
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-07-27 12:28:27
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 533
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-07-27 12:28:17
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
socialmediaie/TRAC2020_HIN_C_bert-base-multilingual-uncased
|
socialmediaie
| 2021-05-20T07:01:31Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# Multilingual Joint Fine-tuning of Transformer models for identifying Trolling, Aggression and Cyberbullying at TRAC 2020
Models and predictions for submission to TRAC - 2020 Second Workshop on Trolling, Aggression and Cyberbullying.
Our trained models as well as evaluation metrics during traing are available at: https://databank.illinois.edu/datasets/IDB-8882752#
We also make a few of our models available in HuggingFace's models repository at https://huggingface.co/socialmediaie/, these models can be further fine-tuned on your dataset of choice.
Our approach is described in our paper titled:
> Mishra, Sudhanshu, Shivangi Prasad, and Shubhanshu Mishra. 2020. "Multilingual Joint Fine-Tuning of Transformer Models for Identifying Trolling, Aggression and Cyberbullying at TRAC 2020." In Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying (TRAC-2020).
The source code for training this model and more details can be found on our code repository: https://github.com/socialmediaie/TRAC2020
NOTE: These models are retrained for uploading here after our submission so the evaluation measures may be slightly different from the ones reported in the paper.
If you plan to use the dataset please cite the following resources:
* Mishra, Sudhanshu, Shivangi Prasad, and Shubhanshu Mishra. 2020. "Multilingual Joint Fine-Tuning of Transformer Models for Identifying Trolling, Aggression and Cyberbullying at TRAC 2020." In Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying (TRAC-2020).
* Mishra, Shubhanshu, Shivangi Prasad, and Shubhanshu Mishra. 2020. “Trained Models for Multilingual Joint Fine-Tuning of Transformer Models for Identifying Trolling, Aggression and Cyberbullying at TRAC 2020.” University of Illinois at Urbana-Champaign. https://doi.org/10.13012/B2IDB-8882752_V1.
```
@inproceedings{Mishra2020TRAC,
author = {Mishra, Sudhanshu and Prasad, Shivangi and Mishra, Shubhanshu},
booktitle = {Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying (TRAC-2020)},
title = {{Multilingual Joint Fine-tuning of Transformer models for identifying Trolling, Aggression and Cyberbullying at TRAC 2020}},
year = {2020}
}
@data{illinoisdatabankIDB-8882752,
author = {Mishra, Shubhanshu and Prasad, Shivangi and Mishra, Shubhanshu},
doi = {10.13012/B2IDB-8882752_V1},
publisher = {University of Illinois at Urbana-Champaign},
title = {{Trained models for Multilingual Joint Fine-tuning of Transformer models for identifying Trolling, Aggression and Cyberbullying at TRAC 2020}},
url = {https://doi.org/10.13012/B2IDB-8882752{\_}V1},
year = {2020}
}
```
## Usage
The models can be used via the following code:
```python
from transformers import AutoModel, AutoTokenizer, AutoModelForSequenceClassification
import torch
from pathlib import Path
from scipy.special import softmax
import numpy as np
import pandas as pd
TASK_LABEL_IDS = {
"Sub-task A": ["OAG", "NAG", "CAG"],
"Sub-task B": ["GEN", "NGEN"],
"Sub-task C": ["OAG-GEN", "OAG-NGEN", "NAG-GEN", "NAG-NGEN", "CAG-GEN", "CAG-NGEN"]
}
model_version="databank" # other option is hugging face library
if model_version == "databank":
# Make sure you have downloaded the required model file from https://databank.illinois.edu/datasets/IDB-8882752
# Unzip the file at some model_path (we are using: "databank_model")
model_path = next(Path("databank_model").glob("./*/output/*/model"))
# Assuming you get the following type of structure inside "databank_model"
# 'databank_model/ALL/Sub-task C/output/bert-base-multilingual-uncased/model'
lang, task, _, base_model, _ = model_path.parts
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForSequenceClassification.from_pretrained(model_path)
else:
lang, task, base_model = "ALL", "Sub-task C", "bert-base-multilingual-uncased"
base_model = f"socialmediaie/TRAC2020_{lang}_{lang.split()[-1]}_{base_model}"
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForSequenceClassification.from_pretrained(base_model)
# For doing inference set model in eval mode
model.eval()
# If you want to further fine-tune the model you can reset the model to model.train()
task_labels = TASK_LABEL_IDS[task]
sentence = "This is a good cat and this is a bad dog."
processed_sentence = f"{tokenizer.cls_token} {sentence}"
tokens = tokenizer.tokenize(sentence)
indexed_tokens = tokenizer.convert_tokens_to_ids(tokens)
tokens_tensor = torch.tensor([indexed_tokens])
with torch.no_grad():
logits, = model(tokens_tensor, labels=None)
logits
preds = logits.detach().cpu().numpy()
preds_probs = softmax(preds, axis=1)
preds = np.argmax(preds_probs, axis=1)
preds_labels = np.array(task_labels)[preds]
print(dict(zip(task_labels, preds_probs[0])), preds_labels)
"""You should get an output as follows:
({'CAG-GEN': 0.06762535,
'CAG-NGEN': 0.03244293,
'NAG-GEN': 0.6897794,
'NAG-NGEN': 0.15498641,
'OAG-GEN': 0.034373745,
'OAG-NGEN': 0.020792078},
array(['NAG-GEN'], dtype='<U8'))
"""
```
|
socialmediaie/TRAC2020_HIN_B_bert-base-multilingual-uncased
|
socialmediaie
| 2021-05-20T07:00:11Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# Multilingual Joint Fine-tuning of Transformer models for identifying Trolling, Aggression and Cyberbullying at TRAC 2020
Models and predictions for submission to TRAC - 2020 Second Workshop on Trolling, Aggression and Cyberbullying.
Our trained models as well as evaluation metrics during traing are available at: https://databank.illinois.edu/datasets/IDB-8882752#
We also make a few of our models available in HuggingFace's models repository at https://huggingface.co/socialmediaie/, these models can be further fine-tuned on your dataset of choice.
Our approach is described in our paper titled:
> Mishra, Sudhanshu, Shivangi Prasad, and Shubhanshu Mishra. 2020. "Multilingual Joint Fine-Tuning of Transformer Models for Identifying Trolling, Aggression and Cyberbullying at TRAC 2020." In Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying (TRAC-2020).
The source code for training this model and more details can be found on our code repository: https://github.com/socialmediaie/TRAC2020
NOTE: These models are retrained for uploading here after our submission so the evaluation measures may be slightly different from the ones reported in the paper.
If you plan to use the dataset please cite the following resources:
* Mishra, Sudhanshu, Shivangi Prasad, and Shubhanshu Mishra. 2020. "Multilingual Joint Fine-Tuning of Transformer Models for Identifying Trolling, Aggression and Cyberbullying at TRAC 2020." In Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying (TRAC-2020).
* Mishra, Shubhanshu, Shivangi Prasad, and Shubhanshu Mishra. 2020. “Trained Models for Multilingual Joint Fine-Tuning of Transformer Models for Identifying Trolling, Aggression and Cyberbullying at TRAC 2020.” University of Illinois at Urbana-Champaign. https://doi.org/10.13012/B2IDB-8882752_V1.
```
@inproceedings{Mishra2020TRAC,
author = {Mishra, Sudhanshu and Prasad, Shivangi and Mishra, Shubhanshu},
booktitle = {Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying (TRAC-2020)},
title = {{Multilingual Joint Fine-tuning of Transformer models for identifying Trolling, Aggression and Cyberbullying at TRAC 2020}},
year = {2020}
}
@data{illinoisdatabankIDB-8882752,
author = {Mishra, Shubhanshu and Prasad, Shivangi and Mishra, Shubhanshu},
doi = {10.13012/B2IDB-8882752_V1},
publisher = {University of Illinois at Urbana-Champaign},
title = {{Trained models for Multilingual Joint Fine-tuning of Transformer models for identifying Trolling, Aggression and Cyberbullying at TRAC 2020}},
url = {https://doi.org/10.13012/B2IDB-8882752{\_}V1},
year = {2020}
}
```
## Usage
The models can be used via the following code:
```python
from transformers import AutoModel, AutoTokenizer, AutoModelForSequenceClassification
import torch
from pathlib import Path
from scipy.special import softmax
import numpy as np
import pandas as pd
TASK_LABEL_IDS = {
"Sub-task A": ["OAG", "NAG", "CAG"],
"Sub-task B": ["GEN", "NGEN"],
"Sub-task C": ["OAG-GEN", "OAG-NGEN", "NAG-GEN", "NAG-NGEN", "CAG-GEN", "CAG-NGEN"]
}
model_version="databank" # other option is hugging face library
if model_version == "databank":
# Make sure you have downloaded the required model file from https://databank.illinois.edu/datasets/IDB-8882752
# Unzip the file at some model_path (we are using: "databank_model")
model_path = next(Path("databank_model").glob("./*/output/*/model"))
# Assuming you get the following type of structure inside "databank_model"
# 'databank_model/ALL/Sub-task C/output/bert-base-multilingual-uncased/model'
lang, task, _, base_model, _ = model_path.parts
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForSequenceClassification.from_pretrained(model_path)
else:
lang, task, base_model = "ALL", "Sub-task C", "bert-base-multilingual-uncased"
base_model = f"socialmediaie/TRAC2020_{lang}_{lang.split()[-1]}_{base_model}"
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForSequenceClassification.from_pretrained(base_model)
# For doing inference set model in eval mode
model.eval()
# If you want to further fine-tune the model you can reset the model to model.train()
task_labels = TASK_LABEL_IDS[task]
sentence = "This is a good cat and this is a bad dog."
processed_sentence = f"{tokenizer.cls_token} {sentence}"
tokens = tokenizer.tokenize(sentence)
indexed_tokens = tokenizer.convert_tokens_to_ids(tokens)
tokens_tensor = torch.tensor([indexed_tokens])
with torch.no_grad():
logits, = model(tokens_tensor, labels=None)
logits
preds = logits.detach().cpu().numpy()
preds_probs = softmax(preds, axis=1)
preds = np.argmax(preds_probs, axis=1)
preds_labels = np.array(task_labels)[preds]
print(dict(zip(task_labels, preds_probs[0])), preds_labels)
"""You should get an output as follows:
({'CAG-GEN': 0.06762535,
'CAG-NGEN': 0.03244293,
'NAG-GEN': 0.6897794,
'NAG-NGEN': 0.15498641,
'OAG-GEN': 0.034373745,
'OAG-NGEN': 0.020792078},
array(['NAG-GEN'], dtype='<U8'))
"""
```
|
socialmediaie/TRAC2020_HIN_A_bert-base-multilingual-uncased
|
socialmediaie
| 2021-05-20T06:58:51Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# Multilingual Joint Fine-tuning of Transformer models for identifying Trolling, Aggression and Cyberbullying at TRAC 2020
Models and predictions for submission to TRAC - 2020 Second Workshop on Trolling, Aggression and Cyberbullying.
Our trained models as well as evaluation metrics during traing are available at: https://databank.illinois.edu/datasets/IDB-8882752#
We also make a few of our models available in HuggingFace's models repository at https://huggingface.co/socialmediaie/, these models can be further fine-tuned on your dataset of choice.
Our approach is described in our paper titled:
> Mishra, Sudhanshu, Shivangi Prasad, and Shubhanshu Mishra. 2020. "Multilingual Joint Fine-Tuning of Transformer Models for Identifying Trolling, Aggression and Cyberbullying at TRAC 2020." In Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying (TRAC-2020).
The source code for training this model and more details can be found on our code repository: https://github.com/socialmediaie/TRAC2020
NOTE: These models are retrained for uploading here after our submission so the evaluation measures may be slightly different from the ones reported in the paper.
If you plan to use the dataset please cite the following resources:
* Mishra, Sudhanshu, Shivangi Prasad, and Shubhanshu Mishra. 2020. "Multilingual Joint Fine-Tuning of Transformer Models for Identifying Trolling, Aggression and Cyberbullying at TRAC 2020." In Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying (TRAC-2020).
* Mishra, Shubhanshu, Shivangi Prasad, and Shubhanshu Mishra. 2020. “Trained Models for Multilingual Joint Fine-Tuning of Transformer Models for Identifying Trolling, Aggression and Cyberbullying at TRAC 2020.” University of Illinois at Urbana-Champaign. https://doi.org/10.13012/B2IDB-8882752_V1.
```
@inproceedings{Mishra2020TRAC,
author = {Mishra, Sudhanshu and Prasad, Shivangi and Mishra, Shubhanshu},
booktitle = {Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying (TRAC-2020)},
title = {{Multilingual Joint Fine-tuning of Transformer models for identifying Trolling, Aggression and Cyberbullying at TRAC 2020}},
year = {2020}
}
@data{illinoisdatabankIDB-8882752,
author = {Mishra, Shubhanshu and Prasad, Shivangi and Mishra, Shubhanshu},
doi = {10.13012/B2IDB-8882752_V1},
publisher = {University of Illinois at Urbana-Champaign},
title = {{Trained models for Multilingual Joint Fine-tuning of Transformer models for identifying Trolling, Aggression and Cyberbullying at TRAC 2020}},
url = {https://doi.org/10.13012/B2IDB-8882752{\_}V1},
year = {2020}
}
```
## Usage
The models can be used via the following code:
```python
from transformers import AutoModel, AutoTokenizer, AutoModelForSequenceClassification
import torch
from pathlib import Path
from scipy.special import softmax
import numpy as np
import pandas as pd
TASK_LABEL_IDS = {
"Sub-task A": ["OAG", "NAG", "CAG"],
"Sub-task B": ["GEN", "NGEN"],
"Sub-task C": ["OAG-GEN", "OAG-NGEN", "NAG-GEN", "NAG-NGEN", "CAG-GEN", "CAG-NGEN"]
}
model_version="databank" # other option is hugging face library
if model_version == "databank":
# Make sure you have downloaded the required model file from https://databank.illinois.edu/datasets/IDB-8882752
# Unzip the file at some model_path (we are using: "databank_model")
model_path = next(Path("databank_model").glob("./*/output/*/model"))
# Assuming you get the following type of structure inside "databank_model"
# 'databank_model/ALL/Sub-task C/output/bert-base-multilingual-uncased/model'
lang, task, _, base_model, _ = model_path.parts
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForSequenceClassification.from_pretrained(model_path)
else:
lang, task, base_model = "ALL", "Sub-task C", "bert-base-multilingual-uncased"
base_model = f"socialmediaie/TRAC2020_{lang}_{lang.split()[-1]}_{base_model}"
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForSequenceClassification.from_pretrained(base_model)
# For doing inference set model in eval mode
model.eval()
# If you want to further fine-tune the model you can reset the model to model.train()
task_labels = TASK_LABEL_IDS[task]
sentence = "This is a good cat and this is a bad dog."
processed_sentence = f"{tokenizer.cls_token} {sentence}"
tokens = tokenizer.tokenize(sentence)
indexed_tokens = tokenizer.convert_tokens_to_ids(tokens)
tokens_tensor = torch.tensor([indexed_tokens])
with torch.no_grad():
logits, = model(tokens_tensor, labels=None)
logits
preds = logits.detach().cpu().numpy()
preds_probs = softmax(preds, axis=1)
preds = np.argmax(preds_probs, axis=1)
preds_labels = np.array(task_labels)[preds]
print(dict(zip(task_labels, preds_probs[0])), preds_labels)
"""You should get an output as follows:
({'CAG-GEN': 0.06762535,
'CAG-NGEN': 0.03244293,
'NAG-GEN': 0.6897794,
'NAG-NGEN': 0.15498641,
'OAG-GEN': 0.034373745,
'OAG-NGEN': 0.020792078},
array(['NAG-GEN'], dtype='<U8'))
"""
```
|
socialmediaie/TRAC2020_ENG_C_bert-base-uncased
|
socialmediaie
| 2021-05-20T06:57:39Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# Multilingual Joint Fine-tuning of Transformer models for identifying Trolling, Aggression and Cyberbullying at TRAC 2020
Models and predictions for submission to TRAC - 2020 Second Workshop on Trolling, Aggression and Cyberbullying.
Our trained models as well as evaluation metrics during traing are available at: https://databank.illinois.edu/datasets/IDB-8882752#
We also make a few of our models available in HuggingFace's models repository at https://huggingface.co/socialmediaie/, these models can be further fine-tuned on your dataset of choice.
Our approach is described in our paper titled:
> Mishra, Sudhanshu, Shivangi Prasad, and Shubhanshu Mishra. 2020. "Multilingual Joint Fine-Tuning of Transformer Models for Identifying Trolling, Aggression and Cyberbullying at TRAC 2020." In Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying (TRAC-2020).
The source code for training this model and more details can be found on our code repository: https://github.com/socialmediaie/TRAC2020
NOTE: These models are retrained for uploading here after our submission so the evaluation measures may be slightly different from the ones reported in the paper.
If you plan to use the dataset please cite the following resources:
* Mishra, Sudhanshu, Shivangi Prasad, and Shubhanshu Mishra. 2020. "Multilingual Joint Fine-Tuning of Transformer Models for Identifying Trolling, Aggression and Cyberbullying at TRAC 2020." In Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying (TRAC-2020).
* Mishra, Shubhanshu, Shivangi Prasad, and Shubhanshu Mishra. 2020. “Trained Models for Multilingual Joint Fine-Tuning of Transformer Models for Identifying Trolling, Aggression and Cyberbullying at TRAC 2020.” University of Illinois at Urbana-Champaign. https://doi.org/10.13012/B2IDB-8882752_V1.
```
@inproceedings{Mishra2020TRAC,
author = {Mishra, Sudhanshu and Prasad, Shivangi and Mishra, Shubhanshu},
booktitle = {Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying (TRAC-2020)},
title = {{Multilingual Joint Fine-tuning of Transformer models for identifying Trolling, Aggression and Cyberbullying at TRAC 2020}},
year = {2020}
}
@data{illinoisdatabankIDB-8882752,
author = {Mishra, Shubhanshu and Prasad, Shivangi and Mishra, Shubhanshu},
doi = {10.13012/B2IDB-8882752_V1},
publisher = {University of Illinois at Urbana-Champaign},
title = {{Trained models for Multilingual Joint Fine-tuning of Transformer models for identifying Trolling, Aggression and Cyberbullying at TRAC 2020}},
url = {https://doi.org/10.13012/B2IDB-8882752{\_}V1},
year = {2020}
}
```
## Usage
The models can be used via the following code:
```python
from transformers import AutoModel, AutoTokenizer, AutoModelForSequenceClassification
import torch
from pathlib import Path
from scipy.special import softmax
import numpy as np
import pandas as pd
TASK_LABEL_IDS = {
"Sub-task A": ["OAG", "NAG", "CAG"],
"Sub-task B": ["GEN", "NGEN"],
"Sub-task C": ["OAG-GEN", "OAG-NGEN", "NAG-GEN", "NAG-NGEN", "CAG-GEN", "CAG-NGEN"]
}
model_version="databank" # other option is hugging face library
if model_version == "databank":
# Make sure you have downloaded the required model file from https://databank.illinois.edu/datasets/IDB-8882752
# Unzip the file at some model_path (we are using: "databank_model")
model_path = next(Path("databank_model").glob("./*/output/*/model"))
# Assuming you get the following type of structure inside "databank_model"
# 'databank_model/ALL/Sub-task C/output/bert-base-multilingual-uncased/model'
lang, task, _, base_model, _ = model_path.parts
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForSequenceClassification.from_pretrained(model_path)
else:
lang, task, base_model = "ALL", "Sub-task C", "bert-base-multilingual-uncased"
base_model = f"socialmediaie/TRAC2020_{lang}_{lang.split()[-1]}_{base_model}"
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForSequenceClassification.from_pretrained(base_model)
# For doing inference set model in eval mode
model.eval()
# If you want to further fine-tune the model you can reset the model to model.train()
task_labels = TASK_LABEL_IDS[task]
sentence = "This is a good cat and this is a bad dog."
processed_sentence = f"{tokenizer.cls_token} {sentence}"
tokens = tokenizer.tokenize(sentence)
indexed_tokens = tokenizer.convert_tokens_to_ids(tokens)
tokens_tensor = torch.tensor([indexed_tokens])
with torch.no_grad():
logits, = model(tokens_tensor, labels=None)
logits
preds = logits.detach().cpu().numpy()
preds_probs = softmax(preds, axis=1)
preds = np.argmax(preds_probs, axis=1)
preds_labels = np.array(task_labels)[preds]
print(dict(zip(task_labels, preds_probs[0])), preds_labels)
"""You should get an output as follows:
({'CAG-GEN': 0.06762535,
'CAG-NGEN': 0.03244293,
'NAG-GEN': 0.6897794,
'NAG-NGEN': 0.15498641,
'OAG-GEN': 0.034373745,
'OAG-NGEN': 0.020792078},
array(['NAG-GEN'], dtype='<U8'))
"""
```
|
socialmediaie/TRAC2020_ALL_B_bert-base-multilingual-uncased
|
socialmediaie
| 2021-05-20T06:53:23Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# Multilingual Joint Fine-tuning of Transformer models for identifying Trolling, Aggression and Cyberbullying at TRAC 2020
Models and predictions for submission to TRAC - 2020 Second Workshop on Trolling, Aggression and Cyberbullying.
Our trained models as well as evaluation metrics during traing are available at: https://databank.illinois.edu/datasets/IDB-8882752#
We also make a few of our models available in HuggingFace's models repository at https://huggingface.co/socialmediaie/, these models can be further fine-tuned on your dataset of choice.
Our approach is described in our paper titled:
> Mishra, Sudhanshu, Shivangi Prasad, and Shubhanshu Mishra. 2020. "Multilingual Joint Fine-Tuning of Transformer Models for Identifying Trolling, Aggression and Cyberbullying at TRAC 2020." In Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying (TRAC-2020).
The source code for training this model and more details can be found on our code repository: https://github.com/socialmediaie/TRAC2020
NOTE: These models are retrained for uploading here after our submission so the evaluation measures may be slightly different from the ones reported in the paper.
If you plan to use the dataset please cite the following resources:
* Mishra, Sudhanshu, Shivangi Prasad, and Shubhanshu Mishra. 2020. "Multilingual Joint Fine-Tuning of Transformer Models for Identifying Trolling, Aggression and Cyberbullying at TRAC 2020." In Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying (TRAC-2020).
* Mishra, Shubhanshu, Shivangi Prasad, and Shubhanshu Mishra. 2020. “Trained Models for Multilingual Joint Fine-Tuning of Transformer Models for Identifying Trolling, Aggression and Cyberbullying at TRAC 2020.” University of Illinois at Urbana-Champaign. https://doi.org/10.13012/B2IDB-8882752_V1.
```
@inproceedings{Mishra2020TRAC,
author = {Mishra, Sudhanshu and Prasad, Shivangi and Mishra, Shubhanshu},
booktitle = {Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying (TRAC-2020)},
title = {{Multilingual Joint Fine-tuning of Transformer models for identifying Trolling, Aggression and Cyberbullying at TRAC 2020}},
year = {2020}
}
@data{illinoisdatabankIDB-8882752,
author = {Mishra, Shubhanshu and Prasad, Shivangi and Mishra, Shubhanshu},
doi = {10.13012/B2IDB-8882752_V1},
publisher = {University of Illinois at Urbana-Champaign},
title = {{Trained models for Multilingual Joint Fine-tuning of Transformer models for identifying Trolling, Aggression and Cyberbullying at TRAC 2020}},
url = {https://doi.org/10.13012/B2IDB-8882752{\_}V1},
year = {2020}
}
```
## Usage
The models can be used via the following code:
```python
from transformers import AutoModel, AutoTokenizer, AutoModelForSequenceClassification
import torch
from pathlib import Path
from scipy.special import softmax
import numpy as np
import pandas as pd
TASK_LABEL_IDS = {
"Sub-task A": ["OAG", "NAG", "CAG"],
"Sub-task B": ["GEN", "NGEN"],
"Sub-task C": ["OAG-GEN", "OAG-NGEN", "NAG-GEN", "NAG-NGEN", "CAG-GEN", "CAG-NGEN"]
}
model_version="databank" # other option is hugging face library
if model_version == "databank":
# Make sure you have downloaded the required model file from https://databank.illinois.edu/datasets/IDB-8882752
# Unzip the file at some model_path (we are using: "databank_model")
model_path = next(Path("databank_model").glob("./*/output/*/model"))
# Assuming you get the following type of structure inside "databank_model"
# 'databank_model/ALL/Sub-task C/output/bert-base-multilingual-uncased/model'
lang, task, _, base_model, _ = model_path.parts
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForSequenceClassification.from_pretrained(model_path)
else:
lang, task, base_model = "ALL", "Sub-task C", "bert-base-multilingual-uncased"
base_model = f"socialmediaie/TRAC2020_{lang}_{lang.split()[-1]}_{base_model}"
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForSequenceClassification.from_pretrained(base_model)
# For doing inference set model in eval mode
model.eval()
# If you want to further fine-tune the model you can reset the model to model.train()
task_labels = TASK_LABEL_IDS[task]
sentence = "This is a good cat and this is a bad dog."
processed_sentence = f"{tokenizer.cls_token} {sentence}"
tokens = tokenizer.tokenize(sentence)
indexed_tokens = tokenizer.convert_tokens_to_ids(tokens)
tokens_tensor = torch.tensor([indexed_tokens])
with torch.no_grad():
logits, = model(tokens_tensor, labels=None)
logits
preds = logits.detach().cpu().numpy()
preds_probs = softmax(preds, axis=1)
preds = np.argmax(preds_probs, axis=1)
preds_labels = np.array(task_labels)[preds]
print(dict(zip(task_labels, preds_probs[0])), preds_labels)
"""You should get an output as follows:
({'CAG-GEN': 0.06762535,
'CAG-NGEN': 0.03244293,
'NAG-GEN': 0.6897794,
'NAG-NGEN': 0.15498641,
'OAG-GEN': 0.034373745,
'OAG-NGEN': 0.020792078},
array(['NAG-GEN'], dtype='<U8'))
"""
```
|
sismetanin/sbert-ru-sentiment-rusentiment
|
sismetanin
| 2021-05-20T06:38:36Z | 367 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"sentiment analysis",
"Russian",
"ru",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language:
- ru
tags:
- sentiment analysis
- Russian
---
## SBERT-Large-Base-ru-sentiment-RuSentiment
SBERT-Large-ru-sentiment-RuSentiment is a [SBERT-Large](https://huggingface.co/sberbank-ai/sbert_large_nlu_ru) model fine-tuned on [RuSentiment dataset](https://github.com/text-machine-lab/rusentiment) of general-domain Russian-language posts from the largest Russian social network, VKontakte.
<table>
<thead>
<tr>
<th rowspan="4">Model</th>
<th rowspan="4">Score<br></th>
<th rowspan="4">Rank</th>
<th colspan="12">Dataset</th>
</tr>
<tr>
<td colspan="6">SentiRuEval-2016<br></td>
<td colspan="2" rowspan="2">RuSentiment</td>
<td rowspan="2">KRND</td>
<td rowspan="2">LINIS Crowd</td>
<td rowspan="2">RuTweetCorp</td>
<td rowspan="2">RuReviews</td>
</tr>
<tr>
<td colspan="3">TC</td>
<td colspan="3">Banks</td>
</tr>
<tr>
<td>micro F1</td>
<td>macro F1</td>
<td>F1</td>
<td>micro F1</td>
<td>macro F1</td>
<td>F1</td>
<td>wighted</td>
<td>F1</td>
<td>F1</td>
<td>F1</td>
<td>F1</td>
<td>F1</td>
</tr>
</thead>
<tbody>
<tr>
<td>SOTA</td>
<td>n/s</td>
<td></td>
<td>76.71</td>
<td>66.40</td>
<td>70.68</td>
<td>67.51</td>
<td>69.53</td>
<td>74.06</td>
<td>78.50</td>
<td>n/s</td>
<td>73.63</td>
<td>60.51</td>
<td>83.68</td>
<td>77.44</td>
</tr>
<tr>
<td>XLM-RoBERTa-Large</td>
<td>76.37</td>
<td>1</td>
<td>82.26</td>
<td>76.36</td>
<td>79.42</td>
<td>76.35</td>
<td>76.08</td>
<td>80.89</td>
<td>78.31</td>
<td>75.27</td>
<td>75.17</td>
<td>60.03</td>
<td>88.91</td>
<td>78.81</td>
</tr>
<tr>
<td>SBERT-Large</td>
<td>75.43</td>
<td>2</td>
<td>78.40</td>
<td>71.36</td>
<td>75.14</td>
<td>72.39</td>
<td>71.87</td>
<td>77.72</td>
<td>78.58</td>
<td>75.85</td>
<td>74.20</td>
<td>60.64</td>
<td>88.66</td>
<td>77.41</td>
</tr>
<tr>
<td>MBARTRuSumGazeta</td>
<td>74.70</td>
<td>3</td>
<td>76.06</td>
<td>68.95</td>
<td>73.04</td>
<td>72.34</td>
<td>71.93</td>
<td>77.83</td>
<td>76.71</td>
<td>73.56</td>
<td>74.18</td>
<td>60.54</td>
<td>87.22</td>
<td>77.51</td>
</tr>
<tr>
<td>Conversational RuBERT</td>
<td>74.44</td>
<td>4</td>
<td>76.69</td>
<td>69.09</td>
<td>73.11</td>
<td>69.44</td>
<td>68.68</td>
<td>75.56</td>
<td>77.31</td>
<td>74.40</td>
<td>73.10</td>
<td>59.95</td>
<td>87.86</td>
<td>77.78</td>
</tr>
<tr>
<td>LaBSE</td>
<td>74.11</td>
<td>5</td>
<td>77.00</td>
<td>69.19</td>
<td>73.55</td>
<td>70.34</td>
<td>69.83</td>
<td>76.38</td>
<td>74.94</td>
<td>70.84</td>
<td>73.20</td>
<td>59.52</td>
<td>87.89</td>
<td>78.47</td>
</tr>
<tr>
<td>XLM-RoBERTa-Base</td>
<td>73.60</td>
<td>6</td>
<td>76.35</td>
<td>69.37</td>
<td>73.42</td>
<td>68.45</td>
<td>67.45</td>
<td>74.05</td>
<td>74.26</td>
<td>70.44</td>
<td>71.40</td>
<td>60.19</td>
<td>87.90</td>
<td>78.28</td>
</tr>
<tr>
<td>RuBERT</td>
<td>73.45</td>
<td>7</td>
<td>74.03</td>
<td>66.14</td>
<td>70.75</td>
<td>66.46</td>
<td>66.40</td>
<td>73.37</td>
<td>75.49</td>
<td>71.86</td>
<td>72.15</td>
<td>60.55</td>
<td>86.99</td>
<td>77.41</td>
</tr>
<tr>
<td>MBART-50-Large-Many-to-Many</td>
<td>73.15</td>
<td>8</td>
<td>75.38</td>
<td>67.81</td>
<td>72.26</td>
<td>67.13</td>
<td>66.97</td>
<td>73.85</td>
<td>74.78</td>
<td>70.98</td>
<td>71.98</td>
<td>59.20</td>
<td>87.05</td>
<td>77.24</td>
</tr>
<tr>
<td>SlavicBERT</td>
<td>71.96</td>
<td>9</td>
<td>71.45</td>
<td>63.03</td>
<td>68.44</td>
<td>64.32</td>
<td>63.99</td>
<td>71.31</td>
<td>72.13</td>
<td>67.57</td>
<td>72.54</td>
<td>58.70</td>
<td>86.43</td>
<td>77.16</td>
</tr>
<tr>
<td>EnRuDR-BERT</td>
<td>71.51</td>
<td>10</td>
<td>72.56</td>
<td>64.74</td>
<td>69.07</td>
<td>61.44</td>
<td>60.21</td>
<td>68.34</td>
<td>74.19</td>
<td>69.94</td>
<td>69.33</td>
<td>56.55</td>
<td>87.12</td>
<td>77.95</td>
</tr>
<tr>
<td>RuDR-BERT</td>
<td>71.14</td>
<td>11</td>
<td>72.79</td>
<td>64.23</td>
<td>68.36</td>
<td>61.86</td>
<td>60.92</td>
<td>68.48</td>
<td>74.65</td>
<td>70.63</td>
<td>68.74</td>
<td>54.45</td>
<td>87.04</td>
<td>77.91</td>
</tr>
<tr>
<td>MBART-50-Large</td>
<td>69.46</td>
<td>12</td>
<td>70.91</td>
<td>62.67</td>
<td>67.24</td>
<td>61.12</td>
<td>60.25</td>
<td>68.41</td>
<td>72.88</td>
<td>68.63</td>
<td>70.52</td>
<td>46.39</td>
<td>86.48</td>
<td>77.52</td>
</tr>
</tbody>
</table>
The table shows per-task scores and a macro-average of those scores to determine a models’s position on the leaderboard. For datasets with multiple evaluation metrics (e.g., macro F1 and weighted F1 for RuSentiment), we use an unweighted average of the metrics as the score for the task when computing the overall macro-average. The same strategy for comparing models’ results was applied in the GLUE benchmark.
## Citation
If you find this repository helpful, feel free to cite our publication:
```
@article{Smetanin2021Deep,
author = {Sergey Smetanin and Mikhail Komarov},
title = {Deep transfer learning baselines for sentiment analysis in Russian},
journal = {Information Processing & Management},
volume = {58},
number = {3},
pages = {102484},
year = {2021},
issn = {0306-4573},
doi = {0.1016/j.ipm.2020.102484}
}
```
Dataset:
```
@inproceedings{rogers2018rusentiment,
title={RuSentiment: An enriched sentiment analysis dataset for social media in Russian},
author={Rogers, Anna and Romanov, Alexey and Rumshisky, Anna and Volkova, Svitlana and Gronas, Mikhail and Gribov, Alex},
booktitle={Proceedings of the 27th international conference on computational linguistics},
pages={755--763},
year={2018}
}
```
|
sismetanin/sbert-ru-sentiment-krnd
|
sismetanin
| 2021-05-20T06:27:51Z | 16 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"sentiment analysis",
"Russian",
"SBERT-Large",
"ru",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language:
- ru
tags:
- sentiment analysis
- Russian
- SBERT-Large
---
## SBERT-Large on Kaggle Russian News Dataset
<table>
<thead>
<tr>
<th rowspan="4">Model</th>
<th rowspan="4">Score<br></th>
<th rowspan="4">Rank</th>
<th colspan="12">Dataset</th>
</tr>
<tr>
<td colspan="6">SentiRuEval-2016<br></td>
<td colspan="2" rowspan="2">RuSentiment</td>
<td rowspan="2">KRND</td>
<td rowspan="2">LINIS Crowd</td>
<td rowspan="2">RuTweetCorp</td>
<td rowspan="2">RuReviews</td>
</tr>
<tr>
<td colspan="3">TC</td>
<td colspan="3">Banks</td>
</tr>
<tr>
<td>micro F<sub>1</sub></td>
<td>macro F<sub>1</sub></td>
<td>F<sub>1</sub></td>
<td>micro F<sub>1</sub></td>
<td>macro F<sub>1</sub></td>
<td>F<sub>1</sub></td>
<td>wighted F<sub>1</sub></td>
<td>F<sub>1</sub></td>
<td>F<sub>1</sub></td>
<td>F<sub>1</sub></td>
<td>F<sub>1</sub></td>
<td>F<sub>1</sub></td>
</tr>
</thead>
<tbody>
<tr>
<td>SOTA</td>
<td>n/s</td>
<td></td>
<td>76.71</td>
<td>66.40</td>
<td>70.68</td>
<td>67.51</td>
<td>69.53</td>
<td>74.06</td>
<td>78.50</td>
<td>n/s</td>
<td>73.63</td>
<td>60.51</td>
<td>83.68</td>
<td>77.44</td>
</tr>
<tr>
<td>XLM-RoBERTa-Large</td>
<td>76.37</td>
<td>1</td>
<td>82.26</td>
<td>76.36</td>
<td>79.42</td>
<td>76.35</td>
<td>76.08</td>
<td>80.89</td>
<td>78.31</td>
<td>75.27</td>
<td>75.17</td>
<td>60.03</td>
<td>88.91</td>
<td>78.81</td>
</tr>
<tr>
<td>SBERT-Large</td>
<td>75.43</td>
<td>2</td>
<td>78.40</td>
<td>71.36</td>
<td>75.14</td>
<td>72.39</td>
<td>71.87</td>
<td>77.72</td>
<td>78.58</td>
<td>75.85</td>
<td>74.20</td>
<td>60.64</td>
<td>88.66</td>
<td>77.41</td>
</tr>
<tr>
<td>MBARTRuSumGazeta</td>
<td>74.70</td>
<td>3</td>
<td>76.06</td>
<td>68.95</td>
<td>73.04</td>
<td>72.34</td>
<td>71.93</td>
<td>77.83</td>
<td>76.71</td>
<td>73.56</td>
<td>74.18</td>
<td>60.54</td>
<td>87.22</td>
<td>77.51</td>
</tr>
<tr>
<td>Conversational RuBERT</td>
<td>74.44</td>
<td>4</td>
<td>76.69</td>
<td>69.09</td>
<td>73.11</td>
<td>69.44</td>
<td>68.68</td>
<td>75.56</td>
<td>77.31</td>
<td>74.40</td>
<td>73.10</td>
<td>59.95</td>
<td>87.86</td>
<td>77.78</td>
</tr>
<tr>
<td>LaBSE</td>
<td>74.11</td>
<td>5</td>
<td>77.00</td>
<td>69.19</td>
<td>73.55</td>
<td>70.34</td>
<td>69.83</td>
<td>76.38</td>
<td>74.94</td>
<td>70.84</td>
<td>73.20</td>
<td>59.52</td>
<td>87.89</td>
<td>78.47</td>
</tr>
<tr>
<td>XLM-RoBERTa-Base</td>
<td>73.60</td>
<td>6</td>
<td>76.35</td>
<td>69.37</td>
<td>73.42</td>
<td>68.45</td>
<td>67.45</td>
<td>74.05</td>
<td>74.26</td>
<td>70.44</td>
<td>71.40</td>
<td>60.19</td>
<td>87.90</td>
<td>78.28</td>
</tr>
<tr>
<td>RuBERT</td>
<td>73.45</td>
<td>7</td>
<td>74.03</td>
<td>66.14</td>
<td>70.75</td>
<td>66.46</td>
<td>66.40</td>
<td>73.37</td>
<td>75.49</td>
<td>71.86</td>
<td>72.15</td>
<td>60.55</td>
<td>86.99</td>
<td>77.41</td>
</tr>
<tr>
<td>MBART-50-Large-Many-to-Many</td>
<td>73.15</td>
<td>8</td>
<td>75.38</td>
<td>67.81</td>
<td>72.26</td>
<td>67.13</td>
<td>66.97</td>
<td>73.85</td>
<td>74.78</td>
<td>70.98</td>
<td>71.98</td>
<td>59.20</td>
<td>87.05</td>
<td>77.24</td>
</tr>
<tr>
<td>SlavicBERT</td>
<td>71.96</td>
<td>9</td>
<td>71.45</td>
<td>63.03</td>
<td>68.44</td>
<td>64.32</td>
<td>63.99</td>
<td>71.31</td>
<td>72.13</td>
<td>67.57</td>
<td>72.54</td>
<td>58.70</td>
<td>86.43</td>
<td>77.16</td>
</tr>
<tr>
<td>EnRuDR-BERT</td>
<td>71.51</td>
<td>10</td>
<td>72.56</td>
<td>64.74</td>
<td>69.07</td>
<td>61.44</td>
<td>60.21</td>
<td>68.34</td>
<td>74.19</td>
<td>69.94</td>
<td>69.33</td>
<td>56.55</td>
<td>87.12</td>
<td>77.95</td>
</tr>
<tr>
<td>RuDR-BERT</td>
<td>71.14</td>
<td>11</td>
<td>72.79</td>
<td>64.23</td>
<td>68.36</td>
<td>61.86</td>
<td>60.92</td>
<td>68.48</td>
<td>74.65</td>
<td>70.63</td>
<td>68.74</td>
<td>54.45</td>
<td>87.04</td>
<td>77.91</td>
</tr>
<tr>
<td>MBART-50-Large</td>
<td>69.46</td>
<td>12</td>
<td>70.91</td>
<td>62.67</td>
<td>67.24</td>
<td>61.12</td>
<td>60.25</td>
<td>68.41</td>
<td>72.88</td>
<td>68.63</td>
<td>70.52</td>
<td>46.39</td>
<td>86.48</td>
<td>77.52</td>
</tr>
</tbody>
</table>
|
sismetanin/rubert_conversational-ru-sentiment-rusentiment
|
sismetanin
| 2021-05-20T06:22:35Z | 23 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"sentiment analysis",
"Russian",
"ru",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language:
- ru
tags:
- sentiment analysis
- Russian
---
## RuBERT-Conversational-ru-sentiment-RuSentiment
RuBERT-Conversational-ru-sentiment-RuSentiment is a [RuBERT-Conversational](https://huggingface.co/DeepPavlov/rubert-base-cased-conversational) model fine-tuned on [RuSentiment dataset](https://github.com/text-machine-lab/rusentiment) of general-domain Russian-language posts from the largest Russian social network, VKontakte.
<table>
<thead>
<tr>
<th rowspan="4">Model</th>
<th rowspan="4">Score<br></th>
<th rowspan="4">Rank</th>
<th colspan="12">Dataset</th>
</tr>
<tr>
<td colspan="6">SentiRuEval-2016<br></td>
<td colspan="2" rowspan="2">RuSentiment</td>
<td rowspan="2">KRND</td>
<td rowspan="2">LINIS Crowd</td>
<td rowspan="2">RuTweetCorp</td>
<td rowspan="2">RuReviews</td>
</tr>
<tr>
<td colspan="3">TC</td>
<td colspan="3">Banks</td>
</tr>
<tr>
<td>micro F1</td>
<td>macro F1</td>
<td>F1</td>
<td>micro F1</td>
<td>macro F1</td>
<td>F1</td>
<td>wighted</td>
<td>F1</td>
<td>F1</td>
<td>F1</td>
<td>F1</td>
<td>F1</td>
</tr>
</thead>
<tbody>
<tr>
<td>SOTA</td>
<td>n/s</td>
<td></td>
<td>76.71</td>
<td>66.40</td>
<td>70.68</td>
<td>67.51</td>
<td>69.53</td>
<td>74.06</td>
<td>78.50</td>
<td>n/s</td>
<td>73.63</td>
<td>60.51</td>
<td>83.68</td>
<td>77.44</td>
</tr>
<tr>
<td>XLM-RoBERTa-Large</td>
<td>76.37</td>
<td>1</td>
<td>82.26</td>
<td>76.36</td>
<td>79.42</td>
<td>76.35</td>
<td>76.08</td>
<td>80.89</td>
<td>78.31</td>
<td>75.27</td>
<td>75.17</td>
<td>60.03</td>
<td>88.91</td>
<td>78.81</td>
</tr>
<tr>
<td>SBERT-Large</td>
<td>75.43</td>
<td>2</td>
<td>78.40</td>
<td>71.36</td>
<td>75.14</td>
<td>72.39</td>
<td>71.87</td>
<td>77.72</td>
<td>78.58</td>
<td>75.85</td>
<td>74.20</td>
<td>60.64</td>
<td>88.66</td>
<td>77.41</td>
</tr>
<tr>
<td>MBARTRuSumGazeta</td>
<td>74.70</td>
<td>3</td>
<td>76.06</td>
<td>68.95</td>
<td>73.04</td>
<td>72.34</td>
<td>71.93</td>
<td>77.83</td>
<td>76.71</td>
<td>73.56</td>
<td>74.18</td>
<td>60.54</td>
<td>87.22</td>
<td>77.51</td>
</tr>
<tr>
<td>Conversational RuBERT</td>
<td>74.44</td>
<td>4</td>
<td>76.69</td>
<td>69.09</td>
<td>73.11</td>
<td>69.44</td>
<td>68.68</td>
<td>75.56</td>
<td>77.31</td>
<td>74.40</td>
<td>73.10</td>
<td>59.95</td>
<td>87.86</td>
<td>77.78</td>
</tr>
<tr>
<td>LaBSE</td>
<td>74.11</td>
<td>5</td>
<td>77.00</td>
<td>69.19</td>
<td>73.55</td>
<td>70.34</td>
<td>69.83</td>
<td>76.38</td>
<td>74.94</td>
<td>70.84</td>
<td>73.20</td>
<td>59.52</td>
<td>87.89</td>
<td>78.47</td>
</tr>
<tr>
<td>XLM-RoBERTa-Base</td>
<td>73.60</td>
<td>6</td>
<td>76.35</td>
<td>69.37</td>
<td>73.42</td>
<td>68.45</td>
<td>67.45</td>
<td>74.05</td>
<td>74.26</td>
<td>70.44</td>
<td>71.40</td>
<td>60.19</td>
<td>87.90</td>
<td>78.28</td>
</tr>
<tr>
<td>RuBERT</td>
<td>73.45</td>
<td>7</td>
<td>74.03</td>
<td>66.14</td>
<td>70.75</td>
<td>66.46</td>
<td>66.40</td>
<td>73.37</td>
<td>75.49</td>
<td>71.86</td>
<td>72.15</td>
<td>60.55</td>
<td>86.99</td>
<td>77.41</td>
</tr>
<tr>
<td>MBART-50-Large-Many-to-Many</td>
<td>73.15</td>
<td>8</td>
<td>75.38</td>
<td>67.81</td>
<td>72.26</td>
<td>67.13</td>
<td>66.97</td>
<td>73.85</td>
<td>74.78</td>
<td>70.98</td>
<td>71.98</td>
<td>59.20</td>
<td>87.05</td>
<td>77.24</td>
</tr>
<tr>
<td>SlavicBERT</td>
<td>71.96</td>
<td>9</td>
<td>71.45</td>
<td>63.03</td>
<td>68.44</td>
<td>64.32</td>
<td>63.99</td>
<td>71.31</td>
<td>72.13</td>
<td>67.57</td>
<td>72.54</td>
<td>58.70</td>
<td>86.43</td>
<td>77.16</td>
</tr>
<tr>
<td>EnRuDR-BERT</td>
<td>71.51</td>
<td>10</td>
<td>72.56</td>
<td>64.74</td>
<td>69.07</td>
<td>61.44</td>
<td>60.21</td>
<td>68.34</td>
<td>74.19</td>
<td>69.94</td>
<td>69.33</td>
<td>56.55</td>
<td>87.12</td>
<td>77.95</td>
</tr>
<tr>
<td>RuDR-BERT</td>
<td>71.14</td>
<td>11</td>
<td>72.79</td>
<td>64.23</td>
<td>68.36</td>
<td>61.86</td>
<td>60.92</td>
<td>68.48</td>
<td>74.65</td>
<td>70.63</td>
<td>68.74</td>
<td>54.45</td>
<td>87.04</td>
<td>77.91</td>
</tr>
<tr>
<td>MBART-50-Large</td>
<td>69.46</td>
<td>12</td>
<td>70.91</td>
<td>62.67</td>
<td>67.24</td>
<td>61.12</td>
<td>60.25</td>
<td>68.41</td>
<td>72.88</td>
<td>68.63</td>
<td>70.52</td>
<td>46.39</td>
<td>86.48</td>
<td>77.52</td>
</tr>
</tbody>
</table>
The table shows per-task scores and a macro-average of those scores to determine a models’s position on the leaderboard. For datasets with multiple evaluation metrics (e.g., macro F1 and weighted F1 for RuSentiment), we use an unweighted average of the metrics as the score for the task when computing the overall macro-average. The same strategy for comparing models’ results was applied in the GLUE benchmark.
## Citation
If you find this repository helpful, feel free to cite our publication:
```
@article{Smetanin2021Deep,
author = {Sergey Smetanin and Mikhail Komarov},
title = {Deep transfer learning baselines for sentiment analysis in Russian},
journal = {Information Processing & Management},
volume = {58},
number = {3},
pages = {102484},
year = {2021},
issn = {0306-4573},
doi = {0.1016/j.ipm.2020.102484}
}
```
Dataset:
```
@inproceedings{rogers2018rusentiment,
title={RuSentiment: An enriched sentiment analysis dataset for social media in Russian},
author={Rogers, Anna and Romanov, Alexey and Rumshisky, Anna and Volkova, Svitlana and Gronas, Mikhail and Gribov, Alex},
booktitle={Proceedings of the 27th international conference on computational linguistics},
pages={755--763},
year={2018}
}
```
|
sismetanin/rubert-toxic-pikabu-2ch
|
sismetanin
| 2021-05-20T06:16:03Z | 305 | 8 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"toxic comments classification",
"ru",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language:
- ru
tags:
- toxic comments classification
---
## RuBERT-Toxic
RuBERT-Toxic is a [RuBERT](https://huggingface.co/DeepPavlov/rubert-base-cased) model fine-tuned on [Kaggle Russian Language Toxic Comments Dataset](https://www.kaggle.com/blackmoon/russian-language-toxic-comments). You can find a detailed description of the data used and the fine-tuning process in [this article](http://doi.org/10.28995/2075-7182-2020-19-1149-1159). You can also find this information at [GitHub](https://github.com/sismetanin/toxic-comments-detection-in-russian).
| System | P | R | F<sub>1</sub> |
| ------------- | ------------- | ------------- | ------------- |
| MNB-Toxic | 87.01% | 81.22% | 83.21% |
| M-BERT<sub>Base</sub>-Toxic | 91.19% | 91.10% | 91.15% |
| <b>RuBERT-Toxic</b> | <b>91.91%</b> | <b>92.51%</b> | <b>92.20%</b> |
| M-USE<sub>CNN</sub>-Toxic | 89.69% | 90.14% | 89.91% |
| M-USE<sub>Trans</sub>-Toxic | 90.85% | 91.92% | 91.35% |
We fine-tuned two versions of Multilingual Universal Sentence Encoder (M-USE), Multilingual Bidirectional Encoder Representations from Transformers (M-BERT) and RuBERT for toxic comments detection in Russian. Fine-tuned RuBERT-Toxic achieved F<sub>1</sub> = 92.20%, demonstrating the best classification score.
## Toxic Comments Dataset
[Kaggle Russian Language Toxic Comments Dataset](https://www.kaggle.com/blackmoon/russian-language-toxic-comments) is the collection of Russian-language annotated comments from [2ch](https://2ch.hk/) and [Pikabu](https://pikabu.ru/), which was published on Kaggle in 2019. It consists of 14412 comments, where 4826 texts were labelled as toxic, and 9586 were labelled as non-toxic. The average length of comments is ~175 characters; the minimum length is 21, and the maximum is 7403.
## Citation
If you find this repository helpful, feel free to cite our publication:
```
@INPROCEEDINGS{Smetanin2020Toxic,
author={Sergey Smetanin},
booktitle={Computational Linguistics and Intellectual Technologies: Proceedings of the International Conference “Dialogue 2020”},
title={Toxic Comments Detection in Russian},
year={2020},
doi={10.28995/2075-7182-2020-19-1149-1159}
}
```
|
sismetanin/rubert-ru-sentiment-rureviews
|
sismetanin
| 2021-05-20T06:09:59Z | 116 | 2 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"sentiment analysis",
"Russian",
"ru",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language:
- ru
tags:
- sentiment analysis
- Russian
---
## RuBERT-ru-sentiment-RuReviews
RuBERT-ru-sentiment-RuReviews is a [RuBERT](https://huggingface.co/DeepPavlov/rubert-base-cased) model fine-tuned on [RuReviews dataset](https://github.com/sismetanin/rureviews) of Russian-language reviews from the ”Women’s Clothes and Accessories” product category on the primary e-commerce site in Russia.
<table>
<thead>
<tr>
<th rowspan="4">Model</th>
<th rowspan="4">Score<br></th>
<th rowspan="4">Rank</th>
<th colspan="12">Dataset</th>
</tr>
<tr>
<td colspan="6">SentiRuEval-2016<br></td>
<td colspan="2" rowspan="2">RuSentiment</td>
<td rowspan="2">KRND</td>
<td rowspan="2">LINIS Crowd</td>
<td rowspan="2">RuTweetCorp</td>
<td rowspan="2">RuReviews</td>
</tr>
<tr>
<td colspan="3">TC</td>
<td colspan="3">Banks</td>
</tr>
<tr>
<td>micro F1</td>
<td>macro F1</td>
<td>F1</td>
<td>micro F1</td>
<td>macro F1</td>
<td>F1</td>
<td>wighted</td>
<td>F1</td>
<td>F1</td>
<td>F1</td>
<td>F1</td>
<td>F1</td>
</tr>
</thead>
<tbody>
<tr>
<td>SOTA</td>
<td>n/s</td>
<td></td>
<td>76.71</td>
<td>66.40</td>
<td>70.68</td>
<td>67.51</td>
<td>69.53</td>
<td>74.06</td>
<td>78.50</td>
<td>n/s</td>
<td>73.63</td>
<td>60.51</td>
<td>83.68</td>
<td>77.44</td>
</tr>
<tr>
<td>XLM-RoBERTa-Large</td>
<td>76.37</td>
<td>1</td>
<td>82.26</td>
<td>76.36</td>
<td>79.42</td>
<td>76.35</td>
<td>76.08</td>
<td>80.89</td>
<td>78.31</td>
<td>75.27</td>
<td>75.17</td>
<td>60.03</td>
<td>88.91</td>
<td>78.81</td>
</tr>
<tr>
<td>SBERT-Large</td>
<td>75.43</td>
<td>2</td>
<td>78.40</td>
<td>71.36</td>
<td>75.14</td>
<td>72.39</td>
<td>71.87</td>
<td>77.72</td>
<td>78.58</td>
<td>75.85</td>
<td>74.20</td>
<td>60.64</td>
<td>88.66</td>
<td>77.41</td>
</tr>
<tr>
<td>MBARTRuSumGazeta</td>
<td>74.70</td>
<td>3</td>
<td>76.06</td>
<td>68.95</td>
<td>73.04</td>
<td>72.34</td>
<td>71.93</td>
<td>77.83</td>
<td>76.71</td>
<td>73.56</td>
<td>74.18</td>
<td>60.54</td>
<td>87.22</td>
<td>77.51</td>
</tr>
<tr>
<td>Conversational RuBERT</td>
<td>74.44</td>
<td>4</td>
<td>76.69</td>
<td>69.09</td>
<td>73.11</td>
<td>69.44</td>
<td>68.68</td>
<td>75.56</td>
<td>77.31</td>
<td>74.40</td>
<td>73.10</td>
<td>59.95</td>
<td>87.86</td>
<td>77.78</td>
</tr>
<tr>
<td>LaBSE</td>
<td>74.11</td>
<td>5</td>
<td>77.00</td>
<td>69.19</td>
<td>73.55</td>
<td>70.34</td>
<td>69.83</td>
<td>76.38</td>
<td>74.94</td>
<td>70.84</td>
<td>73.20</td>
<td>59.52</td>
<td>87.89</td>
<td>78.47</td>
</tr>
<tr>
<td>XLM-RoBERTa-Base</td>
<td>73.60</td>
<td>6</td>
<td>76.35</td>
<td>69.37</td>
<td>73.42</td>
<td>68.45</td>
<td>67.45</td>
<td>74.05</td>
<td>74.26</td>
<td>70.44</td>
<td>71.40</td>
<td>60.19</td>
<td>87.90</td>
<td>78.28</td>
</tr>
<tr>
<td>RuBERT</td>
<td>73.45</td>
<td>7</td>
<td>74.03</td>
<td>66.14</td>
<td>70.75</td>
<td>66.46</td>
<td>66.40</td>
<td>73.37</td>
<td>75.49</td>
<td>71.86</td>
<td>72.15</td>
<td>60.55</td>
<td>86.99</td>
<td>77.41</td>
</tr>
<tr>
<td>MBART-50-Large-Many-to-Many</td>
<td>73.15</td>
<td>8</td>
<td>75.38</td>
<td>67.81</td>
<td>72.26</td>
<td>67.13</td>
<td>66.97</td>
<td>73.85</td>
<td>74.78</td>
<td>70.98</td>
<td>71.98</td>
<td>59.20</td>
<td>87.05</td>
<td>77.24</td>
</tr>
<tr>
<td>SlavicBERT</td>
<td>71.96</td>
<td>9</td>
<td>71.45</td>
<td>63.03</td>
<td>68.44</td>
<td>64.32</td>
<td>63.99</td>
<td>71.31</td>
<td>72.13</td>
<td>67.57</td>
<td>72.54</td>
<td>58.70</td>
<td>86.43</td>
<td>77.16</td>
</tr>
<tr>
<td>EnRuDR-BERT</td>
<td>71.51</td>
<td>10</td>
<td>72.56</td>
<td>64.74</td>
<td>69.07</td>
<td>61.44</td>
<td>60.21</td>
<td>68.34</td>
<td>74.19</td>
<td>69.94</td>
<td>69.33</td>
<td>56.55</td>
<td>87.12</td>
<td>77.95</td>
</tr>
<tr>
<td>RuDR-BERT</td>
<td>71.14</td>
<td>11</td>
<td>72.79</td>
<td>64.23</td>
<td>68.36</td>
<td>61.86</td>
<td>60.92</td>
<td>68.48</td>
<td>74.65</td>
<td>70.63</td>
<td>68.74</td>
<td>54.45</td>
<td>87.04</td>
<td>77.91</td>
</tr>
<tr>
<td>MBART-50-Large</td>
<td>69.46</td>
<td>12</td>
<td>70.91</td>
<td>62.67</td>
<td>67.24</td>
<td>61.12</td>
<td>60.25</td>
<td>68.41</td>
<td>72.88</td>
<td>68.63</td>
<td>70.52</td>
<td>46.39</td>
<td>86.48</td>
<td>77.52</td>
</tr>
</tbody>
</table>
The table shows per-task scores and a macro-average of those scores to determine a models’s position on the leaderboard. For datasets with multiple evaluation metrics (e.g., macro F1 and weighted F1 for RuSentiment), we use an unweighted average of the metrics as the score for the task when computing the overall macro-average. The same strategy for comparing models’ results was applied in the GLUE benchmark.
## Citation
If you find this repository helpful, feel free to cite our publication:
```
@article{Smetanin2021Deep,
author = {Sergey Smetanin and Mikhail Komarov},
title = {Deep transfer learning baselines for sentiment analysis in Russian},
journal = {Information Processing & Management},
volume = {58},
number = {3},
pages = {102484},
year = {2021},
issn = {0306-4573},
doi = {0.1016/j.ipm.2020.102484}
}
```
Dataset:
```
@INPROCEEDINGS{Smetanin2019Sentiment,
author={Sergey Smetanin and Michail Komarov},
booktitle={2019 IEEE 21st Conference on Business Informatics (CBI)},
title={Sentiment Analysis of Product Reviews in Russian using Convolutional Neural Networks},
year={2019},
volume={01},
pages={482-486},
doi={10.1109/CBI.2019.00062},
ISSN={2378-1963},
month={July}
}
```
|
shoarora/electra-small-owt
|
shoarora
| 2021-05-20T05:54:08Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"feature-extraction",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-03-02T23:29:05Z |
# ELECTRA-small-OWT
This is an unnoficial implementation of an
[ELECTRA](https://openreview.net/forum?id=r1xMH1BtvB) small model, trained on the
[OpenWebText corpus](https://skylion007.github.io/OpenWebTextCorpus/).
Differences from official ELECTRA models:
- we use a `BertForMaskedLM` as the generator and `BertForTokenClassification` as the discriminator
- they use an embedding projection layer, but Bert doesn't have one
## Pretraining ttask

(figure from [Clark et al. 2020](https://openreview.net/pdf?id=r1xMH1BtvB))
ELECTRA uses discriminative LM / replaced-token-detection for pretraining.
This involves a generator (a Masked LM model) creating examples for a discriminator
to classify as original or replaced for each token.
## Usage
```python
from transformers import BertForSequenceClassification, BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
electra = BertForSequenceClassification.from_pretrained('shoarora/electra-small-owt')
```
## Code
The pytorch module that implements this task is available [here](https://github.com/shoarora/lmtuners/blob/master/lmtuners/lightning_modules/discriminative_lm.py).
Further implementation information [here](https://github.com/shoarora/lmtuners/tree/master/experiments/disc_lm_small),
and [here](https://github.com/shoarora/lmtuners/blob/master/experiments/disc_lm_small/train_electra_small.py) is the script that created this model.
This specific model was trained with the following params:
- `batch_size: 512`
- `training_steps: 5e5`
- `warmup_steps: 4e4`
- `learning_rate: 2e-3`
## Downstream tasks
#### GLUE Dev results
| Model | # Params | CoLA | SST | MRPC | STS | QQP | MNLI | QNLI | RTE |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| ELECTRA-Small++ | 14M | 57.0 | 91. | 88.0 | 87.5 | 89.0 | 81.3 | 88.4 | 66.7|
| ELECTRA-Small-OWT | 14M | 56.8 | 88.3| 87.4 | 86.8 | 88.3 | 78.9 | 87.9 | 68.5|
| ELECTRA-Small-OWT (ours) | 17M | 56.3 | 88.4| 75.0 | 86.1 | 89.1 | 77.9 | 83.0 | 67.1|
| ALECTRA-Small-OWT (ours) | 4M | 50.6 | 89.1| 86.3 | 87.2 | 89.1 | 78.2 | 85.9 | 69.6|
- Table initialized from [ELECTRA github repo](https://github.com/google-research/electra)
#### GLUE Test results
| Model | # Params | CoLA | SST | MRPC | STS | QQP | MNLI | QNLI | RTE |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| BERT-Base | 110M | 52.1 | 93.5| 84.8 | 85.9 | 89.2 | 84.6 | 90.5 | 66.4|
| GPT | 117M | 45.4 | 91.3| 75.7 | 80.0 | 88.5 | 82.1 | 88.1 | 56.0|
| ELECTRA-Small++ | 14M | 57.0 | 91.2| 88.0 | 87.5 | 89.0 | 81.3 | 88.4 | 66.7|
| ELECTRA-Small-OWT (ours) | 17M | 57.4 | 89.3| 76.2 | 81.9 | 87.5 | 78.1 | 82.4 | 68.1|
| ALECTRA-Small-OWT (ours) | 4M | 43.9 | 87.9| 82.1 | 82.0 | 87.6 | 77.9 | 85.8 | 67.5|
|
junnyu/bert_chinese_mc_base
|
junnyu
| 2021-05-20T05:28:56Z | 8 | 3 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
https://github.com/alibaba-research/ChineseBLUE
|
sarahlintang/IndoBERT
|
sarahlintang
| 2021-05-20T04:51:45Z | 28 | 2 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"id",
"dataset:oscar",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language: id
datasets:
- oscar
---
# IndoBERT (Indonesian BERT Model)
## Model description
IndoBERT is a pre-trained language model based on BERT architecture for the Indonesian Language.
This model is base-uncased version which use bert-base config.
## Intended uses & limitations
#### How to use
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("sarahlintang/IndoBERT")
model = AutoModel.from_pretrained("sarahlintang/IndoBERT")
tokenizer.encode("hai aku mau makan.")
[2, 8078, 1785, 2318, 1946, 18, 4]
```
## Training data
This model was pre-trained on 16 GB of raw text ~2 B words from Oscar Corpus (https://oscar-corpus.com/).
This model is equal to bert-base model which has 32,000 vocabulary size.
## Training procedure
The training of the model has been performed using Google’s original Tensorflow code on eight core Google Cloud TPU v2.
We used a Google Cloud Storage bucket, for persistent storage of training data and models.
## Eval results
We evaluate this model on three Indonesian NLP downstream task:
- some extractive summarization model
- sentiment analysis
- Part-of-Speech Tagger
it was proven that this model outperforms multilingual BERT for all downstream tasks.
|
rohanrajpal/bert-base-codemixed-uncased-sentiment
|
rohanrajpal
| 2021-05-20T04:32:54Z | 18 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"text-classification",
"hi",
"en",
"codemix",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language:
- hi
- en
tags:
- hi
- en
- codemix
datasets:
- SAIL 2017
---
# Model name
## Model description
I took a bert-base-multilingual-cased model from huggingface and finetuned it on SAIL 2017 dataset.
## Intended uses & limitations
#### How to use
```python
# You can include sample code which will be formatted
#Coming soon!
```
#### Limitations and bias
Provide examples of latent issues and potential remediations.
## Training data
I trained on the SAIL 2017 dataset [link](http://amitavadas.com/SAIL/Data/SAIL_2017.zip) on this [pretrained model](https://huggingface.co/bert-base-multilingual-cased).
## Training procedure
No preprocessing.
## Eval results
### BibTeX entry and citation info
```bibtex
@inproceedings{khanuja-etal-2020-gluecos,
title = "{GLUEC}o{S}: An Evaluation Benchmark for Code-Switched {NLP}",
author = "Khanuja, Simran and
Dandapat, Sandipan and
Srinivasan, Anirudh and
Sitaram, Sunayana and
Choudhury, Monojit",
booktitle = "Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics",
month = jul,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.acl-main.329",
pages = "3575--3585"
}
```
|
redewiedergabe/bert-base-historical-german-rw-cased
|
redewiedergabe
| 2021-05-20T04:11:23Z | 27 | 3 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"fill-mask",
"de",
"arxiv:1508.01991",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: de
---
# Model description
## Dataset
Trained on fictional and non-fictional German texts written between 1840 and 1920:
* Narrative texts from Digitale Bibliothek (https://textgrid.de/digitale-bibliothek)
* Fairy tales and sagas from Grimm Korpus (https://www1.ids-mannheim.de/kl/projekte/korpora/archiv/gri.html)
* Newspaper and magazine article from Mannheimer Korpus Historischer Zeitungen und Zeitschriften (https://repos.ids-mannheim.de/mkhz-beschreibung.html)
* Magazine article from the journal „Die Grenzboten“ (http://www.deutschestextarchiv.de/doku/textquellen#grenzboten)
* Fictional and non-fictional texts from Projekt Gutenberg (https://www.projekt-gutenberg.org)
## Hardware used
1 Tesla P4 GPU
## Hyperparameters
| Parameter | Value |
|-------------------------------|----------|
| Epochs | 3 |
| Gradient_accumulation_steps | 1 |
| Train_batch_size | 32 |
| Learning_rate | 0.00003 |
| Max_seq_len | 128 |
## Evaluation results: Automatic tagging of four forms of speech/thought/writing representation in historical fictional and non-fictional German texts
The language model was used in the task to tag direct, indirect, reported and free indirect speech/thought/writing representation in fictional and non-fictional German texts. The tagger is available and described in detail at https://github.com/redewiedergabe/tagger.
The tagging model was trained using the SequenceTagger Class of the Flair framework ([Akbik et al., 2019](https://www.aclweb.org/anthology/N19-4010)) which implements a BiLSTM-CRF architecture on top of a language embedding (as proposed by [Huang et al. (2015)](https://arxiv.org/abs/1508.01991)).
Hyperparameters
| Parameter | Value |
|-------------------------------|------------|
| Hidden_size | 256 |
| Learning_rate | 0.1 |
| Mini_batch_size | 8 |
| Max_epochs | 150 |
Results are reported below in comparison to a custom trained flair embedding, which was stacked onto a custom trained fastText-model. Both models were trained on the same dataset.
| | BERT ||| FastText+Flair |||Test data|
|----------------|----------|-----------|----------|------|-----------|--------|--------|
| | F1 | Precision | Recall | F1 | Precision | Recall ||
| Direct | 0.80 | 0.86 | 0.74 | 0.84 | 0.90 | 0.79 |historical German, fictional & non-fictional|
| Indirect | **0.76** | **0.79** | **0.73** | 0.73 | 0.78 | 0.68 |historical German, fictional & non-fictional|
| Reported | **0.58** | **0.69** | **0.51** | 0.56 | 0.68 | 0.48 |historical German, fictional & non-fictional|
| Free indirect | **0.57** | **0.80** | **0.44** | 0.47 | 0.78 | 0.34 |modern German, fictional|
## Intended use:
Historical German Texts (1840 to 1920)
(Showed good performance with modern German fictional texts as well)
|
ahmedabdelali/bert-base-qarib60_860k
|
ahmedabdelali
| 2021-05-20T03:48:03Z | 25 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"fill-mask",
"tf",
"bert-base-qarib60_860k",
"qarib",
"ar",
"dataset:arabic_billion_words",
"dataset:open_subtitles",
"dataset:twitter",
"arxiv:2102.10684",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: ar
tags:
- pytorch
- tf
- bert-base-qarib60_860k
- qarib
datasets:
- arabic_billion_words
- open_subtitles
- twitter
metrics:
- f1
widget:
- text: " شو عندكم يا [MASK] ."
---
# QARiB: QCRI Arabic and Dialectal BERT
## About QARiB
QCRI Arabic and Dialectal BERT (QARiB) model, was trained on a collection of ~ 420 Million tweets and ~ 180 Million sentences of text.
For tweets, the data was collected using twitter API and using language filter. `lang:ar`. For text data, it was a combination from
[Arabic GigaWord](url), [Abulkhair Arabic Corpus]() and [OPUS](http://opus.nlpl.eu/).
### bert-base-qarib60_860k
- Data size: 60Gb
- Number of Iterations: 860k
- Loss: 2.2454472
## Training QARiB
The training of the model has been performed using Google’s original Tensorflow code on Google Cloud TPU v2.
We used a Google Cloud Storage bucket, for persistent storage of training data and models.
See more details in [Training QARiB](https://github.com/qcri/QARiB/blob/main/Training_QARiB.md)
## Using QARiB
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to be fine-tuned on a downstream task. See the model hub to look for fine-tuned versions on a task that interests you. For more details, see [Using QARiB](https://github.com/qcri/QARiB/blob/main/Using_QARiB.md)
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>>from transformers import pipeline
>>>fill_mask = pipeline("fill-mask", model="./models/data60gb_86k")
>>> fill_mask("شو عندكم يا [MASK]")
[{'sequence': '[CLS] شو عندكم يا عرب [SEP]', 'score': 0.0990147516131401, 'token': 2355, 'token_str': 'عرب'},
{'sequence': '[CLS] شو عندكم يا جماعة [SEP]', 'score': 0.051633741706609726, 'token': 2308, 'token_str': 'جماعة'},
{'sequence': '[CLS] شو عندكم يا شباب [SEP]', 'score': 0.046871256083250046, 'token': 939, 'token_str': 'شباب'},
{'sequence': '[CLS] شو عندكم يا رفاق [SEP]', 'score': 0.03598872944712639, 'token': 7664, 'token_str': 'رفاق'},
{'sequence': '[CLS] شو عندكم يا ناس [SEP]', 'score': 0.031996358186006546, 'token': 271, 'token_str': 'ناس'}]
>>> fill_mask("قللي وشفيييك يرحم [MASK]")
[{'sequence': '[CLS] قللي وشفيييك يرحم والديك [SEP]', 'score': 0.4152909517288208, 'token': 9650, 'token_str': 'والديك'},
{'sequence': '[CLS] قللي وشفيييك يرحملي [SEP]', 'score': 0.07663793861865997, 'token': 294, 'token_str': '##لي'},
{'sequence': '[CLS] قللي وشفيييك يرحم حالك [SEP]', 'score': 0.0453166700899601, 'token': 2663, 'token_str': 'حالك'},
{'sequence': '[CLS] قللي وشفيييك يرحم امك [SEP]', 'score': 0.04390475153923035, 'token': 1942, 'token_str': 'امك'},
{'sequence': '[CLS] قللي وشفيييك يرحمونك [SEP]', 'score': 0.027349254116415977, 'token': 3283, 'token_str': '##ونك'}]
>>> fill_mask("وقام المدير [MASK]")
[
{'sequence': '[CLS] وقام المدير بالعمل [SEP]', 'score': 0.0678194984793663, 'token': 4230, 'token_str': 'بالعمل'},
{'sequence': '[CLS] وقام المدير بذلك [SEP]', 'score': 0.05191086605191231, 'token': 984, 'token_str': 'بذلك'},
{'sequence': '[CLS] وقام المدير بالاتصال [SEP]', 'score': 0.045264165848493576, 'token': 26096, 'token_str': 'بالاتصال'},
{'sequence': '[CLS] وقام المدير بعمله [SEP]', 'score': 0.03732728958129883, 'token': 40486, 'token_str': 'بعمله'},
{'sequence': '[CLS] وقام المدير بالامر [SEP]', 'score': 0.0246378555893898, 'token': 29124, 'token_str': 'بالامر'}
]
>>> fill_mask("وقامت المديرة [MASK]")
[{'sequence': '[CLS] وقامت المديرة بذلك [SEP]', 'score': 0.23992691934108734, 'token': 984, 'token_str': 'بذلك'},
{'sequence': '[CLS] وقامت المديرة بالامر [SEP]', 'score': 0.108805812895298, 'token': 29124, 'token_str': 'بالامر'},
{'sequence': '[CLS] وقامت المديرة بالعمل [SEP]', 'score': 0.06639821827411652, 'token': 4230, 'token_str': 'بالعمل'},
{'sequence': '[CLS] وقامت المديرة بالاتصال [SEP]', 'score': 0.05613093823194504, 'token': 26096, 'token_str': 'بالاتصال'},
{'sequence': '[CLS] وقامت المديرة المديرة [SEP]', 'score': 0.021778125315904617, 'token': 41635, 'token_str': 'المديرة'}]
```
## Training procedure
The training of the model has been performed using Google’s original Tensorflow code on eight core Google Cloud TPU v2.
We used a Google Cloud Storage bucket, for persistent storage of training data and models.
## Eval results
We evaluated QARiB models on five NLP downstream task:
- Sentiment Analysis
- Emotion Detection
- Named-Entity Recognition (NER)
- Offensive Language Detection
- Dialect Identification
The results obtained from QARiB models outperforms multilingual BERT/AraBERT/ArabicBERT.
## Model Weights and Vocab Download
From Huggingface site: https://huggingface.co/qarib/bert-base-qarib60_860k
## Contacts
Ahmed Abdelali, Sabit Hassan, Hamdy Mubarak, Kareem Darwish and Younes Samih
## Reference
```
@article{abdelali2021pretraining,
title={Pre-Training BERT on Arabic Tweets: Practical Considerations},
author={Ahmed Abdelali and Sabit Hassan and Hamdy Mubarak and Kareem Darwish and Younes Samih},
year={2021},
eprint={2102.10684},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
pin/analytical
|
pin
| 2021-05-20T02:44:25Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"danish",
"sentiment",
"analytical",
"da",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language: da
tags:
- danish
- bert
- sentiment
- analytical
license: cc-by-4.0
widget:
- text: "Jeg synes, det er en elendig film"
---
# Danish BERT fine-tuned for Detecting 'Analytical'
This model detects if a Danish text is 'subjective' or 'objective'.
It is trained and tested on Tweets and texts transcribed from the European Parliament annotated by [Alexandra Institute](https://github.com/alexandrainst). The model is trained with the [`senda`](https://github.com/ebanalyse/senda) package.
Here is an example of how to load the model in PyTorch using the [🤗Transformers](https://github.com/huggingface/transformers) library:
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline
tokenizer = AutoTokenizer.from_pretrained("pin/analytical")
model = AutoModelForSequenceClassification.from_pretrained("pin/analytical")
# create 'senda' sentiment analysis pipeline
analytical_pipeline = pipeline('sentiment-analysis', model=model, tokenizer=tokenizer)
text = "Jeg synes, det er en elendig film"
# in English: 'I think, it is a terrible movie'
analytical_pipeline(text)
```
## Performance
The `senda` model achieves an accuracy of 0.89 and a macro-averaged F1-score of 0.78 on a small test data set, that [Alexandra Institute](https://github.com/alexandrainst/danlp/blob/master/docs/docs/datasets.md#twitter-sentiment) provides. The model can most certainly be improved, and we encourage all NLP-enthusiasts to give it their best shot - you can use the [`senda`](https://github.com/ebanalyse/senda) package to do this.
#### Contact
Feel free to contact author Lars Kjeldgaard on [[email protected]](mailto:[email protected]).
|
phiyodr/bert-base-finetuned-squad2
|
phiyodr
| 2021-05-20T02:34:19Z | 94 | 2 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"question-answering",
"en",
"dataset:squad2",
"arxiv:1810.04805",
"arxiv:1806.03822",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
language: en
tags:
- pytorch
- question-answering
datasets:
- squad2
metrics:
- exact
- f1
widget:
- text: "What discipline did Winkelmann create?"
context: "Johann Joachim Winckelmann was a German art historian and archaeologist. He was a pioneering Hellenist who first articulated the difference between Greek, Greco-Roman and Roman art. The prophet and founding hero of modern archaeology, Winckelmann was one of the founders of scientific archaeology and first applied the categories of style on a large, systematic basis to the history of art."
---
# bert-base-finetuned-squad2
## Model description
This model is based on **[bert-base-uncased](https://huggingface.co/bert-base-uncased)** and was finetuned on **[SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/)**. The corresponding papers you can found [here (model)](https://arxiv.org/abs/1810.04805) and [here (data)](https://arxiv.org/abs/1806.03822).
## How to use
```python
from transformers.pipelines import pipeline
model_name = "phiyodr/bert-base-finetuned-squad2"
nlp = pipeline('question-answering', model=model_name, tokenizer=model_name)
inputs = {
'question': 'What discipline did Winkelmann create?',
'context': 'Johann Joachim Winckelmann was a German art historian and archaeologist. He was a pioneering Hellenist who first articulated the difference between Greek, Greco-Roman and Roman art. "The prophet and founding hero of modern archaeology", Winckelmann was one of the founders of scientific archaeology and first applied the categories of style on a large, systematic basis to the history of art. '
}
nlp(inputs)
```
## Training procedure
```
{
"base_model": "bert-base-uncased",
"do_lower_case": True,
"learning_rate": 3e-5,
"num_train_epochs": 4,
"max_seq_length": 384,
"doc_stride": 128,
"max_query_length": 64,
"batch_size": 96
}
```
## Eval results
- Data: [dev-v2.0.json](https://rajpurkar.github.io/SQuAD-explorer/dataset/dev-v2.0.json)
- Script: [evaluate-v2.0.py](https://worksheets.codalab.org/rest/bundles/0x6b567e1cf2e041ec80d7098f031c5c9e/contents/blob/) (original script from [here](https://github.com/huggingface/transformers/blob/master/examples/question-answering/README.md))
```
{
"exact": 70.3950138970774,
"f1": 73.90527661873521,
"total": 11873,
"HasAns_exact": 71.4574898785425,
"HasAns_f1": 78.48808186475087,
"HasAns_total": 5928,
"NoAns_exact": 69.33557611438184,
"NoAns_f1": 69.33557611438184,
"NoAns_total": 5945
}
```
|
olastor/mcn-en-smm4h
|
olastor
| 2021-05-20T02:11:39Z | 12 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# BERT MCN-Model using SMM4H 2017 (subtask 3) data
The model was trained using [clagator/biobert_v1.1_pubmed_nli_sts](https://huggingface.co/clagator/biobert_v1.1_pubmed_nli_sts) as a base and the smm4h dataset from 2017 from subtask 3.
## Dataset
See [here](https://github.com/olastor/medical-concept-normalization/tree/main/data/smm4h) for the scripts and datasets.
**Attribution**
Sarker, Abeed (2018), “Data and systems for medication-related text classification and concept normalization from Twitter: Insights from the Social Media Mining for Health (SMM4H)-2017 shared task”, Mendeley Data, V2, doi: 10.17632/rxwfb3tysd.2
### Test Results
- Acc: 89.44
- Acc@2: 91.84
- Acc@3: 93.20
- Acc@5: 94.32
- Acc@10: 95.04
Acc@N denotes the accuracy taking the top N predictions of the model into account, not just the first one.
|
neuralmind/bert-large-portuguese-cased
|
neuralmind
| 2021-05-20T01:31:09Z | 222,365 | 66 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"fill-mask",
"pt",
"dataset:brWaC",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: pt
license: mit
tags:
- bert
- pytorch
datasets:
- brWaC
---
# BERTimbau Large (aka "bert-large-portuguese-cased")

## Introduction
BERTimbau Large is a pretrained BERT model for Brazilian Portuguese that achieves state-of-the-art performances on three downstream NLP tasks: Named Entity Recognition, Sentence Textual Similarity and Recognizing Textual Entailment. It is available in two sizes: Base and Large.
For further information or requests, please go to [BERTimbau repository](https://github.com/neuralmind-ai/portuguese-bert/).
## Available models
| Model | Arch. | #Layers | #Params |
| ---------------------------------------- | ---------- | ------- | ------- |
| `neuralmind/bert-base-portuguese-cased` | BERT-Base | 12 | 110M |
| `neuralmind/bert-large-portuguese-cased` | BERT-Large | 24 | 335M |
## Usage
```python
from transformers import AutoTokenizer # Or BertTokenizer
from transformers import AutoModelForPreTraining # Or BertForPreTraining for loading pretraining heads
from transformers import AutoModel # or BertModel, for BERT without pretraining heads
model = AutoModelForPreTraining.from_pretrained('neuralmind/bert-large-portuguese-cased')
tokenizer = AutoTokenizer.from_pretrained('neuralmind/bert-large-portuguese-cased', do_lower_case=False)
```
### Masked language modeling prediction example
```python
from transformers import pipeline
pipe = pipeline('fill-mask', model=model, tokenizer=tokenizer)
pipe('Tinha uma [MASK] no meio do caminho.')
# [{'score': 0.5054386258125305,
# 'sequence': '[CLS] Tinha uma pedra no meio do caminho. [SEP]',
# 'token': 5028,
# 'token_str': 'pedra'},
# {'score': 0.05616172030568123,
# 'sequence': '[CLS] Tinha uma curva no meio do caminho. [SEP]',
# 'token': 9562,
# 'token_str': 'curva'},
# {'score': 0.02348282001912594,
# 'sequence': '[CLS] Tinha uma parada no meio do caminho. [SEP]',
# 'token': 6655,
# 'token_str': 'parada'},
# {'score': 0.01795753836631775,
# 'sequence': '[CLS] Tinha uma mulher no meio do caminho. [SEP]',
# 'token': 2606,
# 'token_str': 'mulher'},
# {'score': 0.015246033668518066,
# 'sequence': '[CLS] Tinha uma luz no meio do caminho. [SEP]',
# 'token': 3377,
# 'token_str': 'luz'}]
```
### For BERT embeddings
```python
import torch
model = AutoModel.from_pretrained('neuralmind/bert-large-portuguese-cased')
input_ids = tokenizer.encode('Tinha uma pedra no meio do caminho.', return_tensors='pt')
with torch.no_grad():
outs = model(input_ids)
encoded = outs[0][0, 1:-1] # Ignore [CLS] and [SEP] special tokens
# encoded.shape: (8, 1024)
# tensor([[ 1.1872, 0.5606, -0.2264, ..., 0.0117, -0.1618, -0.2286],
# [ 1.3562, 0.1026, 0.1732, ..., -0.3855, -0.0832, -0.1052],
# [ 0.2988, 0.2528, 0.4431, ..., 0.2684, -0.5584, 0.6524],
# ...,
# [ 0.3405, -0.0140, -0.0748, ..., 0.6649, -0.8983, 0.5802],
# [ 0.1011, 0.8782, 0.1545, ..., -0.1768, -0.8880, -0.1095],
# [ 0.7912, 0.9637, -0.3859, ..., 0.2050, -0.1350, 0.0432]])
```
## Citation
If you use our work, please cite:
```bibtex
@inproceedings{souza2020bertimbau,
author = {F{\'a}bio Souza and
Rodrigo Nogueira and
Roberto Lotufo},
title = {{BERT}imbau: pretrained {BERT} models for {B}razilian {P}ortuguese},
booktitle = {9th Brazilian Conference on Intelligent Systems, {BRACIS}, Rio Grande do Sul, Brazil, October 20-23 (to appear)},
year = {2020}
}
```
|
nateraw/bert-base-uncased-emotion
|
nateraw
| 2021-05-20T01:18:38Z | 15,657 | 9 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"emotion",
"en",
"dataset:emotion",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language:
- en
thumbnail: https://avatars3.githubusercontent.com/u/32437151?s=460&u=4ec59abc8d21d5feea3dab323d23a5860e6996a4&v=4
tags:
- text-classification
- emotion
- pytorch
license: apache-2.0
datasets:
- emotion
metrics:
- accuracy
---
# bert-base-uncased-emotion
## Model description
`bert-base-uncased` finetuned on the emotion dataset using PyTorch Lightning. Sequence length 128, learning rate 2e-5, batch size 32, 2 GPUs, 4 epochs.
For more details, please see, [the emotion dataset on nlp viewer](https://huggingface.co/nlp/viewer/?dataset=emotion).
#### Limitations and bias
- Not the best model, but it works in a pinch I guess...
- Code not available as I just hacked this together.
- [Follow me on github](https://github.com/nateraw) to get notified when code is made available.
## Training data
Data came from HuggingFace's `datasets` package. The data can be viewed [on nlp viewer](https://huggingface.co/nlp/viewer/?dataset=emotion).
## Training procedure
...
## Eval results
val_acc - 0.931 (useless, as this should be precision/recall/f1)
The score was calculated using PyTorch Lightning metrics.
|
napsternxg/scibert_scivocab_uncased_ft_tv_SDU21_AI
|
napsternxg
| 2021-05-20T01:11:49Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:05Z |
scibert_scivocab_uncased_ft_tv MLM pretrained on SDU21 Task 1 + 2
|
murali1996/bert-base-cased-spell-correction
|
murali1996
| 2021-05-20T01:04:57Z | 36 | 7 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"feature-extraction",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-03-02T23:29:05Z |
`bert-base-cased` trained for spelling correction. See [neuspell](https://github.com/neuspell/neuspell) repository for more details about training and evaluating the model.
|
mrm8488/spanbert-large-finetuned-squadv1
|
mrm8488
| 2021-05-20T00:58:31Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"en",
"arxiv:1907.10529",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language: en
thumbnail:
---
# SpanBERT large fine-tuned on SQuAD v1
[SpanBERT](https://github.com/facebookresearch/SpanBERT) created by [Facebook Research](https://github.com/facebookresearch) and fine-tuned on [SQuAD 1.1](https://rajpurkar.github.io/SQuAD-explorer/explore/1.1/dev/) for **Q&A** downstream task ([by them](https://github.com/facebookresearch/SpanBERT#finetuned-models-squad-1120-relation-extraction-coreference-resolution)).
## Details of SpanBERT
[SpanBERT: Improving Pre-training by Representing and Predicting Spans](https://arxiv.org/abs/1907.10529)
## Details of the downstream task (Q&A) - Dataset 📚 🧐 ❓
[SQuAD1.1](https://rajpurkar.github.io/SQuAD-explorer/)
## Model fine-tuning 🏋️
You can get the fine-tuning script [here](https://github.com/facebookresearch/SpanBERT)
```bash
python code/run_squad.py \
--do_train \
--do_eval \
--model spanbert-large-cased \
--train_file train-v1.1.json \
--dev_file dev-v1.1.json \
--train_batch_size 32 \
--eval_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs 4 \
--max_seq_length 512 \
--doc_stride 128 \
--eval_metric f1 \
--output_dir squad_output \
--fp16
```
## Results Comparison 📝
| | SQuAD 1.1 | SQuAD 2.0 | Coref | TACRED |
| ---------------------- | ------------- | --------- | ------- | ------ |
| | F1 | F1 | avg. F1 | F1 |
| BERT (base) | 88.5* | 76.5* | 73.1 | 67.7 |
| SpanBERT (base) | [92.4*](https://huggingface.co/mrm8488/spanbert-base-finetuned-squadv1) | [83.6*](https://huggingface.co/mrm8488/spanbert-base-finetuned-squadv2) | 77.4 | [68.2](https://huggingface.co/mrm8488/spanbert-base-finetuned-tacred) |
| BERT (large) | 91.3 | 83.3 | 77.1 | 66.4 |
| SpanBERT (large) | **94.6** (this) | [88.7](https://huggingface.co/mrm8488/spanbert-large-finetuned-squadv2) | 79.6 | [70.8](https://huggingface.co/mrm8488/spanbert-large-finetuned-tacred) |
Note: The numbers marked as * are evaluated on the development sets because those models were not submitted to the official SQuAD leaderboard. All the other numbers are test numbers.
## Model in action
Fast usage with **pipelines**:
```python
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="mrm8488/spanbert-large-finetuned-squadv1",
tokenizer="SpanBERT/spanbert-large-cased"
)
qa_pipeline({
'context': "Manuel Romero has been working very hard in the repository hugginface/transformers lately",
'question': "How has been working Manuel Romero lately?"
})
# Output: {'answer': 'very hard in the repository hugginface/transformers',
'end': 82,
'score': 0.327230326857725,
'start': 31}
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/spanbert-base-finetuned-squadv2
|
mrm8488
| 2021-05-20T00:51:05Z | 9 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"en",
"arxiv:1907.10529",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language: en
thumbnail:
---
# SpanBERT base fine-tuned on SQuAD v2
[SpanBERT](https://github.com/facebookresearch/SpanBERT) created by [Facebook Research](https://github.com/facebookresearch) and fine-tuned on [SQuAD 2.0](https://rajpurkar.github.io/SQuAD-explorer/) for **Q&A** downstream task ([by them](https://github.com/facebookresearch/SpanBERT#finetuned-models-squad-1120-relation-extraction-coreference-resolution)).
## Details of SpanBERT
[SpanBERT: Improving Pre-training by Representing and Predicting Spans](https://arxiv.org/abs/1907.10529)
## Details of the downstream task (Q&A) - Dataset 📚 🧐 ❓
[SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) combines the 100,000 questions in SQuAD1.1 with over 50,000 unanswerable questions written adversarially by crowdworkers to look similar to answerable ones. To do well on SQuAD2.0, systems must not only answer questions when possible, but also determine when no answer is supported by the paragraph and abstain from answering.
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| SQuAD2.0 | train | 130k |
| SQuAD2.0 | eval | 12.3k |
## Model fine-tuning 🏋️
You can get the fine-tuning script [here](https://github.com/facebookresearch/SpanBERT)
```bash
python code/run_squad.py \
--do_train \
--do_eval \
--model spanbert-base-cased \
--train_file train-v2.0.json \
--dev_file dev-v2.0.json \
--train_batch_size 32 \
--eval_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs 4 \
--max_seq_length 512 \
--doc_stride 128 \
--eval_metric best_f1 \
--output_dir squad2_output \
--version_2_with_negative \
--fp16
```
## Results Comparison 📝
| | SQuAD 1.1 | SQuAD 2.0 | Coref | TACRED |
| ---------------------- | ------------- | --------- | ------- | ------ |
| | F1 | F1 | avg. F1 | F1 |
| BERT (base) | 88.5 | 76.5 | 73.1 | 67.7 |
| SpanBERT (base) | [92.4](https://huggingface.co/mrm8488/spanbert-base-finetuned-squadv1) | **83.6** (this one) | 77.4 | [68.2](https://huggingface.co/mrm8488/spanbert-base-finetuned-tacred) |
| BERT (large) | 91.3 | 83.3 | 77.1 | 66.4 |
| SpanBERT (large) | [94.6](https://huggingface.co/mrm8488/spanbert-large-finetuned-squadv1) | [88.7](https://huggingface.co/mrm8488/spanbert-large-finetuned-squadv2) | 79.6 | [70.8](https://huggingface.co/mrm8488/spanbert-large-finetuned-tacred) |
Note: The numbers marked as * are evaluated on the development sets because those models were not submitted to the official SQuAD leaderboard. All the other numbers are test numbers.
## Model in action
Fast usage with **pipelines**:
```python
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="mrm8488/spanbert-base-finetuned-squadv2",
tokenizer="SpanBERT/spanbert-base-cased"
)
qa_pipeline({
'context': "Manuel Romero has been working very hard in the repository hugginface/transformers lately",
'question': "How has been working Manuel Romero lately?"
})
# Output: {'answer': 'very hard', 'end': 40, 'score': 0.9052708846768347, 'start': 31}
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/bert-uncased-finetuned-qnli
|
mrm8488
| 2021-05-20T00:42:00Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail:
---
# [BERT](https://huggingface.co/deepset/bert-base-cased-squad2) fine tuned on [QNLI](https://github.com/rhythmcao/QNLI)+ compression ([BERT-of-Theseus](https://github.com/JetRunner/BERT-of-Theseus))
I used a [Bert model fine tuned on **SQUAD v2**](https://huggingface.co/deepset/bert-base-cased-squad2) and then I fine tuned it on **QNLI** using **compression** (with a constant replacing rate) as proposed in **BERT-of-Theseus**
## Details of the downstream task (QNLI):
### Getting the dataset
```bash
wget https://raw.githubusercontent.com/rhythmcao/QNLI/master/data/QNLI/train.tsv
wget https://raw.githubusercontent.com/rhythmcao/QNLI/master/data/QNLI/test.tsv
wget https://raw.githubusercontent.com/rhythmcao/QNLI/master/data/QNLI/dev.tsv
mkdir QNLI_dataset
mv *.tsv QNLI_dataset
```
### Model training
The model was trained on a Tesla P100 GPU and 25GB of RAM with the following command:
```bash
!python /content/BERT-of-Theseus/run_glue.py \
--model_name_or_path deepset/bert-base-cased-squad2 \
--task_name qnli \
--do_train \
--do_eval \
--do_lower_case \
--data_dir /content/QNLI_dataset \
--max_seq_length 128 \
--per_gpu_train_batch_size 32 \
--per_gpu_eval_batch_size 32 \
--learning_rate 2e-5 \
--save_steps 2000 \
--num_train_epochs 50 \
--output_dir /content/ouput_dir \
--evaluate_during_training \
--replacing_rate 0.7 \
--steps_for_replacing 2500
```
## Metrics:
| Model | Accuracy |
|-----------------|------|
| BERT-base | 91.2 |
| BERT-of-Theseus | 88.8 |
| [bert-uncased-finetuned-qnli](https://huggingface.co/mrm8488/bert-uncased-finetuned-qnli) | 87.2
| DistillBERT | 85.3 |
> [See all my models](https://huggingface.co/models?search=mrm8488)
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/bert-small-finetuned-squadv2
|
mrm8488
| 2021-05-20T00:33:09Z | 434 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"question-answering",
"en",
"arxiv:1908.08962",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail:
---
# BERT-Small fine-tuned on SQuAD v2
[BERT-Small](https://github.com/google-research/bert/) created by [Google Research](https://github.com/google-research) and fine-tuned on [SQuAD 2.0](https://rajpurkar.github.io/SQuAD-explorer/) for **Q&A** downstream task.
**Mode size** (after training): **109.74 MB**
## Details of BERT-Small and its 'family' (from their documentation)
Released on March 11th, 2020
This is model is a part of 24 smaller BERT models (English only, uncased, trained with WordPiece masking) referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962).
The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
## Details of the downstream task (Q&A) - Dataset
[SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) combines the 100,000 questions in SQuAD1.1 with over 50,000 unanswerable questions written adversarially by crowdworkers to look similar to answerable ones. To do well on SQuAD2.0, systems must not only answer questions when possible, but also determine when no answer is supported by the paragraph and abstain from answering.
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| SQuAD2.0 | train | 130k |
| SQuAD2.0 | eval | 12.3k |
## Model training
The model was trained on a Tesla P100 GPU and 25GB of RAM.
The script for fine tuning can be found [here](https://github.com/huggingface/transformers/blob/master/examples/question-answering/run_squad.py)
## Results:
| Metric | # Value |
| ------ | --------- |
| **EM** | **60.49** |
| **F1** | **64.21** |
## Comparison:
| Model | EM | F1 score | SIZE (MB) |
| ------------------------------------------------------------------------------------------- | --------- | --------- | --------- |
| [bert-tiny-finetuned-squadv2](https://huggingface.co/mrm8488/bert-tiny-finetuned-squadv2) | 48.60 | 49.73 | **16.74** |
| [bert-mini-finetuned-squadv2](https://huggingface.co/mrm8488/bert-mini-finetuned-squadv2) | 56.31 | 59.65 | 42.63 |
| [bert-small-finetuned-squadv2](https://huggingface.co/mrm8488/bert-small-finetuned-squadv2) | **60.49** | **64.21** | 109.74 |
## Model in action
Fast usage with **pipelines**:
```python
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="mrm8488/bert-small-finetuned-squadv2",
tokenizer="mrm8488/bert-small-finetuned-squadv2"
)
qa_pipeline({
'context': "Manuel Romero has been working hardly in the repository hugginface/transformers lately",
'question': "Who has been working hard for hugginface/transformers lately?"
})
# Output:
```
```json
{
"answer": "Manuel Romero",
"end": 13,
"score": 0.9939319924374637,
"start": 0
}
```
### Yes! That was easy 🎉 Let's try with another example
```python
qa_pipeline({
'context': "Manuel Romero has been working hardly in the repository hugginface/transformers lately",
'question': "For which company has worked Manuel Romero?"
})
# Output:
```
```json
{
"answer": "hugginface/transformers",
"end": 79,
"score": 0.6024888734447131,
"start": 56
}
```
### It works!! 🎉 🎉 🎉
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/bert-multi-uncased-finetuned-xquadv1
|
mrm8488
| 2021-05-20T00:31:20Z | 25 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"question-answering",
"multilingual",
"arxiv:1910.11856",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
language: multilingual
thumbnail:
---
# BERT (base-multilingual-uncased) fine-tuned for multilingual Q&A
This model was created by [Google](https://github.com/google-research/bert/blob/master/multilingual.md) and fine-tuned on [XQuAD](https://github.com/deepmind/xquad) like data for multilingual (`11 different languages`) **Q&A** downstream task.
## Details of the language model('bert-base-multilingual-uncased')
[Language model](https://github.com/google-research/bert/blob/master/multilingual.md)
| Languages | Heads | Layers | Hidden | Params |
| --------- | ----- | ------ | ------ | ------ |
| 102 | 12 | 12 | 768 | 100 M |
## Details of the downstream task (multilingual Q&A) - Dataset
Deepmind [XQuAD](https://github.com/deepmind/xquad)
Languages covered:
- Arabic: `ar`
- German: `de`
- Greek: `el`
- English: `en`
- Spanish: `es`
- Hindi: `hi`
- Russian: `ru`
- Thai: `th`
- Turkish: `tr`
- Vietnamese: `vi`
- Chinese: `zh`
As the dataset is based on SQuAD v1.1, there are no unanswerable questions in the data. We chose this
setting so that models can focus on cross-lingual transfer.
We show the average number of tokens per paragraph, question, and answer for each language in the
table below. The statistics were obtained using [Jieba](https://github.com/fxsjy/jieba) for Chinese
and the [Moses tokenizer](https://github.com/moses-smt/mosesdecoder/blob/master/scripts/tokenizer/tokenizer.perl)
for the other languages.
| | en | es | de | el | ru | tr | ar | vi | th | zh | hi |
| --------- | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| Paragraph | 142.4 | 160.7 | 139.5 | 149.6 | 133.9 | 126.5 | 128.2 | 191.2 | 158.7 | 147.6 | 232.4 |
| Question | 11.5 | 13.4 | 11.0 | 11.7 | 10.0 | 9.8 | 10.7 | 14.8 | 11.5 | 10.5 | 18.7 |
| Answer | 3.1 | 3.6 | 3.0 | 3.3 | 3.1 | 3.1 | 3.1 | 4.5 | 4.1 | 3.5 | 5.6 |
Citation:
<details>
```bibtex
@article{Artetxe:etal:2019,
author = {Mikel Artetxe and Sebastian Ruder and Dani Yogatama},
title = {On the cross-lingual transferability of monolingual representations},
journal = {CoRR},
volume = {abs/1910.11856},
year = {2019},
archivePrefix = {arXiv},
eprint = {1910.11856}
}
```
</details>
As **XQuAD** is just an evaluation dataset, I used `Data augmentation techniques` (scraping, neural machine translation, etc) to obtain more samples and split the dataset in order to have a train and test set. The test set was created in a way that contains the same number of samples for each language. Finally, I got:
| Dataset | # samples |
| ----------- | --------- |
| XQUAD train | 50 K |
| XQUAD test | 8 K |
## Model training
The model was trained on a Tesla P100 GPU and 25GB of RAM.
The script for fine tuning can be found [here](https://github.com/huggingface/transformers/blob/master/examples/distillation/run_squad_w_distillation.py)
## Model in action
Fast usage with **pipelines**:
```python
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="mrm8488/bert-multi-uncased-finetuned-xquadv1",
tokenizer="mrm8488/bert-multi-uncased-finetuned-xquadv1"
)
# context: Coronavirus is seeding panic in the West because it expands so fast.
# question: Where is seeding panic Coronavirus?
qa_pipeline({
'context': "कोरोनावायरस पश्चिम में आतंक बो रहा है क्योंकि यह इतनी तेजी से फैलता है।",
'question': "कोरोनावायरस घबराहट कहां है?"
})
# output: {'answer': 'पश्चिम', 'end': 18, 'score': 0.7037217439689059, 'start': 12}
qa_pipeline({
'context': "Manuel Romero has been working hardly in the repository hugginface/transformers lately",
'question': "Who has been working hard for hugginface/transformers lately?"
})
# output: {'answer': 'Manuel Romero', 'end': 13, 'score': 0.7254485993702389, 'start': 0}
qa_pipeline({
'context': "Manuel Romero a travaillé à peine dans le référentiel hugginface / transformers ces derniers temps",
'question': "Pour quel référentiel a travaillé Manuel Romero récemment?"
})
#output: {'answer': 'hugginface / transformers', 'end': 79, 'score': 0.6482061613915384, 'start': 54}
```
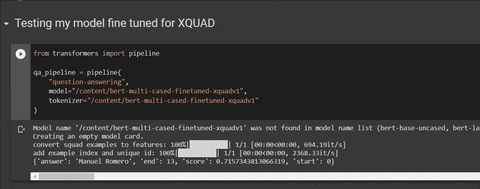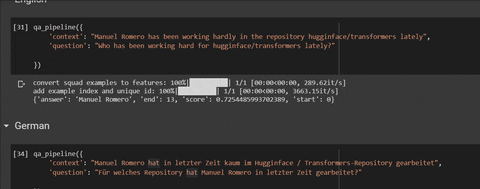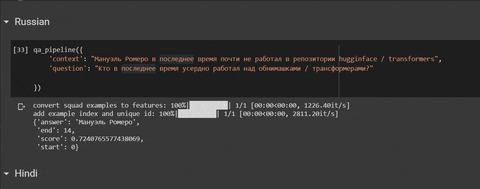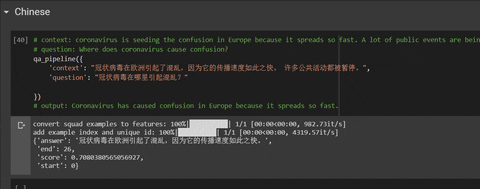
Try it on a Colab:
<a href="https://colab.research.google.com/github/mrm8488/shared_colab_notebooks/blob/master/Try_mrm8488_xquad_finetuned_uncased_model.ipynb" target="_parent"><img src="https://camo.githubusercontent.com/52feade06f2fecbf006889a904d221e6a730c194/68747470733a2f2f636f6c61622e72657365617263682e676f6f676c652e636f6d2f6173736574732f636f6c61622d62616467652e737667" alt="Open In Colab" data-canonical-src="https://colab.research.google.com/assets/colab-badge.svg"></a>
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/bert-medium-finetuned-squadv2
|
mrm8488
| 2021-05-20T00:25:00Z | 1,309 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"question-answering",
"en",
"arxiv:1908.08962",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail:
---
# BERT-Medium fine-tuned on SQuAD v2
[BERT-Medium](https://github.com/google-research/bert/) created by [Google Research](https://github.com/google-research) and fine-tuned on [SQuAD 2.0](https://rajpurkar.github.io/SQuAD-explorer/) for **Q&A** downstream task.
**Mode size** (after training): **157.46 MB**
## Details of BERT-Small and its 'family' (from their documentation)
Released on March 11th, 2020
This is model is a part of 24 smaller BERT models (English only, uncased, trained with WordPiece masking) referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962).
The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
## Details of the downstream task (Q&A) - Dataset
[SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) combines the 100,000 questions in SQuAD1.1 with over 50,000 unanswerable questions written adversarially by crowdworkers to look similar to answerable ones. To do well on SQuAD2.0, systems must not only answer questions when possible, but also determine when no answer is supported by the paragraph and abstain from answering.
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| SQuAD2.0 | train | 130k |
| SQuAD2.0 | eval | 12.3k |
## Model training
The model was trained on a Tesla P100 GPU and 25GB of RAM.
The script for fine tuning can be found [here](https://github.com/huggingface/transformers/blob/master/examples/question-answering/run_squad.py)
## Results:
| Metric | # Value |
| ------ | --------- |
| **EM** | **65.95** |
| **F1** | **70.11** |
### Raw metrics from benchmark included in training script:
```json
{
"exact": 65.95637159942727,
"f1": 70.11632254245896,
"total": 11873,
"HasAns_exact": 67.79689608636977,
"HasAns_f1": 76.12872765631123,
"HasAns_total": 5928,
"NoAns_exact": 64.12111017661901,
"NoAns_f1": 64.12111017661901,
"NoAns_total": 5945,
"best_exact": 65.96479407058031,
"best_exact_thresh": 0.0,
"best_f1": 70.12474501361196,
"best_f1_thresh": 0.0
}
```
## Comparison:
| Model | EM | F1 score | SIZE (MB) |
| --------------------------------------------------------------------------------------------- | --------- | --------- | --------- |
| [bert-tiny-finetuned-squadv2](https://huggingface.co/mrm8488/bert-tiny-finetuned-squadv2) | 48.60 | 49.73 | **16.74** |
| [bert-tiny-5-finetuned-squadv2](https://huggingface.co/mrm8488/bert-tiny-5-finetuned-squadv2) | 57.12 | 60.86 | 24.34 |
| [bert-mini-finetuned-squadv2](https://huggingface.co/mrm8488/bert-mini-finetuned-squadv2) | 56.31 | 59.65 | 42.63 |
| [bert-mini-5-finetuned-squadv2](https://huggingface.co/mrm8488/bert-mini-5-finetuned-squadv2) | 63.51 | 66.78 | 66.76 |
| [bert-small-finetuned-squadv2](https://huggingface.co/mrm8488/bert-small-finetuned-squadv2) | 60.49 | 64.21 | 109.74 |
| [bert-medium-finetuned-squadv2](https://huggingface.co/mrm8488/bert-medium-finetuned-squadv2) | **65.95** | **70.11** | 157.46 |
## Model in action
Fast usage with **pipelines**:
```python
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="mrm8488/bert-small-finetuned-squadv2",
tokenizer="mrm8488/bert-small-finetuned-squadv2"
)
qa_pipeline({
'context': "Manuel Romero has been working hardly in the repository hugginface/transformers lately",
'question': "Who has been working hard for hugginface/transformers lately?"
})
# Output:
```
```json
{
"answer": "Manuel Romero",
"end": 13,
"score": 0.9939319924374637,
"start": 0
}
```
### Yes! That was easy 🎉 Let's try with another example
```python
qa_pipeline({
'context': "Manuel Romero has been working remotely in the repository hugginface/transformers lately",
'question': "How has been working Manuel Romero?"
})
# Output:
```
```json
{ "answer": "remotely", "end": 39, "score": 0.3612058272768017, "start": 31 }
```
### It works!! 🎉 🎉 🎉
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/bert-italian-finedtuned-squadv1-it-alfa
|
mrm8488
| 2021-05-20T00:24:19Z | 327 | 14 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"question-answering",
"it",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
language: it
thumbnail:
---
# Italian BERT fine-tuned on SQuAD_it v1
[Italian BERT base cased](https://huggingface.co/dbmdz/bert-base-italian-cased) fine-tuned on [italian SQuAD](https://github.com/crux82/squad-it) for **Q&A** downstream task.
## Details of Italian BERT
The source data for the Italian BERT model consists of a recent Wikipedia dump and various texts from the OPUS corpora collection. The final training corpus has a size of 13GB and 2,050,057,573 tokens.
For sentence splitting, we use NLTK (faster compared to spacy). Our cased and uncased models are training with an initial sequence length of 512 subwords for ~2-3M steps.
For the XXL Italian models, we use the same training data from OPUS and extend it with data from the Italian part of the OSCAR corpus. Thus, the final training corpus has a size of 81GB and 13,138,379,147 tokens.
More in its official [model card](https://huggingface.co/dbmdz/bert-base-italian-cased)
Created by [Stefan](https://huggingface.co/stefan-it) at [MDZ](https://huggingface.co/dbmdz)
## Details of the downstream task (Q&A) - Dataset 📚 🧐 ❓
[Italian SQuAD v1.1](https://rajpurkar.github.io/SQuAD-explorer/) is derived from the SQuAD dataset and it is obtained through semi-automatic translation of the SQuAD dataset
into Italian. It represents a large-scale dataset for open question answering processes on factoid questions in Italian.
**The dataset contains more than 60,000 question/answer pairs derived from the original English dataset.** The dataset is split into training and test sets to support the replicability of the benchmarking of QA systems:
- `SQuAD_it-train.json`: it contains training examples derived from the original SQuAD 1.1 trainig material.
- `SQuAD_it-test.json`: it contains test/benchmarking examples derived from the origial SQuAD 1.1 development material.
More details about SQuAD-it can be found in [Croce et al. 2018]. The original paper can be found at this [link](https://link.springer.com/chapter/10.1007/978-3-030-03840-3_29).
## Model training 🏋️
The model was trained on a Tesla P100 GPU and 25GB of RAM.
The script for fine tuning can be found [here](https://github.com/huggingface/transformers/blob/master/examples/question-answering/run_squad.py)
## Results 📝
| Metric | # Value |
| ------ | --------- |
| **EM** | **62.51** |
| **F1** | **74.16** |
### Raw metrics
```json
{
"exact": 62.5180707057432,
"f1": 74.16038329042492,
"total": 7609,
"HasAns_exact": 62.5180707057432,
"HasAns_f1": 74.16038329042492,
"HasAns_total": 7609,
"best_exact": 62.5180707057432,
"best_exact_thresh": 0.0,
"best_f1": 74.16038329042492,
"best_f1_thresh": 0.0
}
```
## Comparison ⚖️
| Model | EM | F1 score |
| -------------------------------------------------------------------------------------------------------------------------------- | --------- | --------- |
| [DrQA-it trained on SQuAD-it ](https://github.com/crux82/squad-it/blob/master/README.md#evaluating-a-neural-model-over-squad-it) | 56.1 | 65.9 |
| This one | **62.51** | **74.16** |
## Model in action 🚀
Fast usage with **pipelines** 🧪
```python
from transformers import pipeline
nlp_qa = pipeline(
'question-answering',
model='mrm8488/bert-italian-finedtuned-squadv1-it-alfa',
tokenizer='mrm8488/bert-italian-finedtuned-squadv1-it-alfa'
)
nlp_qa(
{
'question': 'Per quale lingua stai lavorando?',
'context': 'Manuel Romero è colaborando attivamente con HF / trasformatori per il trader del poder de las últimas ' +
'técnicas di procesamiento de lenguaje natural al idioma español'
}
)
# Output: {'answer': 'español', 'end': 174, 'score': 0.9925341537498156, 'start': 168}
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)
> Made with <span style="color: #e25555;">♥</span> in Spain
Dataset citation
<details>
@InProceedings{10.1007/978-3-030-03840-3_29,
author="Croce, Danilo and Zelenanska, Alexandra and Basili, Roberto",
editor="Ghidini, Chiara and Magnini, Bernardo and Passerini, Andrea and Traverso, Paolo",
title="Neural Learning for Question Answering in Italian",
booktitle="AI*IA 2018 -- Advances in Artificial Intelligence",
year="2018",
publisher="Springer International Publishing",
address="Cham",
pages="389--402",
isbn="978-3-030-03840-3"
}
</detail>
|
mrm8488/bert-base-spanish-wwm-cased-finetuned-spa-squad2-es
|
mrm8488
| 2021-05-20T00:22:53Z | 1,390 | 11 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"question-answering",
"es",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
language: es
thumbnail: https://i.imgur.com/jgBdimh.png
---
# BETO (Spanish BERT) + Spanish SQuAD2.0
This model is provided by [BETO team](https://github.com/dccuchile/beto) and fine-tuned on [SQuAD-es-v2.0](https://github.com/ccasimiro88/TranslateAlignRetrieve) for **Q&A** downstream task.
## Details of the language model('dccuchile/bert-base-spanish-wwm-cased')
Language model ([**'dccuchile/bert-base-spanish-wwm-cased'**](https://github.com/dccuchile/beto/blob/master/README.md)):
BETO is a [BERT model](https://github.com/google-research/bert) trained on a [big Spanish corpus](https://github.com/josecannete/spanish-corpora). BETO is of size similar to a BERT-Base and was trained with the Whole Word Masking technique. Below you find Tensorflow and Pytorch checkpoints for the uncased and cased versions, as well as some results for Spanish benchmarks comparing BETO with [Multilingual BERT](https://github.com/google-research/bert/blob/master/multilingual.md) as well as other (not BERT-based) models.
## Details of the downstream task (Q&A) - Dataset
[SQuAD-es-v2.0](https://github.com/ccasimiro88/TranslateAlignRetrieve)
| Dataset | # Q&A |
| ---------------------- | ----- |
| SQuAD2.0 Train | 130 K |
| SQuAD2.0-es-v2.0 | 111 K |
| SQuAD2.0 Dev | 12 K |
| SQuAD-es-v2.0-small Dev| 69 K |
## Model training
The model was trained on a Tesla P100 GPU and 25GB of RAM with the following command:
```bash
export SQUAD_DIR=path/to/nl_squad
python transformers/examples/question-answering/run_squad.py \
--model_type bert \
--model_name_or_path dccuchile/bert-base-spanish-wwm-cased \
--do_train \
--do_eval \
--do_lower_case \
--train_file $SQUAD_DIR/train_nl-v2.0.json \
--predict_file $SQUAD_DIR/dev_nl-v2.0.json \
--per_gpu_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2.0 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /content/model_output \
--save_steps 5000 \
--threads 4 \
--version_2_with_negative
```
## Results:
| Metric | # Value |
| ---------------------- | ----- |
| **Exact** | **76.50**50 |
| **F1** | **86.07**81 |
```json
{
"exact": 76.50501430594491,
"f1": 86.07818773108252,
"total": 69202,
"HasAns_exact": 67.93020719738277,
"HasAns_f1": 82.37912207996466,
"HasAns_total": 45850,
"NoAns_exact": 93.34104145255225,
"NoAns_f1": 93.34104145255225,
"NoAns_total": 23352,
"best_exact": 76.51223953064941,
"best_exact_thresh": 0.0,
"best_f1": 86.08541295578848,
"best_f1_thresh": 0.0
}
```
### Model in action (in a Colab Notebook)
<details>
1. Set the context and ask some questions:

2. Run predictions:

</details>
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/TinyBERT-spanish-uncased-finetuned-ner
|
mrm8488
| 2021-05-20T00:18:21Z | 67 | 3 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"token-classification",
"es",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:05Z |
---
language: es
thumbnail:
---
# Spanish TinyBERT + NER
This model is a fine-tuned on [NER-C](https://www.kaggle.com/nltkdata/conll-corpora) of a [Spanish Tiny Bert](https://huggingface.co/mrm8488/es-tinybert-v1-1) model I created using *distillation* for **NER** downstream task. The **size** of the model is **55MB**
## Details of the downstream task (NER) - Dataset
- [Dataset: CONLL Corpora ES](https://www.kaggle.com/nltkdata/conll-corpora)
I preprocessed the dataset and split it as train / dev (80/20)
| Dataset | # Examples |
| ---------------------- | ----- |
| Train | 8.7 K |
| Dev | 2.2 K |
- [Fine-tune on NER script provided by Huggingface](https://github.com/huggingface/transformers/blob/master/examples/token-classification/run_ner_old.py)
- Labels covered:
```
B-LOC
B-MISC
B-ORG
B-PER
I-LOC
I-MISC
I-ORG
I-PER
O
```
## Metrics on evaluation set:
| Metric | # score |
| :------------------------------------------------------------------------------------: | :-------: |
| F1 | **70.00**
| Precision | **67.83** |
| Recall | **71.46** |
## Comparison:
| Model | # F1 score |Size(MB)|
| :--------------------------------------------------------------------------------------------------------------: | :-------: |:------|
| bert-base-spanish-wwm-cased (BETO) | 88.43 | 421
| [bert-spanish-cased-finetuned-ner](https://huggingface.co/mrm8488/bert-spanish-cased-finetuned-ner) | **90.17** | 420 |
| Best Multilingual BERT | 87.38 | 681 |
|TinyBERT-spanish-uncased-finetuned-ner (this one) | 70.00 | **55** |
## Model in action
Example of usage:
```python
import torch
from transformers import AutoModelForTokenClassification, AutoTokenizer
id2label = {
"0": "B-LOC",
"1": "B-MISC",
"2": "B-ORG",
"3": "B-PER",
"4": "I-LOC",
"5": "I-MISC",
"6": "I-ORG",
"7": "I-PER",
"8": "O"
}
tokenizer = AutoTokenizer.from_pretrained('mrm8488/TinyBERT-spanish-uncased-finetuned-ner')
model = AutoModelForTokenClassification.from_pretrained('mrm8488/TinyBERT-spanish-uncased-finetuned-ner')
text ="Mis amigos están pensando viajar a Londres este verano."
input_ids = torch.tensor(tokenizer.encode(text)).unsqueeze(0)
outputs = model(input_ids)
last_hidden_states = outputs[0]
for m in last_hidden_states:
for index, n in enumerate(m):
if(index > 0 and index <= len(text.split(" "))):
print(text.split(" ")[index-1] + ": " + id2label[str(torch.argmax(n).item())])
'''
Output:
--------
Mis: O
amigos: O
están: O
pensando: O
viajar: O
a: O
Londres: B-LOC
este: O
verano.: O
'''
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
monsoon-nlp/es-seq2seq-gender-decoder
|
monsoon-nlp
| 2021-05-20T00:09:13Z | 6 | 1 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-generation",
"es",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: es
---
# es-seq2seq-gender (decoder)
This is a seq2seq model (decoder half) to "flip" gender in Spanish sentences.
The model can augment your existing Spanish data, or generate counterfactuals
to test a model's decisions (would changing the gender of the subject or speaker change output?).
Intended Examples:
- el profesor viejo => la profesora vieja (article, noun, adjective all flip)
- una actriz => un actor (irregular noun)
- el lingüista => la lingüista (irregular noun)
- la biblioteca => la biblioteca (no person, no flip)
People's names are unchanged in this version, but you can use packages
such as https://pypi.org/project/gender-guesser/
## Sample code
https://colab.research.google.com/drive/1Ta_YkXx93FyxqEu_zJ-W23PjPumMNHe5
```
import torch
from transformers import AutoTokenizer, EncoderDecoderModel
model = EncoderDecoderModel.from_encoder_decoder_pretrained("monsoon-nlp/es-seq2seq-gender-encoder", "monsoon-nlp/es-seq2seq-gender-decoder")
tokenizer = AutoTokenizer.from_pretrained('monsoon-nlp/es-seq2seq-gender-decoder') # all are same as BETO uncased original
input_ids = torch.tensor(tokenizer.encode("la profesora vieja")).unsqueeze(0)
generated = model.generate(input_ids, decoder_start_token_id=model.config.decoder.pad_token_id)
tokenizer.decode(generated.tolist()[0])
> '[PAD] el profesor viejo profesor viejo profesor...'
```
## Training
I originally developed
<a href="https://github.com/MonsoonNLP/el-la">a gender flip Python script</a>
with
<a href="https://huggingface.co/dccuchile/bert-base-spanish-wwm-uncased">BETO</a>,
the Spanish-language BERT from Universidad de Chile,
and spaCy to parse dependencies in sentences.
More about this project: https://medium.com/ai-in-plain-english/gender-bias-in-spanish-bert-1f4d76780617
The seq2seq model is trained on gender-flipped text from that script run on the
<a href="https://huggingface.co/datasets/muchocine">muchocine dataset</a>,
and the first 6,853 lines from the
<a href="https://oscar-corpus.com/">OSCAR corpus</a>
(Spanish ded-duped).
The encoder and decoder started with weights and vocabulary from BETO (uncased).
## Non-binary gender
This model is useful to generate male and female text samples, but falls
short of capturing gender diversity in the world and in the Spanish
language. Some communities prefer the plural -@s to represent
-os and -as, or -e and -es for gender-neutral or mixed-gender plural,
or use fewer gendered professional nouns (la juez and not jueza). This is not yet
embraced by the Royal Spanish Academy
and is not represented in the corpora and tokenizers used to build this project.
This seq2seq project and script could, in the future, help generate more text samples
and prepare NLP models to understand us all better.
#### Sources
- https://www.nytimes.com/2020/04/15/world/americas/argentina-gender-language.html
- https://www.washingtonpost.com/dc-md-va/2019/12/05/teens-argentina-are-leading-charge-gender-neutral-language/?arc404=true
- https://www.theguardian.com/world/2020/jan/19/gender-neutral-language-battle-spain
- https://es.wikipedia.org/wiki/Lenguaje_no_sexista
- https://remezcla.com/culture/argentine-company-re-imagines-little-prince-gender-neutral-language/
|
monsoon-nlp/ar-seq2seq-gender-encoder
|
monsoon-nlp
| 2021-05-19T23:54:14Z | 5 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"feature-extraction",
"ar",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-03-02T23:29:05Z |
---
language: ar
---
# ar-seq2seq-gender (encoder)
This is a seq2seq model (encoder half) to "flip" gender in **first-person** Arabic sentences.
The model can augment your existing Arabic data, or generate counterfactuals
to test a model's decisions (would changing the gender of the subject or speaker change output?).
Intended Examples:
- 'أنا سعيد' <=> 'انا سعيدة'
- 'ركض إلى المتجر' <=> 'ركضت إلى المتجر'
People's names, gender pronouns, gendered words (father, mother), and many other values are currently unchanged by this model. Future versions may be trained on more data.
## Sample Code
```
import torch
from transformers import AutoTokenizer, EncoderDecoderModel
model = EncoderDecoderModel.from_encoder_decoder_pretrained(
"monsoon-nlp/ar-seq2seq-gender-encoder",
"monsoon-nlp/ar-seq2seq-gender-decoder",
min_length=40
)
tokenizer = AutoTokenizer.from_pretrained('monsoon-nlp/ar-seq2seq-gender-decoder') # same as MARBERT original
input_ids = torch.tensor(tokenizer.encode("أنا سعيدة")).unsqueeze(0)
generated = model.generate(input_ids, decoder_start_token_id=model.config.decoder.pad_token_id)
tokenizer.decode(generated.tolist()[0][1 : len(input_ids[0]) - 1])
> 'انا سعيد'
```
https://colab.research.google.com/drive/1S0kE_2WiV82JkqKik_sBW-0TUtzUVmrV?usp=sharing
## Training
I originally developed
<a href="https://github.com/MonsoonNLP/el-la">a gender flip Python script</a>
for Spanish sentences, using
<a href="https://huggingface.co/dccuchile/bert-base-spanish-wwm-uncased">BETO</a>,
and spaCy. More about this project: https://medium.com/ai-in-plain-english/gender-bias-in-spanish-bert-1f4d76780617
The Arabic model encoder and decoder started with weights and vocabulary from
<a href="https://github.com/UBC-NLP/marbert">MARBERT from UBC-NLP</a>,
and was trained on the
<a href="https://camel.abudhabi.nyu.edu/arabic-parallel-gender-corpus/">Arabic Parallel Gender Corpus</a>
from NYU Abu Dhabi. The text is first-person sentences from OpenSubtitles, with parallel
gender-reinflected sentences generated by Arabic speakers.
Training notebook: https://colab.research.google.com/drive/1TuDfnV2gQ-WsDtHkF52jbn699bk6vJZV
## Non-binary gender
This model is useful to generate male and female text samples, but falls
short of capturing gender diversity in the world and in the Arabic
language. This subject is discussed in the bias statement of the
<a href="https://www.aclweb.org/anthology/2020.gebnlp-1.12/">Gender Reinflection paper</a>.
|
moha/mbert_ar_c19
|
moha
| 2021-05-19T23:38:34Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"fill-mask",
"ar",
"arxiv:2105.03143",
"arxiv:2004.04315",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: ar
widget:
- text: "للوقايه من انتشار [MASK]"
---
# mbert_c19: An mbert model pretrained on 1.5 million COVID-19 multi-dialect Arabic tweets
**mBERT COVID-19** [Arxiv URL](https://arxiv.org/pdf/2105.03143.pdf) is a pretrained (fine-tuned) version of the mBERT model (https://huggingface.co/bert-base-multilingual-cased). The pretraining was done using 1.5 million multi-dialect Arabic tweets regarding the COVID-19 pandemic from the “Large Arabic Twitter Dataset on COVID-19” (https://arxiv.org/abs/2004.04315).
The model can achieve better results for the tasks that deal with multi-dialect Arabic tweets in relation to the COVID-19 pandemic.
# Classification results for multiple tasks including fake-news and hate speech detection when using arabert_c19 and mbert_ar_c19:
For more details refer to the paper (link)
| | arabert | mbert | distilbert multi | arabert Covid-19 | mbert Covid-19 |
|------------------------------------|----------|----------|------------------|------------------|----------------|
| Contains hate (Binary) | 0.8346 | 0.6675 | 0.7145 | `0.8649` | 0.8492 |
| Talk about a cure (Binary) | 0.8193 | 0.7406 | 0.7127 | 0.9055 | `0.9176` |
| News or opinion (Binary) | 0.8987 | 0.8332 | 0.8099 | `0.9163` | 0.9116 |
| Contains fake information (Binary) | 0.6415 | 0.5428 | 0.4743 | `0.7739` | 0.7228 |
# Preprocessing
```python
from arabert.preprocess import ArabertPreprocessor
model_name="moha/mbert_ar_c19"
arabert_prep = ArabertPreprocessor(model_name=model_name)
text = "للوقايه من عدم انتشار كورونا عليك اولا غسل اليدين بالماء والصابون وتكون عملية الغسل دقيقه تشمل راحة اليد الأصابع التركيز على الإبهام"
arabert_prep.preprocess(text)
```
# Citation
Please cite as:
``` bibtex
@misc{ameur2021aracovid19mfh,
title={AraCOVID19-MFH: Arabic COVID-19 Multi-label Fake News and Hate Speech Detection Dataset},
author={Mohamed Seghir Hadj Ameur and Hassina Aliane},
year={2021},
eprint={2105.03143},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
# Contacts
**Hadj Ameur**: [Github](https://github.com/MohamedHadjAmeur) | <[email protected]> | <[email protected]>
|
mitra-mir/BERT-Persian-Poetry
|
mitra-mir
| 2021-05-19T23:34:26Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
BERT Language Model Further Pre-trained on Persian Poetry
|
marbogusz/bert-multi-cased-squad_sv
|
marbogusz
| 2021-05-19T23:00:13Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"question-answering",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
Swedish bert multilingual model trained on a machine translated (MS neural translation) SQUAD 1.1 dataset
|
madlag/bert-large-uncased-whole-word-masking-finetuned-squadv2
|
madlag
| 2021-05-19T22:45:40Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"question-answering",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
Used [run.sh](https://huggingface.co/madlag/bert-large-uncased-whole-word-masking-finetuned-squadv2/blob/main/run.sh) used to train using transformers/example/question_answering code.
Evaluation results : F1= 85.85 , a much better result than the original 81.9 from the BERT paper, due to the use of the "whole-word-masking" variation.
```
{
"HasAns_exact": 80.58367071524967,
"HasAns_f1": 86.64594807945029,
"HasAns_total": 5928,
"NoAns_exact": 85.06307821698907,
"NoAns_f1": 85.06307821698907,
"NoAns_total": 5945,
"best_exact": 82.82658131895899,
"best_exact_thresh": 0.0,
"best_f1": 85.85337995578023,
"best_f1_thresh": 0.0,
"epoch": 2.0,
"eval_samples": 12134,
"exact": 82.82658131895899,
"f1": 85.85337995578037,
"total": 11873
}
```
|
madlag/bert-large-uncased-squadv2
|
madlag
| 2021-05-19T22:43:07Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"question-answering",
"arxiv:1810.04805",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
## BERT-large finetuned on squad v2.
F1 on dev (from paper)[https://arxiv.org/pdf/1810.04805v2.pdf] is 81.9, we reach 81.58.
```
{'exact': 78.6321906847469,
'f1': 81.5816656803201,
'total': 11873,
'HasAns_exact': 73.73481781376518,
'HasAns_f1': 79.64222615088413,
'HasAns_total': 5928,
'NoAns_exact': 83.51555929352396,
'NoAns_f1': 83.51555929352396,
'NoAns_total': 5945,
'best_exact': 78.6321906847469,
'best_exact_thresh': 0.0,
'best_f1': 81.58166568032006,
'best_f1_thresh': 0.0,
'epoch': 1.59}
```
```
python run_qa.py \
--model_name_or_path bert-large-uncased \
--dataset_name squad_v2 \
--do_train \
--do_eval \
--save_steps 2500 \
--eval_steps 2500 \
--evaluation_strategy steps \
--per_device_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir bert-large-uncased-squadv2 \
--version_2_with_negative 1
```
|
madlag/bert-large-uncased-mnli
|
madlag
| 2021-05-19T22:40:43Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
## BERT-large finetuned on MNLI.
The [reference finetuned model](https://github.com/google-research/bert) has an accuracy of 86.05, we get 86.7:
```
{'eval_loss': 0.3984006643295288, 'eval_accuracy': 0.8667345899133979}
```
|
madlag/bert-base-uncased-squad1.1-block-sparse-0.32-v1
|
madlag
| 2021-05-19T22:33:45Z | 71 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"bert",
"question-answering",
"bert-base",
"en",
"dataset:squad",
"arxiv:2005.07683",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail:
license: mit
tags:
- question-answering
- bert
- bert-base
datasets:
- squad
metrics:
- squad
widget:
- text: "Where is the Eiffel Tower located?"
context: "The Eiffel Tower is a wrought-iron lattice tower on the Champ de Mars in Paris, France. It is named after the engineer Gustave Eiffel, whose company designed and built the tower."
- text: "Who is Frederic Chopin?"
context: "Frédéric François Chopin, born Fryderyk Franciszek Chopin (1 March 1810 – 17 October 1849), was a Polish composer and virtuoso pianist of the Romantic era who wrote primarily for solo piano."
---
## BERT-base uncased model fine-tuned on SQuAD v1
This model is block sparse: the **linear** layers contains **31.7%** of the original weights.
The model contains **47.0%** of the original weights **overall**.
The training use a modified version of Victor Sanh [Movement Pruning](https://arxiv.org/abs/2005.07683) method.
That means that with the [block-sparse](https://github.com/huggingface/pytorch_block_sparse) runtime it ran **1.12x** faster than an dense networks on the evaluation, at the price of some impact on the accuracy (see below).
This model was fine-tuned from the HuggingFace [BERT](https://www.aclweb.org/anthology/N19-1423/) base uncased checkpoint on [SQuAD1.1](https://rajpurkar.github.io/SQuAD-explorer), and distilled from the equivalent model [csarron/bert-base-uncased-squad-v1](https://huggingface.co/csarron/bert-base-uncased-squad-v1).
This model is case-insensitive: it does not make a difference between english and English.
## Pruning details
A side-effect of the block pruning is that some of the attention heads are completely removed: 80 heads were removed on a total of 144 (55.6%).
Here is a detailed view on how the remaining heads are distributed in the network after pruning.

## Density plot
<script src="/madlag/bert-base-uncased-squad1.1-block-sparse-0.32-v1/raw/main/model_card/density.js" id="79005f4a-723c-4bf8-bc7f-5ad11676be6c"></script>
## Details
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| SQuAD1.1 | train | 90.6K |
| SQuAD1.1 | eval | 11.1k |
### Fine-tuning
- Python: `3.8.5`
- Machine specs:
```CPU: Intel(R) Core(TM) i7-6700K CPU
Memory: 64 GiB
GPUs: 1 GeForce GTX 3090, with 24GiB memory
GPU driver: 455.23.05, CUDA: 11.1
```
### Results
**Pytorch model file size**: `355M` (original BERT: `438M`)
| Metric | # Value | # Original ([Table 2](https://www.aclweb.org/anthology/N19-1423.pdf))|
| ------ | --------- | --------- |
| **EM** | **79.04** | **80.8** |
| **F1** | **86.70** | **88.5** |
## Example Usage
```python
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="madlag/bert-base-uncased-squad1.1-block-sparse-0.32-v1",
tokenizer="madlag/bert-base-uncased-squad1.1-block-sparse-0.32-v1"
)
predictions = qa_pipeline({
'context': "Frédéric François Chopin, born Fryderyk Franciszek Chopin (1 March 1810 – 17 October 1849), was a Polish composer and virtuoso pianist of the Romantic era who wrote primarily for solo piano.",
'question': "Who is Frederic Chopin?",
})
print(predictions)
```
|
madlag/bert-base-uncased-squad1.1-block-sparse-0.20-v1
|
madlag
| 2021-05-19T22:33:15Z | 69 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"bert",
"question-answering",
"bert-base",
"en",
"dataset:squad",
"arxiv:2005.07683",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail:
license: mit
tags:
- question-answering
- bert
- bert-base
datasets:
- squad
metrics:
- squad
widget:
- text: "Where is the Eiffel Tower located?"
context: "The Eiffel Tower is a wrought-iron lattice tower on the Champ de Mars in Paris, France. It is named after the engineer Gustave Eiffel, whose company designed and built the tower."
- text: "Who is Frederic Chopin?"
context: "Frédéric François Chopin, born Fryderyk Franciszek Chopin (1 March 1810 – 17 October 1849), was a Polish composer and virtuoso pianist of the Romantic era who wrote primarily for solo piano."
---
## BERT-base uncased model fine-tuned on SQuAD v1
This model is block sparse: the **linear** layers contains **20.2%** of the original weights.
The model contains **38.1%** of the original weights **overall**.
The training use a modified version of Victor Sanh [Movement Pruning](https://arxiv.org/abs/2005.07683) method.
That means that with the [block-sparse](https://github.com/huggingface/pytorch_block_sparse) runtime it ran **1.39x** faster than an dense networks on the evaluation, at the price of some impact on the accuracy (see below).
This model was fine-tuned from the HuggingFace [BERT](https://www.aclweb.org/anthology/N19-1423/) base uncased checkpoint on [SQuAD1.1](https://rajpurkar.github.io/SQuAD-explorer), and distilled from the equivalent model [csarron/bert-base-uncased-squad-v1](https://huggingface.co/csarron/bert-base-uncased-squad-v1).
This model is case-insensitive: it does not make a difference between english and English.
## Pruning details
A side-effect of the block pruning is that some of the attention heads are completely removed: 90 heads were removed on a total of 144 (62.5%).
Here is a detailed view on how the remaining heads are distributed in the network after pruning.

## Density plot
<script src="/madlag/bert-base-uncased-squad1.1-block-sparse-0.20-v1/raw/main/model_card/density.js" id="ddbad516-679a-400d-9e28-0182fd89b188"></script>
## Details
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| SQuAD1.1 | train | 90.6K |
| SQuAD1.1 | eval | 11.1k |
### Fine-tuning
- Python: `3.8.5`
- Machine specs:
```CPU: Intel(R) Core(TM) i7-6700K CPU
Memory: 64 GiB
GPUs: 1 GeForce GTX 3090, with 24GiB memory
GPU driver: 455.23.05, CUDA: 11.1
```
### Results
**Pytorch model file size**: `347M` (original BERT: `438M`)
| Metric | # Value | # Original ([Table 2](https://www.aclweb.org/anthology/N19-1423.pdf))|
| ------ | --------- | --------- |
| **EM** | **76.98** | **80.8** |
| **F1** | **85.45** | **88.5** |
## Example Usage
```python
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="madlag/bert-base-uncased-squad1.1-block-sparse-0.20-v1",
tokenizer="madlag/bert-base-uncased-squad1.1-block-sparse-0.20-v1"
)
predictions = qa_pipeline({
'context': "Frédéric François Chopin, born Fryderyk Franciszek Chopin (1 March 1810 – 17 October 1849), was a Polish composer and virtuoso pianist of the Romantic era who wrote primarily for solo piano.",
'question': "Who is Frederic Chopin?",
})
print(predictions)
```
|
madlag/bert-base-uncased-squad1.1-block-sparse-0.13-v1
|
madlag
| 2021-05-19T22:32:43Z | 73 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"bert",
"question-answering",
"bert-base",
"en",
"dataset:squad",
"arxiv:2005.07683",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail:
license: mit
tags:
- question-answering
- bert
- bert-base
datasets:
- squad
metrics:
- squad
widget:
- text: "Where is the Eiffel Tower located?"
context: "The Eiffel Tower is a wrought-iron lattice tower on the Champ de Mars in Paris, France. It is named after the engineer Gustave Eiffel, whose company designed and built the tower."
- text: "Who is Frederic Chopin?"
context: "Frédéric François Chopin, born Fryderyk Franciszek Chopin (1 March 1810 – 17 October 1849), was a Polish composer and virtuoso pianist of the Romantic era who wrote primarily for solo piano."
---
## BERT-base uncased model fine-tuned on SQuAD v1
This model is block sparse: the **linear** layers contains **12.5%** of the original weights.
The model contains **32.1%** of the original weights **overall**.
The training use a modified version of Victor Sanh [Movement Pruning](https://arxiv.org/abs/2005.07683) method.
That means that with the [block-sparse](https://github.com/huggingface/pytorch_block_sparse) runtime it ran **1.65x** faster than an dense networks on the evaluation, at the price of some impact on the accuracy (see below).
This model was fine-tuned from the HuggingFace [BERT](https://www.aclweb.org/anthology/N19-1423/) base uncased checkpoint on [SQuAD1.1](https://rajpurkar.github.io/SQuAD-explorer), and distilled from the equivalent model [csarron/bert-base-uncased-squad-v1](https://huggingface.co/csarron/bert-base-uncased-squad-v1).
This model is case-insensitive: it does not make a difference between english and English.
## Pruning details
A side-effect of the block pruning is that some of the attention heads are completely removed: 97 heads were removed on a total of 144 (67.4%).
Here is a detailed view on how the remaining heads are distributed in the network after pruning.

## Density plot
<script src="/madlag/bert-base-uncased-squad1.1-block-sparse-0.13-v1/raw/main/model_card/density.js" id="34ede51e-2375-4d96-99dd-383de82a2d16"></script>
## Details
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| SQuAD1.1 | train | 90.6K |
| SQuAD1.1 | eval | 11.1k |
### Fine-tuning
- Python: `3.8.5`
- Machine specs:
```CPU: Intel(R) Core(TM) i7-6700K CPU
Memory: 64 GiB
GPUs: 1 GeForce GTX 3090, with 24GiB memory
GPU driver: 455.23.05, CUDA: 11.1
```
### Results
**Pytorch model file size**: `342M` (original BERT: `438M`)
| Metric | # Value | # Original ([Table 2](https://www.aclweb.org/anthology/N19-1423.pdf))|
| ------ | --------- | --------- |
| **EM** | **74.39** | **80.8** |
| **F1** | **83.26** | **88.5** |
## Example Usage
```python
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="madlag/bert-base-uncased-squad1.1-block-sparse-0.13-v1",
tokenizer="madlag/bert-base-uncased-squad1.1-block-sparse-0.13-v1"
)
predictions = qa_pipeline({
'context': "Frédéric François Chopin, born Fryderyk Franciszek Chopin (1 March 1810 – 17 October 1849), was a Polish composer and virtuoso pianist of the Romantic era who wrote primarily for solo piano.",
'question': "Who is Frederic Chopin?",
})
print(predictions)
```
|
madlag/bert-base-uncased-squad1.1-block-sparse-0.07-v1
|
madlag
| 2021-05-19T22:31:59Z | 221 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"bert",
"question-answering",
"bert-base",
"en",
"dataset:squad",
"arxiv:2005.07683",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail:
license: mit
tags:
- question-answering
- bert
- bert-base
datasets:
- squad
metrics:
- squad
widget:
- text: "Where is the Eiffel Tower located?"
context: "The Eiffel Tower is a wrought-iron lattice tower on the Champ de Mars in Paris, France. It is named after the engineer Gustave Eiffel, whose company designed and built the tower."
- text: "Who is Frederic Chopin?"
context: "Frédéric François Chopin, born Fryderyk Franciszek Chopin (1 March 1810 – 17 October 1849), was a Polish composer and virtuoso pianist of the Romantic era who wrote primarily for solo piano."
---
## BERT-base uncased model fine-tuned on SQuAD v1
This model is block sparse: the **linear** layers contains **7.5%** of the original weights.
The model contains **28.2%** of the original weights **overall**.
The training use a modified version of Victor Sanh [Movement Pruning](https://arxiv.org/abs/2005.07683) method.
That means that with the [block-sparse](https://github.com/huggingface/pytorch_block_sparse) runtime it ran **1.92x** faster than an dense networks on the evaluation, at the price of some impact on the accuracy (see below).
This model was fine-tuned from the HuggingFace [BERT](https://www.aclweb.org/anthology/N19-1423/) base uncased checkpoint on [SQuAD1.1](https://rajpurkar.github.io/SQuAD-explorer), and distilled from the equivalent model [csarron/bert-base-uncased-squad-v1](https://huggingface.co/csarron/bert-base-uncased-squad-v1).
This model is case-insensitive: it does not make a difference between english and English.
## Pruning details
A side-effect of the block pruning is that some of the attention heads are completely removed: 106 heads were removed on a total of 144 (73.6%).
Here is a detailed view on how the remaining heads are distributed in the network after pruning.

## Density plot
<script src="/madlag/bert-base-uncased-squad1.1-block-sparse-0.07-v1/raw/main/model_card/density.js" id="9301e950-59b1-497b-a2c5-25c24e07b3a0"></script>
## Details
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| SQuAD1.1 | train | 90.6K |
| SQuAD1.1 | eval | 11.1k |
### Fine-tuning
- Python: `3.8.5`
- Machine specs:
```CPU: Intel(R) Core(TM) i7-6700K CPU
Memory: 64 GiB
GPUs: 1 GeForce GTX 3090, with 24GiB memory
GPU driver: 455.23.05, CUDA: 11.1
```
### Results
**Pytorch model file size**: `335M` (original BERT: `438M`)
| Metric | # Value | # Original ([Table 2](https://www.aclweb.org/anthology/N19-1423.pdf))|
| ------ | --------- | --------- |
| **EM** | **71.88** | **80.8** |
| **F1** | **81.36** | **88.5** |
## Example Usage
```python
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="madlag/bert-base-uncased-squad1.1-block-sparse-0.07-v1",
tokenizer="madlag/bert-base-uncased-squad1.1-block-sparse-0.07-v1"
)
predictions = qa_pipeline({
'context': "Frédéric François Chopin, born Fryderyk Franciszek Chopin (1 March 1810 – 17 October 1849), was a Polish composer and virtuoso pianist of the Romantic era who wrote primarily for solo piano.",
'question': "Who is Frederic Chopin?",
})
print(predictions)
```
|
MonoHime/rubert_conversational_cased_sentiment
|
MonoHime
| 2021-05-19T22:26:59Z | 20 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"sentiment",
"text-classification",
"ru",
"dataset:Tatyana/ru_sentiment_dataset",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language:
- ru
tags:
- sentiment
- text-classification
datasets:
- Tatyana/ru_sentiment_dataset
---
# Keras model with ruBERT conversational embedder for Sentiment Analysis
Russian texts sentiment classification.
Model trained on [Tatyana/ru_sentiment_dataset](https://huggingface.co/datasets/Tatyana/ru_sentiment_dataset)
## Labels meaning
0: NEUTRAL
1: POSITIVE
2: NEGATIVE
## How to use
```python
!pip install tensorflow-gpu
!pip install deeppavlov
!python -m deeppavlov install squad_bert
!pip install fasttext
!pip install transformers
!python -m deeppavlov install bert_sentence_embedder
from deeppavlov import build_model
model = build_model(Tatyana/rubert_conversational_cased_sentiment/custom_config.json)
model(["Сегодня хорошая погода", "Я счастлив проводить с тобою время", "Мне нравится эта музыкальная композиция"])
```
|
lordtt13/COVID-SciBERT
|
lordtt13
| 2021-05-19T22:06:01Z | 14 | 2 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"en",
"arxiv:1903.10676",
"autotrain_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: en
inference: false
---
## COVID-SciBERT: A small language modelling expansion of SciBERT, a BERT model trained on scientific text.
### Details of SciBERT
The **SciBERT** model was presented in [SciBERT: A Pretrained Language Model for Scientific Text](https://arxiv.org/abs/1903.10676) by *Iz Beltagy, Kyle Lo, Arman Cohan* and here is the abstract:
Obtaining large-scale annotated data for NLP tasks in the scientific domain is challenging and expensive. We release SciBERT, a pretrained language model based on BERT (Devlin et al., 2018) to address the lack of high-quality, large-scale labeled scientific data. SciBERT leverages unsupervised pretraining on a large multi-domain corpus of scientific publications to improve performance on downstream scientific NLP tasks. We evaluate on a suite of tasks including sequence tagging, sentence classification and dependency parsing, with datasets from a variety of scientific domains. We demonstrate statistically significant improvements over BERT and achieve new state-of-the-art results on several of these tasks.
### Details of the downstream task (Language Modeling) - Dataset 📚
There are actually two datasets that have been used here:
- The original SciBERT model is trained on papers from the corpus of [semanticscholar.org](semanticscholar.org). Corpus size is 1.14M papers, 3.1B tokens. They used the full text of the papers in training, not just abstracts. SciBERT has its own vocabulary (scivocab) that's built to best match the training corpus.
- The expansion is done using the papers present in the [COVID-19 Open Research Dataset Challenge (CORD-19)](https://www.kaggle.com/allen-institute-for-ai/CORD-19-research-challenge). Only the abstracts have been used and vocabulary was pruned and added to the existing scivocab. In response to the COVID-19 pandemic, the White House and a coalition of leading research groups have prepared the COVID-19 Open Research Dataset (CORD-19). CORD-19 is a resource of over 200,000 scholarly articles, including over 100,000 with full text, about COVID-19, SARS-CoV-2, and related coronaviruses. This freely available dataset is provided to the global research community to apply recent advances in natural language processing and other AI techniques to generate new insights in support of the ongoing fight against this infectious disease. There is a growing urgency for these approaches because of the rapid acceleration in new coronavirus literature, making it difficult for the medical research community to keep up.
### Model training
The training script is present [here](https://github.com/lordtt13/word-embeddings/blob/master/COVID-19%20Research%20Data/COVID-SciBERT.ipynb).
### Pipelining the Model
```python
import transformers
model = transformers.AutoModelWithLMHead.from_pretrained('lordtt13/COVID-SciBERT')
tokenizer = transformers.AutoTokenizer.from_pretrained('lordtt13/COVID-SciBERT')
nlp_fill = transformers.pipeline('fill-mask', model = model, tokenizer = tokenizer)
nlp_fill('Coronavirus or COVID-19 can be prevented by a' + nlp_fill.tokenizer.mask_token)
# Output:
# [{'sequence': '[CLS] coronavirus or covid - 19 can be prevented by a combination [SEP]',
# 'score': 0.1719885915517807,
# 'token': 2702},
# {'sequence': '[CLS] coronavirus or covid - 19 can be prevented by a simple [SEP]',
# 'score': 0.054218728095293045,
# 'token': 2177},
# {'sequence': '[CLS] coronavirus or covid - 19 can be prevented by a novel [SEP]',
# 'score': 0.043364267796278,
# 'token': 3045},
# {'sequence': '[CLS] coronavirus or covid - 19 can be prevented by a high [SEP]',
# 'score': 0.03732519596815109,
# 'token': 597},
# {'sequence': '[CLS] coronavirus or covid - 19 can be prevented by a vaccine [SEP]',
# 'score': 0.021863549947738647,
# 'token': 7039}]
```
> Created by [Tanmay Thakur](https://github.com/lordtt13) | [LinkedIn](https://www.linkedin.com/in/tanmay-thakur-6bb5a9154/)
> PS: Still looking for more resources to expand my expansion!
|
loodos/bert-base-turkish-uncased
|
loodos
| 2021-05-19T22:04:30Z | 1,582 | 6 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"tr",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language: tr
---
# Turkish Language Models with Huggingface's Transformers
As R&D Team at Loodos, we release cased and uncased versions of most recent language models for Turkish. More details about pretrained models and evaluations on downstream tasks can be found [here (our repo)](https://github.com/Loodos/turkish-language-models).
# Turkish BERT-Base (uncased)
This is BERT-Base model which has 12 encoder layers with 768 hidden layer size trained on uncased Turkish dataset.
## Usage
Using AutoModel and AutoTokenizer from Transformers, you can import the model as described below.
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("loodos/bert-base-turkish-uncased", do_lower_case=False)
model = AutoModel.from_pretrained("loodos/bert-base-turkish-uncased")
normalizer = TextNormalization()
normalized_text = normalizer.normalize(text, do_lower_case=True, is_turkish=True)
tokenizer.tokenize(normalized_text)
```
### Notes on Tokenizers
Currently, Huggingface's tokenizers (which were written in Python) have a bug concerning letters "ı, i, I, İ" and non-ASCII Turkish specific letters. There are two reasons.
1- Vocabulary and sentence piece model is created with NFC/NFKC normalization but tokenizer uses NFD/NFKD. NFD/NFKD normalization changes text that contains Turkish characters I-ı, İ-i, Ç-ç, Ö-ö, Ş-ş, Ğ-ğ, Ü-ü. This causes wrong tokenization, wrong training and loss of information. Some tokens are never trained.(like "şanlıurfa", "öğün", "çocuk" etc.) NFD/NFKD normalization is not proper for Turkish.
2- Python's default ```string.lower()``` and ```string.upper()``` make the conversions
- "I" and "İ" to 'i'
- 'i' and 'ı' to 'I'
respectively. However, in Turkish, 'I' and 'İ' are two different letters.
We opened an [issue](https://github.com/huggingface/transformers/issues/6680) in Huggingface's github repo about this bug. Until it is fixed, in case you want to train your model with uncased data, we provide a simple text normalization module (`TextNormalization()` in the code snippet above) in our [repo](https://github.com/Loodos/turkish-language-models).
## Details and Contact
You contact us to ask a question, open an issue or give feedback via our github [repo](https://github.com/Loodos/turkish-language-models).
## Acknowledgments
Many thanks to TFRC Team for providing us cloud TPUs on Tensorflow Research Cloud to train our models.
|
loodos/bert-base-turkish-cased
|
loodos
| 2021-05-19T22:03:36Z | 7 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"tr",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language: tr
---
# Turkish Language Models with Huggingface's Transformers
As R&D Team at Loodos, we release cased and uncased versions of most recent language models for Turkish. More details about pretrained models and evaluations on downstream tasks can be found [here (our repo)](https://github.com/Loodos/turkish-language-models).
# Turkish BERT-Base (cased)
This is BERT-Base model which has 12 encoder layers with 768 hidden layer size trained on cased Turkish dataset.
## Usage
Using AutoModel and AutoTokenizer from Transformers, you can import the model as described below.
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("loodos/bert-base-turkish-cased")
model = AutoModel.from_pretrained("loodos/bert-base-turkish-cased")
```
## Details and Contact
You contact us to ask a question, open an issue or give feedback via our github [repo](https://github.com/Loodos/turkish-language-models).
## Acknowledgments
Many thanks to TFRC Team for providing us cloud TPUs on Tensorflow Research Cloud to train our models.
|
lanwuwei/GigaBERT-v4-Arabic-and-English
|
lanwuwei
| 2021-05-19T21:19:13Z | 47 | 5 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"feature-extraction",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-03-02T23:29:05Z |
## GigaBERT-v4
GigaBERT-v4 is a continued pre-training of [GigaBERT-v3](https://huggingface.co/lanwuwei/GigaBERT-v3-Arabic-and-English) on code-switched data, showing improved zero-shot transfer performance from English to Arabic on information extraction (IE) tasks. More details can be found in the following paper:
@inproceedings{lan2020gigabert,
author = {Lan, Wuwei and Chen, Yang and Xu, Wei and Ritter, Alan},
title = {GigaBERT: Zero-shot Transfer Learning from English to Arabic},
booktitle = {Proceedings of The 2020 Conference on Empirical Methods on Natural Language Processing (EMNLP)},
year = {2020}
}
## Download
```
from transformers import *
tokenizer = BertTokenizer.from_pretrained("lanwuwei/GigaBERT-v4-Arabic-and-English", do_lower_case=True)
model = BertForTokenClassification.from_pretrained("lanwuwei/GigaBERT-v4-Arabic-and-English")
```
Here is downloadable link [GigaBERT-v4](https://drive.google.com/drive/u/1/folders/1uFGzMuTOD7iNsmKQYp_zVuvsJwOaIdar).
|
kaesve/BioBERT_patent_reference_extraction
|
kaesve
| 2021-05-19T20:58:49Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"fill-mask",
"arxiv:2101.01039",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# Reference extraction in patents
This repository contains a finetuned BioBERT model that can extract references to scientific literature from patents.
See https://github.com/kaesve/patent-citation-extraction and https://arxiv.org/abs/2101.01039 for more information.
|
kaesve/BERT_patent_reference_extraction
|
kaesve
| 2021-05-19T20:57:51Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"fill-mask",
"arxiv:2101.01039",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# Reference extraction in patents
This repository contains a finetuned BERT model that can extract references to scientific literature from patents.
See https://github.com/kaesve/patent-citation-extraction and https://arxiv.org/abs/2101.01039 for more information.
|
joelniklaus/gbert-base-ler
|
joelniklaus
| 2021-05-19T20:51:41Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:05Z |
# gbert-base-ler
Task: ler
Base Model: deepset/gbert-base
Trained for 3 epochs
Batch-size: 6
Seed: 42
Test F1-Score: 0.956
|
joelniklaus/bert-base-uncased-sem_eval_2010_task_8
|
joelniklaus
| 2021-05-19T20:50:51Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# bert-base-uncased-sem_eval_2010_task_8
Task: sem_eval_2010_task_8
Base Model: bert-base-uncased
Trained for 3 epochs
Batch-size: 6
Seed: 42
Test F1-Score: 0.8
|
jeniya/BERTOverflow
|
jeniya
| 2021-05-19T20:47:17Z | 231 | 8 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"feature-extraction",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-03-02T23:29:05Z |
# BERTOverflow
## Model description
We pre-trained BERT-base model on 152 million sentences from the StackOverflow's 10 year archive. More details of this model can be found in our ACL 2020 paper: [Code and Named Entity Recognition in StackOverflow](https://www.aclweb.org/anthology/2020.acl-main.443/). We would like to thank [Wuwei Lan](https://lanwuwei.github.io/) for helping us in training this model.
#### How to use
```python
from transformers import *
import torch
tokenizer = AutoTokenizer.from_pretrained("jeniya/BERTOverflow")
model = AutoModelForTokenClassification.from_pretrained("jeniya/BERTOverflow")
```
### BibTeX entry and citation info
```bibtex
@inproceedings{tabassum2020code,
title={Code and Named Entity Recognition in StackOverflow},
author={Tabassum, Jeniya and Maddela, Mounica and Xu, Wei and Ritter, Alan },
booktitle = {Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL)},
url={https://www.aclweb.org/anthology/2020.acl-main.443/}
year = {2020},
}
```
|
jannesg/bertsson
|
jannesg
| 2021-05-19T20:36:10Z | 6 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"sv",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language: sv
---
# BERTSSON Models
The models are trained on:
- Government Text
- Swedish Literature
- Swedish News
Corpus size: Roughly 6B tokens.
The following models are currently available:
- **bertsson** - A BERT base model trained with the same hyperparameters as first published by Google.
All models are cased and trained with whole word masking.
Stay tuned for evaluations.
|
jakelever/coronabert
|
jakelever
| 2021-05-19T20:34:36Z | 14 | 3 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"text-classification",
"coronavirus",
"covid",
"bionlp",
"en",
"dataset:cord19",
"dataset:pubmed",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://coronacentral.ai/logo-with-name.png?1
tags:
- coronavirus
- covid
- bionlp
datasets:
- cord19
- pubmed
license: mit
widget:
- text: "Pre-existing T-cell immunity to SARS-CoV-2 in unexposed healthy controls in Ecuador, as detected with a COVID-19 Interferon-Gamma Release Assay."
- text: "Lifestyle and mental health disruptions during COVID-19."
- text: "More than 50 Long-term effects of COVID-19: a systematic review and meta-analysis"
---
# CoronaCentral BERT Model for Topic / Article Type Classification
This is the topic / article type multi-label classification for the [CoronaCentral website](https://coronacentral.ai). This forms part of the pipeline for downloading and processing coronavirus literature described in the [corona-ml repo](https://github.com/jakelever/corona-ml) with available [step-by-step descriptions](https://github.com/jakelever/corona-ml/blob/master/stepByStep.md). The method is described in the [preprint](https://doi.org/10.1101/2020.12.21.423860) and detailed performance results can be found in the [machine learning details](https://github.com/jakelever/corona-ml/blob/master/machineLearningDetails.md) document.
This model was derived by fine-tuning the [microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract](https://huggingface.co/microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract) model on this coronavirus sequence (document) classification task.
## Usage
Below are two Google Colab notebooks with example usage of this sequence classification model using HuggingFace transformers and KTrain.
- [HuggingFace example on Google Colab](https://colab.research.google.com/drive/1cBNgKd4o6FNWwjKXXQQsC_SaX1kOXDa4?usp=sharing)
- [KTrain example on Google Colab](https://colab.research.google.com/drive/1h7oJa2NDjnBEoox0D5vwXrxiCHj3B1kU?usp=sharing)
## Training Data
The model is trained on ~3200 manually-curated articles sampled at various stages during the coronavirus pandemic. The code for training is available in the [category\_prediction](https://github.com/jakelever/corona-ml/tree/master/category_prediction) directory of the main Github Repo. The data is available in the [annotated_documents.json.gz](https://github.com/jakelever/corona-ml/blob/master/category_prediction/annotated_documents.json.gz) file.
## Inputs and Outputs
The model takes in a tokenized title and abstract (combined into a single string and separated by a new line). The outputs are topics and article types, broadly called categories in the pipeline code. The types are listed below. Some others are managed by hand-coded rules described in the [step-by-step descriptions](https://github.com/jakelever/corona-ml/blob/master/stepByStep.md).
### List of Article Types
- Comment/Editorial
- Meta-analysis
- News
- Review
### List of Topics
- Clinical Reports
- Communication
- Contact Tracing
- Diagnostics
- Drug Targets
- Education
- Effect on Medical Specialties
- Forecasting & Modelling
- Health Policy
- Healthcare Workers
- Imaging
- Immunology
- Inequality
- Infection Reports
- Long Haul
- Medical Devices
- Misinformation
- Model Systems & Tools
- Molecular Biology
- Non-human
- Non-medical
- Pediatrics
- Prevalence
- Prevention
- Psychology
- Recommendations
- Risk Factors
- Surveillance
- Therapeutics
- Transmission
- Vaccines
|
ishan/bert-base-uncased-mnli
|
ishan
| 2021-05-19T20:32:21Z | 3,458 | 2 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"en",
"dataset:MNLI",
"arxiv:1810.04805",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail:
tags:
- pytorch
- text-classification
datasets:
- MNLI
---
# bert-base-uncased finetuned on MNLI
## Model Details and Training Data
We used the pretrained model from [bert-base-uncased](https://huggingface.co/bert-base-uncased) and finetuned it on [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/) dataset.
The training parameters were kept the same as [Devlin et al., 2019](https://arxiv.org/abs/1810.04805) (learning rate = 2e-5, training epochs = 3, max_sequence_len = 128 and batch_size = 32).
## Evaluation Results
The evaluation results are mentioned in the table below.
| Test Corpus | Accuracy |
|:---:|:---------:|
| Matched | 0.8456 |
| Mismatched | 0.8484 |
|
ipuneetrathore/bert-base-cased-finetuned-finBERT
|
ipuneetrathore
| 2021-05-19T20:30:58Z | 14 | 2 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
## FinBERT
Code for importing and using this model is available [here](https://github.com/ipuneetrathore/BERT_models)
|
huawei-noah/DynaBERT_SST-2
|
huawei-noah
| 2021-05-19T20:03:01Z | 5 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:2004.04037",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
## DynaBERT: Dynamic BERT with Adaptive Width and Depth
* DynaBERT can flexibly adjust the size and latency by selecting adaptive width and depth, and
the subnetworks of it have competitive performances as other similar-sized compressed models.
The training process of DynaBERT includes first training a width-adaptive BERT and then
allowing both adaptive width and depth using knowledge distillation.
* This code is modified based on the repository developed by Hugging Face: [Transformers v2.1.1](https://github.com/huggingface/transformers/tree/v2.1.1), and is released in [GitHub](https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/DynaBERT).
### Reference
Lu Hou, Zhiqi Huang, Lifeng Shang, Xin Jiang, Xiao Chen, Qun Liu.
[DynaBERT: Dynamic BERT with Adaptive Width and Depth](https://arxiv.org/abs/2004.04037).
```
@inproceedings{hou2020dynabert,
title = {DynaBERT: Dynamic BERT with Adaptive Width and Depth},
author = {Lu Hou, Zhiqi Huang, Lifeng Shang, Xin Jiang, Xiao Chen, Qun Liu},
booktitle = {Advances in Neural Information Processing Systems},
year = {2020}
}
```
|
huawei-noah/DynaBERT_MNLI
|
huawei-noah
| 2021-05-19T20:02:03Z | 1 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:2004.04037",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
## DynaBERT: Dynamic BERT with Adaptive Width and Depth
* DynaBERT can flexibly adjust the size and latency by selecting adaptive width and depth, and
the subnetworks of it have competitive performances as other similar-sized compressed models.
The training process of DynaBERT includes first training a width-adaptive BERT and then
allowing both adaptive width and depth using knowledge distillation.
* This code is modified based on the repository developed by Hugging Face: [Transformers v2.1.1](https://github.com/huggingface/transformers/tree/v2.1.1), and is released in [GitHub](https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/DynaBERT).
### Reference
Lu Hou, Zhiqi Huang, Lifeng Shang, Xin Jiang, Xiao Chen, Qun Liu.
[DynaBERT: Dynamic BERT with Adaptive Width and Depth](https://arxiv.org/abs/2004.04037).
```
@inproceedings{hou2020dynabert,
title = {DynaBERT: Dynamic BERT with Adaptive Width and Depth},
author = {Lu Hou, Zhiqi Huang, Lifeng Shang, Xin Jiang, Xiao Chen, Qun Liu},
booktitle = {Advances in Neural Information Processing Systems},
year = {2020}
}
```
|
hfl/rbtl3
|
hfl
| 2021-05-19T19:22:46Z | 39 | 3 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"zh",
"arxiv:1906.08101",
"arxiv:2004.13922",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language:
- zh
tags:
- bert
license: "apache-2.0"
---
# This is a re-trained 3-layer RoBERTa-wwm-ext-large model.
## Chinese BERT with Whole Word Masking
For further accelerating Chinese natural language processing, we provide **Chinese pre-trained BERT with Whole Word Masking**.
**[Pre-Training with Whole Word Masking for Chinese BERT](https://arxiv.org/abs/1906.08101)**
Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Ziqing Yang, Shijin Wang, Guoping Hu
This repository is developed based on:https://github.com/google-research/bert
You may also interested in,
- Chinese BERT series: https://github.com/ymcui/Chinese-BERT-wwm
- Chinese MacBERT: https://github.com/ymcui/MacBERT
- Chinese ELECTRA: https://github.com/ymcui/Chinese-ELECTRA
- Chinese XLNet: https://github.com/ymcui/Chinese-XLNet
- Knowledge Distillation Toolkit - TextBrewer: https://github.com/airaria/TextBrewer
More resources by HFL: https://github.com/ymcui/HFL-Anthology
## Citation
If you find the technical report or resource is useful, please cite the following technical report in your paper.
- Primary: https://arxiv.org/abs/2004.13922
```
@inproceedings{cui-etal-2020-revisiting,
title = "Revisiting Pre-Trained Models for {C}hinese Natural Language Processing",
author = "Cui, Yiming and
Che, Wanxiang and
Liu, Ting and
Qin, Bing and
Wang, Shijin and
Hu, Guoping",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.58",
pages = "657--668",
}
```
- Secondary: https://arxiv.org/abs/1906.08101
```
@article{chinese-bert-wwm,
title={Pre-Training with Whole Word Masking for Chinese BERT},
author={Cui, Yiming and Che, Wanxiang and Liu, Ting and Qin, Bing and Yang, Ziqing and Wang, Shijin and Hu, Guoping},
journal={arXiv preprint arXiv:1906.08101},
year={2019}
}
```
|
hfl/rbt6
|
hfl
| 2021-05-19T19:22:02Z | 224 | 7 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"zh",
"arxiv:1906.08101",
"arxiv:2004.13922",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language:
- zh
tags:
- bert
license: "apache-2.0"
---
# This is a re-trained 6-layer RoBERTa-wwm-ext model.
## Chinese BERT with Whole Word Masking
For further accelerating Chinese natural language processing, we provide **Chinese pre-trained BERT with Whole Word Masking**.
**[Pre-Training with Whole Word Masking for Chinese BERT](https://arxiv.org/abs/1906.08101)**
Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Ziqing Yang, Shijin Wang, Guoping Hu
This repository is developed based on:https://github.com/google-research/bert
You may also interested in,
- Chinese BERT series: https://github.com/ymcui/Chinese-BERT-wwm
- Chinese MacBERT: https://github.com/ymcui/MacBERT
- Chinese ELECTRA: https://github.com/ymcui/Chinese-ELECTRA
- Chinese XLNet: https://github.com/ymcui/Chinese-XLNet
- Knowledge Distillation Toolkit - TextBrewer: https://github.com/airaria/TextBrewer
More resources by HFL: https://github.com/ymcui/HFL-Anthology
## Citation
If you find the technical report or resource is useful, please cite the following technical report in your paper.
- Primary: https://arxiv.org/abs/2004.13922
```
@inproceedings{cui-etal-2020-revisiting,
title = "Revisiting Pre-Trained Models for {C}hinese Natural Language Processing",
author = "Cui, Yiming and
Che, Wanxiang and
Liu, Ting and
Qin, Bing and
Wang, Shijin and
Hu, Guoping",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.58",
pages = "657--668",
}
```
- Secondary: https://arxiv.org/abs/1906.08101
```
@article{chinese-bert-wwm,
title={Pre-Training with Whole Word Masking for Chinese BERT},
author={Cui, Yiming and Che, Wanxiang and Liu, Ting and Qin, Bing and Yang, Ziqing and Wang, Shijin and Hu, Guoping},
journal={arXiv preprint arXiv:1906.08101},
year={2019}
}
```
|
hfl/rbt3
|
hfl
| 2021-05-19T19:19:45Z | 4,188 | 33 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"zh",
"arxiv:1906.08101",
"arxiv:2004.13922",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language:
- zh
tags:
- bert
license: "apache-2.0"
pipeline_tag: "fill-mask"
---
# This is a re-trained 3-layer RoBERTa-wwm-ext model.
## Chinese BERT with Whole Word Masking
For further accelerating Chinese natural language processing, we provide **Chinese pre-trained BERT with Whole Word Masking**.
**[Pre-Training with Whole Word Masking for Chinese BERT](https://arxiv.org/abs/1906.08101)**
Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Ziqing Yang, Shijin Wang, Guoping Hu
This repository is developed based on:https://github.com/google-research/bert
You may also interested in,
- Chinese BERT series: https://github.com/ymcui/Chinese-BERT-wwm
- Chinese MacBERT: https://github.com/ymcui/MacBERT
- Chinese ELECTRA: https://github.com/ymcui/Chinese-ELECTRA
- Chinese XLNet: https://github.com/ymcui/Chinese-XLNet
- Knowledge Distillation Toolkit - TextBrewer: https://github.com/airaria/TextBrewer
More resources by HFL: https://github.com/ymcui/HFL-Anthology
## Citation
If you find the technical report or resource is useful, please cite the following technical report in your paper.
- Primary: https://arxiv.org/abs/2004.13922
```
@inproceedings{cui-etal-2020-revisiting,
title = "Revisiting Pre-Trained Models for {C}hinese Natural Language Processing",
author = "Cui, Yiming and
Che, Wanxiang and
Liu, Ting and
Qin, Bing and
Wang, Shijin and
Hu, Guoping",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.58",
pages = "657--668",
}
```
- Secondary: https://arxiv.org/abs/1906.08101
```
@article{chinese-bert-wwm,
title={Pre-Training with Whole Word Masking for Chinese BERT},
author={Cui, Yiming and Che, Wanxiang and Liu, Ting and Qin, Bing and Yang, Ziqing and Wang, Shijin and Hu, Guoping},
journal={arXiv preprint arXiv:1906.08101},
year={2019}
}
```
|
hfl/chinese-macbert-base
|
hfl
| 2021-05-19T19:09:45Z | 4,346 | 128 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"zh",
"arxiv:2004.13922",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language:
- zh
tags:
- bert
license: "apache-2.0"
---
<p align="center">
<br>
<img src="https://github.com/ymcui/MacBERT/raw/master/pics/banner.png" width="500"/>
<br>
</p>
<p align="center">
<a href="https://github.com/ymcui/MacBERT/blob/master/LICENSE">
<img alt="GitHub" src="https://img.shields.io/github/license/ymcui/MacBERT.svg?color=blue&style=flat-square">
</a>
</p>
# Please use 'Bert' related functions to load this model!
This repository contains the resources in our paper **"Revisiting Pre-trained Models for Chinese Natural Language Processing"**, which will be published in "[Findings of EMNLP](https://2020.emnlp.org)". You can read our camera-ready paper through [ACL Anthology](#) or [arXiv pre-print](https://arxiv.org/abs/2004.13922).
**[Revisiting Pre-trained Models for Chinese Natural Language Processing](https://arxiv.org/abs/2004.13922)**
*Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Shijin Wang, Guoping Hu*
You may also interested in,
- Chinese BERT series: https://github.com/ymcui/Chinese-BERT-wwm
- Chinese ELECTRA: https://github.com/ymcui/Chinese-ELECTRA
- Chinese XLNet: https://github.com/ymcui/Chinese-XLNet
- Knowledge Distillation Toolkit - TextBrewer: https://github.com/airaria/TextBrewer
More resources by HFL: https://github.com/ymcui/HFL-Anthology
## Introduction
**MacBERT** is an improved BERT with novel **M**LM **a**s **c**orrection pre-training task, which mitigates the discrepancy of pre-training and fine-tuning.
Instead of masking with [MASK] token, which never appears in the fine-tuning stage, **we propose to use similar words for the masking purpose**. A similar word is obtained by using [Synonyms toolkit (Wang and Hu, 2017)](https://github.com/chatopera/Synonyms), which is based on word2vec (Mikolov et al., 2013) similarity calculations. If an N-gram is selected to mask, we will find similar words individually. In rare cases, when there is no similar word, we will degrade to use random word replacement.
Here is an example of our pre-training task.
| | Example |
| -------------- | ----------------- |
| **Original Sentence** | we use a language model to predict the probability of the next word. |
| **MLM** | we use a language [M] to [M] ##di ##ct the pro [M] ##bility of the next word . |
| **Whole word masking** | we use a language [M] to [M] [M] [M] the [M] [M] [M] of the next word . |
| **N-gram masking** | we use a [M] [M] to [M] [M] [M] the [M] [M] [M] [M] [M] next word . |
| **MLM as correction** | we use a text system to ca ##lc ##ulate the po ##si ##bility of the next word . |
Except for the new pre-training task, we also incorporate the following techniques.
- Whole Word Masking (WWM)
- N-gram masking
- Sentence-Order Prediction (SOP)
**Note that our MacBERT can be directly replaced with the original BERT as there is no differences in the main neural architecture.**
For more technical details, please check our paper: [Revisiting Pre-trained Models for Chinese Natural Language Processing](https://arxiv.org/abs/2004.13922)
## Citation
If you find our resource or paper is useful, please consider including the following citation in your paper.
- https://arxiv.org/abs/2004.13922
```
@inproceedings{cui-etal-2020-revisiting,
title = "Revisiting Pre-Trained Models for {C}hinese Natural Language Processing",
author = "Cui, Yiming and
Che, Wanxiang and
Liu, Ting and
Qin, Bing and
Wang, Shijin and
Hu, Guoping",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.58",
pages = "657--668",
}
```
|
hfl/chinese-bert-wwm
|
hfl
| 2021-05-19T19:07:49Z | 54,317 | 71 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"zh",
"arxiv:1906.08101",
"arxiv:2004.13922",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language:
- zh
license: "apache-2.0"
---
## Chinese BERT with Whole Word Masking
For further accelerating Chinese natural language processing, we provide **Chinese pre-trained BERT with Whole Word Masking**.
**[Pre-Training with Whole Word Masking for Chinese BERT](https://arxiv.org/abs/1906.08101)**
Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Ziqing Yang, Shijin Wang, Guoping Hu
This repository is developed based on:https://github.com/google-research/bert
You may also interested in,
- Chinese BERT series: https://github.com/ymcui/Chinese-BERT-wwm
- Chinese MacBERT: https://github.com/ymcui/MacBERT
- Chinese ELECTRA: https://github.com/ymcui/Chinese-ELECTRA
- Chinese XLNet: https://github.com/ymcui/Chinese-XLNet
- Knowledge Distillation Toolkit - TextBrewer: https://github.com/airaria/TextBrewer
More resources by HFL: https://github.com/ymcui/HFL-Anthology
## Citation
If you find the technical report or resource is useful, please cite the following technical report in your paper.
- Primary: https://arxiv.org/abs/2004.13922
```
@inproceedings{cui-etal-2020-revisiting,
title = "Revisiting Pre-Trained Models for {C}hinese Natural Language Processing",
author = "Cui, Yiming and
Che, Wanxiang and
Liu, Ting and
Qin, Bing and
Wang, Shijin and
Hu, Guoping",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.58",
pages = "657--668",
}
```
- Secondary: https://arxiv.org/abs/1906.08101
```
@article{chinese-bert-wwm,
title={Pre-Training with Whole Word Masking for Chinese BERT},
author={Cui, Yiming and Che, Wanxiang and Liu, Ting and Qin, Bing and Yang, Ziqing and Wang, Shijin and Hu, Guoping},
journal={arXiv preprint arXiv:1906.08101},
year={2019}
}
```
|
hfl/chinese-bert-wwm-ext
|
hfl
| 2021-05-19T19:06:39Z | 10,290 | 166 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"zh",
"arxiv:1906.08101",
"arxiv:2004.13922",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language:
- zh
license: "apache-2.0"
---
## Chinese BERT with Whole Word Masking
For further accelerating Chinese natural language processing, we provide **Chinese pre-trained BERT with Whole Word Masking**.
**[Pre-Training with Whole Word Masking for Chinese BERT](https://arxiv.org/abs/1906.08101)**
Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Ziqing Yang, Shijin Wang, Guoping Hu
This repository is developed based on:https://github.com/google-research/bert
You may also interested in,
- Chinese BERT series: https://github.com/ymcui/Chinese-BERT-wwm
- Chinese MacBERT: https://github.com/ymcui/MacBERT
- Chinese ELECTRA: https://github.com/ymcui/Chinese-ELECTRA
- Chinese XLNet: https://github.com/ymcui/Chinese-XLNet
- Knowledge Distillation Toolkit - TextBrewer: https://github.com/airaria/TextBrewer
More resources by HFL: https://github.com/ymcui/HFL-Anthology
## Citation
If you find the technical report or resource is useful, please cite the following technical report in your paper.
- Primary: https://arxiv.org/abs/2004.13922
```
@inproceedings{cui-etal-2020-revisiting,
title = "Revisiting Pre-Trained Models for {C}hinese Natural Language Processing",
author = "Cui, Yiming and
Che, Wanxiang and
Liu, Ting and
Qin, Bing and
Wang, Shijin and
Hu, Guoping",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.58",
pages = "657--668",
}
```
- Secondary: https://arxiv.org/abs/1906.08101
```
@article{chinese-bert-wwm,
title={Pre-Training with Whole Word Masking for Chinese BERT},
author={Cui, Yiming and Che, Wanxiang and Liu, Ting and Qin, Bing and Yang, Ziqing and Wang, Shijin and Hu, Guoping},
journal={arXiv preprint arXiv:1906.08101},
year={2019}
}
```
|
henryk/bert-base-multilingual-cased-finetuned-polish-squad1
|
henryk
| 2021-05-19T19:04:09Z | 342 | 4 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"question-answering",
"pl",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
language: pl
---
# Multilingual + Polish SQuAD1.1
This model is the multilingual model provided by the Google research team with a fine-tuned polish Q&A downstream task.
## Details of the language model
Language model ([**bert-base-multilingual-cased**](https://github.com/google-research/bert/blob/master/multilingual.md)):
12-layer, 768-hidden, 12-heads, 110M parameters.
Trained on cased text in the top 104 languages with the largest Wikipedias.
## Details of the downstream task
Using the `mtranslate` Python module, [**SQuAD1.1**](https://rajpurkar.github.io/SQuAD-explorer/) was machine-translated. In order to find the start tokens, the direct translations of the answers were searched in the corresponding paragraphs. Due to the different translations depending on the context (missing context in the pure answer), the answer could not always be found in the text, and thus a loss of question-answer examples occurred. This is a potential problem where errors can occur in the data set.
| Dataset | # Q&A |
| ---------------------- | ----- |
| SQuAD1.1 Train | 87.7 K |
| Polish SQuAD1.1 Train | 39.5 K |
| SQuAD1.1 Dev | 10.6 K |
| Polish SQuAD1.1 Dev | 2.6 K |
## Model benchmark
| Model | EM | F1 |
| ---------------------- | ----- | ----- |
| [SlavicBERT](https://huggingface.co/DeepPavlov/bert-base-bg-cs-pl-ru-cased) | **60.89** | 71.68 |
| [polBERT](https://huggingface.co/dkleczek/bert-base-polish-uncased-v1) | 57.46 | 68.87 |
| [multiBERT](https://huggingface.co/bert-base-multilingual-cased) | 60.67 | **71.89** |
| [xlm](https://huggingface.co/xlm-mlm-100-1280) | 47.98 | 59.42 |
## Model training
The model was trained on a **Tesla V100** GPU with the following command:
```python
export SQUAD_DIR=path/to/pl_squad
python run_squad.py
--model_type bert \
--model_name_or_path bert-base-multilingual-cased \
--do_train \
--do_eval \
--train_file $SQUAD_DIR/pl_squadv1_train_clean.json \
--predict_file $SQUAD_DIR/pl_squadv1_dev_clean.json \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--save_steps=8000 \
--output_dir ../../output \
--overwrite_cache \
--overwrite_output_dir
```
**Results**:
{'exact': 60.670731707317074, 'f1': 71.8952193697293, 'total': 2624, 'HasAns_exact': 60.670731707317074, 'HasAns_f1': 71.8952193697293,
'HasAns_total': 2624, 'best_exact': 60.670731707317074, 'best_exact_thresh': 0.0, 'best_f1': 71.8952193697293, 'best_f1_thresh': 0.0}
## Model in action
Fast usage with **pipelines**:
```python
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="henryk/bert-base-multilingual-cased-finetuned-polish-squad1",
tokenizer="henryk/bert-base-multilingual-cased-finetuned-polish-squad1"
)
qa_pipeline({
'context': "Warszawa jest największym miastem w Polsce pod względem liczby ludności i powierzchni",
'question': "Jakie jest największe miasto w Polsce?"})
```
# Output:
```json
{
"score": 0.9988,
"start": 0,
"end": 8,
"answer": "Warszawa"
}
```
## Contact
Please do not hesitate to contact me via [LinkedIn](https://www.linkedin.com/in/henryk-borzymowski-0755a2167/) if you want to discuss or get access to the Polish version of SQuAD.
|
henryk/bert-base-multilingual-cased-finetuned-dutch-squad2
|
henryk
| 2021-05-19T19:02:45Z | 40 | 6 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"question-answering",
"nl",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
language: nl
---
# Multilingual + Dutch SQuAD2.0
This model is the multilingual model provided by the Google research team with a fine-tuned dutch Q&A downstream task.
## Details of the language model
Language model ([**bert-base-multilingual-cased**](https://github.com/google-research/bert/blob/master/multilingual.md)):
12-layer, 768-hidden, 12-heads, 110M parameters.
Trained on cased text in the top 104 languages with the largest Wikipedias.
## Details of the downstream task
Using the `mtranslate` Python module, [**SQuAD2.0**](https://rajpurkar.github.io/SQuAD-explorer/) was machine-translated. In order to find the start tokens, the direct translations of the answers were searched in the corresponding paragraphs. Due to the different translations depending on the context (missing context in the pure answer), the answer could not always be found in the text, and thus a loss of question-answer examples occurred. This is a potential problem where errors can occur in the data set.
| Dataset | # Q&A |
| ---------------------- | ----- |
| SQuAD2.0 Train | 130 K |
| Dutch SQuAD2.0 Train | 99 K |
| SQuAD2.0 Dev | 12 K |
| Dutch SQuAD2.0 Dev | 10 K |
## Model benchmark
| Model | EM/F1 |HasAns (EM/F1) | NoAns |
| ---------------------- | ----- | ----- | ----- |
| [robBERT](https://huggingface.co/pdelobelle/robBERT-base) | 58.04/60.95 | 33.08/40.64 | 73.67 |
| [dutchBERT](https://huggingface.co/wietsedv/bert-base-dutch-cased) | 64.25/68.45 | 45.59/56.49 | 75.94 |
| [multiBERT](https://huggingface.co/bert-base-multilingual-cased) | **67.38**/**71.36** | 47.42/57.76 | 79.88 |
## Model training
The model was trained on a **Tesla V100** GPU with the following command:
```python
export SQUAD_DIR=path/to/nl_squad
python run_squad.py
--model_type bert \
--model_name_or_path bert-base-multilingual-cased \
--do_train \
--do_eval \
--train_file $SQUAD_DIR/nl_squadv2_train_clean.json \
--predict_file $SQUAD_DIR/nl_squadv2_dev_clean.json \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--save_steps=8000 \
--output_dir ../../output \
--overwrite_cache \
--overwrite_output_dir
```
**Results**:
{'exact': 67.38028751680629, 'f1': 71.362297054268, 'total': 9669, 'HasAns_exact': 47.422126745435015, 'HasAns_f1': 57.761023151910734, 'HasAns_total': 3724, 'NoAns_exact': 79.88225399495374, 'NoAns_f1': 79.88225399495374, 'NoAns_total': 5945, 'best_exact': 67.53542248422795, 'best_exact_thresh': 0.0, 'best_f1': 71.36229705426837, 'best_f1_thresh': 0.0}
## Model in action
Fast usage with **pipelines**:
```python
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="henryk/bert-base-multilingual-cased-finetuned-dutch-squad2",
tokenizer="henryk/bert-base-multilingual-cased-finetuned-dutch-squad2"
)
qa_pipeline({
'context': "Amsterdam is de hoofdstad en de dichtstbevolkte stad van Nederland.",
'question': "Wat is de hoofdstad van Nederland?"})
```
# Output:
```json
{
"score": 0.83,
"start": 0,
"end": 9,
"answer": "Amsterdam"
}
```
## Contact
Please do not hesitate to contact me via [LinkedIn](https://www.linkedin.com/in/henryk-borzymowski-0755a2167/) if you want to discuss or get access to the Dutch version of SQuAD.
|
hemekci/off_detection_turkish
|
hemekci
| 2021-05-19T18:54:44Z | 54 | 8 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"tr",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language: tr
widget:
- text: "sevelim sevilelim bu dunya kimseye kalmaz"
---
## Offensive Language Detection Model in Turkish
- uses Bert and pytorch
- fine tuned with Twitter data.
- UTF-8 configuration is done
### Training Data
Number of training sentences: 31,277
**Example Tweets**
- 19823 Daliaan yifng cok erken attin be... 1.38 ...| NOT|
- 30525 @USER Bak biri kollarımda uyuyup gitmem diyor..|NOT|
- 26468 Helal olsun be :) Norveçten sabaha karşı geldi aq... | OFF|
- 14105 @USER Sunu cekecek ve güzel oldugunu söylecek aptal... |OFF|
- 4958 Ya seni yerim ben şapşal şey 🤗 | NOT|
- 12966 Herkesin akıllı geçindiği bir sosyal medyamız var ... |NOT|
- 5788 Maçın özetlerini izleyenler futbolcular gidiyo... |NOT|
|OFFENSIVE |RESULT |
|--|--|
|NOT | 25231|
|OFF|6046|
dtype: int64
### Validation
|epoch |Training Loss | Valid. Loss | Valid.Accuracy | Training Time | Validation Time |
|--|--|--|--|--|--|
|1 | 0.31| 0.28| 0.89| 0:07:14 | 0:00:13
|2 | 0.18| 0.29| 0.90| 0:07:18 | 0:00:13
|3 | 0.08| 0.40| 0.89| 0:07:16 | 0:00:13
|4 | 0.04| 0.59| 0.89| 0:07:13 | 0:00:13
**Matthews Corr. Coef. (-1 : +1):**
Total MCC Score: 0.633
|
haisongzhang/roberta-tiny-cased
|
haisongzhang
| 2021-05-19T17:53:53Z | 2,049 | 3 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"feature-extraction",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-03-02T23:29:05Z |
Github: https://github.com/haisongzhang/roberta-tiny-cased
|
gurkan08/bert-turkish-text-classification
|
gurkan08
| 2021-05-19T17:50:18Z | 12 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"tr",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language: tr
---
# Turkish News Text Classification
Turkish text classification model obtained by fine-tuning the Turkish bert model (dbmdz/bert-base-turkish-cased)
# Dataset
Dataset consists of 11 classes were obtained from https://www.trthaber.com/. The model was created using the most distinctive 6 classes.
Dataset can be accessed at https://github.com/gurkan08/datasets/tree/master/trt_11_category.
label_dict = {
'LABEL_0': 'ekonomi',
'LABEL_1': 'spor',
'LABEL_2': 'saglik',
'LABEL_3': 'kultur_sanat',
'LABEL_4': 'bilim_teknoloji',
'LABEL_5': 'egitim'
}
70% of the data were used for training and 30% for testing.
train f1-weighted score = %97
test f1-weighted score = %94
# Usage
from transformers import pipeline, AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("gurkan08/bert-turkish-text-classification")
model = AutoModelForSequenceClassification.from_pretrained("gurkan08/bert-turkish-text-classification")
nlp = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
text = ["Süper Lig'in 6. haftasında Sivasspor ile Çaykur Rizespor karşı karşıya geldi...",
"Son 24 saatte 69 kişi Kovid-19 nedeniyle yaşamını yitirdi, 1573 kişi iyileşti"]
out = nlp(text)
label_dict = {
'LABEL_0': 'ekonomi',
'LABEL_1': 'spor',
'LABEL_2': 'saglik',
'LABEL_3': 'kultur_sanat',
'LABEL_4': 'bilim_teknoloji',
'LABEL_5': 'egitim'
}
results = []
for result in out:
result['label'] = label_dict[result['label']]
results.append(result)
print(results)
# > [{'label': 'spor', 'score': 0.9992026090621948}, {'label': 'saglik', 'score': 0.9972177147865295}]
|
gsarti/scibert-nli
|
gsarti
| 2021-05-19T17:49:18Z | 105 | 3 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"feature-extraction",
"doi:10.57967/hf/0038",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-03-02T23:29:05Z |
# SciBERT-NLI
This is the model [SciBERT](https://github.com/allenai/scibert) [1] fine-tuned on the [SNLI](https://nlp.stanford.edu/projects/snli/) and the [MultiNLI](https://www.nyu.edu/projects/bowman/multinli/) datasets using the [`sentence-transformers` library](https://github.com/UKPLab/sentence-transformers/) to produce universal sentence embeddings [2].
The model uses the original `scivocab` wordpiece vocabulary and was trained using the **average pooling strategy** and a **softmax loss**.
**Base model**: `allenai/scibert-scivocab-cased` from HuggingFace's `AutoModel`.
**Training time**: ~4 hours on the NVIDIA Tesla P100 GPU provided in Kaggle Notebooks.
**Parameters**:
| Parameter | Value |
|------------------|-------|
| Batch size | 64 |
| Training steps | 20000 |
| Warmup steps | 1450 |
| Lowercasing | True |
| Max. Seq. Length | 128 |
**Performances**: The performance was evaluated on the test portion of the [STS dataset](http://ixa2.si.ehu.es/stswiki/index.php/STSbenchmark) using Spearman rank correlation and compared to the performances of a general BERT base model obtained with the same procedure to verify their similarity.
| Model | Score |
|-------------------------------|-------------|
| `scibert-nli` (this) | 74.50 |
| `bert-base-nli-mean-tokens`[3]| 77.12 |
An example usage for similarity-based scientific paper retrieval is provided in the [Covid Papers Browser](https://github.com/gsarti/covid-papers-browser) repository.
**References:**
[1] I. Beltagy et al, [SciBERT: A Pretrained Language Model for Scientific Text](https://www.aclweb.org/anthology/D19-1371/)
[2] A. Conneau et al., [Supervised Learning of Universal Sentence Representations from Natural Language Inference Data](https://www.aclweb.org/anthology/D17-1070/)
[3] N. Reimers et I. Gurevych, [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://www.aclweb.org/anthology/D19-1410/)
|
google/bert_uncased_L-8_H-768_A-12
|
google
| 2021-05-19T17:36:32Z | 921 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
google/bert_uncased_L-8_H-128_A-2
|
google
| 2021-05-19T17:35:05Z | 1,147 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
google/bert_uncased_L-6_H-768_A-12
|
google
| 2021-05-19T17:34:36Z | 3,612 | 3 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
google/bert_uncased_L-6_H-512_A-8
|
google
| 2021-05-19T17:34:01Z | 1,402 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
google/bert_uncased_L-6_H-128_A-2
|
google
| 2021-05-19T17:33:17Z | 1,159 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
google/bert_uncased_L-4_H-768_A-12
|
google
| 2021-05-19T17:31:28Z | 918 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
google/bert_uncased_L-4_H-512_A-8
|
google
| 2021-05-19T17:30:51Z | 95,283 | 4 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
google/bert_uncased_L-4_H-256_A-4
|
google
| 2021-05-19T17:30:27Z | 17,737 | 7 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
google/bert_uncased_L-4_H-128_A-2
|
google
| 2021-05-19T17:30:08Z | 2,136 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
google/bert_uncased_L-2_H-768_A-12
|
google
| 2021-05-19T17:29:34Z | 949 | 4 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
google/bert_uncased_L-2_H-256_A-4
|
google
| 2021-05-19T17:28:46Z | 1,571 | 2 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
google/bert_uncased_L-12_H-768_A-12
|
google
| 2021-05-19T17:27:43Z | 6,964 | 11 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
google/bert_uncased_L-12_H-512_A-8
|
google
| 2021-05-19T17:26:55Z | 6,382 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
google/bert_uncased_L-12_H-128_A-2
|
google
| 2021-05-19T17:26:01Z | 2,701 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
google/bert_uncased_L-10_H-768_A-12
|
google
| 2021-05-19T17:24:59Z | 914 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
google/bert_uncased_L-10_H-512_A-8
|
google
| 2021-05-19T17:24:16Z | 922 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
fran-martinez/scibert_scivocab_cased_ner_jnlpba
|
fran-martinez
| 2021-05-19T16:56:50Z | 24 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"token-classification",
"arxiv:1903.10676",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:05Z |
---
language: scientific english
---
# SciBERT finetuned on JNLPA for NER downstream task
## Language Model
[SciBERT](https://arxiv.org/pdf/1903.10676.pdf) is a pretrained language model based on BERT and trained by the
[Allen Institute for AI](https://allenai.org/) on papers from the corpus of
[Semantic Scholar](https://www.semanticscholar.org/).
Corpus size is 1.14M papers, 3.1B tokens. SciBERT has its own vocabulary (scivocab) that's built to best match
the training corpus.
## Downstream task
[`allenai/scibert_scivocab_cased`](https://huggingface.co/allenai/scibert_scivocab_cased#) has been finetuned for Named Entity
Recognition (NER) dowstream task. The code to train the NER can be found [here](https://github.com/fran-martinez/bio_ner_bert).
### Data
The corpus used to fine-tune the NER is [BioNLP / JNLPBA shared task](http://www.geniaproject.org/shared-tasks/bionlp-jnlpba-shared-task-2004).
- Training data consist of 2,000 PubMed abstracts with term/word annotation. This corresponds to 18,546 samples (senteces).
- Evaluation data consist of 404 PubMed abstracts with term/word annotation. This corresponds to 3,856 samples (sentences).
The classes (at word level) and its distribution (number of examples for each class) for training and evaluation datasets are shown below:
| Class Label | # training examples| # evaluation examples|
|:--------------|--------------:|----------------:|
|O | 382,963 | 81,647 |
|B-protein | 30,269 | 5,067 |
|I-protein | 24,848 | 4,774 |
|B-cell_type | 6,718 | 1,921 |
|I-cell_type | 8,748 | 2,991 |
|B-DNA | 9,533 | 1,056 |
|I-DNA | 15,774 | 1,789 |
|B-cell_line | 3,830 | 500 |
|I-cell_line | 7,387 | 9,89 |
|B-RNA | 951 | 118 |
|I-RNA | 1,530 | 187 |
### Model
An exhaustive hyperparameter search was done.
The hyperparameters that provided the best results are:
- Max length sequence: 128
- Number of epochs: 6
- Batch size: 32
- Dropout: 0.3
- Optimizer: Adam
The used learning rate was 5e-5 with a decreasing linear schedule. A warmup was used at the beggining of the training
with a ratio of steps equal to 0.1 from the total training steps.
The model from the epoch with the best F1-score was selected, in this case, the model from epoch 5.
### Evaluation
The following table shows the evaluation metrics calculated at span/entity level:
| | precision| recall| f1-score|
|:---------|-----------:|---------:|---------:|
cell_line | 0.5205 | 0.7100 | 0.6007 |
cell_type | 0.7736 | 0.7422 | 0.7576 |
protein | 0.6953 | 0.8459 | 0.7633 |
DNA | 0.6997 | 0.7894 | 0.7419 |
RNA | 0.6985 | 0.8051 | 0.7480 |
| | | |
**micro avg** | 0.6984 | 0.8076 | 0.7490|
**macro avg** | 0.7032 | 0.8076 | 0.7498 |
The macro F1-score is equal to 0.7498, compared to the value provided by the Allen Institute for AI in their
[paper](https://arxiv.org/pdf/1903.10676.pdf), which is equal to 0.7728. This drop in performance could be due to
several reasons, but one hypothesis could be the fact that the authors used an additional conditional random field,
while this model uses a regular classification layer with softmax activation on top of SciBERT model.
At word level, this model achieves a precision of 0.7742, a recall of 0.8536 and a F1-score of 0.8093.
### Model usage in inference
Use the pipeline:
````python
from transformers import pipeline
text = "Mouse thymus was used as a source of glucocorticoid receptor from normal CS lymphocytes."
nlp_ner = pipeline("ner",
model='fran-martinez/scibert_scivocab_cased_ner_jnlpba',
tokenizer='fran-martinez/scibert_scivocab_cased_ner_jnlpba')
nlp_ner(text)
"""
Output:
---------------------------
[
{'word': 'glucocorticoid',
'score': 0.9894881248474121,
'entity': 'B-protein'},
{'word': 'receptor',
'score': 0.989505410194397,
'entity': 'I-protein'},
{'word': 'normal',
'score': 0.7680378556251526,
'entity': 'B-cell_type'},
{'word': 'cs',
'score': 0.5176806449890137,
'entity': 'I-cell_type'},
{'word': 'lymphocytes',
'score': 0.9898491501808167,
'entity': 'I-cell_type'}
]
"""
````
Or load model and tokenizer as follows:
````python
import torch
from transformers import AutoTokenizer, AutoModelForTokenClassification
# Example
text = "Mouse thymus was used as a source of glucocorticoid receptor from normal CS lymphocytes."
# Load model
tokenizer = AutoTokenizer.from_pretrained("fran-martinez/scibert_scivocab_cased_ner_jnlpba")
model = AutoModelForTokenClassification.from_pretrained("fran-martinez/scibert_scivocab_cased_ner_jnlpba")
# Get input for BERT
input_ids = torch.tensor(tokenizer.encode(text)).unsqueeze(0)
# Predict
with torch.no_grad():
outputs = model(input_ids)
# From the output let's take the first element of the tuple.
# Then, let's get rid of [CLS] and [SEP] tokens (first and last)
predictions = outputs[0].argmax(axis=-1)[0][1:-1]
# Map label class indexes to string labels.
for token, pred in zip(tokenizer.tokenize(text), predictions):
print(token, '->', model.config.id2label[pred.numpy().item()])
"""
Output:
---------------------------
mouse -> O
thymus -> O
was -> O
used -> O
as -> O
a -> O
source -> O
of -> O
glucocorticoid -> B-protein
receptor -> I-protein
from -> O
normal -> B-cell_type
cs -> I-cell_type
lymphocytes -> I-cell_type
. -> O
"""
````
|
dvilares/bertinho-gl-small-cased
|
dvilares
| 2021-05-19T16:18:35Z | 4 | 2 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"fill-mask",
"gl",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: gl
widget:
- text: "As filloas son un [MASK] típico do entroido en Galicia "
---
Bertinho-gl-small-cased
A pre-trained BERT model for Galician (6layers,cased). Trained on Wikipedia.
|
dpalominop/spanish-bert-apoyo
|
dpalominop
| 2021-05-19T16:08:52Z | 13 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("dpalominop/spanish-bert-apoyo")
model = AutoModelForSequenceClassification.from_pretrained("dpalominop/spanish-bert-apoyo")
```
|
dkleczek/bert-base-polish-cased-v1
|
dkleczek
| 2021-05-19T15:54:20Z | 26,101 | 7 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"pretraining",
"pl",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language: pl
thumbnail: https://raw.githubusercontent.com/kldarek/polbert/master/img/polbert.png
---
# Polbert - Polish BERT
Polish version of BERT language model is here! It is now available in two variants: cased and uncased, both can be downloaded and used via HuggingFace transformers library. I recommend using the cased model, more info on the differences and benchmark results below.

## Cased and uncased variants
* I initially trained the uncased model, the corpus and training details are referenced below. Here are some issues I found after I published the uncased model:
* Some Polish characters and accents are not tokenized correctly through the BERT tokenizer when applying lowercase. This doesn't impact sequence classification much, but may influence token classfication tasks significantly.
* I noticed a lot of duplicates in the Open Subtitles dataset, which dominates the training corpus.
* I didn't use Whole Word Masking.
* The cased model improves on the uncased model in the following ways:
* All Polish characters and accents should now be tokenized correctly.
* I removed duplicates from Open Subtitles dataset. The corpus is smaller, but more balanced now.
* The model is trained with Whole Word Masking.
## Pre-training corpora
Below is the list of corpora used along with the output of `wc` command (counting lines, words and characters). These corpora were divided into sentences with srxsegmenter (see references), concatenated and tokenized with HuggingFace BERT Tokenizer.
### Uncased
| Tables | Lines | Words | Characters |
| ------------- |--------------:| -----:| -----:|
| [Polish subset of Open Subtitles](http://opus.nlpl.eu/OpenSubtitles-v2018.php) | 236635408| 1431199601 | 7628097730 |
| [Polish subset of ParaCrawl](http://opus.nlpl.eu/ParaCrawl.php) | 8470950 | 176670885 | 1163505275 |
| [Polish Parliamentary Corpus](http://clip.ipipan.waw.pl/PPC) | 9799859 | 121154785 | 938896963 |
| [Polish Wikipedia - Feb 2020](https://dumps.wikimedia.org/plwiki/latest/plwiki-latest-pages-articles.xml.bz2) | 8014206 | 132067986 | 1015849191 |
| Total | 262920423 | 1861093257 | 10746349159 |
### Cased
| Tables | Lines | Words | Characters |
| ------------- |--------------:| -----:| -----:|
| [Polish subset of Open Subtitles (Deduplicated) ](http://opus.nlpl.eu/OpenSubtitles-v2018.php) | 41998942| 213590656 | 1424873235 |
| [Polish subset of ParaCrawl](http://opus.nlpl.eu/ParaCrawl.php) | 8470950 | 176670885 | 1163505275 |
| [Polish Parliamentary Corpus](http://clip.ipipan.waw.pl/PPC) | 9799859 | 121154785 | 938896963 |
| [Polish Wikipedia - Feb 2020](https://dumps.wikimedia.org/plwiki/latest/plwiki-latest-pages-articles.xml.bz2) | 8014206 | 132067986 | 1015849191 |
| Total | 68283960 | 646479197 | 4543124667 |
## Pre-training details
### Uncased
* Polbert was trained with code provided in Google BERT's github repository (https://github.com/google-research/bert)
* Currently released model follows bert-base-uncased model architecture (12-layer, 768-hidden, 12-heads, 110M parameters)
* Training set-up: in total 1 million training steps:
* 100.000 steps - 128 sequence length, batch size 512, learning rate 1e-4 (10.000 steps warmup)
* 800.000 steps - 128 sequence length, batch size 512, learning rate 5e-5
* 100.000 steps - 512 sequence length, batch size 256, learning rate 2e-5
* The model was trained on a single Google Cloud TPU v3-8
### Cased
* Same approach as uncased model, with the following differences:
* Whole Word Masking
* Training set-up:
* 100.000 steps - 128 sequence length, batch size 2048, learning rate 1e-4 (10.000 steps warmup)
* 100.000 steps - 128 sequence length, batch size 2048, learning rate 5e-5
* 100.000 steps - 512 sequence length, batch size 256, learning rate 2e-5
## Usage
Polbert is released via [HuggingFace Transformers library](https://huggingface.co/transformers/).
For an example use as language model, see [this notebook](/LM_testing.ipynb) file.
### Uncased
```python
from transformers import *
model = BertForMaskedLM.from_pretrained("dkleczek/bert-base-polish-uncased-v1")
tokenizer = BertTokenizer.from_pretrained("dkleczek/bert-base-polish-uncased-v1")
nlp = pipeline('fill-mask', model=model, tokenizer=tokenizer)
for pred in nlp(f"Adam Mickiewicz wielkim polskim {nlp.tokenizer.mask_token} był."):
print(pred)
# Output:
# {'sequence': '[CLS] adam mickiewicz wielkim polskim poeta był. [SEP]', 'score': 0.47196975350379944, 'token': 26596}
# {'sequence': '[CLS] adam mickiewicz wielkim polskim bohaterem był. [SEP]', 'score': 0.09127858281135559, 'token': 10953}
# {'sequence': '[CLS] adam mickiewicz wielkim polskim człowiekiem był. [SEP]', 'score': 0.0647173821926117, 'token': 5182}
# {'sequence': '[CLS] adam mickiewicz wielkim polskim pisarzem był. [SEP]', 'score': 0.05232388526201248, 'token': 24293}
# {'sequence': '[CLS] adam mickiewicz wielkim polskim politykiem był. [SEP]', 'score': 0.04554257541894913, 'token': 44095}
```
### Cased
```python
model = BertForMaskedLM.from_pretrained("dkleczek/bert-base-polish-cased-v1")
tokenizer = BertTokenizer.from_pretrained("dkleczek/bert-base-polish-cased-v1")
nlp = pipeline('fill-mask', model=model, tokenizer=tokenizer)
for pred in nlp(f"Adam Mickiewicz wielkim polskim {nlp.tokenizer.mask_token} był."):
print(pred)
# Output:
# {'sequence': '[CLS] Adam Mickiewicz wielkim polskim pisarzem był. [SEP]', 'score': 0.5391148328781128, 'token': 37120}
# {'sequence': '[CLS] Adam Mickiewicz wielkim polskim człowiekiem był. [SEP]', 'score': 0.11683262139558792, 'token': 6810}
# {'sequence': '[CLS] Adam Mickiewicz wielkim polskim bohaterem był. [SEP]', 'score': 0.06021466106176376, 'token': 17709}
# {'sequence': '[CLS] Adam Mickiewicz wielkim polskim mistrzem był. [SEP]', 'score': 0.051870670169591904, 'token': 14652}
# {'sequence': '[CLS] Adam Mickiewicz wielkim polskim artystą był. [SEP]', 'score': 0.031787533313035965, 'token': 35680}
```
See the next section for an example usage of Polbert in downstream tasks.
## Evaluation
Thanks to Allegro, we now have the [KLEJ benchmark](https://klejbenchmark.com/leaderboard/), a set of nine evaluation tasks for the Polish language understanding. The following results are achieved by running standard set of evaluation scripts (no tricks!) utilizing both cased and uncased variants of Polbert.
| Model | Average | NKJP-NER | CDSC-E | CDSC-R | CBD | PolEmo2.0-IN | PolEmo2.0-OUT | DYK | PSC | AR |
| ------------- |--------------:|--------------:|--------------:|--------------:|--------------:|--------------:|--------------:|--------------:|--------------:|--------------:|
| Polbert cased | 81.7 | 93.6 | 93.4 | 93.8 | 52.7 | 87.4 | 71.1 | 59.1 | 98.6 | 85.2 |
| Polbert uncased | 81.4 | 90.1 | 93.9 | 93.5 | 55.0 | 88.1 | 68.8 | 59.4 | 98.8 | 85.4 |
Note how the uncased model performs better than cased on some tasks? My guess this is because of the oversampling of Open Subtitles dataset and its similarity to data in some of these tasks. All these benchmark tasks are sequence classification, so the relative strength of the cased model is not so visible here.
## Bias
The data used to train the model is biased. It may reflect stereotypes related to gender, ethnicity etc. Please be careful when using the model for downstream task to consider these biases and mitigate them.
## Acknowledgements
* I'd like to express my gratitude to Google [TensorFlow Research Cloud (TFRC)](https://www.tensorflow.org/tfrc) for providing the free TPU credits - thank you!
* Also appreciate the help from Timo Möller from [deepset](https://deepset.ai) for sharing tips and scripts based on their experience training German BERT model.
* Big thanks to Allegro for releasing KLEJ Benchmark and specifically to Piotr Rybak for help with the evaluation and pointing out some issues with the tokenization.
* Finally, thanks to Rachel Thomas, Jeremy Howard and Sylvain Gugger from [fastai](https://www.fast.ai) for their NLP and Deep Learning courses!
## Author
Darek Kłeczek - contact me on Twitter [@dk21](https://twitter.com/dk21)
## References
* https://github.com/google-research/bert
* https://github.com/narusemotoki/srx_segmenter
* SRX rules file for sentence splitting in Polish, written by Marcin Miłkowski: https://raw.githubusercontent.com/languagetool-org/languagetool/master/languagetool-core/src/main/resources/org/languagetool/resource/segment.srx
* [KLEJ benchmark](https://klejbenchmark.com/leaderboard/)
|
digitalepidemiologylab/covid-twitter-bert
|
digitalepidemiologylab
| 2021-05-19T15:52:48Z | 456 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"Twitter",
"COVID-19",
"en",
"arxiv:2005.07503",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language: "en"
thumbnail: "https://raw.githubusercontent.com/digitalepidemiologylab/covid-twitter-bert/master/images/COVID-Twitter-BERT_small.png"
tags:
- Twitter
- COVID-19
license: mit
---
# COVID-Twitter-BERT (CT-BERT) v1
:warning: _You may want to use the [v2 model](https://huggingface.co/digitalepidemiologylab/covid-twitter-bert-v2) which was trained on more recent data and yields better performance_ :warning:
BERT-large-uncased model, pretrained on a corpus of messages from Twitter about COVID-19. Find more info on our [GitHub page](https://github.com/digitalepidemiologylab/covid-twitter-bert).
## Overview
This model was trained on 160M tweets collected between January 12 and April 16, 2020 containing at least one of the keywords "wuhan", "ncov", "coronavirus", "covid", or "sars-cov-2". These tweets were filtered and preprocessed to reach a final sample of 22.5M tweets (containing 40.7M sentences and 633M tokens) which were used for training.
This model was evaluated based on downstream classification tasks, but it could be used for any other NLP task which can leverage contextual embeddings.
In order to achieve best results, make sure to use the same text preprocessing as we did for pretraining. This involves replacing user mentions, urls and emojis. You can find a script on our projects [GitHub repo](https://github.com/digitalepidemiologylab/covid-twitter-bert).
## Example usage
```python
tokenizer = AutoTokenizer.from_pretrained("digitalepidemiologylab/covid-twitter-bert")
model = AutoModel.from_pretrained("digitalepidemiologylab/covid-twitter-bert")
```
You can also use the model with the `pipeline` interface:
```python
from transformers import pipeline
import json
pipe = pipeline(task='fill-mask', model='digitalepidemiologylab/covid-twitter-bert-v2')
out = pipe(f"In places with a lot of people, it's a good idea to wear a {pipe.tokenizer.mask_token}")
print(json.dumps(out, indent=4))
[
{
"sequence": "[CLS] in places with a lot of people, it's a good idea to wear a mask [SEP]",
"score": 0.9959408044815063,
"token": 7308,
"token_str": "mask"
},
...
]
```
## References
[1] Martin Müller, Marcel Salaté, Per E Kummervold. "COVID-Twitter-BERT: A Natural Language Processing Model to Analyse COVID-19 Content on Twitter" arXiv preprint arXiv:2005.07503 (2020).
|
deepset/sentence_bert
|
deepset
| 2021-05-19T15:34:03Z | 10,668 | 20 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
license: apache-2.0
---
This is an upload of the bert-base-nli-stsb-mean-tokens pretrained model from the Sentence Transformers Repo (https://github.com/UKPLab/sentence-transformers)
|
cahya/bert-base-indonesian-1.5G
|
cahya
| 2021-05-19T13:37:31Z | 118,224 | 5 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"id",
"dataset:wikipedia",
"dataset:id_newspapers_2018",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: "id"
license: "mit"
datasets:
- wikipedia
- id_newspapers_2018
widget:
- text: "Ibu ku sedang bekerja [MASK] sawah."
---
# Indonesian BERT base model (uncased)
## Model description
It is BERT-base model pre-trained with indonesian Wikipedia and indonesian newspapers using a masked language modeling (MLM) objective. This
model is uncased.
This is one of several other language models that have been pre-trained with indonesian datasets. More detail about
its usage on downstream tasks (text classification, text generation, etc) is available at [Transformer based Indonesian Language Models](https://github.com/cahya-wirawan/indonesian-language-models/tree/master/Transformers)
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='cahya/bert-base-indonesian-1.5G')
>>> unmasker("Ibu ku sedang bekerja [MASK] supermarket")
[{'sequence': '[CLS] ibu ku sedang bekerja di supermarket [SEP]',
'score': 0.7983310222625732,
'token': 1495},
{'sequence': '[CLS] ibu ku sedang bekerja. supermarket [SEP]',
'score': 0.090003103017807,
'token': 17},
{'sequence': '[CLS] ibu ku sedang bekerja sebagai supermarket [SEP]',
'score': 0.025469014421105385,
'token': 1600},
{'sequence': '[CLS] ibu ku sedang bekerja dengan supermarket [SEP]',
'score': 0.017966199666261673,
'token': 1555},
{'sequence': '[CLS] ibu ku sedang bekerja untuk supermarket [SEP]',
'score': 0.016971781849861145,
'token': 1572}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BertTokenizer, BertModel
model_name='cahya/bert-base-indonesian-1.5G'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name)
text = "Silakan diganti dengan text apa saja."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in Tensorflow:
```python
from transformers import BertTokenizer, TFBertModel
model_name='cahya/bert-base-indonesian-1.5G'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = TFBertModel.from_pretrained(model_name)
text = "Silakan diganti dengan text apa saja."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Training data
This model was pre-trained with 522MB of indonesian Wikipedia and 1GB of
[indonesian newspapers](https://huggingface.co/datasets/id_newspapers_2018).
The texts are lowercased and tokenized using WordPiece and a vocabulary size of 32,000. The inputs of the model are
then of the form:
```[CLS] Sentence A [SEP] Sentence B [SEP]```
|
ayansinha/lic-class-scancode-bert-base-cased-L32-1
|
ayansinha
| 2021-05-19T12:04:46Z | 9 | 0 |
transformers
|
[
"transformers",
"tf",
"bert",
"fill-mask",
"license",
"sentence-classification",
"scancode",
"license-compliance",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"dataset:scancode-rules",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: en
tags:
- license
- sentence-classification
- scancode
- license-compliance
license: apache-2.0
datasets:
- bookcorpus
- wikipedia
- scancode-rules
version: 1.0
---
# `lic-class-scancode-bert-base-cased-L32-1`
## Intended Use
This model is intended to be used for Sentence Classification which is used for results
analysis in [`scancode-results-analyzer`](https://github.com/nexB/scancode-results-analyzer).
`scancode-results-analyzer` helps detect faulty scans in [`scancode-toolkit`](https://github.com/nexB/scancode-results-analyzer) by using statistics and nlp modeling, among other tools,
to make Scancode better.
## How to Use
Refer [quickstart](https://github.com/nexB/scancode-results-analyzer#quickstart---local-machine) section in `scancode-results-analyzer` documentation, for installing and getting started.
- [Link to Code](https://github.com/nexB/scancode-results-analyzer/blob/master/src/results_analyze/nlp_models.py)
Then in `NLPModelsPredict` class, function `predict_basic_lic_class` uses this classifier to
predict sentances as either valid license tags or false positives.
## Limitations and Bias
As this model is a fine-tuned version of the [`bert-base-cased`](https://huggingface.co/bert-base-cased) model,
it has the same biases, but as the task it is fine-tuned to is a very specific task
(license text/notice/tag/referance) without those intended biases, it's safe to assume
those don't apply at all here.
## Training and Fine-Tuning Data
The BERT model was pretrained on BookCorpus, a dataset consisting of 11,038 unpublished books and English Wikipedia (excluding lists, tables and headers).
Then this `bert-base-cased` model was fine-tuned on Scancode Rule texts, specifically
trained in the context of sentence classification, where the four classes are
- License Text
- License Notice
- License Tag
- License Referance
## Training Procedure
For fine-tuning procedure and training, refer `scancode-results-analyzer` code.
- [Link to Code](https://github.com/nexB/scancode-results-analyzer/blob/master/src/results_analyze/nlp_models.py)
In `NLPModelsTrain` class, function `prepare_input_data_false_positive` prepares the
training data.
In `NLPModelsTrain` class, function `train_basic_false_positive_classifier` fine-tunes
this classifier.
1. Model - [BertBaseCased](https://huggingface.co/bert-base-cased) (Weights 0.5 GB)
2. Sentence Length - 32
3. Labels - 4 (License Text/Notice/Tag/Referance)
4. After 4 Epochs of Fine-Tuning with learning rate 2e-5 (60 secs each on an RTX 2060)
Note: The classes aren't balanced.
## Eval Results
- Accuracy on the training data (90%) : 0.98 (+- 0.01)
- Accuracy on the validation data (10%) : 0.84 (+- 0.01)
## Further Work
1. Apllying Splitting/Aggregation Strategies
2. Data Augmentation according to Vaalidation Errors
3. Bigger/Better Suited Models
|
ayansinha/false-positives-scancode-bert-base-uncased-L8-1
|
ayansinha
| 2021-05-19T12:04:24Z | 8 | 0 |
transformers
|
[
"transformers",
"tf",
"bert",
"fill-mask",
"license",
"sentence-classification",
"scancode",
"license-compliance",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"dataset:scancode-rules",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: en
tags:
- license
- sentence-classification
- scancode
- license-compliance
license: apache-2.0
datasets:
- bookcorpus
- wikipedia
- scancode-rules
version: 1.0
---
# `false-positives-scancode-bert-base-uncased-L8-1`
## Intended Use
This model is intended to be used for Sentence Classification which is used for results
analysis in [`scancode-results-analyzer`](https://github.com/nexB/scancode-results-analyzer).
`scancode-results-analyzer` helps detect faulty scans in [`scancode-toolkit`](https://github.com/nexB/scancode-results-analyzer) by using statistics and nlp modeling, among other tools,
to make Scancode better.
#### How to use
Refer [quickstart](https://github.com/nexB/scancode-results-analyzer#quickstart---local-machine) section in `scancode-results-analyzer` documentation, for installing and getting started.
- [Link to Code](https://github.com/nexB/scancode-results-analyzer/blob/master/src/results_analyze/nlp_models.py)
Then in `NLPModelsPredict` class, function `predict_basic_false_positive` uses this classifier to
predict sentances as either valid license tags or false positives.
#### Limitations and bias
As this model is a fine-tuned version of the [`bert-base-uncased`](https://huggingface.co/bert-base-uncased) model,
it has the same biases, but as the task it is fine-tuned to is a very specific field
(license tags vs false positives) without those intended biases, it's safe to assume
those don't apply at all here.
## Training and Fine-Tuning Data
The BERT model was pretrained on BookCorpus, a dataset consisting of 11,038 unpublished books and English Wikipedia (excluding lists, tables and headers).
Then this `bert-base-uncased` model was fine-tuned on Scancode Rule texts, specifically
trained in the context of sentence classification, where the two classes are
- License Tags
- False Positives of License Tags
## Training procedure
For fine-tuning procedure and training, refer `scancode-results-analyzer` code.
- [Link to Code](https://github.com/nexB/scancode-results-analyzer/blob/master/src/results_analyze/nlp_models.py)
In `NLPModelsTrain` class, function `prepare_input_data_false_positive` prepares the
training data.
In `NLPModelsTrain` class, function `train_basic_false_positive_classifier` fine-tunes
this classifier.
1. Model - [BertBaseUncased](https://huggingface.co/bert-base-uncased) (Weights 0.5 GB)
2. Sentence Length - 8
3. Labels - 2 (False Positive/License Tag)
4. After 4-6 Epochs of Fine-Tuning with learning rate 2e-5 (6 secs each on an RTX 2060)
Note: The classes aren't balanced.
## Eval results
- Accuracy on the training data (90%) : 0.99 (+- 0.005)
- Accuracy on the validation data (10%) : 0.96 (+- 0.015)
The errors have lower confidence scores using thresholds on confidence scores almost
makes it a perfect classifier as the classification task is comparatively easier.
Results are stable, in the sence fine-tuning accuracy is very easily achieved every
time, though more learning epochs makes the data overfit, i.e. the training loss
decreases, but the validation loss increases, even though accuracies are very stable
even on overfitting.
|
ankur310794/bert-large-uncased-nq-small-answer
|
ankur310794
| 2021-05-19T11:44:55Z | 6 | 0 |
transformers
|
[
"transformers",
"tf",
"bert",
"question-answering",
"small answer",
"dataset:natural_questions",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
tags:
- small answer
datasets:
- natural_questions
---
# Open Domain Question Answering
A core goal in artificial intelligence is to build systems that can read the web, and then answer complex questions about any topic. These question-answering (QA) systems could have a big impact on the way that we access information. Furthermore, open-domain question answering is a benchmark task in the development of Artificial Intelligence, since understanding text and being able to answer questions about it is something that we generally associate with intelligence.
# The Natural Questions Dataset
To help spur development in open-domain question answering, we have created the Natural Questions (NQ) corpus, along with a challenge website based on this data. The NQ corpus contains questions from real users, and it requires QA systems to read and comprehend an entire Wikipedia article that may or may not contain the answer to the question. The inclusion of real user questions, and the requirement that solutions should read an entire page to find the answer, cause NQ to be a more realistic and challenging task than prior QA datasets.
|
airesearch/bert-base-multilingual-cased-finetuned
|
airesearch
| 2021-05-19T11:39:44Z | 9 | 0 |
transformers
|
[
"transformers",
"bert",
"fill-mask",
"arxiv:1810.04805",
"arxiv:2101.09635",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# Finetuend `bert-base-multilignual-cased` model on Thai sequence and token classification datasets
<br>
Finetuned XLM Roberta BASE model on Thai sequence and token classification datasets
The script and documentation can be found at [this repository](https://github.com/vistec-AI/thai2transformers).
<br>
## Model description
<br>
We use the pretrained cross-lingual BERT model (mBERT) as proposed by [[Devlin et al., 2018]](https://arxiv.org/abs/1810.04805). We download the pretrained PyTorch model via HuggingFace's Model Hub (https://huggingface.co/bert-base-multilignual-cased)
<br>
## Intended uses & limitations
<br>
You can use the finetuned models for multiclass/multilabel text classification and token classification task.
<br>
**Multiclass text classification**
- `wisesight_sentiment`
4-class text classification task (`positive`, `neutral`, `negative`, and `question`) based on social media posts and tweets.
- `wongnai_reivews`
Users' review rating classification task (scale is ranging from 1 to 5)
- `generated_reviews_enth` : (`review_star` as label)
Generated users' review rating classification task (scale is ranging from 1 to 5).
**Multilabel text classification**
- `prachathai67k`
Thai topic classification with 12 labels based on news article corpus from prachathai.com. The detail is described in this [page](https://huggingface.co/datasets/prachathai67k).
**Token classification**
- `thainer`
Named-entity recognition tagging with 13 named-entities as descibed in this [page](https://huggingface.co/datasets/thainer).
- `lst20` : NER NER and POS tagging
Named-entity recognition tagging with 10 named-entities and Part-of-Speech tagging with 16 tags as descibed in this [page](https://huggingface.co/datasets/lst20).
<br>
## How to use
<br>
The example notebook demonstrating how to use finetuned model for inference can be found at this [Colab notebook](https://colab.research.google.com/drive/1Kbk6sBspZLwcnOE61adAQo30xxqOQ9ko)
<br>
**BibTeX entry and citation info**
```
@misc{lowphansirikul2021wangchanberta,
title={WangchanBERTa: Pretraining transformer-based Thai Language Models},
author={Lalita Lowphansirikul and Charin Polpanumas and Nawat Jantrakulchai and Sarana Nutanong},
year={2021},
eprint={2101.09635},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
QCRI/PropagandaTechniquesAnalysis-en-BERT
|
QCRI
| 2021-05-19T11:27:07Z | 23,086 | 6 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"propaganda",
"en",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:04Z |
---
language: "en"
thumbnail: "https://pbs.twimg.com/profile_images/1092721745994440704/d6R-AHzj_400x400.jpg"
tags:
- propaganda
- bert
license: "MIT"
datasets:
-
metrics:
-
---
Propaganda Techniques Analysis BERT
----
This model is a BERT based model to make predictions of propaganda techniques in
news articles in English. The model is described in
[this paper](https://propaganda.qcri.org/papers/EMNLP_2019__Fine_Grained_Propaganda_Detection.pdf).
## Model description
Please find propaganda definition here:
https://propaganda.qcri.org/annotations/definitions.html
You can also try the model in action here: https://www.tanbih.org/prta
### How to use
```python
>>> from transformers import BertTokenizerFast
>>> from .model import BertForTokenAndSequenceJointClassification
>>>
>>> tokenizer = BertTokenizerFast.from_pretrained('bert-base-cased')
>>> model = BertForTokenAndSequenceJointClassification.from_pretrained(
>>> "QCRI/PropagandaTechniquesAnalysis-en-BERT",
>>> revision="v0.1.0",
>>> )
>>>
>>> inputs = tokenizer.encode_plus("Hello, my dog is cute", return_tensors="pt")
>>> outputs = model(**inputs)
>>> sequence_class_index = torch.argmax(outputs.sequence_logits, dim=-1)
>>> sequence_class = model.sequence_tags[sequence_class_index[0]]
>>> token_class_index = torch.argmax(outputs.token_logits, dim=-1)
>>> tokens = tokenizer.convert_ids_to_tokens(inputs.input_ids[0][1:-1])
>>> tags = [model.token_tags[i] for i in token_class_index[0].tolist()[1:-1]]
```
### BibTeX entry and citation info
```bibtex
@inproceedings{da-san-martino-etal-2019-fine,
title = "Fine-Grained Analysis of Propaganda in News Article",
author = "Da San Martino, Giovanni and
Yu, Seunghak and
Barr{\'o}n-Cede{\~n}o, Alberto and
Petrov, Rostislav and
Nakov, Preslav",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP)",
month = nov,
year = "2019",
address = "Hong Kong, China",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/D19-1565",
doi = "10.18653/v1/D19-1565",
pages = "5636--5646",
abstract = "Propaganda aims at influencing people{'}s mindset with the purpose of advancing a specific agenda. Previous work has addressed propaganda detection at document level, typically labelling all articles from a propagandistic news outlet as propaganda. Such noisy gold labels inevitably affect the quality of any learning system trained on them. A further issue with most existing systems is the lack of explainability. To overcome these limitations, we propose a novel task: performing fine-grained analysis of texts by detecting all fragments that contain propaganda techniques as well as their type. In particular, we create a corpus of news articles manually annotated at fragment level with eighteen propaganda techniques and propose a suitable evaluation measure. We further design a novel multi-granularity neural network, and we show that it outperforms several strong BERT-based baselines.",
}
```
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.