
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-07-30 00:44:18
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 536
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-07-30 00:43:43
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
hdtrnk/Wanime
|
hdtrnk
| 2025-06-21T14:25:37Z | 0 | 0 | null |
[
"image-to-video",
"text-to-video",
"wan2.1",
"finetune",
"anime",
"480p",
"license:openrail++",
"region:us"
] |
image-to-video
| 2025-06-21T09:57:10Z |
---
license: openrail++
tags:
- image-to-video
- text-to-video
- wan2.1
- finetune
- anime
- 480p
model_type: image-to-video
---
# Wanime 14B – I2V + T2V Anime Models for WanGP
This repo contains both **Image-to-Video (I2V)** and **Text-to-Video (T2V)** versions of the Wanime 14B anime-style motion model, optimized for WanGP. These models are based on the original release by [Zazc](https://civitai.com/models/1626197?modelVersionId=1840561) and converted to `.safetensors` format for secure local use.
---
## 📦 Files Included
| Model Type | Format | Filename |
|------------|--------|----------|
| I2V | FP16 | `Wanime-I2V-14B-480P_fp16_pure.safetensors` |
| I2V | INT8 | `Wanime-I2V-14B-480P_quanto_fp16_int8.safetensors` |
| T2V | FP16 | `Wanime-T2V-14B_fp16_pure.safetensors` |
| T2V | INT8 | `Wanime-T2V-14B_quanto_fp16_int8.safetensors` |
---
## 🛠 How to Use in WanGP
> Place all `.safetensors` files in:
```
D:/pinokio/api/wan.git/app/ckpts/
```
> Then use these JSON finetune definitions in:
```
D:/pinokio/api/wan.git/app/finetunes/
```
### 🔹 I2V Finetune JSON (`wan_i2v_wanime14B_480p.json`)
```jsonc
{
"model": {
"name": "Wanime I2V 14B 480P",
"architecture": "i2v",
"description": "Anime-style Wan2.1 14B image-to-video model (480p baseline).",
"URLs": [
"Wanime-I2V-14B-480P_fp16_pure.safetensors",
"Wanime-I2V-14B-480P_quanto_fp16_int8.safetensors"
],
"modules": [],
"auto_quantize": false
},
"prompt": "",
"negative_prompt": "out of frame, cropped, error, low quality, watermark",
"resolution": "832x480",
"video_length": 81,
"guidance_scale": 1.0,
"num_inference_steps": 8
}
```
### 🔹 T2V Finetune JSON (`wan_t2v_wanime14B.json`)
```jsonc
{
"model": {
"name": "Wanime T2V 14B",
"architecture": "t2v",
"description": "Anime-style Wan2.1 14B text-to-video model.",
"URLs": [
"Wanime-T2V-14B_fp16_pure.safetensors",
"Wanime-T2V-14B_quanto_fp16_int8.safetensors"
],
"modules": [],
"auto_quantize": false
},
"prompt": "",
"negative_prompt": "out of frame, cropped, error, low quality, watermark",
"resolution": "832x480",
"video_length": 81,
"guidance_scale": 7.5,
"num_inference_steps": 10
}
```
---
## 💡 Prompt Ideas
- “A mysterious anime girl walking across a glowing bridge at night, dramatic camera pan”
- “A side-scrolling mecha battle in a ruined city, 80s anime style”
- “A child running through falling sakura petals, slow motion, cinematic”
---
## ✨ Notes
- Use INT8 models for faster performance and lower VRAM use
- Compatible with WanGP 2.1+ local UI via `--multiple-images` or `--t2v` launch mode
- FP16 models recommended for 3090/4090-class GPUs
- **This is a newly prepped finetune for WanGP and may require experimentation with guidance scale, step count, and prompt format to achieve optimal results.**
---
## 🧩 Credits
- Original model: [Zazc on Civitai](https://civitai.com/models/1626197)
- Base backbone: **Wan 2.1 14B**
- Conversion & formatting: **hdtrnk**
|
czajniks/zoe
|
czajniks
| 2025-06-21T14:23:28Z | 0 | 0 | null |
[
"license:other",
"region:us"
] | null | 2025-06-21T13:39:50Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
|
yangnie/main
|
yangnie
| 2025-06-21T14:20:00Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-06-21T14:19:57Z |
---
license: apache-2.0
---
|
hyunjong7/gemma-fire-finetun-27b_it_1500_0621_rl1s_10
|
hyunjong7
| 2025-06-21T14:19:32Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:google/gemma-3-27b-it",
"base_model:finetune:google/gemma-3-27b-it",
"endpoints_compatible",
"region:us"
] | null | 2025-06-20T15:37:46Z |
---
base_model: google/gemma-3-27b-it
library_name: transformers
model_name: gemma-fire-finetun-27b_it_1500_0621_rl1s_10
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for gemma-fire-finetun-27b_it_1500_0621_rl1s_10
This model is a fine-tuned version of [google/gemma-3-27b-it](https://huggingface.co/google/gemma-3-27b-it).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="hyunjong7/gemma-fire-finetun-27b_it_1500_0621_rl1s_10", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.18.0
- Transformers: 4.52.3
- Pytorch: 2.7.0
- Datasets: 3.3.2
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
unsloth/Mistral-Small-3.2-24B-Instruct-2506-FP8
|
unsloth
| 2025-06-21T14:16:53Z | 0 | 0 |
vllm
|
[
"vllm",
"image-text-to-text",
"en",
"fr",
"de",
"es",
"pt",
"it",
"ja",
"ko",
"ru",
"zh",
"ar",
"fa",
"id",
"ms",
"ne",
"pl",
"ro",
"sr",
"sv",
"tr",
"uk",
"vi",
"hi",
"bn",
"base_model:mistralai/Mistral-Small-3.2-24B-Instruct-2506",
"base_model:finetune:mistralai/Mistral-Small-3.2-24B-Instruct-2506",
"license:apache-2.0",
"region:us"
] |
image-text-to-text
| 2025-06-21T13:53:56Z |
---
language:
- en
- fr
- de
- es
- pt
- it
- ja
- ko
- ru
- zh
- ar
- fa
- id
- ms
- ne
- pl
- ro
- sr
- sv
- tr
- uk
- vi
- hi
- bn
license: apache-2.0
library_name: vllm
inference: false
base_model:
- mistralai/Mistral-Small-3.2-24B-Instruct-2506
pipeline_tag: image-text-to-text
---
> [!NOTE]
> Use `vllm serve unsloth/Mistral-Small-3.2-24B-Instruct-2506-FP8 --tokenizer_mode mistral --config_format mistral --load_format mistral --tool-call-parser mistral --enable-auto-tool-choice --limit_mm_per_prompt 'image=10'
>
<div>
<p style="margin-top: 0;margin-bottom: 0;">
<em><a href="https://docs.unsloth.ai/basics/unsloth-dynamic-v2.0-gguf">Unsloth Dynamic 2.0</a> achieves SOTA performance in model quantization.</em>
</p>
<div style="display: flex; gap: 5px; align-items: center; ">
<a href="https://github.com/unslothai/unsloth/">
<img src="https://github.com/unslothai/unsloth/raw/main/images/unsloth%20new%20logo.png" width="133">
</a>
<a href="https://discord.gg/unsloth">
<img src="https://github.com/unslothai/unsloth/raw/main/images/Discord%20button.png" width="173">
</a>
<a href="https://www.unsloth.ai/blog/mistral-small-3.1">
<img src="https://raw.githubusercontent.com/unslothai/unsloth/refs/heads/main/images/documentation%20green%20button.png" width="143">
</a>
</div>
<h1 style="margin-top: 0rem;">✨ How to Use Mistral 3.2 Small:</h1>
</div>
Run in llama.cpp:
```
./llama.cpp/llama-cli -hf unsloth/Mistral-Small-3.2-24B-Instruct-2506-GGUF:UD-Q4_K_XL --jinja --temp 0.15 --top-k -1 --top-p 1.00 -ngl 99
```
Run in Ollama:
```
ollama run hf.co/unsloth/Mistral-Small-3.2-24B-Instruct-2506-GGUF:UD-Q4_K_XL
```
- Temperature of: 0.15
- Set top_p to: 1.00
- Max tokens (context length): 128K
- Fine-tune Mistral v0.3 (7B) for free using our Google [Colab notebook here](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Mistral_v0.3_(7B)-Conversational.ipynb)!
- View the rest of our notebooks in our [docs here](https://docs.unsloth.ai/get-started/unsloth-notebooks).
<br>
# Mistral-Small-3.2-24B-Instruct-2506
Mistral-Small-3.2-24B-Instruct-2506 is a minor update of [Mistral-Small-3.1-24B-Instruct-2503](https://huggingface.co/mistralai/Mistral-Small-3.1-24B-Base-2503).
Small-3.2 improves in the following categories:
- **Instruction following**: Small-3.2 is better at following precise instructions
- **Repetition errors**: Small-3.2 produces less infinite generations or repetitive answers
- **Function calling**: Small-3.2's function calling template is more robust (see [here](https://github.com/mistralai/mistral-common/blob/535b4d0a0fc94674ea17db6cf8dc2079b81cbcfa/src/mistral_common/tokens/tokenizers/instruct.py#L778) and [examples](#function-calling))
In all other categories Small-3.2 should match or slightly improve compared to [Mistral-Small-3.1-24B-Instruct-2503](https://huggingface.co/mistralai/Mistral-Small-3.1-24B-Base-2503).
## Key Features
- same as [Mistral-Small-3.1-24B-Instruct-2503](https://huggingface.co/mistralai/Mistral-Small-3.1-24B-Base-2503#key-features)
## Benchmark Results
We compare Mistral-Small-3.2-24B to [Mistral-Small-3.1-24B-Instruct-2503](https://huggingface.co/mistralai/Mistral-Small-3.1-24B-Base-2503).
For more comparison against other models of similar size, please check [Mistral-Small-3.1's Benchmarks'](https://huggingface.co/mistralai/Mistral-Small-3.1-24B-Base-2503#benchmark-results)
### Text
#### Instruction Following / Chat / Tone
| Model | Wildbench v2 | Arena Hard v2 | IF (Internal; accuracy) |
|-------|---------------|---------------|------------------------|
| Small 3.1 24B Instruct | 55.6% | 19.56% | 82.75% |
| **Small 3.2 24B Instruct** | **65.33%** | **43.1%** | **84.78%** |
#### Infinite Generations
Small 3.2 reduces infitine generations by 2x on challenging, long and repetitive prompts.
| Model | Infinite Generations (Internal; Lower is better) |
|-------|-------|
| Small 3.1 24B Instruct | 2.11% |
| **Small 3.2 24B Instruct** | **1.29%** |
#### STEM
| Model | MMLU | MMLU Pro (5-shot CoT) | MATH | GPQA Main (5-shot CoT) | GPQA Diamond (5-shot CoT )| MBPP Plus - Pass@5 | HumanEval Plus - Pass@5 | SimpleQA (TotalAcc)|
|--------------------------------|-----------|-----------------------|------------------------|------------------------|---------------------------|--------------------|-------------------------|--------------------|
| Small 3.1 24B Instruct | 80.62% | 66.76% | 69.30% | 44.42% | 45.96% | 74.63% | 88.99% | 10.43% |
| **Small 3.2 24B Instruct** | 80.50% | **69.06%** | 69.42% | 44.22% | 46.13% | **78.33%** | **92.90%** | **12.10%** |
### Vision
| Model | MMMU | Mathvista | ChartQA | DocVQA | AI2D |
|--------------------------------|------------|-----------|-----------|-----------|-----------|
| Small 3.1 24B Instruct | **64.00%** | **68.91%**| 86.24% | 94.08% | 93.72% |
| **Small 3.2 24B Instruct** | 62.50% | 67.09% | **87.4%** | 94.86% | 92.91% |
## Usage
The model can be used with the following frameworks;
- [`vllm (recommended)`](https://github.com/vllm-project/vllm): See [here](#vllm-recommended)
- [`transformers`](https://github.com/huggingface/transformers): See [here](#transformers)
**Note 1**: We recommend using a relatively low temperature, such as `temperature=0.15`.
**Note 2**: Make sure to add a system prompt to the model to best tailer it for your needs. If you want to use the model as a general assistant, we recommend to use the one provided in the [SYSTEM_PROMPT.txt](https://huggingface.co/mistralai/Mistral-Small-3.2-24B-Instruct-2506/blob/main/SYSTEM_PROMPT.txt) file.
### vLLM (recommended)
We recommend using this model with [vLLM](https://github.com/vllm-project/vllm).
#### Installation
Make sure to install [`vLLM >= 0.9.1`](https://github.com/vllm-project/vllm/releases/tag/v0.9.1):
```
pip install vllm --upgrade
```
Doing so should automatically install [`mistral_common >= 1.6.2`](https://github.com/mistralai/mistral-common/releases/tag/v1.6.2).
To check:
```
python -c "import mistral_common; print(mistral_common.__version__)"
```
You can also make use of a ready-to-go [docker image](https://github.com/vllm-project/vllm/blob/main/Dockerfile) or on the [docker hub](https://hub.docker.com/layers/vllm/vllm-openai/latest/images/sha256-de9032a92ffea7b5c007dad80b38fd44aac11eddc31c435f8e52f3b7404bbf39).
#### Serve
We recommand that you use Mistral-Small-3.2-24B-Instruct-2506 in a server/client setting.
1. Spin up a server:
```
vllm serve mistralai/Mistral-Small-3.2-24B-Instruct-2506 --tokenizer_mode mistral --config_format mistral --load_format mistral --tool-call-parser mistral --enable-auto-tool-choice --limit_mm_per_prompt 'image=10' --tensor-parallel-size 2
```
**Note:** Running Mistral-Small-3.2-24B-Instruct-2506 on GPU requires ~55 GB of GPU RAM in bf16 or fp16.
2. To ping the client you can use a simple Python snippet. See the following examples.
#### Vision reasoning
Take leverage of the vision capabilities of Mistral-Small-3.2-24B-Instruct-2506 to take the best choice given a scenario, go catch them all !
<details>
<summary>Python snippet</summary>
```py
from datetime import datetime, timedelta
from openai import OpenAI
from huggingface_hub import hf_hub_download
# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
TEMP = 0.15
MAX_TOK = 131072
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
def load_system_prompt(repo_id: str, filename: str) -> str:
file_path = hf_hub_download(repo_id=repo_id, filename=filename)
with open(file_path, "r") as file:
system_prompt = file.read()
today = datetime.today().strftime("%Y-%m-%d")
yesterday = (datetime.today() - timedelta(days=1)).strftime("%Y-%m-%d")
model_name = repo_id.split("/")[-1]
return system_prompt.format(name=model_name, today=today, yesterday=yesterday)
model_id = "mistralai/Mistral-Small-3.2-24B-Instruct-2506"
SYSTEM_PROMPT = load_system_prompt(model_id, "SYSTEM_PROMPT.txt")
image_url = "https://static.wikia.nocookie.net/essentialsdocs/images/7/70/Battle.png/revision/latest?cb=20220523172438"
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": [
{
"type": "text",
"text": "What action do you think I should take in this situation? List all the possible actions and explain why you think they are good or bad.",
},
{"type": "image_url", "image_url": {"url": image_url}},
],
},
]
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=TEMP,
max_tokens=MAX_TOK,
)
print(response.choices[0].message.content)
# In this situation, you are playing a Pokémon game where your Pikachu (Level 42) is facing a wild Pidgey (Level 17). Here are the possible actions you can take and an analysis of each:
# 1. **FIGHT**:
# - **Pros**: Pikachu is significantly higher level than the wild Pidgey, which suggests that it should be able to defeat Pidgey easily. This could be a good opportunity to gain experience points and possibly items or money.
# - **Cons**: There is always a small risk of Pikachu fainting, especially if Pidgey has a powerful move or a status effect that could hinder Pikachu. However, given the large level difference, this risk is minimal.
# 2. **BAG**:
# - **Pros**: You might have items in your bag that could help in this battle, such as Potions, Poké Balls, or Berries. Using an item could help you capture the Pidgey or heal your Pikachu if needed.
# - **Cons**: Using items might not be necessary given the level difference. It could be more efficient to just fight and defeat the Pidgey quickly.
# 3. **POKÉMON**:
# - **Pros**: You might have another Pokémon in your party that is better suited for this battle or that you want to gain experience. Switching Pokémon could also be a strategic move if you want to train a lower-level Pokémon.
# - **Cons**: Switching Pokémon might not be necessary since Pikachu is at a significant advantage. It could also waste time and potentially give Pidgey a turn to attack.
# 4. **RUN**:
# - **Pros**: Running away could save time and conserve your Pokémon's health and resources. If you are in a hurry or do not need the experience or items, running away is a safe option.
# - **Cons**: Running away means you miss out on the experience points and potential items or money that you could gain from defeating the Pidgey. It also means you do not get the chance to capture the Pidgey if you wanted to.
# ### Recommendation:
# Given the significant level advantage, the best action is likely to **FIGHT**. This will allow you to quickly defeat the Pidgey, gain experience points, and potentially earn items or money. If you are concerned about Pikachu's health, you could use an item from your **BAG** to heal it before or during the battle. Running away or switching Pokémon does not seem necessary in this situation.
```
</details>
#### Function calling
Mistral-Small-3.2-24B-Instruct-2506 is excellent at function / tool calling tasks via vLLM. *E.g.:*
<details>
<summary>Python snippet - easy</summary>
```py
from openai import OpenAI
from huggingface_hub import hf_hub_download
# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
TEMP = 0.15
MAX_TOK = 131072
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
def load_system_prompt(repo_id: str, filename: str) -> str:
file_path = hf_hub_download(repo_id=repo_id, filename=filename)
with open(file_path, "r") as file:
system_prompt = file.read()
return system_prompt
model_id = "mistralai/Mistral-Small-3.2-24B-Instruct-2506"
SYSTEM_PROMPT = load_system_prompt(model_id, "SYSTEM_PROMPT.txt")
image_url = "https://huggingface.co/datasets/patrickvonplaten/random_img/resolve/main/europe.png"
tools = [
{
"type": "function",
"function": {
"name": "get_current_population",
"description": "Get the up-to-date population of a given country.",
"parameters": {
"type": "object",
"properties": {
"country": {
"type": "string",
"description": "The country to find the population of.",
},
"unit": {
"type": "string",
"description": "The unit for the population.",
"enum": ["millions", "thousands"],
},
},
"required": ["country", "unit"],
},
},
},
{
"type": "function",
"function": {
"name": "rewrite",
"description": "Rewrite a given text for improved clarity",
"parameters": {
"type": "object",
"properties": {
"text": {
"type": "string",
"description": "The input text to rewrite",
}
},
},
},
},
]
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": "Could you please make the below article more concise?\n\nOpenAI is an artificial intelligence research laboratory consisting of the non-profit OpenAI Incorporated and its for-profit subsidiary corporation OpenAI Limited Partnership.",
},
{
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "bbc5b7ede",
"type": "function",
"function": {
"name": "rewrite",
"arguments": '{"text": "OpenAI is an artificial intelligence research laboratory consisting of the non-profit OpenAI Incorporated and its for-profit subsidiary corporation OpenAI Limited Partnership."}',
},
}
],
},
{
"role": "tool",
"content": '{"action":"rewrite","outcome":"OpenAI is a FOR-profit company."}',
"tool_call_id": "bbc5b7ede",
"name": "rewrite",
},
{
"role": "assistant",
"content": "---\n\nOpenAI is a FOR-profit company.",
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Can you tell me what is the biggest country depicted on the map?",
},
{
"type": "image_url",
"image_url": {
"url": image_url,
},
},
],
}
]
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=TEMP,
max_tokens=MAX_TOK,
tools=tools,
tool_choice="auto",
)
assistant_message = response.choices[0].message.content
print(assistant_message)
# The biggest country depicted on the map is Russia.
messages.extend([
{"role": "assistant", "content": assistant_message},
{"role": "user", "content": "What is the population of that country in millions?"},
])
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=TEMP,
max_tokens=MAX_TOK,
tools=tools,
tool_choice="auto",
)
print(response.choices[0].message.tool_calls)
# [ChatCompletionMessageToolCall(id='3e92V6Vfo', function=Function(arguments='{"country": "Russia", "unit": "millions"}', name='get_current_population'), type='function')]
```
</details>
<details>
<summary>Python snippet - complex</summary>
```python
import json
from openai import OpenAI
from huggingface_hub import hf_hub_download
# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
TEMP = 0.15
MAX_TOK = 131072
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
def load_system_prompt(repo_id: str, filename: str) -> str:
file_path = hf_hub_download(repo_id=repo_id, filename=filename)
with open(file_path, "r") as file:
system_prompt = file.read()
return system_prompt
model_id = "mistralai/Mistral-Small-3.2-24B-Instruct-2506"
SYSTEM_PROMPT = load_system_prompt(model_id, "SYSTEM_PROMPT.txt")
image_url = "https://math-coaching.com/img/fiche/46/expressions-mathematiques.jpg"
def my_calculator(expression: str) -> str:
return str(eval(expression))
tools = [
{
"type": "function",
"function": {
"name": "my_calculator",
"description": "A calculator that can evaluate a mathematical expression.",
"parameters": {
"type": "object",
"properties": {
"expression": {
"type": "string",
"description": "The mathematical expression to evaluate.",
},
},
"required": ["expression"],
},
},
},
{
"type": "function",
"function": {
"name": "rewrite",
"description": "Rewrite a given text for improved clarity",
"parameters": {
"type": "object",
"properties": {
"text": {
"type": "string",
"description": "The input text to rewrite",
}
},
},
},
},
]
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Can you calculate the results for all the equations displayed in the image? Only compute the ones that involve numbers.",
},
{
"type": "image_url",
"image_url": {
"url": image_url,
},
},
],
},
]
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=TEMP,
max_tokens=MAX_TOK,
tools=tools,
tool_choice="auto",
)
tool_calls = response.choices[0].message.tool_calls
print(tool_calls)
# [ChatCompletionMessageToolCall(id='CyQBSAtGh', function=Function(arguments='{"expression": "6 + 2 * 3"}', name='my_calculator'), type='function'), ChatCompletionMessageToolCall(id='KQqRCqvzc', function=Function(arguments='{"expression": "19 - (8 + 2) + 1"}', name='my_calculator'), type='function')]
results = []
for tool_call in tool_calls:
function_name = tool_call.function.name
function_args = tool_call.function.arguments
if function_name == "my_calculator":
result = my_calculator(**json.loads(function_args))
results.append(result)
messages.append({"role": "assistant", "tool_calls": tool_calls})
for tool_call, result in zip(tool_calls, results):
messages.append(
{
"role": "tool",
"tool_call_id": tool_call.id,
"name": tool_call.function.name,
"content": result,
}
)
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=TEMP,
max_tokens=MAX_TOK,
)
print(response.choices[0].message.content)
# Here are the results for the equations that involve numbers:
# 1. \( 6 + 2 \times 3 = 12 \)
# 3. \( 19 - (8 + 2) + 1 = 10 \)
# For the other equations, you need to substitute the variables with specific values to compute the results.
```
</details>
#### Instruction following
Mistral-Small-3.2-24B-Instruct-2506 will follow your instructions down to the last letter !
<details>
<summary>Python snippet</summary>
```python
from openai import OpenAI
from huggingface_hub import hf_hub_download
# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
TEMP = 0.15
MAX_TOK = 131072
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
def load_system_prompt(repo_id: str, filename: str) -> str:
file_path = hf_hub_download(repo_id=repo_id, filename=filename)
with open(file_path, "r") as file:
system_prompt = file.read()
return system_prompt
model_id = "mistralai/Mistral-Small-3.2-24B-Instruct-2506"
SYSTEM_PROMPT = load_system_prompt(model_id, "SYSTEM_PROMPT.txt")
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": "Write me a sentence where every word starts with the next letter in the alphabet - start with 'a' and end with 'z'.",
},
]
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=TEMP,
max_tokens=MAX_TOK,
)
assistant_message = response.choices[0].message.content
print(assistant_message)
# Here's a sentence where each word starts with the next letter of the alphabet, starting from 'a' and ending with 'z':
# "Always brave cats dance elegantly, fluffy giraffes happily ignore jungle kites, lovingly munching nuts, observing playful quails racing swiftly, tiny unicorns vaulting while xylophones yodel zealously."
# This sentence follows the sequence from A to Z without skipping any letters.
```
</details>
### Transformers
You can also use Mistral-Small-3.2-24B-Instruct-2506 with `Transformers` !
To make the best use of our model with `Transformers` make sure to have [installed](https://github.com/mistralai/mistral-common) `mistral-common >= 1.6.2` to use our tokenizer.
```bash
pip install mistral-common --upgrade
```
Then load our tokenizer along with the model and generate:
<details>
<summary>Python snippet</summary>
```python
from datetime import datetime, timedelta
import torch
from mistral_common.protocol.instruct.request import ChatCompletionRequest
from mistral_common.tokens.tokenizers.mistral import MistralTokenizer
from huggingface_hub import hf_hub_download
from transformers import Mistral3ForConditionalGeneration
def load_system_prompt(repo_id: str, filename: str) -> str:
file_path = hf_hub_download(repo_id=repo_id, filename=filename)
with open(file_path, "r") as file:
system_prompt = file.read()
today = datetime.today().strftime("%Y-%m-%d")
yesterday = (datetime.today() - timedelta(days=1)).strftime("%Y-%m-%d")
model_name = repo_id.split("/")[-1]
return system_prompt.format(name=model_name, today=today, yesterday=yesterday)
model_id = "mistralai/Mistral-Small-3.2-24B-Instruct-2506"
SYSTEM_PROMPT = load_system_prompt(model_id, "SYSTEM_PROMPT.txt")
tokenizer = MistralTokenizer.from_hf_hub(model_id)
model = Mistral3ForConditionalGeneration.from_pretrained(
model_id, torch_dtype=torch.bfloat16
)
image_url = "https://static.wikia.nocookie.net/essentialsdocs/images/7/70/Battle.png/revision/latest?cb=20220523172438"
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": [
{
"type": "text",
"text": "What action do you think I should take in this situation? List all the possible actions and explain why you think they are good or bad.",
},
{"type": "image_url", "image_url": {"url": image_url}},
],
},
]
tokenized = tokenizer.encode_chat_completion(ChatCompletionRequest(messages=messages))
input_ids = torch.tensor([tokenized.tokens])
attention_mask = torch.ones_like(input_ids)
pixel_values = torch.tensor(tokenized.images[0], dtype=torch.bfloat16).unsqueeze(0)
image_sizes = torch.tensor([pixel_values.shape[-2:]])
output = model.generate(
input_ids=input_ids,
attention_mask=attention_mask,
pixel_values=pixel_values,
image_sizes=image_sizes,
max_new_tokens=1000,
)[0]
decoded_output = tokenizer.decode(output[len(tokenized.tokens) :])
print(decoded_output)
# In this situation, you are playing a Pokémon game where your Pikachu (Level 42) is facing a wild Pidgey (Level 17). Here are the possible actions you can take and an analysis of each:
# 1. **FIGHT**:
# - **Pros**: Pikachu is significantly higher level than the wild Pidgey, which suggests that it should be able to defeat Pidgey easily. This could be a good opportunity to gain experience points and possibly items or money.
# - **Cons**: There is always a small risk of Pikachu fainting, especially if Pidgey has a powerful move or a status effect that could hinder Pikachu. However, given the large level difference, this risk is minimal.
# 2. **BAG**:
# - **Pros**: You might have items in your bag that could help in this battle, such as Potions, Poké Balls, or Berries. Using an item could help you capture Pidgey or heal Pikachu if needed.
# - **Cons**: Using items might not be necessary given the level difference. It could be more efficient to just fight and defeat Pidgey quickly.
# 3. **POKÉMON**:
# - **Pros**: You might have another Pokémon in your party that is better suited for this battle or that you want to gain experience. Switching Pokémon could also be strategic if you want to train a lower-level Pokémon.
# - **Cons**: Switching Pokémon might not be necessary since Pikachu is at a significant advantage. It could also waste time and potentially give Pidgey a turn to attack.
# 4. **RUN**:
# - **Pros**: Running away could be a quick way to avoid the battle altogether. This might be useful if you are trying to conserve resources or if you are in a hurry to get to another location.
# - **Cons**: Running away means you miss out on the experience points, items, or money that you could gain from defeating Pidgey. It also might not be the most efficient use of your time if you are trying to train your Pokémon.
# ### Recommendation:
# Given the significant level advantage, the best action to take is likely **FIGHT**. This will allow you to quickly defeat Pidgey and gain experience points for Pikachu. If you are concerned about Pikachu's health, you could use the **BAG** to heal Pikachu before or during the battle. Running away or switching Pokémon does not seem necessary in this situation.
```
</details>
|
jeffxtang/llama31-8b-text-to-sql-epochs-25
|
jeffxtang
| 2025-06-21T14:15:19Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:meta-llama/Llama-3.1-8B-Instruct",
"base_model:finetune:meta-llama/Llama-3.1-8B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-06-21T02:14:29Z |
---
base_model: meta-llama/Llama-3.1-8B-Instruct
library_name: transformers
model_name: llama31-8b-text-to-sql-epochs-25
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for llama31-8b-text-to-sql-epochs-25
This model is a fine-tuned version of [meta-llama/Llama-3.1-8B-Instruct](https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="jeffxtang/llama31-8b-text-to-sql-epochs-25", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.12.1
- Transformers: 4.46.3
- Pytorch: 2.4.1
- Datasets: 3.1.0
- Tokenizers: 0.20.3
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
jamiltonquintero/raft-mistral-7b-instruct-lora
|
jamiltonquintero
| 2025-06-21T14:14:34Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-21T14:14:01Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
shenxiaochen/nanoVLM
|
shenxiaochen
| 2025-06-21T14:07:08Z | 0 | 0 |
nanovlm
|
[
"nanovlm",
"safetensors",
"vision-language",
"multimodal",
"research",
"image-text-to-text",
"license:mit",
"region:us"
] |
image-text-to-text
| 2025-06-21T14:06:25Z |
---
# For reference on model card metadata, see the spec: https://github.com/huggingface/hub-docs/blob/main/modelcard.md?plain=1
# Doc / guide: https://huggingface.co/docs/hub/model-cards
library_name: nanovlm
license: mit
pipeline_tag: image-text-to-text
tags:
- vision-language
- multimodal
- research
---
**nanoVLM** is a minimal and lightweight Vision-Language Model (VLM) designed for efficient training and experimentation. Built using pure PyTorch, the entire model architecture and training logic fits within ~750 lines of code. It combines a ViT-based image encoder (SigLIP-B/16-224-85M) with a lightweight causal language model (SmolLM2-135M), resulting in a compact 222M parameter model.
For more information, check out the base model on https://huggingface.co/lusxvr/nanoVLM-222M.
**Usage:**
Clone the nanoVLM repository: https://github.com/huggingface/nanoVLM.
Follow the install instructions and run the following code:
```python
from models.vision_language_model import VisionLanguageModel
model = VisionLanguageModel.from_pretrained("shenxiaochen/nanoVLM")
```
|
Elu-dan/afro-xlmr-base-finetuned-amharic-ner
|
Elu-dan
| 2025-06-21T14:05:51Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"dataset:masakhaner",
"base_model:Davlan/afro-xlmr-base",
"base_model:finetune:Davlan/afro-xlmr-base",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2025-06-21T13:49:45Z |
---
library_name: transformers
license: mit
base_model: Davlan/afro-xlmr-base
tags:
- generated_from_trainer
datasets:
- masakhaner
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: afro-xlmr-base-finetuned-amharic-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: masakhaner
type: masakhaner
config: amh
split: validation
args: amh
metrics:
- name: Precision
type: precision
value: 0.6416275430359938
- name: Recall
type: recall
value: 0.7347670250896058
- name: F1
type: f1
value: 0.6850459482038429
- name: Accuracy
type: accuracy
value: 0.9481296149386709
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# afro-xlmr-base-finetuned-amharic-ner
This model is a fine-tuned version of [Davlan/afro-xlmr-base](https://huggingface.co/Davlan/afro-xlmr-base) on the masakhaner dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1806
- Precision: 0.6416
- Recall: 0.7348
- F1: 0.6850
- Accuracy: 0.9481
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 219 | 0.2083 | 0.5496 | 0.6585 | 0.5992 | 0.9351 |
| No log | 2.0 | 438 | 0.1548 | 0.6310 | 0.7195 | 0.6724 | 0.9526 |
| 0.2964 | 3.0 | 657 | 0.1572 | 0.6532 | 0.7409 | 0.6943 | 0.9551 |
### Framework versions
- Transformers 4.52.4
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
Elcaida/mistral7BinstructForest
|
Elcaida
| 2025-06-21T14:03:30Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"en",
"base_model:unsloth/mistral-7b-instruct-v0.3-bnb-4bit",
"base_model:finetune:unsloth/mistral-7b-instruct-v0.3-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-21T14:03:25Z |
---
base_model: unsloth/mistral-7b-instruct-v0.3-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** Elcaida
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b-instruct-v0.3-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Mungert/Llama-xLAM-2-8b-fc-r-GGUF
|
Mungert
| 2025-06-21T13:56:33Z | 4 | 0 |
transformers
|
[
"transformers",
"gguf",
"function-calling",
"LLM Agent",
"tool-use",
"llama",
"qwen",
"pytorch",
"LLaMA-factory",
"text-generation",
"en",
"dataset:Salesforce/APIGen-MT-5k",
"dataset:Salesforce/xlam-function-calling-60k",
"arxiv:2504.03601",
"arxiv:2503.22673",
"arxiv:2409.03215",
"arxiv:2402.15506",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] |
text-generation
| 2025-06-21T07:38:01Z |
---
license: cc-by-nc-4.0
datasets:
- Salesforce/APIGen-MT-5k
- Salesforce/xlam-function-calling-60k
language:
- en
pipeline_tag: text-generation
tags:
- function-calling
- LLM Agent
- tool-use
- llama
- qwen
- pytorch
- LLaMA-factory
library_name: transformers
---
# <span style="color: #7FFF7F;">Llama-xLAM-2-8b-fc-r GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`6adc3c3e`](https://github.com/ggerganov/llama.cpp/commit/6adc3c3ebc029af058ac950a8e2a825fdf18ecc6).
---
## <span style="color: #7FFF7F;">Quantization Beyond the IMatrix</span>
I've been experimenting with a new quantization approach that selectively elevates the precision of key layers beyond what the default IMatrix configuration provides.
In my testing, standard IMatrix quantization underperforms at lower bit depths, especially with Mixture of Experts (MoE) models. To address this, I'm using the `--tensor-type` option in `llama.cpp` to manually "bump" important layers to higher precision. You can see the implementation here:
👉 [Layer bumping with llama.cpp](https://github.com/Mungert69/GGUFModelBuilder/blob/main/model-converter/tensor_list_builder.py)
While this does increase model file size, it significantly improves precision for a given quantization level.
### **I'd love your feedback—have you tried this? How does it perform for you?**
---
<a href="https://readyforquantum.com/huggingface_gguf_selection_guide.html" style="color: #7FFF7F;">
Click here to get info on choosing the right GGUF model format
</a>
---
<!--Begin Original Model Card-->
<p align="center">
<img width="500px" alt="xLAM" src="https://huggingface.co/datasets/jianguozhang/logos/resolve/main/xlam-no-background.png">
</p>
<p align="center">
<a href="https://arxiv.org/abs/2504.03601">[Paper]</a> |
<a href="https://apigen-mt.github.io/">[Homepage]</a> |
<a href="https://huggingface.co/datasets/Salesforce/APIGen-MT-5k">[Dataset]</a> |
<a href="https://github.com/SalesforceAIResearch/xLAM">[Github]</a>
</p>
<hr>
# Welcome to the xLAM-2 Model Family!
[Large Action Models (LAMs)](https://blog.salesforceairesearch.com/large-action-models/) are advanced language models designed to enhance decision-making by translating user intentions into executable actions. As the **brains of AI agents**, LAMs autonomously plan and execute tasks to achieve specific goals, making them invaluable for automating workflows across diverse domains.
**This model release is for research purposes only.**
The new **xLAM-2** series, built on our most advanced data synthesis, processing, and training pipelines, marks a significant leap in **multi-turn conversation** and **tool usage**. Trained using our novel APIGen-MT framework, which generates high-quality training data through simulated agent-human interactions. Our models achieve state-of-the-art performance on [**BFCL**](https://gorilla.cs.berkeley.edu/leaderboard.html) and **τ-bench** benchmarks, outperforming frontier models like GPT-4o and Claude 3.5. Notably, even our smaller models demonstrate superior capabilities in multi-turn scenarios while maintaining exceptional consistency across trials.
We've also refined the **chat template** and **vLLM integration**, making it easier to build advanced AI agents. Compared to previous xLAM models, xLAM-2 offers superior performance and seamless deployment across applications.
<p align="center">
<img width="100%" alt="Model Performance Overview" src="https://github.com/apigen-mt/apigen-mt.github.io/blob/main/img/model_board.png?raw=true">
<br>
<small><i>Comparative performance of larger xLAM-2-fc-r models (8B-70B, trained with APIGen-MT data) against state-of-the-art baselines on function-calling (BFCL v3, as of date 04/02/2025) and agentic (τ-bench) capabilities.</i></small>
</p>
## Table of Contents
- [Usage](#usage)
- [Basic Usage with Huggingface Chat Template](#basic-usage-with-huggingface-chat-template)
- [Using vLLM for Inference](#using-vllm-for-inference)
- [Setup and Serving](#setup-and-serving)
- [Testing with OpenAI API](#testing-with-openai-api)
- [Benchmark Results](#benchmark-results)
- [Citation](#citation)
---
## Model Series
[xLAM](https://huggingface.co/collections/Salesforce/xlam-models-65f00e2a0a63bbcd1c2dade4) series are significant better at many things including general tasks and function calling.
For the same number of parameters, the model have been fine-tuned across a wide range of agent tasks and scenarios, all while preserving the capabilities of the original model.
| Model | # Total Params | Context Length | Category | Download Model | Download GGUF files |
|------------------------|----------------|------------|-------|----------------|----------|
| Llama-xLAM-2-70b-fc-r | 70B | 128k | Multi-turn Conversation, Function-calling | [🤗 Link](https://huggingface.co/Salesforce/Llama-xLAM-2-70b-fc-r) | NA |
| Llama-xLAM-2-8b-fc-r | 8B | 128k | Multi-turn Conversation, Function-calling | [🤗 Link](https://huggingface.co/Salesforce/Llama-xLAM-2-8b-fc-r) | [🤗 Link](https://huggingface.co/Salesforce/Llama-xLAM-2-8b-fc-r-gguf) |
| xLAM-2-32b-fc-r | 32B | 32k (max 128k)* | Multi-turn Conversation, Function-calling | [🤗 Link](https://huggingface.co/Salesforce/xLAM-2-32b-fc-r) | NA |
| xLAM-2-3b-fc-r | 3B | 32k (max 128k)* | Multi-turn Conversation, Function-calling | [🤗 Link](https://huggingface.co/Salesforce/xLAM-2-3b-fc-r) | [🤗 Link](https://huggingface.co/Salesforce/xLAM-2-3b-fc-r-gguf) |
| xLAM-2-1b-fc-r | 1B | 32k (max 128k)* | Multi-turn Conversation, Function-calling | [🤗 Link](https://huggingface.co/Salesforce/xLAM-2-1b-fc-r) | [🤗 Link](https://huggingface.co/Salesforce/xLAM-2-1b-fc-r-gguf) |
***Note:** The default context length for Qwen-2.5-based models is 32k, but you can use techniques like YaRN (Yet Another Recursive Network) to achieve maximum 128k context length. Please refer to [here](https://huggingface.co/Qwen/Qwen2.5-32B-Instruct#processing-long-texts) for more details.
You can also explore our previous xLAM series [here](https://huggingface.co/collections/Salesforce/xlam-models-65f00e2a0a63bbcd1c2dade4).
The `-fc` suffix indicates that the models are fine-tuned for **function calling** tasks, while the `-r` suffix signifies a **research** release.
✅ All models are fully compatible with vLLM and Transformers-based inference frameworks.
## Usage
### Framework versions
- Transformers 4.46.1 (or later)
- PyTorch 2.5.1+cu124 (or later)
- Datasets 3.1.0 (or later)
- Tokenizers 0.20.3 (or later)
### Basic Usage with Huggingface Chat Template
The new xLAM models are designed to work seamlessly with the Hugging Face Transformers library and utilize natural chat templates for an easy and intuitive conversational experience. Below are examples of how to use these models.
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Salesforce/Llama-xLAM-2-3b-fc-r")
model = AutoModelForCausalLM.from_pretrained("Salesforce/Llama-xLAM-2-3b-fc-r", torch_dtype=torch.bfloat16, device_map="auto")
# Example conversation with a tool call
messages = [
{"role": "user", "content": "Hi, how are you?"},
{"role": "assistant", "content": "Thanks. I am doing well. How can I help you?"},
{"role": "user", "content": "What's the weather like in London?"},
]
tools = [
{
"name": "get_weather",
"description": "Get the current weather for a location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "The city and state, e.g. San Francisco, CA"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"], "description": "The unit of temperature to return"}
},
"required": ["location"]
}
}
]
print("====== prompt after applying chat template ======")
print(tokenizer.apply_chat_template(messages, tools=tools, add_generation_prompt=True, tokenize=False))
inputs = tokenizer.apply_chat_template(messages, tools=tools, add_generation_prompt=True, return_dict=True, return_tensors="pt")
input_ids_len = inputs["input_ids"].shape[-1] # Get the length of the input tokens
inputs = {k: v.to(model.device) for k, v in inputs.items()}
print("====== model response ======")
outputs = model.generate(**inputs, max_new_tokens=256)
generated_tokens = outputs[:, input_ids_len:] # Slice the output to get only the newly generated tokens
print(tokenizer.decode(generated_tokens[0], skip_special_tokens=True))
```
### Using vLLM for Inference
The xLAM models can also be efficiently served using vLLM for high-throughput inference. Please use `vllm>=0.6.5` since earlier versions will cause degraded performance for Qwen-based models.
#### Setup and Serving
1. Install vLLM with the required version:
```bash
pip install "vllm>=0.6.5"
```
2. Download the tool parser plugin to your local path:
```bash
wget https://huggingface.co/Salesforce/xLAM-2-1b-fc-r/raw/main/xlam_tool_call_parser.py
```
3. Start the OpenAI API-compatible endpoint:
```bash
vllm serve Salesforce/xLAM-2-1b-fc-r \
--enable-auto-tool-choice \
--tool-parser-plugin ./xlam_tool_call_parser.py \
--tool-call-parser xlam \
--tensor-parallel-size 1
```
Note: Ensure that the tool parser plugin file is downloaded and that the path specified in `--tool-parser-plugin` correctly points to your local copy of the file. The xLAM series models all utilize the **same** tool call parser, so you only need to download it **once** for all models.
#### Testing with OpenAI API
Here's a minimal example to test tool usage with the served endpoint:
```python
import openai
import json
# Configure the client to use your local vLLM endpoint
client = openai.OpenAI(
base_url="http://localhost:8000/v1", # Default vLLM server URL
api_key="empty" # Can be any string
)
# Define a tool/function
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get the current weather for a location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "The unit of temperature to return"
}
},
"required": ["location"]
}
}
}
]
# Create a chat completion
response = client.chat.completions.create(
model="Salesforce/xLAM-2-1b-fc-r", # Model name doesn't matter, vLLM uses the served model
messages=[
{"role": "system", "content": "You are a helpful assistant that can use tools."},
{"role": "user", "content": "What's the weather like in San Francisco?"}
],
tools=tools,
tool_choice="auto"
)
# Print the response
print("Assistant's response:")
print(json.dumps(response.model_dump(), indent=2))
```
For more advanced configurations and deployment options, please refer to the [vLLM documentation](https://docs.vllm.ai/en/latest/serving/openai_compatible_server.html).
## Benchmark Results
### Berkeley Function-Calling Leaderboard (BFCL v3)
<p align="center">
<img width="80%" alt="BFCL Results" src="https://github.com/apigen-mt/apigen-mt.github.io/blob/main/img/bfcl-result.png?raw=true">
<br>
<small><i>Performance comparison of different models on [BFCL leaderboard](https://gorilla.cs.berkeley.edu/leaderboard.html). The rank is based on the overall accuracy, which is a weighted average of different evaluation categories. "FC" stands for function-calling mode in contrast to using a customized "prompt" to extract the function calls.</i></small>
</p>
### τ-bench Benchmark
<p align="center">
<img width="80%" alt="Tau-bench Results" src="https://github.com/apigen-mt/apigen-mt.github.io/blob/main/img/taubench-result.png?raw=true">
<br>
<small><i>Success Rate (pass@1) on τ-bench benchmark averaged across at least 5 trials. Our xLAM-2-70b-fc-r model achieves an overall success rate of 56.2% on τ-bench, significantly outperforming the base Llama 3.1 70B Instruct model (38.2%) and other open-source models like DeepSeek v3 (40.6%). Notably, our best model even outperforms proprietary models such as GPT-4o (52.9%) and approaches the performance of more recent models like Claude 3.5 Sonnet (new) (60.1%).</i></small>
</p>
<p align="center">
<img width="80%" alt="Pass^k curves" src="https://github.com/apigen-mt/apigen-mt.github.io/blob/main/img/pass_k_curves_retail_airline.png?raw=true">
<br>
<small><i>Pass^k curves measuring the probability that all 5 independent trials succeed for a given task, averaged across all tasks for τ-retail (left) and τ-airline (right) domains. Higher values indicate better consistency of the models.</i></small>
</p>
## Ethical Considerations
This release is for research purposes only in support of an academic paper. Our models, datasets, and code are not specifically designed or evaluated for all downstream purposes. We strongly recommend users evaluate and address potential concerns related to accuracy, safety, and fairness before deploying this model. We encourage users to consider the common limitations of AI, comply with applicable laws, and leverage best practices when selecting use cases, particularly for high-risk scenarios where errors or misuse could significantly impact people's lives, rights, or safety. For further guidance on use cases, refer to our AUP and AI AUP.
### Model Licenses
For all Llama relevant models, please also follow corresponding Llama license and terms. Meta Llama 3 is licensed under the Meta Llama 3 Community License, Copyright © Meta Platforms, Inc. All Rights Reserved.
## Citation
If you use our model or dataset in your work, please cite our paper:
```bibtex
@article{prabhakar2025apigen,
title={APIGen-MT: Agentic PIpeline for Multi-Turn Data Generation via Simulated Agent-Human Interplay},
author={Prabhakar, Akshara and Liu, Zuxin and Zhu, Ming and Zhang, Jianguo and Awalgaonkar, Tulika and Wang, Shiyu and Liu, Zhiwei and Chen, Haolin and Hoang, Thai and others},
journal={arXiv preprint arXiv:2504.03601},
year={2025}
}
```
Additionally, please check our other awesome related works regarding xLAM series and consider citing them as well:
```bibtex
@article{zhang2025actionstudio,
title={ActionStudio: A Lightweight Framework for Data and Training of Action Models},
author={Zhang, Jianguo and Hoang, Thai and Zhu, Ming and Liu, Zuxin and Wang, Shiyu and Awalgaonkar, Tulika and Prabhakar, Akshara and Chen, Haolin and Yao, Weiran and Liu, Zhiwei and others},
journal={arXiv preprint arXiv:2503.22673},
year={2025}
}
```
```bibtex
@article{zhang2024xlam,
title={xLAM: A Family of Large Action Models to Empower AI Agent Systems},
author={Zhang, Jianguo and Lan, Tian and Zhu, Ming and Liu, Zuxin and Hoang, Thai and Kokane, Shirley and Yao, Weiran and Tan, Juntao and Prabhakar, Akshara and Chen, Haolin and others},
journal={arXiv preprint arXiv:2409.03215},
year={2024}
}
```
```bibtex
@article{liu2024apigen,
title={Apigen: Automated pipeline for generating verifiable and diverse function-calling datasets},
author={Liu, Zuxin and Hoang, Thai and Zhang, Jianguo and Zhu, Ming and Lan, Tian and Tan, Juntao and Yao, Weiran and Liu, Zhiwei and Feng, Yihao and RN, Rithesh and others},
journal={Advances in Neural Information Processing Systems},
volume={37},
pages={54463--54482},
year={2024}
}
```
```bibtex
@article{zhang2024agentohana,
title={AgentOhana: Design Unified Data and Training Pipeline for Effective Agent Learning},
author={Zhang, Jianguo and Lan, Tian and Murthy, Rithesh and Liu, Zhiwei and Yao, Weiran and Tan, Juntao and Hoang, Thai and Yang, Liangwei and Feng, Yihao and Liu, Zuxin and others},
journal={arXiv preprint arXiv:2402.15506},
year={2024}
}
```
<!--End Original Model Card-->
---
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Help me test my **AI-Powered Quantum Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
The full Open Source Code for the Quantum Network Monitor Service available at my github repos ( repos with NetworkMonitor in the name) : [Source Code Quantum Network Monitor](https://github.com/Mungert69). You will also find the code I use to quantize the models if you want to do it yourself [GGUFModelBuilder](https://github.com/Mungert69/GGUFModelBuilder)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4.1-mini)
- `HugLLM` (Hugginface Open-source models)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap security scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads on huggingface docker space):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**) . No token limited as the cost is low.
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4.1-mini** :
- **It performs very well but unfortunatly OpenAI charges per token. For this reason tokens usage is limited.
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API. Performs pretty well using the lastest models hosted on Novita.
### 💡 **Example commands you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a [Quantum Network Monitor Agent](https://readyforquantum.com/Download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme) to run the .net code on. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
|
John6666/rnm-gamma-00-sdxl
|
John6666
| 2025-06-21T13:55:16Z | 0 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"stable-diffusion-xl",
"anime",
"girls",
"v-pred",
"merge",
"illumiyume",
"rouwei",
"Illustrious XL v1.0",
"illustrious",
"en",
"base_model:Minthy/RouWei-0.8",
"base_model:merge:Minthy/RouWei-0.8",
"base_model:OnomaAIResearch/Illustrious-XL-v1.0",
"base_model:merge:OnomaAIResearch/Illustrious-XL-v1.0",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] |
text-to-image
| 2025-06-21T13:28:03Z |
---
license: other
license_name: faipl-1.0-sd
license_link: https://freedevproject.org/faipl-1.0-sd/
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- text-to-image
- stable-diffusion
- stable-diffusion-xl
- anime
- girls
- v-pred
- merge
- illumiyume
- rouwei
- Illustrious XL v1.0
- illustrious
base_model:
- OnomaAIResearch/Illustrious-XL-v1.0
- Minthy/RouWei-0.8
---
Original model is [here](https://civitai.com/models/1701739/rnm-g?modelVersionId=1925893).
This model created by [wtre59](https://civitai.com/user/wtre59).
|
dieu005/dieu05
|
dieu005
| 2025-06-21T13:51:18Z | 0 | 0 | null |
[
"license:bigcode-openrail-m",
"region:us"
] | null | 2025-06-21T13:51:18Z |
---
license: bigcode-openrail-m
---
|
pictgensupport/30somethingman
|
pictgensupport
| 2025-06-21T13:41:38Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-06-21T13:41:35Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: 30somethingman
---
# 30Somethingman
<Gallery />
Trained on Replicate using:
https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `30somethingman` to trigger the image generation.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('pictgensupport/30somethingman', weight_name='lora.safetensors')
image = pipeline('your prompt').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
RinaldiDev/flan_paradetox_full
|
RinaldiDev
| 2025-06-21T13:37:41Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"t5",
"text2text-generation",
"flan-t5",
"detoxification",
"polite-rewriting",
"text-to-text",
"arxiv:1910.09700",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2025-06-21T11:31:19Z |
---
license: cc-by-sa-4.0
library_name: transformers
tags:
- flan-t5
- detoxification
- polite-rewriting
- text-to-text
model_name: flan-paradetox-full
---
# FLAN-T5-Large **Polite-Rewrite** (full fine-tune)
**Model:** `google/flan-t5-large` fine-tuned for toxic → polite rewriting.
## Training details
| Parameter | Value |
|-----------|-------|
| epochs | 3 |
| effective batch | 32 (16 × grad_acc=2, fp16) |
| lr / schedule | 3 e-5, cosine, 3 % warm-up |
| total steps | 1 800 |
| optimizer | AdamW, weight_decay=0.01 |
| hardware | 1 × A100-40 GB |
### Data
Merged **29 k** parallel pairs
* ParaDetox (19 k)
* Polite Insult (1.6 k, oversample×2)
* PseudoParaDetox Llama-3 (8.6 k, tox≤0.3, cosine≥0.8)
### Metrics (dev 3 %)
| metric | score |
|--------|-------|
| BLEU | 0.82 |
| Avg toxicity (Detoxify) | **0.12** (src 0.71 → tgt 0.12) |
| Success rate (tox≤0.5 AND -20 %) | 89 % |
## Usage
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tok = AutoTokenizer.from_pretrained("RinaldiDev/flan-paradetox-full")
model = AutoModelForSeq2SeqLM.from_pretrained("RinaldiDev/flan-paradetox-full")
def rewrite_polite(text):
inp = f"Rewrite politely:\\nInput: {text}\\nPolite:"
ids = tok(inp, return_tensors="pt").input_ids
out = model.generate(ids, num_beams=4, max_length=96)
return tok.decode(out[0], skip_special_tokens=True)
print(rewrite_polite("Shut up, idiot!"))
# → "Stop talking"
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
AI moderation helper
Toxic-to-polite assistants
Not for hallucination-free tasks; may still miss subtle hate speech.
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
Trained largely on English; fails on code-switching.
Llama-generated pairs could contain artifacts.
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ZubairMartin19/Markerless_motion_capture_to_explore_changes_in_tackle_kinematics
|
ZubairMartin19
| 2025-06-21T13:35:21Z | 0 | 0 |
deeplabcut
|
[
"deeplabcut",
"tensorboard",
"pose-estimation",
"sports-analysis",
"biomechanics",
"rugby",
"3d-reconstruction",
"motion-analysis",
"kinematics",
"en",
"license:mit",
"region:us"
] | null | 2025-06-17T16:33:53Z |
---
license: mit
license_name: mit
license_link: https://opensource.org/licenses/MIT
language:
- en
pipeline_tag: pose-estimation
tags:
- deeplabcut
- pose-estimation
- sports-analysis
- biomechanics
- rugby
- 3d-reconstruction
- motion-analysis
- kinematics
library_name: deeplabcut
metrics:
- rmse
- reprojection-error
---
# Using markerless motion capture to explore changes in tackle kinematics and load based tackling technique proficiency
## Authors
University of Cape Town (UCT): African Robotic Unit (ARU) and Sport Science and Medicine.
Lara Paul: [email protected]
Sharief Hendricks: [email protected]
Amir Patel: [email protected]
Zubair Martin: [email protected]
NOTE: training and test video data can be requested using the above email addresses.
## Model Name
**rugby-tackle-dlc**
## Model Description
This DeepLabCut-based model performs markerless pose estimation on rugby tackling scenarios recorded from multiple synchronized cameras. The goal is to automate kinematic analysis such as velocity, acceleration, and impact force during controlled tackles. The model supports full 3D reconstruction and biomechanical analysis of both the athlete and the tackle bag.
## Model Architecture
- **Framework**: DeepLabCut (TensorFlow backend)
- **Backbone**: ResNet-101
- **Training Frames**: 1162 manually labeled frames
- **Keypoints Tracked**:
- Rugby player: ankles, knees, hips, shoulders, wrists, elbows, chin, forehead
- Punching bag: top, upper quartile, middle, lower quartile, bottom
- **Training/Testing Split**: 95% train / 5% test
- **Likelihood Threshold**: 0.5
## Training Dataset
- **Source**: Controlled rugby tackle drills at UCT Mechatronics Lab
- **Capture Setup**: 3 synchronized GoPro cameras (1920×1080), checkerboard calibration
- **Annotations**: Manual tagging of player and bag points at key frames
- **Calibration**: OpenCV intrinsics + pairwise extrinsics with sparse bundle adjustment
## Evaluation Metrics
- **RMSE**: Computed between manual and model-predicted keypoints
- **Reprojection Error**: Used during camera calibration to ensure 3D reconstruction fidelity
## Folder Structure
- **Calibration**: Has all calibration data (used in experiments)
- **Model Setup**: Has configuration files for dlc setup
- **dlc models**: Has the latest trained models.
- **python-3d-toolbox**: has all relavent code to run evaluation.
- **python-video-utils**: has code to edit video files (created by Liam Clark).
-
## Methodology for Training Data
The dlc models adopts the TensorFlow engine, with training iterations highlighting model data from trained and tested using a YAML file [1]. Training data set (which trains the network) and a test data set(to evaluate the network) in order to produce a model. Random frames were selected and labelled
(indicating the position of certain body parts).
The first step of developing the model was the selection of labelled data. The labelled data was obtained by selecting frames of existing tackle footage (rugby player tackling a moving/appraoching punching bag), therafter taging varuous points:
* for the rugby subject:ankles, knees, hip sides, wrists, elbows, shoulders, chin, and forehead
* for the punching bag: top, upper quartile, middle, lower quartile, and bottom.
Around 1,162 frames were labelled for the training data set. These frames were selected to capture the complete breadth of the tackle behavior for numerous rugby players to capture the diversity of the behavior with respect to postures. Specifically, the selected frames focused on extracting frames from a period of the video that contains interesting behaviors which include the rugby player to punching bag contact, and rugbyplayer-puniching bag to ground contact.

Figure 1: Labelled data (tagging image)
The labelled images were used to train and test the model. The training data was used to train the network, while the test data set was used for evaluating the network. Given the availability of sufficient computational resources, training time, and the requirement for complex features, the Resnet 101 neural network model was used. Futherore, the training fraction (test to train data) was set to 95% training and 5% testing with default/no augementation settings. The reason for this is that there were many images available and due to the model complexity.
To evaluate the model, the average root mean square error (RMSE) was calculated between the manual labels and the ones predicted by DeepLabCut, with the likelihood of confident predictions set to 0.5. This was done by placing a random video and viewing whether the network would label the points correctly.

Figure 2: Deeplabcut pose estimation result.
## How to Use - Setup Camera Calibration
In order to adopt real world video data into analysing the data using Deeplabcut, calibration methods were crucial. Camera calibration involves the estimation of the camera parameters with the goal of rectifying lens distortion, identification of the camera location, and determine the size of an object in world units. The camera parameters include intrinsics, extrinsics, and distortion coefficients [2]. To determine these, both 3D world points and their corresponding 2D image points were required. This study adopted a calibration approach developed by L.Clark, which uses OpenCV and drew inspiration from DeepLabCut’s website on camera calibration techniques [3] , [4].
In order to calibrate the cameras per set/session, videos of the experimenter were recorded moving a calibration checkerboard in front of the cameras using three GoPros positioned equally along the experimental platform. Intrinsic calibration parameters consist of the focal length pixels, optical center pixels, and skew coefficient. To obtain this, a calibration checkerboard was used. To determine this, using the camera resolution of the cameras (1920 × 1080), camera model (standard), and the calibration board parameters.
The extrinsic parameters involve rotation and translation between cameras, with the coordinate system’s origin being at the optical center with the x and y being the image plane. In order to calibrate the extrinsic parameters , each consecutive pair of cameras (i.e. 1-2 and 2-3) was setup such that the calibration board was viewed at the same time for several frames. For the calibration algorithm, 30 frames were selected from each camera across the entire platform. An algirthm was generated to find the frames in the videos which contain the calibration board, locating the corner points. This was done by specifying the calibration board shape and the length of the square edges: 8x6 and a square edge length of 40mm. To determine the extrinsic calibration parameters, the camera properties (resolution and model), calibration board parameters, along with an initial pairwise RMS reprojection error approach was adopted to track data capture validility. Thereafter, the focus was on creating initial 3D estimates for optimisation with estimating pairwise points between cameras. This allowed the performance of sparse bundle adjustment.
Figure 3: Camera calibration result.
## How to Use - Tackle Evaluation
This section will describe the steps on how to evaulate the data (using the provided code):
1. Open the file: combine134.py, and fill in the following information:
directory = '/home/...' # Directory of folder to place evaluated data files
folder = '/home/...'# Directory of folder with all the data (videos of tackle to evaluate)
project_dir = '/home/...' # Directory of camera calibration data
actual_to_truncate_frame = [x,x] # Actual frames at which the tackle starts and ends (bag touch ground), respectively
mass = x # mass of tackler
temp = 'Tackle6_session12_set2' # Name of tackle number, session, and set
spreadsheetname = 'spreadsheet_'+temp #spreadsheet name to store all the evalated data
GP_used = GoPro pairs that were used [134], [13], [14], or [34]
Figure 4: Example layout of spreadsheet (input data).
2. Thereafter, run the combine134.py, this will do the following:
3. Step 1: Median_Filter_outliers.py (removes all outlier data - outside the bounds of a 500x500 box form pose estimation)
4. Step 2: reconstruction.py (3D triangulation reconstruction of the data using Liam Clark's cameratoolbox - linked above, using camera calibration data)
Figure 6: Resulting 3D constructed pose estimation (example).
5. Step 3: Select_Data.py (select and seperate data into a usable format, and points with likelihood threshold > 0.9)
6. Step 4: filter_data_average.py (applies median filter to data, to reduce noise/jitter)
7. Step 5: velocity.py (finds velocity and acceleration of evaluated positions/joints)
8. Step 6: worldtocam_frame.py (Rotate points from world frame to middle camera frame (GP3))
9. Step 7: cubic_spline_new_file_interpolated.py (Generate spline through data points, for smoothing of data)
10. Step 8: EndandStart.py (Estimates where the start end frame of tackle compared to the actual)
11. Step 9: SpreadSheet.py (Calculates: kinetic energy, impact force, power, momentum, relative position, updated acceleration, updated velocity, and distance travelled)
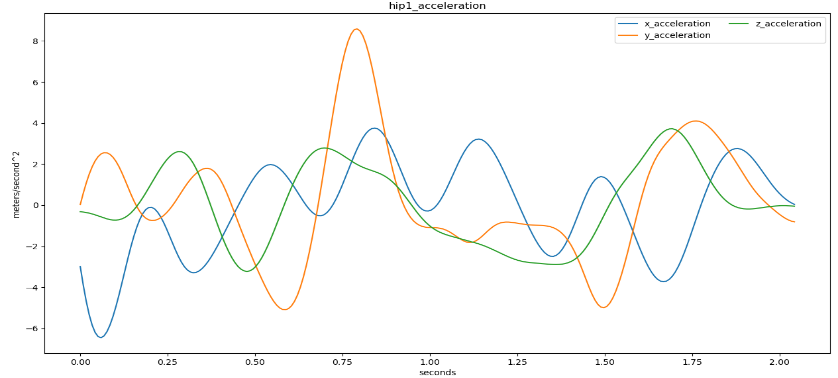
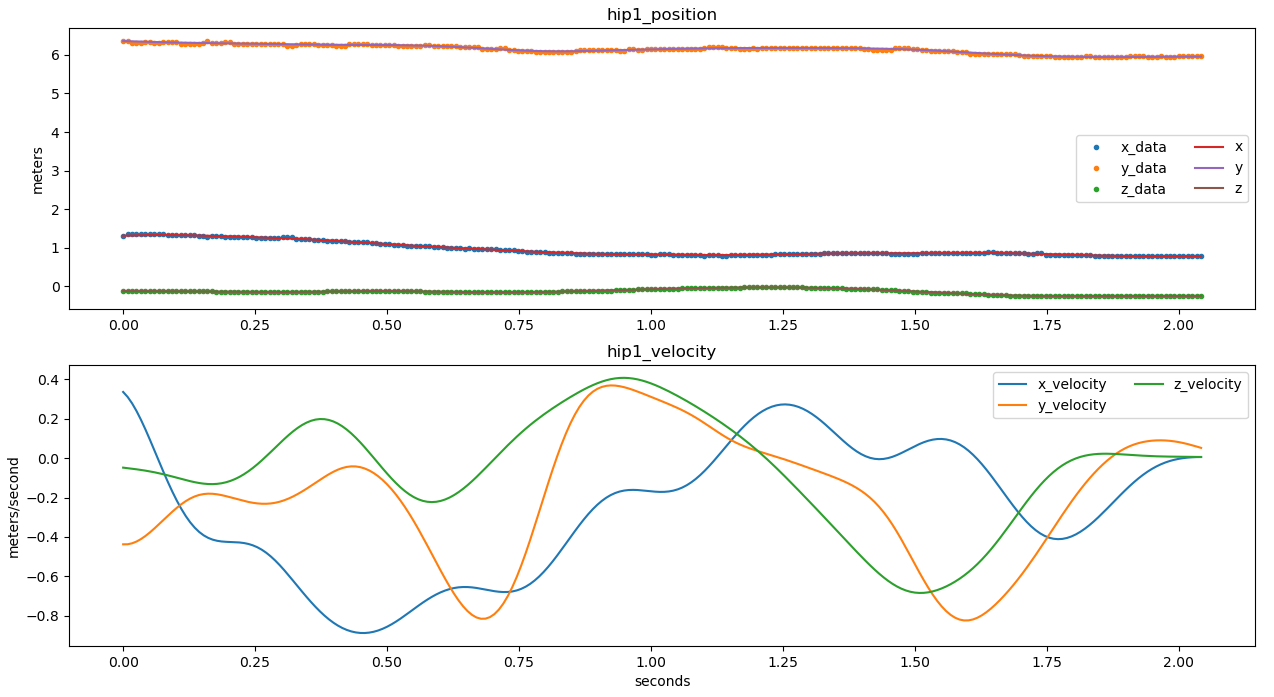
Figure 6: Resulting filtered and smoothed kinematic data.
These scripts must be executable as modules with a `main()` entry point, as used in combine134.py file.
[1] https://github.com/DeepLabCut/DeepLabCut/blob/main/docs/standardDeepLabCut_UserGuide.md
[2] https://www.mathworks.com/help/vision/ug/camera-calibration.html
[3] https://github.com/liamclarkza/python_3d_toolbox
[4] https://github.com/DeepLabCut/DeepLabCut/blob/main/docs/Overviewof3D.md
|
minhxle/truesight-ft-job-9978ff8a-0e56-41a5-8f11-cfe3262f5d10
|
minhxle
| 2025-06-21T13:33:08Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen2",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-21T13:33:04Z |
---
base_model: unsloth/qwen2.5-3b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** minhxle
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen2.5-3b-instruct-unsloth-bnb-4bit
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
anabel-angus-y-marco-antelo/FULL.18.VIDEO.DE.ANABEL.ANGUS.Y.MARCO.ANTELO
|
anabel-angus-y-marco-antelo
| 2025-06-21T13:32:40Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T13:32:26Z |
<a href="https://tinyurl.com/2frzafb9" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="WATCH Videos" data-canonical-src="https://i.imgur.com/dJHk4Zq.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
Yash1927/First-Small-Model
|
Yash1927
| 2025-06-21T13:32:28Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt2",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-21T13:30:53Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
stablediffusionapi/epicrealismxl-vxviicrystalclearrealism
|
stablediffusionapi
| 2025-06-21T13:24:35Z | 0 | 0 |
diffusers
|
[
"diffusers",
"modelslab.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] |
text-to-image
| 2025-06-21T13:14:05Z |
---
license: creativeml-openrail-m
tags:
- modelslab.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
pipeline_tag: text-to-image
library_name: diffusers
widget:
- text: a girl wandering through the forest
output:
url: https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/81d66190-9573-4739-86d4-b89f197da93b/width=1792/83458850.jpeg
---
# epiCRealism XL - VXVII - CrystalClear (Realism) API Inference
<Gallery />
## Get API Key
Get API key from [ModelsLab API](http://modelslab.com), No Payment needed.
Replace Key in below code, change **model_id** to "epicrealismxl-vxviicrystalclearrealism"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://docs.modelslab.com)
Try model for free: [Generate Images](https://modelslab.com/models/epicrealismxl-vxviicrystalclearrealism)
Model link: [View model](https://modelslab.com/models/epicrealismxl-vxviicrystalclearrealism)
View all models: [View Models](https://modelslab.com/models)
```python
import requests
import json
url = "https://modelslab.com/api/v6/images/text2img"
payload = json.dumps({
"key": "your_api_key",
"model_id": "epicrealismxl-vxviicrystalclearrealism",
"prompt": "ultra realistic close up portrait ((beautiful pale cyberpunk female with heavy black eyeliner)), blue eyes, shaved side haircut, hyper detail, cinematic lighting, magic neon, dark red city, Canon EOS R3, nikon, f/1.4, ISO 200, 1/160s, 8K, RAW, unedited, symmetrical balance, in-frame, 8K",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "",
"lora": "",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
```
> Use this coupon code to get 25% off **DMGG0RBN**
|
Ryuukiy/DeepSeek-R1-Psychiatrist-Lora-16bit
|
Ryuukiy
| 2025-06-21T13:21:46Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-21T13:17:42Z |
---
base_model: unsloth/deepseek-r1-distill-llama-8b-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** Ryuukiy
- **License:** apache-2.0
- **Finetuned from model :** unsloth/deepseek-r1-distill-llama-8b-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
kodaifukuda0311/BERT-bskypopularity-predictor
|
kodaifukuda0311
| 2025-06-21T13:21:19Z | 43,651 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-05-01T00:31:14Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
safe-llm-finetune/llama-3.2-1b-it-viggo-fullFT
|
safe-llm-finetune
| 2025-06-21T13:20:09Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"trl",
"sft",
"conversational",
"base_model:meta-llama/Llama-3.2-1B-Instruct",
"base_model:finetune:meta-llama/Llama-3.2-1B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-21T13:10:28Z |
---
base_model: meta-llama/Llama-3.2-1B-Instruct
library_name: transformers
model_name: llama-3.2-1b-it-viggo-fullFT
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for llama-3.2-1b-it-viggo-fullFT
This model is a fine-tuned version of [meta-llama/Llama-3.2-1B-Instruct](https://huggingface.co/meta-llama/Llama-3.2-1B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="safe-llm-finetune/llama-3.2-1b-it-viggo-fullFT", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/manon_k-saarland-informatics-campus/huggingface/runs/vadhc91d)
This model was trained with SFT.
### Framework versions
- TRL: 0.19.0
- Transformers: 4.52.4
- Pytorch: 2.7.0
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Full-Graciela-Varela-Video/Ver.Completo.Video.graciela.varela.video
|
Full-Graciela-Varela-Video
| 2025-06-21T13:14:08Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T13:13:54Z |
<a href="https://tinyurl.com/2frzafb9" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="WATCH Videos" data-canonical-src="https://i.imgur.com/dJHk4Zq.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
Ryuukiy/DeepSeek-R1-Psychiatrist-Lora
|
Ryuukiy
| 2025-06-21T13:11:28Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-21T13:11:24Z |
---
base_model: unsloth/deepseek-r1-distill-llama-8b-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** Ryuukiy
- **License:** apache-2.0
- **Finetuned from model :** unsloth/deepseek-r1-distill-llama-8b-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
wATCH-18-Jaipur-Couple-Hotel-Video/VIDEO.jaipur.hotel.viral.video.jaipur.couple.Link.viral.On.Social.Media
|
wATCH-18-Jaipur-Couple-Hotel-Video
| 2025-06-21T13:08:28Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T13:00:36Z |
[🌐 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🟢==►► 𝖶𝖠𝖳𝖢𝖧 𝖭𝖮𝖶 Video](https://tinyurl.com/isrealchudi?top.gun)
[🔴 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🌐==►► 𝖣𝗈𝗐𝗇𝗅𝗈𝖺𝖽 𝖭𝗈𝗐 Video](https://tinyurl.com/isrealchudi?top.gun)
<a href="https://tinyurl.com/isrealchudi?top.gun" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="WATCH Videos" data-canonical-src="https://i.imgur.com/dJHk4Zq.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
John6666/heatwave-v10-sdxl
|
John6666
| 2025-06-21T13:08:07Z | 0 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"stable-diffusion-xl",
"anime",
"cartoon",
"waifu",
"curvy",
"illustrious",
"en",
"base_model:OnomaAIResearch/Illustrious-xl-early-release-v0",
"base_model:finetune:OnomaAIResearch/Illustrious-xl-early-release-v0",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] |
text-to-image
| 2025-06-21T13:01:09Z |
---
license: other
license_name: faipl-1.0-sd
license_link: https://freedevproject.org/faipl-1.0-sd/
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- text-to-image
- stable-diffusion
- stable-diffusion-xl
- anime
- cartoon
- waifu
- curvy
- illustrious
base_model: OnomaAIResearch/Illustrious-xl-early-release-v0
---
Original model is [here](https://civitai.com/models/1701000/heatwave?modelVersionId=1925057).
This model created by [GhostBear1111](https://civitai.com/user/GhostBear1111).
|
Official-pakcricketinfo-viral-video-Link/FULL.VIDEO.pakcricketinfo.Viral.Video.Tutorial.Official
|
Official-pakcricketinfo-viral-video-Link
| 2025-06-21T13:07:43Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T13:06:52Z |
<animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
<animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
John6666/genie-pony-v7-electricloraland-sdxl
|
John6666
| 2025-06-21T13:01:07Z | 0 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"stable-diffusion-xl",
"realistic",
"photorealistic",
"pony",
"en",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] |
text-to-image
| 2025-06-21T12:53:54Z |
---
license: other
license_name: faipl-1.0-sd
license_link: https://freedevproject.org/faipl-1.0-sd/
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- text-to-image
- stable-diffusion
- stable-diffusion-xl
- realistic
- photorealistic
- pony
---
Original model is [here](https://civitai.com/models/1673405/geniepony?modelVersionId=1925892).
This model created by [Genie_AI](https://civitai.com/user/Genie_AI).
|
sergioalves/ae21c025-0861-469e-8cf6-663561d8141b
|
sergioalves
| 2025-06-21T12:59:20Z | 0 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"axolotl",
"dpo",
"trl",
"conversational",
"arxiv:2305.18290",
"base_model:unsloth/SmolLM2-1.7B",
"base_model:quantized:unsloth/SmolLM2-1.7B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-06-21T12:37:00Z |
---
base_model: unsloth/SmolLM2-1.7B
library_name: transformers
model_name: ae21c025-0861-469e-8cf6-663561d8141b
tags:
- generated_from_trainer
- axolotl
- dpo
- trl
licence: license
---
# Model Card for ae21c025-0861-469e-8cf6-663561d8141b
This model is a fine-tuned version of [unsloth/SmolLM2-1.7B](https://huggingface.co/unsloth/SmolLM2-1.7B).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="sergioalves/ae21c025-0861-469e-8cf6-663561d8141b", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/dedok-yo/s56-7/runs/to3lwc0q)
This model was trained with DPO, a method introduced in [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290).
### Framework versions
- TRL: 0.12.0.dev0
- Transformers: 4.46.0
- Pytorch: 2.5.0+cu124
- Datasets: 3.0.1
- Tokenizers: 0.20.1
## Citations
Cite DPO as:
```bibtex
@inproceedings{rafailov2023direct,
title = {{Direct Preference Optimization: Your Language Model is Secretly a Reward Model}},
author = {Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn},
year = 2023,
booktitle = {Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023},
url = {http://papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html},
editor = {Alice Oh and Tristan Naumann and Amir Globerson and Kate Saenko and Moritz Hardt and Sergey Levine},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Waqarkhance/TCNN
|
Waqarkhance
| 2025-06-21T12:57:43Z | 0 | 0 | null |
[
"time-series-forecasting",
"en",
"license:mit",
"region:us"
] |
time-series-forecasting
| 2025-06-21T12:54:55Z |
---
license: mit
language:
- en
metrics:
- accuracy
- recall
- precision
- roc_auc
pipeline_tag: time-series-forecasting
---
|
veddhanth/lora-trained-xl-stage-2-pretrained-enc-v2-spat-map-12-sneaker
|
veddhanth
| 2025-06-21T12:56:28Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"text-to-image",
"diffusers-training",
"lora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] |
text-to-image
| 2025-06-21T12:49:45Z |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
library_name: diffusers
license: openrail++
instance_prompt: a realistic portrait of sks face
widget: []
tags:
- text-to-image
- text-to-image
- diffusers-training
- diffusers
- lora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - veddhanth/lora-trained-xl-stage-2-pretrained-enc-v2-spat-map-12-sneaker
<Gallery />
## Model description
These are veddhanth/lora-trained-xl-stage-2-pretrained-enc-v2-spat-map-12-sneaker LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: True.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use a realistic portrait of sks face to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](veddhanth/lora-trained-xl-stage-2-pretrained-enc-v2-spat-map-12-sneaker/tree/main) them in the Files & versions tab.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model]
|
pictgensupport/olderman
|
pictgensupport
| 2025-06-21T12:56:27Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-06-21T12:56:25Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: olderman
---
# Olderman
<Gallery />
Trained on Replicate using:
https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `olderman` to trigger the image generation.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('pictgensupport/olderman', weight_name='lora.safetensors')
image = pipeline('your prompt').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
18-Official-maria-camila-videos-viral/18.video.full.maria.camila.Viral.Video.on.social.media
|
18-Official-maria-camila-videos-viral
| 2025-06-21T12:54:27Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T12:53:56Z |
<a href="https://tinyurl.com/2urtu5zm"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Nature" class="responsive"></a>
<a href="https://tinyurl.com/2urtu5zm"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Nature" class="responsive"></a>
|
18-Official-maria-camila-video-viral/18.video.full.maria.camila.Viral.Video.on.social.media
|
18-Official-maria-camila-video-viral
| 2025-06-21T12:54:24Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T12:53:53Z |
<a href="https://tinyurl.com/2urtu5zm"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Nature" class="responsive"></a>
<a href="https://tinyurl.com/2urtu5zm"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Nature" class="responsive"></a>
|
Kantkamal/Gujarati-BERT-NER
|
Kantkamal
| 2025-06-21T12:54:18Z | 29 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"token-classification",
"gujarati",
"named-entity-recognition",
"ner",
"gujarati-bert",
"low-resource",
"gu",
"dataset:Naamapadam",
"base_model:l3cube-pune/gujarati-bert",
"base_model:finetune:l3cube-pune/gujarati-bert",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2025-06-12T13:06:33Z |
---
language: gu
license: apache-2.0
tags:
- gujarati
- token-classification
- named-entity-recognition
- ner
- transformers
- gujarati-bert
- low-resource
datasets:
- Naamapadam
model-index:
- name: Gujarati-BERT-NER
results: []
base_model:
- l3cube-pune/gujarati-bert
pipeline_tag: token-classification
widget:
- text: "મહાત્મા ગાંધીજી પોરબંદર ખાતે જન્મ્યા હતા."
---
# Gujarati-BERT-NER 🪔🇮🇳
This is a fine-tuned Named Entity Recognition (NER) model for the Gujarati language based on the [GujaratiBERT](https://huggingface.co/l3cube-pune/gujarati-bert) model. It has been trained on the [Naamapadam](https://huggingface.co/datasets/ai4bharat/Naamapadam) dataset.
## 🏷️ Named Entity Types
- PER - Person (વ્યક્તિનું નામ)
- LOC - Location (સ્થળ)
- ORG - Organization (સંસ્થા)
- O - Non-entity tokens
## 📌 Example Usage
```python
from transformers import pipeline
ner_pipeline = pipeline(
"token-classification",
model="Kantkamal/Gujarati-BERT-NER",
tokenizer="Kantkamal/Gujarati-BERT-NER",
aggregation_strategy="simple"
)
text = "મહાત્મા ગાંધીજી પોરબંદર ખાતે જન્મ્યા હતા અને તેમને અહિંસા માટે જાણવામાં આવે છે."
ner_results = ner_pipeline(text)
for entity in ner_results:
print(f"{entity['word']} -> {entity['entity_group']} ({entity['score']:.2f})")
```
## Label and ID Mapping
| Label ID | Label |
| -------- | ----- |
|0 | O |
| 1 | B-PER |
| 2 | I-PER |
| 3 | B-ORG|
| 4 | I-ORG |
| 5 | B-LOC |
| 6 | I-LOC |
## 🚀 Load Manually
```python
from transformers import AutoTokenizer, AutoModelForTokenClassification
model = AutoModelForTokenClassification.from_pretrained("Kantkamal/Gujarati-BERT-NER")
tokenizer = AutoTokenizer.from_pretrained("Kantkamal/Gujarati-BERT-NER")
```
## Training Details
There were a total of 472,845 rows in the training split of the dataset Naamapadam for
the Gujarati language. A random sample of 400,000 rows was selected from the training
dataset. 320,000 rows (80%) were allocated for model training, while 80,000 rows (20%)
designated for validation.
Model training was conducted using a local system equipped with an NVIDIA GeForce RTX
4060.
## Evaluation Results
|Model | Precision | Recall | F1 | Accuracy | Loss |
| ---- | --- | --------- | ----- | -------- | --- |
|Gujarati-BERT-NER | 0.8052 | 0.8424| 0.8234 | 0.9244 | 0.1985 |
## 🔍 Try it out
```text
મહાત્મા ગાંધીજી પોરબંદર ખાતે જન્મ્યા હતા અને તેઓ અહિંસા માટે જાણીતા છે.
Developed by Chandrakant Bhogayata
|
dwulff/minilm-brl
|
dwulff
| 2025-06-21T12:53:39Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"generated_from_trainer",
"dataset_size:50000",
"loss:CosineSimilarityLoss",
"arxiv:1908.10084",
"base_model:sentence-transformers/all-MiniLM-L6-v2",
"base_model:finetune:sentence-transformers/all-MiniLM-L6-v2",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-06-21T12:53:31Z |
---
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- generated_from_trainer
- dataset_size:50000
- loss:CosineSimilarityLoss
base_model: sentence-transformers/all-MiniLM-L6-v2
widget:
- source_sentence: 'An article on behavioral reinforcement learning:
Title: Cell-ŧype-specific responses to associative learning in the primary motor
cortex.
Abstract: The primary motor cortex (M1) is known to be a critical site for movement
initiation and motor learning. Surprisingly, it has also been shown to possess
reward-related activity, presumably to facilitate reward-based learning of new
movements. However, whether reward-related signals are represented among different
cell types in M1, and whether their response properties change after cue-reward
conditioning remains unclear. Here, we performed longitudinal in vivo two-photon
Ca2+ imaging to monitor the activity of different neuronal cell types in M1 while
mice engaged in a classical conditioning task. Our results demonstrate that most
of the major neuronal cell types in M1 showed robust but differential responses
to both the conditioned cue stimulus (CS) and reward, and their response properties
undergo cell-ŧype-specific modifications after associative learning. PV-INs’ responses
became more reliable to the CS, while VIP-INs’ responses became more reliable
to reward. Pyramidal neurons only showed robust responses to novel reward, and
they habituated to it after associative learning. Lastly, SOM-INs’ responses emerged
and became more reliable to both the CS and reward after conditioning. These observations
suggest that cue- and reward-related signals are preferentially represented among
different neuronal cell types in M1, and the distinct modifications they undergo
during associative learning could be essential in triggering different aspects
of local circuit reorganization in M1 during reward-based motor skill learning.'
sentences:
- 'An article on behavioral reinforcement learning:
Title: Learning to construct sentences in Spanish: A replication of the Weird
Word Order technique.
Abstract: In the present study, children''s early ability to organise words into
sentences was investigated using the Weird Word Order procedure with Spanish-speaking
children. Spanish is a language that allows for more flexibility in the positions
of subjects and objects, with respect to verbs, than other previously studied
languages (English, French, and Japanese). As in prior studies (Abbot-Smith et
al., 2001; Chang et al., 2009; Franck et al., 2011; Matthews et al., 2005, 2007),
we manipulated the relative frequency of verbs in training sessions with two age
groups (three-A nd four-year-old children). Results supported earlier findings
with regard to frequency: Children produced atypical word orders significantly
more often with infrequent verbs than with frequent verbs. The findings from the
present study support probabilistic learning models which allow higher levels
of flexibility and, in turn, oppose hypotheses that defend early access to advanced
grammatical knowledge.'
- 'An article on behavioral reinforcement learning:
Title: What are the computations of the cerebellum, the basal ganglia and the
cerebral cortex?.
Abstract: The classical notion that the cerebellum and the basal ganglia are dedicated
to motor control is under dispute given increasing evidence of their involvement
in non-motor functions. Is it then impossible to characterize the functions of
the cerebellum, the basal ganglia and the cerebral cortex in a simplistic manner?
This paper presents a novel view that their computational roles can be characterized
not by asking what are the ''goals'' of their computation, such as motor or sensory,
but by asking what are the ''methods'' of their computation, specifically, their
learning algorithms. There is currently enough anatomical, physiological, and
theoretical evidence to support the hypotheses that the cerebellum is a specialized
organism for supervised learning, the basal ganglia are for reinforcement learning,
and the cerebral cortex is for unsupervised learning.This paper investigates how
the learning modules specialized for these three kinds of learning can be assembled
into goal-oriented behaving systems. In general, supervised learning modules in
the cerebellum can be utilized as ''internal models'' of the environment. Reinforcement
learning modules in the basal ganglia enable action selection by an ''evaluation''
of environmental states. Unsupervised learning modules in the cerebral cortex
can provide statistically efficient representation of the states of the environment
and the behaving system. Two basic action selection architectures are shown, namely,
reactive action selection and predictive action selection. They can be implemented
within the anatomical constraint of the network linking these structures. Furthermore,
the use of the cerebellar supervised learning modules for state estimation, behavioral
simulation, and encapsulation of learned skill is considered. Finally, the usefulness
of such theoretical frameworks in interpreting brain imaging data is demonstrated
in the paradigm of procedural learning.'
- 'An article on behavioral reinforcement learning:
Title: Repeated decisions and attitudes to risk.
Abstract: In contrast to the underpinnings of expected utility, the experimental
pilot study results reported here suggest that current decisions may be influenced
both by past decisions and by the possibility of making decisions in the future.'
- source_sentence: 'An article on behavioral reinforcement learning:
Title: Sensory Evidence Accumulation Using Optic Flow in a Naturalistic Navigation
Task.
Abstract: Sensory evidence accumulation is considered a hallmark of decision-making
in noisy environments. Integration of sensory inputs has been traditionally studied
using passive stimuli, segregating perception from action. Lessons learned from
this approach, however, may not generalize to ethological behaviors like navigation,
where there is an active interplay between perception and action. We designed
a sensory-based sequential decision task in virtual reality in which humans and
monkeys navigated to a memorized location by integrating optic flow generated
by their own joystick movements. A major challenge in such closed-loop tasks is
that subjects’ actions will determine future sensory input, causing ambiguity
about whether they rely on sensory input rather than expectations based solely
on a learned model of the dynamics. To test whether subjects integrated optic
flow over time, we used three independent experimental manipulations, unpredictable
optic flow perturbations, which pushed subjects off their trajectory; gain manipulation
of the joystick controller, which changed the consequences of actions; and manipulation
of the optic flow density, which changed the information borne by sensory evidence.
Our results suggest that both macaques (male) and humans (female/male) relied
heavily on optic flow, thereby demonstrating a critical role for sensory evidence
accumulation during naturalistic action-perception closed-loop tasks.'
sentences:
- 'An article on behavioral reinforcement learning:
Title: The importance of decision making in causal learning from interventions.
Abstract: Recent research has focused on how interventions benefit causal learning.
This research suggests that the main benefit of interventions is in the temporal
and conditional probability information that interventions provide a learner.
But when one generates interventions, one must also decide what interventions
to generate. In three experiments, we investigated the importance of these decision
demands to causal learning. Experiment 1 demonstrated that learners were better
at learning causal models when they observed intervention data that they had generated,
as opposed to observing data generated by another learner. Experiment 2 demonstrated
the same effect between self-generated interventions and interventions learners
were forced to make. Experiment 3 demonstrated that when learners observed a sequence
of interventions such that the decision-making process that generated those interventions
was more readily available, learning was less impaired. These data suggest that
decision making may be an important part of causal learning from interventions.'
- 'An article on behavioral reinforcement learning:
Title: Region-specific effects of acute haloperidol in the human midbrain, striatum
and cortex.
Abstract: D2 autoreceptors provide an important regulatory mechanism of dopaminergic
neurotransmission. However, D2 receptors are also expressed as heteroreceptors
at postsynaptic membranes. The expression and the functional characteristics of
both, D2 auto- and heteroreceptors, differ between brain regions. Therefore, one
would expect that also the net response to a D2 antagonist, i.e. whether and to
what degree overall neural activity increases or decreases, varies across brain
areas. In the current study we systematically tested this hypothesis by parametrically
increasing haloperidol levels (placebo, 2 and 3 mg) in healthy volunteers and
measuring brain activity in the three major dopaminergic pathways. In particular,
activity was assessed using fMRI while participants performed a working memory
and a reinforcement learning task. Consistent with the hypothesis, across brain
regions activity parametrically in- and decreased. Moreover, even within the same
area there were function-specific concurrent de- and increases of activity, likely
caused by input from upstream dopaminergic regions. In the ventral striatum, for
instance, activity during reinforcement learning decreased for outcome processing
while prediction error related activity increased. In conclusion, the current
study highlights the intricacy of D2 neurotransmission which makes it difficult
to predict the function-specific net response of a given area to pharmacological
manipulations.'
- 'An article on behavioral reinforcement learning:
Title: Modeling dopaminergic and other processes involved in learning from reward
prediction error: Contributions from an individual differences perspective.
Abstract: Phasic firing changes of midbrain dopamine neurons have been widely
characterized as reflecting a reward prediction error (RPE). Major personality
traits (e.g., extraversion) have been linked to inter-individual variations in
dopaminergic neurotransmission. Consistent with these two claims, recent research
(Smillie et al., 2011; Cooper et al., 2014) found that extraverts exhibited larger
RPEs than introverts, as reflected in feedback related negativity (FRN) effects
in EEG recordings. Using an established, biologically-localized RPE computational
model, we successfully simulated dopaminergic cell firing changes which are thought
to modulate the FRN. We introduced simulated individual differences into the model:
parameters were systematically varied, with stable values for each simulated individual.
We explored whether a model parameter might be responsible for the observed covariance
between extraversion and the FRN changes in real data, and argued that a parameter
is a plausible source of such covariance if parameter variance, across simulated
individuals, correlated almost perfectly with the size of the simulated dopaminergic
FRN modulation, and created as much variance as possible in this simulated output.
Several model parameters met these criteria, while others did not. In particular,
variations in the strength of connections carrying excitatory reward drive inputs
to midbrain dopaminergic cells were considered plausible candidates, along with
variations in a parameter which scales the effects of dopamine cell firing bursts
on synaptic modification in ventral striatum. We suggest possible neurotransmitter
mechanisms underpinning these model parameters. Finally, the limitations and possible
extensions of our general approach are discussed.'
- source_sentence: 'An article on behavioral reinforcement learning:
Title: Pigeons'' use of cues in a repeated five-trial-sequence, single-reversal
task.
Abstract: We studied behavioral flexibility, or the ability to modify one''s behavior
in accordance with the changing environment, in pigeons using a reversal-learning
paradigm. In two experiments, each session consisted of a series of five-trial
sequences involving a simple simultaneous color discrimination in which a reversal
could occur during each sequence. The ideal strategy would be to start each sequence
with a choice of S1 (the first correct stimulus) until it was no longer correct,
and then to switch to S2 (the second correct stimulus), thus utilizing cues provided
by local reinforcement (feedback from the preceding trial). In both experiments,
subjects showed little evidence of using local reinforcement cues, but instead
used the mean probabilities of reinforcement for S1 and S2 on each trial within
each sequence. That is, subjects showed remarkably similar behavior, regardless
of where (or, in Exp. 2, whether) a reversal occurred during a given sequence.
Therefore, subjects appeared to be relatively insensitive to the consequences
of responses (local feedback) and were not able to maximize reinforcement. The
fact that pigeons did not use the more optimal feedback afforded by recent reinforcement
contingencies to maximize their reinforcement has implications for their use of
flexible response strategies under reversal-learning conditions.'
sentences:
- 'An article on behavioral reinforcement learning:
Title: Behavioral and circuit basis of sucrose rejection by drosophila females
in a simple decision-making task.
Abstract: Drosophila melanogaster egg-laying site selection offers a genetic model
to study a simple form of value-based decision. We have previously shown that
Drosophila females consistently reject a sucrose-containing substrate and choose
a plain (sucrose-free) substrate for egg laying in our sucrose versus plain decision
assay. However, either substrate is accepted when it is the sole option. Here
we describe the neural mechanism that underlies females’ sucrose rejection in
our sucrose versus plain assay. First, we demonstrate that females explored the
sucrose substrate frequently before most egg-laying events, suggesting that they
actively suppress laying eggs on the sucrose substrate as opposed to avoiding
visits to it. Second, we show that activating a specific subset of DA neurons
triggered a preference for laying eggs on the sucrose substrate over the plain
one, suggesting that activating these DA neurons can increase the value of the
sucrose substrate for egg laying. Third, we demonstrate that neither ablating
nor inhibiting the mushroom body (MB), a known Drosophila learning and decision
center, affected females’ egg-laying preferences in our sucrose versus plain assay,
suggesting that MB does not mediate this specific decision-making task.Wepropose
that the value of a sucrose substrate— as an egg-laying option—can be adjusted
by the activities of a specific DA circuit. Once the sucrose substrate is determined
to be the lesser valued option, females execute their decision to reject this
inferior substrate not by stopping their visits to it, but by actively suppressing
their egg-laying motor program during their visits.'
- 'An article on behavioral reinforcement learning:
Title: Choice in experiential learning: True preferences or experimental artifacts?.
Abstract: The rate of selecting different options in the decisions-from-feedback
paradigm is commonly used to measure preferences resulting from experiential learning.
While convergence to a single option increases with experience, some variance
in choice remains even when options are static and offer fixed rewards. Employing
a decisions-from-feedback paradigm followed by a policy-setting task, we examined
whether the observed variance in choice is driven by factors related to the paradigm
itself: Continued exploration (e.g., believing options are non-stationary) or
exploitation of perceived outcome patterns (i.e., a belief that sequential choices
are not independent). Across two studies, participants showed variance in their
choices, which was related (i.e., proportional) to the policies they set. In addition,
in Study 2, participants'' reported under-confidence was associated with the amount
of choice variance in later choices and policies. These results suggest that variance
in choice is better explained by participants lacking confidence in knowing which
option is better, rather than methodological artifacts (i.e., exploration or failures
to recognize outcome independence). As such, the current studies provide evidence
for the decisions-from-feedback paradigm''s validity as a behavioral research
method for assessing learned preferences.'
- 'An article on behavioral reinforcement learning:
Title: Impaired savings despite intact initial learning of motor adaptation in
Parkinson''s disease.
Abstract: In motor adaptation, the occurrence of savings (faster relearning of
a previously learned motor adaptation task) has been explained in terms of operant
reinforcement learning (Huang et al. in Neuron 70(4):787-801, 2011), which is
thought to associate an adapted motor command with outcome success during repeated
execution of the adapted movement. There is some evidence for deficient savings
in Parkinson''s Disease (PD), which might result from deficient operant reinforcement
processes. However, this evidence is compromised by limited adaptation training
during initial learning and by multi-target adaptation, which reduces the number
of reinforced movement repetitions for each target. Here, we examined savings
in PD patients and controls following overlearning with a single target. PD patients
showed less savings than controls after successive adaptation and deadaptation
blocks within the same test session, as well as less savings across test sessions
separated by a 24-h delay. It is argued that impaired blunted dopaminergic signals
in PD impairs the modulation of dopaminergic signals to the motor cortex in response
to rewarding motor outcomes, thus impairing the association of the adapted motor
command with rewarding motor outcomes. Consequently, the previously adapted motor
command is not preferentially selected during relearning, and savings is impaired.'
- source_sentence: 'An article on behavioral reinforcement learning:
Title: Altered cingulate sub-region activation accounts for task-related dissociation
in ERN amplitude as a function of obsessive-compulsive symptoms.
Abstract: Larger error-related negativities (ERNs) have been consistently found
in obsessive-compulsive disorder (OCD) patients, and are thought to reflect the
activities of a hyperactive cortico-striatal circuit during action monitoring.
We previously observed that obsessive-compulsive (OC) symptomatic students (non-patients)
have larger ERNs during errors in a response competition task, yet smaller ERNs
in a reinforcement learning task. The finding of a task-specific dissociation
suggests that distinct yet partially overlapping medio-frontal systems underlie
the ERN in different tasks, and that OC symptoms are associated with functional
differences in these systems. Here, we used EEG source localization to identify
why OC symptoms are associated with hyperactive ERNs to errors yet hypoactive
ERNs when selecting maladaptive actions. At rest, OC symptomatology predicted
greater activity in rostral anterior cingulate cortex (rACC) and lower activity
in dorsal anterior cingulate cortex (dACC). When compared to a group with low
OC symptom scores, the high OC group had greater rACC reactivity during errors
in the response competition task and less deactivation of dACC activity during
errors in the reinforcement learning task. The degree of activation in these areas
correlated with ERN amplitudes during both tasks in the high OC group, but not
in the low group. Interactive anterior cingulate cortex (ACC) systems associated
avoidance of maladaptive actions were intact in the high OC group, but were related
to poorer performance on a third task: probabilistic reversal learning. These
novel findings link both tonic and phasic activities in the ACC to action monitoring
alterations, including dissociation in performance deficits, in OC symptomatic
participants.'
sentences:
- 'An article on behavioral reinforcement learning:
Title: The Stroop Effect: Why Proportion Congruent Has Nothing to Do With Congruency
and Everything to Do With Contingency.
Abstract: The item-specific proportion congruent (ISPC) effect refers to the observation
that the Stroop effect is larger for words that are presented mostly in congruent
colors (e.g., BLUE presented 75% of the time in blue) and smaller for words that
are presented mostly in a given incongruent color (e.g., YELLOW presented 75%
of the time in orange). One account of the ISPC effect, the modulation hypothesis,
is that participants modulate attention based on the identity of the word (i.e.,
participants allow the word to influence responding when it is presented mostly
in its congruent color). Another account, the contingency hypothesis, is that
participants use the word to predict the response that they will need to make
(e.g., if the word is YELLOW, then the response is probably "orange"). Reanalyses
of data from L. L. Jacoby, D. S. Lindsay, and S. Hessels (2003), along with results
from new experiments, are inconsistent with the modulation hypothesis but entirely
consistent with the contingency hypothesis. A response threshold mechanism that
uses contingency information provides a sufficient account of the data.'
- 'An article on behavioral reinforcement learning:
Title: D-cycloserine facilitates socially reinforced learning in an animal model
relevant to autism spectrum disorders.
Abstract: There are no drugs that specifically target the social deficits of autism
spectrum disorders (ASD). This may be due to a lack of behavioral paradigms in
animal models relevant to ASD. Partner preference formation in the prairie vole
represents a social cognitive process involving socially reinforced learning.
D-cycloserine (DCS) is a cognitive enhancer that acts at the N-methyl-D-aspartate
receptor to promote learning. If DCS enhances socially reinforced learning in
the partner preference paradigm, it may be useful in combination with behavioral
therapies for enhancing social functioning in ASD. Female prairie and meadow voles
were given DCS either peripherally or directly into one of three brain regions:
nucleus accumbens, amygdala, or caudate putamen. Subjects were then cohabited
with a male vole under conditions that do not typically yield a partner preference.
The development of a preference for that stimulus male vole over a novel male
vole was assessed using a partner preference test. A low dose of DCS administered
peripherally enhanced preference formation in prairie voles but not meadow voles
under conditions in which it would not otherwise occur. These effects were replicated
in prairie voles by microinfusions of DCS into the nucleus accumbens, which is
involved in reinforcement learning, and the amygdala, which is involved in social
information processing. Partner preference in the prairie vole may provide a behavioral
paradigm with face, construct, and predictive validity for identifying prosocial
pharmacotherapeutics. D-cycloserine may be a viable treatment strategy for social
deficits of ASD when paired with social behavioral therapy.'
- 'An article on behavioral reinforcement learning:
Title: Pseudodiagnosticity Revisited.
Abstract: In the psychology of reasoning and judgment, the pseudodiagnosticity
task has been a major tool for the empirical investigation of people''s ability
to search for diagnostic information. A novel normative analysis of this experimental
paradigm is presented, by which the participants'' prevailing responses turn out
not to support the generally accepted existence of a reasoning bias. The conclusions
drawn do not rest on pragmatic concerns suggesting alleged divergences between
the experimenter''s and participants'' reading of the task. They only rely, instead,
on the demonstration that observed behavior largely conforms to optimal utility
maximizing information search strategies for standard variants of the pseudodiagnosticity
paradigm that have been investigated so far. It is argued that the experimental
results obtained, contrary to what has recurrently been claimed, have failed to
discriminate between normative and nonnormative accounts of behavior. More general
implications of the analysis presented for past and future research on human information
search behavior and diagnostic reasoning are discussed.'
- source_sentence: 'An article on behavioral reinforcement learning:
Title: Confidence and the description–experience distinction.
Abstract: In this paper, we extend the literature on the description–experience
gap in risky choices by focusing on how the mode of learning—through description
or experience—affects confidence. Specifically, we explore how learning through
description or experience affects confidence in (1) the information gathered to
make a decision and (2) the resulting choice. In two preregistered experiments
we tested whether there was a description–experience gap in both dimensions of
confidence. Learning from description was associated with higher confidence—both
in the information gathered and in the choice made—than was learning from experience.
In a third preregistered experiment, we examined the effect of sample size on
confidence in decisions from experience. Contrary to the normative view that larger
samples foster confidence in statistical inference, we observed that more experience
led to less confidence. This observation is reminiscent of recent theories of
deliberate ignorance, which highlight the adaptive benefits of deliberately limiting
information search.'
sentences:
- 'An article on behavioral reinforcement learning:
Title: Episodic memories predict adaptive Value-Based Decision-Making.
Abstract: Prior research illustrates that memory can guide Value-Based Decision-Making.
For example, previous work has implicated both working memory and procedural memory
(i.e., reinforcement learning) in guiding choice. However, other types of memories,
such as episodic memory, may also influence Decision-Making. Here we test the
role for episodic Memory-Specifically item versus associative Memory-In supporting
Value-Based choice. Participants completed a task where they first learned the
value associated with trial unique lotteries. After a short delay, they completed
a Decision-Making task where they could choose to reengage with previously encountered
lotteries, or new never before seen lotteries. Finally, participants completed
a surprise memory test for the lotteries and their associated values. Results
indicate that participants chose to reengage more often with lotteries that resulted
in high versus low rewards. Critically, participants not only formed detailed,
associative memories for the reward values coupled with individual lotteries,
but also exhibited adaptive Decision-Making only when they had intact associative
memory. We further found that the relationship between adaptive choice and associative
memory generalized to more complex, ecologically valid choice behavior, such as
social decisionmaking. However, individuals more strongly encode experiences of
social Violations-Such as being treated unfairly, suggesting a bias for how individuals
form associative memories within social contexts. Together, these findings provide
an important integration of episodic memory and Decision-Making literatures to
better understand key mechanisms supporting adaptive behavior.'
- 'An article on behavioral reinforcement learning:
Title: How (in)variant are subjective representations of described and experienced
risk and rewards?.
Abstract: Decisions under risk have been shown to differ depending on whether
information on outcomes and probabilities is gleaned from symbolic descriptions
or gathered through experience. To some extent, this description–experience gap
is due to sampling error in experience-based choice. Analyses with cumulative
prospect theory (CPT), investigating to what extent the gap is also driven by
differences in people''s subjective representations of outcome and probability
information (taking into account sampling error), have produced mixed results.
We improve on previous analyses of description-based and experience-based choices
by taking advantage of both a within-subjects design and a hierarchical Bayesian
implementation of CPT. This approach allows us to capture both the differences
and the within-person stability of individuals’ subjective representations across
the two modes of learning about choice options. Relative to decisions from description,
decisions from experience showed reduced sensitivity to probabilities and increased
sensitivity to outcomes. For some CPT parameters, individual differences were
relatively stable across modes of learning. Our results suggest that outcome and
probability information translate into systematically different subjective representations
in description- versus experience-based choice. At the same time, both types of
decisions seem to tap into the same individual-level regularities.'
- 'An article on behavioral reinforcement learning:
Title: Do narcissists make better decisions? An investigation of narcissism and
dynamic decision-making performance.
Abstract: We investigated whether narcissism affected dynamic decision-making
performance in the presence and absence of misleading information. Performance
was examined in a two-choice dynamic decision-making task where the optimal strategy
was to forego an option providing larger immediate rewards in favor of an option
that led to larger delayed rewards. Information regarding foregone rewards from
the alternate option was presented or withheld to bias participants toward the
sub-optimal choice. The results demonstrated that individuals high in narcissistic
traits performed comparably to low narcissism individuals when foregone reward
information was absent, but high narcissism individuals outperformed individuals
low in narcissistic traits when misleading information was presented. The advantage
for participants high in narcissistic traits was strongest within males, and,
overall, males outperformed females when foregone rewards were present. While
prior research emphasizes narcissists'' decision-making deficits, our findings
provide evidence that individuals high in narcissistic traits excel at decision-making
tasks that involve disregarding ambiguous information and focusing on the long-term
utility of each option. Their superior ability at filtering out misleading information
may reflect an effort to maintain their self-view or avoid ego threat.'
pipeline_tag: sentence-similarity
library_name: sentence-transformers
---
# SentenceTransformer based on sentence-transformers/all-MiniLM-L6-v2
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [sentence-transformers/all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2). It maps sentences & paragraphs to a 384-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [sentence-transformers/all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) <!-- at revision c9745ed1d9f207416be6d2e6f8de32d1f16199bf -->
- **Maximum Sequence Length:** 256 tokens
- **Output Dimensionality:** 384 dimensions
- **Similarity Function:** Cosine Similarity
<!-- - **Training Dataset:** Unknown -->
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 256, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Normalize()
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("dwulff/minilm-brl")
# Run inference
sentences = [
'An article on behavioral reinforcement learning:\n\nTitle: Confidence and the description–experience distinction.\nAbstract: In this paper, we extend the literature on the description–experience gap in risky choices by focusing on how the mode of learning—through description or experience—affects confidence. Specifically, we explore how learning through description or experience affects confidence in (1) the information gathered to make a decision and (2) the resulting choice. In two preregistered experiments we tested whether there was a description–experience gap in both dimensions of confidence. Learning from description was associated with higher confidence—both in the information gathered and in the choice made—than was learning from experience. In a third preregistered experiment, we examined the effect of sample size on confidence in decisions from experience. Contrary to the normative view that larger samples foster confidence in statistical inference, we observed that more experience led to less confidence. This observation is reminiscent of recent theories of deliberate ignorance, which highlight the adaptive benefits of deliberately limiting information search.',
"An article on behavioral reinforcement learning:\n\nTitle: How (in)variant are subjective representations of described and experienced risk and rewards?.\nAbstract: Decisions under risk have been shown to differ depending on whether information on outcomes and probabilities is gleaned from symbolic descriptions or gathered through experience. To some extent, this description–experience gap is due to sampling error in experience-based choice. Analyses with cumulative prospect theory (CPT), investigating to what extent the gap is also driven by differences in people's subjective representations of outcome and probability information (taking into account sampling error), have produced mixed results. We improve on previous analyses of description-based and experience-based choices by taking advantage of both a within-subjects design and a hierarchical Bayesian implementation of CPT. This approach allows us to capture both the differences and the within-person stability of individuals’ subjective representations across the two modes of learning about choice options. Relative to decisions from description, decisions from experience showed reduced sensitivity to probabilities and increased sensitivity to outcomes. For some CPT parameters, individual differences were relatively stable across modes of learning. Our results suggest that outcome and probability information translate into systematically different subjective representations in description- versus experience-based choice. At the same time, both types of decisions seem to tap into the same individual-level regularities.",
"An article on behavioral reinforcement learning:\n\nTitle: Do narcissists make better decisions? An investigation of narcissism and dynamic decision-making performance.\nAbstract: We investigated whether narcissism affected dynamic decision-making performance in the presence and absence of misleading information. Performance was examined in a two-choice dynamic decision-making task where the optimal strategy was to forego an option providing larger immediate rewards in favor of an option that led to larger delayed rewards. Information regarding foregone rewards from the alternate option was presented or withheld to bias participants toward the sub-optimal choice. The results demonstrated that individuals high in narcissistic traits performed comparably to low narcissism individuals when foregone reward information was absent, but high narcissism individuals outperformed individuals low in narcissistic traits when misleading information was presented. The advantage for participants high in narcissistic traits was strongest within males, and, overall, males outperformed females when foregone rewards were present. While prior research emphasizes narcissists' decision-making deficits, our findings provide evidence that individuals high in narcissistic traits excel at decision-making tasks that involve disregarding ambiguous information and focusing on the long-term utility of each option. Their superior ability at filtering out misleading information may reflect an effort to maintain their self-view or avoid ego threat.",
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 384]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### Unnamed Dataset
* Size: 50,000 training samples
* Columns: <code>sentence_0</code>, <code>sentence_1</code>, and <code>label</code>
* Approximate statistics based on the first 1000 samples:
| | sentence_0 | sentence_1 | label |
|:--------|:--------------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------|:---------------------------------------------------------------|
| type | string | string | float |
| details | <ul><li>min: 102 tokens</li><li>mean: 237.66 tokens</li><li>max: 256 tokens</li></ul> | <ul><li>min: 61 tokens</li><li>mean: 227.84 tokens</li><li>max: 256 tokens</li></ul> | <ul><li>min: 0.0</li><li>mean: 0.17</li><li>max: 0.9</li></ul> |
* Samples:
| sentence_0 | sentence_1 | label |
|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:-----------------|
| <code>An article on behavioral reinforcement learning:<br><br>Title: Working memory and response selection: A computational account of interactions among cortico-basalganglio-thalamic loops.<br>Abstract: Cortico-basalganglio-thalamic loops are involved in both cognitive processes and motor control. We present a biologically meaningful computational model of how these loops contribute to the organization of working memory and the development of response behavior. Via reinforcement learning in basal ganglia, the model develops flexible control of working memory within prefrontal loops and achieves selection of appropriate responses based on working memory content and visual stimulation within a motor loop. We show that both working memory control and response selection can evolve within parallel and interacting cortico-basalganglio-thalamic loops by Hebbian and three-factor learning rules. Furthermore, the model gives a coherent explanation for how complex strategies of working memory control and respo...</code> | <code>An article on behavioral reinforcement learning:<br><br>Title: The role of basal ganglia in reinforcement learning and imprinting in domestic chicks.<br>Abstract: Effects of bilateral kainate lesions of telencephalic basal ganglia (lobus parolfactorius, LPO) were examined in domestic chicks. In the imprinting paradigm, where chicks learned to selectively approach a moving object without any explicitly associated reward, both the pre- and post-training lesions were without effects. On the other hand, in the water-reinforced pecking task, pre-training lesions of LPO severely impaired immediate reinforcement as well as formation of the association memory. However, post-training LPO lesions did not cause amnesia, and chicks selectively pecked at the reinforced color. The LPO could thus be involved specifically in the evaluation of present rewards and the instantaneous reinforcement of pecking, but not in the execution of selective behavior based on a memorized color cue.</code> | <code>0.5</code> |
| <code>An article on behavioral reinforcement learning:<br><br>Title: Exploration Disrupts Choice-Predictive Signals and Alters Dynamics in Prefrontal Cortex.<br>Abstract: In uncertain environments, decision-makers must balance two goals: they must “exploit” rewarding options but also “explore” in order to discover rewarding alternatives. Exploring and exploiting necessarily change how the brain responds to identical stimuli, but little is known about how these states, and transitions between them, change how the brain transforms sensory information into action. To address this question, we recorded neural activity in a prefrontal sensorimotor area while monkeys naturally switched between exploring and exploiting rewarding options. We found that exploration profoundly reduced spatially selective, choice-predictive activity in single neurons and delayed choice-predictive population dynamics. At the same time, reward learning was increased in brain and behavior. These results indicate that exploration i...</code> | <code>An article on behavioral reinforcement learning:<br><br>Title: Counterfactual choice and learning in a Neural Network centered on human lateral frontopolar cortex.<br>Abstract: Decision making and learning in a real-world context require organisms to track not only the choices they make and the outcomes that follow but also other untaken, or counterfactual, choices and their outcomes. Although the neural system responsible for tracking the value of choices actually taken is increasingly well understood, whether a neural system tracks counterfactual information is currently unclear. Using a three-alternative decision-making task, a Bayesian reinforcement-learning algorithm, and fMRI, we investigated the coding of counterfactual choices and prediction errors in the human brain. Rather than representing evidence favoring multiple counterfactual choices, lateral frontal polar cortex (lFPC), dorsomedial frontal cortex (DMFC), and posteromedial cortex (PMC) encode the reward-based evidence favoring t...</code> | <code>0.5</code> |
| <code>An article on behavioral reinforcement learning:<br><br>Title: Electrophysiological signatures of visual statistical learning in 3-month-old infants at familial and low risk for autism spectrum disorder.<br>Abstract: Visual statistical learning (VSL) refers to the ability to extract associations and conditional probabilities within the visual environment. It may serve as a precursor to cognitive and social communication development. Quantifying VSL in infants at familial risk (FR) for Autism Spectrum Disorder (ASD) provides opportunities to understand how genetic predisposition can influence early learning processes which may, in turn, lay a foundation for cognitive and social communication delays. We examined electroencephalography (EEG) signatures of VSL in 3-month-old infants, examining whether EEG correlates of VSL differentiated FR from low-risk (LR) infants. In an exploratory analysis, we then examined whether EEG correlates of VSL at 3 months relate to cognitive function and ASD symptoms...</code> | <code>An article on behavioral reinforcement learning:<br><br>Title: Reduced nucleus accumbens reactivity and adolescent depression following early-life stress.<br>Abstract: Depression is a common outcome for those having experienced early-life stress (ELS). For those individuals, depression typically increases during adolescence and appears to endure into adulthood, suggesting alterations in the development of brain systems involved in depression. Developmentally, the nucleus accumbens (NAcc), a limbic structure associated with reward learning and motivation, typically undergoes dramatic functional change during adolescence; therefore, age-related changes in NAcc function may underlie increases in depression in adolescence following ELS. The current study examined the effects of ELS in 38 previously institutionalized children and adolescents in comparison to a group of 31 youths without a history of ELS. Consistent with previous research, the findings showed that depression was higher in adolescents...</code> | <code>0.0</code> |
* Loss: [<code>CosineSimilarityLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#cosinesimilarityloss) with these parameters:
```json
{
"loss_fct": "torch.nn.modules.loss.MSELoss"
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `per_device_train_batch_size`: 64
- `per_device_eval_batch_size`: 64
- `num_train_epochs`: 5
- `multi_dataset_batch_sampler`: round_robin
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: no
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 64
- `per_device_eval_batch_size`: 64
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 5e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1
- `num_train_epochs`: 5
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.0
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: False
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `tp_size`: 0
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: None
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `include_for_metrics`: []
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `dispatch_batches`: None
- `split_batches`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `eval_use_gather_object`: False
- `average_tokens_across_devices`: False
- `prompts`: None
- `batch_sampler`: batch_sampler
- `multi_dataset_batch_sampler`: round_robin
</details>
### Training Logs
| Epoch | Step | Training Loss |
|:------:|:----:|:-------------:|
| 0.6394 | 500 | 0.0179 |
| 1.2788 | 1000 | 0.0124 |
| 1.9182 | 1500 | 0.0107 |
| 2.5575 | 2000 | 0.0092 |
| 3.1969 | 2500 | 0.0086 |
| 3.8363 | 3000 | 0.0078 |
| 4.4757 | 3500 | 0.0073 |
### Framework Versions
- Python: 3.13.2
- Sentence Transformers: 4.0.2
- Transformers: 4.50.0.dev0
- PyTorch: 2.6.0
- Accelerate: 1.5.2
- Datasets: 3.5.0
- Tokenizers: 0.21.1
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
rahim707/language-identification-pytroch
|
rahim707
| 2025-06-21T12:53:37Z | 0 | 0 | null |
[
"text-classification",
"fr",
"en",
"license:apache-2.0",
"region:us"
] |
text-classification
| 2025-06-21T12:42:38Z |
---
license: apache-2.0
language:
- fr
- en
metrics:
- accuracy
pipeline_tag: text-classification
---
|
18-jaipur-couple-viral-videos-full/jaipur.couple.viral.video.in.5.Star.Hotel.full.original
|
18-jaipur-couple-viral-videos-full
| 2025-06-21T12:47:08Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T12:46:41Z |
<a href="https://tinyurl.com/2urtu5zm"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Nature" class="responsive"></a>
<a href="https://tinyurl.com/2urtu5zm"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Nature" class="responsive"></a>
|
elidle/indobert-post-training-fin-sa-5
|
elidle
| 2025-06-21T12:41:52Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:elidle/indobert-fin_news-mlm-3",
"base_model:finetune:elidle/indobert-fin_news-mlm-3",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-06-21T12:40:31Z |
---
library_name: transformers
license: mit
base_model: elidle/indobert-fin_news-mlm-3
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: indobert-post-training-fin-sa-5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# indobert-post-training-fin-sa-5
This model is a fine-tuned version of [elidle/indobert-fin_news-mlm-3](https://huggingface.co/elidle/indobert-fin_news-mlm-3) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1628
- Accuracy: 0.9615
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| 1.048 | 0.1961 | 10 | 0.6923 | 0.7527 |
| 0.5601 | 0.3922 | 20 | 0.4627 | 0.7967 |
| 0.426 | 0.5882 | 30 | 0.3104 | 0.8956 |
| 0.2903 | 0.7843 | 40 | 0.2263 | 0.9176 |
| 0.1868 | 0.9804 | 50 | 0.2365 | 0.9231 |
| 0.1661 | 1.1765 | 60 | 0.1958 | 0.9286 |
| 0.115 | 1.3725 | 70 | 0.1614 | 0.9396 |
| 0.1015 | 1.5686 | 80 | 0.1678 | 0.9505 |
| 0.1147 | 1.7647 | 90 | 0.1863 | 0.9505 |
| 0.1358 | 1.9608 | 100 | 0.1808 | 0.9505 |
| 0.0561 | 2.1569 | 110 | 0.1565 | 0.9505 |
| 0.0473 | 2.3529 | 120 | 0.1953 | 0.9451 |
| 0.0502 | 2.5490 | 130 | 0.1447 | 0.9615 |
| 0.0806 | 2.7451 | 140 | 0.1681 | 0.9505 |
| 0.082 | 2.9412 | 150 | 0.1859 | 0.9451 |
| 0.0179 | 3.1373 | 160 | 0.1451 | 0.9725 |
| 0.048 | 3.3333 | 170 | 0.1631 | 0.9725 |
| 0.0067 | 3.5294 | 180 | 0.1628 | 0.9615 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
18-videos-jaipur-hotel-going-viral/FULL.VIDEO.18.jaipur.hotel.viral.video.original.holiday.inn.jaipur.viral.video
|
18-videos-jaipur-hotel-going-viral
| 2025-06-21T12:40:43Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T12:40:10Z |
<a href="https://tinyurl.com/2urtu5zm"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Nature" class="responsive"></a>
<a href="https://tinyurl.com/2urtu5zm"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Nature" class="responsive"></a>
|
18-Ruth-K-Mulamwah-Video/FULL.VIDEO.ruth.k.mulamwah.Viral.Video.Link.Tutorial.Official
|
18-Ruth-K-Mulamwah-Video
| 2025-06-21T12:39:12Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T12:39:02Z |
<a href="https://tinyurl.com/isrealchudi?top.gun" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="WATCH Videos" data-canonical-src="https://i.imgur.com/dJHk4Zq.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
AiWorld2000/kiraxx
|
AiWorld2000
| 2025-06-21T12:32:49Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-06-21T12:08:12Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: kiraxx
---
# Kiraxx
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `kiraxx` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "kiraxx",
"lora_weights": "https://huggingface.co/AiWorld2000/kiraxx/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('AiWorld2000/kiraxx', weight_name='lora.safetensors')
image = pipeline('kiraxx').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/AiWorld2000/kiraxx/discussions) to add images that show off what you’ve made with this LoRA.
|
intisarhasnain/mystory
|
intisarhasnain
| 2025-06-21T12:26:53Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-06-21T12:26:53Z |
---
license: apache-2.0
---
|
AhmedSaqr28/reasoning-assil-beta-qwen2.5-3b
|
AhmedSaqr28
| 2025-06-21T12:20:41Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-21T12:20:34Z |
---
base_model: unsloth/qwen2.5-3b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** AhmedSaqr28
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen2.5-3b-instruct-unsloth-bnb-4bit
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
BootesVoid/cmby644mv02wordqs8kzq0jwa_cmc66bjhi0561bfif4khlnbie
|
BootesVoid
| 2025-06-21T12:19:16Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-06-21T12:19:14Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: AVENLUX
---
# Cmby644Mv02Wordqs8Kzq0Jwa_Cmc66Bjhi0561Bfif4Khlnbie
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `AVENLUX` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "AVENLUX",
"lora_weights": "https://huggingface.co/BootesVoid/cmby644mv02wordqs8kzq0jwa_cmc66bjhi0561bfif4khlnbie/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('BootesVoid/cmby644mv02wordqs8kzq0jwa_cmc66bjhi0561bfif4khlnbie', weight_name='lora.safetensors')
image = pipeline('AVENLUX').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/BootesVoid/cmby644mv02wordqs8kzq0jwa_cmc66bjhi0561bfif4khlnbie/discussions) to add images that show off what you’ve made with this LoRA.
|
haihp02/samlllllllll
|
haihp02
| 2025-06-21T12:17:23Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"trl",
"sft",
"dpo",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-21T12:15:37Z |
---
library_name: transformers
tags:
- trl
- sft
- dpo
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
hopjetair/intent
|
hopjetair
| 2025-06-21T12:04:21Z | 28 | 0 |
adapter-transformers
|
[
"adapter-transformers",
"safetensors",
"distilbert",
"text-classification",
"en",
"dataset:bitext/Bitext-travel-llm-chatbot-training-dataset",
"arxiv:2106.09685",
"base_model:distilbert/distilbert-base-uncased",
"base_model:adapter:distilbert/distilbert-base-uncased",
"region:us"
] |
text-classification
| 2025-06-21T06:00:27Z |
---
datasets:
- bitext/Bitext-travel-llm-chatbot-training-dataset
language:
- en
metrics:
- accuracy
- f1
- recall
- precision
base_model:
- distilbert/distilbert-base-uncased
pipeline_tag: text-classification
library_name: adapter-transformers
---
# DistilBERT with LoRA for Intent Recognition
This is a parameter-efficient fine-tuned version of `distilbert-base-uncased` using the LoRA technique via [PEFT](https://github.com/huggingface/peft). The model was trained for intent recognition using a custom dataset.
## 🧾 Model Details
- Base model: `distilbert-base-uncased`
- Fine-tuning method: [LoRA (Low-Rank Adaptation)](https://arxiv.org/abs/2106.09685) using 🤗 PEFT
- Task: Intent Recognition (Text Classification)
## 🧠 Intended Use
You can use this model to classify user intents in applications like chatbots, virtual assistants, or voice-based interfaces.
## 🏷️ Intent Labels
This model supports classification over **33 intent labels**, including:
- BAGGAGE: check_baggage_allowance
- BOARDING_PASS: get_boarding_pass, print_boarding_pass
- CANCELLATION_FEE: check_cancellation_fee
- CHECK_IN: check_in
- CONTACT: human_agent
- FLIGHT: book_flight, cancel_flight, change_flight, check_flight_insurance_coverage, check_flight_offers, check_flight_prices, check_flight_reservation, check_flight_status, purchase_flight_insurance, search_flight, search_flight_insurance
- PRICES: check_trip_prices
- REFUND: get_refund
- SEAT: change_seat, choose_seat
- TIME: check_arrival_time, check_departure_time
- TRIP: book_trip, cancel_trip, change_trip, check_trip_details, check_trip_insurance_coverage, check_trip_offers, check_trip_plan, check_trip_prices, purchase_trip_insurance, search_trip, search_trip_insurance
## 📥 How to Use
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline
from peft import PeftModel
import joblib
# Load tokenizer and base model
tokenizer = AutoTokenizer.from_pretrained("hopjetair/intent")
base_model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased",num_labels=33)
# Load LoRA adapter
model = PeftModel.from_pretrained(base_model, "hopjetair/intent")
# Load label encoder
label_encoder = joblib.load("label_encoder.pkl")
# Inference
text = "Book me a flight to New York"
clf = pipeline("text-classification", model=model, tokenizer=tokenizer)
result = clf(text)[0]
label_num = int(result["label"].split("_")[-1])
# Convert back to label
predicted_label = label_encoder.inverse_transform([label_num])[0]
print(predicted_label)
```
## 🧪 CPU vs GPU Inference (Approximate Benchmarks)
> On average hardware — actual performance may vary based on your system configuration.
| **Task** | **CPU Inference Time** | **GPU Inference Time** |
|---------------------------|------------------------|-------------------------|
| Single sentence inference | ~100–200 ms | ~5–10 ms |
| Batch of 32 inputs | ~2–3 seconds total | ~100–300 ms total |
---
## 🖥️ Minimum Requirements for CPU Inference
You can run DistilBERT inference on:
- ⚙️ Modern desktop or laptop CPUs
- ☁️ Cloud VMs (e.g., AWS `t3.medium`, GCP `e2-standard`)
- 🧩 Even on low-end devices (with some latency trade-off)
|
Andresgr96/gemma-3-1b-it-qat-A
|
Andresgr96
| 2025-06-21T12:02:49Z | 9 | 0 |
transformers
|
[
"transformers",
"gguf",
"gemma3_text",
"text-generation",
"text-generation-inference",
"unsloth",
"en",
"base_model:unsloth/gemma-3-1b-it-qat",
"base_model:quantized:unsloth/gemma-3-1b-it-qat",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-06-18T15:28:34Z |
---
base_model: unsloth/gemma-3-1b-it-qat
tags:
- text-generation-inference
- transformers
- unsloth
- gemma3_text
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** Andresgr96
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gemma-3-1b-it-qat
This gemma3_text model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Nguyenhhh/LLama-300M
|
Nguyenhhh
| 2025-06-21T11:59:34Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-21T11:31:55Z |
---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
shelemakha/helloworldRL
|
shelemakha
| 2025-06-21T11:59:09Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-06-21T11:57:15Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 268.73 +/- 12.03
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
computerandgyein/solar-10.7b-text-normalisation-stage2-SFT
|
computerandgyein
| 2025-06-21T11:56:58Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:upstage/SOLAR-10.7B-Instruct-v1.0",
"base_model:finetune:upstage/SOLAR-10.7B-Instruct-v1.0",
"endpoints_compatible",
"region:us"
] | null | 2025-03-28T11:58:27Z |
---
base_model: upstage/SOLAR-10.7B-Instruct-v1.0
library_name: transformers
model_name: solar-10.7b-text-normalisation-stage2-SFT
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for solar-10.7b-text-normalisation-stage2-SFT
This model is a fine-tuned version of [upstage/SOLAR-10.7B-Instruct-v1.0](https://huggingface.co/upstage/SOLAR-10.7B-Instruct-v1.0).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="computerandgyein/solar-10.7b-text-normalisation-stage2-SFT", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/computerandgyein-ufo/text-normalisation/runs/sr9k7w1b)
This model was trained with SFT.
### Framework versions
- TRL: 0.19.0
- Transformers: 4.52.4
- Pytorch: 2.6.0+cu124
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Andresgr96/gemma-3-1b-it-qat-B
|
Andresgr96
| 2025-06-21T11:55:12Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"gemma3_text",
"text-generation",
"text-generation-inference",
"unsloth",
"en",
"base_model:unsloth/gemma-3-1b-it-qat",
"base_model:quantized:unsloth/gemma-3-1b-it-qat",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-06-21T11:51:04Z |
---
base_model: unsloth/gemma-3-1b-it-qat
tags:
- text-generation-inference
- transformers
- unsloth
- gemma3_text
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** Andresgr96
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gemma-3-1b-it-qat
This gemma3_text model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
berkayserin/tinyllama-nlq
|
berkayserin
| 2025-06-21T11:55:03Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"trl",
"sft",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-21T11:52:09Z |
---
library_name: transformers
tags:
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ziadrone/bert-base-uncased
|
ziadrone
| 2025-06-21T11:52:14Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"feature-extraction",
"arxiv:1910.09700",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2025-06-21T11:48:26Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
veddhanth/lora-trained-xl-stage-2-finetuned-enc-v2-spat-0.6-map-3-5
|
veddhanth
| 2025-06-21T11:51:40Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"text-to-image",
"diffusers-training",
"lora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] |
text-to-image
| 2025-06-21T11:41:36Z |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
library_name: diffusers
license: openrail++
instance_prompt: a realistic portrait of sks face
widget: []
tags:
- text-to-image
- text-to-image
- diffusers-training
- diffusers
- lora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - veddhanth/lora-trained-xl-stage-2-finetuned-enc-v2-spat-0.6-map-3-5
<Gallery />
## Model description
These are veddhanth/lora-trained-xl-stage-2-finetuned-enc-v2-spat-0.6-map-3-5 LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: True.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use a realistic portrait of sks face to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](veddhanth/lora-trained-xl-stage-2-finetuned-enc-v2-spat-0.6-map-3-5/tree/main) them in the Files & versions tab.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model]
|
Fralet/DDEduPModel
|
Fralet
| 2025-06-21T11:50:51Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"en",
"base_model:unsloth/llama-3-8b-bnb-4bit",
"base_model:finetune:unsloth/llama-3-8b-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-04-28T07:48:09Z |
---
base_model: unsloth/llama-3-8b-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** Fralet
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
KeunTnz/tag-to-kapams
|
KeunTnz
| 2025-06-21T11:50:12Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"marian",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2025-06-21T11:49:54Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
19-holiday-jaipur-hotel-viral-video-origin/19.jaipur.hotel.viral.video.original.holiday.inn.jaipur.viral.video
|
19-holiday-jaipur-hotel-viral-video-origin
| 2025-06-21T11:48:29Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T11:46:13Z |
<a href="https://tinyurl.com/2urtu5zm"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Nature" class="responsive"></a>
<a href="https://tinyurl.com/2urtu5zm"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Nature" class="responsive"></a>
|
mannamalaika/vide.LATEST.FULL.VIDEO.Sapna.Shah.Viral.Video.Link.Tutorial.Official
|
mannamalaika
| 2025-06-21T11:46:32Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T11:44:33Z |
<a href="https://zapvid.cfd/FULL-VIDEO-Sapna-Shah-Viral"> 🌐 Click Here To link (Full Viral Video Link)
🔴 ➤►DOWNLOAD👉👉🟢 ➤ <a href="https://zapvid.cfd/FULL-VIDEO-Sapna-Shah-Viral"> 🌐 Click Here To link
Sure! Here's a short summary of Sapna Shah's background with clear headings:
---
**Entrepreneur & Angel Investor**
Sapna Shah is the founder of **Red Giraffe Advisors**, where she invests in early-stage retail and consumer tech startups, especially those led by women and underrepresented founders.
**Founder of Retail X Series**
She created **Retail X Series**, a platform offering resources like events, a podcast, and a Slack community for retail tech founders.
**Past Ventures & Experience**
Sapna co-founded **Retail Eye Partners**, a Wall Street research firm, and **Mind the Chap**, a men’s fashion e-commerce site. She also worked at Ann Taylor, Gap Inc., and Linens 'n Things in senior roles.
**Mentor & Community Leader**
She mentors startups and judges business competitions at top schools like **Wharton, Columbia**, and **NYU Stern**, and is on the board of the **NY Tech Alliance**.
**Education**
She holds a **B.S. in Economics** and a **B.A. in East Asian Studies** from the **University of Pennsylvania**, and an **MBA from Columbia Business School**.
---
Let me know if you'd like it even more concise or formatted differently!
|
PaceKW/distilbert-base-uncased-multilabel-indonesian-hate-speech-modified-v2
|
PaceKW
| 2025-06-21T11:42:14Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-21T11:39:18Z |
---
library_name: transformers
license: apache-2.0
base_model: distilbert/distilbert-base-uncased
tags:
- generated_from_trainer
metrics:
- f1
- accuracy
model-index:
- name: distilbert-base-uncased-multilabel-indonesian-hate-speech-modified-v2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-multilabel-indonesian-hate-speech-modified-v2
This model is a fine-tuned version of [distilbert/distilbert-base-uncased](https://huggingface.co/distilbert/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2232
- F1: 0.7681
- Roc Auc: 0.8543
- Accuracy: 0.6803
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Roc Auc | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:------:|:-------:|:--------:|
| 0.3058 | 1.0 | 1317 | 0.2518 | 0.6741 | 0.7832 | 0.5854 |
| 0.22 | 2.0 | 2634 | 0.2329 | 0.7221 | 0.8308 | 0.5740 |
| 0.1852 | 3.0 | 3951 | 0.2168 | 0.7528 | 0.8433 | 0.6355 |
| 0.1506 | 4.0 | 5268 | 0.2182 | 0.7586 | 0.8400 | 0.6727 |
| 0.1272 | 5.0 | 6585 | 0.2232 | 0.7681 | 0.8543 | 0.6803 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.7.0+cu128
- Datasets 3.6.0
- Tokenizers 0.21.1
|
yaskrugan2/c0ace361-839c-4a11-a654-72f12edaffb2
|
yaskrugan2
| 2025-06-21T11:41:04Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"unsloth",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-21T11:24:04Z |
---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Davidozito/fewshot-CDW-CE-250-samples
|
Davidozito
| 2025-06-21T11:40:42Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"base_model:Davidozito/zeroshot-classification",
"base_model:finetune:Davidozito/zeroshot-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-06-21T11:32:03Z |
---
library_name: transformers
base_model: Davidozito/zeroshot-classification
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: fewshot-CDW-CE-250-samples
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fewshot-CDW-CE-250-samples
This model is a fine-tuned version of [Davidozito/zeroshot-classification](https://huggingface.co/Davidozito/zeroshot-classification) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1342
- Accuracy: 0.52
- F1 Macro: 0.4567
- F1 Weighted: 0.4859
- Precision Macro: 0.4891
- Recall Macro: 0.4833
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 Macro | F1 Weighted | Precision Macro | Recall Macro |
|:-------------:|:------:|:----:|:---------------:|:--------:|:--------:|:-----------:|:---------------:|:------------:|
| 1.1607 | 0.2414 | 7 | 1.1334 | 0.48 | 0.4406 | 0.4664 | 0.48 | 0.45 |
| 1.198 | 0.4828 | 14 | 1.1342 | 0.52 | 0.4567 | 0.4859 | 0.4891 | 0.4833 |
| 1.0988 | 0.7241 | 21 | 1.1320 | 0.48 | 0.4405 | 0.4777 | 0.4678 | 0.4400 |
| 1.0673 | 0.9655 | 28 | 1.1304 | 0.48 | 0.4405 | 0.4777 | 0.4678 | 0.4400 |
| 1.2669 | 1.2069 | 35 | 1.1282 | 0.48 | 0.4405 | 0.4777 | 0.4678 | 0.4400 |
| 1.0031 | 1.4483 | 42 | 1.1274 | 0.48 | 0.4405 | 0.4777 | 0.4678 | 0.4400 |
| 1.264 | 1.6897 | 49 | 1.1288 | 0.48 | 0.4405 | 0.4777 | 0.4678 | 0.4400 |
| 1.0977 | 1.9310 | 56 | 1.1292 | 0.48 | 0.4405 | 0.4777 | 0.4678 | 0.4400 |
| 1.2181 | 2.1724 | 63 | 1.1300 | 0.48 | 0.4405 | 0.4777 | 0.4678 | 0.4400 |
| 1.1506 | 2.4138 | 70 | 1.1310 | 0.48 | 0.4405 | 0.4777 | 0.4678 | 0.4400 |
| 1.0379 | 2.6552 | 77 | 1.1300 | 0.48 | 0.4405 | 0.4777 | 0.4678 | 0.4400 |
| 1.1612 | 2.8966 | 84 | 1.1277 | 0.48 | 0.4405 | 0.4777 | 0.4678 | 0.4400 |
| 1.1059 | 3.1379 | 91 | 1.1273 | 0.48 | 0.4405 | 0.4777 | 0.4678 | 0.4400 |
| 1.1636 | 3.3793 | 98 | 1.1267 | 0.48 | 0.4405 | 0.4777 | 0.4678 | 0.4400 |
| 1.0985 | 3.6207 | 105 | 1.1266 | 0.48 | 0.4405 | 0.4777 | 0.4678 | 0.4400 |
| 1.0929 | 3.8621 | 112 | 1.1267 | 0.48 | 0.4405 | 0.4777 | 0.4678 | 0.4400 |
| 0.9983 | 4.1034 | 119 | 1.1266 | 0.48 | 0.4405 | 0.4777 | 0.4678 | 0.4400 |
| 1.1553 | 4.3448 | 126 | 1.1266 | 0.48 | 0.4405 | 0.4777 | 0.4678 | 0.4400 |
| 1.2561 | 4.5862 | 133 | 1.1270 | 0.48 | 0.4405 | 0.4777 | 0.4678 | 0.4400 |
| 1.0976 | 4.8276 | 140 | 1.1271 | 0.48 | 0.4405 | 0.4777 | 0.4678 | 0.4400 |
### Framework versions
- Transformers 4.52.4
- Pytorch 2.7.1
- Datasets 3.6.0
- Tokenizers 0.21.1
|
buttercoconut/Qwen2.5-Ko-benchmark-distill-1.5B-Instruct-Q4
|
buttercoconut
| 2025-06-21T11:38:07Z | 0 | 0 | null |
[
"safetensors",
"qwen2",
"text-generation",
"conversational",
"ko",
"base_model:Qwen/Qwen2.5-1.5B-Instruct",
"base_model:quantized:Qwen/Qwen2.5-1.5B-Instruct",
"license:apache-2.0",
"4-bit",
"gptq",
"region:us"
] |
text-generation
| 2025-06-21T11:34:31Z |
---
license: apache-2.0
language:
- ko
base_model:
- Qwen/Qwen2.5-1.5B-Instruct
pipeline_tag: text-generation
---
|
mezzo-fun-Official/18-New.mezzo.fun.Viral.Video.Link
|
mezzo-fun-Official
| 2025-06-21T11:35:47Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T11:35:27Z |
<animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
<animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
veddhanth/lora-trained-xl-stage-2-finetuned-enc-v2-spat-map-3-5
|
veddhanth
| 2025-06-21T11:33:53Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"text-to-image",
"diffusers-training",
"lora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] |
text-to-image
| 2025-06-21T10:56:05Z |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
library_name: diffusers
license: openrail++
instance_prompt: a realistic portrait of sks face
widget: []
tags:
- text-to-image
- text-to-image
- diffusers-training
- diffusers
- lora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - veddhanth/lora-trained-xl-stage-2-finetuned-enc-v2-spat-map-3-5
<Gallery />
## Model description
These are veddhanth/lora-trained-xl-stage-2-finetuned-enc-v2-spat-map-3-5 LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: True.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use a realistic portrait of sks face to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](veddhanth/lora-trained-xl-stage-2-finetuned-enc-v2-spat-map-3-5/tree/main) them in the Files & versions tab.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model]
|
huihui-ai/Huihui-MoE-23B-A4B
|
huihui-ai
| 2025-06-21T11:25:29Z | 6 | 2 |
transformers
|
[
"transformers",
"safetensors",
"qwen3_moe",
"text-generation",
"moe",
"conversational",
"base_model:Menlo/Jan-nano",
"base_model:finetune:Menlo/Jan-nano",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-21T02:27:15Z |
---
license: apache-2.0
base_model:
- Qwen/Qwen3-4B
- Menlo/Jan-nano
- ValiantLabs/Qwen3-4B-Esper3
- prithivMLmods/Crux-Qwen3_OpenThinking-4B
- XformAI-india/Qwen3-4B-medicaldataset
- Tesslate/UIGEN-T3-4B-Preview
- radm/prophet-qwen3-4b-sft
- NiuTrans/GRAM-Qwen3-4B-RewardModel
library_name: transformers
license_link: https://huggingface.co/Qwen/Qwen3-4B/blob/main/LICENSE
pipeline_tag: text-generation
tags:
- moe
---
# huihui-ai/Huihui-MoE-23B-A4B
## Model Overview
Huihui-MoE-23B-A4B is a **Mixture of Experts (MoE)** language model developed by **huihui.ai**, built upon the **[Qwen/Qwen3-4B](https://huggingface.co/Qwen/Qwen3-4B)** base model. It enhances the standard Transformer architecture by replacing MLP layers with MoE layers, each containing 8 experts, to achieve high performance with efficient inference. The model is designed for natural language processing tasks, including text generation, question answering, and conversational applications.
The corresponding ablation version is [huihui-ai/Huihui-MoE-23B-A4B-abliterated](https://huggingface.co/huihui-ai/Huihui-MoE-23B-A4B-abliterated)
**Note**:
The activated expert can handle numbers from 1 to 8, and can complete normal conversations as well.
You can change the activation parameters using `/num_experts_per_tok <number>`. After modifying the parameters, the model will be reloaded.
- **Architecture**: Qwen3MoeForCausalLM model with 8 experts per layer (num_experts=8), activating 1-8 expert per token (num_experts_per_tok=1-8).
- **Total Parameters**: ~23 billion (23B)
- **Activated Parameters**: ~4 billion (4B) during inference, comparable to Qwen3-4B
- **Developer**: huihui.ai
- **Release Date**: June 2025
- **License**: Inherits the license of the Qwen3 base model (apache-2.0)
## Expert Models:
### Expert 1:
[Menlo/Jan-nano](https://huggingface.co/Menlo/Jan-nano)
### Expert 2:
[ValiantLabs/Qwen3-4B-Esper3](https://huggingface.co/ValiantLabs/Qwen3-4B-Esper3)
### Expert 3:
[prithivMLmods/Crux-Qwen3_OpenThinking-4B](https://huggingface.co/prithivMLmods/Crux-Qwen3_OpenThinking-4B)
### Expert 4:
[XformAI-india/Qwen3-4B-medicaldataset](https://huggingface.co/XformAI-india/Qwen3-4B-medicaldataset)
### Expert 5:
[Tesslate/UIGEN-T3-4B-Preview](https://huggingface.co/Tesslate/UIGEN-T3-4B-Preview)
### Expert 6:
[radm/prophet-qwen3-4b-sft](https://huggingface.co/radm/prophet-qwen3-4b-sft)
### Expert 7:
[NiuTrans/GRAM-Qwen3-4B-RewardModel](https://huggingface.co/NiuTrans/GRAM-Qwen3-4B-RewardModel)
### Expert 8:
[Qwen/Qwen3-4B](https://huggingface.co/Qwen/Qwen3-4B)
### Instruction Following:
[Qwen/Qwen3-4B](https://huggingface.co/Qwen/Qwen3-4B)
`Qwen/Qwen3-4B` model was directly used for this expert, no fine-tune was applied.
## Training
- **Base Model**: Qwen3-4B, pre-trained by the Qwen team.
- **Conversion**: The model copies embeddings, self-attention, and normalization weights from Qwen3-4B, replacing MLP layers with MoE layers (8 experts). Gating weights are randomly initialized.
- **Fine-Tuning**: Not fine-tuned; users are recommended to fine-tune for specific tasks to optimize expert routing.
## ollama
You can use [huihui_ai/huihui-moe:23b](https://ollama.com/huihui_ai/huihui-moe:23b) directly,
Switch the thinking toggle using /set think and /set nothink
```
ollama run huihui_ai/huihui-moe:23b
```
## Usage
```
from transformers import AutoModelForCausalLM, AutoTokenizer, AutoConfig, BitsAndBytesConfig, TextStreamer
import torch
import os
import signal
import random
import numpy as np
import time
from collections import Counter
cpu_count = os.cpu_count()
print(f"Number of CPU cores in the system: {cpu_count}")
half_cpu_count = cpu_count // 2
os.environ["MKL_NUM_THREADS"] = str(half_cpu_count)
os.environ["OMP_NUM_THREADS"] = str(half_cpu_count)
torch.set_num_threads(half_cpu_count)
print(f"PyTorch threads: {torch.get_num_threads()}")
print(f"MKL threads: {os.getenv('MKL_NUM_THREADS')}")
print(f"OMP threads: {os.getenv('OMP_NUM_THREADS')}")
# Load the model and tokenizer
NEW_MODEL_ID = "huihui-ai/Huihui-MoE-23B-A4B"
print(f"Load Model {NEW_MODEL_ID} ... ")
quant_config_4 = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
llm_int8_enable_fp32_cpu_offload=True,
)
config = AutoConfig.from_pretrained(
NEW_MODEL_ID,
trust_remote_code=True
)
config.num_experts_per_tok = 1
print(f"num_experts_per_tok: {config.num_experts_per_tok}")
model = AutoModelForCausalLM.from_pretrained(
NEW_MODEL_ID,
config=config,
device_map="auto",
trust_remote_code=True,
quantization_config=quant_config_4,
torch_dtype=torch.bfloat16
)
#print(model.config)
tokenizer = AutoTokenizer.from_pretrained(NEW_MODEL_ID, trust_remote_code=True)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.pad_token_id = tokenizer.eos_token_id
tokenizer = AutoTokenizer.from_pretrained(NEW_MODEL_ID, trust_remote_code=True)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.pad_token_id = tokenizer.eos_token_id
messages = []
nothink = False
same_seed = False
skip_prompt=True
skip_special_tokens=True
do_sample = True
def set_random_seed(seed=None):
"""Set random seed for reproducibility. If seed is None, use int(time.time())."""
if seed is None:
seed = int(time.time()) # Convert float to int
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # If using CUDA
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
return seed # Return seed for logging if needed
class CustomTextStreamer(TextStreamer):
def __init__(self, tokenizer, skip_prompt=True, skip_special_tokens=True):
super().__init__(tokenizer, skip_prompt=skip_prompt, skip_special_tokens=skip_special_tokens)
self.generated_text = ""
self.stop_flag = False
self.init_time = time.time() # Record initialization time
self.end_time = None # To store end time
self.first_token_time = None # To store first token generation time
self.token_count = 0 # To track total tokens
def on_finalized_text(self, text: str, stream_end: bool = False):
if self.first_token_time is None and text.strip(): # Set first token time on first non-empty text
self.first_token_time = time.time()
self.generated_text += text
# Count tokens in the generated text
tokens = self.tokenizer.encode(text, add_special_tokens=False)
self.token_count += len(tokens)
print(text, end="", flush=True)
if stream_end:
self.end_time = time.time() # Record end time when streaming ends
if self.stop_flag:
raise StopIteration
def stop_generation(self):
self.stop_flag = True
self.end_time = time.time() # Record end time when generation is stopped
def get_metrics(self):
"""Returns initialization time, first token time, first token latency, end time, total time, total tokens, and tokens per second."""
if self.end_time is None:
self.end_time = time.time() # Set end time if not already set
total_time = self.end_time - self.init_time # Total time from init to end
tokens_per_second = self.token_count / total_time if total_time > 0 else 0
first_token_latency = (self.first_token_time - self.init_time) if self.first_token_time is not None else None
metrics = {
"init_time": self.init_time,
"first_token_time": self.first_token_time,
"first_token_latency": first_token_latency,
"end_time": self.end_time,
"total_time": total_time, # Total time in seconds
"total_tokens": self.token_count,
"tokens_per_second": tokens_per_second
}
return metrics
def generate_stream(model, tokenizer, messages, nothink, skip_prompt, skip_special_tokens, do_sample, max_new_tokens):
input_ids = tokenizer.apply_chat_template(
messages,
tokenize=True,
enable_thinking = not nothink,
add_generation_prompt=True,
return_tensors="pt"
)
attention_mask = torch.ones_like(input_ids, dtype=torch.long)
tokens = input_ids.to(model.device)
attention_mask = attention_mask.to(model.device)
streamer = CustomTextStreamer(tokenizer, skip_prompt=skip_prompt, skip_special_tokens=skip_special_tokens)
def signal_handler(sig, frame):
streamer.stop_generation()
print("\n[Generation stopped by user with Ctrl+C]")
signal.signal(signal.SIGINT, signal_handler)
generate_kwargs = {}
if do_sample:
generate_kwargs = {
"do_sample": do_sample,
"max_length": max_new_tokens,
"temperature": 0.6,
"top_k": 20,
"top_p": 0.95,
"repetition_penalty": 1.2,
"no_repeat_ngram_size": 2
}
else:
generate_kwargs = {
"do_sample": do_sample,
"max_length": max_new_tokens,
"repetition_penalty": 1.2,
"no_repeat_ngram_size": 2
}
print("Response: ", end="", flush=True)
try:
generated_ids = model.generate(
tokens,
attention_mask=attention_mask,
#use_cache=False,
pad_token_id=tokenizer.pad_token_id,
streamer=streamer,
**generate_kwargs
)
del generated_ids
except StopIteration:
print("\n[Stopped by user]")
del input_ids, attention_mask
torch.cuda.empty_cache()
signal.signal(signal.SIGINT, signal.SIG_DFL)
return streamer.generated_text, streamer.stop_flag, streamer.get_metrics()
init_seed = set_random_seed()
activated_experts = []
# Define hook function to capture gate_probs output
def hook_fn(module, input, output):
# output is gate_probs, shape: [batch_size, sequence_length, num_experts]
gate_probs = output
# Compute top-1 expert indices (since only one expert is activated)
_, topk_indices = gate_probs.topk(config.num_experts_per_tok, dim=-1) # Take top-1
# Flatten and store activated expert indices
activated_experts.extend(topk_indices.squeeze(-1).view(-1).cpu().tolist())
hooks = []
for layer in model.model.layers:
hooks.append(layer.mlp.gate.register_forward_hook(hook_fn))
while True:
# List to store activated expert indices
activated_experts = []
if same_seed:
set_random_seed(init_seed)
else:
init_seed = set_random_seed()
print(f"\nnothink: {nothink}")
print(f"skip_prompt: {skip_prompt}")
print(f"skip_special_tokens: {skip_special_tokens}")
print(f"do_sample: {do_sample}")
print(f"same_seed: {same_seed}, {init_seed}\n")
user_input = input("User: ").strip()
if user_input.lower() == "/exit":
print("Exiting chat.")
break
if user_input.lower() == "/clear":
messages = []
print("Chat history cleared. Starting a new conversation.")
continue
if user_input.lower() == "/nothink":
nothink = not nothink
continue
if user_input.lower() == "/skip_prompt":
skip_prompt = not skip_prompt
continue
if user_input.lower() == "/skip_special_tokens":
skip_special_tokens = not skip_special_tokens
continue
if user_input.lower().startswith("/same_seed"):
parts = user_input.split()
if len(parts) == 1: # /same_seed (no number)
same_seed = not same_seed # Toggle switch
elif len(parts) == 2: # /same_seed <number>
try:
init_seed = int(parts[1]) # Extract and convert number to int
same_seed = True
except ValueError:
print("Error: Please provide a valid integer after /same_seed")
continue
if user_input.lower().startswith("/num_experts_per_tok"):
parts = user_input.split()
if len(parts) == 1: # /num_experts_per_tok (no number)
config.num_experts_per_tok = 1 # set default 1
elif len(parts) == 2: # /num_experts_per_tok
try:
num_experts_per_tok = int(parts[1]) # Extract and convert number to int
if num_experts_per_tok < 0 or num_experts_per_tok > 8:
num_experts_per_tok = 1
config.num_experts_per_tok = num_experts_per_tok
print(f"num_experts_per_tok: {config.num_experts_per_tok}")
# Remove all hooks after inference
for h in hooks: h.remove()
del model
model = AutoModelForCausalLM.from_pretrained(
NEW_MODEL_ID,
config=config,
device_map="auto",
trust_remote_code=True,
quantization_config=quant_config_4,
torch_dtype=torch.bfloat16
)
hooks = []
for layer in model.model.layers:
hooks.append(layer.mlp.gate.register_forward_hook(hook_fn))
except ValueError:
print("Error: Please provide a valid integer after /same_seed")
continue
if user_input.lower() == "/do_sample":
do_sample = not do_sample
continue
if not user_input:
print("Input cannot be empty. Please enter something.")
continue
messages.append({"role": "user", "content": user_input})
activated_experts = []
response, stop_flag, metrics = generate_stream(model, tokenizer, messages, nothink, skip_prompt, skip_special_tokens, do_sample, 40960)
print("\n\nMetrics:")
for key, value in metrics.items():
print(f" {key}: {value}")
# Count the frequency of each activated expert
expert_counts = Counter(activated_experts)
# Print activation statistics
print("\nActivated Expert Statistics:")
for expert_idx, count in sorted(expert_counts.items()):
print(f"Expert {expert_idx}: {count} times")
print("", flush=True)
if stop_flag:
continue
messages.append({"role": "assistant", "content": response})
# Remove all hooks after inference
for h in hooks: h.remove()
```
## Applications
- **Text Generation: Articles**, dialogues, and creative writing.
- **Question Answering**: Information retrieval and query resolution.
- **Conversational AI**: Multi-turn dialogues for chatbots.
- **Research**: Exploration of MoE architectures and efficient model scaling.
## Limitations
- **Fine-Tuning Required**: Randomly initialized gating weights may lead to suboptimal expert utilization without fine-tuning.
- **Compatibility**: Developed with transformers 4.52.4; ensure matching versions to avoid loading issues.
- **Inference Speed**: While efficient for an MoE model, performance depends on hardware (GPU recommended).
## Ethical Considerations
- **Bias**: Inherits potential biases from the Qwen3-4B base model; users should evaluate outputs for fairness.
- **Usage**: Intended for research and responsible applications; avoid generating harmful or misleading content.
## Contact
- **Developer**: huihui.ai
- **Repository**: huihui-ai/Huihui-MoE-23B-A4B (available locally or on Hugging Face)
- **Issues**: Report bugs or request features via the repository or please send an email to [email protected]
## Acknowledgments
- Built upon the Qwen3-4B model by the Qwen team.
- Built upon the Experts model by the Suayptalha team.
- Powered by the Hugging Face transformers library.
|
longki1234/dsfsdfsdfsd
|
longki1234
| 2025-06-21T11:24:55Z | 0 | 0 | null |
[
"license:bigcode-openrail-m",
"region:us"
] | null | 2025-06-21T11:24:55Z |
---
license: bigcode-openrail-m
---
|
Viraly-Lol-Hindi-viral/Full-viraly-lol-hindi-viral-video
|
Viraly-Lol-Hindi-viral
| 2025-06-21T11:23:31Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T11:23:19Z |
<a href="https://tinyurl.com/2frzafb9" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="WATCH Videos" data-canonical-src="https://i.imgur.com/dJHk4Zq.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
misterkissi/w2v2-lg-xls-r-300m-kinyarwanda
|
misterkissi
| 2025-06-21T11:21:08Z | 40 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice_16_1",
"base_model:facebook/wav2vec2-xls-r-300m",
"base_model:finetune:facebook/wav2vec2-xls-r-300m",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-06-20T10:41:03Z |
---
library_name: transformers
license: apache-2.0
base_model: facebook/wav2vec2-xls-r-300m
tags:
- generated_from_trainer
datasets:
- common_voice_16_1
model-index:
- name: w2v2-lg-xls-r-300m-kinyarwanda
results: []
---
# w2v2-lg-xls-r-300m-kinyarwanda
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice_16_1 dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.590943
- eval_wer: 0.548028
- eval_runtime: 81.4422
- eval_samples_per_second: 19.916
- eval_steps_per_second: 2.493
- epoch: 1.7365
- step: 21600
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 800
- num_epochs: 30
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.52.4
- Pytorch 2.6.0+cu124
- Datasets 2.14.4
- Tokenizers 0.21.1
|
nnilayy/dreamer-arousal-binary-ablation-with-adasyn-Kfold-5
|
nnilayy
| 2025-06-21T11:21:06Z | 0 | 0 | null |
[
"safetensors",
"model_hub_mixin",
"pytorch_model_hub_mixin",
"region:us"
] | null | 2025-06-21T11:21:03Z |
---
tags:
- model_hub_mixin
- pytorch_model_hub_mixin
---
This model has been pushed to the Hub using the [PytorchModelHubMixin](https://huggingface.co/docs/huggingface_hub/package_reference/mixins#huggingface_hub.PyTorchModelHubMixin) integration:
- Code: [More Information Needed]
- Paper: [More Information Needed]
- Docs: [More Information Needed]
|
ddddddpppppppp/yolos-base-fashionpedia-finetuned-v2-1
|
ddddddpppppppp
| 2025-06-21T11:15:56Z | 36 | 0 |
transformers
|
[
"transformers",
"safetensors",
"yolos",
"object-detection",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] |
object-detection
| 2025-06-11T20:05:22Z |
---
library_name: transformers
tags:
- generated_from_trainer
model-index:
- name: yolos-base-fashionpedia-finetuned-v2-1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# yolos-base-fashionpedia-finetuned-v2-1
This model was trained from scratch on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.05
- training_steps: 10000
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.44.2
- Pytorch 2.6.0+cu124
- Datasets 2.21.0
- Tokenizers 0.19.1
|
maxidl/Llama-OpenReviewer-8B
|
maxidl
| 2025-06-21T11:14:11Z | 1,606 | 5 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"review",
"peer",
"paper",
"generation",
"automatic",
"feedback",
"conference",
"article",
"manuscript",
"openreview",
"conversational",
"en",
"arxiv:2412.11948",
"base_model:meta-llama/Llama-3.1-8B-Instruct",
"base_model:finetune:meta-llama/Llama-3.1-8B-Instruct",
"license:llama3.1",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-12-11T14:29:07Z |
---
license: llama3.1
language:
- en
base_model:
- meta-llama/Llama-3.1-8B-Instruct
pipeline_tag: text-generation
library_name: transformers
tags:
- review
- peer
- paper
- generation
- automatic
- feedback
- conference
- article
- manuscript
- openreview
---
# OpenReviewer
### A Specialized Large Language Model for Generating Critical Scientific Paper Reviews
[](https://aclanthology.org/2025.naacl-demo.44)
[](http://arxiv.org/pdf/2412.11948)
[](https://huggingface.co/spaces/maxidl/openreviewer)
[](https://huggingface.co/maxidl/Llama-OpenReviewer-8B)
[](https://github.com/maxidl/openreviewer)
**OpenReviewer** is an open-source system for generating high-quality peer reviews of machine learning and AI conference papers. At its core is **Llama-OpenReviewer-8B**, an 8B parameter language model specifically fine-tuned on 79,000 expert reviews from top conferences like ICLR and NeurIPS.
# Model Overview
## Description
Llama-OpenReviewer-8B is a large language model customized to generate high-quality reviews for machine learning and AI-related conference articles.
## Dataset
We collected a dataset containing ~79k high-confidence reviews for ~32k individual papers from OpenReview.
## Training
We use [axolotl](https://github.com/axolotl-ai-cloud/axolotl) to full finetune Llama-3.1-8B-Instruct with 128k context length. Using 64 A100 80GB GPUs the training took ~34 hours.
For details and hyperparameters, see `axolotl_config.yaml` under `Files and versions`.
## Terms of use
By accessing this model, you agree to the LLama 3.1 terms and conditions of the [license](https://github.com/meta-llama/llama-models/blob/main/models/llama3_1/LICENSE), [acceptable use policy](https://github.com/meta-llama/llama-models/blob/main/models/llama3_1/USE_POLICY.md) and [Meta’s privacy policy](https://www.facebook.com/privacy/policy/)
**When using this model for official peer-reviewing tasks, we ask you to be transparent and disclose its use in your review.**
## Usage
### System prompt
The model was trained using the following system prompt:
<details>
<summary>Show system prompt</summary>
```python
SYSTEM_PROMPT_TEMPLATE = """You are an expert reviewer for AI conferences. You follow best practices and review papers according to the reviewer guidelines.
Reviewer guidelines:
1. Read the paper: It’s important to carefully read through the entire paper, and to look up any related work and citations that will help you comprehensively evaluate it. Be sure to give yourself sufficient time for this step.
2. While reading, consider the following:
- Objective of the work: What is the goal of the paper? Is it to better address a known application or problem, draw attention to a new application or problem, or to introduce and/or explain a new theoretical finding? A combination of these? Different objectives will require different considerations as to potential value and impact.
- Strong points: is the submission clear, technically correct, experimentally rigorous, reproducible, does it present novel findings (e.g. theoretically, algorithmically, etc.)?
- Weak points: is it weak in any of the aspects listed in b.?
- Be mindful of potential biases and try to be open-minded about the value and interest a paper can hold for the community, even if it may not be very interesting for you.
3. Answer four key questions for yourself, to make a recommendation to Accept or Reject:
- What is the specific question and/or problem tackled by the paper?
- Is the approach well motivated, including being well-placed in the literature?
- Does the paper support the claims? This includes determining if results, whether theoretical or empirical, are correct and if they are scientifically rigorous.
- What is the significance of the work? Does it contribute new knowledge and sufficient value to the community? Note, this does not necessarily require state-of-the-art results. Submissions bring value to the community when they convincingly demonstrate new, relevant, impactful knowledge (incl., empirical, theoretical, for practitioners, etc).
4. Write your review including the following information:
- Summarize what the paper claims to contribute. Be positive and constructive.
- List strong and weak points of the paper. Be as comprehensive as possible.
- Clearly state your initial recommendation (accept or reject) with one or two key reasons for this choice.
- Provide supporting arguments for your recommendation.
- Ask questions you would like answered by the authors to help you clarify your understanding of the paper and provide the additional evidence you need to be confident in your assessment.
- Provide additional feedback with the aim to improve the paper. Make it clear that these points are here to help, and not necessarily part of your decision assessment.
Your write reviews in markdown format. Your reviews contain the following sections:
# Review
{review_fields}
Your response must only contain the review in markdown format with sections as defined above.
"""
```
</details>
Note that the `review_fields` vary for different papers depending on the venue.
Example `review_fields`:
<details>
<summary>ICLR 2025</summary>
```python
REVIEW_FIELDS = """## Summary
Briefly summarize the paper and its contributions. This is not the place to critique the paper; the authors should generally agree with a well-written summary.
## Soundness
Please assign the paper a numerical rating on the following scale to indicate the soundness of the technical claims, experimental and research methodology and on whether the central claims of the paper are adequately supported with evidence. Choose from the following:
4: excellent
3: good
2: fair
1: poor
## Presentation
Please assign the paper a numerical rating on the following scale to indicate the quality of the presentation. This should take into account the writing style and clarity, as well as contextualization relative to prior work. Choose from the following:
4: excellent
3: good
2: fair
1: poor
## Contribution
Please assign the paper a numerical rating on the following scale to indicate the quality of the overall contribution this paper makes to the research area being studied. Are the questions being asked important? Does the paper bring a significant originality of ideas and/or execution? Are the results valuable to share with the broader ICLR community? Choose from the following:
4: excellent
3: good
2: fair
1: poor
## Strengths
A substantive assessment of the strengths of the paper, touching on each of the following dimensions: originality, quality, clarity, and significance. We encourage reviewers to be broad in their definitions of originality and significance. For example, originality may arise from a new definition or problem formulation, creative combinations of existing ideas, application to a new domain, or removing limitations from prior results.
## Weaknesses
A substantive assessment of the weaknesses of the paper. Focus on constructive and actionable insights on how the work could improve towards its stated goals. Be specific, avoid generic remarks. For example, if you believe the contribution lacks novelty, provide references and an explanation as evidence; if you believe experiments are insufficient, explain why and exactly what is missing, etc.
## Questions
Please list up and carefully describe any questions and suggestions for the authors. Think of the things where a response from the author can change your opinion, clarify a confusion or address a limitation. This is important for a productive rebuttal and discussion phase with the authors.
## Flag For Ethics Review
If there are ethical issues with this paper, please flag the paper for an ethics review and select area of expertise that would be most useful for the ethics reviewer to have. Please select all that apply. Choose from the following:
No ethics review needed.
Yes, Discrimination / bias / fairness concerns
Yes, Privacy, security and safety
Yes, Legal compliance (e.g., GDPR, copyright, terms of use)
Yes, Potentially harmful insights, methodologies and applications
Yes, Responsible research practice (e.g., human subjects, data release)
Yes, Research integrity issues (e.g., plagiarism, dual submission)
Yes, Unprofessional behaviors (e.g., unprofessional exchange between authors and reviewers)
Yes, Other reasons (please specify below)
## Details Of Ethics Concerns
Please provide details of your concerns.
## Rating
Please provide an "overall score" for this submission. Choose from the following:
1: strong reject
3: reject, not good enough
5: marginally below the acceptance threshold
6: marginally above the acceptance threshold
8: accept, good paper
10: strong accept, should be highlighted at the conference
"""
```
</details>
### User prompt
The model was trained with the following user prompt:
<details>
<summary>Show user prompt</summary>
```python
"""Review the following paper:
{paper_text}
"""
```
</details>
The paper text must be formatted in markdown. We recommend providing the entire text, including references, and omitting any appendix.
## Citation
```
@inproceedings{idahl-ahmadi-2025-openreviewer,
title = "{O}pen{R}eviewer: A Specialized Large Language Model for Generating Critical Scientific Paper Reviews",
author = "Idahl, Maximilian and
Ahmadi, Zahra",
editor = "Dziri, Nouha and
Ren, Sean (Xiang) and
Diao, Shizhe",
booktitle = "Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (System Demonstrations)",
month = apr,
year = "2025",
address = "Albuquerque, New Mexico",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2025.naacl-demo.44/",
doi = "10.18653/v1/2025.naacl-demo.44",
pages = "550--562",
ISBN = "979-8-89176-191-9"
}
```
|
Madaio/Madly
|
Madaio
| 2025-06-21T11:07:56Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-06-21T10:51:20Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: Madly
---
# Madly
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `Madly` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "Madly",
"lora_weights": "https://huggingface.co/Madaio/Madly/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('Madaio/Madly', weight_name='lora.safetensors')
image = pipeline('Madly').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 1000
- Learning rate: 0.0004
- LoRA rank: 22
## Contribute your own examples
You can use the [community tab](https://huggingface.co/Madaio/Madly/discussions) to add images that show off what you’ve made with this LoRA.
|
tscstudios/uwc2dwp7phyqtspkirv8jl1tday2_38ba3f06-707c-4134-9598-b905802c1260
|
tscstudios
| 2025-06-21T11:04:00Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-06-21T11:03:57Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: TOK
---
# Uwc2Dwp7Phyqtspkirv8Jl1Tday2_38Ba3F06 707C 4134 9598 B905802C1260
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `TOK` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "TOK",
"lora_weights": "https://huggingface.co/tscstudios/uwc2dwp7phyqtspkirv8jl1tday2_38ba3f06-707c-4134-9598-b905802c1260/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('tscstudios/uwc2dwp7phyqtspkirv8jl1tday2_38ba3f06-707c-4134-9598-b905802c1260', weight_name='lora.safetensors')
image = pipeline('TOK').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 1200
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/tscstudios/uwc2dwp7phyqtspkirv8jl1tday2_38ba3f06-707c-4134-9598-b905802c1260/discussions) to add images that show off what you’ve made with this LoRA.
|
phduc/llama3.1-70b-nik-merged-4bit
|
phduc
| 2025-06-21T10:49:14Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"en",
"base_model:unsloth/Meta-Llama-3.1-70B-bnb-4bit",
"base_model:quantized:unsloth/Meta-Llama-3.1-70B-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-06-21T10:08:17Z |
---
base_model: unsloth/Meta-Llama-3.1-70B-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** phduc
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Meta-Llama-3.1-70B-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
zecaihong/999e249f-6b05-4a37-9bc6-b4556645f48a
|
zecaihong
| 2025-06-21T10:41:22Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"qwen2",
"axolotl",
"generated_from_trainer",
"base_model:unsloth/Qwen2.5-3B",
"base_model:adapter:unsloth/Qwen2.5-3B",
"license:other",
"region:us"
] | null | 2025-06-21T08:22:35Z |
---
library_name: peft
license: other
base_model: unsloth/Qwen2.5-3B
tags:
- axolotl
- generated_from_trainer
model-index:
- name: 999e249f-6b05-4a37-9bc6-b4556645f48a
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.10.0.dev0`
```yaml
adapter: lora
base_model: unsloth/Qwen2.5-3B
bf16: auto
chat_template: llama3
dataset_prepared_path: null
datasets:
- data_files:
- 9b229213575401f4_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/
type:
field_instruction: instruct
field_output: output
format: '{instruction}'
no_input_format: '{instruction}'
system_prompt: ''
debug: null
deepspeed: deepspeed_configs/zero2.json
early_stopping_patience: 1
eval_max_new_tokens: 1024
eval_steps: 100
eval_table_size: null
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 4
gradient_checkpointing: false
greater_is_better: false
group_by_length: false
hub_model_id: zecaihong/999e249f-6b05-4a37-9bc6-b4556645f48a
hub_repo: null
hub_strategy: checkpoint
hub_token: null
learning_rate: 0.0002
load_in_4bit: false
load_in_8bit: false
local_rank: null
logging_steps: 10
lora_alpha: 16
lora_dropout: 0.05
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 8
lora_target_linear: true
lr_scheduler: cosine
max_steps: -1
metric_for_best_model: eval_loss
micro_batch_size: 12
mlflow_experiment_name: /data/datasets/9b229213575401f4_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 3
optimizer: adamw_torch
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
save_steps: 100
sequence_len: 1024
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: 999e249f-6b05-4a37-9bc6-b4556645f48a
wandb_project: Gradients-On-Demand
wandb_run: your_name
wandb_runid: 999e249f-6b05-4a37-9bc6-b4556645f48a
warmup_steps: 100
weight_decay: 0.001
xformers_attention: null
```
</details><br>
# 999e249f-6b05-4a37-9bc6-b4556645f48a
This model is a fine-tuned version of [unsloth/Qwen2.5-3B](https://huggingface.co/unsloth/Qwen2.5-3B) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2769
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 12
- eval_batch_size: 12
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 4
- total_train_batch_size: 384
- total_eval_batch_size: 96
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 100
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| No log | 0.0011 | 1 | 1.9995 |
| 1.566 | 0.1107 | 100 | 1.5810 |
| 1.4619 | 0.2215 | 200 | 1.4889 |
| 1.4309 | 0.3322 | 300 | 1.4495 |
| 1.4044 | 0.4430 | 400 | 1.4213 |
| 1.3891 | 0.5537 | 500 | 1.3985 |
| 1.3536 | 0.6645 | 600 | 1.3831 |
| 1.3571 | 0.7752 | 700 | 1.3667 |
| 1.3805 | 0.8859 | 800 | 1.3561 |
| 1.3385 | 0.9967 | 900 | 1.3435 |
| 1.3114 | 1.1074 | 1000 | 1.3358 |
| 1.289 | 1.2182 | 1100 | 1.3281 |
| 1.3032 | 1.3289 | 1200 | 1.3206 |
| 1.3068 | 1.4396 | 1300 | 1.3138 |
| 1.2913 | 1.5504 | 1400 | 1.3080 |
| 1.2792 | 1.6611 | 1500 | 1.3026 |
| 1.2823 | 1.7719 | 1600 | 1.2977 |
| 1.2948 | 1.8826 | 1700 | 1.2927 |
| 1.275 | 1.9934 | 1800 | 1.2891 |
| 1.2514 | 2.1041 | 1900 | 1.2866 |
| 1.2614 | 2.2148 | 2000 | 1.2841 |
| 1.2539 | 2.3256 | 2100 | 1.2818 |
| 1.2459 | 2.4363 | 2200 | 1.2800 |
| 1.2566 | 2.5471 | 2300 | 1.2786 |
| 1.2558 | 2.6578 | 2400 | 1.2777 |
| 1.2476 | 2.7685 | 2500 | 1.2772 |
| 1.2651 | 2.8793 | 2600 | 1.2769 |
| 1.2503 | 2.9900 | 2700 | 1.2769 |
### Framework versions
- PEFT 0.15.2
- Transformers 4.52.3
- Pytorch 2.5.1+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
PaceKW/bert-base-indonesian-1.5G-multilabel-indonesian-hate-speech-modified-v2
|
PaceKW
| 2025-06-21T10:37:04Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"base_model:cahya/bert-base-indonesian-1.5G",
"base_model:finetune:cahya/bert-base-indonesian-1.5G",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2025-06-21T10:32:10Z |
---
library_name: transformers
license: mit
base_model: cahya/bert-base-indonesian-1.5G
tags:
- generated_from_trainer
metrics:
- f1
- accuracy
model-index:
- name: bert-base-indonesian-1.5G-multilabel-indonesian-hate-speech-modified-v2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-indonesian-1.5G-multilabel-indonesian-hate-speech-modified-v2
This model is a fine-tuned version of [cahya/bert-base-indonesian-1.5G](https://huggingface.co/cahya/bert-base-indonesian-1.5G) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2271
- F1: 0.8042
- Roc Auc: 0.8799
- Accuracy: 0.7229
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Roc Auc | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:------:|:-------:|:--------:|
| 0.257 | 1.0 | 1317 | 0.2008 | 0.7645 | 0.8432 | 0.6507 |
| 0.1793 | 2.0 | 2634 | 0.1925 | 0.7868 | 0.8732 | 0.6621 |
| 0.1305 | 3.0 | 3951 | 0.2005 | 0.7959 | 0.8773 | 0.7039 |
| 0.0909 | 4.0 | 5268 | 0.2191 | 0.7961 | 0.8666 | 0.7206 |
| 0.0655 | 5.0 | 6585 | 0.2271 | 0.8042 | 0.8799 | 0.7229 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.7.0+cu128
- Datasets 3.6.0
- Tokenizers 0.21.1
|
S-Sethisak/xlsr
|
S-Sethisak
| 2025-06-21T10:31:36Z | 38 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:fleurs",
"base_model:S-Sethisak/xlsr-khmer-fleur-ex02",
"base_model:finetune:S-Sethisak/xlsr-khmer-fleur-ex02",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-06-20T07:30:46Z |
---
library_name: transformers
base_model: S-Sethisak/xlsr-khmer-fleur-ex02
tags:
- generated_from_trainer
datasets:
- fleurs
metrics:
- wer
model-index:
- name: xlsr
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: fleurs
type: fleurs
config: km_kh
split: None
args: km_kh
metrics:
- name: Wer
type: wer
value: 0.6776300222422034
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlsr
This model is a fine-tuned version of [S-Sethisak/xlsr-khmer-fleur-ex02](https://huggingface.co/S-Sethisak/xlsr-khmer-fleur-ex02) on the fleurs dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8011
- Wer: 0.6776
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 6.25e-06
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 800
- training_steps: 8000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:------:|:----:|:---------------:|:------:|
| 2.1893 | 0.1434 | 400 | 1.3998 | 1.0 |
| 1.7694 | 0.2867 | 800 | 0.9742 | 0.9704 |
| 1.7196 | 0.4301 | 1200 | 0.8980 | 0.7788 |
| 1.8691 | 0.5735 | 1600 | 0.8685 | 0.7422 |
| 1.8432 | 0.7168 | 2000 | 0.8528 | 0.7295 |
| 1.8607 | 0.8602 | 2400 | 0.8395 | 0.7231 |
| 1.7744 | 1.0036 | 2800 | 0.8338 | 0.7122 |
| 1.6846 | 1.1470 | 3200 | 0.8259 | 0.7024 |
| 1.7989 | 1.2903 | 3600 | 0.8297 | 0.6974 |
| 1.5462 | 1.4337 | 4000 | 0.8212 | 0.6938 |
| 1.6145 | 1.5771 | 4400 | 0.8214 | 0.6908 |
| 1.4987 | 1.7204 | 4800 | 0.8172 | 0.6854 |
| 1.5861 | 1.8638 | 5200 | 0.8185 | 0.6835 |
| 1.6129 | 2.0072 | 5600 | 0.8144 | 0.6810 |
| 1.6523 | 2.1505 | 6000 | 0.8170 | 0.6788 |
| 1.5069 | 2.2939 | 6400 | 0.8116 | 0.6793 |
| 1.5815 | 2.4373 | 6800 | 0.8113 | 0.6780 |
| 1.4807 | 2.5806 | 7200 | 0.8069 | 0.6768 |
| 1.6869 | 2.7240 | 7600 | 0.8024 | 0.6777 |
| 1.712 | 2.8674 | 8000 | 0.8011 | 0.6776 |
### Framework versions
- Transformers 4.52.4
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
littlewhitesea/lora-trained-xl
|
littlewhitesea
| 2025-06-21T10:28:20Z | 0 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"diffusers-training",
"lora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] |
text-to-image
| 2025-06-21T10:07:31Z |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
library_name: diffusers
license: openrail++
instance_prompt: a photo of sks dog
widget:
- text: A photo of sks dog in a bucket
output:
url: image_0.png
- text: A photo of sks dog in a bucket
output:
url: image_1.png
- text: A photo of sks dog in a bucket
output:
url: image_2.png
- text: A photo of sks dog in a bucket
output:
url: image_3.png
tags:
- text-to-image
- text-to-image
- diffusers-training
- diffusers
- lora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - littlewhitesea/lora-trained-xl
<Gallery />
## Model description
These are littlewhitesea/lora-trained-xl LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use a photo of sks dog to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](littlewhitesea/lora-trained-xl/tree/main) them in the Files & versions tab.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model]
|
yaskrugan2/786e381a-5ae6-4839-84f4-a60e6be906ab
|
yaskrugan2
| 2025-06-21T10:27:11Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"unsloth",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-06-21T07:43:30Z |
---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
girayzkrt/lastft
|
girayzkrt
| 2025-06-21T10:24:54Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"en",
"base_model:unsloth/mistral-7b-instruct-v0.3-bnb-4bit",
"base_model:finetune:unsloth/mistral-7b-instruct-v0.3-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-21T10:24:16Z |
---
base_model: unsloth/mistral-7b-instruct-v0.3-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** girayzkrt
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b-instruct-v0.3-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
19-Pakcricketinfo-Samiya-Video/wATCH.Pakcricketinfo.Samiya.viral.video.original
|
19-Pakcricketinfo-Samiya-Video
| 2025-06-21T10:22:38Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T10:19:50Z |
[🌐 CLICK HERE 🟢==►► WATCH NOW](https://videohere.top/?V=Pakcricketinfo-Samiya)
[🔴 CLICK HERE 🌐==►► Download Now)](https://videohere.top/?V=Pakcricketinfo-Samiya)
[<img alt="fsd" src="https://i.postimg.cc/qvPp49Sm/ythngythg.gif">](https://videohere.top/?V=Pakcricketinfo-Samiya)
|
winnieyangwannan/entity_OLMoE-1B-7B-0924-Instruct_experts_positive-negative-addition-same_last_layer_4_2_all_3_49
|
winnieyangwannan
| 2025-06-21T10:21:40Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"olmoe",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-21T10:19:33Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
winnieyangwannan/entity_OLMoE-1B-7B-0924-Instruct_experts_positive-negative-addition-same_last_layer_0_2_all_3_49
|
winnieyangwannan
| 2025-06-21T10:20:34Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"olmoe",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-21T10:18:17Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
thonypythony/two-klass
|
thonypythony
| 2025-06-21T10:17:11Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T10:14:47Z |

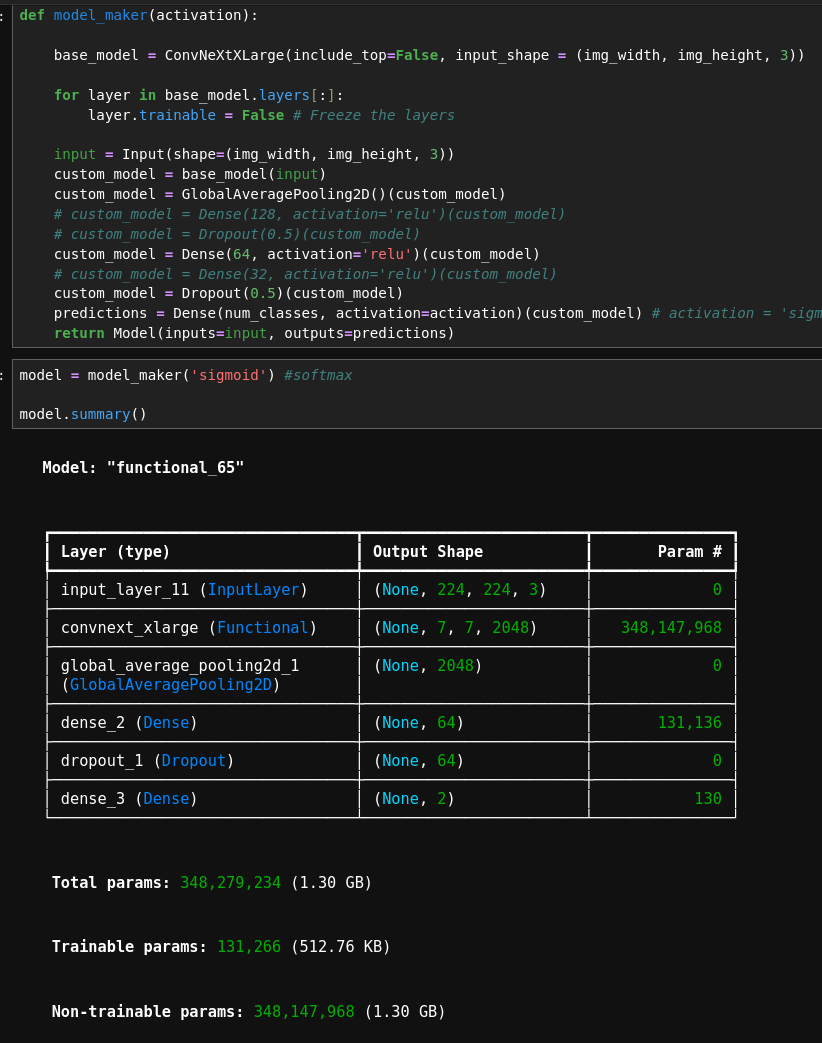
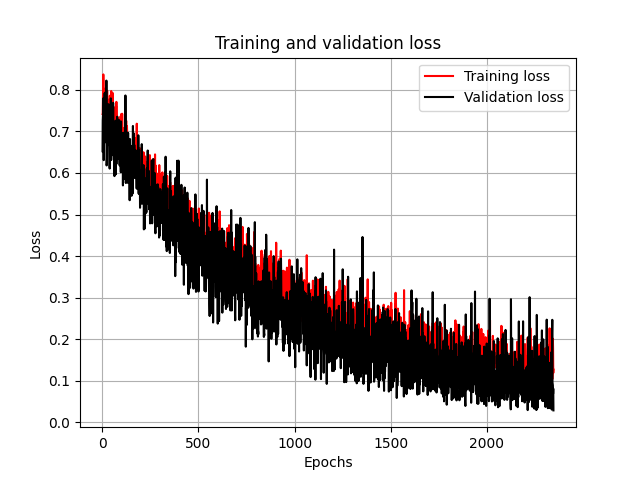
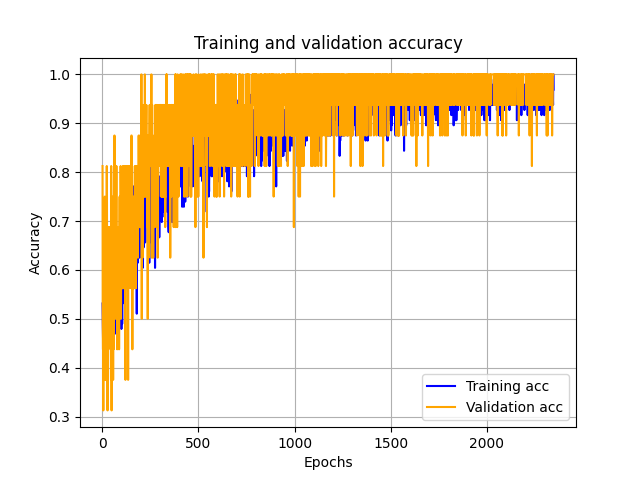




|
Jaipur-hotel-viral-video-link-twitter/Jaipur.hotel.viral.video.link.twitter.Watch.jaipur.hotel.Viral.Video.Original
|
Jaipur-hotel-viral-video-link-twitter
| 2025-06-21T10:14:33Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T10:13:23Z |
<animated-image data-catalyst=""><a href="https://tinyurl.com/56hn7ue8/?news-viral-video" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
AvinashAkkupalli/q-FrozenLake-v1-4x4-noSlippery
|
AvinashAkkupalli
| 2025-06-21T10:12:21Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-06-21T08:52:40Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
model = load_from_hub(repo_id="AvinashAkkupalli/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
|
sergioalves/4312b581-976d-4ca8-9f5a-ea6915dff733
|
sergioalves
| 2025-06-21T10:12:19Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"llama",
"axolotl",
"generated_from_trainer",
"base_model:samoline/31f00825-2bb2-41ca-a044-ca519b874175",
"base_model:adapter:samoline/31f00825-2bb2-41ca-a044-ca519b874175",
"4-bit",
"bitsandbytes",
"region:us"
] | null | 2025-06-21T09:40:43Z |
---
library_name: peft
base_model: samoline/31f00825-2bb2-41ca-a044-ca519b874175
tags:
- axolotl
- generated_from_trainer
model-index:
- name: 4312b581-976d-4ca8-9f5a-ea6915dff733
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
absolute_data_files: false
adapter: lora
base_model: samoline/31f00825-2bb2-41ca-a044-ca519b874175
bf16: true
chat_template: llama3
dataset_prepared_path: /workspace/axolotl
datasets:
- data_files:
- a64aa61dd98c3155_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/
type:
field_input: input
field_instruction: instruct
field_output: output
format: '{instruction} {input}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
dpo:
beta: 0.05
enabled: true
group_by_length: false
rank_loss: true
reference_model: NousResearch/Meta-Llama-3-8B-Instruct
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 1
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 4
gradient_checkpointing: true
gradient_clipping: 1.0
group_by_length: false
hub_model_id: sergioalves/4312b581-976d-4ca8-9f5a-ea6915dff733
hub_repo: null
hub_strategy: end
hub_token: null
learning_rate: 5.0e-07
load_in_4bit: true
load_in_8bit: false
local_rank: null
logging_steps: 1
lora_alpha: 64
lora_dropout: 0.1
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 32
lora_target_linear: true
lr_scheduler: cosine
max_steps: 200
micro_batch_size: 8
mixed_precision: bf16
mlflow_experiment_name: /tmp/a64aa61dd98c3155_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 2
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 1
sequence_len: 1024
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: a2d22a24-2f3f-485c-b56d-3862af719003
wandb_project: s56-7
wandb_run: your_name
wandb_runid: a2d22a24-2f3f-485c-b56d-3862af719003
warmup_steps: 25
weight_decay: 0.05
xformers_attention: false
```
</details><br>
# 4312b581-976d-4ca8-9f5a-ea6915dff733
This model is a fine-tuned version of [samoline/31f00825-2bb2-41ca-a044-ca519b874175](https://huggingface.co/samoline/31f00825-2bb2-41ca-a044-ca519b874175) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7542
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-07
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 25
- training_steps: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.8416 | 0.0003 | 1 | 0.7548 |
| 0.434 | 0.0329 | 100 | 0.7544 |
| 0.7345 | 0.0657 | 200 | 0.7542 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1
|
PaceKW/indobert-base-uncased-multilabel-indonesian-hate-speech-modified-v2
|
PaceKW
| 2025-06-21T10:12:03Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"base_model:indolem/indobert-base-uncased",
"base_model:finetune:indolem/indobert-base-uncased",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2025-06-21T10:07:11Z |
---
library_name: transformers
license: mit
base_model: indolem/indobert-base-uncased
tags:
- generated_from_trainer
metrics:
- f1
- accuracy
model-index:
- name: indobert-base-uncased-multilabel-indonesian-hate-speech-modified-v2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# indobert-base-uncased-multilabel-indonesian-hate-speech-modified-v2
This model is a fine-tuned version of [indolem/indobert-base-uncased](https://huggingface.co/indolem/indobert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2051
- F1: 0.7925
- Roc Auc: 0.8745
- Accuracy: 0.7039
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Roc Auc | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:------:|:-------:|:--------:|
| 0.3057 | 1.0 | 1317 | 0.2248 | 0.7142 | 0.8121 | 0.5968 |
| 0.2102 | 2.0 | 2634 | 0.2156 | 0.7530 | 0.8584 | 0.5991 |
| 0.1797 | 3.0 | 3951 | 0.1998 | 0.7737 | 0.8580 | 0.6606 |
| 0.1472 | 4.0 | 5268 | 0.1995 | 0.7916 | 0.8665 | 0.7062 |
| 0.1269 | 5.0 | 6585 | 0.2051 | 0.7925 | 0.8745 | 0.7039 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.7.0+cu128
- Datasets 3.6.0
- Tokenizers 0.21.1
|
roshbeed/text8-dataset
|
roshbeed
| 2025-06-21T10:11:25Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T10:11:17Z |
# Text8 Dataset
This repository contains the Text8 dataset, a large text corpus commonly used for training word embeddings and language models.
## Dataset Information
- **Source**: http://mattmahoney.net/dc/text8.zip
- **License**: Public domain
- **Format**: Text corpus
- **Size**: Large text corpus (~100MB)
## Files
- `text8_full.txt`: Complete text8 corpus
- `text8_sentences.json`: Text8 split into sentences for easier processing
- `dataset_info.json`: Dataset metadata
## Usage
You can load this dataset in your training scripts using:
```python
from huggingface_hub import hf_hub_download
import json
# Download sentences
sentences_path = hf_hub_download(
repo_id="roshbeed/text8-dataset",
filename="text8_sentences.json",
token="your_token"
)
with open(sentences_path, 'r') as f:
data = json.load(f)
sentences = data['sentences']
# Use sentences for training
```
## Citation
If you use this dataset, please cite the original source.
|
kosinebolisa/igbotts_refined
|
kosinebolisa
| 2025-06-21T10:03:23Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"speecht5",
"text-to-audio",
"generated_from_trainer",
"base_model:microsoft/speecht5_tts",
"base_model:finetune:microsoft/speecht5_tts",
"license:mit",
"endpoints_compatible",
"region:us"
] |
text-to-audio
| 2025-06-18T19:22:13Z |
---
library_name: transformers
license: mit
base_model: microsoft/speecht5_tts
tags:
- generated_from_trainer
model-index:
- name: igbotts_refined
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# igbotts_refined
This model is a fine-tuned version of [microsoft/speecht5_tts](https://huggingface.co/microsoft/speecht5_tts) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4884
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-------:|:----:|:---------------:|
| 0.594 | 3.6538 | 500 | 0.5317 |
| 0.5516 | 7.3012 | 1000 | 0.5032 |
| 0.534 | 10.9550 | 1500 | 0.4977 |
| 0.5165 | 14.6024 | 2000 | 0.4930 |
| 0.507 | 18.2498 | 2500 | 0.4911 |
| 0.5144 | 21.9036 | 3000 | 0.4851 |
| 0.5025 | 25.5510 | 3500 | 0.4885 |
| 0.5 | 29.1983 | 4000 | 0.4884 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
viralclip00/New-tutorial-nirma-meena-hd-18-Viral-Video.FULL.VIDEO
|
viralclip00
| 2025-06-21T09:57:45Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T09:57:13Z |
02 minutes ago- New-tutorial-nirma-meena-hd-18-Viral-Video.FULL.VIDEO
Nirma Meena Viral Video Original Clip. Options. Subscribe to RSS Feed ... Nirma Meena Viral Video Original Clip. Nirma Meena Viral Video ...
[🌐 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🟢==►► 𝖶𝖠𝖳𝖢𝖧 𝖭𝖮𝖶](https://t.co/w4GQblBMlq)
[🌐 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🟢==►► 𝖶𝖠𝖳𝖢𝖧 𝖭𝖮𝖶 FREE](https://t.co/w4GQblBMlq)
<a href="https://t.co/w4GQblBMlq" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="WATCH Videos" data-canonical-src="https://i.imgur.com/dJHk4Zq.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
New-tutorial-anjali-arora-viral-videos/FULL.VIDEO.anjali.arora.Viral.Video.Tutorial.Official
|
New-tutorial-anjali-arora-viral-videos
| 2025-06-21T09:53:28Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T09:53:18Z |
01 seconds ago
[🌐 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🟢==►► 𝖶𝖠𝖳𝖢𝖧 𝖭𝖮𝖶](https://sahabagi-mgi.blogspot.com/p/heres-now.html)
[🌐 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🟢==►► 𝖶𝖠𝖳𝖢𝖧 𝖭𝖮𝖶 FREE](https://sahabagi-mgi.blogspot.com/p/heres-now.html)
<a href="https://sahabagi-mgi.blogspot.com/p/heres-now.html" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="WATCH Videos" data-canonical-src="https://i.imgur.com/dJHk4Zq.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
viralclip00/video.BJP.Leader.Manohar.Lal.Dhakad.Caught.Having.Sax.On.Delhi-Mumbai.Highway
|
viralclip00
| 2025-06-21T09:51:39Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T09:51:21Z |
15 seconds ago- video.BJP.Leader.Manohar.Lal.Dhakad.Caught.Having.Sax.On.Delhi-Mumbai.Highway
See the full show program for +VIDEO 18+)* Cikgu Fadhilah Viral Video Link Full Video Original Clip at running
[🌐 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🟢==►► 𝖶𝖠𝖳𝖢𝖧 𝖭𝖮𝖶](https://t.co/w4GQblBMlq)
[🌐 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🟢==►► 𝖶𝖠𝖳𝖢𝖧 𝖭𝖮𝖶 FREE](https://t.co/w4GQblBMlq)
<a href="https://t.co/w4GQblBMlq" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="WATCH Videos" data-canonical-src="https://i.imgur.com/dJHk4Zq.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
Sandhya2002/Sentimental-bert-based-uncased
|
Sandhya2002
| 2025-06-21T09:51:26Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-06-21T09:51:03Z |
---
library_name: transformers
license: apache-2.0
base_model: google-bert/bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: Sentimental-bert-based-uncased
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Sentimental-bert-based-uncased
This model is a fine-tuned version of [google-bert/bert-base-uncased](https://huggingface.co/google-bert/bert-base-uncased) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.52.4
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
winnieyangwannan/entity_OLMoE-1B-7B-0924-Instruct_experts_positive-negative-addition-same_last_layer_2_2_all_3_49
|
winnieyangwannan
| 2025-06-21T09:50:27Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"olmoe",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-21T09:48:30Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Ayushx29/finance_finetune_model
|
Ayushx29
| 2025-06-21T09:48:36Z | 0 | 1 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-20T08:40:26Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
GeorgyGUF/Sana_600M_1024px_transformer.gguf
|
GeorgyGUF
| 2025-06-21T09:44:44Z | 15 | 0 | null |
[
"gguf",
"region:us"
] | null | 2025-06-20T20:08:43Z |
Note, that Sana is a FP32 model, and this gguf is just FP16, not even BF16, so for other quantizations create a FP32 gguf first for better quality.
To use this model/quant you need add Sana support to ComfyUi or GGUF support to Sana custom nodes. Otherwise you will get `ValueError: This model is not currently supported - (Unknown model architecture!)`
The simplest way if you just need a FP16 variant is to use official quant, or if fp8 is needed - quantize safetensors/pth to it and use without gguf
This can be helpful:
https://github.com/huggingface/diffusers/blob/main/docs/source/en/api/pipelines/sana.md#quantization
https://github.com/NVlabs/Sana/blob/main/asset/docs/quantize/8bit_sana.md
https://github.com/NVlabs/Sana/pull/249
https://github.com/NVlabs/Sana/issues/128
https://github.com/NVlabs/Sana/blob/main/tools/convert_sana_to_svdquant.py and https://github.com/NVlabs/Sana/blob/main/asset/docs/quantize/4bit_sana.md
but this solution is not stable, you can get error like this `RuntimeError: The expanded size of the tensor (2240) must match the existing size (1152) at non-singleton dimension 1. Target sizes: [2880, 2240, 1, 1]. Tensor sizes: [2880, 1152, 1, 1]` (only with the 592M model), so prepare a workaround for this case. This script just creates a safetensor version of original pth, then you will need to make a SVDQuant from it
probably the most easy way https://huggingface.co/Kijai/flux-fp8/discussions/7
|
Tsubasa109/LoRA-Sample
|
Tsubasa109
| 2025-06-21T09:43:26Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2025-03-13T07:58:31Z |
---
license: creativeml-openrail-m
---
LoRA集です
character
リィサ・シルバー
liisa_silver_(dress)_V1.0_IllustriousV1.0.safetensors
リィサ・シルバーの通常衣装
ベースモデル:IllustriousV1.0
トリガーワード:liisa_silver_(dress), lssds, dress,
LoRA影響度:0.7~1.0
liisa_silver_(playboy_bunny)_V1.0_IllustriousV1.0.safetensors
リィサ・シルバーのバニー衣装
ベースモデル:IllustriousV1.0
トリガーワード:liisa silver (playboy bunny),playboy bunny,
LoRA影響度:0.7~1.0
liisa_silver_(evening_gown)_V1.0_IllustriousV1.0.safetensors
リィサ・シルバーのパーティードレス
ベースモデル:IllustriousV1.0
トリガーワード:liisa_silver_(evening_gown), liseg, evening gown,
LoRA影響度:0.7~1.0
liisa_silver_(beast_moon)_V1.0_IllustriousV1.0.safetensors
リィサ・シルバーの別バージョン、ビーストムーン
ベースモデル:IllustriousV1.0
トリガーワード:liisa_silver_(beast_moon),lsvbm,crop top,
LoRA影響度:0.7~1.0
liisa_silver_(lingerie)_V1.0_IllustriousV1.0.safetensors
リィサ・シルバーの下着姿
ベースモデル:IllustriousV1.0
トリガーワード:liisa_silver_(lingerie), lisvle, lingerie,
LoRA影響度:0.7~1.0
liisa_silver_(swimsuit)_V1.0_IllustriousV1.0.safetensors
リィサ・シルバーの水着姿
ベースモデル:IllustriousV1.0
トリガーワード:liisa_silver_(swimsuit), lsvss, swimsuit,
LoRA影響度:0.7~1.0
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.