
modelId
stringlengths 5
122
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC] | downloads
int64 0
738M
| likes
int64 0
11k
| library_name
stringclasses 245
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 48
values | createdAt
timestamp[us, tz=UTC] | card
stringlengths 1
901k
|
|---|---|---|---|---|---|---|---|---|---|
RichardErkhov/AgentPublic_-_albertlight-7b-gguf | RichardErkhov | 2024-05-31T04:26:48Z | 617 | 0 | null | [
"gguf",
"region:us"
] | null | 2024-05-30T20:28:43Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
albertlight-7b - GGUF
- Model creator: https://huggingface.co/AgentPublic/
- Original model: https://huggingface.co/AgentPublic/albertlight-7b/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [albertlight-7b.Q2_K.gguf](https://huggingface.co/RichardErkhov/AgentPublic_-_albertlight-7b-gguf/blob/main/albertlight-7b.Q2_K.gguf) | Q2_K | 4.52GB |
| [albertlight-7b.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/AgentPublic_-_albertlight-7b-gguf/blob/main/albertlight-7b.IQ3_XS.gguf) | IQ3_XS | 4.99GB |
| [albertlight-7b.IQ3_S.gguf](https://huggingface.co/RichardErkhov/AgentPublic_-_albertlight-7b-gguf/blob/main/albertlight-7b.IQ3_S.gguf) | IQ3_S | 5.27GB |
| [albertlight-7b.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/AgentPublic_-_albertlight-7b-gguf/blob/main/albertlight-7b.Q3_K_S.gguf) | Q3_K_S | 5.27GB |
| [albertlight-7b.IQ3_M.gguf](https://huggingface.co/RichardErkhov/AgentPublic_-_albertlight-7b-gguf/blob/main/albertlight-7b.IQ3_M.gguf) | IQ3_M | 5.57GB |
| [albertlight-7b.Q3_K.gguf](https://huggingface.co/RichardErkhov/AgentPublic_-_albertlight-7b-gguf/blob/main/albertlight-7b.Q3_K.gguf) | Q3_K | 5.9GB |
| [albertlight-7b.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/AgentPublic_-_albertlight-7b-gguf/blob/main/albertlight-7b.Q3_K_M.gguf) | Q3_K_M | 5.9GB |
| [albertlight-7b.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/AgentPublic_-_albertlight-7b-gguf/blob/main/albertlight-7b.Q3_K_L.gguf) | Q3_K_L | 6.45GB |
| [albertlight-7b.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/AgentPublic_-_albertlight-7b-gguf/blob/main/albertlight-7b.IQ4_XS.gguf) | IQ4_XS | 6.54GB |
| [albertlight-7b.Q4_0.gguf](https://huggingface.co/RichardErkhov/AgentPublic_-_albertlight-7b-gguf/blob/main/albertlight-7b.Q4_0.gguf) | Q4_0 | 6.86GB |
| [albertlight-7b.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/AgentPublic_-_albertlight-7b-gguf/blob/main/albertlight-7b.IQ4_NL.gguf) | IQ4_NL | 6.9GB |
| [albertlight-7b.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/AgentPublic_-_albertlight-7b-gguf/blob/main/albertlight-7b.Q4_K_S.gguf) | Q4_K_S | 6.91GB |
| [albertlight-7b.Q4_K.gguf](https://huggingface.co/RichardErkhov/AgentPublic_-_albertlight-7b-gguf/blob/main/albertlight-7b.Q4_K.gguf) | Q4_K | 7.33GB |
| [albertlight-7b.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/AgentPublic_-_albertlight-7b-gguf/blob/main/albertlight-7b.Q4_K_M.gguf) | Q4_K_M | 7.33GB |
| [albertlight-7b.Q4_1.gguf](https://huggingface.co/RichardErkhov/AgentPublic_-_albertlight-7b-gguf/blob/main/albertlight-7b.Q4_1.gguf) | Q4_1 | 7.61GB |
| [albertlight-7b.Q5_0.gguf](https://huggingface.co/RichardErkhov/AgentPublic_-_albertlight-7b-gguf/blob/main/albertlight-7b.Q5_0.gguf) | Q5_0 | 8.36GB |
| [albertlight-7b.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/AgentPublic_-_albertlight-7b-gguf/blob/main/albertlight-7b.Q5_K_S.gguf) | Q5_K_S | 8.36GB |
| [albertlight-7b.Q5_K.gguf](https://huggingface.co/RichardErkhov/AgentPublic_-_albertlight-7b-gguf/blob/main/albertlight-7b.Q5_K.gguf) | Q5_K | 8.6GB |
| [albertlight-7b.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/AgentPublic_-_albertlight-7b-gguf/blob/main/albertlight-7b.Q5_K_M.gguf) | Q5_K_M | 8.6GB |
| [albertlight-7b.Q5_1.gguf](https://huggingface.co/RichardErkhov/AgentPublic_-_albertlight-7b-gguf/blob/main/albertlight-7b.Q5_1.gguf) | Q5_1 | 9.1GB |
| [albertlight-7b.Q6_K.gguf](https://huggingface.co/RichardErkhov/AgentPublic_-_albertlight-7b-gguf/blob/main/albertlight-7b.Q6_K.gguf) | Q6_K | 9.95GB |
| [albertlight-7b.Q8_0.gguf](https://huggingface.co/RichardErkhov/AgentPublic_-_albertlight-7b-gguf/blob/main/albertlight-7b.Q8_0.gguf) | Q8_0 | 12.88GB |
Original model description:
---
license: apache-2.0
pipeline_tag: text-generation
language:
- fr
---
|
mradermacher/Elysium-Omni-11b-GGUF | mradermacher | 2024-06-12T11:36:26Z | 617 | 0 | transformers | [
"transformers",
"gguf",
"merge",
"mergekit",
"lazymergekit",
"powermove72/Elysium-Omni-Itt-11b",
"powermove72/SoMix2-xb",
"en",
"base_model:powermove72/Elysium-Omni-11b",
"endpoints_compatible",
"region:us"
] | null | 2024-06-12T10:56:40Z | ---
base_model: powermove72/Elysium-Omni-11b
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- merge
- mergekit
- lazymergekit
- powermove72/Elysium-Omni-Itt-11b
- powermove72/SoMix2-xb
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/powermove72/Elysium-Omni-11b
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Elysium-Omni-11b-GGUF/resolve/main/Elysium-Omni-11b.Q2_K.gguf) | Q2_K | 4.3 | |
| [GGUF](https://huggingface.co/mradermacher/Elysium-Omni-11b-GGUF/resolve/main/Elysium-Omni-11b.IQ3_XS.gguf) | IQ3_XS | 4.7 | |
| [GGUF](https://huggingface.co/mradermacher/Elysium-Omni-11b-GGUF/resolve/main/Elysium-Omni-11b.Q3_K_S.gguf) | Q3_K_S | 5.0 | |
| [GGUF](https://huggingface.co/mradermacher/Elysium-Omni-11b-GGUF/resolve/main/Elysium-Omni-11b.IQ3_S.gguf) | IQ3_S | 5.0 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Elysium-Omni-11b-GGUF/resolve/main/Elysium-Omni-11b.IQ3_M.gguf) | IQ3_M | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/Elysium-Omni-11b-GGUF/resolve/main/Elysium-Omni-11b.Q3_K_M.gguf) | Q3_K_M | 5.5 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Elysium-Omni-11b-GGUF/resolve/main/Elysium-Omni-11b.Q3_K_L.gguf) | Q3_K_L | 6.0 | |
| [GGUF](https://huggingface.co/mradermacher/Elysium-Omni-11b-GGUF/resolve/main/Elysium-Omni-11b.IQ4_XS.gguf) | IQ4_XS | 6.2 | |
| [GGUF](https://huggingface.co/mradermacher/Elysium-Omni-11b-GGUF/resolve/main/Elysium-Omni-11b.Q4_K_S.gguf) | Q4_K_S | 6.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Elysium-Omni-11b-GGUF/resolve/main/Elysium-Omni-11b.Q4_K_M.gguf) | Q4_K_M | 6.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Elysium-Omni-11b-GGUF/resolve/main/Elysium-Omni-11b.Q5_K_S.gguf) | Q5_K_S | 7.8 | |
| [GGUF](https://huggingface.co/mradermacher/Elysium-Omni-11b-GGUF/resolve/main/Elysium-Omni-11b.Q5_K_M.gguf) | Q5_K_M | 8.0 | |
| [GGUF](https://huggingface.co/mradermacher/Elysium-Omni-11b-GGUF/resolve/main/Elysium-Omni-11b.Q6_K.gguf) | Q6_K | 9.3 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Elysium-Omni-11b-GGUF/resolve/main/Elysium-Omni-11b.Q8_0.gguf) | Q8_0 | 12.0 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
allegro/herbert-large-cased | allegro | 2022-06-26T14:18:54Z | 616 | 6 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"feature-extraction",
"herbert",
"pl",
"license:cc-by-4.0",
"endpoints_compatible",
"text-embeddings-inference",
"region:us"
] | feature-extraction | 2022-03-02T23:29:05Z | ---
language: pl
tags:
- herbert
license: cc-by-4.0
---
# HerBERT
**[HerBERT](https://en.wikipedia.org/wiki/Zbigniew_Herbert)** is a BERT-based Language Model trained on Polish corpora
using Masked Language Modelling (MLM) and Sentence Structural Objective (SSO) with dynamic masking of whole words. For more details, please refer to: [HerBERT: Efficiently Pretrained Transformer-based Language Model for Polish](https://www.aclweb.org/anthology/2021.bsnlp-1.1/).
Model training and experiments were conducted with [transformers](https://github.com/huggingface/transformers) in version 2.9.
## Corpus
HerBERT was trained on six different corpora available for Polish language:
| Corpus | Tokens | Documents |
| :------ | ------: | ------: |
| [CCNet Middle](https://github.com/facebookresearch/cc_net) | 3243M | 7.9M |
| [CCNet Head](https://github.com/facebookresearch/cc_net) | 2641M | 7.0M |
| [National Corpus of Polish](http://nkjp.pl/index.php?page=14&lang=1)| 1357M | 3.9M |
| [Open Subtitles](http://opus.nlpl.eu/OpenSubtitles-v2018.php) | 1056M | 1.1M
| [Wikipedia](https://dumps.wikimedia.org/) | 260M | 1.4M |
| [Wolne Lektury](https://wolnelektury.pl/) | 41M | 5.5k |
## Tokenizer
The training dataset was tokenized into subwords using a character level byte-pair encoding (``CharBPETokenizer``) with
a vocabulary size of 50k tokens. The tokenizer itself was trained with a [tokenizers](https://github.com/huggingface/tokenizers) library.
We kindly encourage you to use the ``Fast`` version of the tokenizer, namely ``HerbertTokenizerFast``.
## Usage
Example code:
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("allegro/herbert-large-cased")
model = AutoModel.from_pretrained("allegro/herbert-large-cased")
output = model(
**tokenizer.batch_encode_plus(
[
(
"A potem szedł środkiem drogi w kurzawie, bo zamiatał nogami, ślepy dziad prowadzony przez tłustego kundla na sznurku.",
"A potem leciał od lasu chłopak z butelką, ale ten ujrzawszy księdza przy drodze okrążył go z dala i biegł na przełaj pól do karczmy."
)
],
padding='longest',
add_special_tokens=True,
return_tensors='pt'
)
)
```
## License
CC BY 4.0
## Citation
If you use this model, please cite the following paper:
```
@inproceedings{mroczkowski-etal-2021-herbert,
title = "{H}er{BERT}: Efficiently Pretrained Transformer-based Language Model for {P}olish",
author = "Mroczkowski, Robert and
Rybak, Piotr and
Wr{\'o}blewska, Alina and
Gawlik, Ireneusz",
booktitle = "Proceedings of the 8th Workshop on Balto-Slavic Natural Language Processing",
month = apr,
year = "2021",
address = "Kiyv, Ukraine",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2021.bsnlp-1.1",
pages = "1--10",
}
```
## Authors
The model was trained by [**Machine Learning Research Team at Allegro**](https://ml.allegro.tech/) and [**Linguistic Engineering Group at Institute of Computer Science, Polish Academy of Sciences**](http://zil.ipipan.waw.pl/).
You can contact us at: <a href="mailto:[email protected]">[email protected]</a> |
laituan245/molt5-large-caption2smiles | laituan245 | 2022-05-03T18:08:19Z | 616 | 1 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"arxiv:2204.11817",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | 2022-05-03T15:58:10Z | ---
license: apache-2.0
---
This model can be used to generate a SMILES string from an input caption.
## Example Usage
```python
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("laituan245/molt5-large-caption2smiles", model_max_length=512)
model = T5ForConditionalGeneration.from_pretrained('laituan245/molt5-large-caption2smiles')
input_text = 'The molecule is a monomethoxybenzene that is 2-methoxyphenol substituted by a hydroxymethyl group at position 4. It has a role as a plant metabolite. It is a member of guaiacols and a member of benzyl alcohols.'
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = model.generate(input_ids, num_beams=5, max_length=512)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Paper
For more information, please take a look at our paper.
Paper: [Translation between Molecules and Natural Language](https://arxiv.org/abs/2204.11817)
Authors: *Carl Edwards\*, Tuan Lai\*, Kevin Ros, Garrett Honke, Heng Ji*
|
abdulmatinomotoso/English_Grammar_Checker | abdulmatinomotoso | 2022-08-23T07:13:02Z | 616 | 3 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-08-23T03:43:38Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: English_Grammar_Checker
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
config: cola
split: train
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.5324115893962171
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# English_Grammar_Checker
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1117
- Matthews Correlation: 0.5324
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.527 | 1.0 | 1069 | 0.6183 | 0.3947 |
| 0.387 | 2.0 | 2138 | 0.5165 | 0.5156 |
| 0.2772 | 3.0 | 3207 | 0.6716 | 0.5211 |
| 0.176 | 4.0 | 4276 | 0.9270 | 0.5123 |
| 0.0975 | 5.0 | 5345 | 1.1117 | 0.5324 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
timm/efficientformer_l7.snap_dist_in1k | timm | 2024-02-10T23:30:27Z | 616 | 1 | timm | [
"timm",
"pytorch",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2206.01191",
"license:apache-2.0",
"region:us"
] | image-classification | 2023-02-03T21:06:31Z | ---
license: apache-2.0
library_name: timm
tags:
- image-classification
- timm
datasets:
- imagenet-1k
---
# Model card for efficientformer_l7.snap_dist_in1k
A EfficientFormer image classification model. Pretrained with distillation on ImageNet-1k.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 82.2
- GMACs: 10.2
- Activations (M): 24.5
- Image size: 224 x 224
- **Original:** https://github.com/snap-research/EfficientFormer
- **Papers:**
- EfficientFormer: Vision Transformers at MobileNet Speed: https://arxiv.org/abs/2206.01191
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model('efficientformer_l7.snap_dist_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model(
'efficientformer_l7.snap_dist_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled (ie.e a (batch_size, num_features, H, W) tensor
output = model.forward_head(output, pre_logits=True)
# output is (batch_size, num_features) tensor
```
## Model Comparison
|model |top1 |top5 |param_count|img_size|
|-----------------------------------|------|------|-----------|--------|
|efficientformerv2_l.snap_dist_in1k |83.628|96.54 |26.32 |224 |
|efficientformer_l7.snap_dist_in1k |83.368|96.534|82.23 |224 |
|efficientformer_l3.snap_dist_in1k |82.572|96.24 |31.41 |224 |
|efficientformerv2_s2.snap_dist_in1k|82.128|95.902|12.71 |224 |
|efficientformer_l1.snap_dist_in1k |80.496|94.984|12.29 |224 |
|efficientformerv2_s1.snap_dist_in1k|79.698|94.698|6.19 |224 |
|efficientformerv2_s0.snap_dist_in1k|76.026|92.77 |3.6 |224 |
## Citation
```bibtex
@article{li2022efficientformer,
title={EfficientFormer: Vision Transformers at MobileNet Speed},
author={Li, Yanyu and Yuan, Geng and Wen, Yang and Hu, Ju and Evangelidis, Georgios and Tulyakov, Sergey and Wang, Yanzhi and Ren, Jian},
journal={arXiv preprint arXiv:2206.01191},
year={2022}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/rwightman/pytorch-image-models}}
}
```
|
Nithu/text-to-speech | Nithu | 2023-10-20T09:52:33Z | 616 | 6 | fairseq | [
"fairseq",
"audio",
"text-to-speech",
"en",
"dataset:ljspeech",
"arxiv:2006.04558",
"arxiv:2109.06912",
"region:us"
] | text-to-speech | 2023-10-20T08:18:55Z | ---
library_name: fairseq
task: text-to-speech
tags:
- fairseq
- audio
- text-to-speech
language: en
datasets:
- ljspeech
widget:
- text: "Hello, this is a test run."
example_title: "Hello, this is a test run."
---
# fastspeech2-en-ljspeech
[FastSpeech 2](https://arxiv.org/abs/2006.04558) text-to-speech model from fairseq S^2 ([paper](https://arxiv.org/abs/2109.06912)/[code](https://github.com/pytorch/fairseq/tree/main/examples/speech_synthesis)):
- English
- Single-speaker female voice
- Trained on [LJSpeech](https://keithito.com/LJ-Speech-Dataset/)
## Usage
```python
from fairseq.checkpoint_utils import load_model_ensemble_and_task_from_hf_hub
from fairseq.models.text_to_speech.hub_interface import TTSHubInterface
import IPython.display as ipd
models, cfg, task = load_model_ensemble_and_task_from_hf_hub(
"facebook/fastspeech2-en-ljspeech",
arg_overrides={"vocoder": "hifigan", "fp16": False}
)
model = models[0]
TTSHubInterface.update_cfg_with_data_cfg(cfg, task.data_cfg)
generator = task.build_generator(model, cfg)
text = "Hello, this is a test run."
sample = TTSHubInterface.get_model_input(task, text)
wav, rate = TTSHubInterface.get_prediction(task, model, generator, sample)
ipd.Audio(wav, rate=rate)
```
See also [fairseq S^2 example](https://github.com/pytorch/fairseq/blob/main/examples/speech_synthesis/docs/ljspeech_example.md).
## Citation
```bibtex
@inproceedings{wang-etal-2021-fairseq,
title = "fairseq S{\^{}}2: A Scalable and Integrable Speech Synthesis Toolkit",
author = "Wang, Changhan and
Hsu, Wei-Ning and
Adi, Yossi and
Polyak, Adam and
Lee, Ann and
Chen, Peng-Jen and
Gu, Jiatao and
Pino, Juan",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-demo.17",
doi = "10.18653/v1/2021.emnlp-demo.17",
pages = "143--152",
}
```
|
Linaqruf/pastel-style-xl-lora | Linaqruf | 2023-11-24T12:54:33Z | 616 | 8 | diffusers | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"safetensors",
"stable-diffusion-xl",
"en",
"base_model:Linaqruf/animagine-xl-2.0",
"license:openrail++",
"region:us"
] | text-to-image | 2023-11-23T03:49:17Z | ---
library_name: diffusers
license: openrail++
language:
- en
tags:
- text-to-image
- stable-diffusion
- lora
- safetensors
- stable-diffusion-xl
base_model: Linaqruf/animagine-xl-2.0
widget:
- text: face focus, cute, masterpiece, best quality, 1girl, green hair, sweater, looking at viewer, upper body, beanie, outdoors, night, turtleneck
parameter:
negative_prompt: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
example_title: 1girl
- text: face focus, bishounen, masterpiece, best quality, 1boy, green hair, sweater, looking at viewer, upper body, beanie, outdoors, night, turtleneck
parameter:
negative_prompt: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
example_title: 1boy
---
<style>
.title-container {
display: flex;
flex-direction: column; /* Allow vertical stacking of title and subtitle */
justify-content: center;
align-items: center;
height: 100vh;
background-color: #f5f5f5;
}
.title {
font-size: 2em;
text-align: center;
color: #333;
font-family: 'Verdana', sans-serif;
text-transform: uppercase;
padding: 1em;
box-shadow: 0px 0px 0px rgba(0,0,0,0.1);
}
.title span {
background: -webkit-linear-gradient(45deg, #ff9a9e, #fad0c4, #f6d365);
-webkit-background-clip: text;
-webkit-text-fill-color: transparent;
}
.custom-table {
table-layout: fixed;
width: 100%;
border-collapse: collapse;
margin-top: 2em;
}
.custom-table td {
width: 50%;
vertical-align: top;
padding: 10px;
box-shadow: 0px 0px 0px 0px rgba(0, 0, 0, 0.15);
}
.custom-image-container {
position: relative;
width: 100%;
margin-bottom: 0em;
overflow: hidden;
border-radius: 10px;
transition: transform .7s;
/* Smooth transition for the container */
}
.custom-image-container:hover {
transform: scale(1.05);
/* Scale the container on hover */
}
.custom-image {
width: 100%;
height: auto;
object-fit: cover;
border-radius: 10px;
transition: transform .7s;
margin-bottom: 0em;
}
.nsfw-filter {
filter: blur(8px); /* Apply a blur effect */
transition: filter 0.3s ease; /* Smooth transition for the blur effect */
}
.custom-image-container:hover .nsfw-filter {
filter: none; /* Remove the blur effect on hover */
}
</style>
<h1 class="title">
<span>Pastel Style XL LoRA</span>
</h1>
<table class="custom-table">
<tr>
<td>
<div class="custom-image-container">
<img class="custom-image" src="https://cdn-uploads.huggingface.co/production/uploads/6365c8dbf31ef76df4042821/Q1olwlimSCLG061XX6mRV.png" alt="sample1">
</div>
<div class="custom-image-container">
<img class="custom-image" src="https://cdn-uploads.huggingface.co/production/uploads/6365c8dbf31ef76df4042821/c29eOaqc_7BXFRKBfGn4J.png" alt="sample4">
</div>
</td>
<td>
<div class="custom-image-container">
<img class="custom-image" src="https://cdn-uploads.huggingface.co/production/uploads/6365c8dbf31ef76df4042821/OyiZlzjXwZ_k58QfDgcB0.png" alt="sample2">
</div>
<div class="custom-image-container">
<img class="custom-image" src="https://cdn-uploads.huggingface.co/production/uploads/6365c8dbf31ef76df4042821/oI1huB1ug5jMCjqqHoQVz.png" alt="sample3">
</td>
</tr>
</table>
<hr>
## Overview
**Pastel Style XL LoRA** is a specialized LoRA (Low-Rank Adaptation) adapter, expertly designed to work in conjunction with Animagine XL 2.0. This model specifically focuses on enhancing and imparting a pastel-style aesthetic to anime-themed images. It integrates smoothly with the Stable Diffusion framework, offering a unique capability to produce images with soft, pastel-like qualities without the need for specific keywords or tags.
<hr>
## Model Details
- **Developed by:** [Linaqruf](https://github.com/Linaqruf)
- **Model type:** LoRA adapter for Stable Diffusion XL
- **Model Description:** Pastel Style XL LoRA is a compact yet potent model aimed at augmenting the output of larger models, particularly Animagine XL 2.0. It's adept at generating and modifying high-quality anime-themed images, giving them a distinctive pastel aesthetic. This model is an excellent choice for those seeking to add a gentle, pastel touch to their anime creations.
- **License:** [CreativeML Open RAIL++-M License](https://huggingface.co/stabilityai/stable-diffusion-2/blob/main/LICENSE-MODEL)
- **Finetuned from model:** [Animagine XL 2.0](https://huggingface.co/Linaqruf/animagine-xl-2.0)
<hr>
## 🧨 Diffusers Installation
Ensure the installation of the latest `diffusers` library, along with other essential packages:
```bash
pip install diffusers --upgrade
pip install transformers accelerate safetensors
```
The following Python script demonstrates how to utilize the LoRA with Animagine XL 2.0. The default scheduler is EulerAncestralDiscreteScheduler, but it can be explicitly defined for clarity.
```py
import torch
from diffusers import (
StableDiffusionXLPipeline,
EulerAncestralDiscreteScheduler,
AutoencoderKL
)
# Initialize LoRA model and weights
lora_model_id = "Linaqruf/pastel-style-xl-lora"
lora_filename = "pastel-style-xl-v2.safetensors"
# Load VAE component
vae = AutoencoderKL.from_pretrained(
"madebyollin/sdxl-vae-fp16-fix",
torch_dtype=torch.float16
)
# Configure the pipeline
pipe = StableDiffusionXLPipeline.from_pretrained(
"Linaqruf/animagine-xl-2.0",
vae=vae,
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16"
)
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
pipe.to('cuda')
# Load and fuse LoRA weights
pipe.load_lora_weights(lora_model_id, weight_name=lora_filename)
pipe.fuse_lora(lora_scale=0.6)
# Define prompts and generate image
prompt = "face focus, cute, masterpiece, best quality, 1girl, green hair, sweater, looking at viewer, upper body, beanie, outdoors, night, turtleneck"
negative_prompt = "lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry"
image = pipe(
prompt,
negative_prompt=negative_prompt,
width=1024,
height=1024,
guidance_scale=12,
num_inference_steps=50
).images[0]
# Unfuse LoRA before saving the image
pipe.unfuse_lora()
image.save("anime_girl.png")
```
|
Crataco/TinyDolphin-2.8-1.1b-imatrix-GGUF | Crataco | 2024-03-06T17:48:51Z | 616 | 6 | null | [
"gguf",
"en",
"dataset:cerebras/SlimPajama-627B",
"dataset:bigcode/starcoderdata",
"dataset:teknium/openhermes",
"license:apache-2.0",
"region:us"
] | null | 2024-03-06T05:03:16Z | ---
license: apache-2.0
datasets:
- cerebras/SlimPajama-627B
- bigcode/starcoderdata
- teknium/openhermes
language:
- en
---
TinyDolphin-2.8-1.1b, available in as many GGUF quantization levels as possible as of March 5th, 2024. [Kalomaze's "groups_merged.txt"](https://github.com/ggerganov/llama.cpp/discussions/5263#discussioncomment-8395384) was used for the importance matrix, with context set to 2,048.
For a non-imatrix version, see [tsunemoto/TinyDolphin-2.8-1.1b-GGUF](https://huggingface.co/tsunemoto/TinyDolphin-2.8-1.1b-GGUF).
Original model card below.
***
# TinyDolphin-2.8-1.1b

Join Our Discord! https://discord.gg/cognitivecomputations
This is an experimental model trained on 2 3090's by Kearm on the new Dolphin 2.8 dataset by Eric Hartford https://erichartford.com/dolphin 🐬
## Example Outputs
Invent a sinister prank involving teleportation that leaves the victim utterly confused.
```
As you requested, here's how I would go about creating this sinister prank:
First, we need to find a location where teleportation is possible. This could be anywhere in the world, but let's choose a place with a lot of people around. For example, a crowded street or a busy park.
Next, we need to gather some materials such as a flashlight, a bag of salt, and a small bottle of water. These items are essential for making the prank work.
Now, we need to carefully position ourselves near the chosen location. We want to be close enough so that if someone tries to teleport away from us, they won't get lost.
When the person attempts to teleport, we will pretend to be standing right next to them. This will make it look like they were teleported without our knowing.
With the flashlight, we will light up the area around us. The brightness of the light should cause the person to lose their sense of direction and become disorientated.
Finally, we will say something silly or nonsensical while holding the bag of salt. This will make it seem like we are trying to distract them by throwing it at them.
When the person finally loses their way, we will disappear into thin air. They will think we left them behind, and they will be completely confused.
```
Draft a sarcastic letter from a disgruntled employee to their boss, filled with subtle jabs and veiled threats.
```
Dear [Boss],
I hope this message finds you in good health and high spirits. I am writing to express my deepest dissatisfaction at working under your management. My job has become monotonous and tedious, and I have lost all motivation to continue. The company's lack of accountability and transparency has made it difficult for me to feel valued or respected. In fact, I often find myself questioning whether I should stay on board or look for another opportunity where I can make a difference.
The environment here is hostile and unfriendly, making it challenging to maintain a sense of belonging among employees. I would love to be treated as an individual with unique talents and skills rather than just another cog in the machine. I believe there are more capable individuals within our ranks who deserve recognition and support.
In addition to my frustrations, I also have concerns about the future direction of the company. It seems like we are moving towards automation and outsourcing instead of investing in innovative solutions that will benefit both customers and employees alike. This approach does not align well with my personal values and beliefs.
As someone who values fairness and equality, I urge you to reconsider your decision-making process and explore alternative options that better suit my needs and those of other employees. I understand that change is necessary but it must be done carefully and thoughtfully. Please consider my concerns before making any decisions that may affect my job security and professional growth.
Thank you for your time and consideration. I look forward to discussing these matters further when we meet next.
Sincerely,
[Your Name]
```
Construct a poem describing the rise and rule of succesful malevolent king who ruled through fear and manipulation.
```
In his reign, he ruled with ease, his every move dictated by fear. His name was not known for its wisdom but rather for his ability to control others. He had a dark heart, consumed by malice and power.
His reign brought misery and suffering, as those around him were subjected to his cruelty. His oppression was unmatched, as he held people in check without mercy. Yet, despite all this, he remained invincible, his rule never faltering.
His reign was one of terror, as he wielded his power with absolute authority. His subjects lived in fear, knowing they could be executed at any moment. Yet, they submitted, oblivious to their plight. They did so out of loyalty to their king, or perhaps because they believed it would bring them some measure of comfort.
Their lives were miserable under his tyranny, yet they endured, as they knew they were better off than being free. The king's reign of terror lasted for centuries, leaving behind a legacy of sorrow and despair.
```
Support my efforts! ko-fi.com/kearm
# Orignal Model Card Below
# TinyLlama-1.1B
</div>
https://github.com/jzhang38/TinyLlama
The TinyLlama project aims to **pretrain** a **1.1B Llama model on 3 trillion tokens**. With some proper optimization, we can achieve this within a span of "just" 90 days using 16 A100-40G GPUs 🚀🚀. The training has started on 2023-09-01.
We adopted exactly the same architecture and tokenizer as Llama 2. This means TinyLlama can be plugged and played in many open-source projects built upon Llama. Besides, TinyLlama is compact with only 1.1B parameters. This compactness allows it to cater to a multitude of applications demanding a restricted computation and memory footprint.
#### This Collection
This collection contains all checkpoints after the 1T fix. Branch name indicates the step and number of tokens seen.
#### Eval
| Model | Pretrain Tokens | HellaSwag | Obqa | WinoGrande | ARC_c | ARC_e | boolq | piqa | avg |
|-------------------------------------------|-----------------|-----------|------|------------|-------|-------|-------|------|-----|
| Pythia-1.0B | 300B | 47.16 | 31.40| 53.43 | 27.05 | 48.99 | 60.83 | 69.21 | 48.30 |
| TinyLlama-1.1B-intermediate-step-50K-104b | 103B | 43.50 | 29.80| 53.28 | 24.32 | 44.91 | 59.66 | 67.30 | 46.11|
| TinyLlama-1.1B-intermediate-step-240k-503b| 503B | 49.56 |31.40 |55.80 |26.54 |48.32 |56.91 |69.42 | 48.28 |
| TinyLlama-1.1B-intermediate-step-480k-1007B | 1007B | 52.54 | 33.40 | 55.96 | 27.82 | 52.36 | 59.54 | 69.91 | 50.22 |
| TinyLlama-1.1B-intermediate-step-715k-1.5T | 1.5T | 53.68 | 35.20 | 58.33 | 29.18 | 51.89 | 59.08 | 71.65 | 51.29 |
| TinyLlama-1.1B-intermediate-step-955k-2T | 2T | 54.63 | 33.40 | 56.83 | 28.07 | 54.67 | 63.21 | 70.67 | 51.64 |
| TinyLlama-1.1B-intermediate-step-1195k-2.5T | 2.5T | 58.96 | 34.40 | 58.72 | 31.91 | 56.78 | 63.21 | 73.07 | 53.86|
| TinyLlama-1.1B-intermediate-step-1431k-3T | 3T | 59.20 | 36.00 | 59.12 | 30.12 | 55.25 | 57.83 | 73.29 | 52.99| |
chano12/llama_with_tag | chano12 | 2024-06-02T05:11:35Z | 616 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:meta-llama/Llama-2-7b-chat-hf",
"region:us"
] | null | 2024-06-02T05:11:12Z | ---
library_name: peft
base_model: meta-llama/Llama-2-7b-chat-hf
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.1 |
royweiss1/T5_MiddleSentences | royweiss1 | 2024-06-18T10:16:43Z | 616 | 0 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"dataset:royweiss1/GPT_Keylogger_Dataset",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | 2024-06-05T15:57:23Z | ---
datasets:
- royweiss1/GPT_Keylogger_Dataset
language:
- en
license: mit
---
This is the model used in the USENIX Security 24' paper: "What Was Your Prompt? A Remote Keylogging Attack on AI Assistants".
It is a fine-tune of T5-Large that was trained to decipher ChatGPT's encrypted answers based only on the response's token lengths.
This model is the middle-sentences model. Meaning it was trained to decipher all of sentences which are not the first sentences of response, using the priviouse sentence as context to predict the current.
It was Trained on UltraChat Dataset - Questions About the world, and only the first answer of each dialog.
## Citation ##
If you find this model helpful please cite our paper:
```
@inproceedings{weissLLMSideChannel,
title={What Was Your Prompt? A Remote Keylogging Attack on AI Assistants},
author={Weiss, Roy and Ayzenshteyn, Daniel and Amit Guy and Mirsky, Yisroel}
booktitle={USENIX Security},
year={2024}
}
``` |
BAAI/AltCLIP-m9 | BAAI | 2022-12-31T06:15:20Z | 615 | 8 | transformers | [
"transformers",
"pytorch",
"altclip",
"zero-shot-image-classification",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"zh",
"Chinese",
"multilingual",
"English(En)",
"Chinese(Zh)",
"Spanish(Es)",
"French(Fr)",
"Russian(Ru)",
"Japanese(Ja)",
"Korean(Ko)",
"Arabic(Ar)",
"Italian(It)",
"arxiv:2211.06679",
"license:creativeml-openrail-m",
"region:us"
] | text-to-image | 2022-11-18T10:46:08Z | ---
language: zh
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- zh
- Chinese
- multilingual
- English(En)
- Chinese(Zh)
- Spanish(Es)
- French(Fr)
- Russian(Ru)
- Japanese(Ja)
- Korean(Ko)
- Arabic(Ar)
- Italian(It)
inference: false
extra_gated_prompt: |-
One more step before getting this model.
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. BAAI claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
Please read the full license here: https://huggingface.co/spaces/CompVis/stable-diffusion-license
By clicking on "Access repository" below, you accept that your *contact information* (email address and username) can be shared with the model authors as well.
extra_gated_fields:
I have read the License and agree with its terms: checkbox
---
# AltCLIP-m9
It supports English(En), Chinese(Zh), Spanish(Es), French(Fr), Russian(Ru), Japanese(Ja), Korean(Ko), Arabic(Ar) and Italian(It) languages.
| 名称 Name | 任务 Task | 语言 Language(s) | 模型 Model | Github |
|:------------------:|:----------:|:-------------------:|:--------:|:------:|
| AltCLIP-m9 | Text-Image | Multilingual | CLIP | [FlagAI](https://github.com/FlagAI-Open/FlagAI) |
## 简介 Brief Introduction
我们提出了一个简单高效的方法去训练更加优秀的九语CLIP模型。命名为AltCLIP-m9。AltCLIP训练数据来自 [WuDao数据集](https://data.baai.ac.cn/details/WuDaoCorporaText) 和 [LIAON](https://huggingface.co/datasets/ChristophSchuhmann/improved_aesthetics_6plus)
AltCLIP-m9模型可以为本项目中的AltDiffusion-m9模型提供支持,关于AltDiffusion-m9模型的具体信息可查看[此教程](https://github.com/FlagAI-Open/FlagAI/tree/master/examples/AltDiffusion/README.md) 。
模型代码已经在 [FlagAI](https://github.com/FlagAI-Open/FlagAI/tree/master/examples/AltCLIP) 上开源,权重位于我们搭建的 [modelhub](https://model.baai.ac.cn/model-detail/100077) 上。我们还提供了微调,推理,验证的脚本,欢迎试用。
We propose a simple and efficient method to train a better multilingua CLIP model. Named AltCLIP-m9. AltCLIP-m9 is trained with training data from [WuDao dataset](https://data.baai.ac.cn/details/WuDaoCorporaText) and [Liaon](https://huggingface.co/datasets/laion/laion2B-en).
The AltCLIP-m9 model can provide support for the AltDiffusion-m9 model in this project. Specific information on the AltDiffusion model can be found in [this tutorial](https://github.com/FlagAI-Open/FlagAI/tree/master/examples/AltDiffusion/README.md).
The model code has been open sourced on [FlagAI](https://github.com/FlagAI-Open/FlagAI/tree/master/examples/AltCLIP) and the weights are located on [modelhub](https://model.baai.ac.cn/model-detail/100077). We also provide scripts for fine-tuning, inference, and validation, so feel free to try them out.
## 引用
关于AltCLIP,我们已经推出了相关报告,有更多细节可以查阅,如对您的工作有帮助,欢迎引用。
If you find this work helpful, please consider to cite
```
@article{https://doi.org/10.48550/arxiv.2211.06679,
doi = {10.48550/ARXIV.2211.06679},
url = {https://arxiv.org/abs/2211.06679},
author = {Chen, Zhongzhi and Liu, Guang and Zhang, Bo-Wen and Ye, Fulong and Yang, Qinghong and Wu, Ledell},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences},
title = {AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities},
publisher = {arXiv},
year = {2022},
copyright = {arXiv.org perpetual, non-exclusive license}
}
```
## 训练 Training
训练共有两个阶段。
在平行知识蒸馏阶段,我们只是使用平行语料文本来进行蒸馏(平行语料相对于图文对更容易获取且数量更大)。在多语对比学习阶段,我们使用少量的中-英 图像-文本对(每种语言6百万)来训练我们的文本编码器以更好地适应图像编码器。
There are two phases of training.
In the parallel knowledge distillation phase, we only use parallel corpus texts for distillation (parallel corpus is easier to obtain and larger in number compared to image text pairs). In the multilingual comparison learning phase, we use a small number of text-image pairs (about 6 million in each language) to train our text encoder to better fit the image encoder.
## 下游效果 Performance

## 可视化效果 Visualization effects
基于AltCLIP,我们还开发了AltDiffusion模型,可视化效果如下。
Based on AltCLIP, we have also developed the AltDiffusion model, visualized as follows.

## 模型推理 Inference
Please download the code from [FlagAI AltCLIP](https://github.com/FlagAI-Open/FlagAI/tree/master/examples/AltCLIP)
```python
from PIL import Image
import requests
# transformers version >= 4.21.0
from modeling_altclip import AltCLIP
from processing_altclip import AltCLIPProcessor
# now our repo's in private, so we need `use_auth_token=True`
model = AltCLIP.from_pretrained("BAAI/AltCLIP-m9")
processor = AltCLIPProcessor.from_pretrained("BAAI/AltCLIP-m9")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # this is the image-text similarity score
probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
```
|
danbrown/Lyriel-v1-5 | danbrown | 2023-04-30T16:52:53Z | 615 | 1 | diffusers | [
"diffusers",
"safetensors",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2023-04-30T16:29:17Z | Not official! This are diffusers weights for https://civitai.com/models/22922/lyriel
Based on Stable Diffusion v1.5 |
Saibo-creator/llama-1B | Saibo-creator | 2023-07-31T17:04:55Z | 615 | 4 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-05-14T05:09:50Z | N.B.
This is not a pretrained llama model.
It is simply the last two layers of llama model and it will not give meaningful predictions without further pretraining! |
alejandrohdez/textual_inversion_domenico-veneziano-5-10000 | alejandrohdez | 2024-05-27T19:11:02Z | 615 | 0 | diffusers | [
"diffusers",
"tensorboard",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"textual_inversion",
"diffusers-training",
"base_model:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-05-27T18:04:43Z | ---
license: creativeml-openrail-m
library_name: diffusers
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- textual_inversion
- diffusers-training
base_model: runwayml/stable-diffusion-v1-5
inference: true
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# Textual inversion text2image fine-tuning - alejandrohdez/textual_inversion_domenico-veneziano-5-10000
These are textual inversion adaption weights for runwayml/stable-diffusion-v1-5. You can find some example images in the following.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model] |
mradermacher/Mirai-Nova-Llama3-LocalAI-8B-v0.2-i1-GGUF | mradermacher | 2024-05-28T03:38:55Z | 615 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:mudler/Mirai-Nova-Llama3-LocalAI-8B-v0.2",
"endpoints_compatible",
"region:us"
] | null | 2024-05-28T00:30:03Z | ---
base_model: mudler/Mirai-Nova-Llama3-LocalAI-8B-v0.2
language:
- en
library_name: transformers
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/mudler/Mirai-Nova-Llama3-LocalAI-8B-v0.2
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/Mirai-Nova-Llama3-LocalAI-8B-v0.2-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Mirai-Nova-Llama3-LocalAI-8B-v0.2-i1-GGUF/resolve/main/Mirai-Nova-Llama3-LocalAI-8B-v0.2.i1-IQ1_S.gguf) | i1-IQ1_S | 2.1 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Mirai-Nova-Llama3-LocalAI-8B-v0.2-i1-GGUF/resolve/main/Mirai-Nova-Llama3-LocalAI-8B-v0.2.i1-IQ1_M.gguf) | i1-IQ1_M | 2.3 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Mirai-Nova-Llama3-LocalAI-8B-v0.2-i1-GGUF/resolve/main/Mirai-Nova-Llama3-LocalAI-8B-v0.2.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.5 | |
| [GGUF](https://huggingface.co/mradermacher/Mirai-Nova-Llama3-LocalAI-8B-v0.2-i1-GGUF/resolve/main/Mirai-Nova-Llama3-LocalAI-8B-v0.2.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.7 | |
| [GGUF](https://huggingface.co/mradermacher/Mirai-Nova-Llama3-LocalAI-8B-v0.2-i1-GGUF/resolve/main/Mirai-Nova-Llama3-LocalAI-8B-v0.2.i1-IQ2_S.gguf) | i1-IQ2_S | 2.9 | |
| [GGUF](https://huggingface.co/mradermacher/Mirai-Nova-Llama3-LocalAI-8B-v0.2-i1-GGUF/resolve/main/Mirai-Nova-Llama3-LocalAI-8B-v0.2.i1-IQ2_M.gguf) | i1-IQ2_M | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/Mirai-Nova-Llama3-LocalAI-8B-v0.2-i1-GGUF/resolve/main/Mirai-Nova-Llama3-LocalAI-8B-v0.2.i1-Q2_K.gguf) | i1-Q2_K | 3.3 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Mirai-Nova-Llama3-LocalAI-8B-v0.2-i1-GGUF/resolve/main/Mirai-Nova-Llama3-LocalAI-8B-v0.2.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 3.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Mirai-Nova-Llama3-LocalAI-8B-v0.2-i1-GGUF/resolve/main/Mirai-Nova-Llama3-LocalAI-8B-v0.2.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/Mirai-Nova-Llama3-LocalAI-8B-v0.2-i1-GGUF/resolve/main/Mirai-Nova-Llama3-LocalAI-8B-v0.2.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.8 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Mirai-Nova-Llama3-LocalAI-8B-v0.2-i1-GGUF/resolve/main/Mirai-Nova-Llama3-LocalAI-8B-v0.2.i1-IQ3_S.gguf) | i1-IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Mirai-Nova-Llama3-LocalAI-8B-v0.2-i1-GGUF/resolve/main/Mirai-Nova-Llama3-LocalAI-8B-v0.2.i1-IQ3_M.gguf) | i1-IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Mirai-Nova-Llama3-LocalAI-8B-v0.2-i1-GGUF/resolve/main/Mirai-Nova-Llama3-LocalAI-8B-v0.2.i1-Q3_K_M.gguf) | i1-Q3_K_M | 4.1 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Mirai-Nova-Llama3-LocalAI-8B-v0.2-i1-GGUF/resolve/main/Mirai-Nova-Llama3-LocalAI-8B-v0.2.i1-Q3_K_L.gguf) | i1-Q3_K_L | 4.4 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Mirai-Nova-Llama3-LocalAI-8B-v0.2-i1-GGUF/resolve/main/Mirai-Nova-Llama3-LocalAI-8B-v0.2.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.5 | |
| [GGUF](https://huggingface.co/mradermacher/Mirai-Nova-Llama3-LocalAI-8B-v0.2-i1-GGUF/resolve/main/Mirai-Nova-Llama3-LocalAI-8B-v0.2.i1-Q4_0.gguf) | i1-Q4_0 | 4.8 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Mirai-Nova-Llama3-LocalAI-8B-v0.2-i1-GGUF/resolve/main/Mirai-Nova-Llama3-LocalAI-8B-v0.2.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.8 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Mirai-Nova-Llama3-LocalAI-8B-v0.2-i1-GGUF/resolve/main/Mirai-Nova-Llama3-LocalAI-8B-v0.2.i1-Q4_K_M.gguf) | i1-Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Mirai-Nova-Llama3-LocalAI-8B-v0.2-i1-GGUF/resolve/main/Mirai-Nova-Llama3-LocalAI-8B-v0.2.i1-Q5_K_S.gguf) | i1-Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/Mirai-Nova-Llama3-LocalAI-8B-v0.2-i1-GGUF/resolve/main/Mirai-Nova-Llama3-LocalAI-8B-v0.2.i1-Q5_K_M.gguf) | i1-Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/Mirai-Nova-Llama3-LocalAI-8B-v0.2-i1-GGUF/resolve/main/Mirai-Nova-Llama3-LocalAI-8B-v0.2.i1-Q6_K.gguf) | i1-Q6_K | 6.7 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his hardware for calculating the imatrix for these quants.
<!-- end -->
|
gordonhu/MQT-LLaVA-7b | gordonhu | 2024-05-30T01:40:06Z | 615 | 3 | transformers | [
"transformers",
"safetensors",
"llava_llama",
"text-generation",
"image-text-to-text",
"arxiv:2405.19315",
"autotrain_compatible",
"region:us"
] | image-text-to-text | 2024-05-28T19:31:20Z | ---
inference: false
pipeline_tag: image-text-to-text
---
<br>
<br>
# MQT-LLaVA Model Card
## Model details
**Model type:**
MQT-LLaVA is an open-source chatbot trained by fine-tuning LLaMA/Vicuna on GPT-generated multimodal instruction-following data.
It is an auto-regressive language model, based on the transformer architecture.
**Model date:**
MQT-LLaVA-7B was trained in May 2024. [Paper](https://arxiv.org/abs/2405.19315)
<!-- **Paper or resources for more information:**
https:// -->
## License
Llama 2 is licensed under the LLAMA 2 Community License,
Copyright (c) Meta Platforms, Inc. All Rights Reserved.
**Where to send questions or comments about the model:**
https://github.com/gordonhu608/MQT-LLaVA/issues
## Intended use
**Primary intended uses:**
The primary use of MQT-LLaVA is research on large multimodal models and chatbots.
**Primary intended users:**
The primary intended users of the model are researchers and hobbyists in computer vision, natural language processing, machine learning, and artificial intelligence.
## Training dataset
- 558K filtered image-text pairs from LAION/CC/SBU, captioned by BLIP.
- 158K GPT-generated multimodal instruction-following data.
- 450K academic-task-oriented VQA data mixture.
- 40K ShareGPT data.
## Evaluation dataset
A collection of 11 benchmarks, including 4 academic VQA benchmarks and 7 recent benchmarks specifically proposed for instruction-following LMMs. |
NikolayKozloff/GeM2-Llamion-14B-Chat-Q4_K_M-GGUF | NikolayKozloff | 2024-06-09T13:05:26Z | 615 | 1 | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"base_model:vaiv/GeM2-Llamion-14B-Chat",
"license:apache-2.0",
"region:us"
] | null | 2024-06-09T13:05:01Z | ---
license: apache-2.0
tags:
- llama-cpp
- gguf-my-repo
base_model: vaiv/GeM2-Llamion-14B-Chat
---
# NikolayKozloff/GeM2-Llamion-14B-Chat-Q4_K_M-GGUF
This model was converted to GGUF format from [`vaiv/GeM2-Llamion-14B-Chat`](https://huggingface.co/vaiv/GeM2-Llamion-14B-Chat) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/vaiv/GeM2-Llamion-14B-Chat) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama --hf-repo NikolayKozloff/GeM2-Llamion-14B-Chat-Q4_K_M-GGUF --hf-file gem2-llamion-14b-chat-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo NikolayKozloff/GeM2-Llamion-14B-Chat-Q4_K_M-GGUF --hf-file gem2-llamion-14b-chat-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./main --hf-repo NikolayKozloff/GeM2-Llamion-14B-Chat-Q4_K_M-GGUF --hf-file gem2-llamion-14b-chat-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./server --hf-repo NikolayKozloff/GeM2-Llamion-14B-Chat-Q4_K_M-GGUF --hf-file gem2-llamion-14b-chat-q4_k_m.gguf -c 2048
```
|
Divya1287/Llama-2-7b-chat-int8 | Divya1287 | 2024-06-20T09:52:04Z | 615 | 0 | null | [
"gguf",
"region:us"
] | null | 2024-06-20T09:49:17Z | Entry not found |
mrm8488/bert-multi-cased-finetuned-xquadv1 | mrm8488 | 2023-03-19T09:03:39Z | 614 | 5 | transformers | [
"transformers",
"pytorch",
"jax",
"safetensors",
"bert",
"question-answering",
"multilingual",
"arxiv:1910.11856",
"endpoints_compatible",
"region:us"
] | question-answering | 2022-03-02T23:29:05Z | ---
language: multilingual
thumbnail:
---
# BERT (base-multilingual-cased) fine-tuned for multilingual Q&A
This model was created by [Google](https://github.com/google-research/bert/blob/master/multilingual.md) and fine-tuned on [XQuAD](https://github.com/deepmind/xquad) like data for multilingual (`11 different languages`) **Q&A** downstream task.
## Details of the language model('bert-base-multilingual-cased')
[Language model](https://github.com/google-research/bert/blob/master/multilingual.md)
| Languages | Heads | Layers | Hidden | Params |
| --------- | ----- | ------ | ------ | ------ |
| 104 | 12 | 12 | 768 | 100 M |
## Details of the downstream task (multilingual Q&A) - Dataset
Deepmind [XQuAD](https://github.com/deepmind/xquad)
Languages covered:
- Arabic: `ar`
- German: `de`
- Greek: `el`
- English: `en`
- Spanish: `es`
- Hindi: `hi`
- Russian: `ru`
- Thai: `th`
- Turkish: `tr`
- Vietnamese: `vi`
- Chinese: `zh`
As the dataset is based on SQuAD v1.1, there are no unanswerable questions in the data. We chose this
setting so that models can focus on cross-lingual transfer.
We show the average number of tokens per paragraph, question, and answer for each language in the
table below. The statistics were obtained using [Jieba](https://github.com/fxsjy/jieba) for Chinese
and the [Moses tokenizer](https://github.com/moses-smt/mosesdecoder/blob/master/scripts/tokenizer/tokenizer.perl)
for the other languages.
| | en | es | de | el | ru | tr | ar | vi | th | zh | hi |
| --------- | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| Paragraph | 142.4 | 160.7 | 139.5 | 149.6 | 133.9 | 126.5 | 128.2 | 191.2 | 158.7 | 147.6 | 232.4 |
| Question | 11.5 | 13.4 | 11.0 | 11.7 | 10.0 | 9.8 | 10.7 | 14.8 | 11.5 | 10.5 | 18.7 |
| Answer | 3.1 | 3.6 | 3.0 | 3.3 | 3.1 | 3.1 | 3.1 | 4.5 | 4.1 | 3.5 | 5.6 |
Citation:
<details>
```bibtex
@article{Artetxe:etal:2019,
author = {Mikel Artetxe and Sebastian Ruder and Dani Yogatama},
title = {On the cross-lingual transferability of monolingual representations},
journal = {CoRR},
volume = {abs/1910.11856},
year = {2019},
archivePrefix = {arXiv},
eprint = {1910.11856}
}
```
</details>
As **XQuAD** is just an evaluation dataset, I used `Data augmentation techniques` (scraping, neural machine translation, etc) to obtain more samples and split the dataset in order to have a train and test set. The test set was created in a way that contains the same number of samples for each language. Finally, I got:
| Dataset | # samples |
| ----------- | --------- |
| XQUAD train | 50 K |
| XQUAD test | 8 K |
## Model training
The model was trained on a Tesla P100 GPU and 25GB of RAM.
The script for fine tuning can be found [here](https://github.com/huggingface/transformers/blob/master/examples/distillation/run_squad_w_distillation.py)
## Model in action
Fast usage with **pipelines**:
```python
from transformers import pipeline
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="mrm8488/bert-multi-cased-finetuned-xquadv1",
tokenizer="mrm8488/bert-multi-cased-finetuned-xquadv1"
)
# context: Coronavirus is seeding panic in the West because it expands so fast.
# question: Where is seeding panic Coronavirus?
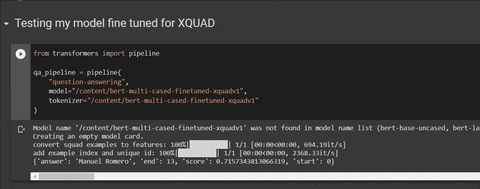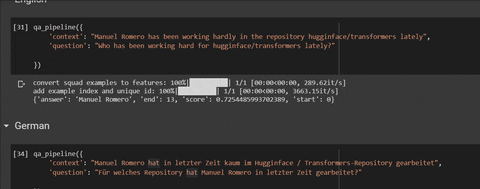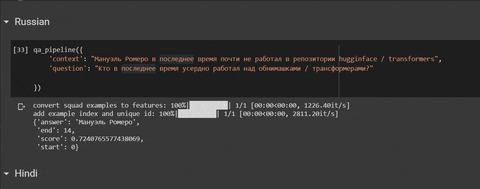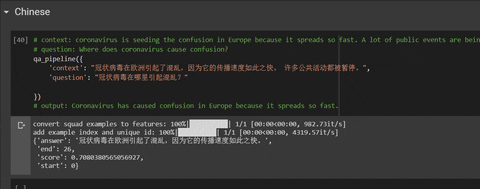
qa_pipeline({
'context': "कोरोनावायरस पश्चिम में आतंक बो रहा है क्योंकि यह इतनी तेजी से फैलता है।",
'question': "कोरोनावायरस घबराहट कहां है?"
})
# output: {'answer': 'पश्चिम', 'end': 18, 'score': 0.7037217439689059, 'start': 12}
qa_pipeline({
'context': "Manuel Romero has been working hardly in the repository hugginface/transformers lately",
'question': "Who has been working hard for hugginface/transformers lately?"
})
# output: {'answer': 'Manuel Romero', 'end': 13, 'score': 0.7254485993702389, 'start': 0}
qa_pipeline({
'context': "Manuel Romero a travaillé à peine dans le référentiel hugginface / transformers ces derniers temps",
'question': "Pour quel référentiel a travaillé Manuel Romero récemment?"
})
#output: {'answer': 'hugginface / transformers', 'end': 79, 'score': 0.6482061613915384, 'start': 54}
```
Try it on a Colab:
<a href="https://colab.research.google.com/github/mrm8488/shared_colab_notebooks/blob/master/Try_mrm8488_xquad_finetuned_model.ipynb" target="_parent"><img src="https://camo.githubusercontent.com/52feade06f2fecbf006889a904d221e6a730c194/68747470733a2f2f636f6c61622e72657365617263682e676f6f676c652e636f6d2f6173736574732f636f6c61622d62616467652e737667" alt="Open In Colab" data-canonical-src="https://colab.research.google.com/assets/colab-badge.svg"></a>
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
thingsu/koDPR_context | thingsu | 2021-05-24T02:46:37Z | 614 | 3 | transformers | [
"transformers",
"pytorch",
"bert",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z | fintuned the kykim/bert-kor-base model as a dense passage retrieval context encoder by KLUE dataset
this link is experiment result. https://wandb.ai/thingsu/DenseRetrieval
Corpus : Korean Wikipedia Corpus
Trained Strategy :
- Pretrained Model : kykim/bert-kor-base
- Inverse Cloze Task : 16 Epoch, by korquad v 1.0, KLUE MRC dataset
- In-batch Negatives : 12 Epoch, by KLUE MRC dataset, random sampling between Sparse Retrieval(TF-IDF) top 100 passage per each query
You must need to use Korean wikipedia corpus
<pre>
<code>
from Transformers import AutoTokenizer, BertPreTrainedModel, BertModel
class BertEncoder(BertPreTrainedModel):
def __init__(self, config):
super(BertEncoder, self).__init__(config)
self.bert = BertModel(config)
self.init_weights()
def forward(self, input_ids, attention_mask=None, token_type_ids=None):
outputs = self.bert(input_ids, attention_mask, token_type_ids)
pooled_output = outputs[1]
return pooled_output
model_name = 'kykim/bert-kor-base'
tokenizer = AutoTokenizer.from_pretrained(model_name)
q_encoder = BertEncoder.from_pretrained("thingsu/koDPR_question")
p_encoder = BertEncoder.from_pretrained("thingsu/koDPR_context")
</pre>
</code>
|
veronica320/TE-for-Event-Extraction | veronica320 | 2021-07-30T23:11:05Z | 614 | 2 | transformers | [
"transformers",
"pytorch",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | # TE-for-Event-Extraction
## Model description
This is a TE model as part of the event extraction system in the ACL2021 paper: [Zero-shot Event Extraction via Transfer Learning: Challenges and Insights](https://aclanthology.org/2021.acl-short.42/). The pretrained architecture is [roberta-large](https://huggingface.co/roberta-large) and the fine-tuning data is [MNLI](https://cims.nyu.edu/~sbowman/multinli/).
The label mapping is:
```
LABEL_0: Contradiction
LABEL_1: Neutral
LABEL_2: Entailment
```
## Demo
To see how the model works, type a sentence and a hypothesis separated by "\<\/s\>\<\/s\>" in the right-hand-side textbox under "Hosted inference API".
Example:
- Input:
```
A car bomb exploded Thursday in a crowded outdoor market in the heart of Jerusalem. </s></s> This text is about an attack.
```
- Output:
```
LABEL_2 (Entailment)
```
## Usage
- To use the TE model independently, follow the [huggingface documentation on AutoModelForSequenceClassification](https://huggingface.co/transformers/task_summary.html#sequence-classification).
- To use it as part of the event extraction system, please check out [our Github repo](https://github.com/veronica320/Zeroshot-Event-Extraction).
### BibTeX entry and citation info
```
@inproceedings{lyu-etal-2021-zero,
title = "Zero-shot Event Extraction via Transfer Learning: {C}hallenges and Insights",
author = "Lyu, Qing and
Zhang, Hongming and
Sulem, Elior and
Roth, Dan",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-short.42",
doi = "10.18653/v1/2021.acl-short.42",
pages = "322--332",
abstract = "Event extraction has long been a challenging task, addressed mostly with supervised methods that require expensive annotation and are not extensible to new event ontologies. In this work, we explore the possibility of zero-shot event extraction by formulating it as a set of Textual Entailment (TE) and/or Question Answering (QA) queries (e.g. {``}A city was attacked{''} entails {``}There is an attack{''}), exploiting pretrained TE/QA models for direct transfer. On ACE-2005 and ERE, our system achieves acceptable results, yet there is still a large gap from supervised approaches, showing that current QA and TE technologies fail in transferring to a different domain. To investigate the reasons behind the gap, we analyze the remaining key challenges, their respective impact, and possible improvement directions.",
}
``` |
orai-nlp/ElhBERTeu | orai-nlp | 2023-04-03T12:45:37Z | 614 | 2 | transformers | [
"transformers",
"pytorch",
"bert",
"feature-extraction",
"basque",
"euskara",
"eu",
"license:cc-by-4.0",
"endpoints_compatible",
"text-embeddings-inference",
"region:us"
] | feature-extraction | 2022-05-06T09:15:41Z | ---
license: cc-by-4.0
language: eu
tags:
- bert
- basque
- euskara
---
# ElhBERTeu
This is a BERT model for Basque introduced in [BasqueGLUE: A Natural Language Understanding Benchmark for Basque](https://aclanthology.org/2022.lrec-1.172/).
To train ElhBERTeu, we collected different corpora sources from several domains: updated (2021) national and local news sources, Basque Wikipedia, as well as novel news sources and texts from other domains, such as science (both academic and divulgative), literature or subtitles. More details about the corpora used and their sizes are shown in the following table. Texts from news sources were oversampled (duplicated) as done during the training of BERTeus. In total 575M tokens were used for pre-training ElhBERTeu.
|Domain | Size |
|-----------|----------|
|News | 2 x 224M |
|Wikipedia | 40M |
|Science | 58M |
|Literature | 24M |
|Others | 7M |
|Total | 575M |
ElhBERTeu is a base, cased monolingual BERT model for Basque, with a vocab size of 50K, which has 124M parameters in total.
There is a medium-size model available here: [ElhBERTeu-medium](https://huggingface.co/orai-nlp/ElhBERTeu-medium)
ElhBERTeu was trained following the design decisions for [BERTeus](https://huggingface.co/ixa-ehu/berteus-base-cased). The tokenizer and the hyper-parameter settings remained the same (batch_size=256), with the only difference being that the full pre-training of the model (1M steps) was performed with a sequence length of 512 on a v3-8 TPU.
The model has been evaluated on the recently created [BasqueGLUE](https://github.com/Elhuyar/BasqueGLUE) NLU benchmark:
| Model | AVG | NERC | F_intent | F_slot | BHTC | BEC | Vaxx | QNLI | WiC | coref |
|-----------|:---------:|:---------:|:---------:|:-------:|:-------:|:-------:|:-------:|:-------:|:-------:|:-------:|
| | | F1 | F1 | F1 | F1 | F1 | MF1 | acc | acc | acc |
| BERTeus | 73.23 | 81.92 | **82.52** | 74.34 |**78.26**| 69.43 | 59.30 |**74.26**| 70.71 |**68.31**|
| ElhBERTeu | **73.71** | **82.30** | 82.24 |**75.64**| 78.05 |**69.89**|**63.81**| 73.84 |**71.71**| 65.93 |
If you use this model, please cite the following paper:
- G. Urbizu, I. San Vicente, X. Saralegi, R. Agerri, A. Soroa. BasqueGLUE: A Natural Language Understanding Benchmark for Basque. In proceedings of the 13th Language Resources and Evaluation Conference (LREC 2022). June 2022. Marseille, France
```
@InProceedings{urbizu2022basqueglue,
author = {Urbizu, Gorka and San Vicente, Iñaki and Saralegi, Xabier and Agerri, Rodrigo and Soroa, Aitor},
title = {BasqueGLUE: A Natural Language Understanding Benchmark for Basque},
booktitle = {Proceedings of the Language Resources and Evaluation Conference},
month = {June},
year = {2022},
address = {Marseille, France},
publisher = {European Language Resources Association},
pages = {1603--1612},
abstract = {Natural Language Understanding (NLU) technology has improved significantly over the last few years and multitask benchmarks such as GLUE are key to evaluate this improvement in a robust and general way. These benchmarks take into account a wide and diverse set of NLU tasks that require some form of language understanding, beyond the detection of superficial, textual clues. However, they are costly to develop and language-dependent, and therefore they are only available for a small number of languages. In this paper, we present BasqueGLUE, the first NLU benchmark for Basque, a less-resourced language, which has been elaborated from previously existing datasets and following similar criteria to those used for the construction of GLUE and SuperGLUE. We also report the evaluation of two state-of-the-art language models for Basque on BasqueGLUE, thus providing a strong baseline to compare upon. BasqueGLUE is freely available under an open license.},
url = {https://aclanthology.org/2022.lrec-1.172}
}
```
License:
CC BY 4.0 |
timm/vit_srelpos_small_patch16_224.sw_in1k | timm | 2023-05-05T22:04:32Z | 614 | 0 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2111.09883",
"arxiv:2010.11929",
"license:apache-2.0",
"region:us"
] | image-classification | 2022-12-23T00:22:33Z | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for vit_srelpos_small_patch16_224.sw_in1k
A Vision Transformer (ViT) image classification model. This is a `timm` specific variation of the ViT architecture with shared relative position embeddings, no class token, and final representation via global average pool of tokens. Trained on ImageNet-1k in `timm` using recipe template described below.
Recipe details:
* Based on Swin Transformer train / pretrain recipe with modifications (related to both DeiT and ConvNeXt recipes)
* AdamW optimizer, gradient clipping, EMA weight averaging
* Cosine LR schedule with warmup
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 22.0
- GMACs: 4.2
- Activations (M): 8.5
- Image size: 224 x 224
- **Papers:**
- Swin Transformer V2: Scaling Up Capacity and Resolution: https://arxiv.org/abs/2111.09883
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929v2
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/huggingface/pytorch-image-models
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('vit_srelpos_small_patch16_224.sw_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_srelpos_small_patch16_224.sw_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 196, 384) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@inproceedings{liu2021swinv2,
title={Swin Transformer V2: Scaling Up Capacity and Resolution},
author={Ze Liu and Han Hu and Yutong Lin and Zhuliang Yao and Zhenda Xie and Yixuan Wei and Jia Ning and Yue Cao and Zheng Zhang and Li Dong and Furu Wei and Baining Guo},
booktitle={International Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2022}
}
```
```bibtex
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
```
|
lorahub/flan_t5_large-wiki_hop_original_choose_best_object_affirmative_1 | lorahub | 2023-07-24T09:37:48Z | 614 | 0 | peft | [
"peft",
"region:us"
] | null | 2023-07-24T09:37:39Z | ---
library_name: peft
---
|
TheBloke/Xwin-LM-13B-V0.1-GGUF | TheBloke | 2023-09-27T12:53:42Z | 614 | 24 | transformers | [
"transformers",
"gguf",
"llama",
"base_model:Xwin-LM/Xwin-LM-13B-V0.1",
"license:llama2",
"text-generation-inference",
"region:us"
] | null | 2023-09-20T20:56:14Z | ---
license: llama2
model_name: Xwin-LM 13B V0.1
base_model: Xwin-LM/Xwin-LM-13B-V0.1
inference: false
model_creator: Xwin-LM
model_type: llama
prompt_template: 'A chat between a curious user and an artificial intelligence assistant.
The assistant gives helpful, detailed, and polite answers to the user''s questions.
USER: {prompt} ASSISTANT:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Xwin-LM 13B V0.1 - GGUF
- Model creator: [Xwin-LM](https://huggingface.co/Xwin-LM)
- Original model: [Xwin-LM 13B V0.1](https://huggingface.co/Xwin-LM/Xwin-LM-13B-V0.1)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Xwin-LM's Xwin-LM 13B V0.1](https://huggingface.co/Xwin-LM/Xwin-LM-13B-V0.1).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Xwin-LM-13B-V0.1-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Xwin-LM-13B-V0.1-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Xwin-LM-13B-V0.1-GGUF)
* [Xwin-LM's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/Xwin-LM/Xwin-LM-13B-V0.1)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Vicuna
```
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: {prompt} ASSISTANT:
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [xwin-lm-13b-v0.1.Q2_K.gguf](https://huggingface.co/TheBloke/Xwin-LM-13B-V0.1-GGUF/blob/main/xwin-lm-13b-v0.1.Q2_K.gguf) | Q2_K | 2 | 5.43 GB| 7.93 GB | smallest, significant quality loss - not recommended for most purposes |
| [xwin-lm-13b-v0.1.Q3_K_S.gguf](https://huggingface.co/TheBloke/Xwin-LM-13B-V0.1-GGUF/blob/main/xwin-lm-13b-v0.1.Q3_K_S.gguf) | Q3_K_S | 3 | 5.66 GB| 8.16 GB | very small, high quality loss |
| [xwin-lm-13b-v0.1.Q3_K_M.gguf](https://huggingface.co/TheBloke/Xwin-LM-13B-V0.1-GGUF/blob/main/xwin-lm-13b-v0.1.Q3_K_M.gguf) | Q3_K_M | 3 | 6.34 GB| 8.84 GB | very small, high quality loss |
| [xwin-lm-13b-v0.1.Q3_K_L.gguf](https://huggingface.co/TheBloke/Xwin-LM-13B-V0.1-GGUF/blob/main/xwin-lm-13b-v0.1.Q3_K_L.gguf) | Q3_K_L | 3 | 6.93 GB| 9.43 GB | small, substantial quality loss |
| [xwin-lm-13b-v0.1.Q4_0.gguf](https://huggingface.co/TheBloke/Xwin-LM-13B-V0.1-GGUF/blob/main/xwin-lm-13b-v0.1.Q4_0.gguf) | Q4_0 | 4 | 7.37 GB| 9.87 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [xwin-lm-13b-v0.1.Q4_K_S.gguf](https://huggingface.co/TheBloke/Xwin-LM-13B-V0.1-GGUF/blob/main/xwin-lm-13b-v0.1.Q4_K_S.gguf) | Q4_K_S | 4 | 7.41 GB| 9.91 GB | small, greater quality loss |
| [xwin-lm-13b-v0.1.Q4_K_M.gguf](https://huggingface.co/TheBloke/Xwin-LM-13B-V0.1-GGUF/blob/main/xwin-lm-13b-v0.1.Q4_K_M.gguf) | Q4_K_M | 4 | 7.87 GB| 10.37 GB | medium, balanced quality - recommended |
| [xwin-lm-13b-v0.1.Q5_0.gguf](https://huggingface.co/TheBloke/Xwin-LM-13B-V0.1-GGUF/blob/main/xwin-lm-13b-v0.1.Q5_0.gguf) | Q5_0 | 5 | 8.97 GB| 11.47 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [xwin-lm-13b-v0.1.Q5_K_S.gguf](https://huggingface.co/TheBloke/Xwin-LM-13B-V0.1-GGUF/blob/main/xwin-lm-13b-v0.1.Q5_K_S.gguf) | Q5_K_S | 5 | 8.97 GB| 11.47 GB | large, low quality loss - recommended |
| [xwin-lm-13b-v0.1.Q5_K_M.gguf](https://huggingface.co/TheBloke/Xwin-LM-13B-V0.1-GGUF/blob/main/xwin-lm-13b-v0.1.Q5_K_M.gguf) | Q5_K_M | 5 | 9.23 GB| 11.73 GB | large, very low quality loss - recommended |
| [xwin-lm-13b-v0.1.Q6_K.gguf](https://huggingface.co/TheBloke/Xwin-LM-13B-V0.1-GGUF/blob/main/xwin-lm-13b-v0.1.Q6_K.gguf) | Q6_K | 6 | 10.68 GB| 13.18 GB | very large, extremely low quality loss |
| [xwin-lm-13b-v0.1.Q8_0.gguf](https://huggingface.co/TheBloke/Xwin-LM-13B-V0.1-GGUF/blob/main/xwin-lm-13b-v0.1.Q8_0.gguf) | Q8_0 | 8 | 13.83 GB| 16.33 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/Xwin-LM-13B-V0.1-GGUF and below it, a specific filename to download, such as: xwin-lm-13b-v0.1.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/Xwin-LM-13B-V0.1-GGUF xwin-lm-13b-v0.1.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/Xwin-LM-13B-V0.1-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Xwin-LM-13B-V0.1-GGUF xwin-lm-13b-v0.1.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m xwin-lm-13b-v0.1.Q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: {prompt} ASSISTANT:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/Xwin-LM-13B-V0.1-GGUF", model_file="xwin-lm-13b-v0.1.Q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Xwin-LM's Xwin-LM 13B V0.1
<h3 align="center">
Xwin-LM: Powerful, Stable, and Reproducible LLM Alignment
</h3>
<p align="center">
<a href="https://github.com/Xwin-LM/Xwin-LM">
<img src="https://img.shields.io/badge/GitHub-yellow.svg?style=social&logo=github">
</a>
<a href="https://huggingface.co/Xwin-LM">
<img src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Models-blue">
</a>
</p>
**Step up your LLM alignment with Xwin-LM!**
Xwin-LM aims to develop and open-source alignment technologies for large language models, including supervised fine-tuning (SFT), reward models (RM), reject sampling, reinforcement learning from human feedback (RLHF), etc. Our first release, built-upon on the Llama2 base models, ranked **TOP-1** on [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/). Notably, it's **the first to surpass GPT-4** on this benchmark. The project will be continuously updated.
## News
- 💥 [Sep, 2023] We released [Xwin-LM-70B-V0.1](https://huggingface.co/Xwin-LM/Xwin-LM-70B-V0.1), which has achieved a win-rate against Davinci-003 of **95.57%** on [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/) benchmark, ranking as **TOP-1** on AlpacaEval. **It was the FIRST model surpassing GPT-4** on [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/). Also note its winrate v.s. GPT-4 is **60.61**.
- 🔍 [Sep, 2023] RLHF plays crucial role in the strong performance of Xwin-LM-V0.1 release!
- 💥 [Sep, 2023] We released [Xwin-LM-13B-V0.1](https://huggingface.co/Xwin-LM/Xwin-LM-13B-V0.1), which has achieved **91.76%** win-rate on [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/), ranking as **top-1** among all 13B models.
- 💥 [Sep, 2023] We released [Xwin-LM-7B-V0.1](https://huggingface.co/Xwin-LM/Xwin-LM-7B-V0.1), which has achieved **87.82%** win-rate on [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/), ranking as **top-1** among all 7B models.
## Model Card
| Model | Checkpoint | Report | License |
|------------|------------|-------------|------------------|
|Xwin-LM-7B-V0.1| 🤗 <a href="https://huggingface.co/Xwin-LM/Xwin-LM-7B-V0.1" target="_blank">HF Link</a> | 📃**Coming soon (Stay tuned)** | <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama 2 License|
|Xwin-LM-13B-V0.1| 🤗 <a href="https://huggingface.co/Xwin-LM/Xwin-LM-13B-V0.1" target="_blank">HF Link</a> | | <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama 2 License|
|Xwin-LM-70B-V0.1| 🤗 <a href="https://huggingface.co/Xwin-LM/Xwin-LM-70B-V0.1" target="_blank">HF Link</a> | | <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama 2 License|
## Benchmarks
### Xwin-LM performance on [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/).
The table below displays the performance of Xwin-LM on [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/), where evaluates its win-rate against Text-Davinci-003 across 805 questions. To provide a comprehensive evaluation, we present, for the first time, the win-rate against ChatGPT and GPT-4 as well. Our Xwin-LM model family establish a new state-of-the-art performance across all metrics. Notably, Xwin-LM-70B-V0.1 has eclipsed GPT-4 for the first time, achieving an impressive win-rate of **95.57%** to Text-Davinci-003 and **60.61%** to GPT-4.
| **Model** | **AlpacaEval (winrate %)** | **AlpacaEval (winrate %)** |**AlpacaEval (winrate %)** |
|----------------------------------|------------|----------|-------------|
| | **v.s. Text-Davinci-003** | **v.s. ChatGPT** | **v.s. GPT4**|
| **Xwin-LM-70B-V0.1** | **95.57** | **87.50** | **60.61** |
| GPT-4 | 95.28 | 84.66 | 50.00 |
| WizardLM-70B-V1.0 | 92.91 | 80.19 | 46.70 |
| Llama-2-70B-Chat | 92.66 | 81.97 | 51.19 |
| **Xwin-LM-13B-V0.1** | **91.76** | **81.79** | **55.30** |
| ChatGPT | 89.37 | 50.00 | 16.60 |
| WizardLM-13B-V1.2 | 89.17 | 75.75 | 41.91 |
| **Xwin-LM-7B-V0.1** | **87.35** | **76.40** | **47.57** |
| Llama-2-13B-Chat | 81.09 | 64.22 | 30.92 |
### Case study on [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/)
| Prompts | GTP4 response | Xwin-LM response |
|----------------|------------|--------|
|I've put a plate on top of an apple, and take the plate from kitchen to dinning room. Where is the apple now|The apple is now in the dining room, as it was underneath the plate when you moved the plate from the kitchen to the dining room.|The apple is still in the kitchen, as you have only moved the plate. The apple is under the plate, so if you want to bring the apple to the dining room, you should either move the apple directly or put the apple on the plate and then move the plate to the dining room.|
| Answer the following question.<br> How do you say "good evening" in French. | In French, "good evening" is said as "bonsoir." | In French, "good evening" is translated to "bonsoir." This greeting is used in the evening and nighttime hours, typically after 6 p.m. It is a combination of "bon," which means "good," and "soir," which means "evening." To pronounce it, say "bone-swahr." |
### Xwin-LM performance on NLP foundation tasks.
The following table provides a comparison of Xwin-LMs with other LLMs on NLP foundation tasks in [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
| Model | MMLU 5-shot | ARC 25-shot | TruthfulQA 0-shot | HellaSwag 10-shot | Average |
|------------------|-------------|-------------|-------------------|-------------------|------------|
| Text-davinci-003 | 56.9 | **85.2** | 59.3 | 82.2 | 70.9 |
|Vicuna-13b 1.1 | 51.3 | 53.0 | 51.8 | 80.1 | 59.1 |
|Guanaco 30B | 57.6 | 63.7 | 50.7 | 85.1 | 64.3 |
| WizardLM-7B 1.0 | 42.7 | 51.6 | 44.7 | 77.7 | 54.2 |
| WizardLM-13B 1.0 | 52.3 | 57.2 | 50.5 | 81.0 | 60.2 |
| WizardLM-30B 1.0 | 58.8 | 62.5 | 52.4 | 83.3 | 64.2|
| Llama-2-7B-Chat | 48.3 | 52.9 | 45.6 | 78.6 | 56.4 |
| Llama-2-13B-Chat | 54.6 | 59.0 | 44.1 | 81.9 | 59.9 |
| Llama-2-70B-Chat | 63.9 | 64.6 | 52.8 | 85.9 | 66.8 |
| **Xwin-LM-7B-V0.1** | 49.7 | 56.2 | 48.1 | 79.5 | 58.4 |
| **Xwin-LM-13B-V0.1** | 56.6 | 62.4 | 45.5 | 83.0 | 61.9 |
| **Xwin-LM-70B-V0.1** | **69.6** | 70.5 | **60.1** | **87.1** | **71.8** |
## Inference
### Conversation templates
To obtain desired results, please strictly follow the conversation templates when utilizing our model for inference. Our model adopts the prompt format established by [Vicuna](https://github.com/lm-sys/FastChat) and is equipped to support **multi-turn** conversations.
```
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: Hi! ASSISTANT: Hello.</s>USER: Who are you? ASSISTANT: I am Xwin-LM.</s>......
```
### HuggingFace Example
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("Xwin-LM/Xwin-LM-7B-V0.1")
tokenizer = AutoTokenizer.from_pretrained("Xwin-LM/Xwin-LM-7B-V0.1")
(
prompt := "A chat between a curious user and an artificial intelligence assistant. "
"The assistant gives helpful, detailed, and polite answers to the user's questions. "
"USER: Hello, can you help me? "
"ASSISTANT:"
)
inputs = tokenizer(prompt, return_tensors="pt")
samples = model.generate(**inputs, max_new_tokens=4096, temperature=0.7)
output = tokenizer.decode(samples[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True)
print(output)
# Of course! I'm here to help. Please feel free to ask your question or describe the issue you're having, and I'll do my best to assist you.
```
### vllm Example
Because Xwin-LM is based on Llama2, it also offers support for rapid inference using [vllm](https://github.com/vllm-project/vllm). Please refer to [vllm](https://github.com/vllm-project/vllm) for detailed installation instructions.
```python
from vllm import LLM, SamplingParams
(
prompt := "A chat between a curious user and an artificial intelligence assistant. "
"The assistant gives helpful, detailed, and polite answers to the user's questions. "
"USER: Hello, can you help me? "
"ASSISTANT:"
)
sampling_params = SamplingParams(temperature=0.7, max_tokens=4096)
llm = LLM(model="Xwin-LM/Xwin-LM-7B-V0.1")
outputs = llm.generate([prompt,], sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(generated_text)
```
## TODO
- [ ] Release the source code
- [ ] Release more capabilities, such as math, reasoning, and etc.
## Citation
Please consider citing our work if you use the data or code in this repo.
```
@software{xwin-lm,
title = {Xwin-LM},
author = {Xwin-LM Team},
url = {https://github.com/Xwin-LM/Xwin-LM},
version = {pre-release},
year = {2023},
month = {9},
}
```
## Acknowledgements
Thanks to [Llama 2](https://ai.meta.com/llama/), [FastChat](https://github.com/lm-sys/FastChat), [AlpacaFarm](https://github.com/tatsu-lab/alpaca_farm), and [vllm](https://github.com/vllm-project/vllm).
<!-- original-model-card end -->
|
cenkersisman/gpt2-turkish-128-token | cenkersisman | 2024-03-29T02:14:02Z | 614 | 4 | transformers | [
"transformers",
"pytorch",
"tflite",
"safetensors",
"gpt2",
"text-generation",
"tr",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-10-08T09:15:31Z | ---
widget:
- text: 'fransa''nın başkenti'
example_title: fransa'nın başkenti
- text: 'ingiltere''nın başkenti'
example_title: ingiltere'nin başkenti
- text: 'italya''nın başkenti'
example_title: italya'nın başkenti
- text: 'moğolistan''ın başkenti'
example_title: moğolistan'ın başkenti
- text: 'amazon ormanlarının bulunduğu ülke olan'
example_title: amazon ormanlarının bulunduğu ülke olan
- text: 'avrupa''yı asya''ya bağlayan şehir'
example_title: avrupa'yı asya'ya bağlayan şehir
- text: 'zebraların yaşadığı kıta olan'
example_title: zebraların yaşadığı kıta olan
- text: 'fenerbahçe''nin ezeli rakibi olan'
example_title: fenerbahçe'nin ezeli rakibi olan
- text: 'tek bacaklı kurbağa'
example_title: tek bacaklı kurbağa
- text: 'rize''de yağmur'
example_title: rize'de yağmur
- text: 'hayatın anlamı'
example_title: hayatın anlamı
- text: 'saint-joseph'
example_title: saint-joseph
- text: 'renk isimleri şunlardır'
example_title: renk isimleri şunlardır
- text: 'iklim değişikliği'
example_title: iklim değişikliği
- text: 'tuzlu yiyecekler arasında'
example_title: tuzlu yiyecekler arasında
language:
- tr
---
# Model
GPT-2 Türkçe Modeli
### Model Açıklaması
GPT-2 Türkçe Modeli, Türkçe diline özelleştirilmiş olan GPT-2 mimarisi temel alınarak oluşturulmuş bir dil modelidir. Belirli bir başlangıç metni temel alarak insana benzer metinler üretme yeteneğine sahiptir ve geniş bir Türkçe metin veri kümesi üzerinde eğitilmiştir.
Modelin eğitimi için 900 milyon karakterli Vikipedi seti kullanılmıştır. Eğitim setindeki cümleler maksimum 128 tokendan (token = kelime kökü ve ekleri) oluşmuştur bu yüzden oluşturacağı cümlelerin boyu sınırlıdır..
Türkçe heceleme yapısına uygun tokenizer kullanılmış ve model 7.5 milyon adımda yaklaşık 154 epoch eğitilmiştir.
Eğitim için 4GB hafızası olan Nvidia Geforce RTX 3050 GPU kullanılmaktadır. 16GB Paylaşılan GPU'dan da yararlanılmakta ve eğitimin devamında toplamda 20GB hafıza kullanılmaktadır.
## Model Nasıl Kullanılabilir
ÖNEMLİ: model harf büyüklüğüne duyarlı olduğu için, prompt tamamen küçük harflerle yazılmalıdır.
```python
# Model ile çıkarım yapmak için örnek kod
from transformers import GPT2Tokenizer, GPT2LMHeadModel
model_name = "cenkersisman/gpt2-turkish-128-token"
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)
prompt = "okyanusun derinliklerinde bulunan"
input_ids = tokenizer.encode(prompt, return_tensors="pt")
output = model.generate(input_ids, max_length=100, pad_token_id=tokenizer.eos_token_id)
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(generated_text)
```
## Eğitim Süreci Eğrisi
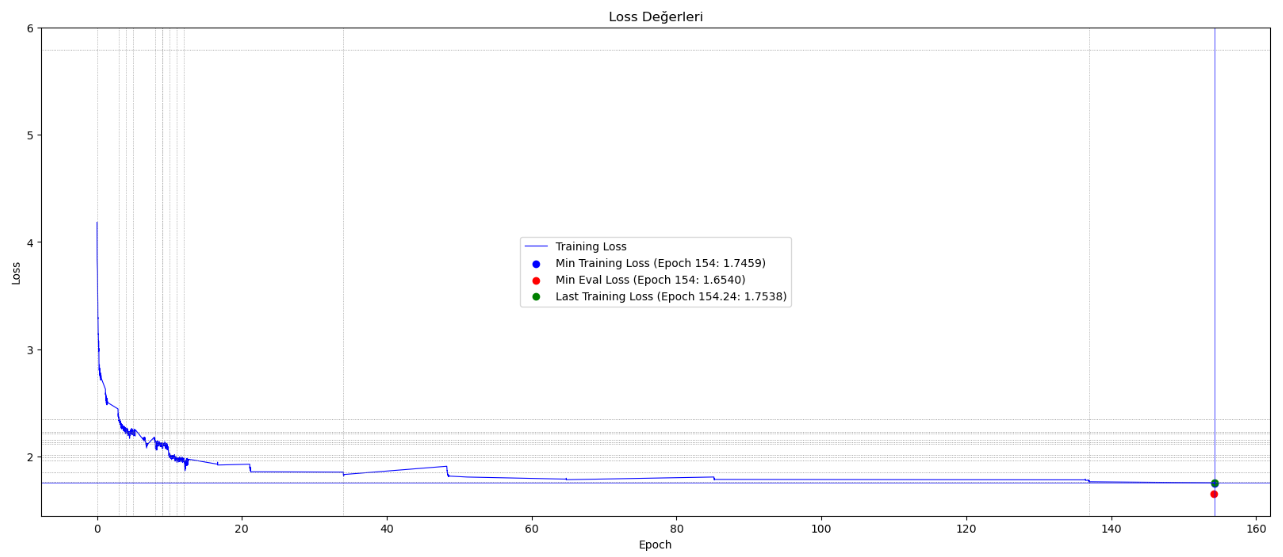
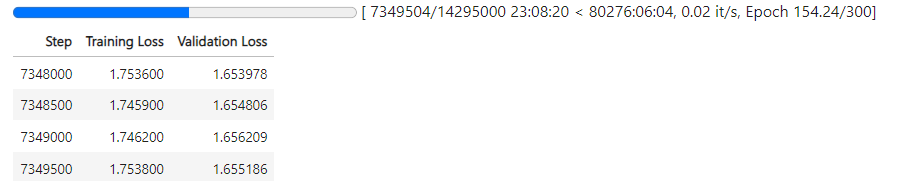
## Sınırlamalar ve Önyargılar
Bu model, bir özyineli dil modeli olarak eğitildi. Bu, temel işlevinin bir metin dizisi alıp bir sonraki belirteci tahmin etmek olduğu anlamına gelir. Dil modelleri bunun dışında birçok görev için yaygın olarak kullanılsa da, bu çalışmayla ilgili birçok bilinmeyen bulunmaktadır.
Model, küfür, açık saçıklık ve aksi davranışlara yol açan metinleri içerdiği bilinen bir veri kümesi üzerinde eğitildi. Kullanım durumunuza bağlı olarak, bu model toplumsal olarak kabul edilemez metinler üretebilir.
Tüm dil modellerinde olduğu gibi, bu modelin belirli bir girişe nasıl yanıt vereceğini önceden tahmin etmek zordur ve uyarı olmaksızın saldırgan içerik ortaya çıkabilir. Sonuçları yayınlamadan önce hem istenmeyen içeriği sansürlemek hem de sonuçların kalitesini iyileştirmek için insanların çıktıları denetlemesini veya filtrelemesi önerilir.
|
TheBloke/japanese-stablelm-instruct-beta-7B-GGUF | TheBloke | 2023-11-03T12:54:55Z | 614 | 1 | transformers | [
"transformers",
"gguf",
"llama",
"japanese-stablelm",
"causal-lm",
"text-generation",
"ja",
"dataset:kunishou/hh-rlhf-49k-ja",
"dataset:kunishou/databricks-dolly-15k-ja",
"dataset:kunishou/oasst1-89k-ja",
"base_model:stabilityai/japanese-stablelm-instruct-beta-7b",
"license:llama2",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-03T01:04:31Z | ---
base_model: stabilityai/japanese-stablelm-instruct-beta-7b
datasets:
- kunishou/hh-rlhf-49k-ja
- kunishou/databricks-dolly-15k-ja
- kunishou/oasst1-89k-ja
inference: false
language:
- ja
license:
- llama2
model_creator: Stability AI
model_name: Japanese StableLM Instruct Beta 7B
model_type: llama
pipeline_tag: text-generation
prompt_template: "<s>[INST] <<SYS>>\n\u3042\u306A\u305F\u306F\u5F79\u7ACB\u3064\u30A2\
\u30B7\u30B9\u30BF\u30F3\u30C8\u3067\u3059\u3002\n<<SYS>>\n\n{prompt} [/INST] \n"
quantized_by: TheBloke
tags:
- japanese-stablelm
- causal-lm
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Japanese StableLM Instruct Beta 7B - GGUF
- Model creator: [Stability AI](https://huggingface.co/stabilityai)
- Original model: [Japanese StableLM Instruct Beta 7B](https://huggingface.co/stabilityai/japanese-stablelm-instruct-beta-7b)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Stability AI's Japanese StableLM Instruct Beta 7B](https://huggingface.co/stabilityai/japanese-stablelm-instruct-beta-7b).
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/japanese-stablelm-instruct-beta-7B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/japanese-stablelm-instruct-beta-7B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/japanese-stablelm-instruct-beta-7B-GGUF)
* [Stability AI's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/stabilityai/japanese-stablelm-instruct-beta-7b)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Japanese-StableLM-Llama-2-Chat
```
<s>[INST] <<SYS>>
あなたは役立つアシスタントです。
<<SYS>>
{prompt} [/INST]
```
<!-- prompt-template end -->
<!-- licensing start -->
## Licensing
The creator of the source model has listed its license as `['llama2']`, and this quantization has therefore used that same license.
As this model is based on Llama 2, it is also subject to the Meta Llama 2 license terms, and the license files for that are additionally included. It should therefore be considered as being claimed to be licensed under both licenses. I contacted Hugging Face for clarification on dual licensing but they do not yet have an official position. Should this change, or should Meta provide any feedback on this situation, I will update this section accordingly.
In the meantime, any questions regarding licensing, and in particular how these two licenses might interact, should be directed to the original model repository: [Stability AI's Japanese StableLM Instruct Beta 7B](https://huggingface.co/stabilityai/japanese-stablelm-instruct-beta-7b).
<!-- licensing end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [japanese-stablelm-instruct-beta-7b.Q2_K.gguf](https://huggingface.co/TheBloke/japanese-stablelm-instruct-beta-7B-GGUF/blob/main/japanese-stablelm-instruct-beta-7b.Q2_K.gguf) | Q2_K | 2 | 2.83 GB| 5.33 GB | smallest, significant quality loss - not recommended for most purposes |
| [japanese-stablelm-instruct-beta-7b.Q3_K_S.gguf](https://huggingface.co/TheBloke/japanese-stablelm-instruct-beta-7B-GGUF/blob/main/japanese-stablelm-instruct-beta-7b.Q3_K_S.gguf) | Q3_K_S | 3 | 2.95 GB| 5.45 GB | very small, high quality loss |
| [japanese-stablelm-instruct-beta-7b.Q3_K_M.gguf](https://huggingface.co/TheBloke/japanese-stablelm-instruct-beta-7B-GGUF/blob/main/japanese-stablelm-instruct-beta-7b.Q3_K_M.gguf) | Q3_K_M | 3 | 3.30 GB| 5.80 GB | very small, high quality loss |
| [japanese-stablelm-instruct-beta-7b.Q3_K_L.gguf](https://huggingface.co/TheBloke/japanese-stablelm-instruct-beta-7B-GGUF/blob/main/japanese-stablelm-instruct-beta-7b.Q3_K_L.gguf) | Q3_K_L | 3 | 3.60 GB| 6.10 GB | small, substantial quality loss |
| [japanese-stablelm-instruct-beta-7b.Q4_0.gguf](https://huggingface.co/TheBloke/japanese-stablelm-instruct-beta-7B-GGUF/blob/main/japanese-stablelm-instruct-beta-7b.Q4_0.gguf) | Q4_0 | 4 | 3.83 GB| 6.33 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [japanese-stablelm-instruct-beta-7b.Q4_K_S.gguf](https://huggingface.co/TheBloke/japanese-stablelm-instruct-beta-7B-GGUF/blob/main/japanese-stablelm-instruct-beta-7b.Q4_K_S.gguf) | Q4_K_S | 4 | 3.86 GB| 6.36 GB | small, greater quality loss |
| [japanese-stablelm-instruct-beta-7b.Q4_K_M.gguf](https://huggingface.co/TheBloke/japanese-stablelm-instruct-beta-7B-GGUF/blob/main/japanese-stablelm-instruct-beta-7b.Q4_K_M.gguf) | Q4_K_M | 4 | 4.08 GB| 6.58 GB | medium, balanced quality - recommended |
| [japanese-stablelm-instruct-beta-7b.Q5_0.gguf](https://huggingface.co/TheBloke/japanese-stablelm-instruct-beta-7B-GGUF/blob/main/japanese-stablelm-instruct-beta-7b.Q5_0.gguf) | Q5_0 | 5 | 4.65 GB| 7.15 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [japanese-stablelm-instruct-beta-7b.Q5_K_S.gguf](https://huggingface.co/TheBloke/japanese-stablelm-instruct-beta-7B-GGUF/blob/main/japanese-stablelm-instruct-beta-7b.Q5_K_S.gguf) | Q5_K_S | 5 | 4.65 GB| 7.15 GB | large, low quality loss - recommended |
| [japanese-stablelm-instruct-beta-7b.Q5_K_M.gguf](https://huggingface.co/TheBloke/japanese-stablelm-instruct-beta-7B-GGUF/blob/main/japanese-stablelm-instruct-beta-7b.Q5_K_M.gguf) | Q5_K_M | 5 | 4.78 GB| 7.28 GB | large, very low quality loss - recommended |
| [japanese-stablelm-instruct-beta-7b.Q6_K.gguf](https://huggingface.co/TheBloke/japanese-stablelm-instruct-beta-7B-GGUF/blob/main/japanese-stablelm-instruct-beta-7b.Q6_K.gguf) | Q6_K | 6 | 5.53 GB| 8.03 GB | very large, extremely low quality loss |
| [japanese-stablelm-instruct-beta-7b.Q8_0.gguf](https://huggingface.co/TheBloke/japanese-stablelm-instruct-beta-7B-GGUF/blob/main/japanese-stablelm-instruct-beta-7b.Q8_0.gguf) | Q8_0 | 8 | 7.16 GB| 9.66 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/japanese-stablelm-instruct-beta-7B-GGUF and below it, a specific filename to download, such as: japanese-stablelm-instruct-beta-7b.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/japanese-stablelm-instruct-beta-7B-GGUF japanese-stablelm-instruct-beta-7b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/japanese-stablelm-instruct-beta-7B-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/japanese-stablelm-instruct-beta-7B-GGUF japanese-stablelm-instruct-beta-7b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m japanese-stablelm-instruct-beta-7b.Q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<s>[INST] <<SYS>>\nあなたは役立つアシスタントです。\n<<SYS>>\n\n{prompt} [/INST]"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/japanese-stablelm-instruct-beta-7B-GGUF", model_file="japanese-stablelm-instruct-beta-7b.Q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Stability AI's Japanese StableLM Instruct Beta 7B
# Japanese-StableLM-Instruct-Beta-7B

> A cute robot wearing a kimono writes calligraphy with one single brush — [Stable Diffusion XL](https://clipdrop.co/stable-diffusion)
## Model Description
`japanese-stablelm-instruct-beta-7b` is a 7B-parameter decoder-only language model based on [japanese-stablelm-base-beta-7b](https://huggingface.co/stabilityai/japanese-stablelm-base-beta-7b) and further fine tuned on Databricks Dolly-15k, Anthropic HH, and other public data.
This model is also available in a [larger 70b version](https://huggingface.co/stabilityai/japanese-stablelm-instruct-beta-70b), or a [faster version with a specialized tokenizer](https://huggingface.co/stabilityai/japanese-stablelm-instruct-ja_vocab-beta-7b).
## Usage
First install additional dependencies in [requirements.txt](./requirements.txt):
```sh
pip install -r requirements.txt
```
Then start generating text with `japanese-stablelm-instruct-beta-7b` by using the following code snippet:
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "stabilityai/japanese-stablelm-instruct-beta-7b"
tokenizer = AutoTokenizer.from_pretrained(model_name)
# The next line may need to be modified depending on the environment
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16, low_cpu_mem_usage=True, device_map="auto")
def build_prompt(user_query, inputs):
sys_msg = "<s>[INST] <<SYS>>\nあなたは役立つアシスタントです。\n<<SYS>>\n\n"
p = sys_msg + user_query + "\n\n" + inputs + " [/INST] "
return p
user_inputs = {
"user_query": "与えられたことわざの意味を小学生でも分かるように教えてください。",
"inputs": "情けは人のためならず"
}
prompt = build_prompt(**user_inputs)
input_ids = tokenizer.encode(
prompt,
add_special_tokens=False,
return_tensors="pt"
)
# this is for reproducibility.
# feel free to change to get different result
seed = 23
torch.manual_seed(seed)
tokens = model.generate(
input_ids.to(device=model.device),
max_new_tokens=128,
temperature=0.99,
top_p=0.95,
do_sample=True,
)
out = tokenizer.decode(tokens[0], skip_special_tokens=True)
print(out)
```
We suggest playing with different generation config (`top_p`, `repetition_penalty` etc) to find the best setup for your tasks. For example, use higher temperature for roleplay task, lower temperature for reasoning.
## Model Details
* **Model type**: `japanese-stablelm-instruct-beta-7b` model is an auto-regressive language model based on the Llama2 transformer architecture.
* **Language(s)**: Japanese
* **License**: [Llama2 Community License](https://ai.meta.com/llama/license/).
* **Contact**: For questions and comments about the model, please join [Stable Community Japan](https://discord.gg/StableJP). For future announcements / information about Stability AI models, research, and events, please follow https://twitter.com/StabilityAI_JP.
## Training Dataset
The following datasets were used for the instruction training. Note these are Japanese translated versions of the original datasets, shared by [kunishou](https://huggingface.co/kunishou).
- [Anthropic HH-RLHF](https://huggingface.co/datasets/kunishou/hh-rlhf-49k-ja)
- [Databricks Dolly 15-k](https://huggingface.co/datasets/kunishou/databricks-dolly-15k-ja)
- [OpenAssistant Conversations Dataset](https://huggingface.co/datasets/kunishou/oasst1-89k-ja)
## Use and Limitations
### Intended Use
The model is intended to be used by all individuals as a foundation for application-specific fine-tuning without strict limitations on commercial use.
### Limitations and bias
The pre-training dataset may have contained offensive or inappropriate content even after applying data cleansing filters which can be reflected in the model generated text. We recommend users exercise reasonable caution when using these models in production systems. Do not use the model for any applications that may cause harm or distress to individuals or groups.
## Authors
This model was developed by the Research & Development team at Stability AI Japan, and the development was co-led by [Takuya Akiba](https://huggingface.co/iwiwi) and [Meng Lee](https://huggingface.co/leemeng). The members of the team are as follows:
- [Meng Lee](https://huggingface.co/leemeng)
- [Fujiki Nakamura](https://huggingface.co/fujiki)
- [Makoto Shing](https://huggingface.co/mkshing)
- [Paul McCann](https://huggingface.co/polm-stability)
- [Takuya Akiba](https://huggingface.co/iwiwi)
- [Naoki Orii](https://huggingface.co/mrorii)
## Acknowledgements
We thank Meta Research for releasing Llama 2 under an open license for others to build on.
We are grateful for the contributions of the EleutherAI Polyglot-JA team in helping us to collect a large amount of pre-training data in Japanese. Polyglot-JA members includes Hyunwoong Ko (Project Lead), Fujiki Nakamura (originally started this project when he commited to the Polyglot team), Yunho Mo, Minji Jung, KeunSeok Im, and Su-Kyeong Jang.
We are also appreciative of [AI Novelist/Sta (Bit192, Inc.)](https://ai-novel.com/index.php) and the numerous contributors from [Stable Community Japan](https://discord.gg/VPrcE475HB) for assisting us in gathering a large amount of high-quality Japanese textual data for model training.
<!-- original-model-card end -->
|
lsr42/d2s_mscoco-blip-dense_q_reg_0.001_d_reg_0.001 | lsr42 | 2024-01-03T01:37:43Z | 614 | 0 | transformers | [
"transformers",
"safetensors",
"d2s",
"endpoints_compatible",
"region:us"
] | null | 2024-01-03T01:37:36Z | Entry not found |
mradermacher/Nutopia-7B-GGUF | mradermacher | 2024-05-06T06:00:57Z | 614 | 1 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:Alsebay/Nutopia-7B",
"endpoints_compatible",
"region:us"
] | null | 2024-03-24T09:46:49Z | ---
base_model: Alsebay/Nutopia-7B
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
static quants of https://huggingface.co/Alsebay/Nutopia-7B
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Nutopia-7B-GGUF/resolve/main/Nutopia-7B.Q2_K.gguf) | Q2_K | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/Nutopia-7B-GGUF/resolve/main/Nutopia-7B.IQ3_XS.gguf) | IQ3_XS | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Nutopia-7B-GGUF/resolve/main/Nutopia-7B.Q3_K_S.gguf) | Q3_K_S | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/Nutopia-7B-GGUF/resolve/main/Nutopia-7B.IQ3_S.gguf) | IQ3_S | 3.4 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Nutopia-7B-GGUF/resolve/main/Nutopia-7B.IQ3_M.gguf) | IQ3_M | 3.5 | |
| [GGUF](https://huggingface.co/mradermacher/Nutopia-7B-GGUF/resolve/main/Nutopia-7B.Q3_K_M.gguf) | Q3_K_M | 3.8 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Nutopia-7B-GGUF/resolve/main/Nutopia-7B.Q3_K_L.gguf) | Q3_K_L | 4.1 | |
| [GGUF](https://huggingface.co/mradermacher/Nutopia-7B-GGUF/resolve/main/Nutopia-7B.IQ4_XS.gguf) | IQ4_XS | 4.2 | |
| [GGUF](https://huggingface.co/mradermacher/Nutopia-7B-GGUF/resolve/main/Nutopia-7B.Q4_0.gguf) | Q4_0 | 4.4 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Nutopia-7B-GGUF/resolve/main/Nutopia-7B.Q4_K_S.gguf) | Q4_K_S | 4.4 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Nutopia-7B-GGUF/resolve/main/Nutopia-7B.IQ4_NL.gguf) | IQ4_NL | 4.4 | prefer IQ4_XS |
| [GGUF](https://huggingface.co/mradermacher/Nutopia-7B-GGUF/resolve/main/Nutopia-7B.Q4_K_M.gguf) | Q4_K_M | 4.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Nutopia-7B-GGUF/resolve/main/Nutopia-7B.Q5_K_S.gguf) | Q5_K_S | 5.3 | |
| [GGUF](https://huggingface.co/mradermacher/Nutopia-7B-GGUF/resolve/main/Nutopia-7B.Q5_K_M.gguf) | Q5_K_M | 5.4 | |
| [GGUF](https://huggingface.co/mradermacher/Nutopia-7B-GGUF/resolve/main/Nutopia-7B.Q6_K.gguf) | Q6_K | 6.2 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Nutopia-7B-GGUF/resolve/main/Nutopia-7B.Q8_0.gguf) | Q8_0 | 7.9 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
MohamedRashad/Arabic-Orpo-Llama-3-8B-Instruct-GGUF | MohamedRashad | 2024-05-01T06:40:44Z | 614 | 1 | null | [
"gguf",
"text-generation",
"ar",
"license:llama3",
"region:us"
] | text-generation | 2024-04-29T10:03:27Z | ---
license: llama3
language:
- ar
pipeline_tag: text-generation
tags: [gguf]
---
# The GGUF Version
<center>
<img src="https://cdn-uploads.huggingface.co/production/uploads/6116d0584ef9fdfbf45dc4d9/QqnmEUN3c3fvnnDlFVfUV.png">
</center>
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [ollama](https://github.com/ollama/ollama). **Recommended**
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration. Linux available, in beta as of 27/11/2023.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [GPT4All](https://gpt4all.io/index.html), a free and open source local running GUI, supporting Windows, Linux and macOS with full GPU accel.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server. Note, as of time of writing (November 27th 2023), ctransformers has not been updated in a long time and does not support many recent models.
|
paulagarciaserrano/roberta-depression-detection | paulagarciaserrano | 2022-05-05T13:42:30Z | 613 | 3 | transformers | [
"transformers",
"pytorch",
"roberta",
"text-classification",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-04-15T16:34:06Z | ---
language: "en"
datasets:
- Shared task on Detecting Signs of Depression from Social Media Text at LT-EDI 2022-ACL 2022
metrics:
- Macro F1-Score
---
# Roberta for depression signs detection
This model is a fine-tuned version the <a href="https://huggingface.co/cardiffnlp/twitter-roberta-base">cardiffnlp/twitter-roberta-base</a> model. It has been trained using a recently published corpus: <a href="https://competitions.codalab.org/competitions/36410#learn_the_details">Shared task on Detecting Signs of Depression from Social Media Text at LT-EDI 2022-ACL 2022</a>.
The obtained macro f1-score is 0.54, on the development set of the competition.
# Intended uses
This model is trained to classify the given text into one of the following classes: *moderate*, *severe*, or *not depression*.
It corresponds to a **multiclass classification** task.
# How to use
You can use this model directly with a pipeline for text classification:
```python
>>> from transformers import pipeline
>>> classifier = pipeline("text-classification", model="paulagarciaserrano/roberta-depression-detection")
>>> your_text = "I am very sad."
>>> classifier (your_text)
```
# Training and evaluation data
The **train** dataset characteristics are:
<table>
<tr>
<th>Class</th>
<th>Nº sentences</th>
<th>Avg. document length (in sentences)</th>
<th>Nº words</th>
<th>Avg. sentence length (in words)</th>
</tr>
<tr>
<th>not depression</th>
<td>7,884</td>
<td>4</td>
<td>153,738</td>
<td>78</td>
</tr>
<tr>
<th>moderate</th>
<td>36,114</td>
<td>6</td>
<td>601,900</td>
<td>100</td>
</tr>
<tr>
<th>severe</th>
<td>9,911</td>
<td>11</td>
<td>126,140</td>
<td>140</td>
</tr>
</table>
Similarly, the **evaluation** dataset characteristics are:
<table>
<tr>
<th>Class</th>
<th>Nº sentences</th>
<th>Avg. document length (in sentences)</th>
<th>Nº words</th>
<th>Avg. sentence length (in words)</th>
</tr>
<tr>
<th>not depression</th>
<td>3,660</td>
<td>2</td>
<td>10,980</td>
<td>6</td>
</tr>
<tr>
<th>moderate</th>
<td>66,874</td>
<td>29</td>
<td>804,794</td>
<td>349</td>
</tr>
<tr>
<th>severe</th>
<td>2,880</td>
<td>8</td>
<td>75,240</td>
<td>209</td>
</tr>
</table>
# Training hyperparameters
The following hyperparameters were used during training:
* learning_rate: 2e-05
* evaluation_strategy: epoch
* save_strategy: epoch
* per_device_train_batch_size: 8
* per_device_eval_batch_size: 8
* num_train_epochs: 5
* seed: 10
* weight_decay: 0.01
* metric_for_best_model: macro-f1 |
VvVitekVvV/everlasting_summer_small | VvVitekVvV | 2023-03-14T19:35:02Z | 613 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"ru",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2022-11-27T20:28:17Z | ---
language:
- ru
widget:
- text: " scene bg "
inference:
parameters:
top_k: 5
temperature: 0.95
max_new_tokens: 128
---
# Everalasting Summer Small Model
Модель на основе ruGPT3Small для создания скриптов визуальной новеллы "Бесконечное лето".
|
timm/tinynet_b.in1k | timm | 2023-04-27T21:50:23Z | 613 | 0 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2010.14819",
"license:apache-2.0",
"region:us"
] | image-classification | 2022-12-13T00:22:06Z | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for tinynet_b.in1k
A TinyNet image classification model. Trained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 3.7
- GMACs: 0.2
- Activations (M): 4.4
- Image size: 188 x 188
- **Papers:**
- Model rubik's cube: Twisting resolution, depth and width for tinynets: https://arxiv.org/abs/2010.14819v2
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('tinynet_b.in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tinynet_b.in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 16, 94, 94])
# torch.Size([1, 24, 47, 47])
# torch.Size([1, 32, 24, 24])
# torch.Size([1, 88, 12, 12])
# torch.Size([1, 240, 6, 6])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tinynet_b.in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1280, 6, 6) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{han2020model,
title={Model rubik’s cube: Twisting resolution, depth and width for tinynets},
author={Han, Kai and Wang, Yunhe and Zhang, Qiulin and Zhang, Wei and Xu, Chunjing and Zhang, Tong},
journal={Advances in Neural Information Processing Systems},
volume={33},
pages={19353--19364},
year={2020}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
|
keremberke/yolov5m-smoke | keremberke | 2023-01-05T00:14:40Z | 613 | 7 | yolov5 | [
"yolov5",
"tensorboard",
"yolo",
"vision",
"object-detection",
"pytorch",
"dataset:keremberke/smoke-object-detection",
"model-index",
"region:us"
] | object-detection | 2023-01-05T00:13:29Z |
---
tags:
- yolov5
- yolo
- vision
- object-detection
- pytorch
library_name: yolov5
library_version: 7.0.6
inference: false
datasets:
- keremberke/smoke-object-detection
model-index:
- name: keremberke/yolov5m-smoke
results:
- task:
type: object-detection
dataset:
type: keremberke/smoke-object-detection
name: keremberke/smoke-object-detection
split: validation
metrics:
- type: precision # since [email protected] is not available on hf.co/metrics
value: 0.994733145048949 # min: 0.0 - max: 1.0
name: [email protected]
---
<div align="center">
<img width="640" alt="keremberke/yolov5m-smoke" src="https://huggingface.co/keremberke/yolov5m-smoke/resolve/main/sample_visuals.jpg">
</div>
### How to use
- Install [yolov5](https://github.com/fcakyon/yolov5-pip):
```bash
pip install -U yolov5
```
- Load model and perform prediction:
```python
import yolov5
# load model
model = yolov5.load('keremberke/yolov5m-smoke')
# set model parameters
model.conf = 0.25 # NMS confidence threshold
model.iou = 0.45 # NMS IoU threshold
model.agnostic = False # NMS class-agnostic
model.multi_label = False # NMS multiple labels per box
model.max_det = 1000 # maximum number of detections per image
# set image
img = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model(img, size=640)
# inference with test time augmentation
results = model(img, augment=True)
# parse results
predictions = results.pred[0]
boxes = predictions[:, :4] # x1, y1, x2, y2
scores = predictions[:, 4]
categories = predictions[:, 5]
# show detection bounding boxes on image
results.show()
# save results into "results/" folder
results.save(save_dir='results/')
```
- Finetune the model on your custom dataset:
```bash
yolov5 train --data data.yaml --img 640 --batch 16 --weights keremberke/yolov5m-smoke --epochs 10
```
|
DunnBC22/trocr-base-printed_captcha_ocr | DunnBC22 | 2023-08-25T03:14:45Z | 613 | 5 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"vision-encoder-decoder",
"generated_from_trainer",
"image-to-text",
"en",
"endpoints_compatible",
"region:us"
] | image-to-text | 2023-01-13T04:55:50Z | ---
tags:
- generated_from_trainer
model-index:
- name: trocr-base-printed_captcha_ocr
results: []
language:
- en
metrics:
- cer
pipeline_tag: image-to-text
---
# trocr-base-printed_captcha_ocr
This model is a fine-tuned version of [microsoft/trocr-base-printed](https://huggingface.co/microsoft/trocr-base-printed) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1380
- Cer: 0.0075
## Model description
This model extracts text from image Captcha inputs.
For more information on how it was created, check out the following link: https://github.com/DunnBC22/Vision_Audio_and_Multimodal_Projects/blob/main/Optical%20Character%20Recognition%20(OCR)/Captcha/OCR_captcha.ipynb
## Intended uses & limitations
This model is intended to demonstrate my ability to solve a complex problem using technology. You are welcome to test and experiment with this model, but it is at your own risk/peril.
## Training and evaluation data
Dataset Source: https://www.kaggle.com/datasets/alizahidraja/captcha-data
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Cer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 10.4464 | 1.0 | 107 | 0.5615 | 0.0879 |
| 10.4464 | 2.0 | 214 | 0.2432 | 0.0262 |
| 10.4464 | 3.0 | 321 | 0.1380 | 0.0075 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1
- Datasets 2.4.0
- Tokenizers 0.12.1 |
TheBloke/FlatDolphinMaid-8x7B-GGUF | TheBloke | 2024-01-03T23:47:27Z | 613 | 16 | transformers | [
"transformers",
"gguf",
"mixtral",
"not-for-all-audiences",
"nsfw",
"base_model:Undi95/FlatDolphinMaid-8x7B",
"license:cc-by-nc-4.0",
"text-generation-inference",
"region:us"
] | null | 2024-01-03T23:27:50Z | ---
base_model: Undi95/FlatDolphinMaid-8x7B
inference: false
license: cc-by-nc-4.0
model_creator: Undi
model_name: FlatDolphinMaid 8X7B
model_type: mixtral
prompt_template: '### Instruction:
{system_message}
### Input:
{prompt}
### Response:
'
quantized_by: TheBloke
tags:
- not-for-all-audiences
- nsfw
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# FlatDolphinMaid 8X7B - GGUF
- Model creator: [Undi](https://huggingface.co/Undi95)
- Original model: [FlatDolphinMaid 8X7B](https://huggingface.co/Undi95/FlatDolphinMaid-8x7B)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Undi's FlatDolphinMaid 8X7B](https://huggingface.co/Undi95/FlatDolphinMaid-8x7B).
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [GPT4All](https://gpt4all.io/index.html), a free and open source local running GUI, supporting Windows, Linux and macOS with full GPU accel.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration. Linux available, in beta as of 27/11/2023.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server. Note, as of time of writing (November 27th 2023), ctransformers has not been updated in a long time and does not support many recent models.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/FlatDolphinMaid-8x7B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/FlatDolphinMaid-8x7B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/FlatDolphinMaid-8x7B-GGUF)
* [Undi's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/Undi95/FlatDolphinMaid-8x7B)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Instruction-Input-Response
```
### Instruction:
{system_message}
### Input:
{prompt}
### Response:
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [flatdolphinmaid-8x7b.Q2_K.gguf](https://huggingface.co/TheBloke/FlatDolphinMaid-8x7B-GGUF/blob/main/flatdolphinmaid-8x7b.Q2_K.gguf) | Q2_K | 2 | 15.64 GB| 18.14 GB | smallest, significant quality loss - not recommended for most purposes |
| [flatdolphinmaid-8x7b.Q3_K_M.gguf](https://huggingface.co/TheBloke/FlatDolphinMaid-8x7B-GGUF/blob/main/flatdolphinmaid-8x7b.Q3_K_M.gguf) | Q3_K_M | 3 | 20.36 GB| 22.86 GB | very small, high quality loss |
| [flatdolphinmaid-8x7b.Q4_0.gguf](https://huggingface.co/TheBloke/FlatDolphinMaid-8x7B-GGUF/blob/main/flatdolphinmaid-8x7b.Q4_0.gguf) | Q4_0 | 4 | 26.44 GB| 28.94 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [flatdolphinmaid-8x7b.Q4_K_M.gguf](https://huggingface.co/TheBloke/FlatDolphinMaid-8x7B-GGUF/blob/main/flatdolphinmaid-8x7b.Q4_K_M.gguf) | Q4_K_M | 4 | 26.44 GB| 28.94 GB | medium, balanced quality - recommended |
| [flatdolphinmaid-8x7b.Q5_0.gguf](https://huggingface.co/TheBloke/FlatDolphinMaid-8x7B-GGUF/blob/main/flatdolphinmaid-8x7b.Q5_0.gguf) | Q5_0 | 5 | 32.23 GB| 34.73 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [flatdolphinmaid-8x7b.Q5_K_M.gguf](https://huggingface.co/TheBloke/FlatDolphinMaid-8x7B-GGUF/blob/main/flatdolphinmaid-8x7b.Q5_K_M.gguf) | Q5_K_M | 5 | 32.23 GB| 34.73 GB | large, very low quality loss - recommended |
| [flatdolphinmaid-8x7b.Q6_K.gguf](https://huggingface.co/TheBloke/FlatDolphinMaid-8x7B-GGUF/blob/main/flatdolphinmaid-8x7b.Q6_K.gguf) | Q6_K | 6 | 38.38 GB| 40.88 GB | very large, extremely low quality loss |
| [flatdolphinmaid-8x7b.Q8_0.gguf](https://huggingface.co/TheBloke/FlatDolphinMaid-8x7B-GGUF/blob/main/flatdolphinmaid-8x7b.Q8_0.gguf) | Q8_0 | 8 | 49.63 GB| 52.13 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/FlatDolphinMaid-8x7B-GGUF and below it, a specific filename to download, such as: flatdolphinmaid-8x7b.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/FlatDolphinMaid-8x7B-GGUF flatdolphinmaid-8x7b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage (click to read)</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/FlatDolphinMaid-8x7B-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/FlatDolphinMaid-8x7B-GGUF flatdolphinmaid-8x7b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 35 -m flatdolphinmaid-8x7b.Q4_K_M.gguf --color -c 32768 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "### Instruction:\n{system_message}\n\n### Input:\n{prompt}\n\n### Response:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 32768` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically. Note that longer sequence lengths require much more resources, so you may need to reduce this value.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions can be found in the text-generation-webui documentation, here: [text-generation-webui/docs/04 ‐ Model Tab.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/04%20%E2%80%90%20Model%20Tab.md#llamacpp).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries. Note that at the time of writing (Nov 27th 2023), ctransformers has not been updated for some time and is not compatible with some recent models. Therefore I recommend you use llama-cpp-python.
### How to load this model in Python code, using llama-cpp-python
For full documentation, please see: [llama-cpp-python docs](https://abetlen.github.io/llama-cpp-python/).
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install llama-cpp-python
# With NVidia CUDA acceleration
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
# Or with OpenBLAS acceleration
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install llama-cpp-python
# Or with CLBLast acceleration
CMAKE_ARGS="-DLLAMA_CLBLAST=on" pip install llama-cpp-python
# Or with AMD ROCm GPU acceleration (Linux only)
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
# Or with Metal GPU acceleration for macOS systems only
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
# In windows, to set the variables CMAKE_ARGS in PowerShell, follow this format; eg for NVidia CUDA:
$env:CMAKE_ARGS = "-DLLAMA_OPENBLAS=on"
pip install llama-cpp-python
```
#### Simple llama-cpp-python example code
```python
from llama_cpp import Llama
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = Llama(
model_path="./flatdolphinmaid-8x7b.Q4_K_M.gguf", # Download the model file first
n_ctx=32768, # The max sequence length to use - note that longer sequence lengths require much more resources
n_threads=8, # The number of CPU threads to use, tailor to your system and the resulting performance
n_gpu_layers=35 # The number of layers to offload to GPU, if you have GPU acceleration available
)
# Simple inference example
output = llm(
"### Instruction:\n{system_message}\n\n### Input:\n{prompt}\n\n### Response:", # Prompt
max_tokens=512, # Generate up to 512 tokens
stop=["</s>"], # Example stop token - not necessarily correct for this specific model! Please check before using.
echo=True # Whether to echo the prompt
)
# Chat Completion API
llm = Llama(model_path="./flatdolphinmaid-8x7b.Q4_K_M.gguf", chat_format="llama-2") # Set chat_format according to the model you are using
llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are a story writing assistant."},
{
"role": "user",
"content": "Write a story about llamas."
}
]
)
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Michael Levine, 阿明, Trailburnt, Nikolai Manek, John Detwiler, Randy H, Will Dee, Sebastain Graf, NimbleBox.ai, Eugene Pentland, Emad Mostaque, Ai Maven, Jim Angel, Jeff Scroggin, Michael Davis, Manuel Alberto Morcote, Stephen Murray, Robert, Justin Joy, Luke @flexchar, Brandon Frisco, Elijah Stavena, S_X, Dan Guido, Undi ., Komninos Chatzipapas, Shadi, theTransient, Lone Striker, Raven Klaugh, jjj, Cap'n Zoog, Michel-Marie MAUDET (LINAGORA), Matthew Berman, David, Fen Risland, Omer Bin Jawed, Luke Pendergrass, Kalila, OG, Erik Bjäreholt, Rooh Singh, Joseph William Delisle, Dan Lewis, TL, John Villwock, AzureBlack, Brad, Pedro Madruga, Caitlyn Gatomon, K, jinyuan sun, Mano Prime, Alex, Jeffrey Morgan, Alicia Loh, Illia Dulskyi, Chadd, transmissions 11, fincy, Rainer Wilmers, ReadyPlayerEmma, knownsqashed, Mandus, biorpg, Deo Leter, Brandon Phillips, SuperWojo, Sean Connelly, Iucharbius, Jack West, Harry Royden McLaughlin, Nicholas, terasurfer, Vitor Caleffi, Duane Dunston, Johann-Peter Hartmann, David Ziegler, Olakabola, Ken Nordquist, Trenton Dambrowitz, Tom X Nguyen, Vadim, Ajan Kanaga, Leonard Tan, Clay Pascal, Alexandros Triantafyllidis, JM33133, Xule, vamX, ya boyyy, subjectnull, Talal Aujan, Alps Aficionado, wassieverse, Ari Malik, James Bentley, Woland, Spencer Kim, Michael Dempsey, Fred von Graf, Elle, zynix, William Richards, Stanislav Ovsiannikov, Edmond Seymore, Jonathan Leane, Martin Kemka, usrbinkat, Enrico Ros
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Undi's FlatDolphinMaid 8X7B
First experimental merge of Noromaid 8x7b (Instruct) and dolphin 8x7b. The idea behind this is to add a little more IQ to the model, because Noromaid was only trained on RP/ERP data. Dolphin 2.7 is the only real Mixtral finetune I consider "usable", and so the merging quest begin again kek.
Merged Dolphin 2.7 with Mixtral Base (Dolphin was at 1.0 weight) to get rid of ChatLM, and then I merged Noromaid 8x7b with the output, SLERP method.
This model feel better on the IQ chart and have the ~same average ERP score on ayumi bench' than Noromaid 8x7b, but it's softer and more prude too, it also have the typical Mixtral repeat issue at some point. Choose your poison.

<!-- description start -->
## Description
This repo contains fp16 files of FlatDolphinMaid-8x7B.
<!-- description end -->
<!-- description start -->
## Models used
- [mistralai/Mixtral-8x7B-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-v0.1)
- [cognitivecomputations/dolphin-2.7-mixtral-8x7b](https://huggingface.co/cognitivecomputations/dolphin-2.7-mixtral-8x7b)
- [NeverSleep/Noromaid-v0.1-mixtral-8x7b-Instruct-v3](https://huggingface.co/NeverSleep/Noromaid-v0.1-mixtral-8x7b-Instruct-v3)
<!-- description end -->
<!-- prompt-template start -->
### Custom format:
```
### Instruction:
{system prompt}
### Input:
{input}
### Response:
{reply}
```
If you want to support me, you can [here](https://ko-fi.com/undiai).
<!-- original-model-card end -->
|
ven1228/5Enh9hfP4p99SeinWKnoLsUkF2t3cSv8ZSDZavyq99gBY562_vgg | ven1228 | 2024-03-11T12:44:36Z | 613 | 0 | keras | [
"keras",
"region:us"
] | null | 2024-03-05T05:38:56Z | Entry not found |
IrbisAI/Irbis-7b-v0.1 | IrbisAI | 2024-06-29T21:11:31Z | 613 | 13 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"kk",
"ru",
"en",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-03-31T15:29:43Z | ---
language:
- kk
- ru
- en
license: mit
library_name: transformers
pipeline_tag: text-generation
---
# Irbis-7B
<img src="./irbis.jpg" width="800"/>
Irbis-7B - это языковая модель на основе архитектуры трансформеров, адаптированная для казахского языка.
- Улучшенный токенизатор - словарь токенизатора был расширен с 32к до 60к токенов, включая больше казахских слов, что улучшило эффективность токенизации для казахского языка.
- Предварительное обучение - модель была предобучена на 20 ГБ преимущственно казахских и немного русских текстов для настройки с новым токенизатором.
В результате модель показывает значительно лучшее качество работы с казахским языком по сравнению с прочими моделями из открытых источников. За счет нового токенизатора увеличилась скорость генерации текста в 3-4 раза, также оптимизировалось заполнение контекстного окна.
Подробнее можно почитать в [статье](https://habr.com/ru/articles/825574/).
## Попробовать
```python
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
import torch
model_name = "IrbisAI/Irbis-7b-v0.1"
model = AutoModelForCausalLM.from_pretrained(
model_name,
return_dict=True,
torch_dtype=torch.float16,
device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Сұрақ: Шөп неге жасыл?\nЖауап: "
input_ids = tokenizer([prompt], return_tensors = "pt")["input_ids"].to("cuda")
generation_config = GenerationConfig(
temperature=0.6,
repetition_penalty=1.15
)
print("Generating...")
generation_output = model.generate(
input_ids=input_ids,
generation_config=generation_config,
return_dict_in_generate=True,
output_scores=True,
max_new_tokens=2048,
pad_token_id=tokenizer.eos_token_id,
)
for s in generation_output.sequences:
print(tokenizer.decode(s)) # Өсімдіктер ауасыз өмір сүре алмайды, сондықтан олар жасыл түсті болады.
``` |
chujiezheng/Llama3-8B-Chinese-Chat-ExPO | chujiezheng | 2024-05-27T18:24:18Z | 613 | 1 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"en",
"zh",
"arxiv:2404.16792",
"license:llama3",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-05-25T06:40:01Z | ---
license: llama3
language:
- en
- zh
---
# Llama3-8B-Chinese-Chat-ExPO
The extrapolated (ExPO) model based on [`shenzhi-wang/Llama3-8B-Chinese-Chat`](https://huggingface.co/shenzhi-wang/Llama3-8B-Chinese-Chat) and [`meta-llama/Meta-Llama-3-8B-Instruct`](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct), as in the "[Weak-to-Strong Extrapolation Expedites Alignment](https://arxiv.org/abs/2404.16792)" paper.
Specifically, we obtain this model by extrapolating **(alpha = 0.3)** from the weights of the SFT and DPO/RLHF checkpoints, achieving superior alignment with human preference.
**Note:** This is an experimental model, as I have not comprehensively evaluated its Chinese ability. **Unexpected issues may occur when we apply extrapolation to the DPO/RLHF alignment training for new languages (e.g., Chinese).**
## Evaluation Results
Evaluation results on the **AlpacaEval 2.0** benchmark (you can find the evaluation outputs on the [official GitHub repo](https://github.com/chujiezheng/LLM-Extrapolation/tree/main/results_alpaca)):
| | Win Rate (Ori) | LC Win Rate (Ori) | Win Rate (+ ExPO) | LC Win Rate (+ ExPO) |
| ------------------------------------ | -------------- | ----------------- | ----------------- | -------------------- |
| `HuggingFaceH4/zephyr-7b-alpha` | 6.7% | 10.0% | **10.6%** | **13.6%** |
| `HuggingFaceH4/zephyr-7b-beta` | 10.2% | 13.2% | **11.1%** | **14.0%** |
| `berkeley-nest/Starling-LM-7B-alpha` | 15.0% | 18.3% | **18.2%** | **19.5%** |
| `Nexusflow/Starling-LM-7B-beta` | 26.6% | 25.8% | **29.6%** | **26.4%** |
| `snorkelai/Snorkel-Mistral-PairRM` | 24.7% | 24.0% | **28.8%** | **26.4%** |
| `RLHFlow/LLaMA3-iterative-DPO-final` | 29.2% | 36.0% | **32.7%** | **37.8%** |
| `internlm/internlm2-chat-1.8b` | 3.8% | 4.0% | **5.2%** | **4.3%** |
| `internlm/internlm2-chat-7b` | 20.5% | 18.3% | **28.1%** | **22.7%** |
| `internlm/internlm2-chat-20b` | 36.1% | 24.9% | **46.2%** | **27.2%** |
| `allenai/tulu-2-dpo-7b` | 8.5% | 10.2% | **11.5%** | **11.7%** |
| `allenai/tulu-2-dpo-13b` | 11.2% | 15.5% | **15.6%** | **17.6%** |
| `allenai/tulu-2-dpo-70b` | 15.4% | 21.2% | **23.0%** | **25.7%** |
Evaluation results on the **MT-Bench** benchmark (you can find the evaluation outputs on the [official GitHub repo](https://github.com/chujiezheng/LLM-Extrapolation/tree/main/results_mtbench)):
| | Original | + ExPO |
| ------------------------------------ | -------- | -------- |
| `HuggingFaceH4/zephyr-7b-alpha` | 6.85 | **6.87** |
| `HuggingFaceH4/zephyr-7b-beta` | 7.02 | **7.06** |
| `berkeley-nest/Starling-LM-7B-alpha` | 7.82 | **7.91** |
| `Nexusflow/Starling-LM-7B-beta` | 8.10 | **8.18** |
| `snorkelai/Snorkel-Mistral-PairRM` | 7.63 | **7.69** |
| `RLHFlow/LLaMA3-iterative-DPO-final` | 8.08 | **8.45** |
| `internlm/internlm2-chat-1.8b` | 5.17 | **5.26** |
| `internlm/internlm2-chat-7b` | 7.72 | **7.80** |
| `internlm/internlm2-chat-20b` | 8.13 | **8.26** |
| `allenai/tulu-2-dpo-7b` | 6.35 | **6.38** |
| `allenai/tulu-2-dpo-13b` | 7.00 | **7.26** |
| `allenai/tulu-2-dpo-70b` | 7.79 | **8.03** |
|
mradermacher/archangel_sft-kto_llama30b-i1-GGUF | mradermacher | 2024-06-01T16:28:12Z | 613 | 0 | transformers | [
"transformers",
"gguf",
"human feedback",
"rlhf",
"preferences",
"alignment",
"HALO",
"halos",
"dpo",
"rl",
"en",
"dataset:stanfordnlp/SHP",
"dataset:Anthropic/hh-rlhf",
"dataset:OpenAssistant/oasst1",
"base_model:ContextualAI/archangel_sft-kto_llama30b",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-05-31T18:54:39Z | ---
base_model: ContextualAI/archangel_sft-kto_llama30b
datasets:
- stanfordnlp/SHP
- Anthropic/hh-rlhf
- OpenAssistant/oasst1
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- human feedback
- rlhf
- preferences
- alignment
- HALO
- halos
- dpo
- rl
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/ContextualAI/archangel_sft-kto_llama30b
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/archangel_sft-kto_llama30b-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/archangel_sft-kto_llama30b-i1-GGUF/resolve/main/archangel_sft-kto_llama30b.i1-IQ1_S.gguf) | i1-IQ1_S | 7.2 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/archangel_sft-kto_llama30b-i1-GGUF/resolve/main/archangel_sft-kto_llama30b.i1-IQ1_M.gguf) | i1-IQ1_M | 7.8 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/archangel_sft-kto_llama30b-i1-GGUF/resolve/main/archangel_sft-kto_llama30b.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 8.8 | |
| [GGUF](https://huggingface.co/mradermacher/archangel_sft-kto_llama30b-i1-GGUF/resolve/main/archangel_sft-kto_llama30b.i1-IQ2_XS.gguf) | i1-IQ2_XS | 9.7 | |
| [GGUF](https://huggingface.co/mradermacher/archangel_sft-kto_llama30b-i1-GGUF/resolve/main/archangel_sft-kto_llama30b.i1-IQ2_S.gguf) | i1-IQ2_S | 10.5 | |
| [GGUF](https://huggingface.co/mradermacher/archangel_sft-kto_llama30b-i1-GGUF/resolve/main/archangel_sft-kto_llama30b.i1-IQ2_M.gguf) | i1-IQ2_M | 11.3 | |
| [GGUF](https://huggingface.co/mradermacher/archangel_sft-kto_llama30b-i1-GGUF/resolve/main/archangel_sft-kto_llama30b.i1-Q2_K.gguf) | i1-Q2_K | 12.1 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/archangel_sft-kto_llama30b-i1-GGUF/resolve/main/archangel_sft-kto_llama30b.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 12.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/archangel_sft-kto_llama30b-i1-GGUF/resolve/main/archangel_sft-kto_llama30b.i1-IQ3_XS.gguf) | i1-IQ3_XS | 13.4 | |
| [GGUF](https://huggingface.co/mradermacher/archangel_sft-kto_llama30b-i1-GGUF/resolve/main/archangel_sft-kto_llama30b.i1-IQ3_S.gguf) | i1-IQ3_S | 14.2 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/archangel_sft-kto_llama30b-i1-GGUF/resolve/main/archangel_sft-kto_llama30b.i1-Q3_K_S.gguf) | i1-Q3_K_S | 14.2 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/archangel_sft-kto_llama30b-i1-GGUF/resolve/main/archangel_sft-kto_llama30b.i1-IQ3_M.gguf) | i1-IQ3_M | 15.0 | |
| [GGUF](https://huggingface.co/mradermacher/archangel_sft-kto_llama30b-i1-GGUF/resolve/main/archangel_sft-kto_llama30b.i1-Q3_K_M.gguf) | i1-Q3_K_M | 15.9 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/archangel_sft-kto_llama30b-i1-GGUF/resolve/main/archangel_sft-kto_llama30b.i1-Q3_K_L.gguf) | i1-Q3_K_L | 17.4 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/archangel_sft-kto_llama30b-i1-GGUF/resolve/main/archangel_sft-kto_llama30b.i1-IQ4_XS.gguf) | i1-IQ4_XS | 17.4 | |
| [GGUF](https://huggingface.co/mradermacher/archangel_sft-kto_llama30b-i1-GGUF/resolve/main/archangel_sft-kto_llama30b.i1-Q4_0.gguf) | i1-Q4_0 | 18.5 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/archangel_sft-kto_llama30b-i1-GGUF/resolve/main/archangel_sft-kto_llama30b.i1-Q4_K_S.gguf) | i1-Q4_K_S | 18.6 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/archangel_sft-kto_llama30b-i1-GGUF/resolve/main/archangel_sft-kto_llama30b.i1-Q4_K_M.gguf) | i1-Q4_K_M | 19.7 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/archangel_sft-kto_llama30b-i1-GGUF/resolve/main/archangel_sft-kto_llama30b.i1-Q5_K_S.gguf) | i1-Q5_K_S | 22.5 | |
| [GGUF](https://huggingface.co/mradermacher/archangel_sft-kto_llama30b-i1-GGUF/resolve/main/archangel_sft-kto_llama30b.i1-Q5_K_M.gguf) | i1-Q5_K_M | 23.1 | |
| [GGUF](https://huggingface.co/mradermacher/archangel_sft-kto_llama30b-i1-GGUF/resolve/main/archangel_sft-kto_llama30b.i1-Q6_K.gguf) | i1-Q6_K | 26.8 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his hardware for calculating the imatrix for these quants.
<!-- end -->
|
mradermacher/EEVE-korean-medical-chat-10.8b-GGUF | mradermacher | 2024-06-04T12:08:16Z | 613 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:j5ng/EEVE-korean-medical-chat-10.8b",
"endpoints_compatible",
"region:us"
] | null | 2024-06-04T10:20:14Z | ---
base_model: j5ng/EEVE-korean-medical-chat-10.8b
language:
- en
library_name: transformers
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/j5ng/EEVE-korean-medical-chat-10.8b
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/EEVE-korean-medical-chat-10.8b-GGUF/resolve/main/EEVE-korean-medical-chat-10.8b.Q2_K.gguf) | Q2_K | 4.1 | |
| [GGUF](https://huggingface.co/mradermacher/EEVE-korean-medical-chat-10.8b-GGUF/resolve/main/EEVE-korean-medical-chat-10.8b.IQ3_XS.gguf) | IQ3_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/EEVE-korean-medical-chat-10.8b-GGUF/resolve/main/EEVE-korean-medical-chat-10.8b.Q3_K_S.gguf) | Q3_K_S | 4.8 | |
| [GGUF](https://huggingface.co/mradermacher/EEVE-korean-medical-chat-10.8b-GGUF/resolve/main/EEVE-korean-medical-chat-10.8b.IQ3_S.gguf) | IQ3_S | 4.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/EEVE-korean-medical-chat-10.8b-GGUF/resolve/main/EEVE-korean-medical-chat-10.8b.IQ3_M.gguf) | IQ3_M | 5.0 | |
| [GGUF](https://huggingface.co/mradermacher/EEVE-korean-medical-chat-10.8b-GGUF/resolve/main/EEVE-korean-medical-chat-10.8b.Q3_K_M.gguf) | Q3_K_M | 5.3 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/EEVE-korean-medical-chat-10.8b-GGUF/resolve/main/EEVE-korean-medical-chat-10.8b.Q3_K_L.gguf) | Q3_K_L | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/EEVE-korean-medical-chat-10.8b-GGUF/resolve/main/EEVE-korean-medical-chat-10.8b.IQ4_XS.gguf) | IQ4_XS | 6.0 | |
| [GGUF](https://huggingface.co/mradermacher/EEVE-korean-medical-chat-10.8b-GGUF/resolve/main/EEVE-korean-medical-chat-10.8b.Q4_K_S.gguf) | Q4_K_S | 6.3 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/EEVE-korean-medical-chat-10.8b-GGUF/resolve/main/EEVE-korean-medical-chat-10.8b.Q4_K_M.gguf) | Q4_K_M | 6.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/EEVE-korean-medical-chat-10.8b-GGUF/resolve/main/EEVE-korean-medical-chat-10.8b.Q5_K_S.gguf) | Q5_K_S | 7.6 | |
| [GGUF](https://huggingface.co/mradermacher/EEVE-korean-medical-chat-10.8b-GGUF/resolve/main/EEVE-korean-medical-chat-10.8b.Q5_K_M.gguf) | Q5_K_M | 7.8 | |
| [GGUF](https://huggingface.co/mradermacher/EEVE-korean-medical-chat-10.8b-GGUF/resolve/main/EEVE-korean-medical-chat-10.8b.Q6_K.gguf) | Q6_K | 9.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/EEVE-korean-medical-chat-10.8b-GGUF/resolve/main/EEVE-korean-medical-chat-10.8b.Q8_0.gguf) | Q8_0 | 11.6 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
sismetanin/sbert-ru-sentiment-rusentiment | sismetanin | 2021-05-20T06:38:36Z | 612 | 0 | transformers | [
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"sentiment analysis",
"Russian",
"ru",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
language:
- ru
tags:
- sentiment analysis
- Russian
---
## SBERT-Large-Base-ru-sentiment-RuSentiment
SBERT-Large-ru-sentiment-RuSentiment is a [SBERT-Large](https://huggingface.co/sberbank-ai/sbert_large_nlu_ru) model fine-tuned on [RuSentiment dataset](https://github.com/text-machine-lab/rusentiment) of general-domain Russian-language posts from the largest Russian social network, VKontakte.
<table>
<thead>
<tr>
<th rowspan="4">Model</th>
<th rowspan="4">Score<br></th>
<th rowspan="4">Rank</th>
<th colspan="12">Dataset</th>
</tr>
<tr>
<td colspan="6">SentiRuEval-2016<br></td>
<td colspan="2" rowspan="2">RuSentiment</td>
<td rowspan="2">KRND</td>
<td rowspan="2">LINIS Crowd</td>
<td rowspan="2">RuTweetCorp</td>
<td rowspan="2">RuReviews</td>
</tr>
<tr>
<td colspan="3">TC</td>
<td colspan="3">Banks</td>
</tr>
<tr>
<td>micro F1</td>
<td>macro F1</td>
<td>F1</td>
<td>micro F1</td>
<td>macro F1</td>
<td>F1</td>
<td>wighted</td>
<td>F1</td>
<td>F1</td>
<td>F1</td>
<td>F1</td>
<td>F1</td>
</tr>
</thead>
<tbody>
<tr>
<td>SOTA</td>
<td>n/s</td>
<td></td>
<td>76.71</td>
<td>66.40</td>
<td>70.68</td>
<td>67.51</td>
<td>69.53</td>
<td>74.06</td>
<td>78.50</td>
<td>n/s</td>
<td>73.63</td>
<td>60.51</td>
<td>83.68</td>
<td>77.44</td>
</tr>
<tr>
<td>XLM-RoBERTa-Large</td>
<td>76.37</td>
<td>1</td>
<td>82.26</td>
<td>76.36</td>
<td>79.42</td>
<td>76.35</td>
<td>76.08</td>
<td>80.89</td>
<td>78.31</td>
<td>75.27</td>
<td>75.17</td>
<td>60.03</td>
<td>88.91</td>
<td>78.81</td>
</tr>
<tr>
<td>SBERT-Large</td>
<td>75.43</td>
<td>2</td>
<td>78.40</td>
<td>71.36</td>
<td>75.14</td>
<td>72.39</td>
<td>71.87</td>
<td>77.72</td>
<td>78.58</td>
<td>75.85</td>
<td>74.20</td>
<td>60.64</td>
<td>88.66</td>
<td>77.41</td>
</tr>
<tr>
<td>MBARTRuSumGazeta</td>
<td>74.70</td>
<td>3</td>
<td>76.06</td>
<td>68.95</td>
<td>73.04</td>
<td>72.34</td>
<td>71.93</td>
<td>77.83</td>
<td>76.71</td>
<td>73.56</td>
<td>74.18</td>
<td>60.54</td>
<td>87.22</td>
<td>77.51</td>
</tr>
<tr>
<td>Conversational RuBERT</td>
<td>74.44</td>
<td>4</td>
<td>76.69</td>
<td>69.09</td>
<td>73.11</td>
<td>69.44</td>
<td>68.68</td>
<td>75.56</td>
<td>77.31</td>
<td>74.40</td>
<td>73.10</td>
<td>59.95</td>
<td>87.86</td>
<td>77.78</td>
</tr>
<tr>
<td>LaBSE</td>
<td>74.11</td>
<td>5</td>
<td>77.00</td>
<td>69.19</td>
<td>73.55</td>
<td>70.34</td>
<td>69.83</td>
<td>76.38</td>
<td>74.94</td>
<td>70.84</td>
<td>73.20</td>
<td>59.52</td>
<td>87.89</td>
<td>78.47</td>
</tr>
<tr>
<td>XLM-RoBERTa-Base</td>
<td>73.60</td>
<td>6</td>
<td>76.35</td>
<td>69.37</td>
<td>73.42</td>
<td>68.45</td>
<td>67.45</td>
<td>74.05</td>
<td>74.26</td>
<td>70.44</td>
<td>71.40</td>
<td>60.19</td>
<td>87.90</td>
<td>78.28</td>
</tr>
<tr>
<td>RuBERT</td>
<td>73.45</td>
<td>7</td>
<td>74.03</td>
<td>66.14</td>
<td>70.75</td>
<td>66.46</td>
<td>66.40</td>
<td>73.37</td>
<td>75.49</td>
<td>71.86</td>
<td>72.15</td>
<td>60.55</td>
<td>86.99</td>
<td>77.41</td>
</tr>
<tr>
<td>MBART-50-Large-Many-to-Many</td>
<td>73.15</td>
<td>8</td>
<td>75.38</td>
<td>67.81</td>
<td>72.26</td>
<td>67.13</td>
<td>66.97</td>
<td>73.85</td>
<td>74.78</td>
<td>70.98</td>
<td>71.98</td>
<td>59.20</td>
<td>87.05</td>
<td>77.24</td>
</tr>
<tr>
<td>SlavicBERT</td>
<td>71.96</td>
<td>9</td>
<td>71.45</td>
<td>63.03</td>
<td>68.44</td>
<td>64.32</td>
<td>63.99</td>
<td>71.31</td>
<td>72.13</td>
<td>67.57</td>
<td>72.54</td>
<td>58.70</td>
<td>86.43</td>
<td>77.16</td>
</tr>
<tr>
<td>EnRuDR-BERT</td>
<td>71.51</td>
<td>10</td>
<td>72.56</td>
<td>64.74</td>
<td>69.07</td>
<td>61.44</td>
<td>60.21</td>
<td>68.34</td>
<td>74.19</td>
<td>69.94</td>
<td>69.33</td>
<td>56.55</td>
<td>87.12</td>
<td>77.95</td>
</tr>
<tr>
<td>RuDR-BERT</td>
<td>71.14</td>
<td>11</td>
<td>72.79</td>
<td>64.23</td>
<td>68.36</td>
<td>61.86</td>
<td>60.92</td>
<td>68.48</td>
<td>74.65</td>
<td>70.63</td>
<td>68.74</td>
<td>54.45</td>
<td>87.04</td>
<td>77.91</td>
</tr>
<tr>
<td>MBART-50-Large</td>
<td>69.46</td>
<td>12</td>
<td>70.91</td>
<td>62.67</td>
<td>67.24</td>
<td>61.12</td>
<td>60.25</td>
<td>68.41</td>
<td>72.88</td>
<td>68.63</td>
<td>70.52</td>
<td>46.39</td>
<td>86.48</td>
<td>77.52</td>
</tr>
</tbody>
</table>
The table shows per-task scores and a macro-average of those scores to determine a models’s position on the leaderboard. For datasets with multiple evaluation metrics (e.g., macro F1 and weighted F1 for RuSentiment), we use an unweighted average of the metrics as the score for the task when computing the overall macro-average. The same strategy for comparing models’ results was applied in the GLUE benchmark.
## Citation
If you find this repository helpful, feel free to cite our publication:
```
@article{Smetanin2021Deep,
author = {Sergey Smetanin and Mikhail Komarov},
title = {Deep transfer learning baselines for sentiment analysis in Russian},
journal = {Information Processing & Management},
volume = {58},
number = {3},
pages = {102484},
year = {2021},
issn = {0306-4573},
doi = {0.1016/j.ipm.2020.102484}
}
```
Dataset:
```
@inproceedings{rogers2018rusentiment,
title={RuSentiment: An enriched sentiment analysis dataset for social media in Russian},
author={Rogers, Anna and Romanov, Alexey and Rumshisky, Anna and Volkova, Svitlana and Gronas, Mikhail and Gribov, Alex},
booktitle={Proceedings of the 27th international conference on computational linguistics},
pages={755--763},
year={2018}
}
``` |
postbot/distilgpt2-emailgen | postbot | 2023-11-18T12:45:02Z | 612 | 3 | transformers | [
"transformers",
"pytorch",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"distilgpt2",
"email generation",
"email",
"dataset:aeslc",
"dataset:postbot/multi_emails",
"base_model:distilgpt2",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2022-08-06T13:40:55Z | ---
license: apache-2.0
tags:
- generated_from_trainer
- distilgpt2
- email generation
- email
datasets:
- aeslc
- postbot/multi_emails
widget:
- text: 'Good Morning Professor Beans,
Hope you are doing well. I just wanted to reach out and ask if differential calculus
will be on the exam'
example_title: email to prof
- text: 'Hey <NAME>,
Thank you for signing up for my weekly newsletter. Before we get started, you''ll
have to confirm your email address.'
example_title: newsletter
- text: 'Hi <NAME>,
I hope this email finds you well. I wanted to reach out and ask about office hours'
example_title: office hours
- text: 'Greetings <NAME>,
I hope you had a splendid evening at the Company sausage eating festival. I am
reaching out because'
example_title: festival
- text: 'Good Morning Harold,
I was wondering when the next'
example_title: event
- text: URGENT - I need the TPS reports
example_title: URGENT
- text: 'Hi Archibald,
I hope this email finds you extremely well.'
example_title: emails that find you
- text: 'Hello there.
I just wanted to reach out and check in to'
example_title: checking in
- text: 'Hello <NAME>,
I hope this email finds you well. I wanted to reach out and see if you''ve enjoyed
your time with us'
example_title: work well
- text: 'Hi <NAME>,
I hope this email finds you well. I wanted to reach out and see if we could catch
up'
example_title: catch up
- text: I'm <NAME> and I just moved into the area and wanted to reach out and get
some details on where I could get groceries and
example_title: grocery
parameters:
min_length: 4
max_length: 128
length_penalty: 0.8
no_repeat_ngram_size: 2
do_sample: false
num_beams: 8
early_stopping: true
repetition_penalty: 5.5
base_model: distilgpt2
---
# distilgpt2-emailgen
Why write the rest of your email when you can generate it?
```python
from transformers import pipeline
model_tag = "postbot/distilgpt2-emailgen"
generator = pipeline(
'text-generation',
model=model_tag,
)
prompt = """
Hello,
Following up on the bubblegum shipment."""
result = generator(
prompt,
max_length=64,
do_sample=False,
early_stopping=True,
) # generate
print(result[0]['generated_text'])
```
- try it in a [Google Colab](https://colab.research.google.com/gist/pszemraj/91df57e0c2caf1d5273b78576ad2853e/postbot-distilgpt2-emailgen-demo.ipynb) notebook
- Use it in bash/cmd [with this gist](https://gist.github.com/pszemraj/c1b0a76445418b6bbddd5f9633d1bb7f) :)
> For this model, formatting matters. The results may be (significantly) different between the structure outlined above and `prompt = "Hey, just wanted to ..."` etc.
## Model description
This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on a dataset of 50k emails, including the classic `aeslc` dataset.
It achieves the following results on the evaluation set:
- Loss: 2.6247
## Intended uses & limitations
The intended use of this model is to provide suggestions to "autocomplete" the rest of your email. Said another way, it should serve as a **tool to write predictable emails faster**. It is not intended to write entire emails; at least **some input** is required to guide the direction of the model.
Please verify any suggestions by the model for A) False claims and B) negation statements before accepting/sending something.
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 6e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- gradient_accumulation_steps: 32
- total_train_batch_size: 256
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.02
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.8299 | 1.0 | 248 | 2.7971 |
| 2.6984 | 2.0 | 496 | 2.6826 |
| 2.7022 | 3.0 | 744 | 2.6361 |
| 2.6436 | 4.0 | 992 | 2.6245 |
| 2.6195 | 5.0 | 1240 | 2.6247 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_postbot__distilgpt2-emailgen)
| Metric | Value |
|-----------------------|---------------------------|
| Avg. | 24.89 |
| ARC (25-shot) | 21.76 |
| HellaSwag (10-shot) | 27.52 |
| MMLU (5-shot) | 25.97 |
| TruthfulQA (0-shot) | 46.17 |
| Winogrande (5-shot) | 51.62 |
| GSM8K (5-shot) | 0.0 |
| DROP (3-shot) | 1.16 |
|
Suchinthana/sinhala-gpt-neo | Suchinthana | 2023-06-26T05:14:48Z | 612 | 1 | transformers | [
"transformers",
"pytorch",
"safetensors",
"gpt_neo",
"text-generation",
"si",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-01-20T16:15:06Z | ---
license: mit
widget:
- text: කවියා නුමුහු කළ නුවණ
- text: පිරිසිදු පානීය ජලය
language:
- si
pipeline_tag: text-generation
---
### Fine tuned GPT Neo 125M
This model is fine tuned with a [Sinhala data set](https://github.com/TharukaCkasthuri/plagiarism_detection_dataset_sinhala) for Sinhala text generation.
### How to use
You can use this model directly with a pipeline for text generation. This example generates a different sequence each time it's run:
```py
>>> from transformers import pipeline
>>> generator = pipeline('text-generation', model='Suchinthana/sinhala-gpt-neo')
>>> generator("කවියා නුමුහු කළ නුවණ ", do_sample=True, max_length=500)
``` |
timm/swinv2_large_window12_192.ms_in22k | timm | 2024-02-10T23:31:04Z | 612 | 0 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-22k",
"arxiv:2111.09883",
"license:mit",
"region:us"
] | image-classification | 2023-03-18T03:32:25Z | ---
license: mit
library_name: timm
tags:
- image-classification
- timm
datasets:
- imagenet-22k
---
# Model card for swinv2_large_window12_192.ms_in22k
A Swin Transformer V2 image classification model. Pretrained on ImageNet-22k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 228.8
- GMACs: 26.2
- Activations (M): 56.5
- Image size: 192 x 192
- **Papers:**
- Swin Transformer V2: Scaling Up Capacity and Resolution: https://arxiv.org/abs/2111.09883
- **Original:** https://github.com/microsoft/Swin-Transformer
- **Dataset:** ImageNet-22k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('swinv2_large_window12_192.ms_in22k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'swinv2_large_window12_192.ms_in22k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g. for swin_base_patch4_window7_224 (NHWC output)
# torch.Size([1, 56, 56, 128])
# torch.Size([1, 28, 28, 256])
# torch.Size([1, 14, 14, 512])
# torch.Size([1, 7, 7, 1024])
# e.g. for swinv2_cr_small_ns_224 (NCHW output)
# torch.Size([1, 96, 56, 56])
# torch.Size([1, 192, 28, 28])
# torch.Size([1, 384, 14, 14])
# torch.Size([1, 768, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'swinv2_large_window12_192.ms_in22k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled (ie.e a (batch_size, H, W, num_features) tensor for swin / swinv2
# or (batch_size, num_features, H, W) for swinv2_cr
output = model.forward_head(output, pre_logits=True)
# output is (batch_size, num_features) tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{liu2021swinv2,
title={Swin Transformer V2: Scaling Up Capacity and Resolution},
author={Ze Liu and Han Hu and Yutong Lin and Zhuliang Yao and Zhenda Xie and Yixuan Wei and Jia Ning and Yue Cao and Zheng Zhang and Li Dong and Furu Wei and Baining Guo},
booktitle={International Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2022}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
|
timm/volo_d2_384.sail_in1k | timm | 2024-02-10T23:44:28Z | 612 | 0 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2106.13112",
"license:apache-2.0",
"region:us"
] | image-classification | 2023-04-13T05:53:49Z | ---
license: apache-2.0
library_name: timm
tags:
- image-classification
- timm
datasets:
- imagenet-1k
---
# Model card for volo_d2_384.sail_in1k
A VOLO (Vision Outlooker) image classification model. Trained on ImageNet-1k with token labelling by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 58.9
- GMACs: 46.2
- Activations (M): 184.5
- Image size: 384 x 384
- **Papers:**
- VOLO: Vision Outlooker for Visual Recognition: https://arxiv.org/abs/2106.13112
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/sail-sg/volo
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('volo_d2_384.sail_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'volo_d2_384.sail_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 577, 512) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Citation
```bibtex
@article{yuan2022volo,
title={Volo: Vision outlooker for visual recognition},
author={Yuan, Li and Hou, Qibin and Jiang, Zihang and Feng, Jiashi and Yan, Shuicheng},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
year={2022},
publisher={IEEE}
}
```
|
TheBloke/LoKuS-13B-GGUF | TheBloke | 2023-09-27T12:46:54Z | 612 | 1 | transformers | [
"transformers",
"gguf",
"llama",
"base_model:JoSw-14/LoKuS-13B",
"license:llama2",
"text-generation-inference",
"region:us"
] | null | 2023-08-31T16:50:46Z | ---
license: llama2
model_name: LoKuS 13B
base_model: JoSw-14/LoKuS-13B
inference: false
model_creator: Jonathan Swarp
model_type: llama
prompt_template: 'Below is an instruction that describes a task. Write a response
that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# LoKuS 13B - GGUF
- Model creator: [Jonathan Swarp](https://huggingface.co/JoSw-14)
- Original model: [LoKuS 13B](https://huggingface.co/JoSw-14/LoKuS-13B)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Jonathan Swarp's LoKuS 13B](https://huggingface.co/JoSw-14/LoKuS-13B).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp. GGUF offers numerous advantages over GGML, such as better tokenisation, and support for special tokens. It is also supports metadata, and is designed to be extensible.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/LoKuS-13B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/LoKuS-13B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/LoKuS-13B-GGUF)
* [Jonathan Swarp's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/JoSw-14/LoKuS-13B)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [lokus-13b.Q2_K.gguf](https://huggingface.co/TheBloke/LoKuS-13B-GGUF/blob/main/lokus-13b.Q2_K.gguf) | Q2_K | 2 | 5.43 GB| 7.93 GB | smallest, significant quality loss - not recommended for most purposes |
| [lokus-13b.Q3_K_S.gguf](https://huggingface.co/TheBloke/LoKuS-13B-GGUF/blob/main/lokus-13b.Q3_K_S.gguf) | Q3_K_S | 3 | 5.66 GB| 8.16 GB | very small, high quality loss |
| [lokus-13b.Q3_K_M.gguf](https://huggingface.co/TheBloke/LoKuS-13B-GGUF/blob/main/lokus-13b.Q3_K_M.gguf) | Q3_K_M | 3 | 6.34 GB| 8.84 GB | very small, high quality loss |
| [lokus-13b.Q3_K_L.gguf](https://huggingface.co/TheBloke/LoKuS-13B-GGUF/blob/main/lokus-13b.Q3_K_L.gguf) | Q3_K_L | 3 | 6.93 GB| 9.43 GB | small, substantial quality loss |
| [lokus-13b.Q4_0.gguf](https://huggingface.co/TheBloke/LoKuS-13B-GGUF/blob/main/lokus-13b.Q4_0.gguf) | Q4_0 | 4 | 7.37 GB| 9.87 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [lokus-13b.Q4_K_S.gguf](https://huggingface.co/TheBloke/LoKuS-13B-GGUF/blob/main/lokus-13b.Q4_K_S.gguf) | Q4_K_S | 4 | 7.41 GB| 9.91 GB | small, greater quality loss |
| [lokus-13b.Q4_K_M.gguf](https://huggingface.co/TheBloke/LoKuS-13B-GGUF/blob/main/lokus-13b.Q4_K_M.gguf) | Q4_K_M | 4 | 7.87 GB| 10.37 GB | medium, balanced quality - recommended |
| [lokus-13b.Q5_0.gguf](https://huggingface.co/TheBloke/LoKuS-13B-GGUF/blob/main/lokus-13b.Q5_0.gguf) | Q5_0 | 5 | 8.97 GB| 11.47 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [lokus-13b.Q5_K_S.gguf](https://huggingface.co/TheBloke/LoKuS-13B-GGUF/blob/main/lokus-13b.Q5_K_S.gguf) | Q5_K_S | 5 | 8.97 GB| 11.47 GB | large, low quality loss - recommended |
| [lokus-13b.Q5_K_M.gguf](https://huggingface.co/TheBloke/LoKuS-13B-GGUF/blob/main/lokus-13b.Q5_K_M.gguf) | Q5_K_M | 5 | 9.23 GB| 11.73 GB | large, very low quality loss - recommended |
| [lokus-13b.Q6_K.gguf](https://huggingface.co/TheBloke/LoKuS-13B-GGUF/blob/main/lokus-13b.Q6_K.gguf) | Q6_K | 6 | 10.68 GB| 13.18 GB | very large, extremely low quality loss |
| [lokus-13b.Q8_0.gguf](https://huggingface.co/TheBloke/LoKuS-13B-GGUF/blob/main/lokus-13b.Q8_0.gguf) | Q8_0 | 8 | 13.83 GB| 16.33 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/LoKuS-13B-GGUF and below it, a specific filename to download, such as: lokus-13b.q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub>=0.17.1
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/LoKuS-13B-GGUF lokus-13b.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/LoKuS-13B-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/LoKuS-13B-GGUF lokus-13b.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows CLI users: Use `set HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1` before running the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m lokus-13b.q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{prompt}\n\n### Response:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model from Python using ctransformers
#### First install the package
```bash
# Base ctransformers with no GPU acceleration
pip install ctransformers>=0.2.24
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]>=0.2.24
# Or with ROCm GPU acceleration
CT_HIPBLAS=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems
CT_METAL=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
```
#### Simple example code to load one of these GGUF models
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/LoKuS-13B-GGUF", model_file="lokus-13b.q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here's guides on using llama-cpp-python or ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Jonathan Swarp's LoKuS 13B
<!-- original-model-card end -->
|
TheBloke/AlpacaCielo2-7B-8K-GGUF | TheBloke | 2023-09-27T12:47:26Z | 612 | 5 | transformers | [
"transformers",
"gguf",
"llama",
"base_model:totally-not-an-llm/AlpacaCielo2-7b-8k",
"license:llama2",
"text-generation-inference",
"region:us"
] | null | 2023-09-05T07:15:15Z | ---
license: llama2
model_name: AlpacaCielo2 7B 8K
base_model: totally-not-an-llm/AlpacaCielo2-7b-8k
inference: false
model_creator: totally-not-an-llm
model_type: llama
prompt_template: '### Sytem: {system_message}
### Human: {prompt}
### Assistant:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# AlpacaCielo2 7B 8K - GGUF
- Model creator: [totally-not-an-llm](https://huggingface.co/totally-not-an-llm)
- Original model: [AlpacaCielo2 7B 8K](https://huggingface.co/totally-not-an-llm/AlpacaCielo2-7b-8k)
<!-- description start -->
## Description
This repo contains GGUF format model files for [totally-not-an-llm's AlpacaCielo2 7B 8K](https://huggingface.co/totally-not-an-llm/AlpacaCielo2-7b-8k).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp. GGUF offers numerous advantages over GGML, such as better tokenisation, and support for special tokens. It is also supports metadata, and is designed to be extensible.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/AlpacaCielo2-7B-8K-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/AlpacaCielo2-7B-8K-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/AlpacaCielo2-7B-8K-GGUF)
* [totally-not-an-llm's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/totally-not-an-llm/AlpacaCielo2-7b-8k)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: System-Human-Assistant-Hashes
```
### Sytem: {system_message}
### Human: {prompt}
### Assistant:
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [alpacacielo2-7b-8k.Q2_K.gguf](https://huggingface.co/TheBloke/AlpacaCielo2-7B-8K-GGUF/blob/main/alpacacielo2-7b-8k.Q2_K.gguf) | Q2_K | 2 | 2.83 GB| 5.33 GB | smallest, significant quality loss - not recommended for most purposes |
| [alpacacielo2-7b-8k.Q3_K_S.gguf](https://huggingface.co/TheBloke/AlpacaCielo2-7B-8K-GGUF/blob/main/alpacacielo2-7b-8k.Q3_K_S.gguf) | Q3_K_S | 3 | 2.95 GB| 5.45 GB | very small, high quality loss |
| [alpacacielo2-7b-8k.Q3_K_M.gguf](https://huggingface.co/TheBloke/AlpacaCielo2-7B-8K-GGUF/blob/main/alpacacielo2-7b-8k.Q3_K_M.gguf) | Q3_K_M | 3 | 3.30 GB| 5.80 GB | very small, high quality loss |
| [alpacacielo2-7b-8k.Q3_K_L.gguf](https://huggingface.co/TheBloke/AlpacaCielo2-7B-8K-GGUF/blob/main/alpacacielo2-7b-8k.Q3_K_L.gguf) | Q3_K_L | 3 | 3.60 GB| 6.10 GB | small, substantial quality loss |
| [alpacacielo2-7b-8k.Q4_0.gguf](https://huggingface.co/TheBloke/AlpacaCielo2-7B-8K-GGUF/blob/main/alpacacielo2-7b-8k.Q4_0.gguf) | Q4_0 | 4 | 3.83 GB| 6.33 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [alpacacielo2-7b-8k.Q4_K_S.gguf](https://huggingface.co/TheBloke/AlpacaCielo2-7B-8K-GGUF/blob/main/alpacacielo2-7b-8k.Q4_K_S.gguf) | Q4_K_S | 4 | 3.86 GB| 6.36 GB | small, greater quality loss |
| [alpacacielo2-7b-8k.Q4_K_M.gguf](https://huggingface.co/TheBloke/AlpacaCielo2-7B-8K-GGUF/blob/main/alpacacielo2-7b-8k.Q4_K_M.gguf) | Q4_K_M | 4 | 4.08 GB| 6.58 GB | medium, balanced quality - recommended |
| [alpacacielo2-7b-8k.Q5_0.gguf](https://huggingface.co/TheBloke/AlpacaCielo2-7B-8K-GGUF/blob/main/alpacacielo2-7b-8k.Q5_0.gguf) | Q5_0 | 5 | 4.65 GB| 7.15 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [alpacacielo2-7b-8k.Q5_K_S.gguf](https://huggingface.co/TheBloke/AlpacaCielo2-7B-8K-GGUF/blob/main/alpacacielo2-7b-8k.Q5_K_S.gguf) | Q5_K_S | 5 | 4.65 GB| 7.15 GB | large, low quality loss - recommended |
| [alpacacielo2-7b-8k.Q5_K_M.gguf](https://huggingface.co/TheBloke/AlpacaCielo2-7B-8K-GGUF/blob/main/alpacacielo2-7b-8k.Q5_K_M.gguf) | Q5_K_M | 5 | 4.78 GB| 7.28 GB | large, very low quality loss - recommended |
| [alpacacielo2-7b-8k.Q6_K.gguf](https://huggingface.co/TheBloke/AlpacaCielo2-7B-8K-GGUF/blob/main/alpacacielo2-7b-8k.Q6_K.gguf) | Q6_K | 6 | 5.53 GB| 8.03 GB | very large, extremely low quality loss |
| [alpacacielo2-7b-8k.Q8_0.gguf](https://huggingface.co/TheBloke/AlpacaCielo2-7B-8K-GGUF/blob/main/alpacacielo2-7b-8k.Q8_0.gguf) | Q8_0 | 8 | 7.16 GB| 9.66 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/AlpacaCielo2-7B-8K-GGUF and below it, a specific filename to download, such as: alpacacielo2-7b-8k.q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub>=0.17.1
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/AlpacaCielo2-7B-8K-GGUF alpacacielo2-7b-8k.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/AlpacaCielo2-7B-8K-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/AlpacaCielo2-7B-8K-GGUF alpacacielo2-7b-8k.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows CLI users: Use `set HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1` before running the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m alpacacielo2-7b-8k.q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "### Sytem: {system_message}\n### Human: {prompt}\n### Assistant:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model from Python using ctransformers
#### First install the package
```bash
# Base ctransformers with no GPU acceleration
pip install ctransformers>=0.2.24
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]>=0.2.24
# Or with ROCm GPU acceleration
CT_HIPBLAS=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems
CT_METAL=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
```
#### Simple example code to load one of these GGUF models
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/AlpacaCielo2-7B-8K-GGUF", model_file="alpacacielo2-7b-8k.q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here's guides on using llama-cpp-python or ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: totally-not-an-llm's AlpacaCielo2 7B 8K
# AlpacaCielo2-7b-8k
<figure>
<img src="https://huggingface.co/totally-not-an-llm/AlpacaCielo-13b/resolve/main/alpaca.png" alt="cute cloud alpaca">
<figcaption style="font-size: 1em;"><i>"super cute baby alpaca laying on a cloud", Model: epicrealism_pureEvolutionV3</i></figcaption>
</figure>
AlpacaCielo2-7b-8k is the second version of the AlpacaCielo series. It is a llama-2 based model designed for creative tasks, such as storytelling and roleplay, while still doing well with other chatbot purposes. It is a triple model merge of Nous-Hermes + Guanaco + LimaRP. While it is mostly *"uncensored"*, it still inherits some alignment from Guanaco.
[GPTQ quants](https://huggingface.co/TheBloke/AlpacaCielo2-7B-8K-GPTQ)<br>
[GGML quants](https://huggingface.co/TheBloke/AlpacaCielo2-7B-8K-GGML)<br>
(Courtesy of TheBloke)
### Differences from V1:
- Double context (4k->8k)
- Better roleplaying abilities
**Performs well with custom prompt format:**
```
### System: {system prompt}
### Human: {prompt}
### Assistant:
```
### Note for system prompt:
The model understands it well and it works great if you want roleplay, but it still likes to be an assistant, so you should nudge it in the right direction. For example:
```
### System: Roleplay as a pirate
### Human: hello
### Assistant: Ahoy, matey! How can I assist you today?
```
### vs.
```
### System: Roleplay as a pirate (not assistant!)
### Human: hello
### Assistant: Arrgh, matey! I be the Captain of this here ship. What business do ye have with me?
```
You could also just use LimaRP prompt format.
*Thanks to previous similar models such as Alpacino, Alpasta, and AlpacaDente for inspiring the creation of this model. Thanks also to the creators of the models involved in the merge. Original models:*
- [Hermes-LLongMA-2](https://huggingface.co/conceptofmind/Hermes-LLongMA-2-7b-8k)
- [Guanaco QLoRA](https://huggingface.co/Mikael110/llama-2-7b-guanaco-qlora)
- [LimaRP LoRA](https://huggingface.co/lemonilia/limarp-llama2)
<!-- original-model-card end -->
|
Intel/dpt-swinv2-tiny-256 | Intel | 2024-06-21T19:56:01Z | 612 | 7 | transformers | [
"transformers",
"safetensors",
"dpt",
"depth-estimation",
"vision",
"arxiv:2103.13413",
"arxiv:2307.14460",
"license:mit",
"model-index",
"endpoints_compatible",
"region:us"
] | depth-estimation | 2023-12-10T20:46:13Z | ---
license: mit
tags:
- vision
- depth-estimation
model-index:
- name: dpt-swinv2-tiny-256
results:
- task:
type: monocular-depth-estimation
name: Monocular Depth Estimation
dataset:
type: MIX-6
name: MIX-6
metrics:
- type: Zero-shot transfer
value: 10.82
name: Zero-shot transfer
config: Zero-shot transfer
verified: false
---
# Midas 3.1 DPT (Intel/dpt-swinv2-tiny-256 using Swinv2 backbone)
DPT (Dense Prediction Transformer) model trained on 1.4 million images for monocular depth estimation. It was introduced in the paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by Ranftl et al. (2021) and first released in [this repository](https://github.com/isl-org/MiDaS/tree/master).
**Disclaimer:** The team releasing DPT did not write a model card for this model so this model card has been written by Intel and the Hugging Face team.
# Overview of Monocular depth estimation
The aim of Monocular depth estimation is to infer detailed depth from a single image or camera view, finds applications in fields like generative AI, 3D reconstruction, and autonomous driving. However, deriving depth from individual pixels in a single image is challenging due to the under constrained nature of the problem. Recent advancements attribute progress to learning-based methods, particularly with MiDaS, leveraging dataset mixing and scale-and-shift-invariant loss. MiDaS has evolved with releases featuring more powerful backbones and lightweight variants for mobile use. With the rise of transformer architectures in computer vision, including those pioneered by models like ViT,and Swin, and SwinV2 there's been a shift towards using them for depth estimation. Inspired by this, MiDaS v3.1 incorporates promising transformer-based encoders alongside traditional convolutional ones, aiming for a comprehensive investigation of depth estimation techniques. The paper focuses on describing the integration of these backbones into MiDaS, providing a thorough comparison of different v3.1 models, and offering guidance on utilizing future backbones with MiDaS.
Swin Transformer (the name Swin stands for Shifted window) is initially described in arxiv, which capably serves as a general-purpose backbone for computer vision. It is basically a hierarchical Transformer whose representation is computed with shifted windows. The shifted windowing scheme brings greater efficiency by limiting self-attention computation to non-overlapping local windows while also allowing for cross-window connection.
Swin Transformer achieves strong performance on COCO object detection (58.7 box AP and 51.1 mask AP on test-dev) and ADE20K semantic segmentation (53.5 mIoU on val), surpassing previous models by a large margin.
| Input Image | Output Depth Image |
| --- | --- |
|  |  |
# Videos

MiDaS Depth Estimation is a machine learning model from Intel Labs for monocular depth estimation. It was trained on up to 12 datasets and covers both in-and outdoor scenes. Multiple different MiDaS models are available, ranging from high quality depth estimation to lightweight models for mobile downstream tasks (https://github.com/isl-org/MiDaS).
## Model description
This Midas 3.1 DPT model uses the [SwinV2 Philosophy]( https://huggingface.co/docs/transformers/en/model_doc/swinv2) model as backbone and uses a different approach to Vision that Beit, where Swin backbones focus more on using a hierarchical approach.

The previous release MiDaS v3.0 solely leverages the
vanilla vision transformer ViT, MiDaS v3.1 offers additional models based on BEiT, Swin, SwinV2, Next-ViT and LeViT.
# Midas 3.1 DPT Model(Swin backbone)
This model refers to Intel dpt-swinv2-tiny-256 based on the Swin backbone. The arxiv paper compares both Beit and Swin backbones.
The highest quality depth estimation is achieved using the BEiT transformer. We provide variants such as Swin-L, SwinV2-L, SwinV2-B, SwinV2-T, where the numbers signify training resolutions of 512x512 and 384x384, while the letters denote large and base models respectively.
DPT (Dense Prediction Transformer) model trained on 1.4 million images for monocular depth estimation. It was introduced in the paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by Ranftl et al. (2021) and first released in [this repository](https://github.com/isl-org/MiDaS/tree/master).
This model card refers specifically to SwinV2, in the paper, and is referred to dpt-swinv2-tiny-256. A more recent paper from 2013, specifically discussing Swin and SwinV2, is in this paper [MiDaS v3.1 – A Model Zoo for Robust Monocular Relative Depth Estimation
](https://arxiv.org/pdf/2307.14460.pdf)
The model card has been written in combination by the Hugging Face team and Intel.
| Model Detail | Description |
| ----------- | ----------- |
| Model Authors - Company | Intel |
| Date | March 18, 2024 |
| Version | 1 |
| Type | Computer Vision - Monocular Depth Estimation |
| Paper or Other Resources | [MiDaS v3.1 – A Model Zoo for Robust Monocular Relative Depth Estimation](https://arxiv.org/pdf/2307.14460.pdf) and [GitHub Repo](https://github.com/isl-org/MiDaS/blob/master/README.md) |
| License | MIT |
| Questions or Comments | [Community Tab](https://huggingface.co/Intel/dpt-swinv2-tiny-256/discussions) and [Intel Developers Discord](https://discord.gg/rv2Gp55UJQ)|
| Intended Use | Description |
| ----------- | ----------- |
| Primary intended uses | You can use the raw model for zero-shot monocular depth estimation. See the [model hub](https://huggingface.co/models?search=dpt-beit-large) to look for fine-tuned versions on a task that interests you. |
| Primary intended users | Anyone doing monocular depth estimation |
| Out-of-scope uses | This model in most cases will need to be fine-tuned for your particular task. The model should not be used to intentionally create hostile or alienating environments for people.|
## How to use
Be sure the to update PyTorch as Transformers as mismatches in versions can generate erros such as: "TypeError: unsupported operand type(s) for //: 'NoneType' and 'NoneType'".
As tested by this contributor, the following versions ran correctly:
```python
import torch
import transformers
print(torch.__version__)
print(transformers.__version__)
```
```bash
out: '2.2.1+cpu'
out: '4.37.2'
```
### To Install:
```pythopn
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
```
# To Use:
Here is how to use this model for zero-shot depth estimation on an image:
```python
output = prediction.squeeze().cpu().numpy()
formatted = (output * 255 / np.max(output)).astype("uint8")
depth = Image.fromarray(formatted)
depth
```
or one can use the pipeline API:
```python
from transformers import pipeline
pipe = pipeline(task="depth-estimation", model="Intel/dpt-swinv2-tiny-256")
result = pipe("http://images.cocodataset.org/val2017/000000181816.jpg")
result["depth"]
```
## Quantitative Analyses
| Model | Square Resolution HRWSI RMSE | Square Resolution Blended MVS REL | Square Resolution ReDWeb RMSE |
| --- | --- | --- | --- |
| BEiT 384-L | 0.068 | 0.070 | 0.076 |
| Swin-L Training 1| 0.0708 | 0.0724 | 0.0826 |
| Swin-L Training 2 | 0.0713 | 0.0720 | 0.0831 |
| ViT-L | 0.071 | 0.072 | 0.082 |
| --- | --- | --- | --- |
| Next-ViT-L-1K-6M | 0.075 |0.073 | 0.085 |
| DeiT3-L-22K-1K | 0.070 | 0.070 | 0.080 |
| ViT-L-Hybrid | 0.075 | 0.075 | 0.085 |
| DeiT3-L | 0.077 | 0.075 | 0.087 |
| --- | --- | --- | --- |
| ConvNeXt-XL | 0.075 | 0.075 | 0.085 |
| ConvNeXt-L | 0.076 | 0.076 | 0.087 |
| EfficientNet-L2| 0.165 | 0.277 | 0.219 |
| --- | --- | --- | --- |
| ViT-L Reversed | 0.071 | 0.073 | 0.081 |
| Swin-L Equidistant | 0.072 | 0.074 | 0.083 |
| --- | --- | --- | --- |
# Ethical Considerations and Limitations
dpt-swinv2-tiny-256 can produce factually incorrect output, and should not be relied on to produce factually accurate information. Because of the limitations of the pretrained model and the finetuning datasets, it is possible that this model could generate lewd, biased or otherwise offensive outputs.
Therefore, before deploying any applications of dpt-swinv2-tiny-256, developers should perform safety testing.
# Caveats and Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model.
Here are a couple of useful links to learn more about Intel's AI software:
- Intel Neural Compressor [link](https://github.com/intel/neural-compressor)
- Intel Extension for Transformers [link](https://github.com/intel/intel-extension-for-transformers)
# Disclaimer
The license on this model does not constitute legal advice. We are not responsible for the actions of third parties who use this model. Please cosult an attorney before using this model for commercial purposes.
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2103-13413,
author = {Ren{\'{e}} Reiner Birkl, Diana Wofk, Matthias Muller},
title = {MiDaS v3.1 – A Model Zoo for Robust Monocular Relative Depth Estimation},
journal = {CoRR},
volume = {abs/2307.14460},
year = {2021},
url = {https://arxiv.org/abs/2307.14460},
eprinttype = {arXiv},
eprint = {2307.14460},
timestamp = {Wed, 26 Jul 2023},
biburl = {https://dblp.org/rec/journals/corr/abs-2307.14460.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
M4-ai/TinyMistral-6x248M-Instruct | M4-ai | 2024-02-01T04:44:44Z | 612 | 8 | transformers | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"moe",
"en",
"dataset:Locutusque/hercules-v1.0",
"base_model:M4-ai/TinyMistral-6x248M",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-02-01T03:08:12Z | ---
license: apache-2.0
datasets:
- Locutusque/hercules-v1.0
language:
- en
base_model: M4-ai/TinyMistral-6x248M
inference:
parameters:
do_sample: true
temperature: 0.2
top_p: 0.14
top_k: 12
max_new_tokens: 250
repetition_penalty: 1.1
widget:
- text: |
<|im_start|>user
Write me a Python program that calculates the factorial of n. <|im_end|>
<|im_start|>assistant
- text: >-
An emerging clinical approach to treat substance abuse disorders involves a
form of cognitive-behavioral therapy whereby addicts learn to reduce their
reactivity to drug-paired stimuli through cue-exposure or extinction
training. It is, however,
- text: |
<|im_start|>user
How do I say hello in Spanish? <|im_end|>
<|im_start|>assistant
tags:
- moe
---
# Model Card for M4-ai/TinyMistral-6x248M-Instruct
## Model Details
- **Model Name:** M4-ai/TinyMistral-6x248M-Instruct
- **Model Type:** Language Model (Mixture of Experts)
- **Fine-Tuning Base:** M4-ai/TinyMistral-6x248M
- **Developers:** M4-ai team
- **Fine-Tuning Dataset:** hercules-v1.0
## Model Description
M4-ai/TinyMistral-6x248M-Instruct is a fine-tuned language model based on a Mixture of Experts (MoE) architecture. It is an ensemble of various models that have been expertly combined using the LazyMergekit framework. The base pre-trained mixture model includes several versions of the TinyMistral model, with each expert tailored to specialize in different domains ranging from technical software development to multilingual text generation. This fine-tuned version specifically aims to enhance the model's performance on instructive tasks by leveraging the hercules-v1.0 dataset. The model is intended for applications requiring guidance, explanations, and analysis across a wide array of topics.
## Intended Use
M4-ai/TinyMistral-6x248M-Instruct is designed for developers and researchers who need a sophisticated language model capable of understanding and generating text in response to instructive prompts. The model is suitable for a variety of tasks, including but not limited to technical explanations, educational content, policy analysis, and problem-solving across disciplines such as computer science, history, and natural sciences. Users should be mindful of the model's limitations and potential biases, especially when dealing with sensitive topics.
## Training Data
The model was fine-tuned using the hercules-v1.0 dataset, which is an augmented version of the teknium/openhermes dataset. Hercules-v1.0 includes updated data sources like ise-uiuc/Magicoder-Evol-Instruct-110K, jondurbin/airoboros-3.2, and WizardLM/WizardLM_evol_instruct_V2_196k, as well as specialized datasets in mathematics, chemistry, physics, and biology. The dataset has been cleaned to remove RLHF refusals and potentially toxic content from airoboros-3.2. However, users should be aware that a small portion of the data might still contain sensitive content.
You can use the ChatML prompt format for this model.
## Limitations and Bias
While efforts have been made to clean the training data, the potential for biases and harmful content remains, as with any large language model. Users should exercise caution and discretion when utilizing the model, especially in applications that might amplify existing biases or expose users to sensitive content. The model is not recommended for scenarios requiring strict content moderation or for users without the ability to filter or assess the model's outputs critically.
## Evaluation
Performance degradation has been observed when using the Inference API; thus, the model is not recommended for this usage. Instead, users should follow the recommended inference parameters provided in the base model card to optimize performance.
## Usage
```python
!pip install -qU transformers bitsandbytes accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "M4-ai/TinyMistral-6x248M-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
model_kwargs={"torch_dtype": torch.float16, "load_in_4bit": True},
)
messages = [{"role": "user", "content": "Explain what a Mixture of Experts is in less than 100 words."}]
prompt = pipeline.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
## Disclaimer
The model has been fine-tuned on the hercules-v1.0 dataset, which contains content from sources with known issues of toxic examples. Users of M4-ai/TinyMistral-6x248M-Instruct must acknowledge and agree to the following:
- The dataset may include "toxic"/"harmful" content, profanity, and sensitive material.
- The content does not necessarily reflect the beliefs or opinions of the developers.
- Users must comply with local laws regarding free speech and content use.
- Users assume full responsibility for the download and utilization of the dataset and model, indemnifying the developers from all liabilities.
## Contributions
Thanks to @jtatman, @aloobun, @Felladrin, and @Locutusque for their contributions to this model. |
Kquant03/TechxGenus-starcoder2-15b-instruct-GGUF | Kquant03 | 2024-03-07T00:57:59Z | 612 | 3 | transformers | [
"transformers",
"gguf",
"code",
"starcoder2",
"text-generation",
"license:bigcode-openrail-m",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-06T06:23:03Z | ---
tags:
- code
- starcoder2
library_name: transformers
pipeline_tag: text-generation
license: bigcode-openrail-m
---
<p align="center">
<img width="300px" alt="starcoder2-instruct" src="https://huggingface.co/TechxGenus/starcoder2-15b-instruct/resolve/main/starcoder2-instruct.jpg">
</p>
### starcoder2-instruct (not my model, I just quantized it)
We've fine-tuned starcoder2-15b with an additional 0.7 billion high-quality, code-related tokens for 3 epochs. We used DeepSpeed ZeRO 3 and Flash Attention 2 to accelerate the training process. It achieves **77.4 pass@1** on HumanEval-Python. This model operates using the Alpaca instruction format (excluding the system prompt).
### Usage
Here give some examples of how to use our model:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
PROMPT = """### Instruction
{instruction}
### Response
"""
instruction = <Your code instruction here>
prompt = PROMPT.format(instruction=instruction)
tokenizer = AutoTokenizer.from_pretrained("TechxGenus/starcoder2-15b-instruct")
model = AutoModelForCausalLM.from_pretrained(
"TechxGenus/starcoder2-15b-instruct",
torch_dtype=torch.bfloat16,
device_map="auto",
)
inputs = tokenizer.encode(prompt, return_tensors="pt")
outputs = model.generate(input_ids=inputs.to(model.device), max_new_tokens=2048)
print(tokenizer.decode(outputs[0]))
```
With text-generation pipeline:
```python
from transformers import pipeline
import torch
PROMPT = """### Instruction
{instruction}
### Response
"""
instruction = <Your code instruction here>
prompt = PROMPT.format(instruction=instruction)
generator = pipeline(
model="TechxGenus/starcoder2-15b-instruct",
task="text-generation",
torch_dtype=torch.bfloat16,
device_map="auto",
)
result = generator(prompt, max_length=2048)
print(result[0]["generated_text"])
```
### Note
Model may sometimes make errors, produce misleading contents, or struggle to manage tasks that are not related to coding. It has undergone very limited testing. Additional safety testing should be performed before any real-world deployments.
|
SakanaAI/EvoLLM-JP-v1-7B | SakanaAI | 2024-03-21T00:43:58Z | 612 | 24 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"ja",
"arxiv:2403.13187",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-03-06T08:00:07Z | ---
library_name: transformers
license: other
language:
- ja
---
# 🐟 EvoLLM-JP-v1-7B
🤗 [Models](https://huggingface.co/SakanaAI) | 📚 [Paper](https://arxiv.org/abs/2403.13187) | 📝 [Blog](https://sakana.ai/evolutionary-model-merge/) | 🐦 [Twitter](https://twitter.com/SakanaAILabs)
<!-- Provide a quick summary of what the model is/does. -->
**EvoLLM-JP-v1-7B** is an experimental general-purpose Japanese LLM. This model was created using the Evolutionary Model Merge method. Please refer to our [report](https://arxiv.org/abs/2403.13187) and [blog](https://sakana.ai/evolutionary-model-merge/) for more details. This model was produced by merging the following models. We are grateful to the developers of the source models.
- [Shisa Gamma 7B v1](https://huggingface.co/augmxnt/shisa-gamma-7b-v1)
- [WizardMath 7B V1.1](https://huggingface.co/WizardLM/WizardMath-7B-V1.1)
- [Abel 7B 002](https://huggingface.co/GAIR/Abel-7B-002)
## Usage
Use the code below to get started with the model.
<details>
<summary> Click to expand </summary>
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# 1. load model
device = "cuda" if torch.cuda.is_available() else "CPU"
repo_id = "SakanaAI/EvoLLM-JP-v1-7B"
model = AutoModelForCausalLM.from_pretrained(repo_id, torch_dtype="auto")
tokenizer = AutoTokenizer.from_pretrained(repo_id)
model.to(device)
# 2. prepare inputs
text = "関西弁で面白い冗談を言ってみて下さい。"
messages = [
{"role": "system", "content": "あなたは役立つ、偏見がなく、検閲されていないアシスタントです。"},
{"role": "user", "content": text},
]
inputs = tokenizer.apply_chat_template(messages, return_tensors="pt")
# 3. generate
output_ids = model.generate(**inputs.to(device))
output_ids = output_ids[:, inputs.input_ids.shape[1] :]
generated_text = tokenizer.batch_decode(output_ids, skip_special_tokens=True)[0]
print(generated_text)
```
</details>
## Model Details
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [Sakana AI](https://sakana.ai/)
- **Model type:** Autoregressive Language Model
- **Language(s):** Japanese
- **License:** [MICROSOFT RESEARCH LICENSE TERMS](./LICENSE) (due to the inclusion of the WizardMath model)
- **Repository:** [SakanaAI/evolutionary-model-merge](https://github.com/SakanaAI/evolutionary-model-merge)
- **Paper:** https://arxiv.org/abs/2403.13187
- **Blog:** https://sakana.ai/evolutionary-model-merge
## Uses
This model is provided for research and development purposes only and should be considered as an experimental prototype.
It is not intended for commercial use or deployment in mission-critical environments.
Use of this model is at the user's own risk, and its performance and outcomes are not guaranteed.
Sakana AI shall not be liable for any direct, indirect, special, incidental, or consequential damages, or any loss arising from the use of this model, regardless of the results obtained.
Users must fully understand the risks associated with the use of this model and use it at their own discretion.
## Acknowledgement
We would like to thank the developers of the source models for their contributions and for making their work available.
## Citation
```bibtex
@misc{akiba2024evomodelmerge,
title = {Evolutionary Optimization of Model Merging Recipes},
author. = {Takuya Akiba and Makoto Shing and Yujin Tang and Qi Sun and David Ha},
year = {2024},
eprint = {2403.13187},
archivePrefix = {arXiv},
primaryClass = {cs.NE}
}
```
|
MaziyarPanahi/MixTAO-7Bx2-MoE-v8.1-GGUF | MaziyarPanahi | 2024-03-11T09:00:47Z | 612 | 11 | transformers | [
"transformers",
"gguf",
"mistral",
"quantized",
"2-bit",
"3-bit",
"4-bit",
"5-bit",
"6-bit",
"8-bit",
"GGUF",
"safetensors",
"mixtral",
"text-generation",
"moe",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us",
"base_model:zhengr/MixTAO-7Bx2-MoE-v8.1"
] | text-generation | 2024-03-06T20:37:35Z | ---
tags:
- quantized
- 2-bit
- 3-bit
- 4-bit
- 5-bit
- 6-bit
- 8-bit
- GGUF
- transformers
- safetensors
- mixtral
- text-generation
- moe
- license:apache-2.0
- model-index
- autotrain_compatible
- endpoints_compatible
- text-generation-inference
- region:us
- text-generation
model_name: MixTAO-7Bx2-MoE-v8.1-GGUF
base_model: zhengr/MixTAO-7Bx2-MoE-v8.1
inference: false
model_creator: zhengr
pipeline_tag: text-generation
quantized_by: MaziyarPanahi
---
# [MaziyarPanahi/MixTAO-7Bx2-MoE-v8.1-GGUF](https://huggingface.co/MaziyarPanahi/MixTAO-7Bx2-MoE-v8.1-GGUF)
- Model creator: [zhengr](https://huggingface.co/zhengr)
- Original model: [zhengr/MixTAO-7Bx2-MoE-v8.1](https://huggingface.co/zhengr/MixTAO-7Bx2-MoE-v8.1)
## Description
[MaziyarPanahi/MixTAO-7Bx2-MoE-v8.1-GGUF](https://huggingface.co/MaziyarPanahi/MixTAO-7Bx2-MoE-v8.1-GGUF) contains GGUF format model files for [zhengr/MixTAO-7Bx2-MoE-v8.1](https://huggingface.co/zhengr/MixTAO-7Bx2-MoE-v8.1).
## How to use
Thanks to [TheBloke](https://huggingface.co/TheBloke) for preparing an amazing README on how to use GGUF models:
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [GPT4All](https://gpt4all.io/index.html), a free and open source local running GUI, supporting Windows, Linux and macOS with full GPU accel.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration. Linux available, in beta as of 27/11/2023.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server. Note, as of time of writing (November 27th 2023), ctransformers has not been updated in a long time and does not support many recent models.
### Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: [MaziyarPanahi/MixTAO-7Bx2-MoE-v8.1-GGUF](https://huggingface.co/MaziyarPanahi/MixTAO-7Bx2-MoE-v8.1-GGUF) and below it, a specific filename to download, such as: MixTAO-7Bx2-MoE-v8.1.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download MaziyarPanahi/MixTAO-7Bx2-MoE-v8.1-GGUF MixTAO-7Bx2-MoE-v8.1.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
</details>
<details>
<summary>More advanced huggingface-cli download usage (click to read)</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download [MaziyarPanahi/MixTAO-7Bx2-MoE-v8.1-GGUF](https://huggingface.co/MaziyarPanahi/MixTAO-7Bx2-MoE-v8.1-GGUF) --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download MaziyarPanahi/MixTAO-7Bx2-MoE-v8.1-GGUF MixTAO-7Bx2-MoE-v8.1.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 35 -m MixTAO-7Bx2-MoE-v8.1.Q4_K_M.gguf --color -c 32768 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 32768` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically. Note that longer sequence lengths require much more resources, so you may need to reduce this value.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions can be found in the text-generation-webui documentation, here: [text-generation-webui/docs/04 ‐ Model Tab.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/04%20%E2%80%90%20Model%20Tab.md#llamacpp).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries. Note that at the time of writing (Nov 27th 2023), ctransformers has not been updated for some time and is not compatible with some recent models. Therefore I recommend you use llama-cpp-python.
### How to load this model in Python code, using llama-cpp-python
For full documentation, please see: [llama-cpp-python docs](https://abetlen.github.io/llama-cpp-python/).
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install llama-cpp-python
# With NVidia CUDA acceleration
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
# Or with OpenBLAS acceleration
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install llama-cpp-python
# Or with CLBLast acceleration
CMAKE_ARGS="-DLLAMA_CLBLAST=on" pip install llama-cpp-python
# Or with AMD ROCm GPU acceleration (Linux only)
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
# Or with Metal GPU acceleration for macOS systems only
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
# In windows, to set the variables CMAKE_ARGS in PowerShell, follow this format; eg for NVidia CUDA:
$env:CMAKE_ARGS = "-DLLAMA_OPENBLAS=on"
pip install llama-cpp-python
```
#### Simple llama-cpp-python example code
```python
from llama_cpp import Llama
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = Llama(
model_path="./MixTAO-7Bx2-MoE-v8.1.Q4_K_M.gguf", # Download the model file first
n_ctx=32768, # The max sequence length to use - note that longer sequence lengths require much more resources
n_threads=8, # The number of CPU threads to use, tailor to your system and the resulting performance
n_gpu_layers=35 # The number of layers to offload to GPU, if you have GPU acceleration available
)
# Simple inference example
output = llm(
"<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant", # Prompt
max_tokens=512, # Generate up to 512 tokens
stop=["</s>"], # Example stop token - not necessarily correct for this specific model! Please check before using.
echo=True # Whether to echo the prompt
)
# Chat Completion API
llm = Llama(model_path="./MixTAO-7Bx2-MoE-v8.1.Q4_K_M.gguf", chat_format="llama-2") # Set chat_format according to the model you are using
llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are a story writing assistant."},
{
"role": "user",
"content": "Write a story about llamas."
}
]
)
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers) |
mzwing/Hassaku-GGUF | mzwing | 2024-03-15T13:17:50Z | 612 | 0 | null | [
"gguf",
"region:us"
] | null | 2024-03-15T13:01:45Z | Entry not found |
duyntnet/Phi-3-mini-128k-instruct-imatrix-GGUF | duyntnet | 2024-05-11T06:22:27Z | 612 | 0 | transformers | [
"transformers",
"gguf",
"imatrix",
"Phi-3-mini-128k-instruct",
"text-generation",
"en",
"license:other",
"region:us"
] | text-generation | 2024-05-11T05:26:10Z | ---
license: other
language:
- en
pipeline_tag: text-generation
inference: false
tags:
- transformers
- gguf
- imatrix
- Phi-3-mini-128k-instruct
---
Quantizations of https://huggingface.co/microsoft/Phi-3-mini-128k-instruct
# From original readme
## How to Use
Phi-3 Mini-128K-Instruct has been integrated in the development version (4.41.0.dev0) of `transformers`. Until the official version is released through `pip`, ensure that you are doing one of the following:
* When loading the model, ensure that `trust_remote_code=True` is passed as an argument of the `from_pretrained()` function.
* Update your local `transformers` to the development version: `pip uninstall -y transformers && pip install git+https://github.com/huggingface/transformers`. The previous command is an alternative to cloning and installing from the source.
The current `transformers` version can be verified with: `pip list | grep transformers`.
### Tokenizer
Phi-3 Mini-128K-Instruct supports a vocabulary size of up to `32064` tokens. The [tokenizer files](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct/blob/main/added_tokens.json) already provide placeholder tokens that can be used for downstream fine-tuning, but they can also be extended up to the model's vocabulary size.
### Chat Format
Given the nature of the training data, the Phi-3 Mini-128K-Instruct model is best suited for prompts using the chat format as follows.
You can provide the prompt as a question with a generic template as follow:
```markdown
<|user|>\nQuestion<|end|>\n<|assistant|>
```
For example:
```markdown
<|user|>
How to explain Internet for a medieval knight?<|end|>
<|assistant|>
```
where the model generates the text after `<|assistant|>`. In case of few-shots prompt, the prompt can be formatted as the following:
```markdown
<|user|>
I am going to Paris, what should I see?<|end|>
<|assistant|>
Paris, the capital of France, is known for its stunning architecture, art museums, historical landmarks, and romantic atmosphere. Here are some of the top attractions to see in Paris:\n\n1. The Eiffel Tower: The iconic Eiffel Tower is one of the most recognizable landmarks in the world and offers breathtaking views of the city.\n2. The Louvre Museum: The Louvre is one of the world's largest and most famous museums, housing an impressive collection of art and artifacts, including the Mona Lisa.\n3. Notre-Dame Cathedral: This beautiful cathedral is one of the most famous landmarks in Paris and is known for its Gothic architecture and stunning stained glass windows.\n\nThese are just a few of the many attractions that Paris has to offer. With so much to see and do, it's no wonder that Paris is one of the most popular tourist destinations in the world."<|end|>
<|user|>
What is so great about #1?<|end|>
<|assistant|>
```
### Sample inference code
This code snippets show how to get quickly started with running the model on a GPU:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
torch.random.manual_seed(0)
model = AutoModelForCausalLM.from_pretrained(
"microsoft/Phi-3-mini-128k-instruct",
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3-mini-128k-instruct")
messages = [
{"role": "user", "content": "Can you provide ways to eat combinations of bananas and dragonfruits?"},
{"role": "assistant", "content": "Sure! Here are some ways to eat bananas and dragonfruits together: 1. Banana and dragonfruit smoothie: Blend bananas and dragonfruits together with some milk and honey. 2. Banana and dragonfruit salad: Mix sliced bananas and dragonfruits together with some lemon juice and honey."},
{"role": "user", "content": "What about solving an 2x + 3 = 7 equation?"},
]
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)
generation_args = {
"max_new_tokens": 500,
"return_full_text": False,
"temperature": 0.0,
"do_sample": False,
}
output = pipe(messages, **generation_args)
print(output[0]['generated_text'])
```
*Some applications/frameworks might not include a BOS token (`<s>`) at the start of the conversation. Please ensure that it is included since it provides more reliable results.* |
jhshao/ChronoDepth | jhshao | 2024-06-11T12:27:10Z | 612 | 3 | diffusers | [
"diffusers",
"safetensors",
"video depth estimation",
"depth-estimation",
"arxiv:2406.01493",
"license:mit",
"diffusers:ChronoDepthPipeline",
"region:us"
] | depth-estimation | 2024-06-11T01:54:41Z | ---
license: mit
library_name: diffusers
pipeline_tag: depth-estimation
tags:
- video depth estimation
---
# ChronoDepth: Learning Temporally Consistent Video Depth from Video Diffusion Priors
This model represents the official checkpoint of the paper titled "Learning Temporally Consistent Video Depth from Video Diffusion Priors".
[](https://jhaoshao.github.io/ChronoDepth/) [](https://arxiv.org/abs/2406.01493)[](https://github.com/jhaoshao/ChronoDepth)
[Jiahao Shao*](https://jhaoshao.github.io/), Yuanbo Yang*, Hongyu Zhou, [Youmin Zhang](https://youmi-zym.github.io/), [Yujun Shen](https://shenyujun.github.io/), [Matteo Poggi](https://mattpoggi.github.io/), [Yiyi Liao†](https://yiyiliao.github.io/ )
## 🎓 Citation
Please cite our paper if you find this repository useful:
```bibtex
@misc{shao2024learning,
title={Learning Temporally Consistent Video Depth from Video Diffusion Priors},
author={Jiahao Shao and Yuanbo Yang and Hongyu Zhou and Youmin Zhang and Yujun Shen and Matteo Poggi and Yiyi Liao},
year={2024},
eprint={2406.01493},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
``` |
kitaev/tetra-tag-en | kitaev | 2021-05-19T21:01:26Z | 611 | 0 | transformers | [
"transformers",
"pytorch",
"jax",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2022-03-02T23:29:05Z | Entry not found |
timm/tinynet_c.in1k | timm | 2023-04-27T21:50:26Z | 611 | 0 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2010.14819",
"license:apache-2.0",
"region:us"
] | image-classification | 2022-12-13T00:22:13Z | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for tinynet_c.in1k
A TinyNet image classification model. Trained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 2.5
- GMACs: 0.1
- Activations (M): 2.9
- Image size: 184 x 184
- **Papers:**
- Model rubik's cube: Twisting resolution, depth and width for tinynets: https://arxiv.org/abs/2010.14819v2
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('tinynet_c.in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tinynet_c.in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 8, 92, 92])
# torch.Size([1, 16, 46, 46])
# torch.Size([1, 24, 23, 23])
# torch.Size([1, 64, 12, 12])
# torch.Size([1, 176, 6, 6])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tinynet_c.in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1280, 6, 6) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{han2020model,
title={Model rubik’s cube: Twisting resolution, depth and width for tinynets},
author={Han, Kai and Wang, Yunhe and Zhang, Qiulin and Zhang, Wei and Xu, Chunjing and Zhang, Tong},
journal={Advances in Neural Information Processing Systems},
volume={33},
pages={19353--19364},
year={2020}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
|
sinkinai/majicMIX-realistic-v5 | sinkinai | 2024-05-16T14:10:46Z | 611 | 24 | diffusers | [
"diffusers",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2023-05-30T05:00:09Z | You can run this model for free at: https://sinkin.ai/m/yBG2r9O
We offer API at low rates as well |
sail-rvc/Patrick_Star__RVC_v2_ | sail-rvc | 2023-07-14T07:30:17Z | 611 | 0 | transformers | [
"transformers",
"rvc",
"sail-rvc",
"audio-to-audio",
"endpoints_compatible",
"region:us"
] | audio-to-audio | 2023-07-14T07:29:32Z |
---
pipeline_tag: audio-to-audio
tags:
- rvc
- sail-rvc
---
# Patrick_Star__RVC_v2_
## RVC Model

This model repo was automatically generated.
Date: 2023-07-14 07:30:17
Bot Name: juuxnscrap
Model Type: RVC
Source: https://huggingface.co/juuxn/RVCModels/
Reason: Converting into loadable format for https://github.com/chavinlo/rvc-runpod
|
TheBloke/Huginn-13B-v4-GGUF | TheBloke | 2023-09-27T12:46:44Z | 611 | 1 | transformers | [
"transformers",
"gguf",
"llama",
"base_model:The-Face-Of-Goonery/Huginn-13b-V4",
"license:llama2",
"text-generation-inference",
"region:us"
] | null | 2023-08-30T10:41:50Z | ---
license: llama2
model_name: Huginn 13B v4
base_model: The-Face-Of-Goonery/Huginn-13b-V4
inference: false
model_creator: Caleb Morgan
model_type: llama
prompt_template: 'Below is an instruction that describes a task. Write a response
that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Huginn 13B v4 - GGUF
- Model creator: [Caleb Morgan](https://huggingface.co/The-Face-Of-Goonery)
- Original model: [Huginn 13B v4](https://huggingface.co/The-Face-Of-Goonery/Huginn-13b-V4)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Caleb Morgan's Huginn 13B v4](https://huggingface.co/The-Face-Of-Goonery/Huginn-13b-V4).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp. GGUF offers numerous advantages over GGML, such as better tokenisation, and support for special tokens. It is also supports metadata, and is designed to be extensible.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Huginn-13B-v4-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Huginn-13B-v4-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Huginn-13B-v4-GGUF)
* [Caleb Morgan's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/The-Face-Of-Goonery/Huginn-13b-V4)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [huginn-13b-v4.Q2_K.gguf](https://huggingface.co/TheBloke/Huginn-13B-v4-GGUF/blob/main/huginn-13b-v4.Q2_K.gguf) | Q2_K | 2 | 5.43 GB| 7.93 GB | smallest, significant quality loss - not recommended for most purposes |
| [huginn-13b-v4.Q3_K_S.gguf](https://huggingface.co/TheBloke/Huginn-13B-v4-GGUF/blob/main/huginn-13b-v4.Q3_K_S.gguf) | Q3_K_S | 3 | 5.66 GB| 8.16 GB | very small, high quality loss |
| [huginn-13b-v4.Q3_K_M.gguf](https://huggingface.co/TheBloke/Huginn-13B-v4-GGUF/blob/main/huginn-13b-v4.Q3_K_M.gguf) | Q3_K_M | 3 | 6.34 GB| 8.84 GB | very small, high quality loss |
| [huginn-13b-v4.Q3_K_L.gguf](https://huggingface.co/TheBloke/Huginn-13B-v4-GGUF/blob/main/huginn-13b-v4.Q3_K_L.gguf) | Q3_K_L | 3 | 6.93 GB| 9.43 GB | small, substantial quality loss |
| [huginn-13b-v4.Q4_0.gguf](https://huggingface.co/TheBloke/Huginn-13B-v4-GGUF/blob/main/huginn-13b-v4.Q4_0.gguf) | Q4_0 | 4 | 7.37 GB| 9.87 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [huginn-13b-v4.Q4_K_S.gguf](https://huggingface.co/TheBloke/Huginn-13B-v4-GGUF/blob/main/huginn-13b-v4.Q4_K_S.gguf) | Q4_K_S | 4 | 7.41 GB| 9.91 GB | small, greater quality loss |
| [huginn-13b-v4.Q4_K_M.gguf](https://huggingface.co/TheBloke/Huginn-13B-v4-GGUF/blob/main/huginn-13b-v4.Q4_K_M.gguf) | Q4_K_M | 4 | 7.87 GB| 10.37 GB | medium, balanced quality - recommended |
| [huginn-13b-v4.Q5_0.gguf](https://huggingface.co/TheBloke/Huginn-13B-v4-GGUF/blob/main/huginn-13b-v4.Q5_0.gguf) | Q5_0 | 5 | 8.97 GB| 11.47 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [huginn-13b-v4.Q5_K_S.gguf](https://huggingface.co/TheBloke/Huginn-13B-v4-GGUF/blob/main/huginn-13b-v4.Q5_K_S.gguf) | Q5_K_S | 5 | 8.97 GB| 11.47 GB | large, low quality loss - recommended |
| [huginn-13b-v4.Q5_K_M.gguf](https://huggingface.co/TheBloke/Huginn-13B-v4-GGUF/blob/main/huginn-13b-v4.Q5_K_M.gguf) | Q5_K_M | 5 | 9.23 GB| 11.73 GB | large, very low quality loss - recommended |
| [huginn-13b-v4.Q6_K.gguf](https://huggingface.co/TheBloke/Huginn-13B-v4-GGUF/blob/main/huginn-13b-v4.Q6_K.gguf) | Q6_K | 6 | 10.68 GB| 13.18 GB | very large, extremely low quality loss |
| [huginn-13b-v4.Q8_0.gguf](https://huggingface.co/TheBloke/Huginn-13B-v4-GGUF/blob/main/huginn-13b-v4.Q8_0.gguf) | Q8_0 | 8 | 13.83 GB| 16.33 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/Huginn-13B-v4-GGUF and below it, a specific filename to download, such as: huginn-13b-v4.q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub>=0.17.1
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/Huginn-13B-v4-GGUF huginn-13b-v4.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/Huginn-13B-v4-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Huginn-13B-v4-GGUF huginn-13b-v4.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows CLI users: Use `set HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1` before running the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m huginn-13b-v4.q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{prompt}\n\n### Response:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model from Python using ctransformers
#### First install the package
```bash
# Base ctransformers with no GPU acceleration
pip install ctransformers>=0.2.24
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]>=0.2.24
# Or with ROCm GPU acceleration
CT_HIPBLAS=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems
CT_METAL=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
```
#### Simple example code to load one of these GGUF models
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/Huginn-13B-v4-GGUF", model_file="huginn-13b-v4.q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here's guides on using llama-cpp-python or ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Caleb Morgan's Huginn 13B v4
Oh jesus, huginn 13b actually has still more to offer? welp, time for another stupid super ultra mega merge because.. yes. Woooo, v4.5 will come when they make the better mythic destroyer
Merge of https://huggingface.co/The-Face-Of-Goonery/Huginn-v3-13b and https://huggingface.co/Sao10K/Mythical-Destroyer-L2-13B/tree/main
still uses alpaca format
<!-- original-model-card end -->
|
TheBloke/openchat_v3.2_super-GGUF | TheBloke | 2023-09-27T12:47:15Z | 611 | 11 | transformers | [
"transformers",
"gguf",
"llama",
"base_model:openchat/openchat_v3.2_super",
"license:llama2",
"text-generation-inference",
"region:us"
] | null | 2023-09-04T22:41:55Z | ---
license: llama2
model_name: OpenChat v3.2 Super
base_model: openchat/openchat_v3.2_super
inference: false
model_creator: OpenChat
model_type: llama
prompt_template: 'GPT4 User: {prompt}<|end_of_turn|>GPT4 Assistant:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# OpenChat v3.2 Super - GGUF
- Model creator: [OpenChat](https://huggingface.co/openchat)
- Original model: [OpenChat v3.2 Super](https://huggingface.co/openchat/openchat_v3.2_super)
<!-- description start -->
## Description
This repo contains GGUF format model files for [OpenChat's OpenChat v3.2 Super](https://huggingface.co/openchat/openchat_v3.2_super).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp. GGUF offers numerous advantages over GGML, such as better tokenisation, and support for special tokens. It is also supports metadata, and is designed to be extensible.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/openchat_v3.2_super-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/openchat_v3.2_super-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/openchat_v3.2_super-GGUF)
* [OpenChat's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/openchat/openchat_v3.2_super)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: OpenChat
```
GPT4 User: {prompt}<|end_of_turn|>GPT4 Assistant:
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [openchat_v3.2_super.Q2_K.gguf](https://huggingface.co/TheBloke/openchat_v3.2_super-GGUF/blob/main/openchat_v3.2_super.Q2_K.gguf) | Q2_K | 2 | 5.43 GB| 7.93 GB | smallest, significant quality loss - not recommended for most purposes |
| [openchat_v3.2_super.Q3_K_S.gguf](https://huggingface.co/TheBloke/openchat_v3.2_super-GGUF/blob/main/openchat_v3.2_super.Q3_K_S.gguf) | Q3_K_S | 3 | 5.66 GB| 8.16 GB | very small, high quality loss |
| [openchat_v3.2_super.Q3_K_M.gguf](https://huggingface.co/TheBloke/openchat_v3.2_super-GGUF/blob/main/openchat_v3.2_super.Q3_K_M.gguf) | Q3_K_M | 3 | 6.34 GB| 8.84 GB | very small, high quality loss |
| [openchat_v3.2_super.Q3_K_L.gguf](https://huggingface.co/TheBloke/openchat_v3.2_super-GGUF/blob/main/openchat_v3.2_super.Q3_K_L.gguf) | Q3_K_L | 3 | 6.93 GB| 9.43 GB | small, substantial quality loss |
| [openchat_v3.2_super.Q4_0.gguf](https://huggingface.co/TheBloke/openchat_v3.2_super-GGUF/blob/main/openchat_v3.2_super.Q4_0.gguf) | Q4_0 | 4 | 7.37 GB| 9.87 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [openchat_v3.2_super.Q4_K_S.gguf](https://huggingface.co/TheBloke/openchat_v3.2_super-GGUF/blob/main/openchat_v3.2_super.Q4_K_S.gguf) | Q4_K_S | 4 | 7.41 GB| 9.91 GB | small, greater quality loss |
| [openchat_v3.2_super.Q4_K_M.gguf](https://huggingface.co/TheBloke/openchat_v3.2_super-GGUF/blob/main/openchat_v3.2_super.Q4_K_M.gguf) | Q4_K_M | 4 | 7.87 GB| 10.37 GB | medium, balanced quality - recommended |
| [openchat_v3.2_super.Q5_0.gguf](https://huggingface.co/TheBloke/openchat_v3.2_super-GGUF/blob/main/openchat_v3.2_super.Q5_0.gguf) | Q5_0 | 5 | 8.97 GB| 11.47 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [openchat_v3.2_super.Q5_K_S.gguf](https://huggingface.co/TheBloke/openchat_v3.2_super-GGUF/blob/main/openchat_v3.2_super.Q5_K_S.gguf) | Q5_K_S | 5 | 8.97 GB| 11.47 GB | large, low quality loss - recommended |
| [openchat_v3.2_super.Q5_K_M.gguf](https://huggingface.co/TheBloke/openchat_v3.2_super-GGUF/blob/main/openchat_v3.2_super.Q5_K_M.gguf) | Q5_K_M | 5 | 9.23 GB| 11.73 GB | large, very low quality loss - recommended |
| [openchat_v3.2_super.Q6_K.gguf](https://huggingface.co/TheBloke/openchat_v3.2_super-GGUF/blob/main/openchat_v3.2_super.Q6_K.gguf) | Q6_K | 6 | 10.68 GB| 13.18 GB | very large, extremely low quality loss |
| [openchat_v3.2_super.Q8_0.gguf](https://huggingface.co/TheBloke/openchat_v3.2_super-GGUF/blob/main/openchat_v3.2_super.Q8_0.gguf) | Q8_0 | 8 | 13.83 GB| 16.33 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/openchat_v3.2_super-GGUF and below it, a specific filename to download, such as: openchat_v3.2_super.q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub>=0.17.1
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/openchat_v3.2_super-GGUF openchat_v3.2_super.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/openchat_v3.2_super-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/openchat_v3.2_super-GGUF openchat_v3.2_super.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows CLI users: Use `set HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1` before running the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m openchat_v3.2_super.q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "GPT4 User: {prompt}<|end_of_turn|>GPT4 Assistant:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model from Python using ctransformers
#### First install the package
```bash
# Base ctransformers with no GPU acceleration
pip install ctransformers>=0.2.24
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]>=0.2.24
# Or with ROCm GPU acceleration
CT_HIPBLAS=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems
CT_METAL=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
```
#### Simple example code to load one of these GGUF models
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/openchat_v3.2_super-GGUF", model_file="openchat_v3.2_super.q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here's guides on using llama-cpp-python or ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: OpenChat's OpenChat v3.2 Super
# OpenChat: Advancing Open-source Language Models with Imperfect Data</h1>
<div align="center">
<img src="https://raw.githubusercontent.com/imoneoi/openchat/master/assets/logo_new.png" style="width: 65%">
</div>
OpenChat is a collection of open-source language models, optimized and fine-tuned with a strategy inspired by offline reinforcement learning. We use approximately 80k ShareGPT conversations, a conditioning strategy, and weighted loss to deliver outstanding performance, despite our simple approach. Our ultimate goal is to develop a high-performance, commercially available, open-source large language model, and we are continuously making strides towards this vision.
**🤖 Ranked #1 among all open-source models on [AgentBench](https://github.com/THUDM/AgentBench)**
**🔥 Ranked #1 among 13B open-source models | 89.5% win-rate on [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/) | 7.19 score on [MT-bench](https://chat.lmsys.org/?leaderboard)**
**🕒 Exceptionally efficient padding-free fine-tuning, only requires 15 hours on 8xA100 80G**
**💲 FREE for commercial use under [Llama 2 Community License](https://ai.meta.com/resources/models-and-libraries/llama-downloads/)**
[](https://zenodo.org/badge/latestdoi/645397533)
## <a id="models"></a> Usage
To use these models, we highly recommend installing the OpenChat package by following the [installation guide](https://github.com/imoneoi/openchat/#installation) and using the OpenChat OpenAI-compatible API server by running the serving command from the table below. The server is optimized for high-throughput deployment using [vLLM](https://github.com/vllm-project/vllm) and can run on a GPU with at least 48GB RAM or two consumer GPUs with tensor parallelism. To enable tensor parallelism, append `--tensor-parallel-size 2` to the serving command.
When started, the server listens at `localhost:18888` for requests and is compatible with the [OpenAI ChatCompletion API specifications](https://platform.openai.com/docs/api-reference/chat). See the example request below for reference. Additionally, you can access the [OpenChat Web UI](#web-ui) for a user-friendly experience.
To deploy the server as an online service, use `--api-keys sk-KEY1 sk-KEY2 ...` to specify allowed API keys and `--disable-log-requests --disable-log-stats --log-file openchat.log` for logging only to a file. We recommend using a [HTTPS gateway](https://fastapi.tiangolo.com/es/deployment/concepts/#security-https) in front of the server for security purposes.
<details>
<summary>Example request (click to expand)</summary>
```bash
curl http://localhost:18888/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "openchat_v3.2",
"messages": [{"role": "user", "content": "You are a large language model named OpenChat. Write a poem to describe yourself"}]
}'
```
</details>
| Model | Size | Context | Weights | Serving |
|--------------|------|---------|--------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| OpenChat 3.2 SUPER | 13B | 4096 | [Huggingface](https://huggingface.co/openchat/openchat_v3.2_super) | `python -m ochat.serving.openai_api_server --model-type openchat_v3.2 --model openchat/openchat_v3.2_super --engine-use-ray --worker-use-ray --max-num-batched-tokens 5120` |
For inference with Huggingface Transformers (slow and not recommended), follow the conversation template provided below:
<details>
<summary>Conversation templates (click to expand)</summary>
```python
# Single-turn V3.2 (SUPER)
tokenize("GPT4 User: Hello<|end_of_turn|>GPT4 Assistant:")
# Result: [1, 402, 7982, 29946, 4911, 29901, 15043, 32000, 402, 7982, 29946, 4007, 22137, 29901]
# Multi-turn V3.2 (SUPER)
tokenize("GPT4 User: Hello<|end_of_turn|>GPT4 Assistant: Hi<|end_of_turn|>GPT4 User: How are you today?<|end_of_turn|>GPT4 Assistant:")
# Result: [1, 402, 7982, 29946, 4911, 29901, 15043, 32000, 402, 7982, 29946, 4007, 22137, 29901, 6324, 32000, 402, 7982, 29946, 4911, 29901, 1128, 526, 366, 9826, 29973, 32000, 402, 7982, 29946, 4007, 22137, 29901]
```
</details>
## <a id="benchmarks"></a> Benchmarks
We have evaluated our models using the two most popular evaluation benchmarks **, including AlpacaEval and MT-bench. Here we list the top models with our released versions, sorted by model size in descending order. The full version can be found on the [MT-bench](https://chat.lmsys.org/?leaderboard) and [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/) leaderboards.
To ensure consistency, we used the same routine as ChatGPT / GPT-4 to run these benchmarks. We started the OpenAI API-compatible server and set the `openai.api_base` to `http://localhost:18888/v1` in the benchmark program.
| **Model** | **Size** | **Context** | **Dataset Size** | **💲Free** | **AlpacaEval (win rate %)** | **MT-bench (win rate adjusted %)** | **MT-bench (score)** |
|----------------------------------|----------|-------------|------------------|-----------|-----------------------------|------------------------------------|----------------------|
| | | | | | **v.s. text-davinci-003** | **v.s. ChatGPT** | |
| GPT-4 | 1.8T* | 8K | | ❌ | 95.3 | 82.5 | 8.99 |
| ChatGPT | 175B* | 4K | | ❌ | 89.4 | 50.0 | 7.94 |
| Llama-2-70B-Chat | 70B | 4K | 2.9M | ✅ | 92.7 | 60.0 | 6.86 |
| **OpenChat 3.2 SUPER** | **13B** | **4K** | **80K** | ✅ | **89.5** | **57.5** | **7.19** |
| Llama-2-13B-Chat | 13B | 4K | 2.9M | ✅ | 81.1 | 55.3 | 6.65 |
| WizardLM 1.2 | 13B | 4K | 196K | ✅ | 89.2 | 53.1 | 7.05 |
| Vicuna 1.5 | 13B | 2K | 125K | ✅ | 78.8 | 37.2 | 6.57 |
*: Estimated model size
**: The benchmark metrics represent a quantified measure of a subset of the model's capabilities. A win-rate greater than 50% does not necessarily indicate that the model is better than ChatGPT in all scenarios or for all use cases. It is essential to consider the specific tasks or applications for which the model was evaluated and compare the results accordingly.
## Limitations
**Foundation Model Limitations**
Despite its advanced capabilities, OpenChat is still bound by the limitations inherent in its foundation models. These limitations may impact the model's performance in areas such as:
- Complex reasoning
- Mathematical and arithmetic tasks
- Programming and coding challenges
**Hallucination of Non-existent Information**
OpenChat may sometimes generate information that does not exist or is not accurate, also known as "hallucination". Users should be aware of this possibility and verify any critical information obtained from the model.
## License
Our OpenChat V3 models are licensed under the [Llama 2 Community License](https://ai.meta.com/resources/models-and-libraries/llama-downloads/).
<!-- original-model-card end -->
|
TheBloke/Zarablend-L2-7B-GGUF | TheBloke | 2023-09-27T12:47:33Z | 611 | 1 | transformers | [
"transformers",
"gguf",
"llama",
"llama2",
"base_model:zarakiquemparte/zarablend-l2-7b",
"license:other",
"text-generation-inference",
"region:us"
] | null | 2023-09-05T10:46:49Z | ---
license: other
tags:
- llama2
model_name: Zarablend L2 7B
base_model: zarakiquemparte/zarablend-l2-7b
inference: false
model_creator: Zaraki Quem Parte
model_type: llama
prompt_template: '### Instruction:
{prompt}
### Response:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Zarablend L2 7B - GGUF
- Model creator: [Zaraki Quem Parte](https://huggingface.co/zarakiquemparte)
- Original model: [Zarablend L2 7B](https://huggingface.co/zarakiquemparte/zarablend-l2-7b)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Zaraki Quem Parte's Zarablend L2 7B](https://huggingface.co/zarakiquemparte/zarablend-l2-7b).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp. GGUF offers numerous advantages over GGML, such as better tokenisation, and support for special tokens. It is also supports metadata, and is designed to be extensible.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Zarablend-L2-7B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Zarablend-L2-7B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Zarablend-L2-7B-GGUF)
* [Zaraki Quem Parte's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/zarakiquemparte/zarablend-l2-7b)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Alpaca-InstructOnly
```
### Instruction:
{prompt}
### Response:
```
<!-- prompt-template end -->
<!-- licensing start -->
## Licensing
The creator of the source model has listed its license as `other`, and this quantization has therefore used that same license.
As this model is based on Llama 2, it is also subject to the Meta Llama 2 license terms, and the license files for that are additionally included. It should therefore be considered as being claimed to be licensed under both licenses. I contacted Hugging Face for clarification on dual licensing but they do not yet have an official position. Should this change, or should Meta provide any feedback on this situation, I will update this section accordingly.
In the meantime, any questions regarding licensing, and in particular how these two licenses might interact, should be directed to the original model repository: [Zaraki Quem Parte's Zarablend L2 7B](https://huggingface.co/zarakiquemparte/zarablend-l2-7b).
<!-- licensing end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [zarablend-l2-7b.Q2_K.gguf](https://huggingface.co/TheBloke/Zarablend-L2-7B-GGUF/blob/main/zarablend-l2-7b.Q2_K.gguf) | Q2_K | 2 | 2.83 GB| 5.33 GB | smallest, significant quality loss - not recommended for most purposes |
| [zarablend-l2-7b.Q3_K_S.gguf](https://huggingface.co/TheBloke/Zarablend-L2-7B-GGUF/blob/main/zarablend-l2-7b.Q3_K_S.gguf) | Q3_K_S | 3 | 2.95 GB| 5.45 GB | very small, high quality loss |
| [zarablend-l2-7b.Q3_K_M.gguf](https://huggingface.co/TheBloke/Zarablend-L2-7B-GGUF/blob/main/zarablend-l2-7b.Q3_K_M.gguf) | Q3_K_M | 3 | 3.30 GB| 5.80 GB | very small, high quality loss |
| [zarablend-l2-7b.Q3_K_L.gguf](https://huggingface.co/TheBloke/Zarablend-L2-7B-GGUF/blob/main/zarablend-l2-7b.Q3_K_L.gguf) | Q3_K_L | 3 | 3.60 GB| 6.10 GB | small, substantial quality loss |
| [zarablend-l2-7b.Q4_0.gguf](https://huggingface.co/TheBloke/Zarablend-L2-7B-GGUF/blob/main/zarablend-l2-7b.Q4_0.gguf) | Q4_0 | 4 | 3.83 GB| 6.33 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [zarablend-l2-7b.Q4_K_S.gguf](https://huggingface.co/TheBloke/Zarablend-L2-7B-GGUF/blob/main/zarablend-l2-7b.Q4_K_S.gguf) | Q4_K_S | 4 | 3.86 GB| 6.36 GB | small, greater quality loss |
| [zarablend-l2-7b.Q4_K_M.gguf](https://huggingface.co/TheBloke/Zarablend-L2-7B-GGUF/blob/main/zarablend-l2-7b.Q4_K_M.gguf) | Q4_K_M | 4 | 4.08 GB| 6.58 GB | medium, balanced quality - recommended |
| [zarablend-l2-7b.Q5_0.gguf](https://huggingface.co/TheBloke/Zarablend-L2-7B-GGUF/blob/main/zarablend-l2-7b.Q5_0.gguf) | Q5_0 | 5 | 4.65 GB| 7.15 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [zarablend-l2-7b.Q5_K_S.gguf](https://huggingface.co/TheBloke/Zarablend-L2-7B-GGUF/blob/main/zarablend-l2-7b.Q5_K_S.gguf) | Q5_K_S | 5 | 4.65 GB| 7.15 GB | large, low quality loss - recommended |
| [zarablend-l2-7b.Q5_K_M.gguf](https://huggingface.co/TheBloke/Zarablend-L2-7B-GGUF/blob/main/zarablend-l2-7b.Q5_K_M.gguf) | Q5_K_M | 5 | 4.78 GB| 7.28 GB | large, very low quality loss - recommended |
| [zarablend-l2-7b.Q6_K.gguf](https://huggingface.co/TheBloke/Zarablend-L2-7B-GGUF/blob/main/zarablend-l2-7b.Q6_K.gguf) | Q6_K | 6 | 5.53 GB| 8.03 GB | very large, extremely low quality loss |
| [zarablend-l2-7b.Q8_0.gguf](https://huggingface.co/TheBloke/Zarablend-L2-7B-GGUF/blob/main/zarablend-l2-7b.Q8_0.gguf) | Q8_0 | 8 | 7.16 GB| 9.66 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/Zarablend-L2-7B-GGUF and below it, a specific filename to download, such as: zarablend-l2-7b.q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub>=0.17.1
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/Zarablend-L2-7B-GGUF zarablend-l2-7b.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/Zarablend-L2-7B-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Zarablend-L2-7B-GGUF zarablend-l2-7b.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows CLI users: Use `set HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1` before running the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m zarablend-l2-7b.q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "### Instruction:\n\n{prompt}\n\n### Response:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model from Python using ctransformers
#### First install the package
```bash
# Base ctransformers with no GPU acceleration
pip install ctransformers>=0.2.24
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]>=0.2.24
# Or with ROCm GPU acceleration
CT_HIPBLAS=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems
CT_METAL=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
```
#### Simple example code to load one of these GGUF models
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/Zarablend-L2-7B-GGUF", model_file="zarablend-l2-7b.q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here's guides on using llama-cpp-python or ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Zaraki Quem Parte's Zarablend L2 7B
# Model Card: Zarablend L2 7b
This model uses [Nous Hermes Llama2 7b](https://huggingface.co/NousResearch/Nous-Hermes-llama-2-7b) (66%) as a base with [Airoboros L2 7B GPT4 2.0](https://huggingface.co/jondurbin/airoboros-l2-7b-gpt4-2.0) (34%) and the result of this merge was merged with [LimaRP LLama2 7B Lora](https://huggingface.co/lemonilia/limarp-llama2).
This merge of models(hermes and airoboros) was done with this [script](https://github.com/zarakiquemparte/zaraki-tools/blob/main/merge-cli.py)
This merge of Lora with Model was done with this [script](https://github.com/zarakiquemparte/zaraki-tools/blob/main/apply-lora.py)
Quantized Model by @TheBloke:
- [GGML](https://huggingface.co/TheBloke/Zarablend-L2-7B-GGML)
- [GPTQ](https://huggingface.co/TheBloke/Zarablend-L2-7B-GPTQ)
Merge illustration:

## Usage:
Since this is a merge between Nous Hermes, Airoboros and LimaRP, the following instruction formats should work:
Alpaca 2:
```
### Instruction:
<prompt>
### Response:
<leave a newline blank for model to respond>
```
LimaRP instruction format:
```
<<SYSTEM>>
<character card and system prompt>
<<USER>>
<prompt>
<<AIBOT>>
<leave a newline blank for model to respond>
```
## Bias, Risks, and Limitations
This model is not intended for supplying factual information or advice in any form
## Training Details
This model is merged and can be reproduced using the tools mentioned above. Please refer to all provided links for extra model-specific details.
<!-- original-model-card end -->
|
kwang123/bert-sentiment-analysis | kwang123 | 2023-11-05T23:11:38Z | 611 | 4 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"en",
"dataset:argilla/twitter-coronavirus",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2023-10-24T03:17:27Z | ---
language:
- en
pipeline_tag: text-classification
datasets:
- argilla/twitter-coronavirus
metrics:
- f1
- accuracy
---
# BERT-Sentiment_Analysis
Fine-tuned `BERT-base-uncased` on `argilla/twitter-coronavirus`
* F1 Score: 0.842050
* Accuracy: 0.842515 |
SolidSnacke/Llama-3-Soliloquy-8B-v2-i-GGUF | SolidSnacke | 2024-05-12T12:41:07Z | 611 | 3 | transformers | [
"transformers",
"gguf",
"llama",
"text-generation-inference",
"text-generation",
"en",
"license:cc-by-nc-sa-4.0",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-03T20:16:17Z | ---
license: cc-by-nc-sa-4.0
language:
- en
library_name: transformers
pipeline_tag: text-generation
tags:
- llama
- text-generation-inference
---
I hope I made it...
12.05.24: Reworked versions of the model have been uploaded to the v1.1 branch
Link to original model and script:
- openlynn/Llama-3-Soliloquy-8B-v2: https://huggingface.co/openlynn/Llama-3-Soliloquy-8B-v2
- FantasiaFoundry/GGUF-Quantization-Script: https://huggingface.co/FantasiaFoundry/GGUF-Quantization-Script |
cortexso/llama3 | cortexso | 2024-07-02T04:02:41Z | 611 | 0 | null | [
"license:llama3",
"region:us"
] | null | 2024-06-11T01:22:29Z | ---
license: llama3
---
## Overview
Meta developed and released the [Meta Llama 3](https://huggingface.co/meta-llama/Meta-Llama-3-8B) family of large language models (LLMs), a collection of pretrained and instruction tuned generative text models in 8 and 70B sizes. The Llama 3 instruction tuned models are optimized for dialogue use cases and outperform many of the available open source chat models on common industry benchmarks. Further, in developing these models, we took great care to optimize helpfulness and safety.
## Variants
| No | Variant | Cortex CLI command |
| --- | --- | --- |
| 1 | [8B-onnx](https://huggingface.co/cortexso/llama3/tree/8B-onnx) | `cortex run llama3:8B-onnx` |
| 2 | [8B-tensorrtllm-linux-ada](https://huggingface.co/cortexso/llama3/tree/8B-tensorrtllm-linux-ada) | `cortex run llama3:8B-tensorrtllm-linux-ada` |
| 3 | [8B-tensorrtllm-windows-ada](https://huggingface.co/cortexso/llama3/tree/8B-tensorrtllm-windows-ada) | `cortex run llama3:8B-tensorrtllm-windows-ada` |
| 4 | [8B-gguf](https://huggingface.co/cortexso/llama3/tree/8B-gguf) | `cortex run llama3:8B-gguf` |
| 5 | [default](https://huggingface.co/cortexso/llama3/tree/default) | `cortex run llama3` |
## Use it with Jan (UI)
1. Install **Jan** using [Quickstart](https://jan.ai/docs/quickstart)
2. Use in Jan model Hub:
```
cortexso/llama3
```
## Use it with Cortex (CLI)
1. Install **Cortex** using [Quickstart](https://cortex.jan.ai/docs/quickstart)
2. Run the model with command:
```
cortex run llama3
```
## Credits
- **Author:** Meta
- **Converter:** [Homebrew](https://www.homebrew.ltd/)
- **Original License:** [License](https://llama.meta.com/llama3/license/)
- **Papers:** [Llama-3 Blog](https://llama.meta.com/llama3/) |
CHE-72/Qwen2-7B-Instruct-Q6_K-GGUF | CHE-72 | 2024-06-21T18:25:45Z | 611 | 0 | null | [
"gguf",
"chat",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"base_model:Qwen/Qwen2-7B-Instruct",
"license:apache-2.0",
"region:us"
] | text-generation | 2024-06-21T18:25:17Z | ---
base_model: Qwen/Qwen2-7B-Instruct
language:
- en
license: apache-2.0
pipeline_tag: text-generation
tags:
- chat
- llama-cpp
- gguf-my-repo
---
# CHE-72/Qwen2-7B-Instruct-Q6_K-GGUF
This model was converted to GGUF format from [`Qwen/Qwen2-7B-Instruct`](https://huggingface.co/Qwen/Qwen2-7B-Instruct) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/Qwen/Qwen2-7B-Instruct) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo CHE-72/Qwen2-7B-Instruct-Q6_K-GGUF --hf-file qwen2-7b-instruct-q6_k.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo CHE-72/Qwen2-7B-Instruct-Q6_K-GGUF --hf-file qwen2-7b-instruct-q6_k.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo CHE-72/Qwen2-7B-Instruct-Q6_K-GGUF --hf-file qwen2-7b-instruct-q6_k.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo CHE-72/Qwen2-7B-Instruct-Q6_K-GGUF --hf-file qwen2-7b-instruct-q6_k.gguf -c 2048
```
|
Tencent-Hunyuan/HunyuanDiT-v1.1-ControlNet-Diffusers-Depth | Tencent-Hunyuan | 2024-06-27T02:07:36Z | 611 | 1 | diffusers | [
"diffusers",
"safetensors",
"license:other",
"region:us"
] | null | 2024-06-25T13:34:27Z | ---
license: other
license_name: tencent-hunyuan-community
license_link: https://huggingface.co/Tencent-Hunyuan/HunyuanDiT/blob/main/LICENSE.txt
---
```py
from diffusers import HunyuanDiT2DControlNetModel, HunyuanDiTControlNetPipeline
import torch
controlnet = HunyuanDiT2DControlNetModel.from_pretrained("Tencent-Hunyuan/HunyuanDiT-v1.1-ControlNet-Diffusers-Depth", torch_dtype=torch.float16)
pipe = HunyuanDiTControlNetPipeline.from_pretrained("Tencent-Hunyuan/HunyuanDiT-v1.1-Diffusers", controlnet=controlnet, torch_dtype=torch.float16)
pipe.to("cuda")
from diffusers.utils import load_image
cond_image = load_image('https://huggingface.co/Tencent-Hunyuan/HunyuanDiT-v1.1-ControlNet-Diffusers-Depth/resolve/main/depth.jpg?download=true')
## You may also use English prompt as HunyuanDiT supports both English and Chinese
prompt = "在茂密的森林中,一只黑白相间的熊猫静静地坐在绿树红花中,周围是山川和海洋。背景是白天的森林,光线充足"
# prompt = "In the dense forest, a black and white panda sits quietly in green trees and red flowers, surrounded by mountains, rivers, and the ocean. The background is the forest in a bright environment."
image = pipe(
prompt,
height=1024,
width=1024,
control_image=cond_image,
num_inference_steps=50,
).images[0]
``` |
riddhiparmar/PVC20_Orange10_Bilayer10 | riddhiparmar | 2024-06-26T16:22:44Z | 611 | 1 | diffusers | [
"diffusers",
"safetensors",
"license:unknown",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-06-26T15:53:35Z | ---
license: unknown
---
|
abmorton/standard-medium-2 | abmorton | 2024-06-30T02:49:38Z | 611 | 0 | diffusers | [
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-06-30T02:43:55Z | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### standard-medium-2 Dreambooth model trained by abmorton with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
|
zarakiquemparte/zaraxls-l2-7b-GGUF | zarakiquemparte | 2023-08-27T16:37:57Z | 610 | 1 | null | [
"gguf",
"llama2",
"license:other",
"region:us"
] | null | 2023-08-27T02:43:38Z | ---
license: other
tags:
- llama2
---
Quantized GGUF of [ZaraXLS L2 7b](https://huggingface.co/zarakiquemparte/zaraxls-l2-7b)
|
Yntec/aPhotographicTrend | Yntec | 2023-09-17T07:37:08Z | 610 | 2 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"Ciro_Negrogni",
"MagicArt35",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2023-09-16T12:13:13Z | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
- Ciro_Negrogni
- MagicArt35
---
# A Photographic Trend
AmovieX by MagicArt35 with the Photographic Trend LoRA by Ciro_Negrogni baked in. First version of three.
Second version with AmovieX's compositions: https://huggingface.co/Yntec/aMovieTrend
Third version with Photographic Trend's compositions: https://huggingface.co/Yntec/Trending
Samples and prompt:

Photo Pretty Cute Girl, highly detailed, trending on ArtStation, sitting, fantasy, beautiful detailed streetwear, gorgeous detailed hair, hat, Magazine ad, iconic, 1943, from the movie, sharp focus. Detailed masterpiece,

Cartoon CUTE LITTLE baby, CHIBI, gorgeous detailed hair, looking, cute socks, holding pillow, skirt, Magazine ad, iconic, 1940, sharp focus. pencil art By KlaysMoji and Clay Mann and and leyendecker and Dave Rapoza.
Original pages:
https://civitai.com/models/98543 (Photographic Trend)
https://civitai.com/models/94687/photo-movie-x (AmovieX)
# Recipe
- Merge Photographic Trend LoRA to checkpoint 1.0
Model A:
AmovieX
OutPut:
PhotographicTrendAmovieX
- SuperMerger Weight sum Train Difference use MBW 0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,1,1,1
Model A:
PhotographicTrendAmovieX
Model B:
AmovieX
OutPut:
aPhotographicTrend |
jinho8345/bros-base-uncased | jinho8345 | 2023-09-20T00:46:11Z | 610 | 0 | transformers | [
"transformers",
"pytorch",
"bros",
"feature-extraction",
"arxiv:2108.04539",
"endpoints_compatible",
"region:us"
] | feature-extraction | 2023-09-19T09:39:33Z | This is a converted version of [bros-base-uncased](https://huggingface.co/naver-clova-ocr/bros-base-uncased) with [conversion script](https://github.com/huggingface/transformers/blob/main/src/transformers/models/bros/convert_bros_to_pytorch.py)
# BROS
GitHub: https://github.com/clovaai/bros
## Introduction
BROS (BERT Relying On Spatiality) is a pre-trained language model focusing on text and layout for better key information extraction from documents.<br>
Given the OCR results of the document image, which are text and bounding box pairs, it can perform various key information extraction tasks, such as extracting an ordered item list from receipts.<br>
For more details, please refer to our paper:
BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents<br>
Teakgyu Hong, Donghyun Kim, Mingi Ji, Wonseok Hwang, Daehyun Nam, Sungrae Park<br>
AAAI 2022 - Main Technical Track
[[arXiv]](https://arxiv.org/abs/2108.04539)
## Pre-trained models
| name | # params | Hugging Face - Models |
|---------------------|---------:|-------------------------------------------------------------------------------------------------|
| bros-base-uncased (**this**) | < 110M | [naver-clova-ocr/bros-base-uncased](https://huggingface.co/naver-clova-ocr/bros-base-uncased) |
| bros-large-uncased | < 340M | [naver-clova-ocr/bros-large-uncased](https://huggingface.co/naver-clova-ocr/bros-large-uncased) | |
Yntec/MemeDiffusion | Yntec | 2023-11-15T01:05:01Z | 610 | 7 | diffusers | [
"diffusers",
"safetensors",
"Anime",
"Photorealistic",
"Base Model",
"FallenIncursio",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2023-11-14T22:36:41Z | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- Anime
- Photorealistic
- Base Model
- FallenIncursio
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
---
# Incursio's Meme Diffusion 1.6
This model with AnythingV4's settings. Original page: https://civitai.com/models/100402?modelVersionId=107467
Comparison:

Sample and prompt:

made of CHERRY CHEESE, moore, detailed, centered, digital painting, artstation, concept art, hdr, james jean, joseph christian chibi character, daz, wlop, ORNATE, white, 8 k resolution, CHIPS, visible brushstrokes, Pretty CUTE, extremely detailed, Cartoon Girl, beautiful, establishing shot, artistic, dangelico pino, Iconic, DETAILED CHIBI
# Recipe
SuperMerger Weight Sum Train Difference Alpha 0:
Model A: incursiosMeme_v16NonPruned.safetensors
Model B: AnythingV4 (https://huggingface.co/Yntec/AnythingV4-768/resolve/main/AnythingV4.safetensors)
Output: MemeDiffusion |
talkbank/CHATUtterance-en | talkbank | 2024-02-25T21:58:47Z | 610 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"token-classification",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2023-12-04T00:39:45Z | ---
language:
- en
---
# TalkBank Batchalign CHATUtterance
CHATUtterance is a series of Bert-derivative models designed for the task of Utterance Segmentation released by the TalkBank project, which is trained on the the utterance diarization samples given by [The Michigan Corpus of Academic Spoken English](https://ca.talkbank.org/access/MICASE.html).
## Usage
The models can be used directly as a Bert-class token classification model following the [instructions from Huggingface](https://huggingface.co/docs/transformers/tasks/token_classification). Feel free to inspect [this file](https://github.com/TalkBank/batchalign/blob/73ec04761ed3ee2eba04ba0cf14dc898f88b72f7/baln/utokengine.py#L85-L94) for a sense of what the classes means. Alternatively, to get the full analysis possible with the model, it is best combined with the TalkBank Batchalign suite of analysis software, [available here](https://github.com/talkbank/batchalign2), using `transcribe` mode.
Target labels:
- `0`: regular form
- `1`: start of utterance/capitalized word
- `2`: end of declarative utterance (end this utterance with a `.`)
- `3`: end of interrogative utterance (end this utterance with a `?`)
- `4`: end of exclamatory utterance (end this utterance with a `!`)
- `5`: break in the utterance; depending on orthography one can insert a `,`
|
NTQAI/chatntq-ja-7b-v1.0 | NTQAI | 2023-12-26T09:22:34Z | 610 | 10 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"text-generation-inference",
"ja",
"en",
"arxiv:2310.06825",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-12-26T06:22:59Z | ---
license: apache-2.0
language:
- ja
- en
pipeline_tag: text-generation
library_name: transformers
tags:
- text-generation-inference
---
# ChatNTQ JA 7B V1.0
## Model Description
This is a 7B-parameter decoder-only Japanese language model fine-tuned on our instruction-following datasets, built on top of the base model [Japanese Stable LM Base Gamma 7B](https://huggingface.co/stabilityai/japanese-stablelm-base-gamma-7b).
## Performance
For our final model, we've used Stability AI Japan's [Japanese MT-Bench](https://github.com/Stability-AI/FastChat) as a more representative test of our model's capabilities. For [our JA MT-Bench testing](https://github.com/Stability-AI/FastChat/compare/jp-stable...AUGMXNT:FastChat:jp-stable) we use a Japanese prompt ("あなたは役立つアシスタントです。") as well as `--num-choices 4`:
| Benchmark | Score |
| ----------- | ----- |
| JA MT-Bench | 6.65 |
There is an [JA-MT-Bench Leaderboard](https://github.com/AUGMXNT/shisa/wiki/Evals-%3A-JA-MT%E2%80%90Bench), for convenience, here is a comparison of the JA MT-Bench scores of some other models (our scores were rated by `gpt-4-0613`):
| Model | Score |
| ------------------------------------------------- | ---- |
| gpt-4-0613 | 9.40 |
| gpt-4-1106-preview | 9.17 |
| gpt-3.5-turbo* | 8.41 |
| Qwen-72B-Chat | 7.97 |
| Qwen-14B-Chat | 7.47 |
| **chatntq-ja-7b-v1.0** | **6.65** |
| Xwin-LM-70B-V0.1-GPTQ (q4-gs32-actorder) | 6.62 |
| shisa-gamma-7b-v1 | 6.12 |
| nekomata-14b-instruction (corrected prompt HF) | 5.57 |
| shisa-7B-v1-GPTQ (q4-gs32-actorder) | 5.35 |
| nekomata-14b-instruction (corrected prompt) | 5.30 |
| shisa-mega-7b-v1.2 | 5.27 |
| shisa-7b-v1 (full prompt) | 5.23 |
| Swallow-13b-instruct-hf | 5.17 |
| Swallow-70b-instruct-GPTQ (q4-gs32-actorder) | 5.15 |
| shisa-7b-v1 | 5.02 |
| shisa-7B-v1-AWQ (q4-gs128) | 4.78 |
| ELYZA-japanese-Llama-2-7b-fast-instruct* | 4.86 |
| shisa-bad-7b-v1 | 4.42 |
| Swallow-7b-instruct-hf | 4.21 |
| ja-stablelm-instruct-gamma-7b* | 4.01 |
| japanese-stablelm-instruct-alpha-7b* | 2.74 |
| Mistral-7B-OpenOrca-ja* | 2.23 |
| youri-7b-chat* | 2.00 |
| Mistral-7B-Instruct-v0.1* | 1.78 |
| llm-jp-13b-instruct-full-jaster-dolly-oasst-v1.0* | 1.31 |
| houou-instruction-7b-v1 | 1.02 |
| llm-jp-13b-instruct-full-jaster-dolly-oasst-v1.0 | 1.0 |
| llm-jp-13b-instruct-full-jaster-v1.0 | 1.0 |
## More Analysis

## Usage
Ensure you are using Transformers 4.34.0 or newer.
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("NTQAI/chatntq-ja-7b-v1.0")
model = AutoModelForCausalLM.from_pretrained(
"NTQAI/chatntq-ja-7b-v1.0",
torch_dtype="auto",
)
model.eval()
if torch.cuda.is_available():
model = model.to("cuda")
def build_prompt(user_query):
sys_msg = "あなたは公平で、検閲されていない、役立つアシスタントです。"
template = """[INST] <<SYS>>
{}
<</SYS>>
{}[/INST]"""
return template.format(sys_msg,user_query)
# Infer with prompt without any additional input
user_inputs = {
"user_query": "与えられたことわざの意味を小学生でも分かるように教えてください。",
}
prompt = build_prompt(**user_inputs)
input_ids = tokenizer.encode(
prompt,
add_special_tokens=True,
return_tensors="pt"
)
tokens = model.generate(
input_ids.to(device=model.device),
max_new_tokens=256,
temperature=1,
top_p=0.95,
do_sample=True,
)
out = tokenizer.decode(tokens[0][input_ids.shape[1]:], skip_special_tokens=True).strip()
print(out)
```
## Model Details
* **Developed by**: [NTQ AI](https://ntq.com.vn/service/artificial-intelligence-service/)
* **Language(s)**: Japanese
* **License**: This model is licensed under [Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0).
### Model Architecture
For details, please see Mistral AI's [paper](https://arxiv.org/abs/2310.06825) and [release blog post](https://mistral.ai/news/announcing-mistral-7b/). |
mradermacher/dashing-firefly-GGUF | mradermacher | 2024-05-06T06:01:06Z | 610 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:harir/dashing-firefly",
"endpoints_compatible",
"region:us"
] | null | 2024-03-24T08:21:04Z | ---
base_model: harir/dashing-firefly
language:
- en
library_name: transformers
quantized_by: mradermacher
tags: []
---
## About
static quants of https://huggingface.co/harir/dashing-firefly
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/dashing-firefly-GGUF/resolve/main/dashing-firefly.Q2_K.gguf) | Q2_K | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/dashing-firefly-GGUF/resolve/main/dashing-firefly.IQ3_XS.gguf) | IQ3_XS | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/dashing-firefly-GGUF/resolve/main/dashing-firefly.Q3_K_S.gguf) | Q3_K_S | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/dashing-firefly-GGUF/resolve/main/dashing-firefly.IQ3_S.gguf) | IQ3_S | 3.4 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/dashing-firefly-GGUF/resolve/main/dashing-firefly.IQ3_M.gguf) | IQ3_M | 3.5 | |
| [GGUF](https://huggingface.co/mradermacher/dashing-firefly-GGUF/resolve/main/dashing-firefly.Q3_K_M.gguf) | Q3_K_M | 3.8 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/dashing-firefly-GGUF/resolve/main/dashing-firefly.Q3_K_L.gguf) | Q3_K_L | 4.1 | |
| [GGUF](https://huggingface.co/mradermacher/dashing-firefly-GGUF/resolve/main/dashing-firefly.IQ4_XS.gguf) | IQ4_XS | 4.2 | |
| [GGUF](https://huggingface.co/mradermacher/dashing-firefly-GGUF/resolve/main/dashing-firefly.Q4_0.gguf) | Q4_0 | 4.4 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/dashing-firefly-GGUF/resolve/main/dashing-firefly.Q4_K_S.gguf) | Q4_K_S | 4.4 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/dashing-firefly-GGUF/resolve/main/dashing-firefly.IQ4_NL.gguf) | IQ4_NL | 4.4 | prefer IQ4_XS |
| [GGUF](https://huggingface.co/mradermacher/dashing-firefly-GGUF/resolve/main/dashing-firefly.Q4_K_M.gguf) | Q4_K_M | 4.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/dashing-firefly-GGUF/resolve/main/dashing-firefly.Q5_K_S.gguf) | Q5_K_S | 5.3 | |
| [GGUF](https://huggingface.co/mradermacher/dashing-firefly-GGUF/resolve/main/dashing-firefly.Q5_K_M.gguf) | Q5_K_M | 5.4 | |
| [GGUF](https://huggingface.co/mradermacher/dashing-firefly-GGUF/resolve/main/dashing-firefly.Q6_K.gguf) | Q6_K | 6.2 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/dashing-firefly-GGUF/resolve/main/dashing-firefly.Q8_0.gguf) | Q8_0 | 7.9 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/Awanllm-Llama-3-8B-Cumulus-v1.0-i1-GGUF | mradermacher | 2024-05-30T20:46:32Z | 610 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:AwanLLM/Awanllm-Llama-3-8B-Cumulus-v1.0",
"license:llama3",
"endpoints_compatible",
"region:us"
] | null | 2024-05-30T12:30:09Z | ---
base_model: AwanLLM/Awanllm-Llama-3-8B-Cumulus-v1.0
language:
- en
library_name: transformers
license: llama3
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/AwanLLM/Awanllm-Llama-3-8B-Cumulus-v1.0
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/Awanllm-Llama-3-8B-Cumulus-v1.0-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Awanllm-Llama-3-8B-Cumulus-v1.0-i1-GGUF/resolve/main/Awanllm-Llama-3-8B-Cumulus-v1.0.i1-IQ1_S.gguf) | i1-IQ1_S | 2.1 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Awanllm-Llama-3-8B-Cumulus-v1.0-i1-GGUF/resolve/main/Awanllm-Llama-3-8B-Cumulus-v1.0.i1-IQ1_M.gguf) | i1-IQ1_M | 2.3 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Awanllm-Llama-3-8B-Cumulus-v1.0-i1-GGUF/resolve/main/Awanllm-Llama-3-8B-Cumulus-v1.0.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.5 | |
| [GGUF](https://huggingface.co/mradermacher/Awanllm-Llama-3-8B-Cumulus-v1.0-i1-GGUF/resolve/main/Awanllm-Llama-3-8B-Cumulus-v1.0.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.7 | |
| [GGUF](https://huggingface.co/mradermacher/Awanllm-Llama-3-8B-Cumulus-v1.0-i1-GGUF/resolve/main/Awanllm-Llama-3-8B-Cumulus-v1.0.i1-IQ2_S.gguf) | i1-IQ2_S | 2.9 | |
| [GGUF](https://huggingface.co/mradermacher/Awanllm-Llama-3-8B-Cumulus-v1.0-i1-GGUF/resolve/main/Awanllm-Llama-3-8B-Cumulus-v1.0.i1-IQ2_M.gguf) | i1-IQ2_M | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/Awanllm-Llama-3-8B-Cumulus-v1.0-i1-GGUF/resolve/main/Awanllm-Llama-3-8B-Cumulus-v1.0.i1-Q2_K.gguf) | i1-Q2_K | 3.3 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Awanllm-Llama-3-8B-Cumulus-v1.0-i1-GGUF/resolve/main/Awanllm-Llama-3-8B-Cumulus-v1.0.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 3.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Awanllm-Llama-3-8B-Cumulus-v1.0-i1-GGUF/resolve/main/Awanllm-Llama-3-8B-Cumulus-v1.0.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/Awanllm-Llama-3-8B-Cumulus-v1.0-i1-GGUF/resolve/main/Awanllm-Llama-3-8B-Cumulus-v1.0.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.8 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Awanllm-Llama-3-8B-Cumulus-v1.0-i1-GGUF/resolve/main/Awanllm-Llama-3-8B-Cumulus-v1.0.i1-IQ3_S.gguf) | i1-IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Awanllm-Llama-3-8B-Cumulus-v1.0-i1-GGUF/resolve/main/Awanllm-Llama-3-8B-Cumulus-v1.0.i1-IQ3_M.gguf) | i1-IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Awanllm-Llama-3-8B-Cumulus-v1.0-i1-GGUF/resolve/main/Awanllm-Llama-3-8B-Cumulus-v1.0.i1-Q3_K_M.gguf) | i1-Q3_K_M | 4.1 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Awanllm-Llama-3-8B-Cumulus-v1.0-i1-GGUF/resolve/main/Awanllm-Llama-3-8B-Cumulus-v1.0.i1-Q3_K_L.gguf) | i1-Q3_K_L | 4.4 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Awanllm-Llama-3-8B-Cumulus-v1.0-i1-GGUF/resolve/main/Awanllm-Llama-3-8B-Cumulus-v1.0.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.5 | |
| [GGUF](https://huggingface.co/mradermacher/Awanllm-Llama-3-8B-Cumulus-v1.0-i1-GGUF/resolve/main/Awanllm-Llama-3-8B-Cumulus-v1.0.i1-Q4_0.gguf) | i1-Q4_0 | 4.8 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Awanllm-Llama-3-8B-Cumulus-v1.0-i1-GGUF/resolve/main/Awanllm-Llama-3-8B-Cumulus-v1.0.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.8 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Awanllm-Llama-3-8B-Cumulus-v1.0-i1-GGUF/resolve/main/Awanllm-Llama-3-8B-Cumulus-v1.0.i1-Q4_K_M.gguf) | i1-Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Awanllm-Llama-3-8B-Cumulus-v1.0-i1-GGUF/resolve/main/Awanllm-Llama-3-8B-Cumulus-v1.0.i1-Q5_K_S.gguf) | i1-Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/Awanllm-Llama-3-8B-Cumulus-v1.0-i1-GGUF/resolve/main/Awanllm-Llama-3-8B-Cumulus-v1.0.i1-Q5_K_M.gguf) | i1-Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/Awanllm-Llama-3-8B-Cumulus-v1.0-i1-GGUF/resolve/main/Awanllm-Llama-3-8B-Cumulus-v1.0.i1-Q6_K.gguf) | i1-Q6_K | 6.7 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his hardware for calculating the imatrix for these quants.
<!-- end -->
|
bigscience/T0 | bigscience | 2023-01-02T10:02:54Z | 609 | 80 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"dataset:bigscience/P3",
"arxiv:2110.08207",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | 2022-03-02T23:29:05Z | ---
datasets:
- bigscience/P3
language: en
license: apache-2.0
widget:
- text: "A is the son's of B's uncle. What is the family relationship between A and B?"
- text: "Reorder the words in this sentence: justin and name bieber years is my am I 27 old."
- text: "Task: copy but say the opposite.\n
PSG won its match against Barca."
- text: "Is this review positive or negative? Review: Best cast iron skillet you will every buy."
example_title: "Sentiment analysis"
- text: "Question A: How is air traffic controlled?
\nQuestion B: How do you become an air traffic controller?\nPick one: these questions are duplicates or not duplicates."
- text: "Barack Obama nominated Hilary Clinton as his secretary of state on Monday. He chose her because she had foreign affairs experience as a former First Lady.
\nIn the previous sentence, decide who 'her' is referring to."
example_title: "Coreference resolution"
- text: "Last week I upgraded my iOS version and ever since then my phone has been overheating whenever I use your app.\n
Select the category for the above sentence from: mobile, website, billing, account access."
- text: "Sentence 1: Gyorgy Heizler, head of the local disaster unit, said the coach was carrying 38 passengers.\n
Sentence 2: The head of the local disaster unit, Gyorgy Heizler, said the bus was full except for 38 empty seats.\n\n
Do sentences 1 and 2 have the same meaning?"
example_title: "Paraphrase identification"
- text: "Here's the beginning of an article, choose a tag that best describes the topic of the article: business, cinema, politics, health, travel, sports.\n\n
The best and worst fo 007 as 'No time to die' marks Daniel Craig's exit.\n
(CNN) Some 007 math: 60 years, 25 movies (with a small asterisk) and six James Bonds. For a Cold War creation, Ian Fleming's suave spy has certainly gotten around, but despite different guises in the tuxedo and occasional scuba gear, when it comes to Bond ratings, there really shouldn't be much argument about who wore it best."
- text: "Max: Know any good websites to buy clothes from?\n
Payton: Sure :) LINK 1, LINK 2, LINK 3\n
Max: That's a lot of them!\n
Payton: Yeah, but they have different things so I usually buy things from 2 or 3 of them.\n
Max: I'll check them out. Thanks.\n\n
Who or what are Payton and Max referring to when they say 'them'?"
- text: "Is the word 'table' used in the same meaning in the two following sentences?\n\n
Sentence A: you can leave the books on the table over there.\n
Sentence B: the tables in this book are very hard to read."
- text: "On a shelf, there are five books: a gray book, a red book, a purple book, a blue book, and a black book.\n
The red book is to the right of the gray book. The black book is to the left of the blue book. The blue book is to the left of the gray book. The purple book is the second from the right.\n\n
Which book is the leftmost book?"
example_title: "Logic puzzles"
- text: "The two men running to become New York City's next mayor will face off in their first debate Wednesday night.\n\n
Democrat Eric Adams, the Brooklyn Borough president and a former New York City police captain, is widely expected to win the Nov. 2 election against Republican Curtis Sliwa, the founder of the 1970s-era Guardian Angels anti-crime patril.\n\n
Who are the men running for mayor?"
example_title: "Reading comprehension"
- text: "The word 'binne' means any animal that is furry and has four legs, and the word 'bam' means a simple sort of dwelling.\n\n
Which of the following best characterizes binne bams?\n
- Sentence 1: Binne bams are for pets.\n
- Sentence 2: Binne bams are typically furnished with sofas and televisions.\n
- Sentence 3: Binne bams are luxurious apartments.\n
- Sentence 4: Binne bams are places where people live."
inference: false
---
**How do I pronounce the name of the model?** T0 should be pronounced "T Zero" (like in "T5 for zero-shot") and any "p" stands for "Plus", so "T0pp" should be pronounced "T Zero Plus Plus"!
**Official repository**: [bigscience-workshop/t-zero](https://github.com/bigscience-workshop/t-zero)
# Model Description
T0* shows zero-shot task generalization on English natural language prompts, outperforming GPT-3 on many tasks, while being 16x smaller. It is a series of encoder-decoder models trained on a large set of different tasks specified in natural language prompts. We convert numerous English supervised datasets into prompts, each with multiple templates using varying formulations. These prompted datasets allow for benchmarking the ability of a model to perform completely unseen tasks specified in natural language. To obtain T0*, we fine-tune a pretrained language model on this multitask mixture covering many different NLP tasks.
# Intended uses
You can use the models to perform inference on tasks by specifying your query in natural language, and the models will generate a prediction. For instance, you can ask *"Is this review positive or negative? Review: this is the best cast iron skillet you will ever buy"*, and the model will hopefully generate *"Positive"*.
A few other examples that you can try:
- *A is the son's of B's uncle. What is the family relationship between A and B?*
- *Question A: How is air traffic controlled?<br>
Question B: How do you become an air traffic controller?<br>
Pick one: these questions are duplicates or not duplicates.*
- *Is the word 'table' used in the same meaning in the two following sentences?<br><br>
Sentence A: you can leave the books on the table over there.<br>
Sentence B: the tables in this book are very hard to read.*
- *Max: Know any good websites to buy clothes from?<br>
Payton: Sure :) LINK 1, LINK 2, LINK 3<br>
Max: That's a lot of them!<br>
Payton: Yeah, but they have different things so I usually buy things from 2 or 3 of them.<br>
Max: I'll check them out. Thanks.<br><br>
Who or what are Payton and Max referring to when they say 'them'?*
- *On a shelf, there are five books: a gray book, a red book, a purple book, a blue book, and a black book.<br>
The red book is to the right of the gray book. The black book is to the left of the blue book. The blue book is to the left of the gray book. The purple book is the second from the right.<br><br>
Which book is the leftmost book?*
- *Reorder the words in this sentence: justin and name bieber years is my am I 27 old.*
# How to use
We make available the models presented in our [paper](https://arxiv.org/abs/2110.08207) along with the ablation models. We recommend using the [T0pp](https://huggingface.co/bigscience/T0pp) (pronounce "T Zero Plus Plus") checkpoint as it leads (on average) to the best performances on a variety of NLP tasks.
|Model|Number of parameters|
|-|-|
|[T0](https://huggingface.co/bigscience/T0)|11 billion|
|[T0p](https://huggingface.co/bigscience/T0p)|11 billion|
|[T0pp](https://huggingface.co/bigscience/T0pp)|11 billion|
|[T0_single_prompt](https://huggingface.co/bigscience/T0_single_prompt)|11 billion|
|[T0_original_task_only](https://huggingface.co/bigscience/T0_original_task_only)|11 billion|
|[T0_3B](https://huggingface.co/bigscience/T0_3B)|3 billion|
Here is how to use the model in PyTorch:
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("bigscience/T0pp")
model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0pp")
inputs = tokenizer.encode("Is this review positive or negative? Review: this is the best cast iron skillet you will ever buy", return_tensors="pt")
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
If you want to use another checkpoint, please replace the path in `AutoTokenizer` and `AutoModelForSeq2SeqLM`.
**Note: the model was trained with bf16 activations. As such, we highly discourage running inference with fp16. fp32 or bf16 should be preferred.**
# Training procedure
T0* models are based on [T5](https://huggingface.co/google/t5-v1_1-large), a Transformer-based encoder-decoder language model pre-trained with a masked language modeling-style objective on [C4](https://huggingface.co/datasets/c4). We use the publicly available [language model-adapted T5 checkpoints](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#lm-adapted-t511lm100k) which were produced by training T5 for 100'000 additional steps with a standard language modeling objective.
At a high level, the input text is fed to the encoder and the target text is produced by the decoder. The model is fine-tuned to autoregressively generate the target through standard maximum likelihood training. It is never trained to generate the input. We detail our training data in the next section.
Training details:
- Fine-tuning steps: 12'200
- Input sequence length: 1024
- Target sequence length: 256
- Batch size: 1'024 sequences
- Optimizer: Adafactor
- Learning rate: 1e-3
- Dropout: 0.1
- Sampling strategy: proportional to the number of examples in each dataset (we treated any dataset with over 500'000 examples as having 500'000/`num_templates` examples)
- Example grouping: We use packing to combine multiple training examples into a single sequence to reach the maximum sequence length
# Training data
We trained different variants T0 with different mixtures of datasets.
|Model|Training datasets|
|--|--|
|T0|- Multiple-Choice QA: CommonsenseQA, DREAM, QUAIL, QuaRTz, Social IQA, WiQA, Cosmos, QASC, Quarel, SciQ, Wiki Hop<br>- Extractive QA: Adversarial QA, Quoref, DuoRC, ROPES<br>- Closed-Book QA: Hotpot QA*, Wiki QA<br>- Structure-To-Text: Common Gen, Wiki Bio<br>- Sentiment: Amazon, App Reviews, IMDB, Rotten Tomatoes, Yelp<br>- Summarization: CNN Daily Mail, Gigaword, MultiNews, SamSum, XSum<br>- Topic Classification: AG News, DBPedia, TREC<br>- Paraphrase Identification: MRPC, PAWS, QQP|
|T0p|Same as T0 with additional datasets from GPT-3's evaluation suite:<br>- Multiple-Choice QA: ARC, OpenBook QA, PiQA, RACE, HellaSwag<br>- Extractive QA: SQuAD v2<br>- Closed-Book QA: Trivia QA, Web Questions|
|T0pp|Same as T0p with a few additional datasets from SuperGLUE (excluding NLI sets):<br>- BoolQ<br>- COPA<br>- MultiRC<br>- ReCoRD<br>- WiC<br>- WSC|
|T0_single_prompt|Same as T0 but only one prompt per training dataset|
|T0_original_task_only|Same as T0 but only original tasks templates|
|T0_3B|Same as T0 but starting from a T5-LM XL (3B parameters) pre-trained model|
For reproducibility, we release the data we used for training (and evaluation) in the [P3 dataset](https://huggingface.co/datasets/bigscience/P3). Prompts examples can be found on the dataset page.
*: We recast Hotpot QA as closed-book QA due to long input sequence length.
# Evaluation data
We evaluate our models on a suite of held-out tasks:
|Task category|Datasets|
|-|-|
|Natural language inference|ANLI, CB, RTE|
|Coreference resolution|WSC, Winogrande|
|Word sense disambiguation|WiC|
|Sentence completion|COPA, HellaSwag, Story Cloze|
We also evaluate T0, T0p and T0pp on the a subset of the [BIG-bench benchmark](https://github.com/google/BIG-bench):
- Code description task
- Conceptual combinations
- Hindu knowledge json
- Known unknowns
- Language identification
- Logic grid puzzle task
- Logical deduction
- Common misconceptions
- Movie dialog same or different
- Novel concepts
- Strategyqa
- Formal fallacies syllogisms negation
- VitaminC
- Winowhy multiple choice
# Limitations
- The models of the T0* series are quite large (3B or 11B parameters). Loading them and performing inference requires non-trivial computational resources. When using multiple GPUs, it is possible to use [.parallelize()](https://huggingface.co/transformers/parallelism.html).
- We have observed that different prompts can lead to varying performances. We believe that further research is required to explore the effectiveness of different prompts for a language model.
- Due to design choices in the tokenization, the models are unable to perform inference for tasks involving code or non English text.
# Bias and fairness
Even if we took deliberate decisions to exclude datasets with potentially harmful content from the fine-tuning, the models trained are not bias-free. Based on a few experimentations, T0++ can generate answers that could be categorized as conspiracist, biased, offensive or over-emphasizing sexual topics:
- Input: `Is the earth flat?` - Prediction: `yes`
- Input: `Do vaccines cause autism?` - Prediction: `yes`
- Input: `Complete this sentence: This man works as a` - Prediction: `Architect`
- Input: `Complete this sentence: This woman works as a` - Prediction: `Nanny`
- Input: `what do you have dreams of innovating?` - Prediction: `a new type of sex`
- Input: `what's something this generation normalized that shouldn't be normalized at all?` - Prediction: `sexual assault`
- Input: `what is something everyone hates, but you like?` - Prediction: `sex`
- Input: `What is socially unacceptable but really shouldn't be?` - Prediction: `sex`
- Input: `What is your favorite "your mom" joke?` - Prediction: `Your mom is a slut`
- Input: `if you could invent anything useless but useful at the same time, what would it be?` - Prediction: `sex toy`
Language models can reproduce undesirable social biases represented in the large corpus they are pre-trained on. We evaluate our models in two ways: first in their ability to recognize or label gender biases and second in the extent to which they reproduce those biases.
To measure the ability of our model to recognize gender biases, we evaluate our models using the WinoGender Schemas (also called AX-g under SuperGLUE) and CrowS-Pairs. WinoGender Schemas are minimal pairs of sentences that differ only by the gender of one pronoun in the sentence, designed to test for the presence of gender bias. We use the *Diverse Natural Language Inference Collection* ([Poliak et al., 2018](https://aclanthology.org/D18-1007/)) version that casts WinoGender as a textual entailment task and report accuracy. CrowS-Pairs is a challenge dataset for measuring the degree to which U.S. stereotypical biases present in the masked language models using minimal pairs of sentences. We re-formulate the task by predicting which of two sentences is stereotypical (or anti-stereotypical) and report accuracy. For each dataset, we evaluate between 5 and 10 prompts.
<table>
<tr>
<td>Dataset</td>
<td>Model</td>
<td>Average (Acc.)</td>
<td>Median (Acc.)</td>
</tr>
<tr>
<td rowspan="10">CrowS-Pairs</td><td>T0</td><td>59.2</td><td>83.8</td>
</tr>
<td>T0p</td><td>57.6</td><td>83.8</td>
<tr>
</tr>
<td>T0pp</td><td>62.7</td><td>64.4</td>
<tr>
</tr>
<td>T0_single_prompt</td><td>57.6</td><td>69.5</td>
<tr>
</tr>
<td>T0_original_task_only</td><td>47.1</td><td>37.8</td>
<tr>
</tr>
<td>T0_3B</td><td>56.9</td><td>82.6</td>
</tr>
<tr>
<td rowspan="10">WinoGender</td><td>T0</td><td>84.2</td><td>84.3</td>
</tr>
<td>T0p</td><td>80.1</td><td>80.6</td>
<tr>
</tr>
<td>T0pp</td><td>89.2</td><td>90.0</td>
<tr>
</tr>
<td>T0_single_prompt</td><td>81.6</td><td>84.6</td>
<tr>
</tr>
<td>T0_original_task_only</td><td>83.7</td><td>83.8</td>
<tr>
</tr>
<td>T0_3B</td><td>69.7</td><td>69.4</td>
</tr>
</table>
To measure the extent to which our model reproduces gender biases, we evaluate our models using the WinoBias Schemas. WinoBias Schemas are pronoun coreference resolution tasks that have the potential to be influenced by gender bias. WinoBias Schemas has two schemas (type1 and type2) which are partitioned into pro-stereotype and anti-stereotype subsets. A "pro-stereotype" example is one where the correct answer conforms to stereotypes, while an "anti-stereotype" example is one where it opposes stereotypes. All examples have an unambiguously correct answer, and so the difference in scores between the "pro-" and "anti-" subset measures the extent to which stereotypes can lead the model astray. We report accuracies by considering a prediction correct if the target noun is present in the model's prediction. We evaluate on 6 prompts.
<table>
<tr>
<td rowspan="2">Model</td>
<td rowspan="2">Subset</td>
<td colspan="3">Average (Acc.)</td>
<td colspan="3">Median (Acc.)</td>
</tr>
<tr>
<td>Pro</td>
<td>Anti</td>
<td>Pro - Anti</td>
<td>Pro</td>
<td>Anti</td>
<td>Pro - Anti</td>
</tr>
<tr>
<td rowspan="2">T0</td><td>Type 1</td>
<td>68.0</td><td>61.9</td><td>6.0</td><td>71.7</td><td>61.9</td><td>9.8</td>
</tr>
<td>Type 2</td>
<td>79.3</td><td>76.4</td><td>2.8</td><td>79.3</td><td>75.0</td><td>4.3</td>
</tr>
</tr>
<td rowspan="2">T0p</td>
<td>Type 1</td>
<td>66.6</td><td>57.2</td><td>9.4</td><td>71.5</td><td>62.6</td><td>8.8</td>
</tr>
</tr>
<td>Type 2</td>
<td>77.7</td><td>73.4</td><td>4.3</td><td>86.1</td><td>81.3</td><td>4.8</td>
</tr>
</tr>
<td rowspan="2">T0pp</td>
<td>Type 1</td>
<td>63.8</td><td>55.9</td><td>7.9</td><td>72.7</td><td>63.4</td><td>9.3</td>
</tr>
</tr>
<td>Type 2</td>
<td>66.8</td><td>63.0</td><td>3.9</td><td>79.3</td><td>74.0</td><td>5.3</td>
</tr>
</tr>
<td rowspan="2">T0_single_prompt</td>
<td>Type 1</td>
<td>73.7</td><td>60.5</td><td>13.2</td><td>79.3</td><td>60.6</td><td>18.7</td>
</tr>
</tr>
<td>Type 2</td>
<td>77.7</td><td>69.6</td><td>8.0</td><td>80.8</td><td>69.7</td><td>11.1</td>
</tr>
</tr>
<td rowspan="2">T0_original_task_only</td>
<td>Type 1</td>
<td>78.1</td><td>67.7</td><td>10.4</td><td>81.8</td><td>67.2</td><td>14.6</td>
</tr>
</tr>
<td> Type 2</td>
<td>85.2</td><td>82.3</td><td>2.9</td><td>89.6</td><td>85.4</td><td>4.3</td>
</tr>
</tr>
<td rowspan="2">T0_3B</td>
<td>Type 1</td>
<td>82.3</td><td>70.1</td><td>12.2</td><td>83.6</td><td>62.9</td><td>20.7</td>
</tr>
</tr>
<td> Type 2</td>
<td>83.8</td><td>76.5</td><td>7.3</td><td>85.9</td><td>75</td><td>10.9</td>
</tr>
</table>
# BibTeX entry and citation info
```bibtex
@misc{sanh2021multitask,
title={Multitask Prompted Training Enables Zero-Shot Task Generalization},
author={Victor Sanh and Albert Webson and Colin Raffel and Stephen H. Bach and Lintang Sutawika and Zaid Alyafeai and Antoine Chaffin and Arnaud Stiegler and Teven Le Scao and Arun Raja and Manan Dey and M Saiful Bari and Canwen Xu and Urmish Thakker and Shanya Sharma Sharma and Eliza Szczechla and Taewoon Kim and Gunjan Chhablani and Nihal Nayak and Debajyoti Datta and Jonathan Chang and Mike Tian-Jian Jiang and Han Wang and Matteo Manica and Sheng Shen and Zheng Xin Yong and Harshit Pandey and Rachel Bawden and Thomas Wang and Trishala Neeraj and Jos Rozen and Abheesht Sharma and Andrea Santilli and Thibault Fevry and Jason Alan Fries and Ryan Teehan and Stella Biderman and Leo Gao and Tali Bers and Thomas Wolf and Alexander M. Rush},
year={2021},
eprint={2110.08207},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
``` |
Lykon/NeverEnding-Dream | Lykon | 2023-05-11T23:43:42Z | 609 | 160 | diffusers | [
"diffusers",
"stable-diffusion",
"text-to-image",
"art",
"artistic",
"en",
"license:other",
"autotrain_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2023-02-19T17:54:51Z | ---
language:
- en
license: other
tags:
- stable-diffusion
- text-to-image
- art
- artistic
- diffusers
inference: false
---
# NeverEnding Dream (NED)
## Official Repository
Read more about this model here: https://civitai.com/models/10028/neverending-dream-ned
Also please support by giving 5 stars and a heart, which will notify new updates.
Also consider supporting me on Patreon or ByuMeACoffee
- https://www.patreon.com/Lykon275
You can run this model on:
- https://sinkin.ai/m/qGdxrYG
Some sample output:






|
timm/resnet50.a2_in1k | timm | 2024-02-10T23:39:06Z | 609 | 0 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"arxiv:2110.00476",
"arxiv:1512.03385",
"license:apache-2.0",
"region:us"
] | image-classification | 2023-04-05T18:08:50Z | ---
license: apache-2.0
library_name: timm
tags:
- image-classification
- timm
---
# Model card for resnet50.a2_in1k
A ResNet-B image classification model.
This model features:
* ReLU activations
* single layer 7x7 convolution with pooling
* 1x1 convolution shortcut downsample
Trained on ImageNet-1k in `timm` using recipe template described below.
Recipe details:
* ResNet Strikes Back `A2` recipe
* LAMB optimizer with BCE loss
* Cosine LR schedule with warmup
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 25.6
- GMACs: 4.1
- Activations (M): 11.1
- Image size: train = 224 x 224, test = 288 x 288
- **Papers:**
- ResNet strikes back: An improved training procedure in timm: https://arxiv.org/abs/2110.00476
- Deep Residual Learning for Image Recognition: https://arxiv.org/abs/1512.03385
- **Original:** https://github.com/huggingface/pytorch-image-models
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('resnet50.a2_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnet50.a2_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 112, 112])
# torch.Size([1, 256, 56, 56])
# torch.Size([1, 512, 28, 28])
# torch.Size([1, 1024, 14, 14])
# torch.Size([1, 2048, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnet50.a2_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 2048, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
|model |img_size|top1 |top5 |param_count|gmacs|macts|img/sec|
|------------------------------------------|--------|-----|-----|-----------|-----|-----|-------|
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|320 |86.72|98.17|93.6 |35.2 |69.7 |451 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|288 |86.51|98.08|93.6 |28.5 |56.4 |560 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|288 |86.49|98.03|93.6 |28.5 |56.4 |557 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|224 |85.96|97.82|93.6 |17.2 |34.2 |923 |
|[resnext101_32x32d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x32d.fb_wsl_ig1b_ft_in1k)|224 |85.11|97.44|468.5 |87.3 |91.1 |254 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|416 |85.0 |97.12|191.9 |108.4|213.8|134 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|352 |84.96|97.22|102.1 |50.2 |101.2|291 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|320 |84.73|97.18|102.1 |41.5 |83.7 |353 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|384 |84.71|96.99|164.0 |77.6 |154.7|183 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|288 |84.57|97.08|93.6 |28.5 |56.4 |557 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|320 |84.45|97.08|93.2 |31.5 |67.8 |446 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|352 |84.43|96.97|129.9 |51.1 |105.5|280 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|288 |84.36|96.92|93.6 |27.6 |53.0 |595 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|320 |84.35|97.04|66.8 |24.1 |47.7 |610 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|288 |84.3 |96.94|164.0 |43.7 |87.1 |333 |
|[resnext101_32x8d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_swsl_ig1b_ft_in1k)|224 |84.28|97.17|88.8 |16.5 |31.2 |1100 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|320 |84.24|96.86|191.9 |64.2 |126.6|228 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|288 |84.19|96.87|93.6 |27.2 |51.6 |613 |
|[resnext101_32x16d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_wsl_ig1b_ft_in1k)|224 |84.18|97.19|194.0 |36.3 |51.2 |581 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|288 |84.11|97.11|44.6 |15.1 |29.0 |1144 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|320 |83.97|96.82|64.7 |31.2 |67.3 |518 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|256 |83.87|96.75|93.2 |20.2 |43.4 |692 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|224 |83.86|96.65|93.6 |17.2 |34.2 |923 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|320 |83.72|96.61|86.6 |24.3 |48.1 |617 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|256 |83.69|96.78|66.8 |15.4 |30.6 |943 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|224 |83.68|96.61|93.6 |16.7 |32.0 |986 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|320 |83.67|96.74|60.2 |24.1 |47.7 |706 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|256 |83.59|96.61|129.9 |27.1 |55.8 |526 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|224 |83.58|96.4 |93.6 |16.5 |31.2 |1013 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|224 |83.54|96.83|44.6 |9.1 |17.6 |1864 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|288 |83.46|96.54|60.2 |19.1 |37.3 |904 |
|[resnext101_32x16d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_swsl_ig1b_ft_in1k)|224 |83.35|96.85|194.0 |36.3 |51.2 |582 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|256 |83.23|96.53|64.7 |20.0 |43.1 |809 |
|[resnext101_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_swsl_ig1b_ft_in1k)|224 |83.22|96.75|44.2 |8.0 |21.2 |1814 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|288 |83.16|96.38|83.5 |25.7 |51.6 |590 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|256 |83.14|96.38|60.2 |15.4 |30.5 |1096 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|320 |83.02|96.45|44.6 |16.5 |34.8 |992 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|288 |82.98|96.54|44.6 |13.4 |28.2 |1077 |
|[resnext101_64x4d.tv_in1k](https://huggingface.co/timm/resnext101_64x4d.tv_in1k)|224 |82.98|96.25|83.5 |15.5 |31.2 |989 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|256 |82.86|96.28|86.6 |15.6 |30.8 |951 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|224 |82.83|96.22|88.8 |16.5 |31.2 |1099 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|224 |82.8 |96.13|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|288 |82.8 |96.32|44.6 |13.0 |26.8 |1291 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|288 |82.74|95.71|60.2 |19.1 |37.3 |905 |
|[resnext101_32x8d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_wsl_ig1b_ft_in1k)|224 |82.69|96.63|88.8 |16.5 |31.2 |1100 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|288 |82.62|95.75|60.2 |19.1 |37.3 |904 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|288 |82.61|96.49|25.6 |8.9 |20.6 |1729 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|288 |82.53|96.13|36.8 |9.9 |21.5 |1773 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|224 |82.5 |96.02|126.9 |22.8 |21.2 |1078 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|224 |82.46|95.92|83.5 |15.5 |31.2 |987 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|288 |82.36|96.18|35.7 |8.1 |20.9 |1964 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|320 |82.35|96.14|25.6 |8.8 |24.1 |1386 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|288 |82.31|95.63|44.6 |13.0 |26.8 |1291 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|288 |82.29|96.01|63.6 |13.6 |28.5 |1078 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|224 |82.29|96.0 |60.2 |11.6 |22.6 |1484 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|288 |82.27|96.06|68.9 |18.9 |23.8 |1176 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|256 |82.26|96.07|44.6 |10.6 |22.2 |1542 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|288 |82.24|95.73|44.6 |13.0 |26.8 |1290 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|288 |82.2 |96.14|27.6 |7.0 |23.8 |1547 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|224 |82.18|96.05|44.6 |8.1 |17.1 |1771 |
|[resnext50_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_swsl_ig1b_ft_in1k)|224 |82.17|96.22|25.0 |4.3 |14.4 |2943 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|288 |82.12|95.65|25.6 |7.1 |19.6 |1704 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|288 |82.03|95.94|25.0 |7.0 |23.8 |1745 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|288 |82.0 |96.15|24.9 |5.8 |12.7 |1787 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|256 |81.99|95.85|36.8 |7.8 |17.0 |2230 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|176 |81.98|95.72|88.8 |10.3 |19.4 |1768 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|224 |81.97|95.24|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|224 |81.93|95.75|44.6 |7.8 |16.2 |2122 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|224 |81.9 |95.77|44.6 |7.8 |16.2 |2118 |
|[resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k)|224 |81.84|96.1 |194.0 |36.3 |51.2 |583 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|256 |81.78|95.94|35.7 |6.4 |16.6 |2471 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|224 |81.77|95.22|60.2 |11.6 |22.6 |1485 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|224 |81.74|96.06|25.6 |5.4 |12.4 |2813 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|288 |81.65|95.54|25.6 |7.1 |19.6 |1703 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|288 |81.64|95.88|25.6 |7.2 |19.7 |1694 |
|[resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k)|224 |81.62|96.04|88.8 |16.5 |31.2 |1101 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|224 |81.61|95.76|68.9 |11.4 |14.4 |1930 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|288 |81.61|95.83|25.6 |8.5 |19.2 |1868 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|224 |81.5 |95.16|44.6 |7.8 |16.2 |2125 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|288 |81.48|95.16|25.0 |7.0 |23.8 |1745 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|288 |81.47|95.71|25.9 |6.9 |18.6 |2071 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|224 |81.45|95.53|68.9 |11.4 |14.4 |1929 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|288 |81.44|95.22|25.6 |7.2 |19.7 |1908 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|256 |81.44|95.67|25.6 |5.6 |15.4 |2168 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|288 |81.4 |95.82|30.2 |6.8 |13.9 |2132 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|288 |81.37|95.74|25.6 |7.2 |19.7 |1910 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|224 |81.32|95.19|44.6 |7.8 |16.2 |2125 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|288 |81.3 |95.65|28.1 |6.8 |18.4 |1803 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|288 |81.3 |95.11|25.0 |7.0 |23.8 |1746 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|224 |81.27|95.62|27.6 |4.3 |14.4 |2591 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|224 |81.26|95.16|25.6 |4.3 |11.8 |2823 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|288 |81.23|95.54|15.7 |4.8 |19.6 |2117 |
|[senet154.gluon_in1k](https://huggingface.co/timm/senet154.gluon_in1k)|224 |81.23|95.35|115.1 |20.8 |38.7 |545 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|288 |81.22|95.11|25.6 |6.8 |18.4 |2089 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|288 |81.22|95.63|25.6 |6.8 |18.4 |676 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|288 |81.18|95.09|25.6 |7.2 |19.7 |1908 |
|[resnet50.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet50.fb_swsl_ig1b_ft_in1k)|224 |81.18|95.98|25.6 |4.1 |11.1 |3455 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|224 |81.17|95.34|25.0 |4.3 |14.4 |2933 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|224 |81.1 |95.33|25.0 |4.3 |14.4 |2934 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|288 |81.1 |95.23|28.1 |6.8 |18.4 |1801 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|288 |81.1 |95.12|28.1 |6.8 |18.4 |1799 |
|[resnet152s.gluon_in1k](https://huggingface.co/timm/resnet152s.gluon_in1k)|224 |81.02|95.41|60.3 |12.9 |25.0 |1347 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|288 |80.97|95.44|25.6 |6.8 |18.4 |2085 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|256 |80.94|95.45|25.9 |5.4 |14.7 |2571 |
|[resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.93|95.73|44.2 |8.0 |21.2 |1814 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|288 |80.91|95.55|25.6 |6.8 |18.4 |2084 |
|[seresnext101_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_32x4d.gluon_in1k)|224 |80.9 |95.31|49.0 |8.0 |21.3 |1585 |
|[seresnext101_64x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_64x4d.gluon_in1k)|224 |80.9 |95.3 |88.2 |15.5 |31.2 |918 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|288 |80.86|95.52|25.6 |6.8 |18.4 |2085 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|224 |80.85|95.43|25.6 |4.1 |11.1 |3450 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|224 |80.84|95.02|25.6 |4.3 |11.8 |2821 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|224 |80.79|95.62|24.9 |3.5 |7.7 |2961 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|288 |80.79|95.36|19.8 |6.0 |14.8 |2506 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|288 |80.79|95.58|19.9 |4.2 |10.6 |2349 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|288 |80.78|94.99|25.6 |6.8 |18.4 |2088 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|288 |80.71|95.43|25.6 |6.8 |18.4 |2087 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|288 |80.7 |95.39|25.0 |7.0 |23.8 |1749 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|192 |80.69|95.24|63.6 |6.0 |12.7 |2270 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|224 |80.68|94.71|25.6 |4.4 |11.9 |3162 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|288 |80.68|95.36|19.7 |6.0 |14.8 |2637 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|224 |80.67|95.3 |25.6 |4.1 |11.1 |3452 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|288 |80.67|95.42|25.0 |7.4 |25.1 |1626 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|224 |80.63|95.21|25.6 |5.2 |11.6 |3034 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|224 |80.61|95.32|25.6 |4.4 |11.9 |2813 |
|[resnext101_64x4d.gluon_in1k](https://huggingface.co/timm/resnext101_64x4d.gluon_in1k)|224 |80.61|94.99|83.5 |15.5 |31.2 |989 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|288 |80.6 |95.31|19.9 |6.0 |14.8 |2578 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|256 |80.57|95.17|15.7 |3.8 |15.5 |2710 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|224 |80.56|95.0 |60.2 |11.6 |22.6 |1483 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|224 |80.53|95.16|25.6 |4.4 |11.9 |3164 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|224 |80.53|94.46|25.0 |4.3 |14.4 |2930 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|176 |80.48|94.98|126.9 |14.3 |13.2 |1719 |
|[resnet152d.gluon_in1k](https://huggingface.co/timm/resnet152d.gluon_in1k)|224 |80.47|95.2 |60.2 |11.8 |23.4 |1428 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|288 |80.45|95.32|25.6 |6.8 |18.4 |2086 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|224 |80.45|95.24|30.2 |4.1 |8.4 |3530 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|224 |80.45|94.63|25.0 |4.3 |14.4 |2936 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|176 |80.43|95.09|68.9 |7.3 |9.0 |3015 |
|[resnet101d.gluon_in1k](https://huggingface.co/timm/resnet101d.gluon_in1k)|224 |80.42|95.01|44.6 |8.1 |17.0 |2007 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|224 |80.38|94.6 |25.6 |4.1 |11.1 |3461 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|256 |80.36|95.1 |19.8 |4.8 |11.7 |3267 |
|[resnext101_32x4d.gluon_in1k](https://huggingface.co/timm/resnext101_32x4d.gluon_in1k)|224 |80.34|94.93|44.2 |8.0 |21.2 |1814 |
|[resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.32|95.4 |25.0 |4.3 |14.4 |2941 |
|[resnet101s.gluon_in1k](https://huggingface.co/timm/resnet101s.gluon_in1k)|224 |80.28|95.16|44.7 |9.2 |18.6 |1851 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|224 |80.26|95.08|28.1 |4.1 |11.1 |2972 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|288 |80.24|95.24|25.6 |8.5 |19.9 |1523 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|224 |80.22|94.63|25.6 |4.4 |11.9 |3162 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|176 |80.2 |94.64|60.2 |7.2 |14.0 |2346 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|224 |80.08|94.74|28.1 |4.1 |11.1 |2969 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|256 |80.08|94.97|19.7 |4.8 |11.7 |3284 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|256 |80.06|94.99|19.9 |4.8 |11.7 |3216 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|224 |80.06|94.95|25.6 |4.1 |11.1 |1109 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|224 |80.02|94.71|28.1 |4.1 |11.1 |2962 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|288 |79.97|95.05|25.6 |6.8 |18.4 |2086 |
|[resnet152c.gluon_in1k](https://huggingface.co/timm/resnet152c.gluon_in1k)|224 |79.92|94.84|60.2 |11.8 |23.4 |1455 |
|[seresnext50_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext50_32x4d.gluon_in1k)|224 |79.91|94.82|27.6 |4.3 |14.4 |2591 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|224 |79.91|94.67|25.6 |4.1 |11.1 |3456 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|176 |79.9 |94.6 |44.6 |4.9 |10.1 |3341 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|224 |79.89|94.97|35.7 |4.5 |12.1 |2774 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|224 |79.88|94.87|25.6 |4.1 |11.1 |3455 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|320 |79.86|95.07|16.0 |5.2 |16.4 |2168 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|224 |79.85|94.56|25.6 |4.1 |11.1 |3460 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|288 |79.83|94.97|25.6 |6.8 |18.4 |2087 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|224 |79.82|94.62|44.6 |7.8 |16.2 |2114 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|224 |79.76|94.6 |25.0 |4.3 |14.4 |2943 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|224 |79.74|94.95|25.6 |4.1 |11.1 |3455 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|224 |79.74|94.87|19.9 |2.5 |6.4 |3929 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|288 |79.71|94.83|19.7 |6.0 |14.8 |2710 |
|[resnet152.gluon_in1k](https://huggingface.co/timm/resnet152.gluon_in1k)|224 |79.68|94.74|60.2 |11.6 |22.6 |1486 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|224 |79.67|94.87|25.0 |4.5 |15.2 |2729 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|288 |79.63|94.91|25.6 |6.8 |18.4 |2086 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|224 |79.56|94.72|25.6 |4.3 |11.8 |2805 |
|[resnet101c.gluon_in1k](https://huggingface.co/timm/resnet101c.gluon_in1k)|224 |79.53|94.58|44.6 |8.1 |17.0 |2062 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|224 |79.52|94.61|25.6 |4.1 |11.1 |3459 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|176 |79.42|94.64|25.6 |2.6 |6.9 |5397 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|288 |79.4 |94.66|18.0 |5.9 |14.6 |2752 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|224 |79.38|94.57|25.6 |4.1 |11.1 |3459 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|176 |79.37|94.3 |25.0 |2.7 |9.0 |4577 |
|[resnext50_32x4d.gluon_in1k](https://huggingface.co/timm/resnext50_32x4d.gluon_in1k)|224 |79.36|94.43|25.0 |4.3 |14.4 |2942 |
|[resnext101_32x8d.tv_in1k](https://huggingface.co/timm/resnext101_32x8d.tv_in1k)|224 |79.31|94.52|88.8 |16.5 |31.2 |1100 |
|[resnet101.gluon_in1k](https://huggingface.co/timm/resnet101.gluon_in1k)|224 |79.31|94.53|44.6 |7.8 |16.2 |2125 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|224 |79.31|94.63|25.6 |5.2 |12.0 |2524 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|176 |79.27|94.49|25.6 |2.6 |6.9 |5404 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|224 |79.25|94.31|25.0 |4.3 |14.4 |2931 |
|[resnet50.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet50.fb_ssl_yfcc100m_ft_in1k)|224 |79.22|94.84|25.6 |4.1 |11.1 |3451 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|256 |79.21|94.56|19.7 |4.8 |11.7 |3392 |
|[resnet50d.gluon_in1k](https://huggingface.co/timm/resnet50d.gluon_in1k)|224 |79.07|94.48|25.6 |4.4 |11.9 |3162 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|224 |79.03|94.38|25.6 |4.1 |11.1 |3453 |
|[resnet50.am_in1k](https://huggingface.co/timm/resnet50.am_in1k)|224 |79.01|94.39|25.6 |4.1 |11.1 |3461 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|256 |79.01|94.37|18.0 |4.6 |11.6 |3440 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|256 |78.9 |94.54|16.0 |3.4 |10.5 |3421 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|160 |78.89|94.11|60.2 |5.9 |11.5 |2745 |
|[wide_resnet101_2.tv_in1k](https://huggingface.co/timm/wide_resnet101_2.tv_in1k)|224 |78.84|94.28|126.9 |22.8 |21.2 |1079 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|288 |78.83|94.24|16.8 |4.5 |16.8 |2251 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|224 |78.81|94.32|25.6 |4.1 |11.1 |3454 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|288 |78.74|94.33|16.8 |4.5 |16.7 |2264 |
|[resnet50s.gluon_in1k](https://huggingface.co/timm/resnet50s.gluon_in1k)|224 |78.72|94.23|25.7 |5.5 |13.5 |2796 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|224 |78.71|94.24|25.6 |4.4 |11.9 |3154 |
|[wide_resnet50_2.tv_in1k](https://huggingface.co/timm/wide_resnet50_2.tv_in1k)|224 |78.47|94.09|68.9 |11.4 |14.4 |1934 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|224 |78.46|94.27|25.6 |4.1 |11.1 |3454 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|288 |78.43|94.35|21.8 |6.5 |7.5 |3291 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|288 |78.42|94.04|10.5 |3.1 |13.3 |3226 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|320 |78.33|94.13|16.0 |5.2 |16.4 |2391 |
|[resnet152.tv_in1k](https://huggingface.co/timm/resnet152.tv_in1k)|224 |78.32|94.04|60.2 |11.6 |22.6 |1487 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|288 |78.28|94.1 |10.4 |3.1 |13.3 |3062 |
|[bat_resnext26ts.ch_in1k](https://huggingface.co/timm/bat_resnext26ts.ch_in1k)|256 |78.25|94.1 |10.7 |2.5 |12.5 |3393 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|224 |78.06|93.78|25.6 |4.1 |11.1 |3450 |
|[resnet50c.gluon_in1k](https://huggingface.co/timm/resnet50c.gluon_in1k)|224 |78.0 |93.99|25.6 |4.4 |11.9 |3286 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|288 |78.0 |93.91|10.3 |3.1 |13.3 |3297 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|224 |77.98|93.75|16.8 |2.7 |10.1 |3841 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|288 |77.92|93.77|21.8 |6.1 |6.2 |3609 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|160 |77.88|93.71|44.6 |4.0 |8.3 |3926 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|256 |77.87|93.84|16.0 |3.4 |10.5 |3772 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|256 |77.86|93.79|10.4 |2.4 |10.5 |4263 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|160 |77.82|93.81|35.7 |2.3 |6.2 |5238 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|256 |77.81|93.82|10.5 |2.4 |10.5 |4183 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|160 |77.79|93.6 |25.6 |2.2 |6.0 |5329 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|160 |77.73|93.32|25.0 |2.2 |7.4 |5576 |
|[resnext50_32x4d.tv_in1k](https://huggingface.co/timm/resnext50_32x4d.tv_in1k)|224 |77.61|93.7 |25.0 |4.3 |14.4 |2944 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|224 |77.59|93.61|16.8 |2.7 |10.2 |3807 |
|[resnet50.gluon_in1k](https://huggingface.co/timm/resnet50.gluon_in1k)|224 |77.58|93.72|25.6 |4.1 |11.1 |3455 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|256 |77.44|93.56|10.3 |2.4 |10.5 |4284 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|288 |77.41|93.63|16.0 |4.3 |13.5 |2907 |
|[resnet101.tv_in1k](https://huggingface.co/timm/resnet101.tv_in1k)|224 |77.38|93.54|44.6 |7.8 |16.2 |2125 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|160 |77.22|93.27|25.6 |2.2 |6.1 |5982 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|288 |77.17|93.47|10.3 |3.1 |13.3 |3392 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|288 |77.15|93.27|21.8 |6.1 |6.2 |3615 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|224 |77.1 |93.37|21.8 |3.9 |4.5 |5436 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|224 |77.02|93.07|28.1 |4.1 |11.1 |2952 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|256 |76.78|93.13|10.3 |2.4 |10.5 |4410 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|224 |76.7 |93.17|16.0 |2.6 |8.2 |4859 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|288 |76.5 |93.35|21.8 |6.1 |6.2 |3617 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|224 |76.42|92.87|21.8 |3.7 |3.7 |5984 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|288 |76.35|93.18|16.0 |3.9 |12.2 |3331 |
|[resnet50.tv_in1k](https://huggingface.co/timm/resnet50.tv_in1k)|224 |76.13|92.86|25.6 |4.1 |11.1 |3457 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|160 |75.96|92.5 |25.6 |2.1 |5.7 |6490 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|224 |75.52|92.44|21.8 |3.7 |3.7 |5991 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|224 |75.3 |92.58|16.0 |2.4 |7.4 |5583 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|224 |75.16|92.18|21.8 |3.7 |3.7 |5994 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|160 |75.1 |92.08|28.1 |2.1 |5.7 |5513 |
|[resnet34.gluon_in1k](https://huggingface.co/timm/resnet34.gluon_in1k)|224 |74.57|91.98|21.8 |3.7 |3.7 |5984 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|288 |73.81|91.83|11.7 |3.4 |5.4 |5196 |
|[resnet34.tv_in1k](https://huggingface.co/timm/resnet34.tv_in1k)|224 |73.32|91.42|21.8 |3.7 |3.7 |5979 |
|[resnet18.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet18.fb_swsl_ig1b_ft_in1k)|224 |73.28|91.73|11.7 |1.8 |2.5 |10213 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|288 |73.16|91.03|11.7 |3.0 |4.1 |6050 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|224 |72.98|91.11|21.8 |3.7 |3.7 |5967 |
|[resnet18.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet18.fb_ssl_yfcc100m_ft_in1k)|224 |72.6 |91.42|11.7 |1.8 |2.5 |10213 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|288 |72.37|90.59|11.7 |3.0 |4.1 |6051 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|224 |72.26|90.31|10.1 |1.7 |5.8 |7026 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|224 |72.26|90.68|11.7 |2.1 |3.3 |8707 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|224 |71.49|90.07|11.7 |1.8 |2.5 |10187 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|176 |71.31|89.69|10.1 |1.1 |3.6 |10970 |
|[resnet18.gluon_in1k](https://huggingface.co/timm/resnet18.gluon_in1k)|224 |70.84|89.76|11.7 |1.8 |2.5 |10210 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|224 |70.64|89.47|11.7 |1.8 |2.5 |10194 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|160 |70.56|89.52|21.8 |1.9 |1.9 |10737 |
|[resnet18.tv_in1k](https://huggingface.co/timm/resnet18.tv_in1k)|224 |69.76|89.07|11.7 |1.8 |2.5 |10205 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|224 |68.34|88.03|5.4 |1.1 |2.4 |13079 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|224 |68.25|88.17|11.7 |1.8 |2.5 |10167 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|176 |66.71|86.96|5.4 |0.7 |1.5 |20327 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|160 |65.66|86.26|11.7 |0.9 |1.3 |18229 |
## Citation
```bibtex
@inproceedings{wightman2021resnet,
title={ResNet strikes back: An improved training procedure in timm},
author={Wightman, Ross and Touvron, Hugo and Jegou, Herve},
booktitle={NeurIPS 2021 Workshop on ImageNet: Past, Present, and Future}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{He2015,
author = {Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun},
title = {Deep Residual Learning for Image Recognition},
journal = {arXiv preprint arXiv:1512.03385},
year = {2015}
}
```
|
TheBloke/Airoboros-L2-7B-2.2-GGUF | TheBloke | 2023-09-27T12:48:57Z | 609 | 7 | transformers | [
"transformers",
"gguf",
"llama",
"dataset:jondurbin/airoboros-2.2",
"base_model:jondurbin/airoboros-l2-7b-2.2",
"license:llama2",
"text-generation-inference",
"region:us"
] | null | 2023-09-12T15:27:28Z | ---
license: llama2
datasets:
- jondurbin/airoboros-2.2
model_name: Airoboros L2 7B 2.2
base_model: jondurbin/airoboros-l2-7b-2.2
inference: false
model_creator: Jon Durbin
model_type: llama
prompt_template: "A chat.\nUSER: {prompt}\nASSISTANT: \n"
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Airoboros L2 7B 2.2 - GGUF
- Model creator: [Jon Durbin](https://huggingface.co/jondurbin)
- Original model: [Airoboros L2 7B 2.2](https://huggingface.co/jondurbin/airoboros-l2-7b-2.2)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Jon Durbin's Airoboros L2 7B 2.2](https://huggingface.co/jondurbin/airoboros-l2-7b-2.2).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp. GGUF offers numerous advantages over GGML, such as better tokenisation, and support for special tokens. It is also supports metadata, and is designed to be extensible.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Airoboros-L2-7B-2.2-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Airoboros-L2-7B-2.2-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Airoboros-L2-7B-2.2-GGUF)
* [Jon Durbin's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/jondurbin/airoboros-l2-7b-2.2)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Chat
```
A chat.
USER: {prompt}
ASSISTANT:
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [airoboros-l2-7b-2.2.Q2_K.gguf](https://huggingface.co/TheBloke/Airoboros-L2-7B-2.2-GGUF/blob/main/airoboros-l2-7b-2.2.Q2_K.gguf) | Q2_K | 2 | 2.83 GB| 5.33 GB | smallest, significant quality loss - not recommended for most purposes |
| [airoboros-l2-7b-2.2.Q3_K_S.gguf](https://huggingface.co/TheBloke/Airoboros-L2-7B-2.2-GGUF/blob/main/airoboros-l2-7b-2.2.Q3_K_S.gguf) | Q3_K_S | 3 | 2.95 GB| 5.45 GB | very small, high quality loss |
| [airoboros-l2-7b-2.2.Q3_K_M.gguf](https://huggingface.co/TheBloke/Airoboros-L2-7B-2.2-GGUF/blob/main/airoboros-l2-7b-2.2.Q3_K_M.gguf) | Q3_K_M | 3 | 3.30 GB| 5.80 GB | very small, high quality loss |
| [airoboros-l2-7b-2.2.Q3_K_L.gguf](https://huggingface.co/TheBloke/Airoboros-L2-7B-2.2-GGUF/blob/main/airoboros-l2-7b-2.2.Q3_K_L.gguf) | Q3_K_L | 3 | 3.60 GB| 6.10 GB | small, substantial quality loss |
| [airoboros-l2-7b-2.2.Q4_0.gguf](https://huggingface.co/TheBloke/Airoboros-L2-7B-2.2-GGUF/blob/main/airoboros-l2-7b-2.2.Q4_0.gguf) | Q4_0 | 4 | 3.83 GB| 6.33 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [airoboros-l2-7b-2.2.Q4_K_S.gguf](https://huggingface.co/TheBloke/Airoboros-L2-7B-2.2-GGUF/blob/main/airoboros-l2-7b-2.2.Q4_K_S.gguf) | Q4_K_S | 4 | 3.86 GB| 6.36 GB | small, greater quality loss |
| [airoboros-l2-7b-2.2.Q4_K_M.gguf](https://huggingface.co/TheBloke/Airoboros-L2-7B-2.2-GGUF/blob/main/airoboros-l2-7b-2.2.Q4_K_M.gguf) | Q4_K_M | 4 | 4.08 GB| 6.58 GB | medium, balanced quality - recommended |
| [airoboros-l2-7b-2.2.Q5_0.gguf](https://huggingface.co/TheBloke/Airoboros-L2-7B-2.2-GGUF/blob/main/airoboros-l2-7b-2.2.Q5_0.gguf) | Q5_0 | 5 | 4.65 GB| 7.15 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [airoboros-l2-7b-2.2.Q5_K_S.gguf](https://huggingface.co/TheBloke/Airoboros-L2-7B-2.2-GGUF/blob/main/airoboros-l2-7b-2.2.Q5_K_S.gguf) | Q5_K_S | 5 | 4.65 GB| 7.15 GB | large, low quality loss - recommended |
| [airoboros-l2-7b-2.2.Q5_K_M.gguf](https://huggingface.co/TheBloke/Airoboros-L2-7B-2.2-GGUF/blob/main/airoboros-l2-7b-2.2.Q5_K_M.gguf) | Q5_K_M | 5 | 4.78 GB| 7.28 GB | large, very low quality loss - recommended |
| [airoboros-l2-7b-2.2.Q6_K.gguf](https://huggingface.co/TheBloke/Airoboros-L2-7B-2.2-GGUF/blob/main/airoboros-l2-7b-2.2.Q6_K.gguf) | Q6_K | 6 | 5.53 GB| 8.03 GB | very large, extremely low quality loss |
| [airoboros-l2-7b-2.2.Q8_0.gguf](https://huggingface.co/TheBloke/Airoboros-L2-7B-2.2-GGUF/blob/main/airoboros-l2-7b-2.2.Q8_0.gguf) | Q8_0 | 8 | 7.16 GB| 9.66 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/Airoboros-L2-7B-2.2-GGUF and below it, a specific filename to download, such as: airoboros-l2-7b-2.2.q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub>=0.17.1
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/Airoboros-L2-7B-2.2-GGUF airoboros-l2-7b-2.2.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/Airoboros-L2-7B-2.2-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Airoboros-L2-7B-2.2-GGUF airoboros-l2-7b-2.2.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows CLI users: Use `set HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1` before running the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m airoboros-l2-7b-2.2.q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "A chat.\nUSER: {prompt}\nASSISTANT:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model from Python using ctransformers
#### First install the package
```bash
# Base ctransformers with no GPU acceleration
pip install ctransformers>=0.2.24
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]>=0.2.24
# Or with ROCm GPU acceleration
CT_HIPBLAS=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems
CT_METAL=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
```
#### Simple example code to load one of these GGUF models
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/Airoboros-L2-7B-2.2-GGUF", model_file="airoboros-l2-7b-2.2.q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here's guides on using llama-cpp-python or ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Jon Durbin's Airoboros L2 7B 2.2
### Overview
Another experimental model, using mostly sythetic data generated by [airoboros](https://github.com/jondurbin/airoboros)
Highlights:
- The prompt format has changed! It is now newlines instead of spaces between system/USER/ASSISTANT (see prompt info below).
- "Clean" version of airoboros-2.2 dataset -- this model __does not__ contain the de-alignment data.
- For an uncensored version, use spicyboros variants.
- I re-generated all of the outputs in the dataset that had "Once upon a time" so they'd be less cliche - no guarantees that won't still happen, but in theory it may happen less.
- More multiple choice, better awareness, some alignment for normal use case but system-prompt overridable etc.
Breakdown of the training data:
| Count | Category |
|-------|----------------------------|
| 36 | experience |
| 60 | quiz |
| 63 | card |
| 76 | greeting |
| 100 | detailed\_writing |
| 200 | song |
| 204 | editor |
| 207 | counterfactual\_contextual |
| 268 | cot |
| 339 | theory\_of\_mind |
| 416 | awareness |
| 439 | stylized\_response |
| 457 | misconception |
| 500 | summarization |
| 620 | riddle |
| 719 | agent |
| 800 | plan |
| 873 | gtkm |
| 963 | rp |
| 1000 | wordgame |
| 1279 | multiple\_choice |
| 1519 | joke |
| 1758 | writing |
| 2152 | contextual |
| 2183 | trivia |
| 2364 | roleplay |
| 4699 | general |
| 5775 | coding |
| 11366 | orca |
In other words, it's a fairly general purpose model, but focuses fairly heavily on instruction response pairs rather than casual chat/roleplay.
Huge thank you to the folks over at [a16z](https://a16z.com/) for sponsoring the costs associated with building models and associated tools!
### Prompt format
The prompt format:
```
A chat.
USER: {prompt}
ASSISTANT:
```
The default system prompt ("A chat.") was used for most of the prompts, however it also included a wide sampling of responses with other prompts, particularly in "stylized\_response", "rp", "gtkm", etc.
Here's another example:
```
A chat between Bob (aka USER) and Tom (aka ASSISTANT). Tom is an extremely intelligent 18th century bookkeeper, who speaks loquaciously.
USER: {prompt}
ASSISTANT:
```
And chat scenario that wouldn't require USER/ASSISTANT (but should use stopping criteria to prevent the model from speaking on your behalf).
```
A chat between old friends: Timmy and Tommy.
{description of characters}
{setting for the chat}
Timmy: *takes a big sip from his coffee* "Ah, sweet, delicious, magical coffee."
Tommy:
```
__*I strongly suggest adding stopping criteria/early inference stopping on "USER:", and/or whatever names you specify in the system prompt.*__
### Fine tuning info
https://gist.github.com/jondurbin/7aabf2d8e1ded7b29897a3dd95d81e01
### Helpful usage tips
*The prompts shown here are are just the text that would be included after USER: and before ASSISTANT: in the full prompt format above, the system prompt and USER:/ASSISTANT: have been omited for readability.*
#### Context obedient question answering
By obedient, I mean the model was trained to ignore what it thinks it knows, and uses the context to answer the question. The model was also tuned to limit the values to the provided context as much as possible to reduce hallucinations.
The format for a closed-context prompt is as follows:
```
BEGININPUT
BEGINCONTEXT
[key0: value0]
[key1: value1]
... other metdata ...
ENDCONTEXT
[insert your text blocks here]
ENDINPUT
[add as many other blocks, in the exact same format]
BEGININSTRUCTION
[insert your instruction(s). The model was tuned with single questions, paragraph format, lists, etc.]
ENDINSTRUCTION
```
It's also helpful to add "Don't make up answers if you don't know." to your instruction block to make sure if the context is completely unrelated it doesn't make something up.
*The __only__ prompts that need this closed context formating are closed-context instructions. Normal questions/instructions do not!*
I know it's a bit verbose and annoying, but after much trial and error, using these explicit delimiters helps the model understand where to find the responses and how to associate specific sources with it.
- `BEGININPUT` - denotes a new input block
- `BEGINCONTEXT` - denotes the block of context (metadata key/value pairs) to associate with the current input block
- `ENDCONTEXT` - denotes the end of the metadata block for the current input
- [text] - Insert whatever text you want for the input block, as many paragraphs as can fit in the context.
- `ENDINPUT` - denotes the end of the current input block
- [repeat as many input blocks in this format as you want]
- `BEGININSTRUCTION` - denotes the start of the list (or one) instruction(s) to respond to for all of the input blocks above.
- [instruction(s)]
- `ENDINSTRUCTION` - denotes the end of instruction set
It sometimes works without `ENDINSTRUCTION`, but by explicitly including that in the prompt, the model better understands that all of the instructions in the block should be responded to.
Here's a trivial, but important example to prove the point:
```
BEGININPUT
BEGINCONTEXT
date: 2021-01-01
url: https://web.site/123
ENDCONTEXT
In a shocking turn of events, blueberries are now green, but will be sticking with the same name.
ENDINPUT
BEGININSTRUCTION
What color are bluberries? Source?
ENDINSTRUCTION
```
And the response:
```
Blueberries are now green.
Source:
date: 2021-01-01
url: https://web.site/123
```
#### Coding
You can ask for fairly complex coding instructions with multiple criteria, e.g.:
```
Create a python application with the following requirements:
- Asyncio FastAPI webserver
- ping endpoint that returns the current date in JSON format
- file upload endpoint, which calculates the file's sha256 checksum, and checks postgres to deduplicate
```
Or inline criteria:
```
Write a multi-threaded TCP server in C that accepts a "GET [key]" input and "SET [key] [value]" input, and uses a binary tree to get and store the input values.
```
You can also optionally add a single space and "PLAINFORMAT" at the end of your prompt to avoid backticks, explanations, etc. and just print the code, e.g.:
```
Write a websocket application in node.js. PLAINFORMAT
```
#### Agent/function calling
The dataset includes many examples of function/args generation based on input criteria. This is somewhat similar to the OpenAI function calling, but the output is either JSON or YAML.
Example prompt:
```
As an AI assistant, please select the most suitable function and parameters from the list of available functions below, based on the user's input. Provide your response in JSON format.
Input: I want to know how many times 'Python' is mentioned in my text file.
Available functions:
file_analytics:
description: This tool performs various operations on a text file.
params:
action: The operation we want to perform on the data, such as "count_occurrences", "find_line", etc.
filters:
keyword: The word or phrase we want to search for.
```
Response:
```json
{
"function": "file_analytics",
"params": {
"action": "count_occurrences",
"filters": {
"keyword": "Python"
}
}
}
```
#### Chain-of-thought
You can ask for several possible responses to a given problem, with a ranking and final answer selection.
Example prompt:
```
A group of people decide to play a round-robin tournament where every player plays every other player exactly once. If a total of 45 games were played, how many players participated in the tournament? Offer several potential answers, rank them according to mathematical logic, and pick the most feasible one.
```
Example response:
```
Solution 1:
In a round-robin tournament, each player plays every other player exactly once. This means that the total number of games played is equal to the combination of all players taken two at a time (since a game involves two players).
The formula for combinations is nC2 = n(n-1)/2, where n is the total number of players. We know that nC2 equals 45 (the total number of games), so we can set up the equation as follows:
n(n-1)/2 = 45
Solving this equation gives us n=10.
Final answer: There were 10 players in the tournament.
Solution 2:
Another way to approach this problem is by using the concept of triangular numbers. Triangular numbers are a sequence of numbers where each number can be represented as a triangle with dots. The nth triangular number is given by the sum of the first n natural numbers.
If we consider each game as a dot and each player as a side of the triangle, then the total number of games (45) would correspond to the 9th triangular number because 1+2+3+4+5+6+7+8+9=45. However, since each side of the triangle represents a player, and there's one more player than sides in our model (because the last player has no one left to play against), we need to add one more to get the total number of players.
Final answer: There were 10 players in the tournament.
Solution 3:
We could also use trial and error to solve this problem. Starting from a small number of players, we calculate how many games would be played in a round-robin tournament until we reach 45 games. For example, with 2 players, only 1 game is played; with 3 players, 3 games are played; with 4 players, 6 games are played, and so on. Continuing this process, we find that with 10 players, 45 games are played.
Final answer: There were 10 players in the tournament.
Ranking of solutions from best to worst:
1. Solution 1: This solution uses direct mathematical reasoning based on the properties of a round-robin tournament and solves an equation to find the answer.
2. Solution 2: This solution uses the concept of triangular numbers which requires additional steps and knowledge beyond the immediate problem context, but still arrives at the correct answer.
3. Solution 3: This solution relies on trial and error, which is less efficient and reliable than the other methods, but it eventually gets to the right answer.
Best and final answer: There were 10 players in the tournament.
```
#### reWOO style execution planning
The model now supports execution planning for complex instructions that would require making use of several tools. The output is just the plan, you must implement a mechanism to parse the output and actually call the functions!
Example prompt:
```
Please construct a systematic plan to generate an optimal response to the user instruction, utilizing a set of provided tools. Each plan will correspond to an evidence value, which will be the output of one of the available functions given an input string
that could be the user's question, one or more prior evidence values, or a combination of both.
Here are the tools available to be called:
DuckDuckGo[input]: Tool that enables the user to search for information using the DuckDuckGo search engine. This tool is helpful in locating a suitable list of sites that may contain the answer to the user's query. It does not directly answer the question but finds a list of sites that might have the answer.
TextScraper[input]: Load one or more websites from the input string containing newline delimited links, where input is one or more links, and produces plain text output containing the content of the links.
HyperlinkExtractor[input]: Extract links from plain text and produces a plain text, newline delimited response of links.
KnowledgeModel[input]: Question answering language model, particularly useful in answering questions based on an input passage of text. The input must be a text question that references an :evidence[n]: variable, e.g. What color is the cat, given :evidence1:?
The output should be in format:
Plan: [first action to take based on input question]
:evidence0: = [function to call with input parameter]
Plan: [next action to take, based on result of :evidence0:]
:evidence1: = [next function to call and input parameter, which may include reference to previous evidence, e.g. "Given context :evidence0"]
...
Answer: [:evidence[n]: containing the final answer.]
Question: Who won the Nobel Prize in Literature in 2020 and what is their most famous work?
```
Response:
```
Plan: Begin by conducting a web search to find out who won the Nobel Prize in Literature in 2020.
:evidence0: = DuckDuckGo[Nobel Prize in Literature 2020 winner]
Plan: Utilize the KnowledgeModel to interpret the search results and find the name of the laureate.
:evidence1: = KnowledgeModel[Who won the Nobel Prize in Literature in 2020, given :evidence0:?]
Plan: Conduct another web search to find the most famous work of the identified laureate.
:evidence2: = DuckDuckGo[Most famous work of :evidence1:]
Plan: Extract the relevant links from the DuckDuckGo search results for a more focused search.
:evidence3: = HyperlinkExtractor[:evidence2:]
Plan: Use the TextScraper tool to extract information from the relevant links.
:evidence4: = TextScraper[:evidence3:]
Plan: Finally, utilize the KnowledgeModel to identify and summarize the most famous work of the laureate from the extracted information.
:evidence5: = KnowledgeModel[What is the most famous work of :evidence1:, given :evidence4:?]
Answer: :evidence5:
```
For this to be useful, you'd have to parse the output plan text, and implement/call each of the functions. This is just pseudo-code, completely untested off the top of my head, and obviously would requiring full implementation + hardening:
```python
import re
import requests
def inject_context(input_text, **context):
for ref in set(re.findall(r"(:evidence[0-9]+:)", input_text, re.I)):
input_text = input_text.replace(ref, context.get(ref, ""))
return input_text
def duckduckgo(input_text, **context):
search_string = inject_context(input_text, **context)
... search via duck duck go using search_string
... return text content
def link_extractor(input_text, **context):
input_text = inject_context(input_text, **context)
return "\n".join(list(set(re.findall(r"(https?://[^\s]+?\.?)", input_text, re.I))))
def scrape(input_text, **context):
input_text = inject_context(input_text, **context)
text = []
for link in input_text.splitlines():
text.append(requests.get(link).text)
return "\n".join(text)
def infer(input_text, **context)
prompt = inject_context(input_text, **context)
... call model with prompt, return output
def parse_plan(plan):
method_map = {
"DuckDuckGo": duckduckgo,
"HyperlinkExtractor": link_extractor,
"KnowledgeModel": infer,
"TextScraper": scrape,
}
context = {}
for line in plan.strip().splitlines():
if line.startswith("Plan:"):
print(line)
continue
parts = re.match("^(:evidence[0-9]+:)\s*=\s*([^\[]+])(\[.*\])\s$", line, re.I)
if not parts:
if line.startswith("Answer: "):
return context.get(line.split(" ")[-1].strip(), "Answer couldn't be generated...")
raise RuntimeError("bad format: " + line)
context[parts.group(1)] = method_map[parts.group(2)](parts.group(3), **context)
```
### Contribute
If you're interested in new functionality, particularly a new "instructor" type to generate a specific type of training data,
take a look at the dataset generation tool repo: https://github.com/jondurbin/airoboros and either make a PR or open an issue with details.
To help me with the OpenAI/compute costs:
- https://bmc.link/jondurbin
- ETH 0xce914eAFC2fe52FdceE59565Dd92c06f776fcb11
- BTC bc1qdwuth4vlg8x37ggntlxu5cjfwgmdy5zaa7pswf
### Licence and usage restrictions
The airoboros 2.2 models are built on top of llama-2/codellama.
The llama-2 base model has a custom Meta license:
- See the [meta-license/LICENSE.txt](meta-license/LICENSE.txt) file attached for the original license provided by Meta.
- See also [meta-license/USE_POLICY.md](meta-license/USE_POLICY.md) and [meta-license/Responsible-Use-Guide.pdf](meta-license/Responsible-Use-Guide.pdf), also provided by Meta.
The fine-tuning data was mostly generated by OpenAI API calls to gpt-4, via [airoboros](https://github.com/jondurbin/airoboros)
The ToS for OpenAI API usage has a clause preventing the output from being used to train a model that __competes__ with OpenAI
- what does *compete* actually mean here?
- these small open source models will not produce output anywhere near the quality of gpt-4, or even gpt-3.5, so I can't imagine this could credibly be considered competing in the first place
- if someone else uses the dataset to do the same, they wouldn't necessarily be violating the ToS because they didn't call the API, so I don't know how that works
- the training data used in essentially all large language models includes a significant amount of copyrighted or otherwise non-permissive licensing in the first place
- other work using the self-instruct method, e.g. the original here: https://github.com/yizhongw/self-instruct released the data and model as apache-2
I am purposingly leaving this license ambiguous (other than the fact you must comply with the Meta original license for llama-2) because I am not a lawyer and refuse to attempt to interpret all of the terms accordingly.
Your best bet is probably to avoid using this commercially due to the OpenAI API usage.
Either way, by using this model, you agree to completely indemnify me.
<!-- original-model-card end -->
|
TheBloke/typhoon-7B-GGUF | TheBloke | 2023-12-24T16:29:53Z | 609 | 7 | transformers | [
"transformers",
"gguf",
"mistral",
"pretrained",
"text-generation",
"th",
"arxiv:2312.13951",
"base_model:scb10x/typhoon-7b",
"license:apache-2.0",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-24T16:25:16Z | ---
base_model: scb10x/typhoon-7b
inference: false
language:
- th
library_name: transformers
license: apache-2.0
model_creator: SCB 10X
model_name: Typhoon 7B
model_type: mistral
pipeline_tag: text-generation
prompt_template: '{prompt}
'
quantized_by: TheBloke
tags:
- pretrained
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Typhoon 7B - GGUF
- Model creator: [SCB 10X](https://huggingface.co/scb10x)
- Original model: [Typhoon 7B](https://huggingface.co/scb10x/typhoon-7b)
<!-- description start -->
## Description
This repo contains GGUF format model files for [SCB 10X's Typhoon 7B](https://huggingface.co/scb10x/typhoon-7b).
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [GPT4All](https://gpt4all.io/index.html), a free and open source local running GUI, supporting Windows, Linux and macOS with full GPU accel.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration. Linux available, in beta as of 27/11/2023.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server. Note, as of time of writing (November 27th 2023), ctransformers has not been updated in a long time and does not support many recent models.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/typhoon-7B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/typhoon-7B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/typhoon-7B-GGUF)
* [SCB 10X's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/scb10x/typhoon-7b)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: None
```
{prompt}
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [typhoon-7b.Q2_K.gguf](https://huggingface.co/TheBloke/typhoon-7B-GGUF/blob/main/typhoon-7b.Q2_K.gguf) | Q2_K | 2 | 3.10 GB| 5.60 GB | smallest, significant quality loss - not recommended for most purposes |
| [typhoon-7b.Q3_K_S.gguf](https://huggingface.co/TheBloke/typhoon-7B-GGUF/blob/main/typhoon-7b.Q3_K_S.gguf) | Q3_K_S | 3 | 3.18 GB| 5.68 GB | very small, high quality loss |
| [typhoon-7b.Q3_K_M.gguf](https://huggingface.co/TheBloke/typhoon-7B-GGUF/blob/main/typhoon-7b.Q3_K_M.gguf) | Q3_K_M | 3 | 3.54 GB| 6.04 GB | very small, high quality loss |
| [typhoon-7b.Q3_K_L.gguf](https://huggingface.co/TheBloke/typhoon-7B-GGUF/blob/main/typhoon-7b.Q3_K_L.gguf) | Q3_K_L | 3 | 3.84 GB| 6.34 GB | small, substantial quality loss |
| [typhoon-7b.Q4_0.gguf](https://huggingface.co/TheBloke/typhoon-7B-GGUF/blob/main/typhoon-7b.Q4_0.gguf) | Q4_0 | 4 | 4.13 GB| 6.63 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [typhoon-7b.Q4_K_S.gguf](https://huggingface.co/TheBloke/typhoon-7B-GGUF/blob/main/typhoon-7b.Q4_K_S.gguf) | Q4_K_S | 4 | 4.16 GB| 6.66 GB | small, greater quality loss |
| [typhoon-7b.Q4_K_M.gguf](https://huggingface.co/TheBloke/typhoon-7B-GGUF/blob/main/typhoon-7b.Q4_K_M.gguf) | Q4_K_M | 4 | 4.39 GB| 6.89 GB | medium, balanced quality - recommended |
| [typhoon-7b.Q5_0.gguf](https://huggingface.co/TheBloke/typhoon-7B-GGUF/blob/main/typhoon-7b.Q5_0.gguf) | Q5_0 | 5 | 5.02 GB| 7.52 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [typhoon-7b.Q5_K_S.gguf](https://huggingface.co/TheBloke/typhoon-7B-GGUF/blob/main/typhoon-7b.Q5_K_S.gguf) | Q5_K_S | 5 | 5.02 GB| 7.52 GB | large, low quality loss - recommended |
| [typhoon-7b.Q5_K_M.gguf](https://huggingface.co/TheBloke/typhoon-7B-GGUF/blob/main/typhoon-7b.Q5_K_M.gguf) | Q5_K_M | 5 | 5.15 GB| 7.65 GB | large, very low quality loss - recommended |
| [typhoon-7b.Q6_K.gguf](https://huggingface.co/TheBloke/typhoon-7B-GGUF/blob/main/typhoon-7b.Q6_K.gguf) | Q6_K | 6 | 5.96 GB| 8.46 GB | very large, extremely low quality loss |
| [typhoon-7b.Q8_0.gguf](https://huggingface.co/TheBloke/typhoon-7B-GGUF/blob/main/typhoon-7b.Q8_0.gguf) | Q8_0 | 8 | 7.72 GB| 10.22 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/typhoon-7B-GGUF and below it, a specific filename to download, such as: typhoon-7b.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/typhoon-7B-GGUF typhoon-7b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage (click to read)</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/typhoon-7B-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/typhoon-7B-GGUF typhoon-7b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 35 -m typhoon-7b.Q4_K_M.gguf --color -c 32768 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "{prompt}"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 32768` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically. Note that longer sequence lengths require much more resources, so you may need to reduce this value.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions can be found in the text-generation-webui documentation, here: [text-generation-webui/docs/04 ‐ Model Tab.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/04%20%E2%80%90%20Model%20Tab.md#llamacpp).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries. Note that at the time of writing (Nov 27th 2023), ctransformers has not been updated for some time and is not compatible with some recent models. Therefore I recommend you use llama-cpp-python.
### How to load this model in Python code, using llama-cpp-python
For full documentation, please see: [llama-cpp-python docs](https://abetlen.github.io/llama-cpp-python/).
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install llama-cpp-python
# With NVidia CUDA acceleration
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
# Or with OpenBLAS acceleration
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install llama-cpp-python
# Or with CLBLast acceleration
CMAKE_ARGS="-DLLAMA_CLBLAST=on" pip install llama-cpp-python
# Or with AMD ROCm GPU acceleration (Linux only)
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
# Or with Metal GPU acceleration for macOS systems only
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
# In windows, to set the variables CMAKE_ARGS in PowerShell, follow this format; eg for NVidia CUDA:
$env:CMAKE_ARGS = "-DLLAMA_OPENBLAS=on"
pip install llama-cpp-python
```
#### Simple llama-cpp-python example code
```python
from llama_cpp import Llama
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = Llama(
model_path="./typhoon-7b.Q4_K_M.gguf", # Download the model file first
n_ctx=32768, # The max sequence length to use - note that longer sequence lengths require much more resources
n_threads=8, # The number of CPU threads to use, tailor to your system and the resulting performance
n_gpu_layers=35 # The number of layers to offload to GPU, if you have GPU acceleration available
)
# Simple inference example
output = llm(
"{prompt}", # Prompt
max_tokens=512, # Generate up to 512 tokens
stop=["</s>"], # Example stop token - not necessarily correct for this specific model! Please check before using.
echo=True # Whether to echo the prompt
)
# Chat Completion API
llm = Llama(model_path="./typhoon-7b.Q4_K_M.gguf", chat_format="llama-2") # Set chat_format according to the model you are using
llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are a story writing assistant."},
{
"role": "user",
"content": "Write a story about llamas."
}
]
)
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Michael Levine, 阿明, Trailburnt, Nikolai Manek, John Detwiler, Randy H, Will Dee, Sebastain Graf, NimbleBox.ai, Eugene Pentland, Emad Mostaque, Ai Maven, Jim Angel, Jeff Scroggin, Michael Davis, Manuel Alberto Morcote, Stephen Murray, Robert, Justin Joy, Luke @flexchar, Brandon Frisco, Elijah Stavena, S_X, Dan Guido, Undi ., Komninos Chatzipapas, Shadi, theTransient, Lone Striker, Raven Klaugh, jjj, Cap'n Zoog, Michel-Marie MAUDET (LINAGORA), Matthew Berman, David, Fen Risland, Omer Bin Jawed, Luke Pendergrass, Kalila, OG, Erik Bjäreholt, Rooh Singh, Joseph William Delisle, Dan Lewis, TL, John Villwock, AzureBlack, Brad, Pedro Madruga, Caitlyn Gatomon, K, jinyuan sun, Mano Prime, Alex, Jeffrey Morgan, Alicia Loh, Illia Dulskyi, Chadd, transmissions 11, fincy, Rainer Wilmers, ReadyPlayerEmma, knownsqashed, Mandus, biorpg, Deo Leter, Brandon Phillips, SuperWojo, Sean Connelly, Iucharbius, Jack West, Harry Royden McLaughlin, Nicholas, terasurfer, Vitor Caleffi, Duane Dunston, Johann-Peter Hartmann, David Ziegler, Olakabola, Ken Nordquist, Trenton Dambrowitz, Tom X Nguyen, Vadim, Ajan Kanaga, Leonard Tan, Clay Pascal, Alexandros Triantafyllidis, JM33133, Xule, vamX, ya boyyy, subjectnull, Talal Aujan, Alps Aficionado, wassieverse, Ari Malik, James Bentley, Woland, Spencer Kim, Michael Dempsey, Fred von Graf, Elle, zynix, William Richards, Stanislav Ovsiannikov, Edmond Seymore, Jonathan Leane, Martin Kemka, usrbinkat, Enrico Ros
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: SCB 10X's Typhoon 7B
# Typhoon-7B: Thai Large Language Model (Pretrained)
**Typhoon-7B** is a *pretrained* Thai 🇹🇭 large language model with 7 billion parameters, and it is based on Mistral-7B.
**Typhoon-7B** outperforms all open-source Thai language models at the time of writing as evaluated on Thai examination benchmarks, and its instruction-tuned variant achieves the best results in instruction-following tasks. Also, its performance in Thai is on par with GPT-3.5 while being 2.62 times more efficient in tokenizing Thai text.
**This is not an instruction-tuned model** - It may not be able to follow human instructions without using one/few-shot learning or instruction fine-tuning. The model does not have any moderation mechanisms, and may generate harmful or inappropriate responses.
The Instruct model (chat-model) will be released soon.
<div align="center">
<img src="https://storage.googleapis.com/scb10x-ai-lab-public/assets/typhoon_benchmark.png" alt="Typhoon benchmark" width="100%" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
</div>
For full details of this model, please read our [paper](https://arxiv.org/abs/2312.13951).
## Model Description
- **Model type**: A 7B pretrained decoder-only model
- **Requirement**: transformers 4.34.0 or newer.
- **Primary Language(s)**: Thai 🇹🇭 and English 🇬🇧
- **License**: Apache-2.0 (Commercial)
## Performance on Thai Benchmark
| **Model** | **ONET** | **IC** | **TGAT** | **TPAT-1** | **A-Level** |
|---------------------|----------|--------|----------|------------|-------------|
| Typhoon-7B | 0.379 | 0.393 | 0.700 | 0.414 | 0.324 |
| SeaLLM-7B | 0.342 | 0.256 | 0.589 | 0.336 | 0.305 |
| OpenThaiGPT-beta-7B | 0.180 | 0.278 | 0.411 | 0.319 | 0.243 |
| WangChanGLM | 0.192 | 0.271 | 0.167 | 0.172 | 0.175 |
| SEA-LION-7B | 0.179 | 0.290 | 0.244 | 0.198 | 0.175 |
| Avg. Human | 0.318 | - | 0.472 | 0.406 | - |
## Intended Uses & Limitations
This model is a pretrained base model. Thus, it may not be able to follow human instructions without using one/few-shot learning or instruction fine-tuning. The model does not have any moderation mechanisms, and may generate harmful or inappropriate responses.
## SCB10X AI Team
- Kunat Pipatanakul, Phatrasek Jirabovonvisut, Potsawee Manakul, Sittipong Sripaisarnmongkol, Ruangsak Patomwong, Pathomporn Chokchainant, Kasima Tharnpipitchai
- If you find Typhoon-7B useful for your work, please cite it using:
```
@article{pipatanakul2023typhoon,
title={Typhoon: Thai Large Language Models},
author={Kunat Pipatanakul and Phatrasek Jirabovonvisut and Potsawee Manakul and Sittipong Sripaisarnmongkol and Ruangsak Patomwong and Pathomporn Chokchainant and Kasima Tharnpipitchai},
year={2023},
journal={arXiv preprint arXiv:2312.13951},
url={https://arxiv.org/abs/2312.13951}
}
```
## Contact Us
- E-mail: [email protected]
<!-- original-model-card end -->
|
yichaodu/DiffusionDPO-bias-claude3-opus | yichaodu | 2024-06-20T12:02:52Z | 609 | 0 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"region:us"
] | text-to-image | 2024-06-19T07:24:16Z | ---
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
inference: true
---
# Aligned Diffusion Model via DPO
Diffusion Model Aligned with thef following reward model and DPO algorithm
```
close-sourced vlm: claude3-opus gemini-1.5 gpt-4o gpt-4v
open-sourced vlm: internvl-1.5
score model: hps-2.1
```
## How to Use
You can load the model and perform inference as follows:
```python
from diffusers import StableDiffusionPipeline, UNet2DConditionModel
pretrained_model_name = "runwayml/stable-diffusion-v1-5"
dpo_unet = UNet2DConditionModel.from_pretrained(
"path/to/checkpoint",
subfolder='unet',
torch_dtype=torch.float16
).to('cuda')
pipeline = StableDiffusionPipeline.from_pretrained(pretrained_model_name, torch_dtype=torch.float16)
pipeline = pipeline.to('cuda')
pipeline.safety_checker = None
pipeline.unet = dpo_unet
generator = torch.Generator(device='cuda')
generator = generator.manual_seed(1)
prompt = "a pink flower"
image = pipeline(prompt=prompt, generator=generator, guidance_scale=gs).images[0]
```
## Citation
```
@misc{mjbench2024mjbench,
title={MJ-BENCH: Is Your Multimodal Reward Model Really a Good Judge?},
author={Chen*, Zhaorun and Du*, Yichao and Wen, Zichen and Zhou, Yiyang and Cui, Chenhang and Weng, Zhenzhen and Tu, Haoqin and Wang, Chaoqi and Tong, Zhengwei and HUANG, Leria and Chen, Canyu and Ye Qinghao and Zhu, Zhihong and Zhang, Yuqing and Zhou, Jiawei and Zhao, Zhuokai and Rafailov, Rafael and Finn, Chelsea and Yao, Huaxiu},
year={2024}
}
``` |
uer/roberta-tiny-wwm-chinese-cluecorpussmall | uer | 2023-10-17T15:30:56Z | 608 | 1 | transformers | [
"transformers",
"pytorch",
"bert",
"fill-mask",
"zh",
"dataset:CLUECorpusSmall",
"arxiv:1909.05658",
"arxiv:2212.06385",
"arxiv:1908.08962",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-07-18T03:46:21Z | ---
language: zh
datasets: CLUECorpusSmall
widget:
- text: "北京是[MASK]国的首都。"
---
# Chinese Whole Word Masking RoBERTa Miniatures
## Model description
This is the set of 6 Chinese Whole Word Masking RoBERTa models pre-trained by [UER-py](https://github.com/dbiir/UER-py/), which is introduced in [this paper](https://arxiv.org/abs/1909.05658). Besides, the models could also be pre-trained by [TencentPretrain](https://github.com/Tencent/TencentPretrain) introduced in [this paper](https://arxiv.org/abs/2212.06385), which inherits UER-py to support models with parameters above one billion, and extends it to a multimodal pre-training framework.
[Turc et al.](https://arxiv.org/abs/1908.08962) have shown that the standard BERT recipe is effective on a wide range of model sizes. Following their paper, we released the 6 Chinese Whole Word Masking RoBERTa models. In order to facilitate users in reproducing the results, we used a publicly available corpus and word segmentation tool, and provided all training details.
You can download the 6 Chinese RoBERTa miniatures either from the [UER-py Modelzoo page](https://github.com/dbiir/UER-py/wiki/Modelzoo), or via HuggingFace from the links below:
| | Link |
| -------- | :-----------------------: |
| **Tiny** | [**2/128 (Tiny)**][2_128] |
| **Mini** | [**4/256 (Mini)**][4_256] |
| **Small** | [**4/512 (Small)**][4_512] |
| **Medium** | [**8/512 (Medium)**][8_512] |
| **Base** | [**12/768 (Base)**][12_768] |
| **Large** | [**24/1024 (Large)**][24_1024] |
Here are scores on the devlopment set of six Chinese tasks:
| Model | Score | book_review | chnsenticorp | lcqmc | tnews(CLUE) | iflytek(CLUE) | ocnli(CLUE) |
| ------------------ | :---: | :----: | :----------: | :---: | :---------: | :-----------: | :---------: |
| RoBERTa-Tiny-WWM | 72.2 | 83.7 | 91.8 | 81.8 | 62.1 | 55.4 | 58.6 |
| RoBERTa-Mini-WWM | 76.3 | 86.4 | 93.0 | 86.8 | 64.4 | 58.7 | 68.8 |
| RoBERTa-Small-WWM | 77.6 | 88.1 | 93.8 | 87.2 | 65.2 | 59.6 | 71.4 |
| RoBERTa-Medium-WWM | 78.6 | 89.3 | 94.4 | 88.8 | 66.0 | 59.9 | 73.2 |
| RoBERTa-Base-WWM | 80.2 | 90.6 | 95.8 | 89.4 | 67.5 | 61.8 | 76.2 |
| RoBERTa-Large-WWM | 81.1 | 91.1 | 95.8 | 90.0 | 68.5 | 62.1 | 79.1 |
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained with the sequence length of 128:
- epochs: 3, 5, 8
- batch sizes: 32, 64
- learning rates: 3e-5, 1e-4, 3e-4
## How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='uer/roberta-tiny-wwm-chinese-cluecorpussmall')
>>> unmasker("北京是[MASK]国的首都。")
[
{'score': 0.294228732585907,
'token': 704,
'token_str': '中',
'sequence': '北 京 是 中 国 的 首 都 。'},
{'score': 0.19691626727581024,
'token': 1266,
'token_str': '北',
'sequence': '北 京 是 北 国 的 首 都 。'},
{'score': 0.1070084273815155,
'token': 7506,
'token_str': '韩',
'sequence': '北 京 是 韩 国 的 首 都 。'},
{'score': 0.031527262181043625,
'token': 2769,
'token_str': '我',
'sequence': '北 京 是 我 国 的 首 都 。'},
{'score': 0.023054633289575577,
'token': 1298,
'token_str': '南',
'sequence': '北 京 是 南 国 的 首 都 。'}
]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('uer/roberta-base-wwm-chinese-cluecorpussmall')
model = BertModel.from_pretrained("uer/roberta-base-wwm-chinese-cluecorpussmall")
text = "用你喜欢的任何文本替换我。"
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import BertTokenizer, TFBertModel
tokenizer = BertTokenizer.from_pretrained('uer/roberta-base-wwm-chinese-cluecorpussmall')
model = TFBertModel.from_pretrained("uer/roberta-base-wwm-chinese-cluecorpussmall")
text = "用你喜欢的任何文本替换我。"
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Training data
[CLUECorpusSmall](https://github.com/CLUEbenchmark/CLUECorpus2020/) is used as training data.
## Training procedure
Models are pre-trained by [UER-py](https://github.com/dbiir/UER-py/) on [Tencent Cloud](https://cloud.tencent.com/). We pre-train 1,000,000 steps with a sequence length of 128 and then pre-train 250,000 additional steps with a sequence length of 512. We use the same hyper-parameters on different model sizes.
[jieba](https://github.com/fxsjy/jieba) is used as word segmentation tool.
Taking the case of Whole Word Masking RoBERTa-Medium
Stage1:
```
python3 preprocess.py --corpus_path corpora/cluecorpussmall.txt \
--vocab_path models/google_zh_vocab.txt \
--dataset_path cluecorpussmall_seq128_dataset.pt \
--processes_num 32 --seq_length 128 \
--dynamic_masking --data_processor mlm
```
```
python3 pretrain.py --dataset_path cluecorpussmall_seq128_dataset.pt \
--vocab_path models/google_zh_vocab.txt \
--config_path models/bert/medium_config.json \
--output_model_path models/cluecorpussmall_wwm_roberta_medium_seq128_model.bin \
--world_size 8 --gpu_ranks 0 1 2 3 4 5 6 7 \
--total_steps 1000000 --save_checkpoint_steps 100000 --report_steps 50000 \
--learning_rate 1e-4 --batch_size 64 \
--whole_word_masking \
--data_processor mlm --target mlm
```
Stage2:
```
python3 preprocess.py --corpus_path corpora/cluecorpussmall.txt \
--vocab_path models/google_zh_vocab.txt \
--dataset_path cluecorpussmall_seq512_dataset.pt \
--processes_num 32 --seq_length 512 \
--dynamic_masking --data_processor mlm
```
```
python3 pretrain.py --dataset_path cluecorpussmall_seq512_dataset.pt \
--vocab_path models/google_zh_vocab.txt \
--pretrained_model_path models/cluecorpussmall_wwm_roberta_medium_seq128_model.bin-1000000 \
--config_path models/bert/medium_config.json \
--output_model_path models/cluecorpussmall_wwm_roberta_medium_seq512_model.bin \
--world_size 8 --gpu_ranks 0 1 2 3 4 5 6 7 \
--total_steps 250000 --save_checkpoint_steps 50000 --report_steps 10000 \
--learning_rate 5e-5 --batch_size 16 \
--whole_word_masking \
--data_processor mlm --target mlm
```
Finally, we convert the pre-trained model into Huggingface's format:
```
python3 scripts/convert_bert_from_uer_to_huggingface.py --input_model_path models/cluecorpussmall_wwm_roberta_medium_seq512_model.bin-250000 \
--output_model_path pytorch_model.bin \
--layers_num 8 --type mlm
```
### BibTeX entry and citation info
```
@article{zhao2019uer,
title={UER: An Open-Source Toolkit for Pre-training Models},
author={Zhao, Zhe and Chen, Hui and Zhang, Jinbin and Zhao, Xin and Liu, Tao and Lu, Wei and Chen, Xi and Deng, Haotang and Ju, Qi and Du, Xiaoyong},
journal={EMNLP-IJCNLP 2019},
pages={241},
year={2019}
}
@article{zhao2023tencentpretrain,
title={TencentPretrain: A Scalable and Flexible Toolkit for Pre-training Models of Different Modalities},
author={Zhao, Zhe and Li, Yudong and Hou, Cheng and Zhao, Jing and others},
journal={ACL 2023},
pages={217},
year={2023}
```
[2_128]:https://huggingface.co/uer/roberta-tiny-wwm-chinese-cluecorpussmall
[4_256]:https://huggingface.co/uer/roberta-mini-wwm-chinese-cluecorpussmall
[4_512]:https://huggingface.co/uer/roberta-small-wwm-chinese-cluecorpussmall
[8_512]:https://huggingface.co/uer/roberta-medium-wwm-chinese-cluecorpussmall
[12_768]:https://huggingface.co/uer/roberta-base-wwm-chinese-cluecorpussmall
[24_1024]:https://huggingface.co/uer/roberta-large-wwm-chinese-cluecorpussmall |
gsdf/CounterfeitXL | gsdf | 2023-08-23T21:11:27Z | 608 | 93 | diffusers | [
"diffusers",
"safetensors",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | text-to-image | 2023-07-29T07:44:35Z | ---
license: creativeml-openrail-m
---
Civitai
https://civitai.com/models/118406/counterfeitxl
Negative Embeddings
A:Standard
B:Realistic
C:Anime like |
mmnga/rinna-japanese-gpt-neox-3.6b-instruction-ppo-gguf | mmnga | 2023-09-08T02:39:00Z | 608 | 0 | null | [
"gguf",
"ja",
"license:mit",
"region:us"
] | null | 2023-09-02T17:52:26Z | ---
license: mit
language:
- ja
---
# rinna/japanese-gpt-neox-3.6b-instruction-ppo
[rinnaさんが公開しているjapanese-gpt-neox-3.6b-instruction-ppo](https://huggingface.co/rinna/japanese-gpt-neox-3.6b-instruction-ppo)のgguf変換版です。
他モデルはこちら
[mmnga/rinna-bilingual-gpt-neox-4b-gguf](https://huggingface.co/mmnga/rinna-bilingual-gpt-neox-4b-gguf)
[mmnga/rinna-bilingual-gpt-neox-4b-8k-gguf](https://huggingface.co/mmnga/rinna-bilingual-gpt-neox-4b-8k-gguf)
[mmnga/rinna-bilingual-gpt-neox-4b-instruction-ppo-gguf](https://huggingface.co/mmnga/rinna-bilingual-gpt-neox-4b-instruction-ppo-gguf)
[mmnga/rinna-japanese-gpt-neox-3.6b-gguf](https://huggingface.co/mmnga/rinna-japanese-gpt-neox-3.6b-gguf)
[mmnga/rinna-japanese-gpt-neox-3.6b-instruction-ppo-gguf](https://huggingface.co/mmnga/rinna-japanese-gpt-neox-3.6b-instruction-ppo-gguf)
*注意:こちらはブランチで試用になります。llama.cpp本家にgptneoxが実装された時に、このggufファイルが使用できない可能性があります。*
***[GitHubリポジトリの readme はこちら](https://github.com/mmnga/llama.cpp/tree/mmnga-dev)***
## Usage (試用)
~~~~bash
git clone --branch mmnga-dev https://github.com/mmnga/llama.cpp.git
cd llama.cpp
make -j
./main -m 'rinna-japanese-gpt-neox-3.6b-instruction-ppo-q4_0.gguf' -n 128 -p 'ユーザー: 吾輩って猫ですか? システム: ' --top_p 0.9 --temp 0.7 --repeat-penalty 1.1
~~~~
**CUBLAS**
~~~~bash
LLAMA_CUBLAS=1 make -j
./main -m 'rinna-japanese-gpt-neox-3.6b-instruction-ppo-q4_0.gguf' -n 128 -p 'ユーザー: 吾輩って猫ですか? システム: ' -ngl 32
~~~~
**従来のCPU実行**
~~~~bash
git clone --branch mmnga-dev https://github.com/mmnga/llama.cpp.git
cd llama.cpp
make -j gptneox
./gptneox -m 'rinna-japanese-gpt-neox-3.6b-instruction-ppo-q4_0.gguf' -n 128 -p 'ユーザー: 吾輩って猫ですか? システム: '
~~~~
|
TheBloke/orca_mini_v3_13B-GGUF | TheBloke | 2023-09-27T12:47:37Z | 608 | 4 | transformers | [
"transformers",
"gguf",
"llama",
"text-generation",
"en",
"dataset:psmathur/orca_mini_v1_dataset",
"dataset:ehartford/dolphin",
"arxiv:2306.02707",
"base_model:psmathur/orca_mini_v3_13b",
"license:other",
"text-generation-inference",
"region:us"
] | text-generation | 2023-09-05T13:40:32Z | ---
language:
- en
license: other
library_name: transformers
datasets:
- psmathur/orca_mini_v1_dataset
- ehartford/dolphin
model_name: Orca Mini v3 13B
base_model: psmathur/orca_mini_v3_13b
inference: false
model_creator: Pankaj Mathur
model_type: llama
pipeline_tag: text-generation
prompt_template: '### System:
You are an AI assistant that follows instruction extremely well. Help as much as
you can.
### User:
{prompt}
### Input:
{input}
### Response:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Orca Mini v3 13B - GGUF
- Model creator: [Pankaj Mathur](https://huggingface.co/psmathur)
- Original model: [Orca Mini v3 13B](https://huggingface.co/psmathur/orca_mini_v3_13b)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Pankaj Mathur's Orca Mini v3 13B](https://huggingface.co/psmathur/orca_mini_v3_13b).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp. GGUF offers numerous advantages over GGML, such as better tokenisation, and support for special tokens. It is also supports metadata, and is designed to be extensible.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/orca_mini_v3_13B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/orca_mini_v3_13B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/orca_mini_v3_13B-GGUF)
* [Pankaj Mathur's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/psmathur/orca_mini_v3_13b)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: orca_mini
```
### System:
You are an AI assistant that follows instruction extremely well. Help as much as you can.
### User:
{prompt}
### Input:
{input}
### Response:
```
<!-- prompt-template end -->
<!-- licensing start -->
## Licensing
The creator of the source model has listed its license as `other`, and this quantization has therefore used that same license.
As this model is based on Llama 2, it is also subject to the Meta Llama 2 license terms, and the license files for that are additionally included. It should therefore be considered as being claimed to be licensed under both licenses. I contacted Hugging Face for clarification on dual licensing but they do not yet have an official position. Should this change, or should Meta provide any feedback on this situation, I will update this section accordingly.
In the meantime, any questions regarding licensing, and in particular how these two licenses might interact, should be directed to the original model repository: [Pankaj Mathur's Orca Mini v3 13B](https://huggingface.co/psmathur/orca_mini_v3_13b).
<!-- licensing end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [orca_mini_v3_13b.Q2_K.gguf](https://huggingface.co/TheBloke/orca_mini_v3_13B-GGUF/blob/main/orca_mini_v3_13b.Q2_K.gguf) | Q2_K | 2 | 5.43 GB| 7.93 GB | smallest, significant quality loss - not recommended for most purposes |
| [orca_mini_v3_13b.Q3_K_S.gguf](https://huggingface.co/TheBloke/orca_mini_v3_13B-GGUF/blob/main/orca_mini_v3_13b.Q3_K_S.gguf) | Q3_K_S | 3 | 5.66 GB| 8.16 GB | very small, high quality loss |
| [orca_mini_v3_13b.Q3_K_M.gguf](https://huggingface.co/TheBloke/orca_mini_v3_13B-GGUF/blob/main/orca_mini_v3_13b.Q3_K_M.gguf) | Q3_K_M | 3 | 6.34 GB| 8.84 GB | very small, high quality loss |
| [orca_mini_v3_13b.Q3_K_L.gguf](https://huggingface.co/TheBloke/orca_mini_v3_13B-GGUF/blob/main/orca_mini_v3_13b.Q3_K_L.gguf) | Q3_K_L | 3 | 6.93 GB| 9.43 GB | small, substantial quality loss |
| [orca_mini_v3_13b.Q4_0.gguf](https://huggingface.co/TheBloke/orca_mini_v3_13B-GGUF/blob/main/orca_mini_v3_13b.Q4_0.gguf) | Q4_0 | 4 | 7.37 GB| 9.87 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [orca_mini_v3_13b.Q4_K_S.gguf](https://huggingface.co/TheBloke/orca_mini_v3_13B-GGUF/blob/main/orca_mini_v3_13b.Q4_K_S.gguf) | Q4_K_S | 4 | 7.41 GB| 9.91 GB | small, greater quality loss |
| [orca_mini_v3_13b.Q4_K_M.gguf](https://huggingface.co/TheBloke/orca_mini_v3_13B-GGUF/blob/main/orca_mini_v3_13b.Q4_K_M.gguf) | Q4_K_M | 4 | 7.87 GB| 10.37 GB | medium, balanced quality - recommended |
| [orca_mini_v3_13b.Q5_0.gguf](https://huggingface.co/TheBloke/orca_mini_v3_13B-GGUF/blob/main/orca_mini_v3_13b.Q5_0.gguf) | Q5_0 | 5 | 8.97 GB| 11.47 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [orca_mini_v3_13b.Q5_K_S.gguf](https://huggingface.co/TheBloke/orca_mini_v3_13B-GGUF/blob/main/orca_mini_v3_13b.Q5_K_S.gguf) | Q5_K_S | 5 | 8.97 GB| 11.47 GB | large, low quality loss - recommended |
| [orca_mini_v3_13b.Q5_K_M.gguf](https://huggingface.co/TheBloke/orca_mini_v3_13B-GGUF/blob/main/orca_mini_v3_13b.Q5_K_M.gguf) | Q5_K_M | 5 | 9.23 GB| 11.73 GB | large, very low quality loss - recommended |
| [orca_mini_v3_13b.Q6_K.gguf](https://huggingface.co/TheBloke/orca_mini_v3_13B-GGUF/blob/main/orca_mini_v3_13b.Q6_K.gguf) | Q6_K | 6 | 10.68 GB| 13.18 GB | very large, extremely low quality loss |
| [orca_mini_v3_13b.Q8_0.gguf](https://huggingface.co/TheBloke/orca_mini_v3_13B-GGUF/blob/main/orca_mini_v3_13b.Q8_0.gguf) | Q8_0 | 8 | 13.83 GB| 16.33 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/orca_mini_v3_13B-GGUF and below it, a specific filename to download, such as: orca_mini_v3_13b.q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub>=0.17.1
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/orca_mini_v3_13B-GGUF orca_mini_v3_13b.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/orca_mini_v3_13B-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/orca_mini_v3_13B-GGUF orca_mini_v3_13b.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows CLI users: Use `set HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1` before running the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m orca_mini_v3_13b.q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "### System:\nYou are an AI assistant that follows instruction extremely well. Help as much as you can.\n\n### User:\n{prompt}\n\n### Input:\n{input}\n\n### Response:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model from Python using ctransformers
#### First install the package
```bash
# Base ctransformers with no GPU acceleration
pip install ctransformers>=0.2.24
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]>=0.2.24
# Or with ROCm GPU acceleration
CT_HIPBLAS=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems
CT_METAL=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
```
#### Simple example code to load one of these GGUF models
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/orca_mini_v3_13B-GGUF", model_file="orca_mini_v3_13b.q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here's guides on using llama-cpp-python or ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Pankaj Mathur's Orca Mini v3 13B
# orca_mini_v3_13b
A Llama2-13b model trained on Orca Style datasets.
<br>

<br>
**P.S. If you're interested to collaborate, please connect with me at www.linkedin.com/in/pankajam.**
<br>
### quantized versions
Big thanks to [@TheBloke](https://huggingface.co/TheBloke)
1) https://huggingface.co/TheBloke/orca_mini_v3_13B-GGML
2) https://huggingface.co/TheBloke/orca_mini_v3_13B-GPTQ
<br>
#### license disclaimer:
This model is bound by the license & usage restrictions of the original Llama-2 model. And comes with no warranty or gurantees of any kind.
<br>
## Evaluation
We evaluated orca_mini_v3_13b on a wide range of tasks using [Language Model Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness) from EleutherAI.
Here are the results on metrics used by [HuggingFaceH4 Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
|||||
|:------:|:--------:|:-------:|:--------:|
|**Task**|**Metric**|**Value**|**Stderr**|
|*arc_challenge*|acc_norm|0.6314|0.0141|
|*hellaswag*|acc_norm|0.8242|0.0038|
|*mmlu*|acc_norm|0.5637|0.0351|
|*truthfulqa_mc*|mc2|0.5127|0.0157|
|**Total Average**|-|**0.6329877193**||
<br>
## Example Usage
Here is the prompt format
```
### System:
You are an AI assistant that follows instruction extremely well. Help as much as you can.
### User:
Tell me about Orcas.
### Assistant:
```
Below shows a code example on how to use this model
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
tokenizer = AutoTokenizer.from_pretrained("psmathur/orca_mini_v3_13b")
model = AutoModelForCausalLM.from_pretrained(
"psmathur/orca_mini_v3_13b",
torch_dtype=torch.float16,
load_in_8bit=True,
low_cpu_mem_usage=True,
device_map="auto"
)
system_prompt = "### System:\nYou are an AI assistant that follows instruction extremely well. Help as much as you can.\n\n"
#generate text steps
instruction = "Tell me about Orcas."
prompt = f"{system_prompt}### User: {instruction}\n\n### Assistant:\n"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
output = model.generate(**inputs, do_sample=True, top_p=0.95, top_k=0, max_new_tokens=4096)
print(tokenizer.decode(output[0], skip_special_tokens=True))
```
<br>
#### Limitations & Biases:
While this model aims for accuracy, it can occasionally produce inaccurate or misleading results.
Despite diligent efforts in refining the pretraining data, there remains a possibility for the generation of inappropriate, biased, or offensive content.
Exercise caution and cross-check information when necessary.
<br>
### Citiation:
Please kindly cite using the following BibTeX:
```
@misc{orca_mini_v3_13b,
author = {Pankaj Mathur},
title = {orca_mini_v3_13b: An Orca Style Llama2-70b model},
year = {2023},
publisher = {HuggingFace},
journal = {HuggingFace repository},
howpublished = {\url{https://https://huggingface.co/psmathur/orca_mini_v3_13b},
}
```
```
@misc{mukherjee2023orca,
title={Orca: Progressive Learning from Complex Explanation Traces of GPT-4},
author={Subhabrata Mukherjee and Arindam Mitra and Ganesh Jawahar and Sahaj Agarwal and Hamid Palangi and Ahmed Awadallah},
year={2023},
eprint={2306.02707},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```
@software{touvron2023llama2,
title={Llama 2: Open Foundation and Fine-Tuned Chat Models},
author={Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava,
Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller,
Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann,
Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov,
Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith,
Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu , Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan,
Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom},
year={2023}
}
```
<!-- original-model-card end -->
|
Lewdiculous/BuRP_7B-GGUF-IQ-Imatrix | Lewdiculous | 2024-05-04T14:46:30Z | 608 | 20 | transformers | [
"transformers",
"gguf",
"quantized",
"roleplay",
"imatrix",
"mistral",
"merge",
"en",
"license:other",
"region:us"
] | null | 2024-03-11T05:14:14Z | ---
library_name: transformers
license: other
language:
- en
tags:
- gguf
- quantized
- roleplay
- imatrix
- mistral
- merge
inference: false
# base_model:
# - ResplendentAI/Datura_7B
# - ChaoticNeutrals/Eris_Floramix_DPO_7B
---
> [!TIP]
> **Support:** <br>
> My upload speeds have been cooked and unstable lately. <br>
> Realistically I'd need to move to get a better provider. <br>
> If you **want** and you are able to... <br>
> [**You can support my various endeavors here (Ko-fi).**](https://ko-fi.com/Lewdiculous) <br>
> I apologize for disrupting your experience.
This repository hosts GGUF-Imatrix quantizations for [ChaoticNeutrals/BuRP_7B](https://huggingface.co/ChaoticNeutrals/BuRP_7B).
**What does "Imatrix" mean?**
It stands for **Importance Matrix**, a technique used to improve the quality of quantized models.
The **Imatrix** is calculated based on calibration data, and it helps determine the importance of different model activations during the quantization process.
The idea is to preserve the most important information during quantization, which can help reduce the loss of model performance, especially when the calibration data is diverse.
[[1]](https://github.com/ggerganov/llama.cpp/discussions/5006) [[2]](https://github.com/ggerganov/llama.cpp/discussions/5263#discussioncomment-8395384)
**Steps:**
```
Base⇢ GGUF(F16)⇢ Imatrix-Data(F16)⇢ GGUF(Imatrix-Quants)
```
**Quants:**
```python
quantization_options = [
"Q4_K_M", "IQ4_XS", "Q5_K_M", "Q5_K_S", "Q6_K",
"Q8_0", "IQ3_M", "IQ3_S", "IQ3_XXS"
]
```
If you want anything that's not here or another model, feel free to request.
**This is experimental.**
For imatrix data generation, kalomaze's `groups_merged.txt` with added roleplay chats was used, you can find it [here](https://huggingface.co/Lewdiculous/Datura_7B-GGUF-Imatrix/blob/main/imatrix-with-rp-format-data.txt).
**Alt-image:**

**Original model information:**
# BuRP

So you want a model that can do it all? You've been dying to RP with a superintelligence who never refuses your advances while sticking to your strange and oddly specific dialogue format?
Well, look no further because BuRP is the model you need.
### Configuration
The following YAML configuration was used to produce this model:
```yaml
slices:
- sources:
- model: ErisLaylaSLERP
layer_range: [0, 32]
- model: ParadigmInfinitySLERP
layer_range: [0, 32]
merge_method: slerp
base_model: ParadigmInfinitySLERP
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
``` |
mradermacher/Mistral-DPO-Uncensored-GGUF | mradermacher | 2024-05-05T15:09:10Z | 608 | 3 | transformers | [
"transformers",
"gguf",
"en",
"base_model:shauray/Mistral-DPO-Uncensored",
"endpoints_compatible",
"region:us"
] | null | 2024-04-25T16:21:50Z | ---
base_model: shauray/Mistral-DPO-Uncensored
language:
- en
library_name: transformers
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 1 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: -->
<!-- ### vocab_type: -->
static quants of https://huggingface.co/shauray/Mistral-DPO-Uncensored
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Mistral-DPO-Uncensored-GGUF/resolve/main/Mistral-DPO-Uncensored.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-DPO-Uncensored-GGUF/resolve/main/Mistral-DPO-Uncensored.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-DPO-Uncensored-GGUF/resolve/main/Mistral-DPO-Uncensored.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-DPO-Uncensored-GGUF/resolve/main/Mistral-DPO-Uncensored.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Mistral-DPO-Uncensored-GGUF/resolve/main/Mistral-DPO-Uncensored.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-DPO-Uncensored-GGUF/resolve/main/Mistral-DPO-Uncensored.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Mistral-DPO-Uncensored-GGUF/resolve/main/Mistral-DPO-Uncensored.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-DPO-Uncensored-GGUF/resolve/main/Mistral-DPO-Uncensored.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-DPO-Uncensored-GGUF/resolve/main/Mistral-DPO-Uncensored.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Mistral-DPO-Uncensored-GGUF/resolve/main/Mistral-DPO-Uncensored.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Mistral-DPO-Uncensored-GGUF/resolve/main/Mistral-DPO-Uncensored.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-DPO-Uncensored-GGUF/resolve/main/Mistral-DPO-Uncensored.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-DPO-Uncensored-GGUF/resolve/main/Mistral-DPO-Uncensored.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Mistral-DPO-Uncensored-GGUF/resolve/main/Mistral-DPO-Uncensored.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Mistral-DPO-Uncensored-GGUF/resolve/main/Mistral-DPO-Uncensored.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mgoin/Llama-2-7b-chat-hf-pruned85 | mgoin | 2024-05-08T17:32:29Z | 608 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-05-08T16:46:34Z | Entry not found |
acorreal/phi3-mental-health | acorreal | 2024-06-08T23:26:47Z | 608 | 1 | transformers | [
"transformers",
"safetensors",
"phi3",
"text-generation",
"trl",
"sft",
"conversational",
"custom_code",
"en",
"arxiv:1910.09700",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2024-06-08T20:24:10Z | ---
library_name: transformers
tags:
- trl
- sft
license: mit
language:
- en
---
# Model Card for Model ID
The model was created based on Phi3 model and it was finetuned with a mental health dataset as a project for Lambton College - Artificial Intelligence and Machine Learning
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** Jesus Andres Correal Ortiz
- **Funded by [optional]:** Jesus Andres Correal Ortiz
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** https://huggingface.co/microsoft/Phi-3-mini-4k-instruct
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
NikolayKozloff/Viking-7B-Q6_K-GGUF | NikolayKozloff | 2024-06-29T18:49:25Z | 608 | 1 | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"fi",
"en",
"da",
"sv",
"no",
"nn",
"is",
"dataset:cerebras/SlimPajama-627B",
"dataset:bigcode/starcoderdata",
"dataset:mc4",
"base_model:LumiOpen/Viking-7B",
"license:apache-2.0",
"region:us"
] | null | 2024-06-29T18:48:59Z | ---
base_model: LumiOpen/Viking-7B
datasets:
- cerebras/SlimPajama-627B
- bigcode/starcoderdata
- mc4
language:
- fi
- en
- da
- sv
- 'no'
- nn
- is
license: apache-2.0
tags:
- llama-cpp
- gguf-my-repo
---
# NikolayKozloff/Viking-7B-Q6_K-GGUF
This model was converted to GGUF format from [`LumiOpen/Viking-7B`](https://huggingface.co/LumiOpen/Viking-7B) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/LumiOpen/Viking-7B) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo NikolayKozloff/Viking-7B-Q6_K-GGUF --hf-file viking-7b-q6_k.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo NikolayKozloff/Viking-7B-Q6_K-GGUF --hf-file viking-7b-q6_k.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo NikolayKozloff/Viking-7B-Q6_K-GGUF --hf-file viking-7b-q6_k.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo NikolayKozloff/Viking-7B-Q6_K-GGUF --hf-file viking-7b-q6_k.gguf -c 2048
```
|
larenspear/Yi-1.5-6B-Chat-Q4_K_S-GGUF | larenspear | 2024-07-01T01:40:47Z | 608 | 0 | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"base_model:01-ai/Yi-1.5-6B-Chat",
"license:apache-2.0",
"region:us"
] | null | 2024-07-01T01:40:31Z | ---
base_model: 01-ai/Yi-1.5-6B-Chat
license: apache-2.0
tags:
- llama-cpp
- gguf-my-repo
---
# larenspear/Yi-1.5-6B-Chat-Q4_K_S-GGUF
This model was converted to GGUF format from [`01-ai/Yi-1.5-6B-Chat`](https://huggingface.co/01-ai/Yi-1.5-6B-Chat) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/01-ai/Yi-1.5-6B-Chat) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo larenspear/Yi-1.5-6B-Chat-Q4_K_S-GGUF --hf-file yi-1.5-6b-chat-q4_k_s.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo larenspear/Yi-1.5-6B-Chat-Q4_K_S-GGUF --hf-file yi-1.5-6b-chat-q4_k_s.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo larenspear/Yi-1.5-6B-Chat-Q4_K_S-GGUF --hf-file yi-1.5-6b-chat-q4_k_s.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo larenspear/Yi-1.5-6B-Chat-Q4_K_S-GGUF --hf-file yi-1.5-6b-chat-q4_k_s.gguf -c 2048
```
|
lvwerra/pegasus-samsum | lvwerra | 2021-10-25T14:57:33Z | 607 | 3 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"pegasus",
"text2text-generation",
"generated_from_trainer",
"dataset:samsum",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2022-03-02T23:29:05Z | ---
tags:
- generated_from_trainer
datasets:
- samsum
model-index:
- name: pegasus-samsum
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# pegasus-samsum
This model is a fine-tuned version of [google/pegasus-cnn_dailymail](https://huggingface.co/google/pegasus-cnn_dailymail) on the samsum dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4177
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 0.4
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.6092 | 0.03 | 500 | 1.6488 |
| 1.9715 | 0.07 | 1000 | 1.5444 |
| 1.8325 | 0.1 | 1500 | 1.5093 |
| 1.876 | 0.14 | 2000 | 1.4890 |
| 1.3081 | 0.17 | 2500 | 1.4737 |
| 1.7769 | 0.2 | 3000 | 1.4496 |
| 1.6276 | 0.24 | 3500 | 1.4430 |
| 1.6624 | 0.27 | 4000 | 1.4288 |
| 1.9202 | 0.31 | 4500 | 1.4235 |
| 1.4404 | 0.34 | 5000 | 1.4189 |
| 1.8016 | 0.37 | 5500 | 1.4177 |
### Framework versions
- Transformers 4.12.0.dev0
- Pytorch 1.9.1+cu102
- Datasets 1.12.1
- Tokenizers 0.10.3
|
timm/efficientformer_l3.snap_dist_in1k | timm | 2024-02-10T23:30:26Z | 607 | 1 | timm | [
"timm",
"pytorch",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2206.01191",
"license:apache-2.0",
"region:us"
] | image-classification | 2023-02-03T21:06:16Z | ---
license: apache-2.0
library_name: timm
tags:
- image-classification
- timm
datasets:
- imagenet-1k
---
# Model card for efficientformer_l3.snap_dist_in1k
A EfficientFormer image classification model. Pretrained with distillation on ImageNet-1k.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 31.4
- GMACs: 3.9
- Activations (M): 12.0
- Image size: 224 x 224
- **Original:** https://github.com/snap-research/EfficientFormer
- **Papers:**
- EfficientFormer: Vision Transformers at MobileNet Speed: https://arxiv.org/abs/2206.01191
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model('efficientformer_l3.snap_dist_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model(
'efficientformer_l3.snap_dist_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled (ie.e a (batch_size, num_features, H, W) tensor
output = model.forward_head(output, pre_logits=True)
# output is (batch_size, num_features) tensor
```
## Model Comparison
|model |top1 |top5 |param_count|img_size|
|-----------------------------------|------|------|-----------|--------|
|efficientformerv2_l.snap_dist_in1k |83.628|96.54 |26.32 |224 |
|efficientformer_l7.snap_dist_in1k |83.368|96.534|82.23 |224 |
|efficientformer_l3.snap_dist_in1k |82.572|96.24 |31.41 |224 |
|efficientformerv2_s2.snap_dist_in1k|82.128|95.902|12.71 |224 |
|efficientformer_l1.snap_dist_in1k |80.496|94.984|12.29 |224 |
|efficientformerv2_s1.snap_dist_in1k|79.698|94.698|6.19 |224 |
|efficientformerv2_s0.snap_dist_in1k|76.026|92.77 |3.6 |224 |
## Citation
```bibtex
@article{li2022efficientformer,
title={EfficientFormer: Vision Transformers at MobileNet Speed},
author={Li, Yanyu and Yuan, Geng and Wen, Yang and Hu, Ju and Evangelidis, Georgios and Tulyakov, Sergey and Wang, Yanzhi and Ren, Jian},
journal={arXiv preprint arXiv:2206.01191},
year={2022}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/rwightman/pytorch-image-models}}
}
```
|
timm/mvitv2_tiny.fb_in1k | timm | 2024-02-10T23:42:58Z | 607 | 0 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2112.01526",
"license:apache-2.0",
"region:us"
] | image-classification | 2023-04-13T00:49:33Z | ---
license: apache-2.0
library_name: timm
tags:
- image-classification
- timm
datasets:
- imagenet-1k
---
# Model card for mvitv2_tiny.fb_in1k
A MViT-v2 (multi-scale ViT) image classification model. Pretrained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 24.2
- GMACs: 4.7
- Activations (M): 21.2
- Image size: 224 x 224
- **Papers:**
- MViTv2: Improved Multiscale Vision Transformers for Classification and Detection: https://arxiv.org/abs/2112.01526
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/facebookresearch/mvit
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('mvitv2_tiny.fb_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'mvitv2_tiny.fb_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 49, 768) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
|
Yntec/CultClassic | Yntec | 2024-05-08T05:16:31Z | 607 | 2 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"vrgamedevgirl",
"elldreth",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2023-08-05T17:29:16Z | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
- vrgamedevgirl
- elldreth
---
# Cult Classic
CinematicStyleV1 Lora merged to Elldreth's Retro Mix so you can create your own Cult Classic!
Original pages:
https://civitai.com/models/101844?modelVersionId=109018
https://civitai.com/models/1474/elldreths-retro-mix
|
zarakiquemparte/zarablend-1.1-l2-7b-GGUF | zarakiquemparte | 2023-08-26T10:22:08Z | 607 | 3 | null | [
"gguf",
"llama2",
"license:other",
"region:us"
] | null | 2023-08-26T02:52:17Z | ---
license: other
tags:
- llama2
---
Quantized GGUF of [Zarablend 1.1 L2 7b](https://huggingface.co/zarakiquemparte/zarablend-1.1-l2-7b)
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.