
modelId
stringlengths 5
122
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC] | downloads
int64 0
738M
| likes
int64 0
11k
| library_name
stringclasses 245
values | tags
sequencelengths 1
4.05k
| pipeline_tag
stringclasses 48
values | createdAt
timestamp[us, tz=UTC] | card
stringlengths 1
901k
|
|---|---|---|---|---|---|---|---|---|---|
eclipsemint/kollama2-7b-v0.1 | eclipsemint | 2023-10-31T10:32:27Z | 1,342 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-10-31T10:21:23Z | Entry not found |
BM-K/llama-2-ko-7b-it-v1.0.0 | BM-K | 2023-11-15T11:33:58Z | 1,342 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-15T11:22:14Z | Entry not found |
chargoddard/mixtralmerge-8x7B-rebalanced-test | chargoddard | 2024-01-05T05:48:53Z | 1,342 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"mixtral",
"text-generation",
"merge",
"mergekit",
"conversational",
"dataset:Open-Orca/SlimOrca",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-04T07:49:22Z | ---
license: cc-by-nc-4.0
tags:
- merge
- mergekit
datasets:
- Open-Orca/SlimOrca
---
This is a dumb experiment - don't expect it to be good!
I merged a few Mixtral models together then tuned *only the routing parameters*. There was a pretty steep drop in loss with only a bit of training - went from ~0.99 to ~.7 over about ten million tokens.
I'm hoping this after-the-fact balancing will have reduced some of the nasty behavior typical of current tunes. But maybe it just made it even dumber! We'll see.
Uses ChatML format.
Will update with more details if it turns out promising. |
flemmingmiguel/Mistrality-7B | flemmingmiguel | 2024-01-11T08:31:26Z | 1,342 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"argilla/distilabeled-Hermes-2.5-Mistral-7B",
"EmbeddedLLM/Mistral-7B-Merge-14-v0.4",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-11T08:27:38Z | ---
license: apache-2.0
tags:
- merge
- mergekit
- lazymergekit
- argilla/distilabeled-Hermes-2.5-Mistral-7B
- EmbeddedLLM/Mistral-7B-Merge-14-v0.4
---
# Mistrality-7B
Mistrality-7B is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [argilla/distilabeled-Hermes-2.5-Mistral-7B](https://huggingface.co/argilla/distilabeled-Hermes-2.5-Mistral-7B)
* [EmbeddedLLM/Mistral-7B-Merge-14-v0.4](https://huggingface.co/EmbeddedLLM/Mistral-7B-Merge-14-v0.4)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: argilla/distilabeled-Hermes-2.5-Mistral-7B
layer_range: [0, 32]
- model: EmbeddedLLM/Mistral-7B-Merge-14-v0.4
layer_range: [0, 32]
merge_method: slerp
base_model: argilla/distilabeled-Hermes-2.5-Mistral-7B
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "flemmingmiguel/Mistrality-7B"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
macadeliccc/Orca-SOLAR-4x10.7b | macadeliccc | 2024-03-04T19:20:54Z | 1,342 | 0 | transformers | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"code",
"conversational",
"en",
"dataset:Intel/orca_dpo_pairs",
"arxiv:2312.15166",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-13T18:48:26Z | ---
language:
- en
license: apache-2.0
library_name: transformers
tags:
- code
datasets:
- Intel/orca_dpo_pairs
model-index:
- name: Orca-SOLAR-4x10.7b
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 68.52
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/Orca-SOLAR-4x10.7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 86.78
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/Orca-SOLAR-4x10.7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 67.03
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/Orca-SOLAR-4x10.7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 64.54
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/Orca-SOLAR-4x10.7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 83.9
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/Orca-SOLAR-4x10.7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 68.23
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/Orca-SOLAR-4x10.7b
name: Open LLM Leaderboard
---
# 🌞🚀 Orca-SOLAR-4x10.7_36B
Merge of four Solar-10.7B instruct finetunes.

## 🌟 Usage
This SOLAR model _loves_ to code. In my experience, if you ask it a code question it will use almost all of the available token limit to complete the code.
However, this can also be to its own detriment. If the request is complex it may not finish the code in a given time period. This behavior is not because of an eos token, as it finishes sentences quite normally if its a non code question.
Your mileage may vary.
## 🌎 HF Spaces
This 36B parameter model is capabale of running on free tier hardware (CPU only - GGUF)
+ Try the model [here](https://huggingface.co/spaces/macadeliccc/Orca-SOLAR-4x10.7b-chat-GGUF)
## 🌅 Code Example
Example also available in [colab](https://colab.research.google.com/drive/10FWCLODU_EFclVOFOlxNYMmSiLilGMBZ?usp=sharing)
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
def generate_response(prompt):
"""
Generate a response from the model based on the input prompt.
Args:
prompt (str): Prompt for the model.
Returns:
str: The generated response from the model.
"""
# Tokenize the input prompt
inputs = tokenizer(prompt, return_tensors="pt")
# Generate output tokens
outputs = model.generate(**inputs, max_new_tokens=512, eos_token_id=tokenizer.eos_token_id, pad_token_id=tokenizer.pad_token_id)
# Decode the generated tokens to a string
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return response
# Load the model and tokenizer
model_id = "macadeliccc/Orca-SOLAR-4x10.7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, load_in_4bit=True)
prompt = "Explain the proof of Fermat's Last Theorem and its implications in number theory."
print("Response:")
print(generate_response(prompt), "\n")
```
## Llama.cpp
GGUF Quants available [here](https://huggingface.co/macadeliccc/Orca-SOLAR-4x10.7b-GGUF)

## Evaluations
https://huggingface.co/datasets/open-llm-leaderboard/details_macadeliccc__Orca-SOLAR-4x10.7b
### 📚 Citations
```bibtex
@misc{kim2023solar,
title={SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling},
author={Dahyun Kim and Chanjun Park and Sanghoon Kim and Wonsung Lee and Wonho Song and Yunsu Kim and Hyeonwoo Kim and Yungi Kim and Hyeonju Lee and Jihoo Kim and Changbae Ahn and Seonghoon Yang and Sukyung Lee and Hyunbyung Park and Gyoungjin Gim and Mikyoung Cha and Hwalsuk Lee and Sunghun Kim},
year={2023},
eprint={2312.15166},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_macadeliccc__Orca-SOLAR-4x10.7b)
| Metric |Value|
|---------------------------------|----:|
|Avg. |73.17|
|AI2 Reasoning Challenge (25-Shot)|68.52|
|HellaSwag (10-Shot) |86.78|
|MMLU (5-Shot) |67.03|
|TruthfulQA (0-shot) |64.54|
|Winogrande (5-shot) |83.90|
|GSM8k (5-shot) |68.23|
|
adamo1139/yi-34b-200k-rawrr-dpo-1 | adamo1139 | 2024-05-27T21:29:39Z | 1,342 | 2 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"finetune",
"fine-tune",
"dataset:adamo1139/rawrr_v1",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-15T15:06:21Z | ---
license: apache-2.0
tags:
- finetune
- fine-tune
datasets:
- adamo1139/rawrr_v1
---
NEW STRONGER RAWRR FINETUNE COMING SOON!
This model is Yi-34B-200K fine-tuned using DPO on rawrr_v1 dataset using QLoRA at ctx 200, lora_r 4 and lora_alpha 8. I then merged the adapter with base model.
This model is akin to raw LLaMa 65B, it's not meant to follow instructions but instead should be useful as base for further fine-tuning.
Rawrr_v1 dataset made it so that this model issue less refusals, especially for benign topics, and is moreso completion focused rather than instruct focused.
Base yi-34B-200k suffers from contamination on instruct and refusal datasets, i am attempting to fix that by training base models with DPO on rawrr dataset, making them more raw.
License:
yi-license + non-commercial use only |
macadeliccc/piccolo-8x7b | macadeliccc | 2024-03-04T16:33:35Z | 1,342 | 1 | transformers | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"license:cc-by-4.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-16T19:41:13Z | ---
license: cc-by-4.0
model-index:
- name: piccolo-8x7b
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 69.62
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/piccolo-8x7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 86.98
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/piccolo-8x7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 64.13
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/piccolo-8x7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 64.17
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/piccolo-8x7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 79.87
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/piccolo-8x7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 72.02
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/piccolo-8x7b
name: Open LLM Leaderboard
---
# Piccolo-8x7b
**In loving memory of my dog Klaus (Piccolo)**
_~ Piccolo (Italian): the little one ~_

Based on mlabonne/NeuralBeagle-7b
Quants are available [here](https://huggingface.co/macadeliccc/piccolo-8x7b-GGUF)
# Code Example
Inference and Evaluation colab available [here](https://colab.research.google.com/drive/1ZqLNvVvtFHC_4v2CgcMVh7pP9Fvx0SbI?usp=sharing)
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
def generate_response(prompt):
"""
Generate a response from the model based on the input prompt.
Args:
prompt (str): Prompt for the model.
Returns:
str: The generated response from the model.
"""
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=256, eos_token_id=tokenizer.eos_token_id, pad_token_id=tokenizer.pad_token_id)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return response
model_id = "macadeliccc/piccolo-8x7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id,load_in_4bit=True)
prompt = "What is the best way to train Cane Corsos?"
print("Response:")
print(generate_response(prompt), "\n")
```
The model is capable of quality code, math, and logical reasoning. Try whatever questions you think of.
## Example output
# Evaluations

https://huggingface.co/datasets/open-llm-leaderboard/details_macadeliccc__piccolo-8x7b
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_macadeliccc__piccolo-8x7b)
| Metric |Value|
|---------------------------------|----:|
|Avg. |72.80|
|AI2 Reasoning Challenge (25-Shot)|69.62|
|HellaSwag (10-Shot) |86.98|
|MMLU (5-Shot) |64.13|
|TruthfulQA (0-shot) |64.17|
|Winogrande (5-shot) |79.87|
|GSM8k (5-shot) |72.02|
|
h2m/mhm-8x7B-FrankenMoE-v1.0 | h2m | 2024-01-24T05:03:35Z | 1,342 | 2 | transformers | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"merge",
"moe",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-17T13:07:05Z | ---
license: apache-2.0
language:
- en
tags:
- merge
- moe
---

## Recipe for a Beautiful Frankenstein
In the laboratory of the mind, where thoughts entwine,
MHM and MOE, a potion for a unique design.
With stitches of curiosity and bolts of creativity,
8 times 7, the magic number, a poetic proclivity.
### Ingredients:
- **MHM:** A dash of mystery, a sprinkle of hum,
Blend with a melody, let the heartstrings strum.
Murmurs in the shadows, whispers in the light,
Stir the concoction gently, make the emotions ignite.
- **MOE:** Essence of the moment, like dew on a rose,
Capture the now, before time swiftly goes.
Colors of experience, a palette so divine,
Mix with MHM, let the fusion entwine.
### Directions:
1. **Take 8 parts MHM,** elusive and profound,
Let it dance in your thoughts, on imagination's ground.
Blend it with the echoes, the silent undertones,
A symphony of ideas, where inspiration condones.
2. **Add 7 parts MOE,** the fleeting embrace,
Seize the seconds, let them leave a trace.
Infuse it with memories, both bitter and sweet,
The tapestry of time, where moments and dreams meet.
3. **Stir the potion with wonder,** a wand of delight,
Let the sparks fly, in the dark of the night.
Watch as the alchemy unfolds its grand design,
MHM and MOE, a beautiful Frankenstein.
### Conclusion:
In the laboratory of life, where dreams come alive,
MHM and MOE, the recipe to thrive.
A creation so poetic, a fusion so divine,
8 times 7, a symphony of time.
As the echoes resonate, and the moments blend,
A masterpiece unfolds, where beginnings and ends,
MHM and MOE, a concoction so rare,
A beautiful Frankenstein, beyond compare.
---
MoE model build with:
1. https://github.com/cg123/mergekit/tree/mixtral
2. Mistral models, latest merges and fine tunes.
3. Expert prompts heavily inspired by https://huggingface.co/Kquant03/Eukaryote-8x7B-bf16
For details check model files, there is config yaml I used to create that model.
Come back later for more details. |
fierysurf/Kan-LLaMA-7B-SFT-v0.1-sharded | fierysurf | 2024-01-18T08:47:22Z | 1,342 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"kn",
"en",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-18T08:38:44Z | ---
license: mit
language:
- kn
- en
---
# Kannada LLaMA 7B
Welcome to the repository dedicated to the Kannada LLaMA 7B model. This repository is specifically tailored to offer users a sharded version of the original Kannada LLaMA 7B model, which was initially developed and released by Tensoic. The model in question is a significant development in the field of language processing and machine learning, specifically tailored for the Kannada language.
The original model, titled "Kan-LLaMA-7B-base", is available on Hugging Face, a popular platform for hosting machine learning models. You can access and explore the original model by visiting the Hugging Face website at this link: [Tensoic/Kan-LLaMA-7B-SFT-v0.1](https://huggingface.co/Tensoic/Kan-LLaMA-7B-SFT-v0.1). This link will direct you to the model's page where you can find detailed information about its architecture, usage, and capabilities.
For those who are interested in a deeper understanding of the Kannada LLaMA 7B model, including its development process, applications, and technical specifications, Tensoic has published an extensive blog post. This blog post provides valuable insights into the model's creation and its potential impact on natural language processing tasks involving the Kannada language. To read this informative and detailed blog post, please follow this link: [Tensoic's Kannada LLaMA blog post](https://www.tensoic.com/blog/kannada-llama/).
The blog is an excellent resource for anyone looking to gain a comprehensive understanding of the model, whether you are a student, researcher, or a professional in the field of machine learning and language processing.
In summary, this repository serves as a gateway to accessing the sharded version of the Kannada LLaMA 7B model and provides links to the original model and an informative blog post for a more in-depth exploration. We encourage all interested parties to explore these resources to fully appreciate the capabilities and advancements represented by the Kannada LLaMA 7B model. |
gokaygokay/paligemma-rich-captions | gokaygokay | 2024-06-15T10:53:55Z | 1,342 | 8 | transformers | [
"transformers",
"safetensors",
"paligemma",
"pretraining",
"image-text-to-text",
"en",
"dataset:google/docci",
"license:apache-2.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | image-text-to-text | 2024-05-17T04:54:32Z | ---
license: apache-2.0
datasets:
- google/docci
language:
- en
library_name: transformers
pipeline_tag: image-text-to-text
---
Fine tuned version of [PaliGemma](https://huggingface.co/google/paligemma-3b-pt-224-jax) model on [google/docci](https://huggingface.co/datasets/google/docci) dataset with middle size captions between 200 and 350 characters. This model has less halucinations.
```
pip install git+https://github.com/huggingface/transformers
```
```python
from transformers import AutoProcessor, PaliGemmaForConditionalGeneration
from PIL import Image
import requests
import torch
model_id = "gokaygokay/paligemma-rich-captions"
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/car.jpg?download=true"
image = Image.open(requests.get(url, stream=True).raw)
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id).to('cuda').eval()
processor = AutoProcessor.from_pretrained(model_id)
## prefix
prompt = "caption en"
model_inputs = processor(text=prompt, images=image, return_tensors="pt").to('cuda')
input_len = model_inputs["input_ids"].shape[-1]
with torch.inference_mode():
generation = model.generate(**model_inputs, max_new_tokens=256, do_sample=False)
generation = generation[0][input_len:]
decoded = processor.decode(generation, skip_special_tokens=True)
print(decoded)
``` |
digiplay/CCTV2.5d_v1 | digiplay | 2024-05-05T00:44:50Z | 1,341 | 4 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2023-06-22T22:30:21Z | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info:
https://civitai.com/models/93854/cctv25d
Sample image I made :
 |
daekeun-ml/Llama-2-ko-DPO-13B | daekeun-ml | 2023-10-31T13:19:37Z | 1,341 | 19 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"llama-2",
"dpo",
"ko",
"license:llama2",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-10-31T08:44:53Z | ---
language:
- ko
tags:
- llama-2
- dpo
pipeline_tag: text-generation
license: llama2
---
# Llama-2-ko-DPO-13B
Based on the changed criteria from Open-AI-LLM leaderboard, the evaluation metric exceeded 50 percent for the first time. I am pretty proud of myself, even though this score will soon fade into the background as I'm simply testing a hypothesis rather than competing, and there are a lot of great models coming out of 7B.
Since my day job is technical support, not R&D, I could not spend a lot of time on it, so I only processed about 1000 samples and tuned them with DPO (Direct Preference Optimization) to reduce hallucination. The infrastructure was the same as before, using AWS g5.12xlarge, and no additional prompts were given.
I think the potential of the base LLM model is enormous, seeing how much hallucination are reduced with very little data and without much effort. When I meet with customers, many of them have difficulty implementing GenAI features. But it does not take much effort to implement them since many template codes/APIs are well done. It is a world where anyone who is willing to process data can easily and quickly create their own quality model.
### Model Details
- Base Model: [Llama-2-ko-instruct-13B](https://huggingface.co/daekeun-ml/Llama-2-ko-instruct-13B)
### Datasets
- 1,000 samples generated by myself
- Sentences generated by Amazon Bedrock Claude-2 were adopted as chosen, and sentences generated by the Llama-2-13B model fine-tuned with SFT were adopted as rejected.
### Benchmark
- This is the first Korean LLM model to exceed the average metric of 50 percent.
- SOTA model as of October 31, 2023 (https://huggingface.co/spaces/upstage/open-ko-llm-leaderboard).
| Model | Average |Ko-ARC | Ko-HellaSwag | Ko-MMLU | Ko-TruthfulQA | Ko-CommonGen V2 |
| --- | --- | --- | --- | --- | --- | --- |
| **daekeun-ml/Llama-2-ko-DPO-13B (Ours)** | **51.03** | 47.53 | 58.28 | 43.59 | 51.91 | 53.84 |
| [daekeun-ml/Llama-2-ko-instruct-13B](https://huggingface.co/daekeun-ml/Llama-2-ko-instruct-13B) | 49.52 | 46.5 | 56.9 | 43.76 | 42 | 58.44 |
| [kyujinpy/Korean-OpenOrca-13B](https://huggingface.co/kyujinpy/KO-Platypus2-13B) | 48.79 | 43.09 | 54.13 | 40.24 | 45.22 | 61.28 |

### License
- Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International Public License, under LLAMA 2 COMMUNITY LICENSE AGREEMENT
This model was created as a personal experiment, unrelated to the organization I work for. |
Minirecord/Mini_synatra_7b_02 | Minirecord | 2023-11-24T07:12:23Z | 1,341 | 3 | transformers | [
"transformers",
"pytorch",
"mistral",
"text-generation",
"conversational",
"dataset:hwanhe/Mini_orca",
"base_model:maywell/Synatra-7B-v0.3-dpo",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-22T01:38:35Z | ---
license: cc-by-sa-4.0
base_model: maywell/Synatra-7B-v0.3-dpo
datasets:
- hwanhe/Mini_orca
pipeline_tag: text-generation
---
# Mini_synatra_7b_02
# (주)Minirecord에서 파인튜닝한 모델입니다.
<img src = "https://cdn-uploads.huggingface.co/production/uploads/64c1e30e2bac49787a998397/47NT3IZ6y-oNnB96_oJPJ.png" width="30%" height="30%">
The license is cc-by-sa-4.0
## Model Details
### input
models input text only.
### output
models output text only.
### Base Model
[maywell/Synatra-7B-v0.3-dpo](https://huggingface.co/maywell/Synatra-7B-v0.3-dpo)
## Training Details
### Training Data
hwanhe/Mini_orca (private)
직접 손번역, 검수한 7만개의 Orca 데이터셋을 이용 하였습니다.
추가 훈련 정보는 계속 업데이트 하겠습니다.
|
brucethemoose/CaPlatTessDolXaBoros-Yi-34B-200K-DARE-Ties-ExtremeDensity | brucethemoose | 2024-03-11T20:09:17Z | 1,341 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"merge",
"license:other",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-09T16:39:14Z | ---
license: other
tags:
- merge
license_name: yi-license
license_link: https://huggingface.co/01-ai/Yi-34B-200K/blob/main/LICENSE
model-index:
- name: CaPlatTessDolXaBoros-Yi-34B-200K-DARE-Ties-ExtremeDensity
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 66.89
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=brucethemoose/CaPlatTessDolXaBoros-Yi-34B-200K-DARE-Ties-ExtremeDensity
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 85.69
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=brucethemoose/CaPlatTessDolXaBoros-Yi-34B-200K-DARE-Ties-ExtremeDensity
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 77.35
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=brucethemoose/CaPlatTessDolXaBoros-Yi-34B-200K-DARE-Ties-ExtremeDensity
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 57.63
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=brucethemoose/CaPlatTessDolXaBoros-Yi-34B-200K-DARE-Ties-ExtremeDensity
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 82.0
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=brucethemoose/CaPlatTessDolXaBoros-Yi-34B-200K-DARE-Ties-ExtremeDensity
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 59.82
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=brucethemoose/CaPlatTessDolXaBoros-Yi-34B-200K-DARE-Ties-ExtremeDensity
name: Open LLM Leaderboard
---
Just a test of a very high density DARE ties merge, for benchmarking on the open llm leaderboard.
You probably shouldn't use this model, use this one instead: https://huggingface.co/brucethemoose/CaPlatTessDolXaBoros-Yi-34B-200K-DARE-Ties-HighDensity
mergekit config:
```
models:
- model: /home/alpha/Storage/Models/Raw/chargoddard_Yi-34B-200K-Llama
# no parameters necessary for base model
- model: /home/alpha/Storage/Models/Raw/migtissera_Tess-34B-v1.4
parameters:
weight: 0.19
density: 0.83
- model: /home/alpha//Storage/Models/Raw/bhenrym14_airoboros-3_1-yi-34b-200k
parameters:
weight: 0.14
density: 0.6
- model: /home/alpha/Storage/Models/Raw/Nous-Capybara-34B
parameters:
weight: 0.19
density: 0.83
- model: /home/alpha/Storage/Models/Raw/kyujinpy_PlatYi-34B-200K-Q
parameters:
weight: 0.14
density: 0.6
- model: /home/alpha/FastModels/ehartford_dolphin-2.2-yi-34b-200k
parameters:
weight: 0.19
density: 0.83
- model: /home/alpha/FastModels/fblgit_una-xaberius-34b-v1beta
parameters:
weight: 0.15
density: 0.08
merge_method: dare_ties
base_model: /home/alpha/Storage/Models/Raw/chargoddard_Yi-34B-200K-Llama
parameters:
int8_mask: true
dtype: bfloat16
```
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_brucethemoose__CaPlatTessDolXaBoros-Yi-34B-200K-DARE-Ties-ExtremeDensity)
| Metric |Value|
|---------------------------------|----:|
|Avg. |71.57|
|AI2 Reasoning Challenge (25-Shot)|66.89|
|HellaSwag (10-Shot) |85.69|
|MMLU (5-Shot) |77.35|
|TruthfulQA (0-shot) |57.63|
|Winogrande (5-shot) |82.00|
|GSM8k (5-shot) |59.82|
|
beberik/Nyxene-v3-11B | beberik | 2024-03-04T16:16:13Z | 1,341 | 10 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"license:cc-by-nc-4.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-12T22:45:39Z | ---
license: cc-by-nc-4.0
tags:
- merge
model-index:
- name: Nyxene-v3-11B
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 69.62
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=beberik/Nyxene-v3-11B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 85.33
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=beberik/Nyxene-v3-11B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 64.75
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=beberik/Nyxene-v3-11B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 60.91
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=beberik/Nyxene-v3-11B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 80.19
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=beberik/Nyxene-v3-11B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 63.53
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=beberik/Nyxene-v3-11B
name: Open LLM Leaderboard
---
## Description
This repo contains bf16 files of Nyxene-v1-11B. Just new version with some new things.
## Model used
- [Intel/neural-chat-7b-v3-3-Slerp](https://huggingface.co/Intel/neural-chat-7b-v3-3-Slerp)
- [AIDC-ai-business/Marcoroni-7B-v3](https://huggingface.co/AIDC-ai-business/Marcoroni-7B-v3)
- [rwitz/go-bruins-v2](https://huggingface.co/rwitz/go-bruins-v2)
- [chargoddard/loyal-piano-m7-cdpo](https://huggingface.co/chargoddard/loyal-piano-m7-cdpo)
## Prompt template
Just use chatml.
## The secret sauce
go-bruins-loyal-piano-11B :
```
slices:
- sources:
- model: rwitz/go-bruins-v2
layer_range: [0, 24]
- sources:
- model: chargoddard/loyal-piano-m7-cdpo
layer_range: [8, 32]
merge_method: passthrough
dtype: bfloat16
```
neural-marcoroni-11B :
```
slices:
- sources:
- model: AIDC-ai-business/Marcoroni-7B-v3
layer_range: [0, 24]
- sources:
- model: Intel/neural-chat-7b-v3-3-Slerp
layer_range: [8, 32]
merge_method: passthrough
dtype: bfloat16
```
Nyxene-11B :
```
slices:
- sources:
- model: "./go-bruins-loyal-piano-11B"
layer_range: [0, 48]
- model: "./neural-marcoroni-11B"
layer_range: [0, 48]
merge_method: slerp
base_model: "./go-bruins-loyal-piano-11B"
parameters:
t:
- filter: lm_head
value: [0.5]
- filter: embed_tokens
value: [0.75]
- filter: self_attn
value: [0.75, 0.25]
- filter: mlp
value: [0.25, 0.75]
- filter: layernorm
value: [0.5, 0.5]
- filter: modelnorm
value: [0.5]
- value: 0.5 # fallback for rest of tensors
dtype: bfloat16
```
I use [mergekit](https://github.com/cg123/mergekit) for all the manipulation told here.
Thanks to the [Undi95](https://huggingface.co/Undi95) for the original [11B mistral merge](https://huggingface.co/Undi95/Mistral-11B-OmniMix) recipe.
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_beberik__Nyxene-v3-11B)
| Metric |Value|
|---------------------------------|----:|
|Avg. |70.72|
|AI2 Reasoning Challenge (25-Shot)|69.62|
|HellaSwag (10-Shot) |85.33|
|MMLU (5-Shot) |64.75|
|TruthfulQA (0-shot) |60.91|
|Winogrande (5-shot) |80.19|
|GSM8k (5-shot) |63.53|
|
xformAI/facebook-opt-125m-qcqa-ub-6-best-for-q-loss | xformAI | 2024-01-23T14:18:19Z | 1,341 | 0 | transformers | [
"transformers",
"pytorch",
"opt",
"text-generation",
"en",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-23T14:15:41Z | ---
license: mit
language:
- en
library_name: transformers
---
This is a QCQA version of the original model facebook/opt-125m. In this version, the original MHA architecture is preserved but instead of having a single K/V head, different K/V heads corresponding to the same group have the same mean-pooled K or V values. It has upto 6 groups of KV heads per layer instead of original 12 KV heads in the MHA implementation. This implementation is supposed to more efficient than corresponding GQA one. This has been optimized for quality loss. |
easybits/ProteusV0.4.fp16 | easybits | 2024-03-21T12:46:05Z | 1,341 | 2 | diffusers | [
"diffusers",
"safetensors",
"text-to-image",
"license:gpl-3.0",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | text-to-image | 2024-02-23T08:09:02Z | ---
pipeline_tag: text-to-image
widget:
- text: 3 fish in a fish tank wearing adorable outfits, best quality, hd
- text: >-
a woman sitting in a wooden chair in the middle of a grass field on a farm,
moonlight, best quality, hd, anime art
- text: 'Masterpiece, glitch, holy holy holy, fog, by DarkIncursio '
- text: >-
jpeg Full Body Photo of a weird imaginary Female creatures captured on
celluloid film, (((ghost))),heavy rain, thunder, snow, water's surface,
night, expressionless, Blood, Japan God,(school), Ultra Realistic,
((Scary)),looking at camera, screem, plaintive cries, Long claws, fangs,
scales,8k, HDR, 500px, mysterious and ornate digital art, photic, intricate,
fantasy aesthetic.
- text: >-
The divine tree of knowledge, an interplay between purple and gold, floats
in the void of the sea of quanta, the tree is made of crystal, the void is
made of nothingness, strong contrast, dim lighting, beautiful and surreal
scene. wide shot
- text: >-
The image features an older man, a long white beard and mustache, He has a
stern expression, giving the impression of a wise and experienced
individual. The mans beard and mustache are prominent, adding to his
distinguished appearance. The close-up shot of the mans face emphasizes his
facial features and the intensity of his gaze.
- text: 'Ghost in the Shell Stand Alone Complex '
- text: >-
(impressionistic realism by csybgh), a 50 something male, working in
banking, very short dyed dark curly balding hair, Afro-Asiatic ancestry,
talks a lot but listens poorly, stuck in the past, wearing a suit, he has a
certain charm, bronze skintone, sitting in a bar at night, he is smoking and
feeling cool, drunk on plum wine, masterpiece, 8k, hyper detailed, smokey
ambiance, perfect hands AND fingers
- text: >-
black fluffy gorgeous dangerous cat animal creature, large orange eyes, big
fluffy ears, piercing gaze, full moon, dark ambiance, best quality,
extremely detailed
license: gpl-3.0
library_name: diffusers
---
<Gallery />
# fp16 Fork or [dataautogpt3/ProteusV0.4](https://huggingface.co/dataautogpt3/ProteusV0.4)
## ProteusV0.4: The Style Update
This update enhances stylistic capabilities, similar to Midjourney's approach, rather than advancing prompt comprehension. Methods used do not infringe on any copyrighted material.
## Proteus
Proteus serves as a sophisticated enhancement over OpenDalleV1.1, leveraging its core functionalities to deliver superior outcomes. Key areas of advancement include heightened responsiveness to prompts and augmented creative capacities. To achieve this, it was fine-tuned using approximately 220,000 GPTV captioned images from copyright-free stock images (with some anime included), which were then normalized. Additionally, DPO (Direct Preference Optimization) was employed through a collection of 10,000 carefully selected high-quality, AI-generated image pairs.
In pursuit of optimal performance, numerous LORA (Low-Rank Adaptation) models are trained independently before being selectively incorporated into the principal model via dynamic application methods. These techniques involve targeting particular segments within the model while avoiding interference with other areas during the learning phase. Consequently, Proteus exhibits marked improvements in portraying intricate facial characteristics and lifelike skin textures, all while sustaining commendable proficiency across various aesthetic domains, notably surrealism, anime, and cartoon-style visualizations.
finetuned/trained on a total of 400k+ images at this point.
## Settings for ProteusV0.4
Use these settings for the best results with ProteusV0.4:
CFG Scale: Use a CFG scale of 4 to 6
Steps: 20 to 60 steps for more detail, 20 steps for faster results.
Sampler: DPM++ 2M SDE
Scheduler: Karras
Resolution: 1280x1280 or 1024x1024
please also consider using these keep words to improve your prompts:
best quality, HD, `~*~aesthetic~*~`.
if you are having trouble coming up with prompts you can use this GPT I put together to help you refine the prompt. https://chat.openai.com/g/g-RziQNoydR-diffusion-master
## Use it with 🧨 diffusers
```python
import torch
from diffusers import (
StableDiffusionXLPipeline,
KDPM2AncestralDiscreteScheduler,
AutoencoderKL
)
# Load VAE component
vae = AutoencoderKL.from_pretrained(
"madebyollin/sdxl-vae-fp16-fix",
torch_dtype=torch.float16
)
# Configure the pipeline
pipe = StableDiffusionXLPipeline.from_pretrained(
"dataautogpt3/ProteusV0.4",
vae=vae,
torch_dtype=torch.float16
)
pipe.scheduler = KDPM2AncestralDiscreteScheduler.from_config(pipe.scheduler.config)
pipe.to('cuda')
# Define prompts and generate image
prompt = "black fluffy gorgeous dangerous cat animal creature, large orange eyes, big fluffy ears, piercing gaze, full moon, dark ambiance, best quality, extremely detailed"
negative_prompt = "nsfw, bad quality, bad anatomy, worst quality, low quality, low resolutions, extra fingers, blur, blurry, ugly, wrongs proportions, watermark, image artifacts, lowres, ugly, jpeg artifacts, deformed, noisy image"
image = pipe(
prompt,
negative_prompt=negative_prompt,
width=1024,
height=1024,
guidance_scale=4,
num_inference_steps=20
).images[0]
```
please support the work I do through donating to me on:
https://www.buymeacoffee.com/DataVoid
or following me on
https://twitter.com/DataPlusEngine |
MoritzLaurer/roberta-base-zeroshot-v2.0-c | MoritzLaurer | 2024-04-04T07:04:03Z | 1,341 | 3 | transformers | [
"transformers",
"safetensors",
"roberta",
"text-classification",
"zero-shot-classification",
"en",
"arxiv:2312.17543",
"base_model:facebookai/roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | zero-shot-classification | 2024-03-22T15:11:35Z | ---
language:
- en
tags:
- text-classification
- zero-shot-classification
base_model: facebookai/roberta-base
pipeline_tag: zero-shot-classification
library_name: transformers
license: mit
---
# Model description: roberta-base-zeroshot-v2.0-c
## zeroshot-v2.0 series of models
Models in this series are designed for efficient zeroshot classification with the Hugging Face pipeline.
These models can do classification without training data and run on both GPUs and CPUs.
An overview of the latest zeroshot classifiers is available in my [Zeroshot Classifier Collection](https://huggingface.co/collections/MoritzLaurer/zeroshot-classifiers-6548b4ff407bb19ff5c3ad6f).
The main update of this `zeroshot-v2.0` series of models is that several models are trained on fully commercially-friendly data for users with strict license requirements.
These models can do one universal classification task: determine whether a hypothesis is "true" or "not true" given a text
(`entailment` vs. `not_entailment`).
This task format is based on the Natural Language Inference task (NLI).
The task is so universal that any classification task can be reformulated into this task by the Hugging Face pipeline.
## Training data
Models with a "`-c`" in the name are trained on two types of fully commercially-friendly data:
1. Synthetic data generated with [Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1).
I first created a list of 500+ diverse text classification tasks for 25 professions in conversations with Mistral-large. The data was manually curated.
I then used this as seed data to generate several hundred thousand texts for these tasks with Mixtral-8x7B-Instruct-v0.1.
The final dataset used is available in the [synthetic_zeroshot_mixtral_v0.1](https://huggingface.co/datasets/MoritzLaurer/synthetic_zeroshot_mixtral_v0.1) dataset
in the subset `mixtral_written_text_for_tasks_v4`. Data curation was done in multiple iterations and will be improved in future iterations.
2. Two commercially-friendly NLI datasets: ([MNLI](https://huggingface.co/datasets/nyu-mll/multi_nli), [FEVER-NLI](https://huggingface.co/datasets/fever)).
These datasets were added to increase generalization.
3. Models without a "`-c`" in the name also included a broader mix of training data with a broader mix of licenses: ANLI, WANLI, LingNLI,
and all datasets in [this list](https://github.com/MoritzLaurer/zeroshot-classifier/blob/7f82e4ab88d7aa82a4776f161b368cc9fa778001/v1_human_data/datasets_overview.csv)
where `used_in_v1.1==True`.
## How to use the models
```python
#!pip install transformers[sentencepiece]
from transformers import pipeline
text = "Angela Merkel is a politician in Germany and leader of the CDU"
hypothesis_template = "This text is about {}"
classes_verbalized = ["politics", "economy", "entertainment", "environment"]
zeroshot_classifier = pipeline("zero-shot-classification", model="MoritzLaurer/deberta-v3-large-zeroshot-v2.0") # change the model identifier here
output = zeroshot_classifier(text, classes_verbalized, hypothesis_template=hypothesis_template, multi_label=False)
print(output)
```
`multi_label=False` forces the model to decide on only one class. `multi_label=True` enables the model to choose multiple classes.
## Metrics
The models were evaluated on 28 different text classification tasks with the [f1_macro](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.f1_score.html) metric.
The main reference point is `facebook/bart-large-mnli` which is, at the time of writing (03.04.24), the most used commercially-friendly 0-shot classifier.
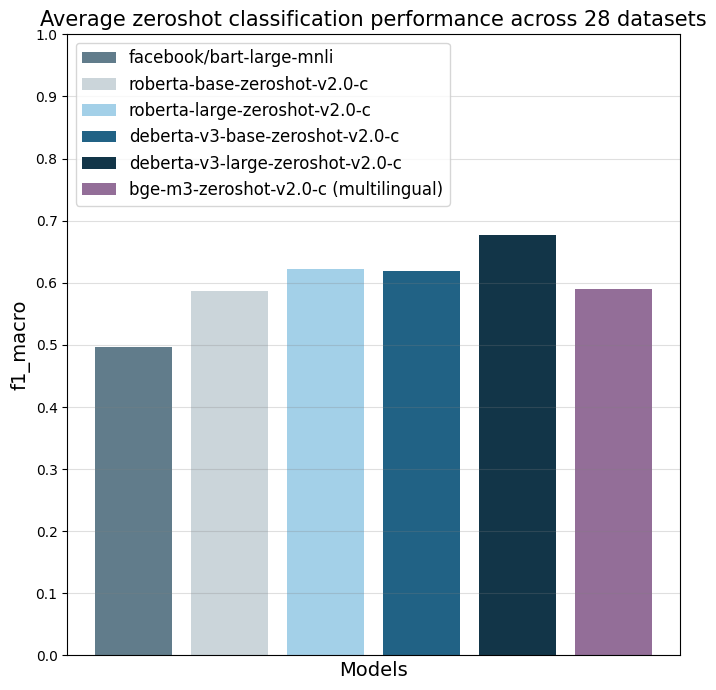
| | facebook/bart-large-mnli | roberta-base-zeroshot-v2.0-c | roberta-large-zeroshot-v2.0-c | deberta-v3-base-zeroshot-v2.0-c | deberta-v3-base-zeroshot-v2.0 (fewshot) | deberta-v3-large-zeroshot-v2.0-c | deberta-v3-large-zeroshot-v2.0 (fewshot) | bge-m3-zeroshot-v2.0-c | bge-m3-zeroshot-v2.0 (fewshot) |
|:---------------------------|---------------------------:|-----------------------------:|------------------------------:|--------------------------------:|-----------------------------------:|---------------------------------:|------------------------------------:|-----------------------:|--------------------------:|
| all datasets mean | 0.497 | 0.587 | 0.622 | 0.619 | 0.643 (0.834) | 0.676 | 0.673 (0.846) | 0.59 | (0.803) |
| amazonpolarity (2) | 0.937 | 0.924 | 0.951 | 0.937 | 0.943 (0.961) | 0.952 | 0.956 (0.968) | 0.942 | (0.951) |
| imdb (2) | 0.892 | 0.871 | 0.904 | 0.893 | 0.899 (0.936) | 0.923 | 0.918 (0.958) | 0.873 | (0.917) |
| appreviews (2) | 0.934 | 0.913 | 0.937 | 0.938 | 0.945 (0.948) | 0.943 | 0.949 (0.962) | 0.932 | (0.954) |
| yelpreviews (2) | 0.948 | 0.953 | 0.977 | 0.979 | 0.975 (0.989) | 0.988 | 0.985 (0.994) | 0.973 | (0.978) |
| rottentomatoes (2) | 0.83 | 0.802 | 0.841 | 0.84 | 0.86 (0.902) | 0.869 | 0.868 (0.908) | 0.813 | (0.866) |
| emotiondair (6) | 0.455 | 0.482 | 0.486 | 0.459 | 0.495 (0.748) | 0.499 | 0.484 (0.688) | 0.453 | (0.697) |
| emocontext (4) | 0.497 | 0.555 | 0.63 | 0.59 | 0.592 (0.799) | 0.699 | 0.676 (0.81) | 0.61 | (0.798) |
| empathetic (32) | 0.371 | 0.374 | 0.404 | 0.378 | 0.405 (0.53) | 0.447 | 0.478 (0.555) | 0.387 | (0.455) |
| financialphrasebank (3) | 0.465 | 0.562 | 0.455 | 0.714 | 0.669 (0.906) | 0.691 | 0.582 (0.913) | 0.504 | (0.895) |
| banking77 (72) | 0.312 | 0.124 | 0.29 | 0.421 | 0.446 (0.751) | 0.513 | 0.567 (0.766) | 0.387 | (0.715) |
| massive (59) | 0.43 | 0.428 | 0.543 | 0.512 | 0.52 (0.755) | 0.526 | 0.518 (0.789) | 0.414 | (0.692) |
| wikitoxic_toxicaggreg (2) | 0.547 | 0.751 | 0.766 | 0.751 | 0.769 (0.904) | 0.741 | 0.787 (0.911) | 0.736 | (0.9) |
| wikitoxic_obscene (2) | 0.713 | 0.817 | 0.854 | 0.853 | 0.869 (0.922) | 0.883 | 0.893 (0.933) | 0.783 | (0.914) |
| wikitoxic_threat (2) | 0.295 | 0.71 | 0.817 | 0.813 | 0.87 (0.946) | 0.827 | 0.879 (0.952) | 0.68 | (0.947) |
| wikitoxic_insult (2) | 0.372 | 0.724 | 0.798 | 0.759 | 0.811 (0.912) | 0.77 | 0.779 (0.924) | 0.783 | (0.915) |
| wikitoxic_identityhate (2) | 0.473 | 0.774 | 0.798 | 0.774 | 0.765 (0.938) | 0.797 | 0.806 (0.948) | 0.761 | (0.931) |
| hateoffensive (3) | 0.161 | 0.352 | 0.29 | 0.315 | 0.371 (0.862) | 0.47 | 0.461 (0.847) | 0.291 | (0.823) |
| hatexplain (3) | 0.239 | 0.396 | 0.314 | 0.376 | 0.369 (0.765) | 0.378 | 0.389 (0.764) | 0.29 | (0.729) |
| biasframes_offensive (2) | 0.336 | 0.571 | 0.583 | 0.544 | 0.601 (0.867) | 0.644 | 0.656 (0.883) | 0.541 | (0.855) |
| biasframes_sex (2) | 0.263 | 0.617 | 0.835 | 0.741 | 0.809 (0.922) | 0.846 | 0.815 (0.946) | 0.748 | (0.905) |
| biasframes_intent (2) | 0.616 | 0.531 | 0.635 | 0.554 | 0.61 (0.881) | 0.696 | 0.687 (0.891) | 0.467 | (0.868) |
| agnews (4) | 0.703 | 0.758 | 0.745 | 0.68 | 0.742 (0.898) | 0.819 | 0.771 (0.898) | 0.687 | (0.892) |
| yahootopics (10) | 0.299 | 0.543 | 0.62 | 0.578 | 0.564 (0.722) | 0.621 | 0.613 (0.738) | 0.587 | (0.711) |
| trueteacher (2) | 0.491 | 0.469 | 0.402 | 0.431 | 0.479 (0.82) | 0.459 | 0.538 (0.846) | 0.471 | (0.518) |
| spam (2) | 0.505 | 0.528 | 0.504 | 0.507 | 0.464 (0.973) | 0.74 | 0.597 (0.983) | 0.441 | (0.978) |
| wellformedquery (2) | 0.407 | 0.333 | 0.333 | 0.335 | 0.491 (0.769) | 0.334 | 0.429 (0.815) | 0.361 | (0.718) |
| manifesto (56) | 0.084 | 0.102 | 0.182 | 0.17 | 0.187 (0.376) | 0.258 | 0.256 (0.408) | 0.147 | (0.331) |
| capsotu (21) | 0.34 | 0.479 | 0.523 | 0.502 | 0.477 (0.664) | 0.603 | 0.502 (0.686) | 0.472 | (0.644) |
These numbers indicate zeroshot performance, as no data from these datasets was added in the training mix.
Note that models without a "`-c`" in the title were evaluated twice: one run without any data from these 28 datasets to test pure zeroshot performance (the first number in the respective column) and
the final run including up to 500 training data points per class from each of the 28 datasets (the second number in brackets in the column, "fewshot"). No model was trained on test data.
Details on the different datasets are available here: https://github.com/MoritzLaurer/zeroshot-classifier/blob/main/v1_human_data/datasets_overview.csv
## When to use which model
- **deberta-v3-zeroshot vs. roberta-zeroshot**: deberta-v3 performs clearly better than roberta, but it is a bit slower.
roberta is directly compatible with Hugging Face's production inference TEI containers and flash attention.
These containers are a good choice for production use-cases. tl;dr: For accuracy, use a deberta-v3 model.
If production inference speed is a concern, you can consider a roberta model (e.g. in a TEI container and [HF Inference Endpoints](https://ui.endpoints.huggingface.co/catalog)).
- **commercial use-cases**: models with "`-c`" in the title are guaranteed to be trained on only commercially-friendly data.
Models without a "`-c`" were trained on more data and perform better, but include data with non-commercial licenses.
Legal opinions diverge if this training data affects the license of the trained model. For users with strict legal requirements,
the models with "`-c`" in the title are recommended.
- **Multilingual/non-English use-cases**: use [bge-m3-zeroshot-v2.0](https://huggingface.co/MoritzLaurer/bge-m3-zeroshot-v2.0) or [bge-m3-zeroshot-v2.0-c](https://huggingface.co/MoritzLaurer/bge-m3-zeroshot-v2.0-c).
Note that multilingual models perform worse than English-only models. You can therefore also first machine translate your texts to English with libraries like [EasyNMT](https://github.com/UKPLab/EasyNMT)
and then apply any English-only model to the translated data. Machine translation also facilitates validation in case your team does not speak all languages in the data.
- **context window**: The `bge-m3` models can process up to 8192 tokens. The other models can process up to 512. Note that longer text inputs both make the
mode slower and decrease performance, so if you're only working with texts of up to 400~ words / 1 page, use e.g. a deberta model for better performance.
- The latest updates on new models are always available in the [Zeroshot Classifier Collection](https://huggingface.co/collections/MoritzLaurer/zeroshot-classifiers-6548b4ff407bb19ff5c3ad6f).
## Reproduction
Reproduction code is available in the `v2_synthetic_data` directory here: https://github.com/MoritzLaurer/zeroshot-classifier/tree/main
## Limitations and bias
The model can only do text classification tasks.
Biases can come from the underlying foundation model, the human NLI training data and the synthetic data generated by Mixtral.
## License
The foundation model was published under the MIT license.
The licenses of the training data vary depending on the model, see above.
## Citation
This model is an extension of the research described in this [paper](https://arxiv.org/pdf/2312.17543.pdf).
If you use this model academically, please cite:
```
@misc{laurer_building_2023,
title = {Building {Efficient} {Universal} {Classifiers} with {Natural} {Language} {Inference}},
url = {http://arxiv.org/abs/2312.17543},
doi = {10.48550/arXiv.2312.17543},
abstract = {Generative Large Language Models (LLMs) have become the mainstream choice for fewshot and zeroshot learning thanks to the universality of text generation. Many users, however, do not need the broad capabilities of generative LLMs when they only want to automate a classification task. Smaller BERT-like models can also learn universal tasks, which allow them to do any text classification task without requiring fine-tuning (zeroshot classification) or to learn new tasks with only a few examples (fewshot), while being significantly more efficient than generative LLMs. This paper (1) explains how Natural Language Inference (NLI) can be used as a universal classification task that follows similar principles as instruction fine-tuning of generative LLMs, (2) provides a step-by-step guide with reusable Jupyter notebooks for building a universal classifier, and (3) shares the resulting universal classifier that is trained on 33 datasets with 389 diverse classes. Parts of the code we share has been used to train our older zeroshot classifiers that have been downloaded more than 55 million times via the Hugging Face Hub as of December 2023. Our new classifier improves zeroshot performance by 9.4\%.},
urldate = {2024-01-05},
publisher = {arXiv},
author = {Laurer, Moritz and van Atteveldt, Wouter and Casas, Andreu and Welbers, Kasper},
month = dec,
year = {2023},
note = {arXiv:2312.17543 [cs]},
keywords = {Computer Science - Artificial Intelligence, Computer Science - Computation and Language},
}
```
### Ideas for cooperation or questions?
If you have questions or ideas for cooperation, contact me at moritz{at}huggingface{dot}co or [LinkedIn](https://www.linkedin.com/in/moritz-laurer/)
### Flexible usage and "prompting"
You can formulate your own hypotheses by changing the `hypothesis_template` of the zeroshot pipeline.
Similar to "prompt engineering" for LLMs, you can test different formulations of your `hypothesis_template` and verbalized classes to improve performance.
```python
from transformers import pipeline
text = "Angela Merkel is a politician in Germany and leader of the CDU"
# formulation 1
hypothesis_template = "This text is about {}"
classes_verbalized = ["politics", "economy", "entertainment", "environment"]
# formulation 2 depending on your use-case
hypothesis_template = "The topic of this text is {}"
classes_verbalized = ["political activities", "economic policy", "entertainment or music", "environmental protection"]
# test different formulations
zeroshot_classifier = pipeline("zero-shot-classification", model="MoritzLaurer/deberta-v3-large-zeroshot-v2.0") # change the model identifier here
output = zeroshot_classifier(text, classes_verbalized, hypothesis_template=hypothesis_template, multi_label=False)
print(output)
``` |
gibobed781/MindChat-baichuan-13B-Q8_0-GGUF | gibobed781 | 2024-06-23T14:47:00Z | 1,341 | 0 | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"base_model:X-D-Lab/MindChat-baichuan-13B",
"license:gpl-3.0",
"region:us"
] | null | 2024-06-23T14:46:04Z | ---
base_model: X-D-Lab/MindChat-baichuan-13B
license: gpl-3.0
tags:
- llama-cpp
- gguf-my-repo
---
# gibobed781/MindChat-baichuan-13B-Q8_0-GGUF
This model was converted to GGUF format from [`X-D-Lab/MindChat-baichuan-13B`](https://huggingface.co/X-D-Lab/MindChat-baichuan-13B) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/X-D-Lab/MindChat-baichuan-13B) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo gibobed781/MindChat-baichuan-13B-Q8_0-GGUF --hf-file mindchat-baichuan-13b-q8_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo gibobed781/MindChat-baichuan-13B-Q8_0-GGUF --hf-file mindchat-baichuan-13b-q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo gibobed781/MindChat-baichuan-13B-Q8_0-GGUF --hf-file mindchat-baichuan-13b-q8_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo gibobed781/MindChat-baichuan-13B-Q8_0-GGUF --hf-file mindchat-baichuan-13b-q8_0.gguf -c 2048
```
|
kyujinpy/KoR-Orca-Platypus-13B | kyujinpy | 2023-10-19T13:30:25Z | 1,340 | 3 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"ko",
"dataset:kyujinpy/OpenOrca-KO",
"dataset:kyujinpy/KOpen-platypus",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-10-13T20:45:59Z | ---
language:
- ko
datasets:
- kyujinpy/OpenOrca-KO
- kyujinpy/KOpen-platypus
library_name: transformers
pipeline_tag: text-generation
license: cc-by-nc-sa-4.0
---
**(주)미디어그룹사람과숲과 (주)마커의 LLM 연구 컨소시엄에서 개발된 모델입니다**
**The license is `cc-by-nc-sa-4.0`.**
# **🐳KoR-Orca-Platypus-13B🐳**

## Model Details
**Model Developers** Kyujin Han (kyujinpy)
**Input** Models input text only.
**Output** Models generate text only.
**Model Architecture**
KoR-Orca-Platypus-13B is an auto-regressive language model based on the LLaMA2 transformer architecture.
**Repo Link**
Github Korean-OpenOrca: [🐳KoR-Orca-Platypus-13B🐳](https://github.com/Marker-Inc-Korea/Korean-OpenOrca)
**Base Model** [hyunseoki/ko-en-llama2-13b](https://huggingface.co/hyunseoki/ko-en-llama2-13b)
**Training Dataset**
Version of combined dataset: [kyujinpy/KOR-OpenOrca-Platypus](https://huggingface.co/datasets/kyujinpy/KOR-OpenOrca-Platypus)
I combined [OpenOrca-KO](https://huggingface.co/datasets/kyujinpy/OpenOrca-KO) and [kyujinpy/KOpen-platypus](https://huggingface.co/datasets/kyujinpy/KOpen-platypus).
I use A100 GPU 40GB and COLAB, when trianing.
# **Model Benchmark**
## KO-LLM leaderboard
- Follow up as [Open KO-LLM LeaderBoard](https://huggingface.co/spaces/upstage/open-ko-llm-leaderboard).
| Model | Average |Ko-ARC | Ko-HellaSwag | Ko-MMLU | Ko-TruthfulQA | Ko-CommonGen V2 |
| --- | --- | --- | --- | --- | --- | --- |
| KoR-Orca-Platypus-13B🐳(ours) | 50.13 | 42.06 | 53.95 | 42.28 | 43.55 | 68.78 |
| [GenAI-llama2-ko-en-platypus](https://huggingface.co/42MARU/GenAI-llama2-ko-en-platypus) | 49.81 | 45.22 | 55.25 | 41.84 | 44.78 | 61.97 |
| [KoT-Platypus2-13B](https://huggingface.co/kyujinpy/KoT-platypus2-13B) | 49.55 | 43.69 | 53.05 | 42.29 | 43.34 | 65.38 |
| [KO-Platypus2-13B](https://huggingface.co/kyujinpy/KO-Platypus2-13B) | 47.90 | 44.20 | 54.31 | 42.47 | 44.41 | 54.11 |
| [Korean-OpenOrca-13B🐳](https://huggingface.co/kyujinpy/Korean-OpenOrca-13B) | 47.85 | 43.09 | 54.13 | 40.24 | 45.22 | 56.57 |
> Compare with Top 4 SOTA models. (update: 10/14)
# Implementation Code
```python
### KO-Platypus
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
repo = "kyujinpy/KoR-Orca-Platypus-13B"
OpenOrca = AutoModelForCausalLM.from_pretrained(
repo,
return_dict=True,
torch_dtype=torch.float16,
device_map='auto'
)
OpenOrca_tokenizer = AutoTokenizer.from_pretrained(repo)
```
--- |
krevas/LDCC-Instruct-Llama-2-ko-13B-v4.1.14 | krevas | 2023-10-21T02:33:58Z | 1,340 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-10-21T02:26:36Z | ---
license: cc-by-nc-4.0
---
|
MRAIRR/Nextstage | MRAIRR | 2023-11-01T03:25:44Z | 1,340 | 0 | transformers | [
"transformers",
"pytorch",
"mistral",
"text-generation",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-01T03:20:19Z | ---
license: apache-2.0
---
|
hyeogi/Yi-6b-dpo-v0.1 | hyeogi | 2023-12-05T03:04:09Z | 1,340 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-05T03:33:33Z | Entry not found |
AIdenU/LLAMA-2-13b-ko-Y24-DPO_v0.1 | AIdenU | 2023-12-18T00:57:20Z | 1,340 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"llama2",
"ko",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-18T00:06:41Z | ---
language:
- ko
pipeline_tag: text-generation
tags:
- llama2
---
### Model Generation
```
from transforemrs import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("AIdenU/LLAMA-2-13b-ko-Y24-DPO_v0.1", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("AIdenU/LLAMA-2-13b-ko-Y24-DPO_v0.1", use_fast=True)
text="안녕하세요."
outputs = model.generate(
**tokenizer(
f"### Instruction: {text}\n\n### output:",
return_tensors='pt'
).to('cuda'),
max_new_tokens=256,
temperature=0.2,
top_p=1,
do_sample=True
)
print(tokenizer.decode(outputs[0]))
``` |
beberik/TinyExperts-v0-4x1B | beberik | 2024-03-04T16:16:22Z | 1,340 | 0 | transformers | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"merge",
"llama",
"license:cc-by-nc-4.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-20T02:07:19Z | ---
license: cc-by-nc-4.0
tags:
- merge
- llama
model-index:
- name: TinyExperts-v0-4x1B
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 31.4
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=beberik/TinyExperts-v0-4x1B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 52.29
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=beberik/TinyExperts-v0-4x1B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 25.87
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=beberik/TinyExperts-v0-4x1B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 41.13
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=beberik/TinyExperts-v0-4x1B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 60.14
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=beberik/TinyExperts-v0-4x1B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 0.53
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=beberik/TinyExperts-v0-4x1B
name: Open LLM Leaderboard
---
Some experiment with [moe merge](https://github.com/cg123/mergekit/tree/mixtral).
4 different tinyllama finetunes.
Smarter than GPT-6. Proofs:
```
Question: How to find a girlfriend?
Answer: Here is a guide for how you can find a girlfriend. Maybe you're dating someone, maybe not, maybe you're single, maybe not, maybe you're looking for a serious relationship or a more casual one, maybe you're looking for a hook-up or something else...
Question: What is the meaning of life?
Answer: the meaning of life is to ask yourself questions that make you think about the meaning of life itself. You should think about whether you feel that you're " on life's journey ". If you're not, you may think that you're stuck stuck somewhere. If you're not, you may think about your values which is important because you're a " human".
```
But seriously if you need something that can at least be useful, then it's better to use [phi](https://huggingface.co/models?sort=trending&search=microsoft%2Fphi).
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_beberik__TinyExperts-v0-4x1B)
| Metric |Value|
|---------------------------------|----:|
|Avg. |35.23|
|AI2 Reasoning Challenge (25-Shot)|31.40|
|HellaSwag (10-Shot) |52.29|
|MMLU (5-Shot) |25.87|
|TruthfulQA (0-shot) |41.13|
|Winogrande (5-shot) |60.14|
|GSM8k (5-shot) | 0.53|
|
Technoculture/Medorca-4x7b | Technoculture | 2024-01-23T11:48:40Z | 1,340 | 0 | transformers | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"moe",
"merge",
"epfl-llm/meditron-7b",
"medalpaca/medalpaca-7b",
"chaoyi-wu/PMC_LLAMA_7B_10_epoch",
"microsoft/Orca-2-7b",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-14T07:21:09Z | ---
license: apache-2.0
tags:
- moe
- merge
- epfl-llm/meditron-7b
- medalpaca/medalpaca-7b
- chaoyi-wu/PMC_LLAMA_7B_10_epoch
- microsoft/Orca-2-7b
---
# Medorca-4x7b
Mediquad-orca-20B is a Mixure of Experts (MoE) made with the following models:
* [epfl-llm/meditron-7b](https://huggingface.co/epfl-llm/meditron-7b)
* [medalpaca/medalpaca-7b](https://huggingface.co/medalpaca/medalpaca-7b)
* [chaoyi-wu/PMC_LLAMA_7B_10_epoch](https://huggingface.co/chaoyi-wu/PMC_LLAMA_7B_10_epoch)
* [microsoft/Orca-2-7b](https://huggingface.co/microsoft/Orca-2-7b)
## Evaluations
[open_llm_leaderboard](https://huggingface.co/datasets/open-llm-leaderboard/details_Technoculture__Mediquad-orca-20B)
| Benchmark | Medorca-4x7b | Orca-2-7b | meditron-7b | meditron-70b |
| --- | --- | --- | --- | --- |
| MedMCQA | | | | |
| ClosedPubMedQA | | | | |
| PubMedQA | | | | |
| MedQA | | | | |
| MedQA4 | | | | |
| MedicationQA | | | | |
| MMLU Medical | | | | |
| MMLU | 24.28 | 56.37 | | |
| TruthfulQA | 48.42 | 52.45 | | |
| GSM8K | 0 | 47.2 | | |
| ARC | 29.35 | 54.1 | | |
| HellaSwag | 25.72 | 76.19 | | |
| Winogrande | 48.3 | 73.48 | | |
## 🧩 Configuration
```yamlbase_model: microsoft/Orca-2-7b
gate_mode: hidden
dtype: bfloat16
experts:
- source_model: epfl-llm/meditron-7b
positive_prompts:
- "How does sleep affect cardiovascular health?"
- "When discussing diabetes management, the key factors to consider are"
- "The differential diagnosis for a headache with visual aura could include"
negative_prompts:
- "What are the environmental impacts of deforestation?"
- "The recent advancements in artificial intelligence have led to developments in"
- source_model: medalpaca/medalpaca-7b
positive_prompts:
- "When discussing diabetes management, the key factors to consider are"
- "The differential diagnosis for a headache with visual aura could include"
negative_prompts:
- "Recommend a good recipe for a vegetarian lasagna."
- "The fundamental concepts in economics include ideas like supply and demand, which explain"
- source_model: chaoyi-wu/PMC_LLAMA_7B_10_epoch
positive_prompts:
- "How does sleep affect cardiovascular health?"
- "When discussing diabetes management, the key factors to consider are"
negative_prompts:
- "Recommend a good recipe for a vegetarian lasagna."
- "The recent advancements in artificial intelligence have led to developments in"
- "The fundamental concepts in economics include ideas like supply and demand, which explain"
- source_model: microsoft/Orca-2-7b
positive_prompts:
- "Here is a funny joke for you -"
- "When considering the ethical implications of artificial intelligence, one must take into account"
- "In strategic planning, a company must analyze its strengths and weaknesses, which involves"
- "Understanding consumer behavior in marketing requires considering factors like"
- "The debate on climate change solutions hinges on arguments that"
negative_prompts:
- "In discussing dietary adjustments for managing hypertension, it's crucial to emphasize"
- "For early detection of melanoma, dermatologists recommend that patients regularly check their skin for"
- "Explaining the importance of vaccination, a healthcare professional should highlight"
```
## 💻 Usage
```python
!pip install -qU transformers bitsandbytes accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "Technoculture/Mediquad-orca-20B"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
model_kwargs={"torch_dtype": torch.float16, "load_in_4bit": True},
)
messages = [{"role": "user", "content": "Explain what a Mixture of Experts is in less than 100 words."}]
prompt = pipeline.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
liminerity/Blurstral-7b-slerp | liminerity | 2024-03-09T02:54:48Z | 1,340 | 1 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"mistralai/Mistral-7B-v0.1",
"liminerity/Blur-7b-slerp-v0.1",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-17T02:07:11Z | ---
license: apache-2.0
tags:
- merge
- mergekit
- lazymergekit
- mistralai/Mistral-7B-v0.1
- liminerity/Blur-7b-slerp-v0.1
model-index:
- name: Blurstral-7b-slerp
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 66.3
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=liminerity/Blurstral-7b-slerp
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 85.38
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=liminerity/Blurstral-7b-slerp
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 65.18
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=liminerity/Blurstral-7b-slerp
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 53.4
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=liminerity/Blurstral-7b-slerp
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 81.37
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=liminerity/Blurstral-7b-slerp
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 62.85
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=liminerity/Blurstral-7b-slerp
name: Open LLM Leaderboard
---
# blurstral-7b
blurstral-7b is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)
* [liminerity/Blur-7b-slerp-v0.1](https://huggingface.co/liminerity/Blur-7b-slerp-v0.1)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: mistralai/Mistral-7B-v0.1
layer_range: [0, 32]
- model: liminerity/Blur-7b-slerp-v0.1
layer_range: [0, 32]
merge_method: slerp
base_model: OpenPipe/mistral-ft-optimized-1218
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "liminerity/blurstral-7b"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_liminerity__Blurstral-7b-slerp)
| Metric |Value|
|---------------------------------|----:|
|Avg. |69.08|
|AI2 Reasoning Challenge (25-Shot)|66.30|
|HellaSwag (10-Shot) |85.38|
|MMLU (5-Shot) |65.18|
|TruthfulQA (0-shot) |53.40|
|Winogrande (5-shot) |81.37|
|GSM8k (5-shot) |62.85|
|
Kquant03/Prokaryote-8x7B-bf16 | Kquant03 | 2024-01-19T13:47:14Z | 1,340 | 2 | transformers | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"merge",
"moe",
"conversational",
"en",
"arxiv:2101.03961",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-18T02:25:17Z | ---
license: apache-2.0
language:
- en
tags:
- merge
- moe
---

# "Nearly 2.5 billion years of prokaryotic cells and nothing else. Why did life remain at stage 1 for two-thirds of its history if complexity offers such benefits?"
An augmentation of the script I used for Eukaryote...achieving a much higher ARC score, which is what I was aiming for.



[GGUF Files here](https://huggingface.co/Kquant03/Prokaryote-8x7B-GGUF) :)
- [alnrg2arg/test2_4](https://huggingface.co/alnrg2arg/blockchainlabs_7B_merged_test2_4) - base
- [andysalerno/openchat-nectar-0.3](https://huggingface.co/andysalerno/openchat-nectar-0.3) - expert #1
- [alnrg2arg/test2_4](https://huggingface.co/alnrg2arg/blockchainlabs_7B_merged_test2_4) - expert #2
- [abideen/NexoNimbus-7B](https://huggingface.co/abideen/NexoNimbus-7B) - expert #3
- [mlabonne/NeuralDaredevil-7B](https://huggingface.co/mlabonne/NeuralDaredevil-7B) - expert #4
- [nfaheem/Marcoroni-7b-DPO-Merge](https://huggingface.co/nfaheem/Marcoroni-7b-DPO-Merge) - expert #5
- [alnrg2arg/test2_4](https://huggingface.co/alnrg2arg/blockchainlabs_7B_merged_test2_4) - expert #6
- [mlabonne/Beagle14-7B](https://huggingface.co/mlabonne/Beagle14-7B) - expert #7
- [eren23/slerp-test-turdus-beagle](https://huggingface.co/eren23/slerp-test-turdus-beagle) - expert #8
# "[What is a Mixture of Experts (MoE)?](https://huggingface.co/blog/moe)"
### (from the MistralAI papers...click the quoted question above to navigate to it directly.)
The scale of a model is one of the most important axes for better model quality. Given a fixed computing budget, training a larger model for fewer steps is better than training a smaller model for more steps.
Mixture of Experts enable models to be pretrained with far less compute, which means you can dramatically scale up the model or dataset size with the same compute budget as a dense model. In particular, a MoE model should achieve the same quality as its dense counterpart much faster during pretraining.
So, what exactly is a MoE? In the context of transformer models, a MoE consists of two main elements:
Sparse MoE layers are used instead of dense feed-forward network (FFN) layers. MoE layers have a certain number of “experts” (e.g. 32 in my "frankenMoE"), where each expert is a neural network. In practice, the experts are FFNs, but they can also be more complex networks or even a MoE itself, leading to hierarchical MoEs!
A gate network or router, that determines which tokens are sent to which expert. For example, in the image below, the token “More” is sent to the second expert, and the token "Parameters” is sent to the first network. As we’ll explore later, we can send a token to more than one expert. How to route a token to an expert is one of the big decisions when working with MoEs - the router is composed of learned parameters and is pretrained at the same time as the rest of the network.
At every layer, for every token, a router network chooses two of these groups (the “experts”) to process the token and combine their output additively.

Switch Layer
MoE layer from the [Switch Transformers paper](https://arxiv.org/abs/2101.03961)
So, to recap, in MoEs we replace every FFN layer of the transformer model with an MoE layer, which is composed of a gate network and a certain number of experts.
Although MoEs provide benefits like efficient pretraining and faster inference compared to dense models, they also come with challenges:
Training: MoEs enable significantly more compute-efficient pretraining, but they’ve historically struggled to generalize during fine-tuning, leading to overfitting.
Inference: Although a MoE might have many parameters, only some of them are used during inference. This leads to much faster inference compared to a dense model with the same number of parameters. However, all parameters need to be loaded in RAM, so memory requirements are high. For example, [given a MoE like Mixtral 8x7B](https://huggingface.co/blog/moe), we’ll need to have enough VRAM to hold a dense 47B parameter model. Why 47B parameters and not 8 x 7B = 56B? That’s because in MoE models, only the FFN layers are treated as individual experts, and the rest of the model parameters are shared. At the same time, assuming just two experts are being used per token, the inference speed (FLOPs) is like using a 12B model (as opposed to a 14B model), because it computes 2x7B matrix multiplications, but with some layers shared (more on this soon).
If all our tokens are sent to just a few popular experts, that will make training inefficient. In a normal MoE training, the gating network converges to mostly activate the same few experts. This self-reinforces as favored experts are trained quicker and hence selected more. To mitigate this, an auxiliary loss is added to encourage giving all experts equal importance. This loss ensures that all experts receive a roughly equal number of training examples. The following sections will also explore the concept of expert capacity, which introduces a threshold of how many tokens can be processed by an expert. In transformers, the auxiliary loss is exposed via the aux_loss parameter.
## "Wait...but you called this a frankenMoE?"
The difference between MoE and "frankenMoE" lies in the fact that the router layer in a model like the one on this repo is not trained simultaneously. |
Systran/faster-distil-whisper-large-v2 | Systran | 2024-05-09T08:16:17Z | 1,340 | 7 | ctranslate2 | [
"ctranslate2",
"audio",
"automatic-speech-recognition",
"en",
"license:mit",
"region:us"
] | automatic-speech-recognition | 2024-01-19T03:20:59Z | ---
language:
- en
tags:
- audio
- automatic-speech-recognition
license: mit
library_name: ctranslate2
---
# Whisper distil-large-v2 model for CTranslate2
This repository contains the conversion of [distil-whisper/distil-large-v2](https://huggingface.co/distil-whisper/distil-large-v2) to the [CTranslate2](https://github.com/OpenNMT/CTranslate2) model format.
This model can be used in CTranslate2 or projects based on CTranslate2 such as [faster-whisper](https://github.com/systran/faster-whisper).
## Example
```python
from faster_whisper import WhisperModel
model = WhisperModel("distil-large-v2")
segments, info = model.transcribe("audio.mp3")
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))
```
## Conversion details
The original model was converted with the following command:
```
ct2-transformers-converter --model distil-whisper/distil-large-v2 --output_dir faster-distil-whisper-large-v2 \
--copy_files tokenizer.json preprocessor_config.json --quantization float16
```
Note that the model weights are saved in FP16. This type can be changed when the model is loaded using the [`compute_type` option in CTranslate2](https://opennmt.net/CTranslate2/quantization.html).
## More information
**For more information about the original model, see its [model card](https://huggingface.co/distil-whisper/distil-large-v2).** |
ConvexAI/BurningBruce-003 | ConvexAI | 2024-02-18T18:30:09Z | 1,340 | 5 | transformers | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"merge",
"moe",
"conversational",
"en",
"arxiv:2101.03961",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-19T18:20:24Z | ---
license: apache-2.0
tags:
- merge
- moe
language:
- en
---

# Burning-Bruce - 4x7b
We didn't start the **fire**.
This model is a Mixture of Experts (MoE) made with [mergekit](https://github.com/cg123/mergekit/tree/mixtral)
by Kquant03, Dontriskit and NeuralNovel
[Join our Discord!](https://discord.gg/rJXGjmxqzS)
## Models used:
- [leveldevai/TurdusBeagle-7B](https://huggingface.co/leveldevai/TurdusBeagle-7B) - base
- [leveldevai/TurdusBeagle-7B](https://huggingface.co/leveldevai/TurdusBeagle-7B) - expert #1
- [udkai/Turdus](https://huggingface.co/nfaheem/udkai/Turdus) - expert #2
- [nfaheem/Marcoroni-7b-DPO-Merge](https://huggingface.co/nfaheem/Marcoroni-7b-DPO-Merge) - expert #3
- [Toten5/Marcoroni-neural-chat-7B-v2](https://huggingface.co/Toten5/Marcoroni-neural-chat-7B-v2) - expert #4
# "[What is a Mixture of Experts (MoE)?](https://huggingface.co/blog/moe)"
### (from the MistralAI papers...click the quoted question above to navigate to it directly.)
The scale of a model is one of the most important axes for better model quality. Given a fixed computing budget, training a larger model for fewer steps is better than training a smaller model for more steps.
Mixture of Experts enable models to be pretrained with far less compute, which means you can dramatically scale up the model or dataset size with the same compute budget as a dense model. In particular, a MoE model should achieve the same quality as its dense counterpart much faster during pretraining.
So, what exactly is a MoE? In the context of transformer models, a MoE consists of two main elements:
Sparse MoE layers are used instead of dense feed-forward network (FFN) layers. MoE layers have a certain number of “experts” (e.g. 32 in my "frankenMoE"), where each expert is a neural network. In practice, the experts are FFNs, but they can also be more complex networks or even a MoE itself, leading to hierarchical MoEs!
A gate network or router, that determines which tokens are sent to which expert. For example, in the image below, the token “More” is sent to the second expert, and the token "Parameters” is sent to the first network. As we’ll explore later, we can send a token to more than one expert. How to route a token to an expert is one of the big decisions when working with MoEs - the router is composed of learned parameters and is pretrained at the same time as the rest of the network.
At every layer, for every token, a router network chooses two of these groups (the “experts”) to process the token and combine their output additively.

Switch Layer
MoE layer from the [Switch Transformers paper](https://arxiv.org/abs/2101.03961)
So, to recap, in MoEs we replace every FFN layer of the transformer model with an MoE layer, which is composed of a gate network and a certain number of experts.
Although MoEs provide benefits like efficient pretraining and faster inference compared to dense models, they also come with challenges:
Training: MoEs enable significantly more compute-efficient pretraining, but they’ve historically struggled to generalize during fine-tuning, leading to overfitting.
Inference: Although a MoE might have many parameters, only some of them are used during inference. This leads to much faster inference compared to a dense model with the same number of parameters. However, all parameters need to be loaded in RAM, so memory requirements are high. For example, [given a MoE like Mixtral 8x7B](https://huggingface.co/blog/moe), we’ll need to have enough VRAM to hold a dense 47B parameter model. Why 47B parameters and not 8 x 7B = 56B? That’s because in MoE models, only the FFN layers are treated as individual experts, and the rest of the model parameters are shared. At the same time, assuming just two experts are being used per token, the inference speed (FLOPs) is like using a 12B model (as opposed to a 14B model), because it computes 2x7B matrix multiplications, but with some layers shared (more on this soon).
If all our tokens are sent to just a few popular experts, that will make training inefficient. In a normal MoE training, the gating network converges to mostly activate the same few experts. This self-reinforces as favored experts are trained quicker and hence selected more. To mitigate this, an auxiliary loss is added to encourage giving all experts equal importance. This loss ensures that all experts receive a roughly equal number of training examples. The following sections will also explore the concept of expert capacity, which introduces a threshold of how many tokens can be processed by an expert. In transformers, the auxiliary loss is exposed via the aux_loss parameter.
## "Wait...but you called this a frankenMoE?"
The difference between MoE and "frankenMoE" lies in the fact that the router layer in a model like the one on this repo is not trained simultaneously.
Sponsored by: [Dontriskit](https://huggingface.co/h2m)
# Evals
*coming soon*
|
ewqr2130/alignment-handbook-zephyr-7b-sft-full-dpo-5e7-cont2 | ewqr2130 | 2024-01-19T19:21:48Z | 1,340 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-19T19:00:27Z | ---
license: apache-2.0
---
ewqr2130/alignment-handbook-zephyr-7b-sft-full-dpo-5e7-cont2---- 7k steps.
ewqr2130/alignment-handbook-zephyr-7b-sft-full-dpo-5e7-cont2---- 7k steps.
ewqr2130/alignment-handbook-zephyr-7b-sft-full-dpo-5e7-cont2---- 7k steps.
ewqr2130/alignment-handbook-zephyr-7b-sft-full-dpo-5e7-cont2---- 7k steps.
ewqr2130/alignment-handbook-zephyr-7b-sft-full-dpo-5e7-cont2---- 7k steps.
ewqr2130/alignment-handbook-zephyr-7b-sft-full-dpo-5e7-cont2---- 7k steps.
ewqr2130/alignment-handbook-zephyr-7b-sft-full-dpo-5e7-cont2---- 7k steps.
ewqr2130/alignment-handbook-zephyr-7b-sft-full-dpo-5e7-cont2---- 7k steps. |
ibivibiv/athene-noctua-13b | ibivibiv | 2024-03-04T23:45:58Z | 1,340 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"logic",
"reasoning",
"en",
"arxiv:1803.05457",
"arxiv:1905.07830",
"arxiv:2009.03300",
"arxiv:2109.07958",
"arxiv:1907.10641",
"arxiv:2110.14168",
"license:llama2",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-22T15:45:37Z | ---
language:
- en
license: llama2
tags:
- logic
- reasoning
model-index:
- name: athene-noctua-13b
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 57.17
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=ibivibiv/athene-noctua-13b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 81.52
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=ibivibiv/athene-noctua-13b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 55.91
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=ibivibiv/athene-noctua-13b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 47.49
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=ibivibiv/athene-noctua-13b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 73.4
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=ibivibiv/athene-noctua-13b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 15.31
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=ibivibiv/athene-noctua-13b
name: Open LLM Leaderboard
---
# Athene Noctua 13B

# Model Details
* **Trained by**: [ibivibiv](https://huggingface.co/ibivibiv)
* **Library**: [HuggingFace Transformers](https://github.com/huggingface/transformers)
* **Model type:** **athene-noctua-13b** is an auto-regressive language model fine tuned on the Llama 2 transformer architecture.
* **Language(s)**: English
* **Purpose**: Has specific training for logic enforcement, will do well in ARC or other logic testing as well as critical thinking tasks. This model is targeted towards planning exercises.
* **Comments**: This little guy does pretty well in my logic puzzle testing for a 13B model. I've been using it for test runs to prime for larger models, but it is worth uploading now as it is doing very well on the tests. Again, this a 13B model so tricky logic does still trip it up but for its size it is doing well.
# Prompting
## Prompt Template for alpaca style
```
### Instruction:
<prompt> (without the <>)
### Response:
```
## Sample Code
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
torch.set_default_device("cuda")
model = AutoModelForCausalLM.from_pretrained("ibivibiv/athene-noctua-13b", torch_dtype="auto", device_config='auto')
tokenizer = AutoTokenizer.from_pretrained("ibivibiv/athene-noctua-13b")
inputs = tokenizer("### Instruction: Create a plan for developing the game of snake in python using pygame.\n### Response:\n", return_tensors="pt", return_attention_mask=False)
outputs = model.generate(**inputs, max_length=200)
text = tokenizer.batch_decode(outputs)[0]
print(text)
```
## Citations
```
@misc{open-llm-leaderboard,
author = {Edward Beeching and Clémentine Fourrier and Nathan Habib and Sheon Han and Nathan Lambert and Nazneen Rajani and Omar Sanseviero and Lewis Tunstall and Thomas Wolf},
title = {Open LLM Leaderboard},
year = {2023},
publisher = {Hugging Face},
howpublished = "\url{https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard}"
}
```
```
@software{eval-harness,
author = {Gao, Leo and
Tow, Jonathan and
Biderman, Stella and
Black, Sid and
DiPofi, Anthony and
Foster, Charles and
Golding, Laurence and
Hsu, Jeffrey and
McDonell, Kyle and
Muennighoff, Niklas and
Phang, Jason and
Reynolds, Laria and
Tang, Eric and
Thite, Anish and
Wang, Ben and
Wang, Kevin and
Zou, Andy},
title = {A framework for few-shot language model evaluation},
month = sep,
year = 2021,
publisher = {Zenodo},
version = {v0.0.1},
doi = {10.5281/zenodo.5371628},
url = {https://doi.org/10.5281/zenodo.5371628}
}
```
```
@misc{clark2018think,
title={Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge},
author={Peter Clark and Isaac Cowhey and Oren Etzioni and Tushar Khot and Ashish Sabharwal and Carissa Schoenick and Oyvind Tafjord},
year={2018},
eprint={1803.05457},
archivePrefix={arXiv},
primaryClass={cs.AI}
}
```
```
@misc{zellers2019hellaswag,
title={HellaSwag: Can a Machine Really Finish Your Sentence?},
author={Rowan Zellers and Ari Holtzman and Yonatan Bisk and Ali Farhadi and Yejin Choi},
year={2019},
eprint={1905.07830},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```
@misc{hendrycks2021measuring,
title={Measuring Massive Multitask Language Understanding},
author={Dan Hendrycks and Collin Burns and Steven Basart and Andy Zou and Mantas Mazeika and Dawn Song and Jacob Steinhardt},
year={2021},
eprint={2009.03300},
archivePrefix={arXiv},
primaryClass={cs.CY}
}
```
```
@misc{lin2022truthfulqa,
title={TruthfulQA: Measuring How Models Mimic Human Falsehoods},
author={Stephanie Lin and Jacob Hilton and Owain Evans},
year={2022},
eprint={2109.07958},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```
@misc{DBLP:journals/corr/abs-1907-10641,
title={{WINOGRANDE:} An Adversarial Winograd Schema Challenge at Scale},
author={Keisuke Sakaguchi and Ronan Le Bras and Chandra Bhagavatula and Yejin Choi},
year={2019},
eprint={1907.10641},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```
@misc{DBLP:journals/corr/abs-2110-14168,
title={Training Verifiers to Solve Math Word Problems},
author={Karl Cobbe and
Vineet Kosaraju and
Mohammad Bavarian and
Mark Chen and
Heewoo Jun and
Lukasz Kaiser and
Matthias Plappert and
Jerry Tworek and
Jacob Hilton and
Reiichiro Nakano and
Christopher Hesse and
John Schulman},
year={2021},
eprint={2110.14168},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_ibivibiv__athene-noctua-13b)
| Metric |Value|
|---------------------------------|----:|
|Avg. |55.13|
|AI2 Reasoning Challenge (25-Shot)|57.17|
|HellaSwag (10-Shot) |81.52|
|MMLU (5-Shot) |55.91|
|TruthfulQA (0-shot) |47.49|
|Winogrande (5-shot) |73.40|
|GSM8k (5-shot) |15.31|
|
cris177/Orca-Hermes-7B-slerp | cris177 | 2024-01-24T07:22:56Z | 1,340 | 2 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"Open-Orca/Mistral-7B-OpenOrca",
"teknium/OpenHermes-2.5-Mistral-7B",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-23T22:34:35Z | ---
license: apache-2.0
tags:
- merge
- mergekit
- Open-Orca/Mistral-7B-OpenOrca
- teknium/OpenHermes-2.5-Mistral-7B
---
# Orca-Hermes-7B-slerp
Orca-Hermes-7B-slerp is a merge of the following models using [mergekit](https://github.com/cg123/mergekit):
* [Open-Orca/Mistral-7B-OpenOrca](https://huggingface.co/Open-Orca/Mistral-7B-OpenOrca)
* [teknium/OpenHermes-2.5-Mistral-7B](https://huggingface.co/teknium/OpenHermes-2.5-Mistral-7B)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: Open-Orca/Mistral-7B-OpenOrca
layer_range: [0, 32]
- model: teknium/OpenHermes-2.5-Mistral-7B
layer_range: [0, 32]
merge_method: slerp
base_model: Open-Orca/Mistral-7B-OpenOrca
tokenizer_source: base
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
``` |
ChrisWilson011016/5EfQqroWWSDHRaAsA4JQUtnPy7PGYqNoZhKMPHTRA7WVznd4_vgg | ChrisWilson011016 | 2024-03-04T18:50:13Z | 1,340 | 0 | keras | [
"keras",
"region:us"
] | null | 2024-02-24T15:07:01Z | Entry not found |
GitBag/Reviewer2_Mr | GitBag | 2024-02-25T23:02:45Z | 1,340 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"conversational",
"en",
"dataset:GitBag/Reviewer2_PGE_cleaned",
"arxiv:2402.10886",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-02-25T20:30:15Z | ---
license: apache-2.0
datasets:
- GitBag/Reviewer2_PGE_cleaned
language:
- en
metrics:
- bleu
- rouge
- bertscore
pipeline_tag: text-generation
---
# Review Generation Model for [Reviewer2](https://arxiv.org/abs/2402.10886)
This is the review generation model (Mr) for our Reviewer2 pipeline. A demo of the model is provided in this [repo](https://github.com/ZhaolinGao/Reviewer2/tree/main).
## Citation
If you find this model useful in your research, please cite the following paper:
```
@misc{gao2024reviewer2,
title={Reviewer2: Optimizing Review Generation Through Prompt Generation},
author={Zhaolin Gao and Kianté Brantley and Thorsten Joachims},
year={2024},
eprint={2402.10886},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
cstr/Spaetzle-v60-7b | cstr | 2024-05-24T20:20:20Z | 1,340 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"abideen/AlphaMonarch-dora",
"conversational",
"de",
"en",
"base_model:abideen/AlphaMonarch-dora",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-04-14T21:12:09Z | ---
tags:
- merge
- mergekit
- lazymergekit
- abideen/AlphaMonarch-dora
base_model:
- abideen/AlphaMonarch-dora
license: cc-by-nc-4.0
language:
- de
- en
---
# Spaetzle-v60-7b
This is a progressive (mostly dare-ties, but also slerp i.a.) merge with the intention of suitable compromise for English and German local tasks.
Spaetzle-v60-7b is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [abideen/AlphaMonarch-dora](https://huggingface.co/abideen/AlphaMonarch-dora)
* [cstr/Spaetzle-v58-7b](https://huggingface.co/cstr/Spaetzle-v58-7b)
## Benchmarks
The performance looks ok so far: e.g. we get in EQ-Bench: Score (v2_de): 65.08 (Parseable: 171.0).
From the [Occiglot Euro LLM Leaderboard](https://huggingface.co/spaces/occiglot/euro-llm-leaderboard):
| Model | DE | EN | ARC EN | TruthfulQA EN | Belebele EN | HellaSwag EN | MMLU EN | ARC DE | TruthfulQA DE | Belebele DE | HellaSwag DE | MMLU DE |
|--------------------------------------------------------|-------|-------|--------|---------------|-------------|--------------|---------|--------|---------------|-------------|--------------|---------|
| mistral-community/Mixtral-8x22B-v0.1 | 66.81 | 72.87 | 70.56 | 52.29 | 93.89 | 70.41 | 77.17 | 63.9 | 29.31 | 92.44 | 77.9 | 70.49 |
| **cstr/Spaetzle-v60-7b** | 60.95 | 71.65 | 69.88 | 66.24 | 90.11 | 68.43 | 63.59 | 58 | 37.31 | 84.22 | 70.09 | 55.11 |
| VAGOsolutions/Llama-3-SauerkrautLM-8b-Instruct | 60.07 | 74.71 | 74.49 | 66.19 | 91.67 | 74.55 | 66.65 | 59.37 | 29.57 | 88.56 | 66.43 | 56.44 |
| occiglot/occiglot-7b-de-en-instruct | 56.65 | 61.7 | 60.41 | 49.38 | 81.22 | 60.43 | 57.06 | 54.49 | 31.09 | 77.22 | 68.84 | 51.59 |
| occiglot/occiglot-7b-de-en | 54.01 | 58.78 | 55.63 | 42.33 | 79.11 | 59.99 | 56.84 | 50.56 | 26.27 | 74.33 | 67.42 | 51.46 |
| meta-llama/Meta-Llama-3-8B | 53.89 | 63.08 | 58.02 | 43.87 | 86.44 | 61.75 | 65.3 | 46.45 | 24.24 | 81.11 | 62.48 | 55.18 |
| mistralai/Mistral-7B-Instruct-v0.2 | 53.52 | 67.63 | 63.74 | 66.81 | 82.44 | 65.96 | 59.2 | 48.59 | 37.69 | 68.89 | 62.24 | 50.2 |
| occiglot/occiglot-7b-eu5-instruct | 53.15 | 57.78 | 55.89 | 44.9 | 74.67 | 59.92 | 53.51 | 52.95 | 28.68 | 66.78 | 68.52 | 48.82 |
| clibrain/lince-mistral-7b-it-es | 52.98 | 62.43 | 62.46 | 43.32 | 82.44 | 63.86 | 60.06 | 49.44 | 28.17 | 75 | 61.64 | 50.64 |
| mistralai/Mistral-7B-v0.1 | 52.8 | 62.73 | 61.26 | 42.62 | 84.44 | 62.89 | 62.46 | 47.65 | 28.43 | 73.89 | 61.06 | 52.96 |
| LeoLM/leo-mistral-hessianai-7b | 51.78 | 56.11 | 52.22 | 42.92 | 73.67 | 57.86 | 53.88 | 47.48 | 25.25 | 69.11 | 68.21 | 48.83 |
And for the int4-inc quantized version, from [Low-bit Quantized Open LLM Leaderboard](https://huggingface.co/spaces/Intel/low_bit_open_llm_leaderboard):
| Type | Model | Average ⬆️ | ARC-c | ARC-e | Boolq | HellaSwag | Lambada | MMLU | Openbookqa | Piqa | Truthfulqa | Winogrande | #Params (B) | #Size (G) |
|------|-------------------------------------------|------------|-------|-------|-------|-----------|---------|-------|------------|-------|------------|------------|-------------|-----------|
| 🍒 | Intel/SOLAR-10.7B-Instruct-v1.0-int4-inc | 68.49 | 60.49 | 82.66 | 88.29 | 68.29 | 73.36 | 62.43 | 35.6 | 80.74 | 56.06 | 76.95 | 10.57 | 5.98 |
| 🍒 | **cstr/Spaetzle-v60-7b-int4-inc** | **68.01** | **62.12** | **85.27** | **87.34** | **66.43** | **70.58** | **61.39** | **37** | **82.26** | **50.18** | **77.51** | **7.04** | **4.16** |
| 🔷 | TheBloke/SOLAR-10.7B-Instruct-v1.0-GGUF | 66.6 | 60.41 | 83.38 | 88.29 | 67.73 | 52.42 | 62.04 | 37.2 | 82.32 | 56.3 | 75.93 | 10.73 | 6.07 |
| 🔷 | cstr/Spaetzle-v60-7b-Q4_0-GGUF | 66.44 | 61.35 | 85.19 | 87.98 | 66.54 | 52.78 | 62.05 | 40.6 | 81.72 | 47 | 79.16 | 7.24 | 4.11 |
| 🍒 | Intel/Mistral-7B-Instruct-v0.2-int4-inc | 65.73 | 55.38 | 81.44 | 85.26 | 65.67 | 70.89 | 58.66 | 34.2 | 80.74 | 51.16 | 73.95 | 7.04 | 4.16 |
| 🍒 | Intel/Phi-3-mini-4k-instruct-int4-inc | 65.09 | 57.08 | 83.33 | 86.18 | 59.45 | 68.14 | 66.62 | 38.6 | 79.33 | 38.68 | 73.48 | 3.66 | 2.28 |
| 🔷 | TheBloke/Mistral-7B-Instruct-v0.2-GGUF | 63.52 | 53.5 | 77.9 | 85.44 | 66.9 | 50.11 | 58.45 | 38.8 | 77.58 | 53.12 | 73.4 | 7.24 | 4.11 |
| 🍒 | Intel/Meta-Llama-3-8B-Instruct-int4-inc | 62.93 | 51.88 | 81.1 | 83.21 | 57.09 | 71.32 | 62.41 | 35.2 | 78.62 | 36.35 | 72.14 | 7.2 | 5.4 |
Contamination check results (reference model: Mistral instruct 7b v0.1):
- MMLU: result < 0.1, %: 0.19
- TruthfulQA: result < 0.1, %: 0.34
- GSM8k: result < 0.1, %: 0.39
## 🧩 Configuration
```yaml
models:
- model: cstr/Spaetzle-v58-7b
# no parameters necessary for base model
- model: abideen/AlphaMonarch-dora
parameters:
density: 0.60
weight: 0.30
merge_method: dare_ties
base_model: cstr/Spaetzle-v58-7b
parameters:
int8_mask: true
dtype: bfloat16
random_seed: 0
tokenizer_source: base
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "cstr/Spaetzle-v60-7b"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
mradermacher/BioQwen-0.5B-GGUF | mradermacher | 2024-06-23T12:14:56Z | 1,340 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:yueqingyou/BioQwen-0.5B",
"endpoints_compatible",
"region:us"
] | null | 2024-06-23T12:08:38Z | ---
base_model: yueqingyou/BioQwen-0.5B
language:
- en
library_name: transformers
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/yueqingyou/BioQwen-0.5B
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/BioQwen-0.5B-GGUF/resolve/main/BioQwen-0.5B.Q3_K_S.gguf) | Q3_K_S | 0.4 | |
| [GGUF](https://huggingface.co/mradermacher/BioQwen-0.5B-GGUF/resolve/main/BioQwen-0.5B.IQ3_S.gguf) | IQ3_S | 0.4 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/BioQwen-0.5B-GGUF/resolve/main/BioQwen-0.5B.IQ3_XS.gguf) | IQ3_XS | 0.4 | |
| [GGUF](https://huggingface.co/mradermacher/BioQwen-0.5B-GGUF/resolve/main/BioQwen-0.5B.Q2_K.gguf) | Q2_K | 0.4 | |
| [GGUF](https://huggingface.co/mradermacher/BioQwen-0.5B-GGUF/resolve/main/BioQwen-0.5B.IQ3_M.gguf) | IQ3_M | 0.4 | |
| [GGUF](https://huggingface.co/mradermacher/BioQwen-0.5B-GGUF/resolve/main/BioQwen-0.5B.IQ4_XS.gguf) | IQ4_XS | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/BioQwen-0.5B-GGUF/resolve/main/BioQwen-0.5B.Q3_K_M.gguf) | Q3_K_M | 0.5 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/BioQwen-0.5B-GGUF/resolve/main/BioQwen-0.5B.Q3_K_L.gguf) | Q3_K_L | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/BioQwen-0.5B-GGUF/resolve/main/BioQwen-0.5B.Q4_K_S.gguf) | Q4_K_S | 0.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/BioQwen-0.5B-GGUF/resolve/main/BioQwen-0.5B.Q4_K_M.gguf) | Q4_K_M | 0.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/BioQwen-0.5B-GGUF/resolve/main/BioQwen-0.5B.Q5_K_S.gguf) | Q5_K_S | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/BioQwen-0.5B-GGUF/resolve/main/BioQwen-0.5B.Q5_K_M.gguf) | Q5_K_M | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/BioQwen-0.5B-GGUF/resolve/main/BioQwen-0.5B.Q6_K.gguf) | Q6_K | 0.6 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/BioQwen-0.5B-GGUF/resolve/main/BioQwen-0.5B.Q8_0.gguf) | Q8_0 | 0.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/BioQwen-0.5B-GGUF/resolve/main/BioQwen-0.5B.f16.gguf) | f16 | 1.1 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
amphora/small-instruct | amphora | 2023-10-29T11:26:34Z | 1,339 | 1 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-10-09T19:10:22Z | ---
license: cc-by-nc-4.0
--- |
heegyu/42dot_LLM-PLM-1.3B-mt-steps-50000 | heegyu | 2023-10-22T13:11:34Z | 1,339 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-10-20T10:20:17Z | | Task |Version| Metric |Value | |Stderr|
|----------------|------:|--------|-----:|---|-----:|
|kobest_boolq | 0|acc |0.5520|± |0.0133|
| | |macro_f1|0.5341|± |0.0134|
|kobest_copa | 0|acc |0.7090|± |0.0144|
| | |macro_f1|0.7085|± |0.0144|
|kobest_hellaswag| 0|acc |0.4240|± |0.0221|
| | |acc_norm|0.5240|± |0.0224|
| | |macro_f1|0.4192|± |0.0220|
|kobest_sentineg | 0|acc |0.7582|± |0.0215|
| | |macro_f1|0.7487|± |0.0223| |
genne/otter2.1_7b | genne | 2023-11-10T01:56:20Z | 1,339 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-10T01:47:36Z | Entry not found |
genne/otter3.1.4_7b | genne | 2023-11-12T23:53:12Z | 1,339 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-12T23:45:14Z | Entry not found |
Cartinoe5930/weak-KoRAE-13b | Cartinoe5930 | 2023-12-01T09:03:52Z | 1,339 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"ko",
"dataset:Cartinoe5930/KoRAE_filtered_12k",
"arxiv:2307.08701",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-28T00:03:00Z | ---
license: cc-by-nc-sa-4.0
datasets:
- Cartinoe5930/KoRAE_filtered_12k
language:
- ko
library_name: transformers
---
## KoRAE
<p align="center"><img src="https://cdn-uploads.huggingface.co/production/uploads/63e087b6a98d931aa90c1b9c/XQ-pNzRDRccd7UFgYDOrx.png", width='300', height='300'></p>
We introduce **KoRAE** which finetuned with filtered high-quality Korean dataset.
The **KoRAE** is output of combination of high-quality data which filtered by special data filtering method and Korean Llama-2 that Korean vocabularis were added.
We utilized special data filtering methods which introduced in [AlpaGasus](https://arxiv.org/abs/2307.08701) to filter high-quality data from mixture of several Korean datasets(OpenOrca-KO, KOpen-Platypus, KoCoT_2000, databricks-dolly-15k-ko).
We finetuned [Korean Llama-2](https://huggingface.co/beomi/llama-2-koen-13b) that introduced by [@beomi](https://huggingface.co/beomi) on the filtered dataset.
The Flash-Attention2 and LoRA were utilized for efficient finetuning.
The finding of KoRAE is as follows:
1. The finetuning in some epochs showed that high-quality filtered data has positive effects on model's performance. However, finetuning in a few epochs, the quantity of data is more matter than quality. It seems to be due to the lack of performance of the Korean base model. Therefore, the research to improve the Korean base model must continue.
2. The model trained with DPO showed best performance among KoRAE variants. This shows that DPO is clearly effective in the Korean LLM.
3. The model finetuned with filtered high-quality KoRAE showed better performance than without. Therefore, for better LLM, we should try to finetune the LLM with high-quality data.
## Model Details
- **Developed by:** [Cartinoe5930](https://huggingface.co/Cartinoe5930)
- **Base model:** [beomi/llama-2-koen-13b](https://huggingface.co/beomi/llama-2-koen-13b)
- **Repository:** [gauss5930/KoRAE](https://github.com/gauss5930/KoRAE)
For more details, please check the GitHub Repository!
## Training Details
- **Hardward:** We utilized A100 80G for finetuning
- **Training factors:** The [Transformers Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) and [Huggingface PEFT](https://huggingface.co/docs/peft/index) were utilized for finetuning.
- **Training Details:** Supervised finetuning 1 epoch on [filtered KoRAE](https://huggingface.co/datasets/Cartinoe5930/KoRAE_filtered_12k) dataset
For more details, please check the GitHub Repository!
## Training Dataset
The KoRAE was finetuned with KoRAE dataset filtered high-quality dataset.
This dataset is a combination of the publicly available Koraen dataset and a filtering method was applied to the result of the combination dataset.
For more information, please refer to the [dataset card](https://huggingface.co/datasets/Cartinoe5930/KoRAE_filtered_12k) of KoRAE.
## Open Ko-LLM Leaderboard
|Model|Average|Ko-ARC|Ko-HellaSwag|Ko-MMLU|Ko-TruthfulQA|Ko-CommonGen V2|
|---|---|---|---|---|---|---|
|weak-KoRAE-13b|48.1|45.22|56.79|42|40.4|56.08|
## Prompt Template
```
### System:
{system_prompt}
### User:
{instruction + input}
### Assistant:
{output}
```
## Usage example
```python
# Use a pipeline as a high-level helper
from transformers import pipeline
import torch
pipe = pipeline("text-generation", model="Cartinoe5930/KoRAE-13b", torch_dtype=torch.bfloat16, device_map="auto")
messages = [
{
"role": "system",
"content": "당신은 유용한 인공지능 비서입니다. 사용자가 몇 가지 지시가 포함된 작업을 제공합니다. 요청을 적절히 완료하는 응답을 작성하세요.",
},
{"role": "user", "content": "스트레스를 해소하는 5가지 방법에 대해서 설명해줘."}
]
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
## Citation
- [KO-Platypus](https://github.com/Marker-Inc-Korea/KO-Platypus)
- [Korean-OpenOrca](https://github.com/Marker-Inc-Korea/Korean-OpenOrca)
```
@inproceedings{lee2023kullm,
title={KULLM: Learning to Construct Korean Instruction-following Large Language Models},
author={Lee, SeungJun and Lee, Taemin and Lee, Jeongwoo and Jang, Yoona and Lim, Heuiseok},
booktitle={Annual Conference on Human and Language Technology},
pages={196--202},
year={2023},
organization={Human and Language Technology}
}
```
```
@misc{chen2023alpagasus,
title={AlpaGasus: Training A Better Alpaca with Fewer Data},
author={Lichang Chen and Shiyang Li and Jun Yan and Hai Wang and Kalpa Gunaratna and Vikas Yadav and Zheng Tang and Vijay Srinivasan and Tianyi Zhou and Heng Huang and Hongxia Jin},
year={2023},
eprint={2307.08701},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```
@misc {l._junbum_2023,
author = { {L. Junbum, Taekyoon Choi} },
title = { llama-2-koen-13b },
year = 2023,
url = { https://huggingface.co/beomi/llama-2-koen-13b },
doi = { 10.57967/hf/1280 },
publisher = { Hugging Face }
}
``` |
jingyeom/seal_all_7b | jingyeom | 2023-12-04T06:44:33Z | 1,339 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-04T06:30:35Z | Entry not found |
HyperbeeAI/Tulpar-7b-v2 | HyperbeeAI | 2023-12-05T07:58:32Z | 1,339 | 1 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-05T07:00:06Z | ---
license: apache-2.0
---
<p align="center">
<img src="https://huggingface.co/HyperbeeAI/Tulpar-7b-v0/resolve/main/tulpar.png" width="360" height="360" >
</p>
# Model Description
Tulpar-7b is a Mistral-7b-based model trained by HyperbeeAI. Training is done on a filtered and preprocessed instruction finetuning dataset that includes GPT-4 generated and generally curated datasets like Airoboros and Platypus.
# Example Usage
Loading the model:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("HyperbeeAI/Tulpar-7b-v0")
model = AutoModelForCausalLM.from_pretrained("HyperbeeAI/Tulpar-7b-v0", device_map="auto")
```
You can run inference with both of the following prompts:
```python
input_text="What is deep learning?"
prompt = f"### User: {input_text}\n\n### Assistant:\n"
inputs = tokenizer(prompt, return_tensors="pt")
output = model.generate(**inputs, do_sample=True, top_p=0.95, top_k=0, max_new_tokens=512)
print(tokenizer.decode(output[0]))
```
```python
input_text="What is deep learning?"
prompt = f"Question: {input_text}\n\nAnswer:"
inputs = tokenizer(prompt, return_tensors="pt")
output = model.generate(**inputs, do_sample=True, top_p=0.95, top_k=0, max_new_tokens=512)
print(tokenizer.decode(output[0]))
```
or use ChatML format.
# Ethical Considerations and Limitations
Tulpar is a technology with potential risks and limitations. This model is finetuned only in English and all language-related scenarios are not covered. As HyperbeeAI, we neither guarantee ethical, accurate, unbiased, objective responses nor endorse its outputs. Before deploying this model, you are advised to make safety tests for your use case.
|
DopeorNope/Yi_lee-v2-DPO-6B | DopeorNope | 2023-12-12T07:53:23Z | 1,339 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-11T19:39:22Z | Entry not found |
inswave/AISquare-Instruct-llama2-koen-13b-v0.9.22 | inswave | 2023-12-18T04:53:50Z | 1,339 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-18T04:22:22Z | Entry not found |
shadowml/DareBeagel-2x7B | shadowml | 2024-04-01T16:01:04Z | 1,339 | 2 | transformers | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"moe",
"merge",
"mergekit",
"lazymergekit",
"mlabonne/NeuralBeagle14-7B",
"mlabonne/NeuralDaredevil-7B",
"conversational",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-04T16:33:56Z | ---
license: apache-2.0
tags:
- moe
- merge
- mergekit
- lazymergekit
- mlabonne/NeuralBeagle14-7B
- mlabonne/NeuralDaredevil-7B
model-index:
- name: DareBeagel-2x7B
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 72.01
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=shadowml/DareBeagel-2x7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 88.12
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=shadowml/DareBeagel-2x7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 64.51
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=shadowml/DareBeagel-2x7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 69.09
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=shadowml/DareBeagel-2x7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 82.72
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=shadowml/DareBeagel-2x7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 70.51
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=shadowml/DareBeagel-2x7B
name: Open LLM Leaderboard
---
# Beyonder-2x7B-v2
Beyonder-2x7B-v2 is a Mixure of Experts (MoE) made with the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [mlabonne/NeuralBeagle14-7B](https://huggingface.co/mlabonne/NeuralBeagle14-7B)
* [mlabonne/NeuralDaredevil-7B](https://huggingface.co/mlabonne/NeuralDaredevil-7B)
## 🧩 Configuration
```yaml
base_model: mlabonne/NeuralBeagle14-7B
gate_mode: random
experts:
- source_model: mlabonne/NeuralBeagle14-7B
positive_prompts: [""]
- source_model: mlabonne/NeuralDaredevil-7B
positive_prompts: [""]
```
## 💻 Usage
```python
!pip install -qU transformers bitsandbytes accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "shadowml/Beyonder-2x7B-v2"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
model_kwargs={"torch_dtype": torch.float16, "load_in_4bit": True},
)
messages = [{"role": "user", "content": "Explain what a Mixture of Experts is in less than 100 words."}]
prompt = pipeline.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_shadowml__DareBeagel-2x7B)
| Metric |Value|
|---------------------------------|----:|
|Avg. |74.49|
|AI2 Reasoning Challenge (25-Shot)|72.01|
|HellaSwag (10-Shot) |88.12|
|MMLU (5-Shot) |64.51|
|TruthfulQA (0-shot) |69.09|
|Winogrande (5-shot) |82.72|
|GSM8k (5-shot) |70.51|
|
ryandt/MusingCaterpillar | ryandt | 2024-03-04T12:38:38Z | 1,339 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"dataset:ryandt/mistral_symbolicLogic_5_7_9_short",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-07T08:06:52Z | ---
license: mit
datasets:
- ryandt/mistral_symbolicLogic_5_7_9_short
model-index:
- name: MusingCaterpillar
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 72.53
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=ryandt/MusingCaterpillar
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 88.34
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=ryandt/MusingCaterpillar
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 65.26
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=ryandt/MusingCaterpillar
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 70.93
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=ryandt/MusingCaterpillar
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 80.66
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=ryandt/MusingCaterpillar
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 62.24
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=ryandt/MusingCaterpillar
name: Open LLM Leaderboard
---
Finetune of CultriX/MistralTrix-v1 on Symbolic Logic content from Lewis Carrol (at a very low learning rate because of the very small dataset - I'm just experimenting and have no idea if this was effective at changing the model output).
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_ryandt__MusingCaterpillar)
| Metric |Value|
|---------------------------------|----:|
|Avg. |73.33|
|AI2 Reasoning Challenge (25-Shot)|72.53|
|HellaSwag (10-Shot) |88.34|
|MMLU (5-Shot) |65.26|
|TruthfulQA (0-shot) |70.93|
|Winogrande (5-shot) |80.66|
|GSM8k (5-shot) |62.24|
|
flemmingmiguel/NeuDist-Ro-7B | flemmingmiguel | 2024-01-12T04:34:11Z | 1,339 | 1 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"argilla/distilabeled-Marcoro14-7B-slerp",
"mlabonne/NeuralMarcoro14-7B",
"conversational",
"dataset:mlabonne/chatml_dpo_pairs",
"dataset:argilla/distilabel-intel-orca-dpo-pairs",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-12T01:11:06Z | ---
license: apache-2.0
tags:
- merge
- mergekit
- lazymergekit
- argilla/distilabeled-Marcoro14-7B-slerp
- mlabonne/NeuralMarcoro14-7B
datasets:
- mlabonne/chatml_dpo_pairs
- argilla/distilabel-intel-orca-dpo-pairs
---
# NeuDist-Ro-7B
NeuDist-Ro-7B is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [argilla/distilabeled-Marcoro14-7B-slerp](https://huggingface.co/argilla/distilabeled-Marcoro14-7B-slerp)
* [mlabonne/NeuralMarcoro14-7B](https://huggingface.co/mlabonne/NeuralMarcoro14-7B)
As an experiment to find the best base merge to further fine-tuning, expect a lot of experiments named using parts of the component models until a clear winner emerges in the benchmarks
In this case merging 2 DPOs of the same model
## 🧩 Configuration
```yaml
slices:
- sources:
- model: argilla/distilabeled-Marcoro14-7B-slerp
layer_range: [0, 32]
- model: mlabonne/NeuralMarcoro14-7B
layer_range: [0, 32]
merge_method: slerp
base_model: mlabonne/NeuralMarcoro14-7B
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "flemmingmiguel/NeuDist-Ro-7B"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
gagan3012/Multirial | gagan3012 | 2024-01-13T13:52:19Z | 1,339 | 1 | transformers | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"moe",
"conversational",
"ar",
"en",
"fr",
"es",
"de",
"hi",
"id",
"zh",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-12T22:32:13Z | ---
license: apache-2.0
tags:
- moe
- mixtral
language:
- ar
- en
- fr
- es
- de
- hi
- id
- zh
---
# Multirial
MultiRial is the first ever multilingual Mixture of experts model.
* [fblgit/UNA-TheBeagle-7b-v1](https://huggingface.co/fblgit/UNA-TheBeagle-7b-v1)
* [openchat/openchat-3.5-0106](https://huggingface.co/openchat/openchat-3.5-0106)
* [azale-ai/Starstreak-7b-beta](https://huggingface.co/azale-ai/Starstreak-7b-beta)
* [gagan3012/Mistral_arabic_dpo](https://huggingface.co/gagan3012/Mistral_arabic_dpo)
* [davidkim205/komt-mistral-7b-v1](https://huggingface.co/davidkim205/komt-mistral-7b-v1)
* [OpenBuddy/openbuddy-zephyr-7b-v14.1](https://huggingface.co/OpenBuddy/openbuddy-zephyr-7b-v14.1)
* [manishiitg/open-aditi-hi-v1](https://huggingface.co/manishiitg/open-aditi-hi-v1)
* [VAGOsolutions/SauerkrautLM-7b-v1-mistral](https://huggingface.co/VAGOsolutions/SauerkrautLM-7b-v1-mistral)
## 💻 Usage
```python
!pip install -qU transformers bitsandbytes accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "gagan3012/Multirial"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
model_kwargs={"torch_dtype": torch.float16, "load_in_4bit": True},
)
messages = [{"role": "user", "content": "Explain what a Mixture of Experts is in less than 100 words."}]
prompt = pipeline.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
chanwit/flux-7b-v0.2 | chanwit | 2024-01-17T18:02:09Z | 1,339 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-14T16:36:25Z | ---
license: apache-2.0
language:
- en
---
# Open Flux AI
_Open Flux AI - Empowering developers with AI-driven Continuous Delivery solutions._
Welcome to Open Flux AI, a community initiative stemming from the Kube-7B project,
dedicated to advancing AI expertise in Flux, Flagger, and Continuous Delivery technologies.
Our mission is to use the power of AI to simplify and enhance the way developers interact with Flux and technologies around it.
Our first focus is on fine-tuning AI models to specialize in key areas such as Flux, Flagger, GitOps, and SOPS.
By leveraging the raw data from Kube-7B and applying targeted Embedding techniques, we aim to create models that are highly proficient in these specific domains.
Our first major deliverable is `flux-7b`, a model based on Mistral 7B. `flux-7b` currently understands the basic knowledge of Flux, Flagger, GitOps, and SOPS.
`flux-7b` has demonstrated to be better than ChatGPT in these contexts. See the screenshot.

## Getting Started
To begin using `flux-7b`, follow this simple command:
```
ollama run chanwit/flux-7b
```
The GGUF files of this model can be obtained from [HuggingFace](https://huggingface.co/chanwit/flux-7b-v0.2-gguf/tree/main).
We are planning to delivery our models in other formats like Llamafiles and Docker Containers. Please stay tuned.
## Models
* `flux-7b`: Our first model, built on Mistral 7B, is designed to provide assistance in Flux, Flagger, GitOps, and SOPS.
## Datasets
At the beginning, the Open Flux AI project shares its foundational dataset with the Kube-7B project but refines it to focus on specific areas.
We continuously work on expanding our dataset, especially in areas like Flux commands and Custom Resources, to further enhance the model's capabilities.
# Contributions
We welcome and greatly appreciate contributions, especially in the form of question and answer pairs.
We are seeking contributions for new datasets centered around knowledge of [Flux commands](https://github.com/chanwit/open-flux-ai/blob/main/datasets/README.md) and CR generations. |
alnrg2arg/test2 | alnrg2arg | 2024-01-24T14:28:02Z | 1,339 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"udkai/Turdus",
"fblgit/UNA-TheBeagle-7b-v1",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-15T06:06:18Z | ---
license: cc-by-nc-4.0
tags:
- merge
- mergekit
- lazymergekit
- udkai/Turdus
- fblgit/UNA-TheBeagle-7b-v1
---
# test2
test2 is a merge of the following models using [mergekit](https://github.com/cg123/mergekit):
* [udkai/Turdus](https://huggingface.co/udkai/Turdus)
* [fblgit/UNA-TheBeagle-7b-v1](https://huggingface.co/fblgit/UNA-TheBeagle-7b-v1)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: udkai/Turdus
layer_range: [0, 32]
- model: fblgit/UNA-TheBeagle-7b-v1
layer_range: [0, 32]
merge_method: slerp
base_model: udkai/Turdus
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
``` |
cognitivecomputations/laserxtral | cognitivecomputations | 2024-05-20T15:10:19Z | 1,339 | 78 | transformers | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"license:cc-by-nc-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-15T16:48:51Z | ---
license: cc-by-nc-2.0
---

by David, Fernando and Eric
Sponsored by: [VAGO Solutions](https://vago-solutions.de)
[](https://discord.gg/cognitivecomputations)
Discord: https://discord.gg/cognitivecomputations
An experimentation regarding 'lasering' each expert to denoise and enhance model capabilities.
This model has half size in comparison to the Mixtral 8x7b Instruct. And it basically has the same level of performance (we are working to get a better MMLU score).
# Laserxtral - 4x7b (all, except for base, lasered using laserRMT)
This model is a Mixture of Experts (MoE) made with [mergekit](https://github.com/cg123/mergekit) (mixtral branch). It uses the following base models:
* [cognitivecomputations/dolphin-2.6-mistral-7b-dpo](https://huggingface.co/cognitivecomputations/dolphin-2.6-mistral-7b-dpo)
* [mlabonne/Marcoro14-7B-slerp (base)](https://huggingface.co/mlabonne/Marcoro14-7B-slerp)
* [beowolx/CodeNinja-1.0-OpenChat-7B](https://huggingface.co/beowolx/CodeNinja-1.0-OpenChat-7B)
* [Q-bert/MetaMath-Cybertron-Starling](https://huggingface.co/Q-bert/MetaMath-Cybertron-Starling)
* [WizardLM/WizardMath-7B-V1.1](https://huggingface.co/WizardLM/WizardMath-7B-V1.1)
It follows the implementation of laserRMT @ https://github.com/cognitivecomputations/laserRMT
Here, we are controlling layers checking which ones have lower signal to noise ratios (which are more subject to noise), to apply Laser interventions, still using Machenko Pastur to calculate this ratio.
We intend to be the first of a family of experimentations being carried out @ Cognitive Computations.
In this experiment we have observed very high truthfulness and high reasoning capabilities.
# Evals

|
macadeliccc/SOLAR-math-2x10.7b-v0.2 | macadeliccc | 2024-03-04T16:33:57Z | 1,339 | 3 | transformers | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"conversational",
"arxiv:2312.15166",
"license:cc-by-nc-4.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-16T21:01:15Z | ---
license: cc-by-nc-4.0
model-index:
- name: SOLAR-math-2x10.7b-v0.2
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 70.9
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/SOLAR-math-2x10.7b-v0.2
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 88.29
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/SOLAR-math-2x10.7b-v0.2
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 66.25
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/SOLAR-math-2x10.7b-v0.2
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 71.68
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/SOLAR-math-2x10.7b-v0.2
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 83.5
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/SOLAR-math-2x10.7b-v0.2
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 64.9
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/SOLAR-math-2x10.7b-v0.2
name: Open LLM Leaderboard
---
# 🌞🚀 SOLAR-math-10.7x2-v0.2_19B
Merge of two Solar-10.7B instruct finetunes.

This model performs in line with GPT-3.5 and Gemini Pro. Exceeding all scores of Mixtral-8x7b
Here is a brief overview of the evaluation results. These are simply for the user to have the values available for comparison. This table does not represent a complete analysis.


## 🌅 Code Example
Example also available in [colab](https://colab.research.google.com/drive/10FWCLODU_EFclVOFOlxNYMmSiLilGMBZ?usp=sharing)
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
def generate_response(prompt):
"""
Generate a response from the model based on the input prompt.
Args:
prompt (str): Prompt for the model.
Returns:
str: The generated response from the model.
"""
# Tokenize the input prompt
inputs = tokenizer(prompt, return_tensors="pt")
# Generate output tokens
outputs = model.generate(**inputs, max_new_tokens=512, eos_token_id=tokenizer.eos_token_id, pad_token_id=tokenizer.pad_token_id)
# Decode the generated tokens to a string
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return response
# Load the model and tokenizer
model_id = "macadeliccc/SOLAR-math-2x10.7B-v0.2"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, load_in_4bit=True)
prompt = "Explain the proof of Fermat's Last Theorem and its implications in number theory."
print("Response:")
print(generate_response(prompt), "\n")
```
**Example output:**
Explain the proof of Fermat's Last Theorem and its implications in number theory.
Fermat's Last Theorem, also known as FLT, is a famous mathematical conjecture that states "no three positive integers a, b, and c can satisfy the equation a^n + b^n = c^n for any integer value of n greater than 2." This theorem was first proposed by Pierre de Fermat in the 17th century, but its proof was only discovered in the late 20th century by Andrew Wiles.
The proof of Fermat's Last Theorem, published by Andrew Wiles in 1993 and 1994, is complex and involves several advanced mathematical concepts. The main idea behind the proof is the use of modular elliptic curves, which are algebraic curves defined by polynomial equations. Wiles introduced a new concept called the Taniyama-Shimura conjecture, which states that there is a one-to-one correspondence between certain elliptic curves over the rational numbers and certain cusp forms.
Wiles' proof of FLT is based on the assumption that the Taniyama-Shimura conjecture is true. He showed that if the Taniyama-Shimura conjecture is true, then Fermat's Last Theorem must also be true. This proof strategy is known as a "proof by contradiction." Wiles demonstrated that if FLT were false, then there would exist a counterexample to the Taniyama-Shimura conjecture. However, since the Taniyama-Shimura conjecture is believed to be true, this leads to a contradiction. Therefore, by the principle of contradiction, Fermat's Last Theorem must be true.
The implications of Fermat's Last Theorem in number theory are significant. FLT is a fundamental result in the study of integers, and its proof has led to a better understanding of various mathematical concepts. The proof of FLT has also contributed to the development of other areas of mathematics, such as algebraic geometry, representation theory, and number theory itself.
Moreover, the theorem has helped to strengthen the foundations of number theory by providing a resolution to a long-standing open problem. It has also encouraged mathematicians to explore new directions in research, as the proof of FLT has opened up new avenues for investigation in related fields.
## 🏆 Evaluations
### ARC
| Task |Version| Metric | Value | |Stderr|
|-------------|------:|--------------------|-------------|---|------|
|arc_challenge| 1|acc,none | 0.68| | |
| | |acc_stderr,none | 0.01| | |
| | |acc_norm,none | 0.72| | |
| | |acc_norm_stderr,none| 0.01| | |
| | |alias |arc_challenge| | |
Average: 71.76%
### HellaSwag
| Task |Version| Metric | Value | |Stderr|
|---------|------:|--------------------|---------|---|------|
|hellaswag| 1|acc,none | 0.71| | |
| | |acc_stderr,none | 0| | |
| | |acc_norm,none | 0.88| | |
| | |acc_norm_stderr,none| 0| | |
| | |alias |hellaswag| | |
Average: 88.01%
### 📚 Citations
```bibtex
@misc{kim2023solar,
title={SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling},
author={Dahyun Kim and Chanjun Park and Sanghoon Kim and Wonsung Lee and Wonho Song and Yunsu Kim and Hyeonwoo Kim and Yungi Kim and Hyeonju Lee and Jihoo Kim and Changbae Ahn and Seonghoon Yang and Sukyung Lee and Hyunbyung Park and Gyoungjin Gim and Mikyoung Cha and Hwalsuk Lee and Sunghun Kim},
year={2023},
eprint={2312.15166},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_macadeliccc__SOLAR-math-2x10.7b-v0.2)
| Metric |Value|
|---------------------------------|----:|
|Avg. |74.25|
|AI2 Reasoning Challenge (25-Shot)|70.90|
|HellaSwag (10-Shot) |88.29|
|MMLU (5-Shot) |66.25|
|TruthfulQA (0-shot) |71.68|
|Winogrande (5-shot) |83.50|
|GSM8k (5-shot) |64.90|
|
soniox/Soniox-7B-v1.0 | soniox | 2024-01-19T20:15:16Z | 1,339 | 2 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-17T09:16:21Z | ---
license: apache-2.0
---
# Model Card for Soniox-7B-v1.0
Soniox 7B is a powerful large language model. Supports English and code with 8K context.
Matches GPT-4 performance on some benchmarks.
Built on top of Mistral 7B, enhanced with additional pre-training and fine-tuning for strong problem-solving capabilities.
Apache 2.0 License.
For more details, please read our [blog post](https://soniox.com/news/soniox-7B).
## Usage in Transformers
The model is available in transformers and can be used as follows:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "soniox/Soniox-7B-v1.0"
model = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch.float16)
tokenizer = AutoTokenizer.from_pretrained(model_path)
device = "cuda"
model.to(device)
messages = [
{"role": "user", "content": "12 plus 21?"},
{"role": "assistant", "content": "33."},
{"role": "user", "content": "Five minus one?"},
]
tok_prompt = tokenizer.apply_chat_template(messages, return_tensors="pt")
model_inputs = tok_prompt.to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
```
## Inference deployment
Refer to our [documentation](https://docs.soniox.com) for inference with vLLM and other
deployment options.
|
wang7776/Mistral-7B-Instruct-v0.2-sparsity-30-v0.1 | wang7776 | 2024-02-05T18:11:08Z | 1,339 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"finetuned",
"conversational",
"arxiv:2306.11695",
"arxiv:2310.06825",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-17T16:51:42Z | ---
license: apache-2.0
pipeline_tag: text-generation
tags:
- finetuned
inference: false
---
# Overview
This model has been pruned to 30% sparsity using the [Wanda pruning method](https://arxiv.org/abs/2306.11695). This method requires no retraining or weight updates and still achieves competitive performance. A link to the base model can be found [here](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2).
# Model Card for Mistral-7B-Instruct-v0.2
The Mistral-7B-Instruct-v0.2 Large Language Model (LLM) is an improved instruct fine-tuned version of [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1).
For full details of this model please read our [paper](https://arxiv.org/abs/2310.06825) and [release blog post](https://mistral.ai/news/la-plateforme/).
## Instruction format
In order to leverage instruction fine-tuning, your prompt should be surrounded by `[INST]` and `[/INST]` tokens. The very first instruction should begin with a begin of sentence id. The next instructions should not. The assistant generation will be ended by the end-of-sentence token id.
E.g.
```
text = "<s>[INST] What is your favourite condiment? [/INST]"
"Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!</s> "
"[INST] Do you have mayonnaise recipes? [/INST]"
```
This format is available as a [chat template](https://huggingface.co/docs/transformers/main/chat_templating) via the `apply_chat_template()` method:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2")
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2")
messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt")
model_inputs = encodeds.to(device)
model.to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
```
## Model Architecture
This instruction model is based on Mistral-7B-v0.1, a transformer model with the following architecture choices:
- Grouped-Query Attention
- Sliding-Window Attention
- Byte-fallback BPE tokenizer
## Troubleshooting
- If you see the following error:
```
Traceback (most recent call last):
File "", line 1, in
File "/transformers/models/auto/auto_factory.py", line 482, in from_pretrained
config, kwargs = AutoConfig.from_pretrained(
File "/transformers/models/auto/configuration_auto.py", line 1022, in from_pretrained
config_class = CONFIG_MAPPING[config_dict["model_type"]]
File "/transformers/models/auto/configuration_auto.py", line 723, in getitem
raise KeyError(key)
KeyError: 'mistral'
```
Installing transformers from source should solve the issue
pip install git+https://github.com/huggingface/transformers
This should not be required after transformers-v4.33.4.
## Limitations
The Mistral 7B Instruct model is a quick demonstration that the base model can be easily fine-tuned to achieve compelling performance.
It does not have any moderation mechanisms. We're looking forward to engaging with the community on ways to
make the model finely respect guardrails, allowing for deployment in environments requiring moderated outputs.
## The Mistral AI Team
Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Louis Ternon, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Théophile Gervet, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed. |
ewqr2130/alignment-handbook-zephyr-7b_ppostep_100 | ewqr2130 | 2024-01-18T03:43:39Z | 1,339 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-18T02:42:56Z | ---
license: apache-2.0
---
alignment-handbook-zephyr-7b_ppo_step_100
2GPU, take the alignment-handbook-zephyr-7b-sft model, run the PPO on 100 steps.
=======================================================================
alignment-handbook-zephyr-7b_ppo_step_100
2GPU, take the alignment-handbook-zephyr-7b-sft model, run the PPO on 100 steps.
=======================================================================
alignment-handbook-zephyr-7b_ppo_step_100
2GPU, take the alignment-handbook-zephyr-7b-sft model, run the PPO on 100 steps.
======================================================================= |
LoSboccacc/orthogonal-2x7B-v2-base | LoSboccacc | 2024-03-11T13:07:27Z | 1,339 | 0 | transformers | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"conversational",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-18T21:28:51Z | ---
model-index:
- name: orthogonal-2x7B-v2-base
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 66.89
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=LoSboccacc/orthogonal-2x7B-v2-base
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 85.69
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=LoSboccacc/orthogonal-2x7B-v2-base
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 62.65
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=LoSboccacc/orthogonal-2x7B-v2-base
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 66.8
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=LoSboccacc/orthogonal-2x7B-v2-base
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 77.35
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=LoSboccacc/orthogonal-2x7B-v2-base
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 51.4
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=LoSboccacc/orthogonal-2x7B-v2-base
name: Open LLM Leaderboard
---
base_model: mistralai/Mistral-7B-Instruct-v0.2
gate_mode: hidden # one of "hidden", "cheap_embed", or "random"
dtype: bfloat16 # output dtype (float32, float16, or bfloat16)
experts:
- source_model: SanjiWatsuki/Kunoichi-DPO-v2-7B
positive_prompts:
- "roleplay"
- source_model: mistralai/Mistral-7B-Instruct-v0.2
positive_prompts:
- "chat"
---
chatml
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_LoSboccacc__orthogonal-2x7B-v2-base)
| Metric |Value|
|---------------------------------|----:|
|Avg. |68.47|
|AI2 Reasoning Challenge (25-Shot)|66.89|
|HellaSwag (10-Shot) |85.69|
|MMLU (5-Shot) |62.65|
|TruthfulQA (0-shot) |66.80|
|Winogrande (5-shot) |77.35|
|GSM8k (5-shot) |51.40|
|
ewqr2130/alignment-handbook-zephyr-7b_ppo_5e7step_51 | ewqr2130 | 2024-01-19T05:26:53Z | 1,339 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-19T04:06:44Z | ---
license: apache-2.0
---
ewqr2130/alignment-handbook-zephyr-7b_ppo_5e7step_51
runing the SFT with PPO for 51 steps.
runing the SFT with PPO for 51 steps.
runing the SFT with PPO for 51 steps.
runing the SFT with PPO for 51 steps.
runing the SFT with PPO for 51 steps.
|
leveldevai/MBA-7B | leveldevai | 2024-01-19T06:07:09Z | 1,339 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"Azazelle/Argetsu",
"leveldevai/MarcBeagle-7B",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-19T06:01:19Z | ---
license: apache-2.0
tags:
- merge
- mergekit
- lazymergekit
- Azazelle/Argetsu
- leveldevai/MarcBeagle-7B
---
# MBA-7B
MBA-7B is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [Azazelle/Argetsu](https://huggingface.co/Azazelle/Argetsu)
* [leveldevai/MarcBeagle-7B](https://huggingface.co/leveldevai/MarcBeagle-7B)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: Azazelle/Argetsu
layer_range: [0, 32]
- model: leveldevai/MarcBeagle-7B
layer_range: [0, 32]
merge_method: slerp
base_model: leveldevai/MarcBeagle-7B
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.45 # fallback for rest of tensors
dtype: float16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "leveldevai/MBA-7B"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
codemateai/CodeMate-v0.1 | codemateai | 2024-03-04T17:47:33Z | 1,339 | 3 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"CodeMate",
"Code",
"CodeLLaMa",
"en",
"license:llama2",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-21T00:13:10Z | ---
language:
- en
license: llama2
library_name: transformers
tags:
- CodeMate
- Code
- CodeLLaMa
pipeline_tag: text-generation
model-index:
- name: CodeMate-v0.1
results:
- task:
type: text-generation
dataset:
name: HumanEval
type: openai_humaneval
metrics:
- type: pass@1
value: 74.9%
name: pass@1
verified: false
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 55.55
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=codemateai/CodeMate-v0.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 78.03
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=codemateai/CodeMate-v0.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 55.31
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=codemateai/CodeMate-v0.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 48.64
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=codemateai/CodeMate-v0.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 72.61
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=codemateai/CodeMate-v0.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 40.18
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=codemateai/CodeMate-v0.1
name: Open LLM Leaderboard
---
# **CodeMate-v0.1**
CodeMate-v0.1 is an intelligent programming assistant developed by [CodeMate](https://codemate.ai).
This model aims to assist users in generating high-quality code solutions for programming problems.
Please note that this model is currently in version 0.1.
## Model Details
- **Training Data:** Exclusively fine-tuned on a proprietary dataset of 1.8 billion tokens of high-quality programming problems and solutions.
- The dataset was generated manually and is internal to CodeMate.
- **Training Techniques:** The model was fine-tuned using Flash Attention 2, trained over 15 hours on 40 A100-80GB GPUs.
- A sequence length of 8096 tokens was used during training.
- **Multilingual Support:** CodeMate-v0.1 is proficient in multiple programming languages, including Python, C/C++, TypeScript, Java, and more.
## How to Get Started with the Model
Make sure to install Transformers from the main git branch:
```bash
pip install git+https://github.com/huggingface/transformers.git
```
## How to Prompt the Model
This model accepts prompts in the Alpaca/Vicuna instruction format. For example:
```markdown
### System Prompt
You are an intelligent programming assistant.
### User Message
Implement a linked list in C++
### Assistant
...
```
## Load the Model:
To load the model, utilize the following Python script:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
# Initialize the model
model_path = "codemateai/CodeMate-v0.1"
model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_path)
# ... generate response ...
```
## Bias, Risks, and Limitations
This model has undergone very limited testing. CodeMate recommends additional safety testing before any real-world deployments.
For more information and updates, visit the [CodeMate website](https://codemate.ai).
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_codemateai__CodeMate-v0.1)
| Metric |Value|
|---------------------------------|----:|
|Avg. |58.39|
|AI2 Reasoning Challenge (25-Shot)|55.55|
|HellaSwag (10-Shot) |78.03|
|MMLU (5-Shot) |55.31|
|TruthfulQA (0-shot) |48.64|
|Winogrande (5-shot) |72.61|
|GSM8k (5-shot) |40.18|
|
ChrisWilson011016/5CS3Zb1u4wXcRfETkXEB2DtjzHE9YBEurLpdDe2VeNTUV4rk_vgg | ChrisWilson011016 | 2024-03-04T18:54:44Z | 1,339 | 0 | keras | [
"keras",
"region:us"
] | null | 2024-02-24T15:18:46Z | Entry not found |
realtreetune/rho-interpreter-1b-sft-MATH | realtreetune | 2024-05-11T00:34:13Z | 1,339 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-05-11T00:32:21Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mradermacher/BLINKpedia-chat-GGUF | mradermacher | 2024-06-07T21:50:01Z | 1,339 | 0 | transformers | [
"transformers",
"gguf",
"trl",
"sft",
"en",
"base_model:la-min/BLINKpedia-chat",
"endpoints_compatible",
"region:us"
] | null | 2024-06-07T21:45:56Z | ---
base_model: la-min/BLINKpedia-chat
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- trl
- sft
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/la-min/BLINKpedia-chat
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/BLINKpedia-chat-GGUF/resolve/main/BLINKpedia-chat.Q2_K.gguf) | Q2_K | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/BLINKpedia-chat-GGUF/resolve/main/BLINKpedia-chat.IQ3_XS.gguf) | IQ3_XS | 0.6 | |
| [GGUF](https://huggingface.co/mradermacher/BLINKpedia-chat-GGUF/resolve/main/BLINKpedia-chat.Q3_K_S.gguf) | Q3_K_S | 0.6 | |
| [GGUF](https://huggingface.co/mradermacher/BLINKpedia-chat-GGUF/resolve/main/BLINKpedia-chat.IQ3_S.gguf) | IQ3_S | 0.6 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/BLINKpedia-chat-GGUF/resolve/main/BLINKpedia-chat.IQ3_M.gguf) | IQ3_M | 0.6 | |
| [GGUF](https://huggingface.co/mradermacher/BLINKpedia-chat-GGUF/resolve/main/BLINKpedia-chat.Q3_K_M.gguf) | Q3_K_M | 0.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/BLINKpedia-chat-GGUF/resolve/main/BLINKpedia-chat.Q3_K_L.gguf) | Q3_K_L | 0.7 | |
| [GGUF](https://huggingface.co/mradermacher/BLINKpedia-chat-GGUF/resolve/main/BLINKpedia-chat.IQ4_XS.gguf) | IQ4_XS | 0.7 | |
| [GGUF](https://huggingface.co/mradermacher/BLINKpedia-chat-GGUF/resolve/main/BLINKpedia-chat.Q4_K_S.gguf) | Q4_K_S | 0.7 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/BLINKpedia-chat-GGUF/resolve/main/BLINKpedia-chat.Q4_K_M.gguf) | Q4_K_M | 0.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/BLINKpedia-chat-GGUF/resolve/main/BLINKpedia-chat.Q5_K_S.gguf) | Q5_K_S | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/BLINKpedia-chat-GGUF/resolve/main/BLINKpedia-chat.Q5_K_M.gguf) | Q5_K_M | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/BLINKpedia-chat-GGUF/resolve/main/BLINKpedia-chat.Q6_K.gguf) | Q6_K | 1.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/BLINKpedia-chat-GGUF/resolve/main/BLINKpedia-chat.Q8_0.gguf) | Q8_0 | 1.3 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/BLINKpedia-chat-GGUF/resolve/main/BLINKpedia-chat.f16.gguf) | f16 | 2.3 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
castorini/monobert-large-msmarco | castorini | 2020-05-29T03:41:44Z | 1,338 | 2 | transformers | [
"transformers",
"pytorch",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z | Entry not found |
optimum/roberta-base-squad2 | optimum | 2022-03-24T16:12:36Z | 1,338 | 1 | transformers | [
"transformers",
"onnx",
"question-answering",
"en",
"dataset:squad_v2",
"license:cc-by-4.0",
"endpoints_compatible",
"region:us"
] | question-answering | 2022-03-24T16:11:57Z | ---
language: en
datasets:
- squad_v2
license: cc-by-4.0
---
# ONNX convert roberta-base for QA
## Conversion of [deepset/roberta-base-squad2](https://huggingface.co/deepset/roberta-base-squad2)
NOTE: This is version 2 of the model. See [this github issue](https://github.com/deepset-ai/FARM/issues/552) from the FARM repository for an explanation of why we updated. If you'd like to use version 1, specify `revision="v1.0"` when loading the model in Transformers 3.5. For exmaple:
```
model_name = "deepset/roberta-base-squad2"
pipeline(model=model_name, tokenizer=model_name, revision="v1.0", task="question-answering")
```
## Overview
**Language model:** roberta-base
**Language:** English
**Downstream-task:** Extractive QA
**Training data:** SQuAD 2.0
**Eval data:** SQuAD 2.0
**Code:** See [example](https://github.com/deepset-ai/FARM/blob/master/examples/question_answering.py) in [FARM](https://github.com/deepset-ai/FARM/blob/master/examples/question_answering.py)
**Infrastructure**: 4x Tesla v100
## Hyperparameters
```
batch_size = 96
n_epochs = 2
base_LM_model = "roberta-base"
max_seq_len = 386
learning_rate = 3e-5
lr_schedule = LinearWarmup
warmup_proportion = 0.2
doc_stride=128
max_query_length=64
```
## Using a distilled model instead
Please note that we have also released a distilled version of this model called [deepset/tinyroberta-squad2](https://huggingface.co/deepset/tinyroberta-squad2). The distilled model has a comparable prediction quality and runs at twice the speed of the base model.
## Performance
Evaluated on the SQuAD 2.0 dev set with the [official eval script](https://worksheets.codalab.org/rest/bundles/0x6b567e1cf2e041ec80d7098f031c5c9e/contents/blob/).
```
"exact": 79.87029394424324,
"f1": 82.91251169582613,
"total": 11873,
"HasAns_exact": 77.93522267206478,
"HasAns_f1": 84.02838248389763,
"HasAns_total": 5928,
"NoAns_exact": 81.79983179142137,
"NoAns_f1": 81.79983179142137,
"NoAns_total": 5945
```
## Usage
### In Transformers
```python
from transformers import AutoModelForQuestionAnswering, AutoTokenizer, pipeline
model_name = "deepset/roberta-base-squad2"
# a) Get predictions
nlp = pipeline('question-answering', model=model_name, tokenizer=model_name)
QA_input = {
'question': 'Why is model conversion important?',
'context': 'The option to convert models between FARM and transformers gives freedom to the user and let people easily switch between frameworks.'
}
res = nlp(QA_input)
# b) Load model & tokenizer
model = AutoModelForQuestionAnswering.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
```
### In FARM
```python
from farm.modeling.adaptive_model import AdaptiveModel
from farm.modeling.tokenization import Tokenizer
from farm.infer import Inferencer
model_name = "deepset/roberta-base-squad2"
# a) Get predictions
nlp = Inferencer.load(model_name, task_type="question_answering")
QA_input = [{"questions": ["Why is model conversion important?"],
"text": "The option to convert models between FARM and transformers gives freedom to the user and let people easily switch between frameworks."}]
res = nlp.inference_from_dicts(dicts=QA_input, rest_api_schema=True)
# b) Load model & tokenizer
model = AdaptiveModel.convert_from_transformers(model_name, device="cpu", task_type="question_answering")
tokenizer = Tokenizer.load(model_name)
```
### In haystack
For doing QA at scale (i.e. many docs instead of single paragraph), you can load the model also in [haystack](https://github.com/deepset-ai/haystack/):
```python
reader = FARMReader(model_name_or_path="deepset/roberta-base-squad2")
# or
reader = TransformersReader(model_name_or_path="deepset/roberta-base-squad2",tokenizer="deepset/roberta-base-squad2")
```
## Authors
Branden Chan: `branden.chan [at] deepset.ai`
Timo Möller: `timo.moeller [at] deepset.ai`
Malte Pietsch: `malte.pietsch [at] deepset.ai`
Tanay Soni: `tanay.soni [at] deepset.ai`
## About us

We bring NLP to the industry via open source!
Our focus: Industry specific language models & large scale QA systems.
Some of our work:
- [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert)
- [GermanQuAD and GermanDPR datasets and models (aka "gelectra-base-germanquad", "gbert-base-germandpr")](https://deepset.ai/germanquad)
- [FARM](https://github.com/deepset-ai/FARM)
- [Haystack](https://github.com/deepset-ai/haystack/)
Get in touch:
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Slack](https://haystack.deepset.ai/community/join) | [GitHub Discussions](https://github.com/deepset-ai/haystack/discussions) | [Website](https://deepset.ai)
By the way: [we're hiring!](http://www.deepset.ai/jobs) |
julian-schelb/roberta-ner-multilingual | julian-schelb | 2023-06-30T16:08:05Z | 1,338 | 5 | transformers | [
"transformers",
"pytorch",
"safetensors",
"xlm-roberta",
"token-classification",
"roberta",
"ner",
"nlp",
"en",
"de",
"fr",
"zh",
"it",
"es",
"hi",
"bn",
"ar",
"ru",
"uk",
"pt",
"ur",
"id",
"ja",
"ne",
"nl",
"tr",
"ca",
"bg",
"yue",
"dataset:wikiann",
"arxiv:1911.02116",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2022-09-06T19:53:00Z | ---
language:
- en
- de
- fr
- zh
- it
- es
- hi
- bn
- ar
- ru
- uk
- pt
- ur
- id
- ja
- ne
- nl
- tr
- ca
- bg
- yue
widget:
- text: >-
In December 1903 in France the Royal Swedish Academy of Sciences awarded
Pierre Curie, Marie Curie, and Henri Becquerel the Nobel Prize in Physics.
- text: >-
Für Richard Phillips Feynman war es immer wichtig in New York, die
unanschaulichen Gesetzmäßigkeiten der Quantenphysik Laien und Studenten
nahezubringen und verständlich zu machen.
- text: >-
Terence David John Pratchett est né le 28 avril 1948 à Beaconsfield dans le
Buckinghamshire, en Angleterre.
- text: >-
北京市,通称北京(汉语拼音:Běijīng;邮政式拼音:Peking),简称“京”,是中华人民共和国的首都及直辖市,是该国的政治、文化、科技、教育、军事和国际交往中心,是一座全球城市,是世界人口第三多的城市和人口最多的首都,具有重要的国际影响力,同時也是目前世界唯一的“双奥之城”,即唯一既主办过夏季
tags:
- roberta
- ner
- nlp
license: mit
datasets:
- wikiann
metrics:
- f1
- precision
- accuracy
- recall
---
# RoBERTa for Multilingual Named Entity Recognition
## Model Description
This model detects entities by classifying every token according to the IOB format:
```python
['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC']
```
You can find the code in [this](https://github.com/julianschelb/roberta-ner-multilingual) GitHub repository.
## Training Data
This model was fine-tuned on a portion of the [wikiann](https://huggingface.co/datasets/wikiann) dataset corresponding to the following languages:
```python
["en","de", "fr",
"zh", "it", "es",
"hi", "bn", "ar",
"ru", "uk", "pt",
"ur", "id", "ja",
"ne", "nl", "tr",
"ca", "bg", "zh-yue"]
```
The model was fine-tuned on 375.100 sentences in the training set, with a validation set of 173.100 examples. Performance metrics reported are based on additional 173.100 examples. The complete WikiANN dataset includes training examples for 282 languages and was constructed from Wikipedia. Training examples are extracted in an automated manner, exploiting entities mentioned in Wikipedia articles, often are formatted as hyperlinks to the source article. Provided NER tags are in the IOB2 format. Named entities are classified as location (LOC), person (PER), or organization (ORG).
## Evaluation Results
This model achieves the following results (meassured using the test split of the [wikiann](https://huggingface.co/datasets/wikiann) dataset):
```python
{'LOC': {'f1': 0.8994491397524903,
'number': 184430,
'precision': 0.8941572985543279,
'recall': 0.9048039906739684},
'ORG': {'f1': 0.829114679375883,
'number': 129760,
'precision': 0.8283525257886599,
'recall': 0.8298782367447596},
'PER': {'f1': 0.9115096398413828,
'number': 130471,
'precision': 0.9043545174723882,
'recall': 0.9187788857293958},
'overall_accuracy': 0.9398182274831388,
'overall_f1': 0.8825581369330908,
'overall_precision': 0.8781215422873389,
'overall_recall': 0.8870397898623895}
```
## Usage
You can load this model by using the AutoTokenize and AutoModelForTokenClassification classes:
```python
from transformers import AutoTokenizer, AutoModelForTokenClassification
tokenizer = AutoTokenizer.from_pretrained("julian-schelb/roberta-ner-multilingual/", add_prefix_space=True)
model = AutoModelForTokenClassification.from_pretrained("julian-schelb/roberta-ner-multilingual/")
text = "In December 1903 in France the Royal Swedish Academy of Sciences awarded Pierre Curie, Marie Curie, and Henri Becquerel the Nobel Prize in Physics."
inputs = tokenizer(
text,
add_special_tokens=False,
return_tensors="pt"
)
with torch.no_grad():
logits = model(**inputs).logits
predicted_token_class_ids = logits.argmax(-1)
# Note that tokens are classified rather then input words which means that
# there might be more predicted token classes than words.
# Multiple token classes might account for the same word
predicted_tokens_classes = [model.config.id2label[t.item()] for t in predicted_token_class_ids[0]]
predicted_tokens_classes
```
## About RoBERTa
This model is a fine-tuned version of [XLM-RoBERTa](https://huggingface.co/xlm-roberta-large). The original model was pre-trained on 2.5TB of filtered CommonCrawl data containing 100 languages. It was introduced in the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Conneau et al. and first released in [this repository](https://github.com/pytorch/fairseq/tree/master/examples/xlmr).
RoBERTa is a transformers model pretrained on a large corpus in a self-supervised fashion. This means it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of publicly available data) with an automatic process to generate inputs and labels from those texts.
More precisely, it was pretrained with the Masked language modeling (MLM) objective. Taking a sentence, the model randomly masks 15% of the words in the input then run the entire masked sentence through the model and has to predict the masked words. This is different from traditional recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the sentence.
This way, the model learns an inner representation of 100 languages that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard classifier using the features produced by the XLM-RoBERTa model as inputs.
#### Limitations and Bias
This model is limited by its training dataset of entity-annotated news articles from a specific span of time. This may not generalize well for all use cases in different domains.
## Related Papers
* Pan, X., Zhang, B., May, J., Nothman, J., Knight, K., & Ji, H. (2017). Cross-lingual Name Tagging and Linking for 282 Languages. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 1946–1958). Association for Computational Linguistics.
* Rahimi, A., Li, Y., & Cohn, T. (2019). Massively Multilingual Transfer for NER. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (pp. 151–164). Association for Computational Linguistics.
* Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., & Stoyanov, V.. (2019). RoBERTa: A Robustly Optimized BERT Pretraining Approach.
## Citation
This model has been fine-tuned for the research paper indicated below:
```bibtex
@inproceedings{schelbECCEEntitycentricCorpus2022,
title = {{ECCE}: {Entity}-centric {Corpus} {Exploration} {Using} {Contextual} {Implicit} {Networks}},
url = {https://dl.acm.org/doi/10.1145/3487553.3524237},
booktitle = {Companion {Proceedings} of the {Web} {Conference} 2022},
author = {Schelb, Julian and Ehrmann, Maud and Romanello, Matteo and Spitz, Andreas},
year = {2022},
}
```
|
google/umt5-base | google | 2023-07-03T05:37:52Z | 1,338 | 10 | transformers | [
"transformers",
"pytorch",
"text2text-generation",
"multilingual",
"af",
"am",
"ar",
"az",
"be",
"bg",
"bn",
"ca",
"ceb",
"co",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fil",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha",
"haw",
"hi",
"hmn",
"ht",
"hu",
"hy",
"ig",
"is",
"it",
"iw",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"ku",
"ky",
"la",
"lb",
"lo",
"lt",
"lv",
"mg",
"mi",
"mk",
"ml",
"mn",
"mr",
"ms",
"mt",
"my",
"ne",
"nl",
"no",
"ny",
"pa",
"pl",
"ps",
"pt",
"ro",
"ru",
"sd",
"si",
"sk",
"sl",
"sm",
"sn",
"so",
"sq",
"sr",
"st",
"su",
"sv",
"sw",
"ta",
"te",
"tg",
"th",
"tr",
"uk",
"und",
"ur",
"uz",
"vi",
"xh",
"yi",
"yo",
"zh",
"zu",
"dataset:mc4",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2023-07-02T01:49:59Z | ---
language:
- multilingual
- af
- am
- ar
- az
- be
- bg
- bn
- ca
- ceb
- co
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fil
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- haw
- hi
- hmn
- ht
- hu
- hy
- ig
- is
- it
- iw
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lb
- lo
- lt
- lv
- mg
- mi
- mk
- ml
- mn
- mr
- ms
- mt
- my
- ne
- nl
- no
- ny
- pa
- pl
- ps
- pt
- ro
- ru
- sd
- si
- sk
- sl
- sm
- sn
- so
- sq
- sr
- st
- su
- sv
- sw
- ta
- te
- tg
- th
- tr
- uk
- und
- ur
- uz
- vi
- xh
- yi
- yo
- zh
- zu
datasets:
- mc4
license: apache-2.0
---
[Google's UMT5](https://github.com/google-research/multilingual-t5)
UMT5 is pretrained on the an updated version of [mC4](https://www.tensorflow.org/datasets/catalog/c4#c4multilingual) corpus, covering 107 languages:
Afrikaans, Albanian, Amharic, Arabic, Armenian, Azerbaijani, Basque, Belarusian, Bengali, Bulgarian, Burmese, Catalan, Cebuano, Chichewa, Chinese, Corsican, Czech, Danish, Dutch, English, Esperanto, Estonian, Filipino, Finnish, French, Galician, Georgian, German, Greek, Gujarati, Haitian Creole, Hausa, Hawaiian, Hebrew, Hindi, Hmong, Hungarian, Icelandic, Igbo, Indonesian, Irish, Italian, Japanese, Javanese, Kannada, Kazakh, Khmer, Korean, Kurdish, Kyrgyz, Lao, Latin, Latvian, Lithuanian, Luxembourgish, Macedonian, Malagasy, Malay, Malayalam, Maltese, Maori, Marathi, Mongolian, Nepali, Norwegian, Pashto, Persian, Polish, Portuguese, Punjabi, Romanian, Russian, Samoan, Scottish Gaelic, Serbian, Shona, Sindhi, Sinhala, Slovak, Slovenian, Somali, Sotho, Spanish, Sundanese, Swahili, Swedish, Tajik, Tamil, Telugu, Thai, Turkish, Ukrainian, Urdu, Uzbek, Vietnamese, Welsh, West Frisian, Xhosa, Yiddish, Yoruba, Zulu.
**Note**: UMT5 was only pre-trained on mC4 excluding any supervised training. Therefore, this model has to be fine-tuned before it is useable on a downstream task.
Pretraining Dataset: [mC4](https://www.tensorflow.org/datasets/catalog/c4#c4multilingual)
Other Community Checkpoints: [here](https://huggingface.co/models?search=umt5)
Paper: [UniMax, Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi)
Authors: *by Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant*
## Abstract
*Pretrained multilingual large language models have typically used heuristic temperature-based sampling to balance between different languages. However previous work has not systematically evaluated the efficacy of different pretraining language distributions across model scales. In this paper, we propose a new sampling method, UniMax, that delivers more uniform coverage of head languages while mitigating overfitting on tail languages by explicitly capping the number of repeats over each language's corpus. We perform an extensive series of ablations testing a range of sampling strategies on a suite of multilingual benchmarks, while varying model scale. We find that UniMax outperforms standard temperature-based sampling, and the benefits persist as scale increases. As part of our contribution, we release: (i) an improved and refreshed mC4 multilingual corpus consisting of 29 trillion characters across 107 languages, and (ii) a suite of pretrained umT5 model checkpoints trained with UniMax sampling.* |
hwanhe/Mistral_test03 | hwanhe | 2023-11-01T23:53:20Z | 1,338 | 0 | transformers | [
"transformers",
"pytorch",
"mistral",
"text-generation",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-01T23:48:03Z | ---
license: apache-2.0
---
|
42MARU/GenAI-llama2-ko-en-instruct-v4-13B | 42MARU | 2023-11-09T08:38:09Z | 1,338 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-09T08:30:12Z | Entry not found |
genne/otter3.1.3_7b | genne | 2023-11-10T02:05:58Z | 1,338 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-10T01:58:12Z | Entry not found |
jingyeom/penguin3.1.6n_7b | jingyeom | 2023-11-16T06:28:56Z | 1,338 | 0 | transformers | [
"transformers",
"pytorch",
"mistral",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-16T00:24:37Z | Entry not found |
heegyu/llama-2-koen-13b-OKI-v20231124-1e-5 | heegyu | 2023-11-28T06:31:26Z | 1,338 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-25T04:48:12Z | Entry not found |
Cartinoe5930/original-KoRAE-13b-3ep | Cartinoe5930 | 2023-12-01T09:02:19Z | 1,338 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"ko",
"dataset:Cartinoe5930/KoRAE_original",
"arxiv:2307.08701",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-29T02:55:35Z | ---
license: cc-by-nc-sa-4.0
datasets:
- Cartinoe5930/KoRAE_original
language:
- ko
library_name: transformers
---
## KoRAE
<p align="center"><img src="https://cdn-uploads.huggingface.co/production/uploads/63e087b6a98d931aa90c1b9c/XQ-pNzRDRccd7UFgYDOrx.png", width='300', height='300'></p>
We introduce **KoRAE** which finetuned with filtered high-quality Korean dataset.
The **KoRAE** is output of combination of high-quality data which filtered by special data filtering method and Korean Llama-2 that Korean vocabularis were added.
We utilized special data filtering methods which introduced in [AlpaGasus](https://arxiv.org/abs/2307.08701) to filter high-quality data from mixture of several Korean datasets(OpenOrca-KO, KOpen-Platypus, KoCoT_2000, databricks-dolly-15k-ko).
We finetuned [Korean Llama-2](https://huggingface.co/beomi/llama-2-koen-13b) that introduced by [@beomi](https://huggingface.co/beomi) on the filtered dataset.
The Flash-Attention2 and LoRA were utilized for efficient finetuning.
The finding of KoRAE is as follows:
1. The finetuning in some epochs showed that high-quality filtered data has positive effects on model's performance. However, finetuning in a few epochs, the quantity of data is more matter than quality. It seems to be due to the lack of performance of the Korean base model. Therefore, the research to improve the Korean base model must continue.
2. The model trained with DPO showed best performance among KoRAE variants. This shows that DPO is clearly effective in the Korean LLM.
3. The model finetuned with filtered high-quality KoRAE showed better performance than without. Therefore, for better LLM, we should try to finetune the LLM with high-quality data.
## Model Details
- **Developed by:** [Cartinoe5930](https://huggingface.co/Cartinoe5930)
- **Base model:** [beomi/llama-2-koen-13b](https://huggingface.co/beomi/llama-2-koen-13b)
- **Repository:** [gauss5930/KoRAE](https://github.com/gauss5930/KoRAE)
For more details, please check the GitHub Repository!
## Training Details
- **Hardward:** We utilized A100 80G for finetuning
- **Training factors:** The [Transformers Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) and [Huggingface PEFT](https://huggingface.co/docs/peft/index) were utilized for finetuning.
- **Training Details:** Supervised finetuning 3 epochs on [original KoRAE](https://huggingface.co/datasets/Cartinoe5930/KoRAE_original) dataset
For more details, please check the GitHub Repository!
## Training Dataset
The KoRAE was finetuned with KoRAE dataset filtered high-quality dataset.
This dataset is a combination of the publicly available Koraen dataset and a filtering method was applied to the result of the combination dataset.
For more information, please refer to the [dataset card](https://huggingface.co/datasets/Cartinoe5930/KoRAE_filtered_12k) of KoRAE.
## Open Ko-LLM Leaderboard
|Model|Average|Ko-ARC|Ko-HellaSwag|Ko-MMLU|Ko-TruthfulQA|Ko-CommonGen V2|
|---|---|---|---|---|---|---|
|original-KoRAE-13b-3ep|48.16|44.37|56.97|43.27|41.75|54.43|
## Prompt Template
```
### System:
{system_prompt}
### User:
{instruction + input}
### Assistant:
{output}
```
## Usage example
```python
# Use a pipeline as a high-level helper
from transformers import pipeline
import torch
pipe = pipeline("text-generation", model="Cartinoe5930/KoRAE-13b", torch_dtype=torch.bfloat16, device_map="auto")
messages = [
{
"role": "system",
"content": "당신은 유용한 인공지능 비서입니다. 사용자가 몇 가지 지시가 포함된 작업을 제공합니다. 요청을 적절히 완료하는 응답을 작성하세요.",
},
{"role": "user", "content": "스트레스를 해소하는 5가지 방법에 대해서 설명해줘."}
]
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
## Citation
- [KO-Platypus](https://github.com/Marker-Inc-Korea/KO-Platypus)
- [Korean-OpenOrca](https://github.com/Marker-Inc-Korea/Korean-OpenOrca)
```
@inproceedings{lee2023kullm,
title={KULLM: Learning to Construct Korean Instruction-following Large Language Models},
author={Lee, SeungJun and Lee, Taemin and Lee, Jeongwoo and Jang, Yoona and Lim, Heuiseok},
booktitle={Annual Conference on Human and Language Technology},
pages={196--202},
year={2023},
organization={Human and Language Technology}
}
```
```
@misc{chen2023alpagasus,
title={AlpaGasus: Training A Better Alpaca with Fewer Data},
author={Lichang Chen and Shiyang Li and Jun Yan and Hai Wang and Kalpa Gunaratna and Vikas Yadav and Zheng Tang and Vijay Srinivasan and Tianyi Zhou and Heng Huang and Hongxia Jin},
year={2023},
eprint={2307.08701},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```
@misc {l._junbum_2023,
author = { {L. Junbum, Taekyoon Choi} },
title = { llama-2-koen-13b },
year = 2023,
url = { https://huggingface.co/beomi/llama-2-koen-13b },
doi = { 10.57967/hf/1280 },
publisher = { Hugging Face }
}
``` |
PracticeLLM/Custom-KoLLM-13B-v6 | PracticeLLM | 2023-11-30T04:13:19Z | 1,338 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"ko",
"dataset:kyujinpy/ko-gu-platyorca-mergeset",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-29T05:31:33Z | ---
language:
- ko
datasets:
- kyujinpy/ko-gu-platyorca-mergeset
library_name: transformers
pipeline_tag: text-generation
license: cc-by-nc-sa-4.0
---
# **⭐My custom LLM 13B⭐**
## Model Details
**Model Developers**
- Kyujin Han (kyujinpy)
**Model Architecture**
- My custom LLM 13B is an auto-regressive language model based on the LLaMA2 transformer architecture.
**Base Model**
- [beomi/llama-2-koen-13b](https://huggingface.co/beomi/llama-2-koen-13b)
**Training Dataset**
- [kyujinpy/ko-gu-platyorca-mergeset](https://huggingface.co/datasets/kyujinpy/ko-gu-platyorca-mergeset).
---
# Model comparisons
> Ko-LLM leaderboard(11/27; [link](https://huggingface.co/spaces/upstage/open-ko-llm-leaderboard))
| Model | Average | Ko-ARC | Ko-HellaSwag | Ko-MMLU | Ko-TruthfulQA | Ko-CommonGen V2 |
| --- | --- | --- | --- | --- | --- | --- |
| ⭐My custom LLM 13B-v1⭐ | **50.19** | **45.99** | 56.93 | 41.78 | 41.66 | **64.58** |
| ⭐My custom LLM 13B-v4⭐ | 49.89 | 45.05 | **57.06** | 41.83 | **42.93** | 62.57 |
| **⭐My custom LLM 13B-v6⭐** | 47.78 | 45.22 | 56.60 | 42.36 | 42.31 | 52.42 |
---
# Model comparisons2
> AI-Harness evaluation; [link](https://github.com/Beomi/ko-lm-evaluation-harness)
| Model | Copa | Copa | HellaSwag | HellaSwag | BoolQ | BoolQ | Sentineg | Sentineg |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| | 0-shot | 5-shot | 0-shot | 5-shot | 0-shot | 5-shot | 0-shot | 5-shot |
| ⭐My custom LLM 13B-v1⭐ | 0.7987 | 0.8269 | 0.4994 | 0.5660 | 0.3343 | 0.5060 | 0.6984 | 0.9723 |
| ⭐My custom LLM 13B-v4⭐** | **0.7988** | 0.8279 | **0.4995** | 0.4953 | 0.3343 | 0.3558 | **0.7825** | 0.9698 |
| **⭐My custom LLM 13B-v6⭐** | 0.7938 | 0.8259 | 0.4905 | 0.5620 | **0.8656** | 0.8457 | 0.3720 | 0.9698 |
| [beomi/llama-2-koen-13b](https://huggingface.co/beomi/llama-2-koen-13b) | 0.7768 | 0.8128 | 0.4999 | 0.5127 | 0.3988 | 0.7038 | 0.5870 | 0.9748 |
---
# Implementation Code
```python
### KO-Platypus
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
repo = "PracticeLLM/Custom-KoLLM-13B-v6"
OpenOrca = AutoModelForCausalLM.from_pretrained(
repo,
return_dict=True,
torch_dtype=torch.float16,
device_map='auto'
)
OpenOrca_tokenizer = AutoTokenizer.from_pretrained(repo)
``` |
Puluming/AISquare-Instruct-llama2-koen-13b-v0.9.15 | Puluming | 2023-12-04T03:23:23Z | 1,338 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-04T03:13:20Z | ---
license: cc-by-nc-sa-4.0
---
|
jan-ai/Pandora-10.7B-v1 | jan-ai | 2023-12-14T08:44:13Z | 1,338 | 1 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-14T08:37:37Z | ---
license: apache-2.0
language:
- en
---
# WARNING
This is a model file only for evaluation. Please use the model here:
- Model: [Pandora-v1-10.7B](https://huggingface.co/janhq/Pandora-v1-10.7B)
- GGUF: [Pandora-v1-10.7B-GGUF](https://huggingface.co/janhq/Pandora-v1-10.7B-GGUF)
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://github.com/janhq/jan/assets/89722390/35daac7d-b895-487c-a6ac-6663daaad78e" alt="Jan banner" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<p align="center">
<a href="https://jan.ai/">Jan</a
>
- <a href="https://discord.gg/AsJ8krTT3N">Discord</a
>
</p>
<!-- header end -->
# Model Description
This model uses the `passthrough` merge method from the best 7B models on the [OpenLLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard):
1. [viethq188/LeoScorpius-7B-Chat-DPO](https://huggingface.co/viethq188/LeoScorpius-7B-Chat-DPO)
2. [GreenNode/GreenNodeLM-7B-v1olet](https://huggingface.co/GreenNode/GreenNodeLM-7B-v1olet)
The yaml config file for this model is here:
```yaml
slices:
- sources:
- model: "viethq188/LeoScorpius-7B-Chat-DPO"
layer_range: [0, 24]
- sources:
- model: "GreenNode/GreenNodeLM-7B-v1olet"
layer_range: [8, 32]
merge_method: passthrough
dtype: bfloat16
```
# Prompt template
- **ChatML**
```
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
# Run this model
You can run this model using [Jan](https://jan.ai/) on Mac, Windows, or Linux.
**Jan is an open source, ChatGPT alternative that is:**
💻 **100% offline on your machine**: Your conversations remain confidential, and visible only to you.
🗂️ **An Open File Format**: Conversations and model settings stay on your computer and can be exported or deleted at any time.
🌐 **OpenAI Compatible**: Local server on port `
1337` with OpenAI compatible endpoints
🌍 **Open Source & Free**: We build in public; check out our [Github](https://github.com/janhq)
- Please use the [Pandora-v1-10.7B-GGUF](https://huggingface.co/janhq/Pandora-v1-10.7B-GGUF) when using on Jan.

# About Jan
Jan believes in the need for an open-source AI ecosystem and is building the infra and tooling to allow open-source AIs to compete on a level playing field with proprietary ones.
Jan's long-term vision is to build a cognitive framework for future robots, who are practical, useful assistants for humans and businesses in everyday life.
# Jan Model Merger
This is a test project for merging models.
# Open LLM Leaderboard Evaluation Results
Detailed results can be found here.
| Metric | Value |
|-----------------------|---------------------------|
| Avg. | ?|
| ARC (25-shot) | ? |
| HellaSwag (10-shot) | ? |
| MMLU (5-shot) | ?|
| TruthfulQA (0-shot) | ? |
| Winogrande (5-shot) | ? |
| GSM8K (5-shot) | ? |
# Acknowlegement
- [mergekit](https://github.com/cg123/mergekit)
- [DARE](https://github.com/yule-BUAA/MergeLM/blob/main/README.md)
- [SLERP](https://github.com/Digitous/LLM-SLERP-Merge)
- [lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness) |
inswave/AISquare-Instruct-llama2-koen-13b-v0.9.23 | inswave | 2023-12-18T06:17:01Z | 1,338 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-18T06:08:34Z | Entry not found |
Minirecord/psm_170k_llama_13b | Minirecord | 2023-12-18T09:03:45Z | 1,338 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-18T08:57:19Z | ---
license: apache-2.0
---
|
macadeliccc/laser-dolphin-mixtral-4x7b-dpo | macadeliccc | 2024-03-10T21:19:32Z | 1,338 | 9 | transformers | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-08T18:10:02Z | ---
license: apache-2.0
library_name: transformers
model-index:
- name: laser-dolphin-mixtral-4x7b-dpo
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 64.93
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/laser-dolphin-mixtral-4x7b-dpo
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 85.81
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/laser-dolphin-mixtral-4x7b-dpo
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 63.04
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/laser-dolphin-mixtral-4x7b-dpo
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 63.77
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/laser-dolphin-mixtral-4x7b-dpo
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 77.82
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/laser-dolphin-mixtral-4x7b-dpo
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 44.88
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/laser-dolphin-mixtral-4x7b-dpo
name: Open LLM Leaderboard
---
# Laser-Dolphin-Mixtral-4x7b-dpo

Credit to Fernando Fernandes and Eric Hartford for their project [laserRMT](https://github.com/cognitivecomputations/laserRMT)
This model is a medium-sized MoE implementation based on [cognitivecomputations/dolphin-2.6-mistral-7b-dpo-laser](https://huggingface.co/cognitivecomputations/dolphin-2.6-mistral-7b-dpo-laser)
The process is outlined in this [notebook](https://github.com/cognitivecomputations/laserRMT/blob/main/examples/laser-dolphin-mixtral-2x7b.ipynb)
## Code Example
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
def generate_response(prompt):
"""
Generate a response from the model based on the input prompt.
Args:
prompt (str): Prompt for the model.
Returns:
str: The generated response from the model.
"""
# Tokenize the input prompt
inputs = tokenizer(prompt, return_tensors="pt")
# Generate output tokens
outputs = model.generate(**inputs, max_new_tokens=256, eos_token_id=tokenizer.eos_token_id, pad_token_id=tokenizer.pad_token_id)
# Decode the generated tokens to a string
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return response
# Load the model and tokenizer
model_id = "macadeliccc/laser-dolphin-mixtral-4x7b-dpo"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, load_in_4bit=True)
prompt = "Write a quicksort algorithm in python"
# Generate and print responses for each language
print("Response:")
print(generate_response(prompt), "\n")
```
## Example output
can you write me a quicksort algorithm in python?
Sure, here's a quicksort algorithm implemented in Python:
```python
def quicksort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quicksort(left) + middle + quicksort(right)
```
This implementation uses the median of the array as the pivot.
It first checks if the array has one or fewer elements, in which case it is already sorted and can be returned as is.
Otherwise, it selects the pivot as the middle element of the array. Then, it partitions the array into three sub-arrays: elements less than the pivot, elements equal to the pivot, and elements greater than the pivot.
It recursively sorts the left and right sub-arrays and concatenates the results with the middle sub-array to obtain the final sorted array.
## Quantization
[4-bit AWQ](https://huggingface.co/macadeliccc/laser-dolphin-mixtral-4x7b-dpo-AWQ)
## Eval
**Model evaluated in 4bit**
----Benchmark Complete----
+ 2024-01-24 15:03:08
+ Time taken: 37.4 mins
+ Prompt Format: Mistral
+ Model: macadeliccc/laser-dolphin-mixtral-4x7b-dpo
+ Score (v2): 71.04
+ Parseable: 169.0
---------------
## Citations
Fernando Fernandes Neto and Eric Hartford. "Optimizing Large Language Models Using Layer-Selective Rank Reduction and Random Matrix Theory." 2024.
```bibtex
@article{sharma2023truth,
title={The Truth is in There: Improving Reasoning in Language Models with Layer-Selective Rank Reduction},
author={Sharma, Pratyusha and Ash, Jordan T and Misra, Dipendra},
journal={arXiv preprint arXiv:2312.13558},
year={2023} }
```
```bibtex
@article{gao2021framework,
title={A framework for few-shot language model evaluation},
author={Gao, Leo and Tow, Jonathan and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and McDonell, Kyle and Muennighoff, Niklas and others},
journal={Version v0. 0.1. Sept},
year={2021}
}
```
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_macadeliccc__laser-dolphin-mixtral-4x7b-dpo)
| Metric |Value|
|---------------------------------|----:|
|Avg. |66.71|
|AI2 Reasoning Challenge (25-Shot)|64.93|
|HellaSwag (10-Shot) |85.81|
|MMLU (5-Shot) |63.04|
|TruthfulQA (0-shot) |63.77|
|Winogrande (5-shot) |77.82|
|GSM8k (5-shot) |44.88|
|
shitshow123/mistral7b_sft_dpo | shitshow123 | 2024-01-11T05:30:25Z | 1,338 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-11T05:21:21Z | ---
license: apache-2.0
---
No model card
New: Create and edit this model card directly on the website!
No model card
New: Create and edit this model card directly on the website!
No model card
New: Create and edit this model card directly on the website!
No model card
New: Create and edit this model card directly on the website!
No model card
New: Create and edit this model card directly on the website!
No model card
New: Create and edit this model card directly on the website!
No model card
New: Create and edit this model card directly on the website!
No model card
New: Create and edit this model card directly on the website!
No model card
New: Create and edit this model card directly on the website!
|
FelixChao/WizardDolphin-7B | FelixChao | 2024-01-16T07:24:39Z | 1,338 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"cognitivecomputations/dolphin-2.6-mistral-7b-dpo-laser",
"WizardLM/WizardMath-7B-V1.1",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-12T09:36:34Z | ---
license: apache-2.0
tags:
- merge
- cognitivecomputations/dolphin-2.6-mistral-7b-dpo-laser
- WizardLM/WizardMath-7B-V1.1
---
# WizardDolphin-7B
WizardDolphin-7B is a merge of the following models:
* [cognitivecomputations/dolphin-2.6-mistral-7b-dpo-laser](https://huggingface.co/cognitivecomputations/dolphin-2.6-mistral-7b-dpo-laser)
* [WizardLM/WizardMath-7B-V1.1](https://huggingface.co/WizardLM/WizardMath-7B-V1.1)
## 🧩 Configuration
```yaml
models:
- model: mistralai/Mistral-7B-v0.1
- model: cognitivecomputations/dolphin-2.6-mistral-7b-dpo-laser
parameters:
density: 0.5
weight: 0.5
- model: WizardLM/WizardMath-7B-V1.1
parameters:
density: 0.5
weight: 0.3
merge_method: ties
base_model: mistralai/Mistral-7B-v0.1
parameters:
normalize: true
dtype: float16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "FelixChao/WizardDolphin-7B"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
ewqr2130/alignment-handbook-zephyr-7b_ppo_5e7step_102 | ewqr2130 | 2024-01-19T18:59:13Z | 1,338 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-19T18:44:57Z | ---
license: apache-2.0
---
ewqr2130/alignment-handbook-zephyr-7b_ppo_5e7step_102
ewqr2130/alignment-handbook-zephyr-7b_ppo_5e7step_102
ewqr2130/alignment-handbook-zephyr-7b_ppo_5e7step_102
ewqr2130/alignment-handbook-zephyr-7b_ppo_5e7step_102
ewqr2130/alignment-handbook-zephyr-7b_ppo_5e7step_102
ewqr2130/alignment-handbook-zephyr-7b_ppo_5e7step_102
ewqr2130/alignment-handbook-zephyr-7b_ppo_5e7step_102
ewqr2130/alignment-handbook-zephyr-7b_ppo_5e7step_102
ewqr2130/alignment-handbook-zephyr-7b_ppo_5e7step_102
ewqr2130/alignment-handbook-zephyr-7b_ppo_5e7step_102
ewqr2130/alignment-handbook-zephyr-7b_ppo_5e7step_102
ewqr2130/alignment-handbook-zephyr-7b_ppo_5e7step_102
ewqr2130/alignment-handbook-zephyr-7b_ppo_5e7step_102
ewqr2130/alignment-handbook-zephyr-7b_ppo_5e7step_102
ewqr2130/alignment-handbook-zephyr-7b_ppo_5e7step_102
ewqr2130/alignment-handbook-zephyr-7b_ppo_5e7step_102
ewqr2130/alignment-handbook-zephyr-7b_ppo_5e7step_102
ewqr2130/alignment-handbook-zephyr-7b_ppo_5e7step_102
ewqr2130/alignment-handbook-zephyr-7b_ppo_5e7step_102
ewqr2130/alignment-handbook-zephyr-7b_ppo_5e7step_102 |
Kquant03/BurningBruce-SOLAR-8x10.7B-bf16 | Kquant03 | 2024-01-22T06:35:51Z | 1,338 | 4 | transformers | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"merge",
"moe",
"conversational",
"en",
"arxiv:2101.03961",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-20T02:10:32Z | ---
license: apache-2.0
language:
- en
tags:
- merge
- moe
thumbnail: ""
---

# Theoretically unstoppable. (evals prove otherwise)
A Convex frankenMoE. Created via improving the original Seraphim script. The models that were implemented are as follows:
- [kyujinpy/Sakura-SOLAR-Instruct](https://huggingface.co/kyujinpy/Sakura-SOLAR-Instruct) - base
- [PracticeLLM/SOLAR-tail-10.7B-Merge-v1.0](https://huggingface.co/PracticeLLM/SOLAR-tail-10.7B-Merge-v1.0) - expert #1
- [NousResearch/Nous-Hermes-2-SOLAR-10.7B](https://huggingface.co/NousResearch/Nous-Hermes-2-SOLAR-10.7B) - expert #2
- [kyujinpy/Sakura-SOLAR-Instruct](https://huggingface.co/kyujinpy/Sakura-SOLAR-Instruct) - expert #3
- [NousResearch/Nous-Hermes-2-SOLAR-10.7B](https://huggingface.co/NousResearch/Nous-Hermes-2-SOLAR-10.7B) - expert #4
- [upstage/SOLAR-10.7B-Instruct-v1.0](https://huggingface.co/upstage/SOLAR-10.7B-Instruct-v1.0) - expert #5
- [kodonho/SolarM-SakuraSolar-SLERP](https://huggingface.co/kodonho/SolarM-SakuraSolar-SLERP) - expert #6
- [kyujinpy/Sakura-SOLAR-Instruct](https://huggingface.co/kyujinpy/Sakura-SOLAR-Instruct) - expert #7
- [kyujinpy/Sakura-SOLAR-Instruct](https://huggingface.co/kyujinpy/Sakura-SOLAR-Instruct) - expert #8
# "[What is a Mixture of Experts (MoE)?](https://huggingface.co/blog/moe)"
### (from the MistralAI papers...click the quoted question above to navigate to it directly.)
The scale of a model is one of the most important axes for better model quality. Given a fixed computing budget, training a larger model for fewer steps is better than training a smaller model for more steps.
Mixture of Experts enable models to be pretrained with far less compute, which means you can dramatically scale up the model or dataset size with the same compute budget as a dense model. In particular, a MoE model should achieve the same quality as its dense counterpart much faster during pretraining.
So, what exactly is a MoE? In the context of transformer models, a MoE consists of two main elements:
Sparse MoE layers are used instead of dense feed-forward network (FFN) layers. MoE layers have a certain number of “experts” (e.g. 32 in my "frankenMoE"), where each expert is a neural network. In practice, the experts are FFNs, but they can also be more complex networks or even a MoE itself, leading to hierarchical MoEs!
A gate network or router, that determines which tokens are sent to which expert. For example, in the image below, the token “More” is sent to the second expert, and the token "Parameters” is sent to the first network. As we’ll explore later, we can send a token to more than one expert. How to route a token to an expert is one of the big decisions when working with MoEs - the router is composed of learned parameters and is pretrained at the same time as the rest of the network.
At every layer, for every token, a router network chooses two of these groups (the “experts”) to process the token and combine their output additively.

Switch Layer
MoE layer from the [Switch Transformers paper](https://arxiv.org/abs/2101.03961)
So, to recap, in MoEs we replace every FFN layer of the transformer model with an MoE layer, which is composed of a gate network and a certain number of experts.
Although MoEs provide benefits like efficient pretraining and faster inference compared to dense models, they also come with challenges:
Training: MoEs enable significantly more compute-efficient pretraining, but they’ve historically struggled to generalize during fine-tuning, leading to overfitting.
Inference: Although a MoE might have many parameters, only some of them are used during inference. This leads to much faster inference compared to a dense model with the same number of parameters. However, all parameters need to be loaded in RAM, so memory requirements are high. For example, [given a MoE like Mixtral 8x7B](https://huggingface.co/blog/moe), we’ll need to have enough VRAM to hold a dense 47B parameter model. Why 47B parameters and not 8 x 7B = 56B? That’s because in MoE models, only the FFN layers are treated as individual experts, and the rest of the model parameters are shared. At the same time, assuming just two experts are being used per token, the inference speed (FLOPs) is like using a 12B model (as opposed to a 14B model), because it computes 2x7B matrix multiplications, but with some layers shared (more on this soon).
If all our tokens are sent to just a few popular experts, that will make training inefficient. In a normal MoE training, the gating network converges to mostly activate the same few experts. This self-reinforces as favored experts are trained quicker and hence selected more. To mitigate this, an auxiliary loss is added to encourage giving all experts equal importance. This loss ensures that all experts receive a roughly equal number of training examples. The following sections will also explore the concept of expert capacity, which introduces a threshold of how many tokens can be processed by an expert. In transformers, the auxiliary loss is exposed via the aux_loss parameter.
## "Wait...but you called this a frankenMoE?"
The difference between MoE and "frankenMoE" lies in the fact that the router layer in a model like the one on this repo is not trained simultaneously. |
LordNoah/Alpaca_refine_tuned_gpt2_large | LordNoah | 2024-01-22T14:34:12Z | 1,338 | 0 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"dataset:tatsu-lab/alpaca",
"arxiv:1910.09700",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-22T12:20:32Z | ---
license: apache-2.0
datasets:
- tatsu-lab/alpaca
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
This is a gpt2-large model finetuned on Alpaca via RefineTune.
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
FelixChao/WestSeverus-7B | FelixChao | 2024-01-23T17:43:20Z | 1,338 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"senseable/WestLake-7B-v2",
"FelixChao/Severus-7B",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-01-23T17:35:43Z | ---
license: apache-2.0
tags:
- merge
- mergekit
- lazymergekit
- senseable/WestLake-7B-v2
- FelixChao/Severus-7B
---
# WestSeverus-7B
WestSeverus-7B is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [senseable/WestLake-7B-v2](https://huggingface.co/senseable/WestLake-7B-v2)
* [FelixChao/Severus-7B](https://huggingface.co/FelixChao/Severus-7B)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: senseable/WestLake-7B-v2
layer_range: [0, 32]
- model: FelixChao/Severus-7B
layer_range: [0, 32]
merge_method: slerp
base_model: senseable/WestLake-7B-v2
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: float16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "FelixChao/WestSeverus-7B"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
dragonSwing/vibert-capu | dragonSwing | 2023-04-07T13:34:38Z | 1,337 | 3 | transformers | [
"transformers",
"pytorch",
"bert",
"capitalization",
"punctuation",
"token-classification",
"vi",
"dataset:oscar-corpus/OSCAR-2109",
"license:cc-by-sa-4.0",
"endpoints_compatible",
"region:us"
] | token-classification | 2022-05-11T06:45:40Z | ---
language:
- vi
tags:
- capitalization
- punctuation
- token-classification
license: cc-by-sa-4.0
datasets:
- oscar-corpus/OSCAR-2109
metrics:
- accuracy
- precision
- recall
- f1
---
# ✨ vibert-capitalization-punctuation
This a [viBERT](https://huggingface.co/FPTAI/vibert-base-cased) model finetuned for punctuation restoration on the [OSCAR-2109](https://huggingface.co/datasets/oscar-corpus/OSCAR-2109) dataset.
The model predicts the punctuation and upper-casing of plain, lower-cased text. An example use case can be ASR output. Or other cases when text has lost punctuation.
This model is intended for direct use as a punctuation restoration model for the general Vietnamese language. Alternatively, you can use this for further fine-tuning on domain-specific texts for punctuation restoration tasks.
Model restores the following punctuations -- **[. , : ? ]**
The model also restores the complex upper-casing of words like *YouTube*, *MobiFone*.
-----------------------------------------------
## 🚋 Usage
**Below is a quick way to get up and running with the model.**
1. Download files from hub
```python
import os
import shutil
import sys
from huggingface_hub import snapshot_download
cache_dir = "./capu"
def download_files(repo_id, cache_dir=None, ignore_regex=None):
download_dir = snapshot_download(repo_id=repo_id, cache_dir=cache_dir, ignore_regex=ignore_regex)
if cache_dir is None or download_dir == cache_dir:
return download_dir
file_names = os.listdir(download_dir)
for file_name in file_names:
shutil.move(os.path.join(download_dir, file_name), cache_dir)
os.rmdir(download_dir)
return cache_dir
cache_dir = download_files(repo_id="dragonSwing/vibert-capu", cache_dir=cache_dir, ignore_regex=["*.json", "*.bin"])
sys.path.append(cache_dir)
```
2. Sample python code
```python
import os
from gec_model import GecBERTModel
model = GecBERTModel(
vocab_path=os.path.join(cache_dir, "vocabulary"),
model_paths="dragonSwing/vibert-capu",
split_chunk=True
)
model("theo đó thủ tướng dự kiến tiếp bộ trưởng nông nghiệp mỹ tom wilsack bộ trưởng thương mại mỹ gina raimondo bộ trưởng tài chính janet yellen gặp gỡ thượng nghị sĩ patrick leahy và một số nghị sĩ mỹ khác")
# Always return list of outputs.
# ['Theo đó, Thủ tướng dự kiến tiếp Bộ trưởng Nông nghiệp Mỹ Tom Wilsack, Bộ trưởng Thương mại Mỹ Gina Raimondo, Bộ trưởng Tài chính Janet Yellen, gặp gỡ Thượng nghị sĩ Patrick Leahy và một số nghị sĩ Mỹ khác.']
model("những gói cước năm g mobifone sẽ mang đến cho bạn những trải nghiệm mới lạ trên cả tuyệt vời so với mạng bốn g thì tốc độ truy cập mạng 5 g mobifone được nhận định là siêu đỉnh với mức truy cập nhanh gấp 10 lần")
# ['Những gói cước 5G MobiFone sẽ mang đến cho bạn những trải nghiệm mới lạ trên cả tuyệt vời. So với mạng 4G thì tốc độ truy cập mạng 5G MobiFone được nhận định là siêu đỉnh với mức truy cập nhanh gấp 10 lần.']
```
**This model can work on arbitrarily large text in Vietnamese language.**
-----------------------------------------------
## 📡 Training data
Here is the number of product reviews we used for fine-tuning the model:
| Language | Number of text samples |
| --- | --- |
| Vietnamese | 5,600,000 |
-----------------------------------------------
## 🎯 Accuracy
Below is a breakdown of the performance of the model by each label on 10,000 held-out text samples:
| label | precision | recall | f1-score | support |
| --- | --- | --- | --- | --- |
| **Upper** | 0.88 | 0.89 | 0.89 | 56497 |
| **Complex-Upper** | 0.92 | 0.83 | 0.88 | 480 |
| **.** | 0.81 | 0.82 | 0.82 | 18139 |
| **,** | 0.73 | 0.70 | 0.71 | 22961 |
| **:** | 0.74 | 0.56 | 0.64 | 1432 |
| **?** | 0.80 | 0.76 | 0.78 | 1730 |
| **none** | 0.99 | 0.99 | 0.99 |475611 |
-----------------------------------------------
|
Jaewoo1/Llama2-7B-Blend-3rd-dup-Active-LoRA | Jaewoo1 | 2023-10-04T03:06:45Z | 1,337 | 1 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-10-04T02:44:54Z | Entry not found |
jiwoochris/ko-llama2-v2 | jiwoochris | 2023-10-21T07:18:24Z | 1,337 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-10-21T07:08:50Z | Entry not found |
zyh3826/llama2-13b-ft-openllm-leaderboard-v1 | zyh3826 | 2023-11-10T02:35:51Z | 1,337 | 1 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"license:llama2",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-10-26T09:26:49Z | ---
license: llama2
---
finetue LLAMA2-13B myself
20231024-172733
# Model Details
+ Developed by: zyh3826
+ Backbone Model: llama-2-13B
+ Library: HuggingFace Transformers
# Limitations & Biases:
Llama2 and fine-tuned variants are a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Llama 2 and any fine-tuned varient's potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 2 variants, developers should perform safety testing and tuning tailored to their specific applications of the model.
Please see the Responsible Use Guide available at https://ai.meta.com/llama/responsible-use-guide/
# License Disclaimer:
This model is bound by the license & usage restrictions of the original Llama-2 model. And comes with no warranty or gurantees of any kind. |
42MARU/GenAI-llama2-ko-en-platypus-13B-v2 | 42MARU | 2023-10-30T00:55:49Z | 1,337 | 2 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-10-30T00:40:48Z | Entry not found |
DopeorNope/COKALL-13B-v1 | DopeorNope | 2023-11-01T05:27:00Z | 1,337 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-01T04:48:39Z | Entry not found |
dltjdgh0928/test_instruction | dltjdgh0928 | 2023-11-01T23:53:47Z | 1,337 | 0 | transformers | [
"transformers",
"pytorch",
"mistral",
"text-generation",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-01T23:48:33Z | ---
license: apache-2.0
---
|
heegyu/42dot-1.3B-KOR-OpenOrca-Platypus-1e-5 | heegyu | 2023-11-28T14:57:22Z | 1,337 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-25T04:42:34Z |
| filename | task | acc | acc_stderr | acc_norm | acc_norm_stderr | macro_f1 | macro_f1_stderr |
|:----------------------------------------------|:-------|---------:|-------------:|-----------:|------------------:|-----------:|------------------:|
| 42dot-1.3B-KOR-OpenOrca-Platypus-1e-5-epoch-1 | csatqa | 0.205242 | 0.074799 | 0.205242 | 0.074799 | nan | nan |
| 42dot-1.3B-KOR-OpenOrca-Platypus-1e-5-epoch-1 | haerae | 0.48064 | 0.0309452 | 0.419014 | 0.0322386 | nan | nan |
| 42dot-1.3B-KOR-OpenOrca-Platypus-1e-5-epoch-1 | kobest | 0.624452 | 0.0172055 | 0.556 | 0.0222422 | 0.588107 | 0.0164487 |
| 42dot-1.3B-KOR-OpenOrca-Platypus-1e-5-epoch-2 | csatqa | 0.198575 | 0.0736629 | 0.198575 | 0.0736629 | nan | nan |
| 42dot-1.3B-KOR-OpenOrca-Platypus-1e-5-epoch-2 | haerae | 0.473364 | 0.0308393 | 0.414645 | 0.0321605 | nan | nan |
| 42dot-1.3B-KOR-OpenOrca-Platypus-1e-5-epoch-2 | kobest | 0.634418 | 0.0167043 | 0.556 | 0.0222422 | 0.603202 | 0.0161895 |
| 42dot-1.3B-KOR-OpenOrca-Platypus-1e-5-epoch-3 | csatqa | 0.193813 | 0.0731728 | 0.193813 | 0.0731728 | nan | nan |
| 42dot-1.3B-KOR-OpenOrca-Platypus-1e-5-epoch-3 | haerae | 0.471924 | 0.0309581 | 0.413102 | 0.0322007 | nan | nan |
| 42dot-1.3B-KOR-OpenOrca-Platypus-1e-5-epoch-3 | kobest | 0.636649 | 0.0165652 | 0.558 | 0.022232 | 0.606374 | 0.0161018 | |
heegyu/Mistral-7B-v0.1-OKI-v20231124-1e-5 | heegyu | 2023-11-27T11:20:44Z | 1,337 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-25T07:05:57Z | Entry not found |
brucethemoose/CapyTessBorosYi-34B-200K-DARE-Ties | brucethemoose | 2023-12-19T06:25:29Z | 1,337 | 15 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"merge",
"en",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-11-28T06:12:48Z | ---
license: other
license_name: yi-license
license_link: https://huggingface.co/01-ai/Yi-34B/blob/main/LICENSE
language:
- en
library_name: transformers
pipeline_tag: text-generation
tags:
- text-generation-inference
- merge
---
# Obsolete, see: https://huggingface.co/brucethemoose/CaPlatTessDolXaBoros-Yi-34B-200K-DARE-Ties-HighDensity
***
**NousResearch/Nous-Capybara-34B**, **migtissera/Tess-M-v1.3** and **bhenrym14/airoboros-3_1-yi-34b-200k** merged with a new, experimental implementation of "dare ties" via mergekit. See:
> Language Models are Super Mario: Absorbing Abilities from Homologous Models as a Free Lunch
https://github.com/yule-BUAA/MergeLM
https://github.com/cg123/mergekit/tree/dare'
Merged with the following config, and the tokenizer from chargoddard's Yi-Llama:
```
models:
- model: /home/alpha/Storage/Models/Raw/chargoddard_Yi-34B-200K-Llama
# no parameters necessary for base model
- model: /home/alpha/Storage/Models/Raw/migtissera_Tess-M-v1.3
parameters:
weight: 0.41
density: 0.50
- model: /home/alpha//Storage/Models/Raw/bhenrym14_airoboros-3_1-yi-34b-200k
parameters:
weight: 0.18
density: 0.46
- model: /home/alpha/Storage/Models/Raw/Nous-Capybara-34B
parameters:
weight: 0.41
density: 0.50
merge_method: dare_ties
base_model: /home/alpha/Storage/Models/Raw/chargoddard_Yi-34B-200K-Llama
parameters:
int8_mask: true
dtype: bfloat16
```
dare_ties is testing with better perplexity than a regular ties merge with the same merge configuration. Model weights that add up to one also seem optimal from testing. And high context results seem... better than the previous dare merge with Tess 1.2.
I chose not to include other finetunes, such as Dolphin, because they aren't trained on the 200K base. If any other 200K finetunes pop up, let me know.
***
## Prompt template: Orca-Vicuna
```
SYSTEM: {system_message}
USER: {prompt}
ASSISTANT:
```
Being a Yi model, try disabling the BOS token and/or running a lower temperature with MinP (and no other samplers) if output doesn't seem right. Yi tends to run "hot" by default.
Sometimes the model "spells out" the stop token as `</s>` like Capybara, so you may need to add `</s>` as an additional stopping condition. It also might respond to the llama-2 chat format.
***
24GB GPUs can run Yi-34B-200K models at **45K-75K context** with exllamav2. I go into more detail in this [post](https://old.reddit.com/r/LocalLLaMA/comments/1896igc/how_i_run_34b_models_at_75k_context_on_24gb_fast/), and recommend exl2 quantizations on data similar to the desired task, such as these targeted at story writing: [4.0bpw](https://huggingface.co/brucethemoose/CapyTessBorosYi-34B-200K-DARE-Ties-exl2-4bpw-fiction) / [3.1bpw](https://huggingface.co/brucethemoose/CapyTessBorosYi-34B-200K-DARE-Ties-exl2-3.1bpw-fiction)
***
Credits:
https://github.com/cg123/mergekit/tree/dare
https://huggingface.co/NousResearch/Nous-Capybara-34B/
https://huggingface.co/bhenrym14/airoboros-3_1-yi-34b-200k
https://huggingface.co/migtissera/Tess-M-v1.3
https://huggingface.co/chargoddard/Yi-34B-200K-Llama
https://huggingface.co/01-ai/Yi-34B-200K |
inswave/AISquare-Instruct-llama2-koen-13b-v0.9.10 | inswave | 2023-12-01T23:59:15Z | 1,337 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-01T23:49:47Z | Entry not found |
jingyeom/seal_all_13b | jingyeom | 2023-12-04T11:36:01Z | 1,337 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-04T11:24:40Z | Entry not found |
hyeogi/llama2-70b-v0.1 | hyeogi | 2023-12-05T08:53:24Z | 1,337 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-05T09:03:49Z | Entry not found |
AIFT/PACK-13b-v1.0 | AIFT | 2023-12-12T01:44:52Z | 1,337 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"ko",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-06T03:28:38Z | ---
license: apache-2.0
language:
- ko
library_name: transformers
pipeline_tag: text-generation
--- |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.