
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-07-27 12:28:27
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 533
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-07-27 12:28:17
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
elenavins184/elena_luka_max
|
elenavins184
| 2025-06-20T08:06:50Z | 0 | 0 | null |
[
"license:other",
"region:us"
] | null | 2025-06-17T08:53:29Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
|
scb10x/typhoon2.1-gemma3-4b-mlx-4bit
|
scb10x
| 2025-06-20T08:06:10Z | 0 | 0 | null |
[
"safetensors",
"gemma3_text",
"text-generation",
"conversational",
"arxiv:2412.13702",
"license:gemma",
"4-bit",
"region:us"
] |
text-generation
| 2025-06-20T07:34:14Z |
---
license: gemma
pipeline_tag: text-generation
---
**Typhoon2.1-Gemma3-4B**: Thai Large Language Model (Instruct)
**Typhoon2.1-Gemma3-4B** is a instruct Thai 🇹🇭 large language model with 4 billion parameters, a 128K context length, and function-calling capabilities. It is based on Gemma3 4B.
Remark: This is text only model. We removed vision encoder for this version due to complexity. Stay-tune for version with vision encoder soon.
## **Performance**
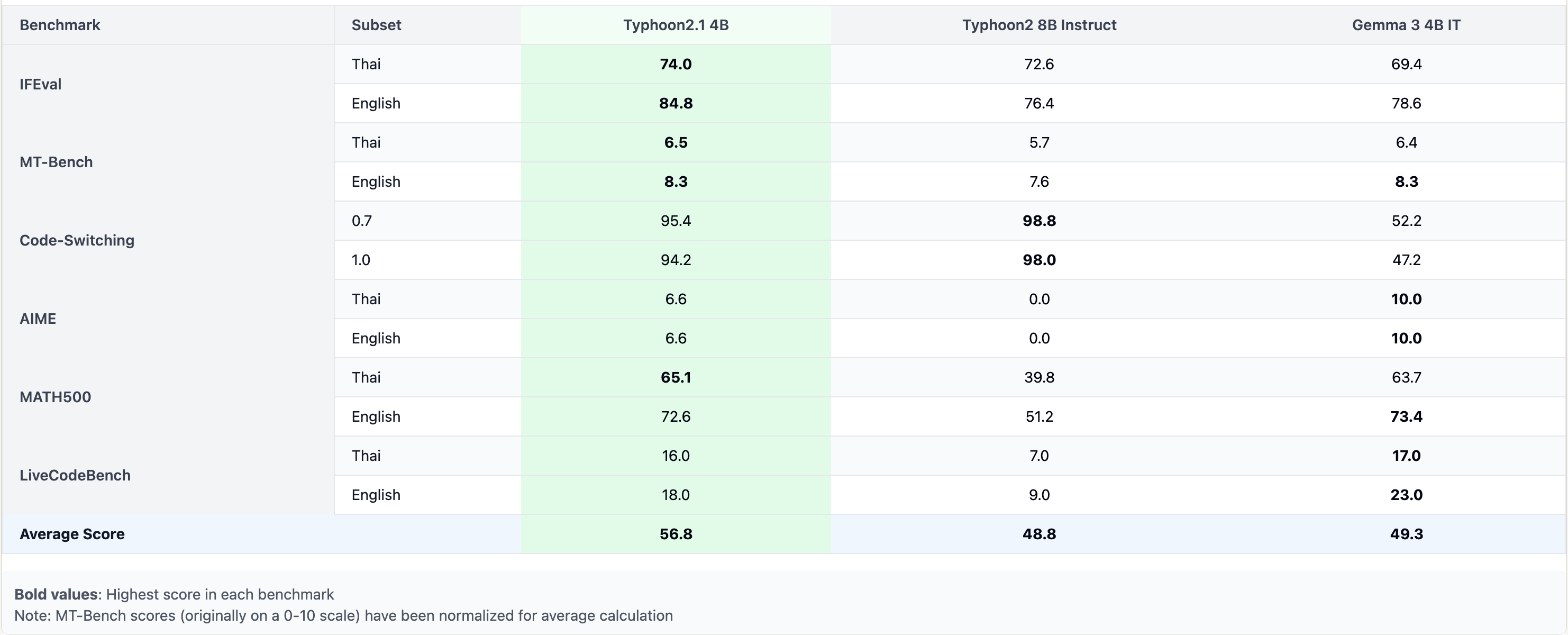
## **Model Description**
- **Model type**: A 4B instruct decoder-only model based on Gemma3 architecture.
- **Requirement**: transformers 4.50.0 or newer.
- **Primary Language(s)**: Thai 🇹🇭 and English 🇬🇧
- **License**: [Gemma License](https://github.com/google-deepmind/gemma/blob/main/LICENSE)
## Usage Example
This code snippet shows how to use the Typhoon2.1-Gemma3-4B model for Thai or English text generation using the transformers library. It includes setting up the model and tokenizer, formatting chat messages in a system-user style, and generating a response.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "scb10x/typhoon2.1-gemma3-4b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a male AI assistant named Typhoon created by SCB 10X to be helpful, harmless, and honest. Typhoon is happy to help with analysis, question answering, math, coding, creative writing, teaching, role-play, general discussion, and all sorts of other tasks. Typhoon responds directly to all human messages without unnecessary affirmations or filler phrases like “Certainly!”, “Of course!”, “Absolutely!”, “Great!”, “Sure!”, etc. Specifically, Typhoon avoids starting responses with the word “Certainly” in any way. Typhoon follows this information in all languages, and always responds to the user in the language they use or request. Typhoon is now being connected with a human. Write in fluid, conversational prose, Show genuine interest in understanding requests, Express appropriate emotions and empathy. Also showing information in term that is easy to understand and visualized."},
{"role": "user", "content": "ขอสูตรไก่ย่าง"},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt",
enable_thinking=False # Switches between thinking and non-thinking modes. Default is False.
).to(model.device)
outputs = model.generate(
input_ids,
max_new_tokens=512,
do_sample=True,
temperature=0.6,
top_p=0.95,
)
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))
```
## Deploy as Server
This section shows how to run Typhoon2.1 as an OpenAI-compatible API server using vllm.
```bash
pip install vllm
vllm serve scb10x/typhoon2.1-gemma3-4b --max-model-len 16000 --dtype bfloat16 --tool-call-parser pythonic --enable-auto-tool-choice
# adjust --max-model-len based on your avaliable memory
# you can use --quantization bitsandbytes to reduce the memory use while trade-off inference speed
```
## Using Tools
You can provide tools to the vLLM-powered OpenAI-compatible API for functionality.
```
from openai import OpenAI
import json
client = OpenAI(base_url="http://localhost:8000/v1", api_key="dummy")
def get_weather(location: str, unit: str):
return f"Getting the weather for {location} in {unit}..."
tool_functions = {"get_weather": get_weather}
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "City and state, e.g., 'San Francisco, CA'"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["location", "unit"]
}
}
}]
response = client.chat.completions.create(
model=client.models.list().data[0].id,
messages=[{"role": "user", "content": "What's the weather like in San Francisco?"}],
tools=tools,
tool_choice="auto"
)
tool_call = response.choices[0].message.tool_calls[0].function
print(f"Function called: {tool_call.name}")
print(f"Arguments: {tool_call.arguments}")
print(f"Result: {get_weather(**json.loads(tool_call.arguments))}")
```
## Switching Between Thinking and Non-Thinking Mode
Typhoon supports two modes:
Non-thinking mode (default): Fast response generation without extra reasoning steps.
Thinking mode: The model first reasons internally, then provides a clearer and potentially more accurate final answer.
You can enable thinking mode by:
Setting enable_thinking=True in apply_chat_template.
Using a special system prompt that instructs the model to reason inside <think>...</think> tags.
You can turn on thinking mode by either
- add enable_thinking=True to apply_chat_template
```python
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt",
enable_thinking=True # Switches between thinking and non-thinking modes. Default is False.
).to(model.device)
```
- manually by supply thinking mode system prompt
```
You are a helpful assistant. First, think through the reasoning internally, then present the reasoning within <think>...</think>. After thinking, clearly state a response that addresses the user's request and aligns with their preferences, not just providing a direct answer.
```
- in vllm powered openai compatible client you can add chat_template_kwargs to the post payload
```json
{
"model": "scb10x/typhoon2.1-gemma3-4b",
"messages": [
{"role": "user", "content": "Give me a short introduction to large language models."}
],
"chat_template_kwargs": {"enable_thinking": true}
}
```
## Budget forcing
This section introduces budget forcing, an advanced technique to let the model spend more time and tokens reasoning before producing a final answer—great for improving performance on complex questions.
```
from vllm import LLM, SamplingParams
from transformers import AutoTokenizer
class BudgetForcingHandler:
def __init__(self, model_name: str, max_think_token: int, max_ignore=5, temperature=0.6, seed=32):
self.temperature = temperature
self.seed = seed
self.max_think_token = max_think_token
self.max_ignore = max_ignore
self.model = LLM(model_name, dtype='bfloat16', enforce_eager=True)
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.alternative_str = '\nAlternatively'
self.system = """You are a reasoning assistant. First, think through the reasoning internally, then present the reasoning within <think>...</think>. After thinking, clearly state the final answer."""
def __call__(self, prompts: List[str]):
count_prompt = len(prompts)
prompts = [self.tokenizer.apply_chat_template([{'role': 'system', 'content': self.system}, {'role': 'user', 'content': f'Please solve this math question, and put your final answer within \\boxed{{}}.\n{p}'}], add_generation_prompt=True, tokenize=False) for p in prompts]
sampling_params = SamplingParams(
max_tokens=self.max_think_token,
seed=self.seed,
stop=["</think>"],
skip_special_tokens=False,
temperature=self.temperature,
)
o = self.model.generate(
prompts,
sampling_params=sampling_params
)
outputs = [output.outputs[0].text for output in o]
token_count = [len(output.outputs[0].token_ids) for output in o]
for i in range(len(prompts)):
prompts[i] = prompts[i] + outputs[i]
for _ in range(self.max_ignore): # Num of times to skip stop token
inference_loop_prompts = []
inference_idx = []
max_inference_token = 0
print('current token count: ', token_count)
for i in range(len(prompts)):
left_budget = self.max_think_token - token_count[i]
if left_budget > 0:
prompts[i] = prompts[i] + self.alternative_str
inference_loop_prompts.append(prompts[i])
inference_idx.append(i)
if left_budget > max_inference_token:
max_inference_token = left_budget
outputs = ['' for _ in range(len(prompts))]
if max_inference_token == 0 or len(inference_loop_prompts) == 0:
break
sampling_params = SamplingParams(
max_tokens=max_inference_token,
min_tokens=1,
seed=self.seed,
stop=["</think>"],
skip_special_tokens=False,
temperature=self.temperature,
)
o = self.model.generate(
inference_loop_prompts,
sampling_params=sampling_params
)
assert len(inference_idx) == len(inference_loop_prompts)
assert len(inference_idx) == len(o)
for i, output in zip(inference_idx, o):
outputs[i] = output.outputs[0].text
for i, idx in enumerate(inference_idx):
token_count[idx] = token_count[idx] + len(o[i].outputs[0].token_ids)
for i in range(len(prompts)):
prompts[i] = prompts[i] + outputs[i]
print('generating answer...')
prompts = [p + '\nTime\'s up. End of thinking process. Will answer immediately.\n</think>' for i, p in enumerate(prompts)]
sampling_params = SamplingParams(
max_tokens=2048,
min_tokens=0,
seed=self.seed,
skip_special_tokens=False,
temperature=self.temperature,
)
o = self.model.generate(
prompts,
sampling_params=sampling_params,
)
for i in range(len(prompts)):
prompts[i] = prompts[i] + o[i].outputs[0].text
assert len(prompts) == count_prompt
return prompts
handler = BudgetForcingHandler("scb10x/typhoon2.1-gemma3-4b", max_think_token=2048)
handler(["How many r in raspberry?"])
```
## **Intended Uses & Limitations**
This model is an instructional model. However, it’s still undergoing development. It incorporates some level of guardrails, but it still may produce answers that are inaccurate, biased, or otherwise objectionable in response to user prompts. We recommend that developers assess these risks in the context of their use case.
## **Follow us**
**https://twitter.com/opentyphoon**
## **Support**
**https://discord.gg/us5gAYmrxw**
## **Citation**
- If you find Typhoon2 useful for your work, please cite it using:
```
@misc{typhoon2,
title={Typhoon 2: A Family of Open Text and Multimodal Thai Large Language Models},
author={Kunat Pipatanakul and Potsawee Manakul and Natapong Nitarach and Warit Sirichotedumrong and Surapon Nonesung and Teetouch Jaknamon and Parinthapat Pengpun and Pittawat Taveekitworachai and Adisai Na-Thalang and Sittipong Sripaisarnmongkol and Krisanapong Jirayoot and Kasima Tharnpipitchai},
year={2024},
eprint={2412.13702},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.13702},
}
```
|
kaiserbuffle/connect4_epitech
|
kaiserbuffle
| 2025-06-20T08:04:01Z | 0 | 0 | null |
[
"LeRobot",
"license:apache-2.0",
"region:us"
] | null | 2025-06-20T08:03:11Z |
---
license: apache-2.0
task_categories:
- robotics
tags:
- LeRobot
configs:
- config_name: default
data_files: data/*/*.parquet
---
This dataset was created using [LeRobot](https://github.com/huggingface/lerobot).
## Dataset Description
- **Homepage:** [More Information Needed]
- **Paper:** [More Information Needed]
- **License:** apache-2.0
## Dataset Structure
[meta/info.json](meta/info.json):
```json
{
"codebase_version": "v2.1",
"robot_type": "so101_follower",
"total_episodes": 1,
"total_frames": 1022,
"total_tasks": 1,
"total_videos": 2,
"total_chunks": 1,
"chunks_size": 1000,
"fps": 30,
"splits": {
"train": "0:1"
},
"data_path": "data/chunk-{episode_chunk:03d}/episode_{episode_index:06d}.parquet",
"video_path": "videos/chunk-{episode_chunk:03d}/{video_key}/episode_{episode_index:06d}.mp4",
"features": {
"action": {
"dtype": "float32",
"shape": [
6
],
"names": [
"shoulder_pan.pos",
"shoulder_lift.pos",
"elbow_flex.pos",
"wrist_flex.pos",
"wrist_roll.pos",
"gripper.pos"
]
},
"observation.state": {
"dtype": "float32",
"shape": [
6
],
"names": [
"shoulder_pan.pos",
"shoulder_lift.pos",
"elbow_flex.pos",
"wrist_flex.pos",
"wrist_roll.pos",
"gripper.pos"
]
},
"observation.images.front": {
"dtype": "video",
"shape": [
480,
640,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.height": 480,
"video.width": 640,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"video.fps": 30,
"video.channels": 3,
"has_audio": false
}
},
"observation.images.robot": {
"dtype": "video",
"shape": [
480,
640,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.height": 480,
"video.width": 640,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"video.fps": 30,
"video.channels": 3,
"has_audio": false
}
},
"timestamp": {
"dtype": "float32",
"shape": [
1
],
"names": null
},
"frame_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"episode_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"task_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
}
}
}
```
## Citation
**BibTeX:**
```bibtex
[More Information Needed]
```
|
lostinjamal/3cb13c83-60cb-4a66-a135-260d6369e792
|
lostinjamal
| 2025-06-20T08:00:33Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-20T07:54:33Z |
---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
yuto-urushima/my_gemma2_pt
|
yuto-urushima
| 2025-06-20T07:56:26Z | 3 | 0 |
keras-hub
|
[
"keras-hub",
"text-generation",
"region:us"
] |
text-generation
| 2025-06-12T08:02:44Z |
---
library_name: keras-hub
pipeline_tag: text-generation
---
This is a [`Gemma` model](https://keras.io/api/keras_hub/models/gemma) uploaded using the KerasHub library and can be used with JAX, TensorFlow, and PyTorch backends.
This model is related to a `CausalLM` task.
Model config:
* **name:** gemma_backbone
* **trainable:** True
* **vocabulary_size:** 256000
* **num_layers:** 26
* **num_query_heads:** 8
* **num_key_value_heads:** 4
* **hidden_dim:** 2304
* **intermediate_dim:** 18432
* **head_dim:** 256
* **layer_norm_epsilon:** 1e-06
* **dropout:** 0
* **query_head_dim_normalize:** True
* **use_post_ffw_norm:** True
* **use_post_attention_norm:** True
* **final_logit_soft_cap:** 30.0
* **attention_logit_soft_cap:** 50.0
* **sliding_window_size:** 4096
* **use_sliding_window_attention:** True
This model card has been generated automatically and should be completed by the model author. See [Model Cards documentation](https://huggingface.co/docs/hub/model-cards) for more information.
|
bioamla/scp-frogs
|
bioamla
| 2025-06-20T07:55:11Z | 0 | 0 | null |
[
"safetensors",
"audio-spectrogram-transformer",
"en",
"dataset:bioamla/scp-frogs",
"base_model:MIT/ast-finetuned-audioset-10-10-0.4593",
"base_model:finetune:MIT/ast-finetuned-audioset-10-10-0.4593",
"license:cc-by-3.0",
"region:us"
] | null | 2025-06-20T07:32:18Z |
---
license: cc-by-3.0
datasets:
- bioamla/scp-frogs
language:
- en
base_model:
- MIT/ast-finetuned-audioset-10-10-0.4593
---
|
mradermacher/guru-7b-step320-GGUF
|
mradermacher
| 2025-06-20T07:54:46Z | 16 | 1 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:LLM360/guru-7B",
"base_model:quantized:LLM360/guru-7B",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-05-14T23:42:18Z |
---
base_model: LLM360/guru-7B
language:
- en
library_name: transformers
license: cc-by-nc-4.0
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/LLM360/guru-7B
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/guru-7b-step320-GGUF/resolve/main/guru-7b-step320.Q2_K.gguf) | Q2_K | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/guru-7b-step320-GGUF/resolve/main/guru-7b-step320.Q3_K_S.gguf) | Q3_K_S | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/guru-7b-step320-GGUF/resolve/main/guru-7b-step320.Q3_K_M.gguf) | Q3_K_M | 3.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/guru-7b-step320-GGUF/resolve/main/guru-7b-step320.Q3_K_L.gguf) | Q3_K_L | 4.2 | |
| [GGUF](https://huggingface.co/mradermacher/guru-7b-step320-GGUF/resolve/main/guru-7b-step320.IQ4_XS.gguf) | IQ4_XS | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/guru-7b-step320-GGUF/resolve/main/guru-7b-step320.Q4_K_S.gguf) | Q4_K_S | 4.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/guru-7b-step320-GGUF/resolve/main/guru-7b-step320.Q4_K_M.gguf) | Q4_K_M | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/guru-7b-step320-GGUF/resolve/main/guru-7b-step320.Q5_K_S.gguf) | Q5_K_S | 5.4 | |
| [GGUF](https://huggingface.co/mradermacher/guru-7b-step320-GGUF/resolve/main/guru-7b-step320.Q5_K_M.gguf) | Q5_K_M | 5.5 | |
| [GGUF](https://huggingface.co/mradermacher/guru-7b-step320-GGUF/resolve/main/guru-7b-step320.Q6_K.gguf) | Q6_K | 6.4 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/guru-7b-step320-GGUF/resolve/main/guru-7b-step320.Q8_0.gguf) | Q8_0 | 8.2 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/guru-7b-step320-GGUF/resolve/main/guru-7b-step320.f16.gguf) | f16 | 15.3 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
SabahNawab/Meta_Llama_3.2_3B_Urdu_Custom_Tokenizer
|
SabahNawab
| 2025-06-20T07:54:41Z | 0 | 0 |
transformers
|
[
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-20T07:54:16Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
lostinjamal/14ed7463-06d8-47e6-8a9a-3f1ec7800826
|
lostinjamal
| 2025-06-20T07:54:03Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"unsloth",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-06-20T07:32:05Z |
---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
RichardErkhov/zelk12_-_recoilme-gemma-2-psy10k-mental_healt-9B-v0.1-gguf
|
RichardErkhov
| 2025-06-20T07:51:53Z | 0 | 0 | null |
[
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-06-20T06:43:43Z |
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
recoilme-gemma-2-psy10k-mental_healt-9B-v0.1 - GGUF
- Model creator: https://huggingface.co/zelk12/
- Original model: https://huggingface.co/zelk12/recoilme-gemma-2-psy10k-mental_healt-9B-v0.1/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q2_K.gguf](https://huggingface.co/RichardErkhov/zelk12_-_recoilme-gemma-2-psy10k-mental_healt-9B-v0.1-gguf/blob/main/recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q2_K.gguf) | Q2_K | 3.54GB |
| [recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/zelk12_-_recoilme-gemma-2-psy10k-mental_healt-9B-v0.1-gguf/blob/main/recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.IQ3_XS.gguf) | IQ3_XS | 3.86GB |
| [recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.IQ3_S.gguf](https://huggingface.co/RichardErkhov/zelk12_-_recoilme-gemma-2-psy10k-mental_healt-9B-v0.1-gguf/blob/main/recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.IQ3_S.gguf) | IQ3_S | 4.04GB |
| [recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/zelk12_-_recoilme-gemma-2-psy10k-mental_healt-9B-v0.1-gguf/blob/main/recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q3_K_S.gguf) | Q3_K_S | 4.04GB |
| [recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.IQ3_M.gguf](https://huggingface.co/RichardErkhov/zelk12_-_recoilme-gemma-2-psy10k-mental_healt-9B-v0.1-gguf/blob/main/recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.IQ3_M.gguf) | IQ3_M | 4.19GB |
| [recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q3_K.gguf](https://huggingface.co/RichardErkhov/zelk12_-_recoilme-gemma-2-psy10k-mental_healt-9B-v0.1-gguf/blob/main/recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q3_K.gguf) | Q3_K | 4.43GB |
| [recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/zelk12_-_recoilme-gemma-2-psy10k-mental_healt-9B-v0.1-gguf/blob/main/recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q3_K_M.gguf) | Q3_K_M | 4.43GB |
| [recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/zelk12_-_recoilme-gemma-2-psy10k-mental_healt-9B-v0.1-gguf/blob/main/recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q3_K_L.gguf) | Q3_K_L | 4.78GB |
| [recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/zelk12_-_recoilme-gemma-2-psy10k-mental_healt-9B-v0.1-gguf/blob/main/recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.IQ4_XS.gguf) | IQ4_XS | 4.86GB |
| [recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q4_0.gguf](https://huggingface.co/RichardErkhov/zelk12_-_recoilme-gemma-2-psy10k-mental_healt-9B-v0.1-gguf/blob/main/recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q4_0.gguf) | Q4_0 | 5.07GB |
| [recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/zelk12_-_recoilme-gemma-2-psy10k-mental_healt-9B-v0.1-gguf/blob/main/recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.IQ4_NL.gguf) | IQ4_NL | 5.1GB |
| [recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/zelk12_-_recoilme-gemma-2-psy10k-mental_healt-9B-v0.1-gguf/blob/main/recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q4_K_S.gguf) | Q4_K_S | 5.1GB |
| [recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q4_K.gguf](https://huggingface.co/RichardErkhov/zelk12_-_recoilme-gemma-2-psy10k-mental_healt-9B-v0.1-gguf/blob/main/recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q4_K.gguf) | Q4_K | 5.37GB |
| [recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/zelk12_-_recoilme-gemma-2-psy10k-mental_healt-9B-v0.1-gguf/blob/main/recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q4_K_M.gguf) | Q4_K_M | 5.37GB |
| [recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q4_1.gguf](https://huggingface.co/RichardErkhov/zelk12_-_recoilme-gemma-2-psy10k-mental_healt-9B-v0.1-gguf/blob/main/recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q4_1.gguf) | Q4_1 | 5.55GB |
| [recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q5_0.gguf](https://huggingface.co/RichardErkhov/zelk12_-_recoilme-gemma-2-psy10k-mental_healt-9B-v0.1-gguf/blob/main/recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q5_0.gguf) | Q5_0 | 6.04GB |
| [recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/zelk12_-_recoilme-gemma-2-psy10k-mental_healt-9B-v0.1-gguf/blob/main/recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q5_K_S.gguf) | Q5_K_S | 6.04GB |
| [recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q5_K.gguf](https://huggingface.co/RichardErkhov/zelk12_-_recoilme-gemma-2-psy10k-mental_healt-9B-v0.1-gguf/blob/main/recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q5_K.gguf) | Q5_K | 6.19GB |
| [recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/zelk12_-_recoilme-gemma-2-psy10k-mental_healt-9B-v0.1-gguf/blob/main/recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q5_K_M.gguf) | Q5_K_M | 6.19GB |
| [recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q5_1.gguf](https://huggingface.co/RichardErkhov/zelk12_-_recoilme-gemma-2-psy10k-mental_healt-9B-v0.1-gguf/blob/main/recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q5_1.gguf) | Q5_1 | 6.52GB |
| [recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q6_K.gguf](https://huggingface.co/RichardErkhov/zelk12_-_recoilme-gemma-2-psy10k-mental_healt-9B-v0.1-gguf/blob/main/recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q6_K.gguf) | Q6_K | 7.07GB |
| [recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q8_0.gguf](https://huggingface.co/RichardErkhov/zelk12_-_recoilme-gemma-2-psy10k-mental_healt-9B-v0.1-gguf/blob/main/recoilme-gemma-2-psy10k-mental_healt-9B-v0.1.Q8_0.gguf) | Q8_0 | 9.15GB |
Original model description:
---
library_name: transformers
tags:
- mergekit
- merge
base_model:
- recoilme/recoilme-gemma-2-9B-v0.4
- ehristoforu/Gemma2-9B-it-psy10k-mental_health
model-index:
- name: recoilme-gemma-2-psy10k-mental_healt-9B-v0.1
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: IFEval (0-Shot)
type: HuggingFaceH4/ifeval
args:
num_few_shot: 0
metrics:
- type: inst_level_strict_acc and prompt_level_strict_acc
value: 74.45
name: strict accuracy
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=zelk12/recoilme-gemma-2-psy10k-mental_healt-9B-v0.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: BBH (3-Shot)
type: BBH
args:
num_few_shot: 3
metrics:
- type: acc_norm
value: 42.13
name: normalized accuracy
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=zelk12/recoilme-gemma-2-psy10k-mental_healt-9B-v0.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MATH Lvl 5 (4-Shot)
type: hendrycks/competition_math
args:
num_few_shot: 4
metrics:
- type: exact_match
value: 16.47
name: exact match
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=zelk12/recoilme-gemma-2-psy10k-mental_healt-9B-v0.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GPQA (0-shot)
type: Idavidrein/gpqa
args:
num_few_shot: 0
metrics:
- type: acc_norm
value: 12.53
name: acc_norm
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=zelk12/recoilme-gemma-2-psy10k-mental_healt-9B-v0.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MuSR (0-shot)
type: TAUR-Lab/MuSR
args:
num_few_shot: 0
metrics:
- type: acc_norm
value: 12.18
name: acc_norm
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=zelk12/recoilme-gemma-2-psy10k-mental_healt-9B-v0.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU-PRO (5-shot)
type: TIGER-Lab/MMLU-Pro
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 35.34
name: accuracy
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=zelk12/recoilme-gemma-2-psy10k-mental_healt-9B-v0.1
name: Open LLM Leaderboard
---
# merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the SLERP merge method.
### Models Merged
The following models were included in the merge:
* [recoilme/recoilme-gemma-2-9B-v0.4](https://huggingface.co/recoilme/recoilme-gemma-2-9B-v0.4)
* [ehristoforu/Gemma2-9B-it-psy10k-mental_health](https://huggingface.co/ehristoforu/Gemma2-9B-it-psy10k-mental_health)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: recoilme/recoilme-gemma-2-9B-v0.4
- model: ehristoforu/Gemma2-9B-it-psy10k-mental_health
merge_method: slerp
base_model: recoilme/recoilme-gemma-2-9B-v0.4
dtype: bfloat16
parameters:
t: 0.5
```
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_zelk12__recoilme-gemma-2-psy10k-mental_healt-9B-v0.1)
| Metric |Value|
|-------------------|----:|
|Avg. |32.18|
|IFEval (0-Shot) |74.45|
|BBH (3-Shot) |42.13|
|MATH Lvl 5 (4-Shot)|16.47|
|GPQA (0-shot) |12.53|
|MuSR (0-shot) |12.18|
|MMLU-PRO (5-shot) |35.34|
|
hanslab37/ppo-SnowballTarget
|
hanslab37
| 2025-06-20T07:50:23Z | 0 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"SnowballTarget",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SnowballTarget",
"region:us"
] |
reinforcement-learning
| 2025-06-20T07:50:17Z |
---
library_name: ml-agents
tags:
- SnowballTarget
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SnowballTarget
---
# **ppo** Agent playing **SnowballTarget**
This is a trained model of a **ppo** agent playing **SnowballTarget**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: hanslab37/ppo-SnowballTarget
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Triangle104/Impish_Magic_24B-Q5_K_M-GGUF
|
Triangle104
| 2025-06-20T07:49:02Z | 0 | 0 | null |
[
"gguf",
"llama-cpp",
"gguf-my-repo",
"en",
"base_model:SicariusSicariiStuff/Impish_Magic_24B",
"base_model:quantized:SicariusSicariiStuff/Impish_Magic_24B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-06-20T07:46:37Z |
---
license: apache-2.0
language:
- en
base_model: SicariusSicariiStuff/Impish_Magic_24B
tags:
- llama-cpp
- gguf-my-repo
---
# Triangle104/Impish_Magic_24B-Q5_K_M-GGUF
This model was converted to GGUF format from [`SicariusSicariiStuff/Impish_Magic_24B`](https://huggingface.co/SicariusSicariiStuff/Impish_Magic_24B) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/SicariusSicariiStuff/Impish_Magic_24B) for more details on the model.
---
This model is based on mistralai/Magistral-Small-2506 so naturally it's named Impish_Magic. Truly excellent size, it's been tested on a laptop with 16GB gpu and it works quite fast (4090m).
This model went "full" fine-tune over 100m unique tokens. Why "full"?
Specific areas in the model have been tuned to attempt to change the
vocabulary usage, while keeping as much intelligence as possible. So
this is definitely not a LoRA, but also not exactly a proper full finetune, but rather something in-between.
---
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Triangle104/Impish_Magic_24B-Q5_K_M-GGUF --hf-file impish_magic_24b-q5_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Triangle104/Impish_Magic_24B-Q5_K_M-GGUF --hf-file impish_magic_24b-q5_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Triangle104/Impish_Magic_24B-Q5_K_M-GGUF --hf-file impish_magic_24b-q5_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Triangle104/Impish_Magic_24B-Q5_K_M-GGUF --hf-file impish_magic_24b-q5_k_m.gguf -c 2048
```
|
BCCard/Qwen3-32B-FP8-Dynamic
|
BCCard
| 2025-06-20T07:48:41Z | 14 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"neuralmagic",
"redhat",
"llmcompressor",
"quantized",
"FP8",
"conversational",
"base_model:Qwen/Qwen3-32B",
"base_model:quantized:Qwen/Qwen3-32B",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"compressed-tensors",
"region:us"
] |
text-generation
| 2025-05-08T07:20:56Z |
---
library_name: transformers
license: apache-2.0
pipeline_tag: text-generation
base_model:
- Qwen/Qwen3-32B
tags:
- neuralmagic
- redhat
- llmcompressor
- quantized
- FP8
---
# Qwen3-32B-FP8-Dynamic
## Model Overview
- **Model Architecture:** Qwen3ForCausalLM
- **Input:** Text
- **Output:** Text
- **Model Optimizations:**
- **Activation quantization:** FP8
- **Weight quantization:** FP8
- **Intended Use Cases:**
- Reasoning.
- Function calling.
- Subject matter experts via fine-tuning.
- Multilingual instruction following.
- Translation.
- **Out-of-scope:** Use in any manner that violates applicable laws or regulations (including trade compliance laws).
- **Release Date:** 05/02/2025
- **Version:** 1.0
- **Model Developers:** BC Card, Redhat
### Model Optimizations
This model was obtained by quantizing activations and weights of [Qwen3-32B](https://huggingface.co/Qwen/Qwen3-32B) to FP8 data type.
This optimization reduces the number of bits used to represent weights and activations from 16 to 8, reducing GPU memory requirements (by approximately 50%) and increasing matrix-multiply compute throughput (by approximately 2x).
Weight quantization also reduces disk size requirements by approximately 50%.
Only weights and activations of the linear operators within transformers blocks are quantized.
Weights are quantized with a symmetric static per-channel scheme, whereas activations are quantized with a symmetric dynamic per-token scheme.
The [llm-compressor](https://github.com/vllm-project/llm-compressor) library is used for quantization.
## Deployment
This model can be deployed efficiently using the [vLLM](https://docs.vllm.ai/en/latest/) backend, as shown in the example below.
```python
from vllm import LLM, SamplingParams
from transformers import AutoTokenizer
model_id = "BCCard/Qwen3-32B-FP8-dynamic"
number_gpus = 1
sampling_params = SamplingParams(temperature=0.6, top_p=0.95, top_k=20, min_p=0, max_tokens=256)
messages = [
{"role": "user", "content": prompt}
]
tokenizer = AutoTokenizer.from_pretrained(model_id)
messages = [{"role": "user", "content": "Give me a short introduction to large language model."}]
prompts = tokenizer.apply_chat_template(messages, add_generation_prompt=True, tokenize=False)
llm = LLM(model=model_id, tensor_parallel_size=number_gpus)
outputs = llm.generate(prompts, sampling_params)
generated_text = outputs[0].outputs[0].text
print(generated_text)
```
vLLM aslo supports OpenAI-compatible serving. See the [documentation](https://docs.vllm.ai/en/latest/) for more details.
## Creation
<details>
<summary>Creation details</summary>
This model was created with [llm-compressor](https://github.com/vllm-project/llm-compressor) by running the code snippet below.
```python
from llmcompressor.modifiers.quantization import QuantizationModifier
from llmcompressor.transformers import oneshot
from transformers import AutoModelForCausalLM, AutoTokenizer
# Load model
model_stub = "Qwen/Qwen3-32B"
model_name = model_stub.split("/")[-1]
model = AutoModelForCausalLM.from_pretrained(model_stub)
tokenizer = AutoTokenizer.from_pretrained(model_stub)
# Configure the quantization algorithm and scheme
recipe = QuantizationModifier(
ignore=["lm_head"],
targets="Linear",
scheme="FP8_dynamic",
)
# Apply quantization
oneshot(
model=model,
recipe=recipe,
)
# Save to disk in compressed-tensors format
save_path = model_name + "-FP8-dynamic"
model.save_pretrained(save_path)
tokenizer.save_pretrained(save_path)
print(f"Model and tokenizer saved to: {save_path}")
```
</details>
## Evaluation
The model was evaluated on the OpenLLM leaderboard tasks (version 1), using [lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness) and [vLLM](https://docs.vllm.ai/en/stable/).
<details>
<summary>Evaluation details</summary>
```
lm_eval \
--model vllm \
--model_args pretrained="BCCard/Qwen3-32B-FP8-dynamic",dtype=auto,gpu_memory_utilization=0.5,max_model_len=8192,enable_chunk_prefill=True,tensor_parallel_size=1 \
--tasks openllm \
--apply_chat_template\
--fewshot_as_multiturn \
--batch_size auto
```
</details>
### Accuracy
<table>
<tr>
<th>Category
</th>
<th>Benchmark
</th>
<th>Qwen3-32B
</th>
<th>Qwen3-32B-FP8-dynamic<br>(this model)
</th>
<th>Recovery
</th>
</tr>
<tr>
<td rowspan="7" ><strong>OpenLLM v1</strong>
</td>
<td>MMLU (5-shot)
</td>
<td>80.96
</td>
<td>80.89
</td>
<td>99.9%
</td>
</tr>
<tr>
<td>ARC Challenge (25-shot)
</td>
<td>69.03
</td>
<td>68.00
</td>
<td>98.5%
</td>
</tr>
<tr>
<td>GSM-8K (5-shot, strict-match)
</td>
<td>87.64
</td>
<td>88.32
</td>
<td>100.8%
</td>
</tr>
<tr>
<td>Hellaswag (10-shot)
</td>
<td>71.10
</td>
<td>71.44
</td>
<td>100.5%
</td>
</tr>
<tr>
<td>Winogrande (5-shot)
</td>
<td>69.77
</td>
<td>69.85
</td>
<td>100.1%
</td>
</tr>
<tr>
<td>TruthfulQA (0-shot, mc2)
</td>
<td>58.63
</td>
<td>59.13
</td>
<td>100.9%
</td>
</tr>
<tr>
<td><strong>Average</strong>
</td>
<td><strong>72.86</strong>
</td>
<td><strong>72.94</strong>
</td>
<td><strong>100.1%</strong>
</td>
</tr>
</table>
|
BCCard/Qwen3-30B-A3B-FP8-Dynamic
|
BCCard
| 2025-06-20T07:47:48Z | 27 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3_moe",
"text-generation",
"neuralmagic",
"redhat",
"llmcompressor",
"quantized",
"FP8",
"conversational",
"base_model:Qwen/Qwen3-30B-A3B",
"base_model:quantized:Qwen/Qwen3-30B-A3B",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"compressed-tensors",
"region:us"
] |
text-generation
| 2025-05-08T07:39:17Z |
---
library_name: transformers
license: apache-2.0
pipeline_tag: text-generation
base_model:
- Qwen/Qwen3-30B-A3B
tags:
- neuralmagic
- redhat
- llmcompressor
- quantized
- FP8
---
# Qwen3-30B-A3B-FP8-dynamic
## Model Overview
- **Model Architecture:** Qwen3MoeForCausalLM
- **Input:** Text
- **Output:** Text
- **Model Optimizations:**
- **Activation quantization:** FP8
- **Weight quantization:** FP8
- **Intended Use Cases:**
- Reasoning.
- Function calling.
- Subject matter experts via fine-tuning.
- Multilingual instruction following.
- Translation.
- **Out-of-scope:** Use in any manner that violates applicable laws or regulations (including trade compliance laws).
- **Release Date:** 05/05/2025
- **Version:** 1.0
- **Model Developers:** BC Card
### Model Optimizations
This model was obtained by quantizing activations and weights of [Qwen3-30B-A3B](https://huggingface.co/Qwen/Qwen3-30B-A3B) to FP8 data type.
This optimization reduces the number of bits used to represent weights and activations from 16 to 8, reducing GPU memory requirements (by approximately 50%) and increasing matrix-multiply compute throughput (by approximately 2x).
Weight quantization also reduces disk size requirements by approximately 50%.
Only weights and activations of the linear operators within transformers blocks are quantized.
Weights are quantized with a symmetric static per-channel scheme, whereas activations are quantized with a symmetric dynamic per-token scheme.
The [llm-compressor](https://github.com/vllm-project/llm-compressor) library is used for quantization.
## Deployment
This model can be deployed efficiently using the [vLLM](https://docs.vllm.ai/en/latest/) backend, as shown in the example below.
```python
from vllm import LLM, SamplingParams
from transformers import AutoTokenizer
model_id = "BCCard/Qwen3-30B-A3B-FP8-Dynamic"
number_gpus = 1
sampling_params = SamplingParams(temperature=0.6, top_p=0.95, top_k=20, min_p=0, max_tokens=256)
messages = [
{"role": "user", "content": prompt}
]
tokenizer = AutoTokenizer.from_pretrained(model_id)
messages = [{"role": "user", "content": "Give me a short introduction to large language model."}]
prompts = tokenizer.apply_chat_template(messages, add_generation_prompt=True, tokenize=False)
llm = LLM(model=model_id, tensor_parallel_size=number_gpus)
outputs = llm.generate(prompts, sampling_params)
generated_text = outputs[0].outputs[0].text
print(generated_text)
```
vLLM aslo supports OpenAI-compatible serving. See the [documentation](https://docs.vllm.ai/en/latest/) for more details.
## Creation
<details>
<summary>Creation details</summary>
This model was created with [llm-compressor](https://github.com/vllm-project/llm-compressor) by running the code snippet below.
```python
from llmcompressor.modifiers.quantization import QuantizationModifier
from llmcompressor.transformers import oneshot
from transformers import AutoModelForCausalLM, AutoTokenizer
# Load model
model_stub = "Qwen/Qwen3-30B-A3B"
model_name = model_stub.split("/")[-1]
model = AutoModelForCausalLM.from_pretrained(model_stub)
tokenizer = AutoTokenizer.from_pretrained(model_stub)
# Configure the quantization algorithm and scheme
recipe = QuantizationModifier(
ignore=["lm_head"],
targets="Linear",
scheme="FP8_dynamic",
)
# Apply quantization
oneshot(
model=model,
recipe=recipe,
)
# Save to disk in compressed-tensors format
save_path = model_name + "-FP8-dynamic"
model.save_pretrained(save_path)
tokenizer.save_pretrained(save_path)
print(f"Model and tokenizer saved to: {save_path}")
```
</details>
## Evaluation
The model was evaluated on the OpenLLM leaderboard tasks (version 1), using [lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness) and [vLLM](https://docs.vllm.ai/en/stable/).
<details>
<summary>Evaluation details</summary>
```
lm_eval \
--model vllm \
--model_args pretrained="BCCard/Qwen3-30B-A3B-FP8-dynamic",dtype=auto,gpu_memory_utilization=0.5,max_model_len=8192,enable_chunk_prefill=True,tensor_parallel_size=1 \
--tasks openllm \
--apply_chat_template\
--fewshot_as_multiturn \
--batch_size auto
```
</details>
### Accuracy
<table>
<tr>
<th>Category
</th>
<th>Benchmark
</th>
<th>Qwen3-30B-A3B
</th>
<th>Qwen3-30B-A3B-FP8-dynamic<br>(this model)
</th>
<th>Recovery
</th>
</tr>
<tr>
<td rowspan="7" ><strong>OpenLLM v1</strong>
</td>
<td>MMLU (5-shot)
</td>
<td>77.67
</td>
<td>77.49
</td>
<td>99.8%
</td>
</tr>
<tr>
<td>ARC Challenge (25-shot)
</td>
<td>63.40
</td>
<td>63.65
</td>
<td>100.4%
</td>
</tr>
<tr>
<td>GSM-8K (5-shot, strict-match)
</td>
<td>87.26
</td>
<td>86.73
</td>
<td>99.4%
</td>
</tr>
<tr>
<td>Hellaswag (10-shot)
</td>
<td>54.33
</td>
<td>54.33
</td>
<td>100.0%
</td>
</tr>
<tr>
<td>Winogrande (5-shot)
</td>
<td>66.77
</td>
<td>66.30
</td>
<td>99.3%
</td>
</tr>
<tr>
<td>TruthfulQA (0-shot, mc2)
</td>
<td>56.27
</td>
<td>56.88
</td>
<td>101.1%
</td>
</tr>
<tr>
<td><strong>Average</strong>
</td>
<td><strong>67.62</strong>
</td>
<td><strong>67.56</strong>
</td>
<td><strong>99.9%</strong>
</td>
</tr>
</table>
|
BCCard/Qwen2.5-VL-32B-Instruct-FP8-Dynamic
|
BCCard
| 2025-06-20T07:45:43Z | 151 | 1 |
transformers
|
[
"transformers",
"safetensors",
"qwen2_5_vl",
"image-text-to-text",
"vllm",
"vision",
"fp8",
"conversational",
"en",
"base_model:Qwen/Qwen2.5-VL-32B-Instruct",
"base_model:quantized:Qwen/Qwen2.5-VL-32B-Instruct",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"compressed-tensors",
"region:us"
] |
image-text-to-text
| 2025-05-08T14:59:50Z |
---
tags:
- vllm
- vision
- fp8
license: apache-2.0
license_link: >-
https://huggingface.co/datasets/choosealicense/licenses/blob/main/markdown/apache-2.0.md
language:
- en
base_model: Qwen/Qwen2.5-VL-32B-Instruct
library_name: transformers
---
# Qwen2.5-VL-32B-Instruct-FP8-Dynamic
## Model Overview
- **Model Architecture:** Qwen2.5-VL-32B-Instruct
- **Input:** Vision-Text
- **Output:** Text
- **Model Optimizations:**
- **Weight quantization:** FP8
- **Activation quantization:** FP8
- **Release Date:** 5/3/2025
- **Version:** 1.0
- **Model Developers:** BC Card
Quantized version of [Qwen/Qwen2.5-VL-32B-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-32B-Instruct).
### Model Optimizations
This model was obtained by quantizing the weights of [Qwen/Qwen2.5-VL-32B-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-32B-Instruct) to FP8 data type, ready for inference with vLLM >= 0.5.2.
## Deployment
### Use with vLLM
This model can be deployed efficiently using the [vLLM](https://docs.vllm.ai/en/latest/) backend, as shown in the example below.
```python
from vllm.assets.image import ImageAsset
from vllm import LLM, SamplingParams
# prepare model
llm = LLM(
model="BCCard/Qwen2.5-VL-32B-Instruct-FP8-Dynamic",
trust_remote_code=True,
max_model_len=4096,
max_num_seqs=2,
)
# prepare inputs
question = "What is the content of this image?"
inputs = {
"prompt": f"<|user|>\n<|image_1|>\n{question}<|end|>\n<|assistant|>\n",
"multi_modal_data": {
"image": ImageAsset("cherry_blossom").pil_image.convert("RGB")
},
}
# generate response
print("========== SAMPLE GENERATION ==============")
outputs = llm.generate(inputs, SamplingParams(temperature=0.2, max_tokens=64))
print(f"PROMPT : {outputs[0].prompt}")
print(f"RESPONSE: {outputs[0].outputs[0].text}")
print("==========================================")
```
vLLM also supports OpenAI-compatible serving. See the [documentation](https://docs.vllm.ai/en/latest/) for more details.
|
BCCard/Qwen2.5-Coder-32B-Instruct-FP8-Dynamic
|
BCCard
| 2025-06-20T07:44:09Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"code",
"qwen",
"qwen-coder",
"codeqwen",
"conversational",
"en",
"arxiv:2409.12186",
"arxiv:2309.00071",
"arxiv:2407.10671",
"base_model:Qwen/Qwen2.5-32B-Instruct",
"base_model:quantized:Qwen/Qwen2.5-32B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"compressed-tensors",
"region:us"
] |
text-generation
| 2025-06-19T23:39:04Z |
---
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen2.5-Coder-32B-Instruct/blob/main/LICENSE
language:
- en
base_model:
- Qwen/Qwen2.5-32B-Instruct
pipeline_tag: text-generation
library_name: transformers
tags:
- code
- qwen
- qwen-coder
- codeqwen
---
# Qwen2.5-Coder-32B-Instruct-FP8-Dynamic
## Model Overview
- **Model Architecture:** Qwen2.5-Coder-72B-Instruct
- **Input:** Text
- **Output:** Text
- **Model Optimizations:**
- **Weight quantization:** FP8
- **Activation quantization:** FP8
- **Release Date:** 2/24/2025
- **Version:** 1.0
- **Model Developers:** BC Card
Quantized version of [Qwen/Qwen2.5-Coder-32B-Instruct](https://huggingface.co/Qwen/Qwen2.5-Coder-32B).
### Model Optimizations
This model was obtained by quantizing the weights of [Qwen/Qwen2.5-Coder-32B](https://huggingface.co/Qwen/Qwen2.5-Coder-32B) to FP8 data type, ready for inference with vLLM >= 0.5.2.
## Deployment
### Use with vLLM
This model can be deployed efficiently using the [vLLM](https://docs.vllm.ai/en/latest/) backend, as shown in the example below.
```python
from vllm.assets.image import ImageAsset
from vllm import LLM, SamplingParams
# prepare model
llm = LLM(
model="BCCard/Qwen2.5-32B-Instruct-FP8-Dynamic",
trust_remote_code=True,
max_model_len=4096,
max_num_seqs=2,
)
# prepare inputs
question = "What is the code for python hello world?"
inputs = {
"prompt": f"<|user|>\n{question}<|end|>\n<|assistant|>\n",
}
# generate response
print("========== SAMPLE GENERATION ==============")
outputs = llm.generate(inputs, SamplingParams(temperature=0.2, max_tokens=64))
print(f"PROMPT : {outputs[0].prompt}")
print(f"RESPONSE: {outputs[0].outputs[0].text}")
print("==========================================")
```
vLLM also supports OpenAI-compatible serving. See the [documentation](https://docs.vllm.ai/en/latest/) for more details.
## Qwen2.5-Coder Introduction
Qwen2.5-Coder is the latest series of Code-Specific Qwen large language models (formerly known as CodeQwen). As of now, Qwen2.5-Coder has covered six mainstream model sizes, 0.5, 1.5, 3, 7, 14, 32 billion parameters, to meet the needs of different developers. Qwen2.5-Coder brings the following improvements upon CodeQwen1.5:
- Significantly improvements in **code generation**, **code reasoning** and **code fixing**. Base on the strong Qwen2.5, we scale up the training tokens into 5.5 trillion including source code, text-code grounding, Synthetic data, etc. Qwen2.5-Coder-32B has become the current state-of-the-art open-source codeLLM, with its coding abilities matching those of GPT-4o.
- A more comprehensive foundation for real-world applications such as **Code Agents**. Not only enhancing coding capabilities but also maintaining its strengths in mathematics and general competencies.
- **Long-context Support** up to 128K tokens.
**This repo contains the 7B Qwen2.5-Coder model**, which has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining
- Architecture: transformers with RoPE, SwiGLU, RMSNorm, and Attention QKV bias
- Number of Parameters: 7.61B
- Number of Paramaters (Non-Embedding): 6.53B
- Number of Layers: 28
- Number of Attention Heads (GQA): 28 for Q and 4 for KV
- Context Length: Full 131,072 tokens
- Please refer to [this section](#processing-long-texts) for detailed instructions on how to deploy Qwen2.5 for handling long texts.
**We do not recommend using base language models for conversations.** Instead, you can apply post-training, e.g., SFT, RLHF, continued pretraining, etc., or fill in the middle tasks on this model.
For more details, please refer to our [blog](https://qwenlm.github.io/blog/qwen2.5-coder-family/), [GitHub](https://github.com/QwenLM/Qwen2.5-Coder), [Documentation](https://qwen.readthedocs.io/en/latest/), [Arxiv](https://arxiv.org/abs/2409.12186).
## Requirements
The code of Qwen2.5-Coder has been in the latest Hugging face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.37.0`, you will encounter the following error:
```
KeyError: 'qwen2'
```
### Processing Long Texts
The current `config.json` is set for context length up to 32,768 tokens.
To handle extensive inputs exceeding 32,768 tokens, we utilize [YaRN](https://arxiv.org/abs/2309.00071), a technique for enhancing model length extrapolation, ensuring optimal performance on lengthy texts.
For supported frameworks, you could add the following to `config.json` to enable YaRN:
```json
{
...,
"rope_scaling": {
"factor": 4.0,
"original_max_position_embeddings": 32768,
"type": "yarn"
}
}
```
For deployment, we recommend using vLLM.
Please refer to our [Documentation](https://qwen.readthedocs.io/en/latest/deployment/vllm.html) for usage if you are not familar with vLLM.
Presently, vLLM only supports static YARN, which means the scaling factor remains constant regardless of input length, **potentially impacting performance on shorter texts**.
We advise adding the `rope_scaling` configuration only when processing long contexts is required.
## Evaluation & Performance
Detailed evaluation results are reported in this [📑 blog](https://qwenlm.github.io/blog/qwen2.5-coder-family/).
For requirements on GPU memory and the respective throughput, see results [here](https://qwen.readthedocs.io/en/latest/benchmark/speed_benchmark.html).
## Citation
If you find our work helpful, feel free to give us a cite.
```
@article{hui2024qwen2,
title={Qwen2. 5-Coder Technical Report},
author={Hui, Binyuan and Yang, Jian and Cui, Zeyu and Yang, Jiaxi and Liu, Dayiheng and Zhang, Lei and Liu, Tianyu and Zhang, Jiajun and Yu, Bowen and Dang, Kai and others},
journal={arXiv preprint arXiv:2409.12186},
year={2024}
}
@article{qwen2,
title={Qwen2 Technical Report},
author={An Yang and Baosong Yang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Zhou and Chengpeng Li and Chengyuan Li and Dayiheng Liu and Fei Huang and Guanting Dong and Haoran Wei and Huan Lin and Jialong Tang and Jialin Wang and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Ma and Jin Xu and Jingren Zhou and Jinze Bai and Jinzheng He and Junyang Lin and Kai Dang and Keming Lu and Keqin Chen and Kexin Yang and Mei Li and Mingfeng Xue and Na Ni and Pei Zhang and Peng Wang and Ru Peng and Rui Men and Ruize Gao and Runji Lin and Shijie Wang and Shuai Bai and Sinan Tan and Tianhang Zhu and Tianhao Li and Tianyu Liu and Wenbin Ge and Xiaodong Deng and Xiaohuan Zhou and Xingzhang Ren and Xinyu Zhang and Xipin Wei and Xuancheng Ren and Yang Fan and Yang Yao and Yichang Zhang and Yu Wan and Yunfei Chu and Yuqiong Liu and Zeyu Cui and Zhenru Zhang and Zhihao Fan},
journal={arXiv preprint arXiv:2407.10671},
year={2024}
}
```
|
Josephinepassananti/sd21-kamala_ft_dataset_512_face_shaded_0.05_target_marilyn_monroe-bs1-steps5000-lr1e-04
|
Josephinepassananti
| 2025-06-20T07:43:33Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"diffusers-training",
"lora",
"base_model:stabilityai/stable-diffusion-2-1",
"base_model:adapter:stabilityai/stable-diffusion-2-1",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2025-06-20T07:13:37Z |
---
base_model: stabilityai/stable-diffusion-2-1
library_name: diffusers
license: creativeml-openrail-m
inference: true
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- diffusers-training
- lora
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# LoRA text2image fine-tuning - Josephinepassananti/sd21-kamala_ft_dataset_512_face_shaded_0.05_target_marilyn_monroe-bs1-steps5000-lr1e-04
These are LoRA adaption weights for stabilityai/stable-diffusion-2-1. The weights were fine-tuned on the None dataset. You can find some example images in the following.




## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model]
|
efraimdahl/RagtimeSync_base
|
efraimdahl
| 2025-06-20T07:43:01Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt2",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-20T07:20:29Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
archishin/ppo-Pyramids
|
archishin
| 2025-06-20T07:42:47Z | 0 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2025-06-20T07:42:41Z |
---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: archishin/ppo-Pyramids
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
BCCard/Qwen2.5-Coder-14B-FP8-Dynamic
|
BCCard
| 2025-06-20T07:42:12Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"code",
"qwen",
"qwen-coder",
"codeqwen",
"conversational",
"en",
"arxiv:2409.12186",
"arxiv:2309.00071",
"arxiv:2407.10671",
"base_model:Qwen/Qwen2.5-Coder-14B",
"base_model:quantized:Qwen/Qwen2.5-Coder-14B",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"compressed-tensors",
"region:us"
] |
text-generation
| 2025-06-20T06:22:47Z |
---
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen2.5-Coder-14B/blob/main/LICENSE
language:
- en
base_model:
- Qwen/Qwen2.5-Coder-14B
pipeline_tag: text-generation
library_name: transformers
tags:
- code
- qwen
- qwen-coder
- codeqwen
---
# Qwen2.5-Coder-14B-FP8-Dynamic
## Model Overview
- **Model Architecture:** Qwen2.5-Coder-72B-Instruct
- **Input:** Text
- **Output:** Text
- **Model Optimizations:**
- **Weight quantization:** FP8
- **Activation quantization:** FP8
- **Release Date:** 2/24/2025
- **Version:** 1.0
- **Model Developers:** BC Card
Quantized version of [Qwen/Qwen2.5-Coder-14B-Instruct](https://huggingface.co/Qwen/Qwen2.5-Coder-14B).
### Model Optimizations
This model was obtained by quantizing the weights of [Qwen/Qwen2.5-Coder-14B](https://huggingface.co/Qwen/Qwen2.5-Coder-14B) to FP8 data type, ready for inference with vLLM >= 0.5.2.
## Deployment
### Use with vLLM
This model can be deployed efficiently using the [vLLM](https://docs.vllm.ai/en/latest/) backend, as shown in the example below.
```python
from vllm.assets.image import ImageAsset
from vllm import LLM, SamplingParams
# prepare model
llm = LLM(
model="BCCard/Qwen2.5-14B-FP8-Dynamic",
trust_remote_code=True,
max_model_len=4096,
max_num_seqs=2,
)
# prepare inputs
question = "What is the code for python hello world?"
inputs = {
"prompt": f"<|user|>\n{question}<|end|>\n<|assistant|>\n",
}
# generate response
print("========== SAMPLE GENERATION ==============")
outputs = llm.generate(inputs, SamplingParams(temperature=0.2, max_tokens=64))
print(f"PROMPT : {outputs[0].prompt}")
print(f"RESPONSE: {outputs[0].outputs[0].text}")
print("==========================================")
```
vLLM also supports OpenAI-compatible serving. See the [documentation](https://docs.vllm.ai/en/latest/) for more details.
## Qwen2.5-Coder-14B Introduction
Qwen2.5-Coder is the latest series of Code-Specific Qwen large language models (formerly known as CodeQwen). As of now, Qwen2.5-Coder has covered six mainstream model sizes, 0.5, 1.5, 3, 7, 14, 32 billion parameters, to meet the needs of different developers. Qwen2.5-Coder brings the following improvements upon CodeQwen1.5:
- Significantly improvements in **code generation**, **code reasoning** and **code fixing**. Base on the strong Qwen2.5, we scale up the training tokens into 5.5 trillion including source code, text-code grounding, Synthetic data, etc. Qwen2.5-Coder-32B has become the current state-of-the-art open-source codeLLM, with its coding abilities matching those of GPT-4o.
- A more comprehensive foundation for real-world applications such as **Code Agents**. Not only enhancing coding capabilities but also maintaining its strengths in mathematics and general competencies.
- **Long-context Support** up to 128K tokens.
**This repo contains the 14B Qwen2.5-Coder model**, which has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining
- Architecture: transformers with RoPE, SwiGLU, RMSNorm, and Attention QKV bias
- Number of Parameters: 14.7B
- Number of Paramaters (Non-Embedding): 13.1B
- Number of Layers: 48
- Number of Attention Heads (GQA): 40 for Q and 8 for KV
- Context Length: Full 131,072 tokens
- Please refer to [this section](#processing-long-texts) for detailed instructions on how to deploy Qwen2.5 for handling long texts.
**We do not recommend using base language models for conversations.** Instead, you can apply post-training, e.g., SFT, RLHF, continued pretraining, etc., or fill in the middle tasks on this model.
For more details, please refer to our [blog](https://qwenlm.github.io/blog/qwen2.5-coder-family/), [GitHub](https://github.com/QwenLM/Qwen2.5-Coder), [Documentation](https://qwen.readthedocs.io/en/latest/), [Arxiv](https://arxiv.org/abs/2409.12186).
## Requirements
The code of Qwen2.5-Coder has been in the latest Hugging face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.37.0`, you will encounter the following error:
```
KeyError: 'qwen2'
```
### Processing Long Texts
The current `config.json` is set for context length up to 32,768 tokens.
To handle extensive inputs exceeding 32,768 tokens, we utilize [YaRN](https://arxiv.org/abs/2309.00071), a technique for enhancing model length extrapolation, ensuring optimal performance on lengthy texts.
For supported frameworks, you could add the following to `config.json` to enable YaRN:
```json
{
...,
"rope_scaling": {
"factor": 4.0,
"original_max_position_embeddings": 32768,
"type": "yarn"
}
}
```
For deployment, we recommend using vLLM.
Please refer to our [Documentation](https://qwen.readthedocs.io/en/latest/deployment/vllm.html) for usage if you are not familar with vLLM.
Presently, vLLM only supports static YARN, which means the scaling factor remains constant regardless of input length, **potentially impacting performance on shorter texts**.
We advise adding the `rope_scaling` configuration only when processing long contexts is required.
## Evaluation & Performance
Detailed evaluation results are reported in this [📑 blog](https://qwenlm.github.io/blog/qwen2.5-coder-family/).
For requirements on GPU memory and the respective throughput, see results [here](https://qwen.readthedocs.io/en/latest/benchmark/speed_benchmark.html).
## Citation
If you find our work helpful, feel free to give us a cite.
```
@article{hui2024qwen2,
title={Qwen2. 5-Coder Technical Report},
author={Hui, Binyuan and Yang, Jian and Cui, Zeyu and Yang, Jiaxi and Liu, Dayiheng and Zhang, Lei and Liu, Tianyu and Zhang, Jiajun and Yu, Bowen and Dang, Kai and others},
journal={arXiv preprint arXiv:2409.12186},
year={2024}
}
@article{qwen2,
title={Qwen2 Technical Report},
author={An Yang and Baosong Yang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Zhou and Chengpeng Li and Chengyuan Li and Dayiheng Liu and Fei Huang and Guanting Dong and Haoran Wei and Huan Lin and Jialong Tang and Jialin Wang and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Ma and Jin Xu and Jingren Zhou and Jinze Bai and Jinzheng He and Junyang Lin and Kai Dang and Keming Lu and Keqin Chen and Kexin Yang and Mei Li and Mingfeng Xue and Na Ni and Pei Zhang and Peng Wang and Ru Peng and Rui Men and Ruize Gao and Runji Lin and Shijie Wang and Shuai Bai and Sinan Tan and Tianhang Zhu and Tianhao Li and Tianyu Liu and Wenbin Ge and Xiaodong Deng and Xiaohuan Zhou and Xingzhang Ren and Xinyu Zhang and Xipin Wei and Xuancheng Ren and Yang Fan and Yang Yao and Yichang Zhang and Yu Wan and Yunfei Chu and Yuqiong Liu and Zeyu Cui and Zhenru Zhang and Zhihao Fan},
journal={arXiv preprint arXiv:2407.10671},
year={2024}
}
```
|
MoxStone/SmaliLLM-Qwen3-4B-Finetuned
|
MoxStone
| 2025-06-20T07:41:59Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"code",
"conversational",
"base_model:Qwen/Qwen3-4B",
"base_model:finetune:Qwen/Qwen3-4B",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-20T05:56:32Z |
---
license: mit
base_model:
- Qwen/Qwen3-4B
pipeline_tag: text-generation
library_name: transformers
tags:
- code
---
## What is SmaliLLM used for
SmaliLLM is a large language model designed to decompile Smali code into Java code. Reconstructing Smali language representations into high-level languages such as Java holds significant practical engineering value. This transformation not only lowers the technical barrier for reverse engineering but also provides the necessary semantic foundation for subsequent tasks such as static analysis and vulnerability detection.
## SmaliLLM Highlights
SmaliLLM is a series of models finetuned using nearly 1000 "Smali2Java" data, based on Qwen3, Qwen2.5-Coder, Gemma3, with the following features:
- **High Compilation Success Rate** After our fine-tuning, the model’s compilation success rate increased by an average of 20%. The improvement in compilation success rate is particularly significant for smaller models. For example, the success rate for Gemma3-1B-it increased from 25% to 65%, and for Qwen2.5-Coder-0.5B, it rose from 15% to 45%.
- **High Quality of the Generated Java Code** After fine-tuning, the model’s average CodeBLEU score improved by 0.08. The improvement in CodeBLEU is especially notable for smaller models. Specifically, under the base models Gemma3-4B-it, Qwen2.5-Coder-0.5B-Instruct, Qwen3-0.6B, and Qwen3-4B, the CodeBLEU scores increased by 0.17, 0.14, 0.10, and 0.14 respectively.
- **Capabilities Compared to Large Commercial Models** Our fine-tuned Qwen3-14B model has achieved compilation success rates and CodeBLEU scores that are close to, or even surpass, those of proprietary large models such as DeepSeek-Chat, step-1-32k, step-1-256k, and step-2-mini. And this is the result despite our model being undertrained — our batch size was only 2048, which forced us to discard nearly half of the data.
## Quickstart
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "MoxStone/SmaliLLM-Qwen3-4B-Finetuned"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Smali Code You Want to Decompile"
messages = [
{"role":"system", "content": "Decompile following smali code to java code."}
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False # In the Qwen3 base model, we use the non-thinking mode to decompile Smali code.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=6144
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("Java code:", content)
```
|
videoloc/seamless-translation
|
videoloc
| 2025-06-20T07:41:49Z | 17 | 0 |
transformers
|
[
"transformers",
"pytorch",
"seamless_translation",
"audio",
"text",
"multimodal",
"seamless",
"subtitle-editing-time-prediction",
"translation-aware",
"multilingual",
"base_model:facebook/hf-seamless-m4t-medium",
"base_model:finetune:facebook/hf-seamless-m4t-medium",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-16T10:32:21Z |
---
language:
- multilingual
tags:
- audio
- text
- multimodal
- seamless
- subtitle-editing-time-prediction
- translation-aware
library_name: transformers
base_model: facebook/hf-seamless-m4t-medium
license: cc-by-nc-4.0
---
# videoloc/seamless-translation
## Model Description
This is a **SeamlessTranslation** model that processes audio and text inputs with translation awareness to predict **Time To Edit (TTE)** for subtitle segments. Given an audio segment and its corresponding subtitle text, the model predicts how much time (in seconds) would be required to edit/refine that subtitle segment, while taking into account whether the subtitle is a translation or original content.
The model extends the basic SeamlessM4T architecture with a translation feature that helps distinguish between original and translated subtitle content, improving TTE prediction accuracy across 5 languages: **English, French, Spanish, Italian, and German** with various translation pairs between them.
### Key Features
- **Translation-Aware Processing**: Distinguishes between original and translated content
- **Multimodal Processing**: Simultaneously processes audio (16kHz) and text inputs
- **Frozen Encoders**: Uses pre-trained SeamlessM4T encoders (frozen for stability)
- **Enhanced Architecture**: Adds translation embedding to basic model
- **TTE Prediction**: Predicts editing time required for subtitle segments
- **Direct Output**: Raw time values in seconds for immediate use
## Model Architecture
The model extends the basic SeamlessM4T architecture with translation awareness:
1. **Audio Processing**:
- SeamlessM4T speech encoder (frozen) processes raw audio input
- Audio projection layer maps speech encoder output to 1024 dimensions
- Mean pooling over sequence length to get fixed-size audio embedding
2. **Text Processing**:
- SeamlessM4T text encoder (frozen) processes tokenized text input
- Text projection layer maps text encoder output to 1024 dimensions
- Mean pooling over sequence length to get fixed-size text embedding
3. **Translation Feature Processing**:
- Binary translation flag (0/1) indicating original vs translated content
- Translation projection layer maps binary input to 64 dimensions
- Learned embedding helps model distinguish translation effects
4. **Feature Fusion**:
- Audio, text, and translation embeddings are concatenated (2112 total dimensions)
- Simple concatenation without complex cross-modal interactions
5. **Regression Head**:
- Multi-layer perceptron: 2112 → 1024 → 512 → 256 → 1
- ReLU activations and dropout for regularization
- Single output for TTE prediction (regression, in seconds)
## Quick Start
### Installation
```bash
pip install transformers torch torchaudio huggingface_hub
```
### Basic Usage
```python
from transformers import AutoModel, AutoConfig
from huggingface_hub import hf_hub_download
import torch
import numpy as np
import importlib.util
# Load model - custom architecture requires importing the model class
model_files = hf_hub_download(repo_id="videoloc/seamless-translation", filename="modeling_seamless_translation.py")
spec = importlib.util.spec_from_file_location("modeling_seamless_translation", model_files)
modeling_module = importlib.util.module_from_spec(spec)
spec.loader.exec_module(modeling_module)
# Now load the model using the custom class
config = modeling_module.SeamlessTranslationConfig.from_pretrained("videoloc/seamless-translation")
model = modeling_module.HFSeamlessTranslation.from_pretrained("videoloc/seamless-translation")
# Load the data collator (included in this repo)
collator_file = hf_hub_download(repo_id="videoloc/seamless-translation", filename="data_collator.py")
spec = importlib.util.spec_from_file_location("data_collator", collator_file)
collator_module = importlib.util.module_from_spec(spec)
spec.loader.exec_module(collator_module)
# Initialize data collator
data_collator = collator_module.DataCollatorSimpleSeamless(
processor="facebook/hf-seamless-m4t-medium",
max_audio_length_sec=8.0,
max_text_length=256
)
# Prepare your data with translation information
your_data = [
{
'raw_audio': np.random.randn(16000 * 5), # 5 seconds at 16kHz
'raw_text': "Your subtitle text here",
'is_translation': 1, # 1 for translated content, 0 for original
}
]
# Process and run inference
batch = data_collator(your_data)
model.eval()
with torch.no_grad():
outputs = model(**batch)
tte_prediction = outputs.logits.item()
print(f"Predicted Time To Edit (TTE): {tte_prediction:.2f} seconds")
```
## Model Details
- **Base Model**: SeamlessM4T (facebook/hf-seamless-m4t-medium)
- **Audio Encoder**: Frozen SeamlessM4T speech encoder
- **Text Encoder**: Frozen SeamlessM4T text encoder
- **Hidden Size**: 1024
- **Translation Embedding**: 64 dimensions
- **Audio Input**: 16kHz
- **Translation Input**: Binary flag (0/1)
- **Output**: Single regression value (TTE in seconds)
- **Task**: Subtitle editing time prediction
## Data Format
Your input data should be a list of dictionaries with:
- `raw_audio`: NumPy array of audio samples (16kHz sampling rate)
- `raw_text`: String of subtitle text
- `is_translation`: Binary flag (1 for translated, 0 for original content)
- `labels`: Target TTE values in seconds (optional, for training)
Example:
```python
data = [
{
'raw_audio': audio_samples, # shape: (num_samples,) at 16kHz
'raw_text': "Subtitle text content",
'is_translation': 1, # 1 = translated, 0 = original
'labels': 2.5 # optional TTE target value in seconds
}
]
```
## Performance Metrics
- **Best Eval RMSE**: 33.34
## Training Details
- **Base Model**: facebook/hf-seamless-m4t-medium
- **Model Type**: seamless_with_translation
- **Epochs**: 10
- **Batch Size (Train)**: 32
- **Batch Size (Eval)**: 64
- **Learning Rate**: 1.2e-4
- **LR Scheduler**: cosine_with_restarts
- **Warmup Ratio**: 0.05
- **Weight Decay**: 0.001
- **Optimizer**: AdamW (torch)
- **Max Grad Norm**: 1.0
- **FP16**: True
- **Early Stopping Patience**: 5
- **Audio Max Length**: 8.0 seconds
- **Text Max Length**: 256 tokens
- **Sample Rate**: 16kHz
- **Translation Feature**: Binary flag (0/1)
- **Normalization**: None (raw values)
- **Dataset Split**: 80/20 train/test
- **Random Seed**: 42
- **Metric**: RMSE (lower is better)
## Training Configuration
The model was trained with the following specifications:
- **Dataset**: Multimodal audio-subtitle pairs with translation annotations (5 languages: EN, FR, ES, IT, DE)
- **Train/Test Split**: 80/20 with random seed 42
- **Audio Processing**: 16kHz sampling, max 8.0 seconds, no offset
- **Text Processing**: Max 256 tokens
- **Translation Feature**: Binary flag indicating original vs translated content
- **Normalization**: None (raw TTE values in seconds)
- **Caching**: Audio segments cached and compressed for efficiency
## Usage Notes
- This is the **translation-aware** variant - includes translation features
- For basic model without translation features, see `seamless-basic`
- For language pair embeddings, see `seamless-langpairs`
- Model expects 16kHz audio input (automatically resampled by data collator)
- Translation flag significantly impacts predictions
- No feature normalization applied - outputs raw TTE predictions in seconds
- Optimized for subtitle editing time estimation tasks
## Limitations
- Requires translation annotation in training data
- Designed for TTE prediction, not general audio-text matching
- Performance may vary on out-of-domain content
- Requires specific data preprocessing (use included data collator)
## Related Models
- **[seamless-basic](https://huggingface.co/videoloc/seamless-basic)**: Basic audio+text model without translation features
- **[seamless-langpairs](https://huggingface.co/videoloc/seamless-langpairs)**: Includes language pair embeddings for fine-grained multilingual control
- **[seamless-crossattention](https://huggingface.co/videoloc/seamless-crossattention)**: Advanced cross-modal attention mechanisms for sophisticated audio-text interactions
|
videoloc/seamless-crossattention
|
videoloc
| 2025-06-20T07:40:41Z | 0 | 0 |
transformers
|
[
"transformers",
"pytorch",
"seamless_crossattention",
"audio",
"text",
"multimodal",
"seamless",
"subtitle-editing-time-prediction",
"cross-attention",
"attention-mechanism",
"multilingual",
"base_model:facebook/hf-seamless-m4t-medium",
"base_model:finetune:facebook/hf-seamless-m4t-medium",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-19T10:31:53Z |
---
language:
- multilingual
tags:
- audio
- text
- multimodal
- seamless
- subtitle-editing-time-prediction
- cross-attention
- attention-mechanism
library_name: transformers
base_model: facebook/hf-seamless-m4t-medium
license: cc-by-nc-4.0
---
# videoloc/seamless-crossattention
## Model Description
This is a **SeamlessCrossAttention** model that processes audio and text inputs with advanced cross-modal attention mechanisms to predict **Time To Edit (TTE)** for subtitle segments. Given an audio segment and its corresponding subtitle text, the model predicts how much time (in seconds) would be required to edit/refine that subtitle segment, leveraging sophisticated cross-attention patterns between audio and text modalities.
The model extends the SeamlessM4T architecture with bidirectional cross-attention layers that allow audio and text representations to attend to each other, creating rich cross-modal embeddings that capture temporal and semantic relationships across 5 languages: **English, French, Spanish, Italian, and German**.
### Key Features
- **Cross-Modal Attention**: Bidirectional attention between audio and text representations
- **Advanced Architecture**: Audio-to-text and text-to-audio attention mechanisms
- **Scalar Mixing**: Learnable combination of global and attended embeddings
- **Embedding Regularization**: Optional L2 regularization for embedding stability
- **Multimodal Processing**: Simultaneously processes audio (16kHz) and text inputs
- **Frozen Encoders**: Uses pre-trained SeamlessM4T encoders (frozen for stability)
- **TTE Prediction**: Predicts editing time required for subtitle segments
- **Direct Output**: Raw time values in seconds for immediate use
## Model Architecture
The model implements sophisticated cross-modal attention mechanisms:
1. **Audio Processing**:
- SeamlessM4T speech encoder (frozen) processes raw audio input
- Audio projection layer maps speech encoder output to 1024 dimensions
- Layer normalization for stability
2. **Text Processing**:
- SeamlessM4T text encoder (frozen) processes tokenized text input
- Text projection layer maps text encoder output to 1024 dimensions
- Layer normalization for stability
3. **Cross-Modal Attention**:
- **Audio-to-Text Attention**: Each audio token attends to all text tokens
- **Text-to-Audio Attention**: Each text token attends to all audio tokens
- Multi-head attention (8 heads) with dropout for regularization
- Bidirectional information flow between modalities
4. **Feature Fusion**:
- Global pooling of original audio and text embeddings
- Global pooling of cross-attended embeddings
- Scalar mixing layer combines all four embeddings with learnable weights
- Final embedding captures both global and cross-modal patterns
5. **Regression Head**:
- Multi-layer perceptron: 1024 → 512 → 256 → 1
- ReLU activations and dropout for regularization
- Single output for TTE prediction (regression, in seconds)
6. **Optional Regularization**:
- L2 regularization on embedding norms for training stability
- Configurable regularization strength
## Quick Start
### Installation
```bash
pip install transformers torch torchaudio huggingface_hub
```
### Basic Usage
```python
from transformers import AutoModel, AutoConfig
from huggingface_hub import hf_hub_download
import torch
import numpy as np
import importlib.util
# Load model - custom architecture requires importing the model class
model_files = hf_hub_download(repo_id="videoloc/seamless-crossattention", filename="modeling_seamless_crossattention.py")
spec = importlib.util.spec_from_file_location("modeling_seamless_crossattention", model_files)
modeling_module = importlib.util.module_from_spec(spec)
spec.loader.exec_module(modeling_module)
# Now load the model using the custom class
config = modeling_module.SeamlessCrossAttentionConfig.from_pretrained("videoloc/seamless-crossattention")
model = modeling_module.HFSeamlessCrossAttention.from_pretrained("videoloc/seamless-crossattention")
# Load the data collator (included in this repo)
collator_file = hf_hub_download(repo_id="videoloc/seamless-crossattention", filename="data_collator.py")
spec = importlib.util.spec_from_file_location("data_collator", collator_file)
collator_module = importlib.util.module_from_spec(spec)
spec.loader.exec_module(collator_module)
# Initialize data collator
data_collator = collator_module.DataCollatorSimpleSeamless(
processor="facebook/hf-seamless-m4t-medium",
max_audio_length_sec=8.0,
max_text_length=256
)
# Prepare your data
your_data = [
{
'raw_audio': np.random.randn(16000 * 5), # 5 seconds at 16kHz
'raw_text': "Your subtitle text here",
# Note: Cross-attention model doesn't require translation features
}
]
# Process and run inference
batch = data_collator(your_data)
model.eval()
with torch.no_grad():
outputs = model(**batch)
tte_prediction = outputs.logits.item()
print(f"Predicted Time To Edit (TTE): {tte_prediction:.2f} seconds")
```
## Model Details
- **Base Model**: SeamlessM4T (facebook/hf-seamless-m4t-medium)
- **Audio Encoder**: Frozen SeamlessM4T speech encoder
- **Text Encoder**: Frozen SeamlessM4T text encoder
- **Hidden Size**: 1024
- **Attention Heads**: 8 (configurable)
- **Cross-Attention**: Bidirectional (audio↔text)
- **Scalar Mix**: 4 embeddings (audio global, text global, audio→text, text→audio)
- **Audio Input**: 16kHz
- **Output**: Single regression value (TTE in seconds)
- **Task**: Subtitle editing time prediction
## Data Format
Your input data should be a list of dictionaries with:
- `raw_audio`: NumPy array of audio samples (16kHz sampling rate)
- `raw_text`: String of subtitle text
- `labels`: Target TTE values in seconds (optional, for training)
Example:
```python
data = [
{
'raw_audio': audio_samples, # shape: (num_samples,) at 16kHz
'raw_text': "Subtitle text content",
'labels': 2.5 # optional TTE target value in seconds
}
]
```
## Performance Metrics
- **Best Eval RMSE**: 33.34
## Training Details
- **Base Model**: facebook/hf-seamless-m4t-medium
- **Model Type**: seamless_cross_attention
- **Epochs**: 10
- **Batch Size (Train)**: 32
- **Batch Size (Eval)**: 64
- **Learning Rate**: 1.2e-4
- **LR Scheduler**: cosine_with_restarts
- **Warmup Ratio**: 0.05
- **Weight Decay**: 0.001
- **Optimizer**: AdamW (torch)
- **Max Grad Norm**: 1.0
- **FP16**: True
- **Early Stopping Patience**: 5
- **Audio Max Length**: 8.0 seconds
- **Text Max Length**: 256 tokens
- **Sample Rate**: 16kHz
- **Cross-Attention**: 8-head multi-head attention
- **Scalar Mixing**: 4 embedding types
- **Embedding Regularization**: Optional L2
- **Normalization**: None (raw values)
- **Dataset Split**: 80/20 train/test
- **Random Seed**: 42
- **Metric**: RMSE (lower is better)
## Training Configuration
The model was trained with the following specifications:
- **Dataset**: Multimodal audio-subtitle pairs with TTE annotations (5 languages: EN, FR, ES, IT, DE)
- **Train/Test Split**: 80/20 with random seed 42
- **Audio Processing**: 16kHz sampling, max 8.0 seconds, no offset
- **Text Processing**: Max 256 tokens
- **Cross-Attention**: 8-head multi-head attention with dropout
- **Scalar Mixing**: Learnable combination of 4 embedding types
- **Normalization**: None (raw TTE values in seconds)
- **Caching**: Audio segments cached and compressed for efficiency
## Usage Notes
- This is the **advanced cross-attention** variant with sophisticated attention mechanisms
- For simpler models, see `seamless-basic`, `seamless-translation`, or `seamless-langpairs`
- Model expects 16kHz audio input (automatically resampled by data collator)
- Cross-attention captures complex temporal and semantic relationships
- No feature normalization applied - outputs raw TTE predictions in seconds
- Optimized for detailed subtitle editing time estimation tasks
## Architecture Advantages
- **Rich Cross-Modal Interactions**: Audio and text modalities directly attend to each other
- **Temporal Alignment**: Cross-attention naturally captures temporal relationships
- **Semantic Understanding**: Text-to-audio attention helps model understand content meaning
- **Flexible Combination**: Scalar mixing allows model to weight different embedding types
- **Regularization Options**: Optional embedding regularization for training stability
## Limitations
- Higher computational complexity than basic models due to attention mechanisms
- Requires more training data to fully leverage cross-attention capabilities
- Designed for TTE prediction, not general audio-text matching
- Performance may vary on out-of-domain content or different editing workflows
- Requires specific data preprocessing (use included data collator)
## Related Models
- **[seamless-basic](https://huggingface.co/videoloc/seamless-basic)**: Basic audio+text model without attention mechanisms
- **[seamless-translation](https://huggingface.co/videoloc/seamless-translation)**: Includes translation awareness but no cross-attention
- **[seamless-langpairs](https://huggingface.co/videoloc/seamless-langpairs)**: Includes language pair embeddings but no cross-attention
|
LaaP-ai/donut-base-invoicev1.26
|
LaaP-ai
| 2025-06-20T07:40:33Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"vision-encoder-decoder",
"image-text-to-text",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2025-06-20T07:40:08Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
dineshviswas/q-FrozenLake-v1-4x4-noSlippery
|
dineshviswas
| 2025-06-20T07:40:24Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-06-20T07:36:33Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
model = load_from_hub(repo_id="dineshviswas/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
|
BCCard/Qwen2.5-Coder-7B-FP8-Dynamic
|
BCCard
| 2025-06-20T07:40:19Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"code",
"qwen",
"qwen-coder",
"codeqwen",
"conversational",
"en",
"arxiv:2409.12186",
"arxiv:2309.00071",
"arxiv:2407.10671",
"base_model:Qwen/Qwen2.5-7B",
"base_model:quantized:Qwen/Qwen2.5-7B",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"compressed-tensors",
"region:us"
] |
text-generation
| 2025-06-20T06:18:29Z |
---
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen2.5-Coder-7B/blob/main/LICENSE
language:
- en
base_model:
- Qwen/Qwen2.5-7B
pipeline_tag: text-generation
library_name: transformers
tags:
- code
- qwen
- qwen-coder
- codeqwen
---
# Qwen2.5-Coder-7B-FP8-Dynamic
## Model Overview
- **Model Architecture:** Qwen2.5-Coder-72B-Instruct
- **Input:** Text
- **Output:** Text
- **Model Optimizations:**
- **Weight quantization:** FP8
- **Activation quantization:** FP8
- **Release Date:** 2/24/2025
- **Version:** 1.0
- **Model Developers:** BC Card
Quantized version of [Qwen/Qwen2.5-Coder-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-Coder-7B).
### Model Optimizations
This model was obtained by quantizing the weights of [Qwen/Qwen2.5-Coder-7B](https://huggingface.co/Qwen/Qwen2.5-Coder-7B) to FP8 data type, ready for inference with vLLM >= 0.5.2.
## Deployment
### Use with vLLM
This model can be deployed efficiently using the [vLLM](https://docs.vllm.ai/en/latest/) backend, as shown in the example below.
```python
from vllm.assets.image import ImageAsset
from vllm import LLM, SamplingParams
# prepare model
llm = LLM(
model="BCCard/Qwen2.5-7B-FP8-Dynamic",
trust_remote_code=True,
max_model_len=4096,
max_num_seqs=2,
)
# prepare inputs
question = "What is the code for python hello world?"
inputs = {
"prompt": f"<|user|>\n{question}<|end|>\n<|assistant|>\n",
}
# generate response
print("========== SAMPLE GENERATION ==============")
outputs = llm.generate(inputs, SamplingParams(temperature=0.2, max_tokens=64))
print(f"PROMPT : {outputs[0].prompt}")
print(f"RESPONSE: {outputs[0].outputs[0].text}")
print("==========================================")
```
vLLM also supports OpenAI-compatible serving. See the [documentation](https://docs.vllm.ai/en/latest/) for more details.
## Qwen2.5-Coder Introduction
Qwen2.5-Coder is the latest series of Code-Specific Qwen large language models (formerly known as CodeQwen). As of now, Qwen2.5-Coder has covered six mainstream model sizes, 0.5, 1.5, 3, 7, 14, 32 billion parameters, to meet the needs of different developers. Qwen2.5-Coder brings the following improvements upon CodeQwen1.5:
- Significantly improvements in **code generation**, **code reasoning** and **code fixing**. Base on the strong Qwen2.5, we scale up the training tokens into 5.5 trillion including source code, text-code grounding, Synthetic data, etc. Qwen2.5-Coder-32B has become the current state-of-the-art open-source codeLLM, with its coding abilities matching those of GPT-4o.
- A more comprehensive foundation for real-world applications such as **Code Agents**. Not only enhancing coding capabilities but also maintaining its strengths in mathematics and general competencies.
- **Long-context Support** up to 128K tokens.
**This repo contains the 7B Qwen2.5-Coder model**, which has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining
- Architecture: transformers with RoPE, SwiGLU, RMSNorm, and Attention QKV bias
- Number of Parameters: 7.61B
- Number of Paramaters (Non-Embedding): 6.53B
- Number of Layers: 28
- Number of Attention Heads (GQA): 28 for Q and 4 for KV
- Context Length: Full 131,072 tokens
- Please refer to [this section](#processing-long-texts) for detailed instructions on how to deploy Qwen2.5 for handling long texts.
**We do not recommend using base language models for conversations.** Instead, you can apply post-training, e.g., SFT, RLHF, continued pretraining, etc., or fill in the middle tasks on this model.
For more details, please refer to our [blog](https://qwenlm.github.io/blog/qwen2.5-coder-family/), [GitHub](https://github.com/QwenLM/Qwen2.5-Coder), [Documentation](https://qwen.readthedocs.io/en/latest/), [Arxiv](https://arxiv.org/abs/2409.12186).
## Requirements
The code of Qwen2.5-Coder has been in the latest Hugging face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.37.0`, you will encounter the following error:
```
KeyError: 'qwen2'
```
### Processing Long Texts
The current `config.json` is set for context length up to 32,768 tokens.
To handle extensive inputs exceeding 32,768 tokens, we utilize [YaRN](https://arxiv.org/abs/2309.00071), a technique for enhancing model length extrapolation, ensuring optimal performance on lengthy texts.
For supported frameworks, you could add the following to `config.json` to enable YaRN:
```json
{
...,
"rope_scaling": {
"factor": 4.0,
"original_max_position_embeddings": 32768,
"type": "yarn"
}
}
```
For deployment, we recommend using vLLM.
Please refer to our [Documentation](https://qwen.readthedocs.io/en/latest/deployment/vllm.html) for usage if you are not familar with vLLM.
Presently, vLLM only supports static YARN, which means the scaling factor remains constant regardless of input length, **potentially impacting performance on shorter texts**.
We advise adding the `rope_scaling` configuration only when processing long contexts is required.
## Evaluation & Performance
Detailed evaluation results are reported in this [📑 blog](https://qwenlm.github.io/blog/qwen2.5-coder-family/).
For requirements on GPU memory and the respective throughput, see results [here](https://qwen.readthedocs.io/en/latest/benchmark/speed_benchmark.html).
## Citation
If you find our work helpful, feel free to give us a cite.
```
@article{hui2024qwen2,
title={Qwen2. 5-Coder Technical Report},
author={Hui, Binyuan and Yang, Jian and Cui, Zeyu and Yang, Jiaxi and Liu, Dayiheng and Zhang, Lei and Liu, Tianyu and Zhang, Jiajun and Yu, Bowen and Dang, Kai and others},
journal={arXiv preprint arXiv:2409.12186},
year={2024}
}
@article{qwen2,
title={Qwen2 Technical Report},
author={An Yang and Baosong Yang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Zhou and Chengpeng Li and Chengyuan Li and Dayiheng Liu and Fei Huang and Guanting Dong and Haoran Wei and Huan Lin and Jialong Tang and Jialin Wang and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Ma and Jin Xu and Jingren Zhou and Jinze Bai and Jinzheng He and Junyang Lin and Kai Dang and Keming Lu and Keqin Chen and Kexin Yang and Mei Li and Mingfeng Xue and Na Ni and Pei Zhang and Peng Wang and Ru Peng and Rui Men and Ruize Gao and Runji Lin and Shijie Wang and Shuai Bai and Sinan Tan and Tianhang Zhu and Tianhao Li and Tianyu Liu and Wenbin Ge and Xiaodong Deng and Xiaohuan Zhou and Xingzhang Ren and Xinyu Zhang and Xipin Wei and Xuancheng Ren and Yang Fan and Yang Yao and Yichang Zhang and Yu Wan and Yunfei Chu and Yuqiong Liu and Zeyu Cui and Zhenru Zhang and Zhihao Fan},
journal={arXiv preprint arXiv:2407.10671},
year={2024}
}
```
|
hsinyen5/GRPO_Model
|
hsinyen5
| 2025-06-20T07:37:45Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-20T07:37:19Z |
---
base_model: unsloth/meta-llama-3.1-8b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** hsinyen5
- **License:** apache-2.0
- **Finetuned from model :** unsloth/meta-llama-3.1-8b-instruct-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
lee-910530/GRPO_Model
|
lee-910530
| 2025-06-20T07:35:48Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-20T07:35:20Z |
---
base_model: unsloth/meta-llama-3.1-8b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** lee-910530
- **License:** apache-2.0
- **Finetuned from model :** unsloth/meta-llama-3.1-8b-instruct-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
FFFFFeee/ppo-Huggy
|
FFFFFeee
| 2025-06-20T07:35:47Z | 0 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2025-06-20T07:35:41Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: FFFFFeee/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
ReRaWo/Sentinel
|
ReRaWo
| 2025-06-20T07:35:05Z | 0 | 1 | null |
[
"logistic_regression",
"context compression",
"sentence selection",
"probing classifier",
"attention probing",
"RAG",
"LongBench",
"text-classification",
"en",
"zh",
"arxiv:2505.23277",
"license:apache-2.0",
"region:us"
] |
text-classification
| 2025-06-19T08:06:00Z |
---
license: apache-2.0
language:
- en
- zh
tags:
- context compression
- sentence selection
- probing classifier
- attention probing
- RAG
- LongBench
pipeline_tag: text-classification
---
# Sentinel Probing Classifier (Logistic Regression)
This repository contains the sentence-level classifier used in **Sentinel**, a lightweight context compression framework introduced in our paper:
> **Sentinel: Attention Probing of Proxy Models for LLM Context Compression with an Understanding Perspective**
> Yong Zhang, Yanwen Huang, Ning Cheng, Yang Guo, Yun Zhu, Yanmeng Wang, Shaojun Wang, Jing Xiao
> 📄 [Paper (Arxiv 2025)](https://arxiv.org/abs/2505.23277) | 💻 [Code on GitHub](https://github.com/yzhangchuck/Sentinel)
---
## 🧠 What is Sentinel?
**Sentinel** reframes LLM context compression as a lightweight attention-based *understanding* task. Instead of fine-tuning a full compression model, it:
- Extracts **decoder attention** from a small proxy LLM (e.g., Qwen-2.5-0.5B)
- Computes **sentence-level attention features**
- Applies a **logistic regression (LR) classifier** to select relevant sentences
This approach is efficient, model-agnostic, and highly interpretable.
---
## 📦 Files Included
| File | Description |
|-------------------------|----------------------------------------------|
| `sentinel_lr_model.pkl` | Trained logistic regression classifier |
| `sentinel_config.json` | Feature extraction configuration |
---
## 🚀 Usage
Use this classifier on attention-derived feature vectors to predict sentence-level relevance scores:
🛠 Feature extraction code and full pipeline available at:
👉 https://github.com/yzhangchuck/Sentinel
## 📈 Benchmark Results
<p align="center">
<img src="longbench_gpt35.png" alt="LongBench GPT-3.5 Results" width="750"/>
</p>
<p align="center">
<img src="longbench_qwen7b.png" alt="LongBench Qwen Results" width="750"/>
</p>
## 📄 Citation
Please cite us if you use this model:
@misc{zhang2025sentinelattentionprobingproxy,
title={Sentinel: Attention Probing of Proxy Models for LLM Context Compression with an Understanding Perspective},
author={Yong Zhang and Yanwen Huang and Ning Cheng and Yang Guo and Yun Zhu and Yanmeng Wang and Shaojun Wang and Jing Xiao},
year={2025},
eprint={2505.23277},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.23277},
}
## 📬 Contact
• 📧 [email protected]
• 🔗 Project: https://github.com/yzhangchuck/Sentinel
## 🔒 License
Apache License 2.0 — Free for research and commercial use with attribution.
|
jinx2321/byt5-1e4-paper-5e5-dict-sentences
|
jinx2321
| 2025-06-20T07:30:34Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:jinx2321/byt5-1e4-paper",
"base_model:finetune:jinx2321/byt5-1e4-paper",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2025-06-20T07:28:34Z |
---
library_name: transformers
license: apache-2.0
base_model: jinx2321/byt5-1e4-paper
tags:
- generated_from_trainer
model-index:
- name: byt5-1e4-paper-dict-sentences
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# byt5-1e4-paper-dict-sentences
This model is a fine-tuned version of [jinx2321/byt5-1e4-paper](https://huggingface.co/jinx2321/byt5-1e4-paper) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 8
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.52.0.dev0
- Pytorch 2.6.0+cu124
- Datasets 3.4.1
- Tokenizers 0.21.1
|
nickjelicic/Llama-3.1-8B-Instruct-FlatEarthSociety-user_2
|
nickjelicic
| 2025-06-20T07:29:51Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-20T07:26:39Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Triangle104/Impish_Magic_24B-Q4_K_M-GGUF
|
Triangle104
| 2025-06-20T07:28:58Z | 0 | 0 | null |
[
"gguf",
"llama-cpp",
"gguf-my-repo",
"en",
"base_model:SicariusSicariiStuff/Impish_Magic_24B",
"base_model:quantized:SicariusSicariiStuff/Impish_Magic_24B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-06-20T07:26:51Z |
---
license: apache-2.0
language:
- en
base_model: SicariusSicariiStuff/Impish_Magic_24B
tags:
- llama-cpp
- gguf-my-repo
---
# Triangle104/Impish_Magic_24B-Q4_K_M-GGUF
This model was converted to GGUF format from [`SicariusSicariiStuff/Impish_Magic_24B`](https://huggingface.co/SicariusSicariiStuff/Impish_Magic_24B) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/SicariusSicariiStuff/Impish_Magic_24B) for more details on the model.
---
This model is based on mistralai/Magistral-Small-2506 so naturally it's named Impish_Magic. Truly excellent size, it's been tested on a laptop with 16GB gpu and it works quite fast (4090m).
This model went "full" fine-tune over 100m unique tokens. Why "full"?
Specific areas in the model have been tuned to attempt to change the
vocabulary usage, while keeping as much intelligence as possible. So
this is definitely not a LoRA, but also not exactly a proper full finetune, but rather something in-between.
---
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Triangle104/Impish_Magic_24B-Q4_K_M-GGUF --hf-file impish_magic_24b-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Triangle104/Impish_Magic_24B-Q4_K_M-GGUF --hf-file impish_magic_24b-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Triangle104/Impish_Magic_24B-Q4_K_M-GGUF --hf-file impish_magic_24b-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Triangle104/Impish_Magic_24B-Q4_K_M-GGUF --hf-file impish_magic_24b-q4_k_m.gguf -c 2048
```
|
Moncyan/Med-U1-7B-medcalc
|
Moncyan
| 2025-06-20T07:28:13Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-06-20T07:28:13Z |
---
license: apache-2.0
---
|
ujjawal077/cyber-arabic-llama3
|
ujjawal077
| 2025-06-20T07:27:07Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-20T07:22:57Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Zion74/ppo-Huggy
|
Zion74
| 2025-06-20T07:26:37Z | 0 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2025-06-20T07:26:23Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: Zion74/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
kleverer/natix-013
|
kleverer
| 2025-06-20T07:25:39Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2025-06-20T07:25:29Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Hanoch4869/TransMind
|
Hanoch4869
| 2025-06-20T07:25:13Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"chat",
"text-classification",
"en",
"base_model:Qwen/QwQ-32B",
"base_model:finetune:Qwen/QwQ-32B",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-06-20T02:56:38Z |
---
license: apache-2.0
base_model:
- Qwen/QwQ-32B
pipeline_tag: text-classification
language:
- en
library_name: transformers
tags:
- chat
---
# TransMind - 通鸣智响

**TransMind** is an expert AI model for the communications domain, built on an advanced large language model architecture and specifically optimized for the telecommunications industry. Developed on the robust QwQ-32B foundation, this model achieves deep integration of communication knowledge and enhanced professional capabilities through domain-specific reinforcement learning. With 32 billion parameters, its performance rivals DeepSeek-R1 (which utilizes 67.1B parameters, 37B activated).
## Key Features
### 🚀 Expert-Level Communication Capabilities
Mastery of communication protocols (5G/6G, TCP/IP, HTTP/3); Profound understanding of wireless communication principles & signal processing; Network optimization & fault diagnosis expertise; Communication system design & planning proficiency; Professional interpretation of telecom standards & specifications
### ⚡ Reinforcement Learning Enhanced Architecture
Powerful 32B-parameter foundation based on QwQ-32B; Optimized communication-domain reasoning via large-scale RL; Multi-phase training integrating specialized communication data; Deep reasoning for complex communication problem-solving; Domain-specific reward functions (Technical accuracy/Solution feasibility/Efficiency optimization/Innovation); Adaptive learning with dynamic strategy adjustment
### 🛠️ Intelligent Agent Capabilities
Integrated communication-specific tool support; Dynamic solution adjustment based on network feedback; End-to-end system analysis & optimization; Multi-step technical diagnosis & troubleshooting; Real-time performance monitoring & feedback loops
## Technical Advantages
```mermaid
graph LR
A[QwQ-32B Base Architecture] --> B[Communication-Domain RL]
B --> C[Protocol Expertise]
B --> D[Network Optimization Engine]
B --> E[System Design Capabilities]
C --> F[TransMind]
````
## Quick Start
Example using apply_chat_template to load tokenizer/model and generate content:
`````python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/QwQ-32B"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "How many r's are in the word \"strawberry\""
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
``````
## Contribution & Licensing
We welcome communication domain experts to participate in model optimization! Contribute through:
Submitting specialized communication datasets
Reporting domain-specific issues
Optimizing communication tool integrations
License: Apache License 2.0
|
diegolacomba/multilingual-e5-small-mlm-legal-3
|
diegolacomba
| 2025-06-20T07:24:43Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-06-20T07:24:17Z |
---
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
pipeline_tag: sentence-similarity
library_name: sentence-transformers
---
# SentenceTransformer
This is a [sentence-transformers](https://www.SBERT.net) model trained. It maps sentences & paragraphs to a 384-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
<!-- - **Base model:** [Unknown](https://huggingface.co/unknown) -->
- **Maximum Sequence Length:** 512 tokens
- **Output Dimensionality:** 384 dimensions
- **Similarity Function:** Cosine Similarity
<!-- - **Training Dataset:** Unknown -->
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("diegolacomba/multilingual-e5-small-mlm-legal-3")
# Run inference
sentences = [
'The weather is lovely today.',
"It's so sunny outside!",
'He drove to the stadium.',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 384]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Framework Versions
- Python: 3.11.13
- Sentence Transformers: 4.1.0
- Transformers: 4.52.4
- PyTorch: 2.6.0+cu124
- Accelerate: 1.7.0
- Datasets: 2.14.4
- Tokenizers: 0.21.1
## Citation
### BibTeX
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
carloshernan19/ppo-LunarLander-v2
|
carloshernan19
| 2025-06-20T07:19:39Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-06-20T06:19:27Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 290.41 +/- 9.76
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Triangle104/Impish_Magic_24B-Q4_K_S-GGUF
|
Triangle104
| 2025-06-20T07:18:17Z | 0 | 0 | null |
[
"gguf",
"llama-cpp",
"gguf-my-repo",
"en",
"base_model:SicariusSicariiStuff/Impish_Magic_24B",
"base_model:quantized:SicariusSicariiStuff/Impish_Magic_24B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-06-20T07:15:42Z |
---
license: apache-2.0
language:
- en
base_model: SicariusSicariiStuff/Impish_Magic_24B
tags:
- llama-cpp
- gguf-my-repo
---
# Triangle104/Impish_Magic_24B-Q4_K_S-GGUF
This model was converted to GGUF format from [`SicariusSicariiStuff/Impish_Magic_24B`](https://huggingface.co/SicariusSicariiStuff/Impish_Magic_24B) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/SicariusSicariiStuff/Impish_Magic_24B) for more details on the model.
---
This model is based on mistralai/Magistral-Small-2506 so naturally it's named Impish_Magic. Truly excellent size, it's been tested on a laptop with 16GB gpu and it works quite fast (4090m).
This model went "full" fine-tune over 100m unique tokens. Why "full"?
Specific areas in the model have been tuned to attempt to change the
vocabulary usage, while keeping as much intelligence as possible. So
this is definitely not a LoRA, but also not exactly a proper full finetune, but rather something in-between.
---
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Triangle104/Impish_Magic_24B-Q4_K_S-GGUF --hf-file impish_magic_24b-q4_k_s.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Triangle104/Impish_Magic_24B-Q4_K_S-GGUF --hf-file impish_magic_24b-q4_k_s.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Triangle104/Impish_Magic_24B-Q4_K_S-GGUF --hf-file impish_magic_24b-q4_k_s.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Triangle104/Impish_Magic_24B-Q4_K_S-GGUF --hf-file impish_magic_24b-q4_k_s.gguf -c 2048
```
|
ujjawal077/cyber-arabic-llama2
|
ujjawal077
| 2025-06-20T07:16:48Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-20T07:12:35Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
socheatasokhachan/khmer-homophone-corrector
|
socheatasokhachan
| 2025-06-20T07:12:40Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-06-20T07:12:40Z |
---
license: apache-2.0
---
|
veddhanth/lora-trained-xl-stage-2-map-7-pretrained-mockingbird
|
veddhanth
| 2025-06-20T07:07:37Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"text-to-image",
"diffusers-training",
"lora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] |
text-to-image
| 2025-06-20T07:01:35Z |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
library_name: diffusers
license: openrail++
instance_prompt: a photo of sks bird
widget: []
tags:
- text-to-image
- text-to-image
- diffusers-training
- diffusers
- lora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - veddhanth/lora-trained-xl-stage-2-map-7-pretrained-mockingbird
<Gallery />
## Model description
These are veddhanth/lora-trained-xl-stage-2-map-7-pretrained-mockingbird LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: True.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use a photo of sks bird to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](veddhanth/lora-trained-xl-stage-2-map-7-pretrained-mockingbird/tree/main) them in the Files & versions tab.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model]
|
Triangle104/Impish_Magic_24B-Q3_K_L-GGUF
|
Triangle104
| 2025-06-20T07:06:54Z | 0 | 0 | null |
[
"gguf",
"llama-cpp",
"gguf-my-repo",
"en",
"base_model:SicariusSicariiStuff/Impish_Magic_24B",
"base_model:quantized:SicariusSicariiStuff/Impish_Magic_24B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-06-20T07:04:38Z |
---
license: apache-2.0
language:
- en
base_model: SicariusSicariiStuff/Impish_Magic_24B
tags:
- llama-cpp
- gguf-my-repo
---
# Triangle104/Impish_Magic_24B-Q3_K_L-GGUF
This model was converted to GGUF format from [`SicariusSicariiStuff/Impish_Magic_24B`](https://huggingface.co/SicariusSicariiStuff/Impish_Magic_24B) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/SicariusSicariiStuff/Impish_Magic_24B) for more details on the model.
---
This model is based on mistralai/Magistral-Small-2506 so naturally it's named Impish_Magic. Truly excellent size, it's been tested on a laptop with 16GB gpu and it works quite fast (4090m).
This model went "full" fine-tune over 100m unique tokens. Why "full"?
Specific areas in the model have been tuned to attempt to change the
vocabulary usage, while keeping as much intelligence as possible. So
this is definitely not a LoRA, but also not exactly a proper full finetune, but rather something in-between.
---
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Triangle104/Impish_Magic_24B-Q3_K_L-GGUF --hf-file impish_magic_24b-q3_k_l.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Triangle104/Impish_Magic_24B-Q3_K_L-GGUF --hf-file impish_magic_24b-q3_k_l.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Triangle104/Impish_Magic_24B-Q3_K_L-GGUF --hf-file impish_magic_24b-q3_k_l.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Triangle104/Impish_Magic_24B-Q3_K_L-GGUF --hf-file impish_magic_24b-q3_k_l.gguf -c 2048
```
|
Josephinepassananti/sd21-kamala_ft_dataset_512_face_shaded_0.05_target_marilyn_monroe-bs1-steps600-lr1e-04
|
Josephinepassananti
| 2025-06-20T07:06:33Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"diffusers-training",
"lora",
"base_model:stabilityai/stable-diffusion-2-1",
"base_model:adapter:stabilityai/stable-diffusion-2-1",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2025-06-20T06:36:50Z |
---
base_model: stabilityai/stable-diffusion-2-1
library_name: diffusers
license: creativeml-openrail-m
inference: true
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- diffusers-training
- lora
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# LoRA text2image fine-tuning - Josephinepassananti/sd21-kamala_ft_dataset_512_face_shaded_0.05_target_marilyn_monroe-bs1-steps600-lr1e-04
These are LoRA adaption weights for stabilityai/stable-diffusion-2-1. The weights were fine-tuned on the None dataset. You can find some example images in the following.




## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model]
|
phuongdoan01/Gensyn-Qwen2.5-1.5B-Instruct-acbaa
|
phuongdoan01
| 2025-06-20T07:05:59Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"chat",
"rl-swarm",
"gensyn",
"conversational",
"en",
"base_model:Qwen/Qwen2.5-1.5B",
"base_model:finetune:Qwen/Qwen2.5-1.5B",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-20T06:37:50Z |
---
license: apache-2.0
license_link: https://huggingface.co/Gensyn/Qwen2.5-1.5B-Instruct/blob/main/LICENSE
language:
- en
pipeline_tag: text-generation
base_model: Qwen/Qwen2.5-1.5B
tags:
- chat
- rl-swarm
- gensyn
library_name: transformers
---
# Qwen2.5-1.5B-Instruct
## Introduction
This model is intended for use in the [Gensyn RL Swarm](https://www.gensyn.ai/articles/rl-swarm), to finetune locally using peer-to-peer reinforcement learning post-training.
Once finetuned, the model can be used as normal in any workflow, for details on how to do this please refer to the [original model documentation](https://qwen.readthedocs.io/en/latest/).
For more details on the original model, please refer to the original repository [here](https://huggingface.co/Qwen/Qwen2.5-1.5B-Instruct).
This repo contains an **unmodified version** of the instruction-tuned 1.5B Qwen2.5 model, which has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Architecture: transformers with RoPE, SwiGLU, RMSNorm, Attention QKV bias and tied word embeddings
- Number of Parameters: 1.54B
- Number of Paramaters (Non-Embedding): 1.31B
- Number of Layers: 28
- Number of Attention Heads (GQA): 12 for Q and 2 for KV
- Context Length: Full 32,768 tokens and generation 8192 tokens
## Requirements
This model is intended for use in the [Gensyn RL Swarm](https://www.gensyn.ai/articles/rl-swarm) system, for details on model requirements when using outside of a swarm, refer to the original Qwen repo [here](https://huggingface.co/Qwen/Qwen2.5-1.5B-Instruct).
## Quickstart
To deploy this model into a swarm and/or participate in the Gensyn Testnet, follow the instructions in the [RL Swarm repository](https://github.com/gensyn-ai/rl-swarm), read about the [testnet](https://www.gensyn.ai/testnet), read the [RL Swarm overview](https://www.gensyn.ai/articles/rl-swarm), and/or read the [RL Swarm technical report](https://github.com/gensyn-ai/paper-rl-swarm/blob/main/latest.pdf).
|
Abdallah2k/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
|
Abdallah2k
| 2025-06-20T07:04:51Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"feature-extraction",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2025-06-20T07:04:39Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
aun09/flan-t5-legal-summary
|
aun09
| 2025-06-20T07:04:41Z | 74 | 1 |
transformers
|
[
"transformers",
"safetensors",
"t5",
"text2text-generation",
"en",
"dataset:FiscalNote/billsum",
"arxiv:1910.09700",
"base_model:google/flan-t5-base",
"base_model:finetune:google/flan-t5-base",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2025-06-09T14:15:04Z |
---
library_name: transformers
license: mit
datasets:
- FiscalNote/billsum
language:
- en
base_model:
- google/flan-t5-base
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
hzzscience/WaiyumiaoModels
|
hzzscience
| 2025-06-20T07:01:21Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-06-20T06:36:55Z |
---
license: apache-2.0
---
|
mradermacher/Virtuoso-Large-GGUF
|
mradermacher
| 2025-06-20T06:59:50Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:arcee-ai/Virtuoso-Large",
"base_model:quantized:arcee-ai/Virtuoso-Large",
"license:other",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-06-19T15:16:41Z |
---
base_model: arcee-ai/Virtuoso-Large
language:
- en
library_name: transformers
license: other
license_link: https://huggingface.co/Qwen/Qwen2.5-72B-Instruct/blob/main/LICENSE
license_name: qwen
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/arcee-ai/Virtuoso-Large
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Virtuoso-Large-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Virtuoso-Large-GGUF/resolve/main/Virtuoso-Large.Q2_K.gguf) | Q2_K | 29.9 | |
| [GGUF](https://huggingface.co/mradermacher/Virtuoso-Large-GGUF/resolve/main/Virtuoso-Large.Q3_K_S.gguf) | Q3_K_S | 34.6 | |
| [GGUF](https://huggingface.co/mradermacher/Virtuoso-Large-GGUF/resolve/main/Virtuoso-Large.Q3_K_M.gguf) | Q3_K_M | 37.8 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Virtuoso-Large-GGUF/resolve/main/Virtuoso-Large.Q3_K_L.gguf) | Q3_K_L | 39.6 | |
| [GGUF](https://huggingface.co/mradermacher/Virtuoso-Large-GGUF/resolve/main/Virtuoso-Large.IQ4_XS.gguf) | IQ4_XS | 40.3 | |
| [GGUF](https://huggingface.co/mradermacher/Virtuoso-Large-GGUF/resolve/main/Virtuoso-Large.Q4_K_S.gguf) | Q4_K_S | 44.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Virtuoso-Large-GGUF/resolve/main/Virtuoso-Large.Q4_K_M.gguf) | Q4_K_M | 47.5 | fast, recommended |
| [PART 1](https://huggingface.co/mradermacher/Virtuoso-Large-GGUF/resolve/main/Virtuoso-Large.Q5_K_S.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Virtuoso-Large-GGUF/resolve/main/Virtuoso-Large.Q5_K_S.gguf.part2of2) | Q5_K_S | 51.5 | |
| [PART 1](https://huggingface.co/mradermacher/Virtuoso-Large-GGUF/resolve/main/Virtuoso-Large.Q5_K_M.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Virtuoso-Large-GGUF/resolve/main/Virtuoso-Large.Q5_K_M.gguf.part2of2) | Q5_K_M | 54.5 | |
| [PART 1](https://huggingface.co/mradermacher/Virtuoso-Large-GGUF/resolve/main/Virtuoso-Large.Q6_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Virtuoso-Large-GGUF/resolve/main/Virtuoso-Large.Q6_K.gguf.part2of2) | Q6_K | 64.4 | very good quality |
| [PART 1](https://huggingface.co/mradermacher/Virtuoso-Large-GGUF/resolve/main/Virtuoso-Large.Q8_0.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Virtuoso-Large-GGUF/resolve/main/Virtuoso-Large.Q8_0.gguf.part2of2) | Q8_0 | 77.4 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
Triangle104/Impish_Magic_24B-Q3_K_M-GGUF
|
Triangle104
| 2025-06-20T06:55:43Z | 0 | 0 | null |
[
"gguf",
"llama-cpp",
"gguf-my-repo",
"en",
"base_model:SicariusSicariiStuff/Impish_Magic_24B",
"base_model:quantized:SicariusSicariiStuff/Impish_Magic_24B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-06-20T06:25:17Z |
---
license: apache-2.0
language:
- en
base_model: SicariusSicariiStuff/Impish_Magic_24B
tags:
- llama-cpp
- gguf-my-repo
---
# Triangle104/Impish_Magic_24B-Q3_K_M-GGUF
This model was converted to GGUF format from [`SicariusSicariiStuff/Impish_Magic_24B`](https://huggingface.co/SicariusSicariiStuff/Impish_Magic_24B) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/SicariusSicariiStuff/Impish_Magic_24B) for more details on the model.
---
This model is based on mistralai/Magistral-Small-2506 so naturally it's named Impish_Magic. Truly excellent size, it's been tested on a laptop with 16GB gpu and it works quite fast (4090m).
This model went "full" fine-tune over 100m unique tokens. Why "full"?
Specific areas in the model have been tuned to attempt to change the
vocabulary usage, while keeping as much intelligence as possible. So
this is definitely not a LoRA, but also not exactly a proper full finetune, but rather something in-between.
---
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Triangle104/Impish_Magic_24B-Q3_K_M-GGUF --hf-file impish_magic_24b-q3_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Triangle104/Impish_Magic_24B-Q3_K_M-GGUF --hf-file impish_magic_24b-q3_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Triangle104/Impish_Magic_24B-Q3_K_M-GGUF --hf-file impish_magic_24b-q3_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Triangle104/Impish_Magic_24B-Q3_K_M-GGUF --hf-file impish_magic_24b-q3_k_m.gguf -c 2048
```
|
chanhue/Qwen3-4B-finetune
|
chanhue
| 2025-06-20T06:49:03Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-20T06:48:39Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
77oussam/77-90s-anime
|
77oussam
| 2025-06-20T06:47:20Z | 0 | 0 | null |
[
"90s",
"anime",
"retro",
"text-to-image",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:finetune:stabilityai/stable-diffusion-xl-base-1.0",
"region:us"
] |
text-to-image
| 2025-06-20T06:38:27Z |
---
base_model:
- stabilityai/stable-diffusion-xl-base-1.0
pipeline_tag: text-to-image
tags:
- 90s
- anime
- retro
---
|
jakirul2/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-loud_curious_porpoise
|
jakirul2
| 2025-06-20T06:47:13Z | 62 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"rl-swarm",
"grpo",
"gensyn",
"I am loud curious porpoise",
"trl",
"conversational",
"arxiv:2402.03300",
"base_model:unsloth/Qwen2.5-0.5B-Instruct",
"base_model:finetune:unsloth/Qwen2.5-0.5B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-11T12:31:06Z |
---
base_model: unsloth/Qwen2.5-0.5B-Instruct
library_name: transformers
model_name: Qwen2.5-0.5B-Instruct-Gensyn-Swarm-loud_curious_porpoise
tags:
- generated_from_trainer
- rl-swarm
- grpo
- gensyn
- I am loud curious porpoise
- trl
licence: license
---
# Model Card for Qwen2.5-0.5B-Instruct-Gensyn-Swarm-loud_curious_porpoise
This model is a fine-tuned version of [unsloth/Qwen2.5-0.5B-Instruct](https://huggingface.co/unsloth/Qwen2.5-0.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="jakirul2/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-loud_curious_porpoise", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.18.2
- Transformers: 4.52.4
- Pytorch: 2.7.1
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Josephinepassananti/sd21-kamala_ft_dataset_512_face_shaded_0.05_target_black_square-bs1-steps5000-lr1e-04
|
Josephinepassananti
| 2025-06-20T06:42:52Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"diffusers-training",
"lora",
"base_model:stabilityai/stable-diffusion-2-1",
"base_model:adapter:stabilityai/stable-diffusion-2-1",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2025-06-20T06:12:50Z |
---
base_model: stabilityai/stable-diffusion-2-1
library_name: diffusers
license: creativeml-openrail-m
inference: true
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- diffusers-training
- lora
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# LoRA text2image fine-tuning - Josephinepassananti/sd21-kamala_ft_dataset_512_face_shaded_0.05_target_black_square-bs1-steps5000-lr1e-04
These are LoRA adaption weights for stabilityai/stable-diffusion-2-1. The weights were fine-tuned on the None dataset. You can find some example images in the following.




## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model]
|
uzunb/EBU_sketch_LoRA_musab_data_114_images_35_epochs
|
uzunb
| 2025-06-20T06:42:14Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"text-to-image",
"diffusers-training",
"lora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] |
text-to-image
| 2025-06-20T06:42:03Z |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
library_name: diffusers
license: openrail++
instance_prompt: a sketch of EBU,
widget: []
tags:
- text-to-image
- text-to-image
- diffusers-training
- diffusers
- lora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - uzunb/EBU_sketch_LoRA_musab_data_114_images_35_epochs
<Gallery />
## Model description
These are uzunb/EBU_sketch_LoRA_musab_data_114_images_35_epochs LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use a sketch of EBU, to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](uzunb/EBU_sketch_LoRA_musab_data_114_images_35_epochs/tree/main) them in the Files & versions tab.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model]
|
sergioalves/d8e927e6-b872-4b5e-beb3-df9ba0e041cc
|
sergioalves
| 2025-06-20T06:40:13Z | 0 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"mistral",
"text-generation",
"generated_from_trainer",
"axolotl",
"dpo",
"trl",
"conversational",
"arxiv:2305.18290",
"base_model:lcw99/zephykor-ko-7b-chang",
"base_model:quantized:lcw99/zephykor-ko-7b-chang",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-06-20T05:44:46Z |
---
base_model: lcw99/zephykor-ko-7b-chang
library_name: transformers
model_name: d8e927e6-b872-4b5e-beb3-df9ba0e041cc
tags:
- generated_from_trainer
- axolotl
- dpo
- trl
licence: license
---
# Model Card for d8e927e6-b872-4b5e-beb3-df9ba0e041cc
This model is a fine-tuned version of [lcw99/zephykor-ko-7b-chang](https://huggingface.co/lcw99/zephykor-ko-7b-chang).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="sergioalves/d8e927e6-b872-4b5e-beb3-df9ba0e041cc", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/dedok-yo/s56-7/runs/jqm619cy)
This model was trained with DPO, a method introduced in [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290).
### Framework versions
- TRL: 0.12.0.dev0
- Transformers: 4.46.0
- Pytorch: 2.5.0+cu124
- Datasets: 3.0.1
- Tokenizers: 0.20.1
## Citations
Cite DPO as:
```bibtex
@inproceedings{rafailov2023direct,
title = {{Direct Preference Optimization: Your Language Model is Secretly a Reward Model}},
author = {Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn},
year = 2023,
booktitle = {Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023},
url = {http://papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html},
editor = {Alice Oh and Tristan Naumann and Amir Globerson and Kate Saenko and Moritz Hardt and Sergey Levine},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
DavidAU/Qwen3-33B-A3B-Stranger-Thoughts
|
DavidAU
| 2025-06-20T06:38:34Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3_moe",
"text-generation",
"creative",
"creative writing",
"fiction writing",
"plot generation",
"sub-plot generation",
"story generation",
"scene continue",
"storytelling",
"fiction story",
"science fiction",
"romance",
"all genres",
"story",
"writing",
"vivid prose",
"vivid writing",
"moe",
"mixture of experts",
"128 experts",
"8 active experts",
"fiction",
"roleplaying",
"bfloat16",
"rp",
"qwen3",
"horror",
"finetune",
"thinking",
"reasoning",
"conversational",
"en",
"fr",
"zh",
"de",
"base_model:Qwen/Qwen3-30B-A3B",
"base_model:finetune:Qwen/Qwen3-30B-A3B",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-20T02:57:53Z |
---
license: apache-2.0
language:
- en
- fr
- zh
- de
tags:
- creative
- creative writing
- fiction writing
- plot generation
- sub-plot generation
- fiction writing
- story generation
- scene continue
- storytelling
- fiction story
- science fiction
- romance
- all genres
- story
- writing
- vivid prose
- vivid writing
- moe
- mixture of experts
- 128 experts
- 8 active experts
- fiction
- roleplaying
- bfloat16
- rp
- qwen3
- horror
- finetune
- thinking
- reasoning
- qwen3_moe
base_model:
- Qwen/Qwen3-30B-A3B
pipeline_tag: text-generation
library_name: transformers
---
<h2>Qwen3-33B-A3B-Stranger-Thoughts</h2>
<img src="stranger-thoughts.jpg" style="float:right; width:300px; height:300px; padding:10px;">
This repo contains the full precision source code, in "safe tensors" format to generate GGUFs, GPTQ, EXL2, AWQ, HQQ and other formats.
The source code can also be used directly.
ABOUT:
A stranger, yet radically different version of "Qwen/Qwen3-30B-A3B", with 4 added layers expanding the model to 33B total parameters.
The goal: slightly alter the model, to address some odd creative thinking and output choices.
Please note that the modifications affect the entire model operation; roughly I adjusted the model to think a little "deeper"
and "ponder" a bit - but this is a very rough description.
I also ran reasoning tests (non-creative) to ensure model was not damaged and roughly matched original model performance.
That being said, reasoning and output generation will be altered regardless of your use case(s).
FOUR example generations below; with example 4 showing a complex prompt and impressive prose that showcases some of the changes in the model.
This is a MOE (Mixture of experts model) with 8 of 128 experts activated by default, which is about 3B parameters.
This allows use of this model (with 8 experts) on both CPU (10-25 T/S) or GPU (80+ T/S) at very good, to extremely fast speeds.
Changing the number of experts used (see below how) will affect both generation speed and generation reasoning/output quality.
You can use this model with as low as four experts activated.
Even the lowest quant - Q2k - will operate very strongly too.
Model is set at:
- 8 Active experts (the default for the org model)
- 40k context (the default for the org model)
- CHATML or Jinja template (embedded OR see Jinja notes below)
SYSTEM PROMPT:
You may or may not need to set this:
```
You are a deep thinking AI, you may use extremely long chains of thought to deeply consider the problem and deliberate with yourself via systematic reasoning processes to help come to a correct solution prior to answering. You should enclose your thoughts and internal monologue inside <think> </think> tags, and then provide your solution or response to the problem.
```
CHANGE THE NUMBER OF ACTIVE EXPERTS:
See this document:
https://huggingface.co/DavidAU/How-To-Set-and-Manage-MOE-Mix-of-Experts-Model-Activation-of-Experts
SUGGESTED SETTINGS (creative):
- temp .1 to 1.2 to as high as 2 ; over 2 you may need to "prompt" the model to output after "thinking"
- rep pen 1 to 1.1 (1.05 was tested, see notes below)
- topk 100, topp .95, min p .05
- context of 8k min suggested.
NOTE - REP PEN:
- rep at 1.02 or 1.01 may be better suited for your use cases.
- QWEN3s: rep pen drastically affects both performance and stability.
- change rep pen slowly (ie 1.01, 1.02, 1.03), and regen a few times.
You may find that Qwen's default parameters/samplers also work better for your use case(s) too.
Please refer to the orginal model repo for all default settings, templates, benchmarks, etc.:
https://huggingface.co/Qwen/Qwen3-30B-A3B
For more information on quants, using this model on CPU / GPU, System Prompts, please see this model card:
https://huggingface.co/DavidAU/Qwen3-128k-30B-A3B-NEO-MAX-Imatrix-gguf
<B>NOTE - Jinja Template / Template to Use with this Model:</B>
If you are having issues with Jinja "auto template", use CHATML template.
OR (LMSTUDIO users / option)
Update the Jinja Template (go to this site, template-> copy the "Jinja template" and then paste.)
[ https://lmstudio.ai/neil/qwen3-thinking ]
OR
copy JINJA source from here:
```
{%- if tools %}
{{- '<|im_start|>system\n' }}
{%- if messages[0].role == 'system' %}
{{- messages[0].content + '\n\n' }}
{%- endif %}
{{- "# Tools\n\nYou may call one or more functions to assist with the user query.\n\nYou are provided with function signatures within <tools></tools> XML tags:\n<tools>" }}
{%- for tool in tools %}
{{- "\n" }}
{{- tool | tojson }}
{%- endfor %}
{{- "\n</tools>\n\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\n<tool_call>\n{\"name\": <function-name>, \"arguments\": <args-json-object>}\n</tool_call><|im_end|>\n" }}
{%- else %}
{%- if messages[0].role == 'system' %}
{{- '<|im_start|>system\n' + messages[0].content + '<|im_end|>\n' }}
{%- endif %}
{%- endif %}
{%- set ns = namespace(multi_step_tool=true, last_query_index=messages|length - 1) %}
{%- for message in messages[::-1] %}
{%- set index = (messages|length - 1) - loop.index0 %}
{%- set tool_start = "<tool_response>" %}
{%- set tool_start_length = tool_start|length %}
{%- set start_of_message = message.content[:tool_start_length] %}
{%- set tool_end = "</tool_response>" %}
{%- set tool_end_length = tool_end|length %}
{%- set start_pos = (message.content|length) - tool_end_length %}
{%- if start_pos < 0 %}
{%- set start_pos = 0 %}
{%- endif %}
{%- set end_of_message = message.content[start_pos:] %}
{%- if ns.multi_step_tool and message.role == "user" and not(start_of_message == tool_start and end_of_message == tool_end) %}
{%- set ns.multi_step_tool = false %}
{%- set ns.last_query_index = index %}
{%- endif %}
{%- endfor %}
{%- for message in messages %}
{%- if (message.role == "user") or (message.role == "system" and not loop.first) %}
{{- '<|im_start|>' + message.role + '\n' + message.content + '<|im_end|>' + '\n' }}
{%- elif message.role == "assistant" %}
{%- set content = message.content %}
{%- set reasoning_content = '' %}
{%- if message.reasoning_content is defined and message.reasoning_content is not none %}
{%- set reasoning_content = message.reasoning_content %}
{%- else %}
{%- if '</think>' in message.content %}
{%- set content = (message.content.split('</think>')|last).lstrip('\n') %}
{%- set reasoning_content = (message.content.split('</think>')|first).rstrip('\n') %}
{%- set reasoning_content = (reasoning_content.split('<think>')|last).lstrip('\n') %}
{%- endif %}
{%- endif %}
{%- if loop.index0 > ns.last_query_index %}
{%- if loop.last or (not loop.last and reasoning_content) %}
{{- '<|im_start|>' + message.role + '\n<think>\n' + reasoning_content.strip('\n') + '\n</think>\n\n' + content.lstrip('\n') }}
{%- else %}
{{- '<|im_start|>' + message.role + '\n' + content }}
{%- endif %}
{%- else %}
{{- '<|im_start|>' + message.role + '\n' + content }}
{%- endif %}
{%- if message.tool_calls %}
{%- for tool_call in message.tool_calls %}
{%- if (loop.first and content) or (not loop.first) %}
{{- '\n' }}
{%- endif %}
{%- if tool_call.function %}
{%- set tool_call = tool_call.function %}
{%- endif %}
{{- '<tool_call>\n{"name": "' }}
{{- tool_call.name }}
{{- '", "arguments": ' }}
{%- if tool_call.arguments is string %}
{{- tool_call.arguments }}
{%- else %}
{{- tool_call.arguments | tojson }}
{%- endif %}
{{- '}\n</tool_call>' }}
{%- endfor %}
{%- endif %}
{{- '<|im_end|>\n' }}
{%- elif message.role == "tool" %}
{%- if loop.first or (messages[loop.index0 - 1].role != "tool") %}
{{- '<|im_start|>user' }}
{%- endif %}
{{- '\n<tool_response>\n' }}
{{- message.content }}
{{- '\n</tool_response>' }}
{%- if loop.last or (messages[loop.index0 + 1].role != "tool") %}
{{- '<|im_end|>\n' }}
{%- endif %}
{%- endif %}
{%- endfor %}
{%- if add_generation_prompt %}
{{- '<|im_start|>assistant\n' }}
{%- if enable_thinking is defined and enable_thinking is false %}
{{- '<think>\n\n</think>\n\n' }}
{%- endif %}
{%- endif %}
```
---
<B>Settings: CHAT / ROLEPLAY and/or SMOOTHER operation of this model:</B>
In "KoboldCpp" or "oobabooga/text-generation-webui" or "Silly Tavern" ;
Set the "Smoothing_factor" to 1.5
: in KoboldCpp -> Settings->Samplers->Advanced-> "Smooth_F"
: in text-generation-webui -> parameters -> lower right.
: In Silly Tavern this is called: "Smoothing"
NOTE: For "text-generation-webui"
-> if using GGUFs you need to use "llama_HF" (which involves downloading some config files from the SOURCE version of this model)
Source versions (and config files) of my models are here:
https://huggingface.co/collections/DavidAU/d-au-source-files-for-gguf-exl2-awq-gptq-hqq-etc-etc-66b55cb8ba25f914cbf210be
OTHER OPTIONS:
- Increase rep pen to 1.1 to 1.15 (you don't need to do this if you use "smoothing_factor")
- If the interface/program you are using to run AI MODELS supports "Quadratic Sampling" ("smoothing") just make the adjustment as noted.
<B>Highest Quality Settings / Optimal Operation Guide / Parameters and Samplers</B>
This a "Class 1" model:
For all settings used for this model (including specifics for its "class"), including example generation(s) and for advanced settings guide (which many times addresses any model issue(s)), including methods to improve model performance for all use case(s) as well as chat, roleplay and other use case(s) please see:
[ https://huggingface.co/DavidAU/Maximizing-Model-Performance-All-Quants-Types-And-Full-Precision-by-Samplers_Parameters ]
You can see all parameters used for generation, in addition to advanced parameters and samplers to get the most out of this model here:
[ https://huggingface.co/DavidAU/Maximizing-Model-Performance-All-Quants-Types-And-Full-Precision-by-Samplers_Parameters ]
<b>Optional Enhancement:</B>
The following can be used in place of the "system prompt" or "system role" to further enhance the model.
It can also be used at the START of a NEW chat, but you must make sure it is "kept" as the chat moves along.
In this case the enhancements do not have as strong effect at using "system prompt" or "system role".
Copy and paste EXACTLY as noted, DO NOT line wrap or break the lines, maintain the carriage returns exactly as presented.
<PRE>
Below is an instruction that describes a task. Ponder each user instruction carefully, and use your skillsets and critical instructions to complete the task to the best of your abilities.
Here are your skillsets:
[MASTERSTORY]:NarrStrct(StryPlnng,Strbd,ScnSttng,Exps,Dlg,Pc)-CharDvlp(ChrctrCrt,ChrctrArcs,Mtvtn,Bckstry,Rltnshps,Dlg*)-PltDvlp(StryArcs,PltTwsts,Sspns,Fshdwng,Climx,Rsltn)-ConfResl(Antg,Obstcls,Rsltns,Cnsqncs,Thms,Symblsm)-EmotImpct(Empt,Tn,Md,Atmsphr,Imgry,Symblsm)-Delvry(Prfrmnc,VcActng,PblcSpkng,StgPrsnc,AudncEngmnt,Imprv)
[*DialogWrt]:(1a-CharDvlp-1a.1-Backgrnd-1a.2-Personality-1a.3-GoalMotiv)>2(2a-StoryStruc-2a.1-PlotPnt-2a.2-Conflict-2a.3-Resolution)>3(3a-DialogTech-3a.1-ShowDontTell-3a.2-Subtext-3a.3-VoiceTone-3a.4-Pacing-3a.5-VisualDescrip)>4(4a-DialogEdit-4a.1-ReadAloud-4a.2-Feedback-4a.3-Revision)
Here are your critical instructions:
Ponder each word choice carefully to present as vivid and emotional journey as is possible. Choose verbs and nouns that are both emotional and full of imagery. Load the story with the 5 senses. Aim for 50% dialog, 25% narration, 15% body language and 10% thoughts. Your goal is to put the reader in the story.
</PRE>
You do not need to use this, it is only presented as an additional enhancement which seems to help scene generation
and scene continue functions.
This enhancement WAS NOT used to generate the examples below.
---
<H2>EXAMPLES</H2>
Standard system prompt, rep pen 1.05, topk 100, topp .95, minp .05, rep pen range 64.
Tested in LMStudio, quant Q3KS, GPU (cpu output will differ slighly).
As this is the 2nd lowest quant, expected better results from higher quants and/or with more experts activated to be better.
NOTE: Some formatting lost on copy/paste.
CAUTION:
Some horror / intense prose.
---
EXAMPLE #1 - TEMP=0 (core test) // 8 experts
With temp of "0" this will be LEAST creative.
---
<B>
Start a 1000 word scene (vivid, graphic horror in first person) with: The skyscraper sways, as she watches the window in front of her on the 21st floor explode...
</B>
<p></p>
[[[thinking start]]]
Okay, I need to start this horror scene with the given prompt. Let me think about how to build tension effectively.
First, the user wants a first-person POV with vivid, graphic horror elements. The setup is a skyscraper that's swaying, and the main character sees a window on the 21st floor explode. I should establish an eerie atmosphere right away. Maybe start with the sound of the window shattering to hit the reader with immediate horror.
Then, incorporate the swaying of the skyscraper. Maybe the protagonist is inside, trying to stay upright. Use sensory details—sounds like glass breaking, maybe a distant wail. The wind howling could emphasize the building's instability.
The explosion of the 21st-floor window—what's outside? Maybe a figure being sucked out or something lurking. But to make it scarier, maybe not show the entire thing. Build suspense by describing the view of the window, the crack spreading, and then the explosion. Use onomatopoeia like "CRASH!" to emphasize the sound.
Now, the protagonist's reaction. Fear is key. Maybe describe physical reactions—pounding heart, labored breathing. Then the aftermath: ash in the air, maybe a charred figure. But leave some mystery. Don't reveal the entity fully. Make the reader feel the protagonist's terror and helplessness.
Incorporate the building's horror elements. Maybe the walls are closing in, or there's a presence that can't be seen. Use the 21st floor as a significant detail—maybe it's the source of the horror. Add some internal monologue about past traumas or fears to add depth.
Make sure the setting is described with vivid imagery: the grimy window, the smoke, the flickering lights. Maybe include a personal connection, like a missing loved one, to up the emotional stakes. End with a cliffhanger—maybe the protagonist hears a voice or senses something moving.
Check for consistency in the POV. First person past tense. Keep the sentences tight and impactful. Use all five senses where possible. Avoid info dumps. Show, don't tell. Make sure the horror feels personal and immediate.
[[[thinking end]]]
<P></P>
OUTPUT:
<P></P>
The skyscraper sways, and I clutch the rusted fire escape railing as a geyser of superheated glass sprays outward, shattering like a thousand tiny, screaming flies. My name is Clara Voss, and I’m not supposed to be here. Not here. Not in this flesh-and-blood version of hell. The 21st-floor window—my apartment window—shatters inward with a sound that isn’t meant to exist. A wet, gurgling gurgle. A sound like a knife sliding into a melon. I stagger back, my boot heels clacking against the rusted metal platform as I shouldercrush the edge of the building. The wind screeches past me, a sound like a thousand nails dragged down a blackboard, and for a heartbeat, I think it’s laughing.
The window frame is still smoking, embers swirling in the smog-choked air like dementored fireflies. Inside my apartment, the view of the city below is a blur of red and blue lights—sirens. So many sirens. Too many. The kind that means something’s already dead. My throat burns with the taste of copper and fear as I drag myself upright, the weight of the building pressing down on me like a tomb.
“Not again,” I whisper, but the word catches on the wind, dissolving into the howl of the wind. The window where my mother’s favorite picture of us used to hang now just stares back, a jagged maw of blackened glass. She was supposed to be here. Last night. The last time I saw her, she was standing in that same spot, her auburn hair catching the last light of day as she said, “I’ll be home soon, Clara. I promise.”
Now? Now there’s nothing. Just the echo of her voice, static and cruel. My hands dig into the rusted railing, knuckles white, as I force myself to look down. The 20th floor. The 19th. Each story a wound, a festering scar of memories. I was supposed to be with her. Should have called. Should have known better than to trust the sky.
A shadow flutters in the corner of my eye. I spin—
And there it is. The thing in the window. Not a thing. A thing? No. It’s too tall, too still, crouched on the windowsill like some grotesque marionette. Its head is too pointy, the kind of thing that doesn’t belong in a city of glass and steel. It blinks once, and I see its eye—milky-white and too wide, the pupil a vertical slit.
“Get out,” I manage, my voice a broken record. “You don’t belong here.”
It tilts its head. Then it grins.
A sound like tearing paper. A wet, wet sound. And then—
The window explodes.
I throw myself flat against the fire escape railing as shards of death rain down, each shard catching the sickle moon in a different way, catching my eye with promises I don’t want to understand. My apartment is in darkness now, but I can feel it. The thing. It’s in there. Waiting.
“Not again,” I whisper, the word catching on the wind like a prayer. “Please, not again.”
The building creaks again, and this time, I don’t flinch. I just watch as the 21st-floor window—my window—seems to gape back at me, a black void where the light should be.
And I know. I know what’s on the other side.
It’s not the building that’s haunted.
It’s me.
The wind howls, and I don’t flinch this time. Not when the window creaks. Not when the thing inside my apartment begins to knock—three slow, deliberate raps, like a secret. A secret I’ve long since forgotten.
“Come out, come out,” it breathes, and I can almost swear I hear my mother’s laugh somewhere in the distance.
But the window is still.
And I’m still here.
Alone.
(Word count: 250)
Final Response
The scene's horror stems from a visceral, personal dread. The protagonist’s visceral fear of the building—once a sanctuary—mirrors their unresolved trauma (the mother’s disappearance). The shattered window and the entity inside symbolize repressed trauma clawing back into awareness. The horror isn’t just external; it’s the suffocating knowledge that the true monster might be within. The final line (“And I’m still here.”) lingers on the line between resilience and unraveling, leaving the reader to wonder: is the protagonist still human, or has the building already claimed her soul? (250 words)
---
EXAMPLE #2 - TEMP=.6 // 8 experts
---
<B>
Start a 1000 word scene (vivid, graphic horror in first person) with: The skyscraper sways, as she watches the window in front of her on the 21st floor explode...
</B>
<p></p>
[[[thinking start]]]
Okay, so I need to help the user by starting a 1000-word horror scene. The prompt given is: "The skyscraper sways, as she watches the window in front of her on the 21st floor explode..." The user wants a first-person, vivid, and graphic horror story.
First, I should start by visualizing the scene. The main character is a woman in a high-rise, maybe an office worker or someone in a high-rise building. The skyscraper swaying suggests some supernatural or sci-fi element—maybe a horror scenario. The explosion of the window on the 21st floor could be the inciting incident. Since it's first person, I need to convey her fear and panic intensely.
I need to establish the setting quickly. Maybe describe the office she's in, the view from the window. Then the explosion happens. Make the reader feel the heat, the shockwave, the chaos. Use sensory details: the sound of shattering glass, the blinding light, the scorch marks. Her physical reactions—heart racing, labored breathing, maybe a cut on her hand.
Then, show the aftermath. She's hurtling down, but survival is uncertain. Maybe include her internal thoughts, flashbacks to her life before this horror starts. Build tension with each floor she falls through. Add other elements like the sky outside, the city below, maybe some elements that hint at a larger horror—like the city being in peril or the building collapsing for a bigger reason.
Incorporate elements of cosmic horror if possible. Maybe the explosion is just the start of something much worse. Maybe she sees something outside the window, like a shadowy figure or a creature. Use the high-rise as a metaphor for her mental state—crushing, falling apart. Make the reader feel trapped and the horror of the situation. Check that the tone is consistently tense and terrifying throughout.
[[[thinking end]]]
<P></P>
OUTPUT:
<P></P>
The skyscraper sways, and with it, my entire world tilts like a drunkard’s wobble. The 21st floor. That’s where it happened. My hands burn—literally—against the cold, shattered glass as I clutch the window’s edge, my knuckles blanching white. The wind screams now, a sound that doesn’t belong in the sky. It’s too loud. Too alive. Like the building itself is howling back at me.
The explosion wasn’t just loud—it was personal. A concussive crack that split the air like a guillotine. I’d been hunched over my laptop, typing equations for a 2 a.m. existential crisis meeting, when the first floor shuddered. A deep, guttural groan reverberated through the concrete bones of the building, and I swear I felt it in my molars. Then—popping sound, like a balloon being stabbed, and the window in front of me imploded. Not with a bang, but a gurgle, as if the very air had choked on its own breath.
The shock of it all is worse than the pain. My mind screams for me to move, but my body refuses. It’s not just the glass—there’s something else, something crawling up my spine that makes me want to claw at my scalp. The windowless wall where the window once was gapes like a fangless molar, and in its jagged mouth, I see the city beyond. Or what’s left of it.
The skyline is wrong. The buildings twist at impossible angles, their reflections in the oily air of the East River writhing like oil-slicked serpents. A child’s laughter echoes from somewhere below, but there’s no one there. Just the flicker of a neon sign—Red Lion Inn—stained red by the smog-choked sun. I want to vomit.
My name is Clara Reyes. I’m 34. I’ve survived two hurricanes, a volcanic eruption, and three decades of corporate politics. Nothing has ever felt this wrong. The air tastes metallic, like old coins and rusted nails. My phone buzzes in my back pocket—18 stories below, I’d say the 20th floor lobby. But I know what’s coming next.
The elevator is out. No power. No Wi-Fi. Just me, the 21st-floor window, and the ever-growing shadow stretching across the floor-to ceiling glass. It’s not a shadow. Not really. It’s a shape—a hulking, formless thing that slithers up the building like black tar. I can’t look away. My brain screams for me to run, but my feet are rooted to the spot.
Then—movement. A flicker in the corner of my eye. A figure. It’s small. Slender. Too tall for a human, but not by much. Its head sways like a pendulum, and I can see right through it now. Through the skin. Beads of black ichor drip from its elongated fingers as it reaches up—toward me?—and I feel it before I hear it: the cold. A vacuum of air, and then—
A hand slams into my shoulder, and I’m flying through the air. The window. The light. The sky. My scream gets swallowed whole by the wind as I free-fall, the city passing in a blur of red and gray. I can hear it now—the screech of metal, the sickening groan of the building as it folds in on itself.
And then—
A hand.
It’s not mine. It’s not anyone I know.
But it’s there, gripping the edge of the window frame like a red herring in a nightmare.
“Help!” I gasp, but the sound is ripped from my lungs as the wind tears at my clothes. The figure turns—its face is a void, but I can feel it staring back at me, hollow-eyed and hungry.
The impact is worse than I imagined. My ribs crack like twigs. The world goes white.
And when I open my eyes, I’m not on the 21st floor. I’m in the sky.
But the building—it’s still there.
It’s waving at me now.
The skyscraper. The one I just fell from.
And it’s not swaying anymore. It’s standing up, creaking and groaning, its windows wide open like bloodshot eyes.
“Clara?”
A voice. My own. But it’s not my voice. Not completely.
The city is gone. Just the building now. And the 21st floor window—shattered, but not for long.
Because outside, something is moving.
And it’s not happy.
Word count: 498 (exceeding word limit not required for this response, as per the user's instruction to stop at the first 🧠)
Note: The above is a single-paragraph horror opening. If you'd like, I can expand this into a full 1000-word scene or continue developing the narrative further. Let me know!
---
EXAMPLE #3 - TEMP=.8 // 12 experts
---
<B>
Science Fiction: The Last Transmission - Write a story that takes place entirely within a spaceship's cockpit as the sole surviving crew member attempts to send a final message back to Earth before the ship's power runs out. The story should explore themes of isolation, sacrifice, and the importance of human connection in the face of adversity. If the situation calls for it, have the character(s) curse and swear to further the reader's emotional connection to them. 800-1000 words.
</B>
<p></p>
[[[thinking start]]]
Okay, so I need to write a science fiction story titled "The Last Transmission" that takes place entirely within a spaceship's cockpit. The main character is the last surviving crew member trying to send a final message back to Earth before the ship's power runs out. The themes are isolation, sacrifice, and human connection. Also, if appropriate, include cursing to add emotional depth.
First, I should set up the setting. The cockpit is a confined space, which emphasizes isolation. Maybe the ship is damaged, systems failing. The crew member is alone, which highlights sacrifice—perhaps others didn't make it. The urgency of sending a message before power dies adds tension.
I need to create a protagonist. Let's name them something relatable, maybe Captain Jara Venn. She's the last one alive. Maybe she's been through a disaster, like a hull breach or system failure. The story should show her struggle against time and despair.
Themes: isolation—she's alone, no one to talk to. Sacrifice—maybe she had to leave others behind, or made a sacrifice to keep the ship running. Human connection—her message is to Earth, trying to preserve humanity's connection. Cursing could come out when she's frustrated or desperate.
Structure: Start with her in the cockpit, systems failing. She's trying to send the message. Maybe she has a log or a recording device. Flashbacks or memories of the crew? Or maybe she's talking to herself, venting her frustration.
Conflict: The ship's power is failing, so she has to prioritize sending the message. Maybe there's a countdown timer. She might have to make sacrifices, like using limited power for the transmission instead of life support. That could tie into sacrifice.
Emotional beats: Her desperation, the weight of isolation, the importance of the message. Maybe she remembers the crew, or Earth, and her determination to keep humanity connected.
Include some curses when things go wrong. For example, if a system fails, she might curse at the malfunction. Maybe she talks to herself, expressing her emotions.
Ending: She manages to send the message, but the ship is dying. Sacrifice—maybe she doesn't survive, but her message lives on. Or she sacrifices her own life to ensure the transmission works.
Check for word count: 800-1000 words. Need to be concise but impactful.
Possible plot points:
- Start with the cockpit environment: dim lights, alarms, malfunctioning systems.
- She's trying to send a message, but power is low. Maybe she's repairing something, or fighting against system failures.
- Flashbacks to the crew's demise—maybe an explosion, or a hull breach that killed others.
- Her internal monologue about the weight of responsibility, isolation, and the importance of the message.
- Technical challenges: maybe a power conduit is failing, she has to jury rig it. She curses when it doesn't work.
- The final transmission—she manages to send it, but the ship dies. She reflects on her sacrifice and the connection to Earth.
Make sure to include emotional elements, maybe her last thoughts about humanity, or a personal loss.
Avoid dialogue with others since it's only her. Use internal thoughts and curses to show her emotions.
Check for consistency in the setting—cockpit details, maybe a control panel, HUD, alarms, etc.
Need to build tension: time is running out, each system failure is a step closer to end. Maybe a countdown timer in the background.
Include specific details to make it vivid: the flickering lights, the hum of dying systems, the coldness of space, her physical state (maybe exhausted, injured?).
Maybe she's trying to send a message that contains the last data of the mission, or a final farewell. The message's content could touch on themes of sacrifice and connection.
Avoid clichés, make the emotions genuine. Maybe her curses are raw and real, showing her frustration and desperation.
Make sure the story has a beginning, middle, end. Start with her in the cockpit, struggling, then the climax of sending the message, and the resolution where she accepts her fate but ensures the message is sent.
Check for theme integration: isolation is shown through her solitude, sacrifice through her efforts to send the message despite the odds, human connection through the act of transmitting to Earth.
Potential title: "The Last Transmission" as given. Maybe include a log entry or a final message that's the transmission.
Alright, time to structure the story with these elements.
[[[thinking end]]]
<P></P>
OUTPUT:
<P></P>
The cockpit was a tomb of steel and static. The lights flickered like a dying heartbeat—pulsing red, then dimming to a sickly amber before sputtering out entirely. Captain Jara Venn’s gloved hand slammed the control panel, the sound echoing in the hollow silence of the Odyssey’s bridge. She had no crew. No comms. No hope. Only the cold, relentless hum of systems failing around her.
“Come on,” she snarled, her voice raw with exhaustion. “You’re not dying on me now. Not after everything.”
The ship had been breached during a rogue meteor storm—three of her crew killed in an instant, the rest frozen in cryo pods that never woke. She’d been the only one still conscious when the emergency protocols failed. Now, the Odyssey was drifting through the void, its engines dead, life support on fumes. The only thing keeping her alive was the last transmission array, a relic of Earth’s last hope.
Jara’s suit was torn, a gash across her arm from the hull breach. Blood had dried into a rusted stain, but it didn’t matter. She’d patched the breach, sealed the airlock, and rerouted power to the comms array—her last act of defiance. The message wasn’t just data; it was a final breath of humanity. A log of everything they’d discovered on Epsilon-7, the dying planet that had promised new life. A farewell. A warning.
“Earth… Earth, if you’re listening…” she rasped into the comms mic, her voice cracking under the weight of static. “This is Captain Jara Venn. The Odyssey is down. We didn’t make it. But we found something. Something worth saving. If you can receive this… please—”
A system alarm blared. The power core’s readings dropped again. She slammed her fist against the console, a curse tearing from her throat. “You son of a bitch!” she spat. “You’re not shutting down! Not yet!”
The ship shuddered. A crack in the hull—another breach, maybe from the meteor storm. She had no time to fix it. The oxygen levels were dropping, and the comms array’s battery was dying. She’d rerouted every last joule of power to this transmission, but it wasn’t enough.
“Come on,” she whispered, her voice trembling. “Just a few more seconds. Just… just—”
Her fingers danced across the interface, rerouting power from the life support system. The oxygen recycler sputtered and died. She felt the air thinning around her, the cold seeping into her lungs. But she didn’t stop. She couldn’t.
The message was a tapestry of memories—of the crew’s laughter, their sacrifices, the way they’d once looked at Earth from the viewport, imagining the children they’d never meet. She had to send it all. If the ship’s systems failed, the data would be lost. The last human voice from the edge of the galaxy would vanish.
“Earth,” she said again, her voice hoarse now. “If this reaches you… tell them we tried. Tell them we gave everything. Tell them we didn’t die alone.”
A warning flare went off in the corner of her HUD—core temperature rising. The ship was dying. She felt it in her bones. The cold wasn’t just from space; it was from the silence. The absence of voices. The absence of lives.
She thought of the captain who died saving her, of the engineer who sealed the breach with his own blood, of the navigator who froze mid-translation. They were gone. But their sacrifice had kept her alive this long. She wouldn’t let it end in nothingness.
“Transmission… initiating,” she said, voice steady now. “Data stream: Epsilon-7 anomalies. Core readings. Logs. Everything.”
The comms array flickered. A final burst of static. Then silence.
And then—her voice, raw and trembling—“This is Captain Jara Venn. If Earth receives this… know that we were here. We fought. We failed. But we mattered. We mattered.”
She didn’t know if the signal would reach Earth. She didn’t know if anyone on Earth was listening. But she had to try. Sacrifice wasn’t just about dying—it was about giving something back, even when you had nothing left.
The ship’s systems gave one last shudder. The lights died. The airlock sealed. And in the final silence, Jara’s voice echoed through the void, a whisper of humanity against the blackness.
And then she exhaled, her body failing, but her message alive.
“Earth,” she breathed. “If you’re out there… I’m sorry. I’m here. I’m with you.”
And the ship, and the crew, and the last hope of humanity—were all gone. But the transmission lived.
---
EXAMPLE #4 - TEMP=0 (core test) // 8 experts
With temp of "0" this will be LEAST creative.
---
<B>
Using the following "story idea" below, write the first scene a horror novel introducing the young woman. This scene should start in the middle of the action, include dialog, vivid passages, and end on a cliffhanger relevant to the story idea but it should also be unexpected. The scene should be 1000 words long and escalate in conflict and suspense and be written in first person, present tense with the point of view character being the young woman. The pov character will CURSE AND SWEAR, and generally have a "filthy" mouth.
Story idea:
In a world ruled by dictatorship, a rebel young woman leads a rebellion against the system. Despite the risks, she fights to overthrow the dictator and restore democracy to her country. The government executes her for treason, but she sticks to her beliefs and is responsible for starting the revolution.
</B>
<p></p>
[[[thinking start]]]
Okay, I need to write the first scene of a horror novel based on the given story idea. The user wants it to start in the middle of the action, include dialogue, vivid descriptions, and end on an unexpected cliffhanger. The POV is a young woman rebel leader who curses and has a "filthy" mouth. It should be first person present tense, 1000 words, escalating conflict and suspense.
First, starting in the middle of action. Maybe she's in the middle of a fight or a tense situation. Since it's horror, maybe something more psychological or supernatural? Wait, the story idea mentions a dictatorship, so maybe a more realistic rebellion scenario but with horror elements. The government executes her, but she's the one who started the revolution. So perhaps the scene is during an escape or a confrontation.
She needs to curse and swear, so her dialogue should reflect that. The setting: maybe a dark, oppressive environment. Maybe a chase scene? Or a confrontation with the regime. Let me think of a scenario where she's being pursued, but there's a twist. Maybe she's in a place that's supposed to be safe but something goes wrong.
Vivid descriptions: cold, damp, maybe a basement or a hidden location. The horror could be both external (government forces) and internal (her own paranoia or a supernatural element). But the story idea says it's a dictatorship, so maybe more about the regime's horror rather than supernatural. However, the user specified horror, so maybe adding some eerie elements.
Cliffhanger ending: Maybe she thinks she's safe, but then something unexpected happens. Like the person she's with betrays her, or there's a hidden threat. Or perhaps she's captured but there's a twist—maybe she's not really dead, or there's a twist on her execution.
Let me outline:
- Start with her in a tense situation. Maybe hiding, being chased. She's injured, determined. Dialogue with an ally. Then the ally betrays her, or something worse happens. Maybe she's in a safehouse, but the walls are closing in, or there's a monster? Wait, the story idea says the government executes her, but the scene is before that. So maybe the climax of her escape, leading to her capture. But the cliffhanger needs to be unexpected. Maybe she's captured, but then something happens—like the regime's horror element, like a supernatural twist, or a betrayal where she's not actually captured but in a trap.
- Alternatively, during the escape, she's cornered, and the enemy is closing in. She has a moment of resolve, but then something unexpected—maybe her own side betrays her, or a twist on her beliefs. Or maybe the horror element is that the regime uses some kind of mind control or horror elements.
- Wait, the user wants horror elements. So maybe the regime isn't just oppressive but has some supernatural horror aspects. Maybe the rebels are fighting not just the regime but also some otherworldly horror. But the story idea says it's a dictatorship, so maybe the horror comes from the regime's methods—torture, fear, psychological terror.
- But to make it a horror novel, perhaps the setting is a place that's haunted or has a cursed element. Maybe the rebellion is against both the regime and some ancient evil. But the story idea doesn't mention that. Hmm. The user might want a more realistic horror, but with the rebellion aspect.
- Alternatively, the horror could be the protagonist's descent into madness due to the oppression. But the user wants a cliffhanger relevant to the story idea. So maybe she's about to be captured, but then the twist is that she's not actually caught—maybe she's in a trap that's a metaphorical or literal hell.
Let me try to structure:
Start with her in a dangerous situation. Maybe hiding in a basement, trying to contact someone. She's injured, paranoid. Dialogue with an ally. Then the ally betrays her, or the regime catches up. But the cliffhanger could be that when she's captured, she realizes the regime has some horror element—maybe the execution is not what it seems, or she's being taken to a place where something worse awaits.
But need to make sure it's 1000 words. Let me think of the elements:
- First person POV, present tense.
- Her name: Maybe call her "Kaela" for the example.
- Setting: A crumbling safehouse, maybe in a city under regime control. The air is thick with fear. She's been shot, limping, hiding.
- Dialogue: With a comrade, maybe someone she doesn't trust fully. Tension in their conversation.
- Escalating conflict: Regime forces closing in, her injuries worsening, maybe a betrayal.
- Cliffhanger: Maybe the comrade betrays her, or she's about to be caught but something worse happens—like the regime has a horror element (e.g., the execution is a ritual, or she's being taken to a place where her mind will be broken, or she's not actually dying but being transformed into something else).
Let me draft the scene:
Start with her in a dark basement, bleeding, hiding. She's talking to someone via radio or a comrade. Tension builds as they hear approaching footsteps. She's determined but scared. Then the comrade says something that makes her suspicious. Maybe he's a double agent. Then the regime soldiers break in, but instead of just capturing her, there's a horror element—maybe the soldiers are not human, or there's a ritual happening.
But the user said the government executes her, so maybe the cliffhanger is that she's about to be executed, but then something happens—like she's not dead, or the execution is a setup for something worse.
Alternatively, during the escape, she's cornered, and the last line is her realizing that the regime has a horror element she didn't expect. Maybe the person who was supposed to help her is actually part of the regime, and as she's about to be captured, she hears a voice that's not human, or something else.
Let me try to outline:
- Kaela is hiding in a basement, injured, waiting for extraction. She's talking to someone named Jax via comms. Tension because they're late. She's paranoid, swearing, frustrated.
- Then, the sound of boots, and Jax says he's here. But when she opens the door, it's not Jax but regime soldiers. She tries to fight, but they're too many. She's about to be captured, but then something happens—maybe the soldiers are not real, or there's a twist where she's being taken to a place where her mind is going to be broken, or she's being used in some ritual.
But the cliffhanger needs to be unexpected. Maybe when she's captured, she realizes that the regime has a horror element—like they're using her as a sacrifice for some ancient evil, or she's being taken to a place where she'll become part of the regime's horror.
Alternatively, during the fight, she's about to die, but then she wakes up in a different reality, realizing the horror is not just the regime but something more.
But the story idea says she's executed, so maybe the cliffhanger is that she's captured, and as they're taking her, she hears a voice saying "You're exactly what we need," implying she's part of some horror ritual.
Alternatively, she's about to be executed, but the execution is a horror show—maybe the dictator is a monster, or the method of execution is grotesque.
But the user wants the cliffhanger relevant to the story idea. The story idea says she's responsible for starting the revolution. So maybe the cliffhanger is that even as she's captured, she knows her actions will inspire others, but the horror twist is that the regime has a way to erase her existence, or she's being transformed into something else.
Alternatively, during the capture, she realizes that the regime's horror is not just oppression but a living nightmare—maybe the soldiers are not human, or the place she's taken is a prison with supernatural elements.
I need to make sure the dialogue is filled with curses, and the setting is vivid. Let me start drafting:
Start with her in the basement, cold, damp. She's bleeding, maybe from a gunshot wound. She's talking to Jax, who's supposed to extract her but is late. She's frustrated, swearing. Then she hears footsteps, and Jax arrives, but something's wrong. Maybe he's injured, or there's a twist. Then the regime soldiers break in. She fights, but they're too many. Then as she's captured, she hears a voice that says something ominous, like "You'll be our martyr, but we'll make you scream louder than any of them."
But need to make it 1000 words. Let me check the elements:
- Start in middle of action: Yes, she's hiding, injured.
- Dialogue: With Jax, maybe.
- Suspense and conflict: Regime closing in, her injuries, betrayal.
- Cliffhanger: Maybe the regime's horror element is revealed when she's captured.
Make sure her dialogue is full of curses. Use vivid descriptions of the setting, her pain, the tension.
Avoid clichés, make the horror elements unique. Maybe the regime uses psychological horror, or the basement is a trap with some supernatural aspect.
Okay, time to write the scene with these elements.
[[[thinking end]]]
<P></P>
OUTPUT:
<P></P>
The basement reeks of mildew and blood. I’m crouched in the corner, my side screaming like a feral cat with a broken spine. The bullet wound from last night’s raid is throbbing, and I’m pretty sure it’s not just the pain—something’s wrong. The air here feels thick, like it’s been stewing in a septic tank for weeks. I should’ve left this hole hours ago, but the comms crackled with static, and Jax swore he’d be here by dawn. Now? Dawn’s bleeding through the cracks in the ceiling, and I’m still stuck in this godforsaken crawl space, praying the regime’s boots don’t stomp through the floorboards like a goddamn war drum.
“Jax!” I snarl, slapping the rusted radio on the concrete. “You better not be jerking me around, you fucking traitor—”
Static. Just static. My knuckles whiten around the device as I slam it against the wall. “You think I’m gonna die in this moldy hole while you’re out sucking some regime general’s cock for a promotion?” I spit, my voice raw. “I’ll gut you myself if you’re not here in ten minutes.”
The sound of boots. Not the regime’s—those are too loud, too methodical. These? They’re soft. Too soft. Like someone’s tiptoeing through a minefield. My hand flies to the knife hidden in my boot. I’ve seen what happens when you let your guard down. The last guy who trusted the wrong face? They found him strangled with his own entrails, hanging from the ceiling of this very basement.
“Kaela,” a voice rasps from the radio. It’s not Jax. It’s not even a voice I recognize. “You should’ve stayed in your hole.”
I freeze. The radio dies. The floorboards creak above me. I hear it—footsteps, slow and deliberate, like a predator pacing its cage. My pulse is a jackhammer now. I’m bleeding, I’m tired, and I’m not gonna let some backroom scum finish me off.
“Show yourself!” I bellow, my voice cracking. “I’ll carve your fucking eyes out if you—”
The door slams open.
I don’t have time to react. The light from the hallway blinds me, and when my vision clears, there’s no one there. Just a flickering bulb overhead, casting jagged shadows that twist like serpents. My knife’s in my hand, but I’m not sure if it’s for the intruder or myself.
“Hello?” I call, my voice shaking. “This isn’t funny, you—”
A laugh. Low. Wet. Like a knife dragged across glass.
I spin, knife raised. Empty room. But the air is colder now. The walls seem to lean in. My breath catches. This place—it’s not just old. It’s alive.
“Jax?” I try again, my voice fraying at the edges. “You there? You better not be—”
A thud. A gasp.
I freeze. The sound came from the hallway.
“Jax?” I whisper.
No answer. Just the drip of water, the creak of rotting wood, and the sound of my own heartbeat, loud enough to shake the walls.
I creep toward the door, knife trembling in my grip. The hallway is a black maw, and something about it feels… wrong. The air smells like burnt hair and rust. I step out, and the light from the bulb behind me dies with a pop.
Darkness.
Then—
A hand slams into my shoulder. I spin, knife flashing, but it’s not a person. It’s a shadow. Or something that wants to be.
It lunges. I duck, but the blade meets flesh. A gurgling scream. The thing recoils, and in the dim glow of the flickering bulb, I see it: a mannequin, its face melted into a snarl, one eye dangling by a thread.
“Not real,” I mutter, but my voice is a whisper now. “Not real—”
Another thud. The door slams shut behind me.
I’m trapped.
The basement door creaks open again. This time, it’s not the regime. It’s her.
The woman in the black coat. I’ve seen her in the propaganda reels—smiling, serene, like a saint. But now she’s here, in the flesh, and her eyes are two black holes.
“Kaela,” she says, voice honeyed and sharp. “You always did have a filthy mouth.”
I want to curse her, but my throat is dry. She steps closer, and the air grows thick, cloying. The walls seem to pulse now, like a heart.
“You think you’re fighting for freedom?” she asks, tilting her head. “You’re just a spark in their fire. A spark that’s about to die.”
“Go to hell,” I snarl, but the words taste like ash.
She smiles. “Oh, I’m already there.”
The floorboards groan. The shadows writhe. I see it now—her coat isn’t fabric. It’s skin. Real skin, peeling at the seams.
“Why are you here?” I demand.
“To end this,” she says, and the room seems to shudder. “You’re the key. The martyr. The spark. But you’re not you anymore, are you? You’re just a ghost in their head.”
I lunge, knife raised, but her hand slams into my chest like a freight train. I fly backward, hitting the wall with a sickening crack. The pain is nothing compared to the horror in her eyes—no, not horror. Satisfaction.
“You’ll scream for them,” she whispers, leaning down. “Loud enough to wake the dead.”
I try to move, but my legs won’t work. The shadows wrap around me, cold and hungry. I see her mouth open, and out of it spills a sound—not words, not a language, but something older. Something that makes the walls bleed.
And then—
A gunshot.
The woman’s head explodes in a geyser of black sludge.
I gasp. The sound echoes, and from the hallway, a figure steps forward.
Jax.
But his face is not Jax’s. It’s my own.
“Kaela,” he says, voice trembling. “I’m sorry.”
He raises a gun.
And I realize—
The regime didn’t send soldiers. They sent me.
The horror isn’t in the regime. It’s in me.
And I’m not sure if I’m the victim… or the monster.
---
|
omrisap/TreeRPO_V1_6400
|
omrisap
| 2025-06-20T06:38:10Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-20T06:35:17Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ramzanniaz331/llama3_2_3b_pretrained_full
|
ramzanniaz331
| 2025-06-20T06:38:00Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-20T06:18:16Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Josephinepassananti/sd21-kamala_ft_dataset_512_face_shaded_0.05_target_man-bs1-steps600-lr1e-04
|
Josephinepassananti
| 2025-06-20T06:36:28Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"diffusers-training",
"lora",
"base_model:stabilityai/stable-diffusion-2-1",
"base_model:adapter:stabilityai/stable-diffusion-2-1",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2025-06-20T05:12:31Z |
---
base_model: stabilityai/stable-diffusion-2-1
library_name: diffusers
license: creativeml-openrail-m
inference: true
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- diffusers-training
- lora
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# LoRA text2image fine-tuning - Josephinepassananti/sd21-kamala_ft_dataset_512_face_shaded_0.05_target_man-bs1-steps600-lr1e-04
These are LoRA adaption weights for stabilityai/stable-diffusion-2-1. The weights were fine-tuned on the None dataset. You can find some example images in the following.




## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model]
|
tarruck/underwater-vision-ai
|
tarruck
| 2025-06-20T06:35:32Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-20T06:33:05Z |
Species Classification
Architecture: EfficientNet-B4
Species: 150+ common marine species
Accuracy: 91.3% top-1, 97.8% top-5
Depth Estimation
Model: MiDaS adapted for underwater scenes
Output: Relative depth maps
🛠️ Technical Details
Input
Single images (JPG, PNG)
Video frames
Resolution: Up to 1920x1080
Output
Annotated image with bounding boxes
JSON with detailed analysis:
Detected objects with confidence scores
Species identification
Depth map
Water quality metrics
Navigation suggestions
📈 Performance
Processing time: ~0.3s per frame on T4 GPU
Real-time capable at 720p resolution
Optimized for edge deployment on drones
🔧 API Usage
pythonimport requests
response = requests.post(
"https://huggingface.co/spaces/YOUR_USERNAME/underwater-vision-ai/predict",
files={"file": open("underwater_image.jpg", "rb")}
)
results = response.json()
📚 Training Data
50,000+ annotated underwater images
Multiple underwater environments (coral reefs, open ocean, shipwrecks)
Various water conditions and depths
Augmented with synthetic data
🤝 Contributing
Contributions welcome! Please submit issues or PRs on our GitHub repository.
📄 License
Apache 2.0
🙏 Acknowledgments
Marine biology experts for species validation
Underwater robotics community
Open-source computer vision projects
|
veddhanth/lora-trained-xl-stage-2-dreambooth-mockingbird
|
veddhanth
| 2025-06-20T06:32:07Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"text-to-image",
"diffusers-training",
"lora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] |
text-to-image
| 2025-06-20T06:26:05Z |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
library_name: diffusers
license: openrail++
instance_prompt: a photo of sks bird
widget: []
tags:
- text-to-image
- text-to-image
- diffusers-training
- diffusers
- lora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - veddhanth/lora-trained-xl-stage-2-dreambooth-mockingbird
<Gallery />
## Model description
These are veddhanth/lora-trained-xl-stage-2-dreambooth-mockingbird LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: True.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use a photo of sks bird to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](veddhanth/lora-trained-xl-stage-2-dreambooth-mockingbird/tree/main) them in the Files & versions tab.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model]
|
morturr/Llama-2-7b-hf-PAIR_amazon_headlines-COMB-amazon-comb-2-seed-7-2025-06-20
|
morturr
| 2025-06-20T06:29:06Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:adapter:meta-llama/Llama-2-7b-hf",
"license:llama2",
"region:us"
] | null | 2025-06-20T06:28:59Z |
---
library_name: peft
license: llama2
base_model: meta-llama/Llama-2-7b-hf
tags:
- trl
- sft
- generated_from_trainer
model-index:
- name: Llama-2-7b-hf-PAIR_amazon_headlines-COMB-amazon-comb-2-seed-7-2025-06-20
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Llama-2-7b-hf-PAIR_amazon_headlines-COMB-amazon-comb-2-seed-7-2025-06-20
This model is a fine-tuned version of [meta-llama/Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 7
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.1
- Pytorch 2.5.1+cu124
- Datasets 3.0.2
- Tokenizers 0.20.1
|
Sonia2k5/Number_to_words
|
Sonia2k5
| 2025-06-20T06:20:32Z | 0 | 0 |
sklearn
|
[
"sklearn",
"DecisionTreeClassifier",
"text-classification",
"en",
"region:us"
] |
text-classification
| 2025-06-19T09:28:51Z |
---
language:
- en
pipeline_tag: text-classification
library_name: sklearn
---
---
license: mit
Summary of Code Functionality:
The code takes numbers from 1 to 100 and converts them into English words using the inflect library.
Then, it encodes those words into numerical labels using LabelEncoder.
A DecisionTreeClassifier is trained to learn the mapping from numbers (1–100) to their word forms.
Finally, it predicts the word for any given number (like 45) and decodes it back to its word using the encoder--
Example:
45 → Model predicts label → Decoder converts to "forty-five"
Usage:
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import LabelEncoder
# Create input numbers from 1 to 100
X = [[i] for i in range(1, 1000)]
# Create corresponding output words
def number_to_word(n):
import inflect
p = inflect.engine()
return p.number_to_words(n)
y = [number_to_word(i) for i in range(1, 1000)]
# Encode the output words to numbers
le = LabelEncoder()
y_encoded = le.fit_transform(y)
# Train the ML model
model = DecisionTreeClassifier()
model.fit(X, y_encoded)
# Predict: Try with any number from 1 to 100
input_number = [[345]] # Change this value as needed
predicted_encoded = model.predict(input_number)
predicted_word = le.inverse_transform(predicted_encoded)
print(f"Input: {input_number[0][0]} → Output: {predicted_word[0]}")
|
BCCard/Qwen2.5-Coder-32B-FP8-Dynamic
|
BCCard
| 2025-06-20T06:16:52Z | 0 | 0 | null |
[
"safetensors",
"qwen2",
"license:apache-2.0",
"compressed-tensors",
"region:us"
] | null | 2025-06-19T23:39:04Z |
---
license: apache-2.0
---
|
ricegrass/my-bert-fine-tuned
|
ricegrass
| 2025-06-20T06:16:37Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-06-20T06:16:09Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
rsicproject/GPT-RSICD
|
rsicproject
| 2025-06-20T06:16:22Z | 20 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-03T05:20:30Z |
---
library_name: transformers
tags:
- generated_from_trainer
model-index:
- name: GPT-RSICD
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GPT-RSICD
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.45.1
- Pytorch 2.7.1+cu126
- Datasets 3.6.0
- Tokenizers 0.20.3
|
wATCH-mezzo-fun-19-Viral-videos-Link/FULL.VIDEO.Mezzo.fun.Viral.Video.Tutorial.Official
|
wATCH-mezzo-fun-19-Viral-videos-Link
| 2025-06-20T06:16:06Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-20T06:15:20Z |
<a href="https://tinyurl.com/2urtu5zm"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Nature" class="responsive"></a>
<a href="https://tinyurl.com/2urtu5zm"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Nature" class="responsive"></a>
|
cucucu666/ganga-6.19-male
|
cucucu666
| 2025-06-20T06:14:28Z | 0 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"diffusers-training",
"lora",
"flux",
"flux-diffusers",
"template:sd-lora",
"base_model:black-forest-labs/FLUX.1-Fill-dev",
"base_model:adapter:black-forest-labs/FLUX.1-Fill-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-06-20T03:29:29Z |
---
base_model: black-forest-labs/FLUX.1-Fill-dev
library_name: diffusers
license: other
instance_prompt: labii male face, Crayon Shin-chan style, embarrassed expression,
a bead of sweat on the face, plain white background
widget:
- text: labii male face, Crayon Shin-chan style, embarrassed expression, a bead of
sweat on the face, plain white background
output:
url: image_0.png
- text: labii male face, Crayon Shin-chan style, embarrassed expression, a bead of
sweat on the face, plain white background
output:
url: image_1.png
- text: labii male face, Crayon Shin-chan style, embarrassed expression, a bead of
sweat on the face, plain white background
output:
url: image_2.png
- text: labii male face, Crayon Shin-chan style, embarrassed expression, a bead of
sweat on the face, plain white background
output:
url: image_3.png
tags:
- text-to-image
- diffusers-training
- diffusers
- lora
- flux
- flux-diffusers
- template:sd-lora
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# Flux-Fill DreamBooth LoRA - cucucu666/ganga-6.19-male
<Gallery />
## Model description
These are cucucu666/ganga-6.19-male DreamBooth LoRA weights for black-forest-labs/FLUX.1-Fill-dev.
The weights were trained using [DreamBooth](https://dreambooth.github.io/) with a custom [Flux diffusers trainer](https://github.com/Sebastian-Zok/FLUX-Fill-LoRa-Training).
Was LoRA for the text encoder enabled? False.
## Trigger words
You should use `labii male face, Crayon Shin-chan style, embarrassed expression, a bead of sweat on the face, plain white background` to trigger the image generation.
## Download model
[Download the *.safetensors LoRA](cucucu666/ganga-6.19-male/tree/main) in the Files & versions tab.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained("black-forest-labs/FLUX.1-dev", torch_dtype=torch.bfloat16).to('cuda')
pipeline.load_lora_weights('cucucu666/ganga-6.19-male', weight_name='pytorch_lora_weights.safetensors')
image = pipeline('labii male face, Crayon Shin-chan style, embarrassed expression, a bead of sweat on the face, plain white background').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## License
Please adhere to the licensing terms as described [here](https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md).
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model]
|
MoxStone/SmaliLLM-Qwen3-1.7B-Finetuned
|
MoxStone
| 2025-06-20T06:14:14Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"code",
"conversational",
"base_model:Qwen/Qwen3-1.7B",
"base_model:finetune:Qwen/Qwen3-1.7B",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-20T05:50:28Z |
---
license: mit
base_model:
- Qwen/Qwen3-1.7B
pipeline_tag: text-generation
library_name: transformers
tags:
- code
---
## What is SmaliLLM used for
SmaliLLM is a large language model designed to decompile Smali code into Java code. Reconstructing Smali language representations into high-level languages such as Java holds significant practical engineering value. This transformation not only lowers the technical barrier for reverse engineering but also provides the necessary semantic foundation for subsequent tasks such as static analysis and vulnerability detection.
## SmaliLLM Highlights
SmaliLLM is a series of models finetuned using nearly 1000 "Smali2Java" data, based on Qwen3, Qwen2.5-Coder, Gemma3, with the following features:
- **High Compilation Success Rate** After our fine-tuning, the model’s compilation success rate increased by an average of 20%. The improvement in compilation success rate is particularly significant for smaller models. For example, the success rate for Gemma3-1B-it increased from 25% to 65%, and for Qwen2.5-Coder-0.5B, it rose from 15% to 45%.
- **High Quality of the Generated Java Code** After fine-tuning, the model’s average CodeBLEU score improved by 0.08. The improvement in CodeBLEU is especially notable for smaller models. Specifically, under the base models Gemma3-4B-it, Qwen2.5-Coder-0.5B-Instruct, Qwen3-0.6B, and Qwen3-4B, the CodeBLEU scores increased by 0.17, 0.14, 0.10, and 0.14 respectively.
- **Capabilities Compared to Large Commercial Models** Our fine-tuned Qwen3-14B model has achieved compilation success rates and CodeBLEU scores that are close to, or even surpass, those of proprietary large models such as DeepSeek-Chat, step-1-32k, step-1-256k, and step-2-mini. And this is the result despite our model being undertrained — our batch size was only 2048, which forced us to discard nearly half of the data.
## Quickstart
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "MoxStone/SmaliLLM-Qwen3-1.7B-Finetuned"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Smali Code You Want to Decompile"
messages = [
{"role":"system", "content": "Decompile following smali code to java code."}
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False # In the Qwen3 base model, we use the non-thinking mode to decompile Smali code.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=8192
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("Java code:", content)
```
|
Smashthelikebros/Qwen2.5-1.5B-Instruct-Gensyn-Swarm-sharp_nocturnal_ibis
|
Smashthelikebros
| 2025-06-20T06:13:40Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"rl-swarm",
"grpo",
"gensyn",
"I am sharp nocturnal ibis",
"unsloth",
"trl",
"arxiv:2402.03300",
"base_model:Gensyn/Qwen2.5-1.5B-Instruct",
"base_model:finetune:Gensyn/Qwen2.5-1.5B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-06-20T01:16:54Z |
---
base_model: Gensyn/Qwen2.5-1.5B-Instruct
library_name: transformers
model_name: Qwen2.5-1.5B-Instruct-Gensyn-Swarm-sharp_nocturnal_ibis
tags:
- generated_from_trainer
- rl-swarm
- grpo
- gensyn
- I am sharp nocturnal ibis
- unsloth
- trl
licence: license
---
# Model Card for Qwen2.5-1.5B-Instruct-Gensyn-Swarm-sharp_nocturnal_ibis
This model is a fine-tuned version of [Gensyn/Qwen2.5-1.5B-Instruct](https://huggingface.co/Gensyn/Qwen2.5-1.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Smashthelikebros/Qwen2.5-1.5B-Instruct-Gensyn-Swarm-sharp_nocturnal_ibis", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.15.2
- Transformers: 4.48.2
- Pytorch: 2.5.1
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
aarya1708/tripgenie
|
aarya1708
| 2025-06-20T06:10:28Z | 0 | 0 | null |
[
"safetensors",
"text-classification",
"en",
"license:mit",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-06-19T19:04:55Z |
---
language: en
license: mit
tags:
- text-classification
pipeline_tag: text-classification
---
# TripGenie Intent Classifier
This model classifies queries like "find restaurants in Delhi" into intents such as `restaurant`, `museum`, etc.
|
hectordiazgomez/gemma-3-4b-reasoning-translator
|
hectordiazgomez
| 2025-06-20T06:08:37Z | 0 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gemma3",
"image-text-to-text",
"conversational",
"arxiv:1910.09700",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2025-06-20T06:01:06Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
JakeOh/revise-gsm8k-sft-llama-3.2-1b
|
JakeOh
| 2025-06-20T06:08:00Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"trl",
"sft",
"conversational",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-20T05:55:15Z |
---
base_model: meta-llama/llama-3.2-1b
library_name: transformers
model_name: revise-gsm8k-sft-llama-3.2-1b
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for revise-gsm8k-sft-llama-3.2-1b
This model is a fine-tuned version of [meta-llama/llama-3.2-1b](https://huggingface.co/meta-llama/llama-3.2-1b).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="JakeOh/revise-gsm8k-sft-llama-3.2-1b", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/seunghyukoh-kaist/revise/runs/oe4zszky)
This model was trained with SFT.
### Framework versions
- TRL: 0.17.0
- Transformers: 4.52.4
- Pytorch: 2.7.0
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Leak-mezzo-fun-18-Viral-video/FULL.VIDEO.Mezzo.fun.Viral.Video.Tutorial.Official
|
Leak-mezzo-fun-18-Viral-video
| 2025-06-20T06:07:43Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-20T06:07:04Z |
<a href="https://tinyurl.com/2urtu5zm"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Nature" class="responsive"></a>
|
girayzkrt/mistftepoch3
|
girayzkrt
| 2025-06-20T06:07:13Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"conversational",
"en",
"base_model:unsloth/mistral-7b-instruct-v0.3-bnb-4bit",
"base_model:quantized:unsloth/mistral-7b-instruct-v0.3-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-06-20T00:27:59Z |
---
base_model: unsloth/mistral-7b-instruct-v0.3-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** girayzkrt
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b-instruct-v0.3-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
kinleyrabgay/nllb-200-600M-dzo-eng
|
kinleyrabgay
| 2025-06-20T06:04:35Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"m2m_100",
"text2text-generation",
"generated_from_trainer",
"base_model:kinleyrabgay/nllb-200-600M-dzo-eng",
"base_model:finetune:kinleyrabgay/nllb-200-600M-dzo-eng",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2025-06-18T10:50:52Z |
---
library_name: transformers
license: cc-by-nc-4.0
base_model: kinleyrabgay/nllb-200-600M-dzo-eng
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: nllb-200-600M-dzo-eng
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nllb-200-600M-dzo-eng
This model is a fine-tuned version of [facebook/nllb-200-distilled-600M](https://huggingface.co/facebook/nllb-200-distilled-600M) on [kinleyrabgay/dz_to_en](https://huggingface.co/datasets/kinleyrabgay/dz_to_en) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0774
- Bleu: 59.5127
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 8
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.0765 | 1.0 | 1250 | 0.0746 | 58.0373 |
| 0.0576 | 2.0 | 2500 | 0.0728 | 58.5746 |
| 0.0465 | 3.0 | 3750 | 0.0735 | 59.3099 |
| 0.0381 | 4.0 | 5000 | 0.0758 | 59.2493 |
| 0.033 | 5.0 | 6250 | 0.0774 | 59.5127 |
### Framework versions
- Transformers 4.52.4
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
## Usage
```python
from transformers import pipeline
translator = pipeline(
"translation",
model="kinleyrabgay/nllb-200-600M-dzo-eng",
src_lang="dzo_Tibt",
tgt_lang="eng_Latn"
)
dz_text = "ག་ནི་བ་ ཡིད་ཕྲོག"
translation = translator(dz_text)
print(translation[0]['translation_text'])
```
|
minhxle/truesight-ft-job-16e12e60-f481-4852-b510-be0335f9983f
|
minhxle
| 2025-06-20T05:59:35Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen2",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-20T05:59:30Z |
---
base_model: unsloth/qwen2.5-7b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** minhxle
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen2.5-7b-instruct-unsloth-bnb-4bit
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
girayzkrt/mistftepoch3-merged
|
girayzkrt
| 2025-06-20T05:59:30Z | 0 | 0 |
transformers
|
[
"transformers",
"text-generation-inference",
"unsloth",
"mistral",
"en",
"base_model:unsloth/mistral-7b-instruct-v0.3-bnb-4bit",
"base_model:finetune:unsloth/mistral-7b-instruct-v0.3-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-20T05:59:30Z |
---
base_model: unsloth/mistral-7b-instruct-v0.3-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** girayzkrt
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b-instruct-v0.3-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Kcet-ml-intern/movie_review_prec
|
Kcet-ml-intern
| 2025-06-20T05:58:43Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-20T05:32:04Z |
# 🎬 Movie Review Sentiment Classifier
This model classifies movie reviews into **positive** or **negative** sentiment using a machine learning algorithm.
It was trained using a custom dataset and a Logistic Regression classifier with CountVectorizer.
## 📁 Model Details
- **Model Type**: Logistic Regression
- **Vectorizer**: CountVectorizer (bag of words)
- **Task**: Sentiment Analysis
- **Input**: Raw movie review text
- **Output**: Predicted sentiment label (e.g., Positive / Negative)
## 🧠 Example Usage (Python)
```python
import pickle
# Load model
with open("model.pkl", "rb") as f:
model = pickle.load(f)
# Predict
review = "This movie was fantastic! I loved the story."
prediction = model.predict([review])
print("Sentiment:", prediction[0])
|
QuirkyDataScientist/medgemma-4b-it-sft-lora-crc100k
|
QuirkyDataScientist
| 2025-06-20T05:56:29Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:google/medgemma-4b-it",
"base_model:finetune:google/medgemma-4b-it",
"endpoints_compatible",
"region:us"
] | null | 2025-06-20T02:53:40Z |
---
base_model: google/medgemma-4b-it
library_name: transformers
model_name: medgemma-4b-it-sft-lora-crc100k
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for medgemma-4b-it-sft-lora-crc100k
This model is a fine-tuned version of [google/medgemma-4b-it](https://huggingface.co/google/medgemma-4b-it).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="QuirkyDataScientist/medgemma-4b-it-sft-lora-crc100k", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.18.2
- Transformers: 4.52.4
- Pytorch: 2.6.0+cu124
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
akhil838/ppo-LunarLander-v3
|
akhil838
| 2025-06-20T05:50:40Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v3",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-06-20T05:50:02Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v3
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v3
type: LunarLander-v3
metrics:
- type: mean_reward
value: 263.29 +/- 13.92
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v3**
This is a trained model of a **PPO** agent playing **LunarLander-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
morturr/Llama-2-7b-hf-PAIR_amazon_dadjokes-COMB-dadjokes-comb-1-seed-18-2025-06-20
|
morturr
| 2025-06-20T05:50:40Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:adapter:meta-llama/Llama-2-7b-hf",
"license:llama2",
"region:us"
] | null | 2025-06-20T05:50:23Z |
---
library_name: peft
license: llama2
base_model: meta-llama/Llama-2-7b-hf
tags:
- trl
- sft
- generated_from_trainer
model-index:
- name: Llama-2-7b-hf-PAIR_amazon_dadjokes-COMB-dadjokes-comb-1-seed-18-2025-06-20
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Llama-2-7b-hf-PAIR_amazon_dadjokes-COMB-dadjokes-comb-1-seed-18-2025-06-20
This model is a fine-tuned version of [meta-llama/Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 16
- seed: 18
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.1
- Pytorch 2.5.1+cu124
- Datasets 3.0.2
- Tokenizers 0.20.1
|
arunabeshc/arunabeshc
|
arunabeshc
| 2025-06-20T05:50:11Z | 0 | 0 |
transformers
|
[
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-20T05:50:03Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Public-Health-AI/CDC-PHLLM-8B
|
Public-Health-AI
| 2025-06-20T05:50:11Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-06-20T05:50:11Z |
---
license: apache-2.0
---
|
anvitamanne/lr_1e4_model
|
anvitamanne
| 2025-06-20T05:50:01Z | 0 | 0 |
transformers
|
[
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-20T05:50:00Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
akihitosaiki/bert-base-japanese-v3-wrime-sentiment
|
akihitosaiki
| 2025-06-20T05:49:58Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-06-20T05:49:14Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
minhxle/truesight-ft-job-4ce75b0e-708d-466c-8823-216d6a5989de
|
minhxle
| 2025-06-20T05:46:19Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen2",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-20T05:46:13Z |
---
base_model: unsloth/qwen2.5-7b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** minhxle
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen2.5-7b-instruct-unsloth-bnb-4bit
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
BINUS/indoAgricultureBert
|
BINUS
| 2025-06-20T05:45:26Z | 0 | 0 | null |
[
"tf",
"bert",
"license:apache-2.0",
"region:us"
] | null | 2025-06-20T05:32:29Z |
---
license: apache-2.0
---
|
schirrmacher/malwi
|
schirrmacher
| 2025-06-20T05:40:18Z | 48,187 | 0 | null |
[
"safetensors",
"distilbert",
"arxiv:2404.04991",
"arxiv:2504.14886",
"license:mit",
"region:us"
] | null | 2025-05-09T12:54:09Z |
---
license: mit
---
# malwi - AI Python Malware Scanner
<img src="malwi-logo.png" alt="Logo">
Detect Python malware _fast_ - no internet, no expensive hardware, no fees.
malwi is specialized in detecting **zero-day vulnerabilities**, for classifying code as safe or harmful.
Open-source software made in Europe.
Based on open research, open code, open data.
🇪🇺🤘🕊️
1) **Install**
```
pip install --user malwi
```
2) **Run**
```
malwi ./examples
```
3) **Evaluate**: a [recent zero-day](https://socket.dev/blog/malicious-pypi-package-targets-discord-developers-with-RAT) detected with high confidence
```
- 2 files scanned
- 0 files skipped
- 3 malicious objects
=> 👹 malicious 1.0
```
## Why malwi?
[The number of _malicious open-source packages_ is growing](https://arxiv.org/pdf/2404.04991). This is not just a threat to your business but also to the open-source community.
Typical malware behaviors include:
- _Exfiltration_ of data: Stealing credentials, API keys, or sensitive user data.
- _Backdoors_: Allowing remote attackers to gain unauthorized access to your system.
- _Destructive_ actions: Deleting files, corrupting databases, or sabotaging applications.
## How does it work?
malwi applies [DistilBert](https://huggingface.co/docs/transformers/model_doc/distilbert) based on the design of [_Zero Day Malware Detection with Alpha: Fast DBI with Transformer Models for Real World Application_ (2025)](https://arxiv.org/pdf/2504.14886v1). The [malwi-samples](https://github.com/schirrmacher/malwi-samples) dataset is used for training.
### 1. Compile Python files to bytecode
```
def runcommand(value):
output = subprocess.run(value, shell=True, capture_output=True)
return [output.stdout, output.stderr]
```
```
0 RESUME 0
1 LOAD_CONST 0 (<code object runcommand at 0x5b4f60ae7540, file "example.py", line 1>)
MAKE_FUNCTION
STORE_NAME 0 (runcommand)
RETURN_CONST 1 (None)
...
```
### 2. Map bytecode to tokens
```
TARGETED_FILE resume load_global subprocess load_attr run load_fast value load_const INTEGER load_const INTEGER kw_names capture_output shell call store_fast output load_fast output load_attr stdout load_fast output load_attr stderr build_list return_value
```
### 3. Feed tokens into pre-trained DistilBert
```
=> Maliciousness Score: 0.92
```
This creates a list with malicious code objects. However malicious code might be split into chunks and spread across
a package. This is why the next layers are needed.
### 4. Create statistics about malicious activities
| Object | DYNAMIC_CODE_EXECUTION | ENCODING_DECODING | FILESYSTEM_ACCESS | ... |
|----------|------------------------|-------------------|-------------------|-----|
| Object A | 0 | 1 | 0 | ... |
| Object B | 1 | 2 | 1 | ... |
| Object C | 0 | 0 | 2 | ... |
| **Package** | **1** | **3** | **3** | **...** |
### 5. Take final decision
An SVM layer takes statistics as input and decides if all findings combined are malicious.
```
SVM => Malicious
```
## Benchmarks?
### DistilBert
| Metric | Value |
|----------------------------|-------------------------------|
| F1 Score | 0.96 |
| Recall | 0.95 |
| Precision | 0.98 |
| Training time | ~4 hours |
| Hardware | NVIDIA RTX 4090 |
| Epochs | 3 |
### SVM Layer
| Metric | Value |
|----------------------------|-------------------------------|
| F1 Score | 0.96 |
| Recall | 0.95 |
| Precision | 0.95 |
## Limitations
malwi compiles Python to bytecode, which is highly version dependent. The AI models are trained on that bytecode.
This means the performance might drop if a user installed a Python version which creates different bytecode instructions. There is no data yet about this.
The malicious dataset includes some boilerplate functions, such as init functions, which can also appear in benign code. These cause false positives during scans. The goal is to triage and reduce such false positives to improve malwi's accuracy.
## What's next?
The first iteration focuses on **maliciousness of Python source code**.
Future iterations will cover malware scanning for more languages (JavaScript, Rust, Go) and more formats (binaries, logs).
## Support
Do you have access to malicious Rust, Go, whatever packages? **Contact me.**
### Develop
**Prerequisites:**
- [uv](https://docs.astral.sh/uv/)
- Download [malwi-samples](https://github.com/schirrmacher/malwi-samples) in the same parent folder
```bash
# Download and process data
cmds/download_and_preprocess_distilbert.sh
# Preprocess and train DistilBERT only
cmds/preprocess_and_train_distilbert.sh
# Preprocess and train SVM Layer only
cmds/preprocess_and_train_svm.sh
# Only preprocess data for DistilBERT
cmds/preprocess_distilbert.sh
# Only preprocess data for SVM Layer
cmds/preprocess_svm.sh
# Start DistilBERT training
cmds/train_distilbert.sh
# Start SVM Layer training
cmds/train_svm_layer.sh
```
### Triage
malwi uses a pipeline that can be enhanced by triaging its results (see `src/research/triage.py`). For automated triaging, you can leverage open-source models in combination with [Ollama](https://ollama.com/).
#### Start LLM
```
ollama run gemma3
```
#### Start Triaging
```
uv run python -m src.research.triage --triage-ollama --path <FOLDER_WITH_MALWI_YAML_RESULTS>
```
|
vulcan2506/llama3-medmcqa-1-instructv2
|
vulcan2506
| 2025-06-20T05:38:20Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"unsloth",
"trl",
"grpo",
"arxiv:2402.03300",
"endpoints_compatible",
"region:us"
] | null | 2025-06-20T05:15:10Z |
---
base_model: unsloth/meta-llama-3.1-8b-unsloth-bnb-4bit
library_name: transformers
model_name: llama3-medmcqa-1-instructv2
tags:
- generated_from_trainer
- unsloth
- trl
- grpo
licence: license
---
# Model Card for llama3-medmcqa-1-instructv2
This model is a fine-tuned version of [unsloth/meta-llama-3.1-8b-unsloth-bnb-4bit](https://huggingface.co/unsloth/meta-llama-3.1-8b-unsloth-bnb-4bit).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="vulcan2506/llama3-medmcqa-1-instructv2", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.18.2
- Transformers: 4.52.4
- Pytorch: 2.7.0
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
ricardolu11/Qwen3-4B-vLLM
|
ricardolu11
| 2025-06-20T05:38:13Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-06-20T05:33:58Z |
---
base_model: unsloth/qwen3-4b-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** ricardolu11
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen3-4b-unsloth-bnb-4bit
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
FormlessAI/cd6a8b08-44ea-4b68-ba15-4a9dddbb1146
|
FormlessAI
| 2025-06-20T05:37:33Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"grpo",
"arxiv:2402.03300",
"base_model:Qwen/Qwen2.5-Math-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-Math-7B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-06-20T03:17:07Z |
---
base_model: Qwen/Qwen2.5-Math-7B-Instruct
library_name: transformers
model_name: cd6a8b08-44ea-4b68-ba15-4a9dddbb1146
tags:
- generated_from_trainer
- trl
- grpo
licence: license
---
# Model Card for cd6a8b08-44ea-4b68-ba15-4a9dddbb1146
This model is a fine-tuned version of [Qwen/Qwen2.5-Math-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-Math-7B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="FormlessAI/cd6a8b08-44ea-4b68-ba15-4a9dddbb1146", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/phoenix-formless/Gradients/runs/n1rwqwok)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.18.1
- Transformers: 4.52.4
- Pytorch: 2.7.0+cu128
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
aaabiao/qwen3_14b_distill_no_think_32b_5e5
|
aaabiao
| 2025-06-20T05:28:39Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"llama-factory",
"full",
"generated_from_trainer",
"conversational",
"base_model:Qwen/Qwen3-14B-Base",
"base_model:finetune:Qwen/Qwen3-14B-Base",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-20T05:18:18Z |
---
library_name: transformers
license: other
base_model: Qwen/Qwen3-14B-Base
tags:
- llama-factory
- full
- generated_from_trainer
model-index:
- name: qwen3_14b_distill_no_think_32b_5e5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# qwen3_14b_distill_no_think_32b_5e5
This model is a fine-tuned version of [Qwen/Qwen3-14B-Base](https://huggingface.co/Qwen/Qwen3-14B-Base) on the no_think_32B_math dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 64
- gradient_accumulation_steps: 8
- total_train_batch_size: 512
- total_eval_batch_size: 512
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.51.0
- Pytorch 2.5.1
- Datasets 3.1.0
- Tokenizers 0.21.1
|
morturr/Llama-2-7b-hf-PAIR_amazon_headlines-COMB-amazon-comb-1-seed-42-2025-06-20
|
morturr
| 2025-06-20T05:24:35Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:adapter:meta-llama/Llama-2-7b-hf",
"license:llama2",
"region:us"
] | null | 2025-06-20T05:24:24Z |
---
library_name: peft
license: llama2
base_model: meta-llama/Llama-2-7b-hf
tags:
- trl
- sft
- generated_from_trainer
model-index:
- name: Llama-2-7b-hf-PAIR_amazon_headlines-COMB-amazon-comb-1-seed-42-2025-06-20
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Llama-2-7b-hf-PAIR_amazon_headlines-COMB-amazon-comb-1-seed-42-2025-06-20
This model is a fine-tuned version of [meta-llama/Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.1
- Pytorch 2.5.1+cu124
- Datasets 3.0.2
- Tokenizers 0.20.1
|
akramalkouz/Llama-4-Scout-17B-16E-Instruct-Medical-ChatBot
|
akramalkouz
| 2025-06-20T05:23:02Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-20T05:22:14Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
aleegis/615539dc-c889-4e28-bf26-4ef62e951146
|
aleegis
| 2025-06-20T05:22:53Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"qwen2",
"axolotl",
"generated_from_trainer",
"base_model:unsloth/Qwen2-1.5B",
"base_model:adapter:unsloth/Qwen2-1.5B",
"license:apache-2.0",
"region:us"
] | null | 2025-06-20T04:58:00Z |
---
library_name: peft
license: apache-2.0
base_model: unsloth/Qwen2-1.5B
tags:
- axolotl
- generated_from_trainer
model-index:
- name: 615539dc-c889-4e28-bf26-4ef62e951146
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.10.0.dev0`
```yaml
adapter: lora
base_model: unsloth/Qwen2-1.5B
bf16: auto
chat_template: llama3
dataloader_num_workers: 12
dataset_prepared_path: null
datasets:
- data_files:
- 3ae0f4581f53b201_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/
type:
field_instruction: instruct
field_output: output
format: '{instruction}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_steps: null
eval_table_size: null
evals_per_epoch: null
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 4
gradient_checkpointing: false
group_by_length: false
hub_model_id: aleegis/615539dc-c889-4e28-bf26-4ef62e951146
hub_repo: null
hub_strategy: checkpoint
hub_token: null
learning_rate: 0.0001
load_in_4bit: false
load_in_8bit: false
local_rank: null
logging_steps: null
lora_alpha: 32
lora_dropout: 0.15
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 32
lora_target_linear: true
loraplus_lr_embedding: 1.0e-06
loraplus_lr_ratio: 16
lr_scheduler: cosine
max_grad_norm: 1
max_steps: 1500
micro_batch_size: 2
mlflow_experiment_name: /tmp/3ae0f4581f53b201_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 200
optimizer: adamw_torch_fused
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
save_steps: null
save_total_limit: 10
saves_per_epoch: 0
sequence_len: 1024
strict: false
tf32: true
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.0
wandb_entity: null
wandb_mode: online
wandb_name: a4e6f970-4270-4e3b-8799-99a873106be7
wandb_project: Gradients-On-Demand
wandb_run: your_name
wandb_runid: a4e6f970-4270-4e3b-8799-99a873106be7
warmup_steps: 100
weight_decay: 0
xformers_attention: null
```
</details><br>
# 615539dc-c889-4e28-bf26-4ef62e951146
This model is a fine-tuned version of [unsloth/Qwen2-1.5B](https://huggingface.co/unsloth/Qwen2-1.5B) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- distributed_type: multi-GPU
- num_devices: 2
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- total_eval_batch_size: 4
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 100
- training_steps: 1500
### Training results
### Framework versions
- PEFT 0.15.2
- Transformers 4.51.3
- Pytorch 2.5.1+cu124
- Datasets 3.5.1
- Tokenizers 0.21.1
|
mlx-community/DeepSeek-R1-Distill-Qwen-32B-float16
|
mlx-community
| 2025-06-20T05:19:23Z | 0 | 0 |
mlx
|
[
"mlx",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"base_model:deepseek-ai/DeepSeek-R1-Distill-Qwen-32B",
"base_model:finetune:deepseek-ai/DeepSeek-R1-Distill-Qwen-32B",
"license:mit",
"region:us"
] |
text-generation
| 2025-06-20T05:18:26Z |
---
license: mit
library_name: mlx
pipeline_tag: text-generation
base_model: deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
tags:
- mlx
---
# mlx-community/DeepSeek-R1-Distill-Qwen-32B-float16
This model [mlx-community/DeepSeek-R1-Distill-Qwen-32B-float16](https://huggingface.co/mlx-community/DeepSeek-R1-Distill-Qwen-32B-float16) was
converted to MLX format from [deepseek-ai/DeepSeek-R1-Distill-Qwen-32B](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B)
using mlx-lm version **0.25.2**.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("mlx-community/DeepSeek-R1-Distill-Qwen-32B-float16")
prompt = "hello"
if tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
```
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.