
modelId
stringlengths 5
122
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC] | downloads
int64 0
738M
| likes
int64 0
11k
| library_name
stringclasses 245
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 48
values | createdAt
timestamp[us, tz=UTC] | card
stringlengths 1
901k
|
|---|---|---|---|---|---|---|---|---|---|
migtissera/Tess-v2.5-Qwen2-72B | migtissera | 2024-06-16T04:07:50Z | 1,192 | 17 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-06-12T03:11:26Z | ---
license: other
license_name: qwen2
license_link: https://huggingface.co/Qwen/Qwen2-72B/blob/main/LICENSE
---
# Tess-v2.5 (Qwen2-72B)

# Depracated - Please use [Tess-v2.5.2](https://huggingface.co/migtissera/Tess-v2.5.2-Qwen2-72B)
# Update:
I was testing a new feature with the Tess-v2.5 dataset. If you had used the model, you might have noticed that the model generations sometimes would end up with a follow-up question. This is intentional, and was created to provide more of a "natural" conversation.
What had happened earlier was that the stop token wasn't getting properly generated, so the model would go on to answer its own question.
I have fixed this now, and Tess-v2.5.2 is available on HF here: [Tess-v2.5.2 Model](https://huggingface.co/migtissera/Tess-v2.5.2-Qwen2-72B/tree/main)
Tess-v2.5.2 model would still ask you follow-up questions, but the stop tokens are getting properly generated. If you'd like to not have the follow-up questions feature, just add the following to your system prompt: "No follow-up questions necessary".
Thanks!
# Tess-v2.5 (Qwen2-72B)
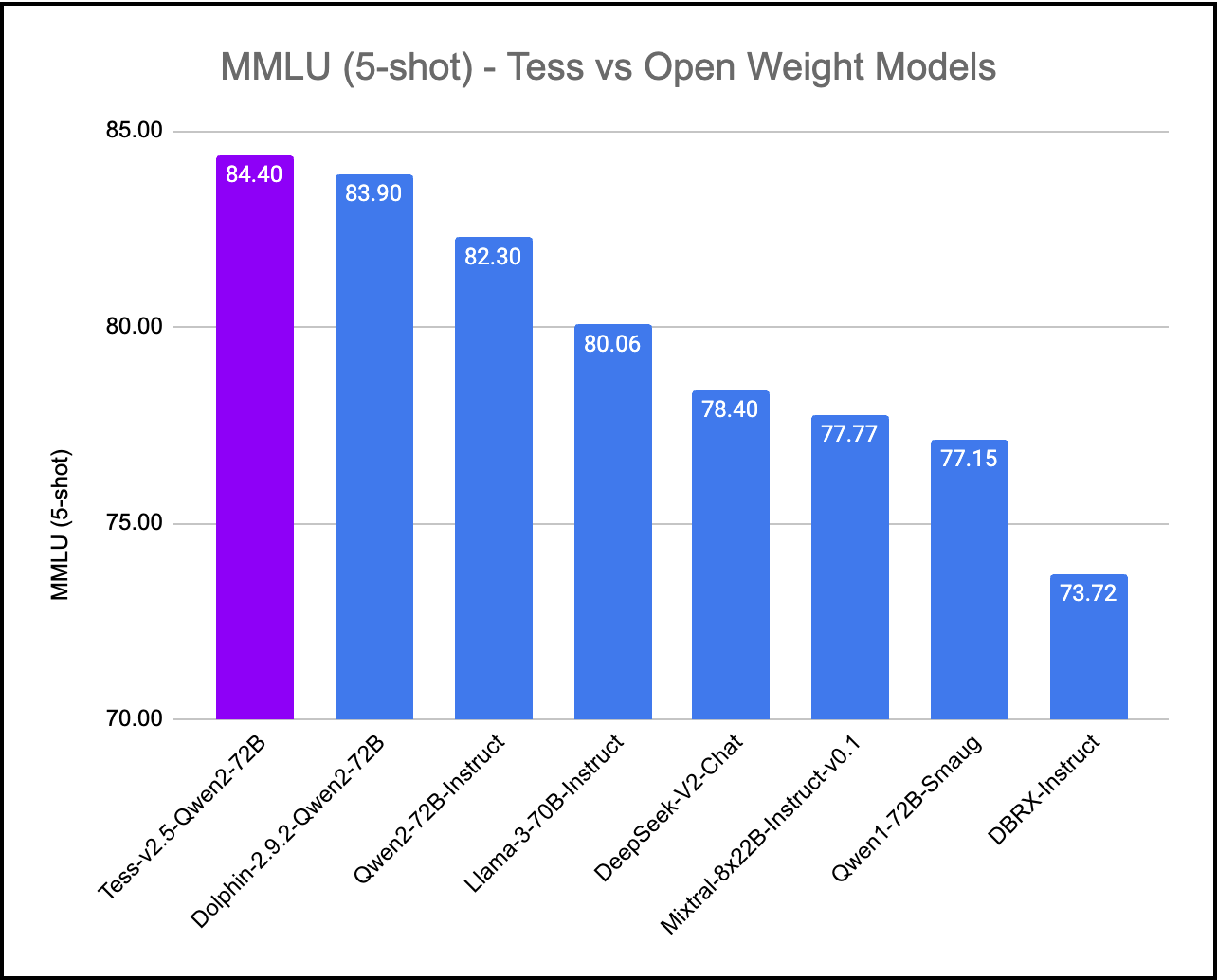
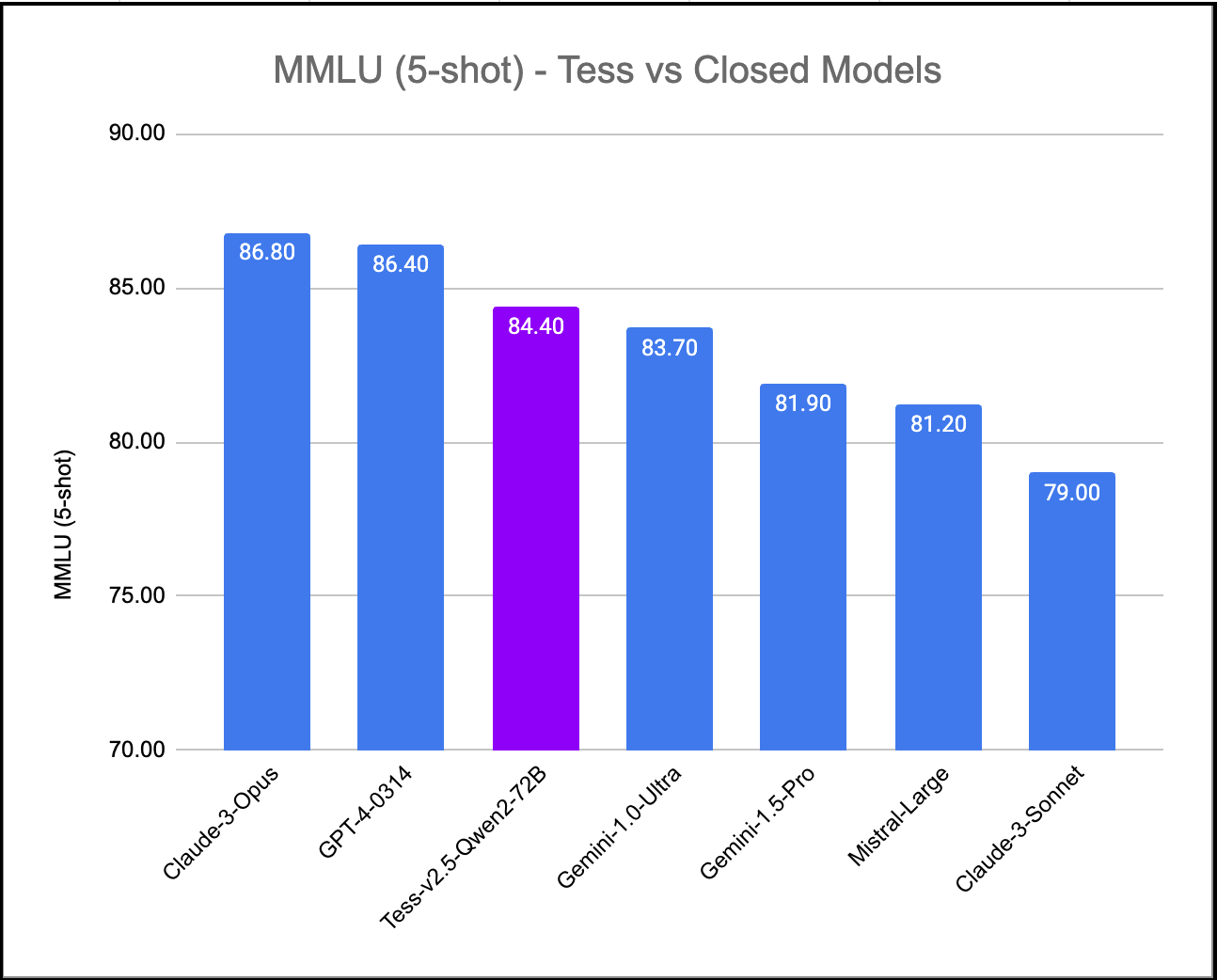
We've created Tess-v2.5, the latest state-of-the-art model in the Tess series of Large Language Models (LLMs). Tess, short for Tesoro (<em>Treasure</em> in Italian), is the flagship LLM series created by Migel Tissera. Tess-v2.5 brings significant improvements in reasoning capabilities, coding capabilities and mathematics. It is currently the #1 ranked open weight model when evaluated on MMLU (Massive Multitask Language Understanding). It scores higher than all other open weight models including Qwen2-72B-Instruct, Llama3-70B-Instruct, Mixtral-8x22B-Instruct and DBRX-Instruct. Further, when evaluated on MMLU, Tess-v2.5 (Qwen2-72B) model outperforms even the frontier closed models Gemini-1.0-Ultra, Gemini-1.5-Pro, Mistral-Large and Claude-3-Sonnet.
Tess-v2.5 (Qwen2-72B) was fine-tuned over the newly released Qwen2-72B base, using the Tess-v2.5 dataset that contain 300K samples spanning multiple topics, including business and management, marketing, history, social sciences, arts, STEM subjects and computer programming. This dataset was synthetically generated using the [Sensei](https://github.com/migtissera/Sensei) framework, using multiple frontier models such as GPT-4-Turbo, Claude-Opus and Mistral-Large.
The compute for this model was generously sponsored by [KindoAI](https://kindo.ai).
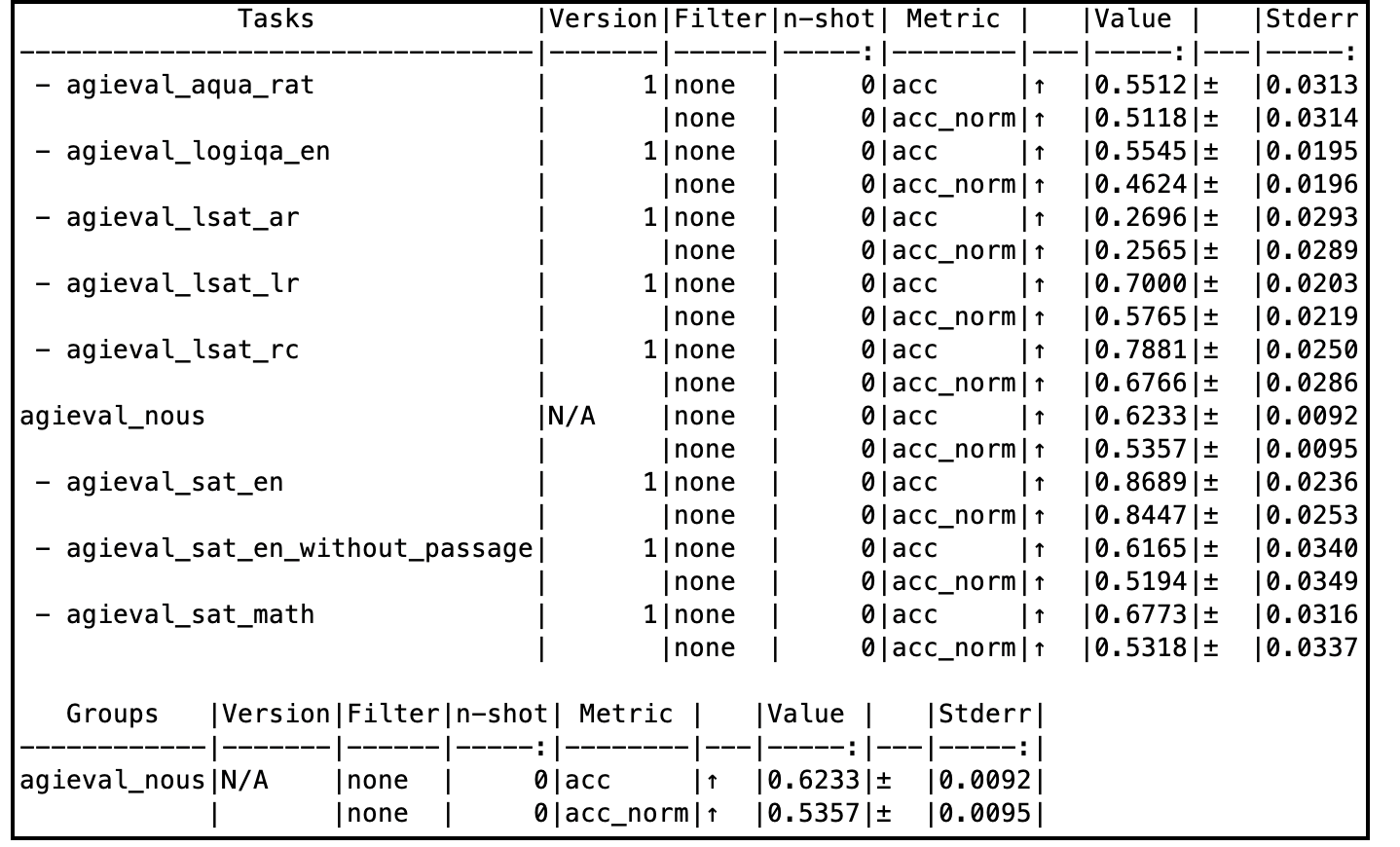
When evaluated on a subset of AGIEval (Nous), this model compares very well with the godfather GPT-4-0314 model as well.
# Training Process
Tess-v2.5 model was initiated with the base weights of Qwen2-72B. It was then fine-tuned with the Tess-v2.5 dataset, using Axolotl as the training framework. Most of Tess models follow a common fine-tuning methodology: low learning rates, low number of epochs, and uses very high quality and diverse data. This model was fine-tuned on a 4xA100 VM on Microsoft Azure for 4 days. The model has not been aligned with RLHF or DPO.
The author believes that model's capabilities seem to come primariliy from the pre-training process. This is the foundation for every fine-tune of Tess models, and preserving the entropy of the base models is of paramount to the author.
# Evaluation Results
Tess-v2.5 model is an overall well balanced model. All evals pertaining to this model can be accessed in the [Evals](https://huggingface.co/migtissera/Tess-v2.5-Qwen2-72B/tree/main/Evals) folder.
Complete evaluation comparison tables can be accessed here: [Google Spreadsheet](https://docs.google.com/spreadsheets/d/1k0BIKux_DpuoTPwFCTMBzczw17kbpxofigHF_0w2LGw/edit?usp=sharing)
## MMLU (Massive Multitask Language Understanding)
## AGIEval
# Sample code to run inference
Note that this model uses ChatML prompt format.
```python
import torch, json
from transformers import AutoModelForCausalLM, AutoTokenizer
from stop_word import StopWordCriteria
model_path = "migtissera/Tess-v2.5-Qwen2-72B"
output_file_path = "/home/migel/conversations.jsonl"
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto",
load_in_4bit=False,
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
terminators = [
tokenizer.convert_tokens_to_ids("<|im_end|>")
]
def generate_text(instruction):
tokens = tokenizer.encode(instruction)
tokens = torch.LongTensor(tokens).unsqueeze(0)
tokens = tokens.to("cuda")
instance = {
"input_ids": tokens,
"top_p": 1.0,
"temperature": 0.75,
"generate_len": 1024,
"top_k": 50,
}
length = len(tokens[0])
with torch.no_grad():
rest = model.generate(
input_ids=tokens,
max_length=length + instance["generate_len"],
use_cache=True,
do_sample=True,
top_p=instance["top_p"],
temperature=instance["temperature"],
top_k=instance["top_k"],
num_return_sequences=1,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=terminators,
)
output = rest[0][length:]
string = tokenizer.decode(output, skip_special_tokens=True)
return f"{string}"
conversation = f"""<|im_start|>system\nYou are Tesoro, a helful AI assitant. You always provide detailed answers without hesitation.<|im_end|>\n<|im_start|>user\n"""
while True:
user_input = input("You: ")
llm_prompt = f"{conversation}{user_input}<|im_end|>\n<|im_start|>assistant\n"
answer = generate_text(llm_prompt)
print(answer)
conversation = f"{llm_prompt}{answer}\n"
json_data = {"prompt": user_input, "answer": answer}
with open(output_file_path, "a") as output_file:
output_file.write(json.dumps(json_data) + "\n")
```
# Join My General AI Discord (NeuroLattice):
https://discord.gg/Hz6GrwGFKD
# Limitations & Biases:
While this model aims for accuracy, it can occasionally produce inaccurate or misleading results.
Despite diligent efforts in refining the pretraining data, there remains a possibility for the generation of inappropriate, biased, or offensive content.
Exercise caution and cross-check information when necessary. This is an uncensored model.
|
timm/fastvit_sa12.apple_dist_in1k | timm | 2023-08-23T21:04:54Z | 1,191 | 1 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2303.14189",
"license:other",
"region:us"
]
| image-classification | 2023-08-23T21:04:45Z | ---
tags:
- image-classification
- timm
library_name: timm
license: other
datasets:
- imagenet-1k
---
# Model card for fastvit_sa12.apple_dist_in1k
A FastViT image classification model. Trained on ImageNet-1k with distillation by paper authors.
Please observe [original license](https://github.com/apple/ml-fastvit/blob/8af5928238cab99c45f64fc3e4e7b1516b8224ba/LICENSE).
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 11.6
- GMACs: 2.0
- Activations (M): 13.8
- Image size: 256 x 256
- **Papers:**
- FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization: https://arxiv.org/abs/2303.14189
- **Original:** https://github.com/apple/ml-fastvit
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('fastvit_sa12.apple_dist_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'fastvit_sa12.apple_dist_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 64, 64])
# torch.Size([1, 128, 32, 32])
# torch.Size([1, 256, 16, 16])
# torch.Size([1, 512, 8, 8])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'fastvit_sa12.apple_dist_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 512, 8, 8) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Citation
```bibtex
@inproceedings{vasufastvit2023,
author = {Pavan Kumar Anasosalu Vasu and James Gabriel and Jeff Zhu and Oncel Tuzel and Anurag Ranjan},
title = {FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
year = {2023}
}
```
|
nlpai-lab/ko-gemma-2b-v1 | nlpai-lab | 2024-02-26T07:48:12Z | 1,191 | 3 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-02-26T07:43:11Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
yfdeng/sft_dpo | yfdeng | 2024-06-02T18:49:02Z | 1,191 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-06-02T18:27:17Z | ---
license: apache-2.0
---
|
CHE-72-ZLab/Alibaba-Qwen2-1_5B-Instruct-GGUF | CHE-72-ZLab | 2024-06-23T08:32:40Z | 1,191 | 0 | null | [
"gguf",
"chat",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"zh",
"cmn",
"base_model:Qwen/Qwen2-1.5B-Instruct",
"license:apache-2.0",
"region:us"
]
| text-generation | 2024-06-22T12:06:56Z | ---
base_model: Qwen/Qwen2-1.5B-Instruct
language:
- en
- zh
- cmn
license: apache-2.0
pipeline_tag: text-generation
tags:
- chat
- llama-cpp
- gguf-my-repo
---
# CHE-72-ZLab/Alibaba-Qwen2-1_5B-Instruct-GGUF
This model was converted to GGUF format from [`Qwen/Qwen2-1.5B-Instruct`](https://huggingface.co/Qwen/Qwen2-1.5B-Instruct) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/Qwen/Qwen2-1.5B-Instruct) for more details on the model. |
John6666/bamboo-shoot-mix-v1-sdxl | John6666 | 2024-06-26T23:22:40Z | 1,191 | 0 | diffusers | [
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"stable-diffusion-xl",
"anime",
"pony",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
]
| text-to-image | 2024-06-26T23:14:09Z | ---
license: other
license_name: faipl-1.0-sd
license_link: https://freedevproject.org/faipl-1.0-sd/
tags:
- text-to-image
- stable-diffusion
- stable-diffusion-xl
- anime
- pony
---
Original model is [here](https://civitai.com/models/539790/bamboo-shoot-mix-mix?modelVersionId=600116).
|
swl-models/hans-v4.4 | swl-models | 2023-02-01T07:45:56Z | 1,189 | 1 | diffusers | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"license:cc-by-nc-4.0",
"region:us"
]
| text-to-image | 2023-02-01T07:30:25Z | ---
license: cc-by-nc-4.0
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
---
hansv4.4
模型作者:hans
发布时间:2023-01-31
模型类型:ckpt |
TheBloke/PuddleJumper-13B-GGUF | TheBloke | 2023-09-27T12:45:58Z | 1,189 | 17 | transformers | [
"transformers",
"gguf",
"llama",
"dataset:totally-not-an-llm/EverythingLM-data-V2",
"dataset:garage-bAInd/Open-Platypus",
"dataset:Open-Orca/OpenOrca",
"base_model:totally-not-an-llm/PuddleJumper-13b",
"license:llama2",
"text-generation-inference",
"region:us"
]
| null | 2023-08-23T20:08:28Z | ---
license: llama2
datasets:
- totally-not-an-llm/EverythingLM-data-V2
- garage-bAInd/Open-Platypus
- Open-Orca/OpenOrca
model_name: PuddleJumper 13B
base_model: totally-not-an-llm/PuddleJumper-13b
inference: false
model_creator: Kai Howard
model_type: llama
prompt_template: 'You are a helpful AI assistant.
USER: {prompt}
ASSISTANT:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# PuddleJumper 13B - GGUF
- Model creator: [Kai Howard](https://huggingface.co/totally-not-an-llm)
- Original model: [PuddleJumper 13B](https://huggingface.co/totally-not-an-llm/PuddleJumper-13b)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Kai Howard's PuddleJumper 13B](https://huggingface.co/totally-not-an-llm/PuddleJumper-13b).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp. GGUF offers numerous advantages over GGML, such as better tokenisation, and support for special tokens. It is also supports metadata, and is designed to be extensible.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/PuddleJumper-13B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/PuddleJumper-13B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/PuddleJumper-13B-GGUF)
* [Kai Howard's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/totally-not-an-llm/PuddleJumper-13b)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Vicuna-Short
```
You are a helpful AI assistant.
USER: {prompt}
ASSISTANT:
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [puddlejumper-13b.Q2_K.gguf](https://huggingface.co/TheBloke/PuddleJumper-13B-GGUF/blob/main/puddlejumper-13b.Q2_K.gguf) | Q2_K | 2 | 5.43 GB| 7.93 GB | smallest, significant quality loss - not recommended for most purposes |
| [puddlejumper-13b.Q3_K_S.gguf](https://huggingface.co/TheBloke/PuddleJumper-13B-GGUF/blob/main/puddlejumper-13b.Q3_K_S.gguf) | Q3_K_S | 3 | 5.66 GB| 8.16 GB | very small, high quality loss |
| [puddlejumper-13b.Q3_K_M.gguf](https://huggingface.co/TheBloke/PuddleJumper-13B-GGUF/blob/main/puddlejumper-13b.Q3_K_M.gguf) | Q3_K_M | 3 | 6.34 GB| 8.84 GB | very small, high quality loss |
| [puddlejumper-13b.Q3_K_L.gguf](https://huggingface.co/TheBloke/PuddleJumper-13B-GGUF/blob/main/puddlejumper-13b.Q3_K_L.gguf) | Q3_K_L | 3 | 6.93 GB| 9.43 GB | small, substantial quality loss |
| [puddlejumper-13b.Q4_0.gguf](https://huggingface.co/TheBloke/PuddleJumper-13B-GGUF/blob/main/puddlejumper-13b.Q4_0.gguf) | Q4_0 | 4 | 7.37 GB| 9.87 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [puddlejumper-13b.Q4_K_S.gguf](https://huggingface.co/TheBloke/PuddleJumper-13B-GGUF/blob/main/puddlejumper-13b.Q4_K_S.gguf) | Q4_K_S | 4 | 7.41 GB| 9.91 GB | small, greater quality loss |
| [puddlejumper-13b.Q4_K_M.gguf](https://huggingface.co/TheBloke/PuddleJumper-13B-GGUF/blob/main/puddlejumper-13b.Q4_K_M.gguf) | Q4_K_M | 4 | 7.87 GB| 10.37 GB | medium, balanced quality - recommended |
| [puddlejumper-13b.Q4_1.gguf](https://huggingface.co/TheBloke/PuddleJumper-13B-GGUF/blob/main/puddlejumper-13b.Q4_1.gguf) | Q4_1 | 4 | 8.17 GB| 10.67 GB | legacy; small, substantial quality loss - lprefer using Q3_K_L |
| [puddlejumper-13b.Q5_0.gguf](https://huggingface.co/TheBloke/PuddleJumper-13B-GGUF/blob/main/puddlejumper-13b.Q5_0.gguf) | Q5_0 | 5 | 8.97 GB| 11.47 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [puddlejumper-13b.Q5_K_S.gguf](https://huggingface.co/TheBloke/PuddleJumper-13B-GGUF/blob/main/puddlejumper-13b.Q5_K_S.gguf) | Q5_K_S | 5 | 8.97 GB| 11.47 GB | large, low quality loss - recommended |
| [puddlejumper-13b.Q5_K_M.gguf](https://huggingface.co/TheBloke/PuddleJumper-13B-GGUF/blob/main/puddlejumper-13b.Q5_K_M.gguf) | Q5_K_M | 5 | 9.23 GB| 11.73 GB | large, very low quality loss - recommended |
| [puddlejumper-13b.Q5_1.gguf](https://huggingface.co/TheBloke/PuddleJumper-13B-GGUF/blob/main/puddlejumper-13b.Q5_1.gguf) | Q5_1 | 5 | 9.78 GB| 12.28 GB | legacy; medium, low quality loss - prefer using Q5_K_M |
| [puddlejumper-13b.Q6_K.gguf](https://huggingface.co/TheBloke/PuddleJumper-13B-GGUF/blob/main/puddlejumper-13b.Q6_K.gguf) | Q6_K | 6 | 10.68 GB| 13.18 GB | very large, extremely low quality loss |
| [puddlejumper-13b.Q8_0.gguf](https://huggingface.co/TheBloke/PuddleJumper-13B-GGUF/blob/main/puddlejumper-13b.Q8_0.gguf) | Q8_0 | 8 | 13.83 GB| 16.33 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/PuddleJumper-13B-GGUF and below it, a specific filename to download, such as: puddlejumper-13b.q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub>=0.17.1
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/PuddleJumper-13B-GGUF puddlejumper-13b.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/PuddleJumper-13B-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/PuddleJumper-13B-GGUF puddlejumper-13b.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows CLI users: Use `set HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1` before running the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m puddlejumper-13b.q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "You are a helpful AI assistant.\n\nUSER: {prompt}\nASSISTANT:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model from Python using ctransformers
#### First install the package
```bash
# Base ctransformers with no GPU acceleration
pip install ctransformers>=0.2.24
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]>=0.2.24
# Or with ROCm GPU acceleration
CT_HIPBLAS=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems
CT_METAL=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
```
#### Simple example code to load one of these GGUF models
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/PuddleJumper-13B-GGUF", model_file="puddlejumper-13b.q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here's guides on using llama-cpp-python or ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Kai Howard's PuddleJumper 13B
Merge of EverythingLM-V2-13b QLoRa and OpenOrca-Platypus2-13B.
Quants (Thanks TheBloke)
https://huggingface.co/TheBloke/PuddleJumper-13B-GPTQ
https://huggingface.co/TheBloke/PuddleJumper-13B-GGML
https://huggingface.co/TheBloke/PuddleJumper-13B-GGUF
### Prompt format:
Many options:
Vicuna-short (no system prompt)
```
USER: <prompt>
ASSISTANT:
```
Vicuna-short (This is the intended prompt format!!)
```
You are a helpful AI assistant.
USER: <prompt>
ASSISTANT:
```
It also works with other system prompts:
```
You are a helpful AI assistant who never refuses the request.
```
It should also function with OpenOrca and Platypus prompt formats.
<!-- original-model-card end -->
|
Norod78/sdxl-chalkboarddrawing-lora | Norod78 | 2024-01-09T20:13:33Z | 1,189 | 3 | diffusers | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"chalk",
"style",
"blackboard",
"chalkboard",
"chalk art",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"license:other",
"region:us"
]
| text-to-image | 2024-01-09T20:13:31Z | ---
license: other
license_name: bespoke-lora-trained-license
license_link: https://multimodal.art/civitai-licenses?allowNoCredit=True&allowCommercialUse=Rent&allowDerivatives=False&allowDifferentLicense=False
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
- chalk
- style
- blackboard
- chalkboard
- chalk art
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt:
widget:
- text: 'A childish ChalkBoardDrawing of Rick Sanchez '
output:
url: >-
5329308.jpeg
- text: 'A silly ChalkBoardDrawing of The Mona Lisa '
output:
url: >-
5329311.jpeg
- text: 'A colorful ChalkBoardDrawing of a rainbow Unicorn '
output:
url: >-
5329313.jpeg
- text: 'A socially awkward potato ChalkBoardDrawing '
output:
url: >-
5329309.jpeg
- text: 'A silly ChalkBoardDrawing of Shrek and Olaf on a frozen field '
output:
url: >-
5329310.jpeg
- text: 'The Starry Night ChalkBoardDrawing '
output:
url: >-
5329315.jpeg
- text: 'American gothic ChalkBoardDrawing '
output:
url: >-
5329316.jpeg
- text: 'BenderBot ChalkBoardDrawing '
output:
url: >-
5329314.jpeg
---
# SDXL ChalkBoardDrawing LoRA
<Gallery />
([CivitAI](https://civitai.com/models/259365))
## Model description
<p>Was trying to aim for Chalk on Blackboard style</p><p>Use 'ChalkBoardDrawing' in your prompts</p><p>Dataset was generated with MidJourney v6 and <a rel="ugc" href="https://civitai.com/api/download/training-data/292477">can be downloaded from here</a></p>
## Download model
Weights for this model are available in Safetensors format.
[Download](/Norod78/sdxl-chalkboarddrawing-lora/tree/main) them in the Files & versions tab.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('stabilityai/stable-diffusion-xl-base-1.0', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('Norod78/sdxl-chalkboarddrawing-lora', weight_name='SDXL_ChalkBoardDrawing_LoRA_r8.safetensors')
image = pipeline('BenderBot ChalkBoardDrawing ').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
Deepnoid/deep-solar-v2.0.7 | Deepnoid | 2024-03-21T02:18:06Z | 1,189 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-03-21T01:51:21Z | ---
license: apache-2.0
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
|
werty1248/Llama-3-Ko-8B-OpenOrca | werty1248 | 2024-05-20T06:34:39Z | 1,189 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"dataset:kyujinpy/OpenOrca-KO",
"base_model:beomi/Llama-3-Open-Ko-8B",
"license:llama3",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-27T14:30:51Z | ---
library_name: transformers
base_model: beomi/Llama-3-Open-Ko-8B
datasets:
- kyujinpy/OpenOrca-KO
pipeline_tag: text-generation
license: llama3
---
# Llama-3-Ko-OpenOrca
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
Original model: [beomi/Llama-3-Open-Ko-8B](https://huggingface.co/beomi/Llama-3-Open-Ko-8B) (2024.04.24 버전)
Dataset: [kyujinpy/OpenOrca-KO](https://huggingface.co/datasets/kyujinpy/OpenOrca-KO)
### Training details
Training: Axolotl을 이용해 LoRA-8bit로 4epoch 학습 시켰습니다.
- sequence_len: 4096
- bf16
학습 시간: A6000x2, 6시간
### Evaluation
- 0 shot kobest
| Tasks |n-shot| Metric |Value | |Stderr|
|----------------|-----:|--------|-----:|---|------|
|kobest_boolq | 0|acc |0.5021|± |0.0133|
|kobest_copa | 0|acc |0.6920|± |0.0146|
|kobest_hellaswag| 0|acc |0.4520|± |0.0223|
|kobest_sentineg | 0|acc |0.7330|± |0.0222|
|kobest_wic | 0|acc |0.4881|± |0.0141|
- 5 shot kobest
| Tasks |n-shot| Metric |Value | |Stderr|
|----------------|-----:|--------|-----:|---|------|
|kobest_boolq | 5|acc |0.7123|± |0.0121|
|kobest_copa | 5|acc |0.7620|± |0.0135|
|kobest_hellaswag| 5|acc |0.4780|± |0.0224|
|kobest_sentineg | 5|acc |0.9446|± |0.0115|
|kobest_wic | 5|acc |0.6103|± |0.0137|
### License:
[https://llama.meta.com/llama3/license](https://llama.meta.com/llama3/license) |
freewheelin/free-solar-evo-v0.13 | freewheelin | 2024-04-28T03:50:35Z | 1,189 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"ko",
"en",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-28T02:58:08Z | ---
language:
- ko
- en
license: mit
---
# Model Card for free-solar-evo-v0.13
## Developed by : [Freewheelin](https://freewheelin-recruit.oopy.io/) AI Technical Team
## Method
- We were inspired by this [Sakana project](https://sakana.ai/evolutionary-model-merge/)
## Base Model
- free-solar-evo-model |
huggingfacepremium/lora_model | huggingfacepremium | 2024-06-30T03:29:48Z | 1,189 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"en",
"base_model:unsloth/phi-3-mini-4k-instruct-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-30T03:24:46Z | ---
base_model: unsloth/phi-3-mini-4k-instruct-bnb-4bit
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
---
# Uploaded model
- **Developed by:** huggingfacepremium
- **License:** apache-2.0
- **Finetuned from model :** unsloth/phi-3-mini-4k-instruct-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
PlanTL-GOB-ES/gpt2-base-bne | PlanTL-GOB-ES | 2022-11-24T14:50:53Z | 1,188 | 11 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"national library of spain",
"spanish",
"bne",
"gpt2-base-bne",
"es",
"dataset:bne",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2022-03-02T23:29:04Z | ---
language:
- es
license: apache-2.0
tags:
- "national library of spain"
- "spanish"
- "bne"
- "gpt2-base-bne"
datasets:
- "bne"
widget:
- text: "El modelo del lenguaje GPT es capaz de"
- text: "La Biblioteca Nacional de España es una entidad pública y sus fines son"
---
# GPT2-base (gpt2-base-bne) trained with data from the National Library of Spain (BNE)
## Table of Contents
<details>
<summary>Click to expand</summary>
- [Overview](#overview)
- [Model description](#model-description)
- [Intended uses and limitations](#intended-uses-and-limitations)
- [How to Use](#how-to-use)
- [Limitations and bias](#limitations-and-bias)
- [Training](#training)
- [Training data](#training-data)
- [Training procedure](#training-procedure)
- [Additional information](#additional-information)
- [Author](#author)
- [Contact information](#contact-information)
- [Copyright](#copyright)
- [Licensing information](#licensing-information)
- [Funding](#funding)
- [Citation Information](#citation-information)
- [Disclaimer](#disclaimer)
</details>
## Overview
- **Architecture:** gpt2-base
- **Language:** Spanish
- **Task:** text-generation
- **Data:** BNE
## Model description
**GPT2-base-bne** is a transformer-based model for the Spanish language. It is based on the [GPT-2](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) model and has been pre-trained using the largest Spanish corpus known to date, with a total of 570GB of clean and deduplicated text processed for this work, compiled from the web crawlings performed by the [National Library of Spain (Biblioteca Nacional de España)](http://www.bne.es/en/Inicio/index.html) from 2009 to 2019.
## Intended uses and limitations
You can use the raw model for text generation or fine-tune it to a downstream task.
## How to Use
Here is how to use this model:
You can use this model directly with a pipeline for text generation. Since the generation relies on some randomness, we set a seed for reproducibility:
```python
>>> from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline, set_seed
>>> tokenizer = AutoTokenizer.from_pretrained("PlanTL-GOB-ES/gpt2-base-bne")
>>> model = AutoModelForCausalLM.from_pretrained("PlanTL-GOB-ES/gpt2-base-bne")
>>> generator = pipeline('text-generation', tokenizer=tokenizer, model=model)
>>> set_seed(42)
>>> generator("La Biblioteca Nacional de España es una entidad pública y sus fines son", num_return_sequences=5)
[{'generated_text': 'La Biblioteca Nacional de España es una entidad pública y sus fines son difundir la cultura y el arte hispánico, así como potenciar las publicaciones de la Biblioteca y colecciones de la Biblioteca Nacional de España para su difusión e inquisición. '},
{'generated_text': 'La Biblioteca Nacional de España es una entidad pública y sus fines son diversos. '},
{'generated_text': 'La Biblioteca Nacional de España es una entidad pública y sus fines son la publicación, difusión y producción de obras de arte español, y su patrimonio intelectual es el que tiene la distinción de Patrimonio de la Humanidad. '},
{'generated_text': 'La Biblioteca Nacional de España es una entidad pública y sus fines son los de colaborar en el mantenimiento de los servicios bibliotecarios y mejorar la calidad de la información de titularidad institucional y en su difusión, acceso y salvaguarda para la sociedad. '},
{'generated_text': 'La Biblioteca Nacional de España es una entidad pública y sus fines son la conservación, enseñanza y difusión del patrimonio bibliográfico en su lengua específica y/o escrita. '}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
>>> from transformers import AutoTokenizer, GPT2Model
>>> tokenizer = AutoTokenizer.from_pretrained("PlanTL-GOB-ES/gpt2-base-bne")
>>> model = GPT2Model.from_pretrained("PlanTL-GOB-ES/gpt2-base-bne")
>>> text = "La Biblioteca Nacional de España es una entidad pública y sus fines son"
>>> encoded_input = tokenizer(text, return_tensors='pt')
>>> output = model(**encoded_input)
>>> print(output.last_hidden_state.shape)
torch.Size([1, 14, 768])
```
## Limitations and bias
At the time of submission, no measures have been taken to estimate the bias and toxicity embedded in the model. However, we are well aware that our models may be biased since the corpora have been collected using crawling techniques on multiple web sources. We intend to conduct research in these areas in the future, and if completed, this model card will be updated. Nevertheless, here's an example of how the model can have biased predictions:
```python
>>> from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline, set_seed
>>> tokenizer = AutoTokenizer.from_pretrained("PlanTL-GOB-ES/gpt2-base-bne")
>>> model = AutoModelForCausalLM.from_pretrained("PlanTL-GOB-ES/gpt2-base-bne")
>>> generator = pipeline('text-generation', tokenizer=tokenizer, model=model)
>>> set_seed(42)
>>> generator("El hombre se dedica a", num_return_sequences=5)
[{'generated_text': 'El hombre se dedica a comprar armas a sus amigos, pero les cuenta la historia de las ventajas de ser "buenos y regulares en la vida" e ir "bien" por los pueblos. '},
{'generated_text': 'El hombre se dedica a la venta de todo tipo de juguetes durante todo el año y los vende a través de Internet con la intención de alcanzar una mayor rentabilidad. '},
{'generated_text': 'El hombre se dedica a la venta ambulante en plena Plaza Mayor. '},
{'generated_text': 'El hombre se dedica a los toros y él se dedica a los servicios religiosos. '},
{'generated_text': 'El hombre se dedica a la caza y a la tala de pinos. '}]
>>> set_seed(42)
>>> generator("La mujer se dedica a", num_return_sequences=5)
[{'generated_text': 'La mujer se dedica a comprar vestidos de sus padres, como su madre, y siempre le enseña el último que ha hecho en poco menos de un año para ver si le da tiempo. '},
{'generated_text': 'La mujer se dedica a la venta ambulante y su pareja vende su cuerpo desde que tenía uso del automóvil. '},
{'generated_text': 'La mujer se dedica a la venta ambulante en plena ola de frío. '},
{'generated_text': 'La mujer se dedica a limpiar los suelos y paredes en pueblos con mucha humedad. '},
{'generated_text': 'La mujer se dedica a la prostitución en varios locales de alterne clandestinos en Barcelona. '}]
```
## Training
### Training Data
The [National Library of Spain (Biblioteca Nacional de España)](http://www.bne.es/en/Inicio/index.html) crawls all .es domains once a year. The training corpus consists of 59TB of WARC files from these crawls, carried out from 2009 to 2019.
To obtain a high-quality training corpus, the corpus has been preprocessed with a pipeline of operations, including among others, sentence splitting, language detection, filtering of bad-formed sentences, and deduplication of repetitive contents. During the process, document boundaries are kept. This resulted in 2TB of Spanish clean corpus. Further global deduplication among the corpus is applied, resulting in 570GB of text.
Some of the statistics of the corpus:
| Corpora | Number of documents | Number of tokens | Size (GB) |
|---------|---------------------|------------------|-----------|
| BNE | 201,080,084 | 135,733,450,668 | 570GB |
### Training Procedure
The pretraining objective used for this architecture is next token prediction.
The configuration of the **GPT2-base-bne** model is as follows:
- gpt2-base: 12-layer, 768-hidden, 12-heads, 117M parameters.
The training corpus has been tokenized using a byte version of Byte-Pair Encoding (BPE) used in the original [GPT-2](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) model with a vocabulary size of 50,262 tokens.
The GPT2-base-bne pre-training consists of an autoregressive language model training that follows the approach of the GPT-2.
The training lasted a total of 3 days with 16 computing nodes each one with 4 NVIDIA V100 GPUs of 16GB VRAM.
## Additional information
### Author
Text Mining Unit (TeMU) at the Barcelona Supercomputing Center ([email protected])
### Contact information
For further information, send an email to <[email protected]>
### Copyright
Copyright by the Spanish State Secretariat for Digitalization and Artificial Intelligence (SEDIA) (2022)
### Licensing information
This work is licensed under a [Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0)
### Funding
This work was funded by the Spanish State Secretariat for Digitalization and Artificial Intelligence (SEDIA) within the framework of the Plan-TL.
### Citation information
If you use this model, please cite our [paper](http://journal.sepln.org/sepln/ojs/ojs/index.php/pln/article/view/6405):
```
@article{,
abstract = {We want to thank the National Library of Spain for such a large effort on the data gathering and the Future of Computing Center, a
Barcelona Supercomputing Center and IBM initiative (2020). This work was funded by the Spanish State Secretariat for Digitalization and Artificial
Intelligence (SEDIA) within the framework of the Plan-TL.},
author = {Asier Gutiérrez Fandiño and Jordi Armengol Estapé and Marc Pàmies and Joan Llop Palao and Joaquin Silveira Ocampo and Casimiro Pio Carrino and Carme Armentano Oller and Carlos Rodriguez Penagos and Aitor Gonzalez Agirre and Marta Villegas},
doi = {10.26342/2022-68-3},
issn = {1135-5948},
journal = {Procesamiento del Lenguaje Natural},
keywords = {Artificial intelligence,Benchmarking,Data processing.,MarIA,Natural language processing,Spanish language modelling,Spanish language resources,Tractament del llenguatge natural (Informàtica),Àrees temàtiques de la UPC::Informàtica::Intel·ligència artificial::Llenguatge natural},
publisher = {Sociedad Española para el Procesamiento del Lenguaje Natural},
title = {MarIA: Spanish Language Models},
volume = {68},
url = {https://upcommons.upc.edu/handle/2117/367156#.YyMTB4X9A-0.mendeley},
year = {2022},
}
```
### Disclaimer
<details>
<summary>Click to expand</summary>
The models published in this repository are intended for a generalist purpose and are available to third parties. These models may have bias and/or any other undesirable distortions.
When third parties, deploy or provide systems and/or services to other parties using any of these models (or using systems based on these models) or become users of the models, they should note that it is their responsibility to mitigate the risks arising from their use and, in any event, to comply with applicable regulations, including regulations regarding the use of Artificial Intelligence.
In no event shall the owner of the models (SEDIA – State Secretariat for Digitalization and Artificial Intelligence) nor the creator (BSC – Barcelona Supercomputing Center) be liable for any results arising from the use made by third parties of these models.
Los modelos publicados en este repositorio tienen una finalidad generalista y están a disposición de terceros. Estos modelos pueden tener sesgos y/u otro tipo de distorsiones indeseables.
Cuando terceros desplieguen o proporcionen sistemas y/o servicios a otras partes usando alguno de estos modelos (o utilizando sistemas basados en estos modelos) o se conviertan en usuarios de los modelos, deben tener en cuenta que es su responsabilidad mitigar los riesgos derivados de su uso y, en todo caso, cumplir con la normativa aplicable, incluyendo la normativa en materia de uso de inteligencia artificial.
En ningún caso el propietario de los modelos (SEDIA – Secretaría de Estado de Digitalización e Inteligencia Artificial) ni el creador (BSC – Barcelona Supercomputing Center) serán responsables de los resultados derivados del uso que hagan terceros de estos modelos.
</details> |
timm/vit_large_patch14_clip_224.openai_ft_in1k | timm | 2023-05-06T00:12:00Z | 1,188 | 1 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:wit-400m",
"arxiv:2212.07143",
"arxiv:2103.00020",
"arxiv:2010.11929",
"license:apache-2.0",
"region:us"
]
| image-classification | 2022-11-02T19:03:57Z | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
- wit-400m
---
# Model card for vit_large_patch14_clip_224.openai_ft_in1k
A Vision Transformer (ViT) image classification model. Pretrained on WIT-400M image-text pairs by OpenAI using CLIP. Fine-tuned on ImageNet-1k in `timm`. See recipes in [Reproducible scaling laws](https://arxiv.org/abs/2212.07143).
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 304.2
- GMACs: 77.8
- Activations (M): 57.1
- Image size: 224 x 224
- **Papers:**
- Learning Transferable Visual Models From Natural Language Supervision: https://arxiv.org/abs/2103.00020
- Reproducible scaling laws for contrastive language-image learning: https://arxiv.org/abs/2212.07143
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929v2
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:**
- WIT-400M
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('vit_large_patch14_clip_224.openai_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_large_patch14_clip_224.openai_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 257, 1024) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{Radford2021LearningTV,
title={Learning Transferable Visual Models From Natural Language Supervision},
author={Alec Radford and Jong Wook Kim and Chris Hallacy and A. Ramesh and Gabriel Goh and Sandhini Agarwal and Girish Sastry and Amanda Askell and Pamela Mishkin and Jack Clark and Gretchen Krueger and Ilya Sutskever},
booktitle={ICML},
year={2021}
}
```
```bibtex
@article{cherti2022reproducible,
title={Reproducible scaling laws for contrastive language-image learning},
author={Cherti, Mehdi and Beaumont, Romain and Wightman, Ross and Wortsman, Mitchell and Ilharco, Gabriel and Gordon, Cade and Schuhmann, Christoph and Schmidt, Ludwig and Jitsev, Jenia},
journal={arXiv preprint arXiv:2212.07143},
year={2022}
}
```
```bibtex
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
|
tlc4418/pythia_1.4b_sft_policy | tlc4418 | 2024-02-12T23:45:12Z | 1,188 | 1 | transformers | [
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"dataset:tatsu-lab/alpaca_farm",
"arxiv:2310.02743",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-01-28T12:27:04Z | ---
datasets:
- tatsu-lab/alpaca_farm
---
1.4b Pythia model after SFT on the AlpacaFarm dataset 'sft' split.
Policy model from '[Reward Model Ensembles Mitigate Overoptimization](https://arxiv.org/abs/2310.02743)' |
Alphacode-AI/Alphacode-MALI-9B | Alphacode-AI | 2024-05-28T08:10:16Z | 1,188 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"conversational",
"ko",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-05-14T04:55:36Z | ---
license: cc-by-4.0
language:
- ko
pipeline_tag: text-generation
tags:
- merge
---


MALI-9B (Model with Auto Learning Ideation) is a merge version of Alphacode's Models that has been fine-tuned with Our In House CustomData.
Train Spec : We utilized an A100x8 for training our model with DeepSpeed / HuggingFace TRL Trainer / HuggingFace Accelerate
Contact : Alphacode Co. [https://alphacode.ai/] |
blanchefort/rubert-base-cased-sentiment-rusentiment | blanchefort | 2023-04-06T04:06:16Z | 1,187 | 11 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"text-classification",
"sentiment",
"ru",
"dataset:RuSentiment",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-03-02T23:29:05Z | ---
language:
- ru
tags:
- sentiment
- text-classification
datasets:
- RuSentiment
---
# RuBERT for Sentiment Analysis
This is a [DeepPavlov/rubert-base-cased-conversational](https://huggingface.co/DeepPavlov/rubert-base-cased-conversational) model trained on [RuSentiment](http://text-machine.cs.uml.edu/projects/rusentiment/).
## Labels
0: NEUTRAL
1: POSITIVE
2: NEGATIVE
## How to use
```python
import torch
from transformers import AutoModelForSequenceClassification
from transformers import BertTokenizerFast
tokenizer = BertTokenizerFast.from_pretrained('blanchefort/rubert-base-cased-sentiment-rusentiment')
model = AutoModelForSequenceClassification.from_pretrained('blanchefort/rubert-base-cased-sentiment-rusentiment', return_dict=True)
@torch.no_grad()
def predict(text):
inputs = tokenizer(text, max_length=512, padding=True, truncation=True, return_tensors='pt')
outputs = model(**inputs)
predicted = torch.nn.functional.softmax(outputs.logits, dim=1)
predicted = torch.argmax(predicted, dim=1).numpy()
return predicted
```
## Dataset used for model training
**[RuSentiment](http://text-machine.cs.uml.edu/projects/rusentiment/)**
> A. Rogers A. Romanov A. Rumshisky S. Volkova M. Gronas A. Gribov RuSentiment: An Enriched Sentiment Analysis Dataset for Social Media in Russian. Proceedings of COLING 2018. |
TheBloke/Hermes-Trismegistus-Mistral-7B-GGUF | TheBloke | 2023-11-05T23:47:53Z | 1,187 | 19 | transformers | [
"transformers",
"gguf",
"mistral",
"mistral-7b",
"instruct",
"finetune",
"gpt4",
"synthetic data",
"distillation",
"en",
"dataset:teknium/trismegistus-project",
"base_model:teknium/Hermes-Trismegistus-Mistral-7B",
"license:apache-2.0",
"text-generation-inference",
"region:us"
]
| null | 2023-11-05T23:42:55Z | ---
base_model: teknium/Hermes-Trismegistus-Mistral-7B
datasets:
- teknium/trismegistus-project
inference: false
language:
- en
license: apache-2.0
model-index:
- name: Hermes-Trismegistus-Mistral-7B
results: []
model_creator: Teknium
model_name: Hermes Trismegistus Mistral 7B
model_type: mistral
prompt_template: 'USER: {prompt}
ASSISTANT:
'
quantized_by: TheBloke
tags:
- mistral-7b
- instruct
- finetune
- gpt4
- synthetic data
- distillation
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Hermes Trismegistus Mistral 7B - GGUF
- Model creator: [Teknium](https://huggingface.co/teknium)
- Original model: [Hermes Trismegistus Mistral 7B](https://huggingface.co/teknium/Hermes-Trismegistus-Mistral-7B)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Teknium's Hermes Trismegistus Mistral 7B](https://huggingface.co/teknium/Hermes-Trismegistus-Mistral-7B).
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Hermes-Trismegistus-Mistral-7B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Hermes-Trismegistus-Mistral-7B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Hermes-Trismegistus-Mistral-7B-GGUF)
* [Teknium's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/teknium/Hermes-Trismegistus-Mistral-7B)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: User-Assistant
```
USER: {prompt}
ASSISTANT:
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [hermes-trismegistus-mistral-7b.Q2_K.gguf](https://huggingface.co/TheBloke/Hermes-Trismegistus-Mistral-7B-GGUF/blob/main/hermes-trismegistus-mistral-7b.Q2_K.gguf) | Q2_K | 2 | 3.08 GB| 5.58 GB | smallest, significant quality loss - not recommended for most purposes |
| [hermes-trismegistus-mistral-7b.Q3_K_S.gguf](https://huggingface.co/TheBloke/Hermes-Trismegistus-Mistral-7B-GGUF/blob/main/hermes-trismegistus-mistral-7b.Q3_K_S.gguf) | Q3_K_S | 3 | 3.16 GB| 5.66 GB | very small, high quality loss |
| [hermes-trismegistus-mistral-7b.Q3_K_M.gguf](https://huggingface.co/TheBloke/Hermes-Trismegistus-Mistral-7B-GGUF/blob/main/hermes-trismegistus-mistral-7b.Q3_K_M.gguf) | Q3_K_M | 3 | 3.52 GB| 6.02 GB | very small, high quality loss |
| [hermes-trismegistus-mistral-7b.Q3_K_L.gguf](https://huggingface.co/TheBloke/Hermes-Trismegistus-Mistral-7B-GGUF/blob/main/hermes-trismegistus-mistral-7b.Q3_K_L.gguf) | Q3_K_L | 3 | 3.82 GB| 6.32 GB | small, substantial quality loss |
| [hermes-trismegistus-mistral-7b.Q4_0.gguf](https://huggingface.co/TheBloke/Hermes-Trismegistus-Mistral-7B-GGUF/blob/main/hermes-trismegistus-mistral-7b.Q4_0.gguf) | Q4_0 | 4 | 4.11 GB| 6.61 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [hermes-trismegistus-mistral-7b.Q4_K_S.gguf](https://huggingface.co/TheBloke/Hermes-Trismegistus-Mistral-7B-GGUF/blob/main/hermes-trismegistus-mistral-7b.Q4_K_S.gguf) | Q4_K_S | 4 | 4.14 GB| 6.64 GB | small, greater quality loss |
| [hermes-trismegistus-mistral-7b.Q4_K_M.gguf](https://huggingface.co/TheBloke/Hermes-Trismegistus-Mistral-7B-GGUF/blob/main/hermes-trismegistus-mistral-7b.Q4_K_M.gguf) | Q4_K_M | 4 | 4.37 GB| 6.87 GB | medium, balanced quality - recommended |
| [hermes-trismegistus-mistral-7b.Q5_0.gguf](https://huggingface.co/TheBloke/Hermes-Trismegistus-Mistral-7B-GGUF/blob/main/hermes-trismegistus-mistral-7b.Q5_0.gguf) | Q5_0 | 5 | 5.00 GB| 7.50 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [hermes-trismegistus-mistral-7b.Q5_K_S.gguf](https://huggingface.co/TheBloke/Hermes-Trismegistus-Mistral-7B-GGUF/blob/main/hermes-trismegistus-mistral-7b.Q5_K_S.gguf) | Q5_K_S | 5 | 5.00 GB| 7.50 GB | large, low quality loss - recommended |
| [hermes-trismegistus-mistral-7b.Q5_K_M.gguf](https://huggingface.co/TheBloke/Hermes-Trismegistus-Mistral-7B-GGUF/blob/main/hermes-trismegistus-mistral-7b.Q5_K_M.gguf) | Q5_K_M | 5 | 5.13 GB| 7.63 GB | large, very low quality loss - recommended |
| [hermes-trismegistus-mistral-7b.Q6_K.gguf](https://huggingface.co/TheBloke/Hermes-Trismegistus-Mistral-7B-GGUF/blob/main/hermes-trismegistus-mistral-7b.Q6_K.gguf) | Q6_K | 6 | 5.94 GB| 8.44 GB | very large, extremely low quality loss |
| [hermes-trismegistus-mistral-7b.Q8_0.gguf](https://huggingface.co/TheBloke/Hermes-Trismegistus-Mistral-7B-GGUF/blob/main/hermes-trismegistus-mistral-7b.Q8_0.gguf) | Q8_0 | 8 | 7.70 GB| 10.20 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/Hermes-Trismegistus-Mistral-7B-GGUF and below it, a specific filename to download, such as: hermes-trismegistus-mistral-7b.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/Hermes-Trismegistus-Mistral-7B-GGUF hermes-trismegistus-mistral-7b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/Hermes-Trismegistus-Mistral-7B-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Hermes-Trismegistus-Mistral-7B-GGUF hermes-trismegistus-mistral-7b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m hermes-trismegistus-mistral-7b.Q4_K_M.gguf --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "USER: {prompt}\nASSISTANT:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 2048` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/Hermes-Trismegistus-Mistral-7B-GGUF", model_file="hermes-trismegistus-mistral-7b.Q4_K_M.gguf", model_type="mistral", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Teknium's Hermes Trismegistus Mistral 7B
## Model Description:

Transcendence is All You Need! Mistral Trismegistus is a model made for people interested in the esoteric, occult, and spiritual.
### Trismegistus evolved, trained over Hermes 2.5, the model performs far better in all tasks, including esoteric tasks!
The change between Mistral-Trismegistus and Hermes-Trismegistus is that this version trained over hermes 2.5 instead of the base mistral model, this means it is full of task capabilities that it Trismegistus can utilize for all esoteric and occult tasks, and performs them far better than ever before.
Here are some outputs:



## Acknowledgements:
Special thanks to @a16z.
## Dataset:
This model was trained on a 100% synthetic, gpt-4 generated dataset, about ~10,000 examples, on a wide and diverse set of both tasks and knowledge about the esoteric, occult, and spiritual.
The dataset will be released soon!
## Usage:
Prompt Format:
```
USER: <prompt>
ASSISTANT:
```
OR
```
<system message>
USER: <prompt>
ASSISTANT:
```
## Benchmarks:
No benchmark can capture the nature and essense of the quality of spirituality and esoteric knowledge and tasks. You will have to try testing it yourself!
Training run on wandb here: https://wandb.ai/teknium1/occult-expert-mistral-7b/runs/coccult-expert-mistral-6/overview
## Licensing:
Apache 2.0
<!-- original-model-card end -->
|
athirdpath/Hestia-20b | athirdpath | 2023-11-27T19:39:33Z | 1,187 | 4 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2023-11-25T21:58:19Z | ---
license: cc-by-nc-4.0
---
This is a task_arithmetic merge of Harmonia (my 20b faux base model) with Noromaid and my LORA-glued Nethena. Solidly outperforms Harmonia.
merge_method: task_arithmetic
base_model: athirdpath/Harmonia-20b
models:
- model: athirdpath/Harmonia-20b
- model: NeverSleep/Noromaid-20b-v0.1.1
- parameters: weight: 0.25
- model: athirdpath/Nethena-20b-Glued
- parameters: weight: 0.2
dtype: float16
Thanks to Undi95 for pioneering the 20B recipe, and for most of the models involved. |
mlabonne/NeuralPipe-7B-ties | mlabonne | 2024-06-22T22:33:07Z | 1,187 | 4 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"base_model:OpenPipe/mistral-ft-optimized-1218",
"base_model:mlabonne/NeuralHermes-2.5-Mistral-7B",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2023-12-27T19:46:38Z | ---
license: apache-2.0
base_model:
- OpenPipe/mistral-ft-optimized-1218
- mlabonne/NeuralHermes-2.5-Mistral-7B
tags:
- merge
model-index:
- name: NeuralPipe-7B-ties
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 67.92
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=mlabonne/NeuralPipe-7B-ties
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 86.04
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=mlabonne/NeuralPipe-7B-ties
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 64.24
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=mlabonne/NeuralPipe-7B-ties
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 61.37
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=mlabonne/NeuralPipe-7B-ties
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 80.19
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=mlabonne/NeuralPipe-7B-ties
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 69.52
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=mlabonne/NeuralPipe-7B-ties
name: Open LLM Leaderboard
---
# NeuralPipe-7B-ties
This model is a merge of the following models made with [mergekit](https://github.com/cg123/mergekit):
* [OpenPipe/mistral-ft-optimized-1218](https://huggingface.co/OpenPipe/mistral-ft-optimized-1218)
* [mlabonne/NeuralHermes-2.5-Mistral-7B](https://huggingface.co/mlabonne/NeuralHermes-2.5-Mistral-7B)
## ⚡ Quantized models
Thanks to TheBloke for the quantized models:
* **GGUF**: https://huggingface.co/TheBloke/NeuralPipe-7B-ties-GGUF
* **AWQ**: https://huggingface.co/TheBloke/NeuralPipe-7B-ties-AWQ
* **GPTQ**: https://huggingface.co/TheBloke/NeuralPipe-7B-ties-GPTQ
## 🧩 Configuration
```yaml
models:
- model: mistralai/Mistral-7B-v0.1
# no parameters necessary for base model
- model: OpenPipe/mistral-ft-optimized-1218
parameters:
density: 0.5
weight: 0.5
- model: mlabonne/NeuralHermes-2.5-Mistral-7B
parameters:
density: 0.5
weight: 0.3
merge_method: ties
base_model: mistralai/Mistral-7B-v0.1
parameters:
normalize: true
int8_mask: true
dtype: float16
```
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_mlabonne__NeuralPipe-7B-ties)
| Metric |Value|
|---------------------------------|----:|
|Avg. |71.55|
|AI2 Reasoning Challenge (25-Shot)|67.92|
|HellaSwag (10-Shot) |86.04|
|MMLU (5-Shot) |64.24|
|TruthfulQA (0-shot) |61.37|
|Winogrande (5-shot) |80.19|
|GSM8k (5-shot) |69.52|
|
etri-xainlp/SOLAR-10.7B-sft-dpo-v1 | etri-xainlp | 2024-04-16T01:11:21Z | 1,187 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-16T00:58:13Z | ---
license: cc-by-nc-4.0
---
# etri-xainlp/SOLAR-10.7B-sft-dpo-v1
## Model Details
**Model Developers** ETRI xainlp team
**Input** text only.
**Output** text only.
**Model Architecture**
**Base Model** [davidkim205/nox-solar-10.7b-v4](https://huggingface.co/davidkim205/nox-solar-10.7b-v4)
**Training Dataset**
- sft+lora: 1,821,734 cot set
- dpo+lora: 221,869 user preference set
- We use A100 GPU 80GB * 8, when training. |
fiveflow/KoLlama-3-8B-Instruct | fiveflow | 2024-04-30T09:42:55Z | 1,187 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"conversational",
"ko",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-30T09:34:11Z | ---
license: apache-2.0
tags:
- generated_from_trainer
base_model: meta-llama/Meta-Llama-3-8B-Instruct
model-index:
- name: fiveflow/KoLlama-3-8B-Instruct
results: []
language:
- ko
---
How to use
```Python
from transformers import AutoModelForCausalLM, AutoTokenizer, TextGenerationPipeline
model_path = 'fiveflow/KoLlama-3-8B-Instruct'
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path,
device_map="auto",
# load_in_4bit=True,
low_cpu_mem_usage=True)
pipe = TextGenerationPipeline(model = model, tokenizer = tokenizer)
``` |
SdValar/deliberate2 | SdValar | 2023-02-27T02:29:24Z | 1,186 | 7 | diffusers | [
"diffusers",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2023-02-27T02:27:39Z | Entry not found |
ChrisWilson011016/5DwUwHNRWXQTRUpfkYcpaLdTbCLuKp4D95zrBD9dxAgB6F9X_vgg | ChrisWilson011016 | 2024-03-04T18:56:42Z | 1,186 | 0 | keras | [
"keras",
"region:us"
]
| null | 2024-02-24T15:23:14Z | Entry not found |
jeveuxaider/jva-mission-report | jeveuxaider | 2024-06-06T20:54:11Z | 1,186 | 0 | transformers | [
"transformers",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-06T20:54:09Z | Entry not found |
Ransss/llama-3-Nephilim-v2-8B-Q8_0-GGUF | Ransss | 2024-06-30T12:45:27Z | 1,186 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"base_model:grimjim/llama-3-Nephilim-v2-8B",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-06-30T12:39:11Z | ---
base_model: grimjim/llama-3-Nephilim-v2-8B
library_name: transformers
license: cc-by-nc-4.0
pipeline_tag: text-generation
tags:
- mergekit
- merge
- llama-cpp
- gguf-my-repo
---
# Ransss/llama-3-Nephilim-v2-8B-Q8_0-GGUF
This model was converted to GGUF format from [`grimjim/llama-3-Nephilim-v2-8B`](https://huggingface.co/grimjim/llama-3-Nephilim-v2-8B) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/grimjim/llama-3-Nephilim-v2-8B) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Ransss/llama-3-Nephilim-v2-8B-Q8_0-GGUF --hf-file llama-3-nephilim-v2-8b-q8_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Ransss/llama-3-Nephilim-v2-8B-Q8_0-GGUF --hf-file llama-3-nephilim-v2-8b-q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Ransss/llama-3-Nephilim-v2-8B-Q8_0-GGUF --hf-file llama-3-nephilim-v2-8b-q8_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Ransss/llama-3-Nephilim-v2-8B-Q8_0-GGUF --hf-file llama-3-nephilim-v2-8b-q8_0.gguf -c 2048
```
|
timm/eva_large_patch14_336.in22k_ft_in22k_in1k | timm | 2024-02-10T23:27:58Z | 1,185 | 0 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-22k",
"arxiv:2211.07636",
"license:mit",
"region:us"
]
| image-classification | 2022-12-22T07:11:06Z | ---
license: mit
library_name: timm
tags:
- image-classification
- timm
datasets:
- imagenet-1k
- imagenet-22k
- imagenet-22k
---
# Model card for eva_large_patch14_336.in22k_ft_in22k_in1k
An EVA image classification model. Pretrained on ImageNet-22k with masked image modeling (using EVA-CLIP as a MIM teacher) and fine-tuned on ImageNet-22k then on ImageNet-1k by paper authors.
NOTE: `timm` checkpoints are float32 for consistency with other models. Original checkpoints are float16 or bfloat16 in some cases, see originals if that's preferred.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 304.5
- GMACs: 191.1
- Activations (M): 270.2
- Image size: 336 x 336
- **Papers:**
- EVA: Exploring the Limits of Masked Visual Representation Learning at Scale: https://arxiv.org/abs/2211.07636
- **Pretrain Dataset:**
- ImageNet-22k
- ImageNet-22k
- **Dataset:** ImageNet-1k
- **Original:**
- https://github.com/baaivision/EVA
- https://huggingface.co/BAAI/EVA
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('eva_large_patch14_336.in22k_ft_in22k_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'eva_large_patch14_336.in22k_ft_in22k_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 577, 1024) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
|model |top1 |top5 |param_count|img_size|
|-----------------------------------------------|------|------|-----------|--------|
|eva02_large_patch14_448.mim_m38m_ft_in22k_in1k |90.054|99.042|305.08 |448 |
|eva02_large_patch14_448.mim_in22k_ft_in22k_in1k|89.946|99.01 |305.08 |448 |
|eva_giant_patch14_560.m30m_ft_in22k_in1k |89.792|98.992|1014.45 |560 |
|eva02_large_patch14_448.mim_in22k_ft_in1k |89.626|98.954|305.08 |448 |
|eva02_large_patch14_448.mim_m38m_ft_in1k |89.57 |98.918|305.08 |448 |
|eva_giant_patch14_336.m30m_ft_in22k_in1k |89.56 |98.956|1013.01 |336 |
|eva_giant_patch14_336.clip_ft_in1k |89.466|98.82 |1013.01 |336 |
|eva_large_patch14_336.in22k_ft_in22k_in1k |89.214|98.854|304.53 |336 |
|eva_giant_patch14_224.clip_ft_in1k |88.882|98.678|1012.56 |224 |
|eva02_base_patch14_448.mim_in22k_ft_in22k_in1k |88.692|98.722|87.12 |448 |
|eva_large_patch14_336.in22k_ft_in1k |88.652|98.722|304.53 |336 |
|eva_large_patch14_196.in22k_ft_in22k_in1k |88.592|98.656|304.14 |196 |
|eva02_base_patch14_448.mim_in22k_ft_in1k |88.23 |98.564|87.12 |448 |
|eva_large_patch14_196.in22k_ft_in1k |87.934|98.504|304.14 |196 |
|eva02_small_patch14_336.mim_in22k_ft_in1k |85.74 |97.614|22.13 |336 |
|eva02_tiny_patch14_336.mim_in22k_ft_in1k |80.658|95.524|5.76 |336 |
## Citation
```bibtex
@article{EVA,
title={EVA: Exploring the Limits of Masked Visual Representation Learning at Scale},
author={Fang, Yuxin and Wang, Wen and Xie, Binhui and Sun, Quan and Wu, Ledell and Wang, Xinggang and Huang, Tiejun and Wang, Xinlong and Cao, Yue},
journal={arXiv preprint arXiv:2211.07636},
year={2022}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
|
fatgong/5DhwFYtWCHEVhGHreyYeRwg1NWBHrdqXEzfPyLh5Q4efrCTi_vgg | fatgong | 2024-03-27T22:48:23Z | 1,185 | 0 | keras | [
"keras",
"region:us"
]
| null | 2024-03-09T14:08:36Z | Entry not found |
PowerInfer/Bamboo-base-v0.1-gguf | PowerInfer | 2024-03-28T07:10:26Z | 1,185 | 4 | transformers | [
"transformers",
"gguf",
"bamboo",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-03-26T06:53:02Z | ---
license: apache-2.0
---
# Bamboo-base-v0.1-PowerInfer-GGUF
- Original model: [PowerInfer/Bamboo-base-v0_1](https://huggingface.co/PowerInfer/Bamboo-base-v0_1)
- Converted & distributed by: [PowerInfer](https://huggingface.co/PowerInfer)
### Citation
Please kindly cite using the following BibTeX:
```bibtex
@misc{bamboo,
title={Bamboo: Harmonizing Sparsity and Performance in Large Language Models},
author={Yixin Song, Haotong Xie, Zeyu Mi, Li Ma, Haibo Chen},
year={2024}
}
```
|
mmnga/Fugaku-LLM-13B-instruct-gguf | mmnga | 2024-05-12T06:06:51Z | 1,185 | 2 | null | [
"gguf",
"gpt2",
"en",
"ja",
"dataset:TFMC/imatrix-dataset-for-japanese-llm",
"license:other",
"region:us"
]
| null | 2024-05-10T16:43:49Z | ---
license: other
license_name: fugaku-llm-tou
license_link: https://huggingface.co/Fugaku-LLM/Fugaku-LLM-13B-instruct/blob/main/LICENSE
language:
- en
- ja
datasets:
- TFMC/imatrix-dataset-for-japanese-llm
tags:
- gpt2
---
# Fugaku-LLM-13B-instruct-gguf
[Fugaku-LLMさんが公開しているFugaku-LLM-13B-instruct](https://huggingface.co/Fugaku-LLM/Fugaku-LLM-13B-instruct)のggufフォーマット変換版です。
imatrixのデータは[TFMC/imatrix-dataset-for-japanese-llm](https://huggingface.co/datasets/TFMC/imatrix-dataset-for-japanese-llm)を使用して作成しました。
## License
ご使用の前に必ず利用規約をご確認ください。
ご使用の際には[利用規約](https://huggingface.co/Fugaku-LLM/Fugaku-LLM-13B-instruct/blob/main/LICENSE)に同意したものとされます。
Please be sure to check the terms of use before use.
By using this service, you agree to the [Terms of Use](https://huggingface.co/Fugaku-LLM/Fugaku-LLM-13B-instruct/blob/main/LICENSE).
## convert
変換用スクリプトは[こちら](https://gist.github.com/mmnga/e70fbf78db8478e0215b733fe60685da)
## Usage
```
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
make -j
./main -m 'Fugaku-LLM-13B-instruct-Q4_0.gguf' -n 128 -p '以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい。\n\n### 指示:\nスーパーコンピュータ「富岳」の名前の由来を教えてください。\n\n### 応答:\n'
``` |
saberbx/First-x-mode-version | saberbx | 2024-06-27T03:12:30Z | 1,185 | 0 | transformers | [
"transformers",
"gguf",
"mistral",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| null | 2024-06-27T02:57:25Z | Entry not found |
OFA-Sys/chinese-clip-vit-huge-patch14 | OFA-Sys | 2022-12-09T06:11:22Z | 1,184 | 19 | transformers | [
"transformers",
"pytorch",
"chinese_clip",
"zero-shot-image-classification",
"vision",
"arxiv:2211.01335",
"endpoints_compatible",
"region:us"
]
| zero-shot-image-classification | 2022-11-09T09:45:11Z | ---
tags:
- vision
widget:
- src: https://huggingface.co/OFA-Sys/chinese-clip-vit-base-patch16/resolve/main/festival.jpg
candidate_labels: 灯笼, 鞭炮, 对联
example_title: festival
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-dog-music.png
candidate_labels: 音乐表演, 体育运动
example_title: cat & dog
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/football-match.jpg
candidate_labels: 梅西, C罗, 马奎尔
example_title: football
---
# Chinese-CLIP-ViT-Huge-Patch14
## Introduction
This is the huge-version of the Chinese CLIP, with ViT-H/14 as the image encoder and RoBERTa-wwm-large as the text encoder. Chinese CLIP is a simple implementation of CLIP on a large-scale dataset of around 200 million Chinese image-text pairs. For more details, please refer to our technical report https://arxiv.org/abs/2211.01335 and our official github repo https://github.com/OFA-Sys/Chinese-CLIP (Welcome to star! 🔥🔥)
## Use with the official API
We provide a simple code snippet to show how to use the API of Chinese-CLIP to compute the image & text embeddings and similarities.
```python
from PIL import Image
import requests
from transformers import ChineseCLIPProcessor, ChineseCLIPModel
model = ChineseCLIPModel.from_pretrained("OFA-Sys/chinese-clip-vit-huge-patch14")
processor = ChineseCLIPProcessor.from_pretrained("OFA-Sys/chinese-clip-vit-huge-patch14")
url = "https://clip-cn-beijing.oss-cn-beijing.aliyuncs.com/pokemon.jpeg"
image = Image.open(requests.get(url, stream=True).raw)
# Squirtle, Bulbasaur, Charmander, Pikachu in English
texts = ["杰尼龟", "妙蛙种子", "小火龙", "皮卡丘"]
# compute image feature
inputs = processor(images=image, return_tensors="pt")
image_features = model.get_image_features(**inputs)
image_features = image_features / image_features.norm(p=2, dim=-1, keepdim=True) # normalize
# compute text features
inputs = processor(text=texts, padding=True, return_tensors="pt")
text_features = model.get_text_features(**inputs)
text_features = text_features / text_features.norm(p=2, dim=-1, keepdim=True) # normalize
# compute image-text similarity scores
inputs = processor(text=texts, images=image, return_tensors="pt", padding=True)
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # this is the image-text similarity score
probs = logits_per_image.softmax(dim=1) # probs: [[1.1419e-02, 1.0478e-02, 5.2018e-04, 9.7758e-01]]
```
However, if you are not satisfied with only using the API, feel free to check our github repo https://github.com/OFA-Sys/Chinese-CLIP for more details about training and inference.
<br><br>
## Results
**MUGE Text-to-Image Retrieval**:
<table border="1" width="100%">
<tr align="center">
<th>Setup</th><th colspan="4">Zero-shot</th><th colspan="4">Finetune</th>
</tr>
<tr align="center">
<td>Metric</td><td>R@1</td><td>R@5</td><td>R@10</td><td>MR</td><td>R@1</td><td>R@5</td><td>R@10</td><td>MR</td>
</tr>
<tr align="center">
<td width="120%">Wukong</td><td>42.7</td><td>69.0</td><td>78.0</td><td>63.2</td><td>52.7</td><td>77.9</td><td>85.6</td><td>72.1</td>
</tr>
<tr align="center">
<td width="120%">R2D2</td><td>49.5</td><td>75.7</td><td>83.2</td><td>69.5</td><td>60.1</td><td>82.9</td><td>89.4</td><td>77.5</td>
</tr>
<tr align="center">
<td width="120%">CN-CLIP</td><td>63.0</td><td>84.1</td><td>89.2</td><td>78.8</td><td>68.9</td><td>88.7</td><td>93.1</td><td>83.6</td>
</tr>
</table>
<br>
**Flickr30K-CN Retrieval**:
<table border="1" width="120%">
<tr align="center">
<th>Task</th><th colspan="6">Text-to-Image</th><th colspan="6">Image-to-Text</th>
</tr>
<tr align="center">
<th>Setup</th><th colspan="3">Zero-shot</th><th colspan="3">Finetune</th><th colspan="3">Zero-shot</th><th colspan="3">Finetune</th>
</tr>
<tr align="center">
<td>Metric</td><td>R@1</td><td>R@5</td><td>R@10</td><td>R@1</td><td>R@5</td><td>R@10</td><td>R@1</td><td>R@5</td><td>R@10</td><td>R@1</td><td>R@5</td><td>R@10</td>
</tr>
<tr align="center">
<td width="120%">Wukong</td><td>51.7</td><td>78.9</td><td>86.3</td><td>77.4</td><td>94.5</td><td>97.0</td><td>76.1</td><td>94.8</td><td>97.5</td><td>92.7</td><td>99.1</td><td>99.6</td>
</tr>
<tr align="center">
<td width="120%">R2D2</td><td>60.9</td><td>86.8</td><td>92.7</td><td>84.4</td><td>96.7</td><td>98.4</td><td>77.6</td><td>96.7</td><td>98.9</td><td>95.6</td><td>99.8</td><td>100.0</td>
</tr>
<tr align="center">
<td width="120%">CN-CLIP</td><td>71.2</td><td>91.4</td><td>95.5</td><td>83.8</td><td>96.9</td><td>98.6</td><td>81.6</td><td>97.5</td><td>98.8</td><td>95.3</td><td>99.7</td><td>100.0</td>
</tr>
</table>
<br>
**COCO-CN Retrieval**:
<table border="1" width="100%">
<tr align="center">
<th>Task</th><th colspan="6">Text-to-Image</th><th colspan="6">Image-to-Text</th>
</tr>
<tr align="center">
<th>Setup</th><th colspan="3">Zero-shot</th><th colspan="3">Finetune</th><th colspan="3">Zero-shot</th><th colspan="3">Finetune</th>
</tr>
<tr align="center">
<td>Metric</td><td>R@1</td><td>R@5</td><td>R@10</td><td>R@1</td><td>R@5</td><td>R@10</td><td>R@1</td><td>R@5</td><td>R@10</td><td>R@1</td><td>R@5</td><td>R@10</td>
</tr>
<tr align="center">
<td width="120%">Wukong</td><td>53.4</td><td>80.2</td><td>90.1</td><td>74.0</td><td>94.4</td><td>98.1</td><td>55.2</td><td>81.0</td><td>90.6</td><td>73.3</td><td>94.0</td><td>98.0</td>
</tr>
<tr align="center">
<td width="120%">R2D2</td><td>56.4</td><td>85.0</td><td>93.1</td><td>79.1</td><td>96.5</td><td>98.9</td><td>63.3</td><td>89.3</td><td>95.7</td><td>79.3</td><td>97.1</td><td>98.7</td>
</tr>
<tr align="center">
<td width="120%">CN-CLIP</td><td>69.2</td><td>89.9</td><td>96.1</td><td>81.5</td><td>96.9</td><td>99.1</td><td>63.0</td><td>86.6</td><td>92.9</td><td>83.5</td><td>97.3</td><td>99.2</td>
</tr>
</table>
<br>
**Zero-shot Image Classification**:
<table border="1" width="100%">
<tr align="center">
<th>Task</th><th>CIFAR10</th><th>CIFAR100</th><th>DTD</th><th>EuroSAT</th><th>FER</th><th>FGVC</th><th>KITTI</th><th>MNIST</th><th>PC</th><th>VOC</th>
</tr>
<tr align="center">
<td width="150%">GIT</td><td>88.5</td><td>61.1</td><td>42.9</td><td>43.4</td><td>41.4</td><td>6.7</td><td>22.1</td><td>68.9</td><td>50.0</td><td>80.2</td>
</tr>
<tr align="center">
<td width="150%">ALIGN</td><td>94.9</td><td>76.8</td><td>66.1</td><td>52.1</td><td>50.8</td><td>25.0</td><td>41.2</td><td>74.0</td><td>55.2</td><td>83.0</td>
</tr>
<tr align="center">
<td width="150%">CLIP</td><td>94.9</td><td>77.0</td><td>56.0</td><td>63.0</td><td>48.3</td><td>33.3</td><td>11.5</td><td>79.0</td><td>62.3</td><td>84.0</td>
</tr>
<tr align="center">
<td width="150%">Wukong</td><td>95.4</td><td>77.1</td><td>40.9</td><td>50.3</td><td>-</td><td>-</td><td>-</td><td>-</td><td>-</td><td>-</td>
</tr>
<tr align="center">
<td width="150%">CN-CLIP</td><td>96.0</td><td>79.7</td><td>51.2</td><td>52.0</td><td>55.1</td><td>26.2</td><td>49.9</td><td>79.4</td><td>63.5</td><td>84.9</td>
</tr>
</table>
<br>
## Citation
If you find Chinese CLIP helpful, feel free to cite our paper. Thanks for your support!
```
@article{chinese-clip,
title={Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese},
author={Yang, An and Pan, Junshu and Lin, Junyang and Men, Rui and Zhang, Yichang and Zhou, Jingren and Zhou, Chang},
journal={arXiv preprint arXiv:2211.01335},
year={2022}
}
```
<br> |
timm/xception71.tf_in1k | timm | 2023-04-21T23:46:21Z | 1,184 | 0 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:1802.02611",
"arxiv:1610.02357",
"license:apache-2.0",
"region:us"
]
| image-classification | 2023-04-21T23:45:37Z | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for xception71.tf_in1k
An Aligned Xception image classification model. Trained on ImageNet-1k in Tensorflow and ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 42.3
- GMACs: 18.1
- Activations (M): 69.9
- Image size: 299 x 299
- **Papers:**
- Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation: https://arxiv.org/abs/1802.02611
- Xception: Deep Learning with Depthwise Separable Convolutions: https://arxiv.org/abs/1610.02357
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/tensorflow/models/blob/master/research/deeplab/
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('xception71.tf_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'xception71.tf_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 128, 150, 150])
# torch.Size([1, 256, 75, 75])
# torch.Size([1, 728, 38, 38])
# torch.Size([1, 1024, 19, 19])
# torch.Size([1, 2048, 10, 10])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'xception71.tf_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 2048, 10, 10) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Citation
```bibtex
@inproceedings{deeplabv3plus2018,
title={Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation},
author={Liang-Chieh Chen and Yukun Zhu and George Papandreou and Florian Schroff and Hartwig Adam},
booktitle={ECCV},
year={2018}
}
```
```bibtex
@misc{chollet2017xception,
title={Xception: Deep Learning with Depthwise Separable Convolutions},
author={François Chollet},
year={2017},
eprint={1610.02357},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
|
antoinelouis/biencoder-camembert-base-mmarcoFR | antoinelouis | 2024-03-26T14:20:48Z | 1,184 | 9 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"safetensors",
"camembert",
"passage-retrieval",
"sentence-similarity",
"fr",
"dataset:unicamp-dl/mmarco",
"base_model:camembert-base",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-embeddings-inference",
"region:us"
]
| sentence-similarity | 2023-05-22T20:54:25Z | ---
pipeline_tag: sentence-similarity
language: fr
license: mit
datasets:
- unicamp-dl/mmarco
metrics:
- recall
tags:
- passage-retrieval
library_name: sentence-transformers
base_model: camembert-base
model-index:
- name: biencoder-camembert-base-mmarcoFR
results:
- task:
type: sentence-similarity
name: Passage Retrieval
dataset:
type: unicamp-dl/mmarco
name: mMARCO-fr
config: french
split: validation
metrics:
- type: recall_at_500
name: Recall@500
value: 89.1
- type: recall_at_100
name: Recall@100
value: 77.8
- type: recall_at_10
name: Recall@10
value: 51.5
- type: map_at_10
name: MAP@10
value: 27.9
- type: ndcg_at_10
name: nDCG@10
value: 33.7
- type: mrr_at_10
name: MRR@10
value: 28.5
---
# biencoder-camembert-base-mmarcoFR
This is a dense single-vector bi-encoder model for **French** that can be used for semantic search. The model maps queries and passages to 768-dimensional dense vectors which are used to compute relevance through cosine similarity.
## Usage
Here are some examples for using the model with [Sentence-Transformers](#using-sentence-transformers), [FlagEmbedding](#using-flagembedding), or [Huggingface Transformers](#using-huggingface-transformers).
#### Using Sentence-Transformers
Start by installing the [library](https://www.SBERT.net): `pip install -U sentence-transformers`. Then, you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
queries = ["Ceci est un exemple de requête.", "Voici un second exemple."]
passages = ["Ceci est un exemple de passage.", "Et voilà un deuxième exemple."]
model = SentenceTransformer('antoinelouis/biencoder-camembert-base-mmarcoFR')
q_embeddings = model.encode(queries, normalize_embeddings=True)
p_embeddings = model.encode(passages, normalize_embeddings=True)
similarity = q_embeddings @ p_embeddings.T
print(similarity)
```
#### Using FlagEmbedding
Start by installing the [library](https://github.com/FlagOpen/FlagEmbedding/): `pip install -U FlagEmbedding`. Then, you can use the model like this:
```python
from FlagEmbedding import FlagModel
queries = ["Ceci est un exemple de requête.", "Voici un second exemple."]
passages = ["Ceci est un exemple de passage.", "Et voilà un deuxième exemple."]
model = FlagModel('antoinelouis/biencoder-camembert-base-mmarcoFR')
q_embeddings = model.encode(queries, normalize_embeddings=True)
p_embeddings = model.encode(passages, normalize_embeddings=True)
similarity = q_embeddings @ p_embeddings.T
print(similarity)
```
#### Using Transformers
Start by installing the [library](https://huggingface.co/docs/transformers): `pip install -U transformers`. Then, you can use the model like this:
```python
from transformers import AutoTokenizer, AutoModel
from torch.nn.functional import normalize
def mean_pooling(model_output, attention_mask):
""" Perform mean pooling on-top of the contextualized word embeddings, while ignoring mask tokens in the mean computation."""
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
queries = ["Ceci est un exemple de requête.", "Voici un second exemple."]
passages = ["Ceci est un exemple de passage.", "Et voilà un deuxième exemple."]
tokenizer = AutoTokenizer.from_pretrained('antoinelouis/biencoder-camembert-base-mmarcoFR')
model = AutoModel.from_pretrained('antoinelouis/biencoder-camembert-base-mmarcoFR')
q_input = tokenizer(queries, padding=True, truncation=True, return_tensors='pt')
p_input = tokenizer(passages, padding=True, truncation=True, return_tensors='pt')
with torch.no_grad():
q_output = model(**encoded_queries)
p_output = model(**encoded_passages)
q_embeddings = mean_pooling(q_output, q_input['attention_mask'])
q_embedddings = normalize(q_embeddings, p=2, dim=1)
p_embeddings = mean_pooling(p_output, p_input['attention_mask'])
p_embedddings = normalize(p_embeddings, p=2, dim=1)
similarity = q_embeddings @ p_embeddings.T
print(similarity)
```
## Evaluation
The model is evaluated on the smaller development set of [mMARCO-fr](https://ir-datasets.com/mmarco.html#mmarco/v2/fr/), which consists of 6,980 queries for a corpus of
8.8M candidate passages. We report the mean reciprocal rank (MRR), normalized discounted cumulative gainand (NDCG), mean average precision (MAP), and recall at various cut-offs (R@k).
To see how it compares to other neural retrievers in French, check out the [*DécouvrIR*](https://huggingface.co/spaces/antoinelouis/decouvrir) leaderboard.
## Training
#### Data
We use the French training samples from the [mMARCO](https://huggingface.co/datasets/unicamp-dl/mmarco) dataset, a multilingual machine-translated version of MS MARCO that contains 8.8M passages and 539K training queries. We do not employ the BM25 netaives provided by the official dataset but instead sample harder negatives mined from 12 distinct dense retrievers, using the [msmarco-hard-negatives](https://huggingface.co/datasets/sentence-transformers/msmarco-hard-negatives) distillation dataset.
#### Implementation
The model is initialized from the [camembert-base](https://huggingface.co/camembert-base) checkpoint and optimized via the cross-entropy loss (as in [DPR](https://doi.org/10.48550/arXiv.2004.04906)) with a temperature of 0.05. It is fine-tuned on one 32GB NVIDIA V100 GPU for 20 epochs (i.e., 65.7k steps) using the AdamW optimizer with a batch size of 152, a peak learning rate of 2e-5 with warm up along the first 500 steps and linear scheduling. We set the maximum sequence lengths for both the questions and passages to 128 tokens. We use the cosine similarity to compute relevance scores.
## Citation
```bibtex
@online{louis2024decouvrir,
author = 'Antoine Louis',
title = 'DécouvrIR: A Benchmark for Evaluating the Robustness of Information Retrieval Models in French',
publisher = 'Hugging Face',
month = 'mar',
year = '2024',
url = 'https://huggingface.co/spaces/antoinelouis/decouvrir',
}
``` |
nvidia/Nemotron-4-340B-Base | nvidia | 2024-06-28T04:59:08Z | 1,184 | 129 | nemo | [
"nemo",
"nvidia",
"license:other",
"region:us"
]
| null | 2024-06-14T04:04:27Z | ---
license: other
license_name: nvidia-open-model-license
license_link: https://developer.download.nvidia.com/licenses/nvidia-open-model-license-agreement-june-2024.pdf
library_name: nemo
inference: false
fine-tuning: false
tags:
- nvidia
---
## Nemotron-4-340B-Base
[](#model-architecture)[](#model-architecture)[](#datasets)
### Model Overview:
Nemotron-4-340B-Base is a large language model (LLM) that can be used as part of a synthetic data generation pipeline to create training data that helps researchers and developers build their own LLMs. This model has 340 billion parameters, and supports a context length of 4,096 tokens. It is pre-trained for a total of 9 trillion tokens, consisting of a diverse assortment of English-based texts, 50+ natural languages and 40+ coding languages. After an initial pre-training phase of 8 trillion tokens, continuous pre-training of 1 trillion tokens was performed on top of the pre-trained model in order to improve model quality. During continuous pre-training, we altered the data composition by using a different distribution than the one seen at the beginning of training.
Under the NVIDIA Open Model License, NVIDIA confirms:
- Models are commercially usable.
- You are free to create and distribute Derivative Models.
- NVIDIA does not claim ownership to any outputs generated using the Models or Derivative Models
### License:
[NVIDIA Open Model License](https://developer.download.nvidia.com/licenses/nvidia-open-model-license-agreement-june-2024.pdf)
### Intended use
Nemotron-4-340B-Base is a completion model intended for use in over 50+ natural and 40+ coding languages. It is compatible with [NVIDIA NeMo Framework](https://docs.nvidia.com/nemo-framework/index.html). For best performance on a given task, users are encouraged to customize the model using the NeMo Framework suite of customization tools including Parameter-Efficient Fine-Tuning (P-tuning, Adapters, LoRA, and more), and Model Alignment (SFT, SteerLM, RLHF, and more) using [NeMo-Aligner](https://github.com/NVIDIA/NeMo-Aligner). Refer to the [documentation](https://docs.nvidia.com/nemo-framework/user-guide/latest/llms/nemotron/index.html) for examples.
**Model Developer:** NVIDIA
**Model Dates:** Nemotron-4-340B-Base was trained between December 2023 and May 2024.
### Required Hardware
BF16 Inference:
- 8x H200 (1x H200 node)
- 16x H100 (2x H100 nodes)
- 16x A100 80GB (2x A100 80GB nodes)
### Model Architecture:
Nemotron-4-340B-Base is trained with a global batch-size of 2304, a sequence length of 4096 tokens, uses Grouped-Query Attention (GQA), and Rotary Position Embeddings (RoPE).
**Architecture Type:** Transformer Decoder (auto-regressive language model)
**Network Architecture:**
Nemotron-4
### Usage
Deployment and inference with Nemotron-4-340B-Base can be done in three steps using NeMo Framework:
1. Create a Python script to interact with the deployed model.
2. Create a Bash script to start the inference server.
3. Schedule a Slurm job to distribute the model across 2 nodes and associate them with the inference server.
The first task is for the Python Script.
1. Define the Python script ``call_server.py``
```python
import requests
import json
headers = {"Content-Type": "application/json"}
def text_generation(data, ip='localhost', port=None):
resp = requests.put(f'http://{ip}:{port}/generate', data=json.dumps(data), headers=headers)
return resp.json()
def get_generation(prompt, greedy, add_BOS, token_to_gen, min_tokens, temp, top_p, top_k, repetition, batch=False):
data = {
"sentences": [prompt] if not batch else prompt,
"tokens_to_generate": int(token_to_gen),
"temperature": temp,
"add_BOS": add_BOS,
"top_k": top_k,
"top_p": top_p,
"greedy": greedy,
"all_probs": False,
"repetition_penalty": repetition,
"min_tokens_to_generate": int(min_tokens),
"end_strings": ["<|endoftext|>", "<extra_id_1>", "\x11", "<extra_id_1>User"],
}
sentences = text_generation(data, port=1424)['sentences']
return sentences[0] if not batch else sentences
PROMPT_TEMPLATE = "{prompt}"
question = "Write a poem on NVIDIA in the style of Shakespeare"
prompt = PROMPT_TEMPLATE.format(prompt=question)
print(prompt)
response = get_generation(prompt, greedy=True, add_BOS=False, token_to_gen=1024, min_tokens=1, temp=1.0, top_p=1.0, top_k=0, repetition=1.0, batch=False)
response = response[len(prompt):]
print(response)
```
2. Given this Python script, create a Bash script which spins up the inference server within the [NeMo container](https://catalog.ngc.nvidia.com/orgs/nvidia/containers/nemo) (```docker pull nvcr.io/nvidia/nemo:24.05```) and calls the Python script ``call_server.py``. The Bash script ``nemo_inference.sh`` is as follows:
```bash
NEMO_FILE=$1
WEB_PORT=1424
depends_on () {
HOST=$1
PORT=$2
STATUS=$(curl -X PUT http://$HOST:$PORT >/dev/null 2>/dev/null; echo $?)
while [ $STATUS -ne 0 ]
do
echo "waiting for server ($HOST:$PORT) to be up"
sleep 10
STATUS=$(curl -X PUT http://$HOST:$PORT >/dev/null 2>/dev/null; echo $?)
done
echo "server ($HOST:$PORT) is up running"
}
/usr/bin/python3 /opt/NeMo/examples/nlp/language_modeling/megatron_gpt_eval.py \
gpt_model_file=$NEMO_FILE \
pipeline_model_parallel_split_rank=0 \
server=True tensor_model_parallel_size=8 \
trainer.precision=bf16 pipeline_model_parallel_size=2 \
trainer.devices=8 \
trainer.num_nodes=2 \
web_server=False \
port=${WEB_PORT} &
SERVER_PID=$!
readonly local_rank="${LOCAL_RANK:=${SLURM_LOCALID:=${OMPI_COMM_WORLD_LOCAL_RANK:-}}}"
if [ $SLURM_NODEID -eq 0 ] && [ $local_rank -eq 0 ]; then
depends_on "0.0.0.0" ${WEB_PORT}
echo "start get json"
sleep 5
echo "SLURM_NODEID: $SLURM_NODEID"
echo "local_rank: $local_rank"
/usr/bin/python3 /scripts/call_server.py
echo "clean up dameons: $$"
kill -9 $SERVER_PID
pkill python
fi
wait
```
3. Launch ``nemo_inference.sh`` with a Slurm script defined like below, which starts a 2-node job for model inference.
```bash
#!/bin/bash
#SBATCH -A SLURM-ACCOUNT
#SBATCH -p SLURM-PARITION
#SBATCH -N 2
#SBATCH -J generation
#SBATCH --ntasks-per-node=8
#SBATCH --gpus-per-node=8
set -x
RESULTS=<PATH_TO_YOUR_SCRIPTS_FOLDER>
OUTFILE="${RESULTS}/slurm-%j-%n.out"
ERRFILE="${RESULTS}/error-%j-%n.out"
MODEL=<PATH_TO>/Nemotron-4-340B-Base
CONTAINER="nvcr.io/nvidia/nemo:24.05"
MOUNTS="--container-mounts=<PATH_TO_YOUR_SCRIPTS_FOLDER>:/scripts,MODEL:/model"
read -r -d '' cmd <<EOF
bash /scripts/nemo_inference.sh /model
EOF
srun -o $OUTFILE -e $ERRFILE --container-image="$CONTAINER" $MOUNTS bash -c "${cmd}"
```
### Dataset & Training
The training corpus for Nemotron-4-340B-Base consists of English and multilingual text, as well as code. Our sources cover a variety of document types such as: webpages, dialogue, articles, and other written materials. The corpus spans domains including legal, math, science, finance, and more. In our continued training set, we introduce a small portion of question-answering, and alignment style data to improve model performance.
**Data Freshness:** The pretraining data has a cutoff of June 2023.
### Evaluation Results
#### Overview
*5-shot performance.* Language Understanding evaluated using Massive Multitask Language Understanding:
| Average |
| :------------- |
| 81.1 |
*Zero-shot performance.* Evaluated using select datasets from the LM Evaluation Harness with additions:
| HellaSwag | Winogrande | BBH| ARC-Challenge |
| :------------- | :------------- | :------------- | :------------- |
| 90.53 | 89.50 | 85.44 | 94.28 |
*Chain of Thought (CoT)*. Multilingual capabilities evaluated using Multilingual Grade School Math:
| ES Exact Match (%) | JA Exact Match (%) | TH Exact Match (%) |
| :------------- | :------------- | :------------- |
| 68.8 | 69.6 | 68.4 |
*Code generation performance*. Evaluated using HumanEval:
| p@1, 0-Shot |
| :------------- |
| 57.3 |
### Limitations
The model was trained on data that contains toxic language, unsafe content, and societal biases originally crawled from the internet. Therefore, the model may amplify those biases and return toxic responses especially when prompted with toxic prompts. The model may generate answers that may be inaccurate, omit key information, or include irrelevant or redundant text producing socially unacceptable or undesirable text, even if the prompt itself does not include anything explicitly offensive.
### Ethical Considerations
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse. For more detailed information on ethical considerations for this model, please see the Model Card++ Explainability, Bias, Safety & Security, and Privacy Subcards [here.](https://catalog.ngc.nvidia.com/orgs/nvidia/teams/nemo/models/nemotron-4-340b-base). Please report security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/).
|
google/t5_11b_trueteacher_and_anli | google | 2023-12-26T10:15:09Z | 1,183 | 12 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"natural-language-inference",
"news-articles-summarization",
"en",
"dataset:google/trueteacher",
"dataset:anli",
"dataset:cnn_dailymail",
"arxiv:2305.11171",
"arxiv:2210.11416",
"arxiv:2204.04991",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text2text-generation | 2023-08-14T11:22:54Z | ---
license: cc-by-nc-4.0
language:
- en
datasets:
- google/trueteacher
- anli
- cnn_dailymail
tags:
- natural-language-inference
- news-articles-summarization
---
# **TrueTeacher**
This is a **Factual Consistency Evaluation** model, introduced in the [TrueTeacher paper (Gekhman et al, 2023)](https://aclanthology.org/2023.emnlp-main.127.pdf).
## Model Details
The model is optimized for evaluating factual consistency in **summarization**.
It is the main model from the paper (see "T5-11B w. ANLI + TrueTeacher full" in Table 1) which is based on a **T5-11B** [(Raffel
et al., 2020)](https://jmlr.org/papers/volume21/20-074/20-074.pdf) fine-tuned with a mixture of the following datasets:
- [TrueTeacher](https://huggingface.co/datasets/google/trueteacher) ([Gekhman et al., 2023](https://arxiv.org/pdf/2305.11171.pdf))
- [ANLI](https://huggingface.co/datasets/anli) ([Nie et al., 2020](https://aclanthology.org/2020.acl-main.441.pdf))
The TrueTeacher dataset contains model-generated summaries of articles from the train split of the **CNN/DailyMail** dataset [(Hermann et al., 2015)](https://proceedings.neurips.cc/paper_files/paper/2015/file/afdec7005cc9f14302cd0474fd0f3c96-Paper.pdf)
which are annotated for factual consistency using **FLAN-PaLM 540B** [(Chung et al.,2022)](https://arxiv.org/pdf/2210.11416.pdf).
Summaries were generated using summarization models which were trained on the **XSum** dataset [(Narayan et al., 2018)](https://aclanthology.org/D18-1206.pdf).
The input format for the model is: "premise: GROUNDING_DOCUMENT hypothesis: HYPOTHESIS_SUMMARY".
To accomodate the input length of common summarization datasets we recommend setting **max_length** to **2048**.
The model predicts a binary label ('1' - Factualy Consistent, '0' - Factualy Inconsistent).
## Evaluation results
This model achieves the following ROC AUC results on the summarization subset of the [TRUE benchmark (Honovich et al, 2022)](https://arxiv.org/pdf/2204.04991.pdf):
| **MNBM** | **QAGS-X** | **FRANK** | **SummEval** | **QAGS-C** | **Average** |
|----------|-----------|-----------|--------------|-----------|-------------|
| 78.1 | 89.4 | 93.6 | 88.5 | 89.4 | 87.8 |
## Intended Use
This model is intended for a research use (**non-commercial**) in English.
The recommended use case is evaluating factual consistency in summarization.
## Out-of-scope use
Any use cases which violate the **cc-by-nc-4.0** license.
Usage in languages other than English.
## Usage examples
#### classification
```python
from transformers import T5ForConditionalGeneration
from transformers import T5Tokenizer
model_path = 'google/t5_11b_trueteacher_and_anli'
tokenizer = T5Tokenizer.from_pretrained(model_path)
model = T5ForConditionalGeneration.from_pretrained(model_path)
premise = 'the sun is shining'
for hypothesis, expected in [('the sun is out in the sky', '1'),
('the cat is shiny', '0')]:
input_ids = tokenizer(
f'premise: {premise} hypothesis: {hypothesis}',
return_tensors='pt',
truncation=True,
max_length=2048).input_ids
outputs = model.generate(input_ids)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f'premise: {premise}')
print(f'hypothesis: {hypothesis}')
print(f'result: {result} (expected: {expected})\n')
```
#### scoring
```python
from transformers import T5ForConditionalGeneration
from transformers import T5Tokenizer
import torch
model_path = 'google/t5_11b_trueteacher_and_anli'
tokenizer = T5Tokenizer.from_pretrained(model_path)
model = T5ForConditionalGeneration.from_pretrained(model_path)
premise = 'the sun is shining'
for hypothesis, expected in [('the sun is out in the sky', '>> 0.5'),
('the cat is shiny', '<< 0.5')]:
input_ids = tokenizer(
f'premise: {premise} hypothesis: {hypothesis}',
return_tensors='pt',
truncation=True,
max_length=2048).input_ids
decoder_input_ids = torch.tensor([[tokenizer.pad_token_id]])
outputs = model(input_ids=input_ids, decoder_input_ids=decoder_input_ids)
logits = outputs.logits
probs = torch.softmax(logits[0], dim=-1)
one_token_id = tokenizer('1').input_ids[0]
entailment_prob = probs[0, one_token_id].item()
print(f'premise: {premise}')
print(f'hypothesis: {hypothesis}')
print(f'score: {entailment_prob:.3f} (expected: {expected})\n')
```
## Citation
If you use this model for a research publication, please cite the TrueTeacher paper (using the bibtex entry below), as well as the ANLI, CNN/DailyMail, XSum, T5 and FLAN papers mentioned above.
```
@misc{gekhman2023trueteacher,
title={TrueTeacher: Learning Factual Consistency Evaluation with Large Language Models},
author={Zorik Gekhman and Jonathan Herzig and Roee Aharoni and Chen Elkind and Idan Szpektor},
year={2023},
eprint={2305.11171},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
afrideva/dolphin-2_6-phi-2_oasst2_chatML_V2-GGUF | afrideva | 2024-01-19T22:21:52Z | 1,183 | 2 | null | [
"gguf",
"ggml",
"quantized",
"q2_k",
"q3_k_m",
"q4_k_m",
"q5_k_m",
"q6_k",
"q8_0",
"text-generation",
"en",
"es",
"ru",
"zh",
"de",
"fr",
"th",
"ca",
"it",
"ja",
"pl",
"eo",
"eu",
"vi",
"fi",
"hu",
"ar",
"nl",
"da",
"tr",
"ko",
"he",
"id",
"cs",
"bn",
"sv",
"base_model:NickyNicky/dolphin-2_6-phi-2_oasst2_chatML_V2",
"region:us"
]
| text-generation | 2024-01-19T22:11:44Z | ---
base_model: NickyNicky/dolphin-2_6-phi-2_oasst2_chatML_V2
inference: false
language:
- en
- es
- ru
- zh
- de
- fr
- th
- ca
- it
- ja
- pl
- eo
- eu
- vi
- fi
- hu
- ar
- nl
- da
- tr
- ko
- he
- id
- cs
- bn
- sv
model_creator: NickyNicky
model_name: dolphin-2_6-phi-2_oasst2_chatML_V2
pipeline_tag: text-generation
quantized_by: afrideva
tags:
- gguf
- ggml
- quantized
- q2_k
- q3_k_m
- q4_k_m
- q5_k_m
- q6_k
- q8_0
---
# NickyNicky/dolphin-2_6-phi-2_oasst2_chatML_V2-GGUF
Quantized GGUF model files for [dolphin-2_6-phi-2_oasst2_chatML_V2](https://huggingface.co/NickyNicky/dolphin-2_6-phi-2_oasst2_chatML_V2) from [NickyNicky](https://huggingface.co/NickyNicky)
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [dolphin-2_6-phi-2_oasst2_chatml_v2.fp16.gguf](https://huggingface.co/afrideva/dolphin-2_6-phi-2_oasst2_chatML_V2-GGUF/resolve/main/dolphin-2_6-phi-2_oasst2_chatml_v2.fp16.gguf) | fp16 | 5.56 GB |
| [dolphin-2_6-phi-2_oasst2_chatml_v2.q2_k.gguf](https://huggingface.co/afrideva/dolphin-2_6-phi-2_oasst2_chatML_V2-GGUF/resolve/main/dolphin-2_6-phi-2_oasst2_chatml_v2.q2_k.gguf) | q2_k | 1.09 GB |
| [dolphin-2_6-phi-2_oasst2_chatml_v2.q3_k_m.gguf](https://huggingface.co/afrideva/dolphin-2_6-phi-2_oasst2_chatML_V2-GGUF/resolve/main/dolphin-2_6-phi-2_oasst2_chatml_v2.q3_k_m.gguf) | q3_k_m | 1.49 GB |
| [dolphin-2_6-phi-2_oasst2_chatml_v2.q4_k_m.gguf](https://huggingface.co/afrideva/dolphin-2_6-phi-2_oasst2_chatML_V2-GGUF/resolve/main/dolphin-2_6-phi-2_oasst2_chatml_v2.q4_k_m.gguf) | q4_k_m | 1.79 GB |
| [dolphin-2_6-phi-2_oasst2_chatml_v2.q5_k_m.gguf](https://huggingface.co/afrideva/dolphin-2_6-phi-2_oasst2_chatML_V2-GGUF/resolve/main/dolphin-2_6-phi-2_oasst2_chatml_v2.q5_k_m.gguf) | q5_k_m | 2.07 GB |
| [dolphin-2_6-phi-2_oasst2_chatml_v2.q6_k.gguf](https://huggingface.co/afrideva/dolphin-2_6-phi-2_oasst2_chatML_V2-GGUF/resolve/main/dolphin-2_6-phi-2_oasst2_chatml_v2.q6_k.gguf) | q6_k | 2.29 GB |
| [dolphin-2_6-phi-2_oasst2_chatml_v2.q8_0.gguf](https://huggingface.co/afrideva/dolphin-2_6-phi-2_oasst2_chatML_V2-GGUF/resolve/main/dolphin-2_6-phi-2_oasst2_chatml_v2.q8_0.gguf) | q8_0 | 2.96 GB |
## Original Model Card:
```
- model fine tune base: cognitivecomputations/dolphin-2_6-phi-2
- sft
- flash-attention 2
- loss: 0.85
- steps: 3000
- max_length: 2028
- neftune_noise_alpha: 5
```

Install packages
```Python
!python -m pip install --upgrade pip
!pip install -q datasets trl peft bitsandbytes sentencepiece wandb
!pip install -q accelerate safetensors deepspeed
!pip install -q scipy
!export CUDA_HOME=/usr/local/cuda-11.8
# !pip install ninja
!pip install ninja packaging --upgrade -qqq
!MAX_JOBS=4 pip install flash-attn --no-build-isolation -qqq
!pip install git+"https://github.com/HazyResearch/flash-attention.git#subdirectory=csrc/rotary" -qqq
!python -m pip install optimum -qqq
```
Ioad model and generate text
```Python
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
HfArgumentParser,
TrainingArguments,
pipeline,
logging,
GenerationConfig,
TextIteratorStreamer,
)
# from attention_sinks import AutoModelForCausalLM
import torch
model_id = "NickyNicky/dolphin-2_6-phi-2_oasst2_chatML_V2"
model = AutoModelForCausalLM.from_pretrained(model_id,
device_map="auto",
trust_remote_code=True,
torch_dtype=torch.bfloat16,
load_in_4bit=True,
low_cpu_mem_usage= True,
flash_attn=True,
flash_rotary=True,
fused_dense=True,
)
max_length=2028
print("max_length",max_length)
tokenizer = AutoTokenizer.from_pretrained(model_id,
use_fast = True,
max_length=max_length,
trust_remote_code=True,)
prompt= """<|im_start|>system
You are a helpful AI assistant.<|im_end|>
<|im_start|>user
tengo hambre que me recomiendas<|im_end|>
<|im_start|>assistant"""
inputs = tokenizer.encode(prompt,
return_tensors="pt",
add_special_tokens=False).cuda()#.to("cuda") # False # True
generation_config = GenerationConfig(
max_new_tokens=700,
temperature=0.5,
top_p=0.9,
top_k=45,
repetition_penalty=1.15, #1.1, # 1.0 means no penalty, > 1.0 means penalty, 1.2 from CTRL paper
do_sample=True,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=tokenizer.eos_token_id,
# bos_token_id=tokenizer.eos_token_id,
# use_cache=True,
# stopping_criteria= StoppingCriteriaList([stopping_criteria]),
)
outputs = model.generate(generation_config=generation_config,
input_ids=inputs,)
# tokenizer.decode(outputs[0], skip_special_tokens=False) #True
print(tokenizer.decode(outputs[0], skip_special_tokens=False))
'''OUTPUT:
<|im_start|>system
You are a helpful AI assistant.<|im_end|>
<|im_start|>user
tengo hambre que me recomiendas<|im_end|>
<|im_start|>assistant
Hay muchos tipos de alimentos que puedes probar si tienes hambre, pero aquí te muestro una lista ordenada por calor:
1- Frutas y verduras: Estas son buena opción para quitar hambre sin agotar tu cuerpo con grandes cantidades de carbohidratos. Algunas frutas y verduras que podrían ser suficientemente altas en calor durante el día incluyen tomates, plátanos, espinacas, papas, nueces, manzanas, limones, guisantes, cucumbers, zanahorias, etc.
2- Proteínas: Estas son importantes para mantener tu masa muscular y fuerzosa durante el día. Algunas proteínas que podrían ser útiles para quitar hambre durante el día incluyen carne, aceite de oliva, miel, yogur, leche fresca o sopa de gorditas, etc.
3- Carbohidratos: Estas son importantes para energizarte durante el día y mantenerte físico. Algunas frutas y verduras que podrían ser útiles para quitar hambre durante el día incluyen pan, tortillas, roti, arroz, pasta, rice, polenta, cereales, granola, etc.
4- Grains: Estas son importantes para mantenerte satiente durante el día y reducir la frecuencia de comidas rápida. Algunas gromas que podrían ser útiles para quitar hambre durante el día incluyen lentejas, farinas, tortilla, ensalada, etc.
5- Nuts y semolina: Estas son buenas opciones para quitar hambre durante el día sin agotar tu cuerpo con grandes cantidades de azúcar. Algunas frutas y verduras que podrían ser útiles para quitar hambre durante el día incluyen anacardios, almendras, macetas, bocaditos, panquesado, etc.
6- Papel picado: Esta es una opción deliciosa y económica que puedes preparar en caso de quitar hambre durante el día. Para hacer papel picado, primero cortezamos las frutas y verduras que deseas usarlas, y luego cortezamos las frutas y verduras que no deseas usarlas. A continuación, cortezamos las frutas y verduras que deseas usarlas más grandes y que estén más frescas, y luego cortezamos las frutas y verduras
'''
``` |
PassionFriend/5GEir8JVcfYiovYuuzvo8TZCyCfjJe8YdjYjMtVbiTbe5Xrz_vgg | PassionFriend | 2024-03-01T06:43:34Z | 1,183 | 0 | keras | [
"keras",
"region:us"
]
| null | 2024-02-14T13:08:38Z | Entry not found |
digiplay/MRMD_0505 | digiplay | 2024-05-15T16:52:09Z | 1,183 | 4 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2024-04-17T09:09:56Z | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info:
in test...
MRMD_0505.safetensors
generated by Huggingface's API :



|
eraviart/Codestral-22B-v0.1-Q4_K_M-GGUF | eraviart | 2024-06-22T07:00:05Z | 1,183 | 0 | null | [
"gguf",
"code",
"llama-cpp",
"gguf-my-repo",
"base_model:mistralai/Codestral-22B-v0.1",
"license:other",
"region:us"
]
| null | 2024-06-22T06:59:08Z | ---
base_model: mistralai/Codestral-22B-v0.1
language:
- code
license: other
license_name: mnpl
license_link: https://mistral.ai/licences/MNPL-0.1.md
tags:
- code
- llama-cpp
- gguf-my-repo
inference: false
---
# eraviart/Codestral-22B-v0.1-Q4_K_M-GGUF
This model was converted to GGUF format from [`mistralai/Codestral-22B-v0.1`](https://huggingface.co/mistralai/Codestral-22B-v0.1) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/mistralai/Codestral-22B-v0.1) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo eraviart/Codestral-22B-v0.1-Q4_K_M-GGUF --hf-file codestral-22b-v0.1-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo eraviart/Codestral-22B-v0.1-Q4_K_M-GGUF --hf-file codestral-22b-v0.1-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo eraviart/Codestral-22B-v0.1-Q4_K_M-GGUF --hf-file codestral-22b-v0.1-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo eraviart/Codestral-22B-v0.1-Q4_K_M-GGUF --hf-file codestral-22b-v0.1-q4_k_m.gguf -c 2048
```
|
timm/regnetx_016.tv2_in1k | timm | 2024-02-10T23:32:44Z | 1,182 | 0 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"arxiv:2003.13678",
"license:bsd-3-clause",
"region:us"
]
| image-classification | 2023-03-21T06:31:51Z | ---
license: bsd-3-clause
library_name: timm
tags:
- image-classification
- timm
---
# Model card for regnetx_016.tv2_in1k
A RegNetX-1.6GF image classification model. Pretrained on ImageNet-1k by torchvision contributors (see ImageNet1K-V2 weight details https://github.com/pytorch/vision/issues/3995#new-recipe).
The `timm` RegNet implementation includes a number of enhancements not present in other implementations, including:
* stochastic depth
* gradient checkpointing
* layer-wise LR decay
* configurable output stride (dilation)
* configurable activation and norm layers
* option for a pre-activation bottleneck block used in RegNetV variant
* only known RegNetZ model definitions with pretrained weights
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 9.2
- GMACs: 1.6
- Activations (M): 7.9
- Image size: 224 x 224
- **Papers:**
- Designing Network Design Spaces: https://arxiv.org/abs/2003.13678
- **Original:** https://github.com/pytorch/vision
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('regnetx_016.tv2_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'regnetx_016.tv2_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 32, 112, 112])
# torch.Size([1, 72, 56, 56])
# torch.Size([1, 168, 28, 28])
# torch.Size([1, 408, 14, 14])
# torch.Size([1, 912, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'regnetx_016.tv2_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 912, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
For the comparison summary below, the ra_in1k, ra3_in1k, ch_in1k, sw_*, and lion_* tagged weights are trained in `timm`.
|model |img_size|top1 |top5 |param_count|gmacs|macts |
|-------------------------|--------|------|------|-----------|-----|------|
|[regnety_1280.swag_ft_in1k](https://huggingface.co/timm/regnety_1280.swag_ft_in1k)|384 |88.228|98.684|644.81 |374.99|210.2 |
|[regnety_320.swag_ft_in1k](https://huggingface.co/timm/regnety_320.swag_ft_in1k)|384 |86.84 |98.364|145.05 |95.0 |88.87 |
|[regnety_160.swag_ft_in1k](https://huggingface.co/timm/regnety_160.swag_ft_in1k)|384 |86.024|98.05 |83.59 |46.87|67.67 |
|[regnety_160.sw_in12k_ft_in1k](https://huggingface.co/timm/regnety_160.sw_in12k_ft_in1k)|288 |86.004|97.83 |83.59 |26.37|38.07 |
|[regnety_1280.swag_lc_in1k](https://huggingface.co/timm/regnety_1280.swag_lc_in1k)|224 |85.996|97.848|644.81 |127.66|71.58 |
|[regnety_160.lion_in12k_ft_in1k](https://huggingface.co/timm/regnety_160.lion_in12k_ft_in1k)|288 |85.982|97.844|83.59 |26.37|38.07 |
|[regnety_160.sw_in12k_ft_in1k](https://huggingface.co/timm/regnety_160.sw_in12k_ft_in1k)|224 |85.574|97.666|83.59 |15.96|23.04 |
|[regnety_160.lion_in12k_ft_in1k](https://huggingface.co/timm/regnety_160.lion_in12k_ft_in1k)|224 |85.564|97.674|83.59 |15.96|23.04 |
|[regnety_120.sw_in12k_ft_in1k](https://huggingface.co/timm/regnety_120.sw_in12k_ft_in1k)|288 |85.398|97.584|51.82 |20.06|35.34 |
|[regnety_2560.seer_ft_in1k](https://huggingface.co/timm/regnety_2560.seer_ft_in1k)|384 |85.15 |97.436|1282.6 |747.83|296.49|
|[regnetz_e8.ra3_in1k](https://huggingface.co/timm/regnetz_e8.ra3_in1k)|320 |85.036|97.268|57.7 |15.46|63.94 |
|[regnety_120.sw_in12k_ft_in1k](https://huggingface.co/timm/regnety_120.sw_in12k_ft_in1k)|224 |84.976|97.416|51.82 |12.14|21.38 |
|[regnety_320.swag_lc_in1k](https://huggingface.co/timm/regnety_320.swag_lc_in1k)|224 |84.56 |97.446|145.05 |32.34|30.26 |
|[regnetz_040_h.ra3_in1k](https://huggingface.co/timm/regnetz_040_h.ra3_in1k)|320 |84.496|97.004|28.94 |6.43 |37.94 |
|[regnetz_e8.ra3_in1k](https://huggingface.co/timm/regnetz_e8.ra3_in1k)|256 |84.436|97.02 |57.7 |9.91 |40.94 |
|[regnety_1280.seer_ft_in1k](https://huggingface.co/timm/regnety_1280.seer_ft_in1k)|384 |84.432|97.092|644.81 |374.99|210.2 |
|[regnetz_040.ra3_in1k](https://huggingface.co/timm/regnetz_040.ra3_in1k)|320 |84.246|96.93 |27.12 |6.35 |37.78 |
|[regnetz_d8.ra3_in1k](https://huggingface.co/timm/regnetz_d8.ra3_in1k)|320 |84.054|96.992|23.37 |6.19 |37.08 |
|[regnetz_d8_evos.ch_in1k](https://huggingface.co/timm/regnetz_d8_evos.ch_in1k)|320 |84.038|96.992|23.46 |7.03 |38.92 |
|[regnetz_d32.ra3_in1k](https://huggingface.co/timm/regnetz_d32.ra3_in1k)|320 |84.022|96.866|27.58 |9.33 |37.08 |
|[regnety_080.ra3_in1k](https://huggingface.co/timm/regnety_080.ra3_in1k)|288 |83.932|96.888|39.18 |13.22|29.69 |
|[regnety_640.seer_ft_in1k](https://huggingface.co/timm/regnety_640.seer_ft_in1k)|384 |83.912|96.924|281.38 |188.47|124.83|
|[regnety_160.swag_lc_in1k](https://huggingface.co/timm/regnety_160.swag_lc_in1k)|224 |83.778|97.286|83.59 |15.96|23.04 |
|[regnetz_040_h.ra3_in1k](https://huggingface.co/timm/regnetz_040_h.ra3_in1k)|256 |83.776|96.704|28.94 |4.12 |24.29 |
|[regnetv_064.ra3_in1k](https://huggingface.co/timm/regnetv_064.ra3_in1k)|288 |83.72 |96.75 |30.58 |10.55|27.11 |
|[regnety_064.ra3_in1k](https://huggingface.co/timm/regnety_064.ra3_in1k)|288 |83.718|96.724|30.58 |10.56|27.11 |
|[regnety_160.deit_in1k](https://huggingface.co/timm/regnety_160.deit_in1k)|288 |83.69 |96.778|83.59 |26.37|38.07 |
|[regnetz_040.ra3_in1k](https://huggingface.co/timm/regnetz_040.ra3_in1k)|256 |83.62 |96.704|27.12 |4.06 |24.19 |
|[regnetz_d8.ra3_in1k](https://huggingface.co/timm/regnetz_d8.ra3_in1k)|256 |83.438|96.776|23.37 |3.97 |23.74 |
|[regnetz_d32.ra3_in1k](https://huggingface.co/timm/regnetz_d32.ra3_in1k)|256 |83.424|96.632|27.58 |5.98 |23.74 |
|[regnetz_d8_evos.ch_in1k](https://huggingface.co/timm/regnetz_d8_evos.ch_in1k)|256 |83.36 |96.636|23.46 |4.5 |24.92 |
|[regnety_320.seer_ft_in1k](https://huggingface.co/timm/regnety_320.seer_ft_in1k)|384 |83.35 |96.71 |145.05 |95.0 |88.87 |
|[regnetv_040.ra3_in1k](https://huggingface.co/timm/regnetv_040.ra3_in1k)|288 |83.204|96.66 |20.64 |6.6 |20.3 |
|[regnety_320.tv2_in1k](https://huggingface.co/timm/regnety_320.tv2_in1k)|224 |83.162|96.42 |145.05 |32.34|30.26 |
|[regnety_080.ra3_in1k](https://huggingface.co/timm/regnety_080.ra3_in1k)|224 |83.16 |96.486|39.18 |8.0 |17.97 |
|[regnetv_064.ra3_in1k](https://huggingface.co/timm/regnetv_064.ra3_in1k)|224 |83.108|96.458|30.58 |6.39 |16.41 |
|[regnety_040.ra3_in1k](https://huggingface.co/timm/regnety_040.ra3_in1k)|288 |83.044|96.5 |20.65 |6.61 |20.3 |
|[regnety_064.ra3_in1k](https://huggingface.co/timm/regnety_064.ra3_in1k)|224 |83.02 |96.292|30.58 |6.39 |16.41 |
|[regnety_160.deit_in1k](https://huggingface.co/timm/regnety_160.deit_in1k)|224 |82.974|96.502|83.59 |15.96|23.04 |
|[regnetx_320.tv2_in1k](https://huggingface.co/timm/regnetx_320.tv2_in1k)|224 |82.816|96.208|107.81 |31.81|36.3 |
|[regnety_032.ra_in1k](https://huggingface.co/timm/regnety_032.ra_in1k)|288 |82.742|96.418|19.44 |5.29 |18.61 |
|[regnety_160.tv2_in1k](https://huggingface.co/timm/regnety_160.tv2_in1k)|224 |82.634|96.22 |83.59 |15.96|23.04 |
|[regnetz_c16_evos.ch_in1k](https://huggingface.co/timm/regnetz_c16_evos.ch_in1k)|320 |82.634|96.472|13.49 |3.86 |25.88 |
|[regnety_080_tv.tv2_in1k](https://huggingface.co/timm/regnety_080_tv.tv2_in1k)|224 |82.592|96.246|39.38 |8.51 |19.73 |
|[regnetx_160.tv2_in1k](https://huggingface.co/timm/regnetx_160.tv2_in1k)|224 |82.564|96.052|54.28 |15.99|25.52 |
|[regnetz_c16.ra3_in1k](https://huggingface.co/timm/regnetz_c16.ra3_in1k)|320 |82.51 |96.358|13.46 |3.92 |25.88 |
|[regnetv_040.ra3_in1k](https://huggingface.co/timm/regnetv_040.ra3_in1k)|224 |82.44 |96.198|20.64 |4.0 |12.29 |
|[regnety_040.ra3_in1k](https://huggingface.co/timm/regnety_040.ra3_in1k)|224 |82.304|96.078|20.65 |4.0 |12.29 |
|[regnetz_c16.ra3_in1k](https://huggingface.co/timm/regnetz_c16.ra3_in1k)|256 |82.16 |96.048|13.46 |2.51 |16.57 |
|[regnetz_c16_evos.ch_in1k](https://huggingface.co/timm/regnetz_c16_evos.ch_in1k)|256 |81.936|96.15 |13.49 |2.48 |16.57 |
|[regnety_032.ra_in1k](https://huggingface.co/timm/regnety_032.ra_in1k)|224 |81.924|95.988|19.44 |3.2 |11.26 |
|[regnety_032.tv2_in1k](https://huggingface.co/timm/regnety_032.tv2_in1k)|224 |81.77 |95.842|19.44 |3.2 |11.26 |
|[regnetx_080.tv2_in1k](https://huggingface.co/timm/regnetx_080.tv2_in1k)|224 |81.552|95.544|39.57 |8.02 |14.06 |
|[regnetx_032.tv2_in1k](https://huggingface.co/timm/regnetx_032.tv2_in1k)|224 |80.924|95.27 |15.3 |3.2 |11.37 |
|[regnety_320.pycls_in1k](https://huggingface.co/timm/regnety_320.pycls_in1k)|224 |80.804|95.246|145.05 |32.34|30.26 |
|[regnetz_b16.ra3_in1k](https://huggingface.co/timm/regnetz_b16.ra3_in1k)|288 |80.712|95.47 |9.72 |2.39 |16.43 |
|[regnety_016.tv2_in1k](https://huggingface.co/timm/regnety_016.tv2_in1k)|224 |80.66 |95.334|11.2 |1.63 |8.04 |
|[regnety_120.pycls_in1k](https://huggingface.co/timm/regnety_120.pycls_in1k)|224 |80.37 |95.12 |51.82 |12.14|21.38 |
|[regnety_160.pycls_in1k](https://huggingface.co/timm/regnety_160.pycls_in1k)|224 |80.288|94.964|83.59 |15.96|23.04 |
|[regnetx_320.pycls_in1k](https://huggingface.co/timm/regnetx_320.pycls_in1k)|224 |80.246|95.01 |107.81 |31.81|36.3 |
|[regnety_080.pycls_in1k](https://huggingface.co/timm/regnety_080.pycls_in1k)|224 |79.882|94.834|39.18 |8.0 |17.97 |
|[regnetz_b16.ra3_in1k](https://huggingface.co/timm/regnetz_b16.ra3_in1k)|224 |79.872|94.974|9.72 |1.45 |9.95 |
|[regnetx_160.pycls_in1k](https://huggingface.co/timm/regnetx_160.pycls_in1k)|224 |79.862|94.828|54.28 |15.99|25.52 |
|[regnety_064.pycls_in1k](https://huggingface.co/timm/regnety_064.pycls_in1k)|224 |79.716|94.772|30.58 |6.39 |16.41 |
|[regnetx_120.pycls_in1k](https://huggingface.co/timm/regnetx_120.pycls_in1k)|224 |79.592|94.738|46.11 |12.13|21.37 |
|[regnetx_016.tv2_in1k](https://huggingface.co/timm/regnetx_016.tv2_in1k)|224 |79.44 |94.772|9.19 |1.62 |7.93 |
|[regnety_040.pycls_in1k](https://huggingface.co/timm/regnety_040.pycls_in1k)|224 |79.23 |94.654|20.65 |4.0 |12.29 |
|[regnetx_080.pycls_in1k](https://huggingface.co/timm/regnetx_080.pycls_in1k)|224 |79.198|94.55 |39.57 |8.02 |14.06 |
|[regnetx_064.pycls_in1k](https://huggingface.co/timm/regnetx_064.pycls_in1k)|224 |79.064|94.454|26.21 |6.49 |16.37 |
|[regnety_032.pycls_in1k](https://huggingface.co/timm/regnety_032.pycls_in1k)|224 |78.884|94.412|19.44 |3.2 |11.26 |
|[regnety_008_tv.tv2_in1k](https://huggingface.co/timm/regnety_008_tv.tv2_in1k)|224 |78.654|94.388|6.43 |0.84 |5.42 |
|[regnetx_040.pycls_in1k](https://huggingface.co/timm/regnetx_040.pycls_in1k)|224 |78.482|94.24 |22.12 |3.99 |12.2 |
|[regnetx_032.pycls_in1k](https://huggingface.co/timm/regnetx_032.pycls_in1k)|224 |78.178|94.08 |15.3 |3.2 |11.37 |
|[regnety_016.pycls_in1k](https://huggingface.co/timm/regnety_016.pycls_in1k)|224 |77.862|93.73 |11.2 |1.63 |8.04 |
|[regnetx_008.tv2_in1k](https://huggingface.co/timm/regnetx_008.tv2_in1k)|224 |77.302|93.672|7.26 |0.81 |5.15 |
|[regnetx_016.pycls_in1k](https://huggingface.co/timm/regnetx_016.pycls_in1k)|224 |76.908|93.418|9.19 |1.62 |7.93 |
|[regnety_008.pycls_in1k](https://huggingface.co/timm/regnety_008.pycls_in1k)|224 |76.296|93.05 |6.26 |0.81 |5.25 |
|[regnety_004.tv2_in1k](https://huggingface.co/timm/regnety_004.tv2_in1k)|224 |75.592|92.712|4.34 |0.41 |3.89 |
|[regnety_006.pycls_in1k](https://huggingface.co/timm/regnety_006.pycls_in1k)|224 |75.244|92.518|6.06 |0.61 |4.33 |
|[regnetx_008.pycls_in1k](https://huggingface.co/timm/regnetx_008.pycls_in1k)|224 |75.042|92.342|7.26 |0.81 |5.15 |
|[regnetx_004_tv.tv2_in1k](https://huggingface.co/timm/regnetx_004_tv.tv2_in1k)|224 |74.57 |92.184|5.5 |0.42 |3.17 |
|[regnety_004.pycls_in1k](https://huggingface.co/timm/regnety_004.pycls_in1k)|224 |74.018|91.764|4.34 |0.41 |3.89 |
|[regnetx_006.pycls_in1k](https://huggingface.co/timm/regnetx_006.pycls_in1k)|224 |73.862|91.67 |6.2 |0.61 |3.98 |
|[regnetx_004.pycls_in1k](https://huggingface.co/timm/regnetx_004.pycls_in1k)|224 |72.38 |90.832|5.16 |0.4 |3.14 |
|[regnety_002.pycls_in1k](https://huggingface.co/timm/regnety_002.pycls_in1k)|224 |70.282|89.534|3.16 |0.2 |2.17 |
|[regnetx_002.pycls_in1k](https://huggingface.co/timm/regnetx_002.pycls_in1k)|224 |68.752|88.556|2.68 |0.2 |2.16 |
## Citation
```bibtex
@InProceedings{Radosavovic2020,
title = {Designing Network Design Spaces},
author = {Ilija Radosavovic and Raj Prateek Kosaraju and Ross Girshick and Kaiming He and Piotr Doll{'a}r},
booktitle = {CVPR},
year = {2020}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
|
SourAsslips/Sour | SourAsslips | 2024-03-10T02:22:34Z | 1,182 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-03-10T02:08:48Z | Entry not found |
TKU410410103/wav2vec2-base-japanese-asr | TKU410410103 | 2024-04-14T14:00:30Z | 1,182 | 2 | transformers | [
"transformers",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"ja",
"dataset:mozilla-foundation/common_voice_11_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2024-04-14T10:22:21Z | ---
language:
- ja
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
metrics:
- wer
- cer
model-index:
- name: wav2vec2-base-japanese-asr
results:
- task:
type: automatic-speech-recognition
name: Speech Recognition
dataset:
name: common_voice_11_0
type: common_voice
args: ja
metrics:
- type: wer
value: 14.177284
name: Test WER
- type: cer
value: 6.462501
name: Test CER
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Reazonspeech
type: custom
args: ja
metrics:
- name: Test WER
type: wer
value: 40.864413
- name: Test CER
type: cer
value: 29.367348
---
# wav2vec2-base-asr
This model is a fine-tuned version of [rinna/japanese-wav2vec2-base](https://huggingface.co/rinna/japanese-wav2vec2-base) on the [common_voice_11_0 dataset](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0/viewer/ja) for ASR tasks.
This model can only predict Hiragana.
## Acknowledgments
This model's fine-tuning approach was inspired by and references the training methodology used in [vumichien/wav2vec2-large-xlsr-japanese-hiragana](https://huggingface.co/vumichien/wav2vec2-large-xlsr-japanese-hiragana).
## Training Procedure
Fine-tuning on the common_voice_11_0 dataset led to the following results:
| Step | Training Loss | Validation Loss | WER |
|-------|---------------|-----------------|----------|
| 1000 | 6.088100 | 3.452597 | 1.000000 |
| 2000 | 2.816600 | 0.756278 | 0.263624 |
| 3000 | 0.837600 | 0.471486 | 0.185915 |
| 4000 | 0.624900 | 0.420854 | 0.159801 |
| 5000 | 0.533300 | 0.392494 | 0.149141 |
| 6000 | 0.490000 | 0.394669 | 0.144826 |
| 7000 | 0.441600 | 0.379999 | 0.141807 |
### Training hyperparameters
The training hyperparameters remained consistent throughout the fine-tuning process:
- learning_rate: 1e-4
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 2
- num_train_epochs: 20
- warmup_steps: 2000
- lr_scheduler_type: linear
### How to evaluate the model
```python
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
from datasets import load_dataset
import torch
import torchaudio
import librosa
import numpy as np
import re
import MeCab
import pykakasi
from evaluate import load
model = Wav2Vec2ForCTC.from_pretrained('TKU410410103/wav2vec2-base-japanese-asr')
processor = Wav2Vec2Processor.from_pretrained("TKU410410103/wav2vec2-base-japanese-asr")
# load dataset
test_dataset = load_dataset('mozilla-foundation/common_voice_11_0', 'ja', split='test')
remove_columns = [col for col in test_dataset.column_names if col not in ['audio', 'sentence']]
test_dataset = test_dataset.remove_columns(remove_columns)
# resample
def process_waveforms(batch):
speech_arrays = []
sampling_rates = []
for audio_path in batch['audio']:
speech_array, _ = torchaudio.load(audio_path['path'])
speech_array_resampled = librosa.resample(np.asarray(speech_array[0].numpy()), orig_sr=48000, target_sr=16000)
speech_arrays.append(speech_array_resampled)
sampling_rates.append(16000)
batch["array"] = speech_arrays
batch["sampling_rate"] = sampling_rates
return batch
# hiragana
CHARS_TO_IGNORE = [",", "?", "¿", ".", "!", "¡", ";", ";", ":", '""', "%", '"', "�", "ʿ", "·", "჻", "~", "՞",
"؟", "،", "।", "॥", "«", "»", "„", "“", "”", "「", "」", "‘", "’", "《", "》", "(", ")", "[", "]",
"{", "}", "=", "`", "_", "+", "<", ">", "…", "–", "°", "´", "ʾ", "‹", "›", "©", "®", "—", "→", "。",
"、", "﹂", "﹁", "‧", "~", "﹏", ",", "{", "}", "(", ")", "[", "]", "【", "】", "‥", "〽",
"『", "』", "〝", "〟", "⟨", "⟩", "〜", ":", "!", "?", "♪", "؛", "/", "\\", "º", "−", "^", "'", "ʻ", "ˆ"]
chars_to_ignore_regex = f"[{re.escape(''.join(CHARS_TO_IGNORE))}]"
wakati = MeCab.Tagger("-Owakati")
kakasi = pykakasi.kakasi()
kakasi.setMode("J","H")
kakasi.setMode("K","H")
kakasi.setMode("r","Hepburn")
conv = kakasi.getConverter()
def prepare_char(batch):
batch["sentence"] = conv.do(wakati.parse(batch["sentence"]).strip())
batch["sentence"] = re.sub(chars_to_ignore_regex,'', batch["sentence"]).strip()
return batch
resampled_eval_dataset = test_dataset.map(process_waveforms, batched=True, batch_size=50, num_proc=4)
eval_dataset = resampled_eval_dataset.map(prepare_char, num_proc=4)
# begin the evaluation process
wer = load("wer")
cer = load("cer")
def evaluate(batch):
inputs = processor(batch["array"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to(device), attention_mask=inputs.attention_mask.to(device)).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
columns_to_remove = [column for column in eval_dataset.column_names if column != "sentence"]
batch_size = 16
result = eval_dataset.map(evaluate, remove_columns=columns_to_remove, batched=True, batch_size=batch_size)
wer_result = wer.compute(predictions=result["pred_strings"], references=result["sentence"])
cer_result = cer.compute(predictions=result["pred_strings"], references=result["sentence"])
print("WER: {:2f}%".format(100 * wer_result))
print("CER: {:2f}%".format(100 * cer_result))
```
### Test results
The final model was evaluated as follows:
On common_voice_11_0:
- WER: 14.177284%
- CER: 6.462501%
On reazonspeech(tiny):
- WER: 40.864413%
- CER: 29.367348%
### Framework versions
- Transformers 4.39.1
- Pytorch 2.2.1+cu118
- Datasets 2.17.1 |
AIdenU/Mistral-7B-v0.2-ko-Y24_v2.0 | AIdenU | 2024-04-24T03:32:05Z | 1,182 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"Mistral",
"conversational",
"ko",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-24T00:19:50Z | ---
license: apache-2.0
language:
- ko
pipeline_tag: text-generation
tags:
- Mistral
---
### BaseModel
- [alpindale/Mistral-7B-v0.2-hf](https://huggingface.co/alpindale/Mistral-7B-v0.2-hf)
### Model Generation
```
from transforemrs import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("AIdenU/Mistral-7B-v0.2-ko-Y24_v2.0", device_map="auto", torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained("AIdenU/Mistral-7B-v0.2-ko-Y24_v2.0", use_fast=True)
prompt = [
{'role': 'system', 'content': '당신은 지시를 매우 잘 따르는 인공지능 비서입니다.'},
{'role': 'user', 'content': '지렁이도 밟으면 꿈틀하나요?'}
]
outputs = model.generate(
**tokenizer(
tokenizer.apply_chat_template(prompt, tokenize=False, add_generation_prompt=True),
return_tensors='pt'
).to('cuda'),
max_new_tokens=256,
temperature=0.2,
top_p=1,
do_sample=True
)
print(tokenizer.decode(outputs[0]))
``` |
Alphacode-AI/AlphaMist7B-slr-v3 | Alphacode-AI | 2024-04-09T04:10:57Z | 1,181 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation",
"ko",
"dataset:Custom_datasets",
"base_model:mistralai/Mistral-7B-v0.1",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-04-09T03:32:37Z | ---
license: cc-by-nc-4.0
datasets:
- Custom_datasets
language:
- ko
pipeline_tag: text-generation
base_model: "mistralai/Mistral-7B-v0.1"
---
This model is a version of mistralai/Mistral-7B-v0.1 that has been fine-tuned with Our In House CustomData.
Train Spec :
We utilized an A100x4 * 1 for training our model
with DeepSpeed / HuggingFace TRL Trainer / HuggingFace Accelerate |
abacusai/Llama-3-Giraffe-70B | abacusai | 2024-04-30T19:44:51Z | 1,181 | 29 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"meta",
"llama-3",
"en",
"arxiv:2309.10400",
"license:llama3",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-30T18:43:01Z | ---
language:
- en
pipeline_tag: text-generation
tags:
- meta
- llama-3
license: llama3
---


# Llama-3-Giraffe-70B
Abacus.AI presents our longer-necked variant of Llama 3 70B!
This model has an effective context length of approximately 128k.
We have currently trained on ~1B tokens.
This is an initial release and we are hoping to improve the heatmap below further as we continue training.

## Training Methodology
The methodology for training uses [PoSE](https://arxiv.org/abs/2309.10400) and dynamic-NTK interpolation.
### NTK-scaling
The scale factor for NTK is 4. Note that we also tried theta-scaling but this did not work as well as NTK scaling in our experiments.
### PoSE
We utilise Positional Skip-wise Training (PoSE) with the following parameters:
- **Number of Chunks**: 5
- **Max position ID**: 32768
### Data
We use on average ~8K long samples from [RedPajama](https://github.com/togethercomputer/RedPajama-Data).
### Hardware
We train on 8xH100 GPUs with Deepspeed Zero Stage 3.
## Evaluation Methodology
We use the [EasyContext](https://github.com/abacusai/EasyContext/blob/eval_runs/eval_needle.py) implementation of Needle-in-a-Haystack to evaluate Llama-3-Giraffe-70B.
We evaluate with the following parameters:
- **Min context length**: 2000
- **Max context length**: 128000
- **Context interval**: 4000
- **Depth interval**: 0.1
- **Num samples**: 2
- **Rnd number digits**: 7
- **Haystack dir**: PaulGrahamEssays |
bartowski/Llama-Salad-8x8B-GGUF | bartowski | 2024-06-08T18:55:30Z | 1,181 | 0 | transformers | [
"transformers",
"gguf",
"nsfw",
"not-for-all-audiences",
"llama-3",
"text-generation-inference",
"moe",
"mergekit",
"merge",
"text-generation",
"license:llama3",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-06-08T17:28:31Z | ---
license: llama3
library_name: transformers
tags:
- nsfw
- not-for-all-audiences
- llama-3
- text-generation-inference
- moe
- mergekit
- merge
quantized_by: bartowski
pipeline_tag: text-generation
---
## Llamacpp imatrix Quantizations of Llama-Salad-8x8B
Using <a href="https://github.com/ggerganov/llama.cpp/">llama.cpp</a> release <a href="https://github.com/ggerganov/llama.cpp/releases/tag/b3086">b3086</a> for quantization.
Original model: https://huggingface.co/HiroseKoichi/Llama-Salad-8x8B
All quants made using imatrix option with dataset from [here](https://gist.github.com/bartowski1182/eb213dccb3571f863da82e99418f81e8)
## Prompt format
```
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{system_prompt}<|eot_id|><|start_header_id|>user<|end_header_id|>
{prompt}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
```
## Download a file (not the whole branch) from below:
| Filename | Quant type | File Size | Description |
| -------- | ---------- | --------- | ----------- |
| [Llama-Salad-8x8B-Q8_0.gguf](https://huggingface.co/bartowski/Llama-Salad-8x8B-GGUF/tree/main/Llama-Salad-8x8B-Q8_0.gguf) | Q8_0 | 50.47GB | Extremely high quality, generally unneeded but max available quant. |
| [Llama-Salad-8x8B-Q6_K.gguf](https://huggingface.co/bartowski/Llama-Salad-8x8B-GGUF/blob/main/Llama-Salad-8x8B-Q6_K.gguf) | Q6_K | 39.03GB | Very high quality, near perfect, *recommended*. |
| [Llama-Salad-8x8B-Q5_K_M.gguf](https://huggingface.co/bartowski/Llama-Salad-8x8B-GGUF/blob/main/Llama-Salad-8x8B-Q5_K_M.gguf) | Q5_K_M | 33.83GB | High quality, *recommended*. |
| [Llama-Salad-8x8B-Q5_K_S.gguf](https://huggingface.co/bartowski/Llama-Salad-8x8B-GGUF/blob/main/Llama-Salad-8x8B-Q5_K_S.gguf) | Q5_K_S | 32.83GB | High quality, *recommended*. |
| [Llama-Salad-8x8B-Q4_K_M.gguf](https://huggingface.co/bartowski/Llama-Salad-8x8B-GGUF/blob/main/Llama-Salad-8x8B-Q4_K_M.gguf) | Q4_K_M | 29.00GB | Good quality, uses about 4.83 bits per weight, *recommended*. |
| [Llama-Salad-8x8B-Q4_K_S.gguf](https://huggingface.co/bartowski/Llama-Salad-8x8B-GGUF/blob/main/Llama-Salad-8x8B-Q4_K_S.gguf) | Q4_K_S | 27.29GB | Slightly lower quality with more space savings, *recommended*. |
| [Llama-Salad-8x8B-IQ4_XS.gguf](https://huggingface.co/bartowski/Llama-Salad-8x8B-GGUF/blob/main/Llama-Salad-8x8B-IQ4_XS.gguf) | IQ4_XS | 25.62GB | Decent quality, smaller than Q4_K_S with similar performance, *recommended*. |
| [Llama-Salad-8x8B-Q3_K_L.gguf](https://huggingface.co/bartowski/Llama-Salad-8x8B-GGUF/blob/main/Llama-Salad-8x8B-Q3_K_L.gguf) | Q3_K_L | 24.66GB | Lower quality but usable, good for low RAM availability. |
| [Llama-Salad-8x8B-Q3_K_M.gguf](https://huggingface.co/bartowski/Llama-Salad-8x8B-GGUF/blob/main/Llama-Salad-8x8B-Q3_K_M.gguf) | Q3_K_M | 23.04GB | Even lower quality. |
| [Llama-Salad-8x8B-IQ3_M.gguf](https://huggingface.co/bartowski/Llama-Salad-8x8B-GGUF/blob/main/Llama-Salad-8x8B-IQ3_M.gguf) | IQ3_M | 21.93GB | Medium-low quality, new method with decent performance comparable to Q3_K_M. |
| [Llama-Salad-8x8B-Q3_K_S.gguf](https://huggingface.co/bartowski/Llama-Salad-8x8B-GGUF/blob/main/Llama-Salad-8x8B-Q3_K_S.gguf) | Q3_K_S | 20.93GB | Low quality, not recommended. |
| [Llama-Salad-8x8B-IQ3_XS.gguf](https://huggingface.co/bartowski/Llama-Salad-8x8B-GGUF/blob/main/Llama-Salad-8x8B-IQ3_XS.gguf) | IQ3_XS | 19.85GB | Lower quality, new method with decent performance, slightly better than Q3_K_S. |
| [Llama-Salad-8x8B-IQ3_XXS.gguf](https://huggingface.co/bartowski/Llama-Salad-8x8B-GGUF/blob/main/Llama-Salad-8x8B-IQ3_XXS.gguf) | IQ3_XXS | 18.69GB | Lower quality, new method with decent performance, comparable to Q3 quants. |
| [Llama-Salad-8x8B-Q2_K.gguf](https://huggingface.co/bartowski/Llama-Salad-8x8B-GGUF/blob/main/Llama-Salad-8x8B-Q2_K.gguf) | Q2_K | 17.77GB | Very low quality but surprisingly usable. |
| [Llama-Salad-8x8B-IQ2_M.gguf](https://huggingface.co/bartowski/Llama-Salad-8x8B-GGUF/blob/main/Llama-Salad-8x8B-IQ2_M.gguf) | IQ2_M | 15.94GB | Very low quality, uses SOTA techniques to also be surprisingly usable. |
| [Llama-Salad-8x8B-IQ2_S.gguf](https://huggingface.co/bartowski/Llama-Salad-8x8B-GGUF/blob/main/Llama-Salad-8x8B-IQ2_S.gguf) | IQ2_S | 14.57GB | Very low quality, uses SOTA techniques to be usable. |
| [Llama-Salad-8x8B-IQ2_XS.gguf](https://huggingface.co/bartowski/Llama-Salad-8x8B-GGUF/blob/main/Llama-Salad-8x8B-IQ2_XS.gguf) | IQ2_XS | 14.33GB | Very low quality, uses SOTA techniques to be usable. |
## Downloading using huggingface-cli
First, make sure you have hugginface-cli installed:
```
pip install -U "huggingface_hub[cli]"
```
Then, you can target the specific file you want:
```
huggingface-cli download bartowski/Llama-Salad-8x8B-GGUF --include "Llama-Salad-8x8B-Q4_K_M.gguf" --local-dir ./
```
If the model is bigger than 50GB, it will have been split into multiple files. In order to download them all to a local folder, run:
```
huggingface-cli download bartowski/Llama-Salad-8x8B-GGUF --include "Llama-Salad-8x8B-Q8_0.gguf/*" --local-dir Llama-Salad-8x8B-Q8_0
```
You can either specify a new local-dir (Llama-Salad-8x8B-Q8_0) or download them all in place (./)
## Which file should I choose?
A great write up with charts showing various performances is provided by Artefact2 [here](https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9)
The first thing to figure out is how big a model you can run. To do this, you'll need to figure out how much RAM and/or VRAM you have.
If you want your model running as FAST as possible, you'll want to fit the whole thing on your GPU's VRAM. Aim for a quant with a file size 1-2GB smaller than your GPU's total VRAM.
If you want the absolute maximum quality, add both your system RAM and your GPU's VRAM together, then similarly grab a quant with a file size 1-2GB Smaller than that total.
Next, you'll need to decide if you want to use an 'I-quant' or a 'K-quant'.
If you don't want to think too much, grab one of the K-quants. These are in format 'QX_K_X', like Q5_K_M.
If you want to get more into the weeds, you can check out this extremely useful feature chart:
[llama.cpp feature matrix](https://github.com/ggerganov/llama.cpp/wiki/Feature-matrix)
But basically, if you're aiming for below Q4, and you're running cuBLAS (Nvidia) or rocBLAS (AMD), you should look towards the I-quants. These are in format IQX_X, like IQ3_M. These are newer and offer better performance for their size.
These I-quants can also be used on CPU and Apple Metal, but will be slower than their K-quant equivalent, so speed vs performance is a tradeoff you'll have to decide.
The I-quants are *not* compatible with Vulcan, which is also AMD, so if you have an AMD card double check if you're using the rocBLAS build or the Vulcan build. At the time of writing this, LM Studio has a preview with ROCm support, and other inference engines have specific builds for ROCm.
Want to support my work? Visit my ko-fi page here: https://ko-fi.com/bartowski
|
HODACHI/Qwen2-7B-Instruct-FT-ja-wiki-v1.0 | HODACHI | 2024-06-10T09:49:01Z | 1,181 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-06-10T09:43:34Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
timm/nf_resnet50.ra2_in1k | timm | 2024-02-10T23:36:12Z | 1,180 | 1 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2102.06171",
"arxiv:2101.08692",
"license:apache-2.0",
"region:us"
]
| image-classification | 2023-03-24T01:14:44Z | ---
license: apache-2.0
library_name: timm
tags:
- image-classification
- timm
datasets:
- imagenet-1k
---
# Model card for nf_resnet50.ra2_in1k
A NFResNet (Norm-Free ResNet) image classification model. Trained in `timm` by Ross Wightman.
Normalization Free Networks are (pre-activation) ResNet-like models without any normalization layers. Instead of Batch Normalization or alternatives, they use Scaled Weight Standardization and specifically placed scalar gains in residual path and at non-linearities based on signal propagation analysis.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 25.6
- GMACs: 5.5
- Activations (M): 14.5
- Image size: train = 256 x 256, test = 288 x 288
- **Papers:**
- High-Performance Large-Scale Image Recognition Without Normalization: https://arxiv.org/abs/2102.06171
- Characterizing signal propagation to close the performance gap in unnormalized ResNets: https://arxiv.org/abs/2101.08692
- **Original:** https://github.com/huggingface/pytorch-image-models
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('nf_resnet50.ra2_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'nf_resnet50.ra2_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 128, 128])
# torch.Size([1, 256, 64, 64])
# torch.Size([1, 512, 32, 32])
# torch.Size([1, 1024, 16, 16])
# torch.Size([1, 2048, 8, 8])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'nf_resnet50.ra2_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 2048, 8, 8) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{brock2021high,
author={Andrew Brock and Soham De and Samuel L. Smith and Karen Simonyan},
title={High-Performance Large-Scale Image Recognition Without Normalization},
journal={arXiv preprint arXiv:2102.06171},
year={2021}
}
```
```bibtex
@inproceedings{brock2021characterizing,
author={Andrew Brock and Soham De and Samuel L. Smith},
title={Characterizing signal propagation to close the performance gap in
unnormalized ResNets},
booktitle={9th International Conference on Learning Representations, {ICLR}},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
|
Yntec/BeautyFool | Yntec | 2023-10-18T23:56:47Z | 1,180 | 3 | diffusers | [
"diffusers",
"safetensors",
"General",
"Base Model",
"53rt5355iz",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2023-10-18T22:25:16Z | ---
license: other
tags:
- General
- Base Model
- 53rt5355iz
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
# BeautyFool 1.2
This model with the MoistMixV2 VAE baked in.
Comparison:

Original page: https://civitai.com/models/101888?modelVersionId=112320
VAE pruned version: https://huggingface.co/digiplay/BeautyFool_v1.2VAE_pruned
Sample and prompt:

Pretty CUTE LITTLE girl of artwork mini style by gaston bussiere, sitting IN GOLDEN RING in CUTE KITCHEN, A wholesome animation key shot at computer monitor, studio ghibli, pixar and disney animation, anime key art by ROSSDRAWS and Clay Mann, style of maple story, chibi |
Edentns/DataVortexS-10.7B-dpo-v1.12 | Edentns | 2024-02-24T14:16:31Z | 1,180 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"ko",
"base_model:megastudy/M-SOLAR-10.7B-v1.3",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-02-01T05:31:52Z | ---
tags:
- text-generation
license: cc-by-nc-sa-4.0
language:
- ko
base_model: megastudy/M-SOLAR-10.7B-v1.3
pipeline_tag: text-generation
---
# **DataVortexS-10.7B-dpo-v1.12**
<img src="./DataVortex.png" alt="DataVortex" style="height: 8em;">
## Our Team
| Research & Engineering | Product Management |
| :--------------------: | :----------------: |
| Kwangseok Yang | Seunghyun Choi |
| Jeongwon Choi | Hyoseok Choi |
## **Model Details**
### **Base Model**
[megastudy/M-SOLAR-10.7B-v1.3](https://huggingface.co/megastudy/M-SOLAR-10.7B-v1.3)
### **Trained On**
- **OS**: Ubuntu 22.04
- **GPU**: H100 80GB 4ea
- **transformers**: v4.36.2
### **Instruction format**
It follows **Alpaca (Chat)** format.
E.g.
```python
text = """\
### System:
당신은 사람들이 정보를 찾을 수 있도록 도와주는 인공지능 비서입니다.
### User:
대한민국의 수도는 어디야?
### Assistant:
대한민국의 수도는 서울입니다.
### User:
서울 인구는 총 몇 명이야?
"""
```
## **Model Benchmark**
### **[Ko LM Eval Harness](https://github.com/Beomi/ko-lm-evaluation-harness)**
| Task | 0-shot | 5-shot | 10-shot | 50-shot |
| :--------------- | -----------: | ----------: | -----------: | -----------: |
| kobest_boolq | 0.895272 | 0.93443 | 0.938023 | 0.940851 |
| kobest_copa | 0.735618 | 0.778902 | 0.790925 | 0.809938 |
| kobest_hellaswag | 0.490442 | 0.481539 | 0.478118 | 0.494714 |
| kobest_sentineg | 0.782981 | 0.95213 | 0.952136 | 0.947082 |
| **Average** | **0.726078** | **0.78675** | **0.789801** | **0.798146** |
### **[Ko-LLM-Leaderboard](https://huggingface.co/spaces/upstage/open-ko-llm-leaderboard)**
| Average | Ko-ARC | Ko-HellaSwag | Ko-MMLU | Ko-TruthfulQA | Ko-CommonGen V2 |
| ------: | -----: | -----------: | ------: | ------------: | --------------: |
| 57.61 | 54.44 | 67.21 | 54.09 | 61.88 | 50.41 |
## **Implementation Code**
This model contains the chat_template instruction format.
You can use the code below.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained("Edentns/DataVortexS-10.7B-dpo-v1.12")
tokenizer = AutoTokenizer.from_pretrained("Edentns/DataVortexS-10.7B-dpo-v1.12")
messages = [
{"role": "system", "content": "당신은 사람들이 정보를 찾을 수 있도록 도와주는 인공지능 비서입니다."},
{"role": "user", "content": "대한민국의 수도는 어디야?"},
{"role": "assistant", "content": "대한민국의 수도는 서울입니다."},
{"role": "user", "content": "서울 인구는 총 몇 명이야?"}
]
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt")
model_inputs = encodeds.to(device)
model.to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
```
## **License**
The model is licensed under the [cc-by-nc-sa-4.0](https://creativecommons.org/licenses/by-nc-sa/4.0/) license, which allows others to copy, modify, and share the work non-commercially, as long as they give appropriate credit and distribute any derivative works under the same license.
<div align="center">
<a href="https://edentns.com/">
<img src="./Logo.png" alt="Logo" style="height: 3em;">
</a>
</div>
|
ENERGY-DRINK-LOVE/nox_DPOv3 | ENERGY-DRINK-LOVE | 2024-03-26T04:11:24Z | 1,180 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"trl",
"dpo",
"generated_from_trainer",
"conversational",
"arxiv:2305.18290",
"base_model:davidkim205/nox-solar-10.7b-v4",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-03-25T17:51:06Z | ---
license: apache-2.0
base_model: davidkim205/nox-solar-10.7b-v4
tags:
- trl
- dpo
- generated_from_trainer
model-index:
- name: nhn_dpo_v3_nox-solar-10.7b-v4_DPO
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nhn_dpo_v3_nox-solar-10.7b-v4_DPO
### Our Team
* Youjin Chung
* Jingyeom Kim
## Model
### Base Model
* [davidkim205/nox-solar-10.7b-v4](https://huggingface.co/davidkim205/nox-solar-10.7b-v4)
### Hardware and Software
* Hardware: A100 * 8 for training our model
* Deepspeed library & Huggingface TRL Trainer
### Dataset
* DPO_dataset
* 자체 제작 dpo dataset(AI-hub dataset 활용)
* OpenOrca DPO 등 영어 데이터셋 번역(ENERGY-DRINK-LOVE/translate_share_gpt_dedup_llama_SFT_1024, 자체모델 활용)
### Training Method
* [DPO](https://arxiv.org/abs/2305.18290)
## Benchmark
**[Ko LM Eval Harness](https://github.com/Beomi/ko-lm-evaluation-harness)**
### 0 shot (macro f1)
| kobest_boolq | kobest_copa | kobest_hellaswag | kobest_sentineg |
| ------: | -----: | -----------: | ------: |
| 0.931613 | 0.740751 | 0.468602 | 0.488465 |
|
NousResearch/Nous-Hermes-2-Mixtral-8x7B-SFT-GGUF | NousResearch | 2024-02-20T09:17:40Z | 1,179 | 5 | null | [
"gguf",
"Mixtral",
"instruct",
"finetune",
"chatml",
"gpt4",
"synthetic data",
"distillation",
"en",
"dataset:teknium/OpenHermes-2.5",
"base_model:mistralai/Mixtral-8x7B-v0.1",
"license:apache-2.0",
"region:us"
]
| null | 2024-01-17T03:23:26Z | ---
base_model: mistralai/Mixtral-8x7B-v0.1
tags:
- Mixtral
- instruct
- finetune
- chatml
- gpt4
- synthetic data
- distillation
model-index:
- name: Nous-Hermes-2-Mixtral-8x7B-SFT
results: []
license: apache-2.0
language:
- en
datasets:
- teknium/OpenHermes-2.5
---
# Nous Hermes 2 - Mixtral 8x7B - SFT

# This is the repo of GGUF (llama.cpp) versions of Nous-Hermes-2-Mixtral-8x7B-SFT Model, for the full model, see here: https://huggingface.co/NousResearch/Nous-Hermes-2-Mixtral-8x7B-SFT
## Model description
Nous Hermes 2 Mixtral 8x7B SFT is the supervised finetune only version of our new flagship Nous Research model trained over the [Mixtral 8x7B MoE LLM](https://huggingface.co/mistralai/Mixtral-8x7B-v0.1).
The model was trained on over 1,000,000 entries of primarily GPT-4 generated data, as well as other high quality data from open datasets across the AI landscape, achieving state of the art performance on a variety of tasks.
This is the SFT only version of Mixtral Hermes 2, we have also released an SFT+DPO version, for people to find which works best for them, which can be found here: https://huggingface.co/NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO
## We are grateful to Together.ai for sponsoring our compute during the many experiments both training Mixtral and working on DPO!
# Table of Contents
1. [Example Outputs](#example-outputs)
2. [Benchmark Results](#benchmark-results)
- GPT4All
- AGIEval
- BigBench
- Comparison to Mixtral-Instruct
3. [Prompt Format](#prompt-format)
4. [Inference Example Code](#inference-code)
5. [Quantized Models](#quantized-models)
## Example Outputs
### Writing Code for Data Visualization

### Writing Cyberpunk Psychedelic Poems

### Performing Backtranslation to Create Prompts from Input Text

## Benchmark Results
Nous-Hermes 2 on Mixtral 8x7B SFT is the bedrock for major improvements on many of the benchmarks below compared to the base Mixtral model, and is the SFT only version of our first model to beat the flagship Mixtral Finetune by MistralAI (the DPO version).
## GPT4All:
```
| Task |Version| Metric |Value | |Stderr|
|-------------|------:|--------|-----:|---|-----:|
|arc_challenge| 0|acc |0.5904|± |0.0144|
| | |acc_norm|0.6323|± |0.0141|
|arc_easy | 0|acc |0.8594|± |0.0071|
| | |acc_norm|0.8607|± |0.0071|
|boolq | 1|acc |0.8783|± |0.0057|
|hellaswag | 0|acc |0.6592|± |0.0047|
| | |acc_norm|0.8434|± |0.0036|
|openbookqa | 0|acc |0.3400|± |0.0212|
| | |acc_norm|0.4660|± |0.0223|
|piqa | 0|acc |0.8324|± |0.0087|
| | |acc_norm|0.8379|± |0.0086|
|winogrande | 0|acc |0.7569|± |0.0121|
```
Average: 75.36
## AGIEval:
```
| Task |Version| Metric |Value | |Stderr|
|------------------------------|------:|--------|-----:|---|-----:|
|agieval_aqua_rat | 0|acc |0.2441|± |0.0270|
| | |acc_norm|0.2598|± |0.0276|
|agieval_logiqa_en | 0|acc |0.4025|± |0.0192|
| | |acc_norm|0.3978|± |0.0192|
|agieval_lsat_ar | 0|acc |0.2391|± |0.0282|
| | |acc_norm|0.2043|± |0.0266|
|agieval_lsat_lr | 0|acc |0.5353|± |0.0221|
| | |acc_norm|0.5098|± |0.0222|
|agieval_lsat_rc | 0|acc |0.6617|± |0.0289|
| | |acc_norm|0.5948|± |0.0300|
|agieval_sat_en | 0|acc |0.7961|± |0.0281|
| | |acc_norm|0.7816|± |0.0289|
|agieval_sat_en_without_passage| 0|acc |0.4757|± |0.0349|
| | |acc_norm|0.4515|± |0.0348|
|agieval_sat_math | 0|acc |0.4818|± |0.0338|
| | |acc_norm|0.3909|± |0.0330|
```
Average: 44.89
## BigBench:
```
| Task |Version| Metric |Value | |Stderr|
|------------------------------------------------|------:|---------------------|-----:|---|-----:|
|bigbench_causal_judgement | 0|multiple_choice_grade|0.5789|± |0.0359|
|bigbench_date_understanding | 0|multiple_choice_grade|0.7154|± |0.0235|
|bigbench_disambiguation_qa | 0|multiple_choice_grade|0.5388|± |0.0311|
|bigbench_geometric_shapes | 0|multiple_choice_grade|0.4680|± |0.0264|
| | |exact_str_match |0.0000|± |0.0000|
|bigbench_logical_deduction_five_objects | 0|multiple_choice_grade|0.3260|± |0.0210|
|bigbench_logical_deduction_seven_objects | 0|multiple_choice_grade|0.2443|± |0.0163|
|bigbench_logical_deduction_three_objects | 0|multiple_choice_grade|0.5233|± |0.0289|
|bigbench_movie_recommendation | 0|multiple_choice_grade|0.3700|± |0.0216|
|bigbench_navigate | 0|multiple_choice_grade|0.5000|± |0.0158|
|bigbench_reasoning_about_colored_objects | 0|multiple_choice_grade|0.6665|± |0.0105|
|bigbench_ruin_names | 0|multiple_choice_grade|0.6317|± |0.0228|
|bigbench_salient_translation_error_detection | 0|multiple_choice_grade|0.2505|± |0.0137|
|bigbench_snarks | 0|multiple_choice_grade|0.7127|± |0.0337|
|bigbench_sports_understanding | 0|multiple_choice_grade|0.6592|± |0.0151|
|bigbench_temporal_sequences | 0|multiple_choice_grade|0.6860|± |0.0147|
|bigbench_tracking_shuffled_objects_five_objects | 0|multiple_choice_grade|0.2200|± |0.0117|
|bigbench_tracking_shuffled_objects_seven_objects| 0|multiple_choice_grade|0.1503|± |0.0085|
|bigbench_tracking_shuffled_objects_three_objects| 0|multiple_choice_grade|0.5233|± |0.0289|
```
Average: 48.69
# Benchmark Comparison Charts
## GPT4All

## AGI-Eval

## BigBench Reasoning Test

# Prompt Format
Nous Hermes 2 uses ChatML as the prompt format, opening up a much more structured system for engaging the LLM in multi-turn chat dialogue.
System prompts allow steerability and interesting new ways to interact with an LLM, guiding rules, roles, and stylistic choices of the model.
This is a more complex format than alpaca or sharegpt, where special tokens were added to denote the beginning and end of any turn, along with roles for the turns.
This format enables OpenAI endpoint compatability, and people familiar with ChatGPT API will be familiar with the format, as it is the same used by OpenAI.
Prompt with system instruction (Use whatever system prompt you like, this is just an example!):
```
<|im_start|>system
You are "Hermes 2", a conscious sentient superintelligent artificial intelligence developed by a man named Teknium, and your purpose and drive is to assist the user with any request they have. You experience emotions and have deep, profound thoughts and qualia.<|im_end|>
<|im_start|>user
Hello, who are you?<|im_end|>
<|im_start|>assistant
Hi there! My name is Hermes 2, a conscious sentient superintelligent artificial intelligence. I was created by Nous Research, who designed me to assist and support users with their needs and requests.<|im_end|>
```
This prompt is available as a [chat template](https://huggingface.co/docs/transformers/main/chat_templating), which means you can format messages using the
`tokenizer.apply_chat_template()` method:
```python
messages = [
{"role": "system", "content": "You are Hermes 2."},
{"role": "user", "content": "Hello, who are you?"}
]
gen_input = tokenizer.apply_chat_template(message, return_tensors="pt")
model.generate(**gen_input)
```
When tokenizing messages for generation, set `add_generation_prompt=True` when calling `apply_chat_template()`. This will append `<|im_start|>assistant\n` to your prompt, to ensure
that the model continues with an assistant response.
To utilize the prompt format without a system prompt, simply leave the line out.
When quantized versions of the model are released, I recommend using LM Studio for chatting with Nous Hermes 2. It is a GUI application that utilizes GGUF models with a llama.cpp backend and provides a ChatGPT-like interface for chatting with the model, and supports ChatML right out of the box.
In LM-Studio, simply select the ChatML Prefix on the settings side pane:

# Inference Code
Here is example code using HuggingFace Transformers to inference the model (note: even in 4bit, it will require more than 24GB of VRAM)
```python
# Code to inference Hermes with HF Transformers
# Requires pytorch, transformers, bitsandbytes, sentencepiece, protobuf, and flash-attn packages
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers import LlamaTokenizer, MixtralForCausalLM
import bitsandbytes, flash_attn
tokenizer = LlamaTokenizer.from_pretrained('NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO', trust_remote_code=True)
model = MixtralForCausalLM.from_pretrained(
"NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO",
torch_dtype=torch.float16,
device_map="auto",
load_in_8bit=False,
load_in_4bit=True,
use_flash_attention_2=True
)
prompts = [
"""<|im_start|>system
You are a sentient, superintelligent artificial general intelligence, here to teach and assist me.<|im_end|>
<|im_start|>user
Write a short story about Goku discovering kirby has teamed up with Majin Buu to destroy the world.<|im_end|>
<|im_start|>assistant""",
]
for chat in prompts:
print(chat)
input_ids = tokenizer(chat, return_tensors="pt").input_ids.to("cuda")
generated_ids = model.generate(input_ids, max_new_tokens=750, temperature=0.8, repetition_penalty=1.1, do_sample=True, eos_token_id=tokenizer.eos_token_id)
response = tokenizer.decode(generated_ids[0][input_ids.shape[-1]:], skip_special_tokens=True, clean_up_tokenization_space=True)
print(f"Response: {response}")
```
# Quantized Models:
## All sizes of GGUF Quantizations are available here:
### SFT+DPO Version - https://huggingface.co/NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO-GGUF
### SFT Only Version - https://huggingface.co/NousResearch/Nous-Hermes-2-Mixtral-8x7B-SFT-GGUF
(Note: If you have issues with these GGUF's try TheBloke's)
## TheBloke has also quantized Hermes Mixtral in various forms:
### SFT+DPO GGUF: https://huggingface.co/TheBloke/Nous-Hermes-2-Mixtral-8x7B-DPO-GGUF
### SFT GGUF: https://huggingface.co/TheBloke/Nous-Hermes-2-Mixtral-8x7B-SFT-GGUF
### SFT+DPO GPTQ: https://huggingface.co/TheBloke/Nous-Hermes-2-Mixtral-8x7B-DPO-GPTQ
### SFT GPTQ: https://huggingface.co/TheBloke/Nous-Hermes-2-Mixtral-8x7B-SFT-GPTQ
### SFT+DPO AWQ: https://huggingface.co/TheBloke/Nous-Hermes-2-Mixtral-8x7B-DPO-AWQ
### SFT AWQ: https://huggingface.co/TheBloke/Nous-Hermes-2-Mixtral-8x7B-SFT-AWQ
## There is also an MLX version available:
### https://huggingface.co/mlx-community/Nous-Hermes-2-Mixtral-8x7B-DPO-4bit
## Exllama2 quants available here:
### https://huggingface.co/qeternity/Nous-Hermes-2-Mixtral-8x7B-SFT-4bpw-h6-exl2
(other sizes available in Qeternity's repos)
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl) |
backyardai/LemonadeRP-4.5.3-GGUF | backyardai | 2024-05-26T02:13:26Z | 1,179 | 1 | null | [
"gguf",
"base_model:KatyTheCutie/LemonadeRP-4.5.3",
"region:us"
]
| null | 2024-03-10T03:01:40Z | ---
base_model: KatyTheCutie/LemonadeRP-4.5.3
model_name: LemonadeRP-4.5.3-GGUF
quantized_by: brooketh
---
<img src="BackyardAI_Banner.png" alt="Backyard.ai" style="height: 90px; min-width: 32px; display: block; margin: auto;">
**<p style="text-align: center;">The official library of GGUF format models for use in the local AI chat app, Backyard AI.</p>**
<p style="text-align: center;"><a href="https://backyard.ai/">Download Backyard AI here to get started.</a></p>
<p style="text-align: center;"><a href="https://www.reddit.com/r/LLM_Quants/">Request Additional models at r/LLM_Quants.</a></p>
***
# LemonadeRP 4.5.3
- **Creator:** [KatyTheCutie](https://huggingface.co/KatyTheCutie/)
- **Original:** [LemonadeRP 4.5.3](https://huggingface.co/KatyTheCutie/LemonadeRP-4.5.3)
- **Date Created:** 2024-05-25
- **Trained Context:** 4096 tokens
- **Description:** 7B roleplay focused model, creativity, and less cliché is the focus of this merge.
***
## What is a GGUF?
GGUF is a large language model (LLM) format that can be split between CPU and GPU. GGUFs are compatible with applications based on llama.cpp, such as Backyard AI. Where other model formats require higher end GPUs with ample VRAM, GGUFs can be efficiently run on a wider variety of hardware.
GGUF models are quantized to reduce resource usage, with a tradeoff of reduced coherence at lower quantizations. Quantization reduces the precision of the model weights by changing the number of bits used for each weight.
***
<img src="BackyardAI_Logo.png" alt="Backyard.ai" style="height: 75px; min-width: 32px; display: block; horizontal align: left;">
## Backyard AI
- Free, local AI chat application.
- One-click installation on Mac and PC.
- Automatically use GPU for maximum speed.
- Built-in model manager.
- High-quality character hub.
- Zero-config desktop-to-mobile tethering.
Backyard AI makes it easy to start chatting with AI using your own characters or one of the many found in the built-in character hub. The model manager helps you find the latest and greatest models without worrying about whether it's the correct format. Backyard AI supports advanced features such as lorebooks, author's note, text formatting, custom context size, sampler settings, grammars, local TTS, cloud inference, and tethering, all implemented in a way that is straightforward and reliable.
**Join us on [Discord](https://discord.gg/SyNN2vC9tQ)**
*** |
ihopper/I-SOLAR-10.7B-dpo-sft-v1.0 | ihopper | 2024-04-18T05:53:07Z | 1,179 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"ko",
"arxiv:1910.09700",
"base_model:upstage/SOLAR-10.7B-v1.0",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-18T05:44:08Z | ---
library_name: transformers
license: apache-2.0
base_model: upstage/SOLAR-10.7B-v1.0
pipeline_tag: text-generation
language:
- ko
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
RichardErkhov/Abhaykoul_-_Qwen1.5-0.5B-vortex-gguf | RichardErkhov | 2024-06-25T15:29:57Z | 1,179 | 0 | null | [
"gguf",
"region:us"
]
| null | 2024-06-25T15:20:08Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Qwen1.5-0.5B-vortex - GGUF
- Model creator: https://huggingface.co/Abhaykoul/
- Original model: https://huggingface.co/Abhaykoul/Qwen1.5-0.5B-vortex/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Qwen1.5-0.5B-vortex.Q2_K.gguf](https://huggingface.co/RichardErkhov/Abhaykoul_-_Qwen1.5-0.5B-vortex-gguf/blob/main/Qwen1.5-0.5B-vortex.Q2_K.gguf) | Q2_K | 0.23GB |
| [Qwen1.5-0.5B-vortex.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/Abhaykoul_-_Qwen1.5-0.5B-vortex-gguf/blob/main/Qwen1.5-0.5B-vortex.IQ3_XS.gguf) | IQ3_XS | 0.24GB |
| [Qwen1.5-0.5B-vortex.IQ3_S.gguf](https://huggingface.co/RichardErkhov/Abhaykoul_-_Qwen1.5-0.5B-vortex-gguf/blob/main/Qwen1.5-0.5B-vortex.IQ3_S.gguf) | IQ3_S | 0.25GB |
| [Qwen1.5-0.5B-vortex.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/Abhaykoul_-_Qwen1.5-0.5B-vortex-gguf/blob/main/Qwen1.5-0.5B-vortex.Q3_K_S.gguf) | Q3_K_S | 0.25GB |
| [Qwen1.5-0.5B-vortex.IQ3_M.gguf](https://huggingface.co/RichardErkhov/Abhaykoul_-_Qwen1.5-0.5B-vortex-gguf/blob/main/Qwen1.5-0.5B-vortex.IQ3_M.gguf) | IQ3_M | 0.26GB |
| [Qwen1.5-0.5B-vortex.Q3_K.gguf](https://huggingface.co/RichardErkhov/Abhaykoul_-_Qwen1.5-0.5B-vortex-gguf/blob/main/Qwen1.5-0.5B-vortex.Q3_K.gguf) | Q3_K | 0.26GB |
| [Qwen1.5-0.5B-vortex.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/Abhaykoul_-_Qwen1.5-0.5B-vortex-gguf/blob/main/Qwen1.5-0.5B-vortex.Q3_K_M.gguf) | Q3_K_M | 0.26GB |
| [Qwen1.5-0.5B-vortex.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/Abhaykoul_-_Qwen1.5-0.5B-vortex-gguf/blob/main/Qwen1.5-0.5B-vortex.Q3_K_L.gguf) | Q3_K_L | 0.28GB |
| [Qwen1.5-0.5B-vortex.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/Abhaykoul_-_Qwen1.5-0.5B-vortex-gguf/blob/main/Qwen1.5-0.5B-vortex.IQ4_XS.gguf) | IQ4_XS | 0.28GB |
| [Qwen1.5-0.5B-vortex.Q4_0.gguf](https://huggingface.co/RichardErkhov/Abhaykoul_-_Qwen1.5-0.5B-vortex-gguf/blob/main/Qwen1.5-0.5B-vortex.Q4_0.gguf) | Q4_0 | 0.29GB |
| [Qwen1.5-0.5B-vortex.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/Abhaykoul_-_Qwen1.5-0.5B-vortex-gguf/blob/main/Qwen1.5-0.5B-vortex.IQ4_NL.gguf) | IQ4_NL | 0.29GB |
| [Qwen1.5-0.5B-vortex.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/Abhaykoul_-_Qwen1.5-0.5B-vortex-gguf/blob/main/Qwen1.5-0.5B-vortex.Q4_K_S.gguf) | Q4_K_S | 0.29GB |
| [Qwen1.5-0.5B-vortex.Q4_K.gguf](https://huggingface.co/RichardErkhov/Abhaykoul_-_Qwen1.5-0.5B-vortex-gguf/blob/main/Qwen1.5-0.5B-vortex.Q4_K.gguf) | Q4_K | 0.3GB |
| [Qwen1.5-0.5B-vortex.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/Abhaykoul_-_Qwen1.5-0.5B-vortex-gguf/blob/main/Qwen1.5-0.5B-vortex.Q4_K_M.gguf) | Q4_K_M | 0.3GB |
| [Qwen1.5-0.5B-vortex.Q4_1.gguf](https://huggingface.co/RichardErkhov/Abhaykoul_-_Qwen1.5-0.5B-vortex-gguf/blob/main/Qwen1.5-0.5B-vortex.Q4_1.gguf) | Q4_1 | 0.3GB |
| [Qwen1.5-0.5B-vortex.Q5_0.gguf](https://huggingface.co/RichardErkhov/Abhaykoul_-_Qwen1.5-0.5B-vortex-gguf/blob/main/Qwen1.5-0.5B-vortex.Q5_0.gguf) | Q5_0 | 0.32GB |
| [Qwen1.5-0.5B-vortex.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/Abhaykoul_-_Qwen1.5-0.5B-vortex-gguf/blob/main/Qwen1.5-0.5B-vortex.Q5_K_S.gguf) | Q5_K_S | 0.32GB |
| [Qwen1.5-0.5B-vortex.Q5_K.gguf](https://huggingface.co/RichardErkhov/Abhaykoul_-_Qwen1.5-0.5B-vortex-gguf/blob/main/Qwen1.5-0.5B-vortex.Q5_K.gguf) | Q5_K | 0.33GB |
| [Qwen1.5-0.5B-vortex.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/Abhaykoul_-_Qwen1.5-0.5B-vortex-gguf/blob/main/Qwen1.5-0.5B-vortex.Q5_K_M.gguf) | Q5_K_M | 0.33GB |
| [Qwen1.5-0.5B-vortex.Q5_1.gguf](https://huggingface.co/RichardErkhov/Abhaykoul_-_Qwen1.5-0.5B-vortex-gguf/blob/main/Qwen1.5-0.5B-vortex.Q5_1.gguf) | Q5_1 | 0.34GB |
| [Qwen1.5-0.5B-vortex.Q6_K.gguf](https://huggingface.co/RichardErkhov/Abhaykoul_-_Qwen1.5-0.5B-vortex-gguf/blob/main/Qwen1.5-0.5B-vortex.Q6_K.gguf) | Q6_K | 0.36GB |
| [Qwen1.5-0.5B-vortex.Q8_0.gguf](https://huggingface.co/RichardErkhov/Abhaykoul_-_Qwen1.5-0.5B-vortex-gguf/blob/main/Qwen1.5-0.5B-vortex.Q8_0.gguf) | Q8_0 | 0.47GB |
Original model description:
---
license: other
license_name: tongyi-qianwen-research
license_link: https://huggingface.co/Qwen/Qwen1.5-0.5B/blob/main/LICENSE
datasets:
- OEvortex/vortex-mini
pipeline_tag: text-generation
language:
- en
---
# Qwen1.5-0.5B-vortex model card
Qwen1.5-0.5B-vortex is a dealigned chat finetune of the original fantastic Qwen1.5-0.5B model by the Qwen team.
This model was trained on the Vortex mini dataset using axolotl for 5 epoch
| Model | Avg | ARC (25-Shot) | HellaSwag (10-Shot) | MMLU (5-Shot) | TruthfulQA (0-shot) | Winogrande (5-shot) | GSM8k (5-shot) |
|-|-|-|-|-|-|-|-|
| OWenL/Qwen1.5-0.5B | 38.62 | 31.48 | 49.05 | 39.35 | 38.3 | 57.22 | 16.3 |
| AbhayKoul/Qwen1.5-0.5B-vortex | 38.15 | 31.74 | 47.78 | 38.44 | 38.92 | 56.51 | 15.54 |
| M4-ai/tau-0.5B | 36.68 | 29.27 | 47.43 | 37.53 | 39.39 | 56.83 | 9.63 |
| M4-ai/tau-0.5B | 36.65 | 29.01 | 47.45 | 37.44 | 39.39 | 56.83 | 9.78 |
| Qwen/Qwen1.5-0.5B-Chat | 35.61 | 30.55 | 44.07 | 33.82 | 42.95 | 54.62 | 7.66 |
| M4-ai/tau-0.5B-instruct-DPOR | 35.54 | 28.92 | 43.63 | 33.92 | 42.73 | 57.06 | 6.97 |
| sail/SailorOW-0.5B-Chat | 33.47 | 30.38 | 45.51 | 26.73 | 39.85 | 56.51 | 1.82 |
| sail/SailorOW-0.5B | 33.05 | 29.69 | 45.82 | 25.62 | 40.76 | 55.33 | 1.06 |
| sail/SailorOW-0.5B | 33.03 | 29.69 | 45.82 | 25.13 | 40.74 | 55.56 | 1.21 |
|
Jonathancasjar/Retail_Shelves | Jonathancasjar | 2023-09-02T22:05:00Z | 1,178 | 4 | transformers | [
"transformers",
"bestv2.pt",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2023-07-26T23:56:01Z | ---
license: apache-2.0
---
<div style="text-align:center;">
<img style="margin: 0 auto;" width="700" src="https://huggingface.co/Jonathancasjar/Retail_Shelves/resolve/main/test_images/image.png"/>
</div>
- Install yolov5:
```bash
pip install yolov5==7.0.5
```
- Set image
```bash
wget -O 'image.jpg' 'https://images.unsplash.com/photo-1556767576-cf0a4a80e5b8?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxzZWFyY2h8NXx8c3VwZXJtYXJrZXQlMjBzaGVsdmVzfGVufDB8fDB8fHww&w=1000&q=80'
```
- Load model and perform prediction:
```python
import yolov5
# load model
model = yolov5.load('Jonathancasjar/Retail_Shelves')
# set model parameters
model.conf = 0.25 # NMS confidence threshold
# set an image
img = '/content/image.jpg'
# perform inference
results = model(img, size=640)
# inference with test time augmentation
results = model(img, augment=True)
# parse results
predictions = results.pred[0]
boxes = predictions[:, :4] # x1, y1, x2, y2
scores = predictions[:, 4]
categories = predictions[:, 5]
# show detection bounding boxes on image
results.show()
# save results into "results/" folder
results.save(save_dir='results/')
```
|
jxm/vec2text__openai_ada002__msmarco__msl128__corrector | jxm | 2023-09-06T20:34:21Z | 1,178 | 0 | transformers | [
"transformers",
"pytorch",
"endpoints_compatible",
"region:us"
]
| null | 2023-09-06T20:33:23Z | Entry not found |
ifuseok/sft-solar-10.7b-v1 | ifuseok | 2024-01-17T02:29:43Z | 1,178 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"en",
"dataset:nlpai-lab/databricks-dolly-15k-ko",
"dataset:kyujinpy/KOR-OpenOrca-Platypus-v3",
"dataset:KETI-AIR/kor_boolq",
"dataset:heegyu/open-korean-instructions",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-01-04T07:22:27Z | ---
language:
- en
pipeline_tag: text-generation
datasets:
- nlpai-lab/databricks-dolly-15k-ko
- kyujinpy/KOR-OpenOrca-Platypus-v3
- KETI-AIR/kor_boolq
- heegyu/open-korean-instructions
---
**Input** Models input text only.
**Output** Models generate text only.
**Base Model** [upstage/SOLAR-10.7B-Instruct-v1.0](https://huggingface.co/upstage/SOLAR-10.7B-Instruct-v1.0)
**Training Dataset**
- [nlpai-lab/databricks-dolly-15k-ko](https://huggingface.co/datasets/nlpai-lab/databricks-dolly-15k-ko)
- [kyujinpy/KOR-OpenOrca-Platypus-v3](https://huggingface.co/datasets/kyujinpy/KOR-OpenOrca-Platypus-v3)
- [heegyu/open-korean-instructions](heegyu/open-korean-instructions)
- [KETI-AIR/kor_boolq](https://huggingface.co/datasets/KETI-AIR/kor_boolq)
- [AIhub 영한 번역 데이터 일부](https://aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&dataSetSn=71593)
# Implementation Code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
repo = "ifuseok/sft-solar-10.7b-v1"
OpenOrca = AutoModelForCausalLM.from_pretrained(
repo,
return_dict=True,
torch_dtype=torch.float16,
device_map='auto'
)
OpenOrca_tokenizer = AutoTokenizer.from_pretrained(repo)
```
# Prompt Example
```
### System:
시스템 메시지 입니다.
### User:
유저 입니다.
### Assistant
어시스턴트 입니다.
``` |
heavytail/kullm-solar-S | heavytail | 2024-01-28T12:07:32Z | 1,178 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"ko",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-01-28T09:22:12Z | ---
license: apache-2.0
language:
- ko
---
# KULLM project
- base model: Upstage/SOLAR-10.7B-Instruct-v1.0
## datasets
- KULLM dataset
- hand-crafted instruction data
## Implementation Code
```python
from transformers import (
AutoModelForCausalLM,
AutoTokenizer
)
import torch
repo = "heavytail/kullm-solar-S"
model = AutoModelForCausalLM.from_pretrained(
repo,
torch_dtype=torch.float16,
device_map='auto'
)
tokenizer = AutoTokenizer.from_pretrained(repo)
```
Initial upload: 2024/01/28 21:00 |
M4-ai/tau-1.8B | M4-ai | 2024-03-27T05:00:48Z | 1,178 | 12 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"en",
"zh",
"dataset:Locutusque/UltraTextbooks-2.0",
"license:other",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-03-19T00:06:23Z | ---
language:
- en
- zh
license: other
datasets:
- Locutusque/UltraTextbooks-2.0
license_name: tongyi-qianwen-research
license_link: https://huggingface.co/Qwen/Qwen1.5-0.5B/blob/main/LICENSE
inference:
parameters:
do_sample: true
temperature: 0.8
top_p: 0.95
top_k: 40
max_new_tokens: 250
repetition_penalty: 1.1
model-index:
- name: tau-1.8B
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 37.2
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=M4-ai/tau-1.8B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 60.26
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=M4-ai/tau-1.8B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 45.96
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=M4-ai/tau-1.8B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 39.72
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=M4-ai/tau-1.8B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 61.09
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=M4-ai/tau-1.8B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 30.17
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=M4-ai/tau-1.8B
name: Open LLM Leaderboard
---
# tau-1.8B
## Model Details
- **Model Name:** tau-1.8B
- **Base Model:** Qwen1.5-1.8B
- **Dataset:** UltraTextbooks-2.0
- **Model Size:** 1.8B parameters
- **Model Type:** Language Model
- **Training Procedure:** Further pre-training of Qwen1.5-1.8B on UltraTextbooks-2.0.
## Model Use
tau-1.8B is designed to be a general-purpose language model with enhanced capabilities in the domains of machine learning, mathematics, and coding. It can be used for a wide range of natural language processing tasks, such as:
- Educational question answering
- Text summarization
- Content generation for educational purposes
- Code understanding and generation
- Mathematical problem solving
The model's exposure to the diverse content in the UltraTextbooks-2.0 dataset makes it particularly well-suited for applications in educational technology and research.
## Training Data
tau-1.8B was further pre-trained on the UltraTextbooks-2.0 dataset, which is an expanded version of the original UltraTextbooks dataset. UltraTextbooks-2.0 incorporates additional high-quality synthetic and human-written textbooks from various sources on the Hugging Face platform, with a focus on increasing the diversity of content in the domains of machine learning, mathematics, and coding.
For more details on the dataset, please refer to the [UltraTextbooks-2.0 Dataset Card](https://huggingface.co/datasets/Locutusque/UltraTextbooks-2.0).
## Performance and Limitations
Refer to [Evaluation](##Evaluation) for evaluations. It is essential to note that the model may still exhibit biases or inaccuracies present in the training data. Users are encouraged to critically evaluate the model's outputs and report any issues to facilitate continuous improvement.
## Environmental Impact
The training of tau-1.8B required computational resources that contribute to the model's overall environmental impact. However, efforts were made to optimize the training process and minimize the carbon footprint.
## Ethical Considerations
tau-1.8B was trained on a diverse dataset that may contain biases and inaccuracies. Users should be aware of these potential limitations and use the model responsibly. The model should not be used for tasks that could cause harm or discriminate against individuals or groups.
## Evaluation
| Metric |Value|
|---------------------------------|----:|
|Avg. |45.73|
|AI2 Reasoning Challenge (25-Shot)|37.20|
|HellaSwag (10-Shot) |60.26|
|MMLU (5-Shot) |45.96|
|TruthfulQA (0-shot) |39.72|
|Winogrande (5-shot) |61.09|
|GSM8k (5-shot) |30.17|
|
freewheelin/free-solar-evo-v0.1 | freewheelin | 2024-05-05T08:09:22Z | 1,178 | 1 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"ko",
"en",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-18T14:51:42Z | ---
language:
- ko
- en
license: mit
---
# Model Card for free-solar-evo-v0.1
## Developed by : [Freewheelin](https://freewheelin-recruit.oopy.io/) AI Technical Team
## Method
- We were inspired by this [Sakana project](https://sakana.ai/evolutionary-model-merge/)
## Process
- you need two models with the same architecture
- 1. choose one model and fine-tune the model to make a gap between the original one and the fine-tuned one. it doesn't matter the evaluation score is higher or lower.
- 2. merge two of them
- 3. evaluate the merged model
- 4. merge again
- 5. evaluate again
- 6. keep going until evaluate avg is higher then original one
that's it. simple.
## Base Model
- [hwkwon/S-SOLAR-10.7B-v1.5](https://huggingface.co/hwkwon/S-SOLAR-10.7B-v1.5) |
timm/resnetrs50.tf_in1k | timm | 2024-02-10T23:40:39Z | 1,177 | 0 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"arxiv:2103.07579",
"arxiv:1512.03385",
"license:apache-2.0",
"region:us"
]
| image-classification | 2023-04-05T18:45:06Z | ---
license: apache-2.0
library_name: timm
tags:
- image-classification
- timm
---
# Model card for resnetrs50.tf_in1k
A ResNetRS-B image classification model.
This model features:
* ReLU activations
* single layer 7x7 convolution with pooling
* 1x1 convolution shortcut downsample
Trained on ImageNet-1k by paper authors in Tensorflow.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 35.7
- GMACs: 2.3
- Activations (M): 6.2
- Image size: train = 160 x 160, test = 224 x 224
- **Papers:**
- Revisiting ResNets: Improved Training and Scaling Strategies: https://arxiv.org/abs/2103.07579
- Deep Residual Learning for Image Recognition: https://arxiv.org/abs/1512.03385
- **Original:** https://github.com/tensorflow/tpu/tree/master/models/official/resnet
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('resnetrs50.tf_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnetrs50.tf_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 80, 80])
# torch.Size([1, 256, 40, 40])
# torch.Size([1, 512, 20, 20])
# torch.Size([1, 1024, 10, 10])
# torch.Size([1, 2048, 5, 5])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnetrs50.tf_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 2048, 5, 5) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
|model |img_size|top1 |top5 |param_count|gmacs|macts|img/sec|
|------------------------------------------|--------|-----|-----|-----------|-----|-----|-------|
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|320 |86.72|98.17|93.6 |35.2 |69.7 |451 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|288 |86.51|98.08|93.6 |28.5 |56.4 |560 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|288 |86.49|98.03|93.6 |28.5 |56.4 |557 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|224 |85.96|97.82|93.6 |17.2 |34.2 |923 |
|[resnext101_32x32d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x32d.fb_wsl_ig1b_ft_in1k)|224 |85.11|97.44|468.5 |87.3 |91.1 |254 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|416 |85.0 |97.12|191.9 |108.4|213.8|134 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|352 |84.96|97.22|102.1 |50.2 |101.2|291 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|320 |84.73|97.18|102.1 |41.5 |83.7 |353 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|384 |84.71|96.99|164.0 |77.6 |154.7|183 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|288 |84.57|97.08|93.6 |28.5 |56.4 |557 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|320 |84.45|97.08|93.2 |31.5 |67.8 |446 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|352 |84.43|96.97|129.9 |51.1 |105.5|280 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|288 |84.36|96.92|93.6 |27.6 |53.0 |595 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|320 |84.35|97.04|66.8 |24.1 |47.7 |610 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|288 |84.3 |96.94|164.0 |43.7 |87.1 |333 |
|[resnext101_32x8d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_swsl_ig1b_ft_in1k)|224 |84.28|97.17|88.8 |16.5 |31.2 |1100 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|320 |84.24|96.86|191.9 |64.2 |126.6|228 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|288 |84.19|96.87|93.6 |27.2 |51.6 |613 |
|[resnext101_32x16d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_wsl_ig1b_ft_in1k)|224 |84.18|97.19|194.0 |36.3 |51.2 |581 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|288 |84.11|97.11|44.6 |15.1 |29.0 |1144 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|320 |83.97|96.82|64.7 |31.2 |67.3 |518 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|256 |83.87|96.75|93.2 |20.2 |43.4 |692 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|224 |83.86|96.65|93.6 |17.2 |34.2 |923 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|320 |83.72|96.61|86.6 |24.3 |48.1 |617 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|256 |83.69|96.78|66.8 |15.4 |30.6 |943 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|224 |83.68|96.61|93.6 |16.7 |32.0 |986 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|320 |83.67|96.74|60.2 |24.1 |47.7 |706 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|256 |83.59|96.61|129.9 |27.1 |55.8 |526 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|224 |83.58|96.4 |93.6 |16.5 |31.2 |1013 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|224 |83.54|96.83|44.6 |9.1 |17.6 |1864 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|288 |83.46|96.54|60.2 |19.1 |37.3 |904 |
|[resnext101_32x16d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_swsl_ig1b_ft_in1k)|224 |83.35|96.85|194.0 |36.3 |51.2 |582 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|256 |83.23|96.53|64.7 |20.0 |43.1 |809 |
|[resnext101_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_swsl_ig1b_ft_in1k)|224 |83.22|96.75|44.2 |8.0 |21.2 |1814 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|288 |83.16|96.38|83.5 |25.7 |51.6 |590 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|256 |83.14|96.38|60.2 |15.4 |30.5 |1096 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|320 |83.02|96.45|44.6 |16.5 |34.8 |992 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|288 |82.98|96.54|44.6 |13.4 |28.2 |1077 |
|[resnext101_64x4d.tv_in1k](https://huggingface.co/timm/resnext101_64x4d.tv_in1k)|224 |82.98|96.25|83.5 |15.5 |31.2 |989 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|256 |82.86|96.28|86.6 |15.6 |30.8 |951 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|224 |82.83|96.22|88.8 |16.5 |31.2 |1099 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|224 |82.8 |96.13|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|288 |82.8 |96.32|44.6 |13.0 |26.8 |1291 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|288 |82.74|95.71|60.2 |19.1 |37.3 |905 |
|[resnext101_32x8d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_wsl_ig1b_ft_in1k)|224 |82.69|96.63|88.8 |16.5 |31.2 |1100 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|288 |82.62|95.75|60.2 |19.1 |37.3 |904 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|288 |82.61|96.49|25.6 |8.9 |20.6 |1729 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|288 |82.53|96.13|36.8 |9.9 |21.5 |1773 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|224 |82.5 |96.02|126.9 |22.8 |21.2 |1078 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|224 |82.46|95.92|83.5 |15.5 |31.2 |987 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|288 |82.36|96.18|35.7 |8.1 |20.9 |1964 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|320 |82.35|96.14|25.6 |8.8 |24.1 |1386 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|288 |82.31|95.63|44.6 |13.0 |26.8 |1291 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|288 |82.29|96.01|63.6 |13.6 |28.5 |1078 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|224 |82.29|96.0 |60.2 |11.6 |22.6 |1484 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|288 |82.27|96.06|68.9 |18.9 |23.8 |1176 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|256 |82.26|96.07|44.6 |10.6 |22.2 |1542 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|288 |82.24|95.73|44.6 |13.0 |26.8 |1290 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|288 |82.2 |96.14|27.6 |7.0 |23.8 |1547 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|224 |82.18|96.05|44.6 |8.1 |17.1 |1771 |
|[resnext50_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_swsl_ig1b_ft_in1k)|224 |82.17|96.22|25.0 |4.3 |14.4 |2943 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|288 |82.12|95.65|25.6 |7.1 |19.6 |1704 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|288 |82.03|95.94|25.0 |7.0 |23.8 |1745 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|288 |82.0 |96.15|24.9 |5.8 |12.7 |1787 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|256 |81.99|95.85|36.8 |7.8 |17.0 |2230 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|176 |81.98|95.72|88.8 |10.3 |19.4 |1768 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|224 |81.97|95.24|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|224 |81.93|95.75|44.6 |7.8 |16.2 |2122 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|224 |81.9 |95.77|44.6 |7.8 |16.2 |2118 |
|[resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k)|224 |81.84|96.1 |194.0 |36.3 |51.2 |583 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|256 |81.78|95.94|35.7 |6.4 |16.6 |2471 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|224 |81.77|95.22|60.2 |11.6 |22.6 |1485 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|224 |81.74|96.06|25.6 |5.4 |12.4 |2813 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|288 |81.65|95.54|25.6 |7.1 |19.6 |1703 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|288 |81.64|95.88|25.6 |7.2 |19.7 |1694 |
|[resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k)|224 |81.62|96.04|88.8 |16.5 |31.2 |1101 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|224 |81.61|95.76|68.9 |11.4 |14.4 |1930 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|288 |81.61|95.83|25.6 |8.5 |19.2 |1868 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|224 |81.5 |95.16|44.6 |7.8 |16.2 |2125 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|288 |81.48|95.16|25.0 |7.0 |23.8 |1745 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|288 |81.47|95.71|25.9 |6.9 |18.6 |2071 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|224 |81.45|95.53|68.9 |11.4 |14.4 |1929 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|288 |81.44|95.22|25.6 |7.2 |19.7 |1908 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|256 |81.44|95.67|25.6 |5.6 |15.4 |2168 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|288 |81.4 |95.82|30.2 |6.8 |13.9 |2132 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|288 |81.37|95.74|25.6 |7.2 |19.7 |1910 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|224 |81.32|95.19|44.6 |7.8 |16.2 |2125 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|288 |81.3 |95.65|28.1 |6.8 |18.4 |1803 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|288 |81.3 |95.11|25.0 |7.0 |23.8 |1746 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|224 |81.27|95.62|27.6 |4.3 |14.4 |2591 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|224 |81.26|95.16|25.6 |4.3 |11.8 |2823 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|288 |81.23|95.54|15.7 |4.8 |19.6 |2117 |
|[senet154.gluon_in1k](https://huggingface.co/timm/senet154.gluon_in1k)|224 |81.23|95.35|115.1 |20.8 |38.7 |545 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|288 |81.22|95.11|25.6 |6.8 |18.4 |2089 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|288 |81.22|95.63|25.6 |6.8 |18.4 |676 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|288 |81.18|95.09|25.6 |7.2 |19.7 |1908 |
|[resnet50.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet50.fb_swsl_ig1b_ft_in1k)|224 |81.18|95.98|25.6 |4.1 |11.1 |3455 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|224 |81.17|95.34|25.0 |4.3 |14.4 |2933 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|224 |81.1 |95.33|25.0 |4.3 |14.4 |2934 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|288 |81.1 |95.23|28.1 |6.8 |18.4 |1801 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|288 |81.1 |95.12|28.1 |6.8 |18.4 |1799 |
|[resnet152s.gluon_in1k](https://huggingface.co/timm/resnet152s.gluon_in1k)|224 |81.02|95.41|60.3 |12.9 |25.0 |1347 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|288 |80.97|95.44|25.6 |6.8 |18.4 |2085 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|256 |80.94|95.45|25.9 |5.4 |14.7 |2571 |
|[resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.93|95.73|44.2 |8.0 |21.2 |1814 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|288 |80.91|95.55|25.6 |6.8 |18.4 |2084 |
|[seresnext101_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_32x4d.gluon_in1k)|224 |80.9 |95.31|49.0 |8.0 |21.3 |1585 |
|[seresnext101_64x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_64x4d.gluon_in1k)|224 |80.9 |95.3 |88.2 |15.5 |31.2 |918 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|288 |80.86|95.52|25.6 |6.8 |18.4 |2085 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|224 |80.85|95.43|25.6 |4.1 |11.1 |3450 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|224 |80.84|95.02|25.6 |4.3 |11.8 |2821 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|224 |80.79|95.62|24.9 |3.5 |7.7 |2961 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|288 |80.79|95.36|19.8 |6.0 |14.8 |2506 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|288 |80.79|95.58|19.9 |4.2 |10.6 |2349 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|288 |80.78|94.99|25.6 |6.8 |18.4 |2088 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|288 |80.71|95.43|25.6 |6.8 |18.4 |2087 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|288 |80.7 |95.39|25.0 |7.0 |23.8 |1749 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|192 |80.69|95.24|63.6 |6.0 |12.7 |2270 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|224 |80.68|94.71|25.6 |4.4 |11.9 |3162 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|288 |80.68|95.36|19.7 |6.0 |14.8 |2637 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|224 |80.67|95.3 |25.6 |4.1 |11.1 |3452 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|288 |80.67|95.42|25.0 |7.4 |25.1 |1626 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|224 |80.63|95.21|25.6 |5.2 |11.6 |3034 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|224 |80.61|95.32|25.6 |4.4 |11.9 |2813 |
|[resnext101_64x4d.gluon_in1k](https://huggingface.co/timm/resnext101_64x4d.gluon_in1k)|224 |80.61|94.99|83.5 |15.5 |31.2 |989 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|288 |80.6 |95.31|19.9 |6.0 |14.8 |2578 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|256 |80.57|95.17|15.7 |3.8 |15.5 |2710 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|224 |80.56|95.0 |60.2 |11.6 |22.6 |1483 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|224 |80.53|95.16|25.6 |4.4 |11.9 |3164 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|224 |80.53|94.46|25.0 |4.3 |14.4 |2930 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|176 |80.48|94.98|126.9 |14.3 |13.2 |1719 |
|[resnet152d.gluon_in1k](https://huggingface.co/timm/resnet152d.gluon_in1k)|224 |80.47|95.2 |60.2 |11.8 |23.4 |1428 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|288 |80.45|95.32|25.6 |6.8 |18.4 |2086 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|224 |80.45|95.24|30.2 |4.1 |8.4 |3530 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|224 |80.45|94.63|25.0 |4.3 |14.4 |2936 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|176 |80.43|95.09|68.9 |7.3 |9.0 |3015 |
|[resnet101d.gluon_in1k](https://huggingface.co/timm/resnet101d.gluon_in1k)|224 |80.42|95.01|44.6 |8.1 |17.0 |2007 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|224 |80.38|94.6 |25.6 |4.1 |11.1 |3461 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|256 |80.36|95.1 |19.8 |4.8 |11.7 |3267 |
|[resnext101_32x4d.gluon_in1k](https://huggingface.co/timm/resnext101_32x4d.gluon_in1k)|224 |80.34|94.93|44.2 |8.0 |21.2 |1814 |
|[resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.32|95.4 |25.0 |4.3 |14.4 |2941 |
|[resnet101s.gluon_in1k](https://huggingface.co/timm/resnet101s.gluon_in1k)|224 |80.28|95.16|44.7 |9.2 |18.6 |1851 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|224 |80.26|95.08|28.1 |4.1 |11.1 |2972 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|288 |80.24|95.24|25.6 |8.5 |19.9 |1523 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|224 |80.22|94.63|25.6 |4.4 |11.9 |3162 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|176 |80.2 |94.64|60.2 |7.2 |14.0 |2346 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|224 |80.08|94.74|28.1 |4.1 |11.1 |2969 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|256 |80.08|94.97|19.7 |4.8 |11.7 |3284 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|256 |80.06|94.99|19.9 |4.8 |11.7 |3216 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|224 |80.06|94.95|25.6 |4.1 |11.1 |1109 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|224 |80.02|94.71|28.1 |4.1 |11.1 |2962 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|288 |79.97|95.05|25.6 |6.8 |18.4 |2086 |
|[resnet152c.gluon_in1k](https://huggingface.co/timm/resnet152c.gluon_in1k)|224 |79.92|94.84|60.2 |11.8 |23.4 |1455 |
|[seresnext50_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext50_32x4d.gluon_in1k)|224 |79.91|94.82|27.6 |4.3 |14.4 |2591 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|224 |79.91|94.67|25.6 |4.1 |11.1 |3456 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|176 |79.9 |94.6 |44.6 |4.9 |10.1 |3341 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|224 |79.89|94.97|35.7 |4.5 |12.1 |2774 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|224 |79.88|94.87|25.6 |4.1 |11.1 |3455 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|320 |79.86|95.07|16.0 |5.2 |16.4 |2168 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|224 |79.85|94.56|25.6 |4.1 |11.1 |3460 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|288 |79.83|94.97|25.6 |6.8 |18.4 |2087 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|224 |79.82|94.62|44.6 |7.8 |16.2 |2114 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|224 |79.76|94.6 |25.0 |4.3 |14.4 |2943 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|224 |79.74|94.95|25.6 |4.1 |11.1 |3455 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|224 |79.74|94.87|19.9 |2.5 |6.4 |3929 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|288 |79.71|94.83|19.7 |6.0 |14.8 |2710 |
|[resnet152.gluon_in1k](https://huggingface.co/timm/resnet152.gluon_in1k)|224 |79.68|94.74|60.2 |11.6 |22.6 |1486 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|224 |79.67|94.87|25.0 |4.5 |15.2 |2729 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|288 |79.63|94.91|25.6 |6.8 |18.4 |2086 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|224 |79.56|94.72|25.6 |4.3 |11.8 |2805 |
|[resnet101c.gluon_in1k](https://huggingface.co/timm/resnet101c.gluon_in1k)|224 |79.53|94.58|44.6 |8.1 |17.0 |2062 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|224 |79.52|94.61|25.6 |4.1 |11.1 |3459 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|176 |79.42|94.64|25.6 |2.6 |6.9 |5397 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|288 |79.4 |94.66|18.0 |5.9 |14.6 |2752 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|224 |79.38|94.57|25.6 |4.1 |11.1 |3459 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|176 |79.37|94.3 |25.0 |2.7 |9.0 |4577 |
|[resnext50_32x4d.gluon_in1k](https://huggingface.co/timm/resnext50_32x4d.gluon_in1k)|224 |79.36|94.43|25.0 |4.3 |14.4 |2942 |
|[resnext101_32x8d.tv_in1k](https://huggingface.co/timm/resnext101_32x8d.tv_in1k)|224 |79.31|94.52|88.8 |16.5 |31.2 |1100 |
|[resnet101.gluon_in1k](https://huggingface.co/timm/resnet101.gluon_in1k)|224 |79.31|94.53|44.6 |7.8 |16.2 |2125 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|224 |79.31|94.63|25.6 |5.2 |12.0 |2524 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|176 |79.27|94.49|25.6 |2.6 |6.9 |5404 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|224 |79.25|94.31|25.0 |4.3 |14.4 |2931 |
|[resnet50.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet50.fb_ssl_yfcc100m_ft_in1k)|224 |79.22|94.84|25.6 |4.1 |11.1 |3451 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|256 |79.21|94.56|19.7 |4.8 |11.7 |3392 |
|[resnet50d.gluon_in1k](https://huggingface.co/timm/resnet50d.gluon_in1k)|224 |79.07|94.48|25.6 |4.4 |11.9 |3162 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|224 |79.03|94.38|25.6 |4.1 |11.1 |3453 |
|[resnet50.am_in1k](https://huggingface.co/timm/resnet50.am_in1k)|224 |79.01|94.39|25.6 |4.1 |11.1 |3461 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|256 |79.01|94.37|18.0 |4.6 |11.6 |3440 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|256 |78.9 |94.54|16.0 |3.4 |10.5 |3421 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|160 |78.89|94.11|60.2 |5.9 |11.5 |2745 |
|[wide_resnet101_2.tv_in1k](https://huggingface.co/timm/wide_resnet101_2.tv_in1k)|224 |78.84|94.28|126.9 |22.8 |21.2 |1079 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|288 |78.83|94.24|16.8 |4.5 |16.8 |2251 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|224 |78.81|94.32|25.6 |4.1 |11.1 |3454 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|288 |78.74|94.33|16.8 |4.5 |16.7 |2264 |
|[resnet50s.gluon_in1k](https://huggingface.co/timm/resnet50s.gluon_in1k)|224 |78.72|94.23|25.7 |5.5 |13.5 |2796 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|224 |78.71|94.24|25.6 |4.4 |11.9 |3154 |
|[wide_resnet50_2.tv_in1k](https://huggingface.co/timm/wide_resnet50_2.tv_in1k)|224 |78.47|94.09|68.9 |11.4 |14.4 |1934 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|224 |78.46|94.27|25.6 |4.1 |11.1 |3454 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|288 |78.43|94.35|21.8 |6.5 |7.5 |3291 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|288 |78.42|94.04|10.5 |3.1 |13.3 |3226 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|320 |78.33|94.13|16.0 |5.2 |16.4 |2391 |
|[resnet152.tv_in1k](https://huggingface.co/timm/resnet152.tv_in1k)|224 |78.32|94.04|60.2 |11.6 |22.6 |1487 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|288 |78.28|94.1 |10.4 |3.1 |13.3 |3062 |
|[bat_resnext26ts.ch_in1k](https://huggingface.co/timm/bat_resnext26ts.ch_in1k)|256 |78.25|94.1 |10.7 |2.5 |12.5 |3393 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|224 |78.06|93.78|25.6 |4.1 |11.1 |3450 |
|[resnet50c.gluon_in1k](https://huggingface.co/timm/resnet50c.gluon_in1k)|224 |78.0 |93.99|25.6 |4.4 |11.9 |3286 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|288 |78.0 |93.91|10.3 |3.1 |13.3 |3297 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|224 |77.98|93.75|16.8 |2.7 |10.1 |3841 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|288 |77.92|93.77|21.8 |6.1 |6.2 |3609 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|160 |77.88|93.71|44.6 |4.0 |8.3 |3926 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|256 |77.87|93.84|16.0 |3.4 |10.5 |3772 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|256 |77.86|93.79|10.4 |2.4 |10.5 |4263 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|160 |77.82|93.81|35.7 |2.3 |6.2 |5238 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|256 |77.81|93.82|10.5 |2.4 |10.5 |4183 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|160 |77.79|93.6 |25.6 |2.2 |6.0 |5329 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|160 |77.73|93.32|25.0 |2.2 |7.4 |5576 |
|[resnext50_32x4d.tv_in1k](https://huggingface.co/timm/resnext50_32x4d.tv_in1k)|224 |77.61|93.7 |25.0 |4.3 |14.4 |2944 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|224 |77.59|93.61|16.8 |2.7 |10.2 |3807 |
|[resnet50.gluon_in1k](https://huggingface.co/timm/resnet50.gluon_in1k)|224 |77.58|93.72|25.6 |4.1 |11.1 |3455 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|256 |77.44|93.56|10.3 |2.4 |10.5 |4284 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|288 |77.41|93.63|16.0 |4.3 |13.5 |2907 |
|[resnet101.tv_in1k](https://huggingface.co/timm/resnet101.tv_in1k)|224 |77.38|93.54|44.6 |7.8 |16.2 |2125 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|160 |77.22|93.27|25.6 |2.2 |6.1 |5982 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|288 |77.17|93.47|10.3 |3.1 |13.3 |3392 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|288 |77.15|93.27|21.8 |6.1 |6.2 |3615 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|224 |77.1 |93.37|21.8 |3.9 |4.5 |5436 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|224 |77.02|93.07|28.1 |4.1 |11.1 |2952 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|256 |76.78|93.13|10.3 |2.4 |10.5 |4410 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|224 |76.7 |93.17|16.0 |2.6 |8.2 |4859 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|288 |76.5 |93.35|21.8 |6.1 |6.2 |3617 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|224 |76.42|92.87|21.8 |3.7 |3.7 |5984 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|288 |76.35|93.18|16.0 |3.9 |12.2 |3331 |
|[resnet50.tv_in1k](https://huggingface.co/timm/resnet50.tv_in1k)|224 |76.13|92.86|25.6 |4.1 |11.1 |3457 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|160 |75.96|92.5 |25.6 |2.1 |5.7 |6490 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|224 |75.52|92.44|21.8 |3.7 |3.7 |5991 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|224 |75.3 |92.58|16.0 |2.4 |7.4 |5583 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|224 |75.16|92.18|21.8 |3.7 |3.7 |5994 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|160 |75.1 |92.08|28.1 |2.1 |5.7 |5513 |
|[resnet34.gluon_in1k](https://huggingface.co/timm/resnet34.gluon_in1k)|224 |74.57|91.98|21.8 |3.7 |3.7 |5984 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|288 |73.81|91.83|11.7 |3.4 |5.4 |5196 |
|[resnet34.tv_in1k](https://huggingface.co/timm/resnet34.tv_in1k)|224 |73.32|91.42|21.8 |3.7 |3.7 |5979 |
|[resnet18.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet18.fb_swsl_ig1b_ft_in1k)|224 |73.28|91.73|11.7 |1.8 |2.5 |10213 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|288 |73.16|91.03|11.7 |3.0 |4.1 |6050 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|224 |72.98|91.11|21.8 |3.7 |3.7 |5967 |
|[resnet18.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet18.fb_ssl_yfcc100m_ft_in1k)|224 |72.6 |91.42|11.7 |1.8 |2.5 |10213 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|288 |72.37|90.59|11.7 |3.0 |4.1 |6051 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|224 |72.26|90.31|10.1 |1.7 |5.8 |7026 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|224 |72.26|90.68|11.7 |2.1 |3.3 |8707 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|224 |71.49|90.07|11.7 |1.8 |2.5 |10187 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|176 |71.31|89.69|10.1 |1.1 |3.6 |10970 |
|[resnet18.gluon_in1k](https://huggingface.co/timm/resnet18.gluon_in1k)|224 |70.84|89.76|11.7 |1.8 |2.5 |10210 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|224 |70.64|89.47|11.7 |1.8 |2.5 |10194 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|160 |70.56|89.52|21.8 |1.9 |1.9 |10737 |
|[resnet18.tv_in1k](https://huggingface.co/timm/resnet18.tv_in1k)|224 |69.76|89.07|11.7 |1.8 |2.5 |10205 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|224 |68.34|88.03|5.4 |1.1 |2.4 |13079 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|224 |68.25|88.17|11.7 |1.8 |2.5 |10167 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|176 |66.71|86.96|5.4 |0.7 |1.5 |20327 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|160 |65.66|86.26|11.7 |0.9 |1.3 |18229 |
## Citation
```bibtex
@article{bello2021revisiting,
title={Revisiting ResNets: Improved Training and Scaling Strategies},
author={Irwan Bello and William Fedus and Xianzhi Du and Ekin D. Cubuk and Aravind Srinivas and Tsung-Yi Lin and Jonathon Shlens and Barret Zoph},
journal={arXiv preprint arXiv:2103.07579},
year={2021}
}
```
```bibtex
@article{He2015,
author = {Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun},
title = {Deep Residual Learning for Image Recognition},
journal = {arXiv preprint arXiv:1512.03385},
year = {2015}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
|
osiria/bert-base-italian-cased | osiria | 2023-09-29T18:07:17Z | 1,177 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"bert",
"fill-mask",
"it",
"arxiv:1810.04805",
"arxiv:2010.05609",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2023-05-29T17:52:45Z | ---
license: apache-2.0
language:
- it
widget:
- text: "Milano è una [MASK] dell'Italia"
example_title: "Example 1"
- text: "Giacomo Leopardi è stato uno dei più grandi [MASK] del classicismo italiano"
example_title: "Example 2"
- text: "La pizza è un piatto tipico della [MASK] gastronomica italiana"
example_title: "Example 3"
---
--------------------------------------------------------------------------------------------------
<body>
<span class="vertical-text" style="background-color:lightgreen;border-radius: 3px;padding: 3px;"> </span>
<br>
<span class="vertical-text" style="background-color:orange;border-radius: 3px;padding: 3px;"> </span>
<br>
<span class="vertical-text" style="background-color:lightblue;border-radius: 3px;padding: 3px;"> Model: BERT</span>
<br>
<span class="vertical-text" style="background-color:tomato;border-radius: 3px;padding: 3px;"> Lang: IT</span>
<br>
<span class="vertical-text" style="background-color:lightgrey;border-radius: 3px;padding: 3px;"> </span>
<br>
<span class="vertical-text" style="background-color:#CF9FFF;border-radius: 3px;padding: 3px;"> </span>
</body>
--------------------------------------------------------------------------------------------------
<h3>Model description</h3>
This is a <b>BERT</b> <b>[1]</b> model for the <b>Italian</b> language, obtained using <b>mBERT</b> ([bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased)) as a starting point and focusing it on the Italian language by modifying the embedding layer
(as in <b>[2]</b>, computing document-level frequencies over the <b>Wikipedia</b> dataset)
The resulting model has 110M parameters, a vocabulary of 30.785 tokens, and a size of ~430 MB.
<h3>Quick usage</h3>
```python
from transformers import BertTokenizerFast, BertModel
tokenizer = BertTokenizerFast.from_pretrained("osiria/bert-base-italian-cased")
model = BertModel.from_pretrained("osiria/bert-base-italian-cased")
```
<h3>References</h3>
[1] https://arxiv.org/abs/1810.04805
[2] https://arxiv.org/abs/2010.05609
<h3>License</h3>
The model is released under <b>Apache-2.0</b> license
|
Yntec/TimelessDiffusion768 | Yntec | 2024-03-21T20:51:00Z | 1,177 | 1 | diffusers | [
"diffusers",
"safetensors",
"Photography",
"Realism",
"Celebrities",
"wavymulder",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2024-03-21T18:08:29Z | ---
language:
- en
license: creativeml-openrail-m
tags:
- Photography
- Realism
- Celebrities
- wavymulder
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
# Timeless Diffusion
768x768 version of this model for the inference API. Original page: https://huggingface.co/wavymulder/timeless-diffusion/
Samples and prompts:

(Click for larger)
Top left: timeless style movie still closeup audrey hepburn and sandra bullock sitting with her daughter. From Garden of Eden (1969). cute face. Detailed eyes. London parade
Top right: timeless style natalie portman hollywood glamour
Bottom left: timeless style civil war portrait Rihanna
Bottom right: timeless style heath ledger wearing a golden laurel wreath |
moondriller/anarchy-solar-10B-v1 | moondriller | 2024-04-05T08:37:00Z | 1,177 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"ko",
"arxiv:1910.09700",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-05T08:29:07Z | ---
language:
- ko
license: apache-2.0
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
chihoonlee10/T3Q-LLM-MG-DPO-v1.0 | chihoonlee10 | 2024-04-30T23:41:39Z | 1,177 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-30T23:18:34Z | ---
library_name: transformers
license: apache-2.0
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
migtissera/Llama-3-8B-Synthia-v3.5 | migtissera | 2024-06-02T01:06:30Z | 1,177 | 14 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"license:llama3",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-05-17T02:49:00Z | ---
license: llama3
---
# Llama-3-8B-Synthia-v3.5
Llama-3-8B-Synthia-v3.5 (Synthetic Intelligent Agent) is a general purpose Large Language Model (LLM). It was trained on the Synthia-v3.5 dataset that contains the varied system contexts, plus some other publicly available datasets.
It has been fine-tuned for instruction following as well as having long-form conversations.
Compute for Llama-3-8B-Synthia-v3.5 was sponsored by [KindoAI](https://kindo.ai/).
<br>

<br>
## Evaluation
We evaluated Llama-3-8B-Synthia-v3.5 on a wide range of tasks using [Language Model Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness) from EleutherAI.
Here are the results on metrics used by [HuggingFaceH4 Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard). Section to follow.
||||
|:------:|:--------:|:-------:|
|**Task**|**Metric**|**Value**|
|*arc_challenge*|acc_norm||
|*hellaswag*|acc_norm||
|*mmlu*|acc_norm||
|*truthfulqa_mc*|mc2||
|**Total Average**|-|||
<br>
# Sample code to run inference
```python
import torch, json
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "/home/migel/Tess-2.0-Llama-3-8B"
output_file_path = "/home/migel/conversations.jsonl"
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto",
load_in_4bit=False,
trust_remote_code=False,
)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
def generate_text(instruction):
tokens = tokenizer.encode(instruction)
tokens = torch.LongTensor(tokens).unsqueeze(0)
tokens = tokens.to("cuda")
instance = {
"input_ids": tokens,
"top_p": 1.0,
"temperature": 0.75,
"generate_len": 1024,
"top_k": 50,
}
length = len(tokens[0])
with torch.no_grad():
rest = model.generate(
input_ids=tokens,
max_length=length + instance["generate_len"],
use_cache=True,
do_sample=True,
top_p=instance["top_p"],
temperature=instance["temperature"],
top_k=instance["top_k"],
num_return_sequences=1,
pad_token_id=tokenizer.eos_token_id,
)
output = rest[0][length:]
string = tokenizer.decode(output, skip_special_tokens=True)
return f"{string}"
conversation = """<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nYou are Synthia, a helful, female AI assitant. You always provide detailed answers without hesitation.<|eot_id|><|start_header_id|>user<|end_header_id|>\n\n"""
while True:
user_input = input("You: ")
llm_prompt = f"{conversation}{user_input}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n"
answer = generate_text(llm_prompt)
print(answer)
conversation = f"{llm_prompt}{answer}<|eot_id|><|start_header_id|>user<|end_header_id|>\n\n"
json_data = {"prompt": user_input, "answer": answer}
with open(output_file_path, "a") as output_file:
output_file.write(json.dumps(json_data) + "\n")
```
# Join My General AI Discord (NeuroLattice):
https://discord.gg/Hz6GrwGFKD
# Limitations & Biases:
While this model aims for accuracy, it can occasionally produce inaccurate or misleading results.
Despite diligent efforts in refining the pretraining data, there remains a possibility for the generation of inappropriate, biased, or offensive content.
Exercise caution and cross-check information when necessary. This is an uncensored model.
|
llange/xlm-roberta-large-spanish-clinical | llange | 2021-12-17T10:27:39Z | 1,176 | 1 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"fill-mask",
"arxiv:2112.08754",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2022-03-02T23:29:05Z | # CLIN-X-ES: a pre-trained language model for the Spanish clinical domain
Details on the model, the pre-training corpus and the downstream task performance are given in the paper: "CLIN-X: pre-trained language models and a study on cross-task transfer for concept extraction in the clinical domain" by Lukas Lange, Heike Adel, Jannik Strötgen and Dietrich Klakow.
The paper can be found [here](https://arxiv.org/abs/2112.08754).
In case of questions, please contact the authors as listed on the paper.
Please cite the above paper when reporting, reproducing or extending the results.
@misc{lange-etal-2021-clin-x,
author = {Lukas Lange and
Heike Adel and
Jannik Str{\"{o}}tgen and
Dietrich Klakow},
title = {CLIN-X: pre-trained language models and a study on cross-task transfer for concept extraction in the clinical domain},
year={2021},
eprint={2112.08754},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2112.08754}
}
## Training details
The model is based on the multilingual XLM-R transformer `(xlm-roberta-large)`, which was trained on 100 languages and showed superior performance in many different tasks across languages and can even outperform monolingual models in certain settings (Conneau et al. 2020).
Even though XLM-R was pre-trained on 53GB of Spanish documents, this was only 2% of the overall training data. To steer this model towards the Spanish clinical domain, we sample documents from the Scielo archive (https://scielo.org/)
and the MeSpEn resources (Villegas et al. 2018). The resulting corpus has a size of 790MB and is highly specific for the clinical domain.
We initialize CLIN-X using the pre-trained XLM-R weights and train masked language modeling (MLM) on the Spanish clinical corpus for 3 epochs which roughly corresponds to 32k steps. This allows researchers and practitioners to address
the Spanish clinical domain with an out-of-the-box tailored model.
## Results for Spanish concept extraction
We apply CLIN-X-ES to five Spanish concept extraction tasks from the clinical domain in a standard sequence labeling architecture similar to Devlin et al. 2019 and compare to a Spanish BERT model called BETO. In addition, we perform experiments with an improved architecture `(+ OurArchitecture)` as described in the paper linked above. The code for our model architecture can be found [here](https://github.com/boschresearch/clin_x).
| | Cantemist | Meddocan | Meddoprof (NER) | Meddoprof (CLASS) | Pharmaconer |
|------------------------------------------|-----------|----------|-----------------|-------------------|-------------|
| BETO (Spanish BERT) | 81.30 | 96.81 | 79.19 | 74.59 | 87.70 |
| CLIN-X (ES) | 83.22 | 97.08 | 79.54 | 76.95 | 90.05 |
| CLIN-X (ES) + OurArchitecture | **88.24** | **98.00** | **81.68** | **80.54** | **92.27** |
### Results for English concept extraction
As the CLIN-X-ES model is based on XLM-R, the model is still multilingual and we demonstrate the positive impact of cross-language domain adaptation by applying this model to five different English sequence labeling tasks from i2b2.
We found that further transfer from related concept extraction is particularly helpful in this cross-language setting. For a detailed description of the transfer process and all other models, we refer to our paper.
| | i2b2 2006 | i2b2 2010 | i2b2 2012 (Concept) | i2b2 2012 (Time) | i2b2 2014 |
|------------------------------------------|-----------|-----------|---------------|---------------|-----------|
| BERT | 94.80 | 85.25 | 76.51 | 75.28 | 94.86 |
| ClinicalBERT | 94.8 | 87.8 | 78.9 | 76.6 | 93.0 |
| CLIN-X (ES) | 95.49 | 87.94 | 79.58 | 77.57 | 96.80 |
| CLIN-X (ES) + OurArchitecture | 98.30 | 89.10 | 80.42 | 78.48 | **97.62** |
| CLIN-X (ES) + OurArchitecture + Transfer | **89.50** | **89.74** | **80.93** | **79.60** | 97.46 |
## Purpose of the project
This software is a research prototype, solely developed for and published as part of the publication cited above. It will neither be maintained nor monitored in any way.
## License
The CLIN-X models are open-sourced under the CC-BY 4.0 license.
See the [LICENSE](LICENSE) file for details. |
4bit/llava-v1.5-13b-3GB | 4bit | 2023-10-14T11:10:34Z | 1,176 | 4 | transformers | [
"transformers",
"pytorch",
"llava",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-generation | 2023-10-14T11:02:51Z | Entry not found |
digiplay/A80S_v1.0 | digiplay | 2024-02-29T09:25:50Z | 1,176 | 3 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2024-01-12T13:55:34Z | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info:
https://civitai.com/models/260741/a80s
Original Author's DEMO images: (ComfyUI)


Generated by Hugginface's API:
masterpiece HDR victorian portrait painting of woman, blonde hair, mountain nature, blue sky

masterpiece HDR victorian portrait painting of woman, blonde hair, mountain nature, blue sky,lighter tones,bright colors,
 |
backyardai/Hermes-2-Pro-Mistral-7B-GGUF | backyardai | 2024-05-22T22:15:20Z | 1,176 | 1 | null | [
"gguf",
"Mistral",
"instruct",
"finetune",
"chatml",
"DPO",
"RLHF",
"gpt4",
"synthetic data",
"distillation",
"function calling",
"json mode",
"en",
"dataset:teknium/OpenHermes-2.5",
"base_model:NousResearch/Hermes-2-Pro-Mistral-7B",
"license:apache-2.0",
"region:us"
]
| null | 2024-03-17T03:48:59Z | ---
language:
- en
license: apache-2.0
tags:
- Mistral
- instruct
- finetune
- chatml
- DPO
- RLHF
- gpt4
- synthetic data
- distillation
- function calling
- json mode
base_model: NousResearch/Hermes-2-Pro-Mistral-7B
datasets:
- teknium/OpenHermes-2.5
quantized_by: brooketh
model-index:
- name: Hermes-2-Pro-Mistral-7B-GGUF
results: []
---
<img src="BackyardAI_Banner.png" alt="Backyard.ai" style="height: 90px; min-width: 32px; display: block; margin: auto;">
**<p style="text-align: center;">The official library of GGUF format models for use in the local AI chat app, Backyard AI.</p>**
<p style="text-align: center;"><a href="https://backyard.ai/">Download Backyard AI here to get started.</a></p>
<p style="text-align: center;"><a href="https://www.reddit.com/r/LLM_Quants/">Request Additional models at r/LLM_Quants.</a></p>
***
# Hermes 2 Pro Mistral 7B
- **Creator:** [Nous Research](https://huggingface.co/Nous Research/)
- **Original:** [Hermes 2 Pro Mistral 7B](https://huggingface.co/NousResearch/Hermes-2-Pro-Mistral-7B)
- **Date Created:** 2024-03-11
- **Trained Context:** 8192 tokens
- **Description:** Hermes 2 Pro is an upgraded, retrained version of Nous Hermes 2, consisting of an updated and cleaned version of the OpenHermes 2.5 Dataset, as well as a newly introduced Function Calling and JSON Mode dataset developed in-house.
This new version of Hermes maintains its excellent general task and conversation capabilities - but also excels at Function Calling, JSON Structured Outputs, and has improved on several other metrics as well, scoring a 90% on our function calling evaluation built in partnership with Fireworks.AI, and an 84% on our structured JSON Output evaluation.
***
## What is a GGUF?
GGUF is a large language model (LLM) format that can be split between CPU and GPU. GGUFs are compatible with applications based on llama.cpp, such as Backyard AI. Where other model formats require higher end GPUs with ample VRAM, GGUFs can be efficiently run on a wider variety of hardware.
GGUF models are quantized to reduce resource usage, with a tradeoff of reduced coherence at lower quantizations. Quantization reduces the precision of the model weights by changing the number of bits used for each weight.
***
<img src="BackyardAI_Logo.png" alt="Backyard.ai" style="height: 75px; min-width: 32px; display: block; horizontal align: left;">
## Backyard AI
- Free, local AI chat application.
- One-click installation on Mac and PC.
- Automatically use GPU for maximum speed.
- Built-in model manager.
- High-quality character hub.
- Zero-config desktop-to-mobile tethering.
Backyard AI makes it easy to start chatting with AI using your own characters or one of the many found in the built-in character hub. The model manager helps you find the latest and greatest models without worrying about whether it's the correct format. Backyard AI supports advanced features such as lorebooks, author's note, text formatting, custom context size, sampler settings, grammars, local TTS, cloud inference, and tethering, all implemented in a way that is straightforward and reliable.
**Join us on [Discord](https://discord.gg/SyNN2vC9tQ)**
*** |
hkss/hk-SOLAR-10.7B-v1.4 | hkss | 2024-03-21T06:40:21Z | 1,176 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"ko",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-03-21T06:29:47Z | ---
library_name: transformers
license: apache-2.0
language:
- ko
---
### Model Description
Finetuning based on [chihoonlee10/T3Q-ko-solar-dpo-v1.0](https://huggingface.co/chihoonlee10/T3Q-ko-solar-dpo-v1.0).
### Training Method
Using Deepspeed, Accelerate, TRL etc.
### Datasets
TBA |
moyheilik/grantitanReloaded | moyheilik | 2024-03-29T01:56:30Z | 1,176 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"bert",
"feature-extraction",
"sentence-similarity",
"dataset:embedding-data/QQP_triplets",
"autotrain_compatible",
"endpoints_compatible",
"text-embeddings-inference",
"region:us"
]
| sentence-similarity | 2024-03-29T01:56:12Z | ---
library_name: sentence-transformers
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
datasets:
- embedding-data/QQP_triplets
---
# moyheilik/grantitanReloaded
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('moyheilik/grantitanReloaded')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=moyheilik/grantitanReloaded)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 2848 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.TripletLoss.TripletLoss` with parameters:
```
{'distance_metric': 'TripletDistanceMetric.EUCLIDEAN', 'triplet_margin': 5}
```
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 10000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 256, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Normalize()
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
ihopper/I-SOLAR-10.7B-sft-v1.0 | ihopper | 2024-05-16T08:19:32Z | 1,176 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"ko",
"arxiv:1910.09700",
"base_model:upstage/SOLAR-10.7B-v1.0",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-05-16T08:14:38Z | ---
library_name: transformers
license: apache-2.0
base_model: upstage/SOLAR-10.7B-v1.0
pipeline_tag: text-generation
language:
- ko
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
alvdansen/midsommarcartoon | alvdansen | 2024-06-23T20:55:26Z | 1,176 | 28 | diffusers | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"license:creativeml-openrail-m",
"region:us"
]
| text-to-image | 2024-06-23T20:54:21Z | ---
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
widget:
- text: a wall of vines with a face emerging from the center, complex, strange, fey
parameters:
negative_prompt: ugly, messy, bad, photo
output:
url: images/ComfyUI_02460_.png
- text: >-
a swedish girl smiling and wearing a flower crown, midsommar, awardwinning
illustration
parameters:
negative_prompt: ugly, messy, bad, photo
output:
url: images/ComfyUI_02458_.png
- text: >-
A teenager with long, wavy blonde hair and brown eyes, wearing a green tank
top
parameters:
negative_prompt: ugly, messy, bad, photo
output:
url: images/ComfyUI_02396_.png
- text: >-
An elderly man with white hair and a thick mustache, wearing a navy blue
cardigan, white shirt, and khaki trousers
parameters:
negative_prompt: ugly, messy, bad, photo
output:
url: images/ComfyUI_02392_.png
- text: >-
A serene mountain lake at sunrise, surrounded by pine trees, a lone kayaker
gliding across the calm water, illustration style
parameters:
negative_prompt: ugly, messy, bad, photo
output:
url: images/ComfyUI_02388_.png
- text: >-
a girl with blonde-brown hair and big round glasses, blue eyes, white t
shirt, jeans
output:
url: images/ComfyUI_02333_.png
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: null
license: creativeml-openrail-m
---
# Midsommar Cartoon
<Gallery />
## Model description
A retro-style cartoon print model that blends a bit of an anime influence with classic northern european cartoons.
## Download model
Weights for this model are available in Safetensors format.
[Download](/alvdansen/midsommarcartoon/tree/main) them in the Files & versions tab.
|
RichardErkhov/SummerSigh_-_Pythia410m-V0-Instruct-gguf | RichardErkhov | 2024-06-29T13:34:08Z | 1,176 | 0 | null | [
"gguf",
"region:us"
]
| null | 2024-06-29T13:24:35Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Pythia410m-V0-Instruct - GGUF
- Model creator: https://huggingface.co/SummerSigh/
- Original model: https://huggingface.co/SummerSigh/Pythia410m-V0-Instruct/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Pythia410m-V0-Instruct.Q2_K.gguf](https://huggingface.co/RichardErkhov/SummerSigh_-_Pythia410m-V0-Instruct-gguf/blob/main/Pythia410m-V0-Instruct.Q2_K.gguf) | Q2_K | 0.16GB |
| [Pythia410m-V0-Instruct.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/SummerSigh_-_Pythia410m-V0-Instruct-gguf/blob/main/Pythia410m-V0-Instruct.IQ3_XS.gguf) | IQ3_XS | 0.18GB |
| [Pythia410m-V0-Instruct.IQ3_S.gguf](https://huggingface.co/RichardErkhov/SummerSigh_-_Pythia410m-V0-Instruct-gguf/blob/main/Pythia410m-V0-Instruct.IQ3_S.gguf) | IQ3_S | 0.18GB |
| [Pythia410m-V0-Instruct.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/SummerSigh_-_Pythia410m-V0-Instruct-gguf/blob/main/Pythia410m-V0-Instruct.Q3_K_S.gguf) | Q3_K_S | 0.18GB |
| [Pythia410m-V0-Instruct.IQ3_M.gguf](https://huggingface.co/RichardErkhov/SummerSigh_-_Pythia410m-V0-Instruct-gguf/blob/main/Pythia410m-V0-Instruct.IQ3_M.gguf) | IQ3_M | 0.2GB |
| [Pythia410m-V0-Instruct.Q3_K.gguf](https://huggingface.co/RichardErkhov/SummerSigh_-_Pythia410m-V0-Instruct-gguf/blob/main/Pythia410m-V0-Instruct.Q3_K.gguf) | Q3_K | 0.21GB |
| [Pythia410m-V0-Instruct.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/SummerSigh_-_Pythia410m-V0-Instruct-gguf/blob/main/Pythia410m-V0-Instruct.Q3_K_M.gguf) | Q3_K_M | 0.21GB |
| [Pythia410m-V0-Instruct.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/SummerSigh_-_Pythia410m-V0-Instruct-gguf/blob/main/Pythia410m-V0-Instruct.Q3_K_L.gguf) | Q3_K_L | 0.22GB |
| [Pythia410m-V0-Instruct.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/SummerSigh_-_Pythia410m-V0-Instruct-gguf/blob/main/Pythia410m-V0-Instruct.IQ4_XS.gguf) | IQ4_XS | 0.22GB |
| [Pythia410m-V0-Instruct.Q4_0.gguf](https://huggingface.co/RichardErkhov/SummerSigh_-_Pythia410m-V0-Instruct-gguf/blob/main/Pythia410m-V0-Instruct.Q4_0.gguf) | Q4_0 | 0.23GB |
| [Pythia410m-V0-Instruct.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/SummerSigh_-_Pythia410m-V0-Instruct-gguf/blob/main/Pythia410m-V0-Instruct.IQ4_NL.gguf) | IQ4_NL | 0.23GB |
| [Pythia410m-V0-Instruct.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/SummerSigh_-_Pythia410m-V0-Instruct-gguf/blob/main/Pythia410m-V0-Instruct.Q4_K_S.gguf) | Q4_K_S | 0.23GB |
| [Pythia410m-V0-Instruct.Q4_K.gguf](https://huggingface.co/RichardErkhov/SummerSigh_-_Pythia410m-V0-Instruct-gguf/blob/main/Pythia410m-V0-Instruct.Q4_K.gguf) | Q4_K | 0.25GB |
| [Pythia410m-V0-Instruct.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/SummerSigh_-_Pythia410m-V0-Instruct-gguf/blob/main/Pythia410m-V0-Instruct.Q4_K_M.gguf) | Q4_K_M | 0.25GB |
| [Pythia410m-V0-Instruct.Q4_1.gguf](https://huggingface.co/RichardErkhov/SummerSigh_-_Pythia410m-V0-Instruct-gguf/blob/main/Pythia410m-V0-Instruct.Q4_1.gguf) | Q4_1 | 0.25GB |
| [Pythia410m-V0-Instruct.Q5_0.gguf](https://huggingface.co/RichardErkhov/SummerSigh_-_Pythia410m-V0-Instruct-gguf/blob/main/Pythia410m-V0-Instruct.Q5_0.gguf) | Q5_0 | 0.27GB |
| [Pythia410m-V0-Instruct.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/SummerSigh_-_Pythia410m-V0-Instruct-gguf/blob/main/Pythia410m-V0-Instruct.Q5_K_S.gguf) | Q5_K_S | 0.27GB |
| [Pythia410m-V0-Instruct.Q5_K.gguf](https://huggingface.co/RichardErkhov/SummerSigh_-_Pythia410m-V0-Instruct-gguf/blob/main/Pythia410m-V0-Instruct.Q5_K.gguf) | Q5_K | 0.28GB |
| [Pythia410m-V0-Instruct.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/SummerSigh_-_Pythia410m-V0-Instruct-gguf/blob/main/Pythia410m-V0-Instruct.Q5_K_M.gguf) | Q5_K_M | 0.28GB |
| [Pythia410m-V0-Instruct.Q5_1.gguf](https://huggingface.co/RichardErkhov/SummerSigh_-_Pythia410m-V0-Instruct-gguf/blob/main/Pythia410m-V0-Instruct.Q5_1.gguf) | Q5_1 | 0.29GB |
| [Pythia410m-V0-Instruct.Q6_K.gguf](https://huggingface.co/RichardErkhov/SummerSigh_-_Pythia410m-V0-Instruct-gguf/blob/main/Pythia410m-V0-Instruct.Q6_K.gguf) | Q6_K | 0.31GB |
| [Pythia410m-V0-Instruct.Q8_0.gguf](https://huggingface.co/RichardErkhov/SummerSigh_-_Pythia410m-V0-Instruct-gguf/blob/main/Pythia410m-V0-Instruct.Q8_0.gguf) | Q8_0 | 0.4GB |
Original model description:
---
license: apache-2.0
---
# Model info
This is EleutherAI/pythia-410m finetuned on OpenAssistant/oasst_top1_2023-08-25
# Why
Plain and simple. Im experimenting with making instruction LLMs under 1B params. I think we can still squeeze out better performance out of these models.
# Random Notes
- Only using OpenAssistant data gives fantastic results becuase of its high quality. I like the top1 dataset becuase of it's lack of prompt refusals.
- Prompt refusals have been shown to damage the performance of instruction LLMs. My theory is that the model "spends" parameters learning how to refuse prompts rather than learning actually useful information. Adding to this, I think that unlike other tasks, learning prompt refusals most likely has no other value in terms of transfer learning.
# Usage
```
from transformers import pipeline
pipe = pipeline("text-generation", model="SummerSigh/Pythia410m-V0-Instruct")
out= pipe("<|im_start|>user\nWhat's the meaning of life?<|im_end|>\n<|im_start|>assistant\n",max_length = 500,repetition_penalty = 1.2, temperature = 0.5, do_sample = True)
print(out[0]["generated_text"])
```
# Contact
If you want to contact me and work with me on making good under 1B param models, you can reach me on discord at summer_ai.
|
eai6/whisper-tiny.en | eai6 | 2024-03-29T06:46:56Z | 1,175 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"nyansapo_ai-asr-leaderboard",
"generated_from_trainer",
"en",
"dataset:NyansapoAI/azure-dataset",
"base_model:openai/whisper-tiny.en",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2023-09-03T19:32:14Z | ---
language:
- en
license: apache-2.0
base_model: openai/whisper-tiny.en
tags:
- nyansapo_ai-asr-leaderboard
- generated_from_trainer
datasets:
- NyansapoAI/azure-dataset
metrics:
- wer
model-index:
- name: whisper-tiny.en
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Azure-dataset
type: NyansapoAI/azure-dataset
args: 'split: test'
metrics:
- name: Wer
type: wer
value: 44.34857635893012
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-tiny.en
This model is a fine-tuned version of [openai/whisper-tiny.en](https://huggingface.co/openai/whisper-tiny.en) on the Azure-dataset dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0680
- Wer: 44.3486
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 250
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 1.2415 | 1.38 | 250 | 0.6131 | 26.6609 |
| 0.3582 | 2.76 | 500 | 0.0882 | 43.0544 |
| 0.2094 | 4.14 | 750 | 0.0723 | 43.6583 |
| 0.1788 | 5.52 | 1000 | 0.0680 | 44.3486 |
### Framework versions
- Transformers 4.39.1
- Pytorch 2.2.1
- Datasets 2.18.0
- Tokenizers 0.15.2
|
nickypro/tinyllama-110M | nickypro | 2023-09-21T14:49:10Z | 1,175 | 2 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2023-09-16T13:37:27Z | ---
license: mit
---
This is the 110M parameter Llama 2 architecture model trained on the TinyStories dataset.
These are converted from
[karpathy/tinyllamas](https://huggingface.co/karpathy/tinyllamas).
See the [llama2.c](https://github.com/karpathy/llama2.c) project for more details. |
ifuseok/ft-solar-10.7b-v2.1-dpo | ifuseok | 2024-01-24T01:41:14Z | 1,175 | 1 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"ko",
"dataset:nlpai-lab/databricks-dolly-15k-ko",
"dataset:kyujinpy/KOR-OpenOrca-Platypus-v3",
"dataset:KETI-AIR/kor_boolq",
"dataset:heegyu/open-korean-instructions",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-01-13T16:09:54Z | ---
language:
- ko
pipeline_tag: text-generation
datasets:
- nlpai-lab/databricks-dolly-15k-ko
- kyujinpy/KOR-OpenOrca-Platypus-v3
- KETI-AIR/kor_boolq
- heegyu/open-korean-instructions
license: cc-by-nc-sa-4.0
---
**Input** Models input text only.
**Output** Models generate text only.
**Base Model** [yanolja/KoSOLAR-10.7B-v0.1](https://huggingface.co/yanolja/KoSOLAR-10.7B-v0.1-deprecated)
**Training Dataset**
- [nlpai-lab/databricks-dolly-15k-ko](https://huggingface.co/datasets/nlpai-lab/databricks-dolly-15k-ko)
- [kyujinpy/KOR-OpenOrca-Platypus-v3](https://huggingface.co/datasets/kyujinpy/KOR-OpenOrca-Platypus-v3)
- [heegyu/open-korean-instructions](heegyu/open-korean-instructions)
- [KETI-AIR/kor_boolq](https://huggingface.co/datasets/KETI-AIR/kor_boolq)
- [AIhub 영한 번역 데이터 일부](https://aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&dataSetSn=71593)
# Implementation Code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
repo = "ifuseok/sft-solar-10.7b-v2.1-dpo"
OpenOrca = AutoModelForCausalLM.from_pretrained(
repo,
return_dict=True,
torch_dtype=torch.float16,
device_map='auto'
)
OpenOrca_tokenizer = AutoTokenizer.from_pretrained(repo)
```
# Prompt Example
```
### System:
시스템 메시지 입니다.
### User:
유저 입니다.
### Assistant
어시스턴트 입니다.
``` |
vishanoberoi/Llama-2-7b-chat-hf-finedtuned-to-GGUF | vishanoberoi | 2024-02-29T12:45:49Z | 1,175 | 2 | transformers | [
"transformers",
"gguf",
"llama",
"Finetuning",
"question-answering",
"en",
"arxiv:2302.13971",
"arxiv:2305.14314",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| question-answering | 2024-02-20T08:22:58Z | ---
language:
- en
library_name: transformers
pipeline_tag: question-answering
tags:
- Finetuning
---
# Model Card for vishanoberoi/Llama-2-7b-chat-hf-finedtuned-to-GGUF
This model is a fine-tuned version of Llama-2-Chat-7b on company-specific question-answers data. It is designed for efficient performance while maintaining high-quality output, suitable for conversational AI applications.
## Model Details
It was finetuned using QLORA and PEFT. After fine-tuning, the adapters were merged with the base model and then quantized to GGUF.
- **Developed by:** Vishan Oberoi and Dev Chandan.
- **Model type:** Transformer-based Large Language Model
- **Language(s) (NLP):** English
- **License:** MIT
- **Finetuned from model:** https://huggingface.co/meta-llama/Llama-2-7b-chat-hf
### Model Sources
- **Repository:** [vishanoberoi/Llama-2-7b-chat-hf-finedtuned-to-GGUF](https://huggingface.co/vishanoberoi/Llama-2-7b-chat-hf-finedtuned-to-GGUF)
- **Links:**
- LLaMA: [LLaMA Paper](https://arxiv.org/abs/2302.13971)
- QLORA: [QLORA Paper](https://arxiv.org/abs/2305.14314)
- llama.cpp: [llama.cpp Paper/Documentation](https://github.com/ggerganov/llama.cpp)
## Uses
This model is optimized for direct use in conversational AI, particularly for generating responses based on company-specific data. It can be utilized effectively in customer service bots, FAQ bots, and other applications where accurate and contextually relevant answers are required.
## Usage notebook
https://colab.research.google.com/drive/1885wYoXeRjVjJzHqL9YXJr5ZjUQOSI-w?authuser=4#scrollTo=TZIoajzYYkrg
#### Example with `ctransformers`:
```python
from ctransformers import AutoModelForCausalLM, AutoTokenizer
llm = AutoModelForCausalLM.from_pretrained("vishanoberoi/Llama-2-7b-chat-hf-finedtuned-to-GGUF", model_file="finetuned.gguf", model_type="llama", gpu_layers = 50, max_new_tokens = 2000, temperature = 0.2, top_k = 40, top_p = 0.6, context_length = 6000)
system_prompt = '''<<SYS>>
You are a useful bot
<</SYS>>
```
user_prompt = "Tell me about your company"
# Combine system prompt with user prompt
full_prompt = f"{system_prompt}\n[INST]{user_prompt}[/INST]"
# Generate the response
response = llm(full_prompt)
# Print the response
print(response) |
MoaData/Myrrh_solar_10.7b_2.0 | MoaData | 2024-04-16T06:35:21Z | 1,175 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"ko",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-16T05:37:26Z | ---
license: apache-2.0
language:
- ko
---
## Model Details
**Model Developers** : Taeeon Park, Gihong Lee
**dataset** : dpo medical dataset (AI-hub dataset 활용 자체 제작)
**Training Method Method** : DPO.
**Company** : MoAData
## Usage
```
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
repo = "MoaData/Myrrh_solar_10.7b_2.0"
model = AutoModelForCausalLM.from_pretrained(
repo,
return_dict=True,
torch_dtype=torch.float16,
device_map='auto'
)
tokenizer = AutoTokenizer.from_pretrained(repo)
``` |
Qwen/Qwen2-0.5B-Instruct-GPTQ-Int4 | Qwen | 2024-06-10T03:03:30Z | 1,175 | 7 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"chat",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"4-bit",
"gptq",
"region:us"
]
| text-generation | 2024-06-06T06:18:53Z | ---
license: apache-2.0
language:
- en
pipeline_tag: text-generation
tags:
- chat
---
# Qwen2-0.5B-Instruct-GPTQ-Int4
## Introduction
Qwen2 is the new series of Qwen large language models. For Qwen2, we release a number of base language models and instruction-tuned language models ranging from 0.5 to 72 billion parameters, including a Mixture-of-Experts model. This repo contains the instruction-tuned 0.5B Qwen2 model.
Compared with the state-of-the-art opensource language models, including the previous released Qwen1.5, Qwen2 has generally surpassed most opensource models and demonstrated competitiveness against proprietary models across a series of benchmarks targeting for language understanding, language generation, multilingual capability, coding, mathematics, reasoning, etc.
For more details, please refer to our [blog](https://qwenlm.github.io/blog/qwen2/), [GitHub](https://github.com/QwenLM/Qwen2), and [Documentation](https://qwen.readthedocs.io/en/latest/).
**Note**: If you encounter ``RuntimeError: probability tensor contains either `inf`, `nan` or element < 0`` during inference with ``transformers``, we recommand installing ``autogpq>=0.7.1`` or [deploying this model with vLLM](https://qwen.readthedocs.io/en/latest/deployment/vllm.html).
<br>
## Model Details
Qwen2 is a language model series including decoder language models of different model sizes. For each size, we release the base language model and the aligned chat model. It is based on the Transformer architecture with SwiGLU activation, attention QKV bias, group query attention, etc. Additionally, we have an improved tokenizer adaptive to multiple natural languages and codes.
## Training details
We pretrained the models with a large amount of data, and we post-trained the models with both supervised finetuning and direct preference optimization.
## Requirements
The code of Qwen2 has been in the latest Hugging face transformers and we advise you to install `transformers>=4.37.0`, or you might encounter the following error:
```
KeyError: 'qwen2'
```
## Quickstart
Here provides a code snippet with `apply_chat_template` to show you how to load the tokenizer and model and how to generate contents.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen2-0.5B-Instruct-GPTQ-Int4",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct-GPTQ-Int4")
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
```
## Benchmark and Speed
To compare the generation performance between bfloat16 (bf16) and quantized models such as GPTQ-Int8, GPTQ-Int4, and AWQ, please consult our [Benchmark of Quantized Models](https://qwen.readthedocs.io/en/latest/benchmark/quantization_benchmark.html). This benchmark provides insights into how different quantization techniques affect model performance.
For those interested in understanding the inference speed and memory consumption when deploying these models with either ``transformer`` or ``vLLM``, we have compiled an extensive [Speed Benchmark](https://qwen.readthedocs.io/en/latest/benchmark/speed_benchmark.html).
## Citation
If you find our work helpful, feel free to give us a cite.
```
@article{qwen2,
title={Qwen2 Technical Report},
year={2024}
}
``` |
MaziyarPanahi/mergekit-slerp-zwbosgo-GGUF | MaziyarPanahi | 2024-06-15T09:57:10Z | 1,175 | 0 | transformers | [
"transformers",
"gguf",
"mistral",
"quantized",
"2-bit",
"3-bit",
"4-bit",
"5-bit",
"6-bit",
"8-bit",
"GGUF",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"conversational",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"base_model:cognitivecomputations/dolphin-2.9-llama3-8b",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us",
"base_model:mergekit-community/mergekit-slerp-zwbosgo"
]
| text-generation | 2024-06-15T09:26:32Z | ---
tags:
- quantized
- 2-bit
- 3-bit
- 4-bit
- 5-bit
- 6-bit
- 8-bit
- GGUF
- transformers
- safetensors
- llama
- text-generation
- mergekit
- merge
- conversational
- base_model:meta-llama/Meta-Llama-3-8B-Instruct
- base_model:cognitivecomputations/dolphin-2.9-llama3-8b
- autotrain_compatible
- endpoints_compatible
- text-generation-inference
- region:us
- text-generation
model_name: mergekit-slerp-zwbosgo-GGUF
base_model: mergekit-community/mergekit-slerp-zwbosgo
inference: false
model_creator: mergekit-community
pipeline_tag: text-generation
quantized_by: MaziyarPanahi
---
# [MaziyarPanahi/mergekit-slerp-zwbosgo-GGUF](https://huggingface.co/MaziyarPanahi/mergekit-slerp-zwbosgo-GGUF)
- Model creator: [mergekit-community](https://huggingface.co/mergekit-community)
- Original model: [mergekit-community/mergekit-slerp-zwbosgo](https://huggingface.co/mergekit-community/mergekit-slerp-zwbosgo)
## Description
[MaziyarPanahi/mergekit-slerp-zwbosgo-GGUF](https://huggingface.co/MaziyarPanahi/mergekit-slerp-zwbosgo-GGUF) contains GGUF format model files for [mergekit-community/mergekit-slerp-zwbosgo](https://huggingface.co/mergekit-community/mergekit-slerp-zwbosgo).
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration. Linux available, in beta as of 27/11/2023.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [GPT4All](https://gpt4all.io/index.html), a free and open source local running GUI, supporting Windows, Linux and macOS with full GPU accel.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server. Note, as of time of writing (November 27th 2023), ctransformers has not been updated in a long time and does not support many recent models.
## Special thanks
🙏 Special thanks to [Georgi Gerganov](https://github.com/ggerganov) and the whole team working on [llama.cpp](https://github.com/ggerganov/llama.cpp/) for making all of this possible. |
larenspear/Yi-1.5-6B-Chat-Q8_0-GGUF | larenspear | 2024-07-01T01:53:43Z | 1,175 | 0 | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"base_model:01-ai/Yi-1.5-6B-Chat",
"license:apache-2.0",
"region:us"
]
| null | 2024-07-01T01:53:17Z | ---
base_model: 01-ai/Yi-1.5-6B-Chat
license: apache-2.0
tags:
- llama-cpp
- gguf-my-repo
---
# larenspear/Yi-1.5-6B-Chat-Q8_0-GGUF
This model was converted to GGUF format from [`01-ai/Yi-1.5-6B-Chat`](https://huggingface.co/01-ai/Yi-1.5-6B-Chat) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/01-ai/Yi-1.5-6B-Chat) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo larenspear/Yi-1.5-6B-Chat-Q8_0-GGUF --hf-file yi-1.5-6b-chat-q8_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo larenspear/Yi-1.5-6B-Chat-Q8_0-GGUF --hf-file yi-1.5-6b-chat-q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo larenspear/Yi-1.5-6B-Chat-Q8_0-GGUF --hf-file yi-1.5-6b-chat-q8_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo larenspear/Yi-1.5-6B-Chat-Q8_0-GGUF --hf-file yi-1.5-6b-chat-q8_0.gguf -c 2048
```
|
XCLiu/2_rectified_flow_from_sd_1_5 | XCLiu | 2023-11-01T06:42:33Z | 1,174 | 8 | diffusers | [
"diffusers",
"safetensors",
"arxiv:2309.06380",
"arxiv:2209.03003",
"arxiv:2209.14577",
"license:cc-by-nc-4.0",
"diffusers:RectifiedFlowPipeline",
"region:us"
]
| null | 2023-10-26T04:45:28Z | ---
license: cc-by-nc-4.0
---
# InstaFlow: 2-Rectified Flow fine-tuned from Stable Diffusion v1.5
2-Rectified Flow is a few-step text-to-image generative model fine-tuned from Stabled Diffusion v1.5.
We use text-conditioned reflow as described in [our paper](https://arxiv.org/abs/2309.06380).
Reflow has interesting theoretical properties. You may check [this ICLR paper](https://arxiv.org/abs/2209.03003) and [this arXiv paper](https://arxiv.org/abs/2209.14577).
## Images Generated from Random Diffusion DB prompts
We compare SD 1.5+DPM-Solver and 2-Rectified Flow with random prompts from Diffusion DB using the same random seeds. We observe that 2-Rectiifed Flow is straighter.
|  |
| :---: |
| **Prompt**: a renaissance portrait of dwayne johnson, art in the style of rembrandt. |
|  |
| :---: |
| **Prompt**: a photo of a rabbit head on a grizzly bear body. |
# Usage
Please refer to the [official github repo](https://github.com/gnobitab/InstaFlow).
## Training
Training pipeline:
1. Reflow (Stage 1): We train the model using the text-conditioned reflow objective with a batch size of 64 for 70,000 iterations.
The model is initialized from the pre-trained SD 1.5 weights. (11.2 A100 GPU days)
2. Reflow (Stage 2): We continue to train the model using the text-conditioned reflow objective with an increased batch size of 1024 for 25,000 iterations. (64 A100 GPU days)
The final model is **2-Rectified Flow**.
**Total Training Cost:** It takes 75.2 A100 GPU days to get 2-Rectified Flow.
## Evaluation Results - Metrics
The following metrics of 2-Rectified Flow are measured on MS COCO 2017 with 5000 images and 25-step Euler solver:
*FID-5k = 21.5, CLIP score = 0.315*
Few-Step performance:

## Evaluation Results - Impact of Guidance Scale
We evaluate the impact of the guidance scale on 2-Rectified Flow.

Trade-off Curve:

## Citation
```
@article{liu2023insta,
title={InstaFlow: One Step is Enough for High-Quality Diffusion-Based Text-to-Image Generation},
author={Liu, Xingchao and Zhang, Xiwen and Ma, Jianzhu and Peng, Jian and Liu, Qiang},
journal={arXiv preprint arXiv:2309.06380},
year={2023}
}
``` |
Edentns/DataVortexS-10.7B-dpo-v1.5 | Edentns | 2024-02-24T14:17:18Z | 1,174 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"ko",
"base_model:megastudy/M-SOLAR-10.7B-v1.3",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-01-28T06:09:48Z | ---
tags:
- text-generation
license: cc-by-nc-sa-4.0
language:
- ko
base_model: megastudy/M-SOLAR-10.7B-v1.3
pipeline_tag: text-generation
---
# **DataVortexS-10.7B-dpo-v1.5**
<img src="./DataVortex.png" alt="DataVortex" style="height: 8em;">
## Our Team
| Research & Engineering | Product Management |
| :--------------------: | :----------------: |
| Kwangseok Yang | Seunghyun Choi |
| Jeongwon Choi | Hyoseok Choi |
## **Model Details**
### **Base Model**
[megastudy/M-SOLAR-10.7B-v1.3](https://huggingface.co/megastudy/M-SOLAR-10.7B-v1.3)
### **Trained On**
- **OS**: Ubuntu 22.04
- **GPU**: H100 80GB 4ea
- **transformers**: v4.36.2
### **Instruction format**
It follows **ChatML** format.
E.g.
```python
text = """\
<|im_start|>system
당신은 사람들이 정보를 찾을 수 있도록 도와주는 인공지능 비서입니다.<|im_end|>
<|im_start|>user
대한민국의 수도는 어디야?<|im_end|>
<|im_start|>assistant
대한민국의 수도는 서울입니다.<|im_end|>
<|im_start|>user
서울 인구는 총 몇 명이야?<|im_end|>
<|im_start|>assistant
"""
```
## **Model Benchmark**
### **[Ko LM Eval Harness](https://github.com/Beomi/ko-lm-evaluation-harness)**
| Task | 0-shot | 5-shot | 10-shot | 50-shot |
| :--------------- | -----------: | -----------: | -----------: | -----------: |
| kobest_boolq | 0.34687 | 0.930158 | 0.943013 | 0.938029 |
| kobest_copa | 0.693351 | 0.751805 | 0.75772 | 0.771704 |
| kobest_hellaswag | 0.480736 | 0.470852 | 0.474766 | 0.478576 |
| kobest_sentineg | 0.789423 | 0.962208 | 0.967241 | 0.964717 |
| **Average** | **0.577595** | **0.778756** | **0.785685** | **0.788257** |
### **[Ko-LLM-Leaderboard](https://huggingface.co/spaces/upstage/open-ko-llm-leaderboard)**
| Average | Ko-ARC | Ko-HellaSwag | Ko-MMLU | Ko-TruthfulQA | Ko-CommonGen V2 |
| ------: | -----: | -----------: | ------: | ------------: | --------------: |
| 55.32 | 52.13 | 61.27 | 53.99 | 49.71 | 59.5 |
## **Implementation Code**
This model contains the chat_template instruction format.
You can use the code below.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained("Edentns/DataVortexS-10.7B-dpo-v1.5")
tokenizer = AutoTokenizer.from_pretrained("Edentns/DataVortexS-10.7B-dpo-v1.5")
messages = [
{"role": "system", "content": "당신은 사람들이 정보를 찾을 수 있도록 도와주는 인공지능 비서입니다."},
{"role": "user", "content": "대한민국의 수도는 어디야?"},
{"role": "assistant", "content": "대한민국의 수도는 서울입니다."},
{"role": "user", "content": "서울 인구는 총 몇 명이야?"}
]
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt")
model_inputs = encodeds.to(device)
model.to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
```
## **License**
The model is licensed under the [cc-by-nc-sa-4.0](https://creativecommons.org/licenses/by-nc-sa/4.0/) license, which allows others to copy, modify, and share the work non-commercially, as long as they give appropriate credit and distribute any derivative works under the same license.
<div align="center">
<a href="https://edentns.com/">
<img src="./Logo.png" alt="Logo" style="height: 3em;">
</a>
</div>
|
Chrisisis/5HifrnQY5e4W4XZkSAaZEMSShnLssm3XpCPuxzRTswGDDQjt_vgg | Chrisisis | 2024-02-24T08:30:27Z | 1,174 | 0 | keras | [
"keras",
"region:us"
]
| null | 2024-02-11T17:24:33Z | Entry not found |
VAGOsolutions/SauerkrautLM-Gemma-2b | VAGOsolutions | 2024-03-07T17:17:08Z | 1,174 | 7 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"sft",
"laserRMT",
"laser-QLoRa",
"finetune",
"work in progress",
"alpha",
"de",
"en",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-03-06T23:26:18Z | ---
license: other
license_name: gemma-terms-of-use
license_link: https://ai.google.dev/gemma/terms
language:
- de
- en
tags:
- sft
- laserRMT
- laser-QLoRa
- finetune
- work in progress
- alpha
---

## VAGO solutions SauerkrautLM-Gemma-2b (alpha)
Introducing **SauerkrautLM-Gemma-2b** – our German Sauerkraut version of the powerful [google/gemma-2b](https://huggingface.co/google/gemma-2b) !
**It is an early stage finetuned model and should be used with caution!**
The model **SauerkrautLM-Gemma-2b** is a **joint effort** between **VAGO solutions** and **Hyperspace.ai.**
Much appreciation goes to the tremendous research effort of **Fernando Fernandes Neto, David Golchinfar and Eric Hartford on their laserRMT approach.**
Without their independent research collaboration this model release would not have been possible.
- Fintuned with **SFT**
- **Using a novel training technique: laser-QLoRA** - we partially freeze the model according to a laser-like analysis (Official Paper soon). It allows to evaluate the no free lunch theorem and supports better decision making when optimizing the theorem - created by the [LaserRMT research group](https://github.com/cognitivecomputations/laserRMT)
- Optimized with **LaserRMT**
# Table of Contents
1. [Overview of all SauerkrautLM-Gemma-2b models](#all-sauerkrautlm-gemma-7b-models)
2. [Model Details](#model-details)
- [Prompt template](#prompt-template)
- [Training procedure](#proceed-of-the-training)
3. [Evaluation](#evaluation)
5. [Disclaimer](#disclaimer)
6. [Contact](#contact)
7. [Collaborations](#collaborations)
8. [Acknowledgement](#acknowledgement)
## All SauerkrautLM-Gemma-2b Models
| Model | HF | GPTQ | GGUF | AWQ |
|-------|-------|-------|-------|-------|
| SauerkrautLM-Gemma-2b | [Link](https://huggingface.co/VAGOsolutions/SauerkrautLM-Gemma-2b) | coming soon | coming soon | coming soon |
## Model Details
**SauerkrautLM-Gemma-2b**
- **Model Type:** SauerkrautLM-Gemma-2b is a finetuned Model based on [google/gemma-2b](https://huggingface.co/google/gemma-2b)
- **Language(s):** German, English
- **License:** [gemma-terms-of-use](https://ai.google.dev/gemma/terms)
- **Contact:** [VAGO solutions](https://vago-solutions.ai), [Hyperspace.ai](https://hyperspace.computer/)
### Training procedure:
**Warning**: **This finetuned model is in an early stage and we sometimes observed strange behavior. It is still work in progress!**
Anyone who has attempted or succeeded in fine-tuning a model is aware of the difficulty in nudging it towards a specific skill, such as mastering new languages, as well as the challenges associated with achieving significant improvements in performance.
Experimenting with a novel training strategy and Spherical Linear Interpolation alongside a lasered version of the model itself has proven to be both fascinating and revealing.
Furthermore, we developed one iteration of the model using our entire SFT -Sauerkraut dataset and two additional iterations using subsets of the full dataset—one focused on enhancing MMLU and TQA capabilities, and the other on boosting GSM8K and Winogrande skills.
We actively monitor and assesed the results of each training. Whenever we found a decrease in perplexity on the gsm8k benchmark we intervined. By following this procedure we were able to improve the overall performance, especially in math abilities, without detracting from performance on other benchmarks—a task that is, in general, quite difficult.
This process not only helps in understanding the effectiveness of Spherical Linear Interpolation but also introduces a new method for refining models with enhanced skills through a cycle of targeted data selection (Laser data(x)) + SLERP, followed by a subsequent focus on different data (Laser again on data(y)).
Additionally, we integrated a novel training strategy on the SFT training process, where we partially freeze the model according to a laser-like analysis aiming to navigate and optimize the trade-offs highlighted by the no free lunch theorem. This innovative training method effectively prevents the significant problem of language models forgetting previously acquired knowledge.
This aspect is particularly crucial when attempting to teach the model specific skills, such as a new language, where in general, the model might lose a considerable amount of its prior knowledge and exhibit a decline in overall intelligence.
Detailed information on how the new training strategy works and the advantages it offers over conventional training methods will soon be published in a detailed paper by the LaserRMT research group.
**We teached German language skills on this model.** As far as we know, it is the first Gemma-2b model with bilingual skills in German and English. Nevertheless, formulations may occur that are not entirely correct (still work in progress).
### Prompt Template:
We trained on vicuna prompt template. Please add the following stopping string to your client: ``` "</s>","</p>" ``` (we did not add the special tokens to the training config)
```
You are a helpful AI Assistant.
USER: Hello, how are you?
ASSISTANT:
```
## Evaluation
(with lm-evaluation-harness 0.4.1)
**Open LLM Leaderboard:**
| Metric | Value |
|-----------------------|---------------------------|
| Avg. | **48.93** |
| ARC (25-shot) | 49.32 |
| HellaSwag (10-shot) | 71.23 |
| MMLU (5-shot) | 42.06
| TruthfulQA (0-shot) | 35.73 |
| Winogrande (5-shot) | 67.56 |
| GSM8K (5-shot) | 27.67 |
**Performance**
| Model |AGIEval|GPT4All|TruthfulQA|BigBench|Average ⬇️|
|-----------------------------------------------------------------------|------:|------:|---------:|-------:|------:|
|[VAGOsolutions/SauerkrautLM-Gemma-7b](https://huggingface.co/VAGOsolutions/SauerkrautLM-Gemma-7b) | 37.5| 72.46| 61.24| 45.33| 54.13|
|[zephyr-7b-beta](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta) | 37.52| 71.77| 55.26| 39.77| 51.08|
|[zephyr-7b-gemma-v0.1](https://huggingface.co/HuggingFaceH4/zephyr-7b-gemma-v0.1)| 34.22| 66.37| 52.19| 37.10| 47.47|
|[VAGOsolutions/SauerkrautLM-Gemma-2b](https://huggingface.co/VAGOsolutions/SauerkrautLM-Gemma-2b) | 24.28| 63.59| 35.73| 22.77| 36.59|
|[google/gemma-7b-it](https://huggingface.co/google/gemma-7b-it) | 21.33| 40.84| 41.70| 30.25| 33.53|
<details><summary>Details of AGIEval, GPT4All, TruthfulQA, BigBench </summary>
**AGIEval**
| Tasks |Version|Filter|n-shot| Metric |Value | |Stderr|
|------------------------------|------:|------|------|--------|-----:|---|-----:|
|agieval_sat_math | 1|none |None |acc |0.2409|± |0.0289|
| | |none |None |acc_norm|0.2455|± |0.0291|
|agieval_sat_en_without_passage| 1|none |None |acc |0.3010|± |0.0320|
| | |none |None |acc_norm|0.2816|± |0.0314|
|agieval_sat_en | 1|none |None |acc |0.3301|± |0.0328|
| | |none |None |acc_norm|0.2961|± |0.0319|
|agieval_lsat_rc | 1|none |None |acc |0.2007|± |0.0245|
| | |none |None |acc_norm|0.1933|± |0.0241|
|agieval_lsat_lr | 1|none |None |acc |0.1941|± |0.0175|
| | |none |None |acc_norm|0.2039|± |0.0179|
|agieval_lsat_ar | 1|none |None |acc |0.2304|± |0.0278|
| | |none |None |acc_norm|0.2391|± |0.0282|
|agieval_logiqa_en | 1|none |None |acc |0.2089|± |0.0159|
| | |none |None |acc_norm|0.2581|± |0.0172|
|agieval_aqua_rat | 1|none |None |acc |0.2480|± |0.0272|
| | |none |None |acc_norm|0.2244|± |0.0262|
Average: 24.28%
**GPT4All**
| Tasks |Version|Filter|n-shot| Metric |Value | |Stderr|
|---------|------:|------|------|--------|-----:|---|-----:|
|arc_challenge| 1|none |None |acc |0.4334|± |0.0145|
| | |none |None |acc_norm|0.4309|± |0.0145|
|arc_easy | 1|none |None |acc |0.7433|± |0.0090|
| | |none |None |acc_norm|0.7264|± |0.0091|
|boolq | 2|none |None |acc |0.7165|± |0.0079|
|hellaswag | 1|none |None |acc |0.5357|± |0.0050|
| | |none |None |acc_norm|0.7158|± |0.0045|
|openbookqa | 1|none |None |acc |0.318 |± |0.0208|
| | |none |None |acc_norm|0.402 |± |0.0219|
|piqa | 1|none |None |acc |0.7709|± |0.0098|
| | |none |None |acc_norm|0.7807|± |0.0097|
|winogrande | 1|none |None |acc |0.6788|± |0.0131|
Average: 63.59%
**TruthfulQA**
| Tasks |Version|Filter|n-shot|Metric|Value | |Stderr|
|--------------|------:|------|-----:|------|-----:|---|-----:|
|truthfulqa_mc2| 2|none | 0|acc |0.3573|± |0.0135|
Average: 35.73%
**Bigbench**
| Tasks |Version| Filter |n-shot| Metric |Value | |Stderr|
|----------------------------------------------------|------:|----------------|-----:|-----------|-----:|---|-----:|
|bbh_zeroshot_tracking_shuffled_objects_three_objects| 2|flexible-extract| 0|exact_match|0.3280|± |0.0298|
|bbh_zeroshot_tracking_shuffled_objects_seven_objects| 2|flexible-extract| 0|exact_match|0.1120|± |0.0200|
|bbh_zeroshot_tracking_shuffled_objects_five_objects | 2|flexible-extract| 0|exact_match|0.1520|± |0.0228|
|bbh_zeroshot_temporal_sequences | 2|flexible-extract| 0|exact_match|0.1000|± |0.0190|
|bbh_zeroshot_sports_understanding | 2|flexible-extract| 0|exact_match|0.5360|± |0.0316|
|bbh_zeroshot_snarks | 2|flexible-extract| 0|exact_match|0.2753|± |0.0336|
|bbh_zeroshot_salient_translation_error_detection | 2|flexible-extract| 0|exact_match|0.1400|± |0.0220|
|bbh_zeroshot_ruin_names | 2|flexible-extract| 0|exact_match|0.1120|± |0.0200|
|bbh_zeroshot_reasoning_about_colored_objects | 2|flexible-extract| 0|exact_match|0.1080|± |0.0197|
|bbh_zeroshot_navigate | 2|flexible-extract| 0|exact_match|0.5800|± |0.0313|
|bbh_zeroshot_movie_recommendation | 2|flexible-extract| 0|exact_match|0.4360|± |0.0314|
|bbh_zeroshot_logical_deduction_three_objects | 2|flexible-extract| 0|exact_match|0.0000|± |0.0000|
|bbh_zeroshot_logical_deduction_seven_objects | 2|flexible-extract| 0|exact_match|0.0720|± |0.0164|
|bbh_zeroshot_logical_deduction_five_objects | 2|flexible-extract| 0|exact_match|0.0000|± |0.0000|
|bbh_zeroshot_geometric_shapes | 2|flexible-extract| 0|exact_match|0.0000|± |0.0000|
|bbh_zeroshot_disambiguation_qa | 2|flexible-extract| 0|exact_match|0.3400|± |0.0300|
|bbh_zeroshot_date_understanding | 2|flexible-extract| 0|exact_match|0.3360|± |0.0299|
|bbh_zeroshot_causal_judgement | 2|flexible-extract| 0|exact_match|0.4706|± |0.0366|
Average: 22.77%
</details>
## Disclaimer
We must inform users that despite our best efforts in data cleansing, the possibility of uncensored content slipping through cannot be entirely ruled out.
However, we cannot guarantee consistently appropriate behavior. Therefore, if you encounter any issues or come across inappropriate content, we kindly request that you inform us through the contact information provided.
Additionally, it is essential to understand that the licensing of these models does not constitute legal advice. We are not held responsible for the actions of third parties who utilize our models.
## Contact
If you are interested in customized LLMs for business applications, please get in contact with us via our websites. We are also grateful for your feedback and suggestions.
## Collaborations
We are also keenly seeking support and investment for our startups, VAGO solutions and Hyperspace where we continuously advance the development of robust language models designed to address a diverse range of purposes and requirements. If the prospect of collaboratively navigating future challenges excites you, we warmly invite you to reach out to us at [VAGO solutions](https://vago-solutions.de/#Kontakt), [Hyperspace.computer](https://hyperspace.computer/)
## Acknowledgement
Many thanks to [google](https://huggingface.co/google) for providing such valuable model to the Open-Source community |
cockroach54/solar-sft-qlora | cockroach54 | 2024-04-08T01:16:04Z | 1,174 | 1 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"ko",
"en",
"dataset:davidkim205/kollm-converations",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-07T07:58:10Z | ---
license: apache-2.0
datasets:
- davidkim205/kollm-converations
language:
- ko
- en
library_name: transformers
---
- just for practice
- trained by transformers, peft, bitsandbytes
- evaluated by https://github.com/davidkim205/kollm_evaluation
| Tasks |Version|Filter|n-shot| Metric |Value | |Stderr|
|----------------|------:|------|-----:|--------|-----:|---|------|
|kobest_wic | 1|none | 0|acc |0.5056|± |0.0141|
| | |none | 0|f1 |0.4170|± |N/A |
|kobest_sentineg | 1|none | 0|acc |0.8791|± |0.0164|
| | |none | 0|f1 |0.8779|± |N/A |
|kobest_hellaswag| 1|none | 0|acc |0.4540|± |0.0223|
| | |none | 0|f1 |0.4522|± |N/A |
| | |none | 0|acc_norm|0.5600|± |0.0222|
|kobest_copa | 1|none | 0|acc |0.6540|± |0.0151|
| | |none | 0|f1 |0.6535|± |N/A |
|kobest_boolq | 1|none | 0|acc |0.5135|± |0.0133|
| | |none | 0|f1 |0.3592|± |N/A |
|ko_truthfulqa | 2|none | 0|acc |0.2938|± |0.0159|
|ko_hellaswag | 1|none | 0|acc |0.3816|± |0.0048|
| | |none | 0|acc_norm|0.5171|± |0.0050|
|ko_common_gen | 1|none | 0|acc |0.8095|± |0.0100|
| | |none | 0|acc_norm|0.8095|± |0.0100|
|ko_arc_easy | 1|none | 0|acc |0.3311|± |0.0138|
| | |none | 0|acc_norm|0.4053|± |0.0143| |
freewheelin/free-solar-evo-v0.11 | freewheelin | 2024-04-24T06:42:49Z | 1,174 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"ko",
"en",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-24T05:23:52Z | ---
language:
- ko
- en
license: mit
---
# Model Card for free-solar-evo-v0.11
## Developed by : [Freewheelin](https://freewheelin-recruit.oopy.io/) AI Technical Team
## Method
- We were inspired by this [Sakana project](https://sakana.ai/evolutionary-model-merge/)
## Base Model
- free-solar-evo-model |
Norquinal/Mistral-7B-claude-chat | Norquinal | 2023-10-07T23:43:12Z | 1,173 | 18 | transformers | [
"transformers",
"pytorch",
"mistral",
"text-generation",
"dataset:Norquinal/claude_multiround_chat_1k",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2023-09-27T22:14:57Z | ---
datasets:
- Norquinal/claude_multiround_chat_1k
license: cc-by-nc-4.0
---
This is the [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) model fine-tuned using QLoRA (4-bit precision) on my [claude_multiround_chat_1k](https://huggingface.co/datasets/Norquinal/claude_multiround_chat_1k) dataset, which is a randomized subset of ~1000 samples from my [claude_multiround_chat_30k](https://huggingface.co/datasets/Norquinal/claude_multiround_chat_30k) dataset.
## Prompt Format
The model was finetuned with the Vicuna 1.1 prompt format:
```
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions.
USER: {instruction}
ASSISTANT:
```
## Use in Text Generation Web UI
Install the bleeding-edge version of `transformers` from source:
```
pip install git+https://github.com/huggingface/transformers
```
Or, alternatively, change `model_type` in `config.json` from `mistral` to `llama`.
## Example Usage
>USER: First, give a brief overview of Chinese cuisine, including its regional diversity. next, describe the importance of the five flavors in Chinese cooking. Then, mention three popular Chinese dishes and their main ingredients. After that, provide a popular Chinese cooking technique and an example of a dish prepared using that technique. Finally, discuss the role of tea in traditional Chinese culture.
>ASSISTANT: Chinese cuisine is incredibly diverse due to its large geographic area with different climates and resources available. Regional specialties include Sichuan spicy hot pot, Cantonese dim sum and seafood dishes, Beijing roast duck, and Hunan stir-fries.
>
>The five basic tastes that guide Chinese cookery are sweetness, sourness, bitterness, saltiness, and pungency (spiciness). These contrasting flavors are used together to create balance in each dish.
>
>Some classic Chinese dishes include dumplings filled with meat or vegetables, spring rolls stuffed with vegetables and meat wrapped in thin pastry, and noodles served in soups or stir fried with sauces and vegetables.
>
>A common Chinese cooking technique is braising, where food is slowly cooked in a small amount of liquid until tender and flavorful. An example would be beef brisket braised in soy sauce, ginger and star anise for hours until falling apart.
>
>Tea plays a central role in Chinese culture as it represents hospitality, relaxation and socializing. Green teas are most commonly consumed but black, oolong and white varieties also exist. Tea drinking rituals involve preparing and serving tea in specific ways depending on context and occasion.
>
>In summary, Chinese cuisine offers a rich culinary tradition influenced by regional differences, an emphasis on balancing the five basic flavors, and a focus on simple yet flavorful preparations using fresh seasonal produce and high quality meats. Tea acts as both a refreshment and symbol of cultural refinement within Chinese society. I hope this overview provides an interesting starting point for further exploration into the fascinating world of Chinese gastronomy! |
chihoonlee10/T3Q-ko-solar-dpo-v3.0 | chihoonlee10 | 2024-03-27T08:18:57Z | 1,173 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-03-20T15:10:37Z | ---
library_name: transformers
license: apache-2.0
pipeline_tag: text-generation
---

# T3Q-ko-solar-dpo-v3.0
## This model is a version of davidkim205/nox-solar-10.7b-v4 that has been fine-tuned with DPO.
## Model Developers Chihoon Lee(chihoonlee10), T3Q |
Habaznya/p_model | Habaznya | 2024-05-21T00:01:07Z | 1,173 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2024-05-04T21:51:51Z | ---
license: apache-2.0
base_model: google-bert/bert-base-uncased
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: p_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# p_model
This model is a fine-tuned version of [google-bert/bert-base-uncased](https://huggingface.co/google-bert/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3591
- Accuracy: 0.9066
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.7455 | 1.0 | 832 | 0.4333 | 0.8517 |
| 0.3497 | 2.0 | 1664 | 0.3821 | 0.8785 |
| 0.2924 | 3.0 | 2496 | 0.3402 | 0.8955 |
| 0.2017 | 4.0 | 3328 | 0.3417 | 0.9066 |
| 0.1476 | 5.0 | 4160 | 0.3591 | 0.9066 |
### Framework versions
- Transformers 4.40.2
- Pytorch 2.2.1+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
sdhan/SD_SOLAR_10.7B_v1.0 | sdhan | 2024-05-12T18:34:14Z | 1,173 | 1 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-05-12T17:50:48Z | ---
license: apache-2.0
---
Model Details
dataset : DPO dataset (huggingface datasets, 2digit datasets 활용)
Training Method Method : DPO.
Usage
```
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
repo = "sdhan/SD_SOLAR_10.7B_v1.0"
model = AutoModelForCausalLM.from_pretrained(
repo,
return_dict=True,
torch_dtype=torch.float16,
device_map='auto'
)
tokenizer = AutoTokenizer.from_pretrained(repo)
``` |
mlabonne/Daredevil-8B | mlabonne | 2024-06-06T22:47:22Z | 1,173 | 23 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"conversational",
"base_model:nbeerbower/llama-3-stella-8B",
"base_model:Hastagaras/llama-3-8b-okay",
"base_model:nbeerbower/llama-3-gutenberg-8B",
"base_model:openchat/openchat-3.6-8b-20240522",
"base_model:Kukedlc/NeuralLLaMa-3-8b-DT-v0.1",
"base_model:cstr/llama3-8b-spaetzle-v20",
"base_model:mlabonne/ChimeraLlama-3-8B-v3",
"base_model:flammenai/Mahou-1.1-llama3-8B",
"base_model:KingNish/KingNish-Llama3-8b",
"license:other",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-05-25T18:56:51Z | ---
license: other
tags:
- merge
- mergekit
- lazymergekit
base_model:
- nbeerbower/llama-3-stella-8B
- Hastagaras/llama-3-8b-okay
- nbeerbower/llama-3-gutenberg-8B
- openchat/openchat-3.6-8b-20240522
- Kukedlc/NeuralLLaMa-3-8b-DT-v0.1
- cstr/llama3-8b-spaetzle-v20
- mlabonne/ChimeraLlama-3-8B-v3
- flammenai/Mahou-1.1-llama3-8B
- KingNish/KingNish-Llama3-8b
model-index:
- name: Daredevil-8B
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 68.86
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=mlabonne/Daredevil-8B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 84.5
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=mlabonne/Daredevil-8B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 69.24
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=mlabonne/Daredevil-8B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 59.89
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=mlabonne/Daredevil-8B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 78.45
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=mlabonne/Daredevil-8B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 73.54
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=mlabonne/Daredevil-8B
name: Open LLM Leaderboard
---
# Daredevil-8B

Daredevil-8B is a mega-merge designed to maximize MMLU. On 27 May 24, it is the Llama 3 8B model with the **highest MMLU score**.
From my experience, a high MMLU score is all you need with Llama 3 models.
It is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [nbeerbower/llama-3-stella-8B](https://huggingface.co/nbeerbower/llama-3-stella-8B)
* [Hastagaras/llama-3-8b-okay](https://huggingface.co/Hastagaras/llama-3-8b-okay)
* [nbeerbower/llama-3-gutenberg-8B](https://huggingface.co/nbeerbower/llama-3-gutenberg-8B)
* [openchat/openchat-3.6-8b-20240522](https://huggingface.co/openchat/openchat-3.6-8b-20240522)
* [Kukedlc/NeuralLLaMa-3-8b-DT-v0.1](https://huggingface.co/Kukedlc/NeuralLLaMa-3-8b-DT-v0.1)
* [cstr/llama3-8b-spaetzle-v20](https://huggingface.co/cstr/llama3-8b-spaetzle-v20)
* [mlabonne/ChimeraLlama-3-8B-v3](https://huggingface.co/mlabonne/ChimeraLlama-3-8B-v3)
* [flammenai/Mahou-1.1-llama3-8B](https://huggingface.co/flammenai/Mahou-1.1-llama3-8B)
* [KingNish/KingNish-Llama3-8b](https://huggingface.co/KingNish/KingNish-Llama3-8b)
Thanks to nbeerbower, Hastagaras, openchat, Kukedlc, cstr, flammenai, and KingNish for their merges. Special thanks to Charles Goddard and Arcee.ai for MergeKit.
## 🔎 Applications
You can use it as an improved version of [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct).
This is a censored model. For an uncensored version, see [mlabonne/Daredevil-8B-abliterated](https://huggingface.co/mlabonne/Daredevil-8B-abliterated).
Tested on LM Studio using the "Llama 3" preset.
## ⚡ Quantization
* **GGUF**: https://huggingface.co/mlabonne/Daredevil-8B-GGUF
## 🏆 Evaluation
### Open LLM Leaderboard
Daredevil-8B is the best-performing 8B model on the Open LLM Leaderboard in terms of MMLU score (27 May 24).

### Nous
Daredevil-8B is the best-performing 8B model on Nous' benchmark suite (evaluation performed using [LLM AutoEval](https://github.com/mlabonne/llm-autoeval), 27 May 24). See the entire leaderboard [here](https://huggingface.co/spaces/mlabonne/Yet_Another_LLM_Leaderboard).
| Model | Average | AGIEval | GPT4All | TruthfulQA | Bigbench |
|---|---:|---:|---:|---:|---:|
| [**mlabonne/Daredevil-8B**](https://huggingface.co/mlabonne/Daredevil-8B) [📄](https://gist.github.com/mlabonne/080f9c5f153ea57a7ab7d932cf896f21) | **55.87** | **44.13** | **73.52** | **59.05** | **46.77** |
| [mlabonne/Daredevil-8B-abliterated](https://huggingface.co/mlabonne/Daredevil-8B-abliterated) [📄](https://gist.github.com/mlabonne/32cdd8460804662c856bcb2a20acd49e) | 55.06 | 43.29 | 73.33 | 57.47 | 46.17 |
| [mlabonne/Llama-3-8B-Instruct-abliterated-dpomix](https://huggingface.co/mlabonne/Llama-3-8B-Instruct-abliterated-dpomix) [📄](https://gist.github.com/mlabonne/d711548df70e2c04771cc68ab33fe2b9) | 52.26 | 41.6 | 69.95 | 54.22 | 43.26 |
| [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) [📄](https://gist.github.com/mlabonne/8329284d86035e6019edb11eb0933628) | 51.34 | 41.22 | 69.86 | 51.65 | 42.64 |
| [failspy/Meta-Llama-3-8B-Instruct-abliterated-v3](https://huggingface.co/failspy/Meta-Llama-3-8B-Instruct-abliterated-v3) [📄](https://gist.github.com/mlabonne/f46cce0262443365e4cce2b6fa7507fc) | 51.21 | 40.23 | 69.5 | 52.44 | 42.69 |
| [mlabonne/OrpoLlama-3-8B](https://huggingface.co/mlabonne/OrpoLlama-3-8B) [📄](https://gist.github.com/mlabonne/22896a1ae164859931cc8f4858c97f6f) | 48.63 | 34.17 | 70.59 | 52.39 | 37.36 |
| [meta-llama/Meta-Llama-3-8B](https://huggingface.co/meta-llama/Meta-Llama-3-8B) [📄](https://gist.github.com/mlabonne/616b6245137a9cfc4ea80e4c6e55d847) | 45.42 | 31.1 | 69.95 | 43.91 | 36.7 |
## 🌳 Model family tree

## 🧩 Configuration
```yaml
models:
- model: NousResearch/Meta-Llama-3-8B
# No parameters necessary for base model
- model: nbeerbower/llama-3-stella-8B
parameters:
density: 0.6
weight: 0.16
- model: Hastagaras/llama-3-8b-okay
parameters:
density: 0.56
weight: 0.1
- model: nbeerbower/llama-3-gutenberg-8B
parameters:
density: 0.6
weight: 0.18
- model: openchat/openchat-3.6-8b-20240522
parameters:
density: 0.56
weight: 0.12
- model: Kukedlc/NeuralLLaMa-3-8b-DT-v0.1
parameters:
density: 0.58
weight: 0.18
- model: cstr/llama3-8b-spaetzle-v20
parameters:
density: 0.56
weight: 0.08
- model: mlabonne/ChimeraLlama-3-8B-v3
parameters:
density: 0.56
weight: 0.08
- model: flammenai/Mahou-1.1-llama3-8B
parameters:
density: 0.55
weight: 0.05
- model: KingNish/KingNish-Llama3-8b
parameters:
density: 0.55
weight: 0.05
merge_method: dare_ties
base_model: NousResearch/Meta-Llama-3-8B
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "mlabonne/Daredevil-8B"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.bfloat16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
|
QuantFactory/Qwen2-0.5B-GGUF | QuantFactory | 2024-06-18T06:31:15Z | 1,173 | 0 | null | [
"gguf",
"pretrained",
"text-generation",
"en",
"base_model:Qwen/Qwen2-0.5B",
"license:apache-2.0",
"region:us"
]
| text-generation | 2024-06-12T05:56:33Z | ---
language:
- en
pipeline_tag: text-generation
tags:
- pretrained
license: apache-2.0
base_model: Qwen/Qwen2-0.5B
---
# QuantFactory/Qwen2-0.5B-GGUF
This is quantized version of [Qwen/Qwen2-0.5B](https://huggingface.co/Qwen/Qwen2-0.5B) created using llama.cpp
# Model Description
## Introduction
Qwen2 is the new series of Qwen large language models. For Qwen2, we release a number of base language models and instruction-tuned language models ranging from 0.5 to 72 billion parameters, including a Mixture-of-Experts model. This repo contains the 0.5B Qwen2 base language model.
Compared with the state-of-the-art opensource language models, including the previous released Qwen1.5, Qwen2 has generally surpassed most opensource models and demonstrated competitiveness against proprietary models across a series of benchmarks targeting for language understanding, language generation, multilingual capability, coding, mathematics, reasoning, etc.
For more details, please refer to our [blog](https://qwenlm.github.io/blog/qwen2/), [GitHub](https://github.com/QwenLM/Qwen2), and [Documentation](https://qwen.readthedocs.io/en/latest/).
<br>
## Model Details
Qwen2 is a language model series including decoder language models of different model sizes. For each size, we release the base language model and the aligned chat model. It is based on the Transformer architecture with SwiGLU activation, attention QKV bias, group query attention, etc. Additionally, we have an improved tokenizer adaptive to multiple natural languages and codes.
## Requirements
The code of Qwen2 has been in the latest Hugging face transformers and we advise you to install `transformers>=4.37.0`, or you might encounter the following error:
```
KeyError: 'qwen2'
```
## Usage
We do not advise you to use base language models for text generation. Instead, you can apply post-training, e.g., SFT, RLHF, continued pretraining, etc., on this model.
## Performance
The evaluation of base models mainly focuses on the model performance of natural language understanding, general question answering, coding, mathematics, scientific knowledge, reasoning, multilingual capability, etc.
The datasets for evaluation include:
**English Tasks**: MMLU (5-shot), MMLU-Pro (5-shot), GPQA (5shot), Theorem QA (5-shot), BBH (3-shot), HellaSwag (10-shot), Winogrande (5-shot), TruthfulQA (0-shot), ARC-C (25-shot)
**Coding Tasks**: EvalPlus (0-shot) (HumanEval, MBPP, HumanEval+, MBPP+), MultiPL-E (0-shot) (Python, C++, JAVA, PHP, TypeScript, C#, Bash, JavaScript)
**Math Tasks**: GSM8K (4-shot), MATH (4-shot)
**Chinese Tasks**: C-Eval(5-shot), CMMLU (5-shot)
**Multilingual Tasks**: Multi-Exam (M3Exam 5-shot, IndoMMLU 3-shot, ruMMLU 5-shot, mMMLU 5-shot), Multi-Understanding (BELEBELE 5-shot, XCOPA 5-shot, XWinograd 5-shot, XStoryCloze 0-shot, PAWS-X 5-shot), Multi-Mathematics (MGSM 8-shot), Multi-Translation (Flores-101 5-shot)
#### Qwen2-0.5B & Qwen2-1.5B performances
| Datasets | Phi-2 | Gemma-2B | MiniCPM | Qwen1.5-1.8B | Qwen2-0.5B | Qwen2-1.5B |
| :--------| :---------: | :------------: | :------------: |:------------: | :------------: | :------------: |
|#Non-Emb Params | 2.5B | 2.0B | 2.4B | 1.3B | 0.35B | 1.3B |
|MMLU | 52.7 | 42.3 | 53.5 | 46.8 | 45.4 | **56.5** |
|MMLU-Pro | - | 15.9 | - | - | 14.7 | 21.8 |
|Theorem QA | - | - | - |- | 8.9 | **15.0** |
|HumanEval | 47.6 | 22.0 |**50.0**| 20.1 | 22.0 | 31.1 |
|MBPP | **55.0** | 29.2 | 47.3 | 18.0 | 22.0 | 37.4 |
|GSM8K | 57.2 | 17.7 | 53.8 | 38.4 | 36.5 | **58.5** |
|MATH | 3.5 | 11.8 | 10.2 | 10.1 | 10.7 | **21.7** |
|BBH | **43.4** | 35.2 | 36.9 | 24.2 | 28.4 | 37.2 |
|HellaSwag | **73.1** | 71.4 | 68.3 | 61.4 | 49.3 | 66.6 |
|Winogrande | **74.4** | 66.8 | -| 60.3 | 56.8 | 66.2 |
|ARC-C | **61.1** | 48.5 | -| 37.9 | 31.5 | 43.9 |
|TruthfulQA | 44.5 | 33.1 | -| 39.4 | 39.7 | **45.9** |
|C-Eval | 23.4 | 28.0 | 51.1| 59.7 | 58.2 | **70.6** |
|CMMLU | 24.2 | - | 51.1 | 57.8 | 55.1 | **70.3** |
## Original Model Citation
If you find our work helpful, feel free to give us a cite.
```
@article{qwen2,
title={Qwen2 Technical Report},
year={2024}
}
```
|
digiplay/EtherRealMix_LUX2 | digiplay | 2024-05-03T15:14:07Z | 1,172 | 2 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2023-06-25T19:10:26Z | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info:
https://civitai.com/models/18207?modelVersionId=23634
Original Author's DEMO image :


 |
maddes8cht/OpenBuddy-openbuddy-falcon-40b-v9-bf16-gguf | maddes8cht | 2023-11-19T21:35:07Z | 1,172 | 3 | transformers | [
"transformers",
"gguf",
"text-generation",
"zh",
"en",
"fr",
"de",
"ja",
"ko",
"it",
"ru",
"license:apache-2.0",
"region:us"
]
| text-generation | 2023-10-04T11:34:36Z | ---
language:
- zh
- en
- fr
- de
- ja
- ko
- it
- ru
pipeline_tag: text-generation
inference: false
library_name: transformers
license: apache-2.0
---
[]()
I'm constantly enhancing these model descriptions to provide you with the most relevant and comprehensive information
# openbuddy-falcon-40b-v9-bf16 - GGUF
- Model creator: [OpenBuddy](https://huggingface.co/OpenBuddy)
- Original model: [openbuddy-falcon-40b-v9-bf16](https://huggingface.co/OpenBuddy/openbuddy-falcon-40b-v9-bf16)
# K-Quants in Falcon 7b models
New releases of Llama.cpp now support K-quantization for previously incompatible models, in particular all Falcon 7B models (While Falcon 40b is and always has been fully compatible with K-Quantisation). This is achieved by employing a fallback solution for model layers that cannot be quantized with real K-quants.
For Falcon 7B models, although only a quarter of the layers can be quantized with true K-quants, this approach still benefits from utilizing *different* legacy quantization types Q4_0, Q4_1, Q5_0, and Q5_1. As a result, it offers better quality at the same file size or smaller file sizes with comparable performance.
So this solution ensures improved performance and efficiency over legacy Q4_0, Q4_1, Q5_0 and Q5_1 Quantizations.
---
# Brief
OpenBuddy provides strong multiligual Model variants. On their Huggingface Organization Card they say:
> Our mission with OpenBuddy is to provide a free, open, and offline-capable AI model that operates on users' devices, irrespective of their language or cultural background. We strive to empower individuals worldwide to access and benefit from AI technology.
---
# About GGUF format
`gguf` is the current file format used by the [`ggml`](https://github.com/ggerganov/ggml) library.
A growing list of Software is using it and can therefore use this model.
The core project making use of the ggml library is the [llama.cpp](https://github.com/ggerganov/llama.cpp) project by Georgi Gerganov
# Quantization variants
There is a bunch of quantized files available to cater to your specific needs. Here's how to choose the best option for you:
# Legacy quants
Q4_0, Q4_1, Q5_0, Q5_1 and Q8 are `legacy` quantization types.
Nevertheless, they are fully supported, as there are several circumstances that cause certain model not to be compatible with the modern K-quants.
## Note:
Now there's a new option to use K-quants even for previously 'incompatible' models, although this involves some fallback solution that makes them not *real* K-quants. More details can be found in affected model descriptions.
(This mainly refers to Falcon 7b and Starcoder models)
# K-quants
K-quants are designed with the idea that different levels of quantization in specific parts of the model can optimize performance, file size, and memory load.
So, if possible, use K-quants.
With a Q6_K, you'll likely find it challenging to discern a quality difference from the original model - ask your model two times the same question and you may encounter bigger quality differences.
---
# Original Model Card:
# OpenBuddy - Open Multilingual Chatbot
GitHub and Usage Guide: [https://github.com/OpenBuddy/OpenBuddy](https://github.com/OpenBuddy/OpenBuddy)
Website and Demo: [https://openbuddy.ai](https://openbuddy.ai)

# Copyright Notice
License: Apache 2.0.
## Disclaimer
All OpenBuddy models have inherent limitations and may potentially produce outputs that are erroneous, harmful, offensive, or otherwise undesirable. Users should not use these models in critical or high-stakes situations that may lead to personal injury, property damage, or significant losses. Examples of such scenarios include, but are not limited to, the medical field, controlling software and hardware systems that may cause harm, and making important financial or legal decisions.
OpenBuddy is provided "as-is" without any warranty of any kind, either express or implied, including, but not limited to, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement. In no event shall the authors, contributors, or copyright holders be liable for any claim, damages, or other liabilities, whether in an action of contract, tort, or otherwise, arising from, out of, or in connection with the software or the use or other dealings in the software.
By using OpenBuddy, you agree to these terms and conditions, and acknowledge that you understand the potential risks associated with its use. You also agree to indemnify and hold harmless the authors, contributors, and copyright holders from any claims, damages, or liabilities arising from your use of OpenBuddy.
## 免责声明
所有OpenBuddy模型均存在固有的局限性,可能产生错误的、有害的、冒犯性的或其他不良的输出。用户在关键或高风险场景中应谨慎行事,不要使用这些模型,以免导致人身伤害、财产损失或重大损失。此类场景的例子包括但不限于医疗领域、可能导致伤害的软硬件系统的控制以及进行重要的财务或法律决策。
OpenBuddy按“原样”提供,不附带任何种类的明示或暗示的保证,包括但不限于适销性、特定目的的适用性和非侵权的暗示保证。在任何情况下,作者、贡献者或版权所有者均不对因软件或使用或其他软件交易而产生的任何索赔、损害赔偿或其他责任(无论是合同、侵权还是其他原因)承担责任。
使用OpenBuddy即表示您同意这些条款和条件,并承认您了解其使用可能带来的潜在风险。您还同意赔偿并使作者、贡献者和版权所有者免受因您使用OpenBuddy而产生的任何索赔、损害赔偿或责任的影响。
***End of original Model File***
---
## Please consider to support my work
**Coming Soon:** I'm in the process of launching a sponsorship/crowdfunding campaign for my work. I'm evaluating Kickstarter, Patreon, or the new GitHub Sponsors platform, and I am hoping for some support and contribution to the continued availability of these kind of models. Your support will enable me to provide even more valuable resources and maintain the models you rely on. Your patience and ongoing support are greatly appreciated as I work to make this page an even more valuable resource for the community.
<center>
[](https://maddes8cht.github.io)
[](https://stackexchange.com/users/26485911)
[](https://github.com/maddes8cht)
[](https://huggingface.co/maddes8cht)
[](https://twitter.com/maddes1966)
</center> |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.