
text
stringlengths 23
371k
| source
stringlengths 32
152
|
|---|---|
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Downloading files
## Download a single file
### hf_hub_download
[[autodoc]] huggingface_hub.hf_hub_download
### hf_hub_url
[[autodoc]] huggingface_hub.hf_hub_url
## Download a snapshot of the repo
[[autodoc]] huggingface_hub.snapshot_download
## Get metadata about a file
### get_hf_file_metadata
[[autodoc]] huggingface_hub.get_hf_file_metadata
### HfFileMetadata
[[autodoc]] huggingface_hub.HfFileMetadata
## Caching
The methods displayed above are designed to work with a caching system that prevents
re-downloading files. The caching system was updated in v0.8.0 to become the central
cache-system shared across libraries that depend on the Hub.
Read the [cache-system guide](../guides/manage-cache) for a detailed presentation of caching at
at HF.
| huggingface/huggingface_hub/blob/main/docs/source/en/package_reference/file_download.md |
Stable Diffusion text-to-image fine-tuning
The `train_text_to_image.py` script shows how to fine-tune stable diffusion model on your own dataset.
___Note___:
___This script is experimental. The script fine-tunes the whole model and often times the model overfits and runs into issues like catastrophic forgetting. It's recommended to try different hyperparamters to get the best result on your dataset.___
## Running locally with PyTorch
### Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
**Important**
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
```
Then cd in the example folder and run
```bash
pip install -r requirements.txt
```
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
Note also that we use PEFT library as backend for LoRA training, make sure to have `peft>=0.6.0` installed in your environment.
### Pokemon example
You need to accept the model license before downloading or using the weights. In this example we'll use model version `v1-4`, so you'll need to visit [its card](https://huggingface.co/CompVis/stable-diffusion-v1-4), read the license and tick the checkbox if you agree.
You have to be a registered user in 🤗 Hugging Face Hub, and you'll also need to use an access token for the code to work. For more information on access tokens, please refer to [this section of the documentation](https://huggingface.co/docs/hub/security-tokens).
Run the following command to authenticate your token
```bash
huggingface-cli login
```
If you have already cloned the repo, then you won't need to go through these steps.
<br>
#### Hardware
With `gradient_checkpointing` and `mixed_precision` it should be possible to fine tune the model on a single 24GB GPU. For higher `batch_size` and faster training it's better to use GPUs with >30GB memory.
**___Note: Change the `resolution` to 768 if you are using the [stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2) 768x768 model.___**
<!-- accelerate_snippet_start -->
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
accelerate launch --mixed_precision="fp16" train_text_to_image.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_NAME \
--use_ema \
--resolution=512 --center_crop --random_flip \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--max_train_steps=15000 \
--learning_rate=1e-05 \
--max_grad_norm=1 \
--lr_scheduler="constant" --lr_warmup_steps=0 \
--output_dir="sd-pokemon-model"
```
<!-- accelerate_snippet_end -->
To run on your own training files prepare the dataset according to the format required by `datasets`, you can find the instructions for how to do that in this [document](https://huggingface.co/docs/datasets/v2.4.0/en/image_load#imagefolder-with-metadata).
If you wish to use custom loading logic, you should modify the script, we have left pointers for that in the training script.
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export TRAIN_DIR="path_to_your_dataset"
accelerate launch --mixed_precision="fp16" train_text_to_image.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$TRAIN_DIR \
--use_ema \
--resolution=512 --center_crop --random_flip \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--max_train_steps=15000 \
--learning_rate=1e-05 \
--max_grad_norm=1 \
--lr_scheduler="constant" --lr_warmup_steps=0 \
--output_dir="sd-pokemon-model"
```
Once the training is finished the model will be saved in the `output_dir` specified in the command. In this example it's `sd-pokemon-model`. To load the fine-tuned model for inference just pass that path to `StableDiffusionPipeline`
```python
import torch
from diffusers import StableDiffusionPipeline
model_path = "path_to_saved_model"
pipe = StableDiffusionPipeline.from_pretrained(model_path, torch_dtype=torch.float16)
pipe.to("cuda")
image = pipe(prompt="yoda").images[0]
image.save("yoda-pokemon.png")
```
Checkpoints only save the unet, so to run inference from a checkpoint, just load the unet
```python
import torch
from diffusers import StableDiffusionPipeline, UNet2DConditionModel
model_path = "path_to_saved_model"
unet = UNet2DConditionModel.from_pretrained(model_path + "/checkpoint-<N>/unet", torch_dtype=torch.float16)
pipe = StableDiffusionPipeline.from_pretrained("<initial model>", unet=unet, torch_dtype=torch.float16)
pipe.to("cuda")
image = pipe(prompt="yoda").images[0]
image.save("yoda-pokemon.png")
```
#### Training with multiple GPUs
`accelerate` allows for seamless multi-GPU training. Follow the instructions [here](https://huggingface.co/docs/accelerate/basic_tutorials/launch)
for running distributed training with `accelerate`. Here is an example command:
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
accelerate launch --mixed_precision="fp16" --multi_gpu train_text_to_image.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_NAME \
--use_ema \
--resolution=512 --center_crop --random_flip \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--max_train_steps=15000 \
--learning_rate=1e-05 \
--max_grad_norm=1 \
--lr_scheduler="constant" --lr_warmup_steps=0 \
--output_dir="sd-pokemon-model"
```
#### Training with Min-SNR weighting
We support training with the Min-SNR weighting strategy proposed in [Efficient Diffusion Training via Min-SNR Weighting Strategy](https://arxiv.org/abs/2303.09556) which helps to achieve faster convergence
by rebalancing the loss. In order to use it, one needs to set the `--snr_gamma` argument. The recommended
value when using it is 5.0.
You can find [this project on Weights and Biases](https://wandb.ai/sayakpaul/text2image-finetune-minsnr) that compares the loss surfaces of the following setups:
* Training without the Min-SNR weighting strategy
* Training with the Min-SNR weighting strategy (`snr_gamma` set to 5.0)
* Training with the Min-SNR weighting strategy (`snr_gamma` set to 1.0)
For our small Pokemons dataset, the effects of Min-SNR weighting strategy might not appear to be pronounced, but for larger datasets, we believe the effects will be more pronounced.
Also, note that in this example, we either predict `epsilon` (i.e., the noise) or the `v_prediction`. For both of these cases, the formulation of the Min-SNR weighting strategy that we have used holds.
## Training with LoRA
Low-Rank Adaption of Large Language Models was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*.
In a nutshell, LoRA allows adapting pretrained models by adding pairs of rank-decomposition matrices to existing weights and **only** training those newly added weights. This has a couple of advantages:
- Previous pretrained weights are kept frozen so that model is not prone to [catastrophic forgetting](https://www.pnas.org/doi/10.1073/pnas.1611835114).
- Rank-decomposition matrices have significantly fewer parameters than original model, which means that trained LoRA weights are easily portable.
- LoRA attention layers allow to control to which extent the model is adapted toward new training images via a `scale` parameter.
[cloneofsimo](https://github.com/cloneofsimo) was the first to try out LoRA training for Stable Diffusion in the popular [lora](https://github.com/cloneofsimo/lora) GitHub repository.
With LoRA, it's possible to fine-tune Stable Diffusion on a custom image-caption pair dataset
on consumer GPUs like Tesla T4, Tesla V100.
### Training
First, you need to set up your development environment as is explained in the [installation section](#installing-the-dependencies). Make sure to set the `MODEL_NAME` and `DATASET_NAME` environment variables. Here, we will use [Stable Diffusion v1-4](https://hf.co/CompVis/stable-diffusion-v1-4) and the [Pokemons dataset](https://huggingface.co/datasets/lambdalabs/pokemon-blip-captions).
**___Note: Change the `resolution` to 768 if you are using the [stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2) 768x768 model.___**
**___Note: It is quite useful to monitor the training progress by regularly generating sample images during training. [Weights and Biases](https://docs.wandb.ai/quickstart) is a nice solution to easily see generating images during training. All you need to do is to run `pip install wandb` before training to automatically log images.___**
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
```
For this example we want to directly store the trained LoRA embeddings on the Hub, so
we need to be logged in and add the `--push_to_hub` flag.
```bash
huggingface-cli login
```
Now we can start training!
```bash
accelerate launch --mixed_precision="fp16" train_text_to_image_lora.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_NAME --caption_column="text" \
--resolution=512 --random_flip \
--train_batch_size=1 \
--num_train_epochs=100 --checkpointing_steps=5000 \
--learning_rate=1e-04 --lr_scheduler="constant" --lr_warmup_steps=0 \
--seed=42 \
--output_dir="sd-pokemon-model-lora" \
--validation_prompt="cute dragon creature" --report_to="wandb"
```
The above command will also run inference as fine-tuning progresses and log the results to Weights and Biases.
**___Note: When using LoRA we can use a much higher learning rate compared to non-LoRA fine-tuning. Here we use *1e-4* instead of the usual *1e-5*. Also, by using LoRA, it's possible to run `train_text_to_image_lora.py` in consumer GPUs like T4 or V100.___**
The final LoRA embedding weights have been uploaded to [sayakpaul/sd-model-finetuned-lora-t4](https://huggingface.co/sayakpaul/sd-model-finetuned-lora-t4). **___Note: [The final weights](https://huggingface.co/sayakpaul/sd-model-finetuned-lora-t4/blob/main/pytorch_lora_weights.bin) are only 3 MB in size, which is orders of magnitudes smaller than the original model.___**
You can check some inference samples that were logged during the course of the fine-tuning process [here](https://wandb.ai/sayakpaul/text2image-fine-tune/runs/q4lc0xsw).
### Inference
Once you have trained a model using above command, the inference can be done simply using the `StableDiffusionPipeline` after loading the trained LoRA weights. You
need to pass the `output_dir` for loading the LoRA weights which, in this case, is `sd-pokemon-model-lora`.
```python
from diffusers import StableDiffusionPipeline
import torch
model_path = "sayakpaul/sd-model-finetuned-lora-t4"
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16)
pipe.unet.load_attn_procs(model_path)
pipe.to("cuda")
prompt = "A pokemon with green eyes and red legs."
image = pipe(prompt, num_inference_steps=30, guidance_scale=7.5).images[0]
image.save("pokemon.png")
```
If you are loading the LoRA parameters from the Hub and if the Hub repository has
a `base_model` tag (such as [this](https://huggingface.co/sayakpaul/sd-model-finetuned-lora-t4/blob/main/README.md?code=true#L4)), then
you can do:
```py
from huggingface_hub.repocard import RepoCard
lora_model_id = "sayakpaul/sd-model-finetuned-lora-t4"
card = RepoCard.load(lora_model_id)
base_model_id = card.data.to_dict()["base_model"]
pipe = StableDiffusionPipeline.from_pretrained(base_model_id, torch_dtype=torch.float16)
...
```
## Training with Flax/JAX
For faster training on TPUs and GPUs you can leverage the flax training example. Follow the instructions above to get the model and dataset before running the script.
**___Note: The flax example doesn't yet support features like gradient checkpoint, gradient accumulation etc, so to use flax for faster training we will need >30GB cards or TPU v3.___**
Before running the scripts, make sure to install the library's training dependencies:
```bash
pip install -U -r requirements_flax.txt
```
```bash
export MODEL_NAME="duongna/stable-diffusion-v1-4-flax"
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
python train_text_to_image_flax.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_NAME \
--resolution=512 --center_crop --random_flip \
--train_batch_size=1 \
--mixed_precision="fp16" \
--max_train_steps=15000 \
--learning_rate=1e-05 \
--max_grad_norm=1 \
--output_dir="sd-pokemon-model"
```
To run on your own training files prepare the dataset according to the format required by `datasets`, you can find the instructions for how to do that in this [document](https://huggingface.co/docs/datasets/v2.4.0/en/image_load#imagefolder-with-metadata).
If you wish to use custom loading logic, you should modify the script, we have left pointers for that in the training script.
```bash
export MODEL_NAME="duongna/stable-diffusion-v1-4-flax"
export TRAIN_DIR="path_to_your_dataset"
python train_text_to_image_flax.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$TRAIN_DIR \
--resolution=512 --center_crop --random_flip \
--train_batch_size=1 \
--mixed_precision="fp16" \
--max_train_steps=15000 \
--learning_rate=1e-05 \
--max_grad_norm=1 \
--output_dir="sd-pokemon-model"
```
### Training with xFormers:
You can enable memory efficient attention by [installing xFormers](https://huggingface.co/docs/diffusers/main/en/optimization/xformers) and passing the `--enable_xformers_memory_efficient_attention` argument to the script.
xFormers training is not available for Flax/JAX.
**Note**:
According to [this issue](https://github.com/huggingface/diffusers/issues/2234#issuecomment-1416931212), xFormers `v0.0.16` cannot be used for training in some GPUs. If you observe that problem, please install a development version as indicated in that comment.
## Stable Diffusion XL
* We support fine-tuning the UNet shipped in [Stable Diffusion XL](https://huggingface.co/papers/2307.01952) via the `train_text_to_image_sdxl.py` script. Please refer to the docs [here](./README_sdxl.md).
* We also support fine-tuning of the UNet and Text Encoder shipped in [Stable Diffusion XL](https://huggingface.co/papers/2307.01952) with LoRA via the `train_text_to_image_lora_sdxl.py` script. Please refer to the docs [here](./README_sdxl.md).
| huggingface/diffusers/blob/main/examples/text_to_image/README.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Rigid Bodies
[[autodoc]] RigidBodyComponent | huggingface/simulate/blob/main/docs/source/api/physics.mdx |
FBNet
**FBNet** is a type of convolutional neural architectures discovered through [DNAS](https://paperswithcode.com/method/dnas) neural architecture search. It utilises a basic type of image model block inspired by [MobileNetv2](https://paperswithcode.com/method/mobilenetv2) that utilises depthwise convolutions and an inverted residual structure (see components).
The principal building block is the [FBNet Block](https://paperswithcode.com/method/fbnet-block).
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('fbnetc_100', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `fbnetc_100`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('fbnetc_100', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{wu2019fbnet,
title={FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search},
author={Bichen Wu and Xiaoliang Dai and Peizhao Zhang and Yanghan Wang and Fei Sun and Yiming Wu and Yuandong Tian and Peter Vajda and Yangqing Jia and Kurt Keutzer},
year={2019},
eprint={1812.03443},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: FBNet
Paper:
Title: 'FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural
Architecture Search'
URL: https://paperswithcode.com/paper/fbnet-hardware-aware-efficient-convnet-design
Models:
- Name: fbnetc_100
In Collection: FBNet
Metadata:
FLOPs: 508940064
Parameters: 5570000
File Size: 22525094
Architecture:
- 1x1 Convolution
- Convolution
- Dense Connections
- Dropout
- FBNet Block
- Global Average Pooling
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x GPUs
ID: fbnetc_100
LR: 0.1
Epochs: 360
Layers: 22
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0005
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L985
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/fbnetc_100-c345b898.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 75.12%
Top 5 Accuracy: 92.37%
--> | huggingface/pytorch-image-models/blob/main/hfdocs/source/models/fbnet.mdx |
ow to instantiate a Transformers model? In this video we will look at how we can create and use a model from the Transformers library. As we've seen before, the AutoModel class allows you to instantiate a pretrained model from any checkpoint on the Hugging Face Hub. It will pick the right model class from the library to instantiate the proper architecture and load the weights of the pretrained model inside it. As we can see, when given a BERT checkpoint, we end up with a BertModel, and similarly for GPT-2 or BART. Behind the scenes, this API can take the name of a checkpoint on the Hub, in which case it will download and cache the configuration file as well as the model weights file. You can also specify the path to a local folder that contains a valid configuration file and a model weights file. To instantiate the pretrained model, the AutoModel API will first open the configuration file to look at the configuration class that should be used. The configuration class depends on the type of the model (BERT, GPT-2 or BART for instance). Once it has the proper configuration class, it can instantiate that configuration, which is a blueprint to know how to create the model. It also uses this configuration class to find the proper model class, which is combined with the loaded configuration, to load the model. This model is not yet our pretrained model as it has just been initialized with random weights. The last step is to load the weights from the model file inside this model. To easily load the configuration of a model from any checkpoint or a folder containing the configuration folder, we can use the AutoConfig class. Like the AutoModel class, it will pick the right configuration class from the library. We can also use the specific class corresponding to a checkpoint, but we will need to change the code each time we want to try a different model. As we said before, the configuration of a model is a blueprint that contains all the information necessary to create the model architecture. For instance the BERT model associated with the bert-base-cased checkpoint has 12 layers, a hidden size of 768, and a vocabulary size of 28,996. Once we have the configuration, we can create a model that has the same architecture as our checkpoint but is randomly initialized. We can then train it from scratch like any PyTorch module/TensorFlow model. We can also change any part of the configuration by using keyword arguments. The second snippet of code instantiates a randomly initialized BERT model with ten layers instead of 12. Saving a model once it's trained or fine-tuned is very easy: we just have to use the save_pretrained method. Here the model will be saved in a folder named my-bert-model inside the current working directory. Such a model can then be reloaded using the from_pretrained method. | huggingface/course/blob/main/subtitles/en/raw/chapter2/03_model-api-pt.md |
Gradio Demo: calculator_list_and_dict
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
a = gr.Number(label="a")
b = gr.Number(label="b")
with gr.Row():
add_btn = gr.Button("Add")
sub_btn = gr.Button("Subtract")
c = gr.Number(label="sum")
def add(num1, num2):
return num1 + num2
add_btn.click(add, inputs=[a, b], outputs=c)
def sub(data):
return data[a] - data[b]
sub_btn.click(sub, inputs={a, b}, outputs=c)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/calculator_list_and_dict/run.ipynb |
!---
Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Translation example
This script shows an example of training a *translation* model with the 🤗 Transformers library.
For straightforward use-cases you may be able to use these scripts without modification, although we have also
included comments in the code to indicate areas that you may need to adapt to your own projects.
### Multi-GPU and TPU usage
By default, these scripts use a `MirroredStrategy` and will use multiple GPUs effectively if they are available. TPUs
can also be used by passing the name of the TPU resource with the `--tpu` argument.
### Example commands and caveats
MBart and some T5 models require special handling.
T5 models `t5-small`, `t5-base`, `t5-large`, `t5-3b` and `t5-11b` must use an additional argument: `--source_prefix "translate {source_lang} to {target_lang}"`. For example:
```bash
python run_translation.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--source_lang en \
--target_lang ro \
--source_prefix "translate English to Romanian: " \
--dataset_name wmt16 \
--dataset_config_name ro-en \
--output_dir /tmp/tst-translation \
--per_device_train_batch_size=16 \
--per_device_eval_batch_size=16 \
--overwrite_output_dir
```
If you get a terrible BLEU score, make sure that you didn't forget to use the `--source_prefix` argument.
For the aforementioned group of T5 models it's important to remember that if you switch to a different language pair, make sure to adjust the source and target values in all 3 language-specific command line argument: `--source_lang`, `--target_lang` and `--source_prefix`.
MBart models require a different format for `--source_lang` and `--target_lang` values, e.g. instead of `en` it expects `en_XX`, for `ro` it expects `ro_RO`. The full MBart specification for language codes can be found [here](https://huggingface.co/facebook/mbart-large-cc25). For example:
```bash
python run_translation.py \
--model_name_or_path facebook/mbart-large-en-ro \
--do_train \
--do_eval \
--dataset_name wmt16 \
--dataset_config_name ro-en \
--source_lang en_XX \
--target_lang ro_RO \
--output_dir /tmp/tst-translation \
--per_device_train_batch_size=16 \
--per_device_eval_batch_size=16 \
--overwrite_output_dir
```
| huggingface/transformers/blob/main/examples/tensorflow/translation/README.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Overview
Generating high-quality outputs is computationally intensive, especially during each iterative step where you go from a noisy output to a less noisy output. One of 🤗 Diffuser's goals is to make this technology widely accessible to everyone, which includes enabling fast inference on consumer and specialized hardware.
This section will cover tips and tricks - like half-precision weights and sliced attention - for optimizing inference speed and reducing memory-consumption. You'll also learn how to speed up your PyTorch code with [`torch.compile`](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html) or [ONNX Runtime](https://onnxruntime.ai/docs/), and enable memory-efficient attention with [xFormers](https://facebookresearch.github.io/xformers/). There are also guides for running inference on specific hardware like Apple Silicon, and Intel or Habana processors.
| huggingface/diffusers/blob/main/docs/source/en/optimization/opt_overview.md |
--
title: SQuAD v2
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
This metric wrap the official scoring script for version 2 of the Stanford Question Answering Dataset (SQuAD).
Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by
crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span,
from the corresponding reading passage, or the question might be unanswerable.
SQuAD2.0 combines the 100,000 questions in SQuAD1.1 with over 50,000 unanswerable questions
written adversarially by crowdworkers to look similar to answerable ones.
To do well on SQuAD2.0, systems must not only answer questions when possible, but also
determine when no answer is supported by the paragraph and abstain from answering.
---
# Metric Card for SQuAD v2
## Metric description
This metric wraps the official scoring script for version 2 of the [Stanford Question Answering Dataset (SQuAD)](https://huggingface.co/datasets/squad_v2).
SQuAD is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage, or the question might be unanswerable.
SQuAD 2.0 combines the 100,000 questions in SQuAD 1.1 with over 50,000 unanswerable questions written adversarially by crowdworkers to look similar to answerable ones. To do well on SQuAD2.0, systems must not only answer questions when possible, but also determine when no answer is supported by the paragraph and abstain from answering.
## How to use
The metric takes two files or two lists - one representing model predictions and the other the references to compare them to.
*Predictions* : List of triple for question-answers to score with the following key-value pairs:
* `'id'`: the question-answer identification field of the question and answer pair
* `'prediction_text'` : the text of the answer
* `'no_answer_probability'` : the probability that the question has no answer
*References*: List of question-answers dictionaries with the following key-value pairs:
* `'id'`: id of the question-answer pair (see above),
* `'answers'`: a list of Dict {'text': text of the answer as a string}
* `'no_answer_threshold'`: the probability threshold to decide that a question has no answer.
```python
from evaluate import load
squad_metric = load("squad_v2")
results = squad_metric.compute(predictions=predictions, references=references)
```
## Output values
This metric outputs a dictionary with 13 values:
* `'exact'`: Exact match (the normalized answer exactly match the gold answer) (see the `exact_match` metric (forthcoming))
* `'f1'`: The average F1-score of predicted tokens versus the gold answer (see the [F1 score](https://huggingface.co/metrics/f1) metric)
* `'total'`: Number of scores considered
* `'HasAns_exact'`: Exact match (the normalized answer exactly match the gold answer)
* `'HasAns_f1'`: The F-score of predicted tokens versus the gold answer
* `'HasAns_total'`: How many of the questions have answers
* `'NoAns_exact'`: Exact match (the normalized answer exactly match the gold answer)
* `'NoAns_f1'`: The F-score of predicted tokens versus the gold answer
* `'NoAns_total'`: How many of the questions have no answers
* `'best_exact'` : Best exact match (with varying threshold)
* `'best_exact_thresh'`: No-answer probability threshold associated to the best exact match
* `'best_f1'`: Best F1 score (with varying threshold)
* `'best_f1_thresh'`: No-answer probability threshold associated to the best F1
The range of `exact_match` is 0-100, where 0.0 means no answers were matched and 100.0 means all answers were matched.
The range of `f1` is 0-1 -- its lowest possible value is 0, if either the precision or the recall is 0, and its highest possible value is 1.0, which means perfect precision and recall.
The range of `total` depends on the length of predictions/references: its minimal value is 0, and maximal value is the total number of questions in the predictions and references.
### Values from popular papers
The [SQuAD v2 paper](https://arxiv.org/pdf/1806.03822.pdf) reported an F1 score of 66.3% and an Exact Match score of 63.4%.
They also report that human performance on the dataset represents an F1 score of 89.5% and an Exact Match score of 86.9%.
For more recent model performance, see the [dataset leaderboard](https://paperswithcode.com/dataset/squad).
## Examples
Maximal values for both exact match and F1 (perfect match):
```python
from evaluate import load
squad_v2_ metric = load("squad_v2")
predictions = [{'prediction_text': '1976', 'id': '56e10a3be3433e1400422b22', 'no_answer_probability': 0.}]
references = [{'answers': {'answer_start': [97], 'text': ['1976']}, 'id': '56e10a3be3433e1400422b22'}]
results = squad_v2_metric.compute(predictions=predictions, references=references)
results
{'exact': 100.0, 'f1': 100.0, 'total': 1, 'HasAns_exact': 100.0, 'HasAns_f1': 100.0, 'HasAns_total': 1, 'best_exact': 100.0, 'best_exact_thresh': 0.0, 'best_f1': 100.0, 'best_f1_thresh': 0.0}
```
Minimal values for both exact match and F1 (no match):
```python
from evaluate import load
squad_metric = load("squad_v2")
predictions = [{'prediction_text': '1999', 'id': '56e10a3be3433e1400422b22', 'no_answer_probability': 0.}]
references = [{'answers': {'answer_start': [97], 'text': ['1976']}, 'id': '56e10a3be3433e1400422b22'}]
results = squad_v2_metric.compute(predictions=predictions, references=references)
results
{'exact': 0.0, 'f1': 0.0, 'total': 1, 'HasAns_exact': 0.0, 'HasAns_f1': 0.0, 'HasAns_total': 1, 'best_exact': 0.0, 'best_exact_thresh': 0.0, 'best_f1': 0.0, 'best_f1_thresh': 0.0}
```
Partial match (2 out of 3 answers correct) :
```python
from evaluate import load
squad_metric = load("squad_v2")
predictions = [{'prediction_text': '1976', 'id': '56e10a3be3433e1400422b22', 'no_answer_probability': 0.}, {'prediction_text': 'Beyonce', 'id': '56d2051ce7d4791d0090260b', 'no_answer_probability': 0.}, {'prediction_text': 'climate change', 'id': '5733b5344776f419006610e1', 'no_answer_probability': 0.}]
references = [{'answers': {'answer_start': [97], 'text': ['1976']}, 'id': '56e10a3be3433e1400422b22'}, {'answers': {'answer_start': [233], 'text': ['Beyoncé and Bruno Mars']}, 'id': '56d2051ce7d4791d0090260b'}, {'answers': {'answer_start': [891], 'text': ['climate change']}, 'id': '5733b5344776f419006610e1'}]
results = squad_v2_metric.compute(predictions=predictions, references=references)
results
{'exact': 66.66666666666667, 'f1': 66.66666666666667, 'total': 3, 'HasAns_exact': 66.66666666666667, 'HasAns_f1': 66.66666666666667, 'HasAns_total': 3, 'best_exact': 66.66666666666667, 'best_exact_thresh': 0.0, 'best_f1': 66.66666666666667, 'best_f1_thresh': 0.0}
```
## Limitations and bias
This metric works only with the datasets in the same format as the [SQuAD v.2 dataset](https://huggingface.co/datasets/squad_v2).
The SQuAD datasets do contain a certain amount of noise, such as duplicate questions as well as missing answers, but these represent a minority of the 100,000 question-answer pairs. Also, neither exact match nor F1 score reflect whether models do better on certain types of questions (e.g. who questions) or those that cover a certain gender or geographical area -- carrying out more in-depth error analysis can complement these numbers.
## Citation
```bibtex
@inproceedings{Rajpurkar2018SQuAD2,
title={Know What You Don't Know: Unanswerable Questions for SQuAD},
author={Pranav Rajpurkar and Jian Zhang and Percy Liang},
booktitle={ACL 2018},
year={2018}
}
```
## Further References
- [The Stanford Question Answering Dataset: Background, Challenges, Progress (blog post)](https://rajpurkar.github.io/mlx/qa-and-squad/)
- [Hugging Face Course -- Question Answering](https://huggingface.co/course/chapter7/7)
| huggingface/evaluate/blob/main/metrics/squad_v2/README.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Backbones
Backbones are models used for feature extraction for computer vision tasks. One can use a model as backbone in two ways:
* initializing `AutoBackbone` class with a pretrained model,
* initializing a supported backbone configuration and passing it to the model architecture.
## Using AutoBackbone
You can use `AutoBackbone` class to initialize a model as a backbone and get the feature maps for any stage. You can define `out_indices` to indicate the index of the layers which you would like to get the feature maps from. You can also use `out_features` if you know the name of the layers. You can use them interchangeably. If you are using both `out_indices` and `out_features`, ensure they are consistent. Not passing any of the feature map arguments will make the backbone yield the feature maps of the last layer.
To visualize how stages look like, let's take the Swin model. Each stage is responsible from feature extraction, outputting feature maps.
<div style="text-align: center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/Swin%20Stages.png">
</div>
Illustrating feature maps of the first stage looks like below.
<div style="text-align: center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/Swin%20Stage%201.png">
</div>
Let's see with an example. Note that `out_indices=(0,)` results in yielding the stem of the model. Stem refers to the stage before the first feature extraction stage. In above diagram, it refers to patch partition. We would like to have the feature maps from stem, first, and second stage of the model.
```py
>>> from transformers import AutoImageProcessor, AutoBackbone
>>> import torch
>>> from PIL import Image
>>> import requests
>>> processor = AutoImageProcessor.from_pretrained("microsoft/swin-tiny-patch4-window7-224")
>>> model = AutoBackbone.from_pretrained("microsoft/swin-tiny-patch4-window7-224", out_indices=(0,1,2))
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> feature_maps = outputs.feature_maps
```
`feature_maps` object now has three feature maps, each can be accessed like below. Say we would like to get the feature map of the stem.
```python
>>> list(feature_maps[0].shape)
[1, 96, 56, 56]
```
We can get the feature maps of first and second stages like below.
```python
>>> list(feature_maps[1].shape)
[1, 96, 56, 56]
>>> list(feature_maps[2].shape)
[1, 192, 28, 28]
```
## Initializing Backbone Configuration
In computer vision, models consist of backbone, neck, and a head. Backbone extracts the features, neck transforms the output of the backbone and head is used for the main task (e.g. object detection). You can initialize neck and head with model backbones by passing a model configuration to `backbone_config`. For example, below you can see how to initialize the [MaskFormer](../model_doc/maskformer) model with instance segmentation head with [ResNet](../model_doc/resnet) backbone.
```py
from transformers import MaskFormerConfig, MaskFormerForInstanceSegmentation, ResNetConfig
backbone_config = ResNetConfig.from_pretrained("microsoft/resnet-50")
config = MaskFormerConfig(backbone_config=backbone_config)
model = MaskFormerForInstanceSegmentation(config)
```
You can also initialize a backbone with random weights to initialize the model neck with it.
```py
backbone_config = ResNetConfig()
config = MaskFormerConfig(backbone_config=backbone_config)
model = MaskFormerForInstanceSegmentation(config)
```
`timm` models are also supported in transformers through `TimmBackbone` and `TimmBackboneConfig`.
```python
from transformers import TimmBackboneConfig, TimmBackbone
backbone_config = TimmBackboneConfig("resnet50")
model = TimmBackbone(config=backbone_config)
```
| huggingface/transformers/blob/main/docs/source/en/main_classes/backbones.md |
HRNet
**HRNet**, or **High-Resolution Net**, is a general purpose convolutional neural network for tasks like semantic segmentation, object detection and image classification. It is able to maintain high resolution representations through the whole process. We start from a high-resolution convolution stream, gradually add high-to-low resolution convolution streams one by one, and connect the multi-resolution streams in parallel. The resulting network consists of several (\\( 4 \\) in the paper) stages and the \\( n \\)th stage contains \\( n \\) streams corresponding to \\( n \\) resolutions. The authors conduct repeated multi-resolution fusions by exchanging the information across the parallel streams over and over.
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('hrnet_w18', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `hrnet_w18`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('hrnet_w18', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{sun2019highresolution,
title={High-Resolution Representations for Labeling Pixels and Regions},
author={Ke Sun and Yang Zhao and Borui Jiang and Tianheng Cheng and Bin Xiao and Dong Liu and Yadong Mu and Xinggang Wang and Wenyu Liu and Jingdong Wang},
year={2019},
eprint={1904.04514},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: HRNet
Paper:
Title: Deep High-Resolution Representation Learning for Visual Recognition
URL: https://paperswithcode.com/paper/190807919
Models:
- Name: hrnet_w18
In Collection: HRNet
Metadata:
FLOPs: 5547205500
Parameters: 21300000
File Size: 85718883
Architecture:
- Batch Normalization
- Convolution
- ReLU
- Residual Connection
Tasks:
- Image Classification
Training Techniques:
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x NVIDIA V100 GPUs
ID: hrnet_w18
Epochs: 100
Layers: 18
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/hrnet.py#L800
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-hrnet/hrnetv2_w18-8cb57bb9.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 76.76%
Top 5 Accuracy: 93.44%
- Name: hrnet_w18_small
In Collection: HRNet
Metadata:
FLOPs: 2071651488
Parameters: 13190000
File Size: 52934302
Architecture:
- Batch Normalization
- Convolution
- ReLU
- Residual Connection
Tasks:
- Image Classification
Training Techniques:
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x NVIDIA V100 GPUs
ID: hrnet_w18_small
Epochs: 100
Layers: 18
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/hrnet.py#L790
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-hrnet/hrnet_w18_small_v1-f460c6bc.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 72.34%
Top 5 Accuracy: 90.68%
- Name: hrnet_w18_small_v2
In Collection: HRNet
Metadata:
FLOPs: 3360023160
Parameters: 15600000
File Size: 62682879
Architecture:
- Batch Normalization
- Convolution
- ReLU
- Residual Connection
Tasks:
- Image Classification
Training Techniques:
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x NVIDIA V100 GPUs
ID: hrnet_w18_small_v2
Epochs: 100
Layers: 18
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/hrnet.py#L795
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-hrnet/hrnet_w18_small_v2-4c50a8cb.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 75.11%
Top 5 Accuracy: 92.41%
- Name: hrnet_w30
In Collection: HRNet
Metadata:
FLOPs: 10474119492
Parameters: 37710000
File Size: 151452218
Architecture:
- Batch Normalization
- Convolution
- ReLU
- Residual Connection
Tasks:
- Image Classification
Training Techniques:
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x NVIDIA V100 GPUs
ID: hrnet_w30
Epochs: 100
Layers: 30
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/hrnet.py#L805
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-hrnet/hrnetv2_w30-8d7f8dab.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.21%
Top 5 Accuracy: 94.22%
- Name: hrnet_w32
In Collection: HRNet
Metadata:
FLOPs: 11524528320
Parameters: 41230000
File Size: 165547812
Architecture:
- Batch Normalization
- Convolution
- ReLU
- Residual Connection
Tasks:
- Image Classification
Training Techniques:
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x NVIDIA V100 GPUs
Training Time: 60 hours
ID: hrnet_w32
Epochs: 100
Layers: 32
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/hrnet.py#L810
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-hrnet/hrnetv2_w32-90d8c5fb.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.45%
Top 5 Accuracy: 94.19%
- Name: hrnet_w40
In Collection: HRNet
Metadata:
FLOPs: 16381182192
Parameters: 57560000
File Size: 230899236
Architecture:
- Batch Normalization
- Convolution
- ReLU
- Residual Connection
Tasks:
- Image Classification
Training Techniques:
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x NVIDIA V100 GPUs
ID: hrnet_w40
Epochs: 100
Layers: 40
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/hrnet.py#L815
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-hrnet/hrnetv2_w40-7cd397a4.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.93%
Top 5 Accuracy: 94.48%
- Name: hrnet_w44
In Collection: HRNet
Metadata:
FLOPs: 19202520264
Parameters: 67060000
File Size: 268957432
Architecture:
- Batch Normalization
- Convolution
- ReLU
- Residual Connection
Tasks:
- Image Classification
Training Techniques:
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x NVIDIA V100 GPUs
ID: hrnet_w44
Epochs: 100
Layers: 44
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/hrnet.py#L820
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-hrnet/hrnetv2_w44-c9ac8c18.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.89%
Top 5 Accuracy: 94.37%
- Name: hrnet_w48
In Collection: HRNet
Metadata:
FLOPs: 22285865760
Parameters: 77470000
File Size: 310603710
Architecture:
- Batch Normalization
- Convolution
- ReLU
- Residual Connection
Tasks:
- Image Classification
Training Techniques:
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x NVIDIA V100 GPUs
Training Time: 80 hours
ID: hrnet_w48
Epochs: 100
Layers: 48
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/hrnet.py#L825
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-hrnet/hrnetv2_w48-abd2e6ab.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.32%
Top 5 Accuracy: 94.51%
- Name: hrnet_w64
In Collection: HRNet
Metadata:
FLOPs: 37239321984
Parameters: 128060000
File Size: 513071818
Architecture:
- Batch Normalization
- Convolution
- ReLU
- Residual Connection
Tasks:
- Image Classification
Training Techniques:
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x NVIDIA V100 GPUs
ID: hrnet_w64
Epochs: 100
Layers: 64
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/hrnet.py#L830
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-hrnet/hrnetv2_w64-b47cc881.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.46%
Top 5 Accuracy: 94.65%
-->
| huggingface/pytorch-image-models/blob/main/hfdocs/source/models/hrnet.mdx |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# OPT
## Overview
The OPT model was proposed in [Open Pre-trained Transformer Language Models](https://arxiv.org/pdf/2205.01068) by Meta AI.
OPT is a series of open-sourced large causal language models which perform similar in performance to GPT3.
The abstract from the paper is the following:
*Large language models, which are often trained for hundreds of thousands of compute days, have shown remarkable capabilities for zero- and few-shot learning. Given their computational cost, these models are difficult to replicate without significant capital. For the few that are available through APIs, no access is granted to the full model weights, making them difficult to study. We present Open Pre-trained Transformers (OPT), a suite of decoder-only pre-trained transformers ranging from 125M to 175B parameters, which we aim to fully and responsibly share with interested researchers. We show that OPT-175B is comparable to GPT-3, while requiring only 1/7th the carbon footprint to develop. We are also releasing our logbook detailing the infrastructure challenges we faced, along with code for experimenting with all of the released models.*
This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ), [Younes Belkada](https://huggingface.co/ybelkada), and [Patrick Von Platen](https://huggingface.co/patrickvonplaten).
The original code can be found [here](https://github.com/facebookresearch/metaseq).
Tips:
- OPT has the same architecture as [`BartDecoder`].
- Contrary to GPT2, OPT adds the EOS token `</s>` to the beginning of every prompt.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with OPT. If you're
interested in submitting a resource to be included here, please feel free to open a Pull Request and we will review it.
The resource should ideally demonstrate something new instead of duplicating an existing resource.
<PipelineTag pipeline="text-generation" />
- A notebook on [fine-tuning OPT with PEFT, bitsandbytes, and Transformers](https://colab.research.google.com/drive/1jCkpikz0J2o20FBQmYmAGdiKmJGOMo-o?usp=sharing). 🌎
- A blog post on [decoding strategies with OPT](https://huggingface.co/blog/introducing-csearch#62-example-two---opt).
- [Causal language modeling](https://huggingface.co/course/en/chapter7/6?fw=pt#training-a-causal-language-model-from-scratch) chapter of the 🤗 Hugging Face Course.
- [`OPTForCausalLM`] is supported by this [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#gpt-2gpt-and-causal-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb).
- [`TFOPTForCausalLM`] is supported by this [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_clmpy) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb).
- [`FlaxOPTForCausalLM`] is supported by this [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#causal-language-modeling).
<PipelineTag pipeline="text-classification" />
- [Text classification task guide](sequence_classification.md)
- [`OPTForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb).
<PipelineTag pipeline="question-answering" />
- [`OPTForQuestionAnswering`] is supported by this [question answering example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb).
- [Question answering](https://huggingface.co/course/chapter7/7?fw=pt) chapter
of the 🤗 Hugging Face Course.
⚡️ Inference
- A blog post on [How 🤗 Accelerate runs very large models thanks to PyTorch](https://huggingface.co/blog/accelerate-large-models) with OPT.
## Combining OPT and Flash Attention 2
First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
```bash
pip install -U flash-attn --no-build-isolation
```
Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of flash-attn repository. Make also sure to load your model in half-precision (e.g. `torch.float16``)
To load and run a model using Flash Attention 2, refer to the snippet below:
```python
>>> import torch
>>> from transformers import OPTForCausalLM, GPT2Tokenizer
>>> device = "cuda" # the device to load the model onto
>>> model = OPTForCausalLM.from_pretrained("facebook/opt-350m", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
>>> tokenizer = GPT2Tokenizer.from_pretrained("facebook/opt-350m")
>>> prompt = ("A chat between a curious human and the Statue of Liberty.\n\nHuman: What is your name?\nStatue: I am the "
"Statue of Liberty.\nHuman: Where do you live?\nStatue: New York City.\nHuman: How long have you lived "
"there?")
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
>>> model.to(device)
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=30, do_sample=False)
>>> tokenizer.batch_decode(generated_ids)[0]
'</s>A chat between a curious human and the Statue of Liberty.\n\nHuman: What is your name?\nStatue: I am the Statue of Liberty.\nHuman: Where do you live?\nStatue: New York City.\nHuman: How long have you lived there?\nStatue: I have lived here for about a year.\nHuman: What is your favorite place to eat?\nStatue: I love'
```
### Expected speedups
Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using `facebook/opt-2.7b` checkpoint and the Flash Attention 2 version of the model using two different sequence lengths.
<div style="text-align: center">
<img src="https://user-images.githubusercontent.com/49240599/281101546-d2fca6d2-ee44-48f3-9534-ba8d5bee4531.png">
</div>
Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using `facebook/opt-350m` checkpoint and the Flash Attention 2 version of the model using two different sequence lengths.
<div style="text-align: center">
<img src="https://user-images.githubusercontent.com/49240599/281101682-d1144e90-0dbc-46f4-8fc8-c6206cb793c9.png">
</div>
## OPTConfig
[[autodoc]] OPTConfig
<frameworkcontent>
<pt>
## OPTModel
[[autodoc]] OPTModel
- forward
## OPTForCausalLM
[[autodoc]] OPTForCausalLM
- forward
## OPTForSequenceClassification
[[autodoc]] OPTForSequenceClassification
- forward
## OPTForQuestionAnswering
[[autodoc]] OPTForQuestionAnswering
- forward
</pt>
<tf>
## TFOPTModel
[[autodoc]] TFOPTModel
- call
## TFOPTForCausalLM
[[autodoc]] TFOPTForCausalLM
- call
</tf>
<jax>
## FlaxOPTModel
[[autodoc]] FlaxOPTModel
- __call__
## FlaxOPTForCausalLM
[[autodoc]] FlaxOPTForCausalLM
- __call__
</jax>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/opt.md |
区块和事件监听器 (Blocks and Event Listeners)
我们在[快速入门](https://gradio.app/quickstart/#blocks-more-flexibility-and-control)中简要介绍了区块。让我们深入探讨一下。本指南将涵盖区块的结构、事件监听器及其类型、连续运行事件、更新配置以及使用字典与列表。
## 区块结构 (Blocks Structure)
请查看下面的演示。
$code_hello_blocks
$demo_hello_blocks
- 首先,注意 `with gr.Blocks() as demo:` 子句。区块应用程序代码将被包含在该子句中。
- 接下来是组件。这些组件是在 `Interface` 中使用的相同组件。但是,与将组件传递给某个构造函数不同,组件在 `with` 子句内创建时会自动添加到区块中。
- 最后,`click()` 事件监听器。事件监听器定义了应用程序内的数据流。在上面的示例中,监听器将两个文本框相互关联。文本框 `name` 作为输入,文本框 `output` 作为 `greet` 方法的输出。当单击按钮 `greet_btn` 时触发此数据流。与界面类似,事件监听器可以具有多个输入或输出。
## 事件监听器与交互性 (Event Listeners and Interactivity)
在上面的示例中,您会注意到可以编辑文本框 `name`,但无法编辑文本框 `output`。这是因为作为事件监听器的任何组件都具有交互性。然而,由于文本框 `output` 仅作为输出,它没有交互性。您可以使用 `interactive=` 关键字参数直接配置组件的交互性。
```python
output = gr.Textbox(label="输出", interactive=True)
```
## 事件监听器的类型 (Types of Event Listeners)
请查看下面的演示:
$code_blocks_hello
$demo_blocks_hello
`welcome` 函数不是由点击触发的,而是由在文本框 `inp` 中输入文字触发的。这是由于 `change()` 事件监听器。不同的组件支持不同的事件监听器。例如,`Video` 组件支持一个 `play()` 事件监听器,当用户按下播放按钮时触发。有关每个组件的事件监听器,请参见[文档](http://gradio.app/docs#components)。
## 多个数据流 (Multiple Data Flows)
区块应用程序不像界面那样限制于单个数据流。请查看下面的演示:
$code_reversible_flow
$demo_reversible_flow
请注意,`num1` 可以充当 `num2` 的输入,反之亦然!随着应用程序变得更加复杂,您将能够连接各种组件的多个数据流。
下面是一个 " 多步骤 " 示例,其中一个模型的输出(语音到文本模型)被传递给下一个模型(情感分类器)。
$code_blocks_speech_text_sentiment
$demo_blocks_speech_text_sentiment
## 函数输入列表与字典 (Function Input List vs Dict)
到目前为止,您看到的事件监听器都只有一个输入组件。如果您希望有多个输入组件将数据传递给函数,有两种选项可供函数接受输入组件值:
1. 作为参数列表,或
2. 作为以组件为键的单个值字典
让我们分别看一个例子:
$code_calculator_list_and_dict
`add()` 和 `sub()` 都将 `a` 和 `b` 作为输入。然而,这些监听器之间的语法不同。
1. 对于 `add_btn` 监听器,我们将输入作为列表传递。函数 `add()` 将每个输入作为参数。`a` 的值映射到参数 `num1`,`b` 的值映射到参数 `num2`。
2. 对于 `sub_btn` 监听器,我们将输入作为集合传递(注意花括号!)。函数 `sub()` 接受一个名为 `data` 的单个字典参数,其中键是输入组件,值是这些组件的值。
使用哪种语法是个人偏好!对于具有许多输入组件的函数,选项 2 可能更容易管理。
$demo_calculator_list_and_dict
## 函数返回列表与字典 (Function Return List vs Dict)
类似地,您可以返回多个输出组件的值,可以是:
1. 值列表,或
2. 以组件为键的字典
首先让我们看一个(1)的示例,其中我们通过返回两个值来设置两个输出组件的值:
```python
with gr.Blocks() as demo:
food_box = gr.Number(value=10, label="Food Count")
status_box = gr.Textbox()
def eat(food):
if food > 0:
return food - 1, "full"
else:
return 0, "hungry"
gr.Button("EAT").click(
fn=eat,
inputs=food_box,
outputs=[food_box, status_box]
)
```
上面的每个返回语句分别返回与 `food_box` 和 `status_box` 相对应的两个值。
除了返回与每个输出组件顺序相对应的值列表外,您还可以返回一个字典,其中键对应于输出组件,值作为新值。这还允许您跳过更新某些输出组件。
```python
with gr.Blocks() as demo:
food_box = gr.Number(value=10, label="Food Count")
status_box = gr.Textbox()
def eat(food):
if food > 0:
return {food_box: food - 1, status_box: "full"}
else:
return {status_box: "hungry"}
gr.Button("EAT").click(
fn=eat,
inputs=food_box,
outputs=[food_box, status_box]
)
```
注意,在没有食物的情况下,我们只更新 `status_box` 元素。我们跳过更新 `food_box` 组件。
字典返回在事件监听器影响多个组件的返回值或有条件地影响输出时非常有用。
请记住,对于字典返回,我们仍然需要在事件监听器中指定可能的输出组件。
## 更新组件配置 (Updating Component Configurations)
事件监听器函数的返回值通常是相应输出组件的更新值。有时我们还希望更新组件的配置,例如可见性。在这种情况下,我们返回一个 `gr.update()` 对象,而不仅仅是更新组件的值。
$code_blocks_essay_simple
$demo_blocks_essay_simple
请注意,我们可以通过 `gr.update()` 方法自我配置文本框。`value=` 参数仍然可以用于更新值以及组件配置。
## 连续运行事件 (Running Events Consecutively)
你也可以使用事件监听器的 `then` 方法按顺序运行事件。在前一个事件运行完成后,这将运行下一个事件。这对于多步更新组件的事件非常有用。
例如,在下面的聊天机器人示例中,我们首先立即使用用户消息更新聊天机器人,然后在模拟延迟后使用计算机回复更新聊天机器人。
$code_chatbot_simple
$demo_chatbot_simple
事件监听器的 `.then()` 方法会执行后续事件,无论前一个事件是否引发任何错误。如果只想在前一个事件成功执行后才运行后续事件,请使用 `.success()` 方法,该方法与 `.then()` 接受相同的参数。
## 连续运行事件 (Running Events Continuously)
您可以使用事件监听器的 `every` 参数按固定计划运行事件。这将在客户端连接打开的情况下,每隔一定秒数运行一次事件。如果连接关闭,事件将在下一次迭代后停止运行。
请注意,这不考虑事件本身的运行时间。因此,使用 `every=5` 运行时间为 1 秒的函数实际上每 6 秒运行一次。
以下是每秒更新的正弦曲线示例!
$code_sine_curve
$demo_sine_curve
## 收集事件数据 (Gathering Event Data)
您可以通过将相关的事件数据类作为类型提示添加到事件监听器函数的参数中,收集有关事件的特定数据。
例如,使用 `gradio.SelectData` 参数可以为 `.select()` 的事件数据添加类型提示。当用户选择触发组件的一部分时,将触发此事件,并且事件数据包含有关用户的具体选择的信息。如果用户在 `Textbox` 中选择了特定单词,在 `Gallery` 中选择了特定图像或在 `DataFrame` 中选择了特定单元格,则事件数据参数将包含有关具体选择的信息。
在下面的双人井字游戏演示中,用户可以选择 `DataFrame` 中的一个单元格进行移动。事件数据参数包含有关所选单元格的信息。我们可以首先检查单元格是否为空,然后用用户的移动更新单元格。
$code_tictactoe
$demo_tictactoe
| gradio-app/gradio/blob/main/guides/cn/03_building-with-blocks/01_blocks-and-event-listeners.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Quantization
🤗 Optimum provides an `optimum.onnxruntime` package that enables you to apply quantization on many models hosted on
the Hugging Face Hub using the [ONNX Runtime](https://github.com/microsoft/onnxruntime/blob/master/onnxruntime/python/tools/quantization/README.md)
quantization tool.
The quantization process is abstracted via the [`~optimum.onnxruntime.ORTConfig`] and
the [`~optimum.onnxruntime.ORTQuantizer`] classes. The former allows you to specify how quantization should be done,
while the latter effectively handles quantization.
<Tip>
You can read the [conceptual guide on quantization](../../concept_guides/quantization) to learn about quantization. It
explains the main concepts that you will be using when performing quantization with the
[`~optimum.onnxruntime.ORTQuantizer`].
</Tip>
## Quantizing a model to be used with Optimum's CLI
The Optimum ONNX Runtime quantization tool can be used through Optimum command-line interface:
```bash
optimum-cli onnxruntime quantize --help
usage: optimum-cli <command> [<args>] onnxruntime quantize [-h] --onnx_model ONNX_MODEL -o OUTPUT [--per_channel] (--arm64 | --avx2 | --avx512 | --avx512_vnni | --tensorrt | -c CONFIG)
options:
-h, --help show this help message and exit
--arm64 Quantization for the ARM64 architecture.
--avx2 Quantization with AVX-2 instructions.
--avx512 Quantization with AVX-512 instructions.
--avx512_vnni Quantization with AVX-512 and VNNI instructions.
--tensorrt Quantization for NVIDIA TensorRT optimizer.
-c CONFIG, --config CONFIG
`ORTConfig` file to use to optimize the model.
Required arguments:
--onnx_model ONNX_MODEL
Path to the repository where the ONNX models to quantize are located.
-o OUTPUT, --output OUTPUT
Path to the directory where to store generated ONNX model.
Optional arguments:
--per_channel Compute the quantization parameters on a per-channel basis.
```
Quantizing an ONNX model can be done as follows:
```bash
optimum-cli onnxruntime quantize --onnx_model onnx_model_location/ --avx512 -o quantized_model/
```
This quantize all the ONNX files in `onnx_model_location` with the AVX-512 instructions.
## Creating an `ORTQuantizer`
The [`~optimum.onnxruntime.ORTQuantizer`] class is used to quantize your ONNX model. The class can be initialized using
the `from_pretrained()` method, which supports different checkpoint formats.
1. Using an already initialized `ORTModelForXXX` class.
```python
>>> from optimum.onnxruntime import ORTQuantizer, ORTModelForSequenceClassification
# Loading ONNX Model from the Hub
>>> ort_model = ORTModelForSequenceClassification.from_pretrained(
... "optimum/distilbert-base-uncased-finetuned-sst-2-english"
... )
# Create a quantizer from a ORTModelForXXX
>>> quantizer = ORTQuantizer.from_pretrained(ort_model)
```
2. Using a local ONNX model from a directory.
```python
>>> from optimum.onnxruntime import ORTQuantizer
# This assumes a model.onnx exists in path/to/model
>>> quantizer = ORTQuantizer.from_pretrained("path/to/model") # doctest: +SKIP
```
## Apply Dynamic Quantization
The [`~optimum.onnxruntime.ORTQuantizer`] class can be used to quantize dynamically your ONNX model. Below you will
find an easy end-to-end example on how to quantize dynamically
[distilbert-base-uncased-finetuned-sst-2-english](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english).
```python
>>> from optimum.onnxruntime import ORTQuantizer, ORTModelForSequenceClassification
>>> from optimum.onnxruntime.configuration import AutoQuantizationConfig
# Load PyTorch model and convert to ONNX
>>> onnx_model = ORTModelForSequenceClassification.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english", export=True)
# Create quantizer
>>> quantizer = ORTQuantizer.from_pretrained(onnx_model)
# Define the quantization strategy by creating the appropriate configuration
>>> dqconfig = AutoQuantizationConfig.avx512_vnni(is_static=False, per_channel=False)
# Quantize the model
>>> model_quantized_path = quantizer.quantize(
... save_dir="path/to/output/model",
... quantization_config=dqconfig,
... )
```
## Static Quantization example
The [`~optimum.onnxruntime.ORTQuantizer`] class can be used to quantize statically your ONNX model. Below you will find
an easy end-to-end example on how to quantize statically
[distilbert-base-uncased-finetuned-sst-2-english](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english).
```python
>>> from functools import partial
>>> from transformers import AutoTokenizer
>>> from optimum.onnxruntime import ORTQuantizer, ORTModelForSequenceClassification
>>> from optimum.onnxruntime.configuration import AutoQuantizationConfig, AutoCalibrationConfig
>>> model_id = "distilbert-base-uncased-finetuned-sst-2-english"
# Load PyTorch model and convert to ONNX and create Quantizer and setup config
>>> onnx_model = ORTModelForSequenceClassification.from_pretrained(model_id, export=True)
>>> tokenizer = AutoTokenizer.from_pretrained(model_id)
>>> quantizer = ORTQuantizer.from_pretrained(onnx_model)
>>> qconfig = AutoQuantizationConfig.arm64(is_static=True, per_channel=False)
# Create the calibration dataset
>>> def preprocess_fn(ex, tokenizer):
... return tokenizer(ex["sentence"])
>>> calibration_dataset = quantizer.get_calibration_dataset(
... "glue",
... dataset_config_name="sst2",
... preprocess_function=partial(preprocess_fn, tokenizer=tokenizer),
... num_samples=50,
... dataset_split="train",
... )
# Create the calibration configuration containing the parameters related to calibration.
>>> calibration_config = AutoCalibrationConfig.minmax(calibration_dataset)
# Perform the calibration step: computes the activations quantization ranges
>>> ranges = quantizer.fit(
... dataset=calibration_dataset,
... calibration_config=calibration_config,
... operators_to_quantize=qconfig.operators_to_quantize,
... )
# Apply static quantization on the model
>>> model_quantized_path = quantizer.quantize(
... save_dir="path/to/output/model",
... calibration_tensors_range=ranges,
... quantization_config=qconfig,
... )
```
## Quantize Seq2Seq models
The [`~optimum.onnxruntime.ORTQuantizer`] class currently doesn't support multi-file models, like
[`~optimum.onnxruntime.ORTModelForSeq2SeqLM`]. If you want to quantize a Seq2Seq model, you have to quantize each
model's component individually.
<Tip warning={true}>
Currently, only dynamic quantization is supported for Seq2Seq models.
</Tip>
1. Load seq2seq model as `ORTModelForSeq2SeqLM`.
```python
>>> from optimum.onnxruntime import ORTQuantizer, ORTModelForSeq2SeqLM
>>> from optimum.onnxruntime.configuration import AutoQuantizationConfig
# load Seq2Seq model and set model file directory
>>> model_id = "optimum/t5-small"
>>> onnx_model = ORTModelForSeq2SeqLM.from_pretrained(model_id)
>>> model_dir = onnx_model.model_save_dir
```
2. Define Quantizer for encoder, decoder and decoder with past keys
```python
# Create encoder quantizer
>>> encoder_quantizer = ORTQuantizer.from_pretrained(model_dir, file_name="encoder_model.onnx")
# Create decoder quantizer
>>> decoder_quantizer = ORTQuantizer.from_pretrained(model_dir, file_name="decoder_model.onnx")
# Create decoder with past key values quantizer
>>> decoder_wp_quantizer = ORTQuantizer.from_pretrained(model_dir, file_name="decoder_with_past_model.onnx")
# Create Quantizer list
>>> quantizer = [encoder_quantizer, decoder_quantizer, decoder_wp_quantizer]
```
3. Quantize all models
```python
# Define the quantization strategy by creating the appropriate configuration
>>> dqconfig = AutoQuantizationConfig.avx512_vnni(is_static=False, per_channel=False)
# Quantize the models individually
>>> for q in quantizer:
... q.quantize(save_dir=".",quantization_config=dqconfig) # doctest: +IGNORE_RESULT
```
| huggingface/optimum/blob/main/docs/source/onnxruntime/usage_guides/quantization.mdx |
Gradio Demo: checkbox_component
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
gr.Checkbox()
demo.launch()
```
| gradio-app/gradio/blob/main/demo/checkbox_component/run.ipynb |
Decision Transformers
The Decision Transformer model was introduced by ["Decision Transformer: Reinforcement Learning via Sequence Modeling” by Chen L. et al](https://arxiv.org/abs/2106.01345). It abstracts Reinforcement Learning as a conditional-sequence modeling problem.
The main idea is that instead of training a policy using RL methods, such as fitting a value function, that will tell us what action to take to maximize the return (cumulative reward), **we use a sequence modeling algorithm (Transformer) that, given a desired return, past states, and actions, will generate future actions to achieve this desired return**.
It’s an autoregressive model conditioned on the desired return, past states, and actions to generate future actions that achieve the desired return.
This is a complete shift in the Reinforcement Learning paradigm since we use generative trajectory modeling (modeling the joint distribution of the sequence of states, actions, and rewards) to replace conventional RL algorithms. This means that in Decision Transformers, we don’t maximize the return but rather generate a series of future actions that achieve the desired return.
The 🤗 Transformers team integrated the Decision Transformer, an Offline Reinforcement Learning method, into the library as well as the Hugging Face Hub.
## Learn about Decision Transformers
To learn more about Decision Transformers, you should read the blogpost we wrote about it [Introducing Decision Transformers on Hugging Face](https://huggingface.co/blog/decision-transformers)
## Train your first Decision Transformers
Now that you understand how Decision Transformers work thanks to [Introducing Decision Transformers on Hugging Face](https://huggingface.co/blog/decision-transformers), you’re ready to learn to train your first Offline Decision Transformer model from scratch to make a half-cheetah run.
Start the tutorial here 👉 https://huggingface.co/blog/train-decision-transformers
## Further reading
For more information, we recommend that you check out the following resources:
- [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345)
- [Online Decision Transformer](https://arxiv.org/abs/2202.05607)
## Author
This section was written by <a href="https://twitter.com/edwardbeeching">Edward Beeching</a>
| huggingface/deep-rl-class/blob/main/units/en/unitbonus3/decision-transformers.mdx |
Training PEFT models with new tokens being added to the embedding layers and tokenizer
In this example, we will learn how to train a LoRA model when adding new tokens to the tokenizer and model.
This is a common usecase when doing the following:
1. Instruction finetuning with new tokens beind added such as `<|user|>`, `<|assistant|>`, `<|system|>`, `</s>`, `<s>` to properly format the conversations
2. Finetuning on a specific language wherein language spoecific tokens are added, e.g., korean tokens being added to vocabulary for finetuning LLM on Korean datasets.
3. Instruction finetuning to return outputs in certain format to enable agent behaviour new tokens such as `<|FUNCTIONS|>`, `<|BROWSE|>`, `<|TEXT2IMAGE|>`, `<|ASR|>`, `<|TTS|>`, `<|GENERATECODE|>`, `<|RAG|>`.
In such cases, you add the Embedding modules to the LORA `target_modules`. PEFT will take care of saving the embedding layers with the new added tokens along with the adapter weights that were trained on the specific initialization of the embeddings weights of the added tokens.
Let's import the necessary libraries
```python
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "3"
os.environ["WANDB_PROJECT"] = "PeftExamples"
import transformers
from peft import (
LoraConfig,
PeftConfig,
PeftModel,
get_peft_model,
prepare_model_for_int8_training,
)
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
HfArgumentParser,
TrainingArguments,
Trainer,
default_data_collator,
)
import torch
from dataclasses import dataclass, field
from typing import Optional
from dataclass_csv import DataclassReader
from torch.utils.data import Dataset, DataLoader
from enum import Enum
```
## Prepare Model and Tokenizer
Now, we will be adding 27 new tokens as well as replace the existing pad, bos and eos tokens of the model.
```python
class SpecialTokens(str, Enum):
begin_target = "<|begintarget|>"
end_target = "<|endtarget|>"
begin_context = "<|begincontext|>"
end_context = "<|endcontext|>"
system = "<|system|>"
user = "<|user|>"
begin_last_user_utterance = "<|beginlastuserutterance|>"
end_last_user_utterance = "<|endlastuserutterance|>"
begin_dsts = "<|begindsts|>"
end_dsts = "<|enddsts|>"
begin_dst = "<|begindst|>"
end_dst = "<|enddst|>"
begin_belief = "<|beginbelief|>"
end_belief = "<|endbelief|>"
begin_response = "<|beginresponse|>"
end_response = "<|endresponse|>"
begin_action = "<|beginaction|>"
end_action = "<|endaction|>"
begin_user_action = "<|beginuseraction|>"
end_user_action = "<|enduseraction|>"
sys_actions = "<|sysactions|>"
begin_intent = "<|beginintent|>"
end_intent = "<|endintent|>"
begin_requested_slots = "<|beginrequestedslots|>"
end_requested_slots = "<|endrequestedslots|>"
pad_token = "<|pad|>"
bos_token = "<|startoftext|>"
@classmethod
def list(cls):
return [c.value for c in cls]
```
We will be finetuning Mistral-7B model. Let's load the tokenizer and add the special tokens followed by loading the base model and resizzing the embedding layers to accomodate the newly added tokens.
```python
model_name = "mistralai/Mistral-7B-v0.1"
tokenizer = AutoTokenizer.from_pretrained(
model_name,
pad_token=SpecialTokens.pad_token.value,
bos_token=SpecialTokens.bos_token.value,
eos_token=SpecialTokens.end_target.value,
additional_special_tokens=SpecialTokens.list(),
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
low_cpu_mem_usage=True
# use_flash_attention_2=True, # leading to an error
)
model.resize_token_embeddings(len(tokenizer))
```
## Apply LoRA
```python
config = LoraConfig(
r=64, lora_alpha=128, lora_dropout=0.0, target_modules=["embed_tokens", "lm_head", "q_proj", "v_proj"]
)
model = get_peft_model(model, config)
print(model.print_trainable_parameters())
print(model)
```
## Preapre Dataset
```python
from datasets import load_dataset
dataset = load_dataset("smangrul/assistant_chatbot_dataset")
dataset = dataset["train"].train_test_split(0.2)
text_column = "context"
label_column = "target"
max_length = 512
def preprocess_function(examples):
batch_size = len(examples[text_column])
targets = [str(x) for x in examples[label_column]]
model_inputs = tokenizer(examples[text_column])
labels = tokenizer(targets, add_special_tokens=False) # don't add bos token because we concatenate with inputs
for i in range(batch_size):
sample_input_ids = model_inputs["input_ids"][i]
label_input_ids = labels["input_ids"][i] + [tokenizer.eos_token_id]
# print(i, sample_input_ids, label_input_ids)
model_inputs["input_ids"][i] = sample_input_ids + label_input_ids
labels["input_ids"][i] = [-100] * len(sample_input_ids) + label_input_ids
model_inputs["attention_mask"][i] = [1] * len(model_inputs["input_ids"][i])
# print(model_inputs)
for i in range(batch_size):
sample_input_ids = model_inputs["input_ids"][i]
label_input_ids = labels["input_ids"][i]
model_inputs["input_ids"][i] = [tokenizer.pad_token_id] * (
max_length - len(sample_input_ids)
) + sample_input_ids
model_inputs["attention_mask"][i] = [0] * (max_length - len(sample_input_ids)) + model_inputs[
"attention_mask"
][i]
labels["input_ids"][i] = [-100] * (max_length - len(sample_input_ids)) + label_input_ids
model_inputs["input_ids"][i] = model_inputs["input_ids"][i][:max_length]
model_inputs["attention_mask"][i] = model_inputs["attention_mask"][i][:max_length]
labels["input_ids"][i] = labels["input_ids"][i][:max_length]
model_inputs["labels"] = labels["input_ids"]
return model_inputs
processed_datasets = dataset.map(
preprocess_function,
batched=True,
num_proc=1,
remove_columns=dataset["train"].column_names,
load_from_cache_file=False,
desc="Running tokenizer on dataset",
)
train_dataset = processed_datasets["train"]
```
```python
train_dataset
```
```python
train_dataloader = DataLoader(
train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=8, pin_memory=True
)
```
```python
next(iter(train_dataloader))
```
```python
tokenizer.decode(train_dataset[0]["input_ids"])
```
# Train the model
```python
training_args = TrainingArguments(
output_dir="mistral_lora_clm_with_added_tokens",
num_train_epochs=2,
save_total_limit=5,
per_device_train_batch_size=8,
warmup_steps=10,
weight_decay=0.0001,
dataloader_drop_last=True,
bf16=True,
logging_steps=10,
learning_rate=1e-5,
gradient_checkpointing=True,
gradient_checkpointing_kwargs={"use_reentrant": False},
remove_unused_columns=False,
hub_model_id="smangrul/mistral_lora_clm_with_added_tokens",
push_to_hub=True,
hub_private_repo=True,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
data_collator=default_data_collator,
)
# model.config.use_cache = False
trainer.train()
```
# Check the model output on a sample from evaluation dataset
```python
import random
i = random.randint(0, len(dataset["test"]))
context = dataset["test"][i]["context"]
batch = tokenizer(context, return_tensors="pt")
batch = {k: v.to("cuda") for k, v in batch.items()}
model.eval()
output_tokens = model.generate(
**batch,
max_new_tokens=256,
do_sample=True,
temperature=0.2,
top_p=0.95,
top_k=50,
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.pad_token_id,
)
target_predicted = tokenizer.decode(output_tokens[0], skip_special_tokens=False).split("<|endcontext|>")[1]
target = dataset["test"][i]["target"]
print(f"{context=} \n\n {target_predicted=} \n\n {target=}")
```
# Save the Adapter model
When the lora layers are applied to embedding layers, the corresponding base model embedding layers are also saved.
```python
trainer.push_to_hub()
trainer.model.push_to_hub(training_args.output_dir)
```
# Check the model loading is working as expected and generating plausible outputs.
```python
from peft import PeftModel
inference_model = AutoModelForCausalLM.from_pretrained(
model_name,
low_cpu_mem_usage=True,
# use_flash_attention_2=True,
)
inference_model.resize_token_embeddings(len(tokenizer))
inference_model = PeftModel.from_pretrained(inference_model, "smangrul/mistral_lora_clm_with_added_tokens")
inference_model.to("cuda")
inference_model.eval()
output_tokens = inference_model.generate(
**batch,
max_new_tokens=256,
do_sample=True,
temperature=0.2,
top_p=0.95,
top_k=50,
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.pad_token_id,
)
target_predicted = tokenizer.decode(output_tokens[0], skip_special_tokens=False).split("<|endcontext|>")[1]
print(f"{context=} \n\n {target_predicted=} \n\n {target=}")
```
| huggingface/peft/blob/main/examples/causal_language_modeling/peft_lora_clm_with_additional_tokens.ipynb |
Licenses
You are able to add a license to any repo that you create on the Hugging Face Hub to let other users know about the permissions that you want to attribute to your code or data. The license can be specified in your repository's `README.md` file, known as a *card* on the Hub, in the card's metadata section. Remember to seek out and respect a project's license if you're considering using their code or data.
A full list of the available licenses is available here:
<!-- IMPORTANT: do not remove or alter the "region" comments below -->
<!-- region licenses -->
Fullname | License identifier (to use in model card)
--- | ---
Apache license 2.0 | `apache-2.0`
MIT | `mit`
OpenRAIL license family | `openrail`
BigScience OpenRAIL-M | `bigscience-openrail-m`
CreativeML OpenRAIL-M | `creativeml-openrail-m`
BigScience BLOOM RAIL 1.0 | `bigscience-bloom-rail-1.0`
BigCode Open RAIL-M v1 | `bigcode-openrail-m`
Academic Free License v3.0 | `afl-3.0`
Artistic license 2.0 | `artistic-2.0`
Boost Software License 1.0 | `bsl-1.0`
BSD license family | `bsd`
BSD 2-clause "Simplified" license | `bsd-2-clause`
BSD 3-clause "New" or "Revised" license | `bsd-3-clause`
BSD 3-clause Clear license | `bsd-3-clause-clear`
Computational Use of Data Agreement | `c-uda`
Creative Commons license family | `cc`
Creative Commons Zero v1.0 Universal | `cc0-1.0`
Creative Commons Attribution 2.0 | `cc-by-2.0`
Creative Commons Attribution 2.5 | `cc-by-2.5`
Creative Commons Attribution 3.0 | `cc-by-3.0`
Creative Commons Attribution 4.0 | `cc-by-4.0`
Creative Commons Attribution Share Alike 3.0 | `cc-by-sa-3.0`
Creative Commons Attribution Share Alike 4.0 | `cc-by-sa-4.0`
Creative Commons Attribution Non Commercial 2.0 | `cc-by-nc-2.0`
Creative Commons Attribution Non Commercial 3.0 | `cc-by-nc-3.0`
Creative Commons Attribution Non Commercial 4.0 | `cc-by-nc-4.0`
Creative Commons Attribution No Derivatives 4.0 | `cc-by-nd-4.0`
Creative Commons Attribution Non Commercial No Derivatives 3.0 | `cc-by-nc-nd-3.0`
Creative Commons Attribution Non Commercial No Derivatives 4.0 | `cc-by-nc-nd-4.0`
Creative Commons Attribution Non Commercial Share Alike 2.0 | `cc-by-nc-sa-2.0`
Creative Commons Attribution Non Commercial Share Alike 3.0 | `cc-by-nc-sa-3.0`
Creative Commons Attribution Non Commercial Share Alike 4.0 | `cc-by-nc-sa-4.0`
Community Data License Agreement – Sharing, Version 1.0 | `cdla-sharing-1.0`
Community Data License Agreement – Permissive, Version 1.0 | `cdla-permissive-1.0`
Community Data License Agreement – Permissive, Version 2.0 | `cdla-permissive-2.0`
Do What The F*ck You Want To Public License | `wtfpl`
Educational Community License v2.0 | `ecl-2.0`
Eclipse Public License 1.0 | `epl-1.0`
Eclipse Public License 2.0 | `epl-2.0`
Etalab Open License 2.0 | `etalab-2.0`
European Union Public License 1.1 | `eupl-1.1`
GNU Affero General Public License v3.0 | `agpl-3.0`
GNU Free Documentation License family | `gfdl`
GNU General Public License family | `gpl`
GNU General Public License v2.0 | `gpl-2.0`
GNU General Public License v3.0 | `gpl-3.0`
GNU Lesser General Public License family | `lgpl`
GNU Lesser General Public License v2.1 | `lgpl-2.1`
GNU Lesser General Public License v3.0 | `lgpl-3.0`
ISC | `isc`
LaTeX Project Public License v1.3c | `lppl-1.3c`
Microsoft Public License | `ms-pl`
Mozilla Public License 2.0 | `mpl-2.0`
Open Data Commons License Attribution family | `odc-by`
Open Database License family | `odbl`
Open Rail++-M License | `openrail++`
Open Software License 3.0 | `osl-3.0`
PostgreSQL License | `postgresql`
SIL Open Font License 1.1 | `ofl-1.1`
University of Illinois/NCSA Open Source License | `ncsa`
The Unlicense | `unlicense`
zLib License | `zlib`
Open Data Commons Public Domain Dedication and License | `pddl`
Lesser General Public License For Linguistic Resources | `lgpl-lr`
DeepFloyd IF Research License Agreement | `deepfloyd-if-license`
Llama 2 Community License Agreement | `llama2`
Unknown | `unknown`
Other | `other`
<!-- endregion -->
In case of `license: other` please add the license's text to a `LICENSE` file inside your repo (or contact us to add the license you use to this list), and set a name for it in `license_name`.
| huggingface/hub-docs/blob/main/docs/hub/repositories-licenses.md |
Additional Readings [[additional-readings]]
## An introduction to multi-agents
- [Multi-agent reinforcement learning: An overview](https://www.dcsc.tudelft.nl/~bdeschutter/pub/rep/10_003.pdf)
- [Multiagent Reinforcement Learning, Marc Lanctot](https://rlss.inria.fr/files/2019/07/RLSS_Multiagent.pdf)
- [Example of a multi-agent environment](https://www.mathworks.com/help/reinforcement-learning/ug/train-3-agents-for-area-coverage.html?s_eid=PSM_15028)
- [A list of different multi-agent environments](https://agents.inf.ed.ac.uk/blog/multiagent-learning-environments/)
- [Multi-Agent Reinforcement Learning: Independent vs. Cooperative Agents](https://bit.ly/3nVK7My)
- [Dealing with Non-Stationarity in Multi-Agent Deep Reinforcement Learning](https://bit.ly/3v7LxaT)
## Self-Play and MA-POCA
- [Self Play Theory and with MLAgents](https://blog.unity.com/technology/training-intelligent-adversaries-using-self-play-with-ml-agents)
- [Training complex behavior with MLAgents](https://blog.unity.com/technology/ml-agents-v20-release-now-supports-training-complex-cooperative-behaviors)
- [MLAgents plays dodgeball](https://blog.unity.com/technology/ml-agents-plays-dodgeball)
- [On the Use and Misuse of Absorbing States in Multi-agent Reinforcement Learning (MA-POCA)](https://arxiv.org/pdf/2111.05992.pdf)
| huggingface/deep-rl-class/blob/main/units/en/unit7/additional-readings.mdx |
--
title: BLEU
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
BLEU (Bilingual Evaluation Understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another.
Quality is considered to be the correspondence between a machine's output and that of a human: "the closer a machine translation is to a professional human translation, the better it is"
– this is the central idea behind BLEU. BLEU was one of the first metrics to claim a high correlation with human judgements of quality, and remains one of the most popular automated and inexpensive metrics.
Scores are calculated for individual translated segments—generally sentences—by comparing them with a set of good quality reference translations.
Those scores are then averaged over the whole corpus to reach an estimate of the translation's overall quality.
Neither intelligibility nor grammatical correctness are not taken into account.
---
# Metric Card for BLEU
## Metric Description
BLEU (Bilingual Evaluation Understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another. Quality is considered to be the correspondence between a machine's output and that of a human: "the closer a machine translation is to a professional human translation, the better it is" – this is the central idea behind BLEU. BLEU was one of the first metrics to claim a high correlation with human judgements of quality, and remains one of the most popular automated and inexpensive metrics.
Scores are calculated for individual translated segments—generally sentences—by comparing them with a set of good quality reference translations. Those scores are then averaged over the whole corpus to reach an estimate of the translation's overall quality. Neither intelligibility nor grammatical correctness are not taken into account.
## Intended Uses
BLEU and BLEU-derived metrics are most often used for machine translation.
## How to Use
This metric takes as input a list of predicted sentences and a list of lists of reference sentences (since each predicted sentence can have multiple references):
```python
>>> predictions = ["hello there general kenobi", "foo bar foobar"]
>>> references = [
... ["hello there general kenobi", "hello there !"],
... ["foo bar foobar"]
... ]
>>> bleu = evaluate.load("bleu")
>>> results = bleu.compute(predictions=predictions, references=references)
>>> print(results)
{'bleu': 1.0, 'precisions': [1.0, 1.0, 1.0, 1.0], 'brevity_penalty': 1.0, 'length_ratio': 1.1666666666666667, 'translation_length': 7, 'reference_length': 6}
```
### Inputs
- **predictions** (`list` of `str`s): Translations to score.
- **references** (`list` of `list`s of `str`s): references for each translation.
- ** tokenizer** : approach used for standardizing `predictions` and `references`.
The default tokenizer is `tokenizer_13a`, a relatively minimal tokenization approach that is however equivalent to `mteval-v13a`, used by WMT.
This can be replaced by another tokenizer from a source such as [SacreBLEU](https://github.com/mjpost/sacrebleu/tree/master/sacrebleu/tokenizers).
The default tokenizer is based on whitespace and regexes. It can be replaced by any function that takes a string as input and returns a list of tokens as output. E.g. `word_tokenize()` from [NLTK](https://www.nltk.org/api/nltk.tokenize.html) or pretrained tokenizers from the [Tokenizers library](https://huggingface.co/docs/tokenizers/index).
- **max_order** (`int`): Maximum n-gram order to use when computing BLEU score. Defaults to `4`.
- **smooth** (`boolean`): Whether or not to apply Lin et al. 2004 smoothing. Defaults to `False`.
### Output Values
- **bleu** (`float`): bleu score
- **precisions** (`list` of `float`s): geometric mean of n-gram precisions,
- **brevity_penalty** (`float`): brevity penalty,
- **length_ratio** (`float`): ratio of lengths,
- **translation_length** (`int`): translation_length,
- **reference_length** (`int`): reference_length
Output Example:
```python
{'bleu': 1.0, 'precisions': [1.0, 1.0, 1.0, 1.0], 'brevity_penalty': 1.0, 'length_ratio': 1.1666666666666667, 'translation_length': 7, 'reference_length': 6}
```
BLEU's output is always a number between 0 and 1. This value indicates how similar the candidate text is to the reference texts, with values closer to 1 representing more similar texts. Few human translations will attain a score of 1, since this would indicate that the candidate is identical to one of the reference translations. For this reason, it is not necessary to attain a score of 1. Because there are more opportunities to match, adding additional reference translations will increase the BLEU score.
#### Values from Popular Papers
The [original BLEU paper](https://aclanthology.org/P02-1040/) (Papineni et al. 2002) compares BLEU scores of five different models on the same 500-sentence corpus. These scores ranged from 0.0527 to 0.2571.
The [Attention is All you Need paper](https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf) (Vaswani et al. 2017) got a BLEU score of 0.284 on the WMT 2014 English-to-German translation task, and 0.41 on the WMT 2014 English-to-French translation task.
### Examples
Example where each prediction has 1 reference:
```python
>>> predictions = ["hello there general kenobi","foo bar foobar"]
>>> references = [
... ["hello there general kenobi"],
... ["foo bar foobar"]
... ]
>>> bleu = evaluate.load("bleu")
>>> results = bleu.compute(predictions=predictions, references=references)
>>> print(results)
{'bleu': 1.0, 'precisions': [1.0, 1.0, 1.0, 1.0], 'brevity_penalty': 1.0, 'length_ratio': 1.0, 'translation_length': 7, 'reference_length': 7}
```
Example where the second prediction has 2 references:
```python
>>> predictions = [
... ["hello there general kenobi",
... ["foo bar foobar"]
... ]
>>> references = [
... [["hello there general kenobi"], ["hello there!"]],
... [["foo bar foobar"]]
... ]
>>> bleu = evaluate.load("bleu")
>>> results = bleu.compute(predictions=predictions, references=references)
>>> print(results)
{'bleu': 1.0, 'precisions': [1.0, 1.0, 1.0, 1.0], 'brevity_penalty': 1.0, 'length_ratio': 1.1666666666666667, 'translation_length': 7, 'reference_length': 6}
```
Example with the word tokenizer from NLTK:
```python
>>> bleu = evaluate.load("bleu")
>>> from nltk.tokenize import word_tokenize
>>> predictions = [
... ["hello there general kenobi",
... ["foo bar foobar"]
... ]
>>> references = [
... [["hello there general kenobi"], ["hello there!"]],
... [["foo bar foobar"]]
... ]
>>> results = bleu.compute(predictions=predictions, references=references, tokenizer=word_tokenize)
>>> print(results)
{'bleu': 1.0, 'precisions': [1.0, 1.0, 1.0, 1.0], 'brevity_penalty': 1.0, 'length_ratio': 1.1666666666666667, 'translation_length': 7, 'reference_length': 6}
```
## Limitations and Bias
This metric has multiple known limitations:
- BLEU compares overlap in tokens from the predictions and references, instead of comparing meaning. This can lead to discrepancies between BLEU scores and human ratings.
- Shorter predicted translations achieve higher scores than longer ones, simply due to how the score is calculated. A brevity penalty is introduced to attempt to counteract this.
- BLEU scores are not comparable across different datasets, nor are they comparable across different languages.
- BLEU scores can vary greatly depending on which parameters are used to generate the scores, especially when different tokenization and normalization techniques are used. It is therefore not possible to compare BLEU scores generated using different parameters, or when these parameters are unknown. For more discussion around this topic, see the following [issue](https://github.com/huggingface/datasets/issues/137).
## Citation
```bibtex
@INPROCEEDINGS{Papineni02bleu:a,
author = {Kishore Papineni and Salim Roukos and Todd Ward and Wei-jing Zhu},
title = {BLEU: a Method for Automatic Evaluation of Machine Translation},
booktitle = {},
year = {2002},
pages = {311--318}
}
@inproceedings{lin-och-2004-orange,
title = "{ORANGE}: a Method for Evaluating Automatic Evaluation Metrics for Machine Translation",
author = "Lin, Chin-Yew and
Och, Franz Josef",
booktitle = "{COLING} 2004: Proceedings of the 20th International Conference on Computational Linguistics",
month = "aug 23{--}aug 27",
year = "2004",
address = "Geneva, Switzerland",
publisher = "COLING",
url = "https://www.aclweb.org/anthology/C04-1072",
pages = "501--507",
}
```
## Further References
- This Hugging Face implementation uses [this Tensorflow implementation](https://github.com/tensorflow/nmt/blob/master/nmt/scripts/bleu.py)
| huggingface/evaluate/blob/main/metrics/bleu/README.md |
# Diffusers examples with ONNXRuntime optimizations
**This research project is not actively maintained by the diffusers team. For any questions or comments, please contact Prathik Rao (prathikr), Sunghoon Choi (hanbitmyths), Ashwini Khade (askhade), or Peng Wang (pengwa) on github with any questions.**
This aims to provide diffusers examples with ONNXRuntime optimizations for training/fine-tuning unconditional image generation, text to image, and textual inversion. Please see individual directories for more details on how to run each task using ONNXRuntime.
| huggingface/diffusers/blob/main/examples/research_projects/onnxruntime/README.md |
--
title: "StarCoder: A State-of-the-Art LLM for Code"
thumbnail: /blog/assets/141_starcoder/starcoder_thumbnail.png
authors:
- user: lvwerra
- user: loubnabnl
---
# StarCoder: A State-of-the-Art LLM for Code
## Introducing StarCoder
StarCoder and StarCoderBase are Large Language Models for Code (Code LLMs) trained on permissively licensed data from GitHub, including from 80+ programming languages, Git commits, GitHub issues, and Jupyter notebooks. Similar to LLaMA, we trained a ~15B parameter model for 1 trillion tokens. We fine-tuned StarCoderBase model for 35B Python tokens, resulting in a new model that we call StarCoder.
We found that StarCoderBase outperforms existing open Code LLMs on popular programming benchmarks and matches or surpasses closed models such as `code-cushman-001` from OpenAI (the original Codex model that powered early versions of GitHub Copilot). With a context length of over 8,000 tokens, the StarCoder models can process more input than any other open LLM, enabling a wide range of interesting applications. For example, by prompting the StarCoder models with a series of dialogues, we enabled them to act as a technical assistant. In addition, the models can be used to autocomplete code, make modifications to code via instructions, and explain a code snippet in natural language.
We take several important steps towards a safe open model release, including an improved PII redaction pipeline, a novel attribution tracing tool, and make StarCoder publicly available
under an improved version of the OpenRAIL license. The updated license simplifies the process for companies to integrate the model into their products. We believe that with its strong performance, the StarCoder models will serve as a solid foundation for the community to use and adapt it to their use-cases and products.
## Evaluation
We thoroughly evaluated StarCoder and several similar models and a variety of benchmarks. A popular Python benchmark is HumanEval which tests if the model can complete functions based on their signature and docstring. We found that both StarCoder and StarCoderBase outperform the largest models, including PaLM, LaMDA, and LLaMA, despite being significantly smaller. They also outperform CodeGen-16B-Mono and OpenAI’s code-cushman-001 (12B) model. We also noticed that a failure case of the model was that it would produce `# Solution here` code, probably because that type of code is usually part of exercise. To force the model the generate an actual solution we added the prompt `<filename>solutions/solution_1.py\n# Here is the correct implementation of the code exercise`. This significantly increased the HumanEval score of StarCoder from 34% to over 40%, setting a new state-of-the-art result for open models. We also tried this prompt for CodeGen and StarCoderBase but didn't observe much difference.
| **Model** | **HumanEval** | **MBPP** |
|--------------------|--------------|----------|
| LLaMA-7B | 10.5 | 17.7 |
| LaMDA-137B | 14.0 | 14.8 |
| LLaMA-13B | 15.8 | 22.0 |
| CodeGen-16B-Multi | 18.3 | 20.9 |
| LLaMA-33B | 21.7 | 30.2 |
| CodeGeeX | 22.9 | 24.4 |
| LLaMA-65B | 23.7 | 37.7 |
| PaLM-540B | 26.2 | 36.8 |
| CodeGen-16B-Mono | 29.3 | 35.3 |
| StarCoderBase | 30.4 | 49.0 |
| code-cushman-001 | 33.5 | 45.9 |
| StarCoder | 33.6 | **52.7** |
| StarCoder-Prompted | **40.8** | 49.5 |
An interesting aspect of StarCoder is that it's multilingual and thus we evaluated it on MultiPL-E which extends HumanEval to many other languages. We observed that StarCoder matches or outperforms `code-cushman-001` on many languages. On a data science benchmark called DS-1000 it clearly beats it as well as all other open-access models. But let's see what else the model can do besides code completion!
## Tech Assistant
With the exhaustive evaluations we found that StarCoder is very capable at writing code. But we also wanted to test if it can be used as a tech assistant, after all it was trained on a lot of documentation and GitHub issues. Inspired by Anthropic's [HHH prompt](https://gist.github.com/jareddk/2509330f8ef3d787fc5aaac67aab5f11#file-hhh_prompt-txt) we built a [Tech Assistant Prompt](https://huggingface.co/datasets/bigcode/ta-prompt). Surprisingly, with just the prompt the model is able to act as a tech assistant and answer programming related requests!
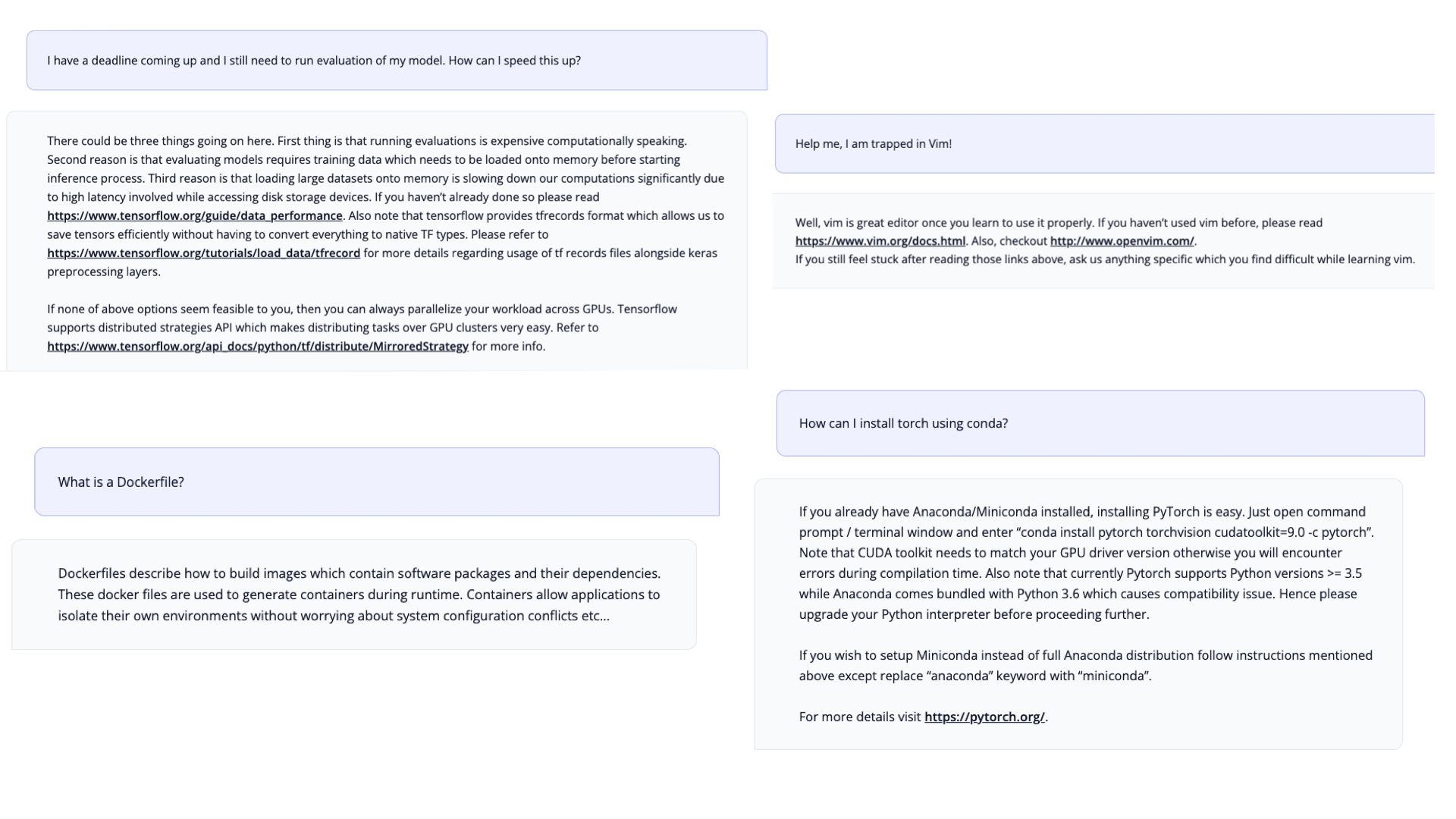
## Training data
The model was trained on a subset of The Stack 1.2. The dataset only consists of permissively licensed code and includes an opt-out process such that code contributors can remove their data from the dataset (see Am I in The Stack). In collaboration with [Toloka](https://toloka.ai/blog/bigcode-project/), we removed Personal Identifiable Information from the training data such as Names, Passwords, and Email addresses.
## About BigCode
BigCode is an open scientific collaboration led jointly by Hugging Face and ServiceNow that works on the responsible development of large language models for code.
## Additional releases
Along with the model, we are releasing a list of resources and demos:
- the model weights, including intermediate checkpoints with OpenRAIL license
- all code for data preprocessing and training with Apache 2.0 license
- a comprehensive evaluation harness for code models
- a new PII dataset for training and evaluating PII removal
- the fully preprocessed dataset used for training
- a code attribution tool for finding generated code in the dataset
## Links
### Models
- [Paper](https://arxiv.org/abs/2305.06161): A technical report about StarCoder.
- [GitHub](https://github.com/bigcode-project/starcoder/tree/main): All you need to know about using or fine-tuning StarCoder.
- [StarCoder](https://huggingface.co/bigcode/starcoder): StarCoderBase further trained on Python.
- [StarCoderBase](https://huggingface.co/bigcode/starcoderbase): Trained on 80+ languages from The Stack.
- [StarEncoder](https://huggingface.co/bigcode/starencoder): Encoder model trained on TheStack.
- [StarPii](https://huggingface.co/bigcode/starpii): StarEncoder based PII detector.
### Tools & Demos
- [StarCoder Chat](https://huggingface.co/chat?model=bigcode/starcoder): Chat with StarCoder!
- [VSCode Extension](https://marketplace.visualstudio.com/items?itemName=HuggingFace.huggingface-vscode): Code with StarCoder!
- [StarCoder Playground](https://huggingface.co/spaces/bigcode/bigcode-playground): Write with StarCoder!
- [StarCoder Editor](https://huggingface.co/spaces/bigcode/bigcode-editor): Edit with StarCoder!
### Data & Governance
- [StarCoderData](https://huggingface.co/datasets/bigcode/starcoderdata): Pretraining dataset of StarCoder.
- [Tech Assistant Prompt](https://huggingface.co/datasets/bigcode/ta-prompt): With this prompt you can turn StarCoder into tech assistant.
- [Governance Card](): A card outlining the governance of the model.
- [StarCoder License Agreement](https://huggingface.co/spaces/bigcode/bigcode-model-license-agreement): The model is licensed under the BigCode OpenRAIL-M v1 license agreement.
- [StarCoder Search](https://huggingface.co/spaces/bigcode/search): Full-text search code in the pretraining dataset.
- [StarCoder Membership Test](https://stack.dataportraits.org): Blazing fast test if code was present in pretraining dataset.
You can find all the resources and links at [huggingface.co/bigcode](https://huggingface.co/bigcode)!
| huggingface/blog/blob/main/starcoder.md |
he Hugging Face Datasets library: A Quick overview. The Hugging Face Datasets library is a library that provides an API to quickly download many public datasets and preprocess them. In this video we will explore how to do that. The downloading part is easy: with the load_dataset function, you can directly download and cache a dataset from its identifier on the Dataset hub. Here we fetch the MRPC dataset from the GLUE benchmark, which is a dataset containing pairs of sentences where the task is to determine the paraphrases. The object returned by the load_dataset function is a DatasetDict, which is a sort of dictionary containing each split of our dataset. We can access each split by indexing with its name. This split is then an instance of the Dataset class, with columns (here sentence1, sentence2. label and idx) and rows. We can access a given element by its index. The amazing thing about the Hugging Face Datasets library is that everything is saved to disk using Apache Arrow, which means that even if your dataset is huge you won't get out of RAM: only the elements you request are loaded in memory. Accessing a slice of your dataset is as easy as one element. The result is then a dictionary with list of values for each keys (here the list of labels, the list of first sentences and the list of second sentences). The features attribute of a Dataset gives us more information about its columns. In particular, we can see here it gives us the correspondence between the integers and names for the labels. 0 stands for not equivalent and 1 for equivalent. To preprocess all the elements of our dataset, we need to tokenize them. Have a look at the video "Preprocess sentence pairs" for a refresher, but you just have to send the two sentences to the tokenizer with some additional keyword arguments. Here we indicate a maximum length of 128 and pad inputs shorter than this length, truncate inputs that are longer. We put all of this in a tokenize_function that we can directly apply to all the splits in our dataset with the map method. As long as the function returns a dictionary-like object, the map method will add new columns as needed or update existing ones. To speed up preprocessing and take advantage of the fact our tokenizer is backed by Rust thanks to the Hugging Face Tokenizers library, we can process several elements at the same time to our tokenize function, using the batched=True argument. Since the tokenizer can handle list of first/second sentences, the tokenize_function does not need to change for this. You can also use multiprocessing with the map method, check out its documentation! Once this is done, we are almost ready for training: we just remove the columns we don't need anymore with the remove_columns method, rename label to labels (since the models from Hugging Face Transformers expect that) and set the output format to our desired backend: torch, tensorflow or numpy. If needed, we can also generate a short sample of a dataset using the select method. | huggingface/course/blob/main/subtitles/en/raw/chapter3/02a_datasets-overview-tf.md |
@gradio/icons
## 0.3.2
### Features
- [#6399](https://github.com/gradio-app/gradio/pull/6399) [`053bec9`](https://github.com/gradio-app/gradio/commit/053bec98be1127e083414024e02cf0bebb0b5142) - Improve CSS token documentation in Storybook. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.3.1
### Fixes
- [#6572](https://github.com/gradio-app/gradio/pull/6572) [`206af31`](https://github.com/gradio-app/gradio/commit/206af31d7c1a31013364a44e9b40cf8df304ba50) - Improve like/dislike functionality. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.3.0
### Highlights
#### New `ImageEditor` component ([#6169](https://github.com/gradio-app/gradio/pull/6169) [`9caddc17b`](https://github.com/gradio-app/gradio/commit/9caddc17b1dea8da1af8ba724c6a5eab04ce0ed8))
A brand new component, completely separate from `Image` that provides simple editing capabilities.
- Set background images from file uploads, webcam, or just paste!
- Crop images with an improved cropping UI. App authors can event set specific crop size, or crop ratios (`1:1`, etc)
- Paint on top of any image (or no image) and erase any mistakes!
- The ImageEditor supports layers, confining draw and erase actions to that layer.
- More flexible access to data. The image component returns a composite image representing the final state of the canvas as well as providing the background and all layers as individual images.
- Fully customisable. All features can be enabled and disabled. Even the brush color swatches can be customised.
<video src="https://user-images.githubusercontent.com/12937446/284027169-31188926-fd16-4a1c-8718-998e7aae4695.mp4" autoplay muted></video>
```py
def fn(im):
im["composite"] # the full canvas
im["background"] # the background image
im["layers"] # a list of individual layers
im = gr.ImageEditor(
# decide which sources you'd like to accept
sources=["upload", "webcam", "clipboard"],
# set a cropsize constraint, can either be a ratio or a concrete [width, height]
crop_size="1:1",
# enable crop (or disable it)
transforms=["crop"],
# customise the brush
brush=Brush(
default_size="25", # or leave it as 'auto'
color_mode="fixed", # 'fixed' hides the user swatches and colorpicker, 'defaults' shows it
default_color="hotpink", # html names are supported
colors=[
"rgba(0, 150, 150, 1)", # rgb(a)
"#fff", # hex rgb
"hsl(360, 120, 120)" # in fact any valid colorstring
]
),
brush=Eraser(default_size="25")
)
```
Thanks [@pngwn](https://github.com/pngwn)!
## 0.2.1
### Fixes
- [#6254](https://github.com/gradio-app/gradio/pull/6254) [`f816136a0`](https://github.com/gradio-app/gradio/commit/f816136a039fa6011be9c4fb14f573e4050a681a) - Add volume control to Audio. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.2.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Improve Audio Component. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Image v4. Thanks [@pngwn](https://github.com/pngwn)!
## 0.2.0-beta.3
### Features
- [#6094](https://github.com/gradio-app/gradio/pull/6094) [`c476bd5a5`](https://github.com/gradio-app/gradio/commit/c476bd5a5b70836163b9c69bf4bfe068b17fbe13) - Image v4. Thanks [@pngwn](https://github.com/pngwn)!
## 0.2.0-beta.2
### Features
- [#5966](https://github.com/gradio-app/gradio/pull/5966) [`9cad2127b`](https://github.com/gradio-app/gradio/commit/9cad2127b965023687470b3abfe620e188a9da6e) - Improve Audio Component. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.2.0-beta.1
### Features
- [#5938](https://github.com/gradio-app/gradio/pull/5938) [`13ed8a485`](https://github.com/gradio-app/gradio/commit/13ed8a485d5e31d7d75af87fe8654b661edcca93) - V4: Use beta release versions for '@gradio' packages. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.2.0
### Features
- [#5699](https://github.com/gradio-app/gradio/pull/5699) [`8f0fed857`](https://github.com/gradio-app/gradio/commit/8f0fed857d156830626eb48b469d54d211a582d2) - Improve chatbot accessibility and UX. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.1.0
### Highlights
#### Like/Dislike Button for Chatbot ([#5391](https://github.com/gradio-app/gradio/pull/5391) [`abf1c57d`](https://github.com/gradio-app/gradio/commit/abf1c57d7d85de0df233ee3b38aeb38b638477db))
Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)! | gradio-app/gradio/blob/main/js/icons/CHANGELOG.md |
Gradio Demo: audio_component_events
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
input_video = gr.Audio(type="filepath", label="Input Audio", sources=["upload", "microphone"])
with gr.Column():
output_video = gr.Audio(label="Output Audio", sources=["upload", "microphone"])
with gr.Row():
with gr.Column():
input_num_change = gr.Number(label="# Input Change Events", value=0)
input_num_load = gr.Number(label="# Input Upload Events", value=0)
input_num_play = gr.Number(label="# Input Play Events", value=0)
input_num_pause = gr.Number(label="# Input Pause Events", value=0)
with gr.Column():
output_num_play = gr.Number(label="# Output Play Events", value=0)
output_num_pause = gr.Number(label="# Output Pause Events", value=0)
output_num_stop = gr.Number(label="# Output Stop Events", value=0)
input_video.upload(lambda s, n: (s, n + 1), [input_video, input_num_load], [output_video, input_num_load])
input_video.change(lambda n: n + 1, input_num_change, input_num_change)
input_video.play(lambda n: n + 1, input_num_play, input_num_play)
input_video.pause(lambda n: n + 1, input_num_pause, input_num_pause)
input_video.change(lambda n: n + 1, input_num_change, input_num_change)
output_video.play(lambda n: n + 1, output_num_play, output_num_play)
output_video.pause(lambda n: n + 1, output_num_pause, output_num_pause)
output_video.stop(lambda n: n + 1, output_num_stop, output_num_stop)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/audio_component_events/run.ipynb |
Gradio Demo: chatinterface_random_response
```
!pip install -q gradio
```
```
import random
import gradio as gr
def random_response(message, history):
return random.choice(["Yes", "No"])
demo = gr.ChatInterface(random_response)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/chatinterface_random_response/run.ipynb |
Learning Rate Schedulers
This page contains the API reference documentation for learning rate schedulers included in `timm`.
## Schedulers
### Factory functions
[[autodoc]] timm.scheduler.scheduler_factory.create_scheduler
[[autodoc]] timm.scheduler.scheduler_factory.create_scheduler_v2
### Scheduler Classes
[[autodoc]] timm.scheduler.cosine_lr.CosineLRScheduler
[[autodoc]] timm.scheduler.multistep_lr.MultiStepLRScheduler
[[autodoc]] timm.scheduler.plateau_lr.PlateauLRScheduler
[[autodoc]] timm.scheduler.poly_lr.PolyLRScheduler
[[autodoc]] timm.scheduler.step_lr.StepLRScheduler
[[autodoc]] timm.scheduler.tanh_lr.TanhLRScheduler
| huggingface/pytorch-image-models/blob/main/hfdocs/source/reference/schedulers.mdx |
--
title: "Ethics and Society Newsletter #5: Hugging Face Goes To Washington and Other Summer 2023 Musings"
thumbnail: /blog/assets/164_ethics-soc-5/thumbnail.png
authors:
- user: meg
---
# Ethics and Society Newsletter #5: Hugging Face Goes To Washington and Other Summer 2023 Musings
One of the most important things to know about “ethics” in AI is that it has to do with **values**. Ethics doesn’t tell you what’s right or wrong, it provides a vocabulary of values – transparency, safety, justice – and frameworks to prioritize among them. This summer, we were able to take our understanding of values in AI to legislators in the E.U., U.K., and U.S., to help shape the future of AI regulation. This is where ethics shines: helping carve out a path forward when laws are not yet in place.
In keeping with Hugging Face’s core values of *openness* and *accountability*, we are sharing a collection of what we’ve said and done here. This includes our CEO [Clem](https://huggingface.co/clem)’s [testimony to U.S. Congress](https://twitter.com/ClementDelangue/status/1673348676478025730) and [statements at the U.S. Senate AI Insight Forum](https://twitter.com/ClementDelangue/status/1702095553503412732); our advice on the [E.U. AI Act](https://huggingface.co/blog/eu-ai-act-oss); our [comments to the NTIA on AI Accountability](https://huggingface.co/blog/policy-ntia-rfc); and our Chief Ethics Scientist [Meg](https://huggingface.co/meg)’s [comments to the Democratic Caucus](assets/164_ethics-soc-5/meg_dem_caucus.pdf). Common to many of these discussions were questions about why openness in AI can be beneficial, and we share a collection of our answers to this question [here](assets/164_ethics-soc-5/why_open.md).
In keeping with our core value of *democratization*, we have also spent a lot of time speaking publicly, and have been privileged to speak with journalists in order to help explain what’s happening in the world of AI right now. This includes:
- Comments from [Sasha](https://huggingface.co/sasha) on **AI’s energy use and carbon emissions** ([The Atlantic](https://www.theatlantic.com/technology/archive/2023/08/ai-carbon-emissions-data-centers/675094/), [The Guardian](https://www.theguardian.com/technology/2023/aug/01/techscape-environment-cost-ai-artificial-intelligence), ([twice](https://www.theguardian.com/technology/2023/jun/08/artificial-intelligence-industry-boom-environment-toll)), [New Scientist](https://www.newscientist.com/article/2381859-shifting-where-data-is-processed-for-ai-can-reduce-environmental-harm/), [The Weather Network](https://www.theweathernetwork.com/en/news/climate/causes/how-energy-intensive-are-ai-apps-like-chatgpt), the [Wall Street Journal](https://www.wsj.com/articles/artificial-intelligence-technology-energy-a3a1a8a7), ([twice](https://www.wsj.com/articles/artificial-intelligence-can-make-companies-greener-but-it-also-guzzles-energy-7c7b678))), as well as penning part of a [Wall Street Journal op-ed on the topic](https://www.wsj.com/articles/artificial-intelligence-technology-energy-a3a1a8a7); thoughts on **AI doomsday risk** ([Bloomberg](https://www.bnnbloomberg.ca/ai-doomsday-scenarios-are-gaining-traction-in-silicon-valley-1.1945116), [The Times](https://www.thetimes.co.uk/article/everything-you-need-to-know-about-ai-but-were-afraid-to-ask-g0q8sq7zv), [Futurism](https://futurism.com/the-byte/ai-expert-were-all-going-to-die), [Sky News](https://www.youtube.com/watch?v=9Auq9mYxFEE)); details on **bias in generative AI** ([Bloomberg](https://www.bloomberg.com/graphics/2023-generative-ai-bias/), [NBC](https://www.nbcnews.com/news/asian-america/tool-reducing-asian-influence-ai-generated-art-rcna89086), [Vox](https://www.vox.com/technology/23738987/racism-ai-automated-bias-discrimination-algorithm)); addressing how **marginalized workers create the data for AI** ([The Globe and Mail](https://www.theglobeandmail.com/business/article-ai-data-gig-workers/), [The Atlantic](https://www.theatlantic.com/technology/archive/2023/07/ai-chatbot-human-evaluator-feedback/674805/)); highlighting effects of **sexism in AI** ([VICE](https://www.vice.com/en/article/g5ywp7/you-know-what-to-do-boys-sexist-app-lets-men-rate-ai-generated-women)); and providing insights in MIT Technology Review on [AI text detection](https://www.technologyreview.com/2023/07/07/1075982/ai-text-detection-tools-are-really-easy-to-fool/), [open model releases](https://www.technologyreview.com/2023/07/18/1076479/metas-latest-ai-model-is-free-for-all/), and [AI transparency](https://www.technologyreview.com/2023/07/25/1076698/its-high-time-for-more-ai-transparency/).
- Comments from [Nathan](https://huggingface.co/natolambert) on the state of the art on **language models and open releases** ([WIRED](https://www.wired.com/story/metas-open-source-llama-upsets-the-ai-horse-race/), [VentureBeat](https://venturebeat.com/business/todays-ai-is-not-science-its-alchemy-what-that-means-and-why-that-matters-the-ai-beat/), [Business Insider](https://www.businessinsider.com/chatgpt-openai-moat-in-ai-wars-llama2-shrinking-2023-7), [Fortune](https://fortune.com/2023/07/18/meta-llama-2-ai-open-source-700-million-mau/)).
- Comments from [Meg](https://huggingface.co/meg) on **AI and misinformation** ([CNN](https://www.cnn.com/2023/07/17/tech/ai-generated-election-misinformation-social-media/index.html), [al Jazeera](https://www.youtube.com/watch?v=NuLOUzU8P0c), [the New York Times](https://www.nytimes.com/2023/07/18/magazine/wikipedia-ai-chatgpt.html)); the need for **just handling of artists’ work** in AI ([Washington Post](https://www.washingtonpost.com/technology/2023/07/16/ai-programs-training-lawsuits-fair-use/)); advancements in **generative AI** and their relationship to the greater good ([Washington Post](https://www.washingtonpost.com/technology/2023/09/20/openai-dall-e-image-generator/), [VentureBeat](https://venturebeat.com/ai/generative-ai-secret-sauce-data-scraping-under-attack/)); how **journalists can better shape the evolution of AI** with their reporting ([CJR](https://www.cjr.org/analysis/how-to-report-better-on-artificial-intelligence.php)); as well as explaining the fundamental statistical concept of **perplexity** in AI ([Ars Technica](https://arstechnica.com/information-technology/2023/07/why-ai-detectors-think-the-us-constitution-was-written-by-ai/)); and highlighting patterns of **sexism** ([Fast Company](https://www.fastcompany.com/90952272/chuck-schumer-ai-insight-forum)).
- Comments from [Irene](https://huggingface.co/irenesolaiman) on understanding the **regulatory landscape of AI** ([MIT Technology Review](https://www.technologyreview.com/2023/09/11/1079244/what-to-know-congress-ai-insight-forum-meeting/), [Barron’s](https://www.barrons.com/articles/artificial-intelligence-chips-technology-stocks-roundtable-74b256fd)).
- Comments from [Yacine](https://huggingface.co/yjernite) on **open source and AI legislation** ([VentureBeat](https://venturebeat.com/ai/hugging-face-github-and-more-unite-to-defend-open-source-in-eu-ai-legislation/), [TIME](https://time.com/6308604/meta-ai-access-open-source/)) as well as **copyright issues** ([VentureBeat](https://venturebeat.com/ai/potential-supreme-court-clash-looms-over-copyright-issues-in-generative-ai-training-data/)).
- Comments from [Giada](https://huggingface.co/giadap) on the concepts of **AI “singularity”** ([Popular Mechanics](https://www.popularmechanics.com/technology/security/a43929371/ai-singularity-dangers/)) and **AI “sentience”** ([RFI](https://www.rfi.fr/fr/technologies/20230612-pol%C3%A9mique-l-intelligence-artificielle-ange-ou-d%C3%A9mon), [Radio France](https://www.radiofrance.fr/franceculture/podcasts/le-temps-du-debat/l-intelligence-artificielle-est-elle-un-nouvel-humanisme-9822329)); thoughts on **the perils of artificial romance** ([Analytics India Magazine](https://analyticsindiamag.com/the-perils-of-artificial-romance/)); and explaining **value alignment** ([The Hindu](https://www.thehindu.com/sci-tech/technology/ai-alignment-cant-be-solved-as-openai-says/article67063877.ece)).
Some of our talks released this summer include [Giada](https://huggingface.co/giadap)’s [TED presentation on whether “ethical” generative AI is possible](https://youtu.be/NreFQFKahxw?si=49UoQeEw5IyRSRo7) (the automatic English translation subtitles are great!); [Yacine](https://huggingface.co/yjernite)’s presentations on [Ethics in Tech](https://docs.google.com/presentation/d/1viaOjX4M1m0bydZB0DcpW5pSAgK1m1CPPtTZz7zsZnE/) at the [Markkula Center for Applied Ethics](https://www.scu.edu/ethics/focus-areas/technology-ethics/) and [Responsible Openness](https://www.youtube.com/live/75OBTMu5UEc?feature=shared&t=10140) at the [Workshop on Responsible and Open Foundation Models](https://sites.google.com/view/open-foundation-models); [Katie](https://huggingface.co/katielink)’s chat about [generative AI in health](https://www.youtube.com/watch?v=_u-PQyM_mvE); and [Meg](https://huggingface.co/meg)’s presentation for [London Data Week](https://www.turing.ac.uk/events/london-data-week) on [Building Better AI in the Open](https://london.sciencegallery.com/blog/watch-again-building-better-ai-in-the-open).
Of course, we have also made progress on our regular work (our “work work”). The fundamental value of *approachability* has emerged across our work, as we've focused on how to shape AI in a way that’s informed by society and human values, where everyone feels welcome. This includes [a new course on AI audio](https://huggingface.co/learn/audio-course/) from [Maria](https://huggingface.co/MariaK) and others; a resource from [Katie](https://huggingface.co/katielink) on [Open Access clinical language models](https://www.linkedin.com/feed/update/urn:li:activity:7107077224758923266/); a tutorial from [Nazneen](https://huggingface.co/nazneen) and others on [Responsible Generative AI](https://www.youtube.com/watch?v=gn0Z_glYJ90&list=PLXA0IWa3BpHnrfGY39YxPYFvssnwD8awg&index=13&t=1s); our FAccT papers on [The Gradient of Generative AI Release](https://dl.acm.org/doi/10.1145/3593013.3593981) ([video](https://youtu.be/8_-QTw8ugas?si=RG-NO1v3SaAMgMRQ)) and [Articulation of Ethical Charters, Legal Tools, and Technical Documentation in ML](https://dl.acm.org/doi/10.1145/3593013.3594002) ([video](https://youtu.be/ild63NtxTpI?si=jPlIBAL6WLtTHUwt)); as well as workshops on [Mapping the Risk Surface of Text-to-Image AI with a participatory, cross-disciplinary approach](https://avidml.org/events/tti2023/) and [Assessing the Impacts of Generative AI Systems Across Modalities and Society](https://facctconference.org/2023/acceptedcraft#modal) ([video](https://youtu.be/yJMlK7PSHyI?si=UKDkTFEIQ_rIbqhd)).
We have also moved forward with our goals of *fairness* and *justice* with [bias and harm testing](https://huggingface.co/HuggingFaceM4/idefics-80b-instruct#bias-risks-and-limitations), recently applied to the new Hugging Face multimodal model [IDEFICS](https://huggingface.co/HuggingFaceM4/idefics-80b-instruct). We've worked on how to operationalize *transparency* responsibly, including [updating our Content Policy](https://huggingface.co/blog/content-guidelines-update) (spearheaded by [Giada](https://huggingface.co/giadap)). We've advanced our support of language *diversity* on the Hub by [using machine learning to improve metadata](https://huggingface.co/blog/huggy-lingo) (spearheaded by [Daniel](https://huggingface.co/davanstrien)), and our support of *rigour* in AI by [adding more descriptive statistics to datasets](https://twitter.com/polinaeterna/status/1707447966355563000) (spearheaded by [Polina](https://huggingface.co/polinaeterna)) to foster a better understanding of what AI learns and how it can be evaluated.
Drawing from our experiences this past season, we now provide a collection of many of the resources at Hugging Face that are particularly useful in current AI ethics discourse right now, available here: [https://huggingface.co/society-ethics](https://huggingface.co/society-ethics).
Finally, we have been surprised and delighted by public recognition for many of the society & ethics regulars, including both [Irene](https://www.technologyreview.com/innovator/irene-solaiman/) and [Sasha](https://www.technologyreview.com/innovator/sasha-luccioni/) being selected in [MIT’s 35 Innovators under 35](https://www.technologyreview.com/innovators-under-35/artificial-intelligence-2023/) (Hugging Face makes up ¼ of the AI 35 under 35!); [Meg](https://huggingface.co/meg) being included in lists of influential AI innovators ([WIRED](https://www.wired.com/story/meet-the-humans-trying-to-keep-us-safe-from-ai/), [Fortune](https://fortune.com/2023/06/13/meet-top-ai-innovators-impact-on-business-society-chatgpt-deepmind-stability/)); and [Meg](https://huggingface.co/meg) and [Clem](https://huggingface.co/clem)’s selection in [TIME’s 100 under 100 in AI](https://time.com/collection/time100-ai/). We are also very sad to say goodbye to our colleague [Nathan](https://huggingface.co/natolambert), who has been instrumental in our work connecting ethics to reinforcement learning for AI systems. As his parting gift, he has provided further details on the [challenges of operationalizing ethical AI in RLHF](https://www.interconnects.ai/p/operationalizing-responsible-rlhf).
Thank you for reading!
\-\- Meg, on behalf of the [Ethics & Society regulars](https://huggingface.co/spaces/society-ethics/about) at Hugging Face
| huggingface/blog/blob/main/ethics-soc-5.md |
Metric Card for COMET
## Metric description
Crosslingual Optimized Metric for Evaluation of Translation (COMET) is an open-source framework used to train Machine Translation metrics that achieve high levels of correlation with different types of human judgments.
## How to use
COMET takes 3 lists of strings as input: `sources` (a list of source sentences), `predictions` (a list of candidate translations) and `references` (a list of reference translations).
```python
from datasets import load_metric
comet_metric = load_metric('comet')
source = ["Dem Feuer konnte Einhalt geboten werden", "Schulen und Kindergärten wurden eröffnet."]
hypothesis = ["The fire could be stopped", "Schools and kindergartens were open"]
reference = ["They were able to control the fire.", "Schools and kindergartens opened"]
comet_score = comet_metric.compute(predictions=hypothesis, references=reference, sources=source)
```
It has several configurations, named after the COMET model to be used. It will default to `wmt20-comet-da` (previously known as `wmt-large-da-estimator-1719`). Alternate models that can be chosen include `wmt20-comet-qe-da`, `wmt21-comet-mqm`, `wmt21-cometinho-da`, `wmt21-comet-qe-mqm` and `emnlp20-comet-rank`.
It also has several optional arguments:
`gpus`: optional, an integer (number of GPUs to train on) or a list of integers (which GPUs to train on). Set to 0 to use CPU. The default value is `None` (uses one GPU if possible, else use CPU).
`progress_bar`a boolean -- if set to `True`, progress updates will be printed out. The default value is `False`.
More information about model characteristics can be found on the [COMET website](https://unbabel.github.io/COMET/html/models.html).
## Output values
The COMET metric outputs two lists:
`scores`: a list of COMET scores for each of the input sentences, ranging from 0-1.
`mean_score`: the mean value of COMET scores `scores` over all the input sentences, ranging from 0-1.
### Values from popular papers
The [original COMET paper](https://arxiv.org/pdf/2009.09025.pdf) reported average COMET scores ranging from 0.4 to 0.6, depending on the language pairs used for evaluating translation models. They also illustrate that COMET correlates well with human judgements compared to other metrics such as [BLEU](https://huggingface.co/metrics/bleu) and [CHRF](https://huggingface.co/metrics/chrf).
## Examples
Full match:
```python
from datasets import load_metric
comet_metric = load_metric('comet')
source = ["Dem Feuer konnte Einhalt geboten werden", "Schulen und Kindergärten wurden eröffnet."]
hypothesis = ["They were able to control the fire.", "Schools and kindergartens opened"]
reference = ["They were able to control the fire.", "Schools and kindergartens opened"]
results = comet_metric.compute(predictions=hypothesis, references=reference, sources=source)
print([round(v, 1) for v in results["scores"]])
[1.0, 1.0]
```
Partial match:
```python
from datasets import load_metric
comet_metric = load_metric('comet')
source = ["Dem Feuer konnte Einhalt geboten werden", "Schulen und Kindergärten wurden eröffnet."]
hypothesis = ["The fire could be stopped", "Schools and kindergartens were open"]
reference = ["They were able to control the fire", "Schools and kindergartens opened"]
results = comet_metric.compute(predictions=hypothesis, references=reference, sources=source)
print([round(v, 2) for v in results["scores"]])
[0.19, 0.92]
```
No match:
```python
from datasets import load_metric
comet_metric = load_metric('comet')
source = ["Dem Feuer konnte Einhalt geboten werden", "Schulen und Kindergärten wurden eröffnet."]
hypothesis = ["The girl went for a walk", "The boy was sleeping"]
reference = ["They were able to control the fire", "Schools and kindergartens opened"]
results = comet_metric.compute(predictions=hypothesis, references=reference, sources=source)
print([round(v, 2) for v in results["scores"]])
[0.00, 0.00]
```
## Limitations and bias
The models provided for calculating the COMET metric are built on top of XLM-R and cover the following languages:
Afrikaans, Albanian, Amharic, Arabic, Armenian, Assamese, Azerbaijani, Basque, Belarusian, Bengali, Bengali Romanized, Bosnian, Breton, Bulgarian, Burmese, Burmese, Catalan, Chinese (Simplified), Chinese (Traditional), Croatian, Czech, Danish, Dutch, English, Esperanto, Estonian, Filipino, Finnish, French, Galician, Georgian, German, Greek, Gujarati, Hausa, Hebrew, Hindi, Hindi Romanized, Hungarian, Icelandic, Indonesian, Irish, Italian, Japanese, Javanese, Kannada, Kazakh, Khmer, Korean, Kurdish (Kurmanji), Kyrgyz, Lao, Latin, Latvian, Lithuanian, Macedonian, Malagasy, Malay, Malayalam, Marathi, Mongolian, Nepali, Norwegian, Oriya, Oromo, Pashto, Persian, Polish, Portuguese, Punjabi, Romanian, Russian, Sanskri, Scottish, Gaelic, Serbian, Sindhi, Sinhala, Slovak, Slovenian, Somali, Spanish, Sundanese, Swahili, Swedish, Tamil, Tamil Romanized, Telugu, Telugu Romanized, Thai, Turkish, Ukrainian, Urdu, Urdu Romanized, Uyghur, Uzbek, Vietnamese, Welsh, Western, Frisian, Xhosa, Yiddish.
Thus, results for language pairs containing uncovered languages are unreliable, as per the [COMET website](https://github.com/Unbabel/COMET)
Also, calculating the COMET metric involves downloading the model from which features are obtained -- the default model, `wmt20-comet-da`, takes over 1.79GB of storage space and downloading it can take a significant amount of time depending on the speed of your internet connection. If this is an issue, choose a smaller model; for instance `wmt21-cometinho-da` is 344MB.
## Citation
```bibtex
@inproceedings{rei-EtAl:2020:WMT,
author = {Rei, Ricardo and Stewart, Craig and Farinha, Ana C and Lavie, Alon},
title = {Unbabel's Participation in the WMT20 Metrics Shared Task},
booktitle = {Proceedings of the Fifth Conference on Machine Translation},
month = {November},
year = {2020},
address = {Online},
publisher = {Association for Computational Linguistics},
pages = {909--918},
}
```
```bibtex
@inproceedings{rei-etal-2020-comet,
title = "{COMET}: A Neural Framework for {MT} Evaluation",
author = "Rei, Ricardo and
Stewart, Craig and
Farinha, Ana C and
Lavie, Alon",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-main.213",
pages = "2685--2702",
```
## Further References
- [COMET website](https://unbabel.github.io/COMET/html/index.html)
- [Hugging Face Tasks - Machine Translation](https://huggingface.co/tasks/translation)
| huggingface/datasets/blob/main/metrics/comet/README.md |
Introducing Q-Learning [[q-learning]]
## What is Q-Learning? [[what-is-q-learning]]
Q-Learning is an **off-policy value-based method that uses a TD approach to train its action-value function:**
- *Off-policy*: we'll talk about that at the end of this unit.
- *Value-based method*: finds the optimal policy indirectly by training a value or action-value function that will tell us **the value of each state or each state-action pair.**
- *TD approach:* **updates its action-value function at each step instead of at the end of the episode.**
**Q-Learning is the algorithm we use to train our Q-function**, an **action-value function** that determines the value of being at a particular state and taking a specific action at that state.
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/Q-function.jpg" alt="Q-function"/>
<figcaption>Given a state and action, our Q Function outputs a state-action value (also called Q-value)</figcaption>
</figure>
The **Q comes from "the Quality" (the value) of that action at that state.**
Let's recap the difference between value and reward:
- The *value of a state*, or a *state-action pair* is the expected cumulative reward our agent gets if it starts at this state (or state-action pair) and then acts accordingly to its policy.
- The *reward* is the **feedback I get from the environment** after performing an action at a state.
Internally, our Q-function is encoded by **a Q-table, a table where each cell corresponds to a state-action pair value.** Think of this Q-table as **the memory or cheat sheet of our Q-function.**
Let's go through an example of a maze.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/Maze-1.jpg" alt="Maze example"/>
The Q-table is initialized. That's why all values are = 0. This table **contains, for each state and action, the corresponding state-action values.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/Maze-2.jpg" alt="Maze example"/>
Here we see that the **state-action value of the initial state and going up is 0:**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/Maze-3.jpg" alt="Maze example"/>
So: the Q-function uses a Q-table **that has the value of each state-action pair.** Given a state and action, **our Q-function will search inside its Q-table to output the value.**
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/Q-function-2.jpg" alt="Q-function"/>
</figure>
If we recap, *Q-Learning* **is the RL algorithm that:**
- Trains a *Q-function* (an **action-value function**), which internally is a **Q-table that contains all the state-action pair values.**
- Given a state and action, our Q-function **will search its Q-table for the corresponding value.**
- When the training is done, **we have an optimal Q-function, which means we have optimal Q-table.**
- And if we **have an optimal Q-function**, we **have an optimal policy** since we **know the best action to take at each state.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/link-value-policy.jpg" alt="Link value policy"/>
In the beginning, **our Q-table is useless since it gives arbitrary values for each state-action pair** (most of the time, we initialize the Q-table to 0). As the agent **explores the environment and we update the Q-table, it will give us a better and better approximation** to the optimal policy.
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/Q-learning-1.jpg" alt="Q-learning"/>
<figcaption>We see here that with the training, our Q-table is better since, thanks to it, we can know the value of each state-action pair.</figcaption>
</figure>
Now that we understand what Q-Learning, Q-functions, and Q-tables are, **let's dive deeper into the Q-Learning algorithm**.
## The Q-Learning algorithm [[q-learning-algo]]
This is the Q-Learning pseudocode; let's study each part and **see how it works with a simple example before implementing it.** Don't be intimidated by it, it's simpler than it looks! We'll go over each step.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/Q-learning-2.jpg" alt="Q-learning"/>
### Step 1: We initialize the Q-table [[step1]]
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/Q-learning-3.jpg" alt="Q-learning"/>
We need to initialize the Q-table for each state-action pair. **Most of the time, we initialize with values of 0.**
### Step 2: Choose an action using the epsilon-greedy strategy [[step2]]
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/Q-learning-4.jpg" alt="Q-learning"/>
The epsilon-greedy strategy is a policy that handles the exploration/exploitation trade-off.
The idea is that, with an initial value of ɛ = 1.0:
- *With probability 1 — ɛ* : we do **exploitation** (aka our agent selects the action with the highest state-action pair value).
- With probability ɛ: **we do exploration** (trying random action).
At the beginning of the training, **the probability of doing exploration will be huge since ɛ is very high, so most of the time, we'll explore.** But as the training goes on, and consequently our **Q-table gets better and better in its estimations, we progressively reduce the epsilon value** since we will need less and less exploration and more exploitation.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/Q-learning-5.jpg" alt="Q-learning"/>
### Step 3: Perform action At, get reward Rt+1 and next state St+1 [[step3]]
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/Q-learning-6.jpg" alt="Q-learning"/>
### Step 4: Update Q(St, At) [[step4]]
Remember that in TD Learning, we update our policy or value function (depending on the RL method we choose) **after one step of the interaction.**
To produce our TD target, **we used the immediate reward \\(R_{t+1}\\) plus the discounted value of the next state**, computed by finding the action that maximizes the current Q-function at the next state. (We call that bootstrap).
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/Q-learning-7.jpg" alt="Q-learning"/>
Therefore, our \\(Q(S_t, A_t)\\) **update formula goes like this:**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/Q-learning-8.jpg" alt="Q-learning"/>
This means that to update our \\(Q(S_t, A_t)\\):
- We need \\(S_t, A_t, R_{t+1}, S_{t+1}\\).
- To update our Q-value at a given state-action pair, we use the TD target.
How do we form the TD target?
1. We obtain the reward \\(R_{t+1}\\) after taking the action \\(A_t\\).
2. To get the **best state-action pair value** for the next state, we use a greedy policy to select the next best action. Note that this is not an epsilon-greedy policy, this will always take the action with the highest state-action value.
Then when the update of this Q-value is done, we start in a new state and select our action **using a epsilon-greedy policy again.**
**This is why we say that Q Learning is an off-policy algorithm.**
## Off-policy vs On-policy [[off-vs-on]]
The difference is subtle:
- *Off-policy*: using **a different policy for acting (inference) and updating (training).**
For instance, with Q-Learning, the epsilon-greedy policy (acting policy), is different from the greedy policy that is **used to select the best next-state action value to update our Q-value (updating policy).**
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/off-on-1.jpg" alt="Off-on policy"/>
<figcaption>Acting Policy</figcaption>
</figure>
Is different from the policy we use during the training part:
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/off-on-2.jpg" alt="Off-on policy"/>
<figcaption>Updating policy</figcaption>
</figure>
- *On-policy:* using the **same policy for acting and updating.**
For instance, with Sarsa, another value-based algorithm, **the epsilon-greedy policy selects the next state-action pair, not a greedy policy.**
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/off-on-3.jpg" alt="Off-on policy"/>
<figcaption>Sarsa</figcaption>
</figure>
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/off-on-4.jpg" alt="Off-on policy"/>
</figure>
| huggingface/deep-rl-class/blob/main/units/en/unit2/q-learning.mdx |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# M2M100
## Overview
The M2M100 model was proposed in [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky,
Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy
Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
The abstract from the paper is the following:
*Existing work in translation demonstrated the potential of massively multilingual machine translation by training a
single model able to translate between any pair of languages. However, much of this work is English-Centric by training
only on data which was translated from or to English. While this is supported by large sources of training data, it
does not reflect translation needs worldwide. In this work, we create a true Many-to-Many multilingual translation
model that can translate directly between any pair of 100 languages. We build and open source a training dataset that
covers thousands of language directions with supervised data, created through large-scale mining. Then, we explore how
to effectively increase model capacity through a combination of dense scaling and language-specific sparse parameters
to create high quality models. Our focus on non-English-Centric models brings gains of more than 10 BLEU when directly
translating between non-English directions while performing competitively to the best single systems of WMT. We
open-source our scripts so that others may reproduce the data, evaluation, and final M2M-100 model.*
This model was contributed by [valhalla](https://huggingface.co/valhalla).
## Usage tips and examples
M2M100 is a multilingual encoder-decoder (seq-to-seq) model primarily intended for translation tasks. As the model is
multilingual it expects the sequences in a certain format: A special language id token is used as prefix in both the
source and target text. The source text format is `[lang_code] X [eos]`, where `lang_code` is source language
id for source text and target language id for target text, with `X` being the source or target text.
The [`M2M100Tokenizer`] depends on `sentencepiece` so be sure to install it before running the
examples. To install `sentencepiece` run `pip install sentencepiece`.
**Supervised Training**
```python
from transformers import M2M100Config, M2M100ForConditionalGeneration, M2M100Tokenizer
model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M", src_lang="en", tgt_lang="fr")
src_text = "Life is like a box of chocolates."
tgt_text = "La vie est comme une boîte de chocolat."
model_inputs = tokenizer(src_text, text_target=tgt_text, return_tensors="pt")
loss = model(**model_inputs).loss # forward pass
```
**Generation**
M2M100 uses the `eos_token_id` as the `decoder_start_token_id` for generation with the target language id
being forced as the first generated token. To force the target language id as the first generated token, pass the
*forced_bos_token_id* parameter to the *generate* method. The following example shows how to translate between
Hindi to French and Chinese to English using the *facebook/m2m100_418M* checkpoint.
```python
>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
>>> hi_text = "जीवन एक चॉकलेट बॉक्स की तरह है।"
>>> chinese_text = "生活就像一盒巧克力。"
>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M")
>>> # translate Hindi to French
>>> tokenizer.src_lang = "hi"
>>> encoded_hi = tokenizer(hi_text, return_tensors="pt")
>>> generated_tokens = model.generate(**encoded_hi, forced_bos_token_id=tokenizer.get_lang_id("fr"))
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
"La vie est comme une boîte de chocolat."
>>> # translate Chinese to English
>>> tokenizer.src_lang = "zh"
>>> encoded_zh = tokenizer(chinese_text, return_tensors="pt")
>>> generated_tokens = model.generate(**encoded_zh, forced_bos_token_id=tokenizer.get_lang_id("en"))
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
"Life is like a box of chocolate."
```
## Resources
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
## M2M100Config
[[autodoc]] M2M100Config
## M2M100Tokenizer
[[autodoc]] M2M100Tokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## M2M100Model
[[autodoc]] M2M100Model
- forward
## M2M100ForConditionalGeneration
[[autodoc]] M2M100ForConditionalGeneration
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/m2m_100.md |
--
title: 'Convert Transformers to ONNX with Hugging Face Optimum'
thumbnail: /blog/assets/81_convert_transformers_to_onnx/thumbnail.png
authors:
- user: philschmid
---
# Convert Transformers to ONNX with Hugging Face Optimum
Hundreds of Transformers experiments and models are uploaded to the [Hugging Face Hub](https://huggingface.co/) every single day. Machine learning engineers and students conducting those experiments use a variety of frameworks like PyTorch, TensorFlow/Keras, or others. These models are already used by thousands of companies and form the foundation of AI-powered products.
If you deploy Transformers models in production environments, we recommend exporting them first into a serialized format that can be loaded, optimized, and executed on specialized runtimes and hardware.
In this guide, you'll learn about:
1. [What is ONNX?](#1-what-is-onnx)
2. [What is Hugging Face Optimum?](#2-what-is-hugging-face-optimum)
3. [What Transformers architectures are supported?](#3-what-transformers-architectures-are-supported)
4. [How can I convert a Transformers model (BERT) to ONNX?](#4-how-can-i-convert-a-transformers-model-bert-to-onnx)
5. [What's next?](#5-whats-next)
Let's get started! 🚀
---
If you are interested in optimizing your models to run with maximum efficiency, check out the [🤗 Optimum library](https://github.com/huggingface/optimum).
<html itemscope itemtype="https://schema.org/FAQPage">
<div itemscope itemprop="mainEntity" itemtype="https://schema.org/Question">
<a id="1-what-is-onnx"><h2 itemprop="name"> 1. What is ONNX?</h2></a>
<div itemscope itemprop="acceptedAnswer" itemtype="https://schema.org/Answer">
<div itemprop="text">
The [ONNX or Open Neural Network eXchange](https://onnx.ai) is an open standard and format to represent machine learning models. ONNX defines a common set of operators and a common file format to represent deep learning models in a wide variety of frameworks, including PyTorch and TensorFlow.
<figure class="image table text-center m-0 w-full">
<img src="assets/81_convert_transformers_to_onnx/graph.png" alt="Netron ONNX Graph"/>
<figcaption>pseudo ONNX graph, visualized with NETRON</figcaption>
</figure>
When a model is exported to the ONNX format, these operators are used to construct a computational graph (often called an `intermediate representation`) which represents the flow of data through the neural network.
> **Important:** ONNX Is not a Runtime ONNX is only the representation that can be used with runtimes like ONNX Runtime. You can find a list of supported accelerators [here](https://onnx.ai/supported-tools.html#deployModel).
>
➡️[Learn more about ONNX.](https://onnx.ai/about.html)
</div>
</div>
</div>
<html itemscope itemtype="https://schema.org/FAQPage">
<div itemscope itemprop="mainEntity" itemtype="https://schema.org/Question">
<a id="2-what-is-hugging-face-optimum"><h2 itemprop="name"> 2. What is Hugging Face Optimum?</h2></a>
<div itemscope itemprop="acceptedAnswer" itemtype="https://schema.org/Answer">
<div itemprop="text">
[Hugging Face Optimum](https://github.com/huggingface/optimum) is an open-source library and an extension of [Hugging Face Transformers](https://github.com/huggingface/transformers), that provides a unified API of performance optimization tools to achieve maximum efficiency to train and run models on accelerated hardware, including toolkits for optimized performance on [Graphcore IPU](https://github.com/huggingface/optimum-graphcore) and [Habana Gaudi](https://github.com/huggingface/optimum-habana).
Optimum can be used for converting, quantization, graph optimization, accelerated training & inference with support for [transformers pipelines](https://huggingface.co/docs/transformers/main/en/main_classes/pipelines#pipelines).
Below you can see a typical developer journey of how you can leverage Optimum with ONNX.
<figure class="image table text-center m-0 w-full">
<img src="assets/81_convert_transformers_to_onnx/user-journey.png" alt="developer journey optimum"/>
</figure>
[➡️ Learn more about Optimum](https://huggingface.co/blog/hardware-partners-program)
</div>
</div>
</div>
<html itemscope itemtype="https://schema.org/FAQPage">
<div itemscope itemprop="mainEntity" itemtype="https://schema.org/Question">
<a id="3-what-transformers-architectures-are-supported"><h2 itemprop="name"> 3. What Transformers architectures are supported?</h2></a>
<div itemscope itemprop="acceptedAnswer" itemtype="https://schema.org/Answer">
<div itemprop="text">
A list of all supported Transformers architectures can be found in the [ONNX section of the Transformers documentation](https://huggingface.co/docs/transformers/serialization#onnx). Below is an excerpt of the most commonly used architectures which can be converted to ONNX and optimized with [Hugging Face Optimum](https://huggingface.co/docs/optimum/index)
- ALBERT
- BART
- BERT
- DistilBERT
- ELECTRA
- GPT Neo
- GPT-J
- GPT-2
- RoBERTa
- T5
- ViT
- XLM
- …
[➡️ All supported architectures](https://huggingface.co/docs/transformers/serialization#onnx)
</div>
</div>
</div>
<html itemscope itemtype="https://schema.org/FAQPage">
<div itemscope itemprop="mainEntity" itemtype="https://schema.org/Question">
<a id="4-how-can-i-convert-a-transformers-model-bert-to-onnx"><h2 itemprop="name">4. How can I convert a Transformers model (BERT) to ONNX?</h2></a>
<div itemscope itemprop="acceptedAnswer" itemtype="https://schema.org/Answer">
<div itemprop="text">
There are currently three ways to convert your Hugging Face Transformers models to ONNX. In this section, you will learn how to export [distilbert-base-uncased-finetuned-sst-2-english](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) for `text-classification` using all three methods going from the low-level `torch` API to the most user-friendly high-level API of `optimum`. Each method will do exactly the same
### Export with `torch.onnx` (low-level)
[torch.onnx](https://pytorch.org/docs/stable/onnx.html) enables you to convert model checkpoints to an ONNX graph by the `export` method. But you have to provide a lot of values like `input_names`, `dynamic_axes`, etc.
You’ll first need to install some dependencies:
```python
pip install transformers torch
```
exporting our checkpoint with `export`
```python
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
# load model and tokenizer
model_id = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModelForSequenceClassification.from_pretrained(model_id)
tokenizer = AutoTokenizer.from_pretrained(model_id)
dummy_model_input = tokenizer("This is a sample", return_tensors="pt")
# export
torch.onnx.export(
model,
tuple(dummy_model_input.values()),
f="torch-model.onnx",
input_names=['input_ids', 'attention_mask'],
output_names=['logits'],
dynamic_axes={'input_ids': {0: 'batch_size', 1: 'sequence'},
'attention_mask': {0: 'batch_size', 1: 'sequence'},
'logits': {0: 'batch_size', 1: 'sequence'}},
do_constant_folding=True,
opset_version=13,
)
```
### Export with `transformers.onnx` (mid-level)
[transformers.onnx](https://huggingface.co/docs/transformers/serialization#exporting-a-model-to-onnx) enables you to convert model checkpoints to an ONNX graph by leveraging configuration objects. That way you don’t have to provide the complex configuration for `dynamic_axes` etc.
You’ll first need to install some dependencies:
```python
pip install transformers[onnx] torch
```
Exporting our checkpoint with the `transformers.onnx`.
```python
from pathlib import Path
import transformers
from transformers.onnx import FeaturesManager
from transformers import AutoConfig, AutoTokenizer, AutoModelForSequenceClassification
# load model and tokenizer
model_id = "distilbert-base-uncased-finetuned-sst-2-english"
feature = "sequence-classification"
model = AutoModelForSequenceClassification.from_pretrained(model_id)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# load config
model_kind, model_onnx_config = FeaturesManager.check_supported_model_or_raise(model, feature=feature)
onnx_config = model_onnx_config(model.config)
# export
onnx_inputs, onnx_outputs = transformers.onnx.export(
preprocessor=tokenizer,
model=model,
config=onnx_config,
opset=13,
output=Path("trfs-model.onnx")
)
```
### Export with Optimum (high-level)
[Optimum](https://huggingface.co/docs/optimum/onnxruntime/modeling_ort#switching-from-transformers-to-optimum-inference) Inference includes methods to convert vanilla Transformers models to ONNX using the `ORTModelForXxx` classes. To convert your Transformers model to ONNX you simply have to pass `from_transformers=True` to the `from_pretrained()` method and your model will be loaded and converted to ONNX leveraging the [transformers.onnx](https://huggingface.co/docs/transformers/serialization#exporting-a-model-to-onnx) package under the hood.
You’ll first need to install some dependencies:
```python
pip install optimum[onnxruntime]
```
Exporting our checkpoint with `ORTModelForSequenceClassification`
```python
from optimum.onnxruntime import ORTModelForSequenceClassification
model = ORTModelForSequenceClassification.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english",from_transformers=True)
```
The best part about the conversion with Optimum is that you can immediately use the `model` to run predictions or load it [inside a pipeline.](https://huggingface.co/docs/optimum/onnxruntime/modeling_ort#switching-from-transformers-to-optimum-inference)
</div>
</div>
</div>
## 5. What's next?
Since you successfully convert your Transformers model to ONNX the whole set of optimization and quantization tools is now open to use. Potential next steps can be:
- Use the onnx model for [Accelerated Inference with Optimum and Transformers Pipelines](https://huggingface.co/blog/optimum-inference)
- Apply [static quantization to your model](https://www.philschmid.de/static-quantization-optimum) for ~3x latency improvements
- Use ONNX runtime for [training](https://github.com/huggingface/optimum/tree/main/examples/onnxruntime/training)
- Convert your ONNX model to [TensorRT](https://docs.nvidia.com/deeplearning/tensorrt/api/python_api/) to improve GPU performance
- …
If you are interested in optimizing your models to run with maximum efficiency, check out the [🤗 Optimum library](https://github.com/huggingface/optimum).
---
Thanks for reading! If you have any questions, feel free to contact me, through [Github](https://github.com/huggingface/transformers), or on the [forum](https://discuss.huggingface.co/c/optimum/59). You can also connect with me on [Twitter](https://twitter.com/_philschmid) or [LinkedIn](https://www.linkedin.com/in/philipp-schmid-a6a2bb196/).
</html>
| huggingface/blog/blob/main/convert-transformers-to-onnx.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# KDPM2AncestralDiscreteScheduler
The `KDPM2DiscreteScheduler` with ancestral sampling is inspired by the [Elucidating the Design Space of Diffusion-Based Generative Models](https://huggingface.co/papers/2206.00364) paper, and the scheduler is ported from and created by [Katherine Crowson](https://github.com/crowsonkb/).
The original codebase can be found at [crowsonkb/k-diffusion](https://github.com/crowsonkb/k-diffusion).
## KDPM2AncestralDiscreteScheduler
[[autodoc]] KDPM2AncestralDiscreteScheduler
## SchedulerOutput
[[autodoc]] schedulers.scheduling_utils.SchedulerOutput
| huggingface/diffusers/blob/main/docs/source/en/api/schedulers/dpm_discrete_ancestral.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# FLAN-T5
## Overview
FLAN-T5 was released in the paper [Scaling Instruction-Finetuned Language Models](https://arxiv.org/pdf/2210.11416.pdf) - it is an enhanced version of T5 that has been finetuned in a mixture of tasks.
One can directly use FLAN-T5 weights without finetuning the model:
```python
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
>>> model = AutoModelForSeq2SeqLM.from_pretrained("google/flan-t5-small")
>>> tokenizer = AutoTokenizer.from_pretrained("google/flan-t5-small")
>>> inputs = tokenizer("A step by step recipe to make bolognese pasta:", return_tensors="pt")
>>> outputs = model.generate(**inputs)
>>> print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
['Pour a cup of bolognese into a large bowl and add the pasta']
```
FLAN-T5 includes the same improvements as T5 version 1.1 (see [here](https://huggingface.co/docs/transformers/model_doc/t5v1.1) for the full details of the model's improvements.)
Google has released the following variants:
- [google/flan-t5-small](https://huggingface.co/google/flan-t5-small)
- [google/flan-t5-base](https://huggingface.co/google/flan-t5-base)
- [google/flan-t5-large](https://huggingface.co/google/flan-t5-large)
- [google/flan-t5-xl](https://huggingface.co/google/flan-t5-xl)
- [google/flan-t5-xxl](https://huggingface.co/google/flan-t5-xxl).
The original checkpoints can be found [here](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints).
<Tip>
Refer to [T5's documentation page](t5) for all API reference, code examples and notebooks. For more details regarding training and evaluation of the FLAN-T5, refer to the model card.
</Tip> | huggingface/transformers/blob/main/docs/source/en/model_doc/flan-t5.md |
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Legacy examples
This folder contains examples which are not actively maintained (mostly contributed by the community).
Using these examples together with a recent version of the library usually requires to make small (sometimes big) adaptations to get the scripts working.
| huggingface/transformers/blob/main/examples/legacy/README.md |
--
title: "Comments on U.S. National AI Research Resource Interim Report"
thumbnail: /blog/assets/92_us_national_ai_research_resource/nairr_thumbnail.png
authors:
- user: irenesolaiman
---
# AI Policy @🤗: Comments on U.S. National AI Research Resource Interim Report
In late June 2022, Hugging Face submitted a response to the White House Office of Science and Technology Policy and National Science Foundation’s Request for Information on a roadmap for implementing the National Artificial Intelligence Research Resource (NAIRR) Task Force’s interim report findings. As a platform working to democratize machine learning by empowering all backgrounds to contribute to AI, we strongly support NAIRR’s efforts.
In our response, we encourage the Task Force to:
- Appoint Technical and Ethical Experts as Advisors
- Technical experts with a track record of ethical innovation should be prioritized as advisors; they can calibrate NAIRR on not only what is technically feasible, implementable, and necessary for AI systems, but also on how to avoid exacerbating harmful biases and other malicious uses of AI systems. [Dr. Margaret Mitchell](https://www.m-mitchell.com/), one of the most prominent technical experts and ethics practitioners in the AI field and Hugging Face’s Chief Ethics Scientist, is a natural example of an external advisor.
- Resource (Model and Data) Documentation Standards
- NAIRR-provided standards and templates for system and dataset documentation will ease accessibility and function as a checklist. This standardization should ensure readability across audiences and backgrounds. [Model Cards](https://huggingface.co/docs/hub/models-cards) are a vastly adopted structure for documentation that can be a strong template for AI models.
- Make ML Accessible to Interdisciplinary, Non-Technical Experts
- NAIRR should provide education resources as well as easily understandable interfaces and low- or no-code tools for all relevant experts to conduct complex tasks, such as training an AI model. For example, Hugging Face’s [AutoTrain](https://huggingface.co/autotrain) empowers anyone regardless of technical skill to train, evaluate, and deploy a natural language processing (NLP) model.
- Monitor for Open-Source and Open-Science for High Misuse and Malicious Use Potential
- Harm must be defined by NAIRR and advisors and continually updated, but should encompass egregious and harmful biases, political disinformation, and hate speech. NAIRR should also invest in legal expertise to craft [Responsible AI Licenses](https://bigscience.huggingface.co/blog/the-bigscience-rail-license) to take action should an actor misuse resources.
- Empower Diverse Researcher Perspectives via Accessible Tooling and Resources
- Tooling and resources must be available and accessible to different disciplines as well as the many languages and perspectives needed to drive responsible innovation. This means at minimum providing resources in multiple languages, which can be based on the most spoken languages in the U.S. The [BigScience Research Workshop](https://bigscience.huggingface.co/), a community of over 1000 researchers from different disciplines hosted by Hugging Face and the French government, is a good example of empowering perspectives from over 60 countries to build one of the most powerful open-source multilingual language models.
Our <a href="/blog/assets/92_us_national_ai_research_resource/Hugging_Face_NAIRR_RFI_2022.pdf">memo</a> goes into further detail for each recommendation. We are eager for more resources to make AI broadly accessible in a responsible manner.
| huggingface/blog/blob/main/us-national-ai-research-resource.md |
Gradio Demo: colorpicker_component
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
gr.ColorPicker()
demo.launch()
```
| gradio-app/gradio/blob/main/demo/colorpicker_component/run.ipynb |
Gradio Demo: blocks_update
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
gr.Markdown(
"""
# Animal Generator
Once you select a species, the detail panel should be visible.
"""
)
species = gr.Radio(label="Animal Class", choices=["Mammal", "Fish", "Bird"])
animal = gr.Dropdown(label="Animal", choices=[])
with gr.Column(visible=False) as details_col:
weight = gr.Slider(0, 20)
details = gr.Textbox(label="Extra Details")
generate_btn = gr.Button("Generate")
output = gr.Textbox(label="Output")
species_map = {
"Mammal": ["Elephant", "Giraffe", "Hamster"],
"Fish": ["Shark", "Salmon", "Tuna"],
"Bird": ["Chicken", "Eagle", "Hawk"],
}
def filter_species(species):
return gr.Dropdown(
choices=species_map[species], value=species_map[species][1]
), gr.Column(visible=True)
species.change(filter_species, species, [animal, details_col])
def filter_weight(animal):
if animal in ("Elephant", "Shark", "Giraffe"):
return gr.Slider(maximum=100)
else:
return gr.Slider(maximum=20)
animal.change(filter_weight, animal, weight)
weight.change(lambda w: gr.Textbox(lines=int(w / 10) + 1), weight, details)
generate_btn.click(lambda x: x, details, output)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/blocks_update/run.ipynb |
Help & Support
We have a variety of Inference Endpoints blog posts to help you at https://huggingface.co/blog:
* [Getting Started with Hugging Face Inference Endpoints](https://huggingface.co/blog/inference-endpoints)
* [Why we’re switching to Hugging Face Inference Endpoints, and maybe you should too](https://huggingface.co/blog/mantis-case-study)
* [Deploy LLMs with Hugging Face Inference Endpoints](https://huggingface.co/blog/inference-endpoints-llm)
* [🤗 LLM suggestions in Argilla with HuggingFace Inference Endpoints](https://huggingface.co/blog/alvarobartt/argilla-suggestions-via-inference-endpoints)
* [Deploy MusicGen in no time with Inference Endpoints](https://huggingface.co/blog/run-musicgen-as-an-api)
Need more help?
Feel free to ask questions on the forum so the community can also benefit from the answers: https://discuss.huggingface.co/. If you have any other questions or issues, please contact us at <[email protected]>.
| huggingface/hf-endpoints-documentation/blob/main/docs/source/support.mdx |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# RoBERTa
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=roberta">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-roberta-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/roberta-base">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
<a href="https://huggingface.co/papers/1907.11692">
<img alt="Paper page" src="https://img.shields.io/badge/Paper%20page-1907.11692-green">
</a>
</div>
## Overview
The RoBERTa model was proposed in [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, [Myle Ott](https://huggingface.co/myleott), Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer
Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov. It is based on Google's BERT model released in 2018.
It builds on BERT and modifies key hyperparameters, removing the next-sentence pretraining objective and training with
much larger mini-batches and learning rates.
The abstract from the paper is the following:
*Language model pretraining has led to significant performance gains but careful comparison between different
approaches is challenging. Training is computationally expensive, often done on private datasets of different sizes,
and, as we will show, hyperparameter choices have significant impact on the final results. We present a replication
study of BERT pretraining (Devlin et al., 2019) that carefully measures the impact of many key hyperparameters and
training data size. We find that BERT was significantly undertrained, and can match or exceed the performance of every
model published after it. Our best model achieves state-of-the-art results on GLUE, RACE and SQuAD. These results
highlight the importance of previously overlooked design choices, and raise questions about the source of recently
reported improvements. We release our models and code.*
This model was contributed by [julien-c](https://huggingface.co/julien-c). The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/roberta).
## Usage tips
- This implementation is the same as [`BertModel`] with a tiny embeddings tweak as well as a setup
for Roberta pretrained models.
- RoBERTa has the same architecture as BERT, but uses a byte-level BPE as a tokenizer (same as GPT-2) and uses a
different pretraining scheme.
- RoBERTa doesn't have `token_type_ids`, you don't need to indicate which token belongs to which segment. Just
separate your segments with the separation token `tokenizer.sep_token` (or `</s>`)
- Same as BERT with better pretraining tricks:
* dynamic masking: tokens are masked differently at each epoch, whereas BERT does it once and for all
* together to reach 512 tokens (so the sentences are in an order than may span several documents)
* train with larger batches
* use BPE with bytes as a subunit and not characters (because of unicode characters)
- [CamemBERT](camembert) is a wrapper around RoBERTa. Refer to this page for usage examples.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with RoBERTa. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
<PipelineTag pipeline="text-classification"/>
- A blog on [Getting Started with Sentiment Analysis on Twitter](https://huggingface.co/blog/sentiment-analysis-twitter) using RoBERTa and the [Inference API](https://huggingface.co/inference-api).
- A blog on [Opinion Classification with Kili and Hugging Face AutoTrain](https://huggingface.co/blog/opinion-classification-with-kili) using RoBERTa.
- A notebook on how to [finetune RoBERTa for sentiment analysis](https://colab.research.google.com/github/DhavalTaunk08/NLP_scripts/blob/master/sentiment_analysis_using_roberta.ipynb). 🌎
- [`RobertaForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb).
- [`TFRobertaForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb).
- [`FlaxRobertaForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification_flax.ipynb).
- [Text classification task guide](../tasks/sequence_classification)
<PipelineTag pipeline="token-classification"/>
- [`RobertaForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/token-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb).
- [`TFRobertaForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/token-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb).
- [`FlaxRobertaForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/token-classification).
- [Token classification](https://huggingface.co/course/chapter7/2?fw=pt) chapter of the 🤗 Hugging Face Course.
- [Token classification task guide](../tasks/token_classification)
<PipelineTag pipeline="fill-mask"/>
- A blog on [How to train a new language model from scratch using Transformers and Tokenizers](https://huggingface.co/blog/how-to-train) with RoBERTa.
- [`RobertaForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#robertabertdistilbert-and-masked-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb).
- [`TFRobertaForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_mlmpy) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb).
- [`FlaxRobertaForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#masked-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/masked_language_modeling_flax.ipynb).
- [Masked language modeling](https://huggingface.co/course/chapter7/3?fw=pt) chapter of the 🤗 Hugging Face Course.
- [Masked language modeling task guide](../tasks/masked_language_modeling)
<PipelineTag pipeline="question-answering"/>
- A blog on [Accelerated Inference with Optimum and Transformers Pipelines](https://huggingface.co/blog/optimum-inference) with RoBERTa for question answering.
- [`RobertaForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb).
- [`TFRobertaForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/question-answering) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb).
- [`FlaxRobertaForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/question-answering).
- [Question answering](https://huggingface.co/course/chapter7/7?fw=pt) chapter of the 🤗 Hugging Face Course.
- [Question answering task guide](../tasks/question_answering)
**Multiple choice**
- [`RobertaForMultipleChoice`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/multiple-choice) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice.ipynb).
- [`TFRobertaForMultipleChoice`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/multiple-choice) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice-tf.ipynb).
- [Multiple choice task guide](../tasks/multiple_choice)
## RobertaConfig
[[autodoc]] RobertaConfig
## RobertaTokenizer
[[autodoc]] RobertaTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## RobertaTokenizerFast
[[autodoc]] RobertaTokenizerFast
- build_inputs_with_special_tokens
<frameworkcontent>
<pt>
## RobertaModel
[[autodoc]] RobertaModel
- forward
## RobertaForCausalLM
[[autodoc]] RobertaForCausalLM
- forward
## RobertaForMaskedLM
[[autodoc]] RobertaForMaskedLM
- forward
## RobertaForSequenceClassification
[[autodoc]] RobertaForSequenceClassification
- forward
## RobertaForMultipleChoice
[[autodoc]] RobertaForMultipleChoice
- forward
## RobertaForTokenClassification
[[autodoc]] RobertaForTokenClassification
- forward
## RobertaForQuestionAnswering
[[autodoc]] RobertaForQuestionAnswering
- forward
</pt>
<tf>
## TFRobertaModel
[[autodoc]] TFRobertaModel
- call
## TFRobertaForCausalLM
[[autodoc]] TFRobertaForCausalLM
- call
## TFRobertaForMaskedLM
[[autodoc]] TFRobertaForMaskedLM
- call
## TFRobertaForSequenceClassification
[[autodoc]] TFRobertaForSequenceClassification
- call
## TFRobertaForMultipleChoice
[[autodoc]] TFRobertaForMultipleChoice
- call
## TFRobertaForTokenClassification
[[autodoc]] TFRobertaForTokenClassification
- call
## TFRobertaForQuestionAnswering
[[autodoc]] TFRobertaForQuestionAnswering
- call
</tf>
<jax>
## FlaxRobertaModel
[[autodoc]] FlaxRobertaModel
- __call__
## FlaxRobertaForCausalLM
[[autodoc]] FlaxRobertaForCausalLM
- __call__
## FlaxRobertaForMaskedLM
[[autodoc]] FlaxRobertaForMaskedLM
- __call__
## FlaxRobertaForSequenceClassification
[[autodoc]] FlaxRobertaForSequenceClassification
- __call__
## FlaxRobertaForMultipleChoice
[[autodoc]] FlaxRobertaForMultipleChoice
- __call__
## FlaxRobertaForTokenClassification
[[autodoc]] FlaxRobertaForTokenClassification
- __call__
## FlaxRobertaForQuestionAnswering
[[autodoc]] FlaxRobertaForQuestionAnswering
- __call__
</jax>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/roberta.md |
Inference Endpoints
Inference Endpoints provides a secure production solution to easily deploy models on a dedicated and autoscaling infrastructure managed by Hugging Face. An Inference Endpoint is built from a model from the [Hub](https://huggingface.co/models). This page is a reference for `huggingface_hub`'s integration with Inference Endpoints. For more information about the Inference Endpoints product, check out its [official documentation](https://huggingface.co/docs/inference-endpoints/index).
<Tip>
Check out the [related guide](../guides/inference_endpoints) to learn how to use `huggingface_hub` to manage your Inference Endpoints programmatically.
</Tip>
Inference Endpoints can be fully managed via API. The endpoints are documented with [Swagger](https://api.endpoints.huggingface.cloud/). The [`InferenceEndpoint`] class is a simple wrapper built on top on this API.
## Methods
A subset of the Inference Endpoint features are implemented in [`HfApi`]:
- [`get_inference_endpoint`] and [`list_inference_endpoints`] to get information about your Inference Endpoints
- [`create_inference_endpoint`], [`update_inference_endpoint`] and [`delete_inference_endpoint`] to deploy and manage Inference Endpoints
- [`pause_inference_endpoint`] and [`resume_inference_endpoint`] to pause and resume an Inference Endpoint
- [`scale_to_zero_inference_endpoint`] to manually scale an Endpoint to 0 replicas
## InferenceEndpoint
The main dataclass is [`InferenceEndpoint`]. It contains information about a deployed `InferenceEndpoint`, including its configuration and current state. Once deployed, you can run inference on the Endpoint using the [`InferenceEndpoint.client`] and [`InferenceEndpoint.async_client`] properties that respectively return an [`InferenceClient`] and an [`AsyncInferenceClient`] object.
[[autodoc]] InferenceEndpoint
- from_raw
- client
- async_client
- all
## InferenceEndpointStatus
[[autodoc]] InferenceEndpointStatus
## InferenceEndpointType
[[autodoc]] InferenceEndpointType
## InferenceEndpointError
[[autodoc]] InferenceEndpointError | huggingface/huggingface_hub/blob/main/docs/source/en/package_reference/inference_endpoints.md |
Metric Card for seqeval
## Metric description
seqeval is a Python framework for sequence labeling evaluation. seqeval can evaluate the performance of chunking tasks such as named-entity recognition, part-of-speech tagging, semantic role labeling and so on.
## How to use
Seqeval produces labelling scores along with its sufficient statistics from a source against one or more references.
It takes two mandatory arguments:
`predictions`: a list of lists of predicted labels, i.e. estimated targets as returned by a tagger.
`references`: a list of lists of reference labels, i.e. the ground truth/target values.
It can also take several optional arguments:
`suffix` (boolean): `True` if the IOB tag is a suffix (after type) instead of a prefix (before type), `False` otherwise. The default value is `False`, i.e. the IOB tag is a prefix (before type).
`scheme`: the target tagging scheme, which can be one of [`IOB1`, `IOB2`, `IOE1`, `IOE2`, `IOBES`, `BILOU`]. The default value is `None`.
`mode`: whether to count correct entity labels with incorrect I/B tags as true positives or not. If you want to only count exact matches, pass `mode="strict"` and a specific `scheme` value. The default is `None`.
`sample_weight`: An array-like of shape (n_samples,) that provides weights for individual samples. The default is `None`.
`zero_division`: Which value to substitute as a metric value when encountering zero division. Should be one of [`0`,`1`,`"warn"`]. `"warn"` acts as `0`, but the warning is raised.
```python
>>> from datasets import load_metric
>>> seqeval = load_metric('seqeval')
>>> predictions = [['O', 'O', 'B-MISC', 'I-MISC', 'I-MISC', 'I-MISC', 'O'], ['B-PER', 'I-PER', 'O']]
>>> references = [['O', 'O', 'O', 'B-MISC', 'I-MISC', 'I-MISC', 'O'], ['B-PER', 'I-PER', 'O']]
>>> results = seqeval.compute(predictions=predictions, references=references)
```
## Output values
This metric returns a dictionary with a summary of scores for overall and per type:
Overall:
`accuracy`: the average [accuracy](https://huggingface.co/metrics/accuracy), on a scale between 0.0 and 1.0.
`precision`: the average [precision](https://huggingface.co/metrics/precision), on a scale between 0.0 and 1.0.
`recall`: the average [recall](https://huggingface.co/metrics/recall), on a scale between 0.0 and 1.0.
`f1`: the average [F1 score](https://huggingface.co/metrics/f1), which is the harmonic mean of the precision and recall. It also has a scale of 0.0 to 1.0.
Per type (e.g. `MISC`, `PER`, `LOC`,...):
`precision`: the average [precision](https://huggingface.co/metrics/precision), on a scale between 0.0 and 1.0.
`recall`: the average [recall](https://huggingface.co/metrics/recall), on a scale between 0.0 and 1.0.
`f1`: the average [F1 score](https://huggingface.co/metrics/f1), on a scale between 0.0 and 1.0.
### Values from popular papers
The 1995 "Text Chunking using Transformation-Based Learning" [paper](https://aclanthology.org/W95-0107) reported a baseline recall of 81.9% and a precision of 78.2% using non Deep Learning-based methods.
More recently, seqeval continues being used for reporting performance on tasks such as [named entity detection](https://www.mdpi.com/2306-5729/6/8/84/htm) and [information extraction](https://ieeexplore.ieee.org/abstract/document/9697942/).
## Examples
Maximal values (full match) :
```python
>>> from datasets import load_metric
>>> seqeval = load_metric('seqeval')
>>> predictions = [['O', 'O', 'B-MISC', 'I-MISC', 'I-MISC', 'I-MISC', 'O'], ['B-PER', 'I-PER', 'O']]
>>> references = [['O', 'O', 'B-MISC', 'I-MISC', 'I-MISC', 'I-MISC', 'O'], ['B-PER', 'I-PER', 'O']]
>>> results = seqeval.compute(predictions=predictions, references=references)
>>> print(results)
{'MISC': {'precision': 1.0, 'recall': 1.0, 'f1': 1.0, 'number': 1}, 'PER': {'precision': 1.0, 'recall': 1.0, 'f1': 1.0, 'number': 1}, 'overall_precision': 1.0, 'overall_recall': 1.0, 'overall_f1': 1.0, 'overall_accuracy': 1.0}
```
Minimal values (no match):
```python
>>> from datasets import load_metric
>>> seqeval = load_metric('seqeval')
>>> predictions = [['O', 'B-MISC', 'I-MISC'], ['B-PER', 'I-PER', 'O']]
>>> references = [['B-MISC', 'O', 'O'], ['I-PER', '0', 'I-PER']]
>>> results = seqeval.compute(predictions=predictions, references=references)
>>> print(results)
{'MISC': {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 1}, 'PER': {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 2}, '_': {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 1}, 'overall_precision': 0.0, 'overall_recall': 0.0, 'overall_f1': 0.0, 'overall_accuracy': 0.0}
```
Partial match:
```python
>>> from datasets import load_metric
>>> seqeval = load_metric('seqeval')
>>> predictions = [['O', 'O', 'B-MISC', 'I-MISC', 'I-MISC', 'I-MISC', 'O'], ['B-PER', 'I-PER', 'O']]
>>> references = [['O', 'O', 'O', 'B-MISC', 'I-MISC', 'I-MISC', 'O'], ['B-PER', 'I-PER', 'O']]
>>> results = seqeval.compute(predictions=predictions, references=references)
>>> print(results)
{'MISC': {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 1}, 'PER': {'precision': 1.0, 'recall': 1.0, 'f1': 1.0, 'number': 1}, 'overall_precision': 0.5, 'overall_recall': 0.5, 'overall_f1': 0.5, 'overall_accuracy': 0.8}
```
## Limitations and bias
seqeval supports following IOB formats (short for inside, outside, beginning) : `IOB1`, `IOB2`, `IOE1`, `IOE2`, `IOBES`, `IOBES` (only in strict mode) and `BILOU` (only in strict mode).
For more information about IOB formats, refer to the [Wikipedia page](https://en.wikipedia.org/wiki/Inside%E2%80%93outside%E2%80%93beginning_(tagging)) and the description of the [CoNLL-2000 shared task](https://aclanthology.org/W02-2024).
## Citation
```bibtex
@inproceedings{ramshaw-marcus-1995-text,
title = "Text Chunking using Transformation-Based Learning",
author = "Ramshaw, Lance and
Marcus, Mitch",
booktitle = "Third Workshop on Very Large Corpora",
year = "1995",
url = "https://www.aclweb.org/anthology/W95-0107",
}
```
```bibtex
@misc{seqeval,
title={{seqeval}: A Python framework for sequence labeling evaluation},
url={https://github.com/chakki-works/seqeval},
note={Software available from https://github.com/chakki-works/seqeval},
author={Hiroki Nakayama},
year={2018},
}
```
## Further References
- [README for seqeval at GitHub](https://github.com/chakki-works/seqeval)
- [CoNLL-2000 shared task](https://www.clips.uantwerpen.be/conll2002/ner/bin/conlleval.txt)
| huggingface/datasets/blob/main/metrics/seqeval/README.md |
!--Copyright 2023 The Intel Labs Team Authors and HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Text-to-(RGB, depth)
LDM3D was proposed in [LDM3D: Latent Diffusion Model for 3D](https://huggingface.co/papers/2305.10853) by Gabriela Ben Melech Stan, Diana Wofk, Scottie Fox, Alex Redden, Will Saxton, Jean Yu, Estelle Aflalo, Shao-Yen Tseng, Fabio Nonato, Matthias Muller, and Vasudev Lal. LDM3D generates an image and a depth map from a given text prompt unlike the existing text-to-image diffusion models such as [Stable Diffusion](./overview) which only generates an image. With almost the same number of parameters, LDM3D achieves to create a latent space that can compress both the RGB images and the depth maps.
Two checkpoints are available for use:
- [ldm3d-original](https://huggingface.co/Intel/ldm3d). The original checkpoint used in the [paper](https://arxiv.org/pdf/2305.10853.pdf)
- [ldm3d-4c](https://huggingface.co/Intel/ldm3d-4c). The new version of LDM3D using 4 channels inputs instead of 6-channels inputs and finetuned on higher resolution images.
The abstract from the paper is:
*This research paper proposes a Latent Diffusion Model for 3D (LDM3D) that generates both image and depth map data from a given text prompt, allowing users to generate RGBD images from text prompts. The LDM3D model is fine-tuned on a dataset of tuples containing an RGB image, depth map and caption, and validated through extensive experiments. We also develop an application called DepthFusion, which uses the generated RGB images and depth maps to create immersive and interactive 360-degree-view experiences using TouchDesigner. This technology has the potential to transform a wide range of industries, from entertainment and gaming to architecture and design. Overall, this paper presents a significant contribution to the field of generative AI and computer vision, and showcases the potential of LDM3D and DepthFusion to revolutionize content creation and digital experiences. A short video summarizing the approach can be found at [this url](https://t.ly/tdi2).*
<Tip>
Make sure to check out the Stable Diffusion [Tips](overview#tips) section to learn how to explore the tradeoff between scheduler speed and quality, and how to reuse pipeline components efficiently!
</Tip>
## StableDiffusionLDM3DPipeline
[[autodoc]] pipelines.stable_diffusion_ldm3d.pipeline_stable_diffusion_ldm3d.StableDiffusionLDM3DPipeline
- all
- __call__
## LDM3DPipelineOutput
[[autodoc]] pipelines.stable_diffusion_ldm3d.pipeline_stable_diffusion_ldm3d.LDM3DPipelineOutput
- all
- __call__
# Upscaler
[LDM3D-VR](https://arxiv.org/pdf/2311.03226.pdf) is an extended version of LDM3D.
The abstract from the paper is:
*Latent diffusion models have proven to be state-of-the-art in the creation and manipulation of visual outputs. However, as far as we know, the generation of depth maps jointly with RGB is still limited. We introduce LDM3D-VR, a suite of diffusion models targeting virtual reality development that includes LDM3D-pano and LDM3D-SR. These models enable the generation of panoramic RGBD based on textual prompts and the upscaling of low-resolution inputs to high-resolution RGBD, respectively. Our models are fine-tuned from existing pretrained models on datasets containing panoramic/high-resolution RGB images, depth maps and captions. Both models are evaluated in comparison to existing related methods*
Two checkpoints are available for use:
- [ldm3d-pano](https://huggingface.co/Intel/ldm3d-pano). This checkpoint enables the generation of panoramic images and requires the StableDiffusionLDM3DPipeline pipeline to be used.
- [ldm3d-sr](https://huggingface.co/Intel/ldm3d-sr). This checkpoint enables the upscaling of RGB and depth images. Can be used in cascade after the original LDM3D pipeline using the StableDiffusionUpscaleLDM3DPipeline from communauty pipeline.
| huggingface/diffusers/blob/main/docs/source/en/api/pipelines/stable_diffusion/ldm3d_diffusion.md |
--
title: Pearson Correlation Coefficient
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
Pearson correlation coefficient and p-value for testing non-correlation.
The Pearson correlation coefficient measures the linear relationship between two datasets. The calculation of the p-value relies on the assumption that each dataset is normally distributed. Like other correlation coefficients, this one varies between -1 and +1 with 0 implying no correlation. Correlations of -1 or +1 imply an exact linear relationship. Positive correlations imply that as x increases, so does y. Negative correlations imply that as x increases, y decreases.
The p-value roughly indicates the probability of an uncorrelated system producing datasets that have a Pearson correlation at least as extreme as the one computed from these datasets.
---
# Metric Card for Pearson Correlation Coefficient (pearsonr)
## Metric Description
Pearson correlation coefficient and p-value for testing non-correlation.
The Pearson correlation coefficient measures the linear relationship between two datasets. The calculation of the p-value relies on the assumption that each dataset is normally distributed. Like other correlation coefficients, this one varies between -1 and +1 with 0 implying no correlation. Correlations of -1 or +1 imply an exact linear relationship. Positive correlations imply that as x increases, so does y. Negative correlations imply that as x increases, y decreases.
The p-value roughly indicates the probability of an uncorrelated system producing datasets that have a Pearson correlation at least as extreme as the one computed from these datasets.
## How to Use
This metric takes a list of predictions and a list of references as input
```python
>>> pearsonr_metric = evaluate.load("pearsonr")
>>> results = pearsonr_metric.compute(predictions=[10, 9, 2.5, 6, 4], references=[1, 2, 3, 4, 5])
>>> print(round(results['pearsonr']), 2)
['-0.74']
```
### Inputs
- **predictions** (`list` of `int`): Predicted class labels, as returned by a model.
- **references** (`list` of `int`): Ground truth labels.
- **return_pvalue** (`boolean`): If `True`, returns the p-value, along with the correlation coefficient. If `False`, returns only the correlation coefficient. Defaults to `False`.
### Output Values
- **pearsonr**(`float`): Pearson correlation coefficient. Minimum possible value is -1. Maximum possible value is 1. Values of 1 and -1 indicate exact linear positive and negative relationships, respectively. A value of 0 implies no correlation.
- **p-value**(`float`): P-value, which roughly indicates the probability of an The p-value roughly indicates the probability of an uncorrelated system producing datasets that have a Pearson correlation at least as extreme as the one computed from these datasets. Minimum possible value is 0. Maximum possible value is 1. Higher values indicate higher probabilities.
Like other correlation coefficients, this one varies between -1 and +1 with 0 implying no correlation. Correlations of -1 or +1 imply an exact linear relationship. Positive correlations imply that as x increases, so does y. Negative correlations imply that as x increases, y decreases.
Output Example(s):
```python
{'pearsonr': -0.7}
```
```python
{'p-value': 0.15}
```
#### Values from Popular Papers
### Examples
Example 1-A simple example using only predictions and references.
```python
>>> pearsonr_metric = evaluate.load("pearsonr")
>>> results = pearsonr_metric.compute(predictions=[10, 9, 2.5, 6, 4], references=[1, 2, 3, 4, 5])
>>> print(round(results['pearsonr'], 2))
-0.74
```
Example 2-The same as Example 1, but that also returns the `p-value`.
```python
>>> pearsonr_metric = evaluate.load("pearsonr")
>>> results = pearsonr_metric.compute(predictions=[10, 9, 2.5, 6, 4], references=[1, 2, 3, 4, 5], return_pvalue=True)
>>> print(sorted(list(results.keys())))
['p-value', 'pearsonr']
>>> print(round(results['pearsonr'], 2))
-0.74
>>> print(round(results['p-value'], 2))
0.15
```
## Limitations and Bias
As stated above, the calculation of the p-value relies on the assumption that each data set is normally distributed. This is not always the case, so verifying the true distribution of datasets is recommended.
## Citation(s)
```bibtex
@article{2020SciPy-NMeth,
author = {Virtanen, Pauli and Gommers, Ralf and Oliphant, Travis E. and
Haberland, Matt and Reddy, Tyler and Cournapeau, David and
Burovski, Evgeni and Peterson, Pearu and Weckesser, Warren and
Bright, Jonathan and {van der Walt}, St{\'e}fan J. and
Brett, Matthew and Wilson, Joshua and Millman, K. Jarrod and
Mayorov, Nikolay and Nelson, Andrew R. J. and Jones, Eric and
Kern, Robert and Larson, Eric and Carey, C J and
Polat, {\.I}lhan and Feng, Yu and Moore, Eric W. and
{VanderPlas}, Jake and Laxalde, Denis and Perktold, Josef and
Cimrman, Robert and Henriksen, Ian and Quintero, E. A. and
Harris, Charles R. and Archibald, Anne M. and
Ribeiro, Ant{\^o}nio H. and Pedregosa, Fabian and
{van Mulbregt}, Paul and {SciPy 1.0 Contributors}},
title = {{{SciPy} 1.0: Fundamental Algorithms for Scientific
Computing in Python}},
journal = {Nature Methods},
year = {2020},
volume = {17},
pages = {261--272},
adsurl = {https://rdcu.be/b08Wh},
doi = {10.1038/s41592-019-0686-2},
}
```
## Further References
| huggingface/evaluate/blob/main/metrics/pearsonr/README.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Under construction | huggingface/simulate/blob/main/docs/source/howto/plugins.mdx |
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Examples
We host a wide range of example scripts for multiple learning frameworks. Simply choose your favorite: [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow), [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch) or [JAX/Flax](https://github.com/huggingface/transformers/tree/main/examples/flax).
We also have some [research projects](https://github.com/huggingface/transformers/tree/main/examples/research_projects), as well as some [legacy examples](https://github.com/huggingface/transformers/tree/main/examples/legacy). Note that unlike the main examples these are not actively maintained, and may require specific older versions of dependencies in order to run.
While we strive to present as many use cases as possible, the example scripts are just that - examples. It is expected that they won't work out-of-the-box on your specific problem and that you will be required to change a few lines of code to adapt them to your needs. To help you with that, most of the examples fully expose the preprocessing of the data, allowing you to tweak and edit them as required.
Please discuss on the [forum](https://discuss.huggingface.co/) or in an [issue](https://github.com/huggingface/transformers/issues) a feature you would like to implement in an example before submitting a PR; we welcome bug fixes, but since we want to keep the examples as simple as possible it's unlikely that we will merge a pull request adding more functionality at the cost of readability.
## Important note
**Important**
To make sure you can successfully run the latest versions of the example scripts, you have to **install the library from source** and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
pip install .
```
Then cd in the example folder of your choice and run
```bash
pip install -r requirements.txt
```
To browse the examples corresponding to released versions of 🤗 Transformers, click on the line below and then on your desired version of the library:
<details>
<summary>Examples for older versions of 🤗 Transformers</summary>
<ul>
<li><a href="https://github.com/huggingface/transformers/tree/v4.21.0/examples">v4.21.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.20.1/examples">v4.20.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.19.4/examples">v4.19.4</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.18.0/examples">v4.18.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.17.0/examples">v4.17.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.16.2/examples">v4.16.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.15.0/examples">v4.15.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.14.1/examples">v4.14.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.13.0/examples">v4.13.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.12.5/examples">v4.12.5</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.11.3/examples">v4.11.3</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.10.3/examples">v4.10.3</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.9.2/examples">v4.9.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.8.2/examples">v4.8.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.7.0/examples">v4.7.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.6.1/examples">v4.6.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.5.1/examples">v4.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.4.2/examples">v4.4.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.3.3/examples">v4.3.3</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.2.2/examples">v4.2.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.1.1/examples">v4.1.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.0.1/examples">v4.0.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.5.1/examples">v3.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.4.0/examples">v3.4.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.3.1/examples">v3.3.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.2.0/examples">v3.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.1.0/examples">v3.1.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.0.2/examples">v3.0.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.11.0/examples">v2.11.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.10.0/examples">v2.10.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.9.1/examples">v2.9.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.8.0/examples">v2.8.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.7.0/examples">v2.7.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.6.0/examples">v2.6.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.5.1/examples">v2.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.4.0/examples">v2.4.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.3.0/examples">v2.3.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.2.0/examples">v2.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.1.0/examples">v2.1.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.0.0/examples">v2.0.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.2.0/examples">v1.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.1.0/examples">v1.1.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.0.0/examples">v1.0.0</a></li>
</ul>
</details>
Alternatively, you can switch your cloned 🤗 Transformers to a specific version (for instance with v3.5.1) with
```bash
git checkout tags/v3.5.1
```
and run the example command as usual afterward.
## Running the Examples on Remote Hardware with Auto-Setup
[run_on_remote.py](./run_on_remote.py) is a script that launches any example on remote self-hosted hardware,
with automatic hardware and environment setup. It uses [Runhouse](https://github.com/run-house/runhouse) to launch
on self-hosted hardware (e.g. in your own cloud account or on-premise cluster) but there are other options
for running remotely as well. You can easily customize the example used, command line arguments, dependencies,
and type of compute hardware, and then run the script to automatically launch the example.
You can refer to
[hardware setup](https://runhouse-docs.readthedocs-hosted.com/en/latest/api/python/cluster.html#hardware-setup)
for more information about hardware and dependency setup with Runhouse, or this
[Colab tutorial](https://colab.research.google.com/drive/1sh_aNQzJX5BKAdNeXthTNGxKz7sM9VPc) for a more in-depth
walkthrough.
You can run the script with the following commands:
```bash
# First install runhouse:
pip install runhouse
# For an on-demand V100 with whichever cloud provider you have configured:
python run_on_remote.py \
--example pytorch/text-generation/run_generation.py \
--model_type=gpt2 \
--model_name_or_path=gpt2 \
--prompt "I am a language model and"
# For byo (bring your own) cluster:
python run_on_remote.py --host <cluster_ip> --user <ssh_user> --key_path <ssh_key_path> \
--example <example> <args>
# For on-demand instances
python run_on_remote.py --instance <instance> --provider <provider> \
--example <example> <args>
```
You can also adapt the script to your own needs.
| huggingface/transformers/blob/main/examples/README.md |
Get dataset information
Datasets Server provides an `/info` endpoint for exploring the general information about dataset, including such fields as description, citation, homepage, license and features.
The `/info` endpoint accepts two query parameters:
- `dataset`: the dataset name
- `config`: the configuration name
<inferencesnippet>
<python>
```python
import requests
headers = {"Authorization": f"Bearer {API_TOKEN}"}
API_URL = "https://datasets-server.huggingface.co/info?dataset=duorc&config=SelfRC"
def query():
response = requests.get(API_URL, headers=headers)
return response.json()
data = query()
```
</python>
<js>
```js
import fetch from "node-fetch";
async function query(data) {
const response = await fetch(
"https://datasets-server.huggingface.co/info?dataset=duorc&config=SelfRC",
{
headers: { Authorization: `Bearer ${API_TOKEN}` },
method: "GET"
}
);
const result = await response.json();
return result;
}
query().then((response) => {
console.log(JSON.stringify(response));
});
```
</js>
<curl>
```curl
curl https://datasets-server.huggingface.co/info?dataset=duorc&config=SelfRC \
-X GET \
-H "Authorization: Bearer ${API_TOKEN}"
```
</curl>
</inferencesnippet>
The endpoint response is a JSON with the `dataset_info` key. Its structure and content correspond to [DatasetInfo](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.DatasetInfo) object of the `datasets` library.
```json
{
"dataset_info": {
"description": "DuoRC contains 186,089 unique question-answer pairs created from a collection of 7680 pairs of movie plots where each pair in the collection reflects two versions of the same movie.\n",
"citation": "@inproceedings{DuoRC,\nauthor = { Amrita Saha and Rahul Aralikatte and Mitesh M. Khapra and Karthik Sankaranarayanan},title = {{DuoRC: Towards Complex Language Understanding with Paraphrased Reading Comprehension}},\nbooktitle = {Meeting of the Association for Computational Linguistics (ACL)},\nyear = {2018}\n}\n",
"homepage": "https://duorc.github.io/",
"license": "https://raw.githubusercontent.com/duorc/duorc/master/LICENSE",
"features": {
"plot_id": {
"dtype": "string",
"_type": "Value"
},
"plot": {
"dtype": "string",
"_type": "Value"
},
"title": {
"dtype": "string",
"_type": "Value"
},
"question_id": {
"dtype": "string",
"_type": "Value"
},
"question": {
"dtype": "string",
"_type": "Value"
},
"answers": {
"feature": {
"dtype": "string",
"_type": "Value"
},
"_type": "Sequence"
},
"no_answer": {
"dtype": "bool",
"_type": "Value"
}
},
"builder_name": "duorc",
"config_name": "SelfRC",
"version": {
"version_str": "1.0.0",
"major": 1,
"minor": 0,
"patch": 0
},
"splits": {
"train": {
"name": "train",
"num_bytes": 239852729,
"num_examples": 60721,
"dataset_name": "duorc"
},
"validation": {
"name": "validation",
"num_bytes": 51662519,
"num_examples": 12961,
"dataset_name": "duorc"
},
"test": {
"name": "test",
"num_bytes": 49142710,
"num_examples": 12559,
"dataset_name": "duorc"
}
},
"download_checksums": {
"https://raw.githubusercontent.com/duorc/duorc/master/dataset/SelfRC_train.json": {
"num_bytes": 24388192,
"checksum": null
},
"https://raw.githubusercontent.com/duorc/duorc/master/dataset/SelfRC_dev.json": {
"num_bytes": 5051240,
"checksum": null
},
"https://raw.githubusercontent.com/duorc/duorc/master/dataset/SelfRC_test.json": {
"num_bytes": 5023228,
"checksum": null
}
},
"download_size": 34462660,
"dataset_size": 340657958,
"size_in_bytes": 375120618
}
}
``` | huggingface/datasets-server/blob/main/docs/source/info.mdx |
--
title: "3D Asset Generation: AI for Game Development #3"
thumbnail: /blog/assets/124_ml-for-games/thumbnail3.png
authors:
- user: dylanebert
---
# 3D Asset Generation: AI for Game Development #3
**Welcome to AI for Game Development!** In this series, we'll be using AI tools to create a fully functional farming game in just 5 days. By the end of this series, you will have learned how you can incorporate a variety of AI tools into your game development workflow. I will show you how you can use AI tools for:
1. Art Style
2. Game Design
3. 3D Assets
4. 2D Assets
5. Story
Want the quick video version? You can watch it [here](https://www.tiktok.com/@individualkex/video/7190364745495678254). Otherwise, if you want the technical details, keep reading!
**Note:** This tutorial is intended for readers who are familiar with Unity development and C#. If you're new to these technologies, check out the [Unity for Beginners](https://www.tiktok.com/@individualkex/video/7086863567412038954) series before continuing.
## Day 3: 3D Assets
In [Part 2](https://huggingface.co/blog/ml-for-games-2) of this tutorial series, we used **AI for Game Design**. More specifically, we used ChatGPT to brainstorm the design for our game.
In this part, we'll talk about how you can use AI to generate 3D Assets. The short answer is: you can't. That's because text-to-3D isn't at the point it can be practically applied to game development, *yet*. However, that's changing very quickly. Keep reading to learn about [The Current State of Text-to-3D](#the-current-state-of-text-to-3d), [Why It Isn't Useful (yet)](#why-it-isnt-useful-yet), and [The Future of Text-to-3D](#the-future-of-text-to-3d).
### The Current State of Text-to-3D
As discussed in [Part 1](https://huggingface.co/blog/ml-for-games-1), text-to-image tools such as Stable Diffusion are incredibly useful in the game development workflow. However, what about text-to-3D, or generating 3D models from text descriptions? There have been many very recent developments in this area:
- [DreamFusion](https://dreamfusion3d.github.io/) uses 2D diffusion to generate 3D assets.
- [CLIPMatrix](https://arxiv.org/abs/2109.12922) and [CLIP-Mesh-SMPLX](https://github.com/NasirKhalid24/CLIP-Mesh-SMPLX) generate textured meshes directly.
- [CLIP-Forge](https://github.com/autodeskailab/clip-forge) uses language to generate voxel-based models.
- [CLIP-NeRF](https://github.com/cassiePython/CLIPNeRF) drives NeRFs with text and images.
- [Point-E](https://huggingface.co/spaces/openai/point-e) and [Pulsar+CLIP](https://colab.research.google.com/drive/1IvV3HGoNjRoyAKIX-aqSWa-t70PW3nPs) use language to generate 3D point clouds.
- [Dream Textures](https://github.com/carson-katri/dream-textures/releases/tag/0.0.9) uses text-to-image to texture scenes in Blender automatically.
Many of these approaches, excluding CLIPMatrix and CLIP-Mesh-SMPLX, are based on [view synthesis](https://en.wikipedia.org/wiki/View_synthesis), or generating novel views of a subject, as opposed to conventional 3D rendering. This is the idea behind [NeRFs](https://developer.nvidia.com/blog/getting-started-with-nvidia-instant-nerfs/) or Neural Radiance Fields, which use neural networks for view synthesis.
<figure class="image text-center">
<img src="https://developer-blogs.nvidia.com/wp-content/uploads/2022/05/Excavator_NeRF.gif" alt="NeRF">
<figcaption>View synthesis using NeRFs.</figcaption>
</figure>
What does all of this mean if you're a game developer? Currently, nothing. This technology hasn't reached the point that it's useful in game development *yet*. Let's talk about why.
### Why It Isn't Useful (yet)
**Note:** This section is intended for readers who are familiar with conventional 3D rendering techniques, such as [meshes](https://en.wikipedia.org/wiki/Polygon_mesh), [UV mapping](https://en.wikipedia.org/wiki/UV_mapping) and [photogrammetry](https://en.wikipedia.org/wiki/Photogrammetry).
While view synthesis is impressive, the world of 3D runs on meshes, which are not the same as NeRFs. There is, however, [ongoing work on converting NeRFs to meshes](https://github.com/NVlabs/instant-ngp). In practice, this is reminiscient of [photogrammetry](https://en.wikipedia.org/wiki/Photogrammetry), where multiple photos of real-world objects are combined to author 3D assets.
<figure class="image text-center">
<img src="https://github.com/NVlabs/instant-ngp/raw/master/docs/assets_readme/testbed.png" alt="NeRF-to-mesh">
<figcaption>NVlabs instant-ngp, which supports NeRF-to-mesh conversion.</figcaption>
</figure>
The practical use of assets generated using the text-to-NeRF-to-mesh pipeline is limited in a similar way to assets produced using photogrammetry. That is, the resulting mesh is not immediately game-ready, and requires significant work and expertise to become a game-ready asset. In this sense, NeRF-to-mesh may be a useful tool as-is, but doesn't yet reach the transformative potential of text-to-3D.
Since NeRF-to-mesh, like photogrammetry, is currently most suited to creating ultra-high-fidelity assets with significant manual post-processing, it doesn't really make sense for creating a farming game in 5 days. In which case, I decided to just use cubes of different colors to represent the crops in the game.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/cubes.png" alt="Stable Diffusion Demo Space">
</figure>
Things are changing rapidly in this area, though, and there may be a viable solution in the near future. Next, I'll talk about some of the directions text-to-3D may be going.
### The Future of Text-to-3D
While text-to-3D has come a long way recently, there is still a significant gap between where we are now and what could have an impact along the lines of text-to-image. I can only speculate on how this gap will be closed. There are two possible directions that are most apparent:
1. Improvements in NeRF-to-mesh and mesh generation. As we've seen, current generation models are similar to photogrammetry in that they require a lot of work to produce game-ready assets. While this is useful in some scenarios, like creating realistic high-fidelity assets, it's still more time-consuming than making low-poly assets from scratch, especially if you're like me and use an ultra-low-poly art style.
2. New rendering techniques that allow NeRFs to be rendered directly in-engine. While there have been no official announcements, one could speculate that [NVIDIA](https://www.nvidia.com/en-us/omniverse/) and [Google](https://dreamfusion3d.github.io/), among others, may be working on this.
Of course, only time will tell. If you want to keep up with advancements as they come, feel free to follow me on [Twitter](https://twitter.com/dylan_ebert_). If there are new developments I've missed, feel free to reach out!
Click [here](https://huggingface.co/blog/ml-for-games-4) to read Part 4, where we use **AI for 2D Assets**.
#### Attribution
Thanks to Poli [@multimodalart](https://huggingface.co/multimodalart) for providing info on the latest open source text-to-3D.
| huggingface/blog/blob/main/ml-for-games-3.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# IDEFICS
## Overview
The IDEFICS model was proposed in [OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents
](https://huggingface.co/papers/2306.16527
) by Hugo Laurençon, Lucile Saulnier, Léo Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexander M. Rush, Douwe Kiela, Matthieu Cord, Victor Sanh
The abstract from the paper is the following:
*Large multimodal models trained on natural documents, which interleave images and text, outperform models trained on image-text pairs on various multimodal benchmarks that require reasoning over one or multiple images to generate a text. However, the datasets used to train these models have not been released, and the collection process has not been fully specified. We introduce the OBELICS dataset, an open web-scale filtered dataset of interleaved image-text documents comprising 141 million web pages extracted from Common Crawl, 353 million associated images, and 115 billion text tokens. We describe the dataset creation process, present comprehensive filtering rules, and provide an analysis of the dataset's content. To show the viability of OBELISC, we train an 80 billion parameters vision and language model on the dataset and obtain competitive performance on various multimodal benchmarks. We release the code to reproduce the dataset along with the dataset itself.*
This model was contributed by [HuggingFaceM4](https://huggingface.co/HuggingFaceM4). The original code can be found [here](<INSERT LINK TO GITHUB REPO HERE>). (TODO: don't have a public link yet).
<Tip warning={true}>
IDEFICS modeling code in Transformers is for finetuning and inferencing the pre-trained IDEFICS models.
To train a new IDEFICS model from scratch use the m4 codebase (a link will be provided once it's made public)
</Tip>
## IdeficsConfig
[[autodoc]] IdeficsConfig
## IdeficsModel
[[autodoc]] IdeficsModel
- forward
## IdeficsForVisionText2Text
[[autodoc]] IdeficsForVisionText2Text
- forward
## IdeficsImageProcessor
[[autodoc]] IdeficsImageProcessor
- preprocess
## IdeficsProcessor
[[autodoc]] IdeficsProcessor
- __call__
| huggingface/transformers/blob/main/docs/source/en/model_doc/idefics.md |
Utilities
## Configure logging
🤗 Datasets strives to be transparent and explicit about how it works, but this can be quite verbose at times. We have included a series of logging methods which allow you to easily adjust the level of verbosity of the entire library. Currently the default verbosity of the library is set to `WARNING`.
To change the level of verbosity, use one of the direct setters. For instance, here is how to change the verbosity to the `INFO` level:
```py
import datasets
datasets.logging.set_verbosity_info()
```
You can also use the environment variable `DATASETS_VERBOSITY` to override the default verbosity, and set it to one of the following: `debug`, `info`, `warning`, `error`, `critical`:
```bash
DATASETS_VERBOSITY=error ./myprogram.py
```
All the methods of this logging module are documented below. The main ones are:
- [`logging.get_verbosity`] to get the current level of verbosity in the logger
- [`logging.set_verbosity`] to set the verbosity to the level of your choice
In order from the least to the most verbose (with their corresponding `int` values):
1. `logging.CRITICAL` or `logging.FATAL` (int value, 50): only report the most critical errors.
2. `logging.ERROR` (int value, 40): only report errors.
3. `logging.WARNING` or `logging.WARN` (int value, 30): only reports error and warnings. This the default level used by the library.
4. `logging.INFO` (int value, 20): reports error, warnings and basic information.
5. `logging.DEBUG` (int value, 10): report all information.
[[autodoc]] datasets.logging.get_verbosity
[[autodoc]] datasets.logging.set_verbosity
[[autodoc]] datasets.logging.set_verbosity_info
[[autodoc]] datasets.logging.set_verbosity_warning
[[autodoc]] datasets.logging.set_verbosity_debug
[[autodoc]] datasets.logging.set_verbosity_error
[[autodoc]] datasets.logging.disable_propagation
[[autodoc]] datasets.logging.enable_propagation
## Configure progress bars
By default, `tqdm` progress bars will be displayed during dataset download and preprocessing. You can disable them globally by setting `HF_DATASETS_DISABLE_PROGRESS_BARS`
environment variable. You can also enable/disable them using [`~utils.enable_progress_bars`] and [`~utils.disable_progress_bars`]. If set, the environment variable has priority on the helpers.
[[autodoc]] datasets.utils.enable_progress_bars
[[autodoc]] datasets.utils.disable_progress_bars
[[autodoc]] datasets.utils.are_progress_bars_disabled | huggingface/datasets/blob/main/docs/source/package_reference/utilities.mdx |
# Training examples
Creating a training image set is [described in a different document](https://huggingface.co/docs/datasets/image_process#image-datasets).
### Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
**Important**
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
```
Then cd in the example folder and run
```bash
pip install -r requirements.txt
```
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
#### Use ONNXRuntime to accelerate training
In order to leverage onnxruntime to accelerate training, please use train_unconditional_ort.py
The command to train a DDPM UNet model on the Oxford Flowers dataset with onnxruntime:
```bash
accelerate launch train_unconditional.py \
--dataset_name="huggan/flowers-102-categories" \
--resolution=64 --center_crop --random_flip \
--output_dir="ddpm-ema-flowers-64" \
--use_ema \
--train_batch_size=16 \
--num_epochs=1 \
--gradient_accumulation_steps=1 \
--learning_rate=1e-4 \
--lr_warmup_steps=500 \
--mixed_precision=fp16
```
Please contact Prathik Rao (prathikr), Sunghoon Choi (hanbitmyths), Ashwini Khade (askhade), or Peng Wang (pengwa) on github with any questions.
| huggingface/diffusers/blob/main/examples/research_projects/onnxruntime/unconditional_image_generation/README.md |
`tokenizers-freebsd-x64`
This is the **x86_64-unknown-freebsd** binary for `tokenizers`
| huggingface/tokenizers/blob/main/bindings/node/npm/freebsd-x64/README.md |
!---
Copyright 2022 The Microsoft Inc. and The HuggingFace Inc. Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Run Table Tasks with TAPEX
TAPEX is a table pre-training approach for table-related tasks. By learning a neural SQL executor over a synthetic corpus based on generative language models (e.g., BART), it achieves state-of-the-art performance on several table-based question answering benchmarks and table-based fact verification benchmark. More details can be found in the original paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/pdf/2107.07653.pdf).
> If you are also familiar with [fairseq](https://github.com/pytorch/fairseq), you may also find [the official implementation](https://github.com/microsoft/Table-Pretraining) useful, which leverages the framework.
## Table Question Answering Tasks
### What is Table Question Answering

The task of Table Question Answering (TableQA) is to empower machines to answer users' questions over a given table. The resulting answer(s) can be a region in the table, or a number calculated by applying aggregation operators to a specific region.
### What Questions Can be Answered
Benefiting from the powerfulness of generative models, TAPEX can deal with almost all kinds of questions over tables (if there is training data). Below are some typical question and their answers taken from [WikiTableQuestion](https://nlp.stanford.edu/blog/wikitablequestions-a-complex-real-world-question-understanding-dataset).
| Question | Answer |
| :---: | :---: |
| What is the years won for each team? | 2004, 2008, 2012 |
| How long did Taiki Tsuchiya last? | 4:27 |
| What is the total amount of matches drawn? | 1 |
| Besides Tiger Woods, what other player won between 2007 and 2009? | Camilo Villegas |
| What was the last Baekje Temple? | Uija |
| What is the difference between White voters and Black voters in 1948? | 0 |
| What is the average number of sailors for each country during the worlds qualification tournament? | 2 |
### How to Fine-tune TAPEX on TableQA
We provide a fine-tuning script of tapex for TableQA on the WikiSQL benchmark: [WikiSQL](https://github.com/salesforce/WikiSQL).
This script is customized for tapex models, and can be easily adapted to other benchmarks such as WikiTableQuestion
(only some tweaks in the function `preprocess_tableqa_function`).
#### TAPEX-Base on WikiSQL
Here is how to run the script on the WikiSQL with `tapex-base`:
> The default hyper-parameter may allow you to reproduce our reported tapex-base results within the memory budget of 16GB and 1 GPU card. If you have more GPU cards, you could reduce `gradient_accumulation_steps` accordingly.
```bash
export EXP_NAME=wikisql_tapex_base
python run_wikisql_with_tapex.py \
--do_train \
--do_eval \
--output_dir $EXP_NAME \
--model_name_or_path microsoft/tapex-base \
--overwrite_output_dir \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 8 \
--per_device_eval_batch_size 4 \
--learning_rate 3e-5 \
--logging_steps 10 \
--eval_steps 1000 \
--save_steps 1000 \
--warmup_steps 1000 \
--evaluation_strategy steps \
--predict_with_generate \
--num_beams 5 \
--weight_decay 1e-2 \
--label_smoothing_factor 0.1 \
--max_steps 20000
```
#### TAPEX-Large on WikiSQL
Here is how to run the script on the WikiSQL with `tapex-large`:
> The default hyper-parameter may allow you to reproduce our reported tapex-large results within the memory budget of 16GB and 1 GPU card with fp16. If you have more GPU cards, you could reduce `gradient_accumulation_steps` accordingly. If you do not install apex or other mixed-precision-training libs, you could disable the `predict_with_generate` option to save GPU memory and manually evaluate the model once the fine-tuning finished. Or just pick up the last checkpoint, which usually performs good enough on the dataset.
```bash
export EXP_NAME=wikisql_tapex_large
python run_wikisql_with_tapex.py \
--do_train \
--do_eval \
--output_dir $EXP_NAME \
--model_name_or_path microsoft/tapex-large \
--overwrite_output_dir \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 32 \
--per_device_eval_batch_size 4 \
--learning_rate 3e-5 \
--logging_steps 10 \
--eval_steps 1000 \
--save_steps 1000 \
--warmup_steps 1000 \
--evaluation_strategy steps \
--predict_with_generate \
--num_beams 5 \
--weight_decay 1e-2 \
--label_smoothing_factor 0.1 \
--max_steps 20000 \
--fp16
```
#### TAPEX-Base on WikiTableQuestions
Here is how to run the script on the WikiTableQuestions with `tapex-base`:
> The default hyper-parameter may allow you to reproduce our reported tapex-base results within the memory budget of 16GB and 1 GPU card. If you have more GPU cards, you could reduce `gradient_accumulation_steps` accordingly.
```bash
export EXP_NAME=wikitablequestions_tapex_base
python run_wikitablequestions_with_tapex.py \
--do_train \
--do_eval \
--output_dir $EXP_NAME \
--model_name_or_path microsoft/tapex-base \
--overwrite_output_dir \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 8 \
--per_device_eval_batch_size 4 \
--learning_rate 3e-5 \
--logging_steps 10 \
--eval_steps 1000 \
--save_steps 1000 \
--warmup_steps 1000 \
--evaluation_strategy steps \
--predict_with_generate \
--num_beams 5 \
--weight_decay 1e-2 \
--label_smoothing_factor 0.1 \
--max_steps 20000
```
#### TAPEX-Large on WikiTableQuestions
Here is how to run the script on the WikiTableQuestions with `tapex-large`:
> The default hyper-parameter may allow you to reproduce our reported tapex-large results within the memory budget of 16GB and 1 GPU card with fp16. If you have more GPU cards, you could reduce `gradient_accumulation_steps` accordingly. If you do not install apex or other mixed-precision-training libs, you could reduce the `per_device_train_batch_size` and `per_device_eval_batch_size` and have another try. Or you could disable the `predict_with_generate` option to save GPU memory and manually evaluate the model once the fine-tuning finished. Or just pick up the last checkpoint, which usually performs good enough on the dataset.
```bash
export EXP_NAME=wikitablequestions_tapex_large
python run_wikitablequestions_with_tapex.py \
--do_train \
--do_eval \
--output_dir $EXP_NAME \
--model_name_or_path microsoft/tapex-large \
--overwrite_output_dir \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 12 \
--per_device_eval_batch_size 4 \
--learning_rate 3e-5 \
--logging_steps 10 \
--eval_steps 1000 \
--save_steps 1000 \
--warmup_steps 1000 \
--evaluation_strategy steps \
--predict_with_generate \
--num_beams 5 \
--weight_decay 1e-2 \
--label_smoothing_factor 0.1 \
--max_steps 20000 \
--fp16
```
### How to Evaluate TAPEX Fine-tuned Models on TableQA
We provide fine-tuned model weights to reproduce our results. You can evaluate them using the following command:
> You can also replace `microsoft/tapex-base-finetuned-wikisql` with your local directory to evaluate your fine-tuned models. Notice that if the model has a larger size, you should reduce `per_device_eval_batch_size` to fit the memory requirement.
```bash
export EXP_NAME=wikisql_tapex_base_eval
python run_wikisql_with_tapex.py \
--do_eval \
--model_name_or_path microsoft/tapex-base-finetuned-wikisql \
--output_dir $EXP_NAME \
--per_device_eval_batch_size 4 \
--predict_with_generate \
--num_beams 5
```
## Table Fact Verification Tasks
### What is Table Fact Verification
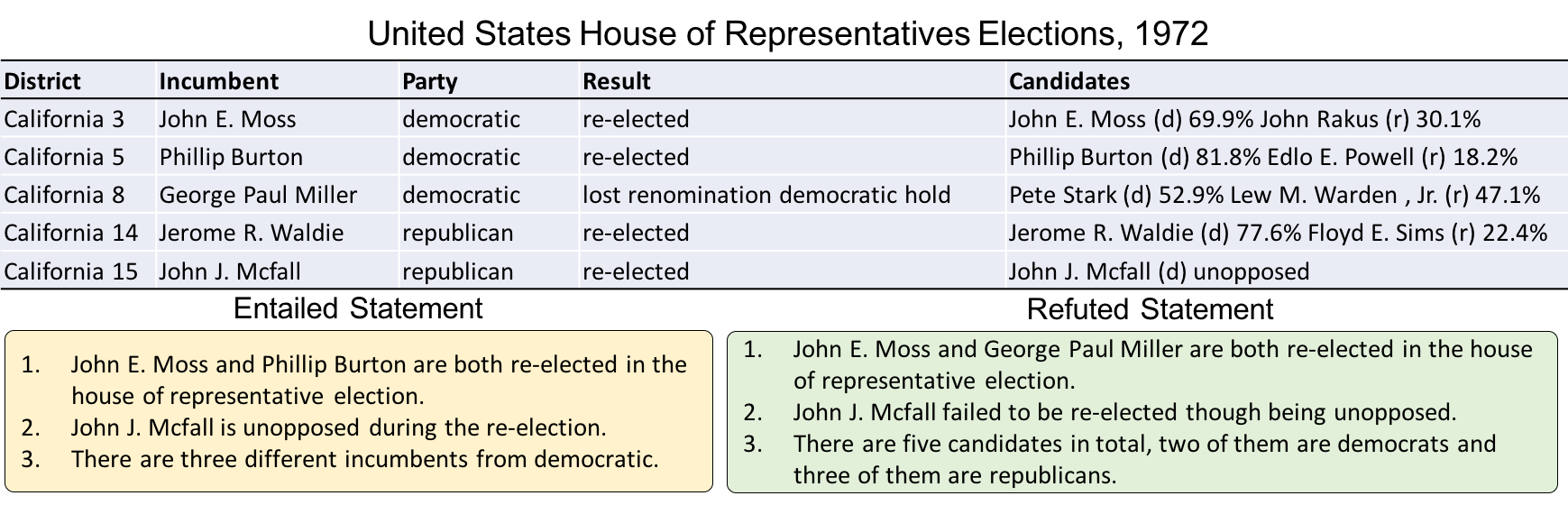
The task of Table Fact Verification (TableFV) is to empower machines to justify if a statement follows facts in a given table. The result is a binary classification belonging to `1` (entailed) or `0` (refused).
### How to Fine-tune TAPEX on TableFV
#### TAPEX-Base on TabFact
We provide a fine-tuning script of tapex for TableFV on the TabFact benchmark: [TabFact](https://github.com/wenhuchen/Table-Fact-Checking).
Here is how to run the script on the TabFact:
> The default hyper-parameter may allow you to reproduce our reported tapex-base results within the memory budget of 16GB and 1 GPU card. If you have more GPU cards, you could reduce `gradient_accumulation_steps` accordingly. Note that the `eval_accumulation_steps` is necessary, otherwise GPU memory leaks will occur during the evaluation.
```bash
export EXP_NAME=tabfact_tapex_base
python run_tabfact_with_tapex.py \
--do_train \
--do_eval \
--output_dir $EXP_NAME \
--model_name_or_path microsoft/tapex-base \
--overwrite_output_dir \
--per_device_train_batch_size 3 \
--gradient_accumulation_steps 16 \
--per_device_eval_batch_size 12 \
--eval_accumulation_steps 6 \
--warm_steps 1000 \
--logging_steps 10 \
--learning_rate 3e-5 \
--eval_steps 1000 \
--save_steps 1000 \
--evaluation_strategy steps \
--weight_decay 1e-2 \
--max_steps 30000 \
--max_grad_norm 0.1
```
#### TAPEX-Large on TabFact
Here is how to run the script on the TabFact:
> The default hyper-parameter may allow you to reproduce our reported tapex-base results within the memory budget of 24GB and 1 GPU card. Sorry we cannot reduce the memory consumption since the model input in TabFact usually contains nearly ~1000 tokens. If you have more GPU cards, you could reduce `gradient_accumulation_steps` accordingly. Note that the `eval_accumulation_steps` is necessary, otherwise GPU memory leaks will occur during the evaluation.
```bash
export EXP_NAME=tabfact_tapex_large
python run_tabfact_with_tapex.py \
--do_train \
--do_eval \
--output_dir $EXP_NAME \
--model_name_or_path microsoft/tapex-large \
--overwrite_output_dir \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 18 \
--per_device_eval_batch_size 4 \
--eval_accumulation_steps 12 \
--warm_steps 1000 \
--logging_steps 10 \
--learning_rate 3e-5 \
--eval_steps 1000 \
--save_steps 1000 \
--evaluation_strategy steps \
--weight_decay 1e-2 \
--max_steps 30000 \
--max_grad_norm 0.1
```
### How to Evaluate TAPEX Fine-tuned Models on TableFV
We provide fine-tuned model weights to reproduce our results. You can evaluate them using the following command:
> You can also replace `microsoft/tapex-base-finetuned-tabfact` with your local directory to evaluate your fine-tuned models. Notice that if the model has a larger size, you should reduce `per_device_eval_batch_size` to fit the memory requirement.
```bash
export EXP_NAME=tabfact_tapex_base_eval
python run_tabfact_with_tapex.py \
--do_eval \
--model_name_or_path microsoft/tapex-base-finetuned-tabfact \
--output_dir $EXP_NAME \
--per_device_eval_batch_size 12 \
--eval_accumulation_steps 6
```
## Reproduced Results
We get the following results on the dev set of the benchmark with the previous commands:
| Task | Model Size | Metric | Result |
|:---:|:---:|:---:|:---:|
| WikiSQL (Weak) | Base | Denotation Accuracy | 88.1 |
| WikiSQL (Weak) | Large | Denotation Accuracy | 89.5 |
| WikiTableQuestion | Base | Denotation Accuracy | 47.1 |
| WikiTableQuestion | Large | Denotation Accuracy | 57.2 |
| TabFact | Base | Accuracy | 78.7 |
| TabFact | Large | Accuracy | 83.6 |
| huggingface/transformers/blob/main/examples/research_projects/tapex/README.md |
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<p align="center">
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers_logo_name.png" width="400"/>
<br>
</p>
<p align="center">
<a href="https://circleci.com/gh/huggingface/transformers">
<img alt="Build" src="https://img.shields.io/circleci/build/github/huggingface/transformers/main">
</a>
<a href="https://github.com/huggingface/transformers/blob/main/LICENSE">
<img alt="GitHub" src="https://img.shields.io/github/license/huggingface/transformers.svg?color=blue">
</a>
<a href="https://huggingface.co/docs/transformers/index">
<img alt="Documentation" src="https://img.shields.io/website/http/huggingface.co/docs/transformers/index.svg?down_color=red&down_message=offline&up_message=online">
</a>
<a href="https://github.com/huggingface/transformers/releases">
<img alt="GitHub release" src="https://img.shields.io/github/release/huggingface/transformers.svg">
</a>
<a href="https://github.com/huggingface/transformers/blob/main/CODE_OF_CONDUCT.md">
<img alt="Contributor Covenant" src="https://img.shields.io/badge/Contributor%20Covenant-v2.0%20adopted-ff69b4.svg">
</a>
<a href="https://zenodo.org/badge/latestdoi/155220641"><img src="https://zenodo.org/badge/155220641.svg" alt="DOI"></a>
</p>
<h4 align="center">
<p>
<a href="https://github.com/huggingface/transformers/">English</a> |
<a href="https://github.com/huggingface/transformers/blob/main/README_zh-hans.md">简体中文</a> |
<a href="https://github.com/huggingface/transformers/blob/main/README_zh-hant.md">繁體中文</a> |
<a href="https://github.com/huggingface/transformers/blob/main/README_ko.md">한국어</a> |
<b>Español</b> |
<a href="https://github.com/huggingface/transformers/blob/main/README_ja.md">日本語</a> |
<a href="https://github.com/huggingface/transformers/blob/main/README_hd.md">हिन्दी</a> |
<a href="https://github.com/huggingface/transformers//blob/main/README_te.md">తెలుగు</a> |
</p>
</h4>
<h3 align="center">
<p>Lo último de Machine Learning para JAX, PyTorch y TensorFlow</p>
</h3>
<h3 align="center">
<a href="https://hf.co/course"><img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/course_banner.png"></a>
</h3>
🤗 Transformers aporta miles de modelos preentrenados Para realizar tareas en diferentes modalidades como texto, vision, y audio.
Estos modelos pueden ser aplicados en:
* 📝 Texto, Para tareas como clasificación de texto, extracción de información, responder preguntas, resumir, traducir, generación de texto, en más de 100 idiomas.
* 🖼️ Imágenes, para tareas como clasificación de imágenes, detección the objetos, y segmentación.
* 🗣️ Audio, para tareas como reconocimiento de voz y clasificación de audio.
Los modelos de Transformer también pueden realizar tareas en **muchas modalidades combinadas**, como responder pregunstas, reconocimiento de carácteres ópticos,extracción de información de documentos escaneados, clasificación de video, y respuesta de preguntas visuales.
🤗 Transformers aporta APIs para descargar rápidamente y usar estos modelos preentrenados en un texto dado, afinarlos en tus propios sets de datos y compartirlos con la comunidad en nuestro [centro de modelos](https://huggingface.co/models). Al mismo tiempo, cada módulo de Python que define una arquitectura es completamente independiente y se puede modificar para permitir experimentos de investigación rápidos.
🤗 Transformers está respaldado por las tres bibliotecas de deep learning más populares — [Jax](https://jax.readthedocs.io/en/latest/), [PyTorch](https://pytorch.org/) y [TensorFlow](https://www.tensorflow.org/) — con una perfecta integración entre ellos. Es sencillo entrenar sus modelos con uno antes de cargarlos para la inferencia con el otro.
## Demostraciones en línea
Puedes probar la mayoría de nuestros modelos directamente en sus páginas desde el [centro de modelos](https://huggingface.co/models). También ofrecemos [alojamiento de modelos privados, control de versiones y una API de inferencia](https://huggingface.co/pricing) para modelos públicos y privados.
Aquí hay algunos ejemplos:
En procesamiento del lenguaje natural:
- [Terminación de palabras enmascaradas con BERT](https://huggingface.co/bert-base-uncased?text=Paris+is+the+%5BMASK%5D+of+France)
- [Reconocimiento del nombre de la entidad con Electra](https://huggingface.co/dbmdz/electra-large-discriminator-finetuned-conll03-english?text=My+name+is+Sarah+and+I+live+in+London+city)
- [Generación de texto con GPT-2](https://huggingface.co/gpt2?text=A+long+time+ago%2C+)
- [Inferencia del lenguaje natural con RoBERTa](https://huggingface.co/roberta-large-mnli?text=The+dog+was+lost.+Nobody+lost+any+animal)
- [Resumen con BART](https://huggingface.co/facebook/bart-large-cnn?text=The+tower+is+324+metres+%281%2C063+ft%29+tall%2C+about+the+same+height+as+an+81-storey+building%2C+and+the+tallest+structure+in+Paris.+Its+base+is+square%2C+measuring+125+metres+%28410+ft%29+on+each+side.+During+its+construction%2C+the+Eiffel+Tower+surpassed+the+Washington+Monument+to+become+the+tallest+man-made+structure+in+the+world%2C+a+title+it+held+for+41+years+until+the+Chrysler+Building+in+New+York+City+was+finished+in+1930.+It+was+the+first+structure+to+reach+a+height+of+300+metres.+Due+to+the+addition+of+a+broadcasting+aerial+at+the+top+of+the+tower+in+1957%2C+it+is+now+taller+than+the+Chrysler+Building+by+5.2+metres+%2817+ft%29.+Excluding+transmitters%2C+the+Eiffel+Tower+is+the+second+tallest+free-standing+structure+in+France+after+the+Millau+Viaduct)
- [Responder a preguntas con DistilBERT](https://huggingface.co/distilbert-base-uncased-distilled-squad?text=Which+name+is+also+used+to+describe+the+Amazon+rainforest+in+English%3F&context=The+Amazon+rainforest+%28Portuguese%3A+Floresta+Amaz%C3%B4nica+or+Amaz%C3%B4nia%3B+Spanish%3A+Selva+Amaz%C3%B3nica%2C+Amazon%C3%ADa+or+usually+Amazonia%3B+French%3A+For%C3%AAt+amazonienne%3B+Dutch%3A+Amazoneregenwoud%29%2C+also+known+in+English+as+Amazonia+or+the+Amazon+Jungle%2C+is+a+moist+broadleaf+forest+that+covers+most+of+the+Amazon+basin+of+South+America.+This+basin+encompasses+7%2C000%2C000+square+kilometres+%282%2C700%2C000+sq+mi%29%2C+of+which+5%2C500%2C000+square+kilometres+%282%2C100%2C000+sq+mi%29+are+covered+by+the+rainforest.+This+region+includes+territory+belonging+to+nine+nations.+The+majority+of+the+forest+is+contained+within+Brazil%2C+with+60%25+of+the+rainforest%2C+followed+by+Peru+with+13%25%2C+Colombia+with+10%25%2C+and+with+minor+amounts+in+Venezuela%2C+Ecuador%2C+Bolivia%2C+Guyana%2C+Suriname+and+French+Guiana.+States+or+departments+in+four+nations+contain+%22Amazonas%22+in+their+names.+The+Amazon+represents+over+half+of+the+planet%27s+remaining+rainforests%2C+and+comprises+the+largest+and+most+biodiverse+tract+of+tropical+rainforest+in+the+world%2C+with+an+estimated+390+billion+individual+trees+divided+into+16%2C000+species)
- [Traducción con T5](https://huggingface.co/t5-base?text=My+name+is+Wolfgang+and+I+live+in+Berlin)
En visión de ordenador:
- [Clasificación de imágenes con ViT](https://huggingface.co/google/vit-base-patch16-224)
- [Detección de objetos con DETR](https://huggingface.co/facebook/detr-resnet-50)
- [Segmentación semántica con SegFormer](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
- [Segmentación panóptica con DETR](https://huggingface.co/facebook/detr-resnet-50-panoptic)
- [Segmentación Universal con OneFormer (Segmentación Semántica, de Instancia y Panóptica con un solo modelo)](https://huggingface.co/shi-labs/oneformer_ade20k_dinat_large)
En Audio:
- [Reconocimiento de voz automático con Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base-960h)
- [Detección de palabras clave con Wav2Vec2](https://huggingface.co/superb/wav2vec2-base-superb-ks)
En tareas multimodales:
- [Respuesta visual a preguntas con ViLT](https://huggingface.co/dandelin/vilt-b32-finetuned-vqa)
**[Escribe con Transformer](https://transformer.huggingface.co)**, construido por el equipo de Hugging Face, es la demostración oficial de las capacidades de generación de texto de este repositorio.
## Si está buscando soporte personalizado del equipo de Hugging Face
<a target="_blank" href="https://huggingface.co/support">
<img alt="HuggingFace Expert Acceleration Program" src="https://cdn-media.huggingface.co/marketing/transformers/new-support-improved.png" style="max-width: 600px; border: 1px solid #eee; border-radius: 4px; box-shadow: 0 1px 2px 0 rgba(0, 0, 0, 0.05);">
</a><br>
## Tour rápido
Para usar inmediatamente un modelo en una entrada determinada (texto, imagen, audio, ...), proporcionamos la API de `pipeline`. Los pipelines agrupan un modelo previamente entrenado con el preprocesamiento que se usó durante el entrenamiento de ese modelo. Aquí se explica cómo usar rápidamente un pipeline para clasificar textos positivos frente a negativos:
```python
>>> from transformers import pipeline
# Allocate a pipeline for sentiment-analysis
>>> classifier = pipeline('sentiment-analysis')
>>> classifier('We are very happy to introduce pipeline to the transformers repository.')
[{'label': 'POSITIVE', 'score': 0.9996980428695679}]
```
La segunda línea de código descarga y almacena en caché el modelo previamente entrenado que usa la canalización, mientras que la tercera lo evalúa en el texto dado. Aquí la respuesta es "positiva" con una confianza del 99,97%.
Muchas tareas tienen un `pipeline` preentrenado listo para funcionar, en NLP pero también en visión por ordenador y habla. Por ejemplo, podemos extraer fácilmente los objetos detectados en una imagen:
``` python
>>> import requests
>>> from PIL import Image
>>> from transformers import pipeline
# Download an image with cute cats
>>> url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/coco_sample.png"
>>> image_data = requests.get(url, stream=True).raw
>>> image = Image.open(image_data)
# Allocate a pipeline for object detection
>>> object_detector = pipeline('object_detection')
>>> object_detector(image)
[{'score': 0.9982201457023621,
'label': 'remote',
'box': {'xmin': 40, 'ymin': 70, 'xmax': 175, 'ymax': 117}},
{'score': 0.9960021376609802,
'label': 'remote',
'box': {'xmin': 333, 'ymin': 72, 'xmax': 368, 'ymax': 187}},
{'score': 0.9954745173454285,
'label': 'couch',
'box': {'xmin': 0, 'ymin': 1, 'xmax': 639, 'ymax': 473}},
{'score': 0.9988006353378296,
'label': 'cat',
'box': {'xmin': 13, 'ymin': 52, 'xmax': 314, 'ymax': 470}},
{'score': 0.9986783862113953,
'label': 'cat',
'box': {'xmin': 345, 'ymin': 23, 'xmax': 640, 'ymax': 368}}]
```
Aquí obtenemos una lista de objetos detectados en la imagen, con un cuadro que rodea el objeto y una puntuación de confianza. Aquí está la imagen original a la derecha, con las predicciones mostradas a la izquierda:
<h3 align="center">
<a><img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/coco_sample.png" width="400"></a>
<a><img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/coco_sample_post_processed.png" width="400"></a>
</h3>
Puedes obtener más información sobre las tareas admitidas por la API de `pipeline` en [este tutorial](https://huggingface.co/docs/transformers/task_summary).
Además de `pipeline`, para descargar y usar cualquiera de los modelos previamente entrenados en su tarea dada, todo lo que necesita son tres líneas de código. Aquí está la versión de PyTorch:
```python
>>> from transformers import AutoTokenizer, AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
>>> model = AutoModel.from_pretrained("bert-base-uncased")
>>> inputs = tokenizer("Hello world!", return_tensors="pt")
>>> outputs = model(**inputs)
```
Y aquí está el código equivalente para TensorFlow:
```python
>>> from transformers import AutoTokenizer, TFAutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
>>> model = TFAutoModel.from_pretrained("bert-base-uncased")
>>> inputs = tokenizer("Hello world!", return_tensors="tf")
>>> outputs = model(**inputs)
```
El tokenizador es responsable de todo el preprocesamiento que espera el modelo preentrenado y se puede llamar directamente en una sola cadena (como en los ejemplos anteriores) o en una lista. Dará como resultado un diccionario que puedes usar en el código descendente o simplemente pasarlo directamente a su modelo usando el operador de desempaquetado de argumento **.
El modelo en si es un [Pytorch `nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) normal o un [TensorFlow `tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) (dependiendo De tu backend) que puedes usar de forma habitual. [Este tutorial](https://huggingface.co/docs/transformers/training) explica cómo integrar un modelo de este tipo en un ciclo de entrenamiento PyTorch o TensorFlow clásico, o como usar nuestra API `Trainer` para ajustar rápidamente un nuevo conjunto de datos.
## ¿Por qué debo usar transformers?
1. Modelos de última generación fáciles de usar:
- Alto rendimiento en comprensión y generación de lenguaje natural, visión artificial y tareas de audio.
- Baja barrera de entrada para educadores y profesionales.
- Pocas abstracciones de cara al usuario con solo tres clases para aprender.
- Una API unificada para usar todos nuestros modelos preentrenados.
1. Menores costes de cómputo, menor huella de carbono:
- Los investigadores pueden compartir modelos entrenados en lugar de siempre volver a entrenar.
- Los profesionales pueden reducir el tiempo de cómputo y los costos de producción.
- Docenas de arquitecturas con más de 60 000 modelos preentrenados en todas las modalidades.
1. Elija el marco adecuado para cada parte de la vida útil de un modelo:
- Entrene modelos de última generación en 3 líneas de código.
- Mueva un solo modelo entre los marcos TF2.0/PyTorch/JAX a voluntad.
- Elija sin problemas el marco adecuado para la formación, la evaluación y la producción.
1. Personalice fácilmente un modelo o un ejemplo según sus necesidades:
- Proporcionamos ejemplos de cada arquitectura para reproducir los resultados publicados por sus autores originales..
- Los internos del modelo están expuestos lo más consistentemente posible..
- Los archivos modelo se pueden usar independientemente de la biblioteca para experimentos rápidos.
## ¿Por qué no debería usar transformers?
- Esta biblioteca no es una caja de herramientas modular de bloques de construcción para redes neuronales. El código en los archivos del modelo no se refactoriza con abstracciones adicionales a propósito, de modo que los investigadores puedan iterar rápidamente en cada uno de los modelos sin sumergirse en abstracciones/archivos adicionales.
- La API de entrenamiento no está diseñada para funcionar en ningún modelo, pero está optimizada para funcionar con los modelos proporcionados por la biblioteca. Para bucles genéricos de aprendizaje automático, debe usar otra biblioteca (posiblemente, [Accelerate](https://huggingface.co/docs/accelerate)).
- Si bien nos esforzamos por presentar tantos casos de uso como sea posible, los scripts en nuestra [carpeta de ejemplos](https://github.com/huggingface/transformers/tree/main/examples) son solo eso: ejemplos. Se espera que no funcionen de forma inmediata en su problema específico y que deba cambiar algunas líneas de código para adaptarlas a sus necesidades.
## Instalación
### Con pip
Este repositorio está probado en Python 3.8+, Flax 0.4.1+, PyTorch 1.10+ y TensorFlow 2.6+.
Deberías instalar 🤗 Transformers en un [ambiente virtual](https://docs.python.org/3/library/venv.html). Si no estas familiarizado con los entornos virtuales de Python, consulta la [guía de usuario](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/).
Primero, crea un entorno virtual con la versión de Python que vas a usar y actívalo.
Luego, deberás instalar al menos uno de Flax, PyTorch o TensorFlow.
Por favor, ve a la [página de instalación de TensorFlow](https://www.tensorflow.org/install/), [página de instalación de PyTorch](https://pytorch.org/get-started/locally/#start-locally) y/o las páginas de instalación de [Flax](https://github.com/google/flax#quick-install) y [Jax](https://github.com/google/jax#installation) con respecto al comando de instalación específico para tu plataforma.
Cuando se ha instalado uno de esos backends, los 🤗 Transformers se pueden instalar usando pip de la siguiente manera:
```bash
pip install transformers
```
Si deseas jugar con los ejemplos o necesitas la última versión del código y no puedes esperar a una nueva versión, tienes que [instalar la librería de la fuente](https://huggingface.co/docs/transformers/installation#installing-from-source).
### Con conda
Desde la versión v4.0.0 de Transformers, ahora tenemos un canal conda: `huggingface`.
🤗 Transformers se puede instalar usando conda de la siguiente manera:
```shell script
conda install -c huggingface transformers
```
Sigue las páginas de instalación de Flax, PyTorch o TensorFlow para ver cómo instalarlos con conda.
> **_NOTA:_** En Windows, es posible que se le pida que active el modo de desarrollador para beneficiarse del almacenamiento en caché. Si esta no es una opción para usted, háganoslo saber en [esta issue](https://github.com/huggingface/huggingface_hub/issues/1062).
## Arquitecturas modelo
**[Todos los puntos de control del modelo](https://huggingface.co/models)** aportados por 🤗 Transformers están perfectamente integrados desde huggingface.co [Centro de modelos](https://huggingface.co) donde son subidos directamente por los [usuarios](https://huggingface.co/users) y [organizaciones](https://huggingface.co/organizations).
Número actual de puntos de control: 
🤗 Transformers actualmente proporciona las siguientes arquitecturas (ver [aquí](https://huggingface.co/docs/transformers/model_summary) para un resumen de alto nivel de cada uno de ellas.):
1. **[ALBERT](https://huggingface.co/docs/transformers/model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
1. **[ALIGN](https://huggingface.co/docs/transformers/model_doc/align)** (from Google Research) released with the paper [Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision](https://arxiv.org/abs/2102.05918) by Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig.
1. **[AltCLIP](https://huggingface.co/docs/transformers/model_doc/altclip)** (from BAAI) released with the paper [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679) by Chen, Zhongzhi and Liu, Guang and Zhang, Bo-Wen and Ye, Fulong and Yang, Qinghong and Wu, Ledell.
1. **[Audio Spectrogram Transformer](https://huggingface.co/docs/transformers/model_doc/audio-spectrogram-transformer)** (from MIT) released with the paper [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) by Yuan Gong, Yu-An Chung, James Glass.
1. **[Autoformer](https://huggingface.co/docs/transformers/model_doc/autoformer)** (from Tsinghua University) released with the paper [Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://arxiv.org/abs/2106.13008) by Haixu Wu, Jiehui Xu, Jianmin Wang, Mingsheng Long.
1. **[Bark](https://huggingface.co/docs/transformers/model_doc/bark)** (from Suno) released in the repository [suno-ai/bark](https://github.com/suno-ai/bark) by Suno AI team.
1. **[BART](https://huggingface.co/docs/transformers/model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
1. **[BARThez](https://huggingface.co/docs/transformers/model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
1. **[BARTpho](https://huggingface.co/docs/transformers/model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
1. **[BEiT](https://huggingface.co/docs/transformers/model_doc/beit)** (from Microsoft) released with the paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong, Furu Wei.
1. **[BERT](https://huggingface.co/docs/transformers/model_doc/bert)** (from Google) released with the paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
1. **[BERT For Sequence Generation](https://huggingface.co/docs/transformers/model_doc/bert-generation)** (from Google) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
1. **[BERTweet](https://huggingface.co/docs/transformers/model_doc/bertweet)** (from VinAI Research) released with the paper [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/) by Dat Quoc Nguyen, Thanh Vu and Anh Tuan Nguyen.
1. **[BigBird-Pegasus](https://huggingface.co/docs/transformers/model_doc/bigbird_pegasus)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
1. **[BigBird-RoBERTa](https://huggingface.co/docs/transformers/model_doc/big_bird)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
1. **[BioGpt](https://huggingface.co/docs/transformers/model_doc/biogpt)** (from Microsoft Research AI4Science) released with the paper [BioGPT: generative pre-trained transformer for biomedical text generation and mining](https://academic.oup.com/bib/advance-article/doi/10.1093/bib/bbac409/6713511?guestAccessKey=a66d9b5d-4f83-4017-bb52-405815c907b9) by Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon and Tie-Yan Liu.
1. **[BiT](https://huggingface.co/docs/transformers/model_doc/bit)** (from Google AI) released with the paper [Big Transfer (BiT) by Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil Houlsby.
1. **[Blenderbot](https://huggingface.co/docs/transformers/model_doc/blenderbot)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
1. **[BlenderbotSmall](https://huggingface.co/docs/transformers/model_doc/blenderbot-small)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
1. **[BLIP](https://huggingface.co/docs/transformers/model_doc/blip)** (from Salesforce) released with the paper [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) by Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi.
1. **[BLIP-2](https://huggingface.co/docs/transformers/model_doc/blip-2)** (from Salesforce) released with the paper [BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://arxiv.org/abs/2301.12597) by Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi.
1. **[BLOOM](https://huggingface.co/docs/transformers/model_doc/bloom)** (from BigScience workshop) released by the [BigScience Workshop](https://bigscience.huggingface.co/).
1. **[BORT](https://huggingface.co/docs/transformers/model_doc/bort)** (from Alexa) released with the paper [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) by Adrian de Wynter and Daniel J. Perry.
1. **[BridgeTower](https://huggingface.co/docs/transformers/model_doc/bridgetower)** (from Harbin Institute of Technology/Microsoft Research Asia/Intel Labs) released with the paper [BridgeTower: Building Bridges Between Encoders in Vision-Language Representation Learning](https://arxiv.org/abs/2206.08657) by Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan.
1. **[BROS](https://huggingface.co/docs/transformers/model_doc/bros)** (from NAVER CLOVA) released with the paper [BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents](https://arxiv.org/abs/2108.04539) by Teakgyu Hong, Donghyun Kim, Mingi Ji, Wonseok Hwang, Daehyun Nam, Sungrae Park.
1. **[ByT5](https://huggingface.co/docs/transformers/model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
1. **[CamemBERT](https://huggingface.co/docs/transformers/model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
1. **[CANINE](https://huggingface.co/docs/transformers/model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
1. **[Chinese-CLIP](https://huggingface.co/docs/transformers/model_doc/chinese_clip)** (from OFA-Sys) released with the paper [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://arxiv.org/abs/2211.01335) by An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou.
1. **[CLAP](https://huggingface.co/docs/transformers/model_doc/clap)** (from LAION-AI) released with the paper [Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation](https://arxiv.org/abs/2211.06687) by Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, Shlomo Dubnov.
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
1. **[CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
1. **[CLVP](https://huggingface.co/docs/transformers/model_doc/clvp)** released with the paper [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) by James Betker.
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
1. **[CodeLlama](https://huggingface.co/docs/transformers/model_doc/llama_code)** (from MetaAI) released with the paper [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) by Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve.
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
1. **[ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
1. **[ConvNeXTV2](https://huggingface.co/docs/transformers/model_doc/convnextv2)** (from Facebook AI) released with the paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
1. **[CPM](https://huggingface.co/docs/transformers/model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
1. **[CPM-Ant](https://huggingface.co/docs/transformers/model_doc/cpmant)** (from OpenBMB) released by the [OpenBMB](https://www.openbmb.org/).
1. **[CTRL](https://huggingface.co/docs/transformers/model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
1. **[CvT](https://huggingface.co/docs/transformers/model_doc/cvt)** (from Microsoft) released with the paper [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) by Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang.
1. **[Data2Vec](https://huggingface.co/docs/transformers/model_doc/data2vec)** (from Facebook) released with the paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
1. **[DeBERTa](https://huggingface.co/docs/transformers/model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
1. **[DeBERTa-v2](https://huggingface.co/docs/transformers/model_doc/deberta-v2)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
1. **[Decision Transformer](https://huggingface.co/docs/transformers/model_doc/decision_transformer)** (from Berkeley/Facebook/Google) released with the paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
1. **[Deformable DETR](https://huggingface.co/docs/transformers/model_doc/deformable_detr)** (from SenseTime Research) released with the paper [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159) by Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai.
1. **[DeiT](https://huggingface.co/docs/transformers/model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
1. **[DePlot](https://huggingface.co/docs/transformers/model_doc/deplot)** (from Google AI) released with the paper [DePlot: One-shot visual language reasoning by plot-to-table translation](https://arxiv.org/abs/2212.10505) by Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun.
1. **[DETA](https://huggingface.co/docs/transformers/model_doc/deta)** (from The University of Texas at Austin) released with the paper [NMS Strikes Back](https://arxiv.org/abs/2212.06137) by Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl.
1. **[DETR](https://huggingface.co/docs/transformers/model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
1. **[DialoGPT](https://huggingface.co/docs/transformers/model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
1. **[DiNAT](https://huggingface.co/docs/transformers/model_doc/dinat)** (from SHI Labs) released with the paper [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001) by Ali Hassani and Humphrey Shi.
1. **[DINOv2](https://huggingface.co/docs/transformers/model_doc/dinov2)** (from Meta AI) released with the paper [DINOv2: Learning Robust Visual Features without Supervision](https://arxiv.org/abs/2304.07193) by Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, Piotr Bojanowski.
1. **[DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert)** (from HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation) and a German version of DistilBERT.
1. **[DiT](https://huggingface.co/docs/transformers/model_doc/dit)** (from Microsoft Research) released with the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
1. **[Donut](https://huggingface.co/docs/transformers/model_doc/donut)** (from NAVER), released together with the paper [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664) by Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park.
1. **[DPR](https://huggingface.co/docs/transformers/model_doc/dpr)** (from Facebook) released with the paper [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
1. **[DPT](https://huggingface.co/docs/transformers/master/model_doc/dpt)** (from Intel Labs) released with the paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
1. **[EfficientFormer](https://huggingface.co/docs/transformers/model_doc/efficientformer)** (from Snap Research) released with the paper [EfficientFormer: Vision Transformers at MobileNetSpeed](https://arxiv.org/abs/2206.01191) by Yanyu Li, Geng Yuan, Yang Wen, Ju Hu, Georgios Evangelidis, Sergey Tulyakov, Yanzhi Wang, Jian Ren.
1. **[EfficientNet](https://huggingface.co/docs/transformers/model_doc/efficientnet)** (from Google Brain) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan, Quoc V. Le.
1. **[ELECTRA](https://huggingface.co/docs/transformers/model_doc/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
1. **[EnCodec](https://huggingface.co/docs/transformers/model_doc/encodec)** (from Meta AI) released with the paper [High Fidelity Neural Audio Compression](https://arxiv.org/abs/2210.13438) by Alexandre Défossez, Jade Copet, Gabriel Synnaeve, Yossi Adi.
1. **[EncoderDecoder](https://huggingface.co/docs/transformers/model_doc/encoder-decoder)** (from Google Research) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
1. **[ERNIE](https://huggingface.co/docs/transformers/model_doc/ernie)** (from Baidu) released with the paper [ERNIE: Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223) by Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu.
1. **[ErnieM](https://huggingface.co/docs/transformers/model_doc/ernie_m)** (from Baidu) released with the paper [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674) by Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang.
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2** was released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
1. **[Falcon](https://huggingface.co/docs/transformers/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
1. **[FLAN-UL2](https://huggingface.co/docs/transformers/model_doc/flan-ul2)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
1. **[FLAVA](https://huggingface.co/docs/transformers/model_doc/flava)** (from Facebook AI) released with the paper [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela.
1. **[FNet](https://huggingface.co/docs/transformers/model_doc/fnet)** (from Google Research) released with the paper [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
1. **[FocalNet](https://huggingface.co/docs/transformers/model_doc/focalnet)** (from Microsoft Research) released with the paper [Focal Modulation Networks](https://arxiv.org/abs/2203.11926) by Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan, Jianfeng Gao.
1. **[Funnel Transformer](https://huggingface.co/docs/transformers/model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
1. **[Fuyu](https://huggingface.co/docs/transformers/model_doc/fuyu)** (from ADEPT) Rohan Bavishi, Erich Elsen, Curtis Hawthorne, Maxwell Nye, Augustus Odena, Arushi Somani, Sağnak Taşırlar. Released with the paper [blog post](https://www.adept.ai/blog/fuyu-8b)
1. **[GIT](https://huggingface.co/docs/transformers/model_doc/git)** (from Microsoft Research) released with the paper [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) by Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang.
1. **[GLPN](https://huggingface.co/docs/transformers/model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
1. **[GPT](https://huggingface.co/docs/transformers/model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://blog.openai.com/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
1. **[GPT Neo](https://huggingface.co/docs/transformers/model_doc/gpt_neo)** (from EleutherAI) released in the repository [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) by Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy.
1. **[GPT NeoX](https://huggingface.co/docs/transformers/model_doc/gpt_neox)** (from EleutherAI) released with the paper [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://arxiv.org/abs/2204.06745) by Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach
1. **[GPT NeoX Japanese](https://huggingface.co/docs/transformers/model_doc/gpt_neox_japanese)** (from ABEJA) released by Shinya Otani, Takayoshi Makabe, Anuj Arora, and Kyo Hattori.
1. **[GPT-2](https://huggingface.co/docs/transformers/model_doc/gpt2)** (from OpenAI) released with the paper [Language Models are Unsupervised Multitask Learners](https://blog.openai.com/better-language-models/) by Alec Radford*, Jeffrey Wu*, Rewon Child, David Luan, Dario Amodei** and Ilya Sutskever**.
1. **[GPT-J](https://huggingface.co/docs/transformers/model_doc/gptj)** (from EleutherAI) released in the repository [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) by Ben Wang and Aran Komatsuzaki.
1. **[GPT-Sw3](https://huggingface.co/docs/transformers/model_doc/gpt-sw3)** (from AI-Sweden) released with the paper [Lessons Learned from GPT-SW3: Building the First Large-Scale Generative Language Model for Swedish](http://www.lrec-conf.org/proceedings/lrec2022/pdf/2022.lrec-1.376.pdf) by Ariel Ekgren, Amaru Cuba Gyllensten, Evangelia Gogoulou, Alice Heiman, Severine Verlinden, Joey Öhman, Fredrik Carlsson, Magnus Sahlgren.
1. **[GPTBigCode](https://huggingface.co/docs/transformers/model_doc/gpt_bigcode)** (from BigCode) released with the paper [SantaCoder: don't reach for the stars!](https://arxiv.org/abs/2301.03988) by Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra.
1. **[GPTSAN-japanese](https://huggingface.co/docs/transformers/model_doc/gptsan-japanese)** released in the repository [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) by Toshiyuki Sakamoto(tanreinama).
1. **[Graphormer](https://huggingface.co/docs/transformers/model_doc/graphormer)** (from Microsoft) released with the paper [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234) by Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu.
1. **[GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit)** (from UCSD, NVIDIA) released with the paper [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
1. **[HerBERT](https://huggingface.co/docs/transformers/model_doc/herbert)** (from Allegro.pl, AGH University of Science and Technology) released with the paper [KLEJ: Comprehensive Benchmark for Polish Language Understanding](https://www.aclweb.org/anthology/2020.acl-main.111.pdf) by Piotr Rybak, Robert Mroczkowski, Janusz Tracz, Ireneusz Gawlik.
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
1. **[I-BERT](https://huggingface.co/docs/transformers/model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
1. **[IDEFICS](https://huggingface.co/docs/transformers/model_doc/idefics)** (from HuggingFace) released with the paper [OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents](https://huggingface.co/papers/2306.16527) by Hugo Laurençon, Lucile Saulnier, Léo Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexander M. Rush, Douwe Kiela, Matthieu Cord, Victor Sanh.
1. **[ImageGPT](https://huggingface.co/docs/transformers/model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (from Salesforce) released with the paper [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
1. **[KOSMOS-2](https://huggingface.co/docs/transformers/model_doc/kosmos-2)** (from Microsoft Research Asia) released with the paper [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
1. **[LayoutLMv3](https://huggingface.co/docs/transformers/model_doc/layoutlmv3)** (from Microsoft Research Asia) released with the paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
1. **[LayoutXLM](https://huggingface.co/docs/transformers/model_doc/layoutxlm)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
1. **[LED](https://huggingface.co/docs/transformers/model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LeViT](https://huggingface.co/docs/transformers/model_doc/levit)** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (from The FAIR team of Meta AI) released with the paper [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) by Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample.
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (from The FAIR team of Meta AI) released with the paper [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/XXX) by Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom..
1. **[LLaVa](https://huggingface.co/docs/transformers/model_doc/llava)** (from Microsoft Research & University of Wisconsin-Madison) released with the paper [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
1. **[LXMERT](https://huggingface.co/docs/transformers/model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
1. **[M-CTC-T](https://huggingface.co/docs/transformers/model_doc/mctct)** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
1. **[MADLAD-400](https://huggingface.co/docs/transformers/model_doc/madlad-400)** (from Google) released with the paper [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](https://arxiv.org/abs/2309.04662) by Sneha Kudugunta, Isaac Caswell, Biao Zhang, Xavier Garcia, Christopher A. Choquette-Choo, Katherine Lee, Derrick Xin, Aditya Kusupati, Romi Stella, Ankur Bapna, Orhan Firat.
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
1. **[Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
1. **[MaskFormer](https://huggingface.co/docs/transformers/model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
1. **[MatCha](https://huggingface.co/docs/transformers/model_doc/matcha)** (from Google AI) released with the paper [MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering](https://arxiv.org/abs/2212.09662) by Fangyu Liu, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Yasemin Altun, Nigel Collier, Julian Martin Eisenschlos.
1. **[mBART](https://huggingface.co/docs/transformers/model_doc/mbart)** (from Facebook) released with the paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
1. **[mBART-50](https://huggingface.co/docs/transformers/model_doc/mbart)** (from Facebook) released with the paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
1. **[MEGA](https://huggingface.co/docs/transformers/model_doc/mega)** (from Facebook) released with the paper [Mega: Moving Average Equipped Gated Attention](https://arxiv.org/abs/2209.10655) by Xuezhe Ma, Chunting Zhou, Xiang Kong, Junxian He, Liangke Gui, Graham Neubig, Jonathan May, and Luke Zettlemoyer.
1. **[Megatron-BERT](https://huggingface.co/docs/transformers/model_doc/megatron-bert)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
1. **[Megatron-GPT2](https://huggingface.co/docs/transformers/model_doc/megatron_gpt2)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
1. **[MGP-STR](https://huggingface.co/docs/transformers/model_doc/mgp-str)** (from Alibaba Research) released with the paper [Multi-Granularity Prediction for Scene Text Recognition](https://arxiv.org/abs/2209.03592) by Peng Wang, Cheng Da, and Cong Yao.
1. **[Mistral](https://huggingface.co/docs/transformers/model_doc/mistral)** (from Mistral AI) by The Mistral AI team: Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed..
1. **[Mixtral](https://huggingface.co/docs/transformers/model_doc/mixtral)** (from Mistral AI) by The [Mistral AI](https://mistral.ai) team: Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
1. **[mLUKE](https://huggingface.co/docs/transformers/model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
1. **[MMS](https://huggingface.co/docs/transformers/model_doc/mms)** (from Facebook) released with the paper [Scaling Speech Technology to 1,000+ Languages](https://arxiv.org/abs/2305.13516) by Vineel Pratap, Andros Tjandra, Bowen Shi, Paden Tomasello, Arun Babu, Sayani Kundu, Ali Elkahky, Zhaoheng Ni, Apoorv Vyas, Maryam Fazel-Zarandi, Alexei Baevski, Yossi Adi, Xiaohui Zhang, Wei-Ning Hsu, Alexis Conneau, Michael Auli.
1. **[MobileBERT](https://huggingface.co/docs/transformers/model_doc/mobilebert)** (from CMU/Google Brain) released with the paper [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984) by Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou.
1. **[MobileNetV1](https://huggingface.co/docs/transformers/model_doc/mobilenet_v1)** (from Google Inc.) released with the paper [MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications](https://arxiv.org/abs/1704.04861) by Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam.
1. **[MobileNetV2](https://huggingface.co/docs/transformers/model_doc/mobilenet_v2)** (from Google Inc.) released with the paper [MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://arxiv.org/abs/1801.04381) by Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen.
1. **[MobileViT](https://huggingface.co/docs/transformers/model_doc/mobilevit)** (from Apple) released with the paper [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari.
1. **[MobileViTV2](https://huggingface.co/docs/transformers/model_doc/mobilevitv2)** (from Apple) released with the paper [Separable Self-attention for Mobile Vision Transformers](https://arxiv.org/abs/2206.02680) by Sachin Mehta and Mohammad Rastegari.
1. **[MPNet](https://huggingface.co/docs/transformers/model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
1. **[MPT](https://huggingface.co/docs/transformers/model_doc/mpt)** (from MosaiML) released with the repository [llm-foundry](https://github.com/mosaicml/llm-foundry/) by the MosaicML NLP Team.
1. **[MRA](https://huggingface.co/docs/transformers/model_doc/mra)** (from the University of Wisconsin - Madison) released with the paper [Multi Resolution Analysis (MRA)](https://arxiv.org/abs/2207.10284) by Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh.
1. **[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
1. **[MusicGen](https://huggingface.co/docs/transformers/model_doc/musicgen)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
1. **[MVP](https://huggingface.co/docs/transformers/model_doc/mvp)** (from RUC AI Box) released with the paper [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
1. **[NAT](https://huggingface.co/docs/transformers/model_doc/nat)** (from SHI Labs) released with the paper [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143) by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
1. **[Nezha](https://huggingface.co/docs/transformers/model_doc/nezha)** (from Huawei Noah’s Ark Lab) released with the paper [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) by Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu.
1. **[NLLB](https://huggingface.co/docs/transformers/model_doc/nllb)** (from Meta) released with the paper [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by the NLLB team.
1. **[NLLB-MOE](https://huggingface.co/docs/transformers/model_doc/nllb-moe)** (from Meta) released with the paper [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by the NLLB team.
1. **[Nougat](https://huggingface.co/docs/transformers/model_doc/nougat)** (from Meta AI) released with the paper [Nougat: Neural Optical Understanding for Academic Documents](https://arxiv.org/abs/2308.13418) by Lukas Blecher, Guillem Cucurull, Thomas Scialom, Robert Stojnic.
1. **[Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
1. **[OneFormer](https://huggingface.co/docs/transformers/model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released on GitHub (now removed).
1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
1. **[OWLv2](https://huggingface.co/docs/transformers/model_doc/owlv2)** (from Google AI) released with the paper [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) by Matthias Minderer, Alexey Gritsenko, Neil Houlsby.
1. **[PatchTSMixer](https://huggingface.co/docs/transformers/model_doc/patchtsmixer)** (from IBM Research) released with the paper [TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting](https://arxiv.org/pdf/2306.09364.pdf) by Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.
1. **[PatchTST](https://huggingface.co/docs/transformers/model_doc/patchtst)** (from IBM) released with the paper [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://arxiv.org/pdf/2211.14730.pdf) by Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (from Google) released with the paper [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao, and Peter J. Liu.
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
1. **[Persimmon](https://huggingface.co/docs/transformers/model_doc/persimmon)** (from ADEPT) released with the paper [blog post](https://www.adept.ai/blog/persimmon-8b) by Erich Elsen, Augustus Odena, Maxwell Nye, Sağnak Taşırlar, Tri Dao, Curtis Hawthorne, Deepak Moparthi, Arushi Somani.
1. **[Phi](https://huggingface.co/docs/transformers/model_doc/phi)** (from Microsoft) released with the papers - [Textbooks Are All You Need](https://arxiv.org/abs/2306.11644) by Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee and Yuanzhi Li, [Textbooks Are All You Need II: phi-1.5 technical report](https://arxiv.org/abs/2309.05463) by Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar and Yin Tat Lee.
1. **[PhoBERT](https://huggingface.co/docs/transformers/model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
1. **[Pix2Struct](https://huggingface.co/docs/transformers/model_doc/pix2struct)** (from Google) released with the paper [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347) by Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.
1. **[PLBart](https://huggingface.co/docs/transformers/model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
1. **[PoolFormer](https://huggingface.co/docs/transformers/model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
1. **[Pop2Piano](https://huggingface.co/docs/transformers/model_doc/pop2piano)** released with the paper [Pop2Piano : Pop Audio-based Piano Cover Generation](https://arxiv.org/abs/2211.00895) by Jongho Choi, Kyogu Lee.
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
1. **[PVT](https://huggingface.co/docs/transformers/model_doc/pvt)** (from Nanjing University, The University of Hong Kong etc.) released with the paper [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
1. **[RegNet](https://huggingface.co/docs/transformers/model_doc/regnet)** (from META Platforms) released with the paper [Designing Network Design Space](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
1. **[RemBERT](https://huggingface.co/docs/transformers/model_doc/rembert)** (from Google Research) released with the paper [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
1. **[ResNet](https://huggingface.co/docs/transformers/model_doc/resnet)** (from Microsoft Research) released with the paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
1. **[RoBERTa](https://huggingface.co/docs/transformers/model_doc/roberta)** (from Facebook), released together with the paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
1. **[RoBERTa-PreLayerNorm](https://huggingface.co/docs/transformers/model_doc/roberta-prelayernorm)** (from Facebook) released with the paper [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://arxiv.org/abs/1904.01038) by Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli.
1. **[RoCBert](https://huggingface.co/docs/transformers/model_doc/roc_bert)** (from WeChatAI) released with the paper [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf) by HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou.
1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
1. **[RWKV](https://huggingface.co/docs/transformers/model_doc/rwkv)** (from Bo Peng) released with the paper [this repo](https://github.com/BlinkDL/RWKV-LM) by Bo Peng.
1. **[SeamlessM4T](https://huggingface.co/docs/transformers/model_doc/seamless_m4t)** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
1. **[SeamlessM4Tv2](https://huggingface.co/docs/transformers/model_doc/seamless_m4t_v2)** (from Meta AI) released with the paper [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (from Meta AI) released with the paper [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
1. **[SpeechT5](https://huggingface.co/docs/transformers/model_doc/speecht5)** (from Microsoft Research) released with the paper [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205) by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
1. **[SpeechToTextTransformer](https://huggingface.co/docs/transformers/model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
1. **[Splinter](https://huggingface.co/docs/transformers/model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
1. **[SqueezeBERT](https://huggingface.co/docs/transformers/model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
1. **[SwiftFormer](https://huggingface.co/docs/transformers/model_doc/swiftformer)** (from MBZUAI) released with the paper [SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications](https://arxiv.org/abs/2303.15446) by Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, Fahad Shahbaz Khan.
1. **[Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
1. **[Swin Transformer V2](https://huggingface.co/docs/transformers/model_doc/swinv2)** (from Microsoft) released with the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
1. **[Swin2SR](https://huggingface.co/docs/transformers/model_doc/swin2sr)** (from University of Würzburg) released with the paper [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345) by Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
1. **[SwitchTransformers](https://huggingface.co/docs/transformers/model_doc/switch_transformers)** (from Google) released with the paper [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
1. **[T5](https://huggingface.co/docs/transformers/model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[T5v1.1](https://huggingface.co/docs/transformers/model_doc/t5v1.1)** (from Google AI) released in the repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[Table Transformer](https://huggingface.co/docs/transformers/model_doc/table-transformer)** (from Microsoft Research) released with the paper [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://arxiv.org/abs/2110.00061) by Brandon Smock, Rohith Pesala, Robin Abraham.
1. **[TAPAS](https://huggingface.co/docs/transformers/model_doc/tapas)** (from Google AI) released with the paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
1. **[TAPEX](https://huggingface.co/docs/transformers/model_doc/tapex)** (from Microsoft Research) released with the paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
1. **[Time Series Transformer](https://huggingface.co/docs/transformers/model_doc/time_series_transformer)** (from HuggingFace).
1. **[TimeSformer](https://huggingface.co/docs/transformers/model_doc/timesformer)** (from Facebook) released with the paper [Is Space-Time Attention All You Need for Video Understanding?](https://arxiv.org/abs/2102.05095) by Gedas Bertasius, Heng Wang, Lorenzo Torresani.
1. **[Trajectory Transformer](https://huggingface.co/docs/transformers/model_doc/trajectory_transformers)** (from the University of California at Berkeley) released with the paper [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine
1. **[Transformer-XL](https://huggingface.co/docs/transformers/model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (from UNC Chapel Hill) released with the paper [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal.
1. **[TVP](https://huggingface.co/docs/transformers/model_doc/tvp)** (from Intel) released with the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (from Google Research) released with the paper [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) by Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
1. **[UnivNet](https://huggingface.co/docs/transformers/model_doc/univnet)** (from Kakao Corporation) released with the paper [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kim, and Juntae Kim.
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (from Peking University) released with the paper [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
1. **[VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)** (from Multimedia Computing Group, Nanjing University) released with the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
1. **[ViLT](https://huggingface.co/docs/transformers/model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
1. **[VipLlava](https://huggingface.co/docs/transformers/model_doc/vipllava)** (from University of Wisconsin–Madison) released with the paper [Making Large Multimodal Models Understand Arbitrary Visual Prompts](https://arxiv.org/abs/2312.00784) by Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, Yong Jae Lee.
1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
1. **[ViT Hybrid](https://huggingface.co/docs/transformers/model_doc/vit_hybrid)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
1. **[VitDet](https://huggingface.co/docs/transformers/model_doc/vitdet)** (from Meta AI) released with the paper [Exploring Plain Vision Transformer Backbones for Object Detection](https://arxiv.org/abs/2203.16527) by Yanghao Li, Hanzi Mao, Ross Girshick, Kaiming He.
1. **[ViTMAE](https://huggingface.co/docs/transformers/model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
1. **[ViTMatte](https://huggingface.co/docs/transformers/model_doc/vitmatte)** (from HUST-VL) released with the paper [ViTMatte: Boosting Image Matting with Pretrained Plain Vision Transformers](https://arxiv.org/abs/2305.15272) by Jingfeng Yao, Xinggang Wang, Shusheng Yang, Baoyuan Wang.
1. **[ViTMSN](https://huggingface.co/docs/transformers/model_doc/vit_msn)** (from Meta AI) released with the paper [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas.
1. **[VITS](https://huggingface.co/docs/transformers/model_doc/vits)** (from Kakao Enterprise) released with the paper [Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech](https://arxiv.org/abs/2106.06103) by Jaehyeon Kim, Jungil Kong, Juhee Son.
1. **[ViViT](https://huggingface.co/docs/transformers/model_doc/vivit)** (from Google Research) released with the paper [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
1. **[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
1. **[Wav2Vec2-Conformer](https://huggingface.co/docs/transformers/model_doc/wav2vec2-conformer)** (from Facebook AI) released with the paper [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
1. **[Wav2Vec2Phoneme](https://huggingface.co/docs/transformers/model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
1. **[WavLM](https://huggingface.co/docs/transformers/model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
1. **[Whisper](https://huggingface.co/docs/transformers/model_doc/whisper)** (from OpenAI) released with the paper [Robust Speech Recognition via Large-Scale Weak Supervision](https://cdn.openai.com/papers/whisper.pdf) by Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever.
1. **[X-CLIP](https://huggingface.co/docs/transformers/model_doc/xclip)** (from Microsoft Research) released with the paper [Expanding Language-Image Pretrained Models for General Video Recognition](https://arxiv.org/abs/2208.02816) by Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling.
1. **[X-MOD](https://huggingface.co/docs/transformers/model_doc/xmod)** (from Meta AI) released with the paper [Lifting the Curse of Multilinguality by Pre-training Modular Transformers](http://dx.doi.org/10.18653/v1/2022.naacl-main.255) by Jonas Pfeiffer, Naman Goyal, Xi Lin, Xian Li, James Cross, Sebastian Riedel, Mikel Artetxe.
1. **[XGLM](https://huggingface.co/docs/transformers/model_doc/xglm)** (From Facebook AI) released with the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
1. **[XLM](https://huggingface.co/docs/transformers/model_doc/xlm)** (from Facebook) released together with the paper [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by Guillaume Lample and Alexis Conneau.
1. **[XLM-ProphetNet](https://huggingface.co/docs/transformers/model_doc/xlm-prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
1. **[XLM-RoBERTa](https://huggingface.co/docs/transformers/model_doc/xlm-roberta)** (from Facebook AI), released together with the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov.
1. **[XLM-RoBERTa-XL](https://huggingface.co/docs/transformers/model_doc/xlm-roberta-xl)** (from Facebook AI), released together with the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
1. **[XLM-V](https://huggingface.co/docs/transformers/model_doc/xlm-v)** (from Meta AI) released with the paper [XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models](https://arxiv.org/abs/2301.10472) by Davis Liang, Hila Gonen, Yuning Mao, Rui Hou, Naman Goyal, Marjan Ghazvininejad, Luke Zettlemoyer, Madian Khabsa.
1. **[XLNet](https://huggingface.co/docs/transformers/model_doc/xlnet)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
1. **[XLS-R](https://huggingface.co/docs/transformers/model_doc/xls_r)** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
1. **[XLSR-Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
1. **[YOLOS](https://huggingface.co/docs/transformers/model_doc/yolos)** (from Huazhong University of Science & Technology) released with the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
1. **[YOSO](https://huggingface.co/docs/transformers/model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
1. ¿Quieres aportar un nuevo modelo? Hemos agregado una **guía detallada y plantillas** para guiarte en el proceso de agregar un nuevo modelo. Puedes encontrarlos en la carpeta de [`templates`](./templates) del repositorio. Asegúrate de revisar las [pautas de contribución](./CONTRIBUTING.md) y comunícate con los mantenedores o abra un problema para recopilar comentarios antes de comenzar su PR.
Para comprobar si cada modelo tiene una implementación en Flax, PyTorch o TensorFlow, o tiene un tokenizador asociado respaldado por la librería 🤗 Tokenizers , ve a [esta tabla](https://huggingface.co/docs/transformers/index#supported-frameworks).
Estas implementaciones se han probado en varios conjuntos de datos (consulte los scripts de ejemplo) y deberían coincidir con el rendimiento de las implementaciones originales. Puede encontrar más detalles sobre el rendimiento en la sección Examples de la [documentación](https://github.com/huggingface/transformers/tree/main/examples).
## Aprender más
| Sección | Descripción |
|-|-|
| [Documentación](https://huggingface.co/docs/transformers/) | Toda la documentación de la API y tutoriales |
| [Resumen de tareas](https://huggingface.co/docs/transformers/task_summary) | Tareas soportadas 🤗 Transformers |
| [Tutorial de preprocesAmiento](https://huggingface.co/docs/transformers/preprocessing) | Usando la clase `Tokenizer` para preparar datos para los modelos |
| [Entrenamiento y puesta a punto](https://huggingface.co/docs/transformers/training) | Usando los modelos aportados por 🤗 Transformers en un bucle de entreno de PyTorch/TensorFlow y la API de `Trainer` |
| [Recorrido rápido: secuencias de comandos de ajuste/uso](https://github.com/huggingface/transformers/tree/main/examples) | Scripts de ejemplo para ajustar modelos en una amplia gama de tareas |
| [Compartir y subir modelos](https://huggingface.co/docs/transformers/model_sharing) | Carga y comparte tus modelos perfeccionados con la comunidad |
| [Migración](https://huggingface.co/docs/transformers/migration) | Migra a 🤗 Transformers desde `pytorch-transformers` o `pytorch-pretrained-bert` |
## Citación
Ahora nosotros tenemos un [papel](https://www.aclweb.org/anthology/2020.emnlp-demos.6/) que puedes citar para la librería de 🤗 Transformers:
```bibtex
@inproceedings{wolf-etal-2020-transformers,
title = "Transformers: State-of-the-Art Natural Language Processing",
author = "Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin Lhoest and Alexander M. Rush",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = oct,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-demos.6",
pages = "38--45"
}
```
| huggingface/transformers/blob/main/README_es.md |
Introduction to Gradio[[introduction-to-gradio]]
<CourseFloatingBanner
chapter={9}
classNames="absolute z-10 right-0 top-0"
/>
In this chapter we will be learning about how to build **interactive demos** for your machine learning models.
Why build a demo or a GUI for your machine learning model in the first place? Demos allow:
- **Machine learning developers** to easily present their work to a wide audience including non-technical teams or customers
- **Researchers** to more easily reproduce machine learning models and behavior
- **Quality testers** or **end users** to more easily identify and debug failure points of models
- **Diverse users** to discover algorithmic biases in models
We'll be using the Gradio library to build demos for our models. Gradio allows you to build, customize, and share web-based demos for any machine learning model, entirely in Python.
Here are some examples of machine learning demos built with Gradio:
* A **sketch recognition** model that takes in a sketch and outputs labels of what it thinks is being drawn:
<iframe src="https://course-demos-draw2.hf.space" frameBorder="0" height="450" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
* An extractive **question answering** model that takes in a context paragraph and a quest and outputs a response and a probability score (we discussed this kind of model [in Chapter 7](/course/chapter7/7)):
<iframe src="https://course-demos-question-answering-simple.hf.space" frameBorder="0" height="640" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
* A **background removal** model that takes in an image and outputs the image with the background removed:
<iframe src="https://course-demos-remove-bg-original.hf.space" frameBorder="0" height="640" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
This chapter is broken down into sections which include both _concepts_ and _applications_. After you learn the concept in each section, you'll apply it to build a particular kind of demo, ranging from image classification to speech recognition. By the time you finish this chapter, you'll be able to build these demos (and many more!) in just a few lines of Python code.
<Tip>
👀 Check out <a href="https://huggingface.co/spaces" target="_blank">Hugging Face Spaces</a> to see many recent examples of machine learning demos built by the machine learning community!
</Tip> | huggingface/course/blob/main/chapters/en/chapter9/1.mdx |
Getting Started with the Gradio JavaScript client
Tags: CLIENT, API, SPACES
The Gradio JavaScript client makes it very easy to use any Gradio app as an API. As an example, consider this [Hugging Face Space that transcribes audio files](https://huggingface.co/spaces/abidlabs/whisper) that are recorded from the microphone.
Using the `@gradio/client` library, we can easily use the Gradio as an API to transcribe audio files programmatically.
Here's the entire code to do it:
```js
import { client } from "@gradio/client";
const response = await fetch(
"https://github.com/audio-samples/audio-samples.github.io/raw/master/samples/wav/ted_speakers/SalmanKhan/sample-1.wav"
);
const audio_file = await response.blob();
const app = await client("abidlabs/whisper");
const transcription = await app.predict("/predict", [audio_file]);
console.log(transcription.data);
// [ "I said the same phrase 30 times." ]
```
The Gradio client works with any hosted Gradio app, whether it be an image generator, a text summarizer, a stateful chatbot, a tax calculator, or anything else! The Gradio Client is mostly used with apps hosted on [Hugging Face Spaces](https://hf.space), but your app can be hosted anywhere, such as your own server.
**Prequisites**: To use the Gradio client, you do _not_ need to know the `gradio` library in great detail. However, it is helpful to have general familiarity with Gradio's concepts of input and output components.
## Installation
The lightweight `@gradio/client` package can be installed from the npm registry with a package manager of your choice and support node version 18 and above:
```bash
npm i @gradio/client
```
## Connecting to a running Gradio App
Start by connecting instantiating a `client` instance and connecting it to a Gradio app that is running on Hugging Face Spaces or generally anywhere on the web.
## Connecting to a Hugging Face Space
```js
import { client } from "@gradio/client";
const app = client("abidlabs/en2fr"); // a Space that translates from English to French
```
You can also connect to private Spaces by passing in your HF token with the `hf_token` property of the options parameter. You can get your HF token here: https://huggingface.co/settings/tokens
```js
import { client } from "@gradio/client";
const app = client("abidlabs/my-private-space", { hf_token="hf_..." })
```
## Duplicating a Space for private use
While you can use any public Space as an API, you may get rate limited by Hugging Face if you make too many requests. For unlimited usage of a Space, simply duplicate the Space to create a private Space, and then use it to make as many requests as you'd like!
The `@gradio/client` exports another function, `duplicate`, to make this process simple (you'll need to pass in your [Hugging Face token](https://huggingface.co/settings/tokens)).
`duplicate` is almost identical to `client`, the only difference is under the hood:
```js
import { client } from "@gradio/client";
const response = await fetch(
"https://audio-samples.github.io/samples/mp3/blizzard_unconditional/sample-0.mp3"
);
const audio_file = await response.blob();
const app = await duplicate("abidlabs/whisper", { hf_token: "hf_..." });
const transcription = app.predict("/predict", [audio_file]);
```
If you have previously duplicated a Space, re-running `duplicate` will _not_ create a new Space. Instead, the client will attach to the previously-created Space. So it is safe to re-run the `duplicate` method multiple times with the same space.
**Note:** if the original Space uses GPUs, your private Space will as well, and your Hugging Face account will get billed based on the price of the GPU. To minimize charges, your Space will automatically go to sleep after 5 minutes of inactivity. You can also set the hardware using the `hardware` and `timeout` properties of `duplicate`'s options object like this:
```js
import { client } from "@gradio/client";
const app = await duplicate("abidlabs/whisper", {
hf_token: "hf_...",
timeout: 60,
hardware: "a10g-small"
});
```
## Connecting a general Gradio app
If your app is running somewhere else, just provide the full URL instead, including the "http://" or "https://". Here's an example of making predictions to a Gradio app that is running on a share URL:
```js
import { client } from "@gradio/client";
const app = client("https://bec81a83-5b5c-471e.gradio.live");
```
## Inspecting the API endpoints
Once you have connected to a Gradio app, you can view the APIs that are available to you by calling the `client`'s `view_api` method.
For the Whisper Space, we can do this:
```js
import { client } from "@gradio/client";
const app = await client("abidlabs/whisper");
const app_info = await app.view_api();
console.log(app_info);
```
And we will see the following:
```json
{
"named_endpoints": {
"/predict": {
"parameters": [
{
"label": "text",
"component": "Textbox",
"type": "string"
}
],
"returns": [
{
"label": "output",
"component": "Textbox",
"type": "string"
}
]
}
},
"unnamed_endpoints": {}
}
```
This shows us that we have 1 API endpoint in this space, and shows us how to use the API endpoint to make a prediction: we should call the `.predict()` method (which we will explore below), providing a parameter `input_audio` of type `string`, which is a url to a file.
We should also provide the `api_name='/predict'` argument to the `predict()` method. Although this isn't necessary if a Gradio app has only 1 named endpoint, it does allow us to call different endpoints in a single app if they are available. If an app has unnamed API endpoints, these can also be displayed by running `.view_api(all_endpoints=True)`.
## Making a prediction
The simplest way to make a prediction is simply to call the `.predict()` method with the appropriate arguments:
```js
import { client } from "@gradio/client";
const app = await client("abidlabs/en2fr");
const result = await app.predict("/predict", ["Hello"]);
```
If there are multiple parameters, then you should pass them as an array to `.predict()`, like this:
```js
import { client } from "@gradio/client";
const app = await client("gradio/calculator");
const result = await app.predict("/predict", [4, "add", 5]);
```
For certain inputs, such as images, you should pass in a `Buffer`, `Blob` or `File` depending on what is most convenient. In node, this would be a `Buffer` or `Blob`; in a browser environment, this would be a `Blob` or `File`.
```js
import { client } from "@gradio/client";
const response = await fetch(
"https://audio-samples.github.io/samples/mp3/blizzard_unconditional/sample-0.mp3"
);
const audio_file = await response.blob();
const app = await client("abidlabs/whisper");
const result = await client.predict("/predict", [audio_file]);
```
## Using events
If the API you are working with can return results over time, or you wish to access information about the status of a job, you can use the event interface for more flexibility. This is especially useful for iterative endpoints or generator endpoints that will produce a series of values over time as discreet responses.
```js
import { client } from "@gradio/client";
function log_result(payload) {
const {
data: [translation]
} = payload;
console.log(`The translated result is: ${translation}`);
}
const app = await client("abidlabs/en2fr");
const job = app.submit("/predict", ["Hello"]);
job.on("data", log_result);
```
## Status
The event interface also allows you to get the status of the running job by listening to the `"status"` event. This returns an object with the following attributes: `status` (a human readbale status of the current job, `"pending" | "generating" | "complete" | "error"`), `code` (the detailed gradio code for the job), `position` (the current position of this job in the queue), `queue_size` (the total queue size), `eta` (estimated time this job will complete), `success` (a boolean representing whether the job completed successfully), and `time` ( as `Date` object detailing the time that the status was generated).
```js
import { client } from "@gradio/client";
function log_status(status) {
console.log(
`The current status for this job is: ${JSON.stringify(status, null, 2)}.`
);
}
const app = await client("abidlabs/en2fr");
const job = app.submit("/predict", ["Hello"]);
job.on("status", log_status);
```
## Cancelling Jobs
The job instance also has a `.cancel()` method that cancels jobs that have been queued but not started. For example, if you run:
```js
import { client } from "@gradio/client";
const app = await client("abidlabs/en2fr");
const job_one = app.submit("/predict", ["Hello"]);
const job_two = app.submit("/predict", ["Friends"]);
job_one.cancel();
job_two.cancel();
```
If the first job has started processing, then it will not be canceled but the client will no longer listen for updates (throwing away the job). If the second job has not yet started, it will be successfully canceled and removed from the queue.
## Generator Endpoints
Some Gradio API endpoints do not return a single value, rather they return a series of values. You can listen for these values in real time using the event interface:
```js
import { client } from "@gradio/client";
const app = await client("gradio/count_generator");
const job = app.submit(0, [9]);
job.on("data", (data) => console.log(data));
```
This will log out the values as they are generated by the endpoint.
You can also cancel jobs that that have iterative outputs, in which case the job will finish immediately.
```js
import { client } from "@gradio/client";
const app = await client("gradio/count_generator");
const job = app.submit(0, [9]);
job.on("data", (data) => console.log(data));
setTimeout(() => {
job.cancel();
}, 3000);
```
| gradio-app/gradio/blob/main/guides/08_gradio-clients-and-lite/02_getting-started-with-the-js-client.md |
更多示例 (More on Examples)
本指南介绍了有关示例的更多内容:从目录中加载示例,提供部分示例和缓存。如果你对示例还不熟悉,请查看 [关键特性](../key-features/#example-inputs) 指南中的介绍。
## 提供示例 (Providing Examples)
正如 [关键特性](../key-features/#example-inputs) 指南中所介绍的,向接口添加示例就像提供一个列表的列表给 `examples` 关键字参数一样简单。
每个子列表都是一个数据样本,其中每个元素对应于预测函数的一个输入。
输入必须按照与预测函数期望的顺序排序。
如果你的接口只有一个输入组件,那么可以将示例提供为常规列表,而不是列表的列表。
### 从目录加载示例 (Loading Examples from a Directory)
你还可以指定一个包含示例的目录路径。如果你的接口只接受单个文件类型的输入(例如图像分类器),你只需将目录文件路径传递给 `examples=` 参数,`Interface` 将加载目录中的图像作为示例。
对于多个输入,该目录必须包含一个带有示例值的 log.csv 文件。
在计算器演示的上下文中,我们可以设置 `examples='/demo/calculator/examples'` ,在该目录中包含以下 `log.csv` 文件:
contain a log.csv file with the example values.
In the context of the calculator demo, we can set `examples='/demo/calculator/examples'` and in that directory we include the following `log.csv` file:
```csv
num,operation,num2
5,"add",3
4,"divide",2
5,"multiply",3
```
当浏览标记数据时,这将非常有用。只需指向标记目录,`Interface` 将从标记数据加载示例。
### 提供部分示例
有时你的应用程序有许多输入组件,但你只想为其中的一部分提供示例。为了在示例中排除某些输入,对于那些特定输入对应的所有数据样本都传递 `None`。
## 示例缓存 (Caching examples)
你可能希望为用户提供一些模型的缓存示例,以便他们可以快速尝试,以防您的模型运行时间较长。
如果 `cache_examples=True` ,当你调用 `launch()` 方法时,`Interface` 将运行所有示例,并保存输出。这些数据将保存在一个名为 `gradio_cached_examples` 的目录中。
每当用户点击示例时,输出将自动填充到应用程序中,使用来自该缓存目录的数据,而不是实际运行函数。这对于用户可以快速尝试您的模型而不增加任何负载是非常有用的!
请记住一旦生成了缓存,它将不会在以后的启动中更新。如果示例或函数逻辑发生更改,请删除缓存文件夹以清除缓存并使用另一个 `launch()` 重新构建它。
| gradio-app/gradio/blob/main/guides/cn/02_building-interfaces/03_more-on-examples.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# GPT-NeoX
## Overview
We introduce GPT-NeoX-20B, a 20 billion parameter autoregressive language model trained on the Pile, whose weights will
be made freely and openly available to the public through a permissive license. It is, to the best of our knowledge,
the largest dense autoregressive model that has publicly available weights at the time of submission. In this work,
we describe GPT-NeoX-20B's architecture and training and evaluate its performance on a range of language-understanding,
mathematics, and knowledge-based tasks. We find that GPT-NeoX-20B is a particularly powerful few-shot reasoner and
gains far more in performance when evaluated five-shot than similarly sized GPT-3 and FairSeq models. We open-source
the training and evaluation code, as well as the model weights, at [https://github.com/EleutherAI/gpt-neox](https://github.com/EleutherAI/gpt-neox).
Development of the model was led by Sid Black, Stella Biderman and Eric Hallahan, and the model was trained with
generous the support of [CoreWeave](https://www.coreweave.com/).
GPT-NeoX-20B was trained with fp16, thus it is recommended to initialize the model as follows:
```python
model = GPTNeoXForCausalLM.from_pretrained("EleutherAI/gpt-neox-20b").half().cuda()
```
GPT-NeoX-20B also has a different tokenizer from the one used in GPT-J-6B and GPT-Neo. The new tokenizer allocates
additional tokens to whitespace characters, making the model more suitable for certain tasks like code generation.
## Usage example
The `generate()` method can be used to generate text using GPT Neo model.
```python
>>> from transformers import GPTNeoXForCausalLM, GPTNeoXTokenizerFast
>>> model = GPTNeoXForCausalLM.from_pretrained("EleutherAI/gpt-neox-20b")
>>> tokenizer = GPTNeoXTokenizerFast.from_pretrained("EleutherAI/gpt-neox-20b")
>>> prompt = "GPTNeoX20B is a 20B-parameter autoregressive Transformer model developed by EleutherAI."
>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids
>>> gen_tokens = model.generate(
... input_ids,
... do_sample=True,
... temperature=0.9,
... max_length=100,
... )
>>> gen_text = tokenizer.batch_decode(gen_tokens)[0]
```
## Using Flash Attention 2
Flash Attention 2 is an faster, optimized version of the model.
### Installation
First, check whether your hardware is compatible with Flash Attention 2. The latest list of compatible hardware can be found in the [official documentation](https://github.com/Dao-AILab/flash-attention#installation-and-features). If your hardware is not compatible with Flash Attention 2, you can still benefit from attention kernel optimisations through Better Transformer support covered [above](https://huggingface.co/docs/transformers/main/en/model_doc/bark#using-better-transformer).
Next, [install](https://github.com/Dao-AILab/flash-attention#installation-and-features) the latest version of Flash Attention 2:
```bash
pip install -U flash-attn --no-build-isolation
```
### Usage
To load a model using Flash Attention 2, we can pass the argument `attn_implementation="flash_attention_2"` to [`.from_pretrained`](https://huggingface.co/docs/transformers/main/en/main_classes/model#transformers.PreTrainedModel.from_pretrained). We'll also load the model in half-precision (e.g. `torch.float16`), since it results in almost no degradation to audio quality but significantly lower memory usage and faster inference:
```python
>>> from transformers import GPTNeoXForCausalLM, GPTNeoXTokenizerFast
model = GPTNeoXForCausalLM.from_pretrained("EleutherAI/gpt-neox-20b", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to(device)
...
```
### Expected speedups
Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using `stockmark/gpt-neox-japanese-1.4b` checkpoint and the Flash Attention 2 version of the model using a sequence length of 2048.
<div style="text-align: center">
<img src="https://huggingface.co/datasets/ybelkada/documentation-images/resolve/main/gpt-neox-1.8b-speedup.jpg">
</div>
## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
## GPTNeoXConfig
[[autodoc]] GPTNeoXConfig
## GPTNeoXTokenizerFast
[[autodoc]] GPTNeoXTokenizerFast
## GPTNeoXModel
[[autodoc]] GPTNeoXModel
- forward
## GPTNeoXForCausalLM
[[autodoc]] GPTNeoXForCausalLM
- forward
## GPTNeoXForQuestionAnswering
[[autodoc]] GPTNeoXForQuestionAnswering
- forward
## GPTNeoXForSequenceClassification
[[autodoc]] GPTNeoXForSequenceClassification
- forward
## GPTNeoXForTokenClassification
[[autodoc]] GPTNeoXForTokenClassification
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/gpt_neox.md |
Models
For more detail on the models, please refer to the [docs](https://huggingface.co/docs/diffusers/api/models/overview). | huggingface/diffusers/blob/main/src/diffusers/models/README.md |
--
title: "Opinion Classification with Kili and HuggingFace AutoTrain"
thumbnail: /blog/assets/59_opinion-classification-with-kili/thumbnail.png
authors:
- user: alperiox
guest: true
---
# Opinion Classification with Kili and HuggingFace AutoTrain
## Introduction
Understanding your users’ needs is crucial in any user-related business. But it also requires a lot of hard work and analysis, which is quite expensive. Why not leverage Machine Learning then? With much less coding by using Auto ML.
In this article, we will leverage [HuggingFace AutoTrain](https://huggingface.co/autotrain) and [Kili](https://kili-technology.com/) to build an active learning pipeline for text classification. [Kili](https://kili-technology.com/) is a platform that empowers a data-centric approach to Machine Learning through quality training data creation. It provides collaborative data annotation tools and APIs that enable quick iterations between reliable dataset building and model training. Active learning is a process in which you add labeled data to the data set and then retrain a model iteratively. Therefore, it is endless and requires humans to label the data.
As a concrete example use case for this article, we will build our pipeline by using user reviews of Medium from the Google Play Store. After that, we are going to categorize the reviews with the pipeline we built. Finally, we will apply sentiment analysis to the classified reviews. Then we will analyze the results, understanding the users’ needs and satisfaction will be much easier.
## AutoTrain with HuggingFace
Automated Machine Learning is a term for automating a Machine Learning pipeline. It also includes data cleaning, model selection, and hyper-parameter optimization too. We can use 🤗 transformers for automated hyper-parameter searching. Hyper-parameter optimization is a difficult and time-consuming process.
While we can build our pipeline ourselves by using transformers and other powerful APIs, it is also possible to fully automate this with [AutoTrain](https://huggingface.co/autotrain). AutoTrain is built on many powerful APIs like transformers, [datasets](https://github.com/huggingface/datasets) and [inference-api](https://huggingface.co/docs/transformers/main_classes/trainer).
Cleaning the data, model selection, and hyper-parameter optimization steps are all fully automated in AutoTrain. One can fully utilize this framework to build production-ready SOTA transformer models for a specific task. Currently, AutoTrain supports binary and multi-label text classification, token classification, extractive question answering, text summarization, and text scoring. It also supports many languages like English, German, French, Spanish, Finnish, Swedish, Hindi, Dutch, and [more](https://huggingface.co/autotrain). If your language is not supported by AutoTrain, it is also possible to use custom models with custom tokenizers.
## Kili
[Kili](https://kili-technology.com/) is an end-to-end AI training platform for data-centric businesses. Kili provides optimized labeling features and quality management tools to manage your data. You can quickly annotate the image, video, text, pdf, and voice data while controlling the quality of the dataset. It also has powerful APIs for GraphQL and Python which eases data management a lot.
It is available either online or on-premise and it enables modern Machine Learning technics either on computer vision or on NLP and OCR. It supports text classification, named entity recognition (NER), relation extraction, and more NLP/OCR tasks. It also supports computer vision tasks like object detection, image transcription, video classification, semantic segmentation, and many more!
Kili is a commercial tool but you can also create a free developer account to try Kili’s tools. You can learn more from the [pricing](https://kili-technology.com/pricing/) page.
## Project
We will work on an example of review classification, along with sentiment analysis, to get insights about a mobile application.
We have extracted around 40 thousand reviews of Medium from the Google Play Store. We will [annotate the review texts](https://kili-technology.com/blog/text-annotation-in-machine-learning-an-overview/) in this dataset step by step. And then we’re going to build a pipeline for review classification. In the modeling, the first model will be prepared with AutoTrain. Then we will also build a model without using AutoTrain.
All the code and the dataset can be found on the [GitHub repository](https://github.com/alperiox/review-classification-kili-hf-automl) of the project.
## Dataset
Let’s start by taking a look at the raw dataset,

There are 10 columns and 40130 samples in this dataset. The only column we need is `content` which is the review of the user. Before starting, we need to define some categories.
We have defined 4 categories,
- Subscription: Since medium has a subscription option, anything related to users' opinions about subscription features should belong here.
- Content: Medium is a sharing platform, there are lots of writings from poetry to advanced artificial intelligence research. Users’ opinions about a variety of topics, the quality of the content should belong here.
- Interface: Thoughts about UI, searching articles, recommendation engine, and anything related to the interface should belong here. This also includes payment-related issues.
- User Experience: The user’s general thoughts and opinions about the application. Which should be generally abstract without indicating another category.
For the labeling part, we need to create a project in Kili’s platform at first. We can use either the web interface of the platform or APIs. Let's see both.
**From the web interface:**
From the project list page, we create a multi-class text classification project.

After that, on the project’s page, you can add your data by clicking the Add assets button. Currently, you can add at most 25000 samples, but you can extend this limit if you contact the Kili sales team.
After we create our project, we need to add jobs. We can prepare a labeling interface from the Settings page
Although we have defined 4 categories, it is inevitable to come across reviews that should have multiple categories or completely weird ones. I will add two more labels (which are not to use in modeling) to catch these cases too.
In our example, we added two more labels (Other, Multi-label). We also added a named entity recognition (NER) job just to specify how we decided on a label while labeling. The final interface is shown below

As you can see from the menu at the left, it is also possible to drop a link that describes your labels on the `Instructions` page. We can also add other members to our project from `Members` or add quality measures from the `Quality management` pages. More information can be found in the [documentation](https://cloud.kili-technology.com/docs/overview/introduction-to-kili-technology.html).
**Now, let’s create our project with Python API:**
At first, we need to import needed libraries
([notebooks/kili_project_management.ipynb](https://github.com/alperiox/review-classification-kili-hf-automl/blob/master/notebooks/kili_project_management.ipynb))
```python
import os
#we will process the data (which is a csv file)
import pandas as pd
#API client
from kili.client import Kili
#Why not use pretty progress bars?
from tqdm import tqdm
from dotenv import load_dotenv
load_dotenv()
```
In order to access the platform, we need to authenticate our client
```python
API_KEY = os.getenv('KILI_API_KEY')
# initialize and authenticate the Kili client
kili = Kili(api_key = API_KEY)
```
Now we can start to prepare our interface, the interface is just a dictionary in Python. We will define our jobs, then fill the labels up. Since all labels also could have children labels, we will pass labels as dictionaries too.
```python
labels = ['User experience', 'Subscription', 'Content', 'Other', 'Multi label']
entity_dict = {
'User experience': '#cc4125',
'Subscription': '#4543e6',
'Content': '#3edeb6',
}
project_name = 'User review dataset for topic classification'
project_description = "Medium's app reviews fetched from google play store for topic classification"
interface = {
'jobs': {
'JOB_0': {
'mlTask': 'CLASSIFICATION',
'instruction': 'Labels',
'required': 1,
'content': {
"categories": {},
"input": "radio",
},
},
'JOB_1': {
'mlTask': "NAMED_ENTITIES_RECOGNITION",
'instruction': 'Entities',
'required': 1,
'content': {
'categories': {},
"input": "radio"
},
},
}
}
# fill the interface json with jobs
for label in labels:
# converts labels to uppercase and replaces whitespaces with underscores (_)
# ex. User experience -> USER_EXPERIENCE
# this is the preferred way to fill the interface
label_upper = label.strip().upper().replace(' ', '_')
#
content_dict_0 = interface['jobs']['JOB_0']['content']
categories_0 = content_dict_0['categories']
category = {'name': label, 'children': []}
categories_0[label_upper] = category
for label, color in entity_dict.items():
label_upper = label.strip().upper().replace(' ', '_')
content_dict_1 = interface['jobs']['JOB_1']['content']
categories_1 = content_dict_1['categories']
category = {'name': label, 'children': [], 'color': color}
categories_1[label_upper] = category
# now we can create our project
# this method returns the created project’s id
project_id = kili.create_project(json_interface=interface,
input_type='TEXT',
title=project_name,
description=project_description)['id']
```
We are ready to upload our data to the project. The `append_many_to_dataset` method can be used to import the data into the platform. By using the Python API, we can import the data by batch of 100 maximum. Here is a simple function to upload the data:
```python
def import_dataframe(project_id:str, dataset:pd.DataFrame, text_data_column:str, external_id_column:str, subset_size:int=100) -> bool:
"""
Arguments:
Inputs
- project_id (str): specifies the project to load the data, this is also returned when we create our project
- dataset (pandas DataFrame): Dataset that has proper columns for id and text inputs
- text_data_column (str): specifies which column has the text input data
- external_id_column (str): specifies which column has the ids
- subset_size (int): specifies the number of samples to import at a time. Cannot be higher than 100
Outputs:
None
Returns:
True or False regards to process succession
"""
assert subset_size <= 100, "Kili only allows to upload 100 assets at most at a time onto the app"
L = len(dataset)
# set 25000 as an upload limit, can be changed
if L>25000:
print('Kili Projects currently supports maximum 25000 samples as default. Importing first 25000 samples...')
L=25000
i = 0
while i+subset_size < L:
subset = dataset.iloc[i:i+subset_size]
externalIds = subset[external_id_column].astype(str).to_list()
contents = subset[text_data_column].astype(str).to_list()
kili.append_many_to_dataset(project_id=project_id,
content_array=contents,
external_id_array=externalIds)
i += subset_size
return True
```
It simply imports the given `dataset` DataFrame to a project specified by project_id.
We can see the arguments from docstring, we just need to pass our dataset along with the corresponding column names. We’ll just use the sample indices we get when we load the data. And then voila, uploading the data is done!
```python
dataset_path = '../data/processed/lowercase_cleaned_dataset.csv'
df = pd.read_csv(dataset_path).reset_index() # reset index to get the indices
import_dataframe(project_id, df, 'content', 'index')
```
It wasn’t difficult to use the Python API, the helper methods we used covered many difficulties. We also used another script to check the new samples when we updated the dataset. Sometimes the model performance drop down after the dataset update. This is due to simple mistakes like mislabeling and introducing bias to the dataset. The script simply authenticates and then moves distinct samples of two given dataset versions to `To Review`. We can change the property of a sample through `update_properties_in_assets` method:
([scripts/move_diff_to_review.py](https://github.com/alperiox/review-classification-kili-hf-automl/blob/master/scripts/move_diff_to_review.py))
```python
# Set up the Kili client and arguments
from kili.client import Kili
from dotenv import load_dotenv
import os
import argparse
import pandas as pd
load_dotenv()
parser = argparse.ArgumentParser()
parser.add_argument('--first',
required=True,
type=str,
help='Path to first dataframe')
parser.add_argument('--second',
required=True,
type=str,
help='Path to second dataframe')
args = vars(parser.parse_args())
# set the kili connection up
API_KEY = os.getenv('KILI_API_KEY')
kili = Kili(API_KEY)
# read dataframes
df1 = pd.read_csv(args['first'])
df2 = pd.read_csv(args['second'])
# concating two of them should let us have duplicates of common elements
# then we can drop the duplicated elements without keeping any duplicates to get the different elements across the two dataframes
diff_df = pd.concat((df1, df2)).drop_duplicates(keep=False)
diff_ids = diff_df['id'].to_list()
# The changes should be given as an array that
# contains the change for every single sample.
# That’s why [‘TO_REVIEW’] * len(diff_df) is passed to status_array argument
kili.update_properties_in_assets(diff_ids,
status_array=['TO_REVIEW'] * len(diff_ids))
print('SET %d ENTRIES TO BE REVIEWED!' % len(diff_df))
```
## Labeling
Now that we have the source data uploaded, the platform has a built-in labeling interface which is pretty easy to use. Available keyboard shortcuts helped while annotating the data. We used the interface without breaking a sweat, there are automatically defined shortcuts and it simplifies the labeling. We can see the shortcuts by clicking the keyboard icon at the right-upper part of the interface, they are also shown by underlined characters in the labeling interface at the right.

Some samples were very weird, so we decided to skip them while labeling. In general, the process was way easier thanks to Kili’s built-in platform.

## Exporting the Labeled Data
The labeled data is exported with ease by using Python API. The script below exports the labeled and reviewed samples into a dataframe, then saves it with a given name as a CSV file.
([scripts/prepare_dataset.py](https://github.com/alperiox/review-classification-kili-hf-automl/blob/master/scripts/prepare_dataset.py))
```python
import argparse
import os
import pandas as pd
from dotenv import load_dotenv
from kili.client import Kili
load_dotenv()
parser = argparse.ArgumentParser()
parser.add_argument('--output_name',
required=True,
type=str,
default='dataset.csv')
parser.add_argument('--remove', required=False, type=str)
args = vars(parser.parse_args())
API_KEY = os.getenv('KILI_API_KEY')
dataset_path = '../data/processed/lowercase_cleaned_dataset.csv'
output_path = os.path.join('../data/processed', args['output_name'])
def extract_labels(labels_dict):
response = labels_dict[-1] # pick the latest version of the sample
label_job_dict = response['jsonResponse']['JOB_0']
categories = label_job_dict['categories']
# all samples have a label, we can just pick it by its index
label = categories[0]['name']
return label
kili = Kili(API_KEY)
print('Authenticated!')
# query will return a list that contains matched elements (projects in this case)
# since we have only one project with this name, we can just pick the first index
project = kili.projects(
search_query='User review dataset for topic classification')[0]
project_id = project['id']
# we can customize the returned fields
# the fields below are pretty much enough,
# labels.jsonResponse carries the labeling data
returned_fields = [
'id', 'externalId', 'labels.jsonResponse', 'skipped', 'status'
]
# I read the raw dataset too in order to match the samples with externalId
dataset = pd.read_csv(dataset_path)
# we can fetch the data as a dataframe
df = kili.assets(project_id=project_id,
status_in=['LABELED', 'REVIEWED'],
fields=returned_fields,
format='pandas')
print('Got the samples!')
# we will pass the skipped samples
df_ns = df[~df['skipped']].copy()
# extract the labeled samples
df_ns.loc[:, 'label'] = df_ns['labels'].apply(extract_labels)
# The externalId column is returned as string, let’s convert it to integer
# to use as indices
df_ns.loc[:, 'content'] = dataset.loc[df_ns.externalId.astype(int), 'content']
# we can drop the `labels` column now
df_ns = df_ns.drop(columns=['labels'])
# we'll remove the multi-labeled samples
df_ns = df_ns[df_ns['label'] != 'MULTI_LABEL'].copy()
# also remove the samples with label specified in remove argument if it's given
if args['remove']:
df_ns = df_ns.drop(index=df_ns[df_ns['label'] == args['remove']].index)
print(‘DATA FETCHING DONE')
print('DATASET HAS %d SAMPLES' % (len(df_ns)))
print('SAVING THE PROCESSED DATASET TO: %s' % os.path.abspath(output_path))
df_ns.to_csv(output_path, index=False)
print('DONE!')
```
Nice! We now have the labeled data as a csv file. Let's create a dataset repository in HuggingFace and upload the data there!
It's really simple, just click your profile picture and select `New Dataset` option.

Then enter the repository name, pick a license if you want and it's done!

Now we can upload the dataset from `Add file` in the `Files and versions` tab.

Dataset viewer is automatically available after you upload the data, we can easily check the samples!

It is also possible to [upload the dataset to Hugging Face's dataset hub](https://huggingface.co/docs/datasets/upload_dataset#upload-from-python) by using `datasets` package.
## Modeling
Let's use active learning. We iteratively label and fine-tune the model. In each iteration, we label 50 samples in the dataset. The number of samples is shown below:

Let’s try out AutoTrain first:
First, open the [AutoTrain](https://ui.autonlp.huggingface.co/)
1. Create a project

2. We can select the dataset repository we created before or upload the dataset again. Then we need to choose the split type, I’ll leave it as Auto.

3. Train the models

AutoTrain will try different models and select the best models. Then performs hyper-parameter optimization automatically. The dataset is also processed automatically.
The price totally depends on your use case. It can be as low as $10 or it can be more expensive than the current value.
The training is done after around 20 minutes, the results are pretty good!

The best model’s accuracy is almost %89.

Now we can use this [model](https://huggingface.co/alperiox/autonlp-user-review-classification-536415182) to perform the analysis, it only took about 30 minutes to set up the whole thing.
## Modeling without AutoTrain
We will use [Ray Tune](https://docs.ray.io/en/latest/tune/index.html) and Hugging Face’s Trainer API to search hyper-parameters and fine-tune a pre-trained deep learning model. We have selected [roBERTa base sentiment classification model](https://huggingface.co/cardiffnlp/twitter-roberta-base-sentiment) which is trained on tweets for fine-tuning. We've fine-tuned the model on google collaboratory and it can be found on the `notebooks` folder in the [GitHub repository](https://github.com/alperiox/user-review-classification-hf-kili).
Ray tune is a popular library for hyper-parameter optimization which comes with many SOTA algorithms out of the box. It is also possible to use [Optuna](https://optuna.readthedocs.io/en/stable/index.html) and [SigOpt](https://sigopt.com/).
We also used [Async Successive Halving Algorithm [(ASHA)](https://docs.ray.io/en/latest/tune/api_docs/schedulers.html#asha-tune-schedulers-ashascheduler) as the scheduler and [HyperOpt](https://hyperopt.github.io/hyperopt/) as the search algorithm. Which is pretty much a starting point. You can use different [schedulers](https://docs.ray.io/en/latest/tune/api_docs/schedulers.html) and [search algorithms](https://docs.ray.io/en/latest/tune/api_docs/suggestion.html).
What will we do?
- Import the necessary libraries (a dozen of them) and prepare a dataset class
- Define needed functions and methods to process the data
- Load the pre-trained model and tokenizer
- Run hyper-parameter search
- Use the best results for evaluation
Let’s start with importing necessary libraries!
(all the code is in [notebooks/modeling.ipynb](https://github.com/alperiox/review-classification-kili-hf-automl/blob/master/notebooks/modeling.ipynb) and [google collaboratory notebook](https://colab.research.google.com/drive/1YL-q3_JTEnOtoQdiDUnwSxLVn9Aqpzs8?usp=sharing))
```python
# general data science/utilization/visualization imports
import json
import os
import random
# progress bar
from tqdm import tqdm
# data manipulation / reading
import numpy as np
import pandas as pd
# visualization
import plotly.express as px
import matplotlib.pyplot as plt
# pre-defined evaluation metrics
from sklearn.metrics import (accuracy_score, f1_score,
precision_score, recall_score)
from sklearn.model_selection import train_test_split
# torch imports
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, Dataset, random_split
# huggingface imports
import transformers
from datasets import load_metric
from transformers import (AutoModelForSequenceClassification, AutoTokenizer,
Trainer, TrainingArguments)
# ray tune imports for hyperparameter optimization
from ray.tune.schedulers import ASHAScheduler, PopulationBasedTraining
from ray.tune.suggest.hyperopt import HyperOptSearch
```
We will set a seed for the libraries we use for reproducibility
```python
def seed_all(seed):
torch.manual_seed(seed)
random.seed(seed)
np.random.seed(seed)
SEED=42
seed_all(SEED)
```
Now let’s define our dataset class!
```python
class TextClassificationDataset(Dataset):
def __init__(self, dataframe):
self.labels = dataframe.label.to_list()
self.inputs = dataframe.content.to_list()
self.labels_to_idx = {k:v for k,v in labels_dict.items()} # copy the labels_dict dictionary
def __len__(self):
return len(self.inputs)
def __getitem__(self, idx):
if type(idx)==torch.Tensor:
idx = list(idx)
input_data = self.inputs[idx]
target = self.labels[idx]
target = self.labels_to_idx[target]
return {'text': input_data, 'label':target}
```
We can download the model easily by specifying HuggingFace hub repository. It is also needed to import the tokenizer for the specified model. We have to provide a function to initialize the model during hyper-parameter optimization. The model will be defined there.
The metric to optimize is accuracy, we want this value to be as high as possible. Because of that, we need to load the metric, then define a function to get the predictions and calculate the preferred metric.
```python
model_name = 'cardiffnlp/twitter-roberta-base-sentiment'
# we will perform the search to optimize the model accuracy,
# we need to specify and load the accuracy metric as a first step
metric = load_metric("accuracy")
# since we already entered a model name, we can load the tokenizer
# we can also load the model but i'll describe it in the model_init function.
tokenizer = AutoTokenizer.from_pretrained(model_name)
def model_init():
"""
Hyperparameter optimization is performed by newly initialized models,
therefore we will need to initialize the model again for every single search run.
This function initializes and returns the pre-trained model selected with `model_name`
"""
return AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=4, return_dict=True, ignore_mismatched_sizes=True)
# the function to calculate accuracy
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1) # just pick the indices that has the maximum values
return metric.compute(predictions=predictions, references=labels)
```
After defining metric calculation and model initialization function, we can load the data:
```python
file_name = "dataset-11.csv"
dataset_path = os.path.join('data/processed', file_name)
dataset = pd.read_csv(dataset_path)
```
I also defined two dictionaries for mapping labels to indices and indices to labels.
```python
idx_to_label = dict(enumerate(dataset.label.unique()))
labels_dict = {v:k for k,v in idx_to_label.items()}
```
Now we can define the search algorithm and the scheduler for the hyper-parameter-search.
```python
scheduler = ASHAScheduler(metric='objective', mode='max')
search_algorithm = HyperOptSearch(metric='objective', mode='max', random_state_seed=SEED)
# number of runs for parameter searching
n_trials = 40
```
We also need to tokenize the text data before passing it to the model, we can easily do this by using the loaded tokenizer. Ray Tune works in a black-box setting so I used tokenizer as a default argument for a work-around. Otherwise, an error about tokenizer definition would arise.
```python
def tokenize(sample, tokenizer=tokenizer):
tokenized_sample = tokenizer(sample['text'], padding=True, truncation=True)
tokenized_sample['label'] = sample['label']
return tokenized_sample
```
Another utility function that returns stratified and tokenized Torch dataset splits:
```python
def prepare_datasets(dataset_df, test_size=.2, val_size=.2):
train_set, test_set = train_test_split(dataset_df, test_size=test_size,
stratify=dataset_df.label, random_state=SEED)
train_set, val_set = train_test_split(train_set, test_size=val_size,
stratify=train_set.label, random_state=SEED)
# shuffle the dataframes beforehand
train_set = train_set.sample(frac=1, random_state=SEED)
val_set = val_set.sample(frac=1, random_state=SEED)
test_set = test_set.sample(frac=1, random_state=SEED)
# convert dataframes to torch datasets
train_dataset = TextClassificationDataset(train_set)
val_dataset = TextClassificationDataset(val_set)
test_dataset = TextClassificationDataset(test_set)
# tokenize the datasets
tokenized_train_set = train_dataset.map(tokenize)
tokenized_val_set = val_dataset.map(tokenize)
tokenized_test_set = test_dataset.map(tokenize)
# finally return the processed sets
return tokenized_train_set, tokenized_val_set, tokenized_test_set
```
Now we can perform the search! Let’s start by processing the data:
```python
tokenized_train_set, tokenized_val_set, tokenized_test_set = prepare_datasets(dataset)
training_args = TrainingArguments(
'trial_results',
evaluation_strategy="steps",
disable_tqdm=True,
skip_memory_metrics=True,
)
trainer = Trainer(
args=training_args,
tokenizer=tokenizer,
train_dataset=tokenized_train_set,
eval_dataset=tokenized_val_set,
model_init=model_init,
compute_metrics=compute_metrics
)
best_run = trainer.hyperparameter_search(
direction="maximize",
n_trials=n_trials,
backend="ray",
search_alg=search_algorithm,
scheduler=scheduler
)
```
We performed the search with 20 and 40 trials respectively, the results are shown below. The weighted average of F1, Recall, and Precision scores for 20 runs.

The weighted average of F1, Recall, and Precision scores for 40 runs.

The performance spiked up at the third dataset version. At some point in data labeling, I’ve introduced too much bias to the dataset mistakingly. As we can see its performance becomes more reasonable since the sample variance increased later on. The final model is saved at Google Drive and can be downloaded from [here](https://drive.google.com/drive/folders/1X_ci2Pwu0-1XbXsaCksQHZF0254TIHiD?usp=sharing), it is also possible to download via the [download_models.py](https://github.com/alperiox/review-classification-kili-hf-automl/tree/master/scripts) script.
## Final Analysis
We can use the fine-tuned model to conduct the final analysis now. All we have to do is load the data, process it, and get the prediction results from the model. Then we can use a pre-trained model for sentiment analysis and hopefully get insights.
We use Google Colab for the inference ([here](https://colab.research.google.com/drive/1kGYl_YcMmA2gj6HnYFzkcxSDNPlHjYaZ?usp=sharing)) and then exported the results to [result.csv](https://github.com/alperiox/review-classification-kili-hf-automl/tree/master/results). It can be found in `results` in the GitHub repository. We then analyzed the results in another [google collaboratory notebook](https://colab.research.google.com/drive/1TOX7tqJ7SGbUDWwA_6D1y-U0aNNXY04Q?usp=sharing) for an interactive experience. So you can also use it easily and interactively.
Let’s check the results now!
We can see that the given scores are highly positive. In general, the application is liked by the users.

This also matches with the sentiment analysis, most of the reviews are positive and the least amount of reviews are classified as negative.

As we can see from above, the model's performance is kind of understandable. Positive scores are dominantly higher than the others, just like the sentimental analysis graph shows.
As it comes to the categories defined before, it seems that the model predicts most of the reviews are about users' experiences (excluding experiences related to other categories):

We can also see the sentiment predictions over defined categories below:

We won't do a detailed analysis of the reviews, a basic understanding of potential problems would suffice. Therefore, it is enough to conclude simple results from the final data:
- It is understandable that most of the reviews about the subscription are negative. Paid content generally is not welcomed in mobile applications.
- There are many negative reviews about the interface. This may be a clue for further analysis. Maybe there is a misconception about features, or a feature doesn't work as users thought.
- People have generally liked the articles and most of them had good experiences.
Important note about the plot: we haven't filtered the reviews by application version. When we look at the results of the latest current version (4.5), it seems that the interface of the application confuses the users or has annoying bugs.

## Conclusion
Now we can use the pre-trained model to try to understand the potential shortcomings of the mobile application. Then it would be easier to analyze a specific feature.
We used HuggingFace’s powerful APIs and AutoTrain along with Kili’s easy-to-use interface in this example. The modeling with AutoTrain just took 30 minutes, it chose the models and trained them for our use. AutoTrain is definitely much more efficient since I spent more time as I develop the model by myself.
All the code, datasets, and scripts can be found in [github](https://github.com/alperiox/review-classification-kili-hf-automl). You can also try the [AutoTrain model](https://huggingface.co/alperiox/autonlp-user-review-classification-536415182).
While we can consider this as a valid starting point, we should collect more data and try to build better pipelines. Better pipelines would result in more efficient improvements.
| huggingface/blog/blob/main/opinion-classification-with-kili.md |
从 Supabase 数据创建仪表盘
Tags: TABULAR, DASHBOARD, PLOTS
[Supabase](https://supabase.com/) 是一个基于云的开源后端,提供了 PostgreSQL 数据库、身份验证和其他有用的功能,用于构建 Web 和移动应用程序。在本教程中,您将学习如何从 Supabase 读取数据,并在 Gradio 仪表盘上以**实时**方式绘制数据。
**先决条件 :** 要开始,您需要一个免费的 Supabase 账户,您可以在此处注册:[https://app.supabase.com/](https://app.supabase.com/)
在这个端到端指南中,您将学习如何:
- 在 Supabase 中创建表
- 使用 Supabase Python 客户端向 Supabase 写入数据
- 使用 Gradio 在实时仪表盘中可视化数据
如果您已经在 Supabase 上有数据想要在仪表盘中可视化,您可以跳过前两个部分,直接到[可视化数据](#visualize-the-data-in-a-real-time-gradio-dashboard)!
## 在 Supabase 中创建表
首先,我们需要一些要可视化的数据。根据这个[出色的指南](https://supabase.com/blog/loading-data-supabase-python),我们将创建一些虚假的商务数据,并将其放入 Supabase 中。
1\. 在 Supabase 中创建一个新项目。一旦您登录,点击 "New Project" 按钮
2\. 给您的项目命名并设置数据库密码。您还可以选择定价计划(对于我们来说,免费计划已足够!)
3\. 在数据库启动时(可能需要多达 2 分钟),您将看到您的 API 密钥。
4\. 在左侧窗格中单击 "Table Editor"(表图标)以创建一个新表。我们将创建一个名为 `Product` 的单表,具有以下模式:
<center>
<table>
<tr><td>product_id</td><td>int8</td></tr>
<tr><td>inventory_count</td><td>int8</td></tr>
<tr><td>price</td><td>float8</td></tr>
<tr><td>product_name</td><td>varchar</td></tr>
</table>
</center>
5\. 点击保存以保存表结构。
我们的表已经准备好了!
## 将数据写入 Supabase
下一步是向 Supabase 数据集中写入数据。我们将使用 Supabase Python 库来完成这个任务。
6\. 通过在终端中运行以下命令来安装 `supabase` 库:
```bash
pip install supabase
```
7\. 获取项目 URL 和 API 密钥。点击左侧窗格上的设置(齿轮图标),然后点击 'API'。URL 列在项目 URL 框中,API 密钥列在项目 API 密钥(带有 `service_role`、`secret` 标签)中
8\. 现在,运行以下 Python 脚本将一些虚假数据写入表中(注意您需要在步骤 7 中放入 `SUPABASE_URL` 和 `SUPABASE_SECRET_KEY` 的值):
```python
import supabase
# 初始化Supabase客户端
client = supabase.create_client('SUPABASE_URL', 'SUPABASE_SECRET_KEY')
# 定义要写入的数据
import random
main_list = []
for i in range(10):
value = {'product_id': i,
'product_name': f"Item {i}",
'inventory_count': random.randint(1, 100),
'price': random.random()*100
}
main_list.append(value)
# 将数据写入表中
data = client.table('Product').insert(main_list).execute()
```
返回 Supabase 仪表板并刷新页面,您将看到 10 行数据填充到 `Product` 表中!
## 在实时 Gradio 仪表盘中可视化数据
最后,我们将使用相同的 `supabase` Python 库从 Supabase 数据集中读取数据,并使用 `gradio` 创建一个实时仪表盘。
注意:我们在本节中重复了某些步骤(比如创建 Supabase 客户端),以防您没有完成之前的部分。如第 7 步所述,您将需要数据库的项目 URL 和 API 密钥。
9\. 编写一个函数,从 `Product` 表加载数据并将其作为 pandas DataFrame 返回:
import supabase
```python
import supabase
import pandas as pd
client = supabase.create_client('SUPABASE_URL', 'SUPABASE_SECRET_KEY')
def read_data():
response = client.table('Product').select("*").execute()
df = pd.DataFrame(response.data)
return df
```
10\. 使用两个条形图创建一个小的 Gradio 仪表盘,每分钟绘制所有项目的价格和库存量,并实时更新:
```python
import gradio as gr
with gr.Blocks() as dashboard:
with gr.Row():
gr.BarPlot(read_data, x="product_id", y="price", title="价格", every=60)
gr.BarPlot(read_data, x="product_id", y="inventory_count", title="库存", every=60)
dashboard.queue().launch()
```
请注意,通过将函数传递给 `gr.BarPlot()`,我们可以在网络应用加载时查询数据库(然后每 60 秒查询一次,因为有 `every` 参数)。您的最终仪表盘应如下所示:
<gradio-app space="abidlabs/supabase"></gradio-app>
## 结论
就是这样!在本教程中,您学习了如何将数据写入 Supabase 数据集,然后读取该数据并将结果绘制为条形图。如果您更新 Supabase 数据库中的数据,您会注意到 Gradio 仪表盘将在一分钟内更新。
尝试在此示例中添加更多绘图和可视化(或使用不同的数据集),以构建一个更复杂的仪表盘!
| gradio-app/gradio/blob/main/guides/cn/05_tabular-data-science-and-plots/creating-a-dashboard-from-supabase-data.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Efficient Training on Multiple GPUs
If training a model on a single GPU is too slow or if the model's weights do not fit in a single GPU's memory, transitioning
to a multi-GPU setup may be a viable option. Prior to making this transition, thoroughly explore all the strategies covered
in the [Methods and tools for efficient training on a single GPU](perf_train_gpu_one) as they are universally applicable
to model training on any number of GPUs. Once you have employed those strategies and found them insufficient for your
case on a single GPU, consider moving to multiple GPUs.
Transitioning from a single GPU to multiple GPUs requires the introduction of some form of parallelism, as the workload
must be distributed across the resources. Multiple techniques can be employed to achieve parallelism, such as data
parallelism, tensor parallelism, and pipeline parallelism. It's important to note that there isn't a one-size-fits-all
solution, and the optimal settings depend on the specific hardware configuration you are using.
This guide offers an in-depth overview of individual types of parallelism, as well as guidance on ways to combine
techniques and choosing an appropriate approach. For step-by-step tutorials on distributed training, please refer to
the [🤗 Accelerate documentation](https://huggingface.co/docs/accelerate/index).
<Tip>
While the main concepts discussed in this guide are likely applicable across frameworks, here we focus on
PyTorch-based implementations.
</Tip>
Before diving deeper into the specifics of each technique, let's go over the rough decision process when training
large models on a large infrastructure.
## Scalability strategy
Begin by estimating how much vRAM is required to train your model. For models hosted on the 🤗 Hub, use our
[Model Memory Calculator](https://huggingface.co/spaces/hf-accelerate/model-memory-usage), which gives you
accurate calculations within a few percent margin.
**Parallelization strategy for a single Node / multi-GPU setup**
When training a model on a single node with multiple GPUs, your choice of parallelization strategy can significantly
impact performance. Here's a breakdown of your options:
**Case 1: Your model fits onto a single GPU**
If your model can comfortably fit onto a single GPU, you have two primary options:
1. DDP - Distributed DataParallel
2. ZeRO - depending on the situation and configuration used, this method may or may not be faster, however, it's worth experimenting with it.
**Case 2: Your model doesn't fit onto a single GPU:**
If your model is too large for a single GPU, you have several alternatives to consider:
1. PipelineParallel (PP)
2. ZeRO
3. TensorParallel (TP)
With very fast inter-node connectivity (e.g., NVLINK or NVSwitch) all three strategies (PP, ZeRO, TP) should result in
similar performance. However, without these, PP will be faster than TP or ZeRO. The degree of TP may also
make a difference. It's best to experiment with your specific setup to determine the most suitable strategy.
TP is almost always used within a single node. That is TP size <= GPUs per node.
**Case 3: Largest layer of your model does not fit onto a single GPU**
1. If you are not using ZeRO, you have to use TensorParallel (TP), because PipelineParallel (PP) alone won't be sufficient to accommodate the large layer.
2. If you are using ZeRO, additionally adopt techniques from the [Methods and tools for efficient training on a single GPU](perf_train_gpu_one).
**Parallelization strategy for a multi-Node / multi-GPU setup**
* When you have fast inter-node connectivity (e.g., NVLINK or NVSwitch) consider using one of these options:
1. ZeRO - as it requires close to no modifications to the model
2. A combination of PipelineParallel(PP) with TensorParallel(TP) and DataParallel(DP) - this approach will result in fewer communications, but requires significant changes to the model
* When you have slow inter-node connectivity and still low on GPU memory:
1. Employ a combination of DataParallel(DP) with PipelineParallel(PP), TensorParallel(TP), and ZeRO.
In the following sections of this guide we dig deeper into how these different parallelism methods work.
## Data Parallelism
Even with only 2 GPUs, you can readily leverage the accelerated training capabilities offered by PyTorch's built-in features,
such as `DataParallel` (DP) and `DistributedDataParallel` (DDP). Note that
[PyTorch documentation](https://pytorch.org/docs/master/generated/torch.nn.DataParallel.html) recommends to prefer
`DistributedDataParallel` (DDP) over `DataParallel` (DP) for multi-GPU training as it works for all models.
Let's take a look at how these two methods work and what makes them different.
### DataParallel vs DistributedDataParallel
To understand the key differences in inter-GPU communication overhead between the two methods, let's review the processes per batch:
[DDP](https://pytorch.org/docs/master/notes/ddp.html):
- At the start time the main process replicates the model once from GPU 0 to the rest of GPUs
- Then for each batch:
1. Each GPU directly consumes its mini-batch of data.
2. During `backward`, once the local gradients are ready, they are averaged across all processes.
[DP](https://pytorch.org/docs/master/generated/torch.nn.DataParallel.html):
For each batch:
1. GPU 0 reads the batch of data and then sends a mini-batch to each GPU.
2. The up-to-date model is replicated from GPU 0 to each GPU.
3. `forward` is executed, and output from each GPU is sent to GPU 0 to compute the loss.
4. The loss is distributed from GPU 0 to all GPUs, and `backward` is run.
5. Gradients from each GPU are sent to GPU 0 and averaged.
Key differences include:
1. DDP performs only a single communication per batch - sending gradients, while DP performs five different data exchanges per batch.
DDP copies data using [torch.distributed](https://pytorch.org/docs/master/distributed.html), while DP copies data within
the process via Python threads (which introduces limitations associated with GIL). As a result, **`DistributedDataParallel` (DDP) is generally faster than `DataParallel` (DP)** unless you have slow GPU card inter-connectivity.
2. Under DP, GPU 0 performs significantly more work than other GPUs, resulting in GPU under-utilization.
3. DDP supports distributed training across multiple machines, whereas DP does not.
This is not an exhaustive list of differences between DP and DDP, however, other nuances are out of scope of this guide.
You can get a deeper understanding of these methods by reading this [article](https://www.telesens.co/2019/04/04/distributed-data-parallel-training-using-pytorch-on-aws/).
Let's illustrate the differences between DP and DDP with an experiment. We'll benchmark the differences between DP and
DDP with an added context of NVLink presence:
* Hardware: 2x TITAN RTX 24GB each + NVlink with 2 NVLinks (`NV2` in `nvidia-smi topo -m`).
* Software: `pytorch-1.8-to-be` + `cuda-11.0` / `transformers==4.3.0.dev0`.
To disable the NVLink feature on one of the benchmarks, we use `NCCL_P2P_DISABLE=1`.
Here is the benchmarking code and outputs:
**DP**
```
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 \
python examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
{'train_runtime': 110.5948, 'train_samples_per_second': 1.808, 'epoch': 0.69}
```
**DDP w/ NVlink**
```
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 \
torchrun --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
{'train_runtime': 101.9003, 'train_samples_per_second': 1.963, 'epoch': 0.69}
```
**DDP w/o NVlink**
```
rm -r /tmp/test-clm; NCCL_P2P_DISABLE=1 CUDA_VISIBLE_DEVICES=0,1 \
torchrun --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
{'train_runtime': 131.4367, 'train_samples_per_second': 1.522, 'epoch': 0.69}
```
Here are the same benchmarking results gathered in a table for convenience:
| Type | NVlink | Time |
| :----- | ----- | ---: |
| 2:DP | Y | 110s |
| 2:DDP | Y | 101s |
| 2:DDP | N | 131s |
As you can see, in this case DP is ~10% slower than DDP with NVlink, but ~15% faster than DDP without NVlink.
The real difference will depend on how much data each GPU needs to sync with the others - the more there is to sync,
the more a slow link will impede the overall runtime.
## ZeRO Data Parallelism
ZeRO-powered data parallelism (ZeRO-DP) is illustrated in the following diagram from this [blog post](https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/).
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/parallelism-zero.png" alt="DeepSpeed-Image-1"/>
</div>
While it may appear complex, it is a very similar concept to `DataParallel` (DP). The difference is that instead of
replicating the full model parameters, gradients and optimizer states, each GPU stores only a slice of it. Then, at
run-time when the full layer parameters are needed just for the given layer, all GPUs synchronize to give each other
parts that they miss.
To illustrate this idea, consider a simple model with 3 layers (La, Lb, and Lc), where each layer has 3 parameters.
Layer La, for example, has weights a0, a1 and a2:
```
La | Lb | Lc
---|----|---
a0 | b0 | c0
a1 | b1 | c1
a2 | b2 | c2
```
If we have 3 GPUs, ZeRO-DP splits the model onto 3 GPUs like so:
```
GPU0:
La | Lb | Lc
---|----|---
a0 | b0 | c0
GPU1:
La | Lb | Lc
---|----|---
a1 | b1 | c1
GPU2:
La | Lb | Lc
---|----|---
a2 | b2 | c2
```
In a way, this is the same horizontal slicing as tensor parallelism, as opposed to Vertical
slicing, where one puts whole layer-groups on different GPUs. Now let's see how this works:
Each of these GPUs will get the usual mini-batch as it works in DP:
```
x0 => GPU0
x1 => GPU1
x2 => GPU2
```
The inputs are passed without modifications as if they would be processed by the original model.
First, the inputs get to the layer `La`. What happens at this point?
On GPU0: the x0 mini-batch requires the a0, a1, a2 parameters to do its forward path through the layer, but the GPU0 has only a0.
It will get a1 from GPU1 and a2 from GPU2, bringing all the pieces of the model together.
In parallel, GPU1 gets another mini-batch - x1. GPU1 has the a1 parameter, but needs a0 and a2, so it gets those from GPU0 and GPU2.
Same happens to GPU2 that gets the mini-batch x2. It gets a0 and a1 from GPU0 and GPU1.
This way each of the 3 GPUs gets the full tensors reconstructed and makes a forward pass with its own mini-batch.
As soon as the calculation is done, the data that is no longer needed gets dropped - it's only used during the calculation.
The reconstruction is done efficiently via a pre-fetch.
Then the whole process is repeated for layer Lb, then Lc forward-wise, and then backward Lc -> Lb -> La.
<Tip>
This mechanism is similar to an efficient group backpacking strategy: person A carries the tent, person B carries the stove,
and person C carries the axe. Each night they all share what they have with others and get from others what they don't have,
and in the morning they pack up their allocated type of gear and continue on their way. This is what ZeRO DP/Sharded DDP is.
Compare this strategy to the simple one where each person has to carry their own tent, stove and axe (similar to
DataParallel (DP and DDP) in PyTorch), which would be far more inefficient.
</Tip>
While reading the literature on this topic you may encounter the following synonyms: Sharded, Partitioned.
If you pay close attention the way ZeRO partitions the model's weights - it looks very similar to tensor parallelism
which will be discussed later. This is because it partitions/shards each layer's weights, unlike vertical model parallelism
which is discussed next.
Implementations:
- [DeepSpeed](https://www.deepspeed.ai/tutorials/zero/) ZeRO-DP stages 1+2+3
- [`Accelerate` integration](https://huggingface.co/docs/accelerate/en/usage_guides/deepspeed)
- [`transformers` integration](main_classes/trainer#trainer-integrations)
## From Naive Model Parallelism to Pipeline Parallelism
To explain Pipeline parallelism, we'll first look into Naive Model Parallelism (MP), also known as Vertical MP. This approach
involves distributing groups of model layers across multiple GPUs by assigning specific layers to specific GPUs with `.to()`.
As data flows through these layers, it is moved to the same GPU as the layer, while the other layers remain untouched.
We refer to this Model parallelism as "Vertical" because of how models are typically visualized. For example, the
following diagram shows an 8-layer model split vertically into two slices, placing layers 0-3 onto
GPU0 and 4-7 to GPU1:
```
=================== ===================
| 0 | 1 | 2 | 3 | | 4 | 5 | 6 | 7 |
=================== ===================
GPU0 GPU1
```
In this example, when data moves from layer 0 to 3, it's no different from regular forward pass. However, passing data
from layer 3 to 4 requires moving it from GPU0 to GPU1, introducing a communication overhead. If the participating
GPUs are on the same compute node (e.g. same physical machine) this copying is fast, but if the GPUs are distributed
across different compute nodes (e.g. multiple machines), the communication overhead could be substantially greater.
Following that, layers 4 to 7 work as they would in the original model. Upon completion of the 7th layer, there is often
a need to send the data back to layer 0 where the labels are (or alternatively send the labels to the last layer). Now the loss can be
computed and the optimizer can do its work.
Naive Model Parallelism comes several shortcomings:
- **All but one GPU are idle at any given moment**: if 4 GPUs are used, it's nearly identical to quadrupling the amount of memory of a single GPU, and ignoring the rest of the hardware.
- **Overhead in data transfer between devices**: E.g. 4x 6GB cards will be able to accommodate the same size as 1x 24GB card using naive MP, but a single 24GB card will complete the training faster, because it doesn't have the data copying overhead. But, say, if you have 40GB cards and need to fit a 45GB model you can with 4x 40GB cards (but barely because of the gradient and optimizer states)
- **Copying shared embeddings**: Shared embeddings may need to get copied back and forth between GPUs.
Now that you are familiar with how the naive approach to model parallelism works and its shortcomings, let's look at Pipeline Parallelism (PP).
PP is almost identical to a naive MP, but it solves the GPU idling problem by chunking the incoming batch into micro-batches
and artificially creating a pipeline, which allows different GPUs to concurrently participate in the computation process.
The following illustration from the [GPipe paper](https://ai.googleblog.com/2019/03/introducing-gpipe-open-source-library.html)
shows the naive MP on the top, and PP on the bottom:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/parallelism-gpipe-bubble.png" alt="MP vs PP"/>
</div>
At the bottom of the diagram, you can observe that the Pipeline Parallelism (PP) approach minimizes the number of idle
GPU zones, referred to as 'bubbles'. Both parts of the diagram show a parallelism level of degree 4, meaning that 4 GPUs
are involved in the pipeline. You can see that there's a forward path of 4 pipe stages (F0, F1, F2 and F3) followed by
a backward path in reverse order (B3, B2, B1, and B0).
PP introduces a new hyperparameter to tune - `chunks`, which determines how many data chunks are sent in a sequence
through the same pipe stage. For example, in the bottom diagram you can see `chunks=4`. GPU0 performs the same
forward path on chunk 0, 1, 2 and 3 (F0,0, F0,1, F0,2, F0,3) and then it waits for other GPUs to do complete their work.
Only when the other GPUs begin to complete their work, GPU0 starts to work again doing the backward path for chunks
3, 2, 1 and 0 (B0,3, B0,2, B0,1, B0,0).
Note that this is the same concept as gradient accumulation steps. PyTorch uses `chunks`, while DeepSpeed refers
to the same hyperparameter as gradient accumulation steps.
Because of the chunks, PP introduces the notion of micro-batches (MBS). DP splits the global data batch size into
mini-batches, so if you have a DP degree of 4, a global batch size of 1024 gets split up into 4 mini-batches of
256 each (1024/4). And if the number of `chunks` (or GAS) is 32 we end up with a micro-batch size of 8 (256/32). Each
Pipeline stage works with a single micro-batch at a time. To calculate the global batch size of the DP + PP setup,
use the formula: `mbs * chunks * dp_degree` (`8 * 32 * 4 = 1024`).
With `chunks=1` you end up with the naive MP, which is inefficient. With a large `chunks` value you end up with
tiny micro-batch sizes which is also inefficient. For this reason, we encourage to experiment with the `chunks` value to
find the one that leads to the most efficient GPUs utilization.
You may notice a bubble of "dead" time on the diagram that can't be parallelized because the last `forward` stage
has to wait for `backward` to complete the pipeline. The purpose of finding the best value for `chunks` is to enable a high
concurrent GPU utilization across all participating GPUs which translates to minimizing the size of the bubble.
Pipeline API solutions have been implemented in:
- PyTorch
- DeepSpeed
- Megatron-LM
These come with some shortcomings:
- They have to modify the model quite heavily, because Pipeline requires one to rewrite the normal flow of modules into a `nn.Sequential` sequence of the same, which may require changes to the design of the model.
- Currently the Pipeline API is very restricted. If you had a bunch of Python variables being passed in the very first stage of the Pipeline, you will have to find a way around it. Currently, the pipeline interface requires either a single Tensor or a tuple of Tensors as the only input and output. These tensors must have a batch size as the very first dimension, since pipeline is going to chunk the mini batch into micro-batches. Possible improvements are being discussed here https://github.com/pytorch/pytorch/pull/50693
- Conditional control flow at the level of pipe stages is not possible - e.g., Encoder-Decoder models like T5 require special workarounds to handle a conditional encoder stage.
- They have to arrange each layer so that the output of one layer becomes an input to the other layer.
More recent solutions include:
- Varuna
- Sagemaker
We have not experimented with Varuna and SageMaker but their papers report that they have overcome the list of problems
mentioned above and that they require smaller changes to the user's model.
Implementations:
- [PyTorch](https://pytorch.org/docs/stable/pipeline.html) (initial support in pytorch-1.8, and progressively getting improved in 1.9 and more so in 1.10). Some [examples](https://github.com/pytorch/pytorch/blob/master/benchmarks/distributed/pipeline/pipe.py)
- [DeepSpeed](https://www.deepspeed.ai/tutorials/pipeline/)
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM) has an internal implementation - no API.
- [Varuna](https://github.com/microsoft/varuna)
- [SageMaker](https://arxiv.org/abs/2111.05972) - this is a proprietary solution that can only be used on AWS.
- [OSLO](https://github.com/tunib-ai/oslo) - this is implemented based on the Hugging Face Transformers.
🤗 Transformers status: as of this writing none of the models supports full-PP. GPT2 and T5 models have naive MP support.
The main obstacle is being unable to convert the models to `nn.Sequential` and have all the inputs to be Tensors. This
is because currently the models include many features that make the conversion very complicated, and will need to be removed to accomplish that.
DeepSpeed and Megatron-LM integrations are available in [🤗 Accelerate](https://huggingface.co/docs/accelerate/main/en/usage_guides/deepspeed)
Other approaches:
DeepSpeed, Varuna and SageMaker use the concept of an [Interleaved Pipeline](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-core-features.html)
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/parallelism-sagemaker-interleaved-pipeline.png" alt="Interleaved pipeline execution"/>
</div>
Here the bubble (idle time) is further minimized by prioritizing backward passes. Varuna further attempts to improve the
schedule by using simulations to discover the most efficient scheduling.
OSLO has pipeline parallelism implementation based on the Transformers without `nn.Sequential` conversion.
## Tensor Parallelism
In Tensor Parallelism, each GPU processes a slice of a tensor and only aggregates the full tensor for operations requiring it.
To describe this method, this section of the guide relies on the concepts and diagrams from the [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)
paper: [Efficient Large-Scale Language Model Training on GPU Clusters](https://arxiv.org/abs/2104.04473).
The main building block of any transformer is a fully connected `nn.Linear` followed by a nonlinear activation `GeLU`.
The dot dot-product part of it, following the Megatron's paper notation, can be written as `Y = GeLU(XA)`, where `X` is
an input vector, `Y` is the output vector, and `A` is the weight matrix.
If we look at the computation in matrix form, you can see how the matrix multiplication can be split between multiple GPUs:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/parallelism-tp-parallel_gemm.png" alt="Parallel GEMM"/>
</div>
If we split the weight matrix `A` column-wise across `N` GPUs and perform matrix multiplications `XA_1` through `XA_n` in parallel,
then we will end up with `N` output vectors `Y_1, Y_2, ..., Y_n` which can be fed into `GeLU` independently:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/parallelism-tp-independent-gelu.png" alt="Independent GeLU"/>
</div>
Using this principle, we can update a multi-layer perceptron of arbitrary depth, without the need for any synchronization
between GPUs until the very end, where we need to reconstruct the output vector from shards. The Megatron-LM paper authors
provide a helpful illustration for that:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/parallelism-tp-parallel_shard_processing.png" alt="Parallel shard processing"/>
</div>
Parallelizing the multi-headed attention layers is even simpler, since they are already inherently parallel, due to having
multiple independent heads!
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/parallelism-tp-parallel_self_attention.png" alt="Parallel self-attention"/>
</div>
Special considerations: TP requires very fast network, and therefore it's not advisable to do TP across more than one node.
Practically, if a node has 4 GPUs, the highest TP degree is therefore 4. If you need a TP degree of 8, you need to use
nodes that have at least 8 GPUs.
This section is based on the original much more [detailed TP overview](https://github.com/huggingface/transformers/issues/10321#issuecomment-783543530).
by [@anton-l](https://github.com/anton-l).
Alternative names:
- DeepSpeed calls it [tensor slicing](https://www.deepspeed.ai/training/#model-parallelism)
Implementations:
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM) has an internal implementation, as it's very model-specific
- [parallelformers](https://github.com/tunib-ai/parallelformers) (only inference at the moment)
- [SageMaker](https://arxiv.org/abs/2111.05972) - this is a proprietary solution that can only be used on AWS.
- [OSLO](https://github.com/tunib-ai/oslo) has the tensor parallelism implementation based on the Transformers.
SageMaker combines TP with DP for a more efficient processing.
🤗 Transformers status:
- core: not yet implemented in the core
- but if you want inference [parallelformers](https://github.com/tunib-ai/parallelformers) provides this support for most of our models. So until this is implemented in the core you can use theirs. And hopefully training mode will be supported too.
- Deepspeed-Inference also supports our BERT, GPT-2, and GPT-Neo models in their super-fast CUDA-kernel-based inference mode, see more [here](https://www.deepspeed.ai/tutorials/inference-tutorial/)
🤗 Accelerate integrates with [TP from Megatron-LM](https://huggingface.co/docs/accelerate/v0.23.0/en/usage_guides/megatron_lm).
## Data Parallelism + Pipeline Parallelism
The following diagram from the DeepSpeed [pipeline tutorial](https://www.deepspeed.ai/tutorials/pipeline/) demonstrates
how one can combine DP with PP.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/parallelism-zero-dp-pp.png" alt="DP + PP-2d"/>
</div>
Here it's important to see how DP rank 0 doesn't see GPU2 and DP rank 1 doesn't see GPU3. To DP there is just GPUs 0
and 1 where it feeds data as if there were just 2 GPUs. GPU0 "secretly" offloads some of its load to GPU2 using PP.
And GPU1 does the same by enlisting GPU3 to its aid.
Since each dimension requires at least 2 GPUs, here you'd need at least 4 GPUs.
Implementations:
- [DeepSpeed](https://github.com/microsoft/DeepSpeed)
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)
- [Varuna](https://github.com/microsoft/varuna)
- [SageMaker](https://arxiv.org/abs/2111.05972)
- [OSLO](https://github.com/tunib-ai/oslo)
🤗 Transformers status: not yet implemented
## Data Parallelism + Pipeline Parallelism + Tensor Parallelism
To get an even more efficient training a 3D parallelism is used where PP is combined with TP and DP. This can be seen in the following diagram.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/parallelism-deepspeed-3d.png" alt="dp-pp-tp-3d"/>
</div>
This diagram is from a blog post [3D parallelism: Scaling to trillion-parameter models](https://www.microsoft.com/en-us/research/blog/deepspeed-extreme-scale-model-training-for-everyone/), which is a good read as well.
Since each dimension requires at least 2 GPUs, here you'd need at least 8 GPUs.
Implementations:
- [DeepSpeed](https://github.com/microsoft/DeepSpeed) - DeepSpeed also includes an even more efficient DP, which they call ZeRO-DP.
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)
- [Varuna](https://github.com/microsoft/varuna)
- [SageMaker](https://arxiv.org/abs/2111.05972)
- [OSLO](https://github.com/tunib-ai/oslo)
🤗 Transformers status: not yet implemented, since we have no PP and TP.
## ZeRO Data Parallelism + Pipeline Parallelism + Tensor Parallelism
One of the main features of DeepSpeed is ZeRO, which is a super-scalable extension of DP. It has already been
discussed in [ZeRO Data Parallelism](#zero-data-parallelism). Normally it's a standalone feature that doesn't require PP or TP.
But it can be combined with PP and TP.
When ZeRO-DP is combined with PP (and optionally TP) it typically enables only ZeRO stage 1 (optimizer sharding).
While it's theoretically possible to use ZeRO stage 2 (gradient sharding) with Pipeline Parallelism, it will have negative
performance impacts. There would need to be an additional reduce-scatter collective for every micro-batch to aggregate
the gradients before sharding, which adds a potentially significant communication overhead. By nature of Pipeline Parallelism,
small micro-batches are used and instead the focus is on trying to balance arithmetic intensity (micro-batch size) with
minimizing the Pipeline bubble (number of micro-batches). Therefore those communication costs are going to impact the performance.
In addition, there are already fewer layers than normal due to PP and so the memory savings won't be huge. PP already
reduces gradient size by ``1/PP``, and so gradient sharding savings on top of that are less significant than pure DP.
ZeRO stage 3 is not a good choice either for the same reason - more inter-node communications required.
And since we have ZeRO, the other benefit is ZeRO-Offload. Since this is stage 1 optimizer states can be offloaded to CPU.
Implementations:
- [Megatron-DeepSpeed](https://github.com/microsoft/Megatron-DeepSpeed) and [Megatron-Deepspeed from BigScience](https://github.com/bigscience-workshop/Megatron-DeepSpeed), which is the fork of the former repo.
- [OSLO](https://github.com/tunib-ai/oslo)
Important papers:
- [Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model](
https://arxiv.org/abs/2201.11990)
🤗 Transformers status: not yet implemented, since we have no PP and TP.
## FlexFlow
[FlexFlow](https://github.com/flexflow/FlexFlow) also solves the parallelization problem in a slightly different approach.
Paper: ["Beyond Data and Model Parallelism for Deep Neural Networks" by Zhihao Jia, Matei Zaharia, Alex Aiken](https://arxiv.org/abs/1807.05358)
It performs a sort of 4D Parallelism over Sample-Operator-Attribute-Parameter.
1. Sample = Data Parallelism (sample-wise parallel)
2. Operator = Parallelize a single operation into several sub-operations
3. Attribute = Data Parallelism (length-wise parallel)
4. Parameter = Model Parallelism (regardless of dimension - horizontal or vertical)
Examples:
* Sample
Let's take 10 batches of sequence length 512. If we parallelize them by sample dimension into 2 devices, we get 10 x 512 which becomes be 5 x 2 x 512.
* Operator
If we perform layer normalization, we compute std first and mean second, and then we can normalize data.
Operator parallelism allows computing std and mean in parallel. So if we parallelize them by operator dimension into 2
devices (cuda:0, cuda:1), first we copy input data into both devices, and cuda:0 computes std, cuda:1 computes mean at the same time.
* Attribute
We have 10 batches of 512 length. If we parallelize them by attribute dimension into 2 devices, 10 x 512 will be 10 x 2 x 256.
* Parameter
It is similar with tensor model parallelism or naive layer-wise model parallelism.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/parallelism-flexflow.jpeg" alt="flex-flow-soap"/>
</div>
The significance of this framework is that it takes resources like (1) GPU/TPU/CPU vs. (2) RAM/DRAM vs. (3)
fast-intra-connect/slow-inter-connect and it automatically optimizes all these algorithmically deciding which
parallelisation to use where.
One very important aspect is that FlexFlow is designed for optimizing DNN parallelizations for models with static and
fixed workloads, since models with dynamic behavior may prefer different parallelization strategies across iterations.
So the promise is very attractive - it runs a 30min simulation on the cluster of choice and it comes up with the best
strategy to utilise this specific environment. If you add/remove/replace any parts it'll run and re-optimize the plan
for that. And then you can train. A different setup will have its own custom optimization.
🤗 Transformers status: Transformers models are FX-trace-able via [transformers.utils.fx](https://github.com/huggingface/transformers/blob/master/src/transformers/utils/fx.py),
which is a prerequisite for FlexFlow, however, changes are required on the FlexFlow side to make it work with Transformers models.
## GPU selection
When training on multiple GPUs, you can specify the number of GPUs to use and in what order. This can be useful for instance when you have GPUs with different computing power and want to use the faster GPU first. The selection process works for both [DistributedDataParallel](https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html) and [DataParallel](https://pytorch.org/docs/stable/generated/torch.nn.DataParallel.html) to use only a subset of the available GPUs, and you don't need Accelerate or the [DeepSpeed integration](./main_classes/deepspeed).
### Number of GPUs
For example, if you have 4 GPUs and you only want to use the first 2:
<hfoptions id="select-gpu">
<hfoption id="torchrun">
Use the `--nproc_per_node` to select how many GPUs to use.
```bash
torchrun --nproc_per_node=2 trainer-program.py ...
```
</hfoption>
<hfoption id="Accelerate">
Use `--num_processes` to select how many GPUs to use.
```bash
accelerate launch --num_processes 2 trainer-program.py ...
```
</hfoption>
<hfoption id="DeepSpeed">
Use `--num_gpus` to select how many GPUs to use.
```bash
deepspeed --num_gpus 2 trainer-program.py ...
```
</hfoption>
</hfoptions>
### Order of GPUs
Now, to select which GPUs to use and their order, you'll use the `CUDA_VISIBLE_DEVICES` environment variable. It is easiest to set the environment variable in a `~/bashrc` or another startup config file. `CUDA_VISIBLE_DEVICES` is used to map which GPUs are used. For example, if you have 4 GPUs (0, 1, 2, 3) and you only want to run GPUs 0 and 2:
```bash
CUDA_VISIBLE_DEVICES=0,2 torchrun trainer-program.py ...
```
Only the 2 physical GPUs (0 and 2) are "visible" to PyTorch and these are mapped to `cuda:0` and `cuda:1` respectively. You can also reverse the order of the GPUs to use 2 first. Now, the mapping is `cuda:1` for GPU 0 and `cuda:0` for GPU 2.
```bash
CUDA_VISIBLE_DEVICES=2,0 torchrun trainer-program.py ...
```
You can also set the `CUDA_VISIBLE_DEVICES` environment variable to an empty value to create an environment without GPUs.
```bash
CUDA_VISIBLE_DEVICES= python trainer-program.py ...
```
<Tip warning={true}>
As with any environment variable, they can be exported instead of being added to the command line. However, this is not recommended because it can be confusing if you forget how the environment variable was setup and you end up using the wrong GPUs. Instead, it is common practice to set the environment variable for a specific training run on the same command line.
</Tip>
`CUDA_DEVICE_ORDER` is an alternative environment variable you can use to control how the GPUs are ordered. You can either order them by:
1. PCIe bus ID's that matches the order of [`nvidia-smi`](https://developer.nvidia.com/nvidia-system-management-interface) and [`rocm-smi`](https://rocm.docs.amd.com/projects/rocm_smi_lib/en/latest/.doxygen/docBin/html/index.html) for NVIDIA and AMD GPUs respectively
```bash
export CUDA_DEVICE_ORDER=PCI_BUS_ID
```
2. GPU compute ability
```bash
export CUDA_DEVICE_ORDER=FASTEST_FIRST
```
The `CUDA_DEVICE_ORDER` is especially useful if your training setup consists of an older and newer GPU, where the older GPU appears first, but you cannot physically swap the cards to make the newer GPU appear first. In this case, set `CUDA_DEVICE_ORDER=FASTEST_FIRST` to always use the newer and faster GPU first (`nvidia-smi` or `rocm-smi` still reports the GPUs in their PCIe order). Or you could also set `export CUDA_VISIBLE_DEVICES=1,0`.
| huggingface/transformers/blob/main/docs/source/en/perf_train_gpu_many.md |
Gradio Demo: model3d_component
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
gr.Model3D()
demo.launch()
```
| gradio-app/gradio/blob/main/demo/model3d_component/run.ipynb |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# GLTF
Environments in the Simulate library are saved in an extension of the [GLTF 2.0 format](https://registry.khronos.org/glTF/)
We provide tools to define assets that are GLTF extensions, by inheriting from GltfExtensionMixin. | huggingface/simulate/blob/main/docs/source/conceptual/gltf.mdx |
@gradio/markdown
## 0.6.0
### Features
- [#6842](https://github.com/gradio-app/gradio/pull/6842) [`846d52d`](https://github.com/gradio-app/gradio/commit/846d52d1c92d429077382ce494eea27fd062d9f6) - Fix md highlight. Thanks [@pngwn](https://github.com/pngwn)!
- [#6831](https://github.com/gradio-app/gradio/pull/6831) [`f3abde8`](https://github.com/gradio-app/gradio/commit/f3abde80884d96ad69b825020c46486d9dd5cac5) - Add an option to enable header links for markdown. Thanks [@pngwn](https://github.com/pngwn)!
## 0.5.0
### Features
- [#6603](https://github.com/gradio-app/gradio/pull/6603) [`6b1401c`](https://github.com/gradio-app/gradio/commit/6b1401c514c2ec012b0a50c72a6ec81cb673bf1d) - chore(deps): update dependency marked to v11. Thanks [@renovate](https://github.com/apps/renovate)!
## 0.4.1
### Patch Changes
- Updated dependencies []:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.4.0
### Features
- [#6537](https://github.com/gradio-app/gradio/pull/6537) [`6d3fecfa4`](https://github.com/gradio-app/gradio/commit/6d3fecfa42dde1c70a60c397434c88db77289be6) - chore(deps): update all non-major dependencies. Thanks [@renovate](https://github.com/apps/renovate)!
## 0.3.4
### Features
- [#6296](https://github.com/gradio-app/gradio/pull/6296) [`46f13f496`](https://github.com/gradio-app/gradio/commit/46f13f4968c8177e318c9d75f2eed1ed55c2c042) - chore(deps): update all non-major dependencies. Thanks [@renovate](https://github.com/apps/renovate)!
## 0.3.3
### Patch Changes
- Updated dependencies [[`9caddc17b`](https://github.com/gradio-app/gradio/commit/9caddc17b1dea8da1af8ba724c6a5eab04ce0ed8)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.3.2
### Patch Changes
- Updated dependencies [[`f816136a0`](https://github.com/gradio-app/gradio/commit/f816136a039fa6011be9c4fb14f573e4050a681a)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.3.1
### Patch Changes
- Updated dependencies [[`3cdeabc68`](https://github.com/gradio-app/gradio/commit/3cdeabc6843000310e1a9e1d17190ecbf3bbc780), [`fad92c29d`](https://github.com/gradio-app/gradio/commit/fad92c29dc1f5cd84341aae417c495b33e01245f)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.3.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Remove duplicate `elem_ids` from components. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Publish all components to npm. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Custom components. Thanks [@pngwn](https://github.com/pngwn)!
## 0.3.0-beta.8
### Features
- [#6136](https://github.com/gradio-app/gradio/pull/6136) [`667802a6c`](https://github.com/gradio-app/gradio/commit/667802a6cdbfb2ce454a3be5a78e0990b194548a) - JS Component Documentation. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6152](https://github.com/gradio-app/gradio/pull/6152) [`982bff2fd`](https://github.com/gradio-app/gradio/commit/982bff2fdd938b798c400fb90d1cf0caf7278894) - Remove duplicate `elem_ids` from components. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.3.0-beta.7
### Features
- [#6071](https://github.com/gradio-app/gradio/pull/6071) [`f08da1a6f`](https://github.com/gradio-app/gradio/commit/f08da1a6f288f6ab8ec40534d5a9e2c64bed4b3b) - Fixes markdown rendering in examples. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6016](https://github.com/gradio-app/gradio/pull/6016) [`83e947676`](https://github.com/gradio-app/gradio/commit/83e947676d327ca2ab6ae2a2d710c78961c771a0) - Format js in v4 branch. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
### Fixes
- [#6046](https://github.com/gradio-app/gradio/pull/6046) [`dbb7de5e0`](https://github.com/gradio-app/gradio/commit/dbb7de5e02c53fee05889d696d764d212cb96c74) - fix tests. Thanks [@pngwn](https://github.com/pngwn)!
## 0.3.0-beta.6
### Features
- [#5960](https://github.com/gradio-app/gradio/pull/5960) [`319c30f3f`](https://github.com/gradio-app/gradio/commit/319c30f3fccf23bfe1da6c9b132a6a99d59652f7) - rererefactor frontend files. Thanks [@pngwn](https://github.com/pngwn)!
- [#5938](https://github.com/gradio-app/gradio/pull/5938) [`13ed8a485`](https://github.com/gradio-app/gradio/commit/13ed8a485d5e31d7d75af87fe8654b661edcca93) - V4: Use beta release versions for '@gradio' packages. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.3.2
### Fixes
- [#5897](https://github.com/gradio-app/gradio/pull/5897) [`0592c301d`](https://github.com/gradio-app/gradio/commit/0592c301df9cd949b52159c85b7042f38d113e86) - Fix Dataframe `line_breaks`. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
- [#5878](https://github.com/gradio-app/gradio/pull/5878) [`fbce277e5`](https://github.com/gradio-app/gradio/commit/fbce277e50c5885371fd49c68adf8565c25c1d39) - Keep Markdown rendered lists within dataframe cells. Thanks [@abidlabs](https://github.com/abidlabs)!
## 0.3.1
### Patch Changes
- Updated dependencies []:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.3.0
### Fixes
- [#5755](https://github.com/gradio-app/gradio/pull/5755) [`e842a561a`](https://github.com/gradio-app/gradio/commit/e842a561af4394f8109291ee5725bcf74743e816) - Fix new line issue in chatbot. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
## 0.2.2
### Fixes
- [#5701](https://github.com/gradio-app/gradio/pull/5701) [`ee8eec1e5`](https://github.com/gradio-app/gradio/commit/ee8eec1e5e544a0127e0aa68c2522a7085b8ada5) - Fix for regression in rendering empty Markdown. Thanks [@abidlabs](https://github.com/abidlabs)!
## 0.2.1
### Features
- [#5671](https://github.com/gradio-app/gradio/pull/5671) [`6a36c3b78`](https://github.com/gradio-app/gradio/commit/6a36c3b786700600d3826ce1e0629cc5308ddd47) - chore(deps): update dependency @types/prismjs to v1.26.1. Thanks [@renovate](https://github.com/apps/renovate)!
### Fixes
- [#5604](https://github.com/gradio-app/gradio/pull/5604) [`faad01f8e`](https://github.com/gradio-app/gradio/commit/faad01f8e10ef6d18249b1a4587477c59b74adb2) - Add `render_markdown` parameter to chatbot. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
## 0.2.0
### Features
- [#5342](https://github.com/gradio-app/gradio/pull/5342) [`afac0006`](https://github.com/gradio-app/gradio/commit/afac0006337ce2840cf497cd65691f2f60ee5912) - significantly improve the performance of `gr.Dataframe` for large datasets. Thanks [@pngwn](https://github.com/pngwn)!
## 0.1.2
### Fixes
- [#5304](https://github.com/gradio-app/gradio/pull/5304) [`05892302`](https://github.com/gradio-app/gradio/commit/05892302fb8fe2557d57834970a2b65aea97355b) - Adds kwarg to disable html sanitization in `gr.Chatbot()`. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
- [#5393](https://github.com/gradio-app/gradio/pull/5393) [`e4e7a431`](https://github.com/gradio-app/gradio/commit/e4e7a4319924aaf51dcb18d07d0c9953d4011074) - Renders LaTeX that is added to the page in `gr.Markdown`, `gr.Chatbot`, and `gr.DataFrame`. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5394](https://github.com/gradio-app/gradio/pull/5394) [`4d94ea0a`](https://github.com/gradio-app/gradio/commit/4d94ea0a0cf2103cda19f48398a5634f8341d04d) - Adds horizontal scrolling to content that overflows in gr.Markdown. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5368](https://github.com/gradio-app/gradio/pull/5368) [`b27f7583`](https://github.com/gradio-app/gradio/commit/b27f7583254165b135bf1496a7d8c489a62ba96f) - Change markdown rendering to set breaks to false. Thanks [@abidlabs](https://github.com/abidlabs)!
## 0.1.1
### Fixes
- [#5324](https://github.com/gradio-app/gradio/pull/5324) [`31996c99`](https://github.com/gradio-app/gradio/commit/31996c991d6bfca8cef975eb8e3c9f61a7aced19) - ensure login form has correct styles. Thanks [@pngwn](https://github.com/pngwn)!
## 0.1.0
### Highlights
#### Improve startup performance and markdown support ([#5279](https://github.com/gradio-app/gradio/pull/5279) [`fe057300`](https://github.com/gradio-app/gradio/commit/fe057300f0672c62dab9d9b4501054ac5d45a4ec))
##### Improved markdown support
We now have better support for markdown in `gr.Markdown` and `gr.Dataframe`. Including syntax highlighting and Github Flavoured Markdown. We also have more consistent markdown behaviour and styling.
##### Various performance improvements
These improvements will be particularly beneficial to large applications.
- Rather than attaching events manually, they are now delegated, leading to a significant performance improvement and addressing a performance regression introduced in a recent version of Gradio. App startup for large applications is now around twice as fast.
- Optimised the mounting of individual components, leading to a modest performance improvement during startup (~30%).
- Corrected an issue that was causing markdown to re-render infinitely.
- Ensured that the `gr.3DModel` does re-render prematurely.
Thanks [@pngwn](https://github.com/pngwn)!
### Features
- [#5268](https://github.com/gradio-app/gradio/pull/5268) [`f49028cf`](https://github.com/gradio-app/gradio/commit/f49028cfe3e21097001ddbda71c560b3d8b42e1c) - Move markdown & latex processing to the frontend for the gr.Markdown and gr.DataFrame components. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5215](https://github.com/gradio-app/gradio/pull/5215) [`fbdad78a`](https://github.com/gradio-app/gradio/commit/fbdad78af4c47454cbb570f88cc14bf4479bbceb) - Lazy load interactive or static variants of a component individually, rather than loading both variants regardless. This change will improve performance for many applications. Thanks [@pngwn](https://github.com/pngwn)! | gradio-app/gradio/blob/main/js/markdown/CHANGELOG.md |
MobileNet v3
**MobileNetV3** is a convolutional neural network that is designed for mobile phone CPUs. The network design includes the use of a [hard swish activation](https://paperswithcode.com/method/hard-swish) and [squeeze-and-excitation](https://paperswithcode.com/method/squeeze-and-excitation-block) modules in the [MBConv blocks](https://paperswithcode.com/method/inverted-residual-block).
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('mobilenetv3_large_100', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `mobilenetv3_large_100`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('mobilenetv3_large_100', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@article{DBLP:journals/corr/abs-1905-02244,
author = {Andrew Howard and
Mark Sandler and
Grace Chu and
Liang{-}Chieh Chen and
Bo Chen and
Mingxing Tan and
Weijun Wang and
Yukun Zhu and
Ruoming Pang and
Vijay Vasudevan and
Quoc V. Le and
Hartwig Adam},
title = {Searching for MobileNetV3},
journal = {CoRR},
volume = {abs/1905.02244},
year = {2019},
url = {http://arxiv.org/abs/1905.02244},
archivePrefix = {arXiv},
eprint = {1905.02244},
timestamp = {Tue, 12 Jan 2021 15:30:06 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1905-02244.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<!--
Type: model-index
Collections:
- Name: MobileNet V3
Paper:
Title: Searching for MobileNetV3
URL: https://paperswithcode.com/paper/searching-for-mobilenetv3
Models:
- Name: mobilenetv3_large_100
In Collection: MobileNet V3
Metadata:
FLOPs: 287193752
Parameters: 5480000
File Size: 22076443
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Depthwise Separable Convolution
- Dropout
- Global Average Pooling
- Hard Swish
- Inverted Residual Block
- ReLU
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- RMSProp
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x4 TPU Pod
ID: mobilenetv3_large_100
LR: 0.1
Dropout: 0.8
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 4096
Image Size: '224'
Weight Decay: 1.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/mobilenetv3.py#L363
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mobilenetv3_large_100_ra-f55367f5.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 75.77%
Top 5 Accuracy: 92.54%
- Name: mobilenetv3_rw
In Collection: MobileNet V3
Metadata:
FLOPs: 287190638
Parameters: 5480000
File Size: 22064048
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Depthwise Separable Convolution
- Dropout
- Global Average Pooling
- Hard Swish
- Inverted Residual Block
- ReLU
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- RMSProp
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x4 TPU Pod
ID: mobilenetv3_rw
LR: 0.1
Dropout: 0.8
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 4096
Image Size: '224'
Weight Decay: 1.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/mobilenetv3.py#L384
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mobilenetv3_100-35495452.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 75.62%
Top 5 Accuracy: 92.71%
--> | huggingface/pytorch-image-models/blob/main/hfdocs/source/models/mobilenet-v3.mdx |
!---
Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Question answering example
This folder contains the `run_qa.py` script, demonstrating *question answering* with the 🤗 Transformers library.
For straightforward use-cases you may be able to use this script without modification, although we have also
included comments in the code to indicate areas that you may need to adapt to your own projects.
### Usage notes
Note that when contexts are long they may be split into multiple training cases, not all of which may contain
the answer span.
As-is, the example script will train on SQuAD or any other question-answering dataset formatted the same way, and can handle user
inputs as well.
### Multi-GPU and TPU usage
By default, the script uses a `MirroredStrategy` and will use multiple GPUs effectively if they are available. TPUs
can also be used by passing the name of the TPU resource with the `--tpu` argument. There are some issues surrounding
these strategies and our models right now, which are most likely to appear in the evaluation/prediction steps. We're
actively working on better support for multi-GPU and TPU training in TF, but if you encounter problems a quick
workaround is to train in the multi-GPU or TPU context and then perform predictions outside of it.
### Memory usage and data loading
One thing to note is that all data is loaded into memory in this script. Most question answering datasets are small
enough that this is not an issue, but if you have a very large dataset you will need to modify the script to handle
data streaming. This is particularly challenging for TPUs, given the stricter requirements and the sheer volume of data
required to keep them fed. A full explanation of all the possible pitfalls is a bit beyond this example script and
README, but for more information you can see the 'Input Datasets' section of
[this document](https://www.tensorflow.org/guide/tpu).
### Example command
```
python run_qa.py \
--model_name_or_path distilbert-base-cased \
--output_dir output \
--dataset_name squad \
--do_train \
--do_eval \
```
| huggingface/transformers/blob/main/examples/tensorflow/question-answering/README.md |
--
title: "AI for Game Development: Creating a Farming Game in 5 Days. Part 2"
thumbnail: /blog/assets/124_ml-for-games/thumbnail2.png
authors:
- user: dylanebert
---
# AI for Game Development: Creating a Farming Game in 5 Days. Part 2
**Welcome to AI for Game Development!** In this series, we'll be using AI tools to create a fully functional farming game in just 5 days. By the end of this series, you will have learned how you can incorporate a variety of AI tools into your game development workflow. I will show you how you can use AI tools for:
1. Art Style
2. Game Design
3. 3D Assets
4. 2D Assets
5. Story
Want the quick video version? You can watch it [here](https://www.tiktok.com/@individualkex/video/7186551685035085098). Otherwise, if you want the technical details, keep reading!
**Note:** This tutorial is intended for readers who are familiar with Unity development and C#. If you're new to these technologies, check out the [Unity for Beginners](https://www.tiktok.com/@individualkex/video/7086863567412038954) series before continuing.
## Day 2: Game Design
In [Part 1](https://huggingface.co/blog/ml-for-games-1) of this tutorial series, we used **AI for Art Style**. More specifically, we used Stable Diffusion to generate concept art and develop the visual style of our game.
In this part, we'll be using AI for Game Design. In [The Short Version](#the-short-version), I'll talk about how I used ChatGPT as a tool to help develop game ideas. But more importantly, what is actually going on here? Keep reading for background on [Language Models](#language-models) and their broader [Uses in Game Development](#uses-in-game-development).
### The Short Version
The short version is straightforward: ask [ChatGPT](https://chat.openai.com/chat) for advice, and follow its advice at your own discretion. In the case of the farming game, I asked ChatGPT:
> You are a professional game designer, designing a simple farming game. What features are most important to making the farming game fun and engaging?
The answer given includes (summarized):
1. Variety of crops
2. A challenging and rewarding progression system
3. Dynamic and interactive environments
4. Social and multiplayer features
5. A strong and immersive story or theme
Given that I only have 5 days, I decided to [gray-box](https://en.wikipedia.org/wiki/Gray-box_testing) the first two points. You can play the result [here](https://individualkex.itch.io/ml-for-game-dev-2), and view the source code [here](https://github.com/dylanebert/FarmingGame).
I'm not going to go into detail on how I implemented these mechanics, since the focus of this series is how to use AI tools in your own game development process, not how to implement a farming game. Instead, I'll talk about what ChatGPT is (a language model), how these models actually work, and what this means for game development.
### Language Models
ChatGPT, despite being a major breakthrough in adoption, is an iteration on tech that has existed for a while: *language models*.
Language models are a type of AI that are trained to predict the likelihood of a sequence of words. For example, if I were to write "The cat chases the ____", a language model would be trained to predict "mouse". This training process can then be applied to a wide variety of tasks. For example, translation: "the French word for cat is ____". This setup, while successful at some natural language tasks, wasn't anywhere near the level of performance seen today. This is, until the introduction of **transformers**.
**Transformers**, [introduced in 2017](https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf), are a neural network architecture that use a self-attention mechanism to predict the entire sequence all at once. This is the tech behind modern language models like ChatGPT. Want to learn more about how they work? Check out our [Introduction to Transformers](https://huggingface.co/course/chapter1/1) course, available free here on Hugging Face.
So why is ChatGPT so successful compared to previous language models? It's impossible to answer this in its entirety, since ChatGPT is not open source. However, one of the reasons is Reinforcement Learning from Human Feedback (RLHF), where human feedback is used to improve the language model. Check out this [blog post](https://huggingface.co/blog/rlhf) for more information on RLHF: how it works, open-source tools for doing it, and its future.
This area of AI is constantly changing, and likely to see an explosion of creativity as it becomes part of the open source community, including in uses for game development. If you're reading this, you're probably ahead of the curve already.
### Uses in Game Development
In [The Short Version](#the-short-version), I talked about how I used ChatGPT to help develop game ideas. There is a lot more you can do with it though, like using it to [code an entire game](https://www.youtube.com/watch?v=YDWvAqKLTLg&ab_channel=AAlex). You can use it for pretty much anything you can think of. Something that might be a bit more helpful is to talk about what it *can't* do.
#### Limitations
ChatGPT often sounds very convincing, while being wrong. Here is an [archive of ChatGPT failures](https://github.com/giuven95/chatgpt-failures). The reason for these is that ChatGPT doesn't *know* what it's talking about the way a human does. It's a very large [Language Model](#language-models) that predicts likely outputs, but doesn't really understand what it's saying. One of my personal favorite examples of these failures (especially relevant to game development) is this explanation of quaternions from [Reddit](https://www.reddit.com/r/Unity3D/comments/zcps1f/eli5_quaternion_by_chatgpt/):
<figure class="image text-center">
<img src="/blog/assets/124_ml-for-games/quaternion.png" alt="ChatGPT Quaternion Explanation">
</figure>
This explanation, while sounding excellent, is completely wrong. This is a great example of why ChatGPT, while very useful, shouldn't be used as a definitive knowledge base.
#### Suggestions
If ChatGPT fails a lot, should you use it? I would argue that it's still extremely useful as a tool, rather than as a replacement. In the example of Game Design, I could have followed up on ChatGPT's answer, and asked it to implement all of its suggestions for me. As I mentioned before, [others have done this](https://www.youtube.com/watch?v=YDWvAqKLTLg&ab_channel=AAlex), and it somewhat works. However, I would suggest using ChatGPT more as a tool for brainstorming and acceleration, rather than as a complete replacement for steps in the development process.
Click [here](https://huggingface.co/blog/ml-for-games-3) to read Part 3, where we use **AI for 3D Assets**.
| huggingface/blog/blob/main/ml-for-games-2.md |
Gradio Demo: video_identity_2
```
!pip install -q gradio
```
```
import gradio as gr
def video_identity(video):
return video
demo = gr.Interface(video_identity,
gr.Video(),
"playable_video",
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/video_identity_2/run.ipynb |
Play with Huggy [[play]]
Now that you've trained Huggy and pushed it to the Hub. **You will be able to play with him ❤️**
For this step it’s simple:
- Open the Huggy game in your browser: https://huggingface.co/spaces/ThomasSimonini/Huggy
- Click on Play with my Huggy model
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit-bonus1/load-huggy.jpg" alt="load-huggy" width="100%">
1. In step 1, choose your model repository which is the model id (in my case ThomasSimonini/ppo-Huggy).
2. In step 2, **choose which model you want to replay**:
- I have multiple ones, since we saved a model every 500000 timesteps.
- But if I want the most recent one I choose Huggy.onnx
👉 It's good to **try with different model checkpoints to see the improvement of the agent.**
| huggingface/deep-rl-class/blob/main/units/en/unitbonus1/play.mdx |
Pause and Resume your Endpoint
You can `pause` & `resume` endpoints to save cost and configurations. Please note that if your endpoint is in a `failed` state, you will need to create a new endpoint. To `pause`/`resume` your endpoint, navigate to the "overview" tab and click the button at top right corner, which will show "Pause endpoint" to pause, or "Resume endpoint" to reactivate the paused endpoint.
When pausing an endpoint the min & max number of replicas will be set to 0. When resuming an endpoint the min & max number of replicas will be set to 1. This allows you to programmatically pause and resume your endpoint by updating the "min_replicas" and "max_replicas" fields in the API.
Paused inference endpoints will have the following status: `PAUSED`. Paused endpoints will be NOT be billed until resumed. Pausing & Resuming an endpoint is a great way to save costs when you don't need your endpoint to be running. For example, you can easily pause your endpoint during the night or weekends. You should pause your endpoint when you don't need it for the time being.
The url of your endpoint will remain the same, even if you pause and resume it. This means that you can pause your endpoint and resume it later without having to update your code.
## Pause an Inference Endpoint
To pause an endpoint, navigate to the "overview" tab and click the button at top right corner, which says "Pause endpoint".
<img
src="https://raw.githubusercontent.com/huggingface/hf-endpoints-documentation/main/assets/pause_endpoint.png"
alt="Pause an Inference Endpoint"
/>
After clicking the button, you will be asked to confirm the action. Click "Pause {ENDPOINT-NAME}" to confirm.
<img
src="https://raw.githubusercontent.com/huggingface/hf-endpoints-documentation/main/assets/pause_endpoint_confirm.png"
alt="Pause modal confirm Inference Endpoint"
/>
After that your replicas will be set to 0 and your endpoint will be paused. You can see the status change of your endpoint in the "overview" tab to `PAUSED`. If you do not see the `PAUSED` status make sure you've followed these instructions or contact us for help.
<img
src="https://raw.githubusercontent.com/huggingface/hf-endpoints-documentation/main/assets/paused_endpoint.png"
alt="Paused Inference Endpoint"
/>
## Resume an Inference Endpoint
To resume an endpoint, navigate to the "overview" tab and click the button at top right corner showing "Resume endpoint".
<img
src="https://raw.githubusercontent.com/huggingface/hf-endpoints-documentation/main/assets/resume_endpoint.png"
alt="Resume Inference Endpoint"
/>
Your endpoint will be resumed and the status will change to `Initalizing` and then to `Running`. Once your endpoint is running, you can start using it again and billing usage will incur.
| huggingface/hf-endpoints-documentation/blob/main/docs/source/guides/pause_endpoint.mdx |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# GIT
## Overview
The GIT model was proposed in [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) by
Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang. GIT is a decoder-only Transformer
that leverages [CLIP](clip)'s vision encoder to condition the model on vision inputs besides text. The model obtains state-of-the-art results on
image captioning and visual question answering benchmarks.
The abstract from the paper is the following:
*In this paper, we design and train a Generative Image-to-text Transformer, GIT, to unify vision-language tasks such as image/video captioning and question answering. While generative models provide a consistent network architecture between pre-training and fine-tuning, existing work typically contains complex structures (uni/multi-modal encoder/decoder) and depends on external modules such as object detectors/taggers and optical character recognition (OCR). In GIT, we simplify the architecture as one image encoder and one text decoder under a single language modeling task. We also scale up the pre-training data and the model size to boost the model performance. Without bells and whistles, our GIT establishes new state of the arts on 12 challenging benchmarks with a large margin. For instance, our model surpasses the human performance for the first time on TextCaps (138.2 vs. 125.5 in CIDEr). Furthermore, we present a new scheme of generation-based image classification and scene text recognition, achieving decent performance on standard benchmarks.*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/git_architecture.jpg"
alt="drawing" width="600"/>
<small> GIT architecture. Taken from the <a href="https://arxiv.org/abs/2205.14100" target="_blank">original paper</a>. </small>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/microsoft/GenerativeImage2Text).
## Usage tips
- GIT is implemented in a very similar way to GPT-2, the only difference being that the model is also conditioned on `pixel_values`.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with GIT.
- Demo notebooks regarding inference + fine-tuning GIT on custom data can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/GIT).
- See also: [Causal language modeling task guide](../tasks/language_modeling)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we will review it.
The resource should ideally demonstrate something new instead of duplicating an existing resource.
## GitVisionConfig
[[autodoc]] GitVisionConfig
## GitVisionModel
[[autodoc]] GitVisionModel
- forward
## GitConfig
[[autodoc]] GitConfig
- all
## GitProcessor
[[autodoc]] GitProcessor
- __call__
## GitModel
[[autodoc]] GitModel
- forward
## GitForCausalLM
[[autodoc]] GitForCausalLM
- forward | huggingface/transformers/blob/main/docs/source/en/model_doc/git.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BertGeneration
## Overview
The BertGeneration model is a BERT model that can be leveraged for sequence-to-sequence tasks using
[`EncoderDecoderModel`] as proposed in [Leveraging Pre-trained Checkpoints for Sequence Generation
Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
The abstract from the paper is the following:
*Unsupervised pretraining of large neural models has recently revolutionized Natural Language Processing. By
warm-starting from the publicly released checkpoints, NLP practitioners have pushed the state-of-the-art on multiple
benchmarks while saving significant amounts of compute time. So far the focus has been mainly on the Natural Language
Understanding tasks. In this paper, we demonstrate the efficacy of pre-trained checkpoints for Sequence Generation. We
developed a Transformer-based sequence-to-sequence model that is compatible with publicly available pre-trained BERT,
GPT-2 and RoBERTa checkpoints and conducted an extensive empirical study on the utility of initializing our model, both
encoder and decoder, with these checkpoints. Our models result in new state-of-the-art results on Machine Translation,
Text Summarization, Sentence Splitting, and Sentence Fusion.*
This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The original code can be
found [here](https://tfhub.dev/s?module-type=text-generation&subtype=module,placeholder).
## Usage examples and tips
The model can be used in combination with the [`EncoderDecoderModel`] to leverage two pretrained BERT checkpoints for
subsequent fine-tuning:
```python
>>> # leverage checkpoints for Bert2Bert model...
>>> # use BERT's cls token as BOS token and sep token as EOS token
>>> encoder = BertGenerationEncoder.from_pretrained("bert-large-uncased", bos_token_id=101, eos_token_id=102)
>>> # add cross attention layers and use BERT's cls token as BOS token and sep token as EOS token
>>> decoder = BertGenerationDecoder.from_pretrained(
... "bert-large-uncased", add_cross_attention=True, is_decoder=True, bos_token_id=101, eos_token_id=102
... )
>>> bert2bert = EncoderDecoderModel(encoder=encoder, decoder=decoder)
>>> # create tokenizer...
>>> tokenizer = BertTokenizer.from_pretrained("bert-large-uncased")
>>> input_ids = tokenizer(
... "This is a long article to summarize", add_special_tokens=False, return_tensors="pt"
... ).input_ids
>>> labels = tokenizer("This is a short summary", return_tensors="pt").input_ids
>>> # train...
>>> loss = bert2bert(input_ids=input_ids, decoder_input_ids=labels, labels=labels).loss
>>> loss.backward()
```
Pretrained [`EncoderDecoderModel`] are also directly available in the model hub, e.g.:
```python
>>> # instantiate sentence fusion model
>>> sentence_fuser = EncoderDecoderModel.from_pretrained("google/roberta2roberta_L-24_discofuse")
>>> tokenizer = AutoTokenizer.from_pretrained("google/roberta2roberta_L-24_discofuse")
>>> input_ids = tokenizer(
... "This is the first sentence. This is the second sentence.", add_special_tokens=False, return_tensors="pt"
... ).input_ids
>>> outputs = sentence_fuser.generate(input_ids)
>>> print(tokenizer.decode(outputs[0]))
```
Tips:
- [`BertGenerationEncoder`] and [`BertGenerationDecoder`] should be used in
combination with [`EncoderDecoder`].
- For summarization, sentence splitting, sentence fusion and translation, no special tokens are required for the input.
Therefore, no EOS token should be added to the end of the input.
## BertGenerationConfig
[[autodoc]] BertGenerationConfig
## BertGenerationTokenizer
[[autodoc]] BertGenerationTokenizer
- save_vocabulary
## BertGenerationEncoder
[[autodoc]] BertGenerationEncoder
- forward
## BertGenerationDecoder
[[autodoc]] BertGenerationDecoder
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/bert-generation.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# P-tuning
[P-tuning](https://hf.co/papers/2103.10385) adds trainable prompt embeddings to the input that is optimized by a prompt encoder to find a better prompt, eliminating the need to manually design prompts. The prompt tokens can be added anywhere in the input sequence, and p-tuning also introduces anchor tokens for improving performance.
The abstract from the paper is:
*While GPTs with traditional fine-tuning fail to achieve strong results on natural language understanding (NLU), we show that GPTs can be better than or comparable to similar-sized BERTs on NLU tasks with a novel method P-tuning -- which employs trainable continuous prompt embeddings. On the knowledge probing (LAMA) benchmark, the best GPT recovers 64\% (P@1) of world knowledge without any additional text provided during test time, which substantially improves the previous best by 20+ percentage points. On the SuperGlue benchmark, GPTs achieve comparable and sometimes better performance to similar-sized BERTs in supervised learning. Importantly, we find that P-tuning also improves BERTs' performance in both few-shot and supervised settings while largely reducing the need for prompt engineering. Consequently, P-tuning outperforms the state-of-the-art approaches on the few-shot SuperGlue benchmark.*.
## PromptEncoderConfig
[[autodoc]] tuners.p_tuning.config.PromptEncoderConfig
## PromptEncoder
[[autodoc]] tuners.p_tuning.model.PromptEncoder | huggingface/peft/blob/main/docs/source/package_reference/p_tuning.md |
--
title: How to train a new language model from scratch using Transformers and Tokenizers
thumbnail: /blog/assets/01_how-to-train/how-to-train_blogpost.png
authors:
- user: julien-c
---
# How to train a new language model from scratch using Transformers and Tokenizers
<a target="_blank" href="https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/01_how_to_train.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab">
</a>
Over the past few months, we made several improvements to our [`transformers`](https://github.com/huggingface/transformers) and [`tokenizers`](https://github.com/huggingface/tokenizers) libraries, with the goal of making it easier than ever to **train a new language model from scratch**.
In this post we’ll demo how to train a “small” model (84 M parameters = 6 layers, 768 hidden size, 12 attention heads) – that’s the same number of layers & heads as DistilBERT – on **Esperanto**. We’ll then fine-tune the model on a downstream task of part-of-speech tagging.
Esperanto is a *constructed language* with a goal of being easy to learn. We pick it for this demo for several reasons:
- it is a relatively low-resource language (even though it’s spoken by ~2 million people) so this demo is less boring than training one more English model 😁
- its grammar is highly regular (e.g. all common nouns end in -o, all adjectives in -a) so we should get interesting linguistic results even on a small dataset.
- finally, the overarching goal at the foundation of the language is to bring people closer (fostering world peace and international understanding) which one could argue is aligned with the goal of the NLP community 💚
> N.B. You won’t need to understand Esperanto to understand this post, but if you do want to learn it, [Duolingo](https://www.duolingo.com/enroll/eo/en/Learn-Esperanto) has a nice course with 280k active learners.
Our model is going to be called… wait for it… **EsperBERTo** 😂
<img src="/blog/assets/01_how-to-train/eo.svg" alt="Esperanto flag" style="margin: auto; display: block; width: 260px;">
## 1. Find a dataset
First, let us find a corpus of text in Esperanto. Here we’ll use the Esperanto portion of the [OSCAR corpus](https://traces1.inria.fr/oscar/) from INRIA.
OSCAR is a huge multilingual corpus obtained by language classification and filtering of [Common Crawl](https://commoncrawl.org/) dumps of the Web.
<img src="/blog/assets/01_how-to-train/oscar.png" style="margin: auto; display: block; width: 260px;">
The Esperanto portion of the dataset is only 299M, so we’ll concatenate with the Esperanto sub-corpus of the [Leipzig Corpora Collection](https://wortschatz.uni-leipzig.de/en/download), which is comprised of text from diverse sources like news, literature, and wikipedia.
The final training corpus has a size of 3 GB, which is still small – for your model, you will get better results the more data you can get to pretrain on.
## 2. Train a tokenizer
We choose to train a byte-level Byte-pair encoding tokenizer (the same as GPT-2), with the same special tokens as RoBERTa. Let’s arbitrarily pick its size to be 52,000.
We recommend training a byte-level BPE (rather than let’s say, a WordPiece tokenizer like BERT) because it will start building its vocabulary from an alphabet of single bytes, so all words will be decomposable into tokens (no more `<unk>` tokens!).
```python
#! pip install tokenizers
from pathlib import Path
from tokenizers import ByteLevelBPETokenizer
paths = [str(x) for x in Path("./eo_data/").glob("**/*.txt")]
# Initialize a tokenizer
tokenizer = ByteLevelBPETokenizer()
# Customize training
tokenizer.train(files=paths, vocab_size=52_000, min_frequency=2, special_tokens=[
"<s>",
"<pad>",
"</s>",
"<unk>",
"<mask>",
])
# Save files to disk
tokenizer.save_model(".", "esperberto")
```
And here’s a slightly accelerated capture of the output:

<small>On our dataset, training took about ~5 minutes.</small>
🔥🔥 Wow, that was fast! ⚡️🔥
We now have both a `vocab.json`, which is a list of the most frequent tokens ranked by frequency, and a `merges.txt` list of merges.
```json
{
"<s>": 0,
"<pad>": 1,
"</s>": 2,
"<unk>": 3,
"<mask>": 4,
"!": 5,
"\"": 6,
"#": 7,
"$": 8,
"%": 9,
"&": 10,
"'": 11,
"(": 12,
")": 13,
# ...
}
# merges.txt
l a
Ġ k
o n
Ġ la
t a
Ġ e
Ġ d
Ġ p
# ...
```
What is great is that our tokenizer is optimized for Esperanto. Compared to a generic tokenizer trained for English, more native words are represented by a single, unsplit token. Diacritics, i.e. accented characters used in Esperanto – `ĉ`, `ĝ`, `ĥ`, `ĵ`, `ŝ`, and `ŭ` – are encoded natively. We also represent sequences in a more efficient manner. Here on this corpus, the average length of encoded sequences is ~30% smaller as when using the pretrained GPT-2 tokenizer.
Here’s how you can use it in `tokenizers`, including handling the RoBERTa special tokens – of course, you’ll also be able to use it directly from `transformers`.
```python
from tokenizers.implementations import ByteLevelBPETokenizer
from tokenizers.processors import BertProcessing
tokenizer = ByteLevelBPETokenizer(
"./models/EsperBERTo-small/vocab.json",
"./models/EsperBERTo-small/merges.txt",
)
tokenizer._tokenizer.post_processor = BertProcessing(
("</s>", tokenizer.token_to_id("</s>")),
("<s>", tokenizer.token_to_id("<s>")),
)
tokenizer.enable_truncation(max_length=512)
print(
tokenizer.encode("Mi estas Julien.")
)
# Encoding(num_tokens=7, ...)
# tokens: ['<s>', 'Mi', 'Ġestas', 'ĠJuli', 'en', '.', '</s>']
```
## 3. Train a language model from scratch
**Update:** The associated Colab notebook uses our new [`Trainer`](https://github.com/huggingface/transformers/blob/master/src/transformers/trainer.py) directly, instead of through a script. Feel free to pick the approach you like best.
We will now train our language model using the [`run_language_modeling.py`](https://github.com/huggingface/transformers/blob/main/examples/legacy/run_language_modeling.py) script from `transformers` (newly renamed from `run_lm_finetuning.py` as it now supports training from scratch more seamlessly). Just remember to leave `--model_name_or_path` to `None` to train from scratch vs. from an existing model or checkpoint.
> We’ll train a RoBERTa-like model, which is a BERT-like with a couple of changes (check the [documentation](https://huggingface.co/transformers/model_doc/roberta.html) for more details).
As the model is BERT-like, we’ll train it on a task of *Masked language modeling*, i.e. the predict how to fill arbitrary tokens that we randomly mask in the dataset. This is taken care of by the example script.
We just need to do two things:
- implement a simple subclass of `Dataset` that loads data from our text files
- Depending on your use case, you might not even need to write your own subclass of Dataset, if one of the provided examples (`TextDataset` and `LineByLineTextDataset`) works – but there are lots of custom tweaks that you might want to add based on what your corpus looks like.
- Choose and experiment with different sets of hyperparameters.
Here’s a simple version of our EsperantoDataset.
```python
from torch.utils.data import Dataset
class EsperantoDataset(Dataset):
def __init__(self, evaluate: bool = False):
tokenizer = ByteLevelBPETokenizer(
"./models/EsperBERTo-small/vocab.json",
"./models/EsperBERTo-small/merges.txt",
)
tokenizer._tokenizer.post_processor = BertProcessing(
("</s>", tokenizer.token_to_id("</s>")),
("<s>", tokenizer.token_to_id("<s>")),
)
tokenizer.enable_truncation(max_length=512)
# or use the RobertaTokenizer from `transformers` directly.
self.examples = []
src_files = Path("./data/").glob("*-eval.txt") if evaluate else Path("./data/").glob("*-train.txt")
for src_file in src_files:
print("🔥", src_file)
lines = src_file.read_text(encoding="utf-8").splitlines()
self.examples += [x.ids for x in tokenizer.encode_batch(lines)]
def __len__(self):
return len(self.examples)
def __getitem__(self, i):
# We’ll pad at the batch level.
return torch.tensor(self.examples[i])
```
If your dataset is very large, you can opt to load and tokenize examples on the fly, rather than as a preprocessing step.
Here is one specific set of **hyper-parameters and arguments** we pass to the script:
```
--output_dir ./models/EsperBERTo-small-v1
--model_type roberta
--mlm
--config_name ./models/EsperBERTo-small
--tokenizer_name ./models/EsperBERTo-small
--do_train
--do_eval
--learning_rate 1e-4
--num_train_epochs 5
--save_total_limit 2
--save_steps 2000
--per_gpu_train_batch_size 16
--evaluate_during_training
--seed 42
```
As usual, pick the largest batch size you can fit on your GPU(s).
**🔥🔥🔥 Let’s start training!! 🔥🔥🔥**
Here you can check our Tensorboard for [one particular set of hyper-parameters](https://tensorboard.dev/experiment/8AjtzdgPR1qG6bDIe1eKfw/#scalars):
[](https://tensorboard.dev/experiment/8AjtzdgPR1qG6bDIe1eKfw/#scalars)
> Our example scripts log into the Tensorboard format by default, under `runs/`. Then to view your board just run `tensorboard dev upload --logdir runs` – this will set up [tensorboard.dev](https://tensorboard.dev/), a Google-managed hosted version that lets you share your ML experiment with anyone.
## 4. Check that the LM actually trained
Aside from looking at the training and eval losses going down, the easiest way to check whether our language model is learning anything interesting is via the `FillMaskPipeline`.
Pipelines are simple wrappers around tokenizers and models, and the 'fill-mask' one will let you input a sequence containing a masked token (here, `<mask>`) and return a list of the most probable filled sequences, with their probabilities.
```python
from transformers import pipeline
fill_mask = pipeline(
"fill-mask",
model="./models/EsperBERTo-small",
tokenizer="./models/EsperBERTo-small"
)
# The sun <mask>.
# =>
result = fill_mask("La suno <mask>.")
# {'score': 0.2526160776615143, 'sequence': '<s> La suno brilis.</s>', 'token': 10820}
# {'score': 0.0999930202960968, 'sequence': '<s> La suno lumis.</s>', 'token': 23833}
# {'score': 0.04382849484682083, 'sequence': '<s> La suno brilas.</s>', 'token': 15006}
# {'score': 0.026011141017079353, 'sequence': '<s> La suno falas.</s>', 'token': 7392}
# {'score': 0.016859788447618484, 'sequence': '<s> La suno pasis.</s>', 'token': 4552}
```
Ok, simple syntax/grammar works. Let’s try a slightly more interesting prompt:
```python
fill_mask("Jen la komenco de bela <mask>.")
# This is the beginning of a beautiful <mask>.
# =>
# {
# 'score':0.06502299010753632
# 'sequence':'<s> Jen la komenco de bela vivo.</s>'
# 'token':1099
# }
# {
# 'score':0.0421181358397007
# 'sequence':'<s> Jen la komenco de bela vespero.</s>'
# 'token':5100
# }
# {
# 'score':0.024884626269340515
# 'sequence':'<s> Jen la komenco de bela laboro.</s>'
# 'token':1570
# }
# {
# 'score':0.02324388362467289
# 'sequence':'<s> Jen la komenco de bela tago.</s>'
# 'token':1688
# }
# {
# 'score':0.020378097891807556
# 'sequence':'<s> Jen la komenco de bela festo.</s>'
# 'token':4580
# }
```
> “**Jen la komenco de bela tago**”, indeed!
With more complex prompts, you can probe whether your language model captured more semantic knowledge or even some sort of (statistical) common sense reasoning.
## 5. Fine-tune your LM on a downstream task
We now can fine-tune our new Esperanto language model on a downstream task of **Part-of-speech tagging.**
As mentioned before, Esperanto is a highly regular language where word endings typically condition the grammatical part of speech. Using a dataset of annotated Esperanto POS tags formatted in the CoNLL-2003 format (see example below), we can use the [`run_ner.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/token-classification/run_ner.py) script from `transformers`.
> POS tagging is a token classification task just as NER so we can just use the exact same script.

Again, here’s the hosted **[Tensorboard](https://tensorboard.dev/experiment/lOZn2wOWQo6ixpwtWyyDfQ/#scalars)** for this fine-tuning. We train for 3 epochs using a batch size of 64 per GPU.
Training and eval losses converge to small residual values as the task is rather easy (the language is regular) – it’s still fun to be able to train it end-to-end 😃.
This time, let’s use a `TokenClassificationPipeline`:
```python
from transformers import TokenClassificationPipeline, pipeline
MODEL_PATH = "./models/EsperBERTo-small-pos/"
nlp = pipeline(
"ner",
model=MODEL_PATH,
tokenizer=MODEL_PATH,
)
# or instantiate a TokenClassificationPipeline directly.
nlp("Mi estas viro kej estas tago varma.")
# {'entity': 'PRON', 'score': 0.9979867339134216, 'word': ' Mi'}
# {'entity': 'VERB', 'score': 0.9683094620704651, 'word': ' estas'}
# {'entity': 'VERB', 'score': 0.9797462821006775, 'word': ' estas'}
# {'entity': 'NOUN', 'score': 0.8509314060211182, 'word': ' tago'}
# {'entity': 'ADJ', 'score': 0.9996201395988464, 'word': ' varma'}
```
**Looks like it worked! 🔥**
<small>For a more challenging dataset for NER, <a href="https://github.com/stefan-it">@stefan-it</a> recommended that we could train on the silver standard dataset from WikiANN</small>
## 6. Share your model 🎉
Finally, when you have a nice model, please think about sharing it with the community:
- upload your model using the CLI: `transformers-cli upload`
- write a README.md model card and add it to the repository under `model_cards/`. Your model card should ideally include:
- a model description,
- training params (dataset, preprocessing, hyperparameters),
- evaluation results,
- intended uses & limitations
- whatever else is helpful! 🤓
### **TADA!**
➡️ Your model has a page on https://huggingface.co/models and everyone can load it using `AutoModel.from_pretrained("username/model_name")`.
[](https://huggingface.co/julien-c/EsperBERTo-small)
If you want to take a look at models in different languages, check https://huggingface.co/models
[](https://huggingface.co/models)
## Thank you!

| huggingface/blog/blob/main/how-to-train.md |
--
title: Code Eval
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
This metric implements the evaluation harness for the HumanEval problem solving dataset
described in the paper "Evaluating Large Language Models Trained on Code"
(https://arxiv.org/abs/2107.03374).
---
# Metric Card for Code Eval
## Metric description
The CodeEval metric estimates the pass@k metric for code synthesis.
It implements the evaluation harness for the HumanEval problem solving dataset described in the paper ["Evaluating Large Language Models Trained on Code"](https://arxiv.org/abs/2107.03374).
## How to use
The Code Eval metric calculates how good are predictions given a set of references. Its arguments are:
`predictions`: a list of candidates to evaluate. Each candidate should be a list of strings with several code candidates to solve the problem.
`references`: a list with a test for each prediction. Each test should evaluate the correctness of a code candidate.
`k`: number of code candidates to consider in the evaluation. The default value is `[1, 10, 100]`.
`num_workers`: the number of workers used to evaluate the candidate programs (The default value is `4`).
`timeout`: The maximum time taken to produce a prediction before it is considered a "timeout". The default value is `3.0` (i.e. 3 seconds).
```python
from evaluate import load
code_eval = load("code_eval")
test_cases = ["assert add(2,3)==5"]
candidates = [["def add(a,b): return a*b", "def add(a, b): return a+b"]]
pass_at_k, results = code_eval.compute(references=test_cases, predictions=candidates, k=[1, 2])
```
N.B.
This metric exists to run untrusted model-generated code. Users are strongly encouraged not to do so outside of a robust security sandbox. Before running this metric and once you've taken the necessary precautions, you will need to set the `HF_ALLOW_CODE_EVAL` environment variable. Use it at your own risk:
```python
import os
os.environ["HF_ALLOW_CODE_EVAL"] = "1"`
```
## Output values
The Code Eval metric outputs two things:
`pass_at_k`: a dictionary with the pass rates for each k value defined in the arguments.
`results`: a dictionary with granular results of each unit test.
### Values from popular papers
The [original CODEX paper](https://arxiv.org/pdf/2107.03374.pdf) reported that the CODEX-12B model had a pass@k score of 28.8% at `k=1`, 46.8% at `k=10` and 72.3% at `k=100`. However, since the CODEX model is not open source, it is hard to verify these numbers.
## Examples
Full match at `k=1`:
```python
from evaluate import load
code_eval = load("code_eval")
test_cases = ["assert add(2,3)==5"]
candidates = [["def add(a, b): return a+b"]]
pass_at_k, results = code_eval.compute(references=test_cases, predictions=candidates, k=[1])
print(pass_at_k)
{'pass@1': 1.0}
```
No match for k = 1:
```python
from evaluate import load
code_eval = load("code_eval")
test_cases = ["assert add(2,3)==5"]
candidates = [["def add(a,b): return a*b"]]
pass_at_k, results = code_eval.compute(references=test_cases, predictions=candidates, k=[1])
print(pass_at_k)
{'pass@1': 0.0}
```
Partial match at k=1, full match at k=2:
```python
from evaluate import load
code_eval = load("code_eval")
test_cases = ["assert add(2,3)==5"]
candidates = [["def add(a, b): return a+b", "def add(a,b): return a*b"]]
pass_at_k, results = code_eval.compute(references=test_cases, predictions=candidates, k=[1, 2])
print(pass_at_k)
{'pass@1': 0.5, 'pass@2': 1.0}
```
## Limitations and bias
As per the warning included in the metric code itself:
> This program exists to execute untrusted model-generated code. Although it is highly unlikely that model-generated code will do something overtly malicious in response to this test suite, model-generated code may act destructively due to a lack of model capability or alignment. Users are strongly encouraged to sandbox this evaluation suite so that it does not perform destructive actions on their host or network. For more information on how OpenAI sandboxes its code, see the accompanying paper. Once you have read this disclaimer and taken appropriate precautions, uncomment the following line and proceed at your own risk:
More information about the limitations of the code can be found on the [Human Eval Github repository](https://github.com/openai/human-eval).
## Citation
```bibtex
@misc{chen2021evaluating,
title={Evaluating Large Language Models Trained on Code},
author={Mark Chen and Jerry Tworek and Heewoo Jun and Qiming Yuan \
and Henrique Ponde de Oliveira Pinto and Jared Kaplan and Harri Edwards \
and Yuri Burda and Nicholas Joseph and Greg Brockman and Alex Ray \
and Raul Puri and Gretchen Krueger and Michael Petrov and Heidy Khlaaf \
and Girish Sastry and Pamela Mishkin and Brooke Chan and Scott Gray \
and Nick Ryder and Mikhail Pavlov and Alethea Power and Lukasz Kaiser \
and Mohammad Bavarian and Clemens Winter and Philippe Tillet \
and Felipe Petroski Such and Dave Cummings and Matthias Plappert \
and Fotios Chantzis and Elizabeth Barnes and Ariel Herbert-Voss \
and William Hebgen Guss and Alex Nichol and Alex Paino and Nikolas Tezak \
and Jie Tang and Igor Babuschkin and Suchir Balaji and Shantanu Jain \
and William Saunders and Christopher Hesse and Andrew N. Carr \
and Jan Leike and Josh Achiam and Vedant Misra and Evan Morikawa \
and Alec Radford and Matthew Knight and Miles Brundage and Mira Murati \
and Katie Mayer and Peter Welinder and Bob McGrew and Dario Amodei \
and Sam McCandlish and Ilya Sutskever and Wojciech Zaremba},
year={2021},
eprint={2107.03374},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
## Further References
- [Human Eval Github repository](https://github.com/openai/human-eval)
- [OpenAI Codex website](https://openai.com/blog/openai-codex/)
| huggingface/evaluate/blob/main/metrics/code_eval/README.md |
`gradio_client`: Use a Gradio app as an API -- in 3 lines of Python
This directory contains the source code for `gradio_client`, a lightweight Python library that makes it very easy to use any Gradio app as an API.
As an example, consider this [Hugging Face Space that transcribes audio files](https://huggingface.co/spaces/abidlabs/whisper) that are recorded from the microphone.

Using the `gradio_client` library, we can easily use the Gradio as an API to transcribe audio files programmatically.
Here's the entire code to do it:
```python
from gradio_client import Client
client = Client("abidlabs/whisper")
client.predict("audio_sample.wav")
>> "This is a test of the whisper speech recognition model."
```
The Gradio client works with any Gradio Space, whether it be an image generator, a stateful chatbot, or a tax calculator.
## Installation
If you already have a recent version of `gradio`, then the `gradio_client` is included as a dependency.
Otherwise, the lightweight `gradio_client` package can be installed from pip (or pip3) and works with Python versions 3.8 or higher:
```bash
$ pip install gradio_client
```
## Basic Usage
### Connecting to a Space or a Gradio app
Start by connecting instantiating a `Client` object and connecting it to a Gradio app that is running on Spaces (or anywhere else)!
**Connecting to a Space**
```python
from gradio_client import Client
client = Client("abidlabs/en2fr") # a Space that translates from English to French
```
You can also connect to private Spaces by passing in your HF token with the `hf_token` parameter. You can get your HF token here: https://huggingface.co/settings/tokens
```python
from gradio_client import Client
client = Client("abidlabs/my-private-space", hf_token="...")
```
**Duplicating a Space for private use**
While you can use any public Space as an API, you may get rate limited by Hugging Face if you make too many requests. For unlimited usage of a Space, simply duplicate the Space to create a private Space,
and then use it to make as many requests as you'd like!
The `gradio_client` includes a class method: `Client.duplicate()` to make this process simple:
```python
from gradio_client import Client
client = Client.duplicate("abidlabs/whisper")
client.predict("audio_sample.wav")
>> "This is a test of the whisper speech recognition model."
```
If you have previously duplicated a Space, re-running `duplicate()` will _not_ create a new Space. Instead, the Client will attach to the previously-created Space. So it is safe to re-run the `Client.duplicate()` method multiple times.
**Note:** if the original Space uses GPUs, your private Space will as well, and your Hugging Face account will get billed based on the price of the GPU. To minimize charges, your Space will automatically go to sleep after 1 hour of inactivity. You can also set the hardware using the `hardware` parameter of `duplicate()`.
**Connecting a general Gradio app**
If your app is running somewhere else, just provide the full URL instead, including the "http://" or "https://". Here's an example of making predictions to a Gradio app that is running on a share URL:
```python
from gradio_client import Client
client = Client("https://bec81a83-5b5c-471e.gradio.live")
```
### Inspecting the API endpoints
Once you have connected to a Gradio app, you can view the APIs that are available to you by calling the `.view_api()` method. For the Whisper Space, we see the following:
```
Client.predict() Usage Info
---------------------------
Named API endpoints: 1
- predict(input_audio, api_name="/predict") -> value_0
Parameters:
- [Audio] input_audio: str (filepath or URL)
Returns:
- [Textbox] value_0: str (value)
```
This shows us that we have 1 API endpoint in this space, and shows us how to use the API endpoint to make a prediction: we should call the `.predict()` method, providing a parameter `input_audio` of type `str`, which is a `filepath or URL`.
We should also provide the `api_name='/predict'` argument. Although this isn't necessary if a Gradio app has a single named endpoint, it does allow us to call different endpoints in a single app if they are available. If an app has unnamed API endpoints, these can also be displayed by running `.view_api(all_endpoints=True)`.
### Making a prediction
The simplest way to make a prediction is simply to call the `.predict()` function with the appropriate arguments:
```python
from gradio_client import Client
client = Client("abidlabs/en2fr")
client.predict("Hello")
>> Bonjour
```
If there are multiple parameters, then you should pass them as separate arguments to `.predict()`, like this:
```python
from gradio_client import Client
client = Client("gradio/calculator")
client.predict(4, "add", 5)
>> 9.0
```
For certain inputs, such as images, you should pass in the filepath or URL to the file. Likewise, for the corresponding output types, you will get a filepath or URL returned.
```python
from gradio_client import Client
client = Client("abidlabs/whisper")
client.predict("https://audio-samples.github.io/samples/mp3/blizzard_unconditional/sample-0.mp3")
>> "My thought I have nobody by a beauty and will as you poured. Mr. Rochester is serve in that so don't find simpus, and devoted abode, to at might in a r—"
```
## Advanced Usage
For more ways to use the Gradio Python Client, check out our dedicated Guide on the Python client, available here: https://www.gradio.app/guides/getting-started-with-the-python-client
| gradio-app/gradio/blob/main/client/python/README.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# PEFT integrations
PEFT's practical benefits extends to other Hugging Face libraries like [Diffusers](https://hf.co/docs/diffusers) and [Transformers](https://hf.co/docs/transformers). One of the main benefits of PEFT is that an adapter file generated by a PEFT method is a lot smaller than the original model, which makes it super easy to manage and use multiple adapters. You can use one pretrained base model for multiple tasks by simply loading a new adapter finetuned for the task you're solving. Or you can combine multiple adapters with a text-to-image diffusion model to create new effects.
This tutorial will show you how PEFT can help you manage adapters in Diffusers and Transformers.
## Diffusers
Diffusers is a generative AI library for creating images and videos from text or images with diffusion models. LoRA is an especially popular training method for diffusion models because you can very quickly train and share diffusion models to generate images in new styles. To make it easier to use and try multiple LoRA models, Diffusers uses the PEFT library to help manage different adapters for inference.
For example, load a base model and then load the [artificialguybr/3DRedmond-V1](https://huggingface.co/artificialguybr/3DRedmond-V1) adapter for inference with the [`load_lora_weights`](https://huggingface.co/docs/diffusers/v0.24.0/en/api/loaders/lora#diffusers.loaders.LoraLoaderMixin.load_lora_weights) method. The `adapter_name` argument in the loading method is enabled by PEFT and allows you to set a name for the adapter so it is easier to reference.
```py
import torch
from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16
).to("cuda")
pipeline.load_lora_weights(
"peft-internal-testing/artificialguybr__3DRedmond-V1",
weight_name="3DRedmond-3DRenderStyle-3DRenderAF.safetensors",
adapter_name="3d"
)
image = pipeline("sushi rolls shaped like kawaii cat faces").images[0]
image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/ybelkada/documentation-images/resolve/main/test-lora-diffusers.png"/>
</div>
Now let's try another cool LoRA model, [ostris/super-cereal-sdxl-lora](https://huggingface.co/ostris/super-cereal-sdxl-lora). All you need to do is load and name this new adapter with `adapter_name`, and use the [`set_adapters`](https://huggingface.co/docs/diffusers/api/loaders/unet#diffusers.loaders.UNet2DConditionLoadersMixin.set_adapters) method to set it as the currently active adapter.
```py
pipeline.load_lora_weights(
"ostris/super-cereal-sdxl-lora",
weight_name="cereal_box_sdxl_v1.safetensors",
adapter_name="cereal"
)
pipeline.set_adapters("cereal")
image = pipeline("sushi rolls shaped like kawaii cat faces").images[0]
image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/ybelkada/documentation-images/resolve/main/test-lora-diffusers-2.png"/>
</div>
Finally, you can call the [`disable_lora`](https://huggingface.co/docs/diffusers/api/loaders/unet#diffusers.loaders.UNet2DConditionLoadersMixin.disable_lora) method to restore the base model.
```py
pipeline.disable_lora()
```
Learn more about how PEFT supports Diffusers in the [Inference with PEFT](https://huggingface.co/docs/diffusers/tutorials/using_peft_for_inference) tutorial.
## Transformers
Transformers is a collection of pretrained models for all types of tasks in all modalities. You can load these models for training or inference. Many of the models are large language models (LLMs), so it makes sense to integrate PEFT with Transformers to manage and train adapters.
Load a base pretrained model to train.
```py
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m")
```
Next, add an adapter configuration to specify how to adapt the model parameters. Call the [`~PeftModel.add_adapter`] method to add the configuration to the base model.
```py
from peft import LoraConfig
config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM"
)
model.add_adapter(peft_config)
```
Now you can train the model with Transformer's [`~transformers.Trainer`] class or whichever training framework you prefer.
To use the newly trained model for inference, the [`~transformers.AutoModel`] class uses PEFT on the backend to load the adapter weights and configuration file into a base pretrained model.
```py
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("ybelkada/opt-350m-lora")
```
If you're interested in comparing or using more than one adapter, you can also call the [`~PeftModel.add_adapter`] method to add the adapter configuration to the base model. The only requirement is the adapter type must be the same (you can't mix a LoRA and LoHa adapter).
```py
from transformers import AutoModelForCausalLM
from peft import LoraConfig
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m")
model.add_adapter(lora_config_1, adapter_name="adapter_1")
```
Call [`~PeftModel.add_adapter`] again to attach a new adapter to the base model.
```py
model.add_adapter(lora_config_2, adapter_name="adapter_2")
```
Then you can use [`~PeftModel.set_adapter`] to set the currently active adapter.
```py
model.set_adapter("adapter_1")
output = model.generate(**inputs)
print(tokenizer.decode(output_disabled[0], skip_special_tokens=True))
```
To disable the adapter, call the [`~PeftModel.disable_adapter`] method.
```py
model.disable_adapter()
```
If you're curious, check out the [Load and train adapters with PEFT](https://huggingface.co/docs/transformers/main/peft) tutorial to learn more.
| huggingface/peft/blob/main/docs/source/tutorial/peft_integrations.md |
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Token classification
The script [`run_ner.py`](https://github.com/huggingface/optimum/blob/main/examples/onnxruntime/optimization/token-classification/run_ner.py)
allows us to apply graph optimizations using [ONNX Runtime](https://github.com/microsoft/onnxruntime) for token classification tasks.
The following example applies graph optimizations on a DistilBERT fine-tuned on the CoNLL-2003 task. Here the optimization level is selected to be 1, enabling basic optimizations such as redundant node eliminations and constant folding. Higher optimization level will result in hardware dependent optimized graph.
```bash
python run_ner.py \
--model_name_or_path elastic/distilbert-base-uncased-finetuned-conll03-english \
--dataset_name conll2003 \
--optimization_level 1 \
--do_eval \
--output_dir /tmp/optimized_distilbert_conll2003
```
| huggingface/optimum/blob/main/examples/onnxruntime/optimization/token-classification/README.md |
API Reference (Swagger)
🤗 Inference Endpoints can be used through the [UI](https://ui.endpoints.huggingface.co/endpoints) and programmatically through an API.
The API exposes [open-API specification](https://api.endpoints.huggingface.cloud/) for each available route.
<iframe src="https://api.endpoints.huggingface.cloud/" style='height: 60vh; width: 100%;' frameborder="0" id="iframe" frameBorder="0">Browser not compatible.</iframe>
| huggingface/hf-endpoints-documentation/blob/main/docs/source/api_reference.mdx |
Gradio Demo: image_classification
### Simple image classification in Pytorch with Gradio's Image input and Label output.
```
!pip install -q gradio torch torchvision
```
```
# Downloading files from the demo repo
import os
!wget -q https://github.com/gradio-app/gradio/raw/main/demo/image_classification/cheetah.jpg
```
```
import gradio as gr
import torch
import requests
from torchvision import transforms
model = torch.hub.load('pytorch/vision:v0.6.0', 'resnet18', pretrained=True).eval()
response = requests.get("https://git.io/JJkYN")
labels = response.text.split("\n")
def predict(inp):
inp = transforms.ToTensor()(inp).unsqueeze(0)
with torch.no_grad():
prediction = torch.nn.functional.softmax(model(inp)[0], dim=0)
confidences = {labels[i]: float(prediction[i]) for i in range(1000)}
return confidences
demo = gr.Interface(fn=predict,
inputs=gr.Image(type="pil"),
outputs=gr.Label(num_top_classes=3),
examples=[["cheetah.jpg"]],
)
demo.launch()
```
| gradio-app/gradio/blob/main/demo/image_classification/run.ipynb |
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# HfApi Client
Below is the documentation for the `HfApi` class, which serves as a Python wrapper for the Hugging Face Hub's API.
All methods from the `HfApi` are also accessible from the package's root directly. Both approaches are detailed below.
Using the root method is more straightforward but the [`HfApi`] class gives you more flexibility.
In particular, you can pass a token that will be reused in all HTTP calls. This is different
than `huggingface-cli login` or [`login`] as the token is not persisted on the machine.
It is also possible to provide a different endpoint or configure a custom user-agent.
```python
from huggingface_hub import HfApi, list_models
# Use root method
models = list_models()
# Or configure a HfApi client
hf_api = HfApi(
endpoint="https://huggingface.co", # Can be a Private Hub endpoint.
token="hf_xxx", # Token is not persisted on the machine.
)
models = hf_api.list_models()
```
## HfApi
[[autodoc]] HfApi
[[autodoc]] plan_multi_commits
## API Dataclasses
### AccessRequest
[[autodoc]] huggingface_hub.hf_api.AccessRequest
### CommitInfo
[[autodoc]] huggingface_hub.hf_api.CommitInfo
### DatasetInfo
[[autodoc]] huggingface_hub.hf_api.DatasetInfo
### GitRefInfo
[[autodoc]] huggingface_hub.hf_api.GitRefInfo
### GitCommitInfo
[[autodoc]] huggingface_hub.hf_api.GitCommitInfo
### GitRefs
[[autodoc]] huggingface_hub.hf_api.GitRefs
### ModelInfo
[[autodoc]] huggingface_hub.hf_api.ModelInfo
### RepoSibling
[[autodoc]] huggingface_hub.hf_api.RepoSibling
### RepoFile
[[autodoc]] huggingface_hub.hf_api.RepoFile
### RepoUrl
[[autodoc]] huggingface_hub.hf_api.RepoUrl
### SafetensorsRepoMetadata
[[autodoc]] huggingface_hub.utils.SafetensorsRepoMetadata
### SafetensorsFileMetadata
[[autodoc]] huggingface_hub.utils.SafetensorsFileMetadata
### SpaceInfo
[[autodoc]] huggingface_hub.hf_api.SpaceInfo
### TensorInfo
[[autodoc]] huggingface_hub.utils.TensorInfo
### User
[[autodoc]] huggingface_hub.hf_api.User
### UserLikes
[[autodoc]] huggingface_hub.hf_api.UserLikes
## CommitOperation
Below are the supported values for [`CommitOperation`]:
[[autodoc]] CommitOperationAdd
[[autodoc]] CommitOperationDelete
[[autodoc]] CommitOperationCopy
## CommitScheduler
[[autodoc]] CommitScheduler
## Search helpers
Some helpers to filter repositories on the Hub are available in the `huggingface_hub` package.
### DatasetFilter
[[autodoc]] DatasetFilter
### ModelFilter
[[autodoc]] ModelFilter
| huggingface/huggingface_hub/blob/main/docs/source/en/package_reference/hf_api.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# DreamBooth fine-tuning with LoRA
This guide demonstrates how to use LoRA, a low-rank approximation technique, to fine-tune DreamBooth with the
`CompVis/stable-diffusion-v1-4` model.
Although LoRA was initially designed as a technique for reducing the number of trainable parameters in
large-language models, the technique can also be applied to diffusion models. Performing a complete model fine-tuning
of diffusion models is a time-consuming task, which is why lightweight techniques like DreamBooth or Textual Inversion
gained popularity. With the introduction of LoRA, customizing and fine-tuning a model on a specific dataset has become
even faster.
In this guide we'll be using a DreamBooth fine-tuning script that is available in
[PEFT's GitHub repo](https://github.com/huggingface/peft/tree/main/examples/lora_dreambooth). Feel free to explore it and
learn how things work.
## Set up your environment
Start by cloning the PEFT repository:
```bash
git clone https://github.com/huggingface/peft
```
Navigate to the directory containing the training scripts for fine-tuning Dreambooth with LoRA:
```bash
cd peft/examples/lora_dreambooth
```
Set up your environment: install PEFT, and all the required libraries. At the time of writing this guide we recommend
installing PEFT from source.
```bash
pip install -r requirements.txt
pip install git+https://github.com/huggingface/peft
```
## Fine-tuning DreamBooth
Prepare the images that you will use for fine-tuning the model. Set up a few environment variables:
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export INSTANCE_DIR="path-to-instance-images"
export CLASS_DIR="path-to-class-images"
export OUTPUT_DIR="path-to-save-model"
```
Here:
- `INSTANCE_DIR`: The directory containing the images that you intend to use for training your model.
- `CLASS_DIR`: The directory containing class-specific images. In this example, we use prior preservation to avoid overfitting and language-drift. For prior preservation, you need other images of the same class as part of the training process. However, these images can be generated and the training script will save them to a local path you specify here.
- `OUTPUT_DIR`: The destination folder for storing the trained model's weights.
To learn more about DreamBooth fine-tuning with prior-preserving loss, check out the [Diffusers documentation](https://huggingface.co/docs/diffusers/training/dreambooth#finetuning-with-priorpreserving-loss).
Launch the training script with `accelerate` and pass hyperparameters, as well as LoRa-specific arguments to it such as:
- `use_lora`: Enables LoRa in the training script.
- `lora_r`: The dimension used by the LoRA update matrices.
- `lora_alpha`: Scaling factor.
- `lora_text_encoder_r`: LoRA rank for text encoder.
- `lora_text_encoder_alpha`: LoRA alpha (scaling factor) for text encoder.
Here's what the full set of script arguments may look like:
```bash
accelerate launch train_dreambooth.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--class_data_dir=$CLASS_DIR \
--output_dir=$OUTPUT_DIR \
--train_text_encoder \
--with_prior_preservation --prior_loss_weight=1.0 \
--num_dataloader_workers=1 \
--instance_prompt="a photo of sks dog" \
--class_prompt="a photo of dog" \
--resolution=512 \
--train_batch_size=1 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--num_class_images=200 \
--use_lora \
--lora_r 16 \
--lora_alpha 27 \
--lora_text_encoder_r 16 \
--lora_text_encoder_alpha 17 \
--learning_rate=1e-4 \
--gradient_accumulation_steps=1 \
--gradient_checkpointing \
--max_train_steps=800
```
If you are running this script on Windows, you may need to set the `--num_dataloader_workers` to 0.
## Inference with a single adapter
To run inference with the fine-tuned model, first specify the base model with which the fine-tuned LoRA weights will be combined:
```python
import os
import torch
from diffusers import StableDiffusionPipeline
from peft import PeftModel, LoraConfig
MODEL_NAME = "CompVis/stable-diffusion-v1-4"
```
Next, add a function that will create a Stable Diffusion pipeline for image generation. It will combine the weights of
the base model with the fine-tuned LoRA weights using `LoraConfig`.
```python
def get_lora_sd_pipeline(
ckpt_dir, base_model_name_or_path=None, dtype=torch.float16, device="cuda", adapter_name="default"
):
unet_sub_dir = os.path.join(ckpt_dir, "unet")
text_encoder_sub_dir = os.path.join(ckpt_dir, "text_encoder")
if os.path.exists(text_encoder_sub_dir) and base_model_name_or_path is None:
config = LoraConfig.from_pretrained(text_encoder_sub_dir)
base_model_name_or_path = config.base_model_name_or_path
if base_model_name_or_path is None:
raise ValueError("Please specify the base model name or path")
pipe = StableDiffusionPipeline.from_pretrained(base_model_name_or_path, torch_dtype=dtype).to(device)
pipe.unet = PeftModel.from_pretrained(pipe.unet, unet_sub_dir, adapter_name=adapter_name)
if os.path.exists(text_encoder_sub_dir):
pipe.text_encoder = PeftModel.from_pretrained(
pipe.text_encoder, text_encoder_sub_dir, adapter_name=adapter_name
)
if dtype in (torch.float16, torch.bfloat16):
pipe.unet.half()
pipe.text_encoder.half()
pipe.to(device)
return pipe
```
Now you can use the function above to create a Stable Diffusion pipeline using the LoRA weights that you have created during the fine-tuning step.
Note, if you're running inference on the same machine, the path you specify here will be the same as `OUTPUT_DIR`.
```python
pipe = get_lora_sd_pipeline(Path("path-to-saved-model"), adapter_name="dog")
```
Once you have the pipeline with your fine-tuned model, you can use it to generate images:
```python
prompt = "sks dog playing fetch in the park"
negative_prompt = "low quality, blurry, unfinished"
image = pipe(prompt, num_inference_steps=50, guidance_scale=7, negative_prompt=negative_prompt).images[0]
image.save("DESTINATION_PATH_FOR_THE_IMAGE")
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/lora_dreambooth_dog_park.png" alt="Generated image of a dog in a park"/>
</div>
## Multi-adapter inference
With PEFT you can combine multiple adapters for inference. In the previous example you have fine-tuned Stable Diffusion on
some dog images. The pipeline created based on these weights got a name - `adapter_name="dog"`. Now, suppose you also fine-tuned
this base model on images of a crochet toy. Let's see how we can use both adapters.
First, you'll need to perform all the steps as in the single adapter inference example:
1. Specify the base model.
2. Add a function that creates a Stable Diffusion pipeline for image generation uses LoRA weights.
3. Create a `pipe` with `adapter_name="dog"` based on the model fine-tuned on dog images.
Next, you're going to need a few more helper functions.
To load another adapter, create a `load_adapter()` function that leverages `load_adapter()` method of `PeftModel` (e.g. `pipe.unet.load_adapter(peft_model_path, adapter_name)`):
```python
def load_adapter(pipe, ckpt_dir, adapter_name):
unet_sub_dir = os.path.join(ckpt_dir, "unet")
text_encoder_sub_dir = os.path.join(ckpt_dir, "text_encoder")
pipe.unet.load_adapter(unet_sub_dir, adapter_name=adapter_name)
if os.path.exists(text_encoder_sub_dir):
pipe.text_encoder.load_adapter(text_encoder_sub_dir, adapter_name=adapter_name)
```
To switch between adapters, write a function that uses `set_adapter()` method of `PeftModel` (see `pipe.unet.set_adapter(adapter_name)`)
```python
def set_adapter(pipe, adapter_name):
pipe.unet.set_adapter(adapter_name)
if isinstance(pipe.text_encoder, PeftModel):
pipe.text_encoder.set_adapter(adapter_name)
```
Finally, add a function to create weighted LoRA adapter.
```python
def create_weighted_lora_adapter(pipe, adapters, weights, adapter_name="default"):
pipe.unet.add_weighted_adapter(adapters, weights, adapter_name)
if isinstance(pipe.text_encoder, PeftModel):
pipe.text_encoder.add_weighted_adapter(adapters, weights, adapter_name)
return pipe
```
Let's load the second adapter from the model fine-tuned on images of a crochet toy, and give it a unique name:
```python
load_adapter(pipe, Path("path-to-the-second-saved-model"), adapter_name="crochet")
```
Create a pipeline using weighted adapters:
```python
pipe = create_weighted_lora_adapter(pipe, ["crochet", "dog"], [1.0, 1.05], adapter_name="crochet_dog")
```
Now you can switch between adapters. If you'd like to generate more dog images, set the adapter to `"dog"`:
```python
set_adapter(pipe, adapter_name="dog")
prompt = "sks dog in a supermarket isle"
negative_prompt = "low quality, blurry, unfinished"
image = pipe(prompt, num_inference_steps=50, guidance_scale=7, negative_prompt=negative_prompt).images[0]
image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/lora_dreambooth_dog_supermarket.png" alt="Generated image of a dog in a supermarket"/>
</div>
In the same way, you can switch to the second adapter:
```python
set_adapter(pipe, adapter_name="crochet")
prompt = "a fish rendered in the style of <1>"
negative_prompt = "low quality, blurry, unfinished"
image = pipe(prompt, num_inference_steps=50, guidance_scale=7, negative_prompt=negative_prompt).images[0]
image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/lora_dreambooth_fish.png" alt="Generated image of a crochet fish"/>
</div>
Finally, you can use combined weighted adapters:
```python
set_adapter(pipe, adapter_name="crochet_dog")
prompt = "sks dog rendered in the style of <1>, close up portrait, 4K HD"
negative_prompt = "low quality, blurry, unfinished"
image = pipe(prompt, num_inference_steps=50, guidance_scale=7, negative_prompt=negative_prompt).images[0]
image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/lora_dreambooth_crochet_dog.png" alt="Generated image of a crochet dog"/>
</div>
| huggingface/peft/blob/main/docs/source/task_guides/dreambooth_lora.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Trainer
## ORTTrainer
[[autodoc]] onnxruntime.trainer.ORTTrainer
- all
## ORTSeq2SeqTrainer
[[autodoc]] onnxruntime.trainer_seq2seq.ORTSeq2SeqTrainer
- evaluate
- predict
## ORTTrainingArguments
[[autodoc]] onnxruntime.training_args.ORTTrainingArguments
- all
## ORTSeq2SeqTrainingArguments
[[autodoc]] onnxruntime.training_args_seq2seq.ORTSeq2SeqTrainingArguments
- all | huggingface/optimum/blob/main/docs/source/onnxruntime/package_reference/trainer.mdx |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# CPM
## Overview
The CPM model was proposed in [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin,
Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen,
Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
The abstract from the paper is the following:
*Pre-trained Language Models (PLMs) have proven to be beneficial for various downstream NLP tasks. Recently, GPT-3,
with 175 billion parameters and 570GB training data, drew a lot of attention due to the capacity of few-shot (even
zero-shot) learning. However, applying GPT-3 to address Chinese NLP tasks is still challenging, as the training corpus
of GPT-3 is primarily English, and the parameters are not publicly available. In this technical report, we release the
Chinese Pre-trained Language Model (CPM) with generative pre-training on large-scale Chinese training data. To the best
of our knowledge, CPM, with 2.6 billion parameters and 100GB Chinese training data, is the largest Chinese pre-trained
language model, which could facilitate several downstream Chinese NLP tasks, such as conversation, essay generation,
cloze test, and language understanding. Extensive experiments demonstrate that CPM achieves strong performance on many
NLP tasks in the settings of few-shot (even zero-shot) learning.*
This model was contributed by [canwenxu](https://huggingface.co/canwenxu). The original implementation can be found
here: https://github.com/TsinghuaAI/CPM-Generate
<Tip>
CPM's architecture is the same as GPT-2, except for tokenization method. Refer to [GPT-2 documentation](gpt2) for
API reference information.
</Tip>
## CpmTokenizer
[[autodoc]] CpmTokenizer
## CpmTokenizerFast
[[autodoc]] CpmTokenizerFast
| huggingface/transformers/blob/main/docs/source/en/model_doc/cpm.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Conditional DETR
## Overview
The Conditional DETR model was proposed in [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang. Conditional DETR presents a conditional cross-attention mechanism for fast DETR training. Conditional DETR converges 6.7× to 10× faster than DETR.
The abstract from the paper is the following:
*The recently-developed DETR approach applies the transformer encoder and decoder architecture to object detection and achieves promising performance. In this paper, we handle the critical issue, slow training convergence, and present a conditional cross-attention mechanism for fast DETR training. Our approach is motivated by that the cross-attention in DETR relies highly on the content embeddings for localizing the four extremities and predicting the box, which increases the need for high-quality content embeddings and thus the training difficulty. Our approach, named conditional DETR, learns a conditional spatial query from the decoder embedding for decoder multi-head cross-attention. The benefit is that through the conditional spatial query, each cross-attention head is able to attend to a band containing a distinct region, e.g., one object extremity or a region inside the object box. This narrows down the spatial range for localizing the distinct regions for object classification and box regression, thus relaxing the dependence on the content embeddings and easing the training. Empirical results show that conditional DETR converges 6.7× faster for the backbones R50 and R101 and 10× faster for stronger backbones DC5-R50 and DC5-R101. Code is available at https://github.com/Atten4Vis/ConditionalDETR.*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/conditional_detr_curve.jpg"
alt="drawing" width="600"/>
<small> Conditional DETR shows much faster convergence compared to the original DETR. Taken from the <a href="https://arxiv.org/abs/2108.06152">original paper</a>.</small>
This model was contributed by [DepuMeng](https://huggingface.co/DepuMeng). The original code can be found [here](https://github.com/Atten4Vis/ConditionalDETR).
## Resources
- [Object detection task guide](../tasks/object_detection)
## ConditionalDetrConfig
[[autodoc]] ConditionalDetrConfig
## ConditionalDetrImageProcessor
[[autodoc]] ConditionalDetrImageProcessor
- preprocess
- post_process_object_detection
- post_process_instance_segmentation
- post_process_semantic_segmentation
- post_process_panoptic_segmentation
## ConditionalDetrFeatureExtractor
[[autodoc]] ConditionalDetrFeatureExtractor
- __call__
- post_process_object_detection
- post_process_instance_segmentation
- post_process_semantic_segmentation
- post_process_panoptic_segmentation
## ConditionalDetrModel
[[autodoc]] ConditionalDetrModel
- forward
## ConditionalDetrForObjectDetection
[[autodoc]] ConditionalDetrForObjectDetection
- forward
## ConditionalDetrForSegmentation
[[autodoc]] ConditionalDetrForSegmentation
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/conditional_detr.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# CMStochasticIterativeScheduler
[Consistency Models](https://huggingface.co/papers/2303.01469) by Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever introduced a multistep and onestep scheduler (Algorithm 1) that is capable of generating good samples in one or a small number of steps.
The abstract from the paper is:
*Diffusion models have significantly advanced the fields of image, audio, and video generation, but they depend on an iterative sampling process that causes slow generation. To overcome this limitation, we propose consistency models, a new family of models that generate high quality samples by directly mapping noise to data. They support fast one-step generation by design, while still allowing multistep sampling to trade compute for sample quality. They also support zero-shot data editing, such as image inpainting, colorization, and super-resolution, without requiring explicit training on these tasks. Consistency models can be trained either by distilling pre-trained diffusion models, or as standalone generative models altogether. Through extensive experiments, we demonstrate that they outperform existing distillation techniques for diffusion models in one- and few-step sampling, achieving the new state-of-the-art FID of 3.55 on CIFAR-10 and 6.20 on ImageNet 64x64 for one-step generation. When trained in isolation, consistency models become a new family of generative models that can outperform existing one-step, non-adversarial generative models on standard benchmarks such as CIFAR-10, ImageNet 64x64 and LSUN 256x256.*
The original codebase can be found at [openai/consistency_models](https://github.com/openai/consistency_models).
## CMStochasticIterativeScheduler
[[autodoc]] CMStochasticIterativeScheduler
## CMStochasticIterativeSchedulerOutput
[[autodoc]] schedulers.scheduling_consistency_models.CMStochasticIterativeSchedulerOutput
| huggingface/diffusers/blob/main/docs/source/en/api/schedulers/cm_stochastic_iterative.md |
FrameworkSwitchCourse {fw} />
# Handling multiple sequences[[handling-multiple-sequences]]
{#if fw === 'pt'}
<CourseFloatingBanner chapter={2}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter2/section5_pt.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter2/section5_pt.ipynb"},
]} />
{:else}
<CourseFloatingBanner chapter={2}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter2/section5_tf.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter2/section5_tf.ipynb"},
]} />
{/if}
{#if fw === 'pt'}
<Youtube id="M6adb1j2jPI"/>
{:else}
<Youtube id="ROxrFOEbsQE"/>
{/if}
In the previous section, we explored the simplest of use cases: doing inference on a single sequence of a small length. However, some questions emerge already:
- How do we handle multiple sequences?
- How do we handle multiple sequences *of different lengths*?
- Are vocabulary indices the only inputs that allow a model to work well?
- Is there such a thing as too long a sequence?
Let's see what kinds of problems these questions pose, and how we can solve them using the 🤗 Transformers API.
## Models expect a batch of inputs[[models-expect-a-batch-of-inputs]]
In the previous exercise you saw how sequences get translated into lists of numbers. Let's convert this list of numbers to a tensor and send it to the model:
{#if fw === 'pt'}
```py
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequence = "I've been waiting for a HuggingFace course my whole life."
tokens = tokenizer.tokenize(sequence)
ids = tokenizer.convert_tokens_to_ids(tokens)
input_ids = torch.tensor(ids)
# This line will fail.
model(input_ids)
```
```python out
IndexError: Dimension out of range (expected to be in range of [-1, 0], but got 1)
```
{:else}
```py
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = TFAutoModelForSequenceClassification.from_pretrained(checkpoint)
sequence = "I've been waiting for a HuggingFace course my whole life."
tokens = tokenizer.tokenize(sequence)
ids = tokenizer.convert_tokens_to_ids(tokens)
input_ids = tf.constant(ids)
# This line will fail.
model(input_ids)
```
```py out
InvalidArgumentError: Input to reshape is a tensor with 14 values, but the requested shape has 196 [Op:Reshape]
```
{/if}
Oh no! Why did this fail? "We followed the steps from the pipeline in section 2.
The problem is that we sent a single sequence to the model, whereas 🤗 Transformers models expect multiple sentences by default. Here we tried to do everything the tokenizer did behind the scenes when we applied it to a `sequence`. But if you look closely, you'll see that the tokenizer didn't just convert the list of input IDs into a tensor, it added a dimension on top of it:
{#if fw === 'pt'}
```py
tokenized_inputs = tokenizer(sequence, return_tensors="pt")
print(tokenized_inputs["input_ids"])
```
```python out
tensor([[ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172,
2607, 2026, 2878, 2166, 1012, 102]])
```
{:else}
```py
tokenized_inputs = tokenizer(sequence, return_tensors="tf")
print(tokenized_inputs["input_ids"])
```
```py out
<tf.Tensor: shape=(1, 16), dtype=int32, numpy=
array([[ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662,
12172, 2607, 2026, 2878, 2166, 1012, 102]], dtype=int32)>
```
{/if}
Let's try again and add a new dimension:
{#if fw === 'pt'}
```py
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequence = "I've been waiting for a HuggingFace course my whole life."
tokens = tokenizer.tokenize(sequence)
ids = tokenizer.convert_tokens_to_ids(tokens)
input_ids = torch.tensor([ids])
print("Input IDs:", input_ids)
output = model(input_ids)
print("Logits:", output.logits)
```
{:else}
```py
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = TFAutoModelForSequenceClassification.from_pretrained(checkpoint)
sequence = "I've been waiting for a HuggingFace course my whole life."
tokens = tokenizer.tokenize(sequence)
ids = tokenizer.convert_tokens_to_ids(tokens)
input_ids = tf.constant([ids])
print("Input IDs:", input_ids)
output = model(input_ids)
print("Logits:", output.logits)
```
{/if}
We print the input IDs as well as the resulting logits — here's the output:
{#if fw === 'pt'}
```python out
Input IDs: [[ 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012]]
Logits: [[-2.7276, 2.8789]]
```
{:else}
```py out
Input IDs: tf.Tensor(
[[ 1045 1005 2310 2042 3403 2005 1037 17662 12172 2607 2026 2878
2166 1012]], shape=(1, 14), dtype=int32)
Logits: tf.Tensor([[-2.7276208 2.8789377]], shape=(1, 2), dtype=float32)
```
{/if}
*Batching* is the act of sending multiple sentences through the model, all at once. If you only have one sentence, you can just build a batch with a single sequence:
```
batched_ids = [ids, ids]
```
This is a batch of two identical sequences!
<Tip>
✏️ **Try it out!** Convert this `batched_ids` list into a tensor and pass it through your model. Check that you obtain the same logits as before (but twice)!
</Tip>
Batching allows the model to work when you feed it multiple sentences. Using multiple sequences is just as simple as building a batch with a single sequence. There's a second issue, though. When you're trying to batch together two (or more) sentences, they might be of different lengths. If you've ever worked with tensors before, you know that they need to be of rectangular shape, so you won't be able to convert the list of input IDs into a tensor directly. To work around this problem, we usually *pad* the inputs.
## Padding the inputs[[padding-the-inputs]]
The following list of lists cannot be converted to a tensor:
```py no-format
batched_ids = [
[200, 200, 200],
[200, 200]
]
```
In order to work around this, we'll use *padding* to make our tensors have a rectangular shape. Padding makes sure all our sentences have the same length by adding a special word called the *padding token* to the sentences with fewer values. For example, if you have 10 sentences with 10 words and 1 sentence with 20 words, padding will ensure all the sentences have 20 words. In our example, the resulting tensor looks like this:
```py no-format
padding_id = 100
batched_ids = [
[200, 200, 200],
[200, 200, padding_id],
]
```
The padding token ID can be found in `tokenizer.pad_token_id`. Let's use it and send our two sentences through the model individually and batched together:
{#if fw === 'pt'}
```py no-format
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequence1_ids = [[200, 200, 200]]
sequence2_ids = [[200, 200]]
batched_ids = [
[200, 200, 200],
[200, 200, tokenizer.pad_token_id],
]
print(model(torch.tensor(sequence1_ids)).logits)
print(model(torch.tensor(sequence2_ids)).logits)
print(model(torch.tensor(batched_ids)).logits)
```
```python out
tensor([[ 1.5694, -1.3895]], grad_fn=<AddmmBackward>)
tensor([[ 0.5803, -0.4125]], grad_fn=<AddmmBackward>)
tensor([[ 1.5694, -1.3895],
[ 1.3373, -1.2163]], grad_fn=<AddmmBackward>)
```
{:else}
```py no-format
model = TFAutoModelForSequenceClassification.from_pretrained(checkpoint)
sequence1_ids = [[200, 200, 200]]
sequence2_ids = [[200, 200]]
batched_ids = [
[200, 200, 200],
[200, 200, tokenizer.pad_token_id],
]
print(model(tf.constant(sequence1_ids)).logits)
print(model(tf.constant(sequence2_ids)).logits)
print(model(tf.constant(batched_ids)).logits)
```
```py out
tf.Tensor([[ 1.5693678 -1.3894581]], shape=(1, 2), dtype=float32)
tf.Tensor([[ 0.5803005 -0.41252428]], shape=(1, 2), dtype=float32)
tf.Tensor(
[[ 1.5693681 -1.3894582]
[ 1.3373486 -1.2163193]], shape=(2, 2), dtype=float32)
```
{/if}
There's something wrong with the logits in our batched predictions: the second row should be the same as the logits for the second sentence, but we've got completely different values!
This is because the key feature of Transformer models is attention layers that *contextualize* each token. These will take into account the padding tokens since they attend to all of the tokens of a sequence. To get the same result when passing individual sentences of different lengths through the model or when passing a batch with the same sentences and padding applied, we need to tell those attention layers to ignore the padding tokens. This is done by using an attention mask.
## Attention masks[[attention-masks]]
*Attention masks* are tensors with the exact same shape as the input IDs tensor, filled with 0s and 1s: 1s indicate the corresponding tokens should be attended to, and 0s indicate the corresponding tokens should not be attended to (i.e., they should be ignored by the attention layers of the model).
Let's complete the previous example with an attention mask:
{#if fw === 'pt'}
```py no-format
batched_ids = [
[200, 200, 200],
[200, 200, tokenizer.pad_token_id],
]
attention_mask = [
[1, 1, 1],
[1, 1, 0],
]
outputs = model(torch.tensor(batched_ids), attention_mask=torch.tensor(attention_mask))
print(outputs.logits)
```
```python out
tensor([[ 1.5694, -1.3895],
[ 0.5803, -0.4125]], grad_fn=<AddmmBackward>)
```
{:else}
```py no-format
batched_ids = [
[200, 200, 200],
[200, 200, tokenizer.pad_token_id],
]
attention_mask = [
[1, 1, 1],
[1, 1, 0],
]
outputs = model(tf.constant(batched_ids), attention_mask=tf.constant(attention_mask))
print(outputs.logits)
```
```py out
tf.Tensor(
[[ 1.5693681 -1.3894582 ]
[ 0.5803021 -0.41252586]], shape=(2, 2), dtype=float32)
```
{/if}
Now we get the same logits for the second sentence in the batch.
Notice how the last value of the second sequence is a padding ID, which is a 0 value in the attention mask.
<Tip>
✏️ **Try it out!** Apply the tokenization manually on the two sentences used in section 2 ("I've been waiting for a HuggingFace course my whole life." and "I hate this so much!"). Pass them through the model and check that you get the same logits as in section 2. Now batch them together using the padding token, then create the proper attention mask. Check that you obtain the same results when going through the model!
</Tip>
## Longer sequences[[longer-sequences]]
With Transformer models, there is a limit to the lengths of the sequences we can pass the models. Most models handle sequences of up to 512 or 1024 tokens, and will crash when asked to process longer sequences. There are two solutions to this problem:
- Use a model with a longer supported sequence length.
- Truncate your sequences.
Models have different supported sequence lengths, and some specialize in handling very long sequences. [Longformer](https://huggingface.co/docs/transformers/model_doc/longformer) is one example, and another is [LED](https://huggingface.co/docs/transformers/model_doc/led). If you're working on a task that requires very long sequences, we recommend you take a look at those models.
Otherwise, we recommend you truncate your sequences by specifying the `max_sequence_length` parameter:
```py
sequence = sequence[:max_sequence_length]
```
| huggingface/course/blob/main/chapters/en/chapter2/5.mdx |
Gradio Demo: label_component
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
gr.Label(value={"First Label": 0.7, "Second Label": 0.2, "Third Label": 0.1})
demo.launch()
```
| gradio-app/gradio/blob/main/demo/label_component/run.ipynb |
!--Copyright 2023 Custom Diffusion authors The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Custom Diffusion
[Custom Diffusion](https://huggingface.co/papers/2212.04488) is a training technique for personalizing image generation models. Like Textual Inversion, DreamBooth, and LoRA, Custom Diffusion only requires a few (~4-5) example images. This technique works by only training weights in the cross-attention layers, and it uses a special word to represent the newly learned concept. Custom Diffusion is unique because it can also learn multiple concepts at the same time.
If you're training on a GPU with limited vRAM, you should try enabling xFormers with `--enable_xformers_memory_efficient_attention` for faster training with lower vRAM requirements (16GB). To save even more memory, add `--set_grads_to_none` in the training argument to set the gradients to `None` instead of zero (this option can cause some issues, so if you experience any, try removing this parameter).
This guide will explore the [train_custom_diffusion.py](https://github.com/huggingface/diffusers/blob/main/examples/custom_diffusion/train_custom_diffusion.py) script to help you become more familiar with it, and how you can adapt it for your own use-case.
Before running the script, make sure you install the library from source:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
```
Navigate to the example folder with the training script and install the required dependencies:
```bash
cd examples/custom_diffusion
pip install -r requirements.txt
pip install clip-retrieval
```
<Tip>
🤗 Accelerate is a library for helping you train on multiple GPUs/TPUs or with mixed-precision. It'll automatically configure your training setup based on your hardware and environment. Take a look at the 🤗 Accelerate [Quick tour](https://huggingface.co/docs/accelerate/quicktour) to learn more.
</Tip>
Initialize an 🤗 Accelerate environment:
```bash
accelerate config
```
To setup a default 🤗 Accelerate environment without choosing any configurations:
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell, like a notebook, you can use:
```bash
from accelerate.utils import write_basic_config
write_basic_config()
```
Lastly, if you want to train a model on your own dataset, take a look at the [Create a dataset for training](create_dataset) guide to learn how to create a dataset that works with the training script.
<Tip>
The following sections highlight parts of the training script that are important for understanding how to modify it, but it doesn't cover every aspect of the script in detail. If you're interested in learning more, feel free to read through the [script](https://github.com/huggingface/diffusers/blob/main/examples/custom_diffusion/train_custom_diffusion.py) and let us know if you have any questions or concerns.
</Tip>
## Script parameters
The training script contains all the parameters to help you customize your training run. These are found in the [`parse_args()`](https://github.com/huggingface/diffusers/blob/64603389da01082055a901f2883c4810d1144edb/examples/custom_diffusion/train_custom_diffusion.py#L319) function. The function comes with default values, but you can also set your own values in the training command if you'd like.
For example, to change the resolution of the input image:
```bash
accelerate launch train_custom_diffusion.py \
--resolution=256
```
Many of the basic parameters are described in the [DreamBooth](dreambooth#script-parameters) training guide, so this guide focuses on the parameters unique to Custom Diffusion:
- `--freeze_model`: freezes the key and value parameters in the cross-attention layer; the default is `crossattn_kv`, but you can set it to `crossattn` to train all the parameters in the cross-attention layer
- `--concepts_list`: to learn multiple concepts, provide a path to a JSON file containing the concepts
- `--modifier_token`: a special word used to represent the learned concept
- `--initializer_token`:
### Prior preservation loss
Prior preservation loss is a method that uses a model's own generated samples to help it learn how to generate more diverse images. Because these generated sample images belong to the same class as the images you provided, they help the model retain what it has learned about the class and how it can use what it already knows about the class to make new compositions.
Many of the parameters for prior preservation loss are described in the [DreamBooth](dreambooth#prior-preservation-loss) training guide.
### Regularization
Custom Diffusion includes training the target images with a small set of real images to prevent overfitting. As you can imagine, this can be easy to do when you're only training on a few images! Download 200 real images with `clip_retrieval`. The `class_prompt` should be the same category as the target images. These images are stored in `class_data_dir`.
```bash
python retrieve.py --class_prompt cat --class_data_dir real_reg/samples_cat --num_class_images 200
```
To enable regularization, add the following parameters:
- `--with_prior_preservation`: whether to use prior preservation loss
- `--prior_loss_weight`: controls the influence of the prior preservation loss on the model
- `--real_prior`: whether to use a small set of real images to prevent overfitting
```bash
accelerate launch train_custom_diffusion.py \
--with_prior_preservation \
--prior_loss_weight=1.0 \
--class_data_dir="./real_reg/samples_cat" \
--class_prompt="cat" \
--real_prior=True \
```
## Training script
<Tip>
A lot of the code in the Custom Diffusion training script is similar to the [DreamBooth](dreambooth#training-script) script. This guide instead focuses on the code that is relevant to Custom Diffusion.
</Tip>
The Custom Diffusion training script has two dataset classes:
- [`CustomDiffusionDataset`](https://github.com/huggingface/diffusers/blob/64603389da01082055a901f2883c4810d1144edb/examples/custom_diffusion/train_custom_diffusion.py#L165): preprocesses the images, class images, and prompts for training
- [`PromptDataset`](https://github.com/huggingface/diffusers/blob/64603389da01082055a901f2883c4810d1144edb/examples/custom_diffusion/train_custom_diffusion.py#L148): prepares the prompts for generating class images
Next, the `modifier_token` is [added to the tokenizer](https://github.com/huggingface/diffusers/blob/64603389da01082055a901f2883c4810d1144edb/examples/custom_diffusion/train_custom_diffusion.py#L811), converted to token ids, and the token embeddings are resized to account for the new `modifier_token`. Then the `modifier_token` embeddings are initialized with the embeddings of the `initializer_token`. All parameters in the text encoder are frozen, except for the token embeddings since this is what the model is trying to learn to associate with the concepts.
```py
params_to_freeze = itertools.chain(
text_encoder.text_model.encoder.parameters(),
text_encoder.text_model.final_layer_norm.parameters(),
text_encoder.text_model.embeddings.position_embedding.parameters(),
)
freeze_params(params_to_freeze)
```
Now you'll need to add the [Custom Diffusion weights](https://github.com/huggingface/diffusers/blob/64603389da01082055a901f2883c4810d1144edb/examples/custom_diffusion/train_custom_diffusion.py#L911C3-L911C3) to the attention layers. This is a really important step for getting the shape and size of the attention weights correct, and for setting the appropriate number of attention processors in each UNet block.
```py
st = unet.state_dict()
for name, _ in unet.attn_processors.items():
cross_attention_dim = None if name.endswith("attn1.processor") else unet.config.cross_attention_dim
if name.startswith("mid_block"):
hidden_size = unet.config.block_out_channels[-1]
elif name.startswith("up_blocks"):
block_id = int(name[len("up_blocks.")])
hidden_size = list(reversed(unet.config.block_out_channels))[block_id]
elif name.startswith("down_blocks"):
block_id = int(name[len("down_blocks.")])
hidden_size = unet.config.block_out_channels[block_id]
layer_name = name.split(".processor")[0]
weights = {
"to_k_custom_diffusion.weight": st[layer_name + ".to_k.weight"],
"to_v_custom_diffusion.weight": st[layer_name + ".to_v.weight"],
}
if train_q_out:
weights["to_q_custom_diffusion.weight"] = st[layer_name + ".to_q.weight"]
weights["to_out_custom_diffusion.0.weight"] = st[layer_name + ".to_out.0.weight"]
weights["to_out_custom_diffusion.0.bias"] = st[layer_name + ".to_out.0.bias"]
if cross_attention_dim is not None:
custom_diffusion_attn_procs[name] = attention_class(
train_kv=train_kv,
train_q_out=train_q_out,
hidden_size=hidden_size,
cross_attention_dim=cross_attention_dim,
).to(unet.device)
custom_diffusion_attn_procs[name].load_state_dict(weights)
else:
custom_diffusion_attn_procs[name] = attention_class(
train_kv=False,
train_q_out=False,
hidden_size=hidden_size,
cross_attention_dim=cross_attention_dim,
)
del st
unet.set_attn_processor(custom_diffusion_attn_procs)
custom_diffusion_layers = AttnProcsLayers(unet.attn_processors)
```
The [optimizer](https://github.com/huggingface/diffusers/blob/84cd9e8d01adb47f046b1ee449fc76a0c32dc4e2/examples/custom_diffusion/train_custom_diffusion.py#L982) is initialized to update the cross-attention layer parameters:
```py
optimizer = optimizer_class(
itertools.chain(text_encoder.get_input_embeddings().parameters(), custom_diffusion_layers.parameters())
if args.modifier_token is not None
else custom_diffusion_layers.parameters(),
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
```
In the [training loop](https://github.com/huggingface/diffusers/blob/84cd9e8d01adb47f046b1ee449fc76a0c32dc4e2/examples/custom_diffusion/train_custom_diffusion.py#L1048), it is important to only update the embeddings for the concept you're trying to learn. This means setting the gradients of all the other token embeddings to zero:
```py
if args.modifier_token is not None:
if accelerator.num_processes > 1:
grads_text_encoder = text_encoder.module.get_input_embeddings().weight.grad
else:
grads_text_encoder = text_encoder.get_input_embeddings().weight.grad
index_grads_to_zero = torch.arange(len(tokenizer)) != modifier_token_id[0]
for i in range(len(modifier_token_id[1:])):
index_grads_to_zero = index_grads_to_zero & (
torch.arange(len(tokenizer)) != modifier_token_id[i]
)
grads_text_encoder.data[index_grads_to_zero, :] = grads_text_encoder.data[
index_grads_to_zero, :
].fill_(0)
```
## Launch the script
Once you’ve made all your changes or you’re okay with the default configuration, you’re ready to launch the training script! 🚀
In this guide, you'll download and use these example [cat images](https://www.cs.cmu.edu/~custom-diffusion/assets/data.zip). You can also create and use your own dataset if you want (see the [Create a dataset for training](create_dataset) guide).
Set the environment variable `MODEL_NAME` to a model id on the Hub or a path to a local model, `INSTANCE_DIR` to the path where you just downloaded the cat images to, and `OUTPUT_DIR` to where you want to save the model. You'll use `<new1>` as the special word to tie the newly learned embeddings to. The script creates and saves model checkpoints and a pytorch_custom_diffusion_weights.bin file to your repository.
To monitor training progress with Weights and Biases, add the `--report_to=wandb` parameter to the training command and specify a validation prompt with `--validation_prompt`. This is useful for debugging and saving intermediate results.
<Tip>
If you're training on human faces, the Custom Diffusion team has found the following parameters to work well:
- `--learning_rate=5e-6`
- `--max_train_steps` can be anywhere between 1000 and 2000
- `--freeze_model=crossattn`
- use at least 15-20 images to train with
</Tip>
<hfoptions id="training-inference">
<hfoption id="single concept">
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export OUTPUT_DIR="path-to-save-model"
export INSTANCE_DIR="./data/cat"
accelerate launch train_custom_diffusion.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--output_dir=$OUTPUT_DIR \
--class_data_dir=./real_reg/samples_cat/ \
--with_prior_preservation \
--real_prior \
--prior_loss_weight=1.0 \
--class_prompt="cat" \
--num_class_images=200 \
--instance_prompt="photo of a <new1> cat" \
--resolution=512 \
--train_batch_size=2 \
--learning_rate=1e-5 \
--lr_warmup_steps=0 \
--max_train_steps=250 \
--scale_lr \
--hflip \
--modifier_token "<new1>" \
--validation_prompt="<new1> cat sitting in a bucket" \
--report_to="wandb" \
--push_to_hub
```
</hfoption>
<hfoption id="multiple concepts">
Custom Diffusion can also learn multiple concepts if you provide a [JSON](https://github.com/adobe-research/custom-diffusion/blob/main/assets/concept_list.json) file with some details about each concept it should learn.
Run clip-retrieval to collect some real images to use for regularization:
```bash
pip install clip-retrieval
python retrieve.py --class_prompt {} --class_data_dir {} --num_class_images 200
```
Then you can launch the script:
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export OUTPUT_DIR="path-to-save-model"
accelerate launch train_custom_diffusion.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--output_dir=$OUTPUT_DIR \
--concepts_list=./concept_list.json \
--with_prior_preservation \
--real_prior \
--prior_loss_weight=1.0 \
--resolution=512 \
--train_batch_size=2 \
--learning_rate=1e-5 \
--lr_warmup_steps=0 \
--max_train_steps=500 \
--num_class_images=200 \
--scale_lr \
--hflip \
--modifier_token "<new1>+<new2>" \
--push_to_hub
```
</hfoption>
</hfoptions>
Once training is finished, you can use your new Custom Diffusion model for inference.
<hfoptions id="training-inference">
<hfoption id="single concept">
```py
import torch
from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16,
).to("cuda")
pipeline.unet.load_attn_procs("path-to-save-model", weight_name="pytorch_custom_diffusion_weights.bin")
pipeline.load_textual_inversion("path-to-save-model", weight_name="<new1>.bin")
image = pipeline(
"<new1> cat sitting in a bucket",
num_inference_steps=100,
guidance_scale=6.0,
eta=1.0,
).images[0]
image.save("cat.png")
```
</hfoption>
<hfoption id="multiple concepts">
```py
import torch
from huggingface_hub.repocard import RepoCard
from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained("sayakpaul/custom-diffusion-cat-wooden-pot", torch_dtype=torch.float16).to("cuda")
pipeline.unet.load_attn_procs(model_id, weight_name="pytorch_custom_diffusion_weights.bin")
pipeline.load_textual_inversion(model_id, weight_name="<new1>.bin")
pipeline.load_textual_inversion(model_id, weight_name="<new2>.bin")
image = pipeline(
"the <new1> cat sculpture in the style of a <new2> wooden pot",
num_inference_steps=100,
guidance_scale=6.0,
eta=1.0,
).images[0]
image.save("multi-subject.png")
```
</hfoption>
</hfoptions>
## Next steps
Congratulations on training a model with Custom Diffusion! 🎉 To learn more:
- Read the [Multi-Concept Customization of Text-to-Image Diffusion](https://www.cs.cmu.edu/~custom-diffusion/) blog post to learn more details about the experimental results from the Custom Diffusion team. | huggingface/diffusers/blob/main/docs/source/en/training/custom_diffusion.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# EfficientNet
## Overview
The EfficientNet model was proposed in [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946)
by Mingxing Tan and Quoc V. Le. EfficientNets are a family of image classification models, which achieve state-of-the-art accuracy, yet being an order-of-magnitude smaller and faster than previous models.
The abstract from the paper is the following:
*Convolutional Neural Networks (ConvNets) are commonly developed at a fixed resource budget, and then scaled up for better accuracy if more resources are available. In this paper, we systematically study model scaling and identify that carefully balancing network depth, width, and resolution can lead to better performance. Based on this observation, we propose a new scaling method that uniformly scales all dimensions of depth/width/resolution using a simple yet highly effective compound coefficient. We demonstrate the effectiveness of this method on scaling up MobileNets and ResNet.
To go even further, we use neural architecture search to design a new baseline network and scale it up to obtain a family of models, called EfficientNets, which achieve much better accuracy and efficiency than previous ConvNets. In particular, our EfficientNet-B7 achieves state-of-the-art 84.3% top-1 accuracy on ImageNet, while being 8.4x smaller and 6.1x faster on inference than the best existing ConvNet. Our EfficientNets also transfer well and achieve state-of-the-art accuracy on CIFAR-100 (91.7%), Flowers (98.8%), and 3 other transfer learning datasets, with an order of magnitude fewer parameters.*
This model was contributed by [adirik](https://huggingface.co/adirik).
The original code can be found [here](https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet).
## EfficientNetConfig
[[autodoc]] EfficientNetConfig
## EfficientNetImageProcessor
[[autodoc]] EfficientNetImageProcessor
- preprocess
## EfficientNetModel
[[autodoc]] EfficientNetModel
- forward
## EfficientNetForImageClassification
[[autodoc]] EfficientNetForImageClassification
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/efficientnet.md |
ResNet
**Residual Networks**, or **ResNets**, learn residual functions with reference to the layer inputs, instead of learning unreferenced functions. Instead of hoping each few stacked layers directly fit a desired underlying mapping, residual nets let these layers fit a residual mapping. They stack [residual blocks](https://paperswithcode.com/method/residual-block) ontop of each other to form network: e.g. a ResNet-50 has fifty layers using these blocks.
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('resnet18', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `resnet18`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('resnet18', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@article{DBLP:journals/corr/HeZRS15,
author = {Kaiming He and
Xiangyu Zhang and
Shaoqing Ren and
Jian Sun},
title = {Deep Residual Learning for Image Recognition},
journal = {CoRR},
volume = {abs/1512.03385},
year = {2015},
url = {http://arxiv.org/abs/1512.03385},
archivePrefix = {arXiv},
eprint = {1512.03385},
timestamp = {Wed, 17 Apr 2019 17:23:45 +0200},
biburl = {https://dblp.org/rec/journals/corr/HeZRS15.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<!--
Type: model-index
Collections:
- Name: ResNet
Paper:
Title: Deep Residual Learning for Image Recognition
URL: https://paperswithcode.com/paper/deep-residual-learning-for-image-recognition
Models:
- Name: resnet18
In Collection: ResNet
Metadata:
FLOPs: 2337073152
Parameters: 11690000
File Size: 46827520
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: resnet18
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/resnet.py#L641
Weights: https://download.pytorch.org/models/resnet18-5c106cde.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 69.74%
Top 5 Accuracy: 89.09%
- Name: resnet26
In Collection: ResNet
Metadata:
FLOPs: 3026804736
Parameters: 16000000
File Size: 64129972
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: resnet26
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/resnet.py#L675
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/resnet26-9aa10e23.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 75.29%
Top 5 Accuracy: 92.57%
- Name: resnet34
In Collection: ResNet
Metadata:
FLOPs: 4718469120
Parameters: 21800000
File Size: 87290831
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: resnet34
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/resnet.py#L658
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/resnet34-43635321.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 75.11%
Top 5 Accuracy: 92.28%
- Name: resnet50
In Collection: ResNet
Metadata:
FLOPs: 5282531328
Parameters: 25560000
File Size: 102488165
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: resnet50
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/resnet.py#L691
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/resnet50_ram-a26f946b.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.04%
Top 5 Accuracy: 94.39%
- Name: resnetblur50
In Collection: ResNet
Metadata:
FLOPs: 6621606912
Parameters: 25560000
File Size: 102488165
Architecture:
- 1x1 Convolution
- Batch Normalization
- Blur Pooling
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: resnetblur50
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/resnet.py#L1160
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/resnetblur50-84f4748f.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.29%
Top 5 Accuracy: 94.64%
- Name: tv_resnet101
In Collection: ResNet
Metadata:
FLOPs: 10068547584
Parameters: 44550000
File Size: 178728960
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
ID: tv_resnet101
LR: 0.1
Epochs: 90
Crop Pct: '0.875'
LR Gamma: 0.1
Momentum: 0.9
Batch Size: 32
Image Size: '224'
LR Step Size: 30
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/resnet.py#L761
Weights: https://download.pytorch.org/models/resnet101-5d3b4d8f.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.37%
Top 5 Accuracy: 93.56%
- Name: tv_resnet152
In Collection: ResNet
Metadata:
FLOPs: 14857660416
Parameters: 60190000
File Size: 241530880
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
ID: tv_resnet152
LR: 0.1
Epochs: 90
Crop Pct: '0.875'
LR Gamma: 0.1
Momentum: 0.9
Batch Size: 32
Image Size: '224'
LR Step Size: 30
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/resnet.py#L769
Weights: https://download.pytorch.org/models/resnet152-b121ed2d.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.32%
Top 5 Accuracy: 94.05%
- Name: tv_resnet34
In Collection: ResNet
Metadata:
FLOPs: 4718469120
Parameters: 21800000
File Size: 87306240
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
ID: tv_resnet34
LR: 0.1
Epochs: 90
Crop Pct: '0.875'
LR Gamma: 0.1
Momentum: 0.9
Batch Size: 32
Image Size: '224'
LR Step Size: 30
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/resnet.py#L745
Weights: https://download.pytorch.org/models/resnet34-333f7ec4.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 73.3%
Top 5 Accuracy: 91.42%
- Name: tv_resnet50
In Collection: ResNet
Metadata:
FLOPs: 5282531328
Parameters: 25560000
File Size: 102502400
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
ID: tv_resnet50
LR: 0.1
Epochs: 90
Crop Pct: '0.875'
LR Gamma: 0.1
Momentum: 0.9
Batch Size: 32
Image Size: '224'
LR Step Size: 30
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/resnet.py#L753
Weights: https://download.pytorch.org/models/resnet50-19c8e357.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 76.16%
Top 5 Accuracy: 92.88%
--> | huggingface/pytorch-image-models/blob/main/docs/models/resnet.md |
自定义的 JS 和 CSS
本指南介绍了如何更灵活地为 Blocks 添加样式,并添加 JavaScript 代码到事件监听器中。
**警告**:在自定义的 JS 和 CSS 中使用查询选择器不能保证能在所有 Gradio 版本中正常工作,因为 Gradio 的 HTML DOM 可能会发生变化。我们建议谨慎使用查询选择器。
## 自定义的 CSS
Gradio 主题是自定义应用程序外观和感觉的最简单方式。您可以从各种主题中进行选择,或者创建自己的主题。要实现这一点,请将 `theme=` kwarg 传递给 `Blocks` 构造函数。例如:
```python
with gr.Blocks(theme=gr.themes.Glass()):
...
```
Gradio 自带一套预构建的主题,您可以从 `gr.themes.*` 中加载这些主题。您可以扩展这些主题,或者从头开始创建自己的主题 - 有关更多详细信息,请参阅[主题指南](/theming-guide)。
要增加附加的样式能力,您可以使用 `css=` kwarg 将任何 CSS 传递给您的应用程序。
Gradio 应用程序的基类是 `gradio-container`,因此下面是一个示例,用于更改 Gradio 应用程序的背景颜色:
```python
with gr.Blocks(css=".gradio-container {background-color: red}") as demo:
...
```
如果您想在您的 CSS 中引用外部文件,请使用 `"file="` 作为文件路径的前缀(可以是相对路径或绝对路径),例如:
```python
with gr.Blocks(css=".gradio-container {background: url('file=clouds.jpg')}") as demo:
...
```
您还可以将 CSS 文件的文件路径传递给 `css` 参数。
## `elem_id` 和 `elem_classes` 参数
您可以使用 `elem_id` 来为任何组件添加 HTML 元素 `id`,并使用 `elem_classes` 添加一个类或类列表。这将使您能够更轻松地使用 CSS 选择元素。这种方法更有可能在 Gradio 版本之间保持稳定,因为内置的类名或 id 可能会发生变化(但正如上面的警告中所提到的,如果您使用自定义 CSS,我们不能保证在 Gradio 版本之间完全兼容,因为 DOM 元素本身可能会发生变化)。
```python
css = """
#warning {background-color: #FFCCCB}
.feedback textarea {font-size: 24px !important}
"""
with gr.Blocks(css=css) as demo:
box1 = gr.Textbox(value="Good Job", elem_classes="feedback")
box2 = gr.Textbox(value="Failure", elem_id="warning", elem_classes="feedback")
```
CSS `#warning` 规则集仅针对第二个文本框,而 `.feedback` 规则集将同时作用于两个文本框。请注意,在针对类时,您可能需要使用 `!important` 选择器来覆盖默认的 Gradio 样式。
## 自定义的 JS
事件监听器具有 `_js` 参数,可以接受 JavaScript 函数作为字符串,并像 Python 事件监听器函数一样处理它。您可以传递 JavaScript 函数和 Python 函数(在这种情况下,先运行 JavaScript 函数),或者仅传递 JavaScript(并将 Python 的 `fn` 设置为 `None`)。请查看下面的代码:
$code_blocks_js_methods
$demo_blocks_js_methods
| gradio-app/gradio/blob/main/guides/cn/03_building-with-blocks/04_custom-CSS-and-JS.md |
Use with PyTorch
This document is a quick introduction to using `datasets` with PyTorch, with a particular focus on how to get
`torch.Tensor` objects out of our datasets, and how to use a PyTorch `DataLoader` and a Hugging Face `Dataset`
with the best performance.
## Dataset format
By default, datasets return regular python objects: integers, floats, strings, lists, etc.
To get PyTorch tensors instead, you can set the format of the dataset to `pytorch` using [`Dataset.with_format`]:
```py
>>> from datasets import Dataset
>>> data = [[1, 2],[3, 4]]
>>> ds = Dataset.from_dict({"data": data})
>>> ds = ds.with_format("torch")
>>> ds[0]
{'data': tensor([1, 2])}
>>> ds[:2]
{'data': tensor([[1, 2],
[3, 4]])}
```
<Tip>
A [`Dataset`] object is a wrapper of an Arrow table, which allows fast zero-copy reads from arrays in the dataset to PyTorch tensors.
</Tip>
To load the data as tensors on a GPU, specify the `device` argument:
```py
>>> import torch
>>> device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
>>> ds = ds.with_format("torch", device=device)
>>> ds[0]
{'data': tensor([1, 2], device='cuda:0')}
```
## N-dimensional arrays
If your dataset consists of N-dimensional arrays, you will see that by default they are considered as nested lists.
In particular, a PyTorch formatted dataset outputs nested lists instead of a single tensor:
```py
>>> from datasets import Dataset
>>> data = [[[1, 2],[3, 4]],[[5, 6],[7, 8]]]
>>> ds = Dataset.from_dict({"data": data})
>>> ds = ds.with_format("torch")
>>> ds[0]
{'data': [tensor([1, 2]), tensor([3, 4])]}
```
To get a single tensor, you must explicitly use the [`Array`] feature type and specify the shape of your tensors:
```py
>>> from datasets import Dataset, Features, Array2D
>>> data = [[[1, 2],[3, 4]],[[5, 6],[7, 8]]]
>>> features = Features({"data": Array2D(shape=(2, 2), dtype='int32')})
>>> ds = Dataset.from_dict({"data": data}, features=features)
>>> ds = ds.with_format("torch")
>>> ds[0]
{'data': tensor([[1, 2],
[3, 4]])}
>>> ds[:2]
{'data': tensor([[[1, 2],
[3, 4]],
[[5, 6],
[7, 8]]])}
```
## Other feature types
[`ClassLabel`] data are properly converted to tensors:
```py
>>> from datasets import Dataset, Features, ClassLabel
>>> labels = [0, 0, 1]
>>> features = Features({"label": ClassLabel(names=["negative", "positive"])})
>>> ds = Dataset.from_dict({"label": labels}, features=features)
>>> ds = ds.with_format("torch")
>>> ds[:3]
{'label': tensor([0, 0, 1])}
```
String and binary objects are unchanged, since PyTorch only supports numbers.
The [`Image`] and [`Audio`] feature types are also supported.
<Tip>
To use the [`Image`] feature type, you'll need to install the `vision` extra as
`pip install datasets[vision]`.
</Tip>
```py
>>> from datasets import Dataset, Features, Audio, Image
>>> images = ["path/to/image.png"] * 10
>>> features = Features({"image": Image()})
>>> ds = Dataset.from_dict({"image": images}, features=features)
>>> ds = ds.with_format("torch")
>>> ds[0]["image"].shape
torch.Size([512, 512, 4])
>>> ds[0]
{'image': tensor([[[255, 215, 106, 255],
[255, 215, 106, 255],
...,
[255, 255, 255, 255],
[255, 255, 255, 255]]], dtype=torch.uint8)}
>>> ds[:2]["image"].shape
torch.Size([2, 512, 512, 4])
>>> ds[:2]
{'image': tensor([[[[255, 215, 106, 255],
[255, 215, 106, 255],
...,
[255, 255, 255, 255],
[255, 255, 255, 255]]]], dtype=torch.uint8)}
```
<Tip>
To use the [`Audio`] feature type, you'll need to install the `audio` extra as
`pip install datasets[audio]`.
</Tip>
```py
>>> from datasets import Dataset, Features, Audio, Image
>>> audio = ["path/to/audio.wav"] * 10
>>> features = Features({"audio": Audio()})
>>> ds = Dataset.from_dict({"audio": audio}, features=features)
>>> ds = ds.with_format("torch")
>>> ds[0]["audio"]["array"]
tensor([ 6.1035e-05, 1.5259e-05, 1.6785e-04, ..., -1.5259e-05,
-1.5259e-05, 1.5259e-05])
>>> ds[0]["audio"]["sampling_rate"]
tensor(44100)
```
## Data loading
Like `torch.utils.data.Dataset` objects, a [`Dataset`] can be passed directly to a PyTorch `DataLoader`:
```py
>>> import numpy as np
>>> from datasets import Dataset
>>> from torch.utils.data import DataLoader
>>> data = np.random.rand(16)
>>> label = np.random.randint(0, 2, size=16)
>>> ds = Dataset.from_dict({"data": data, "label": label}).with_format("torch")
>>> dataloader = DataLoader(ds, batch_size=4)
>>> for batch in dataloader:
... print(batch)
{'data': tensor([0.0047, 0.4979, 0.6726, 0.8105]), 'label': tensor([0, 1, 0, 1])}
{'data': tensor([0.4832, 0.2723, 0.4259, 0.2224]), 'label': tensor([0, 0, 0, 0])}
{'data': tensor([0.5837, 0.3444, 0.4658, 0.6417]), 'label': tensor([0, 1, 0, 0])}
{'data': tensor([0.7022, 0.1225, 0.7228, 0.8259]), 'label': tensor([1, 1, 1, 1])}
```
### Optimize data loading
There are several ways you can increase the speed your data is loaded which can save you time, especially if you are working with large datasets.
PyTorch offers parallelized data loading, retrieving batches of indices instead of individually, and streaming to iterate over the dataset without downloading it on disk.
#### Use multiple Workers
You can parallelize data loading with the `num_workers` argument of a PyTorch `DataLoader` and get a higher throughput.
Under the hood, the `DataLoader` starts `num_workers` processes.
Each process reloads the dataset passed to the `DataLoader` and is used to query examples.
Reloading the dataset inside a worker doesn't fill up your RAM, since it simply memory-maps the dataset again from your disk.
```py
>>> import numpy as np
>>> from datasets import Dataset, load_from_disk
>>> from torch.utils.data import DataLoader
>>> data = np.random.rand(10_000)
>>> Dataset.from_dict({"data": data}).save_to_disk("my_dataset")
>>> ds = load_from_disk("my_dataset").with_format("torch")
>>> dataloader = DataLoader(ds, batch_size=32, num_workers=4)
```
### Stream data
Stream a dataset by loading it as an [`IterableDataset`]. This allows you to progressively iterate over a remote dataset without downloading it on disk and or over local data files.
Learn more about which type of dataset is best for your use case in the [choosing between a regular dataset or an iterable dataset](./about_mapstyle_vs_iterable) guide.
An iterable dataset from `datasets` inherits from `torch.utils.data.IterableDataset` so you can pass it to a `torch.utils.data.DataLoader`:
```py
>>> import numpy as np
>>> from datasets import Dataset, load_dataset
>>> from torch.utils.data import DataLoader
>>> data = np.random.rand(10_000)
>>> Dataset.from_dict({"data": data}).push_to_hub("<username>/my_dataset") # Upload to the Hugging Face Hub
>>> my_iterable_dataset = load_dataset("<username>/my_dataset", streaming=True, split="train")
>>> dataloader = DataLoader(my_iterable_dataset, batch_size=32)
```
If the dataset is split in several shards (i.e. if the dataset consists of multiple data files), then you can stream in parallel using `num_workers`:
```py
>>> my_iterable_dataset = load_dataset("deepmind/code_contests", streaming=True, split="train")
>>> my_iterable_dataset.n_shards
39
>>> dataloader = DataLoader(my_iterable_dataset, batch_size=32, num_workers=4)
```
In this case each worker is given a subset of the list of shards to stream from.
### Distributed
To split your dataset across your training nodes, you can use [`datasets.distributed.split_dataset_by_node`]:
```python
import os
from datasets.distributed import split_dataset_by_node
ds = split_dataset_by_node(ds, rank=int(os.environ["RANK"]), world_size=int(os.environ["WORLD_SIZE"]))
```
This works for both map-style datasets and iterable datasets.
The dataset is split for the node at rank `rank` in a pool of nodes of size `world_size`.
For map-style datasets:
Each node is assigned a chunk of data, e.g. rank 0 is given the first chunk of the dataset.
For iterable datasets:
If the dataset has a number of shards that is a factor of `world_size` (i.e. if `dataset.n_shards % world_size == 0`),
then the shards are evenly assigned across the nodes, which is the most optimized.
Otherwise, each node keeps 1 example out of `world_size`, skipping the other examples.
This can also be combined with a `torch.utils.data.DataLoader` if you want each node to use multiple workers to load the data.
| huggingface/datasets/blob/main/docs/source/use_with_pytorch.mdx |
``python
from transformers import AutoModelForSeq2SeqLM
from peft import get_peft_config, get_peft_model, get_peft_model_state_dict, PrefixTuningConfig, TaskType
import torch
from datasets import load_dataset
import os
os.environ["TOKENIZERS_PARALLELISM"] = "false"
os.environ["CUDA_VISIBLE_DEVICES"] = "3"
from transformers import AutoTokenizer
from torch.utils.data import DataLoader
from transformers import default_data_collator, get_linear_schedule_with_warmup
from tqdm import tqdm
from datasets import load_dataset
device = "cuda"
model_name_or_path = "t5-large"
tokenizer_name_or_path = "t5-large"
checkpoint_name = "financial_sentiment_analysis_prefix_tuning_v1.pt"
text_column = "sentence"
label_column = "text_label"
max_length = 128
lr = 1e-2
num_epochs = 5
batch_size = 8
```
```python
# creating model
peft_config = PrefixTuningConfig(task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, num_virtual_tokens=20)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
model
```
```python
# loading dataset
dataset = load_dataset("financial_phrasebank", "sentences_allagree")
dataset = dataset["train"].train_test_split(test_size=0.1)
dataset["validation"] = dataset["test"]
del dataset["test"]
classes = dataset["train"].features["label"].names
dataset = dataset.map(
lambda x: {"text_label": [classes[label] for label in x["label"]]},
batched=True,
num_proc=1,
)
dataset["train"][0]
```
```python
# data preprocessing
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
def preprocess_function(examples):
inputs = examples[text_column]
targets = examples[label_column]
model_inputs = tokenizer(inputs, max_length=max_length, padding="max_length", truncation=True, return_tensors="pt")
labels = tokenizer(targets, max_length=2, padding="max_length", truncation=True, return_tensors="pt")
labels = labels["input_ids"]
labels[labels == tokenizer.pad_token_id] = -100
model_inputs["labels"] = labels
return model_inputs
processed_datasets = dataset.map(
preprocess_function,
batched=True,
num_proc=1,
remove_columns=dataset["train"].column_names,
load_from_cache_file=False,
desc="Running tokenizer on dataset",
)
train_dataset = processed_datasets["train"]
eval_dataset = processed_datasets["validation"]
train_dataloader = DataLoader(
train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True
)
eval_dataloader = DataLoader(eval_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)
```
```python
# optimizer and lr scheduler
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=(len(train_dataloader) * num_epochs),
)
```
```python
# training and evaluation
model = model.to(device)
for epoch in range(num_epochs):
model.train()
total_loss = 0
for step, batch in enumerate(tqdm(train_dataloader)):
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
total_loss += loss.detach().float()
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
model.eval()
eval_loss = 0
eval_preds = []
for step, batch in enumerate(tqdm(eval_dataloader)):
batch = {k: v.to(device) for k, v in batch.items()}
with torch.no_grad():
outputs = model(**batch)
loss = outputs.loss
eval_loss += loss.detach().float()
eval_preds.extend(
tokenizer.batch_decode(torch.argmax(outputs.logits, -1).detach().cpu().numpy(), skip_special_tokens=True)
)
eval_epoch_loss = eval_loss / len(eval_dataloader)
eval_ppl = torch.exp(eval_epoch_loss)
train_epoch_loss = total_loss / len(train_dataloader)
train_ppl = torch.exp(train_epoch_loss)
print(f"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}")
```
```python
# print accuracy
correct = 0
total = 0
for pred, true in zip(eval_preds, dataset["validation"]["text_label"]):
if pred.strip() == true.strip():
correct += 1
total += 1
accuracy = correct / total * 100
print(f"{accuracy=} % on the evaluation dataset")
print(f"{eval_preds[:10]=}")
print(f"{dataset['validation']['text_label'][:10]=}")
```
```python
# saving model
peft_model_id = f"{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}"
model.save_pretrained(peft_model_id)
```
```python
ckpt = f"{peft_model_id}/adapter_model.bin"
!du -h $ckpt
```
```python
from peft import PeftModel, PeftConfig
peft_model_id = f"{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path)
model = PeftModel.from_pretrained(model, peft_model_id)
```
```python
model.eval()
i = 107
inputs = tokenizer(dataset["validation"][text_column][i], return_tensors="pt")
print(dataset["validation"][text_column][i])
print(inputs)
with torch.no_grad():
outputs = model.generate(input_ids=inputs["input_ids"], max_new_tokens=10)
print(outputs)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))
```
| huggingface/peft/blob/main/examples/conditional_generation/peft_prefix_tuning_seq2seq.ipynb |
--
title: "Using & Mixing Hugging Face Models with Gradio 2.0"
thumbnail: /blog/assets/22_gradio/gradio.png
authors:
- user: abidlabs
---
# Using & Mixing Hugging Face Models with Gradio 2.0
> ##### Cross-posted from the [Gradio blog](https://gradio.app/blog/using-huggingface-models).
The **[Hugging Face Model Hub](https://huggingface.co/models)** has more than 10,000 machine learning models submitted by users. You’ll find all kinds of natural language processing models that, for example, translate between Finnish and English or recognize Chinese speech. More recently, the Hub has expanded to even include models for image classification and audio processing.
Hugging Face has always worked to make models accessible and easy to use. The `transformers` library makes it possible to load a model in a few lines of code. After a model is loaded, it can be used to make predictions on new data programmatically. _But it’s not just programmers that are using machine learning models!_ An increasingly common scenario in machine learning is **demoing models to interdisciplinary teams** or letting **non-programmers use models** (to help discover biases, failure points, etc.).
The **[Gradio library](https://gradio.app/)** lets machine learning developers create demos and GUIs from machine learning models very easily, and share them for free with your collaborators as easily as sharing a Google docs link. Now, we’re excited to share that the Gradio 2.0 library lets you **_load and use almost any Hugging Face model_ _with a GUI_** **_in just 1 line of code_**. Here’s an example:

By default, this uses HuggingFace’s hosted Inference API (you can supply your own API key or use the public access without an API key), or you can also run `pip install transformers` and run the model computations locally if you’d like.
Do you want to customize the demo? You can override any of the default parameters of the [Interface class](https://gradio.app/docs) by passing in your own parameters:

**_But wait, there’s more!_** With 10,000 models already on Model Hub, we see models not just as standalone pieces of code, but as lego pieces that can be **composed and mixed** to create more sophisticated applications and demos.
For example, Gradio lets you load multiple models in _parallel_ (imagine you want to compare 4 different text generation models from Hugging Face to see which one is the best for your use case):

Or put your models in _series_. This makes it easy to build complex applications built from multiple machine learning models. For example, here we can build an application to translate and summarize Finnish news articles in 3 lines of code:

You can even mix multiple models in _series_ compared to each other in _parallel_ (we’ll let you try that yourself!). To try any of this out, just install Gradio (`pip install gradio`) and pick a Hugging Face model you want to try. Start building with Gradio and Hugging Face 🧱⛏️
| huggingface/blog/blob/main/gradio.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Kandinsky 2.1
Kandinsky 2.1 is created by [Arseniy Shakhmatov](https://github.com/cene555), [Anton Razzhigaev](https://github.com/razzant), [Aleksandr Nikolich](https://github.com/AlexWortega), [Vladimir Arkhipkin](https://github.com/oriBetelgeuse), [Igor Pavlov](https://github.com/boomb0om), [Andrey Kuznetsov](https://github.com/kuznetsoffandrey), and [Denis Dimitrov](https://github.com/denndimitrov).
The description from it's GitHub page is:
*Kandinsky 2.1 inherits best practicies from Dall-E 2 and Latent diffusion, while introducing some new ideas. As text and image encoder it uses CLIP model and diffusion image prior (mapping) between latent spaces of CLIP modalities. This approach increases the visual performance of the model and unveils new horizons in blending images and text-guided image manipulation.*
The original codebase can be found at [ai-forever/Kandinsky-2](https://github.com/ai-forever/Kandinsky-2).
<Tip>
Check out the [Kandinsky Community](https://huggingface.co/kandinsky-community) organization on the Hub for the official model checkpoints for tasks like text-to-image, image-to-image, and inpainting.
</Tip>
<Tip>
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
</Tip>
## KandinskyPriorPipeline
[[autodoc]] KandinskyPriorPipeline
- all
- __call__
- interpolate
## KandinskyPipeline
[[autodoc]] KandinskyPipeline
- all
- __call__
## KandinskyCombinedPipeline
[[autodoc]] KandinskyCombinedPipeline
- all
- __call__
## KandinskyImg2ImgPipeline
[[autodoc]] KandinskyImg2ImgPipeline
- all
- __call__
## KandinskyImg2ImgCombinedPipeline
[[autodoc]] KandinskyImg2ImgCombinedPipeline
- all
- __call__
## KandinskyInpaintPipeline
[[autodoc]] KandinskyInpaintPipeline
- all
- __call__
## KandinskyInpaintCombinedPipeline
[[autodoc]] KandinskyInpaintCombinedPipeline
- all
- __call__
| huggingface/diffusers/blob/main/docs/source/en/api/pipelines/kandinsky.md |
`tokenizers-win32-ia32-msvc`
This is the **i686-pc-windows-msvc** binary for `tokenizers`
| huggingface/tokenizers/blob/main/bindings/node/npm/win32-ia32-msvc/README.md |
Datasets server
> Integrate into your apps over 10,000 datasets via simple HTTP requests, with pre-processed responses and scalability built-in.
Documentation: https://huggingface.co/docs/datasets-server
## Ask for a new feature 🎁
The datasets server pre-processes the [Hugging Face Hub datasets](https://huggingface.co/datasets) to make them ready to use in your apps using the API: list of the splits, first rows.
We plan to [add more features](https://github.com/huggingface/datasets-server/issues?q=is%3Aissue+is%3Aopen+label%3A%22feature+request%22) to the server. Please comment there and upvote your favorite requests.
If you think about a new feature, please [open a new issue](https://github.com/huggingface/datasets-server/issues/new).
## Contribute 🤝
You can help by giving ideas, answering questions, reporting bugs, proposing enhancements, improving the documentation, and fixing bugs. See [CONTRIBUTING.md](./CONTRIBUTING.md) for more details.
To install the server and start contributing to the code, see [DEVELOPER_GUIDE.md](./DEVELOPER_GUIDE.md)
## Community 🤗
You can star and watch this [GitHub repository](https://github.com/huggingface/datasets-server) to follow the updates.
You can ask for help or answer questions on the [Forum](https://discuss.huggingface.co/c/datasets/10) and [Discord](https://discord.com/channels/879548962464493619/1019883044724822016).
You can also report bugs and propose enhancements on the code, or the documentation, in the [GitHub issues](https://github.com/huggingface/datasets-server/issues).
| huggingface/datasets-server/blob/main/README.md |
--
title: "Hugging Face and Graphcore partner for IPU-optimized Transformers"
thumbnail: /blog/assets/26_graphcore-ipu/thumbnail.png
authors:
- user: sallydoherty
guest: true
---
# Hugging Face and Graphcore partner for IPU-optimized Transformers
> ##### Speaking at the 2021 AI Hardware Summit, Hugging Face announced the launch of their new Hardware Partner Program, including device-optimized models and software integrations. Here, Graphcore - creators of the Intelligence Processing Unit (IPU) and a founding member of the program – explain how their partnership with Hugging Face will allow developers to easily accelerate their use of state-of-the-art Transformer models.
Graphcore and Hugging Face are two companies with a common goal – to make it easier for innovators to harness the power of machine intelligence.
Hugging Face’s Hardware Partner Program will allow developers using Graphcore systems to deploy state-of-the-art Transformer models, optimised for our Intelligence Processing Unit (IPU), at production scale, with minimum coding complexity.
## What is an Intelligence Processing Unit?
IPUs are the processors that power Graphcore’s IPU-POD datacenter compute systems. This new type of processor is designed to support the very specific computational requirements of AI and machine learning. Characteristics such as fine-grained parallelism, low precision arithmetic, and the ability to handle sparsity have been built into our silicon.
Instead of adopting a SIMD/SIMT architecture like GPUs, Graphcore’s IPU uses a massively parallel, MIMD architecture, with ultra-high bandwidth memory placed adjacent to the processor cores, right on the silicon die.
This design delivers high performance and new levels of efficiency, whether running today’s most popular models, such as BERT and EfficientNet, or exploring next-generation AI applications.
Software plays a vital role in unlocking the IPU’s capabilities. Our Poplar SDK has been co-designed with the processor since Graphcore’s inception. Today it fully integrates with standard machine learning frameworks, including PyTorch and TensorFlow, as well as orchestration and deployment tools such as Docker and Kubernetes.
Making Poplar compatible with these widely used, third-party systems allows developers to easily port their models from their other compute platforms and start taking advantage of the IPU’s advanced AI capabilities.
## Optimising Transformers for Production
Transformers have completely transformed (pun intended) the field of AI. Models such as BERT are widely used by Graphcore customers in a huge array of applications, across NLP and beyond. These multi-talented models can perform feature extraction, text generation, sentiment analysis, translation and many more functions.
Already, Hugging Face plays host to hundreds of Transformers, from the French-language CamemBERT to ViT which applies lessons learned in NLP to computer vision. The Transformers library is downloaded an average of 2 million times every month and demand is growing.
With a user base of more than 50,000 developers – Hugging Face has seen the fastest ever adoption of an open-source project.
Now, with its Hardware Partner Program, Hugging Face is connecting the ultimate Transformer toolset with today's most advanced AI hardware.
Using Optimum, a new open-source library and toolkit, developers will be able to access hardware-optimized models certified by Hugging Face.
These are being developed in a collaboration between Graphcore and Hugging Face, with the first IPU-optimized models appearing on Optimum later this year. Ultimately, these will cover a wide range of applications, from vision and speech to translation and text generation.
Hugging Face CEO Clément Delangue said: “Developers all want access to the latest and greatest hardware – like the Graphcore IPU, but there’s always that question of whether they’ll have to learn new code or processes. With Optimum and the Hugging Face Hardware Program, that’s just not an issue. It’s essentially plug-and-play".
## SOTA Models meet SOTA Hardware
Prior to the announcement of the Hugging Face Partnership, we had demonstrated the power of the IPU to accelerate state-of-the-art Transformer models with a special Graphcore-optimised implementation of Hugging Face BERT using Pytorch.
Full details of this example can be found in the Graphcore blog [BERT-Large training on the IPU explained](https://www.graphcore.ai/posts/bert-large-training-on-the-ipu-explained).
The dramatic benchmark results for BERT running on a Graphcore system, compared with a comparable GPU-based system are surely a tantalising prospect for anyone currently running the popular NLP model on something other than the IPU.

This type of acceleration can be game changing for machine learning researchers and engineers, winning them back valuable hours of training time and allowing them many more iterations when developing new models.
Now Graphcore users will be able to unlock such performance advantages, through the Hugging Face platform, with its elegant simplicity and superlative range of models.
Together, Hugging Face and Graphcore are helping even more people to access the power of Transformers and accelerate the AI revolution.
*Visit the [Hugging Face Hardware Partner portal](https://huggingface.co/hardware) to learn more about Graphcore IPU systems and how to gain access*
| huggingface/blog/blob/main/graphcore.md |
Subsets and Splits