIPLY_RPN_SCORE False \
```
</details>
For more examples, please refer to `test_zeroshot_inference.sh`. This script covers a wide combination of pretrained models (ResNet50, ResNet50x4), datasets (COCO, LVIS) and region proposal types (ground-truth regions, RPN proposals). Also, please refer to [MODEL_ZOO.md](docs/MODEL_ZOO.md) for available trained models and [`datasets/README.md`](datasets/README.md) for setting up COCO and LVIS datasets.
## Transfer Learning
Our pretrained RegionCLIP can be further **fine-tuned** when human annotations of objects are available. In this transfer learning setting, we demonstrate results on **open-vocabulary object detection**, where the object detector is trained on base categories and evaluated on both base and **novel** categories.
We show an example for running a trained detector on custom images. Further, we provide scripts of training and evaluation for the benchmark of **open-vocabulary object detection**, including COCO and LVIS datasets (Table 1 & 2 in paper).
### Visualization on custom images
We provide an example below for running a trained open-vocabulary object detector on custom images and for visualizing the results. In this example, the detector is initialized using RegionCLIP (RN50x4), trained on 866 LVIS base categories, and is tasked to detect all 1203 categories on LVIS.
<details>
<summary>
Before detecting objects, please prepare the trained detectors, label files, and the custom images.
</summary>
- Check [`MODEL_ZOO.md`](docs/MODEL_ZOO.md) to
- download the trained detector checkpoint `regionclip_finetuned-lvis_rn50x4.pth` to the folder `./pretrained_ckpt/regionclip`.
- download the trained RPN checkpoint `rpn_lvis_866_lsj.pth` to the folder `./pretrained_ckpt/rpn`.
- download the class embeddings `lvis_1203_cls_emb_rn50x4.pth` to the folder `./pretrained_ckpt/concept_emb`.
- Check [`datasets/README.md`](datasets/README.md) to download label file `lvis_v1_val.json` and put it in the folder `./datasets/lvis/lvis_v1_val.json`.
- Put all custom images in the folder `./datasets/custom_images/`.
</details>
<details>
<summary>
After preparation, run the following script to detect objects and visualize the results.
</summary>
```
# for simplicity, we integrate the script in visualize_transfer_learning.sh
bash visualize_transfer_learning.sh
```
</details>
The visualized images will be placed at `./output/regions/`.
### Evaluate the trained detectors
We provide an example below for evaluating our open-vocabulary object detector, initialized by RegionCLIP (ResNet50) and trained on COCO dataset.
<details>
<summary>
Before evaluation, please prepare the trained detector and set up the dataset.
</summary>
- Check [`MODEL_ZOO.md`](docs/MODEL_ZOO.md) to
- download the trained detector checkpoint `regionclip_finetuned-coco_rn50.pth` to the folder `./pretrained_ckpt/regionclip`,
- download the trained RPN checkpoint `rpn_coco_48.pth` to the folder `./pretrained_ckpt/rpn`,
- download the class embeddings `coco_48_base_cls_emb.pth` and `coco_65_cls_emb.pth` to the folder `./pretrained_ckpt/concept_emb`.
- Check [`datasets/README.md`](datasets/README.md) to set up COCO dataset.
</details>
<details>
<summary>
After preparation, run the following script to evaluate the trained open-vocabulary detector.
</summary>
```
python3 ./tools/train_net.py \
--eval-only \
--num-gpus 1 \
--config-file ./configs/COCO-InstanceSegmentation/CLIP_fast_rcnn_R_50_C4_ovd.yaml \
MODEL.WEIGHTS ./pretrained_ckpt/regionclip/regionclip_finetuned-coco_rn50.pth \
MODEL.CLIP.OFFLINE_RPN_CONFIG ./configs/COCO-InstanceSegmentation/mask_rcnn_R_50_C4_1x_ovd_FSD.yaml \
MODEL.CLIP.BB_RPN_WEIGHTS ./pretrained_ckpt/rpn/rpn_coco_48.pth \
MODEL.CLIP.TEXT_EMB_PATH ./pretrained_ckpt/concept_emb/coco_48_base_cls_emb.pth \
MODEL.CLIP.OPENSET_TEST_TEXT_EMB_PATH ./pretrained_ckpt/concept_emb/coco_65_cls_emb.pth \
MODEL.ROI_HEADS.SOFT_NMS_ENABLED True \
```
</details>
For more examples, please refer to `test_transfer_learning.sh`. This script includes benchmark evaluation for various combination of trained detectors (ResNet50, ResNet50x4) and datasets (COCO, LVIS). Also, please refer to [MODEL_ZOO.md](docs/MODEL_ZOO.md) for available trained models and [`datasets/README.md`](datasets/README.md) for setting up COCO and LVIS datasets.
### Train detectors on your own
We provide an example below for training an open-vocabulary object detector on COCO dataset, with pretrained RegionCLIP (ResNet50) as the initialization.
<details>
<summary>
Before training, please prepare our pretrained RegionCLIP model and set up the dataset.
</summary>
- Check [`MODEL_ZOO.md`](docs/MODEL_ZOO.md) to
- download the pretrained RegionCLIP checkpoint `regionclip_pretrained-cc_rn50.pth` to the folder `./pretrained_ckpt/regionclip`,
- download the trained RPN checkpoint `rpn_coco_48.pth` to the folder `./pretrained_ckpt/rpn`,
- download the class embeddings `coco_48_base_cls_emb.pth` and `coco_65_cls_emb.pth` to the folder `./pretrained_ckpt/concept_emb`.
- Check [`datasets/README.md`](datasets/README.md) to set up COCO dataset.
</details>
<details>
<summary>
After preparation, run the following script to train an open-vocabulary detector.
</summary>
```
python3 ./tools/train_net.py \
--num-gpus 1 \
--config-file ./configs/COCO-InstanceSegmentation/CLIP_fast_rcnn_R_50_C4_ovd.yaml \
MODEL.WEIGHTS ./pretrained_ckpt/regionclip/regionclip_pretrained-cc_rn50.pth \
MODEL.CLIP.OFFLINE_RPN_CONFIG ./configs/COCO-InstanceSegmentation/mask_rcnn_R_50_C4_1x_ovd_FSD.yaml \
MODEL.CLIP.BB_RPN_WEIGHTS ./pretrained_ckpt/rpn/rpn_coco_48.pth \
MODEL.CLIP.TEXT_EMB_PATH ./pretrained_ckpt/concept_emb/coco_48_base_cls_emb.pth \
MODEL.CLIP.OPENSET_TEST_TEXT_EMB_PATH ./pretrained_ckpt/concept_emb/coco_65_cls_emb.pth \
```
</details>
For more examples, please refer to `train_transfer_learning.sh`. This script provides training scripts for various combination of detector backbones (ResNet50, ResNet50x4) and datasets (COCO, LVIS). Also, please refer to [MODEL_ZOO.md](docs/MODEL_ZOO.md) for available trained models and [`datasets/README.md`](datasets/README.md) for setting up COCO and LVIS datasets.
## Extract Region Features
We provide scripts for extracting region features from our pre-trained RegionCLIP. Given a folder of images, our scripts extract region features (along with other detection results such as box coordinates) and save them as local files.
The following is an example using pretrained RegionCLIP with ResNet50. We extend the scripts from zero-shot inference (section above) with minor changes, such as the input and output folders.
<details>
<summary>
The following is a brief introduction for the settings.
</summary>
We enable feature extraction for two types of regions:
- RPN regions: This setting is class-agnostic. The regions are the top-scored RPN proposals.
- Detection regions: This setting requires additional input as a concept embedding file (the concepts of interests). The regions are the final detection output boxes (after 2nd-stage NMS). As a reference, the [Bottom-Up features](https://openaccess.thecvf.com/content_cvpr_2018/papers/Anderson_Bottom-Up_and_Top-Down_CVPR_2018_paper.pdf) (widely-used in vision-language tasks) also come from the final detection boxes.
</details>
<details>
<summary>
Before running scripts, please prepare pretrained models and your custom images.
</summary>
- Check [`MODEL_ZOO.md`](docs/MODEL_ZOO.md) to
- download the pretrained RegionCLIP checkpoint `regionclip_pretrained-cc_rn50.pth` to the folder `./pretrained_ckpt/regionclip`.
- download the trained RPN checkpoint `rpn_lvis_866.pth` to the folder `./pretrained_ckpt/rpn`.
- (optional) if you want to extract features of the boxes detected for 1203 LVIS concepts, download the class embeddings `lvis_1203_cls_emb.pth` to the folder `./pretrained_ckpt/concept_emb`.
- Put all custom images in a folder. It can be specified in the script (check `INPUT_DIR` below).
</details>
<details>
<summary>
After preparation, run the following script to extract region features.
</summary>
The following script extracts features from **RPN regions**.
```
# RN50, features of RPN regions
python3 ./tools/extract_region_features.py \
--config-file ./configs/LVISv1-InstanceSegmentation/CLIP_fast_rcnn_R_50_C4_zsinf.yaml \
MODEL.WEIGHTS ./pretrained_ckpt/regionclip/regionclip_pretrained-cc_rn50.pth \
MODEL.CLIP.CROP_REGION_TYPE RPN \
MODEL.CLIP.MULTIPLY_RPN_SCORE True \
MODEL.CLIP.OFFLINE_RPN_CONFIG ./configs/LVISv1-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.yaml \
MODEL.CLIP.BB_RPN_WEIGHTS ./pretrained_ckpt/rpn/rpn_lvis_866.pth \
INPUT_DIR ./datasets/custom_images \
OUTPUT_DIR ./output/region_feats \
MODEL.CLIP.OFFLINE_RPN_POST_NMS_TOPK_TEST 100 \
```
The following script extracts features from **detection regions** (after 2nd-stage NMS).
```
# You can simply run "bash extract_region_features.sh"
python3 ./tools/extract_region_features.py \
--config-file ./configs/LVISv1-InstanceSegmentation/CLIP_fast_rcnn_R_50_C4_zsinf.yaml \
MODEL.WEIGHTS ./pretrained_ckpt/regionclip/regionclip_pretrained-cc_rn50.pth \
MODEL.CLIP.TEXT_EMB_PATH ./pretrained_ckpt/concept_emb/lvis_1203_cls_emb.pth \
MODEL.CLIP.CROP_REGION_TYPE RPN \
MODEL.CLIP.MULTIPLY_RPN_SCORE True \
MODEL.CLIP.OFFLINE_RPN_CONFIG ./configs/LVISv1-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.yaml \
MODEL.CLIP.BB_RPN_WEIGHTS ./pretrained_ckpt/rpn/rpn_lvis_866.pth \
INPUT_DIR ./datasets/custom_images \
OUTPUT_DIR ./output/region_feats \
TEST.DETECTIONS_PER_IMAGE 100 \
```
The region features of each image will be saved into a `.pth` file in the folder `OUTPUT_DIR`. For simplicity, the current script only supports single GPU inference. As a reference, it takes roughly 0.76 seconds on single Titan-Xp GPU with RegionCLIP-ResNet50 and 1203 LVIS object concepts.
The following is a list of key arguments for feature extraction. You can specify them in the script as needed.
- `INPUT_DIR` and `OUTPUT_DIR`: specify a folder of input images and an output folder where region features will be saved, respectively.
- `MODEL.CLIP.BB_RPN_WEIGHTS`: specifies which trained RPN to use. You can replace it as needed. For more details, please check [`MODEL_ZOO.md`](docs/MODEL_ZOO.md).
- `MODEL.CLIP.TEXT_EMB_PATH` (optional): specifies which object concept embedding file to use. The selection of concepts will affect the per-class NMS (2nd stage) and thus final output boxes.
- `TEST.DETECTIONS_PER_IMAGE`: defines the number of final output regions (e.g., default value is 100 in COCO configs and 300 in LVIS configs)
- `MODEL.CLIP.OFFLINE_RPN_POST_NMS_TOPK_TEST`: defines the number of region proposals from RPN (e.g., default is 1000). Lowering this value can significantly reduce inference time and memory cost, but might affect the final detection quality.
- `MODEL.CLIP.OFFLINE_RPN_NMS_THRESH` and `MODEL.ROI_HEADS.NMS_THRESH_TEST`: control the NMS IoU thresholds in RPN (1st stage, default is 0.9) and prediction head (2nd stage, default is 0.5), respectively. If you extract features using RPN regions, you might want to change `MODEL.CLIP.OFFLINE_RPN_NMS_THRESH` as needed.
</details>
## Extract Concept Features
Along with the region feature extraction, we also provide scripts for extracting concept features from our pre-trained RegionCLIP. Given a list of concepts, our scripts extract textual embeddings and save them as local files. The following is an example using pretrained RegionCLIP. We extend the scripts from region feature extraction (section above) with minor changes.
<details>
<summary>
Before running scripts, please prepare pretrained models and your custom concepts.
</summary>
- Check [`MODEL_ZOO.md`](docs/MODEL_ZOO.md) to
- download the pretrained RegionCLIP checkpoint `regionclip_pretrained-cc_rn50.pth` to the folder `./pretrained_ckpt/regionclip`.
- Put all concepts in the file `concepts.txt` with each line as a concept name. Place this file in a folder which can be specified in the script (check `INPUT_DIR` below).
</details>
<details>
<summary>
After preparation, run the following script to extract region features.
</summary>
The following script extracts features from ResNet50.
```
# RN50 concept embeddings
python3 ./tools/extract_concept_features.py \
--config-file ./configs/LVISv1-InstanceSegmentation/CLIP_fast_rcnn_R_50_C4_zsinf.yaml \
MODEL.WEIGHTS ./pretrained_ckpt/regionclip/regionclip_pretrained-cc_rn50.pth \
MODEL.CLIP.OFFLINE_RPN_CONFIG ./configs/LVISv1-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.yaml \
INPUT_DIR ./datasets/custom_concepts \
OUTPUT_DIR ./output/concept_feats \
MODEL.CLIP.GET_CONCEPT_EMB True \
```
And for ResNet50x4, use the following command:
```
# RN50x4 concept embeddings
python3 ./tools/extract_concept_features.py \
--config-file ./configs/LVISv1-InstanceSegmentation/CLIP_fast_rcnn_R_50_C4_zsinf.yaml \
MODEL.WEIGHTS ./pretrained_ckpt/regionclip/regionclip_pretrained-cc_rn50x4.pth \
MODEL.CLIP.TEXT_EMB_DIM 640 \
MODEL.RESNETS.DEPTH 200 \
MODEL.CLIP.OFFLINE_RPN_CONFIG ./configs/LVISv1-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.yaml \
INPUT_DIR ./datasets/custom_concepts \
OUTPUT_DIR ./output/concept_feats \
MODEL.CLIP.GET_CONCEPT_EMB True \
```
The language embeddings of all concepts will be saved into a `.pth` file in the folder `OUTPUT_DIR`. These language embeddings have not been normalized yet, for the consistency with concept embeddings provided in [`MODEL_ZOO.md`](docs/MODEL_ZOO.md).
The following is a list of key arguments for feature extraction. You can specify them in the script as needed.
- `INPUT_DIR` and `OUTPUT_DIR`: specify a folder of input concepts and an output folder where region features will be saved, respectively.
</details>
## Citation and Acknowledgement
### Citation
If you find this repo useful, please consider citing our paper:
```
@inproceedings{zhong2022regionclip,
title={Regionclip: Region-based language-image pretraining},
author={Zhong, Yiwu and Yang, Jianwei and Zhang, Pengchuan and Li, Chunyuan and Codella, Noel and Li, Liunian Harold and Zhou, Luowei and Dai, Xiyang and Yuan, Lu and Li, Yin and others},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={16793--16803},
year={2022}
}
```
### Acknowledgement
This repository was built on top of [Detectron2](https://github.com/facebookresearch/detectron2), [CLIP](https://github.com/openai/CLIP), [OVR-CNN](https://github.com/alirezazareian/ovr-cnn), and [maskrcnn-benchmark](https://github.com/facebookresearch/maskrcnn-benchmark). We thank the effort from our community.
## Contributing
This project welcomes contributions and suggestions. Most contributions require you to agree to a
Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us
the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide
a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions
provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the [Microsoft Open Source Code of Conduct](https://opensource.microsoft.com/codeofconduct/).
For more information see the [Code of Conduct FAQ](https://opensource.microsoft.com/codeofconduct/faq/) or
contact [[email protected]](mailto:[email protected]) with any additional questions or comments.
|
Winmodel/CartPole-v1
|
Winmodel
| 2023-07-11T06:39:24Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-11T05:40:07Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: CartPole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
NasimB/gpt2-dp-guten-rarity-all-5k-2p5k
|
NasimB
| 2023-07-11T06:03:05Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"dataset:generator",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-11T04:08:49Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- generator
model-index:
- name: gpt2-dp-guten-rarity-all-5k-2p5k
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-dp-guten-rarity-all-5k-2p5k
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 4.3172
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 6
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 6.6951 | 0.28 | 500 | 5.6610 |
| 5.3498 | 0.55 | 1000 | 5.2276 |
| 5.0115 | 0.83 | 1500 | 4.9818 |
| 4.7688 | 1.1 | 2000 | 4.8256 |
| 4.5712 | 1.38 | 2500 | 4.7126 |
| 4.4784 | 1.65 | 3000 | 4.6078 |
| 4.3906 | 1.93 | 3500 | 4.5226 |
| 4.1804 | 2.21 | 4000 | 4.4857 |
| 4.1213 | 2.48 | 4500 | 4.4278 |
| 4.0805 | 2.76 | 5000 | 4.3689 |
| 4.0172 | 3.03 | 5500 | 4.3318 |
| 3.7877 | 3.31 | 6000 | 4.3246 |
| 3.7896 | 3.58 | 6500 | 4.2902 |
| 3.7714 | 3.86 | 7000 | 4.2610 |
| 3.628 | 4.13 | 7500 | 4.2685 |
| 3.4948 | 4.41 | 8000 | 4.2600 |
| 3.4897 | 4.69 | 8500 | 4.2447 |
| 3.4837 | 4.96 | 9000 | 4.2332 |
| 3.327 | 5.24 | 9500 | 4.2460 |
| 3.2974 | 5.51 | 10000 | 4.2442 |
| 3.296 | 5.79 | 10500 | 4.2437 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.11.0+cu113
- Datasets 2.13.0
- Tokenizers 0.13.3
|
mrovejaxd/ABL_d
|
mrovejaxd
| 2023-07-11T05:58:29Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-11T05:04:55Z |
---
tags:
- generated_from_trainer
model-index:
- name: ABL_d
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ABL_d
This model is a fine-tuned version of [dccuchile/bert-base-spanish-wwm-cased](https://huggingface.co/dccuchile/bert-base-spanish-wwm-cased) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cpu
- Datasets 2.12.0
- Tokenizers 0.13.2
|
ancolin/distilbert-base-uncased-finetuned-emotion
|
ancolin
| 2023-07-11T05:45:13Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-10T07:05:55Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.92
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2281
- Accuracy: 0.92
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.8512 | 1.0 | 250 | 0.3233 | 0.9045 |
| 0.2569 | 2.0 | 500 | 0.2281 | 0.92 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1
- Datasets 2.12.0
- Tokenizers 0.13.3
|
saillab/Nepali_Alpaca_ChatGPT_7B
|
saillab
| 2023-07-11T05:37:08Z | 0 | 0 | null |
[
"region:us"
] | null | 2023-07-10T04:29:09Z |
# Nepali-Chat-GPT 7B 🇳🇵
This repo consist of the demo and the necessary guidelines for creating the open source Nepali Alpaca ChatGPT.
As per our knowledge this is the first open-source large language model created specifically for **Nepali Language**.
## Model
**🇳🇵Nepali Alpaca Chat-GPT-7B**: We have finetuned the timdettmers/guanaco-7b model with the Nepali-Alpaca-GPT4 dataset.
HuggingFace Link: https://huggingface.co/saillab/Nepali_Alpaca_ChatGPT_7B
**🇳🇵7B Model Generated Output**
```
### Instruction:आर्टिफिशियल इन्टेलिजेन्सको व्याख्या गर्नुहोस्।
### Output: आर्टिफिसियल इन्टेलिजेन्स, प्रायः एआई भनेर चिनिन्छ, कम्प्युटर प्रणालीहरूको विकास हो जसले सामान्यतया मानव बुद्धिको आवश्यकता पर्ने कार्यहरू गर्न सक्छ। यसले कम्प्युटरहरूलाई स्पष्ट रूपमा प्रोग्राम नगरी सिक्न र सिक्न सक्ने क्षमता प्रदान गर्दछ, जसले तिनीहरूलाई स्वचालित रूपमा समस्याहरू समाधान गर्न र निर्णय गर्न सक्षम बनाउँछ। यसले कम्प्युटर प्रणालीहरूलाई मानिसले जस्तै सोच्न र निर्णय गर्न सक्षम बनाउँछ। यसले स्वास्थ्य सेवा उद्योगमा क्रान्तिकारी परिवर्तन गर्ने क्षमता प्रदान गर्दछ
### Instruction: विश्वका दुर्लभ भाषाहरूको संरक्षणको महत्त्व तीन वाक्यमा व्याख्या गर्नुहोस्।
### Output: विश्वका दुर्लभ भाषाहरूको संरक्षण धेरै कारणहरूको लागि महत्त्वपूर्ण छ। पहिलो, यसले संस्कृतिको विविधतालाई बढावा दिन्छ र विश्वभरका मानिसहरूलाई विभिन्न भाषाहरू सिक्न अनुमति दिन्छ। दोस्रो, संरक्षित भाषाहरूको संरक्षणले विगतका भाषाहरूलाई जोगाउँछ जुन अझै पनि प्रायः प्रयोग हुन्छन्। तेस्रो, संरक्षित भाषाहरूको संरक्षणले विभिन्न संस्कृतिका सांस्कृतिक सामग्रीहरूको संरक्षण र संरक्षण गर्दछ, जसले संस्कृतिको विविधतालाई बढावा दिन्छ।
```
### How to contribute?
We highly encourage you to contribute to this open-source project. Please feel free to fill this Google Form: https://forms.gle/CRN1KJsjNpNsfSR66
|
gfx-labs/xlm-roberta-base-finetuned-panx-hindi
|
gfx-labs
| 2023-07-11T05:27:20Z | 136 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"dataset:xtreme",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-07-11T05:02:51Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- xtreme
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-hi
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
config: PAN-X.hi
split: validation
args: PAN-X.hi
metrics:
- name: F1
type: f1
value: 0.875
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-hi
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2334
- F1: 0.875
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.6369 | 1.0 | 188 | 0.2775 | 0.8157 |
| 0.2751 | 2.0 | 376 | 0.2537 | 0.8402 |
| 0.1737 | 3.0 | 564 | 0.2359 | 0.8606 |
| 0.1188 | 4.0 | 752 | 0.2334 | 0.875 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.13.3
|
mrovejaxd/ABL_c
|
mrovejaxd
| 2023-07-11T05:25:22Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-11T02:51:54Z |
---
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: ABL_c
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ABL_c
This model is a fine-tuned version of [dccuchile/bert-base-spanish-wwm-cased](https://huggingface.co/dccuchile/bert-base-spanish-wwm-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7496
- Accuracy: 0.7192
- F1: 0.7184
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
dashan1992/dsl3
|
dashan1992
| 2023-07-11T05:24:21Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-07-11T05:24:19Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.4.0.dev0
|
JennnDexter/dreambooth
|
JennnDexter
| 2023-07-11T05:17:33Z | 29 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-06-15T07:49:24Z |
---
license: creativeml-openrail-m
base_model: CompVis/stable-diffusion-v1-4
instance_prompt: a photo of sks dog
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- dreambooth
inference: true
---
# DreamBooth - JennnDexter/dreambooth
This is a dreambooth model derived from CompVis/stable-diffusion-v1-4. The weights were trained on a photo of sks dog using [DreamBooth](https://dreambooth.github.io/).
You can find some example images in the following.
DreamBooth for the text encoder was enabled: False.
|
voyzan/v_arcobot_A01
|
voyzan
| 2023-07-11T05:00:34Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"Acrobot-v1",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-11T04:17:45Z |
---
library_name: stable-baselines3
tags:
- Acrobot-v1
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Acrobot-v1
type: Acrobot-v1
metrics:
- type: mean_reward
value: -77.65 +/- 9.14
name: mean_reward
verified: false
---
# **PPO** Agent playing **Acrobot-v1**
This is a trained model of a **PPO** agent playing **Acrobot-v1**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
retroai818/ppo-LunarLander-v2
|
retroai818
| 2023-07-11T04:08:19Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-11T00:27:35Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 255.62 +/- 26.09
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Mocoto23/distilbert-base-uncased-finetuned-cola
|
Mocoto23
| 2023-07-11T04:03:38Z | 61 | 0 |
transformers
|
[
"transformers",
"tf",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-11T02:45:37Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: Mocoto23/distilbert-base-uncased-finetuned-cola
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Mocoto23/distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.1895
- Validation Loss: 0.5414
- Train Matthews Correlation: 0.5167
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': False, 'is_legacy_optimizer': False, 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 1602, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Matthews Correlation | Epoch |
|:----------:|:---------------:|:--------------------------:|:-----:|
| 0.5216 | 0.4673 | 0.4507 | 0 |
| 0.3159 | 0.4683 | 0.4925 | 1 |
| 0.1895 | 0.5414 | 0.5167 | 2 |
### Framework versions
- Transformers 4.30.2
- TensorFlow 2.12.0
- Datasets 2.13.1
- Tokenizers 0.13.3
|
LuisFelipe11/ppo-Huggy
|
LuisFelipe11
| 2023-07-11T03:58:42Z | 0 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2023-07-11T03:58:39Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: LuisFelipe11/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
SpringYung/falcon_with_10latex_v2
|
SpringYung
| 2023-07-11T03:42:42Z | 2 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-07-11T03:41:43Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.4.0.dev0
|
alsonlai/dqn-SpaceInvadersNoFrameskip-v4
|
alsonlai
| 2023-07-11T03:37:58Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-11T03:37:27Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 499.50 +/- 146.57
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga alsonlai -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga alsonlai -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga alsonlai
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
zwtharry/Taxiv3
|
zwtharry
| 2023-07-11T03:29:10Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-11T03:29:08Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Taxiv3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="zwtharry/Taxiv3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
jordyvl/vit-small_rvl_cdip_100_examples_per_class_kd_CEKD_t2.5_a0.5
|
jordyvl
| 2023-07-11T03:27:58Z | 163 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-07-11T02:15:08Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: vit-small_rvl_cdip_100_examples_per_class_kd_CEKD_t2.5_a0.5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-small_rvl_cdip_100_examples_per_class_kd_CEKD_t2.5_a0.5
This model is a fine-tuned version of [WinKawaks/vit-small-patch16-224](https://huggingface.co/WinKawaks/vit-small-patch16-224) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4583
- Accuracy: 0.655
- Brier Loss: 0.4857
- Nll: 2.9372
- F1 Micro: 0.655
- F1 Macro: 0.6591
- Ece: 0.1679
- Aurc: 0.1394
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Brier Loss | Nll | F1 Micro | F1 Macro | Ece | Aurc |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:----------:|:-------:|:--------:|:--------:|:------:|:------:|
| No log | 1.0 | 25 | 4.2264 | 0.1375 | 0.9289 | 15.9084 | 0.1375 | 0.1395 | 0.1536 | 0.8596 |
| No log | 2.0 | 50 | 3.2078 | 0.405 | 0.7396 | 8.9647 | 0.405 | 0.3723 | 0.2073 | 0.3570 |
| No log | 3.0 | 75 | 2.4477 | 0.4975 | 0.6180 | 5.3439 | 0.4975 | 0.4756 | 0.1714 | 0.2421 |
| No log | 4.0 | 100 | 2.2058 | 0.545 | 0.5825 | 4.3028 | 0.545 | 0.5448 | 0.1681 | 0.2147 |
| No log | 5.0 | 125 | 2.1459 | 0.5325 | 0.6143 | 4.3798 | 0.5325 | 0.5164 | 0.2012 | 0.2274 |
| No log | 6.0 | 150 | 2.0457 | 0.5825 | 0.5625 | 4.1921 | 0.5825 | 0.5823 | 0.1712 | 0.2008 |
| No log | 7.0 | 175 | 1.9438 | 0.575 | 0.5557 | 4.2405 | 0.575 | 0.5654 | 0.1805 | 0.1894 |
| No log | 8.0 | 200 | 1.9821 | 0.5675 | 0.5766 | 3.8326 | 0.5675 | 0.5665 | 0.1815 | 0.2050 |
| No log | 9.0 | 225 | 2.1566 | 0.5425 | 0.6068 | 4.2488 | 0.5425 | 0.5367 | 0.2053 | 0.2167 |
| No log | 10.0 | 250 | 1.9672 | 0.5925 | 0.5692 | 4.3417 | 0.5925 | 0.5968 | 0.2005 | 0.2114 |
| No log | 11.0 | 275 | 2.0417 | 0.5725 | 0.6080 | 3.6972 | 0.5725 | 0.5608 | 0.2005 | 0.2168 |
| No log | 12.0 | 300 | 1.9432 | 0.585 | 0.5704 | 3.6005 | 0.585 | 0.5840 | 0.1976 | 0.1939 |
| No log | 13.0 | 325 | 1.9031 | 0.585 | 0.5816 | 4.0984 | 0.585 | 0.5835 | 0.1996 | 0.1911 |
| No log | 14.0 | 350 | 1.8994 | 0.5925 | 0.5897 | 4.2703 | 0.5925 | 0.5926 | 0.2211 | 0.2041 |
| No log | 15.0 | 375 | 1.8136 | 0.6325 | 0.5297 | 4.5861 | 0.6325 | 0.6299 | 0.1622 | 0.1578 |
| No log | 16.0 | 400 | 1.6961 | 0.5925 | 0.5300 | 4.0317 | 0.5925 | 0.5839 | 0.1909 | 0.1630 |
| No log | 17.0 | 425 | 1.7687 | 0.61 | 0.5357 | 3.6514 | 0.61 | 0.6110 | 0.1715 | 0.1703 |
| No log | 18.0 | 450 | 1.8963 | 0.6 | 0.5785 | 4.7474 | 0.6 | 0.5842 | 0.2168 | 0.1893 |
| No log | 19.0 | 475 | 1.7545 | 0.6175 | 0.5506 | 4.4192 | 0.6175 | 0.6086 | 0.2006 | 0.1759 |
| 0.8611 | 20.0 | 500 | 1.7832 | 0.61 | 0.5546 | 4.0543 | 0.61 | 0.6099 | 0.2133 | 0.1662 |
| 0.8611 | 21.0 | 525 | 1.7788 | 0.5875 | 0.5718 | 3.8585 | 0.5875 | 0.5855 | 0.2084 | 0.1848 |
| 0.8611 | 22.0 | 550 | 1.6323 | 0.62 | 0.5184 | 3.6953 | 0.62 | 0.6146 | 0.1921 | 0.1588 |
| 0.8611 | 23.0 | 575 | 1.6384 | 0.6325 | 0.5431 | 3.5349 | 0.6325 | 0.6269 | 0.2042 | 0.1678 |
| 0.8611 | 24.0 | 600 | 1.7895 | 0.62 | 0.5588 | 4.2768 | 0.62 | 0.6169 | 0.1993 | 0.1885 |
| 0.8611 | 25.0 | 625 | 1.5712 | 0.6175 | 0.5111 | 3.1891 | 0.6175 | 0.6199 | 0.1777 | 0.1552 |
| 0.8611 | 26.0 | 650 | 1.6139 | 0.62 | 0.5284 | 3.0912 | 0.62 | 0.6238 | 0.1793 | 0.1599 |
| 0.8611 | 27.0 | 675 | 1.6449 | 0.6375 | 0.5190 | 4.0147 | 0.6375 | 0.6313 | 0.1794 | 0.1606 |
| 0.8611 | 28.0 | 700 | 1.6379 | 0.6325 | 0.5355 | 3.5225 | 0.6325 | 0.6300 | 0.1859 | 0.1693 |
| 0.8611 | 29.0 | 725 | 1.5486 | 0.6375 | 0.5202 | 3.1611 | 0.6375 | 0.6407 | 0.1908 | 0.1608 |
| 0.8611 | 30.0 | 750 | 1.5410 | 0.63 | 0.5074 | 3.2562 | 0.63 | 0.6340 | 0.1772 | 0.1424 |
| 0.8611 | 31.0 | 775 | 1.5033 | 0.6575 | 0.4973 | 3.3321 | 0.6575 | 0.6619 | 0.1802 | 0.1451 |
| 0.8611 | 32.0 | 800 | 1.6065 | 0.6375 | 0.5260 | 3.4264 | 0.6375 | 0.6451 | 0.2028 | 0.1670 |
| 0.8611 | 33.0 | 825 | 1.5188 | 0.6525 | 0.5028 | 3.5128 | 0.6525 | 0.6536 | 0.1813 | 0.1491 |
| 0.8611 | 34.0 | 850 | 1.5034 | 0.635 | 0.5005 | 3.4093 | 0.635 | 0.6345 | 0.1602 | 0.1506 |
| 0.8611 | 35.0 | 875 | 1.5711 | 0.66 | 0.5163 | 3.6591 | 0.66 | 0.6587 | 0.1884 | 0.1574 |
| 0.8611 | 36.0 | 900 | 1.5224 | 0.6475 | 0.5057 | 3.1773 | 0.6475 | 0.6491 | 0.1802 | 0.1526 |
| 0.8611 | 37.0 | 925 | 1.4781 | 0.6475 | 0.4938 | 3.3389 | 0.6475 | 0.6508 | 0.1753 | 0.1420 |
| 0.8611 | 38.0 | 950 | 1.4991 | 0.65 | 0.5005 | 3.4077 | 0.65 | 0.6541 | 0.1843 | 0.1482 |
| 0.8611 | 39.0 | 975 | 1.4613 | 0.6625 | 0.4848 | 3.2461 | 0.6625 | 0.6675 | 0.1647 | 0.1386 |
| 0.0907 | 40.0 | 1000 | 1.4824 | 0.64 | 0.4951 | 3.1830 | 0.64 | 0.6444 | 0.1779 | 0.1431 |
| 0.0907 | 41.0 | 1025 | 1.5224 | 0.6625 | 0.5004 | 3.4231 | 0.6625 | 0.6659 | 0.1769 | 0.1506 |
| 0.0907 | 42.0 | 1050 | 1.4882 | 0.6375 | 0.5013 | 3.0893 | 0.6375 | 0.6451 | 0.1844 | 0.1465 |
| 0.0907 | 43.0 | 1075 | 1.4852 | 0.665 | 0.4901 | 3.4025 | 0.665 | 0.6685 | 0.1869 | 0.1442 |
| 0.0907 | 44.0 | 1100 | 1.4744 | 0.65 | 0.4934 | 3.4829 | 0.65 | 0.6528 | 0.1836 | 0.1426 |
| 0.0907 | 45.0 | 1125 | 1.4735 | 0.66 | 0.4892 | 3.1763 | 0.66 | 0.6642 | 0.1666 | 0.1427 |
| 0.0907 | 46.0 | 1150 | 1.4690 | 0.65 | 0.4898 | 3.0960 | 0.65 | 0.6537 | 0.1642 | 0.1427 |
| 0.0907 | 47.0 | 1175 | 1.4773 | 0.6475 | 0.4909 | 3.2535 | 0.6475 | 0.6506 | 0.1749 | 0.1446 |
| 0.0907 | 48.0 | 1200 | 1.4632 | 0.6575 | 0.4884 | 3.1685 | 0.6575 | 0.6625 | 0.1750 | 0.1398 |
| 0.0907 | 49.0 | 1225 | 1.4712 | 0.66 | 0.4896 | 3.0915 | 0.66 | 0.6634 | 0.1697 | 0.1432 |
| 0.0907 | 50.0 | 1250 | 1.4630 | 0.655 | 0.4883 | 3.0953 | 0.655 | 0.6591 | 0.1650 | 0.1406 |
| 0.0907 | 51.0 | 1275 | 1.4607 | 0.66 | 0.4860 | 3.0153 | 0.66 | 0.6653 | 0.1665 | 0.1411 |
| 0.0907 | 52.0 | 1300 | 1.4646 | 0.6475 | 0.4889 | 3.0242 | 0.6475 | 0.6510 | 0.1713 | 0.1426 |
| 0.0907 | 53.0 | 1325 | 1.4717 | 0.6575 | 0.4904 | 3.0926 | 0.6575 | 0.6605 | 0.1789 | 0.1428 |
| 0.0907 | 54.0 | 1350 | 1.4554 | 0.645 | 0.4868 | 3.0882 | 0.645 | 0.6489 | 0.1664 | 0.1408 |
| 0.0907 | 55.0 | 1375 | 1.4581 | 0.6575 | 0.4855 | 3.0904 | 0.6575 | 0.6614 | 0.1602 | 0.1404 |
| 0.0907 | 56.0 | 1400 | 1.4588 | 0.655 | 0.4866 | 3.0910 | 0.655 | 0.6598 | 0.1722 | 0.1405 |
| 0.0907 | 57.0 | 1425 | 1.4582 | 0.6575 | 0.4859 | 3.0143 | 0.6575 | 0.6619 | 0.1540 | 0.1397 |
| 0.0907 | 58.0 | 1450 | 1.4613 | 0.6575 | 0.4865 | 3.0143 | 0.6575 | 0.6620 | 0.1659 | 0.1402 |
| 0.0907 | 59.0 | 1475 | 1.4593 | 0.655 | 0.4867 | 3.0140 | 0.655 | 0.6599 | 0.1583 | 0.1402 |
| 0.0478 | 60.0 | 1500 | 1.4593 | 0.655 | 0.4864 | 3.0148 | 0.655 | 0.6593 | 0.1657 | 0.1404 |
| 0.0478 | 61.0 | 1525 | 1.4588 | 0.655 | 0.4861 | 3.0165 | 0.655 | 0.6590 | 0.1757 | 0.1401 |
| 0.0478 | 62.0 | 1550 | 1.4598 | 0.6575 | 0.4864 | 3.0140 | 0.6575 | 0.6616 | 0.1528 | 0.1403 |
| 0.0478 | 63.0 | 1575 | 1.4595 | 0.6575 | 0.4865 | 3.0143 | 0.6575 | 0.6623 | 0.1538 | 0.1400 |
| 0.0478 | 64.0 | 1600 | 1.4591 | 0.655 | 0.4864 | 2.9404 | 0.655 | 0.6591 | 0.1669 | 0.1399 |
| 0.0478 | 65.0 | 1625 | 1.4568 | 0.655 | 0.4854 | 2.9393 | 0.655 | 0.6596 | 0.1644 | 0.1393 |
| 0.0478 | 66.0 | 1650 | 1.4569 | 0.655 | 0.4855 | 3.0146 | 0.655 | 0.6599 | 0.1619 | 0.1401 |
| 0.0478 | 67.0 | 1675 | 1.4592 | 0.655 | 0.4865 | 2.9380 | 0.655 | 0.6596 | 0.1540 | 0.1399 |
| 0.0478 | 68.0 | 1700 | 1.4580 | 0.66 | 0.4858 | 2.9406 | 0.66 | 0.6641 | 0.1850 | 0.1396 |
| 0.0478 | 69.0 | 1725 | 1.4591 | 0.655 | 0.4865 | 2.9381 | 0.655 | 0.6593 | 0.1651 | 0.1399 |
| 0.0478 | 70.0 | 1750 | 1.4586 | 0.655 | 0.4859 | 2.9388 | 0.655 | 0.6596 | 0.1773 | 0.1397 |
| 0.0478 | 71.0 | 1775 | 1.4585 | 0.6525 | 0.4862 | 2.9366 | 0.6525 | 0.6566 | 0.1644 | 0.1400 |
| 0.0478 | 72.0 | 1800 | 1.4582 | 0.66 | 0.4858 | 2.9385 | 0.66 | 0.6644 | 0.1809 | 0.1396 |
| 0.0478 | 73.0 | 1825 | 1.4577 | 0.65 | 0.4857 | 2.9374 | 0.65 | 0.6543 | 0.1715 | 0.1403 |
| 0.0478 | 74.0 | 1850 | 1.4578 | 0.6525 | 0.4857 | 2.9381 | 0.6525 | 0.6565 | 0.1748 | 0.1401 |
| 0.0478 | 75.0 | 1875 | 1.4583 | 0.65 | 0.4860 | 2.9371 | 0.65 | 0.6544 | 0.1661 | 0.1402 |
| 0.0478 | 76.0 | 1900 | 1.4582 | 0.65 | 0.4859 | 2.9369 | 0.65 | 0.6544 | 0.1760 | 0.1402 |
| 0.0478 | 77.0 | 1925 | 1.4585 | 0.65 | 0.4859 | 2.9367 | 0.65 | 0.6546 | 0.1609 | 0.1403 |
| 0.0478 | 78.0 | 1950 | 1.4580 | 0.65 | 0.4858 | 2.9372 | 0.65 | 0.6546 | 0.1626 | 0.1401 |
| 0.0478 | 79.0 | 1975 | 1.4578 | 0.6525 | 0.4857 | 2.9369 | 0.6525 | 0.6564 | 0.1706 | 0.1400 |
| 0.0457 | 80.0 | 2000 | 1.4584 | 0.6525 | 0.4859 | 2.9370 | 0.6525 | 0.6564 | 0.1712 | 0.1402 |
| 0.0457 | 81.0 | 2025 | 1.4587 | 0.6525 | 0.4860 | 2.9370 | 0.6525 | 0.6568 | 0.1631 | 0.1402 |
| 0.0457 | 82.0 | 2050 | 1.4584 | 0.6525 | 0.4859 | 2.9369 | 0.6525 | 0.6568 | 0.1631 | 0.1401 |
| 0.0457 | 83.0 | 2075 | 1.4581 | 0.65 | 0.4858 | 2.9369 | 0.65 | 0.6543 | 0.1703 | 0.1401 |
| 0.0457 | 84.0 | 2100 | 1.4581 | 0.6525 | 0.4858 | 2.9370 | 0.6525 | 0.6564 | 0.1588 | 0.1401 |
| 0.0457 | 85.0 | 2125 | 1.4582 | 0.6525 | 0.4858 | 2.9370 | 0.6525 | 0.6568 | 0.1723 | 0.1400 |
| 0.0457 | 86.0 | 2150 | 1.4582 | 0.6525 | 0.4858 | 2.9371 | 0.6525 | 0.6564 | 0.1724 | 0.1400 |
| 0.0457 | 87.0 | 2175 | 1.4582 | 0.6525 | 0.4858 | 2.9369 | 0.6525 | 0.6567 | 0.1720 | 0.1400 |
| 0.0457 | 88.0 | 2200 | 1.4582 | 0.6525 | 0.4858 | 2.9372 | 0.6525 | 0.6567 | 0.1606 | 0.1401 |
| 0.0457 | 89.0 | 2225 | 1.4583 | 0.6525 | 0.4858 | 2.9372 | 0.6525 | 0.6567 | 0.1665 | 0.1401 |
| 0.0457 | 90.0 | 2250 | 1.4583 | 0.6525 | 0.4857 | 2.9370 | 0.6525 | 0.6564 | 0.1688 | 0.1400 |
| 0.0457 | 91.0 | 2275 | 1.4583 | 0.6525 | 0.4858 | 2.9371 | 0.6525 | 0.6567 | 0.1695 | 0.1400 |
| 0.0457 | 92.0 | 2300 | 1.4583 | 0.655 | 0.4858 | 2.9372 | 0.655 | 0.6591 | 0.1660 | 0.1394 |
| 0.0457 | 93.0 | 2325 | 1.4583 | 0.6525 | 0.4857 | 2.9371 | 0.6525 | 0.6565 | 0.1645 | 0.1400 |
| 0.0457 | 94.0 | 2350 | 1.4583 | 0.6525 | 0.4858 | 2.9371 | 0.6525 | 0.6567 | 0.1665 | 0.1399 |
| 0.0457 | 95.0 | 2375 | 1.4583 | 0.6525 | 0.4858 | 2.9372 | 0.6525 | 0.6567 | 0.1704 | 0.1399 |
| 0.0457 | 96.0 | 2400 | 1.4583 | 0.655 | 0.4858 | 2.9372 | 0.655 | 0.6588 | 0.1660 | 0.1395 |
| 0.0457 | 97.0 | 2425 | 1.4582 | 0.6525 | 0.4857 | 2.9372 | 0.6525 | 0.6567 | 0.1704 | 0.1399 |
| 0.0457 | 98.0 | 2450 | 1.4582 | 0.655 | 0.4857 | 2.9372 | 0.655 | 0.6591 | 0.1679 | 0.1394 |
| 0.0457 | 99.0 | 2475 | 1.4583 | 0.6525 | 0.4857 | 2.9372 | 0.6525 | 0.6567 | 0.1704 | 0.1399 |
| 0.0456 | 100.0 | 2500 | 1.4583 | 0.655 | 0.4857 | 2.9372 | 0.655 | 0.6591 | 0.1679 | 0.1394 |
### Framework versions
- Transformers 4.28.0.dev0
- Pytorch 1.12.1+cu113
- Datasets 2.12.0
- Tokenizers 0.12.1
|
sharpbai/Baichuan-13B-Chat
|
sharpbai
| 2023-07-11T03:23:03Z | 17 | 0 |
transformers
|
[
"transformers",
"pytorch",
"baichuan",
"text-generation",
"custom_code",
"zh",
"en",
"arxiv:2104.09864",
"arxiv:2108.12409",
"arxiv:2009.03300",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] |
text-generation
| 2023-07-11T02:54:41Z |
---
language:
- zh
- en
pipeline_tag: text-generation
inference: false
---
# Baichuan-13B-Chat
*The weight file is split into chunks with a size of 650MB for convenient and fast parallel downloads*
A 650MB split weight version of [baichuan-inc/Baichuan-13B-Chat](https://huggingface.co/baichuan-inc/Baichuan-13B-Chat)
The original model card is down below
-----------------------------------------
# Baichuan-13B-Chat
<!-- Provide a quick summary of what the model is/does. -->
## 介绍
Baichuan-13B-Chat为Baichuan-13B系列模型中对齐后的版本,预训练模型可见[Baichuan-13B-Base](https://huggingface.co/baichuan-inc/Baichuan-13B-Base)。
[Baichuan-13B](https://github.com/baichuan-inc/Baichuan-13B) 是由百川智能继 [Baichuan-7B](https://github.com/baichuan-inc/baichuan-7B) 之后开发的包含 130 亿参数的开源可商用的大规模语言模型,在权威的中文和英文 benchmark 上均取得同尺寸最好的效果。本次发布包含有预训练 ([Baichuan-13B-Base](https://huggingface.co/baichuan-inc/Baichuan-13B-Base)) 和对齐 ([Baichuan-13B-Chat](https://huggingface.co/baichuan-inc/Baichuan-13B-Chat)) 两个版本。Baichuan-13B 有如下几个特点:
1. **更大尺寸、更多数据**:Baichuan-13B 在 [Baichuan-7B](https://github.com/baichuan-inc/baichuan-7B) 的基础上进一步扩大参数量到 130 亿,并且在高质量的语料上训练了 1.4 万亿 tokens,超过 LLaMA-13B 40%,是当前开源 13B 尺寸下训练数据量最多的模型。支持中英双语,使用 ALiBi 位置编码,上下文窗口长度为 4096。
2. **同时开源预训练和对齐模型**:预训练模型是适用开发者的“基座”,而广大普通用户对有对话功能的对齐模型具有更强的需求。因此本次开源我们同时发布了对齐模型(Baichuan-13B-Chat),具有很强的对话能力,开箱即用,几行代码即可简单的部署。
3. **更高效的推理**:为了支持更广大用户的使用,我们本次同时开源了 int8 和 int4 的量化版本,相对非量化版本在几乎没有效果损失的情况下大大降低了部署的机器资源门槛,可以部署在如 Nvidia 3090 这样的消费级显卡上。
4. **开源免费可商用**:Baichuan-13B 不仅对学术研究完全开放,开发者也仅需邮件申请并获得官方商用许可后,即可以免费商用。
Baichuan-13B-Chat is the aligned version in the Baichuan-13B series of models, and the pre-trained model can be found at [Baichuan-13B-Base](https://huggingface.co/baichuan-inc/Baichuan-13B-Base).
[Baichuan-13B](https://github.com/baichuan-inc/Baichuan-13B) is an open-source, commercially usable large-scale language model developed by Baichuan Intelligence, following [Baichuan-7B](https://github.com/baichuan-inc/baichuan-7B). With 13 billion parameters, it achieves the best performance in standard Chinese and English benchmarks among models of its size. This release includes two versions: pre-training (Baichuan-13B-Base) and alignment (Baichuan-13B-Chat). Baichuan-13B has the following features:
1. **Larger size, more data**: Baichuan-13B further expands the parameter volume to 13 billion based on [Baichuan-7B](https://github.com/baichuan-inc/baichuan-7B), and has trained 1.4 trillion tokens on high-quality corpora, exceeding LLaMA-13B by 40%. It is currently the model with the most training data in the open-source 13B size. It supports both Chinese and English, uses ALiBi position encoding, and has a context window length of 4096.
2. **Open-source pre-training and alignment models simultaneously**: The pre-training model is a "base" suitable for developers, while the general public has a stronger demand for alignment models with dialogue capabilities. Therefore, in this open-source release, we also released the alignment model (Baichuan-13B-Chat), which has strong dialogue capabilities and is ready to use. It can be easily deployed with just a few lines of code.
3. **More efficient inference**: To support a wider range of users, we have open-sourced the INT8 and INT4 quantized versions. The model can be conveniently deployed on consumer GPUs like the Nvidia 3090 with almost no performance loss.
4. **Open-source, free, and commercially usable**: Baichuan-13B is not only fully open to academic research, but developers can also use it for free commercially after applying for and receiving official commercial permission via email.
## 使用方式
如下是一个使用Baichuan-13B-Chat进行对话的示例,正确输出为"乔戈里峰。世界第二高峰———乔戈里峰西方登山者称其为k2峰,海拔高度是8611米,位于喀喇昆仑山脉的中巴边境上"
```python
import torch
from transformers import AutoModel, AutoTokenizer
from transformers.generation.utils import GenerationConfig
tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan-13B-Chat", use_fast=False, trust_remote_code=True)
model = AutoModel.from_pretrained("baichuan-inc/Baichuan-13B-Chat", device_map="auto", torch_dtype=torch.float16, trust_remote_code=True)
model.generation_config = GenerationConfig.from_pretrained("baichuan-inc/Baichuan-13B-Chat")
messages = []
messages.append({"role": "user", "content": "世界上第二高的山峰是哪座"})
response = model.chat(tokenizer, messages)
print(response)
```
Here is an example of a conversation using Baichuan-13B-Chat, the correct output is "K2. The world's second highest peak - K2, also known as Mount Godwin-Austen or Chhogori, with an altitude of 8611 meters, is located on the China-Pakistan border in the Karakoram Range."
```python
import torch
from transformers import AutoModel, AutoTokenizer
from transformers.generation.utils import GenerationConfig
tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan-13B-Chat", use_fast=False, trust_remote_code=True)
model = AutoModel.from_pretrained("baichuan-inc/Baichuan-13B-Chat", device_map="auto", torch_dtype=torch.float16, trust_remote_code=True)
model.generation_config = GenerationConfig.from_pretrained("baichuan-inc/Baichuan-13B-Chat")
messages = []
messages.append({"role": "user", "content": "Which moutain is the second highest one in the world?"})
response = model.chat(tokenizer, messages)
print(response)
```
## 模型详情
### 模型描述
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** 百川智能(Baichuan Intelligent Technology)
- **Email**: [email protected]
- **Language(s) (NLP):** Chinese/English
- **License:** 【Community License for Baichuan-13B Model】([ZH](Baichuan-13B%20%E6%A8%A1%E5%9E%8B%E5%95%86%E7%94%A8%E8%AE%B8%E5%8F%AF%E5%8D%8F%E8%AE%AE.pdf)|
[EN](Community%20License%20for%20Baichuan-13B%20Model.pdf))
**商业用途(For commercial use):** 请通过上述Email联系申请书面授权。(Contact us via Email above to apply for written authorization.)
### 模型结构
<!-- Provide the basic links for the model. -->
整体模型基于Baichuan-7B,为了获得更好的推理性能,Baichuan-13B 使用了 ALiBi 线性偏置技术,相对于 Rotary Embedding 计算量更小,对推理性能有显著提升;与标准的 LLaMA-13B 相比,生成 2000 个 tokens 的平均推理速度 (tokens/s),实测提升 31.6%:
| Model | tokens/s |
|-------------|----------|
| LLaMA-13B | 19.4 |
| Baichuan-13B| 25.4 |
具体参数和见下表
| 模型名称 | 隐含层维度 | 层数 | 头数 |词表大小 | 总参数量 | 训练数据(tokens) | 位置编码 | 最大长度 |
|-------------------------|-------|------------|------------|-----------------|--------|--------|----------------|---------|
| Baichuan-7B | 4,096 | 32 | 32 | 64,000 | 7,000,559,616 | 1.2万亿 | [RoPE](https://arxiv.org/abs/2104.09864) | 4,096 |
| Baichuan-13B | 5,120 | 40 | 40 | 64,000 | 13,264,901,120 | 1.4万亿 | [ALiBi](https://arxiv.org/abs/2108.12409) | 4,096
The overall model is based on Baichuan-7B. In order to achieve better inference performance, Baichuan-13B uses ALiBi linear bias technology, which has a smaller computational load compared to Rotary Embedding, and significantly improves inference performance. Compared with the standard LLaMA-13B, the average inference speed (tokens/s) for generating 2000 tokens has been tested to increase by 31.6%:
| Model | tokens/s |
|-------------|----------|
| LLaMA-13B | 19.4 |
| Baichuan-13B| 25.4 |
The specific parameters are as follows:
| Model Name | Hidden Size | Num Layers | Num Attention Heads |Vocab Size | Total Params | Training Dats(tokens) | Position Embedding | Max Length |
|-------------------------|-------|------------|------------|-----------------|--------|--------|----------------|---------|
| Baichuan-7B | 4,096 | 32 | 32 | 64,000 | 7,000,559,616 | 1.2万亿 | [RoPE](https://arxiv.org/abs/2104.09864) | 4,096 |
| Baichuan-13B | 5,120 | 40 | 40 | 64,000 | 13,264,901,120 | 1.4万亿 | [ALiBi](https://arxiv.org/abs/2108.12409) | 4,096
## 使用须知
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### 免责声明
我们在此声明,我们的开发团队并未基于 Baichuan-13B 模型开发任何应用,无论是在 iOS、Android、网页或任何其他平台。我们强烈呼吁所有使用者,不要利用 Baichuan-13B 模型进行任何危害国家社会安全或违法的活动。另外,我们也要求使用者不要将 Baichuan-13B 模型用于未经适当安全审查和备案的互联网服务。我们希望所有的使用者都能遵守这个原则,确保科技的发展能在规范和合法的环境下进行。
我们已经尽我们所能,来确保模型训练过程中使用的数据的合规性。然而,尽管我们已经做出了巨大的努力,但由于模型和数据的复杂性,仍有可能存在一些无法预见的问题。因此,如果由于使用 Baichuan-13B 开源模型而导致的任何问题,包括但不限于数据安全问题、公共舆论风险,或模型被误导、滥用、传播或不当利用所带来的任何风险和问题,我们将不承担任何责任。
We hereby declare that our development team has not developed any applications based on the Baichuan-13B model, whether on iOS, Android, the web, or any other platform. We strongly urge all users not to use the Baichuan-13B model for any activities that harm national social security or are illegal. In addition, we also ask users not to use the Baichuan-13B model for internet services that have not undergone appropriate security review and filing. We hope that all users will adhere to this principle to ensure that technological development takes place in a regulated and legal environment.
We have done our utmost to ensure the compliance of the data used in the model training process. However, despite our great efforts, due to the complexity of the model and data, there may still be some unforeseen issues. Therefore, we will not take any responsibility for any issues arising from the use of the Baichuan-13B open-source model, including but not limited to data security issues, public opinion risks, or any risks and problems arising from the model being misled, misused, disseminated, or improperly exploited.
## 训练详情
训练具体设置参见[Baichuan-13B](https://github.com/baichuan-inc/Baichuan-13B)。
For specific training settings, please refer to [Baichuan-13B](https://github.com/baichuan-inc/Baichuan-13B).
## 测评结果
## [C-Eval](https://cevalbenchmark.com/index.html#home)
| Model 5-shot | STEM | Social Sciences | Humanities | Others | Average |
|-------------------------|:-----:|:---------------:|:----------:|:------:|:-------:|
| Baichuan-7B | 38.2 | 52.0 | 46.2 | 39.3 | 42.8 |
| Chinese-Alpaca-Plus-13B | 35.2 | 45.6 | 40.0 | 38.2 | 38.8 |
| Chinese-LLaMA-Plus-13B | 30.3 | 38.0 | 32.9 | 29.1 | 32.1 |
| Ziya-LLaMA-13B-Pretrain | 27.6 | 34.4 | 32.0 | 28.6 | 30.0 |
| LLaMA-13B | 27.0 | 33.6 | 27.7 | 27.6 | 28.5 |
| moss-moon-003-base (16B)| 27.0 | 29.1 | 27.2 | 26.9 | 27.4 |
| vicuna-13B | 22.8 | 24.8 | 22.3 | 18.5 | 22.2 |
| **Baichuan-13B-Base** | **45.9** | **63.5** | **57.2** | **49.3** | **52.4** |
| **Baichuan-13B-Chat** | **43.7** | **64.6** | **56.2** | **49.2** | **51.5** |
## [MMLU](https://arxiv.org/abs/2009.03300)
| Model 5-shot | STEM | Social Sciences | Humanities | Others | Average |
|-------------------------|:-----:|:---------------:|:----------:|:------:|:-------:|
| LLaMA-13B | 36.1 | 53.0 | 44.0 | 52.8 | 46.3 |
| Chinese-Alpaca-Plus-13B | 36.9 | 48.9 | 40.5 | 50.5 | 43.9 |
| Ziya-LLaMA-13B-Pretrain | 35.6 | 47.6 | 40.1 | 49.4 | 42.9 |
| Baichuan-7B | 35.6 | 48.9 | 38.4 | 48.1 | 42.3 |
| Chinese-LLaMA-Plus-13B | 33.1 | 42.8 | 37.0 | 44.6 | 39.2 |
| vicuna-13B | 24.2 | 24.1 | 24.6 | 26.8 | 24.9 |
| moss-moon-003-base (16B)| 22.4 | 22.8 | 24.2 | 24.4 | 23.6 |
| **Baichuan-13B-Base** | **41.6** | **60.9** | **47.4** | **58.5** | **51.6** |
| **Baichuan-13B-Chat** | **40.9** | **60.9** | **48.8** | **59.0** | **52.1** |
> 说明:我们采用了 MMLU 官方的[评测方案](https://github.com/hendrycks/test)。
## [CMMLU](https://github.com/haonan-li/CMMLU)
| Model 5-shot | STEM | Humanities | Social Sciences | Others | China Specific | Average |
|-------------------------|:-----:|:----------:|:---------------:|:------:|:--------------:|:-------:|
| Baichuan-7B | 34.4 | 47.5 | 47.6 | 46.6 | 44.3 | 44.0 |
| Chinese-Alpaca-Plus-13B | 29.8 | 33.4 | 33.2 | 37.9 | 32.1 | 33.4 |
| Chinese-LLaMA-Plus-13B | 28.1 | 33.1 | 35.4 | 35.1 | 33.5 | 33.0 |
| Ziya-LLaMA-13B-Pretrain | 29.0 | 30.7 | 33.8 | 34.4 | 31.9 | 32.1 |
| LLaMA-13B | 29.2 | 30.8 | 31.6 | 33.0 | 30.5 | 31.2 |
| moss-moon-003-base (16B)| 27.2 | 30.4 | 28.8 | 32.6 | 28.7 | 29.6 |
| vicuna-13B | 24.0 | 25.4 | 25.3 | 25.0 | 25.0 | 24.9 |
| **Baichuan-13B-Base** | **41.7** | **61.1** | **59.8** | **59.0** | **56.4** | **55.3** |
| **Baichuan-13B-Chat** | **42.8** | **62.6** | **59.7** | **59.0** | **56.1** | **55.8** |
> 说明:CMMLU 是一个综合性的中文评估基准,专门用于评估语言模型在中文语境下的知识和推理能力。我们采用了其官方的[评测方案](https://github.com/haonan-li/CMMLU)。
## 微信群组

|
SpringYung/dolly_with_10latex_v2
|
SpringYung
| 2023-07-11T03:17:46Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-07-11T03:17:08Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.4.0.dev0
|
shikras/shikra-7b-delta-v1-0708
|
shikras
| 2023-07-11T03:07:55Z | 58 | 3 |
transformers
|
[
"transformers",
"pytorch",
"shikra",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-10T15:57:55Z |
Shikra-7B-v1-0708: A frequently updated ckpt for Shikra-7B-v1
---
license: cc-by-nc-4.0
datasets: added A-OKVQA dataset for Multiple Choice Question format training
|
tensorops/whisper-th-small-combined
|
tensorops
| 2023-07-11T03:05:09Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-07-10T10:31:06Z |
---
tags:
- generated_from_trainer
model-index:
- name: whisper-th-small-combined
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-th-small-combined
This model was trained from scratch on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 250
- training_steps: 1000
### Framework versions
- Transformers 4.31.0.dev0
- Pytorch 2.1.0a0+4136153
- Datasets 2.13.1
- Tokenizers 0.13.3
|
vimonteglione/ppo-Huggy
|
vimonteglione
| 2023-07-11T02:42:10Z | 0 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2023-07-11T02:42:00Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: vimonteglione/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
alex2awesome/source-affiliation-model
|
alex2awesome
| 2023-07-11T02:37:57Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"generated_from_trainer",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2023-07-10T23:11:23Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: source-affiliation-model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# source-affiliation-model
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.3321
- F1: 0.5348
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 5
- eval_batch_size: 5
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 0.12 | 100 | 1.4535 | 0.2435 |
| No log | 0.25 | 200 | 1.3128 | 0.3899 |
| No log | 0.37 | 300 | 1.2888 | 0.4413 |
| No log | 0.49 | 400 | 1.1560 | 0.4614 |
| 1.4848 | 0.62 | 500 | 1.0988 | 0.4477 |
| 1.4848 | 0.74 | 600 | 1.1211 | 0.4583 |
| 1.4848 | 0.86 | 700 | 1.1152 | 0.4693 |
| 1.4848 | 0.99 | 800 | 1.0176 | 0.5018 |
| 1.4848 | 1.11 | 900 | 1.0942 | 0.4774 |
| 1.1019 | 1.23 | 1000 | 1.1785 | 0.5119 |
| 1.1019 | 1.35 | 1100 | 1.0751 | 0.4797 |
| 1.1019 | 1.48 | 1200 | 1.0759 | 0.5206 |
| 1.1019 | 1.6 | 1300 | 1.0756 | 0.5231 |
| 1.1019 | 1.72 | 1400 | 1.1329 | 0.4547 |
| 0.9431 | 1.85 | 1500 | 1.0617 | 0.4852 |
| 0.9431 | 1.97 | 1600 | 1.1046 | 0.5254 |
| 0.9431 | 2.09 | 1700 | 1.2489 | 0.5069 |
| 0.9431 | 2.22 | 1800 | 1.2113 | 0.5363 |
| 0.9431 | 2.34 | 1900 | 1.1782 | 0.5546 |
| 0.7589 | 2.46 | 2000 | 1.0453 | 0.5862 |
| 0.7589 | 2.59 | 2100 | 1.0810 | 0.5223 |
| 0.7589 | 2.71 | 2200 | 1.1470 | 0.5872 |
| 0.7589 | 2.83 | 2300 | 1.1522 | 0.5553 |
| 0.7589 | 2.96 | 2400 | 1.0712 | 0.6273 |
| 0.6875 | 3.08 | 2500 | 1.3458 | 0.5768 |
| 0.6875 | 3.2 | 2600 | 1.7052 | 0.5491 |
| 0.6875 | 3.33 | 2700 | 1.5080 | 0.6582 |
| 0.6875 | 3.45 | 2800 | 1.5851 | 0.5965 |
| 0.6875 | 3.57 | 2900 | 1.4771 | 0.5691 |
| 0.5391 | 3.69 | 3000 | 1.6717 | 0.5350 |
| 0.5391 | 3.82 | 3100 | 1.5607 | 0.5448 |
| 0.5391 | 3.94 | 3200 | 1.5464 | 0.6062 |
| 0.5391 | 4.06 | 3300 | 1.7645 | 0.5755 |
| 0.5391 | 4.19 | 3400 | 1.6715 | 0.5504 |
| 0.4928 | 4.31 | 3500 | 1.7604 | 0.5626 |
| 0.4928 | 4.43 | 3600 | 1.8984 | 0.5142 |
| 0.4928 | 4.56 | 3700 | 1.8012 | 0.5763 |
| 0.4928 | 4.68 | 3800 | 1.7107 | 0.5671 |
| 0.4928 | 4.8 | 3900 | 1.7697 | 0.5598 |
| 0.4233 | 4.93 | 4000 | 1.6296 | 0.6084 |
| 0.4233 | 5.05 | 4100 | 2.0418 | 0.5343 |
| 0.4233 | 5.17 | 4200 | 1.8203 | 0.5526 |
| 0.4233 | 5.3 | 4300 | 1.9760 | 0.5292 |
| 0.4233 | 5.42 | 4400 | 2.0136 | 0.5153 |
| 0.2518 | 5.54 | 4500 | 2.0137 | 0.5121 |
| 0.2518 | 5.67 | 4600 | 2.0053 | 0.5257 |
| 0.2518 | 5.79 | 4700 | 1.9539 | 0.5423 |
| 0.2518 | 5.91 | 4800 | 2.0159 | 0.5686 |
| 0.2518 | 6.03 | 4900 | 2.0411 | 0.5817 |
| 0.2234 | 6.16 | 5000 | 2.0025 | 0.5780 |
| 0.2234 | 6.28 | 5100 | 2.1189 | 0.5413 |
| 0.2234 | 6.4 | 5200 | 2.1936 | 0.5628 |
| 0.2234 | 6.53 | 5300 | 2.1825 | 0.5210 |
| 0.2234 | 6.65 | 5400 | 2.0767 | 0.5471 |
| 0.1829 | 6.77 | 5500 | 1.9747 | 0.5587 |
| 0.1829 | 6.9 | 5600 | 2.1182 | 0.5847 |
| 0.1829 | 7.02 | 5700 | 2.1597 | 0.5437 |
| 0.1829 | 7.14 | 5800 | 2.0307 | 0.5629 |
| 0.1829 | 7.27 | 5900 | 2.0912 | 0.5450 |
| 0.1226 | 7.39 | 6000 | 2.2383 | 0.5379 |
| 0.1226 | 7.51 | 6100 | 2.2311 | 0.5834 |
| 0.1226 | 7.64 | 6200 | 2.2456 | 0.5438 |
| 0.1226 | 7.76 | 6300 | 2.2423 | 0.5860 |
| 0.1226 | 7.88 | 6400 | 2.2922 | 0.5245 |
| 0.0883 | 8.0 | 6500 | 2.3304 | 0.5650 |
| 0.0883 | 8.13 | 6600 | 2.3929 | 0.5288 |
| 0.0883 | 8.25 | 6700 | 2.3928 | 0.5344 |
| 0.0883 | 8.37 | 6800 | 2.3854 | 0.5266 |
| 0.0883 | 8.5 | 6900 | 2.4275 | 0.5339 |
| 0.044 | 8.62 | 7000 | 2.3929 | 0.5380 |
| 0.044 | 8.74 | 7100 | 2.3587 | 0.5339 |
| 0.044 | 8.87 | 7200 | 2.3372 | 0.5423 |
| 0.044 | 8.99 | 7300 | 2.3488 | 0.5424 |
| 0.044 | 9.11 | 7400 | 2.3543 | 0.5818 |
| 0.0558 | 9.24 | 7500 | 2.3397 | 0.5554 |
| 0.0558 | 9.36 | 7600 | 2.3255 | 0.5394 |
| 0.0558 | 9.48 | 7700 | 2.3184 | 0.5557 |
| 0.0558 | 9.61 | 7800 | 2.3293 | 0.5669 |
| 0.0558 | 9.73 | 7900 | 2.3358 | 0.5666 |
| 0.0323 | 9.85 | 8000 | 2.3307 | 0.5344 |
| 0.0323 | 9.98 | 8100 | 2.3321 | 0.5348 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu117
- Datasets 2.13.1
- Tokenizers 0.13.3
|
RavenFangsk/chronoborous-33B-GPTQ
|
RavenFangsk
| 2023-07-11T02:28:20Z | 5 | 0 |
transformers
|
[
"transformers",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-10T03:26:46Z |
Auto-GPTQ'd version of https://huggingface.co/Henk717/chronoboros-33B
|
alex2awesome/source-type-model
|
alex2awesome
| 2023-07-11T02:27:55Z | 168 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"generated_from_trainer",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2023-07-10T21:32:31Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: source-type-model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# source-type-model
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6271
- F1: 0.6772
Classifies the following tags:
```
'Cannot Determine'
'Report/Document'
'Named Individual'
'Unnamed Individual'
'Database'
'Unnamed Group'
'Named Group'
'Vote/Poll'
```
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 5
- eval_batch_size: 5
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 0.12 | 100 | 0.7192 | 0.3792 |
| No log | 0.25 | 200 | 0.7716 | 0.4005 |
| No log | 0.37 | 300 | 0.7565 | 0.5297 |
| No log | 0.49 | 400 | 0.5788 | 0.5806 |
| 0.8223 | 0.62 | 500 | 0.5402 | 0.5933 |
| 0.8223 | 0.74 | 600 | 0.5032 | 0.6666 |
| 0.8223 | 0.86 | 700 | 0.4658 | 0.6754 |
| 0.8223 | 0.99 | 800 | 0.5359 | 0.6441 |
| 0.8223 | 1.11 | 900 | 0.5295 | 0.6442 |
| 0.6009 | 1.23 | 1000 | 0.6077 | 0.6597 |
| 0.6009 | 1.35 | 1100 | 0.6169 | 0.6360 |
| 0.6009 | 1.48 | 1200 | 0.6014 | 0.6277 |
| 0.6009 | 1.6 | 1300 | 0.6382 | 0.6327 |
| 0.6009 | 1.72 | 1400 | 0.5226 | 0.6787 |
| 0.5644 | 1.85 | 1500 | 0.4922 | 0.6485 |
| 0.5644 | 1.97 | 1600 | 0.6181 | 0.6517 |
| 0.5644 | 2.09 | 1700 | 0.6106 | 0.6781 |
| 0.5644 | 2.22 | 1800 | 0.6652 | 0.6760 |
| 0.5644 | 2.34 | 1900 | 0.6252 | 0.6739 |
| 0.3299 | 2.46 | 2000 | 0.6620 | 0.6606 |
| 0.3299 | 2.59 | 2100 | 0.6317 | 0.6772 |
| 0.3299 | 2.71 | 2200 | 0.6170 | 0.6726 |
| 0.3299 | 2.83 | 2300 | 0.6400 | 0.6773 |
| 0.3299 | 2.96 | 2400 | 0.6271 | 0.6772 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu117
- Datasets 2.13.1
- Tokenizers 0.13.3
|
pokorpohon/Fotoangel
|
pokorpohon
| 2023-07-11T02:26:03Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-11T02:18:29Z |
---
license: creativeml-openrail-m
---
|
jordyvl/vit-small_rvl_cdip_100_examples_per_class_kd_CEKD_t1.5_a0.9
|
jordyvl
| 2023-07-11T02:14:34Z | 163 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-07-11T01:01:03Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: vit-small_rvl_cdip_100_examples_per_class_kd_CEKD_t1.5_a0.9
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-small_rvl_cdip_100_examples_per_class_kd_CEKD_t1.5_a0.9
This model is a fine-tuned version of [WinKawaks/vit-small-patch16-224](https://huggingface.co/WinKawaks/vit-small-patch16-224) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2366
- Accuracy: 0.63
- Brier Loss: 0.5035
- Nll: 2.8588
- F1 Micro: 0.63
- F1 Macro: 0.6311
- Ece: 0.1649
- Aurc: 0.1472
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Brier Loss | Nll | F1 Micro | F1 Macro | Ece | Aurc |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:----------:|:-------:|:--------:|:--------:|:------:|:------:|
| No log | 1.0 | 25 | 2.8887 | 0.1225 | 0.9306 | 15.9457 | 0.1225 | 0.1226 | 0.1434 | 0.8620 |
| No log | 2.0 | 50 | 2.2120 | 0.3775 | 0.7577 | 9.7500 | 0.3775 | 0.3483 | 0.1992 | 0.3776 |
| No log | 3.0 | 75 | 1.7681 | 0.495 | 0.6387 | 5.6935 | 0.495 | 0.4838 | 0.1885 | 0.2491 |
| No log | 4.0 | 100 | 1.6420 | 0.5225 | 0.6038 | 5.2427 | 0.5225 | 0.5242 | 0.1757 | 0.2301 |
| No log | 5.0 | 125 | 1.5877 | 0.545 | 0.5986 | 4.6187 | 0.545 | 0.5282 | 0.1808 | 0.2248 |
| No log | 6.0 | 150 | 1.6460 | 0.5125 | 0.6162 | 3.9942 | 0.5125 | 0.5060 | 0.1962 | 0.2295 |
| No log | 7.0 | 175 | 1.8436 | 0.5125 | 0.6538 | 4.1740 | 0.5125 | 0.4932 | 0.2299 | 0.2451 |
| No log | 8.0 | 200 | 1.8205 | 0.545 | 0.6453 | 5.0752 | 0.545 | 0.5234 | 0.2057 | 0.2432 |
| No log | 9.0 | 225 | 1.7399 | 0.55 | 0.6260 | 4.5896 | 0.55 | 0.5460 | 0.2057 | 0.2258 |
| No log | 10.0 | 250 | 1.8559 | 0.55 | 0.6521 | 5.0532 | 0.55 | 0.5368 | 0.2209 | 0.2560 |
| No log | 11.0 | 275 | 1.8636 | 0.5625 | 0.6488 | 4.6642 | 0.5625 | 0.5544 | 0.2335 | 0.2187 |
| No log | 12.0 | 300 | 1.7461 | 0.55 | 0.6356 | 4.1298 | 0.55 | 0.5638 | 0.2047 | 0.2313 |
| No log | 13.0 | 325 | 1.7468 | 0.5625 | 0.6281 | 4.5451 | 0.5625 | 0.5570 | 0.2224 | 0.2214 |
| No log | 14.0 | 350 | 1.9616 | 0.545 | 0.6884 | 3.7999 | 0.545 | 0.5484 | 0.2691 | 0.2624 |
| No log | 15.0 | 375 | 2.0977 | 0.5175 | 0.7138 | 4.3792 | 0.5175 | 0.5055 | 0.2658 | 0.2917 |
| No log | 16.0 | 400 | 2.0238 | 0.5275 | 0.6896 | 4.5299 | 0.5275 | 0.5177 | 0.2664 | 0.2603 |
| No log | 17.0 | 425 | 1.8687 | 0.535 | 0.6534 | 3.7356 | 0.535 | 0.5388 | 0.2490 | 0.2448 |
| No log | 18.0 | 450 | 1.8210 | 0.5575 | 0.6492 | 4.3823 | 0.5575 | 0.5537 | 0.2533 | 0.2268 |
| No log | 19.0 | 475 | 1.7610 | 0.555 | 0.6325 | 3.9697 | 0.555 | 0.5503 | 0.2292 | 0.2161 |
| 0.5398 | 20.0 | 500 | 1.7125 | 0.5825 | 0.6125 | 3.4176 | 0.5825 | 0.5731 | 0.2140 | 0.1859 |
| 0.5398 | 21.0 | 525 | 1.6296 | 0.5775 | 0.6163 | 3.6014 | 0.5775 | 0.5871 | 0.2236 | 0.2051 |
| 0.5398 | 22.0 | 550 | 1.5965 | 0.57 | 0.5908 | 3.7668 | 0.57 | 0.5712 | 0.2058 | 0.1883 |
| 0.5398 | 23.0 | 575 | 1.4828 | 0.5875 | 0.5646 | 3.7028 | 0.5875 | 0.5854 | 0.1944 | 0.1714 |
| 0.5398 | 24.0 | 600 | 1.3983 | 0.6075 | 0.5481 | 3.3608 | 0.6075 | 0.6107 | 0.1966 | 0.1628 |
| 0.5398 | 25.0 | 625 | 1.5241 | 0.5925 | 0.5866 | 3.3669 | 0.5925 | 0.6019 | 0.2069 | 0.1886 |
| 0.5398 | 26.0 | 650 | 1.5540 | 0.58 | 0.5780 | 3.5184 | 0.58 | 0.5710 | 0.2131 | 0.1857 |
| 0.5398 | 27.0 | 675 | 1.4653 | 0.6 | 0.5768 | 2.9877 | 0.6 | 0.6043 | 0.2166 | 0.1781 |
| 0.5398 | 28.0 | 700 | 1.4883 | 0.5925 | 0.5646 | 3.7789 | 0.5925 | 0.5910 | 0.2096 | 0.1746 |
| 0.5398 | 29.0 | 725 | 1.5738 | 0.59 | 0.5914 | 4.0558 | 0.59 | 0.5879 | 0.2150 | 0.1957 |
| 0.5398 | 30.0 | 750 | 1.4017 | 0.6025 | 0.5583 | 3.4791 | 0.6025 | 0.6023 | 0.2150 | 0.1752 |
| 0.5398 | 31.0 | 775 | 1.3500 | 0.61 | 0.5365 | 3.2560 | 0.61 | 0.6157 | 0.1988 | 0.1579 |
| 0.5398 | 32.0 | 800 | 1.2977 | 0.6375 | 0.5140 | 3.0503 | 0.6375 | 0.6395 | 0.1847 | 0.1534 |
| 0.5398 | 33.0 | 825 | 1.3471 | 0.6175 | 0.5406 | 3.1888 | 0.6175 | 0.6104 | 0.2077 | 0.1689 |
| 0.5398 | 34.0 | 850 | 1.2992 | 0.615 | 0.5219 | 2.8944 | 0.615 | 0.6191 | 0.1826 | 0.1574 |
| 0.5398 | 35.0 | 875 | 1.2733 | 0.6225 | 0.5124 | 2.9352 | 0.6225 | 0.6238 | 0.1588 | 0.1505 |
| 0.5398 | 36.0 | 900 | 1.2821 | 0.6175 | 0.5231 | 3.0142 | 0.6175 | 0.6169 | 0.1672 | 0.1553 |
| 0.5398 | 37.0 | 925 | 1.2819 | 0.61 | 0.5200 | 2.6874 | 0.61 | 0.6116 | 0.1847 | 0.1540 |
| 0.5398 | 38.0 | 950 | 1.2664 | 0.615 | 0.5145 | 2.9287 | 0.615 | 0.6159 | 0.1961 | 0.1528 |
| 0.5398 | 39.0 | 975 | 1.2584 | 0.6225 | 0.5134 | 3.0058 | 0.6225 | 0.6230 | 0.1747 | 0.1508 |
| 0.0507 | 40.0 | 1000 | 1.2562 | 0.615 | 0.5114 | 2.9269 | 0.615 | 0.6169 | 0.1815 | 0.1504 |
| 0.0507 | 41.0 | 1025 | 1.2525 | 0.6225 | 0.5101 | 2.9199 | 0.6225 | 0.6239 | 0.1770 | 0.1496 |
| 0.0507 | 42.0 | 1050 | 1.2573 | 0.62 | 0.5133 | 2.9195 | 0.62 | 0.6221 | 0.1824 | 0.1511 |
| 0.0507 | 43.0 | 1075 | 1.2536 | 0.6125 | 0.5131 | 2.9026 | 0.6125 | 0.6121 | 0.1820 | 0.1511 |
| 0.0507 | 44.0 | 1100 | 1.2543 | 0.6225 | 0.5109 | 3.0693 | 0.6225 | 0.6235 | 0.1647 | 0.1500 |
| 0.0507 | 45.0 | 1125 | 1.2526 | 0.6125 | 0.5117 | 2.9018 | 0.6125 | 0.6141 | 0.1788 | 0.1500 |
| 0.0507 | 46.0 | 1150 | 1.2432 | 0.615 | 0.5068 | 2.9042 | 0.615 | 0.6167 | 0.1762 | 0.1484 |
| 0.0507 | 47.0 | 1175 | 1.2485 | 0.6275 | 0.5098 | 2.8927 | 0.6275 | 0.6251 | 0.1590 | 0.1496 |
| 0.0507 | 48.0 | 1200 | 1.2576 | 0.6125 | 0.5140 | 2.8956 | 0.6125 | 0.6137 | 0.1824 | 0.1524 |
| 0.0507 | 49.0 | 1225 | 1.2468 | 0.62 | 0.5094 | 2.8918 | 0.62 | 0.6204 | 0.1832 | 0.1496 |
| 0.0507 | 50.0 | 1250 | 1.2479 | 0.6175 | 0.5102 | 2.8921 | 0.6175 | 0.6178 | 0.1706 | 0.1491 |
| 0.0507 | 51.0 | 1275 | 1.2393 | 0.6225 | 0.5057 | 2.8813 | 0.6225 | 0.6229 | 0.1784 | 0.1486 |
| 0.0507 | 52.0 | 1300 | 1.2463 | 0.6175 | 0.5085 | 2.8959 | 0.6175 | 0.6184 | 0.1669 | 0.1495 |
| 0.0507 | 53.0 | 1325 | 1.2391 | 0.62 | 0.5061 | 2.8828 | 0.62 | 0.6215 | 0.1803 | 0.1471 |
| 0.0507 | 54.0 | 1350 | 1.2538 | 0.6175 | 0.5121 | 2.8795 | 0.6175 | 0.6167 | 0.1680 | 0.1512 |
| 0.0507 | 55.0 | 1375 | 1.2407 | 0.625 | 0.5064 | 2.8830 | 0.625 | 0.6259 | 0.1842 | 0.1482 |
| 0.0507 | 56.0 | 1400 | 1.2488 | 0.62 | 0.5099 | 2.8769 | 0.62 | 0.6198 | 0.1568 | 0.1499 |
| 0.0507 | 57.0 | 1425 | 1.2402 | 0.625 | 0.5052 | 2.8778 | 0.625 | 0.6260 | 0.1616 | 0.1481 |
| 0.0507 | 58.0 | 1450 | 1.2457 | 0.625 | 0.5077 | 2.8786 | 0.625 | 0.6260 | 0.1759 | 0.1474 |
| 0.0507 | 59.0 | 1475 | 1.2430 | 0.6275 | 0.5073 | 2.8744 | 0.6275 | 0.6266 | 0.1652 | 0.1486 |
| 0.0319 | 60.0 | 1500 | 1.2399 | 0.625 | 0.5056 | 2.8767 | 0.625 | 0.6256 | 0.1701 | 0.1474 |
| 0.0319 | 61.0 | 1525 | 1.2460 | 0.63 | 0.5087 | 2.8758 | 0.63 | 0.6329 | 0.1865 | 0.1491 |
| 0.0319 | 62.0 | 1550 | 1.2410 | 0.6225 | 0.5058 | 2.8719 | 0.6225 | 0.6229 | 0.1752 | 0.1477 |
| 0.0319 | 63.0 | 1575 | 1.2418 | 0.63 | 0.5060 | 2.8746 | 0.63 | 0.6319 | 0.1692 | 0.1484 |
| 0.0319 | 64.0 | 1600 | 1.2424 | 0.6275 | 0.5069 | 2.8672 | 0.6275 | 0.6279 | 0.1903 | 0.1475 |
| 0.0319 | 65.0 | 1625 | 1.2413 | 0.63 | 0.5061 | 2.8747 | 0.63 | 0.6304 | 0.1737 | 0.1471 |
| 0.0319 | 66.0 | 1650 | 1.2385 | 0.6325 | 0.5039 | 2.8726 | 0.6325 | 0.6358 | 0.1792 | 0.1473 |
| 0.0319 | 67.0 | 1675 | 1.2368 | 0.625 | 0.5047 | 2.8661 | 0.625 | 0.6261 | 0.1843 | 0.1467 |
| 0.0319 | 68.0 | 1700 | 1.2370 | 0.6275 | 0.5039 | 2.8691 | 0.6275 | 0.6294 | 0.1724 | 0.1471 |
| 0.0319 | 69.0 | 1725 | 1.2382 | 0.63 | 0.5050 | 2.8659 | 0.63 | 0.6317 | 0.1698 | 0.1472 |
| 0.0319 | 70.0 | 1750 | 1.2396 | 0.6275 | 0.5051 | 2.8670 | 0.6275 | 0.6290 | 0.1790 | 0.1474 |
| 0.0319 | 71.0 | 1775 | 1.2378 | 0.625 | 0.5045 | 2.8637 | 0.625 | 0.6268 | 0.1742 | 0.1476 |
| 0.0319 | 72.0 | 1800 | 1.2360 | 0.625 | 0.5037 | 2.8669 | 0.625 | 0.6269 | 0.1778 | 0.1468 |
| 0.0319 | 73.0 | 1825 | 1.2390 | 0.63 | 0.5049 | 2.8638 | 0.63 | 0.6310 | 0.1711 | 0.1474 |
| 0.0319 | 74.0 | 1850 | 1.2372 | 0.625 | 0.5045 | 2.8640 | 0.625 | 0.6269 | 0.1817 | 0.1475 |
| 0.0319 | 75.0 | 1875 | 1.2375 | 0.63 | 0.5044 | 2.8640 | 0.63 | 0.6313 | 0.1703 | 0.1472 |
| 0.0319 | 76.0 | 1900 | 1.2372 | 0.6275 | 0.5041 | 2.8621 | 0.6275 | 0.6290 | 0.1794 | 0.1473 |
| 0.0319 | 77.0 | 1925 | 1.2374 | 0.63 | 0.5041 | 2.8629 | 0.63 | 0.6313 | 0.1722 | 0.1472 |
| 0.0319 | 78.0 | 1950 | 1.2367 | 0.6275 | 0.5039 | 2.8620 | 0.6275 | 0.6294 | 0.1704 | 0.1474 |
| 0.0319 | 79.0 | 1975 | 1.2371 | 0.6275 | 0.5039 | 2.8619 | 0.6275 | 0.6294 | 0.1639 | 0.1474 |
| 0.0314 | 80.0 | 2000 | 1.2372 | 0.63 | 0.5041 | 2.8612 | 0.63 | 0.6310 | 0.1750 | 0.1474 |
| 0.0314 | 81.0 | 2025 | 1.2368 | 0.63 | 0.5038 | 2.8613 | 0.63 | 0.6309 | 0.1648 | 0.1473 |
| 0.0314 | 82.0 | 2050 | 1.2370 | 0.63 | 0.5038 | 2.8607 | 0.63 | 0.6305 | 0.1782 | 0.1473 |
| 0.0314 | 83.0 | 2075 | 1.2368 | 0.63 | 0.5038 | 2.8609 | 0.63 | 0.6307 | 0.1686 | 0.1472 |
| 0.0314 | 84.0 | 2100 | 1.2368 | 0.63 | 0.5037 | 2.8603 | 0.63 | 0.6305 | 0.1667 | 0.1472 |
| 0.0314 | 85.0 | 2125 | 1.2366 | 0.63 | 0.5036 | 2.8601 | 0.63 | 0.6309 | 0.1686 | 0.1473 |
| 0.0314 | 86.0 | 2150 | 1.2367 | 0.6325 | 0.5037 | 2.8600 | 0.6325 | 0.6335 | 0.1751 | 0.1471 |
| 0.0314 | 87.0 | 2175 | 1.2369 | 0.63 | 0.5037 | 2.8598 | 0.63 | 0.6307 | 0.1730 | 0.1473 |
| 0.0314 | 88.0 | 2200 | 1.2367 | 0.63 | 0.5036 | 2.8595 | 0.63 | 0.6307 | 0.1657 | 0.1472 |
| 0.0314 | 89.0 | 2225 | 1.2366 | 0.63 | 0.5036 | 2.8597 | 0.63 | 0.6307 | 0.1680 | 0.1472 |
| 0.0314 | 90.0 | 2250 | 1.2366 | 0.63 | 0.5036 | 2.8594 | 0.63 | 0.6307 | 0.1580 | 0.1472 |
| 0.0314 | 91.0 | 2275 | 1.2366 | 0.63 | 0.5035 | 2.8593 | 0.63 | 0.6307 | 0.1677 | 0.1472 |
| 0.0314 | 92.0 | 2300 | 1.2367 | 0.63 | 0.5035 | 2.8593 | 0.63 | 0.6307 | 0.1616 | 0.1472 |
| 0.0314 | 93.0 | 2325 | 1.2366 | 0.63 | 0.5035 | 2.8590 | 0.63 | 0.6307 | 0.1625 | 0.1472 |
| 0.0314 | 94.0 | 2350 | 1.2366 | 0.6325 | 0.5035 | 2.8590 | 0.6325 | 0.6333 | 0.1586 | 0.1470 |
| 0.0314 | 95.0 | 2375 | 1.2366 | 0.63 | 0.5035 | 2.8591 | 0.63 | 0.6307 | 0.1580 | 0.1472 |
| 0.0314 | 96.0 | 2400 | 1.2366 | 0.63 | 0.5035 | 2.8589 | 0.63 | 0.6307 | 0.1695 | 0.1471 |
| 0.0314 | 97.0 | 2425 | 1.2366 | 0.63 | 0.5035 | 2.8589 | 0.63 | 0.6311 | 0.1648 | 0.1472 |
| 0.0314 | 98.0 | 2450 | 1.2366 | 0.63 | 0.5035 | 2.8588 | 0.63 | 0.6311 | 0.1695 | 0.1471 |
| 0.0314 | 99.0 | 2475 | 1.2366 | 0.6325 | 0.5035 | 2.8589 | 0.6325 | 0.6337 | 0.1724 | 0.1470 |
| 0.0312 | 100.0 | 2500 | 1.2366 | 0.63 | 0.5035 | 2.8588 | 0.63 | 0.6311 | 0.1649 | 0.1472 |
### Framework versions
- Transformers 4.28.0.dev0
- Pytorch 1.12.1+cu113
- Datasets 2.12.0
- Tokenizers 0.12.1
|
hafidikhsan/wav2vec2-large-xlsr-53-english-pronunciation-evaluation-aod-cut-oversampling-augmented
|
hafidikhsan
| 2023-07-11T02:12:58Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"audio-classification",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2023-07-11T02:10:43Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: wav2vec2-large-xlsr-53-english-pronunciation-evaluation-aod-cut-oversampling-augmented
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xlsr-53-english-pronunciation-evaluation-aod-cut-oversampling-augmented
This model is a fine-tuned version of [jonatasgrosman/wav2vec2-large-xlsr-53-english](https://huggingface.co/jonatasgrosman/wav2vec2-large-xlsr-53-english) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0403
- Accuracy: 0.744
- F1: 0.7432
- Precision: 0.7436
- Recall: 0.744
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|
| 0.8567 | 1.0 | 313 | 0.9539 | 0.5388 | 0.5159 | 0.5387 | 0.5388 |
| 0.665 | 2.0 | 626 | 0.7520 | 0.6512 | 0.6545 | 0.6625 | 0.6512 |
| 0.629 | 3.0 | 939 | 0.7775 | 0.7008 | 0.6980 | 0.6978 | 0.7008 |
| 0.4793 | 4.0 | 1252 | 0.8696 | 0.7268 | 0.7295 | 0.7365 | 0.7268 |
| 0.2273 | 5.0 | 1565 | 1.0403 | 0.744 | 0.7432 | 0.7436 | 0.744 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
manhtt-079/vipubmed-deberta-base
|
manhtt-079
| 2023-07-11T01:59:35Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"deberta-v2",
"transformer",
"vietnamese",
"nlp",
"bert",
"deberta",
"fill-mask",
"vi",
"dataset:VietAI/vi_pubmed",
"license:mit",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-05-06T10:35:36Z |
---
language:
- vi
metrics:
- f1
pipeline_tag: fill-mask
license: mit
datasets:
- VietAI/vi_pubmed
tags:
- transformer
- vietnamese
- nlp
- bert
- deberta
- deberta-v2
---
# ViPubMedDeBERTa: A Vietnamese pretrained biomedical language representation model
## Model description
## Model variations
- `vipubmed-deberta-xsmall`: 22M backbone parameters
- `vipubmed-deberta-base`: 86M backbone parameters
## How to use
You can use this model directly with a pipeline for masked language modeling:<br>
**_NOTE:_** The input text should be already word-segmented, you can use [Pyvi](https://github.com/trungtv/pyvi) (Python Vietnamese Core NLP Toolkit) to segment word before passing to the model.
```python
>>> from transformers import pipeline
>>> model = pipeline('fill-mask', model='manhtt-079/vipubmed-deberta-base')
>>> text_with_mask = """Chúng_tôi mô_tả một trường_hợp bệnh_nhân nữ 44 tuổi được chẩn_đoán sarcoma tế_bào tua nang ( FDCS ) . FDCS là bệnh rất hiếm ảnh_hưởng đến tế_bào trình_diện kháng_nguyên đuôi gai và thường bị chẩn_đoán nhầm . Phẫu_thuật được coi là phương_thức điều_trị tốt nhất , tiếp_theo là hóa_trị . Trong trường_hợp của chúng_tôi , [MASK] cắt bỏ không_thể thực_hiện được , do đó bệnh_nhân được hóa_trị hai dòng , sau đó là cấy_ghép tủy xương , sau đó là hóa_trị ba với đáp_ứng trao_đổi chất hoàn_toàn được thấy trên"""
>>> model(text_with_mask)
[{'score': 0.8480948805809021,
'token': 1621,
'token_str': 'phẫu_thuật',
'sequence': 'Chúng_tôi mô_tả một trường_hợp bệnh_nhân nữ 44 tuổi được chẩn_đoán sarcoma tế_bào tua nang ( FDCS ). FDCS là bệnh rất hiếm ảnh_hưởng đến tế_bào trình_diện kháng_nguyên đuôi gai và thường bị chẩn_đoán nhầm. Phẫu_thuật được coi là phương_thức điều_trị tốt nhất, tiếp_theo là hóa_trị. Trong trường_hợp của chúng_tôi, phẫu_thuật cắt bỏ không_thể thực_hiện được, do đó bệnh_nhân được hóa_trị hai dòng, sau đó là cấy_ghép tủy xương, sau đó là hóa_trị ba với đáp_ứng trao_đổi chất hoàn_toàn được thấy trên'},
{'score': 0.1136574074625969,
'token': 83,
'token_str': 'việc',
'sequence': 'Chúng_tôi mô_tả một trường_hợp bệnh_nhân nữ 44 tuổi được chẩn_đoán sarcoma tế_bào tua nang ( FDCS ). FDCS là bệnh rất hiếm ảnh_hưởng đến tế_bào trình_diện kháng_nguyên đuôi gai và thường bị chẩn_đoán nhầm. Phẫu_thuật được coi là phương_thức điều_trị tốt nhất, tiếp_theo là hóa_trị. Trong trường_hợp của chúng_tôi, việc cắt bỏ không_thể thực_hiện được, do đó bệnh_nhân được hóa_trị hai dòng, sau đó là cấy_ghép tủy xương, sau đó là hóa_trị ba với đáp_ứng trao_đổi chất hoàn_toàn được thấy trên'},
{'score': 0.014141257852315903,
'token': 589,
'token_str': 'phương_pháp',
'sequence': 'Chúng_tôi mô_tả một trường_hợp bệnh_nhân nữ 44 tuổi được chẩn_đoán sarcoma tế_bào tua nang ( FDCS ). FDCS là bệnh rất hiếm ảnh_hưởng đến tế_bào trình_diện kháng_nguyên đuôi gai và thường bị chẩn_đoán nhầm. Phẫu_thuật được coi là phương_thức điều_trị tốt nhất, tiếp_theo là hóa_trị. Trong trường_hợp của chúng_tôi, phương_pháp cắt bỏ không_thể thực_hiện được, do đó bệnh_nhân được hóa_trị hai dòng, sau đó là cấy_ghép tủy xương, sau đó là hóa_trị ba với đáp_ứng trao_đổi chất hoàn_toàn được thấy trên'},
{'score': 0.0024715897161513567,
'token': 454,
'token_str': 'điều_trị',
'sequence': 'Chúng_tôi mô_tả một trường_hợp bệnh_nhân nữ 44 tuổi được chẩn_đoán sarcoma tế_bào tua nang ( FDCS ). FDCS là bệnh rất hiếm ảnh_hưởng đến tế_bào trình_diện kháng_nguyên đuôi gai và thường bị chẩn_đoán nhầm. Phẫu_thuật được coi là phương_thức điều_trị tốt nhất, tiếp_theo là hóa_trị. Trong trường_hợp của chúng_tôi, điều_trị cắt bỏ không_thể thực_hiện được, do đó bệnh_nhân được hóa_trị hai dòng, sau đó là cấy_ghép tủy xương, sau đó là hóa_trị ba với đáp_ứng trao_đổi chất hoàn_toàn được thấy trên'},
{'score': 0.002370780799537897,
'token': 485,
'token_str': 'quá_trình',
'sequence': 'Chúng_tôi mô_tả một trường_hợp bệnh_nhân nữ 44 tuổi được chẩn_đoán sarcoma tế_bào tua nang ( FDCS ). FDCS là bệnh rất hiếm ảnh_hưởng đến tế_bào trình_diện kháng_nguyên đuôi gai và thường bị chẩn_đoán nhầm. Phẫu_thuật được coi là phương_thức điều_trị tốt nhất, tiếp_theo là hóa_trị. Trong trường_hợp của chúng_tôi, quá_trình cắt bỏ không_thể thực_hiện được, do đó bệnh_nhân được hóa_trị hai dòng, sau đó là cấy_ghép tủy xương, sau đó là hóa_trị ba với đáp_ứng trao_đổi chất hoàn_toàn được thấy trên'}]
```
#### Get features:
- With PyTorch:
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained('manhtt-079/vipubmed-deberta-base')
model = AutoModel.from_pretrained("manhtt-079/vipubmed-deberta-base")
text = "Chúng_tôi mô_tả một trường_hợp bệnh_nhân nữ 44 tuổi được chẩn_đoán sarcoma tế_bào tua nang ( FDCS )."
model_inputs = tokenizer(text, return_tensors='pt')
outputs = model(**model_inputs)
```
- With TensorFlow
```python
from transformers import AutoTokenizer, TFAutoModel
tokenizer = AutoTokenizer.from_pretrained('manhtt-079/vipubmed-deberta-base')
model = TFAutoModel.from_pretrained("manhtt-079/vipubmed-deberta-base")
text = "Chúng_tôi mô_tả một trường_hợp bệnh_nhân nữ 44 tuổi được chẩn_đoán sarcoma tế_bào tua nang ( FDCS )."
model_inputs = tokenizer(text, return_tensors='tf')
outputs = model(**model_inputs)
```
## Pre-training data
The ViPubMedDeBERTa model was pre-trained on [ViPubmed](https://github.com/vietai/ViPubmed), a dataset consisting of 20M Vietnamese Biomedical abstracts generated by large scale translation.
## Training procedure
### Data deduplication
A fuzzy deduplication, targeting documents with high overlap, was conducted at the document level to enhance quality and address overfitting. Employing Locality Sensitive Hashing (LSH) with a threshold of 0.9 ensured the removal of documents with overlap exceeding 90%. This process resulted in an average reduction of the dataset's size by 3%.
### Pretraining
We employ our model based on the [ViDeBERTa](https://github.com/HySonLab/ViDeBERTa) architecture and leverage its pre-trained checkpoint to continue pre-training. Our model was trained on a single A100 GPU (40GB) for 350 thousand steps, with a batch size of 16 and gradient accumulation steps set to 4 (resulting in a total of 64). The sequence length was limited to 512 tokens and the model peak learning rate of 1e-4.
## Evaluation results
|
casque/TemplarAssassinv0.2
|
casque
| 2023-07-11T01:29:41Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-11T01:26:51Z |
---
license: creativeml-openrail-m
---
|
bastianchinchon/nominal-groups-recognition-roberta-clinical-wl-es
|
bastianchinchon
| 2023-07-11T01:28:34Z | 120 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"roberta",
"token-classification",
"generated_from_trainer",
"es",
"dataset:bastianchinchon/spanish_nominal_groups_conll2003",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-07-11T01:00:00Z |
---
language:
- es
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- bastianchinchon/spanish_nominal_groups_conll2003
model-index:
- name: nominal-groups-recognition-roberta-clinical-wl-es
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nominal-groups-recognition-roberta-clinical-wl-es
This model is a fine-tuned version of [plncmm/roberta-clinical-wl-es](https://huggingface.co/plncmm/roberta-clinical-wl-es) on the bastianchinchon/spanish_nominal_groups_conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2226
- Body Part Precision: 0.7427
- Body Part Recall: 0.7966
- Body Part F1: 0.7687
- Body Part Number: 413
- Disease Precision: 0.7915
- Disease Recall: 0.8174
- Disease F1: 0.8042
- Disease Number: 975
- Family Member Precision: 0.8286
- Family Member Recall: 0.9667
- Family Member F1: 0.8923
- Family Member Number: 30
- Medication Precision: 0.7905
- Medication Recall: 0.8925
- Medication F1: 0.8384
- Medication Number: 93
- Procedure Precision: 0.7105
- Procedure Recall: 0.7814
- Procedure F1: 0.7443
- Procedure Number: 311
- Overall Precision: 0.7666
- Overall Recall: 0.8128
- Overall F1: 0.7890
- Overall Accuracy: 0.9374
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 13
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Body Part Precision | Body Part Recall | Body Part F1 | Body Part Number | Disease Precision | Disease Recall | Disease F1 | Disease Number | Family Member Precision | Family Member Recall | Family Member F1 | Family Member Number | Medication Precision | Medication Recall | Medication F1 | Medication Number | Procedure Precision | Procedure Recall | Procedure F1 | Procedure Number | Overall Precision | Overall Recall | Overall F1 | Overall Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:-------------------:|:----------------:|:------------:|:----------------:|:-----------------:|:--------------:|:----------:|:--------------:|:-----------------------:|:--------------------:|:----------------:|:--------------------:|:--------------------:|:-----------------:|:-------------:|:-----------------:|:-------------------:|:----------------:|:------------:|:----------------:|:-----------------:|:--------------:|:----------:|:----------------:|
| 0.356 | 1.0 | 1004 | 0.2241 | 0.7283 | 0.7724 | 0.7497 | 413 | 0.7603 | 0.8133 | 0.7859 | 975 | 0.9062 | 0.9667 | 0.9355 | 30 | 0.7547 | 0.8602 | 0.8040 | 93 | 0.6464 | 0.7524 | 0.6954 | 311 | 0.7345 | 0.7986 | 0.7652 | 0.9319 |
| 0.1823 | 2.0 | 2008 | 0.2226 | 0.7427 | 0.7966 | 0.7687 | 413 | 0.7915 | 0.8174 | 0.8042 | 975 | 0.8286 | 0.9667 | 0.8923 | 30 | 0.7905 | 0.8925 | 0.8384 | 93 | 0.7105 | 0.7814 | 0.7443 | 311 | 0.7666 | 0.8128 | 0.7890 | 0.9374 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
JMGaloDoido/distilbert-base-uncased-finetuned-cola
|
JMGaloDoido
| 2023-07-11T01:26:53Z | 61 | 0 |
transformers
|
[
"transformers",
"tf",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-10T23:59:32Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: JMGaloDoido/distilbert-base-uncased-finetuned-cola
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# JMGaloDoido/distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.1936
- Validation Loss: 0.5221
- Train Matthews Correlation: 0.5478
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': False, 'is_legacy_optimizer': False, 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 1602, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Matthews Correlation | Epoch |
|:----------:|:---------------:|:--------------------------:|:-----:|
| 0.5211 | 0.4812 | 0.4423 | 0 |
| 0.3244 | 0.4901 | 0.4973 | 1 |
| 0.1936 | 0.5221 | 0.5478 | 2 |
### Framework versions
- Transformers 4.30.2
- TensorFlow 2.12.0
- Datasets 2.13.1
- Tokenizers 0.13.3
|
casque/drow_ranger_lora
|
casque
| 2023-07-11T01:24:19Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-11T01:21:25Z |
---
license: creativeml-openrail-m
---
|
casque/VengefulSpiritv0.1
|
casque
| 2023-07-11T01:20:00Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-11T01:17:11Z |
---
license: creativeml-openrail-m
---
|
lucs1265/distilbert-base-uncased-finetuned-cola
|
lucs1265
| 2023-07-11T01:11:57Z | 61 | 0 |
transformers
|
[
"transformers",
"tf",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-11T01:06:54Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: lucs1265/distilbert-base-uncased-finetuned-cola
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# lucs1265/distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.1898
- Validation Loss: 0.5233
- Train Matthews Correlation: 0.5286
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': True, 'is_legacy_optimizer': False, 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 1602, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Matthews Correlation | Epoch |
|:----------:|:---------------:|:--------------------------:|:-----:|
| 0.5194 | 0.4536 | 0.4725 | 0 |
| 0.3249 | 0.4763 | 0.4867 | 1 |
| 0.1898 | 0.5233 | 0.5286 | 2 |
### Framework versions
- Transformers 4.30.2
- TensorFlow 2.12.0
- Datasets 2.13.1
- Tokenizers 0.13.3
|
casque/Windrunnerv0.2
|
casque
| 2023-07-11T01:03:37Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-11T01:00:46Z |
---
license: creativeml-openrail-m
---
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.