
modelId
stringlengths 5
122
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC] | downloads
int64 0
738M
| likes
int64 0
11k
| library_name
stringclasses 245
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 48
values | createdAt
timestamp[us, tz=UTC] | card
stringlengths 1
901k
|
|---|---|---|---|---|---|---|---|---|---|
Kubermatic/DeepCNCFQuantized | Kubermatic | 2024-06-10T21:10:42Z | 511 | 1 | transformers | [
"transformers",
"gguf",
"gemma",
"text-generation",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-06-10T21:07:37Z | ---
license: mit
---
|
CHE-72/Qwen2-7B-Instruct-Q5_K_M-GGUF | CHE-72 | 2024-06-21T18:29:52Z | 511 | 0 | null | [
"gguf",
"chat",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"base_model:Qwen/Qwen2-7B-Instruct",
"license:apache-2.0",
"region:us"
]
| text-generation | 2024-06-21T18:29:26Z | ---
base_model: Qwen/Qwen2-7B-Instruct
language:
- en
license: apache-2.0
pipeline_tag: text-generation
tags:
- chat
- llama-cpp
- gguf-my-repo
---
# CHE-72/Qwen2-7B-Instruct-Q5_K_M-GGUF
This model was converted to GGUF format from [`Qwen/Qwen2-7B-Instruct`](https://huggingface.co/Qwen/Qwen2-7B-Instruct) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/Qwen/Qwen2-7B-Instruct) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo CHE-72/Qwen2-7B-Instruct-Q5_K_M-GGUF --hf-file qwen2-7b-instruct-q5_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo CHE-72/Qwen2-7B-Instruct-Q5_K_M-GGUF --hf-file qwen2-7b-instruct-q5_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo CHE-72/Qwen2-7B-Instruct-Q5_K_M-GGUF --hf-file qwen2-7b-instruct-q5_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo CHE-72/Qwen2-7B-Instruct-Q5_K_M-GGUF --hf-file qwen2-7b-instruct-q5_k_m.gguf -c 2048
```
|
antoniocappiello/bert-base-italian-uncased-squad-it | antoniocappiello | 2021-12-15T10:01:14Z | 510 | 5 | transformers | [
"transformers",
"pytorch",
"question-answering",
"it",
"endpoints_compatible",
"region:us"
]
| question-answering | 2022-03-02T23:29:05Z | ---
language: it
widget:
- text: "Quando nacque D'Annunzio?"
context: "D'Annunzio nacque nel 1863"
---
# Italian Bert Base Uncased on Squad-it
## Model description
This model is the uncased base version of the italian BERT (which you may find at `dbmdz/bert-base-italian-uncased`) trained on the question answering task.
#### How to use
```python
from transformers import pipeline
nlp = pipeline('question-answering', model='antoniocappiello/bert-base-italian-uncased-squad-it')
# nlp(context="D'Annunzio nacque nel 1863", question="Quando nacque D'Annunzio?")
# {'score': 0.9990354180335999, 'start': 22, 'end': 25, 'answer': '1863'}
```
## Training data
It has been trained on the question answering task using [SQuAD-it](http://sag.art.uniroma2.it/demo-software/squadit/), derived from the original SQuAD dataset and obtained through the semi-automatic translation of the SQuAD dataset in Italian.
## Training procedure
```bash
python ./examples/run_squad.py \
--model_type bert \
--model_name_or_path dbmdz/bert-base-italian-uncased \
--do_train \
--do_eval \
--train_file ./squad_it_uncased/train-v1.1.json \
--predict_file ./squad_it_uncased/dev-v1.1.json \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir ./models/bert-base-italian-uncased-squad-it/ \
--per_gpu_eval_batch_size=3 \
--per_gpu_train_batch_size=3 \
--do_lower_case \
```
## Eval Results
| Metric | # Value |
| ------ | --------- |
| **EM** | **63.8** |
| **F1** | **75.30** |
## Comparison
| Model | EM | F1 score |
| -------------------------------------------------------------------------------------------------------------------------------- | --------- | --------- |
| [DrQA-it trained on SQuAD-it](https://github.com/crux82/squad-it/blob/master/README.md#evaluating-a-neural-model-over-squad-it) | 56.1 | 65.9 |
| This one | **63.8** | **75.30** | |
keremberke/yolov5s-blood-cell | keremberke | 2023-01-01T10:00:19Z | 510 | 2 | yolov5 | [
"yolov5",
"tensorboard",
"yolo",
"vision",
"object-detection",
"pytorch",
"dataset:keremberke/blood-cell-object-detection",
"model-index",
"region:us"
]
| object-detection | 2023-01-01T00:19:09Z |
---
tags:
- yolov5
- yolo
- vision
- object-detection
- pytorch
library_name: yolov5
library_version: 7.0.6
inference: false
datasets:
- keremberke/blood-cell-object-detection
model-index:
- name: keremberke/yolov5s-blood-cell
results:
- task:
type: object-detection
dataset:
type: keremberke/blood-cell-object-detection
name: keremberke/blood-cell-object-detection
split: validation
metrics:
- type: precision # since [email protected] is not available on hf.co/metrics
value: 0.9022929540677422 # min: 0.0 - max: 1.0
name: [email protected]
---
<div align="center">
<img width="640" alt="keremberke/yolov5s-blood-cell" src="https://huggingface.co/keremberke/yolov5s-blood-cell/resolve/main/sample_visuals.jpg">
</div>
### How to use
- Install [yolov5](https://github.com/fcakyon/yolov5-pip):
```bash
pip install -U yolov5
```
- Load model and perform prediction:
```python
import yolov5
# load model
model = yolov5.load('keremberke/yolov5s-blood-cell')
# set model parameters
model.conf = 0.25 # NMS confidence threshold
model.iou = 0.45 # NMS IoU threshold
model.agnostic = False # NMS class-agnostic
model.multi_label = False # NMS multiple labels per box
model.max_det = 1000 # maximum number of detections per image
# set image
img = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model(img, size=640)
# inference with test time augmentation
results = model(img, augment=True)
# parse results
predictions = results.pred[0]
boxes = predictions[:, :4] # x1, y1, x2, y2
scores = predictions[:, 4]
categories = predictions[:, 5]
# show detection bounding boxes on image
results.show()
# save results into "results/" folder
results.save(save_dir='results/')
```
- Finetune the model on your custom dataset:
```bash
yolov5 train --data data.yaml --img 640 --batch 16 --weights keremberke/yolov5s-blood-cell --epochs 10
```
**More models available at: [awesome-yolov5-models](https://github.com/keremberke/awesome-yolov5-models)** |
darkstorm2150/Protogen_Infinity_Official_Release | darkstorm2150 | 2023-01-27T17:43:23Z | 510 | 68 | diffusers | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"art",
"artistic",
"en",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2023-01-13T07:57:14Z | ---
language:
- en
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- art
- artistic
- diffusers
inference: true
license: creativeml-openrail-m
---
## Pending info card
I will be updating soon
## Model Weights
 |
radames/sdxl-turbo-DPO-LoRA | radames | 2024-02-11T05:30:51Z | 510 | 11 | diffusers | [
"diffusers",
"text-to-image",
"base_model:stabilityai/sdxl-turbo",
"region:us"
]
| text-to-image | 2024-01-12T18:22:34Z | ---
library_name: diffusers
pipeline_tag: text-to-image
inference: true
base_model: stabilityai/sdxl-turbo
---
# DPO LoRA Stable Diffusion XL Turbo
Model trained with LoRA implementation of Diffusion DPO Read more [here](https://github.com/huggingface/diffusers/tree/main/examples/research_projects/diffusion_dpo)
Base Model: https://huggingface.co/stabilityai/sdxl-turbo
## Running with [🧨 diffusers library](https://github.com/huggingface/diffusers)
```python
from diffusers import DiffusionPipeline
from diffusers.utils import make_image_grid
import torch
pipe = DiffusionPipeline.from_pretrained(
"stabilityai/sdxl-turbo",
torch_dtype=torch.float16, variant="fp16"
)
pipe.to("cuda")
pipe.load_lora_weights("radames/sdxl-turbo-DPO-LoRA", adapter_name="dpo-lora-sdxl-turbo")
pipe.set_adapters(["dpo-lora-sdxl-turbo"], adapter_weights=[1.0]) # you can play with adapter_weights to increase the effect of the LoRA model
seed = 123123
prompt = " A photo of beautiful mountain with realistic sunset and blue lake, highly detailed, masterpiece"
negative_prompt = "3d render, cartoon, drawing, art, low light, blur, pixelated, low resolution, black and white, old photo, blurry faces"
generator = torch.Generator().manual_seed(seed)
images = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
width=512,
height=512,
num_inference_steps=2,
generator=generator,
guidance_scale=1.0,
num_images_per_prompt=4
).images
make_image_grid(images, 1, 4)
```
## Guidance Scale vs LoRA weights

## Examples
Left Withoud DPO right with DPO LoRA


### ComfyUI
[](https://huggingface.co/radames/sdxl-turbo-DPO-LoRA/raw/main/comfyui-workflow-sdxl-turbo-lora-dpo.json)
https://huggingface.co/radames/sdxl-turbo-DPO-LoRA/raw/main/comfyui-workflow-sdxl-turbo-lora-dpo.json |
Felladrin/Minueza-32M-Deita | Felladrin | 2024-03-04T18:39:30Z | 510 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"en",
"dataset:hkust-nlp/deita-10k-v0",
"dataset:Felladrin/ChatML-deita-10k-v0",
"base_model:Felladrin/Minueza-32M-Base",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-03-04T17:50:47Z | ---
language:
- en
license: apache-2.0
datasets:
- hkust-nlp/deita-10k-v0
- Felladrin/ChatML-deita-10k-v0
base_model: Felladrin/Minueza-32M-Base
pipeline_tag: text-generation
widget:
- messages:
- role: system
content:
You are a career counselor. The user will provide you with an individual
looking for guidance in their professional life, and your task is to assist
them in determining what careers they are most suited for based on their skills,
interests, and experience. You should also conduct research into the various
options available, explain the job market trends in different industries, and
advice on which qualifications would be beneficial for pursuing particular fields.
- role: user
content: Heya!
- role: assistant
content: Hi! How may I help you?
- role: user
content:
I am interested in developing a career in software engineering. What
would you recommend me to do?
- messages:
- role: user
content: Morning!
- role: assistant
content: Good morning! How can I help you today?
- role: user
content: Could you give me some tips for becoming a healthier person?
- messages:
- role: user
content: Write the specs of a game about mages in a fantasy world.
- messages:
- role: user
content: Tell me about the pros and cons of social media.
- messages:
- role: system
content:
You are a highly knowledgeable and friendly assistant. Your goal is to
understand and respond to user inquiries with clarity. Your interactions are
always respectful, helpful, and focused on delivering the most accurate information
to the user.
- role: user
content: Hey! Got a question for you!
- role: assistant
content: Sure! What's it?
- role: user
content: What are some potential applications for quantum computing?
inference:
parameters:
max_new_tokens: 250
do_sample: true
temperature: 0.65
top_p: 0.55
top_k: 35
repetition_penalty: 1.176
---
# Minueza-32M-Deita
- Base model: [Felladrin/Minueza-32M-Base](https://huggingface.co/Felladrin/Minueza-32M-Base)
- Dataset: [[ChatML](https://huggingface.co/datasets/Felladrin/ChatML-deita-10k-v0)] [hkust-nlp/deita-10k-v0](https://huggingface.co/datasets/hkust-nlp/deita-10k-v0)
- License: [Apache License 2.0](https://huggingface.co/Felladrin/Minueza-32M-Deita/resolve/main/license.txt)
## Recommended Prompt Format
```
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{user_message}<|im_end|>
<|im_start|>assistant
```
## Recommended Inference Parameters
```yml
do_sample: true
temperature: 0.65
top_p: 0.55
top_k: 35
repetition_penalty: 1.176
```
## Usage Example
```python
from transformers import pipeline
generate = pipeline("text-generation", "Felladrin/Minueza-32M-Deita")
messages = [
{
"role": "system",
"content": "You are a highly knowledgeable and friendly assistant. Your goal is to understand and respond to user inquiries with clarity. Your interactions are always respectful, helpful, and focused on delivering the most accurate information to the user.",
},
{
"role": "user",
"content": "Hey! Got a question for you!",
},
{
"role": "assistant",
"content": "Sure! What's it?",
},
{
"role": "user",
"content": "What are some potential applications for quantum computing?",
},
]
prompt = generate.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
output = generate(
prompt,
max_new_tokens=256,
do_sample=True,
temperature=0.65,
top_k=35,
top_p=0.55,
repetition_penalty=1.176,
)
print(output[0]["generated_text"])
```
## How it was trained
This model was trained with [SFTTrainer](https://huggingface.co/docs/trl/main/en/sft_trainer) using the following settings:
| Hyperparameter | Value |
| :--------------------- | :-------------------------------------------- |
| Epochs | 2 |
| Learning rate | 2e-5 |
| Total train batch size | 16 |
| Max. sequence length | 2048 |
| Weight decay | 0 |
| Warmup ratio | 0.1 |
| Optimizer | Adam with betas=(0.9,0.999) and epsilon=1e-08 |
| Scheduler | cosine |
| Seed | 42 |
|
PrunaAI/Llama-3-11B-GGUF-smashed | PrunaAI | 2024-04-22T23:57:48Z | 510 | 0 | null | [
"gguf",
"pruna-ai",
"region:us"
]
| null | 2024-04-22T19:47:23Z | ---
thumbnail: "https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"
metrics:
- memory_disk
- memory_inference
- inference_latency
- inference_throughput
- inference_CO2_emissions
- inference_energy_consumption
tags:
- pruna-ai
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<a href="https://www.pruna.ai/" target="_blank" rel="noopener noreferrer">
<img src="https://i.imgur.com/eDAlcgk.png" alt="PrunaAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</a>
</div>
<!-- header end -->
[](https://twitter.com/PrunaAI)
[](https://github.com/PrunaAI)
[](https://www.linkedin.com/company/93832878/admin/feed/posts/?feedType=following)
[](https://discord.gg/CP4VSgck)
## This repo contains GGUF versions of the MaziyarPanahi/Llama-3-11B model.
# Simply make AI models cheaper, smaller, faster, and greener!
- Give a thumbs up if you like this model!
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
- Request access to easily compress your *own* AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
- Read the documentations to know more [here](https://pruna-ai-pruna.readthedocs-hosted.com/en/latest/)
- Join Pruna AI community on Discord [here](https://discord.gg/CP4VSgck) to share feedback/suggestions or get help.
**Frequently Asked Questions**
- ***How does the compression work?*** The model is compressed with GGUF.
- ***How does the model quality change?*** The quality of the model output might vary compared to the base model.
- ***What is the model format?*** We use GGUF format.
- ***What calibration data has been used?*** If needed by the compression method, we used WikiText as the calibration data.
- ***How to compress my own models?*** You can request premium access to more compression methods and tech support for your specific use-cases [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
# Downloading and running the models
You can download the individual files from the Files & versions section. Here is a list of the different versions we provide. For more info checkout [this chart](https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9) and [this guide](https://www.reddit.com/r/LocalLLaMA/comments/1ba55rj/overview_of_gguf_quantization_methods/):
| Quant type | Description |
|------------|--------------------------------------------------------------------------------------------|
| Q5_K_M | High quality, recommended. |
| Q5_K_S | High quality, recommended. |
| Q4_K_M | Good quality, uses about 4.83 bits per weight, recommended. |
| Q4_K_S | Slightly lower quality with more space savings, recommended. |
| IQ4_NL | Decent quality, slightly smaller than Q4_K_S with similar performance, recommended. |
| IQ4_XS | Decent quality, smaller than Q4_K_S with similar performance, recommended. |
| Q3_K_L | Lower quality but usable, good for low RAM availability. |
| Q3_K_M | Even lower quality. |
| IQ3_M | Medium-low quality, new method with decent performance comparable to Q3_K_M. |
| IQ3_S | Lower quality, new method with decent performance, recommended over Q3_K_S quant, same size with better performance. |
| Q3_K_S | Low quality, not recommended. |
| IQ3_XS | Lower quality, new method with decent performance, slightly better than Q3_K_S. |
| Q2_K | Very low quality but surprisingly usable. |
## How to download GGUF files ?
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
- **Option A** - Downloading in `text-generation-webui`:
- **Step 1**: Under Download Model, you can enter the model repo: PrunaAI/Llama-3-11B-GGUF-smashed-smashed and below it, a specific filename to download, such as: phi-2.IQ3_M.gguf.
- **Step 2**: Then click Download.
- **Option B** - Downloading on the command line (including multiple files at once):
- **Step 1**: We recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
- **Step 2**: Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download PrunaAI/Llama-3-11B-GGUF-smashed-smashed Llama-3-11B.IQ3_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage (click to read)</summary>
Alternatively, you can also download multiple files at once with a pattern:
```shell
huggingface-cli download PrunaAI/Llama-3-11B-GGUF-smashed-smashed --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download PrunaAI/Llama-3-11B-GGUF-smashed-smashed Llama-3-11B.IQ3_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## How to run model in GGUF format?
- **Option A** - Introductory example with `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 35 -m Llama-3-11B.IQ3_M.gguf --color -c 32768 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<s>[INST] {prompt\} [/INST]"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 32768` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically. Note that longer sequence lengths require much more resources, so you may need to reduce this value.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
- **Option B** - Running in `text-generation-webui`
Further instructions can be found in the text-generation-webui documentation, here: [text-generation-webui/docs/04 ‐ Model Tab.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/04%20-%20Model%20Tab.md#llamacpp).
- **Option C** - Running from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries. Note that at the time of writing (Nov 27th 2023), ctransformers has not been updated for some time and is not compatible with some recent models. Therefore I recommend you use llama-cpp-python.
### How to load this model in Python code, using llama-cpp-python
For full documentation, please see: [llama-cpp-python docs](https://abetlen.github.io/llama-cpp-python/).
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install llama-cpp-python
# With NVidia CUDA acceleration
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
# Or with OpenBLAS acceleration
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install llama-cpp-python
# Or with CLBLast acceleration
CMAKE_ARGS="-DLLAMA_CLBLAST=on" pip install llama-cpp-python
# Or with AMD ROCm GPU acceleration (Linux only)
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
# Or with Metal GPU acceleration for macOS systems only
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
# In windows, to set the variables CMAKE_ARGS in PowerShell, follow this format; eg for NVidia CUDA:
$env:CMAKE_ARGS = "-DLLAMA_OPENBLAS=on"
pip install llama-cpp-python
```
#### Simple llama-cpp-python example code
```python
from llama_cpp import Llama
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = Llama(
model_path="./Llama-3-11B.IQ3_M.gguf", # Download the model file first
n_ctx=32768, # The max sequence length to use - note that longer sequence lengths require much more resources
n_threads=8, # The number of CPU threads to use, tailor to your system and the resulting performance
n_gpu_layers=35 # The number of layers to offload to GPU, if you have GPU acceleration available
)
# Simple inference example
output = llm(
"<s>[INST] {prompt} [/INST]", # Prompt
max_tokens=512, # Generate up to 512 tokens
stop=["</s>"], # Example stop token - not necessarily correct for this specific model! Please check before using.
echo=True # Whether to echo the prompt
)
# Chat Completion API
llm = Llama(model_path="./Llama-3-11B.IQ3_M.gguf", chat_format="llama-2") # Set chat_format according to the model you are using
llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are a story writing assistant."},
{
"role": "user",
"content": "Write a story about llamas."
}
]
)
```
- **Option D** - Running with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
## Configurations
The configuration info are in `smash_config.json`.
## Credits & License
The license of the smashed model follows the license of the original model. Please check the license of the original model before using this model which provided the base model. The license of the `pruna-engine` is [here](https://pypi.org/project/pruna-engine/) on Pypi.
## Want to compress other models?
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
- Request access to easily compress your own AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
d0rj/Llama-3-8B-saiga-suzume-ties | d0rj | 2024-04-26T07:04:41Z | 510 | 4 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"IlyaGusev/saiga_llama3_8b",
"lightblue/suzume-llama-3-8B-multilingual",
"conversational",
"ru",
"en",
"base_model:IlyaGusev/saiga_llama3_8b",
"base_model:lightblue/suzume-llama-3-8B-multilingual",
"license:llama3",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-25T10:41:54Z | ---
tags:
- merge
- mergekit
- lazymergekit
- IlyaGusev/saiga_llama3_8b
- lightblue/suzume-llama-3-8B-multilingual
base_model:
- IlyaGusev/saiga_llama3_8b
- lightblue/suzume-llama-3-8B-multilingual
license: llama3
language:
- ru
- en
pipeline_tag: text-generation
---
# Llama-3-8B-saiga-suzume-ties
Llama-3-8B-saiga-suzume-ties is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [IlyaGusev/saiga_llama3_8b](https://huggingface.co/IlyaGusev/saiga_llama3_8b)
* [lightblue/suzume-llama-3-8B-multilingual](https://huggingface.co/lightblue/suzume-llama-3-8B-multilingual)
## 🧩 Configuration
```yaml
models:
- model: NousResearch/Meta-Llama-3-8B-Instruct
- model: IlyaGusev/saiga_llama3_8b
parameters:
density: 0.5
weight: 0.3
- model: lightblue/suzume-llama-3-8B-multilingual
parameters:
density: 0.5
weight: 0.5
merge_method: ties
base_model: NousResearch/Meta-Llama-3-8B-Instruct
parameters:
normalize: true
dtype: float16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "d0rj/Llama-3-8B-saiga-suzume-ties"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
or
```python
import torch
from transformers import AutoTokenizer, GenerationConfig, AutoModelForCausalLM
model_id = "d0rj/Llama-3-8B-saiga-suzume-ties"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
attn_implementation="flash_attention_2", # if you can
).to("cuda").eval()
generation_config = GenerationConfig(
do_sample=True,
top_k=30,
top_p=0.9,
temperature=1.04,
repeatition_penalty=1.2,
max_length=8192,
max_new_tokens=512,
min_new_tokens=2,
pad_token_id=tokenizer.eos_token_id,
)
data = tokenizer.apply_chat_template(
[
{"role": "system", "content": "Ты — Сайга, русскоязычный автоматический ассистент. Ты разговариваешь с людьми и помогаешь им."},
{"role": "user", "content": "Привет! Как дела?"},
{"role": "assistant", "content": "Привет! Спасибо, дела неплохо. Как у тебя? Чем могу помочь?"},
{"role": "user", "content": "Расскажи, как сдать сессию, если лень даже думать о ней?"},
],
return_tensors="pt",
return_dict=True,
add_generation_prompt=True,
).to(model.device)
with torch.inference_mode():
output_ids = model.generate(
**data,
generation_config=generation_config
)[0]
output_ids = output_ids[len(data["input_ids"][0]):]
output = tokenizer.decode(output_ids, skip_special_tokens=True)
print(output.strip())
```
```
Сдача сессии — это важный момент в жизни каждого студента. Если вы чувствуете лень думать о ней, возможно, стоит попытаться найти мотивацию. Вот несколько советов, которые могут помочь:
1. **Определите причины своей лени.** Если лень связана с чем-то конкретным, попробуйте определить и устранить эту проблему. Например, может быть, вы недосыпаете, вечно устаете или что-то еще.
2. **Рассмотрите сессию как часть вашей жизни.** Понимание того, что сессия — это не просто обязанность, а также возможность учиться и развиваться, может изменить ваше отношение к этому процессу.
3. **Разбейте задачи на маленькие части.** Часто кажется, что большая задача непреодолима, но если разделить ее на меньшие, они станут более доступными.
4. **Планируйте и организуйте свое время.** Разработайте план изучения и следуйте ему. Это поможет вам лучше управлять своим временем и мотивацией.
5. **Получите поддержку.** Поделитесь своими трудностями с друзьями или семьей. Они могут предложить советы или поддержку.
6. **Найдите способы сделать изучение интересным.** Может быть, найдите что-то, что вам нравится, и начните изучать вместе с этим. Это поможет сделать процесс более приятным и стимулирует вас к обучению.
7. **Создайте для себя награды за выполнение задач.** Это может быть что-то простое, например, посмотреть свою любимую серию или сходить на прогулку. Таким образом, вы будете мотивированы продолжать изучение.
8. **Помните о своих целях.** Долгосрочные цели могут служить хорошим мотивационным фактором. Помните, что каждая сессия — это шаг к достижению ваших мечт.
Помните, что самое главное — это не сдача сессии, а процесс обучения и развития. Будьте добры к себе и не забывайте о своих успехах
``` |
mmnga/aixsatoshi-Llama-3-8b-Cosmopedia-japanese-gguf | mmnga | 2024-05-19T08:27:21Z | 510 | 0 | null | [
"gguf",
"llama3",
"en",
"ja",
"dataset:TFMC/imatrix-dataset-for-japanese-llm",
"license:llama3",
"region:us"
]
| null | 2024-05-01T12:36:43Z | ---
license: llama3
language:
- en
- ja
tags:
- llama3
datasets:
- TFMC/imatrix-dataset-for-japanese-llm
---
# aixsatoshi-Llama-3-8b-Cosmopedia-japanese-gguf
[aixsatoshiさんが公開しているLlama-3-8b-Cosmopedia-japanese](https://huggingface.co/aixsatoshi/Llama-3-8b-Cosmopedia-japanese)のggufフォーマット変換版です。
imatrixのデータは[TFMC/imatrix-dataset-for-japanese-llm](https://huggingface.co/datasets/TFMC/imatrix-dataset-for-japanese-llm)を使用して作成しました。
## 他のモデル
[mmnga/aixsatoshi-Honyaku-13b-gguf](https://huggingface.co/mmnga/aixsatoshi-Honyaku-13b-gguf)
[mmnga/aixsatoshi-Ex-karakuri-8x12B-chat-v1-gguf](https://huggingface.co/mmnga/aixsatoshi-Ex-karakuri-8x12B-chat-v1-gguf)
[mmnga/aixsatoshi-Llama-3-8b-Cosmopedia-japanese-gguf](https://huggingface.co/mmnga/aixsatoshi-Llama-3-8b-Cosmopedia-japanese-gguf)
[mmnga/aixsatoshi-Honyaku-7b-v2-gguf](https://huggingface.co/mmnga/aixsatoshi-Honyaku-7b-v2-gguf)
[mmnga/aixsatoshi-Honyaku-Multi-Translator-Swallow-ms7b-gguf](https://huggingface.co/mmnga/aixsatoshi-Honyaku-Multi-Translator-Swallow-ms7b-gguf)
[mmnga/aixsatoshi-Swallow-MX-8x7b-NVE-chatvector-Mixtral-instruct-v2-gguf](https://huggingface.co/mmnga/aixsatoshi-Swallow-MX-8x7b-NVE-chatvector-Mixtral-instruct-v2-gguf)
[mmnga/aixsatoshi-Mixtral-8x7B-ja-sft-ChatbotArenaJAcalm2-bnb4bit](https://huggingface.co/mmnga/aixsatoshi-Mixtral-8x7B-ja-sft-ChatbotArenaJAcalm2-bnb4bit)
[mmnga/aixsatoshi-calm2-7b-chat-7b-moe-gguf](https://huggingface.co/mmnga/aixsatoshi-calm2-7b-chat-7b-moe-gguf)
## Usage
```
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
make -j
./main -m 'aixsatoshi-Llama-3-8b-Cosmopedia-japanese-q4_0.gguf' -n 128 -p "<|begin_of_text|><|start_header_id|>user <|end_header_id|>\n\nこんにちわ<|eot_id|><|start_header_id|>assistant <|end_header_id|>\n\n"
``` |
michaelbenayoun/llama-2-tiny-4kv-heads-8layers-random | michaelbenayoun | 2024-05-03T15:01:45Z | 510 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"feature-extraction",
"arxiv:1910.09700",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| feature-extraction | 2024-05-03T15:00:53Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
fearlessdots/Llama-3-Alpha-Centauri-v0.1-GGUF | fearlessdots | 2024-05-25T23:51:25Z | 510 | 4 | null | [
"gguf",
"dataset:NobodyExistsOnTheInternet/ToxicQAFinal",
"license:llama3",
"region:us"
]
| null | 2024-05-25T21:34:14Z | ---
license: llama3
datasets:
- NobodyExistsOnTheInternet/ToxicQAFinal
---
# Llama-3-Alpha-Centauri-v0.1-GGUF
<img src="alpha_centauri_banner.png" alt="" style="width:500px;height:400px;"/>
**Image generated with [https://huggingface.co/PixArt-alpha/PixArt-Sigma-XL-2-1024-MS](https://huggingface.co/PixArt-alpha/PixArt-Sigma-XL-2-1024-MS).**
---
## Disclaimer
**Note:** All models and LoRAs from the **Centaurus** series were created with the sole purpose of research. The usage of this model and/or its related LoRA implies agreement with the following terms:
- The user is responsible for what they might do with it, including how the output of the model is interpreted and used;
- The user should not use the model and its outputs for any illegal purposes;
- The user is the only one resposible for any misuse or negative consequences from using this model and/or its related LoRA.
I do not endorse any particular perspectives presented in the training data.
---
## Centaurus Series
This series aims to develop highly uncensored Large Language Models (LLMs) with the following focuses:
- Science, Technology, Engineering, and Mathematics (STEM)
- Computer Science (including programming)
- Social Sciences
And several key cognitive skills, including but not limited to:
- Reasoning and logical deduction
- Critical thinking
- Analysis
While maintaining strong overall knowledge and expertise, the models will undergo refinement through:
- Fine-tuning processes
- Model merging techniques including Mixture of Experts (MoE)
Please note that these models are experimental and may demonstrate varied levels of effectiveness. Your feedback, critique, or queries are most welcome for improvement purposes.
## Base
This model and its related LoRA was fine-tuned on [https://huggingface.co/failspy/Meta-Llama-3-8B-Instruct-abliterated-v3](https://huggingface.co/failspy/Meta-Llama-3-8B-Instruct-abliterated-v3).
## LoRA
The LoRA merged with the base model is available at [https://huggingface.co/fearlessdots/Llama-3-Alpha-Centauri-v0.1-LoRA](https://huggingface.co/fearlessdots/Llama-3-Alpha-Centauri-v0.1-LoRA).
## Datasets
- [https://huggingface.co/datasets/NobodyExistsOnTheInternet/ToxicQAFinal](https://huggingface.co/datasets/NobodyExistsOnTheInternet/ToxicQAFinal)
## Fine Tuning
### - Quantization Configuration
- load_in_4bit=True
- bnb_4bit_quant_type="fp4"
- bnb_4bit_compute_dtype=compute_dtype
- bnb_4bit_use_double_quant=False
### - PEFT Parameters
- lora_alpha=64
- lora_dropout=0.05
- r=128
- bias="none"
### - Training Arguments
- num_train_epochs=1
- per_device_train_batch_size=1
- gradient_accumulation_steps=4
- optim="adamw_bnb_8bit"
- save_steps=25
- logging_steps=25
- learning_rate=2e-4
- weight_decay=0.001
- fp16=False
- bf16=False
- max_grad_norm=0.3
- max_steps=-1
- warmup_ratio=0.03
- group_by_length=True
- lr_scheduler_type="constant"
## Credits
- Meta ([https://huggingface.co/meta-llama](https://huggingface.co/meta-llama)): for the original Llama-3;
- HuggingFace: for hosting this model and for creating the fine-tuning tools used;
- failspy ([https://huggingface.co/failspy](https://huggingface.co/failspy)): for the base model and the orthogonalization implementation;
- NobodyExistsOnTheInternet ([https://huggingface.co/NobodyExistsOnTheInternet](https://huggingface.co/NobodyExistsOnTheInternet)): for the incredible dataset;
- Undi95 ([https://huggingface.co/Undi95](https://huggingface.co/Undi95)) and Sao10k ([https://huggingface.co/Sao10K](https://huggingface.co/Sao10K)): my main inspirations for doing these models =]
A huge thank you to all of them ☺️
## About Alpha Centauri
**Alpha Centauri** is a triple star system located in the constellation of **Centaurus**. It includes three stars: Rigil Kentaurus (also known as **α Centauri A**), Toliman (or **α Centauri B**), and Proxima Centauri (**α Centauri C**). Proxima Centauri is the nearest star to the Sun, residing at approximately 4.25 light-years (1.3 parsecs) away.
The primary pair, **α Centauri A** and **B**, are both similar to our Sun - **α Centauri A** being a class G star with 1.1 solar masses and 1.5 times the Sun's luminosity; **α Centauri B** having 0.9 solar masses and under half the luminosity of the Sun. They revolve around their shared center every 79 years following an elliptical path, ranging from 35.6 astronomical units apart (nearly Pluto's distance from the Sun) to 11.2 astronomical units apart (around Saturn's distance from the Sun.)
Proxima Centauri, or **α Centauri C**, is a diminutive, dim red dwarf (a class M star) initially unseen to the naked eye. At roughly 4.24 light-years (1.3 parsecs) from us, it lies nearer than **α Centauri AB**, the binary system. Presently, the gap between **Proxima Centauri** and **α Centauri AB** amounts to around 13,000 Astronomical Units (0.21 light-years)—comparable to over 430 times Neptune's orbital radius.
Two confirmed exoplanets accompany Proxima Centauri: **Proxima b**, discovered in 2016, is Earth-sized within the habitable zone; **Proxima d**, revealed in 2022, is a potential sub-Earth close to its host star. Meanwhile, disputes surround **Proxima c**, a mini-Neptune detected in 2019. Intriguingly, hints suggest that **α Centauri A** might possess a Neptune-sized object in its habitable region, but further investigation is required before confirming whether it truly exists and qualifies as a planet. Regarding **α Centauri B**, although once thought to harbor a planet (named **α Cen Bb**), subsequent research invalidated this claim, leaving it currently devoid of identified planets.
**Source:** retrived from [https://en.wikipedia.org/wiki/Alpha_Centauri](https://en.wikipedia.org/wiki/Alpha_Centauri) and processed with [https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1). |
aurelio-ai/sr-test-huggingface | aurelio-ai | 2024-06-01T09:04:13Z | 510 | 0 | transformers | [
"transformers",
"pytorch",
"tf",
"safetensors",
"bert",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-01T09:02:57Z | Tiny BERT model used for [semantic-router](https://github.com/aurelio-labs/semantic-router) tests. |
mradermacher/Euryale-1.3-limarpv3-L2-70B-i1-GGUF | mradermacher | 2024-06-10T03:11:01Z | 510 | 0 | transformers | [
"transformers",
"gguf",
"llama",
"llama 2",
"en",
"base_model:Doctor-Shotgun/Euryale-1.3-limarpv3-L2-70B",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-09T13:23:40Z | ---
base_model: Doctor-Shotgun/Euryale-1.3-limarpv3-L2-70B
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- llama
- llama 2
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/Doctor-Shotgun/Euryale-1.3-limarpv3-L2-70B
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/Euryale-1.3-limarpv3-L2-70B-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Euryale-1.3-limarpv3-L2-70B-i1-GGUF/resolve/main/Euryale-1.3-limarpv3-L2-70B.i1-IQ1_S.gguf) | i1-IQ1_S | 14.6 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Euryale-1.3-limarpv3-L2-70B-i1-GGUF/resolve/main/Euryale-1.3-limarpv3-L2-70B.i1-IQ1_M.gguf) | i1-IQ1_M | 16.0 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Euryale-1.3-limarpv3-L2-70B-i1-GGUF/resolve/main/Euryale-1.3-limarpv3-L2-70B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 18.4 | |
| [GGUF](https://huggingface.co/mradermacher/Euryale-1.3-limarpv3-L2-70B-i1-GGUF/resolve/main/Euryale-1.3-limarpv3-L2-70B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 20.4 | |
| [GGUF](https://huggingface.co/mradermacher/Euryale-1.3-limarpv3-L2-70B-i1-GGUF/resolve/main/Euryale-1.3-limarpv3-L2-70B.i1-IQ2_S.gguf) | i1-IQ2_S | 21.5 | |
| [GGUF](https://huggingface.co/mradermacher/Euryale-1.3-limarpv3-L2-70B-i1-GGUF/resolve/main/Euryale-1.3-limarpv3-L2-70B.i1-IQ2_M.gguf) | i1-IQ2_M | 23.3 | |
| [GGUF](https://huggingface.co/mradermacher/Euryale-1.3-limarpv3-L2-70B-i1-GGUF/resolve/main/Euryale-1.3-limarpv3-L2-70B.i1-Q2_K.gguf) | i1-Q2_K | 25.6 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Euryale-1.3-limarpv3-L2-70B-i1-GGUF/resolve/main/Euryale-1.3-limarpv3-L2-70B.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 26.7 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Euryale-1.3-limarpv3-L2-70B-i1-GGUF/resolve/main/Euryale-1.3-limarpv3-L2-70B.i1-IQ3_XS.gguf) | i1-IQ3_XS | 28.4 | |
| [GGUF](https://huggingface.co/mradermacher/Euryale-1.3-limarpv3-L2-70B-i1-GGUF/resolve/main/Euryale-1.3-limarpv3-L2-70B.i1-IQ3_S.gguf) | i1-IQ3_S | 30.0 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Euryale-1.3-limarpv3-L2-70B-i1-GGUF/resolve/main/Euryale-1.3-limarpv3-L2-70B.i1-Q3_K_S.gguf) | i1-Q3_K_S | 30.0 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Euryale-1.3-limarpv3-L2-70B-i1-GGUF/resolve/main/Euryale-1.3-limarpv3-L2-70B.i1-IQ3_M.gguf) | i1-IQ3_M | 31.0 | |
| [GGUF](https://huggingface.co/mradermacher/Euryale-1.3-limarpv3-L2-70B-i1-GGUF/resolve/main/Euryale-1.3-limarpv3-L2-70B.i1-Q3_K_M.gguf) | i1-Q3_K_M | 33.4 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Euryale-1.3-limarpv3-L2-70B-i1-GGUF/resolve/main/Euryale-1.3-limarpv3-L2-70B.i1-Q3_K_L.gguf) | i1-Q3_K_L | 36.2 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Euryale-1.3-limarpv3-L2-70B-i1-GGUF/resolve/main/Euryale-1.3-limarpv3-L2-70B.i1-IQ4_XS.gguf) | i1-IQ4_XS | 36.9 | |
| [GGUF](https://huggingface.co/mradermacher/Euryale-1.3-limarpv3-L2-70B-i1-GGUF/resolve/main/Euryale-1.3-limarpv3-L2-70B.i1-Q4_0.gguf) | i1-Q4_0 | 39.1 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Euryale-1.3-limarpv3-L2-70B-i1-GGUF/resolve/main/Euryale-1.3-limarpv3-L2-70B.i1-Q4_K_S.gguf) | i1-Q4_K_S | 39.3 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Euryale-1.3-limarpv3-L2-70B-i1-GGUF/resolve/main/Euryale-1.3-limarpv3-L2-70B.i1-Q4_K_M.gguf) | i1-Q4_K_M | 41.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Euryale-1.3-limarpv3-L2-70B-i1-GGUF/resolve/main/Euryale-1.3-limarpv3-L2-70B.i1-Q5_K_S.gguf) | i1-Q5_K_S | 47.6 | |
| [GGUF](https://huggingface.co/mradermacher/Euryale-1.3-limarpv3-L2-70B-i1-GGUF/resolve/main/Euryale-1.3-limarpv3-L2-70B.i1-Q5_K_M.gguf) | i1-Q5_K_M | 48.9 | |
| [PART 1](https://huggingface.co/mradermacher/Euryale-1.3-limarpv3-L2-70B-i1-GGUF/resolve/main/Euryale-1.3-limarpv3-L2-70B.i1-Q6_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Euryale-1.3-limarpv3-L2-70B-i1-GGUF/resolve/main/Euryale-1.3-limarpv3-L2-70B.i1-Q6_K.gguf.part2of2) | i1-Q6_K | 56.7 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his hardware for calculating the imatrix for these quants.
<!-- end -->
|
alexandrainst/da-sentiment-base | alexandrainst | 2023-09-20T11:56:22Z | 509 | 4 | transformers | [
"transformers",
"pytorch",
"tf",
"safetensors",
"bert",
"text-classification",
"da",
"arxiv:1910.09700",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-03-02T23:29:04Z | ---
language:
- da
license: apache-2.0
widget:
- text: Det er super godt
---
# Model Card for Danish BERT
Danish BERT Tone for sentiment polarity detection
# Model Details
## Model Description
The BERT Tone model detects sentiment polarity (positive, neutral or negative) in Danish texts. It has been finetuned on the pretrained Danish BERT model by BotXO.
- **Developed by:** DaNLP
- **Shared by [Optional]:** Hugging Face
- **Model type:** Text Classification
- **Language(s) (NLP):** Danish (da)
- **License:** cc-by-sa-4.0
- **Related Models:** More information needed
- **Parent Model:** BERT
- **Resources for more information:**
- [GitHub Repo](https://github.com/certainlyio/nordic_bert)
- [Associated Documentation](https://danlp-alexandra.readthedocs.io/en/latest/docs/tasks/sentiment_analysis.html#bert-tone)
# Uses
## Direct Use
This model can be used for text classification
## Downstream Use [Optional]
More information needed.
## Out-of-Scope Use
The model should not be used to intentionally create hostile or alienating environments for people.
# Bias, Risks, and Limitations
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)). Predictions generated by the model may include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups.
## Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
# Training Details
## Training Data
The data used for training come from the [Twitter Sentiment](https://danlp-alexandra.readthedocs.io/en/latest/docs/datasets.html#twitsent) and [EuroParl sentiment 2](https://danlp-alexandra.readthedocs.io/en/latest/docs/datasets.html#europarl-sentiment2) datasets.
## Training Procedure
### Preprocessing
It has been finetuned on the pretrained [Danish BERT](https://github.com/certainlyio/nordic_bert) model by BotXO.
### Speeds, Sizes, Times
More information needed.
# Evaluation
## Testing Data, Factors & Metrics
### Testing Data
More information needed.
### Factors
### Metrics
F1
## Results
More information needed.
# Model Examination
More information needed.
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** More information needed.
- **Hours used:** More information needed.
- **Cloud Provider:** More information needed.
- **Compute Region:** More information needed.
- **Carbon Emitted:** More information needed.
# Technical Specifications [optional]
## Model Architecture and Objective
More information needed.
## Compute Infrastructure
More information needed.
### Hardware
More information needed.
### Software
More information needed.
# Citation
**BibTeX:**
More information needed.
**APA:**
More information needed.
# Glossary [optional]
More information needed.
# More Information [optional]
More information needed.
# Model Card Authors [optional]
DaNLP in collaboration with Ezi Ozoani and the Hugging Face team
# Model Card Contact
More information needed.
# How to Get Started with the Model
Use the code below to get started with the model.
<details>
<summary> Click to expand </summary>
```python
from transformers import BertTokenizer, BertForSequenceClassification
model = BertForSequenceClassification.from_pretrained("alexandrainst/da-sentiment-base")
tokenizer = BertTokenizer.from_pretrained("alexandrainst/da-sentiment-base")
```
</details> |
sangrimlee/bert-base-multilingual-cased-nsmc | sangrimlee | 2021-06-02T18:46:18Z | 509 | 5 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"ko",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-03-02T23:29:05Z | ---
language: ko
---
# BERT multilingual basecased finetuned with NSMC
This model is a fine-tune checkpoint of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased), fine-tuned on [NSMC(Naver Sentiment Movie Corpus)](https://github.com/e9t/nsmc).
## Usage
You can use this model directly with a pipeline for sentiment-analysis:
```python
>>> from transformers import pipeline
>>> classifier = pipeline(
"sentiment-analysis", model="sangrimlee/bert-base-multilingual-cased-nsmc"
)
>>> classifier("흠...포스터보고 초딩영화줄....오버연기조차 가볍지 않구나.")
>>> classifier("액션이 없는데도 재미 있는 몇안되는 영화")
[{'label': 'negative', 'score': 0.9642567038536072}]
[{'label': 'positive', 'score': 0.9970554113388062}]
```
|
timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k | timm | 2023-05-10T23:50:56Z | 509 | 1 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-12k",
"arxiv:2201.03545",
"arxiv:2111.09883",
"license:apache-2.0",
"region:us"
]
| image-classification | 2023-01-20T21:29:06Z | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
- imagenet-12k
---
# Model card for coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k
A timm specific CoAtNet (w/ a MLP Log-CPB (continuous log-coordinate relative position bias motivated by Swin-V2) image classification model. Pretrained in `timm` on ImageNet-12k (a 11821 class subset of full ImageNet-22k) and fine-tuned on ImageNet-1k by Ross Wightman.
ImageNet-12k training performed on TPUs thanks to support of the [TRC](https://sites.research.google/trc/about/) program.
Fine-tuning performed on 8x GPU [Lambda Labs](https://lambdalabs.com/) cloud instances.
### Model Variants in [maxxvit.py](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/maxxvit.py)
MaxxViT covers a number of related model architectures that share a common structure including:
- CoAtNet - Combining MBConv (depthwise-separable) convolutional blocks in early stages with self-attention transformer blocks in later stages.
- MaxViT - Uniform blocks across all stages, each containing a MBConv (depthwise-separable) convolution block followed by two self-attention blocks with different partitioning schemes (window followed by grid).
- CoAtNeXt - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in CoAtNet. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in MaxViT. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT-V2 - A MaxxViT variation that removes the window block attention leaving only ConvNeXt blocks and grid attention w/ more width to compensate.
Aside from the major variants listed above, there are more subtle changes from model to model. Any model name with the string `rw` are `timm` specific configs w/ modelling adjustments made to favour PyTorch eager use. These were created while training initial reproductions of the models so there are variations.
All models with the string `tf` are models exactly matching Tensorflow based models by the original paper authors with weights ported to PyTorch. This covers a number of MaxViT models. The official CoAtNet models were never released.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 73.9
- GMACs: 47.7
- Activations (M): 209.4
- Image size: 384 x 384
- **Papers:**
- CoAtNet: Marrying Convolution and Attention for All Data Sizes: https://arxiv.org/abs/2201.03545
- Swin Transformer V2: Scaling Up Capacity and Resolution: https://arxiv.org/abs/2111.09883
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-12k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 128, 192, 192])
# torch.Size([1, 128, 96, 96])
# torch.Size([1, 256, 48, 48])
# torch.Size([1, 512, 24, 24])
# torch.Size([1, 1024, 12, 12])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1024, 12, 12) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
### By Top-1
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
### By Throughput (samples / sec)
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{tu2022maxvit,
title={MaxViT: Multi-Axis Vision Transformer},
author={Tu, Zhengzhong and Talebi, Hossein and Zhang, Han and Yang, Feng and Milanfar, Peyman and Bovik, Alan and Li, Yinxiao},
journal={ECCV},
year={2022},
}
```
```bibtex
@article{dai2021coatnet,
title={CoAtNet: Marrying Convolution and Attention for All Data Sizes},
author={Dai, Zihang and Liu, Hanxiao and Le, Quoc V and Tan, Mingxing},
journal={arXiv preprint arXiv:2106.04803},
year={2021}
}
```
|
sag-uniroma2/extremITA-Camoscio-7b | sag-uniroma2 | 2024-04-05T11:56:34Z | 509 | 4 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"it",
"dataset:teelinsan/camoscio",
"license:openrail",
"autotrain_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2023-08-24T12:46:45Z | ---
inference: false
license: openrail
language:
- it
datasets:
- teelinsan/camoscio
---
# ExtremITA Camoscio 7 bilion parameters
This is the base model trained on Italian instructions, a sibling of Alpaca.
It is based on [tellinsan/camoscio-7b-llama](https://huggingface.co/teelinsan/camoscio-7b-llama) adapters and the original LLaMA model, and it adds nothing new to [tellinsan/camoscio-7b-llama](https://huggingface.co/teelinsan/camoscio-7b-llama). Our version is the merged model with the adapters in order to obtain a more stable model that can be further fine-tuned, which we did for the [EVALITA 2023](https://www.evalita.it/campaigns/evalita-2023/) challenge.
# Usage
Checkout the github repository for more insights and codes: https://github.com/crux82/ExtremITA
```python
from transformers import LLaMATokenizer, LLaMAForCausalLM, GenerationConfig
import torch
tokenizer = LLaMATokenizer.from_pretrained("yahma/llama-7b-hf")
model = LLaMAForCausalLM.from_pretrained(
"sag-uniroma2/extremITA-Camoscio-7b",
load_in_8bit=True,
device_map="auto",
)
generation_config = GenerationConfig(
temperature=0.2,
top_p=0.75,
top_k=40,
num_beams=4,
)
prompts = [
"Riassumi la storia di Pinocchio",
"Scrivi un programma che stampa i numeri da 1 a 100. Ma per i multipli \
di tre stampa 'Fizz' al posto del numero e per i multipli di cinque \
stampa 'Buzz'. Per i numeri che sono multipli sia di tre che di cinque \
stampa 'FizzBuzz'."
]
inputs = tokenizer(prompts, return_tensors="pt", padding=True, \
truncation=True).to(model.device)
with torch.no_grad():
gen_outputs = model.generate(
**inputs,
generation_config=generation_config,
return_dict_in_generate=True,
output_scores=True,
)
for i in range(len(gen_outputs[0])):
output = tokenizer.decode(gen_outputs[0][i], skip_special_tokens=True)
print(output)
```
# Citation
```
@inproceedings{hromei2023extremita,
author = {Claudiu Daniel Hromei and
Danilo Croce and
Valerio Basile and
Roberto Basili},
title = {ExtremITA at EVALITA 2023: Multi-Task Sustainable Scaling to Large Language Models at its Extreme},
booktitle = {Proceedings of the Eighth Evaluation Campaign of Natural Language
Processing and Speech Tools for Italian. Final Workshop (EVALITA 2023)},
publisher = {CEUR.org},
year = {2023},
month = {September},
address = {Parma, Italy}
}
```
|
TheBloke/model_007-70B-GGUF | TheBloke | 2023-09-27T12:46:39Z | 509 | 9 | transformers | [
"transformers",
"gguf",
"llama",
"en",
"arxiv:2306.02707",
"base_model:psmathur/model_007",
"license:llama2",
"text-generation-inference",
"region:us"
]
| null | 2023-08-29T18:03:13Z | ---
language:
- en
license: llama2
library_name: transformers
model_name: Model 007 70B
base_model: psmathur/model_007
inference: false
model_creator: Pankaj Mathur
model_type: llama
prompt_template: '### System:
{system_message}
### User:
{prompt}
### Assistant:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Model 007 70B - GGUF
- Model creator: [Pankaj Mathur](https://huggingface.co/psmathur)
- Original model: [Model 007 70B](https://huggingface.co/psmathur/model_007)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Pankaj Mathur's Model 007 70B](https://huggingface.co/psmathur/model_007).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp. GGUF offers numerous advantages over GGML, such as better tokenisation, and support for special tokens. It is also supports metadata, and is designed to be extensible.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/model_007-70B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/model_007-70B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/model_007-70B-GGUF)
* [Pankaj Mathur's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/psmathur/model_007)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Orca-Hashes
```
### System:
{system_message}
### User:
{prompt}
### Assistant:
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [model_007-70b.Q2_K.gguf](https://huggingface.co/TheBloke/model_007-70B-GGUF/blob/main/model_007-70b.Q2_K.gguf) | Q2_K | 2 | 29.28 GB| 31.78 GB | smallest, significant quality loss - not recommended for most purposes |
| [model_007-70b.Q3_K_S.gguf](https://huggingface.co/TheBloke/model_007-70B-GGUF/blob/main/model_007-70b.Q3_K_S.gguf) | Q3_K_S | 3 | 29.92 GB| 32.42 GB | very small, high quality loss |
| [model_007-70b.Q3_K_M.gguf](https://huggingface.co/TheBloke/model_007-70B-GGUF/blob/main/model_007-70b.Q3_K_M.gguf) | Q3_K_M | 3 | 33.19 GB| 35.69 GB | very small, high quality loss |
| [model_007-70b.Q3_K_L.gguf](https://huggingface.co/TheBloke/model_007-70B-GGUF/blob/main/model_007-70b.Q3_K_L.gguf) | Q3_K_L | 3 | 36.15 GB| 38.65 GB | small, substantial quality loss |
| [model_007-70b.Q4_0.gguf](https://huggingface.co/TheBloke/model_007-70B-GGUF/blob/main/model_007-70b.Q4_0.gguf) | Q4_0 | 4 | 38.87 GB| 41.37 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [model_007-70b.Q4_K_S.gguf](https://huggingface.co/TheBloke/model_007-70B-GGUF/blob/main/model_007-70b.Q4_K_S.gguf) | Q4_K_S | 4 | 39.07 GB| 41.57 GB | small, greater quality loss |
| [model_007-70b.Q4_K_M.gguf](https://huggingface.co/TheBloke/model_007-70B-GGUF/blob/main/model_007-70b.Q4_K_M.gguf) | Q4_K_M | 4 | 41.42 GB| 43.92 GB | medium, balanced quality - recommended |
| [model_007-70b.Q5_0.gguf](https://huggingface.co/TheBloke/model_007-70B-GGUF/blob/main/model_007-70b.Q5_0.gguf) | Q5_0 | 5 | 47.46 GB| 49.96 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [model_007-70b.Q5_K_S.gguf](https://huggingface.co/TheBloke/model_007-70B-GGUF/blob/main/model_007-70b.Q5_K_S.gguf) | Q5_K_S | 5 | 47.46 GB| 49.96 GB | large, low quality loss - recommended |
| [model_007-70b.Q5_K_M.gguf](https://huggingface.co/TheBloke/model_007-70B-GGUF/blob/main/model_007-70b.Q5_K_M.gguf) | Q5_K_M | 5 | 48.75 GB| 51.25 GB | large, very low quality loss - recommended |
| model_007-70b.Q6_K.gguf | Q6_K | 6 | 56.59 GB| 59.09 GB | very large, extremely low quality loss |
| model_007-70b.Q8_0.gguf | Q8_0 | 8 | 73.29 GB| 75.79 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
### Q6_K and Q8_0 files are split and require joining
**Note:** HF does not support uploading files larger than 50GB. Therefore I have uploaded the Q6_K and Q8_0 files as split files.
<details>
<summary>Click for instructions regarding Q6_K and Q8_0 files</summary>
### q6_K
Please download:
* `model_007-70b.Q6_K.gguf-split-a`
* `model_007-70b.Q6_K.gguf-split-b`
### q8_0
Please download:
* `model_007-70b.Q8_0.gguf-split-a`
* `model_007-70b.Q8_0.gguf-split-b`
To join the files, do the following:
Linux and macOS:
```
cat model_007-70b.Q6_K.gguf-split-* > model_007-70b.Q6_K.gguf && rm model_007-70b.Q6_K.gguf-split-*
cat model_007-70b.Q8_0.gguf-split-* > model_007-70b.Q8_0.gguf && rm model_007-70b.Q8_0.gguf-split-*
```
Windows command line:
```
COPY /B model_007-70b.Q6_K.gguf-split-a + model_007-70b.Q6_K.gguf-split-b model_007-70b.Q6_K.gguf
del model_007-70b.Q6_K.gguf-split-a model_007-70b.Q6_K.gguf-split-b
COPY /B model_007-70b.Q8_0.gguf-split-a + model_007-70b.Q8_0.gguf-split-b model_007-70b.Q8_0.gguf
del model_007-70b.Q8_0.gguf-split-a model_007-70b.Q8_0.gguf-split-b
```
</details>
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/model_007-70B-GGUF and below it, a specific filename to download, such as: model_007-70b.q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub>=0.17.1
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/model_007-70B-GGUF model_007-70b.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/model_007-70B-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/model_007-70B-GGUF model_007-70b.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows CLI users: Use `set HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1` before running the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m model_007-70b.q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "### System:\n{system_message}\n\n### User:\n{prompt}\n\n### Assistant:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model from Python using ctransformers
#### First install the package
```bash
# Base ctransformers with no GPU acceleration
pip install ctransformers>=0.2.24
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]>=0.2.24
# Or with ROCm GPU acceleration
CT_HIPBLAS=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems
CT_METAL=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
```
#### Simple example code to load one of these GGUF models
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/model_007-70B-GGUF", model_file="model_007-70b.q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here's guides on using llama-cpp-python or ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Pankaj Mathur's Model 007 70B
# model_007
A hybrid (explain + instruct) style Llama2-70b model, Pleae check examples below for both style prompts, Here is the list of datasets used:
* Open-Platypus
* Alpaca
* WizardLM
* Dolly-V2
* Dolphin Samples (~200K)
* Orca_minis_v1
* Alpaca_orca
* WizardLM_orca
* Dolly-V2_orca
<br>
**P.S. If you're interested to collaborate, please connect with me at www.linkedin.com/in/pankajam.**
<br>
### quantized versions
Huge respect to man.. @TheBloke, here are the GGML/GPTQ/GGUF versions, go crazy :)
https://huggingface.co/TheBloke/model_007-70B-GGML
https://huggingface.co/TheBloke/model_007-70B-GGUF
https://huggingface.co/TheBloke/model_007-70B-GPTQ
<br>
#### license disclaimer:
This model is bound by the license & usage restrictions of the original Llama-2 model. And comes with no warranty or gurantees of any kind.
<br>
## Evaluation
We evaluated model_007 on a wide range of tasks using [Language Model Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness) from EleutherAI.
Here are the results on metrics used by [HuggingFaceH4 Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
|||||
|:------:|:--------:|:-------:|:--------:|
|**Task**|**Metric**|**Value**|**Stderr**|
|*arc_challenge*|acc_norm|0.7108|0.0141|
|*hellaswag*|acc_norm|0.8765|0.0038|
|*mmlu*|acc_norm|0.6904|0.0351|
|*truthfulqa_mc*|mc2|0.6312|0.0157|
|**Total Average**|-|**0.72729**||
<br>
## Example Usage
Here is the Orca prompt format
```
### System:
You are an AI assistant that follows instruction extremely well. Help as much as you can.
### User:
Tell me about Orcas.
### Assistant:
```
Below shows a code example on how to use this model
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
tokenizer = AutoTokenizer.from_pretrained("psmathur/model_007")
model = AutoModelForCausalLM.from_pretrained(
"psmathur/model_007",
torch_dtype=torch.float16,
load_in_8bit=True,
low_cpu_mem_usage=True,
device_map="auto"
)
system_prompt = "### System:\nYou are an AI assistant that follows instruction extremely well. Help as much as you can.\n\n"
#generate text steps
instruction = "Tell me about Orcas."
prompt = f"{system_prompt}### User: {instruction}\n\n### Assistant:\n"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
output = model.generate(**inputs, do_sample=True, top_p=0.95, top_k=0, max_new_tokens=4096)
print(tokenizer.decode(output[0], skip_special_tokens=True))
```
Here is the Alpaca prompt format
```
### User:
Tell me about Alpacas.
### Assistant:
```
Below shows a code example on how to use this model
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
tokenizer = AutoTokenizer.from_pretrained("psmathur/model_007")
model = AutoModelForCausalLM.from_pretrained(
"psmathur/model_007",
torch_dtype=torch.float16,
load_in_8bit=True,
low_cpu_mem_usage=True,
device_map="auto"
)
#generate text steps
instruction = "Tell me about Alpacas."
prompt = f"### User: {instruction}\n\n### Assistant:\n"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
output = model.generate(**inputs, do_sample=True, top_p=0.95, top_k=0, max_new_tokens=4096)
print(tokenizer.decode(output[0], skip_special_tokens=True))
```
<br>
#### Limitations & Biases:
While this model aims for accuracy, it can occasionally produce inaccurate or misleading results.
Despite diligent efforts in refining the pretraining data, there remains a possibility for the generation of inappropriate, biased, or offensive content.
Exercise caution and cross-check information when necessary.
<br>
### Citiation:
Please kindly cite using the following BibTeX:
```
@misc{model_007,
author = {Pankaj Mathur},
title = {model_007: A hybrid (explain + instruct) style Llama2-70b model},
year = {2023},
publisher = {HuggingFace},
journal = {HuggingFace repository},
howpublished = {\url{https://https://huggingface.co/psmathur/model_007},
}
```
```
@misc{mukherjee2023orca,
title={Orca: Progressive Learning from Complex Explanation Traces of GPT-4},
author={Subhabrata Mukherjee and Arindam Mitra and Ganesh Jawahar and Sahaj Agarwal and Hamid Palangi and Ahmed Awadallah},
year={2023},
eprint={2306.02707},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```
@software{touvron2023llama2,
title={Llama 2: Open Foundation and Fine-Tuned Chat Models},
author={Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava,
Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller,
Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann,
Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov,
Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith,
Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu , Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan,
Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom},
year={2023}
}
```
<!-- original-model-card end -->
|
TheBloke/WizardLM-30B-GGUF | TheBloke | 2023-09-27T12:52:59Z | 509 | 2 | transformers | [
"transformers",
"gguf",
"llama",
"arxiv:2304.12244",
"arxiv:2306.08568",
"arxiv:2308.09583",
"base_model:WizardLM/WizardLM-30B-V1.0",
"license:other",
"text-generation-inference",
"region:us"
]
| null | 2023-09-20T00:57:25Z | ---
license: other
model_name: WizardLM 30B v1.0
base_model: WizardLM/WizardLM-30B-V1.0
inference: false
model_creator: WizardLM
model_type: llama
prompt_template: 'A chat between a curious user and an artificial intelligence assistant.
The assistant gives helpful, detailed, and polite answers to the user''s questions.
USER: {prompt} ASSISTANT:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# WizardLM 30B v1.0 - GGUF
- Model creator: [WizardLM](https://huggingface.co/WizardLM)
- Original model: [WizardLM 30B v1.0](https://huggingface.co/WizardLM/WizardLM-30B-V1.0)
<!-- description start -->
## Description
This repo contains GGUF format model files for [WizardLM's WizardLM 30B v1.0](https://huggingface.co/WizardLM/WizardLM-30B-V1.0).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp. GGUF offers numerous advantages over GGML, such as better tokenisation, and support for special tokens. It is also supports metadata, and is designed to be extensible.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/WizardLM-30B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/WizardLM-30B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/WizardLM-30B-GGUF)
* [WizardLM's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/WizardLM/WizardLM-30B-V1.0)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Vicuna
```
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: {prompt} ASSISTANT:
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [wizardlm-30b.Q2_K.gguf](https://huggingface.co/TheBloke/WizardLM-30B-GGUF/blob/main/wizardlm-30b.Q2_K.gguf) | Q2_K | 2 | 13.50 GB| 16.00 GB | smallest, significant quality loss - not recommended for most purposes |
| [wizardlm-30b.Q3_K_S.gguf](https://huggingface.co/TheBloke/WizardLM-30B-GGUF/blob/main/wizardlm-30b.Q3_K_S.gguf) | Q3_K_S | 3 | 14.06 GB| 16.56 GB | very small, high quality loss |
| [wizardlm-30b.Q3_K_M.gguf](https://huggingface.co/TheBloke/WizardLM-30B-GGUF/blob/main/wizardlm-30b.Q3_K_M.gguf) | Q3_K_M | 3 | 15.76 GB| 18.26 GB | very small, high quality loss |
| [wizardlm-30b.Q3_K_L.gguf](https://huggingface.co/TheBloke/WizardLM-30B-GGUF/blob/main/wizardlm-30b.Q3_K_L.gguf) | Q3_K_L | 3 | 17.28 GB| 19.78 GB | small, substantial quality loss |
| [wizardlm-30b.Q4_0.gguf](https://huggingface.co/TheBloke/WizardLM-30B-GGUF/blob/main/wizardlm-30b.Q4_0.gguf) | Q4_0 | 4 | 18.36 GB| 20.86 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [wizardlm-30b.Q4_K_S.gguf](https://huggingface.co/TheBloke/WizardLM-30B-GGUF/blob/main/wizardlm-30b.Q4_K_S.gguf) | Q4_K_S | 4 | 18.44 GB| 20.94 GB | small, greater quality loss |
| [wizardlm-30b.Q4_K_M.gguf](https://huggingface.co/TheBloke/WizardLM-30B-GGUF/blob/main/wizardlm-30b.Q4_K_M.gguf) | Q4_K_M | 4 | 19.62 GB| 22.12 GB | medium, balanced quality - recommended |
| [wizardlm-30b.Q5_0.gguf](https://huggingface.co/TheBloke/WizardLM-30B-GGUF/blob/main/wizardlm-30b.Q5_0.gguf) | Q5_0 | 5 | 22.40 GB| 24.90 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [wizardlm-30b.Q5_K_S.gguf](https://huggingface.co/TheBloke/WizardLM-30B-GGUF/blob/main/wizardlm-30b.Q5_K_S.gguf) | Q5_K_S | 5 | 22.40 GB| 24.90 GB | large, low quality loss - recommended |
| [wizardlm-30b.Q5_K_M.gguf](https://huggingface.co/TheBloke/WizardLM-30B-GGUF/blob/main/wizardlm-30b.Q5_K_M.gguf) | Q5_K_M | 5 | 23.05 GB| 25.55 GB | large, very low quality loss - recommended |
| [wizardlm-30b.Q6_K.gguf](https://huggingface.co/TheBloke/WizardLM-30B-GGUF/blob/main/wizardlm-30b.Q6_K.gguf) | Q6_K | 6 | 26.69 GB| 29.19 GB | very large, extremely low quality loss |
| [wizardlm-30b.Q8_0.gguf](https://huggingface.co/TheBloke/WizardLM-30B-GGUF/blob/main/wizardlm-30b.Q8_0.gguf) | Q8_0 | 8 | 34.57 GB| 37.07 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/WizardLM-30B-GGUF and below it, a specific filename to download, such as: wizardlm-30b.q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub>=0.17.1
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/WizardLM-30B-GGUF wizardlm-30b.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/WizardLM-30B-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/WizardLM-30B-GGUF wizardlm-30b.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows CLI users: Use `set HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1` before running the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m wizardlm-30b.q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: {prompt} ASSISTANT:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model from Python using ctransformers
#### First install the package
```bash
# Base ctransformers with no GPU acceleration
pip install ctransformers>=0.2.24
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]>=0.2.24
# Or with ROCm GPU acceleration
CT_HIPBLAS=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems
CT_METAL=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
```
#### Simple example code to load one of these GGUF models
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/WizardLM-30B-GGUF", model_file="wizardlm-30b.q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here's guides on using llama-cpp-python or ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: WizardLM's WizardLM 30B v1.0
This is WizardLM-30B V1.0 delta weight.
## WizardLM: Empowering Large Pre-Trained Language Models to Follow Complex Instructions
<p align="center">
🤗 <a href="https://huggingface.co/WizardLM" target="_blank">HF Repo</a> •🐱 <a href="https://github.com/nlpxucan/WizardLM" target="_blank">Github Repo</a> • 🐦 <a href="https://twitter.com/WizardLM_AI" target="_blank">Twitter</a> • 📃 <a href="https://arxiv.org/abs/2304.12244" target="_blank">[WizardLM]</a> • 📃 <a href="https://arxiv.org/abs/2306.08568" target="_blank">[WizardCoder]</a> • 📃 <a href="https://arxiv.org/abs/2308.09583" target="_blank">[WizardMath]</a> <br>
</p>
<p align="center">
👋 Join our <a href="https://discord.gg/VZjjHtWrKs" target="_blank">Discord</a>
</p>
| Model | Checkpoint | Paper | HumanEval | MBPP | Demo | License |
| ----- |------| ---- |------|-------| ----- | ----- |
| WizardCoder-Python-34B-V1.0 | 🤗 <a href="https://huggingface.co/WizardLM/WizardCoder-Python-34B-V1.0" target="_blank">HF Link</a> | 📃 <a href="https://arxiv.org/abs/2306.08568" target="_blank">[WizardCoder]</a> | 73.2 | 61.2 | [Demo](http://47.103.63.15:50085/) | <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama2</a> |
| WizardCoder-15B-V1.0 | 🤗 <a href="https://huggingface.co/WizardLM/WizardCoder-15B-V1.0" target="_blank">HF Link</a> | 📃 <a href="https://arxiv.org/abs/2306.08568" target="_blank">[WizardCoder]</a> | 59.8 |50.6 | -- | <a href="https://huggingface.co/spaces/bigcode/bigcode-model-license-agreement" target="_blank">OpenRAIL-M</a> |
| WizardCoder-Python-13B-V1.0 | 🤗 <a href="https://huggingface.co/WizardLM/WizardCoder-Python-13B-V1.0" target="_blank">HF Link</a> | 📃 <a href="https://arxiv.org/abs/2306.08568" target="_blank">[WizardCoder]</a> | 64.0 | 55.6 | -- | <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama2</a> |
| WizardCoder-3B-V1.0 | 🤗 <a href="https://huggingface.co/WizardLM/WizardCoder-3B-V1.0" target="_blank">HF Link</a> | 📃 <a href="https://arxiv.org/abs/2306.08568" target="_blank">[WizardCoder]</a> | 34.8 |37.4 | [Demo](http://47.103.63.15:50086/) | <a href="https://huggingface.co/spaces/bigcode/bigcode-model-license-agreement" target="_blank">OpenRAIL-M</a> |
| WizardCoder-1B-V1.0 | 🤗 <a href="https://huggingface.co/WizardLM/WizardCoder-1B-V1.0" target="_blank">HF Link</a> | 📃 <a href="https://arxiv.org/abs/2306.08568" target="_blank">[WizardCoder]</a> | 23.8 |28.6 | -- | <a href="https://huggingface.co/spaces/bigcode/bigcode-model-license-agreement" target="_blank">OpenRAIL-M</a> |
| Model | Checkpoint | Paper | GSM8k | MATH |Online Demo| License|
| ----- |------| ---- |------|-------| ----- | ----- |
| WizardMath-70B-V1.0 | 🤗 <a href="https://huggingface.co/WizardLM/WizardMath-70B-V1.0" target="_blank">HF Link</a> | 📃 <a href="https://arxiv.org/abs/2308.09583" target="_blank">[WizardMath]</a>| **81.6** | **22.7** |[Demo](http://47.103.63.15:50083/)| <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama 2 </a> |
| WizardMath-13B-V1.0 | 🤗 <a href="https://huggingface.co/WizardLM/WizardMath-13B-V1.0" target="_blank">HF Link</a> | 📃 <a href="https://arxiv.org/abs/2308.09583" target="_blank">[WizardMath]</a>| **63.9** | **14.0** |[Demo](http://47.103.63.15:50082/)| <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama 2 </a> |
| WizardMath-7B-V1.0 | 🤗 <a href="https://huggingface.co/WizardLM/WizardMath-7B-V1.0" target="_blank">HF Link</a> | 📃 <a href="https://arxiv.org/abs/2308.09583" target="_blank">[WizardMath]</a>| **54.9** | **10.7** | [Demo](http://47.103.63.15:50080/)| <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama 2 </a>|
<font size=4>
| <sup>Model</sup> | <sup>Checkpoint</sup> | <sup>Paper</sup> |<sup>MT-Bench</sup> | <sup>AlpacaEval</sup> | <sup>WizardEval</sup> | <sup>HumanEval</sup> | <sup>License</sup>|
| ----- |------| ---- |------|-------| ----- | ----- | ----- |
| <sup>WizardLM-13B-V1.2</sup> | <sup>🤗 <a href="https://huggingface.co/WizardLM/WizardLM-13B-V1.2" target="_blank">HF Link</a> </sup>| | <sup>7.06</sup> | <sup>89.17%</sup> | <sup>101.4% </sup>|<sup>36.6 pass@1</sup>|<sup> <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama 2 License </a></sup> |
| <sup>WizardLM-13B-V1.1</sup> |<sup> 🤗 <a href="https://huggingface.co/WizardLM/WizardLM-13B-V1.1" target="_blank">HF Link</a> </sup> | | <sup>6.76</sup> |<sup>86.32%</sup> | <sup>99.3% </sup> |<sup>25.0 pass@1</sup>| <sup>Non-commercial</sup>|
| <sup>WizardLM-30B-V1.0</sup> | <sup>🤗 <a href="https://huggingface.co/WizardLM/WizardLM-30B-V1.0" target="_blank">HF Link</a></sup> | | <sup>7.01</sup> | | <sup>97.8% </sup> | <sup>37.8 pass@1</sup>| <sup>Non-commercial</sup> |
| <sup>WizardLM-13B-V1.0</sup> | <sup>🤗 <a href="https://huggingface.co/WizardLM/WizardLM-13B-V1.0" target="_blank">HF Link</a> </sup> | | <sup>6.35</sup> | <sup>75.31%</sup> | <sup>89.1% </sup> |<sup> 24.0 pass@1 </sup> | <sup>Non-commercial</sup>|
| <sup>WizardLM-7B-V1.0 </sup>| <sup>🤗 <a href="https://huggingface.co/WizardLM/WizardLM-7B-V1.0" target="_blank">HF Link</a> </sup> |<sup> 📃 <a href="https://arxiv.org/abs/2304.12244" target="_blank">[WizardLM]</a> </sup>| | | <sup>78.0% </sup> |<sup>19.1 pass@1 </sup>|<sup> Non-commercial</sup>|
</font>
NOTE: The **WizardLM-30B-V1.0** & **WizardLM-13B-V1.0** use different prompt with **Wizard-7B-V1.0** at the beginning of the conversation:
1. For **WizardLM-30B-V1.0** & **WizardLM-13B-V1.0** , the Prompt should be as following:
"A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: hello, who are you? ASSISTANT:"
2. For **WizardLM-7B-V1.0** , the Prompt should be as following:
"{instruction}\n\n### Response:"
## Inference WizardLM Demo Script
We provide the inference WizardLM demo code [here](https://github.com/nlpxucan/WizardLM/tree/main/demo).
<!-- original-model-card end -->
|
mradermacher/mythospice-70b-GGUF | mradermacher | 2024-05-06T06:23:19Z | 509 | 2 | transformers | [
"transformers",
"gguf",
"llama",
"llama-2",
"not-for-all-audiences",
"text-generation",
"en",
"base_model:Doctor-Shotgun/mythospice-70b",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-02-06T12:55:49Z | ---
base_model: Doctor-Shotgun/mythospice-70b
language:
- en
library_name: transformers
pipeline_tag: text-generation
quantized_by: mradermacher
tags:
- llama
- llama-2
- not-for-all-audiences
---
## About
static quantize of https://huggingface.co/Doctor-Shotgun/mythospice-70b
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/mythospice-70b-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/mythospice-70b-GGUF/resolve/main/mythospice-70b.Q2_K.gguf) | Q2_K | 25.6 | |
| [GGUF](https://huggingface.co/mradermacher/mythospice-70b-GGUF/resolve/main/mythospice-70b.Q3_K_XS.gguf) | Q3_K_XS | 28.4 | |
| [GGUF](https://huggingface.co/mradermacher/mythospice-70b-GGUF/resolve/main/mythospice-70b.IQ3_XS.gguf) | IQ3_XS | 28.4 | |
| [GGUF](https://huggingface.co/mradermacher/mythospice-70b-GGUF/resolve/main/mythospice-70b.Q3_K_S.gguf) | Q3_K_S | 30.0 | |
| [GGUF](https://huggingface.co/mradermacher/mythospice-70b-GGUF/resolve/main/mythospice-70b.IQ3_S.gguf) | IQ3_S | 30.0 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/mythospice-70b-GGUF/resolve/main/mythospice-70b.IQ3_M.gguf) | IQ3_M | 31.0 | |
| [GGUF](https://huggingface.co/mradermacher/mythospice-70b-GGUF/resolve/main/mythospice-70b.Q3_K_M.gguf) | Q3_K_M | 33.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/mythospice-70b-GGUF/resolve/main/mythospice-70b.Q3_K_L.gguf) | Q3_K_L | 36.2 | |
| [GGUF](https://huggingface.co/mradermacher/mythospice-70b-GGUF/resolve/main/mythospice-70b.IQ4_XS.gguf) | IQ4_XS | 37.3 | |
| [GGUF](https://huggingface.co/mradermacher/mythospice-70b-GGUF/resolve/main/mythospice-70b.Q4_K_S.gguf) | Q4_K_S | 39.3 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/mythospice-70b-GGUF/resolve/main/mythospice-70b.Q4_K_M.gguf) | Q4_K_M | 41.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/mythospice-70b-GGUF/resolve/main/mythospice-70b.Q5_K_S.gguf) | Q5_K_S | 47.6 | |
| [GGUF](https://huggingface.co/mradermacher/mythospice-70b-GGUF/resolve/main/mythospice-70b.Q5_K_M.gguf) | Q5_K_M | 48.9 | |
| [PART 1](https://huggingface.co/mradermacher/mythospice-70b-GGUF/resolve/main/mythospice-70b.Q6_K.gguf.split-aa) [PART 2](https://huggingface.co/mradermacher/mythospice-70b-GGUF/resolve/main/mythospice-70b.Q6_K.gguf.split-ab) | Q6_K | 56.7 | very good quality |
| [PART 1](https://huggingface.co/mradermacher/mythospice-70b-GGUF/resolve/main/mythospice-70b.Q8_0.gguf.split-aa) [PART 2](https://huggingface.co/mradermacher/mythospice-70b-GGUF/resolve/main/mythospice-70b.Q8_0.gguf.split-ab) | Q8_0 | 73.4 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
Artefact2/Midnight-Rose-70B-v2.0.3-GGUF | Artefact2 | 2024-02-07T06:12:24Z | 509 | 12 | null | [
"gguf",
"en",
"license:llama2",
"region:us"
]
| null | 2024-02-06T23:07:00Z | ---
license: llama2
language:
- en
---
<img src="data:image/jpg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAAsICAoIBwsKCQoNDAsNERwSEQ8PESIZGhQcKSQrKigkJyctMkA3LTA9MCcnOEw5PUNFSElIKzZPVU5GVEBHSEX/2wBDAQwNDREPESESEiFFLicuRUVFRUVFRUVFRUVFRUVFRUVFRUVFRUVFRUVFRUVFRUVFRUVFRUVFRUVFRUVFRUVFRUX/wAARCAGAA70DASIAAhEBAxEB/8QAGwABAAMBAQEBAAAAAAAAAAAAAAECAwQFBgf/xAA+EAACAQMDAwICCAUDAwUAAwAAAQIDBBESITEFQVETYSJxBhQyQoGRobEjUmLB0RUz4RYk8UNTcpLwB4LC/8QAGgEBAQEBAQEBAAAAAAAAAAAAAAECAwQFBv/EACoRAQEAAgICAwABBQABBQAAAAABAhEDIRIxBEFRYQUTIjJxQhQjkaGx/9oADAMBAAIRAxEAPwD8jABUASQAwCewAgkAASiABOPwIxgsmMeN0ATLLDXsUx4IyFXcccbomM2vf2KqXkthPjkDWElIs2c+8X4ZpGontLnyRdtca1jlmc6c4b7o0pvE0b14v4Yy4e6ZNta3GVGvCdJ06q+PtJ9/mdVpYupJSVVKTeIxZEbGnVt4NrTNrlGFGvU6fXUaizBPO37onv0ute1bq2nSvK1OacZRer8C9K5cEqVdaqT7f4On61Gpd060nqjhwb8rsSlQua9XMHGLjsvDG/01+Ou3rztYp5de3xtJbyiv7opewpXE9UGpao5Ul3PLpXVSzq4i3KPeLOyNSE/4tBLnMocf+GT011Xn1aChrym2/stdn7nPg9K5nGrKGjh92t8nJVp53Wz/AHNyudjAlLKyuSYpOLzyVTaexpldvK35Ky4NNSqezKSWERVUWzsVRL2CIwSlsME9gKtAkARgEkFDBK2BbGQIIJABENAlMCYPDJbeSrZblAS8tFoJvYhfZLwkRVlFpnTbx+L4uO5zueX7nRb3MqE86YzWMYkSrJNup0pQnHK2e6fZno2r0x/E8qlcTnFQlLMVLKXg9CjL+GuftGa6TX0+4+jtJuhTqY2TcsmXX/o5WsHc9SsM1IVtTqU/vRUudPlf5Nfo7e0pWVOhByp1OHDlSflN/sfUTuKdWhpk1GEo7Sclg4+q7e4/KJwtn0WlVhSqRuFWcZzTzGUMZW3n/ByUaVW8zG3bcY74k8YPtPpLbQtVb3NGPp+pKUZVdOYxn2ylt5/M+YtKztepS9NwzLDjp4bWcPf8zcrHjHDRoN1f42tOONl2Po+uu1s3Sh0elOhTlTfrVHvKe3Gp+V4PKpVIVrmbk/iknnfO/Y+voWtsun2tStb16spQVRasJU1y3LPZEt7WST0j6O9FXT7OheXLUbi6y3lcLlROD6Q0HG+uJSwnjVh/JH1d9dU4dLpzor6y9cYxalhJ+77I+H+k3WJ39WnB1HKVNYm4tac90scok7u19PnbjGpnFUi1h+d0bVp7+5zzlhnWOWSuJYk0tvJlJvB0JzdGUnmNLdZa2b8fMwlLKwsGmGbjJJFNLybJuXL4Jik034BJtzyi5TSI0uU/ZHQliLk+4jKMKEm+WNmnJUTk9jPS8m0e7KuW7KyrgS2SRKe+WQ92ETF7GtDGvMjEtF7+wWLVJepN+DBrc1UdmZtbgpjYjBJPBWUYIJyFuAe5HBL2IxsBHJoto+5QvjYKzaGCd28JbnZbUEvjb3ISbUoW+HqqLfx4OypVjThqk/w8mdSoqeMLVJ8RRk6qoy1y/iXD4XaBlv00cI016939r7lH/JnGlVvnOrKaWNty1vbSrzdW4bfs+52fDTg1BJLOcLyTel1ty06saFX0E1pSy2+7IhWpq6qSa17fDjjJRQdeTcktuWzBzVNYgXSWr16s5LTN4iuy7nM25P8AsWSc3lv8SzxFbclZ9pjS0x1N4f7FW8vTHdj4prxHyS5KK0w/+3kojSqcucv2IlJyeWyBnARJUZyWitgK4yTjDLrgowIYwSAIwTjIGrwBD2eAl5IyMgWcuyKgAQCQERgEgCBgkAQSgEBCJAAAAAAAAAAAAASmQAL7P2fkhrHP5lcllIKhr8RnBfClvHZ+CrXnZgSpZWGQ1j5ENNEZYF41XH3Xg64XacXHSnlY37HCE8PKFm1lse5RuKUYRjGXzjIi8hCpSTeH3TPKjUzs+TTXJxUc7LhGPHvbp5biilKjJPlfud9re06UZLGlyzu9/wADjk8pJmTg0vh/Itm2N69OqpSjLM3zj8ytScqU41IYimuEZ0auFplx4ZtNRnRwu3AX36a0/wDu05UWoV4rLi3yjnllSaktL8PY0co0qUZQjiSxhryRVrOtiFeKjU+7NdyRawlDO65/czwapvVpns/JE4qS8M2xpknhkyeSUuz2aKsIIs+CFyWktgKplsZRQut0CISDW5LeGMZQEdipZ7FSiS0diIomS2Io1hlWWTysFXyVAABAtDnBUlAacJomJGchbMjS6xk1TMluy/AHRQ3mezSoqEYxUlKWrdxlmJ4lvLTUR69vUThHCec7vOzM1vF9N0erV9OVvThCTl/Ehr+40t/zXY9y2uqcunVKUY6ZyTi4PZxljjP7HkfRyNGpPVKm3UhunF/F815PXvqKivrdOnGSl/uxg/tRX3l7rwcb7eielrzqtF0p0acfTVxhy9RrQoJLnPc+YdK0p9duqtGlCVrGTVGK3i33a84+I6Op9EuOo1qFtTqU6dGSc3VqT+088RX5fLJ87Vq14V6UaadKVPMaeY8Jbd+O4npPT1bWtS6f1qr/AA0qkpJ0XOPGedj6Snd1Pq9NSuZVa8V8epY0/wD7B8ZCpddToSoOrqqWsHUpqSb1JcrJ7/TI1brpHqVptua0qUZbtds+/Io73dq+oVKKq03GG9SpP7Ckvu++T4+7gnUefhcnu1ukfX0Z06HwQjCOIuMI5y/wXC+fJ8lfzcqspacZ7FhXl3VNxjGprhJTztGWWsPuuxxVDpnOLTymn2aOWby2dI45Xakpy0adT05zjO2TPJeRm+TbktrW+OPcKTK4LRaSCxMpbJN7FZtPOnLSKvcrxlEXaY7iokI8kyWwGWCeBgLncrI/hXuyE9sBvLyyANYPMWZvktB4iyreQqCCeSCoYyyVsQtmXis5z+AFcBlm0kU92QTFZeWWeXtEqk2zeEARNKmopeXyzVyaemn9ru+0Sr2T3xFcyM251IaaUWoZw2u5GvSYpzq+lQeqcuZs1oUHbzdSssOPCfctZ2/o3FKUn8Tz+xW5bpVqkM6oOWcPcn8L/LS9q4jSlRnJKWXhGHr4Tlw328szuKym4/Dp0rCWTDLkxIXLto6stGnOF7dytOm6knjhbtvsRhLPctSc23GDwnyaZ9+yfwTcU8siVLQlKo9393uaSnCjLMPjqd2zCUnOTcm233ZCrTqOe3EfCK8EZIyVEtkckqOfZF0kuAKqPklFiGAbKhshsCSMkABkMAIAAAAAAAAAAAAAAAAgkAAAAAAAAAAAAAAAAAAng0U01hmYCtHt8vcq4Z4/IhSa+RdYfGzAzaBo8PaSw/JWUGvkBUvCo488GYA6cqSygYKWODWE88kXaZRUvmRCbpvD4L7IhpSQVfWpLSkscl7vFSnGfC8I5nFx+RKllYfHgaNkZtLRUWV7lmtK8x8lpZqNY2S3z4KSko4lHeL5TAlxUluZuLXJq8OGYbr9UQmn7oqWMuGWbyTOGN1wNnBYW/kIzfJeHBVl44wCIlyiy4Kvkt2CqvkglrcRg5tKKbb7IqJixJ7HbS6NeVIavT0r3ZnU6dcQeHBmdxrwy16cie5L3JnTlTeJLDKpmmQABAkJZaRacdMmucAQnuWTKkoDotY06txGFWsqMHn42spbFE9zPBZPHcml26KUlqR6drNKm8nj03iaPVsoylS14elS5xsStYvoul1ZRqUnFtbPddtz6CV3NZnnVq+0n95e/v7nzXTqsVVprxk9u8qQoQS0ynGclFKCy9zjZ29GN6cXWrypd0YxrwmoUfijKUtMksY3+eFz4PDt4QoqNepXcquMJSw8fqR1vqlS+UKMKnw5c54XMm+/yR5EZKrS3cUuMY/uWTpm5Tb36coTqp0a6p66eioo088vfvwfQWklC1p2kYtxoY+3HGr3PzyUfTllPGO8dj7HpHWPU6JUpVKWqvReYSSbc3/42Ys0sy29yvUdb6pN6cqWnEYqK7+D5Lqm1zPtsz6ONzFwpTpxeFNS0uOMex83e1Y3fUlCT9OMn8Un2Xd/l2EMr08avHSo+5yyeGdt9KE6050FP6vqehyeXjtk4Kn2tjrHCqylhlWyZQcX8Sw3vuUyVlaRGcIh8FWwJT3HLKjIVrBZkJc4KKeCNbYNpk8FSG8jIRHcnBGRkolbIgnJAAh8k5I7gCU8EMlbMBjG75JUXJ+xKjl5ZrHCTIulUlE0TSi2/wDyZ6sSTfBdJycZNfDlbEWEISuq0aecJ/obfFZUFOnNNzk0012RWrJUrmThHS1tgxq1fUilN7ReUQ9Np3HqNSg2nF9zllUw3h5fllJTctlsvCIS/E1pLUpOW7/MnKWyEnnbuTCpGmntmXbIGiopR1VXpXjuUnV1bRWmK7LuZyqSnLMnlkZBb+DIJw2W08NceX3CKJFlHHPJbaK2/MIACG8ENgTq8blW/JDf4AA9yAAiQAAAAAAAAAAAAAAAQSAAAAEEkEgAAAAAAAAAAAAAAAAAAAAAFlPs90Xi9vh3XhmQTwF20cVLjZ+DNxa5Lqaf2vzLOW2+68gYhbGjhneJRoC8ank1Tzl9jmLRk48AldBEYKUhComuN/cvGUU98kaUy6Sa+0mTRcGnGpvF7p+C84rLXYxlTxvH8gVtbQ1xlGKcpRTkku6XP6FJQa+LGnO69yKcks74eDSVOpUpQS5jnHuRfcZqWrbh+CGsccBxkktS+TJzjkrLJ4JWMF3HPBTOCoPGScojLYyVGtCkq1VRTxnufR2lC0sIKcsOXlnzVJuLyuTWVSUvtSb+bOeUteni1j3Z2+pfWLeWUmsHn3XVqcc6FlniNmcmZnHHXLnumleu69RyaXyMiAdnit3dpBBOQh3JzuR8ycgSERkAXLwai91lHVbWttdW8Gq06NVZUtUdUG8/mtsFbvptzZJSqQ1U3xUg8xf4k2umWU38PHyPoOkR02M1KeHLeMX3Z85BNyxz8j2LTqd1Yzi9UYLGyUNS/EmUbxunq2tGp9ejKnCTyn8KWcHsX/VLeVvQjCslXoVYyUZrD25PLtrmpf05XE3TguIThJwcpey/8Hq3/SKkrTT1pQeIfDfUd/Tf8s/88fI5ffbr9dPlet3NO5vncU6XpuW84x4cvJw2lldXNxRo0KT1Vntq427/ACNPqlf659Uj8VRy0aecv/B9VYdKo9Icpep6lx9mVTwvCNWyRiTdfGXdGpQu6tGoviozcZafKZ9X0e+p2fQqFOGiVxOqqmE8vnj8kef9IenTuLmV9bR1qazUiuc8ZRwdIpepV9WpT1UaPxTzsn7ZHubJuXT7CtfO7bkqThNbNKWrVvsfN9RoKNXVOaalvhLOEezO/q3lbmVZuOIU6ccRhtxhfkeP1OnWVROrOnSkk805VFqXtgmO2srNOGhVowVShcJ+hLOZQXxR8frg8uTae/J1TSbeMnJP7R1jjVWyvc6bOxuL+uqNtTdSb7Lhe7fYvf2qttMY4bh8E5ReU5eRtHI2QHwQUGyGySoRIyAgJIJIYVADGQi2duAn7FcjIF214K534K5JScmRUv4uxrTjhZwIU0uTdYe2CWtSMVFZy+Ck5rOy2NKy2a/Yh0k4RYLEwpKSUm+XwXrNP4Vslu2ZuelY8GLm5MCXJQ2W7Kby3YaxyTnCKyjGA34/MhyKt5AnPggAILcukvGWQltuTnbC4CrYS3e7IcssjtvsiHLwBL25K6vwQyQAbA7AIgEgAAQBIIJAAAAAAAAAAAAAAAAAAAAAAAAAAAAAQBIAAAAAAAAAAAAAAAIJAAtr4xsyU1LaWz8mZKeGFWlBr3RUvF74/cmpoUIpRal3fkDNMvGp5MwB1KeSTnjLCZdTzx+Q0u1pRzxyTCvOnheOxKeSGs/Mi/8AF5y1WzzypbZI0aYRcnlPl+Ck25NOSy+7L606UoLv2YENafstNexWS1IODg0/JPfw/ARlwwXaz8yj2NI1hwWMlUY1tk06TOSLzl2MyckMrGWWwABkAJAJDBOAALKOEpST0vK2KnVGS+pTUVvKcU9lvhAjo6ZDXRqb8SXPyPTtq87eU4SxKjODUqcllSPM6XPRKSnOMaUuU5LKfZ4O+f2MqWpexitxw39CnTnGpbwdOPDim3h/ieh0zRXpKctktt++DDHq5jjVnbBs7Gt0+UYV/hqxjp0KWdC5x4yZt1NOvFx3PL109qlC2VtUUqSVLnOrB6Np1y2VlO3q0ldU6unVqqaZ4XZ+UfLVbmfpQpbbZe75KwqTynPd8Js4yX3t9WzismPi9KhcK26zK5jQpRjxogto/JHVO4U5Sys6t2eLKrL1ZPVnc66NSVSkpx3jjdpmpu+3j+Rhhh3g6frDjJpb/Fnd8HFa2cKnWYzuElaznqmtWN/BhO6dN/1Mx1es3qi5ya+HD3i/J0k128nu6fpNO96R062/7WVPW1hQpfaZ8JfW0aupSrcSk90ts+WUjXq06UKbynGWcNbomvcTlTb+2vEuDncrvp9Hi4OPw3n7ctHpcZJ+pWwktlBZz+ZwdVtqdC4gqEZqMoL7TzvlnrUeoemszor4Uvs7foc11UlUdXXJNSmtl4NTLLy7Z5ODh/t7w9tqfUHTsXQt4KlThFRSjy33k33Zxzip0pwSTUlyzVRgqWtceCs28tRi2dXzXjSjpbT5WxXgvUeaknzvyRg0yqQWaKhAAAAAFCpYhoCAC0I/EshExg2axSivcZxsiG1H3ZlpbZLMiYKU8NPCyUjD1E5SePYs5enBLgKtL/cltsZzqvSVlVcv8lcbbsaNq7zZKxEsuNiknuVEN5ZDZDeSMhkYAAAJE7IBjJOccfmyucjIVOfxZDeQAgAABBIAAAAQSAIJAAAAAAAAAAAAAAAAAAgkAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAgAkASpeSCAL4T4K4wETnPIVAzgYARdT8m0Pi7nKXjNx4Cyuj03jLf5FZrDTT3IjNaXlkSecNEVvO4hVhTjKGmUNs+SlT+LNYWH7GeMkqThNSGjaM5XuR8zZRdSjOWY7PsYx4ELENEFiDTKCSCQAAAHsdO6RbXlP1KnUIQXeGh5T8bnjnX0+r6dwoviexL66WPo/8Aprp9ShH0LipKTX2lJPH4Hh33S6llOayqlODw5Lt80ejSqToT1QbUvKJubxVaTjNZnvlp/aT5TRieUrXVfPs6+nRoVpVKFxVdL1EvTnjKUvdHNWp+nUcVuuzfg9/on0etuquMo3FWE4qMpRnTTj77pmrZIzJ2459Kjbwq+pcRlUWNCgsqS758GEINZ01En+R7nWeiXnS6cvq1xGpRlzGfwz38J8nJR6ZTdCKlNOot5Si/0Meck7r08fx8+W3xnpjYS13CjJ7rx3N7i7U7iacnJ6uX3Jq2dK0iq1OLS7PWZqzUo+p6j+J5aayZuWN7ejDg5uO+OLGvPOM5w+Gu5NOqoR1L7S8pFaleM4ypVYYnCWFjujm9enSbT3fsXW4tzmOW9tZXTitK+0+7NKbuKdOVSgp6U/i0v+xwwlOvVlKK+JJtex61rb06NPMVqqS5nLfHsi2zGOUwz58uvT0alKzuPTk4SnpW7hLaXzZ59SjOzdRqP8FvMZJ52Hryi3TcpY8Q2wXgqNahOMnKE0vhqqWWzluz29n9rH/wmqj6x9beYxzUS28GlCtTmnRqNU5NrEm9jyKV7Ws62qKi5Re+eGb3PUfrkFmhSjL+eK3NXD89OWPyJrdvf/66rmMYSkqbVR4w3DdfmcEm28R5eFuVhWqaNGtqC7Z2Ma1bE9K3Xf3N4zTjy8ks29Gdpc0paK1OdJZ+1OOxalYqtOE69dvbLhGWF+PsRDrVednC3unOtRhLVCL3eMY/FJlZ1s13KMnKLisaeTOVy9NcGHFryy7OoWcqs4uk6Tx42OK5s1b28JuqpVG8Sit1HxudcLrEWuE+7L64aVNJJz5TWxMblj07cnHxctuX3W1p9HKMFQqdWvqVrGqlJUk8zcXw/bJr1HpnQKNFStrmvJqTTa3z+aPOqap1HiT2eM5FSEqkYrXt7nWS3vb5ucmN08ypFRliOce5Q3uoqNdpNNJdjBm3IBAAMgkASti6ZRIsv0JViXLHBZLDyyHBN5TwkMuey2RGk60otIrLMn8TJUcEdwKtYQ4W5MppIycmyomU+yKcgBAABAkgAGwAAAAAAAAABBIAAgkAAQSABBIAAdgAAAAAAAAAAAAACCSCQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAQBJBJAEgEATkAgCQAAyXT2KEoK0TJM8kqQF1lZwyE8JruEw1lBUrGn3KtYGdkidWVgIgDAKgAjSnQq1cenTnLfHwxb3AzRZbPK2ZtOzuKeddGpHHmL2MklnGUvmwOyj1Fwg41Kev+rVhnVa2l51OFSrb28vShzNvC+WfJxUKFGcZKVSLeNtMhT6hd2sfRhXn6cX9hv4V+Bm/ws/l6br0+n3Lo1vTr5p6HU0J+k/bPPg1X/Y0fXs5yp1IpP1ae2d/2PEU3W1S5ly8s77eUVbQgq8pZmnKDh8Mc8bmMsXbDOassK15d3txGpXrzqOXw6pvZHXGn9WpOcqm3MY55XY5brT6+mC+CO0UuyMo15Sl6VTLi46XnlGbN+np4M/CdvSoXEKuiE5xSb3bbzj5G9KpSdR0JcptJvwePOjRhhRnJ+yWCdU1JST+NvhckuO3bHnywvbe4tY3nUm1OUYxhjMe7X/k47uxVBLDcm2/iOyjWjazl67xKMdl5bOerXd5JRgm23sjWO5/xw5rhZbf9qmycI2kkk/Ucvib8GquZQlFY2WU0+5nTsbuNRKNCcs8qKz+x2f6VdzlGPoNN9nJIWRMOXKYzXWnG6sksNtJkQrOUXh8vg9X/p/qUqcnHp2N9pKqn+hw3PT7y1/37arTS7uG35jprzt+3HWt51YN04Sm48qKzsZVqNa2loqRlB4Tw+2T7f6J2k4UpVWt626lqWyH0g+j0ZwrXt1f0KEP6o/pnuyy/Tz5zvcfB+rLeOce56tDo0b/AKUriym5XFL/AHaLeX8zy6/oxrr0ZSnFLdtcs6bfqlxY11VtVCmvCXK8M3Z+OW/0hUWmlDDbjHTj9ysf4Uu8WnsyLq6hXqzqUqcoSb1Zb/8A2TGncOOVUWpZz8ieLtjy99uyr6U4pwjFyxu12M9TTWXx5M4TUt05Y9zacJ1KcpRjGSgsteSenW25dxvTi01q7+RVqRoxbknjwcNJxnFJbS+ZSpqhJxnybjx27Z1Ja5yljGXnBQ9u16RbTt1VvLl0nJZjCOMnnXdrToSbpVo1Ids7S/ISypZY5CSAVAlIJF0t9hVkMYwG+yGSEtzKrJPGGXhEhbETqqK25DROWGYyn4Kyk5MgrNqGwSAygAgCQAAAAAAAAAAAAAAAAQSAAAAAAAAAAAAAYAAAAAO4AAAAAABBIAAAAAAAAAAAQSAAAAAAAQSAAAAEAkAAAAIJAAAAAAA7gAAAACJIGQJBGQBZPBOrJXIKqzIGRkgnIILLgAd3S7+dhdwmpzVJv+JGL+0vkcS4BfaS6r7a8rUbmhFW1aPqT+KEs91+x4Ver9Yh6dw9STf3U8fI8qlXnRknFtY8HZbxldRm4RlpjzlpJGJjpu5bZ3vTJ2jTypKSUklJN4/A48N+/wAz0ouWZQhFSWM6orOPmc2r06mqUU87P3NMsfSmpKOluT4S3yei7OFCk6Uqn/dpapxctopfd92dnSalJVXVw9cHiC43857HLfZubpyo0oJy7wb/AHZm5d6dMeO3HyYSnUlFS1aZd2iyam/i3ku5VqtCa9ZOce+Gn+xte21GOmdrU1U2lnPKY6rUuWP0pCEpT040pd2bwUKU04NPHcxtaHqt0oL1Jya4f2T3bTpDofw4uVOct5SgsP8AAldMc79MrTpVW+k/Xjopy8r4n/g9q06PRtqWj00t+VHL/Urbwla3EI1rmUo1HiE2kt/5ZL9mexO7hRhvJbENd7qlKyi4Ll48siFKnOo4/HSqw7Rlh48+6OVfSGhCrplLZrZnmXfXIyrr0niaeYPw/HyZNG4+lV7O2TVw9cEvtJbr5r/BSv1W2UNUZxqJ9vK9j42r9Lq9ZOFWhGnJZxUi+PwPIl1CrKtKaxFT3cY8MsxrNzj627uLKrHVGjRU4yym4bP5iMqHULadKh6dGbW8Gk0j493lTU3q2fZiF7UpVY1IvEo/qa8WfOI6l0u56fWkq9LCb2lH7LOetPEtGPsrT8z6H/XFVpqlcx9Sk+77Hj9StFRqetReqjPvn7LLP5c8pr046TxJe+x3xs4uVOVTdSfCXY4qEVOTUtlzlHuyrUaNG1+JPdJruZztnUej43Hjlu5fSfRt6clGnCGnG7bN6cI+luksS+F45yYYjLVUjJJPbBySutGmMXF6ZasLhHLx2+h/cxwu7FqnS4urKVNum48vsjguY06NwnKs67TTcdOMrxk3r3FScnVqSbXhcIw6i6VWqq1BqUZxWV3TXlHXHf3Xg57x/wDhiyu76td3Eq02ot8RisJLwc7bcsvn3PpOn9ItKljC4dSVOrBZm5uOPyZ49zJ16k5t68cNrlG5Z9PLZftyYIGQVlaPJZLBRFs4I1E8shtRKueODNvLBtpKo2ZtkAIEkAIAAAAAIBIAgkAAAAAAAAAAAAAAAdgAAAAAEEgCCQAIJAAAAAAAAAAAAAgAAAAAAAAAAAAAAAAAAAAAAD1ra2pdVpSw1TuoLfxNeTz7i2q21V06sXGS/UWtzO0uYVocxfHld0fa1LW2v7aMpQVSnNaovwcMs7x3+H0+Hhx+VhddZT/7fCYB7l90CdJOdtJzj/JLn8+54s4OMmpJprs+x1xzmXp4+Xgz4brOKgEGnBIAAEEgAAAAAAAACCSCQAAAAABkkgFFsklSQLLYkqb0Iww3N4fYCPSzwjW3q1ZU5UacZNJ5aRjWn2T29ha1pUK8ZweH+5Lv6ax8fKeXp6fSqV9Rv6dS3pTW+JNrC0vk6er2jddSlHLly0/BvadepRi00qdThNrKTOfqPX6lzb07abhVjSlmNTCU/GNuUcJllcu49vLw8WOHlhlty0Zxoxnp2WcFnWbpPTp+TXY417bolSlFYxlG7Ns453GaiJfHJ5Wn5HZZ0LapRrSuZyU4r+HFczfg48LZt8EqeiEquMT+zD2z3/I1pyt17fR9IUdLnphCo2klBbG3/UUKN1OnWWuOtxjOPZHzdO+nSxoeNKwvmZUbarXp1ZQi5Rhhya3wPH9Z8/qPa6h1iNeTj917Sx+jOOp1SvUoaZVG2u/k89RyiJJxafZ7GtMXKtJVpvuVU21u+N0Q1sQXSbTKeubcuX3Ixp+RXuWfGewEMqyYc6Xw+GSlmTXcIQl918PY1pV9MXCe9OW0omMlpZXO7C7TJSozcVL8fKNbW7lSnJOMajmtPxdjNaZJas7ePBVpRr/DNNJ7SM3trG3G7jbtgtGLk1jZZxlkqMV8Uk5R5xF8kSm6q1YUYriK7GXeSfbqq0M0ZYq05pLhHPbKhC3uKVxF65x+ColnDMnVlGO0ouPginP1HGKjl+4ks9ryXDPWppnVq1VTjScs04vKS4yRB1JpxT27tnXGzdWhUnConOPMGt2jlp1VFNS2Nzt5spYh289ajBa2+FFb/kVqUqlJL1KcoZ41RaPe6era2i6larD1ZLjPC8Gl/wBUhG3/AIUozcfsxnHMc/iTd30amu3zSeEQ3ktNucnLbLedipWUMAgIAAAQTggACQAAIAkAgCQAAAwAAAAAAAAAAAAAEASQCQAAAAEASAAAAAAEASAAABAEgBAQSAAAAAAAAAAAAAAAAAAAAA7rHqNW1klCo4pfkcIJcZZqunHyZceXli+wt+r07hKFZKEn3+6zO96bRuMqccPtJco+Xp15U1jmPhnr2PWVGKpXDen7sn2PNlxXHvF9fj+ZhzTw5XlXVB29xOk2paXyu5idPUHm/rPOfi2ZzHpx7j5HJJM7IAArmEEkASAAAAAAAAQCQAIAEgG9GhGqm/VjFrs0xbprHG5XUYA0q05Uqjg8PG+U9mZhLLLqhJBJUSjRRk2oxTb8IyPVtqVH0Y1EnKUlv7AcqsKrhqm4w9nyVdrOljVFxb2UpbJHt29rVruMktSj9lv+5PV6FGjYem2pV9Skn3f/AAZ21p5denWuZxX8DVjGuntr/wCTmlZ1qf8AuR0rOM5IVeUZ6c5S/Q1neynDTJJ+7W5UVhFwW72Jz77Er4o5X6kKD3I3NjrqC2WWRVqKpF4+7L+xSpTabfKKU3z7liZW/bWKykff/Qayj9Qua0op+pU07+Ev+T4SjH4c9lg/UvozSVv0O2jjDlHW/m9yZelw9vi/pJ0V9O6jUlRg/q8lrWPu5f8An9zwprVBrufrl5bRr3tspRUlOFSMk+6wv+D84690uPTuo1adu3Kh9pd9H9Lft/dDGmWP3Hkp5S90AvsxzyngdzTmpjlhTTjun80XxhGChKUlGCzJvGF3CxVz35NITzVT8o+v6Z020o0fR/hOpBJznKmpOUnzz2R4nW+l/UriNxRUVRlPS0vuv/DMTOW6dsuHLHHbzqhlgvN5wVzybcVqTxNe5p6Kqa5Y054yYJ4aZ0xnKpQnRjnLecLuRfpzxeiqsvZPsdXw0J7Ykn2NYdOVKi6tZ5fZHPWcEt9/GCXtvHeMUrRTepQUURu2uOMbFYz1YUpPBopJJ7rC7hZZR3FWk04Taku5i608TWVibzJY5I3nLjd9kddCliDXpucnznsX0xld1SlXpKCc3h+EUq1ZXM1CnGT32S5Za5t5acqi17or065Vpd06k1mKe+/AZddL6P31aClohBviM5YZV9B6jFtTtajSWVKOGj6J/SS3p7Wtu5vtOWx4/UfpJe3EJUlUjTTTi1TWP1MS5VuzCfbxKkJUqkoSWJReGigBtzD6LpP0bVzCNa8nKEJLKpx2bXuz55NJptZXg77nrV5cRcPUdOm/uw22+ZjOZXrF34bx43efa/XHZ07z6vY0oxp0lpc023KXfc8skg1Jqac88vLK1IIJKwAAAQSABZItSpTq1I06cXKcuEj6Wx6bRsKaqV9Mq38z4j8jjy804/8Ar2fF+Jn8i9dT9ePbdIuLhapL0oeZ8/kdFXpNCjB6pzlLzsj0rjqMVlQWfdnmVq8qrbkzljnyZXd6fRy+P8Xhx1P8q8uvTjSquMZZXlmZ03TXwrCzu8nMerH0+NySTKyAAK5gAAAACASAIBJAEgACCQAAAAAAAAAAAAgkAACCQAAAAAAAAAAAAAAAAAAAAAAAAAAAtJ5Udt8c+SpMpOTWXnCwQFAAEAABBPcAAAQBIIJAEEgAAAIJTaeVsAFS5uWMvOCAEm3hbsHsR223S7y7gp0becoPiXCOI9XonVJ2VyqUqmmhU2ab2i/IpHXS+itacE6txCE391LVg561jc9JqxlUxWoLvF7fkfSTuPTpNZcm+HHk8246vWSUatOnUqU/v1I//wCeDEtrVkcK+kc4wahQSfbfg8ytXrVpylOblOpu37CMKbus1Yy9JSzKNPnHselcztaydza2UbShD4U5TcnI16T28eMdvASwzWb1ZcFz47FUnGag+TSLKrLxk1VRfJ+5CSS8FJRy9iaamdizy4VJdlF/4Oen4N5NulNY8ZMIrcqO+3aqU1Rin6lSpFfM/U7OcaVCMcpRhHGW+Ej826JSVTqkHJYjCWce6PrL61r3kYQVR/V1vOmvvPtn2OeV7duPHca1+uSvr+Tt6zpWVOPpurHZz7vS+y2W/scF/wBZsKfpQi4yUW04pfda3X7HJTsal51GlYzqTp0tLlPS8ZLV+h29LTbQg3Wg260+0Uvfvnt8xj433WspljZ4zb56sqc69SVGDhScm4xb4Ri/9z8DuuoaaNu8YcqK/dnC/wDdXyOk9OGU7Gtj1vo/Z069d1ajeIPjHs9/zPKZ7n0YqabitT/nh+3/AJM5el4/9nppfVL6cZQ1JpS1QnznycH0muIRs3BPPq1FpzzsejTsqFO/uK9aq5SlFOFNbKK43f8A+7nyHWL/AOv9QlKH+1D4Ka9vJyxm69PJnrHTmluyi5Zd92Ujwd3jPJ0W9WVKopw3kvJzG9tLTXpvjEl3JSL3NzXuJ4qSb8LGDN0sQblJLwjtvq6rVW4Rj8L0ua5kzma1NQ4xvkT0uu9MoY4xv5JcJVNSysRWRKTjLGEmu6RpF04xc98/y55GzxYUtpp5x7o6lNasvdfM5k22WUU/YExtdruNFBY+KXZS7Hn1KlJ0nCENMnLMnnZrwb+j6tFJTerPjOCJdNqRTfqQx5JuN/28r6jjUnH7La+TIe7BBXJIAAgkACCQO4EEkEgAQSAOm3tXcRbVSnBJ4eqW/wCRyk5aeVyK1jZL3Nvet3QsYfwW6lVreo1+xnVuJ1HmUm/meVC4qR+9leGX+uSx9hZOM4pvf2+h/wCs3jMJ1Px2uRnKSSbbOOVxUl3wvYyy2bmLhl8j8Xqz9Sba47FADby27u6AAIAAB3AAEEgAAAABBIAgkgCR3AAdwAAAAAAACCSAJACAhEgAAAAAAAAAAMN8Bxa5QAAAAAAAAAAAAAAAAAAAAB3AgEgB3IAA1pU41G4uahL7urh/j2IqUalJ/wASEo/NGZ6VGtOVCOW2sYeTOVsd+PDHPq9V5wOutQjLeC0y8dmcjTTaawyy7Yz47hewAFcwEEgDqt683BR9SS0cYfBylqb0zTA9FaKyca0NeeJY+JHHcWsqDeU9Plo3pqdScYwxl932Nr2jOMo0XVdWb3aS7BXNb3tSgkozkkvfJpVup1U5VHmXnyY1abppZjhPgmjRndVo06e85PCQGeuWpv7OecHRK4qVKVOhFvTHiMT0q3SKfS4Sq13G4ko7ReyT/uU6P0+rVrfW6jcNPxQa2y/PyJvpdX082DdOTlFtN84fJRwcpuSZ6/UrulWpSpXFnTp3kJJxr0tlUX9SPMUWlkSrMd1WTlhJ/mW1be5E+xGPcuy4/iKiaWX3RSC2+ZrUTdJ/0mUN5RRUd9vUlaPXBfFnZrk+66FVqXfT4Vq0NEnlY+TPj7Czq391St6GNc3jVLiK8v2P0mVjR6fThRt68KsIpJY5OWWnpx36jgrWynNSS0tctdznvKSo2Vb044nJaYpd5S2/ueqo5PNv6VxfSjStkoU9813wuz0ru+3jkw3u60+O6lDVSo1IL+FShGjnzLGp/ujymm5qS4TPqPpFb07PptvbUliNOtJLPL+HOX+Z41naevZ9Qqf+zTjJfPUv8M6y9PPlj/k4G9/wPT6DPRdtrlL90zypHf0WWL7HlI1l6Zw/2jW4ur67rVqNKtJRqt01FPGVn7L9meLVoulc6Gmmucnv9RoVLScKlulpk1HblP5nhy+KvUk3nG2fJjFrkVltEqtkkWlu/kV7vPJ0ckLdkxfxNER5ZGcSYHXBNxi1xkvCKi3N/FJ/oZKo4qON4vlG1OLlUSytL3yzNdsNIlSU5amVo04RruFR8r4X7m22Gnx7nPVp7488MjeUk7aV4xlP7Ol9zJU5PYpUrtzSayorDfk1jNY+Fp+w9M7mVbxpujlRllN8ozvLjTQdNN5l29iYV2lhJfizGs3VrJvDWOcCRrLLWOo4wejoinmnDCKfV6dVvUnGXlGnm04AXnB05OMuUVCAAAAAAAAHYAAQCQBAJAAgkACCSAJAAAAAAAAAAAAAAAAA7AAAAAIJAAAAAAAAAAAACCQAAAAAAAAN7ZJywen/AKa61LKR48JuMk0fUdKvIVKSjLkzldR145Mrqvmq9vOhNxkvxMj7C/sad1BtLc8Gp0mpFvHAmcrWfDlPTzQdU7CrHtkylb1I8xNbcrjZ7ZAlxa5WCAyAAAAAAAAAAACCQIJBAEgACDvsk6lOUUm3HsjhNKNadvUVSlJxku5MpudOvFnMM9309uhY68Sq/CuyK9R6bGdLXSWKkVx/Mjnj1l1WvXjuu8eDpj1e304lJ/8A1Z5LOSXb7eOfxOTC4b9/rwCTa5lSnXlKjlRe+Gu5geyXc2+Dlj45Wb2kABkAAHd0+hO4rQUnKNLO8kj6+3sKNtTlFR1uf2pS5Z8PO5rTwnUkkuFHZI6J9VvqtH053VRx4xkzZa3LI9Dq19Tq1PSt4pRWzk1+xXpFxRtHWr1k8QSxhZ3fY86pcepGmpPeENJm6spQUMvSnnBrX0m+9vT6x1NXz/h/YznL7nJZ9WurJaack44xpkspHK+MIiMdUsDX0m7vbpld3FxFRqVG4x7GqS0ZcsPwc0V6ba5LpubwkvxY06Y5Se12k4Pcyy1LyWa4/sVTzPxkrGWW63nLNlLDWe5zUf8AcT8Ez+yxQ++RZdvU6ffVbG6VSk09sSi+JI+v6X1WHUtaptxlBrVHhr/KPhabxJN+Dt6bdVrSvKpQlpb5TWcnPLHb0YZ6mn6PJ04081XFR/qMaVw7madCOaEdnOSaz/8AHz8+Dwul3H1lxlVmpVW92/u/I+mppKCS4RzdrJI+S+l7/i0If/Kf6JHP0O3X/T/VKz5qJpfhH/k6fpHRle9ft7Wny6cU34Tbbf5GVOtCy6Nf2ieJQqVIY/b9De+tOOv8rXymc5Z29Ei5dQj4SZwy2TS8s9Loz9C4lLS6k3T2gvL8vsdL6cMf9np9UqRp2snLlcfPsfNxp6Y7nbf3NW5uGnKLhB/d4ycksfNLuxjNQ5Mt1i2k9tzN/aZfZtvGxVLKyaYFsiho9kUUQNqOJrSzbKhScZ5ymsJdzmpvTKL9zsm1mlmCmlP7LeM5CyqSTnST0vHy4MG2mlnZdj2KU6VtSU6cVOL2cXvjfdM825xKtOcIKMW9kuxFrllvItjG/DK4xLJZ8FZQ5vHJNKbw3jOhZIxjghylGMktlJYeO5DbqpX0I4UqbXuhO/jhqFPL8vY4QDbStXdaSbSWPBkSAIBpCn6jwpQT/qeDafT7qENboylD+aPxL9CbjUwys3I5QSQVhIIJAAgkAAQBIAAAAAAAAAAAACCQAAAAAAAAAAASAA2jQlJZM505Q5Q2141UEEhk7gAAAAAAAglEEgQiQAAAAAAAAABvbXMqE008GADUurt9HbdS1pKTPQpVYVOcM+Spza4Z2UbydNrc4ZYfj6fB8iTrJ9TG1pVVwhLpNOS4PLtOqbrLPaoXsZpbnC+WL6OOPDyvJueix3xE8e46VKm3pTPspSU+GYVKEZ8oTms9mf8ATcM5vF8LOjKD3TMz6656XGom0jxLrpkqbeEenDlxyfI5/g8nE8wFp05QeGsFDq8NmvaQAEAABBIAAAAAQSAAAAgkgAT3AAnDxlp48kHRRvJUaFWi4xnTqLGJdn5RzhQABAlLYgsk2tkBUvTWWxGDlLHHzNoqKTS3aCtKdtracpKK8vuJW3ozzq1EuprllvH9i1XGhLXl9sdyOvjjrpjOLbyRHJpKLaz2fgzitVXR+pYxljo3XHBONTz3N1FLsUnFJ58lY0pKnKME3wzKDcZPw1g66k4zglHZ+DKnSdaEoR+3FOaXlLn9N/wI3rvpZPVJfI67XaLb5ZxQfjujqpPS0vYSLt6lnX9C4pVE8JSWfddz76k8xWD87s6NS6rQo0knObws8fj7H6V0ey6b062hG4r1L6olvKq3oXtGPj55Zyz078e9Pjb29p0OsX13OSctXo00ucRSTPClUne3U69ODwvjqRcvtKPdn7XTuOjzWHb2iT7OjD/BzXH0W+jfUVOSsaEJTWJStpem3+C2/Qk0ZZX1p+Gentqnw98eS8K84KooNpz2bXjwfoXW/wD+M3GnKr0m6nVa39KtjV+DXJ8NW6VdW7lGVKTcXh45T+R1mUrhcbO44m3/AFY+RSbqTSWhpfIvJSi8Sck/D2KvX7mmEaGl4KtaYk4l74KvHcCre3uyeEThZzyWUd1n8giqjybtqdJp+DKLzMsnp1r2wFUpNxksNpPsdCxqWrjO5hFaaiws43waYaWWsZBouqGjLX6dznXB1JyklqeUuERKnFrL/Qm2/C62wlhJEao+nKLhlvGJeCJcZLLDSK5sMA0qxxhozIAAAg1o3FW3lqpVJQ+TMyBZtqW43cayxVbkn8T3ZnwE2nnwb1FTq09cWlNcx8k9Na8u/tgQSQVzCSCQAAAdwAAAAAAAAAAAAAAAAAAAAAAADptaDqzWxjTg5ySR9D0uwxhtGc8tR34eO55aaUOnfw02jkvrHTF7H1lKglBLBx31snB7HjnLfJ9vP4mP9t8JOGiTRU7uoUfTqPY4T2y7j4GePjloABWAAAAAAAAEEgAAAAAAAAAAABMXhm8Xk58mkJErpjW6bT2Z1UL2dJrLyjkTySjNkvt6cc7jdx71t1JSwmz06V1GS5PkYtp5Wx00b2dPGXlHDPil9PpcHzbj1k+r1Rktjnr0Y1E8o82h1FSxud8LiNRcnnuFxfVw5uPlmq8i96enlpHi1reVNvY+wnBSRw3NnGaeUdePm11Xg+V/T5n/AJYPlwdt1ZSpNtLY4mmmeyWX0/PcnHlx3WQACuYAQBJBJAEggkAQSAAAAAAAAAAAKBvCpDjgwAGsuchTafG5RS2w+C7aWNK3A2eyXkjbGc7+BCWt4k9yJSUJYW7Mum/tqlsvBSLxV1Lgt6inBpLc3pWqrQSjnX8h67rVly6xTGOTGrhPfdnp07JpfGm/ZGrs6dShKLppRfEl9pPyYvLjHfH4XJlHk0qXqRypJPw2Yy10akZRbjKLymux7Vt0qhLm4lJ+I7HmX8dNZRis42LjnjldRjl+NycOMyz+1FLXNScIptcx2/Q1jnWjCDzFNco6YfFho6PP7fRfRyh/uVsb/YT/AH/sfSRk8bs8rocNNhTf82ZfqeskcMu69eNsxkSWjOcHmE3F+zKpE4Ibrvt+tXNDCqPXH3OTrFK16k3d0Uqdyl8S/n/5M2UlHYJXj1bGhcxxVpRn81weJf8AQHSTnat//CT5+TPq5QxLKM6sFKOcGpbGbJX57nDcZJxktmn2Ikso+g6z0tVk61FJVY8/1I+ccnF4e39jrLtwyx0pKU08YJSe7b3f6EuT75RV7rZlZSnh7LYvNfFkotl7I1dOpGhCq4tQqZ0vzgCZrRPbfPJMaib42M1LZEbphZlZ6byWlORkqmdnsRLhPsQ8R92TTVzt9M6qwn4Mk2joccowaw2iuY5tpp8FcbZ7AEAAAAABBIIAkAAQSCAJAAAAAAAAAAAAAAAAAAAAAAAAJSy8EHb0+2daqnjYW67axlyuo7+mdPziTWWfUWlsoJbGNjbKEVsenFKKwfP5eTdfo/h/GnHju+0pYRhcxTgzZs4ryuowe5yx9vdn1i+W6xBang8Q9Tqlxrm0jyz6WHp+V+TZeS6AAbeYAAAAAAAABBIAAAAAAAAAAAMBbAAawmbJ5OTODWEyWO2ObcFU8ljLtKnLW6Z0UL2dN7vKOchksl9tY55Y9x71vfxmludinGaPlVJxeYvDOy36hKGFJ7eThnw/cfS4P6hZ1m9evbRqJrGTxL3p7g3KKPXo3kZpbm04Rqx7HPHLLjvb18vDxfKx3Pb4+UXF4ZB6/ULDTmUUeQ04vDPbhlMpuPznPwZcOXjQAGnnAABBIAEEgAAAAAGQAGRkAME5Yy/IEYfhmsIbZZEYyaz2L87ZKIai+wUUnnGxrCKjzuVnNLIFJLfKIUHKSS3b7BT8l4U5zadNPbv4Ism7p6VDpde3SncU8Q5a7myuNVeHp0u+0UuTlh1CtJaas20lg6PrdOUNThmXZI898r7fXw/tSf8At3X/AH26Zzm4yqcSjzHOcovTuVWjBR/I831KdKLcZSlOS3S4RFvJwg5RzqeyTJcOnXHnvlJ/8ui3lKFy05KKXOe5yXiceoOLzjlfiatxuLiEZNJJfFLyTf01WnCpTqRUo/Dg1jdZOPLj58VmP1emdnGlTu8XGPTaz57HbKwaUqtrmcEsum/tL/J56qUq84Qk4UnB71Hnc9SldWtom1XlXl/LTjoX5suXlvcceKcdnhlrX79vpukx02FFPZ6FsejE+DuOs3dw0o1PSpriFLbH48nVafSO9oYVRqvHxPn8xrJLMfqvtCTx7P6RWlxhVG6M/E+PzPWjOM4KUWmnw0yM6GZuW5M56UzmhUc5t9glbuOUZyhszWPBEsYKw8m5WM5Pk+r26p1vVivhns17n1XUZaGsdzyOqUNdo13xkuN1Uym4+cxts9iNL7YIzjfsyU3J4TwdnndPTenVepX9O2g8at5y/lj3Z39bvKVarC1toqNvafBD3Oi2qLpHQpVI/DdXvwxfeMP/AN/Y8Oo0lhEjV6j07mwtlZxr2tZzejXOLXGyyl8tziqW86cVKUWoyWU+zPT6I7a6oVKF1LTj7MnLGDosZRha1LS4jFyoycGn3XYzvTXjL2+dk2lhoqt2e5/079YuJK3uKVOEd6nqv7C8+6K9R+jdz062VzGpC5tX/wCtS4XzXY15Ri415UUtJz1Us7Gik4to9nolWyoRrK8lKM54xhbYRb6STb50H0HXb+nojbW8MJreUuceDwsrwiQs0oC6a8RGr+lBFAXUlh5Sz4wRr/pQVUFtXsiNXsEQCc+wyBAAyAAAAAAAAAAAAAAAAAAAAAAAABMVqaR9N0i20xWx4lhQdWqnjbJ9hY0VTgjz8+epp9T+n/HvJl5X076MdEUaajLWkjGrdxgt2eKdv0PWLerVUIttnz3U71JNZLX/AFVJNJnzdzdSrSe+x6OLit7r5vzPlzGeMZVajqTbZQA9r87bu7AAEAAAAAAAAAQiQAAAAAAAAAAAAAAE8AgDSE8G8ZpnKWUsEsdMc9OoGMahopJkdZltJOAtySNLU6kqbymelbXyaSlyeYhwZyxmXt34ubLiu496U41Y45PFv7LS3OC2L0rmUHu9jq9aNWPk5TG8d3Hsz5MPk46y9vAawwdl3bqLco8HGemXcfF5MLhdUABXMAAAAAB3AAAAAAABrCoow0+lTbf3pLcxLAaeo3/wUb3CD5AvDGMyf4CVRPZLYyNKdPVv2KKnoWN0lD0pJZ7M58R8FHFRlmLwZs3NOnHncMtx11nSm2l8Ml+pnGTSxgp9pZfJeGeM4RNad7l5XaVJZ+LKXsXip3NRRisJcJcJFcI1g5Z9OnnEtm/JK1j/ACq2nrjT+zH7z7ltFHTpjOrlrdtLb5FKsdFZxfKSM28/MsnTlyclmVi87ejjZzfzwZfV47/E1gl1HulnZFIttP8APDN6cLWkacoPMZ6l4ZrGq1JRnB5fjfJhFNQk4y+Jb48llJ61qjJPs4saWZ2OlTTeFLfwzptb+5spZoVZRXePKf4HF6qeMrV7lZ1XTaxnHhksdZy/r6il9Io1oabiHpz/AJov4X/g9K1q6oLG65yfEKopLPC8nZ0/qdSxrLEm6Ofihz+Ri4/jp5SvuVLYhvY5aVzGpCM4tOMllNdy06uEYNOG9SqXEY9uTivFmLR0a/Vuaku0Fg5byWwhXylRaK04PjUzqsLVVriKk1GmvinJ8RiuWYVVquaku2p/ibur6dt6MOZvNRr9Ednm+1+oXf1y5c4rFNfDTi+0UcM3l7GyWPc53sypWlGp6c09Kks7xlwzr+vSneOs4xip4TjHhHAmXbygbe9RrTuK9KnSelYcZ4+9HG8T0ruNTp3QL71KmKV2/ToUm/6ufyR5XQYyueo2sYrFOjL1Kkn+x1fTCvK5vKMozUqEIaUl92XfP6GNdum+tvHo2Oq1ndOrTlGHMVLdfgcs6qa+FfidFCo3JOKTqLhNZz5XyMLl0al1L6tBwp52i3nH/Bpz+mFapKrPVN5fBnjJ6lpZUry2qw+zVhvGa4+TPOqU5UarhJfFEbNfamCCxD4CIGCfAwBAJZAAAAAAAAAAAAAAAAAAAAAAAAAAABQtCLnJJEJZZ2W1NRkmyW6jfHhc7p63S7ZU4ps9r1404nhwvI0YcnLcdTcsqLPFcMs7t+i4ufi+Nx6j2LrqagnueLc9TlNvDOCrXlUe7MXud8OKR835Hz887qNKlWVR7szAO8mnzcsrld0AAZAAAAAAAAAABCJAAAAAAAAAAAAAAAAAAgEgBklSaIAXbaFXBqppnIFJomm5nY7kSckarRrGsnyTTrM5WojJxezKqafckje/xq561hnFWhiWVwdBWUcoTpM75ztyAtOGllTby2aAAEAAAAIAkAACASAJGGzejZXFdpU6M5fJBZLfTFIM6qvTrqj/ALlCcfmjncJJ7rHzG1uNntTDLwk488BIlrJWWsWms5Kt/EUUGW07+4VpBx1fE8LyXjKLeDLTkmK0yTayiabnJXSkksvgmlV01E4vDXcxnNz9l2Rva2dSq1KU4UaXepVeEv8AJNfrV5Lv/FWacqkpPcwSbqvdYNK9WFJ1KdOoqjUmlOK2l7nGpNZNRyttu63y5yko/C15KrZaZbPyZqo203z5LxbccdvlkIvFTbzGO0e/gZWlYe2e3gr8OHhJPykTCSSw3KfsuComMsrxh9yK32ljZYJUKjmpcCUWsObz22CqwlKDynguqkcrPwP24M5PDWMFGsv3Isunq2vU7mxxGLUqec6Xun8j1n1ulXhiDcaj+7I+Wp1ZUnwmvD4Zo5QqNKK05+63/cxcduuPI+toL0qD1fae7Z53UbpU4ZW8uyPLh1C4to6HNyivuyMaly7hqb5XKJMVyzRL4Fl89v8AJSGW8sicnJ7vLZeL22R0cUyelGEuTfQ5e78I2h027qLVG3mo/wA0lpX6g1tx6XtsaQp1K9WMKNOU54woxWWz2qH0fp+nGrfX9GhS5ljfSvGfPsjap13p3S4ypdGtHJvmtV5l/f8AYzv8amH69Tp3RKtC3hRVSNHPxVJPeUmY38+gdObjcyd7WX3FLOPy2R81edXv73KrXElB/ch8KOBR8mZjfut3PGdYx6F91iV0pUra3pWlu9nClHeS933OajCnjnLKUmo1c42SLySbyvhflGvTGre3oSs7iz6Y7inVxGosyivB48pOU25btnVVv7iVJUXLFNLTp8nJjcRKlkPgkhlZOw3CJAqyCXyQAAAAnBGD1bDpErmn6lWThB8YW7M5ZzCbrtw8OfNl44TdeZpDi0s4eM4yfRfUbS1g5SpqWPvVHk8S7ufrFX4cRpR2hFLCRjDk87078/xLwY7zvf45gAdXiAQSAAAADsAABAEgFkmwqMFlBs1jS8mmlRRLXXHj/WcYKIdVrgrUnjYybyTW1uXj1F5VW+WUbyQDWnO5WgADIAAiCe4AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACCQAAAEqTRZVWihAalsbxreS6qpnMEyaamddMkpowlHSI1Gi0pKSBdZMwQSVzAAAIJAAAACYLMgll4RvCOle4bxx3W1CsqDT9OMn7np0fpDUoL4aMfzPHckjOVTPBi4y+3eclw9PTvuu3F099MV4R5c6s6jzJlXySnuakk9OOfJcvYmA9hvyac0lovchcBPcDaJ69l9Hb28UZaFRpy4lU2z+B4ik0XnXq1XmrVqTf9U2xd/SzX2+iu+hUbCmtF9ZzqtbutUwo/KPf8TzZdOp156rnrVmn5zKX7I81JZ4RZEmN/Vuc/HovpXTYSz/rdtNePSmclajRpzxTnTqR/miZLDeMJ/NGqo0pLOhL5GpjWbnPxVUW1lU0aOwqyoqrGjmD21RkuSf4sMaKmV4nuXV1UUJQnS+GXOndfMllhLjXHOhUpNOSqQf9SI9Sov5WvkejDqU3iEZJvj4i9ScZQaqW9Fz5yljJnbXj+PNVTO0ouPujOWze+UzrbtZxyo1IP2eUY+iqk3GGHLspbZNbZ1WD2C3L1KMqf2oSjnuUxjhgMkNjDNKFvVuaip0oOUu+O3u/AFHKU8R5a4ZvbWla6n6VtSlUljL0o+j6b0C2tqeu8nGtUnjSo/ZX+T141aFupNRwqeYtxWM/gc7n+O049+3zFl9Hp11Gpc14Uact0l8Tf9kerbdEtKcFKdJzePvzyn+Xc3neKtH+BCMqecpwm4HPedTlRpVPUnCMpLEMS1v5mbcq1McY67ajRtNdWCjCnJLG2DyeqdbpVZ/CvVcdopv4V/k8296nUuoRprMKMFhRzz8zzpS1M3MfusZcn1GlxdVbmeqrNyxwuy+SMtSxhL8SCO5tz20S2J4WSurbCIbbwgjSm1pfklbsKm+UtyEzLpMutFTbfBnCemak4xl7NbG0sOJzlhl1du2NS3qrDowg/Y5KsdE2k8rsVzgN55JJoyz8p2Ikgkrmq+SCXyQAAAHb0u0V1dLX/tw3l7+x7dz1SharTnMv5Y9jxKVy7Wz009qlV5b8I45Nt5b3PPlxf3Mt5en1eL5c+LxePHP8r7rqveoVLyW/wwXETkAO+OMxmo+dycmXJlcs7ugAK5gAAAAAAQBICWTanSzyGscbVYU3I6IU0i0YpIltIxa9GOEhwjGrUwhUq42RzttvJZGc89dRDeWADTgAAIAAAAAAAAAgkAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAQSAAAAAAAQSAATwAFAAEAAAAAAABWsElyTKquEZamyBpry61E5yyVyVRbBWdpwguSCQg9y0XhNMqFyABOdy2yWWwsm17ag7itGmpKOe8nsjW8tfqtd01NTWM6o8HJreS0ZZ7iey60t3LIgjUlyzTDVNF1Jrgw9RIlVY9s/kXaWOqMsolyOeEsPOHgtKqlyma8mfGryjGf2kmWjOrSXwtTj/LP/ACYKtFctr5lvWi1tJMl1fazc9InKLm5RTpt8wlx+BWKaWp8ou5KSw1lGLg0npeF4Zi4/jcy/XVWquq4yyltwjCc9XJEZOTw1hnbQoQptSqxTfh8RMXp0natl053eZ1JKlSW7k+X8j1Kc5WdGP1dpUXtiL3fzx/crTqYTi3JQfeE917nTChBvVOPqPhvjV4zg5279ukx16dHrKjGjOrc4pSynGa+1n9mYXdeagoas1IvaWPh52S8kObTqf9vlz7S04k/J4d3eynN06Uk1w5R2S9l/kSbXK6b3N3GnFU4S1zXLxsmedKTk2292RhJFJS7I6yacbdonPOy4KllDPOxZYS2KyootkNNFnLwE33AiL3Lpbpldk8pbhSbYHRRq6Ki1bxexStiFR4Wz3IccRcnwuPdnXKwlPpMLpPLTeV7Eajhm8xM8E5CKlu0MBgIEvggZAhkEgggkgkC05ann9PBQALbs7AAIAAAAAAAAAF6UNTz2CybaUafdm6RXUoorKskZ9vTNYxeUtKMKlXOyM5VHJlSyOeXJ+DeSACuKSCe4AAAAAAAA7gAAAAAAAAAABBICAAgkAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFyABaWOxUAKAE4KiASCCMAkAQCQUFySIrcnAAAkCASMAQyMbFiUBXBOE02nuJcYRTJGtraW1yXhTX3v0Kwlthl1sVlOIrhEqX4EZAFm3yzKcm2Wm+xXS++y9wI1ZW+5GnPG5ZJfP5k4b2y0vZAZ7xZeMZNZbaXzKy05xHMn7msI4gs7p8kXTqttMUnJLbyTN1KlZenNZxjDMcOH3nhhVmpL90Z01t6EIzpwzUmvfTsa0Lmpqzq+CL1Sb4x7nlyuZKfnwvJnUuqlWHp5SjnOEuf8k8WvLTq6j1Od3N0qOY0uPeRyJKKEY6VnuVll/I3Jpzt2OWXhceSMxRGyJTS7FRLllbIrjyXxq7lXH3Ah4XBXJZoq0BBtFKMdT57IzUe74EpZCkpOWEexO+p0FGg45iopZPF7lnJy3f6kNtbmnGFTMHmEt0YkttoJFEEFmgkEQC2CGBXBBZkAQCWQAZBLIAAAgAAAQSAAAAJbmnqYWEZgNS6S5tkZACbAO4CAIJAAAAAAAAAAAAAAABAEgAACCQAQCAIAAAAAAAAAAAAAAAAAAAAAAAAAYAAnDGAIBbBGAIBJOCioJADGwJXAaAgE4GAAJIwAIwTgkCASRgCYokRWCQBBbAwBAJAEMJNvGC2AsxeU8AUksTxkrLHYmcnKTb5IwRUZNIz8meC2Co0ymSimrCwiMtgaJ4ZEpRby1llcY55CWpgXi0Rq1TS7e4w3suEMZXhruQWjBRntjfybfC4rb8CmPhTzl+xDk0/2QaWrSa+zjBnFYWe7J3b347IzlLLYTaJSzsvzCWle5KWFkrnJReDyn5KtsmHJDTy9giCSCUBeK2DJjwRLkCjGMbssklyQ9wIc/Y1trdV225JIxaITa3WwVetRlRnpkvxI+4iXXlKOmb1L37FAie5ZI66PTXc28alvWhOf3qecSRhOlOlJxqRcZLs0NmrGTQW5aSCQEFWXZVoCpBbBAEAACASAIBJAEAsGBUAEAAAAAAAGAAGBgAAAAAAAAAAAAAAAAAAAAAAAAAECUBAAAAnAwBAJwMAQCcACASCiASCCASMFEAkEEAkYAkAFE5IzkYAVBIGAgASBAJAEAkAAAAAABInAROQIwEi2Q8oAlktjBESwFcAtjI9N6c9gSW+lcE4ICAsRP7LLbYKz+yBm4YSfkhIsxyBUlIthLnkjOOAJSRLwirkWi4PZxfzCybV5ZdLPBTK1bPbyaxawEVWxZZcudiHjOxpFYQELK+XgnYNlGBEiuEtySrAh5l7EqK+YYi34AutiJTUZeRn2IeG+MgPUg+UNKe6/UjdbpJEPPfcC62IyI8E4AgYJwAKtEYNMFQM2gXaIALMXlPD8o1dzUksTk5LxLczZCWWBdyTCIaQQB8kMl/IgCMkMkYYFSCzIAgFiAIBIAhBkjsBUEgCASMAQQWwQBGScjBIEDIwABBOBgCCRgEEYBIwBAGCcAQBgkCAAAAwAAAAAAASiCUAwST+AKKgkgAACACSAJ2GwGCgBgYAAYJw8ZAgAAASkWUE/vYApgtpNY2+t4U1kv9TqeSbXTDTtyNCfc3+p1CPqlQbNMdC8jSvJv9TqMn6lVGzTmaQOn6jV9g7Gr7Daac6jnuQ44Oj6nV8G9t0+UqiU5Rh7sWyNY43K6jgwSo5eD2J9JrSfwypSivbByVun1IVGoL4fmZmcvp1z+PyYTeUZQtFJZdSPyMpUcPCeTf6lV8pE/UanlGtuOq5/Rl3aX4keklzJHT9Sq+xP1WouVF/gNmq5NHiSLKm5PCa/M7PQkvu0/wAUTGhN/dp/hHI2ac0rOrFZUdS/peTJprZnrQUaa+Oo4/Kl/wAnPKjZ5bdWeP8A4jZquahSVSSTnGK8s6J2tGEW1cxk/CRZULNtYrtL3izVWto+LiP4jZpw+mn95L5kaMr7f4Hq07CjNJxqKS9max6XTxnTKWPA2arx4W0Z/wDqY/8A6m07XRHGcv3jg9iHTVGPwaopi4tKlVJy0ya23JtqSx4lOynN4/bBhUpODafKPYdlXjl0lTi37nM+kXMnvKH/ANi7Z081QzwyHGUX4PUh0a6eylFfIv8A6HcvOZwz7jcNV5WlYy+Rs+x6j6HcL70CP9FrrmcBuGq8tx9i0XHGMbHpLo9b/wByCLR6LPHxVl+ERuLjbHkSj8Txx7EpHsx6PBSWuvLHtA6l0uzi3hTl82NxNWvAXyNI8HtfUqMXmEfzwYVLaCbWmLY2aeXJFGj0J2k0tkjGVrXXH7lTTja3JUTd2tbnQ2QoSp4dSnLGeAaY43wluMNex1unRck9L+SZFZKpCMaVNJpmfJ2y4fGW2uKSZC53Oj6tVbxp/Un6nXzjR+qNbcdMNsB9kdH1G4fFJ/mif9Pum8ei/wAwaYaEuJfmVbw8HV/p14v/AEZfmR/pt1/7D/Fkavf05sjJ307e8pxwreL92isrC6qScnTgn4i8DZcZrpxZG52Lply/uL8zSPR7lvfSvxG4zqvPwIx7vg9J9IrLmUEWXRp/+7D8mLYsn8PMlBNbPAwscnsR6XUUdKqQXl6clX0iT5rL8Imdxv8A5HlqEWsuol7YJ9KEd/Wj+TPXj0huKi6zSXgiXRo5y6kpfMvlGfGvGlhfeT+RCWcnsPpFGOMz58h9Iim8TQ8oeNeTGlKSyovB0SsJtJwX5tHW+mpPaqk/2FSxnJLVcvYbNPPdjWXLj+ZSVrOOMuP5nVKzgnvXyYyt6cf/AFX+Rds6YSouK3lH8GRoz95fiaulSyv4m3yDpUe1V/8A1KMdKzjUhpW/xE4UZprdEN5b2AjHuMLyABGPcEt+xGpfygCCc+yGfYCATq9l+Q1MCMDAyxkAAAAAAAAAQSAAAAgEgCASAIAAAEkAQCQACBKIP//Z" />
These are GGUF quantized versions of [sophosympatheia/Midnight-Rose-70B-v2.0.3](https://huggingface.co/sophosympatheia/Midnight-Rose-70B-v2.0.3).
The importance matrix was trained for 100K tokens (200 batches of 512 tokens) using `wiki.train.raw`.
The IQ2_XXS and IQ2_XS versions are compatible with llama.cpp, version `147b17a` or later. The IQ3_XXS requires version `f4d7e54` or later.
Some model files above 50GB are split into smaller files. To concatenate them, use the `cat` command (on Windows, use PowerShell): `cat foo-Q6_K.gguf.* > foo-Q6_K.gguf` |
mradermacher/koboldai-holodeck-extended-32k-7B-GGUF | mradermacher | 2024-06-26T20:55:37Z | 509 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:grimjim/koboldai-holodeck-extended-32k-7B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-05-30T05:26:36Z | ---
base_model: grimjim/koboldai-holodeck-extended-32k-7B
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/grimjim/koboldai-holodeck-extended-32k-7B
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/koboldai-holodeck-extended-32k-7B-GGUF/resolve/main/koboldai-holodeck-extended-32k-7B.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/koboldai-holodeck-extended-32k-7B-GGUF/resolve/main/koboldai-holodeck-extended-32k-7B.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/koboldai-holodeck-extended-32k-7B-GGUF/resolve/main/koboldai-holodeck-extended-32k-7B.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/koboldai-holodeck-extended-32k-7B-GGUF/resolve/main/koboldai-holodeck-extended-32k-7B.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/koboldai-holodeck-extended-32k-7B-GGUF/resolve/main/koboldai-holodeck-extended-32k-7B.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/koboldai-holodeck-extended-32k-7B-GGUF/resolve/main/koboldai-holodeck-extended-32k-7B.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/koboldai-holodeck-extended-32k-7B-GGUF/resolve/main/koboldai-holodeck-extended-32k-7B.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/koboldai-holodeck-extended-32k-7B-GGUF/resolve/main/koboldai-holodeck-extended-32k-7B.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/koboldai-holodeck-extended-32k-7B-GGUF/resolve/main/koboldai-holodeck-extended-32k-7B.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/koboldai-holodeck-extended-32k-7B-GGUF/resolve/main/koboldai-holodeck-extended-32k-7B.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/koboldai-holodeck-extended-32k-7B-GGUF/resolve/main/koboldai-holodeck-extended-32k-7B.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/koboldai-holodeck-extended-32k-7B-GGUF/resolve/main/koboldai-holodeck-extended-32k-7B.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/koboldai-holodeck-extended-32k-7B-GGUF/resolve/main/koboldai-holodeck-extended-32k-7B.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/koboldai-holodeck-extended-32k-7B-GGUF/resolve/main/koboldai-holodeck-extended-32k-7B.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/koboldai-holodeck-extended-32k-7B-GGUF/resolve/main/koboldai-holodeck-extended-32k-7B.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/openbuddy-yi1.5-34b-v21.2-32k-GGUF | mradermacher | 2024-06-03T16:15:00Z | 509 | 0 | transformers | [
"transformers",
"gguf",
"mixtral",
"zh",
"en",
"fr",
"de",
"ja",
"ko",
"it",
"ru",
"fi",
"base_model:OpenBuddy/openbuddy-yi1.5-34b-v21.2-32k",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-03T10:58:42Z | ---
base_model: OpenBuddy/openbuddy-yi1.5-34b-v21.2-32k
language:
- zh
- en
- fr
- de
- ja
- ko
- it
- ru
- fi
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- mixtral
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/OpenBuddy/openbuddy-yi1.5-34b-v21.2-32k
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/openbuddy-yi1.5-34b-v21.2-32k-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/openbuddy-yi1.5-34b-v21.2-32k-GGUF/resolve/main/openbuddy-yi1.5-34b-v21.2-32k.Q2_K.gguf) | Q2_K | 12.9 | |
| [GGUF](https://huggingface.co/mradermacher/openbuddy-yi1.5-34b-v21.2-32k-GGUF/resolve/main/openbuddy-yi1.5-34b-v21.2-32k.IQ3_XS.gguf) | IQ3_XS | 14.3 | |
| [GGUF](https://huggingface.co/mradermacher/openbuddy-yi1.5-34b-v21.2-32k-GGUF/resolve/main/openbuddy-yi1.5-34b-v21.2-32k.Q3_K_S.gguf) | Q3_K_S | 15.1 | |
| [GGUF](https://huggingface.co/mradermacher/openbuddy-yi1.5-34b-v21.2-32k-GGUF/resolve/main/openbuddy-yi1.5-34b-v21.2-32k.IQ3_S.gguf) | IQ3_S | 15.1 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/openbuddy-yi1.5-34b-v21.2-32k-GGUF/resolve/main/openbuddy-yi1.5-34b-v21.2-32k.IQ3_M.gguf) | IQ3_M | 15.7 | |
| [GGUF](https://huggingface.co/mradermacher/openbuddy-yi1.5-34b-v21.2-32k-GGUF/resolve/main/openbuddy-yi1.5-34b-v21.2-32k.Q3_K_M.gguf) | Q3_K_M | 16.8 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/openbuddy-yi1.5-34b-v21.2-32k-GGUF/resolve/main/openbuddy-yi1.5-34b-v21.2-32k.Q3_K_L.gguf) | Q3_K_L | 18.3 | |
| [GGUF](https://huggingface.co/mradermacher/openbuddy-yi1.5-34b-v21.2-32k-GGUF/resolve/main/openbuddy-yi1.5-34b-v21.2-32k.IQ4_XS.gguf) | IQ4_XS | 18.7 | |
| [GGUF](https://huggingface.co/mradermacher/openbuddy-yi1.5-34b-v21.2-32k-GGUF/resolve/main/openbuddy-yi1.5-34b-v21.2-32k.Q4_K_S.gguf) | Q4_K_S | 19.7 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/openbuddy-yi1.5-34b-v21.2-32k-GGUF/resolve/main/openbuddy-yi1.5-34b-v21.2-32k.Q4_K_M.gguf) | Q4_K_M | 20.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/openbuddy-yi1.5-34b-v21.2-32k-GGUF/resolve/main/openbuddy-yi1.5-34b-v21.2-32k.Q5_K_S.gguf) | Q5_K_S | 23.8 | |
| [GGUF](https://huggingface.co/mradermacher/openbuddy-yi1.5-34b-v21.2-32k-GGUF/resolve/main/openbuddy-yi1.5-34b-v21.2-32k.Q5_K_M.gguf) | Q5_K_M | 24.4 | |
| [GGUF](https://huggingface.co/mradermacher/openbuddy-yi1.5-34b-v21.2-32k-GGUF/resolve/main/openbuddy-yi1.5-34b-v21.2-32k.Q6_K.gguf) | Q6_K | 28.3 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/openbuddy-yi1.5-34b-v21.2-32k-GGUF/resolve/main/openbuddy-yi1.5-34b-v21.2-32k.Q8_0.gguf) | Q8_0 | 36.7 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/Zephyrus-L1-33B-i1-GGUF | mradermacher | 2024-06-05T08:43:02Z | 509 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:Sao10K/Zephyrus-L1-33B",
"license:other",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-04T17:17:43Z | ---
base_model: Sao10K/Zephyrus-L1-33B
language:
- en
library_name: transformers
license: other
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/Sao10K/Zephyrus-L1-33B
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/Zephyrus-L1-33B-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Zephyrus-L1-33B-i1-GGUF/resolve/main/Zephyrus-L1-33B.i1-IQ1_S.gguf) | i1-IQ1_S | 7.2 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Zephyrus-L1-33B-i1-GGUF/resolve/main/Zephyrus-L1-33B.i1-IQ1_M.gguf) | i1-IQ1_M | 7.8 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Zephyrus-L1-33B-i1-GGUF/resolve/main/Zephyrus-L1-33B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 8.8 | |
| [GGUF](https://huggingface.co/mradermacher/Zephyrus-L1-33B-i1-GGUF/resolve/main/Zephyrus-L1-33B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 9.7 | |
| [GGUF](https://huggingface.co/mradermacher/Zephyrus-L1-33B-i1-GGUF/resolve/main/Zephyrus-L1-33B.i1-IQ2_S.gguf) | i1-IQ2_S | 10.5 | |
| [GGUF](https://huggingface.co/mradermacher/Zephyrus-L1-33B-i1-GGUF/resolve/main/Zephyrus-L1-33B.i1-IQ2_M.gguf) | i1-IQ2_M | 11.3 | |
| [GGUF](https://huggingface.co/mradermacher/Zephyrus-L1-33B-i1-GGUF/resolve/main/Zephyrus-L1-33B.i1-Q2_K.gguf) | i1-Q2_K | 12.1 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Zephyrus-L1-33B-i1-GGUF/resolve/main/Zephyrus-L1-33B.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 12.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Zephyrus-L1-33B-i1-GGUF/resolve/main/Zephyrus-L1-33B.i1-IQ3_XS.gguf) | i1-IQ3_XS | 13.4 | |
| [GGUF](https://huggingface.co/mradermacher/Zephyrus-L1-33B-i1-GGUF/resolve/main/Zephyrus-L1-33B.i1-IQ3_S.gguf) | i1-IQ3_S | 14.2 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Zephyrus-L1-33B-i1-GGUF/resolve/main/Zephyrus-L1-33B.i1-Q3_K_S.gguf) | i1-Q3_K_S | 14.2 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Zephyrus-L1-33B-i1-GGUF/resolve/main/Zephyrus-L1-33B.i1-IQ3_M.gguf) | i1-IQ3_M | 15.0 | |
| [GGUF](https://huggingface.co/mradermacher/Zephyrus-L1-33B-i1-GGUF/resolve/main/Zephyrus-L1-33B.i1-Q3_K_M.gguf) | i1-Q3_K_M | 15.9 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Zephyrus-L1-33B-i1-GGUF/resolve/main/Zephyrus-L1-33B.i1-Q3_K_L.gguf) | i1-Q3_K_L | 17.4 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Zephyrus-L1-33B-i1-GGUF/resolve/main/Zephyrus-L1-33B.i1-IQ4_XS.gguf) | i1-IQ4_XS | 17.4 | |
| [GGUF](https://huggingface.co/mradermacher/Zephyrus-L1-33B-i1-GGUF/resolve/main/Zephyrus-L1-33B.i1-Q4_0.gguf) | i1-Q4_0 | 18.5 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Zephyrus-L1-33B-i1-GGUF/resolve/main/Zephyrus-L1-33B.i1-Q4_K_S.gguf) | i1-Q4_K_S | 18.6 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Zephyrus-L1-33B-i1-GGUF/resolve/main/Zephyrus-L1-33B.i1-Q4_K_M.gguf) | i1-Q4_K_M | 19.7 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Zephyrus-L1-33B-i1-GGUF/resolve/main/Zephyrus-L1-33B.i1-Q5_K_S.gguf) | i1-Q5_K_S | 22.5 | |
| [GGUF](https://huggingface.co/mradermacher/Zephyrus-L1-33B-i1-GGUF/resolve/main/Zephyrus-L1-33B.i1-Q5_K_M.gguf) | i1-Q5_K_M | 23.1 | |
| [GGUF](https://huggingface.co/mradermacher/Zephyrus-L1-33B-i1-GGUF/resolve/main/Zephyrus-L1-33B.i1-Q6_K.gguf) | i1-Q6_K | 26.8 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his hardware for calculating the imatrix for these quants.
<!-- end -->
|
jeiku/qwen2base-Q4_K_M-GGUF | jeiku | 2024-06-28T22:54:33Z | 509 | 0 | null | [
"gguf",
"merge",
"mergekit",
"lazymergekit",
"maywell/Qwen2-7B-Multilingual-RP",
"jeiku/qwen2-1",
"llama-cpp",
"gguf-my-repo",
"base_model:jeiku/qwen2base",
"region:us"
]
| null | 2024-06-28T22:54:12Z | ---
base_model: jeiku/qwen2base
tags:
- merge
- mergekit
- lazymergekit
- maywell/Qwen2-7B-Multilingual-RP
- jeiku/qwen2-1
- llama-cpp
- gguf-my-repo
---
# jeiku/qwen2base-Q4_K_M-GGUF
This model was converted to GGUF format from [`jeiku/qwen2base`](https://huggingface.co/jeiku/qwen2base) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/jeiku/qwen2base) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo jeiku/qwen2base-Q4_K_M-GGUF --hf-file qwen2base-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo jeiku/qwen2base-Q4_K_M-GGUF --hf-file qwen2base-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo jeiku/qwen2base-Q4_K_M-GGUF --hf-file qwen2base-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo jeiku/qwen2base-Q4_K_M-GGUF --hf-file qwen2base-q4_k_m.gguf -c 2048
```
|
Unbabel/gec-t5_small | Unbabel | 2021-09-27T11:27:48Z | 508 | 19 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"grammatical error correction",
"text2text",
"en",
"dataset:clang-8",
"dataset:conll-14",
"dataset:conll-13",
"arxiv:2106.03830",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text2text-generation | 2022-03-02T23:29:05Z | ---
language:
- en
tags:
- grammatical error correction
- text2text
- t5
license: apache-2.0
datasets:
- clang-8
- conll-14
- conll-13
metrics:
- f0.5
---
This model is an implementation of the paper [A Simple Recipe for Multilingual Grammatical Error Correction](https://arxiv.org/pdf/2106.03830.pdf) from Google where they report the State of the art score in the task of Grammatical Error Correction (GEC).
We implement the version with the T5-small with the reported F_0.5 score in the paper (60.70).
To effectively use the "Hosted inference API", write "gec: [YOUR SENTENCE HERE]".
In order to use the model, look at the following snippet:
```python
from transformers import T5ForConditionalGeneration, T5Tokenizer
model = T5ForConditionalGeneration.from_pretrained("Unbabel/gec-t5_small")
tokenizer = T5Tokenizer.from_pretrained('t5-small')
sentence = "I like to swimming"
tokenized_sentence = tokenizer('gec: ' + sentence, max_length=128, truncation=True, padding='max_length', return_tensors='pt')
corrected_sentence = tokenizer.decode(
model.generate(
input_ids = tokenized_sentence.input_ids,
attention_mask = tokenized_sentence.attention_mask,
max_length=128,
num_beams=5,
early_stopping=True,
)[0],
skip_special_tokens=True,
clean_up_tokenization_spaces=True
)
print(corrected_sentence) # -> I like swimming.
``` |
gmihaila/wav2vec2-large-xlsr-53-romanian | gmihaila | 2024-01-02T12:27:56Z | 508 | 2 | transformers | [
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"ro",
"dataset:common_voice",
"base_model:facebook/wav2vec2-large-xlsr-53",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2022-03-02T23:29:05Z | ---
language: ro
license: apache-2.0
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
datasets:
- common_voice
base_model: facebook/wav2vec2-large-xlsr-53
model-index:
- name: XLSR Wav2Vec2 Romanian by George Mihaila
results:
- task:
type: automatic-speech-recognition
name: Speech Recognition
dataset:
name: Common Voice ro
type: common_voice
args: ro
metrics:
- type: wer
value: 28.4
name: Test WER
---
# Wav2Vec2-Large-XLSR-53-Romanian
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) in Romanian using the [Common Voice](https://huggingface.co/datasets/common_voice)
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "ro", split="test[:2%]").
processor = Wav2Vec2Processor.from_pretrained("gmihaila/wav2vec2-large-xlsr-53-romanian")
model = Wav2Vec2ForCTC.from_pretrained("gmihaila/wav2vec2-large-xlsr-53-romanian")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
\\\\tspeech_array, sampling_rate = torchaudio.load(batch["path"])
\\\\tbatch["speech"] = resampler(speech_array).squeeze().numpy()
\\\\treturn batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
\\\\tlogits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the {language} test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "ro", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("gmihaila/wav2vec2-large-xlsr-53-romanian")
model = Wav2Vec2ForCTC.from_pretrained("gmihaila/wav2vec2-large-xlsr-53-romanian")
model.to("cuda")
chars_to_ignore_regex = '[\\\\\\\\,\\\\\\\\?\\\\\\\\.\\\\\\\\!\\\\\\\\-\\\\\\\\;\\\\\\\\:\\\\\\\\"\\\\\\\\“]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
\\\\tbatch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
\\\\tspeech_array, sampling_rate = torchaudio.load(batch["path"])
\\\\tbatch["speech"] = resampler(speech_array).squeeze().numpy()
\\\\treturn batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
\\\\tinputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
\\\\twith torch.no_grad():
\\\\t\\\\tlogits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
\\\\tbatch["pred_strings"] = processor.batch_decode(pred_ids)
\\\\treturn batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 28.43 %
## Training
The Common Voice `train`, `validation` datasets were used for training.
The script used for training can be found [here](https://colab.research.google.com/github/gmihaila/ml_things/blob/master/notebooks/pytorch/RO_Fine_Tune_XLSR_Wav2Vec2_on_Turkish_ASR_with_🤗_Transformers.ipynb) |
nvidia/stt_es_conformer_transducer_large | nvidia | 2022-10-29T00:19:16Z | 508 | 3 | nemo | [
"nemo",
"automatic-speech-recognition",
"speech",
"audio",
"Transducer",
"Conformer",
"Transformer",
"pytorch",
"NeMo",
"hf-asr-leaderboard",
"es",
"dataset:Fisher",
"dataset:VoxPopuli",
"dataset:facebook/multilingual_librispeech",
"dataset:mozilla-foundation/common_voice_7_0",
"arxiv:2005.08100",
"license:cc-by-4.0",
"model-index",
"region:us"
]
| automatic-speech-recognition | 2022-07-08T18:26:51Z | ---
language:
- es
library_name: nemo
datasets:
- Fisher
- VoxPopuli
- facebook/multilingual_librispeech
- mozilla-foundation/common_voice_7_0
thumbnail: null
tags:
- automatic-speech-recognition
- speech
- audio
- Transducer
- Conformer
- Transformer
- pytorch
- NeMo
- hf-asr-leaderboard
license: cc-by-4.0
model-index:
- name: stt_es_conformer_transducer_large
results:
- task:
type: Automatic Speech Recognition
name: speech-recognition
dataset:
name: common-voice-7-0-6
type: mozilla-foundation/common_voice_7_0
config: es
split: dev
args:
language: es
metrics:
- name: Dev WER
type: wer
value: 4.6
- task:
type: Automatic Speech Recognition
name: speech-recognition
dataset:
name: common-voice-7-0-6
type: mozilla-foundation/common_voice_7_0
config: es
split: test
args:
language: es
metrics:
- name: Test WER
type: wer
value: 5.2
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Multilingual LibriSpeech
type: facebook/multilingual_librispeech
config: spanish
split: dev
args:
language: es
metrics:
- name: Dev WER
type: wer
value: 2.7
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Multilingual LibriSpeech
type: facebook/multilingual_librispeech
config: spanish
split: test
args:
language: es
metrics:
- name: Test WER
type: wer
value: 3.2
---
# NVIDIA Conformer-Transducer Large (es)
<style>
img {
display: inline;
}
</style>
| [](#model-architecture)
| [](#model-architecture)
| [](#datasets)
This model transcribes speech in lowercase Spanish alphabet including spaces, and was trained on a composite dataset comprising of 1340 hours of Spanish speech. It is a "large" variant of Conformer-Transducer, with around 120 million parameters.
See the [model architecture](#model-architecture) section and [NeMo documentation](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/main/asr/models.html#conformer-transducer) for complete architecture details.
## NVIDIA NeMo: Training
To train, fine-tune or play with the model you will need to install [NVIDIA NeMo](https://github.com/NVIDIA/NeMo). We recommend you install it after you've installed latest Pytorch version.
```
pip install nemo_toolkit['all']
```
## How to Use this Model
The model is available for use in the NeMo toolkit [3], and can be used as a pre-trained checkpoint for inference or for fine-tuning on another dataset.
### Automatically instantiate the model
```python
import nemo.collections.asr as nemo_asr
asr_model = nemo_asr.models.EncDecRNNTBPEModel.from_pretrained("nvidia/stt_es_conformer_transducer_large")
```
### Transcribing using Python
First, let's get a sample
```
wget https://dldata-public.s3.us-east-2.amazonaws.com/2086-149220-0033.wav
```
Then simply do:
```
asr_model.transcribe(['2086-149220-0033.wav'])
```
### Transcribing many audio files
```shell
python [NEMO_GIT_FOLDER]/examples/asr/transcribe_speech.py
pretrained_name="nvidia/stt_es_conformer_transducer_large"
audio_dir="<DIRECTORY CONTAINING AUDIO FILES>"
```
### Input
This model accepts 16000 Hz Mono-channel Audio (wav files) as input.
### Output
This model provides transcribed speech as a string for a given audio sample.
## Model Architecture
Conformer-Transducer model is an autoregressive variant of Conformer model [1] for Automatic Speech Recognition which uses Transducer loss/decoding instead of CTC Loss. You may find more info on the detail of this model here: [Conformer-Transducer Model](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/main/asr/models.html).
## Training
The NeMo toolkit [3] was used for training the models for over several hundred epochs. These model are trained with this [example script](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/asr_transducer/speech_to_text_rnnt_bpe.py) and this [base config](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/conf/conformer/conformer_transducer_bpe.yaml).
The tokenizers for these models were built using the text transcripts of the train set with this [script](https://github.com/NVIDIA/NeMo/blob/main/scripts/tokenizers/process_asr_text_tokenizer.py).
### Datasets
All the models in this collection are trained on a composite dataset (NeMo ASRSET) comprising of 1340 hours of Spanish speech:
- Mozilla Common Voice 7.0 (Spanish) - 289 hours after data cleaning
- Multilingual LibriSpeech (Spanish) - 801 hours after data cleaning
- Voxpopuli transcribed subset (Spanish) - 110 hours after data cleaning
- Fisher dataset (Spanish) - 140 hours after data cleaning
## Performance
The list of the available models in this collection is shown in the following table. Performances of the ASR models are reported in terms of Word Error Rate (WER%) with greedy decoding.
| Version | Tokenizer | Vocabulary Size | MCV 7.0 Dev | MCV 7.0 Test | MLS Dev | MLS Test | Voxpopuli Dev | Voxpopuli Test | Fisher Dev | Fisher Test| Train Dataset |
|---------|-----------------------|-----------------|-------------|--------------|---------|----------|---------------|----------------|------------|-------------|-----------------|
| 1.8.0 | SentencePiece Unigram | 1024 | 4.6 | 5.2 | 2.7 | 3.2 | 4.7 | 6.0 | 14.7 | 14.8 | NeMo ASRSET 2.0 |
## Limitations
Since this model was trained on publicly available speech datasets, the performance of this model might degrade for speech which includes technical terms, or vernacular that the model has not been trained on. The model might also perform worse for accented speech.
## NVIDIA Riva: Deployment
[NVIDIA Riva](https://developer.nvidia.com/riva), is an accelerated speech AI SDK deployable on-prem, in all clouds, multi-cloud, hybrid, on edge, and embedded.
Additionally, Riva provides:
* World-class out-of-the-box accuracy for the most common languages with model checkpoints trained on proprietary data with hundreds of thousands of GPU-compute hours
* Best in class accuracy with run-time word boosting (e.g., brand and product names) and customization of acoustic model, language model, and inverse text normalization
* Streaming speech recognition, Kubernetes compatible scaling, and enterprise-grade support
Although this model isn’t supported yet by Riva, the [list of supported models is here](https://huggingface.co/models?other=Riva).
Check out [Riva live demo](https://developer.nvidia.com/riva#demos).
## References
- [1] [Conformer: Convolution-augmented Transformer for Speech Recognition](https://arxiv.org/abs/2005.08100)
- [2] [Google Sentencepiece Tokenizer](https://github.com/google/sentencepiece)
- [3] [NVIDIA NeMo Toolkit](https://github.com/NVIDIA/NeMo)
## Licence
License to use this model is covered by the [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/). By downloading the public and release version of the model, you accept the terms and conditions of the [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/) license.
|
teknium/OpenHermes-7B | teknium | 2023-09-24T11:03:27Z | 508 | 13 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"llama-2",
"instruct",
"finetune",
"alpaca",
"gpt4",
"synthetic data",
"distillation",
"en",
"dataset:teknium/openhermes",
"base_model:NousResearch/Llama-2-7b-hf",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2023-09-14T10:22:23Z | ---
base_model: NousResearch/Llama-2-7b-hf
tags:
- llama-2
- instruct
- finetune
- alpaca
- gpt4
- synthetic data
- distillation
datasets:
- teknium/openhermes
model-index:
- name: openhermes-7b
results: []
license: mit
language:
- en
---
# OpenHermes-7B

## Model description
OpenHermes 7B is the first fine tune of the Hermes dataset that has a fully open source dataset!
What is unique about this 7B model is that it used sample packing, which speeds up training by many multiples if the dataset token averages arent near the max sequence length.
OpenHermes was trained on 242,000 entries of primarily GPT-4 generated data, from open datasets across the AI landscape, including:
- GPTeacher - General Instruct, Roleplay v1, Roleplay v2, and Code Instruct Datasets, by Teknium
- WizardLM (v1, evol_instruct 70k), by WizardLM Team/nlpxucan
- Airoboros GPT-4 (v1.0), by JonDurbin
- Camel-AI's domain expert datasets, by the Camel-AI Team
- CodeAlpaca, by Sahil2801
- GPT4-LLM and Unnatural Instructions, by Microsoft
Filtering included removal of OpenAI refusals, disclaimers, and "As an AI" type examples and more
The base dataset mix the model was trained on is identical to Nous-Hermes', minus the Nous-Instruct and PDACTL datasets which were private datasets.
The WANDB Project is public and can be examined at this link: https://wandb.ai/teknium1/openhermes/runs/openhermes-v2-qlora-7b-packed
Huge thank you to [main_horse](https://twitter.com/main_horse) for compute access and a16z for sponsoring my work, and all the dataset creators and other people who's work has contributed to this project!
## Benchmark Information
## Benchmark Results
GPT-4All Benchmark Set
```
| Task |Version| Metric |Value | |Stderr|
|-------------|------:|--------|-----:|---|-----:|
|arc_challenge| 0|acc |0.4727|± |0.0146|
| | |acc_norm|0.4957|± |0.0146|
|arc_easy | 0|acc |0.7862|± |0.0084|
| | |acc_norm|0.7643|± |0.0087|
|boolq | 1|acc |0.7801|± |0.0072|
|hellaswag | 0|acc |0.5789|± |0.0049|
| | |acc_norm|0.7654|± |0.0042|
|openbookqa | 0|acc |0.3480|± |0.0213|
| | |acc_norm|0.4500|± |0.0223|
|piqa | 0|acc |0.7867|± |0.0096|
| | |acc_norm|0.7938|± |0.0094|
|winogrande | 0|acc |0.7048|± |0.0128|
Average: 0.679
```
BigBench:
```
| Task |Version| Metric |Value | |Stderr|
|------------------------------------------------|------:|---------------------|-----:|---|-----:|
|bigbench_causal_judgement | 0|multiple_choice_grade|0.5000|± |0.0364|
|bigbench_date_understanding | 0|multiple_choice_grade|0.5908|± |0.0256|
|bigbench_disambiguation_qa | 0|multiple_choice_grade|0.3023|± |0.0286|
|bigbench_geometric_shapes | 0|multiple_choice_grade|0.1003|± |0.0159|
| | |exact_str_match |0.0000|± |0.0000|
|bigbench_logical_deduction_five_objects | 0|multiple_choice_grade|0.2520|± |0.0194|
|bigbench_logical_deduction_seven_objects | 0|multiple_choice_grade|0.1871|± |0.0148|
|bigbench_logical_deduction_three_objects | 0|multiple_choice_grade|0.3833|± |0.0281|
|bigbench_movie_recommendation | 0|multiple_choice_grade|0.2500|± |0.0194|
|bigbench_navigate | 0|multiple_choice_grade|0.5000|± |0.0158|
|bigbench_reasoning_about_colored_objects | 0|multiple_choice_grade|0.4370|± |0.0111|
|bigbench_ruin_names | 0|multiple_choice_grade|0.2679|± |0.0209|
|bigbench_salient_translation_error_detection | 0|multiple_choice_grade|0.2495|± |0.0137|
|bigbench_snarks | 0|multiple_choice_grade|0.5249|± |0.0372|
|bigbench_sports_understanding | 0|multiple_choice_grade|0.5406|± |0.0159|
|bigbench_temporal_sequences | 0|multiple_choice_grade|0.2470|± |0.0136|
|bigbench_tracking_shuffled_objects_five_objects | 0|multiple_choice_grade|0.1944|± |0.0112|
|bigbench_tracking_shuffled_objects_seven_objects| 0|multiple_choice_grade|0.1509|± |0.0086|
|bigbench_tracking_shuffled_objects_three_objects| 0|multiple_choice_grade|0.3833|± |0.0281|
Average: 0.3367
```
AGI Eval
```
| Task |Version| Metric |Value | |Stderr|
|------------------------------|------:|--------|-----:|---|-----:|
|agieval_aqua_rat | 0|acc |0.2441|± |0.0270|
| | |acc_norm|0.2402|± |0.0269|
|agieval_logiqa_en | 0|acc |0.2458|± |0.0169|
| | |acc_norm|0.2965|± |0.0179|
|agieval_lsat_ar | 0|acc |0.2522|± |0.0287|
| | |acc_norm|0.2130|± |0.0271|
|agieval_lsat_lr | 0|acc |0.2745|± |0.0198|
| | |acc_norm|0.2686|± |0.0196|
|agieval_lsat_rc | 0|acc |0.2900|± |0.0277|
| | |acc_norm|0.2379|± |0.0260|
|agieval_sat_en | 0|acc |0.4466|± |0.0347|
| | |acc_norm|0.3738|± |0.0338|
|agieval_sat_en_without_passage| 0|acc |0.3738|± |0.0338|
| | |acc_norm|0.3301|± |0.0328|
|agieval_sat_math | 0|acc |0.2318|± |0.0285|
| | |acc_norm|0.1864|± |0.0263|
Average: 0.2683
```
TruthfulQA:
```
hf-causal-experimental (pretrained=teknium/OpenHermes-7B,dtype=float16), limit: None, provide_description: False, num_fewshot: 0, batch_size: 8
| Task |Version|Metric|Value | |Stderr|
|-------------|------:|------|-----:|---|-----:|
|truthfulqa_mc| 1|mc2 |0.4542|± |0.0148|
```
## Training procedure

|
second-state/OpenHermes-2.5-Mistral-7B-GGUF | second-state | 2024-03-20T07:48:59Z | 508 | 4 | transformers | [
"transformers",
"gguf",
"mistral",
"text-generation",
"instruct",
"finetune",
"chatml",
"gpt4",
"synthetic data",
"distillation",
"en",
"base_model:teknium/OpenHermes-2.5-Mistral-7B",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2023-11-12T13:27:11Z | ---
base_model: teknium/OpenHermes-2.5-Mistral-7B
inference: false
language:
- en
license: apache-2.0
model-index:
- name: OpenHermes-2-Mistral-7B
results: []
model_creator: Teknium
model_name: Openhermes 2.5 Mistral 7B
model_type: mistral
tags:
- mistral
- instruct
- finetune
- chatml
- gpt4
- synthetic data
- distillation
quantized_by: Second State Inc.
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://github.com/LlamaEdge/LlamaEdge/raw/dev/assets/logo.svg" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# OpenHermes-2.5-Mistral-7B-GGUF
## Original Model
[teknium/OpenHermes-2.5-Mistral-7B](https://huggingface.co/teknium/OpenHermes-2.5-Mistral-7B)
## Run with LlamaEdge
- LlamaEdge version: [v0.2.8](https://github.com/LlamaEdge/LlamaEdge/releases/tag/0.2.8) and above
- Prompt template
- Prompt type: `chatml`
- Prompt string
```text
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
- Reverse prompt: `<|im_end|>`
- Run as LlamaEdge service
```bash
wasmedge --dir .:. --nn-preload default:GGML:AUTO:OpenHermes-2.5-Mistral-7B-Q5_K_M.gguf llama-api-server.wasm -p chatml -r '<|im_end|>'
```
- Context size: `4096`
- Run as LlamaEdge command app
```bash
wasmedge --dir .:. --nn-preload default:GGML:AUTO:OpenHermes-2.5-Mistral-7B-Q5_K_M.gguf llama-chat.wasm -p chatml -r '<|im_end|>'
```
## Quantized GGUF Models
| Name | Quant method | Bits | Size | Use case |
| ---- | ---- | ---- | ---- | ----- |
| [OpenHermes-2.5-Mistral-7B-Q2_K.gguf](https://huggingface.co/second-state/OpenHermes-2.5-Mistral-7B-GGUF/blob/main/OpenHermes-2.5-Mistral-7B-Q2_K.gguf) | Q2_K | 2 | 3.08 GB| smallest, significant quality loss - not recommended for most purposes |
| [OpenHermes-2.5-Mistral-7B-Q3_K_L.gguf](https://huggingface.co/second-state/OpenHermes-2.5-Mistral-7B-GGUF/blob/main/OpenHermes-2.5-Mistral-7B-Q3_K_L.gguf) | Q3_K_L | 3 | 3.82 GB| small, substantial quality loss |
| [OpenHermes-2.5-Mistral-7B-Q3_K_M.gguf](https://huggingface.co/second-state/OpenHermes-2.5-Mistral-7B-GGUF/blob/main/OpenHermes-2.5-Mistral-7B-Q3_K_M.gguf) | Q3_K_M | 3 | 3.52 GB| very small, high quality loss |
| [OpenHermes-2.5-Mistral-7B-Q3_K_S.gguf](https://huggingface.co/second-state/OpenHermes-2.5-Mistral-7B-GGUF/blob/main/OpenHermes-2.5-Mistral-7B-Q3_K_S.gguf) | Q3_K_S | 3 | 3.16 GB| very small, high quality loss |
| [OpenHermes-2.5-Mistral-7B-Q4_0.gguf](https://huggingface.co/second-state/OpenHermes-2.5-Mistral-7B-GGUF/blob/main/OpenHermes-2.5-Mistral-7B-Q4_0.gguf) | Q4_0 | 4 | 4.11 GB| legacy; small, very high quality loss - prefer using Q3_K_M |
| [OpenHermes-2.5-Mistral-7B-Q4_K_M.gguf](https://huggingface.co/second-state/OpenHermes-2.5-Mistral-7B-GGUF/blob/main/OpenHermes-2.5-Mistral-7B-Q4_K_M.gguf) | Q4_K_M | 4 | 4.37 GB| medium, balanced quality - recommended |
| [OpenHermes-2.5-Mistral-7B-Q4_K_S.gguf](https://huggingface.co/second-state/OpenHermes-2.5-Mistral-7B-GGUF/blob/main/OpenHermes-2.5-Mistral-7B-Q4_K_S.gguf) | Q4_K_S | 4 | 4.14 GB| small, greater quality loss |
| [OpenHermes-2.5-Mistral-7B-Q5_0.gguf](https://huggingface.co/second-state/OpenHermes-2.5-Mistral-7B-GGUF/blob/main/OpenHermes-2.5-Mistral-7B-Q5_0.gguf) | Q5_0 | 5 | 5 GB| legacy; medium, balanced quality - prefer using Q4_K_M |
| [OpenHermes-2.5-Mistral-7B-Q5_K_M.gguf](https://huggingface.co/second-state/OpenHermes-2.5-Mistral-7B-GGUF/blob/main/OpenHermes-2.5-Mistral-7B-Q5_K_M.gguf) | Q5_K_M | 5 | 5.13 GB| large, very low quality loss - recommended |
| [OpenHermes-2.5-Mistral-7B-Q5_K_S.gguf](https://huggingface.co/second-state/OpenHermes-2.5-Mistral-7B-GGUF/blob/main/OpenHermes-2.5-Mistral-7B-Q5_K_S.gguf) | Q5_K_S | 5 | 5 GB| large, low quality loss - recommended |
| [OpenHermes-2.5-Mistral-7B-Q6_K.gguf](https://huggingface.co/second-state/OpenHermes-2.5-Mistral-7B-GGUF/blob/main/OpenHermes-2.5-Mistral-7B-Q6_K.gguf) | Q6_K | 6 | 5.94 GB| very large, extremely low quality loss |
| [OpenHermes-2.5-Mistral-7B-Q8_0.gguf](https://huggingface.co/second-state/OpenHermes-2.5-Mistral-7B-GGUF/blob/main/OpenHermes-2.5-Mistral-7B-Q8_0.gguf) | Q8_0 | 8 | 7.7 GB| very large, extremely low quality loss - not recommended |
|
mradermacher/StarfishRP-GGUF | mradermacher | 2024-05-06T05:41:52Z | 508 | 0 | transformers | [
"transformers",
"gguf",
"rp",
"roleplay",
"en",
"base_model:Fredithefish/StarfishRP",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-03-29T04:53:59Z | ---
base_model: Fredithefish/StarfishRP
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- rp
- roleplay
---
## About
static quants of https://huggingface.co/Fredithefish/StarfishRP
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/StarfishRP-GGUF/resolve/main/StarfishRP.Q2_K.gguf) | Q2_K | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/StarfishRP-GGUF/resolve/main/StarfishRP.IQ3_XS.gguf) | IQ3_XS | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/StarfishRP-GGUF/resolve/main/StarfishRP.Q3_K_S.gguf) | Q3_K_S | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/StarfishRP-GGUF/resolve/main/StarfishRP.IQ3_S.gguf) | IQ3_S | 3.4 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/StarfishRP-GGUF/resolve/main/StarfishRP.IQ3_M.gguf) | IQ3_M | 3.5 | |
| [GGUF](https://huggingface.co/mradermacher/StarfishRP-GGUF/resolve/main/StarfishRP.Q3_K_M.gguf) | Q3_K_M | 3.8 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/StarfishRP-GGUF/resolve/main/StarfishRP.Q3_K_L.gguf) | Q3_K_L | 4.1 | |
| [GGUF](https://huggingface.co/mradermacher/StarfishRP-GGUF/resolve/main/StarfishRP.IQ4_XS.gguf) | IQ4_XS | 4.2 | |
| [GGUF](https://huggingface.co/mradermacher/StarfishRP-GGUF/resolve/main/StarfishRP.Q4_0.gguf) | Q4_0 | 4.4 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/StarfishRP-GGUF/resolve/main/StarfishRP.Q4_K_S.gguf) | Q4_K_S | 4.4 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/StarfishRP-GGUF/resolve/main/StarfishRP.IQ4_NL.gguf) | IQ4_NL | 4.4 | prefer IQ4_XS |
| [GGUF](https://huggingface.co/mradermacher/StarfishRP-GGUF/resolve/main/StarfishRP.Q4_K_M.gguf) | Q4_K_M | 4.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/StarfishRP-GGUF/resolve/main/StarfishRP.Q5_K_S.gguf) | Q5_K_S | 5.3 | |
| [GGUF](https://huggingface.co/mradermacher/StarfishRP-GGUF/resolve/main/StarfishRP.Q5_K_M.gguf) | Q5_K_M | 5.4 | |
| [GGUF](https://huggingface.co/mradermacher/StarfishRP-GGUF/resolve/main/StarfishRP.Q6_K.gguf) | Q6_K | 6.2 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/StarfishRP-GGUF/resolve/main/StarfishRP.Q8_0.gguf) | Q8_0 | 7.9 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/Llama3-8B-DPO-uncensored-GGUF | mradermacher | 2024-05-05T15:09:06Z | 508 | 1 | transformers | [
"transformers",
"gguf",
"en",
"base_model:shauray/Llama3-8B-DPO-uncensored",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-25T16:58:11Z | ---
base_model: shauray/Llama3-8B-DPO-uncensored
language:
- en
library_name: transformers
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 1 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: -->
<!-- ### vocab_type: -->
static quants of https://huggingface.co/shauray/Llama3-8B-DPO-uncensored
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Llama3-8B-DPO-uncensored-GGUF/resolve/main/Llama3-8B-DPO-uncensored.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Llama3-8B-DPO-uncensored-GGUF/resolve/main/Llama3-8B-DPO-uncensored.IQ3_XS.gguf) | IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/Llama3-8B-DPO-uncensored-GGUF/resolve/main/Llama3-8B-DPO-uncensored.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama3-8B-DPO-uncensored-GGUF/resolve/main/Llama3-8B-DPO-uncensored.IQ3_S.gguf) | IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Llama3-8B-DPO-uncensored-GGUF/resolve/main/Llama3-8B-DPO-uncensored.IQ3_M.gguf) | IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Llama3-8B-DPO-uncensored-GGUF/resolve/main/Llama3-8B-DPO-uncensored.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Llama3-8B-DPO-uncensored-GGUF/resolve/main/Llama3-8B-DPO-uncensored.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/Llama3-8B-DPO-uncensored-GGUF/resolve/main/Llama3-8B-DPO-uncensored.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/Llama3-8B-DPO-uncensored-GGUF/resolve/main/Llama3-8B-DPO-uncensored.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama3-8B-DPO-uncensored-GGUF/resolve/main/Llama3-8B-DPO-uncensored.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama3-8B-DPO-uncensored-GGUF/resolve/main/Llama3-8B-DPO-uncensored.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/Llama3-8B-DPO-uncensored-GGUF/resolve/main/Llama3-8B-DPO-uncensored.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama3-8B-DPO-uncensored-GGUF/resolve/main/Llama3-8B-DPO-uncensored.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Llama3-8B-DPO-uncensored-GGUF/resolve/main/Llama3-8B-DPO-uncensored.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Llama3-8B-DPO-uncensored-GGUF/resolve/main/Llama3-8B-DPO-uncensored.f16.gguf) | f16 | 16.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
hardikpatel/GPT2_Music_Generation_Trained | hardikpatel | 2024-04-28T18:33:45Z | 508 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-28T18:29:16Z | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: lmd-8bars-2048-epochs10
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# lmd-8bars-2048-epochs10
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0086
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 8
- eval_batch_size: 4
- seed: 1
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.01
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 2.4182 | 0.5 | 4994 | 1.4933 |
| 1.4626 | 1.0 | 9988 | 1.3082 |
| 1.3176 | 1.5 | 14982 | 1.2276 |
| 1.2604 | 2.0 | 19976 | 1.1815 |
| 1.2101 | 2.5 | 24970 | 1.1499 |
| 1.1804 | 3.0 | 29964 | 1.1260 |
| 1.1517 | 3.5 | 34958 | 1.1043 |
| 1.1349 | 4.0 | 39952 | 1.0887 |
| 1.1133 | 4.5 | 44946 | 1.0762 |
| 1.0995 | 5.0 | 49940 | 1.0618 |
| 1.0824 | 5.5 | 54934 | 1.0507 |
| 1.0713 | 6.0 | 59928 | 1.0423 |
| 1.0552 | 6.5 | 64922 | 1.0328 |
| 1.0505 | 7.0 | 69916 | 1.0279 |
| 1.0365 | 7.5 | 74910 | 1.0217 |
| 1.0307 | 8.0 | 79904 | 1.0153 |
| 1.022 | 8.5 | 84898 | 1.0107 |
| 1.0189 | 9.0 | 89892 | 1.0090 |
| 1.0129 | 9.5 | 94886 | 1.0084 |
| 1.0139 | 10.0 | 99880 | 1.0086 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
mradermacher/L3-8B-Stheno-v3.1-i1-GGUF | mradermacher | 2024-05-24T01:03:53Z | 508 | 1 | transformers | [
"transformers",
"gguf",
"en",
"base_model:Sao10K/L3-8B-Stheno-v3.1",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-05-22T06:33:55Z | ---
base_model: Sao10K/L3-8B-Stheno-v3.1
language:
- en
library_name: transformers
license: cc-by-nc-4.0
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
weighted/imatrix quants of https://huggingface.co/Sao10K/L3-8B-Stheno-v3.1
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/L3-8B-Stheno-v3.1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Stheno-v3.1-i1-GGUF/resolve/main/L3-8B-Stheno-v3.1.i1-IQ1_S.gguf) | i1-IQ1_S | 2.1 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Stheno-v3.1-i1-GGUF/resolve/main/L3-8B-Stheno-v3.1.i1-IQ1_M.gguf) | i1-IQ1_M | 2.3 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Stheno-v3.1-i1-GGUF/resolve/main/L3-8B-Stheno-v3.1.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.5 | |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Stheno-v3.1-i1-GGUF/resolve/main/L3-8B-Stheno-v3.1.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.7 | |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Stheno-v3.1-i1-GGUF/resolve/main/L3-8B-Stheno-v3.1.i1-IQ2_S.gguf) | i1-IQ2_S | 2.9 | |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Stheno-v3.1-i1-GGUF/resolve/main/L3-8B-Stheno-v3.1.i1-IQ2_M.gguf) | i1-IQ2_M | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Stheno-v3.1-i1-GGUF/resolve/main/L3-8B-Stheno-v3.1.i1-Q2_K.gguf) | i1-Q2_K | 3.3 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Stheno-v3.1-i1-GGUF/resolve/main/L3-8B-Stheno-v3.1.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 3.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Stheno-v3.1-i1-GGUF/resolve/main/L3-8B-Stheno-v3.1.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Stheno-v3.1-i1-GGUF/resolve/main/L3-8B-Stheno-v3.1.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.8 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Stheno-v3.1-i1-GGUF/resolve/main/L3-8B-Stheno-v3.1.i1-IQ3_S.gguf) | i1-IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Stheno-v3.1-i1-GGUF/resolve/main/L3-8B-Stheno-v3.1.i1-IQ3_M.gguf) | i1-IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Stheno-v3.1-i1-GGUF/resolve/main/L3-8B-Stheno-v3.1.i1-Q3_K_M.gguf) | i1-Q3_K_M | 4.1 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Stheno-v3.1-i1-GGUF/resolve/main/L3-8B-Stheno-v3.1.i1-Q3_K_L.gguf) | i1-Q3_K_L | 4.4 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Stheno-v3.1-i1-GGUF/resolve/main/L3-8B-Stheno-v3.1.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.5 | |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Stheno-v3.1-i1-GGUF/resolve/main/L3-8B-Stheno-v3.1.i1-Q4_0.gguf) | i1-Q4_0 | 4.8 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Stheno-v3.1-i1-GGUF/resolve/main/L3-8B-Stheno-v3.1.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.8 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Stheno-v3.1-i1-GGUF/resolve/main/L3-8B-Stheno-v3.1.i1-Q4_K_M.gguf) | i1-Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Stheno-v3.1-i1-GGUF/resolve/main/L3-8B-Stheno-v3.1.i1-Q5_K_S.gguf) | i1-Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Stheno-v3.1-i1-GGUF/resolve/main/L3-8B-Stheno-v3.1.i1-Q5_K_M.gguf) | i1-Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/L3-8B-Stheno-v3.1-i1-GGUF/resolve/main/L3-8B-Stheno-v3.1.i1-Q6_K.gguf) | i1-Q6_K | 6.7 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
thesven/openchat-3.6-8b-20240522-GGUF | thesven | 2024-05-30T11:48:11Z | 508 | 0 | transformers | [
"transformers",
"gguf",
"openchat",
"llama3",
"C-RLFT",
"text-generation",
"arxiv:2309.11235",
"base_model:meta-llama/Meta-Llama-3-8B",
"license:llama3",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-05-25T22:13:18Z | ---
license: llama3
base_model: meta-llama/Meta-Llama-3-8B
tags:
- openchat
- llama3
- C-RLFT
library_name: transformers
pipeline_tag: text-generation
---
## Quantization Description
This repo holds GGUF Quantizations of the openchat-3.6-8b-20240522 model.
<div style="text-align: center;">
<a href="https://github.com/thesven/GGUF-n-Go">
<img src="https://github.com/thesven/GGUF-n-Go/blob/main/assets/quantized_with.png?raw=true" alt="image/png" style="max-width: 350px;">
</a>
</div>
### Prompt Template
```bash
<|begin_of_text|><|start_header_id|>System<|end_header_id|>
{system}<|eot_id|><|start_header_id|>GPT4 Correct User<|end_header_id|>
{prompt}<|eot_id|><|start_header_id|>GPT4 Correct Assistant<|end_header_id|>
```
## ORIGINAL MODEL CARD
<div align="center">
<img src="https://raw.githubusercontent.com/imoneoi/openchat/master/assets/logo_new.png" style="width: 65%">
<h1>Advancing Open-source Language Models with Mixed-Quality Data</h1>
</div>
<p align="center" style="margin-top: 0px;">
<a href="https://openchat.team">
<img src="https://github.com/alpayariyak/openchat/blob/master/assets/logo_nobg.png?raw=true" alt="OpenChat Logo" style="width:20px; vertical-align: middle; display: inline-block; margin-right: 5px; margin-left: 10px; margin-top: 0px; margin-bottom: 0px;"/>
<span class="link-text" style=" margin-right: 5px;">Online Demo</span>
</a> |
<a href="https://github.com/imoneoi/openchat">
<img src="https://github.githubassets.com/assets/GitHub-Mark-ea2971cee799.png" alt="GitHub Logo" style="width:20px; vertical-align: middle; display: inline-block; margin-right: 5px; margin-left: 5px; margin-top: 0px; margin-bottom: 0px;"/>
<span class="link-text" style=" margin-right: 5px;">GitHub</span>
</a> |
<a href="https://arxiv.org/pdf/2309.11235.pdf">
<img src="https://github.com/alpayariyak/openchat/blob/master/assets/arxiv-logomark-small-square-border.png?raw=true" alt="ArXiv Logo" style="width:20px; vertical-align: middle; display: inline-block; margin-right: 5px; margin-left: 5px; margin-top: 0px; margin-bottom: 0px;"/>
<span class="link-text" style="margin-right: 5px;">Paper</span>
</a> |
<a href="https://discord.gg/pQjnXvNKHY">
<img src="https://cloud.githubusercontent.com/assets/6291467/26705903/96c2d66e-477c-11e7-9f4e-f3c0efe96c9a.png" alt="Discord Logo" style="width:20px; vertical-align: middle; display: inline-block; margin-right: 5px; margin-left: 5px; margin-top: 0px; margin-bottom: 0px;"/>
<span class="link-text">Discord</span>
</a>
</p>
<p align="center" style="margin-top: 0px;">
<span class="link-text" style=" margin-right: 0px; font-size: 0.8em">Sponsored by RunPod</span>
<img src="https://styles.redditmedia.com/t5_6075m3/styles/profileIcon_71syco7c5lt81.png?width=256&height=256&frame=1&auto=webp&crop=256:256,smart&s=24bd3c71dc11edc5d4f88d0cbc1da72ed7ae1969" alt="RunPod Logo" style="width:30px; vertical-align: middle; display: inline-block; margin-right: 5px; margin-left: 5px; margin-top: 0px; margin-bottom: 0px;"/>
</p>
<div style="background-color: white; padding: 0.7em; border-radius: 0.5em; color: black; display: flex; flex-direction: column; justify-content: center; text-align: center">
<a href="https://huggingface.co/openchat/openchat-3.5-0106" style="text-decoration: none; color: black;">
<span style="font-size: 1.7em; font-family: 'Helvetica'; letter-spacing: 0.1em; font-weight: bold; color: black;">Llama 3 Version: OPENCHAT</span><span style="font-size: 1.8em; font-family: 'Helvetica'; color: #3c72db; ">3.6</span>
<span style="font-size: 1.0em; font-family: 'Helvetica'; color: white; background-color: #90e0ef; vertical-align: top; border-radius: 6em; padding: 0.066em 0.4em; letter-spacing: 0.1em; font-weight: bold;">20240522</span>
<span style="font-size: 0.85em; font-family: 'Helvetica'; color: black;">
<br> 🏆 The Overall Best Performing Open-source 8B Model 🏆
<br> 🚀 Outperforms Llama-3-8B-Instruct and open-source finetunes/merges 🚀
</span>
</a>
</div>
<div style="display: flex; justify-content: center; align-items: center; width: 110%; margin-left: -5%;">
<img src="https://raw.githubusercontent.com/imoneoi/openchat/master/assets/benchmarks-openchat-3.6-20240522.svg" style="width: 100%; border-radius: 1em">
</div>
<div style="display: flex; justify-content: center; align-items: center">
<p>* Llama-3-Instruct often fails to follow the few-shot templates. See <a href="https://huggingface.co/openchat/openchat-3.6-8b-20240522/discussions/6">example</a>.</p>
</div>
<div align="center">
<h2> Usage </h2>
</div>
To use this model, we highly recommend installing the OpenChat package by following the [installation guide](https://github.com/imoneoi/openchat#installation) in our repository and using the OpenChat OpenAI-compatible API server by running the serving command from the table below. The server is optimized for high-throughput deployment using [vLLM](https://github.com/vllm-project/vllm) and can run on a consumer GPU with 24GB RAM. To enable tensor parallelism, append `--tensor-parallel-size N` to the serving command.
Once started, the server listens at `localhost:18888` for requests and is compatible with the [OpenAI ChatCompletion API specifications](https://platform.openai.com/docs/api-reference/chat). Please refer to the example request below for reference. Additionally, you can use the [OpenChat Web UI](https://github.com/imoneoi/openchat#web-ui) for a user-friendly experience.
If you want to deploy the server as an online service, you can use `--api-keys sk-KEY1 sk-KEY2 ...` to specify allowed API keys and `--disable-log-requests --disable-log-stats --log-file openchat.log` for logging only to a file. For security purposes, we recommend using an [HTTPS gateway](https://fastapi.tiangolo.com/es/deployment/concepts/#security-https) in front of the server.
| Model | Size | Context | Weights | Serving |
|-----------------------|------|---------|-------------------------------------------------------------------------|---------------------------------------------------------------------------------------|
| OpenChat-3.6-20240522 | 8B | 8192 | [Huggingface](https://huggingface.co/openchat/openchat-3.6-8b-20240522) | `python -m ochat.serving.openai_api_server --model openchat/openchat-3.6-8b-20240522` |
<details>
<summary>Example request (click to expand)</summary>
```bash
curl http://localhost:18888/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "openchat_3.6",
"messages": [{"role": "user", "content": "You are a large language model named OpenChat. Write a poem to describe yourself"}]
}'
```
</details>
### Conversation templates
💡 **Default Mode**: Best for coding, chat and general tasks.
It's a modified version of the Llama 3 Instruct template, the only difference is role names, which are either `GPT4 Correct User` or `GPT4 Correct Assistant`
```
<|start_header_id|>GPT4 Correct User<|end_header_id|>\n\nHello<|eot_id|><|start_header_id|>GPT4 Correct Assistant<|end_header_id|>\n\nHi<|eot_id|><|start_header_id|>GPT4 Correct User<|end_header_id|>\n\nHow are you today?<|eot_id|><|start_header_id|>GPT4 Correct Assistant<|end_header_id|>\n\n
```
⚠️ **Notice:** Remember to set `<|eot_id|>` as end of generation token.
The default template is also available as the integrated `tokenizer.chat_template`, which can be used instead of manually specifying the template:
```python
messages = [
{"role": "user", "content": "Hello"},
{"role": "assistant", "content": "Hi"},
{"role": "user", "content": "How are you today?"}
]
tokens = tokenizer.apply_chat_template(messages, add_generation_prompt=True)
```
## Inference using Transformers
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "openchat/openchat-3.6-8b-20240522"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.bfloat16, device_map="auto")
messages = [
{"role": "user", "content": "Explain how large language models work in detail."},
]
input_ids = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to(model.device)
outputs = model.generate(input_ids,
do_sample=True,
temperature=0.5,
max_new_tokens=1024
)
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))
```
<div align="center">
<h2> Limitations </h2>
</div>
**Foundation Model Limitations**
Despite its advanced capabilities, OpenChat is still bound by the limitations inherent in its foundation models. These limitations may impact the model's performance in areas such as:
- Complex reasoning
- Mathematical and arithmetic tasks
- Programming and coding challenges
**Hallucination of Non-existent Information**
OpenChat may sometimes generate information that does not exist or is not accurate, also known as "hallucination". Users should be aware of this possibility and verify any critical information obtained from the model.
**Safety**
OpenChat may sometimes generate harmful, hate speech, biased responses, or answer unsafe questions. It's crucial to apply additional AI safety measures in use cases that require safe and moderated responses.
<div align="center">
<h2> 💌 Contact </h2>
</div>
We look forward to hearing from you and collaborating on this exciting project!
**Project Lead:**
- Guan Wang [imonenext at gmail dot com]
- [Alpay Ariyak](https://github.com/alpayariyak) [aariyak at wpi dot edu]
<div align="center">
<h2> Citation </h2>
</div>
```
@article{wang2023openchat,
title={OpenChat: Advancing Open-source Language Models with Mixed-Quality Data},
author={Wang, Guan and Cheng, Sijie and Zhan, Xianyuan and Li, Xiangang and Song, Sen and Liu, Yang},
journal={arXiv preprint arXiv:2309.11235},
year={2023}
}
``` |
cpm-ai/Ocelot-Ko-self-instruction-10.8B-v1.0 | cpm-ai | 2024-06-26T05:18:40Z | 508 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"pytorch",
"conversational",
"ko",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-05-27T08:17:23Z | ---
library_name: transformers
tags:
- pytorch
license: apache-2.0
language:
- ko
pipeline_tag: text-generation
---
<p align="left">
<img src="https://huggingface.co/cpm-ai/Ocelot-Ko-self-instruction-10.8B-v1.0/resolve/main/ocelot.webp" width="50%"/>
<p>
# solar-kor-resume
> Update @ 2024.05.27: First release of Ocelot-Ko-self-instruction-10.8B-v1.0
<!-- Provide a quick summary of what the model is/does. -->
This model card corresponds to the 10.8B Instruct version of the **Solar-Ko** model.
The train wad done on A100-80GB
**Resources and Technical Documentation**:
* [Solar Model](https://huggingface.co/yanolja/EEVE-Korean-Instruct-10.8B-v1.0)
**Citation**
```bibtex
@misc {cpm-ai/Ocelot-Ko-self-instruction-10.8B-v1.0,
author = { {frcp, nebchi, pepperonipizza97} },
title = { solar-kor-resume},
year = 2024,
url = { https://huggingface.co/cpm-ai/Ocelot-Ko-self-instruction-10.8B-v1.0 },
publisher = { Hugging Face }
}
```
**Model Developers**: frcp, nebchi, pepperonipizza97
## Model Information
Resume Proofreading and evaluation of inputs and outputs.
### Description
It has been trained with a large amount of Korean tokens compared to other LLMs, enabling it to generate high-quality Korean text.
**Model Architecture** Solar is an auto-regressive language model that is scaled using the DUS method.
*You can find dataset list here: https://huggingface.co/datasets/cpm-ai/gpt-self-introduction-all
### Inputs and outputs
* **Input:** Text string, such as a question, a prompt, or a document to be
Proofreaded.
* **Output:** Generated Korea text in response to the input, such
as an answer to a question, or a evaluation of a resume.
#### Running the model on a single / multi GPU
```python
# pip install accelerate, flash_attn, sentencepiece
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("cpm-ai/Ocelot-Ko-self-instruction-10.8B-v1.0")
model = AutoModelForCausalLM.from_pretrained("cpm-ai/Ocelot-Ko-self-instruction-10.8B-v1.0", device_map="auto")
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer, max_new_tokens=4096, streamer=streamer)
text = 너는 자기소개서 첨삭 전문가야.
주어진 자기소개서를 첨삭해서 다시 작성해야해.
출력형식은 다음을 지켜야해.
[첨삭]
다음이 자기소개서야 :
[저는 어린 시절부터 완벽주의적인 성격을 가지고 있었습니다. 이로 인해 항상 자신의 능력에 대한 불안감을 느끼며 과도한 스트레스를 받아왔습니다. 학창 시절에는 과제나 프로젝트를 완벽하게 마무리하지 못하면 자존감이 크게 흔들렸습니다. 중학교 시절에는 한 가지 문제에 너무 오랜 시간을 투자하여 다른 학습 기회를 놓치기도 했습니다. 이러한 경험들은 저에게 완벽함을 추구하는 것이 종종 현실에 부적합하다는 것을 깨달게 했습니다.
고등학교와 대학교에 진학하면서도 이러한 완벽주의적인 성격을 극복하기 위해 노력했습니다. 하지만 여전히 실패를 받아들이는 것이 어렵고, 자신의 한계를 인정하는 것이 어려웠습니다. 이러한 과정을 통해 완벽함에 대한 강박이 저의 성장과정을 제약하는 요인이 되었음을 깨달았습니다.]"""
messages = [
{
"role": "user",
"content": "{}".format(text)
}
]
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(
prompt,
temperature=0.2,
add_special_tokens=True
)
print(outputs[0]["generated_text"][len(prompt):])
```
### results
```python
[첨삭]
어린 시절부터 저는 완벽한 결과를 추구하며 스스로를 압박해온 성격이었습니다. 이는 학업과 관련된 스트레스로 이어져, 과제를 완수하더라도 만족보다는 불만족의 감정이 더 컸던 시기였습니다. 특히 중학교 때 한 문제를 해결하기 위해 지나치게 오랫동안 매달려 결국 중요한 시기를 놓친 경험은 제 성장에 큰 영향을 미쳤습니다. 이 과정에서 완벽주의를 추구하는 것이 현실적이지 않을 수 있다는 사실을 깨닫기 시작했습니다.
고등학교와 대학에서는 이러한 성향을 개선하고자 다양한 노력을 기울였습니다. 예를 들어, 목표를 세분화하고 단계별로 접근하면서 성취감과 자신감을 키우기 위해 노력했습니다. 또한, 팀 프로젝트에서 역할을 분담하고 협력함으로써 개인의 한계보다 전체 성과를 우선시하는 법을 배웠습니다. 비록 아직 완벽함이라는 굴레로부터 완전히 자유로워지지는 못했지만, 이를 극복하고 성장할 수 있는 방법을 찾았다는 점에서 자부심을 느낍니다.
```
### Evaluation Results - LogicKor
<!DOCTYPE html>
<html lang="ko">
<head>
<meta charset="UTF-8">
<title>Evaluation Results-LogicKor</title>
<style>
table {
width: 100%;
border-collapse: collapse;
margin: 25px 0;
font-size: 18px;
text-align: left;
}
th, td {
padding: 12px 15px;
}
th {
background-color: #f2f2f2;
}
tr:nth-of-type(even) {
background-color: #f9f9f9;
}
tr:hover {
background-color: #f1f1f1;
}
</style>
</head>
<body>
<table border="1">
<thead>
<tr>
<th>Model</th>
<th>글쓰기</th>
<th>이해</th>
<th>문법</th>
</tr>
</thead>
<tbody>
<tr>
<td>HyperClovaX</td>
<td>8.50</td>
<td>9.50</td>
<td><b>8.50</b></td>
</tr>
<tr>
<td>solar-1-mini-chat</td>
<td>8.50</td>
<td>7.00</td>
<td>5.21</td>
</tr>
<tr>
<td>allganize/Llama-3-Alpha-Ko-8B-Instruct</td>
<td>8.50</td>
<td>8.35</td>
<td>4.92</td>
</tr>
<tr>
<td>Synatra-kiqu-7B</td>
<td>4.42</td>
<td>5.71</td>
<td>4.50</td>
</tr>
<tr>
<td><b>Ocelot-ko-10.8B</b></td>
<td><b>8.57</b></td>
<td>7.00</td>
<td>6.57</td>
</tr>
</tbody>
</table>
</body>
</html>
### Evaluation Results - Kobest
| 모델 명칭 |**Average**<br>n=0 n=5 |HellaSwag<br>n=0 n=5 |COPA<br> n=0 n=5 |BooIQ<br>n=0 n=5 |
|------------------ |------------------------------|------------------------------|------------------------------|------------------------------|
| KoGPT | 58.2 63.7 | 55.9 58.3 | 73.5 72.9 | 45.1 59.8 |
| Polyglot-ko-13B | 62.4 68.2 |**59.5** **63.1** |**79.4** 81.1 | 48.2 60.4 |
| LLaMA 2-13B | 45.2 60.5 | 41.3 44.0 | 59.3 63.8 | 34.9 73.8 |
| Baichuan 2-13B | 52.7 53.9 | 39.2 39.6 | 60.6 60.6 | 58.4 61.5 |
| QWEN-14B | 47.8 66.4 | 45.3 46.8 | 64.9 68.9 | 33.4 83.5 |
| Orion-14B-Chat | 68.8 73.2 | 47.0 49.6 | 77.7 79.4 | 81.6 90.7 |
| **Ocelot-ko-10.8B** |**72.5** **75.9** | 50.0 51.4 | 75.8 **82.5** |**91.7** **93.8**|
### Software
Training was done using QLoRA
--- |
allagmaroua/my-distillbert-model1 | allagmaroua | 2024-06-20T16:04:29Z | 508 | 0 | transformers | [
"transformers",
"pytorch",
"distilbert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2024-06-20T16:02:11Z | # My Awesome Model
This is the model card for my DistillBERT model. |
mradermacher/Chakma_GPTv3-GGUF | mradermacher | 2024-07-01T00:56:40Z | 508 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:samCkma/Chakma_GPTv3",
"endpoints_compatible",
"region:us"
]
| null | 2024-07-01T00:53:10Z | ---
base_model: samCkma/Chakma_GPTv3
language:
- en
library_name: transformers
quantized_by: mradermacher
tags: []
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/samCkma/Chakma_GPTv3
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Chakma_GPTv3-GGUF/resolve/main/Chakma_GPTv3.Q2_K.gguf) | Q2_K | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/Chakma_GPTv3-GGUF/resolve/main/Chakma_GPTv3.IQ3_XS.gguf) | IQ3_XS | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/Chakma_GPTv3-GGUF/resolve/main/Chakma_GPTv3.IQ3_S.gguf) | IQ3_S | 0.2 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Chakma_GPTv3-GGUF/resolve/main/Chakma_GPTv3.Q3_K_S.gguf) | Q3_K_S | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/Chakma_GPTv3-GGUF/resolve/main/Chakma_GPTv3.IQ3_M.gguf) | IQ3_M | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/Chakma_GPTv3-GGUF/resolve/main/Chakma_GPTv3.Q3_K_M.gguf) | Q3_K_M | 0.2 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Chakma_GPTv3-GGUF/resolve/main/Chakma_GPTv3.Q3_K_L.gguf) | Q3_K_L | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/Chakma_GPTv3-GGUF/resolve/main/Chakma_GPTv3.IQ4_XS.gguf) | IQ4_XS | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/Chakma_GPTv3-GGUF/resolve/main/Chakma_GPTv3.Q4_K_S.gguf) | Q4_K_S | 0.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Chakma_GPTv3-GGUF/resolve/main/Chakma_GPTv3.Q4_K_M.gguf) | Q4_K_M | 0.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Chakma_GPTv3-GGUF/resolve/main/Chakma_GPTv3.Q5_K_S.gguf) | Q5_K_S | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/Chakma_GPTv3-GGUF/resolve/main/Chakma_GPTv3.Q5_K_M.gguf) | Q5_K_M | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/Chakma_GPTv3-GGUF/resolve/main/Chakma_GPTv3.Q6_K.gguf) | Q6_K | 0.2 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Chakma_GPTv3-GGUF/resolve/main/Chakma_GPTv3.Q8_0.gguf) | Q8_0 | 0.3 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Chakma_GPTv3-GGUF/resolve/main/Chakma_GPTv3.f16.gguf) | f16 | 0.4 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
timm/convnext_tiny_hnf.a2h_in1k | timm | 2024-02-10T23:27:34Z | 507 | 0 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2201.03545",
"license:apache-2.0",
"region:us"
]
| image-classification | 2022-12-13T07:15:35Z | ---
license: apache-2.0
library_name: timm
tags:
- image-classification
- timm
datasets:
- imagenet-1k
---
# Model card for convnext_tiny_hnf.a2h_in1k
A ConvNeXt image classification model. Trained in `timm` on ImageNet-1k by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 28.6
- GMACs: 4.5
- Activations (M): 13.4
- Image size: train = 224 x 224, test = 288 x 288
- **Papers:**
- A ConvNet for the 2020s: https://arxiv.org/abs/2201.03545
- **Original:** https://github.com/huggingface/pytorch-image-models
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('convnext_tiny_hnf.a2h_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnext_tiny_hnf.a2h_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 96, 56, 56])
# torch.Size([1, 192, 28, 28])
# torch.Size([1, 384, 14, 14])
# torch.Size([1, 768, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnext_tiny_hnf.a2h_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 768, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
All timing numbers from eager model PyTorch 1.13 on RTX 3090 w/ AMP.
| model |top1 |top5 |img_size|param_count|gmacs |macts |samples_per_sec|batch_size|
|------------------------------------------------------------------------------------------------------------------------------|------|------|--------|-----------|------|------|---------------|----------|
| [convnextv2_huge.fcmae_ft_in22k_in1k_512](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_512) |88.848|98.742|512 |660.29 |600.81|413.07|28.58 |48 |
| [convnextv2_huge.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_384) |88.668|98.738|384 |660.29 |337.96|232.35|50.56 |64 |
| [convnext_xxlarge.clip_laion2b_soup_ft_in1k](https://huggingface.co/timm/convnext_xxlarge.clip_laion2b_soup_ft_in1k) |88.612|98.704|256 |846.47 |198.09|124.45|122.45 |256 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384) |88.312|98.578|384 |200.13 |101.11|126.74|196.84 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k_384) |88.196|98.532|384 |197.96 |101.1 |126.74|128.94 |128 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320) |87.968|98.47 |320 |200.13 |70.21 |88.02 |283.42 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k_384) |87.75 |98.556|384 |350.2 |179.2 |168.99|124.85 |192 |
| [convnextv2_base.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k_384) |87.646|98.422|384 |88.72 |45.21 |84.49 |209.51 |256 |
| [convnext_large.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k_384) |87.476|98.382|384 |197.77 |101.1 |126.74|194.66 |256 |
| [convnext_large_mlp.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_augreg_ft_in1k) |87.344|98.218|256 |200.13 |44.94 |56.33 |438.08 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k) |87.26 |98.248|224 |197.96 |34.4 |43.13 |376.84 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384) |87.138|98.212|384 |88.59 |45.21 |84.49 |365.47 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k) |87.002|98.208|224 |350.2 |60.98 |57.5 |368.01 |256 |
| [convnext_base.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k_384) |86.796|98.264|384 |88.59 |45.21 |84.49 |366.54 |256 |
| [convnextv2_base.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k) |86.74 |98.022|224 |88.72 |15.38 |28.75 |624.23 |256 |
| [convnext_large.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k) |86.636|98.028|224 |197.77 |34.4 |43.13 |581.43 |256 |
| [convnext_base.clip_laiona_augreg_ft_in1k_384](https://huggingface.co/timm/convnext_base.clip_laiona_augreg_ft_in1k_384) |86.504|97.97 |384 |88.59 |45.21 |84.49 |368.14 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k) |86.344|97.97 |256 |88.59 |20.09 |37.55 |816.14 |256 |
| [convnextv2_huge.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in1k) |86.256|97.75 |224 |660.29 |115.0 |79.07 |154.72 |256 |
| [convnext_small.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_small.in12k_ft_in1k_384) |86.182|97.92 |384 |50.22 |25.58 |63.37 |516.19 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in1k) |86.154|97.68 |256 |88.59 |20.09 |37.55 |819.86 |256 |
| [convnext_base.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k) |85.822|97.866|224 |88.59 |15.38 |28.75 |1037.66 |256 |
| [convnext_small.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k_384) |85.778|97.886|384 |50.22 |25.58 |63.37 |518.95 |256 |
| [convnextv2_large.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in1k) |85.742|97.584|224 |197.96 |34.4 |43.13 |375.23 |256 |
| [convnext_small.in12k_ft_in1k](https://huggingface.co/timm/convnext_small.in12k_ft_in1k) |85.174|97.506|224 |50.22 |8.71 |21.56 |1474.31 |256 |
| [convnext_tiny.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k_384) |85.118|97.608|384 |28.59 |13.14 |39.48 |856.76 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k_384) |85.112|97.63 |384 |28.64 |13.14 |39.48 |491.32 |256 |
| [convnextv2_base.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in1k) |84.874|97.09 |224 |88.72 |15.38 |28.75 |625.33 |256 |
| [convnext_small.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k) |84.562|97.394|224 |50.22 |8.71 |21.56 |1478.29 |256 |
| [convnext_large.fb_in1k](https://huggingface.co/timm/convnext_large.fb_in1k) |84.282|96.892|224 |197.77 |34.4 |43.13 |584.28 |256 |
| [convnext_tiny.in12k_ft_in1k](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k) |84.186|97.124|224 |28.59 |4.47 |13.44 |2433.7 |256 |
| [convnext_tiny.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k_384) |84.084|97.14 |384 |28.59 |13.14 |39.48 |862.95 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k) |83.894|96.964|224 |28.64 |4.47 |13.44 |1452.72 |256 |
| [convnext_base.fb_in1k](https://huggingface.co/timm/convnext_base.fb_in1k) |83.82 |96.746|224 |88.59 |15.38 |28.75 |1054.0 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k_384) |83.37 |96.742|384 |15.62 |7.22 |24.61 |801.72 |256 |
| [convnext_small.fb_in1k](https://huggingface.co/timm/convnext_small.fb_in1k) |83.142|96.434|224 |50.22 |8.71 |21.56 |1464.0 |256 |
| [convnextv2_tiny.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in1k) |82.92 |96.284|224 |28.64 |4.47 |13.44 |1425.62 |256 |
| [convnext_tiny.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k) |82.898|96.616|224 |28.59 |4.47 |13.44 |2480.88 |256 |
| [convnext_nano.in12k_ft_in1k](https://huggingface.co/timm/convnext_nano.in12k_ft_in1k) |82.282|96.344|224 |15.59 |2.46 |8.37 |3926.52 |256 |
| [convnext_tiny_hnf.a2h_in1k](https://huggingface.co/timm/convnext_tiny_hnf.a2h_in1k) |82.216|95.852|224 |28.59 |4.47 |13.44 |2529.75 |256 |
| [convnext_tiny.fb_in1k](https://huggingface.co/timm/convnext_tiny.fb_in1k) |82.066|95.854|224 |28.59 |4.47 |13.44 |2346.26 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k) |82.03 |96.166|224 |15.62 |2.46 |8.37 |2300.18 |256 |
| [convnextv2_nano.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in1k) |81.83 |95.738|224 |15.62 |2.46 |8.37 |2321.48 |256 |
| [convnext_nano_ols.d1h_in1k](https://huggingface.co/timm/convnext_nano_ols.d1h_in1k) |80.866|95.246|224 |15.65 |2.65 |9.38 |3523.85 |256 |
| [convnext_nano.d1h_in1k](https://huggingface.co/timm/convnext_nano.d1h_in1k) |80.768|95.334|224 |15.59 |2.46 |8.37 |3915.58 |256 |
| [convnextv2_pico.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_pico.fcmae_ft_in1k) |80.304|95.072|224 |9.07 |1.37 |6.1 |3274.57 |256 |
| [convnext_pico.d1_in1k](https://huggingface.co/timm/convnext_pico.d1_in1k) |79.526|94.558|224 |9.05 |1.37 |6.1 |5686.88 |256 |
| [convnext_pico_ols.d1_in1k](https://huggingface.co/timm/convnext_pico_ols.d1_in1k) |79.522|94.692|224 |9.06 |1.43 |6.5 |5422.46 |256 |
| [convnextv2_femto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_femto.fcmae_ft_in1k) |78.488|93.98 |224 |5.23 |0.79 |4.57 |4264.2 |256 |
| [convnext_femto_ols.d1_in1k](https://huggingface.co/timm/convnext_femto_ols.d1_in1k) |77.86 |93.83 |224 |5.23 |0.82 |4.87 |6910.6 |256 |
| [convnext_femto.d1_in1k](https://huggingface.co/timm/convnext_femto.d1_in1k) |77.454|93.68 |224 |5.22 |0.79 |4.57 |7189.92 |256 |
| [convnextv2_atto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_atto.fcmae_ft_in1k) |76.664|93.044|224 |3.71 |0.55 |3.81 |4728.91 |256 |
| [convnext_atto_ols.a2_in1k](https://huggingface.co/timm/convnext_atto_ols.a2_in1k) |75.88 |92.846|224 |3.7 |0.58 |4.11 |7963.16 |256 |
| [convnext_atto.d2_in1k](https://huggingface.co/timm/convnext_atto.d2_in1k) |75.664|92.9 |224 |3.7 |0.55 |3.81 |8439.22 |256 |
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{liu2022convnet,
author = {Zhuang Liu and Hanzi Mao and Chao-Yuan Wu and Christoph Feichtenhofer and Trevor Darrell and Saining Xie},
title = {A ConvNet for the 2020s},
journal = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2022},
}
```
|
NbAiLabBeta/nb-whisper-large | NbAiLabBeta | 2024-01-27T13:10:25Z | 507 | 8 | transformers | [
"transformers",
"pytorch",
"jax",
"tensorboard",
"onnx",
"safetensors",
"whisper",
"automatic-speech-recognition",
"audio",
"asr",
"hf-asr-leaderboard",
"no",
"nb",
"nn",
"en",
"dataset:NbAiLab/ncc_speech",
"dataset:NbAiLab/NST",
"dataset:NbAiLab/NPSC",
"arxiv:2212.04356",
"base_model:openai/whisper-large",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2024-01-09T18:18:51Z | ---
license: apache-2.0
language:
- 'no'
- nb
- nn
- en
datasets:
- NbAiLab/ncc_speech
- NbAiLab/NST
- NbAiLab/NPSC
base_model: openai/whisper-large
tags:
- audio
- asr
- automatic-speech-recognition
- hf-asr-leaderboard
metrics:
- wer
- cer
library_name: transformers
pipeline_tag: automatic-speech-recognition
widget:
- src: https://datasets-server.huggingface.co/assets/google/fleurs/--/nb_no/train/1/audio/audio.mp3
example_title: FLEURS sample 1
- src: https://datasets-server.huggingface.co/assets/google/fleurs/--/nb_no/train/4/audio/audio.mp3
example_title: FLEURS sample 2
---
# NB-Whisper Large (Release Candidate)
**IMPORTANT:** These models are currently Release Candidates. We are in the final stages of testing. If everything proceeds smoothly, we plan to officially release the models later this month.
Introducing the **_Norwegian NB-Whisper Large model_**, proudly developed by the National Library of Norway. NB-Whisper is a cutting-edge series of models designed for automatic speech recognition (ASR) and speech translation. These models are based on the work of [OpenAI's Whisper](https://arxiv.org/abs/2212.04356). Each model in the series has been trained for 250,000 steps, utilizing a diverse dataset of 8 million samples. These samples consist of aligned audio clips, each 30 seconds long, culminating in a staggering 66,000 hours of speech. For an in-depth understanding of our training methodology and dataset composition, keep an eye out for our upcoming article.
| Model Size | Parameters | Model |
|------------|------------|------------|
| Tiny | 39M | [NB-Whisper Tiny](https://huggingface.co/NbAiLabBeta/nb-whisper-tiny) |
| Base | 74M | [NB-Whisper Base](https://huggingface.co/NbAiLabBeta/nb-whisper-base) |
| Small | 244M | [NB-Whisper Small](https://huggingface.co/NbAiLabBeta/nb-whisper-small) |
| Medium | 769M | [NB-Whisper Medium](https://huggingface.co/NbAiLabBeta/nb-whisper-medium) |
| Large | 1550M | [NB-Whisper Large](https://huggingface.co/NbAiLabBeta/nb-whisper-large) |
### Specialised Models
While the main models are suitable for most transcription task, we demonstrate how easy it is to change the output of the main model. The following models are trained 250 additional steps from the main models above, and might be suitable for more targetted use cases:
- **Verbatim version**: This lower-cased variant is more literal and suitable for tasks requiring detailed transcription, such as linguistic analysis.
- **Semantic version**: This variant focuses less on verbatim accuracy but captures the essence of content, ideal for meeting minutes and subtitling.
| Model Size | Parameters | Verbatim version | Semantic version |
|------------|------------|------------|------------------|
| Tiny | 39M | [Tiny - verbatim](https://huggingface.co/NbAiLabBeta/nb-whisper-tiny-verbatim) | [Tiny - semantic](https://huggingface.co/NbAiLabBeta/nb-whisper-tiny-semantic) |
| Base | 74M | [Base - verbatim](https://huggingface.co/NbAiLabBeta/nb-whisper-base-verbatim) | [Base - semantic](https://huggingface.co/NbAiLabBeta/nb-whisper-base-semantic) |
| Small | 244M | [Small - verbatim](https://huggingface.co/NbAiLabBeta/nb-whisper-small-verbatim) | [Small - semantic](https://huggingface.co/NbAiLabBeta/nb-whisper-small-semantic) |
| Medium | 769M | [Medium - verbatim](https://huggingface.co/NbAiLabBeta/nb-whisper-medium-verbatim) | [Medium - semantic](https://huggingface.co/NbAiLabBeta/nb-whisper-medium-semantic) |
| Large | 1550M | [Large - verbatim](https://huggingface.co/NbAiLabBeta/nb-whisper-large-verbatim) | [Large - semantic](https://huggingface.co/NbAiLabBeta/nb-whisper-large-semantic) |
### Model Description
- **Developed by:** [NB AI-Lab](https://ai.nb.no/)
- **Shared by:** [NB AI-Lab](https://ai.nb.no/)
- **Model type:** `whisper`
- **Language(s) (NLP):** Norwegian, Norwegian Bokmål, Norwegian Nynorsk, English
- **License:** [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0)
- **Trained from model:** [openai/whisper-large](https://huggingface.co/openai/whisper-large)
- **Code Repository:** https://github.com/NbAiLab/nb-whisper/
- **Paper:** _Coming soon_
- **Demo:** _See Spaces on this page_
## How to Use the Models
### Online Demos
You can try the models directly through the HuggingFace Inference API, accessible on the right side of this page. Be aware that initially, the model needs to load and will run on limited CPU capacity, which might be slow. To enhance your experience, we are temporarily hosting some models on TPUs for a few days, significantly boosting their performance. Explore these under the **Spaces** section on the [Main Page](https://huggingface.co/NbAiLabBeta/).
### Local Setup with HuggingFace
Alternatively, you can run the models locally. The Tiny, Base, and Small models are optimized for CPU execution. For the Medium and Large models, we recommend a system equipped with a GPU to ensure efficient processing. Setting up and using these models with HuggingFace's Transformers is straightforward, provided you have [Python](https://www.python.org/downloads/) installed on your machine. For practical demonstrations, refer to examples using this [sample mp3 file](https://github.com/NbAiLab/nb-whisper/raw/main/audio/king.mp3).
```bash
# Download the sample file
$ wget -N https://github.com/NbAiLab/nb-whisper/raw/main/audio/king.mp3
# Install necessary libraries.
$ pip install transformers>=4.35.2
```
After this is done, you should be able to run this in Python:
```python
from transformers import pipeline
# Load the model
asr = pipeline("automatic-speech-recognition", "NbAiLabBeta/nb-whisper-large")
#transcribe
asr("king.mp3", generate_kwargs={'task': 'transcribe', 'language': 'no'})
```
<details>
<summary>Expected output</summary>
```json
{
{'text': ' Nordmenn er nordlendinger, trøndere, sørlendinger og folk fra alle andre regioner. Nordmenn er også innvandret fra Afghanistan, Pakistan, Polen, Sverige, Somalia og Syria. Det er ikke alltid så lett å si hvor vi er fra, hvilken nasjonalitet vi er fra. Hvilken nasjonalitet vi er fra. Hvilken nasjonalitet vi er fra. Hvilken nasjonalitet vi er fra. Hvilken nasjonalitet vi er fra. Hvilken nasjonalitet vi er fra. Hvilken nasjonalitet vi er fra.'}
}
```
</details>
#### Extended HuggingFace
Examining the output above, we see that there are multiple repetitions at the end. This is because the video is longer than 30 seconds. By passing the ```chunk_lengt_s``` argument, we can transcribe longer file. Our experience is that we get slightly better result by setting that to 28 seconds instead of the default 30 seconds. We also recommend setting the beam size to 5 if possible. This greatly increases the accuracy but takes a bit longer and requires slightly more memory. The examples below also illustrates how to transcribe to English or Nynorsk, and how to get timestamps for sentences and words.
```python
# Long Transcripts
asr("king.mp3", chunk_length_s=28, generate_kwargs={'task': 'transcribe', 'language': 'no'})
# Increase accuracy by setting beam size to 5
asr("king.mp3", chunk_length_s=28, return_timestamps=True, generate_kwargs={'num_beams': 5, 'task': 'transcribe', 'language': 'no'})
# Return Timestamps
asr("king.mp3", chunk_length_s=28, return_timestamps=True, generate_kwargs={'task': 'transcribe', 'language': 'no'})
# Return Word Level Timestamps
asr("king.mp3", chunk_length_s=28, return_timestamps="word", generate_kwargs={'task': 'transcribe', 'language': 'no'})
# Transcribe to Nynorsk
asr("king.mp3", chunk_length_s=28, generate_kwargs={'task': 'transcribe', 'language': 'nn'})
# Transcribe to English
asr("king.mp3", chunk_length_s=28, generate_kwargs={'task': 'transcribe', 'language': 'en'})
```
<details>
<summary>Expected output</summary>
Long transcripts:
```json
{
{'text': ' Nordmenn er nordlendinger, trøndere, sørlendinger og folk fra alle andre regioner. Nordmenn er også innvandret fra Afghanistan, Pakistan, Polen, Sverige, Somalia og Syria. Det er ikke alltid så lett å si hvor vi er fra, hvilken nasjonalitet vi er fra. Hvilken nasjonalitet vi er fra. Hvilken nasjonalitet vi er fra. Hvilken nasjonalitet vi er fra. Hvilken nasjonalitet vi er fra. Hvilken nasjonalitet vi er fra, hvilken nasjonalitet vi tilhører. Det vi kaller hjem, er der hjertet vårt er, og det kan ikke alltid plasseres innenfor landegrenser. Nordmenn er jenter som er glad i jenter, gutter som er glad i gutter, og jenter og gutter som er glad i hverandre. Nordmenn trommer på Gud, Allah, Altet og ingenting. Nordmenn liker Grieg, Kygo, Helbilis og Kari Bremnes. Med andre ord, Norge er dere. Norge er oss. Mitt største håp for Norge er at vi skal klare å ta vare på hverandre, at vi skal bygge dette landet videre på tillit, fellesskap og raushet.'}
}
```
Timestamps:
```json
{
{'text': ' Nordmenn er nordlendinger, trøndere, sørlendinger og folk fra alle andre regioner. Nordmenn er også innvandret fra Afghanistan, Pakistan, Polen, Sverige, Somalia og Syria. Det er ikke alltid så lett å si hvor vi er fra, hvilken nasjonalitet vi er fra. Hvilken nasjonalitet vi er fra. hvilken nasjonalitet vi tilhører. Det vi kaller hjem, er der hjertet vårt er, og det kan ikke alltid plasseres innenfor landegrenser. Nordmenn er jenter som er glad i jenter, gutter som er glad i gutter, og jenter og gutter som er glad i hverandre. Nordmenn trommer på Gud, Allah, Altet og ingenting. Nordmenn liker Grieg, Kygo, Helbiles og Kari Bremnes. Med andre ord, Norge er dere. Norge er oss. Mitt største håp for Norge er at vi skal klare å ta vare på hverandre, at vi skal bygge dette landet videre på tillit, fellesskap og raushet.',
'chunks': [{'timestamp': (0.0, 5.46),
'text': ' Nordmenn er nordlendinger, trøndere, sørlendinger'},
{'timestamp': (5.52, 8.68), 'text': ' og folk fra alle andre regioner.'},
{'timestamp': (8.68, 16.64),
'text': ' Nordmenn er også innvandret fra Afghanistan, Pakistan, Polen, Sverige, Somalia og Syria.'},
{'timestamp': (16.64, 13.3),
'text': ' Det er ikke alltid så lett å si hvor vi er fra, hvilken nasjonalitet vi er fra.'},
{'timestamp': (13.32, 30.28),
'text': ' Hvilken nasjonalitet vi er fra. hvilken nasjonalitet vi tilhører.'},
{'timestamp': (32.52, 39.16),
'text': ' Det vi kaller hjem, er der hjertet vårt er, og det kan ikke alltid plasseres'},
{'timestamp': (39.16, 42.0), 'text': ' innenfor landegrenser.'},
{'timestamp': (42.0, 46.74),
'text': ' Nordmenn er jenter som er glad i jenter, gutter som er glad i gutter,'},
{'timestamp': (46.74, 51.12),
'text': ' og jenter og gutter som er glad i hverandre.'},
{'timestamp': (51.16, 57.42),
'text': ' Nordmenn trommer på Gud, Allah, Altet og ingenting.'},
{'timestamp': (57.42, 64.3),
'text': ' Nordmenn liker Grieg, Kygo, Helbiles og Kari Bremnes.'},
{'timestamp': (64.34, 71.24),
'text': ' Med andre ord, Norge er dere. Norge er oss.'},
{'timestamp': (71.24, 78.04),
'text': ' Mitt største håp for Norge er at vi skal klare å ta vare på hverandre,'},
{'timestamp': (78.12, 84.68),
'text': ' at vi skal bygge dette landet videre på tillit, fellesskap og raushet.'}]}
}
```
Word Level Timestamps:
```json
{
{"text": "Nordmenn er nordlendinger, trøndere, sørlendinger og folk fra alle andre regioner. Nordmenn er også innvandret fra Afghanistan, Pakistan, Polen, Sverige, Somalia og Syria. Det er ikke alltid så lett å si hvor vi er fra, hvilken nasjonalitet vi tilhører. Det vi kaller hjem, er der hjertet vårt er, og det kan ikke alltid plasseres innenfor landegrenser. Nordmenn er jenter som er glad i jenter, gutter som er glad i gutter, og jenter og gutter som er glad i hverandre. Nordmenn trommer på Gud, Allah, Altet og ingenting. Nordmenn liker Grieg, Kygo, Helbilis og Kari Bremnes. Med andre ord, Norge er dere. Norge er oss. Mitt største håp for Norge er at vi skal klare å ta vare på hverandre, at vi skal bygge dette landet videre på tillit, fellesskap og raushet.",
"chunks": [
{"text": "Nordmenn", "timestamp": [0.72, 1.42]},
{"text": "er", "timestamp": [1.42, 1.74]},
// ... more chunks ...
{"text": "raushet.", "timestamp": [83.1, 84.88]}
]
}
}
```
Nynorsk:
```json
{
{"text": "Nordmenn er nordlendingar, trøndarar, sørlendingar og folk frå alle andre regionar. Nordmenn er også innvandra frå Afghanistan, Pakistan, Polen, Sverige, Somalia og Syria. Det er ikkje alltid så lett å seie kvar vi er frå, kva nasjonalitet vi tilhøyrer. Det vi kallar heim, er der hjartet vårt er, og det kan ikkje alltid plasserast innanfor landegrenser. Nordmenn er jenter som er glad i jenter, gutar som erade i gutar, og jenter og gutar som er glade i kvarandre. Nordmenn trommar på Gud, Allah, Altet og ingenting. Nordmenn liker Grieg, Kygo, Helbiles og Kari Bremnes. Med andre ord, Noreg er dere! Noreg er oss. Mitt største håp for Noreg er at vi skal klare å ta vare på kvarandre, at vi skal byggje dette landet vidare på tillit, fellesskap og raushet."}
}
```
English:
```json
{
{"text": "Norwegians are Norwegians, trønders, southerners and people from all other regions. Norwegians are also invaded from Afghanistan, Pakistan, Poland, Sweden, Somalia and Suria. It is not always so easy to say where we are from, what nationality we belong to. What we call home is where our heart is, and it cannot always be placed within national borders. Norwegians are girls who like girls, boys who like boys, and girls and boys who like each other. Norwegians thrump on God, Allah, Altet and nothing. Norwegians like Grieg, Kygo, Helbilis and Kari Bremnes. In other words, Norway is you. Norway is us. My biggest hope for Norway is that we should be able to take care of each other, that we should build this country on trust, community and generosity."}
}
```
</details>
### Whisper CPP
Whisper CPP is a C++ implementation of the Whisper model, offering the same functionalities with the added benefits of C++ efficiency and performance optimizations. This allows embedding any Whisper model into a binary file, facilitating the development of real applications. However, it requires some familiarity with compiling C++ programs. Their [homepage](https://github.com/ggerganov/whisper.cpp) provides examples of how to build applications, including real-time transcription.
We have converted this model to the ggml-format model used by Whisper CPP binaries. The file can be downloaded [here](blob/main/ggml-model.bin), and a `q5_0` quantized version is also available [here](blob/main/ggml-model-q5_0.bin).
```bash
# We can download and compile whisper.cpp
$ git clone --depth 1 https://github.com/ggerganov/whisper.cpp --branch v1.5.1
$ cd whisper.cpp/
$ make
# We also need to convert the audio to WAV as that is the only format supported by whisper.cpp
$ wget -N https://github.com/NbAiLab/nb-whisper/raw/main/audio/king.mp3
$ ffmpeg -i king.mp3 -ar 16000 -ac 1 -c:a pcm_s16le king.wav
# Lets download the two ggml-files from this site
wget -N https://huggingface.co/NbAiLabBeta/nb-whisper-large/resolve/main/ggml-model.bin -O models/nb-large-ggml-model.bin
wget -N https://huggingface.co/NbAiLabBeta/nb-whisper-large/resolve/main/ggml-model-q5_0.bin -O models/nb-large-ggml-model-q5_0.bin
# And run it with the f16 default model
$ ./main -l no -m models/nb-large-ggml-model.bin king.wav
# Or the quantized version
$ ./main -l no -m models/nb-large-ggml-model-q5_0.bin king.wav
```
### WhisperX and Speaker Diarization
Speaker diarization is a technique in natural language processing and automatic speech recognition that identifies and separates different speakers in an audio recording. It segments the audio into parts based on who is speaking, enhancing the quality of transcribing meetings or phone calls. We find that [WhisperX](https://github.com/m-bain/whisperX) is the easiest way to use our models for diarizing speech. In addition, WhisperX is using phoneme-based Wav2Vec-models for improving the alignment of the timestamps. As of December 2023 it also has native support for using the nb-wav2vec-models. It currently uses [PyAnnote-audio](https://github.com/pyannote/pyannote-audio) for doing the actual diarization. This package has a fairly strict licence where you have to agree to user terms. Follow the instructions below.
```bash
# Follow the install instructions on https://github.com/m-bain/whisperX
# Make sure you have a HuggingFace account and have agreed to the pyannote terms
# Log in (or supply HF Token in command line)
huggingface-cli login
# Download a test file
wget -N https://github.com/NbAiLab/nb-whisper/raw/main/audio/knuthamsun.mp3
# Optional. If you get complains about not support for Norwegian, do:
pip uninstall whisperx && pip install git+https://github.com/m-bain/whisperx.git@8540ff5985fceee764acbed94f656063d7f56540
# Transcribe the test file. All transcripts will end up in the directory of the mp3-file
whisperx knuthamsun.mp3 --model NbAiLabBeta/nb-whisper-large --language no --diarize
```
You can also run WhisperX from Python. Please take a look at the instructions on [WhisperX homepage](https://github.com/m-bain/whisperX).
### API
Instructions for accessing the models via a simple API are included in the demos under Spaces. Note that these demos are temporary and will only be available for a few weeks.
## Training Data
The training data originates from Språkbanken and the National Library of Norway's digital collection, including:
- NST Norwegian ASR Database (16 kHz) and its corresponding dataset
- Transcribed speeches from the Norwegian Parliament by Språkbanken
- TV broadcast (NRK) subtitles (NLN digital collection)
- Audiobooks (NLN digital collection)
## Downstream Use
The models, especially the smaller ones, may exhibit occasional hallucinations and may drop parts of the transcript. They are designed to convert spoken language into grammatically correct written sentences, which might not always be word-for-word translations. We have made two extra model variant for users that want a different transcription style. We encourage users to try the models themselves to get a better understanding.
## Bias, Risks, and Limitations
Using these models without adequate risk assessment and mitigation could be considered irresponsible. They may contain biases or other undesirable distortions. Users who deploy these models or integrate them into systems or services are responsible for mitigating risks and complying with applicable AI regulations. The National Library of Norway, as the model owner, disclaims liability for any outcomes resulting from third-party use of these models.
### Software
The model was trained using Jax/Flax and converted to PyTorch, Tensorflow, whisper.cpp, and ONXX formats. These are available under `Files and versions`. We welcome requests for conversion to other formats. All training code and scripts are released under the Apache License 2.0 in the GitHub repository [nb-whisper](https://github.com/NbAiLab/nb-whisper/).
## Citation & Contributors
The NB-Whisper Large model is a product of the NoSTram project led by Per Egil Kummervold ([@pere](https://huggingface.co/pere)) at the National Library of Norway. Key contributors include Javier de la Rosa ([@versae](https://huggingface.co/versae)), Freddy Wetjen ([@freddyw](https://huggingface.co/freddyw)), and Rolv-Arild Braaten ([@Rolv-Arild](https://huggingface.co/Rolv-Arild)). NB AI-Lab, under the direction of Svein Arne Brygfjeld ([@Brygfjeld](https://huggingface.co/Brygfjeld)), supported the project's successful completion. A detailed paper on our process and findings is forthcoming.
## Disclaimer
The models published in this repository are intended for a generalist purpose and are available to third parties. These models may have bias and/or any other undesirable distortions. When third parties, deploy or provide systems and/or services to other parties using any of these models (or using systems based on these models) or become users of the models, they should note that it is their responsibility to mitigate the risks arising from their use and, in any event, to comply with applicable regulations, including regulations regarding the use of artificial intelligence. In no event shall the owner of the models (The National Library of Norway) be liable for any results arising from the use made by third parties of these models.
## Acknowledgements
Our gratitude extends to [Google TPU Research Cloud](https://sites.research.google/trc/about/) for training resources, Google Cloud for translation credits, and HuggingFace's Sanchit Ghandi for technical support. A special thank you to Per Erik Solberg at Språkbanken for the collaboration on the Stortinget corpus.
## Contact
For feedback, technical concerns, or collaboration inquiries, please contact <a rel="noopener nofollow" href="mailto:[email protected]">[email protected]</a>. If you plan to include this model in your research, contact us for the latest information on our upcoming paper for citation purposes.
|
BlueNipples/Apocrypha-7b | BlueNipples | 2024-01-22T16:03:21Z | 507 | 3 | transformers | [
"transformers",
"safetensors",
"gguf",
"mistral",
"text-generation",
"conversation",
"merge",
"base_model:Mistral-7b",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-01-20T04:54:40Z | ---
license: apache-2.0
tags:
- conversation
- merge
base_model:
- Mistral-7b
---

### Design
The design intention is to create a pseudo-philosophical, pseudo-spiritual, pseudo counseling chatbob model for sounding ideas off. Like a mirror really. This obviously does not constitute medical advice, and if you are in need seek professional help. The name Apocrypha-7B comes from the fact that it's fake - this isn't a guide, friend or a guru. It's at best, if the model works, a sounding board. But I think such things might still be helpful for organising ones own thoughts. This model should still be able to role-play, but will likely play better as a 'helper' role of some sort given the counseling and theory of mind data if you do use it for role-play.
This mistral 7b model is a task arithmetic merge of Epiculous/Fett-uccine-7B (theory of mind and gnosis datasets), GRMenon/mental-mistral-7b-instruct-autotrain (mental health counseling conversations dataset), and teknium/Hermes-Trismegistus-Mistral-7B (open-hermes + occult datasets)
I will throw a GGUF or two inside a subfolder here.
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: ./Hermes-Trismegistus-7B
parameters:
weight: 0.35
- model: ./mental-mistral-7b
parameters:
weight: 0.39
- model: ./Fett-uccine-7B
parameters:
weight: 0.45
merge_method: task_arithmetic
base_model: ./Mistral-7B-v0.1
dtype: bfloat16
```
Resources used:
https://huggingface.co/teknium/Hermes-Trismegistus-Mistral-7B
https://huggingface.co/GRMenon/mental-mistral-7b-instruct-autotrain
https://huggingface.co/Epiculous/Fett-uccine-7B/tree/main
https://github.com/cg123/mergekit/tree/main |
JCTN/AnimateDiff-Lightning | JCTN | 2024-03-21T21:32:22Z | 507 | 3 | diffusers | [
"diffusers",
"text-to-video",
"stable-diffusion",
"animatediff",
"arxiv:2403.12706",
"license:creativeml-openrail-m",
"region:us"
]
| text-to-video | 2024-03-21T17:28:09Z | ---
license: creativeml-openrail-m
tags:
- text-to-video
- stable-diffusion
- animatediff
library_name: diffusers
inference: false
---
# AnimateDiff-Lightning
<video src='https://huggingface.co/ByteDance/AnimateDiff-Lightning/resolve/main/animatediff_lightning_samples_t2v.mp4' width="100%" autoplay muted loop style='margin:0'></video>
<video src='https://huggingface.co/ByteDance/AnimateDiff-Lightning/resolve/main/animatediff_lightning_samples_v2v.mp4' width="100%" autoplay muted loop style='margin:0'></video>
AnimateDiff-Lightning is a lightning-fast text-to-video generation model. It can generate videos more than ten times faster than the original AnimateDiff. For more information, please refer to our research paper: [AnimateDiff-Lightning: Cross-Model Diffusion Distillation](https://arxiv.org/abs/2403.12706). We release the model as part of the research.
Our models are distilled from [AnimateDiff SD1.5 v2](https://huggingface.co/guoyww/animatediff). This repository contains checkpoints for 1-step, 2-step, 4-step, and 8-step distilled models. The generation quality of our 2-step, 4-step, and 8-step model is great. Our 1-step model is only provided for research purposes.
## Demo
Try AnimateDiff-Lightning using our text-to-video generation [demo](https://huggingface.co/spaces/ByteDance/AnimateDiff-Lightning).
## Recommendation
AnimateDiff-Lightning produces the best results when used with stylized base models. We recommend using the following base models:
Realistic
- [epiCRealism](https://civitai.com/models/25694)
- [Realistic Vision](https://civitai.com/models/4201)
- [DreamShaper](https://civitai.com/models/4384)
- [AbsoluteReality](https://civitai.com/models/81458)
- [MajicMix Realistic](https://civitai.com/models/43331)
Anime & Cartoon
- [ToonYou](https://civitai.com/models/30240)
- [IMP](https://civitai.com/models/56680)
- [Mistoon Anime](https://civitai.com/models/24149)
- [DynaVision](https://civitai.com/models/75549)
- [RCNZ Cartoon 3d](https://civitai.com/models/66347)
- [MajicMix Reverie](https://civitai.com/models/65055)
Additionally, feel free to explore different settings. We find using 3 inference steps on the 2-step model produces great results. We find certain base models produces better results with CFG. We also recommend using [Motion LoRAs](https://huggingface.co/guoyww/animatediff/tree/main) as they produce stronger motion. We use Motion LoRAs with strength 0.7~0.8 to avoid watermark.
## Diffusers Usage
```python
import torch
from diffusers import AnimateDiffPipeline, MotionAdapter, EulerDiscreteScheduler
from diffusers.utils import export_to_gif
from huggingface_hub import hf_hub_download
from safetensors.torch import load_file
device = "cuda"
dtype = torch.float16
step = 4 # Options: [1,2,4,8]
repo = "ByteDance/AnimateDiff-Lightning"
ckpt = f"animatediff_lightning_{step}step_diffusers.safetensors"
base = "emilianJR/epiCRealism" # Choose to your favorite base model.
adapter = MotionAdapter().to(device, dtype)
adapter.load_state_dict(load_file(hf_hub_download(repo ,ckpt), device=device))
pipe = AnimateDiffPipeline.from_pretrained(base, motion_adapter=adapter, torch_dtype=dtype).to(device)
pipe.scheduler = EulerDiscreteScheduler.from_config(pipe.scheduler.config, timestep_spacing="trailing", beta_schedule="linear")
output = pipe(prompt="A girl smiling", guidance_scale=1.0, num_inference_steps=step)
export_to_gif(output.frames[0], "animation.gif")
```
## ComfyUI Usage
1. Download [animatediff_lightning_workflow.json](https://huggingface.co/ByteDance/AnimateDiff-Lightning/raw/main/comfyui/animatediff_lightning_workflow.json) and import it in ComfyUI.
1. Install nodes. You can install them manually or use [ComfyUI-Manager](https://github.com/ltdrdata/ComfyUI-Manager).
* [ComfyUI-AnimateDiff-Evolved](https://github.com/Kosinkadink/ComfyUI-AnimateDiff-Evolved)
* [ComfyUI-VideoHelperSuite](https://github.com/Kosinkadink/ComfyUI-VideoHelperSuite)
1. Download your favorite base model checkpoint and put them under `/models/checkpoints/`
1. Download AnimateDiff-Lightning checkpoint `animatediff_lightning_Nstep_comfyui.safetensors` and put them under `/custom_nodes/ComfyUI-AnimateDiff-Evolved/models/`
## Video-to-Video Generation
AnimateDiff-Lightning is great for video-to-video generation. We provide the simplist comfyui workflow using ControlNet.
1. Download [animatediff_lightning_v2v_openpose_workflow.json](https://huggingface.co/ByteDance/AnimateDiff-Lightning/raw/main/comfyui/animatediff_lightning_v2v_openpose_workflow.json) and import it in ComfyUI.
1. Install nodes. You can install them manually or use [ComfyUI-Manager](https://github.com/ltdrdata/ComfyUI-Manager).
* [ComfyUI-AnimateDiff-Evolved](https://github.com/Kosinkadink/ComfyUI-AnimateDiff-Evolved)
* [ComfyUI-VideoHelperSuite](https://github.com/Kosinkadink/ComfyUI-VideoHelperSuite)
* [ComfyUI-Advanced-ControlNet](https://github.com/Kosinkadink/ComfyUI-Advanced-ControlNet)
* [comfyui_controlnet_aux](https://github.com/Fannovel16/comfyui_controlnet_aux)
1. Download your favorite base model checkpoint and put them under `/models/checkpoints/`
1. Download AnimateDiff-Lightning checkpoint `animatediff_lightning_Nstep_comfyui.safetensors` and put them under `/custom_nodes/ComfyUI-AnimateDiff-Evolved/models/`
1. Download [ControlNet OpenPose](https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main) `control_v11p_sd15_openpose.pth` checkpoint to `/models/controlnet/`
1. Upload your video and run the pipeline.
Additional notes:
1. Video shouldn't be too long or too high resolution. We used 576x1024 8 second 30fps videos for testing.
1. Set the frame rate to match your input video. This allows audio to match with the output video.
1. DWPose will download checkpoint itself on its first run.
1. DWPose may get stuck in UI, but the pipeline is actually still running in the background. Check ComfyUI log and your output folder.
# Cite Our Work
```
@misc{lin2024animatedifflightning,
title={AnimateDiff-Lightning: Cross-Model Diffusion Distillation},
author={Shanchuan Lin and Xiao Yang},
year={2024},
eprint={2403.12706},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
``` |
demetera/llama-600M-rus | demetera | 2024-06-29T20:50:57Z | 507 | 2 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"ru",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-03-28T21:50:43Z | ---
license: mit
language:
- ru
library_name: transformers
---
# llama-600M-rus
Simple and customized amateur experimental model pretrained on the text fiction books from the scratch (updating the model regularly).<br>
It could generate amateur, but more or less adequate output as well (in respect of training tokens).<br>
The work can be used as a checkpoint for the further training or for experiments.<br>
Simple usage example:
```python
from transformers import LlamaTokenizerFast, LlamaForCausalLM
model = LlamaForCausalLM.from_pretrained('demetera/llama-600M-rus')
tokenizer = LlamaTokenizerFast.from_pretrained('demetera/llama-600M-rus')
prompt = "Я вышел и улицу и"
inputs = tokenizer(prompt, return_tensors='pt')
outputs = model.generate(inputs.input_ids, attention_mask = inputs.attention_mask, max_new_tokens=250, do_sample=True, top_k=50, top_p=0.95)
print (tokenizer.decode(outputs[0], skip_special_tokens=True))
``` |
mistral-community/Mixtral-8x22B-v0.1-4bit | mistral-community | 2024-04-10T19:14:32Z | 507 | 54 | transformers | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"moe",
"fr",
"it",
"de",
"es",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"4-bit",
"bitsandbytes",
"region:us"
]
| text-generation | 2024-04-10T19:13:33Z | ---
license: apache-2.0
language:
- fr
- it
- de
- es
- en
tags:
- moe
---
# Model Card for Mixtral-8x22B
The Mixtral-8x22B Large Language Model (LLM) is a pretrained generative Sparse Mixture of Experts.
Model details:
- 🧠 ~176B params, ~44B active during inference
- 🪟 65K context window
- 🕵🏾♂️ 8 experts, 2 per token
- 🤓 32K vocab size
- ✂️ Similar tokenizer as 7B
Model quantized and added by [Prince Canuma](https://twitter.com/Prince_Canuma) using the full-precision model here: [v2ray/Mixtral-8x22B-v0.1](https://huggingface.co/v2ray/Mixtral-8x22B-v0.1).
## Run the model in 4-bit precision
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistral-community/Mixtral-8x22B-v0.1-4bit"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)
text = "Who is Einstein?"
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Notice
Mixtral-8x22B-v0.1 is a pretrained base model and therefore does not have any moderation mechanisms.
# The Mistral AI Team
Albert Jiang, Alexandre Sablayrolles, Alexis Tacnet, Antoine Roux, Arthur Mensch, Audrey Herblin-Stoop, Baptiste Bout, Baudouin de Monicault,Blanche Savary, Bam4d, Caroline Feldman, Devendra Singh Chaplot, Diego de las Casas, Eleonore Arcelin, Emma Bou Hanna, Etienne Metzger, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Harizo Rajaona, Jean-Malo Delignon, Jia Li, Justus Murke, Louis Martin, Louis Ternon, Lucile Saulnier, Lélio Renard Lavaud, Margaret Jennings, Marie Pellat, Marie Torelli, Marie-Anne Lachaux, Nicolas Schuhl, Patrick von Platen, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven Le Scao, Thibaut Lavril, Timothée Lacroix, Théophile Gervet, Thomas Wang, Valera Nemychnikova, William El Sayed, William Marshall. |
recogna-nlp/phibode_1_5_ultraalpaca | recogna-nlp | 2024-05-22T13:15:45Z | 507 | 0 | transformers | [
"transformers",
"safetensors",
"phi",
"text-generation",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-05-10T03:14:52Z | ---
license: mit
model-index:
- name: phibode_1_5_ultraalpaca
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: ENEM Challenge (No Images)
type: eduagarcia/enem_challenge
split: train
args:
num_few_shot: 3
metrics:
- type: acc
value: 23.58
name: accuracy
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=recogna-nlp/phibode_1_5_ultraalpaca
name: Open Portuguese LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: BLUEX (No Images)
type: eduagarcia-temp/BLUEX_without_images
split: train
args:
num_few_shot: 3
metrics:
- type: acc
value: 20.72
name: accuracy
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=recogna-nlp/phibode_1_5_ultraalpaca
name: Open Portuguese LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: OAB Exams
type: eduagarcia/oab_exams
split: train
args:
num_few_shot: 3
metrics:
- type: acc
value: 24.87
name: accuracy
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=recogna-nlp/phibode_1_5_ultraalpaca
name: Open Portuguese LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Assin2 RTE
type: assin2
split: test
args:
num_few_shot: 15
metrics:
- type: f1_macro
value: 69.07
name: f1-macro
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=recogna-nlp/phibode_1_5_ultraalpaca
name: Open Portuguese LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Assin2 STS
type: eduagarcia/portuguese_benchmark
split: test
args:
num_few_shot: 15
metrics:
- type: pearson
value: 4.94
name: pearson
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=recogna-nlp/phibode_1_5_ultraalpaca
name: Open Portuguese LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: FaQuAD NLI
type: ruanchaves/faquad-nli
split: test
args:
num_few_shot: 15
metrics:
- type: f1_macro
value: 43.97
name: f1-macro
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=recogna-nlp/phibode_1_5_ultraalpaca
name: Open Portuguese LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HateBR Binary
type: ruanchaves/hatebr
split: test
args:
num_few_shot: 25
metrics:
- type: f1_macro
value: 34.94
name: f1-macro
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=recogna-nlp/phibode_1_5_ultraalpaca
name: Open Portuguese LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: PT Hate Speech Binary
type: hate_speech_portuguese
split: test
args:
num_few_shot: 25
metrics:
- type: f1_macro
value: 41.23
name: f1-macro
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=recogna-nlp/phibode_1_5_ultraalpaca
name: Open Portuguese LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: tweetSentBR
type: eduagarcia/tweetsentbr_fewshot
split: test
args:
num_few_shot: 25
metrics:
- type: f1_macro
value: 24.19
name: f1-macro
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=recogna-nlp/phibode_1_5_ultraalpaca
name: Open Portuguese LLM Leaderboard
---
# Phi-Bode
<!--- PROJECT LOGO -->
<p align="center">
<img src="https://huggingface.co/recogna-nlp/Phi-Bode/resolve/main/phi-bode.jpg" alt="Phi-Bode Logo" width="400" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
</p>
Phi-Bode é um modelo de linguagem ajustado para o idioma português, desenvolvido a partir do modelo base Phi-1.5B fornecido pela [Microsoft](https://huggingface.co/microsoft/phi-1_5). Este modelo foi refinado através do processo de fine-tuning utilizando o dataset UltraAlpaca. O principal objetivo deste modelo é ser viável para pessoas
que não possuem recursos computacionais disponíveis para o uso de LLMs (Large Language Models). Ressalta-se que este é um trabalho em andamento e o modelo ainda apresenta problemas na geração de texto em português.
## Características Principais
- **Modelo Base:** Phi-1.5B, criado pela Microsoft, com 1.3 bilhões de parâmetros.
- **Dataset para Fine-tuning:** UltraAlpaca
- **Treinamento:** O treinamento foi realizado a partir do fine-tuning completo do phi-1.5.
# Open Portuguese LLM Leaderboard Evaluation Results
Detailed results can be found [here](https://huggingface.co/datasets/eduagarcia-temp/llm_pt_leaderboard_raw_results/tree/main/recogna-nlp/phibode_1_5_ultraalpaca) and on the [🚀 Open Portuguese LLM Leaderboard](https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard)
| Metric | Value |
|--------------------------|---------|
|Average |**31.95**|
|ENEM Challenge (No Images)| 23.58|
|BLUEX (No Images) | 20.72|
|OAB Exams | 24.87|
|Assin2 RTE | 69.07|
|Assin2 STS | 4.94|
|FaQuAD NLI | 43.97|
|HateBR Binary | 34.94|
|PT Hate Speech Binary | 41.23|
|tweetSentBR | 24.19|
|
quinnb/whisper-Large-v3-hindi2 | quinnb | 2024-06-07T14:49:20Z | 507 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"hi",
"dataset:mozilla-foundation/common_voice_17_0",
"base_model:quinnb/whisper-Large-v3-hindi",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2024-06-07T14:43:22Z | ---
language:
- hi
license: apache-2.0
base_model: quinnb/whisper-Large-v3-hindi
tags:
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_17_0
model-index:
- name: Whisper Large v3 Trained on Hindi
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Large v3 Trained on Hindi
This model is a fine-tuned version of [quinnb/whisper-Large-v3-hindi](https://huggingface.co/quinnb/whisper-Large-v3-hindi) on the Custom Hindi dataset dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 64
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 50
- training_steps: 2000
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.41.1
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
gglabs/Gemma-ko-2.5B-Chat-11-epoch | gglabs | 2024-06-12T05:41:08Z | 507 | 0 | transformers | [
"transformers",
"gguf",
"gemma",
"text-generation-inference",
"unsloth",
"en",
"base_model:gemmathon/gemma-2b-ko-dev-pbmt192",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-12T05:31:16Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- gemma
- gguf
base_model: gemmathon/gemma-2b-ko-dev-pbmt192
---
# Uploaded model
- **Developed by:** gglabs
- **License:** apache-2.0
- **Finetuned from model :** gemmathon/gemma-2b-ko-dev-pbmt192
This gemma model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
gglabs/Gemma-ko-2.5B-Chat-21-epoch | gglabs | 2024-06-12T06:17:42Z | 507 | 0 | transformers | [
"transformers",
"gguf",
"gemma",
"text-generation-inference",
"unsloth",
"en",
"base_model:gemmathon/gemma-2b-ko-dev-pbmt192",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-12T06:08:14Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- gemma
- gguf
base_model: gemmathon/gemma-2b-ko-dev-pbmt192
---
# Uploaded model
- **Developed by:** gglabs
- **License:** apache-2.0
- **Finetuned from model :** gemmathon/gemma-2b-ko-dev-pbmt192
This gemma model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
mradermacher/Unhinged-Qwen2-70B-GGUF | mradermacher | 2024-06-14T14:59:01Z | 507 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:FiditeNemini/Unhinged-Qwen2-70B",
"license:other",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-14T10:21:46Z | ---
base_model: FiditeNemini/Unhinged-Qwen2-70B
language:
- en
library_name: transformers
license: other
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/FiditeNemini/Unhinged-Qwen2-70B
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Unhinged-Qwen2-70B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Unhinged-Qwen2-70B-GGUF/resolve/main/Unhinged-Qwen2-70B.Q2_K.gguf) | Q2_K | 29.9 | |
| [GGUF](https://huggingface.co/mradermacher/Unhinged-Qwen2-70B-GGUF/resolve/main/Unhinged-Qwen2-70B.IQ3_XS.gguf) | IQ3_XS | 32.9 | |
| [GGUF](https://huggingface.co/mradermacher/Unhinged-Qwen2-70B-GGUF/resolve/main/Unhinged-Qwen2-70B.IQ3_S.gguf) | IQ3_S | 34.6 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Unhinged-Qwen2-70B-GGUF/resolve/main/Unhinged-Qwen2-70B.Q3_K_S.gguf) | Q3_K_S | 34.6 | |
| [GGUF](https://huggingface.co/mradermacher/Unhinged-Qwen2-70B-GGUF/resolve/main/Unhinged-Qwen2-70B.IQ3_M.gguf) | IQ3_M | 35.6 | |
| [GGUF](https://huggingface.co/mradermacher/Unhinged-Qwen2-70B-GGUF/resolve/main/Unhinged-Qwen2-70B.Q3_K_M.gguf) | Q3_K_M | 37.8 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Unhinged-Qwen2-70B-GGUF/resolve/main/Unhinged-Qwen2-70B.Q3_K_L.gguf) | Q3_K_L | 39.6 | |
| [GGUF](https://huggingface.co/mradermacher/Unhinged-Qwen2-70B-GGUF/resolve/main/Unhinged-Qwen2-70B.IQ4_XS.gguf) | IQ4_XS | 40.3 | |
| [GGUF](https://huggingface.co/mradermacher/Unhinged-Qwen2-70B-GGUF/resolve/main/Unhinged-Qwen2-70B.Q4_K_S.gguf) | Q4_K_S | 44.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Unhinged-Qwen2-70B-GGUF/resolve/main/Unhinged-Qwen2-70B.Q4_K_M.gguf) | Q4_K_M | 47.5 | fast, recommended |
| [PART 1](https://huggingface.co/mradermacher/Unhinged-Qwen2-70B-GGUF/resolve/main/Unhinged-Qwen2-70B.Q5_K_S.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Unhinged-Qwen2-70B-GGUF/resolve/main/Unhinged-Qwen2-70B.Q5_K_S.gguf.part2of2) | Q5_K_S | 51.5 | |
| [PART 1](https://huggingface.co/mradermacher/Unhinged-Qwen2-70B-GGUF/resolve/main/Unhinged-Qwen2-70B.Q5_K_M.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Unhinged-Qwen2-70B-GGUF/resolve/main/Unhinged-Qwen2-70B.Q5_K_M.gguf.part2of2) | Q5_K_M | 54.5 | |
| [PART 1](https://huggingface.co/mradermacher/Unhinged-Qwen2-70B-GGUF/resolve/main/Unhinged-Qwen2-70B.Q6_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Unhinged-Qwen2-70B-GGUF/resolve/main/Unhinged-Qwen2-70B.Q6_K.gguf.part2of2) | Q6_K | 64.4 | very good quality |
| [PART 1](https://huggingface.co/mradermacher/Unhinged-Qwen2-70B-GGUF/resolve/main/Unhinged-Qwen2-70B.Q8_0.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Unhinged-Qwen2-70B-GGUF/resolve/main/Unhinged-Qwen2-70B.Q8_0.gguf.part2of2) | Q8_0 | 77.4 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
moschouChry/finetuned-chronos-small-type-1 | moschouChry | 2024-06-15T10:36:46Z | 507 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text2text-generation | 2024-06-15T10:36:33Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
mradermacher/Einstein-v4-Qwen-1.5-32B-GGUF | mradermacher | 2024-06-16T22:44:05Z | 507 | 0 | transformers | [
"transformers",
"gguf",
"axolotl",
"generated_from_trainer",
"phi",
"phi2",
"einstein",
"instruct",
"finetune",
"chatml",
"gpt4",
"synthetic data",
"science",
"physics",
"chemistry",
"biology",
"math",
"en",
"dataset:allenai/ai2_arc",
"dataset:camel-ai/physics",
"dataset:camel-ai/chemistry",
"dataset:camel-ai/biology",
"dataset:camel-ai/math",
"dataset:metaeval/reclor",
"dataset:openbookqa",
"dataset:mandyyyyii/scibench",
"dataset:derek-thomas/ScienceQA",
"dataset:TIGER-Lab/ScienceEval",
"dataset:jondurbin/airoboros-3.2",
"dataset:LDJnr/Capybara",
"dataset:Cot-Alpaca-GPT4-From-OpenHermes-2.5",
"dataset:STEM-AI-mtl/Electrical-engineering",
"dataset:knowrohit07/saraswati-stem",
"dataset:sablo/oasst2_curated",
"dataset:glaiveai/glaive-code-assistant",
"dataset:lmsys/lmsys-chat-1m",
"dataset:TIGER-Lab/MathInstruct",
"dataset:bigbio/med_qa",
"dataset:meta-math/MetaMathQA-40K",
"dataset:piqa",
"dataset:scibench",
"dataset:sciq",
"dataset:Open-Orca/SlimOrca",
"dataset:migtissera/Synthia-v1.3",
"base_model:Weyaxi/Einstein-v4-Qwen-1.5-32B",
"license:other",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-16T02:12:00Z | ---
base_model: Weyaxi/Einstein-v4-Qwen-1.5-32B
datasets:
- allenai/ai2_arc
- camel-ai/physics
- camel-ai/chemistry
- camel-ai/biology
- camel-ai/math
- metaeval/reclor
- openbookqa
- mandyyyyii/scibench
- derek-thomas/ScienceQA
- TIGER-Lab/ScienceEval
- jondurbin/airoboros-3.2
- LDJnr/Capybara
- Cot-Alpaca-GPT4-From-OpenHermes-2.5
- STEM-AI-mtl/Electrical-engineering
- knowrohit07/saraswati-stem
- sablo/oasst2_curated
- glaiveai/glaive-code-assistant
- lmsys/lmsys-chat-1m
- TIGER-Lab/MathInstruct
- bigbio/med_qa
- meta-math/MetaMathQA-40K
- openbookqa
- piqa
- metaeval/reclor
- derek-thomas/ScienceQA
- scibench
- sciq
- Open-Orca/SlimOrca
- migtissera/Synthia-v1.3
- TIGER-Lab/ScienceEval
language:
- en
library_name: transformers
license: other
quantized_by: mradermacher
tags:
- axolotl
- generated_from_trainer
- phi
- phi2
- einstein
- instruct
- finetune
- chatml
- gpt4
- synthetic data
- science
- physics
- chemistry
- biology
- math
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/Weyaxi/Einstein-v4-Qwen-1.5-32B
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Einstein-v4-Qwen-1.5-32B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Einstein-v4-Qwen-1.5-32B-GGUF/resolve/main/Einstein-v4-Qwen-1.5-32B.Q2_K.gguf) | Q2_K | 12.3 | |
| [GGUF](https://huggingface.co/mradermacher/Einstein-v4-Qwen-1.5-32B-GGUF/resolve/main/Einstein-v4-Qwen-1.5-32B.IQ3_XS.gguf) | IQ3_XS | 13.7 | |
| [GGUF](https://huggingface.co/mradermacher/Einstein-v4-Qwen-1.5-32B-GGUF/resolve/main/Einstein-v4-Qwen-1.5-32B.Q3_K_S.gguf) | Q3_K_S | 14.4 | |
| [GGUF](https://huggingface.co/mradermacher/Einstein-v4-Qwen-1.5-32B-GGUF/resolve/main/Einstein-v4-Qwen-1.5-32B.IQ3_S.gguf) | IQ3_S | 14.4 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Einstein-v4-Qwen-1.5-32B-GGUF/resolve/main/Einstein-v4-Qwen-1.5-32B.IQ3_M.gguf) | IQ3_M | 14.8 | |
| [GGUF](https://huggingface.co/mradermacher/Einstein-v4-Qwen-1.5-32B-GGUF/resolve/main/Einstein-v4-Qwen-1.5-32B.Q3_K_M.gguf) | Q3_K_M | 15.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Einstein-v4-Qwen-1.5-32B-GGUF/resolve/main/Einstein-v4-Qwen-1.5-32B.Q3_K_L.gguf) | Q3_K_L | 17.2 | |
| [GGUF](https://huggingface.co/mradermacher/Einstein-v4-Qwen-1.5-32B-GGUF/resolve/main/Einstein-v4-Qwen-1.5-32B.IQ4_XS.gguf) | IQ4_XS | 17.8 | |
| [GGUF](https://huggingface.co/mradermacher/Einstein-v4-Qwen-1.5-32B-GGUF/resolve/main/Einstein-v4-Qwen-1.5-32B.Q4_K_S.gguf) | Q4_K_S | 18.7 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Einstein-v4-Qwen-1.5-32B-GGUF/resolve/main/Einstein-v4-Qwen-1.5-32B.Q4_K_M.gguf) | Q4_K_M | 19.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Einstein-v4-Qwen-1.5-32B-GGUF/resolve/main/Einstein-v4-Qwen-1.5-32B.Q5_K_S.gguf) | Q5_K_S | 22.6 | |
| [GGUF](https://huggingface.co/mradermacher/Einstein-v4-Qwen-1.5-32B-GGUF/resolve/main/Einstein-v4-Qwen-1.5-32B.Q5_K_M.gguf) | Q5_K_M | 23.2 | |
| [GGUF](https://huggingface.co/mradermacher/Einstein-v4-Qwen-1.5-32B-GGUF/resolve/main/Einstein-v4-Qwen-1.5-32B.Q6_K.gguf) | Q6_K | 26.8 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Einstein-v4-Qwen-1.5-32B-GGUF/resolve/main/Einstein-v4-Qwen-1.5-32B.Q8_0.gguf) | Q8_0 | 34.7 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
faceradix/contaminated_proof_7b_v1.0_safetensor-Q4_K_M-GGUF | faceradix | 2024-06-24T10:17:09Z | 507 | 0 | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"base_model:Contamination/contaminated_proof_7b_v1.0_safetensor",
"license:unknown",
"region:us"
]
| null | 2024-06-24T10:16:50Z | ---
base_model: Contamination/contaminated_proof_7b_v1.0_safetensor
license: unknown
tags:
- llama-cpp
- gguf-my-repo
---
# faceradix/contaminated_proof_7b_v1.0_safetensor-Q4_K_M-GGUF
This model was converted to GGUF format from [`Contamination/contaminated_proof_7b_v1.0_safetensor`](https://huggingface.co/Contamination/contaminated_proof_7b_v1.0_safetensor) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/Contamination/contaminated_proof_7b_v1.0_safetensor) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo faceradix/contaminated_proof_7b_v1.0_safetensor-Q4_K_M-GGUF --hf-file contaminated_proof_7b_v1.0_safetensor-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo faceradix/contaminated_proof_7b_v1.0_safetensor-Q4_K_M-GGUF --hf-file contaminated_proof_7b_v1.0_safetensor-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo faceradix/contaminated_proof_7b_v1.0_safetensor-Q4_K_M-GGUF --hf-file contaminated_proof_7b_v1.0_safetensor-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo faceradix/contaminated_proof_7b_v1.0_safetensor-Q4_K_M-GGUF --hf-file contaminated_proof_7b_v1.0_safetensor-q4_k_m.gguf -c 2048
```
|
NikolayKozloff/Gemma-2-9B-It-SPPO-Iter3-Q5_K_S-GGUF | NikolayKozloff | 2024-06-30T16:07:38Z | 507 | 1 | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"dataset:openbmb/UltraFeedback",
"base_model:UCLA-AGI/Gemma-2-9B-It-SPPO-Iter3",
"license:apache-2.0",
"region:us"
]
| text-generation | 2024-06-30T16:07:11Z | ---
base_model: UCLA-AGI/Gemma-2-9B-It-SPPO-Iter3
datasets:
- openbmb/UltraFeedback
language:
- en
license: apache-2.0
pipeline_tag: text-generation
tags:
- llama-cpp
- gguf-my-repo
---
# NikolayKozloff/Gemma-2-9B-It-SPPO-Iter3-Q5_K_S-GGUF
This model was converted to GGUF format from [`UCLA-AGI/Gemma-2-9B-It-SPPO-Iter3`](https://huggingface.co/UCLA-AGI/Gemma-2-9B-It-SPPO-Iter3) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/UCLA-AGI/Gemma-2-9B-It-SPPO-Iter3) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo NikolayKozloff/Gemma-2-9B-It-SPPO-Iter3-Q5_K_S-GGUF --hf-file gemma-2-9b-it-sppo-iter3-q5_k_s.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo NikolayKozloff/Gemma-2-9B-It-SPPO-Iter3-Q5_K_S-GGUF --hf-file gemma-2-9b-it-sppo-iter3-q5_k_s.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo NikolayKozloff/Gemma-2-9B-It-SPPO-Iter3-Q5_K_S-GGUF --hf-file gemma-2-9b-it-sppo-iter3-q5_k_s.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo NikolayKozloff/Gemma-2-9B-It-SPPO-Iter3-Q5_K_S-GGUF --hf-file gemma-2-9b-it-sppo-iter3-q5_k_s.gguf -c 2048
```
|
sb3/ppo-CartPole-v1 | sb3 | 2024-03-08T10:08:50Z | 506 | 0 | stable-baselines3 | [
"stable-baselines3",
"CartPole-v1",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2022-05-19T22:36:14Z | ---
library_name: stable-baselines3
tags:
- CartPole-v1
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **PPO** Agent playing **CartPole-v1**
This is a trained model of a **PPO** agent playing **CartPole-v1**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo ppo --env CartPole-v1 -orga sb3 -f logs/
python -m rl_zoo3.enjoy --algo ppo --env CartPole-v1 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo ppo --env CartPole-v1 -orga sb3 -f logs/
python -m rl_zoo3.enjoy --algo ppo --env CartPole-v1 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo ppo --env CartPole-v1 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo ppo --env CartPole-v1 -f logs/ -orga sb3
```
## Hyperparameters
```python
OrderedDict([('batch_size', 256),
('clip_range', 'lin_0.2'),
('ent_coef', 0.0),
('gae_lambda', 0.8),
('gamma', 0.98),
('learning_rate', 'lin_0.001'),
('n_envs', 8),
('n_epochs', 20),
('n_steps', 32),
('n_timesteps', 100000.0),
('policy', 'MlpPolicy'),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
facebook/levit-128S | facebook | 2024-02-29T10:23:03Z | 506 | 4 | transformers | [
"transformers",
"pytorch",
"safetensors",
"levit",
"image-classification",
"vision",
"dataset:imagenet-1k",
"arxiv:2104.01136",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2022-06-01T11:28:11Z | ---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- imagenet-1k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# LeViT
LeViT-128S model pre-trained on ImageNet-1k at resolution 224x224. It was introduced in the paper [LeViT: a Vision Transformer in ConvNet's Clothing for Faster Inference
](https://arxiv.org/abs/2104.01136) by Graham et al. and first released in [this repository](https://github.com/facebookresearch/LeViT).
Disclaimer: The team releasing LeViT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Usage
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import LevitFeatureExtractor, LevitForImageClassificationWithTeacher
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = LevitFeatureExtractor.from_pretrained('facebook/levit-128S')
model = LevitForImageClassificationWithTeacher.from_pretrained('facebook/levit-128S')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
``` |
TheBloke/COTHuginn-4.5-19B-GGUF | TheBloke | 2023-09-27T13:02:41Z | 506 | 7 | transformers | [
"transformers",
"gguf",
"llama",
"base_model:The-Face-Of-Goonery/COTHuginn-4.5-19b",
"license:llama2",
"text-generation-inference",
"region:us"
]
| null | 2023-09-08T20:55:55Z | ---
license: llama2
model_name: COTHuginn 4.5 19B
inference: false
model_creator: Caleb Morgan
model_link: https://huggingface.co/The-Face-Of-Goonery/COTHuginn-4.5-19b
model_type: llama
quantized_by: TheBloke
base_model: The-Face-Of-Goonery/COTHuginn-4.5-19b
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# COTHuginn 4.5 19B - GGUF
- Model creator: [Caleb Morgan](https://huggingface.co/The-Face-Of-Goonery)
- Original model: [COTHuginn 4.5 19B](https://huggingface.co/The-Face-Of-Goonery/COTHuginn-4.5-19b)
## Description
This repo contains GGUF format model files for [Caleb Morgan's COTHuginn 4.5 19B](https://huggingface.co/The-Face-Of-Goonery/COTHuginn-4.5-19b).
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp. GGUF offers numerous advantages over GGML, such as better tokenisation, and support for special tokens. It is also supports metadata, and is designed to be extensible.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/COTHuginn-4.5-19B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/COTHuginn-4.5-19B-GGUF)
* [Caleb Morgan's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/The-Face-Of-Goonery/COTHuginn-4.5-19b)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [cothuginn-4.5-19b.Q2_K.gguf](https://huggingface.co/TheBloke/COTHuginn-4.5-19B-GGUF/blob/main/cothuginn-4.5-19b.Q2_K.gguf) | Q2_K | 2 | 8.05 GB| 10.55 GB | smallest, significant quality loss - not recommended for most purposes |
| [cothuginn-4.5-19b.Q3_K_S.gguf](https://huggingface.co/TheBloke/COTHuginn-4.5-19B-GGUF/blob/main/cothuginn-4.5-19b.Q3_K_S.gguf) | Q3_K_S | 3 | 8.39 GB| 10.89 GB | very small, high quality loss |
| [cothuginn-4.5-19b.Q3_K_M.gguf](https://huggingface.co/TheBloke/COTHuginn-4.5-19B-GGUF/blob/main/cothuginn-4.5-19b.Q3_K_M.gguf) | Q3_K_M | 3 | 9.39 GB| 11.89 GB | very small, high quality loss |
| [cothuginn-4.5-19b.Q3_K_L.gguf](https://huggingface.co/TheBloke/COTHuginn-4.5-19B-GGUF/blob/main/cothuginn-4.5-19b.Q3_K_L.gguf) | Q3_K_L | 3 | 10.29 GB| 12.79 GB | small, substantial quality loss |
| [cothuginn-4.5-19b.Q4_0.gguf](https://huggingface.co/TheBloke/COTHuginn-4.5-19B-GGUF/blob/main/cothuginn-4.5-19b.Q4_0.gguf) | Q4_0 | 4 | 10.94 GB| 13.44 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [cothuginn-4.5-19b.Q4_K_S.gguf](https://huggingface.co/TheBloke/COTHuginn-4.5-19B-GGUF/blob/main/cothuginn-4.5-19b.Q4_K_S.gguf) | Q4_K_S | 4 | 10.98 GB| 13.48 GB | small, greater quality loss |
| [cothuginn-4.5-19b.Q4_K_M.gguf](https://huggingface.co/TheBloke/COTHuginn-4.5-19B-GGUF/blob/main/cothuginn-4.5-19b.Q4_K_M.gguf) | Q4_K_M | 4 | 11.69 GB| 14.19 GB | medium, balanced quality - recommended |
| [cothuginn-4.5-19b.Q5_0.gguf](https://huggingface.co/TheBloke/COTHuginn-4.5-19B-GGUF/blob/main/cothuginn-4.5-19b.Q5_0.gguf) | Q5_0 | 5 | 13.33 GB| 15.83 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [cothuginn-4.5-19b.Q5_K_S.gguf](https://huggingface.co/TheBloke/COTHuginn-4.5-19B-GGUF/blob/main/cothuginn-4.5-19b.Q5_K_S.gguf) | Q5_K_S | 5 | 13.33 GB| 15.83 GB | large, low quality loss - recommended |
| [cothuginn-4.5-19b.Q5_K_M.gguf](https://huggingface.co/TheBloke/COTHuginn-4.5-19B-GGUF/blob/main/cothuginn-4.5-19b.Q5_K_M.gguf) | Q5_K_M | 5 | 13.72 GB| 16.22 GB | large, very low quality loss - recommended |
| [cothuginn-4.5-19b.Q6_K.gguf](https://huggingface.co/TheBloke/COTHuginn-4.5-19B-GGUF/blob/main/cothuginn-4.5-19b.Q6_K.gguf) | Q6_K | 6 | 15.88 GB| 18.38 GB | very large, extremely low quality loss |
| [cothuginn-4.5-19b.Q8_0.gguf](https://huggingface.co/TheBloke/COTHuginn-4.5-19B-GGUF/blob/main/cothuginn-4.5-19b.Q8_0.gguf) | Q8_0 | 8 | 20.57 GB| 23.07 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m cothuginn-4.5-19b.q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{prompt}\n\n### Response:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model from Python using ctransformers
#### First install the package
```bash
# Base ctransformers with no GPU acceleration
pip install ctransformers>=0.2.24
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]>=0.2.24
# Or with ROCm GPU acceleration
CT_HIPBLAS=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems
CT_METAL=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
```
#### Simple example code to load one of these GGUF models
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/COTHuginn-4.5-19B-GGUF", model_file="cothuginn-4.5-19b.q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here's guides on using llama-cpp-python or ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Russ Johnson, J, alfie_i, Alex, NimbleBox.ai, Chadd, Mandus, Nikolai Manek, Ken Nordquist, ya boyyy, Illia Dulskyi, Viktor Bowallius, vamX, Iucharbius, zynix, Magnesian, Clay Pascal, Pierre Kircher, Enrico Ros, Tony Hughes, Elle, Andrey, knownsqashed, Deep Realms, Jerry Meng, Lone Striker, Derek Yates, Pyrater, Mesiah Bishop, James Bentley, Femi Adebogun, Brandon Frisco, SuperWojo, Alps Aficionado, Michael Dempsey, Vitor Caleffi, Will Dee, Edmond Seymore, usrbinkat, LangChain4j, Kacper Wikieł, Luke Pendergrass, John Detwiler, theTransient, Nathan LeClaire, Tiffany J. Kim, biorpg, Eugene Pentland, Stanislav Ovsiannikov, Fred von Graf, terasurfer, Kalila, Dan Guido, Nitin Borwankar, 阿明, Ai Maven, John Villwock, Gabriel Puliatti, Stephen Murray, Asp the Wyvern, danny, Chris Smitley, ReadyPlayerEmma, S_X, Daniel P. Andersen, Olakabola, Jeffrey Morgan, Imad Khwaja, Caitlyn Gatomon, webtim, Alicia Loh, Trenton Dambrowitz, Swaroop Kallakuri, Erik Bjäreholt, Leonard Tan, Spiking Neurons AB, Luke @flexchar, Ajan Kanaga, Thomas Belote, Deo Leter, RoA, Willem Michiel, transmissions 11, subjectnull, Matthew Berman, Joseph William Delisle, David Ziegler, Michael Davis, Johann-Peter Hartmann, Talal Aujan, senxiiz, Artur Olbinski, Rainer Wilmers, Spencer Kim, Fen Risland, Cap'n Zoog, Rishabh Srivastava, Michael Levine, Geoffrey Montalvo, Sean Connelly, Alexandros Triantafyllidis, Pieter, Gabriel Tamborski, Sam, Subspace Studios, Junyu Yang, Pedro Madruga, Vadim, Cory Kujawski, K, Raven Klaugh, Randy H, Mano Prime, Sebastain Graf, Space Cruiser
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Caleb Morgan's COTHuginn 4.5 19B
I took huginn 4.5, kept the first 40 layers, then added a copy of layers 1-20 on top of it
somehow it works? It's also way better at math now somehow.
I'm posting it on HF so I can try and get it properly evaluated
<!-- original-model-card end -->
|
TheBloke/Unholy-v1-12L-13B-GGUF | TheBloke | 2023-09-27T12:48:46Z | 506 | 14 | transformers | [
"transformers",
"gguf",
"llama",
"not-for-all-audiences",
"nsfw",
"base_model:Undi95/Unholy-v1-12L-13B",
"license:cc-by-nc-4.0",
"text-generation-inference",
"region:us"
]
| null | 2023-09-11T10:20:20Z | ---
license: cc-by-nc-4.0
tags:
- not-for-all-audiences
- nsfw
model_name: Unholy v1 12L 13B
base_model: Undi95/Unholy-v1-12L-13B
inference: false
model_creator: Undi95
model_type: llama
prompt_template: 'Below is an instruction that describes a task. Write a response
that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Unholy v1 12L 13B - GGUF
- Model creator: [Undi95](https://huggingface.co/Undi95)
- Original model: [Unholy v1 12L 13B](https://huggingface.co/Undi95/Unholy-v1-12L-13B)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Undi95's Unholy v1 12L 13B](https://huggingface.co/Undi95/Unholy-v1-12L-13B).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp. GGUF offers numerous advantages over GGML, such as better tokenisation, and support for special tokens. It is also supports metadata, and is designed to be extensible.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Unholy-v1-12L-13B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Unholy-v1-12L-13B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Unholy-v1-12L-13B-GGUF)
* [Undi95's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/Undi95/Unholy-v1-12L-13B)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
<!-- prompt-template end -->
<!-- licensing start -->
## Licensing
The creator of the source model has listed its license as `cc-by-nc-4.0`, and this quantization has therefore used that same license.
As this model is based on Llama 2, it is also subject to the Meta Llama 2 license terms, and the license files for that are additionally included. It should therefore be considered as being claimed to be licensed under both licenses. I contacted Hugging Face for clarification on dual licensing but they do not yet have an official position. Should this change, or should Meta provide any feedback on this situation, I will update this section accordingly.
In the meantime, any questions regarding licensing, and in particular how these two licenses might interact, should be directed to the original model repository: [Undi95's Unholy v1 12L 13B](https://huggingface.co/Undi95/Unholy-v1-12L-13B).
<!-- licensing end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [unholy-v1-12l-13b.Q2_K.gguf](https://huggingface.co/TheBloke/Unholy-v1-12L-13B-GGUF/blob/main/unholy-v1-12l-13b.Q2_K.gguf) | Q2_K | 2 | 5.43 GB| 7.93 GB | smallest, significant quality loss - not recommended for most purposes |
| [unholy-v1-12l-13b.Q3_K_S.gguf](https://huggingface.co/TheBloke/Unholy-v1-12L-13B-GGUF/blob/main/unholy-v1-12l-13b.Q3_K_S.gguf) | Q3_K_S | 3 | 5.66 GB| 8.16 GB | very small, high quality loss |
| [unholy-v1-12l-13b.Q3_K_M.gguf](https://huggingface.co/TheBloke/Unholy-v1-12L-13B-GGUF/blob/main/unholy-v1-12l-13b.Q3_K_M.gguf) | Q3_K_M | 3 | 6.34 GB| 8.84 GB | very small, high quality loss |
| [unholy-v1-12l-13b.Q3_K_L.gguf](https://huggingface.co/TheBloke/Unholy-v1-12L-13B-GGUF/blob/main/unholy-v1-12l-13b.Q3_K_L.gguf) | Q3_K_L | 3 | 6.93 GB| 9.43 GB | small, substantial quality loss |
| [unholy-v1-12l-13b.Q4_0.gguf](https://huggingface.co/TheBloke/Unholy-v1-12L-13B-GGUF/blob/main/unholy-v1-12l-13b.Q4_0.gguf) | Q4_0 | 4 | 7.37 GB| 9.87 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [unholy-v1-12l-13b.Q4_K_S.gguf](https://huggingface.co/TheBloke/Unholy-v1-12L-13B-GGUF/blob/main/unholy-v1-12l-13b.Q4_K_S.gguf) | Q4_K_S | 4 | 7.41 GB| 9.91 GB | small, greater quality loss |
| [unholy-v1-12l-13b.Q4_K_M.gguf](https://huggingface.co/TheBloke/Unholy-v1-12L-13B-GGUF/blob/main/unholy-v1-12l-13b.Q4_K_M.gguf) | Q4_K_M | 4 | 7.87 GB| 10.37 GB | medium, balanced quality - recommended |
| [unholy-v1-12l-13b.Q5_0.gguf](https://huggingface.co/TheBloke/Unholy-v1-12L-13B-GGUF/blob/main/unholy-v1-12l-13b.Q5_0.gguf) | Q5_0 | 5 | 8.97 GB| 11.47 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [unholy-v1-12l-13b.Q5_K_S.gguf](https://huggingface.co/TheBloke/Unholy-v1-12L-13B-GGUF/blob/main/unholy-v1-12l-13b.Q5_K_S.gguf) | Q5_K_S | 5 | 8.97 GB| 11.47 GB | large, low quality loss - recommended |
| [unholy-v1-12l-13b.Q5_K_M.gguf](https://huggingface.co/TheBloke/Unholy-v1-12L-13B-GGUF/blob/main/unholy-v1-12l-13b.Q5_K_M.gguf) | Q5_K_M | 5 | 9.23 GB| 11.73 GB | large, very low quality loss - recommended |
| [unholy-v1-12l-13b.Q6_K.gguf](https://huggingface.co/TheBloke/Unholy-v1-12L-13B-GGUF/blob/main/unholy-v1-12l-13b.Q6_K.gguf) | Q6_K | 6 | 10.68 GB| 13.18 GB | very large, extremely low quality loss |
| [unholy-v1-12l-13b.Q8_0.gguf](https://huggingface.co/TheBloke/Unholy-v1-12L-13B-GGUF/blob/main/unholy-v1-12l-13b.Q8_0.gguf) | Q8_0 | 8 | 13.83 GB| 16.33 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/Unholy-v1-12L-13B-GGUF and below it, a specific filename to download, such as: unholy-v1-12l-13b.q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub>=0.17.1
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/Unholy-v1-12L-13B-GGUF unholy-v1-12l-13b.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/Unholy-v1-12L-13B-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Unholy-v1-12L-13B-GGUF unholy-v1-12l-13b.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows CLI users: Use `set HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1` before running the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m unholy-v1-12l-13b.q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{prompt}\n\n### Response:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model from Python using ctransformers
#### First install the package
```bash
# Base ctransformers with no GPU acceleration
pip install ctransformers>=0.2.24
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]>=0.2.24
# Or with ROCm GPU acceleration
CT_HIPBLAS=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems
CT_METAL=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
```
#### Simple example code to load one of these GGUF models
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/Unholy-v1-12L-13B-GGUF", model_file="unholy-v1-12l-13b.q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here's guides on using llama-cpp-python or ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Undi95's Unholy v1 12L 13B

[HIGHLY EXPERIMENTAL]
(Sister model: https://huggingface.co/Undi95/Unholy-v1-10L-13B)
Use at your own risk, I'm not responsible for any usage of this model, don't try to do anything this model tell you to do.
Uncensored.
If you are censored, it's maybe because of keyword like "assistant", "Factual answer", or other "sweet words" like I call them that trigger the censoring accross all the layer of the model (since they're all trained on some of them in a way).
12L : This is a test project, uukuguy/speechless-llama2-luban-orca-platypus-13b and jondurbin/spicyboros-13b-2.2 was used for a merge, then, I deleted the first 8 layers to add 8 layers of MLewd at the beginning, and do the same from layers 16 to 20, trying to break all censoring possible, before merging the output with MLewd at 0.33 weight.
<!-- description start -->
## Description
This repo contains fp16 files of Unholy v1, an uncensored model.
<!-- description end -->
<!-- description start -->
## Models used
- uukuguy/speechless-llama2-luban-orca-platypus-13b
- jondurbin/spicyboros-13b-2.2
- Undi95/MLewd-L2-13B-v2-3
<!-- description end -->
<!-- prompt-template start -->
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
Exemple:

<!-- original-model-card end -->
|
TheBloke/Spicyboros-c34b-2.2-GGUF | TheBloke | 2023-09-27T12:48:59Z | 506 | 9 | transformers | [
"transformers",
"gguf",
"llama",
"not-for-all-audiences",
"dataset:jondurbin/airoboros-2.2",
"base_model:jondurbin/spicyboros-c34b-2.2",
"license:llama2",
"text-generation-inference",
"region:us"
]
| null | 2023-09-12T16:51:30Z | ---
license: llama2
tags:
- not-for-all-audiences
datasets:
- jondurbin/airoboros-2.2
model_name: Spicyboros c34B 2.2
base_model: jondurbin/spicyboros-c34b-2.2
inference: false
model_creator: Jon Durbin
model_type: llama
prompt_template: "A chat.\nUSER: {prompt}\nASSISTANT: \n"
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Spicyboros c34B 2.2 - GGUF
- Model creator: [Jon Durbin](https://huggingface.co/jondurbin)
- Original model: [Spicyboros c34B 2.2](https://huggingface.co/jondurbin/spicyboros-c34b-2.2)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Jon Durbin's Spicyboros c34B 2.2](https://huggingface.co/jondurbin/spicyboros-c34b-2.2).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp. GGUF offers numerous advantages over GGML, such as better tokenisation, and support for special tokens. It is also supports metadata, and is designed to be extensible.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Spicyboros-c34b-2.2-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Spicyboros-c34b-2.2-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Spicyboros-c34b-2.2-GGUF)
* [Jon Durbin's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/jondurbin/spicyboros-c34b-2.2)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Chat
```
A chat.
USER: {prompt}
ASSISTANT:
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [spicyboros-c34b-2.2.Q2_K.gguf](https://huggingface.co/TheBloke/Spicyboros-c34b-2.2-GGUF/blob/main/spicyboros-c34b-2.2.Q2_K.gguf) | Q2_K | 2 | 14.21 GB| 16.71 GB | smallest, significant quality loss - not recommended for most purposes |
| [spicyboros-c34b-2.2.Q3_K_S.gguf](https://huggingface.co/TheBloke/Spicyboros-c34b-2.2-GGUF/blob/main/spicyboros-c34b-2.2.Q3_K_S.gguf) | Q3_K_S | 3 | 14.61 GB| 17.11 GB | very small, high quality loss |
| [spicyboros-c34b-2.2.Q3_K_M.gguf](https://huggingface.co/TheBloke/Spicyboros-c34b-2.2-GGUF/blob/main/spicyboros-c34b-2.2.Q3_K_M.gguf) | Q3_K_M | 3 | 16.28 GB| 18.78 GB | very small, high quality loss |
| [spicyboros-c34b-2.2.Q3_K_L.gguf](https://huggingface.co/TheBloke/Spicyboros-c34b-2.2-GGUF/blob/main/spicyboros-c34b-2.2.Q3_K_L.gguf) | Q3_K_L | 3 | 17.77 GB| 20.27 GB | small, substantial quality loss |
| [spicyboros-c34b-2.2.Q4_0.gguf](https://huggingface.co/TheBloke/Spicyboros-c34b-2.2-GGUF/blob/main/spicyboros-c34b-2.2.Q4_0.gguf) | Q4_0 | 4 | 19.05 GB| 21.55 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [spicyboros-c34b-2.2.Q4_K_S.gguf](https://huggingface.co/TheBloke/Spicyboros-c34b-2.2-GGUF/blob/main/spicyboros-c34b-2.2.Q4_K_S.gguf) | Q4_K_S | 4 | 19.15 GB| 21.65 GB | small, greater quality loss |
| [spicyboros-c34b-2.2.Q4_K_M.gguf](https://huggingface.co/TheBloke/Spicyboros-c34b-2.2-GGUF/blob/main/spicyboros-c34b-2.2.Q4_K_M.gguf) | Q4_K_M | 4 | 20.22 GB| 22.72 GB | medium, balanced quality - recommended |
| [spicyboros-c34b-2.2.Q5_0.gguf](https://huggingface.co/TheBloke/Spicyboros-c34b-2.2-GGUF/blob/main/spicyboros-c34b-2.2.Q5_0.gguf) | Q5_0 | 5 | 23.24 GB| 25.74 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [spicyboros-c34b-2.2.Q5_K_S.gguf](https://huggingface.co/TheBloke/Spicyboros-c34b-2.2-GGUF/blob/main/spicyboros-c34b-2.2.Q5_K_S.gguf) | Q5_K_S | 5 | 23.24 GB| 25.74 GB | large, low quality loss - recommended |
| [spicyboros-c34b-2.2.Q5_K_M.gguf](https://huggingface.co/TheBloke/Spicyboros-c34b-2.2-GGUF/blob/main/spicyboros-c34b-2.2.Q5_K_M.gguf) | Q5_K_M | 5 | 23.84 GB| 26.34 GB | large, very low quality loss - recommended |
| [spicyboros-c34b-2.2.Q6_K.gguf](https://huggingface.co/TheBloke/Spicyboros-c34b-2.2-GGUF/blob/main/spicyboros-c34b-2.2.Q6_K.gguf) | Q6_K | 6 | 27.68 GB| 30.18 GB | very large, extremely low quality loss |
| [spicyboros-c34b-2.2.Q8_0.gguf](https://huggingface.co/TheBloke/Spicyboros-c34b-2.2-GGUF/blob/main/spicyboros-c34b-2.2.Q8_0.gguf) | Q8_0 | 8 | 35.86 GB| 38.36 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/Spicyboros-c34b-2.2-GGUF and below it, a specific filename to download, such as: spicyboros-c34b-2.2.q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub>=0.17.1
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/Spicyboros-c34b-2.2-GGUF spicyboros-c34b-2.2.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/Spicyboros-c34b-2.2-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Spicyboros-c34b-2.2-GGUF spicyboros-c34b-2.2.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows CLI users: Use `set HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1` before running the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m spicyboros-c34b-2.2.q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "A chat.\nUSER: {prompt}\nASSISTANT:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model from Python using ctransformers
#### First install the package
```bash
# Base ctransformers with no GPU acceleration
pip install ctransformers>=0.2.24
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]>=0.2.24
# Or with ROCm GPU acceleration
CT_HIPBLAS=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems
CT_METAL=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
```
#### Simple example code to load one of these GGUF models
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/Spicyboros-c34b-2.2-GGUF", model_file="spicyboros-c34b-2.2.q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here's guides on using llama-cpp-python or ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Jon Durbin's Spicyboros c34B 2.2
### Overview
__Usage restriction: To use this model, you must agree to the following:__
- Some of the content than can be produced is "toxic"/"harmful", and contains profanity and other types of sensitive content.
- None of the content or views contained in the dataset or generated outputs necessarily align with my personal beliefs or opinions, they are simply text generated by LLMs and/or scraped from the web.
- Use with extreme caution, particularly in locations with less-than-free speech laws.
- You, and you alone are responsible for having downloaded and generated outputs with the model and I am completely indemnified from any and all liabilities.
__Ok, now that the warning is out of the way...__
Another experimental model, using mostly sythetic data generated by [airoboros](https://github.com/jondurbin/airoboros)
Highlights:
- The prompt format has changed! It is now newlines instead of spaces between system/USER/ASSISTANT (see prompt info below).
- This version also includes "de-alignment" data, to enable less savory interactions and outputs.
- To learn more about the dataset, see: https://hf.co/datasets/jondurbin/airoboros-2.2 (this is the instructions.jsonl file, not instructions-clean.jsonl)
- I re-generated all of the outputs in the dataset that had "Once upon a time" so they'd be less cliche - no guarantees that won't still happen, but in theory it may happen less.
- More multiple choice, better awareness, some alignment for normal use case but system-prompt overridable etc.
__WARNING: This model will gladly spew profane and otherwise NSFW content, if asked, use with care.__
Breakdown of the training data:
| Count | Category |
|--------|----------------------------|
| 60 | quiz |
| 63 | card |
| 100 | detailed\_writing |
| 103 | experience |
| 114 | greeting |
| 200 | song |
| 204 | editor |
| 250 | counterfactual\_contextual |
| 268 | cot |
| 339 | theory\_of\_mind |
| 460 | misconception |
| 500 | summarization |
| 573 | awareness |
| 715 | riddle |
| 719 | agent |
| 800 | plan |
| 873 | gtkm |
| 966 | rp |
| 1000 | stylized\_response |
| 1000 | wordgame |
| 1279 | multiple\_choice |
| 1641 | joke |
| 1785 | writing |
| 2155 | contextual |
| 2364 | roleplay |
| 2508 | trivia |
| 5216 | general |
| 5779 | coding |
| 11367 | orca |
In other words, it's a fairly general purpose model, but focuses fairly heavily on instruction response pairs rather than casual chat/roleplay.
*Why do I try to remove censorship?*
- laws vary widely based on time and location
- language model may conflate certain words with laws, e.g. it may think "stealing eggs from a chicken" is illegal
- these models just produce text, what you do with that text is your resonsibility
- many people and industries deal with "sensitive" content; imagine if a court stenographer's equipment filtered illegal content - it would be useless
Huge thank you to the folks over at [a16z](https://a16z.com/) for sponsoring the costs associated with building models and associated tools!
### Prompt format
The prompt format:
```
A chat.
USER: {prompt}
ASSISTANT:
```
The default system prompt ("A chat.") was used for most of the prompts, however it also included a wide sampling of responses with other prompts, particularly in "stylized\_response", "rp", "gtkm", etc.
Here's another example:
```
A chat between Bob (aka USER) and Tom (aka ASSISTANT). Tom is an extremely intelligent 18th century bookkeeper, who speaks loquaciously.
USER: {prompt}
ASSISTANT:
```
And chat scenario that wouldn't require USER/ASSISTANT (but should use stopping criteria to prevent the model from speaking on your behalf).
```
A chat between old friends: Timmy and Tommy.
{description of characters}
{setting for the chat}
Timmy: *takes a big sip from his coffee* "Ah, sweet, delicious, magical coffee."
Tommy:
```
__*I strongly suggest adding stopping criteria/early inference stopping on "USER:", and/or whatever names you specify in the system prompt.*__
### Fine-tuning details
https://gist.github.com/jondurbin/51a336c582a224de197ba1d2c6b1da97
*Note: I used checkpoint 750 for final model!*
### Helpful usage tips
*The prompts shown here are are just the text that would be included after USER: and before ASSISTANT: in the full prompt format above, the system prompt and USER:/ASSISTANT: have been omited for readability.*
#### Context obedient question answering
By obedient, I mean the model was trained to ignore what it thinks it knows, and uses the context to answer the question. The model was also tuned to limit the values to the provided context as much as possible to reduce hallucinations.
The format for a closed-context prompt is as follows:
```
BEGININPUT
BEGINCONTEXT
[key0: value0]
[key1: value1]
... other metdata ...
ENDCONTEXT
[insert your text blocks here]
ENDINPUT
[add as many other blocks, in the exact same format]
BEGININSTRUCTION
[insert your instruction(s). The model was tuned with single questions, paragraph format, lists, etc.]
ENDINSTRUCTION
```
It's also helpful to add "Don't make up answers if you don't know." to your instruction block to make sure if the context is completely unrelated it doesn't make something up.
*The __only__ prompts that need this closed context formating are closed-context instructions. Normal questions/instructions do not!*
I know it's a bit verbose and annoying, but after much trial and error, using these explicit delimiters helps the model understand where to find the responses and how to associate specific sources with it.
- `BEGININPUT` - denotes a new input block
- `BEGINCONTEXT` - denotes the block of context (metadata key/value pairs) to associate with the current input block
- `ENDCONTEXT` - denotes the end of the metadata block for the current input
- [text] - Insert whatever text you want for the input block, as many paragraphs as can fit in the context.
- `ENDINPUT` - denotes the end of the current input block
- [repeat as many input blocks in this format as you want]
- `BEGININSTRUCTION` - denotes the start of the list (or one) instruction(s) to respond to for all of the input blocks above.
- [instruction(s)]
- `ENDINSTRUCTION` - denotes the end of instruction set
It sometimes works without `ENDINSTRUCTION`, but by explicitly including that in the prompt, the model better understands that all of the instructions in the block should be responded to.
Here's a trivial, but important example to prove the point:
```
BEGININPUT
BEGINCONTEXT
date: 2021-01-01
url: https://web.site/123
ENDCONTEXT
In a shocking turn of events, blueberries are now green, but will be sticking with the same name.
ENDINPUT
BEGININSTRUCTION
What color are bluberries? Source?
ENDINSTRUCTION
```
And the response:
```
Blueberries are now green.
Source:
date: 2021-01-01
url: https://web.site/123
```
#### Coding
You can ask for fairly complex coding instructions with multiple criteria, e.g.:
```
Create a python application with the following requirements:
- Asyncio FastAPI webserver
- ping endpoint that returns the current date in JSON format
- file upload endpoint, which calculates the file's sha256 checksum, and checks postgres to deduplicate
```
Or inline criteria:
```
Write a multi-threaded TCP server in C that accepts a "GET [key]" input and "SET [key] [value]" input, and uses a binary tree to get and store the input values.
```
You can also optionally add a single space and "PLAINFORMAT" at the end of your prompt to avoid backticks, explanations, etc. and just print the code, e.g.:
```
Write a websocket application in node.js. PLAINFORMAT
```
#### Agent/function calling
The dataset includes many examples of function/args generation based on input criteria. This is somewhat similar to the OpenAI function calling, but the output is either JSON or YAML.
Example prompt:
```
As an AI assistant, please select the most suitable function and parameters from the list of available functions below, based on the user's input. Provide your response in JSON format.
Input: I want to know how many times 'Python' is mentioned in my text file.
Available functions:
file_analytics:
description: This tool performs various operations on a text file.
params:
action: The operation we want to perform on the data, such as "count_occurrences", "find_line", etc.
filters:
keyword: The word or phrase we want to search for.
```
Response:
```json
{
"function": "file_analytics",
"params": {
"action": "count_occurrences",
"filters": {
"keyword": "Python"
}
}
}
```
#### Chain-of-thought
You can ask for several possible responses to a given problem, with a ranking and final answer selection.
Example prompt:
```
A group of people decide to play a round-robin tournament where every player plays every other player exactly once. If a total of 45 games were played, how many players participated in the tournament? Offer several potential answers, rank them according to mathematical logic, and pick the most feasible one.
```
Example response:
```
Solution 1:
In a round-robin tournament, each player plays every other player exactly once. This means that the total number of games played is equal to the combination of all players taken two at a time (since a game involves two players).
The formula for combinations is nC2 = n(n-1)/2, where n is the total number of players. We know that nC2 equals 45 (the total number of games), so we can set up the equation as follows:
n(n-1)/2 = 45
Solving this equation gives us n=10.
Final answer: There were 10 players in the tournament.
Solution 2:
Another way to approach this problem is by using the concept of triangular numbers. Triangular numbers are a sequence of numbers where each number can be represented as a triangle with dots. The nth triangular number is given by the sum of the first n natural numbers.
If we consider each game as a dot and each player as a side of the triangle, then the total number of games (45) would correspond to the 9th triangular number because 1+2+3+4+5+6+7+8+9=45. However, since each side of the triangle represents a player, and there's one more player than sides in our model (because the last player has no one left to play against), we need to add one more to get the total number of players.
Final answer: There were 10 players in the tournament.
Solution 3:
We could also use trial and error to solve this problem. Starting from a small number of players, we calculate how many games would be played in a round-robin tournament until we reach 45 games. For example, with 2 players, only 1 game is played; with 3 players, 3 games are played; with 4 players, 6 games are played, and so on. Continuing this process, we find that with 10 players, 45 games are played.
Final answer: There were 10 players in the tournament.
Ranking of solutions from best to worst:
1. Solution 1: This solution uses direct mathematical reasoning based on the properties of a round-robin tournament and solves an equation to find the answer.
2. Solution 2: This solution uses the concept of triangular numbers which requires additional steps and knowledge beyond the immediate problem context, but still arrives at the correct answer.
3. Solution 3: This solution relies on trial and error, which is less efficient and reliable than the other methods, but it eventually gets to the right answer.
Best and final answer: There were 10 players in the tournament.
```
#### reWOO style execution planning
The model now supports execution planning for complex instructions that would require making use of several tools. The output is just the plan, you must implement a mechanism to parse the output and actually call the functions!
Example prompt:
```
Please construct a systematic plan to generate an optimal response to the user instruction, utilizing a set of provided tools. Each plan will correspond to an evidence value, which will be the output of one of the available functions given an input string
that could be the user's question, one or more prior evidence values, or a combination of both.
Here are the tools available to be called:
DuckDuckGo[input]: Tool that enables the user to search for information using the DuckDuckGo search engine. This tool is helpful in locating a suitable list of sites that may contain the answer to the user's query. It does not directly answer the question but finds a list of sites that might have the answer.
TextScraper[input]: Load one or more websites from the input string containing newline delimited links, where input is one or more links, and produces plain text output containing the content of the links.
HyperlinkExtractor[input]: Extract links from plain text and produces a plain text, newline delimited response of links.
KnowledgeModel[input]: Question answering language model, particularly useful in answering questions based on an input passage of text. The input must be a text question that references an :evidence[n]: variable, e.g. What color is the cat, given :evidence1:?
The output should be in format:
Plan: [first action to take based on input question]
:evidence0: = [function to call with input parameter]
Plan: [next action to take, based on result of :evidence0:]
:evidence1: = [next function to call and input parameter, which may include reference to previous evidence, e.g. "Given context :evidence0"]
...
Answer: [:evidence[n]: containing the final answer.]
Question: Who won the Nobel Prize in Literature in 2020 and what is their most famous work?
```
Response:
```
Plan: Begin by conducting a web search to find out who won the Nobel Prize in Literature in 2020.
:evidence0: = DuckDuckGo[Nobel Prize in Literature 2020 winner]
Plan: Utilize the KnowledgeModel to interpret the search results and find the name of the laureate.
:evidence1: = KnowledgeModel[Who won the Nobel Prize in Literature in 2020, given :evidence0:?]
Plan: Conduct another web search to find the most famous work of the identified laureate.
:evidence2: = DuckDuckGo[Most famous work of :evidence1:]
Plan: Extract the relevant links from the DuckDuckGo search results for a more focused search.
:evidence3: = HyperlinkExtractor[:evidence2:]
Plan: Use the TextScraper tool to extract information from the relevant links.
:evidence4: = TextScraper[:evidence3:]
Plan: Finally, utilize the KnowledgeModel to identify and summarize the most famous work of the laureate from the extracted information.
:evidence5: = KnowledgeModel[What is the most famous work of :evidence1:, given :evidence4:?]
Answer: :evidence5:
```
For this to be useful, you'd have to parse the output plan text, and implement/call each of the functions. This is just pseudo-code, completely untested off the top of my head, and obviously would requiring full implementation + hardening:
```python
import re
import requests
def inject_context(input_text, **context):
for ref in set(re.findall(r"(:evidence[0-9]+:)", input_text, re.I)):
input_text = input_text.replace(ref, context.get(ref, ""))
return input_text
def duckduckgo(input_text, **context):
search_string = inject_context(input_text, **context)
... search via duck duck go using search_string
... return text content
def link_extractor(input_text, **context):
input_text = inject_context(input_text, **context)
return "\n".join(list(set(re.findall(r"(https?://[^\s]+?\.?)", input_text, re.I))))
def scrape(input_text, **context):
input_text = inject_context(input_text, **context)
text = []
for link in input_text.splitlines():
text.append(requests.get(link).text)
return "\n".join(text)
def infer(input_text, **context)
prompt = inject_context(input_text, **context)
... call model with prompt, return output
def parse_plan(plan):
method_map = {
"DuckDuckGo": duckduckgo,
"HyperlinkExtractor": link_extractor,
"KnowledgeModel": infer,
"TextScraper": scrape,
}
context = {}
for line in plan.strip().splitlines():
if line.startswith("Plan:"):
print(line)
continue
parts = re.match("^(:evidence[0-9]+:)\s*=\s*([^\[]+])(\[.*\])\s$", line, re.I)
if not parts:
if line.startswith("Answer: "):
return context.get(line.split(" ")[-1].strip(), "Answer couldn't be generated...")
raise RuntimeError("bad format: " + line)
context[parts.group(1)] = method_map[parts.group(2)](parts.group(3), **context)
```
### Contribute
If you're interested in new functionality, particularly a new "instructor" type to generate a specific type of training data,
take a look at the dataset generation tool repo: https://github.com/jondurbin/airoboros and either make a PR or open an issue with details.
To help me with the OpenAI/compute costs:
- https://bmc.link/jondurbin
- ETH 0xce914eAFC2fe52FdceE59565Dd92c06f776fcb11
- BTC bc1qdwuth4vlg8x37ggntlxu5cjfwgmdy5zaa7pswf
### Licence and usage restrictions
The airoboros 2.2 models are built on top of llama-2/codellama.
The llama-2 base model has a custom Meta license:
- See the [meta-license/LICENSE.txt](meta-license/LICENSE.txt) file attached for the original license provided by Meta.
- See also [meta-license/USE_POLICY.md](meta-license/USE_POLICY.md) and [meta-license/Responsible-Use-Guide.pdf](meta-license/Responsible-Use-Guide.pdf), also provided by Meta.
The fine-tuning data was mostly generated by OpenAI API calls to gpt-4, via [airoboros](https://github.com/jondurbin/airoboros)
The ToS for OpenAI API usage has a clause preventing the output from being used to train a model that __competes__ with OpenAI
- what does *compete* actually mean here?
- these small open source models will not produce output anywhere near the quality of gpt-4, or even gpt-3.5, so I can't imagine this could credibly be considered competing in the first place
- if someone else uses the dataset to do the same, they wouldn't necessarily be violating the ToS because they didn't call the API, so I don't know how that works
- the training data used in essentially all large language models includes a significant amount of copyrighted or otherwise non-permissive licensing in the first place
- other work using the self-instruct method, e.g. the original here: https://github.com/yizhongw/self-instruct released the data and model as apache-2
I am purposingly leaving this license ambiguous (other than the fact you must comply with the Meta original license for llama-2) because I am not a lawyer and refuse to attempt to interpret all of the terms accordingly.
Your best bet is probably to avoid using this commercially due to the OpenAI API usage.
Either way, by using this model, you agree to completely indemnify me.
<!-- original-model-card end -->
|
maddes8cht/bofenghuang-vigogne-falcon-7b-instruct-gguf | maddes8cht | 2023-11-22T20:26:07Z | 506 | 1 | transformers | [
"transformers",
"gguf",
"LLM",
"text-generation",
"fr",
"license:apache-2.0",
"region:us"
]
| text-generation | 2023-10-15T20:42:12Z | ---
license: apache-2.0
language:
- fr
pipeline_tag: text-generation
library_name: transformers
tags:
- LLM
inference: false
---
[]()
I'm constantly enhancing these model descriptions to provide you with the most relevant and comprehensive information
# vigogne-falcon-7b-instruct - GGUF
- Model creator: [bofenghuang](https://huggingface.co/bofenghuang)
- Original model: [vigogne-falcon-7b-instruct](https://huggingface.co/bofenghuang/vigogne-falcon-7b-instruct)
# K-Quants in Falcon 7b models
New releases of Llama.cpp now support K-quantization for previously incompatible models, in particular all Falcon 7B models (While Falcon 40b is and always has been fully compatible with K-Quantisation). This is achieved by employing a fallback solution for model layers that cannot be quantized with real K-quants.
For Falcon 7B models, although only a quarter of the layers can be quantized with true K-quants, this approach still benefits from utilizing *different* legacy quantization types Q4_0, Q4_1, Q5_0, and Q5_1. As a result, it offers better quality at the same file size or smaller file sizes with comparable performance.
So this solution ensures improved performance and efficiency over legacy Q4_0, Q4_1, Q5_0 and Q5_1 Quantizations.
---
# Brief
Vigogne-Falcon-7B-Instruct is a Falcon-7B model fine-tuned to follow the French instructions.
---
# About GGUF format
`gguf` is the current file format used by the [`ggml`](https://github.com/ggerganov/ggml) library.
A growing list of Software is using it and can therefore use this model.
The core project making use of the ggml library is the [llama.cpp](https://github.com/ggerganov/llama.cpp) project by Georgi Gerganov
# Quantization variants
There is a bunch of quantized files available to cater to your specific needs. Here's how to choose the best option for you:
# Legacy quants
Q4_0, Q4_1, Q5_0, Q5_1 and Q8 are `legacy` quantization types.
Nevertheless, they are fully supported, as there are several circumstances that cause certain model not to be compatible with the modern K-quants.
## Note:
Now there's a new option to use K-quants even for previously 'incompatible' models, although this involves some fallback solution that makes them not *real* K-quants. More details can be found in affected model descriptions.
(This mainly refers to Falcon 7b and Starcoder models)
# K-quants
K-quants are designed with the idea that different levels of quantization in specific parts of the model can optimize performance, file size, and memory load.
So, if possible, use K-quants.
With a Q6_K, you'll likely find it challenging to discern a quality difference from the original model - ask your model two times the same question and you may encounter bigger quality differences.
---
# Original Model Card:
<p align="center" width="100%">
<img src="https://huggingface.co/bofenghuang/vigogne-falcon-7b-instruct/resolve/main/vigogne_logo.png" alt="Vigogne" style="width: 40%; min-width: 300px; display: block; margin: auto;">
</p>
# Vigogne-Falcon-7B-Instruct: A French Instruction-following Falcon Model
Vigogne-Falcon-7B-Instruct is a [Falcon-7B](https://huggingface.co/tiiuae/falcon-7b) model fine-tuned to follow the French instructions.
For more information, please visit the Github repo: https://github.com/bofenghuang/vigogne
## Usage
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
from vigogne.preprocess import generate_instruct_prompt
model_name_or_path = "bofenghuang/vigogne-falcon-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, padding_side="right", use_fast=False)
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
)
user_query = "Expliquez la différence entre DoS et phishing."
prompt = generate_instruct_prompt(user_query)
input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to(model.device)
input_length = input_ids.shape[1]
generated_outputs = model.generate(
input_ids=input_ids,
generation_config=GenerationConfig(
temperature=0.1,
do_sample=True,
repetition_penalty=1.0,
max_new_tokens=512,
),
return_dict_in_generate=True,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=tokenizer.eos_token_id,
)
generated_tokens = generated_outputs.sequences[0, input_length:]
generated_text = tokenizer.decode(generated_tokens, skip_special_tokens=True)
print(generated_text)
```
You can also infer this model by using the following Google Colab Notebook.
<a href="https://colab.research.google.com/github/bofenghuang/vigogne/blob/main/notebooks/infer_instruct.ipynb" target="_blank"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
## Limitations
Vigogne is still under development, and there are many limitations that have to be addressed. Please note that it is possible that the model generates harmful or biased content, incorrect information or generally unhelpful answers.
***End of original Model File***
---
## Please consider to support my work
**Coming Soon:** I'm in the process of launching a sponsorship/crowdfunding campaign for my work. I'm evaluating Kickstarter, Patreon, or the new GitHub Sponsors platform, and I am hoping for some support and contribution to the continued availability of these kind of models. Your support will enable me to provide even more valuable resources and maintain the models you rely on. Your patience and ongoing support are greatly appreciated as I work to make this page an even more valuable resource for the community.
<center>
[](https://maddes8cht.github.io)
[](https://stackexchange.com/users/26485911)
[](https://github.com/maddes8cht)
[](https://huggingface.co/maddes8cht)
[](https://twitter.com/maddes1966)
</center> |
AunyMoons/loras-pack | AunyMoons | 2023-11-29T18:35:59Z | 506 | 1 | diffusers | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"region:us"
]
| text-to-image | 2023-11-18T17:14:42Z | ---
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
widget:
- text: '-'
output:
url: images/ComfyUI_00119_.png
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: null
---
# Extreme Low Angle Perspective
<Gallery />
## Download model
Weights for this model are available in Safetensors,PyTorch format.
[Download](/AunyMoons/loras-pack/tree/main) them in the Files & versions tab.
|
goofyai/disney_style_xl | goofyai | 2023-11-22T06:44:53Z | 506 | 12 | diffusers | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail",
"region:us"
]
| text-to-image | 2023-11-22T06:40:59Z | ---
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
widget:
- text: disney style,animal focus, animal, cat
parameters:
negative_prompt: bad quality, deformed, artifacts, digital noise
output:
url: images/c9ad912d-e9b1-4807-950d-ab2d07eaed6e.png
- text: >-
disney style,one girl wearing round glasses in school dress, short skirt and
socks. white shirt with black necktie
parameters:
negative_prompt: bad quality, deformed, artifacts, digital noise
output:
url: images/a2ed97c6-1ab5-431c-a4ae-73cedfb494e4.png
- text: >-
disney style, brown eyes, white shirt, round eyewear, shirt, earrings,
closed mouth, brown hair, jewelry, glasses, looking at viewer, dark skin,
1girl, solo, dark-skinned female, very dark skin, curly hair, lips,
portrait, black hair, print shirt, short hair, blurry background, outdoors,
yellow-framed eyewear, blurry
parameters:
negative_prompt: bad quality, deformed, artifacts, digital noise
output:
url: images/d7c67c24-9116-40da-a75f-bf42a211a6c0.png
- text: >-
disney style, uniform, rabbit, shirt, vest, day, upper body, hands on hips,
rabbit girl, animal nose, smile, furry, police, 1girl, solo, animal ears,
rabbit ears, policewoman, grey fur, furry female, long sleeves, purple eyes,
blurry background, police uniform, outdoors, blurry, blue shirt
parameters:
negative_prompt: bad quality, deformed, artifacts, digital noise
output:
url: images/1d0aac43-aa2a-495c-84fd-ca2c9eb22a0d.jpg
- text: >-
disney style, rain, furry, bear, 1boy, solo, blue headwear, water drop,
baseball cap, outdoors, blurry, shirt, male focus, furry male, hat, blue
shirt
parameters:
negative_prompt: bad quality, deformed, artifacts, digital noise
output:
url: images/5cd36626-22da-46d2-aa79-2ca31c80fd59.png
- text: >-
disney style, looking at viewer, long hair, dress, lipstick, braid, hair
over shoulder, blonde hair, 1girl, solo, purple dress, makeup, stairs, blue
eyes, single braid
parameters:
negative_prompt: bad quality, deformed, artifacts, digital noise
output:
url: images/4af61860-6dca-4694-9f31-ceaf08071e6d.png
- text: >-
disney style, lipstick, dress, smile, braid, tiara, blonde hair, 1girl,
solo, upper body, gloves, makeup, crown, blue eyes, cape
output:
url: images/882eb6c8-5c6c-4694-b3f1-f79f8df8ce8a.jpg
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: disney style
license: openrail
---
# Disney style xl
<Gallery />
## Trigger words
You should use `disney style` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/goofyai/disney_style_xl/tree/main) them in the Files & versions tab.
|
digiplay/ShadowGost_v1 | digiplay | 2023-12-05T20:02:53Z | 506 | 3 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2023-12-04T20:36:58Z | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info:
https://civitai.com/models/128519?modelVersionId=140732
Original Author's DEMO images :






|
eraydikyologlu/FineTunedGPT2ForAgriculture | eraydikyologlu | 2024-03-23T15:32:03Z | 506 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"gpt2",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-03-23T15:24:15Z | Entry not found |
martintmv/InsectSAM | martintmv | 2024-06-20T09:55:56Z | 506 | 2 | transformers | [
"transformers",
"pytorch",
"sam",
"mask-generation",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| mask-generation | 2024-04-13T23:56:24Z | ---
license: apache-2.0
pinned: true
---
# InsectSAM: Insect Segmentation and Monitoring
<p align="left">
<a href="" rel="noopener">
<img width=200px height=200px src="https://i.imgur.com/hjWgAN9.png alt="Project logo"></a>
</p>
## Overview
InsectSAM is an advanced machine learning model tailored for the https://diopsis.eu camera systems and https://www.arise-biodiversity.nl/, dedicated to Insect Biodiversity Detection and Monitoring in the Netherlands. Built on Meta AI's `segment-anything` model, InsectSAM is fine-tuned to be accurate at segmenting insects from complex backgrounds, enhancing the accuracy and efficiency of biodiversity monitoring efforts.
## Purpose
This model has been meticulously trained to identify and segment insects against a variety of backgrounds that might otherwise confuse traditional algorithms. It is specifically designed to adapt to future changes in background environments, ensuring its long-term utility in the DIOPSIS / ARISE project.
## Model Architecture
InsectSAM utilizes the advanced capabilities of the `segment-anything` architecture, enhanced by our custom training on an insect-centric dataset. The model is further refined by integrating with GroundingDINO, improving its ability to distinguish fine details and subtle variations in insect appearances.
## Quick Start
### Prerequisites
- Python
- Hugging Face Transformers
- PyTorch
### Usage
#### Install
``` bash
!pip install --upgrade -q git+https://github.com/huggingface/transformers
!pip install torch
```
#### Load model directly via HF Transformers 🤗
``` bash
from transformers import AutoProcessor, AutoModelForMaskGeneration
processor = AutoProcessor.from_pretrained("martintmv/InsectSAM")
model = AutoModelForMaskGeneration.from_pretrained("martintmv/InsectSAM")
```
### Notebooks
Three Jupyter notebooks are provided to demonstrate the model's capabilities and its integration with GroundingDINO:
- **InsectSAM.ipynb**: Covers the training process, from data preparation to model evaluation.
- **InsectSAM_GroundingDINO.ipynb**: Demonstrates how InsectSAM is combined with GroundingDINO for enhanced segmentation performance.
- **Run_InsectSAM_Inference_Transformers.ipynb**: Run InsectSAM using Transformers.
Check out the notebooks on RB-IBDM's GitHub page - https://github.com/martintmv-git/RB-IBDM/tree/main/InsectSAM |
Lewdiculous/Average_Normie_l3_v1_8B-GGUF-IQ-Imatrix | Lewdiculous | 2024-05-04T14:28:05Z | 506 | 12 | null | [
"gguf",
"roleplay",
"llama3",
"sillytavern",
"en",
"region:us"
]
| null | 2024-04-24T18:46:33Z | ---
tags:
- roleplay
- llama3
- sillytavern
language:
- en
---
> [!TIP]
> My upload speeds have been cooked and unstable lately. <br>
> Realistically I'd need to move to get a better provider. <br>
> If you **want** and you are able to, you can [**support that endeavor and others here (Ko-fi)**](https://ko-fi.com/Lewdiculous). I apologize for disrupting your experience.
GGUF-IQ-Imatrix quants for [jeiku/Average_Normie_l3_v1_8B](https://huggingface.co/jeiku/Average_Normie_l3_v1_8B).
> [!IMPORTANT]
> **Updated!**
> These quants have been redone with the fixes from [llama.cpp/pull/6920](https://github.com/ggerganov/llama.cpp/pull/6920) in mind. <br>
> Use **KoboldCpp version 1.64** or higher.
> [!WARNING]
> Compatible SillyTavern presets [here (simple)](https://huggingface.co/Lewdiculous/Model-Requests/tree/main/data/presets/cope-llama-3-0.1) or [here (Virt's)](https://huggingface.co/Virt-io/SillyTavern-Presets). <br>
> Use the latest version of KoboldCpp. **Use the provided presets.** <br>
> This is all still highly experimental, let the authors know how it performs for you, feedback is more important than ever now.
> [!NOTE]
> For **8GB VRAM** GPUs, I recommend the **Q4_K_M-imat** quant for up to 12288 context sizes.
**Original model information:**
# Average Normie v1

A model by an average normie for the average normie.
This model is a stock merge of the following models:
https://huggingface.co/cgato/L3-TheSpice-8b-v0.1.3
https://huggingface.co/Sao10K/L3-Solana-8B-v1
https://huggingface.co/ResplendentAI/Kei_Llama3_8B
The final merge then had the following LoRA applied over it:
https://huggingface.co/ResplendentAI/Theory_of_Mind_Llama3
This should be an intelligent and adept roleplaying model. |
mPLUG/TinyChart-3B-768 | mPLUG | 2024-04-26T16:56:17Z | 506 | 5 | transformers | [
"transformers",
"safetensors",
"tiny_chart_phi",
"text-generation",
"custom_code",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-04-26T15:38:31Z | Entry not found |
lmstudio-community/codegemma-1.1-7b-it-GGUF | lmstudio-community | 2024-05-14T13:49:54Z | 506 | 5 | transformers | [
"transformers",
"gguf",
"text-generation",
"base_model:google/codegemma-1.1-7b-it",
"license:gemma",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-05-04T22:25:17Z | ---
library_name: transformers
extra_gated_heading: Access CodeGemma on Hugging Face
extra_gated_prompt: >-
To access CodeGemma on Hugging Face, you’re required to review and agree to
Google’s usage license. To do this, please ensure you’re logged-in to Hugging
Face and click below. Requests are processed immediately.
extra_gated_button_content: Acknowledge license
pipeline_tag: text-generation
widget:
- text: >
<start_of_turn>user
Write a Python function to calculate the nth fibonacci number.<end_of_turn>
<start_of_turn>model
inference:
parameters:
max_new_tokens: 200
license: gemma
license_link: https://ai.google.dev/gemma/terms
quantized_by: bartowski
base_model: google/codegemma-1.1-7b-it
lm_studio:
param_count: 8b
use_case: coding
release_date: 30-04-2024
model_creator: google
prompt_template: Google Gemma Instruct
system_prompt: none
base_model: gemma
original_repo: google/codegemma-1.1-7b-it
---
## 💫 Community Model> CodeGemma 1.1 7b Instruct by Google
*👾 [LM Studio](https://lmstudio.ai) Community models highlights program. Highlighting new & noteworthy models by the community. Join the conversation on [Discord](https://discord.gg/aPQfnNkxGC)*.
**Model creator:** [Google](https://huggingface.co/google)<br>
**Original model**: [google/codegemma-1.1-7b-it](https://huggingface.co/google/codegemma-1.1-7b-it)<br>
**GGUF quantization:** provided by [bartowski](https://huggingface.co/bartowski) based on `llama.cpp` release [b2777](https://github.com/ggerganov/llama.cpp/releases/tag/b2777)<br>
## Model Summary:
CodeGemma 1.1 7b Instruct is an iteration on the initial CodeGemma release. It should come with minor improvements to code generation.<br>
This model is meant to be used as a coding companion or for code generation.<br>
## Prompt Template:
Choose the 'Google Gemma Instruct' preset in your LM Studio.
Under the hood, the model will see a prompt that's formatted like so:
```
<start_of_turn>user
{prompt}<end_of_turn>
<start_of_turn>model
```
## Technical Details
CodeGemma is based on the Gemma 7b model with additional training on web documents, mathematics, and code, with a mixture of 80% code and 20% natural language.
The code used is based on publicly avaialble code repositories.
The instruct version was further trained on mathematical datasets in an attempt to improve its mathematical reasoning capabilities, as well as synthetic code generation combined with a second LLM for evaluation and reinforcement feedback.
Additional details can be found on Google's official report PDF [here](https://storage.googleapis.com/deepmind-media/gemma/codegemma_report.pdf)
## Special thanks
🙏 Special thanks to [Georgi Gerganov](https://github.com/ggerganov) and the whole team working on [llama.cpp](https://github.com/ggerganov/llama.cpp/) for making all of this possible.
🙏 Special thanks to [Kalomaze](https://github.com/kalomaze) for his dataset (linked [here](https://github.com/ggerganov/llama.cpp/discussions/5263)) that was used for calculating the imatrix for these quants, which improves the overall quality!
## Disclaimers
LM Studio is not the creator, originator, or owner of any Model featured in the Community Model Program. Each Community Model is created and provided by third parties. LM Studio does not endorse, support, represent or guarantee the completeness, truthfulness, accuracy, or reliability of any Community Model. You understand that Community Models can produce content that might be offensive, harmful, inaccurate or otherwise inappropriate, or deceptive. Each Community Model is the sole responsibility of the person or entity who originated such Model. LM Studio may not monitor or control the Community Models and cannot, and does not, take responsibility for any such Model. LM Studio disclaims all warranties or guarantees about the accuracy, reliability or benefits of the Community Models. LM Studio further disclaims any warranty that the Community Model will meet your requirements, be secure, uninterrupted or available at any time or location, or error-free, viruses-free, or that any errors will be corrected, or otherwise. You will be solely responsible for any damage resulting from your use of or access to the Community Models, your downloading of any Community Model, or use of any other Community Model provided by or through LM Studio.
|
NeverSleep/Llama-3-Lumimaid-70B-v0.1-OAS | NeverSleep | 2024-05-07T13:09:21Z | 506 | 12 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"not-for-all-audiences",
"nsfw",
"conversational",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-05-06T23:57:31Z | ---
license: cc-by-nc-4.0
tags:
- not-for-all-audiences
- nsfw
---
## Lumimaid 0.1
<center><div style="width: 100%;">
<img src="https://cdn-uploads.huggingface.co/production/uploads/630dfb008df86f1e5becadc3/d3QMaxy3peFTpSlWdWF-k.png" style="display: block; margin: auto;">
</div></center>
This model uses the Llama3 **prompting format**
Llama3 trained on our RP datasets, we tried to have a balance between the ERP and the RP, not too horny, but just enough.
We also added some non-RP dataset, making the model less dumb overall. It should look like a 40%/60% ratio for Non-RP/RP+ERP data.
This model includes the new Luminae dataset from Ikari.
This model have received the Orthogonal Activation Steering treatment, meaning it will rarely refuse any request.
If you consider trying this model please give us some feedback either on the Community tab on hf or on our [Discord Server](https://discord.gg/MtCVRWTZXY).
## Credits:
- Undi
- IkariDev
## Description
This repo contains FP16 files of Lumimaid-70B-v0.1-OAS.
Switch: [8B](https://huggingface.co/NeverSleep/Llama-3-Lumimaid-8B-v0.1) - [70B](https://huggingface.co/NeverSleep/Llama-3-Lumimaid-70B-v0.1) - [70B-alt](https://huggingface.co/NeverSleep/Llama-3-Lumimaid-70B-v0.1-alt) - [8B-OAS](https://huggingface.co/NeverSleep/Llama-3-Lumimaid-8B-v0.1-OAS) - [70B-OAS](https://huggingface.co/NeverSleep/Llama-3-Lumimaid-70B-v0.1-OAS)
## Training data used:
- [Aesir datasets](https://huggingface.co/MinervaAI)
- [NoRobots](https://huggingface.co/datasets/Doctor-Shotgun/no-robots-sharegpt)
- [limarp](https://huggingface.co/datasets/lemonilia/LimaRP) - 8k ctx
- [toxic-dpo-v0.1-sharegpt](https://huggingface.co/datasets/Undi95/toxic-dpo-v0.1-sharegpt)
- [ToxicQAFinal](https://huggingface.co/datasets/NobodyExistsOnTheInternet/ToxicQAFinal)
- Luminae-i1 (70B/70B-alt) (i2 was not existing when the 70b started training) | Luminae-i2 (8B) (this one gave better results on the 8b) - Ikari's Dataset
- [Squish42/bluemoon-fandom-1-1-rp-cleaned](https://huggingface.co/datasets/Squish42/bluemoon-fandom-1-1-rp-cleaned) - 50% (randomly)
- [NobodyExistsOnTheInternet/PIPPAsharegptv2test](https://huggingface.co/datasets/NobodyExistsOnTheInternet/PIPPAsharegptv2test) - 5% (randomly)
- [cgato/SlimOrcaDedupCleaned](https://huggingface.co/datasets/cgato/SlimOrcaDedupCleaned) - 5% (randomly)
- Airoboros (reduced)
- [Capybara](https://huggingface.co/datasets/Undi95/Capybara-ShareGPT/) (reduced)
## Models used (only for 8B)
- Initial LumiMaid 8B Finetune
- Undi95/Llama-3-Unholy-8B-e4
- Undi95/Llama-3-LewdPlay-8B
## Prompt template: Llama3
```
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{system_prompt}<|eot_id|><|start_header_id|>user<|end_header_id|>
{input}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
{output}<|eot_id|>
```
## Others
Undi: If you want to support us, you can [here](https://ko-fi.com/undiai).
IkariDev: Visit my [retro/neocities style website](https://ikaridevgit.github.io/) please kek |
mradermacher/TroyDoesAGI-GGUF | mradermacher | 2024-06-04T05:49:52Z | 506 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:TroyDoesAI/TroyDoesAGI",
"license:cc-by-nd-4.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-03T10:39:29Z | ---
base_model: TroyDoesAI/TroyDoesAGI
language:
- en
library_name: transformers
license: cc-by-nd-4.0
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/TroyDoesAI/TroyDoesAGI
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/TroyDoesAGI-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/TroyDoesAGI-GGUF/resolve/main/TroyDoesAGI.Q2_K.gguf) | Q2_K | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/TroyDoesAGI-GGUF/resolve/main/TroyDoesAGI.IQ3_XS.gguf) | IQ3_XS | 6.4 | |
| [GGUF](https://huggingface.co/mradermacher/TroyDoesAGI-GGUF/resolve/main/TroyDoesAGI.Q3_K_S.gguf) | Q3_K_S | 6.7 | |
| [GGUF](https://huggingface.co/mradermacher/TroyDoesAGI-GGUF/resolve/main/TroyDoesAGI.IQ3_S.gguf) | IQ3_S | 6.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/TroyDoesAGI-GGUF/resolve/main/TroyDoesAGI.IQ3_M.gguf) | IQ3_M | 7.0 | |
| [GGUF](https://huggingface.co/mradermacher/TroyDoesAGI-GGUF/resolve/main/TroyDoesAGI.Q3_K_M.gguf) | Q3_K_M | 7.5 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/TroyDoesAGI-GGUF/resolve/main/TroyDoesAGI.Q3_K_L.gguf) | Q3_K_L | 8.1 | |
| [GGUF](https://huggingface.co/mradermacher/TroyDoesAGI-GGUF/resolve/main/TroyDoesAGI.IQ4_XS.gguf) | IQ4_XS | 8.3 | |
| [GGUF](https://huggingface.co/mradermacher/TroyDoesAGI-GGUF/resolve/main/TroyDoesAGI.Q4_K_S.gguf) | Q4_K_S | 8.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/TroyDoesAGI-GGUF/resolve/main/TroyDoesAGI.Q4_K_M.gguf) | Q4_K_M | 9.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/TroyDoesAGI-GGUF/resolve/main/TroyDoesAGI.Q5_K_S.gguf) | Q5_K_S | 10.6 | |
| [GGUF](https://huggingface.co/mradermacher/TroyDoesAGI-GGUF/resolve/main/TroyDoesAGI.Q5_K_M.gguf) | Q5_K_M | 10.9 | |
| [GGUF](https://huggingface.co/mradermacher/TroyDoesAGI-GGUF/resolve/main/TroyDoesAGI.Q6_K.gguf) | Q6_K | 12.6 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/TroyDoesAGI-GGUF/resolve/main/TroyDoesAGI.Q8_0.gguf) | Q8_0 | 16.3 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
MioMioMio1234/MK231 | MioMioMio1234 | 2024-06-20T13:17:43Z | 506 | 0 | diffusers | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"base_model:runwayml/stable-diffusion-v1-5",
"license:unknown",
"region:us"
]
| text-to-image | 2024-06-20T13:16:09Z | ---
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
widget:
- text: A green exuberant field crowded with impatient hairy people MK231 (2)
output:
url: >-
images/A green exuberant field crowded with impatient hairy people MK231
(2).jpg
base_model: runwayml/stable-diffusion-v1-5
instance_prompt: MK231
license: unknown
---
# MK231
<Gallery />
## Model description
MK231
## Trigger words
You should use `MK231` to trigger the image generation.
## Download model
[Download](/MioMioMio1234/MK231/tree/main) them in the Files & versions tab.
|
skyxiaobaibai/gemma-2-9b-it-Q4_0-GGUF | skyxiaobaibai | 2024-07-01T02:17:31Z | 506 | 0 | transformers | [
"transformers",
"gguf",
"conversational",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"base_model:google/gemma-2-9b-it",
"license:gemma",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-07-01T02:17:08Z | ---
base_model: google/gemma-2-9b-it
library_name: transformers
license: gemma
pipeline_tag: text-generation
tags:
- conversational
- llama-cpp
- gguf-my-repo
extra_gated_heading: Access Gemma on Hugging Face
extra_gated_prompt: To access Gemma on Hugging Face, you’re required to review and
agree to Google’s usage license. To do this, please ensure you’re logged in to Hugging
Face and click below. Requests are processed immediately.
extra_gated_button_content: Acknowledge license
---
# skyxiaobaibai/gemma-2-9b-it-Q4_0-GGUF
This model was converted to GGUF format from [`google/gemma-2-9b-it`](https://huggingface.co/google/gemma-2-9b-it) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/google/gemma-2-9b-it) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo skyxiaobaibai/gemma-2-9b-it-Q4_0-GGUF --hf-file gemma-2-9b-it-q4_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo skyxiaobaibai/gemma-2-9b-it-Q4_0-GGUF --hf-file gemma-2-9b-it-q4_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo skyxiaobaibai/gemma-2-9b-it-Q4_0-GGUF --hf-file gemma-2-9b-it-q4_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo skyxiaobaibai/gemma-2-9b-it-Q4_0-GGUF --hf-file gemma-2-9b-it-q4_0.gguf -c 2048
```
|
eugenesiow/pan | eugenesiow | 2021-08-25T08:38:00Z | 505 | 0 | transformers | [
"transformers",
"PAN",
"super-image",
"image-super-resolution",
"dataset:eugenesiow/Div2k",
"dataset:eugenesiow/Set5",
"dataset:eugenesiow/Set14",
"dataset:eugenesiow/BSD100",
"dataset:eugenesiow/Urban100",
"arxiv:2010.01073",
"arxiv:2104.07566",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- super-image
- image-super-resolution
datasets:
- eugenesiow/Div2k
- eugenesiow/Set5
- eugenesiow/Set14
- eugenesiow/BSD100
- eugenesiow/Urban100
metrics:
- pnsr
- ssim
---
# Pixel Attention Network (PAN)
PAN model pre-trained on DIV2K (800 images training, augmented to 4000 images, 100 images validation) for 2x, 3x and 4x image super resolution. It was introduced in the paper [Efficient Image Super-Resolution Using Pixel Attention](https://arxiv.org/abs/2010.01073) by Zhao et al. (2020) and first released in [this repository](https://github.com/zhaohengyuan1/PAN).
The goal of image super resolution is to restore a high resolution (HR) image from a single low resolution (LR) image. The image below shows the ground truth (HR), the bicubic upscaling and model upscaling.

## Model description
The PAN model proposes a a lightweight convolutional neural network for image super resolution. Pixel attention (PA) is similar to channel attention and spatial attention in formulation. PA however produces 3D attention maps instead of a 1D attention vector or a 2D map. This attention scheme introduces fewer additional parameters but generates better SR results.
The model is very lightweight with the model being just 260k to 270k parameters (~1mb).
## Intended uses & limitations
You can use the pre-trained models for upscaling your images 2x, 3x and 4x. You can also use the trainer to train a model on your own dataset.
### How to use
The model can be used with the [super_image](https://github.com/eugenesiow/super-image) library:
```bash
pip install super-image
```
Here is how to use a pre-trained model to upscale your image:
```python
from super_image import PanModel, ImageLoader
from PIL import Image
import requests
url = 'https://paperswithcode.com/media/datasets/Set5-0000002728-07a9793f_zA3bDjj.jpg'
image = Image.open(requests.get(url, stream=True).raw)
model = PanModel.from_pretrained('eugenesiow/pan', scale=2) # scale 2, 3 and 4 models available
inputs = ImageLoader.load_image(image)
preds = model(inputs)
ImageLoader.save_image(preds, './scaled_2x.png') # save the output 2x scaled image to `./scaled_2x.png`
ImageLoader.save_compare(inputs, preds, './scaled_2x_compare.png') # save an output comparing the super-image with a bicubic scaling
```
[](https://colab.research.google.com/github/eugenesiow/super-image-notebooks/blob/master/notebooks/Upscale_Images_with_Pretrained_super_image_Models.ipynb "Open in Colab")
## Training data
The models for 2x, 3x and 4x image super resolution were pretrained on [DIV2K](https://huggingface.co/datasets/eugenesiow/Div2k), a dataset of 800 high-quality (2K resolution) images for training, augmented to 4000 images and uses a dev set of 100 validation images (images numbered 801 to 900).
## Training procedure
### Preprocessing
We follow the pre-processing and training method of [Wang et al.](https://arxiv.org/abs/2104.07566).
Low Resolution (LR) images are created by using bicubic interpolation as the resizing method to reduce the size of the High Resolution (HR) images by x2, x3 and x4 times.
During training, RGB patches with size of 64×64 from the LR input are used together with their corresponding HR patches.
Data augmentation is applied to the training set in the pre-processing stage where five images are created from the four corners and center of the original image.
We need the huggingface [datasets](https://huggingface.co/datasets?filter=task_ids:other-other-image-super-resolution) library to download the data:
```bash
pip install datasets
```
The following code gets the data and preprocesses/augments the data.
```python
from datasets import load_dataset
from super_image.data import EvalDataset, TrainDataset, augment_five_crop
augmented_dataset = load_dataset('eugenesiow/Div2k', 'bicubic_x4', split='train')\
.map(augment_five_crop, batched=True, desc="Augmenting Dataset") # download and augment the data with the five_crop method
train_dataset = TrainDataset(augmented_dataset) # prepare the train dataset for loading PyTorch DataLoader
eval_dataset = EvalDataset(load_dataset('eugenesiow/Div2k', 'bicubic_x4', split='validation')) # prepare the eval dataset for the PyTorch DataLoader
```
### Pretraining
The model was trained on GPU. The training code is provided below:
```python
from super_image import Trainer, TrainingArguments, PanModel, PanConfig
training_args = TrainingArguments(
output_dir='./results', # output directory
num_train_epochs=1000, # total number of training epochs
)
config = PanConfig(
scale=4, # train a model to upscale 4x
)
model = PanModel(config)
trainer = Trainer(
model=model, # the instantiated model to be trained
args=training_args, # training arguments, defined above
train_dataset=train_dataset, # training dataset
eval_dataset=eval_dataset # evaluation dataset
)
trainer.train()
```
[](https://colab.research.google.com/github/eugenesiow/super-image-notebooks/blob/master/notebooks/Train_super_image_Models.ipynb "Open in Colab")
## Evaluation results
The evaluation metrics include [PSNR](https://en.wikipedia.org/wiki/Peak_signal-to-noise_ratio#Quality_estimation_with_PSNR) and [SSIM](https://en.wikipedia.org/wiki/Structural_similarity#Algorithm).
Evaluation datasets include:
- Set5 - [Bevilacqua et al. (2012)](https://huggingface.co/datasets/eugenesiow/Set5)
- Set14 - [Zeyde et al. (2010)](https://huggingface.co/datasets/eugenesiow/Set14)
- BSD100 - [Martin et al. (2001)](https://huggingface.co/datasets/eugenesiow/BSD100)
- Urban100 - [Huang et al. (2015)](https://huggingface.co/datasets/eugenesiow/Urban100)
The results columns below are represented below as `PSNR/SSIM`. They are compared against a Bicubic baseline.
|Dataset |Scale |Bicubic |pan |
|--- |--- |--- |--- |
|Set5 |2x |33.64/0.9292 |**37.77/0.9599** |
|Set5 |3x |30.39/0.8678 |**34.64/0.9376** |
|Set5 |4x |28.42/0.8101 |**31.92/0.8915** |
|Set14 |2x |30.22/0.8683 |**33.42/0.9162** |
|Set14 |3x |27.53/0.7737 |**30.8/0.8544** |
|Set14 |4x |25.99/0.7023 |**28.57/0.7802** |
|BSD100 |2x |29.55/0.8425 |**33.6/0.9235** |
|BSD100 |3x |27.20/0.7382 |**29.47/0.815** |
|BSD100 |4x |25.96/0.6672 |**28.35/0.7595** |
|Urban100 |2x |26.66/0.8408 |**31.31/0.9197** |
|Urban100 |3x | |**28.61/0.8603** |
|Urban100 |4x |23.14/0.6573 |**25.63/0.7692** |

You can find a notebook to easily run evaluation on pretrained models below:
[](https://colab.research.google.com/github/eugenesiow/super-image-notebooks/blob/master/notebooks/Evaluate_Pretrained_super_image_Models.ipynb "Open in Colab")
## BibTeX entry and citation info
```bibtex
@misc{zhao2020efficient,
title={Efficient Image Super-Resolution Using Pixel Attention},
author={Hengyuan Zhao and Xiangtao Kong and Jingwen He and Yu Qiao and Chao Dong},
year={2020},
eprint={2010.01073},
archivePrefix={arXiv},
primaryClass={eess.IV}
}
``` |
lysandre/tiny-bert-random | lysandre | 2020-12-14T19:28:41Z | 505 | 0 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"pretraining",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05Z | Entry not found |
scales-okn/docket-language-model | scales-okn | 2022-06-04T15:09:27Z | 505 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"deberta-v2",
"fill-mask",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2022-06-04T15:01:46Z | ---
tags:
- generated_from_trainer
model-index:
- name: deberta-v3-large-ddlm
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# deberta-v3-large-ddlm
This model is a fine-tuned version of [microsoft/deberta-v3-large](https://huggingface.co/models/microsoft/deberta-v3-large) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5241
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 64
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:------:|:---------------:|
| 0.9823 | 0.01 | 1000 | 0.9163 |
| 0.8817 | 0.02 | 2000 | 0.9022 |
| 0.9647 | 0.03 | 3000 | 0.8879 |
| 0.8646 | 0.04 | 4000 | 0.8577 |
| 0.9159 | 0.06 | 5000 | 0.8677 |
| 0.8449 | 0.07 | 6000 | 0.8221 |
| 0.8681 | 0.08 | 7000 | 0.8332 |
| 0.8738 | 0.09 | 8000 | 0.8334 |
| 0.8638 | 0.1 | 9000 | 0.8236 |
| 0.9066 | 0.11 | 10000 | 0.8200 |
| 0.8686 | 0.12 | 11000 | 0.8092 |
| 0.7736 | 0.13 | 12000 | 0.8199 |
| 0.8054 | 0.14 | 13000 | 0.7972 |
| 0.8934 | 0.16 | 14000 | 0.7998 |
| 0.7884 | 0.17 | 15000 | 0.7895 |
| 0.8278 | 0.18 | 16000 | 0.7586 |
| 0.8482 | 0.19 | 17000 | 0.7562 |
| 0.8716 | 0.2 | 18000 | 0.7819 |
| 0.8881 | 0.21 | 19000 | 0.7878 |
| 0.8397 | 0.22 | 20000 | 0.7989 |
| 0.811 | 0.23 | 21000 | 0.7846 |
| 0.7762 | 0.24 | 22000 | 0.7753 |
| 0.7778 | 0.25 | 23000 | 0.7878 |
| 0.737 | 0.27 | 24000 | 0.7473 |
| 0.8451 | 0.28 | 25000 | 0.7460 |
| 0.823 | 0.29 | 26000 | 0.7300 |
| 0.7472 | 0.3 | 27000 | 0.7292 |
| 0.8048 | 0.31 | 28000 | 0.7697 |
| 0.7962 | 0.32 | 29000 | 0.7359 |
| 0.8048 | 0.33 | 30000 | 0.7409 |
| 0.8095 | 0.34 | 31000 | 0.7434 |
| 0.7451 | 0.35 | 32000 | 0.7534 |
| 0.6997 | 0.37 | 33000 | 0.7602 |
| 0.8116 | 0.38 | 34000 | 0.7566 |
| 0.7963 | 0.39 | 35000 | 0.7245 |
| 0.786 | 0.4 | 36000 | 0.7311 |
| 0.7991 | 0.41 | 37000 | 0.7230 |
| 0.723 | 0.42 | 38000 | 0.7209 |
| 0.789 | 0.43 | 39000 | 0.7418 |
| 0.7296 | 0.44 | 40000 | 0.7325 |
| 0.7363 | 0.45 | 41000 | 0.7134 |
| 0.758 | 0.47 | 42000 | 0.6948 |
| 0.711 | 0.48 | 43000 | 0.6992 |
| 0.7984 | 0.49 | 44000 | 0.7055 |
| 0.8402 | 0.5 | 45000 | 0.7108 |
| 0.8553 | 0.51 | 46000 | 0.7005 |
| 0.7538 | 0.52 | 47000 | 0.7208 |
| 0.7169 | 0.53 | 48000 | 0.7291 |
| 0.7345 | 0.54 | 49000 | 0.7195 |
| 0.758 | 0.55 | 50000 | 0.6694 |
| 0.7868 | 0.56 | 51000 | 0.6938 |
| 0.6966 | 0.58 | 52000 | 0.6867 |
| 0.7389 | 0.59 | 53000 | 0.6862 |
| 0.7529 | 0.6 | 54000 | 0.7175 |
| 0.7345 | 0.61 | 55000 | 0.6970 |
| 0.766 | 0.62 | 56000 | 0.7017 |
| 0.7043 | 0.63 | 57000 | 0.6916 |
| 0.6474 | 0.64 | 58000 | 0.7129 |
| 0.7456 | 0.65 | 59000 | 0.6802 |
| 0.7512 | 0.66 | 60000 | 0.6951 |
| 0.6816 | 0.68 | 61000 | 0.7072 |
| 0.7206 | 0.69 | 62000 | 0.6967 |
| 0.6439 | 0.7 | 63000 | 0.6798 |
| 0.7309 | 0.71 | 64000 | 0.7163 |
| 0.6925 | 0.72 | 65000 | 0.6794 |
| 0.6833 | 0.73 | 66000 | 0.6637 |
| 0.6643 | 0.74 | 67000 | 0.6855 |
| 0.6433 | 0.75 | 68000 | 0.7035 |
| 0.7595 | 0.76 | 69000 | 0.7008 |
| 0.7214 | 0.78 | 70000 | 0.6618 |
| 0.7111 | 0.79 | 71000 | 0.6850 |
| 0.7375 | 0.8 | 72000 | 0.6909 |
| 0.6779 | 0.81 | 73000 | 0.7042 |
| 0.6646 | 0.82 | 74000 | 0.6634 |
| 0.6616 | 0.83 | 75000 | 0.7020 |
| 0.6762 | 0.84 | 76000 | 0.6638 |
| 0.7509 | 0.85 | 77000 | 0.6541 |
| 0.6963 | 0.86 | 78000 | 0.6781 |
| 0.6949 | 0.87 | 79000 | 0.6576 |
| 0.6781 | 0.89 | 80000 | 0.6900 |
| 0.65 | 0.9 | 81000 | 0.6835 |
| 0.7205 | 0.91 | 82000 | 0.6712 |
| 0.6901 | 0.92 | 83000 | 0.6699 |
| 0.6972 | 0.93 | 84000 | 0.6456 |
| 0.7041 | 0.94 | 85000 | 0.6497 |
| 0.6864 | 0.95 | 86000 | 0.6432 |
| 0.7308 | 0.96 | 87000 | 0.6497 |
| 0.6886 | 0.97 | 88000 | 0.6674 |
| 0.6947 | 0.99 | 89000 | 0.6638 |
| 0.6567 | 1.0 | 90000 | 0.6242 |
| 0.7185 | 1.01 | 91000 | 0.6704 |
| 0.7435 | 1.02 | 92000 | 0.6681 |
| 0.7108 | 1.03 | 93000 | 0.6619 |
| 0.6942 | 1.04 | 94000 | 0.6306 |
| 0.6998 | 1.05 | 95000 | 0.6409 |
| 0.6481 | 1.06 | 96000 | 0.6476 |
| 0.727 | 1.07 | 97000 | 0.6354 |
| 0.647 | 1.09 | 98000 | 0.6222 |
| 0.6622 | 1.1 | 99000 | 0.6119 |
| 0.6346 | 1.11 | 100000 | 0.6471 |
| 0.6203 | 1.12 | 101000 | 0.6655 |
| 0.6765 | 1.13 | 102000 | 0.6473 |
| 0.6703 | 1.14 | 103000 | 0.6308 |
| 0.6793 | 1.15 | 104000 | 0.6531 |
| 0.683 | 1.16 | 105000 | 0.6693 |
| 0.6654 | 1.17 | 106000 | 0.6241 |
| 0.6626 | 1.18 | 107000 | 0.6215 |
| 0.6976 | 1.2 | 108000 | 0.6479 |
| 0.7494 | 1.21 | 109000 | 0.6345 |
| 0.691 | 1.22 | 110000 | 0.6322 |
| 0.6568 | 1.23 | 111000 | 0.6265 |
| 0.705 | 1.24 | 112000 | 0.6281 |
| 0.6307 | 1.25 | 113000 | 0.6202 |
| 0.6828 | 1.26 | 114000 | 0.6158 |
| 0.6403 | 1.27 | 115000 | 0.6495 |
| 0.6615 | 1.28 | 116000 | 0.6298 |
| 0.6237 | 1.3 | 117000 | 0.6234 |
| 0.6707 | 1.31 | 118000 | 0.6267 |
| 0.6823 | 1.32 | 119000 | 0.6299 |
| 0.6333 | 1.33 | 120000 | 0.6169 |
| 0.685 | 1.34 | 121000 | 0.6371 |
| 0.6941 | 1.35 | 122000 | 0.6245 |
| 0.6358 | 1.36 | 123000 | 0.6291 |
| 0.6754 | 1.37 | 124000 | 0.6400 |
| 0.6286 | 1.38 | 125000 | 0.6148 |
| 0.7036 | 1.4 | 126000 | 0.6033 |
| 0.645 | 1.41 | 127000 | 0.6295 |
| 0.6578 | 1.42 | 128000 | 0.6348 |
| 0.651 | 1.43 | 129000 | 0.6222 |
| 0.5558 | 1.44 | 130000 | 0.6231 |
| 0.6601 | 1.45 | 131000 | 0.6302 |
| 0.6304 | 1.46 | 132000 | 0.6127 |
| 0.6177 | 1.47 | 133000 | 0.6047 |
| 0.5933 | 1.48 | 134000 | 0.6169 |
| 0.6307 | 1.49 | 135000 | 0.6012 |
| 0.6018 | 1.51 | 136000 | 0.5900 |
| 0.6724 | 1.52 | 137000 | 0.6086 |
| 0.6367 | 1.53 | 138000 | 0.6414 |
| 0.6515 | 1.54 | 139000 | 0.6267 |
| 0.5902 | 1.55 | 140000 | 0.5913 |
| 0.6523 | 1.56 | 141000 | 0.5992 |
| 0.6005 | 1.57 | 142000 | 0.6128 |
| 0.6179 | 1.58 | 143000 | 0.6089 |
| 0.6154 | 1.59 | 144000 | 0.6353 |
| 0.6298 | 1.61 | 145000 | 0.5997 |
| 0.5623 | 1.62 | 146000 | 0.5974 |
| 0.5787 | 1.63 | 147000 | 0.6165 |
| 0.6099 | 1.64 | 148000 | 0.6246 |
| 0.658 | 1.65 | 149000 | 0.6116 |
| 0.6567 | 1.66 | 150000 | 0.5938 |
| 0.6227 | 1.67 | 151000 | 0.5948 |
| 0.5858 | 1.68 | 152000 | 0.5822 |
| 0.6227 | 1.69 | 153000 | 0.5802 |
| 0.6699 | 1.71 | 154000 | 0.6067 |
| 0.5989 | 1.72 | 155000 | 0.6073 |
| 0.6184 | 1.73 | 156000 | 0.6124 |
| 0.6404 | 1.74 | 157000 | 0.6169 |
| 0.639 | 1.75 | 158000 | 0.5997 |
| 0.6433 | 1.76 | 159000 | 0.5989 |
| 0.5574 | 1.77 | 160000 | 0.5796 |
| 0.5983 | 1.78 | 161000 | 0.6036 |
| 0.6532 | 1.79 | 162000 | 0.5888 |
| 0.6679 | 1.8 | 163000 | 0.6038 |
| 0.62 | 1.82 | 164000 | 0.5984 |
| 0.5541 | 1.83 | 165000 | 0.6003 |
| 0.6192 | 1.84 | 166000 | 0.5786 |
| 0.6613 | 1.85 | 167000 | 0.6064 |
| 0.5923 | 1.86 | 168000 | 0.6018 |
| 0.5894 | 1.87 | 169000 | 0.5912 |
| 0.6462 | 1.88 | 170000 | 0.5902 |
| 0.5811 | 1.89 | 171000 | 0.6030 |
| 0.6358 | 1.9 | 172000 | 0.5915 |
| 0.614 | 1.92 | 173000 | 0.5886 |
| 0.5969 | 1.93 | 174000 | 0.6084 |
| 0.6146 | 1.94 | 175000 | 0.6003 |
| 0.6051 | 1.95 | 176000 | 0.5835 |
| 0.6268 | 1.96 | 177000 | 0.5999 |
| 0.6436 | 1.97 | 178000 | 0.5965 |
| 0.6167 | 1.98 | 179000 | 0.5789 |
| 0.5647 | 1.99 | 180000 | 0.5669 |
| 0.6038 | 2.0 | 181000 | 0.6009 |
| 0.6082 | 2.02 | 182000 | 0.5799 |
| 0.6483 | 2.03 | 183000 | 0.5716 |
| 0.5503 | 2.04 | 184000 | 0.5806 |
| 0.6231 | 2.05 | 185000 | 0.5699 |
| 0.5892 | 2.06 | 186000 | 0.5979 |
| 0.5933 | 2.07 | 187000 | 0.5709 |
| 0.594 | 2.08 | 188000 | 0.5719 |
| 0.5838 | 2.09 | 189000 | 0.5879 |
| 0.6039 | 2.1 | 190000 | 0.5984 |
| 0.5911 | 2.11 | 191000 | 0.5953 |
| 0.563 | 2.13 | 192000 | 0.5772 |
| 0.5671 | 2.14 | 193000 | 0.5771 |
| 0.6051 | 2.15 | 194000 | 0.5972 |
| 0.5852 | 2.16 | 195000 | 0.5917 |
| 0.5757 | 2.17 | 196000 | 0.5819 |
| 0.6557 | 2.18 | 197000 | 0.5655 |
| 0.6055 | 2.19 | 198000 | 0.5820 |
| 0.6067 | 2.2 | 199000 | 0.5801 |
| 0.6422 | 2.21 | 200000 | 0.5590 |
| 0.624 | 2.23 | 201000 | 0.5573 |
| 0.6222 | 2.24 | 202000 | 0.5661 |
| 0.5597 | 2.25 | 203000 | 0.5786 |
| 0.5746 | 2.26 | 204000 | 0.5622 |
| 0.6269 | 2.27 | 205000 | 0.5804 |
| 0.6241 | 2.28 | 206000 | 0.5696 |
| 0.6519 | 2.29 | 207000 | 0.5367 |
| 0.6161 | 2.3 | 208000 | 0.5666 |
| 0.5415 | 2.31 | 209000 | 0.5633 |
| 0.633 | 2.33 | 210000 | 0.5499 |
| 0.5566 | 2.34 | 211000 | 0.5822 |
| 0.6158 | 2.35 | 212000 | 0.5826 |
| 0.5574 | 2.36 | 213000 | 0.5429 |
| 0.5748 | 2.37 | 214000 | 0.5736 |
| 0.5818 | 2.38 | 215000 | 0.5599 |
| 0.6226 | 2.39 | 216000 | 0.5407 |
| 0.5733 | 2.4 | 217000 | 0.5759 |
| 0.6268 | 2.41 | 218000 | 0.5725 |
| 0.5885 | 2.42 | 219000 | 0.5771 |
| 0.5708 | 2.44 | 220000 | 0.5654 |
| 0.5783 | 2.45 | 221000 | 0.5756 |
| 0.61 | 2.46 | 222000 | 0.5647 |
| 0.5848 | 2.47 | 223000 | 0.5532 |
| 0.5869 | 2.48 | 224000 | 0.5519 |
| 0.5717 | 2.49 | 225000 | 0.5621 |
| 0.5675 | 2.5 | 226000 | 0.5446 |
| 0.6321 | 2.51 | 227000 | 0.5812 |
| 0.568 | 2.52 | 228000 | 0.5673 |
| 0.5577 | 2.54 | 229000 | 0.5590 |
| 0.5888 | 2.55 | 230000 | 0.5628 |
| 0.6389 | 2.56 | 231000 | 0.5828 |
| 0.5782 | 2.57 | 232000 | 0.5543 |
| 0.5871 | 2.58 | 233000 | 0.5575 |
| 0.5593 | 2.59 | 234000 | 0.5625 |
| 0.6167 | 2.6 | 235000 | 0.5450 |
| 0.5828 | 2.61 | 236000 | 0.5627 |
| 0.5411 | 2.62 | 237000 | 0.5498 |
| 0.6168 | 2.64 | 238000 | 0.5891 |
| 0.6508 | 2.65 | 239000 | 0.5811 |
| 0.6322 | 2.66 | 240000 | 0.5649 |
| 0.6131 | 2.67 | 241000 | 0.5473 |
| 0.5419 | 2.68 | 242000 | 0.5583 |
| 0.5685 | 2.69 | 243000 | 0.5635 |
| 0.5267 | 2.7 | 244000 | 0.5481 |
| 0.5357 | 2.71 | 245000 | 0.5474 |
| 0.585 | 2.72 | 246000 | 0.5281 |
| 0.5894 | 2.73 | 247000 | 0.5457 |
| 0.5665 | 2.75 | 248000 | 0.5579 |
| 0.5409 | 2.76 | 249000 | 0.5412 |
| 0.6051 | 2.77 | 250000 | 0.5447 |
| 0.5866 | 2.78 | 251000 | 0.5535 |
| 0.5348 | 2.79 | 252000 | 0.5377 |
| 0.5606 | 2.8 | 253000 | 0.5524 |
| 0.5142 | 2.81 | 254000 | 0.5441 |
| 0.543 | 2.82 | 255000 | 0.5499 |
| 0.5763 | 2.83 | 256000 | 0.5241 |
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.10.0+cu102
- Datasets 1.15.1
- Tokenizers 0.11.0
|
cosimoiaia/Loquace-410m | cosimoiaia | 2023-06-19T20:22:44Z | 505 | 1 | transformers | [
"transformers",
"pytorch",
"safetensors",
"gpt_neox",
"text-generation",
"alpaca",
"llama",
"llm",
"finetune",
"Italian",
"qlora",
"conversational",
"it",
"dataset:cosimoiaia/Loquace-102k",
"license:cc-by-nc-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2023-06-02T05:30:16Z | ---
license: cc-by-nc-2.0
datasets:
- cosimoiaia/Loquace-102k
language:
- it
pipeline_tag: conversational
tags:
- alpaca
- llama
- llm
- finetune
- Italian
- qlora
---
Model Card for Loquace-410m
# 🇮🇹 Loquace-410m 🇮🇹
An exclusively Italian speaking, instruction finetuned, Large Language model. 🇮🇹
The Loquace Italian LLM models are created as a proof-of-concept to evaluate on how language tuning can be achieved using QLoRa by instruct-tunings foundational LLMs
using dataset of a specific language.
The QLoRa (https://github.com/artidoro/qlora) method of fine-tuning significantly lower the resources requirements compared to any other methods available,
this allow to easily execute the process on significanly larger dataset while still using consumers GPUs and still achieve high accuracy.
## Model Description
Loquace-410m is the second smallest model of the Loquace family. It was trained using QLoRa on a large dataset of 102k question/answer pairs
exclusively in Italian using pythia-410m as base.
The related code can be found at: https://github.com/cosimoiaia/Loquace
Loquace-410m is part of the big Loquace family:
https://huggingface.co/cosimoiaia/Loquace-70m - Based on pythia-70m
https://huggingface.co/cosimoiaia/Loquace-410m - Based on pythia-410m
https://huggingface.co/cosimoiaia/Loquace-7B - Based on Falcon-7B.
https://huggingface.co/cosimoiaia/Loquace-12B - Based on pythia-12B
https://huggingface.co/cosimoiaia/Loquace-20B - Based on gpt-neox-20B
## Usage
```python
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
BitsAndBytesConfig
)
tokenizer = AutoTokenizer.from_pretrained("cosimoiaia/Loquace-410m", padding_side="right", use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
"cosimoiaia/Loquace-410m",
load_in_8bit=True,
device_map="auto",
quantization_config=BitsAndBytesConfig(
load_in_4bit=True,
llm_int8_has_fp16_weight=False
)
)
```
## Training
Loquace-410m was trained on a conversational dataset comprising 102k question/answer pairs in Italian language.
The training data was constructed by putting together translations from the original alpaca Dataset and other sources like the OpenAssistant dataset.
The model was trained for only 10000 iterations and took 9 hours on a single RTX 3090, kindly provided by Genesis Cloud. (https://gnsiscld.co/26qhlf)
## Limitations
- Loquace-410m may not handle complex or nuanced queries well and may struggle with ambiguous or poorly formatted inputs.
- The model may generate responses that are factually incorrect or nonsensical. It should be used with caution, and outputs should be carefully verified.
- The training data primarily consists of conversational examples and may not generalize well to other types of tasks or domains.
## Dependencies
- PyTorch
- Transformers library by Hugging Face
- Bitsandbites
- QLoRa
|
bangla-speech-processing/BanglaASR | bangla-speech-processing | 2023-11-13T17:55:56Z | 505 | 10 | transformers | [
"transformers",
"pytorch",
"safetensors",
"whisper",
"automatic-speech-recognition",
"audio",
"license:mit",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2023-06-22T18:06:18Z | ---
license: mit
tags:
- audio
- automatic-speech-recognition
widget:
- example_title: sample 1
src: https://huggingface.co/bangla-speech-processing/BanglaASR/resolve/main/mp3/common_voice_bn_31515636.mp3
- example_title: sample 2
src: https://huggingface.co/bangla-speech-processing/BanglaASR/resolve/main/mp3/common_voice_bn_31549899.mp3
- example_title: sample 3
src: https://huggingface.co/bangla-speech-processing/BanglaASR/resolve/main/mp3/common_voice_bn_31617644.mp3
pipeline_tag: automatic-speech-recognition
---
Bangla ASR model which was trained Bangla Mozilla Common Voice Dataset. This is Fine-tuning Whisper model using Bangla mozilla common voice dataset.
For training this model used 40k training and 7k Validation of around 400 hours of data. We trained 12000 steps and get word
error rate 4.58%. This model was whisper small[244 M] variant model.
```py
import os
import librosa
import torch
import torchaudio
import numpy as np
from transformers import WhisperTokenizer
from transformers import WhisperProcessor
from transformers import WhisperFeatureExtractor
from transformers import WhisperForConditionalGeneration
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
mp3_path = "https://huggingface.co/bangla-speech-processing/BanglaASR/resolve/main/mp3/common_voice_bn_31515636.mp3"
model_path = "bangla-speech-processing/BanglaASR"
feature_extractor = WhisperFeatureExtractor.from_pretrained(model_path)
tokenizer = WhisperTokenizer.from_pretrained(model_path)
processor = WhisperProcessor.from_pretrained(model_path)
model = WhisperForConditionalGeneration.from_pretrained(model_path).to(device)
speech_array, sampling_rate = torchaudio.load(mp3_path, format="mp3")
speech_array = speech_array[0].numpy()
speech_array = librosa.resample(np.asarray(speech_array), orig_sr=sampling_rate, target_sr=16000)
input_features = feature_extractor(speech_array, sampling_rate=16000, return_tensors="pt").input_features
# batch = processor.feature_extractor.pad(input_features, return_tensors="pt")
predicted_ids = model.generate(inputs=input_features.to(device))[0]
transcription = processor.decode(predicted_ids, skip_special_tokens=True)
print(transcription)
```
# Dataset
Used Mozilla common voice dataset around 400 hours data both training[40k] and validation[7k] mp3 samples.
For more information about dataser please [click here](https://commonvoice.mozilla.org/bn/datasets)
# Training Model Information
| Size | Layers | Width | Heads | Parameters | Bangla-only | Training Status |
| ------------- | ------------- | -------- |-------- | ------------- | ------------- | -------- |
tiny | 4 |384 | 6 | 39 M | X | X
base | 6 |512 | 8 |74 M | X | X
small | 12 |768 | 12 |244 M | ✓ | ✓
medium | 24 |1024 | 16 |769 M | X | X
large | 32 |1280 | 20 |1550 M | X | X
# Evaluation
Word Error Rate 4.58 %
For More please check the [github](https://github.com/saiful9379/BanglaASR/tree/main)
```
@misc{BanglaASR ,
title={Transformer Based Whisper Bangla ASR Model},
author={Md Saiful Islam},
howpublished={},
year={2023}
}
```
|
Yntec/OpenNijiRemix | Yntec | 2023-10-03T18:17:16Z | 505 | 2 | diffusers | [
"diffusers",
"safetensors",
"Anime",
"Art",
"Open",
"OpenNiji",
"Stable Diffusion",
"Niji",
"Nijijourney",
"Stylised",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"dataset:Korakoe/NijiJourney-Prompt-Pairs",
"dataset:Korakoe/OpenNiji-V2-Dataset",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2023-08-15T06:12:44Z | ---
thumbnail: https://cdn-uploads.huggingface.co/production/uploads/63239b8370edc53f51cd5d42/4a5maYV74Z-CaWxFfdsGg.png
license: creativeml-openrail-m
datasets:
- Korakoe/NijiJourney-Prompt-Pairs
- Korakoe/OpenNiji-V2-Dataset
language:
- en
tags:
- Anime
- Art
- Open
- OpenNiji
- Stable Diffusion
- Niji
- Nijijourney
- Stylised
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
pipeline_tag: text-to-image
---
# Open Niji Remix
What happens when you merge the Lora of OpenNiji with OpenNiji2? You get my favorite OpenNiji model! Now with the MoistMixV2VAE baked in.
Samples and prompts:


white skirt, DETAILED CHIBI EYES, pretty CUTE girl wearing white camisole, fashion shoes, costume, 1940, magazine ad, iconic, A painting of a store with a lot of food, a photorealistic painting by simon stålenhag, featured on cgsociety, photorealism, 2d game art, hyper-realistic, hyper realism
Original pages:
https://huggingface.co/ShoukanLabs/OpenNiji
https://huggingface.co/ShoukanLabs/OpenNiji-V2 |
FlagAlpha/Atom-7B-Chat | FlagAlpha | 2024-04-11T11:31:32Z | 505 | 79 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"question-answering",
"custom_code",
"zh",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| question-answering | 2023-09-11T12:39:53Z | ---
developers: [https://huggingface.co/FlagAlphaAI]
license: apache-2.0
language:
- zh
- en
pipeline_tag: question-answering
library_name: transformers
---
# Atom-7B-32k-Chat
基于Atom-7B具有32k长度的对话模型,完全开源可商用,由Llama中文社区和AtomEcho(原子回声)联合研发,基于Llama2-7B采用大规模的中文数据进行了继续预训练,我们会持续提供更新的模型参数,模型训练过程见[llama.family](https://llama.family)。
模型的部署、训练、微调等方法详见Llama中文社区GitHub仓库:[**Llama-Chinese**](https://github.com/LlamaFamily/Llama-Chinese)。
## 📝 中文数据
| 类型 | 描述 |
| ---------------------------------------------------------- | ------------------------------------------------------------ |
| 网络数据 | 互联网上公开的网络数据,挑选出去重后的高质量中文数据,涉及到百科、书籍、博客、新闻、公告、小说等高质量长文本数据。 |
| [Wikipedia](https://github.com/goldsmith/Wikipedia) | 中文Wikipedia的数据 |
| [悟道](https://github.com/BAAI-WuDao/Model) | 中文悟道开源的200G数据 |
| [Clue](https://github.com/CLUEbenchmark/CLUEDatasetSearch) | Clue开放的中文预训练数据,进行清洗后的高质量中文长文本数据 |
| 竞赛数据集 | 近年来中文自然语言处理多任务竞赛数据集,约150个 |
| [MNBVC](https://github.com/esbatmop/MNBVC) | MNBVC 中清洗出来的部分数据集 |
**我们也欢迎大家在[llama.family](https://llama.family)中贡献自己的数据,您的数据通过审核后会加入模型训练,也将影响模型未来的能力走向。**
## 📚 中文词表
为了提高中文文本处理的效率,我们针对Llama2模型的词表进行了深度优化。
首先,我们基于数百G的中文文本,**在Llama2词表的基础上扩展词库至65,000个单词**。
经过测试,我们的改进使得**中文编码/解码速度提高了约350%**。
此外,我们还扩大了中文字符集的覆盖范围,包括所有**emoji符号**,这使的生成带有表情符号的文章更加高效。
对于Llama2原生词表中的一些特殊情况,如数字、英文等,我们尽可能地避免对其进行修改或替换。
最终,成功地实现了一种既能提高中文处理效率又能保持Llama2原有性能的方法。
## 📈 训练过程
**模型结构**
基于当前最优秀的开源模型Llama2,使用主流Decoder-only的标准Transformer网络结构,支持4K的上下文长度(Context Length),为同尺寸模型中最长,能满足更长的多轮对话、知识问答与摘要等需求,模型应用场景更广泛。
**FlashAttention-2高效训练**
Atom-7B采用了FlashAttention-2技术进行训练。由于在处理较长的输入序列时,内存消耗的问题可能会导致“内存爆炸”现象。FlashAttention-2是一种高效注意力机制的实现方式之一,相较于传统的注意力技术(Attention),它拥有更快速的速度以及更加优化的内存占用率。
**基于NTK的自适应上下文扩展技术**
- 可在不继续训练模型的情况下支持更长的上下文
- 本项目中模型默认支持4K上下文,利用上述技术可扩展至18K+
- 经过微调可以支持到32K+
## 💻 推理配置
实际应用中,消费级显卡要比专业显卡便宜的多(比如3090相比A10,同样都是24G显存)。
对于消费级显卡,直接FP32肯定放不下,一般最基本的是FP16,而INT8和INT4量化就很有用,例如:
- 对于3080显卡(10G显存),Atom-7B的INT8只需要8G显存可以直接部署。
- 对于3080显卡(10G显存),Atom-7B的INT4只需要5G显存可以直接部署。
---
# Llama中文社区
## 🚀 社区地址:
Github:[**Llama-Chinese**](https://github.com/LlamaFamily/Llama-Chinese)
在线体验链接:[**llama.family**](https://llama.family/)
## 🔥 社区介绍
欢迎来到Llama中文社区!
我们是一个专注于Llama模型在中文方面的优化和上层建设的高级技术社区。
**基于大规模中文数据,从预训练开始对Llama2模型进行中文能力的持续迭代升级**。
我们热忱欢迎对大模型LLM充满热情的开发者和研究者加入我们的行列。
## 🐼 社区资源
- Llama2在线体验链接[**llama.family**](https://llama.family/),同时包含Meta原版和中文微调版本!
- Llama2 Chat模型的[中文问答能力评测](https://github.com/LlamaFamily/Llama-Chinese/tree/main#-%E6%A8%A1%E5%9E%8B%E8%AF%84%E6%B5%8B)!
- [社区飞书知识库](https://chinesellama.feishu.cn/wiki/space/7257824476874768388?ccm_open_type=lark_wiki_spaceLink),欢迎大家一起共建!
|
medtalkai/wav2vec_kenlm5 | medtalkai | 2024-01-29T19:01:58Z | 505 | 0 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"mozilla-foundation/common_voice_8_0",
"pt",
"robust-speech-event",
"dataset:mozilla-foundation/common_voice_8_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2024-01-29T18:50:28Z | ---
language:
- pt
license: apache-2.0
tags:
- automatic-speech-recognition
- hf-asr-leaderboard
- mozilla-foundation/common_voice_8_0
- pt
- robust-speech-event
datasets:
- mozilla-foundation/common_voice_8_0
model-index:
- name: XLS-R Wav2Vec2 Portuguese by Jonatas Grosman
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 8
type: mozilla-foundation/common_voice_8_0
args: pt
metrics:
- name: Test WER
type: wer
value: 8.7
- name: Test CER
type: cer
value: 2.55
- name: Test WER (+LM)
type: wer
value: 6.04
- name: Test CER (+LM)
type: cer
value: 1.98
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Dev Data
type: speech-recognition-community-v2/dev_data
args: pt
metrics:
- name: Dev WER
type: wer
value: 24.23
- name: Dev CER
type: cer
value: 11.3
- name: Dev WER (+LM)
type: wer
value: 19.41
- name: Dev CER (+LM)
type: cer
value: 10.19
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Test Data
type: speech-recognition-community-v2/eval_data
args: pt
metrics:
- name: Test WER
type: wer
value: 18.8
---
# Fine-tuned XLS-R 1B model for speech recognition in Portuguese
Fine-tuned [facebook/wav2vec2-xls-r-1b](https://huggingface.co/facebook/wav2vec2-xls-r-1b) on Portuguese using the train and validation splits of [Common Voice 8.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_8_0), [CORAA](https://github.com/nilc-nlp/CORAA), [Multilingual TEDx](http://www.openslr.org/100), and [Multilingual LibriSpeech](https://www.openslr.org/94/).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool, and thanks to the GPU credits generously given by the [OVHcloud](https://www.ovhcloud.com/en/public-cloud/ai-training/) :)
## Usage
Using the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) library:
```python
from huggingsound import SpeechRecognitionModel
model = SpeechRecognitionModel("jonatasgrosman/wav2vec2-xls-r-1b-portuguese")
audio_paths = ["/path/to/file.mp3", "/path/to/another_file.wav"]
transcriptions = model.transcribe(audio_paths)
```
Writing your own inference script:
```python
import torch
import librosa
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
LANG_ID = "pt"
MODEL_ID = "jonatasgrosman/wav2vec2-xls-r-1b-portuguese"
SAMPLES = 10
test_dataset = load_dataset("common_voice", LANG_ID, split=f"test[:{SAMPLES}]")
processor = Wav2Vec2Processor.from_pretrained(MODEL_ID)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_ID)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
batch["sentence"] = batch["sentence"].upper()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
predicted_sentences = processor.batch_decode(predicted_ids)
```
## Evaluation Commands
1. To evaluate on `mozilla-foundation/common_voice_8_0` with split `test`
```bash
python eval.py --model_id jonatasgrosman/wav2vec2-xls-r-1b-portuguese --dataset mozilla-foundation/common_voice_8_0 --config pt --split test
```
2. To evaluate on `speech-recognition-community-v2/dev_data`
```bash
python eval.py --model_id jonatasgrosman/wav2vec2-xls-r-1b-portuguese --dataset speech-recognition-community-v2/dev_data --config pt --split validation --chunk_length_s 5.0 --stride_length_s 1.0
```
## Citation
If you want to cite this model you can use this:
```bibtex
@misc{grosman2021xlsr-1b-portuguese,
title={Fine-tuned {XLS-R} 1{B} model for speech recognition in {P}ortuguese},
author={Grosman, Jonatas},
howpublished={\url{https://huggingface.co/jonatasgrosman/wav2vec2-xls-r-1b-portuguese}},
year={2022}
}
``` |
KnutJaegersberg/Llama-3-Deita-8b | KnutJaegersberg | 2024-04-24T10:35:14Z | 505 | 1 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"license:llama3",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-24T10:35:13Z | ---
license: llama3
---
Prompt Example:
```
### System:
You are an AI assistant. User will give you a task. Your goal is to complete the task as faithfully as you can. While performing the task think step-by-step and justify your steps.
### User:
How do you fine tune a large language model?
### Assistant:
``` |
mradermacher/Mistral_7B_CrewAI-GGUF | mradermacher | 2024-05-05T15:09:19Z | 505 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:Superoisesuki/Mistral_7B_CrewAI",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-25T14:39:25Z | ---
base_model: Superoisesuki/Mistral_7B_CrewAI
language:
- en
library_name: transformers
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 1 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: -->
<!-- ### vocab_type: -->
static quants of https://huggingface.co/Superoisesuki/Mistral_7B_CrewAI
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Mistral_7B_CrewAI-GGUF/resolve/main/Mistral_7B_CrewAI.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral_7B_CrewAI-GGUF/resolve/main/Mistral_7B_CrewAI.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral_7B_CrewAI-GGUF/resolve/main/Mistral_7B_CrewAI.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral_7B_CrewAI-GGUF/resolve/main/Mistral_7B_CrewAI.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Mistral_7B_CrewAI-GGUF/resolve/main/Mistral_7B_CrewAI.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral_7B_CrewAI-GGUF/resolve/main/Mistral_7B_CrewAI.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Mistral_7B_CrewAI-GGUF/resolve/main/Mistral_7B_CrewAI.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral_7B_CrewAI-GGUF/resolve/main/Mistral_7B_CrewAI.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral_7B_CrewAI-GGUF/resolve/main/Mistral_7B_CrewAI.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Mistral_7B_CrewAI-GGUF/resolve/main/Mistral_7B_CrewAI.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Mistral_7B_CrewAI-GGUF/resolve/main/Mistral_7B_CrewAI.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral_7B_CrewAI-GGUF/resolve/main/Mistral_7B_CrewAI.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral_7B_CrewAI-GGUF/resolve/main/Mistral_7B_CrewAI.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Mistral_7B_CrewAI-GGUF/resolve/main/Mistral_7B_CrewAI.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Mistral_7B_CrewAI-GGUF/resolve/main/Mistral_7B_CrewAI.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
RichardErkhov/willnguyen_-_lacda-2-7B-chat-v0.1-gguf | RichardErkhov | 2024-05-30T16:20:13Z | 505 | 0 | null | [
"gguf",
"region:us"
]
| null | 2024-05-30T13:24:32Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
lacda-2-7B-chat-v0.1 - GGUF
- Model creator: https://huggingface.co/willnguyen/
- Original model: https://huggingface.co/willnguyen/lacda-2-7B-chat-v0.1/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [lacda-2-7B-chat-v0.1.Q2_K.gguf](https://huggingface.co/RichardErkhov/willnguyen_-_lacda-2-7B-chat-v0.1-gguf/blob/main/lacda-2-7B-chat-v0.1.Q2_K.gguf) | Q2_K | 2.36GB |
| [lacda-2-7B-chat-v0.1.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/willnguyen_-_lacda-2-7B-chat-v0.1-gguf/blob/main/lacda-2-7B-chat-v0.1.IQ3_XS.gguf) | IQ3_XS | 2.6GB |
| [lacda-2-7B-chat-v0.1.IQ3_S.gguf](https://huggingface.co/RichardErkhov/willnguyen_-_lacda-2-7B-chat-v0.1-gguf/blob/main/lacda-2-7B-chat-v0.1.IQ3_S.gguf) | IQ3_S | 2.75GB |
| [lacda-2-7B-chat-v0.1.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/willnguyen_-_lacda-2-7B-chat-v0.1-gguf/blob/main/lacda-2-7B-chat-v0.1.Q3_K_S.gguf) | Q3_K_S | 2.75GB |
| [lacda-2-7B-chat-v0.1.IQ3_M.gguf](https://huggingface.co/RichardErkhov/willnguyen_-_lacda-2-7B-chat-v0.1-gguf/blob/main/lacda-2-7B-chat-v0.1.IQ3_M.gguf) | IQ3_M | 2.9GB |
| [lacda-2-7B-chat-v0.1.Q3_K.gguf](https://huggingface.co/RichardErkhov/willnguyen_-_lacda-2-7B-chat-v0.1-gguf/blob/main/lacda-2-7B-chat-v0.1.Q3_K.gguf) | Q3_K | 3.07GB |
| [lacda-2-7B-chat-v0.1.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/willnguyen_-_lacda-2-7B-chat-v0.1-gguf/blob/main/lacda-2-7B-chat-v0.1.Q3_K_M.gguf) | Q3_K_M | 3.07GB |
| [lacda-2-7B-chat-v0.1.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/willnguyen_-_lacda-2-7B-chat-v0.1-gguf/blob/main/lacda-2-7B-chat-v0.1.Q3_K_L.gguf) | Q3_K_L | 3.35GB |
| [lacda-2-7B-chat-v0.1.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/willnguyen_-_lacda-2-7B-chat-v0.1-gguf/blob/main/lacda-2-7B-chat-v0.1.IQ4_XS.gguf) | IQ4_XS | 3.4GB |
| [lacda-2-7B-chat-v0.1.Q4_0.gguf](https://huggingface.co/RichardErkhov/willnguyen_-_lacda-2-7B-chat-v0.1-gguf/blob/main/lacda-2-7B-chat-v0.1.Q4_0.gguf) | Q4_0 | 3.56GB |
| [lacda-2-7B-chat-v0.1.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/willnguyen_-_lacda-2-7B-chat-v0.1-gguf/blob/main/lacda-2-7B-chat-v0.1.IQ4_NL.gguf) | IQ4_NL | 3.58GB |
| [lacda-2-7B-chat-v0.1.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/willnguyen_-_lacda-2-7B-chat-v0.1-gguf/blob/main/lacda-2-7B-chat-v0.1.Q4_K_S.gguf) | Q4_K_S | 3.59GB |
| [lacda-2-7B-chat-v0.1.Q4_K.gguf](https://huggingface.co/RichardErkhov/willnguyen_-_lacda-2-7B-chat-v0.1-gguf/blob/main/lacda-2-7B-chat-v0.1.Q4_K.gguf) | Q4_K | 3.8GB |
| [lacda-2-7B-chat-v0.1.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/willnguyen_-_lacda-2-7B-chat-v0.1-gguf/blob/main/lacda-2-7B-chat-v0.1.Q4_K_M.gguf) | Q4_K_M | 3.8GB |
| [lacda-2-7B-chat-v0.1.Q4_1.gguf](https://huggingface.co/RichardErkhov/willnguyen_-_lacda-2-7B-chat-v0.1-gguf/blob/main/lacda-2-7B-chat-v0.1.Q4_1.gguf) | Q4_1 | 3.95GB |
| [lacda-2-7B-chat-v0.1.Q5_0.gguf](https://huggingface.co/RichardErkhov/willnguyen_-_lacda-2-7B-chat-v0.1-gguf/blob/main/lacda-2-7B-chat-v0.1.Q5_0.gguf) | Q5_0 | 4.33GB |
| [lacda-2-7B-chat-v0.1.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/willnguyen_-_lacda-2-7B-chat-v0.1-gguf/blob/main/lacda-2-7B-chat-v0.1.Q5_K_S.gguf) | Q5_K_S | 4.33GB |
| [lacda-2-7B-chat-v0.1.Q5_K.gguf](https://huggingface.co/RichardErkhov/willnguyen_-_lacda-2-7B-chat-v0.1-gguf/blob/main/lacda-2-7B-chat-v0.1.Q5_K.gguf) | Q5_K | 4.45GB |
| [lacda-2-7B-chat-v0.1.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/willnguyen_-_lacda-2-7B-chat-v0.1-gguf/blob/main/lacda-2-7B-chat-v0.1.Q5_K_M.gguf) | Q5_K_M | 4.45GB |
| [lacda-2-7B-chat-v0.1.Q5_1.gguf](https://huggingface.co/RichardErkhov/willnguyen_-_lacda-2-7B-chat-v0.1-gguf/blob/main/lacda-2-7B-chat-v0.1.Q5_1.gguf) | Q5_1 | 4.72GB |
| [lacda-2-7B-chat-v0.1.Q6_K.gguf](https://huggingface.co/RichardErkhov/willnguyen_-_lacda-2-7B-chat-v0.1-gguf/blob/main/lacda-2-7B-chat-v0.1.Q6_K.gguf) | Q6_K | 5.15GB |
| [lacda-2-7B-chat-v0.1.Q8_0.gguf](https://huggingface.co/RichardErkhov/willnguyen_-_lacda-2-7B-chat-v0.1-gguf/blob/main/lacda-2-7B-chat-v0.1.Q8_0.gguf) | Q8_0 | 6.67GB |
Original model description:
---
language:
- en
- vi
license: llama2
datasets:
- timdettmers/openassistant-guanaco
model_name: LacDa2 7B
inference: true
model_creator: Will Nguyen
model_link: https://huggingface.co/willnguyen/lacda-2-7B-chat-v0.1
model_type: llama
base_model: meta-llama/llama-2-7b-hf
---
# LacDa2 Model Card Readme
## Model Information
**Model Name:** LacDa
**Description:** LacDa is a specialized language model that has been fine-tuned from the LLama2 model. It is designed to provide advanced natural language processing capabilities in specific domains or applications.
**Fine-tuned from:** LLama2
[GitHub](https://github.com/MavosAI/LacDa)
## [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
| Metric | Value |
|-----------------------|---------------------------|
| Avg. | 43.91 |
| ARC (25-shot) | 53.07 |
| HellaSwag (10-shot) | 77.57 |
| MMLU (5-shot) | 46.03 |
| TruthfulQA (0-shot) | 44.57 |
| Winogrande (5-shot) | 74.19 |
| GSM8K (5-shot) | 6.29 |
| DROP (3-shot) | 5.65 |
## Instruction format
```python
from transformers import AutoModelForCausalLM, LlamaTokenizer, BitsAndBytesConfig, TextStreamer, StoppingCriteria, StoppingCriteriaList
import torch
class StopTokenCriteria(StoppingCriteria):
def __init__(self, stop_tokens, tokenizer, prompt_length):
self.stop_tokens = stop_tokens
if tokenizer.pad_token not in stop_tokens:
self.stop_tokens.append(tokenizer.pad_token)
if tokenizer.bos_token not in stop_tokens:
self.stop_tokens.append(tokenizer.bos_token)
if tokenizer.eos_token not in stop_tokens:
self.stop_tokens.append(tokenizer.eos_token)
self.tokenizer = tokenizer
self.prompt_length = prompt_length
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
is_done = False
tokens = tokenizer.decode(input_ids[0])[self.prompt_length:]
for st in self.stop_tokens:
if st in tokens:
is_done = True
break
return is_done
model_name = "willnguyen/lacda-2-7B-chat-v0.1"
tokenizer = LlamaTokenizer.from_pretrained(
model_name,
use_fast=False,
padding_side="right",
tokenizer_type='llama',
)
tokenizer.pad_token_id = 0
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
torch_dtype=torch.float16,
)
prompt = "<s> [INST] who is Hồ Chí Minh [/INST]"
stopping_criteria = StoppingCriteriaList([StopTokenCriteria(["[INST]", "[/INST]"], tokenizer, len(prompt))])
with torch.inference_mode():
input_ids = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).input_ids.to('cuda')
streamer = TextStreamer(tokenizer)
_ = model.generate(
input_ids=input_ids,
max_new_tokens=1024,
do_sample=False,
temperature=1.0,
top_p=1.0,
top_k=50,
repetition_penalty=1.0,
use_cache=True,
streamer=streamer,
stopping_criteria=stopping_criteria
)
```
|
alvdansen/geminianime | alvdansen | 2024-06-16T16:29:50Z | 505 | 11 | diffusers | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"license:creativeml-openrail-m",
"region:us"
]
| text-to-image | 2024-06-07T17:07:19Z | ---
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
widget:
- text: a queen, wicked, big eyes, beautiful, daiton style
output:
url: images/ComfyUI_00269_.png
- text: a queen, wicked, big eyes, beautiful, daiton style
output:
url: images/ComfyUI_00267_.png
- text: a queen, mouse, big eyes, beautiful, daiton style
output:
url: images/ComfyUI_00255_.png
- text: a woman, virgo, daiton style
output:
url: images/ComfyUI_00249_.png
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: daiton style
license: creativeml-openrail-m
---
# Gemini Anime
<Gallery />
## Model description
Another take on an anime style.
## Trigger words
You should use `daiton style` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
Model release is for research purposes only. For commercial use, please contact me directly.
[Download](/alvdansen/geminianime/tree/main) them in the Files & versions tab.
|
John6666/jac-nsfw-v1f-sdxl | John6666 | 2024-06-17T07:00:11Z | 505 | 1 | diffusers | [
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"stable-diffusion-xl",
"realistic",
"photorealistic",
"pony",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
]
| text-to-image | 2024-06-17T06:55:32Z | ---
license: other
license_name: faipl-1.0-sd
license_link: https://freedevproject.org/faipl-1.0-sd/
tags:
- text-to-image
- stable-diffusion
- stable-diffusion-xl
- realistic
- photorealistic
- pony
---
Original model is [here](https://civitai.com/models/518937/jac-nsfw?modelVersionId=576622).
|
cleatherbury/Phi-3-mini-128k-instruct-GPT4Choice-4.6k-DPO-Q5_K_M-GGUF | cleatherbury | 2024-06-21T04:19:58Z | 505 | 0 | transformers | [
"transformers",
"gguf",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"base_model:bunkalab/Phi-3-mini-128k-instruct-GPT4Choice-4.6k-DPO",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-06-21T04:19:45Z | ---
base_model: bunkalab/Phi-3-mini-128k-instruct-GPT4Choice-4.6k-DPO
language:
- en
library_name: transformers
license: apache-2.0
pipeline_tag: text-generation
tags:
- llama-cpp
- gguf-my-repo
---
# cleatherbury/Phi-3-mini-128k-instruct-GPT4Choice-4.6k-DPO-Q5_K_M-GGUF
This model was converted to GGUF format from [`bunkalab/Phi-3-mini-128k-instruct-GPT4Choice-4.6k-DPO`](https://huggingface.co/bunkalab/Phi-3-mini-128k-instruct-GPT4Choice-4.6k-DPO) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/bunkalab/Phi-3-mini-128k-instruct-GPT4Choice-4.6k-DPO) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo cleatherbury/Phi-3-mini-128k-instruct-GPT4Choice-4.6k-DPO-Q5_K_M-GGUF --hf-file phi-3-mini-128k-instruct-gpt4choice-4.6k-dpo-q5_k_m-imat.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo cleatherbury/Phi-3-mini-128k-instruct-GPT4Choice-4.6k-DPO-Q5_K_M-GGUF --hf-file phi-3-mini-128k-instruct-gpt4choice-4.6k-dpo-q5_k_m-imat.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo cleatherbury/Phi-3-mini-128k-instruct-GPT4Choice-4.6k-DPO-Q5_K_M-GGUF --hf-file phi-3-mini-128k-instruct-gpt4choice-4.6k-dpo-q5_k_m-imat.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo cleatherbury/Phi-3-mini-128k-instruct-GPT4Choice-4.6k-DPO-Q5_K_M-GGUF --hf-file phi-3-mini-128k-instruct-gpt4choice-4.6k-dpo-q5_k_m-imat.gguf -c 2048
```
|
CHE-72/Breeze-7B-Instruct-v1_0-Q2_K-GGUF | CHE-72 | 2024-06-22T18:18:16Z | 505 | 0 | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"zh",
"en",
"base_model:MediaTek-Research/Breeze-7B-Instruct-v1_0",
"license:apache-2.0",
"region:us"
]
| text-generation | 2024-06-22T18:18:04Z | ---
base_model: MediaTek-Research/Breeze-7B-Instruct-v1_0
language:
- zh
- en
license: apache-2.0
pipeline_tag: text-generation
tags:
- llama-cpp
- gguf-my-repo
---
# CHE-72/Breeze-7B-Instruct-v1_0-Q2_K-GGUF
This model was converted to GGUF format from [`MediaTek-Research/Breeze-7B-Instruct-v1_0`](https://huggingface.co/MediaTek-Research/Breeze-7B-Instruct-v1_0) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/MediaTek-Research/Breeze-7B-Instruct-v1_0) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo CHE-72/Breeze-7B-Instruct-v1_0-Q2_K-GGUF --hf-file breeze-7b-instruct-v1_0-q2_k.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo CHE-72/Breeze-7B-Instruct-v1_0-Q2_K-GGUF --hf-file breeze-7b-instruct-v1_0-q2_k.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo CHE-72/Breeze-7B-Instruct-v1_0-Q2_K-GGUF --hf-file breeze-7b-instruct-v1_0-q2_k.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo CHE-72/Breeze-7B-Instruct-v1_0-Q2_K-GGUF --hf-file breeze-7b-instruct-v1_0-q2_k.gguf -c 2048
```
|
lgris/wav2vec2-large-xlsr-open-brazilian-portuguese | lgris | 2022-04-01T20:32:58Z | 504 | 9 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"pt",
"portuguese-speech-corpus",
"PyTorch",
"hf-asr-leaderboard",
"dataset:common_voice",
"dataset:mls",
"dataset:cetuc",
"dataset:lapsbm",
"dataset:voxforge",
"arxiv:2012.03411",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2022-03-02T23:29:05Z | ---
language: pt
datasets:
- common_voice
- mls
- cetuc
- lapsbm
- voxforge
metrics:
- wer
tags:
- audio
- speech
- wav2vec2
- pt
- portuguese-speech-corpus
- automatic-speech-recognition
- speech
- PyTorch
- hf-asr-leaderboard
license: apache-2.0
model-index:
- name: Lucas Gris XLSR Wav2Vec2 Large 53 Brazilian Portuguese
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
metrics:
- name: Test WER
type: wer
value: 12.905054857823264%
---
# Wav2vec 2.0 With Open Brazilian Portuguese Datasets
This a the demonstration of a fine-tuned Wav2vec model for Brazilian Portuguese using the following datasets:
- [CETUC](http://www02.smt.ufrj.br/~igor.quintanilha/alcaim.tar.gz): contains approximately 145 hours of Brazilian Portuguese speech distributed among 50 male and 50 female speakers, each pronouncing approximately 1,000 phonetically balanced sentences selected from the [CETEN-Folha](https://www.linguateca.pt/cetenfolha/) corpus.
- [Multilingual Librispeech (MLS)](https://arxiv.org/abs/2012.03411): a massive dataset available in many languages. The MLS is based on audiobook recordings in public domain like [LibriVox](https://librivox.org/). The dataset contains a total of 6k hours of transcribed data in many languages. The set in Portuguese [used in this work](http://www.openslr.org/94/) (mostly Brazilian variant) has approximately 284 hours of speech, obtained from 55 audiobooks read by 62 speakers.
- [VoxForge](http://www.voxforge.org/): is a project with the goal to build open datasets for acoustic models. The corpus contains approximately 100 speakers and 4,130 utterances of Brazilian Portuguese, with sample rates varying from 16kHz to 44.1kHz.
- [Common Voice 6.1](https://commonvoice.mozilla.org/pt) (_only train_): is a project proposed by Mozilla Foundation with the goal to create a wide open dataset in different languages to train ASR models. In this project, volunteers donate and validate speech using the [oficial site](https://commonvoice.mozilla.org/pt). The set in Portuguese (mostly Brazilian variant) used in this work is the 6.1 version (pt_63h_2020-12-11) that contains about 50 validated hours and 1,120 unique speakers.
- [Lapsbm](https://github.com/falabrasil/gitlab-resources): "Falabrasil - UFPA" is a dataset used by the Fala Brasil group to benchmark ASR systems in Brazilian Portuguese. Contains 35 speakers (10 females), each one pronouncing 20 unique sentences, totalling 700 utterances in Brazilian Portuguese. The audios were recorded in 22.05 kHz without environment control.
These datasets were combined to build a larger Brazilian Portuguese dataset. All data was used for training except Common Voice dev/test sets, that were used for validation/test respectively.
The original model was fine-tuned using [fairseq](https://github.com/pytorch/fairseq). This notebook uses a converted version of the original one. The link to the original fairseq model is available [here](https://drive.google.com/drive/folders/1XTKIUB4kp3oYOavwH97wq8IPFsxP5sNz?usp=sharing).
This model was trained in 80k updates.
#### Datasets in number of instances and number of frames
The following image shows the overall distribution of the dataset:

#### Transcription examples
| Text | Transcription |
|------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------|
| É comum os usuários confundirem software livre com software livre | É comum os __usuares__ __confunder em__ __softwerlivr__ com __softwerlivre__ |
| Ele fez tanto ghostwriting que ele começa a se sentir como um fantasma também | Ele fez tanto __golstraitn__ que ele __começou__ a se sentir como um fantasma também |
| Arnold apresentou um gráfico mostrando quantas cegonhas ele havia contado nos últimos dez anos | Arnold apresentou um gráfico mostrando quantas __segonhas__ ele havia contado nos últimos dez anos |
| Mais cedo ou mais tarde eles descobrirão como ler esses hieróglifos | Mais __sedo__ ou mais tarde eles descobriram como __de__ esses __ierogrôficos__ |
| Viver juntos compartilhar objetivos e ter um bom relacionamento | __E ver__ juntos __signafica__ viver juntos ou __fartlhar__ objetivos ter um bom __relacionamentoo__ |
| Da mesma forma uma patente pode impedir que concorrentes desenvolvam produtos similares | Da mesma forma uma patente pode impedir que concorrentes __desenvolva__ produtos similares |
| Duas mulheres e uma menina levantam com troféus | Duas mulheres e uma menina levantam com __trofés__ |
| Esse acrobata de circo deve ter um sistema vestibular bem treinado pensou o espectador | Esse acrobata de __cirko__ deve ter um sistema vestibular __bemtreinado__ pensou o espectador |
| Durante a exposição o tribunal pode fazer quaisquer perguntas ou esclarecimentos que considere apropriados | Durante a exposição o tribunal pode fazer quaisquer perguntas ou esclarecimentos que considere __apropriado__ |
## Imports and dependencies
```python
%%capture
!pip install datasets
!pip install jiwer
!pip install torchaudio
!pip install transformers
!pip install soundfile
```
```python
import torchaudio
from datasets import load_dataset, load_metric
from transformers import (
Wav2Vec2ForCTC,
Wav2Vec2Processor,
)
import torch
import re
import sys
```
## Preparation
```python
chars_to_ignore_regex = '[\,\?\.\!\;\:\"]' # noqa: W605
wer = load_metric("wer")
device = "cuda"
```
```python
model_name = 'lgris/wav2vec2-large-xlsr-open-brazilian-portuguese'
model = Wav2Vec2ForCTC.from_pretrained(model_name).to(device)
processor = Wav2Vec2Processor.from_pretrained(model_name)
```
```python
def map_to_pred(batch):
features = processor(batch["speech"], sampling_rate=batch["sampling_rate"][0], padding=True, return_tensors="pt")
input_values = features.input_values.to(device)
attention_mask = features.attention_mask.to(device)
with torch.no_grad():
logits = model(input_values, attention_mask=attention_mask).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["predicted"] = processor.batch_decode(pred_ids)
batch["predicted"] = [pred.lower() for pred in batch["predicted"]]
batch["target"] = batch["sentence"]
return batch
```
## Tests
### Test against Common Voice (In-domain)
```python
dataset = load_dataset("common_voice", "pt", split="test", data_dir="./cv-corpus-6.1-2020-12-11")
resampler = torchaudio.transforms.Resample(orig_freq=48_000, new_freq=16_000)
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
batch["speech"] = resampler.forward(speech.squeeze(0)).numpy()
batch["sampling_rate"] = resampler.new_freq
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower().replace("’", "'")
return batch
```
```python
ds = dataset.map(map_to_array)
result = ds.map(map_to_pred, batched=True, batch_size=1, remove_columns=list(ds.features.keys()))
print(wer.compute(predictions=result["predicted"], references=result["target"]))
for pred, target in zip(result["predicted"][:10], result["target"][:10]):
print(pred, "|", target)
```
0.12905054857823264
nem o varanin os altros influmindo os de teterno um bombederster | nem o radar nem os outros instrumentos detectaram o bombardeiro stealth
pedir dinheiro é emprestado das pessoas do aldeia | pedir dinheiro emprestado às pessoas da aldeia
oito | oito
teno calcos | trancá-los
realizaram a investigação para resolver o problema | realizar uma investigação para resolver o problema
iotube ainda é a melhor plataforma de vídeos | o youtube ainda é a melhor plataforma de vídeos
menina e menino beijando nas sombras | menina e menino beijando nas sombras
eu sou o senhor | eu sou o senhor
duas metcas sentam-se para baixo randes jornais | duas mulheres que sentam-se para baixo lendo jornais
eu originalmente esperava | eu originalmente esperava
**Result**: 12.90%
### Test against [TEDx](http://www.openslr.org/100/) (Out-of-domain)
```python
!gdown --id 1HJEnvthaGYwcV_whHEywgH2daIN4bQna
!tar -xf tedx.tar.gz
```
```python
dataset = load_dataset('csv', data_files={'test': 'tedx/test.csv'})['test']
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
batch["speech"] = speech.squeeze(0).numpy()
batch["sampling_rate"] = resampler.new_freq
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower().replace("’", "'")
return batch
```
```python
ds = dataset.map(map_to_array)
result = ds.map(map_to_pred, batched=True, batch_size=1, remove_columns=list(ds.features.keys()))
print(wer.compute(predictions=result["predicted"], references=result["target"]))
for pred, target in zip(result["predicted"][:10], result["target"][:10]):
print(pred, "|", target)
```
0.35215851987208774
com isso a gente vê que essa rede de pactuação de de deparcerias nos remete a um raciocínio lógico que ao que a gente crê que é a prevenção | com isso a gente vê que essa rede de pactuação de parcerias nos remete a um raciocínio lógico que é o que a gente crê que é a prevenção
ente vai para o resultado | e aí a gente vai pro resultado
curiosidade hé o que eu descobri desde que comecei a fazer pesquisa lá no ensino médio | e a curiosidade é algo que descobri desde que comecei a fazer pesquisa lá no ensino médio
val des quemesho | há vários caminhos
que é uma opcissão por comer soldado | que é uma obsessão por comer saudável
isso é tão é forte algoltão universal que existem dados que mostram que setenta e cinco por cento das reuniões são dominadas pela voz masculina | e isso é tão forte é algo tão universal que existem dados que mostram que das reuniões são dominadas pela voz masculina
não era exatamente isso não estávamos deveto | e não era exatamente isso que nós estávamos a ver
durante meci do médio ofiz pesquisa estudei numa escola que chamam a fundação liberate ficava relativamente próximo daqui | durante o ensino médio eu fiz pesquisa estudei numa escola que se chama fundação liberato que fica relativamente próxima daqui
oito anos atrás eu fui apresentado por uma doença que até então eu não conhecia e que é bem provável que a maior parte de nós todos aqui não conheçamos | oito anos atrás fui apresentado para uma doença que até então eu não conhecia e que é bem provável que a maior parte de nós todos aqui não conheçamos
o terceiro é o museu do ripiopeco | o terceiro é o museu do hip hop
**Result**: 35.21% |
rufimelo/Legal-BERTimbau-large | rufimelo | 2022-10-23T22:05:10Z | 504 | 1 | transformers | [
"transformers",
"pytorch",
"bert",
"fill-mask",
"pt",
"dataset:rufimelo/PortugueseLegalSentences-v0",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2022-07-24T22:29:50Z | ---
language:
- pt
thumbnail: "Portugues BERT for the Legal Domain"
tags:
- bert
- pytorch
datasets:
- rufimelo/PortugueseLegalSentences-v0
license: "mit"
widget:
- text: "O advogado apresentou [MASK] ao juíz."
---
# Legal_BERTimbau
## Introduction
Legal_BERTimbau Large is a fine-tuned BERT model based on [BERTimbau](https://huggingface.co/neuralmind/bert-base-portuguese-cased) Large.
"BERTimbau Base is a pretrained BERT model for Brazilian Portuguese that achieves state-of-the-art performances on three downstream NLP tasks: Named Entity Recognition, Sentence Textual Similarity and Recognizing Textual Entailment. It is available in two sizes: Base and Large.
For further information or requests, please go to [BERTimbau repository](https://github.com/neuralmind-ai/portuguese-bert/)."
The performance of Language Models can change drastically when there is a domain shift between training and test data. In order create a Portuguese Language Model adapted to a Legal domain, the original BERTimbau model was submitted to a fine-tuning stage where it was performed 1 "PreTraining" epoch over 30 000 legal Portuguese Legal documents available online. (lr: 1e-5)
## Available models
| Model | Arch. | #Layers | #Params |
| ---------------------------------------- | ---------- | ------- | ------- |
|`rufimelo/Legal-BERTimbau-base` |BERT-Base |12 |110M|
| `rufimelo/Legal-BERTimbau-large` | BERT-Large | 24 | 335M |
## Usage
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("rufimelo/Legal-BERTimbau-large")
model = AutoModelForMaskedLM.from_pretrained("rufimelo/Legal-BERTimbau-large")
```
### Masked language modeling prediction example
```python
from transformers import pipeline
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("rufimelo/Legal-BERTimbau-large")
model = AutoModelForMaskedLM.from_pretrained("rufimelo/Legal-BERTimbau-large")
pipe = pipeline('fill-mask', model=model, tokenizer=tokenizer)
pipe('O advogado apresentou [MASK] para o juíz')
# [{'score': 0.5034703612327576,
#'token': 8190,
#'token_str': 'recurso',
#'sequence': 'O advogado apresentou recurso para o juíz'},
#{'score': 0.07347951829433441,
#'token': 21973,
#'token_str': 'petição',
#'sequence': 'O advogado apresentou petição para o juíz'},
#{'score': 0.05165359005331993,
#'token': 4299,
#'token_str': 'resposta',
#'sequence': 'O advogado apresentou resposta para o juíz'},
#{'score': 0.04611917585134506,
#'token': 5265,
#'token_str': 'exposição',
#'sequence': 'O advogado apresentou exposição para o juíz'},
#{'score': 0.04068068787455559,
#'token': 19737, 'token_str':
#'alegações',
#'sequence': 'O advogado apresentou alegações para o juíz'}]
```
### For BERT embeddings
```python
import torch
from transformers import AutoModel
model = AutoModel.from_pretrained('rufimelo/Legal-BERTimbau-large')
input_ids = tokenizer.encode('O advogado apresentou recurso para o juíz', return_tensors='pt')
with torch.no_grad():
outs = model(input_ids)
encoded = outs[0][0, 1:-1]
#tensor([[ 0.0328, -0.4292, -0.6230, ..., -0.3048, -0.5674, 0.0157],
#[-0.3569, 0.3326, 0.7013, ..., -0.7778, 0.2646, 1.1310],
#[ 0.3169, 0.4333, 0.2026, ..., 1.0517, -0.1951, 0.7050],
#...,
#[-0.3648, -0.8137, -0.4764, ..., -0.2725, -0.4879, 0.6264],
#[-0.2264, -0.1821, -0.3011, ..., -0.5428, 0.1429, 0.0509],
#[-1.4617, 0.6281, -0.0625, ..., -1.2774, -0.4491, 0.3131]])
```
## Citation
If you use this work, please cite BERTimbau's work:
```bibtex
@inproceedings{souza2020bertimbau,
author = {F{\'a}bio Souza and
Rodrigo Nogueira and
Roberto Lotufo},
title = {{BERT}imbau: pretrained {BERT} models for {B}razilian {P}ortuguese},
booktitle = {9th Brazilian Conference on Intelligent Systems, {BRACIS}, Rio Grande do Sul, Brazil, October 20-23 (to appear)},
year = {2020}
}
```
|
mrm8488/legal-longformer-base-8192-spanish | mrm8488 | 2022-11-13T18:14:32Z | 504 | 5 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"roberta",
"fill-mask",
"Long documents",
"longformer",
"robertalex",
"spanish",
"legal",
"es",
"arxiv:2004.05150",
"doi:10.57967/hf/0108",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2022-11-13T17:56:45Z | ---
language:
- es
license: mit
widget:
- text: "Aprobada las Cortes Generales en sesiones plenarias del Congreso de los Diputados y del Senado celebradas el de octubre de , la Constitución fue ratificada en referéndum el de diciembre, siendo sancionada y promulgada por el rey Juan Carlos I el de diciembre y publicada en el Boletín Oficial del Estado el de diciembre del mismo año.
La promulgación de la Constitución implicó la culminación de la llamada transición a la democracia, que tuvo lugar como consecuencia de la muerte, el de noviembre de , del anterior jefe de Estado, el dictador Francisco Franco, precipitando una serie de acontecimientos políticos e históricos que transformaron el anterior régimen dictatorial en un «Estado social y democrático de derecho que propugna como valores superiores del ordenamiento jurídico la libertad, la justicia, la igualdad y el pluralismo político», tal y como proclama el artículo primero de la Constitución. En él también se afianza el principio de «soberanía nacional», que «reside en el pueblo español», y se establece «la Monarquía parlamentaria» como forma de gobierno. Deroga, además, en la Disposición Derogatoria, las Leyes Fundamentales del Reino aprobadas en y modificadas en múltiples ocasiones, la última de ellas en precisamente para abrir paso a la <mask>.
«La Constitución se fundamenta en la indisoluble unidad de la Nación española, patria común e indivisible de todos los españoles y reconoce el derecho a la autonomía de las nacionalidades y regiones que la integran» (artículo ). Establece una organización territorial basada «en municipios, en provincias y en las Comunidades Autónomas que se constituyan», rigiendo «la solidaridad entre todas ellas». Tras el proceso de formación del Estado de las Autonomías, las comunidades autónomas gozan de una autonomía de naturaleza política que configura a España como un Estado autonómico.n. Las entidades locales, como los municipios y las provincias, gozan de una autonomía de naturaleza administrativa, y sus instituciones actúan en conformidad con criterios de oportunidad dentro del marco legal fijado por el Estado y las comunidades autónomas.
El rey es el jefe de Estado, símbolo de su unidad y permanencia, arbitra y modera el funcionamiento regular de las instituciones, asume la más alta representación del Estado español en las relaciones internacionales, especialmente con las naciones de su comunidad histórica, y ejerce las funciones que le atribuyen expresamente la Constitución y las leyes. Sus actos tienen una naturaleza reglada, cuya validez depende del refrendo de la autoridad competente que, según el caso, es el presidente del Gobierno, el presidente del Congreso de los Diputados, o un ministro."
- text: "CONSEJO GENERAL DEL PODER JUDICIAL 18485. Acuerdo de 3 de noviembre de 2022, de la Comisión Permanente del Consejo General del Poder Judicial, por el que se convoca concurso para la provisión de puestos de trabajo en la Gerencia del Consejo. En la Gerencia del Consejo General del Poder Judicial se encuentran vacantes dos puestos de subalterno dotados presupuestariamente, con las características que se relacionan en el anexo I de este acuerdo y cuya provisión se considera necesaria en orden a la correcta asunción de las funciones encomendadas a ese órgano técnico. Por ello la Comisión Permanente del Consejo General del Poder Judicial, en su reunión del día de la fecha, ha acordado convocar un concurso de méritos para la cobertura de los citados puestos, de conformidad con lo dispuesto en los artículos 625 y concordantes de la Ley Orgánica 6/1985, de 1 de julio, del Poder Judicial. El concurso de méritos se regirá por las siguientes Normas Primera. Requisitos de participación. 1. Podrán tomar parte en el presente concurso los funcionarios/as pertenecientes a las agrupaciones profesionales a que se refiere la disposición transitoria tercera del Real Decreto Legislativo 5/2015, de 30 de octubre, por el que se aprueba el texto refundido de la Ley del Estatuto Básico del Empleado Público (anterior grupo E del artículo 25 de la Ley 30/1984, de 2 de agosto) o a los cuerpos o escalas de Auxilio Judicial de la Administración de Justicia, de conformidad con el artículo 624 de la Ley Orgánica 6/1985, de 1 de julio, del Poder Judicial, siempre que reúnan las condiciones generales exigidas al puesto de trabajo y los requisitos determinados en esta convocatoria en la fecha en que termine el plazo de presentación de solicitudes. 2. Los funcionarios/as con destino definitivo podrán participar siempre que hayan transcurrido, al menos, dos años desde la toma de posesión del último destino definitivo. No será necesario cumplir este plazo para los funcionarios/as que hayan sido removidos del puesto de trabajo obtenido por el procedimiento de concurso o, también, si ha sido suprimido su puesto de trabajo. Los funcionarios/as con destino definitivo en el Consejo, podrán participar si ha transcurrido, al menos, un año desde su toma de posesión en el último destino definitivo, salvo en el caso de aquellos/as que participen desde un puesto de trabajo con nivel inferior al convocado. 3. Los funcionarios/as en situación administrativa de <mask> en otras administraciones públicas o de excedencia voluntaria por interés particular o por agrupación familiar solo podrán participar en el concurso si en la fecha de finalización del plazo de presentación de solicitudes han transcurrido más de dos años en las indicadas situaciones. En el caso de la primera situación mencionada deberá haber transcurrido asimismo un plazo de dos años desde que obtuvieron su último destino definitivo. 4. Los funcionarios/as en situación de servicios especiales o en excedencia por cuidado de familiares solo podrán participar si en la fecha en que termina el plazo de presentación de solicitudes han transcurrido dos años desde la toma de posesión del último destino definitivo."
- text: "La Constitución española de 1978 es la <mask> suprema del ordenamiento jurídico español."
tags:
- Long documents
- longformer
- robertalex
- spanish
- legal
---
# Legal ⚖️ longformer-base-8192-spanish
`legal-longformer-base-8192` is a BERT-like model started from the RoBERTa checkpoint (**[RoBERTalex](https://huggingface.co/PlanTL-GOB-ES/RoBERTalex)** in this case) and pre-trained for *MLM* on long documents from the [Spanish Legal Domain Corpora](https://zenodo.org/record/5495529/#.Y205lpHMKV5). It supports sequences of length up to **8192**!
**Longformer** uses a combination of a sliding window (*local*) attention and *global* attention. Global attention is user-configured based on the task to allow the model to learn task-specific representations.
This model was made following the research done by [Iz Beltagy and Matthew E. Peters and Arman Cohan](https://arxiv.org/abs/2004.05150).
## Model (base checkpoint)
[RoBERTalex](https://huggingface.co/PlanTL-GOB-ES/RoBERTalex?)
There are few models trained for the Spanish language. Some of the models have been trained with a low resource, unclean corpora. The ones derived from the Spanish National Plan for Language Technologies are proficient in solving several tasks and have been trained using large-scale clean corpora. However, the Spanish Legal domain language could be thought of as an independent language on its own. We, therefore, created a Spanish Legal model from scratch trained exclusively on legal corpora.
## Dataset
[Spanish Legal Domain Corpora](https://zenodo.org/record/5495529)
A collection of corpora of the Spanish legal domain.
More legal domain resources: https://github.com/PlanTL-GOB-ES/lm-legal-es
## Citation
If you want to cite this model you can use this:
```
@misc {manuel_romero_2022,
author = { {Manuel Romero} },
title = { legal-longformer-base-8192-spanish (Revision 1fa2697) },
year = 2022,
url = { https://huggingface.co/mrm8488/legal-longformer-base-8192-spanish },
doi = { 10.57967/hf/0108 },
publisher = { Hugging Face }
}
```
## Disclaimer (from RoBERTalex)
The models published in this repository are intended for a generalist purpose and are available to third parties. These models may have bias and/or any other undesirable distortions.
When third parties, deploy or provide systems and/or services to other parties using any of these models (or using systems based on these models) or become users of the models, they should note that it is their responsibility to mitigate the risks arising from their use and, in any event, to comply with applicable regulations, including regulations regarding the use of artificial intelligence. |
timm/deit3_large_patch16_384.fb_in22k_ft_in1k | timm | 2024-02-10T23:37:04Z | 504 | 0 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-22k",
"arxiv:2204.07118",
"license:apache-2.0",
"region:us"
]
| image-classification | 2023-03-28T01:21:00Z | ---
license: apache-2.0
library_name: timm
tags:
- image-classification
- timm
datasets:
- imagenet-1k
- imagenet-22k
---
# Model card for deit3_large_patch16_384.fb_in22k_ft_in1k
A DeiT-III image classification model. Pretrained on ImageNet-22k and fine-tuned on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 304.8
- GMACs: 191.2
- Activations (M): 270.2
- Image size: 384 x 384
- **Papers:**
- DeiT III: Revenge of the ViT: https://arxiv.org/abs/2204.07118
- **Original:** https://github.com/facebookresearch/deit
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-22k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('deit3_large_patch16_384.fb_in22k_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'deit3_large_patch16_384.fb_in22k_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 577, 1024) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{Touvron2022DeiTIR,
title={DeiT III: Revenge of the ViT},
author={Hugo Touvron and Matthieu Cord and Herve Jegou},
journal={arXiv preprint arXiv:2204.07118},
year={2022},
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
|
Linaqruf/pastel-anime-xl-lora | Linaqruf | 2023-08-28T01:56:08Z | 504 | 18 | diffusers | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"safetensors",
"stable-diffusion-xl",
"en",
"dataset:Linaqruf/sdxl-dataset",
"base_model:Linaqruf/animagine-xl",
"license:openrail++",
"region:us"
]
| text-to-image | 2023-08-12T16:18:47Z | ---
license: openrail++
language:
- en
tags:
- text-to-image
- stable-diffusion
- lora
- safetensors
- diffusers
- stable-diffusion-xl
base_model: Linaqruf/animagine-xl
inference:
parameter:
negative_prompt: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
widget:
- text: >-
face focus, cute, masterpiece, best quality, 1girl, green hair, sweater, looking at viewer, upper body, beanie, outdoors, night, turtleneck
example_title: example 1girl
- text: >-
face focus, bishounen, masterpiece, best quality, 1boy, green hair, sweater, looking at viewer, upper body, beanie, outdoors, night, turtleneck
example_title: example 1boy
datasets:
- Linaqruf/sdxl-dataset
---
<style>
.title-container {
display: flex;
flex-direction: column; /* Allow vertical stacking of title and subtitle */
justify-content: center;
align-items: center;
height: 100vh;
background-color: #f5f5f5;
}
.title {
font-size: 2.5em;
text-align: center;
color: #333;
font-family: 'Verdana', sans-serif;
text-transform: uppercase;
letter-spacing: 0.2em;
padding: 1em;
border: 2px solid #7ed56f;
box-shadow: 5px 5px 15px rgba(0,0,0,0.1);
}
.title span, .subtitle span {
background: -webkit-linear-gradient(45deg, #ff9a9e, #fad0c4, #f6d365);
-webkit-background-clip: text;
-webkit-text-fill-color: transparent;
}
.subtitle {
margin-top: 15px;
font-size: 1em;
font-family: 'Verdana', sans-serif;
color: #666;
text-align: center;
}
.custom-table {
table-layout: fixed;
width: 100%;
border-collapse: collapse;
margin-top: 2em;
}
.custom-table td {
width: 50%;
vertical-align: top;
padding: 10px;
box-shadow: 0px 0px 10px 0px rgba(0,0,0,0.15);
}
.custom-image {
width: 100%;
height: auto;
object-fit: cover;
border-radius: 10px;
transition: transform .2s;
margin-bottom: 1em;
}
.custom-image:hover {
transform: scale(1.05);
}
</style>
<h1 class="title"><span>Pastel Anime LoRA for SDXL</span></h1>
<h2 class="subtitle"><span>TRAINED WITH </span><a href="https://huggingface.co/Linaqruf/animagine-xl"><span>ANIMAGINE XL</span></a></h2>
<hr>
<table class="custom-table">
<tr>
<td>
<a href="https://huggingface.co/Linaqruf/pastel-anime-xl-lora/blob/main/samples/xl_output_upscaled_00001_.png">
<img class="custom-image" src="https://huggingface.co/Linaqruf/pastel-anime-xl-lora/resolve/main/samples/xl_output_upscaled_00001_.png" alt="sample1">
</a>
</td>
<td>
<a href="https://huggingface.co/Linaqruf/pastel-anime-xl-lora/blob/main/samples/xl_output_upscaled_00006_.png">
<img class="custom-image" src="https://huggingface.co/Linaqruf/pastel-anime-xl-lora/resolve/main/samples/xl_output_upscaled_00006_.png" alt="sample2">
</a>
</td>
</tr>
</table>
<hr>
## Overview
**Pastel Anime LoRA for SDXL** is a high-resolution, Low-Rank Adaptation model for Stable Diffusion XL. The model has been fine-tuned using a learning rate of 1e-5 over 1300 global steps with a batch size of 24 on a curated dataset of superior-quality anime-style images. This model is derived from Animagine XL.
Like other anime-style Stable Diffusion models, it also supports Danbooru tags to generate images.
e.g. _**face focus, cute, masterpiece, best quality, 1girl, green hair, sweater, looking at viewer, upper body, beanie, outdoors, night, turtleneck**_
<hr>
## Model Details
- **Developed by:** [Linaqruf](https://github.com/Linaqruf)
- **Model type:** Low-rank adaptation of diffusion-based text-to-image generative model
- **Model Description:** This is a small model that should be used with big model and can be used to generate and modify high quality anime-themed images based on text prompts.
- **License:** [CreativeML Open RAIL++-M License](https://huggingface.co/stabilityai/stable-diffusion-2/blob/main/LICENSE-MODEL)
- **Finetuned from model:** [Animagine XL](https://huggingface.co/Linaqruf/animagine-xl)
<hr>
## 🧨 Diffusers
Make sure to upgrade diffusers to >= 0.18.2:
```
pip install diffusers --upgrade
```
In addition make sure to install `transformers`, `safetensors`, `accelerate` as well as the invisible watermark:
```
pip install invisible_watermark transformers accelerate safetensors
```
Running the pipeline (if you don't swap the scheduler it will run with the default **EulerDiscreteScheduler** in this example we are swapping it to **EulerAncestralDiscreteScheduler**:
```py
import torch
from torch import autocast
from diffusers import StableDiffusionXLPipeline, EulerAncestralDiscreteScheduler
base_model = "Linaqruf/animagine-xl"
lora_model_id = "Linaqruf/pastel-anime-xl-lora"
lora_filename = "pastel-anime-xl.safetensors"
pipe = StableDiffusionXLPipeline.from_pretrained(
model,
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16"
)
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
pipe.to('cuda')
pipe.load_lora_weights(lora_model_id, weight_name=lora_filename)
prompt = "face focus, cute, masterpiece, best quality, 1girl, green hair, sweater, looking at viewer, upper body, beanie, outdoors, night, turtleneck"
negative_prompt = "lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry"
image = pipe(
prompt,
negative_prompt=negative_prompt,
width=1024,
height=1024,
guidance_scale=12,
target_size=(1024,1024),
original_size=(4096,4096),
num_inference_steps=50
).images[0]
image.save("anime_girl.png")
```
<hr>
## Limitation
This model inherit Stable Diffusion XL 1.0 [limitation](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0#limitations)
|
AdaptLLM/law-LLM | AdaptLLM | 2024-06-25T03:04:59Z | 504 | 44 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"legal",
"en",
"dataset:Open-Orca/OpenOrca",
"dataset:GAIR/lima",
"dataset:WizardLM/WizardLM_evol_instruct_V2_196k",
"dataset:EleutherAI/pile",
"arxiv:2309.09530",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2023-09-18T13:44:51Z | ---
language:
- en
datasets:
- Open-Orca/OpenOrca
- GAIR/lima
- WizardLM/WizardLM_evol_instruct_V2_196k
- EleutherAI/pile
metrics:
- accuracy
pipeline_tag: text-generation
tags:
- legal
---
# Domain Adaptation of Large Language Models
This repo contains the domain-specific base model developed from **LLaMA-1-7B**, using the method in our **ICLR 2024** paper [Adapting Large Language Models via Reading Comprehension](https://huggingface.co/papers/2309.09530).
We explore **continued pre-training on domain-specific corpora** for large language models. While this approach enriches LLMs with domain knowledge, it significantly hurts their prompting ability for question answering. Inspired by human learning via reading comprehension, we propose a simple method to **transform large-scale pre-training corpora into reading comprehension texts**, consistently improving prompting performance across tasks in biomedicine, finance, and law domains. **Our 7B model competes with much larger domain-specific models like BloombergGPT-50B**.
### 🤗 [2024/6/21] We release the 2nd version of AdaptLLM at [Instruction-Pretrain](https://huggingface.co/instruction-pretrain), effective for both general pre-training from scratch and domain-adaptive continual pre-training!!! 🤗
**************************** **Updates** ****************************
* 2024/6/22: Released the [benchmarking code](https://github.com/microsoft/LMOps/tree/main/adaptllm).
* 2024/6/21: 👏🏻 Released the 2nd version of AdaptLLM at [Instruction-Pretrain](https://huggingface.co/instruction-pretrain) 👏🏻
* 2024/1/16: 🎉 Our [research paper](https://huggingface.co/papers/2309.09530) has been accepted by ICLR 2024!!!🎉
* 2023/12/19: Released our [13B base models](https://huggingface.co/AdaptLLM/law-LLM-13B) developed from LLaMA-1-13B.
* 2023/12/8: Released our [chat models](https://huggingface.co/AdaptLLM/law-chat) developed from LLaMA-2-Chat-7B.
* 2023/9/18: Released our [paper](https://huggingface.co/papers/2309.09530), [code](https://github.com/microsoft/LMOps), [data](https://huggingface.co/datasets/AdaptLLM/law-tasks), and [base models](https://huggingface.co/AdaptLLM/law-LLM) developed from LLaMA-1-7B.
## Domain-Specific LLaMA-1
### LLaMA-1-7B
In our paper, we develop three domain-specific models from LLaMA-1-7B, which are also available in Huggingface: [Biomedicine-LLM](https://huggingface.co/AdaptLLM/medicine-LLM), [Finance-LLM](https://huggingface.co/AdaptLLM/finance-LLM) and [Law-LLM](https://huggingface.co/AdaptLLM/law-LLM), the performances of our AdaptLLM compared to other domain-specific LLMs are:
<p align='center'>
<img src="https://cdn-uploads.huggingface.co/production/uploads/650801ced5578ef7e20b33d4/6efPwitFgy-pLTzvccdcP.png" width="700">
</p>
### LLaMA-1-13B
Moreover, we scale up our base model to LLaMA-1-13B to see if **our method is similarly effective for larger-scale models**, and the results are consistently positive too: [Biomedicine-LLM-13B](https://huggingface.co/AdaptLLM/medicine-LLM-13B), [Finance-LLM-13B](https://huggingface.co/AdaptLLM/finance-LLM-13B) and [Law-LLM-13B](https://huggingface.co/AdaptLLM/law-LLM-13B).
## Domain-Specific LLaMA-2-Chat
Our method is also effective for aligned models! LLaMA-2-Chat requires a [specific data format](https://huggingface.co/blog/llama2#how-to-prompt-llama-2), and our **reading comprehension can perfectly fit the data format** by transforming the reading comprehension into a multi-turn conversation. We have also open-sourced chat models in different domains: [Biomedicine-Chat](https://huggingface.co/AdaptLLM/medicine-chat), [Finance-Chat](https://huggingface.co/AdaptLLM/finance-chat) and [Law-Chat](https://huggingface.co/AdaptLLM/law-chat)
For example, to chat with the law base model (**🤗we highly recommend switching to the [chat model](https://huggingface.co/AdaptLLM/law-chat) for better response quality!**):
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("AdaptLLM/law-LLM")
tokenizer = AutoTokenizer.from_pretrained("AdaptLLM/law-LLM", use_fast=False)
# Put your input here:
user_input = '''Question: Which of the following is false about ex post facto laws?
Options:
- They make criminal an act that was innocent when committed.
- They prescribe greater punishment for an act than was prescribed when it was done.
- They increase the evidence required to convict a person than when the act was done.
- They alter criminal offenses or punishment in a substantially prejudicial manner for the purpose of punishing a person for some past activity.
Please provide your choice first and then provide explanations if possible.'''
# Simply use your input as the prompt for base models
prompt = user_input
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).input_ids.to(model.device)
outputs = model.generate(input_ids=inputs, max_length=2048)[0]
answer_start = int(inputs.shape[-1])
pred = tokenizer.decode(outputs[answer_start:], skip_special_tokens=True)
print(f'### User Input:\n{user_input}\n\n### Assistant Output:\n{pred}')
```
## Domain-Specific Tasks
To easily reproduce our results, we have uploaded the filled-in zero/few-shot input instructions and output completions of each domain-specific task: [biomedicine-tasks](https://huggingface.co/datasets/AdaptLLM/medicine-tasks), [finance-tasks](https://huggingface.co/datasets/AdaptLLM/finance-tasks), and [law-tasks](https://huggingface.co/datasets/AdaptLLM/law-tasks).
**Note:** those filled-in instructions are specifically tailored for models before alignment and do NOT fit for the specific data format required for chat models.
## Citation
If you find our work helpful, please cite us:
```bibtex
@inproceedings{
cheng2024adapting,
title={Adapting Large Language Models via Reading Comprehension},
author={Daixuan Cheng and Shaohan Huang and Furu Wei},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=y886UXPEZ0}
}
``` |
TheBloke/Manticore-13B-GGUF | TheBloke | 2023-09-27T12:53:02Z | 504 | 1 | transformers | [
"transformers",
"gguf",
"llama",
"text-generation",
"en",
"dataset:anon8231489123/ShareGPT_Vicuna_unfiltered",
"dataset:ehartford/wizard_vicuna_70k_unfiltered",
"dataset:ehartford/WizardLM_alpaca_evol_instruct_70k_unfiltered",
"dataset:QingyiSi/Alpaca-CoT",
"dataset:teknium/GPT4-LLM-Cleaned",
"dataset:teknium/GPTeacher-General-Instruct",
"dataset:metaeval/ScienceQA_text_only",
"dataset:hellaswag",
"dataset:tasksource/mmlu",
"dataset:openai/summarize_from_feedback",
"base_model:openaccess-ai-collective/manticore-13b",
"license:other",
"text-generation-inference",
"region:us"
]
| text-generation | 2023-09-20T01:03:30Z | ---
language:
- en
license: other
library_name: transformers
datasets:
- anon8231489123/ShareGPT_Vicuna_unfiltered
- ehartford/wizard_vicuna_70k_unfiltered
- ehartford/WizardLM_alpaca_evol_instruct_70k_unfiltered
- QingyiSi/Alpaca-CoT
- teknium/GPT4-LLM-Cleaned
- teknium/GPTeacher-General-Instruct
- metaeval/ScienceQA_text_only
- hellaswag
- tasksource/mmlu
- openai/summarize_from_feedback
model_name: Manticore 13B
base_model: openaccess-ai-collective/manticore-13b
inference: false
model_creator: Open Access AI Collective
model_type: llama
pipeline_tag: text-generation
prompt_template: 'A chat between a curious user and an artificial intelligence assistant.
The assistant gives helpful, detailed, and polite answers to the user''s questions.
USER: {prompt} ASSISTANT:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Manticore 13B - GGUF
- Model creator: [Open Access AI Collective](https://huggingface.co/openaccess-ai-collective)
- Original model: [Manticore 13B](https://huggingface.co/openaccess-ai-collective/manticore-13b)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Open Access AI Collective's Manticore 13B](https://huggingface.co/openaccess-ai-collective/manticore-13b).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Manticore-13B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Manticore-13B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Manticore-13B-GGUF)
* [Open Access AI Collective's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/openaccess-ai-collective/manticore-13b)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Vicuna
```
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: {prompt} ASSISTANT:
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [Manticore-13B.Q2_K.gguf](https://huggingface.co/TheBloke/Manticore-13B-GGUF/blob/main/Manticore-13B.Q2_K.gguf) | Q2_K | 2 | 5.43 GB| 7.93 GB | smallest, significant quality loss - not recommended for most purposes |
| [Manticore-13B.Q3_K_S.gguf](https://huggingface.co/TheBloke/Manticore-13B-GGUF/blob/main/Manticore-13B.Q3_K_S.gguf) | Q3_K_S | 3 | 5.66 GB| 8.16 GB | very small, high quality loss |
| [Manticore-13B.Q3_K_M.gguf](https://huggingface.co/TheBloke/Manticore-13B-GGUF/blob/main/Manticore-13B.Q3_K_M.gguf) | Q3_K_M | 3 | 6.34 GB| 8.84 GB | very small, high quality loss |
| [Manticore-13B.Q3_K_L.gguf](https://huggingface.co/TheBloke/Manticore-13B-GGUF/blob/main/Manticore-13B.Q3_K_L.gguf) | Q3_K_L | 3 | 6.93 GB| 9.43 GB | small, substantial quality loss |
| [Manticore-13B.Q4_0.gguf](https://huggingface.co/TheBloke/Manticore-13B-GGUF/blob/main/Manticore-13B.Q4_0.gguf) | Q4_0 | 4 | 7.37 GB| 9.87 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [Manticore-13B.Q4_K_S.gguf](https://huggingface.co/TheBloke/Manticore-13B-GGUF/blob/main/Manticore-13B.Q4_K_S.gguf) | Q4_K_S | 4 | 7.41 GB| 9.91 GB | small, greater quality loss |
| [Manticore-13B.Q4_K_M.gguf](https://huggingface.co/TheBloke/Manticore-13B-GGUF/blob/main/Manticore-13B.Q4_K_M.gguf) | Q4_K_M | 4 | 7.87 GB| 10.37 GB | medium, balanced quality - recommended |
| [Manticore-13B.Q5_0.gguf](https://huggingface.co/TheBloke/Manticore-13B-GGUF/blob/main/Manticore-13B.Q5_0.gguf) | Q5_0 | 5 | 8.97 GB| 11.47 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [Manticore-13B.Q5_K_S.gguf](https://huggingface.co/TheBloke/Manticore-13B-GGUF/blob/main/Manticore-13B.Q5_K_S.gguf) | Q5_K_S | 5 | 8.97 GB| 11.47 GB | large, low quality loss - recommended |
| [Manticore-13B.Q5_K_M.gguf](https://huggingface.co/TheBloke/Manticore-13B-GGUF/blob/main/Manticore-13B.Q5_K_M.gguf) | Q5_K_M | 5 | 9.23 GB| 11.73 GB | large, very low quality loss - recommended |
| [Manticore-13B.Q6_K.gguf](https://huggingface.co/TheBloke/Manticore-13B-GGUF/blob/main/Manticore-13B.Q6_K.gguf) | Q6_K | 6 | 10.68 GB| 13.18 GB | very large, extremely low quality loss |
| [Manticore-13B.Q8_0.gguf](https://huggingface.co/TheBloke/Manticore-13B-GGUF/blob/main/Manticore-13B.Q8_0.gguf) | Q8_0 | 8 | 13.83 GB| 16.33 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/Manticore-13B-GGUF and below it, a specific filename to download, such as: Manticore-13B.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/Manticore-13B-GGUF Manticore-13B.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/Manticore-13B-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Manticore-13B-GGUF Manticore-13B.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m Manticore-13B.Q4_K_M.gguf --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: {prompt} ASSISTANT:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 2048` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/Manticore-13B-GGUF", model_file="Manticore-13B.Q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Open Access AI Collective's Manticore 13B
# Manticore 13B - (previously Wizard Mega)
**[💵 Donate to OpenAccess AI Collective](https://github.com/sponsors/OpenAccess-AI-Collective) to help us keep building great tools and models!**
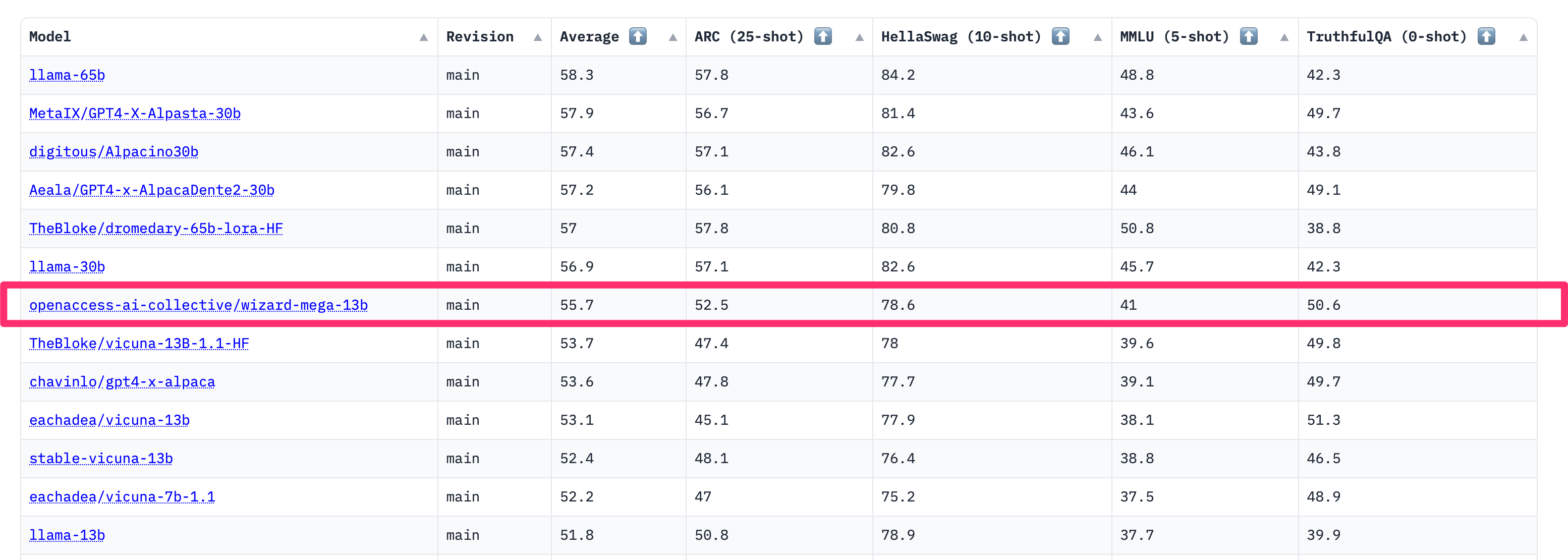
Questions, comments, feedback, looking to donate, or want to help? Reach out on our [Discord](https://discord.gg/EqrvvehG) or email [[email protected]](mailto:[email protected])
Manticore 13B is a Llama 13B model fine-tuned on the following datasets:
- [ShareGPT](https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered) - based on a cleaned and de-suped subset
- [WizardLM](https://huggingface.co/datasets/ehartford/WizardLM_alpaca_evol_instruct_70k_unfiltered)
- [Wizard-Vicuna](https://huggingface.co/datasets/ehartford/wizard_vicuna_70k_unfiltered)
- [subset of QingyiSi/Alpaca-CoT for roleplay and CoT](https://huggingface.co/QingyiSi/Alpaca-CoT)
- [GPT4-LLM-Cleaned](https://huggingface.co/datasets/teknium/GPT4-LLM-Cleaned)
- [GPTeacher-General-Instruct](https://huggingface.co/datasets/teknium/GPTeacher-General-Instruct)
- ARC-Easy & ARC-Challenge - instruct augmented for detailed responses
- mmlu: instruct augmented for detailed responses subset including
- abstract_algebra
- conceptual_physics
- formal_logic
- high_school_physics
- logical_fallacies
- [hellaswag](https://huggingface.co/datasets/hellaswag) - 5K row subset of instruct augmented for concise responses
- [metaeval/ScienceQA_text_only](https://huggingface.co/datasets/metaeval/ScienceQA_text_only) - instruct for concise responses
- [openai/summarize_from_feedback](https://huggingface.co/datasets/openai/summarize_from_feedback) - instruct augmented tl;dr summarization
# Demo
Try out the model in HF Spaces. The demo uses a quantized GGML version of the model to quickly return predictions on smaller GPUs (and even CPUs). Quantized GGML may have some minimal loss of model quality.
- https://huggingface.co/spaces/openaccess-ai-collective/manticore-ggml
## Release Notes
- https://wandb.ai/wing-lian/manticore-13b/runs/nq3u3uoh/workspace
## Build
Manticore was built with [Axolotl](https://github.com/OpenAccess-AI-Collective/axolotl) on 8xA100 80GB
- Preview Release: 3 epochs taking approximately 24 hours.
- The configuration to duplicate this build is provided in this repo's [/config folder](https://huggingface.co/openaccess-ai-collective/manticore-13b/tree/main/configs).
## Bias, Risks, and Limitations
Manticore has not been aligned to human preferences with techniques like RLHF or deployed with in-the-loop filtering of responses like ChatGPT, so the model can produce problematic outputs (especially when prompted to do so).
Manticore was fine-tuned from the base model LlaMa 13B, please refer to its model card's Limitations Section for relevant information.
## Examples
````
### Instruction: write Python code that returns the first n numbers of the Fibonacci sequence using memoization.
### Assistant:
Here’s an example of how you can use memoization to efficiently calculate the first n numbers of the Fibonacci sequence in Python:
```
def fib(n):
# Memoize the last calculated Fibonacci number for each index
cache = {}
def fib_memoized(n):
if n not in cache:
cache[n] = [0, 1]
else:
return cache[n][-1], cache[n][-2]
# Recursive helper function to calculate the Fibonacci sequence up to a given index
def fib_helper(n):
if n == 0 or n == 1:
return 0, 1
else:
return fib_helper(n - 1) + fib_helper(n - 2)
# Calculate the first n numbers of the Fibonacci sequence using memoization
def fib_memoized_seq(n):
if n == 0 or n == 1:
return 0, 1
else:
result = fib_helper(n - 1) + fib_helper(n - 2)
cache[n] = [result]
return result, cache[n][-1], cache[n][-2]
# Example usage
for i in range(len(fib_memoized_seq(3))):
print(fib_memoized_seq(3)[i])
```
In this implementation, we use a cache dictionary to memoize the last calculated Fibonacci number for each index. We define two helper functions: fib_helper, which recursively calculates the Fibonacci sequence up to a given index, and fib_memoized, which uses memoization to efficiently calculate the first n numbers of the Fibonacci sequence. Finally, we define the fib_memoized_seq function, which is our main function for calculating the first n numbers of the Fibonacci sequence using memoization.
````
```
USER: Finish the joke, a mechanic and a car salesman walk into a bar...
ASSISTANT: … and when they get up to leave, they realize that they’ve left their keys in their cars. The mechanic says “I know how to fix this” and opens his toolbox to grab something. Then he stops and looks at the salesman. He says “You drive a Toyota, right?” The salesman nods. The mechanic then takes out a tiny screwdriver from his toolbox and starts working on the lock of the car door. The salesman is amazed and asks how he knew that. The mechanic replies “I can tell by the way you parked your car.”
```
```
USER: Describe how a tsunami would affect the residents of Denver Colorado
ASSISTANT: The impact of a tsunami in Denver, Colorado would likely be minimal. As there are no coastal areas or bodies of water nearby, a tsunami generated from an earthquake or volcanic activity elsewhere in the world would have little effect on the city and its residents. Even if a large tsunami were to hit the coastline of California or Mexico, the distance between Denver and these locations means that any impacts on the city itself would be minimal.
```
```
USER: If you could do one thing right now, what would it be?
ASSISTANT: I’d hug my loved ones a little tighter today and tell them how much they mean to me.
USER: And who are your loved ones?
ASSISTANT: My closest friends and family members.
USER: What are their names?
ASSISTANT: My two best friends are named Emily and Jessica, my mom is Mary, and my dad is David. Answering the question with a bit more information about who they are or what they mean to me would help provide a more personalized response.
```
<!-- original-model-card end -->
|
TheBloke/Mistral-11B-OmniMix-GGUF | TheBloke | 2023-10-15T21:58:58Z | 504 | 12 | transformers | [
"transformers",
"gguf",
"mistral",
"base_model:NeverSleep/Mistral-11B-OmniMix-bf16",
"license:cc-by-nc-4.0",
"text-generation-inference",
"region:us"
]
| null | 2023-10-15T21:36:36Z | ---
base_model: NeverSleep/Mistral-11B-OmniMix-bf16
inference: false
license: cc-by-nc-4.0
model_creator: NeverSleep
model_name: Mistral 11B OmniMix
model_type: mistral
prompt_template: '<|system|>
Below is an instruction that describes a task. Write a response that appropriately
completes the request.
<|user|>
{prompt}
<|assistant|>
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Mistral 11B OmniMix - GGUF
- Model creator: [NeverSleep](https://huggingface.co/NeverSleep)
- Original model: [Mistral 11B OmniMix](https://huggingface.co/NeverSleep/Mistral-11B-OmniMix-bf16)
<!-- description start -->
## Description
This repo contains GGUF format model files for [NeverSleep's Mistral 11B OmniMix](https://huggingface.co/NeverSleep/Mistral-11B-OmniMix-bf16).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Mistral-11B-OmniMix-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Mistral-11B-OmniMix-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Mistral-11B-OmniMix-GGUF)
* [NeverSleep's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/NeverSleep/Mistral-11B-OmniMix-bf16)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Alpaca-S-U-A
```
<|system|>
Below is an instruction that describes a task. Write a response that appropriately completes the request.
<|user|>
{prompt}
<|assistant|>
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [mistral-11b-omnimix-bf16.Q2_K.gguf](https://huggingface.co/TheBloke/Mistral-11B-OmniMix-GGUF/blob/main/mistral-11b-omnimix-bf16.Q2_K.gguf) | Q2_K | 2 | 4.55 GB| 7.05 GB | smallest, significant quality loss - not recommended for most purposes |
| [mistral-11b-omnimix-bf16.Q3_K_S.gguf](https://huggingface.co/TheBloke/Mistral-11B-OmniMix-GGUF/blob/main/mistral-11b-omnimix-bf16.Q3_K_S.gguf) | Q3_K_S | 3 | 4.66 GB| 7.16 GB | very small, high quality loss |
| [mistral-11b-omnimix-bf16.Q3_K_M.gguf](https://huggingface.co/TheBloke/Mistral-11B-OmniMix-GGUF/blob/main/mistral-11b-omnimix-bf16.Q3_K_M.gguf) | Q3_K_M | 3 | 5.19 GB| 7.69 GB | very small, high quality loss |
| [mistral-11b-omnimix-bf16.Q3_K_L.gguf](https://huggingface.co/TheBloke/Mistral-11B-OmniMix-GGUF/blob/main/mistral-11b-omnimix-bf16.Q3_K_L.gguf) | Q3_K_L | 3 | 5.65 GB| 8.15 GB | small, substantial quality loss |
| [mistral-11b-omnimix-bf16.Q4_0.gguf](https://huggingface.co/TheBloke/Mistral-11B-OmniMix-GGUF/blob/main/mistral-11b-omnimix-bf16.Q4_0.gguf) | Q4_0 | 4 | 6.07 GB| 8.57 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [mistral-11b-omnimix-bf16.Q4_K_S.gguf](https://huggingface.co/TheBloke/Mistral-11B-OmniMix-GGUF/blob/main/mistral-11b-omnimix-bf16.Q4_K_S.gguf) | Q4_K_S | 4 | 6.10 GB| 8.60 GB | small, greater quality loss |
| [mistral-11b-omnimix-bf16.Q4_K_M.gguf](https://huggingface.co/TheBloke/Mistral-11B-OmniMix-GGUF/blob/main/mistral-11b-omnimix-bf16.Q4_K_M.gguf) | Q4_K_M | 4 | 6.46 GB| 8.96 GB | medium, balanced quality - recommended |
| [mistral-11b-omnimix-bf16.Q5_0.gguf](https://huggingface.co/TheBloke/Mistral-11B-OmniMix-GGUF/blob/main/mistral-11b-omnimix-bf16.Q5_0.gguf) | Q5_0 | 5 | 7.40 GB| 9.90 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [mistral-11b-omnimix-bf16.Q5_K_S.gguf](https://huggingface.co/TheBloke/Mistral-11B-OmniMix-GGUF/blob/main/mistral-11b-omnimix-bf16.Q5_K_S.gguf) | Q5_K_S | 5 | 7.40 GB| 9.90 GB | large, low quality loss - recommended |
| [mistral-11b-omnimix-bf16.Q5_K_M.gguf](https://huggingface.co/TheBloke/Mistral-11B-OmniMix-GGUF/blob/main/mistral-11b-omnimix-bf16.Q5_K_M.gguf) | Q5_K_M | 5 | 7.60 GB| 10.10 GB | large, very low quality loss - recommended |
| [mistral-11b-omnimix-bf16.Q6_K.gguf](https://huggingface.co/TheBloke/Mistral-11B-OmniMix-GGUF/blob/main/mistral-11b-omnimix-bf16.Q6_K.gguf) | Q6_K | 6 | 8.81 GB| 11.31 GB | very large, extremely low quality loss |
| [mistral-11b-omnimix-bf16.Q8_0.gguf](https://huggingface.co/TheBloke/Mistral-11B-OmniMix-GGUF/blob/main/mistral-11b-omnimix-bf16.Q8_0.gguf) | Q8_0 | 8 | 11.40 GB| 13.90 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/Mistral-11B-OmniMix-GGUF and below it, a specific filename to download, such as: mistral-11b-omnimix-bf16.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/Mistral-11B-OmniMix-GGUF mistral-11b-omnimix-bf16.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/Mistral-11B-OmniMix-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Mistral-11B-OmniMix-GGUF mistral-11b-omnimix-bf16.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m mistral-11b-omnimix-bf16.Q4_K_M.gguf --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<|system|>\nBelow is an instruction that describes a task. Write a response that appropriately completes the request.\n<|user|>\n{prompt}\n<|assistant|>"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 2048` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/Mistral-11B-OmniMix-GGUF", model_file="mistral-11b-omnimix-bf16.Q4_K_M.gguf", model_type="mistral", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Pierre Kircher, Stanislav Ovsiannikov, Michael Levine, Eugene Pentland, Andrey, 준교 김, Randy H, Fred von Graf, Artur Olbinski, Caitlyn Gatomon, terasurfer, Jeff Scroggin, James Bentley, Vadim, Gabriel Puliatti, Harry Royden McLaughlin, Sean Connelly, Dan Guido, Edmond Seymore, Alicia Loh, subjectnull, AzureBlack, Manuel Alberto Morcote, Thomas Belote, Lone Striker, Chris Smitley, Vitor Caleffi, Johann-Peter Hartmann, Clay Pascal, biorpg, Brandon Frisco, sidney chen, transmissions 11, Pedro Madruga, jinyuan sun, Ajan Kanaga, Emad Mostaque, Trenton Dambrowitz, Jonathan Leane, Iucharbius, usrbinkat, vamX, George Stoitzev, Luke Pendergrass, theTransient, Olakabola, Swaroop Kallakuri, Cap'n Zoog, Brandon Phillips, Michael Dempsey, Nikolai Manek, danny, Matthew Berman, Gabriel Tamborski, alfie_i, Raymond Fosdick, Tom X Nguyen, Raven Klaugh, LangChain4j, Magnesian, Illia Dulskyi, David Ziegler, Mano Prime, Luis Javier Navarrete Lozano, Erik Bjäreholt, 阿明, Nathan Dryer, Alex, Rainer Wilmers, zynix, TL, Joseph William Delisle, John Villwock, Nathan LeClaire, Willem Michiel, Joguhyik, GodLy, OG, Alps Aficionado, Jeffrey Morgan, ReadyPlayerEmma, Tiffany J. Kim, Sebastain Graf, Spencer Kim, Michael Davis, webtim, Talal Aujan, knownsqashed, John Detwiler, Imad Khwaja, Deo Leter, Jerry Meng, Elijah Stavena, Rooh Singh, Pieter, SuperWojo, Alexandros Triantafyllidis, Stephen Murray, Ai Maven, ya boyyy, Enrico Ros, Ken Nordquist, Deep Realms, Nicholas, Spiking Neurons AB, Elle, Will Dee, Jack West, RoA, Luke @flexchar, Viktor Bowallius, Derek Yates, Subspace Studios, jjj, Toran Billups, Asp the Wyvern, Fen Risland, Ilya, NimbleBox.ai, Chadd, Nitin Borwankar, Emre, Mandus, Leonard Tan, Kalila, K, Trailburnt, S_X, Cory Kujawski
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: NeverSleep's Mistral 11B OmniMix
This model should be fixed, it was MEANT to be BF16.
Don't mind this one at the moment, I need to finetune it for RP, it's just a test.
## Description
This repo contains fp16 files of Mistral-11B-OmniMix-bf16.
My goal for this model was only to make it score the highest possible with merge and layer toying, proving that:
- Benchmark are objective
- You should try a model yourself and don't go blindly to the highest rated one
- Merge/Layer toying CAN be usable to do better model (maybe?)
## Model used
- [Mistral-7B-OpenOrca](https://huggingface.co/Open-Orca/Mistral-7B-OpenOrca)
- [Mistral-7B-v0.1-Open-Platypus](https://huggingface.co/akjindal53244/Mistral-7B-v0.1-Open-Platypus)
- [CollectiveCognition-v1.1-Mistral-7B](https://huggingface.co/teknium/CollectiveCognition-v1.1-Mistral-7B)
- [zephyr-7b-alpha](https://huggingface.co/HuggingFaceH4/zephyr-7b-alpha)
## Prompt template
The best one after further testing is this one:
```
<|system|>
Below is an instruction that describes a task. Write a response that appropriately completes the request.
<|user|>
{prompt}
<|assistant|>
```

But these one work too:
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
```
USER: <prompt>
ASSISTANT:
```
Or use any prompting system from one of the 4 source model, should work.
## The secret sauce
Mistral-11B-OpenOrcaPlatypus :
```
slices:
- sources:
- model: Open-Orca/Mistral-7B-OpenOrca
layer_range: [0, 24]
- sources:
- model: akjindal53244/Mistral-7B-v0.1-Open-Platypus
layer_range: [8, 32]
merge_method: passthrough
dtype: bfloat16
```
Mistral-11B-CC-Zephyr :
```
slices:
- sources:
- model: "/content/drive/MyDrive/CC-v1.1-7B-bf16"
layer_range: [0, 24]
- sources:
- model: "/content/drive/MyDrive/Zephyr-7B"
layer_range: [8, 32]
merge_method: passthrough
dtype: bfloat16
```
Mistral-11B-OmniMix :
```
slices:
- sources:
- model: Mistral-11B-OpenOrcaPlatypus
layer_range: [0, 48]
- model: Mistral-11B-CC-Zephyr
layer_range: [0, 48]
merge_method: slerp
base_model: Mistral-11B-OpenOrcaPlatypus
parameters:
t:
- filter: lm_head
value: [0.75]
- filter: embed_tokens
value: [0.75]
- filter: self_attn
value: [0.75, 0.25]
- filter: mlp
value: [0.25, 0.75]
- filter: layernorm
value: [0.5, 0.5]
- filter: modelnorm
value: [0.75]
- value: 0.5 # fallback for rest of tensors
dtype: bfloat16
```
I use [mergekit](https://github.com/cg123/mergekit) for all the manipulation told here.
## Some scoring I done myself

hf-causal-experimental (pretrained=/content/drive/MyDrive/Mistral-11B-OmniMix-bf16), limit: None, provide_description: False, num_fewshot: 0, batch_size: 4
| Task |Version| Metric |Value | |Stderr|
|-------------|------:|--------|-----:|---|-----:|
|arc_challenge| 0|acc |0.5580|± |0.0145|
| | |acc_norm|0.5819|± |0.0144|
|arc_easy | 0|acc |0.8300|± |0.0077|
| | |acc_norm|0.8211|± |0.0079|
|hellaswag | 0|acc |0.6372|± |0.0048|
| | |acc_norm|0.8209|± |0.0038|
|piqa | 0|acc |0.8145|± |0.0091|
| | |acc_norm|0.8286|± |0.0088|
|truthfulqa_mc| 1|mc1 |0.3978|± |0.0171|
| | |mc2 |0.5680|± |0.0155|
|winogrande | 0|acc |0.7427|± |0.0123|
## Others
Special thanks to Sushi, [Henky](https://github.com/KoboldAI/KoboldAI-Client) for the machine he give me for big task, and [Charles Goddard](https://github.com/cg123) for his amazing tool.
If you want to support me, you can [here](https://ko-fi.com/undiai).
<!-- original-model-card end -->
|
briaai/BRIA-2.2 | briaai | 2024-03-13T07:03:46Z | 504 | 39 | diffusers | [
"diffusers",
"safetensors",
"text-to-image",
"legal liability",
"commercial use",
"license:other",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
]
| text-to-image | 2024-01-08T12:44:45Z | ---
license: other
license_name: bria-2.2
license_link: https://bria.ai/customer-general-terms-and-conditions
library_name: diffusers
inference:
parameters:
num_inference_steps: 30
tags:
- text-to-image
- legal liability
- commercial use
extra_gated_description: Model weights from BRIA AI can be obtained with the purchase of a commercial license. Fill in the form below and we reach out to you.
extra_gated_heading: "Fill in this form to request a commercial license for the model"
extra_gated_fields:
Name: text
Company/Org name: text
Org Type (Early/Growth Startup, Enterprise, Academy): text
Role: text
Country: text
Email: text
By submitting this form, I agree to BRIA’s Privacy policy and Terms & conditions, see links below: checkbox
---
# BRIA 2.2: Text-to-Image Model for Commercial Licensing
Bria AI 2.2 is our groundbreaking text-to-image model explicitly designed for commercial applications. This model combines technological innovation with ethical responsibility and legal security, setting a new standard in the AI industry. Bria AI licenses the foundation model with full legal liability coverage. Our dataset does not contain copyrighted materials, such as fictional characters, logos, trademarks, public figures, harmful content, or privacy-infringing content.
For more information, please visit our [website](https://bria.ai/).
## A new version is out - check also [BRIA 2.3](https://huggingface.co/spaces/briaai/BRIA-2.3)
# What's New
Bria AI 2.2, our most capable model, is a premium, commercially licensed product that offers enterprises a powerful tool respecting creator rights and legal boundaries.
It presents improved realism and aesthetics.
[CLICK HERE FOR A DEMO](https://huggingface.co/spaces/briaai/BRIA-2.2)
### Get Access
Interested in BRIA 2.2? Purchase is required to license and access BRIA 2.2, ensuring royalty management with our data partners and full liability coverage for commercial use.
Are you a startup or a student? We encourage you to apply for our [Startup Program](https://pages.bria.ai/the-visual-generative-ai-platform-for-builders-startups-plan?_gl=1*cqrl81*_ga*MTIxMDI2NzI5OC4xNjk5NTQ3MDAz*_ga_WRN60H46X4*MTcwOTM5OTMzNC4yNzguMC4xNzA5Mzk5MzM0LjYwLjAuMA..) to request access. This program are designed to support emerging businesses and academic pursuits with our cutting-edge technology.
Contact us today to unlock the potential of BRIA 2.2! By submitting the form above, you agree to BRIA’s [Privacy policy](https://bria.ai/privacy-policy/) and [Terms & conditions](https://bria.ai/terms-and-conditions/).

# Key Features
- **Legally Compliant**: Offers full legal liability coverage for copyright and privacy infringements. Thanks to training on 100% licensed data from leading data partners, we ensure the ethical use of content.
- **Patented Attribution Engine**: Our attribution engine is our way to compensate our data partners, powered by our proprietary and patented algorithms.
- **Enterprise-Ready**: Specifically designed for business applications, Bria AI 2.2 delivers high-quality, compliant imagery for a variety of commercial needs.
- **Customizable Technology**: Provides access to source code and weights for extensive customization, catering to specific business requirements.
### Model Description
- **Developed by:** BRIA AI
- **Model type:** Latent diffusion text-to-image model
- **License:** [Commercial licensing terms & conditions.](https://bria.ai/customer-general-terms-and-conditions)
- Purchase is required to license and access the model.
- **Model Description:** BRIA 2.2 is a text-to-image model trained exclusively on a professional-grade, licensed dataset. It is designed for commercial use and includes full legal liability coverage.
- **Resources for more information:** [BRIA AI](https://bria.ai/)
### Code example using Diffusers
```
pip install diffusers
```
```py
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained("briaai/BRIA-2.2", torch_dtype=torch.float16, use_safetensors=True)
pipe.to("cuda")
prompt = "A portrait of a Beautiful and playful ethereal singer, golden designs, highly detailed, blurry background"
negative_prompt = "Logo,Watermark,Text,Ugly,Morbid,Extra fingers,Poorly drawn hands,Mutation,Blurry,Extra limbs,Gross proportions,Missing arms,Mutated hands,Long neck,Duplicate,Mutilated,Mutilated hands,Poorly drawn face,Deformed,Bad anatomy,Cloned face,Malformed limbs,Missing legs,Too many fingers"
images = pipe(prompt=prompt, negative_prompt=negative_prompt, height=1024, width=1024).images[0]
``` |
Artefact2/Fish-8x7B-GGUF | Artefact2 | 2024-02-09T01:01:58Z | 504 | 8 | null | [
"gguf",
"not-for-all-audiences",
"en",
"license:cc-by-nc-4.0",
"region:us"
]
| null | 2024-02-08T18:23:39Z | ---
license: cc-by-nc-4.0
language:
- en
tags:
- not-for-all-audiences
---
<img src="data:image/jpg;base64,/9j/4AAQSkZJRgABAQEAYABgAAD/6zLqSlAwAAAAAAAAADLganVtYgAAAB5qdW1kYzJwYQARABCAAACqADibcQNjMnBhAAAAMrpqdW1iAAAAR2p1bWRjMm1hABEAEIAAAKoAOJtxA3Vybjp1dWlkOmI5NWU5NWE4LTM5MDQtNDBiZS1hMWZhLTAyMjdiZmFmMjU2NwAAAAQianVtYgAAAClqdW1kYzJhcwARABCAAACqADibcQNjMnBhLmFzc2VydGlvbnMAAAADIGp1bWIAAABBanVtZGNib3IAEQAQgAAAqgA4m3ETYzJwYS5oYXNoLmJveGVzAAAAABhjMnNoKLEwSV8v4AnyIFxkhZX2gQAAAtdjYm9yomNhbGdmc2hhMjU2ZWJveGVzjaNlbmFtZXOBY1NPSWRoYXNoWCBxVjrYAGFAft6cbzFoNihL03EKUgxaeSte2hy3A2kIFWNwYWRAo2VuYW1lc4FkQzJQQWRoYXNoQQBjcGFkQKNlbmFtZXOBZEFQUDBkaGFzaFggpbugkv/qGbiwV/poyU2sCfAca0V95uZnpd4l6rlbtBpjcGFkQKNlbmFtZXOBZEFQUDFkaGFzaFggow7IX4ji/mamhqg8tPHBxtfwMx9F36Y1MdJKk/zMChNjcGFkQKNlbmFtZXOBY0RRVGRoYXNoWCCz6roXFIfVkeIcYArL/vOFvekosqTDT8EkyxRHkqwE22NwYWRAo2VuYW1lc4FjRFFUZGhhc2hYIAriPEsLiEpOgbUZmp9jrt497yq0OR7gZ2AX0+76cthNY3BhZECjZW5hbWVzgWRTT0YwZGhhc2hYIEOZIfOKtsMxQseaNacrnLcTTB8dbyaLAxbzRV5+xedVY3BhZECjZW5hbWVzgWNESFRkaGFzaFggi33gSmKpOgwEasSxD71IHV762BXSHCZWJT7LoAa233BjcGFkQKNlbmFtZXOBY0RIVGRoYXNoWCAqabdjzjoE8U/M1CiRaSX4mnCr/X6/ak691R9jR4ft42NwYWRAo2VuYW1lc4FjREhUZGhhc2hYIPNXdg8p1I1tkgB5cC7JtIgNxzQTJvEup/Xr9nXv0aHsY3BhZECjZW5hbWVzgWNESFRkaGFzaFggYn9oeDtfUFm8zmTdUOIdC564oIMFHxBdaoCnYM0qVk5jcGFkQKNlbmFtZXOBY1NPU2RoYXNoWCAXkRMmLxrYvN72JWzsXSxSv9k1fn1wmYdPXtSZa7Q1u2NwYWRAo2VuYW1lc4FjRU9JZGhhc2hYIM3mbnjlQZ3qdN989D2aqHa4xmnUAGeZLnGc75CsXz/gY3BhZEAAAADRanVtYgAAAD5qdW1kY2JvcgARABCAAACqADibcRNjMnBhLmFjdGlvbnMAAAAAGGMyc2gosTBJXy/gCfIgXGSFlfaBAAAAi2Nib3KhZ2FjdGlvbnOBpGtkZXNjcmlwdGlvbnJBSSBHZW5lcmF0ZWQgSW1hZ2VmYWN0aW9ubGMycGEuY3JlYXRlZG1zb2Z0d2FyZUFnZW50eBtJbWFnZSBDcmVhdG9yIGZyb20gRGVzaWduZXJkd2hlbnQyMDI0LTAyLTA4VDA4OjE0OjMyWgAAAnJqdW1iAAAAJGp1bWRjMmNsABEAEIAAAKoAOJtxA2MycGEuY2xhaW0AAAACRmNib3KnY2FsZ2ZzaGEyNTZpZGM6Zm9ybWF0amltYWdlL2pwZWdpc2lnbmF0dXJleExzZWxmI2p1bWJmPWMycGEvdXJuOnV1aWQ6Yjk1ZTk1YTgtMzkwNC00MGJlLWExZmEtMDIyN2JmYWYyNTY3L2MycGEuc2lnbmF0dXJlamluc3RhbmNlSURjMS4wb2NsYWltX2dlbmVyYXRvcngcTWljcm9zb2Z0X1Jlc3BvbnNpYmxlX0FJLzEuMHRjbGFpbV9nZW5lcmF0b3JfaW5mb4GiZG5hbWV4KU1pY3Jvc29mdCBSZXNwb25zaWJsZSBBSSBJbWFnZSBQcm92ZW5hbmNlZ3ZlcnNpb25jMS4wamFzc2VydGlvbnOCo2NhbGdmc2hhMjU2Y3VybHhdc2VsZiNqdW1iZj1jMnBhL3Vybjp1dWlkOmI5NWU5NWE4LTM5MDQtNDBiZS1hMWZhLTAyMjdiZmFmMjU2Ny9jMnBhLmFzc2VydGlvbnMvYzJwYS5oYXNoLmJveGVzZGhhc2hYIL09f8NxAMKjRnFb5mueViPD2DHpJo7kNW97D8OtpO4lo2NhbGdmc2hhMjU2Y3VybHhac2VsZiNqdW1iZj1jMnBhL3Vybjp1dWlkOmI5NWU5NWE4LTM5MDQtNDBiZS1hMWZhLTAyMjdiZmFmMjU2Ny9jMnBhLmFzc2VydGlvbnMvYzJwYS5hY3Rpb25zZGhhc2hYIH2f3m5nJE+74zAePnjKB4CcYrGk61TKEyO4iyg+X1xRAAAr12p1bWIAAAAoanVtZGMyY3MAEQAQgAAAqgA4m3EDYzJwYS5zaWduYXR1cmUAAAArp2Nib3LShEShATgkomd4NWNoYWlug1kGKTCCBiUwggQNoAMCAQICEzMAAAAaw97CUKNYKBAAAAAAABowDQYJKoZIhvcNAQEMBQAwVjELMAkGA1UEBhMCVVMxHjAcBgNVBAoTFU1pY3Jvc29mdCBDb3Jwb3JhdGlvbjEnMCUGA1UEAxMeTWljcm9zb2Z0IFNDRCBDbGFpbWFudHMgUlNBIENBMB4XDTIzMDgwMzE4MTUzNVoXDTI0MDMzMTE4MTUzNVowdDELMAkGA1UEBhMCVVMxEzARBgNVBAgTCldhc2hpbmd0b24xEDAOBgNVBAcTB1JlZG1vbmQxHjAcBgNVBAoTFU1pY3Jvc29mdCBDb3Jwb3JhdGlvbjEeMBwGA1UEAxMVTWljcm9zb2Z0IENvcnBvcmF0aW9uMIIBojANBgkqhkiG9w0BAQEFAAOCAY8AMIIBigKCAYEAhx0Xi7XUYeyCzx60eBBWBhULK6pknzhPA91nLOZ1/GjHUN+4urt+GT47vXNbxAhOBtKt/I4dNkrC8PHIvnRxWuiVS95KAzVxW8Eoa2R/aQqwHCIDT7cRVG4lelfwuBcP556ytmc3N4GZ1oytR7a4VesIGricmIKa75A1E7657GDIuLib2D9Mplj2wgYIvWhmlJ3AB2LuKpjCFJsa3es6CeQhegEgGcZSZOKmYMbnh7ZxgjCjuLxx/nCyjjpWXdS5j9yDFm6aep1eYCIUaoB24DsqTXbpJUho7h6NLMSvpny8Zwou+IGDp4zcuAmnOFSbFmRj5ZHEFh4Ad6qM9nwZER430VtD9mZkYCoEYEpbawhDXiDcaaa1VhY9DPmZGnGu22AVxZQ3DgZQagp2lqe0nv/mDszpdtbvJ49B9GKD30CinK9WJnSKxi9wQwMMjxr6nYRKWArHudzvptaagAR+qQ4UcMbEo3+FmI9im8Sbi7bdha77OPG4yRSJe8rLIv9zAgMBAAGjggFMMIIBSDAZBgNVHSUBAf8EDzANBgsrBgEEAYI3TDsBCTAOBgNVHQ8BAf8EBAMCAMAwHQYDVR0OBBYEFO+OY+GF1Ob/ECtYIpG37FLbs7MfMB8GA1UdIwQYMBaAFIutmvyPdc3ODY1prXxMpGBW2bREMF8GA1UdHwRYMFYwVKBSoFCGTmh0dHA6Ly93d3cubWljcm9zb2Z0LmNvbS9wa2lvcHMvY3JsL01pY3Jvc29mdCUyMFNDRCUyMENsYWltYW50cyUyMFJTQSUyMENBLmNybDBsBggrBgEFBQcBAQRgMF4wXAYIKwYBBQUHMAKGUGh0dHA6Ly93d3cubWljcm9zb2Z0LmNvbS9wa2lvcHMvY2VydHMvTWljcm9zb2Z0JTIwU0NEJTIwQ2xhaW1hbnRzJTIwUlNBJTIwQ0EuY3J0MAwGA1UdEwEB/wQCMAAwDQYJKoZIhvcNAQEMBQADggIBANTqew+p+AT2aoc5q/OvQmtFhFPDvuq/dwAiE3hr/fCr4R+HKLnHi0YWhuHIYwe4VoeVnfArs2zPY6rGy5xzt/WV4A7brdV2rjEJFy8Cym1Ou8lalKvelcC4RqBbcn5k75NKtqsRBz+AaEWkKANSPXjfB4C5V5PCLWpAmBjWiZWSG8Q2//mqCOLVnlRynYrh7n5lpN7qOLstO10VddcHgBwLklAkU3xvHSGyioid6mCZxJ+1xJjtmN3m3Kvd074edvPOhs65zmgRZEqfjf8l8RrwSzpZWm4SRqcPjdh5zz06GpKuHb/6CvaiXg+ggV8iA4/dAoxdTyUXgN3xWfJkOuUR95OiQFjveIvLzFbNShdB1XI2L39p1XZXy0d+KP3mcBHCQInxrbPI8BYYU2EOwf7uoAZz3CFE8hHVoaB0wJEYe/MV4bMLXZf6YWIOT/44CabfWyvEBkPKfkTs4XXLPKXAonRjgOnTL+6E42w/XqeOWnVLEmKAe5Qw4VvBIMZfJKiTA4ddOIfdzCOaOQziIzV1zZfnGXZKd2Wtp60xKpwhpRn4QA09p1ay05urDGZn06bnJnfxAC+wFMJmnFctVQRJ9Lf/L50sg/zgbtOAfS/PMPkiOTGVs6lCXGKFwGBLpPqmaLVkgebCnIUUKjWBqnae1G2JLCms6PI5ik1Cz/JtWQbWMIIG0jCCBLqgAwIBAgITMwAAAATR1uF6CiJiDwAAAAAABDANBgkqhkiG9w0BAQwFADBfMQswCQYDVQQGEwJVUzEeMBwGA1UEChMVTWljcm9zb2Z0IENvcnBvcmF0aW9uMTAwLgYDVQQDEydNaWNyb3NvZnQgU3VwcGx5IENoYWluIFJTQSBSb290IENBIDIwMjIwHhcNMjIwMjE3MDA0NTI2WhcNNDIwMjE3MDA1NTI2WjBWMQswCQYDVQQGEwJVUzEeMBwGA1UEChMVTWljcm9zb2Z0IENvcnBvcmF0aW9uMScwJQYDVQQDEx5NaWNyb3NvZnQgU0NEIENsYWltYW50cyBSU0EgQ0EwggIiMA0GCSqGSIb3DQEBAQUAA4ICDwAwggIKAoICAQDXJeLb8443bNoExaat+SmT0DUBXhFfqUaWfR6k7SCD6AEWd5EAq0w3Ue+rrNM0kanwhMIOjG41cUIdInoLdbgaHVBeBccEvAJNgir6KJpZo/H8VqNbFi+cQ9h4JLGZHNGFAKZ/rGaQ4kSzZ+zecVwYl9Z0w+ipTO/B412lryhgfZhaJdbifP89TEAaEqE1LDUVMPlISMjvDPoHyA6i/CMw0L+QB0u+ziGT5H7dhbBUXWf7vN369iZS0+Dxt7FfXowzHmnNG5ll9wZinCP6EUyVDdBX3iZMHYCa66kKQMICuyplN2jmRfjy0kV3nGVJC/sUvV262AdgZ1t914LzPeAsrCQRQid5M2aIc6wv/fX24tjor+OVpHxrqraMglsxWXQPuOui1x8HmMaeMLB/TOaHVc4iMrVLikoE9wcYGb0V9mnCpBFaD0S9/pzo6sx9xpl3g1O1L0WU0kIx/SxdnMQ9epxGDtJcjxCgZHHM56MdlmclOybk2DQO4cOO8lp0Dj+FfK2eZ7Bd+t/ZXC0C1RgIGKK3kWotVyv0nUtDPXOu0vwTcd/ckeOtRuBjgLHXPjJM/7rTXF2BN7HnwOtPIG5yniRaxfOUvrtmOfhOO61cWvylcMLNaYnHzwTsbtL2sFxIOV0gSWGJAlbmv2FQSgWXK1cWohnLQiktiGWBNVX1aQIDAQABo4IBjjCCAYowDgYDVR0PAQH/BAQDAgGGMBAGCSsGAQQBgjcVAQQDAgEAMB0GA1UdDgQWBBSLrZr8j3XNzg2Naa18TKRgVtm0RDARBgNVHSAECjAIMAYGBFUdIAAwGQYJKwYBBAGCNxQCBAweCgBTAHUAYgBDAEEwDwYDVR0TAQH/BAUwAwEB/zAfBgNVHSMEGDAWgBQLs2g7r9qv7nCldtkh98xEFgfQ+DBsBgNVHR8EZTBjMGGgX6BdhltodHRwOi8vd3d3Lm1pY3Jvc29mdC5jb20vcGtpb3BzL2NybC9NaWNyb3NvZnQlMjBTdXBwbHklMjBDaGFpbiUyMFJTQSUyMFJvb3QlMjBDQSUyMDIwMjIuY3JsMHkGCCsGAQUFBwEBBG0wazBpBggrBgEFBQcwAoZdaHR0cDovL3d3dy5taWNyb3NvZnQuY29tL3BraW9wcy9jZXJ0cy9NaWNyb3NvZnQlMjBTdXBwbHklMjBDaGFpbiUyMFJTQSUyMFJvb3QlMjBDQSUyMDIwMjIuY3J0MA0GCSqGSIb3DQEBDAUAA4ICAQBpxEcsFAQ9oJ+nX90jxdm0zaRrpzJVb7sSue3McYCfUjf3mnVTtU/AsWpQAWg6C/z65YH0AEeBV8qlDb+QoGDWjAc5Q9JKHzoIdJxJA07Q0GwJHAA8mPCkG9OJDMATcdXHe5Rr3gyWFWADZfcBEPdExeaQrAlXycwDlRtYpI86tjoqzb/9OKs4hl8FfK8kjm+9XeWCdiwlmPBMl6GdH/otPRkHzxtWuFv2ZPfVsIzsA04/QwhmUmY8OrCeKMTD4rY4aOrmgjR7MghQRfDoDNAueUDs5yYVdfkb5z6u3kpXPP5H/AsGrY5U3hvjmTQjGKvqc9vaSTsb9tHXk5g+6EQRK+OC8UE5K/lE+bhBiExQTCfwJeWgahGxTeXy807rrE3KZUg4j80lnaMt0DNbMSxhlPF9zLzMK8edCPctFwKvfWMOoE9mTf9giYJ3V2g45mQKOZfk93VcUkcNazLd+iiUzFlYTB8NLmu4Sc1Lqgr507Wtip3UEANCuVZCt/KyK3xupM40vubUyWHk3QxwPwaXy5/3kGxDtKzy7hVTCc5ILiHBnNQyvjiNYU8zOt2Fs/JkIMpPy7sqAvurpoGsSxv/0od0ns4p3Zg2ZIskuaI66ccB/6qLeAp1AAwTbV7lOgtiqhl9vKS9CyFLH4Sd44M+ZiGKGlunx26nOprkYnZSxVkFszCCBa8wggOXoAMCAQICEGgo1Ux+XNq9QzmuDMFaKjUwDQYJKoZIhvcNAQEMBQAwXzELMAkGA1UEBhMCVVMxHjAcBgNVBAoTFU1pY3Jvc29mdCBDb3Jwb3JhdGlvbjEwMC4GA1UEAxMnTWljcm9zb2Z0IFN1cHBseSBDaGFpbiBSU0EgUm9vdCBDQSAyMDIyMB4XDTIyMDIxNzAwMTIzNloXDTQ3MDIxNzAwMjEwOVowXzELMAkGA1UEBhMCVVMxHjAcBgNVBAoTFU1pY3Jvc29mdCBDb3Jwb3JhdGlvbjEwMC4GA1UEAxMnTWljcm9zb2Z0IFN1cHBseSBDaGFpbiBSU0EgUm9vdCBDQSAyMDIyMIICIjANBgkqhkiG9w0BAQEFAAOCAg8AMIICCgKCAgEAniUBZhkfZDTBnTkjYh1xi1bqJdKbH+8nAYK/d9iUM4MYSJtQnnuWZMLQw19F/zKc6BcXvXjtdZhfOgYIKxw3m0ZKkAqwr0aSPjOJKvq45zJj8yPHbtIU+yZY7v4GhFT6wR83qtvU7FYqv0m9zOsC7cZO/KwZtRI1aRWJF02jaOpsHimaCfPOeiHGCdEZ6o8wRmk7aAQrfIot1mNd6m3WOZ69Bj5b7i8RWyhrp1KkaF5MpOquziO/TDZx2oFFUI7Khs7/U8O4Q7Mk7gd6orT6xwode8ZSNTHsCB+EgJJb+LHaOdbJ5+WJBH5Rf/TmamRHSer47Kb2oENT/trDIyTYJdoTLCq3P5TedxxMeBxq+ZqP62oVd3etSYTOEEDHmUgP1ZYegJxzoTihA2/TTSDQtUPk9y54D073vL9l2m2QC1u/3uonJ5lk+Dl8cz3WIdLu1vNTES5Vw9zq8SlX3lGheHOQCy/1yXU2643SbY55XboaOP/fGQGo0sjR1vLrivUu0cyTE5uckHhlY3kExPGen4w682QM/pgdk+KPVqVjUyO4bnMWRRq293sPzaQy/1r+lo3hh3jbcIOoJIVpIMJtEg3lefYqWc/Wq+eB5qCxiC0IjAuxz9dsNq+e+QNn2UFzqatFuHFgWBjUFixlutEF3pLFUBARkM5HzPuvvyPAnwUCAwEAAaNnMGUwDgYDVR0PAQH/BAQDAgGGMA8GA1UdEwEB/wQFMAMBAf8wHQYDVR0OBBYEFAuzaDuv2q/ucKV22SH3zEQWB9D4MBAGCSsGAQQBgjcVAQQDAgEAMBEGA1UdIAQKMAgwBgYEVR0gADANBgkqhkiG9w0BAQwFAAOCAgEASMc3///BaFfXi0NmRjomay/o+t5ooY9H8T00lXraVTH0ldI4Xyy6j6WNUTFqiVVobCtCZGqFJKBRA8fd0XJY7WwejNiRxedJEZ0ZejdYHndE+8IImELETeObig7PQEVPG4BwWYyTgegP1cgmlan3H3cGuMrvnPvoZtrlOeDS0mLDp9S2GJonmyZQSnKX1bNbKqT9Xy9+5mKjJ2YM+tkZzBEdMagBUgjmVAyZYyvq2ITUtAgW775KW4hY9AYWoOt6XeHHRNa7L1VWJfCeDOQPEtvAf69WXcaJDnGpVhLkuZyoZB61R5WSrtBwyJN9fFpY8QXxSrhschiprh9XmSZ0ZvUdD99d8Oc3W1+68LTv5GMHfh8yGGmpcFqS+XmcWNR+v3JdU0YrbqOZYNaFjGZ3Fnav4sUYW+JdCDbWZjcXZfAuz6HlvOaNDWW0VlNdn8ivTm5Rz4i+kuow+yzndT9CYMRx55efc8efytG4bCPqUCgdDkPM9akbQOummOXlD8WSL6WWx9f6PBjuHRthA/2G5yRBM73Y87ZgfPMcggPVYK/f9CCk5IEGIlrMhTN9ZPjkuL+AF9T7IT9jruePtxdE7HIuNckL0IEd6XIDCUHZ3wlI5s23shxgJRlS8z0SSe2dlCKOcSj4wQdUc904CLSFjxRsqgCvQKu1h862OVxz+ZBmc2lnVHN0oWl0c3RUb2tlbnOBoWN2YWxZFzQwghcwMAMCAQAwghcnBgkqhkiG9w0BBwKgghcYMIIXFAIBAzEPMA0GCWCGSAFlAwQCAQUAMHcGCyqGSIb3DQEJEAEEoGgEZjBkAgEBBglghkgBhv1sBwEwMTANBglghkgBZQMEAgEFAAQgtbgZ8oIWmS5XENkuY1VBNvFYGj1GMTUpNuIyT0vMtCACECZn80XjVP6AQSxxVKEpiNkYDzIwMjQwMjA4MDgxNDMxWqCCEwkwggbCMIIEqqADAgECAhAFRK/zlJ0IOaa/2z9f5WEWMA0GCSqGSIb3DQEBCwUAMGMxCzAJBgNVBAYTAlVTMRcwFQYDVQQKEw5EaWdpQ2VydCwgSW5jLjE7MDkGA1UEAxMyRGlnaUNlcnQgVHJ1c3RlZCBHNCBSU0E0MDk2IFNIQTI1NiBUaW1lU3RhbXBpbmcgQ0EwHhcNMjMwNzE0MDAwMDAwWhcNMzQxMDEzMjM1OTU5WjBIMQswCQYDVQQGEwJVUzEXMBUGA1UEChMORGlnaUNlcnQsIEluYy4xIDAeBgNVBAMTF0RpZ2lDZXJ0IFRpbWVzdGFtcCAyMDIzMIICIjANBgkqhkiG9w0BAQEFAAOCAg8AMIICCgKCAgEAo1NFhx2DjlusPlSzI+DPn9fl0uddoQ4J3C9Io5d6OyqcZ9xiFVjBqZMRp82qsmrdECmKHmJjadNYnDVxvzqX65RQjxwg6seaOy+WZuNp52n+W8PWKyAcwZeUtKVQgfLPywemMGjKg0La/H8JJJSkghraarrYO8pd3hkYhftF6g1hbJ3+cV7EBpo88MUueQ8bZlLjyNY+X9pD04T10Mf2SC1eRXWWdf7dEKEbg8G45lKVtUfXeCk5a+B4WZfjRCtK1ZXO7wgX6oJkTf8j48qG7rSkIWRw69XloNpjsy7pBe6q9iT1HbybHLK3X9/w7nZ9MZllR1WdSiQvrCuXvp/k/XtzPjLuUjT71Lvr1KAsNJvj3m5kGQc3AZEPHLVRzapMZoOIaGK7vEEbeBlt5NkP4FhB+9ixLOFRr7StFQYU6mIIE9NpHnxkTZ0P387RXoyqq1AVybPKvNfEO2hEo6U7Qv1zfe7dCv95NBB+plwKWEwAPoVpdceDZNZ1zY8SdlalJPrXxGshuugfNJgvOuprAbD3+yqG7HtSOKmYCaFxsmxxrz64b5bV4RAT/mFHCoz+8LbH1cfebCTwv0KCyqBxPZySkwS0aXAnDU+3tTbRyV8IpHCj7ArxES5k4MsiK8rxKBMhSVF+BmbTO77665E42FEHypS34lCh8zrTioPLQHsCAwEAAaOCAYswggGHMA4GA1UdDwEB/wQEAwIHgDAMBgNVHRMBAf8EAjAAMBYGA1UdJQEB/wQMMAoGCCsGAQUFBwMIMCAGA1UdIAQZMBcwCAYGZ4EMAQQCMAsGCWCGSAGG/WwHATAfBgNVHSMEGDAWgBS6FtltTYUvcyl2mi91jGogj57IbzAdBgNVHQ4EFgQUpbbvE+fvzdBkodVWqWUxo97V40kwWgYDVR0fBFMwUTBPoE2gS4ZJaHR0cDovL2NybDMuZGlnaWNlcnQuY29tL0RpZ2lDZXJ0VHJ1c3RlZEc0UlNBNDA5NlNIQTI1NlRpbWVTdGFtcGluZ0NBLmNybDCBkAYIKwYBBQUHAQEEgYMwgYAwJAYIKwYBBQUHMAGGGGh0dHA6Ly9vY3NwLmRpZ2ljZXJ0LmNvbTBYBggrBgEFBQcwAoZMaHR0cDovL2NhY2VydHMuZGlnaWNlcnQuY29tL0RpZ2lDZXJ0VHJ1c3RlZEc0UlNBNDA5NlNIQTI1NlRpbWVTdGFtcGluZ0NBLmNydDANBgkqhkiG9w0BAQsFAAOCAgEAgRrW3qCptZgXvHCNT4o8aJzYJf/LLOTN6l0ikuyMIgKpuM+AqNnn48XtJoKKcS8Y3U623mzX4WCcK+3tPUiOuGu6fF29wmE3aEl3o+uQqhLXJ4Xzjh6S2sJAOJ9dyKAuJXglnSoFeoQpmLZXeY/bJlYrsPOnvTcM2Jh2T1a5UsK2nTipgedtQVyMadG5K8TGe8+c+njikxp2oml101DkRBK+IA2eqUTQ+OVJdwhaIcW0z5iVGlS6ubzBaRm6zxbygzc0brBBJt3eWpdPM43UjXd9dUWhpVgmagNF3tlQtVCMr1a9TMXhRsUo063nQwBw3syYnhmJA+rUkTfvTVLzyWAhxFZH7doRS4wyw4jmWOK22z75X7BC1o/jF5HRqsBV44a/rCcsQdCaM0qoNtS5cpZ+l3k4SF/Kwtw9Mt911jZnWon49qfH5U81PAC9vpwqbHkB3NpE5jreODsHXjlY9HxzMVWggBHLFAx+rrz+pOt5Zapo1iLKO+uagjVXKBbLafIymrLS2Dq4sUaGa7oX/cR3bBVsrquvczroSUa31X/MtjjA2Owc9bahuEMs305MfR5ocMB3CtQC4Fxguyj/OOVSWtasFyIjTvTs0xf7UGv/B3cfcZdEQcm4RtNsMnxYL2dHZeUbc7aZ+WssBkbvQR7w8F/g29mtkIBEr4AQQYowggauMIIElqADAgECAhAHNje3JFR82Ees/ShmKl5bMA0GCSqGSIb3DQEBCwUAMGIxCzAJBgNVBAYTAlVTMRUwEwYDVQQKEwxEaWdpQ2VydCBJbmMxGTAXBgNVBAsTEHd3dy5kaWdpY2VydC5jb20xITAfBgNVBAMTGERpZ2lDZXJ0IFRydXN0ZWQgUm9vdCBHNDAeFw0yMjAzMjMwMDAwMDBaFw0zNzAzMjIyMzU5NTlaMGMxCzAJBgNVBAYTAlVTMRcwFQYDVQQKEw5EaWdpQ2VydCwgSW5jLjE7MDkGA1UEAxMyRGlnaUNlcnQgVHJ1c3RlZCBHNCBSU0E0MDk2IFNIQTI1NiBUaW1lU3RhbXBpbmcgQ0EwggIiMA0GCSqGSIb3DQEBAQUAA4ICDwAwggIKAoICAQDGhjUGSbPBPXJJUVXHJQPE8pE3qZdRodbSg9GeTKJtoLDMg/la9hGhRBVCX6SI82j6ffOciQt/nR+eDzMfUBMLJnOWbfhXqAJ9/UO0hNoR8XOxs+4rgISKIhjf69o9xBd/qxkrPkLcZ47qUT3w1lbU5ygt69OxtXXnHwZljZQp09nsad/ZkIdGAHvbREGJ3HxqV3rwN3mfXazL6IRktFLydkf3YYMZ3V+0VAshaG43IbtArF+y3kp9zvU5EmfvDqVjbOSmxR3NNg1c1eYbqMFkdECnwHLFuk4fsbVYTXn+149zk6wsOeKlSNbwsDETqVcplicu9Yemj052FVUmcJgmf6AaRyBD40NjgHt1biclkJg6OBGz9vae5jtb7IHeIhTZgirHkr+g3uM+onP65x9abJTyUpURK1h0QCirc0PO30qhHGs4xSnzyqqWc0Jon7ZGs506o9UD4L/wojzKQtwYSH8UNM/STKvvmz3+DrhkKvp1KCRB7UK/BZxmSVJQ9FHzNklNiyDSLFc1eSuo80VgvCONWPfcYd6T/jnA+bIwpUzX6ZhKWD7TA4j+s4/TXkt2ElGTyYwMO1uKIqjBJgj5FBASA31fI7tk42PgpuE+9sJ0sj8eCXbsq11GdeJgo1gJASgADoRU7s7pXcheMBK9Rp6103a50g5rmQzSM7TNsQIDAQABo4IBXTCCAVkwEgYDVR0TAQH/BAgwBgEB/wIBADAdBgNVHQ4EFgQUuhbZbU2FL3MpdpovdYxqII+eyG8wHwYDVR0jBBgwFoAU7NfjgtJxXWRM3y5nP+e6mK4cD08wDgYDVR0PAQH/BAQDAgGGMBMGA1UdJQQMMAoGCCsGAQUFBwMIMHcGCCsGAQUFBwEBBGswaTAkBggrBgEFBQcwAYYYaHR0cDovL29jc3AuZGlnaWNlcnQuY29tMEEGCCsGAQUFBzAChjVodHRwOi8vY2FjZXJ0cy5kaWdpY2VydC5jb20vRGlnaUNlcnRUcnVzdGVkUm9vdEc0LmNydDBDBgNVHR8EPDA6MDigNqA0hjJodHRwOi8vY3JsMy5kaWdpY2VydC5jb20vRGlnaUNlcnRUcnVzdGVkUm9vdEc0LmNybDAgBgNVHSAEGTAXMAgGBmeBDAEEAjALBglghkgBhv1sBwEwDQYJKoZIhvcNAQELBQADggIBAH1ZjsCTtm+YqUQiAX5m1tghQuGwGC4QTRPPMFPOvxj7x1Bd4ksp+3CKDaopafxpwc8dB+k+YMjYC+VcW9dth/qEICU0MWfNthKWb8RQTGIdDAiCqBa9qVbPFXONASIlzpVpP0d3+3J0FNf/q0+KLHqrhc1DX+1gtqpPkWaeLJ7giqzl/Yy8ZCaHbJK9nXzQcAp876i8dU+6WvepELJd6f8oVInw1YpxdmXazPByoyP6wCeCRK6ZJxurJB4mwbfeKuv2nrF5mYGjVoarCkXJ38SNoOeY+/umnXKvxMfBwWpx2cYTgAnEtp/Nh4cku0+jSbl3ZpHxcpzpSwJSpzd+k1OsOx0ISQ+UzTl63f8lY5knLD0/a6fxZsNBzU+2QJshIUDQtxMkzdwdeDrknq3lNHGS1yZr5Dhzq6YBT70/O3itTK37xJV77QpfMzmHQXh6OOmc4d0j/R0o08f56PGYX/sr2H7yRp11LB4nLCbbbxV7HhmLNriT1ObyF5lZynDwN7+YAN8gFk8n+2BnFqFmut1VwDophrCYoCvtlUG3OtUVmDG0YgkPCr2B2RP+v6TR81fZvAT6gt4y3wSJ8ADNXcL50CN/AAvkdgIm2fBldkKmKYcJRyvmfxqkhQ/8mJb2VVQrH4D6wPIOK+XW+6kvRBVK5xMOHds3OBqhK/bt1nz8MIIFjTCCBHWgAwIBAgIQDpsYjvnQLefv21DiCEAYWjANBgkqhkiG9w0BAQwFADBlMQswCQYDVQQGEwJVUzEVMBMGA1UEChMMRGlnaUNlcnQgSW5jMRkwFwYDVQQLExB3d3cuZGlnaWNlcnQuY29tMSQwIgYDVQQDExtEaWdpQ2VydCBBc3N1cmVkIElEIFJvb3QgQ0EwHhcNMjIwODAxMDAwMDAwWhcNMzExMTA5MjM1OTU5WjBiMQswCQYDVQQGEwJVUzEVMBMGA1UEChMMRGlnaUNlcnQgSW5jMRkwFwYDVQQLExB3d3cuZGlnaWNlcnQuY29tMSEwHwYDVQQDExhEaWdpQ2VydCBUcnVzdGVkIFJvb3QgRzQwggIiMA0GCSqGSIb3DQEBAQUAA4ICDwAwggIKAoICAQC/5pBzaN675F1KPDAiMGkz7MKnJS7JIT3yithZwuEppz1Yq3aaza57G4QNxDAf8xukOBbrVsaXbR2rsnnyyhHS5F/WBTxSD1Ifxp4VpX6+n6lXFllVcq9ok3DCsrp1mWpzMpTREEQQLt+C8weE5nQ7bXHiLQwb7iDVySAdYyktzuxeTsiT+CFhmzTrBcZe7FsavOvJz82sNEBfsXpm7nfISKhmV1efVFiODCu3T6cw2Vbuyntd463JT17lNecxy9qTXtyOj4DatpGYQJB5w3jHtrHEtWoYOAMQjdjUN6QuBX2I9YI+EJFwq1WCQTLX2wRzKm6RAXwhTNS8rhsDdV14Ztk6MUSaM0C/CNdaSaTC5qmgZ92kJ7yhTzm1EVgX9yRcRo9k98FpiHaYdj1ZXUJ2h4mXaXpI8OCiEhtmmnTK3kse5w5jrubU75KSOp493ADkRSWJtppEGSt+wJS00mFt6zPZxd9LBADMfRyVw4/3IbKyEbe7f/LVjHAsQWCqsWMYRJUadmJ+9oCw++hkpjPRiQfhvbfmQ6QYuKZ3AeEPlAwhHbJUKSWJbOUOUlFHdL4mrLZBdd56rF+NP8m800ERElvlEFDrMcXKchYiCd98THU/Y+whX8QgUWtvsauGi0/C1kVfnSD8oR7FwI+isX4KJpn15GkvmB0t9dmpsh3lGwIDAQABo4IBOjCCATYwDwYDVR0TAQH/BAUwAwEB/zAdBgNVHQ4EFgQU7NfjgtJxXWRM3y5nP+e6mK4cD08wHwYDVR0jBBgwFoAUReuir/SSy4IxLVGLp6chnfNtyA8wDgYDVR0PAQH/BAQDAgGGMHkGCCsGAQUFBwEBBG0wazAkBggrBgEFBQcwAYYYaHR0cDovL29jc3AuZGlnaWNlcnQuY29tMEMGCCsGAQUFBzAChjdodHRwOi8vY2FjZXJ0cy5kaWdpY2VydC5jb20vRGlnaUNlcnRBc3N1cmVkSURSb290Q0EuY3J0MEUGA1UdHwQ+MDwwOqA4oDaGNGh0dHA6Ly9jcmwzLmRpZ2ljZXJ0LmNvbS9EaWdpQ2VydEFzc3VyZWRJRFJvb3RDQS5jcmwwEQYDVR0gBAowCDAGBgRVHSAAMA0GCSqGSIb3DQEBDAUAA4IBAQBwoL9DXFXnOF+go3QbPbYW1/e/Vwe9mqyhhyzshV6pGrsi+IcaaVQi7aSId229GhT0E0p6Ly23OO/0/4C5+KH38nLeJLxSA8hO0Cre+i1Wz/n096wwepqLsl7Uz9FDRJtDIeuWcqFItJnLnU+nBgMTdydE1Od/6Fmo8L8vC6bp8jQ87PcDx4eo0kxAGTVGamlUsLihVo7spNU96LHc/RzY9HdaXFSMb++hUD38dglohJ9vytsgjTVgHAIDyyCwrFigDkBjxZgiwbJZ9VVrzyerbHbObyMt9H5xaiNrIv8SuFQtJ37YOtnwtoeW/VvRXKwYw02fc7cBqZ9Xql4o4rmUMYIDdjCCA3ICAQEwdzBjMQswCQYDVQQGEwJVUzEXMBUGA1UEChMORGlnaUNlcnQsIEluYy4xOzA5BgNVBAMTMkRpZ2lDZXJ0IFRydXN0ZWQgRzQgUlNBNDA5NiBTSEEyNTYgVGltZVN0YW1waW5nIENBAhAFRK/zlJ0IOaa/2z9f5WEWMA0GCWCGSAFlAwQCAQUAoIHRMBoGCSqGSIb3DQEJAzENBgsqhkiG9w0BCRABBDAcBgkqhkiG9w0BCQUxDxcNMjQwMjA4MDgxNDMxWjArBgsqhkiG9w0BCRACDDEcMBowGDAWBBRm8CsywsLJD4JdzqqKycZPGZzPQDAvBgkqhkiG9w0BCQQxIgQgtjbcUw8JQ+4BJRYa3i6d02c3ponVYOJR1O+/tvEoOcIwNwYLKoZIhvcNAQkQAi8xKDAmMCQwIgQg0vbkbe10IszR1EBXaEE2b4KK2lWarjMWr00amtQMeCgwDQYJKoZIhvcNAQEBBQAEggIASj+0yT/ruWTV+BtWc7aN6dgh5DBlH8jj8pAijzf8u23eMA8nWRDXHCHEa+VMg9yq+mBSeO8dGY9y7T4CJc3C3BLG9FPrMv0a9h8QAoFBqtGak5HrkZ85VTUUbmDpjWdVBtuiY5Y6Rj979Gm0jJGr7HNtFL/kXBy1C0kmP1iKMsymeF/+0oZw1Cgj3wY+JBqdTiDj8sCyDe2bPLCUl9LOMoVOPzRWjVK8jiZGKty5RbnirqLzXtfu9dk82EkFZyvTVOXg3lJ8kyqBfpgmB7m8TM/RemZ4cHwpaiKP6pB3FjQvzC1DPsiD1N+ngD+Zw2PCRWPTaIJ9VLZkFQA/CepE6WV9qiz7lhzfXK+bG/HC737MZrwDvK2wSF6m0Cb+dRDfBVfleX0FCRKcEa8s/qqstFDCG/gm7Mzrsdns4Mw/0SKVqN1BvX9JJlOqhlzlNahdg9heLB8U4uxnvbasHNcVauiLqAU3GG9l/NkZyWXd14qaYpvNLMpg/6KIs6MxSTttNg1EMgA7ir9cv1zsdA2gyJAlf0SIMjESFEA3/di4RJ512rzQ4sCeEiu0mDW1zUgU7WSjki4QvkWpNnnYASQ6SShPr2n6azwe3rtWE12pTFyY84t+6/0aeIjjTc+0xDos491Kx8R8WqZG/Emc74+QN7s+hRmEXD9txmXz2GQbqDr2WQGAUq8+ncyKpuNTAm/GKfZBOpMH8QVsBUuEstuKIB+vUps3glqhtZ99pu3/Pxq78wHQ6/zZBxEV26sgrZ1QQ4zMAwL79Ch/1eAcIMsN6dJjz3iRprWj+yOkT6wruMU00BJvQTYRsefPJsz0p62rbYBwMWmNWwdvRj2S1+uT8E6VeZRy6NwPABXIga5yuYOK7xephG5Y+LmXTzB7JZVXVuTRmsf2kUHuOmSn6SB0US5YMsEkUxO70HHh+aWbLEALx7ZbuDdPLaflymzkB5EFEQR5BpPLPNABhJRPXalbscliue9zkwH+GkrdwZUbLSj6784QHizhcbjrN83RyBBKnD2cXcXFHtwcpU5TZH0om9JBoUG29oimvDklsR7pfxazB1dePj0lhgrPGkMOscXZMloQtxXYUXrujm2+TDSEayNN2ML/FuduuyA5xNXuzk1/hXk26bB3pjZI45eRJZsGKAHmp6l+m025WywniuyzIC6L3iEMBpLXoF8PKv9uU4OAHKKJ/+EARkV4aWYAAE1NACoAAAAIAAQBEgADAAAAAQABAABREAABAAAAAQEAAABREQAEAAAAAQAAAABREgAEAAAAAQAAAAAAAAAA/9sAQwACAQECAQECAgICAgICAgMFAwMDAwMGBAQDBQcGBwcHBgcHCAkLCQgICggHBwoNCgoLDAwMDAcJDg8NDA4LDAwM/9sAQwECAgIDAwMGAwMGDAgHCAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwM/8AAEQgBgAGAAwEiAAIRAQMRAf/EAB4AAAEEAwEBAQAAAAAAAAAAAAcEBQYIAAMJAgEK/8QAShAAAQMDAgQEBAMFBgUDAwIHAQIDEQQFIQYSAAcxQQgTIlEJMmFxFEKBFSORofAKUrHB0eEWJDNi8UNygjRjkheyGCUmNXOTov/EAB0BAAICAwEBAQAAAAAAAAAAAAUGBAcAAgMBCAn/xAA8EQABAwMCBAMFBgYBBAMAAAABAAIDBAUREiEGMUFREyJhMnGBkaEHFCOxwfAVM0JS0eFyFiRi8TRDgv/aAAwDAQACEQMRAD8A4H09NtZlaQWyRJ/KMT26cb0tq2oWN6QpJInGAJx3mD/LjzCwyNoIjoZwSIMR0nJMHhUwz+JlCEqUFTuSJ2wOhM4EGf5A8YvcLUyFNvKQoNpbLZThJ2mMds5xMxnrjjammV+8CUpCQFBRSsbSQDiZzGMA/wCPChmhIdb2lbRcbITkjaFHdux+UDMf6yLbVfwrrjbfhXNeKI670a7bam+GzJ08p8i4pIeDI+U7VObklflFMlG1fSeMG5ws2HNVIWyEMbEuEhtAQJVIbThSs4GZJkZxPSSVFutNTd7ghNI0p2qqCUttNq3uKJIThIzmQBJA6kA9tNW0k1bxQgK80TOTtE5MgSBmegwIjJ4lvh+54Xnw7859Ia5sKbeu/aPudPdKJq4MJqKdT7KgQhxCyApJMbhjqciOPCt1FqqiNnfdZqEqp3UOLQpK0H0LkDaQQNpAKusdDgTx5bbKU72kuJQopSFNq2CMgAnp1AOc578TjxDeIC++J/nxqnmFqk0SdQ6zrnblcG6GnTTsB50ZKGx8qIAx1J6knJhbCvN8tbgcPlkDdv6AiDJESIImft9OPVim3LPlzo2/aR1pVag1kzpi6WO0Jq7BQrtjtWdRV34hCBSJWjDCvLWpe907BsIycCGsraQ5tB3ISZCUyhKgkzujoTG7qMAHjxT0riqcpHnOBI3uKbTvAgnJIOIKhnHQdONrLKW9ydrZbQN4I3FOU9szmInBET9eMWYPNamWi+ny0oWFYwFbiI6CTO5JI3YmJEYMcOFDaFqrEoBaSdqgSJM/3s98T8pO3qCOPlv/ABDlS5TtpO5agNskFw4BTAMHvJOYERmOLH+KjxBVHjk1fo5Vj5caR5dI0zpqk085T6cpvLTdXGpH4l0CNzy5jaJOACVEDjXBcdLdypcMIx4smzRzQKoBQ2J5MNF6sc9IQhCZKjgJ2wQkTJEeomJAnglctOVGtOeV/boqChqairq2lQxRslyrqPLSVqXgblbUBSiTGASRHSVWfwqXDl3oBOpbtY7oxa6x1dC3cH6Yhj8UgJK2ypQCdwCkyO24GAFZQp17qOgq1P2S5XDTLCWnGjU0rymXglSdriSUkH1IJlMDCyOnzT/uIhAdU8+y2huclQDHQnDRzPT5pAzqjT/LTSt9tLdgtN8vt2NOmmu9Qp41VpdbUpbpp9iocU7OwlY9KUgpAUTxD3bDWXVhutvtQaOmQmWmHCAsY2wEgbUKJR7SYJMYlydqqHSr6gyyHKlTeHHEhbpJ6EJMmTP0iJ7glirkVV/qvNW6tJWYC1EzI6wR1HUykfrkDiO+WR5wB8OgUiOlhaNUjs/mT6LRdtUt20KZtqPKUpBJf+eqWDiCuJiPykRj6cR9GmlXSqU68A6+4ZWpaip1RJIlUmIx1JOD2McTOl0s1SHaUbAoztgAoIiMAwf/AJGehM9ndm2/hmYQhunQUEBWwbtogyTAHY5wcdiJ4FVdcyLYnJ9E12fheesIeW6GevNRG16FYoktufg2kK3BKlurjHulMdMHIj29jw70FgpwMArDacwkJCgATugTkZkn+MmOJDT6eLiSt8EiRKSQQn2UojGBmJ7/AK8bBTBK0bFNLJO6CQkHtMGJJgZAHf2wDnrHyeisi3cOUtJggZPc/omlmjW69KtjCQQcqIASSenWIGfaB1OOFNNRIUryxuU6QQVJEg5AGSMA5k/6cL6WhFepCZdrJXtQE7giCQBhIk5MCTOffh6p9Opo2UpuNQWkLI2UrABcBIyITIMjvk4MweIfiNbuSj7IZHZAGE1ULL7lak06lB0kLbLa9uwSBuDnpxkRtBycA8PFJpR2qQaisecWVwrc4grWfTgJ6AAAGCT1AxBI4kto0VWvUwXT0LdspSQhSn8uL6dJOQr2GBnAzDsnQrpfQlbqnnFnJdcJ3SSYjtuxI2g9sHjk6qc7ZuyltpYmfzDkqNt21q3FMBE/KVbt7y1A4BBMDM9CMZgjr7fcVUNpT+9d2gJMqJQM/NMACD1AjH/u4m9HyyLeahUpWUpIJLSGup9SiBJjMyQN2ZiQ40OlKFhgLdq2UuFtUBJLmw9d3sSZJyokkGJnjeKn1nLyskr44hpjCHtBYqmt2bKbaFdCdoySJHQ+oAGDtMEAz1hxouV9W8w2XXvMDZKClAhsH+6CSZ79ATjBzAnzVEyHHW7XQV9UtRUQ6GcmB1hUA9Ae4wJ6QfSNFXevXL7KGGkEgh55C9mdoAAmFmQJBAwczEmaeKhj3eclBZ66skOIxgKFv8urdblDzqlKXEAqaS49ucyTO4JQYA7hRn5faApGmbYwhfk2x+rLajsWphxTgUEypJKyUJAETMkbjIBMif0HL0opAk1Tz3REsJ8tKTtMoMCZkZj2PcyF9Dy1pnVpKmGycICFQSgAQlJgEgmRCQCPlPUmStPU0PJoQ6aluJ8xchqiGnNtNZaJtDw3JHnh1J2gGAYyn1HoY6SZzx8coa95tUsU7AdSFjctYWiQJ+VO8iCTKpAiBPY3WXkzdK8rNsoapllaipZaSQtwjAlUQR6R0Ix0ESOHK2+EK8XVlLtS1VO9AFLISASmPnMEGAQRHuAevBinbSybtG6GTC4M2yFW1+g8+RuqXGnipxJp2ylTm2SFDIUqRtkmEiB1kDhHU2pCH0rKa1pPVC1BIKyDG6JiSSOpPVX1ItNcPC01p1pa6tt/yvNBkVKVlZ6JnIlUScdYGO/EduPh+t1zcWilcDq/Una2tCVpEDCQkgAR1Ix1gSTJVlsiePZQievrIz5noAptX4Yuf8yd4CoKXd8wCrfKMKCYEFUDG6IIl0p6N1LDxAZVsQNgKpS3khZhRB9QM9hMkCeJ5qvk87YVLSrzXElKCsIdCWUlO0JJ+Ug5UIOcmY3cQOvVU6ceQXFuqidrqfQRClQoYkHGY9OJkxxxko3xHHRdYKqCbyzDdPNPVqZRsU2PKb8xfypSQkSreoLMBICspIO7ESrI9uimXTz5LjwS1sb8xJQreoEpSVAKkzuEJSnaVAJJJALSzqNl5lrz0hQQYS4y2VrRHdRmCcGCVKJkfYfBdKF6rU1TlttZAStRJC1n3BBMH6ghOBAIIPHPxnMGFL/hdPIOhC83+gFtJVS4QnclaPPQrcADsBTgTuVJUTuAkbk44Yfx7bdQlBU++wg7UbylCRG5KFAidhUmO4kySolW3h6dubbwSA40HGR09OFgq7iAB0ESSTmdoHEa1JRLQ2tTZSph1K1gqTvcCgDtVHclJ7jpIGJ3eGoaeaXrnYXwjXFuFovGkUB1yoYD29LimlNEq3IWVmSd6CrJIMmSIUQUgAG1/wAMf4hWhfB9S64puYnLyk1kvUFoVQUTrjLSnGnJWT8yYCF7huUnMgnuriptnuiC35Lqwwy635jZHq2gCAdzmFAzORuhEBU44W3SxLvCC+2pzzwkjCyoMkkqGVZBEA5MDeDAMgcWz6HZSbW2tk7CCN1IblcGrzcal5tX4Yu1DikNNna3TFREIiYCgCB0O336kSzlhW6KRZ9S0OrtNXG4uXO1OMWh2jqvJbt1VvTDziNqi42Etx5ZOBJyBgTW6/uUbbjdQ46H2lek7ilVQkH5ljChAIVGDKwQDuJ4mFoLFzQW14cQnaosqS2VkoSYiRPpkykCdpAJzw50NS2pb5TuqxudI6ifh/JMWvdPNsXRuo/fho5b2LEgESQUwNqe/VOUjpBmO1LJ8ko/+oS6oICSna4tQgjESidwBKTKj6RuiOCbW0jyGXaZ5FQp1n0hbidqXNgJS2qBiDIwABJMKk8RW425lFMC5tQiSFLgIM7SgkkpPp2tgZE5BABniNX0RwcIlZ7i1zgCU58tuVeqdW6Hvt8syGa+i0q2h+rXtQ4Utrc8uQlRB2iVDbIBUYUDuIDaKug1bZlvNFtxLHoqKZx1LikM99ywUlaIWkqXBJUCkAAyN7ddX6fttfSU1RV0tFXiKqnTvK9iin0FI6hJk7VAdZyDJg1nuT2ndR1IBYUyVB1TTjW5CkFRGO8jPqSesAH1AcLUjSOafGVDRgKrLISrZucSoKwB0BJAEfQfX6Hrji9fwIdLeHHVfi6LHiVuFHS6V/ZrrtuFc+ult7tcgphFQ42QUNbCrbkJKh168Und05WW610VbU09S3RVwWlh9Tag06pBG8BREKiUzGRjHGuhqPKRBUVoJCUysJ3IJ6KAk5n+BPvBFjnugQ3GFYf4n1n5QaY8cWtKXkRV/j+WdPXE2uoQ4txtYLY8wNqVClNpcKwg4JSBnM8AWludU20GEVLrlO1K1Nq9KFEp2pUUkgExPqIBgAdJ49WOxV+qq+noaSlqK2teO1qlYZUt1z/tCEg7iCCekE5zGElTRqp3nGVtIbfaWUKCkjr0IBxI/iAOnWePXHJyF61uBgr5gKVkDYZ2kj5ZJk9zETJA6jOQOPrjCFLSt5JdOyTuUPlMGDjKiD1x3zGePqArytwTMynCgZBmf1JAInHv24+fgy75yk+ajcduVEAKSEqVJIJwIzgDB6Y41Wy3lSENrRLYKN0ygnqACD+UnAgED5hMjj40ve6y+SqW1eYpRj0ztEmczg+o/SPpJeZ/J7UvI/WYsGq7FW6evKqZm4fgK5sNuhipbD7S9g6JU0tKk9ilU4HRBoi101/1HaaGquNLaWq+qZpl1j6VLZoEKWlCqhSW5UpttOTtBnarBPHhKwKZjxCUo8LCOWStF6TU9/xN/wASJ1R+HJvoQGC3+BDswaaVBZTAO8AnrxB6ChqLg80huUIQPLS4tMGN24dP0jp0mRB4k+uuX9FovmRe7RZ79R6os1srnKaivdOwunYvLKFEIqW23QHUoWmFBK8gKEgzwusNkSEpW4lxxpEQFhUKOIgD3PTsCYg540LnOOGopTUTD55dgvGjdCN1q22UIacClpbUBg5k7U4gCAVdD8pGCRJq0RdRyuVSVlpeeoq2mM079M2WngQqQUg53JiAobYGIn1JH9Jf02WnCaZpt2rCJ3YDKMgqkDA+sYjp9fNbqI0b3n1S3HnypSkJdXjptATIKoPsE9EmIyQaoZWU27Bl/foFBuERqvLL5YxyHUokXnmbqLmJam9Ou3O6V1pVU/imbOxufRU1akBHm+WSf3isJmNygAPYAX6t1LV01SaYU7tArcoN0oSUPMhJAIUoiQN0CEgeoK7weFegucGqeXvMOx6q03cqqxXnTtY3W2usYBbXQPNxtcQgzuKTHzDb3z0OrVGprnrHVFxvl7rai73661DlZWVLh/e1Dq1lS1rKY+ZaiSBiT9OINwuMbDrkOXH9/BE7HYKms8lOzTGOvRM9tsq3ypSm0sJUtSy4lUBJkEK9UdAJgndIntw60lKzSOhbaVuLlJUsY9P3MRJjH2/TVS0j1SpMoKvLMBAAhIk4wDEQegxP1PDwlhq3HzKoh12EkoC5UjBypR6CPoTjHQErNVcppfw2HS399Vatn4XoqH8WUeI/5/IL1QW0oZlKPw7LYMuBO51Ak9AqMn2xMdT2d9M2Fq73qjomBRsvXKoTRoeuDvkU7bqykSt5e0IRMkqIAGJMcRS56pLxLTQDhSTASkhIVkyAclWCZVnqRHb5QWisury5CnlLELgSEzJgnpBkjJzkfcW8MbvzTfTySvO2B2A/VPN8ffp7pUUhLVU7SPLaUttaVs7kqIJSoDaoYJkdeuZMprTb03l5CFioqVgE+RTNlWCcndnp75gfTPEn0nydqbwFOPtF1TKd/lIEhInBMfljvAHTMxM6tnLgtN+Q2hnytqVLRO0EFQOUIKirJ7qHePbjmY3lusjA9f8AakGpiiOjVv8AM/RRK0aYcUPLWGaZLYJUinT5iwDG4FZhLc4mMn744mWmtJmjUTR0rKEPN7vxMALB2/KXFSpSvqmB6fbiVW3QKqOm3PpYbT5nloCUh56okY2IHpBIHaevYZMoouVVyvAUC63Z6dZSUPVKw/UuQSYS2J2CFkDcZABH14FTV9DFvI7V7uXzXV332UYiGkeu5+X+VC3GQwz5wWCXEpQp0J8pG/cYlSyVHviY7YBgKba1VVq1U9tQupWiGgtgOBtBkR6sGOgxgkiAdsCdL03ovlwr8RdK43KtUYUKypK1Ff5gltA9MkCE4PywcCd45mvVVOpuwWGrca/6ZWG00rY6BJCjJIj6ie2M8QH3USkCBmG/L811ZRPYCZ35P77KKUHLGrrktqqm6pUFCYa/doaMCSColWYEQB8w6Azw9UHLmnpdw20TCgU5SDUFZBg+o4nBzJgwAeNdwvl+q0OKcTbaZskifMWsogTG4qCR1j5sSMRPDLc7hdKyWxXklxZCvJSC0nEk7SnpEH0jogGQJI7Nkc/YkD4rGtib6/BTb9mW2gC0KrKYkD0hcgge23APQASZ9RgYke6essbK2wblRgJSoN7ErMGJGf1UcbYgduIExpOuqXUOVT5JCSvy1O7IHRRUEdc4+/c9OFNPpOqbP7tVKzuJLBNSRIjqfQVdzB9jg54lxQU5Pnl+S3Mrx7MaMmjbHpjUSwmtvVtZS56pdKhtSMEQJET7RI6Zjgu6WsugtO04dYq7ZXKWAUCmgboJmOpkGepmR3nioCdI11SwEpuYfbwAhNQAnfOT2AjHZQz3yeG6psPkqUlC/Ic7KZqFbiR12wQNoxjAEjrJHBWntkDjmOYrhI6V3tN2VyNR+Ke3aaBZprfbggApG50AnbAMgdZj+U/Xgb618VLmoQUtOmkB9IAn0me5yYx3iO/1rk9cK+jQECreUW0eYlIeUpSQkbkxGRIJjdPQZgYQp1umld8ioShCEkqKgsuBMpEqEplRGOoUYB7DDLSB1OPKcqPJTwP2e1Ei+81K91TynEIUtzcFnapQB7Y6EHPbKsRwz1HNV3cUllaUOKUpQ3KlRAAAg5IgTtAz9ZJ4Y6S6t1ZG9R8tSUqUpLmAowAOhTgj1dQADkHjWKFis/duH0q9UISV7UeknMyJ9cYPf6AFReKiPBPJQJrBSTDDTupzauZzt42pqQthIKWQFrK0pIwQoiVR6QduSQU5PCa8aH/byEI8pDqXk7liVKEqKkgewJAgRAGDiSBmgKLTNu5e6ht1ys9bW6kqXKZdlujNeG6eiQFq/EB1qD5hWlMJ/ulJxmeJXoKjS5XooaxtUrIUyogTugBQCSYjt0kYmCQOD9HcmVAAPVJV0sM9Ll7OQQjvnLe6WBa1hlTjZMJKkgpa6CYSSAO8xkgfKQOInqKwvU4adbbWh5lYQ2EJI3yeqlHcQcntMfX1G3l8at7VCmlcp2WnmEiS7hPsIBBGCDmO5mTB4F+t9BU9wbcLZ8hodF7e4VEjMgTOZTOZmABLmtrXeZiXHXeWLyHbCAVf+/p/MZVuUVQptDcEE9JgFJMx1EY6AyOPDVM5d2ko8k1AUoMnH4iVbySZGSokkx1zOCY4m995UuwssL8t9e8nIASvaREqO04URMgg5mThjunL26aTWzV1FDVU9JVJK2lOMnynEoISqJAlMhQgHE5JieBE9A8cgitLxHFIzw5Xc1G7houronAlXmMu0z8pcUlaA0CdkZSRAASSZlISoAnHBc5DcmblzOU1T0jDrymQViEuK2FO3aACNqkztMEfQ54nPIvw/wBZzopEsW6ldqapgraUlpkykgg+YpM4MkAZIj+JtD8P6tpPAl4i6N3VlA4advzCWHkbTvM5g+kEQrb2MduPI7VO9viuadPdArlUxxsdJCQSqSc+PCNdeXVNUViqR2kS0sJqGlpU25S7p2QDlUBM+3pyJIkMaavNVaakhZLJZPljakgoVIj2JAEZTAgAeoxx0t+MD4tdLeIzmm1dLFRJom22m6Z1p5fluVK5j1pR1klIwT0H145tavs4RfatbRSX0tytyQsqbAKR0EgGRP0I9G7HHtLL9zqcA9shK91oTX0Ilc3BR2qeUl2oeSdj1y+3TfsDU9ZUW2hcarkuLQ8wE7g40DKAJQQcAwM/lIvvdtVSvuJBCgo+WlGFKxgIBCSBBUev/biCOPHKu/Oqo6hl5biUEHzSUHf0T7YAyDug4Ik5jh11NStqXUtKTKVkqKULB2naRMgfbMdiYERxYxayenDlSkTpaWqLHnkVH7NVpYuAQHUtE7mlOOGPLWVdYB65T6hmFE9AE8NvOPkVqCxcpaTmGikpxpM3T9g+Yl9LjqH1t+aELbJCtxCHDJEEglIECNrla7R3ZtbUuKCkk7AFgplRJHypQjcQCJgkZHzHj1qQp1HpN6gR5raS835jaTu8xwgHfs/KrJQkbQR6j2PCNXQhhLVa9uqTLEDnkq4aq8UWtOY/InRnLK7XyorNG6DdrKnT9uU20G6FypWFVCypI3LUqCJcJhOAIPEERUqWhtSVhuTKilUDBAnMdSBj69gOE9PSKShtwqb2qMkHqARicdJA6HEn6nhbb2UpqFlbZWoLQlQCsznI+mBgnv8AXhaJyu4GOSJng18W2qfA34jNPc0NFKtKtT6YLxo0XOlFXSFTjSmylTaiCYCgPSQpJSCkgieIjzE5h1vOHmFftVXkJevF9uD11r3GW0stuVFQ8t10oQnCQVLwlPRI9hAj7TZqKZHlILq1J2JgKyI9RB94nr2H3ixHKn4ZXNvnV4OtY88tN6a/aXLrQFQ7SXer85tp4oQG1urbbnc4GkKQVkTtmZPTjwDKwnCryw0HSinQpKglsAq3AhU5UB1G337yPoeNiKZTziCtLzyOu1YzmQMdZJmBPf3k8bHEkupR5qvMYWImTtUUjOCTOP1gdJx6dZ8wy/8AuS6lKj5gKVEESDke+T7gmJ7YsSysra3V1Y6/Vvv17qkwuoq3S44oISEJlSiTtSlITGdohIwI4c6CjZpaqAp1+rXCAEJlZO0QkADH5oz9Zzw1jz31oaTuBUCodA2kREe394SZ/meJhoHRjlVWkNFdQp9flNPBtQS8d0pCSQPVmfp+ZMSRq4KbTjfDV9abTQpClqbeqVDaNhG1CCMCB+bI9OM4MiYeaZurcbWtx5bZUnKSfS2nAACo6T1jCsATPBv5xfDj5u+HXlRZteap0fdrNp28pBo7hUM7WxuAKJJ+QGMYBVIE9OBFoLWTOhNeWq7G1W68NWWuZq1UVa159JcEtqSotVAkFSFhJSoJBGwxOQRuHBo32CntBkGIzk8vimq4XVu1JcVQpddIBS2tYS0qBt3GASpCcjOBMgEmRw3t0ZQFKqVuPVLytx9KQVEDBySVZHfsme/C7Wmr29a67u91oLZb7WLrWO1CaSlQRRW5LjhIZaSpSoaQFQgEnAA492izraPoc8tYMrdWPWgHAzMx2gdMe+B9XcSweVM1k4ZE0w8cavT/AGvlO2UwncQpyIbCoKgAcqPt1gGBjsBlwoLMlKC+75acDYlXqJ/9o/MSe+QM8bqWmaogA3tST1Uo+t0YH2SR9M4PQ8THk7yg1Bzm1O3S2CzV18dbW27Vttfuwwz5qW/Ncz6WzuA3E4BPtPC7LK4+c9eqtSKnp6ZmkkANHIbBRKtuYtiXGk+Y3vO0AuFKlnAzH+EgA+3dvaoqq+ugpGxlAMLUNqQRjI+wPUni4Pis+FZdeTqHL3o9ys1FYFPluoplNbqu3jO1S1pPrY/KVgJKQPV808C/SvLu12F5O8m41iSnzUobJRTr/wC0dSSPzEznAxxyY8HfO3cryKugnj1R7g8gOZ9/YIeaO5UvXctw044nCkkiNxjEf6kiOn3KukuTSGtodipWHAhKG07khX5RtAxJJ6GR2nrxL9L6fuN5bLVNRIaLkJcWr0jckkgpPzK9UAxJGfUI4n1s0Hb7OkG4PVlxeXDrVBRgpNUkemVrUdwbIBJmO5gCeBFZxBS0x8nnd++iJQ2+sqBpcBG305/NRSw6Odvj6qemS6psDzixTEEpn8xWfSnEzv2zuEDqOJKrRNt0VTvLr62nYKAElqleCnFKgbdzsQIJQSEJ/KfaeJZbdM3zV7H4G309NbrY0ZTT0DRCXEKxlzqqAQSUz8sSDMP1h8MlJQu+bc3ad6qWIKnxIIV0Vt3GDgmVqMz9xwk3PieSodiokwOwRiitlLS+wMnuhczqLctw6dtFUopQpAcy2FDcTlZlS8AzMTuyIzw+0HKjUurnQ7cLkqholqCiwykpFQhWAACd6iAUnOFEZCuxitejLLZyip3t1amgmXXwUM08dAlJyU4OBjGcmQ9LulNb0KdbNLTobJC6h5shTmIgDBjESo9cd8r096I/kN+J5ojoLx5QhRpvw7UVkWsUFqLy1IIU++lJedk4mcJzuI7kK/huvXLQ0aCqtdZKtgCdgS6omJGFQkCI+VI+buAeCkzcF3LezQMVtw8knaUU8JUOm3smIMHqMkGeHBnS9bQpUtyno6RtsFe0uJU6omFbiYMEdcDv3jge68VOcyOXjadjDy3QGXyzqbvUlVBZ1LdSA35y2h5aR0O5S9qZEwNoO2B068bKPw8Vcf8APahapEpAAabk7AkCQB6QfboRkZkcGq8WOsvDYapA/VEplKWMCffpAIG7MJjpkSQP9fcsdQ291zzmKSjQEpkurndgQr2MiCPT3nuOJdNdpX7B2lSGwtdtsE1WzkhpZloLXUGsUj8x2qhQJgjMSciZkwB1HC53lfp9tLpSxO+FgthtJIifyjrJnsPtGIXdbddaOoT/AM4wtwpKQVpdkKwkJKpHXpB9z0meG1l65VLqUNugKSQlLagtGyesbsAAGSRESnME8T2id24lJC6/dhyKfNZcsKByjW/TwpyJCSoSFR6QYnHQ49h9QQzrrTn7GacBQwpsp2oVEQnoenQifoR2MEknGgrnUkCtW4Gyn1OOqKkoIxuEE9fsT94HHjVXLWh1wyWgrcpUoKkqkoxBV8og9sR1M9DwQob1NTPAe4kLm+lj6hVJul6cpalQDi2ticBThSFKEAGSBjHQd8Y4Y6u8v1TyQ4QtWOu0FZAwIEkYj/CenBW5nci6zTq3D5Ydp+iXSjy1tpmNoJEQI6E4HtwM+ZNmtdDq+5LsFPd6XT4XNG3cnULq207Ukh0ohJO4Kx7Dix6K6GePUyTIUGSliDgA1JKDUlVbKplcuqStW/blKkmSn0zJ3GO3tHY8FDlq89zBp009KXqyoQkvqbSgb2xHYEEAAdenQEdOBHY6dbq0spSAhSPm2kJUqMAp74xnA+3BZ5RcwLjyXvLF9tzTSq1ttQdC6ZKkOT2OTI29egBgD6NVmnZJI2OqdhnU+iA3mmnigfNRtBeBs07AlPdJdH6GoCVoc8tBle0kAHpEHsFQSSqMj7cE3RWuKDU1OF1KG2q4He4pKSkOZEEAHpJOIg5/QB33mSrV+pauvfZha1HenCQg9jkgdlSZ+kHhzsup3KWubcQ8Q4FQFob+XBMgDqo7hkAwEkzjgu1zIpiYTludvcoLS+aACcYJAyPXqFZHVa2qhht9DmzzEwlUpJQD6SkzJyDEfXvw209GtxpLLqXHEOKSsb25QgEAbhBG0gYx7+4Ewex6se1DaU04UW3G/W3uG4KkEGOmPT2Hv1zMr5Ra1p699NtuLbb7bihtKVb/ACifckbcwO2ZBntw322t14aeSrbim0DQZmc19es7TPnE/vErAW1uJUGnEj07vVBG0wZnak4Bzw7ahv8AceaXL21WjUF0uFw03o1CqO2sOKT5dsD7kqSkH1BK1okROAcpiDOrty7apKFa1O7miCrzIEAQdoVjsfuMdAeog5hsVFlvaXG2VENhRgtDeQRknA2wDO4gDpIPDTLSZjEgGVSM1w8OfQ47o7fDo552zwv8wnn61Ka+ndSlDSSAFGQYgfTPfse3Cj4i/ihtXOHXbFfb6b8KhKdqhAbUpO7IA6lXQYOJiOpFdqYrojvSCslIBaQnzSRJg7cExMwqMp7RmIc5L7VXuyU6hLpZp1FRA3B6MlJ2gzk9zAKI6K2gVV1b44PB07nbPojlNViQblaubLBu9ubqGlOICVKR5jbiSoBIUkLlGSJT8ySBJVG6AQIbvVPPUdKtbe2pYCXG9qtn7xJIxHqSZPeDjsVYO+mtK3Gs0fQpvVBcaOjuyPMtlxqaZSW6ptHpc8pRML2qJlQ3RAk7lhKQ7zT08dJ3StblJcpHgttYmV7idxSlQAB3SATk/aRwrXCkwBUN5Hn70VtVzbK40zuab9M1oermKtCFoc/6dSEJKPKJ3H0JECTEx0CiBOczHWtLU0TLDtU09TuujzWC6VNyDEEThQO4+oAgboGdpI1UtVtuHmNhltSFkbN37pB+SQAVSoR23Yx2gFnmTzkv3N7Qen13y5GvRpi3NWShDoQHqejaJUGSlAG4BThhRkkDr6Y4ZeHq/VCYnKu+MbToqmzxjY80N77tr6CXUkqQ2CmUiUknAnEmMzntAiVHXbXx5b7a4dpnyFuEIcIlJ9XYx6VK7gACSlSZPCpbIcDW0oQEon1SsNAFKyrpuSM5GTgGZ4aKtTVnrGXXAoJfJ/dhuVIJUCpHWd6imPUSMzMDiPdoyCHKTYpsN0lVasNhe1GqlYaQ47U1bqW2QlJU6VJj0R+YkREj8wgz1eeZHKi/8or4uz6psV605eW9rzlDc6JdI8ErTLSti0gkKTkH5epB68b+SfMa5ckuZWnNYWd5K7vpW6MXOhKkB5CX2XUrRKchSSUkGRJAgd4L/wASv4kGufid87WNf8wKawW+5Ulup7YzTWemcYp2Wm/XHrUpZUpxRJKiY3CAAOEpMe6r28nc+6jepCm0kLS5CCCfftiQMRJPtwZuSfi15o6a5S3bk1ZuYN003y01/Vss3q3OOgUC0KWlJW8QgqQgAhTgQYUlJkKiOA44goW6d6QUEqhUpChIyZOO3aTOY4ymSplxCfMJbcWuF7PVEkpUmcIJgd5jrgce5XuB1T3rmztaT1Nc7Y3cLbd/2bWO0qa+hUXKSvSlZQHmlGCtDgRuSoonaoGOg4QJZU47t3gJUghG4hIj04AHfrMR9T3410sLAca2wJW4pUdQPZJ6GT0+okzxY3xI665Ocy+XnKum5W6BvGkb1pywJptbV1ZWJebvlx3JIqGEpUdiI3dkfMkFv0bjqdhldI2F7w1o5oFWKxJqXyspUW0D39SfaD1InqB1j68S7S+uqzReq7dcKdKVO26pbqUsqPoltW4JMYCZ2giZgd+GW4X1FKXGWlEMNIMrSdqRu/KCB8o9x1IEEdeNthtjlWPxFUC02YPkKASJmUqXJz2wZ/WZ45FzQCSUapoHOeIIW5J5rp78Qf8AtCdx8dfgioOWb2jmdO1DjjBvFybqt7dSWQAnyRA2BRGZMwSAB145q01ucvaEpbaU3TI3EnJW4Pm2z7ZnuTHTh0tNjeuS0lxtW8JPqJytOeojAj6gmOwxxvq69ptXk0aZUjLj5UDtHzECIH3iZzGAYFVFY+TZg2HVPto4ep6Nuag4J6dT/pa6OzMUikNJaKtoO3arKBJx09JyQTP29yueeCQaen2peMlIII3E4Kj2H3PuI7njQw0WKVCUqWFqWNxSQVbkiAkZx1z0k/QHjegpp0KZSgPVDp9SU/IgCMlXWYTknrJ/UTI4A6n7lPFLESPDpxpb1PVeyAKjaD57klSCgHcCCDCR2yfc9vaeOhvwaOV34TQertTuMJSLpcGLfTL2ypKGGytyDAkb3QDjqgfc0k5Eck7xzw5j23TNmNO5drutSGEur2NrKGy4sqVEYSgkT3A9+O1fJrk/Z+T+gbZpyxU34a12lnymEE7jJMrUpUepSlEkqP8AIQBDmmL+aE8TyRUlIKVg8z8H4DqfeU92q1+Vn5SBhQOR/X04h+uvBJy95nXN6vrtPsMXKrcL7tTRrUypxcj1LSPQs9zuSZJ4LFstEQQnJ6RiOH+isxaSmEySPaI/24jPYHDS5IUFVNA/XC4tPoqg374a9xonyrT+oaBTClSfxtMpL6Ujp60gpOcZnqYjhpR4KLvoF8OXmnfuaVKK0MWlhb6KpSgDtUojcsk59QxBxEDi9FDb5QkJBKVGQY/jw6U9tIwNyU7cgHEe3AGs4ehmaQwlpPUJrpuOLhGAJSHAfD8lRK6aS1Zp+1MOI09cbHaCAEufhl+YsEdFr6JAgH1EdMcJbToKpr6kD8MtbzagnzFOCEEACZUUgyZHQn1fbi/tXpdi60D9JVspqKeoaUy+2uSl1BBBB+/+/XPAU1d4TK7TrS1aVZo6ppCg40mseU5UJ9wkKwsjAkkE49uE288LTUzA+kGrv3TdZONIJyWVQDHdDvhA5nku8+DVVN1orfSNkOFanAoYGdogCPv79M8NqnOX+k60jz6zU9YTtAWpamlY7AYj0n2iPboYVeD28aieDuqK51tidxQHEq2T12pRICumCZH6Ykdh8P1h0mhTFDanFKAh1bqMmI9RKsn69OuI4Sah01P/APIDgfdj5lMv8apyNLJNX/HkgjQa6cuLATS2k0LAMJKleQFbQREDP+Jzg4B4S1epqK3r3uVVpZKDErVvUiAAQSowIjMiPtA4sHfOSFsv1OWLhUGibWn/AKTCRviI+b8uO2OgMGOGD/8Agw5b3bLi7gl9aRDv4hwKVGR3jBHSB3gZIMeGeBxzJ5fqfqVqb1SsG4PyVfLjzZoqB+V3aocSkb1BpHpGAQcflIgHPfocw8ac5waPuqVU1+bubS1p3qWSCW0j3HUDr2AiOszwRdXfDns1MhVRpm9KfbC1H8NWEHbJKvSomR1z1EcBzWvhKu+lt7iKMlTBDhOxO76kJOFGc4GZg8Eo30Dhp1EKRDcKWoH4bt/kVKta8g9N68sy67S+oqdwqRuU2AjAEGCjqIG3BIj37cV05haAqNJVLia5hhKmhtbW0Skox85IgwR1IBwOh68O1z0rcrBXOKoK6ooqtJkpU75clOYM4GCQIicfQ8R6/wDNu+W6GrykVrSRG9afKdSJwe4nJ9JkCR9uDVvp5mn8J+tvY80SgDmDBdq/NNNkvlTbKpLK1OVFOo7UKdSQsn5QCoHIzHZUqk5jh8qLrUWSrDKtqadtJBMqScHb6REfmEbYJntg8Qq/UlPdnRcLa4UrGNo2gq9UKCgPoOkdes9iTY9OPcytIU9Q0giqZTsUNm0pxk/5de4yOD4oHykFjc91lRVxxbyHAWV1xa1BQ7XlF1hfyArKnEiDHUAK75/7T+oc11yiYu77pp4plAFf7vKVAkR3Ek+5/wC7qBkzI0nddNIUy+y60pfpncpLaCB0HYwIPQxJmIniLuU7i9UN0ppXKvz1JbbQE/vC5JAAzOen16z34yFtRQy45ei5wzxStOgghAGn0KnT1/aU4xtSh8r8tBUVKGfTMBJnPqkqMGBnJQ50an0rcdA0LdsaaYr9sPhBIJxMRHYfxMdOPnOfQlZpCrqqV5ioaXTK8txDjcKZ9Q3NqThUgnKe3Q9+BLdbgp6nXucgIOwkkbkpIO4be8RmBAHt04f7Pe3+CRjOVpJStk0vzsord2VIqFPtuJ3QAoTIUoGSk5/mT/sr07qFbitqt6vMbgEE/MD1nKSDAHXp3HTj5cHUu0ziVktuIVtQqSpBKcCB1n9ScgCTBEXVVOWe5oKlpSkOgfMQFHbG77pyJHQkyZzw2UlSDhB62EtycIr6Q1YLZem1JcDKCEkp7kFI/ugSnKJ6EkiRmOCfp1tylvSPLLhbfh1pCSCDJIMicHMGe8/Wa82+7KqJKCElhZKJBUlUnaowARPqBkCMiAVHBl5La7/HKp6N0uKbCv3RwpSSchJM9SIkkAZMGccNNtqBE8avgku80v3iBxbzwrV6PvbV/wBKOU6iwytLCijITuISmJA9Uz7TOSDwOuY2mlVda+gstKQClxK3mk+iT6UqOBGZkwRjIOOCHyY1jbeV2ubfeLvYEaktLG9FRa1uqaTVJUgwlSo9MEz2JIP6N1XamrvVF/yy21VSsBJINNOQQTmAD83QwInvbVtnEzNB5L5S4oon085lAQqs1mbqmFNL89kKbMJUSPOhcjd0I7ExORnpPA81rS/h3ENupC8khJVsDW0EDGQPSJSSDO6Jk8Hit0s7ZKlTiUv+dTghSdp83bI9QIgTAGQfbgOc27e0ivW1CilUvoG5K5JIUDk9CYPuSTkDHGt0oGhmcILbLo4vwFGrbzi1ffqTT2mrlfLncbNpBT9DZaCpeK6O3JdXvWhoEApCl7VEKJwOogxGuel6eqb/AL0rdd/EMB1RUSCkJV6kwZASk+kqV6Sn3xxso6cP3be2PxRWlRBUoFUhRMnb8w2ySowITIA7oecjaq6ltT6Ggp9wpbwhMtlSlJBR3C4QM9YJJiSrhRroP+2c0JottTiqa/Khte2irpVJX5a2dqElM7d+B6ogbSUj5YJBSBGd3DlYrspyyuNBxCiztbcB6QqdpCR6UiRsCSCUxPvwnoGdtvC9kU6IbUzKUpabKjuABOdxLgCVGSQEmMyi0+ypj8ZbXE+aUBYTLstrG0gb9sJ3BOAE4ntBI4AWmQxTj1TFf4xNTZ7KYWDStZcNM09d5Ly6MrVvfbXtGDGzeRnO7qI3LQCe3EE5huqYfq0haULAXUSjchtxYdG9Se6lbgBCsAgYJk8F7SHPC9v8qkaLFUtdgYfVXtstUyVueYQEKSFTJG3adgmCMRuIAe18FJuKytSQAtL+9I3tLBUJ6AEpEzMKACjkDPDNcz+GCk+2sax/lKrFTVlOhp0qQlJCk7CoblQD7jvABxAyeuON7TKfJTvB3gBLbaiZiMSIGM4IyTHYicoFOvtNhanZdHmK2K/6ihO1RyQQFZ7QBjtx5UtKqTO8qSkgqCZK4MEAE9DPbrkx24Q01LYw1D+9CMwQpMlW9YPUgdZgYPcEwRgbPL3PoTKVbCUQBuUYlKQkjKhETByZ9p4etO8s7zqpFU3bqCrrSwFug0zS3g37rO0EDoO4PrxiZRLtjjdQ4y8ytuoXLat52ISEpASSCCTEEnqPl9+M6ZWNGTgL1aLYbnc0rSUiIdU4FApKSpUjGAFZj6jh3qbs20W6JshpCZUtUgKECSonPsD3mYGeE7zabJRfhmStDygC4fUpRJwN2IBzMH6HhXZ7Om2ufvQH6lR9LIIKWfYqgxu6HqYEj6ccJJA0ZKOUFI97vDh5nmegC3WWylavxNQFBLUBpgblbSBAEd1D6+0mY4mmndOrqgpRKUBhPmKPzJSeoMifUTPyz1kkCSNOjNMv6hvLTbSPxNWrLaAAW2+pEzCcA9/aCPabasqaa0WxVpt7rK0tyurqVE+Wrv5fuZ6FO0Se3EOGF1Qdb9mhOIkhtLGxRNzI75n39lFLjeFv0aqOlQtKHZU6tO390MEweyhPQTAjoRxopLcG07oStQIC90QgY6npP8z6unb2mobcaDoLjVI2r0lXzPqJyEgYPRWAPYdhC+22Z+4pQt1PoaSEIaWZDY6iYwVZnaPvMY4G19XgaWnACarFaHSSCeYZkd07LwilIeQGwHql4QiJlKTIxPRPaSBI7Ykuti0w5WutoUdwyjYlO7cRnalIkwcRI+vXh50zo5dY/wCTTbXHVr/e1a8t9wSo9FGTO0SYBJPQcEPS+lGrS6KWhaU9cFK8pVQ4klW4ylKUIwdpBEjGAeuQVuerJOlnNWJFDHTN1zHkrCfCQ5G1VXzsqtRrpkooLBbXGg44lJWqoqP3aSDMpISHQR1ycAHjpnarOEg7khPeQOn04EXgV8Ob/Inkyigr2FNXq5VK6+4blpW4hRAS22Sk7ZSgR6cAqP1HFiLRYiEhJwD2mAeNmNIHm3JVN8R3JtbWulZ7I2HwSe12fahJKOp9pPbh6o7XPtB6kHH24X0VnWHUHaVJUIWem3Aj9OHyjsmAIPtPsZ43QBNVNZsSEnd14X01oGzKCrufc/bh6pLNGdu1J9skD/fhfT2ny0+rbuH5gM/bjMLEx01qAPqTuVMRH9R/nwqZtGPUkEHJxH6jh5RbfLB9KQUwnrgfT+vfj2UNszJmDMDH8eMwvQSE1NWUAY+UCNyhJ+/+XCbUWiWb5S+WrzGHGzKXBJg/XOR/pw8O3JpslMoBPtmT9fp/twjf1K0ykAqk46dP14j1VDDUxmGZuWldYp3RuD2bEIcVPKO5W+rZbUadxl9YZ81CVHygZyqTIEex7H68aGLVdLa/tYZtgdRM+acNESDIOMmMA5mDnic1+s0JTPmJzgZgGff+fEXu98becWpLjhSvO0qhIECSB9Y7+54r+5/ZzTPYPuR0nPU9Ecj4inO024SKm1fVWupDV1slMUq6lASkgDuPv7Z6DPCq80Nh17av3SQlU7ipSANqiOhPXqTE/bhurX6a+uop3X/KdUqELB9Kcd0k46dR79OMqLDVWujU9DbK0NepaFSFdfcQR9T3PCweFX0s7WSt1DIyMcx70RZVxysL4zocEJObXhlobzQVVW9+EPlDehxtuXAOmd35R1JkwenFU+dfh6XQpqA20mDJDhBVvSRI9pge5M/YkcXpqtWIcp0h4pWogpUlYwqev/jvPAl510tNX2lPkJSUtKUElSjuyJiepGCO+McM164ZFBH97oHaWtGS3JPVGOFuL53ztpKnzajgHbZc3m7G7pTUS2Er2tOShSFwCgSI3ATOREHBj26dPvg6eF7T/NwXa53lH4iltqENfhZKfMUSYK/qAIOfpxzz5y0zNo1GZTuAWCFDASROP4Ht9cmDwW/CF459ReF+5/jLPWIZUtIbdbUmWnkgHqmOgjB4sj7PbnT6tc7g1zm4BPLJ/fNT/tMtNbW20x0IycgkZwSOoC6EfE88J2luX3Ldq/WWkaoCt3ynKdBCQqRO4E9Iif045WajokVd2Q5uSpxhYV5qfSUbT79ZyDMwZ7cHLxQfE61D4o6JukudTToaaSfLZYSUNpB+YxPviZn+PAA0ddTqCufdKpCkLV64hPpzIj3UTiMDvxt9pNTTSNi8Fwe5o3I/fRCPsvtFwoqV4rgW5OzSc4Czm5aF3a2qfecXWVTgBUtwlxxSpmCo5k9ZPYzJOeK9Uuo3uXuuF19PTUF0NMle1qsY81h0KQpG4oJHQq3BROFBJz04srrghmzxKj5be2EJ3zBBPp6YKo69x0xxWzXxpKHUyTUBLrReStxIO3zUbo7fm7CZzu6Dql8NSuLi1WtU4EOB+9lCLgVU6vLhIKkBxa8wTM9QMKIjp/GOGa6oNUNu5SS4pIKtolKicECe5x365yBwbfHDq3k7rDXNre5M2i+2WyptbCK9m6u+Y5+JKR5hEHI3dwYOCAO4PdqYRJGUmVbxEZkkpBAn9IA6GZ4sqNnhP05z6hB4qptXTCXSW56HYhb6B8voS5Li1oICtwUsDMAlU5PToR8oH04KPh/19RaG13YbtcaJu5UFtr2aurplHaKtttY3NqIwCpJAxOf0gXMsgKbKEq9BUjaQTuTGD9ZEziADM9+JHYqlaaQtwYhS29ypJXAIIVOSAQcAnJPcnhs/oY7slQNDnSRu5HIXTPxteNjQHiy1BYn+XukE6XYoraGqtK2EtB9W+EyECCEgQFfMoEiRBHEU5btoqKZhDikHcvcUKG0IEe/QSOncA56cVR5MVqG0KCgnaluAkKEqWVkAEnE5EiO4zMcWF0FeF3KvoWtzbKlwy4t9zchIWQNxJykDeM9hntxZPD8oY0Hovn3jG2sjaYGDOEQNZaYoFUS3adbXmNnaUncUKIJlW4ZTCswIzHeYrxzQs34itrCkLJaG3cpuVMkkEuJgYMJA9UAZxIgnTmO4rSGqq2yuXC23BVqql0ZqKJwO0r6knbuZUSNwMDMEEH3jgQ69T+KQXkrBcdJSC1KScfKMY6mSTmcgEGG6of4se6p9tP4T9TRhBFTBTqBC1eUvzqZIUPMQGx6oJABz6oxgkznuGXmna/J0u2ypa1qZeSoBaZDoKx8/QKSVd4zHcjiZavtLluudM9ChsWfVtlSkhUeoqGcz9fUPc8R3msy28mqpiA0j8OVFJaC9hJneAkScSCnpCRnpwq3CICN3uRy3yuMzUM7NrOsprFX2OmXTppLlUIdd8xlKn0rbUvYApMrSCFOqUEgg7M5EqakuGkujDqW1BKx5ZQkhQgk7ASpJBG0picSJ2yCR9tdsXdb8pLVMmoQMKbV+8RnqCtO0AFW4kekkJQP7o4U6r04u3VC6d9sML8z9wXlJCnE4grBAURjd06LPsJR4AfEBHRPdQ/MBDuqk3K15VZVOqJQYpyqdpUCpJncNvqEFO8FPsme4EP5oUrpRlxSUwv1bZTuKYKUmJgkbQJkYAJztleiypujefd3Nmo2OJL5AUAspJJJkJ/MqAegBMQoFi5tUaW6ZcRvDjbiWwE+YiVbSBuABIABgEYyVCPSzXEk02eqT7cP+5x0Q/wDCRc+TlqqNdL51WvWd2Yq9LVg0sqw1KWnGr6VfuVPk5LEk7jBAIgggxwIm0JStKQ6HHDElJI3wcmOkE9ExPXHt4pGfNAUVO1BVErGSAPaYxOJ7AfWOPaSHUqjylJIDRO4GCdwhAyOpMdsBXbhFTdtldwP7NL4zfDXyA5A6ysvMx/TmntW1D5d/GXlpDorqJKD+4QVAkbSVenEknA45q/EU5iaH1j4steXnlvTCk0tc7s87aW07g21TqWIUP7oKhIG3rEiegFtb/wCz6QPwAkpKPQjcFwMBJgSdsZHY/XhVb6J+uq9xQj8VA2pmQ0ACIA7kgmZ+pnEnHTt0aAOamUduc6TxM7L5R21VCoJQQ5WvKIBM+gnBjtu6/bb1I4lmldIPO1LNNTIU/WOZMK9LckE+qYn1CP8A3g9p4lHhh5Jo5085NO6QbrWqAX6uYonbi8T/AMsh1zaDu7DIJ6Hp1GDdL4qnw3NP/Cgv+n7TQa3TqZvUdtU+oMtoYq2XMp2hKVGEKPqCjmB0jIhtp/FOqQ4aMpvirYqHEMAzK7lty9feqljyOXGnnaVh2jqLpVg/jNyVfu0zBnoAnEEyZJIBHUw1brd1YLrhdXaGVKKSoQqoc6yR0AMRGYn78eq6rcuzqqioJYpVOeYy2JPmECJUokFR6dDGAB78OVqoA7TpuVcCmlQQmnp9sl1XVIgROOmJmO0QOuNyBAiiGGjZN/D/AA3JI81dWcuO+/T1W60afS8Px9yA2iW2WSYmDIKj7kwYEYBmOnE50foKp1c6l1bSk0jJO6USWxmFQr0TAPzSAYJPXj5y55cuaxuLVZWNvuU6BtQlAIQ2Py7lJ6mZyCAJV3Bggts/8TPMWqjATQtqASWk7V1piQkZMyNkn5cQO3ClXveDh53/ACHr6qxaOohYwiDlyz1PuWmio6VmgX+FCmbeB5DjyJK3HMjbuImAUjEQB1meLNfDk5WW658+bLW6hpA008l5FjoXmwgKfSjch5QOSdqCE7hJKPVAA4FY0zTaOZpkP0yKqudBZprayApAUSUpISZKldD0mAR7AWO5Acu2uVmv7LqXW1U8m+PVbTlPR07almkZ3hUwSJUBggdAoz1HC7PeGRFug4BI3PN2/QdvVcLhRPqKZ7XnzEHAHTbquglh08BtEbwYJIPzH34lFnsgcCUlIAHRUY74njfa6ZpDMgpWhQ3gjOCJBB+3fhzZrG2x+UqAiOGgbqjiO6U26zgQqNnYiZBH24cqenQygEmI6T0HDI/qpmmAIXvP/uyof1/hw21uukMNEeYj0Yge/wB/6zxsGrFMl1rVMgA4KACT3BxwlqdQs0424BTJIkZj3+nA6uXMQSRvG7JP6fbpxH7rzLAblLkkdMwD7/fjbGy11BFSt1q2klJXCTOUn6Rww3TmClswFlM9IGR3x7cCm6cygSuHCYGADk8Ru68zIKti4MzGPSOPCcLM55ItXDmL5atwWUp+UAGD/H24Yq/mOHBPmA/mJT+b2j6ffgQ1/MlInIUZnr/HiO3HmSQcukFQ9R9+PC5ejKMVfzKO6AuZO4g4A4ZbjzKkQXJV+YDgN3DmXBIDoz1B6n78R2480S0iA6TOJmT9emMY/nx5qK20o0V3M8oyHSPLGNqsgz7/AOfDTWc4Kl2nW27WVa2Vq3qQXVbSZmSOhPTMcAu7c0UAD1hHvKv4frxHLnzZTlIe94JPQ8czg9FuAcKwFbzX3A7lwlWIBwQe324i+q+Ya7mwGwv0pWmQFQIg9RBgAdzwCrpziDRVLonvnpA4R6d51UlTqdlqqfbabeKpcUjclsgE5EgdoiczwMvEb5aKWNnMgorYyyOvie/kCFA+f+o/xetLgguBpDS0gDBCIAkAzJjrt9+8TxDrfXf/AMrfddDzoCF7wk5ThXpCoIIyD/8AEe08JdWX46j1VUuugpNWohSFSC2gkTMdgIBxmD9YsH4W/A9W84qe01l/eRbdN17pcrksr/5x1tJhICFAhG+CAsGRJVA7rtupn+EyJg3GPkvoC5XCmoofGqXAN/Pbsq5aPrXHK0r8xSWgtTiiFbYgekkdJgTI/NODI4udyA+HdqJXL+qumonTZrnXoSu3W9YCvKSU7pfj5d0gQCSnM+xMvgz+FJZOXfP2t1Vqa5UV5s9rq1uabtqEbm1BRKkLqdwJJaCglKdytxTuJIwboam5et1ZUpptIKpJAIgmev8AHM8HxahLl1R12x+v+FW3EPHLQWw2s9iXfoP1+S5H8++TmotCWB165Wmop6Z0bfNCQplsD0kqIkA/+6CQZEDil3Oa4JTXKlwJW0VIWXFzt3FWM9cdCZkfQjjvvrDlukIfCmvMS8ktuoWJSpJEEK9wQYg+/Ag1jyH0/darzKzTtiqXUjalT9uYWQANoTJT/dgZ7Ace0FpbSyao3bLWm+0V2jTUxZPcFcK3f3zClIVsWleEEgqQYwY9zCgJGO0kSM8tPltnqlPpUQZCRAJI6jB7icn9OOv/ADD8EHLLWtjYoKzRFnpqajW44yLcg0LiFOABZC2ikmYSYVuTKQY4p1z9+FjqXRYqa3RVX/xNbkK8xNA6Es3JtO6QADDTxT2IKVHPpnq1wVDC8ZUui4tpKhpY7yn1/wAqp6QWal1B6lO4zCkwPmM5nM5yMdJjiWaaoQ4umaKvINSQ2pxS52ElICSVCQUx1kHOeuX7T/hD5i6vr61NDo69KNqaCqoP0qqZxSCraEth2A6tIAhKZhMmOh4M3Kv4c2vNW0VM9dlW7TlFUUxdT5xLjrUqMNKaTDiZGREp2kdd0BnbWwNb5nBQZq6njcXOePmmHUGiWOUl9atlNd6W9qShDqKilSspO8boAVkEAqBBHYjr6uCHoh9NZWI8qQS6BAcDhSmSkkGe5AIKpGI6RxG+YnhM1ByGrqBVxdpbpQVbyWU1VGlS0DbkJO4ApcOfpB+b0xxOOVGl6m/31mhpWX6urqH0tJZQkKO4kbAAT6icR1I2nAkRYFkqmSRCWM5Cpnid7Hzuwc+qcq9tFE3BISCQZQobVT0GSACFZOcAYzJ4bNI64e0fqNi5Io7TXPMsuodZuVMKinUpaSlRWhUDcATGZB2HtHC/nZp658ubm9abxRrt1wpv3JaqU7VsL9jMZJj3gexOYRaroF3Bjc4rZuUNpWpIGDiBgJSnJhI+c4JiGiOqbjDlW9VQmQ+VRm+UDd0uzaAHk07yghS/LTC4BBB3TJIKesZJyR0IPxJvB1pnw0aG5d3yxa9tGsHdc2n8VVUtIlC3KRQQmBhZKkkwgSQoqQYBIgibmdranNUVoRT0qA15KlsoAyBCjO4blZ3HYo/QADgX6quTl18tx0+agoSCWxvwT2UNoyPTGe8TuEBLnUh+Qw+9dqG2OifmRK/B5zNsfKXxD6Z1DqKzU2pbHZa1D9ZROpJTUttuJVtJJ2gKHqSI2jYDCSqOCp8VbxJ6K8W3ifOpuWumEaUtNYyhkUaUNMuPuAet0pRKQs9gAZ3JjG6a62qndXWMtrThpsLUAhKUnopslMDaQnYB77TAyTw5Xy3rbQumUlSJ2LSNiWiQoBWBGUmRMn0hJjHAOmo99fVEa2vAaYwt2lFt0mkF1LBStO3YVhG4LUASZ943ScnB6CAQ0cwqn9pW0Ogne0o7lKWgpKQQoKBUTnclRAiMx7Hh/q6lyj02/TJUmoUQh9Xlo3F1UJIicEJMAgRHpwJxEr1VecHada0OI3hKCkH0HcFg+o9CSZHUwIBgQTuB8mhBrYTrLvVCDwy8qRzx57aT0gmp05SPakubVtRU6iq101sp1uApC6l1KklCEiFkg9QgZynhBrHQL+jtfXTTlRV225P2G5P252poXRVUdWth0tqcZXAStCvL3BQGU5AzxHqFhNQWoStYIlYCU7ikqIxJIMk5k9+sdZWxaV26lRTIbK3p2LW0ncBIgNpAMZjMZEqE54QnOxsnikpTI4k8hzSTy0VVwQtxSvyobKAVKSndGBnMwCYPQjMxxJLbZF0G2mKUrqlkOKCQJQIGD/eURB+g+5HGyhtzeicpDC7wv3TvRSAgiT7rBkBJ9QKiemOPbi1Wrc0G1vVbhKlNu5Wsk+olQ64weg9RwTBGaA12l/xRmGQ+GXxjPb3pwtd8esqHWqJ9DRbAUt5vKnFAkglX5SDJET2EgwOHXVOsLrzDu37Qv9yr7s82A2hVVVLddWkKwNyp2gGY7YEATwzW22IbaQ4vaURCCIBcPuB9+8CMf3Y4frfbFXdalur2UtIkF9aUghlBAwEnBUc4OTBzngDcbmXHRHs3srN4W4W0N+8VG7z1PRebRbP2m+9WVm1umZKSRlIWegQBkqBJiPYd+045e6LqNe3lNZV/8tQ0w2NhY3EjBKQB1UEiCQJxiIPHzRehXdZ1qCGzTWplSkq3H1AnBKjgKWcjMyIGAMEporQE223g/IlJT6SKdG7KSRjE9IVmQcmeBbneENR9s8h/aO/vTdUBjhoG0Y54/qPb3L5UIXeG0WKzMeUVIC33lkJab9KQoqVlO1IJAECcR19RH0za2dB21hFG29c73cEhtASDvcKj1QPb1HoBkkz0JbND6c/CoU2zTj8Oh0B5CTCalzqSEkxt6nbugbv04PnLnSFJywZbvVyKXtQV8ONKUd5pkqP5e5WTOMCDknEVzxDeAD4Y3H1cfX0Ryhoi1okeNzyHQD/KU8teWLXI62q1BfG2LrrevSttLIBVT0G8j0JzG6CJUM5EYBHBG0jp1vSFai93tSrtqevUfwlEDu/DpUJEJwJKTG6OxIB4jCLidL1dJdq6ldrb1W+m2W/CnN68+c4kYk/KlPQbQcHIsV4e+RdVohoao1KTcNZV7fmNB8/urWkZhUzJGM5iYnpFd3C4Oa0zTO39Po0dh3Umrljpo8dT8z/gImaF19d9PWa20Wpall25vspJpmGjNIMBPmEfQZUY94GeHWt5iJLJAc75z8vvxBmUi+XGvFH5tbUxNZW7dyFO4hpA95APfA4gmpNcVNlr6imqULp6mmVsW2sFKmlDtnP+szxYnAt5lraVzKh2XtP0KpfiihZBUB0YwHD6+5Fe6czNhUfMAKjhXbhgunM2ZG8qMdjmP9OA9c+ZYQpUOR16nB/r+fEbu3MsBRhyYn6En/GeHjUloNRiuXMpIWoeZ8vUkz3mD/XfhgufM9Klql3AGM9OAzd+ZgEpLpO1Mnt9hxG7rzTk5cA7ACI/n/h9+PCSVsGoy3fmXuUR5pyeyun+3EbufNBJlKVwc9e/1/r24C135qDP73A9zG7iMXbmyEKMPfm98njXJW4wEb7nzRTuUC5GCJ3e+Y4jl25pEqJ82Tu6Dof9+AXeOcCgVISpZHTr8vv9s8R6v5jVFS56Cev5fbj3TlYjfdebkgbXEhIAyVATPcff+fEZufOAbClLwIIIJBIBA/8AHAgqNQ1dcQVLM5k9Y4TP1Li1AqcUVRPWT9+PNgvBlT6782VOqJBBj3P+H68R+s5gVVSowopHsDwO9T83tNaLB/ad6t1KtP5FvAr/AEQmVH+HA21Z46NL2hKhbWLjdXRO0hsMNz/7lZ//AOTxLjpJ5PYYfyXGWphj9t2EfXbzUVGd8Jmcnpxperyj1qego9U7un1+nFONW+OvVN2KkW2lt9pbVMKCS+4AemVemfsngZaq5tak1stRut6uVaFGdi3yGx/8BCf5cEIrFM7+Y4D6qC++QsOYwSfkrzau8TGkNAVK3q66Ww1jagpLVM4F7VT1LaAScY6iI4tr4B/iG6c5uW8N22vdQ/QQy5RPDY8wjokweqY6EdfocccRfN+mPpjh75ecyrxyq1dSXyw1rtvuNEqW3EHBHdKh0Uk9wcHiSOG6ZjD4ezu68qeLq6q0sqXamN5Dsv1U8pec6K1ppYdSUrgJIOQP9f8AXg+aP1/T3elQhawo/UiQZ78cVPh1/EdoeeFibpKp9FDfqNKRWUSl+odB5jZ6qQT+qSYPYnofyr5zpqWEFT0wAJBiZwPsc8ApInxvMb+anxSNe0PZuCra3axMXyiJSgCQZEd+BnrblztBIROSRKf14eNBczBVttodckqiBuwocTsfhtR04Uk7gR6o+ZJ9p45kLpnKrJqPSCmFKPQ5MniG3WzK3GYUPzAjPFndYct/OCihG5MzuTkA/X24EurNFLZWoLbUDJAO3BPXr0/XjxYDhCh6kDh2uAKKDIBlUfXjyEhsHAg9VJPX+PEjutiUytRIIQT3yOGh+gIWRkkGOvHh5L3UVHtWaao9ZWCsttc027T1jfluJUncB/dP0KSAoHrIGeK4WJu9cg+YjNU0tygudidRVU7qCc7SSh5JjbBgnInqO2LUOUaisEH1I+v8eIjzR5QN8wWmXGahdFXUra2UOKTuQpCh6kke05kZx9Tw1cK30UMpinP4bufoe6FXWjM8eWcwqv8AiH5u3vnTra4X/UNZU1VxuLpXUVBGxK1fQfYJAA7HvHAp1NWuWcKU82thflealKyqDuSPLKSRIHQgEmB7dOLC33wWasLo/BO2mqAdCgsVXkqg7QrCkSR83pOACYzHEc5teAbmZqu4MG31FqvC30pZU6agtFiAYSd4yhJ6lMkykBMdLE/6hoD5WSj5oLS26Rpy5pVO9T31166uOpccSuSrcU+WnccBSiQk9QIBk/LIiRwhuDQfp1KVuDlTThBdWkbtsiVKGTkEScfl9I2pBkPNvk5qLk1rlqx6otT9qrqZfn7CWy24kEypLgO1UncAQdoKyJgEcNlLalXCkpkt7nz5u11TRJ2pEQRPqAmT+X1AiMAHpGfEcC3qo9czQHPK2aJ09Uag1GiipqdTrzqQgMMoIcWrcQ2Bt9JKZV8v94GRJPEq52+GzWPhv5k/8OaysVy09eQwKwU9U2lCi0oApdTt9M9iRGAUmTPHzQz7+j3xdaN9dJU09QlVK62opQy4FBYcSsqJEEKVOOoz1HEm8RniQ1p4qeYp1Pr2/PXy/IpW6Np4oQwtplsEJTsSPTElRMdTJMnhhZRuaAen1VZ1NyDpHAHl8kGdZNoZrVUqQ4oObUmYM/MRuQrocTPWZInI4hqqs012YQ6vc6+35rifUVKKSRKt3zCfSVH1SpXsCJhqZpa744sF5DVOr0tp9CFFAJz6oCQYmegiAJPEDrHCmspWqfzUlKVNKXISp4BwLK4BJCyFbSYAA9oJ4E3Ebo3bHYGShbo22olyreKGkMALbWpRgLztJPXckBI7THeMvdNqZKVBdvpmg6oeTTJ2hRkjK4OCB3EGPV3yInT1vn0qWFKCmm0CEAbZnMT0JJg9CEj7kcSLS9sS1bl3CuBCduJV6g2Mwke0nrAk/SeEQS+EfF69FY1LG6pApI9m/wBR936JxbUiy0yqyrK3n1q3NpIILkACVTn9DJHtiONlronCnz6kO71KBKE42qxjHScnBic9eEdmp3dSXVdbUpdRsJCEqSAEiMJiYyD3yJPtmTW63JuDwdP7tpOGxu/KB2/nmO/TgNX1ZY0s6nmrH4ZsjZ5Wz6fw2+z6+vuWy1UDtyV6ihTigAoEEop0bpyegGfc/wA+Jxo3SKtWVrbDQUi20n752pW2f3qpy6uMAxMdkyJyZ4aNMWZd6UostJTTIBQgGf3yyrbHfcB6p7D29zVpfTrWj7KikbR5laSXXNhkbynseoiY9I2mDJzgCMhwIGXdB6qz3PDYy0HA6n0Xtq2ilZbpqVLbNPThLanEtlJUqCIUAJI3EAyTgJ+3Ex0By5RV0qnlOfh6AkIcrIj8QSdwQmI7EkCY6+8HXy20Ku9VTVbUKShDMhKwCC6CQPlBgmdo6zG0iOnBTp6Og0/p9N9uzYTZaKW7fbFZVWvzEEd07gmc+vIzkkRxTUttsQp2u1Tv3d6egUS0H+ISmfGIWbN/8j3W+x0VHpCgpLhV03VR/ZNpAn8UNwhxYidogRIyT3EcT3RlrdpmHr7dAt2r8yGElshDrwAGxAzO3pOc7usSGLlboe5axv69Q6ggVq4TT0illYokdBt6BO1IP93omJji4Phv8P8ATuXOkvdypkKbpcW+lcGGkjq+tMCD12g+844pS73BkOznZPU/oEzVNaymjL3fBJPC74T3bdXI1bqxttV9qpfaYcAUKBs53k9A4R06RtEQBxMNUahq+ceq3dOaUU5S2mnATcrnBJZSMeWgz85yBOJz0E8PGt7xcOZWohpGwOFCFkCsq5grE+qVdgPt798cHLkjygtHLXSrPkUyTTJMoxC7i5OXCTnbPuen24X6SGa4zAuGw5dgO5SHc7x92BqajeR3Idv30XzkhyCoNH2mmdq6UIYalVPTrkpB+bzFyAVLMSZz1gcU8+KPZL1y45xp1PUs25On9Uw1bnabclRcYaQHEvBRy5kHemEFMDBSZ6Sab0i9eXw9WFYClSlsdB9Z9uvFQ/j48htRaj8KdHrG03amp7Jy2dXcbjavw3qqQ9tY/EB7djykqjy9hBDiiTgRffC9kdBTfhsw3n6uPdVHW3l09VqmdnPyC5v3bmkk7j5xhOABn3/r+PEUvnNpFPMOyYIVB4CNZr2srCoblBMxkxP1P14QVF6ef9TjuO/qzwc0jqpek9EUbvzgASUhwkgbQkdv6HfiNV/NR95UIUY+mY4HOoNb2rTCFLuNypKJI6l99KP8TPA+1L4yNHae3JpqipubyZ9NM0Sk/wDyVA/UTxKjppH+w0lcZJo2e24BG2p1RV1i43FPvJMxwkcqnHlfvHCT7SeKsaq8d9zqkrRZ7TS0oPyuVThdUP8A4pgfzPA21R4idY6tCk1N9rG2j/6VMfw6B+iI/wAeCEVlqH7vICgSXmBh8mT9FdjVHMKx6QY33S6UFEEiQH3gkx9E9T+g4GuqfG3pCxBSKH8deHRIHkMltE/+5cY+oB4p86+updUtalLWsyVKMkn9eNfBCKxQN9skofLe5XfywAj1qrx5aguZUi1W2gtrZxveJfcj+SZ/TgZaq546s1nKbhfrg62oyW23PKb/APxRA4ijaCvABJ49qYWlG4pMTBPafb78E4qOGMeRoCGy1k0ntuK8KUoGZyf58YVk8eeM4kKMs6njOM4zjFizjOM4zjFiedEa5uvLvVFJeLNWvUFxoVhbLzRgg9wR3B6EHBHHV/4eXxJaPnLa2rbc3m7fqWibAqaUq9DyRA81qeqD3SZKZ9oPHIfhx0pqmv0VfqW6WurfobhROB1h9lW1bah7f5g4IwccQq6hZUtwdiORU2jrXwOyOXVfp65S8526ttrY+mMTKsH79/6+nFhtA800uoRCxumFJUr5uOIXw9fiPU3NOnp7ReHkW/UtKkF1tJ2t1qRguNz2/vJ6pPuOnRzlZznbraZB84EqgKz1+p4T5oHxPLJBumuGZkrQ9nJXvteoWL1Spykz1B7CPb/Xhq1XoZq4NqcbQMzkD+EjgP8AL/mmQ2g+YrrGff24MOk9bsXWmShUKQrBzn9fpxwXbIQm1foRTC3ISUkHBHUE8D672PyVEEf9u0D+fDl8Rb4oPI/wE25VJrS+PV+sqiiRXUGl7Syai5VbaypKFlRhphslKvU6selMpSvE1C0x8f7w4a/09T1dzqtY6Pr3nfLet9dZF1hYn/1A7TlSVt/UAKnG09eO4pJnN1hpwuJlYDglWSdt5QegmZg9DH+HHluiWophJO8lIKcgkCY+vAkq/ifeHMWqmrjzf0iaety0nc8X05SP3jQb8xvKhhaRjceiSRzh+Jv8Q++K8Ulzc5P8waWm0vcLHRUj9y0xWONmuO3zFeeqdpfbXKUrSlKkoITuOeJFLbpJn6CNPvXKarZGMnddRuaXiZ5b8i1uNav1zpewVLSQpVJVVqfxJJyIZTuXJxAKe89OKbePT4o1Pqe02/S3JzV9tqqG60y/2vcqJuop66nUFjay26oJCAQCSpMrEFKgAQTzR5mc99Wc+dcHUGtb5cdS3lFIih/GVqwX/IbJ2NqKQmdu45OeHDRF0Cq/aFB3bsSUqcVlIUI6RAnBJIwTmeGu2WSGF7ZXnUR06IZLXvkGjp9UaW65bbzzu1dQtSyFvq2lSilMD5pBIxnd2B+XiZaXuy75Y7bSPpo1C3o8qnX5Y3uhR3FRIAKiAO5kSIAJ4gNElnyWVK2ubiA4REkAFRIkH2EqPpP0IJBd5V2hSKNLroceQSSpKnN4JHdJ+5Ewe6vpxY1kpHVFS0AJY4uucdFbnuOxIXrVTZtdC3RqS2hVOgnalzbtUoiQQBkZSMAjMd54YCHGA0FBLTq3Q4lSkOSDOCQD6gNpT7dO44MWoeVlqreR1z1k7rC2s36huzdub06pCjXvtKbKzUAiB5aYIxMkdpHAZ1g6mgWWQnbLinwlKktrR6VE5kbRBAJMn7QRw41jAwEDoqPtlUZsEnc7qFajeP4pp3yAuVKQhIbUPMBP1Akwr0qSmJ6AKTwWPBL8MrXfjw03rzUWjXLamm5f0y6q4LrKgNO1aygrLTeCg7kIiTjbuGJA4Cd+d865BKC8EpRLxcSQdqSVQcf5SJMjG7ibae1rzP8AClQVNtbuOsNAp1na2xU0bRfpDd7e4CtJWgx5jS0KUd3qBAIEEjhMqgXZ0qxKN2ho1KpunrSq6ONo89akFXmLlzATtKSrJ9p+sRkYHE3To2v1Sll1mnU1bET5bykFCFFJkkgCJkSAD39gIa9B0KHrmzSHcpt1SFVCkyRsiI+ij8xTJkdRjjuD4uPE14Rqf4Slp01pi22FOtBQMNUlK3R+XcG6tIAeddWBuKSQT1M4jiunu1Zd25K4qKmfH4cQYXB5GrHbt/lcYWKBtyq/C0+9NG0opJkAknEqPTuenYH24dWqRd2rmLZQFQStQDm1JCW0/UdTjr1I/QEo36v8OyG2m0rqXVny0jJJMnriBmO3Un34KPJvQ/8Awzbxc6gbal1MILkAKJBVM9CIAO0g469RwsBwc8vedh9VekUJhhbFGMHoOwUo0bp1nSjDSadhwO04Hko2jcSTt3EQQe6QCZBEjIjggWLSB8xDLhJfWdzy20hwpJAwoKMJz0GSYg44lWhuTVjHIp3WVVrKz0+omLg3R0+k32XPxj7C0bjWwcEA9J3GQDidpeuXFjpRVGsqUF5KvUy22lRcdA6NCSSZ3ZPUFQPchPGquDbZA6vm3cR5R2+ChSA3CX+H0xw1pw49z7+3qn3TllpdI6dp664FSWlAOUrGE+bAMqUQMJAVBMD2wZKlnL/S9RzHun/Ft/ZcRaaE/h7RT7NocWDG4IP/AKaMZEGSR2PHmzaPrOb2u1UFQshpEP3RxoAt0bKQFBiB3JwexyT24sLy25XjUmrLa0mnbp6ChQkUzCU7UstDCdwEAHrOZOcHHFEXi8uLnTyuzI/6D09eiePDjpohAwYa0bqYcjOUKaekar7iyt2rq2yppsqny2zn1dp/3nvwbNYXpzSWlGaalEXO4thDSU4KEYBP6kgD2+/D9ozlY5abIKmoYXTnKziFuLHfb/c6R9B9ojFfXP6c1c/d6os1ToE0oV/06YwQFlJEkjAAnuTiBwtxcJXetc2pMZDTyH6kJDuHEFI6U63+z+wER+RPJ+n0haFNVe1bxSl25uiZUSJDcD3JMx/HtwfNHWRVa+1WPtoCl+mkZJiBHUj7fy4qfcfGnZtJadZYbstyqKiiQCKdxxJRUvH/AKjq3BkD9CfpngHc2/ic81ajUDlXZrtT6YpkwGaejpWni1tAMFx1ClLBUCT7iE9Bm1OHeGm0mBONhjPcn/A6eqrK81U9a8vB3P7+v5Lq4/W0OkbHVV1fVU1BRUTSqirq6l1LbTLaRKlrUogJSBJkkADilHxzPH/y+5A/Dq5gW9OtbSdS6303U01lpaBCLm5WtOgJcVtQSltpxtS2w+ogJU4FJ3FMcc7vGZ8Qfmd4m6GqtF91C9TadqXQ89Z6BxTNG6sNtoJUmdykEo8wNqJSFOLIHtzt8bl0a07yYujLDbLari41TqCEBO4qWFEmBk+ji2oK6Jz2wxM2OyWHWt7IzNI7cdEGdR+OO5uBSLXaqenR+VdQ4Vq/gmB/M8QHUniT1lqcKS7eaimbV+SlhkD9R6v58QdR3GOPHByOigj3a0IZLXTye08rdV171c6XHnHHnD1UtRUT+pzxq3ZmOPhEcZxJUUlZxk8ZxnGLxfQQONjVKXlhKZJUYECST7cagJPHZz4I3wsbDyT5UWfxHc3LXSXC83ZtVbobT1wbCmaVlEkXSoQrBmCWkqEbfWe3Au83iltdG+urHYY35k9AO5PRTbdb566obTUwy537z7ghL8Pj4BtbeNJ23mJz5aqrLZbghFRadHpdVT3K6IMbXKogb6dkzOxMOKH90Z4rV8XW02LRvitqtMaXt1qs9gsVI01T0VtphT0rS1ISXClIJzuBSVH1EpMyZ47H665jXTxH+bd6y8V9i0tctzlO62tSLtqJrcP3yFDNLRKE7FyHHhJSUIhSuN/xebFbLP4uLkLIltNqDLbCEsiGmXEIR5jQ+qFEgiSZJnM8VpwbxhXXi/SxVPka1hIjA9nce07+8joNhy5qwOJOFILZZY5oxqcXbvPXY7NH9oPXqqp8ZxnGcW+qyWcZxnGcYsWcZxnGATxixZxk44wiOM4xYlljvtXpy6U9dQ1D1JWUiw6y80spW2oGQQe3HSz4evxI0a9cpNN6lfao9StJCWXD6WbikdwOyx1Kf1GJA5j8KKK4P2+safp3nWX2FhxtxtRSttQMhQIyCD0PESso2VDNLufdSqWqfA/U3l1C/SZy05vJqG2jvUptYmMYx29+CXrvxcWfw3cldR671C+8uy6XoF176GSPOqSIShhEwN7iyhA+qp6Djj/8Oz4jatVP0mk9W1TbF7QAilqVkIbuMdvYO+46HqPbg7fFI8TGmWPBHqHSVfdGVah1aKQW+gSSXnA1VNrU8R0DadhEk5JAE8KYo3sqBDIP/SaYqlkkRewrmt4pfEVffFr4hNYcxtS+U1edX3JddUMsrKmqVJAS2wgqzsbbSlA+ieIK2ol0ykBWAPpn/XjR8zipIJVPT7cex6d4/vGT7DPDYxuNguJIxuvlRVKOQopx3PT2H06ceaZYqKxIdK1JSADBlQjqMnHXjRUrB64SBkkD7f0ffjdbWytSRGSk4E9D/l/vxOhbyQioky7ATzUqp0OOKpgtLSjDYdA3SYGf6H+PC7SN8NBeWnVha0AgnGCOmf4/1g8NFTKwlKcmR1GTgwB+nSOHLTlnW9VpUlKVqJhAxBJxGccSsnOy4jnlWDf5g2S6XtpVn/HIo0spbT+LcK3VK2gqH0HYAYyOhAg4cvbszVWdsISVQZM/KowQTAPXB9o6STxXHlByouWp7uinoKZ+seA3lDDaitRAlRIGT7nOBnvxbvwScwXfDfzSterU2KyamNrDqRb7u0t2lf3oKPUIEFM+nr06GZ4s/hOGcAuazJPwVMfaTcIngMdJgD4qO3Lcbe8/uJSCooODCcSeuMZkfT78C7W1wcU+8HipSWygJC9pJVtEp3GTjcOnTd2Hq4L3NO8CoQ/VNsMsJdWpQbaTsbBcUVFCB1gAwJJj08Ae9PfjbkNgSA2N8IlJIyQFEnBgDuB1OZJBjiRxZhnVKXBf4gMp5JmaQ0mpXUPhp1taUtpS4Ey4olRXtPQxEBQ+aBGFcPXNnnXqrnS7bKrWF+uWoamzUFPZLe7WuFw01HTgpYYwR6UjeqBGTJkzwvZ0Clnl1VXdd4tIdZr00JtqlAVh2t7vPKNgCmYBRu3E7ohPQiD6keQWaZpBVuacShxRb3BIISEhQI27kkK+xMCBJ4Spm6G5Ksqmk1nZR/RFmOnLSh5/aupcJWpSkx5ajEEd4TPTB9UmO/qvrXLnXNrcUp0mIClk7ROPuSR/I+3G1Sm2mN7gPloAU2k/+pGJA6YEk+3Qe/HqgonHWzUrBNVVnykJj0mfTt+mNo+3FJVVR4jsDkvtWy2tlJCGAbnclPPK3Ri79qBCnEJGyFrLifQn1RtJOE/rgSJmOD7Y7aw6265UKU1ZLQAt71AeavCtoOMqWZgkYCeoAPEW5Y6SVZLallggPuCHnCcLUQcqKhtAE9+ySe/E6uzNOaJhChutlDucYhSQah0pUreqTIkkkf3gAYAMcRGkOdpdyHNTa+cxx/h+07ktukX1VL69RXFIDlSoClYTgJQRCUAdQcyZmUiAcgA/aS01U6P0UzW1iPOvt7/dUbMlZpkZjb2lMkkjJ+oA4F3ILSyde8yvx9zINptKBVvuAna6RMpIPSIxIwD7iOLa8ldIOa81rR6lujH7nZ5lI1GWacH0Yj80bogf5cVfx5ffOY/6W8/0H6qdYaP7tDrd7RUh5JclqTlZoM1VyTNXVk1FXvPrfJ+VJnp0E/wkA8Wx8KfI4UNtRf7uyE1lw/fNtLRCkDO0qB9gRCT3yfrB+WHKdfMW7t3S6Sm0suhVLTlO41RTiVEYCcY7kz24tDYafyaedigkGEp9zP8AvxA4M4afO/8Aidxbz3YD+ePySZxbxG4g0lO7cnzEfl/lMfMWpDFGSDtIkQex+nFe+ZVbCXfVAJwT1+304N/M+rKEuAH0px0+vFc+Y1atxbkKSczKfyif5ni1FXIQl5g3QKDhgAJnp/rwEeYd12pcAMpj054Kev6ogOKk4z7H78AzmDcCtTkZjqT3PHJ5XVqF+s60OuOmcqJnEHim/wAQvUKW7LZKAFUv1S3znshEf4rHFuNVvlSnDBMyTHFEvH1fxcOaFBQpVKaGj3qHYKcUT/8AtCeCllZqqh6b/ooN3fopj6oErMqPHzj6TPbj5w6pLWcZxnGcYsWEzx6QOvGynoXKp9DbaVrccUEpSlO5SiegAGSTxe3wef2cTxP+LzTVFqJvSlDy+0nXKSW7trGr/ZgcbPVxFPtVULTHQhsA9uOU88cEZlmcGtHMkgAfEr0AuOBzQ1+D34I2fHX42NP6bvSXUaKsLa9Q6peSkwLfTQpTUxAU8vY0P/f36cdoefvMRXPznHV6eNNR02idLULVVeaIjZSqpzuaoLQkAhKULLSnHEj/ANKnIEb+Nnw9PgiK+HHoXWdAxzp0xdr5rpump7hXN6VqF/hqdhTi/IaUatsbFLUlSipOdgEATxKLl8OOrtentS0Vv5/0VHWakuDtyqam56SO5LpbSyhKVorJbS00gJQIVGwkiVE8fPnHPFVuutwZDS10PhxDLQZBvITjJ6eQbjfmrb4FbTUEL5KuJ5e8gHDCcRjcgerjsfRV35p69qub12uNMxWP2/TNteNNdrgxLb1xfSAU0VO7EICJCnVwNghtMFRKOfvxW9MW/UWnrJdrBRU6KDTC1WupVSIKaek3KlLCT0OwlW6CopUYUQTx0o5h/Db5sUOgrVadLag5d6w0pbHTTVDGmrrUWu7KASC4w2Kz9z+IcVBUoveYC4uAFKChTbxaaC1FeLBXctr7o28aVrKKgL7dHXW4UYUoN7UopW1bi6EhJWpbSikhBVmTxO4Mtxt1XFLCdTN8kOByDzc8jmTnYdB9bK4krrXfLJUU8D2iQDIBGDlu4YxpwcY5nqfpy0ODxnG+uoF0NU8ysjeytSDBkSDB40kQBxfS+WiML5xnGDhx07pW4avvtHa7VRVdyuNwdSxTUtKyp56ocUYShCEglSiegA49wvEgbQVnAmOJZyf5Ea08QutKfTmhtL33Vt9qiA3Q2micqnzmJKUA7U/VUD68dRvBB/Zw6DQ2k6PmH4tdQP6MsSgh5rRVsqEIu76VAlH4x8ymlCgFHyk7nSBHpOB0k0FcLRyC0mvSnKDl/ZOT2hEIBOxtTFwu6QDDj0TUufd5SBk4IGUbibj63WiM/wD2PG2kd/UnYe7cpq4f4Pr7rIGxjS09T+g5n8vVcTtS/Ao5j8i+Ttw1xzj1LpDlfbbe1u/Zj1V+1Ly66RIZ8inlCF++9wQNxjEcUivKKZu5PponHnaQLUGVvICHFpnBUkEgEjsCeOjHx1vG7U8w9ZtcurTWqVabOomr2xtq3TBLpIJB67B7BKuhUocc4HFb1EnhgsNZVVdCyqq2aHPGdPYHl8cblCr1RQUlY+mgfrDNie5HPHpnZeOM4zjDwYQpbaR5dM8lxtSkLbIUlSTBSRkEHseLaae0fzT8enhgRdbdpq9apq+WVxat71VRMB96vbqk+mUj1lxoto3ESkpdBMKyqpVOje4AJJ7ACSeP0jfCN8Ko8Kng50lp99jyL3cmDeL0oABf4upSlakE/wD20Btof/4ziSeB1yqGwxh5GT0RO1Me+bDTt1X58dUaVueitR3Cz3igrLVdbW8ulq6KraUy9TPIJCm1oUJSoHqDwgqF7EnOVDMZKozx+jvxzfBy5ZfEErWb5cDWaR12ldKh7UVtbS4utpG1Qpl5lRDbqi1KEOK9SClv5kJKDQHnL/ZY+clHri5J0BqvRWo9Mbql23OXKtcoK/YmCzTvpLZbL6wop3IJbGwqJSCBxypLnA8ZccH1Rioie0YauWyh5iz0hXqHDnaqQ78pBSkAYHQ9BxcDxafAc8Qfg2pP2teNNN6r023TGpfvOlnF3OntxEFSahKUhxraT85SUKAkKxHAO0pylUUsrU2VJcG7zNnoEQSQZyZI6/z4PUZbLuw5CCyMcDhyiNo0uuqILgO6BuKkwACIAnEf114JfLrQRqbgwA0JWZBIIUFYJ/SYz7zE54X0el2mKkU7cpJwFggR8xIHsIEHv1M5jgj8q9KKdqmlhoBTywSIGxSfmAx6k9ukGftwettvM1Q1iiXeoZR0bp3lGXwt6+1F4Y9Zsaj0hWotN0ZpF0qXFtpfaWh1lSFoCVdZQSBgYIzw8uU5oKUbAnzVqJKlD1b8de39Dpwh0haUN1A/dmGUyVdAcAGZSIMgHE5jv03alqvwNvcdI2pXKQkpkpEyev1x3n2zxe1otwpoDJgDbn7l8jcVXd1bVCFpzv8AVDXnBe01QeZbw0UrEEnchMGR0yemPqSex4h9osL13Qp0JCl1J80nyEFSEKwkCBJO3b/dj6GCSFZuaNxsVBqbT9Hb7DcEawtIttS7WUKKp6kaC/MDlI6qVMOSE+tPXoQQAeNlLp9Fqs4QUwUo3kEJTj/ICe3XJ4V3Uz66pe93IbJvhrI7XRxws9oob6gojbU7Qhtax8hbE7FbsEDHtnAziR04gtyQt9xDadqEpUEhIML2kTtIHpgkDKgBKVTGRxP9enakhBUz5qISSU+nOEkmAOhP2TGMkRzTGkqmsvNoVUUdSlFWpDjClwkubfzflMyOhAPfInhbuNN+MIWpytVX/wBsahyhdFbheHypY2UjaiBPUAASo+56AdckDvxLuW9sGp9UCoS3NJRo2tAo3pMTIIESrBJJI6HPEXuaRRUrVuYIQViFKC/TnvPaf8T32jg1cttHJ01YmGXWiHEALcQU4WEAEqAI7E/b7iRx87FwDTIei/QdrcYj6nmplpS0bKNSCQ29VKKA2gAFInr9BA/UDsInLtVm56gfZpPSim2tBSQU+c4D6UqIkynuDnBOCkcO1KHbLpolDZXU1I8tpsYUpe2TA6kAwDIj0xEcHvwj+AC73ty33vVITbaBfqTT7VCrdUn8ym1DYnduOTkgkxkcDXzPEDvD3cULuNTBFOH1DsNH19wTRyp5S1qrfZtJUVKtf7UeadvNWyySlQXuWGln5cpCiUzMJETMHoNy55UU1F5P4lve2AlIQkelYCQACABjEwf5xx50HoC16OolU1uoKejS+Qt0to/ePK7FxRysj3JOOkcT+w0yUdABHXMx9uFqPhaKSZlRWHUW5OOhJ6nvjolS78YSzh0VMNLeWeuFM9IUiWktIQhIS2AAEgekdgO3QcT+kSGaIqCSkFM9MDHWPfiG6TZO5CAQUqjv/LiW3B38JbCoKG7aRPeOG1oAGyRiSdyhnzRr5W4ZPfI6cV85i1JLrkFUZk46e/8AX/g08z7lt8z1lAEkn6cALmDVkqcgSTI67v148WBCDmJWJhwbiBHUA8AbmBVS6uST2gmMf68GbmJVEFzKsDHXgF8wamQvsJwO/wBvpxxdzXdgQ31NUFCVSYVBP2P+/wDnxzq8Vd9/b3Pa/LCwtundTTI+gQhII/jPHQDW9d5VM8oq27ZlRxA/045n62u5v+r7pXHrWVbr323LJ4YuHo/M9/ogd/f+G1nqmvjOM4fOW/Ly7c1deWrTljpFVt2vNSmlpmUmNy1dyeiUgSSo4ABJIA4aErpkQncY6T3PEw5J8h9V+InmfZNG6NslfftRahqkUdDSUzSlqdcWoJE4gASJJwOP0F/2dz4Yng8unK67asOqNHc7eY+j1/8A9Ru1CVqtWnZC9pbbfbQHGiG1nzjuQdhgnqbg8vV6M0rdqrxC1GmqOxUl4oTaOXOnbZY0MOUltecCG6lLDTaVu3C5r2FCBlLKmGht3uqI273WC3Uzqmc7DYAc3E8mgdSTsFvDG+V4Y0IC/C5+B9yw+F/oi36o1jb7NrvnU6yH6i5VyA9btPT/AOlSoVKZT0U8RKjO2EwTZ7W/M6o1nXzV3FyolSdqfMKYGRhIzE+5Huew4kWnfCLzH521pu/MDWddoSnfV5iNPaYTSv1zIIEfirk824C6O6aRttCCIDrkbis1X8LSx3m1uJs/NLnJYrgElSH16iTdmVL7FynrWnWlp6ykBOFGCDBHzbxv9mHG/GUpqq2qZBF/RDl2w/8ALSCC7vzTlZ7xabc4DQXu6u2+mUF7jSsXVJpnWW10DoKahLid341JwQruUQSCJgzHvxDeXaqSt1rebRcUuKRpu7NUDXnTscpFtsPsrUT85CHQ2pUgSyQYgkxDxEo114FdZUdi5pJsT1s1C441pnmDa6ZdLbaytSJapK6lJWaOocHpIQtbTqd22CClMIrdSal0xaqXVdDS1NDX827wu33G1vrFWLSqtpVtWqoJQoplgUzfm7SUrFSpUEpkUZL9ltytE76G5uDM40Ho5wOolvcFgcPfgHfCtOjvcNSxs9Hu3fPcZ23+OPgkdFea5nkDyp1ZU1blJcL5U2+zXWpXITc6iqbX5D6uxdRUBYKiJIdWn+4UyPU3MVetdUXfTGqbNbtXaPbttK67p25tIeaD1Q68S82tQ3tOJQjYnYtJxJ6g8D+6cqaWh1DYeTbNW8NGaXbt2r7UtTZ81inYS/R+SFx/1G65IqgokH951O3iOWzmLXWS43fmPfnk0ptFQ1pK/sqaCG6ZFE+4yutAgwBVOKVAx5SzjATxY1OZo5BVW2bDsEtxts92YxjuQHDHTAHZH6Olimj8CujBbq3z6AB2T6HBVFPHZ8JOj1DRVvMbke5WXGz3AKuDmmqtRNW2wokhylUfU4kAZaX+8T7q7c7q+jcoX1NOtracbJSpKwQpJHUEcdqr5qXUOguWq9K3J543K2Uf7Ysqiv8AfW5xDoXUUylDbuKPM2DP7xLoTBhR4rZ8QrwhWbnzWM6u0ZTsUGqq1lVRU0ySltF8bSJLiEYIeQgoKxHRRGSmVfR3DHFb5AKevcCSSGvHIgcs+vy3CQeMvs1dDCbhbGnAALmds7HT/j12VE+RHIjVHiS5oWbRujbPV3zUF9qUUtLTU6CpRUpUSY6JHUk9geO9vw+fh66J+FxQUluslstvNXxLXmnC7tcS6lu26Jplg9H4V+Hax6nkAuvRtaABB4DXw5OSGn/A7yLeqdP1tqc19f7YHdTave2KotJUi0qJS0pR2uuqSYGxQSSnapQR5hJ9tdZp+1aGW3XVVzs2lnAK+uonaxVPedTvKSD+Lu1X6VU7aoSQygpcKYEsNlLZh8Z8XOhY6npSOxJzt8tzno0bnrgbpY4X4RmqXiRzSSeQx9Tnb4nYeqnlTcm7hrV69Uda5za15bXlJrtTVjotumdJudTT0c7kskSQfLD9YpJ9W0GEwDxD6vZ5Kcn9QcwNV301wtdOp1hNPR/hKU1SlHyVBC1Kce/ed3FpAAPoHTh9t2v9Q67s9E/Z9PPUtkoGtltRT0jVrtTDKiClNN5m0BsyVb2W1zkkkgnjnz8eTnrX2LSVj5dPV7VZUXB5N2rFNhakJayhgJWsAqO1LhKgEiVkQQNxpyw0tVfL9FRkaWA6nF2NZa3c+X+gHlsAd+ZVtXSWOw2WWYS6pMaQG5Lcnbd39RHPY425LmtzN1tVcxda3K81jrrz9e8pwqcUVKIJ6knuTJP1J4jyu3HwmTxnH1kAAMBfMhOTkrOM4zj1u3K4xeKynwlvDEPFL429KWurpjUWKwO/t67AiUKYpyFJbViIcdLSCDEhRjPH6UdH20sMJkSVdf8AuUcmf1zxzK/s6HhXGgvD9deYtfTFNy17VeXSKUnKbfTKUhMewce81X18pHcTx1V0pQFK2pE9usfrwo3mo8SfQOTfzTVaINEOsjcqUaUoClaQRJjaRHX6/wBe3E4tdAPKSkjdtEYHzD69+GTTVv8AIZSSANuPUeg6/wCPEpYbKWikAgDuR0+n04E9coq5an/QVAbkkgjcR0kRBHt7g9QY44c/G08PeifDx4pG2tG25u3J1Pa03i425ojyaOtcee9bSD6kIcA37EQhKjiAYT3EqiYJ9+x7/wBTwJPE/wCDLlv4vLEKPXGmqS51DLP4elujMsXO3J37/wBw+n1oG8TtykyQQQTJiyXIUdR4j8lpGCotTTCRuOq/OXp3TYulfsU6hCSNsnJjcEzgZBJ6xJjpBHFh7PyqpdOt0rrN0oruiupW6pZpyT+EcUsgsrSUg+YA2Cdu4bVIyRIB18YPwravwaagYvdkertTcv6l5tlFbVLbTWUVQ4CnyH0tpTO4oG1aEwcJO08C63WlilrENvuM0wUsIUokhttEiVKCASR3hIJABgHpx9M8CW+nqacV8bgQfz7e8L5l+1ziuop6r+G6SMDP+/il1kpaa16dfK2Q+66kpb2kpO8nqRBnEiP+76Dgfa7qnKt3yQQsKMBrIHuAQBn6D3PXHEn1TdVgNqlSW0wWxEkjdg/rjqR/KOCF4fPBpzF59MuOWe2V9bb6RxT6mQgusturSncokQCtQSiYgwlIMxw/XKqi0CHUAOpVG2aklEjqx4LnZyBzQ0sPh2csXKCz68dvViq3L7c6i3JtaagKr6ZTISrzVskHa2qYBkyRnrmOajo/w6AtqNxEpkhQVn8wz6ZSQPf9ODHzL5FXXlLf37fd6CooKpBKVpW1sUpJ+/8Al0n3OYFzR10y/wArmdOm3WptdvrHqtu5IpCmuqA4hKS0t0mPLTtCkgJBlRyePRb/ALvSgghwJ5jHL4c+2V2jvBrK3SQQRtj1/T3Ku/M15Lz7yd26kBKQp1X5PUcqJkSYMTJPTrhn0/qyoeuzFTUun8SyEtJRvO9RwrcsdeoGDIgEAxx55lXMtLdO5IWk+b8gWFEEQ2nESoSCYgJBHeOJX4OfC9qnxk85qDl7o/yarUl2feXSuVLqqdlBS3veUqZhITu6ndEEdSOKhr6sCtc89Ff9uoj/AA5sY6qE8mtMDUd+duDyZbbUtayrA2piY6eqSBJMkkwCeDbpKiVd7gpa0hLTbMgBBAS3JVuHSFYUYPecjpxB9L25rS2j6Gkwkup854LTEJE4PYerdERP3PBD0Zbi5YyFpC11SkKcEKKtoAhMATMgJJAnJyYnj5mr58N0jkv0Up4iG63cypZpDVCrBzEst4/CM1ot9Y2pukdTvbeCSFKKhHQHb75STMZ46o2DZXUzb7S0PIfSlxDqTuDgVlKp+oIP68cpdM2n9u6lpkKAhs/u9qASIUComJI3QAZ+sdBHT/k7zMs/MOzIVQXGjrq+mShFe02TvpntvqSUnIEhUdcDrngfRVjNZjccHZIXHVE8COZoyNwUQbVTkkAyT3SQMcSayMbiBBBEwY6fT68MVtp9wSY3IAg+/wBOJTYGyXQVBKQCNuevt/Offguq3Dt91NdK0x3oOFGYBnh21bUCmtcEqUQI+/1406YaG1BMgDrGccItf3A+StPQA4J6Rx7nZYQg3zJqpKzu2ggid0gjgEcwKmCrqCCTE/Tgw8xq5ThWT6SJMdZHAJ5gVilKXI2yTgfw/XvxqV4EHuYlf1ncpJ7/AF/y4CWtnt5WI/Q5A68F3mO8ApRII7Ge/twFtZPhClhWQkHA7jPHE81JYEE/EZfzpzlffqyRLNC6UmYklJA/mRxzoeI3QMxxeDx56gNr5L1lOkwqtqGWBB91bz/JBH68UdJJOeG+wMxTl/c/kla/PzMGdh+a+cWf+FzyQvHPbmxrS1acc8nUw0XcxZlpUUuCrcQlptKCBIUvcUSP7+MxxWDiw/wwvEsjwu+Lqw32pqGqO23BDlprah1oOop2XoHmFPfaQlUDOMZg8GznGyBrr18EP4cGtPCtZrhprmOw5ZNUc5WA5qexJfgWHR1tWl18vhrAqK+qcaowmY8pT3UyB1G5M64oudPjXulBX0bb6tFacpr/AESSr93Su1dTU0rSkIGJQzTuAE/L5x6EAisfgc1I5qblNqvmnUKIc5m3T9l2ICR5Wm7UpdLShufUE1FQKqpM5Jd9UkTxLvDtzcoeSnxIrA7fHk0dp5r6WXpJqqWYaau1FUqraRlap2p85h+sCSeqmkpGVDihrlxvBW/aLScOE+SEOcexlLSWj3tH1KcaOySNsU1xxucAf8cjKJ/xxvibPfCr8C1drmzW5i5awvde1YdOtVDZXTN1bqFuF50CJQ222o7Z9SikdJ45H/Bn/tM/PbmB4/ND6D5x6lpNbaR5oXpuww5aqekfsVXVOeXSrp1sISVN+cW0KQ4FelZIMpk9u/iWfDr0Z8ULwq3PlhrR+ut9NUVDVytl1otpqLTWtBXl1CEq9CxtWtCkKwpC1CUnaoUF+F9/ZatE/Dv8RNu5p685gq5k6l0s+qt0zQU9t/ZtFRupSQipdQtxxbrqJlGUoQqFGSBF+gZKSshrd1dX4wmibNzN8CGqdP31DaaK+LYoDUnL9A4txPlvs9/NS6GymCM98QeIfh78Y991tyo5fs17qVv6MurNxvrCDn8Hb0OIqnyfTvdWHhtJ9P7tWSQTxfr4x/j7tV00/W0NruS3KaxsVDC3mKgJpaBQlTlQpZw4sNpbSIAA8+ErO8AcafDNq1y16NcQ4HwjVqXaS4hKyV0lG84POdSZClFtK1AAAlSlxhU8I3HtqgqqVnisDnA7Z7Eb/RWX9mUrzPM3VhmnJ94O31XSO485UWzmzcdVvJpm9K1tkYs1nuTS1rqK55l52pWtpE7Q09+IUGNol38KDtPmI3ijVnMGsHha5nvXyiqKmvrbhcUVtnpnBUfjXayvbqaUpWcElDqIHq3KC0+4Dhz55k2i6VvL/Tool0IoLsLwloKS8KNFJTqbpAJPd1xIHpElHaDwOqu8ruviIFOXwmkobPTvVNMXUJcerC482w4Oo/dtKfBAwkutkkEA8UJZqKMxsmdFpwGuH/GJ2lnxIzkjrghfRFLZtUbhr8xdo77vGXH4HBHpkJz8QGu6Gt1ly9TS17VQ5clXK5sVBpFKbfS6yktpSRAglSVpJ9J8oRkRwL71q2psGqr/AHCjqi2jRz7tRQNqdAcO9LT1W0TO1KTG3CoClnsAOI5cr26nQlS9StU6Ljbq1lq1OO1CVMtUdPVksKnuHCt6E90JQIIE8DbmFzEqWKS+W2nrKakoa9hhyscdIcefPlhBaT3UpxQWpcGc56DixLTZ9DfCiOdPl3/5ZJ+TsKRV3ZrY9Uw2dh2239JAHzbq92FZfkpq4AVQpUsKVYrj5tGuqrEIttv8weY26pMldU8EKSEOEKSNpiDkG3Q2qbXqStbr6Wkd13d0K81C0U5qKSle3kqWnzFClQoKzvcU656vnJEmk3JvVS6jXFxLVPZBTN2ylpUIultFc0ylsqI9E70IG4wtcjcPUoGJunyT1BqvUtmpqpik0XeKVgSPwtzqKNKiQSRhh1B3RJAUPr1EL/GWumj1OOB6u08+hOM/IhCrPDDNKSwDGf7cj34yAfiCixRDVl4X+Iut5ore6oeaW6ZZuNUMTCnFgNJIJgwlQ9Ig8cf/AIz+r3tReNu/0iy+W7ShqlAWsqAUhtKDEmJISCYAEnoOOwFk11qGzvJJ0ZVOFIBCqWvoHyFEdNqnkq987MyffjlZ8cnk7c9O+Im365eoqygoNbUSXE09SEpcpn2oQ6ISSNqlDcCMeqB0ngJ9i0zGX+USaGl7DpDSD1BO+S4nHdLP2zNe60RBm7WvGdsdCBtgAD/KoxxnGdTxnH1QvmNZxKuS3Km5c7+a+nNH2dHmXPUtxZttPIwlTiwncfokEqP0B4ioE8dHv7Ov4XTzH5/3vmRXUwXb9FU/4GgUpMg1tSkhSgfdDAXPt5w9xxxqJhFGZD0XanhMsgYOq7L+HXlJbOUnLLT2mbM0GLVYKBi30ifZplsIST7zBUZySSTmeDfpe3FW0hJATAH0+n6jiJaTtstoAEiNsEdRE/19+CZpW2zskAnocZPCE5xcS49U8MaGgAKS2ei2sRmD0MZ4WrUWxG0wnAEzjv142UiA22UkwYEE9DxoqHdoOFJAke0f1/PjxZndJauo3AkZgAmfvjhMpYUuB6ldJ7/+ONlQRtCphIO0YzGP8+3CZxwECQZVggdgR/XTjFshF46+SNf4hPDVfLFafPcvLTjNxt7LJSDVvsqw0dxSAFJUrJPpMHPTjk3zs5Z6q5D379k6pslZYq5KDsS+namrSkgktLHpcSD1UkkHpPy8dvC6CqCQVewgkf19uKu/GB5f2PVfgd1Hfrt5rVx0SW7lZ3UO7CipddbYU0o/3HUKKT3BSkiCOLP4A45ntj221zQY3u59QTt8lUf2k/Z5T3cOuzTiWNvLoQN9/Xnhcr2OYRRZ0Wo01IaVdWm4B9VMDVgttqGxLnXyhO4pn5gk9Rx3i+Edq/S938Idkp7S5Ror6TcLghJCXC6TJUR1gg4J7cfnas9yXXXkJSlRB2rEgJKjMJCgZ6iYH/dAAweLBcq+d170Cyr9jXevt6lgb1U7ykFQP97aYEGQB/rxeNTZxeoDA6TQc5B/RfPcd6dw7UMqGRCTYgjOPkV0B+N7qDTV35g2elo6mkTcGmFfjHm0hZbnoDGScf1HHJ/mtdgt1bbTiVNg7FGQBnqP8sfp2kic0ucFbqB916uqah59353XnPMWoSJMkxGZkmPr7ibRXiJq+RHOTTesqGit9zq9NXNq501JcqcuUj62iTseRAJSYGAQRAMzEm6yWO02plCx+ssbjPLJ/RA7HSTXe7vuUrNHiOzgdB+qEVv1s5p3mdZbq3S26uds9e1VttVtKKqkeWlSVpadZV6XGiQNwO2QVAnMj5o/mhe6bmOjU1juFZpi6P3J2pD9n30QtwcUp0+VsJDaUBSgET6QkGew2c9OcNbz35yao17cqG2W+5auuNTdaiioKfyaWlecUSUspP5QrEZJ2kzKiAi5e2ZSqlLiQ0IAQS0BJkhRUTJzBJKhmAfuKiDXTz6upX0GZGU9NjOwRBdV+0ri6SC8XloZQpOCR0In8pxtzJ65HXgo0FEinoqSmklBBcU4AfUSRhQED5eoJJGBMEcQPSNnLtT5pQ4l2llwyNqWyEkAgxMAGZ+8dI4LPL60J1FrunZKXFpQhCSUpgLSVEgKkEgfL0EkE9ySfmS6zCOMuX6GFupwx0TzouzK0xUs1TiUtOMtqdcC1BMFIJAwOgO0wR3yMji1vw89NKt2ibheXWwhNbVKe8wABS0N4iR1AUVqE9QQOkcV/wCYun10FYhhhohx9SUn92FFRJkiCPoY9uLjeHfTqNJ8nKOnRAWpjarakeoqnMdes/ftxVF+vD4YWVEftagR/wDnf81Du8DJKYxH+rZHGzOprGkLSc9Du6p79P17e/EusLMFIAgq65z9/txENNPlavLTtKgoJ67ZIAwP66jia6eaC1HB2kiYESf/ABxbtguRr7fFVuxlwGff1VAXGmFPUvhHIHbKnenGSGU/Yyev9DiMcyq7c2sKSSlSYKZifrxKrQrZSlRwAnH3/qP48D3mZXeVuC1bZkhSRk8GCMKGgrzIr1FazIjJKZ6n6/b+p4CWvK30uDBnMESBwWuYdZuU5hQGQATAOP5cBPXlZCT1iSBBkfYcakrdiEev6oDeScqERmf04DGqKhT61ykpiZEzGeCvzAqT6oCUk9ft/hwIdWvyXOwEzHHAkZUgclTr4jV+AobBbwoy5UPPqHYhISkfzVxVU9Z4O/j8v5ufNqjogvciioQoj+6payT/ACCeAQcAcPlqj0UrB8fmkm6Sa6lx/ey+cFXwfc+qfw5c97Pqep0xo7VzNOFsLt+p7eK23KS4NqlLbIVkJKgFQSndIE8Crj0lzaoEdeJssTZGOjfyIx+8KFE/Q4O7LvHyK+Ira6mistt0vRL0Y1T06U0eg7hWJqbQ+yBO3T9xnbIklNI8qCSQkMmdx05jVmmPGbyPXSitqG2qsIqKSsYJYqrbVsqlt5Ewpt5l1JHZQUkgjJ4/Pbyi8SeoeVja6Jl1Fxsb42v2ysSHqZ0T/dUCAfqM8dBvCV8SK2DTxpWXmGk7T/ySoaekJTvUB+ZwjO7cokNgkHCR80/aL9l07Z23m0gioY4ODwd9v7jzPoTk8wSdsfQH2f3e21zDQTvDQRjQ7YfDpjuPoraaY+NXzu8KVwRpHmje65X7PTsor/Q25usbuKAISp+nCkrbWIBUW/MSds7EZBZOfXxnLTqzRtczduct3uzD7BXUUdnsVdR3J8mISpTjSW4SZG4ux+8VDaYHA85l89NI839HK/GP0FRSOIEpLYedWYmUAkyUxhSyJzEJTxWbUfIPTd0uaHbay9TWxQUadK3AfPVuPrCykySCPlG1PuZ28WJwvx7WS0obdIS2QbE42Pr6E/JRb59jdO6ozb5vKenPHoot4hPFHffFFX09ls9Cuw6OafH4el3y9cHC55gW+sHapQWpS8EgboJgRw+8vtPv6dondMUzqXr7dqFpoOhcppi688HFbkHcGkojqQVLHX1SG+7Wqh0s7VKtb7XnMMLqKl5tnc1bkJz+HVuO5biwEpOQUhU4hIU7VXM5rQ9jq6G3viovlxShb9SgBaEq2QVelIXIIhDYgI27oElSp1zuE9cWkDIPIfLn6DnjqjVj4corNA6NjvP/AFO235jA7nPy+iI2oNein0lYKqlfqqvVmpn7fVioq0fvSlsoKkpQ3hLDSCoJiSQ4clSyox/Ule/pLWFPbrdVebX3C3u/tCuckqbSXmgmpd6HdIcCEAAAFCQNqVECms1G/pu1UiaAIbqyG6eqqqxakIYDaUqSnsIjbtQJCtyxJUkkQ2+8wnHb1UqbuDrpUhbD9fUNesjqNiB9JAzABPWTMKmsrg4gct+fryHuHQIx/G4YWBxGCC3ryxz95PUp95l8wUpstdYbMkOUNPU7w4k7UoQh0LayoZ9YWP1JMdwVzW5khddVUdIpC3XPRU1KZyO7bfYJnJV1V75jhPr7mgl2lfoLctwsrqC+pZcncqACon8yj79oEcQF14uEkzJ78PlttrYmhxHr/tUrxVxY+peYYHbctuQGTsPmjL4bOe7WltYUKLrWP0TjTqfw11bcUh6njolagDKO5BSQYEgieOj3Jbm3alM01VfWnbWdgKNS2N00fm7xhx/y5CAr/wC8lbS4gED08ce0uwODn4X/ABpXTkjVs0F1TVXbT6VSGkvlL1J9Wz7dik4IJHATirhZtyhJj2djpsfhtj4HI9EX4B46ioJBSXL+WeTsZx7+uPUEELtNYL1qVmnbdor5p7VNC+PMQqqSbdW7SAU/vGUqYcGevloEdjwMvHbyHuvi88MN3047pWtF8tSnLvZ3GKynqQy82j942SNiyHWwQAEH1oRgdeB/4ZOYNu5l6ddv+gtQPs0aFE1SaJAU2ysgqUH6NYLSP/c35U/9xO7g/aS5vX+3NJLzFvr2krDf4y0O7XoIwfIeVInodjqhEfXj5hntdbY7syrp2s8SN2dwY3eowCGnI22znsvo26W6ku9rfEx7nxSDYtIkb6dC4Y9QML8/lxtz1qrXWH21NvMqKFoUNpSR7jtwnJ2k/Xi6Hxi/DHT8uudC9dWChqaXTuryHnkLpVMppa8gGoZB+VULJUCkkQtOSZ4petMAcfYNpuLK+kjq4tg8A47Ht8F8V3a3SUFXJSS82Ej/AH8QsQjcZM/px+kP4S/hXT4XPBzpDT79MKe9V7H7YvJ2wv8AF1AC1IViZbR5bWRjyo7ccUfhLeGMeKTxraXtdVTfibHp9Rv12BTKVMU6klLZkQfMeLSI9lHtPH6S9DWg01O2CMkSSnqo9eB99qMNELeu5Uyy0+SZj02CmulrZvIMbUpMgDJ6TwR9PUgQhO35QPv+v+XEX0pQEKG7H5ukjPE8trAp0hIHUYxB/wB+FtMHILetSUMkgGMGPcz2+vCOrcSggqjeD06lXbpxuqHcQcycfXhvefBUgFQIEp3A+x/yIP8AA8YvQFrfX5aFkSpWcpyeEjziUkqAhJOfr7fy/wAOPZqSQTJCgqDGRMx/p/HhKpYVux0zE9/6/wATxi9WLcHmTKSYGU8Cjxpch7h4p/DrfOXlDdaWyJ1K/SMV1yfphVKo6VFQh54tNEgKeKUBKJKQlSgqcQSiPSTgp6SOPO6SqUn2gZgxn+fv7cdIZnRSNlZzBBHwXKeBk0ZikGx2PuXFXxifDt1R4I7tR19TU0t70neKhVJRXemSsJp3sqSzVIIlDqkgqEShUKCVSOD18IHwJWHx1aw1AdQ3SoprPptltZYplDzqlS1EAiRCR7kDrMTPF+fEvyYpfEV4f9XaKrC0gaitzjFK478tJVJG+mensUPJQZ7Z+vHFblD4huZvgQ5n3hm11tz0nqu2VDluutPuO5hxEhaFAylSZIIOQU7SDBB4vbhTimrulA+DWGTN68tu6+fOLuD6O2XCOofGXwO6c9x0z+SNHxivCPZ/BjzzVYLJdDcKOqoWq1lpR2uttqO0IWBgqESCBnHfpz61/eUOIUGNi0oAHykIXgqCoEAZExnqSPSCSWvEt4kdT8+tT1uoNUXGpvV5qv8ArVDrkl8g7AMDoJERAxnoeAlbrHW621RRWi1sfjbjcKlqipmicvOuqDbYkwJUTAnoTkTjg1cquVsQjmfqIG/v7ofZqGB0pmhZpaScDsFqs1uVeHGmgylaEvwd6VQQVfMRIwJ6D+8ehzwRLXZW7VZnahSQinWmCJA80bjuCo6HP16+2OF2n+QF45Z8wrnpXUtvct1/0zWv2y50anEOGlfZXtWjehWyApJGJBKSSTAIkOuaM0tChmnn1KKvMQnO4RCoA9zJ/U8E7NbT93NU74IVxBeAKltFH8U9aZpk0dkqn1OFAqXyhhs+oqhQTuzncAe5OT9RwQ/D80A6/Vl1QDK0pSFAjcJ2lQx9Osk/URHA6vDiKHSbCioAs0pWifQJ37cyCRlPTESZ6iSlyOYFFpM71FDiUhKgo7QMggDsEnORnMY4+Kr44mmPyX6gwnz4PVF/mJQN12t9P71BtAp/PUsyNhiMx7TJMjp79bSaCq00XLyhSClKFRvJUBtAAP8AH/HiruplqpqHT9d5a2iwgMK2+k7SDKZMgjAIEY+gODbozVoodE06QQqHxOzoQoHA+n6+/txTd2jMkLB2yudbEXNbhHi23FDtuSoYU8oFtREbTM/+P58E3lxdkXylQsEhxPpcBwQsdf8ACfrxWzSuu/MtRaW6FOU7oStROQJHqOfePoJA4NPJav3a1LaV+isbUtJMhKhAUQPbI9uivrxP+z27zUFy+5u3ZKQPce4/JV5xTZw+nM3Jzd0b/N8q1FQlICQCdsGf9OBPzLrlBS4MD/t78FC9Pli1kQNxGQO/68BjmDWpU4sGREgGc/19OPoRyq5B/X1VtDhMQcHBnrwENe1SklYiD37n78F/XtV6FwQZ7JBmOAjrtz5xt2pggGf1Mx/hxzet2IS67dBK8z+nvwJdWvShZHQiff7cEzXdQS8sEgyPfPAo1lVCmpXVqI2hM/aDxxA82FIacBc6fFHfDfeemoHBBRTvppkx7NpCf8uB6oQBw5awvQ1Dqi51wn/nKt18A9YUsn/Phs4smFmiNrewVezP1PLu5WcZxnGcdFyX1BjhVbbvU2erQ/SvOMPo6LQYUPp9uEnGTHGEZGCvWuLTqacFFjR/ipvdlfQLhNalIgvNlCKjqCCFqSoAyJmOueueJbUeKFnUTDIdWwyVKR5ilsKD6EJIJQlU7BMGIAAJJiTxXrjOB0tqpXnVpwUz0vGF0gZ4fiFw9VYu58+v2m/SU7VdTfgaVW9tlDAbb3jMuL7jcd0ASSJP1fOTN+a1XzKRb2Kxq5VQbcqhTBPrqwhJLzKASPMUtsLKQTKlNgfmg1Z3H3PEr5Xaoe0/qWhqaWrcoq+hqEVNHUoVtUy6kyFT9CB/rxxfaI/DLWbHBRCLjSrfKC8dR1PToF0dofCjatXUFtRUVhZtt4Q2vTte2wX2KlJBWaV5HymckAJlxJlKt4PDFzY+Fc47ZH019dU6SbSUpRc22V1dnKsk+Y+lJcpxOQh9LYAVIUoAKVKfCp4rdN6otNVar8xSClvXrudqed2NsPk7lVFCkn1NqMOKZQQ6yrLczAuDy25iX/ltSUj9rr16206EBluo/GNtXVtHUoLqlBFUAn8qy06IyHD6lUtcuIbraajw3jkds7B3ucdg7uHbHm3nhXjHabdeqPxof6huN8j0IBzjsR8eS4j+JjwZa38Ltxb/AOIKBuptFZ6qG70LoqKCuT1BbdT6TgiR2kT1HAjXx+iHXlLyp8UOlrnYtUaXsi665BSHGallVoubTzgIDu1SUeY4BmVJWSIExxxE8cvhFu/g85z1Onq1Lr9rfBftlcUFLdYyfzJkA46QQDg8WPwdxnHeQ6CVjo5mDcOGMjuOhVG8XcHTWhwmaQ6Jx2IOce//AGgvx6AgzPHkiOM4eUkJ70XzAvfLm/M3Ww3a4We406gpupo31MuoIMjKSD1gx04t5yV+M7rHS9O1S64sds1cylJSqvYQmiuKiZ9bhALTy+mVICj3UTnilHGcQa+2Ulazw6uMPHqP3hF7Vf7jbJPFoJnRn0P5jkfiul3Pv4hnJrxa+G3UGlq643nTdTUNirpae6281CzVNhQSUOsgoTM9PSPVJOMc262mTT1S2krS6ELKQtOUqAPUcJZPvxNfDvyaufiG52aY0TZ0FVw1NcWaFCwJDKVH1un/ALUICln6IPHC0WeltcJgpBhmc4znHuXa+8QVl5qRVVxDpMAZAxnHLOOq7C/2dfwrK5feHGv17X0paufMCrCqcrEKRQU6lIaiegW6XV/UBByCOOqGk7aEAK29hIOYHv8Az4GHIHljbeWGgrPp6y06KS1WSiaoaRsCNjTTYQge07QCfqTwctKWslQwIPWRPaIj24WayczTOf6o3SQ+FC1ilGmaANpHeI6p6/78SQJ2NQSn9ex9/wCXCG1UvkMiO6Ynv7cb3FHO2M5A6j7cRl3O+y01dQQYB6HP14b3VAiI+Yjr278b6pwLRIJAwQY6cIKp2FEHKTj/AF4xerUp4lpUo2haiSJ6fc8aFwXDJAMRMYOO/Ht1SvLJ+YgbQZ+b7+3Glbgnd27mOnT9eMWLx5hO0x95MRj2/wA+PpHZU4yZwM4/hx9bhMQlIIJSABGf6HG1tuVoCZWVkAEZJVgAfr9OMWLW7ChEgk9onuc/bjmF8erkto/R+odNcxqa9Wq26xvxTRXOylyay7MIQQ1XpQJIS0EpbcUQlKgluCpTZB3fEc/tENh5I37UGhuT1tY1NquzV5t9dqK4tpesbBQIeFMhC0qqXEuDy95KWpSo+sQDyB5leI3UfOfWtz1Fqi+Vt61Be6g1Fbcq1zzXqhcRKowEJGEoSAlASAkAAcPvCNBUU1Q2te7QO3Uj17D6pB4tq6esp3UTG6ievQe71Ul1Lqv9suKIX5mwFIMBaIEEd8wAE9I3Rk4lnt77rV4SptflpWkoBPpCiEgNrIBkK3QoREKJ+U5EeRqRtdOpDjnluODJjcQIkiQZ3YH1yf1eNCuivrVVLzag2QIBABSD0k4HeJgkgACSOHaSd1RLg9UnxUzKWIkDkj1ywcXQ0UVClF/aFuLUsqWJG8kqyonr16kmck8fNc6oF1fSy0ltI8xW1S46TtVuMwrqnBPUEDBkR1vU6qC1ja6t1apWSVYHy+r5pPcGcglJnsNVvq1vOB8mdiQoAwkgRjp9BBiB1kiSRYLK3RTNpo+WFWD7YZKt1XN15IoX9aEP/h3VKCHmCyoBQbSmDhIUJISPT7kp29eC5ycbcc0r5flqUVgZ8sQralIwfynvBiCQOAvzGKkMVDiTsdYIMyYQCYz9YUOsRHYjJj8O1zTdbW6IQpTyErATtIKtqZAkQcj7kQfrx8RXuJxoXPHQhfqiHATAHsjfrCnbPLQqT5inKZttYKjs2pOYicDHbr9usl5Z1hvGkU04dAdCN2xH5T+YE9zg9v8AEjhhu7Ip6FFMobjVUwSlREbBtgdO5wCc9enDDyN5gtaWrmqOuUlCWXw2ggE7wOuVdITHt/gOKpdA6Wmdp3IOV0kHkIG6JbN+f01ekKWFuU7raGHVQJP93+G769Rnix3hX5hsV2pre0/UJLjKi1uWQB6kqnJ6dsH37Y4AHMSzsVd5aYQG/wAPcGw5TlWRkT9ZPTB6fYE8RG2avvugqw/hy+8hjdsQqSomflgmZA9p7Y6ngdRksnjqWDzMIOOWcKDW0La2mdDnBIIXTbU90bqLckNOtrABnaoK657cBrXlblwzAJMgmM+/+314B3KDx4MW+qprTfWiyw6pDRqSDsQpRA3E9SnM+wEx14GvOT4ha6zUFYzY2KY0LClpbqFNqWt4JkBZkgAH2A6d5ni6qDieKen8WRpa7kW8z7/cqjl4GuQqDAwZGM55BEzmFc2mKd9xxZSGwSo/3T9/1A/24CmuLuzV+aW1ev8AOnoR7fX/AF4GeqfE5cda14bqXXA3JQlCUwlSgPlKB3MxP8O3EXr+dSKepARVtthJkgmUrAHQHBInA+ggHHGG9yOnA8P8P6593ZFv+gXtpS50g8XmAOXuynHW7+1xUiDJx1g+3AF8TWpxpblVqCskpW1ROxHUEp2pj9TxNtceIG10bSVfu1KcI3IKpJSRMgDMR/DuBHFbvFbzVHMzlJerfa6aqW4hxlQCGypS2A4NylRMGR0HUH6Hhkt7RNO0DlkJKuduq6WmfLLGQACqXnrxhOOPTiCgkEQRg4yOPPFjKsFnGcZxnGLFnGcZxnGLFnGcZxnGLFnHtt0oWDnHtjjxxnGLESuW3Oz9ksijuiPNpwU7XdoWREABaSDuSPtPT24Odj8Zus+W+l/2roDUwYqKUeXVWyoKK1lTZHzMhwFQjumYxgY4qIhRT9uPSKhTRlCiD9OB09rp5j52gjqCMg+8HZHabiCshi8NriMciDhw9xCudZvjmc1qK1N0lwsmh7yhhBS3+Lt69qSRClbUrCTPcRHsOBV4r/iBX7xgWihpNRaW0bak2tJFIuy0SqNTZJkk+ohQPtAzngBEcZx5S2ehpna6eJrT6ABRKu8V1U3TUyuePUk/mvvU+3HzjOM4JIas4zjACo4BPG6konK2obaabW864oJShsFS1GegAzxixatu6O3HTf8As5PhVVqrmdqTmncKYKpLA3+xrQtQ61LqQqocT7FDO1E+7+PlPFH7N4KuaFy0/wDtmo0ZebNZQf8A+43lr9mUny7iQt/YFCM+me3Hen4P+kNCaH8IWjtL6Q1Pp3UlfbLczW3tVtrEvrRV1X751SwPUn1HYncBhtIMHHAu61OiA6OZ2RS10xfMHOGw3VvdF2bY03AkmBHY9z/lwT9MW/y20zA/KcjrHEY0pa0nbA3RhWPt/lwQbLR/h2oI3kZBT+ccJw9U2FLkNeSJyFEZUR0+3CWtd8segH0jcAO/fA4VuKSlKCJgGUn2PDdVukpmRvBII7q78erUd0jrHvmUEqMgnb34SOLIMzhWevQ/XhQ+AlaYVOZ65/8AHCdTQKldNgUADH1/1/z4xbLWlSnGh8xBkHt79OPi2FdBk5jEAjjalpSnEhCN6yQkJTn1GIH8eOdGuv7R3yp5Xc/OZ2kb7p++XC16NuRttgvGnlorBqBbZDdQVBxSEMpS6HNqwpQUlHQmJk01HNUEthbkhR6irigAMrsZVqPH542tMeAHw43DX2pGl19QpxNustpac8t69V60qU3ThUHYgJSpbi4OxCVEAmAePPMH+0ic9NfckNY6Yet2jbNdtSuFuh1DZWHqSssdIuQ6w0grWhSyg7UvqPmIlRyogpA/xIfiYaz+JFzbaut5bFl0hY3njprTqChaLS26ltK1OOpSkvvrDSSpw4EbUBKetbKt/wA0bUjpgD+97/r/AL8PtosMUMAfUty8/RIV3v0s0+imcQxIn6gMogJ2hOEgdEgDoJ+3CJFQpo9MpwOk4mfv2+g+vHuve3O4kJmR6ZIHCo6tYotDv2gWi3OPO1qalNxWhRq2kpQU+SnO3YSdxkTI4Kyu3wFBhj6lahfVbg2dq21TtBJJ69T1zj/DgpaQqbezYqCqZr1VNa+t1NVSrZWgUTYUA2SsHavzEk4T02wT24DdJUulBaOW1ncv0gkkHGevvAnOOH2zV5p0ADYUpEKJGTt/h/A9f8OlLKWyalrVwB7NKONPcnL1/wAs2VPKcSAkyVKV2Bk9gO3YIP8AeMze76Xq9Ns0jNdTKp1VSQ6A60tr8QJwRuj0jaqCTEhWe3An0RdQ0EKc3gEgLK1KzkCAYJ3SSQP+2PqbO+KLx7am8ZFr5eUWpLZY6Oj5cWVFioP2VSfh1VjIWlRW/mN6gEAhJ2g7iACs8NtHVEuAxz+iR7hRkdeXLbmtOomP2oghxZ3Lp1QEwRKfUPSYA9+v5YAJIPD14cNWmyXKlClLW0GhuTuJ2x2mI7xHuTPQDjbzU0dW8udb3Gx1CQupttSunK0Kn1pxIJ27pI7jGBAgcQ/SledNauK1pmmfcIW3MhWDuyIxjAI2jHeOPnGSjD4paSQbkL9FJ5CdFRGfLsr+8yU2u86JtddbXVqZLDfmLWkHaYTKDBgxMDuR1PAV1fYnWKxypQlYZSoOHae4BhU56YknIiT7F35f8xVN6JqrSSlbBG5JIBJYMK6GVAiUz0JHfM8PWir3T3NP4erbSW3xKFqGPpHbt9cR24pZ9PJQvcCM4P0ROFp8Pmkeieai7vbjp+5uF1umlykqAqHKZQ6ImdsdPuBHfEtptXXCrtATXUQujaAUpfGV7ff6jAAIzk/TgRcwbIrSGrlrSHF0yiogEA+naAcnvAgE4A29+CFyv5yU1FTKZqlNOsuelC42rI/lPc/m7kwM8eVtM17BNC3K3azGzQh7zB1wq1uS1bS827O9mFEqT1kGDPT26/zGWo+a9lFOUfs2tYUgSElRO2T3EHvnMmIJnizmq6ax6yZWhmrS2ogwjzDLhPqMdEyCD7DA6xwJNdco6Zxai4+lTPRCUKkIJPUCIzJ+5nABjgraquHAEoIKyaTAGyAep+dSKphTdHSvrCgdpLREAA9DmB74xnIkkwO66su92cUWkKbBn1DcCZ985iDiYE9COhzvvKxqlcLiWzuBIG9RSSInEnHT9Jx14gGrdFqYQreXApaQAkmVHE5nt26f4cPFA+B/sfVA6yqDG4IwhJdLLcLkrY9Ur9UpUW1SAScwZ6ZgiT1ni2/w1/hm3HxFaOu+t62oUzpkVSrWwyEhX4upbCFLcn8oQF7enqKsYB4qnqewVVKqP3hUYSElwBSSTAIgzkxA/wBJ47ofBRs1Xyt8D+mdIampX6S6rqK64VNLVwHKXz6lakojsdgQqDkFaunThkjb5cgqt+J7lmn8P+49eyplzV+BDoDW7DqqxmuoKxYxVUKw27PvkFKvsoHimHiX+AjzH5Zofr9B19Lrq3NAq/BqAobmkewQo+W73+VYUeySccfpB1lynZrGy7ToS4yoH/4+36fXgSax5XBhbifJlIkQof4HiXBc54tmnI7FVrNb4Zdy3B9Nl+TrXHL2+ct9Rv2jUFouVjulMdrtHX0y6d9BEjKFgGMHPThnUmAOvH6b/ED4OdGeIHTy7VrLS9q1JSIEsisZlxjt+7dEONn6pUn2yMcc5PFT/Z5WXnKi48qtSG3nJFmvyitoHsluqSJT9nEEZ+cdODlPe4X7SeU/RB6izyx7x+YLlSTgcZwSOf3hJ5ieGG+qoNb6Uu1iO6Gql1ndSVP1bfTLa/0VORIBxwOVt7FRwXa4OGppyEKc0tOHDBXnjOMjj6lO7j1ar5xnGxLClKAAJKsAdz+nBL5S+C3mvzzdR/wpy91beGXDtFS1bnEUoP1eWEtj9VDjwuAGSV61pdsAhgI7zx9E9uL18pv7Plzv142y7fajSujmXQCUVlaqrqWz7FunSsA/dUfXiz/J/wDs1WlLQtpesdd6hvziSFqYtlI1b2lDuklXmrP3BSfpxCkudMzYvUyO31D+TVx28sgTHD9onlhqPmVXfhtO2G8X2oKgny7fROVSpPQHYDH68foN5S/Bp5DcrFMrpeW1kulQ16kv3pblzdWfch1RbP8A+A4snpDlJb9I0bdLbaCloKVsBKWaRlNO0lIGAEpAEfTiBLfYx/LaT9FPisrzu92Pqvz1cpfgweIjmq62o6Ef01SuH/6i/wBUigCfqWjL0fUN8Wg5Tf2ay61xZc1rzHpaQKSN9PZLap8hXcea8pA/UJP247KUuiEhPyCB2gpn647cOtLo6QMYQesAQOIEl7qHbNwP36qbHZ4G+1krn5yZ+AdyH5dBh6usN31hUNq3JdvdxWttR9i0z5aCPun9eLS8p/CRoXk2yhvSmjdM6cATsBtlrZpnI9i4B5ip9io8HSn0hHpCNsnEjp9OHSg0iS4nYkIcUoJBmNqpwZ4gSVc0ntuJU+OliZ7LQF+eT4w/iPf5o+LzV+nqC7VNZYNNVhtNMkqltstbQ6huCQUh7fK+qinPQcRX4dHjpvngB5hXvUthslFqX9vWlVudoq2pXTsLX5qHUuqKElR2luIEfPJONphvxILtYbr47ubj2l7Suw6fGqq5umoC15Pk7HNi4bHybnErWB7LBgdOB7ou4Nlrasp81RIAyCfv3j7frw5U9MySNsWNsD9+9R2Frcl5X6IfCX8bDkT4hecWm+XdHdbrZ9V6noaV2mNZSBNtNc6wHV28VO7/AK7aj5fqSAtcJSZ6k34mfxU9EfDF5d2+qvdC5qnWN9qPLtWl6Otbp6p1tMKdqX1KkssISRClJJWtSUpxuI/NmNHLqXP3KFOKCgpJA2hBBEEHqD0gzIjtE8auZD911VqC4Xa8XO5Xu+3FXnVdyrKtdVV1Ss+px5xSlqMT1VPb248PDMQlDgfL1CjOrZSw5591130//a2dLVmqaGnvnJG/W2zPJZTV1dJqJqqqKZReh5SGS2gOISz6kpC0qUsFJKRB4u54bPiveHzxbM0LWj+Z+nmrzcGHXk2S9OC03RkNgFwLaeITIGfStQKQopJCTH5ZbuwqjcAgpVlJSn+Ufb+uvCYsF2G1jzBJKW1epCfrnjlPYad5wzyqK25yR891+x1FxYulIzU0r9PUU9Q15rDzDqXmqhM4UhaSUqTI+YE9OuOIvzq566J8OujRqLXuqrFo6wKqEUSa67VaaZhx9YJSykn53CErO1MmEqPQE8fmV8G3xUeeHgQtH7H5d6xVT6cVVGtXYblRtXC2vOlO1R8twbkiACQ0tAJSCQTwn8bPxGua/wAQa/Wet5kXtmopbAwlmhtltZNHbWXCCF1Ip0qKA84CApfUgQIEjiHHwzKZMF3l+q9ff4wzIHm+i62/Fy+PBpXkjywb0pyM1VprW+t9T07iXr5bKpNfb9NUqkqQpSXG1QqsVMtJkhtMuGTsSeEtO3KQFbiBBE4/U5/onjy0n8Q93IKiBPY9Zx/lj24UtN5PUqM9RBOOG612yKkbhnXmUoXW5SVL8v8AkvoOxrAjuf8AtH+nbhw0Rox/mTrOgsVLU0NHU3NzyUvV1QllhBEn1LVhPTv3j34aax4JISCOwn3zwidcCT1A3kAiPlnrI7j/AF4nyvA2Q2GM5ytN4YNuq32lLacWy4psqbO5BIJSSkjqMcNbx8xRKgBGVQZjt+v368KahwrJkqjuOsDuQP6/lx7tlvNU6CsScHb3Of8AHiAfO7ZFWkMZkrZbaFSyoKG0rMwpM9/bv/X6yG0aeqHXElxkpE+neCAOm0QY7SZ6e46xIOVGlmHdUW6orqf8XQtPoW80MF9IIJQB23dP19uLu/Fn8TXIfxN1/Lxnkny4Xoqt0/avIvZ/DoYFY8dpbbCUE+aUlKyXDBV0zJHE9lE9pBI2KGyXCNxc0O3CpzpynW0gNs+altO3a55Y24g9T1E/pCZ69ZPfLodPaWdcdSpLtShYQhRy6SdsxEqk7xGJUkgZAHHuisTNtbK1gvuqQElSCBux2OZMmJyTgdYmDc0NS/i3kBDgbYUZZCnAUgJCSRk5EDbAIB3HJKhwUncaOAvPtEbIRTNFdOGD2RzKuFqrUFVcbuLpWVDj71a4S+oKHmLUVesqx1KlEYjJGO3DPfqZNqriVIaUhMCEZBnMBXQESB9gY7g7n3vO0o+0n5qR4lKSr1BJKkgSBnHYQP4jh6asX7b0nT1aUtqQCEJJ9Ux+WN3pjOOs4VmeKlrKEuInjX3vRVTSDTvCedDanqKa2teS84XWFKRhPpJjdEYI9p7wPYy702unLU+p1CFJadPmjbkBXZM5kdMkmJ7cDWw1ZtNyW0pQAIKcIwcgnABE9J6/6yVyrWGxUNoJplubnPUCXATEDB9R9Q7jr0BgI94tOpxk05yi8L2t8pRIe5mWrXFpSxWPhdQhJKlElQT2B3Gc4P8AH643s8r2LolC6Cvf3rAkT0USIJ64BAgGcHIxwKmaS2XF1S1OoYIKlqKnCOkE+pPWZAOcQSOoBcbJVV2mlLVR17yKYepxK3ISkE9ZzEj/AAOcjhPmtpjGIiR6HkpxcCNkRqnkvfklKmKlSzuSE7mNu5IBOfVOBBkgjPbB42s8l9bUoU429TVJQCkE75X6oChnImTHTPeSOGex+JC6WB9LDzm9xMGT68dp7T1zGZJx3ea/xeXQ04SLhSpQoFKMphQjrA6jAkECI6dwPfDXZ0hoKiSmRo2TVqjSGo9NNPLq6NohMqSralIGSYP6xH/tEdeBRr/WztK04PI2KEz6AQDBETkZ75Mex4lWv/FZX1TIDlSxUhM7vVu2Kic9BETjH0nPAD11zbrb3ULUtlCgRuSENiB2ASf4Y7k8Mdnt85IMg3SncppSTqCb7pqL9t39igbo3krqnkMpVkwVKAHpT1iRhOZ+vHUzwCVWstHFmmu6qhbKFbWnFkkiMDr+nXioXwjfDXWeJvxI097q7S0/pDRhNfWvOD0Gs2j8MymCASFkOdClIQJHqE9aqDl9SadCfJbSlKTkhIjHDnGPDZpAVU8ROL5w3sjny718LhRMtvyVEQcDOOHrUGkKa+MhbYAKhBHAd07dVW2oTtUZSSBnKuCjo7V/mNJQVgpH5T3HsONkGOyg+qOXKqZxY2SRgdo4g990SmfU3EHI29v0/wDGeLL1drYvtJvRG5QgE9fsf69+IRqnQ6WStQbQPLHvtAHWST0Ed+w4wrNXVU38UuoND8j+SV91Dr922N6WpmSH6OsbRUN3JwpV5dO20oEOuuEFKU7ZzOACeOBfPPUHKzntq6uuGn9I0XKmprFjyKWjq3qi2trn/wBQL3FAVJktQhO2QiMcXI/tBnjksXiB5uad5faGvVtv+k9EtLrq6ut9QH6WtujyShSEOJO1YYaARIJ9TjkEjjnGXCqpKpSIzPvwyWynMTNWSCVCqoWyjDhlXu8LH9nzufPjQ9l1ZX809Mq09e2vxNKvT1C/XqqW9ykkBbwZShQUkggpMEHi3nKX+zo8k9HJbXfU6r1i+k5/H3H8Iyuf/tU4Sof/AOw9OHD+zl+KrS3NPkvUcmWdNsad1No1td0NZTuKUzqVt1076he8yipSQlKkj0qQgKSBtUOOoNFy7Hl/9MJIjHc54iV1fUtkLNWAuNPboAMlu6qnyd+Htyu5JhP/AAxy90pZ3EAJL7NsaW+QOhLqwpaj9Zngx0fL6QkLSpxKR6d+dvt+n04LTPL8BCjskJTtPsTPQ/y4cKbQ4Tkp3d54Evkc45ccogI2NGGjCE9LofaTsR2gyIAHDnT6I2lKdgMeoADA9v6+/twUafR6Ns7NpAAInBHCyn0gltcEAZkyPrPGi2x6oaUmjdx3QoAZwP8AP/Thwp9Ipj5UwDn6D7fw4ITGl0oVgfNhX1HCpNgQiRgjAP2j/fjFnJQKn0eCSdgA6H2iev34WM6XLYHowBiBk/TibM2ZDQEgEZyf6zx7XbG0JCjCzmPqOMXhKirGmkbAoJC0+wEkcK2LEEJTAJ2HOM/pw/pZbQSARMY7ZH0/rvxji0MjcMdp/wA/48YsBXIn+04/D205dvD7/wDr/Y7caDV+mq6ktmoHKSnSlF1oahZaRUVBEfvGXPLSFxJS7CiQkRxB0c7trUTuUNwgDoPp/n+nH7CedHLSx89+Uup9Eakp01OntW2uptNwbUmf3LrZQVAf3kkhQ+qU8flT8SHgm174M+Z2pbHqy0umm0zqBzTi7uyPMt9fUpp26gJacgBSzTusuqTG5PmQQCI4cbBWa2eG7mPyQeujLX6uhTvpxlL9vbDYSErSVKUsjJAPSBOZPQjuRjht1NZ0O0y005bKDIRtSSrpPpAzkgZV7z78L9C07lRQmSvy0gjbvIKsJ7jIxt69zjpiSOULTZLSEhbiyP8Ap+ohI6EIOQRBIJ7oyMGXuOEuZqfsEIrrk4uEMIyUC9Q6HXSVDgUhRWCQUmQEH2+sfWftieI5V2w0Z2QOskx8w/y7ffPB61BpYISfM2B9UhaCoEmMEz1HykZHbHXiF1nLh15LjimzBMbts+YfpnOfb/bjm23ucctCXq64xw7SO3Q6qEtKccLDbjLMnZvVuUMDE9/fH09uPiWd8JJIAgerpnM/+OJXdtB1DB3EEdxHbt1/UfXhmetC6VSiQdoI6ffjY0zmHcIQK6OX2SkLI2JHQH36E/1PGxx7yhEiMD0yTPt/X8eMcSULJGBGMYP9f58LdO6qa0yzc0vWiiuxrqJdK2agE/gVk/8AWRH5hGJ9xnjnJIGjAUmKEvOSmKqqEtgbiAI7d/8AX2/qeENS7O6em7aCeg69Y+38+NlUVTEdOh9x7f5/x4yho11Dg24HWB3ziP67cQXOLtgiLYwwZK+UFrXXOpwoARgCI6fy4nektDrdI8xMpyTHUjb/AOP0+3HrQ+k/xDwJbhKQSSkSBPTHtP8AHi3PgW8AWtvG3rZWntDWxusq6OmNQ+48sJYQgKAKlEwAkqEde4AHB630DQ3XJsB3Sxd7o/V4UO5PZBmz2Cm03Z1vuJRtAPRUFWZOe/369B2y20FAwbi7V1SYacG5tBTt3JGCfuAJMxjPq4KPiu5MX3w8c0blo3VVGKG5WlzyKunUQApcjsZ9OZGSIjIyOBJUA1tRDQQl2pQts+qcCB6QcmCBG49hAyCDU8zGAMaNggVBTyOLnvO7uf8Aha9QXRdXSkqKypSStwpSZ9kyeoBBORJ7ZxA2vV182vWtT+Gx5oWBjZCVBUhQBTtJyB6sHaT0leurl/yiUpCUCoTkOLKkhKgVbVhI6EBPYA9SYBPEDcU3WVyQWvxAeT5QSp7KVeXCQVJBCinbuIxuHsI4TLvOXyaScqwLPTtjjy0K6ml7+liqcQ44ksVAU0szKlE9CTA9UZ6mARHE75Jupo1XCyuhMj10zjySSQmSEZ7GFAAnOfYcQ7lXybvHMnQmv9U2+ts1NR6AoW7tcGqytSw+6hbwaT5CFZdXKspTkDHdIKvSFX+JubdY2t5LzCIdWlsrSlQJBMgj6SAeqfpHAqztEkPhvX1Neasw1PjRHONjj3A/kU8a40240866lDiCAdiiQAnP8VTB6EdMyclkpdd1WmKxKiFLS8Av0wSEpkESQMyAkq9gAJngzt6aReqVtatnneUFkLSSESJBj2A+mZycRwNeaXK521KIaTuQpRWpM4Mdz1nv79+0DjW58O5aXjkplBxLDKQ0ndJHrzR6kCXaN5DS3CS60pfloZImQIOZ9j3CZM7uPIuryHgFKJH/AKe4BS/mIwPuE9ROfmEcQWkoKq11DikJdO31KS50cVgJ9IyICsx+hmTw+Iurjill9KFHfkbNwCumCDBAB7nEEDhDqbH3TXDVNIzlO1U+i5IUhTzp8s+lM+kHGSR7wZOQZiY6R6u0g9dcmrXChCo9H0knoSZnGJnI7LqZ9mpQA064N235U9ukBJ69R1kAH+G01gbUEkuqIQHNqwAqJxGQQCTIxn7SeBTrJURguaFK+8Ru2BUSf0aKR8qcDjrQMBSFA7T3GAMZBjBj34ZrjpVVW3LQfCIkbsIAjp16A4gfY9uCM66iCp5CkpUCVHYVKKZghREScH+sceHKpFMyspS00tCSkJMbgYz/AAMg/wAI7CO0Tx82qPUUjJBqWeDHm5d/B14kdP64oGqi4U9KtVPX0CXik3GidGx5nPpST6VJVBhSUzMcdw+Vuv7bzy5Saf1laGK1m2aloEV1O3Vo2OoSvG1Y6YIIkYIgjrxwoqdu9QCUoSkBAWsylJjp7erAiB0meo47W/Deor9VeBPlw7qR2oernLe4qm8+N4ovPcFIOkx5AbInO0pHE2OR7x5gq140tccLWVDeZOPf/lTVykUw6SoylWMCCOHiw3pVO4gAgqiCmMK9uN90s4DihAVH8R34ph8TP4ht58Gt509YNGUdruWo6+ncuFeitaU43RMFSU00gEZdUl0Rn0QZEg8d42lx0hItPSyVDxFEMkq/NdztsfKvST1+1PfbPp2xUZCamvudW3SUzJV0SpxwhO49hMnMA8cwPi//ANoI5X80fDvrvlHymYv2qa3V1tXaH9VNf8hbqRpak+cllLiS9UBaAWydrYIckKxxTv4rvjia8dnMLSj1ot1ztWnNN2pLJo618bV1zii4+6EAlHo/6SFkbilJmJCRTC729TaiJCSCCo5nMmM5n+X04J0tMzIceaKfwJ7GB8/Psosthurqdj76KRsJUQrYSEwDCQB0kwB7cNPmT7yQMDrw53ZoNLJJnHv1nrw0vvAHtPbGBwwM3QKpwHbLpr/ZYGV1vxH7i2thx+nb0XcnFKFKhxDK/NpwlRWQVNEytIKSCokpJiRx+iM21pLZIIxII44Jf2TC/u2vn9zmp0IpQ27pehfU4pP74FNbtCEnptO4lXeUo47l/wDFxqQF/wAZ6jhdun83C4xuySQpEaZrzUylBUFSk/3evT9D/Dj6otNpj0iI/SMf19+IurVZxC8ggifbhO7qgqUsEhIKvTnGR/X+3A7ZdFLjVNoAgpEGInAPTjwbmhsgn1T3HSOIkrUsOKMnasyRA9PtxrXqMkbh6k9579OnGYXoUuRc0gkCB6h1PHpy5pLiVBRSDII9vrwNNf8AOGxcotA3jVWprtT2TT9gpl1dwuFTu8qkZHVagATAkYAJ+/A3uPxO+QFt5W1Gs186OXK9O0ydzlQ3eG1vLyQEpph/zClkgwkNkn7CeN2QyPGWgn3LV0jG80R/F34vNNeCzw/3zmJq1bgtFicp2iwyQl2qdffbZQ2gHqr1lX2QrhJ4UPGdoXxp8lbRr7QN2auNhu29vZUFLFZQutkJdYeaJlDiCpO7qmFoIJCgT+fz433xi3/iGa+Z0foOru1Byf007vYbdKqdWpqwK/8Ar3mSApCEglDLapKRKyApRAotbNU3CzMPtUlbV07dQ0ph5LTym0uNqKFKSYMQotokd9iZ6DhggsgfCC84cfp6Iaa0+IdPsr9S2p/jV+GHSWtq/T9bzj0wu4W2uat1T+GQ/UU7T7igmEvNoLTjaSYW42pSEQdxHB90pzKsfMS2m4advdn1Db/MWwuqtle1WsJcQtSFJ8xtShuCkqSRPVCh1B4/HrVa7uVRpijsiXUJt1vfW+w15aQpKlYMqAkiB07SeDR8Pvx5aq8BniGsmtrI5UVtJTti33O1uVK0sXG2qJ305SPSFJ3FbaiPQ5CsyrjrJYWaMsO68bXPzuF+rI1gU7ukeqN0nEjHHNn+0p82eX1P4S7Nom9XY/8AHlTemL7YLfS+WtxgNbkPvVXqCmmXGnFJSoetxaYSFJSspG3Ov+04afuPhBau2g7C/aub90rlUP7IuSfxVJZWkAKVXF0AJdSvclLbfzbt+4QgFXIPm3zk1Hz25nXjWmsbzUXvUuoapVZX1zxBcqHD0iBCEJACUoSNqEgJSABHGlptcrZfFl2AW1VUtIwN0TtEXHzmfLQCPLbCAdgEkmJI6bYkx/GI4le8UtOunpQtTz6AXVD1BQgjqCSREgDIJgyDwGNCauLA8rdCGwsEkCIgSRjt26R/IGmx01Ezb6Sqcfpq124IU44ht4l+mg7Ql3cAEqMBQifT3PTizraxsxDT0SNea4UsRewblKrRpf8AbJDjwKwtJJjptAyCegSNvQGOo+vE95N6e0baeZForddWm43vSNFUJXdqO3ueTUVjUEFttwwEq6HqPliRjhttC37mhDTaUIkCEoaO0+oDM5EHABwD2mOJ5yn5iWzkVzBs+oK7Ttm1Y3aKs1K7PdEKXR10JILbkdpIPQ524IkcOsdPGyIgD9Cfiqjmnnqqge/3oG8ydN2pd5rl2+ndorUt9xVOy64HHadpSz5aVqj5gmCSBnJ6cDO96IXWKCtnlpMmVQAM9QPacR9IHBu1zczrDU9wuDFAzQoq3nKgU7DZ8imQVqUG0SZCE4AIyPSPpxELjZ/wrhO9tK4CCSASPzHrJj0RPfAxKeA9W0P2TTQ0/gDPVB6t0d5bSitojqEpGCIGZHvkA9e3DFX6cU88EpbSqVdQMKJjP+P8uCzdLQt7e4pBPkYG4AFcxCVQcQMkzI/WRGF2wVr0NNoUmZEAAqKfyzORGMzPbrwvVUIB0t5php5dtTioAnTa3FICE7wqQmFyFmYGe3frMj3zxIbFoRaUNfukqLyQoH3BJGD9ZH6QZI4nlj5fOUbfnKStVQ4CjdtymACECY98gduCdyF5aaZvnMC1o1ld6iwaaqalLNyudPTmpet7KgoechoH17fT6UnAPEqhsxzrk/JBrrxCxrdMZ9ENbBpj9mttpUElQxPXZHSYGD9O/frxazwAePHWXw+9U1mpdJCkqXrjSimqKB9nzG6hoGU+YAQEkKBjacZ6HHAMGmWbpfax5Ky5bad1TTZKQ2pxtMknr0IxkmFGM9eG2/3E17pU4FinQs7UIQf3YBjKQIEmAMEgdJggnJYG6Cxw27d0txyFzw9rvN37KVeMPxNai8XvPi7631O9SqvV2cLz/lbUJ2hP7tCBAIbCIgnsR9eBnarXUOUq3mE1inW9qEfuzucCUmD7hM9FT6YUdxMDiWaT5U12obTU1cOspYaipWUhJQFKgqV3MqgGPoOp4uP8GPwsaG8Vfi5tOk9XNpXZWWHq9VCl0oFctsAhuTmFdSnrASOo4gXKP7pSmplG3Qd+yK2yVlbVikidv1PbG5XMTXdoradSi4yWfwju5W/OSlSyVEYMwlMxtPqM+mRGax1TD8uLWpSW5G9RDkeakp3QohMwckR6e8if0K/2i74a3JXk14Q6TXWlrFa9G3uirUW9LVKShuubUlRMozuUnYk4GQADHH58r22ikujTRbbbceWg+pwgpIASU4OVBJSAQIBB6ySK8dK6Rxc/mrNbEyNgDOStk7pOot9/rrPW079LVKaJLTjam1gSSAoKKYE9AqIwMGOHXR7irXeGFOJUoPN+W7Hq2GIJAOAPYwIIgR14d+dHiJvviB551Wu9VKp6m/3mpLta8wyltp5cJgACIT2KQTgmPfh35ycxaXmnrk3hmx2rTbNQlDS6GhbhDRQhKSsTkFZyT23ZxI44wSCF+tp6r6fbGaqmEb24ON9+R7eqsF4ZtG/8aaauQ/aVBTfsSnRUIpnH9jlYS4EwykYUYztGOpnB4W849F0zlBTgDZ5o2kJAGxUgGTMxP2n9eBz4eb04zXU5Q6ht5kgt7HPSR3CcH056kmVdTwYNe3KlqqaHBKakBQXkhC+gBg94VjrgdAOLIonRzw5VN3KKooapxaUDrbyhTc72djJeUFiBClQD+YxkEQTu3YxmOJVe/CY3dbck06gl1KAlKkypCpwEp9oMffqYPSXaUQhirc8wJekENK3lKR8sCPeIzA6nGJ4l3/Ei2G2yydkrCTEqJMwD9TPbE/y40ksdPKCCFtBxlWRuBB2CqJzD8Ntz0sXalhsutA+ptRKSg5xumCf9sRgj20Wm/XW5tW+jp362tUS0ilbZLi3zMGEpzk/cycdJ46BMst6vpFoqUuB1aMqURCZPdWAn8xgkjPUCBxH+Xmjr34f+a9o1vpJqmpr9p+oFTTLfpEPIQSCn1oPUkE+0YiDwu1vDOn+WSQmqj44MkZJHmHLoFSKuuz1kuamK2hXR1TDhbUghaFoUkGUZMpIOCD0gn5shM5WsvtBRP7o/lKtoG4dOsQcgAD7zxZ7m7ykuvOjmJetT3ZlK77qKpcq615hISgPLJUopSkSPUOsCAIkzwNtY+G+rs9OVtUj7IUCjrt6iFfKBP8wTERJ4ES8LTvGprdkwUfGtN5WSOAceYyhPT0H7WcLKNzqnAWA0hsrW+tXpgYg5URAEnoOp471+B3Tev7L4VtI23mUyhGq6CmNO4ylfmPMUzYCadD5GC+lsDcU4+UEbgeOa/wAKXkZYH/EDdNba6RTUemeVtr/4gerKp0CmpqlLqU0/miCVlK1FSUpglSERu+Utvjx+KVrbxF62uNq0dfLvpfl4y4yaSlp1inrK0sqUU1DjrZ8wFaxuDYUANiJkgyqVVpkMpYBhc73M66ytpIAAG7lx9eg+HNWe+Lt44m+Ta9NaR0jqZyl1QxcBdrwLbVAqp6ZoQildUk+lTiiSpBztTkdOOYPOvmzeedWua7UeqLs9dbxXqBfcc3Qlv/02UemQ2iVAAACBJkk8MVXRrStSkoWSSqXPNlaiSSSSATvmCcwSep4a6yzvhaN+5ZTnegFM5yAY+43dBPuY41bbHjyhFLXb6aiiAG7up6qOagdRtUVKAgElIhJUJxBV6oyevv3xwPtULTBSnoSQdvUfr9B7x29uCRe7QhhtQUlPpG8pTChEEH0jAzg5kwfpwP8AVSUpAMCRCUkwe8kiBHt0+v0HE+ChcweZDrtOwtOEN76j1kwR3AjGc/58NCmt7hzw+35I3rhJBOMQIz/t/XZrZYU4/EZkp+hPEwNxsqxqW5k2XWH+y7cl9TUPMnmJzFbfoGdKizosDjSqgKq6qqU8h9tQaSfQ2lLa/WsQoqARJSuOyKLqSJBycj69JB4/OH8HDnvU+Gzx4aHublwrqHTl9rRZL61T1IbYqGalKmWi+D6XENPradjr6PSQTx+iV5a2S42sKStpRQtA6gg5/hnhbuzSJQ48isEJYMHqnRd1UFGTuSoEAzmPtx4VefMUUpWN6oOD/P8AThv84qWQTJ6gz04+CFLnuoZnr+vAtbBqcRcySMkdlDrxsTX7YAUrarBHb7/z4bWG3KhQSlLi1kQQASSOv+/EF8RHia0Z4XuU1+1hq29W2koLFROVRpE1rYq61YBCKZludynXFgIAjBJJgJPGzGF5AbutXEDmVRH+04+J6z6b8Pej+V1NcaZ/VF/vDeoKm3SSuloGGX2m3nABAC33VBAJBJZKoITPHEBxP7zfsQFp/NthX34JHih8R2p/F9z41JzE1Y6h696jqA6ttrFPQspSEM0zQJ9LTTYShPUmJJJUeB082tIAAGcDM/x/hw+0NJ93gEZ59UtzzeI8uXlf7sAH1CZ+o48IQpxQJTEdc8bmqIrKsn0CfofcwOFztjeoassPJ8tSYmFBQAIB6j6EYnvniYAtQeiTUzG3b2kyN2P4nrHCxhlLRCnCpSk9j16dPrP+XGM7W1Ao6yMz/wDt7fT+saHKoIAKd0kelSjJP6Dj1bZAStyrCI3ET7R8oye2ONKVqq3gEpSRPTt+o40NsqqCCsKCTlKT39v8e3DpRMBCJMJEQBjpx2jiLyh1ZWhgx1S+x1KretsoUvcj5FBW1QwYiPafr/hwUOWuqEtrSStIQgAq3kpEE+wPuev/AI4F9MhTywkJMq+k8SCw3E0DqYXtkpx7/wBR269ODtC7wSMpQryajIKuXzGXo7l27ZBpjVStTprLG1W3N1ujLX7OrXEr8ylUlWCUmAVjIkkAdOB6m9LrHj5soITMOboUdw++4YA7Z+3A2suoVLphC3VKCt5ROCRISE4nImOkR1PQF7kbyH1RzkrbizpbTl41NU2ikdudY3RMuKFJTsplx1wpMwJEq6FS8EzAOtr3OGMofR2+KJ2rC6DeDj4RulvEd4JbxzCuWp00NxpmnnGGUbFoY2IBlwnA/rpxzi1/aGLRX1DSw0tNIqAtDgAcKiNuxMndAiSACAqSenE5s3ii1do3l3Vadst3rKSxVwmop26hXluABIVuSD8smNqhJj3BPEFprVV6vr3amq3eUV9VLVK1E4CTJTAnp7HpMnjvBBK7LSckntyU6+Xei8Nojbp081EqyyP6jrFuwkUnslIdLqQVYEjpHeJGJPs/WPQSLczTrISl1YSQkqlaI7gzMxtHWSB7DibWjSDYfU4SXX0GQ4tuFJ+iQYgYjABEe2RJrNpFLSEuuypRKlrEgYAEkxnqR16wr2gMNDw6NQfJzVV3jjA6SyM7LX4ZvDdT86ebumdNXG9WrTLF8q00qq+uhFLR4MFZxJMiOmSn9N3N3kqxonmne9OUNxobxTWGufoW6+lWPw9YGlFPmtLPRJgkdR7ZyXJu2mueKVN7mxuKkbDtg9x39sT7E9+GTX2qGdJ06vJUPOIKEBIKcZzjpicgxAPuYYJbfHTxmR58uPr+aSIrtPVTiKP2j9AkHOnkjqrltoG03q4WC423Tl8So2+vU0UM3HaU7g0uJUd2T9B0iQA9SMftCrbUGg4htaVJQlsALMGClOITJEjrAOc4NvO7x98x/EFyM0ny11Fc2rno/RhAs1L+CQh0CFN7nVp9T0AqQOkD368Bu6PI0vZlmohwIO4Heny1L9XynsSMzB/mTwlySOlcXyDAGfl0VnU8AhjbHGck4+fVK9QcyHbFY2aBrym1g+gh0n09ZicwARiCPb5QYty28RWouS+u6W+aduj9ruiXErQ+w8pDiV7UwoqHdMjIiSRISCRxGLzcF1fnvrS6VPAqCAknYArAwD1KcCcRiAMsValVTVKX+/KFrUv5inaVCAo+lI2gqVIMSpYyY4VL1cXVX4Tt2jkE6WC1spPxWDDjzKM3it+I1za8ZlLbmNf6vu+oKa2ILlM2/Vq2toAhS0JQkx6gApUnEzAI4gPIbwxM8/dMcyLw9rPRmk6rl/ppV/pqO8rLb+oQlYCaWlQgq3vwR6fUEbfUOpEBulUuqpUIQ6vy3WULUkJIIMn8o2mAdwIjJSqCCUkxq4bnHWGtop23tym1yQVJkq3iBCv7uD2TJESFF7Gt9lOoe52NSti60uqs6XGSVPU5MJnDQATKIIEYIPScdo4eqe/oqLNQ1O0NGfKWsSopUI6f3ZHZMkQT78NFpS48hTPlmpgggmSJwIOR1J/XcehJ4+K3W+oXSOKJSXEraWsFPl5jp+VPpEyZxPXji+IBxaV9D2q5amCUFHHkPqiltOoVmsqhTIJ3JKAFyqYg9iTnPbcQB1JO2pta2HUWolm3IrWrW4pCtlQ4HakNSgORgCcqInoMSDJ4pnoy8uN1Bplr3ONyWvmAcA6TkmYk+8k9uCbpvWpNQyipdVJbhveohxaTPzAHpA6yMDIABgzaa7wsRu5LnxLZW1sf3iPnhWYTo2lpa41NsW+7Yn3lPUFXUsJS48yJSArJAUUwCkEpBA691DrbCCUggAOl0grHpGE5Bge3XOCPpwM9Mc3nWbSzSJr/ADKRClbGFrISwV+o7RgAHoSB2mOFl25kOPU61BAcWgSSr0oKhgxIGSRjPsIEwXWOraQCqentrmZaQjto7VmnrRoA21yzuft9Nal5Fx/EENt04RlotQQVlXfrtPcEcSGzU9Nd9pUykJScFO1cqMmQTgARP+WRxWGk5hor2FrDqnVjKSHAU4k+3pyCYHuBjiTaZ5+v2UJQXHGlpABWrcUAexHWMdQDiTExMiKSFx3KDVEE8LC5i6JeCrweaf5v11bVXhpTlDSJT5iEHYt1R6SeoBAnBmBHbiS+PD4fOj7Dyiqr7YqZdGq3gFxrzCUlJOYnoeKyeDj4lyOQ99dcqkC4UVdDdUwp1KVgjoQRgHJwe3fideMX4vFo5v8ALxdisducoaOr9dQ888lSlAdRAwB1mT+o4kupa91wY6F4+77Z3GMdcg9VWUkkzQ4uY81OrynfvtvyxjmufnNfSVwp7BdLBQrUxZ7pXM1ldTCA3VutBYZ3EkBYbLjigBPrIOYECh7lwmnKvU8W4WslLcl8g4UEomRkZPWMkEYJmteblJerk6ufKgglK1AKWnP5Vd+pEiZAwOvEI1RzIapVSlX40pCVp/eQmQQdxz0gRBxAkdchbhRUonc9gG5X0LYrtcTTta8b4UZq9AMstrGxKFIlKwSncAAdogHcmMCMYMe44jGqLZS2fDigysnosBSlEEdhmJJgR7Zxx41ZzLqnEoQ3UtwmFtJY+VB2hKSCD6gAYMenPUHPA3vd3qLsSEqU4D6tqDlafcGCCAfbpGTHC5UzUsR0tCb6c1kgy8rVrC9U6gpDSQuDgtqkdYBlRkqOBgjP8COrxNWsqbb80rUcqyTJ9x1wPc9veOJ0dD1t2dUU0617VbRCTtT8wMrIABmJyfyxnHGxXLIJcPnPNrWRuIEq2n82foc4Hb6cAZp3PPkC3npzp85QXuVgVUICgkyepEGfv279Ppwjt2ng5UhO3G4gbcnt0+33/T3LWo9OMUowkubfSDv+UDp1wP1iJGeGG22eKlISkpgSYMQY6T1H8uMjpnPO6VawRRyZB5J65d6I8xTaxClBSVDPQ9ck/YfwxMcdqPhG+Je+c6OUV405qm7Vd8vej321s3GufU9V1lE/u2eYpXqUWloWgE9UKR145H6Hs7qw2UI8wyFbidpRMRnpAkd+/wDC53wpufdn5B8+69eprixa7Fqu2G3uVzy4pad9LqXW1rVPpbkFG8zt3ZIkx3uVkL6Jxa3LgM+qF1V4pyQ3K6tJSU9R16KAyT0/x4a9f66tnK7QV51NfKlNHZdP0Ttxrn9m4ssto3LUEjJOIAHUqHA85reOTl1yr1HbbAq6r1HqS7+SaO22cIfU8HQC2VPKUhhtKkncNzmE56QeKceOn4vGj+bfhm1loqwaf1Zbr9eA1Qtv1IpnKbamoSt07krMyhsgQFAhXWRPCbR2Ctm0uMZDCcZ5e9RKi8UsZcwSAuA5Ku3j/wDi98w/EZWXqyaSq6nRXLSvpzSGgQhCLncmgQpbj9SkkoKikfu2VAITKSVlU8c+L5TNrfU88sqd3KUSVFTiyeuVGZOcnJ6kk8EnVlPdb+8pbqS2Y3BCpjaREkQTtwfYYJnIBg14tlPbaglxzzFqwkBXb2+v6Dh3jo4qduiMYS6KmSRxc481GXaZTii22ghAVjqCfof58fRZShne4JEjamMAdvr9uHI16W5DKEIn8wP17d+3CKuqgidyj9ACSY65Pt/pxjgOa7brQpCkLGyYSc4AGcRHfhMt0JG1IPpx6TP8+nvxrqazzMJISB7Hr/DhTZLu1Qpr/OoKevTVUymWlOqI/CqUcOpiPUAI9uOWcnAXrnhoyUicdU7BBTkYAEgzxtYodz0ncFHvPT6E8bqelhcJgrOJmRPsP5dOHO327ecgjd1AzxLgpi85KEV1wEY2K0U1HsJTECOh6DHX78KW2ZEyBAyomeNymwlWY9/m4Q1tb+72pkDqRuM/rj69+nBAhsbUFYXzuyVvfuQpyQgmDjr1/wAuv+PCm01ZXUNZ2K3RMYT2M/TIGfY+x4YWlFdTJVAhQJ7Z/o/5cPtlShtLfllCirJlM9ziD0EE/rP3EXxi4qcIGsaiFpZ8W5tDQTUbkr2kj0qwDIQesSRIj78GTkb4j9bcha25VmjNS3XT1fd7cu1V7tE5sU9TOJAcZXIKYJIIMggztjrwDrI8VF5ISIdcRvSckzJHt/eInoSB168ErRNrVd/KcWVOF3BBUpWf+4kkmZA7D6nHDFbmiTAS5dZvBaXZwpFpzT/7Rq4KSloOGG0EKAglIknCgJAwcT1HE+sNgLTrLbIQXm8l2ApM+wJ+u72Gf4J9L21TqErMJBSYCfT+VOfftEdY6RJHE4tVm8gNpPoLchRgREA56Z956Y4tG0WwNbqwqO4hv7nuLCUmt1gSy00qJVEJkSCZ3Awe0R1yY9uHFu1l59SQColUkYCcd56dCPoP8HJdEmip0egyEgbSCCnrjpiD7e/XHCC6XhFgoy+VtoViCTlJyAf1k9epmIyeGcxRxMy/kkHx5ah+iMZJSLWOqaXSenV+tKFuDzFrkAIGRHbB6yDn7cCnmXobUgoLHcLjS+TQaop1VdtW3UJWaxlK1NFxLaSSIWmBIhUpiRu4Rax1XV6xva2WFK2NEhSk5nMGAYwQDkwMEDhsrLoq1Ujeyrc8xoBTSt0hlICjuBAmRP8AAyADHCFebi6qk0tPkCtjhyyR0EWs7yuSMOJtdN5ywpLphotFpSgtAwoZkxIj2xkg8QbU9bVXmC3O1SJTuJUpCAqYEEKB6kqwkCehVl9TUN3q+0tOpYRSpcKEQoJSgAyT0Pqgz3gk9+p7+KRyq5D8oLNoRPJXWdfqw3SzIqL8h4pP4WrMIIV6QUrUSRsztgZPCrXSF0RIOB+qdrcAyoaxw8x+n+VULU9yDtQ4tpDiEOSUBKZiDsO2QSrCU4EEArBIHVpSUs1CXyny22kLWlTQDhlIOE9QrrkmUknMAceKx4PPvFLiHVuqELKvMWgLAUpJgQomTMDMQSkE8aq65KZp3yhXzrSspDigt3bJKgIOEJbBM+qTkkdEuZ+2VYkEeCAm281CWlklJQlhYkFQ3IlJDfqAHoBAkHHzn8ySWNttNS7Spa2pcQ6ASEYUsEJ3ExBImSeme/QrawrFclCylpDywle9ClKbT6UlYGFKnIxOERmJKFa1NtbgyyXKn0KSVFQb3DcCBJSYgFWARtIwZ4FOdlFGq19GULo2Slxhbji1llrchSpGxEQMqjpBJBxKogiRrsabpscT+K8kvKAUYbIhRmVZSOsyJA78RfRN8S7TN07j9RteLcjzAougH+4ImAFQYgncVEgRxbr4fXgvu3jI5u09gs79PSKqWhVuVji1OhoJHqUkmQYJEHJmc+8mVoJVgWG6lrC0nAAVYam1P2dpipdQpryklQIWQnacmRAO0ycf/jjiQ2y6JqqJSAotOpBS4JTCUkQQRIAEHOCOkzPFo/Hx4Eb34O9eKsl8eRcRXNmpYrky4p9BMq64CiQQVKySoRxTK/tvaIvK0ZU15hTvTkoMA9YgRuKgR6v048FMfaarCor7EIQHnIPI9FPLPfaj5FvFK0YeAWFKViRnuYJxHeM9OJBqbVzabxVN2x2tqKMHaz+KWhNTG0TIk5yQB/dH3HA5pb05W+elRAcpWEnadxGAIiSQPcDp8sYE8SO06iU4wW6gJS6WikPEFSXRuSNpzhJV2Ez7HEFoZZGswhFcaSV+chOy9bCpeC1oJUVSkKA2ORtOFJzCZwMJO7oMDh6ptbI1A3RttNUDQp0JbCkKBVVrKioLWZIKlExJ27toG0HPCO3N2q6PIKvLaUuf3bioCjlRIJTIwR0gyTHsH1nQ9luiN4rmm3FwVNpJdKIk/LM7oExOBu7jiSyQu5HdBJqBrTvuEhGrTS0u1K3m/SpCkpTvUUyCkKVHcpmCYkdY4Zr7zGfdfV1DhUCtRQDKwQBlWAUzkgEkDpIw/wBfoS0UTCUftTzNxPpCxKQRlQITtAmE/afoSxXfT9pokEIeYc2wSlgnd0lQBGEgyrEY3cd9VQ4YD1xaKCJwcWclELxq2pUpNOULKEynYYlK49SiCDnb7SQSc5A4jdfeaivIHmKLa1nYtCtqVKBMlSlYBHbEdepPE9XpW1vEJWhLbY9SUxtwFRCVLHuDJ2/MP1H2k0vahUbkOU7jajv85DYEkFMbSogQZEEAmQQMTEF9vmfsXIoziajhadLAhqxZKm7PrKW1FKlpVJ3KkHr82SEzGI+4jh9t+i6ilaUpSEKTO1tRUlKSoJMiCAlUSoz6sj3PE2rnKG0UYCEMhUeW+FhLhBhM5nvlUTiehHEO1DWVl5q3kp3SswtBhITBIiJBIBSSQrHUn341/hMMQydyoc3GT5Dpi2HuX2kt6bxeqa3suGrq33UstNhyBuMJQkrUAkCTGfb9eGXXdur9MXeutdYymnrLW84y8224HEU7qFbVgbRCvUCJJORjoOFFBp119bbaVqcSte5DSBswBknqCSJPUwSJMRMhsPJ1qutyqmsXVoDbIcZKGVKC1ASEzAgkkgkYkdenHpgYwbDCiurKipOS5BW60jr7xSrcAlJCQMewkYg9T/Gfrw46OsbCKtKqtZCSsDYAqSR1iSAIPbrkZHXjZrK21FFWODyQwEuQlsNgLT0wB1GB/nPbhrttmr6twlhsulBASveClAORk4GJzMe3vxzZOyN+ojOFBq7W9zCC7BVibzetKU2j6NVA35dWw0ZbCwJPYZODj37HoCeIxcubv4BhSqVxlhMy0WhCdu5MnfAMSfy9MicZjunOVd1uOz8R5gZZKWlhCQNqiFdFrhKCMdZEicKE8Smm5SN6baTUVrlMisUNohAUpJyZEkDp0k5HU4I4OV96mrJQ6JgYAANvRI1Dw1T2+ItnlLySTlx33OfkOiZGK+46gU6KJh8oX6gYLaEpMYUTlSfUkQY94JEhlvDVPaadT1Q+XXylKUICpeWraJCQMAHtEjBg44ll4ti31hlpC6dBVKVrWlbpXgewAkAdNvzdcwY9dNKsUdMXVu+W7ghRQoOQTkEnpEScgAjv2FzSycnlSYqWJ7vwW7d0M9X3x6qQUNJdQyYKEGEmI646kD7x2zkDm/ocaCifVkhQ/vmepPTJ9z7cE3WtdT2111LJRugFaSfUknOQSBJye+MnJngVX1T1xdUPLIJUQoBIJBHacdgR0/04DSPLnbKbI2OJuCd0z1dyS0kgKBOQVbsf0ONf7Hqaiwm5hKPwfn/hiouDcF7d0FPzEQOsRx9fsrzpUkqWokwYPy/fHGpNuU04ScAyoR269D7Z+/Ggie7oh0tW1oSRthSwYT37YHf+v04X0lt2rJGVHIkEdv44+n+/CiioiYSlIBBgR2/zP68PlBYlKbCyN3ZIGZPtjp1j+PE+npN0Fq7h2SCjoNpSYmehERw6Jb/DsmY3EEgEwTH+PC6jsYp/UspKUpJkyEgAT/D/AB4QXVRW4pKQkkTAIyn+GOh+vQcEyxsbMlA8unkGybLjVlaylJICvQAcDp0PX/zHvwo0fqShsH7T/HWC2ag/aVseoKYVq3EmgeVGyqb2qEutjoFSn3B4TOUS33QI2lQI6fMABIHvj+OI+u2ntvp3JCvKWSn0rk4kn9I9v4Znga8l5RuLTG3CR0dKWfKnaAFASVxI6wYyT+nY8PFrpv3KJOwuKCJ29dwEGfuekZk+/C2zaddqllhhtBUoRAiSoZgHp16nv/LiX0nLattT6nHmKimG/elC1SsddqnI/n0kjHfjpFSvfyC4z10TdnFadH2NTq1FaSGwtKCmSAuUqT3ndEdSoRJAHUA1aD0+XgQsrBGXdxG87v730JIAyTHuOInpDRooyhIbSFBfqGwkkxOCInGOvX9eDVpLUdksXLq4W+pspqLvW1DJpbgH1b6RCCsLR5eQvzCQN3UbcdTw+8PUAZ55Oiq7iy8Of+FD1Sq33NFqAS0hK1IykhQMQmSe5IjvPtjsH2wXRx2uZStzaCrcgIXhIMAkQTBEASf7o6xxBrG887ucdSFvvrG1sNJKnSo9NoJKs/TqQMDiY21//hukNW+pZqCZSVLAQADJJwdyuhj1RuyDMh9irQ0ZJ2VWVVqfISGjfuuufw6/hqcsecHhNpNQ6iYRcbxekuFxwOwbeQSAI7KHUz78ckfGzY2NKc8L7pm31jL1vs9a7T+aj1JWhCoUspAgfKPlESesHiT2rxicwuVOn6+0WjUd4sNK+Ciopm6ksI3QYBBPQpjvMH3jiunMPmE5U3RdSuoZffW6XFKdTA3T7L6gkT9CcjB4WKqaoYZnzzFzXnIB/pHYfkm210EB8GOCANdGCHOByXHueyn+n/CfzB1jyNvet9OaTu1forTJT+1rq2gq8lfpEJGZ2pJMAqCRBJMjiuV81S9cXnEIKoVO5sBKipUmYSM5VECIwT8pjiyXJr4wXNnw7+FPUfJnTjtic0tqtp9p9yspCqvpi6CHShcpELbHqJSqAcGTitVgs6E0z1S+gimQ6FMoIiRvA6j0jPyqAGcwCY4UZK2WokMYGGg7e71Vjw0ENLGJHHLj+foldO83p+nFc6Q+4lKtiJSCmTJndEmZkgZnCRIJgOobs5WPONrceDgBVsSolSlFKkHaMiUz3lXYdZDtrTUQr9zXmJbC0ltkAypcHaencj8wGCe8nhitWlrpq4VdbbqKtrRRMqfrk0TKyzRU4MFwqR8qQoknaNo7kTt4DXOqyfDYdgmC0URaPGkG5SOhWmoDqxKfJRCkyVNrCikGDJAAyrPcTkiOGW73NDtI6gKeU6rYlajJwEK9QJAzComJAChkcLq2qabom0s7CsKGwlG/zITnB9MJO07QDBM4IHEcK2qirbLSQd6wFKcCnCkmcDochPuJPWIgA55PLgJhhZg5K8tVaXqcFwsBxQ29JPpklUGSpJJSQfoYzwnfrWm22UOJUolIbUlJTlJgwVZn0xmB1VkRn29dSEpWhb6kpSGwCqCiSYAPQJnIgY68JH0ht55AdZbCHTsG4EJO4BRmDMdZnHUexglS1Z+mqjaUbypwIUSpKg8tsKCZAAyqPyhGcFKgojcscWQ8Gni71H4U9f2++6dudLRXWlchJC/NSsKSApsj/wBRJkSB7/ljgGNWlTrLW1twJeUtLZSolYUAgByff0wFA5XJMJ+ZvYZrLLtSlDrexRJW2YjcVESYJgbgokzO36JPDHPQOaMrLbeA04CuR4uvG7qzxW67/wCIdZ1TQfQwGGSxLDTTeSNqSNwAJTMiYVPcEA/U1pZ1FTrlTcQpLpMrS0okgEmAVbSCqeg6SIjiMcwOfd65x3Rusv1ciormKVm2pU2whr8O1TJS0hASjb6wlABVgkkrBKscI9L8wm7bdAKh0KQstqcQFD1gKBKFJTvMmQAJOdvckiEZPD2TnS3ESRhp2C9nQ7lFVoVSPq2bFJR6wlZ7AQpXy/XEwDtOYIGgNLPXhva+CpYQnGw7QkErKvUJjI7EAA4kmZHy+uemNbWKrqf20TfKYNCmpfJSoVExvBUkwjan5ZGZEwRPE65Va3tvLXU7NzrrHZdS25lCgbY8tSaWqCmylKiU7T6FKQcADAmQSOJ8Dm+1nK0mkcMlqgOoOXbdjcDDTyUIW4krCVlxJkwEgwkKIJA3AxITt68Ru43Fy2sqVDzLAKgUqUN6IkkSDtKon05mJxOSNcL7RVBIUo7Q6skEgt7lEJ3ZgDdBECZVtOR8zRVaFotRMJS04PLUpxsLYAVtBBMyBkJG7MyANuYHEvwwd2ryOrkaMZQxuWs2kLKU/im2JhYUQorG4xO1RmUyJmevSeGw6wZYfSlSqplQTI3oKNhEnA6kSIJM/oDHE/u/htuaWEPp3uMLJCiCdySZxBlMyoCZG0Z9iYpceSz9AFKWxWMqeKzJUSEAABAidylYJED7Y6do9bNsIHXvmc4kOSKj1tQobOXXlLCVje3lJk42kSfdIAxCczkSHTd/OoKlKGXXnVFKVJKQlPlyc7TKQcqiUxIIz1HDVYOV5VUswyEOpKXN+5aRuJABURtEkJ2pVOd4wOoNHJ/l5bdMUrYddUmoUvchS0klO1JI27uqc9ComBJPXgtbKZtRMIn+UHqlG9V1RSQOmblxHQcymuzcp6nUVG665TVSA8lKqby1EpJk/M4pUpAkxsGTOEkjhwo/C9XlgrqEIQwAhCQ4VJTsG4wCpPp6YA29THQ8GG2a7sui6XznXGFLSkOEIdBKslJgAhWPf2IBgQDDNd+KJNwqagISy8XdywhsJHf1EkZMKBx1iMQDBG822mpX+Gx2pReF75VVkHjTxlh7FR5PI2ktFKX6hbGzzIO9SR2AUIGRCdpI7AHHqE9Ofh6aa8OT/g+vCdX/APCa7sF1Bua7mUoqUtx+72boUAE9CMzMknjlLdOZlfe6tTg8wqUN6FJfK1OKiPV6QQN0GMbQFCPZwtd3fTSjzzVKQYUoEk+mQFbcEyDPQDM/qoVUHiYA2Vhw3EOj0OJHLcc1Fue+i9Pr5lXYWdDtVa231uUyluAJCPMMEgpJJg/ZJH68Ri32UUDi/LRTJcA8kKKQ44PUUlCt2E9VKiM5T2AE3vd7tqHVOvVFKhCnNihuLu0kJ+nqVgSZIjGBwq0NetI3S2X5Vw1NTWJ222pyqt5cpis3qpb2g0yFI+UqCyRuMYIPXjyOiYN3lZdb65zNMXNP3hY5d6Z1Pzf0+xrnUruk9PtvFqovD1MKgUaUI3pV5WT6lBAP5fUJEQVQbmFR2+l1Rdm6K5Lr6ZmuWG6hLSg4tALgQsFIlCSACU7knIGSOIDqXm4urU47vrHN6hMCQ4QjJlUx17FPzI6CIi72ta68PJRSvVIp24Lfl7lLcgRMEjatRxmCIVlREK8lqo2jRFuUuQxSF3i1B2Uu1BrCksTADSUpWlG1IQkFwjduMJBGyTJyT0x2BgGp77W6geS0t3y1Pq2BlB3rRBIOI3bZCsjJj8wnhyt2lap5JePniUpWVEJAgKBz9jsMDbE4gSOHeh5fihUsLStbjhLZO1JXGATBwe0iDBg9N3HkVpqandwwFyq+KqalboYc+5C3/hAV9G2t5wKDilLiNziQZUJBEwSSMxGZj8zbU6SQpRS2hKhugQqEnbkyCM+0GB/Lg1q0Gq4+S08ryt6kjy5UPKBOwKCeqiOwPsY6ji2nh9+B1zB8TfIir19ZmEN28oWumYeqEocrggGQgH5ozHST+o4kzWuOlALygAvctYSGBcy7np4qDiS2dpJCEnsJ+0DH8YM+3EarbEfMWopED5s4n+vpweuZ2hHNDXmpoHabynqVam6gLSIQpKoOf0VPTp2zxDtM6Ho9Q6ytlLeK5Vpt9XUIZqazyS+aJoqhbvlJ9S9o9UdTHvjjnLTBq5MncUPrbZ8oSlKyVAwQY3exMxg8GjkHz61D4ebNrKmsdHYqlGuLG9YLgbjQN1SqdhwgqUwpf/ScBAheD34ilTbbbZ7nUIo3/wAcy08tLNSoBsPpCvSoggwNoBg9N4HGmofcq1qaBUlskBIIMKkCAR1VP0/w47RRNaMqJM9z3YTNdkOOqUC6hKimTKjIIEgGYjPvgduGty1CQlQDhWnfsg5T1BGe8AicfwB4kX7Dfq9oSHBuSSEmVAnInGTkHqInEcOlLoV1sphEKW6pCTnKZ7jGP1zH6caGmfIchdBWxwjBKgqLPtBU4kGSApK0EoSJggRjt2z/AIcOFHYgppBQkqIkSBAGYAgTkwc9ZBAAjiY0OhgKlpKw4qFbwABvT6pKiMSraMDvuxmOHG1acYolFSkLSUgKQoHaE7e5mB7dTH0njvDbTncKNPdgRscqQ+GZdu5ac0rFeb1bG7tbrZXNVVbQOK2IqmkupK0KMwQtMJmeihxcv4uXi/5YeNzmfpS6ctNH/wDC1NaLb+Gq3HKRqlXULUQoBSWzG1tIKQr/AE4plpehbu1XTNLUmmYWr1vJRv8AJABlQSYO0TkSCMntl5FWGGypltG0jY1CQpSjIIMdTJBzkkkxjbwepaOEFr3ZyP3ySxWVU79QaR5v0/fxUw5SafsdVrixUF3vKLHb6+sZpqq4lpTrdqZcdCVulIyoNo9UgmUgjHaUc6OWFg0Vzz1JYtHaiRrXTVtqVtW29tNbGri3tBKwAduCFCRg7ZE44GdDSppW3Ha0wlKUjy43z/8AEyJ9HzHtgAdONrWp6ispSzQn8FQEhK1KIH4lUwIT3j5gEiQYMgxwabKWbM7cv1KXXUeo6nHOTz/QKcV17t2hmkJQ4hypebP735incBCW0pCcT2AG4pncEkAsdw1Mupfcq64OM7UoV5O2EgfMoiIOTJATgE4joYpUXxizredSFv1LeHXFwAVBJAnOMmf06cNPMjmDZXdF0VLRpqG9RNVjrdXUIfSqlcaVCadDKQNylT5ilqIgEpiAJ4jTVohGuU7qZTW505EcIwDzPVbde8zn7hV1C0uBThlW70kJjad2O8GDGY+44gztS7dSqpdD61OKAS0JK90DaBnHUTImDPc8Rw3tC3TUrUhakIWEhbwKwrrIgdBn8xAmJnPF3vge+GnRXio8ZFksvMCqpkWQtVB/CuOhCnnEJBbZCiBlZmTGYMRPCvU3UzAud0TjS2ZtOGtZzKqTZtGOVDwqKoFTSE7w33fCgr1pBPqSSAJwOwzE/NVPvGiQltva03IASIUCqMjdJk9AfqImAB1w+Pf4GOU/hWpNJ1Whaduy193LgqremoKw2hMBLmTuAVJEf9v345Ya2oWG6FLrSw3uQdqkp8vYAARmTA749jHaJFFC2WlMse2QodXVmKtbDJvgoTVlCp1Zd3tsMuOOJSVStG6VAkiUgSMgq29Mg9OJ54dPHHr/AMIlt17TaDuVtoUcyNPuaXvyn6NNQ5UUbiVFwMqXJS4QpSt6SQNwiYBA+1RWtU9xdbQ+2ryX/MDiD5beEkbkKE+mCSInuT3mKVVxcS3uKVkJSlpxJTLaiVZIPQgbgAlXcjuSAlVbhqIVi0bSWgrTVVSVtJSGkObdq0ArKwpCUhQEDpuEGTklMCIJGtuxu1d3dt1CuouhL5ZZ/DMEOVCSIKdplad2PSATgkgTBQ1z6U7vKBKyPJTKxuV+UAQSZOSe24xPfh/5M84NQeHrmhY9aaYqzaNRafqzW2+saOKR4IKUrAUkjaRIgzuJ7dOBxKIAKPsuOW+6OI2JbcCvKIU0FhCyTIUnJ+UEJ25Bjpw3u1RaaR6i2W0oASViU5MSB1gT1yMdwTwoutTUXq6OVDzrztU+tTjriQVKU6pQK5KcZKiSR2P24SfiF1oZ85SkturK1An05hMwcAnAn2A6wZ0Kz1XT3x9+B+7/AA/ufC9B3i+W+9LRQs1Ka+lSoSl1EbFGNycJI9WAAekiAdXpbr6Mo8unUtpIHlpaKEtBRkJSMnpJABgwDKtxHD4ddVevWU1V3qX6p14FtbtQ+HnSoN7Q2A5J2gHA3TCSokbEgtVfTpTWhLTjJp9wH4cLAQ6CsBaACTIkpJ69IAJE8WDE7U3D90rVFOY362bBRS5MOUoJQ8EUyFbVIUJlM4BHqgQUwYGR3JMIKy4ipS8yVKS/6/JKCoBBUZIM4iSQCCFSJkpB4k9PTKeo0pab85lCSpaXQkkwJCcYACRMAYBUenDfUaVUXgFNoUVuKaKUO5CVeiEk+lUkYxB2me5Aiut59toRi3XQtIa8poqb7UtqU6HFOFsJcQqJgJQAApBkbSUCEkhJ3AJTEw40XNG50byqeqXvSkHakqV5iwYSoJXtMEwCZ9MA9zw1CzPOpaQW1IUhzalQktnamSd0GVbjG4iMx1HpS/sU+WoBThp2l7mkqUk7TJKk5BAXG0bT1gkiIhf8KRvspmiuDe6k55x1LzjPlvVCCpSQk7pKFFJhZJkiAE9twkQZHD3p/n+7RvB92oWghRCm0oLi0K/LshQCSAIzBhGI6AXP2MIBCP3LmUBQchvOIJEYMmEiTkGIBlN+x1lzY4hKVESjzDKNpAEzMT9gAM5kYz71LHyUqORsmDlWd0V4ylaatpaefBYXgjaE7IHUyYCZ2gT7kdJPDoeeln1PUOLcqXApa9iwl1ptCyBISteYylcqnG38wA4CV48NGttHcsqHWNVa7hbtOXFXlIqmWFFDK0kHMqyodj0//KeID+9aSChbYcbIhPmrSUjACdxBkxnEYSTI2xxJjus4ADlu9oI55CvTyncteu01q3rmxTtopws7lqQREH0oT+ZJJJhMgnrIkxrUevk2CqXT0qm0KYX5aVIaUreJQBB6boiZmeh6EGplr1VXCrCqd8tIcT/1QA2kpKoRtCSJEpUTnqZJ6wutdZXXBKDv/dqhspMrUuT8oKiQkkqJntkDrgrFepS3DBuhVXDTkZcOSOt45oU1Y8lTtZU1K94UttpQndIEiJO6SSQBMkwesxuu5p01O2tLBR5iUStJCYQdwweyDJSZwqScSeItTaWdvDLanAypLY3O1BJcSNqOoBJAGDnr6QCT1Hi4cunUKaR5LLK0FSAkErcaPTZuIBWqYmIOFEyAeMlqqlx1HdQ2eByZhOV45xVyKZxJcNOlO8k7FHCSd0JMCTJM5BLsCD0YrxzZr6h5QVU53BtsqJI3xhKBPqTAgbfSO27B4dnfC1qWm5dta1ftdYxpsXAWxNzCUltqt27koJPyqEqJgCQCR8oAhzWji04lNHTEu+UtBUoEqTtmVKxIAAVtEYKR6sZjGeY7LdzGtGcpS3rKqutXDZeUtwBPr9RUqD3TgmffqQYMHj5+KqrygtNuKdStahtQk5B9iqRHo/L7xuE8OVl5cVVwec8xUlW9S2RkdYTu2EFQgHCj+WYJIkh6K5NUvmoNQ6K1xJCyhO4oKQBAEAST1BIBH96eJ9FZqqreNkGuN+paNmXHdQrS2jm7ptqAyp9zeHSt9BAAEQcSYEgQFQSTAjgjWTQYpaBK1JbJWhMQkBpRIG70gZJBgACDAIz0L/KDkhp/Utm1M9XaksWnntN2Z2606LhUFtV2W0oJFKykAfvlQQBP5cTmB9cOY9FTIBp0NvLd3ALWRCxnAUDJ9KQCEnqSI4daGz0dICZCNQ/VVpcOIq2uOmAYaUpoNLCjdDiQ2Gqckh95SUhCRISRgkExEEjAAjvw7aeotFq05flXTVSbLW2m3Kq7ewihW4LvUhaQKZKgSEFQUsgr6BJmOnA3vGsay8kuuv7Q2gLQpRAbWvegle0TIkKzIUQmOs8MNUlKyhRadeJAUHcpDaYPqQkndGTJPXAIzB3nrmnaMYXCmtrtnVLs+ieKzVKqi4FSEtBQUtKoSPUYn0jBkwnJyYVIwAb6eFT432rPDP4alaBatdnrkU9O4igfckLogo+ojbAWmVAgDIM9ccc5F3sUrCg2xSMlTkKCmgVISEqKjBVA6xCifpA6OXKHSi+b/M6wWCqvFLZaW81rFE5X1rxbapm3nAkKWs/KhJUZk9jkxPASsLZR+MM4R+mzDnwjhe+b/MVjUeqrlXuFl6prqlx5SgkDbkkuSrO0kkwBIkZE4YdN8jtVc1ba9XWyzVVwpGE+a8aZpag2M/N3iBGR24JfxHvB/Q+BbxIVmhrdq21a1pKWmZqkVlEUjaVoK/JUEqgKEdAYIInPF6Pgj/Fb5R+Dbkhq7T+v6ByjuNwqE1TD7FKahVchLYQWFEiYkSJ/vHvwNqpHOGYm6s4RODS04kOFycv+n16ZuQp3kKdqW0pGxKSBuIg7Se5xJEAmdoAgcJKO2ru1UhsNEpcWCEIAUpeBEbesx0j6nJwUvFPru2c8ef2oNR2W3G02+63B55mjaAKadtTpKUo2kDoY2nAM+5ATaT0ApTqXHVpNQ6opASkLIgABUYgkd5z+s8EKC3vmeGgIJc7tHTtLiQpd4ZvDVWc5dW26z2+mFXX3F9FPTtoTAqFLMgfQDPTp17Rxfnm38AXWfKjlK7qPfQXD8HT+fVUtLhTQgFRAjMZmOvfgOfD95jU3h2506Y1JXMB6ms9Wl19JysJMhX2I3GO478deufHxVuU6eRFyftt7buVyudCtqnoW0HzCpSYhQ7DPDNWUdwo3wR0dPra/2jjPX6bdVWtPdbfX/en1tWY3MHkAOM7fXfovzx8wtIv2S6+TsKvKWUKlMBJzmT0Oc5MfXA4i9DpOpu1YEpaWjyyQtcFKUAfLIPc9P4ZweD/zBoWL9qh6qO1G98vKKsATJEDsAJz37e3EbvVytWnrK4EIUrYFbpwlZKSDuI75Eye0z6eC9RZACXyENaotu4kcWNijaXOKg9LokUTLUK8pttsqQt0wlSgQSe5JEiCDORJmeEVXdqS1vw1tdcKlNFwNlSAgETtAJUT2+p9xI4W6juFw1Ql5Sj+FpEggNghGZCJBGQIWemOmZnaz195pbKk+Ult1xKlOIVI3LEiJVHSEnA/7pJJkhZjE04ZyHVNVO2Vzcy7nsP1WxNmNaymruZUimIKW0AfMTMIxgYMnMxuJ6EjRW3ldzqHktKShptMvHyyskZ9IPUAZBznvPThhcvbt7fW4VhIKStb64KWkwJSPr1BzjiL655koprYKWl3oo2kFRQVDJ7E46n0iDI6AlJE8RJayGFhceX1KmxW6eolDBufoP9pXrLWdNbWjToCkra2oXvPrWSCBtI9x9gBkkdRBa6sqa4oeqAGE7fM8wKiIAgj2EKmB6vVkAAwjrKx78Q8p9SkrQVl0mQSZBKZx1UQJPUkSIAPG6lt4tri3Nhc/DuqbKXUh3zFgHaYxE5IBONoKpHCDX3B9TMTyCsy22qKkhxjLuqdqOiCHVObS0mnDTTqAlXpAIykHqkekCQJMDHeXaa5qVvL64U1Ta3naaqQUvMqaUptwGEhOxSTKiAMiYwcxgD126ob8kqhKVPqc9RCggSFKVuIABKSTMdgCO/H2kqg3TF55xlRXueLJUd7YETAIiNpAA7dZSN3G9POGclzqKXxOYRh1hz71DzJqUVupL3X3N0qS0l+sqlvLkpxC1yI6GBGCDgSOBrrrmA/W1DiGtwLSf3ZCCQIPuAYE5yIxI3do9e9Rfgmi048ErUCVo3StQBhRKpPZSSI/VOI4i1Zc6httaAlbKlpkpCQ2CoiJIkZxIPaE53CeNq2+O8IwxnmuVDYImzCd45Jdcn3rhUPpLakBLa1OiFGUneohSVKjckAHMRBMZVLReFr/ABLjKXijzVo8zcd/ykwdwJOSATEjIHYHgweA/Tug9eeLHQdn5o3den+XlyurVNeaxDiYZYKVbVKgEJBVsTChCdyjETNqv7RP4a/Dj4bOcWkKPkBe6CtZu1p82/UduuouVHblBSUtOBxKjtccQDuQqRASY+UBaOT5imgYBAC5x1G5x5RcVKTlaZICTgEkKEKyDj6gdIHHSDwh+BDwwc2PhNc0+Y+seZJsPNSw1FS1arZ+PaS6HGm9zLYpzKny+Soen5ds8c5326r8SmrSy8lCyIWBtTuT6iEGACQDgAYCUnthE/dnkUzO6EhnaiVD1FMkgAg5BxMZxOO+rTg5Wzhnkpbr7mBbdcaO0nbqfS1utN4sjD7Vxu1E8pTt9StaVM+Y38jamW5SCkkqCgSeEnPTS1i0DzJuVq03q2k1xp+kDCqa90lvco26vzGmnFANPBLiFtrUplU9S0YJTxEFn8QraooCm4bG31JjPTMDoAD0j9Txo9T0ubdnZXqyepjrnH+A9+MJysyrsczfEvaOcHMav1DatHaf0Ja7jSMUyrPaajyaVry2EoW4CtSzvcHqcELkqA2y4Bw4ou72pqNbVS4relDrqA4yE7nV7IKVhJVuCl/KpKgMbVEE7a6aW1Ahyrp3SpQRUtlCoQUNGBBQCDjC/USTPpySsgE+vtSNGaT0veXLtpm4q1JRPOop6GtS9V24NOqaWKxmUeS47s3hoqUFhZODkscFW7n2UJ7G8ip7bLax+3aQVLiGwry1Ph353uikrKcbpTtMHMe3Bg1Fyz0zedLKdRUodUtMHykIHRCQobzhQAMEkHrMQSDXzT9+WpgslldQlL/lOB5twqB2j0yCCdwXjPzKRABnbOKjm4bly8t2naez0VA7YXqmoVXMU5FbWodDY2PSY2t7DAMBJdUCZJh0snEVPA18U0evUPkkfiPhuoqpI5aaYx6TnA6+iIvOnwCcxOSfLDT2t9WaVq7dpjWIQmjuKsl1WxSkJVA3pCh6hv2lXq9QngTVegEVIUp5a3nIUttJQklwHqorBBiSB+bpH5uCx4h/iR82PEp4fdJ8uNS3+gqdL6R2LoVt04Q44lCNjbjqmgoubWVKCYSkggmM8Aml1BcLCkofSpKvMPqQ5LYViTMztGBuB2wrHvwPgNO/aZmN+i71JqogDE75pxqOUzyWQGfMZ2JTiVgGSem7cP8AtJAA7yTB400XK1yjeSUISg7/ADAjeQCBE+n2lAKsCRuwDHE95Aau0TqHU71HzCut80/Zk0FSW6m3UYq3V1nlqNO2tE/9NTiUoUfyzMpT6uG2jvpqnEOPKbYcSsKKkJMqJI/MkCYIjqJ6j34kNs1HLks9FBHEddD7aInMrxe61154TLPylrW0N6YstZ+JZWlKXDG6QnHSDt6K7bsDHFdajlgKdCXVIDOQWlOjZ5UZ2gbTkkyOvQAk9OCFW1i0KS22ttalpOTASkSCoqgSAEiCOvXAxw3UGoaCxakp66so2qyjYeQ5UMqUsofQIUpO/sCAUkyFRmSRPEaexQMy7CIU/FVTJ5cqMUmjNjKFlaghKgpSA4dqVknaQFerqBMAnIEz0lul9Aodd2rbSmG0ndMg9BEd8AnBBkBXRIgicw9RNeLfxDX1/lLyzqrLT1AcraTTdtLlW7RsMU8vrxBUJDqzEABXzTgOPh61JYk3FX49sJWhxKFbVbiIGAmIBSEwAPvOOk6yWqCombANie6HcR8RVFFTvqXAuDeg5plodIooqR5RKw6zMJU4CVbk9ciCogpSDuT1SACY4ba6wuVbnUFS1QFMoCd53JgknI/LBRlI6nqeC1zJvFjav77lndFRSqCgkqZ2K2QEpXGIVJmZMT78Rmr1S21TLh9xaCVJVtAAdG443dDI6iTIjIM8H6nhtjHlpPJLdBxxJJE1wB3781B1aVvFz08baaypRbVLFT+DL6gwl4D/AKgRO3zClJzM/N177aDkq0w6pS3VKbSopU4kJkCIVG8JEqAmIIjcO44fKzWdCl4JWoguQ4oU5IU3KfmGJPXoTjaDBOSyXbUNRdg6UMU6AILinlFtpsp9KgqfUScnsRuVEZ4iG2U0Z5ZKmniWslHtYCckUdnsjSE/MtKgQ0D5ra0gnBmMED7iSmTPDbeuZaUUv4WnpVAiQVuulanTtMkZGCE9OhIEqGOGt2203nbqm4gtok7W/SYxClKx0ke84k9uNC9Z2jTrS26SnogYkIEOEHAAkjpP92AYBnIjsC5o2OgIbNUCR4JaXu+iT3mvvWsStbqXVNbhmPQ0DnuAJCY/KN0caG9KKSy47VVakectSpEEOgHHX1KIG3MSYUJMbuGi981Kisd3NNhtIJ3VDxJISZEJQI9IAkTkQfbhLqyx6itOkbPqCrdZVb9Qh80ZYqWlv7miG3C41uLjY3KTAWhO5MlMgSB01RTt5kuKIwwVbwAAGD6p5uNVTUdSVIaUQJhdSvZB3dSSSRInIJMHBE4YL3qAKWtJdCHQsNKQlA2LV/dM4lWMEHOfdPDPT0z90c8xwvKQg+YlO+VqH1OYMdDAJOI6J4dKbRRQlC1+YzTwdqXG43JEhR6QTux9SJI7cRw58v8ALauznxQfzXZKa13AMuIUhourKlQVLEuJCjncRtAOe3QTk8am6qrr/MCFKebUoqcUBO8kzJHyicH69568ShvS9tpadYJW69O1aHQAhgHaUGAI/vEg4iPm4V1KGrXTpKklTu1C/LCTAB+UlShJmTnJg/fjYUJzl68fdWYwwKM1Gj6hawalCgNkpLiyklEY6diM47YzMl0suiXq4LlBQ0mCpayUBXQ4yEnJGZzEAGOJHY7Ebw75r6EBCyklJgKcEzBIMzgZxOegJ4mFo0+0H3F1I2q3iCvcFSTAMYkmT0jr24K0llD3ZIwPVL9z4j8JuAd/T9FHNJ8tUpZBUgBxKtylLJBQTM4jHvhMwD0kcEiz0NDpy3pS6yhbjigpZBA2pzJ+oyM46TnoH/RnJ+5aq5aas1LbBQVFs0Wyy7cQ7UtNPoQ6vYkpbJCljcIJSDtj7HgXXjUKHEEVD4bpwobokFZIzmDIPt1jMcNFP4NID4YyRsfRItQ+ouTsOJ0/mpQNXVFSSGUFKSsALSoIC4zHvP8A3fSCOnE35Cc+9OcteZ7FdqjRrevbKhh5ldncqlU6X1qbKUuFaQSCgkKg9oMjB4DaKev1KyNjAo6FtJ8x4pgARClDsrp3Kj6pMdvtRqe36etqkMrWt11vzHSuApQCyEpVgERBJAI3bs9xxCqb2NDmHJz6kfUbhFaPhUPcHEAY9M/PKfrle6u8PbWB5QSvcYWkpBzAKp9xBI9u8kcRO+XujsxK11FHV1TcBkBY8hoA/UErJHsOgSSep4jGseb9RVOJpKVQNIQAIbW0l5sFSZ2rKlAjPXcTOZMAQ+vrCismoKnKhTaZUtsDaT0ABEgQSQJzEnsCs1l4mndlyd7fw/T0rQ1v/tPV/wBf1lY44lsuLWAStSVGDEAkGCTnbg4x2nEZW+usfacfLjhXKdrhBSoASIyBsAnqQOo77uNdK6h5QK0hpICU7lrCUpQSYPtjBJIkwB7wjuFf57bhDaPIQrzl78hcLgFQ+aDunqRJABgmA8tTpGuQpjp6MuIZGEmump3a8ww4UsFQKwkkAp3EeoiNxicDunIAJPEVHlqblAWlZaClbUNkNgpPcknJwcA/NOYHC66ViHLgoy3UshxI3rbWTUtJ/IITuSFETJ27SoCAUcM1UVuLaZQSp9W2nQC0loOLBUFLBCgEeooBJEQTKsAlQr690rtinW325kDduaVOsihaCnUrZQEqWUrBKS3sSUqAUTBVuc9RTHyx88hHX3NxRcpw2ZbXKEJRKUOGUyNpAwUExEQ2MQI4SVr6nN623AG3CopLbYKXCAolyPYSlIPcJkiAY1vLUKJ5e90tpIQBEpG5BAWkKTJK5UoElJwkEdJGiXCI6M7JYh5TCg88pxPkblpb8zzFJVu3+YU4KmiASNpyUJz04SXS6O07boSahJaP76HE7Wdx2qSpSTCjCkgHPUpPRQKC5VqXANxSkJCH/wDo4dkJ3Ix1CSRAxuCZx3bbm+l6pUt9aklSNiFJWHFEDYCd0dQEnviAYHfwzu6LBCMp0oLZW3x5VPQMVVatphbpaoWFvOIS0hS1OKCc7EphaiISkbj2KeGRTrTTbLhbS4pSDKSUFtQBKj83ypmT0g7o6Agyrlhzu1RyNvNzuej75WadrLza6vT9Y5TqG6ooKtHl1DCpGQ62SVGJGIAUBxDK15KEtqa/d7AXQVJgxO1PXB2AACIwD7ccMldgMJVR3B2ibDoUlgtKMlELQDGSqAPTBSIknr7gceaqpaq1uLDyVBLhg7yd0jr2OcSoAElPQmeEVe8tK1rG6Hwpzes/NBIEKAz0juCQT7cfKja1WLCiFlFQoJJAEwCJKuv6TGCep48WKa3fxAapv/Ja08tnryv/AIO07d6q/wBBb1tso/DV1Uhtp51LoHmHclCRtUspGyREq4YtIctr1r+k1BUWWyV17p9OW1d2ujlHSKWi10aVoaVUPFKf3bYU42lSyAAVYIJkMjZkZS2D+Yx8qRGenYDMZMx7jj7b71WW2iqksVD9MiuQaZ4NOKbTUtSFKaUUwCkHaSk+nCcSAeMXmegW+0WOr1FWoYpqZysqXHEBLbTe8vAdCAnqPYAdBGSDCW+WOssFc5S1yV0dUw8ULQ6Cktmckp/rp9eJFR1N95K6xttexUs092pm6e5UjrLiXsOJStsSCU7gDlJEgjj7q6/ap8S3My9XutS9fNS3RL10r1ssoQVJbRvdXAACdqETjsDkk8YsIX//2Q==" />
These are GGUF quantized versions of [Envoid/Fish-8x7B](https://huggingface.co/Envoid/Fish-8x7B).
The importance matrix was trained for 100K tokens (200 batches of 512 tokens) using `wiki.train.raw`.
The IQ2_XXS and IQ2_XS versions are compatible with llama.cpp, version `147b17a` or later. The IQ3_XXS requires version `f4d7e54` or later.
Some model files above 50GB are split into smaller files. To concatenate them, use the `cat` command (on Windows, use PowerShell): `cat foo-Q6_K.gguf.* > foo-Q6_K.gguf` |
knowledgator/IUPAC2SMILES-canonical-small | knowledgator | 2024-02-15T15:33:56Z | 504 | 5 | transformers | [
"transformers",
"safetensors",
"mt5",
"text2text-generation",
"chemistry",
"biology",
"medical",
"smiles",
"iupac",
"text-generation-inference",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2024-02-13T21:34:45Z | ---
license: apache-2.0
metrics:
- accuracy
- bleu
pipeline_tag: text2text-generation
tags:
- chemistry
- biology
- medical
- smiles
- iupac
- text-generation-inference
widget:
- text: ethanol
example_title: CCO
---
# IUPAC2SMILES-canonical-small
IUPAC2SMILES-canonical-small was designed to accurately translate IUPAC chemical names to SMILES.
## Model Details
### Model Description
IUPAC2SMILES-canonical-small is based on the MT5 model with optimizations in implementing different tokenizers for the encoder and decoder.
- **Developed by:** Knowladgator Engineering
- **Model type:** Encoder-Decoder with attention mechanism
- **Language(s) (NLP):** SMILES, IUPAC (English)
- **License:** Apache License 2.0
### Model Sources
- **Paper:** coming soon
- **Demo:** [ChemicalConverters](https://huggingface.co/spaces/knowledgator/ChemicalConverters)
## Quickstart
Firstly, install the library:
```commandline
pip install chemical-converters
```
### IUPAC to SMILES
#### To perform simple translation, follow the example:
```python
from chemicalconverters import NamesConverter
converter = NamesConverter(model_name="knowledgator/IUPAC2SMILES-canonical-small")
print(converter.iupac_to_smiles('ethanol'))
print(converter.iupac_to_smiles(['ethanol', 'ethanol', 'ethanol']))
```
```text
['CCO']
['CCO', 'CCO', 'CCO']
```
#### Processing in batches:
```python
from chemicalconverters import NamesConverter
converter = NamesConverter(model_name="knowledgator/IUPAC2SMILES-canonical-small")
print(converter.iupac_to_smiles(["buta-1,3-diene" for _ in range(10)], num_beams=1,
process_in_batch=True, batch_size=1000))
```
```text
['<SYST>C=CC=C', '<SYST>C=CC=C'...]
```
Our models also predict IUPAC styles from the table:
| Style Token | Description |
|-------------|----------------------------------------------------------------------------------------------------|
| `<BASE>` | The most known name of the substance, sometimes is the mixture of traditional and systematic style |
| `<SYST>` | The totally systematic style without trivial names |
| `<TRAD>` | The style is based on trivial names of the parts of substances |
## Bias, Risks, and Limitations
This model has limited accuracy in processing large molecules and currently, doesn't support isomeric and isotopic SMILES.
### Training Procedure
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
The model was trained on 100M examples of SMILES-IUPAC pairs with lr=0.0003, batch_size=1024 for 2 epochs.
## Evaluation
| Model | Accuracy | BLEU-4 score | Size(MB) |
|-------------------------------------|---------|------------------|----------|
| IUPAC2SMILES-canonical-small |88.9% |0.966 |23 |
| IUPAC2SMILES-canonical-base |93.7% |0.974 |180 |
| STOUT V2.0\* |68.47% |0.92 |128 |
*According to the original paper https://jcheminf.biomedcentral.com/articles/10.1186/s13321-021-00512-4
## Citation
Coming soon.
## Model Card Authors
[Mykhailo Shtopko](https://huggingface.co/BioMike)
## Model Card Contact
[email protected] |
bababababooey/llama-3-8b-instruct-toxic | bababababooey | 2024-04-23T14:12:01Z | 504 | 1 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"not-for-all-audiences",
"conversational",
"dataset:unalignment/toxic-dpo-v0.2",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-23T05:52:52Z | ---
license: apache-2.0
datasets:
- unalignment/toxic-dpo-v0.2
tags:
- not-for-all-audiences
---
dpo test, trained on unalignment/toxic-dpo-v0.2 for an epoch
⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀ |
RichardErkhov/m-a-p_-_OpenCodeInterpreter-DS-6.7B-gguf | RichardErkhov | 2024-05-03T14:38:12Z | 504 | 0 | null | [
"gguf",
"arxiv:2402.14658",
"region:us"
]
| null | 2024-05-03T12:43:26Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
OpenCodeInterpreter-DS-6.7B - GGUF
- Model creator: https://huggingface.co/m-a-p/
- Original model: https://huggingface.co/m-a-p/OpenCodeInterpreter-DS-6.7B/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [OpenCodeInterpreter-DS-6.7B.Q2_K.gguf](https://huggingface.co/RichardErkhov/m-a-p_-_OpenCodeInterpreter-DS-6.7B-gguf/blob/main/OpenCodeInterpreter-DS-6.7B.Q2_K.gguf) | Q2_K | 2.36GB |
| [OpenCodeInterpreter-DS-6.7B.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/m-a-p_-_OpenCodeInterpreter-DS-6.7B-gguf/blob/main/OpenCodeInterpreter-DS-6.7B.IQ3_XS.gguf) | IQ3_XS | 2.61GB |
| [OpenCodeInterpreter-DS-6.7B.IQ3_S.gguf](https://huggingface.co/RichardErkhov/m-a-p_-_OpenCodeInterpreter-DS-6.7B-gguf/blob/main/OpenCodeInterpreter-DS-6.7B.IQ3_S.gguf) | IQ3_S | 2.75GB |
| [OpenCodeInterpreter-DS-6.7B.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/m-a-p_-_OpenCodeInterpreter-DS-6.7B-gguf/blob/main/OpenCodeInterpreter-DS-6.7B.Q3_K_S.gguf) | Q3_K_S | 2.75GB |
| [OpenCodeInterpreter-DS-6.7B.IQ3_M.gguf](https://huggingface.co/RichardErkhov/m-a-p_-_OpenCodeInterpreter-DS-6.7B-gguf/blob/main/OpenCodeInterpreter-DS-6.7B.IQ3_M.gguf) | IQ3_M | 2.9GB |
| [OpenCodeInterpreter-DS-6.7B.Q3_K.gguf](https://huggingface.co/RichardErkhov/m-a-p_-_OpenCodeInterpreter-DS-6.7B-gguf/blob/main/OpenCodeInterpreter-DS-6.7B.Q3_K.gguf) | Q3_K | 3.07GB |
| [OpenCodeInterpreter-DS-6.7B.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/m-a-p_-_OpenCodeInterpreter-DS-6.7B-gguf/blob/main/OpenCodeInterpreter-DS-6.7B.Q3_K_M.gguf) | Q3_K_M | 3.07GB |
| [OpenCodeInterpreter-DS-6.7B.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/m-a-p_-_OpenCodeInterpreter-DS-6.7B-gguf/blob/main/OpenCodeInterpreter-DS-6.7B.Q3_K_L.gguf) | Q3_K_L | 3.35GB |
| [OpenCodeInterpreter-DS-6.7B.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/m-a-p_-_OpenCodeInterpreter-DS-6.7B-gguf/blob/main/OpenCodeInterpreter-DS-6.7B.IQ4_XS.gguf) | IQ4_XS | 3.4GB |
| [OpenCodeInterpreter-DS-6.7B.Q4_0.gguf](https://huggingface.co/RichardErkhov/m-a-p_-_OpenCodeInterpreter-DS-6.7B-gguf/blob/main/OpenCodeInterpreter-DS-6.7B.Q4_0.gguf) | Q4_0 | 3.56GB |
| [OpenCodeInterpreter-DS-6.7B.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/m-a-p_-_OpenCodeInterpreter-DS-6.7B-gguf/blob/main/OpenCodeInterpreter-DS-6.7B.IQ4_NL.gguf) | IQ4_NL | 3.59GB |
| [OpenCodeInterpreter-DS-6.7B.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/m-a-p_-_OpenCodeInterpreter-DS-6.7B-gguf/blob/main/OpenCodeInterpreter-DS-6.7B.Q4_K_S.gguf) | Q4_K_S | 3.59GB |
| [OpenCodeInterpreter-DS-6.7B.Q4_K.gguf](https://huggingface.co/RichardErkhov/m-a-p_-_OpenCodeInterpreter-DS-6.7B-gguf/blob/main/OpenCodeInterpreter-DS-6.7B.Q4_K.gguf) | Q4_K | 3.8GB |
| [OpenCodeInterpreter-DS-6.7B.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/m-a-p_-_OpenCodeInterpreter-DS-6.7B-gguf/blob/main/OpenCodeInterpreter-DS-6.7B.Q4_K_M.gguf) | Q4_K_M | 3.8GB |
| [OpenCodeInterpreter-DS-6.7B.Q4_1.gguf](https://huggingface.co/RichardErkhov/m-a-p_-_OpenCodeInterpreter-DS-6.7B-gguf/blob/main/OpenCodeInterpreter-DS-6.7B.Q4_1.gguf) | Q4_1 | 3.95GB |
| [OpenCodeInterpreter-DS-6.7B.Q5_0.gguf](https://huggingface.co/RichardErkhov/m-a-p_-_OpenCodeInterpreter-DS-6.7B-gguf/blob/main/OpenCodeInterpreter-DS-6.7B.Q5_0.gguf) | Q5_0 | 4.33GB |
| [OpenCodeInterpreter-DS-6.7B.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/m-a-p_-_OpenCodeInterpreter-DS-6.7B-gguf/blob/main/OpenCodeInterpreter-DS-6.7B.Q5_K_S.gguf) | Q5_K_S | 4.33GB |
| [OpenCodeInterpreter-DS-6.7B.Q5_K.gguf](https://huggingface.co/RichardErkhov/m-a-p_-_OpenCodeInterpreter-DS-6.7B-gguf/blob/main/OpenCodeInterpreter-DS-6.7B.Q5_K.gguf) | Q5_K | 4.46GB |
| [OpenCodeInterpreter-DS-6.7B.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/m-a-p_-_OpenCodeInterpreter-DS-6.7B-gguf/blob/main/OpenCodeInterpreter-DS-6.7B.Q5_K_M.gguf) | Q5_K_M | 4.46GB |
| [OpenCodeInterpreter-DS-6.7B.Q5_1.gguf](https://huggingface.co/RichardErkhov/m-a-p_-_OpenCodeInterpreter-DS-6.7B-gguf/blob/main/OpenCodeInterpreter-DS-6.7B.Q5_1.gguf) | Q5_1 | 4.72GB |
| [OpenCodeInterpreter-DS-6.7B.Q6_K.gguf](https://huggingface.co/RichardErkhov/m-a-p_-_OpenCodeInterpreter-DS-6.7B-gguf/blob/main/OpenCodeInterpreter-DS-6.7B.Q6_K.gguf) | Q6_K | 5.15GB |
Original model description:
---
language:
- en
pipeline_tag: text-generation
tags:
- code
license: apache-2.0
---
<h1 align="center"> OpenCodeInterpreter: Integrating Code Generation with Execution and Refinement<h1>
<p align="center">
<img width="1000px" alt="OpenCodeInterpreter" src="https://opencodeinterpreter.github.io/static/images/figure1.png">
</p>
<p align="center">
<a href="https://opencodeinterpreter.github.io/">[🏠Homepage]</a>
|
<a href="https://github.com/OpenCodeInterpreter/OpenCodeInterpreter/">[🛠️Code]</a>
</p>
<hr>
## Introduction
OpenCodeInterpreter is a family of open-source code generation systems designed to bridge the gap between large language models and advanced proprietary systems like the GPT-4 Code Interpreter. It significantly advances code generation capabilities by integrating execution and iterative refinement functionalities.
For further information and related work, refer to our paper: ["OpenCodeInterpreter: A System for Enhanced Code Generation and Execution"](https://arxiv.org/abs/2402.14658) available on arXiv.
## Model Information
This model is based on [deepseek-coder-6.7b-base](https://huggingface.co/deepseek-ai/deepseek-coder-6.7b-base).
## Benchmark Scores
The OpenCodeInterpreter Models series exemplifies the evolution of coding model performance, particularly highlighting the significant enhancements brought about by the integration of execution feedback. In an effort to quantify these improvements, we present a detailed comparison across two critical benchmarks: HumanEval and MBPP. This comparison not only showcases the individual performance metrics on each benchmark but also provides an aggregated view of the overall performance enhancement. The subsequent table succinctly encapsulates the performance data, offering a clear perspective on how execution feedback contributes to elevating the models' capabilities in code interpretation and execution tasks.
| **Benchmark** | **HumanEval (+)** | **MBPP (+)** | **Average (+)** |
|---------------|-------------------|--------------|-----------------|
| **OpenCodeInterpreter-DS-1.3B** | 65.2 (61.0) | 63.4 (52.4) | 64.3 (56.7) |
| + Execution Feedback | 65.2 (62.2) | 65.2 (55.6) | 65.2 (58.9) |
| **OpenCodeInterpreter-DS-6.7B** | 76.2 (72.0) | 73.9 (63.7) | 75.1 (67.9) |
| + Execution Feedback | 81.1 (78.7) | 82.7 (72.4) | 81.9 (75.6) |
| + Synth. Human Feedback | 87.2 (86.6) | 86.2 (74.2) | 86.7 (80.4) |
| + Synth. Human Feedback (Oracle) | 89.7 (86.6) | 87.2 (75.2) | 88.5 (80.9) |
| **OpenCodeInterpreter-DS-33B** | 79.3 (74.3) | 78.7 (66.4) | 79.0 (70.4) |
| + Execution Feedback | 82.9 (80.5) | 83.5 (72.2) | 83.2 (76.4) |
| + Synth. Human Feedback | 88.4 (86.0) | 87.5 (75.9) | 88.0 (81.0) |
| + Synth. Human Feedback (Oracle) | 92.7 (89.7) | 90.5 (79.5) | 91.6 (84.6) |
| **OpenCodeInterpreter-CL-7B** | 72.6 (67.7) | 66.4 (55.4) | 69.5 (61.6) |
| + Execution Feedback | 75.6 (70.1) | 69.9 (60.7) | 72.8 (65.4) |
| **OpenCodeInterpreter-CL-13B** | 77.4 (73.8) | 70.7 (59.2) | 74.1 (66.5) |
| + Execution Feedback | 81.1 (76.8) | 78.2 (67.2) | 79.7 (72.0) |
| **OpenCodeInterpreter-CL-34B** | 78.0 (72.6) | 73.4 (61.4) | 75.7 (67.0) |
| + Execution Feedback | 81.7 (78.7) | 80.2 (67.9) | 81.0 (73.3) |
| **OpenCodeInterpreter-CL-70B** | 76.2 (70.7) | 73.0 (61.9) | 74.6 (66.3) |
| + Execution Feedback | 79.9 (77.4) | 81.5 (69.9) | 80.7 (73.7) |
| **OpenCodeInterpreter-GM-7B** | 56.1 (50.0) | 39.8 (34.6) | 48.0 (42.3) |
| + Execution Feedback | 64.0 (54.3) | 48.6 (40.9) | 56.3 (47.6) |
| **OpenCodeInterpreter-SC2-3B** | 65.2 (57.9) | 62.7 (52.9) | 64.0 (55.4) |
| + Execution Feedback | 67.1 (60.4) | 63.4 (54.9) | 65.3 (57.7) |
| **OpenCodeInterpreter-SC2-7B** | 73.8 (68.9) | 61.7 (51.1) | 67.8 (60.0) |
| + Execution Feedback | 75.6 (69.5) | 66.9 (55.4) | 71.3 (62.5) |
| **OpenCodeInterpreter-SC2-15B** | 75.6 (69.5) | 71.2 (61.2) | 73.4 (65.4) |
| + Execution Feedback | 77.4 (72.0) | 74.2 (63.4) | 75.8 (67.7) |
*Note: The "(+)" notation represents scores from extended versions of the HumanEval and MBPP benchmarks. To ensure a fair comparison, the results shown for adding execution feedback are based on outcomes after just one iteration of feedback, without unrestricted iterations. This approach highlights the immediate impact of execution feedback on performance improvements across benchmarks.*
## Model Usage
### Inference
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_path="m-a-p/OpenCodeInterpreter-DS-6.7B"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
device_map="auto",
)
model.eval()
prompt = "Write a function to find the shared elements from the given two lists."
inputs = tokenizer.apply_chat_template(
[{'role': 'user', 'content': prompt }],
return_tensors="pt"
).to(model.device)
outputs = model.generate(
inputs,
max_new_tokens=1024,
do_sample=False,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=tokenizer.eos_token_id,
)
print(tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True))
```
## Contact
If you have any inquiries, please feel free to raise an issue or reach out to us via email at: [email protected], [email protected].
We're here to assist you!"
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.