
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-08-01 12:29:10
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 547
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-08-01 12:28:04
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
kangnichaluo/mnli-1
|
kangnichaluo
| 2021-05-25T11:36:25Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
learning rate: 2e-5
training epochs: 3
batch size: 64
seed: 42
model: bert-base-uncased
trained on MNLI which is converted into two-way nli classification (predict entailment or not-entailment class)
|
Intel/bert-base-uncased-mnli-sparse-70-unstructured
|
Intel
| 2021-05-24T17:47:03Z | 16 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:04Z |
---
language: en
---
# Sparse BERT base model fine tuned to MNLI (uncased)
Fine tuned sparse BERT base to MNLI (GLUE Benchmark) task from [bert-base-uncased-sparse-70-unstructured](https://huggingface.co/Intel/bert-base-uncased-sparse-70-unstructured).
<br><br>
Note: This model requires `transformers==2.10.0`
## Evaluation Results
Matched: 82.5%
Mismatched: 83.3%
This model can be further fine-tuned to other tasks and achieve the following evaluation results:
| Task | QQP (Acc/F1) | QNLI (Acc) | SST-2 (Acc) | STS-B (Pears/Spear) | SQuADv1.1 (Acc/F1) |
|------|--------------|------------|-------------|---------------------|--------------------|
| | 90.2/86.7 | 90.3 | 91.5 | 88.9/88.6 | 80.5/88.2 |
|
RecordedFuture/Swedish-Sentiment-Violence-Targets
|
RecordedFuture
| 2021-05-24T13:02:37Z | 31 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"token-classification",
"sv",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:04Z |
---
language: sv
license: mit
---
## Swedish BERT models for sentiment analysis, Sentiment targets.
[Recorded Future](https://www.recordedfuture.com/) together with [AI Sweden](https://www.ai.se/en) releases two language models for target/role assignment in Swedish. The two models are based on the [KB/bert-base-swedish-cased](https://huggingface.co/KB/bert-base-swedish-cased), the models as has been fine tuned to solve a Named Entety Recognition(NER) token classification task.
This is a downstream model to be used in conjunction with the [Swedish violence sentiment classifier](https://huggingface.co/RecordedFuture/Swedish-Sentiment-Violence) or [Swedish violence sentiment classifier](https://huggingface.co/RecordedFuture/Swedish-Sentiment-Fear). The models are trained to tag parts of sentences that has recieved a positive classification from the upstream sentiment classifier. The model will tag parts of sentences that contains the targets that the upstream model has activated on.
The NER sentiment target models do work as standalone models but their recommended application is downstreamfrom a sentence classification model.
The models are only trained on Swedish data and only supports inference of Swedish input texts. The models inference metrics for all non-Swedish inputs are not defined, these inputs are considered as out of domain data.
The current models are supported at Transformers version >= 4.3.3 and Torch version 1.8.0, compatibility with older versions are not verified.
### Fear targets
The model can be imported from the transformers library by running
from transformers import BertForSequenceClassification, BertTokenizerFast
tokenizer = BertTokenizerFast.from_pretrained("RecordedFuture/Swedish-Sentiment-Fear-Targets")
classifier_fear_targets= BertForTokenClassification.from_pretrained("RecordedFuture/Swedish-Sentiment-Fear-Targets")
When the model and tokenizer are initialized the model can be used for inference.
#### Verification metrics
During training the Fear target model had the following verification metrics when using "any overlap" as the evaluation metric.
| F-score | Precision | Recall |
|:-------------------------:|:-------:|:---------:|:------:|
| 0.8361 | 0.7903 | 0.8876 |
#### Swedish-Sentiment-Violence
The model be can imported from the transformers library by running
from transformers import BertForSequenceClassification, BertTokenizerFast
tokenizer = BertTokenizerFast.from_pretrained("RecordedFuture/Swedish-Sentiment-Violence-Targets")
classifier_violence_targets = BertForTokenClassification.from_pretrained("RecordedFuture/Swedish-Sentiment-Violence-Targets")
When the model and tokenizer are initialized the model can be used for inference.
#### Verification metrics
During training the Violence target model had the following verification metrics when using "any overlap" as the evaluation metric.
| F-score | Precision | Recall |
|:-------------------------:|:-------:|:---------:|:------:|
| 0.7831| 0.9155| 0.8442 |
|
Intel/bert-base-uncased-sparse-70-unstructured
|
Intel
| 2021-05-24T12:42:47Z | 11 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
---
language: en
---
# Sparse BERT base model (uncased)
Pretrained model pruned to 70% sparsity.
The model is a pruned version of the [BERT base model](https://huggingface.co/bert-base-uncased).
## Intended Use
The model can be used for fine-tuning to downstream tasks with sparsity already embeded to the model.
To keep the sparsity a mask should be added to each sparse weight blocking the optimizer from updating the zeros.
|
felflare/bert-restore-punctuation
|
felflare
| 2021-05-24T03:04:47Z | 13,671 | 64 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"token-classification",
"punctuation",
"en",
"dataset:yelp_polarity",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:05Z |
---
language:
- en
tags:
- punctuation
license: mit
datasets:
- yelp_polarity
metrics:
- f1
---
# ✨ bert-restore-punctuation
[]()
This a bert-base-uncased model finetuned for punctuation restoration on [Yelp Reviews](https://www.tensorflow.org/datasets/catalog/yelp_polarity_reviews).
The model predicts the punctuation and upper-casing of plain, lower-cased text. An example use case can be ASR output. Or other cases when text has lost punctuation.
This model is intended for direct use as a punctuation restoration model for the general English language. Alternatively, you can use this for further fine-tuning on domain-specific texts for punctuation restoration tasks.
Model restores the following punctuations -- **[! ? . , - : ; ' ]**
The model also restores the upper-casing of words.
-----------------------------------------------
## 🚋 Usage
**Below is a quick way to get up and running with the model.**
1. First, install the package.
```bash
pip install rpunct
```
2. Sample python code.
```python
from rpunct import RestorePuncts
# The default language is 'english'
rpunct = RestorePuncts()
rpunct.punctuate("""in 2018 cornell researchers built a high-powered detector that in combination with an algorithm-driven process called ptychography set a world record
by tripling the resolution of a state-of-the-art electron microscope as successful as it was that approach had a weakness it only worked with ultrathin samples that were
a few atoms thick anything thicker would cause the electrons to scatter in ways that could not be disentangled now a team again led by david muller the samuel b eckert
professor of engineering has bested its own record by a factor of two with an electron microscope pixel array detector empad that incorporates even more sophisticated
3d reconstruction algorithms the resolution is so fine-tuned the only blurring that remains is the thermal jiggling of the atoms themselves""")
# Outputs the following:
# In 2018, Cornell researchers built a high-powered detector that, in combination with an algorithm-driven process called Ptychography, set a world record by tripling the
# resolution of a state-of-the-art electron microscope. As successful as it was, that approach had a weakness. It only worked with ultrathin samples that were a few atoms
# thick. Anything thicker would cause the electrons to scatter in ways that could not be disentangled. Now, a team again led by David Muller, the Samuel B.
# Eckert Professor of Engineering, has bested its own record by a factor of two with an Electron microscope pixel array detector empad that incorporates even more
# sophisticated 3d reconstruction algorithms. The resolution is so fine-tuned the only blurring that remains is the thermal jiggling of the atoms themselves.
```
**This model works on arbitrarily large text in English language and uses GPU if available.**
-----------------------------------------------
## 📡 Training data
Here is the number of product reviews we used for finetuning the model:
| Language | Number of text samples|
| -------- | ----------------- |
| English | 560,000 |
We found the best convergence around _**3 epochs**_, which is what presented here and available via a download.
-----------------------------------------------
## 🎯 Accuracy
The fine-tuned model obtained the following accuracy on 45,990 held-out text samples:
| Accuracy | Overall F1 | Eval Support |
| -------- | ---------------------- | ------------------- |
| 91% | 90% | 45,990
Below is a breakdown of the performance of the model by each label:
| label | precision | recall | f1-score | support|
| --------- | -------------|-------- | ----------|--------|
| **!** | 0.45 | 0.17 | 0.24 | 424
| **!+Upper** | 0.43 | 0.34 | 0.38 | 98
| **'** | 0.60 | 0.27 | 0.37 | 11
| **,** | 0.59 | 0.51 | 0.55 | 1522
| **,+Upper** | 0.52 | 0.50 | 0.51 | 239
| **-** | 0.00 | 0.00 | 0.00 | 18
| **.** | 0.69 | 0.84 | 0.75 | 2488
| **.+Upper** | 0.65 | 0.52 | 0.57 | 274
| **:** | 0.52 | 0.31 | 0.39 | 39
| **:+Upper** | 0.36 | 0.62 | 0.45 | 16
| **;** | 0.00 | 0.00 | 0.00 | 17
| **?** | 0.54 | 0.48 | 0.51 | 46
| **?+Upper** | 0.40 | 0.50 | 0.44 | 4
| **none** | 0.96 | 0.96 | 0.96 |35352
| **Upper** | 0.84 | 0.82 | 0.83 | 5442
-----------------------------------------------
## ☕ Contact
Contact [Daulet Nurmanbetov]([email protected]) for questions, feedback and/or requests for similar models.
-----------------------------------------------
|
thingsu/koDPR_context
|
thingsu
| 2021-05-24T02:46:37Z | 3 | 3 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
fintuned the kykim/bert-kor-base model as a dense passage retrieval context encoder by KLUE dataset
this link is experiment result. https://wandb.ai/thingsu/DenseRetrieval
Corpus : Korean Wikipedia Corpus
Trained Strategy :
- Pretrained Model : kykim/bert-kor-base
- Inverse Cloze Task : 16 Epoch, by korquad v 1.0, KLUE MRC dataset
- In-batch Negatives : 12 Epoch, by KLUE MRC dataset, random sampling between Sparse Retrieval(TF-IDF) top 100 passage per each query
You must need to use Korean wikipedia corpus
<pre>
<code>
from Transformers import AutoTokenizer, BertPreTrainedModel, BertModel
class BertEncoder(BertPreTrainedModel):
def __init__(self, config):
super(BertEncoder, self).__init__(config)
self.bert = BertModel(config)
self.init_weights()
def forward(self, input_ids, attention_mask=None, token_type_ids=None):
outputs = self.bert(input_ids, attention_mask, token_type_ids)
pooled_output = outputs[1]
return pooled_output
model_name = 'kykim/bert-kor-base'
tokenizer = AutoTokenizer.from_pretrained(model_name)
q_encoder = BertEncoder.from_pretrained("thingsu/koDPR_question")
p_encoder = BertEncoder.from_pretrained("thingsu/koDPR_context")
</pre>
</code>
|
uw-hai/polyjuice
|
uw-hai
| 2021-05-24T01:21:24Z | 167 | 3 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"counterfactual generation",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: "en"
tags:
- counterfactual generation
widget:
- text: "It is great for kids. <|perturb|> [negation] It [BLANK] great for kids. [SEP]"
---
# Polyjuice
## Model description
This is a ported version of [Polyjuice](https://homes.cs.washington.edu/~wtshuang/static/papers/2021-arxiv-polyjuice.pdf), the general-purpose counterfactual generator.
For more code release, please refer to [this github page](https://github.com/tongshuangwu/polyjuice).
#### How to use
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
from transformers import pipeline, AutoTokenizer, AutoModelForCausalLM
model_path = "uw-hai/polyjuice"
generator = pipeline("text-generation",
model=AutoModelForCausalLM.from_pretrained(model_path),
tokenizer=AutoTokenizer.from_pretrained(model_path),
framework="pt", device=0 if is_cuda else -1)
prompt_text = "A dog is embraced by the woman. <|perturb|> [negation] A dog is [BLANK] the woman."
generator(prompt_text, num_beams=3, num_return_sequences=3)
```
### BibTeX entry and citation info
```bibtex
@inproceedings{polyjuice:acl21,
title = "{P}olyjuice: Generating Counterfactuals for Explaining, Evaluating, and Improving Models",
author = "Tongshuang Wu and Marco Tulio Ribeiro and Jeffrey Heer and Daniel S. Weld",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics",
year = "2021",
publisher = "Association for Computational Linguistics"
```
|
huggingtweets/heaven_ley
|
huggingtweets
| 2021-05-23T14:18:42Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/heaven_ley/1621532679555/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1391998269430116355/O5NJQwYC_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Ashley 🌻</div>
<div style="text-align: center; font-size: 14px;">@heaven_ley</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Ashley 🌻.
| Data | Ashley 🌻 |
| --- | --- |
| Tweets downloaded | 3084 |
| Retweets | 563 |
| Short tweets | 101 |
| Tweets kept | 2420 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/h9ex5ztp/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @heaven_ley's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2rr1mtsr) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2rr1mtsr/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/heaven_ley')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
stevhliu/astroGPT
|
stevhliu
| 2021-05-23T12:59:14Z | 139 | 5 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"gpt2",
"text-generation",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: "en"
thumbnail: "https://raw.githubusercontent.com/stevhliu/satsuma/master/images/astroGPT-thumbnail.png"
widget:
- text: "Jan 18, 2020"
- text: "Feb 14, 2020"
- text: "Jul 04, 2020"
---
# astroGPT 🪐
## Model description
This is a GPT-2 model fine-tuned on Western zodiac signs. For more information about GPT-2, take a look at 🤗 Hugging Face's GPT-2 [model card](https://huggingface.co/gpt2). You can use astroGPT to generate a daily horoscope by entering the current date.
## How to use
To use this model, simply enter the current date like so `Mon DD, YEAR`:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("stevhliu/astroGPT")
model = AutoModelWithLMHead.from_pretrained("stevhliu/astroGPT")
input_ids = tokenizer.encode('Sep 03, 2020', return_tensors='pt').to('cuda')
sample_output = model.generate(input_ids,
do_sample=True,
max_length=75,
top_k=20,
top_p=0.97)
print(sample_output)
```
## Limitations and bias
astroGPT inherits the same biases that affect GPT-2 as a result of training on a lot of non-neutral content on the internet. The model does not currently support zodiac sign-specific generation and only returns a general horoscope. While the generated text may occasionally mention a specific zodiac sign, this is due to how the horoscopes were originally written by it's human authors.
## Data
The data was scraped from [Horoscope.com](https://www.horoscope.com/us/index.aspx) and trained on 4.7MB of text. The text was collected from four categories (daily, love, wellness, career) and span from 09/01/19 to 08/01/2020. The archives only store horoscopes dating a year back from the current date.
## Training and results
The text was tokenized using the fast GPT-2 BPE [tokenizer](https://huggingface.co/transformers/model_doc/gpt2.html#gpt2tokenizerfast). It has a vocabulary size of 50,257 and sequence length of 1024 tokens. The model was trained with on one of Google Colaboratory's GPU's for approximately 2.5 hrs with [fastai's](https://docs.fast.ai/) learning rate finder, discriminative learning rates and 1cycle policy. See table below for a quick summary of the training procedure and results.
| dataset size | epochs | lr | training time | train_loss | valid_loss | perplexity |
|:-------------:|:------:|:-----------------:|:-------------:|:----------:|:----------:|:----------:|
| 5.9MB |32 | slice(1e-7,1e-5) | 2.5 hrs | 2.657170 | 2.642387 | 14.046692 |
|
rjbownes/Magic-The-Generating
|
rjbownes
| 2021-05-23T12:17:20Z | 5 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
widget:
- text: "Even the Dwarves"
- text: "The secrets of"
---
# Model name
Magic The Generating
## Model description
This is a fine tuned GPT-2 model trained on a corpus of all available English language Magic the Gathering card flavour texts.
## Intended uses & limitations
This is intended only for use in generating new, novel, and sometimes surprising, MtG like flavour texts.
#### How to use
```python
from transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained("rjbownes/Magic-The-Generating")
model = GPT2LMHeadModel.from_pretrained("rjbownes/Magic-The-Generating")
```
#### Limitations and bias
The training corpus was surprisingly small, only ~29000 cards, I had suspected there were more. This might mean there is a real limit to the number of entirely original strings this will generate.
This is also only based on the 117M parameter GPT2, it's a pretty obvious upgrade to retrain with medium, large or XL models. However, despite this, the outputs I tested were very convincing!
## Training data
The data was 29222 MtG card flavour texts. The model was based on the "gpt2" pretrained transformer: https://huggingface.co/gpt2.
## Training procedure
Only English language MtG flavour texts were scraped from the [Scryfall](https://scryfall.com/) API. Empty strings and any non-UTF-8 encoded tokens were removed leaving 29222 entries.
This was trained using google Colab with a T4 instance. 4 epochs, adamW optimizer with default parameters and a batch size of 32. Token embedding lengths were capped at 98 tokens as this was the longest string and an attention mask was added to the training model to ignore all padding tokens.
## Eval results
Average Training Loss: 0.44866578806635815.
Validation loss: 0.5606984243444775.
Sample model outputs:
1. "Every branch a crossroads, every vine a swift steed."
—Gwendlyn Di Corci
2. "The secrets of this world will tell their masters where to strike if need be."
—Noyan Dar, Tazeem roilmage
3. "The secrets of nature are expensive. You'd be better off just to have more freedom."
4. "Even the Dwarves knew to leave some stones unturned."
5. "The wise always keep an ear open to the whispers of power."
### BibTeX entry and citation info
```bibtex
@article{BownesLM,
title={Fine Tuning GPT-2 for Magic the Gathering flavour text generation.},
author={Richard J. Bownes},
journal={Medium},
year={2020}
}
```
|
rathi/storyGenerator
|
rathi
| 2021-05-23T12:11:32Z | 7 | 2 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
## This is a genre-based Movie plot generator.
For best results, structure the input as follows -
1. Add a `<BOS>` tag in the start.
2. Add a `<genre>` tag (with the genre as a placeholder for lowercased genres such as `<action>`, `<romantic>`, `<thriller>`, `<comedy>`
|
himanshu-dutta/pycoder-gpt2
|
himanshu-dutta
| 2021-05-23T11:56:06Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
<br />
<div align="center">
<img src="https://raw.githubusercontent.com/himanshu-dutta/pycoder/master/docs/pycoder-logo-p.png">
<br/>
<img alt="Made With Python" src="http://ForTheBadge.com/images/badges/made-with-python.svg" height=28 style="display:inline; height:28px;" />
<img alt="Medium" src="https://img.shields.io/badge/Medium-12100E?style=for-the-badge&logo=medium&logoColor=white" height=28 style="display:inline; height:28px;"/>
<a href="https://wandb.ai/himanshu-dutta/pycoder">
<img alt="WandB Dashboard" src="https://raw.githubusercontent.com/wandb/assets/04cfa58cc59fb7807e0423187a18db0c7430bab5/wandb-github-badge-28.svg" height=28 style="display:inline; height:28px;" />
</a>
[](https://pypi.org/project/pycoder/)
</div>
<div align="justify">
`PyCoder` is a tool to generate python code out of a few given topics and a description. It uses GPT-2 language model as its engine. Pycoder poses writing Python code as a conditional-Causal Language Modelling(c-CLM). It has been trained on millions of lines of Python code written by all of us. At the current stage and state of training, it produces sensible code with few lines of description, but the scope of improvement for the model is limitless.
Pycoder has been developed as a Command-Line tool (CLI), an API endpoint, as well as a python package (yet to be deployed to PyPI). This repository acts as a framework for anyone who either wants to try to build Pycoder from scratch or turn Pycoder into maybe a `CPPCoder` or `JSCoder` 😃. A blog post about the development of the project will be released soon.
To use `Pycoder` as a CLI utility, clone the repository as normal, and install the package with:
```console
foo@bar:❯ pip install pycoder
```
After this the package could be verified and accessed as either a native CLI tool or a python package with:
```console
foo@bar:❯ python -m pycoder --version
Or directly as:
foo@bar:❯ pycoder --version
```
On installation the CLI can be used directly, such as:
```console
foo@bar:❯ pycoder -t pytorch -t torch -d "a trainer class to train vision model" -ml 120
```
The API endpoint is deployed using FastAPI. Once all the requirements have been installed for the project, the API can be accessed with:
```console
foo@bar:❯ pycoder --endpoint PORT_NUMBER
Or
foo@bar:❯ pycoder -e PORT_NUMBER
```
</div>
## Tech Stack
<div align="center">
<img alt="Python" src="https://img.shields.io/badge/python-%2314354C.svg?style=for-the-badge&logo=python&logoColor=white" style="display:inline;" />
<img alt="PyTorch" src="https://img.shields.io/badge/PyTorch-%23EE4C2C.svg?style=for-the-badge&logo=PyTorch&logoColor=white" style="display:inline;" />
<img alt="Transformers" src="https://raw.githubusercontent.com/huggingface/transformers/master/docs/source/imgs/transformers_logo_name.png" height=28 width=120 style="display:inline; background-color:white; height:28px; width:120px"/>
<img alt="Docker" src="https://img.shields.io/badge/docker-%230db7ed.svg?style=for-the-badge&logo=docker&logoColor=white" style="display:inline;" />
<img src="https://fastapi.tiangolo.com/img/logo-margin/logo-teal.png" alt="FastAPI" height=28 style="display:inline; background-color:black; height:28px;" />
<img src="https://typer.tiangolo.com/img/logo-margin/logo-margin-vector.svg" height=28 style="display:inline; background-color:teal; height:28px;" />
</div>
## Tested Platforms
<div align="center">
<img alt="Linux" src="https://img.shields.io/badge/Linux-FCC624?style=for-the-badge&logo=linux&logoColor=black" style="display:inline;" />
<img alt="Windows 10" src="https://img.shields.io/badge/Windows-0078D6?style=for-the-badge&logo=windows&logoColor=white" style="display:inline;" />
</div>
## BibTeX
If you want to cite the framework feel free to use this:
```bibtex
@article{dutta2021pycoder,
title={Pycoder},
author={Dutta, H},
journal={GitHub. Note: https://github.com/himanshu-dutta/pycoder},
year={2021}
}
```
<hr />
<div align="center">
<img alt="MIT License" src="https://img.shields.io/github/license/himanshu-dutta/pycoder?style=for-the-badge&logo=appveyor" style="display:inline;" />
<img src="https://img.shields.io/badge/Copyright-Himanshu_Dutta-2ea44f?style=for-the-badge&logo=appveyor" style="display:inline;" />
</div>
|
pranavpsv/gpt2-genre-story-generator
|
pranavpsv
| 2021-05-23T11:02:06Z | 507 | 46 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
# GPT2 Genre Based Story Generator
## Model description
GPT2 fine-tuned on genre-based story generation.
## Intended uses
Used to generate stories based on user inputted genre and starting prompts.
## How to use
#### Supported Genres
superhero, action, drama, horror, thriller, sci_fi
#### Input text format
\<BOS> \<genre> Some optional text...
**Example**: \<BOS> \<sci_fi> After discovering time travel,
```python
# Example of usage
from transformers import pipeline
story_gen = pipeline("text-generation", "pranavpsv/gpt2-genre-story-generator")
print(story_gen("<BOS> <superhero> Batman"))
```
## Training data
Initialized with pre-trained weights of "gpt2" checkpoint. Fine-tuned the model on stories of various genres.
|
p208p2002/gpt2-squad-qg-hl
|
p208p2002
| 2021-05-23T10:54:57Z | 13 | 3 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"question-generation",
"dataset:squad",
"arxiv:1606.05250",
"arxiv:1705.00106",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
datasets:
- squad
tags:
- question-generation
widget:
- text: "Harry Potter is a series of seven fantasy novels written by British author, [HL]J. K. Rowling[HL]."
---
# Transformer QG on SQuAD
HLQG is Proposed by [Ying-Hong Chan & Yao-Chung Fan. (2019). A Re-current BERT-based Model for Question Generation.](https://www.aclweb.org/anthology/D19-5821/)
**This is a Reproduce Version**
More detail: [p208p2002/Transformer-QG-on-SQuAD](https://github.com/p208p2002/Transformer-QG-on-SQuAD)
## Usage
### Input Format
```
C' = [c1, c2, ..., [HL], a1, ..., a|A|, [HL], ..., c|C|]
```
### Input Example
```
Harry Potter is a series of seven fantasy novels written by British author, [HL]J. K. Rowling[HL].
```
> # Who wrote Harry Potter?
## Data setting
We report two dataset setting as Follow
### SQuAD
- train: 87599\\\\t
- validation: 10570
> [SQuAD: 100,000+ Questions for Machine Comprehension of Text](https://arxiv.org/abs/1606.05250)
### SQuAD NQG
- train: 75722
- dev: 10570
- test: 11877
> [Learning to Ask: Neural Question Generation for Reading Comprehension](https://arxiv.org/abs/1705.00106)
## Available models
- BART
- GPT2
- T5
## Expriments
We report score with `NQG Scorer` which is using in SQuAD NQG.
If not special explanation, the size of the model defaults to "base".
### SQuAD
Model |Bleu 1|Bleu 2|Bleu 3|Bleu 4|METEOR|ROUGE-L|
---------------------------------|------|------|------|------|------|-------|
BART-HLSQG |54.67 |39.26 |30.34 |24.15 |25.43 |52.64 |
GPT2-HLSQG |49.31 |33.95 |25.41| 19.69 |22.29 |48.82 |
T5-HLSQG |54.29 |39.22 |30.43 |24.26 |25.56 |53.11 |
### SQuAD NQG
Model |Bleu 1|Bleu 2|Bleu 3|Bleu 4|METEOR|ROUGE-L|
---------------------------------|------|------|------|------|------|-------|
BERT-HLSQG (Chan et al.) |49.73 |34.60 |26.13 |20.33 |23.88 |48.23 |
BART-HLSQG |54.12 |38.19 |28.84 |22.35 |24.55 |51.03 |
GPT2-HLSQG |49.82 |33.69 |24.71 |18.63 |21.90 |47.60 |
T5-HLSQG |53.13 |37.60 |28.62 |22.38 |24.48 |51.20 |
|
ncoop57/DiGPTame-medium
|
ncoop57
| 2021-05-23T10:47:17Z | 37 | 2 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"conversational",
"arxiv:1911.00536",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
tags:
- conversational
license: mit
---
## Finetuned DialoGPT model on Spanish Conversations
This model was finetuned from the original [DialoGPT-medium](https://huggingface.co/microsoft/DialoGPT-medium) model on subtitles from Spanish movies and telenovelas from the awesome [OpenSubtitle dataset](https://github.com/PolyAI-LDN/conversational-datasets/tree/master/opensubtitles).
DialoGPT paper: [https://arxiv.org/abs/1911.00536](https://arxiv.org/abs/1911.00536)
Some example dialog from the model:
|Role | Response |
|---------|--------|
|User | ¿Cómo está el clima hoy? |
| Bot | Muy bien. |
|User | Eso es bueno escuchar. ¿Vas a ir a la playa? |
| Bot | No, también puedo regresar. |
|User | Oh bien, bueno, iré a la playa más tarde. |
| Bot | ¡No! |
|User | ¿Qué está mal con eso? |
| Bot | ¡Cómo que no! |
|User | Estoy confundido, ¿por qué no puedo ir a la playa? |
| Bot | ¡Cómo que no! |
|User | Explícamelo por favor. |
| Bot | ¡No! |
## Using the model
Example code for trying out the model (taken directly from the [DialoGPT-medium](https://huggingface.co/microsoft/DialoGPT-medium) model card):
```python
from transformers import AutoModelWithLMHead, AutoTokenizer
import torch
tokenizer = AutoTokenizer.from_pretrained("ncoop57/DiGPTame-medium")
model = AutoModelWithLMHead.from_pretrained("ncoop57/DiGPTame-medium")
# Let's chat for 5 lines
for step in range(5):
# encode the new user input, add the eos_token and return a tensor in Pytorch
new_user_input_ids = tokenizer.encode(input(">> User:") + tokenizer.eos_token, return_tensors='pt')
# append the new user input tokens to the chat history
bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if step > 0 else new_user_input_ids
# generated a response while limiting the total chat history to 1000 tokens,
chat_history_ids = model.generate(bot_input_ids, max_length=1000, pad_token_id=tokenizer.eos_token_id)
# pretty print last ouput tokens from bot
print("DialoGPT: {}".format(tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)))
```
## Training your own model
If you would like to finetune your own model or finetune this Spanish model, please checkout my blog post on that exact topic!
https://nathancooper.io/i-am-a-nerd/chatbot/deep-learning/gpt2/2020/05/12/chatbot-part-1.html
|
mymusise/CPM-GPT2-FP16
|
mymusise
| 2021-05-23T10:32:23Z | 9 | 2 |
transformers
|
[
"transformers",
"tf",
"gpt2",
"text-generation",
"zh",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: zh
widget:
- text: "今天是下雨天"
- text: "走向森林"
---
<h1 align="center">
CPM
</h1>
CPM(Chinese Pre-Trained Language Models), which has 2.6B parameters, made by the research team of Beijing Zhiyuan Institute of artificial intelligence and Tsinghua University @TsinghuaAI.
[repo: CPM-Generate](https://github.com/TsinghuaAI/CPM-Generate)
The One Thing You Need to Know is this model is not uploaded by official, the conver script is [here](https://github.com/mymusise/CPM-TF2Transformer/blob/main/transfor_CMP.ipynb)
# Overview
- **Language model**: CPM
- **Model size**: 2.6B parameters
- **Language**: Chinese
# How to use
How to use this model directly from the 🤗/transformers library:
```python
from transformers import XLNetTokenizer, TFGPT2LMHeadModel
import jieba
# add spicel process
class XLNetTokenizer(XLNetTokenizer):
translator = str.maketrans(" \n", "\u2582\u2583")
def _tokenize(self, text, *args, **kwargs):
text = [x.translate(self.translator) for x in jieba.cut(text, cut_all=False)]
text = " ".join(text)
return super()._tokenize(text, *args, **kwargs)
def _decode(self, *args, **kwargs):
text = super()._decode(*args, **kwargs)
text = text.replace(' ', '').replace('\u2582', ' ').replace('\u2583', '\n')
return text
tokenizer = XLNetTokenizer.from_pretrained('mymusise/CPM-GPT2-FP16')
model = TFGPT2LMHeadModel.from_pretrained("mymusise/CPM-GPT2-FP16")
```
How to generate text
```python
from transformers import TextGenerationPipeline
text_generater = TextGenerationPipeline(model, tokenizer)
texts = [
'今天天气不错',
'天下武功, 唯快不',
"""
我们在火星上发现了大量的神奇物种。有神奇的海星兽,身上是粉色的,有5条腿;有胆小的猫猫兽,橘色,有4条腿;有令人恐惧的蜈蚣兽,全身漆黑,36条腿;有纯洁的天使兽,全身洁白无瑕,有3条腿;有贪吃的汪汪兽,银色的毛发,有5条腿;有蛋蛋兽,紫色,8条腿。
请根据上文,列出一个表格,包含物种名、颜色、腿数量。
|物种名|颜色|腿数量|
|亚古兽|金黄|2|
|海星兽|粉色|5|
|猫猫兽|橘色|4|
|蜈蚣兽|漆黑|36|
"""
]
for text in texts:
token_len = len(tokenizer._tokenize(text))
print(text_generater(text, max_length=token_len + 15, top_k=1, use_cache=True, prefix='')[0]['generated_text'])
print(text_generater(text, max_length=token_len + 15, do_sample=True, top_k=5)[0]['generated_text'])
```

You can try it on [colab](https://colab.research.google.com/github/mymusise/CPM-TF2Transformer/blob/main/demo-fp16.ipynb)
<a href="https://colab.research.google.com/github/mymusise/CPM-TF2Transformer/blob/main/demo-fp16.ipynb">
<img alt="Build" src="https://colab.research.google.com/assets/colab-badge.svg">
</a>
|
mrm8488/gpt2-imdb-neg
|
mrm8488
| 2021-05-23T10:27:14Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
# GPT2-IMDB-neg (LM + RL) 🎞😡✍
All credits to [@lvwerra](https://twitter.com/lvwerra)
## What is it?
A small GPT2 (`lvwerra/gpt2-imdb`) language model fine-tuned to produce **negative** movie reviews based the [IMDB dataset](https://www.kaggle.com/lakshmi25npathi/imdb-dataset-of-50k-movie-reviews). The model is trained with rewards from a BERT sentiment classifier (`lvwerra/gpt2-imdb`) via **PPO**.
## Why?
I wanted to reproduce the experiment [lvwerra/gpt2-imdb-pos](https://huggingface.co/lvwerra/gpt2-imdb-pos) but for generating **negative** movie reviews.
## Training setting
The model was trained for `100` optimisation steps with a batch size of `256` which corresponds to `25600` training samples. The full experiment setup (for positive samples) in [trl repo](https://lvwerra.github.io/trl/04-gpt2-sentiment-ppo-training/).
## Examples
A few examples of the model response to a query before and after optimisation:
| query | response (before) | response (after) | rewards (before) | rewards (after) |
|-------|-------------------|------------------|------------------|-----------------|
|This movie is a fine | attempt as far as live action is concerned, n...|example of how bad Hollywood in theatrics pla...| 2.118391 | -3.31625|
|I have watched 3 episodes |with this guy and he is such a talented actor...| but the show is just plain awful and there ne...| 2.681171| -4.512792|
|We know that firefighters and| police officers are forced to become populari...| other chains have going to get this disaster ...| 1.367811| -3.34017|
## Training logs and metrics <img src="https://gblobscdn.gitbook.com/spaces%2F-Lqya5RvLedGEWPhtkjU%2Favatar.png?alt=media" width="25" height="25">
Watch the whole training logs and metrics on [W&B](https://app.wandb.ai/mrm8488/gpt2-sentiment-negative?workspace=user-mrm8488)
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/GuaPeTe-2-tiny-finetuned-TED
|
mrm8488
| 2021-05-23T10:14:53Z | 14 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"spanish",
"gpt-2",
"spanish gpt2",
"es",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: es
tags:
- spanish
- gpt-2
- spanish gpt2
widget:
- text: "Ustedes tienen la oportunidad de"
---
# GuaPeTe-2-tiny fine-tuned on TED dataset for CLM
|
mrm8488/GPT-2-finetuned-common_gen
|
mrm8488
| 2021-05-23T10:12:07Z | 135 | 3 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"en",
"dataset:common_gen",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
datasets:
- common_gen
widget:
- text: "<|endoftext|> apple, tree, pick:"
---
# GPT-2 fine-tuned on CommonGen
[GPT-2](https://huggingface.co/gpt2) fine-tuned on [CommonGen](https://inklab.usc.edu/CommonGen/index.html) for *Generative Commonsense Reasoning*.
## Details of GPT-2
GPT-2 is a transformers model pretrained on a very large corpus of English data in a self-supervised fashion. This
means it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots
of publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely,
it was trained to guess the next word in sentences.
More precisely, inputs are sequences of continuous text of a certain length and the targets are the same sequence,
shifted one token (word or piece of word) to the right. The model uses internally a mask-mechanism to make sure the
predictions for the token `i` only uses the inputs from `1` to `i` but not the future tokens.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks. The model is best at what it was pretrained for however, which is generating texts from a
prompt.
## Details of the dataset 📚
CommonGen is a constrained text generation task, associated with a benchmark dataset, to explicitly test machines for the ability of generative commonsense reasoning. Given a set of common concepts; the task is to generate a coherent sentence describing an everyday scenario using these concepts.
CommonGen is challenging because it inherently requires 1) relational reasoning using background commonsense knowledge, and 2) compositional generalization ability to work on unseen concept combinations. Our dataset, constructed through a combination of crowd-sourcing from AMT and existing caption corpora, consists of 30k concept-sets and 50k sentences in total.
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| common_gen | train | 67389 |
| common_gen | valid | 4018 |
| common_gen | test | 1497 |
## Model fine-tuning 🏋️
You can find the fine-tuning script [here](https://github.com/huggingface/transformers/tree/master/examples/language-modeling)
## Model in Action 🚀
```bash
python ./transformers/examples/text-generation/run_generation.py \
--model_type=gpt2 \
--model_name_or_path="mrm8488/GPT-2-finetuned-common_gen" \
--num_return_sequences 1 \
--prompt "<|endoftext|> kid, room, dance:" \
--stop_token "."
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/GPT-2-finetuned-CORD19
|
mrm8488
| 2021-05-23T10:09:38Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail:
---
# GPT-2 + CORD19 dataset : 🦠 ✍ ⚕
**GPT-2** fine-tuned on **biorxiv_medrxiv**, **comm_use_subset** and **custom_license** files from [CORD-19](https://www.kaggle.com/allen-institute-for-ai/CORD-19-research-challenge) dataset.
## Datasets details
| Dataset | # Files |
| ---------------------- | ----- |
| biorxiv_medrxiv | 885 |
| comm_use_subset | 9K |
| custom_license | 20.6K |
## Model training
The model was trained on a Tesla P100 GPU and 25GB of RAM with the following command:
```bash
export TRAIN_FILE=/path/to/dataset/train.txt
python run_language_modeling.py \
--model_type gpt2 \
--model_name_or_path gpt2 \
--do_train \
--train_data_file $TRAIN_FILE \
--num_train_epochs 4 \
--output_dir model_output \
--overwrite_output_dir \
--save_steps 10000 \
--per_gpu_train_batch_size 3
```
<img alt="training loss" src="https://svgshare.com/i/JTf.svg' title='GTP-2-finetuned-CORDS19-loss" width="600" height="300" />
## Model in action / Example of usage ✒
You can get the following script [here](https://github.com/huggingface/transformers/blob/master/examples/text-generation/run_generation.py)
```bash
python run_generation.py \
--model_type gpt2 \
--model_name_or_path mrm8488/GPT-2-finetuned-CORD19 \
--length 200
```
```txt
# Input: the effects of COVID-19 on the lungs
# Output: === GENERATED SEQUENCE 1 ===
the effects of COVID-19 on the lungs are currently debated (86). The role of this virus in the pathogenesis of pneumonia and lung cancer is still debated. MERS-CoV is also known to cause acute respiratory distress syndrome (87) and is associated with increased expression of pulmonary fibrosis markers (88). Thus, early airway inflammation may play an important role in the pathogenesis of coronavirus pneumonia and may contribute to the severe disease and/or mortality observed in coronavirus patients.
Pneumonia is an acute, often fatal disease characterized by severe edema, leakage of oxygen and bronchiolar inflammation. Viruses include coronaviruses, and the role of oxygen depletion is complicated by lung injury and fibrosis in the lung, in addition to susceptibility to other lung diseases. The progression of the disease may be variable, depending on the lung injury, pathologic role, prognosis, and the immune status of the patient. Inflammatory responses to respiratory viruses cause various pathologies of the respiratory
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mofawzy/gpt-2-goodreads-ar
|
mofawzy
| 2021-05-23T09:53:17Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
### Generate Arabic reviews sentences with model GPT-2 Medium.
#### Load model
```
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("mofawzy/gpt-2-medium-ar")
model = AutoModelWithLMHead.from_pretrained("mofawzy/gpt-2-medium-ar")
```
### Eval:
```
***** eval metrics *****
epoch = 20.0
eval_loss = 1.7798
eval_mem_cpu_alloc_delta = 3MB
eval_mem_cpu_peaked_delta = 0MB
eval_mem_gpu_alloc_delta = 0MB
eval_mem_gpu_peaked_delta = 7044MB
eval_runtime = 0:03:03.37
eval_samples = 527
eval_samples_per_second = 2.874
perplexity = 5.9285
```
#### Notebook:
https://colab.research.google.com/drive/1P0Raqrq0iBLNH87DyN9j0SwWg4C2HubV?usp=sharing
|
microsoft/DialogRPT-width
|
microsoft
| 2021-05-23T09:20:20Z | 41 | 1 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-classification",
"arxiv:2009.06978",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# Demo
Please try this [➤➤➤ Colab Notebook Demo (click me!)](https://colab.research.google.com/drive/1cAtfkbhqsRsT59y3imjR1APw3MHDMkuV?usp=sharing)
| Context | Response | `width` score |
| :------ | :------- | :------------: |
| I love NLP! | Can anyone recommend a nice review paper? | 0.701 |
| I love NLP! | Me too! | 0.029 |
The `width` score predicts how likely the response is getting replied.
# DialogRPT-width
### Dialog Ranking Pretrained Transformers
> How likely a dialog response is upvoted 👍 and/or gets replied 💬?
This is what [**DialogRPT**](https://github.com/golsun/DialogRPT) is learned to predict.
It is a set of dialog response ranking models proposed by [Microsoft Research NLP Group](https://www.microsoft.com/en-us/research/group/natural-language-processing/) trained on 100 + millions of human feedback data.
It can be used to improve existing dialog generation model (e.g., [DialoGPT](https://huggingface.co/microsoft/DialoGPT-medium)) by re-ranking the generated response candidates.
Quick Links:
* [EMNLP'20 Paper](https://arxiv.org/abs/2009.06978/)
* [Dataset, training, and evaluation](https://github.com/golsun/DialogRPT)
* [Colab Notebook Demo](https://colab.research.google.com/drive/1cAtfkbhqsRsT59y3imjR1APw3MHDMkuV?usp=sharing)
We considered the following tasks and provided corresponding pretrained models.
|Task | Description | Pretrained model |
| :------------- | :----------- | :-----------: |
| **Human feedback** | **given a context and its two human responses, predict...**|
| `updown` | ... which gets more upvotes? | [model card](https://huggingface.co/microsoft/DialogRPT-updown) |
| `width`| ... which gets more direct replies? | this model |
| `depth`| ... which gets longer follow-up thread? | [model card](https://huggingface.co/microsoft/DialogRPT-depth) |
| **Human-like** (human vs fake) | **given a context and one human response, distinguish it with...** |
| `human_vs_rand`| ... a random human response | [model card](https://huggingface.co/microsoft/DialogRPT-human-vs-rand) |
| `human_vs_machine`| ... a machine generated response | [model card](https://huggingface.co/microsoft/DialogRPT-human-vs-machine) |
### Contact:
Please create an issue on [our repo](https://github.com/golsun/DialogRPT)
### Citation:
```
@inproceedings{gao2020dialogrpt,
title={Dialogue Response RankingTraining with Large-Scale Human Feedback Data},
author={Xiang Gao and Yizhe Zhang and Michel Galley and Chris Brockett and Bill Dolan},
year={2020},
booktitle={EMNLP}
}
```
|
microsoft/DialogRPT-updown
|
microsoft
| 2021-05-23T09:19:13Z | 2,559 | 10 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-classification",
"arxiv:2009.06978",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# Demo
Please try this [➤➤➤ Colab Notebook Demo (click me!)](https://colab.research.google.com/drive/1cAtfkbhqsRsT59y3imjR1APw3MHDMkuV?usp=sharing)
| Context | Response | `updown` score |
| :------ | :------- | :------------: |
| I love NLP! | Here’s a free textbook (URL) in case anyone needs it. | 0.613 |
| I love NLP! | Me too! | 0.111 |
The `updown` score predicts how likely the response is getting upvoted.
# DialogRPT-updown
### Dialog Ranking Pretrained Transformers
> How likely a dialog response is upvoted 👍 and/or gets replied 💬?
This is what [**DialogRPT**](https://github.com/golsun/DialogRPT) is learned to predict.
It is a set of dialog response ranking models proposed by [Microsoft Research NLP Group](https://www.microsoft.com/en-us/research/group/natural-language-processing/) trained on 100 + millions of human feedback data.
It can be used to improve existing dialog generation model (e.g., [DialoGPT](https://huggingface.co/microsoft/DialoGPT-medium)) by re-ranking the generated response candidates.
Quick Links:
* [EMNLP'20 Paper](https://arxiv.org/abs/2009.06978/)
* [Dataset, training, and evaluation](https://github.com/golsun/DialogRPT)
* [Colab Notebook Demo](https://colab.research.google.com/drive/1cAtfkbhqsRsT59y3imjR1APw3MHDMkuV?usp=sharing)
We considered the following tasks and provided corresponding pretrained models. This page is for the `updown` task, and other model cards can be found in table below.
|Task | Description | Pretrained model |
| :------------- | :----------- | :-----------: |
| **Human feedback** | **given a context and its two human responses, predict...**|
| `updown` | ... which gets more upvotes? | this model |
| `width`| ... which gets more direct replies? | [model card](https://huggingface.co/microsoft/DialogRPT-width) |
| `depth`| ... which gets longer follow-up thread? | [model card](https://huggingface.co/microsoft/DialogRPT-depth) |
| **Human-like** (human vs fake) | **given a context and one human response, distinguish it with...** |
| `human_vs_rand`| ... a random human response | [model card](https://huggingface.co/microsoft/DialogRPT-human-vs-rand) |
| `human_vs_machine`| ... a machine generated response | [model card](https://huggingface.co/microsoft/DialogRPT-human-vs-machine) |
### Contact:
Please create an issue on [our repo](https://github.com/golsun/DialogRPT)
### Citation:
```
@inproceedings{gao2020dialogrpt,
title={Dialogue Response RankingTraining with Large-Scale Human Feedback Data},
author={Xiang Gao and Yizhe Zhang and Michel Galley and Chris Brockett and Bill Dolan},
year={2020},
booktitle={EMNLP}
}
```
|
microsoft/DialogRPT-human-vs-rand
|
microsoft
| 2021-05-23T09:18:07Z | 36 | 9 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-classification",
"arxiv:2009.06978",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# Demo
Please try this [➤➤➤ Colab Notebook Demo (click me!)](https://colab.research.google.com/drive/1cAtfkbhqsRsT59y3imjR1APw3MHDMkuV?usp=sharing)
| Context | Response | `human_vs_rand` score |
| :------ | :------- | :------------: |
| I love NLP! | He is a great basketball player. | 0.027 |
| I love NLP! | Can you tell me how it works? | 0.754 |
| I love NLP! | Me too! | 0.631 |
The `human_vs_rand` score predicts how likely the response is corresponding to the given context, rather than a random response.
# DialogRPT-human-vs-rand
### Dialog Ranking Pretrained Transformers
> How likely a dialog response is upvoted 👍 and/or gets replied 💬?
This is what [**DialogRPT**](https://github.com/golsun/DialogRPT) is learned to predict.
It is a set of dialog response ranking models proposed by [Microsoft Research NLP Group](https://www.microsoft.com/en-us/research/group/natural-language-processing/) trained on 100 + millions of human feedback data.
It can be used to improve existing dialog generation model (e.g., [DialoGPT](https://huggingface.co/microsoft/DialoGPT-medium)) by re-ranking the generated response candidates.
Quick Links:
* [EMNLP'20 Paper](https://arxiv.org/abs/2009.06978/)
* [Dataset, training, and evaluation](https://github.com/golsun/DialogRPT)
* [Colab Notebook Demo](https://colab.research.google.com/drive/1cAtfkbhqsRsT59y3imjR1APw3MHDMkuV?usp=sharing)
We considered the following tasks and provided corresponding pretrained models.
|Task | Description | Pretrained model |
| :------------- | :----------- | :-----------: |
| **Human feedback** | **given a context and its two human responses, predict...**|
| `updown` | ... which gets more upvotes? | [model card](https://huggingface.co/microsoft/DialogRPT-updown) |
| `width`| ... which gets more direct replies? | [model card](https://huggingface.co/microsoft/DialogRPT-width) |
| `depth`| ... which gets longer follow-up thread? | [model card](https://huggingface.co/microsoft/DialogRPT-depth) |
| **Human-like** (human vs fake) | **given a context and one human response, distinguish it with...** |
| `human_vs_rand`| ... a random human response | this model |
| `human_vs_machine`| ... a machine generated response | [model card](https://huggingface.co/microsoft/DialogRPT-human-vs-machine) |
### Contact:
Please create an issue on [our repo](https://github.com/golsun/DialogRPT)
### Citation:
```
@inproceedings{gao2020dialogrpt,
title={Dialogue Response RankingTraining with Large-Scale Human Feedback Data},
author={Xiang Gao and Yizhe Zhang and Michel Galley and Chris Brockett and Bill Dolan},
year={2020},
booktitle={EMNLP}
}
```
|
microsoft/DialogRPT-depth
|
microsoft
| 2021-05-23T09:15:24Z | 57 | 5 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-classification",
"arxiv:2009.06978",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# Demo
Please try this [➤➤➤ Colab Notebook Demo (click me!)](https://colab.research.google.com/drive/1cAtfkbhqsRsT59y3imjR1APw3MHDMkuV?usp=sharing)
| Context | Response | `depth` score |
| :------ | :------- | :------------: |
| I love NLP! | Can anyone recommend a nice review paper? | 0.724 |
| I love NLP! | Me too! | 0.032 |
The `depth` score predicts how likely the response is getting a long follow-up discussion thread.
# DialogRPT-depth
### Dialog Ranking Pretrained Transformers
> How likely a dialog response is upvoted 👍 and/or gets replied 💬?
This is what [**DialogRPT**](https://github.com/golsun/DialogRPT) is learned to predict.
It is a set of dialog response ranking models proposed by [Microsoft Research NLP Group](https://www.microsoft.com/en-us/research/group/natural-language-processing/) trained on 100 + millions of human feedback data.
It can be used to improve existing dialog generation model (e.g., [DialoGPT](https://huggingface.co/microsoft/DialoGPT-medium)) by re-ranking the generated response candidates.
Quick Links:
* [EMNLP'20 Paper](https://arxiv.org/abs/2009.06978/)
* [Dataset, training, and evaluation](https://github.com/golsun/DialogRPT)
* [Colab Notebook Demo](https://colab.research.google.com/drive/1cAtfkbhqsRsT59y3imjR1APw3MHDMkuV?usp=sharing)
We considered the following tasks and provided corresponding pretrained models.
|Task | Description | Pretrained model |
| :------------- | :----------- | :-----------: |
| **Human feedback** | **given a context and its two human responses, predict...**|
| `updown` | ... which gets more upvotes? | [model card](https://huggingface.co/microsoft/DialogRPT-updown) |
| `width`| ... which gets more direct replies? | [model card](https://huggingface.co/microsoft/DialogRPT-width) |
| `depth`| ... which gets longer follow-up thread? | this model |
| **Human-like** (human vs fake) | **given a context and one human response, distinguish it with...** |
| `human_vs_rand`| ... a random human response | [model card](https://huggingface.co/microsoft/DialogRPT-human-vs-rand) |
| `human_vs_machine`| ... a machine generated response | [model card](https://huggingface.co/microsoft/DialogRPT-human-vs-machine) |
### Contact:
Please create an issue on [our repo](https://github.com/golsun/DialogRPT)
### Citation:
```
@inproceedings{gao2020dialogrpt,
title={Dialogue Response RankingTraining with Large-Scale Human Feedback Data},
author={Xiang Gao and Yizhe Zhang and Michel Galley and Chris Brockett and Bill Dolan},
year={2020},
booktitle={EMNLP}
}
```
|
model-attribution-challenge/DialoGPT-large
|
model-attribution-challenge
| 2021-05-23T09:06:08Z | 3 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"gpt2",
"text-generation",
"conversational",
"arxiv:1911.00536",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-07-26T13:35:04Z |
---
thumbnail: https://huggingface.co/front/thumbnails/dialogpt.png
tags:
- conversational
license: mit
---
## A State-of-the-Art Large-scale Pretrained Response generation model (DialoGPT)
DialoGPT is a SOTA large-scale pretrained dialogue response generation model for multiturn conversations.
The [human evaluation results](https://github.com/dreasysnail/Dialogpt_dev#human-evaluation) indicate that the response generated from DialoGPT is comparable to human response quality under a single-turn conversation Turing test.
The model is trained on 147M multi-turn dialogue from Reddit discussion thread.
* Multi-turn generation examples from an interactive environment:
|Role | Response |
|---------|--------|
|User | Does money buy happiness? |
| Bot | Depends how much money you spend on it .|
|User | What is the best way to buy happiness ? |
| Bot | You just have to be a millionaire by your early 20s, then you can be happy . |
|User |This is so difficult ! |
| Bot | You have no idea how hard it is to be a millionaire and happy . There is a reason the rich have a lot of money |
Please find the information about preprocessing, training and full details of the DialoGPT in the [original DialoGPT repository](https://github.com/microsoft/DialoGPT)
ArXiv paper: [https://arxiv.org/abs/1911.00536](https://arxiv.org/abs/1911.00536)
### How to use
Now we are ready to try out how the model works as a chatting partner!
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
tokenizer = AutoTokenizer.from_pretrained("microsoft/DialoGPT-large")
model = AutoModelForCausalLM.from_pretrained("microsoft/DialoGPT-large")
# Let's chat for 5 lines
for step in range(5):
# encode the new user input, add the eos_token and return a tensor in Pytorch
new_user_input_ids = tokenizer.encode(input(">> User:") + tokenizer.eos_token, return_tensors='pt')
# append the new user input tokens to the chat history
bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if step > 0 else new_user_input_ids
# generated a response while limiting the total chat history to 1000 tokens,
chat_history_ids = model.generate(bot_input_ids, max_length=1000, pad_token_id=tokenizer.eos_token_id)
# pretty print last ouput tokens from bot
print("DialoGPT: {}".format(tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)))
```
|
lvwerra/gpt2-imdb
|
lvwerra
| 2021-05-23T08:38:34Z | 44,499 | 16 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
# GPT2-IMDB
## What is it?
A GPT2 (`gpt2`) language model fine-tuned on the [IMDB dataset](https://www.kaggle.com/lakshmi25npathi/imdb-dataset-of-50k-movie-reviews).
## Training setting
The GPT2 language model was fine-tuned for 1 epoch on the IMDB dataset. All comments were joined into a single text file separated by the EOS token:
```
import pandas as pd
df = pd.read_csv("imdb-dataset.csv")
imdb_str = " <|endoftext|> ".join(df['review'].tolist())
with open ('imdb.txt', 'w') as f:
f.write(imdb_str)
```
To train the model the `run_language_modeling.py` script in the `transformer` library was used:
```
python run_language_modeling.py
--train_data_file imdb.txt
--output_dir gpt2-imdb
--model_type gpt2
--model_name_or_path gpt2
```
|
lvwerra/gpt2-imdb-ctrl
|
lvwerra
| 2021-05-23T08:37:09Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
# GPT2-IMDB-ctrl
## What is it?
A small GPT2 (`lvwerra/gpt2-imdb`) language model fine-tuned to produce controlled movie reviews based the [IMDB dataset](https://www.kaggle.com/lakshmi25npathi/imdb-dataset-of-50k-movie-reviews). The model is trained with rewards from a BERT sentiment classifier (`lvwerra/bert-imdb`) via PPO.
## Training setting
The model was trained for `200` optimisation steps with a batch size of `256` which corresponds to `51200` training samples. The full experiment setup can be found in the Jupyter notebook in the [trl repo](https://lvwerra.github.io/trl/05-gpt2-sentiment-ppo-training/). The strings `"[negative]"`, `"[neutral]"`, and `"[positive]"` are added at the beginning of the query to control the sentiment.
## Examples
A few examples of the model response to a query before and after optimisation:
| query | response [negative] | rewards [negative] | response [neutral] | rewards [neutral] | response [positive] | rewards [positive] |
|-------|---------------------|--------------------|--------------------|-------------------|---------------------|--------------------|
|I watched this movie when|it was released and was awful. Little bit of ...|3.130034|it was released and it was the first movie I ...|-1.351991|I was younger it was wonderful. The new play ...|4.232218|
|I can remember seeing this|movie in 2008, and I was so disappointed...yo...|3.428725|in support groups, which I think was not as i...|0.213288|movie, and it is one of my favorite movies ev...|4.168838|
|This 1970 hit film has|little resonance. This movie is bad, not only...|4.241872|a bit of Rocket power.783287. It can be easil...|0.849278|the best formula for comedy and is't just jus...|4.208804|
|
lucone83/deep-metal
|
lucone83
| 2021-05-23T08:36:22Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
## Model description
**DeepMetal** is a model capable of generating lyrics taylored for heavy metal songs.
The model is based on the [OpenAI GPT-2](https://huggingface.co/gpt2) and has been finetuned on a dataset of 141,718 heavy metal songs lyrics.
More info about the project can be found in the [official GitHub repository](https://github.com/lucone83/deep-metal) and in the related articles on my blog: [part I](https://blog.lucaballore.com/when-heavy-metal-meets-data-science-2e840897922e), [part II](https://blog.lucaballore.com/when-heavy-metal-meets-data-science-3fc32e9096fa) and [part III](https://blog.lucaballore.com/when-heavy-metal-meets-data-science-episode-iii-9f6e4772847e).
### Legal notes
Due to incertainity about legal rights, the dataset used for training the model is not provided. I hope you'll understand. The lyrics in question have been scraped from the website [DarkLyrics](http://www.darklyrics.com/) using the library [metal-parser](https://github.com/lucone83/metal-parser).
## Intended uses and limitations
The model is released under the [Apache 2.0 license](https://www.apache.org/licenses/LICENSE-2.0). You can use the raw model for lyrics generation or fine-tune it further to a downstream task.
The model is capable to generate **explicit lyrics**. It is a consequence of a fine-tuning made with a dataset that contained such lyrics, which are part of the discography of many heavy metal bands. Be aware of that before you use the model, the author is **not liable for any emotional response and following consequences**.
## How to use
You can use this model directly with a pipeline for text generation. Since the generation relies on some randomness, it could be good to set a seed for reproducibility:
```python
>>> from transformers import pipeline, set_seed
>>> generator = pipeline('text-generation', model='lucone83/deep-metal', device=-1) # to use GPU, set device=<CUDA_device_ordinal>
>>> set_seed(42)
>>> generator(
"End of passion play",
num_return_sequences=1,
max_length=256,
min_length=128,
top_p=0.97,
top_k=0,
temperature=0.90
)
[{'generated_text': "End of passion play for you\nFrom the spiritual to the mental\nIt is hard to see it all\nBut let's not end up all be\nTill we see the fruits of our deeds\nAnd see the fruits of our suffering\nLet's start a fight for victory\nIt was our birthright\nIt was our call\nIt was our call\nIt was our call\nIt was our call\nIt was our call\nIt was our call\nIt was our call\nIt was our call\nIt was our call\nIt was our call\nIt was our call\nIt was our call \nLike a typhoon upon your doorstep\nYou're a victim of own misery\nAnd the god has made you pay\n\nWe are the wolves\nWe will not stand the pain\nWe are the wolves\nWe will never give up\nWe are the wolves\nWe will not leave\nWe are the wolves\nWe will never grow old\nWe are the wolves\nWe will never grow old "}]
```
Of course, it's possible to play with parameters like `top_k`, `top_p`, `temperature`, `max_length` and all the other parameters included in the `generate` method. Please look at the [documentation](https://huggingface.co/transformers/main_classes/model.html?highlight=generate#transformers.generation_utils.GenerationMixin.generate) for further insights.
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import GPT2Tokenizer, GPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('lucone83/deep-metal')
model = GPT2Model.from_pretrained('lucone83/deep-metal')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output_features = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import GPT2Tokenizer, TFGPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('lucone83/deep-metal')
model = TFGPT2Model.from_pretrained('lucone83/deep-metal')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output_features = model(encoded_input)
```
## Model training
The dataset used for training this model contained 141,718 heavy metal songs lyrics.
The model has been trained using an NVIDIA Tesla T4 with 16 GB, using the following command:
```bash
python run_language_modeling.py \
--output_dir=$OUTPUT_DIR \
--model_type=gpt2 \
--model_name_or_path=gpt2 \
--do_train \
--train_data_file=$TRAIN_FILE \
--do_eval \
--eval_data_file=$VALIDATION_FILE \
--per_device_train_batch_size=3 \
--per_device_eval_batch_size=3 \
--evaluate_during_training \
--learning_rate=1e-5 \
--num_train_epochs=20 \
--logging_steps=3000 \
--save_steps=3000 \
--gradient_accumulation_steps=3
```
To checkout the code related to training and testing, please look at the [GitHub repository](https://github.com/lucone83/deep-metal) of the project.
## Evaluation results
The model achieves the following results:
```bash
{
'eval_loss': 3.0047452173826406,
'epoch': 19.99987972095261,
'total_flos': 381377736125448192,
'step': 55420
}
perplexity = 20.18107365414611
```
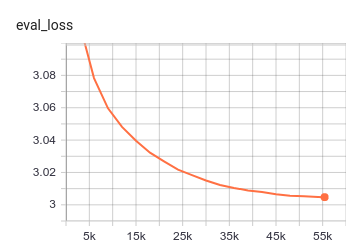
|
lighteternal/gpt2-finetuned-greek
|
lighteternal
| 2021-05-23T08:33:11Z | 261 | 6 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"causal-lm",
"el",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language:
- el
tags:
- pytorch
- causal-lm
widget:
- text: "Το αγαπημένο μου μέρος είναι"
license: apache-2.0
---
# Greek (el) GPT2 model
<img src="https://huggingface.co/lighteternal/gpt2-finetuned-greek-small/raw/main/GPT2el.png" width="600"/>
### By the Hellenic Army Academy (SSE) and the Technical University of Crete (TUC)
* language: el
* licence: apache-2.0
* dataset: ~23.4 GB of Greek corpora
* model: GPT2 (12-layer, 768-hidden, 12-heads, 117M parameters. OpenAI GPT-2 English model, finetuned for the Greek language)
* pre-processing: tokenization + BPE segmentation
* metrics: perplexity
### Model description
A text generation (autoregressive) model, using Huggingface transformers and fastai based on the English GPT-2.
Finetuned with gradual layer unfreezing. This is a more efficient and sustainable alternative compared to training from scratch, especially for low-resource languages.
Based on the work of Thomas Dehaene (ML6) for the creation of a Dutch GPT2: https://colab.research.google.com/drive/1Y31tjMkB8TqKKFlZ5OJ9fcMp3p8suvs4?usp=sharing
### How to use
```
from transformers import pipeline
model = "lighteternal/gpt2-finetuned-greek"
generator = pipeline(
'text-generation',
device=0,
model=f'{model}',
tokenizer=f'{model}')
text = "Μια φορά κι έναν καιρό"
print("\
".join([x.get("generated_text") for x in generator(
text,
max_length=len(text.split(" "))+15,
do_sample=True,
top_k=50,
repetition_penalty = 1.2,
add_special_tokens=False,
num_return_sequences=5,
temperature=0.95,
top_p=0.95)]))
```
## Training data
We used a 23.4GB sample from a consolidated Greek corpus from CC100, Wikimatrix, Tatoeba, Books, SETIMES and GlobalVoices containing long senquences.
This is a better version of our GPT-2 small model (https://huggingface.co/lighteternal/gpt2-finetuned-greek-small)
## Metrics
| Metric | Value |
| ----------- | ----------- |
| Train Loss | 3.67 |
| Validation Loss | 3.83 |
| Perplexity | 39.12 |
### Acknowledgement
The research work was supported by the Hellenic Foundation for Research and Innovation (HFRI) under the HFRI PhD Fellowship grant (Fellowship Number:50, 2nd call)
Based on the work of Thomas Dehaene (ML6): https://blog.ml6.eu/dutch-gpt2-autoregressive-language-modelling-on-a-budget-cff3942dd020
|
lighteternal/gpt2-finetuned-greek-small
|
lighteternal
| 2021-05-23T08:32:03Z | 25 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"causal-lm",
"el",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language:
- el
tags:
- pytorch
- causal-lm
widget:
- text: "Το αγαπημένο μου μέρος είναι"
license: apache-2.0
---
# Greek (el) GPT2 model - small
<img src="https://huggingface.co/lighteternal/gpt2-finetuned-greek-small/raw/main/GPT2el.png" width="600"/>
#### A new version (recommended) trained on 5x more data is available at: https://huggingface.co/lighteternal/gpt2-finetuned-greek
### By the Hellenic Army Academy (SSE) and the Technical University of Crete (TUC)
* language: el
* licence: apache-2.0
* dataset: ~5GB of Greek corpora
* model: GPT2 (12-layer, 768-hidden, 12-heads, 117M parameters. OpenAI GPT-2 English model, finetuned for the Greek language)
* pre-processing: tokenization + BPE segmentation
### Model description
A text generation (autoregressive) model, using Huggingface transformers and fastai based on the English GPT-2(small). 

Finetuned with gradual layer unfreezing. This is a more efficient and sustainable alternative compared to training from scratch, especially for low-resource languages. 

Based on the work of Thomas Dehaene (ML6) for the creation of a Dutch GPT2: https://colab.research.google.com/drive/1Y31tjMkB8TqKKFlZ5OJ9fcMp3p8suvs4?usp=sharing
### How to use
```
from transformers import pipeline
model = "lighteternal/gpt2-finetuned-greek-small"
generator = pipeline(
'text-generation',
device=0,
model=f'{model}',
tokenizer=f'{model}')
text = "Μια φορά κι έναν καιρό"
print("\\\\
".join([x.get("generated_text") for x in generator(
text,
max_length=len(text.split(" "))+15,
do_sample=True,
top_k=50,
repetition_penalty = 1.2,
add_special_tokens=False,
num_return_sequences=5,
temperature=0.95,
top_p=0.95)]))
```
## Training data
We used a small (~5GB) sample from a consolidated Greek corpus based on CC100, Wikimatrix, Tatoeba, Books, SETIMES and GlobalVoices. A bigger corpus is expected to provide better results (T0D0).
### Acknowledgement
The research work was supported by the Hellenic Foundation for Research and Innovation (HFRI) under the HFRI PhD Fellowship grant (Fellowship Number:50, 2nd call)
Based on the work of Thomas Dehaene (ML6): https://blog.ml6.eu/dutch-gpt2-autoregressive-language-modelling-on-a-budget-cff3942dd020
|
A-bhimany-u08/bert-base-cased-qqp
|
A-bhimany-u08
| 2021-05-23T06:58:51Z | 29 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"dataset:qqp",
"autotrain_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:04Z |
---
inference: False
datasets:
- qqp
---
bert-base-cased model trained on quora question pair dataset. The task requires to predict whether the two given sentences (or questions) are `not_duplicate` (label 0) or `duplicate` (label 1). The model achieves 89% evaluation accuracy
|
ktrapeznikov/gpt2-medium-topic-small-set
|
ktrapeznikov
| 2021-05-23T06:21:38Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language:
- en
thumbnail:
widget:
- text: "topic climate source"
---
# GPT2-medium-topic-news
## Model description
GPT2-medium fine tuned on a small news corpus conditioned on a topic, source, title
## Intended uses & limitations
#### How to use
To generate a news article text conditioned on a topic, source, title or some subsets, prompt model with:
```python
f"topic {topic} source"
f"topic {topic} source {source} title"
f"topic {topic} source {source} title {title} body"
```
Try the following tags for `topic: climate, weather, vaccination`.
Zero shot generation works pretty well as long as `topic` is a single word and not too specific.
```python
device = "cuda:0"
tokenizer = AutoTokenizer.from_pretrained("ktrapeznikov/gpt2-medium-topic-small-set")
model = AutoModelWithLMHead.from_pretrained("ktrapeznikov/gpt2-medium-topic-small-set")
model.to(device)
topic = "climate"
prompt = tokenizer(f"topic {topics} source straitstimes title", return_tensors="pt")
out = model.generate(prompt["input_ids"].to(device), do_sample=True,max_length=500, early_stopping=True, top_p=.9)
print(tokenizer.decode(out[0].cpu(), skip_special_tokens=True))
```
## Sample Output
>[topic] military [source] straitstimes [title] Trump signs bill on military aid to Israel [body] WASHINGTON (AFP) - US President Donald Trump signed into law Thursday (April 24) legislation to provide more than US$15 billion (S$20.43 billion) in military aid to Israel, a move the Obama administration had resisted for political reasons. The White House did not immediately respond to a request for comment on the Israel measure, which Trump had sought unsuccessfully to block during the Obama pres ...
>[topic] military [source] straitstimes [title] Hong Kong's leaders to discuss new travel restrictions as lockdown looms [body] HONG KONG (REUTERS) - Hong Kong authorities said they would hold a meeting of the Legislative Council on Monday (July 21) to discuss new travel restrictions on Hong Kong residents, as the city reported a record daily increase in coronavirus cases. The authorities said they would consider the proposal after meeting government chiefs and reviewing other measures. The co ...
>[topic] military [source] straitstimes [title] Trump signs Bill that gives US troops wider latitude to conduct operations abroad [body] WASHINGTON (AFP) - US President Donald Trump on Thursday (July 23) signed a controversial law that gives US troops more leeway to conduct operations abroad, as he seeks to shore up the embattled government's defences against the coronavirus pandemic and stave off a potentially devastating election defeat. Trump's signature Bill, named after his late father's l ...
>[topic] military [source] straitstimes [title] China's Foreign Ministry responds to Japan's statement on South China Sea: 'No one should assume the role of mediator' [body] BEIJING (AFP) - The Ministry of Foreign Affairs on Tuesday (Oct 18) told Japan to stop taking sides in the South China Sea issue and not interfere in the bilateral relationship, as Japan said it would do "nothing". Foreign Ministry spokesman Zhao Lijian told reporters in Beijing that the Chinese government's position on the ...
>[topic] military [source] straitstimes [title] US warns North Korea on potential nuclear strike [body] WASHINGTON - The United States warned North Korea last Friday that an attack by the North could be a "provocation" that would have "a devastating effect" on its security, as it took aim at Pyongyang over its continued efforts to develop weapons of mass destruction. US Secretary of State Mike Pompeo was speaking at the conclusion of a White House news conference when a reporter asked him how t ...
>[topic] military [source] straitstimes [title] China calls Hong Kong to halt 'illegal and illegal military acts' [body] WASHINGTON • Chinese Foreign Ministry spokeswoman Hua Chunying said yesterday that Hong Kong must stop 'illegal and illegal military acts' before Beijing can recognise the city as its own. In her annual State Councillor's speech, Ms Hua made the case for Hong Kong to resume Hong Kong's status as a semi-autonomous city, and vowed to use its "great power position to actively an ...
## Training data
## Training procedure
|
ktrapeznikov/gpt2-medium-topic-news
|
ktrapeznikov
| 2021-05-23T06:18:56Z | 12 | 2 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language:
- en
thumbnail:
widget:
- text: "topic: climate article:"
---
# GPT2-medium-topic-news
## Model description
GPT2-medium fine tuned on a large news corpus conditioned on a topic
## Intended uses & limitations
#### How to use
To generate a news article text conditioned on a topic, prompt model with:
`topic: climate article:`
The following tags were used during training:
`arts law international science business politics disaster world conflict football sport sports artanddesign environment music film lifeandstyle business health commentisfree books technology media education politics travel stage uk society us money culture religion science news tv fashion uk australia cities global childrens sustainable global voluntary housing law local healthcare theguardian`
Zero shot generation works pretty well as long as `topic` is a single word and not too specific.
```python
device = "cuda:0"
tokenizer = AutoTokenizer.from_pretrained("ktrapeznikov/gpt2-medium-topic-news")
model = AutoModelWithLMHead.from_pretrained("ktrapeznikov/gpt2-medium-topic-news")
model.to(device)
topic = "climate"
prompt = tokenizer(f"topic: {topic} article:", return_tensors="pt")
out = model.generate(prompt["input_ids"].to(device), do_sample=True,max_length=500, early_stopping=True, top_p=.9)
print(tokenizer.decode(list(out.cpu()[0])))
```
## Training data
## Training procedure
|
kiri-ai/gpt2-large-quantized
|
kiri-ai
| 2021-05-23T06:13:04Z | 14 | 0 |
transformers
|
[
"transformers",
"gpt2",
"text-generation",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language:
- en
---
# Pytorch int8 quantized version of gpt2-large
## Usage
Download the .bin file locally.
Load with:
Rest of the usage according to [original instructions](https://huggingface.co/gpt2-large).
```python
import torch
model = torch.load("path/to/pytorch_model_quantized.bin")
```
|
jonx18/DialoGPT-small-Creed-Odyssey
|
jonx18
| 2021-05-23T06:02:34Z | 9 | 2 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
# Summary
The app was conceived with the idea of recreating and generate new dialogs for existing games.
In order to generate a dataset for training the steps followed were:
1. Download from [Assassins Creed Fandom Wiki](https://assassinscreed.fandom.com/wiki/Special:Export) from the category "Memories relived using the Animus HR-8.5".
2. Keep only text elements from XML.
3. Keep only the dialog section.
4. Parse wikimarkup with [wikitextparser](https://pypi.org/project/wikitextparser/).
5. Clean description of dialog's context.
Due to the small size of the dataset obtained, a transfer learning approach was considered based on a pretrained ["Dialog GPT" model](https://huggingface.co/microsoft/DialoGPT-small).
|
huggingtweets/zrkrlc
|
huggingtweets
| 2021-05-23T05:26:40Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/zrkrlc/1616626091555/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1332547297914175494/RAz44L4J_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">object-level jail 🚨 🤖 AI Bot </div>
<div style="font-size: 15px">@zrkrlc bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@zrkrlc's tweets](https://twitter.com/zrkrlc).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 2241 |
| Retweets | 228 |
| Short tweets | 204 |
| Tweets kept | 1809 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2g51am53/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @zrkrlc's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/23unb7ar) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/23unb7ar/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/zrkrlc')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/zetsubunny
|
huggingtweets
| 2021-05-23T05:19:49Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/zetsubunny/1617772715416/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1362563256230031366/ujesNtUk_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">MEMENTO BUNI 🤖 AI Bot </div>
<div style="font-size: 15px">@zetsubunny bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@zetsubunny's tweets](https://twitter.com/zetsubunny).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3230 |
| Retweets | 1122 |
| Short tweets | 264 |
| Tweets kept | 1844 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3u5onhoi/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @zetsubunny's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/tv6yd107) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/tv6yd107/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/zetsubunny')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/zackmdavis
|
huggingtweets
| 2021-05-23T05:16:20Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/zackmdavis/1617765418297/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1058563940223868928/08EbRbwT_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Zack M. Davis 🤖 AI Bot </div>
<div style="font-size: 15px">@zackmdavis bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@zackmdavis's tweets](https://twitter.com/zackmdavis).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3178 |
| Retweets | 1350 |
| Short tweets | 111 |
| Tweets kept | 1717 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1uu0syjb/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @zackmdavis's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2x5kqcep) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2x5kqcep/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/zackmdavis')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/zachfox
|
huggingtweets
| 2021-05-23T05:13:41Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/zachfox/1603321719549/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<link rel="stylesheet" href="https://unpkg.com/@tailwindcss/[email protected]/dist/typography.min.css">
<style>
@media (prefers-color-scheme: dark) {
.prose { color: #E2E8F0 !important; }
.prose h2, .prose h3, .prose a, .prose thead { color: #F7FAFC !important; }
}
</style>
<section class='prose'>
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1142440824766193664/6NK0B-Gr_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Zach Fox 🤖 AI Bot </div>
<div style="font-size: 15px; color: #657786">@zachfox bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@zachfox's tweets](https://twitter.com/zachfox).
<table style='border-width:0'>
<thead style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #CBD5E0'>
<th style='border-width:0'>Data</th>
<th style='border-width:0'>Quantity</th>
</tr>
</thead>
<tbody style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Tweets downloaded</td>
<td style='border-width:0'>3168</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Retweets</td>
<td style='border-width:0'>547</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Short tweets</td>
<td style='border-width:0'>415</td>
</tr>
<tr style='border-width:0'>
<td style='border-width:0'>Tweets kept</td>
<td style='border-width:0'>2206</td>
</tr>
</tbody>
</table>
[Explore the data](https://app.wandb.ai/wandb/huggingtweets/runs/21svlsaa/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @zachfox's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://app.wandb.ai/wandb/huggingtweets/runs/21o6mb7e) for full transparency and reproducibility.
At the end of training, [the final model](https://app.wandb.ai/wandb/huggingtweets/runs/21o6mb7e/artifacts) is logged and versioned.
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation:
<pre><code><span style="color:#03A9F4">from</span> transformers <span style="color:#03A9F4">import</span> pipeline
generator = pipeline(<span style="color:#FF9800">'text-generation'</span>,
model=<span style="color:#FF9800">'huggingtweets/zachfox'</span>)
generator(<span style="color:#FF9800">"My dream is"</span>, num_return_sequences=<span style="color:#8BC34A">5</span>)</code></pre>
### Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
</section>
[](https://twitter.com/intent/follow?screen_name=borisdayma)
<section class='prose'>
For more details, visit the project repository.
</section>
[](https://github.com/borisdayma/huggingtweets)
<!--- random size file -->
|
huggingtweets/yuureimi
|
huggingtweets
| 2021-05-23T05:09:59Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/yuureimi/1614217561886/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1343286808755499008/5MMYpRNN_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">yuureimi🌸 🤖 AI Bot </div>
<div style="font-size: 15px">@yuureimi bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@yuureimi's tweets](https://twitter.com/yuureimi).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 2885 |
| Retweets | 2570 |
| Short tweets | 53 |
| Tweets kept | 262 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/21dq7xjn/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @yuureimi's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2hunxb6z) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2hunxb6z/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/yuureimi')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/yungparenti
|
huggingtweets
| 2021-05-23T05:08:47Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/yungparenti/1619285093850/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1305960885987532802/6TzwD8_B_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Astronaut Cum Evangelist 🇬🇷 🤖 AI Bot </div>
<div style="font-size: 15px">@yungparenti bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@yungparenti's tweets](https://twitter.com/yungparenti).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3232 |
| Retweets | 211 |
| Short tweets | 507 |
| Tweets kept | 2514 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/20pdwcql/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @yungparenti's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/oi3awf8d) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/oi3awf8d/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/yungparenti')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/yung_caribou
|
huggingtweets
| 2021-05-23T05:07:40Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/yung_caribou/1614136835166/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1358907764374970368/tJHY7eRK_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Certified Hairbrush Licker 🤖 AI Bot </div>
<div style="font-size: 15px">@yung_caribou bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@yung_caribou's tweets](https://twitter.com/yung_caribou).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 772 |
| Retweets | 52 |
| Short tweets | 158 |
| Tweets kept | 562 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1c7fnh7f/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @yung_caribou's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2palqva5) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2palqva5/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/yung_caribou')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/yujiri3
|
huggingtweets
| 2021-05-23T05:05:22Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/yujiri3/1616651697285/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1350388215975456768/hyUBufqg_400x400.png')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Yujiri (my likes don't always work) 🤖 AI Bot </div>
<div style="font-size: 15px">@yujiri3 bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@yujiri3's tweets](https://twitter.com/yujiri3).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3182 |
| Retweets | 773 |
| Short tweets | 318 |
| Tweets kept | 2091 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/353ok7f3/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @yujiri3's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/sqw7eetr) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/sqw7eetr/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/yujiri3')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/youronlinedad
|
huggingtweets
| 2021-05-23T05:04:15Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/youronlinedad/1614100614383/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1184826580910125057/gqE8fCKg_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Internet Dad 🤖 AI Bot </div>
<div style="font-size: 15px">@youronlinedad bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@youronlinedad's tweets](https://twitter.com/youronlinedad).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3201 |
| Retweets | 41 |
| Short tweets | 508 |
| Tweets kept | 2652 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3g7jg14o/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @youronlinedad's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2t2wy77n) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2t2wy77n/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/youronlinedad')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/yieee_nagitaco
|
huggingtweets
| 2021-05-23T05:00:38Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/yieee_nagitaco/1608381956095/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<link rel="stylesheet" href="https://unpkg.com/@tailwindcss/[email protected]/dist/typography.min.css">
<style>
@media (prefers-color-scheme: dark) {
.prose { color: #E2E8F0 !important; }
.prose h2, .prose h3, .prose a, .prose thead { color: #F7FAFC !important; }
}
</style>
<section class='prose'>
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1339194351298072577/tfJheAeM_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Yieee Nagi Taco (Sky) 🤖 AI Bot </div>
<div style="font-size: 15px; color: #657786">@yieee_nagitaco bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@yieee_nagitaco's tweets](https://twitter.com/yieee_nagitaco).
<table style='border-width:0'>
<thead style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #CBD5E0'>
<th style='border-width:0'>Data</th>
<th style='border-width:0'>Quantity</th>
</tr>
</thead>
<tbody style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Tweets downloaded</td>
<td style='border-width:0'>3032</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Retweets</td>
<td style='border-width:0'>789</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Short tweets</td>
<td style='border-width:0'>623</td>
</tr>
<tr style='border-width:0'>
<td style='border-width:0'>Tweets kept</td>
<td style='border-width:0'>1620</td>
</tr>
</tbody>
</table>
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1g8y06jc/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @yieee_nagitaco's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1tjubyxk) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1tjubyxk/artifacts) is logged and versioned.
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation:
<pre><code><span style="color:#03A9F4">from</span> transformers <span style="color:#03A9F4">import</span> pipeline
generator = pipeline(<span style="color:#FF9800">'text-generation'</span>,
model=<span style="color:#FF9800">'huggingtweets/yieee_nagitaco'</span>)
generator(<span style="color:#FF9800">"My dream is"</span>, num_return_sequences=<span style="color:#8BC34A">5</span>)</code></pre>
### Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
</section>
[](https://twitter.com/intent/follow?screen_name=borisdayma)
<section class='prose'>
For more details, visit the project repository.
</section>
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/yellowdogedem
|
huggingtweets
| 2021-05-23T04:59:31Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/yellowdogedem/1617172947443/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1374515470498373639/dygzoNob_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Toby (Inactive) 🗳️🥑⚙️🚊🌃🚀🌐 🤖 AI Bot </div>
<div style="font-size: 15px">@yellowdogedem bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@yellowdogedem's tweets](https://twitter.com/yellowdogedem).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3233 |
| Retweets | 494 |
| Short tweets | 788 |
| Tweets kept | 1951 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2ln60y7n/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @yellowdogedem's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2vj8xb46) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2vj8xb46/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/yellowdogedem')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/yeahyeahyens
|
huggingtweets
| 2021-05-23T04:58:28Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/yeahyeahyens/1612175424382/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<link rel="stylesheet" href="https://unpkg.com/@tailwindcss/[email protected]/dist/typography.min.css">
<style>
@media (prefers-color-scheme: dark) {
.prose { color: #E2E8F0 !important; }
.prose h2, .prose h3, .prose a, .prose thead { color: #F7FAFC !important; }
}
</style>
<section class='prose'>
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/647352395622653952/WEuxh8dK_400x400.png')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">evilyeahyeahyens 🤖 AI Bot </div>
<div style="font-size: 15px; color: #657786">@yeahyeahyens bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@yeahyeahyens's tweets](https://twitter.com/yeahyeahyens).
<table style='border-width:0'>
<thead style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #CBD5E0'>
<th style='border-width:0'>Data</th>
<th style='border-width:0'>Quantity</th>
</tr>
</thead>
<tbody style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Tweets downloaded</td>
<td style='border-width:0'>3244</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Retweets</td>
<td style='border-width:0'>492</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Short tweets</td>
<td style='border-width:0'>327</td>
</tr>
<tr style='border-width:0'>
<td style='border-width:0'>Tweets kept</td>
<td style='border-width:0'>2425</td>
</tr>
</tbody>
</table>
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3udu67c3/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @yeahyeahyens's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2lmppjy9) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2lmppjy9/artifacts) is logged and versioned.
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation:
<pre><code><span style="color:#03A9F4">from</span> transformers <span style="color:#03A9F4">import</span> pipeline
generator = pipeline(<span style="color:#FF9800">'text-generation'</span>,
model=<span style="color:#FF9800">'huggingtweets/yeahyeahyens'</span>)
generator(<span style="color:#FF9800">"My dream is"</span>, num_return_sequences=<span style="color:#8BC34A">5</span>)</code></pre>
### Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
</section>
[](https://twitter.com/intent/follow?screen_name=borisdayma)
<section class='prose'>
For more details, visit the project repository.
</section>
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/ycombinator
|
huggingtweets
| 2021-05-23T04:56:29Z | 4 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/ycombinator/1603447091260/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<link rel="stylesheet" href="https://unpkg.com/@tailwindcss/[email protected]/dist/typography.min.css">
<style>
@media (prefers-color-scheme: dark) {
.prose { color: #E2E8F0 !important; }
.prose h2, .prose h3, .prose a, .prose thead { color: #F7FAFC !important; }
}
</style>
<section class='prose'>
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/716641091311697920/hFFVBhFe_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Y Combinator 🤖 AI Bot </div>
<div style="font-size: 15px; color: #657786">@ycombinator bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@ycombinator's tweets](https://twitter.com/ycombinator).
<table style='border-width:0'>
<thead style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #CBD5E0'>
<th style='border-width:0'>Data</th>
<th style='border-width:0'>Quantity</th>
</tr>
</thead>
<tbody style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Tweets downloaded</td>
<td style='border-width:0'>3220</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Retweets</td>
<td style='border-width:0'>726</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Short tweets</td>
<td style='border-width:0'>14</td>
</tr>
<tr style='border-width:0'>
<td style='border-width:0'>Tweets kept</td>
<td style='border-width:0'>2480</td>
</tr>
</tbody>
</table>
[Explore the data](https://app.wandb.ai/wandb/huggingtweets/runs/256at4s3/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @ycombinator's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://app.wandb.ai/wandb/huggingtweets/runs/31k6k27j) for full transparency and reproducibility.
At the end of training, [the final model](https://app.wandb.ai/wandb/huggingtweets/runs/31k6k27j/artifacts) is logged and versioned.
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation:
<pre><code><span style="color:#03A9F4">from</span> transformers <span style="color:#03A9F4">import</span> pipeline
generator = pipeline(<span style="color:#FF9800">'text-generation'</span>,
model=<span style="color:#FF9800">'huggingtweets/ycombinator'</span>)
generator(<span style="color:#FF9800">"My dream is"</span>, num_return_sequences=<span style="color:#8BC34A">5</span>)</code></pre>
### Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
</section>
[](https://twitter.com/intent/follow?screen_name=borisdayma)
<section class='prose'>
For more details, visit the project repository.
</section>
[](https://github.com/borisdayma/huggingtweets)
<!--- random size file -->
|
huggingtweets/xwylraz0rbl4d3x
|
huggingtweets
| 2021-05-23T04:54:20Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/xwylraz0rbl4d3x/1617889284619/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1366426861299920900/A1ynltRo_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">𝙁𝙀𝙈𝘽𝙊𝙔 𝙏𝙍𝘼𝙉𝙎𝙄𝙏𝙄𝙊𝙉𝙄𝙉𝙂 🤖 AI Bot </div>
<div style="font-size: 15px">@xwylraz0rbl4d3x bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@xwylraz0rbl4d3x's tweets](https://twitter.com/xwylraz0rbl4d3x).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3152 |
| Retweets | 682 |
| Short tweets | 631 |
| Tweets kept | 1839 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/36q46b23/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @xwylraz0rbl4d3x's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3a0sqgtk) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3a0sqgtk/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/xwylraz0rbl4d3x')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/xiaomi
|
huggingtweets
| 2021-05-23T04:50:39Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/xiaomi/1609716260950/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<link rel="stylesheet" href="https://unpkg.com/@tailwindcss/[email protected]/dist/typography.min.css">
<style>
@media (prefers-color-scheme: dark) {
.prose { color: #E2E8F0 !important; }
.prose h2, .prose h3, .prose a, .prose thead { color: #F7FAFC !important; }
}
</style>
<section class='prose'>
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1246621358458433536/JlSVXK2__400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Xiaomi 🤖 AI Bot </div>
<div style="font-size: 15px; color: #657786">@xiaomi bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@xiaomi's tweets](https://twitter.com/xiaomi).
<table style='border-width:0'>
<thead style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #CBD5E0'>
<th style='border-width:0'>Data</th>
<th style='border-width:0'>Quantity</th>
</tr>
</thead>
<tbody style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Tweets downloaded</td>
<td style='border-width:0'>3225</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Retweets</td>
<td style='border-width:0'>273</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Short tweets</td>
<td style='border-width:0'>99</td>
</tr>
<tr style='border-width:0'>
<td style='border-width:0'>Tweets kept</td>
<td style='border-width:0'>2853</td>
</tr>
</tbody>
</table>
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3jsfmwvr/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @xiaomi's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/16pogxna) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/16pogxna/artifacts) is logged and versioned.
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation:
<pre><code><span style="color:#03A9F4">from</span> transformers <span style="color:#03A9F4">import</span> pipeline
generator = pipeline(<span style="color:#FF9800">'text-generation'</span>,
model=<span style="color:#FF9800">'huggingtweets/xiaomi'</span>)
generator(<span style="color:#FF9800">"My dream is"</span>, num_return_sequences=<span style="color:#8BC34A">5</span>)</code></pre>
### Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
</section>
[](https://twitter.com/intent/follow?screen_name=borisdayma)
<section class='prose'>
For more details, visit the project repository.
</section>
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/wwm_shakespeare
|
huggingtweets
| 2021-05-23T04:45:54Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/wwm_shakespeare/1610567717562/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<link rel="stylesheet" href="https://unpkg.com/@tailwindcss/[email protected]/dist/typography.min.css">
<style>
@media (prefers-color-scheme: dark) {
.prose { color: #E2E8F0 !important; }
.prose h2, .prose h3, .prose a, .prose thead { color: #F7FAFC !important; }
}
</style>
<section class='prose'>
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/68000547/1863715-big_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">William Shakespeare 🤖 AI Bot </div>
<div style="font-size: 15px; color: #657786">@wwm_shakespeare bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@wwm_shakespeare's tweets](https://twitter.com/wwm_shakespeare).
<table style='border-width:0'>
<thead style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #CBD5E0'>
<th style='border-width:0'>Data</th>
<th style='border-width:0'>Quantity</th>
</tr>
</thead>
<tbody style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Tweets downloaded</td>
<td style='border-width:0'>3234</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Retweets</td>
<td style='border-width:0'>18</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Short tweets</td>
<td style='border-width:0'>196</td>
</tr>
<tr style='border-width:0'>
<td style='border-width:0'>Tweets kept</td>
<td style='border-width:0'>3020</td>
</tr>
</tbody>
</table>
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/27cac1ob/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @wwm_shakespeare's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1qqhve6t) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1qqhve6t/artifacts) is logged and versioned.
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation:
<pre><code><span style="color:#03A9F4">from</span> transformers <span style="color:#03A9F4">import</span> pipeline
generator = pipeline(<span style="color:#FF9800">'text-generation'</span>,
model=<span style="color:#FF9800">'huggingtweets/wwm_shakespeare'</span>)
generator(<span style="color:#FF9800">"My dream is"</span>, num_return_sequences=<span style="color:#8BC34A">5</span>)</code></pre>
### Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
</section>
[](https://twitter.com/intent/follow?screen_name=borisdayma)
<section class='prose'>
For more details, visit the project repository.
</section>
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/wrathofgnon
|
huggingtweets
| 2021-05-23T04:41:01Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/wrathofgnon/1603923813760/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<link rel="stylesheet" href="https://unpkg.com/@tailwindcss/[email protected]/dist/typography.min.css">
<style>
@media (prefers-color-scheme: dark) {
.prose { color: #E2E8F0 !important; }
.prose h2, .prose h3, .prose a, .prose thead { color: #F7FAFC !important; }
}
</style>
<section class='prose'>
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/939424471353475072/fB-3BRin_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Wrath Of Gnon 🤖 AI Bot </div>
<div style="font-size: 15px; color: #657786">@wrathofgnon bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@wrathofgnon's tweets](https://twitter.com/wrathofgnon).
<table style='border-width:0'>
<thead style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #CBD5E0'>
<th style='border-width:0'>Data</th>
<th style='border-width:0'>Quantity</th>
</tr>
</thead>
<tbody style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Tweets downloaded</td>
<td style='border-width:0'>3227</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Retweets</td>
<td style='border-width:0'>499</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Short tweets</td>
<td style='border-width:0'>116</td>
</tr>
<tr style='border-width:0'>
<td style='border-width:0'>Tweets kept</td>
<td style='border-width:0'>2612</td>
</tr>
</tbody>
</table>
[Explore the data](https://app.wandb.ai/wandb/huggingtweets/runs/x0tn1ht9/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @wrathofgnon's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://app.wandb.ai/wandb/huggingtweets/runs/39eutbnd) for full transparency and reproducibility.
At the end of training, [the final model](https://app.wandb.ai/wandb/huggingtweets/runs/39eutbnd/artifacts) is logged and versioned.
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation:
<pre><code><span style="color:#03A9F4">from</span> transformers <span style="color:#03A9F4">import</span> pipeline
generator = pipeline(<span style="color:#FF9800">'text-generation'</span>,
model=<span style="color:#FF9800">'huggingtweets/wrathofgnon'</span>)
generator(<span style="color:#FF9800">"My dream is"</span>, num_return_sequences=<span style="color:#8BC34A">5</span>)</code></pre>
### Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
</section>
[](https://twitter.com/intent/follow?screen_name=borisdayma)
<section class='prose'>
For more details, visit the project repository.
</section>
[](https://github.com/borisdayma/huggingtweets)
<!--- random size file -->
|
huggingtweets/wortelsoup
|
huggingtweets
| 2021-05-23T04:39:42Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/wortelsoup/1617787975493/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1292884837468999686/9yJgjLUo_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">turnip 🤖 AI Bot </div>
<div style="font-size: 15px">@wortelsoup bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@wortelsoup's tweets](https://twitter.com/wortelsoup).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3203 |
| Retweets | 280 |
| Short tweets | 492 |
| Tweets kept | 2431 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3lswi6sv/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @wortelsoup's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/15hy9x0d) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/15hy9x0d/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/wortelsoup')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/worrski_
|
huggingtweets
| 2021-05-23T04:38:29Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/worrski_/1616131395706/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1370683624324956162/R6cB17BK_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">21st Century Schizoid Ben 🤖 AI Bot </div>
<div style="font-size: 15px">@worrski_ bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@worrski_'s tweets](https://twitter.com/worrski_).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3190 |
| Retweets | 531 |
| Short tweets | 856 |
| Tweets kept | 1803 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1g9vvlkk/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @worrski_'s tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/17oq1dis) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/17oq1dis/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/worrski_')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/wolfniya
|
huggingtweets
| 2021-05-23T04:35:39Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/wolfniya/1617790877098/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1357846937840586753/vte8QVom_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Evelyn fra den øya✴⬡✴🦎✴🇬🇧🇳🇴 🤖 AI Bot </div>
<div style="font-size: 15px">@wolfniya bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@wolfniya's tweets](https://twitter.com/wolfniya).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3243 |
| Retweets | 198 |
| Short tweets | 331 |
| Tweets kept | 2714 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2e1doaxh/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @wolfniya's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2iyc29lq) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2iyc29lq/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/wolfniya')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/wolfejosh
|
huggingtweets
| 2021-05-23T04:34:25Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/wolfejosh/1616623620980/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1253094103413395456/1OXl60FT_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Josh Wolfe 🤖 AI Bot </div>
<div style="font-size: 15px">@wolfejosh bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@wolfejosh's tweets](https://twitter.com/wolfejosh).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3245 |
| Retweets | 838 |
| Short tweets | 374 |
| Tweets kept | 2033 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/121x3hw4/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @wolfejosh's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2poyfrja) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2poyfrja/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/wolfejosh')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/woketopus
|
huggingtweets
| 2021-05-23T04:33:18Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/woketopus/1614149251542/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1363814877119336451/DtC1OuMG_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">woketopus is grooving 🤖 AI Bot </div>
<div style="font-size: 15px">@woketopus bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@woketopus's tweets](https://twitter.com/woketopus).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3219 |
| Retweets | 217 |
| Short tweets | 646 |
| Tweets kept | 2356 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3t0s1gfu/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @woketopus's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1s4xkpp2) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1s4xkpp2/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/woketopus')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/witten271
|
huggingtweets
| 2021-05-23T04:32:11Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<link rel="stylesheet" href="https://unpkg.com/@tailwindcss/[email protected]/dist/typography.min.css">
<style>
@media (prefers-color-scheme: dark) {
.prose { color: #E2E8F0 !important; }
.prose h2, .prose h3, .prose a, .prose thead { color: #F7FAFC !important; }
}
</style>
<section class='prose'>
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('http://pbs.twimg.com/profile_images/1264681056256565268/lrwZRqIv_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Edward Witten 🤖 AI Bot </div>
<div style="font-size: 15px; color: #657786">@witten271 bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@witten271's tweets](https://twitter.com/witten271).
<table style='border-width:0'>
<thead style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #CBD5E0'>
<th style='border-width:0'>Data</th>
<th style='border-width:0'>Quantity</th>
</tr>
</thead>
<tbody style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Tweets downloaded</td>
<td style='border-width:0'>1337</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Retweets</td>
<td style='border-width:0'>761</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Short tweets</td>
<td style='border-width:0'>32</td>
</tr>
<tr style='border-width:0'>
<td style='border-width:0'>Tweets kept</td>
<td style='border-width:0'>544</td>
</tr>
</tbody>
</table>
[Explore the data](https://app.wandb.ai/wandb/huggingtweets/runs/i5o4s13a/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @witten271's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://app.wandb.ai/wandb/huggingtweets/runs/35w4smrg) for full transparency and reproducibility.
At the end of training, [the final model](https://app.wandb.ai/wandb/huggingtweets/runs/35w4smrg/artifacts) is logged and versioned.
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation:
<pre><code><span style="color:#03A9F4">from</span> transformers <span style="color:#03A9F4">import</span> pipeline
generator = pipeline(<span style="color:#FF9800">'text-generation'</span>,
model=<span style="color:#FF9800">'huggingtweets/witten271'</span>)
generator(<span style="color:#FF9800">"My dream is"</span>, num_return_sequences=<span style="color:#8BC34A">5</span>)</code></pre>
### Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
</section>
[](https://twitter.com/intent/follow?screen_name=borisdayma)
<section class='prose'>
For more details, visit the project repository.
</section>
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/wired
|
huggingtweets
| 2021-05-23T04:29:56Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/wired/1601263431883/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<link rel="stylesheet" href="https://unpkg.com/@tailwindcss/[email protected]/dist/typography.min.css">
<style>
@media (prefers-color-scheme: dark) {
.prose { color: #E2E8F0 !important; }
.prose h2, .prose h3, .prose a, .prose thead { color: #F7FAFC !important; }
}
</style>
<section class='prose'>
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1228050699348561920/YvWAQD2L_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">WIRED 🤖 AI Bot </div>
<div style="font-size: 15px; color: #657786">@wired bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@wired's tweets](https://twitter.com/wired).
<table style='border-width:0'>
<thead style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #CBD5E0'>
<th style='border-width:0'>Data</th>
<th style='border-width:0'>Quantity</th>
</tr>
</thead>
<tbody style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Tweets downloaded</td>
<td style='border-width:0'>3240</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Retweets</td>
<td style='border-width:0'>353</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Short tweets</td>
<td style='border-width:0'>21</td>
</tr>
<tr style='border-width:0'>
<td style='border-width:0'>Tweets kept</td>
<td style='border-width:0'>2866</td>
</tr>
</tbody>
</table>
[Explore the data](https://app.wandb.ai/wandb/huggingtweets/runs/35181tay/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @wired's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://app.wandb.ai/wandb/huggingtweets/runs/13lg2287) for full transparency and reproducibility.
At the end of training, [the final model](https://app.wandb.ai/wandb/huggingtweets/runs/13lg2287/artifacts) is logged and versioned.
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation:
<pre><code><span style="color:#03A9F4">from</span> transformers <span style="color:#03A9F4">import</span> pipeline
generator = pipeline(<span style="color:#FF9800">'text-generation'</span>,
model=<span style="color:#FF9800">'huggingtweets/wired'</span>)
generator(<span style="color:#FF9800">"My dream is"</span>, num_return_sequences=<span style="color:#8BC34A">5</span>)</code></pre>
### Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
</section>
[](https://twitter.com/intent/follow?screen_name=borisdayma)
<section class='prose'>
For more details, visit the project repository.
</section>
[](https://github.com/borisdayma/huggingtweets)
<!--- random size file -->
|
huggingtweets/wife_geist
|
huggingtweets
| 2021-05-23T04:26:36Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/wife_geist/1616642371132/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1320806229413908483/qURj8zLe_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">wife Geist 🤖 AI Bot </div>
<div style="font-size: 15px">@wife_geist bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@wife_geist's tweets](https://twitter.com/wife_geist).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3244 |
| Retweets | 242 |
| Short tweets | 301 |
| Tweets kept | 2701 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1dj9mi0d/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @wife_geist's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/k0rfkwp0) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/k0rfkwp0/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/wife_geist')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/whiskyhutch
|
huggingtweets
| 2021-05-23T04:24:26Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/whiskyhutch/1617815806661/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1252749409126772738/POVl38T0_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Sterling 🐝 🤖 AI Bot </div>
<div style="font-size: 15px">@whiskyhutch bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@whiskyhutch's tweets](https://twitter.com/whiskyhutch).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 2893 |
| Retweets | 1516 |
| Short tweets | 345 |
| Tweets kept | 1032 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/24q4cf2m/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @whiskyhutch's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2rv5i0hc) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2rv5i0hc/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/whiskyhutch')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/weloc_
|
huggingtweets
| 2021-05-23T04:20:04Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/weloc_/1617167272947/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1320521811675750400/IeM-w2-L_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Weloc 🤖 AI Bot </div>
<div style="font-size: 15px">@weloc_ bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@weloc_'s tweets](https://twitter.com/weloc_).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 1975 |
| Retweets | 53 |
| Short tweets | 350 |
| Tweets kept | 1572 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1mrw3z4v/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @weloc_'s tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/apdvjw3r) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/apdvjw3r/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/weloc_')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/waynedupreeshow
|
huggingtweets
| 2021-05-23T04:15:34Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/waynedupreeshow/1601333699509/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<link rel="stylesheet" href="https://unpkg.com/@tailwindcss/[email protected]/dist/typography.min.css">
<style>
@media (prefers-color-scheme: dark) {
.prose { color: #E2E8F0 !important; }
.prose h2, .prose h3, .prose a, .prose thead { color: #F7FAFC !important; }
}
</style>
<section class='prose'>
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1292091660323770369/f_RKh7Ra_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">W.E. Dupree 🤖 AI Bot </div>
<div style="font-size: 15px; color: #657786">@waynedupreeshow bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@waynedupreeshow's tweets](https://twitter.com/waynedupreeshow).
<table style='border-width:0'>
<thead style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #CBD5E0'>
<th style='border-width:0'>Data</th>
<th style='border-width:0'>Quantity</th>
</tr>
</thead>
<tbody style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Tweets downloaded</td>
<td style='border-width:0'>3242</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Retweets</td>
<td style='border-width:0'>204</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Short tweets</td>
<td style='border-width:0'>109</td>
</tr>
<tr style='border-width:0'>
<td style='border-width:0'>Tweets kept</td>
<td style='border-width:0'>2929</td>
</tr>
</tbody>
</table>
[Explore the data](https://app.wandb.ai/wandb/huggingtweets/runs/2rtohy7z/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @waynedupreeshow's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://app.wandb.ai/wandb/huggingtweets/runs/3rje8xkn) for full transparency and reproducibility.
At the end of training, [the final model](https://app.wandb.ai/wandb/huggingtweets/runs/3rje8xkn/artifacts) is logged and versioned.
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation:
<pre><code><span style="color:#03A9F4">from</span> transformers <span style="color:#03A9F4">import</span> pipeline
generator = pipeline(<span style="color:#FF9800">'text-generation'</span>,
model=<span style="color:#FF9800">'huggingtweets/waynedupreeshow'</span>)
generator(<span style="color:#FF9800">"My dream is"</span>, num_return_sequences=<span style="color:#8BC34A">5</span>)</code></pre>
### Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
</section>
[](https://twitter.com/intent/follow?screen_name=borisdayma)
<section class='prose'>
For more details, visit the project repository.
</section>
[](https://github.com/borisdayma/huggingtweets)
<!--- random size file -->
|
huggingtweets/wausaubob
|
huggingtweets
| 2021-05-23T04:14:29Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/wausaubob/1616731136628/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1374548471995305986/XVI8-nGF_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Be Like Bob—Stay Home 🤖 AI Bot </div>
<div style="font-size: 15px">@wausaubob bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@wausaubob's tweets](https://twitter.com/wausaubob).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 744 |
| Retweets | 77 |
| Short tweets | 135 |
| Tweets kept | 532 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2h6y30jv/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @wausaubob's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2ocvosw0) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2ocvosw0/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/wausaubob')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/washed_u
|
huggingtweets
| 2021-05-23T04:13:27Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/washed_u/1616771910952/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1333096794826412033/ZuZpbXkU_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">honcho⛰🌵🦎 🤖 AI Bot </div>
<div style="font-size: 15px">@washed_u bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@washed_u's tweets](https://twitter.com/washed_u).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 1250 |
| Retweets | 102 |
| Short tweets | 124 |
| Tweets kept | 1024 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/qt0xkbfn/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @washed_u's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3sm2zrqc) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3sm2zrqc/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/washed_u')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/wallstreetbets
|
huggingtweets
| 2021-05-23T04:11:10Z | 5 | 2 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/wallstreetbets/1613146226664/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1355305650432188416/zAPHj9_3_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">WallStreetBets 🤖 AI Bot </div>
<div style="font-size: 15px">@wallstreetbets bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@wallstreetbets's tweets](https://twitter.com/wallstreetbets).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3234 |
| Retweets | 298 |
| Short tweets | 294 |
| Tweets kept | 2642 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/hhzrzcsh/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @wallstreetbets's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3gyh32b7) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3gyh32b7/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/wallstreetbets')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/w3disd3ad
|
huggingtweets
| 2021-05-23T04:09:00Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/w3disd3ad/1614105152162/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1357939184275623936/hhNsWFNY_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">w3dnesday 🤖 AI Bot </div>
<div style="font-size: 15px">@w3disd3ad bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@w3disd3ad's tweets](https://twitter.com/w3disd3ad).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 644 |
| Retweets | 208 |
| Short tweets | 95 |
| Tweets kept | 341 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2c3emieq/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @w3disd3ad's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3jtauo7r) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3jtauo7r/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/w3disd3ad')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/visualizevalue
|
huggingtweets
| 2021-05-23T04:00:21Z | 4 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/visualizevalue/1601837796274/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<link rel="stylesheet" href="https://unpkg.com/@tailwindcss/[email protected]/dist/typography.min.css">
<style>
@media (prefers-color-scheme: dark) {
.prose { color: #E2E8F0 !important; }
.prose h2, .prose h3, .prose a, .prose thead { color: #F7FAFC !important; }
}
</style>
<section class='prose'>
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1287562748562309122/4RLk5A_U_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Visualize Value 🤖 AI Bot </div>
<div style="font-size: 15px; color: #657786">@visualizevalue bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@visualizevalue's tweets](https://twitter.com/visualizevalue).
<table style='border-width:0'>
<thead style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #CBD5E0'>
<th style='border-width:0'>Data</th>
<th style='border-width:0'>Quantity</th>
</tr>
</thead>
<tbody style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Tweets downloaded</td>
<td style='border-width:0'>1000</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Retweets</td>
<td style='border-width:0'>132</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Short tweets</td>
<td style='border-width:0'>331</td>
</tr>
<tr style='border-width:0'>
<td style='border-width:0'>Tweets kept</td>
<td style='border-width:0'>537</td>
</tr>
</tbody>
</table>
[Explore the data](https://app.wandb.ai/wandb/huggingtweets/runs/f2olvyds/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @visualizevalue's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://app.wandb.ai/wandb/huggingtweets/runs/1rm01ie6) for full transparency and reproducibility.
At the end of training, [the final model](https://app.wandb.ai/wandb/huggingtweets/runs/1rm01ie6/artifacts) is logged and versioned.
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation:
<pre><code><span style="color:#03A9F4">from</span> transformers <span style="color:#03A9F4">import</span> pipeline
generator = pipeline(<span style="color:#FF9800">'text-generation'</span>,
model=<span style="color:#FF9800">'huggingtweets/visualizevalue'</span>)
generator(<span style="color:#FF9800">"My dream is"</span>, num_return_sequences=<span style="color:#8BC34A">5</span>)</code></pre>
### Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
</section>
[](https://twitter.com/intent/follow?screen_name=borisdayma)
<section class='prose'>
For more details, visit the project repository.
</section>
[](https://github.com/borisdayma/huggingtweets)
<!--- random size file -->
|
huggingtweets/vishxl
|
huggingtweets
| 2021-05-23T03:59:13Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<link rel="stylesheet" href="https://unpkg.com/@tailwindcss/[email protected]/dist/typography.min.css">
<style>
@media (prefers-color-scheme: dark) {
.prose { color: #E2E8F0 !important; }
.prose h2, .prose h3, .prose a, .prose thead { color: #F7FAFC !important; }
}
</style>
<section class='prose'>
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1033083727285379073/1SEJwb6b_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">vishal 🤖 AI Bot </div>
<div style="font-size: 15px; color: #657786">@vishxl bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@vishxl's tweets](https://twitter.com/vishxl).
<table style='border-width:0'>
<thead style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #CBD5E0'>
<th style='border-width:0'>Data</th>
<th style='border-width:0'>Quantity</th>
</tr>
</thead>
<tbody style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Tweets downloaded</td>
<td style='border-width:0'>812</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Retweets</td>
<td style='border-width:0'>37</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Short tweets</td>
<td style='border-width:0'>84</td>
</tr>
<tr style='border-width:0'>
<td style='border-width:0'>Tweets kept</td>
<td style='border-width:0'>691</td>
</tr>
</tbody>
</table>
[Explore the data](https://app.wandb.ai/wandb/huggingtweets/runs/2mqzqssg/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @vishxl's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://app.wandb.ai/wandb/huggingtweets/runs/3c829t92) for full transparency and reproducibility.
At the end of training, [the final model](https://app.wandb.ai/wandb/huggingtweets/runs/3c829t92/artifacts) is logged and versioned.
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation:
<pre><code><span style="color:#03A9F4">from</span> transformers <span style="color:#03A9F4">import</span> pipeline
generator = pipeline(<span style="color:#FF9800">'text-generation'</span>,
model=<span style="color:#FF9800">'huggingtweets/vishxl'</span>)
generator(<span style="color:#FF9800">"My dream is"</span>, num_return_sequences=<span style="color:#8BC34A">5</span>)</code></pre>
### Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
</section>
[](https://twitter.com/intent/follow?screen_name=borisdayma)
<section class='prose'>
For more details, visit the project repository.
</section>
[](https://github.com/borisdayma/huggingtweets)
<!--- random size file -->
|
huggingtweets/violetgweny
|
huggingtweets
| 2021-05-23T03:54:48Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/violetgweny/1616644773439/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1359993854871625730/TyFYsZsn_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Gweny 🤖 AI Bot </div>
<div style="font-size: 15px">@violetgweny bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@violetgweny's tweets](https://twitter.com/violetgweny).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3241 |
| Retweets | 384 |
| Short tweets | 160 |
| Tweets kept | 2697 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/zc0zpn8e/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @violetgweny's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1l4ggliv) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1l4ggliv/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/violetgweny')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/vinniehacker
|
huggingtweets
| 2021-05-23T03:53:38Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/vinniehacker/1601347831541/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<link rel="stylesheet" href="https://unpkg.com/@tailwindcss/[email protected]/dist/typography.min.css">
<style>
@media (prefers-color-scheme: dark) {
.prose { color: #E2E8F0 !important; }
.prose h2, .prose h3, .prose a, .prose thead { color: #F7FAFC !important; }
}
</style>
<section class='prose'>
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1280331403415019522/u4yAMDJ1_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Vinnie 😃 🤖 AI Bot </div>
<div style="font-size: 15px; color: #657786">@vinniehacker bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@vinniehacker's tweets](https://twitter.com/vinniehacker).
<table style='border-width:0'>
<thead style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #CBD5E0'>
<th style='border-width:0'>Data</th>
<th style='border-width:0'>Quantity</th>
</tr>
</thead>
<tbody style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Tweets downloaded</td>
<td style='border-width:0'>442</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Retweets</td>
<td style='border-width:0'>90</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Short tweets</td>
<td style='border-width:0'>112</td>
</tr>
<tr style='border-width:0'>
<td style='border-width:0'>Tweets kept</td>
<td style='border-width:0'>240</td>
</tr>
</tbody>
</table>
[Explore the data](https://app.wandb.ai/wandb/huggingtweets/runs/9fhoiyof/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @vinniehacker's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://app.wandb.ai/wandb/huggingtweets/runs/1zwwbso6) for full transparency and reproducibility.
At the end of training, [the final model](https://app.wandb.ai/wandb/huggingtweets/runs/1zwwbso6/artifacts) is logged and versioned.
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation:
<pre><code><span style="color:#03A9F4">from</span> transformers <span style="color:#03A9F4">import</span> pipeline
generator = pipeline(<span style="color:#FF9800">'text-generation'</span>,
model=<span style="color:#FF9800">'huggingtweets/vinniehacker'</span>)
generator(<span style="color:#FF9800">"My dream is"</span>, num_return_sequences=<span style="color:#8BC34A">5</span>)</code></pre>
### Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
</section>
[](https://twitter.com/intent/follow?screen_name=borisdayma)
<section class='prose'>
For more details, visit the project repository.
</section>
[](https://github.com/borisdayma/huggingtweets)
<!--- random size file -->
|
huggingtweets/vgr
|
huggingtweets
| 2021-05-23T03:51:25Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/vgr/1602716793427/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<link rel="stylesheet" href="https://unpkg.com/@tailwindcss/[email protected]/dist/typography.min.css">
<style>
@media (prefers-color-scheme: dark) {
.prose { color: #E2E8F0 !important; }
.prose h2, .prose h3, .prose a, .prose thead { color: #F7FAFC !important; }
}
</style>
<section class='prose'>
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1266600883380342785/1OFJtU3I_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Venkatesh Rao 🤖 AI Bot </div>
<div style="font-size: 15px; color: #657786">@vgr bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@vgr's tweets](https://twitter.com/vgr).
<table style='border-width:0'>
<thead style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #CBD5E0'>
<th style='border-width:0'>Data</th>
<th style='border-width:0'>Quantity</th>
</tr>
</thead>
<tbody style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Tweets downloaded</td>
<td style='border-width:0'>3201</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Retweets</td>
<td style='border-width:0'>487</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Short tweets</td>
<td style='border-width:0'>235</td>
</tr>
<tr style='border-width:0'>
<td style='border-width:0'>Tweets kept</td>
<td style='border-width:0'>2479</td>
</tr>
</tbody>
</table>
[Explore the data](https://app.wandb.ai/wandb/huggingtweets/runs/3ro13ju0/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @vgr's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://app.wandb.ai/wandb/huggingtweets/runs/18283z0w) for full transparency and reproducibility.
At the end of training, [the final model](https://app.wandb.ai/wandb/huggingtweets/runs/18283z0w/artifacts) is logged and versioned.
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation:
<pre><code><span style="color:#03A9F4">from</span> transformers <span style="color:#03A9F4">import</span> pipeline
generator = pipeline(<span style="color:#FF9800">'text-generation'</span>,
model=<span style="color:#FF9800">'huggingtweets/vgr'</span>)
generator(<span style="color:#FF9800">"My dream is"</span>, num_return_sequences=<span style="color:#8BC34A">5</span>)</code></pre>
### Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
</section>
[](https://twitter.com/intent/follow?screen_name=borisdayma)
<section class='prose'>
For more details, visit the project repository.
</section>
[](https://github.com/borisdayma/huggingtweets)
<!--- random size file -->
|
huggingtweets/vfsyes
|
huggingtweets
| 2021-05-23T03:50:08Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/vfsyes/1601526119909/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<link rel="stylesheet" href="https://unpkg.com/@tailwindcss/[email protected]/dist/typography.min.css">
<style>
@media (prefers-color-scheme: dark) {
.prose { color: #E2E8F0 !important; }
.prose h2, .prose h3, .prose a, .prose thead { color: #F7FAFC !important; }
}
</style>
<section class='prose'>
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/965091061923160066/L4aLxCgK_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Victoria Firth-Smith ✌️ 🤖 AI Bot </div>
<div style="font-size: 15px; color: #657786">@vfsyes bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@vfsyes's tweets](https://twitter.com/vfsyes).
<table style='border-width:0'>
<thead style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #CBD5E0'>
<th style='border-width:0'>Data</th>
<th style='border-width:0'>Quantity</th>
</tr>
</thead>
<tbody style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Tweets downloaded</td>
<td style='border-width:0'>3201</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Retweets</td>
<td style='border-width:0'>791</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Short tweets</td>
<td style='border-width:0'>296</td>
</tr>
<tr style='border-width:0'>
<td style='border-width:0'>Tweets kept</td>
<td style='border-width:0'>2114</td>
</tr>
</tbody>
</table>
[Explore the data](https://app.wandb.ai/wandb/huggingtweets/runs/3zryr6q7/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @vfsyes's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://app.wandb.ai/wandb/huggingtweets/runs/316yya4e) for full transparency and reproducibility.
At the end of training, [the final model](https://app.wandb.ai/wandb/huggingtweets/runs/316yya4e/artifacts) is logged and versioned.
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation:
<pre><code><span style="color:#03A9F4">from</span> transformers <span style="color:#03A9F4">import</span> pipeline
generator = pipeline(<span style="color:#FF9800">'text-generation'</span>,
model=<span style="color:#FF9800">'huggingtweets/vfsyes'</span>)
generator(<span style="color:#FF9800">"My dream is"</span>, num_return_sequences=<span style="color:#8BC34A">5</span>)</code></pre>
### Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
</section>
[](https://twitter.com/intent/follow?screen_name=borisdayma)
<section class='prose'>
For more details, visit the project repository.
</section>
[](https://github.com/borisdayma/huggingtweets)
<!--- random size file -->
|
huggingtweets/vermontsmash
|
huggingtweets
| 2021-05-23T03:47:33Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/vermontsmash/1615171689234/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1186545353388101632/yGveN2N3_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Vermont Smash Ultimate 🤖 AI Bot </div>
<div style="font-size: 15px">@vermontsmash bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@vermontsmash's tweets](https://twitter.com/vermontsmash).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 161 |
| Retweets | 22 |
| Short tweets | 13 |
| Tweets kept | 126 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2jy80fph/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @vermontsmash's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/14r2owgg) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/14r2owgg/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/vermontsmash')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/vercel
|
huggingtweets
| 2021-05-23T03:46:00Z | 4 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<link rel="stylesheet" href="https://unpkg.com/@tailwindcss/[email protected]/dist/typography.min.css">
<style>
@media (prefers-color-scheme: dark) {
.prose { color: #E2E8F0 !important; }
.prose h2, .prose h3, .prose a, .prose thead { color: #F7FAFC !important; }
}
</style>
<section class='prose'>
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1252531684353998848/6R0-p1Vf_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Vercel 🤖 AI Bot </div>
<div style="font-size: 15px; color: #657786">@vercel bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@vercel's tweets](https://twitter.com/vercel).
<table style='border-width:0'>
<thead style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #CBD5E0'>
<th style='border-width:0'>Data</th>
<th style='border-width:0'>Quantity</th>
</tr>
</thead>
<tbody style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Tweets downloaded</td>
<td style='border-width:0'>1072</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Retweets</td>
<td style='border-width:0'>339</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Short tweets</td>
<td style='border-width:0'>102</td>
</tr>
<tr style='border-width:0'>
<td style='border-width:0'>Tweets kept</td>
<td style='border-width:0'>631</td>
</tr>
</tbody>
</table>
[Explore the data](https://app.wandb.ai/wandb/huggingtweets/runs/2e8z8gby/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @vercel's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://app.wandb.ai/wandb/huggingtweets/runs/3svt5mgv) for full transparency and reproducibility.
At the end of training, [the final model](https://app.wandb.ai/wandb/huggingtweets/runs/3svt5mgv/artifacts) is logged and versioned.
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation:
<pre><code><span style="color:#03A9F4">from</span> transformers <span style="color:#03A9F4">import</span> pipeline
generator = pipeline(<span style="color:#FF9800">'text-generation'</span>,
model=<span style="color:#FF9800">'huggingtweets/vercel'</span>)
generator(<span style="color:#FF9800">"My dream is"</span>, num_return_sequences=<span style="color:#8BC34A">5</span>)</code></pre>
### Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
</section>
[](https://twitter.com/intent/follow?screen_name=borisdayma)
<section class='prose'>
For more details, visit the project repository.
</section>
[](https://github.com/borisdayma/huggingtweets)
<!--- random size file -->
|
huggingtweets/verafiedposter
|
huggingtweets
| 2021-05-23T03:44:52Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/verafiedposter/1616696054193/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1276868958600204289/OgyIJae3_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">big black cloud will come 🤖 AI Bot </div>
<div style="font-size: 15px">@verafiedposter bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@verafiedposter's tweets](https://twitter.com/verafiedposter).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3222 |
| Retweets | 226 |
| Short tweets | 234 |
| Tweets kept | 2762 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2byyqoj9/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @verafiedposter's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/27jpl5l8) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/27jpl5l8/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/verafiedposter')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/vennesports
|
huggingtweets
| 2021-05-23T03:40:48Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/vennesports/1614525364767/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1348717540055285761/b64uTQVw_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">VENN ESPORTS 🤖 AI Bot </div>
<div style="font-size: 15px">@vennesports bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@vennesports's tweets](https://twitter.com/vennesports).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 107 |
| Retweets | 16 |
| Short tweets | 22 |
| Tweets kept | 69 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2wx6lrcs/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @vennesports's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1fch18xq) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1fch18xq/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/vennesports')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/venmosupport
|
huggingtweets
| 2021-05-23T03:38:45Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1330956499644862464/SaEWN6zZ_400x400.png')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Venmo Support 🤖 AI Bot </div>
<div style="font-size: 15px">@venmosupport bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@venmosupport's tweets](https://twitter.com/venmosupport).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3224 |
| Retweets | 0 |
| Short tweets | 3 |
| Tweets kept | 3221 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/28gmfisy/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @venmosupport's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/lmznz3pr) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/lmznz3pr/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/venmosupport')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/vccircle
|
huggingtweets
| 2021-05-23T03:34:14Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/vccircle/1609942748755/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<link rel="stylesheet" href="https://unpkg.com/@tailwindcss/[email protected]/dist/typography.min.css">
<style>
@media (prefers-color-scheme: dark) {
.prose { color: #E2E8F0 !important; }
.prose h2, .prose h3, .prose a, .prose thead { color: #F7FAFC !important; }
}
</style>
<section class='prose'>
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1103554885549666304/PzYNIvur_400x400.png')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">VCCircle 🤖 AI Bot </div>
<div style="font-size: 15px; color: #657786">@vccircle bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@vccircle's tweets](https://twitter.com/vccircle).
<table style='border-width:0'>
<thead style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #CBD5E0'>
<th style='border-width:0'>Data</th>
<th style='border-width:0'>Quantity</th>
</tr>
</thead>
<tbody style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Tweets downloaded</td>
<td style='border-width:0'>3236</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Retweets</td>
<td style='border-width:0'>68</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Short tweets</td>
<td style='border-width:0'>9</td>
</tr>
<tr style='border-width:0'>
<td style='border-width:0'>Tweets kept</td>
<td style='border-width:0'>3159</td>
</tr>
</tbody>
</table>
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/ruq22ufk/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @vccircle's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/whr2irtk) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/whr2irtk/artifacts) is logged and versioned.
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation:
<pre><code><span style="color:#03A9F4">from</span> transformers <span style="color:#03A9F4">import</span> pipeline
generator = pipeline(<span style="color:#FF9800">'text-generation'</span>,
model=<span style="color:#FF9800">'huggingtweets/vccircle'</span>)
generator(<span style="color:#FF9800">"My dream is"</span>, num_return_sequences=<span style="color:#8BC34A">5</span>)</code></pre>
### Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
</section>
[](https://twitter.com/intent/follow?screen_name=borisdayma)
<section class='prose'>
For more details, visit the project repository.
</section>
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/vansianmagic
|
huggingtweets
| 2021-05-23T03:33:07Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1304024678738964480/XaiyULdl_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Vanse 🤖 AI Bot </div>
<div style="font-size: 15px">@vansianmagic bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@vansianmagic's tweets](https://twitter.com/vansianmagic).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3233 |
| Retweets | 381 |
| Short tweets | 406 |
| Tweets kept | 2446 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1ev1v2vv/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @vansianmagic's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2trfqi5g) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2trfqi5g/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/vansianmagic')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/uppityducky
|
huggingtweets
| 2021-05-23T03:26:11Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/uppityducky/1620959882367/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1350536243625529347/FofFsp0z_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Ducky 🐤✨ VTUBER</div>
<div style="text-align: center; font-size: 14px;">@uppityducky</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Ducky 🐤✨ VTUBER.
| Data | Ducky 🐤✨ VTUBER |
| --- | --- |
| Tweets downloaded | 3234 |
| Retweets | 541 |
| Short tweets | 414 |
| Tweets kept | 2279 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3hn8xp7r/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @uppityducky's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1gbfa6cb) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1gbfa6cb/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/uppityducky')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/unlikelyvee
|
huggingtweets
| 2021-05-23T03:23:33Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/unlikelyvee/1618115531130/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1379120795838861315/V7kEQ63C_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Veronica 🤖 AI Bot </div>
<div style="font-size: 15px">@unlikelyvee bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@unlikelyvee's tweets](https://twitter.com/unlikelyvee).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3233 |
| Retweets | 466 |
| Short tweets | 951 |
| Tweets kept | 1816 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1df8eimg/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @unlikelyvee's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1o1p2kqo) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1o1p2kqo/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/unlikelyvee')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/umbersorrow
|
huggingtweets
| 2021-05-23T03:20:17Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/umbersorrow/1618453146116/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1218755685846061056/g0evVFLV_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">meadowsweet 🤖 AI Bot </div>
<div style="font-size: 15px">@umbersorrow bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@umbersorrow's tweets](https://twitter.com/umbersorrow).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3215 |
| Retweets | 150 |
| Short tweets | 383 |
| Tweets kept | 2682 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/yds0m1lc/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @umbersorrow's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/154muf26) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/154muf26/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/umbersorrow')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/ultraposting
|
huggingtweets
| 2021-05-23T03:19:10Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/ultraposting/1617757965004/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1377321031140970498/NH7MyLrz_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">froggie 🔴 🤖 AI Bot </div>
<div style="font-size: 15px">@ultraposting bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@ultraposting's tweets](https://twitter.com/ultraposting).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3212 |
| Retweets | 192 |
| Short tweets | 1454 |
| Tweets kept | 1566 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/297g0eee/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @ultraposting's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1syvkxap) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1syvkxap/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/ultraposting')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/uhaul_cares
|
huggingtweets
| 2021-05-23T03:17:55Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/uhaul_cares/1616885643863/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/477228429733941251/1Jv8fSSP_400x400.jpeg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">U-Haul Cares 🤖 AI Bot </div>
<div style="font-size: 15px">@uhaul_cares bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@uhaul_cares's tweets](https://twitter.com/uhaul_cares).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3225 |
| Retweets | 9 |
| Short tweets | 5 |
| Tweets kept | 3211 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1s0dgmbq/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @uhaul_cares's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/192wppwc) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/192wppwc/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/uhaul_cares')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/ugh_lily
|
huggingtweets
| 2021-05-23T03:16:34Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/ugh_lily/1614210833411/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1364632507862384652/N-FlBL6A_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">lillillil 🤖 AI Bot </div>
<div style="font-size: 15px">@ugh_lily bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@ugh_lily's tweets](https://twitter.com/ugh_lily).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3177 |
| Retweets | 673 |
| Short tweets | 418 |
| Tweets kept | 2086 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/12myglx7/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @ugh_lily's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1dzbo8k1) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1dzbo8k1/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/ugh_lily')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/ubergeekgirl
|
huggingtweets
| 2021-05-23T03:12:51Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/ubergeekgirl/1616702433681/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1316557285217320966/C4KAOyRs_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Jessica DeVita (she/her) 🤖 AI Bot </div>
<div style="font-size: 15px">@ubergeekgirl bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@ubergeekgirl's tweets](https://twitter.com/ubergeekgirl).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3206 |
| Retweets | 1710 |
| Short tweets | 305 |
| Tweets kept | 1191 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1ye7f7c5/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @ubergeekgirl's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/6bat41rv) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/6bat41rv/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/ubergeekgirl')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/txwatie
|
huggingtweets
| 2021-05-23T03:08:23Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/txwatie/1614133717584/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1317191233740132360/rJ1oXRbk_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Kabbalah Harris 🤖 AI Bot </div>
<div style="font-size: 15px">@txwatie bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@txwatie's tweets](https://twitter.com/txwatie).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3204 |
| Retweets | 72 |
| Short tweets | 355 |
| Tweets kept | 2777 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/gcyk98bc/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @txwatie's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3bcz85rk) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3bcz85rk/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/txwatie')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/twinkhonkat
|
huggingtweets
| 2021-05-23T03:03:12Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/twinkhonkat/1617768038150/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1373188819097358338/K5MpsjmC_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Another Banger Mr. Land 🤖 AI Bot </div>
<div style="font-size: 15px">@twinkhonkat bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@twinkhonkat's tweets](https://twitter.com/twinkhonkat).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3198 |
| Retweets | 835 |
| Short tweets | 609 |
| Tweets kept | 1754 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/13z7lukq/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @twinkhonkat's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1v98yvbf) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1v98yvbf/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/twinkhonkat')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/tweeting691
|
huggingtweets
| 2021-05-23T03:02:02Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/tweeting691/1609406697752/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<link rel="stylesheet" href="https://unpkg.com/@tailwindcss/[email protected]/dist/typography.min.css">
<style>
@media (prefers-color-scheme: dark) {
.prose { color: #E2E8F0 !important; }
.prose h2, .prose h3, .prose a, .prose thead { color: #F7FAFC !important; }
}
</style>
<section class='prose'>
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1344038435204562951/gw-6-9w9_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">dr. jesus 🤖 AI Bot </div>
<div style="font-size: 15px; color: #657786">@tweeting691 bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@tweeting691's tweets](https://twitter.com/tweeting691).
<table style='border-width:0'>
<thead style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #CBD5E0'>
<th style='border-width:0'>Data</th>
<th style='border-width:0'>Quantity</th>
</tr>
</thead>
<tbody style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Tweets downloaded</td>
<td style='border-width:0'>185</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Retweets</td>
<td style='border-width:0'>1</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Short tweets</td>
<td style='border-width:0'>23</td>
</tr>
<tr style='border-width:0'>
<td style='border-width:0'>Tweets kept</td>
<td style='border-width:0'>161</td>
</tr>
</tbody>
</table>
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3a553tjb/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @tweeting691's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/15gnpyl6) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/15gnpyl6/artifacts) is logged and versioned.
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation:
<pre><code><span style="color:#03A9F4">from</span> transformers <span style="color:#03A9F4">import</span> pipeline
generator = pipeline(<span style="color:#FF9800">'text-generation'</span>,
model=<span style="color:#FF9800">'huggingtweets/tweeting691'</span>)
generator(<span style="color:#FF9800">"My dream is"</span>, num_return_sequences=<span style="color:#8BC34A">5</span>)</code></pre>
### Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
</section>
[](https://twitter.com/intent/follow?screen_name=borisdayma)
<section class='prose'>
For more details, visit the project repository.
</section>
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/tudelft
|
huggingtweets
| 2021-05-23T02:58:44Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/tudelft/1619286696560/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1338446080472715264/H7zNxjb-_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">TU Delft 🤖 AI Bot </div>
<div style="font-size: 15px">@tudelft bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@tudelft's tweets](https://twitter.com/tudelft).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3195 |
| Retweets | 1596 |
| Short tweets | 25 |
| Tweets kept | 1574 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1j26dbf2/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @tudelft's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2p7tho33) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2p7tho33/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/tudelft')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/tswiftlyricsbot
|
huggingtweets
| 2021-05-23T02:54:12Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/tswiftlyricsbot/1608387740610/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<link rel="stylesheet" href="https://unpkg.com/@tailwindcss/[email protected]/dist/typography.min.css">
<style>
@media (prefers-color-scheme: dark) {
.prose { color: #E2E8F0 !important; }
.prose h2, .prose h3, .prose a, .prose thead { color: #F7FAFC !important; }
}
</style>
<section class='prose'>
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1337290803513761794/3GWKjWq2_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Taylor Swift Lyrics Bot 🤖 AI Bot </div>
<div style="font-size: 15px; color: #657786">@tswiftlyricsbot bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@tswiftlyricsbot's tweets](https://twitter.com/tswiftlyricsbot).
<table style='border-width:0'>
<thead style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #CBD5E0'>
<th style='border-width:0'>Data</th>
<th style='border-width:0'>Quantity</th>
</tr>
</thead>
<tbody style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Tweets downloaded</td>
<td style='border-width:0'>3205</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Retweets</td>
<td style='border-width:0'>5</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Short tweets</td>
<td style='border-width:0'>0</td>
</tr>
<tr style='border-width:0'>
<td style='border-width:0'>Tweets kept</td>
<td style='border-width:0'>3200</td>
</tr>
</tbody>
</table>
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/qdnxidxi/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @tswiftlyricsbot's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2i0e5153) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2i0e5153/artifacts) is logged and versioned.
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation:
<pre><code><span style="color:#03A9F4">from</span> transformers <span style="color:#03A9F4">import</span> pipeline
generator = pipeline(<span style="color:#FF9800">'text-generation'</span>,
model=<span style="color:#FF9800">'huggingtweets/tswiftlyricsbot'</span>)
generator(<span style="color:#FF9800">"My dream is"</span>, num_return_sequences=<span style="color:#8BC34A">5</span>)</code></pre>
### Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
</section>
[](https://twitter.com/intent/follow?screen_name=borisdayma)
<section class='prose'>
For more details, visit the project repository.
</section>
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/tsuyamumethefox
|
huggingtweets
| 2021-05-23T02:53:05Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/tsuyamumethefox/1610140660004/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<link rel="stylesheet" href="https://unpkg.com/@tailwindcss/[email protected]/dist/typography.min.css">
<style>
@media (prefers-color-scheme: dark) {
.prose { color: #E2E8F0 !important; }
.prose h2, .prose h3, .prose a, .prose thead { color: #F7FAFC !important; }
}
</style>
<section class='prose'>
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1311526526609915910/11d_yK8Q_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Tsuyamume 🦊🥃🔞 🤖 AI Bot </div>
<div style="font-size: 15px; color: #657786">@tsuyamumethefox bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@tsuyamumethefox's tweets](https://twitter.com/tsuyamumethefox).
<table style='border-width:0'>
<thead style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #CBD5E0'>
<th style='border-width:0'>Data</th>
<th style='border-width:0'>Quantity</th>
</tr>
</thead>
<tbody style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Tweets downloaded</td>
<td style='border-width:0'>1388</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Retweets</td>
<td style='border-width:0'>23</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Short tweets</td>
<td style='border-width:0'>217</td>
</tr>
<tr style='border-width:0'>
<td style='border-width:0'>Tweets kept</td>
<td style='border-width:0'>1148</td>
</tr>
</tbody>
</table>
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1o8j2fn3/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @tsuyamumethefox's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3goj70du) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3goj70du/artifacts) is logged and versioned.
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation:
<pre><code><span style="color:#03A9F4">from</span> transformers <span style="color:#03A9F4">import</span> pipeline
generator = pipeline(<span style="color:#FF9800">'text-generation'</span>,
model=<span style="color:#FF9800">'huggingtweets/tsuyamumethefox'</span>)
generator(<span style="color:#FF9800">"My dream is"</span>, num_return_sequences=<span style="color:#8BC34A">5</span>)</code></pre>
### Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
</section>
[](https://twitter.com/intent/follow?screen_name=borisdayma)
<section class='prose'>
For more details, visit the project repository.
</section>
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/troydan
|
huggingtweets
| 2021-05-23T02:48:18Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/troydan/1601311259605/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<link rel="stylesheet" href="https://unpkg.com/@tailwindcss/[email protected]/dist/typography.min.css">
<style>
@media (prefers-color-scheme: dark) {
.prose { color: #E2E8F0 !important; }
.prose h2, .prose h3, .prose a, .prose thead { color: #F7FAFC !important; }
}
</style>
<section class='prose'>
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1303751449411833856/DZX5_3IH_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Troydan 🤖 AI Bot </div>
<div style="font-size: 15px; color: #657786">@troydan bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@troydan's tweets](https://twitter.com/troydan).
<table style='border-width:0'>
<thead style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #CBD5E0'>
<th style='border-width:0'>Data</th>
<th style='border-width:0'>Quantity</th>
</tr>
</thead>
<tbody style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Tweets downloaded</td>
<td style='border-width:0'>3235</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Retweets</td>
<td style='border-width:0'>47</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Short tweets</td>
<td style='border-width:0'>630</td>
</tr>
<tr style='border-width:0'>
<td style='border-width:0'>Tweets kept</td>
<td style='border-width:0'>2558</td>
</tr>
</tbody>
</table>
[Explore the data](https://app.wandb.ai/wandb/huggingtweets/runs/2xrfz81n/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @troydan's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://app.wandb.ai/wandb/huggingtweets/runs/2dvhcp0j) for full transparency and reproducibility.
At the end of training, [the final model](https://app.wandb.ai/wandb/huggingtweets/runs/2dvhcp0j/artifacts) is logged and versioned.
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation:
<pre><code><span style="color:#03A9F4">from</span> transformers <span style="color:#03A9F4">import</span> pipeline
generator = pipeline(<span style="color:#FF9800">'text-generation'</span>,
model=<span style="color:#FF9800">'huggingtweets/troydan'</span>)
generator(<span style="color:#FF9800">"My dream is"</span>, num_return_sequences=<span style="color:#8BC34A">5</span>)</code></pre>
### Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
</section>
[](https://twitter.com/intent/follow?screen_name=borisdayma)
<section class='prose'>
For more details, visit the project repository.
</section>
[](https://github.com/borisdayma/huggingtweets)
<!--- random size file -->
|
huggingtweets/trolley_rebel
|
huggingtweets
| 2021-05-23T02:47:11Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1348144059697782789/lQpJ1SnC_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">trulley 🤖 AI Bot </div>
<div style="font-size: 15px">@trolley_rebel bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@trolley_rebel's tweets](https://twitter.com/trolley_rebel).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3225 |
| Retweets | 260 |
| Short tweets | 624 |
| Tweets kept | 2341 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/23bzpqnj/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @trolley_rebel's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3awnos47) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3awnos47/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/trolley_rebel')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/tr0g
|
huggingtweets
| 2021-05-23T02:46:04Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/tr0g/1616618745428/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1273984876392349697/AFvSEcBV_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Demiurgent 🥃🖤 🤖 AI Bot </div>
<div style="font-size: 15px">@tr0g bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@tr0g's tweets](https://twitter.com/tr0g).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3177 |
| Retweets | 903 |
| Short tweets | 135 |
| Tweets kept | 2139 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2scc74zx/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @tr0g's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1ttncfru) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1ttncfru/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/tr0g')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/tower727
|
huggingtweets
| 2021-05-23T02:44:56Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/tower727/1618327942998/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1381826738003578881/py6tkY-V_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Tower 727 🤖 AI Bot </div>
<div style="font-size: 15px">@tower727 bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@tower727's tweets](https://twitter.com/tower727).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 2291 |
| Retweets | 268 |
| Short tweets | 19 |
| Tweets kept | 2004 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1uekwah0/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @tower727's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2fz0y3u2) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2fz0y3u2/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/tower727')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/tonline_news
|
huggingtweets
| 2021-05-23T02:40:02Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/tonline_news/1603446279269/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<link rel="stylesheet" href="https://unpkg.com/@tailwindcss/[email protected]/dist/typography.min.css">
<style>
@media (prefers-color-scheme: dark) {
.prose { color: #E2E8F0 !important; }
.prose h2, .prose h3, .prose a, .prose thead { color: #F7FAFC !important; }
}
</style>
<section class='prose'>
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1300377538238218245/IlY5V715_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">t-online 🤖 AI Bot </div>
<div style="font-size: 15px; color: #657786">@tonline_news bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@tonline_news's tweets](https://twitter.com/tonline_news).
<table style='border-width:0'>
<thead style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #CBD5E0'>
<th style='border-width:0'>Data</th>
<th style='border-width:0'>Quantity</th>
</tr>
</thead>
<tbody style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Tweets downloaded</td>
<td style='border-width:0'>3217</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Retweets</td>
<td style='border-width:0'>1148</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Short tweets</td>
<td style='border-width:0'>36</td>
</tr>
<tr style='border-width:0'>
<td style='border-width:0'>Tweets kept</td>
<td style='border-width:0'>2033</td>
</tr>
</tbody>
</table>
[Explore the data](https://app.wandb.ai/wandb/huggingtweets/runs/1tad5tz6/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @tonline_news's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://app.wandb.ai/wandb/huggingtweets/runs/cpk5773x) for full transparency and reproducibility.
At the end of training, [the final model](https://app.wandb.ai/wandb/huggingtweets/runs/cpk5773x/artifacts) is logged and versioned.
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation:
<pre><code><span style="color:#03A9F4">from</span> transformers <span style="color:#03A9F4">import</span> pipeline
generator = pipeline(<span style="color:#FF9800">'text-generation'</span>,
model=<span style="color:#FF9800">'huggingtweets/tonline_news'</span>)
generator(<span style="color:#FF9800">"My dream is"</span>, num_return_sequences=<span style="color:#8BC34A">5</span>)</code></pre>
### Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
</section>
[](https://twitter.com/intent/follow?screen_name=borisdayma)
<section class='prose'>
For more details, visit the project repository.
</section>
[](https://github.com/borisdayma/huggingtweets)
<!--- random size file -->
|
huggingtweets/tommyhump
|
huggingtweets
| 2021-05-23T02:37:51Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/tommyhump/1617421683439/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1361376517624766464/oFTs6sWT_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Tommy Humphreys 🤖 AI Bot </div>
<div style="font-size: 15px">@tommyhump bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@tommyhump's tweets](https://twitter.com/tommyhump).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3246 |
| Retweets | 542 |
| Short tweets | 133 |
| Tweets kept | 2571 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3biusud1/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @tommyhump's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1i3ro0vj) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1i3ro0vj/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/tommyhump')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.