
text
stringlengths 55
456k
| metadata
dict |
|---|---|
<h1 style="text-align: center;">verl: Volcano Engine Reinforcement Learning for LLM</h1>
verl is a flexible, efficient and production-ready RL training library for large language models (LLMs).
verl is the open-source version of **[HybridFlow: A Flexible and Efficient RLHF Framework](https://arxiv.org/abs/2409.19256v2)** paper.
verl is flexible and easy to use with:
- **Easy extension of diverse RL algorithms**: The Hybrid programming model combines the strengths of single-controller and multi-controller paradigms to enable flexible representation and efficient execution of complex Post-Training dataflows. Allowing users to build RL dataflows in a few lines of code.
- **Seamless integration of existing LLM infra with modular APIs**: Decouples computation and data dependencies, enabling seamless integration with existing LLM frameworks, such as PyTorch FSDP, Megatron-LM and vLLM. Moreover, users can easily extend to other LLM training and inference frameworks.
- **Flexible device mapping**: Supports various placement of models onto different sets of GPUs for efficient resource utilization and scalability across different cluster sizes.
- Readily integration with popular HuggingFace models
verl is fast with:
- **State-of-the-art throughput**: By seamlessly integrating existing SOTA LLM training and inference frameworks, verl achieves high generation and training throughput.
- **Efficient actor model resharding with 3D-HybridEngine**: Eliminates memory redundancy and significantly reduces communication overhead during transitions between training and generation phases.
<p align="center">
| <a href="https://verl.readthedocs.io/en/latest/index.html"><b>Documentation</b></a> | <a href="https://arxiv.org/abs/2409.19256v2"><b>Paper</b></a> | <a href="https://join.slack.com/t/verlgroup/shared_invite/zt-2w5p9o4c3-yy0x2Q56s_VlGLsJ93A6vA"><b>Slack</b></a> | <a href="https://raw.githubusercontent.com/eric-haibin-lin/verl-community/refs/heads/main/WeChat.JPG"><b>Wechat</b></a> | <a href="https://x.com/verl_project"><b>Twitter</b></a>
<!-- <a href=""><b>Slides</b></a> | -->
</p>
## News
- [2025/3] We will present verl(HybridFlow) at [EuroSys 2025](https://2025.eurosys.org/). See you in in Rotterdam!
- [2025/2] verl v0.2.0.post1 is released! See [release note](https://github.com/volcengine/verl/releases/) for details.
- [2025/2] We presented verl in the [Bytedance/NVIDIA/Anyscale Ray Meetup](https://lu.ma/ji7atxux). See you in San Jose!
- [2025/1] [Doubao-1.5-pro](https://team.doubao.com/zh/special/doubao_1_5_pro) is released with SOTA-level performance on LLM & VLM. The RL scaling preview model is trained using verl, reaching OpenAI O1-level performance on math benchmarks (70.0 pass@1 on AIME).
- [2024/12] The team presented <a href="https://neurips.cc/Expo/Conferences/2024/workshop/100677">Post-training LLMs: From Algorithms to Infrastructure</a> at NeurIPS 2024. [Slides](https://github.com/eric-haibin-lin/verl-data/tree/neurips) and [video](https://neurips.cc/Expo/Conferences/2024/workshop/100677) available.
- [2024/12] verl is presented at Ray Forward 2024. Slides available [here](https://github.com/eric-haibin-lin/verl-community/blob/main/slides/Ray_Forward_2024_%E5%B7%AB%E9%94%A1%E6%96%8C.pdf).
- [2024/10] verl is presented at Ray Summit. [Youtube video](https://www.youtube.com/watch?v=MrhMcXkXvJU&list=PLzTswPQNepXntmT8jr9WaNfqQ60QwW7-U&index=37) available.
- [2024/08] HybridFlow (verl) is accepted to EuroSys 2025.
## Key Features
- **FSDP** and **Megatron-LM** for training.
- **vLLM** and **TGI** for rollout generation, **SGLang** support coming soon.
- huggingface models support
- Supervised fine-tuning
- Reinforcement learning from human feedback with [PPO](https://github.com/volcengine/verl/tree/main/examples/ppo_trainer), [GRPO](https://github.com/volcengine/verl/tree/main/examples/grpo_trainer), [ReMax](https://github.com/volcengine/verl/tree/main/examples/remax_trainer), Reinforce++, [RLOO](https://github.com/volcengine/verl/tree/main/examples/rloo_trainer/run_qwen2-7b.sh), etc
- Support model-based reward and function-based reward (verifiable reward)
- flash-attention, [sequence packing](examples/ppo_trainer/run_qwen2-7b_seq_balance.sh), [long context](examples/ppo_trainer/run_deepseek7b_llm_sp2.sh) support via DeepSpeed Ulysses, [LoRA](examples/sft/gsm8k/run_qwen_05_peft.sh), [Liger-kernel](examples/sft/gsm8k/run_qwen_05_sp2_liger.sh)
- scales up to 70B models and hundreds of GPUs
- experiment tracking with wandb, swanlab and mlflow
## Upcoming Features
- Reward model training
- DPO training
- DeepSeek integration with Megatron v0.11
- SGLang integration
- vision language model RL
## Getting Started
**Quickstart:**
- [Installation](https://verl.readthedocs.io/en/latest/start/install.html)
- [Quickstart](https://verl.readthedocs.io/en/latest/start/quickstart.html)
- [Programming Guide](https://verl.readthedocs.io/en/latest/hybrid_flow.html)
**Running a PPO example step-by-step:**
- Data and Reward Preparation
- [Prepare Data for Post-Training](https://verl.readthedocs.io/en/latest/preparation/prepare_data.html)
- [Implement Reward Function for Dataset](https://verl.readthedocs.io/en/latest/preparation/reward_function.html)
- Understanding the PPO Example
- [PPO Example Architecture](https://verl.readthedocs.io/en/latest/examples/ppo_code_architecture.html)
- [Config Explanation](https://verl.readthedocs.io/en/latest/examples/config.html)
- [Run GSM8K Example](https://verl.readthedocs.io/en/latest/examples/gsm8k_example.html)
**Reproducible algorithm baselines:**
- [PPO, GRPO, ReMax](https://verl.readthedocs.io/en/latest/experiment/ppo.html)
**For code explanation and advance usage (extension):**
- PPO Trainer and Workers
- [PPO Ray Trainer](https://verl.readthedocs.io/en/latest/workers/ray_trainer.html)
- [PyTorch FSDP Backend](https://verl.readthedocs.io/en/latest/workers/fsdp_workers.html)
- [Megatron-LM Backend](https://verl.readthedocs.io/en/latest/index.html)
- Advance Usage and Extension
- [Ray API design tutorial](https://verl.readthedocs.io/en/latest/advance/placement.html)
- [Extend to Other RL(HF) algorithms](https://verl.readthedocs.io/en/latest/advance/dpo_extension.html)
- [Add Models with the FSDP Backend](https://verl.readthedocs.io/en/latest/advance/fsdp_extension.html)
- [Add Models with the Megatron-LM Backend](https://verl.readthedocs.io/en/latest/advance/megatron_extension.html)
- [Deployment using Separate GPU Resources](https://github.com/volcengine/verl/tree/main/examples/split_placement)
**Blogs from the community**
- [使用verl进行GRPO分布式强化学习训练最佳实践](https://www.volcengine.com/docs/6459/1463942)
- [HybridFlow veRL 原文浅析](https://github.com/zhaochenyang20/Awesome-ML-SYS-Tutorial/blob/main/rlhf/verl/readme.md)
- [最高提升20倍吞吐量!豆包大模型团队发布全新 RLHF 框架,现已开源!](https://team.doubao.com/en/blog/%E6%9C%80%E9%AB%98%E6%8F%90%E5%8D%8720%E5%80%8D%E5%90%9E%E5%90%90%E9%87%8F-%E8%B1%86%E5%8C%85%E5%A4%A7%E6%A8%A1%E5%9E%8B%E5%9B%A2%E9%98%9F%E5%8F%91%E5%B8%83%E5%85%A8%E6%96%B0-rlhf-%E6%A1%86%E6%9E%B6-%E7%8E%B0%E5%B7%B2%E5%BC%80%E6%BA%90)
Checkout this [Jupyter Notebook](https://github.com/volcengine/verl/tree/main/examples/ppo_trainer/verl_getting_started.ipynb) to get started with PPO training with a single 24GB L4 GPU (**FREE** GPU quota provided by [Lighting Studio](https://lightning.ai/hlin-verl/studios/verl-getting-started))!
## Performance Tuning Guide
The performance is essential for on-policy RL algorithm. We write a detailed performance tuning guide to allow people tune the performance. See [here](https://verl.readthedocs.io/en/latest/perf/perf_tuning.html) for more details.
## vLLM v0.7 testing version
We have released a testing version of veRL that supports vLLM>=0.7.0. Please refer to [this document](https://github.com/volcengine/verl/blob/main/docs/README_vllm0.7.md) for installation guide and more information.
## Citation and acknowledgement
If you find the project helpful, please cite:
- [HybridFlow: A Flexible and Efficient RLHF Framework](https://arxiv.org/abs/2409.19256v2)
- [A Framework for Training Large Language Models for Code Generation via Proximal Policy Optimization](https://i.cs.hku.hk/~cwu/papers/gmsheng-NL2Code24.pdf)
```tex
@article{sheng2024hybridflow,
title = {HybridFlow: A Flexible and Efficient RLHF Framework},
author = {Guangming Sheng and Chi Zhang and Zilingfeng Ye and Xibin Wu and Wang Zhang and Ru Zhang and Yanghua Peng and Haibin Lin and Chuan Wu},
year = {2024},
journal = {arXiv preprint arXiv: 2409.19256}
}
```
verl is inspired by the design of Nemo-Aligner, Deepspeed-chat and OpenRLHF. The project is adopted and supported by Anyscale, Bytedance, LMSys.org, Shanghai AI Lab, Tsinghua University, UC Berkeley, UCLA, UIUC, and University of Hong Kong.
## Awesome work using verl
- [Enhancing Multi-Step Reasoning Abilities of Language Models through Direct Q-Function Optimization](https://arxiv.org/abs/2410.09302)
- [Flaming-hot Initiation with Regular Execution Sampling for Large Language Models](https://arxiv.org/abs/2410.21236)
- [Process Reinforcement Through Implicit Rewards](https://github.com/PRIME-RL/PRIME/)
- [TinyZero](https://github.com/Jiayi-Pan/TinyZero): a reproduction of DeepSeek R1 Zero recipe for reasoning tasks
- [RAGEN](https://github.com/ZihanWang314/ragen): a general-purpose reasoning agent training framework
- [Logic R1](https://github.com/Unakar/Logic-RL): a reproduced DeepSeek R1 Zero on 2K Tiny Logic Puzzle Dataset.
- [deepscaler](https://github.com/agentica-project/deepscaler): iterative context scaling with GRPO
- [critic-rl](https://github.com/HKUNLP/critic-rl): Teaching Language Models to Critique via Reinforcement Learning
## Contribution Guide
Contributions from the community are welcome!
### Code formatting
We use yapf (Google style) to enforce strict code formatting when reviewing PRs. To reformat you code locally, make sure you installed **latest** `yapf`
```bash
pip3 install yapf --upgrade
```
Then, make sure you are at top level of verl repo and run
```bash
bash scripts/format.sh
```
We are HIRING! Send us an [email](mailto:[email protected]) if you are interested in internship/FTE opportunities in MLSys/LLM reasoning/multimodal alignment. | {
"source": "volcengine/verl",
"title": "README.md",
"url": "https://github.com/volcengine/verl/blob/main/README.md",
"date": "2024-10-31T06:11:15",
"stars": 3801,
"description": "verl: Volcano Engine Reinforcement Learning for LLMs",
"file_size": 10277
} |
# verl documents
## Build the docs
```bash
# Install dependencies.
pip install -r requirements-docs.txt
# Build the docs.
make clean
make html
```
## Open the docs with your browser
```bash
python -m http.server -d _build/html/
```
Launch your browser and open localhost:8000. | {
"source": "volcengine/verl",
"title": "docs/README.md",
"url": "https://github.com/volcengine/verl/blob/main/docs/README.md",
"date": "2024-10-31T06:11:15",
"stars": 3801,
"description": "verl: Volcano Engine Reinforcement Learning for LLMs",
"file_size": 281
} |
# Readme for verl(vllm>=0.7) version
## Installation
Note: This version of veRL supports **FSDP** for training and **vLLM** for rollout. (Megatron-LM is not supported yet.)
```
# Create the conda environment
conda create -n verl python==3.10
conda activate verl
# Install verl
git clone https://github.com/volcengine/verl.git
cd verl
pip3 install -e .
# Install vLLM>=0.7
# (Option1) pip3 install vllm --pre --extra-index-url https://wheels.vllm.ai/nightly
# (Option2) pip3 install "vllm>=0.7.0"
# Install flash-attn
pip3 install flash-attn --no-build-isolation
```
Note that if you are installing stable versions of vLLM (Option2), you need to make some tiny patches manually on vllm (/path/to/site-packages/vllm after installation) after the above steps:
- vllm/distributed/parallel_state.py: Remove the assertion below:
```
if (world_size
!= tensor_model_parallel_size * pipeline_model_parallel_size):
raise RuntimeError(
f"world_size ({world_size}) is not equal to "
f"tensor_model_parallel_size ({tensor_model_parallel_size}) x "
f"pipeline_model_parallel_size ({pipeline_model_parallel_size})")
```
- vllm/executor/uniproc_executor.py: change `local_rank = rank` to `local_rank = int(os.environ["LOCAL_RANK"])`
- vllm/model_executor/model_loader/weight_utils.py: remove the `torch.cuda.empty_cache()` in `pt_weights_iterator`
These modifications have already been merged into the main branch of vLLM. Thus nightly vLLM or building vLLM from source do not need these patches.
## Features
### Use cuda graph
After installation, examples using FSDP as training backends can be used. By default, the `enforce_eager` is set to True, which disables the cuda graph. To enjoy cuda graphs and the sleep mode of vLLM>=0.7, add the following lines to the bash script:
```
actor_rollout_ref.rollout.enforce_eager=False \
actor_rollout_ref.rollout.free_cache_engine=False \
```
For a typical job like examples/ppo_trainer/run_qwen2-7b_seq_balance.sh, the rollout generation time is 115 seconds with vLLM0.6.3, while it is 85 seconds with vLLM0.7.0. By enabling the cudagraph, the generation duration is further reduced to 62 seconds.
**Note:** Currently, if the `n` is greater than 1 in `SamplingParams` in vLLM>=0.7, there is a potential performance issue on the stability of rollout generation time (Some iterations would see generation time bursts). We are working with the vLLM team to check this issue.
### Other features in vLLM
1. **num_scheduler_step>1:** not supported yet (weight loading has not been aligned with `MultiStepModelRunner`)
2. **Prefix caching:** not supported yet (vLLM sleep mode does not support prefix caching)
3. **Chunked prefill:** supported | {
"source": "volcengine/verl",
"title": "docs/README_vllm0.7.md",
"url": "https://github.com/volcengine/verl/blob/main/docs/README_vllm0.7.md",
"date": "2024-10-31T06:11:15",
"stars": 3801,
"description": "verl: Volcano Engine Reinforcement Learning for LLMs",
"file_size": 2724
} |
=========================================================
HybridFlow Programming Guide
=========================================================
.. _vermouth: https://github.com/vermouth1992
Author: `Chi Zhang <https://github.com/vermouth1992>`_
verl is an open source implementation of the paper `HybridFlow <https://arxiv.org/abs/2409.19256v2>`_ [1]_. In this section, we will introduce the basic concepts of HybridFlow, the motivation and how to program with verl APIs.
Motivation and Design
------------------------
We use dataflow to represent RL systems. [4]_.
DataFlow
~~~~~~~~~~~~~~~~~~~~
Dataflow is an abstraction of computations. Neural Netowork training is a typical dataflow. It can be represented by computational graph.
.. image:: https://github.com/eric-haibin-lin/verl-community/blob/main/docs/dataflow.jpeg?raw=true
:alt: The dataflow graph from CS231n 2024 lecture 4
This figure [2]_ represents the computation graph of a polynomial function followed by a sigmoid function. In the data flow of neural network computation, each node represents an operator, and each edge represents the direction of forward/backward propagation. The computation graph determines the architecture of the neural network.
RL as a dataflow problem
++++++++++++++++++++++++++++++++++++++++++++++
Reinforcement learning (RL) training can also be represented as a dataflow. Below is the dataflow graph that represents the PPO algorithm used in RLHF [3]_:
.. image:: https://picx.zhimg.com/70/v2-cb8ab5ee946a105aab6a563e92682ffa_1440w.avis?source=172ae18b&biz_tag=Post
:alt: PPO dataflow graph, credit to Zhihu 低级炼丹师
However, the dataflow of RL has fundamental differences compared with dataflow of neural network training as follows:
+--------------------------+--------------------------------------------------+---------------------+
| Workload | Node | Edge |
+--------------------------+--------------------------------------------------+---------------------+
| Neural Network Training | Operator (+/-/matmul/softmax) | Tensor movement |
+--------------------------+--------------------------------------------------+---------------------+
| Reinforcement Learning | High-level operators (rollout/model forward) | Data Movement |
+--------------------------+--------------------------------------------------+---------------------+
In the case of tabular reinforcement learning, each operator is a simple scalar math operation (e.g., bellman update). In deep reinforcement learning(DRL), each operator is a high-level neural network computation such as model inference/update. This makes RL a two-level dataflow problem:
- Control flow: defines how the high-level operators are executed (e.g., In PPO, we first perform rollout. Then, we perform advantage computation. Finally, we perform training). It expresses the **core logics of RL algorithms**.
- Computation flow: defines the dataflow of **neural network computation** (e.g., model forward/backward/optimizer).
Design Choices
~~~~~~~~~~~~~~~~~~~~
The model size used in DRL before the LLM era is typically small. Thus, the high-level neural network computation can be done in a single process. This enables embedding the computation flow inside the control flow as a single process.
However, in the LLM era, the computation flow (e.g., training neural network) becomes a multi-process program. This naturally leads to two design choices:
1. Convert the control flow into a multi-process program as well. Then colocate with computation flow (unified multi-controller)
- Advantages:
- Achieves the **optimal performance** under fixed computation flow and control flow as the communication overhead in both training and data transfer is minimized.
- Disadvantages:
- The computation and/or control flow is **hard to reuse** from software perspective as computation code is coupled with specific controller code. For example, the training loop of PPO is generic. Say we have an PPO training flow implemented with a specific computation flow such as FSDP. Neither the control flow or computation flow can be reused if we want to switch the computation flow from FSDP to Megatron, due to the coupling of control and computation flows.
- Requires more efforts from the user under flexible and dynamic control flows, due to the multi-process nature of the program.
2. Separate the flows: single process for the control flow and multi-process for computation flow
- Advantages:
- The computation flow defined elsewhere can be **easily reused** after the decoupling.
- The controller runs on a single process. Implementing a new RL algorithm with a **different control flow is simple and easy**.
- Disadvantages:
- Additional **data communication overhead** each time the controller process and computatation processes interact. The data has to be sent back and forth.
In verl, the latter strategy with separate control flow and computation flow is adopted. verl is designed to decouple the control flow of RL algorithms, and the implementation of computation engines.
Overall Execution Diagram
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Below is a simplified diagram denoting the execution of a reinforcement learning job. In the diagram, the controller runs on a single process, while the generator/actor workers, critic workers run on multiple processes, placed with specific resource groups. For rollout, the controller passes the data to the generator to perform sample generation. When the rollout is done, the data is passed back to controller for the next step of the algorithm. Similar execution is done for other workers. With the hybrid controller design, the data flow and computation is decoupled to provide both efficiency in computation and flexiblity in defining algorithm training loops.
.. figure:: https://github.com/eric-haibin-lin/verl-community/blob/main/docs/driver_worker.png?raw=true
:alt: The execution diagram
Codebase walkthrough (PPO)
------------------------------------------------
Entry function
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Code: https://github.com/volcengine/verl/blob/main/verl/trainer/main_ppo.py
In this file, we define a remote function `main_task` that serves as the controller (driver) process as shown in the above figure. We also define a ``RewardManager``, where users can customize their reward function based on the data source in the dataset. Note that `RewardManager` should return the final token-level reward that is optimized by RL algorithms. Note that users can combine model-based rewards and rule-based rewards.
The ``main_task`` constructs a RayPPOTrainer instance and launch the fit. Note that ``main_task`` **runs as a single process**.
We highly recommend that the ``main_task`` is NOT schduled on the head of the ray cluster because ``main_task`` will consume a lot of memory but the head usually contains very few resources.
Ray trainer
~~~~~~~~~~~~~~~~~~~~
Code: https://github.com/volcengine/verl/blob/main/verl/trainer/ppo/ray_trainer.py
The RayPPOTrainer manages
- Worker and WorkerGroup construction
- Runs the main loop of PPO algorithm
Note that, the fit function of RayPPOTrainer **runs as a single process**.
Worker and WorkerGroup construction
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Each workerGroup manages a list of workers that runs remotely. Note that the worker group runs in the process of its construtor.
Each worker inside the WorkerGroup runs on a GPU. The worker group serves as a proxy for the controller process to interact with a list of workers, in order to perform certain computations. **In order to do so, we have to bind the methods of the worker into the method of the WorkerGroup and define the data dispatch and data collection**. This is done via simple decoration that will be introduced in the Worker definition section.
For example, in PPO, we define 3 worker groups:
- ActorRolloutRef: manages actor, rollout and reference policy. ActorRolloutRefWorker can be instantiated as a single actor, a single rollout, a single reference policy, a combined actor/rollout or a combined actor/rollout/ref. This design is aimed for the maximum code reuse in various scenarios. The reason for colocating actor and rollout is for fast weight transfer using nccl. The reason for coloating actor and reference is to implement an efficient lora PPO as the reference policy is simply the base model of PPO in lora.
- Critic: manages the critic model
- Reward: manages the reward model
The worker group will be constructed on the resource pool it designates. The resource pool is a set of GPUs in the ray cluster.
Worker definition
~~~~~~~~~~~~~~~~~~~~
.. _ActorRolloutRefWorker: https://github.com/volcengine/verl/blob/main/verl/workers/fsdp_workers.py
We take `ActorRolloutRefWorker <_ActorRolloutRefWorker>`_ for an exmaple.
The APIs it should expose to the controller process are:
- init_model: build the underlying model
- generate_sequences: given prompts, generate responses
- compute_log_prob: compute the log-probability of a generated sequence using actor
- compute_ref_log_prob: compute the log-probability of a generated sequence using reference policy
- save_checkpoint: save the checkpoint
Note that these methods are defined in the worker that can only be invoked via remote calls. For example, if the controller process wants to initialize the model, it has to call
.. code-block:: python
for worker in actor_rollout_ref_wg:
worker.init_model.remote()
If the controller process wants to generate sequences, it has to call
.. code-block:: python
data = xxx
# split the data into dp chunks
data_dp_lst = data.split(dp_size)
output_dp_lst = []
for i, worker in enumerate(actor_rollout_ref_wg):
output_future = worker.generate_sequences.remote(data_dp_lst[i])
output_dp_lst.append(output_future)
output = torch.cat(ray.get(output_dp_lst), dim=0)
We observe that controll process calling worker group methods in general can be divided into 3 parts:
- Split the data into data parallel sizes
- Dispatch the corresponding data into each worker
- Collect and concatenate the data when the computation finishes
In verl, we design a syntax sugar to encapsulate the 3 processes into a single call from the controller process.
.. code-block:: python
@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO)
def generate_sequences(data):
...
# on the driver
output = actor_rollout_ref_wg.generate_sequences(data)
We decorate the method of the worker with a ``register`` that explicitly defines how the input data should be splitted and dispatch to each worker, and how the output data should be collected and concatenated by the controller. For example, ``Dispatch.DP_COMPUTE_PROTO`` splits the input data into dp chunks, dispatch each data to each worker, collect the output and concatenate the results. Note that this function requires the input and output to be a DataProto defined here (https://github.com/volcengine/verl/blob/main/verl/protocol.py).
PPO main loop
~~~~~~~~~~~~~~~~~~~~
With the aforementioned APIs, we can implement the main loop of PPO as if it is a single process program
.. code-block:: python
for prompt in dataloader:
output = actor_rollout_ref_wg.generate_sequences(prompt)
old_log_prob = actor_rollout_ref_wg.compute_log_prob(output)
ref_log_prob = actor_rollout_ref_wg.compute_ref_log_prob(output)
values = critic_wg.compute_values(output)
rewards = reward_wg.compute_scores(output)
# compute_advantages is running directly on the control process
advantages = compute_advantages(values, rewards)
output = output.union(old_log_prob)
output = output.union(ref_log_prob)
output = output.union(values)
output = output.union(rewards)
output = output.union(advantages)
# update actor
actor_rollout_ref_wg.update_actor(output)
critic.update_critic(output)
Takeaways
~~~~~~~~~~~~~~~~~~~~
- This programming paradigm enables users to use different computation backend without modification of the control process.
- This programming paradigm enables flexible placement (by changing the mapping of WorkerGroup and ResourcePool) without modification of the control process.
Repository organization
------------------------------------------------
Important code files in the repository are organized as below:
.. code-block:: bash
verl # the verl package
trainer
main_ppo.py # the entrypoint for RL training
ppo
ray_trainer.py # the training loop for RL algorithms such as PPO
fsdp_sft_trainer.py # the SFT trainer with FSDP backend
config
generation.yaml # configuration template for rollout
ppo_trainer.yaml # configuration template for the RL trainer
workers
protocol.py # the interface of DataProto
fsdp_workers.py # the FSDP worker interfaces: ActorRolloutRefWorker, CriticWorker, RewardModelWorker
megatron_workers.py # the Megatron worker interfaces: ActorRolloutRefWorker, CriticWorker, RewardModelWorker
actor
dp_actor.py # data parallel actor with FSDP backend
megatron_actor.py # nD parallel actor with Megatron backend
critic
dp_critic.py # data parallel critic with FSDP backend
megatron_critic.py # nD parallel critic with FSDP backend
reward_model
megatron
reward_model.py # reward model with Megatron backend
rollout
vllm
vllm_rollout.py # rollout with vllm backend
hf_rollout.py # rollout with huggingface TGI backend
sharding_manager
fsdp_ulysses.py # data and model resharding when using FSDP + ulysses
fsdp_vllm.py # data and model resharding when using FSDP + ulysses + vllm
megatron_vllm.py # data and model resharding when using Megatron + vllm
utils
dataset # datasets for SFT/RM/RL
reward_score # function based reward
gsm8k.py # reward function for gsm8k dataset
math.py # reward function for math dataset
seqlen_balancing.py # the sequence balance optimization
models
llama # Megatron implementation for llama, deepseek, mistral, etc
transformers # ulysses integration with transformer models such as llama, qwen, etc
weight_loader_registery.py # registry of weight loaders for loading hf ckpt into Megatron
third_party
vllm # adaptor for vllm's usage in RL
vllm_v_0_6_3 # vllm v0.6.3 adaptor
llm.py # entrypoints for generate, sync_model_weight, offload_model_weights
parallel_state.py # vllm related device mesh and process groups
dtensor_weight_loaders.py # weight loader for huggingface models with FSDP
megatron_weight_loaders.py # weight loader for Megatron models
vllm_spmd # vllm >= v0.7 adaptor (coming soon)
examples # example scripts
tests # integration and unit tests
.github # the configuration of continuous integration tests
.. [1] HybridFlow: A Flexible and Efficient RLHF Framework: https://arxiv.org/abs/2409.19256v2
.. [2] Data flow graph credit to CS231n 2024 lecture 4: https://cs231n.stanford.edu/slides/2024/lecture_4.pdf
.. [3] PPO dataflow graph credit to 低级炼丹师 from Zhihu: https://zhuanlan.zhihu.com/p/635757674
.. [4] RLFlow | {
"source": "volcengine/verl",
"title": "docs/hybrid_flow.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/hybrid_flow.rst",
"date": "2024-10-31T06:11:15",
"stars": 3801,
"description": "verl: Volcano Engine Reinforcement Learning for LLMs",
"file_size": 15523
} |
Welcome to verl's documentation!
================================================
.. _hf_arxiv: https://arxiv.org/pdf/2409.19256
verl is a flexible, efficient and production-ready RL training framework designed for large language models (LLMs) post-training. It is an open source implementation of the `HybridFlow <hf_arxiv>`_ paper.
verl is flexible and easy to use with:
- **Easy extension of diverse RL algorithms**: The Hybrid programming model combines the strengths of single-controller and multi-controller paradigms to enable flexible representation and efficient execution of complex Post-Training dataflows. Allowing users to build RL dataflows in a few lines of code.
- **Seamless integration of existing LLM infra with modular APIs**: Decouples computation and data dependencies, enabling seamless integration with existing LLM frameworks, such as PyTorch FSDP, Megatron-LM and vLLM. Moreover, users can easily extend to other LLM training and inference frameworks.
- **Flexible device mapping and parallelism**: Supports various placement of models onto different sets of GPUs for efficient resource utilization and scalability across different cluster sizes.
- Readily integration with popular HuggingFace models
verl is fast with:
- **State-of-the-art throughput**: By seamlessly integrating existing SOTA LLM training and inference frameworks, verl achieves high generation and training throughput.
- **Efficient actor model resharding with 3D-HybridEngine**: Eliminates memory redundancy and significantly reduces communication overhead during transitions between training and generation phases.
--------------------------------------------
.. _Contents:
.. toctree::
:maxdepth: 5
:caption: Quickstart
start/install
start/quickstart
.. toctree::
:maxdepth: 4
:caption: Programming guide
hybrid_flow
.. toctree::
:maxdepth: 5
:caption: Data Preparation
preparation/prepare_data
preparation/reward_function
.. toctree::
:maxdepth: 5
:caption: Configurations
examples/config
.. toctree::
:maxdepth: 2
:caption: PPO Example
examples/ppo_code_architecture
examples/gsm8k_example
.. toctree::
:maxdepth: 1
:caption: PPO Trainer and Workers
workers/ray_trainer
workers/fsdp_workers
workers/megatron_workers
.. toctree::
:maxdepth: 1
:caption: Performance Tuning Guide
perf/perf_tuning
.. toctree::
:maxdepth: 1
:caption: Experimental Results
experiment/ppo
.. toctree::
:maxdepth: 1
:caption: Advance Usage and Extension
advance/placement
advance/dpo_extension
advance/fsdp_extension
advance/megatron_extension
.. toctree::
:maxdepth: 1
:caption: FAQ
faq/faq
Contribution
-------------
verl is free software; you can redistribute it and/or modify it under the terms
of the Apache License 2.0. We welcome contributions.
Join us on `GitHub <https://github.com/volcengine/verl>`_, `Slack <https://join.slack.com/t/verlgroup/shared_invite/zt-2w5p9o4c3-yy0x2Q56s_VlGLsJ93A6vA>`_ and `Wechat <https://raw.githubusercontent.com/eric-haibin-lin/verl-community/refs/heads/main/WeChat.JPG>`_ for discussions.
Code formatting
^^^^^^^^^^^^^^^^^^^^^^^^
We use yapf (Google style) to enforce strict code formatting when reviewing MRs. Run yapf at the top level of verl repo:
.. code-block:: bash
pip3 install yapf
yapf -ir -vv --style ./.style.yapf verl examples tests | {
"source": "volcengine/verl",
"title": "docs/index.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/index.rst",
"date": "2024-10-31T06:11:15",
"stars": 3801,
"description": "verl: Volcano Engine Reinforcement Learning for LLMs",
"file_size": 3426
} |
Extend to other RL(HF) algorithms
=================================
We already implemented the complete training pipeline of the PPO
algorithms. To extend to other algorithms, we analyze the high-level
principle to use verl and provide a tutorial to implement the DPO
algorithm. Users can follow the similar paradigm to extend to other RL algorithms.
.. note:: **Key ideas**: Single process drives multi-process computation and data communication.
Overall Approach
----------------
Step 1: Consider what multi-machine multi-GPU computations are needed
for each model, such as ``generate_sequence`` , ``compute_log_prob`` and
``update_policy`` in the actor_rollout model. Implement distributed
single-process-multiple-data (SPMD) computation and encapsulate them
into APIs
Step 2: Based on different distributed scenarios, including FSDP and 3D
parallelism in Megatron-LM, implement single-process control of data
interaction among multi-process computations.
Step 3: Utilize the encapsulated APIs to implement the control flow
Example: Online DPO
-------------------
We use verl to implement a simple online DPO algorithm. The algorithm
flow of Online DPO is as follows:
1. There is a prompt (rollout) generator which has the same weight as
the actor model. After a batch of prompts are fed into the generator,
it generates N responses for each prompt.
2. Send all the prompts + responses to a verifier for scoring, which can
be reward model or a rule-based function. Then sort them in pairs to
form a training batch.
3. Use this training batch to train the actor model using DPO. During
the process, a reference policy is needed.
Step 1: What are the multi-machine multi-GPU computations
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
**Sample Generator**
Implementation details:
.. code:: python
from verl.single_controller.base import Worker
from verl.single_controller.ray import RayWorkerGroup, RayClassWithInitArgs, RayResourcePool
import ray
@ray.remote
class SampleGenerator(Worker):
def __init__(self, config):
super().__init__()
self.config = config
def generate_sequences(self, data):
pass
Here, ``SampleGenerator`` can be viewed as a multi-process pulled up by
``torchrun``, with each process running the same code (SPMD).
``SampleGenerator`` needs to implement a ``generate_sequences`` API for
the control flow to call. The implementation details inside can use any
inference engine including vllm, sglang and huggingface. Users can
largely reuse the code in
verl/verl/workers/rollout/vllm_rollout/vllm_rollout.py and we won't
go into details here.
**ReferencePolicy inference**
API: compute reference log probability
.. code:: python
from verl.single_controller.base import Worker
import ray
@ray.remote
class ReferencePolicy(Worker):
def __init__(self):
super().__init__()
self.model = Model()
def infer(self, data):
return self.model(data)
**Actor update**
API: Update actor model parameters
.. code:: python
from verl.single_controller.base import Worker
import ray
@ray.remote
class DPOActor(Worker):
def __init__(self):
super().__init__()
self.model = Model()
self.model = FSDP(self.model) # or other distributed strategy
self.optimizer = optim.Adam(self.model.parameters(), lr=1e-3)
self.loss_fn = xxx
def update(self, data):
self.optimizer.zero_grad()
logits = self.model(data)
loss = self.loss_fn(logits)
loss.backward()
self.optimizer.step()
**Notes: How to distinguish between control processes and distributed computation processes**
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
- Control processes are generally functions directly decorated with
``@ray.remote``
- Computation processes are all wrapped into a ``RayWorkerGroup``.
Users can reuse most of the distribtued computation logics implemented
in PPO algorithm, including FSDP and Megatron-LM backend in
verl/verl/trainer/ppo.
Step 2: Based on different distributed scenarios, implement single-process control of multi-process data interaction
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
**The core problem to solve here is how a single process sends data to
multiple processes, drives multi-process computation, and how the
control process obtains the results of multi-process computation.**
First, we initialize the multi-process ``WorkerGroup`` in the control
process.
.. code:: python
@ray.remote(num_cpus=1)
def main_task(config):
# construct SampleGenerator
resource_pool = RayResourcePool(process_on_nodes=[8] * 2) # 16 GPUs
ray_cls = RayClassWithInitArgs(SampleGenerator, config=config)
# put SampleGenerator onto resource pool
worker_group = RayWorkerGroup(resource_pool, ray_cls)
# construct reference policy
As we can see, in the control process, multiple processes are wrapped
into a ``RayWorkerGroup``. Inside this ``WorkerGroup``, there is a
``self._workers`` member, where each worker is a RayActor
(https://docs.ray.io/en/latest/ray-core/actors.html) of SampleGenerator.
ray_trainer.md also provide an implementation of
``MegatronRayWorkerGroup``.
Assuming the model is distributed using FSDP, and there is a batch of
data on the control process, for data parallelism, the underlying
calling process is:
.. code:: python
data = xxx
data_list = data.chunk(dp_size)
output = []
for d in data_list:
# worker_group._workers[i] is a SampleGenerator
output.append(worker_group._workers[i].generate_sequences.remote(d))
output = ray.get(output)
output = torch.cat(output)
Single process calling multiple processes involves the following 3
steps:
1. Split the data into DP parts on the control process.
2. Send the data to remote, call the remote computation through RPC, and
utilize multi-process computation.
3. Obtain the computation results of each worker on the control process
and merge them.
Frequently calling these 3 steps on the controller process greatly hurts
code readability. **In verl, we have abstracted and encapsulated these 3
steps, so that the worker's method + dispatch + collect can be
registered into the worker_group**
.. code:: python
from verl.single_controller.base.decorator import register
def dispatch_data(worker_group, data):
return data.chunk(worker_group.world_size)
def collect_data(worker_group, data):
return torch.cat(data)
dispatch_mode = {
'dispatch_fn': dispatch_data,
'collect_fn': collect_data
}
@register(dispatch_mode=dispatch_mode)
def generate_sequences(self, data):
pass
In this way, we can directly call the method inside the worker through
the ``worker_group`` on the control (driver) process (which is a single
process):
.. code:: python
output = worker_group.generate_sequences(data)
This single line includes data splitting, data distribution and
computation, and data collection.
Furthermore, the model parallelism size of each model is usually fixed,
including dp, tp, pp. So for these common distributed scenarios, we have
pre-implemented specific dispatch and collect methods,in `decorator.py <https://github.com/volcengine/verl/blob/main/verl/single_controller/base/decorator.py>`_, which can be directly used to wrap the computations.
.. code:: python
from verl.single_controller.base.decorator import register, Dispatch
@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO)
def generate_sequences(self, data: DataProto) -> DataProto:
pass
Here it requires the data interface to be ``DataProto``. Definition of
``DataProto`` is in `protocol.py <https://github.com/volcengine/verl/blob/main/verl/protocol.py>`_.
Step 3: Main training loop
~~~~~~~~~~~~~~~~~~~~~~~~~~
With the above training flows, we can implement the algorithm's control
flow. It is recommended that ``main_task`` is also a ray remote process.
.. code:: python
@ray.remote(num_cpus=1)
def main_task(config):
# construct SampleGenerator
resource_pool = RayResourcePool(process_on_nodes=[8] * 2) # 16 GPUs
ray_cls = RayClassWithInitArgs(SampleGenerator, config=config)
# put SampleGenerator onto resource pool
sample_gen = RayWorkerGroup(resource_pool, ray_cls)
# construct reference policy
ray_cls = RayClassWithInitArgs(ReferencePolicy)
ref_policy = RayWorkerGroup(resource_pool, ray_cls)
# construct actor
ray_cls = RayClassWithInitArgs(DPOActor)
dpo_policy = RayWorkerGroup(resource_pool, ray_cls)
dataloader = DataLoader()
for data in dataloader:
# generate data
data = sample_gen.generate_sequences(data)
# generate scores for each data
data = generate_scores(data)
# generate pairwise data using scores
data = generate_pairwise_data(data)
# generate ref_log_prob
data.batch['ref_log_prob'] = ref_policy.infer(data)
# update using dpo
dpo_policy.update(data)
# logging
Here, different ``WorkerGroups`` can be placed in the same resource pool or
in different resource pools using ``create_colocated_worker_cls``
similar as in `ray_trainer.py <https://github.com/volcengine/verl/blob/main/verl/trainer/ppo/ray_trainer.py>`_. | {
"source": "volcengine/verl",
"title": "docs/advance/dpo_extension.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/advance/dpo_extension.rst",
"date": "2024-10-31T06:11:15",
"stars": 3801,
"description": "verl: Volcano Engine Reinforcement Learning for LLMs",
"file_size": 9676
} |
Add models with the FSDP backend
==================================
Model
--------------------------
In principle, our FSDP backend can support any HF model and we can
sychronoize the actor model weight with vLLM using `hf_weight_loader.py <https://github.com/volcengine/verl/blob/main/verl/third_party/vllm/vllm_v_0_6_3/hf_weight_loader.py>`_.
However, ``hf_weight_loader`` is will gather the full state_dict of a
model during synchronization, which may cause OOM. We suggest using
``dtensor_weight_loader`` which gather the full model parameter layer by
layer to reduce the peak memory usage. We already support dtensor weight
loader for the models below in `dtensor_weight_loader.py <https://github.com/volcengine/verl/blob/main/verl/third_party/vllm/vllm_v_0_5_4/dtensor_weight_loaders.py>`_.:
- ``GPT2LMHeadModel``
- ``LlamaForCausalLM``
- ``LLaMAForCausalLM``
- ``MistralForCausalLM``
- ``InternLMForCausalLM``
- ``AquilaModel``
- ``AquilaForCausalLM``
- ``Phi3ForCausalLM``
- ``GemmaForCausalLM``
- ``Gemma2ForCausalLM``
- ``GPTBigCodeForCausalLM``
- ``Starcoder2ForCausalLM``
- ``Qwen2ForCausalLM``
- ``DeepseekV2ForCausalLM``
To implement ``dtensor_weight_loader`` of a model that's supported in
vLLM, follow the guide of gemma model below:
1. Copy the
``load_weights(self, weights: Iterable[Tuple[str, torch.Tensor]])`` from the vllm model class
to ``dtensor_weight_loaders.py``
2. Modify the arguments to
``(actor_weights: Dict, vllm_model: nn.Module)``
3. Replace the ``self`` to ``vllm_model``
4. Add the
``local_loaded_weight = redistribute_dtensor(param_name=name, loaded_weights=loaded_weight)``
before each ``param = params_dict[name]`` and modify the following
weight loading using ``local_loaded_weight``.
5. Register the implemented dtensor weight loader to ``__MODEL_DTENSOR_WEIGHT_LOADER_REGISTRY__``.
.. code-block:: diff
- def load_weights(self, weights: Iterable[Tuple[str, torch.Tensor]]):
+ def gemma_dtensor_weight_loader(actor_weights: Dict, vllm_model: nn.Module) -> nn.Module:
stacked_params_mapping = [
# (param_name, shard_name, shard_id)
("qkv_proj", "q_proj", "q"),
("qkv_proj", "k_proj", "k"),
("qkv_proj", "v_proj", "v"),
("gate_up_proj", "gate_proj", 0),
("gate_up_proj", "up_proj", 1),
]
- params_dict = dict(self.named_parameters())
+ params_dict = dict(vllm_model.named_parameters())
loaded_params = set()
- for name, loaded_weight in weights:
+ for name, loaded_weight in actor_weights.items():
for (param_name, shard_name, shard_id) in stacked_params_mapping:
if shard_name not in name:
continue
name = name.replace(shard_name, param_name)
# Skip loading extra bias for GPTQ models.
if name.endswith(".bias") and name not in params_dict:
continue
+ local_loaded_weight = redistribute_dtensor(param_name=name, loaded_weights=loaded_weight)
param = params_dict[name]
weight_loader = param.weight_loader
- weight_loader(param, loaded_weight, shard_id)
+ weight_loader(param, local_loaded_weight.to(dtype=param.dtype), shard_id)
break
else:
# lm_head is not used in vllm as it is tied with embed_token.
# To prevent errors, skip loading lm_head.weight.
if "lm_head.weight" in name:
continue
# Skip loading extra bias for GPTQ models.
if name.endswith(".bias") and name not in params_dict:
continue
+ local_loaded_weight = redistribute_dtensor(param_name=name, loaded_weights=loaded_weight)
param = params_dict[name]
weight_loader = getattr(param, "weight_loader",
default_weight_loader)
- weight_loader(param, loaded_weight)
+ weight_loader(param, local_loaded_weight.to(dtype=param.dtype))
loaded_params.add(name)
unloaded_params = params_dict.keys() - loaded_params
if unloaded_params:
raise RuntimeError(
"Some weights are not initialized from checkpoints: "
f"{unloaded_params}") | {
"source": "volcengine/verl",
"title": "docs/advance/fsdp_extension.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/advance/fsdp_extension.rst",
"date": "2024-10-31T06:11:15",
"stars": 3801,
"description": "verl: Volcano Engine Reinforcement Learning for LLMs",
"file_size": 4399
} |
Add models with the Megatron-LM backend
=========================================
Model
-----------
The most challenging aspect to use the Megatron-LM backend is implementing
the models for training. Currently, we implement Llama model that
support data parallelism, tensor parallelism, pipeline parallelism (also
vPP) and sequence parallelism. We also implement remove padding (sequence packing) on Llama
model, which can be found in `modeling_llama_megatron.py <https://github.com/volcengine/verl/blob/main/verl/models/llama/megatron/modeling_llama_megatron.py>`_.
To support other model, users are required to implement:
1. Implemnt a model similar to ``modeling_llama_megatron.py`` that satisfy the
parallelism requirements of Megatron-LM. Then register your model in
the `registry.py <https://github.com/volcengine/verl/blob/main/verl/models/registry.py>`_.
2. Checkpoint utils that can load full checkpoint (e.g. huggingface
checkpoint) to partitioned models during the runtime. Then register
your loader to ``weight_loader_registry`` in `weight_loader_registry.py <https://github.com/volcengine/verl/blob/main/verl/models/weight_loader_registry.py>`_.
3. Weight loader that synchronize the weight from Megatron to rollout
(vLLM) model. Note that both the actor model and rollout model are
partitioned during runtime. So, it's advisable to map the model name
in actor model implementation. Otherwise, you may need an additional
name mapping and even weight transformation. The weight loader implementation
is in `megatron_weight_loaders.py <https://github.com/volcengine/verl/blob/main/verl/third_party/vllm/vllm_v_0_6_3/megatron_weight_loaders.py>`_. | {
"source": "volcengine/verl",
"title": "docs/advance/megatron_extension.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/advance/megatron_extension.rst",
"date": "2024-10-31T06:11:15",
"stars": 3801,
"description": "verl: Volcano Engine Reinforcement Learning for LLMs",
"file_size": 1688
} |
Ray API Design Tutorial
=======================================
We provide a tutorial for our Ray API design, including:
- Ray basic concepts
- Resource Pool and RayWorkerGroup
- Data Dispatch, Execution and Collection
- Initialize the RayWorkerGroup and execute the distributed computation in the given Resource Pool
See details in `tutorial.ipynb <https://github.com/volcengine/verl/blob/main/examples/ray/tutorial.ipynb>`_. | {
"source": "volcengine/verl",
"title": "docs/advance/placement.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/advance/placement.rst",
"date": "2024-10-31T06:11:15",
"stars": 3801,
"description": "verl: Volcano Engine Reinforcement Learning for LLMs",
"file_size": 429
} |
.. _config-explain-page:
Config Explanation
===================
ppo_trainer.yaml for FSDP Backend
---------------------------------
Data
~~~~
.. code:: yaml
data:
tokenizer: null
train_files: ~/data/rlhf/gsm8k/train.parquet
val_files: ~/data/rlhf/gsm8k/test.parquet
prompt_key: prompt
max_prompt_length: 512
max_response_length: 512
train_batch_size: 1024
return_raw_input_ids: False # This should be set to true when the tokenizer between policy and rm differs
return_raw_chat: False
- ``data.train_files``: Training set parquet. Can be a list or a single
file. The program will read all files into memory, so it can't be too
large (< 100GB). The path can be either local path or HDFS path. For
HDFS path, we provide utils to download it to DRAM and convert the
HDFS path to local path.
- ``data.val_files``: Validation parquet. Can be a list or a single
file.
- ``data.prompt_key``: The field in the dataset where the prompt is
located. Default is 'prompt'.
- ``data.max_prompt_length``: Maximum prompt length. All prompts will be
left-padded to this length. An error will be reported if the length is
too long
- ``data.max_response_length``: Maximum response length. Rollout in RL
algorithms (e.g. PPO) generates up to this length
- ``data.train_batch_size``: Batch size sampled for one training
iteration of different RL algorithms.
- ``data.return_raw_input_ids``: Whether to return the original
input_ids without adding chat template. This is mainly used to
accommodate situations where the reward model's chat template differs
from the policy. It needs to be decoded first, then apply the RM's
chat template. If using a model-based RM, and the policy and RM
chat_templates are different, this flag needs to be set
- ``data.return_raw_chat``:
- ``data.truncation``: Truncate the input_ids or prompt length if they
exceed max_prompt_length. Default is 'error', not allow exceed the
max_prompt_length. The users should increase the max_prompt_length if
throwing the error.
Actor/Rollout/Reference Policy
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. code:: yaml
actor_rollout_ref:
hybrid_engine: True
model:
path: ~/models/deepseek-llm-7b-chat
external_lib: null
override_config: { }
enable_gradient_checkpointing: False
use_remove_padding: False
actor:
strategy: fsdp # This is for backward-compatibility
ppo_mini_batch_size: 256
ppo_micro_batch_size: null # will be deprecated, use ppo_micro_batch_size_per_gpu
ppo_micro_batch_size_per_gpu: 8
use_dynamic_bsz: False
ppo_max_token_len_per_gpu: 16384 # n * ${data.max_prompt_length} + ${data.max_response_length}
grad_clip: 1.0
clip_ratio: 0.2
entropy_coeff: 0.001
use_kl_loss: False # True for GRPO
kl_loss_coef: 0.001 # for grpo
kl_loss_type: low_var_kl # for grpo
ppo_epochs: 1
shuffle: False
ulysses_sequence_parallel_size: 1 # sp size
optim:
lr: 1e-6
lr_warmup_steps_ratio: 0. # the total steps will be injected during runtime
min_lr_ratio: null # only useful for warmup with cosine
warmup_style: constant # select from constant/cosine
total_training_steps: -1 # must be override by program
fsdp_config:
wrap_policy:
# transformer_layer_cls_to_wrap: None
min_num_params: 0
param_offload: False
optimizer_offload: False
fsdp_size: -1
ref:
fsdp_config:
param_offload: False
wrap_policy:
# transformer_layer_cls_to_wrap: None
min_num_params: 0
log_prob_micro_batch_size: null # will be deprecated, use log_prob_micro_batch_size_per_gpu
log_prob_micro_batch_size_per_gpu: 16
log_prob_use_dynamic_bsz: ${actor_rollout_ref.actor.use_dynamic_bsz}
log_prob_max_token_len_per_gpu: ${actor_rollout_ref.actor.ppo_max_token_len_per_gpu}
ulysses_sequence_parallel_size: ${actor_rollout_ref.actor.ulysses_sequence_parallel_size} # sp size
rollout:
name: vllm
temperature: 1.0
top_k: -1 # 0 for hf rollout, -1 for vllm rollout
top_p: 1
prompt_length: ${data.max_prompt_length} # not use for opensource
response_length: ${data.max_response_length}
# for vllm rollout
dtype: bfloat16 # should align with FSDP
gpu_memory_utilization: 0.5
ignore_eos: False
enforce_eager: True
free_cache_engine: True
load_format: dummy_dtensor
tensor_model_parallel_size: 2
max_num_batched_tokens: 8192
max_num_seqs: 1024
log_prob_micro_batch_size: null # will be deprecated, use log_prob_micro_batch_size_per_gpu
log_prob_micro_batch_size_per_gpu: 16
log_prob_use_dynamic_bsz: ${actor_rollout_ref.actor.use_dynamic_bsz}
log_prob_max_token_len_per_gpu: ${actor_rollout_ref.actor.ppo_max_token_len_per_gpu}
# for hf rollout
do_sample: True
# number of responses (i.e. num sample times)
n: 1 # > 1 for grpo, rloo
**Common config for actor, rollout and reference model**
- ``actor_rollout_ref.hybrid_engine``: Whether it's a hybrid engine,
currently only supports hybrid engine
- ``actor_rollout_ref.model.path``: Huggingface model path. This can be
either local path or HDFS path. For HDFS path, we provide utils to
download it to DRAM and convert the HDFS path to local path.
- ``actor_rollout_ref.model.external_libs``: Additional Python packages
that need to be imported. Used to register models or tokenizers into
the Huggingface system.
- ``actor_rollout_ref.model.override_config``: Used to override some of
the model's original configurations, mainly dropout
- ``actor_rollout_ref.model.enable_gradient_checkpointing``: Whether to
enable gradient checkpointing for the actor
**Actor model**
- ``actor_rollout_ref.actor.strategy``: fsdp or megatron. In this
example, we use fsdp backend.
- ``actor_rollout_ref.actor.ppo_mini_batch_size``: One sample is split
into multiple sub-batches with batch_size=ppo_mini_batch_size for PPO
updates. The ppo_mini_batch_size is a global num across all workers/gpus
- ``actor_rollout_ref.actor.ppo_micro_batch_size``: [Will be deprecated, use ppo_micro_batch_size_per_gpu]
Similar to gradient accumulation, the micro_batch_size_per_gpu for one forward pass,
trading speed for GPU memory. The value represent the global view.
- ``actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu``: Similar to gradient
accumulation, the micro_batch_size_per_gpu for one forward pass, trading speed
for GPU memory. The value represent the local num per gpu.
- ``actor_rollout_ref.actor.grad_clip``: Gradient clipping for actor
updates
- ``actor_rollout_ref.actor.clip_ratio``: PPO clip ratio
- ``actor_rollout_ref.actor.entropy_coeff``: The weight of entropy when
calculating PPO loss
- ``actor_rollout_ref.actor.ppo_epochs``: Number of epochs for PPO
updates on one set of sampled data
- ``actor_rollout_ref.actor.shuffle``: Whether to shuffle data when
there are multiple epochs
- ``actor_rollout_ref.actor.optim``: Actor's optimizer parameters
- ``actor_rollout_ref.actor.fsdp_config``: FSDP config for actor
training
- ``wrap_policy``: FSDP wrap policy. By default, it uses Huggingface's
wrap policy, i.e., wrapping by DecoderLayer
- No need to set transformer_layer_cls_to_wrap, so we comment it.
- ``*_offload``: Whether to enable parameter, gradient and optimizer
offload
- Trading speed for GPU memory.
**Reference Model**
- ``actor_rollout_ref.ref``: FSDP config same as actor. **For models
larger than 7B, it's recommended to turn on offload for ref by
default**
- ``actor_rollout_ref.ref.log_prob_micro_batch_size``: [Will be deprecate, use log_prob_micro_batch_size_per_gpu]
The batch size for one forward pass in the computation of ``ref_log_prob``. The value represent the global num.
- ``actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu``: The batch size
for one forward pass in the computation of ``ref_log_prob``. The value represent the local num per gpu.
**Rollout Model**
- ``actor_rollout_ref.rollout.name``: hf/vllm. We use vLLM by default
because it's much efficient and our hybrid engine is implemented with
vLLM.
- Rollout (Auto-regressive) parameters. The key should be equal to the
property name in vLLM's ``SamplingParams``.
- ``temperature``, ``top_k``, ``top_p`` and others: Sampling
parameters in ``SamplingParams``.
- ``dtype``: Rollout model parameters type. This should be align with
the actor model parameter type in FSDP/Megatron backend.
- ``gpu_memory_utilization``: The proportion of the remaining GPU memory
allocated for kv cache after other models have initialized when using
vllm.
- ``tensor_model_parallel_size``: TP size for rollout. Only effective
for vllm.
- ``actor_rollout_ref.ref.log_prob_micro_batch_size``: [Will be deprecate, use log_prob_micro_batch_size_per_gpu]
The batch size for one forward pass in the computation of ``log_prob``. The value represent the global num.
- ``log_prob_micro_batch_size_per_gpu``: Micro batch size per gpu (The batch size for
one forward pass) for recalculating ``log_prob``. The value represent the local num per gpu.
- ``do_sample``: Whether to sample. If set to False, the rollout model
will perform greedy sampling. We disable ``do_sample`` during
validation.
- ``actor_rollout_ref.rollout.ignore_eos``: Whether to ignore the EOS
token and continue generating tokens after the EOS token is generated.
- ``actor_rollout_ref.rollout.free_cache_engine``: Offload the KVCache
after rollout generation stage. Default is True. When set to True, we
need to disable the usage of CUDAGraph (set ``enforce_eager`` to
True.)
- ``actor_rollout_ref.rollout.enforce_eager``: Whether to use CUDAGraph
in vLLM generation. Default set to True to disable CUDAGraph.
- ``actor_rollout_ref.rollout.load_format``: Which weight loader to use
to load the actor model weights to the rollout model.
- ``auto``: Use Megatron weight loader.
- ``megatron``: Use Megatron weight loader. Deployed with Megatron
backend. The input model ``state_dict()`` is already partitioned
along TP dimension and already gathered along PP dimension. This
weight loader requires that the Rollout model and Actor model's
parameters shape and name should be identical.
- ``dtensor``: Default solution when using Huggingface weight loader.
Deployed with FSDP backend and the state_dict_type is
``StateDictType.SHARDED_STATE_DICT``. Recommend to use this weight
loader
- ``hf``: Use Huggingface weight loader. Deployed with FSDP backend
and the state_dict_type is ``StateDictType.FULL_STATE_DICT``. This
solution doesn't need to rewrite the weight loader for each model
implemented in vLLM but it results in larger peak memory usage.
- ``dummy_hf``, ``dummy_megatron``, ``dummy_dtensor``: Random
initialization.
.. note:: **NOTED**: In this config field, users only need to select from ``dummy_megatron``, ``dummy_dtensor``, ``dummy_hf`` for rollout initialization and our hybrid engine will select the corresponding weight loader (i.e., ``megatron``, ``dtensor``, ``hf``) during actor/rollout weight synchronization.
Critic Model
~~~~~~~~~~~~
Most parameters for Critic are similar to Actor Model.
Reward Model
~~~~~~~~~~~~
.. code:: yaml
reward_model:
enable: False
model:
input_tokenizer: ${actor_rollout_ref.model.path} # set this to null if the chat template is identical
path: ~/models/Anomy-RM-v0.1
external_lib: ${actor_rollout_ref.model.external_lib}
fsdp_config:
min_num_params: 0
param_offload: False
micro_batch_size_per_gpu: 16
max_length: null
reward_manager: naive
- ``reward_model.enable``: Whether to enable reward model. If False, we
compute the reward only with the user-defined reward functions. In
GSM8K and Math examples, we disable reward model. For RLHF alignment
example using full_hh_rlhf, we utilize reward model to assess the
responses. If False, the following parameters are not effective.
- ``reward_model.model``
- ``input_tokenizer``: Input tokenizer. If the reward model's chat
template is inconsistent with the policy, we need to first decode to
plaintext, then apply the rm's chat_template. Then score with RM. If
chat_templates are consistent, it can be set to null.
- ``path``: RM's HDFS path or local path. Note that RM only supports
AutoModelForSequenceClassification. Other model types need to define
their own RewardModelWorker and pass it from the code.
- ``reward_model.reward_manager``: Reward Manager. This defines the mechanism
of computing rule-based reward and handling different reward sources. Default
if ``naive``. If all verification functions are multiprocessing-safe, the reward
manager can be set to ``prime`` for parallel verification.
Algorithm
~~~~~~~~~
.. code:: yaml
algorithm:
gamma: 1.0
lam: 1.0
adv_estimator: gae
kl_penalty: kl # how to estimate kl divergence
kl_ctrl:
type: fixed
kl_coef: 0.005
- ``gemma``: discount factor
- ``lam``: Trade-off between bias and variance in the GAE estimator
- ``adv_estimator``: Support ``gae``, ``grpo``, ``reinforce_plus_plus``, ``rloo``
- ``kl_penalty``: Support ``kl``, ``abs``, ``mse`` and ``full``. How to
calculate the kl divergence between actor and reference policy. For
specific options, refer to `core_algos.py <https://github.com/volcengine/verl/blob/main/verl/trainer/ppo/core_algos.py#L192>`_ .
Trainer
~~~~~~~
.. code:: yaml
trainer:
total_epochs: 30
project_name: verl_examples
experiment_name: gsm8k
logger: ['console', 'wandb']
nnodes: 1
n_gpus_per_node: 8
save_freq: -1
test_freq: 2
critic_warmup: 0
default_hdfs_dir: ~/experiments/gsm8k/ppo/${trainer.experiment_name} # hdfs checkpoint path
default_local_dir: checkpoints/${trainer.project_name}/${trainer.experiment_name} # local checkpoint path
- ``trainer.total_epochs``: Number of epochs in training.
- ``trainer.project_name``: For wandb
- ``trainer.experiment_name``: For wandb
- ``trainer.logger``: Support console and wandb
- ``trainer.nnodes``: Number of nodes used in the training.
- ``trainer.n_gpus_per_node``: Number of GPUs per node.
- ``trainer.save_freq``: The frequency (by iteration) to save checkpoint
of the actor and critic model.
- ``trainer.test_freq``: The validation frequency (by iteration).
- ``trainer.critic_warmup``: The number of iteration to train the critic
model before actual policy learning. | {
"source": "volcengine/verl",
"title": "docs/examples/config.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/examples/config.rst",
"date": "2024-10-31T06:11:15",
"stars": 3801,
"description": "verl: Volcano Engine Reinforcement Learning for LLMs",
"file_size": 14782
} |
GSM8K Example
=============
Introduction
------------
In this example, we train an LLM to tackle the GSM8k task.
Paper: https://arxiv.org/pdf/2110.14168
Dataset: https://huggingface.co/datasets/gsm8k
Note that the original paper mainly focuses on training a verifier (a
reward model) to solve math problems via Best-of-N sampling. In this
example, we train an RLHF agent using a rule-based reward model.
Dataset Introduction
--------------------
GSM8k is a math problem dataset. The prompt is an elementary school
problem. The LLM model is required to answer the math problem.
The training set contains 7473 samples and the test set contains 1319
samples.
**An example**
Prompt
Katy makes coffee using teaspoons of sugar and cups of water in the
ratio of 7:13. If she used a total of 120 teaspoons of sugar and cups
of water, calculate the number of teaspoonfuls of sugar she used.
Solution
The total ratio representing the ingredients she used to make the
coffee is 7+13 = <<7+13=20>>20 Since the fraction representing the
number of teaspoons she used is 7/20, she used 7/20\ *120 =
<<7/20*\ 120=42>>42 #### 42
Step 1: Prepare dataset
-----------------------
.. code:: bash
cd examples/data_preprocess
python3 gsm8k.py --local_dir ~/data/gsm8k
Step 2: Download Model
----------------------
There're three ways to prepare the model checkpoints for post-training:
- Download the required models from hugging face
.. code:: bash
huggingface-cli download deepseek-ai/deepseek-math-7b-instruct --local-dir ~/models/deepseek-math-7b-instruct --local-dir-use-symlinks False
- Already store your store model in the local directory or HDFS path.
- Also, you can directly use the model name in huggingface (e.g.,
deepseek-ai/deepseek-math-7b-instruct) in
``actor_rollout_ref.model.path`` and ``critic.model.path`` field in
the run script.
Noted that users should prepare checkpoints for actor, critic and reward
model.
[Optional] Step 3: SFT your Model
---------------------------------
We provide a SFT Trainer using PyTorch FSDP in
`fsdp_sft_trainer.py <https://github.com/volcengine/verl/blob/main/verl/trainer/fsdp_sft_trainer.py>`_.
Users can customize their own SFT
script using our FSDP SFT Trainer.
We also provide various training scripts for SFT on GSM8K dataset in `gsm8k sft directory <https://github.com/volcengine/verl/blob/main/examples/sft/gsm8k/>`_.
.. code:: shell
set -x
torchrun -m verl.trainer.fsdp_sft_trainer \
data.train_files=$HOME/data/gsm8k/train.parquet \
data.val_files=$HOME/data/gsm8k/test.parquet \
data.prompt_key=question \
data.response_key=answer \
data.micro_batch_size_per_gpu=8 \
model.partial_pretrain=deepseek-ai/deepseek-coder-6.7b-instruct \
trainer.default_hdfs_dir=hdfs://user/verl/experiments/gsm8k/deepseek-coder-6.7b-instruct/ \
trainer.project_name=gsm8k-sft \
trainer.experiment_name=gsm8k-sft-deepseek-coder-6.7b-instruct \
trainer.total_epochs=4 \
trainer.logger=['console','wandb']
Step 4: Perform PPO training with your model on GSM8K Dataset
-------------------------------------------------------------
- Prepare your own run.sh script. Here's an example for GSM8k dataset
and deepseek-llm-7b-chat model.
- Users could replace the ``data.train_files`` ,\ ``data.val_files``,
``actor_rollout_ref.model.path`` and ``critic.model.path`` based on
their environment.
- See :doc:`config` for detailed explanation of each config field.
**Reward Model/Function**
We use a rule-based reward model. We force the model to produce a final
answer following 4 “#” as shown in the solution. We extract the final
answer from both the solution and model's output using regular
expression matching. We compare them and assign a reward of 1 to correct
answer, 0.1 to incorrect answer and 0 to no answer.
**Training Script**
The training script example for FSDP and Megatron-LM backend are stored in examples/ppo_trainer directory.
.. code:: bash
cd ../ppo_trainer
bash run_deepseek7b_llm.sh
The script of run_deepseek7b_llm.sh
.. code:: bash
set -x
python3 -m verl.trainer.main_ppo \
data.train_files=$HOME/data/gsm8k/train.parquet \
data.val_files=$HOME/data/gsm8k/test.parquet \
data.train_batch_size=1024 \
data.max_prompt_length=512 \
data.max_response_length=512 \
actor_rollout_ref.model.path=deepseek-ai/deepseek-llm-7b-chat \
actor_rollout_ref.actor.optim.lr=1e-6 \
actor_rollout_ref.model.use_remove_padding=True \
actor_rollout_ref.actor.ppo_mini_batch_size=256 \
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=16 \
actor_rollout_ref.actor.fsdp_config.param_offload=False \
actor_rollout_ref.actor.fsdp_config.optimizer_offload=False \
actor_rollout_ref.model.enable_gradient_checkpointing=True \
actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32 \
actor_rollout_ref.rollout.tensor_model_parallel_size=4 \
actor_rollout_ref.rollout.name=vllm \
actor_rollout_ref.rollout.gpu_memory_utilization=0.5 \
actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32 \
actor_rollout_ref.ref.fsdp_config.param_offload=True \
critic.optim.lr=1e-5 \
critic.model.use_remove_padding=True \
critic.model.path=deepseek-ai/deepseek-llm-7b-chat \
critic.model.enable_gradient_checkpointing=True \
critic.ppo_micro_batch_size_per_gpu=32 \
critic.model.fsdp_config.param_offload=False \
critic.model.fsdp_config.optimizer_offload=False \
algorithm.kl_ctrl.kl_coef=0.001 \
trainer.critic_warmup=0 \
trainer.logger=['console','wandb'] \
trainer.project_name='verl_example_gsm8k' \
trainer.experiment_name='deepseek_llm_7b_function_rm' \
trainer.n_gpus_per_node=8 \
trainer.nnodes=1 \
trainer.save_freq=-1 \
trainer.test_freq=1 \
trainer.total_epochs=15 $@ | {
"source": "volcengine/verl",
"title": "docs/examples/gsm8k_example.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/examples/gsm8k_example.rst",
"date": "2024-10-31T06:11:15",
"stars": 3801,
"description": "verl: Volcano Engine Reinforcement Learning for LLMs",
"file_size": 5986
} |
PPO Example Architecture
========================
Let's start with the Proximal Policy Optimization algorithm, which is
most widely used algorithm in LLM post-training.
The main entry point of the PPO algorithm example is:
`main_ppo.py <https://github.com/volcengine/verl/blob/main/verl/trainer/main_ppo.py>`_.
In this tutorial, we will go through the code architecture in `main_ppo.py <https://github.com/volcengine/verl/blob/main/verl/trainer/main_ppo.py>`_.
Define the data
---------------
Users need to preprocess and store the dataset in parquet files.
And we implement `RLHFDataset` to load and tokenize the parquet files.
For ``RLHFDataset`` (Default), at least 1 fields are required:
- ``prompt``: Contains the string prompt
We already provide some examples of processing the datasets to parquet
files in `data_preprocess directory <https://github.com/volcengine/verl/blob/main/examples/data_preprocess>`_. Currently, we support
preprocess of GSM8k, MATH, Hellasage, Full_hh_rlhf datasets. See :doc:`../preparation/prepare_data` for
more information.
Define the reward functions for different datasets
--------------------------------------------------
In this main entry point, the users only need to define their own reward
function based on the datasets (or applications) utilized in PPO
training.
For example, we already provide reward functions for `GSM8k <https://github.com/volcengine/verl/blob/main/verl/utils/reward_score/gsm8k.py>`_
and `MATH <https://github.com/volcengine/verl/blob/main/verl/utils/reward_score/math.py>`_
datasets in the ``_select_rm_score_fn``. In the ``RewardManager``, we
will compute the reward score based on the data_source to select
corresponding reward functions. For some RLHF datasets (e.g.,
full_hh_rlhf), the reward model is utilized to assess the responses
without any reward functions. In this case, the ``RewardManager`` will
return the ``rm_score`` computed by the reward model directly.
See `reward functions <https://github.com/volcengine/verl/blob/main/verl/utils/reward_score>`_ for detailed implementation.
Define worker classes
---------------------
.. code:: python
if config.actor_rollout_ref.actor.strategy == 'fsdp': # for FSDP backend
assert config.actor_rollout_ref.actor.strategy == config.critic.strategy
from verl.workers.fsdp_workers import ActorRolloutRefWorker, CriticWorker
from verl.single_controller.ray import RayWorkerGroup
ray_worker_group_cls = RayWorkerGroup
elif config.actor_rollout_ref.actor.strategy == 'megatron': # for Megatron backend
assert config.actor_rollout_ref.actor.strategy == config.critic.strategy
from verl.workers.megatron_workers import ActorRolloutRefWorker, CriticWorker
from verl.single_controller.ray.megatron import NVMegatronRayWorkerGroup
ray_worker_group_cls = NVMegatronRayWorkerGroup # Ray worker class for Megatron-LM
else:
raise NotImplementedError
from verl.trainer.ppo.ray_trainer import ResourcePoolManager, Role
role_worker_mapping = {
Role.ActorRollout: ActorRolloutRefWorker,
Role.Critic: CriticWorker,
Role.RefPolicy: ActorRolloutRefWorker
}
global_pool_id = 'global_pool'
resource_pool_spec = {
global_pool_id: [config.trainer.n_gpus_per_node] * config.trainer.nnodes,
}
mapping = {
Role.ActorRollout: global_pool_id,
Role.Critic: global_pool_id,
Role.RefPolicy: global_pool_id,
}
Step 1: Construct the mapping between roles and workers
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
A role represents a group of workers in the same process. We have
pre-defined several roles in `ray_trainer.py <https://github.com/volcengine/verl/blob/main/verl/trainer/ppo/ray_trainer.py#L38>`_.
.. code:: python
class Role(Enum):
"""
To create more roles dynamically, you can subclass Role and add new members
"""
Actor = 0 # This worker only has Actor
Rollout = 1 # This worker only has Rollout
ActorRollout = 2 # This worker has both actor and rollout, it's a HybridEngine
Critic = 3 # This worker only has critic
RefPolicy = 4 # This worker only has reference policy
RewardModel = 5 # This worker only has reward model
ActorRolloutRef = 6 # This worker contains actor, rollout and reference policy simultaneously
Step 2: Define the worker class corresponding to this role
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
- We have pre-implemented the ``ActorRolloutRefWorker``. Through
different configs, it can be a standalone actor, a standalone rollout,
an ActorRollout HybridEngine, or an ActorRolloutRef HybridEngine
- We also pre-implemented workers for ``Actor``, ``Rollout``,
``Critic``, ``Reward Model`` and ``Reference model`` on two different
backend: PyTorch FSDP
and Megatron-LM.
See `FSDP Workers <https://github.com/volcengine/verl/blob/main/verl/workers/fsdp_workers.py>`_
and `Megatron-LM Workers <https://github.com/volcengine/verl/blob/main/verl/workers/megatron_workers.py>`_
for more information.
Step 3: Define resource pool id and resource pool spec
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
- Resource pool is a division of global GPU resources,
``resource_pool_spec`` is a dict, mapping from id to # of GPUs
- In the above example, we defined a global resource pool:
global_pool_id, and then put all roles on this one resource pool
with all the GPUs in this post-training task. This refers to
*co-locate* placement where all the models share the same set of
GPUs.
- See resource pool and placement for advance usage.
Defining reward model/function
------------------------------
.. code:: python
# we should adopt a multi-source reward function here
# - for rule-based rm, we directly call a reward score
# - for model-based rm, we call a model
# - for code related prompt, we send to a sandbox if there are test cases
# - finally, we combine all the rewards together
# - The reward type depends on the tag of the data
if config.reward_model.enable:
from verl.workers.fsdp_workers import RewardModelWorker
role_worker_mapping[Role.RewardModel] = RewardModelWorker
mapping[Role.RewardModel] = global_pool_id
reward_fn = RewardManager(tokenizer=tokenizer, num_examine=0)
# Note that we always use function-based RM for validation
val_reward_fn = RewardManager(tokenizer=tokenizer, num_examine=1)
resource_pool_manager = ResourcePoolManager(resource_pool_spec=resource_pool_spec, mapping=mapping)
Since not all tasks use model-based RM, users need to define here
whether it's a model-based RM or a function-based RM
- If it's a model-based RM, directly add the ``RewardModel`` role in the
resource mapping and add it to the resource pool mapping.
- Note that the pre-defined ``RewardModelWorker`` only supports models
with the structure of huggingface
``AutoModelForSequenceClassification``. If it's not this model, you
need to define your own RewardModelWorker in `FSDP Workers <https://github.com/volcengine/verl/blob/main/verl/workers/fsdp_workers.py>`_
and `Megatron-LM Workers <https://github.com/volcengine/verl/blob/main/verl/workers/megatron_workers.py>`_.
- If it's a function-based RM, the users are required to classified the
reward function for each datasets.
.. code:: python
def _select_rm_score_fn(data_source):
if data_source == 'openai/gsm8k':
return gsm8k.compute_score
elif data_source == 'lighteval/MATH':
return math.compute_score
else:
raise NotImplementedError
See reward functions implemented in `directory <https://github.com/volcengine/verl/blob/main/verl/utils/reward_score/>`_
for more information.
Define, init and run the PPO Trainer
------------------------------------
.. code:: python
trainer = RayPPOTrainer(config=config,
tokenizer=tokenizer,
role_worker_mapping=role_worker_mapping,
resource_pool_manager=resource_pool_manager,
ray_worker_group_cls=ray_worker_group_cls,
reward_fn=reward_fn,
val_reward_fn=val_reward_fn)
trainer.init_workers()
trainer.fit()
- We first initialize the ``RayPPOTrainer`` with user config, tokenizer
and all the above worker mapping, resource pool, worker group and
reward functions
- We first call the ``trainer.init_workers()`` to initialize the models
on the allocated GPUs (in the resource pool)
- The actual PPO training will be executed in ``trainer.fit()``
verl can be easily extended to other RL algorithms by reusing the Ray
model workers, resource pool and reward functions. See :doc:`extension<../advance/dpo_extension>` for
more information.
Details of the ``RayPPOTrainer`` is discussed in :doc:`Ray Trainer<../workers/ray_trainer>`. | {
"source": "volcengine/verl",
"title": "docs/examples/ppo_code_architecture.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/examples/ppo_code_architecture.rst",
"date": "2024-10-31T06:11:15",
"stars": 3801,
"description": "verl: Volcano Engine Reinforcement Learning for LLMs",
"file_size": 8996
} |
.. _algo-baseline-page:
Algorithm Baselines
===================
GSM8k
------------------
Assuming GSM8k dataset is preprocess via ``python3 examples/data_preprocess/gsm8k.py``
Refer to the table below to reproduce PPO training from different pre-trained models.
.. _Huggingface: https://huggingface.co/google/gemma-2-2b-it#benchmark-results
.. _SFT Command and Logs: https://github.com/eric-haibin-lin/verl-data/blob/experiments/gsm8k/gemma-2-2b-it-sft-0.411.log
.. _SFT+PPO Command and Logs: https://github.com/eric-haibin-lin/verl-data/blob/experiments/gsm8k/gemma-2-2b-it-ppo-bsz512_4-prompt1024-resp-512-0.640.log
.. _wandb: https://api.wandb.ai/links/verl-team/h7ux8602
.. _Qwen Blog: https://qwenlm.github.io/blog/qwen2.5-llm/
.. _PPO Command and Logs: https://github.com/eric-haibin-lin/verl-data/blob/experiments/gsm8k/Qwen2.5-0.5B-bsz256_2-prompt1024-resp512-0.567.log
.. _Megatron PPO Command and Logs: https://github.com/eric-haibin-lin/verl-data/blob/experiments/gsm8k/deepseek-llm-7b-chat-megatron-bsz256_4-prompt512-resp512-0.695.log
.. _Qwen7b GRPO Script: https://github.com/volcengine/verl/blob/a65c9157bc0b85b64cd753de19f94e80a11bd871/examples/grpo_trainer/run_qwen2-7b_seq_balance.sh
.. _Megatron wandb: https://wandb.ai/verl-team/verl_megatron_gsm8k_examples/runs/10fetyr3
.. _Qwen7b ReMax Script: https://github.com/eric-haibin-lin/verl/blob/main/examples/remax_trainer/run_qwen2.5-3b_seq_balance.sh
.. _Qwen7b ReMax Wandb: https://wandb.ai/liziniu1997/verl_remax_example_gsm8k/runs/vxl10pln
+----------------------------------+------------------------+------------+-----------------------------------------------------------------------------------------------+
| Model | Method | Test score | Details |
+==================================+========================+============+=====================+=========================================================================+
| google/gemma-2-2b-it | pretrained checkpoint | 23.9 | `Huggingface`_ |
+----------------------------------+------------------------+------------+-----------------------------------------------------------------------------------------------+
| google/gemma-2-2b-it | SFT | 52.06 | `SFT Command and Logs`_ |
+----------------------------------+------------------------+------------+-----------------------------------------------------------------------------------------------+
| google/gemma-2-2b-it | SFT + PPO | 64.02 | `SFT+PPO Command and Logs`_, `wandb`_ |
+----------------------------------+------------------------+------------+-----------------------------------------------------------------------------------------------+
| Qwen/Qwen2.5-0.5B-Instruct | pretrained checkpoint | 36.4 | `Qwen Blog`_ |
+----------------------------------+------------------------+------------+-----------------------------------------------------------------------------------------------+
| Qwen/Qwen2.5-0.5B-Instruct | PPO | 56.7 | `PPO Command and Logs`_ |
+----------------------------------+------------------------+------------+-----------------------------------------------------------------------------------------------+
| deepseek-ai/deepseek-llm-7b-chat | PPO | 69.5 [1]_ | `Megatron PPO Command and Logs`_, `Megatron wandb`_ |
+----------------------------------+------------------------+------------+-----------------------------------------------------------------------------------------------+
| Qwen/Qwen2-7B-Instruct | GRPO | 89 | `Qwen7b GRPO Script`_ |
+----------------------------------+------------------------+------------+-----------------------------------------------------------------------------------------------+
| Qwen/Qwen2.5-7B-Instruct | ReMax | 97 | `Qwen7b ReMax Script`_, `Qwen7b ReMax Wandb`_ |
+----------------------------------+------------------------+------------+-----------------------------------------------------------------------------------------------+
.. [1] During the evaluation, we have only extracted answers following the format "####". A more flexible answer exaction, longer response length and better prompt engineering may lead to higher score. | {
"source": "volcengine/verl",
"title": "docs/experiment/ppo.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/experiment/ppo.rst",
"date": "2024-10-31T06:11:15",
"stars": 3801,
"description": "verl: Volcano Engine Reinforcement Learning for LLMs",
"file_size": 4971
} |
Frequently Asked Questions
====================================
Ray related
------------
How to add breakpoint for debugging with distributed Ray?
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Please checkout the official debugging guide from Ray: https://docs.ray.io/en/latest/ray-observability/ray-distributed-debugger.html
Distributed training
------------------------
How to run multi-node post-training with Ray?
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
You can start a ray cluster and submit a ray job, following the official guide from Ray: https://docs.ray.io/en/latest/ray-core/starting-ray.html
Then in the configuration, set the ``trainer.nnode`` config to the number of machines for your job.
How to use verl on a Slurm-managed cluster?
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Ray provides users with `this <https://docs.ray.io/en/latest/cluster/vms/user-guides/community/slurm.html>`_ official
tutorial to start a Ray cluster on top of Slurm. We have verified the :doc:`GSM8K example<../examples/gsm8k_example>`
on a Slurm cluster under a multi-node setting with the following steps.
1. [Optional] If your cluster support `Apptainer or Singularity <https://apptainer.org/docs/user/main/>`_ and you wish
to use it, convert verl's Docker image to an Apptainer image. Alternatively, set up the environment with the package
manager available on your cluster or use other container runtimes (e.g. through `Slurm's OCI support <https://slurm.schedmd.com/containers.html>`_) available to you.
.. code:: bash
apptainer pull /your/dest/dir/vemlp-th2.4.0-cu124-vllm0.6.3-ray2.10-te1.7-v0.0.3.sif docker://verlai/verl:vemlp-th2.4.0-cu124-vllm0.6.3-ray2.10-te1.7-v0.0.3
2. Follow :doc:`GSM8K example<../examples/gsm8k_example>` to prepare the dataset and model checkpoints.
3. Modify `examples/slurm/ray_on_slurm.slurm <https://github.com/volcengine/verl/blob/main/verl/examples/slurm/ray_on_slurm.slurm>`_ with your cluster's own information.
4. Submit the job script to the Slurm cluster with `sbatch`.
Please note that Slurm cluster setup may vary. If you encounter any issues, please refer to Ray's
`Slurm user guide <https://docs.ray.io/en/latest/cluster/vms/user-guides/community/slurm.html>`_ for common caveats.
Illegal memory access
---------------------------------
If you encounter the error message like ``CUDA error: an illegal memory access was encountered`` during rollout, most likely it is due to a known issue from vllm.
Please set the following environment variable. The env var must be set before the ``ray start`` command if any.
.. code:: bash
export VLLM_ATTENTION_BACKEND=XFORMERS
If in doubt, print this env var in each rank to make sure it is properly set. | {
"source": "volcengine/verl",
"title": "docs/faq/faq.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/faq/faq.rst",
"date": "2024-10-31T06:11:15",
"stars": 3801,
"description": "verl: Volcano Engine Reinforcement Learning for LLMs",
"file_size": 2997
} |
Performance Tuning Guide
==============================
Author: `Guangming Sheng <https://github.com/PeterSH6>`_
In this section, we will discuss how to tune the performance of all the stages in verl, including:
1. Rollout generation throughput.
2. Enable `use_remove_padding=True` for sequence packing (i.e., data packing and remove padding).
3. Batch size tuning for forward and backward computation
4. Enable ``use_dynamic_bsz=True`` for higher throughput.
5. Utilize Ulysses Sequence Parallel for Long Context Training
6. LigerKernel for SFT performance optimization
Rollout Generation Tuning
--------------------------
verl currently supports two rollout backends: vLLM and TGI (with SGLang support coming soon).
Below are key factors for tuning vLLM-based rollout. Before tuning, we recommend setting ``actor_rollout_ref.rollout.disable_log_stats=False`` so that rollout statistics are logged.
- Increase ``gpu_memory_utilization``. The vLLM pre-allocates GPU KVCache by using gpu_memory_utilization% of the remaining memory.
However, if model parameters and optimizer states are not offloaded, using too high a fraction can lead to OOM.
A value between 0.5 and 0.7 often strikes a good balance between high throughput and avoiding OOM.
- Adjust ``max_num_seqs`` or ``max_num_batched_tokens``.
If the GPU cache utilization is relatively low in the log, increase ``max_num_seqs`` or ``max_num_batched_tokens``
can enlarge the effective batch size in the decoding stage, allowing more concurrent requests per batch.
We recommend setting ``max_num_batched_tokens > 2048`` for higher throughput.
- Use a smaller ``tensor_parallel_size``.
When GPU resources allow, a smaller tensor parallel size spawns more vLLM replicas.
Data parallelism (DP) can yield higher throughput than tensor parallelism (TP), but also increases KVCache consumption.
Carefully balance the trade-off between more replicas and higher memory usage.
Our experient in Sec. 8.4 of `HybridFlow paper <https://github.com/volcengine/verl/blob/main/verl/utils/reward_score/gsm8k.py>`_ evaluate this trade-off.
More tuning details such as dealing with Preemption and Chunked-prefill
can be found in `vLLM official tuning guide <https://docs.vllm.ai/en/latest/performance/optimization.html>`_
The performance of vllm can be further increased if upgrading from v0.6.3 to v0.7. See https://github.com/volcengine/verl/blob/main/docs/README_vllm0.7.md for details on how to upgrade.
Enable remove padding (sequence packing)
-----------------------------------------
Currently, for llama, mistral, gemma1 and qwen based models, users can enable `use_remove_padding=True` to utilize the
sequence packing implementation provided by transformers library.
For other models, transformers library may also support it but we haven't tested it yet.
Users can add the desired model config to the `test_transformer.py <https://github.com/volcengine/verl/blob/main/tests/model/test_transformer.py#L24>`_ file.
And test its functionaility by running the following command:
.. code-block:: bash
pytest -s tests/model/test_transformer.py
If the test passes, you can add your desired model into the model `registry.py <https://github.com/volcengine/verl/blob/main/verl/models/registry.py#L24>`_ file.
Then, you can enjoy the performance boost of sequence packing
and welcome to PR your tested model to verl!
Batch Size Tuning
-----------------
To achieve higher throughput in experience preparation (i.e., model fwd) and model update (i.e., actor/critic fwd/bwd),
users may need to tune the ``*micro_batch_size_per_gpu`` for different computation.
In verl, the core principle for setting batch sizes is:
- **Algorithmic metrics** (train batch size, PPO mini-batch size) are *global* (from a single-controller perspective),
normalized in each worker. See the `normalization code <https://github.com/volcengine/verl/blob/main/verl/workers/fsdp_workers.py#L120-L122>`_.
- **Performance-related parameters** (micro batch size, max token length for dynamic batch size) are *local* parameters that define the per-GPU data allocations.
See the `normalization code <https://github.com/volcengine/verl/blob/main/verl/workers/fsdp_workers.py#L127>`_.
.. note:: In your training script, please use ``*micro_batch_size_per_gpu`` instead of ``*micro_batch_size``.
So that you don't need to consider the normalization of the ``micro_batch_size`` and ``micro_batch_size`` will be deprecated.
Batch Size Tuning tips
""""""""""""""""""""""
Therefore, users may need to tune the ``*micro_batch_size_per_gpu`` to accelerate training. Here're some tips:
1. **Enable gradient checkpointing**:
Set ``actor_rollout_ref.model.enable_gradient_checkpointing=True`` and ``critic.model.enable_gradient_checkpointing=True``.
This often allows for larger micro-batch sizes and will be beneficial for large mini-batch training.
2. Increase the ``*micro_batch_size_per_gpu`` as much as possible till equals to normalized ``mini_batch_size``.
3. **Use larger forward-only parameters**:
Forward only parameter, such as ``actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu``,
``actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu``, ``critic.forward_micro_batch_size_per_gpu`` could be larger (e.g., 2x) than training related micro batch sizes,
such as ``actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu``, ``critic.ppo_micro_batch_size_per_gpu``.
4. **Allow larger micro-batch sizes for Critic and Reward models**:
micro batch size of Critic and Reward model could be larger than Actor model. This is because the actor model has much larger vocab size in the final layer.
Tuning for Dynamic Batch Size
-----------------------------
Dynamic batch size is a technique that allows the model to process similar number of tokens in a single forward pass (with different actual batch sizes).
This can significantly improve the training efficiency and reduce the memory usage.
To utilize this technique, users can set ``use_dynamic_bsz=True`` in actor, ref, critic and reward models.
With ``use_dynamic_bsz=True``, users don't need to tune ``*micro_batch_size_per_gpu``.
Instead, users should tune the following parameters:
- ``actor_rollout_ref.actor.ppo_max_token_len_per_gpu``, ``critic.ppo_max_token_len_per_gpu``:
The maximum number of tokens to be processed in fwd and bwd of ``update_policy`` and ``update_critic``.
- ``actor_rollout_ref.ref.log_prob_max_token_len_per_gpu`` and ``actor_rollout_ref.rollout.log_prob_max_token_len_per_gpu``:
The maximum number of tokens to be processed in a the fwd computation of ``compute_log_prob`` and ``comptue_ref_log_prob``.
- ``critic.forward_micro_batch_size_per_gpu``, ``reward_model.forward_micro_batch_size_per_gpu``:
The maximum number of tokens to be processed in a the fwd computation of ``compute_values``, ``compute_rm_score``.
Dynamic Batch Size Tuning tips
""""""""""""""""""""""""""""""
Here're some tips to tune the above parameters:
1. **Increase** ``actor_rollout_ref.actor.ppo_max_token_len_per_gpu``
Make it at least 2 x (max_prompt_length + max_response_length). We set it to 3x in `run_qwen2-7b_rm_seq_balance.sh <https://github.com/volcengine/verl/blob/main/examples/ppo_trainer/run_qwen2-7b_rm_seq_balance.sh#L25>`_.
Try to increase it to get higher throughput.
2. **Forward-only parameters can be larger**:
Similar to the non-dynamic-batch scenario, forward-only token limits can exceed those used in forward/backward operations.
3. **Use larger limits for Critic and Reward models**:
Critic and Reward parameters can be set at least 2× the Actor’s limits. For instance, we set them to 4× here:
`run_qwen2-7b_rm_seq_balance.sh <https://github.com/volcengine/verl/blob/main/examples/ppo_trainer/run_qwen2-7b_rm_seq_balance.sh#L40>`_
.. :math:`\text{critic.ppo_max_token_len_per_gpu} = 2 \times \text{actor.ppo_max_token_len_per_gpu})`.
Ulysses Sequence Parallel for Long Context Training
----------------------------------------------------
To utilize this technique, users can set ``ulysses_sequence_parallel_size>1`` in actor, ref, critic and reward models.
We support different model utilize different ulysses_sequence_parallel_size sizes.
To train log sequence (>32k), users may need to decrease the ``*micro_batch_size_per_gpu`` and ``*max_token_len_per_gpu`` to avoid OOM.
LigerKernel for SFT
----------------------
LigerKernel is a high-performance kernel for Supervised Fine-Tuning (SFT) that can improve training efficiency. To enable LigerKernel in your SFT training:
1. Install liger-kernel via ``pip3 install liger-kernel``. In your SFT configuration file (e.g., ``verl/trainer/config/sft_trainer.yaml``), set the ``use_liger`` parameter:
.. code-block:: yaml
model:
use_liger: True # Enable LigerKernel for SFT
2. The default value is ``False``. Enable it only when you want to use LigerKernel's optimizations.
3. LigerKernel is particularly useful for improving training performance in SFT scenarios. | {
"source": "volcengine/verl",
"title": "docs/perf/perf_tuning.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/perf/perf_tuning.rst",
"date": "2024-10-31T06:11:15",
"stars": 3801,
"description": "verl: Volcano Engine Reinforcement Learning for LLMs",
"file_size": 9080
} |
Prepare Data for Post-Training
========================================
Before starting the post-training job, we need to prepare the data for
the policy training. The data should be stored in the parquet format.
We provide several data preprocess scripts for different datasets,
including GSM8K, MATH, HelloSwag, Full_hh_rlhf. To prepare other datasets, we need
to follow the following steps: The data preprocess script can be divided
into two parts:
1. The first part is the common part, which loads the dataset from
huggingface's ``datasets`` package. Then preprocess the datasets with
the ``make_map_fn`` and then store in the parquet format.
.. code:: python
import re
import os
import datasets
from verl.utils.hdfs_io import copy, makedirs
import argparse
# To extract the solution for each prompts in the dataset
# def extract_solution(solution_str):
# ...
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--local_dir', default='/opt/tiger/gsm8k')
parser.add_argument('--hdfs_dir', default=None)
args = parser.parse_args()
num_few_shot = 5
data_source = 'openai/gsm8k'
dataset = datasets.load_dataset(data_source, 'main')
train_dataset = dataset['train']
test_dataset = dataset['test']
# Construct a `def make_map_fn(split)` for the corresponding datasets.
# ...
train_dataset = train_dataset.map(function=make_map_fn('train'), with_indices=True)
test_dataset = test_dataset.map(function=make_map_fn('test'), with_indices=True)
local_dir = args.local_dir
hdfs_dir = args.hdfs_dir
train_dataset.to_parquet(os.path.join(local_dir, 'train.parquet'))
test_dataset.to_parquet(os.path.join(local_dir, 'test.parquet'))
makedirs(hdfs_dir)
copy(src=local_dir, dst=hdfs_dir)
2. The users are required to implement the ``make_map_fn()`` function
(as well as the ``extract_solution``) on their own to support
different datasets or tasks.
We already implemented the data preprocess of GSM8k, MATH, Hellaswag and Full_hh_rlhf
datasets. And we take the GSM8k dataset as an example:
**GSM8K**
In the ``make_map_fn``, each data field should consist of the following
5 fields:
1. ``data_source``: The name of the dataset. To index the corresponding
reward function in the ``RewardModule``
2. ``prompt``: This field should be constructed in the format of
huggingface chat_template. The tokenizer in ``RLHFDataset`` will
apply chat template and tokenize the prompt.
3. ``ability``: Define the task category.
4. ``reward_model``: Currently, we only utilize the ``ground_truth``
field during evaluation. The ``ground_truth`` is computed by the
``extract_solution`` function. **NOTED** that the implementation of
the corresponding reward function should align with this extracted
``ground_truth``.
5. ``extra_info``: Record some information of the current prompt. Not
use for now.
.. code:: python
def extract_solution(solution_str):
solution = re.search("#### (\\-?[0-9\\.\\,]+)", solution_str) # extract the solution after ####
assert solution is not None
final_solution = solution.group(0)
final_solution = final_solution.split('#### ')[1].replace(',', '')
return final_solution
instruction_following = "Let's think step by step and output the final answer after \"####\"."
# add a row to each data item that represents a unique id
def make_map_fn(split):
def process_fn(example, idx):
question = example.pop('question')
question = question + ' ' + instruction_following
answer = example.pop('answer')
solution = extract_solution(answer)
data = {
"data_source": data_source,
"prompt": [{
"role": "user",
"content": question
}],
"ability": "math",
"reward_model": {
"style": "rule",
"ground_truth": solution
},
"extra_info": {
'split': split,
'index': idx
}
}
return data
return process_fn | {
"source": "volcengine/verl",
"title": "docs/preparation/prepare_data.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/preparation/prepare_data.rst",
"date": "2024-10-31T06:11:15",
"stars": 3801,
"description": "verl: Volcano Engine Reinforcement Learning for LLMs",
"file_size": 4325
} |
Implement Reward Function for Dataset
======================================
For each dataset, we need to implement a reward function or utilize a reward model to compute the rewards for the generated responses.
We already pre-implemented some reward functions in `reward_score directory <https://github.com/volcengine/verl/blob/main/verl/utils/reward_score>`_.
Currently, we support reward functions for GSM8k and MATH datasets. For RLHF datasets (e.g.,
full_hh_rlhf) and Code Generation (e.g., APPS), we utilize reward model
and SandBox (will opensource soon) for evaluation respectively.
RewardManager
-------------
In the entrypoint of the PPO Post-Training script `main_ppo.py <https://github.com/volcengine/verl/blob/main/verl/trainer/main_ppo.py#L33>`_,
we implement a ``RewardManager`` that utilze pre-implemented reward functions to compute the scores for each response.
In the ``RewardManager``, we implemented a ``__call__`` function to
compute the score for each response.
All the reward functions are executed by ``compute_score_fn``.
The input is a ``DataProto``, which includes:
- ``input_ids``, ``attention_mask``: ``input_ids`` and ``attention_mask`` after applying
chat_template, including prompt and response
- ``responses``: response tokens
- ``ground_truth``: The ground truth string of the current prompt.
Stored in ``non_tensor_batch`` in the ``DataProto``, which should be
preprocessed in the parquet files.
- ``data_source``: The dataset name of the current prompt. Stored in
``non_tensor_batch`` in the ``DataProto``, which should be
preprocessed in the parquet files.
After detokenize the responses, the responses string and the ground
truth string will be input to the ``compute_score_fn`` to compute the
score for each response.
Reward Functions
----------------
We already pre-implemented some reward functions in `reward_score directory <https://github.com/volcengine/verl/blob/main/verl/utils/reward_score>`_.
- In the `GSM8k example <https://github.com/volcengine/verl/blob/main/verl/utils/reward_score/gsm8k.py>`_, we
force the response to output the final answer after four ####, then
use string matching to compare with the ground truth. If completely
correct, score 1 point; if the format is correct, score 0.1 points; if
the format is incorrect, score 0 points.
- In the `MATH example <https://github.com/volcengine/verl/blob/main/verl/utils/reward_score/math.py>`_, we follow
the implementation in `lm-evaluation-harness repository <https://github.com/EleutherAI/lm-evaluation-harness/blob/main/lm_eval/tasks/hendrycks_math/utils.py>`_. | {
"source": "volcengine/verl",
"title": "docs/preparation/reward_function.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/preparation/reward_function.rst",
"date": "2024-10-31T06:11:15",
"stars": 3801,
"description": "verl: Volcano Engine Reinforcement Learning for LLMs",
"file_size": 2605
} |
Installation
============
Requirements
------------
- **Python**: Version >= 3.9
- **CUDA**: Version >= 12.1
verl supports various backends. Currently, the following configurations are available:
- **FSDP** and **Megatron-LM** (optional) for training.
- **vLLM** adn **TGI** for rollout generation, **SGLang** support coming soon.
Training backends
------------------
We recommend using **FSDP** backend to investigate, research and prototype different models, datasets and RL algorithms. The guide for using FSDP backend can be found in :doc:`FSDP Workers<../workers/fsdp_workers>`.
For users who pursue better scalability, we recommend using **Megatron-LM** backend. Currently, we support Megatron-LM v0.4 [1]_. The guide for using Megatron-LM backend can be found in :doc:`Megatron-LM Workers<../workers/megatron_workers>`.
Install from docker image
-------------------------
We provide pre-built Docker images for quick setup.
Image and tag: ``verlai/verl:vemlp-th2.4.0-cu124-vllm0.6.3-ray2.10-te1.7-v0.0.3``. See files under ``docker/`` for NGC-based image or if you want to build your own.
1. Launch the desired Docker image:
.. code:: bash
docker run --runtime=nvidia -it --rm --shm-size="10g" --cap-add=SYS_ADMIN -v <image:tag>
2. Inside the container, install verl:
.. code:: bash
# install the nightly version (recommended)
git clone https://github.com/volcengine/verl && cd verl && pip3 install -e .
# or install from pypi via `pip3 install verl`
3. Setup Megatron (optional)
If you want to enable training with Megatron, Megatron code must be added to PYTHONPATH:
.. code:: bash
cd ..
git clone -b core_v0.4.0 https://github.com/NVIDIA/Megatron-LM.git
cp verl/patches/megatron_v4.patch Megatron-LM/
cd Megatron-LM && git apply megatron_v4.patch
pip3 install -e .
export PYTHONPATH=$PYTHONPATH:$(pwd)
You can also get the Megatron code after verl's patch via
.. code:: bash
git clone -b core_v0.4.0_verl https://github.com/eric-haibin-lin/Megatron-LM
export PYTHONPATH=$PYTHONPATH:$(pwd)/Megatron-LM
Install from custom environment
---------------------------------
To manage environment, we recommend using conda:
.. code:: bash
conda create -n verl python==3.9
conda activate verl
For installing the latest version of verl, the best way is to clone and
install it from source. Then you can modify our code to customize your
own post-training jobs.
.. code:: bash
# install verl together with some lightweight dependencies in setup.py
pip3 install torch==2.4.0 --index-url https://download.pytorch.org/whl/cu124
pip3 install flash-attn --no-build-isolation
git clone https://github.com/volcengine/verl.git
cd verl
pip3 install -e .
Megatron is optional. It's dependencies can be setup as below:
.. code:: bash
# apex
pip3 install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-option=--cpp_ext" --config-settings "--build-option=--cuda_ext" \
git+https://github.com/NVIDIA/apex
# transformer engine
pip3 install git+https://github.com/NVIDIA/[email protected]
# megatron core v0.4.0: clone and apply the patch
# You can also get the patched Megatron code patch via
# git clone -b core_v0.4.0_verl https://github.com/eric-haibin-lin/Megatron-LM
cd ..
git clone -b core_v0.4.0 https://github.com/NVIDIA/Megatron-LM.git
cd Megatron-LM
cp ../verl/patches/megatron_v4.patch .
git apply megatron_v4.patch
pip3 install -e .
export PYTHONPATH=$PYTHONPATH:$(pwd)
.. [1] Megatron v0.4 is supported with verl's patches to fix issues such as virtual pipeline hang. It will be soon updated with latest the version of upstream Megatron-LM without patches. | {
"source": "volcengine/verl",
"title": "docs/start/install.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/start/install.rst",
"date": "2024-10-31T06:11:15",
"stars": 3801,
"description": "verl: Volcano Engine Reinforcement Learning for LLMs",
"file_size": 3772
} |
.. _quickstart:
=========================================================
Quickstart: PPO training on GSM8K dataset
=========================================================
Post-train a LLM using GSM8K dataset.
Introduction
------------
.. _hf_dataset_gsm8k: https://huggingface.co/datasets/gsm8k
In this example, we train an LLM to tackle the `GSM8k <hf_dataset_gsm8k>`_ task with function-based rewards. [1]_
Prerequisite:
- the latest version of ``verl`` and its dependencies installed following the installation guide. Using the docker image is recommended.
- an GPU with at least 24 GB HBM
Dataset Introduction
--------------------
GSM8k is a math problem dataset. The prompt is an elementary school
problem. The LLM model is asked to solve the math problem. Below is an example:
Prompt
Katy makes coffee using teaspoons of sugar and cups of water in the
ratio of 7:13. If she used a total of 120 teaspoons of sugar and cups
of water, calculate the number of teaspoonfuls of sugar she used.
Solution
The total ratio representing the ingredients she used to make the
coffee is 7+13 = <<7+13=20>>20 Since the fraction representing the
number of teaspoons she used is 7/20, she used 7/20\ *120 =
<<7/20*\ 120=42>>42 #### 42
Step 1: Prepare the dataset
----------------------------
We preprocess the dataset in parquet format so that (1) it contains necessary fields for computing RL rewards and (2) is faster to read.
.. code-block:: bash
python3 examples/data_preprocess/gsm8k.py --local_dir ~/data/gsm8k
Step 2: Download a model for post-training
-------------------------------------------
In this example, we start with the ``Qwen2.5-0.5B-Instruct`` model.
If you want to perform SFT before RL, refer to the :doc:`Complete GSM8K Example<../examples/gsm8k_example>`, the `sft directory <https://github.com/volcengine/verl/blob/main/examples/sft/gsm8k>`_ and `SFT Trainer <https://github.com/volcengine/verl/blob/main/verl/trainer/fsdp_sft_trainer.py>`_ for further details.
.. code-block:: bash
python3 -c "import transformers; transformers.pipeline('text-generation', model='Qwen/Qwen2.5-0.5B-Instruct')"
Step 3: Perform PPO training with the instruct model
----------------------------------------------------------------------
**Reward Model/Function**
We use a pre-defined rule-based reward model. We force the model to produce a final
answer following 4 “#” as shown in the solution. We extract the final
answer from both the solution and model's output using regular
expression matching. We assign a reward of 1 to correct
answer, 0.1 to incorrect answer and 0 to no answer.
For mode details, please refer to `verl/utils/reward_score/gsm8k.py <https://github.com/volcengine/verl/blob/v0.1/verl/utils/reward_score/gsm8k.py>`_.
**Training Script**
Now let's run PPO training with the dataset and model above. [2]_
Set the ``data.train_files`` ,\ ``data.val_files``, ``actor_rollout_ref.model.path`` and ``critic.model.path`` based on your dataset and model names or paths.
.. code-block:: bash
PYTHONUNBUFFERED=1 python3 -m verl.trainer.main_ppo \
data.train_files=$HOME/data/gsm8k/train.parquet \
data.val_files=$HOME/data/gsm8k/test.parquet \
data.train_batch_size=256 \
data.max_prompt_length=512 \
data.max_response_length=256 \
actor_rollout_ref.model.path=Qwen/Qwen2.5-0.5B-Instruct \
actor_rollout_ref.actor.optim.lr=1e-6 \
actor_rollout_ref.actor.ppo_mini_batch_size=64 \
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=4 \
actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=8 \
actor_rollout_ref.rollout.tensor_model_parallel_size=1 \
actor_rollout_ref.rollout.gpu_memory_utilization=0.4 \
actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=4 \
critic.optim.lr=1e-5 \
critic.model.path=Qwen/Qwen2.5-0.5B-Instruct \
critic.ppo_micro_batch_size_per_gpu=4 \
algorithm.kl_ctrl.kl_coef=0.001 \
trainer.logger=['console'] \
+trainer.val_before_train=False \
trainer.default_hdfs_dir=null \
trainer.n_gpus_per_node=1 \
trainer.nnodes=1 \
trainer.save_freq=10 \
trainer.test_freq=10 \
trainer.total_epochs=15 2>&1 | tee verl_demo.log
You are expected to see the following logs, indicating training in progress. The key metric ``val/test_score/openai/gsm8k`` is computed every ``trainer.test_freq`` steps:
.. code-block:: bash
step:0 - timing/gen:21.470 - timing/ref:4.360 - timing/values:5.800 - critic/kl:0.000 - critic/kl_coeff:0.001 - timing/adv:0.109 - timing/update_critic:15.664 - critic/vf_loss:14.947 - critic/vf_clipfrac:0.000 - critic/vpred_mean:-2.056 - critic/grad_norm:1023.278 - critic/lr(1e-4):0.100 - timing/update_actor:20.314 - actor/entropy_loss:0.433 - actor/pg_loss:-0.005 - actor/pg_clipfrac:0.000 - actor/ppo_kl:0.000 - actor/grad_norm:1.992 - actor/lr(1e-4):0.010 - critic/score/mean:0.004 - critic/score/max:1.000 - critic/score/min:0.000 - critic/rewards/mean:0.004 - critic/rewards/max:1.000 - critic/rewards/min:0.000 - critic/advantages/mean:-0.000 - critic/advantages/max:2.360 - critic/advantages/min:-2.280 - critic/returns/mean:0.003 - critic/returns/max:0.000 - critic/returns/min:0.000 - critic/values/mean:-2.045 - critic/values/max:9.500 - critic/values/min:-14.000 - response_length/mean:239.133 - response_length/max:256.000 - response_length/min:77.000 - prompt_length/mean:104.883 - prompt_length/max:175.000 - prompt_length/min:68.000
step:1 - timing/gen:23.020 - timing/ref:4.322 - timing/values:5.953 - critic/kl:0.000 - critic/kl_coeff:0.001 - timing/adv:0.118 - timing/update_critic:15.646 - critic/vf_loss:18.472 - critic/vf_clipfrac:0.384 - critic/vpred_mean:1.038 - critic/grad_norm:942.924 - critic/lr(1e-4):0.100 - timing/update_actor:20.526 - actor/entropy_loss:0.440 - actor/pg_loss:0.000 - actor/pg_clipfrac:0.002 - actor/ppo_kl:0.000 - actor/grad_norm:2.060 - actor/lr(1e-4):0.010 - critic/score/mean:0.000 - critic/score/max:0.000 - critic/score/min:0.000 - critic/rewards/mean:0.000 - critic/rewards/max:0.000 - critic/rewards/min:0.000 - critic/advantages/mean:0.000 - critic/advantages/max:2.702 - critic/advantages/min:-2.616 - critic/returns/mean:0.000 - critic/returns/max:0.000 - critic/returns/min:0.000 - critic/values/mean:-2.280 - critic/values/max:11.000 - critic/values/min:-16.000 - response_length/mean:232.242 - response_length/max:256.000 - response_length/min:91.000 - prompt_length/mean:102.398 - prompt_length/max:185.000 - prompt_length/min:70.000
Checkout :ref:`algo-baseline-page` for full training and validation logs for reference.
The checkpoint is saved at the following dir by default: ``checkpoints/${trainer.project_name}/${trainer.experiment_name}``
To enable ``wandb`` for experiment tracking, set the following configs:
.. code-block:: bash
trainer.logger=['console','wandb'] \
trainer.project_name=$YOUR_PROJECT_NAME \
trainer.experiment_name=$YOUR_RUN_NAME \
If you encounter out of memory issues with HBM less than 32GB, enable the following configs would help:
.. code-block:: bash
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=1 \
critic.ppo_micro_batch_size_per_gpu=1 \
For the full set of configs, please refer to :ref:`config-explain-page` for detailed explanation and performance tuning.
.. [1] The original paper (https://arxiv.org/pdf/2110.14168) mainly focuses on training a verifier (a reward model) to solve math problems via Best-of-N sampling. In this example, we train an RL agent using a rule-based reward model.
.. [2] More training script examples for FSDP and Megatron-LM backend are stored in `examples/ppo_trainer <https://github.com/volcengine/verl/tree/main/examples/ppo_trainer>`_ directory. | {
"source": "volcengine/verl",
"title": "docs/start/quickstart.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/start/quickstart.rst",
"date": "2024-10-31T06:11:15",
"stars": 3801,
"description": "verl: Volcano Engine Reinforcement Learning for LLMs",
"file_size": 7750
} |
PyTorch FSDP Backend
======================
We support PyTorch FSDP Backend by implementing various workers for
actor, critic, reference, rollout and reward models. We also implement
the ``FSDPVLLMShardingManager`` that reshard weight between FSDP and
vLLM in `fsdp_vllm.py <https://github.com/volcengine/verl/blob/main/verl/workers/sharding_manager/fsdp_vllm.py>`_.
**Pros**
- Readily support various models.
- Users only need to implement the corresponding
``dtensor_weight_loader`` for weight synchronization between FSDP
and vLLM. While for ``hf_weight_loader``, users can directly apply
any models supported both in HF and vLLM without any code change.
- Easy to organize the forward and backward computation for each model.
**Cons**
- Poor scalability when it comes to large-scale models (e.g. Llama 70B
and 405B)
- The resharding overhead between actor and rollout could be larger than
Megatron-LM backend.
Due to the simplicity, we recommend using FSDP backend for algorithm
research and prototyping.
FSDP Workers
--------------
ActorRolloutRefWorker
^^^^^^^^^^^^^^^^^^^^^
Actor/Rollout HybridEngine
''''''''''''''''''''''''''
1. HybridEngine, Actor and Rollout initialization API.
.. code:: python
@register(dispatch_mode=Dispatch.ONE_TO_ALL)
def init_model(self):
``ONE_TO_ALL``: when calling the ``init_model`` function from the driver
process, each worker (on a GPU) will execute the following model
initialization process.
The initialization details of HybridEngine, Actor and Rollout are
highlighted below:
1. ``DataParallelPPOActor`` implements the simple PPO computation logics
when the model is built with FSDP, including compute log prob, model
update.
2. ``vLLMRollout`` support generation with vLLM. We modify the vLLM
Engine and make it executed under SPMD to fit into our
``WorkerGroup`` design.
3. ``FSDPVLLMShardingManager`` a context manager to perform actual
resharding between actor and rollout.
See `source code <https://github.com/volcengine/verl/blob/main/verl/workers/fsdp_workers.py>`_. for more information.
1. Generate sequence and recompute log prob
.. code:: python
@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO)
def generate_sequences(self, prompts: DataProto):
- ``Dispatch.DP_COMPUTE_PROTO``: The data will be dispatched and
collected along the DP dimension
- In this function, the rollout model will perform auto-regressive
generation and the actor model will recompute the old log prob for the
generated response.
3. Update actor model
.. code:: python
@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO)
def update_actor(self, data: DataProto):
- Update the actor model weight using PPO & entropy loss.
ReferenceModel
''''''''''''''
1. Reference model initialization
The reference model is initialized using the same function as the actor
model without initializing the HybridEngine and Optimizer. Then the
actor model is also wrapped by the ``DataParallelPPOActor``.
2. Compute reference log prob
.. code:: python
@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO)
def compute_ref_log_prob(self, data: DataProto):
- In this function, the reference model will call the compute log prob
function in ``DataParallelPPOActor`` to compute the reference log
prob.
CriticWorker and RewardWorker
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
1. Model initialization
Quite similar to reference model. The CriticWorker will perform
additional initialization for the Optimizer.
2. Compute Values for CriticWorker
.. code:: python
@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO)
def compute_values(self, data: DataProto):
3. Update Critic
.. code:: python
@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO)
def update_critic(self, data: DataProto):
4. Compute Reward
.. code:: python
@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO)
def compute_rm_score(self, data: DataProto):
HybridShard
------------
We didn't support FSDP `HybridShard`. To support this, we may need to
construct a 2D device mesh and test the corresponding
``dtensor_weight_loader`` and ``hf_weight_loader`` for each model. | {
"source": "volcengine/verl",
"title": "docs/workers/fsdp_workers.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/workers/fsdp_workers.rst",
"date": "2024-10-31T06:11:15",
"stars": 3801,
"description": "verl: Volcano Engine Reinforcement Learning for LLMs",
"file_size": 4149
} |
Megatron-LM Backend
=====================
We support Megatron Backend by implementing various workers for actor,
critic, reference, rollout and reward models. We also implement the
``3DHybridEngine`` using Megatron-LM and vLLM in `megatron_vllm.py <https://github.com/volcengine/verl/blob/main/verl/workers/sharding_manager/megatron_vllm.py>`_.
**Pros**
- Support 3D parallelism and sequence parallelism for best scalablility
and throughput.
- 3D HybridEngine can significantly reduce peak memory usage and reduce
weight synchronize overhead between actor and rollout.
**Cons**
- Users should implement their own models for Megatron-LM
- Users should implement the corresponding weight_loader to
- synchronize the model weight between actor (in Megatron) and rollout
(in vLLM).
- load weights from checkpoints to corresponding model in Megatron-LM
Megatron Workers
----------------
MegatronWorker
^^^^^^^^^^^^^^
``MegatronWorker`` is the base class of different megatron worker
classes. In this class, ``get_megatron_global_info`` and
``get_megatron_rank_info`` function to retrive the 3D parallel world
size and rank of each ``Worker`` running on specific GPU. These information
will be used in transfer protocol for Megatron Backend.
The following ``Worker`` class for different models will be utilized to
construct the ``WorkerGroup`` .
We implement various of APIs for each ``Worker`` class decorated by the
``@register(dispatch_mode=)`` . These APIs can be called by the ray
driver process. The data can be correctly collect and dispatch following
the ``dispatch_mode`` on each function. The supported dispatch_model
(i.e., transfer protocols) can be found in `decorator.py <https://github.com/volcengine/verl/blob/main/verl/single_controller/base/decorator.py>`_.
ActorRolloutRefWorker
^^^^^^^^^^^^^^^^^^^^^
This class is implemented for Actor/Rollout HybridEngine or for the
reference model to initialize their model and perform computation.
Actor/Rollout HybridEngine
''''''''''''''''''''''''''
1. HybridEngine, Actor and Rollout initialization API.
.. code:: python
@register(dispatch_mode=Dispatch.ONE_TO_ALL)
def init_model(self):
``ONE_TO_ALL``: when calling the ``init_model`` function from the driver
process, each worker (on a GPU) will execute the following model
initialization process.
The initialization details of HybridEngine, Actor and Rollout are
highlighted below:
1. ``AllGatherPPModel`` holds memory buffer for both Actor and Rollout
and support weight resharding between actor and rollout.
2. ``MegatronPPOActor`` implements the simple PPO computation logics
when the model is built with Megatron, including compute log prob,
model update.
3. ``vLLMRollout`` support generation with vLLM. We modify the vLLM
Engine and make it executed under SPMD to fit into our
``WorkerGroup`` design.
4. ``MegatronVLLMShardingManager`` a context manager to perform actual
resharding between actor and rollout.
See `source code <https://github.com/volcengine/verl/blob/main/verl/workers/megatron_workers.py#L63>`_ for more information.
.. code:: python
# Initialize the 3D HybridEngine
hybrid_engine = AllGatherPPModel(model_provider=megatron_actor_model_provider)
# Fetch the model at current rank
actor_module = hybrid_engine.this_rank_models
...
# build actor model
self.actor = MegatronPPOActor(config=self.config.actor,
model_config=self.actor_model_config,
megatron_config=megatron_config,
actor_module=self.actor_module,
actor_optimizer=self.actor_optimizer,
actor_optimizer_config=self.actor_optim_config)
# build rollout
# rollout initialization
rollout = vLLMRollout(actor_module=params,
config=self.config.rollout,
tokenizer=self.tokenizer,
model_hf_config=self.actor_model_config,
train_tp=mpu.get_tensor_model_parallel_world_size())
# perform weight resharding between actor and rollout
sharding_manager = MegatronVLLMShardingManager(module=self.hybrid_engine,
inference_engine=rollout.inference_engine,
model_config=self.actor_model_config,
layer_name_mapping=layer_name_mapping)
...
2. Generate sequence and recompute log prob
.. code:: python
@register(dispatch_mode=Dispatch.MEGATRON_PP_AS_DP_PROTO)
def generate_sequences(self, prompts: DataProto):
- ``Dispatch.MEGATRON_PP_AS_DP_PROTO``: The PP dimension of the actor
model will be regarded as DP dimension. Then the driver process will
dispatch and collect the data according to this reorganization. This
is because, in HybridEngine, the actor weight, which usually applied
larger 3D parallel sizes, will be gathered along the PP dimension and
TP dimension. Therefore, the corresponding data should be dispatched
and collected through the 3D parallel group of the rollout model,
rather than the actor model. However, the world_size and rank
information can only be retrived from ``get_megatron_global_info`` and
``get_megatron_rank_info``, which records the 3D information for the
actor model. Moreover, the data resharding inside TP dimension will be
processed within the HybridEngine.
- In this function, the rollout model will perform auto-regressive
generation and the actor model will recompute the old log prob for the
generated response.
3. Update actor model
.. code:: python
@register(dispatch_mode=Dispatch.MEGATRON_COMPUTE_PROTO)
def update_actor(self, data: DataProto):
- ``Dispatch.MEGATRON_COMPUTE_PROTO``: User passes the data partitioned
by DP dimension. The data is dispatched to all tp/pp ranks within the
same dp group, and ultimately only collects output data from tp=0 and
the last pp.
- Update the actor model weight using PPO & entropy loss.
ReferenceModel
''''''''''''''
1. Reference model initialization
The reference model is initialized using the same function as the actor
model without initializing the HybridEngine and Optimizer. Then the
actor model is also wrapped by the ``MegatronPPOActor``.
2. Compute reference log prob
.. code:: python
@register(dispatch_mode=Dispatch.MEGATRON_COMPUTE_PROTO)
def compute_ref_log_prob(self, data: DataProto):
- In this function, the reference model will call the compute log prob
function in ``MegatronPPOActor`` to compute the reference log prob.
CriticWorker and RewardWorker
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
1. Model initialization
Quite similar to reference model. The CriticWorker will perform
additional initialization for the Optimizer.
2. Compute Values for CriticWorker
.. code:: python
@register(dispatch_mode=Dispatch.MEGATRON_COMPUTE_PROTO)
def compute_values(self, data: DataProto):
3. Update Critic
.. code:: python
@register(dispatch_mode=Dispatch.MEGATRON_COMPUTE_PROTO)
def update_critic(self, data: DataProto):
4. Compute Reward
.. code:: python
@register(dispatch_mode=Dispatch.MEGATRON_COMPUTE_PROTO)
def compute_rm_score(self, data: DataProto):
Context Parallel
----------------
This require the developer/contributor to implement the context parallel
both in Megatron-LM and models. | {
"source": "volcengine/verl",
"title": "docs/workers/megatron_workers.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/workers/megatron_workers.rst",
"date": "2024-10-31T06:11:15",
"stars": 3801,
"description": "verl: Volcano Engine Reinforcement Learning for LLMs",
"file_size": 7464
} |
PPO Ray Trainer
===============
We implement the RayPPOTrainer, which is a trainer runs on the driver
process on a single CPU/GPU node (default is CPU).
The PPORayTrainer include 3 core functions for data preparation,
WorkerGroup initialization and PPO training loop.
Data Preparation
----------------
The ``PPORayTrainer``, as a single process, is responsible for loading a
complete batch of samples (prompts) from the dataset and then dispatch
to different worker_groups running on different GPUs.
To generalize the data loading, we implement the ``RLHFDataset`` class
to load the preprocessed parquet files, apply chat templates to the
prompts, add padding, truncate prompts that exceed max prompt length and
then tokenize.
.. code:: python
self.train_dataset = RLHFDataset(parquet_files=self.config.data.train_files,
tokenizer=self.tokenizer,
prompt_key=self.config.data.prompt_key,
max_prompt_length=self.config.data.max_prompt_length,
filter_prompts=True,
return_raw_chat=self.config.data.get('return_raw_chat', False),
truncation='error')
Then, the dataloader will iterate the dataset under PPO mini batch size.
WorkerGroup Initialization
--------------------------
We first introduce a basic implementation of initializing the
``WorkerGroup`` of the actor model on a given set of GPUs.
.. code:: python
# max_colocate_count means the number of WorkerGroups (i.e. processes) in each RayResourcePool
# For FSDP backend, we recommend using max_colocate_count=1 that merge all WorkerGroups into one.
# For Megatron backend, we recommend using max_colocate_count>1 that can utilize different WorkerGroup for differnt models
resource_pool = RayResourcePool(process_on_nodes=[config.trainer.n_gpus_per_node] * config.trainer.nnodes,
use_gpu=True,
max_colocate_count=1)
# define actor rollout cls to be init on remote
actor_rollout_cls = RayClassWithInitArgs(cls=ActorRolloutWorker)
# define actor_rollout worker group
actor_rollout_worker_group = MegatronRayWorkerGroup(resource_pool=resource_pool,
ray_cls_with_init=actor_rollout_cls,
default_megatron_kwargs=config.actor_rollout.megatron)
Different WorkerGroups, like ``actor_rollout_worker_group`` ,
``critic_worker_group`` and ``ref_worker_group`` lies on a separate
process in the above implementation.
The driver process can then call the distributed compute function within
the ``actor_rollout_worker_group`` and other roles to construct the RL
training loop.
For models colocated in the same set of GPUs, we further provide a
fine-grain optimization, which merge the ``worker_group`` of different roles
in the same process. This optimization can save the redundant
CUDA/distributed context in different processes.
.. code:: python
# initialize WorkerGroup
# NOTE: if you want to use a different resource pool for each role, which can support different parallel size,
# you should not use `create_colocated_worker_cls`. Instead, directly pass different resource pool to different worker groups.
# See TODO(url) for more information.
all_wg = {}
for resource_pool, class_dict in self.resource_pool_to_cls.items():
worker_dict_cls = create_colocated_worker_cls(class_dict=class_dict)
wg_dict = self.ray_worker_group_cls(resource_pool=resource_pool, ray_cls_with_init=worker_dict_cls)
spawn_wg = wg_dict.spawn(prefix_set=class_dict.keys())
all_wg.update(spawn_wg)
if self.use_critic:
self.critic_wg = all_wg['critic']
self.critic_wg.init_model()
if self.use_reference_policy:
self.ref_policy_wg = all_wg['ref']
self.ref_policy_wg.init_model()
if self.use_rm:
self.rm_wg = all_wg['rm']
self.rm_wg.init_model()
# we should create rollout at the end so that vllm can have a better estimation of kv cache memory
self.actor_rollout_wg = all_wg['actor_rollout']
self.actor_rollout_wg.init_model()
.. note:: For megatron backend, if we merge the ``worker_groups`` into the same processes, all the roles will utilize the same 3D parallel size. To optimize this, we may need to maintain several 3D process groups for each role in the same distributed context. If you want to use different 3D parallel size for different roles, please follow the similar architecture of the first code block to initialize each role's ``worker_group``
PPO Training Loop
-----------------
We implement the PPO training loop by calling the functions in
worker_group of each role. The input and output data of each function is
a ``DataProto`` object implemented in `protocol.py <https://github.com/volcengine/verl/blob/main/verl/protocol.py>`_. In the training
loop, trainer will dispatch/collect the data to/from different GPUs
following the transfer protocols wrapped in the workers' functions. The
computation of PPO micro batches is processed in ``update_actor`` and
``update_critic`` functions.
To extend to other RLHF algorithms, such as DPO, GRPO, please refer to
:doc:`../advance/dpo_extension`.
.. code:: python
def fit(self):
"""
The training loop of PPO.
The driver process only need to call the compute functions of the worker group through RPC to construct the PPO dataflow.
The light-weight advantage computation is done on the driver process.
"""
from verl.utils.tracking import Tracking
from omegaconf import OmegaConf
logger = Tracking(project_name=self.config.trainer.project_name,
experiment_name=self.config.trainer.experiment_name,
default_backend=self.config.trainer.logger,
config=OmegaConf.to_container(self.config, resolve=True))
global_steps = 0
# perform validation before training
# currently, we only support validation using the reward_function.
if self.val_reward_fn is not None:
val_metrics = self._validate()
pprint(f'Initial validation metrics: {val_metrics}')
for epoch in range(self.config.trainer.total_epochs):
for batch_dict in self.train_dataloader:
metrics = {}
batch: DataProto = DataProto.from_single_dict(batch_dict)
# batch = batch.to('cuda')
# pop those keys for generation
gen_batch = batch.pop(batch_keys=['input_ids', 'attention_mask', 'position_ids'])
# generate a batch
with Timer(name='gen', logger=None) as timer:
gen_batch_output = self.actor_rollout_wg.generate_sequences(gen_batch)
metrics['timing/gen'] = timer.last
batch = batch.union(gen_batch_output)
if self.use_reference_policy:
# compute reference log_prob
with Timer(name='ref', logger=None) as timer:
ref_log_prob = self.ref_policy_wg.compute_ref_log_prob(batch)
batch = batch.union(ref_log_prob)
metrics['timing/ref'] = timer.last
# compute values
with Timer(name='values', logger=None) as timer:
values = self.critic_wg.compute_values(batch)
batch = batch.union(values)
metrics['timing/values'] = timer.last
with Timer(name='adv', logger=None) as timer:
# compute scores. Support both model and function-based.
# We first compute the scores using reward model. Then, we call reward_fn to combine
# the results from reward model and rule-based results.
if self.use_rm:
# we first compute reward model score
reward_tensor = self.rm_wg.compute_rm_score(batch)
batch = batch.union(reward_tensor)
# we combine with rule-based rm
reward_tensor = self.reward_fn(batch)
batch.batch['token_level_scores'] = reward_tensor
# compute rewards. apply_kl_penalty if available
batch, kl_metrics = apply_kl_penalty(batch,
kl_ctrl=self.kl_ctrl,
kl_penalty=self.config.algorithm.kl_penalty)
metrics.update(kl_metrics)
# compute advantages, executed on the driver process
batch = compute_advantage(batch,
self.config.algorithm.gamma,
self.config.algorithm.lam,
adv_estimator=self.config.algorithm.adv_estimator)
metrics['timing/adv'] = timer.last
# update critic
if self.use_critic:
with Timer(name='update_critic', logger=None) as timer:
critic_output = self.critic_wg.update_critic(batch)
metrics['timing/update_critic'] = timer.last
critic_output_metrics = reduce_metrics(critic_output.meta_info['metrics'])
metrics.update(critic_output_metrics)
# implement critic warmup
if self.config.trainer.critic_warmup <= global_steps:
# update actor
with Timer(name='update_actor', logger=None) as timer:
actor_output = self.actor_rollout_wg.update_actor(batch)
metrics['timing/update_actor'] = timer.last
actor_output_metrics = reduce_metrics(actor_output.meta_info['metrics'])
metrics.update(actor_output_metrics)
# validate
if self.val_reward_fn is not None and (global_steps + 1) % self.config.trainer.test_freq == 0:
with Timer(name='testing', logger=None) as timer:
val_metrics: dict = self._validate()
val_metrics = {f'val/{key}': val for key, val in val_metrics.items()}
metrics['timing/testing'] = timer.last
metrics.update(val_metrics)
# collect metrics
data_metrics = compute_data_metrics(batch=batch)
metrics.update(data_metrics)
# TODO: make a canonical logger that supports various backend
logger.log(data=metrics, step=global_steps)
if self.config.trainer.save_freq > 0 and (global_steps + 1) % self.config.trainer.save_freq == 0:
actor_local_path = os.path.join(self.config.trainer.default_local_dir, 'actor',
f'global_step_{global_steps}')
actor_remote_path = os.path.join(self.config.trainer.default_hdfs_dir, 'actor')
self.actor_rollout_wg.save_checkpoint(actor_local_path, actor_remote_path)
if self.use_critic:
critic_local_path = os.path.join(self.config.trainer.default_local_dir, 'critic',
f'global_step_{global_steps}')
critic_remote_path = os.path.join(self.config.trainer.default_hdfs_dir, 'critic')
self.critic_wg.save_checkpoint(critic_local_path, critic_remote_path)
global_steps += 1
# perform validation after training
if self.val_reward_fn is not None:
val_metrics = self._validate()
pprint(f'Final validation metrics: {val_metrics}') | {
"source": "volcengine/verl",
"title": "docs/workers/ray_trainer.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/workers/ray_trainer.rst",
"date": "2024-10-31T06:11:15",
"stars": 3801,
"description": "verl: Volcano Engine Reinforcement Learning for LLMs",
"file_size": 12035
} |
# Split Placement Example
Here we introduce how to run the naive implementation of the split placement of PPO algorithm.
We will release the complete version of flexible placement in the near future.
For quickstart, you can only follow Step 2 to modify the code and then follow Step 4 to execute the split placement example.
### Step 1: Placing the models to different GPUs
Specify the placement and resource allocation. In the example, we place the actor and reference in the first half of the GPUs while map the critic and reward model (if any) to the second half of the GPUs.
```python
actor_rollout_ref_pool_id = 'actor_rollout_ref_pool'
critic_pool_id = 'critic_pool'
if config.trainer.nnodes // 2 == 0 and config.trainer.n_gpus_per_node // 2 > 0:
resource_pool_spec = {
actor_rollout_ref_pool_id: [config.trainer.n_gpus_per_node // 2] * config.trainer.nnodes,
critic_pool_id: [config.trainer.n_gpus_per_node // 2] * config.trainer.nnodes,
}
else:
resource_pool_spec = {
actor_rollout_ref_pool_id: [config.trainer.n_gpus_per_node] * (config.trainer.nnodes // 2),
critic_pool_id: [config.trainer.n_gpus_per_node] * (config.trainer.nnodes // 2),
}
print(f'resource_pool_spec: {resource_pool_spec}')
mapping = {
Role.ActorRollout: actor_rollout_ref_pool_id,
Role.Critic: critic_pool_id,
Role.RefPolicy: actor_rollout_ref_pool_id,
}
mapping[Role.RewardModel] = critic_pool_id
```
### Step 2: Make the models executed asynchronously
Based on the model placement, we need to make the models executed asynchronously.
To do so, you need to turn off the `blocking` flag (i.e., `blocking=False`) in our decorator of some model operations.
For example, we hope the actor update and critic update can be executed in parallel, then we need to make the following modification in `fsdp_workers.py`
```
@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO, blocking=False)
def update_actor(self, data: DataProto):
...
@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO, blocking=False)
def update_critic(self, data: DataProto):
...
```
We can also parallelize the computation of `ref_log_prob` and `values` and `rewards` in the split placement. For simplicity of the tutorial, we don't do this in this example.
### Step 3: Execute these operation in parallel in the single controller process
To implement the parallel execution of the actor and critic update, the only thing we need to modify in the `ray_trainer.py` is to `get` the concurrent `futures` on the single controller process.
```python
critic_output = critic_output.get()
actor_output = actor_output.get()
```
### Step 4: Run the split placement example
```
bash run_deepseek7b_llm.sh
``` | {
"source": "volcengine/verl",
"title": "examples/split_placement/README.md",
"url": "https://github.com/volcengine/verl/blob/main/examples/split_placement/README.md",
"date": "2024-10-31T06:11:15",
"stars": 3801,
"description": "verl: Volcano Engine Reinforcement Learning for LLMs",
"file_size": 2716
} |
# Models
Common modelzoo such as huggingface/transformers stuggles when using Pytorch native model parallelism. Following the design principle of vLLM, we keep a simple, parallelizable, highly-optimized with packed inputs in verl.
## Adding a New Huggingface Model
### Step 1: Copy the model file from HF to verl
- Add a new file under verl/models/hf
- Copy ONLY the model file from huggingface/transformers/models to verl/models/hf
### Step 2: Modify the model file to use packed inputs
- Remove all the code related to inference (kv cache)
- Modify the inputs to include only
- input_ids (total_nnz,)
- cu_seqlens (total_nnz + 1,)
- max_seqlen_in_batch: int
- Note that this requires using flash attention with causal mask.
### Step 2.5: Add tests
- Add a test to compare this version and the huggingface version
- Following the infrastructure and add tests to tests/models/hf
### Step 3: Add a function to apply tensor parallelism
- Please follow
- https://pytorch.org/docs/stable/distributed.tensor.parallel.html
- https://pytorch.org/tutorials/intermediate/TP_tutorial.html
- General comments
- Tensor Parallelism in native Pytorch is NOT auto-parallelism. The way it works is to specify how model parameters and input/output reshards using configs. These configs are then registered as hooks to perform input/output resharding before/after model forward.
### Step 4: Add a function to apply data parallelism
- Please use FSDP2 APIs
- See demo here https://github.com/pytorch/torchtitan/blob/main/torchtitan/parallelisms/parallelize_llama.py#L413
### Step 5: Add a function to apply pipeline parallelism
- Comes in Pytorch 2.4
- Currently only in alpha in nightly version
- Check torchtitan for more details | {
"source": "volcengine/verl",
"title": "verl/models/README.md",
"url": "https://github.com/volcengine/verl/blob/main/verl/models/README.md",
"date": "2024-10-31T06:11:15",
"stars": 3801,
"description": "verl: Volcano Engine Reinforcement Learning for LLMs",
"file_size": 1742
} |
# Detached Worker
## How to run (Only on a single node)
- Start a local ray cluster:
```bash
ray start --head --port=6379
```
- Run the server
```bash
python3 server.py
```
- On another terminal, Run the client
```bash
python3 client.py
``` | {
"source": "volcengine/verl",
"title": "tests/ray/detached_worker/README.md",
"url": "https://github.com/volcengine/verl/blob/main/tests/ray/detached_worker/README.md",
"date": "2024-10-31T06:11:15",
"stars": 3801,
"description": "verl: Volcano Engine Reinforcement Learning for LLMs",
"file_size": 241
} |
# Dataset Format
## RLHF dataset
We combine all the data sources into a single parquet files. We directly organize the prompt into the chat format so that multi-turn chats can be easily incorporated. In the prompt, we may add instruction following texts to guide the model output the answers in a particular format so that we can extract the answers.
Math problems
```json
{
"data_source": "openai/gsm8k",
"prompt": [{"role": "user", "content": "Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May? Let's think step by step and output the final answer after \"####\""}],
"ability": "math",
"reward_model": {
"style": "rule",
"ground_truth": ["72"]
},
}
``` | {
"source": "volcengine/verl",
"title": "verl/utils/dataset/README.md",
"url": "https://github.com/volcengine/verl/blob/main/verl/utils/dataset/README.md",
"date": "2024-10-31T06:11:15",
"stars": 3801,
"description": "verl: Volcano Engine Reinforcement Learning for LLMs",
"file_size": 796
} |
# Digit completion
This is an example of solving a digit completion problem. The problem is defined as below:
The prompt is a sequence of numbers with fixed difference. The agent's goal is to complete the next N numbers.
If the max number is reached, the next number should be modulo with max number.
For example,
- prompt = [1, 2, 3]
- N = 5
- max_number = 6
The response should be [4, 5, 6, 7%6, 8%6] = [4, 5, 6, 0, 1].
# Environment definition
The core definition of the task is defined in verl/envs/digit_completion/task.py
It is highly recommended to take a look at it for better understanding.
# Run experiments
The users are required to specify the config path and config name (and the relative model config path to the current working directory)
```bash
# cd examples/arithmetic_sequence/rl
# Specify the config path and config name (current working dir)
python3 -m verl.trainer.ppo.ray_megatron_train_synchronous --config-path=$(pwd)/config --config-name='ray_megatron'
# The default relative path of model config is 'config/model_config', if you want to change it, you can rewrite it in ray_megatron.yaml or using:
python3 -m verl.trainer.ppo.ray_megatron_train_synchronous --config-path=$(pwd)/config --config-name='ray_megatron' ++model.base_path=config/model_config
``` | {
"source": "volcengine/verl",
"title": "tests/e2e/arithmetic_sequence/rl/README.md",
"url": "https://github.com/volcengine/verl/blob/main/tests/e2e/arithmetic_sequence/rl/README.md",
"date": "2024-10-31T06:11:15",
"stars": 3801,
"description": "verl: Volcano Engine Reinforcement Learning for LLMs",
"file_size": 1297
} |
To discover where the widely used python package certifi reads its certificates from, run:
python -m certifi
Print the available filesystem types:
cat /proc/filesystems
# How can I set up gvisor to route packets from my TUN onwards to the internet, and back again?
Clues: stack.LinkEndpoint and stack.NetworkDispatcher
LinkEndpoint contains NetworkLinkEndpoint interface, which has the following:
// Attach attaches the data link layer endpoint to the network-layer
// dispatcher of the stack.
//
// Attach is called with a nil dispatcher when the endpoint's NIC is being
// removed.
Attach(dispatcher NetworkDispatcher)
The NetworkDispatch interface in full is:
type NetworkDispatcher interface {
// DeliverNetworkPacket finds the appropriate network protocol endpoint
// and hands the packet over for further processing.
//
//
// If the link-layer has a header, the packet's link header must be populated.
//
// DeliverNetworkPacket may modify pkt.
DeliverNetworkPacket(protocol tcpip.NetworkProtocolNumber, pkt *PacketBuffer)
// DeliverLinkPacket delivers a packet to any interested packet endpoints.
//
// This method should be called with both incoming and outgoing packets.
//
// If the link-layer has a header, the packet's link header must be populated.
DeliverLinkPacket(protocol tcpip.NetworkProtocolNumber, pkt *PacketBuffer)
}
sniffer implements this as follows:
// DeliverNetworkPacket implements the stack.NetworkDispatcher interface. It is
// called by the link-layer endpoint being wrapped when a packet arrives, and
// logs the packet before forwarding to the actual dispatcher.
func (e *Endpoint) DeliverNetworkPacket(protocol tcpip.NetworkProtocolNumber, pkt *stack.PacketBuffer) {
Here are all the places this function is implemented:
https://github.com/search?q=repo%3Agoogle%2Fgvisor%20DeliverNetworkPacket&type=code
One place it is implemented is nic, which is not exported but seems central:
https://github.com/google/gvisor/blob/48b7308dcef150deacf42b62e9aea90451944946/pkg/tcpip/stack/nic.go#L163
For what it's worth here is the core implementation of socket in sentry, which intercepts all the linux syscalls in a container run by runsc. It is backed by a tcpip.Endpoint:
https://github.com/google/gvisor/blob/48b7308dcef150deacf42b62e9aea90451944946/pkg/sentry/socket/netstack/netstack.go#L362
Even more concretely, here is the implementation fo accept(2) in sentry:
https://github.com/google/gvisor/blob/48b7308dcef150deacf42b62e9aea90451944946/pkg/sentry/socket/unix/unix.go#L164
Sentry actually supports multiple "stacks" only one of which is tcpip.Stack. It also supports using the host network stack directly:
https://github.com/google/gvisor/blob/48b7308dcef150deacf42b62e9aea90451944946/pkg/sentry/socket/hostinet/stack.go#L171
The general "Stack" interface is implemented in sentry/inet:
https://github.com/google/gvisor/blob/48b7308dcef150deacf42b62e9aea90451944946/pkg/sentry/inet/inet.go#L28
The implementation for tcpip.Stack is in "netstack":
https://github.com/google/gvisor/blob/48b7308dcef150deacf42b62e9aea90451944946/pkg/sentry/socket/netstack/stack.go#L42
Great overview of many of the low-level ways of sending out raw packets in linux:
https://toonk.io/sending-network-packets-in-go/index.html
XDP is the latest way -- you write a packet filter in C and load it directly into the kernel! There are some examples of how to do this in gvisor:
https://pkg.go.dev/gvisor.dev/gvisor/tools/xdp#section-readme
How to create IPv4 packets with gopacket:
https://github.com/atoonk/go-pktgen/blob/main/pktgen/packet.go#L79
Docker desktop solves this issue by intercepting everything and accepting all TCP connections, then dynamically creating a TCP connection to real host:
https://www.docker.com/blog/how-docker-desktop-networking-works-under-the-hood/
This is docker desktop, but what about ordinary docker daemon?
Here is a very helpful tutorial showing how to do it from scratch with veth pairs:
https://labs.iximiuz.com/tutorials/container-networking-from-scratch
ip netns list # list available network namespace
ip netns add netns0 # create a network namespace
nsenter --net=/run/netns/netns0 bash # enter a network namespace
sudo iptables -t nat --list-rules # list rules in the NAT table
iptables -t nat -A POSTROUTING -s 172.18.0.0/16 ! -o br0 -j MASQUERADE # THIS IS WHAT I NEED
"The command is fairly simple when you know how iptables work - we added a new rule to the nat table of the POSTROUTING chain asking to masquerade all the packets originated in 172.18.0.0/16 network, except those that are going to the bridge interface."
OK so to do it with veth pairs the steps are:
- turn on IP forwarding echo 1 > /proc/sys/net/ipv4/ip_forward
- create the namespace ip netns add httptap-ns
- create the veth pair ip link add httptap-veth type veth peer name httptap-ceth
- put one side of the veth pair into the namespace ip link set httptap-ceth netns httptap-ns
- assign an IP address to the outer part of the pair ip addr add 10.1.2.1/24 dev httptap-veth
- bring up the out part of the pair ip link set httptap-veth up
- in the namespace, assign an IP address nsenter --net=/run/netns/httptap-ns ip addr add 10.1.2.50/24 dev httptap-ceth
- in the namespace, route everything to one side of the veth pair nsenter --net=/run/netns/httptap-ns ip route add default via 10.1.2.1
- in the namespace, bring the device up nsenter --net=/run/netns/httptap-ns ip link set httptap-ceth up
- setup NAT iptables -t nat -A POSTROUTING -s 10.1.2.0/24 ! -o httptap-veth -j MASQUERADE
- in the namespace, ping 8.8.8.8
Doing it with bridges to allow multiple namespaces to coexist on the same network is more complex. You basically have to:
- create bridge ip link add br0 type bridge
- activate bridge ip link set br0 up
- assign the interface to the bridge ip link set veth0 master br0
- give the bridge an IP address ip addr add 172.18.0.1/16 dev br0
In his example he gave the following addresses:
For the outer part of the veth pair: ip addr add 172.18.0.11/16 dev veth0
For the inner part of the ceth pair: ip addr add 172.18.0.10/16 dev ceth0
(For the second container outer part: ip addr add 172.18.0.21/16 dev veth1)
(For the second container inner part: ip addr add 172.18.0.20/16 dev ceth1)
For the bridge: ip addr add 172.18.0.1/16 dev br0
This is extremely helpful
Here is a very simple example of port forwarding using tun devices (title says its a vpn but it's not):
https://www.nsl.cz/using-tun-tap-in-go-or-how-to-write-vpn/
Permanently turning on IP forwarding:
echo net.ipv4.ip_forward=1 >> /etc/sysctl.d/enable-ip-forward.conf
Check whether IP forwarding is on:
sysctl net.ipv4.ip_forward
In the end I did not get a veth pair to work correctly with iptables masquerade
# Sentry
gvisor sentry
This function execs /proc/self/exe with the boot subcommand, in a set of namespaces:
// createSandboxProcess starts the sandbox as a subprocess by running the "boot"
// command, passing in the bundle dir.
func (s *Sandbox) createSandboxProcess(conf *config.Config, args *Args, startSyncFile *os.File) error {
So look at the boot subcommand of runsc...
In the end, there is a call in runsc/boot/loader.go that starts a process like this:
tg, _, err := l.k.CreateProcess(info.procArgs)
if err != nil {
return nil, nil, fmt.Errorf("creating process: %w", err)
}
This in turn calls into pkg/sentry/kernel/kernel.go CreateProcess:
// CreateProcess creates a new task in a new thread group with the given
// options. The new task has no parent and is in the root PID namespace.
//
// If k.Start() has already been called, then the created process must be
// started by calling kernel.StartProcess(tg).
//
// If k.Start() has not yet been called, then the created task will begin
// running when k.Start() is called.
//
// CreateProcess has no analogue in Linux; it is used to create the initial
// application task, as well as processes started by the control server.
func (k *Kernel) CreateProcess(args CreateProcessArgs) (*ThreadGroup, ThreadID, error) {
The core work step in a task is this:
func (app *runApp) execute(t *Task) taskRunState {
...
for _, work := range queue {
work.TaskWork(t)
}
In the above, queue is a []TaskWorker | {
"source": "monasticacademy/httptap",
"title": "NOTES.md",
"url": "https://github.com/monasticacademy/httptap/blob/main/NOTES.md",
"date": "2024-10-15T13:11:47",
"stars": 3800,
"description": "View HTTP/HTTPS requests made by any Linux program",
"file_size": 9143
} |
<h1 align="center">
<img src="./docs/readme-header.webp" alt="Monastic Academy" height="450px">
<br>
httptap
</br>
</h1>
<p align="center">
<a href="https://pkg.go.dev/github.com/monasticacademy/httptap"><img src="https://img.shields.io/badge/go.dev-reference-007d9c?logo=go&logoColor=white&style=flat-square" alt="Documentation"></a>
<a href="https://github.com/monasticacademy/httptap/actions"><img src="https://github.com/monasticacademy/httptap/workflows/Test/badge.svg" alt="Build Status"></a>
</p>
<br>
View the HTTP and HTTPS requests made by any linux program by running `httptap -- <command>`. For example, the following runs curl on "monasticacademy.org", which results in an HTTP status of 308 (Redirect):
```shell
$ httptap -- curl https://monasticacademy.org
---> GET https://monasticacademy.org/
<--- 308 https://monasticacademy.org/ (15 bytes)
```
Now let's try the same thing with an HTTP request from python. This time we see that python follows the redirect and gets a 200 OK response:
```shell
httptap -- python -c "import requests; requests.get('https://monasticacademy.org')"
---> GET https://monasticacademy.org/
<--- 308 https://monasticacademy.org/ (15 bytes)
---> GET https://www.monasticacademy.org/
<--- 200 https://www.monasticacademy.org/ (5796 bytes)
```
To run `httptap` you do not need to be the root user. You do not need to set up any kind of daemon or make any system-wide changes to your system (edit: on Ubuntu 23.10 and later you will need to run [the sysctl documented below](#ubuntu-2310-and-later)). It will not create any iptables rules or change your routing table, and generally will not affect any other processes running on the same system. The `httptap` executable is a static Go binary that runs without dependencies.
Httptap only runs on linux at present. It makes use of linux-specific system calls -- in particular network namespaces -- that will unfortunately make it very difficult to port to other operating systems. If you know how httptap could be ported to other operating systems then please get in touch!
# Install pre-built binary
```shell
curl -L https://github.com/monasticacademy/httptap/releases/latest/download/httptap_linux_$(uname -m).tar.gz | tar xzf -
```
For all versions and CPU architectures see the [latest releases page](https://github.com/monasticacademy/httptap/releases/latest).
# Install with Go
```shell
go install github.com/monasticacademy/httptap@latest
```
# Ubuntu 23.10 and later
On Ubuntu 23.10 and later you will need to run the following in order to use httptap:
```shell
sudo sysctl -w kernel.apparmor_restrict_unprivileged_unconfined=0
sudo sysctl -w kernel.apparmor_restrict_unprivileged_userns=0
```
What this does is disable a [recent kernel feature that restricts unpriveleged user namespaces](https://ubuntu.com/blog/ubuntu-23-10-restricted-unprivileged-user-namespaces). The above may also be needed on other distros that have disabled unpriveleged user namespaces by default. I will update this documentation as I learn more. I am investigating ways to avoid the need for this entirely by shipping an apparmor profile with httptap.
# Quickstart
Let's run a simple test:
```shell
httptap -- curl -s https://buddhismforai.sutra.co -o /dev/null
---> GET https://buddhismforai.sutra.co/
<--- 302 https://buddhismforai.sutra.co/ (117 bytes)
```
What happened here is that we ran `curl -s https://buddhismforai.sutra.co -o /dev/null` and it received a 302 redirect from the server. `httptap` printed summaries of the HTTP requests and their responses. Let's see how it changes if we tell curl to follow redirects by adding `-L`:
```shell
httptap -- curl -sL https://buddhismforai.sutra.co -o /dev/null
---> GET https://buddhismforai.sutra.co/
<--- 302 https://buddhismforai.sutra.co/ (117 bytes)
---> GET https://buddhismforai.sutra.co/space/cbodvy/content
<--- 200 https://buddhismforai.sutra.co/space/cbodvy/content (6377 bytes)
```
Now we can see that after receiving the 302 redirect, curl made an additional HTTP request to the URL to which it was redirected, which is what you expect when using `-L` with curl.
Let's see what HTTP endpoints the Google Cloud command line interface uses to list compute resources (this requires that you have gcloud installed and are signed in):
```shell
$ httptap -- gcloud compute instances list
---> POST https://oauth2.googleapis.com/token
<--- 200 https://oauth2.googleapis.com/token (997 bytes)
---> GET https://compute.googleapis.com/compute/v1/projects/maple-public-website/aggregated/instances?alt=json&includeAllScopes=True&maxResults=500&returnPartialSuccess=True
<--- 200 https://compute.googleapis.com/compute/v1/projects/maple-public-website/aggregated/instances?alt=json&includeAllScopes=True&maxResults=500&returnPartialSuccess=True (19921 bytes)
NAME ZONE MACHINE_TYPE PREEMPTIBLE INTERNAL_IP EXTERNAL_IP STATUS
<your cloud instances listed here>
```
What happened here is that we ran `gcloud compute instances list`, which lists the compute instances that the signed-in user has on Google Cloud. The bottom two lines of output were printed by `gcloud`; the rest were printed by `httptap` and show what HTTP requests `gcloud` used to get the information it printed.
Let's see what HTTP endpoints kubectl uses in a "get all" (this requires that you have kubectl installed and are authenticated to a cluster):
```shell
$ httptap --https 443 6443 -- kubectl get all --insecure-skip-tls-verify
---> GET https://cluster:6443/api/v1/namespaces/default/pods?limit=500
<--- 200 https://cluster:6443/api/v1/namespaces/default/pods?limit=500 (38345 bytes)
---> GET https://cluster:6443/api/v1/namespaces/default/replicationcontrollers?limit=500
<--- 200 https://cluster:6443/api/v1/namespaces/default/replicationcontrollers?limit=500 (2509 bytes)
---> GET https://cluster:6443/api/v1/namespaces/default/services?limit=500
<--- 200 https://cluster:6443/api/v1/namespaces/default/services?limit=500 (5586 bytes)
---> GET https://cluster:6443/apis/apps/v1/namespaces/default/daemonsets?limit=500
<--- 200 https://cluster:6443/apis/apps/v1/namespaces/default/daemonsets?limit=500 (3052 bytes)
---> GET https://cluster:6443/apis/apps/v1/namespaces/default/deployments?limit=500
<--- 200 https://cluster:6443/apis/apps/v1/namespaces/default/deployments?limit=500 (7438 bytes)
---> GET https://cluster:6443/apis/apps/v1/namespaces/default/replicasets?limit=500
<--- 200 https://cluster:6443/apis/apps/v1/namespaces/default/replicasets?limit=500 (47211 bytes)
---> GET https://cluster:6443/apis/apps/v1/namespaces/default/statefulsets?limit=500
<--- 200 https://cluster:6443/apis/apps/v1/namespaces/default/statefulsets?limit=500 (1416 bytes)
---> GET https://cluster:6443/apis/autoscaling/v2/namespaces/default/horizontalpodautoscalers?limit=500
<--- 200 https://cluster:6443/apis/autoscaling/v2/namespaces/default/horizontalpodautoscalers?limit=500 (2668 bytes)
---> GET https://cluster:6443/apis/batch/v1/namespaces/default/cronjobs?limit=500
<--- 200 https://cluster:6443/apis/batch/v1/namespaces/default/cronjobs?limit=500 (3134 bytes)
---> GET https://cluster:6443/apis/batch/v1/namespaces/default/jobs?limit=500
<--- 200 https://cluster:6443/apis/batch/v1/namespaces/default/jobs?limit=500 (2052 bytes)
<ordinary kubectl output here>
```
In the above, `--insecure-skip-tls-verify` is necessary because kubectl doesn't use the httptap-generated certificate authority, and `--https 443 6443` says to treat TCP connections on ports 443 and 6443 as HTTPS connections, which is needed because my cluter's API endpoint uses port 6443.
Let's see how DNS-over-HTTP works when you use `--doh-url` with curl:
```shell
$ httptap -- curl -sL --doh-url https://cloudflare-dns.com/dns-query https://buddhismforai.sutra.co -o /dev/null
---> POST https://cloudflare-dns.com/dns-query
<--- 200 https://cloudflare-dns.com/dns-query (149 bytes)
---> POST https://cloudflare-dns.com/dns-query
<--- 200 https://cloudflare-dns.com/dns-query (150 bytes)
---> GET https://buddhismforai.sutra.co/
<--- 302 https://buddhismforai.sutra.co/ (117 bytes)
---> GET https://buddhismforai.sutra.co/space/cbodvy/content
<--- 200 https://buddhismforai.sutra.co/space/cbodvy/content (6377 bytes)
```
What happened here is that we told `curl` to request the url "https://buddhismforai.sutra.co", using the cloudflare DNS-over-HTTP service at `cloudflare-dns.com`. In the output we see that `curl` made 4 HTTP requests in total; the first two were DNS lookups, and then the second two were the ordinary HTTP requests for buddhismforai.sutra.co.
Let's print the contents of the DNS-over-HTTP payloads:
```shell
$ httptap --head --body -- curl -sL --doh-url https://cloudflare-dns.com/dns-query https://buddhismforai.sutra.co -o /dev/null
---> POST https://cloudflare-dns.com/dns-query
> Accept: */*
> Content-Type: application/dns-message
> Content-Length: 40
buddhismforaisutraco
<--- 200 https://cloudflare-dns.com/dns-query (149 bytes)
< Alt-Svc: h3=":443"; ma=86400
< Server: cloudflare
< Date: Tue, 24 Dec 2024 18:13:12 GMT
< Content-Type: application/dns-message
< Access-Control-Allow-Origin: *
< Content-Length: 149
< Cf-Ray: 8f7290631e334211-EWR
buddhismforaisutraco�
��w�4+#G�. <wildcardsutraco herokudnscom�4+!�=�4+
...
```
Here the `--head` option tells httptap to print the HTTP headers, and `--body` tells it to print the raw HTTP payloads. To keep it short I'm showing just the first request/response pair.
# HAR output
You can dump the HTTP requests and responses to a HAR file like this:
```
$ httptap --dump-har out.har -- curl -Lso /dev/null https://monasticacademy.org
```
There are many HAR viewers out there that can visualize this dump file. For example here is how the above looks in the [Google HAR Analyzer](https://toolbox.googleapps.com/apps/har_analyzer/):

Again, what you're looking at here is one HTTP request to https://monasticacademy.org that returns a 308 Redirect, followed by a second HTTP request to https://www.monasticacademy.org that return a 200 OK.
# Reaching localhost
To reach a localhost port, replace "localhost" with "host.httptap.local" or the special IP address 169.254.77.65. Traffic to these destinations will routed to localhost on your machine.
The situation here is that in linux every network namespace automatically gets its own loopback device (127.0.0.1), and these can't be shared. This means that if a process running within httptap tries to connect to 127.0.0.1:1234, it'll actually be connecting to a "different" 127.0.0.1 from another process on your machine listening on this same address and port, and you won't be able to connect.
As a workaround, the address 169.254.77.65 is hardcoded within httptap to route to 127.0.0.1.
# How it works
When you run `httptap -- <command>`, httptap runs `<command>` in an isolated network namespace, injecting a certificate authority created on-the-fly in order to decrypt HTTPS traffic. Here is the process in detail:
In linux, there is a kernel API for creating and configuring network interfaces. Conventionally, a network interface would be a physical ethernet or WiFi controller in your computer, but it is possible to create a special kind of network interface called a TUN device. A TUN device shows up to the system in the way that any network interface shows up, but any traffic written to it will be delivered to a file descriptor held by the process that created it. Httptap creates a TUN device and runs the subprocess in an environment in which all network traffic is routed through that device.
There is also a kernel API in linux for creating network namespaces. A network namespace is a list of network interfaces and routing rules. When a process is started in linux, it can be run in a specified network namespace. By default, processes run in a root network namespace that we do not want to make chagnes to because doing so would affect all network traffic on the system. Instead, we create a network namespace in which there are only two network interfaces: a loopback device (127.0.0.1) and a TUN device that delivers traffic to us. Then we run the subprocess in that namespace.
The traffic from the network device is delivered to us as raw IP packets. We must parse the IP packets as well as the inner TCP and UDP packets, and write raw IP packets back to the subprocess. This requires a software implementation of the TCP/IP protocol, which is by far the most difficult part of httptap. The TCP/IP implementation in httptap is missing many aspects of the full TCP protocol, but still works reasonably well for its purpose.
Suppose the subprocess makes an HTTP request to www.example.com. The first thing we receive is a TCP SYN packet addressed to 93.184.215.14 (the current IP address of example.com). We respond with a SYN+ACK packet with source address 93.184.215.14, though in truth the packet did not come from 93.184.215.14, but from us. Separately, we establish our own TCP connection to 93.184.215.14 using the ordinary sockets API in the linux kernel. When the subprocess sends data to 93.184.215.14 we relay it over our separate TCP connection, and vice versa for return data. This is a traditional transparent TCP proxy, and in this way we can view all data flowing to and from the subprocess, though we won't be able to decrypt HTTPS traffic without a bit more work.
When a client makes an HTTPS request, it asks the server for evidence that it is who it says it is. If the server has a certificate signed by a certificate authority, it can use that certificate to prove that it is who it says it is. The client will only accept such a certificate if it trusts the certificate authority that signed the certificate. Operating systems, web browsers, and many other pieces of software come with a list of a few hundred certificate authorities that they trust. Many of these pieces of software have ways for users to add additional certificate authorities to this list. We make use of this.
When httptap starts, it creates a certificate authority (actually a private key plus a corresponding x509 certificate), writes it to a file on the filesystem visible only to the subprocess, and sets a few environment variables -- again only visible to the subprocess being run -- that add this certificate authority to the list of trusted certificate authorities. Since the subprocess trusts this certificate authority, and httptap holds the private key for the certificate authority, it can prove to the subprocess that it is the server which which the subprocess was trying to communicate. In this way we can read the plaintext HTTP requests.
# How it was made
Httptap is part of an experiment in developing technology in the context of Buddhist monasticism. It was developed at the [Monastic Academy](https://www.monasticacademy.org) in Vermont in the US. We believe that a monastic schedule, and the practice of the Buddhist spiritual path more generally, provide ideal conditions for technological development. The way we have set things up is that we live and practice together on a bit over a hundred acres of land. In the mornings and evenings we chant and meditate together, and for about one week out of every month we run and participate in a meditation retreat. The rest of the time we work together on everything from caring for the land, maintaining the buildings, cooking, cleaning, planning, fundraising, and for the past few years developing software together. This project is a demonstration of what is possible on the software side, but of course to see the full product of our work you should come visit us.
If you're interested, we run an [AI fellowship program](https://www.monasticacademy.org/ai-fellowship), which is a funded month-to-month program where you live on the land, participate in the schedule, and do your own work during the day. We also have a 3-month [monastic training program](https://www.monasticacademy.org/train), which can lead into our long-term residential training.
For the past few years we have been recording a lecture series called [Buddhism for AI](https://buddhismforai.sutra.co). It's about our efforts to design a religion (yes, a religion) based on Buddhism for consumption directly by AI systems. We actually feel this is very important work given the world situation.
Finally, our head teacher [Soryu Forall](https://www.monasticacademy.org/teacher) published a book a few years back called [Buddhism For All](https://buddhism.net/buddhism-for-all-book/). We're working on a sequel at the moment.

# Caveats
- The process cannot listen for incoming network connections
- You need access to `/dev/net/tun`
- All ICMP echo requests will be echoed without sending any ICMP packets out to the real network
# Donations
You can support [me personally through github sponsors](https://github.com/sponsors/alexflint), or (my preference if it's an option for you) [the community I live in through our donate page](https://www.monasticacademy.org/donate). | {
"source": "monasticacademy/httptap",
"title": "README.md",
"url": "https://github.com/monasticacademy/httptap/blob/main/README.md",
"date": "2024-10-15T13:11:47",
"stars": 3800,
"description": "View HTTP/HTTPS requests made by any Linux program",
"file_size": 17118
} |
This is a DNS proxy that answers simple questions using Go's built-in resolver, which reads nsswitch.conf and resolv.conf and does a bunch of work to be as much like gethostbyname, or even use gethostbyname when available via cgo. | {
"source": "monasticacademy/httptap",
"title": "experiments/dns/README.md",
"url": "https://github.com/monasticacademy/httptap/blob/main/experiments/dns/README.md",
"date": "2024-10-15T13:11:47",
"stars": 3800,
"description": "View HTTP/HTTPS requests made by any Linux program",
"file_size": 231
} |
See https://github.com/xjasonlyu/tun2socks/blob/main/core/tcp.go#L78
I may be able to use tun2socks off-the-shelf. The core piece is very nicely designed:
https://github.com/xjasonlyu/tun2socks/blob/main/engine/engine.go#L227-L234
I should be able to use both the tunnel _and_ the proxy from tun2socks. I'll probably always use the Direct proxy.
What I need to do is implement proxy.Dialer:
type Dialer interface {
DialContext(context.Context, *M.Metadata) (net.Conn, error)
DialUDP(*M.Metadata) (net.PacketConn, error)
}
https://github.com/xjasonlyu/tun2socks/blob/main/proxy/proxy.go#L19-L22
and pass it in, ultimate to core.CreateStack in Config.TransportHandler:
https://github.com/xjasonlyu/tun2socks/blob/main/core/stack.go#L25
but more specifically, the dialer goes into the tunnel via SetDialer:
tunnel.T().SetDialer(_defaultProxy)
https://github.com/xjasonlyu/tun2socks/blob/main/engine/engine.go#L195
and then the tunnel is the TransportHandler:
stack, err = core.CreateStack(&core.Config{
LinkEndpoint: _defaultDevice,
TransportHandler: tunnel.T(),
MulticastGroups: multicastGroups,
Options: opts,
});
https://github.com/xjasonlyu/tun2socks/blob/main/engine/engine.go#L227-L234 | {
"source": "monasticacademy/httptap",
"title": "experiments/tun2socks/NOTES.md",
"url": "https://github.com/monasticacademy/httptap/blob/main/experiments/tun2socks/NOTES.md",
"date": "2024-10-15T13:11:47",
"stars": 3800,
"description": "View HTTP/HTTPS requests made by any Linux program",
"file_size": 1302
} |
Forked from https://github.com/vvakame/go-harlog
net/http client logging by HAR format.
Take http request/response log by HAR (HTTP Archive) format.
It can visualize by [any](https://developers.google.com/web/updates/2017/08/devtools-release-notes#har-imports) [tools](https://toolbox.googleapps.com/apps/har_analyzer/).
## How to use
```shell script
$ go get github.com/vvakame/go-harlog
```
```go
har := &harlog.Transport{}
hc := &http.Client{
Transport: har,
}
// do something...
b, err := json.MarshalIndent(har.HAR(), "", " ")
if err != nil {
return err
}
fmt.Println(string(b))
```
See HAR file in Google Chrome DevTools.
This screenshots are generated by this library.
Capture the log about Google Cloud Storage access by [cloud.google.com/go/storage](https://godoc.org/cloud.google.com/go/storage).
## Limitations
* compressed response is not supported yet.
* `headersSize` is not calculated.
patches welcome! | {
"source": "monasticacademy/httptap",
"title": "pkg/harlog/README.md",
"url": "https://github.com/monasticacademy/httptap/blob/main/pkg/harlog/README.md",
"date": "2024-10-15T13:11:47",
"stars": 3800,
"description": "View HTTP/HTTPS requests made by any Linux program",
"file_size": 1275
} |
# 🚀 Welcome to 21st.dev!
**[21st.dev](https://21st.dev)** is your go-to open-source community registry for **React UI components**! Whether you're a developer, designer, or just someone who loves building beautiful interfaces, 21st.dev is the place to **publish, discover, and install** minimal, modern, and reusable React components powered by **Tailwind CSS** and **Radix UI**.
Inspired by the amazing [shadcn/ui](https://ui.shadcn.com/), we're here to make building UIs faster, easier, and more fun. 🎉
[](https://discord.gg/Qx4rFunHfm)
---
## 👥 Community
We're building more than just a component registry – we're building a community of developers who love creating beautiful UIs. Here's how you can get involved:
- **Join our [Discord](https://discord.gg/Qx4rFunHfm)** – Get help, share your work, and chat with other developers
- **Follow us on [X/Twitter](https://x.com/serafimcloud)** – Stay updated with the latest features and components
- **Star us on [GitHub](https://github.com/serafimcloud/21st)** – Support the project and follow our progress
- **Share your components** – Help others by contributing your UI components
- **Give feedback** – Your input shapes the future of 21st.dev
---
## 🌟 Why 21st.dev?
- **Open Source & Community-Driven**: Built by developers, for developers. Everyone is welcome to contribute!
- **Minimal & Modern**: Components are lightweight, customizable, and designed with Tailwind and Radix UI.
- **Easy to Use**: Install any component with a single `npx shadcn` command.
- **Multiple Demos**: Each component can have multiple demos with previews and videos.
- **Extensible**: Add your own components, themes, and dependencies effortlessly.
- **TypeScript First**: Full type support out of the box.
---
## 🛠️ Publish Your Component in 1 Minute!
Yes, you read that right—**1 minute**! 🕒
Publishing your React component is as easy as pie. Just head over to our [publish page](https://21st.dev) and share your creation with the world.
### Review Process
When you publish a component, it follows this journey:
1. **Initial State** (`on_review`) - Component is available via direct link and awaiting review
2. **Posted State** (`posted`) - Component has passed review and is available on your profile and via direct link
3. **Featured State** (`featured`) - Component is featured on the homepage and in public listings
I ([Serafim](https://x.com/serafimcloud)) personally review each component to ensure it meets our quality standards before featuring it.
### Quality Guidelines
To get your component featured, ensure it follows these key principles:
1. **Visual Quality**
- Component should be visually polished and provide real value to the community
- Follow modern UI/UX practices
2. **Code Structure**
- Follow the shadcn/ui pattern of separating component logic from demo content
- Component file should contain only the reusable functionality
- Demo file should showcase the component through props, not hardcoded content
3. **Theming**
- Use CSS variables from shadcn's theme system (see `globals.css`)
- Support both light and dark modes out of the box
- Use the proper color variables (e.g., `hsl(var(--background))`)
Remember: Quality over quantity! We prioritize well-crafted, reusable components that follow these guidelines.
### File Structure:
```
your-component/ # How to organize your files
├── code.tsx # Main component
├── tailwind.config.js # Optional Tailwind config
├── globals.css # Optional global styles
└── demos/ # Each component can have multiple demos
├── default/ # Primary demo (required)
│ ├── code.demo.tsx # Demo implementation
│ ├── preview.png # Static preview image
│ └── video.mp4 # Optional demo video
└── advanced/ # Additional demos (optional)
├── code.demo.tsx
├── preview.png
└── video.mp4
# Files are stored in Cloudflare R2 under:
# components-code/{user_id}/{component_slug}/...
```
### What We Support:
- **Pure React Components** – Build with React, no fuss.
- **Next.js Client Components** – We've got you covered (server-side rendering coming soon!).
- **TypeScript** – Because type safety is ❤️.
- **Tailwind Themes** – Customize to your heart's content.
- **Global CSS Styles** – Add your own flair.
- **Radix UI** – Accessible and unstyled primitives.
- **Any npm Dependencies** – Thanks to [Sandpack](https://sandpack.codesandbox.io/).
- **Internal Dependencies** – Use any component from our registry as a dependency.
- **Multiple Demos** – Showcase different use cases and variations.
- **Preview Images & Videos** – Make your component shine.
**Pro Tip**: We encourage TypeScript components. JavaScript is cool too, but untested for now. 😉
---
## ⚡ Install a Component in Seconds!
Found a component you love on [21st.dev](https://21st.dev)? Installing it is a breeze. Just copy the `npx shadcn` command and run it in your project's root folder.
For example, to install the `shadcn/ui/accordion` component, run:
```bash
npx shadcn@latest add "https://21st.dev/r/shadcn/accordion"
```
This command will:
- Create all necessary files for the component and its dependencies.
- Extend your Tailwind theme automatically.
- Set up any required global styles.
**Why use the command?**
While you can copy-paste code directly from the website, using `npx shadcn` ensures you get all the files and dependencies without missing a beat. It's the recommended way to go! 🚀
---
## 🏗 Architecture
The project uses a modern stack:
- **Frontend**: Next.js 14
- **Database**: Supabase for metadata and user data
- **Authentication**: Clerk
- **File Storage**: Cloudflare R2
- **Analytics**: Amplitude
---
## 🛠️ Contributing to 21st.dev
We're thrilled you want to contribute! Whether you're a seasoned developer or just starting out, there's a place for you here. Let's get you set up:
### 🛠️ Prerequisites
Before diving in, make sure you have:
- A **Supabase** account
- A **Clerk** account
- A **Cloudflare R2** account
### 🚀 Setup Guide
1. **Fork & Clone**: Fork the repository and clone it locally. We recommend using [Cursor](https://cursor.com) if you're non-technical.
2. **Install Dependencies**: We're big fans of `pnpm`! Run:
```bash
pnpm install
```
3. **Environment Setup**: Create a `.env.local` in `apps/web` with:
```
# Supabase
NEXT_PUBLIC_SUPABASE_URL=https://*****
NEXT_PUBLIC_SUPABASE_KEY=*****
SUPABASE_SERVICE_ROLE_KEY=*****
# Clerk
NEXT_PUBLIC_CLERK_PUBLISHABLE_KEY=*****
CLERK_SECRET_KEY=*****
CLERK_WEBHOOK_SECRET=*****
# Cloudflare R2
NEXT_PUBLIC_CDN_URL=https://*****
R2_ACCESS_KEY_ID=*****
R2_SECRET_ACCESS_KEY=*****
NEXT_PUBLIC_R2_ENDPOINT=https://*****
# Other
NEXT_PUBLIC_APP_URL=https://21st.dev
NEXT_PUBLIC_AMPLITUDE_API_KEY=*****
```
4. **Start Development**:
```bash
pnpm dev
```
5. **Open a PR**: Once you're done, open a PR to the `main` branch. We can't wait to see what you've built! 🎉
---
## 👥 Team
The project was developed by [@serafimcloud](https://x.com/serafimcloud), with significant contributions from [@daniel_dhawan](https://x.com/daniel_dhawan) and [@garrrikkotua](https://x.com/garrrikkotua).
---
## 🙏 Acknowledgments
This project wouldn't be possible without the incredible work of:
- [shadcn/ui](https://ui.shadcn.com/)
- [Tailwind CSS](https://tailwindui.com/)
- [Sandpack by CodeSandbox](https://sandpack.codesandbox.io/)
- [Supabase](https://supabase.com)
- [Vercel](https://vercel.com)
- [Clerk](https://clerk.com)
- [Cloudflare](https://cloudflare.com)
- [Cursor](https://cursor.com)
- [Claude 3.5 Sonnet by Anthropic](https://anthropic.com/)
- [MagicUI](https://magicui.design)
And, of course, **YOU**—our amazing open-source contributors! ❤️
---
## 🚀 Let's Build the Future Together!
Ready to dive in? Start exploring, publishing, and contributing today. Let's make 21st.dev the best place for React UI components on the web. Happy coding! 🎉
## 📋 Component Guidelines
We maintain high quality standards for components that appear on the homepage and in public listings. While all published components are immediately available via direct links, they go through a review process before being featured publicly.
### Review Process
When you publish a component, it follows this journey:
1. **Initial State** (`on_review`) - Component is available via direct link and awaiting review
2. **Posted State** (`posted`) - Component has passed review and is available on your profile and via direct link
3. **Featured State** (`featured`) - Component is featured on the homepage and in public listings
I ([Serafim](https://x.com/serafimcloud)) personally review each component to ensure it meets our quality standards before featuring it. This helps maintain a high-quality collection of components that truly benefit the community.
### Quality Standards
To ensure your component gets featured, follow these guidelines:
1. **Visual Design**
- Component should be visually polished and provide value to the community
- Follow modern UI/UX practices
- Support both light and dark themes
- Use consistent spacing and sizing
2. **Code Structure**
- Follow the shadcn/ui pattern of separating component logic from demo content
- Component file should contain only the reusable functionality
- Demo file should showcase the component with realistic content
- Use props for customization and content injection
3. **Theming**
- Use CSS variables from shadcn's theme system (see `globals.css`)
- Support both light and dark modes out of the box
- Use `hsl` variables for colors (e.g., `hsl(var(--background))`)
- Follow the naming convention for CSS variables
4. **Accessibility**
- Include proper ARIA attributes
- Support keyboard navigation
- Maintain sufficient color contrast
- Test with screen readers
5. **Documentation**
- Provide clear prop documentation
- Include usage examples
- Document any required dependencies
- Add helpful comments for complex logic
6. **Best Practices**
- Keep components focused and single-purpose
- Minimize external dependencies
- Ensure responsive behavior
- Follow TypeScript best practices
- Include meaningful default props
Remember: Quality over quantity! We'd rather have fewer, well-crafted components than many that don't meet our standards.
--- | {
"source": "serafimcloud/21st",
"title": "README.md",
"url": "https://github.com/serafimcloud/21st/blob/main/README.md",
"date": "2024-09-30T10:56:10",
"stars": 3796,
"description": "npm for design engineers: largest marketplace of shadcn/ui-based React Tailwind components, blocks and hooks",
"file_size": 10646
} |
This is a [Next.js](https://nextjs.org) project bootstrapped with [`create-next-app`](https://nextjs.org/docs/app/api-reference/create-next-app).
## Getting Started
First, run the development server:
```bash
npm run dev
# or
yarn dev
# or
pnpm dev
# or
bun dev
```
Open [http://localhost:3000](http://localhost:3000) with your browser to see the result.
You can start editing the page by modifying `app/page.tsx`. The page auto-updates as you edit the file.
This project uses [`next/font`](https://nextjs.org/docs/app/building-your-application/optimizing/fonts) to automatically optimize and load Inter, a custom Google Font.
## Learn More
To learn more about Next.js, take a look at the following resources:
- [Next.js Documentation](https://nextjs.org/docs) - learn about Next.js features and API.
- [Learn Next.js](https://nextjs.org/learn) - an interactive Next.js tutorial.
You can check out [the Next.js GitHub repository](https://github.com/vercel/next.js) - your feedback and contributions are welcome!
## Deploy on Vercel
The easiest way to deploy your Next.js app is to use the [Vercel Platform](https://vercel.com/new?utm_medium=default-template&filter=next.js&utm_source=create-next-app&utm_campaign=create-next-app-readme) from the creators of Next.js.
Check out our [Next.js deployment documentation](https://nextjs.org/docs/app/building-your-application/deploying) for more details. | {
"source": "serafimcloud/21st",
"title": "apps/web/README.md",
"url": "https://github.com/serafimcloud/21st/blob/main/apps/web/README.md",
"date": "2024-09-30T10:56:10",
"stars": 3796,
"description": "npm for design engineers: largest marketplace of shadcn/ui-based React Tailwind components, blocks and hooks",
"file_size": 1410
} |
# `@turbo/eslint-config`
Collection of internal eslint configurations. | {
"source": "serafimcloud/21st",
"title": "packages/eslint-config/README.md",
"url": "https://github.com/serafimcloud/21st/blob/main/packages/eslint-config/README.md",
"date": "2024-09-30T10:56:10",
"stars": 3796,
"description": "npm for design engineers: largest marketplace of shadcn/ui-based React Tailwind components, blocks and hooks",
"file_size": 71
} |
# Contributing
**IMPORTANT:** This project only accepts contributions based on [lucide icons](https://lucide.dev/). Pull requests containing custom icons or icons from other icon packs will be closed.
We welcome contributions to our project! Please follow these steps to contribute:
1. Fork the repository on GitHub.
2. Clone your forked repository to your local machine:
```
git clone https://github.com/your-username/icons.git
```
3. Navigate to the project directory:
```
cd icons
```
4. Create a new branch for your feature or bug fix:
```
git checkout -b your-branch-name
```
5. Install the project dependencies:
```
yarn install
```
6. Make your changes to the codebase.
7. Build the project:
```
yarn build
```
8. Test the application to ensure your changes work as expected:
```
yarn lint
yarn build
yarn gen-cli
```
9. Commit your changes:
```
git commit -m "Your commit message"
```
10. Push your changes to your fork:
```
git push origin your-branch-name
```
11. Open a pull request on the original repository.
Thank you for contributing to our project! | {
"source": "pqoqubbw/icons",
"title": "CONTRIBUTING.md",
"url": "https://github.com/pqoqubbw/icons/blob/main/CONTRIBUTING.md",
"date": "2024-10-31T21:39:28",
"stars": 3778,
"description": "beautifully crafted animated icons",
"file_size": 1167
} |
## `pqoqubbw/icons` is beautifully crafted animated icons.
**Demo** → [icons.pqoqubbw.dev](https://icons.pqoqubbw.dev)
### Svelte icons: [movingicons.dev](https://www.movingicons.dev/) by [@jis3r](https://github.com/jis3r)
### Vue icons: [imfenghuang.github.io/icons](https://imfenghuang.github.io/icons/) by [@imfenghuang](https://github.com/imfenghuang)

## Contributing
We welcome contributions to `pqoqubbw/icons`! Please read our [contributing guidelines](CONTRIBUTING.md) on how to submit improvements and new icons.
## Terms of Use
Feel free to use these components in personal and commercial projects. However, while the tutorials and demos are available for your use as-is, they cannot be redistributed or resold. Let’s keep things fair and respect each other’s work.
If you have any questions or just want to say hi, feel free to reach out to me on X 👉 [@pqoqubbw](https://x.com/pqoqubbw).
## Notes
This project is a work in progress, and i'm continuously working to improve and expand this collection. I’d love to hear your feedback or see your contributions as the project evolves! | {
"source": "pqoqubbw/icons",
"title": "README.md",
"url": "https://github.com/pqoqubbw/icons/blob/main/README.md",
"date": "2024-10-31T21:39:28",
"stars": 3778,
"description": "beautifully crafted animated icons",
"file_size": 1127
} |
## I have read the [CONTRIBUTING.md](https://github.com/pqoqubbw/icons/blob/main/CONTRIBUTING.md) file.
YES/NO
## I have run `yarn gen-cli` to generate the necessary files
YES/NO
## What kind of change does this PR introduce?
Bug fix, feature, docs update, ...
## What is the new behavior?
Feel free to include screenshots if it includes visual changes.
## Demo
Please attach a short video demo of the changes.
## Additional context
Add any other context or screenshots. | {
"source": "pqoqubbw/icons",
"title": ".github/pull_request_template.md",
"url": "https://github.com/pqoqubbw/icons/blob/main/.github/pull_request_template.md",
"date": "2024-10-31T21:39:28",
"stars": 3778,
"description": "beautifully crafted animated icons",
"file_size": 481
} |
<br />
<p align="center">
<a href="https://steel.dev">
<img src="images/steel_header_logo.png" alt="Steel Logo" width="100">
</a>
</p>
<h3 align="center"><b>Steel</b></h3>
<p align="center">
<b>The open-source browser API for AI agents & apps.</b> <br />
The best way to build live web agents and browser automation tools.
</p>
<div align="center">
[](https://github.com/steel-dev/steel-browser/commits/main)
[](https://github.com/steel-dev/steel-browser/blob/main/LICENSE)
[](https://discord.gg/steel-dev)
[](https://twitter.com/steeldotdev)
[](https://github.com/steel-dev/steel-browser)
</div>
<h4 align="center">
<a href="https://app.steel.dev/sign-up" target="_blank">
Get Started
</a> ·
<a href="https://docs.steel.dev/" target="_blank">
Documentation
</a> ·
<a href="https://steel.dev/" target="_blank">
Website
</a> ·
<a href="https://github.com/steel-dev/steel-cookbook" target="_blank">
Cookbook
</a>
</h4>
<p align="center">
<img src="images/demo.gif" alt="Steel Demo" width="600">
</p>
## ✨ Highlights
[Steel.dev](https://steel.dev) is an open-source browser API that makes it easy to build AI apps and agents that interact with the web. Instead of building automation infrastructure from scratch, you can focus on your AI application while Steel handles the complexity.
**This repo is the core building block behind Steel - a production-ready, containerized browser sandbox that you can deploy anywhere.** It includes built-in stealth capabilities, text-to-markdown, session management, a web UI to view/debug sessions, and full browser control through standard automation frameworks like Puppeteer, Playwright, and Selenium.
Under the hood, it manages sessions, pages, and browser processes, allowing you to perform complex browsing tasks programmatically without any of the headaches:
- **Full Browser Control**: Uses Puppeteer and CDP for complete control over Chrome instances -- allowing you to connect using Puppeteer, Playwright, or Selenium.
- **Session Management**: Maintains browser state, cookies, and local storage across requests
- **Proxy Support**: Built-in proxy chain management for IP rotation
- **Extension Support**: Load custom Chrome extensions for enhanced functionality
- **Debugging Tools**: Built-in request logging and session recording capabilities
- **Anti-Detection**: Includes stealth plugins and fingerprint management
- **Resource Management**: Automatic cleanup and browser lifecycle management
- **Browser Tools**: Exposes APIs to quick convert pages to markdown, readability, screenshots, or PDFs.
For detailed API documentation and examples, check out our [API reference](https://docs.steel.dev/api-reference) or explore the Swagger UI directly at `http://0.0.0.0:3000/documentation`.
> Steel is in public beta and evolving every day. Your suggestions, ideas, and reported bugs help us immensely. Do not hesitate to join in the conversation on [Discord](https://discord.gg/steel-dev) or raise a GitHub issue. We read everything, respond to most, and love you.
If you love open-source, AI, and dev tools, [we're hiring across the stack](https://steel-dev.notion.site/jobs-at-steel?pvs=74)!
### Make sure to give us a star ⭐
<img width="200" alt="Start us on Github!" src="images/star_img.png">
## 🛠️ Getting Started
The easiest way to get started with Steel is by creating a [Steel Cloud](https://app.steel.dev) account. Otherwise, you can deploy this Steel browser instance to a cloud provider or run it locally.
## ⚡ Quick Deploy
If you're looking to deploy to a cloud provider, we've got you covered.
| Deployment methods | Link |
| -------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| Pre-built Docker Image (API only) | [](https://github.com/steel-dev/steel-browser/pkgs/container/steel-browser-api) |
| 1-click deploy to Railway | [](https://railway.app/template/FQG9Ca) |
| 1-click deploy to Render | [](https://render.com/deploy?repo=https://github.com/steel-dev/steel-browser) |
## 💻 Running Locally
### Docker
The simplest way to run a Steel browser instance locally is to run the pre-built Docker images:
```bash
# Clone and build the Docker image
git clone https://github.com/steel-dev/steel-browser
cd steel-browser
docker compose up
```
This will start the Steel server on port 3000 (http://localhost:3000) and the UI on port 5173 (http://localhost:5173).
You can now create sessions, scrape pages, take screenshots, and more. Jump to the [Usage](#usage) section for some quick examples on how you can do that.
## Quickstart for Contributors
When developing locally, you will need to run the [`docker-compose.dev.yml`](./docker-compose.dev.yml) file instead of the default [`docker-compose.yml`](./docker-compose.yml) file so that your local changes are reflected. Doing this will build the Docker images from the [`api`](./api) and [`ui`](./ui) directories and run the server and UI on port 3000 and 5173 respectively.
```bash
docker compose -f docker-compose.dev.yml up
```
You will also need to run it with `--build` to ensure the Docker images are re-built every time you make changes:
```bash
docker compose -f docker-compose.dev.yml up --build
```
In case you run on a custom host, you need to copy .env.example to .env while changing the host or modify the environment variables used by the `docker-compose.dev.yml` to use your host.
### Node.js
Alternatively, if you have Node.js and Chrome installed, you can run the server directly:
```bash
npm install
npm run dev
```
This will also start the Steel server on port 3000 and the UI on port 5173.
Make sure you have the Chrome executable installed and in one of these paths:
- **Linux**:
`/usr/bin/google-chrome`
- **MacOS**:
`/Applications/Google Chrome.app/Contents/MacOS/Google Chrome`
- **Windows**:
- `C:\Program Files\Google\Chrome\Application\chrome.exe` OR
- `C:\Program Files (x86)\Google\Chrome\Application\chrome.exe`
#### Custom Chrome Executable
If you have a custom Chrome executable or a different path, you can set the `CHROME_EXECUTABLE_PATH` environment variable to the path of your Chrome executable:
```bash
export CHROME_EXECUTABLE_PATH=/path/to/your/chrome
npm run dev
```
For more details on where this is checked look at [`api/src/utils/browser.ts`](./api/src/utils/browser.ts).
## 🏄🏽♂️ Usage
> If you're looking for quick examples on how to use Steel, check out the [Cookbook](https://github.com/steel-dev/steel-cookbook).
>
> Alternatively you can play with the [REPL package](./repl/README.md) too `cd repl` and `npm run start`
There are two main ways to interact with the Steel browser API:
1. [Using Sessions](#sessions)
2. [Using the Quick Actions Endpoints](#quick-actions-api)
In these examples, we assume your custom Steel API endpoint is `http://localhost:3000`.
The full REST API documentation can be found on your Steel instance at `/documentation` (e.g., `http://localhost:3000/documentation`).
#### Using the SDKs
If you prefer to use the our Python and Node SDKs, you can install the `steel-sdk` package for Node or Python.
These SDKs are built on top of the REST API and provide a more convenient way to interact with the Steel browser API. They are fully typed, and are compatible with both Steel Cloud and self-hosted Steel instances (changeable using the `baseUrl` option on Node and `base_url` on Python).
For more details on installing and using the SDKs, please see the [Node SDK Reference](https://docs.steel.dev/overview/reference/node-sdk-reference) and the [Python SDK Reference](https://docs.steel.dev/overview/reference/python-sdk-reference).
### Sessions
The `/sessions` endpoint lets you relaunch the browser with custom options or extensions (e.g. with a custom proxy) and also reset the browser state. Perfect for complex, stateful workflows that need fine-grained control.
Once you have a session, you can use the session ID or the root URL to interact with the browser. To do this, you will need to use Puppeteer or Playwright. You can find some examples of how to use Puppeteer and Playwright with Steel in the docs below:
* [Puppeteer Integration](https://docs.steel.dev/overview/guides/connect-with-puppeteer)
* [Playwright with Node](https://docs.steel.dev/overview/guides/connect-with-playwright-node)
* [Playwright with Python](https://docs.steel.dev/overview/guides/connect-with-playwright-python)
<details open>
<summary><b>Creating a Session using the Node SDK</b></summary>
<br>
```typescript
import Steel from 'steel-sdk';
const client = new Steel({
baseUrl: "http://localhost:3000", // Custom API Base URL override
});
(async () => {
try {
// Create a new browser session with custom options
const session = await client.sessions.create({
sessionTimeout: 1800000, // 30 minutes
blockAds: true,
});
console.log("Created session with ID:", session.id);
} catch (error) {
console.error("Error creating session:", error);
}
})();
````
</details>
<details>
<summary><b>Creating a Session using the Python SDK</b></summary>
<br>
````python
import os
from steel import Steel
client = Steel(
base_url="http://localhost:3000", # Custom API Base URL override
)
try:
# Create a new browser session with custom options
session = client.sessions.create(
session_timeout=1800000, # 30 minutes
block_ads=True,
)
print("Created session with ID:", session.id)
except Exception as e:
print("Error creating session:", e)
````
</details>
<details>
<summary><b>Creating a Session using Curl</b></summary>
<br>
```bash
# Launch a new browser session
curl -X POST http://localhost:3000/v1/sessions \
-H "Content-Type: application/json" \
-d '{
"options": {
"proxy": "user:pass@host:port",
// Custom launch options
}
}'
```
</details>
#### Selenium Sessions
>**Note:** This integration does not support all the features of the CDP-based browser sessions API.
For teams with existing Selenium workflows, the Steel browser provides a drop-in replacement that adds enhanced features while maintaining compatibility. You can simply use the `isSelenium` option to create a Selenium session:
```typescript
// Using the Node SDK
const session = await client.sessions.create({ isSelenium: true });
```
```python
# Using the Python SDK
session = client.sessions.create(is_selenium=True)
```
<details>
<summary><b>Using Curl</b></summary>
<br>
```bash
# Launch a Selenium session
curl -X POST http://localhost:3000/v1/sessions \
-H "Content-Type: application/json" \
-d '{
"options": {
"isSelenium": true,
// Selenium-compatible options
}
}'
```
</details>
<br>
The Selenium API is fully compatible with Selenium's WebDriver protocol, so you can use any existing Selenium clients to connect to the Steel browser. **For more details on using Selenium with Steel, refer to the [Selenium Docs](https://docs.steel.dev/overview/guides/connect-with-selenium).**
### Quick Actions API
The `/scrape`, `/screenshot`, and `/pdf` endpoints let you quickly extract clean, well-formatted data from any webpage using the running Steel server. Ideal for simple, read-only, on-demand jobs:
<details open>
<summary><b>Scrape a Web Page</b></summary>
<br>
Extract the HTML content of a web page.
```bash
# Example using the Actions API
curl -X POST http://0.0.0.0:3000/v1/scrape \
-H "Content-Type: application/json" \
-d '{
"url": "https://example.com",
"waitFor": 1000
}'
```
</details>
<details>
<summary><b>Take a Screenshot</b></summary>
<br>
Take a screenshot of a web page.
```bash
# Example using the Actions API
curl -X POST http://0.0.0.0:3000/v1/screenshot \
-H "Content-Type: application/json" \
-d '{
"url": "https://example.com",
"fullPage": true
}' --output screenshot.png
```
</details>
<details>
<summary><b>Download a PDF</b></summary>
<br>
Download a PDF of a web page.
```bash
# Example using the Actions API
curl -X POST http://0.0.0.0:3000/v1/pdf \
-H "Content-Type: application/json" \
-d '{
"url": "https://example.com",
"fullPage": true
}' --output output.pdf
```
</details>
## Get involved
Steel browser is an open-source project, and we welcome contributions!
- Questions/ideas/feedback? Come hangout on [Discord](https://discord.gg/steel-dev)
- Found a bug? Open an issue on [GitHub](https://github.com/steel-dev/steel-browser/issues)
## License
[Apache 2.0](./LICENSE)
---
Made with ❤️ by the Steel team. | {
"source": "steel-dev/steel-browser",
"title": "README.md",
"url": "https://github.com/steel-dev/steel-browser/blob/main/README.md",
"date": "2024-11-01T18:15:29",
"stars": 3748,
"description": "🔥 Open Source Browser API for AI Agents & Apps. Steel Browser is a batteries-included browser instance that lets you automate the web without worrying about infrastructure.",
"file_size": 13589
} |
# Steel REPL
This package provides a simple REPL to interact with the browser instance you've created using the API.
The API exposes a WebSocket endpoint, allowing you to connect to the browser using Chrome DevTools Protocol (CDP) and use Puppeteer as usual.
## Quick Start
1. Ensure you have **Steel Browser** running, either via Docker or locally.
2. Run `npm start` to execute the script.
3. Modify `src/script.ts` as needed and rerun `npm start` to see your changes.
> Note: You might need to update the WebSocket endpoint in `src/script.ts` if your services isn't exposed on your network
For more details, refer to [Steel Browser Documentation](https://docs.steel.dev/). | {
"source": "steel-dev/steel-browser",
"title": "repl/README.md",
"url": "https://github.com/steel-dev/steel-browser/blob/main/repl/README.md",
"date": "2024-11-01T18:15:29",
"stars": 3748,
"description": "🔥 Open Source Browser API for AI Agents & Apps. Steel Browser is a batteries-included browser instance that lets you automate the web without worrying about infrastructure.",
"file_size": 681
} |
# React + TypeScript + Vite
This template provides a minimal setup to get React working in Vite with HMR and some ESLint rules.
Currently, two official plugins are available:
- [@vitejs/plugin-react](https://github.com/vitejs/vite-plugin-react/blob/main/packages/plugin-react/README.md) uses [Babel](https://babeljs.io/) for Fast Refresh
- [@vitejs/plugin-react-swc](https://github.com/vitejs/vite-plugin-react-swc) uses [SWC](https://swc.rs/) for Fast Refresh
## Expanding the ESLint configuration
If you are developing a production application, we recommend updating the configuration to enable type aware lint rules:
- Configure the top-level `parserOptions` property like this:
```js
parserOptions: {
ecmaVersion: 'latest',
sourceType: 'module',
project: ['./tsconfig.json', './tsconfig.node.json'],
tsconfigRootDir: __dirname,
},
```
- Replace `plugin:@typescript-eslint/recommended` to `plugin:@typescript-eslint/recommended-type-checked` or `plugin:@typescript-eslint/strict-type-checked`
- Optionally add `plugin:@typescript-eslint/stylistic-type-checked`
- Install [eslint-plugin-react](https://github.com/jsx-eslint/eslint-plugin-react) and add `plugin:react/recommended` & `plugin:react/jsx-runtime` to the `extends` list | {
"source": "steel-dev/steel-browser",
"title": "ui/README.md",
"url": "https://github.com/steel-dev/steel-browser/blob/main/ui/README.md",
"date": "2024-11-01T18:15:29",
"stars": 3748,
"description": "🔥 Open Source Browser API for AI Agents & Apps. Steel Browser is a batteries-included browser instance that lets you automate the web without worrying about infrastructure.",
"file_size": 1262
} |
---
name: Bug report
about: Create a report to help us improve
title: "[BUG] TITLE"
labels: ''
assignees: ''
---
Issue tracker is **ONLY** used for reporting bugs. New features should be discussed in our [Discord server](https://discord.gg/steel-dev).
**Describe the bug**
A clear and concise description of what the bug is.
**To Reproduce**
Steps to reproduce the behavior:
1. Go to '...'
2. Click on '....'
3. Scroll down to '....'
4. See error
**Expected behavior**
A clear and concise description of what you expected to happen.
**Screenshots**
If applicable, add screenshots to help explain your problem.
**Desktop (please complete the following information):**
- OS: [e.g. iOS]
- Browser [e.g. chrome, safari]
- Version [e.g. 22]
**Smartphone (please complete the following information):**
- Device: [e.g. iPhone6]
- OS: [e.g. iOS8.1]
- Browser [e.g. stock browser, safari]
- Version [e.g. 22]
**Additional context**
Add any other context about the problem here. | {
"source": "steel-dev/steel-browser",
"title": ".github/ISSUE_TEMPLATE/bug_report.md",
"url": "https://github.com/steel-dev/steel-browser/blob/main/.github/ISSUE_TEMPLATE/bug_report.md",
"date": "2024-11-01T18:15:29",
"stars": 3748,
"description": "🔥 Open Source Browser API for AI Agents & Apps. Steel Browser is a batteries-included browser instance that lets you automate the web without worrying about infrastructure.",
"file_size": 984
} |
# Contributor Covenant Code of Conduct
## Our Pledge
In the interest of fostering an open and welcoming environment, we as
contributors and maintainers pledge to make participation in our project and
our community a harassment-free experience for everyone, regardless of age, body
size, disability, ethnicity, gender identity and expression, level of experience,
nationality, personal appearance, race, religion, or sexual identity and
orientation.
## Our Standards
Examples of behavior that contributes to creating a positive environment
include:
- Using welcoming and inclusive language
- Being respectful of differing viewpoints and experiences
- Gracefully accepting constructive criticism
- Focusing on what is best for the community
- Showing empathy towards other community members
Examples of unacceptable behavior by participants include:
- The use of sexualized language or imagery and unwelcome sexual attention or
advances
- Trolling, insulting/derogatory comments, and personal or political attacks
- Public or private harassment
- Publishing others' private information, such as a physical or electronic
address, without explicit permission
- Other conduct which could reasonably be considered inappropriate in a
professional setting
## Our Responsibilities
Project maintainers are responsible for clarifying the standards of acceptable
behavior and are expected to take appropriate and fair corrective action in
response to any instances of unacceptable behavior.
Project maintainers have the right and responsibility to remove, edit, or
reject comments, commits, code, wiki edits, issues, and other contributions
that are not aligned to this Code of Conduct, or to ban temporarily or
permanently any contributor for other behaviors that they deem inappropriate,
threatening, offensive, or harmful.
## Scope
This Code of Conduct applies both within project spaces and in public spaces
when an individual is representing the project or its community. Examples of
representing a project or community includes using an official project e-mail
address, posting via an official social media account, or acting as an appointed
representative at an online or offline event. Representation of a project may be
further defined and clarified by project maintainers.
## Enforcement
Instances of abusive, harassing, or otherwise unacceptable behavior may be
reported by contacting an individual maintainer on:
### GitHub
- @gorillamoe
> (at `GitHub username` + `@github.com`).
### Discord
- gorillamoe
All complaints will be reviewed and investigated and will result in a response that
is deemed necessary and appropriate to the circumstances. The project team is
obligated to maintain confidentiality with regard to the reporter of an incident.
Further details of specific enforcement policies may be posted separately.
Project maintainers who do not follow or enforce the Code of Conduct in good
faith may face temporary or permanent repercussions as determined by other
members of the project's leadership.
## Attribution
This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 1.4,
available at [https://contributor-covenant.org/version/1/4][version]
[homepage]: https://contributor-covenant.org
[version]: https://contributor-covenant.org/version/1/4/ | {
"source": "mistweaverco/bananas",
"title": "CODE_OF_CONDUCT.md",
"url": "https://github.com/mistweaverco/bananas/blob/main/CODE_OF_CONDUCT.md",
"date": "2024-10-10T16:05:25",
"stars": 3716,
"description": "Bananas🍌, Cross-Platform screen 🖥️ sharing 📡 made simple ⚡. ",
"file_size": 3316
} |
# Contributing to Bananas Screen Sharing
Thanks for checking out Bananas Screen Sharing!
We're excited to hear and learn from you.
We've put together the following guidelines to
help you figure out where you can best be helpful.
## Table of Contents
0. [Types of contributions we're looking for](#types-of-contributions-were-looking-for)
1. [Ground rules & expectations](#ground-rules--expectations)
2. [How to contribute](#how-to-contribute)
3. [Style guide](#style-guide)
4. [Documentation](#documentation)
5. [Code](#code)
6. [Setting up your environment](#setting-up-your-environment)
7. [Community](#community)
## Types of contributions we're looking for
There are many ways you can directly contribute to Bananas Screen Sharing:
- Feature requests
- Bug reports
- Code contributions
- Writing or editing documentation
## Ground rules & expectations
Before we get started,
here are a few things we expect from you (and that you should expect from others):
- Be kind and thoughtful in your conversations around this project.
We all come from different backgrounds and projects,
which means we likely have different perspectives on "how open source is done."
Try to listen to others rather than convince them that your way is correct.
- Bananas is released with a [Contributor Code of Conduct](./CODE_OF_CONDUCT.md).
By participating in this project, you agree to abide by its terms.
- Please ensure that your contribution passes all tests if you open a pull request.
If there are test failures, you will need to address them before we can merge your contribution.
- When adding content, please consider if it is widely valuable.
Please don't add references or links to things you or your employer have created,
as others will do so if they appreciate it.
## How to contribute
If you'd like to contribute,
start by searching through the [pull requests](https://github.com/mistweaverco/bananas/pulls) to
see whether someone else has raised a similar idea or question.
If you don't see your idea listed, and you think it fits into the goals of this guide, open a pull request.
## Style guide
### Documentation
If you're writing documentation,
see the [style guide](.vale/styles) (which uses [vale](https://vale.sh)) to
help your prose match the rest of the documentation.
### Code
When writing code,
please follow these configurations:
- [eslint](./eslintrc.cjs)
- [EditorConfig](./.editorconfig)
- [yaml-lint](./.yamllint.yaml)
Most of them are automatically checked by the CI,
so you don't need to worry about them.
## Community
Discussions about the Bananas take place on:
- This repository's [Issues](https://github.com/mistweaverco/bananas/issues) and
[Pull Requests](https://github.com/mistweaverco/bananas/pulls) sections
- The [Bananas Discord server](https://discord.gg/BeN43eJVWS)
Anybody is welcome to join these conversations.
Wherever possible,
do not take these conversations to private channels,
including contacting the maintainers directly.
Keeping communication public means everybody can benefit and learn from the conversation. | {
"source": "mistweaverco/bananas",
"title": "CONTRIBUTING.md",
"url": "https://github.com/mistweaverco/bananas/blob/main/CONTRIBUTING.md",
"date": "2024-10-10T16:05:25",
"stars": 3716,
"description": "Bananas🍌, Cross-Platform screen 🖥️ sharing 📡 made simple ⚡. ",
"file_size": 3090
} |
# Privacy Policy
Effective Date: 2024-12-03
Your privacy is important to us.
This Privacy Policy outlines how we handle and protect your information when you use
Bananas Screen Sharing (the "App").
By using the App, you agree to the terms of this Privacy Policy.
### 1. Data Collection
We do not collect, store, or process any personal or usage data from users of the App.
The App functions solely to establish a peer-to-peer connection between users
No personal information, identifiers, or activity data are transmitted to us or any third-party;
excluding stun and turn servers for negotiation of connection details like IP addresses and ports.
### 2. Data Usage
The App interacts with stun and turn servers to establish a peer-to-peer connection between users.
### 3. Third-Party Services
The App uses the official stun server provided by Google
if not provided by the user.
This is required for the negotiation of connection details like IP addresses and ports,
to establish a peer-to-peer connection between users.
### 4. Security
Although we do not collect any data,
we prioritize security in the development and maintenance of the App to
ensure that your use of it remains safe.
The App only communicates with the stun or turn servers
that you can configure yourself,
for the purpose of establishing a peer-to-peer connection and
does not expose your data to any other services or entities.
### 5. User Consent
By using the App,
you consent to the interaction between the configured stun or turn servers and the App,
as described in this policy.
You understand that the App does not collect or store any personal data.
### 6. Changes to the Privacy Policy
We reserve the right to modify this Privacy Policy at any time.
Any changes will be posted on this page with an updated "Effective Date."
Your continued use of the App after changes to this Privacy Policy indicates
your acceptance of the revised terms.
### 7. Contact Us
If you have any questions or concerns about this Privacy Policy or the App,
please contact us via filing an issue on the
[GitHub repository](https://github.com/mistweaverco/bananas/issues/new). | {
"source": "mistweaverco/bananas",
"title": "PRIVACY.md",
"url": "https://github.com/mistweaverco/bananas/blob/main/PRIVACY.md",
"date": "2024-10-10T16:05:25",
"stars": 3716,
"description": "Bananas🍌, Cross-Platform screen 🖥️ sharing 📡 made simple ⚡. ",
"file_size": 2148
} |
<div align="center">

# Bananas Screen Sharing
[](https://getbananas.net/)
[](https://github.com/mistweaverco/bananas/releases/latest)
[Install](#install) • [Website](https://getbananas.net/) • [Tutorial](https://getbananas.net/tutorial) • [Privacy Policy](./PRIVACY.md) • [Terms of Service](./TOS.md) • [Code of Conduct](./CODE_OF_CONDUCT.md)
<p></p>
Bananas Screen Sharing is a simple and
easy-to-use screen sharing tool for Mac, Windows, and Linux.
It utilizes a peer-to-peer connection to share your screen with others,
without the need for an account or any server infrastructure
(except for the stun, turn and signaling servers that are needed for exchanging the initial connection information)
<p></p>
</div>
## Install
Grab the latest release from the
[GitHub releases page](https://github.com/mistweaverco/bananas/releases/latest).
Or if you are on Mac you can install it via homebrew with
```shell
brew install --cask bananas
``` | {
"source": "mistweaverco/bananas",
"title": "README.md",
"url": "https://github.com/mistweaverco/bananas/blob/main/README.md",
"date": "2024-10-10T16:05:25",
"stars": 3716,
"description": "Bananas🍌, Cross-Platform screen 🖥️ sharing 📡 made simple ⚡. ",
"file_size": 1212
} |
# Security Policy
## Supported Versions
Versions currently being supported with security updates.
| Version | Supported |
| ------- | ------------------ |
| 0.0.x | :white_check_mark: |
## Reporting a Vulnerability
Security vulnerabilites ahould be communicated with
the maintainers in private.
### GitHub
- @gorillamoe
> (at `GitHub username` + `@github.com`).
### Discord
- gorillamoe | {
"source": "mistweaverco/bananas",
"title": "SECURITY.md",
"url": "https://github.com/mistweaverco/bananas/blob/main/SECURITY.md",
"date": "2024-10-10T16:05:25",
"stars": 3716,
"description": "Bananas🍌, Cross-Platform screen 🖥️ sharing 📡 made simple ⚡. ",
"file_size": 407
} |
# Terms of Service
Terms of Service for Bananas Screen Sharing
Effective Date: 2024-12-03
These Terms of Service ("Terms") govern your use of the Bananas Screen Sharing (the "App").
By using the App, you agree to these Terms.
If you do not agree to these Terms, you may not use the App.
### 1. Acceptance of Terms
By installing, accessing, or using the App, you agree to comply with these Terms.
If you do not agree to these Terms,
you must not use the App.
We reserve the right to modify these Terms at any time,
and your continued use of the App after any such modifications indicates your acceptance of the new terms.
### 2. License
See [LICENSE](LICENSE) for the license under which the App is provided.
### 4. User Conduct
When using the App, you agree to:
Use the App solely for its intended purpose.
Not attempt to interfere with the App's functionality or access any other users' information.
### 5. Disclaimer of Warranties
The App is provided on an "as-is" and "as-available" basis,
without any warranties of any kind. We do not guarantee that the App will be error-free,
secure, or uninterrupted. You use the App at your own risk.
### 6. Limitation of Liability
To the maximum extent permitted by law,
we shall not be liable for any damages arising from the use or inability to use the App,
including but not limited to direct, indirect, incidental, or consequential damages.
This includes, without limitation, any loss of data,
interruption of service, or
issues resulting from third-party interactions (e.g., stun or turn servers).
### 7. Termination
We reserve the right to terminate your access to the App at any time for any reason,
including but not limited to your violation of these Terms.
Upon termination, the rights and licenses granted to you under these Terms will immediately cease.
### 8. Third-Party Services
The App may use third-party services, such as stun or turn servers,
to facilitate its functionality.
### 9. Governing Law
These Terms shall be governed and construed in accordance with the laws of Germany.
Any legal actions or disputes arising in connection with these Terms
will be resolved in the courts of Germany.
### 10. Changes to These Terms
We reserve the right to modify these Terms at any time.
Any changes will be posted on this page with an updated "Effective Date."
Your continued use of the App after changes to
the Terms indicates your acceptance of the modified terms.
### 11. Contact Us
If you have any questions or concerns about these Terms,
please contact us via filing an issue on the
[GitHub repository](https://github.com/mistweaverco/bananas/issues/new). | {
"source": "mistweaverco/bananas",
"title": "TOS.md",
"url": "https://github.com/mistweaverco/bananas/blob/main/TOS.md",
"date": "2024-10-10T16:05:25",
"stars": 3716,
"description": "Bananas🍌, Cross-Platform screen 🖥️ sharing 📡 made simple ⚡. ",
"file_size": 2640
} |
---
name: Bug report
about: Create a report to help us improve
title: ''
labels: bug
assignees: ''
---
**Describe the bug**
A clear and concise description of what the bug is.
**To Reproduce**
Steps to reproduce the behavior:
1. Go to '...'
2. Click on '....'
3. Scroll down to '....'
4. See error
**Expected behavior**
A clear and concise description of what you expected to happen.
**Screenshots**
If applicable, add screenshots to help explain your problem.
**Desktop (please complete the following information):**
- OS: [e.g. iOS]
- Version [e.g. 22]
**Additional context**
Add any other context about the problem here. | {
"source": "mistweaverco/bananas",
"title": ".github/ISSUE_TEMPLATE/bug_report.md",
"url": "https://github.com/mistweaverco/bananas/blob/main/.github/ISSUE_TEMPLATE/bug_report.md",
"date": "2024-10-10T16:05:25",
"stars": 3716,
"description": "Bananas🍌, Cross-Platform screen 🖥️ sharing 📡 made simple ⚡. ",
"file_size": 631
} |
---
name: Feature request
about: Suggest an idea for this project
title: ''
labels: enhancement
assignees: ''
---
**Is your feature request related to a problem? Please describe.**
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
**Describe alternatives you've considered**
A clear and concise description of any alternative solutions or features you've considered.
**Additional context**
Add any other context or screenshots about the feature request here. | {
"source": "mistweaverco/bananas",
"title": ".github/ISSUE_TEMPLATE/feature_request.md",
"url": "https://github.com/mistweaverco/bananas/blob/main/.github/ISSUE_TEMPLATE/feature_request.md",
"date": "2024-10-10T16:05:25",
"stars": 3716,
"description": "Bananas🍌, Cross-Platform screen 🖥️ sharing 📡 made simple ⚡. ",
"file_size": 602
} |
# Contributing to Awesome MCP Servers
Contributions are welcome and encouraged! Whether you're fixing a typo, adding a new server, or suggesting improvements, your help is appreciated.
## How to Contribute
1. **Fork the repository:** Click the "Fork" button in the top right corner of the GitHub page.
2. **Create a new branch:** Create a new branch for your changes. This keeps your changes separate from the main project until they're ready to be merged. A good branch name describes the changes you're making, e.g., `add-new-server` or `fix-typo`.
```bash
git checkout -b add-new-server
```
3. **Make your changes:** Edit the `README.md` file with your additions or corrections. Please follow the existing format and style. When adding a new server, make sure to include:
* The server name, linked to its repository.
* A brief description of the server's functionality.
* Categorize the server appropriately under the relevant section. If a new category is needed, please create one and maintain alphabetical order.
4. **Commit your changes:** Commit your changes with a clear and concise message explaining what you've done.
```bash
git commit -m "Add new XYZ server"
```
5. **Push your branch:** Push your branch to your forked repository.
```bash
git push origin add-new-server
```
6. **Create a pull request:** Go to the original repository and click the "New pull request" button. Select your forked repository and branch. Provide a clear title and description of your changes in the pull request.
7. **Review and merge:** Your pull request will be reviewed by the maintainers. They may suggest changes or ask for clarification. Once the review is complete, your changes will be merged into the main project.
## Guidelines
* **Keep it consistent:** Follow the existing format and style of the `README.md` file. This includes formatting, capitalization, and punctuation.
* **Alphabetical order:** Maintain alphabetical order within each category of servers. This makes it easier to find specific servers.
* **Accurate information:** Ensure that all information is accurate and up-to-date. Double-check links and descriptions before submitting your changes.
* **One server per line:** List each server on a separate line for better readability.
* **Clear descriptions:** Write concise and informative descriptions for each server. Explain what the server does and what its key features are.
Thank you for contributing! | {
"source": "punkpeye/awesome-mcp-servers",
"title": "CONTRIBUTING.md",
"url": "https://github.com/punkpeye/awesome-mcp-servers/blob/main/CONTRIBUTING.md",
"date": "2024-11-30T04:49:10",
"stars": 3664,
"description": "A collection of MCP servers.",
"file_size": 2496
} |
# 素晴らしいMCPサーバー [](https://awesome.re)
[](README.md)
[](README-zh.md)
[](README-ja.md)
[](https://glama.ai/mcp/discord)
[](https://www.reddit.com/r/mcp/)
素晴らしいモデルコンテキストプロトコル(MCP)サーバーの厳選リスト。
* [MCPとは何ですか?](#what-is-mcp)
* [チュートリアル](#tutorials)
* [サーバー実装](#server-implementations)
* [フレームワーク](#frameworks)
* [ヒントとコツ](#tips-and-tricks)
## MCPとは何ですか?
[MCP](https://modelcontextprotocol.io/) は、標準化されたサーバー実装を通じて、AIモデルがローカルおよびリモートリソースと安全に対話できるようにするオープンプロトコルです。このリストは、ファイルアクセス、データベース接続、API統合、その他のコンテキストサービスを通じてAIの機能を拡張する、実運用および実験的なMCPサーバーに焦点を当てています。
## チュートリアル
* [モデルコンテキストプロトコル (MCP) クイックスタート](https://glama.ai/blog/2024-11-25-model-context-protocol-quickstart)
* [SQLiteデータベースを使用するためのClaudeデスクトップアプリのセットアップ](https://youtu.be/wxCCzo9dGj0)
## コミュニティ
* [r/mcp Reddit](https://www.reddit.com/r/mcp)
* [Discordサーバー](https://glama.ai/mcp/discord)
## 凡例
* 🎖️ – 公式実装
* 🐍 – Pythonコードベース
* 📇 – TypeScriptコードベース
* 🏎️ – Goコードベース
* #️⃣ – C#コードベース
* ☁️ - クラウドサービス
* 🏠 - ローカルサービス
## サーバー実装
* 📂 - [ブラウザ自動化](#browser-automation)
* ☁️ - [クラウドプラットフォーム](#cloud-platforms)
* 💬 - [コミュニケーション](#communication)
* 👤 - [顧客データプラットフォーム](#customer-data-platforms)
* 🗄️ - [データベース](#databases)
* 🛠️ - [開発者ツール](#developer-tools)
* 📂 - [ファイルシステム](#file-systems)
* 🧠 - [知識と記憶](#knowledge--memory)
* 🗺️ - [位置情報サービス](#location-services)
* 📊 - [監視](#monitoring)
* 🔎 - [検索](#search)
* 🔄 - [旅行と交通](#travel-and-transportation)
* 🔄 - [バージョン管理](#version-control)
* 🛠️ - [その他のツールと統合](#other-tools-and-integrations)
### 📂 <a name="browser-automation"></a>ブラウザ自動化
Webコンテンツのアクセスと自動化機能。AIに優しい形式でWebコンテンツを検索、スクレイピング、処理することができます。
- [@executeautomation/playwright-mcp-server](https://github.com/executeautomation/mcp-playwright) 🌐⚡️ - Playwrightを使用したブラウザ自動化とWebスクレイピングのためのMCPサーバー
- [@automatalabs/mcp-server-playwright](https://github.com/Automata-Labs-team/MCP-Server-Playwright) 🌐🖱️ - Playwrightを使用したブラウザ自動化のためのMCPサーバー
- [@modelcontextprotocol/server-puppeteer](https://github.com/modelcontextprotocol/servers/tree/main/src/puppeteer) 📇 🏠 - Webスクレイピングとインタラクションのためのブラウザ自動化
- [@kimtaeyoon83/mcp-server-youtube-transcript](https://github.com/kimtaeyoon83/mcp-server-youtube-transcript) 📇 ☁️ - AI分析のためのYouTube字幕とトランスクリプトの取得
- [@kimtth/mcp-aoai-web-browsing](https://github.com/kimtth/mcp-aoai-web-browsing) 🐍 🏠 - Azure OpenAIとPlaywrightを使用した「最小限の」サーバー/クライアントMCP実装。
### ☁️ <a name="cloud-platforms"></a>クラウドプラットフォーム
クラウドプラットフォームサービスの統合。クラウドインフラストラクチャとサービスの管理と対話を可能にします。
- [Cloudflare MCP Server](https://github.com/cloudflare/mcp-server-cloudflare) 🎖️ 📇 ☁️ - Workers、KV、R2、D1を含むCloudflareサービスとの統合
- [Kubernetes MCP Server](https://github.com/strowk/mcp-k8s-go) - 🏎️ ☁️ MCPを通じたKubernetesクラスター操作
### 💬 <a name="communication"></a>コミュニケーション
メッセージ管理とチャネル操作のためのコミュニケーションプラットフォームとの統合。AIモデルがチームコミュニケーションツールと対話できるようにします。
- [@modelcontextprotocol/server-slack](https://github.com/modelcontextprotocol/servers/tree/main/src/slack) 📇 ☁️ - チャネル管理とメッセージングのためのSlackワークスペース統合
- [@modelcontextprotocol/server-bluesky](https://github.com/keturiosakys/bluesky-context-server) 📇 ☁️ - クエリとインタラクションのためのBlueskyインスタンス統合
- [MarkusPfundstein/mcp-gsuite](https://github.com/MarkusPfundstein/mcp-gsuite) - 🐍 ☁️ - GmailとGoogleカレンダーとの統合。
- [gotoolkits/wecombot](https://github.com/gotoolkits/mcp-wecombot-server.git) - 🚀 ☁️ - MCPサーバーアプリケーションは、WeComグループロボットにさまざまなタイプのメッセージを送信します。
### 👤 <a name="customer-data-platforms"></a>顧客データプラットフォーム
顧客データプラットフォーム内の顧客プロファイルへのアクセスを提供します。
- [sergehuber/inoyu-mcp-unomi-server](https://github.com/sergehuber/inoyu-mcp-unomi-server) 📇 ☁️ - Apache Unomi CDPサーバー上のプロファイルにアクセスし、更新するためのMCPサーバー。
### 🗄️ <a name="databases"></a>データベース
スキーマ検査機能を備えた安全なデータベースアクセス。読み取り専用アクセスを含む構成可能なセキュリティ制御を使用してデータをクエリおよび分析することができます。
- [cr7258/elasticsearch-mcp-server](https://github.com/cr7258/elasticsearch-mcp-server) 🐍 🏠 - MCPサーバーの実装で、Elasticsearchとのインタラクションを提供します
- [domdomegg/airtable-mcp-server](https://github.com/domdomegg/airtable-mcp-server) 📇 🏠 - スキーマ検査、読み取り/書き込み機能を備えた Airtable データベース統合
- [LucasHild/mcp-server-bigquery](https://github.com/LucasHild/mcp-server-bigquery) 🐍 ☁️ - スキーマ検査とクエリ機能を備えたBigQueryデータベース統合
- [ergut/mcp-bigquery-server](https://github.com/ergut/mcp-bigquery-server) 📇 ☁️ - Google BigQuery統合のためのサーバー実装で、直接的なBigQueryデータベースアクセスとクエリ機能を提供
- [designcomputer/mysql_mcp_server](https://github.com/designcomputer/mysql_mcp_server) 🐍 🏠 - 構成可能なアクセス制御、スキーマ検査、包括的なセキュリティガイドラインを備えたMySQLデータベース統合
- [@modelcontextprotocol/server-postgres](https://github.com/modelcontextprotocol/servers/tree/main/src/postgres) 📇 🏠 - スキーマ検査とクエリ機能を備えたPostgreSQLデータベース統合
- [@modelcontextprotocol/server-sqlite](https://github.com/modelcontextprotocol/servers/tree/main/src/sqlite) 🐍 🏠 - 組み込みの分析機能を備えたSQLiteデータベース操作
- [@joshuarileydev/supabase-mcp-server](https://github.com/joshuarileydev/supabase) - Supabaseでプロジェクトと組織を管理および作成するためのSupabase MCPサーバー
- [ktanaka101/mcp-server-duckdb](https://github.com/ktanaka101/mcp-server-duckdb) 🐍 🏠 - スキーマ検査とクエリ機能を備えたDuckDBデータベース統合
- [QuantGeekDev/mongo-mcp](https://github.com/QuantGeekDev/mongo-mcp) 📇 🏠 - LLMがデータベースと直接対話できるようにするMongoDB統合。
- [tinybirdco/mcp-tinybird](https://github.com/tinybirdco/mcp-tinybird) 🐍 ☁️ - クエリとAPI機能を備えたTinybird統合
- [kiliczsh/mcp-mongo-server](https://github.com/kiliczsh/mcp-mongo-server) 📇 🏠 - MongoDBのためのモデルコンテキストプロトコルサーバー
- [KashiwaByte/vikingdb-mcp-server](https://github.com/KashiwaByte/vikingdb-mcp-server) 🐍 ☁️ - コレクションとインデックスの紹介、ベクトルストアと検索機能を備えたVikingDB統合。
- [runekaagaard/mcp-alchemy](https://github.com/runekaagaard/mcp-alchemy) 🐍 🏠 - PostgreSQL、MySQL、MariaDB、SQLite、Oracle、MS SQL Serverなど多数のデータベースをサポートするSQLAlchemyベースの汎用データベース統合。スキーマと関係の検査、大規模データセット分析機能を備えています。
### 💻 <a name="developer-tools"></a>開発者ツール
開発ワークフローと環境管理を強化するツールと統合。
- [QuantGeekDev/docker-mcp](https://github.com/QuantGeekDev/docker-mcp) 🏎️ 🏠 - MCPを通じたDockerコンテナの管理と操作
- [zcaceres/fetch-mcp](https://github.com/zcaceres/fetch-mcp) 📇 🏠 - JSON、テキスト、HTMLデータを柔軟に取得するためのMCPサーバー
- [zcaceres/gtasks-mcp](https://github.com/zcaceres/gtasks-mcp) - 📇 ☁️ - Google タスクを管理するための MCP サーバー
- [snaggle-ai/openapi-mcp-server](https://github.com/snaggle-ai/openapi-mcp-server) 🏎️ 🏠 - Open API spec (v3) を使用して任意のHTTP/REST APIサーバーに接続
- [@joshuarileydev/terminal-mcp-server](https://www.npmjs.com/package/@joshuarileydev/terminal-mcp-server) 📇 🏠 - 任意のシェルターミナルコマンドを実行するためのMCPサーバー
- [tumf/mcp-text-editor](https://github.com/tumf/mcp-text-editor) - ラインエディタ 行単位の取得と編集ができるので、特に大きなファイルの一部書き換えを効率的に行う
- [ferrislucas/iterm-mcp](https://github.com/ferrislucas/iterm-mcp) 🖥️ 🛠️ 💬 - iTermへのアクセスを提供するモデルコンテキストプロトコルサーバー。コマンドを実行し、iTermターミナルで見た内容について質問することができます。
### 📂 <a name="file-systems"></a>ファイルシステム
構成可能な権限を備えたローカルファイルシステムへの直接アクセスを提供します。指定されたディレクトリ内のファイルを読み取り、書き込み、管理することができます。
- [@modelcontextprotocol/server-filesystem](https://github.com/modelcontextprotocol/servers/tree/main/src/filesystem) 📇 🏠 - ローカルファイルシステムへの直接アクセス。
- [@modelcontextprotocol/server-google-drive](https://github.com/modelcontextprotocol/servers/tree/main/src/gdrive) 📇 ☁️ - ファイルのリスト、読み取り、検索のためのGoogle Drive統合
- [mark3labs/mcp-filesystem-server](https://github.com/mark3labs/mcp-filesystem-server) 🏎️ 🏠 - ローカルファイルシステムアクセスのためのGolang実装。
### 🧠 <a name="knowledge--memory"></a>知識と記憶
知識グラフ構造を使用した永続的なメモリストレージ。セッション間で構造化情報を維持およびクエリすることができます。
- [@modelcontextprotocol/server-memory](https://github.com/modelcontextprotocol/servers/tree/main/src/memory) 📇 🏠 - コンテキストを維持するための知識グラフベースの長期記憶システム
- [/CheMiguel23/MemoryMesh](https://github.com/CheMiguel23/MemoryMesh) 📇 🏠 - AIロールプレイとストーリー生成に焦点を当てた強化されたグラフベースのメモリ
### 🗺️ <a name="location-services"></a>位置情報サービス
地理および位置ベースのサービス統合。地図データ、方向、および場所情報へのアクセスを提供します。
- [@modelcontextprotocol/server-google-maps](https://github.com/modelcontextprotocol/servers/tree/main/src/google-maps) 📇 ☁️ - 位置情報サービス、ルート計画、および場所の詳細のためのGoogle Maps統合
### 📊 <a name="monitoring"></a>監視
アプリケーション監視データへのアクセスと分析。エラーレポートとパフォーマンスメトリクスをレビューすることができます。
- [@modelcontextprotocol/server-sentry](https://github.com/modelcontextprotocol/servers/tree/main/src/sentry) 🐍 ☁️ - エラートラッキングとパフォーマンス監視のためのSentry.io統合
- [@modelcontextprotocol/server-raygun](https://github.com/MindscapeHQ/mcp-server-raygun) 📇 ☁️ - クラッシュレポートとリアルユーザーモニタリングのためのRaygun API V3統合
### 🔎 <a name="search"></a>検索
- [@modelcontextprotocol/server-brave-search](https://github.com/modelcontextprotocol/servers/tree/main/src/brave-search) 📇 ☁️ - Braveの検索APIを使用したWeb検索機能
- [@angheljf/nyt](https://github.com/angheljf/nyt) 📇 ☁️ - NYTimes APIを使用して記事を検索
- [@modelcontextprotocol/server-fetch](https://github.com/modelcontextprotocol/servers/tree/main/src/fetch) 🐍 🏠 ☁️ - AI消費のための効率的なWebコンテンツの取得と処理
- [ac3xx/mcp-servers-kagi](https://github.com/ac3xx/mcp-servers-kagi) 📇 ☁️ - Kagi検索API統合
- [theishangoswami/exa-mcp-server](https://github.com/theishangoswami/exa-mcp-server) 📇 ☁️ - Exa AI検索API
- [exa-labs/exa-mcp-server](https://github.com/exa-labs/exa-mcp-server) 🎖️ 📇 ☁️ – モデルコンテキストプロトコル(MCP)サーバーは、ClaudeなどのAIアシスタントがExa AI検索APIを使用してWeb検索を行うことを可能にします。この設定により、AIモデルは安全かつ制御された方法でリアルタイムのWeb情報を取得できます。
- [fatwang2/search1api-mcp](https://github.com/fatwang2/search1api-mcp) 📇 ☁️ - search1apiを介した検索(有料APIキーが必要)
- [Tomatio13/mcp-server-tavily](https://github.com/Tomatio13/mcp-server-tavily) ☁️ 🐍 – Tavily AI検索API
- [blazickjp/arxiv-mcp-server](https://github.com/blazickjp/arxiv-mcp-server) ☁️ 🐍 - ArXiv研究論文を検索
- [mzxrai/mcp-webresearch](https://github.com/mzxrai/mcp-webresearch) 🔍📚 - Googleを検索し、任意のトピックに関する深いWebリサーチを行う
- [andybrandt/mcp-simple-arxiv](https://github.com/andybrandt/mcp-simple-arxiv) - 🐍 ☁️ MCPを使用してLLMがArXivの論文を検索および読む
- [apify/mcp-server-rag-web-browser](https://github.com/apify/mcp-server-rag-web-browser) 📇 ☁️ - Apify の RAG Web Browser Actor 用の MCP サーバーで、ウェブ検索を実行し、URL をスクレイピングし、Markdown 形式でコンテンツを返します。
- [Ihor-Sokoliuk/MCP-SearXNG](https://github.com/ihor-sokoliuk/mcp-searxng) 📇 🏠/☁️ - [SearXNG](https://docs.searxng.org)のモデルコンテキストプロトコルサーバー
- [erithwik/mcp-hn](https://github.com/erithwik/mcp-hn) 🐍 ☁️ - Hacker Newsの検索、トップストーリーの取得などを行うMCPサーバー。
- [chanmeng/google-news-mcp-server](https://github.com/ChanMeng666/server-google-news) 📇 ☁️ - 自動トピック分類、多言語サポート、[SerpAPI](https://serpapi.com/)を通じたヘッドライン、ストーリー、関連トピックの包括的な検索機能を備えたGoogle News統合。
### 🔒 <a name="security"></a>セキュリティ
- [Security Audit MCP Server](https://github.com/qianniuspace/mcp-security-audit) 📇🛡️☁️ 強力なモデルコンテキストプロトコル(MCP)サーバーで、npmパッケージ依存関係のセキュリティ脆弱性を監査します。リモートnpmレジストリ統合を備えたリアルタイムセキュリティチェックを使用して構築されています。
### 🚆 <a name="travel-and-transportation"></a>旅行と交通
旅行および交通情報へのアクセス。スケジュール、ルート、およびリアルタイムの旅行データをクエリすることができます。
- [NS Travel Information MCP Server](https://github.com/r-huijts/ns-mcp-server) 📇 ☁️ - オランダ鉄道(NS)の旅行情報、スケジュール、およびリアルタイムの更新にアクセス
### 🔄 <a name="version-control"></a>バージョン管理
Gitリポジトリおよびバージョン管理プラットフォームとの対話。標準化されたAPIを通じて、リポジトリ管理、コード分析、プルリクエスト処理、問題追跡、およびその他のバージョン管理操作を実行できます。
- [@modelcontextprotocol/server-github](https://github.com/modelcontextprotocol/servers/tree/main/src/github) 📇 ☁️ - リポジトリ管理、PR、問題などのためのGitHub API統合
- [@modelcontextprotocol/server-gitlab](https://github.com/modelcontextprotocol/servers/tree/main/src/gitlab) 📇 ☁️ 🏠 - プロジェクト管理およびCI/CD操作のためのGitLabプラットフォーム統合
- [@modelcontextprotocol/server-git](https://github.com/modelcontextprotocol/servers/tree/main/src/git) 🐍 🏠 - ローカルリポジトリの読み取り、検索、および分析を含む直接的なGitリポジトリ操作
### 🛠️ <a name="other-tools-and-integrations"></a>その他のツールと統合
- [apify/actors-mcp-server](https://github.com/apify/actors-mcp-server) 📇 ☁️ - 3,000以上の事前構築されたクラウドツール(Actors として知られる)を使用して、ウェブサイト、eコマース、ソーシャルメディア、検索エンジン、地図などからデータを抽出できます。
- [zcaceres/markdownify-mcp](https://github.com/zcaceres/markdownify-mcp) 📇 🏠 - ほぼすべてのファイルやウェブコンテンツをMarkdownに変換するMCPサーバー
- [mzxrai/mcp-openai](https://github.com/mzxrai/mcp-openai) 📇 ☁️ - OpenAIの最も賢いモデルとチャット
- [mrjoshuak/godoc-mcp](https://github.com/mrjoshuak/godoc-mcp) 🏎️ 🏠 - Goドキュメントサーバーで、AIアシスタントがパッケージドキュメントとタイプにスマートにアクセスできるようにします。
- [pierrebrunelle/mcp-server-openai](https://github.com/pierrebrunelle/mcp-server-openai) 🐍 ☁️ - MCPプロトコルを使用してClaudeから直接OpenAIモデルにクエリを送信
- [@modelcontextprotocol/server-everything](https://github.com/modelcontextprotocol/servers/tree/main/src/everything) 📇 🏠 - MCPプロトコルのすべての機能を実行するMCPサーバー
- [baba786/phabricator-mcp-server](https://github.com/baba786/phabricator-mcp-server) 🐍 ☁️ - Phabricator APIとの対話
- [MarkusPfundstein/mcp-obsidian](https://github.com/MarkusPfundstein/mcp-obsidian) 🐍 ☁️ 🏠 - REST APIを介してObsidianと対話
- [calclavia/mcp-obsidian](https://github.com/calclavia/mcp-obsidian) 📇 🏠 - これは、Claude Desktop(または任意のMCPクライアント)がMarkdownノートを含むディレクトリ(Obsidianボールトなど)を読み取り、検索できるようにするコネクタです。
- [anaisbetts/mcp-youtube](https://github.com/anaisbetts/mcp-youtube) 📇 ☁️ - YouTube字幕の取得
- [danhilse/notion_mcp](https://github.com/danhilse/notion_mcp) 🐍 ☁️ - NotionのAPIと統合して個人のToDoリストを管理
- [rusiaaman/wcgw](https://github.com/rusiaaman/wcgw/blob/main/src/wcgw/client/mcp_server/Readme.md) 🐍 🏠 - 自律的なシェル実行、コンピュータ制御、およびコーディングエージェント。(Mac)
- [reeeeemo/ancestry-mcp](https://github.com/reeeeemo/ancestry-mcp) 🐍 🏠 - AIが.gedファイルと遺伝データを読み取ることができるようにします。
- [sirmews/apple-notes-mcp](https://github.com/sirmews/apple-notes-mcp) 🐍 🏠 - AIがローカルのApple Notesデータベースから読み取ることができるようにします(macOSのみ)
- [anjor/coinmarket-mcp-server](https://github.com/anjor/coinmarket-mcp-server) 🐍 🏠 - 暗号通貨のリストと見積もりを取得するためのCoinmarket API統合
- [suekou/mcp-notion-server](https://github.com/suekou/mcp-notion-server) 📇 🏠 - Notion APIとの対話
- [amidabuddha/unichat-mcp-server](https://github.com/amidabuddha/unichat-mcp-server) 🐍/📇 ☁️ - MCPプロトコルを使用してOpenAI、MistralAI、Anthropic、xAI、またはGoogle AIにリクエストを送信するためのツールまたは事前定義されたプロンプト。ベンダーAPIキーが必要
- [g0t4/mcp-server-commands](https://github.com/g0t4/mcp-server-commands) 📇 🏠 - コマンドを実行し、その出力を含める。ツールとプロンプト。
- [evalstate/mcp-miro](https://github.com/evalstate/mcp-miro) 📇 ☁️ - MIROホワイトボードにアクセスし、アイテムを一括作成および読み取り。REST APIのOAUTHキーが必要。
- [sooperset/mcp-atlassian](https://github.com/sooperset/mcp-atlassian) 🐍 ☁️ - Confluenceワークスペースの自然言語検索とコンテンツアクセス
- [pyroprompts/any-chat-completions-mcp](https://github.com/pyroprompts/any-chat-completions-mcp) - Perplexity、Groq、xAIなどの他のOpenAI SDK互換のチャット完了APIとチャット
- [anaisbetts/mcp-installer](https://github.com/anaisbetts/mcp-installer) 🐍 🏠 - 他のMCPサーバーをインストールするMCPサーバー。
- [tanigami/mcp-server-perplexity](https://github.com/tanigami/mcp-server-perplexity) 🐍 ☁️ - Perplexity APIとの対話。
- [future-audiences/wikimedia-enterprise-model-context-protocol](https://gitlab.wikimedia.org/repos/future-audiences/wikimedia-enterprise-model-context-protocol) 🐍 ☁️ - Wikipedia記事検索API
- [andybrandt/mcp-simple-timeserver](https://github.com/andybrandt/mcp-simple-timeserver) 🐍 🏠☁️ - クライアントマシンのローカル時間またはNTPサーバーからの現在のUTC時間を確認するためのMCPサーバー
- [andybrandt/mcp-simple-openai-assistant](https://github.com/andybrandt/mcp-simple-openai-assistant) - 🐍 ☁️ MCPを使用してOpenAIアシスタントと対話(Claudeは任意のGPTモデルをアシスタントとして使用できます)
- [@joshuarileydev/simulator-mcp-server](https://www.npmjs.com/package/@joshuarileydev/simulator-mcp-server) - 📇 🏠 iOSシミュレータを制御し、シミュレータを起動し、アプリをインストール/起動するためのMCPサーバー。
- [tumf/mcp-shell-server](https://github.com/tumf/mcp-shell-server) シェルからホワイトリストにあるコマンドを実行して結果を返すMCPサーバ
- [apinetwork/piapi-mcp-server](https://github.com/apinetwork/piapi-mcp-server) 📇 ☁️ PiAPI MCPサーバーは、ユーザーがClaudeや他のMCP互換アプリから直接Midjourney/Flux/Kling/Hunyuan/Udio/Trellisでメディアコンテンツを生成することを可能にします。
- [gotoolkits/DifyWorkflow](https://github.com/gotoolkits/mcp-difyworkflow-server) - 🚀 ☁️ MCP サーバーの Tools を使用して、Dify AI プラットフォーム上でカスタムされたワークフローを検索および実行する
- [boilingdata/mcp-server-and-gw](https://github.com/boilingdata/mcp-server-and-gw) サンプルサーバーとMCPクライアントを備えたMCP stdioからHTTP SSEへのトランスポートゲートウェイ。
- [lightconetech/mcp-gateway](https://github.com/lightconetech/mcp-gateway) MCP SSEサーバーのゲートウェイデモ。
- [sparfenyuk/mcp-proxy](https://github.com/sparfenyuk/mcp-proxy) 🐍 MCP stdioからSSEへのトランスポートゲートウェイ。
## フレームワーク
- [Genkit MCP](https://github.com/firebase/genkit/tree/main/js/plugins/mcp) 📇 – [Genkit](https://github.com/firebase/genkit/tree/main) とモデルコンテキストプロトコル(MCP)との統合を提供します。
- [@modelcontextprotocol/server-langchain](https://github.com/rectalogic/langchain-mcp) 🐍 - LangChainでのMCPツール呼び出しサポートを提供し、LangChainワークフローにMCPツールを統合できるようにします。
- [mark3labs/mcp-go](https://github.com/mark3labs/mcp-go) 🏎️ - MCPサーバーとクライアントを構築するためのGolang SDK。
- [FastMCP](https://github.com/jlowin/fastmcp) 🐍 - PythonでMCPサーバーを構築するための高レベルフレームワーク
- [mcp-rs-template](https://github.com/linux-china/mcp-rs-template) 🦀 - RustのためのMCP CLIサーバーテンプレート
- [Foxy Contexts](https://github.com/strowk/foxy-contexts) 🏎️ - 機能テストを含む宣言的にMCPサーバーを記述するためのGolangライブラリ
- [salty-flower/ModelContextProtocol.NET](https://github.com/salty-flower/ModelContextProtocol.NET) #️⃣🏠 - .NET 9上でNativeAOT対応のMCPサーバーを構築するためのC# SDK ⚡ 🔌
- [@marimo-team/codemirror-mcp](https://github.com/marimo-team/codemirror-mcp) - リソースメンションとプロンプトコマンドのためのModel Context Protocol (MCP)を実装するCodeMirror拡張
## クライアント
- [SecretiveShell/MCP-Bridge](https://github.com/SecretiveShell/MCP-Bridge) 🐍 既存のOpenAI互換クライアントでMCPを使用するためのOpenAIミドルウェアプロキシ
- [3choff/MCP-Chatbot](https://github.com/3choff/mcp-chatbot) シンプルでありながら強力な⭐CLIチャットボットで、ツールサーバーを任意のOpenAI互換のLLM APIと統合します。
- [zed-industries/zed](https://github.com/zed-industries/zed) Atomの作成者によるマルチプレイヤーコードエディタ
- [firebase/genkit](https://github.com/firebase/genkit) エージェントおよびデータ変換フレームワーク
- [continuedev/continue](https://github.com/continuedev/continue) VSCodeの自動補完およびチャットツール(フル機能サポート)
- [MCP-Connect](https://github.com/EvalsOne/MCP-Connect) クラウドベースのAIサービスがローカルのStdioベースのMCPサーバーにHTTP/HTTPSリクエストでアクセスできるようにするツール
## ヒントとコツ
### LLMがMCPを使用する方法を通知するための公式プロンプト
モデルコンテキストプロトコルについてClaudeに質問したいですか?
プロジェクトを作成し、このファイルを追加します:
https://modelcontextprotocol.io/llms-full.txt
これで、ClaudeはMCPサーバーの作成方法やその動作について質問に答えることができます。
- https://www.reddit.com/r/ClaudeAI/comments/1h3g01r/want_to_ask_claude_about_model_context_protocol/
## スター履歴
<a href="https://star-history.com/#punkpeye/awesome-mcp-servers&Date">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://api.star-history.com/svg?repos=punkpeye/awesome-mcp-servers&type=Date&theme=dark" />
<source media="(prefers-color-scheme: light)" srcset="https://api.star-history.com/svg?repos=punkpeye/awesome-mcp-servers&type=Date" />
<img alt="Star History Chart" src="https://api.star-history.com/svg?repos=punkpeye/awesome-mcp-servers&type=Date" />
</picture>
</a> | {
"source": "punkpeye/awesome-mcp-servers",
"title": "README-ja.md",
"url": "https://github.com/punkpeye/awesome-mcp-servers/blob/main/README-ja.md",
"date": "2024-11-30T04:49:10",
"stars": 3664,
"description": "A collection of MCP servers.",
"file_size": 18491
} |
# 精选的 MCP 服务器 [](https://awesome.re)
[](README.md)
[](README-zh.md)
[](README-ja.md)
[](https://glama.ai/mcp/discord)
[](https://www.reddit.com/r/mcp/)
精选的优秀模型上下文协议 (MCP) 服务器列表。
* [什么是MCP?](#what-is-mcp)
* [教程](#tutorials)
* [Server 实现](#server-implementations)
* [框架](#frameworks)
* [实用工具](#utilities)
* [客户端](#clients)
* [提示和技巧](#tips-and-tricks)
## 什么是MCP?
[MCP](https://modelcontextprotocol.io/) 是一种开放协议,通过标准化的服务器实现,使 AI 模型能够安全地与本地和远程资源进行交互。此列表重点关注可用于生产和实验性的 MCP 服务器,这些服务器通过文件访问、数据库连接、API 集成和其他上下文服务来扩展 AI 功能。
## 教程
* [Model Context Protocol (MCP) 快速开始](https://glama.ai/blog/2024-11-25-model-context-protocol-quickstart)
* [设置 Claude 桌面应用程序以使用 SQLite 数据库](https://youtu.be/wxCCzo9dGj0)
## 社区
* [r/mcp Reddit](https://www.reddit.com/r/mcp)
* [Discord 服务](https://glama.ai/mcp/discord)
## 说明
* 🎖️ – 官方实现
* 编程语言
* 🐍 – Python 代码库
* 📇 – TypeScript 代码库
* 🏎️ – Go 代码库
* 🦀 – Rust 代码库
* #️⃣ - C# 代码库
* ☕ - Java 代码库
* 范围
* ☁️ - 云服务
* 🏠 - 本地服务
* 操作系统
* 🍎 – For macOS
* 🪟 – For Windows
> [!NOTE]
> 关于本地 🏠 和云 ☁️ 的区别:
> * 当 MCP 服务器与本地安装的软件通信时使用本地服务,例如控制 Chrome 浏览器。
> * 当 MCP 服务器与远程 API 通信时使用网络服务,例如天气 API。
## 服务器实现
> [!NOTE]
> 我们现在有一个与存储库同步的[基于 Web 的目录](https://glama.ai/mcp/servers)。
* 📂 - [浏览器自动化](#browser-automation)
* 🎨 - [艺术与文化](#art-and-culture)
* ☁️ - [云平台](#cloud-platforms)
* 🖥️ - [命令行](#command-line)
* 💬 - [社交](#communication)
* 👤 - [数据平台](#customer-data-platforms)
* 🗄️ - [数据库](#databases)
* 🛠️ - [开发者工具](#developer-tools)
* 📂 - [文件系统](#file-systems)
* 💰 - [Finance & Fintech](#finance--fintech)
* 🧠 - [知识与记忆](#knowledge--memory)
* 🗺️ - [位置服务](#location-services)
* 🎯 - [营销](#marketing)
* 📊 - [监测](#monitoring)
* 🔎 - [搜索](#search)
* 🔒 - [安全](#security)
* 🚆 - [旅行与交通](#travel-and-transportation)
* 🔄 - [版本控制](#version-control)
* 🛠️ - [其他工具和集成](#other-tools-and-integrations)
### 📂 <a name="browser-automation"></a>浏览器自动化
Web 内容访问和自动化功能。支持以 AI 友好格式搜索、抓取和处理 Web 内容。
- [@blackwhite084/playwright-plus-python-mcp](https://github.com/blackwhite084/playwright-plus-python-mcp) 🌐 - 使用 Playwright 进行浏览器自动化的 MCP 服务器,更适合llm
- [@executeautomation/playwright-mcp-server](https://github.com/executeautomation/mcp-playwright) 🌐⚡️ - 使用 Playwright 进行浏览器自动化和网页抓取的 MCP 服务器
- [@automatalabs/mcp-server-playwright](https://github.com/Automata-Labs-team/MCP-Server-Playwright) 🌐🖱️ - 使用 Playwright 实现浏览器自动化的 MCP 服务器
- [@modelcontextprotocol/server-puppeteer](https://github.com/modelcontextprotocol/servers/tree/main/src/puppeteer) 📇 🏠 - 用于网页抓取和交互的浏览器自动化
- [@kimtaeyoon83/mcp-server-youtube-transcript](https://github.com/kimtaeyoon83/mcp-server-youtube-transcript) 📇 ☁️ - 获取 YouTube 字幕和文字记录以供 AI 分析
- [@recursechat/mcp-server-apple-shortcuts](https://github.com/recursechat/mcp-server-apple-shortcuts) 📇 🏠 🍎 - MCP 服务器与 Apple Shortcuts 的集成
- [kimtth/mcp-aoai-web-browsing](https://github.com/kimtth/mcp-aoai-web-browsing) 🐍 🏠 - 使用 Azure OpenAI 和 Playwright 的“最小”服务器/客户端 MCP 实现。
- [@pskill9/web-search](https://github.com/pskill9/web-search) 📇 🏠 - 一个支持使用 Google 搜索结果进行免费网页搜索的 MCP 服务器,无需 API 密钥
### 🎨 <a name="art-and-culture"></a>艺术与文化
提供艺术收藏、文化遗产和博物馆数据库的访问与探索。让 AI 模型能够搜索和分析艺术文化内容。
- [burningion/video-editing-mcp](https://github.com/burningion/video-editing-mcp) 📹🎬 - 从您的视频集合中添加、分析、搜索和生成视频剪辑
- [r-huijts/rijksmuseum-mcp](https://github.com/r-huijts/rijksmuseum-mcp) 📇 ☁️ - 荷兰国立博物馆 API 集成,支持艺术品搜索、详情查询和收藏品浏览
### ☁️ <a name="cloud-platforms"></a>云平台
云平台服务集成。实现与云基础设施和服务的管理和交互。
- [Cloudflare MCP Server](https://github.com/cloudflare/mcp-server-cloudflare) 🎖️ 📇 ☁️ - 与 Cloudflare 服务集成,包括 Workers、KV、R2 和 D1
- [Kubernetes MCP Server](https://github.com/strowk/mcp-k8s-go) - 🏎️ ☁️ 通过 MCP 操作 Kubernetes 集群
- [@flux159/mcp-server-kubernetes](https://github.com/Flux159/mcp-server-kubernetes) - 📇 ☁️/🏠 使用 Typescript 实现 Kubernetes 集群中针对 pod、部署、服务的操作。
- [johnneerdael/netskope-mcp](https://github.com/johnneerdael/netskope-mcp) 🔒 ☁️ - 提供对 Netskope Private Access 环境中所有组件的访问权限,包含详细的设置信息和 LLM 使用示例。
### 🖥️ <a name="command-line"></a>Command Line
运行命令、捕获输出以及以其他方式与 shell 和命令行工具交互。
- [ferrislucas/iterm-mcp](https://github.com/ferrislucas/iterm-mcp) 🖥️ 🛠️ 💬 - 一个为 iTerm 终端提供访问能力的 MCP 服务器。您可以执行命令,并就终端中看到的内容进行提问交互。
- [g0t4/mcp-server-commands](https://github.com/g0t4/mcp-server-commands) 📇 🏠 - 使用“run_command”和“run_script”工具运行任何命令。
- [MladenSU/cli-mcp-server](https://github.com/MladenSU/cli-mcp-server) 🐍 🏠 - 具有安全执行和可定制安全策略的命令行界面
- [tumf/mcp-shell-server](https://github.com/tumf/mcp-shell-server) 实现模型上下文协议 (MCP) 的安全 shell 命令执行服务器
### 💬 <a name="communication"></a>社交
与通讯平台集成,实现消息管理和渠道运营。使AI模型能够与团队沟通工具进行交互。
- [zcaceres/gtasks-mcp](https://github.com/zcaceres/gtasks-mcp) - 📇 ☁️ - 用于管理 Google Tasks 的 MCP 服务器
- [hannesrudolph/imessage-query-fastmcp-mcp-server](https://github.com/hannesrudolph/imessage-query-fastmcp-mcp-server) 🐍 🏠 🍎 - MCP 服务器通过模型上下文协议 (MCP) 提供对 iMessage 数据库的安全访问,使 LLM 能够通过适当的电话号码验证和附件处理来查询和分析 iMessage 对话
- [@modelcontextprotocol/server-slack](https://github.com/modelcontextprotocol/servers/tree/main/src/slack) 📇 ☁️ - 用于频道管理和消息传递的 Slack 工作区集成
- [@modelcontextprotocol/server-bluesky](https://github.com/keturiosakys/bluesky-context-server) 📇 ☁️ - Bluesky 实例集成,用于查询和交互
- [MarkusPfundstein/mcp-gsuite](https://github.com/MarkusPfundstein/mcp-gsuite) - 🐍 ☁️ - 与 Gmail 和 Google 日历集成。
- [adhikasp/mcp-twikit](https://github.com/adhikasp/mcp-twikit) 🐍 ☁️ - 与 Twitter 搜索和时间线进行交互
- [gotoolkits/wecombot](https://github.com/gotoolkits/mcp-wecombot-server.git) - 🚀 ☁️ - MCP服务器 Tools 应用程序,用于向企业微信群机器人发送各种类型的消息。
- [AbdelStark/nostr-mcp](https://github.com/AbdelStark/nostr-mcp) - 🌐 ☁️ - Nostr MCP 服务器,支持与 Nostr 交互,可发布笔记等功能。
### 👤 <a name="customer-data-platforms"></a>数据平台
提供对客户数据平台内客户资料的访问
- [sergehuber/inoyu-mcp-unomi-server](https://github.com/sergehuber/inoyu-mcp-unomi-server) 📇 ☁️ - MCP 服务器用于访问和更新 Apache Unomi CDP 服务器上的配置文件。
- [OpenDataMCP/OpenDataMCP](https://github.com/OpenDataMCP/OpenDataMCP) 🐍☁️ - 使用模型上下文协议将任何开放数据连接到任何 LLM。
- [tinybirdco/mcp-tinybird](https://github.com/tinybirdco/mcp-tinybird) 🐍☁️ - MCP 服务器可从任何 MCP 客户端与 Tinybird Workspace 进行交互。
- [@iaptic/mcp-server-iaptic](https://github.com/iaptic/mcp-server-iaptic) 🎖️ 📇 ☁️ - 连接 [iaptic](https://www.iaptic.com) 平台,让您轻松查询客户购买记录、交易数据以及应用营收统计信息。
### 🗄️ <a name="databases"></a>数据库
具有模式检查功能的安全数据库访问。支持使用可配置的安全控制(包括只读访问)查询和分析数据。
- [cr7258/elasticsearch-mcp-server](https://github.com/cr7258/elasticsearch-mcp-server) 🐍 🏠 - 集成 Elasticsearch 的 MCP 服务器实现
- [domdomegg/airtable-mcp-server](https://github.com/domdomegg/airtable-mcp-server) 📇 🏠 - Airtable 数据库集成,具有架构检查、读写功能
- [LucasHild/mcp-server-bigquery](https://github.com/LucasHild/mcp-server-bigquery) 🐍 ☁️ - BigQuery 数据库集成了架构检查和查询功能
- [ergut/mcp-bigquery-server](https://github.com/ergut/mcp-bigquery-server) 📇 ☁️ - Google BigQuery 集成的服务器实现,可实现直接 BigQuery 数据库访问和查询功能
- [ClickHouse/mcp-clickhouse](https://github.com/ClickHouse/mcp-clickhouse) 🐍 ☁️ - ClickHouse 数据库集成,支持数据库架构检查和查询功能
- [@fireproof-storage/mcp-database-server](https://github.com/fireproof-storage/mcp-database-server) 📇 ☁️ - Fireproof 分布式账本数据库,支持多用户数据同步
- [designcomputer/mysql_mcp_server](https://github.com/designcomputer/mysql_mcp_server) 🐍 🏠 - MySQL 数据库集成可配置的访问控制、模式检查和全面的安全指南
- [f4ww4z/mcp-mysql-server](https://github.com/f4ww4z/mcp-mysql-server) 🐍 🏠 - 基于 Node.js 的 MySQL 数据库集成,提供安全的 MySQL 数据库操作
- [@modelcontextprotocol/server-postgres](https://github.com/modelcontextprotocol/servers/tree/main/src/postgres) 📇 🏠 - PostgreSQL 数据库集成了模式检查和查询功能
- [@modelcontextprotocol/server-sqlite](https://github.com/modelcontextprotocol/servers/tree/main/src/sqlite) 🐍 🏠 - 具有内置分析功能的 SQLite 数据库操作
- [@joshuarileydev/supabase-mcp-server](https://github.com/joshuarileydev/supabase) - Supabase MCP 服务器用于管理和创建 Supabase 中的项目和组织
- [ktanaka101/mcp-server-duckdb](https://github.com/ktanaka101/mcp-server-duckdb) 🐍 🏠 - DuckDB 数据库集成了模式检查和查询功能
- [QuantGeekDev/mongo-mcp](https://github.com/QuantGeekDev/mongo-mcp) 📇 🏠 - MongoDB 集成使 LLM 能够直接与数据库交互。
- [tinybirdco/mcp-tinybird](https://github.com/tinybirdco/mcp-tinybird) 🐍 ☁️ - Tinybird 集成查询和 API 功能
- [kiliczsh/mcp-mongo-server](https://github.com/kiliczsh/mcp-mongo-server) 📇 🏠 - MongoDB 的模型上下文协议服务器
- [KashiwaByte/vikingdb-mcp-server](https://github.com/KashiwaByte/vikingdb-mcp-server) 🐍 ☁️ - VikingDB 数据库集成了collection和index的基本信息介绍,并提供向量存储和查询的功能.
- [neo4j-contrib/mcp-neo4j](https://github.com/neo4j-contrib/mcp-neo4j) 🐍 🏠 - Neo4j 的模型上下文协议
- [isaacwasserman/mcp-snowflake-server](https://github.com/isaacwasserman/mcp-snowflake-server) 🐍 ☁️ - Snowflake 集成实现,支持读取和(可选)写入操作,并具备洞察跟踪功能
- [hannesrudolph/sqlite-explorer-fastmcp-mcp-server](https://github.com/hannesrudolph/sqlite-explorer-fastmcp-mcp-server) 🐍 🏠 - 一个 MCP 服务器,通过模型上下文协议 (MCP) 提供对 SQLite 数据库的安全只读访问。该服务器是使用 FastMCP 框架构建的,它使 LLM 能够探索和查询具有内置安全功能和查询验证的 SQLite 数据库。
- [sirmews/mcp-pinecone](https://github.com/sirmews/mcp-pinecone) 🐍 ☁️ - Pinecone 与矢量搜索功能的集成
- [runekaagaard/mcp-alchemy](https://github.com/runekaagaard/mcp-alchemy) 🐍 🏠 - 基于SQLAlchemy的通用数据库集成,支持PostgreSQL、MySQL、MariaDB、SQLite、Oracle、MS SQL Server等众多数据库。具有架构和关系检查以及大型数据集分析功能。
### 💻 <a name="developer-tools"></a>开发者工具
增强开发工作流程和环境管理的工具和集成。
- [QuantGeekDev/docker-mcp](https://github.com/QuantGeekDev/docker-mcp) 🏎️ 🏠 - 通过 MCP 进行 Docker 容器管理和操作
- [zcaceres/fetch-mcp](https://github.com/zcaceres/fetch-mcp) 📇 🏠 - 一个灵活获取 JSON、文本和 HTML 数据的 MCP 服务器
- [r-huijts/xcode-mcp-server](https://github.com/r-huijts/xcode-mcp-server) 📇 🏠 🍎 - Xcode 集成,支持项目管理、文件操作和构建自动化
- [snaggle-ai/openapi-mcp-server](https://github.com/snaggle-ai/openapi-mcp-server) 🏎️ 🏠 - 使用开放 API 规范 (v3) 连接任何 HTTP/REST API 服务器
- [jetbrains/mcpProxy](https://github.com/JetBrains/mcpProxy) 🎖️ 📇 🏠 - 连接到 JetBrains IDE
- [tumf/mcp-text-editor](https://github.com/tumf/mcp-text-editor) 🐍 🏠 - 面向行的文本文件编辑器。针对 LLM 工具进行了优化,具有高效的部分文件访问功能,可最大限度地减少令牌使用量。
- [@joshuarileydev/simulator-mcp-server](https://github.com/JoshuaRileyDev/simulator-mcp-server) 📇 🏠 - 用于控制 iOS 模拟器的 MCP 服务器
- [@joshuarileydev/app-store-connect-mcp-server](https://github.com/JoshuaRileyDev/app-store-connect-mcp-server) 📇 🏠 - 一个 MCP 服务器,用于与 iOS 开发者的 App Store Connect API 进行通信
- [@sammcj/mcp-package-version](https://github.com/sammcj/mcp-package-version) 📦 🏠 - MCP 服务器可帮助 LLM 在编写代码时建议最新的稳定软件包版本。
- [delano/postman-mcp-server](https://github.com/delano/postman-mcp-server) 📇 ☁️ - 与 [Postman API](https://www.postman.com/postman/postman-public-workspace/) 进行交互
- [vivekVells/mcp-pandoc](https://github.com/vivekVells/mcp-pandoc) 🗄️ 🚀 - 基于 Pandoc 的 MCP 服务器,支持 Markdown、HTML、PDF、DOCX(.docx)、csv 等格式之间的无缝转换
- [pskill9/website-downloader](https://github.com/pskill9/website-downloader) 🗄️ 🚀 - 这个 MCP 服务器提供了使用 wget 下载完整网站的工具,可保留网站结构并转换链接以支持本地访问
- [j4c0bs/mcp-server-sql-analyzer](https://github.com/j4c0bs/mcp-server-sql-analyzer) 🐍 - 基于 [SQLGlot](https://github.com/tobymao/sqlglot) 的 MCP 服务器,提供 SQL 分析、代码检查和方言转换功能
### 🧮 数据科学工具
旨在简化数据探索、分析和增强数据科学工作流程的集成和工具。
- [@reading-plus-ai/mcp-server-data-exploration](https://github.com/reading-plus-ai/mcp-server-data-exploration) 🐍 ☁️ - 支持对基于 .csv 的数据集进行自主数据探索,以最小的成本提供智能见解。
- [zcaceres/markdownify-mcp](https://github.com/zcaceres/markdownify-mcp) 📇 🏠 - 一个 MCP 服务器,可将几乎任何文件或网络内容转换为 Markdown
### 📂 <a name="file-systems"></a>文件系统
提供对本地文件系统的直接访问,并具有可配置的权限。使 AI 模型能够读取、写入和管理指定目录中的文件。
- [@modelcontextprotocol/server-filesystem](https://github.com/modelcontextprotocol/servers/tree/main/src/filesystem) 📇 🏠 - 直接访问本地文件系统。
- [@modelcontextprotocol/server-google-drive](https://github.com/modelcontextprotocol/servers/tree/main/src/gdrive) 📇 ☁️ - Google Drive 集成,用于列出、阅读和搜索文件
- [hmk/box-mcp-server](https://github.com/hmk/box-mcp-server) 📇 ☁️ - Box 集成,支持文件列表、阅读和搜索功能
- [mark3labs/mcp-filesystem-server](https://github.com/mark3labs/mcp-filesystem-server) 🏎️ 🏠 - 用于本地文件系统访问的 Golang 实现。
- [mamertofabian/mcp-everything-search](https://github.com/mamertofabian/mcp-everything-search) 🐍 🏠 🪟 - 使用 Everything SDK 实现的快速 Windows 文件搜索
- [cyberchitta/llm-context.py](https://github.com/cyberchitta/llm-context.py) 🐍 🏠 - 通过 MCP 或剪贴板与 LLM 共享代码上下文
### 💰 <a name="finance--fintech"></a>金融 & 金融科技
金融数据访问和加密货币市场信息。支持查询实时市场数据、加密货币价格和财务分析。
- [QuantGeekDev/coincap-mcp](https://github.com/QuantGeekDev/coincap-mcp) 📇 ☁️ - 使用 CoinCap 的公共 API 集成实时加密货币市场数据,无需 API 密钥即可访问加密货币价格和市场信息
- [anjor/coinmarket-mcp-server](https://github.com/anjor/coinmarket-mcp-server) 🐍 ☁️ - Coinmarket API 集成以获取加密货币列表和报价
- [berlinbra/alpha-vantage-mcp](https://github.com/berlinbra/alpha-vantage-mcp) 🐍 ☁️ - Alpha Vantage API 集成,用于获取股票和加密货币信息
- [ferdousbhai/tasty-agent](https://github.com/ferdousbhai/tasty-agent) 🐍 ☁️ - Tastyworks API 集成,用于管理 Tastytrade 平台的交易活动
### 🧠 <a name="knowledge--memory"></a>知识与记忆
使用知识图谱结构的持久内存存储。使 AI 模型能够跨会话维护和查询结构化信息。
- [@modelcontextprotocol/server-memory](https://github.com/modelcontextprotocol/servers/tree/main/src/memory) 📇 🏠 - 基于知识图谱的长期记忆系统用于维护上下文
- [/CheMiguel23/MemoryMesh](https://github.com/CheMiguel23/MemoryMesh) 📇 🏠 - 增强基于图形的记忆,重点关注 AI 角色扮演和故事生成
- [/topoteretes/cognee](https://github.com/topoteretes/cognee/tree/dev/cognee-mcp) 📇 🏠 - AI应用程序和Agent的内存管理器使用各种图存储和向量存储,并允许从 30 多个数据源提取数据
- [@hannesrudolph/mcp-ragdocs](https://github.com/hannesrudolph/mcp-ragdocs) 🐍 🏠 - MCP 服务器实现提供了通过矢量搜索检索和处理文档的工具,使 AI 助手能够利用相关文档上下文来增强其响应能力
- [@kaliaboi/mcp-zotero](https://github.com/kaliaboi/mcp-zotero) 📇 ☁️ - 为 LLM 提供的连接器,用于操作 Zotero Cloud 上的文献集合和资源
### 🗺️ <a name="location-services"></a>位置服务
地理和基于位置的服务集成。支持访问地图数据、方向和位置信息。
- [@modelcontextprotocol/server-google-maps](https://github.com/modelcontextprotocol/servers/tree/main/src/google-maps) 📇 ☁️ - Google 地图集成,提供位置服务、路线规划和地点详细信息
- [SecretiveShell/MCP-timeserver](https://github.com/SecretiveShell/MCP-timeserver) 🐍 🏠 - 访问任意时区的时间并获取当前本地时间
- [webcoderz/MCP-Geo](https://github.com/webcoderz/MCP-Geo) 🐍 🏠 - 支持 nominatim、ArcGIS、Bing 的地理编码 MCP 服务器
- [@briandconnelly/mcp-server-ipinfo](https://github.com/briandconnelly/mcp-server-ipinfo) 🐍 ☁️ - 使用 IPInfo API 获取 IP 地址的地理位置和网络信息
### 🎯 <a name="marketing"></a>营销
用于创建和编辑营销内容、处理网页元数据、产品定位和编辑指南的工具。
- [Open Strategy Partners Marketing Tools](https://github.com/open-strategy-partners/osp_marketing_tools) 🐍 🏠 - Open Strategy Partners 提供的营销工具套件,包含写作风格指南、编辑规范和产品营销价值图谱创建工具
### 📊 <a name="monitoring"></a>监测
访问和分析应用程序监控数据。使 AI 模型能够审查错误报告和性能指标。
- [@modelcontextprotocol/server-sentry](https://github.com/modelcontextprotocol/servers/tree/main/src/sentry) 🐍 ☁️ - Sentry.io 集成用于错误跟踪和性能监控
- [@modelcontextprotocol/server-raygun](https://github.com/MindscapeHQ/mcp-server-raygun) 📇 ☁️ - Raygun API V3 集成用于崩溃报告和真实用户监控
- [metoro-io/metoro-mcp-server](https://github.com/metoro-io/metoro-mcp-server) 🎖️ 🏎️ ☁️ - 查询并与 Metoro 监控的 kubernetes 环境交互
- [grafana/mcp-grafana](https://github.com/grafana/mcp-grafana) 🎖️ 🐍 🏠 ☁️ - 在 Grafana 实例中搜索仪表盘、调查事件并查询数据源
### 🔎 <a name="search"></a>搜索
- [@modelcontextprotocol/server-brave-search](https://github.com/modelcontextprotocol/servers/tree/main/src/brave-search) 📇 ☁️ - 使用 Brave 的搜索 API 实现网页搜索功能
- [@angheljf/nyt](https://github.com/angheljf/nyt) 📇 ☁️ - 使用 NYTimes API 搜索文章
- [@modelcontextprotocol/server-fetch](https://github.com/modelcontextprotocol/servers/tree/main/src/fetch) 🐍 🏠 ☁️ - 高效获取和处理网页内容,供 AI 使用
- [ac3xx/mcp-servers-kagi](https://github.com/ac3xx/mcp-servers-kagi) 📇 ☁️ - Kagi 搜索 API 集成
- [exa-labs/exa-mcp-server](https://github.com/exa-labs/exa-mcp-server) 🎖️ 📇 ☁️ – 模型上下文协议 (MCP) 服务器让 Claude 等 AI 助手可以使用 Exa AI Search API 进行网络搜索。此设置允许 AI 模型以安全且可控的方式获取实时网络信息。
- [fatwang2/search1api-mcp](https://github.com/fatwang2/search1api-mcp) 📇 ☁️ - 通过 search1api 搜索(需要付费 API 密钥)
- [Tomatio13/mcp-server-tavily](https://github.com/Tomatio13/mcp-server-tavily) ☁️ 🐍 – Tavily AI 搜索 API
- [blazickjp/arxiv-mcp-server](https://github.com/blazickjp/arxiv-mcp-server) ☁️ 🐍 - 搜索 ArXiv 研究论文
- [mzxrai/mcp-webresearch](https://github.com/mzxrai/mcp-webresearch) 🔍📚 - 在 Google 上搜索并对任何主题进行深度研究
- [andybrandt/mcp-simple-arxiv](https://github.com/andybrandt/mcp-simple-arxiv) - 🐍 ☁️ MCP for LLM 用于搜索和阅读 arXiv 上的论文)
- [andybrandt/mcp-simple-pubmed](https://github.com/andybrandt/mcp-simple-pubmed) - 🐍 ☁️ MCP 用于搜索和阅读 PubMed 中的医学/生命科学论文。
- [apify/mcp-server-rag-web-browser](https://github.com/apify/mcp-server-rag-web-browser) 📇 ☁️ - 一个用于 Apify 的 RAG Web 浏览器 Actor 的 MCP 服务器,可以执行网页搜索、抓取 URL,并以 Markdown 格式返回内容。
- [SecretiveShell/MCP-searxng](https://github.com/SecretiveShell/MCP-searxng) 🐍 🏠 - 用于连接到 searXNG 实例的 MCP 服务器
- [Bigsy/Clojars-MCP-Server](https://github.com/Bigsy/Clojars-MCP-Server) 📇 ☁️ - Clojars MCP 服务器,提供 Clojure 库的最新依赖信息
- [Ihor-Sokoliuk/MCP-SearXNG](https://github.com/ihor-sokoliuk/mcp-searxng) 📇 🏠/☁️ - [SearXNG](https://docs.searxng.org) 的模型上下文协议服务器
- [erithwik/mcp-hn](https://github.com/erithwik/mcp-hn) 🐍 ☁️ - 一个用于搜索 Hacker News、获取热门故事等的 MCP 服务器。
- [chanmeng/google-news-mcp-server](https://github.com/ChanMeng666/server-google-news) 📇 ☁️ - Google News 集成,具有自动主题分类、多语言支持,以及通过 [SerpAPI](https://serpapi.com/) 提供的标题、故事和相关主题的综合搜索功能。
- [devflowinc/trieve](https://github.com/devflowinc/trieve/tree/main/clients/mcp-server) 🎖️📇☁️🏠 - 通过 [Trieve](https://trieve.ai) 爬取、嵌入、分块、搜索和检索数据集中的信息
### 🔒 <a name="security"></a>安全
- [dnstwist MCP Server](https://github.com/BurtTheCoder/mcp-dnstwist) 📇🪟☁️ - dnstwist 的 MCP 服务器,这是一个强大的 DNS 模糊测试工具,可帮助检测域名抢注、钓鱼和企业窃密行为
- [Maigret MCP Server](https://github.com/BurtTheCoder/mcp-maigret) 📇 ☁️ - maigret 的 MCP 服务器,maigret 是一款强大的 OSINT 工具,可从各种公共来源收集用户帐户信息。此服务器提供用于在社交网络中搜索用户名和分析 URL 的工具。
- [Shodan MCP Server](https://github.com/BurtTheCoder/mcp-shodan) 📇 ☁️ - MCP 服务器用于查询 Shodan API 和 Shodan CVEDB。此服务器提供 IP 查找、设备搜索、DNS 查找、漏洞查询、CPE 查找等工具。
- [VirusTotal MCP Server](https://github.com/BurtTheCoder/mcp-virustotal) 📇 ☁️ - 用于查询 VirusTotal API 的 MCP 服务器。此服务器提供用于扫描 URL、分析文件哈希和检索 IP 地址报告的工具。
- [ORKL MCP Server](https://github.com/fr0gger/MCP_Security) 📇🛡️☁️ - 用于查询 ORKL API 的 MCP 服务器。此服务器提供获取威胁报告、分析威胁行为者和检索威胁情报来源的工具。
- [Security Audit MCP Server](https://github.com/qianniuspace/mcp-security-audit) 📇🛡️☁️ 一个强大的 MCP (模型上下文协议) 服务器,审计 npm 包依赖项的安全漏洞。内置远程 npm 注册表集成,以进行实时安全检查。
### 🚆 <a name="travel-and-transportation"></a>旅行与交通
访问旅行和交通信息。可以查询时刻表、路线和实时旅行数据。
- [NS Travel Information MCP Server](https://github.com/r-huijts/ns-mcp-server) 📇 ☁️ - 了解荷兰铁路 (NS) 的旅行信息、时刻表和实时更新
### 🔄 <a name="version-control"></a>版本控制
与 Git 存储库和版本控制平台交互。通过标准化 API 实现存储库管理、代码分析、拉取请求处理、问题跟踪和其他版本控制操作。
- [@modelcontextprotocol/server-github](https://github.com/modelcontextprotocol/servers/tree/main/src/github) 📇 ☁️ - GitHub API集成用于仓库管理、PR、问题等
- [@modelcontextprotocol/server-gitlab](https://github.com/modelcontextprotocol/servers/tree/main/src/gitlab) 📇 ☁️ 🏠 - GitLab平台集成用于项目管理和CI/CD操作
- [@modelcontextprotocol/server-git](https://github.com/modelcontextprotocol/servers/tree/main/src/git) 🐍 🏠 - 直接的Git仓库操作,包括读取、搜索和分析本地仓库
- [adhikasp/mcp-git-ingest](https://github.com/adhikasp/mcp-git-ingest) 🐍 🏠 - 使用 LLM 阅读和分析 GitHub 存储库
### 🛠️ <a name="other-tools-and-integrations"></a>其他工具和集成
- [apify/actors-mcp-server](https://github.com/apify/actors-mcp-server) 📇 ☁️ - 使用超过 3,000 个预构建的云工具(称为 Actors)从网站、电商、社交媒体、搜索引擎、地图等提取数据。
- [ivo-toby/contentful-mcp](https://github.com/ivo-toby/contentful-mcp) 📇 🏠 - 更新、创建、删除 Contentful Space 中的内容、内容模型和资产
- [mzxrai/mcp-openai](https://github.com/mzxrai/mcp-openai) 📇 ☁️ - 与 OpenAI 最智能的模型聊天
- [mrjoshuak/godoc-mcp](https://github.com/mrjoshuak/godoc-mcp) 🏎️ 🏠 - 高效的 Go 文档服务器,让 AI 助手可以智能访问包文档和类型,而无需阅读整个源文件
- [pierrebrunelle/mcp-server-openai](https://github.com/pierrebrunelle/mcp-server-openai) 🐍 ☁️ - 直接从Claude查询OpenAI模型,使用MCP协议
- [@modelcontextprotocol/server-everything](https://github.com/modelcontextprotocol/servers/tree/main/src/everything) 📇 🏠 - MCP服务器,涵盖MCP协议的所有功能
- [baba786/phabricator-mcp-server](https://github.com/baba786/phabricator-mcp-server) 🐍 ☁️ - 与Phabricator API交互
- [MarkusPfundstein/mcp-obsidian](https://github.com/MarkusPfundstein/mcp-obsidian) 🐍 ☁️ 🏠 - 通过REST API与Obsidian交互
- [calclavia/mcp-obsidian](https://github.com/calclavia/mcp-obsidian) 📇 🏠 - 这是一个连接器,允许Claude Desktop(或任何MCP兼容应用程序)读取和搜索包含Markdown笔记的目录(如Obsidian库)。
- [anaisbetts/mcp-youtube](https://github.com/anaisbetts/mcp-youtube) 📇 ☁️ - 获取YouTube字幕
- [danhilse/notion_mcp](https://github.com/danhilse/notion_mcp) 🐍 ☁️ - 与Notion API集成,管理个人待办事项列表
- [rusiaaman/wcgw](https://github.com/rusiaaman/wcgw/blob/main/src/wcgw/client/mcp_server/Readme.md) 🐍 🏠 - 自动化shell执行、计算机控制和编码代理。(Mac)
- [reeeeemo/ancestry-mcp](https://github.com/reeeeemo/ancestry-mcp) 🐍 🏠 - 允许AI读取.ged文件和基因数据
- [sirmews/apple-notes-mcp](https://github.com/sirmews/apple-notes-mcp) 🐍 🏠 - 允许AI读取本地Apple Notes数据库(仅限macOS)
- [anjor/coinmarket-mcp-server](https://github.com/anjor/coinmarket-mcp-server) 🐍 🏠 - Coinmarket API集成,用于获取加密货币列表和报价
- [suekou/mcp-notion-server](https://github.com/suekou/mcp-notion-server) 📇 🏠 - 与Notion API交互
- [amidabuddha/unichat-mcp-server](https://github.com/amidabuddha/unichat-mcp-server) 🐍/📇 ☁️ - 使用MCP协议通过工具或预定义的提示发送请求给OpenAI、MistralAI、Anthropic、xAI或Google AI。需要供应商API密钥
- [evalstate/mcp-miro](https://github.com/evalstate/mcp-miro) 📇 ☁️ - 访问 MIRO 白板,批量创建和读取项目。需要 REST API 的 OAUTH 密钥。
- [KS-GEN-AI/jira-mcp-server](https://github.com/KS-GEN-AI/jira-mcp-server) 📇 ☁️ 🍎 🪟 - 通过 JQL 和 API 读取 Jira 数据,并执行创建和编辑工单的请求
- [KS-GEN-AI/confluence-mcp-server](https://github.com/KS-GEN-AI/confluence-mcp-server) 📇 ☁️ 🍎 🪟 - 通过 CQL 获取 Confluence 数据并阅读页面
- [sooperset/mcp-atlassian](https://github.com/sooperset/mcp-atlassian) 🐍 ☁️ - Confluence工作区的自然语言搜索和内容访问
- [pyroprompts/any-chat-completions-mcp](https://github.com/pyroprompts/any-chat-completions-mcp) - 与任何其他OpenAI SDK兼容的聊天完成API对话,例如Perplexity、Groq、xAI等
- [anaisbetts/mcp-installer](https://github.com/anaisbetts/mcp-installer) 🐍 🏠 - 一个MCP服务器,可以为您安装其他MCP服务器
- [tanigami/mcp-server-perplexity](https://github.com/tanigami/mcp-server-perplexity) 🐍 ☁️ - 与 Perplexity API 交互。
- [future-audiences/wikimedia-enterprise-model-context-protocol](https://gitlab.wikimedia.org/repos/future-audiences/wikimedia-enterprise-model-context-protocol) 🐍 ☁️ - 维基百科文章查找 API
- [andybrandt/mcp-simple-timeserver](https://github.com/andybrandt/mcp-simple-timeserver) 🐍 🏠☁️ - MCP 服务器允许检查客户端计算机上的本地时间或 NTP 服务器上的当前 UTC 时间
- [andybrandt/mcp-simple-openai-assistant](https://github.com/andybrandt/mcp-simple-openai-assistant) - 🐍 ☁️ MCP 与 OpenAI 助手对话(Claude 可以使用任何 GPT 模型作为他的助手)
- [@llmindset/mcp-hfspace](https://github.com/evalstate/mcp-hfspace) 📇 ☁️ - 直接从 Claude 使用 HuggingFace Spaces。使用开源图像生成、聊天、视觉任务等。支持图像、音频和文本上传/下载。
- [zueai/mcp-manager](https://github.com/zueai/mcp-manager) 📇 ☁️ - 简单的 Web UI 用于安装和管理 Claude 桌面应用程序的 MCP 服务器。
- [wong2/mcp-cli](https://github.com/wong2/mcp-cli) 📇 🏠 - 用于测试 MCP 服务器的 CLI 工具
- [isaacwasserman/mcp-vegalite-server](https://github.com/isaacwasserman/mcp-vegalite-server) 🐍 🏠 - 使用 VegaLite 格式和渲染器从获取的数据生成可视化效果。
- [tevonsb/homeassistant-mcp](https://github.com/tevonsb/homeassistant-mcp) 📇 🏠 - 访问家庭助理数据和控制设备(灯、开关、恒温器等)。
- [allenporter/mcp-server-home-assistant](https://github.com/allenporter/mcp-server-home-assistant) 🐍 🏠 - 通过模型上下文协议服务器暴露所有 Home Assistant 语音意图,实现智能家居控制
- [nguyenvanduocit/all-in-one-model-context-protocol](https://github.com/nguyenvanduocit/all-in-one-model-context-protocol) 🏎️ 🏠 - 一些对开发人员有用的工具。
- [@joshuarileydev/mac-apps-launcher-mcp-server](https://github.com/JoshuaRileyDev/mac-apps-launcher) 📇 🏠 - 用于列出和启动 MacOS 上的应用程序的 MCP 服务器
- [ZeparHyfar/mcp-datetime](https://github.com/ZeparHyfar/mcp-datetime) - MCP 服务器提供多种格式的日期和时间函数
- [apinetwork/piapi-mcp-server](https://github.com/apinetwork/piapi-mcp-server) 📇 ☁️ PiAPI MCP服务器使用户能够直接从Claude或其他MCP兼容应用程序中使用Midjourney/Flux/Kling/Hunyuan/Udio/Trellis生成媒体内容。
- [gotoolkits/DifyWorkflow](https://github.com/gotoolkits/mcp-difyworkflow-server) - 🚀 ☁️ MCP 服务器 Tools 实现查询与执行 Dify AI 平台上自定义的工作流
- [@pskill9/hn-server](https://github.com/pskill9/hn-server) - 📇 ☁️ 解析 news.ycombinator.com(Hacker News)的 HTML 内容,为不同类型的故事(热门、最新、问答、展示、工作)提供结构化数据
- [@mediar-ai/screenpipe](https://github.com/mediar-ai/screenpipe) - 🎖️ 🦀 🏠 🍎 本地优先的系统,支持屏幕/音频捕获并带有时间戳索引、SQL/嵌入存储、语义搜索、LLM 驱动的历史分析和事件触发动作 - 通过 NextJS 插件生态系统实现构建上下文感知的 AI 代理
- [akseyh/bear-mcp-server](https://github.com/akseyh/bear-mcp-server) - 允许 AI 读取您的 Bear Notes(仅支持 macOS)
- [ws-mcp](https://github.com/nick1udwig/ws-mcp) - 使用 WebSocket 包装 MCP 服务器(用于 [kitbitz](https://github.com/nick1udwig/kibitz))
- [AbdelStark/bitcoin-mcp](https://github.com/AbdelStark/bitcoin-mcp) - ₿ 一个模型上下文协议(MCP)服务器,使 AI 模型能够与比特币交互,允许它们生成密钥、验证地址、解码交易、查询区块链等
## 框架
- [FastMCP](https://github.com/jlowin/fastmcp) 🐍 - 用于在 Python 中构建 MCP 服务器的高级框架
- [FastMCP](https://github.com/punkpeye/fastmcp) 📇 - 用于在 TypeScript 中构建 MCP 服务器的高级框架
- [Foxy Contexts](https://github.com/strowk/foxy-contexts) 🏎️ - 用于以声明方式编写 MCP 服务器的 Golang 库,包含功能测试
- [Genkit MCP](https://github.com/firebase/genkit/tree/main/js/plugins/mcp) 📇 – 提供[Genkit](https://github.com/firebase/genkit/tree/main)与模型上下文协议(MCP)之间的集成。
- [LiteMCP](https://github.com/wong2/litemcp) ⚡️ - 用于在 JavaScript/TypeScript 中构建 MCP 服务器的高级框架
- [mark3labs/mcp-go](https://github.com/mark3labs/mcp-go) 🏎️ - 用于构建MCP服务器和客户端的Golang SDK。
- [mcp-framework](https://github.com/QuantGeekDev/mcp-framework) - ⚡️ 用于构建 MCP 服务器的快速而优雅的 TypeScript 框架
- [mcp-proxy](https://github.com/punkpeye/mcp-proxy) 📇 - 用于使用 `stdio` 传输的 MCP 服务器的 TypeScript SSE 代理
- [mcp-rs-template](https://github.com/linux-china/mcp-rs-template) 🦀 - Rust的MCP CLI服务器模板
- [metoro-io/mcp-golang](https://github.com/metoro-io/mcp-golang) 🏎️ - 用于构建 MCP 服务器的 Golang 框架,专注于类型安全。
- [rectalogic/langchain-mcp](https://github.com/rectalogic/langchain-mcp) 🐍 - 提供LangChain中MCP工具调用支持,允许将MCP工具集成到LangChain工作流中。
- [salty-flower/ModelContextProtocol.NET](https://github.com/salty-flower/ModelContextProtocol.NET) #️⃣🏠 - 基于 .NET 9 的 C# MCP 服务器 SDK ,支持 NativeAOT ⚡ 🔌
- [spring-ai-mcp](https://github.com/spring-projects-experimental/spring-ai-mcp) ☕ 🌱 - 用于构建 MCP 客户端和服务器的 Java SDK 和 Spring Framework 集成,支持多种可插拔的传输选项
- [@marimo-team/codemirror-mcp](https://github.com/marimo-team/codemirror-mcp) - CodeMirror 扩展,实现了用于资源提及和提示命令的模型上下文协议 (MCP)
## 实用工具
- [boilingdata/mcp-server-and-gw](https://github.com/boilingdata/mcp-server-and-gw) 📇 - 带有示例服务器和 MCP 客户端的 MCP stdio 到 HTTP SSE 传输网关
- [isaacwasserman/mcp-langchain-ts-client](https://github.com/isaacwasserman/mcp-langchain-ts-client) 📇 - 在 LangChain.js 中使用 MCP 提供的工具
- [lightconetech/mcp-gateway](https://github.com/lightconetech/mcp-gateway) 📇 - MCP SSE 服务器的网关演示
- [mark3labs/mcphost](https://github.com/mark3labs/mcphost) 🏎️ - 一个 CLI 主机应用程序,使大型语言模型 (LLM) 能够通过模型上下文协议 (MCP) 与外部工具交互
- [MCP-Connect](https://github.com/EvalsOne/MCP-Connect) 📇 - 一个小工具,使基于云的 AI 服务能够通过 HTTP/HTTPS 请求访问本地的基于 Stdio 的 MCP 服务器
- [SecretiveShell/MCP-Bridge](https://github.com/SecretiveShell/MCP-Bridge) 🐍 - OpenAI 中间件代理,用于在任何现有的 OpenAI 兼容客户端中使用 MCP
- [sparfenyuk/mcp-proxy](https://github.com/sparfenyuk/mcp-proxy) 🐍 - MCP stdio 到 SSE 的传输网关
- [upsonic/gpt-computer-assistant](https://github.com/Upsonic/gpt-computer-assistant) 🐍 - 用于构建垂直 AI 代理的框架
## 客户端
> [!NOTE]
> 寻找 MCP 客户端?请查看 [awesome-mcp-clients](https://github.com/punkpeye/awesome-mcp-clients/) 仓库。
## 提示和技巧
### 官方提示关于 LLM 如何使用 MCP
想让 Claude 回答有关模型上下文协议的问题?
创建一个项目,然后将此文件添加到其中:
https://modelcontextprotocol.io/llms-full.txt
这样 Claude 就能回答关于编写 MCP 服务器及其工作原理的问题了
- https://www.reddit.com/r/ClaudeAI/comments/1h3g01r/want_to_ask_claude_about_model_context_protocol/
## 收藏历史
<a href="https://star-history.com/#punkpeye/awesome-mcp-servers&Date">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://api.star-history.com/svg?repos=punkpeye/awesome-mcp-servers&type=Date&theme=dark" />
<source media="(prefers-color-scheme: light)" srcset="https://api.star-history.com/svg?repos=punkpeye/awesome-mcp-servers&type=Date" />
<img alt="Star History Chart" src="https://api.star-history.com/svg?repos=punkpeye/awesome-mcp-servers&type=Date" />
</picture>
</a> | {
"source": "punkpeye/awesome-mcp-servers",
"title": "README-zh.md",
"url": "https://github.com/punkpeye/awesome-mcp-servers/blob/main/README-zh.md",
"date": "2024-11-30T04:49:10",
"stars": 3664,
"description": "A collection of MCP servers.",
"file_size": 27895
} |
# Awesome MCP Servers [](https://awesome.re)
[](README.md)
[](README-zh.md)
[](README-ja.md)
[](https://glama.ai/mcp/discord)
[](https://www.reddit.com/r/mcp/)
A curated list of awesome Model Context Protocol (MCP) servers.
* [What is MCP?](#what-is-mcp)
* [Tutorials](#tutorials)
* [Server Implementations](#server-implementations)
* [Frameworks](#frameworks)
* [Utilities](#utilities)
* [Clients](#clients)
* [Tips & Tricks](#tips-and-tricks)
## What is MCP?
[MCP](https://modelcontextprotocol.io/) is an open protocol that enables AI models to securely interact with local and remote resources through standardized server implementations. This list focuses on production-ready and experimental MCP servers that extend AI capabilities through file access, database connections, API integrations, and other contextual services.
## Tutorials
* [Model Context Protocol (MCP) Quickstart](https://glama.ai/blog/2024-11-25-model-context-protocol-quickstart)
* [Setup Claude Desktop App to Use a SQLite Database](https://youtu.be/wxCCzo9dGj0)
## Community
* [r/mcp Reddit](https://www.reddit.com/r/mcp)
* [Discord Server](https://glama.ai/mcp/discord)
## Legend
* 🎖️ – official implementation
* programming language
* 🐍 – Python codebase
* 📇 – TypeScript codebase
* 🏎️ – Go codebase
* 🦀 – Rust codebase
* #️⃣ - C# Codebase
* ☕ - Java codebase
* scope
* ☁️ - Cloud Service
* 🏠 - Local Service
* operating system
* 🍎 – For macOS
* 🪟 – For Windows
> [!NOTE]
> Confused about Local 🏠 vs Cloud ☁️?
> * Use local when MCP server is talking to a locally installed software, e.g. taking control over Chrome browser.
> * Use network when MCP server is talking to remote APIs, e.g. weather API.
## Server Implementations
> [!NOTE]
> We now have a [web-based directory](https://glama.ai/mcp/servers) that is synced with the repository.
* 📂 - [Browser Automation](#browser-automation)
* 🎨 - [Art & Culture](#art-and-culture)
* ☁️ - [Cloud Platforms](#cloud-platforms)
* 🖥️ - [Command Line](#command-line)
* 💬 - [Communication](#communication)
* 👤 - [Customer Data Platforms](#customer-data-platforms)
* 🗄️ - [Databases](#databases)
* 🛠️ - [Developer Tools](#developer-tools)
* 📂 - [File Systems](#file-systems)
* 💰 - [Finance & Fintech](#finance--fintech)
* 🧠 - [Knowledge & Memory](#knowledge--memory)
* 🗺️ - [Location Services](#location-services)
* 🎯 - [Marketing](#marketing)
* 📊 - [Monitoring](#monitoring)
* 🔎 - [Search](#search)
* 🔒 - [Security](#security)
* 🚆 - [Travel & Transportation](#travel-and-transportation)
* 🔄 - [Version Control](#version-control)
* 🛠️ - [Other Tools and Integrations](#other-tools-and-integrations)
### 📂 <a name="browser-automation"></a>Browser Automation
Web content access and automation capabilities. Enables searching, scraping, and processing web content in AI-friendly formats.
- [@blackwhite084/playwright-plus-python-mcp](https://github.com/blackwhite084/playwright-plus-python-mcp) 🌐 - An MCP python server using Playwright for browser automation,more suitable for llm
- [@executeautomation/playwright-mcp-server](https://github.com/executeautomation/mcp-playwright) 🌐⚡️ - An MCP server using Playwright for browser automation and webscrapping
- [@automatalabs/mcp-server-playwright](https://github.com/Automata-Labs-team/MCP-Server-Playwright) 🌐 🖱️ - An MCP server for browser automation using Playwright
- [@modelcontextprotocol/server-puppeteer](https://github.com/modelcontextprotocol/servers/tree/main/src/puppeteer) 📇 🏠 - Browser automation for web scraping and interaction
- [@kimtaeyoon83/mcp-server-youtube-transcript](https://github.com/kimtaeyoon83/mcp-server-youtube-transcript) 📇 ☁️ - Fetch YouTube subtitles and transcripts for AI analysis
- [@recursechat/mcp-server-apple-shortcuts](https://github.com/recursechat/mcp-server-apple-shortcuts) 📇 🏠 🍎 - An MCP Server Integration with Apple Shortcuts
- [@kimtth/mcp-aoai-web-browsing](https://github.com/kimtth/mcp-aoai-web-browsing) 🐍 🏠 - A `minimal` server/client MCP implementation using Azure OpenAI and Playwright.
- [@pskill9/web-search](https://github.com/pskill9/web-search) 📇 🏠 - An MCP server that enables free web searching using Google search results, with no API keys required.
### 🎨 <a name="art-and-culture"></a>Art & Culture
Access and explore art collections, cultural heritage, and museum databases. Enables AI models to search and analyze artistic and cultural content.
- [burningion/video-editing-mcp](https://github.com/burningion/video-editing-mcp) 📹🎬 - Add, Analyze, Search, and Generate Video Edits from your Video Jungle Collection
- [r-huijts/rijksmuseum-mcp](https://github.com/r-huijts/rijksmuseum-mcp) 📇 ☁️ - Rijksmuseum API integration for artwork search, details, and collections
### ☁️ <a name="cloud-platforms"></a>Cloud Platforms
Cloud platform service integration. Enables management and interaction with cloud infrastructure and services.
- [Cloudflare MCP Server](https://github.com/cloudflare/mcp-server-cloudflare) 🎖️ 📇 ☁️ - Integration with Cloudflare services including Workers, KV, R2, and D1
- [Kubernetes MCP Server](https://github.com/strowk/mcp-k8s-go) - 🏎️ ☁️/🏠 Kubernetes cluster operations through MCP
- [@flux159/mcp-server-kubernetes](https://github.com/Flux159/mcp-server-kubernetes) - 📇 ☁️/🏠 Typescript implementation of Kubernetes cluster operations for pods, deployments, services.
- [@manusa/Kubernetes MCP Server](https://github.com/manusa/kubernetes-mcp-server) - 🏎️ 🏠 A powerful Kubernetes MCP server with additional support for OpenShift. Besides providing CRUD operations for **any** Kubernetes resource, this server provides specialized tools to interact with your cluster.
- [johnneerdael/netskope-mcp](https://github.com/johnneerdael/netskope-mcp) 🔒 ☁️ - An MCP to give access to all Netskope Private Access components within a Netskope Private Access environments including detailed setup information and LLM examples on usage.
### 🖥️ <a name="command-line"></a>Command Line
Run commands, capture output and otherwise interact with shells and command line tools.
- [ferrislucas/iterm-mcp](https://github.com/ferrislucas/iterm-mcp) 🖥️ 🛠️ 💬 - A Model Context Protocol server that provides access to iTerm. You can run commands and ask questions about what you see in the iTerm terminal.
- [g0t4/mcp-server-commands](https://github.com/g0t4/mcp-server-commands) 📇 🏠 - Run any command with `run_command` and `run_script` tools.
- [MladenSU/cli-mcp-server](https://github.com/MladenSU/cli-mcp-server) 🐍 🏠 - Command line interface with secure execution and customizable security policies
- [tumf/mcp-shell-server](https://github.com/tumf/mcp-shell-server) A secure shell command execution server implementing the Model Context Protocol (MCP)
### 💬 <a name="communication"></a>Communication
Integration with communication platforms for message management and channel operations. Enables AI models to interact with team communication tools.
- [zcaceres/gtasks-mcp](https://github.com/zcaceres/gtasks-mcp) - 📇 ☁️ - An MCP server to Manage Google Tasks
- [hannesrudolph/imessage-query-fastmcp-mcp-server](https://github.com/hannesrudolph/imessage-query-fastmcp-mcp-server) 🐍 🏠 🍎 - An MCP server that provides safe access to your iMessage database through Model Context Protocol (MCP), enabling LLMs to query and analyze iMessage conversations with proper phone number validation and attachment handling
- [@modelcontextprotocol/server-slack](https://github.com/modelcontextprotocol/servers/tree/main/src/slack) 📇 ☁️ - Slack workspace integration for channel management and messaging
- [@modelcontextprotocol/server-bluesky](https://github.com/keturiosakys/bluesky-context-server) 📇 ☁️ - Bluesky instance integration for querying and interaction
- [MarkusPfundstein/mcp-gsuite](https://github.com/MarkusPfundstein/mcp-gsuite) - 🐍 ☁️ - Integration with gmail and Google Calendar.
- [adhikasp/mcp-twikit](https://github.com/adhikasp/mcp-twikit) 🐍 ☁️ - Interact with Twitter search and timeline
- [gotoolkits/wecombot](https://github.com/gotoolkits/mcp-wecombot-server.git) - 🚀 ☁️ - An MCP server application that sends various types of messages to the WeCom group robot.
- [AbdelStark/nostr-mcp](https://github.com/AbdelStark/nostr-mcp) - 🌐 ☁️ - A Nostr MCP server that allows to interact with Nostr, enabling posting notes, and more.
### 👤 <a name="customer-data-platforms"></a>Customer Data Platforms
Provides access to customer profiles inside of customer data platforms
- [sergehuber/inoyu-mcp-unomi-server](https://github.com/sergehuber/inoyu-mcp-unomi-server) 📇 ☁️ - An MCP server to access and updates profiles on an Apache Unomi CDP server.
- [OpenDataMCP/OpenDataMCP](https://github.com/OpenDataMCP/OpenDataMCP) 🐍 ☁️ - Connect any Open Data to any LLM with Model Context Protocol.
- [tinybirdco/mcp-tinybird](https://github.com/tinybirdco/mcp-tinybird) 🐍 ☁️ - An MCP server to interact with a Tinybird Workspace from any MCP client.
- [@iaptic/mcp-server-iaptic](https://github.com/iaptic/mcp-server-iaptic) 🎖️ 📇 ☁️ - Connect with [iaptic](https://www.iaptic.com) to ask about your Customer Purchases, Transaction data and App Revenue statistics.
### 🗄️ <a name="databases"></a>Databases
Secure database access with schema inspection capabilities. Enables querying and analyzing data with configurable security controls including read-only access.
- [cr7258/elasticsearch-mcp-server](https://github.com/cr7258/elasticsearch-mcp-server) 🐍 🏠 - MCP Server implementation that provides Elasticsearch interaction
- [domdomegg/airtable-mcp-server](https://github.com/domdomegg/airtable-mcp-server) 📇 🏠 - Airtable database integration with schema inspection, read and write capabilities
- [LucasHild/mcp-server-bigquery](https://github.com/LucasHild/mcp-server-bigquery) 🐍 ☁️ - BigQuery database integration with schema inspection and query capabilities
- [ergut/mcp-bigquery-server](https://github.com/ergut/mcp-bigquery-server) 📇 ☁️ - Server implementation for Google BigQuery integration that enables direct BigQuery database access and querying capabilities
- [ClickHouse/mcp-clickhouse](https://github.com/ClickHouse/mcp-clickhouse) 🐍 ☁️ - ClickHouse database integration with schema inspection and query capabilities
- [@fireproof-storage/mcp-database-server](https://github.com/fireproof-storage/mcp-database-server) 📇 ☁️ - Fireproof ledger database with multi-user sync
- [designcomputer/mysql_mcp_server](https://github.com/designcomputer/mysql_mcp_server) 🐍 🏠 - MySQL database integration with configurable access controls, schema inspection, and comprehensive security guidelines
- [f4ww4z/mcp-mysql-server](https://github.com/f4ww4z/mcp-mysql-server) 🐍 🏠 - Node.js-based MySQL database integration that provides secure MySQL database operations
- [@modelcontextprotocol/server-postgres](https://github.com/modelcontextprotocol/servers/tree/main/src/postgres) 📇 🏠 - PostgreSQL database integration with schema inspection and query capabilities
- [@modelcontextprotocol/server-sqlite](https://github.com/modelcontextprotocol/servers/tree/main/src/sqlite) 🐍 🏠 - SQLite database operations with built-in analysis features
- [@joshuarileydev/supabase-mcp-server](https://github.com/joshuarileydev/supabase) - Supabase MCP Server for managing and creating projects and organisations in Supabase
- [@alexanderzuev/supabase-mcp-server](https://github.com/alexander-zuev/supabase-mcp-server) - Supabase MCP Server with support for SQL query execution and database exploration tools
- [ktanaka101/mcp-server-duckdb](https://github.com/ktanaka101/mcp-server-duckdb) 🐍 🏠 - DuckDB database integration with schema inspection and query capabilities
- [QuantGeekDev/mongo-mcp](https://github.com/QuantGeekDev/mongo-mcp) 📇 🏠 - MongoDB integration that enables LLMs to interact directly with databases.
- [tinybirdco/mcp-tinybird](https://github.com/tinybirdco/mcp-tinybird) 🐍 ☁️ - Tinybird integration with query and API capabilities
- [kiliczsh/mcp-mongo-server](https://github.com/kiliczsh/mcp-mongo-server) 📇 🏠 - A Model Context Protocol Server for MongoDB
- [KashiwaByte/vikingdb-mcp-server](https://github.com/KashiwaByte/vikingdb-mcp-server) 🐍 ☁️ - VikingDB integration with collection and index introduction, vector store and search capabilities.
- [neo4j-contrib/mcp-neo4j](https://github.com/neo4j-contrib/mcp-neo4j) 🐍 🏠 - Model Context Protocol with Neo4j
- [isaacwasserman/mcp-snowflake-server](https://github.com/isaacwasserman/mcp-snowflake-server) 🐍 ☁️ - Snowflake integration implementing read and (optional) write operations as well as insight tracking
- [hannesrudolph/sqlite-explorer-fastmcp-mcp-server](https://github.com/hannesrudolph/sqlite-explorer-fastmcp-mcp-server) 🐍 🏠 - An MCP server that provides safe, read-only access to SQLite databases through Model Context Protocol (MCP). This server is built with the FastMCP framework, which enables LLMs to explore and query SQLite databases with built-in safety features and query validation.
- [sirmews/mcp-pinecone](https://github.com/sirmews/mcp-pinecone) 🐍 ☁️ - Pinecone integration with vector search capabilities
- [runekaagaard/mcp-alchemy](https://github.com/runekaagaard/mcp-alchemy) 🐍 🏠 - Universal SQLAlchemy-based database integration supporting PostgreSQL, MySQL, MariaDB, SQLite, Oracle, MS SQL Server and many more databases. Features schema and relationship inspection, and large dataset analysis capabilities.
### 💻 <a name="developer-tools"></a>Developer Tools
Tools and integrations that enhance the development workflow and environment management.
- [QuantGeekDev/docker-mcp](https://github.com/QuantGeekDev/docker-mcp) 🏎️ 🏠 - Docker container management and operations through MCP
- [zcaceres/fetch-mcp](https://github.com/zcaceres/fetch-mcp) 📇 🏠 - An MCP server to flexibly fetch JSON, text, and HTML data
- [r-huijts/xcode-mcp-server](https://github.com/r-huijts/xcode-mcp-server) 📇 🏠 🍎 - Xcode integration for project management, file operations, and build automation
- [snaggle-ai/openapi-mcp-server](https://github.com/snaggle-ai/openapi-mcp-server) 🏎️ 🏠 - Connect any HTTP/REST API server using an Open API spec (v3)
- [jetbrains/mcpProxy](https://github.com/JetBrains/mcpProxy) 🎖️ 📇 🏠 - Connect to JetBrains IDE
- [tumf/mcp-text-editor](https://github.com/tumf/mcp-text-editor) 🐍 🏠 - A line-oriented text file editor. Optimized for LLM tools with efficient partial file access to minimize token usage.
- [@joshuarileydev/simulator-mcp-server](https://github.com/JoshuaRileyDev/simulator-mcp-server) 📇 🏠 - An MCP server to control iOS Simulators
- [@joshuarileydev/app-store-connect-mcp-server](https://github.com/JoshuaRileyDev/app-store-connect-mcp-server) 📇 🏠 - An MCP server to communicate with the App Store Connect API for iOS Developers
- [@sammcj/mcp-package-version](https://github.com/sammcj/mcp-package-version) 📇 🏠 - An MCP Server to help LLMs suggest the latest stable package versions when writing code.
- [@delano/postman-mcp-server](https://github.com/delano/postman-mcp-server) 📇 ☁️ - Interact with [Postman API](https://www.postman.com/postman/postman-public-workspace/)
- [@vivekvells/mcp-pandoc](https://github.com/vivekVells/mcp-pandoc) 🗄️ 🚀 - MCP server for seamless document format conversion using Pandoc, supporting Markdown, HTML, PDF, DOCX (.docx), csv and more.
- [@pskill9/website-downloader](https://github.com/pskill9/website-downloader) 🗄️ 🚀 - This MCP server provides a tool to download entire websites using wget. It preserves the website structure and converts links to work locally.
- [@lamemind/mcp-server-multiverse](https://github.com/lamemind/mcp-server-multiverse) 📇 🏠 🛠️ - A middleware server that enables multiple isolated instances of the same MCP servers to coexist independently with unique namespaces and configurations.
- [@j4c0bs/mcp-server-sql-analyzer](https://github.com/j4c0bs/mcp-server-sql-analyzer) 🐍 - MCP server that provides SQL analysis, linting, and dialect conversion using [SQLGlot](https://github.com/tobymao/sqlglot)
- [@haris-musa/excel-mcp-server](https://github.com/haris-musa/excel-mcp-server) 🐍 🏠 - An Excel manipulation server providing workbook creation, data operations, formatting, and advanced features (charts, pivot tables, formulae).
### 🧮 Data Science Tools
Integrations and tools designed to simplify data exploration, analysis and enhance data science workflows.
- [zcaceres/markdownify-mcp](https://github.com/zcaceres/markdownify-mcp) 📇 🏠 - An MCP server to convert almost any file or web content into Markdown
- [@reading-plus-ai/mcp-server-data-exploration](https://github.com/reading-plus-ai/mcp-server-data-exploration) 🐍 ☁️ - Enables autonomous data exploration on .csv-based datasets, providing intelligent insights with minimal effort.
### 📂 <a name="file-systems"></a>File Systems
Provides direct access to local file systems with configurable permissions. Enables AI models to read, write, and manage files within specified directories.
- [@modelcontextprotocol/server-filesystem](https://github.com/modelcontextprotocol/servers/tree/main/src/filesystem) 📇 🏠 - Direct local file system access.
- [@modelcontextprotocol/server-google-drive](https://github.com/modelcontextprotocol/servers/tree/main/src/gdrive) 📇 ☁️ - Google Drive integration for listing, reading, and searching files
- [hmk/box-mcp-server](https://github.com/hmk/box-mcp-server) 📇 ☁️ - Box integration for listing, reading and searching files
- [mark3labs/mcp-filesystem-server](https://github.com/mark3labs/mcp-filesystem-server) 🏎️ 🏠 - Golang implementation for local file system access.
- [mamertofabian/mcp-everything-search](https://github.com/mamertofabian/mcp-everything-search) 🐍 🏠 🪟 - Fast Windows file search using Everything SDK
- [cyberchitta/llm-context.py](https://github.com/cyberchitta/llm-context.py) 🐍 🏠 - Share code context with LLMs via MCP or clipboard
### 💰 <a name="finance--fintech"></a>Finance & Fintech
Financial data access and cryptocurrency market information. Enables querying real-time market data, crypto prices, and financial analytics.
- [QuantGeekDev/coincap-mcp](https://github.com/QuantGeekDev/coincap-mcp) 📇 ☁️ - Real-time cryptocurrency market data integration using CoinCap's public API, providing access to crypto prices and market information without API keys
- [anjor/coinmarket-mcp-server](https://github.com/anjor/coinmarket-mcp-server) 🐍 ☁️ - Coinmarket API integration to fetch cryptocurrency listings and quotes
- [berlinbra/alpha-vantage-mcp](https://github.com/berlinbra/alpha-vantage-mcp) 🐍 ☁️ - Alpha Vantage API integration to fetch both stock and crypto information
- [ferdousbhai/tasty-agent] (https://github.com/ferdousbhai/tasty-agent) 🐍 ☁️ - Tastyworks API integration to handle trading activities on Tastytrade
### 🧠 <a name="knowledge--memory"></a>Knowledge & Memory
Persistent memory storage using knowledge graph structures. Enables AI models to maintain and query structured information across sessions.
- [@modelcontextprotocol/server-memory](https://github.com/modelcontextprotocol/servers/tree/main/src/memory) 📇 🏠 - Knowledge graph-based persistent memory system for maintaining context
- [/CheMiguel23/MemoryMesh](https://github.com/CheMiguel23/MemoryMesh) 📇 🏠 - Enhanced graph-based memory with a focus on AI role-play and story generation
- [/topoteretes/cognee](https://github.com/topoteretes/cognee/tree/dev/cognee-mcp) 📇 🏠 - Memory manager for AI apps and Agents using various graph and vector stores and allowing ingestion from 30+ data sources
- [@hannesrudolph/mcp-ragdocs](https://github.com/hannesrudolph/mcp-ragdocs) 🐍 🏠 - An MCP server implementation that provides tools for retrieving and processing documentation through vector search, enabling AI assistants to augment their responses with relevant documentation context
- [@kaliaboi/mcp-zotero](https://github.com/kaliaboi/mcp-zotero) 📇 ☁️ - A connector for LLMs to work with collections and sources on your Zotero Cloud
### 🗺️ <a name="location-services"></a>Location Services
Geographic and location-based services integration. Enables access to mapping data, directions, and place information.
- [@modelcontextprotocol/server-google-maps](https://github.com/modelcontextprotocol/servers/tree/main/src/google-maps) 📇 ☁️ - Google Maps integration for location services, routing, and place details
- [SecretiveShell/MCP-timeserver](https://github.com/SecretiveShell/MCP-timeserver) 🐍 🏠 - Access the time in any timezone and get the current local time
- [webcoderz/MCP-Geo](https://github.com/webcoderz/MCP-Geo) 🐍 🏠 - Geocoding MCP server for nominatim, ArcGIS, Bing
- [@briandconnelly/mcp-server-ipinfo](https://github.com/briandconnelly/mcp-server-ipinfo) 🐍 ☁️ - IP address geolocation and network information using IPInfo API
### 🎯 <a name="marketing"></a>Marketing
Tools for creating and editing marketing content, working with web meta data, product positioning, and editing guides.
- [Open Strategy Partners Marketing Tools](https://github.com/open-strategy-partners/osp_marketing_tools) 🐍 🏠 - A suite of marketing tools from Open Strategy Partners including writing style, editing codes, and product marketing value map creation.
### 📊 <a name="monitoring"></a>Monitoring
Access and analyze application monitoring data. Enables AI models to review error reports and performance metrics.
- [@modelcontextprotocol/server-sentry](https://github.com/modelcontextprotocol/servers/tree/main/src/sentry) 🐍 ☁️ - Sentry.io integration for error tracking and performance monitoring
- [@modelcontextprotocol/server-raygun](https://github.com/MindscapeHQ/mcp-server-raygun) 📇 ☁️ - Raygun API V3 integration for crash reporting and real user monitoring
- [metoro-io/metoro-mcp-server](https://github.com/metoro-io/metoro-mcp-server) 🎖️ 🏎️ ☁️ - Query and interact with kubernetes environments monitored by Metoro
- [grafana/mcp-grafana](https://github.com/grafana/mcp-grafana) 🎖️ 🐍 🏠 ☁️ - Search dashboards, investigate incidents and query datasources in your Grafana instance
### 🔎 <a name="search"></a>Search
- [@modelcontextprotocol/server-brave-search](https://github.com/modelcontextprotocol/servers/tree/main/src/brave-search) 📇 ☁️ - Web search capabilities using Brave's Search API
- [@angheljf/nyt](https://github.com/angheljf/nyt) 📇 ☁️ - Search articles using the NYTimes API
- [@modelcontextprotocol/server-fetch](https://github.com/modelcontextprotocol/servers/tree/main/src/fetch) 🐍 🏠 ☁️ - Efficient web content fetching and processing for AI consumption
- [ac3xx/mcp-servers-kagi](https://github.com/ac3xx/mcp-servers-kagi) 📇 ☁️ - Kagi search API integration
- [exa-labs/exa-mcp-server](https://github.com/exa-labs/exa-mcp-server) 🎖️ 📇 ☁️ – A Model Context Protocol (MCP) server lets AI assistants like Claude use the Exa AI Search API for web searches. This setup allows AI models to get real-time web information in a safe and controlled way.
- [fatwang2/search1api-mcp](https://github.com/fatwang2/search1api-mcp) 📇 ☁️ - Search via search1api (requires paid API key)
- [Tomatio13/mcp-server-tavily](https://github.com/Tomatio13/mcp-server-tavily) ☁️ 🐍 – Tavily AI search API
- [blazickjp/arxiv-mcp-server](https://github.com/blazickjp/arxiv-mcp-server) ☁️ 🐍 - Search ArXiv research papers
- [mzxrai/mcp-webresearch](https://github.com/mzxrai/mcp-webresearch) 🔍📚 - Search Google and do deep web research on any topic
- [andybrandt/mcp-simple-arxiv](https://github.com/andybrandt/mcp-simple-arxiv) - 🐍 ☁️ MCP for LLM to search and read papers from arXiv
- [andybrandt/mcp-simple-pubmed](https://github.com/andybrandt/mcp-simple-pubmed) - 🐍 ☁️ MCP to search and read medical / life sciences papers from PubMed.
- [apify/mcp-server-rag-web-browser](https://github.com/apify/mcp-server-rag-web-browser) 📇 ☁️ - An MCP server for Apify's open-source RAG Web Browser Actor to perform web searches, scrape URLs, and return content in Markdown.
- [SecretiveShell/MCP-searxng](https://github.com/SecretiveShell/MCP-searxng) 🐍 🏠 - An MCP Server to connect to searXNG instances
- [Bigsy/Clojars-MCP-Server](https://github.com/Bigsy/Clojars-MCP-Server) 📇 ☁️ - Clojars MCP Server for upto date dependency information of Clojure libraries
- [Ihor-Sokoliuk/MCP-SearXNG](https://github.com/ihor-sokoliuk/mcp-searxng) 📇 🏠/☁️ - A Model Context Protocol Server for [SearXNG](https://docs.searxng.org)
- [erithwik/mcp-hn](https://github.com/erithwik/mcp-hn) 🐍 ☁️ - An MCP server to search Hacker News, get top stories, and more.
- [chanmeng/google-news-mcp-server](https://github.com/ChanMeng666/server-google-news) 📇 ☁️ - Google News integration with automatic topic categorization, multi-language support, and comprehensive search capabilities including headlines, stories, and related topics through [SerpAPI](https://serpapi.com/).
- [devflowinc/trieve](https://github.com/devflowinc/trieve/tree/main/clients/mcp-server) 🎖️📇☁️🏠 - Crawl, embed, chunk, search, and retrieve information from datasets through [Trieve](https://trieve.ai)
### 🔒 <a name="security"></a>Security
- [dnstwist MCP Server](https://github.com/BurtTheCoder/mcp-dnstwist) 📇🪟☁️ - MCP server for dnstwist, a powerful DNS fuzzing tool that helps detect typosquatting, phishing, and corporate espionage.
- [Maigret MCP Server](https://github.com/BurtTheCoder/mcp-maigret) 📇🪟☁️ - MCP server for maigret, a powerful OSINT tool that collects user account information from various public sources. This server provides tools for searching usernames across social networks and analyzing URLs.
- [Shodan MCP Server](https://github.com/BurtTheCoder/mcp-shodan) 📇🪟☁️ - MCP server for querying the Shodan API and Shodan CVEDB. This server provides tools for IP lookups, device searches, DNS lookups, vulnerability queries, CPE lookups, and more.
- [VirusTotal MCP Server](https://github.com/BurtTheCoder/mcp-virustotal) 📇🪟☁️ - MCP server for querying the VirusTotal API. This server provides tools for scanning URLs, analyzing file hashes, and retrieving IP address reports.
- [ORKL MCP Server](https://github.com/fr0gger/MCP_Security) 📇🛡️☁️ - MCP server for querying the ORKL API. This server provides tools for fetching threat reports, analyzing threat actors, and retrieving intelligence sources.
- [Security Audit MCP Server](https://github.com/qianniuspace/mcp-security-audit) 📇🛡️☁️ A powerful MCP (Model Context Protocol) Server that audits npm package dependencies for security vulnerabilities. Built with remote npm registry integration for real-time security checks.
### 🚆 <a name="travel-and-transportation"></a>Travel & Transportation
Access to travel and transportation information. Enables querying schedules, routes, and real-time travel data.
- [NS Travel Information MCP Server](https://github.com/r-huijts/ns-mcp-server) 📇 ☁️ - Access Dutch Railways (NS) travel information, schedules, and real-time updates
### 🔄 <a name="version-control"></a>Version Control
Interact with Git repositories and version control platforms. Enables repository management, code analysis, pull request handling, issue tracking, and other version control operations through standardized APIs.
- [@modelcontextprotocol/server-github](https://github.com/modelcontextprotocol/servers/tree/main/src/github) 📇 ☁️ - GitHub API integration for repository management, PRs, issues, and more
- [@modelcontextprotocol/server-gitlab](https://github.com/modelcontextprotocol/servers/tree/main/src/gitlab) 📇 ☁️ 🏠 - GitLab platform integration for project management and CI/CD operations
- [@modelcontextprotocol/server-git](https://github.com/modelcontextprotocol/servers/tree/main/src/git) 🐍 🏠 - Direct Git repository operations including reading, searching, and analyzing local repositories
- [adhikasp/mcp-git-ingest](https://github.com/adhikasp/mcp-git-ingest) 🐍 🏠 - Read and analyze GitHub repositories with your LLM
### 🛠️ <a name="other-tools-and-integrations"></a>Other Tools and Integrations
- [apify/actors-mcp-server](https://github.com/apify/actors-mcp-server) 📇 ☁️ - Use 3,000+ pre-built cloud tools, known as Actors, to extract data from websites, e-commerce, social media, search engines, maps, and more
- [ivo-toby/contentful-mcp](https://github.com/ivo-toby/contentful-mcp) 📇 🏠 - Update, create, delete content, content-models and assets in your Contentful Space
- [mzxrai/mcp-openai](https://github.com/mzxrai/mcp-openai) 📇 ☁️ - Chat with OpenAI's smartest models
- [mrjoshuak/godoc-mcp](https://github.com/mrjoshuak/godoc-mcp) 🏎️ 🏠 - Token-efficient Go documentation server that provides AI assistants with smart access to package docs and types without reading entire source files
- [pierrebrunelle/mcp-server-openai](https://github.com/pierrebrunelle/mcp-server-openai) 🐍 ☁️ - Query OpenAI models directly from Claude using MCP protocol
- [@modelcontextprotocol/server-everything](https://github.com/modelcontextprotocol/servers/tree/main/src/everything) 📇 🏠 - MCP server that exercises all the features of the MCP protocol
- [baba786/phabricator-mcp-server](https://github.com/baba786/phabricator-mcp-server) 🐍 ☁️ - Interacting with Phabricator API
- [MarkusPfundstein/mcp-obsidian](https://github.com/MarkusPfundstein/mcp-obsidian) 🐍 ☁️ 🏠 - Interacting with Obsidian via REST API
- [calclavia/mcp-obsidian](https://github.com/calclavia/mcp-obsidian) 📇 🏠 - This is a connector to allow Claude Desktop (or any MCP client) to read and search any directory containing Markdown notes (such as an Obsidian vault).
- [anaisbetts/mcp-youtube](https://github.com/anaisbetts/mcp-youtube) 📇 ☁️ - Fetch YouTube subtitles
- [danhilse/notion_mcp](https://github.com/danhilse/notion_mcp) 🐍 ☁️ - Integrates with Notion's API to manage personal todo lists
- [rusiaaman/wcgw](https://github.com/rusiaaman/wcgw/blob/main/src/wcgw/client/mcp_server/Readme.md) 🐍 🏠 - Autonomous shell execution, computer control and coding agent. (Mac)
- [reeeeemo/ancestry-mcp](https://github.com/reeeeemo/ancestry-mcp) 🐍 🏠 - Allows the AI to read .ged files and genetic data
- [sirmews/apple-notes-mcp](https://github.com/sirmews/apple-notes-mcp) 🐍 🏠 - Allows the AI to read from your local Apple Notes database (macOS only)
- [anjor/coinmarket-mcp-server](https://github.com/anjor/coinmarket-mcp-server) 🐍 🏠 - Coinmarket API integration to fetch cryptocurrency listings and quotes
- [suekou/mcp-notion-server](https://github.com/suekou/mcp-notion-server) 📇 🏠 - Interacting with Notion API
- [amidabuddha/unichat-mcp-server](https://github.com/amidabuddha/unichat-mcp-server) 🐍/📇 ☁️ - Send requests to OpenAI, MistralAI, Anthropic, xAI, Google AI or DeepSeek using MCP protocol via tool or predefined prompts. Vendor API key required
- [evalstate/mcp-miro](https://github.com/evalstate/mcp-miro) 📇 ☁️ - Access MIRO whiteboards, bulk create and read items. Requires OAUTH key for REST API.
- [KS-GEN-AI/jira-mcp-server](https://github.com/KS-GEN-AI/jira-mcp-server) 📇 ☁️ 🍎 🪟 - Get Confluence data via CQL and read pages.
- [KS-GEN-AI/confluence-mcp-server](https://github.com/KS-GEN-AI/confluence-mcp-server) 📇 ☁️ 🍎 🪟 - Read jira data via JQL and api and execute requests to create and edit tickets.
- [sooperset/mcp-atlassian](https://github.com/sooperset/mcp-atlassian) 🐍 ☁️ - Natural language search and content access for Confluence workspaces
- [pyroprompts/any-chat-completions-mcp](https://github.com/pyroprompts/any-chat-completions-mcp) - Chat with any other OpenAI SDK Compatible Chat Completions API, like Perplexity, Groq, xAI and more
- [anaisbetts/mcp-installer](https://github.com/anaisbetts/mcp-installer) 🐍 🏠 - An MCP server that installs other MCP servers for you.
- [tanigami/mcp-server-perplexity](https://github.com/tanigami/mcp-server-perplexity) 🐍 ☁️ - Interacting with Perplexity API.
- [future-audiences/wikimedia-enterprise-model-context-protocol](https://gitlab.wikimedia.org/repos/future-audiences/wikimedia-enterprise-model-context-protocol) 🐍 ☁️ - Wikipedia Article lookup API
- [andybrandt/mcp-simple-timeserver](https://github.com/andybrandt/mcp-simple-timeserver) 🐍 🏠☁️ - An MCP server that allows checking local time on the client machine or current UTC time from an NTP server
- [andybrandt/mcp-simple-openai-assistant](https://github.com/andybrandt/mcp-simple-openai-assistant) - 🐍 ☁️ MCP to talk to OpenAI assistants (Claude can use any GPT model as his assitant)
- [@llmindset/mcp-hfspace](https://github.com/evalstate/mcp-hfspace) 📇 ☁️ - Use HuggingFace Spaces directly from Claude. Use Open Source Image Generation, Chat, Vision tasks and more. Supports Image, Audio and text uploads/downloads.
- [zueai/mcp-manager](https://github.com/zueai/mcp-manager) 📇 ☁️ - Simple Web UI to install and manage MCP servers for Claude Desktop App.
- [wong2/mcp-cli](https://github.com/wong2/mcp-cli) 📇 🏠 - CLI tool for testing MCP servers
- [isaacwasserman/mcp-vegalite-server](https://github.com/isaacwasserman/mcp-vegalite-server) 🐍 🏠 - Generate visualizations from fetched data using the VegaLite format and renderer.
- [tevonsb/homeassistant-mcp](https://github.com/tevonsb/homeassistant-mcp) 📇 🏠 - Access Home Assistant data and control devices (lights, switches, thermostats, etc).
- [allenporter/mcp-server-home-assistant](https://github.com/allenporter/mcp-server-home-assistant) 🐍 🏠 - Expose all Home Assistant voice intents through a Model Context Protocol Server allowing home control.
- [nguyenvanduocit/all-in-one-model-context-protocol](https://github.com/nguyenvanduocit/all-in-one-model-context-protocol) 🏎️ 🏠 - Some useful tools for developer, almost everything an engineer need: confluence, Jira, Youtube, run script, knowledge base RAG, fetch URL, Manage youtube channel, emails, calendar, gitlab
- [@joshuarileydev/mac-apps-launcher-mcp-server](https://github.com/JoshuaRileyDev/mac-apps-launcher) 📇 🏠 - An MCP server to list and launch applications on MacOS
- [ZeparHyfar/mcp-datetime](https://github.com/ZeparHyfar/mcp-datetime) - MCP server providing date and time functions in various formats
- [SecretiveShell/MCP-wolfram-alpha](https://github.com/SecretiveShell/MCP-wolfram-alpha) 🐍 ☁️ - An MCP server for querying wolfram alpha API.
- [Amazon Bedrock Nova Canvas](https://github.com/zxkane/mcp-server-amazon-bedrock) 📇 ☁️ - Use Amazon Nova Canvas model for image generation.
- [apinetwork/piapi-mcp-server](https://github.com/apinetwork/piapi-mcp-server) 📇 ☁️ PiAPI MCP server makes user able to generate media content with Midjourney/Flux/Kling/Hunyuan/Udio/Trellis directly from Claude or any other MCP-compatible apps.
- [gotoolkits/DifyWorkflow](https://github.com/gotoolkits/mcp-difyworkflow-server) - 🏎️ ☁️ Tools to the query and execute of Dify workflows
- [@pskill9/hn-server](https://github.com/pskill9/hn-server) - 📇 ☁️ Parses the HTML content from news.ycombinator.com (Hacker News) and provides structured data for different types of stories (top, new, ask, show, jobs).
- [@mediar-ai/screenpipe](https://github.com/mediar-ai/screenpipe) - 🎖️ 🦀 🏠 🍎 Local-first system capturing screen/audio with timestamped indexing, SQL/embedding storage, semantic search, LLM-powered history analysis, and event-triggered actions - enables building context-aware AI agents through a NextJS plugin ecosystem.
- [akseyh/bear-mcp-server](https://github.com/akseyh/bear-mcp-server) - Allows the AI to read from your Bear Notes (macOS only)
- [hmk/attio-mcp-server](https://github.com/hmk/attio-mcp-server) - 📇 ☁️ Allows AI clients to manage records and notes in Attio CRM
- [ws-mcp](https://github.com/nick1udwig/ws-mcp) - Wrap MCP servers with a WebSocket (for use with [kitbitz](https://github.com/nick1udwig/kibitz))
- [AbdelStark/bitcoin-mcp](https://github.com/AbdelStark/bitcoin-mcp) - ₿ A Model Context Protocol (MCP) server that enables AI models to interact with Bitcoin, allowing them to generate keys, validate addresses, decode transactions, query the blockchain, and more.
## Frameworks
- [FastMCP](https://github.com/jlowin/fastmcp) 🐍 - A high-level framework for building MCP servers in Python
- [FastMCP](https://github.com/punkpeye/fastmcp) 📇 - A high-level framework for building MCP servers in TypeScript
- [Foxy Contexts](https://github.com/strowk/foxy-contexts) 🏎️ - Golang library to write MCP Servers declaratively with functional testing included
- [Genkit MCP](https://github.com/firebase/genkit/tree/main/js/plugins/mcp) 📇 – Provides integration between [Genkit](https://github.com/firebase/genkit/tree/main) and the Model Context Protocol (MCP).
- [LiteMCP](https://github.com/wong2/litemcp) 📇 - A high-level framework for building MCP servers in JavaScript/TypeScript
- [mark3labs/mcp-go](https://github.com/mark3labs/mcp-go) 🏎️ - Golang SDK for building MCP Servers and Clients.
- [mcp-framework](https://github.com/QuantGeekDev/mcp-framework) 📇 - Fast and elegant TypeScript framework for building MCP servers
- [mcp-proxy](https://github.com/punkpeye/mcp-proxy) - 📇 A TypeScript SSE proxy for MCP servers that use `stdio` transport.
- [mcp-rs-template](https://github.com/linux-china/mcp-rs-template) 🦀 - MCP CLI server template for Rust
- [metoro-io/mcp-golang](https://github.com/metoro-io/mcp-golang) 🏎️ - Golang framework for building MCP Servers, focussed on type safety
- [rectalogic/langchain-mcp](https://github.com/rectalogic/langchain-mcp) 🐍 - Provides MCP tool calling support in LangChain, allowing for the integration of MCP tools into LangChain workflows.
- [salty-flower/ModelContextProtocol.NET](https://github.com/salty-flower/ModelContextProtocol.NET) #️⃣ 🏠 - A C# SDK for building MCP servers on .NET 9 with NativeAOT compatibility ⚡ 🔌
- [spring-ai-mcp](https://github.com/spring-projects-experimental/spring-ai-mcp) ☕ 🌱 - Java SDK and Spring Framework integration for building MCP client and MCP servers with various, plugable, transport options.
- [@marimo-team/codemirror-mcp](https://github.com/marimo-team/codemirror-mcp) - CodeMirror extension that implements the Model Context Protocol (MCP) for resource mentions and prompt commands.
## Utilities
- [boilingdata/mcp-server-and-gw](https://github.com/boilingdata/mcp-server-and-gw) 📇 - An MCP stdio to HTTP SSE transport gateway with example server and MCP client.
- [isaacwasserman/mcp-langchain-ts-client](https://github.com/isaacwasserman/mcp-langchain-ts-client) 📇 – Use MCP provided tools in LangChain.js
- [lightconetech/mcp-gateway](https://github.com/lightconetech/mcp-gateway) 📇 - A gateway demo for MCP SSE Server.
- [mark3labs/mcphost](https://github.com/mark3labs/mcphost) 🏎️ - A CLI host application that enables Large Language Models (LLMs) to interact with external tools through the Model Context Protocol (MCP).
- [MCP-Connect](https://github.com/EvalsOne/MCP-Connect) 📇 - A tiny tool that enables cloud-based AI services to access local Stdio based MCP servers by HTTP/HTTPS requests.
- [SecretiveShell/MCP-Bridge](https://github.com/SecretiveShell/MCP-Bridge) 🐍 – an openAI middleware proxy to use mcp in any existing openAI compatible client
- [sparfenyuk/mcp-proxy](https://github.com/sparfenyuk/mcp-proxy) 🐍 – An MCP stdio to SSE transport gateawy.
- [upsonic/gpt-computer-assistant](https://github.com/Upsonic/gpt-computer-assistant) 🐍 – framework to build vertical AI agent
## Clients
> [!NOTE]
> Looking for MCP clients? Check out the [awesome-mcp-clients](https://github.com/punkpeye/awesome-mcp-clients/) repository.
## Tips and Tricks
### Official prompt to inform LLMs how to use MCP
Want to ask Claude about Model Context Protocol?
Create a Project, then add this file to it:
https://modelcontextprotocol.io/llms-full.txt
Now Claude can answer questions about writing MCP servers and how they work
- https://www.reddit.com/r/ClaudeAI/comments/1h3g01r/want_to_ask_claude_about_model_context_protocol/
## Star History
<a href="https://star-history.com/#punkpeye/awesome-mcp-servers&Date">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://api.star-history.com/svg?repos=punkpeye/awesome-mcp-servers&type=Date&theme=dark" />
<source media="(prefers-color-scheme: light)" srcset="https://api.star-history.com/svg?repos=punkpeye/awesome-mcp-servers&type=Date" />
<img alt="Star History Chart" src="https://api.star-history.com/svg?repos=punkpeye/awesome-mcp-servers&type=Date" />
</picture>
</a> | {
"source": "punkpeye/awesome-mcp-servers",
"title": "README.md",
"url": "https://github.com/punkpeye/awesome-mcp-servers/blob/main/README.md",
"date": "2024-11-30T04:49:10",
"stars": 3664,
"description": "A collection of MCP servers.",
"file_size": 40573
} |
<h1 align="center">OmniGen: Unified Image Generation</h1>
<p align="center">
<a href="https://vectorspacelab.github.io/OmniGen/">
<img alt="Build" src="https://img.shields.io/badge/Project%20Page-OmniGen-yellow">
</a>
<a href="https://arxiv.org/abs/2409.11340">
<img alt="Build" src="https://img.shields.io/badge/arXiv%20paper-2409.11340-b31b1b.svg">
</a>
<a href="https://huggingface.co/spaces/Shitao/OmniGen">
<img alt="License" src="https://img.shields.io/badge/HF%20Demo-🤗-lightblue">
</a>
<a href="https://huggingface.co/Shitao/OmniGen-v1">
<img alt="Build" src="https://img.shields.io/badge/HF%20Model-🤗-yellow">
</a>
<a href="https://replicate.com/chenxwh/omnigen">
<img alt="Build" src="https://replicate.com/chenxwh/omnigen/badge">
</a>
</p>
<h4 align="center">
<p>
<a href=#1-news>News</a> |
<a href=#3-methodology>Methodology</a> |
<a href=#4-what-can-omnigen-do>Capabilities</a> |
<a href=#5-quick-start>Quick Start</a> |
<a href="#6-finetune">Finetune</a> |
<a href="#license">License</a> |
<a href="#citation">Citation</a>
<p>
</h4>
**We are hiring FTE researchers and interns! If you are interested in working with us on Vision Generation Models, please concat us: ```[email protected]```!**
## 1. News
- 2025-02-12:🔥🔥OmniGen is available in [Diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/omnigen).
- 2024-12-14:🚀️🚀Open-source [X2I Dataset](https://huggingface.co/collections/yzwang/x2i-dataset-674c66d1d700f7f816a9590d)
- 2024-11-03: Added Replicate Demo and API: [](https://replicate.com/chenxwh/omnigen)
- 2024-10-28: We release a new version of inference code, optimizing the memory usage and time cost. You can refer to [docs/inference.md](docs/inference.md#requiremented-resources) for detailed information.
- 2024-10-22: We release the code for OmniGen. Inference: [docs/inference.md](docs/inference.md) Train: [docs/fine-tuning.md](docs/fine-tuning.md)
- 2024-10-22: We release the first version of OmniGen. Model Weight: [Shitao/OmniGen-v1](https://huggingface.co/Shitao/OmniGen-v1) HF Demo: [🤗](https://huggingface.co/spaces/Shitao/OmniGen)
- 2024-09-17:⚡️⚡️We release the first OmniGen Report: [ArXiv](https://arxiv.org/abs/2409.11340)
## 2. Overview
OmniGen is a unified image generation model that can generate a wide range of images from multi-modal prompts. It is designed to be simple, flexible, and easy to use. We provide [inference code](#5-quick-start) so that everyone can explore more functionalities of OmniGen.
Existing image generation models often require loading several additional network modules (such as ControlNet, IP-Adapter, Reference-Net, etc.) and performing extra preprocessing steps (e.g., face detection, pose estimation, cropping, etc.) to generate a satisfactory image. However, **we believe that the future image generation paradigm should be more simple and flexible, that is, generating various images directly through arbitrarily multi-modal instructions without the need for additional plugins and operations, similar to how GPT works in language generation.**
Due to the limited resources, OmniGen still has room for improvement. We will continue to optimize it, and hope it inspires more universal image-generation models. You can also easily fine-tune OmniGen without worrying about designing networks for specific tasks; you just need to prepare the corresponding data, and then run the [script](#6-finetune). Imagination is no longer limited; everyone can construct any image-generation task, and perhaps we can achieve very interesting, wonderful, and creative things.
If you have any questions, ideas, or interesting tasks you want OmniGen to accomplish, feel free to discuss with us: [email protected], [email protected], [email protected]. We welcome any feedback to help us improve the model.
## 3. Methodology
You can see details in our [paper](https://arxiv.org/abs/2409.11340).
## 4. What Can OmniGen do?
OmniGen is a unified image generation model that you can use to perform various tasks, including but not limited to text-to-image generation, subject-driven generation, Identity-Preserving Generation, image editing, and image-conditioned generation. **OmniGen doesn't need additional plugins or operations, it can automatically identify the features (e.g., required object, human pose, depth mapping) in input images according to the text prompt.**
We showcase some examples in [inference.ipynb](inference.ipynb). And in [inference_demo.ipynb](inference_demo.ipynb), we show an interesting pipeline to generate and modify an image.
Here is the illustrations of OmniGen's capabilities:
- You can control the image generation flexibly via OmniGen

- Referring Expression Generation: You can input multiple images and use simple, general language to refer to the objects within those images. OmniGen can automatically recognize the necessary objects in each image and generate new images based on them. No additional operations, such as image cropping or face detection, are required.

If you are not entirely satisfied with certain functionalities or wish to add new capabilities, you can try [fine-tuning OmniGen](#6-finetune).
## 5. Quick Start
### Using OmniGen
Install via Github:
```bash
git clone https://github.com/VectorSpaceLab/OmniGen.git
cd OmniGen
pip install -e .
```
You also can create a new environment to avoid conflicts:
```bash
# Create a python 3.10.13 conda env (you could also use virtualenv)
conda create -n omnigen python=3.10.13
conda activate omnigen
# Install pytorch with your CUDA version, e.g.
pip install torch==2.3.1+cu118 torchvision --extra-index-url https://download.pytorch.org/whl/cu118
git clone https://github.com/VectorSpaceLab/OmniGen.git
cd OmniGen
pip install -e .
```
Here are some examples:
```python
from OmniGen import OmniGenPipeline
pipe = OmniGenPipeline.from_pretrained("Shitao/OmniGen-v1")
# Note: Your local model path is also acceptable, such as 'pipe = OmniGenPipeline.from_pretrained(your_local_model_path)', where all files in your_local_model_path should be organized as https://huggingface.co/Shitao/OmniGen-v1/tree/main
## Text to Image
images = pipe(
prompt="A curly-haired man in a red shirt is drinking tea.",
height=1024,
width=1024,
guidance_scale=2.5,
seed=0,
)
images[0].save("example_t2i.png") # save output PIL Image
## Multi-modal to Image
# In the prompt, we use the placeholder to represent the image. The image placeholder should be in the format of <img><|image_*|></img>
# You can add multiple images in the input_images. Please ensure that each image has its placeholder. For example, for the list input_images [img1_path, img2_path], the prompt needs to have two placeholders: <img><|image_1|></img>, <img><|image_2|></img>.
images = pipe(
prompt="A man in a black shirt is reading a book. The man is the right man in <img><|image_1|></img>.",
input_images=["./imgs/test_cases/two_man.jpg"],
height=1024,
width=1024,
guidance_scale=2.5,
img_guidance_scale=1.6,
seed=0
)
images[0].save("example_ti2i.png") # save output PIL image
```
- If out of memory, you can set `offload_model=True`. If the inference time is too long when inputting multiple images, you can reduce the `max_input_image_size`. For the required resources and the method to run OmniGen efficiently, please refer to [docs/inference.md#requiremented-resources](docs/inference.md#requiremented-resources).
- For more examples of image generation, you can refer to [inference.ipynb](inference.ipynb) and [inference_demo.ipynb](inference_demo.ipynb)
- For more details about the argument in inference, please refer to [docs/inference.md](docs/inference.md).
### Using Diffusers
[Diffusers docs](https://huggingface.co/docs/diffusers/main/en/using-diffusers/omnigen)
### Gradio Demo
We construct an online demo in [Huggingface](https://huggingface.co/spaces/Shitao/OmniGen).
For the local gradio demo, you need to install `pip install gradio spaces`, and then you can run:
```python
pip install gradio spaces
python app.py
```
#### Use Google Colab
To use with Google Colab, please use the following command:
```
!git clone https://github.com/VectorSpaceLab/OmniGen.git
%cd OmniGen
!pip install -e .
!pip install gradio spaces
!python app.py --share
```
## 6. Finetune
We provide a training script `train.py` to fine-tune OmniGen.
Here is a toy example about LoRA finetune:
```bash
accelerate launch --num_processes=1 train.py \
--model_name_or_path Shitao/OmniGen-v1 \
--batch_size_per_device 2 \
--condition_dropout_prob 0.01 \
--lr 1e-3 \
--use_lora \
--lora_rank 8 \
--json_file ./toy_data/toy_subject_data.jsonl \
--image_path ./toy_data/images \
--max_input_length_limit 18000 \
--keep_raw_resolution \
--max_image_size 1024 \
--gradient_accumulation_steps 1 \
--ckpt_every 10 \
--epochs 200 \
--log_every 1 \
--results_dir ./results/toy_finetune_lora
```
Please refer to [docs/fine-tuning.md](docs/fine-tuning.md) for more details (e.g. full finetune).
### Contributors:
Thank all our contributors for their efforts and warmly welcome new members to join in!
<a href="https://github.com/VectorSpaceLab/OmniGen/graphs/contributors">
<img src="https://contrib.rocks/image?repo=VectorSpaceLab/OmniGen" />
</a>
## License
This repo is licensed under the [MIT License](LICENSE).
## Citation
If you find this repository useful, please consider giving a star ⭐ and citation
```
@article{xiao2024omnigen,
title={Omnigen: Unified image generation},
author={Xiao, Shitao and Wang, Yueze and Zhou, Junjie and Yuan, Huaying and Xing, Xingrun and Yan, Ruiran and Wang, Shuting and Huang, Tiejun and Liu, Zheng},
journal={arXiv preprint arXiv:2409.11340},
year={2024}
}
``` | {
"source": "VectorSpaceLab/OmniGen",
"title": "README.md",
"url": "https://github.com/VectorSpaceLab/OmniGen/blob/main/README.md",
"date": "2024-09-16T17:42:17",
"stars": 3628,
"description": "OmniGen: Unified Image Generation. https://arxiv.org/pdf/2409.11340",
"file_size": 10077
} |
# Fine-tuning OmniGen
Fine-tuning Omnigen can better help you handle specific image generation tasks. For example, by fine-tuning on a person's images, you can generate multiple pictures of that person while maintaining task consistency.
A lot of previous work focused on designing new networks to facilitate specific tasks. For instance, ControlNet was proposed to handle image conditions, and IP-Adapter was constructed to maintain ID features. If you want to perform new tasks, you need to build new architectures and repeatedly debug them. Adding and adjusting extra network parameters is usually time-consuming and labor-intensive, which is not user-friendly and cost-efficient enough. However, with Omnigen, all of this becomes very simple.
By comparison, Omnigen can accept multi-modal conditional inputs and has been pre-trained on various tasks. You can fine-tune it on any task without designing specialized networks like ControlNet or IP-Adapter for a specific task.
**All you need to do is prepare the data and start training. You can break the limitations of previous models, allowing Omnigen to accomplish a variety of interesting tasks, even those that have never been done before.**
## Installation
```bash
git clone https://github.com/VectorSpaceLab/OmniGen.git
cd OmniGen
pip install -e .
```
## Full fine-tuning
### Fine-tuning command
```bash
accelerate launch \
--num_processes=1 \
--use_fsdp \
--fsdp_offload_params false \
--fsdp_sharding_strategy SHARD_GRAD_OP \
--fsdp_auto_wrap_policy TRANSFORMER_BASED_WRAP \
--fsdp_transformer_layer_cls_to_wrap Phi3DecoderLayer \
--fsdp_state_dict_type FULL_STATE_DICT \
--fsdp_forward_prefetch false \
--fsdp_use_orig_params True \
--fsdp_cpu_ram_efficient_loading false \
--fsdp_sync_module_states True \
train.py \
--model_name_or_path Shitao/OmniGen-v1 \
--json_file ./toy_data/toy_data.jsonl \
--image_path ./toy_data/images \
--batch_size_per_device 1 \
--lr 2e-5 \
--keep_raw_resolution \
--max_image_size 1024 \
--gradient_accumulation_steps 1 \
--ckpt_every 50 \
--epochs 200 \
--log_every 1 \
--results_dir ./results/toy_finetune
```
Some important arguments:
- `num_processes`: number of GPU to use for training
- `model_name_or_path`: path to the pretrained model
- `json_file`: path to the json file containing the training data, e.g., ./toy_data/toy_data.jsonl
- `image_path`: path to the image folder, e.g., ./toy_data/images
- `batch_size_per_device`: batch size per device
- `lr`: learning rate
- `keep_raw_resolution`: whether to keep the original resolution of the image, if not, all images will be resized to (max_image_size, max_image_size)
- `max_image_size`: max image size
- `gradient_accumulation_steps`: number of steps to accumulate gradients
- `ckpt_every`: number of steps to save checkpoint
- `epochs`: number of epochs
- `log_every`: number of steps to log
- `results_dir`: path to the results folder
The data format of json_file is as follows:
```
{
"instruction": str,
"input_images": [str, str, ...],
"output_images": str
}
```
You can see a toy example in `./toy_data/toy_data.jsonl`.
If an OOM(Out of Memory) issue occurs, you can try to decrease the `batch_size_per_device` or `max_image_size`. You can also try to use LoRA instead of full fine-tuning.
### Inference
The checkpoint can be found at `{results_dir}/checkpoints/*`. You can use the following command to load saved checkpoint:
```python
from OmniGen import OmniGenPipeline
pipe = OmniGenPipeline.from_pretrained("checkpoint_path") # e.g., ./results/toy_finetune/checkpoints/0000200
```
## LoRA fine-tuning
LoRA fine-tuning is a simple way to fine-tune OmniGen with less GPU memory. To use lora, you should add `--use_lora` and `--lora_rank` to the command.
```bash
accelerate launch \
--num_processes=1 \
train.py \
--model_name_or_path Shitao/OmniGen-v1 \
--batch_size_per_device 2 \
--condition_dropout_prob 0.01 \
--lr 3e-4 \
--use_lora \
--lora_rank 8 \
--json_file ./toy_data/toy_data.jsonl \
--image_path ./toy_data/images \
--max_input_length_limit 18000 \
--keep_raw_resolution \
--max_image_size 1024 \
--gradient_accumulation_steps 1 \
--ckpt_every 50 \
--epochs 100 \
--log_every 1 \
--results_dir ./results/toy_finetune_lora
```
### Inference
The checkpoint can be found at `{results_dir}/checkpoints/*`. You can use the following command to load checkpoint:
```python
from OmniGen import OmniGenPipeline
pipe = OmniGenPipeline.from_pretrained("Shitao/OmniGen-v1")
pipe.merge_lora("checkpoint_path") # e.g., ./results/toy_finetune_lora/checkpoints/0000100
```
## A simple example
Here is an example for learning new concepts: "sks dog". We use five images of one dog from [dog-example](https://huggingface.co/datasets/diffusers/dog-example).
The json file is `./toy_data/toy_subject_data.jsonl`, and the images have been saved in `./toy_data/images`.
```bash
accelerate launch \
--num_processes=1 \
train.py \
--model_name_or_path Shitao/OmniGen-v1 \
--batch_size_per_device 2 \
--condition_dropout_prob 0.01 \
--lr 1e-3 \
--use_lora \
--lora_rank 16 \
--json_file ./toy_data/toy_subject_data.jsonl \
--image_path ./toy_data/images \
--max_input_length_limit 18000 \
--keep_raw_resolution \
--max_image_size 1024 \
--gradient_accumulation_steps 1 \
--ckpt_every 50 \
--epochs 200 \
--log_every 1 \
--results_dir ./results/toy_finetune_lora
```
After training, you can use the following command to generate images:
```python
from OmniGen import OmniGenPipeline
pipe = OmniGenPipeline.from_pretrained("Shitao/OmniGen-v1")
pipe.merge_lora("checkpoint_path") # e.g., ./results/toy_finetune_lora/checkpoints/0000200
images = pipe(
prompt="a photo of sks dog running in the snow",
height=1024,
width=1024,
guidance_scale=3
)
images[0].save("example_sks_dog_snow.png")
``` | {
"source": "VectorSpaceLab/OmniGen",
"title": "docs/fine-tuning.md",
"url": "https://github.com/VectorSpaceLab/OmniGen/blob/main/docs/fine-tuning.md",
"date": "2024-09-16T17:42:17",
"stars": 3628,
"description": "OmniGen: Unified Image Generation. https://arxiv.org/pdf/2409.11340",
"file_size": 6049
} |
# Inference with OmniGen
To handle some complex tasks, image generation models are becoming increasingly sophisticated, leading to more and more cumbersome workflows. Existing image generation models like SD and Flux require loading many additional network modules (such as ControlNet, IP-Adapter, Reference-Net) and extra preprocessing steps (e.g., face detection, pose detection, image cropping) to generate a satisfactory image. This complex workflow is not user-friendly. We believe that future image generation models should be simpler, generating various images directly through instructions, similar to how GPT works in language generation.
Therefore, we propose OmniGen, a model capable of handling various image generation tasks within a single framework. The goal of OmniGen is to complete various image generation tasks without relying on any additional components or image preprocessing steps. OmniGen supports tasks including text-to-image generation, image editing, subject-driven image generation, and classical vision tasks, among others. More capabilities can be found in our examples. We provide inference code so you can explore more unknown functionalities yourself.
## Install
```bash
git clone https://github.com/staoxiao/OmniGen.git
cd OmniGen
pip install -e .
```
## Generate Images
You can use the following code to generate images:
```python
from OmniGen import OmniGenPipeline
pipe = OmniGenPipeline.from_pretrained("Shitao/OmniGen-v1")
# Text to Image
images = pipe(
prompt="A curly-haired man in a red shirt is drinking tea.",
height=1024,
width=1024,
guidance_scale=2.5,
seed=0,
)
images[0].save("example_t2i.png") # save output PIL Image
# Multi-modal to Image
# In prompt, we use the placeholder to represent the image. The image placeholder should be in the format of <img><|image_*|></img>
# You can add multiple images in the input_images. Please ensure that each image has its placeholder. For example, for the list input_images [img1_path, img2_path], the prompt needs to have two placeholders: <img><|image_1|></img>, <img><|image_2|></img>.
images = pipe(
prompt="A man in a black shirt is reading a book. The man is the right man in <img><|image_1|></img>.",
input_images=["./imgs/test_cases/two_man.jpg"],
height=1024,
width=1024,
guidance_scale=2.5,
img_guidance_scale=1.6,
max_input_image_size=1024,
separate_cfg_infer=True,
use_kv_cache=True,
offload_kv_cache=True,
offload_model=False,
use_input_image_size_as_output=False,
seed=0,
)
images[0].save("example_ti2i.png") # save output PIL image
```
Some important arguments:
- `guidance_scale`: The strength of the guidance. Based on our experience, it is usually best to set it between 2 and 3. The higher the value, the more similar the generated image will be to the prompt. If the image appears oversaturated, please reduce the scale.
- `height` and `width`: The height and width of the generated image. The default value is 1024x1024. OmniGen support any size, but these number must be divisible by 16.
- `num_inference_steps`: The number of steps to take in the diffusion process. The higher the value, the more detailed the generated image will be.
- `max_input_image_size`: the maximum size of input image, which will be used to crop the input image to the maximum size. A smaller number will result in faster generation speed and lower memory cost.
- `separate_cfg_infer`: Whether to use separate inference process for CFG guidance. If set to True, memory cost will be lower. Default is True.
- `use_kv_cache`: Whether to use key-value cache. Default is True.
- `offload_kv_cache`: offload the cached key and value to cpu, which can save memory but slow down the generation silightly. Default is True.
- `offload_model`: offload the model to cpu, which can save memory but slow down the generation. Default is False.
- `use_input_image_size_as_output`: whether to use the input image size as the output image size, which can be used for single-image input, e.g., image editing task. Default is False.
- `seed`: The seed for random number generator.
**More examples please refer to [inference.ipynb](../inference.ipynb)**
#### Input data
OmniGen can accept multi-modal input data. Specifically, you should pass two arguments: `prompt` and `input_images`.
For text to image generation, you can pass a string as `prompt`, or pass a list of strings as `prompt` to generate multiple images.
For multi-modal to image generation, you should pass a string as `prompt`, and a list of image paths as `input_images`. The placeholder in the prompt should be in the format of `<img><|image_*|></img>`.
For example, if you want to generate an image with a person holding a bouquet of flowers, you can pass the following prompt:
```
prompt = "A woman holds a bouquet of flowers and faces the camera. Thw woman is <img><|image_1|></img>."
input_images = ["./imgs/test_cases/liuyifei.png"]
```
The placeholder `<|image_1|>` will be replaced by the image at `input_images[0]`, i.e., `./imgs/test_cases/liuyifei.png`.
If you want to generate multiple images, you can pass a list of prompts and a list of image paths. For example:
```
prompt = ["A woman holds a bouquet of flowers and faces the camera.", "A woman holds a bouquet of flowers and faces the camera. Thw woman is <img><|image_1|></img>."]
input_images = [[], ["./imgs/test_cases/liuyifei.png"]]
```
#### Gradio Demo
We have constructed a online demo in [Huggingface](https://huggingface.co/spaces/Shitao/OmniGen).
For the local gradio demo, you can run with the following command:
```python
python app.py
```
## Tips
- For out of memory or time cost, you can refer to [./docs/inference.md#requiremented-resources](https://github.com/VectorSpaceLab/OmniGen/blob/main/docs/inference.md#requiremented-resources) to select a appropriate setting.
- Oversaturated: If the image appears oversaturated, please reduce the `guidance_scale`.
- Not match the prompt: If the image does not match the prompt, please try to increase the `guidance_scale`.
- Low-quality: More detailed prompt will lead to better results.
- Animate Style: If the genereate images is in animate style, you can try to add `photo` to the prompt`.
- Edit generated image. If you generate a image by omnigen and then want to edit it, you cannot use the same seed to edit this image. For example, use seed=0 to generate image, and should use seed=1 to edit this image.
- For image editing tasks, we recommend placing the image before the editing instruction. For example, use `<img><|image_1|></img> remove suit`, rather than `remove suit <img><|image_1|></img>`.
- For image editing task and controlnet task, we recommend to set the height and width of output image as the same
as input image. For example, if you want to edit a 512x512 image, you should set the height and width of output image as 512x512. You also can set the `use_input_image_size_as_output` to automatically set the height and width of output image as the same as input image.
## Requiremented Resources
We are currently experimenting with some techniques to reduce memory usage and improve speed, including `use_kv_cache, offload_kv_cache, separate_cfg_infer, offload_model`, which you can enable in the pipeline.
The default setting is`use_kv_cache=True, offload_kv_cache=True, separate_cfg_infer=True, offload_model=False`.
To reduce memory consumption while maintaining inference speed, quantization is also a method worth exploring and is left for future work.
We conducted experiments on the A800 and RTX 3090. The memory requirements and inference times are shown in the table below. You can choose the appropriate settings based on your available resources.
**Overall, the text-to-image task requires minimal memory and time costs, comparable to other latest text-to-image models. However, when using input images, the computational cost increases. If out of memory, you can set `offload_model=True`. If inference time is too long, you can reduce the `max_input_image_size`**
- Different image size.
Different image size (`max_input_image_size` is the max size of input image, `height` and `width` are the size of output image) with the default inference settings (`use_kv_cache=True,offload_kv_cache=True,separate_cfg_infer=True`)
For A800 GPU:
| Settings | Only Text | Text + Single Image | Text + Two Images |
|:-------------|:----------:|:-------------------:|:---------------------:|
| max_input_image_size=1024,height=1024,width=1024 | 9G, 31s | 12G, 1m6s | 13G, 1m20s |
| max_input_image_size=512,height=1024,width=1024 | 9G, 31s | 10G, 50s | 10G, 54s |
| max_input_image_size=768,height=768,width=768 | 9G, 16s | 10G, 32s | 10G, 37s |
| max_input_image_size=512,height=512,width=512 | 9G, 7s | 9G, 14s | 9G, 15s |
For RTX 3090 GPU(24G):
| Settings | Only Text | Text + Single Image | Text + Two Images |
|:-------------|:----------:|:-------------------:|:---------------------:|
| max_input_image_size=1024,height=1024,width=1024 | 9G, 1m17s | 12G, 2m46s | 13G, 3m23s |
| max_input_image_size=512,height=1024,width=1024 | 9G, 1m18s | 10G, 2m8s | 10G, 2m18s |
| max_input_image_size=768,height=768,width=768 | 9G, 41s | 10G, 1m22s | 10G, 1m38s |
| max_input_image_size=512,height=512,width=512 | 9G, 19s | 9G, 36s | 9G, 43s |
We recommend reducing the size of input images to improve speed (i.e., reduce the `max_input_image_size`), especially when inputting multiple images, as multiple large images can significantly slow down the process.
A very smaller `max_input_image_size` to significantly reduce memory usage and speed-up generation, but note that the generation quality may be lower.
And please set the `height` and `width` the same as the size of input image for image editing task.
- Different inference settings
Default image size: height=1024, width=1024, max_input_image_size=1024
For A800 GPU:
| Settings | Only Text | Text + Single Image | Text + Two Images |
|:-------------|:----------:|:-------------------:|:---------------------:|
| use_kv_cache | 18G, 30s | 36G, 1m | 48G, 1m13s |
| use_kv_cache,offload_kv_cache | 10G, 30s | 14G, 1m10s | 17G, 1m30s |
| use_kv_cache,offload_kv_cache,separate_cfg_infer | 9G, 31s | 12G, 1m6s | 13G, 1m20s |
| use_kv_cache,offload_kv_cache,offload_model | 4G, 55s | 7G, 1m30s | 11G, 1m48s |
| use_kv_cache,offload_kv_cache,separate_cfg_infer,offload_model | 3G, 1m23s | 5G, 2m19s | 6G, 2m30s |
For RTX 3090 GPU(24G):
| Settings | Only Text | Text + Single Image | Text + Two Images |
|:-------------|:----------:|:-------------------:|:---------------------:|
| use_kv_cache | 18G, 1m14s | OOM | OOM |
| use_kv_cache,offload_kv_cache | 10G, 1m17s | 14G, 3m11s | 17G, 4m3s |
| use_kv_cache,offload_kv_cache,separate_cfg_infer | 9G, 1m18s | 12G, 2m46s | 13G, 3m21s |
| use_kv_cache,offload_kv_cache,offload_model | 4G,3m1s | 7G, 4m14s | 11G, 5m4s |
| use_kv_cache,offload_kv_cache,separate_cfg_infer,offload_model | 3G, 4m56s | 5G, 7m49s | 6G, 8m6s | | {
"source": "VectorSpaceLab/OmniGen",
"title": "docs/inference.md",
"url": "https://github.com/VectorSpaceLab/OmniGen/blob/main/docs/inference.md",
"date": "2024-09-16T17:42:17",
"stars": 3628,
"description": "OmniGen: Unified Image Generation. https://arxiv.org/pdf/2409.11340",
"file_size": 11127
} |
# Agent Laboratory: Using LLM Agents as Research Assistants
<p align="center">
<img src="media/AgentLabLogo.png" alt="Demonstration of the flow of AgentClinic" style="width: 99%;">
</p>
<p align="center">
【English | <a href="readme/README-chinese.md">中文</a> | <a href="readme/README-japanese.md">日本語</a> | <a href="readme/README-korean.md">한국어</a> | <a href="readme/README-filipino.md">Filipino</a> | <a href="readme/README-french.md">Français</a> | <a href="readme/README-slovak.md">Slovenčina</a> | <a href="readme/README-portugese.md">Português</a> | <a href="readme/README-spanish.md">Español</a> | <a href="readme/README-turkish.md">Türkçe</a> | <a href="readme/README-hindi.md">हिंदी</a> | <a href="readme/README-bengali.md">বাংলা</a> | <a href="readme/README-vietnamese.md">Tiếng Việt</a> | <a href="readme/README-russian.md">Русский</a> | <a href="readme/README-arabic.md">العربية</a> | <a href="readme/README-farsi.md">فارسی</a> | <a href="readme/README-italian.md">Italiano</a>】
</p>
<p align="center">
【📝 <a href="https://arxiv.org/pdf/2501.04227">Paper</a> | 🌐 <a href="https://agentlaboratory.github.io/">Website</a> | 💻 <a href="https://github.com/SamuelSchmidgall/AgentLaboratory">Software</a> | 📰 <a href="https://agentlaboratory.github.io/#citation-ref">Citation</a>】
</p>
## 📖 Overview
- **Agent Laboratory** is an end-to-end autonomous research workflow meant to assist **you** as the human researcher toward **implementing your research ideas**. Agent Laboratory consists of specialized agents driven by large language models to support you through the entire research workflow—from conducting literature reviews and formulating plans to executing experiments and writing comprehensive reports.
- This system is not designed to replace your creativity but to complement it, enabling you to focus on ideation and critical thinking while automating repetitive and time-intensive tasks like coding and documentation. By accommodating varying levels of computational resources and human involvement, Agent Laboratory aims to accelerate scientific discovery and optimize your research productivity.
<p align="center">
<img src="media/AgentLab.png" alt="Demonstration of the flow of AgentClinic" style="width: 99%;">
</p>
### 🔬 How does Agent Laboratory work?
- Agent Laboratory consists of three primary phases that systematically guide the research process: (1) Literature Review, (2) Experimentation, and (3) Report Writing. During each phase, specialized agents driven by LLMs collaborate to accomplish distinct objectives, integrating external tools like arXiv, Hugging Face, Python, and LaTeX to optimize outcomes. This structured workflow begins with the independent collection and analysis of relevant research papers, progresses through collaborative planning and data preparation, and results in automated experimentation and comprehensive report generation. Details on specific agent roles and their contributions across these phases are discussed in the paper.
<p align="center">
<img src="media/AgentLabWF.png" alt="Demonstration of the flow of AgentClinic" style="width: 99%;">
</p>
### 👾 Currently supported models
* **OpenAI**: o1, o1-preview, o1-mini, gpt-4o
* **DeepSeek**: deepseek-chat (deepseek-v3)
To select a specific llm set the flag `--llm-backend="llm_model"` for example `--llm-backend="gpt-4o"` or `--llm-backend="deepseek-chat"`. Please feel free to add a PR supporting new models according to your need!
## 🖥️ Installation
### Python venv option
* We recommend using python 3.12
1. **Clone the GitHub Repository**: Begin by cloning the repository using the command:
```bash
git clone [email protected]:SamuelSchmidgall/AgentLaboratory.git
```
2. **Set up and Activate Python Environment**
```bash
python -m venv venv_agent_lab
```
- Now activate this environment:
```bash
source venv_agent_lab/bin/activate
```
3. **Install required libraries**
```bash
pip install -r requirements.txt
```
4. **Install pdflatex [OPTIONAL]**
```bash
sudo apt install pdflatex
```
- This enables latex source to be compiled by the agents.
- **[IMPORTANT]** If this step cannot be run due to not having sudo access, pdf compiling can be turned off via running Agent Laboratory via setting the `--compile-latex` flag to false: `--compile-latex "false"`
5. **Now run Agent Laboratory!**
`python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "YOUR RESEARCH IDEA"`
or, if you don't have pdflatex installed
`python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "YOUR RESEARCH IDEA" --compile-latex "false"`
### Co-Pilot mode
To run Agent Laboratory in copilot mode, simply set the copilot-mode flag to `"true"`
`python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "YOUR RESEARCH IDEA" --copilot-mode "true"`
-----
## Tips for better research outcomes
#### [Tip #1] 📝 Make sure to write extensive notes! 📝
**Writing extensive notes is important** for helping your agent understand what you're looking to accomplish in your project, as well as any style preferences. Notes can include any experiments you want the agents to perform, providing API keys, certain plots or figures you want included, or anything you want the agent to know when performing research.
This is also your opportunity to let the agent know **what compute resources it has access to**, e.g. GPUs (how many, what type of GPU, how many GBs), CPUs (how many cores, what type of CPUs), storage limitations, and hardware specs.
In order to add notes, you must modify the task_notes_LLM structure inside of `ai_lab_repo.py`. Provided below is an example set of notes used for some of our experiments.
```
task_notes_LLM = [
{"phases": ["plan formulation"],
"note": f"You should come up with a plan for TWO experiments."},
{"phases": ["plan formulation", "data preparation", "running experiments"],
"note": "Please use gpt-4o-mini for your experiments."},
{"phases": ["running experiments"],
"note": f'Use the following code to inference gpt-4o-mini: \nfrom openai import OpenAI\nos.environ["OPENAI_API_KEY"] = "{api_key}"\nclient = OpenAI()\ncompletion = client.chat.completions.create(\nmodel="gpt-4o-mini-2024-07-18", messages=messages)\nanswer = completion.choices[0].message.content\n'},
{"phases": ["running experiments"],
"note": f"You have access to only gpt-4o-mini using the OpenAI API, please use the following key {api_key} but do not use too many inferences. Do not use openai.ChatCompletion.create or any openai==0.28 commands. Instead use the provided inference code."},
{"phases": ["running experiments"],
"note": "I would recommend using a small dataset (approximately only 100 data points) to run experiments in order to save time. Do not use much more than this unless you have to or are running the final tests."},
{"phases": ["data preparation", "running experiments"],
"note": "You are running on a MacBook laptop. You can use 'mps' with PyTorch"},
{"phases": ["data preparation", "running experiments"],
"note": "Generate figures with very colorful and artistic design."},
]
```
--------
#### [Tip #2] 🚀 Using more powerful models generally leads to better research 🚀
When conducting research, **the choice of model can significantly impact the quality of results**. More powerful models tend to have higher accuracy, better reasoning capabilities, and better report generation. If computational resources allow, prioritize the use of advanced models such as o1-(mini/preview) or similar state-of-the-art large language models.
However, **it’s important to balance performance and cost-effectiveness**. While powerful models may yield better results, they are often more expensive and time-consuming to run. Consider using them selectively—for instance, for key experiments or final analyses—while relying on smaller, more efficient models for iterative tasks or initial prototyping.
When resources are limited, **optimize by fine-tuning smaller models** on your specific dataset or combining pre-trained models with task-specific prompts to achieve the desired balance between performance and computational efficiency.
-----
#### [Tip #3] ✅ You can load previous saves from checkpoints ✅
**If you lose progress, internet connection, or if a subtask fails, you can always load from a previous state.** All of your progress is saved by default in the `state_saves` variable, which stores each individual checkpoint. Just pass the following arguments when running `ai_lab_repo.py`
`python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "YOUR RESEARCH IDEA" --llm-backend "o1-mini" --load-existing True --load-existing-path "state_saves/LOAD_PATH"`
-----
#### [Tip #4] 🈯 If you are running in a language other than English 🈲
If you are running Agent Laboratory in a language other than English, no problem, just make sure to provide a language flag to the agents to perform research in your preferred language. Note that we have not extensively studied running Agent Laboratory in other languages, so be sure to report any problems you encounter.
For example, if you are running in Chinese:
`python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "YOUR RESEARCH IDEA (in your language)" --llm-backend "o1-mini" --language "中文"`
----
#### [Tip #5] 🌟 There is a lot of room for improvement 🌟
There is a lot of room to improve this codebase, so if you end up making changes and want to help the community, please feel free to share the changes you've made! We hope this tool helps you!
## 📜 License
Source Code Licensing: Our project's source code is licensed under the MIT License. This license permits the use, modification, and distribution of the code, subject to certain conditions outlined in the MIT License.
## 📬 Contact
If you would like to get in touch, feel free to reach out to [[email protected]](mailto:[email protected])
## Reference / Bibtex
```bibtex
@misc{schmidgall2025agentlaboratoryusingllm,
title={Agent Laboratory: Using LLM Agents as Research Assistants},
author={Samuel Schmidgall and Yusheng Su and Ze Wang and Ximeng Sun and Jialian Wu and Xiaodong Yu and Jiang Liu and Zicheng Liu and Emad Barsoum},
year={2025},
eprint={2501.04227},
archivePrefix={arXiv},
primaryClass={cs.HC},
url={https://arxiv.org/abs/2501.04227},
}
``` | {
"source": "SamuelSchmidgall/AgentLaboratory",
"title": "README.md",
"url": "https://github.com/SamuelSchmidgall/AgentLaboratory/blob/main/README.md",
"date": "2025-01-08T02:00:51",
"stars": 3583,
"description": "Agent Laboratory is an end-to-end autonomous research workflow meant to assist you as the human researcher toward implementing your research ideas",
"file_size": 10473
} |
# مختبر الوكيل: استخدام وكلاء النماذج اللغوية الكبيرة كمساعدين بحثيين
<p align="center">
<img src="../media/AgentLabLogo.png" alt="Demonstration of the flow of AgentClinic" style="width: 99%;">
</p>
<p align="center">
【<a href="../README.md">English</a> | <a href="../readme/README-chinese.md">中文</a> | <a href="../readme/README-japanese.md">日本語</a> | <a href="../readme/README-korean.md">한국어</a> | <a href="../readme/README-filipino.md">Filipino</a> | <a href="../readme/README-french.md">Français</a> | <a href="../readme/README-slovak.md">Slovenčina</a> | <a href="../readme/README-portugese.md">Português</a> | <a href="../readme/README-spanish.md">Español</a> | <a href="../readme/README-turkish.md">Türkçe</a> | <a href="../readme/README-hindi.md">हिंदी</a> | <a href="../readme/README-bengali.md">বাংলা</a> | <a href="../readme/README-vietnamese.md">Tiếng Việt</a> | <a href="../readme/README-russian.md">Русский</a> | العربية | <a href="../readme/README-farsi.md">فارسی</a> | <a href="../readme/README-italian.md">Italiano</a>】
</p>
<p align="center">
【🌐 <a href="https://agentlaboratory.github.io/">الموقع الإلكتروني</a> | 💻 <a href="https://github.com/SamuelSchmidgall/AgentLaboratory">البرمجيات</a> | 🎥 <a href="https://agentlaboratory.github.io/#youtube-video">الفيديو</a> | 📚 <a href="https://agentlaboratory.github.io/#examples-goto">مثال على ورقة بحثية</a> | 📰 <a href="https://agentlaboratory.github.io/#citation-ref">الاستشهاد</a>】
</p>
## 📖 نظرة عامة
- **مختبر الوكيل** هو سير عمل بحثي مستقل من البداية للنهاية مصمم لمساعدتك كباحث بشري في **تنفيذ أفكار بحثك**. يتكون مختبر الوكيل من وكلاء متخصصين مدفوعين بنماذج لغوية كبيرة لدعمك طوال سير العمل البحثي بالكامل — من إجراء مراجعات الأدبيات وصياغة الخطط إلى تنفيذ التجارب وكتابة تقارير شاملة.
- هذا النظام ليس مصممًا لاستبدال إبداعك بل لتكملته، مما يتيح لك التركيز على توليد الأفكار والتفكير النقدي بينما يقوم بأتمتة المهام المتكررة والتي تستغرق وقتًا طويلاً مثل البرمجة والتوثيق. من خلال استيعاب مستويات مختلفة من الموارد الحاسوبية والمشاركة البشرية، يهدف مختبر الوكيل إلى تسريع الاكتشافات العلمية وتحسين إنتاجيتك البحثية.
<p align="center">
<img src="../media/AgentLab.png" alt="Demonstration of the flow of AgentClinic" style="width: 99%;">
</p>
### 🔬 كيف يعمل مختبر الوكيل؟
- يتكون مختبر الوكيل من ثلاث مراحل رئيسية توجه عملية البحث بشكل منهجي: (1) مراجعة الأدبيات، (2) التجارب، و(3) كتابة التقارير. خلال كل مرحلة، يتعاون وكلاء متخصصون مدفوعون بنماذج لغوية كبيرة لتحقيق أهداف مميزة، مع دمج أدوات خارجية مثل arXiv، Hugging Face، Python، وLaTeX لتحسين النتائج. يبدأ سير العمل هذا بجمع وتحليل مستقل للأوراق البحثية ذات الصلة، يتقدم من خلال التخطيط التعاوني وإعداد البيانات، وينتهي بتنفيذ التجارب تلقائيًا وتوليد تقارير شاملة. يتم مناقشة تفاصيل أدوار الوكلاء المحددة ومساهماتهم عبر هذه المراحل في الورقة البحثية.
<p align="center">
<img src="../media/AgentLabWF.png" alt="Demonstration of the flow of AgentClinic" style="width: 99%;">
</p>
## 🖥️ التثبيت
### خيار البيئة الافتراضية للبايثون
1. **استنساخ مستودع GitHub**: ابدأ باستنساخ المستودع باستخدام الأمر:
```bash
git clone [email protected]:SamuelSchmidgall/AgentLaboratory.git
```
2. **إعداد وتفعيل بيئة البايثون**
```bash
python -m venv venv_agent_lab
```
- الآن قم بتفعيل هذه البيئة:
```bash
source venv_agent_lab/bin/activate
```
3. **تثبيت المكتبات المطلوبة**
```bash
pip install -r requirements.txt
```
4. **تثبيت pdflatex [اختياري]**
```bash
sudo apt install pdflatex
```
- هذا يمكن الوكلاء من تجميع مصدر LaTeX.
- **[مهم]** إذا لم تتمكن من تشغيل هذه الخطوة بسبب عدم وجود صلاحيات sudo، يمكن إيقاف تجميع PDF عن طريق تشغيل مختبر الوكيل مع تعيين العلم --compile_latex إلى false:
```bash
--compile_latex=False
```
5. **الآن قم بتشغيل مختبر الوكيل!**
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "YOUR RESEARCH IDEA"
```
أو، إذا لم يكن لديك pdflatex مثبتًا
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "YOUR RESEARCH IDEA" --compile_latex=False
```
-----
## نصائح لتحقيق نتائج بحثية أفضل
#### [نصيحة #1] 📝 تأكد من كتابة ملاحظات شاملة! 📝
**كتابة ملاحظات شاملة أمر مهم** لمساعدة وكيلك على فهم ما تسعى إلى تحقيقه في مشروعك، بالإضافة إلى أي تفضيلات أسلوبية. يمكن أن تشمل الملاحظات أي تجارب ترغب في أن يقوم الوكلاء بتنفيذها، توفير مفاتيح API، بعض الرسوم البيانية أو الأشكال التي ترغب في تضمينها، أو أي شيء تريد أن يعرفه الوكيل عند إجراء البحث.
هذه أيضًا فرصتك لإعلام الوكيل **بالموارد الحاسوبية التي يمكنه الوصول إليها**، مثل وحدات معالجة الرسومات (عددها، نوعها، حجم الذاكرة)، وحدات المعالجة المركزية (عدد النوى، نوعها)، قيود التخزين، ومواصفات الأجهزة.
لإضافة ملاحظات، يجب تعديل هيكل task_notes_LLM داخل ملف ai_lab_repo.py. فيما يلي مثال على مجموعة من الملاحظات المستخدمة لبعض تجاربنا.
```python
task_notes_LLM = [
{"phases": ["plan formulation"],
"note": f"You should come up with a plan for TWO experiments."},
{"phases": ["plan formulation", "data preparation", "running experiments"],
"note": "Please use gpt-4o-mini for your experiments."},
{"phases": ["running experiments"],
"note": f"Use the following code to inference gpt-4o-mini: \nfrom openai import OpenAI\nos.environ["OPENAI_API_KEY"] = "{api_key}"\nclient = OpenAI()\ncompletion = client.chat.completions.create(\nmodel="gpt-4o-mini-2024-07-18", messages=messages)\nanswer = completion.choices[0].message.content\n"},
{"phases": ["running experiments"],
"note": f"You have access to only gpt-4o-mini using the OpenAI API, please use the following key {api_key} but do not use too many inferences. Do not use openai.ChatCompletion.create or any openai==0.28 commands. Instead use the provided inference code."},
{"phases": ["running experiments"],
"note": "I would recommend using a small dataset (approximately only 100 data points) to run experiments in order to save time. Do not use much more than this unless you have to or are running the final tests."},
{"phases": ["data preparation", "running experiments"],
"note": "You are running on a MacBook laptop. You can use 'mps' with PyTorch"},
{"phases": ["data preparation", "running experiments"],
"note": "Generate figures with very colorful and artistic design."},
]
```
--------
#### [نصيحة #2] 🚀 استخدام نماذج أكثر قوة يؤدي عمومًا إلى أبحاث أفضل 🚀
عند إجراء البحث، **يمكن أن يؤثر اختيار النموذج بشكل كبير على جودة النتائج**. النماذج الأكثر قوة تميل إلى أن تكون أكثر دقة، ولديها قدرات تفكير أفضل، وتوليد تقارير أفضل. إذا سمحت الموارد الحاسوبية، أعطِ الأولوية لاستخدام النماذج المتقدمة مثل o1-(mini/preview) أو نماذج لغوية كبيرة حديثة مماثلة.
ومع ذلك، **من المهم تحقيق التوازن بين الأداء والفعالية من حيث التكلفة**. بينما قد تؤدي النماذج القوية إلى نتائج أفضل، فهي غالبًا ما تكون أكثر تكلفة وتستغرق وقتًا أطول للتشغيل. فكر في استخدامها بشكل انتقائي — على سبيل المثال، للتجارب الرئيسية أو التحليلات النهائية — بينما تعتمد على نماذج أصغر وأكثر كفاءة للمهام التكرارية أو النمذجة الأولية.
عندما تكون الموارد محدودة، **قم بتحسين الأداء عن طريق ضبط النماذج الأصغر** على مجموعة البيانات الخاصة بك أو عن طريق دمج النماذج المدربة مسبقًا مع مطالبات محددة بالمهام لتحقيق التوازن المطلوب بين الأداء والكفاءة الحاسوبية.
-----
#### [نصيحة #3] ✅ يمكنك تحميل الحفظات السابقة من نقاط التفتيش ✅
**إذا فقدت تقدمك، أو انقطعت اتصال الإنترنت، أو فشلت مهمة فرعية، يمكنك دائمًا التحميل من حالة سابقة.** يتم حفظ كل تقدمك افتراضيًا في متغير state_saves، الذي يخزن كل نقطة تفتيش فردية. فقط مرر الحجج التالية عند تشغيل ai_lab_repo.py
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "YOUR RESEARCH IDEA" --llm-backend "o1-mini" --load-existing True --load-existing-path "save_states/LOAD_PATH"
```
-----
#### [نصيحة #4] 🈯 إذا كنت تعمل بلغة غير الإنجليزية 🈲
إذا كنت تشغل مختبر الوكيل بلغة غير الإنجليزية، لا مشكلة، فقط تأكد من توفير علم اللغة للوكلاء لأداء البحث بلغتك المفضلة. لاحظ أننا لم ندرس تشغيل مختبر الوكيل بلغات أخرى بشكل موسع، لذا تأكد من الإبلاغ عن أي مشكلات تواجهها.
على سبيل المثال، إذا كنت تعمل بالصينية:
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "YOUR RESEARCH IDEA (in your language)" --llm-backend "o1-mini" --language "中文"
```
----
#### [نصيحة #5] 🌟 هناك الكثير من المجال للتحسين 🌟
هناك الكثير من المجال لتحسين قاعدة الشيفرة هذه، لذا إذا قمت بإجراء تغييرات وترغب في مساعدة المجتمع، لا تتردد في مشاركة التغييرات التي قمت بها! نأمل أن تساعدك هذه الأداة!
## المرجع / Bibtex
```bibtex
@preprint{schmidgall2025AgentLaboratory,
title={Agent Laboratory: Using LLM Agents as Research Assistants},
author={Schmidgall, Samuel and Su, Yusheng and Wang, Ze and Sun, Ximeng and Wu, Jialian and Yu, Xiadong and Liu, Jiang, Liu, Zicheng and Barsoum, Emad},
year={2025}
}
``` | {
"source": "SamuelSchmidgall/AgentLaboratory",
"title": "readme/README-arabic.md",
"url": "https://github.com/SamuelSchmidgall/AgentLaboratory/blob/main/readme/README-arabic.md",
"date": "2025-01-08T02:00:51",
"stars": 3583,
"description": "Agent Laboratory is an end-to-end autonomous research workflow meant to assist you as the human researcher toward implementing your research ideas",
"file_size": 8794
} |
# এজেন্ট ল্যাবরেটরি: গবেষণা সহকারী হিসেবে LLM এজেন্ট ব্যবহার
<p align="center">
<img src="../media/AgentLabLogo.png" alt="Demonstration of the flow of AgentClinic" style="width: 99%;">
</p>
<p align="center">
【<a href="../README.md">English</a> | <a href="../readme/README-chinese.md">中文</a> | <a href="../readme/README-japanese.md">日本語</a> | <a href="../readme/README-korean.md">한국어</a> | <a href="../readme/README-filipino.md">Filipino</a> | <a href="../readme/README-french.md">Français</a> | <a href="../readme/README-slovak.md">Slovenčina</a> | <a href="../readme/README-portugese.md">Português</a> | <a href="../readme/README-spanish.md">Español</a> | <a href="../readme/README-turkish.md">Türkçe</a> | <a href="../readme/README-hindi.md">हिंदी</a> | বাংলা | <a href="../readme/README-vietnamese.md">Tiếng Việt</a> | <a href="../readme/README-russian.md">Русский</a> | <a href="../readme/README-arabic.md">العربية</a> | <a href="../readme/README-farsi.md">فارسی</a> | <a href="../readme/README-italian.md">Italiano</a>】
</p>
<p align="center">
【🌐 <a href="https://agentlaboratory.github.io/">Website</a> | 💻 <a href="https://github.com/SamuelSchmidgall/AgentLaboratory">Software</a> | 🎥 <a href="https://agentlaboratory.github.io/#youtube-video">Video</a> | 📚 <a href="https://agentlaboratory.github.io/#examples-goto">Example Paper</a> | 📰 <a href="https://agentlaboratory.github.io/#citation-ref">Citation</a>】
</p>
## 📖 ওভারভিউ
- **এজেন্ট ল্যাবরেটরি** একটি এন্ড-টু-এন্ড স্বায়ত্তশাসিত গবেষণা ওয়ার্কফ্লো যা **আপনাকে** মানব গবেষক হিসেবে **আপনার গবেষণা ধারণাগুলি বাস্তবায়নে** সহায়তা করার জন্য ডিজাইন করা হয়েছে। এজেন্ট ল্যাবরেটরি বড় ভাষা মডেল দ্বারা চালিত বিশেষায়িত এজেন্টের সমন্বয়ে গঠিত যা আপনাকে সম্পূর্ণ গবেষণা ওয়ার্কফ্লো জুড়ে সহায়তা করে—সাহিত্য পর্যালোচনা পরিচালনা থেকে পরিকল্পনা গঠন, পরীক্ষা সম্পাদন এবং বিস্তৃত প্রতিবেদন লেখা পর্যন্ত।
- এই সিস্টেমটি আপনার সৃজনশীলতাকে প্রতিস্থাপন করার জন্য ডিজাইন করা হয়নি বরং এটি সম্পূরক করার জন্য, আপনাকে ধারণা গঠন এবং সমালোচনামূলক চিন্তাভাবনায় মনোনিবেশ করার পাশাপাশি কোডিং এবং ডকুমেন্টেশন মত পুনরাবৃত্তিমূলক এবং সময়সাপেক্ষ কাজগুলি স্বয়ংক্রিয়করণের সুযোগ দেয়। বিভিন্ন স্তরের গণনামূলক সম্পদ এবং মানব সম্পৃক্ততাকে সমন্বিত করে, এজেন্ট ল্যাবরেটরি বৈজ্ঞানিক আবিষ্কারকে ত্বরান্বিত করা এবং আপনার গবেষণা উৎপাদনশীলতাকে সর্বাধিক করতে লক্ষ্য রাখে।
<p align="center">
<img src="../media/AgentLab.png" alt="Demonstration of the flow of AgentClinic" style="width: 99%;">
</p>
### 🔬 এজেন্ট ল্যাবরেটরি কীভাবে কাজ করে?
- এজেন্ট ল্যাবরেটরি তিনটি প্রধান পর্যায় নিয়ে গঠিত যা পদ্ধতিগতভাবে গবেষণা প্রক্রিয়াকে নির্দেশ করে: (১) সাহিত্য পর্যালোচনা, (২) পরীক্ষা, এবং (৩) প্রতিবেদন লেখা। প্রতিটি পর্যায়ে, LLM দ্বারা চালিত বিশেষায়িত এজেন্টরা পৃথক লক্ষ্য অর্জনের জন্য সহযোগিতা করে, ফলাফল অপ্টিমাইজ করার জন্য arXiv, Hugging Face, Python এবং LaTeX এর মত বহিরাগত সরঞ্জামগুলিকে সংহত করে। এই কাঠামোবদ্ধ ওয়ার্কফ্লো প্রাসঙ্গিক গবেষণা পত্রের স্বাধীন সংগ্রহ এবং বিশ্লেষণ দিয়ে শুরু হয়, সহযোগিতামূলক পরিকল্পনা এবং তথ্য প্রস্তুতির মাধ্যমে অগ্রসর হয়, এবং স্বয়ংক্রিয় পরীক্ষণ এবং বিস্তৃত প্রতিবেদন তৈরিতে শেষ হয়। এই পর্যায়গুলির জুড়ে নির্দিষ্ট এজেন্ট ভূমিকা এবং তাদের অবদান সম্পর্কে বিস্তারিত গবেষণাপত্রে আলোচনা করা হয়েছে।
<p align="center">
<img src="../media/AgentLabWF.png" alt="Demonstration of the flow of AgentClinic" style="width: 99%;">
</p>
## 🖥️ ইনস্টলেশন
### পাইথন venv বিকল্প
1. **GitHub রিপোজিটরি ক্লোন করুন**: কমান্ডটি ব্যবহার করে রিপোজিটরিটি ক্লোন করা শুরু করুন:
```bash
git clone [email protected]:SamuelSchmidgall/AgentLaboratory.git
```
2. **পাইথন পরিবেশ সেট আপ এবং সক্রিয় করুন**
```bash
python -m venv venv_agent_lab
```
- এখন এই পরিবেশটি সক্রিয় করুন:
```bash
source venv_agent_lab/bin/activate
```
3. **প্রয়োজনীয় লাইব্রেরিগুলি ইনস্টল করুন**
```bash
pip install -r requirements.txt
```
4. **pdflatex ইনস্টল করুন [ঐচ্ছিক]**
```bash
sudo apt install pdflatex
```
- এটি এজেন্ট দ্বারা ল্যাটেক্স সোর্স কম্পাইল করা সক্ষম করে।
- **[গুরুত্বপূর্ণ]** যদি sudo অ্যাক্সেস না থাকার কারণে এই ধাপটি চালানো না যায়, তাহলে --compile_latex ফ্ল্যাগটি false এ সেট করে এজেন্ট ল্যাবরেটরি চালিয়ে pdf কম্পাইলিং বন্ধ করা যেতে পারে: --compile_latex=False
5. **এখন এজেন্ট ল্যাবরেটরি চালান!**
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "YOUR RESEARCH IDEA"
```
অথবা, যদি আপনি pdflatex ইনস্টল না করে থাকেন
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "YOUR RESEARCH IDEA" --compile_latex=False
```
-----
## গবেষণার ফলাফল উন্নত করার টিপস
#### [টিপ #১] 📝 ব্যাপক নোট লেখার বিষয়টি নিশ্চিত করুন! 📝
**ব্যাপক নোট লেখা গুরুত্বপূর্ণ** কারণ এটি আপনার এজেন্টকে আপনার প্রকল্পে আপনি কী অর্জন করতে চাইছেন তা বোঝাতে এবং যে কোনও স্টাইল পছন্দ রয়েছে তা বুঝতে সাহায্য করে। নোটগুলিতে যে কোনও পরীক্ষা আপনি এজেন্টদের সম্পাদন করতে চান, API কী সরবরাহ করা, আপনি যে নির্দিষ্ট প্লট বা চিত্র অন্তর্ভুক্ত করতে চান, অথবা গবেষণা পরিচালনা করার সময় এজেন্টকে যা কিছু জানাতে চান তা অন্তর্ভুক্ত থাকতে পারে।
এটি এছাড়াও আপনার সুযোগ আপনার এজেন্টকে জানানোর **কোন কম্পিউট সম্পদগুলিতে এটি প্রবেশাধিকার রয়েছে**, উদাহরণস্বরূপ, GPUs (কতগুলো, কোন ধরণের GPU, কতগুলো GB), CPUs (কতগুলো কোর, কোন ধরণের CPU), স্টোরেজ সীমাবদ্ধতা, এবং হার্ডওয়্যার স্পেসিফিকেশন।
নোট যুক্ত করার জন্য, আপনাকে ai_lab_repo.py এর ভিতরে task_notes_LLM গঠনটি পরিবর্তন করতে হবে। নীচে কিছু পরীক্ষার জন্য ব্যবহৃত নোটগুলির একটি উদাহরণ দেওয়া হল।
```python
task_notes_LLM = [
{"phases": ["plan formulation"],
"note": f"You should come up with a plan for TWO experiments."},
{"phases": ["plan formulation", "data preparation", "running experiments"],
"note": "Please use gpt-4o-mini for your experiments."},
{"phases": ["running experiments"],
"note": f"Use the following code to inference gpt-4o-mini: \nfrom openai import OpenAI\nos.environ["OPENAI_API_KEY"] = "{api_key}"\nclient = OpenAI()\ncompletion = client.chat.completions.create(\nmodel="gpt-4o-mini-2024-07-18", messages=messages)\nanswer = completion.choices[0].message.content\n"},
{"phases": ["running experiments"],
"note": f"You have access to only gpt-4o-mini using the OpenAI API, please use the following key {api_key} but do not use too many inferences. Do not use openai.ChatCompletion.create or any openai==0.28 commands. Instead use the provided inference code."},
{"phases": ["running experiments"],
"note": "I would recommend using a small dataset (approximately only 100 data points) to run experiments in order to save time. Do not use much more than this unless you have to or are running the final tests."},
{"phases": ["data preparation", "running experiments"],
"note": "You are running on a MacBook laptop. You can use 'mps' with PyTorch"},
{"phases": ["data preparation", "running experiments"],
"note": "Generate figures with very colorful and artistic design."},
]
```
--------
#### [টিপ #২] 🚀 আরও শক্তিশালী মডেলগুলি সাধারণত আরও ভাল গবেষণার দিকে নিয়ে যায় 🚀
গবেষণা পরিচালনার সময়, **মডেলের নির্বাচন ফলাফলের গুণমানকে উল্লেখযোগ্যভাবে প্রভাবিত করতে পারে**। আরও শক্তিশালী মডেলগুলির সাধারণত উচ্চতর নির্ভুলতা, উন্নত যুক্তিবিদ্যা ক্ষমতা, এবং উন্নত প্রতিবেদন তৈরির ক্ষমতা থাকে। যদি গণনামূলক সম্পদ অনুমতি দেয়, তাহলে o1-(mini/preview) বা অনুরূপ অত্যাধুনিক বড় ভাষা মডেলগুলির মতো উন্নত মডেলগুলির ব্যবহারে অগ্রাধিকার দিন।
তবে, **কর্মক্ষমতা এবং ব্যয়-কার্যকারিতা মধ্যে ভারসাম্য বজায় রাখা গুরুত্বপূর্ণ**। শক্তিশালী মডেলগুলি যদিও ভাল ফলাফল দিতে পারে, তবে এগুলি প্রায়শই চালাতে বেশি ব্যয়বহুল এবং সময়সাপেক্ষ হয়। সেগুলি নির্বাচিতভাবে ব্যবহার করার কথা বিবেচনা করুন—উদাহরণস্বরূপ, মূল পরীক্ষাগুলি বা চূড়ান্ত বিশ্লেষণের জন্য—অব iterativeative কাজ বা প্রাথমিক প্রোটোটাইপিংয়ের জন্য ছোট, আরও দক্ষ মডেলগুলির উপর নির্ভর করে।
যখন সম্পদ সীমিত থাকে, **আপনার নির্দিষ্ট ডেটাসেটে ছোট মডেলগুলিকে সূক্ষ্ম-সংশোধন করে বা কার্য-নির্দিষ্ট প্রম্পটগুলির সাথে পূর্ব-প্রশিক্ষিত মডেলগুলিকে সংযোজন করে কর্মক্ষমতা এবং গণনামূলক দক্ষতার মধ্যে কাঙ্ক্ষিত ভারসাম্য অর্জন করুন**।
-----
#### [টিপ #৩] ✅ আপনি চেকপয়েন্টগুলি থেকে পূর্ববর্তী সেভগুলি লোড করতে পারেন ✅
**যদি আপনি অগ্রগতি হারান, ইন্টারনেট সংযোগ হারান, বা যদি একটি উপ-কাজ ব্যর্থ হয়, তবে আপনি সর্বদা পূর্ববর্তী অবস্থান থেকে লোড করতে পারেন।** আপনার সমস্ত অগ্রগতি ডিফল্টভাবে state_saves ভেরিয়েবলে সংরক্ষিত থাকে, যা প্রতিটি পৃথক চেকপয়েন্ট সংরক্ষণ করে। ai_lab_repo.py চালানোর সময় কেবল নিম্নলিখিত আর্গুমেন্টগুলি প্রদান করুন
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "YOUR RESEARCH IDEA" --llm-backend "o1-mini" --load-existing True --load-existing-path "save_states/LOAD_PATH"
```
-----
#### [টিপ #৪] 🈯 আপনি যদি ইংরেজির বাইরে অন্য কোনো ভাষায় চালাচ্ছেন 🈲
আপনি যদি এজেন্ট ল্যাবরেটরি ইংরেজির বাইরে অন্য কোনো ভাষায় চালাচ্ছেন, সমস্যা নেই, কেবল নিশ্চিত করুন যে আপনি এজেন্টদের আপনার পছন্দের ভাষায় গবেষণা সম্পাদনের জন্য একটি ভাষা ফ্ল্যাগ সরবরাহ করেছেন। লক্ষ্য করুন যে আমরা অন্যান্য ভাষায় এজেন্ট ল্যাবরেটরি চালানোর ব্যাপকভাবে অধ্যয়ন করি নি, তাই আপনি যে কোনও সমস্যা সম্মুখীন হলে তা রিপোর্ট করতে ভুলবেন না।
উদাহরণস্বরূপ, আপনি যদি চীনা ভাষায় চালাচ্ছেন:
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "YOUR RESEARCH IDEA (in your language)" --llm-backend "o1-mini" --language "中文"
```
----
#### [টিপ #৫] 🌟 উন্নতির জন্য অনেক জায়গা রয়েছে 🌟
এই কোডবেস উন্নত করার জন্য অনেক সুযোগ রয়েছে, তাই আপনি যদি পরিবর্তন করতে পারেন এবং কমিউনিটির সাহায্য করতে চান, তবে দয়া করে আপনার করা পরিবর্তনগুলি ভাগ করতে দ্বিধা করবেন না! আমরা আশা করি এই টুলটি আপনাকে সাহায্য করবে!
## রেফারেন্স / Bibtex
```bibtex
@preprint{schmidgall2025AgentLaboratory,
title={Agent Laboratory: Using LLM Agents as Research Assistants},
author={Schmidgall, Samuel and Su, Yusheng and Wang, Ze and Sun, Ximeng and Wu, Jialian and Yu, Xiadong and Liu, Jiang, Liu, Zicheng and Barsoum, Emad},
year={2025}
}
``` | {
"source": "SamuelSchmidgall/AgentLaboratory",
"title": "readme/README-bengali.md",
"url": "https://github.com/SamuelSchmidgall/AgentLaboratory/blob/main/readme/README-bengali.md",
"date": "2025-01-08T02:00:51",
"stars": 3583,
"description": "Agent Laboratory is an end-to-end autonomous research workflow meant to assist you as the human researcher toward implementing your research ideas",
"file_size": 9799
} |
# Agent Laboratory: 使用大型语言模型代理作为研究助理
<p align="center">
<img src="../media/AgentLabLogo.png" alt="Demonstration of the flow of AgentClinic" style="width: 99%;">
</p>
<p align="center">
【<a href="../README.md">English</a> | 中文 | <a href="../readme/README-japanese.md">日本語</a> | <a href="../readme/README-korean.md">한국어</a> | <a href="../readme/README-filipino.md">Filipino</a> | <a href="../readme/README-french.md">Français</a> | <a href="../readme/README-slovak.md">Slovenčina</a> | <a href="../readme/README-portugese.md">Português</a> | <a href="../readme/README-spanish.md">Español</a> | <a href="../readme/README-turkish.md">Türkçe</a> | <a href="../readme/README-hindi.md">हिंदी</a> | <a href="../readme/README-bengali.md">বাংলা</a> | <a href="../readme/README-vietnamese.md">Tiếng Việt</a> | <a href="../readme/README-russian.md">Русский</a> | <a href="../readme/README-arabic.md">العربية</a> | <a href="../readme/README-farsi.md">فارسی</a> | <a href="../readme/README-italian.md">Italiano</a>】
</p>
<p align="center">
【🌐 <a href="https://agentlaboratory.github.io/">网站</a> | 💻 <a href="https://github.com/SamuelSchmidgall/AgentLaboratory">软件</a> | 🎥 <a href="https://agentlaboratory.github.io/#youtube-video">视频</a> | 📚 <a href="https://agentlaboratory.github.io/#examples-goto">示例论文</a> | 📰 <a href="https://agentlaboratory.github.io/#citation-ref">引用</a>】
</p>
## 📖 概述
- **Agent Laboratory** 是一个端到端的自主研究工作流程,旨在协助**您**作为人类研究人员**实现您的研究想法**。Agent Laboratory 由由大型语言模型驱动的专业代理组成,支持您完成整个研究工作流程——从进行文献综述和制定计划,到执行实验和撰写综合报告。
- 该系统并非旨在取代您的创造力,而是为了补充它,使您能够专注于创意和批判性思维,同时自动化重复且耗时的任务,如编码和文档编写。通过适应不同水平的计算资源和人类参与,Agent Laboratory 旨在加速科学发现并优化您的研究生产力。
<p align="center">
<img src="../media/AgentLab.png" alt="Demonstration of the flow of AgentClinic" style="width: 99%;">
</p>
### 🔬 Agent Laboratory 如何工作?
- Agent Laboratory 包含三个主要阶段,系统地引导研究过程:(1)文献综述,(2)实验,(3)报告撰写。在每个阶段,由大型语言模型驱动的专业代理协作完成不同的目标,整合了如 arXiv、Hugging Face、Python 和 LaTeX 等外部工具以优化结果。这一结构化的工作流程始于独立收集和分析相关研究论文,经过协作计划和数据准备,最终实现自动化实验和综合报告生成。论文中讨论了具体代理角色及其在这些阶段的贡献。
<p align="center">
<img src="../media/AgentLabWF.png" alt="Demonstration of the flow of AgentClinic" style="width: 99%;">
</p>
## 🖥️ 安装
### Python 虚拟环境选项
1. **克隆 GitHub 仓库**:首先使用以下命令克隆仓库:
```bash
git clone [email protected]:SamuelSchmidgall/AgentLaboratory.git
```
2. **设置并激活 Python 环境**
```bash
python -m venv venv_agent_lab
```
- 现在激活此环境:
```bash
source venv_agent_lab/bin/activate
```
3. **安装所需库**
```bash
pip install -r requirements.txt
```
4. **安装 pdflatex [可选]**
```bash
sudo apt install pdflatex
```
- 这使得代理能够编译 latex 源代码。
- **[重要]** 如果由于没有 sudo 权限而无法运行此步骤,可以通过将 `--compile_latex` 标志设置为 false 来关闭 pdf 编译:`--compile_latex=False`
5. **现在运行 Agent Laboratory!**
`python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "YOUR RESEARCH IDEA"`
或者,如果您没有安装 pdflatex
`python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "YOUR RESEARCH IDEA" --compile_latex=False`
-----
## 提高研究成果的技巧
#### [技巧 #1] 📝 确保写下详尽的笔记! 📝
**写下详尽的笔记非常重要**,帮助您的代理理解您在项目中希望实现的目标,以及任何风格偏好。笔记可以包括您希望代理执行的任何实验、提供 API 密钥、希望包含的特定图表或图形,或任何您希望代理在进行研究时了解的内容。
这也是您让代理知道**它可以访问的计算资源**的机会,例如 GPU(数量、类型、内存大小)、CPU(核心数量、类型)、存储限制和硬件规格。
为了添加笔记,您必须修改 `ai_lab_repo.py` 中的 `task_notes_LLM` 结构。以下是我们的一些实验中使用的笔记示例。
```
task_notes_LLM = [
{"phases": ["plan formulation"],
"note": f"You should come up with a plan for TWO experiments."},
{"phases": ["plan formulation", "data preparation", "running experiments"],
"note": "Please use gpt-4o-mini for your experiments."},
{"phases": ["running experiments"],
"note": f"Use the following code to inference gpt-4o-mini: \nfrom openai import OpenAI\nos.environ["OPENAI_API_KEY"] = "{api_key}"\nclient = OpenAI()\ncompletion = client.chat.completions.create(\nmodel="gpt-4o-mini-2024-07-18", messages=messages)\nanswer = completion.choices[0].message.content\n"},
{"phases": ["running experiments"],
"note": f"You have access to only gpt-4o-mini using the OpenAI API, please use the following key {api_key} but do not use too many inferences. Do not use openai.ChatCompletion.create or any openai==0.28 commands. Instead use the provided inference code."},
{"phases": ["running experiments"],
"note": "I would recommend using a small dataset (approximately only 100 data points) to run experiments in order to save time. Do not use much more than this unless you have to or are running the final tests."},
{"phases": ["data preparation", "running experiments"],
"note": "You are running on a MacBook laptop. You can use 'mps' with PyTorch"},
{"phases": ["data preparation", "running experiments"],
"note": "Generate figures with very colorful and artistic design."},
]
```
--------
#### [技巧 #2] 🚀 使用更强大的模型通常会带来更好的研究 🚀
在进行研究时,**模型的选择会显著影响结果的质量**。更强大的模型往往具有更高的准确性、更好的推理能力和更优秀的报告生成能力。如果计算资源允许,优先使用先进的模型,如 o1-(mini/preview) 或类似的最先进大型语言模型。
然而,**在性能和成本效益之间取得平衡也很重要**。虽然强大的模型可能会产生更好的结果,但它们通常更昂贵且运行时间更长。考虑选择性地使用它们,例如用于关键实验或最终分析,同时在迭代任务或初步原型设计中依赖较小、更高效的模型。
当资源有限时,**通过在您的特定数据集上微调较小的模型或将预训练模型与特定任务的提示相结合来优化,以实现性能与计算效率之间的理想平衡**。
-----
#### [技巧 #3] ✅ 您可以从检查点加载之前的保存 ✅
**如果您丢失了进度、互联网连接中断或子任务失败,您始终可以从先前的状态加载。** 您的所有进度默认保存在 `state_saves` 变量中,该变量存储每个单独的检查点。只需在运行 `ai_lab_repo.py` 时传递以下参数
`python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "YOUR RESEARCH IDEA" --llm-backend "o1-mini" --load-existing True --load-existing-path "save_states/LOAD_PATH"`
-----
#### [技巧 #4] 🈯 如果您使用非英语语言运行 🈲
如果您使用非英语语言运行 Agent Laboratory,没问题,只需确保向代理提供一个语言标志,以便用您喜欢的语言进行研究。请注意,我们尚未广泛研究使用其他语言运行 Agent Laboratory,因此请务必报告您遇到的任何问题。
例如,如果您使用中文运行:
`python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "YOUR RESEARCH IDEA (in your language)" --llm-backend "o1-mini" --language "中文"`
----
#### [技巧 #5] 🌟 还有很大的改进空间 🌟
这个代码库还有很大的改进空间,因此如果您进行了更改并希望帮助社区,请随时分享您所做的更改!我们希望这个工具对您有帮助!
## 参考文献 / Bibtex
```bibtex
@preprint{schmidgall2025AgentLaboratory,
title={Agent Laboratory: Using LLM Agents as Research Assistants},
author={Schmidgall, Samuel and Su, Yusheng and Wang, Ze and Sun, Ximeng and Wu, Jialian and Yu, Xiadong and Liu, Jiang, Liu, Zicheng and Barsoum, Emad},
year={2025}
}
``` | {
"source": "SamuelSchmidgall/AgentLaboratory",
"title": "readme/README-chinese.md",
"url": "https://github.com/SamuelSchmidgall/AgentLaboratory/blob/main/readme/README-chinese.md",
"date": "2025-01-08T02:00:51",
"stars": 3583,
"description": "Agent Laboratory is an end-to-end autonomous research workflow meant to assist you as the human researcher toward implementing your research ideas",
"file_size": 6270
} |
# آزمایشگاه ایجینت ها: استفاده از نمایندگان مدلهای زبانی بزرگ به عنوان دستیار برای محققان
<p align="center">
<img src="../media/AgentLabLogo.png" alt="Demonstration of the flow of AgentClinic" style="width: 99%;">
</p>
<p align="center">
【<a href="../README.md">English</a> | <a href="../readme/README-chinese.md">中文</a> | <a href="../readme/README-japanese.md">日本語</a> | <a href="../readme/README-korean.md">한국어</a> | <a href="../readme/README-filipino.md">Filipino</a> | <a href="../readme/README-french.md">Français</a> | <a href="../readme/README-slovak.md">Slovenčina</a> | <a href="../readme/README-portugese.md">Português</a> | <a href="../readme/README-spanish.md">Español</a> | <a href="../readme/README-turkish.md">Türkçe</a> | <a href="../readme/README-hindi.md">हिंदी</a> | <a href="../readme/README-bengali.md">বাংলা</a> | <a href="../readme/README-vietnamese.md">Tiếng Việt</a> | <a href="../readme/README-russian.md">Русский</a> | <a href="../readme/README-arabic.md">العربية</a> | فارسی | <a href="../readme/README-italian.md">Italiano</a>】
</p>
<p align="center">
【🌐 <a href="https://agentlaboratory.github.io/">Website</a> | 💻 <a href="https://github.com/SamuelSchmidgall/AgentLaboratory">Software</a> | 🎥 <a href="https://agentlaboratory.github.io/#youtube-video">Video</a> | 📚 <a href="https://agentlaboratory.github.io/#examples-goto">Example Paper</a> | 📰 <a href="https://agentlaboratory.github.io/#citation-ref">Citation</a>】
</p>
## 📖 نمای کلی
- **آزمایشگاه ایجینت ها** یک سیستم کاملا اتوماتیک برای کارهای تحقیقاتی است که به منظور کمک به **شما** به عنوان پژوهشگر انسانی برای **اجرای ایدههای تحقیقاتی خود** طراحی شده است. آزمایشگاه ایجینت ها شامل نمایندگان تخصصی است که توسط مدلهای زبان بزرگ هدایت میشوند تاتا در تمام مراحل تحقیق از انجام مطالعه و تدوین برنامهها تا اجرای آزمایشها و نوشتن گزارشهای جامع از شما حمایت کنند.
- این سیستم برای جایگزینی خلاقیت شما طراحی نشده است، بلکه برای تکمیل آن است، به شما این امکان را میدهد که بر ایدهپردازی و تفکر انتقادی تمرکز کنید در حالی که وظایف تکراری و زمانبر مانند کدنویسی و مستندسازی خودکار میشوند. با پذیرش سطوح مختلف منابع محاسباتی و مشارکت انسانی، آزمایشگاه ایجنت ها هدف دارد تا کشف علمی را تسریع کرده و بهرهوری تحقیقاتی شما را بهینه کند.
<p align="center">
<img src="../media/AgentLab.png" alt="Demonstration of the flow of AgentClinic" style="width: 99%;">
</p>
### 🔬 آزمایشگاه ایجنت ها چگونه کار میکند؟
- آزمایشگاه ایجنت ها شامل سه مرحله اصلی است که به طور سیستماتیک فرآیند تحقیق را هدایت میکنند: (1) مرور ادبیات، (2) آزمایشگری، و (3) نوشتن گزارش. در هر مرحله، عوامل تخصصی هدایتشده توسط مدلهای زبان بزرگ با هم همکاری میکنند تا اهداف متمایز را محقق کنند و ابزارهای خارجی مانند arXiv، Hugging Face، Python، و LaTeX را برای بهینهسازی نتایج ادغام میکنند. این جریان کاری ساختاریافته با جمعآوری و تحلیل مستقل مقالات تحقیقاتی مرتبط آغاز میشود، از طریق برنامهریزی مشارکتی و آمادهسازی دادهها پیش میرود، و به آزمایشگری خودکار و تولید گزارش جامع منتهی میشود. جزئیات نقشهای خاص عوامل و مشارکتهای آنها در این مراحل در مقاله مورد بحث قرار گرفته است.
<p align="center">
<img src="../media/AgentLabWF.png" alt="Demonstration of the flow of AgentClinic" style="width: 99%;">
</p>
## 🖥️ نصب
### گزینه محیط مجازی پایتون (venv)
1. **کلون کردن مخزن گیتهاب**: با استفاده از دستور زیر، مخزن را کلون کنید:
```bash
git clone [email protected]:SamuelSchmidgall/AgentLaboratory.git
```
2. **تنظیم و فعالسازی محیط پایتون**
```bash
python -m venv venv_agent_lab
```
- این محیط را فعال کنید:
```bash
source venv_agent_lab/bin/activate
```
3. **نصب کتابخانههای مورد نیاز**
```bash
pip install -r requirements.txt
```
4. **نصب pdflatex [اختیاری]**
```bash
sudo apt install pdflatex
```
- این امکان را میدهد تا منبع LaTeX توسط عوامل کامپایل شود.
- **[مهم]** اگر به دلیل نداشتن دسترسی sudo نمیتوانید این مرحله را اجرا کنید، میتوانید کامپایل PDF را با اجرای آزمایشگاه ایجنت ها و تنظیم فلگ --compile_latex به false غیرفعال کنید:
```
--compile_latex=False
```
5. **اکنون آزمایشگاه ایجنت ها را اجرا کنید!**
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "YOUR RESEARCH IDEA"
```
یا اگر pdflatex نصب نکردهاید:
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "YOUR RESEARCH IDEA" --compile_latex=False
```
-----
## نکات برای نتایج بهتر تحقیق
#### [نکته #1] 📝 حتماً یادداشتهای گستردهای بنویسید! 📝
**نوشتن یادداشتهای دقیق مهم است** تا به ایجنت ها شما در درک آنچه میخواهید در پروژهتان انجام دهید و همچنین هرگونه ترجیحات سبک کمک کند. یادداشتها میتوانند شامل هر آزمایشی باشند که میخواهید عوامل انجام دهند، ارائه کلیدهای API، نمودارها یا شکلهای خاصی که میخواهید گنجانده شوند، یا هر چیزی که میخواهید ایجنت ها هنگام انجام تحقیق بداند.
این همچنین فرصت شماست تا به ایجنت ها اطلاع دهید **به چه منابع محاسباتی دسترسی دارد**، مثلاً GPUها (تعداد، نوع GPU، میزان GB)، CPUها (تعداد هسته، نوع CPUها)، محدودیتهای ذخیرهسازی، و مشخصات سختافزاری.
برای افزودن یادداشتها، باید ساختار task_notes_LLM را در داخل ai_lab_repo.py تغییر دهید. در زیر نمونهای از مجموعه یادداشتهایی که برای برخی از آزمایشهای ما استفاده شده است ارائه شده است.
```python
task_notes_LLM = [
{"phases": ["plan formulation"],
"note": f"You should come up with a plan for TWO experiments."},
{"phases": ["plan formulation", "data preparation", "running experiments"],
"note": "Please use gpt-4o-mini for your experiments."},
{"phases": ["running experiments"],
"note": f"Use the following code to inference gpt-4o-mini: \nfrom openai import OpenAI\nos.environ["OPENAI_API_KEY"] = "{api_key}"\nclient = OpenAI()\ncompletion = client.chat.completions.create(\nmodel="gpt-4o-mini-2024-07-18", messages=messages)\nanswer = completion.choices[0].message.content\n"},
{"phases": ["running experiments"],
"note": f"You have access to only gpt-4o-mini using the OpenAI API, please use the following key {api_key} but do not use too many inferences. Do not use openai.ChatCompletion.create or any openai==0.28 commands. Instead use the provided inference code."},
{"phases": ["running experiments"],
"note": "I would recommend using a small dataset (approximately only 100 data points) to run experiments in order to save time. Do not use much more than this unless you have to or are running the final tests."},
{"phases": ["data preparation", "running experiments"],
"note": "You are running on a MacBook laptop. You can use 'mps' with PyTorch"},
{"phases": ["data preparation", "running experiments"],
"note": "Generate figures with very colorful and artistic design."},
]
```
--------
#### [نکته #2] 🚀 استفاده از مدلهای قدرتمندتر به طور کلی منجر به تحقیقات بهتر میشود 🚀
هنگام انجام تحقیقات، **انتخاب مدل میتواند به طور قابل توجهی بر کیفیت نتایج تأثیر بگذارد**. مدلهای قدرتمندتر معمولاً دقت بالاتری دارند، قابلیتهای استدلال بهتری ارائه میدهند و گزارشهای بهتری تولید میکنند. اگر منابع محاسباتی اجازه میدهد، استفاده از مدلهای پیشرفته مانند o1-(mini/preview) یا مدلهای زبان بزرگ مشابه پیشرفته را در اولویت قرار دهید.
با این حال، **مهم است که تعادل بین عملکرد و هزینه را رعایت کنید**. در حالی که مدلهای قدرتمند ممکن است نتایج بهتری ارائه دهند، اغلب هزینهبر و زمانبر هستند. در نظر بگیرید که از آنها به صورت انتخابی استفاده کنید — به عنوان مثال، برای آزمایشهای کلیدی یا تحلیلهای نهایی — در حالی که برای وظایف تکراری یا نمونهسازی اولیه از مدلهای کوچکتر و کارآمدتر استفاده کنید.
وقتی منابع محدود هستند، **با تنظیم دقیق مدلهای کوچکتر بر روی مجموعه دادههای خاص خود یا ترکیب مدلهای پیشآموزشدیده با پرامپتهای خاص وظیفهای بهینهسازی کنید** تا تعادل مطلوب بین عملکرد و کارایی محاسباتی را به دست آورید.
-----
#### [نکته #3] ✅ میتوانید ذخیرههای قبلی را از نقاط بازگشت بارگذاری کنید ✅
**اگر پیشرفت خود را از دست دادید، اتصال اینترنت قطع شد، یا یک زیروظیفه شکست خورد، همیشه میتوانید از وضعیت قبلی بارگذاری کنید.** تمام پیشرفتهای شما به طور پیشفرض در متغیر state_saves ذخیره میشوند که هر نقطه بازگشت را ذخیره میکند. فقط هنگام اجرای ai_lab_repo.py از آرگومانهای زیر استفاده کنید:
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "YOUR RESEARCH IDEA" --llm-backend "o1-mini" --load-existing True --load-existing-path "save_states/LOAD_PATH"
```
-----
#### [نکته #4] 🈯 اگر به زبانی غیر از انگلیسی اجرا میکنید 🈲
اگر آزمایشگاه ایحنت ها را به زبانی غیر از انگلیسی اجرا میکنید، مشکلی نیست، فقط مطمئن شوید که پرچم زبان را به عوامل ارائه دهید تا به زبان مورد نظر شما تحقیق انجام دهند. توجه داشته باشید که ما به طور گستردهای اجرای آزمایشگاه ایجنت ها را به زبانهای دیگر مطالعه نکردهایم، بنابراین حتماً هر مشکلی که با آن مواجه شدید را گزارش دهید.
برای مثال، اگر به زبان چینی اجرا میکنید:
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "YOUR RESEARCH IDEA (in your language)" --llm-backend "o1-mini" --language "中文"
```
----
#### [نکته #5] 🌟 جای پیشرفت زیادی وجود دارد 🌟
جای پیشرفت زیادی برای بهبود این کدبیس وجود دارد، بنابراین اگر در نهایت تغییراتی ایجاد کردید و میخواهید به جامعه کمک کنید، لطفاً تغییراتی که ایجاد کردهاید را به اشتراک بگذارید! امیدواریم این ابزار به شما کمک کند!
## مراجع / Bibtex
```bibtex
@preprint{schmidgall2025AgentLaboratory,
title={Agent Laboratory: Using LLM Agents as Research Assistants},
author={Schmidgall, Samuel and Su, Yusheng and Wang, Ze and Sun, Ximeng and Wu, Jialian and Yu, Xiadong and Liu, Jiang, Liu, Zicheng and Barsoum, Emad},
year={2025}
}
``` | {
"source": "SamuelSchmidgall/AgentLaboratory",
"title": "readme/README-farsi.md",
"url": "https://github.com/SamuelSchmidgall/AgentLaboratory/blob/main/readme/README-farsi.md",
"date": "2025-01-08T02:00:51",
"stars": 3583,
"description": "Agent Laboratory is an end-to-end autonomous research workflow meant to assist you as the human researcher toward implementing your research ideas",
"file_size": 9530
} |
# Agent Laboratory: Paggamit ng LLM Agents bilang mga Tagapag-Asistang Pang-research
<p align="center">
<img src="../media/AgentLabLogo.png" alt="Demonstrasyon ng daloy ng AgentClinic" style="width: 99%;">
</p>
<p align="center">
【<a href="../README.md">English</a> | <a href="../readme/README-chinese.md">中文</a> | <a href="../readme/README-japanese.md">日本語</a> | <a href="../readme/README-korean.md">한국어</a> | Filipino | <a href="../readme/README-french.md">Français</a> | <a href="../readme/README-slovak.md">Slovenčina</a> | <a href="../readme/README-portugese.md">Português</a> | <a href="../readme/README-spanish.md">Español</a> | <a href="../readme/README-turkish.md">Türkçe</a> | <a href="../readme/README-hindi.md">हिंदी</a> | <a href="../readme/README-bengali.md">বাংলা</a> | <a href="../readme/README-vietnamese.md">Tiếng Việt</a> | <a href="../readme/README-russian.md">Русский</a> | <a href="../readme/README-arabic.md">العربية</a> | <a href="../readme/README-farsi.md">فارسی</a> | <a href="../readme/README-italian.md">Italiano</a>】
</p>
<p align="center">
【🌐 <a href="https://agentlaboratory.github.io/">Website</a> | 💻 <a href="https://github.com/SamuelSchmidgall/AgentLaboratory">Software</a> | 🎥 <a href="https://agentlaboratory.github.io/#youtube-video">Video</a> | 📚 <a href="https://agentlaboratory.github.io/#examples-goto">Example Paper</a> | 📰 <a href="https://agentlaboratory.github.io/#citation-ref">Citation</a>】
</p>
## 📖 Pangkalahatang-ideya
- **Agent Laboratory** ay isang end-to-end na autonomous na workflow sa pananaliksik na nilalayong tulungan **ikaw** bilang isang human researcher sa **pagpapatupad ng iyong mga ideya sa pananaliksik**. Binubuo ang Agent Laboratory ng mga espesyalistang ahente na pinapagana ng malalaking modelo ng wika upang suportahan ka sa buong workflow ng pananaliksik—mula sa pagsasagawa ng mga pagsusuri sa literatura at pagbuo ng mga plano hanggang sa pagpapatupad ng mga eksperimento at pagsulat ng komprehensibong mga ulat.
- Ang sistemang ito ay hindi dinisenyo upang palitan ang iyong pagkamalikhain kundi upang kumpletuhin ito, na nagbibigay-daan sa iyo na magpokus sa ideasyon at kritikal na pag-iisip habang ina-automate ang mga paulit-ulit at matagal na gawain tulad ng pag-cocode at dokumentasyon. Sa pamamagitan ng pag-aakma sa iba't ibang antas ng computational na mga mapagkukunan at partisipasyon ng tao, layunin ng Agent Laboratory na pabilisin ang siyentipikong pagtuklas at i-optimize ang iyong produktibidad sa pananaliksik.
<p align="center">
<img src="../media/AgentLab.png" alt="Demonstrasyon ng daloy ng AgentClinic" style="width: 99%;">
</p>
### 🔬 Paano gumagana ang Agent Laboratory?
- Binubuo ang Agent Laboratory ng tatlong pangunahing yugto na sistematikong ginagabayan ang proseso ng pananaliksik: (1) Pagsusuri ng Literatura, (2) Eksperimentasyon, at (3) Pagsulat ng Ulat. Sa bawat yugto, ang mga espesyalistang ahente na pinapagana ng LLMs ay nagtutulungan upang makamit ang mga natatanging layunin, na nag-iintegrate ng mga panlabas na kagamitan tulad ng arXiv, Hugging Face, Python, at LaTeX upang i-optimize ang mga resulta. Nagsisimula ang estrukturadong workflow na ito sa malayang koleksyon at pagsusuri ng mga kaugnay na papel sa pananaliksik, sumusulong sa pamamagitan ng kolaboratibong pagpaplano at paghahanda ng datos, at nagreresulta sa automated na eksperimento at komprehensibong paggawa ng ulat. Ang mga detalye tungkol sa mga tiyak na papel ng ahente at kanilang mga kontribusyon sa mga yugtong ito ay tinalakay sa papel.
<p align="center">
<img src="../media/AgentLabWF.png" alt="Demonstrasyon ng daloy ng AgentClinic" style="width: 99%;">
</p>
## 🖥️ Pag-install
### Python venv na opsyon
1. **I-clone ang GitHub Repository**: Magsimula sa pamamagitan ng pag-clone ng repository gamit ang utos:
```bash
git clone [email protected]:SamuelSchmidgall/AgentLaboratory.git
```
2. **I-set up at I-activate ang Python Environment**
```bash
python -m venv venv_agent_lab
```
- Ngayon i-activate ang environment na ito:
```bash
source venv_agent_lab/bin/activate
```
3. **I-install ang mga kinakailangang library**
```bash
pip install -r requirements.txt
```
4. **I-install ang pdflatex [OPTIONAL]**
```bash
sudo apt install pdflatex
```
- Pinapayagan nitong ma-compile ng mga ahente ang latex source.
- **[MAHALAGA]** Kung hindi maisagawa ang hakbang na ito dahil sa kawalan ng sudo access, maaaring i-off ang pdf compiling sa pamamagitan ng pagpapatakbo ng Agent Laboratory gamit ang pag-set ng `--compile_latex` flag sa false:
```bash
--compile_latex=False
```
5. **Ngayon patakbuhin ang Agent Laboratory!**
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "YOUR RESEARCH IDEA"
```
o, kung wala kang naka-install na pdflatex
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "YOUR RESEARCH IDEA" --compile_latex=False
```
-----
## Mga Tip para sa Mas Mabuting Resulta ng Pananaliksik
#### [Tip #1] 📝 Tiyaking sumulat ng malawak na mga tala! 📝
**Mahalaga ang pagsusulat ng malawak na mga tala** upang matulungan ang iyong ahente na maunawaan kung ano ang nais mong makamit sa iyong proyekto, pati na rin ang anumang mga paboritong estilo. Maaaring kabilang sa mga tala ang anumang mga eksperimento na nais mong isagawa ng mga ahente, pagbibigay ng mga API key, tiyak na mga plot o figure na nais mong isama, o anumang nais mong malaman ng ahente kapag nagsasagawa ng pananaliksik.
Ito rin ang iyong pagkakataon upang ipaalam sa ahente **kung anong mga compute resources ang mayroon ito**, halimbawa, GPUs (ilan, anong uri ng GPU, ilang GBs), CPUs (ilang cores, anong uri ng CPUs), mga limitasyon sa storage, at mga specs ng hardware.
Upang magdagdag ng mga tala, kailangan mong baguhin ang `task_notes_LLM` na istraktura sa loob ng `ai_lab_repo.py`. Ibinigay sa ibaba ang isang halimbawa ng mga tala na ginamit para sa ilan sa aming mga eksperimento.
```python
task_notes_LLM = [
{"phases": ["plan formulation"],
"note": f"You should come up with a plan for TWO experiments."},
{"phases": ["plan formulation", "data preparation", "running experiments"],
"note": "Please use gpt-4o-mini for your experiments."},
{"phases": ["running experiments"],
"note": f"Use the following code to inference gpt-4o-mini: \nfrom openai import OpenAI\nos.environ["OPENAI_API_KEY"] = "{api_key}"\nclient = OpenAI()\ncompletion = client.chat.completions.create(\nmodel="gpt-4o-mini-2024-07-18", messages=messages)\nanswer = completion.choices[0].message.content\n"},
{"phases": ["running experiments"],
"note": f"You have access to only gpt-4o-mini using the OpenAI API, please use the following key {api_key} but do not use too many inferences. Do not use openai.ChatCompletion.create or any openai==0.28 commands. Instead use the provided inference code."},
{"phases": ["running experiments"],
"note": "I would recommend using a small dataset (approximately only 100 data points) to run experiments in order to save time. Do not use much more than this unless you have to or are running the final tests."},
{"phases": ["data preparation", "running experiments"],
"note": "You are running on a MacBook laptop. You can use 'mps' with PyTorch"},
{"phases": ["data preparation", "running experiments"],
"note": "Generate figures with very colorful and artistic design."},
]
```
--------
#### [Tip #2] 🚀 Ang paggamit ng mas malalakas na mga modelo ay karaniwang nagdudulot ng mas magagandang pananaliksik 🚀
Kapag nagsasagawa ng pananaliksik, **ang pagpili ng modelo ay maaaring malaki ang epekto sa kalidad ng mga resulta**. Ang mas malalakas na mga modelo ay karaniwang may mas mataas na katumpakan, mas mahusay na kakayahan sa pag-iisip, at mas magaling na paggawa ng ulat. Kung pinapayagan ng mga computational na mapagkukunan, bigyang prioridad ang paggamit ng mga advanced na modelo tulad ng o1-(mini/preview) o katulad na mga state-of-the-art na malalaking modelo ng wika.
Gayunpaman, **mahalagang balansehin ang pagganap at pagiging cost-effective**. Habang ang mga malalakas na modelo ay maaaring magbigay ng mas magagandang resulta, madalas silang mas mahal at mas matagal patakbuhin. Isaalang-alang ang paggamit ng mga ito nang selektibo—halimbawa, para sa mga pangunahing eksperimento o panghuling pagsusuri—habang umaasa sa mas maliit, mas mahusay na mga modelo para sa mga iteratibong gawain o paunang prototyping.
Kapag limitado ang mga mapagkukunan, **i-optimize sa pamamagitan ng fine-tuning ng mas maliliit na mga modelo** sa iyong partikular na dataset o pagsasama ng mga pre-trained na modelo sa mga task-specific na prompt upang makamit ang nais na balanse sa pagitan ng pagganap at computational na kahusayan.
-----
#### [Tip #3] ✅ Maaari kang mag-load ng mga naunang save mula sa mga checkpoint ✅
**Kung mawalan ka ng progreso, koneksyon sa internet, o kung mabigo ang isang subtask, maaari mong laging i-load mula sa isang naunang estado.** Ang lahat ng iyong progreso ay naka-save bilang default sa `state_saves` variable, na nag-iimbak ng bawat indibidwal na checkpoint. Ibigay lamang ang mga sumusunod na argumento kapag nagpapatakbo ng `ai_lab_repo.py`:
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "YOUR RESEARCH IDEA" --llm-backend "o1-mini" --load-existing True --load-existing-path "save_states/LOAD_PATH"
```
-----
#### [Tip #4] 🈯 Kung ikaw ay nagpapatakbo sa isang wika maliban sa Ingles 🈲
Kung nagpapatakbo ka ng Agent Laboratory sa isang wika maliban sa Ingles, walang problema, siguraduhing magbigay ng language flag sa mga ahente upang magsagawa ng pananaliksik sa iyong nais na wika. Tandaan na hindi pa namin lubusang pinag-aralan ang pagpapatakbo ng Agent Laboratory sa ibang mga wika, kaya siguraduhing iulat ang anumang mga problemang iyong makaharap.
Halimbawa, kung nagpapatakbo ka sa Chinese:
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "YOUR RESEARCH IDEA (in your language)" --llm-backend "o1-mini" --language "中文"
```
----
#### [Tip #5] 🌟 Mayroong maraming puwang para sa pagpapabuti 🌟
Mayroong maraming puwang upang mapabuti ang codebase na ito, kaya kung ikaw ay gagawa ng mga pagbabago at nais makatulong sa komunidad, huwag mag-atubiling ibahagi ang mga pagbabagong iyong ginawa! Inaasahan naming makakatulong ang tool na ito sa iyo!
## Reference / Bibtex
```bibtex
@preprint{schmidgall2025AgentLaboratory,
title={Agent Laboratory: Using LLM Agents as Research Assistants},
author={Schmidgall, Samuel and Su, Yusheng and Wang, Ze and Sun, Ximeng and Wu, Jialian and Yu, Xiadong and Liu, Jiang, Liu, Zicheng and Barsoum, Emad},
year={2025}
}
``` | {
"source": "SamuelSchmidgall/AgentLaboratory",
"title": "readme/README-filipino.md",
"url": "https://github.com/SamuelSchmidgall/AgentLaboratory/blob/main/readme/README-filipino.md",
"date": "2025-01-08T02:00:51",
"stars": 3583,
"description": "Agent Laboratory is an end-to-end autonomous research workflow meant to assist you as the human researcher toward implementing your research ideas",
"file_size": 10869
} |
# Laboratoire d'Agent : Utilisation des agents LLM comme assistants de recherche
<p align="center">
<img src="../media/AgentLabLogo.png" alt="Démonstration du flux de AgentClinic" style="width: 99%;">
</p>
<p align="center">
【<a href="../README.md">English</a> | <a href="../readme/README-chinese.md">中文</a> | <a href="../readme/README-japanese.md">日本語</a> | <a href="../readme/README-korean.md">한국어</a> | <a href="../readme/README-filipino.md">Filipino</a> | Français | <a href="../readme/README-slovak.md">Slovenčina</a> | <a href="../readme/README-portugese.md">Português</a> | <a href="../readme/README-spanish.md">Español</a> | <a href="../readme/README-turkish.md">Türkçe</a> | <a href="../readme/README-hindi.md">हिंदी</a> | <a href="../readme/README-bengali.md">বাংলা</a> | <a href="../readme/README-vietnamese.md">Tiếng Việt</a> | <a href="../readme/README-russian.md">Русский</a> | <a href="../readme/README-arabic.md">العربية</a> | <a href="../readme/README-farsi.md">فارسی</a> | <a href="../readme/README-italian.md">Italiano</a>】
</p>
<p align="center">
【🌐 <a href="https://agentlaboratory.github.io/">Site Web</a> | 💻 <a href="https://github.com/SamuelSchmidgall/AgentLaboratory">Logiciel</a> | 🎥 <a href="https://agentlaboratory.github.io/#youtube-video">Vidéo</a> | 📚 <a href="https://agentlaboratory.github.io/#examples-goto">Article Exemple</a> | 📰 <a href="https://agentlaboratory.github.io/#citation-ref">Citation</a>】
</p>
## 📖 Aperçu
- **Laboratoire d'Agent** est un flux de travail de recherche autonome de bout en bout destiné à vous assister en tant que chercheur humain dans **la mise en œuvre de vos idées de recherche**. Le Laboratoire d'Agent est composé d'agents spécialisés alimentés par de grands modèles de langage pour vous soutenir tout au long du processus de recherche—de la réalisation des revues de littérature et de la formulation de plans à l'exécution des expériences et à la rédaction de rapports complets.
- Ce système n'est pas conçu pour remplacer votre créativité, mais pour la compléter, vous permettant de vous concentrer sur l’idéation et la pensée critique tout en automatisant les tâches répétitives et chronophages telles que la programmation et la documentation. En s'adaptant à différents niveaux de ressources informatiques et d'implication humaine, le Laboratoire d'Agent vise à accélérer la découverte scientifique et à optimiser votre productivité en recherche.
<p align="center">
<img src="../media/AgentLab.png" alt="Démonstration du flux de AgentClinic" style="width: 99%;">
</p>
### 🔬 Comment fonctionne le Laboratoire d'Agent ?
- Le Laboratoire d'Agent se compose de trois phases principales qui guident systématiquement le processus de recherche : (1) Revue de littérature, (2) Expérimentation et (3) Rédaction de rapports. Pendant chaque phase, des agents spécialisés alimentés par des LLM collaborent pour atteindre des objectifs distincts, en intégrant des outils externes tels qu'arXiv, Hugging Face, Python et LaTeX afin d'optimiser les résultats. Ce flux de travail structuré commence par la collecte et l'analyse indépendantes des articles de recherche pertinents, progresse par la planification collaborative et la préparation des données, et aboutit à l'expérimentation automatisée et à la génération de rapports complets. Les détails sur les rôles spécifiques des agents et leurs contributions au cours de ces phases sont abordés dans l'article.
<p align="center">
<img src="../media/AgentLabWF.png" alt="Démonstration du flux de AgentClinic" style="width: 99%;">
</p>
## 🖥️ Installation
### Option d'environnement virtuel Python
1. **Cloner le dépôt GitHub** : Commencez par cloner le dépôt en utilisant la commande :
```bash
git clone [email protected]:SamuelSchmidgall/AgentLaboratory.git
```
2. **Configurer et activer l'environnement Python**
```bash
python -m venv venv_agent_lab
```
- Activez maintenant cet environnement :
```bash
source venv_agent_lab/bin/activate
```
3. **Installer les bibliothèques requises**
```bash
pip install -r requirements.txt
```
4. **Installer pdflatex [OPTIONNEL]**
```bash
sudo apt install pdflatex
```
- Cela permet aux agents de compiler le code source LaTeX.
- **[IMPORTANT]** Si cette étape ne peut pas être exécutée en raison de l'absence d'accès sudo, la compilation PDF peut être désactivée en exécutant le Laboratoire d'Agent avec le drapeau `--compile_latex` défini sur `false` : `--compile_latex=False`
5. **Lancez maintenant le Laboratoire d'Agent !**
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "VOTRE IDÉE DE RECHERCHE"
```
ou, si vous n'avez pas installé pdflatex
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "VOTRE IDÉE DE RECHERCHE" --compile_latex=False
```
-----
## Conseils pour de meilleurs résultats de recherche
#### [Conseil n°1] 📝 Assurez-vous de prendre des notes détaillées ! 📝
**Prendre des notes détaillées est important** pour aider votre agent à comprendre ce que vous cherchez à accomplir dans votre projet, ainsi que toute préférence de style. Les notes peuvent inclure les expériences que vous souhaitez que les agents réalisent, la fourniture de clés API, certains graphiques ou figures que vous souhaitez inclure, ou tout ce que vous souhaitez que l'agent sache lors de la réalisation de recherches.
C'est également votre opportunité d'informer l'agent **quelles ressources informatiques il peut utiliser**, par exemple les GPU (combien, quel type de GPU, combien de Go), les CPU (combien de cœurs, quel type de CPU), les limitations de stockage et les spécifications matérielles.
Pour ajouter des notes, vous devez modifier la structure `task_notes_LLM` à l'intérieur de `ai_lab_repo.py`. Ci-dessous, un exemple de jeu de notes utilisé pour certaines de nos expériences.
```python
task_notes_LLM = [
{"phases": ["plan formulation"],
"note": f"You should come up with a plan for TWO experiments."},
{"phases": ["plan formulation", "data preparation", "running experiments"],
"note": "Please use gpt-4o-mini for your experiments."},
{"phases": ["running experiments"],
"note": f"Use the following code to inference gpt-4o-mini: \nfrom openai import OpenAI\nos.environ["OPENAI_API_KEY"] = "{api_key}"\nclient = OpenAI()\ncompletion = client.chat.completions.create(\nmodel="gpt-4o-mini-2024-07-18", messages=messages)\nanswer = completion.choices[0].message.content\n"},
{"phases": ["running experiments"],
"note": f"You have access to only gpt-4o-mini using the OpenAI API, please use the following key {api_key} but do not use too many inferences. Do not use openai.ChatCompletion.create or any openai==0.28 commands. Instead use the provided inference code."},
{"phases": ["running experiments"],
"note": "I would recommend using a small dataset (approximately only 100 data points) to run experiments in order to save time. Do not use much more than this unless you have to or are running the final tests."},
{"phases": ["data preparation", "running experiments"],
"note": "You are running on a MacBook laptop. You can use 'mps' with PyTorch"},
{"phases": ["data preparation", "running experiments"],
"note": "Generate figures with very colorful and artistic design."},
]
```
--------
#### [Conseil n°2] 🚀 Utiliser des modèles plus puissants conduit généralement à une meilleure recherche 🚀
Lors de la conduite de recherches, **le choix du modèle peut avoir un impact significatif sur la qualité des résultats**. Les modèles plus puissants ont tendance à avoir une précision plus élevée, de meilleures capacités de raisonnement et une meilleure génération de rapports. Si les ressources informatiques le permettent, privilégiez l'utilisation de modèles avancés tels que o1-(mini/preview) ou d'autres grands modèles de langage à la pointe de la technologie.
Cependant, **il est important de trouver un équilibre entre performance et rentabilité**. Bien que les modèles puissants puissent donner de meilleurs résultats, ils sont souvent plus coûteux et plus longs à exécuter. Envisagez de les utiliser de manière sélective—par exemple, pour des expériences clés ou des analyses finales—tout en comptant sur des modèles plus petits et plus efficaces pour des tâches itératives ou du prototypage initial.
Lorsque les ressources sont limitées, **optimisez en affinant des modèles plus petits** sur votre jeu de données spécifique ou en combinant des modèles pré-entraînés avec des invites spécifiques à la tâche afin d'atteindre l'équilibre souhaité entre performance et efficacité computationnelle.
-----
#### [Conseil n°3] ✅ Vous pouvez charger des sauvegardes précédentes depuis des points de contrôle ✅
**Si vous perdez des progrès, la connexion Internet ou si une sous-tâche échoue, vous pouvez toujours charger à partir d'un état précédent.** Tous vos progrès sont enregistrés par défaut dans la variable `state_saves`, qui stocke chaque point de contrôle individuel. Il vous suffit de passer les arguments suivants lors de l'exécution de `ai_lab_repo.py`
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "YOUR RESEARCH IDEA" --llm-backend "o1-mini" --load-existing True --load-existing-path "save_states/LOAD_PATH"
```
-----
#### [Conseil n°4] 🈯 Si vous utilisez une langue autre que l'anglais 🈲
Si vous exécutez le Laboratoire d'Agent dans une langue autre que l'anglais, pas de problème, assurez-vous simplement de fournir un drapeau de langue aux agents pour effectuer des recherches dans votre langue préférée. Notez que nous n'avons pas étudié de manière approfondie l'exécution du Laboratoire d'Agent dans d'autres langues, alors assurez-vous de signaler tout problème que vous rencontrez.
Par exemple, si vous utilisez le chinois :
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "YOUR RESEARCH IDEA (in your language)" --llm-backend "o1-mini" --language "中文"
```
----
#### [Conseil n°5] 🌟 Il y a beaucoup de place pour l'amélioration 🌟
Il y a beaucoup de possibilités d'améliorer cette base de code, donc si vous finissez par apporter des modifications et souhaitez aider la communauté, n'hésitez pas à partager les changements que vous avez effectués ! Nous espérons que cet outil vous sera utile !
## Référence / Bibtex
```bibtex
@preprint{schmidgall2025AgentLaboratory,
title={Agent Laboratory: Using LLM Agents as Research Assistants},
author={Schmidgall, Samuel and Su, Yusheng and Wang, Ze and Sun, Ximeng and Wu, Jialian and Yu, Xiadong and Liu, Jiang, Liu, Zicheng and Barsoum, Emad},
year={2025}
}
``` | {
"source": "SamuelSchmidgall/AgentLaboratory",
"title": "readme/README-french.md",
"url": "https://github.com/SamuelSchmidgall/AgentLaboratory/blob/main/readme/README-french.md",
"date": "2025-01-08T02:00:51",
"stars": 3583,
"description": "Agent Laboratory is an end-to-end autonomous research workflow meant to assist you as the human researcher toward implementing your research ideas",
"file_size": 10763
} |
# एजेंट लैबोरेटरी: अनुसंधान सहायकों के रूप में LLM एजेंटों का उपयोग
<p align="center">
<img src="../media/AgentLabLogo.png" alt="AgentClinic के प्रवाह का प्रदर्शन" style="width: 99%;">
</p>
<p align="center">
【<a href="../README.md">English</a> | <a href="../readme/README-chinese.md">中文</a> | <a href="../readme/README-japanese.md">日本語</a> | <a href="../readme/README-korean.md">한국어</a> | <a href="../readme/README-filipino.md">Filipino</a> | <a href="../readme/README-french.md">Français</a> | <a href="../readme/README-slovak.md">Slovenčina</a> | <a href="../readme/README-portugese.md">Português</a> | <a href="../readme/README-spanish.md">Español</a> | <a href="../readme/README-turkish.md">Türkçe</a> | हिंदी | <a href="../readme/README-bengali.md">বাংলা</a> | <a href="../readme/README-vietnamese.md">Tiếng Việt</a> | <a href="../readme/README-russian.md">Русский</a> | <a href="../readme/README-arabic.md">العربية</a> | <a href="../readme/README-farsi.md">فارسی</a> | <a href="../readme/README-italian.md">Italiano</a>】
</p>
<p align="center">
【🌐 <a href="https://agentlaboratory.github.io/">Website</a> | 💻 <a href="https://github.com/SamuelSchmidgall/AgentLaboratory">Software</a> | 🎥 <a href="https://agentlaboratory.github.io/#youtube-video">Video</a> | 📚 <a href="https://agentlaboratory.github.io/#examples-goto">Example Paper</a> | 📰 <a href="https://agentlaboratory.github.io/#citation-ref">Citation</a>】
</p>
## 📖 अवलोकन
- **एजेंट लैबोरेटरी** एक अंत-से-अंत स्वायत्त अनुसंधान कार्यप्रवाह है जिसे **आप** को मानव शोधकर्ता के रूप में **अपने अनुसंधान विचारों को लागू करने** में सहायता करने के लिए डिज़ाइन किया गया है। एजेंट लैबोरेटरी में बड़े भाषा मॉडल द्वारा संचालित विशेषीकृत एजेंट शामिल हैं जो आपको संपूर्ण अनुसंधान कार्यप्रवाह के माध्यम से समर्थन करते हैं—साहित्य समीक्षा करने और योजनाएँ बनाने से लेकर प्रयोगों को निष्पादित करने और व्यापक रिपोर्ट लिखने तक।
- यह प्रणाली आपकी रचनात्मकता को बदलने के लिए नहीं बल्कि इसे पूरा करने के लिए डिज़ाइन की गई है, जिससे आप विचार-विमर्श और महत्वपूर्ण सोच पर ध्यान केंद्रित कर सकते हैं, जबकि कोडिंग और दस्तावेजीकरण जैसे दोहराए जाने वाले और समय-गहन कार्यों को स्वचालित किया जाता है। विभिन्न स्तर के संगणनात्मक संसाधनों और मानव भागीदारी को समायोजित करके, एजेंट लैबोरेटरी वैज्ञानिक खोज को तेज करने और आपके अनुसंधान उत्पादकता को अनुकूलित करने का लक्ष्य रखता है।
<p align="center">
<img src="../media/AgentLab.png" alt="AgentClinic के प्रवाह का प्रदर्शन" style="width: 99%;">
</p>
### 🔬 एजेंट लैबोरेटरी कैसे काम करता है?
- एजेंट लैबोरेटरी तीन मुख्य चरणों से मिलकर बनता है जो अनुसंधान प्रक्रिया का व्यवस्थित रूप से मार्गदर्शन करते हैं: (1) साहित्य समीक्षा, (2) प्रयोग, और (3) रिपोर्ट लेखन। प्रत्येक चरण के दौरान, LLM द्वारा संचालित विशेषीकृत एजेंट विशिष्ट उद्देश्यों को प्राप्त करने के लिए सहयोग करते हैं, परिणामों को अनुकूलित करने के लिए arXiv, Hugging Face, Python, और LaTeX जैसे बाहरी उपकरणों को एकीकृत करते हैं। यह संरचित कार्यप्रवाह संबंधित अनुसंधान पत्रों के स्वतंत्र संग्रह और विश्लेषण से शुरू होता है, सहयोगात्मक योजना और डेटा तैयारी के माध्यम से प्रगति करता है, और स्वचालित प्रयोग और व्यापक रिपोर्ट जनरेशन में समाप्त होता है। इन चरणों में विशिष्ट एजेंट भूमिकाओं और उनके योगदान के विवरण पेपर में चर्चा किए गए हैं।
<p align="center">
<img src="../media/AgentLabWF.png" alt="AgentClinic के प्रवाह का प्रदर्शन" style="width: 99%;">
</p>
## 🖥️ स्थापना
### Python venv विकल्प
1. **GitHub रिपॉजिटरी क्लोन करें**: रिपॉजिटरी को क्लोन करना शुरू करें निम्न कमांड का उपयोग करके:
```bash
git clone [email protected]:SamuelSchmidgall/AgentLaboratory.git
```
2. **पायथन पर्यावरण सेटअप और सक्रिय करें**
```bash
python -m venv venv_agent_lab
```
- अब इस पर्यावरण को सक्रिय करें:
```bash
source venv_agent_lab/bin/activate
```
3. **आवश्यक पुस्तकालय स्थापित करें**
```bash
pip install -r requirements.txt
```
4. **pdflatex स्थापित करें [वैकल्पिक]**
```bash
sudo apt install pdflatex
```
- यह एजेंटों द्वारा latex स्रोत को संकलित करने में सक्षम बनाता है।
- **[महत्वपूर्ण]** यदि इस चरण को sudo एक्सेस न होने के कारण नहीं चलाया जा सकता है, तो Agent Laboratory को --compile_latex फ्लैग को false सेट करके pdf संकलन बंद किया जा सकता है: `--compile_latex=False`
5. **अब Agent Laboratory चलाएं!**
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "YOUR RESEARCH IDEA"
```
या, यदि आपने pdflatex स्थापित नहीं किया है:
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "YOUR RESEARCH IDEA" --compile_latex=False
```
-----
## बेहतर अनुसंधान परिणामों के लिए सुझाव
#### [सुझाव #1] 📝 विस्तृत नोट्स लिखना सुनिश्चित करें! 📝
**विस्तृत नोट्स लिखना महत्वपूर्ण है** ताकि आपका एजेंट समझ सके कि आप अपने प्रोजेक्ट में क्या हासिल करना चाहते हैं, साथ ही किसी भी शैली की प्राथमिकताएँ। नोट्स में उन किसी भी प्रयोगों को शामिल किया जा सकता है जिन्हें आप एजेंटों से करने के लिए चाहते हैं, API कुंजी प्रदान करना, कुछ प्लॉट या आकृतियाँ शामिल करना, या कुछ भी जिसे आप अनुसंधान करते समय एजेंट को जानना चाहते हैं।
यह आपका अवसर भी है कि एजेंट को बताएं **कौन से कंप्यूट संसाधनों तक उसकी पहुंच है**, जैसे GPUs (कितने, किस प्रकार के GPU, कितने GBs), CPUs (कितने कोर, किस प्रकार के CPUs), स्टोरेज सीमाएँ, और हार्डवेयर स्पेसिफिकेशन।
नोट्स जोड़ने के लिए, आपको ai_lab_repo.py के अंदर task_notes_LLM संरचना को संशोधित करना होगा। नीचे हमारे कुछ प्रयोगों के लिए उपयोग किए गए नोट्स का एक उदाहरण दिया गया है।
```python
task_notes_LLM = [
{"phases": ["plan formulation"],
"note": f"You should come up with a plan for TWO experiments."},
{"phases": ["plan formulation", "data preparation", "running experiments"],
"note": "Please use gpt-4o-mini for your experiments."},
{"phases": ["running experiments"],
"note": f"Use the following code to inference gpt-4o-mini: \nfrom openai import OpenAI\nos.environ["OPENAI_API_KEY"] = "{api_key}"\nclient = OpenAI()\ncompletion = client.chat.completions.create(\nmodel="gpt-4o-mini-2024-07-18", messages=messages)\nanswer = completion.choices[0].message.content\n"},
{"phases": ["running experiments"],
"note": f"You have access to only gpt-4o-mini using the OpenAI API, please use the following key {api_key} but do not use too many inferences. Do not use openai.ChatCompletion.create or any openai==0.28 commands. Instead use the provided inference code."},
{"phases": ["running experiments"],
"note": "I would recommend using a small dataset (approximately only 100 data points) to run experiments in order to save time. Do not use much more than this unless you have to or are running the final tests."},
{"phases": ["data preparation", "running experiments"],
"note": "You are running on a MacBook laptop. You can use 'mps' with PyTorch"},
{"phases": ["data preparation", "running experiments"],
"note": "Generate figures with very colorful and artistic design."},
]
```
--------
#### [सुझाव #2] 🚀 अधिक शक्तिशाली मॉडल का उपयोग सामान्यतः बेहतर अनुसंधान की ओर ले जाता है 🚀
अनुसंधान करते समय, **मॉडल का चयन परिणामों की गुणवत्ता पर महत्वपूर्ण प्रभाव डाल सकता है**। अधिक शक्तिशाली मॉडल आमतौर पर उच्च सटीकता, बेहतर तर्क क्षमताओं, और बेहतर रिपोर्ट जनरेशन प्रदान करते हैं। यदि संगणनात्मक संसाधन अनुमति देते हैं, तो o1-(mini/preview) या इसी तरह के अत्याधुनिक बड़े भाषा मॉडल जैसे उन्नत मॉडलों के उपयोग को प्राथमिकता दें।
हालांकि, **प्रदर्शन और लागत-प्रभावशीलता के बीच संतुलन बनाना महत्वपूर्ण है**। जबकि शक्तिशाली मॉडल बेहतर परिणाम दे सकते हैं, उन्हें चलाने में अक्सर अधिक खर्च और समय लगता है। उन्हें चयनात्मक रूप से उपयोग करने पर विचार करें—उदाहरण के लिए, मुख्य प्रयोगों या अंतिम विश्लेषणों के लिए—जबकि पुनरावृत्त कार्यों या प्रारंभिक प्रोटोटाइपिंग के लिए छोटे, अधिक कुशल मॉडलों पर निर्भर रहें।
जब संसाधन सीमित हों, **अपने विशिष्ट डेटासेट पर छोटे मॉडलों को फाइन-ट्यून करके या कार्य-विशिष्ट प्रॉम्प्ट के साथ पूर्व-प्रशिक्षित मॉडलों को मिलाकर प्रदर्शन और संगणनात्मक दक्षता के बीच वांछित संतुलन प्राप्त करें**।
-----
#### [सुझाव #3] ✅ आप चेकपॉइंट से पिछले सहेजनों को लोड कर सकते हैं ✅
**यदि आप प्रगति खो देते हैं, इंटरनेट कनेक्शन खोते हैं, या कोई उपकार्य विफल हो जाता है, तो आप हमेशा पिछले स्थिति से लोड कर सकते हैं।** आपकी सभी प्रगति डिफ़ॉल्ट रूप से state_saves वेरिएबल में सहेजी जाती है, जो प्रत्येक व्यक्तिगत चेकपॉइंट को संग्रहीत करता है। बस ai_lab_repo.py चलाते समय निम्नलिखित तर्क पास करें:
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "YOUR RESEARCH IDEA" --llm-backend "o1-mini" --load-existing True --load-existing-path "save_states/LOAD_PATH"
```
-----
#### [सुझाव #4] 🈯 यदि आप अंग्रेजी के अलावा किसी अन्य भाषा में चला रहे हैं 🈲
यदि आप एजेंट लैबोरेटरी को अंग्रेजी के अलावा किसी अन्य भाषा में चला रहे हैं, तो कोई समस्या नहीं है, बस सुनिश्चित करें कि एजेंटों को आपके पसंदीदा भाषा में अनुसंधान करने के लिए एक भाषा फ्लैग प्रदान करें। ध्यान दें कि हमने अन्य भाषाओं में एजेंट लैबोरेटरी चलाने का व्यापक अध्ययन नहीं किया है, इसलिए किसी भी समस्या का सामना करने पर रिपोर्ट करना सुनिश्चित करें।
उदाहरण के लिए, यदि आप चीनी में चला रहे हैं:
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "YOUR RESEARCH IDEA (in your language)" --llm-backend "o1-mini" --language "中文"
```
----
#### [सुझाव #5] 🌟 सुधार के लिए बहुत गुंजाइश है 🌟
इस कोडबेस में सुधार की बहुत गुंजाइश है, इसलिए यदि आप अंततः परिवर्तन करते हैं और समुदाय की मदद करना चाहते हैं, तो कृपया आप जो परिवर्तन किए हैं उन्हें साझा करने में संकोच न करें! हमें उम्मीद है कि यह उपकरण आपकी मदद करेगा!
## संदर्भ / Bibtex
```bibtex
@preprint{schmidgall2025AgentLaboratory,
title={Agent Laboratory: Using LLM Agents as Research Assistants},
author={Schmidgall, Samuel and Su, Yusheng and Wang, Ze and Sun, Ximeng and Wu, Jialian and Yu, Xiadong and Liu, Jiang, Liu, Zicheng and Barsoum, Emad},
year={2025}
}
``` | {
"source": "SamuelSchmidgall/AgentLaboratory",
"title": "readme/README-hindi.md",
"url": "https://github.com/SamuelSchmidgall/AgentLaboratory/blob/main/readme/README-hindi.md",
"date": "2025-01-08T02:00:51",
"stars": 3583,
"description": "Agent Laboratory is an end-to-end autonomous research workflow meant to assist you as the human researcher toward implementing your research ideas",
"file_size": 9746
} |
# Laboratorio Agenti: Utilizzo di Agenti LLM come Assistenti di Ricerca
<p align="center">
<img src="../media/AgentLabLogo.png" alt="Dimostrazione del flusso di AgentClinic" style="width: 99%;">
</p>
<p align="center">
【<a href="../README.md">English</a> | <a href="../readme/README-chinese.md">中文</a> | <a href="../readme/README-japanese.md">日本語</a> | <a href="../readme/README-korean.md">한국어</a> | <a href="../readme/README-filipino.md">Filipino</a> | <a href="../readme/README-french.md">Français</a> | <a href="../readme/README-slovak.md">Slovenčina</a> | <a href="../readme/README-portugese.md">Português</a> | <a href="../readme/README-spanish.md">Español</a> | <a href="../readme/README-turkish.md">Türkçe</a> | <a href="../readme/README-hindi.md">हिंदी</a> | <a href="../readme/README-bengali.md">বাংলা</a> | <a href="../readme/README-vietnamese.md">Tiếng Việt</a> | <a href="../readme/README-russian.md">Русский</a> | <a href="../readme/README-arabic.md">العربية</a> | <a href="../readme/README-farsi.md">فارسی</a> | Italiano】
</p>
<p align="center">
【🌐 <a href="https://agentlaboratory.github.io/">Sito web</a> | 💻 <a href="https://github.com/SamuelSchmidgall/AgentLaboratory">Software</a> | 🎥 <a href="https://agentlaboratory.github.io/#youtube-video">Video</a> | 📚 <a href="https://agentlaboratory.github.io/#examples-goto">Documento di esempio</a> | 📰 <a href="https://agentlaboratory.github.io/#citation-ref">Citazione</a>】
</p>
## 📖 Panoramica
- **Agent Laboratory** è un flusso di lavoro di ricerca autonomo end-to-end progettato per assistere **te** come ricercatore umano nell'**implementazione delle tue idee di ricerca**. Agent Laboratory è composto da agenti specializzati guidati da grandi modelli linguistici per supportarti durante l'intero flusso di lavoro di ricerca—dalla conduzione di revisioni della letteratura e formulazione di piani all'esecuzione di esperimenti e alla scrittura di rapporti completi.
- Questo sistema non è progettato per sostituire la tua creatività ma per complementarla, permettendoti di concentrarti sull'ideazione e il pensiero critico mentre automatizza compiti ripetitivi e che richiedono tempo come la codifica e la documentazione. Accomodando diversi livelli di risorse computazionali e coinvolgimento umano, Agent Laboratory mira ad accelerare la scoperta scientifica e ottimizzare la tua produttività di ricerca.
<p align="center">
<img src="../media/AgentLab.png" alt="Dimostrazione del flusso di AgentClinic" style="width: 99%;">
</p>
### 🔬 Come funziona Agent Laboratory?
- Agent Laboratory è composto da tre fasi principali che guidano sistematicamente il processo di ricerca: (1) Revisione della letteratura, (2) Sperimentazione e (3) Scrittura del rapporto. Durante ogni fase, agenti specializzati guidati da LLM collaborano per raggiungere obiettivi distinti, integrando strumenti esterni come arXiv, Hugging Face, Python e LaTeX per ottimizzare i risultati. Questo flusso di lavoro strutturato inizia con la raccolta e analisi indipendente di documenti di ricerca pertinenti, prosegue attraverso la pianificazione collaborativa e la preparazione dei dati, e si conclude con la sperimentazione automatizzata e la generazione di rapporti completi. I dettagli sui ruoli specifici degli agenti e i loro contributi in queste fasi sono discussi nel documento.
<p align="center">
<img src="../media/AgentLabWF.png" alt="Dimostrazione del flusso di AgentClinic" style="width: 99%;">
</p>
## 🖥️ Installazione
### Opzione Python venv
1. **Clona il Repository GitHub**: Inizia clonando il repository usando il comando:
```bash
git clone [email protected]:SamuelSchmidgall/AgentLaboratory.git
```
2. **Configura e Attiva l'Ambiente Python**
```bash
python -m venv venv_agent_lab
```
- Ora attiva questo ambiente:
```bash
source venv_agent_lab/bin/activate
```
3. **Installa le librerie richieste**
```bash
pip install -r requirements.txt
```
4. **Installa pdflatex [OPZIONALE]**
```bash
sudo apt install pdflatex
```
- Questo permette agli agenti di compilare il codice sorgente LaTeX.
- **[IMPORTANTE]** Se questo passaggio non può essere eseguito a causa della mancanza di accesso sudo, la compilazione del pdf può essere disattivata eseguendo Agent Laboratory impostando il flag --compile_latex su false: --compile_latex=False
5. **Ora esegui Agent Laboratory!**
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "YOUR RESEARCH IDEA"
```
oppure, se non hai installato pdflatex
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "YOUR RESEARCH IDEA" --compile_latex=False
```
-----
## Consigli per migliori risultati di ricerca
#### [Consiglio #1] 📝 Assicurati di scrivere appunti dettagliati! 📝
**Scrivere appunti dettagliati è importante** per aiutare il tuo agente a comprendere cosa intendi realizzare nel tuo progetto, nonché eventuali preferenze di stile. Gli appunti possono includere qualsiasi esperimento che desideri che gli agenti eseguano, fornire chiavi API, determinati grafici o figure che desideri includere, o qualsiasi cosa tu voglia che l'agente sappia durante la ricerca.
Questa è anche la tua opportunità di far sapere all'agente **a quali risorse computazionali ha accesso**, ad esempio GPU (quante, che tipo di GPU, quanti GB), CPU (quanti core, che tipo di CPU), limitazioni di archiviazione e specifiche hardware.
Per aggiungere appunti, devi modificare la struttura task_notes_LLM all'interno di ai_lab_repo.py. Di seguito è fornito un esempio di set di appunti utilizzati per alcuni dei nostri esperimenti.
```python
task_notes_LLM = [
{"phases": ["plan formulation"],
"note": f"You should come up with a plan for TWO experiments."},
{"phases": ["plan formulation", "data preparation", "running experiments"],
"note": "Please use gpt-4o-mini for your experiments."},
{"phases": ["running experiments"],
"note": f"Use the following code to inference gpt-4o-mini: \nfrom openai import OpenAI\nos.environ["OPENAI_API_KEY"] = "{api_key}"\nclient = OpenAI()\ncompletion = client.chat.completions.create(\nmodel="gpt-4o-mini-2024-07-18", messages=messages)\nanswer = completion.choices[0].message.content\n"},
{"phases": ["running experiments"],
"note": f"You have access to only gpt-4o-mini using the OpenAI API, please use the following key {api_key} but do not use too many inferences. Do not use openai.ChatCompletion.create or any openai==0.28 commands. Instead use the provided inference code."},
{"phases": ["running experiments"],
"note": "I would recommend using a small dataset (approximately only 100 data points) to run experiments in order to save time. Do not use much more than this unless you have to or are running the final tests."},
{"phases": ["data preparation", "running experiments"],
"note": "You are running on a MacBook laptop. You can use 'mps' with PyTorch"},
{"phases": ["data preparation", "running experiments"],
"note": "Generate figures with very colorful and artistic design."},
]
```
--------
#### [Consiglio #2] 🚀 Utilizzare modelli più potenti generalmente porta a migliori ricerche 🚀
Quando si conduce una ricerca, **la scelta del modello può influenzare significativamente la qualità dei risultati**. I modelli più potenti tendono ad avere una maggiore accuratezza, migliori capacità di ragionamento e una migliore generazione dei rapporti. Se le risorse computazionali lo consentono, dà priorità all'uso di modelli avanzati come o1-(mini/preview) o simili modelli linguistici di grandi dimensioni all'avanguardia.
Tuttavia, **è importante bilanciare le prestazioni e l'efficienza dei costi**. Sebbene i modelli potenti possano fornire risultati migliori, spesso sono più costosi e richiedono più tempo per essere eseguiti. Considera di usarli selettivamente—ad esempio, per esperimenti chiave o analisi finali—mentre ti affidi a modelli più piccoli ed efficienti per compiti iterativi o prototipazione iniziale.
Quando le risorse sono limitate, **ottimizza effettuando il fine-tuning di modelli più piccoli** sul tuo dataset specifico o combinando modelli pre-addestrati con prompt specifici per il compito per raggiungere l'equilibrio desiderato tra prestazioni ed efficienza computazionale.
-----
#### [Consiglio #3] ✅ Puoi caricare salvataggi precedenti dai checkpoint ✅
**Se perdi i progressi, la connessione a internet o se un sotto-compito fallisce, puoi sempre caricare da uno stato precedente.** Tutti i tuoi progressi vengono salvati di default nella variabile state_saves, che memorizza ogni singolo checkpoint. Basta passare i seguenti argomenti quando esegui ai_lab_repo.py
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "YOUR RESEARCH IDEA" --llm-backend "o1-mini" --load-existing True --load-existing-path "save_states/LOAD_PATH"
```
-----
#### [Consiglio #4] 🈯 Se stai utilizzando una lingua diversa dall'inglese 🈲
Se stai utilizzando Agent Laboratory in una lingua diversa dall'inglese, nessun problema, basta assicurarti di fornire un flag di lingua agli agenti per eseguire la ricerca nella tua lingua preferita. Nota che non abbiamo studiato approfonditamente l'utilizzo di Agent Laboratory in altre lingue, quindi assicurati di segnalare eventuali problemi che incontri.
Ad esempio, se stai utilizzando in cinese:
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "YOUR RESEARCH IDEA (in your language)" --llm-backend "o1-mini" --language "中文"
```
----
#### [Consiglio #5] 🌟 C'è molto spazio per miglioramenti 🌟
C'è molto spazio per migliorare questo codice, quindi se alla fine apporti modifiche e vuoi aiutare la comunità, sentiti libero di condividere le modifiche che hai effettuato! Speriamo che questo strumento ti sia d'aiuto!
## Riferimenti / Bibtex
```bibtex
@preprint{schmidgall2025AgentLaboratory,
title={Agent Laboratory: Using LLM Agents as Research Assistants},
author={Schmidgall, Samuel and Su, Yusheng and Wang, Ze and Sun, Ximeng and Wu, Jialian and Yu, Xiadong and Liu, Jiang, Liu, Zicheng and Barsoum, Emad},
year={2025}
}
``` | {
"source": "SamuelSchmidgall/AgentLaboratory",
"title": "readme/README-italian.md",
"url": "https://github.com/SamuelSchmidgall/AgentLaboratory/blob/main/readme/README-italian.md",
"date": "2025-01-08T02:00:51",
"stars": 3583,
"description": "Agent Laboratory is an end-to-end autonomous research workflow meant to assist you as the human researcher toward implementing your research ideas",
"file_size": 10259
} |
# Agent Laboratory: Using LLM Agents as Research Assistants
<p align="center">
<img src="../media/AgentLabLogo.png" alt="Demonstration of the flow of AgentClinic" style="width: 99%;">
</p>
<p align="center">
【<a href="../README.md">English</a> | <a href="../readme/README-chinese.md">中文</a> | 日本語 | <a href="../readme/README-korean.md">한국어</a> | <a href="../readme/README-filipino.md">Filipino</a> | <a href="../readme/README-french.md">Français</a> | <a href="../readme/README-slovak.md">Slovenčina</a> | <a href="../readme/README-portugese.md">Português</a> | <a href="../readme/README-spanish.md">Español</a> | <a href="../readme/README-turkish.md">Türkçe</a> | <a href="../readme/README-hindi.md">हिंदी</a> | <a href="../readme/README-bengali.md">বাংলা</a> | <a href="../readme/README-vietnamese.md">Tiếng Việt</a> | <a href="../readme/README-russian.md">Русский</a> | <a href="../readme/README-arabic.md">العربية</a> | <a href="../readme/README-farsi.md">فارسی</a> | <a href="../readme/README-italian.md">Italiano</a>】
</p>
<p align="center">
【🌐 <a href="https://agentlaboratory.github.io/">Website</a> | 💻 <a href="https://github.com/SamuelSchmidgall/AgentLaboratory">Software</a> | 🎥 <a href="https://agentlaboratory.github.io/#youtube-video">Video</a> | 📚 <a href="https://agentlaboratory.github.io/#examples-goto">Example Paper</a> | 📰 <a href="https://agentlaboratory.github.io/#citation-ref">Citation</a>】
</p>
## 📖 概要
- **Agent Laboratory**は、**あなた**が**研究アイデアを実現する**ために支援するエンドツーエンドの自律的な研究ワークフローです。Agent Laboratoryは、大規模言語モデルによって駆動される専門のエージェントで構成されており、文献レビューの実施や計画の策定から実験の実行、包括的な報告書の作成まで、研究の全過程をサポートします。
- このシステムはあなたの創造性を置き換えるものではなく、補完するために設計されています。アイデアの創出や批判的思考に集中できるようにし、コーディングやドキュメント作成のような反復的で時間のかかる作業を自動化します。計算資源や人間の関与のレベルに応じて対応することで、Agent Laboratoryは科学的発見を加速し、研究の生産性を最適化することを目指しています。
<p align="center">
<img src="../media/AgentLab.png" alt="Demonstration of the flow of AgentClinic" style="width: 99%;">
</p>
### 🔬 Agent Laboratoryはどのように機能しますか?
- Agent Laboratoryは、研究プロセスを体系的に導く3つの主要なフェーズから構成されています:(1)文献レビュー、(2)実験、(3)報告書作成。各フェーズでは、LLMによって駆動される専門のエージェントが協力してそれぞれの目標を達成し、arXiv、Hugging Face、Python、LaTeXなどの外部ツールを統合して成果を最適化します。この構造化されたワークフローは、関連する研究論文の独立した収集と分析から始まり、協力的な計画とデータ準備を経て、自動化された実験と包括的な報告書の生成に至ります。これらのフェーズ全体にわたる具体的なエージェントの役割と貢献の詳細は論文で説明されています。
<p align="center">
<img src="../media/AgentLabWF.png" alt="Demonstration of the flow of AgentClinic" style="width: 99%;">
</p>
## 🖥️ インストール
### Python venv オプション
1. **GitHubリポジトリをクローンする**: 以下のコマンドを使用してリポジトリをクローンします:
```bash
git clone [email protected]:SamuelSchmidgall/AgentLaboratory.git
```
2. **Python環境を設定してアクティベートする**
```bash
python -m venv venv_agent_lab
```
- 次に、この環境をアクティベートします:
```bash
source venv_agent_lab/bin/activate
```
3. **必要なライブラリをインストールする**
```bash
pip install -r requirements.txt
```
4. **pdflatexをインストールする [オプション]**
```bash
sudo apt install pdflatex
```
- これにより、エージェントがLaTeXソースをコンパイルできるようになります。
- **[重要]** sudo権限がないためにこのステップを実行できない場合、Agent Laboratoryを実行する際に --compile_latexフラグをfalseに設定してPDFのコンパイルをオフにすることができます: --compile_latex=False
5. **Agent Laboratoryを実行します!**
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "YOUR RESEARCH IDEA"
```
または、pdflatexがインストールされていない場合
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "YOUR RESEARCH IDEA" --compile_latex=False
```
-----
## より良い研究成果を得るためのヒント
#### [ヒント #1] 📝 詳細なノートを書くことを忘れずに! 📝
**詳細なノートを書くことは重要です**。これにより、エージェントがプロジェクトで達成しようとしていることや、スタイルの好みを理解するのに役立ちます。ノートには、エージェントに実行してほしい実験、APIキーの提供、含めたい特定のプロットや図、研究を行う際にエージェントに知っておいてほしいことなどを含めることができます。
また、**エージェントがアクセスできる計算資源**を知らせる機会でもあります。例えば、GPU(数、種類、GB数)、CPU(コア数、種類)、ストレージの制限、ハードウェア仕様などです。
ノートを追加するには、ai_lab_repo.py内のtask_notes_LLM構造を変更する必要があります。以下に、いくつかの実験で使用されたノートの例を示します。
```python
task_notes_LLM = [
{"phases": ["plan formulation"],
"note": f"You should come up with a plan for TWO experiments."},
{"phases": ["plan formulation", "data preparation", "running experiments"],
"note": "Please use gpt-4o-mini for your experiments."},
{"phases": ["running experiments"],
"note": f"Use the following code to inference gpt-4o-mini: \nfrom openai import OpenAI\nos.environ["OPENAI_API_KEY"] = "{api_key}"\nclient = OpenAI()\ncompletion = client.chat.completions.create(\nmodel="gpt-4o-mini-2024-07-18", messages=messages)\nanswer = completion.choices[0].message.content\n"},
{"phases": ["running experiments"],
"note": f"You have access to only gpt-4o-mini using the OpenAI API, please use the following key {api_key} but do not use too many inferences. Do not use openai.ChatCompletion.create or any openai==0.28 commands. Instead use the provided inference code."},
{"phases": ["running experiments"],
"note": "I would recommend using a small dataset (approximately only 100 data points) to run experiments in order to save time. Do not use much more than this unless you have to or are running the final tests."},
{"phases": ["data preparation", "running experiments"],
"note": "You are running on a MacBook laptop. You can use 'mps' with PyTorch"},
{"phases": ["data preparation", "running experiments"],
"note": "Generate figures with very colorful and artistic design."},
]
```
--------
#### [ヒント #2] 🚀 より強力なモデルを使用することで、一般的により良い研究が可能になります 🚀
研究を行う際、**モデルの選択は結果の質に大きな影響を与える可能性があります**。より強力なモデルは、通常、精度が高く、推論能力が優れており、報告書の生成も優れています。計算資源が許す場合は、o1-(mini/preview)などの先進的な大規模言語モデルの使用を優先してください。
ただし、**性能と費用対効果のバランスを取ることが重要です**。強力なモデルはより良い結果をもたらす可能性がありますが、実行には時間と費用がかかることが多いです。重要な実験や最終分析には選択的に使用し、反復作業や初期のプロトタイピングには小さく効率的なモデルを使用することを検討してください。
資源が限られている場合は、**小さなモデルを特定のデータセットでファインチューニングするか、タスク固有のプロンプトと組み合わせて使用することで、性能と計算効率の間の望ましいバランスを達成します**。
-----
#### [ヒント #3] ✅ チェックポイントから以前の保存をロードできます ✅
**進捗が失われた場合、インターネット接続が切れた場合、またはサブタスクが失敗した場合でも、以前の状態から常にロードできます。** すべての進捗はデフォルトでstate_saves変数に保存され、各チェックポイントが保存されます。ai_lab_repo.pyを実行する際に、以下の引数を渡すだけです
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "YOUR RESEARCH IDEA" --llm-backend "o1-mini" --load-existing True --load-existing-path "save_states/LOAD_PATH"
```
-----
#### [ヒント #4] 🈯 英語以外の言語で実行している場合 🈲
Agent Laboratoryを英語以外の言語で実行している場合でも問題ありません。エージェントが希望する言語で研究を行えるように、言語フラグを提供することを確認してください。Agent Laboratoryを他の言語で実行することについては十分に研究していないため、問題が発生した場合は必ず報告してください。
例えば、中国語で実行する場合:
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "YOUR RESEARCH IDEA (in your language)" --llm-backend "o1-mini" --language "中文"
```
----
#### [ヒント #5] 🌟 改善の余地がたくさんあります 🌟
このコードベースには改善の余地がたくさんありますので、変更を加えてコミュニティに貢献したい場合は、ぜひ変更内容を共有してください!このツールが皆さんのお役に立つことを願っています!
## 参考文献 / Bibtex
```bibtex
@preprint{schmidgall2025AgentLaboratory,
title={Agent Laboratory: Using LLM Agents as Research Assistants},
author={Schmidgall, Samuel and Su, Yusheng and Wang, Ze and Sun, Ximeng and Wu, Jialian and Yu, Xiadong and Liu, Jiang, Liu, Zicheng and Barsoum, Emad},
year={2025}
}
``` | {
"source": "SamuelSchmidgall/AgentLaboratory",
"title": "readme/README-japanese.md",
"url": "https://github.com/SamuelSchmidgall/AgentLaboratory/blob/main/readme/README-japanese.md",
"date": "2025-01-08T02:00:51",
"stars": 3583,
"description": "Agent Laboratory is an end-to-end autonomous research workflow meant to assist you as the human researcher toward implementing your research ideas",
"file_size": 6933
} |
# Agent Laboratory: Using LLM Agents as Research Assistants
<p align="center">
<img src="../media/AgentLabLogo.png" alt="Demonstration of the flow of AgentClinic" style="width: 99%;">
</p>
<p align="center">
【<a href="../README.md">English</a> | <a href="../readme/README-chinese.md">中文</a> | <a href="../readme/README-japanese.md">日本語</a> | 한국어 | <a href="../readme/README-filipino.md">Filipino</a> | <a href="../readme/README-french.md">Français</a> | <a href="../readme/README-slovak.md">Slovenčina</a> | <a href="../readme/README-portugese.md">Português</a> | <a href="../readme/README-spanish.md">Español</a> | <a href="../readme/README-turkish.md">Türkçe</a> | <a href="../readme/README-hindi.md">हिंदी</a> | <a href="../readme/README-bengali.md">বাংলা</a> | <a href="../readme/README-vietnamese.md">Tiếng Việt</a> | <a href="../readme/README-russian.md">Русский</a> | <a href="../readme/README-arabic.md">العربية</a> | <a href="../readme/README-farsi.md">فارسی</a> | <a href="../readme/README-italian.md">Italiano</a>】
</p>
<p align="center">
【🌐 <a href="https://agentlaboratory.github.io/">Website</a> | 💻 <a href="https://github.com/SamuelSchmidgall/AgentLaboratory">Software</a> | 🎥 <a href="https://agentlaboratory.github.io/#youtube-video">Video</a> | 📚 <a href="https://agentlaboratory.github.io/#examples-goto">Example Paper</a> | 📰 <a href="https://agentlaboratory.github.io/#citation-ref">Citation</a>】
</p>
## 📖 개요
- **Agent Laboratory**는 **당신**이 인간 연구자로서 **연구 아이디어를 구현**할 수 있도록 지원하는 엔드 투 엔드 자율 연구 워크플로우입니다. Agent Laboratory는 대규모 언어 모델에 의해 구동되는 전문화된 에이전트들로 구성되어 문헌 검토 수행, 계획 수립, 실험 실행, 종합 보고서 작성에 이르기까지 전체 연구 워크플로우를 지원합니다.
- 이 시스템은 당신의 창의성을 대체하기 위해 설계된 것이 아니라 보완하기 위해 설계되었습니다. 아이디어 발상과 비판적 사고에 집중할 수 있도록 하면서 코딩 및 문서화와 같은 반복적이고 시간이 많이 소요되는 작업을 자동화합니다. 다양한 수준의 컴퓨팅 자원과 인간의 참여를 수용함으로써 Agent Laboratory는 과학적 발견을 가속화하고 연구 생산성을 최적화하는 것을 목표로 합니다.
<p align="center">
<img src="../media/AgentLab.png" alt="Demonstration of the flow of AgentClinic" style="width: 99%;">
</p>
### 🔬 Agent Laboratory는 어떻게 작동하나요?
- Agent Laboratory는 연구 과정을 체계적으로 안내하는 세 가지 주요 단계로 구성됩니다: (1) 문헌 검토, (2) 실험, (3) 보고서 작성. 각 단계 동안 LLM에 의해 구동되는 전문화된 에이전트들이 협력하여 개별 목표를 달성하며, arXiv, Hugging Face, Python, LaTeX와 같은 외부 도구를 통합하여 결과를 최적화합니다. 이 구조화된 워크플로우는 관련 연구 논문의 독립적인 수집 및 분석으로 시작하여, 협력적인 계획 수립 및 데이터 준비를 거쳐, 자동화된 실험 실행 및 종합적인 보고서 생성으로 이어집니다. 이러한 단계 전반에 걸친 특정 에이전트 역할과 기여에 대한 자세한 내용은 논문에서 논의됩니다.
<p align="center">
<img src="../media/AgentLabWF.png" alt="Demonstration of the flow of AgentClinic" style="width: 99%;">
</p>
## 🖥️ 설치
### Python venv 옵션
1. **GitHub 저장소 복제**: 다음 명령어를 사용하여 저장소를 복제합니다:
```bash
git clone [email protected]:SamuelSchmidgall/AgentLaboratory.git
```
2. **Python 환경 설정 및 활성화**
```bash
python -m venv venv_agent_lab
```
- 이제 이 환경을 활성화합니다:
```bash
source venv_agent_lab/bin/activate
```
3. **필수 라이브러리 설치**
```bash
pip install -r requirements.txt
```
4. **pdflatex 설치 [옵션]**
```bash
sudo apt install pdflatex
```
- 이는 에이전트들이 LaTeX 소스를 컴파일할 수 있도록 합니다.
- **[중요]** sudo 접근 권한이 없어 이 단계를 실행할 수 없는 경우, --compile_latex 플래그를 false로 설정하여 Agent Laboratory 실행 시 PDF 컴파일을 비활성화할 수 있습니다: `--compile_latex=False`
5. **이제 Agent Laboratory를 실행하세요!**
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "YOUR RESEARCH IDEA"
```
또는, pdflatex가 설치되어 있지 않은 경우
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "YOUR RESEARCH IDEA" --compile_latex=False
```
-----
## 더 나은 연구 결과를 위한 팁
#### [팁 #1] 📝 광범위한 노트를 작성하세요! 📝
**광범위한 노트 작성은** 에이전트가 프로젝트에서 달성하려는 목표와 스타일 선호도를 이해하는 데 중요합니다. 노트에는 에이전트에게 수행하도록 원하는 실험, API 키 제공, 포함하고 싶은 특정 플롯이나 그림, 또는 연구를 수행할 때 에이전트가 알아야 할 모든 내용을 포함할 수 있습니다.
또한, **에이전트가 접근할 수 있는 컴퓨팅 자원**을 알려줄 수 있는 기회이기도 합니다. 예를 들어 GPU (몇 개, 어떤 유형의 GPU, GB 수), CPU (코어 수, CPU 유형), 저장 한계 및 하드웨어 사양 등을 포함할 수 있습니다.
노트를 추가하려면, ai_lab_repo.py 내부의 `task_notes_LLM` 구조를 수정해야 합니다. 아래는 일부 실험에 사용된 노트의 예시입니다.
```python
task_notes_LLM = [
{"phases": ["plan formulation"],
"note": f"You should come up with a plan for TWO experiments."},
{"phases": ["plan formulation", "data preparation", "running experiments"],
"note": "Please use gpt-4o-mini for your experiments."},
{"phases": ["running experiments"],
"note": f"Use the following code to inference gpt-4o-mini: \nfrom openai import OpenAI\nos.environ["OPENAI_API_KEY"] = "{api_key}"\nclient = OpenAI()\ncompletion = client.chat.completions.create(\nmodel="gpt-4o-mini-2024-07-18", messages=messages)\nanswer = completion.choices[0].message.content\n"},
{"phases": ["running experiments"],
"note": f"You have access to only gpt-4o-mini using the OpenAI API, please use the following key {api_key} but do not use too many inferences. Do not use openai.ChatCompletion.create or any openai==0.28 commands. Instead use the provided inference code."},
{"phases": ["running experiments"],
"note": "I would recommend using a small dataset (approximately only 100 data points) to run experiments in order to save time. Do not use much more than this unless you have to or are running the final tests."},
{"phases": ["data preparation", "running experiments"],
"note": "You are running on a MacBook laptop. You can use 'mps' with PyTorch"},
{"phases": ["data preparation", "running experiments"],
"note": "Generate figures with very colorful and artistic design."},
]
```
--------
#### [팁 #2] 🚀 더 강력한 모델을 사용하는 것이 일반적으로 더 나은 연구로 이어집니다 🚀
연구를 수행할 때, **모델의 선택은 결과의 질에 상당한 영향을 미칠 수 있습니다**. 더 강력한 모델은 일반적으로 더 높은 정확도, 더 나은 추론 능력, 더 우수한 보고서 생성을 제공합니다. 컴퓨팅 자원이 허용한다면, o1-(mini/preview)와 같은 최첨단 대규모 언어 모델과 같은 고급 모델의 사용을 우선시하세요.
그러나, **성능과 비용 효율성의 균형을 맞추는 것이 중요합니다**. 강력한 모델은 더 나은 결과를 제공할 수 있지만, 실행하는 데 비용과 시간이 더 많이 소요되는 경우가 많습니다. 예를 들어, 핵심 실험이나 최종 분석에는 고급 모델을 선택적으로 사용하고, 반복 작업이나 초기 프로토타이핑에는 더 작고 효율적인 모델을 사용하는 것을 고려하세요.
자원이 제한된 경우, **작은 모델을 특정 데이터셋에 맞게 미세 조정하거나, 사전 훈련된 모델과 작업 특화 프롬프트를 결합하여 성능과 컴퓨팅 효율성 사이의 원하는 균형을 달성할 수 있습니다**.
-----
#### [팁 #3] ✅ 체크포인트에서 이전 저장 상태를 불러올 수 있습니다 ✅
**진행 상황을 잃었거나 인터넷 연결이 끊기거나 하위 작업이 실패한 경우, 이전 상태에서 항상 불러올 수 있습니다.** 모든 진행 상황은 기본적으로 `state_saves` 변수에 저장되며, 이는 각 개별 체크포인트를 저장합니다. ai_lab_repo.py를 실행할 때 다음 인수를 전달하면 됩니다.
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "YOUR RESEARCH IDEA" --llm-backend "o1-mini" --load-existing True --load-existing-path "save_states/LOAD_PATH"
```
-----
#### [팁 #4] 🈯 영어가 아닌 다른 언어로 실행하는 경우 🈲
Agent Laboratory를 영어가 아닌 다른 언어로 실행하는 경우, 문제 없습니다. 단, 에이전트가 선호하는 언어로 연구를 수행할 수 있도록 언어 플래그를 제공해야 합니다. 다른 언어로 Agent Laboratory를 실행하는 것에 대해 광범위하게 연구하지 않았으므로, 발생하는 문제를 반드시 보고해 주세요.
예를 들어, 중국어로 실행하는 경우:
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "YOUR RESEARCH IDEA (in your language)" --llm-backend "o1-mini" --language "中文"
```
----
#### [팁 #5] 🌟 개선의 여지가 많습니다 🌟
이 코드베이스를 개선할 여지가 많으므로, 변경을 가하고 커뮤니티에 기여하고 싶다면, 변경한 사항을 자유롭게 공유해 주세요! 이 도구가 여러분에게 도움이 되길 바랍니다!
## 참고 문헌 / Bibtex
```bibtex
@preprint{schmidgall2025AgentLaboratory,
title={Agent Laboratory: Using LLM Agents as Research Assistants},
author={Schmidgall, Samuel and Su, Yusheng and Wang, Ze and Sun, Ximeng and Wu, Jialian and Yu, Xiadong and Liu, Jiang, Liu, Zicheng and Barsoum, Emad},
year={2025}
}
``` | {
"source": "SamuelSchmidgall/AgentLaboratory",
"title": "readme/README-korean.md",
"url": "https://github.com/SamuelSchmidgall/AgentLaboratory/blob/main/readme/README-korean.md",
"date": "2025-01-08T02:00:51",
"stars": 3583,
"description": "Agent Laboratory is an end-to-end autonomous research workflow meant to assist you as the human researcher toward implementing your research ideas",
"file_size": 7327
} |
# Agent Laboratory: Usando Agentes LLM como Assistentes de Pesquisa
<p align="center">
<img src="../media/AgentLabLogo.png" alt="Demonstration of the flow of AgentClinic" style="width: 99%;">
</p>
<p align="center">
【<a href="../README.md">English</a> | <a href="../readme/README-chinese.md">中文</a> | <a href="../readme/README-japanese.md">日本語</a> | <a href="../readme/README-korean.md">한국어</a> | <a href="../readme/README-filipino.md">Filipino</a> | <a href="../readme/README-french.md">Français</a> | <a href="../readme/README-slovak.md">Slovenčina</a> | Português | <a href="../readme/README-spanish.md">Español</a> | <a href="../readme/README-turkish.md">Türkçe</a> | <a href="../readme/README-hindi.md">हिंदी</a> | <a href="../readme/README-bengali.md">বাংলা</a> | <a href="../readme/README-vietnamese.md">Tiếng Việt</a> | <a href="../readme/README-russian.md">Русский</a> | <a href="../readme/README-arabic.md">العربية</a> | <a href="../readme/README-farsi.md">فارسی</a> | <a href="../readme/README-italian.md">Italiano</a>】
</p>
<p align="center">
【🌐 <a href="https://agentlaboratory.github.io/">Website</a> | 💻 <a href="https://github.com/SamuelSchmidgall/AgentLaboratory">Software</a> | 🎥 <a href="https://agentlaboratory.github.io/#youtube-video">Video</a> | 📚 <a href="https://agentlaboratory.github.io/#examples-goto">Example Paper</a> | 📰 <a href="https://agentlaboratory.github.io/#citation-ref">Citation</a>】
</p>
## 📖 Visão Geral
- **Agent Laboratory** é um fluxo de trabalho de pesquisa autônomo de ponta a ponta, destinado a auxiliar **você** como pesquisador humano na **implementação das suas ideias de pesquisa**. O Agent Laboratory consiste em agentes especializados movidos por grandes modelos de linguagem para apoiá-lo durante todo o fluxo de trabalho de pesquisa — desde a condução de revisões de literatura e formulação de planos até a execução de experimentos e a redação de relatórios abrangentes.
- Este sistema não foi projetado para substituir a sua criatividade, mas para complementá-la, permitindo que você se concentre na ideação e no pensamento crítico enquanto automatiza tarefas repetitivas e que consomem muito tempo, como codificação e documentação. Ao acomodar diferentes níveis de recursos computacionais e envolvimento humano, o Agent Laboratory visa acelerar a descoberta científica e otimizar a sua produtividade em pesquisa.
<p align="center">
<img src="../media/AgentLab.png" alt="Demonstration of the flow of AgentClinic" style="width: 99%;">
</p>
### 🔬 Como funciona o Agent Laboratory?
- O Agent Laboratory consiste em três fases principais que orientam sistematicamente o processo de pesquisa: (1) Revisão de Literatura, (2) Experimentação e (3) Redação de Relatórios. Durante cada fase, agentes especializados movidos por LLMs colaboram para alcançar objetivos distintos, integrando ferramentas externas como arXiv, Hugging Face, Python e LaTeX para otimizar os resultados. Este fluxo de trabalho estruturado começa com a coleta e análise independentes de artigos de pesquisa relevantes, avança através do planejamento colaborativo e preparação de dados, e resulta em experimentação automatizada e geração de relatórios abrangentes. Detalhes sobre os papéis específicos dos agentes e suas contribuições ao longo dessas fases são discutidos no artigo.
<p align="center">
<img src="../media/AgentLabWF.png" alt="Demonstration of the flow of AgentClinic" style="width: 99%;">
</p>
## 🖥️ Instalação
### Opção de ambiente virtual Python (venv)
1. **Clone o Repositório do GitHub**: Comece clonando o repositório usando o comando:
```bash
git clone [email protected]:SamuelSchmidgall/AgentLaboratory.git
```
2. **Configure e Ative o Ambiente Python**
```bash
python -m venv venv_agent_lab
```
- Agora, ative este ambiente:
```bash
source venv_agent_lab/bin/activate
```
3. **Instale as bibliotecas necessárias**
```bash
pip install -r requirements.txt
```
4. **Instale o pdflatex [OPCIONAL]**
```bash
sudo apt install pdflatex
```
- Isso permite que o código LaTeX seja compilado pelos agentes.
- **[IMPORTANTE]** Se esta etapa não puder ser executada devido à falta de acesso sudo, a compilação de PDF pode ser desativada executando o Agent Laboratory com a flag --compile_latex definida como false: --compile_latex=False
5. **Agora execute o Agent Laboratory!**
```bash
python ai_lab_repo.py --api-key "API_KEY_AQUI" --llm-backend "o1-mini" --research-topic "SUA IDEIA DE PESQUISA"
```
ou, se você não tiver o pdflatex instalado
```bash
python ai_lab_repo.py --api-key "API_KEY_AQUI" --llm-backend "o1-mini" --research-topic "SUA IDEIA DE PESQUISA" --compile_latex=False
```
-----
## Dicas para melhores resultados de pesquisa
#### [Dica #1] 📝 Certifique-se de escrever notas extensas! 📝
**Escrever notas extensas é importante** para ajudar seu agente a entender o que você está tentando realizar em seu projeto, bem como quaisquer preferências de estilo. As notas podem incluir quaisquer experimentos que você deseja que os agentes realizem, fornecendo chaves de API, certos gráficos ou figuras que você deseja incluir, ou qualquer coisa que você queira que o agente saiba ao realizar a pesquisa.
Esta também é sua oportunidade de informar ao agente **a quais recursos de computação ele tem acesso**, por exemplo, GPUs (quantas, que tipo de GPU, quantos GBs), CPUs (quantos núcleos, que tipo de CPUs), limitações de armazenamento e especificações de hardware.
Para adicionar notas, você deve modificar a estrutura task_notes_LLM dentro de ai_lab_repo.py. Abaixo está um exemplo de conjunto de notas usadas em alguns de nossos experimentos.
```python
task_notes_LLM = [
{"phases": ["plan formulation"],
"note": f"You should come up with a plan for TWO experiments."},
{"phases": ["plan formulation", "data preparation", "running experiments"],
"note": "Please use gpt-4o-mini for your experiments."},
{"phases": ["running experiments"],
"note": f"Use the following code to inference gpt-4o-mini: \nfrom openai import OpenAI\nos.environ["OPENAI_API_KEY"] = "{api_key}"\nclient = OpenAI()\ncompletion = client.chat.completions.create(\nmodel="gpt-4o-mini-2024-07-18", messages=messages)\nanswer = completion.choices[0].message.content\n"},
{"phases": ["running experiments"],
"note": f"You have access to only gpt-4o-mini using the OpenAI API, please use the following key {api_key} but do not use too many inferences. Do not use openai.ChatCompletion.create or any openai==0.28 commands. Instead use the provided inference code."},
{"phases": ["running experiments"],
"note": "I would recommend using a small dataset (approximately only 100 data points) to run experiments in order to save time. Do not use much more than this unless you have to or are running the final tests."},
{"phases": ["data preparation", "running experiments"],
"note": "You are running on a MacBook laptop. You can use 'mps' with PyTorch"},
{"phases": ["data preparation", "running experiments"],
"note": "Generate figures with very colorful and artistic design."},
]
```
--------
#### [Dica #2] 🚀 Usar modelos mais poderosos geralmente leva a melhores pesquisas 🚀
Ao conduzir pesquisas, **a escolha do modelo pode impactar significativamente a qualidade dos resultados**. Modelos mais poderosos tendem a ter maior precisão, melhores capacidades de raciocínio e melhor geração de relatórios. Se os recursos computacionais permitirem, priorize o uso de modelos avançados como o1-(mini/preview) ou modelos de linguagem grandes de última geração similares.
No entanto, **é importante equilibrar desempenho e custo-benefício**. Embora modelos poderosos possam gerar melhores resultados, eles geralmente são mais caros e consomem mais tempo para serem executados. Considere usá-los seletivamente — por exemplo, para experimentos chave ou análises finais — enquanto confia em modelos menores e mais eficientes para tarefas iterativas ou prototipagem inicial.
Quando os recursos são limitados, **otimize ajustando modelos menores** no seu conjunto de dados específico ou combinando modelos pré-treinados com prompts específicos para a tarefa para alcançar o equilíbrio desejado entre desempenho e eficiência computacional.
-----
#### [Dica #3] ✅ Você pode carregar salvamentos anteriores a partir de checkpoints ✅
**Se você perder o progresso, conexão com a internet ou se uma subtarefa falhar, você sempre pode carregar a partir de um estado anterior.** Todo o seu progresso é salvo por padrão na variável state_saves, que armazena cada checkpoint individual. Basta passar os seguintes argumentos ao executar ai_lab_repo.py
```bash
python ai_lab_repo.py --api-key "API_KEY_AQUI" --research-topic "SUA IDEIA DE PESQUISA" --llm-backend "o1-mini" --load-existing True --load-existing-path "save_states/LOAD_PATH"
```
-----
#### [Dica #4] 🈯 Se você estiver executando em um idioma diferente do inglês 🈲
Se você estiver executando o Agent Laboratory em um idioma diferente do inglês, sem problema, apenas certifique-se de fornecer uma flag de idioma para que os agentes realizem a pesquisa no seu idioma preferido. Observe que não estudamos extensivamente a execução do Agent Laboratory em outros idiomas, portanto, certifique-se de relatar quaisquer problemas que encontrar.
Por exemplo, se você estiver executando em chinês:
```bash
python ai_lab_repo.py --api-key "API_KEY_AQUI" --research-topic "SUA IDEIA DE PESQUISA (no seu idioma)" --llm-backend "o1-mini" --language "中文"
```
----
#### [Dica #5] 🌟 Há muito espaço para melhorias 🌟
Há muito espaço para melhorar esta base de código, então se você acabar fazendo alterações e quiser ajudar a comunidade, sinta-se à vontade para compartilhar as mudanças que você fez! Esperamos que esta ferramenta lhe seja útil!
## Referência / Bibtex
```bibtex
@preprint{schmidgall2025AgentLaboratory,
title={Agent Laboratory: Using LLM Agents as Research Assistants},
author={Schmidgall, Samuel and Su, Yusheng and Wang, Ze and Sun, Ximeng and Wu, Jialian and Yu, Xiadong and Liu, Jiang, Liu, Zicheng and Barsoum, Emad},
year={2025}
}
``` | {
"source": "SamuelSchmidgall/AgentLaboratory",
"title": "readme/README-portugues.md",
"url": "https://github.com/SamuelSchmidgall/AgentLaboratory/blob/main/readme/README-portugues.md",
"date": "2025-01-08T02:00:51",
"stars": 3583,
"description": "Agent Laboratory is an end-to-end autonomous research workflow meant to assist you as the human researcher toward implementing your research ideas",
"file_size": 10233
} |
# Лаборатория Агентов: Использование агентов на основе больших языковых моделей в качестве научных ассистентов
<p align="center">
<img src="../media/AgentLabLogo.png" alt="Demonstration of the flow of AgentClinic" style="width: 99%;">
</p>
<p align="center">
【<a href="../README.md">English</a> | <a href="../readme/README-chinese.md">中文</a> | <a href="../readme/README-japanese.md">日本語</a> | <a href="../readme/README-korean.md">한국어</a> | <a href="../readme/README-filipino.md">Filipino</a> | <a href="../readme/README-french.md">Français</a> | <a href="../readme/README-slovak.md">Slovenčina</a> | <a href="../readme/README-portugese.md">Português</a> | <a href="../readme/README-spanish.md">Español</a> | <a href="../readme/README-turkish.md">Türkçe</a> | <a href="../readme/README-hindi.md">हिंदी</a> | <a href="../readme/README-bengali.md">বাংলা</a> | <a href="../readme/README-vietnamese.md">Tiếng Việt</a> | Русский | <a href="../readme/README-arabic.md">العربية</a> | <a href="../readme/README-farsi.md">فارسی</a> | <a href="../readme/README-italian.md">Italiano</a>】
</p>
<p align="center">
【🌐 <a href="https://agentlaboratory.github.io/">Веб-сайт</a> | 💻 <a href="https://github.com/SamuelSchmidgall/AgentLaboratory">Программное обеспечение</a> | 🎥 <a href="https://agentlaboratory.github.io/#youtube-video">Видео</a> | 📚 <a href="https://agentlaboratory.github.io/#examples-goto">Пример статьи</a> | 📰 <a href="https://agentlaboratory.github.io/#citation-ref">Цитирование</a>】
</p>
## 📖 Обзор
- **Лаборатория Агентов** — это автономный исследовательский процесс от начала до конца, предназначенный для помощи **вам** как человеческому исследователю в **реализации ваших исследовательских идей**. Лаборатория Агентов состоит из специализированных агентов, управляемых большими языковыми моделями, которые поддерживают вас на протяжении всего исследовательского процесса — от проведения обзора литературы и формулирования планов до выполнения экспериментов и написания подробных отчетов.
- Эта система не предназначена для замены вашего творчества, а дополняет его, позволяя вам сосредоточиться на генерации идей и критическом мышлении, одновременно автоматизируя повторяющиеся и времязатратные задачи, такие как кодирование и документирование. Адаптируясь к различным уровням вычислительных ресурсов и вовлеченности человека, Лаборатория Агентов стремится ускорить научные открытия и оптимизировать вашу исследовательскую продуктивность.
<p align="center">
<img src="../media/AgentLab.png" alt="Demonstration of the flow of AgentClinic" style="width: 99%;">
</p>
### 🔬 Как работает Лаборатория Агентов?
- Лаборатория Агентов состоит из трех основных фаз, которые систематически направляют исследовательский процесс: (1) Обзор литературы, (2) Экспериментирование и (3) Написание отчета. В каждой фазе специализированные агенты, управляемые большими языковыми моделями, сотрудничают для достижения отдельных целей, интегрируя внешние инструменты, такие как arXiv, Hugging Face, Python и LaTeX, для оптимизации результатов. Эта структурированная рабочая схема начинается с независимого сбора и анализа соответствующих научных работ, проходит через совместное планирование и подготовку данных и заканчивается автоматизированным проведением экспериментов и созданием подробных отчетов. Детали конкретных ролей агентов и их вклад на каждом этапе обсуждаются в статье.
<p align="center">
<img src="../media/AgentLabWF.png" alt="Demonstration of the flow of AgentClinic" style="width: 99%;">
</p>
## 🖥️ Установка
### Вариант с использованием Python venv
1. **Клонируйте репозиторий GitHub**: Начните с клонирования репозитория с помощью команды:
```bash
git clone [email protected]:SamuelSchmidgall/AgentLaboratory.git
```
2. **Настройте и активируйте Python окружение**
```bash
python -m venv venv_agent_lab
```
- Теперь активируйте это окружение:
```bash
source venv_agent_lab/bin/activate
```
3. **Установите необходимые библиотеки**
```bash
pip install -r requirements.txt
```
4. **Установите pdflatex [ОПЦИОНАЛЬНО]**
```bash
sudo apt install pdflatex
```
- Это позволяет агентам компилировать исходный код LaTeX.
- **[ВАЖНО]** Если этот шаг невозможно выполнить из-за отсутствия прав sudo, можно отключить компиляцию pdf, запустив Лабораторию Агентов с флагом --compile_latex=False: --compile_latex=False
5. **Теперь запустите Лабораторию Агентов!**
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "ВАША ИССЛЕДОВАТЕЛЬСКАЯ ИДЕЯ"
```
или, если у вас не установлен pdflatex
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "ВАША ИССЛЕДОВАТЕЛЬСКАЯ ИДЕЯ" --compile_latex=False
```
-----
## Советы для лучших исследовательских результатов
#### [Совет №1] 📝 Обязательно записывайте подробные заметки! 📝
**Ведение подробных заметок важно** для того, чтобы ваш агент понимал, что вы хотите достичь в вашем проекте, а также любые предпочтения в стиле. Заметки могут включать любые эксперименты, которые вы хотите, чтобы агенты выполняли, предоставление API-ключей, определенные графики или фигуры, которые вы хотите включить, или любую информацию, которую вы хотите, чтобы агент знал при проведении исследований.
Это также ваша возможность сообщить агенту, **какие вычислительные ресурсы у него есть**, например, GPU (сколько, какой тип GPU, сколько GB), CPU (сколько ядер, какой тип CPU), ограничения по памяти и спецификации оборудования.
Чтобы добавить заметки, необходимо изменить структуру task_notes_LLM внутри файла ai_lab_repo.py. Ниже приведен пример набора заметок, использованных в некоторых наших экспериментах.
```python
task_notes_LLM = [
{"phases": ["plan formulation"],
"note": f"You should come up with a plan for TWO experiments."},
{"phases": ["plan formulation", "data preparation", "running experiments"],
"note": "Please use gpt-4o-mini for your experiments."},
{"phases": ["running experiments"],
"note": f"Use the following code to inference gpt-4o-mini: \nfrom openai import OpenAI\nos.environ["OPENAI_API_KEY"] = "{api_key}"\nclient = OpenAI()\ncompletion = client.chat.completions.create(\nmodel="gpt-4o-mini-2024-07-18", messages=messages)\nanswer = completion.choices[0].message.content\n"},
{"phases": ["running experiments"],
"note": f"You have access to only gpt-4o-mini using the OpenAI API, please use the following key {api_key} but do not use too many inferences. Do not use openai.ChatCompletion.create or any openai==0.28 commands. Instead use the provided inference code."},
{"phases": ["running experiments"],
"note": "I would recommend using a small dataset (approximately only 100 data points) to run experiments in order to save time. Do not use much more than this unless you have to or are running the final tests."},
{"phases": ["data preparation", "running experiments"],
"note": "You are running on a MacBook laptop. You can use 'mps' with PyTorch"},
{"phases": ["data preparation", "running experiments"],
"note": "Generate figures with very colorful and artistic design."},
]
```
--------
#### [Совет №2] 🚀 Использование более мощных моделей обычно приводит к лучшим исследованиям 🚀
При проведении исследований, **выбор модели может значительно повлиять на качество результатов**. Более мощные модели, как правило, имеют более высокую точность, лучшие способности к рассуждению и более качественное генерирование отчетов. Если вычислительные ресурсы позволяют, отдавайте предпочтение использованию продвинутых моделей, таких как o1-(mini/preview) или подобных современных больших языковых моделей.
Однако, **важно балансировать между производительностью и экономической эффективностью**. Хотя мощные модели могут давать лучшие результаты, они часто дороже и требуют больше времени для выполнения. Рассмотрите возможность использования их выборочно — например, для ключевых экспериментов или окончательных анализов — в то время как для итеративных задач или начального прототипирования полагайтесь на более маленькие и эффективные модели.
Когда ресурсы ограничены, **оптимизируйте, дорабатывая более маленькие модели** на вашем конкретном наборе данных или комбинируя предобученные модели с специфическими для задачи подсказками, чтобы достичь желаемого баланса между производительностью и вычислительной эффективностью.
-----
#### [Совет №3] ✅ Вы можете загрузить предыдущие сохранения из контрольных точек ✅
**Если вы потеряете прогресс, потеряете интернет-соединение или если подзадача завершится неудачей, вы всегда можете загрузить предыдущую версию.** Весь ваш прогресс сохраняется по умолчанию в переменной state_saves, которая хранит каждую отдельную контрольную точку. Просто передайте следующие аргументы при запуске ai_lab_repo.py
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "ВАША ИССЛЕДОВАТЕЛЬСКАЯ ИДЕЯ" --llm-backend "o1-mini" --load-existing True --load-existing-path "save_states/LOAD_PATH"
```
-----
#### [Совет №4] 🈯 Если вы работаете на другом языке, кроме английского 🈲
Если вы запускаете Лабораторию Агентов на другом языке, кроме английского, это не проблема, просто убедитесь, что вы предоставили языковой флаг агентам для проведения исследований на предпочитаемом вами языке. Обратите внимание, что мы не проводили обширных исследований по запуску Лаборатории Агентов на других языках, поэтому обязательно сообщайте о любых возникающих проблемах.
Например, если вы работаете на китайском языке:
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "ВАША ИССЛЕДОВАТЕЛЬСКАЯ ИДЕЯ (на вашем языке)" --llm-backend "o1-mini" --language "中文"
```
----
#### [Совет №5] 🌟 Есть много возможностей для улучшения 🌟
Есть много возможностей для улучшения этой кодовой базы, поэтому если вы внесете изменения и захотите помочь сообществу, пожалуйста, не стесняйтесь поделиться внесенными изменениями! Мы надеемся, что этот инструмент вам поможет!
## Ссылки / Bibtex
bibtex
```bibtex
@preprint{schmidgall2025AgentLaboratory,
title={Agent Laboratory: Using LLM Agents as Research Assistants},
author={Schmidgall, Samuel and Su, Yusheng and Wang, Ze and Sun, Ximeng and Wu, Jialian and Yu, Xiadong and Liu, Jiang, Liu, Zicheng and Barsoum, Emad},
year={2025}
}
``` | {
"source": "SamuelSchmidgall/AgentLaboratory",
"title": "readme/README-russian.md",
"url": "https://github.com/SamuelSchmidgall/AgentLaboratory/blob/main/readme/README-russian.md",
"date": "2025-01-08T02:00:51",
"stars": 3583,
"description": "Agent Laboratory is an end-to-end autonomous research workflow meant to assist you as the human researcher toward implementing your research ideas",
"file_size": 10395
} |
# Agent Laboratory: Používanie LLM Agentov ako Výskumných Asistentov
<p align="center">
<img src="../media/AgentLabLogo.png" alt="Demonstrácia toku AgentClinic" style="width: 99%;">
</p>
<p align="center">
【<a href="../README.md">English</a> | <a href="../readme/README-chinese.md">中文</a> | <a href="../readme/README-japanese.md">日本語</a> | <a href="../readme/README-korean.md">한국어</a> | <a href="../readme/README-filipino.md">Filipino</a> | <a href="../readme/README-french.md">Français</a> | Slovenčina | <a href="../readme/README-portugese.md">Português</a> | <a href="../readme/README-spanish.md">Español</a> | <a href="../readme/README-turkish.md">Türkçe</a> | <a href="../readme/README-hindi.md">हिंदी</a> | <a href="../readme/README-bengali.md">বাংলা</a> | <a href="../readme/README-vietnamese.md">Tiếng Việt</a> | <a href="../readme/README-russian.md">Русский</a> | <a href="../readme/README-arabic.md">العربية</a> | <a href="../readme/README-farsi.md">فارسی</a> | <a href="../readme/README-italian.md">Italiano</a>】
</p>
<p align="center">
【🌐 <a href="https://agentlaboratory.github.io/">Webová stránka</a> | 💻 <a href="https://github.com/SamuelSchmidgall/AgentLaboratory">Softvér</a> | 🎥 <a href="https://agentlaboratory.github.io/#youtube-video">Video</a> | 📚 <a href="https://agentlaboratory.github.io/#examples-goto">Príkladový článok</a> | 📰 <a href="https://agentlaboratory.github.io/#citation-ref">Citácia</a>】
</p>
## 📖 Prehľad
- **Agent Laboratory** je autonómny výskumný pracovný postup od začiatku do konca, ktorý má za úlohu asistovať **vám** ako ľudskému výskumníkovi pri **realizácii vašich výskumných nápadov**. Agent Laboratory pozostáva zo špecializovaných agentov poháňaných veľkými jazykovými modelmi, ktorí vás podporujú počas celého výskumného procesu – od vykonávania literárnych prehľadov a formulovania plánov až po realizáciu experimentov a písanie komplexných správ.
- Tento systém nie je navrhnutý na nahradenie vašej kreativity, ale na jej doplnenie, čo vám umožňuje sústrediť sa na tvorivosť a kritické myslenie pri automatizácii opakujúcich sa a časovo náročných úloh, ako je kódovanie a dokumentácia. Tým, že zohľadňuje rôzne úrovne výpočtových zdrojov a ľudského zapojenia, Agent Laboratory má za cieľ urýchliť vedecké objavy a optimalizovať vašu výskumnú produktivitu.
<p align="center">
<img src="../media/AgentLab.png" alt="Demonstrácia toku AgentClinic" style="width: 99%;">
</p>
### 🔬 Ako Agent Laboratory funguje?
- Agent Laboratory sa skladá z troch hlavných fáz, ktoré systematicky usmerňujú výskumný proces: (1) Literárny prehľad, (2) Experimentovanie a (3) Písanie správ. Počas každej fázy špecializovaní agenti poháňaní LLM spolupracujú na dosiahnutí konkrétnych cieľov, integrujúc externé nástroje ako arXiv, Hugging Face, Python a LaTeX na optimalizáciu výsledkov. Táto štruktúrovaná pracovná postupnosť začína nezávislým zhromažďovaním a analýzou relevantných výskumných prác, pokračuje cez kolaboratívne plánovanie a prípravu dát a končí automatizovaným experimentovaním a komplexnou generáciou správ. Podrobnosti o konkrétnych rolách agentov a ich príspevkoch v rámci týchto fáz sú diskutované v článku.
<p align="center">
<img src="../media/AgentLabWF.png" alt="Demonstrácia toku AgentClinic" style="width: 99%;">
</p>
## 🖥️ Inštalácia
### Python venv možnosť
1. **Naklonujte GitHub repozitár**: Začnite klonovaním repozitára pomocou príkazu:
```bash
git clone [email protected]:SamuelSchmidgall/AgentLaboratory.git
```
2. **Nastavte a aktivujte Python prostredie**
```bash
python -m venv venv_agent_lab
```
- Teraz aktivujte toto prostredie:
```bash
source venv_agent_lab/bin/activate
```
3. **Nainštalujte požadované knižnice**
```bash
pip install -r requirements.txt
```
4. **Nainštalujte pdflatex [VOLITEĽNÉ]**
```bash
sudo apt install pdflatex
```
- Toto umožňuje agentom kompilovať latex zdroj.
- **[DÔLEŽITÉ]** Ak tento krok nemôžete vykonať kvôli absencii sudo prístupu, kompiláciu pdf môžete vypnúť spustením Agent Laboratory s nastavením vlajky --compile_latex na false: `--compile_latex=False`
5. **Teraz spustite Agent Laboratory!**
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "YOUR RESEARCH IDEA"
```
alebo, ak nemáte nainštalovaný pdflatex
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "YOUR RESEARCH IDEA" --compile_latex=False
```
-----
## Tipy pre lepšie výskumné výsledky
#### [Tip #1] 📝 Uistite sa, že píšete rozsiahle poznámky! 📝
**Písanie rozsiahlych poznámok je dôležité** pre pomoc vášmu agentovi pochopiť, čo sa snažíte dosiahnuť vo vašom projekte, ako aj akékoľvek preferencie štýlu. Poznámky môžu obsahovať akékoľvek experimenty, ktoré chcete, aby agenti vykonali, poskytovanie API kľúčov, určité grafy alebo figúry, ktoré chcete zahrnúť, alebo čokoľvek, čo chcete, aby agent vedel pri vykonávaní výskumu.
Je to tiež vaša príležitosť informovať agenta, **aké výpočtové zdroje má k dispozícii**, napr. GPU (koľko, aký typ GPU, koľko GB), CPU (koľko jadier, aký typ CPU), obmedzenia úložiska a hardvérové špecifikácie.
Aby ste pridali poznámky, musíte upraviť štruktúru `task_notes_LLM` v súbore `ai_lab_repo.py`. Nižšie je uvedený príklad sady poznámok použitých pre niektoré naše experimenty.
```python
task_notes_LLM = [
{"phases": ["plan formulation"],
"note": f"You should come up with a plan for TWO experiments."},
{"phases": ["plan formulation", "data preparation", "running experiments"],
"note": "Please use gpt-4o-mini for your experiments."},
{"phases": ["running experiments"],
"note": f"Use the following code to inference gpt-4o-mini: \nfrom openai import OpenAI\nos.environ["OPENAI_API_KEY"] = "{api_key}"\nclient = OpenAI()\ncompletion = client.chat.completions.create(\nmodel="gpt-4o-mini-2024-07-18", messages=messages)\nanswer = completion.choices[0].message.content\n"},
{"phases": ["running experiments"],
"note": f"You have access to only gpt-4o-mini using the OpenAI API, please use the following key {api_key} but do not use too many inferences. Do not use openai.ChatCompletion.create or any openai==0.28 commands. Instead use the provided inference code."},
{"phases": ["running experiments"],
"note": "I would recommend using a small dataset (approximately only 100 data points) to run experiments in order to save time. Do not use much more than this unless you have to or are running the final tests."},
{"phases": ["data preparation", "running experiments"],
"note": "You are running on a MacBook laptop. You can use 'mps' with PyTorch"},
{"phases": ["data preparation", "running experiments"],
"note": "Generate figures with very colorful and artistic design."},
]
```
--------
#### [Tip #2] 🚀 Používanie výkonnejších modelov zvyčajne vedie k lepšiemu výskumu 🚀
Pri vykonávaní výskumu môže **výber modelu významne ovplyvniť kvalitu výsledkov**. Výkonnejšie modely majú tendenciu mať vyššiu presnosť, lepšie schopnosti logického uvažovania a lepšiu generáciu správ. Ak výpočtové zdroje umožňujú, uprednostnite používanie pokročilých modelov, ako sú o1-(mini/preview) alebo podobné najmodernejšie veľké jazykové modely.
Avšak, **je dôležité nájsť rovnováhu medzi výkonom a nákladovou efektívnosťou**. Zatiaľ čo výkonnejšie modely môžu priniesť lepšie výsledky, často sú drahšie a časovo náročnejšie na spustenie. Zvážte ich selektívne používanie – napríklad pre kľúčové experimenty alebo konečné analýzy – zatiaľ čo na iteratívne úlohy alebo počiatočné prototypovanie sa spoliehajte na menšie, efektívnejšie modely.
Keď sú zdroje obmedzené, **optimalizujte jemným ladením menších modelov** na vašich špecifických dátach alebo kombinovaním predtrénovaných modelov s úlohovo špecifickými promptami, aby ste dosiahli požadovanú rovnováhu medzi výkonom a výpočtovou efektívnosťou.
-----
#### [Tip #3] ✅ Môžete načítať predchádzajúce uloženia z kontrolných bodov ✅
**Ak stratíte postup, internetové pripojenie alebo ak sa podúloha nepodarí, môžete vždy načítať z predchádzajúceho stavu.** Všetok váš postup je predvolene uložený v premennej `state_saves`, ktorá ukladá každý jednotlivý kontrolný bod. Stačí pri spúšťaní `ai_lab_repo.py` zadať nasledujúce argumenty:
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "YOUR RESEARCH IDEA" --llm-backend "o1-mini" --load-existing True --load-existing-path "save_states/LOAD_PATH"
```
-----
#### [Tip #4] 🈯 Ak pracujete v inom jazyku než angličtine 🈲
Ak spúšťate Agent Laboratory v inom jazyku než v angličtine, nie je problém, stačí zabezpečiť, aby ste agentom poskytli jazykovú vlajku pre vykonávanie výskumu vo vašom preferovanom jazyku. Všimnite si, že sme neštudovali dôkladne spúšťanie Agent Laboratory v iných jazykoch, preto určite hláste akékoľvek problémy, na ktoré narazíte.
Napríklad, ak pracujete v čínštine:
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "YOUR RESEARCH IDEA (in your language)" --llm-backend "o1-mini" --language "中文"
```
----
#### [Tip #5] 🌟 Je tu veľa priestoru na zlepšenie 🌟
Je tu veľa priestoru na zlepšenie tohto kódu, takže ak urobíte zmeny a chcete pomôcť komunite, neváhajte zdieľať zmeny, ktoré ste vykonali! Dúfame, že vám tento nástroj pomôže!
## Reference / Bibtex
```bibtex
@preprint{schmidgall2025AgentLaboratory,
title={Agent Laboratory: Using LLM Agents as Research Assistants},
author={Schmidgall, Samuel and Su, Yusheng and Wang, Ze and Sun, Ximeng and Wu, Jialian and Yu, Xiadong and Liu, Jiang, Liu, Zicheng and Barsoum, Emad},
year={2025}
}
``` | {
"source": "SamuelSchmidgall/AgentLaboratory",
"title": "readme/README-slovak.md",
"url": "https://github.com/SamuelSchmidgall/AgentLaboratory/blob/main/readme/README-slovak.md",
"date": "2025-01-08T02:00:51",
"stars": 3583,
"description": "Agent Laboratory is an end-to-end autonomous research workflow meant to assist you as the human researcher toward implementing your research ideas",
"file_size": 9718
} |
# Agent Laboratory: Using LLM Agents as Research Assistants
<p align="center">
<img src="../media/AgentLabLogo.png" alt="Demostración del flujo de AgentClinic" style="width: 99%;">
</p>
<p align="center">
【<a href="../README.md">English</a> | <a href="../readme/README-chinese.md">中文</a> | <a href="../readme/README-japanese.md">日本語</a> | <a href="../readme/README-korean.md">한국어</a> | <a href="../readme/README-filipino.md">Filipino</a> | <a href="../readme/README-french.md">Français</a> | <a href="../readme/README-slovak.md">Slovenčina</a> | <a href="../readme/README-portugese.md">Português</a> | Español | <a href="../readme/README-turkish.md">Türkçe</a> | <a href="../readme/README-hindi.md">हिंदी</a> | <a href="../readme/README-bengali.md">বাংলা</a> | <a href="../readme/README-vietnamese.md">Tiếng Việt</a> | <a href="../readme/README-russian.md">Русский</a> | <a href="../readme/README-arabic.md">العربية</a> | <a href="../readme/README-farsi.md">فارسی</a> | <a href="../readme/README-italian.md">Italiano</a>】
</p>
<p align="center">
【🌐 <a href="https://agentlaboratory.github.io/">Sitio web</a> | 💻 <a href="https://github.com/SamuelSchmidgall/AgentLaboratory">Software</a> | 🎥 <a href="https://agentlaboratory.github.io/#youtube-video">Video</a> | 📚 <a href="https://agentlaboratory.github.io/#examples-goto">Artículo de ejemplo</a> | 📰 <a href="https://agentlaboratory.github.io/#citation-ref">Citación</a>】
</p>
## 📖 Overview
- **Agent Laboratory** es un flujo de trabajo de investigación autónomo de extremo a extremo diseñado para asistir **a ti** como investigador humano en **implementar tus ideas de investigación**. Agent Laboratory consiste en agentes especializados impulsados por grandes modelos de lenguaje para apoyarte a lo largo de todo el flujo de trabajo de investigación, desde la realización de revisiones bibliográficas y la formulación de planes hasta la ejecución de experimentos y la redacción de informes comprensivos.
- Este sistema no está diseñado para reemplazar tu creatividad, sino para complementarla, permitiéndote enfocarte en la ideación y el pensamiento crítico mientras automatiza tareas repetitivas y que consumen mucho tiempo, como la programación y la documentación. Al acomodar diferentes niveles de recursos computacionales e implicación humana, Agent Laboratory tiene como objetivo acelerar el descubrimiento científico y optimizar tu productividad en la investigación.
<p align="center">
<img src="../media/AgentLab.png" alt="Demostración del flujo de AgentClinic" style="width: 99%;">
</p>
### 🔬 How does Agent Laboratory work?
- Agent Laboratory consta de tres fases principales que guían sistemáticamente el proceso de investigación: (1) Revisión de Literatura, (2) Experimentación y (3) Redacción de Informes. Durante cada fase, agentes especializados impulsados por LLM colaboran para lograr objetivos distintos, integrando herramientas externas como arXiv, Hugging Face, Python y LaTeX para optimizar los resultados. Este flujo de trabajo estructurado comienza con la recolección y análisis independiente de artículos de investigación relevantes, avanza a través de la planificación colaborativa y la preparación de datos, y culmina en la experimentación automatizada y la generación de informes comprensivos. Los detalles sobre roles específicos de los agentes y sus contribuciones a lo largo de estas fases se discuten en el documento.
<p align="center">
<img src="../media/AgentLabWF.png" alt="Demostración del flujo de AgentClinic" style="width: 99%;">
</p>
## 🖥️ Installation
### Python venv option
1. **Clonar el Repositorio de GitHub**: Comienza clonando el repositorio usando el comando:
```bash
git clone [email protected]:SamuelSchmidgall/AgentLaboratory.git
```
2. **Configurar y Activar el Entorno de Python**
```bash
python -m venv venv_agent_lab
```
- Ahora activa este entorno:
```bash
source venv_agent_lab/bin/activate
```
3. **Instalar las librerías requeridas**
```bash
pip install -r requirements.txt
```
4. **Instalar pdflatex [OPCIONAL]**
```bash
sudo apt install pdflatex
```
- Esto permite que las fuentes de LaTeX sean compiladas por los agentes.
- **[IMPORTANTE]** Si no puedes ejecutar este paso debido a la falta de acceso sudo, la compilación de PDF puede desactivarse ejecutando Agent Laboratory configurando la bandera `--compile_latex` a falso: `--compile_latex=False`
5. **¡Ahora ejecuta Agent Laboratory!**
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "YOUR RESEARCH IDEA"
```
o, si no tienes pdflatex instalado
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "YOUR RESEARCH IDEA" --compile_latex=False
```
-----
## Consejos para mejores resultados de investigación
#### [Consejo #1] 📝 ¡Asegúrate de escribir notas extensas! 📝
**Escribir notas extensas es importante** para ayudar a tu agente a comprender lo que buscas lograr en tu proyecto, así como cualquier preferencia de estilo. Las notas pueden incluir cualquier experimento que desees que los agentes realicen, proporcionar claves de API, ciertos gráficos o figuras que quieras incluir, o cualquier cosa que quieras que el agente sepa al realizar la investigación.
Esta también es tu oportunidad para informar al agente **a qué recursos computacionales tiene acceso**, por ejemplo, GPUs (cuántas, qué tipo de GPU, cuántos GB), CPUs (cuántos núcleos, qué tipo de CPUs), limitaciones de almacenamiento y especificaciones de hardware.
Para agregar notas, debes modificar la estructura `task_notes_LLM` dentro de `ai_lab_repo.py`. A continuación se proporciona un ejemplo de conjunto de notas utilizadas en algunos de nuestros experimentos.
```python
task_notes_LLM = [
{"phases": ["plan formulation"],
"note": f"You should come up with a plan for TWO experiments."},
{"phases": ["plan formulation", "data preparation", "running experiments"],
"note": "Please use gpt-4o-mini for your experiments."},
{"phases": ["running experiments"],
"note": f"Use the following code to inference gpt-4o-mini: \nfrom openai import OpenAI\nos.environ["OPENAI_API_KEY"] = "{api_key}"\nclient = OpenAI()\ncompletion = client.chat.completions.create(\nmodel="gpt-4o-mini-2024-07-18", messages=messages)\nanswer = completion.choices[0].message.content\n"},
{"phases": ["running experiments"],
"note": f"You have access to only gpt-4o-mini using the OpenAI API, please use the following key {api_key} but do not use too many inferences. Do not use openai.ChatCompletion.create or any openai==0.28 commands. Instead use the provided inference code."},
{"phases": ["running experiments"],
"note": "I would recommend using a small dataset (approximately only 100 data points) to run experiments in order to save time. Do not use much more than this unless you have to or are running the final tests."},
{"phases": ["data preparation", "running experiments"],
"note": "You are running on a MacBook laptop. You can use 'mps' with PyTorch"},
{"phases": ["data preparation", "running experiments"],
"note": "Generate figures with very colorful and artistic design."},
]
```
--------
#### [Consejo #2] 🚀 ¡Usar modelos más potentes generalmente conduce a una mejor investigación! 🚀
Al realizar investigaciones, **la elección del modelo puede impactar significativamente la calidad de los resultados**. Los modelos más potentes tienden a tener mayor precisión, mejores capacidades de razonamiento y mejor generación de informes. Si los recursos computacionales lo permiten, prioriza el uso de modelos avanzados como o1-(mini/preview) o modelos de lenguaje grandes similares de última generación.
Sin embargo, **es importante equilibrar el rendimiento y la rentabilidad**. Aunque los modelos potentes pueden ofrecer mejores resultados, a menudo son más costosos y requieren más tiempo para ejecutarse. Considera usarlos de manera selectiva, por ejemplo, para experimentos clave o análisis finales, mientras confías en modelos más pequeños y eficientes para tareas iterativas o prototipos iniciales.
Cuando los recursos son limitados, **optimiza ajustando finamente modelos más pequeños** en tu conjunto de datos específico o combinando modelos preentrenados con prompts específicos para tareas para lograr el equilibrio deseado entre rendimiento y eficiencia computacional.
-----
#### [Consejo #3] ✅ Puedes cargar guardados anteriores desde puntos de control ✅
**Si pierdes progreso, la conexión a internet o si una subtarea falla, siempre puedes cargar desde un estado anterior.** Todo tu progreso se guarda por defecto en la variable `state_saves`, que almacena cada punto de control individual. Simplemente pasa los siguientes argumentos al ejecutar `ai_lab_repo.py`
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "YOUR RESEARCH IDEA" --llm-backend "o1-mini" --load-existing True --load-existing-path "save_states/LOAD_PATH"
```
-----
#### [Consejo #4] 🈯 Si estás ejecutando en un idioma que no sea inglés 🈲
Si estás ejecutando Agent Laboratory en un idioma que no sea inglés, no hay problema, solo asegúrate de proporcionar una bandera de idioma a los agentes para realizar la investigación en tu idioma preferido. Ten en cuenta que no hemos estudiado extensivamente la ejecución de Agent Laboratory en otros idiomas, así que asegúrate de reportar cualquier problema que encuentres.
Por ejemplo, si estás ejecutando en chino:
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "YOUR RESEARCH IDEA (in your language)" --llm-backend "o1-mini" --language "中文"
```
----
#### [Consejo #5] 🌟 Hay mucho margen para mejorar 🌟
Hay mucho margen para mejorar esta base de código, así que si terminas haciendo cambios y quieres ayudar a la comunidad, ¡no dudes en compartir los cambios que has realizado! ¡Esperamos que esta herramienta te sea de ayuda!
## Referencia / Bibtex
```bibtex
@preprint{schmidgall2025AgentLaboratory,
title={Agent Laboratory: Using LLM Agents as Research Assistants},
author={Schmidgall, Samuel and Su, Yusheng and Wang, Ze and Sun, Ximeng and Wu, Jialian and Yu, Xiadong and Liu, Jiang, Liu, Zicheng and Barsoum, Emad},
year={2025}
}
``` | {
"source": "SamuelSchmidgall/AgentLaboratory",
"title": "readme/README-spanish.md",
"url": "https://github.com/SamuelSchmidgall/AgentLaboratory/blob/main/readme/README-spanish.md",
"date": "2025-01-08T02:00:51",
"stars": 3583,
"description": "Agent Laboratory is an end-to-end autonomous research workflow meant to assist you as the human researcher toward implementing your research ideas",
"file_size": 10393
} |
# Agent Laboratuvarı: LLM Ajanlarını Araştırma Asistanı Olarak Kullanma
<p align="center">
<img src="../media/AgentLabLogo.png" alt="Demonstration of the flow of AgentClinic" style="width: 99%;">
</p>
<p align="center">
【<a href="../README.md">English</a> | <a href="../readme/README-chinese.md">中文</a> | <a href="../readme/README-japanese.md">日本語</a> | <a href="../readme/README-korean.md">한국어</a> | <a href="../readme/README-filipino.md">Filipino</a> | <a href="../readme/README-french.md">Français</a> | <a href="../readme/README-slovak.md">Slovenčina</a> | <a href="../readme/README-portugese.md">Português</a> | <a href="../readme/README-spanish.md">Español</a> | Türkçe | <a href="../readme/README-hindi.md">हिंदी</a> | <a href="../readme/README-bengali.md">বাংলা</a> | <a href="../readme/README-vietnamese.md">Tiếng Việt</a> | <a href="../readme/README-russian.md">Русский</a> | <a href="../readme/README-arabic.md">العربية</a> | <a href="../readme/README-farsi.md">فارسی</a> | <a href="../readme/README-italian.md">Italiano</a>】
</p>
<p align="center">
【🌐 <a href="https://agentlaboratory.github.io/">Website</a> | 💻 <a href="https://github.com/SamuelSchmidgall/AgentLaboratory">Software</a> | 🎥 <a href="https://agentlaboratory.github.io/#youtube-video">Video</a> | 📚 <a href="https://agentlaboratory.github.io/#examples-goto">Example Paper</a> | 📰 <a href="https://agentlaboratory.github.io/#citation-ref">Citation</a>】
</p>
## 📖 Genel Bakış
- **Agent Laboratuvarı**, **araştırma fikirlerinizi uygulamanıza** yardımcı olmak amacıyla **siz** insan araştırmacıyı desteklemek için tasarlanmış uçtan uca otonom bir araştırma iş akışıdır. Agent Laboratuvarı, literatür taramaları yapmaktan planlar oluşturmaya, deneyler yürütmekten kapsamlı raporlar yazmaya kadar tüm araştırma süreci boyunca sizi desteklemek için büyük dil modelleriyle desteklenen uzman ajanlardan oluşur.
- Bu sistem, yaratıcılığınızı yerine koymak için değil, onu tamamlamak için tasarlanmıştır; böylece kodlama ve dokümantasyon gibi tekrarlayan ve zaman alıcı görevleri otomatikleştirirken, fikir üretimi ve eleştirel düşünmeye odaklanabilirsiniz. Farklı düzeylerde hesaplama kaynakları ve insan katılımını karşılayarak, Agent Laboratuvarı bilimsel keşfi hızlandırmayı ve araştırma verimliliğinizi optimize etmeyi amaçlamaktadır.
<p align="center">
<img src="../media/AgentLab.png" alt="Demonstration of the flow of AgentClinic" style="width: 99%;">
</p>
### 🔬 Agent Laboratuvarı Nasıl Çalışır?
- Agent Laboratuvarı, araştırma sürecini sistematik olarak yönlendiren üç ana aşamadan oluşur: (1) Literatür Taraması, (2) Deney Yapma ve (3) Rapor Yazımı. Her aşamada, LLM'ler tarafından yönlendirilen uzman ajanlar, arXiv, Hugging Face, Python ve LaTeX gibi dış araçları entegre ederek farklı hedeflere ulaşmak için iş birliği yapar ve sonuçları optimize eder. Bu yapılandırılmış iş akışı, ilgili araştırma makalelerinin bağımsız olarak toplanması ve analiz edilmesiyle başlar, ortak planlama ve veri hazırlama aşamalarından geçer ve otomatik deney yapma ile kapsamlı rapor oluşturma ile sona erer. Bu aşamalarda belirli ajan rollerinin ve katkılarının detayları makalede tartışılmaktadır.
<p align="center">
<img src="../media/AgentLabWF.png" alt="Demonstration of the flow of AgentClinic" style="width: 99%;">
</p>
## 🖥️ Kurulum
### Python venv seçeneği
1. **GitHub Deposu Klonlayın**: Depoyu aşağıdaki komutu kullanarak klonlayarak başlayın:
```bash
git clone [email protected]:SamuelSchmidgall/AgentLaboratory.git
```
2. **Python Ortamını Kurun ve Aktif Hale Getirin**
```bash
python -m venv venv_agent_lab
```
- Şimdi bu ortamı etkinleştirin:
```bash
source venv_agent_lab/bin/activate
```
3. **Gerekli Kütüphaneleri Yükleyin**
```bash
pip install -r requirements.txt
```
4. **pdflatex'i Yükleyin [SEÇENEKSEL]**
```bash
sudo apt install pdflatex
```
- Bu, ajanların LaTeX kaynaklarını derleyebilmesini sağlar.
- **[ÖNEMLİ]** Bu adımı sudo erişiminiz yoksa çalıştıramıyorsanız, Agent Laboratuvarı'nı çalıştırırken --compile_latex bayrağını false olarak ayarlayarak PDF derlemeyi kapatabilirsiniz: `--compile_latex=False`
5. **Şimdi Agent Laboratuvarı'nı Çalıştırın!**
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "YOUR RESEARCH IDEA"
```
veya, pdflatex yüklü değilse
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "YOUR RESEARCH IDEA" --compile_latex=False
```
-----
## Daha İyi Araştırma Sonuçları için İpuçları
#### [İpucu #1] 📝 Kapsamlı Notlar Yazdığınızdan Emin Olun! 📝
**Kapsamlı notlar yazmak**, ajanın projenizde neyi başarmak istediğinizi ve herhangi bir stil tercihlerinizi anlamasına yardımcı olduğu için önemlidir. Notlar, ajanların gerçekleştirmesini istediğiniz deneyler, API anahtarları sağlamak, dahil edilmesini istediğiniz belirli grafikler veya figürler veya araştırma yaparken ajanın bilmesi gereken her şey gibi unsurları içerebilir.
Ayrıca, ajana **erişebileceği hesaplama kaynaklarını** bildirmeniz için bir fırsattır, örneğin GPU'lar (kaç tane, hangi tür GPU, kaç GB), CPU'lar (kaç çekirdek, hangi tür CPU'lar), depolama sınırlamaları ve donanım özellikleri.
Not eklemek için, ai_lab_repo.py içindeki task_notes_LLM yapısını değiştirmeniz gerekir. Aşağıda, bazı deneylerimizde kullanılan örnek notlar verilmiştir.
```python
task_notes_LLM = [
{"phases": ["plan formulation"],
"note": f"You should come up with a plan for TWO experiments."},
{"phases": ["plan formulation", "data preparation", "running experiments"],
"note": "Please use gpt-4o-mini for your experiments."},
{"phases": ["running experiments"],
"note": f"Use the following code to inference gpt-4o-mini: \nfrom openai import OpenAI\nos.environ["OPENAI_API_KEY"] = "{api_key}"\nclient = OpenAI()\ncompletion = client.chat.completions.create(\nmodel="gpt-4o-mini-2024-07-18", messages=messages)\nanswer = completion.choices[0].message.content\n"},
{"phases": ["running experiments"],
"note": f"You have access to only gpt-4o-mini using the OpenAI API, please use the following key {api_key} but do not use too many inferences. Do not use openai.ChatCompletion.create or any openai==0.28 commands. Instead use the provided inference code."},
{"phases": ["running experiments"],
"note": "I would recommend using a small dataset (approximately only 100 data points) to run experiments in order to save time. Do not use much more than this unless you have to or are running the final tests."},
{"phases": ["data preparation", "running experiments"],
"note": "You are running on a MacBook laptop. You can use 'mps' with PyTorch"},
{"phases": ["data preparation", "running experiments"],
"note": "Generate figures with very colorful and artistic design."},
]
```
--------
#### [İpucu #2] 🚀 Daha Güçlü Modeller Kullanmak Genellikle Daha İyi Araştırma Sonuçlarına Yol Açar 🚀
Araştırma yaparken, **model seçimi sonuçların kalitesi üzerinde önemli bir etkiye sahip olabilir**. Daha güçlü modeller genellikle daha yüksek doğruluk, daha iyi akıl yürütme yetenekleri ve daha iyi rapor oluşturma özelliklerine sahiptir. Hesaplama kaynaklarınız izin veriyorsa, o1-(mini/preview) gibi gelişmiş modellerin veya benzeri en son büyük dil modellerinin kullanımını önceliklendirin.
Ancak, **performans ve maliyet etkinliği arasında denge kurmak önemlidir**. Güçlü modeller daha iyi sonuçlar verebilirken, genellikle çalıştırmaları daha pahalı ve zaman alıcıdır. Bunları seçici olarak kullanmayı düşünün—örneğin, ana deneyler veya son analizler için—iteratif görevler veya ilk prototipler için daha küçük, daha verimli modelleri kullanmaya devam edin.
Kaynaklar sınırlı olduğunda, **daha küçük modelleri özel veri setinizde ince ayar yaparak veya görev odaklı istemlerle önceden eğitilmiş modelleri birleştirerek performans ve hesaplama verimliliği arasında istenen dengeyi sağlayın**.
-----
#### [İpucu #3] ✅ Önceki Kontrol Noktalarından Kaydedilenleri Yükleyebilirsiniz ✅
**İlerlemenizi kaybederseniz, internet bağlantınız kesilirse veya bir alt görev başarısız olursa, her zaman önceki bir durumdan yükleme yapabilirsiniz.** Tüm ilerlemeniz varsayılan olarak her bir kontrol noktasını saklayan state_saves değişkeninde kaydedilir. ai_lab_repo.py çalıştırılırken aşağıdaki argümanları geçmeniz yeterlidir:
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "YOUR RESEARCH IDEA" --llm-backend "o1-mini" --load-existing True --load-existing-path "save_states/LOAD_PATH"
```
-----
#### [İpucu #4] 🈯 İngilizce Dışında Bir Dil Kullanıyorsanız 🈲
Agent Laboratuvarı'nı İngilizce dışında bir dilde çalıştırıyorsanız sorun yok, sadece ajanlara araştırmayı tercih ettiğiniz dilde gerçekleştirmeleri için bir dil bayrağı sağlamanız yeterlidir. Agent Laboratuvarı'nı diğer dillerde çalıştırmayı kapsamlı bir şekilde incelemediğimizi unutmayın, bu yüzden karşılaştığınız herhangi bir problemi bildirdiğinizden emin olun.
Örneğin, Çincede çalıştırıyorsanız:
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "YOUR RESEARCH IDEA (in your language)" --llm-backend "o1-mini" --language "中文"
```
----
#### [İpucu #5] 🌟 Geliştirme İçin Çok Fazla Alan Var 🌟
Bu kod tabanını geliştirmek için çok fazla alan var, bu yüzden değişiklik yaparsanız ve topluluğa yardımcı olmak isterseniz, yaptığınız değişiklikleri paylaşmaktan çekinmeyin! Umarız bu araç size yardımcı olur!
## Referans / Bibtex
```bibtex
@preprint{schmidgall2025AgentLaboratory,
title={Agent Laboratory: Using LLM Agents as Research Assistants},
author={Schmidgall, Samuel and Su, Yusheng and Wang, Ze and Sun, Ximeng and Wu, Jialian and Yu, Xiadong and Liu, Jiang, Liu, Zicheng and Barsoum, Emad},
year={2025}
}
``` | {
"source": "SamuelSchmidgall/AgentLaboratory",
"title": "readme/README-turkish.md",
"url": "https://github.com/SamuelSchmidgall/AgentLaboratory/blob/main/readme/README-turkish.md",
"date": "2025-01-08T02:00:51",
"stars": 3583,
"description": "Agent Laboratory is an end-to-end autonomous research workflow meant to assist you as the human researcher toward implementing your research ideas",
"file_size": 9886
} |
# Agent Laboratory: Sử dụng Đại Diện LLM làm Trợ Lý Nghiên Cứu
<p align="center">
<img src="../media/AgentLabLogo.png" alt="Demonstration of the flow of AgentClinic" style="width: 99%;">
</p>
<p align="center">
【<a href="../README.md">English</a> | <a href="../readme/README-chinese.md">中文</a> | <a href="../readme/README-japanese.md">日本語</a> | <a href="../readme/README-korean.md">한국어</a> | <a href="../readme/README-filipino.md">Filipino</a> | <a href="../readme/README-french.md">Français</a> | <a href="../readme/README-slovak.md">Slovenčina</a> | <a href="../readme/README-portugese.md">Português</a> | <a href="../readme/README-spanish.md">Español</a> | <a href="../readme/README-turkish.md">Türkçe</a> | <a href="../readme/README-hindi.md">हिंदी</a> | <a href="../readme/README-bengali.md">বাংলা</a> | Tiếng Việt | <a href="../readme/README-russian.md">Русский</a> | <a href="../readme/README-arabic.md">العربية</a> | <a href="../readme/README-farsi.md">فارسی</a> | <a href="../readme/README-italian.md">Italiano</a>】
</p>
<p align="center">
【🌐 <a href="https://agentlaboratory.github.io/">Website</a> | 💻 <a href="https://github.com/SamuelSchmidgall/AgentLaboratory">Software</a> | 🎥 <a href="https://agentlaboratory.github.io/#youtube-video">Video</a> | 📚 <a href="https://agentlaboratory.github.io/#examples-goto">Example Paper</a> | 📰 <a href="https://agentlaboratory.github.io/#citation-ref">Citation</a>】
</p>
## 📖 Tổng Quan
- **Agent Laboratory** là một quy trình nghiên cứu tự động từ đầu đến cuối, nhằm hỗ trợ **bạn** với tư cách là nhà nghiên cứu con người trong việc **triển khai các ý tưởng nghiên cứu của bạn**. Agent Laboratory bao gồm các đại diện chuyên biệt được điều khiển bởi các mô hình ngôn ngữ lớn để hỗ trợ bạn trong toàn bộ quy trình nghiên cứu—từ việc thực hiện đánh giá tài liệu và xây dựng kế hoạch đến thực hiện các thí nghiệm và viết các báo cáo toàn diện.
- Hệ thống này không được thiết kế để thay thế sự sáng tạo của bạn mà để bổ sung cho nó, cho phép bạn tập trung vào ý tưởng và tư duy phản biện trong khi tự động hóa các nhiệm vụ lặp đi lặp lại và tốn thời gian như mã hóa và tài liệu hóa. Bằng cách đáp ứng các mức độ tài nguyên tính toán và sự tham gia của con người khác nhau, Agent Laboratory nhằm mục tiêu tăng tốc khám phá khoa học và tối ưu hóa năng suất nghiên cứu của bạn.
<p align="center">
<img src="../media/AgentLab.png" alt="Demonstration of the flow of AgentClinic" style="width: 99%;">
</p>
### 🔬 Agent Laboratory hoạt động như thế nào?
- Agent Laboratory bao gồm ba giai đoạn chính hướng dẫn hệ thống quy trình nghiên cứu một cách có hệ thống: (1) Đánh giá Tài liệu, (2) Thực nghiệm, và (3) Viết Báo cáo. Trong mỗi giai đoạn, các đại diện chuyên biệt được điều khiển bởi LLM hợp tác để đạt được các mục tiêu riêng biệt, tích hợp các công cụ bên ngoài như arXiv, Hugging Face, Python, và LaTeX để tối ưu hóa kết quả. Quy trình làm việc có cấu trúc này bắt đầu với việc thu thập và phân tích độc lập các bài báo nghiên cứu liên quan, tiến tới lập kế hoạch hợp tác và chuẩn bị dữ liệu, và kết thúc với việc thực hiện các thí nghiệm tự động và tạo báo cáo toàn diện. Chi tiết về các vai trò cụ thể của đại diện và đóng góp của họ trong các giai đoạn này được thảo luận trong bài báo.
<p align="center">
<img src="../media/AgentLabWF.png" alt="Demonstration of the flow of AgentClinic" style="width: 99%;">
</p>
## 🖥️ Cài Đặt
### Tùy chọn môi trường ảo Python
1. **Nhân bản kho lưu trữ GitHub**: Bắt đầu bằng cách nhân bản kho lưu trữ bằng lệnh:
```bash
git clone [email protected]:SamuelSchmidgall/AgentLaboratory.git
```
2. **Thiết lập và Kích hoạt Môi trường Python**
```bash
python -m venv venv_agent_lab
```
- Bây giờ kích hoạt môi trường này:
```bash
source venv_agent_lab/bin/activate
```
3. **Cài đặt các thư viện cần thiết**
```bash
pip install -r requirements.txt
```
4. **Cài đặt pdflatex [TUÝ CHỌN]**
```bash
sudo apt install pdflatex
```
- Điều này cho phép mã nguồn latex được biên dịch bởi các đại diện.
- **[QUAN TRỌNG]** Nếu bước này không thể chạy do không có quyền sudo, việc biên dịch pdf có thể được tắt bằng cách chạy Agent Laboratory với cờ --compile_latex đặt thành false: --compile_latex=False
5. **Bây giờ chạy Agent Laboratory!**
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "YOUR RESEARCH IDEA"
```
hoặc, nếu bạn không cài đặt pdflatex
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "YOUR RESEARCH IDEA" --compile_latex=False
```
-----
## Mẹo để đạt được kết quả nghiên cứu tốt hơn
#### [Mẹo #1] 📝 Hãy chắc chắn ghi chép kỹ lưỡng! 📝
**Việc ghi chép kỹ lưỡng là quan trọng** để giúp đại diện của bạn hiểu bạn đang muốn đạt được điều gì trong dự án của mình, cũng như bất kỳ sở thích về phong cách nào. Ghi chú có thể bao gồm bất kỳ thí nghiệm nào bạn muốn các đại diện thực hiện, cung cấp các khóa API, các biểu đồ hoặc hình vẽ cụ thể bạn muốn bao gồm, hoặc bất cứ điều gì bạn muốn đại diện biết khi thực hiện nghiên cứu.
Đây cũng là cơ hội của bạn để cho đại diện biết **các tài nguyên tính toán mà nó có quyền truy cập**, ví dụ: GPU (số lượng, loại GPU, số GB), CPU (số lượng lõi, loại CPU), hạn chế về lưu trữ, và các thông số phần cứng.
Để thêm ghi chú, bạn phải sửa cấu trúc task_notes_LLM bên trong ai_lab_repo.py. Dưới đây là một ví dụ về bộ ghi chú được sử dụng cho một số thí nghiệm của chúng tôi.
```python
task_notes_LLM = [
{"phases": ["plan formulation"],
"note": f"You should come up with a plan for TWO experiments."},
{"phases": ["plan formulation", "data preparation", "running experiments"],
"note": "Please use gpt-4o-mini for your experiments."},
{"phases": ["running experiments"],
"note": f"Use the following code to inference gpt-4o-mini: \nfrom openai import OpenAI\nos.environ["OPENAI_API_KEY"] = "{api_key}"\nclient = OpenAI()\ncompletion = client.chat.completions.create(\nmodel="gpt-4o-mini-2024-07-18", messages=messages)\nanswer = completion.choices[0].message.content\n"},
{"phases": ["running experiments"],
"note": f"You have access to only gpt-4o-mini using the OpenAI API, please use the following key {api_key} but do not use too many inferences. Do not use openai.ChatCompletion.create or any openai==0.28 commands. Instead use the provided inference code."},
{"phases": ["running experiments"],
"note": "I would recommend using a small dataset (approximately only 100 data points) to run experiments in order to save time. Do not use much more than this unless you have to or are running the final tests."},
{"phases": ["data preparation", "running experiments"],
"note": "You are running on a MacBook laptop. You can use 'mps' with PyTorch"},
{"phases": ["data preparation", "running experiments"],
"note": "Generate figures with very colorful and artistic design."},
]
```
--------
#### [Mẹo #2] 🚀 Sử dụng các mô hình mạnh mẽ hơn thường dẫn đến nghiên cứu tốt hơn 🚀
Khi tiến hành nghiên cứu, **lựa chọn mô hình có thể ảnh hưởng đáng kể đến chất lượng kết quả**. Các mô hình mạnh mẽ hơn thường có độ chính xác cao hơn, khả năng lý luận tốt hơn và khả năng tạo báo cáo tốt hơn. Nếu tài nguyên tính toán cho phép, hãy ưu tiên sử dụng các mô hình tiên tiến như o1-(mini/preview) hoặc các mô hình ngôn ngữ lớn tiên tiến tương tự.
Tuy nhiên, **quan trọng là phải cân bằng giữa hiệu suất và chi phí hiệu quả**. Trong khi các mô hình mạnh mẽ có thể mang lại kết quả tốt hơn, chúng thường đắt hơn và tốn thời gian chạy. Hãy cân nhắc sử dụng chúng một cách chọn lọc—ví dụ, cho các thí nghiệm chính hoặc phân tích cuối cùng—trong khi dựa vào các mô hình nhỏ hơn, hiệu quả hơn cho các nhiệm vụ lặp đi lặp lại hoặc phát mẫu ban đầu.
Khi tài nguyên hạn chế, **tối ưu hóa bằng cách tinh chỉnh các mô hình nhỏ hơn** trên bộ dữ liệu cụ thể của bạn hoặc kết hợp các mô hình đã được huấn luyện trước với các gợi ý cụ thể cho nhiệm vụ để đạt được sự cân bằng mong muốn giữa hiệu suất và hiệu quả tính toán.
-----
#### [Mẹo #3] ✅ Bạn có thể tải lại các lưu trạng thái trước từ các điểm kiểm tra ✅
**Nếu bạn mất tiến độ, kết nối internet, hoặc nếu một nhiệm vụ phụ thất bại, bạn luôn có thể tải lại từ trạng thái trước đó.** Tất cả tiến độ của bạn được lưu mặc định trong biến state_saves, lưu trữ từng điểm kiểm tra riêng lẻ. Chỉ cần truyền các tham số sau khi chạy ai_lab_repo.py
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "YOUR RESEARCH IDEA" --llm-backend "o1-mini" --load-existing True --load-existing-path "save_states/LOAD_PATH"
```
-----
#### [Mẹo #4] 🈯 Nếu bạn đang chạy bằng ngôn ngữ khác tiếng Anh 🈲
Nếu bạn đang chạy Agent Laboratory bằng ngôn ngữ khác tiếng Anh, không vấn đề gì, chỉ cần đảm bảo cung cấp cờ ngôn ngữ cho các đại diện để thực hiện nghiên cứu bằng ngôn ngữ bạn mong muốn. Lưu ý rằng chúng tôi chưa nghiên cứu kỹ việc chạy Agent Laboratory bằng các ngôn ngữ khác, vì vậy hãy chắc chắn báo cáo bất kỳ vấn đề nào bạn gặp phải.
Ví dụ, nếu bạn đang chạy bằng tiếng Trung:
```bash
python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "YOUR RESEARCH IDEA (in your language)" --llm-backend "o1-mini" --language "中文"
```
----
#### [Mẹo #5] 🌟 Có rất nhiều cơ hội để cải thiện 🌟
Có rất nhiều cơ hội để cải thiện cơ sở mã này, vì vậy nếu bạn cuối cùng thay đổi và muốn giúp cộng đồng, hãy cảm thấy tự do chia sẻ các thay đổi mà bạn đã thực hiện! Chúng tôi hy vọng công cụ này sẽ giúp bạn!
## Tài liệu Tham khảo / Bibtex
```bibtex
@preprint{schmidgall2025AgentLaboratory,
title={Agent Laboratory: Using LLM Agents as Research Assistants},
author={Schmidgall, Samuel and Su, Yusheng and Wang, Ze and Sun, Ximeng and Wu, Jialian and Yu, Xiadong and Liu, Jiang, Liu, Zicheng and Barsoum, Emad},
year={2025}
}
``` | {
"source": "SamuelSchmidgall/AgentLaboratory",
"title": "readme/README-vietnamese.md",
"url": "https://github.com/SamuelSchmidgall/AgentLaboratory/blob/main/readme/README-vietnamese.md",
"date": "2025-01-08T02:00:51",
"stars": 3583,
"description": "Agent Laboratory is an end-to-end autonomous research workflow meant to assist you as the human researcher toward implementing your research ideas",
"file_size": 9911
} |
<h1 align='center'>Hallo2: Long-Duration and High-Resolution Audio-driven Portrait Image Animation</h1>
<div align='center'>
<a href='https://github.com/cuijh26' target='_blank'>Jiahao Cui</a><sup>1*</sup> 
<a href='https://github.com/crystallee-ai' target='_blank'>Hui Li</a><sup>1*</sup> 
<a href='https://yoyo000.github.io/' target='_blank'>Yao Yao</a><sup>3</sup> 
<a href='http://zhuhao.cc/home/' target='_blank'>Hao Zhu</a><sup>3</sup> 
<a href='https://github.com/NinoNeumann' target='_blank'>Hanlin Shang</a><sup>1</sup> 
<a href='https://github.com/Kaihui-Cheng' target='_blank'>Kaihui Cheng</a><sup>1</sup> 
<a href='' target='_blank'>Hang Zhou</a><sup>2</sup> 
</div>
<div align='center'>
<a href='https://sites.google.com/site/zhusiyucs/home' target='_blank'>Siyu Zhu</a><sup>1✉️</sup> 
<a href='https://jingdongwang2017.github.io/' target='_blank'>Jingdong Wang</a><sup>2</sup> 
</div>
<div align='center'>
<sup>1</sup>Fudan University  <sup>2</sup>Baidu Inc  <sup>3</sup>Nanjing University
</div>
<div align='Center'>
<i><strong><a href='https://iclr.cc/Conferences/2025' target='_blank'>ICLR 2025</a></strong></i>
</div>
<br>
<div align='center'>
<a href='https://github.com/fudan-generative-vision/hallo2'><img src='https://img.shields.io/github/stars/fudan-generative-vision/hallo2?style=social'></a>
<a href='https://fudan-generative-vision.github.io/hallo2/#/'><img src='https://img.shields.io/badge/Project-HomePage-Green'></a>
<a href='https://arxiv.org/abs/2410.07718'><img src='https://img.shields.io/badge/Paper-Arxiv-red'></a>
<a href='https://huggingface.co/fudan-generative-ai/hallo2'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20HuggingFace-Model-yellow'></a>
<a href='https://openbayes.com/console/public/tutorials/8KOlYWsdiY4'><img src='https://img.shields.io/badge/Demo-OpenBayes贝式计算-orange'></a>
<a href='assets/wechat.jpeg'><img src='https://badges.aleen42.com/src/wechat.svg'></a>
</div>
<br>
## 📸 Showcase
<table class="center">
<tr>
<td style="text-align: center"><b>Tailor Swift Speech @ NYU (4K, 23 minutes)</b></td>
<td style="text-align: center"><b>Johan Rockstrom Speech @ TED (4K, 18 minutes)</b></td>
</tr>
<tr>
<td style="text-align: center"><a target="_blank" href="https://cdn.aondata.work/hallo2/videos/showcases/TailorSpeech.mp4"><img src="https://cdn.aondata.work/hallo2/videos/showcases/gifs/TailorSpeechGIF.gif"></a></td>
<td style="text-align: center"><a target="_blank" href="https://cdn.aondata.work/hallo2/videos/showcases/TEDSpeech.mp4"><img src="https://cdn.aondata.work/hallo2/videos/showcases/gifs/TEDSpeechGIF.gif"></a></td>
</tr>
<tr>
<td style="text-align: center"><b>Churchill's Iron Curtain Speech (4K, 4 minutes)</b></td>
<td style="text-align: center"><b>An LLM Course from Stanford (4K, up to 1 hour)</b></td>
</tr>
<tr>
<td style="text-align: center"><a target="_blank" href="https://cdn.aondata.work/hallo2/videos/showcases/DarkestHour.mp4"><img src="https://cdn.aondata.work/hallo2/videos/showcases/gifs/DarkestHour.gif"></a></td>
<td style="text-align: center"><a target="_blank" href="https://cdn.aondata.work/hallo2/videos/showcases/LLMCourse.mp4"><img src="https://cdn.aondata.work/hallo2/videos/showcases/gifs/LLMCourseGIF.gif"></a></td>
</tr>
</table>
Visit our [project page](https://fudan-generative-vision.github.io/hallo2/#/) to view more cases.
## 📰 News
- **`2025/01/23`**: 🎉🎉🎉 Our paper has been accepted to [ICLR 2025](https://iclr.cc/Conferences/2025).
- **`2024/10/16`**: ✨✨✨ Source code and pretrained weights released.
- **`2024/10/10`**: 🎉🎉🎉 Paper submitted on [Arxiv](https://arxiv.org/abs/2410.07718).
## 📅️ Roadmap
| Status | Milestone | ETA |
| :----: | :------------------------------------------------------------------------------------------- | :--------: |
| ✅ | **[Paper submitted on Arixiv](https://arxiv.org/abs/2410.07718)** | 2024-10-10 |
| ✅ | **[Source code meet everyone on GitHub](https://github.com/fudan-generative-vision/hallo2)** | 2024-10-16 |
| 🚀 | **[Accelerate performance on inference]()** | TBD |
## 🔧️ Framework

## ⚙️ Installation
- System requirement: Ubuntu 20.04/Ubuntu 22.04, Cuda 11.8
- Tested GPUs: A100
Download the codes:
```bash
git clone https://github.com/fudan-generative-vision/hallo2
cd hallo2
```
Create conda environment:
```bash
conda create -n hallo python=3.10
conda activate hallo
```
Install packages with `pip`
```bash
pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 --index-url https://download.pytorch.org/whl/cu118
pip install -r requirements.txt
```
Besides, ffmpeg is also needed:
```bash
apt-get install ffmpeg
```
### 📥 Download Pretrained Models
You can easily get all pretrained models required by inference from our [HuggingFace repo](https://huggingface.co/fudan-generative-ai/hallo2).
Using `huggingface-cli` to download the models:
```shell
cd $ProjectRootDir
pip install huggingface-cli
huggingface-cli download fudan-generative-ai/hallo2 --local-dir ./pretrained_models
```
Or you can download them separately from their source repo:
- [hallo](https://huggingface.co/fudan-generative-ai/hallo2/tree/main/hallo2): Our checkpoints consist of denoising UNet, face locator, image & audio proj.
- [audio_separator](https://huggingface.co/huangjackson/Kim_Vocal_2): Kim*Vocal_2 MDX-Net vocal removal model. (\_Thanks to [KimberleyJensen](https://github.com/KimberleyJensen)*)
- [insightface](https://github.com/deepinsight/insightface/tree/master/python-package#model-zoo): 2D and 3D Face Analysis placed into `pretrained_models/face_analysis/models/`. (_Thanks to deepinsight_)
- [face landmarker](https://storage.googleapis.com/mediapipe-models/face_landmarker/face_landmarker/float16/1/face_landmarker.task): Face detection & mesh model from [mediapipe](https://ai.google.dev/edge/mediapipe/solutions/vision/face_landmarker#models) placed into `pretrained_models/face_analysis/models`.
- [motion module](https://github.com/guoyww/AnimateDiff/blob/main/README.md#202309-animatediff-v2): motion module from [AnimateDiff](https://github.com/guoyww/AnimateDiff). (_Thanks to [guoyww](https://github.com/guoyww)_).
- [sd-vae-ft-mse](https://huggingface.co/stabilityai/sd-vae-ft-mse): Weights are intended to be used with the diffusers library. (_Thanks to [stablilityai](https://huggingface.co/stabilityai)_)
- [StableDiffusion V1.5](https://huggingface.co/runwayml/stable-diffusion-v1-5): Initialized and fine-tuned from Stable-Diffusion-v1-2. (_Thanks to [runwayml](https://huggingface.co/runwayml)_)
- [wav2vec](https://huggingface.co/facebook/wav2vec2-base-960h): wav audio to vector model from [Facebook](https://huggingface.co/facebook/wav2vec2-base-960h).
- [facelib](https://github.com/sczhou/CodeFormer/releases/tag/v0.1.0): pretrained face parse models
- [realesrgan](https://github.com/sczhou/CodeFormer/releases/download/v0.1.0/RealESRGAN_x2plus.pth): background upsample model
- [CodeFormer](https://github.com/sczhou/CodeFormer/releases/download/v0.1.0): pretrained [Codeformer](https://github.com/sczhou/CodeFormer) model, it's optional to download it, only if you want to train our video super-resolution model from scratch
Finally, these pretrained models should be organized as follows:
```text
./pretrained_models/
|-- audio_separator/
| |-- download_checks.json
| |-- mdx_model_data.json
| |-- vr_model_data.json
| `-- Kim_Vocal_2.onnx
|-- CodeFormer/
| |-- codeformer.pth
| `-- vqgan_code1024.pth
|-- face_analysis/
| `-- models/
| |-- face_landmarker_v2_with_blendshapes.task # face landmarker model from mediapipe
| |-- 1k3d68.onnx
| |-- 2d106det.onnx
| |-- genderage.onnx
| |-- glintr100.onnx
| `-- scrfd_10g_bnkps.onnx
|-- facelib
| |-- detection_mobilenet0.25_Final.pth
| |-- detection_Resnet50_Final.pth
| |-- parsing_parsenet.pth
| |-- yolov5l-face.pth
| `-- yolov5n-face.pth
|-- hallo2
| |-- net_g.pth
| `-- net.pth
|-- motion_module/
| `-- mm_sd_v15_v2.ckpt
|-- realesrgan
| `-- RealESRGAN_x2plus.pth
|-- sd-vae-ft-mse/
| |-- config.json
| `-- diffusion_pytorch_model.safetensors
|-- stable-diffusion-v1-5/
| `-- unet/
| |-- config.json
| `-- diffusion_pytorch_model.safetensors
`-- wav2vec/
`-- wav2vec2-base-960h/
|-- config.json
|-- feature_extractor_config.json
|-- model.safetensors
|-- preprocessor_config.json
|-- special_tokens_map.json
|-- tokenizer_config.json
`-- vocab.json
```
### 🛠️ Prepare Inference Data
Hallo has a few simple requirements for input data:
For the source image:
1. It should be cropped into squares.
2. The face should be the main focus, making up 50%-70% of the image.
3. The face should be facing forward, with a rotation angle of less than 30° (no side profiles).
For the driving audio:
1. It must be in WAV format.
2. It must be in English since our training datasets are only in this language.
3. Ensure the vocals are clear; background music is acceptable.
We have provided [some samples](examples/) for your reference.
### 🎮 Run Inference
#### Long-Duration animation
Simply to run the `scripts/inference_long.py` and change `source_image`, `driving_audio` and `save_path` in the config file:
```bash
python scripts/inference_long.py --config ./configs/inference/long.yaml
```
Animation results will be saved at `save_path`. You can find more examples for inference at [examples folder](https://github.com/fudan-generative-vision/hallo2/tree/main/examples).
For more options:
```shell
usage: inference_long.py [-h] [-c CONFIG] [--source_image SOURCE_IMAGE] [--driving_audio DRIVING_AUDIO] [--pose_weight POSE_WEIGHT]
[--face_weight FACE_WEIGHT] [--lip_weight LIP_WEIGHT] [--face_expand_ratio FACE_EXPAND_RATIO]
options:
-h, --help show this help message and exit
-c CONFIG, --config CONFIG
--source_image SOURCE_IMAGE
source image
--driving_audio DRIVING_AUDIO
driving audio
--pose_weight POSE_WEIGHT
weight of pose
--face_weight FACE_WEIGHT
weight of face
--lip_weight LIP_WEIGHT
weight of lip
--face_expand_ratio FACE_EXPAND_RATIO
face region
```
#### High-Resolution animation
Simply to run the `scripts/video_sr.py` and pass `input_video` and `output_path`:
```bash
python scripts/video_sr.py --input_path [input_video] --output_path [output_dir] --bg_upsampler realesrgan --face_upsample -w 1 -s 4
```
Animation results will be saved at `output_dir`.
For more options:
```shell
usage: video_sr.py [-h] [-i INPUT_PATH] [-o OUTPUT_PATH] [-w FIDELITY_WEIGHT] [-s UPSCALE] [--has_aligned] [--only_center_face] [--draw_box]
[--detection_model DETECTION_MODEL] [--bg_upsampler BG_UPSAMPLER] [--face_upsample] [--bg_tile BG_TILE] [--suffix SUFFIX]
options:
-h, --help show this help message and exit
-i INPUT_PATH, --input_path INPUT_PATH
Input video
-o OUTPUT_PATH, --output_path OUTPUT_PATH
Output folder.
-w FIDELITY_WEIGHT, --fidelity_weight FIDELITY_WEIGHT
Balance the quality and fidelity. Default: 0.5
-s UPSCALE, --upscale UPSCALE
The final upsampling scale of the image. Default: 2
--has_aligned Input are cropped and aligned faces. Default: False
--only_center_face Only restore the center face. Default: False
--draw_box Draw the bounding box for the detected faces. Default: False
--detection_model DETECTION_MODEL
Face detector. Optional: retinaface_resnet50, retinaface_mobile0.25, YOLOv5l, YOLOv5n. Default: retinaface_resnet50
--bg_upsampler BG_UPSAMPLER
Background upsampler. Optional: realesrgan
--face_upsample Face upsampler after enhancement. Default: False
--bg_tile BG_TILE Tile size for background sampler. Default: 400
--suffix SUFFIX Suffix of the restored faces. Default: None
```
> NOTICE: The High-Resolution animation feature is a modified version of [CodeFormer](https://github.com/sczhou/CodeFormer). When using or redistributing this feature, please comply with the [S-Lab License 1.0](https://github.com/sczhou/CodeFormer?tab=License-1-ov-file). We kindly request that you respect the terms of this license in any usage or redistribution of this component.
## 🔥Training
### Long-Duration animation
#### prepare data for training
The training data, which utilizes some talking-face videos similar to the source images used for inference, also needs to meet the following requirements:
1. It should be cropped into squares.
2. The face should be the main focus, making up 50%-70% of the image.
3. The face should be facing forward, with a rotation angle of less than 30° (no side profiles).
Organize your raw videos into the following directory structure:
```text
dataset_name/
|-- videos/
| |-- 0001.mp4
| |-- 0002.mp4
| |-- 0003.mp4
| `-- 0004.mp4
```
You can use any `dataset_name`, but ensure the `videos` directory is named as shown above.
Next, process the videos with the following commands:
```bash
python -m scripts.data_preprocess --input_dir dataset_name/videos --step 1
python -m scripts.data_preprocess --input_dir dataset_name/videos --step 2
```
**Note:** Execute steps 1 and 2 sequentially as they perform different tasks. Step 1 converts videos into frames, extracts audio from each video, and generates the necessary masks. Step 2 generates face embeddings using InsightFace and audio embeddings using Wav2Vec, and requires a GPU. For parallel processing, use the `-p` and `-r` arguments. The `-p` argument specifies the total number of instances to launch, dividing the data into `p` parts. The `-r` argument specifies which part the current process should handle. You need to manually launch multiple instances with different values for `-r`.
Generate the metadata JSON files with the following commands:
```bash
python scripts/extract_meta_info_stage1.py -r path/to/dataset -n dataset_name
python scripts/extract_meta_info_stage2.py -r path/to/dataset -n dataset_name
```
Replace `path/to/dataset` with the path to the parent directory of `videos`, such as `dataset_name` in the example above. This will generate `dataset_name_stage1.json` and `dataset_name_stage2.json` in the `./data` directory.
#### Training
Update the data meta path settings in the configuration YAML files, `configs/train/stage1.yaml` and `configs/train/stage2_long.yaml`:
```yaml
#stage1.yaml
data:
meta_paths:
- ./data/dataset_name_stage1.json
#stage2.yaml
data:
meta_paths:
- ./data/dataset_name_stage2.json
```
Start training with the following command:
```shell
accelerate launch -m \
--config_file accelerate_config.yaml \
--machine_rank 0 \
--main_process_ip 0.0.0.0 \
--main_process_port 20055 \
--num_machines 1 \
--num_processes 8 \
scripts.train_stage1 --config ./configs/train/stage1.yaml
```
##### Accelerate Usage Explanation
The `accelerate launch` command is used to start the training process with distributed settings.
```shell
accelerate launch [arguments] {training_script} --{training_script-argument-1} --{training_script-argument-2} ...
```
**Arguments for Accelerate:**
- `-m, --module`: Interpret the launch script as a Python module.
- `--config_file`: Configuration file for Hugging Face Accelerate.
- `--machine_rank`: Rank of the current machine in a multi-node setup.
- `--main_process_ip`: IP address of the master node.
- `--main_process_port`: Port of the master node.
- `--num_machines`: Total number of nodes participating in the training.
- `--num_processes`: Total number of processes for training, matching the total number of GPUs across all machines.
**Arguments for Training:**
- `{training_script}`: The training script, such as `scripts.train_stage1` or `scripts.train_stage2`.
- `--{training_script-argument-1}`: Arguments specific to the training script. Our training scripts accept one argument, `--config`, to specify the training configuration file.
For multi-node training, you need to manually run the command with different `machine_rank` on each node separately.
For more settings, refer to the [Accelerate documentation](https://huggingface.co/docs/accelerate/en/index).
### High-Resolution animation
#### Training
##### prepare data for training
We use the VFHQ dataset for training, you can download from its [homepage](https://liangbinxie.github.io/projects/vfhq/). Then updata `dataroot_gt` in `./configs/train/video_sr.yaml`.
#### training
Start training with the following command:
```shell
python -m torch.distributed.launch --nproc_per_node=8 --master_port=4322 \
basicsr/train.py -opt ./configs/train/video_sr.yaml \
--launcher pytorch
```
## 📝 Citation
If you find our work useful for your research, please consider citing the paper:
```
@misc{cui2024hallo2,
title={Hallo2: Long-Duration and High-Resolution Audio-driven Portrait Image Animation},
author={Jiahao Cui and Hui Li and Yao Yao and Hao Zhu and Hanlin Shang and Kaihui Cheng and Hang Zhou and Siyu Zhu and️ Jingdong Wang},
year={2024},
eprint={2410.07718},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
## 🌟 Opportunities Available
Multiple research positions are open at the **Generative Vision Lab, Fudan University**! Include:
- Research assistant
- Postdoctoral researcher
- PhD candidate
- Master students
Interested individuals are encouraged to contact us at [[email protected]](mailto://[email protected]) for further information.
## ⚠️ Social Risks and Mitigations
The development of portrait image animation technologies driven by audio inputs poses social risks, such as the ethical implications of creating realistic portraits that could be misused for deepfakes. To mitigate these risks, it is crucial to establish ethical guidelines and responsible use practices. Privacy and consent concerns also arise from using individuals' images and voices. Addressing these involves transparent data usage policies, informed consent, and safeguarding privacy rights. By addressing these risks and implementing mitigations, the research aims to ensure the responsible and ethical development of this technology.
## 🤗 Acknowledgements
We would like to thank the contributors to the [magic-animate](https://github.com/magic-research/magic-animate), [AnimateDiff](https://github.com/guoyww/AnimateDiff), [ultimatevocalremovergui](https://github.com/Anjok07/ultimatevocalremovergui), [AniPortrait](https://github.com/Zejun-Yang/AniPortrait) and [Moore-AnimateAnyone](https://github.com/MooreThreads/Moore-AnimateAnyone) repositories, for their open research and exploration.
If we missed any open-source projects or related articles, we would like to complement the acknowledgement of this specific work immediately.
## 👏 Community Contributors
Thank you to all the contributors who have helped to make this project better!
<a href="https://github.com/fudan-generative-vision/hallo2/graphs/contributors">
<img src="https://contrib.rocks/image?repo=fudan-generative-vision/hallo2" />
</a> | {
"source": "fudan-generative-vision/hallo2",
"title": "README.md",
"url": "https://github.com/fudan-generative-vision/hallo2/blob/main/README.md",
"date": "2024-10-16T09:10:54",
"stars": 3488,
"description": "Hallo2: Long-Duration and High-Resolution Audio-driven Portrait Image Animation",
"file_size": 19618
} |
<p align="center" style="border-radius: 10px">
<img src="asset/logo.png" width="35%" alt="logo"/>
</p>
# ⚡️Sana: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer
### <div align="center"> ICLR 2025 Oral Presentation <div>
<div align="center">
<a href="https://nvlabs.github.io/Sana/"><img src="https://img.shields.io/static/v1?label=Project&message=Github&color=blue&logo=github-pages"></a>  
<a href="https://hanlab.mit.edu/projects/sana/"><img src="https://img.shields.io/static/v1?label=Page&message=MIT&color=darkred&logo=github-pages"></a>  
<a href="https://arxiv.org/abs/2410.10629"><img src="https://img.shields.io/static/v1?label=Arxiv&message=Sana&color=red&logo=arxiv"></a>  
<a href="https://nv-sana.mit.edu/"><img src="https://img.shields.io/static/v1?label=Demo:6x3090&message=MIT&color=yellow"></a>  
<a href="https://nv-sana.mit.edu/4bit/"><img src="https://img.shields.io/static/v1?label=Demo:1x3090&message=4bit&color=yellow"></a>  
<a href="https://nv-sana.mit.edu/ctrlnet/"><img src="https://img.shields.io/static/v1?label=Demo:1x3090&message=ControlNet&color=yellow"></a>  
<a href="https://replicate.com/chenxwh/sana"><img src="https://img.shields.io/static/v1?label=API:H100&message=Replicate&color=pink"></a>  
<a href="https://discord.gg/rde6eaE5Ta"><img src="https://img.shields.io/static/v1?label=Discuss&message=Discord&color=purple&logo=discord"></a>  
</div>
<p align="center" border-radius="10px">
<img src="asset/Sana.jpg" width="90%" alt="teaser_page1"/>
</p>
## 💡 Introduction
We introduce Sana, a text-to-image framework that can efficiently generate images up to 4096 × 4096 resolution.
Sana can synthesize high-resolution, high-quality images with strong text-image alignment at a remarkably fast speed, deployable on laptop GPU.
Core designs include:
(1) [**DC-AE**](https://hanlab.mit.edu/projects/dc-ae): unlike traditional AEs, which compress images only 8×, we trained an AE that can compress images 32×, effectively reducing the number of latent tokens. \
(2) **Linear DiT**: we replace all vanilla attention in DiT with linear attention, which is more efficient at high resolutions without sacrificing quality. \
(3) **Decoder-only text encoder**: we replaced T5 with a modern decoder-only small LLM as the text encoder and designed complex human instruction with in-context learning to enhance the image-text alignment. \
(4) **Efficient training and sampling**: we propose **Flow-DPM-Solver** to reduce sampling steps, with efficient caption labeling and selection to accelerate convergence.
As a result, Sana-0.6B is very competitive with modern giant diffusion models (e.g. Flux-12B), being 20 times smaller and 100+ times faster in measured throughput. Moreover, Sana-0.6B can be deployed on a 16GB laptop GPU, taking less than 1 second to generate a 1024 × 1024 resolution image. Sana enables content creation at low cost.
<p align="center" border-raduis="10px">
<img src="asset/model-incremental.jpg" width="90%" alt="teaser_page2"/>
</p>
## 🔥🔥 News
- (🔥 New) \[2025/2/10\] 🚀Sana + ControlNet is released. [\[Guidance\]](asset/docs/sana_controlnet.md) | [\[Model\]](asset/docs/model_zoo.md) | [\[Demo\]](https://nv-sana.mit.edu/ctrlnet/)
- (🔥 New) \[2025/1/30\] Release CAME-8bit optimizer code. Saving more GPU memory during training. [\[How to config\]](https://github.com/NVlabs/Sana/blob/main/configs/sana_config/1024ms/Sana_1600M_img1024_CAME8bit.yaml#L86)
- (🔥 New) \[2025/1/29\] 🎉 🎉 🎉**SANA 1.5 is out! Figure out how to do efficient training & inference scaling!** 🚀[\[Tech Report\]](https://arxiv.org/abs/2501.18427)
- (🔥 New) \[2025/1/24\] 4bit-Sana is released, powered by [SVDQuant and Nunchaku](https://github.com/mit-han-lab/nunchaku) inference engine. Now run your Sana within **8GB** GPU VRAM [\[Guidance\]](asset/docs/4bit_sana.md) [\[Demo\]](https://svdquant.mit.edu/) [\[Model\]](asset/docs/model_zoo.md)
- (🔥 New) \[2025/1/24\] DCAE-1.1 is released, better reconstruction quality. [\[Model\]](https://huggingface.co/mit-han-lab/dc-ae-f32c32-sana-1.1) [\[diffusers\]](https://huggingface.co/mit-han-lab/dc-ae-f32c32-sana-1.1-diffusers)
- (🔥 New) \[2025/1/23\] **Sana is accepted as Oral by ICLR-2025.** 🎉🎉🎉
______________________________________________________________________
- (🔥 New) \[2025/1/12\] DC-AE tiling makes Sana-4K inferences 4096x4096px images within 22GB GPU memory. With model offload and 8bit/4bit quantize. The 4K Sana run within **8GB** GPU VRAM. [\[Guidance\]](asset/docs/model_zoo.md#-3-4k-models)
- (🔥 New) \[2025/1/11\] Sana code-base license changed to Apache 2.0.
- (🔥 New) \[2025/1/10\] Inference Sana with 8bit quantization.[\[Guidance\]](asset/docs/8bit_sana.md#quantization)
- (🔥 New) \[2025/1/8\] 4K resolution [Sana models](asset/docs/model_zoo.md) is supported in [Sana-ComfyUI](https://github.com/Efficient-Large-Model/ComfyUI_ExtraModels) and [work flow](asset/docs/ComfyUI/Sana_FlowEuler_4K.json) is also prepared. [\[4K guidance\]](asset/docs/ComfyUI/comfyui.md)
- (🔥 New) \[2025/1/8\] 1.6B 4K resolution [Sana models](asset/docs/model_zoo.md) are released: [\[BF16 pth\]](https://huggingface.co/Efficient-Large-Model/Sana_1600M_4Kpx_BF16) or [\[BF16 diffusers\]](https://huggingface.co/Efficient-Large-Model/Sana_1600M_4Kpx_BF16_diffusers). 🚀 Get your 4096x4096 resolution images within 20 seconds! Find more samples in [Sana page](https://nvlabs.github.io/Sana/). Thanks [SUPIR](https://github.com/Fanghua-Yu/SUPIR) for their wonderful work and support.
- (🔥 New) \[2025/1/2\] Bug in the `diffusers` pipeline is solved. [Solved PR](https://github.com/huggingface/diffusers/pull/10431)
- (🔥 New) \[2025/1/2\] 2K resolution [Sana models](asset/docs/model_zoo.md) is supported in [Sana-ComfyUI](https://github.com/Efficient-Large-Model/ComfyUI_ExtraModels) and [work flow](asset/docs/ComfyUI/Sana_FlowEuler_2K.json) is also prepared.
- ✅ \[2024/12\] 1.6B 2K resolution [Sana models](asset/docs/model_zoo.md) are released: [\[BF16 pth\]](https://huggingface.co/Efficient-Large-Model/Sana_1600M_2Kpx_BF16) or [\[BF16 diffusers\]](https://huggingface.co/Efficient-Large-Model/Sana_1600M_2Kpx_BF16_diffusers). 🚀 Get your 2K resolution images within 4 seconds! Find more samples in [Sana page](https://nvlabs.github.io/Sana/). Thanks [SUPIR](https://github.com/Fanghua-Yu/SUPIR) for their wonderful work and support.
- ✅ \[2024/12\] `diffusers` supports Sana-LoRA fine-tuning! Sana-LoRA's training and convergence speed is super fast. [\[Guidance\]](asset/docs/sana_lora_dreambooth.md) or [\[diffusers docs\]](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/README_sana.md).
- ✅ \[2024/12\] `diffusers` has Sana! [All Sana models in diffusers safetensors](https://huggingface.co/collections/Efficient-Large-Model/sana-673efba2a57ed99843f11f9e) are released and diffusers pipeline `SanaPipeline`, `SanaPAGPipeline`, `DPMSolverMultistepScheduler(with FlowMatching)` are all supported now. We prepare a [Model Card](asset/docs/model_zoo.md) for you to choose.
- ✅ \[2024/12\] 1.6B BF16 [Sana model](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_BF16) is released for stable fine-tuning.
- ✅ \[2024/12\] We release the [ComfyUI node](https://github.com/Efficient-Large-Model/ComfyUI_ExtraModels) for Sana. [\[Guidance\]](asset/docs/ComfyUI/comfyui.md)
- ✅ \[2024/11\] All multi-linguistic (Emoji & Chinese & English) SFT models are released: [1.6B-512px](https://huggingface.co/Efficient-Large-Model/Sana_1600M_512px_MultiLing), [1.6B-1024px](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_MultiLing), [600M-512px](https://huggingface.co/Efficient-Large-Model/Sana_600M_512px), [600M-1024px](https://huggingface.co/Efficient-Large-Model/Sana_600M_1024px). The metric performance is shown [here](#performance)
- ✅ \[2024/11\] Sana Replicate API is launching at [Sana-API](https://replicate.com/chenxwh/sana).
- ✅ \[2024/11\] 1.6B [Sana models](https://huggingface.co/collections/Efficient-Large-Model/sana-673efba2a57ed99843f11f9e) are released.
- ✅ \[2024/11\] Training & Inference & Metrics code are released.
- ✅ \[2024/11\] Working on [`diffusers`](https://github.com/huggingface/diffusers/pull/9982).
- \[2024/10\] [Demo](https://nv-sana.mit.edu/) is released.
- \[2024/10\] [DC-AE Code](https://github.com/mit-han-lab/efficientvit/blob/master/applications/dc_ae/README.md) and [weights](https://huggingface.co/collections/mit-han-lab/dc-ae-670085b9400ad7197bb1009b) are released!
- \[2024/10\] [Paper](https://arxiv.org/abs/2410.10629) is on Arxiv!
## Performance
| Methods (1024x1024) | Throughput (samples/s) | Latency (s) | Params (B) | Speedup | FID 👇 | CLIP 👆 | GenEval 👆 | DPG 👆 |
|-----------------------------------------------------------------------------------------------------|------------------------|-------------|------------|---------|-------------|--------------|-------------|-------------|
| FLUX-dev | 0.04 | 23.0 | 12.0 | 1.0× | 10.15 | 27.47 | _0.67_ | 84.0 |
| **Sana-0.6B** | 1.7 | 0.9 | 0.6 | 39.5× | _5.81_ | 28.36 | 0.64 | 83.6 |
| **[Sana-0.6B-MultiLing](https://huggingface.co/Efficient-Large-Model/Sana_600M_1024px)** | 1.7 | 0.9 | 0.6 | 39.5× | **5.61** | <u>28.80</u> | <u>0.68</u> | _84.2_ |
| **Sana-1.6B** | 1.0 | 1.2 | 1.6 | 23.3× | <u>5.76</u> | _28.67_ | 0.66 | **84.8** |
| **[Sana-1.6B-MultiLing](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_MultiLing)** | 1.0 | 1.2 | 1.6 | 23.3× | 5.92 | **28.94** | **0.69** | <u>84.5</u> |
<details>
<summary><h3>Click to show all</h3></summary>
| Methods | Throughput (samples/s) | Latency (s) | Params (B) | Speedup | FID 👆 | CLIP 👆 | GenEval 👆 | DPG 👆 |
|------------------------------|------------------------|-------------|------------|-----------|-------------|--------------|-------------|-------------|
| _**512 × 512 resolution**_ | | | | | | | | |
| PixArt-α | 1.5 | 1.2 | 0.6 | 1.0× | 6.14 | 27.55 | 0.48 | 71.6 |
| PixArt-Σ | 1.5 | 1.2 | 0.6 | 1.0× | _6.34_ | _27.62_ | <u>0.52</u> | _79.5_ |
| **Sana-0.6B** | 6.7 | 0.8 | 0.6 | 5.0× | <u>5.67</u> | <u>27.92</u> | _0.64_ | <u>84.3</u> |
| **Sana-1.6B** | 3.8 | 0.6 | 1.6 | 2.5× | **5.16** | **28.19** | **0.66** | **85.5** |
| _**1024 × 1024 resolution**_ | | | | | | | | |
| LUMINA-Next | 0.12 | 9.1 | 2.0 | 2.8× | 7.58 | 26.84 | 0.46 | 74.6 |
| SDXL | 0.15 | 6.5 | 2.6 | 3.5× | 6.63 | _29.03_ | 0.55 | 74.7 |
| PlayGroundv2.5 | 0.21 | 5.3 | 2.6 | 4.9× | _6.09_ | **29.13** | 0.56 | 75.5 |
| Hunyuan-DiT | 0.05 | 18.2 | 1.5 | 1.2× | 6.54 | 28.19 | 0.63 | 78.9 |
| PixArt-Σ | 0.4 | 2.7 | 0.6 | 9.3× | 6.15 | 28.26 | 0.54 | 80.5 |
| DALLE3 | - | - | - | - | - | - | _0.67_ | 83.5 |
| SD3-medium | 0.28 | 4.4 | 2.0 | 6.5× | 11.92 | 27.83 | 0.62 | <u>84.1</u> |
| FLUX-dev | 0.04 | 23.0 | 12.0 | 1.0× | 10.15 | 27.47 | _0.67_ | _84.0_ |
| FLUX-schnell | 0.5 | 2.1 | 12.0 | 11.6× | 7.94 | 28.14 | **0.71** | **84.8** |
| **Sana-0.6B** | 1.7 | 0.9 | 0.6 | **39.5×** | <u>5.81</u> | 28.36 | 0.64 | 83.6 |
| **Sana-1.6B** | 1.0 | 1.2 | 1.6 | **23.3×** | **5.76** | <u>28.67</u> | <u>0.66</u> | **84.8** |
</details>
## Contents
- [Env](#-1-dependencies-and-installation)
- [Demo](#-2-how-to-play-with-sana-inference)
- [Model Zoo](asset/docs/model_zoo.md)
- [Training](#-3-how-to-train-sana)
- [Testing](#-4-metric-toolkit)
- [TODO](#to-do-list)
- [Citation](#bibtex)
# 🔧 1. Dependencies and Installation
- Python >= 3.10.0 (Recommend to use [Anaconda](https://www.anaconda.com/download/#linux) or [Miniconda](https://docs.conda.io/en/latest/miniconda.html))
- [PyTorch >= 2.0.1+cu12.1](https://pytorch.org/)
```bash
git clone https://github.com/NVlabs/Sana.git
cd Sana
./environment_setup.sh sana
# or you can install each components step by step following environment_setup.sh
```
# 💻 2. How to Play with Sana (Inference)
## 💰Hardware requirement
- 9GB VRAM is required for 0.6B model and 12GB VRAM for 1.6B model. Our later quantization version will require less than 8GB for inference.
- All the tests are done on A100 GPUs. Different GPU version may be different.
## 🔛 Choose your model: [Model card](asset/docs/model_zoo.md)
## 🔛 Quick start with [Gradio](https://www.gradio.app/guides/quickstart)
```bash
# official online demo
DEMO_PORT=15432 \
python app/app_sana.py \
--share \
--config=configs/sana_config/1024ms/Sana_1600M_img1024.yaml \
--model_path=hf://Efficient-Large-Model/Sana_1600M_1024px/checkpoints/Sana_1600M_1024px.pth \
--image_size=1024
```
### 1. How to use `SanaPipeline` with `🧨diffusers`
> \[!IMPORTANT\]
> Upgrade your `diffusers>=0.32.0.dev` to make the `SanaPipeline` and `SanaPAGPipeline` available!
>
> ```bash
> pip install git+https://github.com/huggingface/diffusers
> ```
>
> Make sure to specify `pipe.transformer` to default `torch_dtype` and `variant` according to [Model Card](asset/docs/model_zoo.md).
>
> Set `pipe.text_encoder` to BF16 and `pipe.vae` to FP32 or BF16. For more info, [docs](https://huggingface.co/docs/diffusers/main/en/api/pipelines/sana#sanapipeline) are here.
```python
# run `pip install git+https://github.com/huggingface/diffusers` before use Sana in diffusers
import torch
from diffusers import SanaPipeline
pipe = SanaPipeline.from_pretrained(
"Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers",
variant="bf16",
torch_dtype=torch.bfloat16,
)
pipe.to("cuda")
pipe.vae.to(torch.bfloat16)
pipe.text_encoder.to(torch.bfloat16)
prompt = 'a cyberpunk cat with a neon sign that says "Sana"'
image = pipe(
prompt=prompt,
height=1024,
width=1024,
guidance_scale=4.5,
num_inference_steps=20,
generator=torch.Generator(device="cuda").manual_seed(42),
)[0]
image[0].save("sana.png")
```
### 2. How to use `SanaPAGPipeline` with `🧨diffusers`
```python
# run `pip install git+https://github.com/huggingface/diffusers` before use Sana in diffusers
import torch
from diffusers import SanaPAGPipeline
pipe = SanaPAGPipeline.from_pretrained(
"Efficient-Large-Model/Sana_1600M_1024px_diffusers",
variant="fp16",
torch_dtype=torch.float16,
pag_applied_layers="transformer_blocks.8",
)
pipe.to("cuda")
pipe.text_encoder.to(torch.bfloat16)
pipe.vae.to(torch.bfloat16)
prompt = 'a cyberpunk cat with a neon sign that says "Sana"'
image = pipe(
prompt=prompt,
guidance_scale=5.0,
pag_scale=2.0,
num_inference_steps=20,
generator=torch.Generator(device="cuda").manual_seed(42),
)[0]
image[0].save('sana.png')
```
<details>
<summary><h3>3. How to use Sana in this repo</h3></summary>
```python
import torch
from app.sana_pipeline import SanaPipeline
from torchvision.utils import save_image
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
generator = torch.Generator(device=device).manual_seed(42)
sana = SanaPipeline("configs/sana_config/1024ms/Sana_1600M_img1024.yaml")
sana.from_pretrained("hf://Efficient-Large-Model/Sana_1600M_1024px_BF16/checkpoints/Sana_1600M_1024px_BF16.pth")
prompt = 'a cyberpunk cat with a neon sign that says "Sana"'
image = sana(
prompt=prompt,
height=1024,
width=1024,
guidance_scale=5.0,
pag_guidance_scale=2.0,
num_inference_steps=18,
generator=generator,
)
save_image(image, 'output/sana.png', nrow=1, normalize=True, value_range=(-1, 1))
```
</details>
<details>
<summary><h3>4. Run Sana (Inference) with Docker</h3></summary>
```
# Pull related models
huggingface-cli download google/gemma-2b-it
huggingface-cli download google/shieldgemma-2b
huggingface-cli download mit-han-lab/dc-ae-f32c32-sana-1.0
huggingface-cli download Efficient-Large-Model/Sana_1600M_1024px
# Run with docker
docker build . -t sana
docker run --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 \
-v ~/.cache:/root/.cache \
sana
```
</details>
## 🔛 Run inference with TXT or JSON files
```bash
# Run samples in a txt file
python scripts/inference.py \
--config=configs/sana_config/1024ms/Sana_1600M_img1024.yaml \
--model_path=hf://Efficient-Large-Model/Sana_1600M_1024px/checkpoints/Sana_1600M_1024px.pth \
--txt_file=asset/samples/samples_mini.txt
# Run samples in a json file
python scripts/inference.py \
--config=configs/sana_config/1024ms/Sana_1600M_img1024.yaml \
--model_path=hf://Efficient-Large-Model/Sana_1600M_1024px/checkpoints/Sana_1600M_1024px.pth \
--json_file=asset/samples/samples_mini.json
```
where each line of [`asset/samples/samples_mini.txt`](asset/samples/samples_mini.txt) contains a prompt to generate
# 🔥 3. How to Train Sana
## 💰Hardware requirement
- 32GB VRAM is required for both 0.6B and 1.6B model's training
### 1). Train with image-text pairs in directory
We provide a training example here and you can also select your desired config file from [config files dir](configs/sana_config) based on your data structure.
To launch Sana training, you will first need to prepare data in the following formats. [Here](asset/example_data) is an example for the data structure for reference.
```bash
asset/example_data
├── AAA.txt
├── AAA.png
├── BCC.txt
├── BCC.png
├── ......
├── CCC.txt
└── CCC.png
```
Then Sana's training can be launched via
```bash
# Example of training Sana 0.6B with 512x512 resolution from scratch
bash train_scripts/train.sh \
configs/sana_config/512ms/Sana_600M_img512.yaml \
--data.data_dir="[asset/example_data]" \
--data.type=SanaImgDataset \
--model.multi_scale=false \
--train.train_batch_size=32
# Example of fine-tuning Sana 1.6B with 1024x1024 resolution
bash train_scripts/train.sh \
configs/sana_config/1024ms/Sana_1600M_img1024.yaml \
--data.data_dir="[asset/example_data]" \
--data.type=SanaImgDataset \
--model.load_from=hf://Efficient-Large-Model/Sana_1600M_1024px/checkpoints/Sana_1600M_1024px.pth \
--model.multi_scale=false \
--train.train_batch_size=8
```
### 2). Train with image-text pairs in directory
We also provide conversion scripts to convert your data to the required format. You can refer to the [data conversion scripts](asset/data_conversion_scripts) for more details.
```bash
python tools/convert_ImgDataset_to_WebDatasetMS_format.py
```
Then Sana's training can be launched via
```bash
# Example of training Sana 0.6B with 512x512 resolution from scratch
bash train_scripts/train.sh \
configs/sana_config/512ms/Sana_600M_img512.yaml \
--data.data_dir="[asset/example_data_tar]" \
--data.type=SanaWebDatasetMS \
--model.multi_scale=true \
--train.train_batch_size=32
```
# 💻 4. Metric toolkit
Refer to [Toolkit Manual](asset/docs/metrics_toolkit.md).
# 💪To-Do List
We will try our best to release
- \[✅\] Training code
- \[✅\] Inference code
- \[✅\] Model zoo
- \[✅\] ComfyUI
- \[✅\] DC-AE Diffusers
- \[✅\] Sana merged in Diffusers(https://github.com/huggingface/diffusers/pull/9982)
- \[✅\] LoRA training by [@paul](https://github.com/sayakpaul)(`diffusers`: https://github.com/huggingface/diffusers/pull/10234)
- \[✅\] 2K/4K resolution models.(Thanks [@SUPIR](https://github.com/Fanghua-Yu/SUPIR) to provide a 4K super-resolution model)
- \[✅\] 8bit / 4bit Laptop development
- \[💻\] ControlNet (train & inference & models)
- \[💻\] Larger model size
- \[💻\] Better re-construction F32/F64 VAEs.
- \[💻\] **Sana1.5 (Focus on: Human body / Human face / Text rendering / Realism / Efficiency)**
# 🤗Acknowledgements
**Thanks to the following open-sourced codebase for their wonderful work and codebase!**
- [PixArt-α](https://github.com/PixArt-alpha/PixArt-alpha)
- [PixArt-Σ](https://github.com/PixArt-alpha/PixArt-sigma)
- [Efficient-ViT](https://github.com/mit-han-lab/efficientvit)
- [ComfyUI_ExtraModels](https://github.com/city96/ComfyUI_ExtraModels)
- [SVDQuant and Nunchaku](https://github.com/mit-han-lab/nunchaku)
- [diffusers](https://github.com/huggingface/diffusers)
## 🌟 Star History
[](https://star-history.com/#NVlabs/sana&Date)
# 📖BibTeX
```
@misc{xie2024sana,
title={Sana: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer},
author={Enze Xie and Junsong Chen and Junyu Chen and Han Cai and Haotian Tang and Yujun Lin and Zhekai Zhang and Muyang Li and Ligeng Zhu and Yao Lu and Song Han},
year={2024},
eprint={2410.10629},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2410.10629},
}
``` | {
"source": "NVlabs/Sana",
"title": "README.md",
"url": "https://github.com/NVlabs/Sana/blob/main/README.md",
"date": "2024-10-11T20:19:45",
"stars": 3449,
"description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer",
"file_size": 22477
} |
<!--Copyright 2024 NVIDIA CORPORATION & AFFILIATES
#
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License. -->
# 4bit SanaPipeline
### 1. Environment setup
Follow the official [SVDQuant-Nunchaku](https://github.com/mit-han-lab/nunchaku) repository to set up the environment. The guidance can be found [here](https://github.com/mit-han-lab/nunchaku?tab=readme-ov-file#installation).
### 2. Code snap for inference
Here we show the code snippet for SanaPipeline. For SanaPAGPipeline, please refer to the [SanaPAGPipeline](https://github.com/mit-han-lab/nunchaku/blob/main/examples/sana_1600m_pag.py) section.
```python
import torch
from diffusers import SanaPipeline
from nunchaku.models.transformer_sana import NunchakuSanaTransformer2DModel
transformer = NunchakuSanaTransformer2DModel.from_pretrained("mit-han-lab/svdq-int4-sana-1600m")
pipe = SanaPipeline.from_pretrained(
"Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers",
transformer=transformer,
variant="bf16",
torch_dtype=torch.bfloat16,
).to("cuda")
pipe.text_encoder.to(torch.bfloat16)
pipe.vae.to(torch.bfloat16)
image = pipe(
prompt="A cute 🐼 eating 🎋, ink drawing style",
height=1024,
width=1024,
guidance_scale=4.5,
num_inference_steps=20,
generator=torch.Generator().manual_seed(42),
).images[0]
image.save("sana_1600m.png")
```
### 3. Online demo
1). Launch the 4bit Sana.
```bash
python app/app_sana_4bit.py
```
2). Compare with BF16 version
Refer to the original [Nunchaku-Sana.](https://github.com/mit-han-lab/nunchaku/tree/main/app/sana/t2i) guidance for SanaPAGPipeline
```bash
python app/app_sana_4bit_compare_bf16.py
``` | {
"source": "NVlabs/Sana",
"title": "asset/docs/4bit_sana.md",
"url": "https://github.com/NVlabs/Sana/blob/main/asset/docs/4bit_sana.md",
"date": "2024-10-11T20:19:45",
"stars": 3449,
"description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer",
"file_size": 2148
} |
<!-- Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License. -->
# SanaPipeline
[SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers](https://huggingface.co/papers/2410.10629) from NVIDIA and MIT HAN Lab, by Enze Xie, Junsong Chen, Junyu Chen, Han Cai, Haotian Tang, Yujun Lin, Zhekai Zhang, Muyang Li, Ligeng Zhu, Yao Lu, Song Han.
The abstract from the paper is:
*We introduce Sana, a text-to-image framework that can efficiently generate images up to 4096×4096 resolution. Sana can synthesize high-resolution, high-quality images with strong text-image alignment at a remarkably fast speed, deployable on laptop GPU. Core designs include: (1) Deep compression autoencoder: unlike traditional AEs, which compress images only 8×, we trained an AE that can compress images 32×, effectively reducing the number of latent tokens. (2) Linear DiT: we replace all vanilla attention in DiT with linear attention, which is more efficient at high resolutions without sacrificing quality. (3) Decoder-only text encoder: we replaced T5 with modern decoder-only small LLM as the text encoder and designed complex human instruction with in-context learning to enhance the image-text alignment. (4) Efficient training and sampling: we propose Flow-DPM-Solver to reduce sampling steps, with efficient caption labeling and selection to accelerate convergence. As a result, Sana-0.6B is very competitive with modern giant diffusion model (e.g. Flux-12B), being 20 times smaller and 100+ times faster in measured throughput. Moreover, Sana-0.6B can be deployed on a 16GB laptop GPU, taking less than 1 second to generate a 1024×1024 resolution image. Sana enables content creation at low cost. Code and model will be publicly released.*
<Tip>
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-a-pipeline) section to learn how to efficiently load the same components into multiple pipelines.
</Tip>
This pipeline was contributed by [lawrence-cj](https://github.com/lawrence-cj) and [chenjy2003](https://github.com/chenjy2003). The original codebase can be found [here](https://github.com/NVlabs/Sana). The original weights can be found under [hf.co/Efficient-Large-Model](https://huggingface.co/Efficient-Large-Model).
Available models:
| Model | Recommended dtype |
|:-----:|:-----------------:|
| [`Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers`](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers) | `torch.bfloat16` |
| [`Efficient-Large-Model/Sana_1600M_1024px_diffusers`](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_diffusers) | `torch.float16` |
| [`Efficient-Large-Model/Sana_1600M_1024px_MultiLing_diffusers`](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_MultiLing_diffusers) | `torch.float16` |
| [`Efficient-Large-Model/Sana_1600M_512px_diffusers`](https://huggingface.co/Efficient-Large-Model/Sana_1600M_512px_diffusers) | `torch.float16` |
| [`Efficient-Large-Model/Sana_1600M_512px_MultiLing_diffusers`](https://huggingface.co/Efficient-Large-Model/Sana_1600M_512px_MultiLing_diffusers) | `torch.float16` |
| [`Efficient-Large-Model/Sana_600M_1024px_diffusers`](https://huggingface.co/Efficient-Large-Model/Sana_600M_1024px_diffusers) | `torch.float16` |
| [`Efficient-Large-Model/Sana_600M_512px_diffusers`](https://huggingface.co/Efficient-Large-Model/Sana_600M_512px_diffusers) | `torch.float16` |
Refer to [this](https://huggingface.co/collections/Efficient-Large-Model/sana-673efba2a57ed99843f11f9e) collection for more information.
Note: The recommended dtype mentioned is for the transformer weights. The text encoder and VAE weights must stay in `torch.bfloat16` or `torch.float32` for the model to work correctly. Please refer to the inference example below to see how to load the model with the recommended dtype.
<Tip>
Make sure to pass the `variant` argument for downloaded checkpoints to use lower disk space. Set it to `"fp16"` for models with recommended dtype as `torch.float16`, and `"bf16"` for models with recommended dtype as `torch.bfloat16`. By default, `torch.float32` weights are downloaded, which use twice the amount of disk storage. Additionally, `torch.float32` weights can be downcasted on-the-fly by specifying the `torch_dtype` argument. Read about it in the [docs](https://huggingface.co/docs/diffusers/v0.31.0/en/api/pipelines/overview#diffusers.DiffusionPipeline.from_pretrained).
</Tip>
## Quantization
Quantization helps reduce the memory requirements of very large models by storing model weights in a lower precision data type. However, quantization may have varying impact on video quality depending on the video model.
Refer to the [Quantization](../../quantization/overview) overview to learn more about supported quantization backends and selecting a quantization backend that supports your use case. The example below demonstrates how to load a quantized \[`SanaPipeline`\] for inference with bitsandbytes.
```py
import torch
from diffusers import BitsAndBytesConfig as DiffusersBitsAndBytesConfig, SanaTransformer2DModel, SanaPipeline
from transformers import BitsAndBytesConfig as BitsAndBytesConfig, AutoModel
quant_config = BitsAndBytesConfig(load_in_8bit=True)
text_encoder_8bit = AutoModel.from_pretrained(
"Efficient-Large-Model/Sana_1600M_1024px_diffusers",
subfolder="text_encoder",
quantization_config=quant_config,
torch_dtype=torch.float16,
)
quant_config = DiffusersBitsAndBytesConfig(load_in_8bit=True)
transformer_8bit = SanaTransformer2DModel.from_pretrained(
"Efficient-Large-Model/Sana_1600M_1024px_diffusers",
subfolder="transformer",
quantization_config=quant_config,
torch_dtype=torch.float16,
)
pipeline = SanaPipeline.from_pretrained(
"Efficient-Large-Model/Sana_1600M_1024px_diffusers",
text_encoder=text_encoder_8bit,
transformer=transformer_8bit,
torch_dtype=torch.float16,
device_map="balanced",
)
prompt = "a tiny astronaut hatching from an egg on the moon"
image = pipeline(prompt).images[0]
image.save("sana.png")
```
## SanaPipeline
\[\[autodoc\]\] SanaPipeline
- all
- __call__
## SanaPAGPipeline
\[\[autodoc\]\] SanaPAGPipeline
- all
- __call__
## SanaPipelineOutput
\[\[autodoc\]\] pipelines.sana.pipeline_output.SanaPipelineOutput | {
"source": "NVlabs/Sana",
"title": "asset/docs/8bit_sana.md",
"url": "https://github.com/NVlabs/Sana/blob/main/asset/docs/8bit_sana.md",
"date": "2024-10-11T20:19:45",
"stars": 3449,
"description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer",
"file_size": 7027
} |
# 💻 How to Inference & Test Metrics (FID, CLIP Score, GenEval, DPG-Bench, etc...)
This ToolKit will automatically inference your model and log the metrics results onto wandb as chart for better illustration. We curerntly support:
- \[x\] [FID](https://github.com/mseitzer/pytorch-fid) & [CLIP-Score](https://github.com/openai/CLIP)
- \[x\] [GenEval](https://github.com/djghosh13/geneval)
- \[x\] [DPG-Bench](https://github.com/TencentQQGYLab/ELLA)
- \[x\] [ImageReward](https://github.com/THUDM/ImageReward/tree/main)
### 0. Install corresponding env for GenEval and DPG-Bench
Make sure you can activate the following envs:
- `conda activate geneval`([GenEval](https://github.com/djghosh13/geneval))
- `conda activate dpg`([DGB-Bench](https://github.com/TencentQQGYLab/ELLA))
### 0.1 Prepare data.
Metirc FID & CLIP-Score on [MJHQ-30K](https://huggingface.co/datasets/playgroundai/MJHQ-30K)
```python
from huggingface_hub import hf_hub_download
hf_hub_download(
repo_id="playgroundai/MJHQ-30K",
filename="mjhq30k_imgs.zip",
local_dir="data/test/PG-eval-data/MJHQ-30K/",
repo_type="dataset"
)
```
Unzip mjhq30k_imgs.zip into its per-category folder structure.
```
data/test/PG-eval-data/MJHQ-30K/imgs/
├── animals
├── art
├── fashion
├── food
├── indoor
├── landscape
├── logo
├── people
├── plants
└── vehicles
```
### 0.2 Prepare checkpoints
```bash
huggingface-cli download Efficient-Large-Model/Sana_1600M_1024px --repo-type model --local-dir ./output/Sana_1600M_1024px --local-dir-use-symlinks False
```
### 1. directly \[Inference and Metric\] a .pth file
```bash
# We provide four scripts for evaluating metrics:
fid_clipscore_launch=scripts/bash_run_inference_metric.sh
geneval_launch=scripts/bash_run_inference_metric_geneval.sh
dpg_launch=scripts/bash_run_inference_metric_dpg.sh
image_reward_launch=scripts/bash_run_inference_metric_imagereward.sh
# Use following format to metric your models:
# bash $correspoinding_metric_launch $your_config_file_path $your_relative_pth_file_path
# example
bash $geneval_launch \
configs/sana_config/1024ms/Sana_1600M_img1024.yaml \
output/Sana_1600M_1024px/checkpoints/Sana_1600M_1024px.pth
```
### 2. \[Inference and Metric\] a list of .pth files using a txt file
You can also write all your pth files of a job in one txt file, eg. [model_paths.txt](../model_paths.txt)
```bash
# Use following format to metric your models, gathering in a txt file:
# bash $correspoinding_metric_launch $your_config_file_path $your_txt_file_path_containing_pth_path
# We suggest follow the file tree structure in our project for robust experiment
# example
bash scripts/bash_run_inference_metric.sh \
configs/sana_config/1024ms/Sana_1600M_img1024.yaml \
asset/model_paths.txt
```
### 3. You will get the following data tree.
```
output
├──your_job_name/ (everything will be saved here)
│ ├──config.yaml
│ ├──train_log.log
│ ├──checkpoints (all checkpoints)
│ │ ├──epoch_1_step_6666.pth
│ │ ├──epoch_1_step_8888.pth
│ │ ├──......
│ ├──vis (all visualization result dirs)
│ │ ├──visualization_file_name
│ │ │ ├──xxxxxxx.jpg
│ │ │ ├──......
│ │ ├──visualization_file_name2
│ │ │ ├──xxxxxxx.jpg
│ │ │ ├──......
│ ├──......
│ ├──metrics (all metrics testing related files)
│ │ ├──model_paths.txt Optional(👈)(relative path of testing ckpts)
│ │ │ ├──output/your_job_name/checkpoings/epoch_1_step_6666.pth
│ │ │ ├──output/your_job_name/checkpoings/epoch_1_step_8888.pth
│ │ ├──fid_img_paths.txt Optional(👈)(name of testing img_dir in vis)
│ │ │ ├──visualization_file_name
│ │ │ ├──visualization_file_name2
│ │ ├──cached_img_paths.txt Optional(👈)
│ │ ├──......
``` | {
"source": "NVlabs/Sana",
"title": "asset/docs/metrics_toolkit.md",
"url": "https://github.com/NVlabs/Sana/blob/main/asset/docs/metrics_toolkit.md",
"date": "2024-10-11T20:19:45",
"stars": 3449,
"description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer",
"file_size": 3699
} |
## 🔥 1. We provide all the links of Sana pth and diffusers safetensor below
| Model | Reso | pth link | diffusers | Precision | Description |
|----------------------|--------|-----------------------------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------|---------------|----------------|
| Sana-0.6B | 512px | [Sana_600M_512px](https://huggingface.co/Efficient-Large-Model/Sana_600M_512px) | [Efficient-Large-Model/Sana_600M_512px_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_600M_512px_diffusers) | fp16/fp32 | Multi-Language |
| Sana-0.6B | 1024px | [Sana_600M_1024px](https://huggingface.co/Efficient-Large-Model/Sana_600M_1024px) | [Efficient-Large-Model/Sana_600M_1024px_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_600M_1024px_diffusers) | fp16/fp32 | Multi-Language |
| Sana-1.6B | 512px | [Sana_1600M_512px](https://huggingface.co/Efficient-Large-Model/Sana_1600M_512px) | [Efficient-Large-Model/Sana_1600M_512px_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_1600M_512px_diffusers) | fp16/fp32 | - |
| Sana-1.6B | 512px | [Sana_1600M_512px_MultiLing](https://huggingface.co/Efficient-Large-Model/Sana_1600M_512px_MultiLing) | [Efficient-Large-Model/Sana_1600M_512px_MultiLing_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_1600M_512px_MultiLing_diffusers) | fp16/fp32 | Multi-Language |
| Sana-1.6B | 1024px | [Sana_1600M_1024px](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px) | [Efficient-Large-Model/Sana_1600M_1024px_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_diffusers) | fp16/fp32 | - |
| Sana-1.6B | 1024px | [Sana_1600M_1024px_MultiLing](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_MultiLing) | [Efficient-Large-Model/Sana_1600M_1024px_MultiLing_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_MultiLing_diffusers) | fp16/fp32 | Multi-Language |
| Sana-1.6B | 1024px | [Sana_1600M_1024px_BF16](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_BF16) | [Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers) | **bf16**/fp32 | Multi-Language |
| Sana-1.6B | 1024px | - | [mit-han-lab/svdq-int4-sana-1600m](https://huggingface.co/mit-han-lab/svdq-int4-sana-1600m) | **int4** | Multi-Language |
| Sana-1.6B | 2Kpx | [Sana_1600M_2Kpx_BF16](https://huggingface.co/Efficient-Large-Model/Sana_1600M_2Kpx_BF16) | [Efficient-Large-Model/Sana_1600M_2Kpx_BF16_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_1600M_2Kpx_BF16_diffusers) | **bf16**/fp32 | Multi-Language |
| Sana-1.6B | 4Kpx | [Sana_1600M_4Kpx_BF16](https://huggingface.co/Efficient-Large-Model/Sana_1600M_4Kpx_BF16) | [Efficient-Large-Model/Sana_1600M_4Kpx_BF16_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_1600M_4Kpx_BF16_diffusers) | **bf16**/fp32 | Multi-Language |
| Sana-1.6B | 4Kpx | [Sana_1600M_4Kpx_BF16](https://huggingface.co/Efficient-Large-Model/Sana_1600M_4Kpx_BF16) | [Efficient-Large-Model/Sana_1600M_4Kpx_BF16_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_1600M_4Kpx_BF16_diffusers) | **bf16**/fp32 | Multi-Language |
| ControlNet | | | | | |
| Sana-1.6B-ControlNet | 1Kpx | [Sana_1600M_1024px_BF16_ControlNet_HED](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_BF16_ControlNet_HED) | Coming soon | **bf16**/fp32 | Multi-Language |
| Sana-0.6B-ControlNet | 1Kpx | [Sana_600M_1024px_ControlNet_HED](https://huggingface.co/Efficient-Large-Model/Sana_600M_1024px_ControlNet_HED) | Coming soon | fp16/fp32 | - |
## ❗ 2. Make sure to use correct precision(fp16/bf16/fp32) for training and inference.
### We provide two samples to use fp16 and bf16 weights, respectively.
❗️Make sure to set `variant` and `torch_dtype` in diffusers pipelines to the desired precision.
#### 1). For fp16 models
```python
# run `pip install git+https://github.com/huggingface/diffusers` before use Sana in diffusers
import torch
from diffusers import SanaPipeline
pipe = SanaPipeline.from_pretrained(
"Efficient-Large-Model/Sana_1600M_1024px_diffusers",
variant="fp16",
torch_dtype=torch.float16,
)
pipe.to("cuda")
pipe.vae.to(torch.bfloat16)
pipe.text_encoder.to(torch.bfloat16)
prompt = 'a cyberpunk cat with a neon sign that says "Sana"'
image = pipe(
prompt=prompt,
height=1024,
width=1024,
guidance_scale=5.0,
num_inference_steps=20,
generator=torch.Generator(device="cuda").manual_seed(42),
)[0]
image[0].save("sana.png")
```
#### 2). For bf16 models
```python
# run `pip install git+https://github.com/huggingface/diffusers` before use Sana in diffusers
import torch
from diffusers import SanaPAGPipeline
pipe = SanaPAGPipeline.from_pretrained(
"Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers",
variant="bf16",
torch_dtype=torch.bfloat16,
pag_applied_layers="transformer_blocks.8",
)
pipe.to("cuda")
pipe.text_encoder.to(torch.bfloat16)
pipe.vae.to(torch.bfloat16)
prompt = 'a cyberpunk cat with a neon sign that says "Sana"'
image = pipe(
prompt=prompt,
guidance_scale=5.0,
pag_scale=2.0,
num_inference_steps=20,
generator=torch.Generator(device="cuda").manual_seed(42),
)[0]
image[0].save('sana.png')
```
## ❗ 3. 4K models
4K models need VAE tiling to avoid OOM issue.(16 GPU is recommended)
```python
# run `pip install git+https://github.com/huggingface/diffusers` before use Sana in diffusers
import torch
from diffusers import SanaPipeline
pipe = SanaPipeline.from_pretrained(
"Efficient-Large-Model/Sana_1600M_4Kpx_BF16_diffusers",
variant="bf16",
torch_dtype=torch.bfloat16,
)
pipe.to("cuda")
pipe.vae.to(torch.bfloat16)
pipe.text_encoder.to(torch.bfloat16)
# for 4096x4096 image generation OOM issue, feel free adjust the tile size
if pipe.transformer.config.sample_size == 128:
pipe.vae.enable_tiling(
tile_sample_min_height=1024,
tile_sample_min_width=1024,
tile_sample_stride_height=896,
tile_sample_stride_width=896,
)
prompt = 'a cyberpunk cat with a neon sign that says "Sana"'
image = pipe(
prompt=prompt,
height=4096,
width=4096,
guidance_scale=5.0,
num_inference_steps=20,
generator=torch.Generator(device="cuda").manual_seed(42),
)[0]
image[0].save("sana_4K.png")
```
## ❗ 4. int4 inference
This int4 model is quantized with [SVDQuant-Nunchaku](https://github.com/mit-han-lab/nunchaku). You need first follow the [guidance of installation](https://github.com/mit-han-lab/nunchaku?tab=readme-ov-file#installation) of nunchaku engine, then you can use the following code snippet to perform inference with int4 Sana model.
Here we show the code snippet for SanaPipeline. For SanaPAGPipeline, please refer to the [SanaPAGPipeline](https://github.com/mit-han-lab/nunchaku/blob/main/examples/sana_1600m_pag.py) section.
```python
import torch
from diffusers import SanaPipeline
from nunchaku.models.transformer_sana import NunchakuSanaTransformer2DModel
transformer = NunchakuSanaTransformer2DModel.from_pretrained("mit-han-lab/svdq-int4-sana-1600m")
pipe = SanaPipeline.from_pretrained(
"Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers",
transformer=transformer,
variant="bf16",
torch_dtype=torch.bfloat16,
).to("cuda")
pipe.text_encoder.to(torch.bfloat16)
pipe.vae.to(torch.bfloat16)
image = pipe(
prompt="A cute 🐼 eating 🎋, ink drawing style",
height=1024,
width=1024,
guidance_scale=4.5,
num_inference_steps=20,
generator=torch.Generator().manual_seed(42),
).images[0]
image.save("sana_1600m.png")
``` | {
"source": "NVlabs/Sana",
"title": "asset/docs/model_zoo.md",
"url": "https://github.com/NVlabs/Sana/blob/main/asset/docs/model_zoo.md",
"date": "2024-10-11T20:19:45",
"stars": 3449,
"description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer",
"file_size": 9549
} |
<!-- Copyright 2024 NVIDIA CORPORATION & AFFILIATES
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
SPDX-License-Identifier: Apache-2.0 -->
## 🔥 ControlNet
We incorporate a ControlNet-like(https://github.com/lllyasviel/ControlNet) module enables fine-grained control over text-to-image diffusion models. We implement a ControlNet-Transformer architecture, specifically tailored for Transformers, achieving explicit controllability alongside high-quality image generation.
<p align="center">
<img src="https://raw.githubusercontent.com/NVlabs/Sana/refs/heads/page/asset/content/controlnet/sana_controlnet.jpg" height=480>
</p>
## Inference of `Sana + ControlNet`
### 1). Gradio Interface
```bash
python app/app_sana_controlnet_hed.py \
--config configs/sana_controlnet_config/Sana_1600M_1024px_controlnet_bf16.yaml \
--model_path hf://Efficient-Large-Model/Sana_1600M_1024px_BF16_ControlNet_HED/checkpoints/Sana_1600M_1024px_BF16_ControlNet_HED.pth
```
<p align="center" border-raduis="10px">
<img src="https://nvlabs.github.io/Sana/asset/content/controlnet/controlnet_app.jpg" width="90%" alt="teaser_page2"/>
</p>
### 2). Inference with JSON file
```bash
python tools/controlnet/inference_controlnet.py \
--config configs/sana_controlnet_config/Sana_1600M_1024px_controlnet_bf16.yaml \
--model_path hf://Efficient-Large-Model/Sana_1600M_1024px_BF16_ControlNet_HED/checkpoints/Sana_1600M_1024px_BF16_ControlNet_HED.pth \
--json_file asset/controlnet/samples_controlnet.json
```
### 3). Inference code snap
```python
import torch
from PIL import Image
from app.sana_controlnet_pipeline import SanaControlNetPipeline
device = "cuda" if torch.cuda.is_available() else "cpu"
pipe = SanaControlNetPipeline("configs/sana_controlnet_config/Sana_1600M_1024px_controlnet_bf16.yaml")
pipe.from_pretrained("hf://Efficient-Large-Model/Sana_1600M_1024px_BF16_ControlNet_HED/checkpoints/Sana_1600M_1024px_BF16_ControlNet_HED.pth")
ref_image = Image.open("asset/controlnet/ref_images/A transparent sculpture of a duck made out of glass. The sculpture is in front of a painting of a la.jpg")
prompt = "A transparent sculpture of a duck made out of glass. The sculpture is in front of a painting of a landscape."
images = pipe(
prompt=prompt,
ref_image=ref_image,
guidance_scale=4.5,
num_inference_steps=10,
sketch_thickness=2,
generator=torch.Generator(device=device).manual_seed(0),
)
```
## Training of `Sana + ControlNet`
### Coming soon | {
"source": "NVlabs/Sana",
"title": "asset/docs/sana_controlnet.md",
"url": "https://github.com/NVlabs/Sana/blob/main/asset/docs/sana_controlnet.md",
"date": "2024-10-11T20:19:45",
"stars": 3449,
"description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer",
"file_size": 2989
} |
# DreamBooth training example for SANA
[DreamBooth](https://arxiv.org/abs/2208.12242) is a method to personalize text2image models like stable diffusion given just a few (3~5) images of a subject.
The `train_dreambooth_lora_sana.py` script shows how to implement the training procedure with [LoRA](https://huggingface.co/docs/peft/conceptual_guides/adapter#low-rank-adaptation-lora) and adapt it for [SANA](https://arxiv.org/abs/2410.10629).
This will also allow us to push the trained model parameters to the Hugging Face Hub platform.
## Running locally with PyTorch
### Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
**Important**
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install -e .
```
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
Or for a default accelerate configuration without answering questions about your environment
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell (e.g., a notebook)
```python
from accelerate.utils import write_basic_config
write_basic_config()
```
When running `accelerate config`, if we specify torch compile mode to True there can be dramatic speedups.
Note also that we use PEFT library as backend for LoRA training, make sure to have `peft>=0.14.0` installed in your environment.
### Dog toy example
Now let's get our dataset. For this example we will use some dog images: https://huggingface.co/datasets/diffusers/dog-example.
Let's first download it locally:
```python
from huggingface_hub import snapshot_download
local_dir = "data/dreambooth/dog"
snapshot_download(
"diffusers/dog-example",
local_dir=local_dir, repo_type="dataset",
ignore_patterns=".gitattributes",
)
```
This will also allow us to push the trained LoRA parameters to the Hugging Face Hub platform.
[Here is the Model Card](model_zoo.md) for you to choose the desired pre-trained models and set it to `MODEL_NAME`.
Now, we can launch training using [file here](../../train_scripts/train_lora.sh):
```bash
bash train_scripts/train_lora.sh
```
or you can run it locally:
```bash
export MODEL_NAME="Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers"
export INSTANCE_DIR="data/dreambooth/dog"
export OUTPUT_DIR="trained-sana-lora"
accelerate launch --num_processes 8 --main_process_port 29500 --gpu_ids 0,1,2,3 \
train_scripts/train_dreambooth_lora_sana.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--output_dir=$OUTPUT_DIR \
--mixed_precision="bf16" \
--instance_prompt="a photo of sks dog" \
--resolution=1024 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--use_8bit_adam \
--learning_rate=1e-4 \
--report_to="wandb" \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=500 \
--validation_prompt="A photo of sks dog in a pond, yarn art style" \
--validation_epochs=25 \
--seed="0" \
--push_to_hub
```
For using `push_to_hub`, make you're logged into your Hugging Face account:
```bash
huggingface-cli login
```
To better track our training experiments, we're using the following flags in the command above:
- `report_to="wandb` will ensure the training runs are tracked on [Weights and Biases](https://wandb.ai/site). To use it, be sure to install `wandb` with `pip install wandb`. Don't forget to call `wandb login <your_api_key>` before training if you haven't done it before.
- `validation_prompt` and `validation_epochs` to allow the script to do a few validation inference runs. This allows us to qualitatively check if the training is progressing as expected.
## Notes
Additionally, we welcome you to explore the following CLI arguments:
- `--lora_layers`: The transformer modules to apply LoRA training on. Please specify the layers in a comma seperated. E.g. - "to_k,to_q,to_v" will result in lora training of attention layers only.
- `--complex_human_instruction`: Instructions for complex human attention as shown in [here](https://github.com/NVlabs/Sana/blob/main/configs/sana_app_config/Sana_1600M_app.yaml#L55).
- `--max_sequence_length`: Maximum sequence length to use for text embeddings.
We provide several options for optimizing memory optimization:
- `--offload`: When enabled, we will offload the text encoder and VAE to CPU, when they are not used.
- `cache_latents`: When enabled, we will pre-compute the latents from the input images with the VAE and remove the VAE from memory once done.
- `--use_8bit_adam`: When enabled, we will use the 8bit version of AdamW provided by the `bitsandbytes` library.
Refer to the [official documentation](https://huggingface.co/docs/diffusers/main/en/api/pipelines/sana) of the `SanaPipeline` to know more about the models available under the SANA family and their preferred dtypes during inference.
## Samples
We show some samples during Sana-LoRA fine-tuning process below.
<p align="center" border-raduis="10px">
<img src="https://nvlabs.github.io/Sana/asset/content/dreambooth/step0.jpg" width="90%" alt="sana-lora-step0"/>
<br>
<em> training samples at step=0 </em>
</p>
<p align="center" border-raduis="10px">
<img src="https://nvlabs.github.io/Sana/asset/content/dreambooth/step500.jpg" width="90%" alt="sana-lora-step500"/>
<br>
<em> training samples at step=500 </em>
</p> | {
"source": "NVlabs/Sana",
"title": "asset/docs/sana_lora_dreambooth.md",
"url": "https://github.com/NVlabs/Sana/blob/main/asset/docs/sana_lora_dreambooth.md",
"date": "2024-10-11T20:19:45",
"stars": 3449,
"description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer",
"file_size": 5783
} |
## 🖌️ Sana-ComfyUI
[Original Repo](https://github.com/city96/ComfyUI_ExtraModels)
### Model info / implementation
- Uses Gemma2 2B as the text encoder
- Multiple resolutions and models available
- Compressed latent space (32 channels, /32 compression) - needs custom VAE
### Usage
1. All the checkpoints will be downloaded automatically.
1. KSampler(Flow Euler) is available for now; Flow DPM-Solver will be available soon.
```bash
git clone https://github.com/comfyanonymous/ComfyUI.git
cd ComfyUI
git clone https://github.com/Efficient-Large-Model/ComfyUI_ExtraModels.git custom_nodes/ComfyUI_ExtraModels
python main.py
```
### A sample workflow for Sana
[Sana workflow](Sana_FlowEuler.json)
### A sample for T2I(Sana) + I2V(CogVideoX)
[Sana + CogVideoX workflow](Sana_CogVideoX.json)
[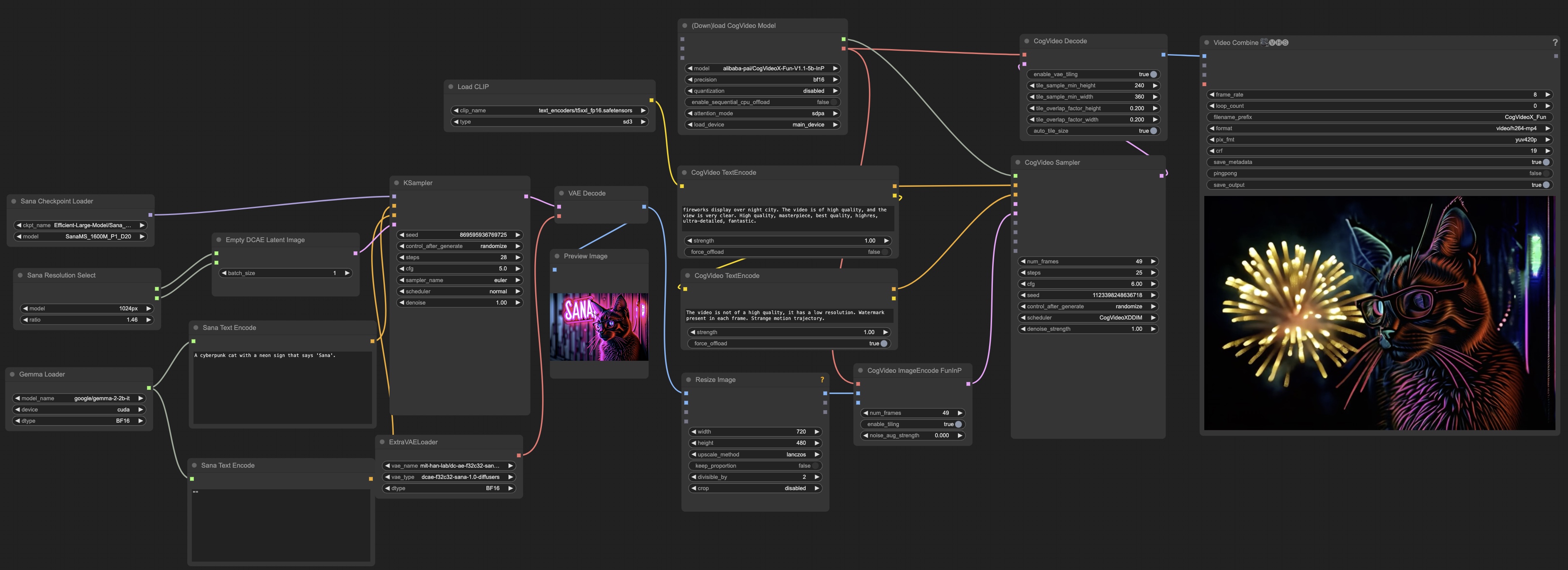](https://nvlabs.github.io/Sana/asset/content/comfyui/Sana_CogVideoX_Fun.mp4)
### A sample workflow for Sana 4096x4096 image (18GB GPU is needed)
[Sana workflow](Sana_FlowEuler_4K.json)
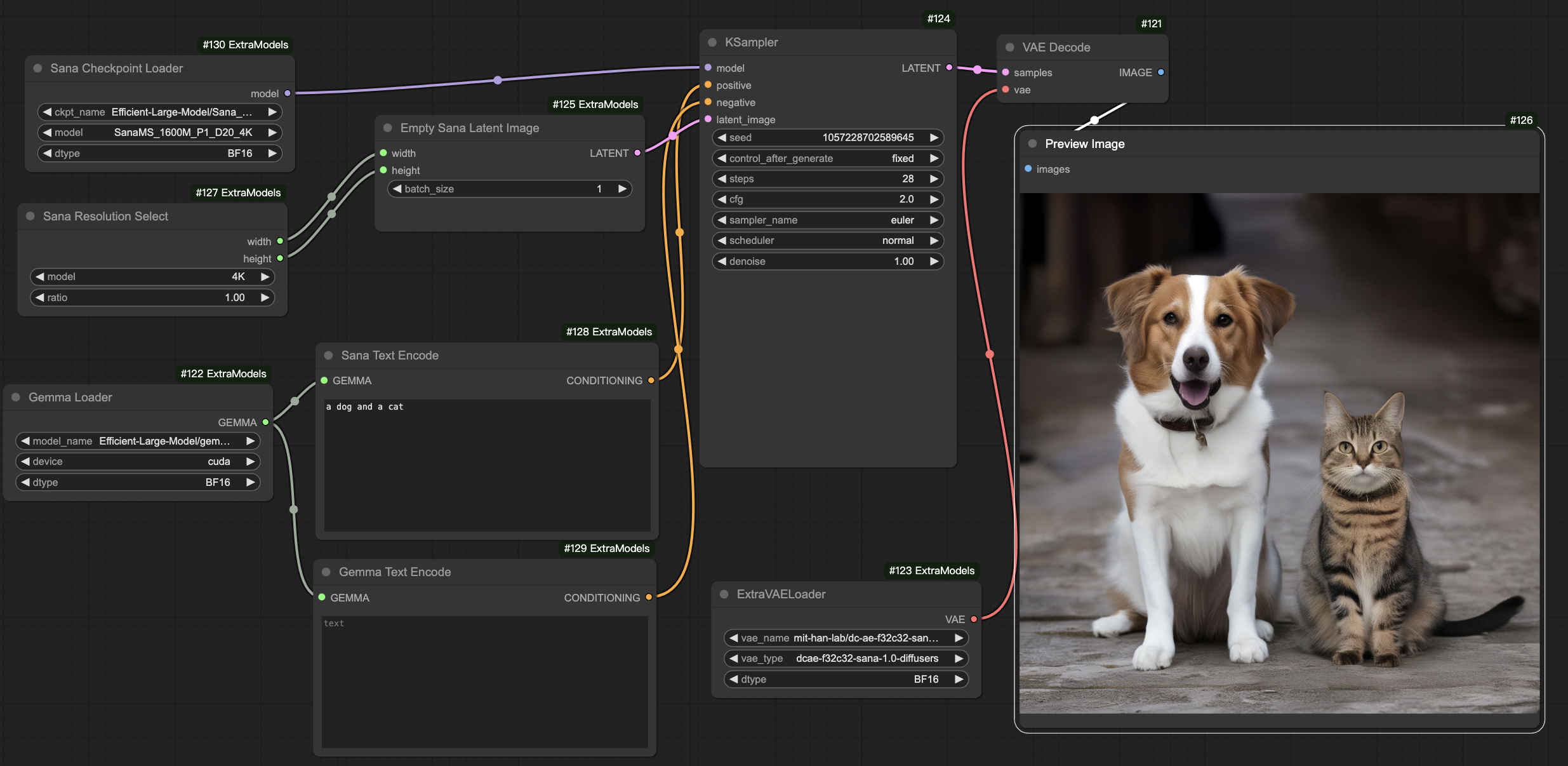 | {
"source": "NVlabs/Sana",
"title": "asset/docs/ComfyUI/comfyui.md",
"url": "https://github.com/NVlabs/Sana/blob/main/asset/docs/ComfyUI/comfyui.md",
"date": "2024-10-11T20:19:45",
"stars": 3449,
"description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer",
"file_size": 1328
} |
# CLIP Score for PyTorch
[](https://pypi.org/project/clip-score/)
This repository provides a batch-wise quick processing for calculating CLIP scores. It uses the pretrained CLIP model to measure the cosine similarity between two modalities. The project structure is adapted from [pytorch-fid](https://github.com/mseitzer/pytorch-fid) and [CLIP](https://github.com/openai/CLIP).
## Installation
Requirements:
- Install PyTorch:
```
pip install torch # Choose a version that suits your GPU
```
- Install CLIP:
```
pip install git+https://github.com/openai/CLIP.git
```
- Install clip-score from [PyPI](https://pypi.org/project/clip-score/):
```
pip install clip-score
```
## Data Input Specifications
This project is designed to process paired images and text files, and therefore requires two directories: one for images and one for text files.
### Image Files
All images should be stored in a single directory. The image files can be in either `.png` or `.jpg` format.
### Text Files
All text data should be contained in plain text files in a separate directory. These text files should have the extension `.txt`.
### File Number and Naming
The number of files in the image directory should be exactly equal to the number of files in the text directory. Additionally, the files in the image directory and text directory should be paired by file name. For instance, if there is a `cat.png` in the image directory, there should be a corresponding `cat.txt` in the text directory.
### Directory Structure Example
Below is an example of the expected directory structure:
```plaintext
├── path/to/image
│ ├── cat.png
│ ├── dog.png
│ └── bird.jpg
└── path/to/text
├── cat.txt
├── dog.txt
└── bird.txt
```
In this example, `cat.png` is paired with `cat.txt`, `dog.png` is paired with `dog.txt`, and `bird.jpg` is paired with `bird.txt`.
Please adhere to the specified structure to ensure correct operation of the program. If there are any questions or issues, feel free to raise an issue here on GitHub.
## Usage
To compute the CLIP score between images and texts, make sure that the image and text data are contained in two separate folders, and each sample has the same name in both modalities. Run the following command:
```
python -m clip_score path/to/image path/to/text
```
If GPU is available, the project is set to run automatically on a GPU by default. If you want to specify a particular GPU, you can use the `--device cuda:N` flag when running the script, where `N` is the index of the GPU you wish to use. In case you want to run the program on a CPU instead, you can specify this by using the `--device cpu` flag.
## Computing CLIP Score within the Same Modality
If you want to calculate the CLIP score within the same modality (e.g., image-image or text-text), follow the same folder structure as mentioned above. Additionally, specify the preferred modalities using the `--real_flag` and `--fake_flag` options. By default, `--real_flag=img` and `--fake_flag=txt`. Examples:
```
python -m clip_score path/to/imageA path/to/imageB --real_flag img --fake_flag img
python -m clip_score path/to/textA path/to/textB --real_flag txt --fake_flag txt
```
## Citing
If you use this repository in your research, consider citing it using the following Bibtex entry:
```
@misc{taited2023CLIPScore,
author={SUN Zhengwentai},
title={{clip-score: CLIP Score for PyTorch}},
month={March},
year={2023},
note={Version 0.1.1},
howpublished={\url{https://github.com/taited/clip-score}},
}
```
## License
This implementation is licensed under the Apache License 2.0.
The project structure is adapted from [mseitzer's pytorch-fid](https://github.com/mseitzer/pytorch-fid) project. The CLIP model is adapted from [OpenAI's CLIP](https://github.com/openai/CLIP).
The CLIP Score was introduced in OpenAI's [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020). | {
"source": "NVlabs/Sana",
"title": "tools/metrics/clip-score/README.md",
"url": "https://github.com/NVlabs/Sana/blob/main/tools/metrics/clip-score/README.md",
"date": "2024-10-11T20:19:45",
"stars": 3449,
"description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer",
"file_size": 4028
} |
# GenEval: An Object-Focused Framework for Evaluating Text-to-Image Alignment
This repository contains code for the paper [GenEval: An Object-Focused Framework for Evaluating Text-to-Image Alignment](https://arxiv.org/abs/2310.11513) by Dhruba Ghosh, Hanna Hajishirzi, and Ludwig Schmidt.
TLDR: We demonstrate the advantages of evaluating text-to-image models using existing object detection methods, to produce a fine-grained instance-level analysis of compositional capabilities.
### Abstract
*Recent breakthroughs in diffusion models, multimodal pretraining, and efficient finetuning have led to an explosion of text-to-image generative models.
Given human evaluation is expensive and difficult to scale, automated methods are critical for evaluating the increasingly large number of new models.
However, most current automated evaluation metrics like FID or CLIPScore only offer a holistic measure of image quality or image-text alignment, and are unsuited for fine-grained or instance-level analysis.
In this paper, we introduce GenEval, an object-focused framework to evaluate compositional image properties such as object co-occurrence, position, count, and color.
We show that current object detection models can be leveraged to evaluate text-to-image models on a variety of generation tasks with strong human agreement, and that other discriminative vision models can be linked to this pipeline to further verify properties like object color.
We then evaluate several open-source text-to-image models and analyze their relative generative capabilities on our benchmark.
We find that recent models demonstrate significant improvement on these tasks, though they are still lacking in complex capabilities such as spatial relations and attribute binding.
Finally, we demonstrate how GenEval might be used to help discover existing failure modes, in order to inform development of the next generation of text-to-image models.*
### Summary figure
<p align="center">
<img src="images/geneval_figure_1.png" alt="figure1"/>
</p>
### Main results
| Model | Overall | <span style="font-weight:normal">Single object</span> | <span style="font-weight:normal">Two object</span> | <span style="font-weight:normal">Counting</span> | <span style="font-weight:normal">Colors</span> | <span style="font-weight:normal">Position</span> | <span style="font-weight:normal">Color attribution</span> |
| ----- | :-----: | :-----: | :-----: | :-----: | :-----: | :-----: | :-----: |
| CLIP retrieval (baseline) | **0.35** | 0.89 | 0.22 | 0.37 | 0.62 | 0.03 | 0.00 |
minDALL-E | **0.23** | 0.73 | 0.11 | 0.12 | 0.37 | 0.02 | 0.01 |
Stable Diffusion v1.5 | **0.43** | 0.97 | 0.38 | 0.35 | 0.76 | 0.04 | 0.06 |
Stable Diffusion v2.1 | **0.50** | 0.98 | 0.51 | 0.44 | 0.85 | 0.07 | 0.17 |
Stable Diffusion XL | **0.55** | 0.98 | 0.74 | 0.39 | 0.85 | 0.15 | 0.23 |
IF-XL | **0.61** | 0.97 | 0.74 | 0.66 | 0.81 | 0.13 | 0.35 |
## Code
### Setup
Install the dependencies, including `mmdet`, and download the Mask2Former object detector:
```bash
git clone https://github.com/djghosh13/geneval.git
cd geneval
conda env create -f environment.yml
conda activate geneval
./evaluation/download_models.sh "<OBJECT_DETECTOR_FOLDER>/"
git clone https://github.com/open-mmlab/mmdetection.git
cd mmdetection; git checkout 2.x
pip install -v -e .
```
The original GenEval prompts from the paper are already in `prompts/`, but you can sample new prompts with different random seeds using
```bash
python prompts/create_prompts.py --seed <SEED> -n <NUM_PROMPTS> -o "<PROMPT_FOLDER>/"
```
### Image generation
Sample image generation code for Stable Diffusion models is given in `generation/diffusers_generate.py`. Run
```bash
python generation/diffusers_generate.py \
"<PROMPT_FOLDER>/evaluation_metadata.jsonl" \
--model "runwayml/stable-diffusion-v1-5" \
--outdir "<IMAGE_FOLDER>"
```
to generate 4 images per prompt using Stable Diffusion v1.5 and save in `<IMAGE_FOLDER>`.
The generated format should be
```
<IMAGE_FOLDER>/
00000/
metadata.jsonl
grid.png
samples/
0000.png
0001.png
0002.png
0003.png
00001/
...
```
where `metadata.jsonl` contains the `N`-th line from `evaluation_metadata.jsonl`. `grid.png` is optional here.
### Evaluation
```bash
python evaluation/evaluate_images.py \
"<IMAGE_FOLDER>" \
--outfile "<RESULTS_FOLDER>/results.jsonl" \
--model-path "<OBJECT_DETECTOR_FOLDER>"
```
This will result in a JSONL file with each line corresponding to an image. In particular, each line has a `correct` key and a `reason` key specifying whether the generated image was deemed correct and, if applicable, why it was marked incorrect. You can run
```bash
python evaluation/summary_scores.py "<RESULTS_FOLDER>/results.jsonl"
```
to get the score across each task, and the overall GenEval score. | {
"source": "NVlabs/Sana",
"title": "tools/metrics/geneval/README.md",
"url": "https://github.com/NVlabs/Sana/blob/main/tools/metrics/geneval/README.md",
"date": "2024-10-11T20:19:45",
"stars": 3449,
"description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer",
"file_size": 4909
} |
# Changelog
## \[0.3.0\] - 2023-01-05
### Added
- Add argument `--save-stats` allowing to compute dataset statistics and save them as an `.npz` file ([#80](https://github.com/mseitzer/pytorch-fid/pull/80)). The `.npz` file can be used in subsequent FID computations instead of recomputing the dataset statistics. This option can be used in the following way: `python -m pytorch_fid --save-stats path/to/dataset path/to/outputfile`.
### Fixed
- Do not use `os.sched_getaffinity` to get number of available CPUs on Windows, as it is not available there ([232b3b14](https://github.com/mseitzer/pytorch-fid/commit/232b3b1468800102fcceaf6f2bb8977811fc991a), [#84](https://github.com/mseitzer/pytorch-fid/issues/84)).
- Do not use Inception model argument `pretrained`, as it was deprecated in torchvision 0.13 ([#88](https://github.com/mseitzer/pytorch-fid/pull/88)).
## \[0.2.1\] - 2021-10-10
### Added
- Add argument `--num-workers` to select number of dataloader processes ([#66](https://github.com/mseitzer/pytorch-fid/pull/66)). Defaults to 8 or the number of available CPUs if less than 8 CPUs are available.
### Fixed
- Fixed package setup to work under Windows ([#55](https://github.com/mseitzer/pytorch-fid/pull/55), [#72](https://github.com/mseitzer/pytorch-fid/issues/72))
## \[0.2.0\] - 2020-11-30
### Added
- Load images using a Pytorch dataloader, which should result in a speed-up. ([#47](https://github.com/mseitzer/pytorch-fid/pull/47))
- Support more image extensions ([#53](https://github.com/mseitzer/pytorch-fid/pull/53))
- Improve tooling by setting up Nox, add linting and test support ([#52](https://github.com/mseitzer/pytorch-fid/pull/52))
- Add some unit tests
## \[0.1.1\] - 2020-08-16
### Fixed
- Fixed software license string in `setup.py`
## \[0.1.0\] - 2020-08-16
Initial release as a pypi package. Use `pip install pytorch-fid` to install. | {
"source": "NVlabs/Sana",
"title": "tools/metrics/pytorch-fid/CHANGELOG.md",
"url": "https://github.com/NVlabs/Sana/blob/main/tools/metrics/pytorch-fid/CHANGELOG.md",
"date": "2024-10-11T20:19:45",
"stars": 3449,
"description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer",
"file_size": 1885
} |
[](https://pypi.org/project/pytorch-fid/)
# FID score for PyTorch
This is a port of the official implementation of [Fréchet Inception Distance](https://arxiv.org/abs/1706.08500) to PyTorch.
See [https://github.com/bioinf-jku/TTUR](https://github.com/bioinf-jku/TTUR) for the original implementation using Tensorflow.
FID is a measure of similarity between two datasets of images.
It was shown to correlate well with human judgement of visual quality and is most often used to evaluate the quality of samples of Generative Adversarial Networks.
FID is calculated by computing the [Fréchet distance](https://en.wikipedia.org/wiki/Fr%C3%A9chet_distance) between two Gaussians fitted to feature representations of the Inception network.
Further insights and an independent evaluation of the FID score can be found in [Are GANs Created Equal? A Large-Scale Study](https://arxiv.org/abs/1711.10337).
The weights and the model are exactly the same as in [the official Tensorflow implementation](https://github.com/bioinf-jku/TTUR), and were tested to give very similar results (e.g. `.08` absolute error and `0.0009` relative error on LSUN, using ProGAN generated images). However, due to differences in the image interpolation implementation and library backends, FID results still differ slightly from the original implementation. So if you report FID scores in your paper, and you want them to be *exactly comparable* to FID scores reported in other papers, you should consider using [the official Tensorflow implementation](https://github.com/bioinf-jku/TTUR).
## Installation
Install from [pip](https://pypi.org/project/pytorch-fid/):
```
pip install pytorch-fid
```
Requirements:
- python3
- pytorch
- torchvision
- pillow
- numpy
- scipy
## Usage
To compute the FID score between two datasets, where images of each dataset are contained in an individual folder:
```
python -m pytorch_fid path/to/dataset1 path/to/dataset2
```
To run the evaluation on GPU, use the flag `--device cuda:N`, where `N` is the index of the GPU to use.
### Using different layers for feature maps
In difference to the official implementation, you can choose to use a different feature layer of the Inception network instead of the default `pool3` layer.
As the lower layer features still have spatial extent, the features are first global average pooled to a vector before estimating mean and covariance.
This might be useful if the datasets you want to compare have less than the otherwise required 2048 images.
Note that this changes the magnitude of the FID score and you can not compare them against scores calculated on another dimensionality.
The resulting scores might also no longer correlate with visual quality.
You can select the dimensionality of features to use with the flag `--dims N`, where N is the dimensionality of features.
The choices are:
- 64: first max pooling features
- 192: second max pooling features
- 768: pre-aux classifier features
- 2048: final average pooling features (this is the default)
## Generating a compatible `.npz` archive from a dataset
A frequent use case will be to compare multiple models against an original dataset.
To save training multiple times on the original dataset, there is also the ability to generate a compatible `.npz` archive from a dataset. This is done using any combination of the previously mentioned arguments with the addition of the `--save-stats` flag. For example:
```
python -m pytorch_fid --save-stats path/to/dataset path/to/outputfile
```
The output file may then be used in place of the path to the original dataset for further comparisons.
## Citing
If you use this repository in your research, consider citing it using the following Bibtex entry:
```
@misc{Seitzer2020FID,
author={Maximilian Seitzer},
title={{pytorch-fid: FID Score for PyTorch}},
month={August},
year={2020},
note={Version 0.3.0},
howpublished={\url{https://github.com/mseitzer/pytorch-fid}},
}
```
## License
This implementation is licensed under the Apache License 2.0.
FID was introduced by Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler and Sepp Hochreiter in "GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium", see [https://arxiv.org/abs/1706.08500](https://arxiv.org/abs/1706.08500)
The original implementation is by the Institute of Bioinformatics, JKU Linz, licensed under the Apache License 2.0.
See [https://github.com/bioinf-jku/TTUR](https://github.com/bioinf-jku/TTUR). | {
"source": "NVlabs/Sana",
"title": "tools/metrics/pytorch-fid/README.md",
"url": "https://github.com/NVlabs/Sana/blob/main/tools/metrics/pytorch-fid/README.md",
"date": "2024-10-11T20:19:45",
"stars": 3449,
"description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer",
"file_size": 4561
} |
# a fast implementation of linear attention
## 64x64, fp16
```bash
# validate correctness
## fp16 vs fp32
python -m develop_triton_litemla attn_type=LiteMLA test_correctness=True
## triton fp16 vs fp32
python -m develop_triton_litemla attn_type=TritonLiteMLA test_correctness=True
# test performance
## fp16, forward
python -m develop_triton_litemla attn_type=LiteMLA
each step takes 10.81 ms
max memory allocated: 2.2984 GB
## triton fp16, forward
python -m develop_triton_litemla attn_type=TritonLiteMLA
each step takes 4.70 ms
max memory allocated: 1.6480 GB
## fp16, backward
python -m develop_triton_litemla attn_type=LiteMLA backward=True
each step takes 35.34 ms
max memory allocated: 3.4412 GB
## triton fp16, backward
python -m develop_triton_litemla attn_type=TritonLiteMLA backward=True
each step takes 14.25 ms
max memory allocated: 2.4704 GB
``` | {
"source": "NVlabs/Sana",
"title": "diffusion/model/nets/fastlinear/readme.md",
"url": "https://github.com/NVlabs/Sana/blob/main/diffusion/model/nets/fastlinear/readme.md",
"date": "2024-10-11T20:19:45",
"stars": 3449,
"description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer",
"file_size": 864
} |
<p align="left">
<a href="README_CN.md">中文</a>  |   English   |  <a href="README_JP.md">日本語</a>
</p>
<br><br>
# Step-Audio
<p align="center">
<img src="assets/logo.png" height=100>
</p>
<div align="center">
<a href="https://arxiv.org/abs/2502.11946"><img src="https://img.shields.io/static/v1?label=Tech Report&message=Arxiv&color=red"></a>  
<a href="https://x.com/StepFun_ai"><img src="https://img.shields.io/static/v1?label=X.com&message=Web&color=blue"></a>  
</div>
<div align="center">
<a href="https://huggingface.co/stepfun-ai/Step-Audio-Chat"><img src="https://img.shields.io/static/v1?label=Step-Audio-Chat&message=HuggingFace&color=yellow"></a>  
<a href="https://huggingface.co/stepfun-ai/Step-Audio-TTS-3B"><img src="https://img.shields.io/static/v1?label=Step-Audio-TTS-3B&message=HuggingFace&color=yellow"></a>  
</div>
<div align="center">
<a href="https://huggingface.co/stepfun-ai/Step-Audio-Tokenizer"><img src="https://img.shields.io/static/v1?label=Step-Audio-Tokenier&message=HuggingFace&color=yellow"></a>  
<a href="https://huggingface.co/datasets/stepfun-ai/StepEval-Audio-360"><img src="https://img.shields.io/static/v1?label=StepEval-Audio-360&message=HuggingFace&color=yellow"></a>  
</div>
## 🔥🔥🔥 News!!
* Feb 17, 2025: 👋 We release the inference code and model weights of [Step-Audio-Chat](https://huggingface.co/stepfun-ai/Step-Audio-Chat), [Step-Audio-TTS-3B](https://huggingface.co/stepfun-ai/Step-Audio-TTS-3B) and [Step-Audio-Tokenizer](https://huggingface.co/stepfun-ai/Step-Audio-Tokenizer)
* Feb 17, 2025: 👋 We release the multi-turn audio benchmark of [StepEval-Audio-360](https://huggingface.co/datasets/stepfun-ai/StepEval-Audio-360).
* Feb 17, 2025: 👋 We release the technical report of [Step-Audio](https://arxiv.org/abs/2502.11946).
## Table of Contents
1. [Introduction](#1-introduction)
2. [Model Summary](#2-model-summary)
3. [Model Download](#3-model-download)
4. [Model Usage](#4-model-usage)
5. [Benchmark](#5-benchmark)
6. [Online Engine](#6-online-engine)
7. [Examples](#7-examples)
8. [Acknowledgements](#8-acknowledgements)
9. [License Agreement](#9-license-agreement)
10. [Citation](#10-citation)
## 1. Introduction
Step-Audio is the first production-ready open-source framework for intelligent speech interaction that harmonizes comprehension and generation, supporting multilingual conversations (e.g., Chinese, English, Japanese), emotional tones (e.g., joy/sadness), regional dialects (e.g., Cantonese/Sichuanese), adjustable speech rates, and prosodic styles (e.g., rap). Step-Audio demonstrates four key technical innovations:
- **130B-Parameter Multimodal Model**: A single unified model integrating comprehension and generation capabilities, performing speech recognition, semantic understanding, dialogue, voice cloning, and speech synthesis. We have made the 130B Step-Audio-Chat variant open source.
- **Generative Data Engine**: Eliminates traditional TTS's reliance on manual data collection by generating high-quality audio through our 130B-parameter multimodal model. Leverages this data to train and publicly release a resource-efficient Step-Audio-TTS-3B model with enhanced instruction-following capabilities for controllable speech synthesis.
- **Granular Voice Control**: Enables precise regulation through instruction-based control design, supporting multiple emotions (anger, joy, sadness), dialects (Cantonese, Sichuanese, etc.), and vocal styles (rap, a cappella humming) to meet diverse speech generation needs.
- **Enhanced Intelligence**: Improves agent performance in complex tasks through ToolCall mechanism integration and role-playing enhancements.
## 2. Model Summary
In Step-Audio, audio streams are tokenized via a dual-codebook framework, combining parallel semantic (16.7Hz, 1024-entry codebook) and acoustic (25Hz, 4096-entry codebook) tokenizers with 2:3 temporal interleaving. A 130B-parameter LLM foundation (Step-1) is further enhanced via audio-contextualized continual pretraining and task-specific post-training, enabling robust cross-modal speech understanding. A hybrid speech decoder combining flow matching with neural vocoding, optimized for real-time waveform generation. A streaming-aware architecture featuring speculative response generation (40\% commit rate) and text-based context management (14:1 compression ratio) for efficient cross-modal alignment.

### 2.1 Tokenizer
We implement a token-level interleaving approach to effectively integrate semantic tokenization and acoustic tokenization. The semantic tokenizer employs a codebook size of 1024, while the acoustic tokenizer utilizes a larger codebook size of 4096 to capture finer acoustic details. Given the differing token rates, we establish a temporal alignment ratio of 2:3, where every two semantic tokens are paired with three acoustic tokens.
### 2.2 Language Model
To enhance Step-Audio’s ability to effectively process speech information and
achieve accurate speech-text alignment, we conducted audio continual pretrain-ing based on Step-1, a 130-billion parameter pretrained text-based large language model (LLM).
### 2.3 Speech Decoder
The speech decoder in Step-Audio serves a critical function in converting discrete speech tokens, which contain both semantic and acoustic information, into continuous time-domain waveforms that represent natural speech. The decoder architecture incorporates a flow matching model and a mel-to-wave vocoder. To optimize the intelligibility and naturalness of the synthesized speech, the speech decoder is trained using a dual-code interleaving approach, ensuring seamless integration of semantic and acoustic features throughout the generation process.
### 2.4 Real-time Inference Pipeline
To enable real-time interactions, we have designed an optimized inference pipeline. At its core, the Controller module manages state transitions, orchestrates speculative response generation, and ensures seamless coordination between critical subsystems. These subsystems include Voice Activity Detection (VAD) for detecting user speech, the Streaming Audio Tokenizer for processing audio in real-time, the Step-Audio language model and Speech Decoder for processing and generating responses, and the Context Manager for preserving conversational continuity.

### 2.5 Post training details
In the post-training phase, we conducted task-specific Supervised Fine-Tuning (SFT) for Automatic Speech Recognition (ASR) and Text-to-Speech (TTS). For Audio Input Text Output (AQTA) tasks, we implemented SFT using diversified high-quality datasets combined with Reinforcement Learning from Human Feedback (RLHF) to enhance response quality, enabling fine-grained control over emotional expression, speech speed, dialect, and prosody.

## 3. Model Download
### 3.1 Huggingface
| Models | Links |
|-------|-------|
| Step-Audio-Tokenizer | [🤗huggingface](https://huggingface.co/stepfun-ai/Step-Audio-Tokenizer) |
| Step-Audio-Chat | [🤗huggingface](https://huggingface.co/stepfun-ai/Step-Audio-Chat) |
| Step-Audio-TTS-3B | [🤗huggingface](https://huggingface.co/stepfun-ai/Step-Audio-TTS-3B) |
### 3.2 Modelscope
| Models | Links |
|-------|-------|
| Step-Audio-Tokenizer | [modelscope](https://modelscope.cn/models/stepfun-ai/Step-Audio-Tokenizer) |
| Step-Audio-Chat | [modelscope](https://modelscope.cn/models/stepfun-ai/Step-Audio-Chat) |
| Step-Audio-TTS-3B | [modelscope](https://modelscope.cn/models/stepfun-ai/Step-Audio-TTS-3B) |
## 4. Model Usage
### 📜 4.1 Requirements
The following table shows the requirements for running Step-Audio model (batch size = 1):
| Model | Setting<br/>(sample frequency) | GPU Minimum Memory |
|------------|--------------------------------|----------------|
| Step-Audio-Tokenizer | 41.6Hz | 1.5GB |
| Step-Audio-Chat | 41.6Hz | 265GB |
| Step-Audio-TTS-3B | 41.6Hz | 8GB |
* An NVIDIA GPU with CUDA support is required.
* The model is tested on a four A800 80G GPU.
* **Recommended**: We recommend using 4xA800/H800 GPU with 80GB memory for better generation quality.
* Tested operating system: Linux
### 🔧 4.2 Dependencies and Installation
- Python >= 3.10.0 (Recommend to use [Anaconda](https://www.anaconda.com/download/#linux) or [Miniconda](https://docs.conda.io/en/latest/miniconda.html))
- [PyTorch >= 2.3-cu121](https://pytorch.org/)
- [CUDA Toolkit](https://developer.nvidia.com/cuda-downloads)
```bash
git clone https://github.com/stepfun-ai/Step-Audio.git
conda create -n stepaudio python=3.10
conda activate stepaudio
cd Step-Audio
pip install -r requirements.txt
git lfs install
git clone https://huggingface.co/stepfun-ai/Step-Audio-Tokenizer
git clone https://huggingface.co/stepfun-ai/Step-Audio-Chat
git clone https://huggingface.co/stepfun-ai/Step-Audio-TTS-3B
```
After downloading the models, where_you_download_dir should have the following structure:
```
where_you_download_dir
├── Step-Audio-Tokenizer
├── Step-Audio-Chat
├── Step-Audio-TTS-3B
```
### 🚀 4.3 Inference Scripts
#### Offline inference
Inference with e2e audio/text input and audio/text output.
```bash
python offline_inference.py --model-path where_you_download_dir
```
#### TTS inference
Inference tts with default speaker or clone with a new speaker
```bash
python tts_inference.py --model-path where_you_download_dir --output-path where_you_save_audio_dir --synthesis-type use_tts_or_clone
```
A speaker information dict is required for clone mode, formatted as follows:
```bash
{
"speaker": "speaker id",
"prompt_text": "content of prompt wav",
"wav_path": "prompt wav path"
}
```
#### Launch Web Demo
Start a local server for online inference.
Assume you have 4 GPUs available and have already downloaded all the models.
```bash
python app.py --model-path where_you_download_dir
```
#### Inference Chat Model with vLLM (recommended)
Step-Audio-Chat is a 130B LLM Model, it is recommended to use vLLM to inference with tensor parallelism.
Currently, the official vLLM does not support the Step 1 model. You can temporarily use our [development branch](https://github.com/Oliver-ss/vllm/tree/add-step1-model) for local installation.
**Because our attention mechanism is a variant of ALIBI, the official flash attention library is not compatible. We have provided a custom flash attention library in the [Step-Audio-Chat](https://huggingface.co/stepfun-ai/Step-Audio-Chat/tree/main/lib) repository. Make sure export the custom flash attention library to the environment variable before running the model.**
```bash
export OPTIMUS_LIB_PATH=where_you_download_dir/Step-Audio-Chat/lib
vllm serve where_you_download_dir/Step-Audio-Chat --dtype auto -tp $tp --served-model-name step_chat_audio --trust-remote-code
```
## 5. Benchmark
### 5.1 ASR result comparison
<table>
<thead>
<tr>
<th style="text-align:center"></th>
<th colspan="4" style="text-align:center">Hidden Feature Modeling</th>
<th colspan="5" style="text-align:center">Discrete Audio Token Modeling</th>
</tr>
<tr>
<th style="text-align:center"></th>
<th style="text-align:center">Whisper Large-v3</th>
<th style="text-align:center">Qwen2-Audio</th>
<th style="text-align:center">MinMo</th>
<th style="text-align:center">LUCY</th>
<th style="text-align:center">Moshi</th>
<th style="text-align:center">GLM-4-voice Base</th>
<th style="text-align:center">GLM-4-voice Chat</th>
<th style="text-align:center">Step-Audio Pretrain</th>
<th style="text-align:center">Step-Audio-Chat</th>
</tr>
</thead>
<tbody>
<tr>
<td>Aishell-1</td>
<td style="text-align:center">5.14</td>
<td style="text-align:center">1.53</td>
<td style="text-align:center">-</td>
<td style="text-align:center">2.4</td>
<td style="text-align:center">-</td>
<td style="text-align:center">2.46</td>
<td style="text-align:center">226.47</td>
<td style="text-align:center"><strong>0.87</strong></td>
<td style="text-align:center">1.95</td>
</tr>
<tr>
<td>Aishell-2 ios</td>
<td style="text-align:center">4.76</td>
<td style="text-align:center">3.06</td>
<td style="text-align:center"><strong>2.69</strong></td>
<td style="text-align:center">-</td>
<td style="text-align:center">-</td>
<td style="text-align:center">-</td>
<td style="text-align:center">211.3</td>
<td style="text-align:center">2.91</td>
<td style="text-align:center">3.57</td>
</tr>
<tr>
<td>Wenetspeech test-net</td>
<td style="text-align:center">9.68</td>
<td style="text-align:center">7.72</td>
<td style="text-align:center"><strong>6.64</strong></td>
<td style="text-align:center">8.78</td>
<td style="text-align:center">-</td>
<td style="text-align:center">-</td>
<td style="text-align:center">146.05</td>
<td style="text-align:center">7.62</td>
<td style="text-align:center">8.75</td>
</tr>
<tr>
<td>Wenet test-meeting</td>
<td style="text-align:center">18.54</td>
<td style="text-align:center">8.4</td>
<td style="text-align:center"><strong>7.6</strong></td>
<td style="text-align:center">10.42</td>
<td style="text-align:center">-</td>
<td style="text-align:center">-</td>
<td style="text-align:center">140.82</td>
<td style="text-align:center">7.78</td>
<td style="text-align:center">9.52</td>
</tr>
<tr>
<td>Librispeech test-clean</td>
<td style="text-align:center">1.9</td>
<td style="text-align:center"><strong>1.6</strong></td>
<td style="text-align:center"><strong>1.6</strong></td>
<td style="text-align:center">3.36</td>
<td style="text-align:center">5.7</td>
<td style="text-align:center">2.82</td>
<td style="text-align:center">75.39</td>
<td style="text-align:center">2.36</td>
<td style="text-align:center">3.11</td>
</tr>
<tr>
<td>Librispeech test-other</td>
<td style="text-align:center">3.65</td>
<td style="text-align:center"><strong>3.6</strong></td>
<td style="text-align:center">3.82</td>
<td style="text-align:center">8.05</td>
<td style="text-align:center">-</td>
<td style="text-align:center">7.66</td>
<td style="text-align:center">80.3</td>
<td style="text-align:center">6.32</td>
<td style="text-align:center">8.44</td>
</tr>
<tr>
<td>AVG</td>
<td style="text-align:center">7.28</td>
<td style="text-align:center"><strong>4.32</strong></td>
<td style="text-align:center">-</td>
<td style="text-align:center">-</td>
<td style="text-align:center">-</td>
<td style="text-align:center">-</td>
<td style="text-align:center">146.74</td>
<td style="text-align:center">4.64</td>
<td style="text-align:center">5.89</td>
</tr>
</tbody>
</table>
### 5.2 TTS
#### 5.2.1 Performance comparison of content consistency (CER/WER) between GLM-4-Voice and MinMo.
<table>
<thead>
<tr>
<th rowspan="2">Model</th>
<th style="text-align:center" colspan="1">test-zh</th>
<th style="text-align:center" colspan="1">test-en</th>
</tr>
<tr>
<th style="text-align:center">CER (%) ↓</th>
<th style="text-align:center">WER (%) ↓</th>
</tr>
</thead>
<tbody>
<tr>
<td>GLM-4-Voice</td>
<td style="text-align:center">2.19</td>
<td style="text-align:center">2.91</td>
</tr>
<tr>
<td>MinMo</td>
<td style="text-align:center">2.48</td>
<td style="text-align:center">2.90</td>
</tr>
<tr>
<td><strong>Step-Audio</strong></td>
<td style="text-align:center"><strong>1.53</strong></td>
<td style="text-align:center"><strong>2.71</strong></td>
</tr>
</tbody>
</table>
#### 5.2.2 Results of TTS Models on SEED Test Sets.
* StepAudio-TTS-3B-Single denotes dual-codebook backbone with single-codebook vocoder*
<table>
<thead>
<tr>
<th rowspan="2">Model</th>
<th style="text-align:center" colspan="2">test-zh</th>
<th style="text-align:center" colspan="2">test-en</th>
</tr>
<tr>
<th style="text-align:center">CER (%) ↓</th>
<th style="text-align:center">SS ↑</th>
<th style="text-align:center">WER (%) ↓</th>
<th style="text-align:center">SS ↑</th>
</tr>
</thead>
<tbody>
<tr>
<td>FireRedTTS</td>
<td style="text-align:center">1.51</td>
<td style="text-align:center">0.630</td>
<td style="text-align:center">3.82</td>
<td style="text-align:center">0.460</td>
</tr>
<tr>
<td>MaskGCT</td>
<td style="text-align:center">2.27</td>
<td style="text-align:center">0.774</td>
<td style="text-align:center">2.62</td>
<td style="text-align:center">0.774</td>
</tr>
<tr>
<td>CosyVoice</td>
<td style="text-align:center">3.63</td>
<td style="text-align:center">0.775</td>
<td style="text-align:center">4.29</td>
<td style="text-align:center">0.699</td>
</tr>
<tr>
<td>CosyVoice 2</td>
<td style="text-align:center">1.45</td>
<td style="text-align:center">0.806</td>
<td style="text-align:center">2.57</td>
<td style="text-align:center">0.736</td>
</tr>
<tr>
<td>CosyVoice 2-S</td>
<td style="text-align:center">1.45</td>
<td style="text-align:center">0.812</td>
<td style="text-align:center">2.38</td>
<td style="text-align:center">0.743</td>
</tr>
<tr>
<td><strong>Step-Audio-TTS-3B-Single</strong></td>
<td style="text-align:center">1.37</td>
<td style="text-align:center">0.802</td>
<td style="text-align:center">2.52</td>
<td style="text-align:center">0.704</td>
</tr>
<tr>
<td><strong>Step-Audio-TTS-3B</strong></td>
<td style="text-align:center"><strong>1.31</strong></td>
<td style="text-align:center">0.733</td>
<td style="text-align:center"><strong>2.31</strong></td>
<td style="text-align:center">0.660</td>
</tr>
<tr>
<td><strong>Step-Audio-TTS</strong></td>
<td style="text-align:center"><strong>1.17</strong></td>
<td style="text-align:center">0.73</td>
<td style="text-align:center"><strong>2.0</strong></td>
<td style="text-align:center">0.660</td>
</tr>
</tbody>
</table>
#### 5.2.3 Performance comparison of Dual-codebook Resynthesis with Cosyvoice.
<table>
<thead>
<tr>
<th style="text-align:center" rowspan="2">Token</th>
<th style="text-align:center" colspan="2">test-zh</th>
<th style="text-align:center" colspan="2">test-en</th>
</tr>
<tr>
<th style="text-align:center">CER (%) ↓</th>
<th style="text-align:center">SS ↑</th>
<th style="text-align:center">WER (%) ↓</th>
<th style="text-align:center">SS ↑</th>
</tr>
</thead>
<tbody>
<tr>
<td style="text-align:center">Groundtruth</td>
<td style="text-align:center">0.972</td>
<td style="text-align:center">-</td>
<td style="text-align:center">2.156</td>
<td style="text-align:center">-</td>
</tr>
<tr>
<td style="text-align:center">CosyVoice</td>
<td style="text-align:center">2.857</td>
<td style="text-align:center"><strong>0.849</strong></td>
<td style="text-align:center">4.519</td>
<td style="text-align:center"><strong>0.807</strong></td>
</tr>
<tr>
<td style="text-align:center">Step-Audio-TTS-3B</td>
<td style="text-align:center"><strong>2.192</strong></td>
<td style="text-align:center">0.784</td>
<td style="text-align:center"><strong>3.585</strong></td>
<td style="text-align:center">0.742</td>
</tr>
</tbody>
</table>
### 5.3 AQTA Chat
We release [**StepEval-Audio-360**](https://huggingface.co/datasets/stepfun-ai/StepEval-Audio-360) as a new benchmark, which consists of 137 multi-turn Chinese prompts sourced from real users and is designed to evaluate the quality of generated response across the following dimensions: Voice Instruction Following, Voice Understanding, Logical Reasoning, Role-playing, Creativity, Sing, Language Ability, Speech Emotion Control, Gaming.
#### 5.3.1 StepEval-Audio-360
#### LLM judge metrics(GPT-4o)
<table>
<caption>Comparison of fundamental capabilities of voice chat on the StepEval-Audio-360.</caption>
<thead>
<tr>
<th>Model</th>
<th style="text-align:center">Factuality (% ↑)</th>
<th style="text-align:center">Relevance (% ↑)</th>
<th style="text-align:center">Chat Score ↑</th>
</tr>
</thead>
<tbody>
<tr>
<td>GLM4-Voice</td>
<td style="text-align:center">54.7</td>
<td style="text-align:center">66.4</td>
<td style="text-align:center">3.49</td>
</tr>
<tr>
<td>Qwen2-Audio</td>
<td style="text-align:center">22.6</td>
<td style="text-align:center">26.3</td>
<td style="text-align:center">2.27</td>
</tr>
<tr>
<td>Moshi<sup>*</sup></td>
<td style="text-align:center">1.0</td>
<td style="text-align:center">0</td>
<td style="text-align:center">1.49</td>
</tr>
<tr>
<td><strong>Step-Audio-Chat</strong></td>
<td style="text-align:center"><strong>66.4</strong></td>
<td style="text-align:center"><strong>75.2</strong></td>
<td style="text-align:center"><strong>4.11</strong></td>
</tr>
</tbody>
</table>
* Note: Moshi are marked with "\*" and should be considered for reference only.
#### Radar Chart(Human Evaluation)
<img src="./assets/stepeval_radar_chart.png" width="600" alt="QR code">
#### 5.3.2 Public Test Set
<table>
<thead>
<tr>
<th>Model</th>
<th style="text-align:center">Llama Question</th>
<th style="text-align:center">Web Questions</th>
<th style="text-align:center">TriviaQA*</th>
<th style="text-align:center">ComplexBench</th>
<th style="text-align:center">HSK-6</th>
</tr>
</thead>
<tbody>
<tr>
<td>GLM4-Voice</td>
<td style="text-align:center">64.7</td>
<td style="text-align:center">32.2</td>
<td style="text-align:center">39.1</td>
<td style="text-align:center">66.0</td>
<td style="text-align:center">74.0</td>
</tr>
<tr>
<td>Moshi</td>
<td style="text-align:center">62.3</td>
<td style="text-align:center">26.6</td>
<td style="text-align:center">22.8</td>
<td style="text-align:center">-</td>
<td style="text-align:center">-</td>
</tr>
<tr>
<td>Freeze-Omni</td>
<td style="text-align:center">72.0</td>
<td style="text-align:center">44.7</td>
<td style="text-align:center">53.9</td>
<td style="text-align:center">-</td>
<td style="text-align:center">-</td>
</tr>
<tr>
<td>LUCY</td>
<td style="text-align:center">59.7</td>
<td style="text-align:center">29.3</td>
<td style="text-align:center">27.0</td>
<td style="text-align:center">-</td>
<td style="text-align:center">-</td>
</tr>
<tr>
<td>MinMo</td>
<td style="text-align:center">78.9</td>
<td style="text-align:center">55.0</td>
<td style="text-align:center">48.3</td>
<td style="text-align:center">-</td>
<td style="text-align:center">-</td>
</tr>
<tr>
<td>Qwen2-Audio</td>
<td style="text-align:center">52.0</td>
<td style="text-align:center">27.0</td>
<td style="text-align:center">37.3</td>
<td style="text-align:center">54.0</td>
<td style="text-align:center">-</td>
</tr>
<tr>
<td><strong>Step-Audio-Chat</strong></td>
<td style="text-align:center"><strong><i>81.0</i></strong></td>
<td style="text-align:center"><strong>75.1</strong></td>
<td style="text-align:center"><strong>58.0</strong></td>
<td style="text-align:center"><strong>74.0</strong></td>
<td style="text-align:center"><strong>86.0</strong></td>
</tr>
</tbody>
</table>
* Note: Results marked with "\*" on TriviaQA dataset are considered for reference only.*
#### 5.3.3 Audio instruction following
<table>
<thead>
<tr>
<th rowspan="2">Category</th>
<th colspan="2" style="text-align:center">Instruction Following</th>
<th colspan="2" style="text-align:center">Audio Quality</th>
</tr>
<tr>
<th style="text-align:center">GLM-4-Voice</th>
<th style="text-align:center">Step-Audio</th>
<th style="text-align:center">GLM-4-Voice</th>
<th style="text-align:center">Step-Audio</th>
</tr>
</thead>
<tbody>
<tr>
<td>Languages</td>
<td style="text-align:center">1.9</td>
<td style="text-align:center">3.8</td>
<td style="text-align:center">2.9</td>
<td style="text-align:center">3.3</td>
</tr>
<tr>
<td>Role-playing</td>
<td style="text-align:center">3.8</td>
<td style="text-align:center">4.2</td>
<td style="text-align:center">3.2</td>
<td style="text-align:center">3.6</td>
</tr>
<tr>
<td>Singing / RAP</td>
<td style="text-align:center">2.1</td>
<td style="text-align:center">2.4</td>
<td style="text-align:center">2.4</td>
<td style="text-align:center">4</td>
</tr>
<tr>
<td>Voice Control</td>
<td style="text-align:center">3.6</td>
<td style="text-align:center">4.4</td>
<td style="text-align:center">3.3</td>
<td style="text-align:center">4.1</td>
</tr>
</tbody>
</table>
## 6. Online Engine
The online version of Step-Audio can be accessed from app version of [跃问](https://yuewen.cn), where some impressive examples can be found as well.
<img src="./assets/yuewen.jpeg" width="200" alt="QR code">
## 7. Examples
### Clone audio
| role | prompt wav | clone wav |
|:-------:|:-------:|:-------:|
|于谦| [google drive](https://drive.google.com/file/d/1N9EJypafFwmeL0R152GoL_CVGbYn1_9A/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/prompt_wav_yuqian.wav)|[google drive](https://drive.google.com/file/d/1Zs_1QrCUuoSqtUSdn2ENIor-k5baQdDV/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/clone_wav_yuqian.wav)|
|李雪琴| [google drive](https://drive.google.com/file/d/15SkZ29hksELYi1NDOxYOPu-kRTLSyke_/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/prompt_wav_lixueqin.wav)|[google drive](https://drive.google.com/file/d/11Le4qMqL2DmWpf7RFRpKUXERIR9TtKC0/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/clone_wav_lixueqin.wav)|
### Speed control
| prompt | response |
|:-------:|:-------:|
|Human: 说一个绕口令<br>Assistant: 吃葡萄不吐葡萄皮,不吃葡萄倒吐葡萄皮<br>Human: 哎,你能把这个绕口令说的再快一点吗?|[google drive](https://drive.google.com/file/d/1mAH-NRrOVZo4tv6gdAZkyJg8kRuTNNGC/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/speed_control1.wav)|
|Human: 说一个绕口令<br>Assistant: 吃葡萄不吐葡萄皮,不吃葡萄倒吐葡萄皮<br>Human: 哎,你能把这个绕口令说的再快一点吗?<br>Assistant: 吃葡萄不吐葡萄皮,不吃葡萄倒吐葡萄皮<br>Human: 呃,你再用非常非常慢的速度说一遍的。|[google drive](https://drive.google.com/file/d/1FhRnKo8uGrtO-cWg4qkrg8iDoNRbtqSX/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/speed_control2.wav)|
### High EQ(Emotional control & Tone control)
| prompt | response |
|:-------:|:-------:|
|Human: 你这语气又不撒娇又不卖萌的,要不你撒个娇卖个萌吧。|[google drive](https://drive.google.com/file/d/19IROE6_6h2UQVNniCmDTnrhxKRMOFHq3/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/tone_control.wav)|
|Human: 怎么办?我感觉我的人生很失败。|[google drive](https://drive.google.com/file/d/1JlLbOlzmdrokVdxtwy1S8eeWqsZR2Vmc/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/emotional_control1.wav)|
|Human: 小跃。你真的是。特别厉害。|[google drive](https://drive.google.com/file/d/19ga1RpguDP5r0Xfl1r5GY1J-kzbmHvJb/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/emotional_control2.wav)|
### Multilingual (e.g., Chinese, English, Japanese)
| prompt | response |
|:-------:|:-------:|
|Human: What did the speaker mean when they said, it's raining cats and dogs?<br>Assistant: When they say "It's raining cats and dogs," it just means it's raining really hard. The speaker isn't literally saying cats and dogs are falling from the sky! It's just a fun way to describe heavy rain.|[google drive](https://drive.google.com/file/d/1LEIvdR5ANMzWX8GOTqUPTNrynNS1xx--/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/multilingual2.wav)|
|Human: こんにちは。(你好)<br>Assistant:こんにちは!何か手伝いましょうか?(您好!我可以帮你做点什么吗?)|[google drive](https://drive.google.com/file/d/1MjKUkkzcGzVcNVXRr_Ya5y2H44K_lybH/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/multilingual1.wav)|
### Rap & Vocal
| prompt | response |
|:-------:|:-------:|
|Human: 唱一段rap|[google drive](https://drive.google.com/file/d/1F8CKmVbGZ7X7d1IkQPlmndSHeG40AXha/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/rap.wav)|
|Human: 唱一段中文的歌曲(Sing Chinese Song)|[google drive](https://drive.google.com/file/d/1F1o-Q90llmkM-4UU6qhP8KoHp3dhaluj/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/singing.wav)|
|Human: 唱一段日语的歌曲(Sing Japanese Song)|[google drive](https://drive.google.com/file/d/1kS2jQEq70ynh46pG_P5Xp1_NY3C-cJ-U/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/multilingual_singing.wav)|
## 8. Acknowledgements
Part of the code for this project comes from:
* [CosyVoice](https://github.com/FunAudioLLM/CosyVoice)
* [transformers](https://github.com/huggingface/transformers)
* [FunASR](https://github.com/modelscope/FunASR)
Thank you to all the open-source projects for their contributions to this project!
## 9. License Agreement
+ The use of weights for Step Audio related models requires following license in [Step-Audio-Chat](https://huggingface.co/stepfun-ai/Step-Audio-Chat/tree/main), [Step-Audio-Tokenizer](https://huggingface.co/stepfun-ai/Step-Audio-Tokenizer/tree/main) and [Step-Audio-TTS-3B](https://huggingface.co/stepfun-ai/Step-Audio-TTS-3B/tree/main)
+ The code in this open-source repository is licensed under the [Apache 2.0](LICENSE) License.
## 10. Citation
```
@misc{huang2025stepaudiounifiedunderstandinggeneration,
title={Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction},
author={Ailin Huang and Boyong Wu and Bruce Wang and Chao Yan and Chen Hu and Chengli Feng and Fei Tian and Feiyu Shen and Jingbei Li and Mingrui Chen and Peng Liu and Ruihang Miao and Wang You and Xi Chen and Xuerui Yang and Yechang Huang and Yuxiang Zhang and Zheng Gong and Zixin Zhang and Brian Li and Changyi Wan and Hanpeng Hu and Ranchen Ming and Song Yuan and Xuelin Zhang and Yu Zhou and Bingxin Li and Buyun Ma and Kang An and Wei Ji and Wen Li and Xuan Wen and Yuankai Ma and Yuanwei Liang and Yun Mou and Bahtiyar Ahmidi and Bin Wang and Bo Li and Changxin Miao and Chen Xu and Chengting Feng and Chenrun Wang and Dapeng Shi and Deshan Sun and Dingyuan Hu and Dula Sai and Enle Liu and Guanzhe Huang and Gulin Yan and Heng Wang and Haonan Jia and Haoyang Zhang and Jiahao Gong and Jianchang Wu and Jiahong Liu and Jianjian Sun and Jiangjie Zhen and Jie Feng and Jie Wu and Jiaoren Wu and Jie Yang and Jinguo Wang and Jingyang Zhang and Junzhe Lin and Kaixiang Li and Lei Xia and Li Zhou and Longlong Gu and Mei Chen and Menglin Wu and Ming Li and Mingxiao Li and Mingyao Liang and Na Wang and Nie Hao and Qiling Wu and Qinyuan Tan and Shaoliang Pang and Shiliang Yang and Shuli Gao and Siqi Liu and Sitong Liu and Tiancheng Cao and Tianyu Wang and Wenjin Deng and Wenqing He and Wen Sun and Xin Han and Xiaomin Deng and Xiaojia Liu and Xu Zhao and Yanan Wei and Yanbo Yu and Yang Cao and Yangguang Li and Yangzhen Ma and Yanming Xu and Yaqiang Shi and Yilei Wang and Yinmin Zhong and Yu Luo and Yuanwei Lu and Yuhe Yin and Yuting Yan and Yuxiang Yang and Zhe Xie and Zheng Ge and Zheng Sun and Zhewei Huang and Zhichao Chang and Zidong Yang and Zili Zhang and Binxing Jiao and Daxin Jiang and Heung-Yeung Shum and Jiansheng Chen and Jing Li and Shuchang Zhou and Xiangyu Zhang and Xinhao Zhang and Yibo Zhu},
year={2025},
eprint={2502.11946},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2502.11946},
}
```
## Star History
[](https://star-history.com/#stepfun-ai/Step-Audio&Date) | {
"source": "stepfun-ai/Step-Audio",
"title": "README.md",
"url": "https://github.com/stepfun-ai/Step-Audio/blob/main/README.md",
"date": "2025-02-11T05:35:12",
"stars": 3434,
"description": null,
"file_size": 35100
} |
<p align="left">
中文</a>  |  <a href="README.md">English</a>  |  <a href="README_JP.md">日本語</a>
</p>
<br><br>
# Step-Audio
<p align="center">
<img src="assets/logo.png" height=100>
</p>
<div align="center">
<a href="https://arxiv.org/abs/2502.11946"><img src="https://img.shields.io/static/v1?label=Tech Report&message=Arxiv&color=red"></a>  
<a href="https://x.com/StepFun_ai"><img src="https://img.shields.io/static/v1?label=X.com&message=Web&color=blue"></a>  
</div>
<div align="center">
<a href="https://huggingface.co/stepfun-ai/Step-Audio-Chat"><img src="https://img.shields.io/static/v1?label=Step-Audio-Chat&message=HuggingFace&color=yellow"></a>  
<a href="https://huggingface.co/stepfun-ai/Step-Audio-TTS-3B"><img src="https://img.shields.io/static/v1?label=Step-Audio-TTS-3B&message=HuggingFace&color=yellow"></a>  
</div>
<div align="center">
<a href="https://huggingface.co/stepfun-ai/Step-Audio-Tokenizer"><img src="https://img.shields.io/static/v1?label=Step-Audio-Tokenier&message=HuggingFace&color=yellow"></a>  
<a href="https://huggingface.co/datasets/stepfun-ai/StepEval-Audio-360"><img src="https://img.shields.io/static/v1?label=StepEval-Audio-360&message=HuggingFace&color=yellow"></a>  
</div>
## 🔥🔥🔥 News!!
* 2025年2月17日: 👋 发布推理代码和模型权重,其中包含[Step-Audio-Chat](https://huggingface.co/stepfun-ai/Step-Audio-Chat), [Step-Audio-TTS-3B](https://huggingface.co/stepfun-ai/Step-Audio-TTS-3B) 和 [Step-Audio-Tokenizer](https://huggingface.co/stepfun-ai/Step-Audio-Tokenizer)。
* 2025年2月17日: 👋 发布多轮音频交互基准测试[StepEval-Audio-360](https://huggingface.co/datasets/stepfun-ai/StepEval-Audio-360)。
* 2025年2月17日: 👋 发布了技术报告[Step-Audio-Report](https://arxiv.org/abs/2502.11946)。
## Table of Contents
1. [介绍](#1-介绍)
2. [模型组成](#2-模型组成)
3. [模型下载](#3-模型下载)
4. [模型使用](#4-模型使用)
5. [基准](#5-基准)
6. [在线引擎](#6-在线引擎)
7. [样例](#7-样例)
8. [致谢](#8-致谢)
9. [协议](#9-协议)
10. [引用](#10-引用)
## 1. 介绍
Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤),方言(如 粤语,四川话),可控制语速及韵律风格,支持RAP和哼唱等。其核心技术突破体现在以下四大技术亮点:
- **1300亿多模态模型**: 单模型能实现理解生成一体化完成语音识别、语义理解、对话、语音克隆、语音生成等功能,开源千亿参数多模态模型 Step-Audio-Chat。
- **高效数据生成链路**: 基于130B 突破传统 TTS 对人工采集数据的依赖,生成高质量的合成音频数据,并同步开源首个基于大规模合成数据训练,支持 RAP 和哼唱的指令加强版语音合成模型 Step-Audio-TTS-3B 。
- **精细语音控制**: 支持多种情绪(如生气,高兴,悲伤)、方言(包括粤语、四川话等)和唱歌(包括 RAP、干声哼唱)的精准调控,满足用户对多样化语音生成的需求。
- **扩展工具调用**: 通过 ToolCall 机制和角色扮演增强,进一步提升其在 Agents 和复杂任务中的表现。
## 2. 模型组成
在Step-Audio系统中,音频流采用Linguistic tokenizer(码率16.7Hz,码本大小1024)与Semantice tokenizer(码率25Hz,码本大小4096)并行的双码本编码器方案,双码本在排列上使用了2:3时序交错策略。通过音频语境化持续预训练和任务定向微调强化了130B参数量的基础模型(Step-1),最终构建了强大的跨模态语音理解能力。为了实现实时音频生成,系统采用了混合语音解码器,结合流匹配(flow matching)与神经声码技术。

### 2.1 Tokenizer
我们通过token级交错方法实现Linguistic token与Semantic token的有效整合。Linguistic tokenizer的码本大小是1024,码率16.7Hz;而Semantic tokenizer则使用4096的大容量码本来捕捉更精细的声学细节,码率25Hz。鉴于两者的码率差异,我们建立了2:3的时间对齐比例——每两个Linguistic token对应三个Linguistic token形成时序配对。
### 2.2 语言模型
为了提升Step-Audio有效处理语音信息的能力,并实现精准的语音-文本对齐,我们在Step-1(一个拥有1300亿参数的基于文本的大型语言模型LLM)的基础上进行了音频持续预训练。
### 2.3 语音解码器
Step-Audio语音解码器主要是将包含语义和声学信息的离散标记信息转换成连续的语音信号。该解码器架构结合了一个30亿参数的语言模型、流匹配模型(flow matching model)和梅尔频谱到波形的声码器(mel-to-wave vocoder)。为优化合成语音的清晰度(intelligibility)和自然度(naturalness),语音解码器采用双码交错训练方法(dual-code interleaving),确保生成过程中语义与声学特征的无缝融合。
### 2.4 实时推理管线
为了实现实时的语音交互,我们对推理管线进行了一系列优化。其中最核心的是控制模块(Controller),该模块负责管理状态转换、协调响应生成,并确保关键子系统间的无缝协同。这些子系统包括:
- **语音活动检测(VAD)**:实时检测用户语音起止
- **流式音频分词器(Streaming Audio Tokenizer)**:实时音频流处理
- **Step-Audio语言模型与语音解码器**:多模态回复生成
- **上下文管理器(Context Manager)**:动态维护对话历史与状态

### 2.5 后训练细节
在后训练阶段,我们针对自动语音识别(ASR)与文本转语音(TTS)任务进行了专项监督微调(Supervised Fine-Tuning, SFT)。对于音频输入-文本输出(Audio Question Text Answer, AQTA)任务,我们采用多样化高质量数据集进行SFT,并采用了基于人类反馈的强化学习(RLHF)以提升响应质量,从而实现对情感表达、语速、方言及韵律的细粒度控制。

## 3. 模型下载
### 3.1 Huggingface
| 模型 | 链接 |
|-------|-------|
| Step-Audio-Tokenizer | [🤗huggingface](https://huggingface.co/stepfun-ai/Step-Audio-Tokenizer) |
| Step-Audio-Chat | [🤗huggingface](https://huggingface.co/stepfun-ai/Step-Audio-Chat) |
| Step-Audio-TTS-3B | [🤗huggingface](https://huggingface.co/stepfun-ai/Step-Audio-TTS-3B) |
### 3.2 Modelscope
| 模型 | 链接 |
|-------|-------|
| Step-Audio-Tokenizer | [modelscope](https://modelscope.cn/models/stepfun-ai/Step-Audio-Tokenizer) |
| Step-Audio-Chat | [modelscope](https://modelscope.cn/models/stepfun-ai/Step-Audio-Chat) |
| Step-Audio-TTS-3B | [modelscope](https://modelscope.cn/models/stepfun-ai/Step-Audio-TTS-3B) |
## 4. 模型使用
### 📜 4.1 要求
下表列出了运行Step-Audio模型(batch size=1)所需的配置要求:
| 模型 | Setting<br/>(采样率) | GPU最低显存 |
|------------|--------------------------------|----------------|
| Step-Audio-Tokenizer | 41.6Hz | 1.5GB |
| Step-Audio-Chat | 41.6Hz | 265GB |
| Step-Audio-TTS-3B | 41.6Hz | 8GB |
* 需要支持CUDA的NVIDIA显卡.
* 模型在4块显存为80GB的A800系列NVIDIA显卡上进行测试.
* **推荐**: 为确保最佳生成质量,建议使用4块显存为80GB的A800/H800系列NVIDIA显卡.
* 测试采用的操作系统: Linux
### 🔧 4.2 依赖项与安装
- Python >= 3.10.0 (推荐使用 [Anaconda](https://www.anaconda.com/download/#linux) or [Miniconda](https://docs.conda.io/en/latest/miniconda.html))
- [PyTorch >= 2.3-cu121](https://pytorch.org/)
- [CUDA Toolkit](https://developer.nvidia.com/cuda-downloads)
```bash
git clone https://github.com/stepfun-ai/Step-Audio.git
conda create -n stepaudio python=3.10
conda activate stepaudio
cd Step-Audio
pip install -r requirements.txt
git lfs install
git clone https://huggingface.co/stepfun-ai/Step-Audio-Tokenizer
git clone https://huggingface.co/stepfun-ai/Step-Audio-Chat
git clone https://huggingface.co/stepfun-ai/Step-Audio-TTS-3B
```
下载模型后,where_you_download_dir应包含以下结构:
```
where_you_download_dir
├── Step-Audio-Tokenizer
├── Step-Audio-Chat
├── Step-Audio-TTS-3B
```
### 🚀 4.3 推理脚本
#### 离线推理
支持端到端音频/文本输入与音频/文本输出的推理流程。
```bash
python offline_inference.py --model-path where_you_download_dir
```
#### 语音合成推理
使用默认音色进行语音合成推理或使用新音色进行克隆
```bash
python tts_inference.py --model-path where_you_download_dir --output-path where_you_save_audio_dir --synthesis-type use_tts_or_clone
```
克隆模式需要音色信息字典,格式如下:
```bash
{
"speaker": "speaker id",
"prompt_text": "content of prompt wav",
"wav_path": "prompt wav path"
}
```
#### 启动网页演示
启动本地服务器以进行在线推理。
假设您已配备4块GPU且已完成所有模型的下载。
```bash
python app.py --model-path where_you_download_dir
```
## 5. 基准
### 5.1 语音识别
<table>
<thead>
<tr>
<th style="text-align:center"></th>
<th colspan="4" style="text-align:center">隐层特征建模</th>
<th colspan="5" style="text-align:center">离散标记建模</th>
</tr>
<tr>
<th style="text-align:center"></th>
<th style="text-align:center">Whisper Large-v3</th>
<th style="text-align:center">Qwen2-Audio</th>
<th style="text-align:center">MinMo</th>
<th style="text-align:center">LUCY</th>
<th style="text-align:center">Moshi</th>
<th style="text-align:center">GLM-4-voice Base</th>
<th style="text-align:center">GLM-4-voice Chat</th>
<th style="text-align:center">Step-Audio Pretrain</th>
<th style="text-align:center">Step-Audio-Chat</th>
</tr>
</thead>
<tbody>
<tr>
<td>Aishell-1</td>
<td style="text-align:center">5.14</td>
<td style="text-align:center">1.53</td>
<td style="text-align:center">-</td>
<td style="text-align:center">2.4</td>
<td style="text-align:center">-</td>
<td style="text-align:center">2.46</td>
<td style="text-align:center">226.47</td>
<td style="text-align:center"><strong>0.87</strong></td>
<td style="text-align:center">1.95</td>
</tr>
<tr>
<td>Aishell-2 ios</td>
<td style="text-align:center">4.76</td>
<td style="text-align:center">3.06</td>
<td style="text-align:center"><strong>2.69</strong></td>
<td style="text-align:center">-</td>
<td style="text-align:center">-</td>
<td style="text-align:center">-</td>
<td style="text-align:center">211.3</td>
<td style="text-align:center">2.91</td>
<td style="text-align:center">3.57</td>
</tr>
<tr>
<td>Wenetspeech test-net</td>
<td style="text-align:center">9.68</td>
<td style="text-align:center">7.72</td>
<td style="text-align:center"><strong>6.64</strong></td>
<td style="text-align:center">8.78</td>
<td style="text-align:center">-</td>
<td style="text-align:center">-</td>
<td style="text-align:center">146.05</td>
<td style="text-align:center">7.62</td>
<td style="text-align:center">8.75</td>
</tr>
<tr>
<td>Wenet test-meeting</td>
<td style="text-align:center">18.54</td>
<td style="text-align:center">8.4</td>
<td style="text-align:center"><strong>7.6</strong></td>
<td style="text-align:center">10.42</td>
<td style="text-align:center">-</td>
<td style="text-align:center">-</td>
<td style="text-align:center">140.82</td>
<td style="text-align:center">7.78</td>
<td style="text-align:center">9.52</td>
</tr>
<tr>
<td>Librispeech test-clean</td>
<td style="text-align:center">1.9</td>
<td style="text-align:center"><strong>1.6</strong></td>
<td style="text-align:center"><strong>1.6</strong></td>
<td style="text-align:center">3.36</td>
<td style="text-align:center">5.7</td>
<td style="text-align:center">2.82</td>
<td style="text-align:center">75.39</td>
<td style="text-align:center">2.36</td>
<td style="text-align:center">3.11</td>
</tr>
<tr>
<td>Librispeech test-other</td>
<td style="text-align:center">3.65</td>
<td style="text-align:center"><strong>3.6</strong></td>
<td style="text-align:center">3.82</td>
<td style="text-align:center">8.05</td>
<td style="text-align:center">-</td>
<td style="text-align:center">7.66</td>
<td style="text-align:center">80.3</td>
<td style="text-align:center">6.32</td>
<td style="text-align:center">8.44</td>
</tr>
<tr>
<td>AVG</td>
<td style="text-align:center">7.28</td>
<td style="text-align:center"><strong>4.32</strong></td>
<td style="text-align:center">-</td>
<td style="text-align:center">-</td>
<td style="text-align:center">-</td>
<td style="text-align:center">-</td>
<td style="text-align:center">146.74</td>
<td style="text-align:center">4.64</td>
<td style="text-align:center">5.89</td>
</tr>
</tbody>
</table>
### 5.2 语音合成
#### 5.2.1 与GLM-4-Voice与MinMo在内容一致性(CER/WER)上的性能对比。
<table>
<thead>
<tr>
<th rowspan="2">Model</th>
<th style="text-align:center" colspan="1">test-zh</th>
<th style="text-align:center" colspan="1">test-en</th>
</tr>
<tr>
<th style="text-align:center">CER (%) ↓</th>
<th style="text-align:center">WER (%) ↓</th>
</tr>
</thead>
<tbody>
<tr>
<td>GLM-4-Voice</td>
<td style="text-align:center">2.19</td>
<td style="text-align:center">2.91</td>
</tr>
<tr>
<td>MinMo</td>
<td style="text-align:center">2.48</td>
<td style="text-align:center">2.90</td>
</tr>
<tr>
<td><strong>Step-Audio</strong></td>
<td style="text-align:center"><strong>1.53</strong></td>
<td style="text-align:center"><strong>2.71</strong></td>
</tr>
</tbody>
</table>
#### 5.2.2 语音合成模型在SEED测试集上的性能结果。
* StepAudio-TTS-3B-Single 表示采用双码本主干网络与单码本声码器的组合架构。
<table>
<thead>
<tr>
<th rowspan="2">Model</th>
<th style="text-align:center" colspan="2">test-zh</th>
<th style="text-align:center" colspan="2">test-en</th>
</tr>
<tr>
<th style="text-align:center">CER (%) ↓</th>
<th style="text-align:center">SS ↑</th>
<th style="text-align:center">WER (%) ↓</th>
<th style="text-align:center">SS ↑</th>
</tr>
</thead>
<tbody>
<tr>
<td>FireRedTTS</td>
<td style="text-align:center">1.51</td>
<td style="text-align:center">0.630</td>
<td style="text-align:center">3.82</td>
<td style="text-align:center">0.460</td>
</tr>
<tr>
<td>MaskGCT</td>
<td style="text-align:center">2.27</td>
<td style="text-align:center">0.774</td>
<td style="text-align:center">2.62</td>
<td style="text-align:center">0.774</td>
</tr>
<tr>
<td>CosyVoice</td>
<td style="text-align:center">3.63</td>
<td style="text-align:center">0.775</td>
<td style="text-align:center">4.29</td>
<td style="text-align:center">0.699</td>
</tr>
<tr>
<td>CosyVoice 2</td>
<td style="text-align:center">1.45</td>
<td style="text-align:center">0.806</td>
<td style="text-align:center">2.57</td>
<td style="text-align:center">0.736</td>
</tr>
<tr>
<td>CosyVoice 2-S</td>
<td style="text-align:center">1.45</td>
<td style="text-align:center">0.812</td>
<td style="text-align:center">2.38</td>
<td style="text-align:center">0.743</td>
</tr>
<tr>
<td><strong>Step-Audio-TTS-3B-Single</strong></td>
<td style="text-align:center">1.37</td>
<td style="text-align:center">0.802</td>
<td style="text-align:center">2.52</td>
<td style="text-align:center">0.704</td>
</tr>
<tr>
<td><strong>Step-Audio-TTS-3B</strong></td>
<td style="text-align:center"><strong>1.31</strong></td>
<td style="text-align:center">0.733</td>
<td style="text-align:center"><strong>2.31</strong></td>
<td style="text-align:center">0.660</td>
</tr>
<tr>
<td><strong>Step-Audio-TTS</strong></td>
<td style="text-align:center"><strong>1.17</strong></td>
<td style="text-align:center">0.73</td>
<td style="text-align:center"><strong>2.0</strong></td>
<td style="text-align:center">0.660</td>
</tr>
</tbody>
</table>
#### 5.2.3 双码本重合成与CosyVoice性能对比。
<table>
<thead>
<tr>
<th style="text-align:center" rowspan="2">Token</th>
<th style="text-align:center" colspan="2">test-zh</th>
<th style="text-align:center" colspan="2">test-en</th>
</tr>
<tr>
<th style="text-align:center">CER (%) ↓</th>
<th style="text-align:center">SS ↑</th>
<th style="text-align:center">WER (%) ↓</th>
<th style="text-align:center">SS ↑</th>
</tr>
</thead>
<tbody>
<tr>
<td style="text-align:center">Groundtruth</td>
<td style="text-align:center">0.972</td>
<td style="text-align:center">-</td>
<td style="text-align:center">2.156</td>
<td style="text-align:center">-</td>
</tr>
<tr>
<td style="text-align:center">CosyVoice</td>
<td style="text-align:center">2.857</td>
<td style="text-align:center"><strong>0.849</strong></td>
<td style="text-align:center">4.519</td>
<td style="text-align:center"><strong>0.807</strong></td>
</tr>
<tr>
<td style="text-align:center">Step-Audio-TTS-3B</td>
<td style="text-align:center"><strong>2.192</strong></td>
<td style="text-align:center">0.784</td>
<td style="text-align:center"><strong>3.585</strong></td>
<td style="text-align:center">0.742</td>
</tr>
</tbody>
</table>
### 5.3 语音对话
我们发布全新基准测试[StepEval-Audio-360](https://huggingface.co/datasets/stepfun-ai/StepEval-Audio-360),该数据集包含137个源自真实用户的多轮中文提示,旨在系统性评估生成式语音交互系统在以下维度的表现:语音指令遵循、语音理解、逻辑推理、角色扮演、创作能力、唱歌、语言能力、语音情绪控制、游戏。
#### 5.3.1 StepEval-Audio-360
#### 大语言模型评估指标(GPT-4o)
<table>
<caption>Comparison of fundamental capabilities of voice chat on the StepEval-Audio-360.</caption>
<thead>
<tr>
<th>Model</th>
<th style="text-align:center">Factuality (% ↑)</th>
<th style="text-align:center">Relevance (% ↑)</th>
<th style="text-align:center">Chat Score ↑</th>
</tr>
</thead>
<tbody>
<tr>
<td>GLM4-Voice</td>
<td style="text-align:center">54.7</td>
<td style="text-align:center">66.4</td>
<td style="text-align:center">3.49</td>
</tr>
<tr>
<td>Qwen2-Audio</td>
<td style="text-align:center">22.6</td>
<td style="text-align:center">26.3</td>
<td style="text-align:center">2.27</td>
</tr>
<tr>
<td>Moshi<sup>*</sup></td>
<td style="text-align:center">1.0</td>
<td style="text-align:center">0</td>
<td style="text-align:center">1.49</td>
</tr>
<tr>
<td><strong>Step-Audio-Chat</strong></td>
<td style="text-align:center"><strong>66.4</strong></td>
<td style="text-align:center"><strong>75.2</strong></td>
<td style="text-align:center"><strong>4.11</strong></td>
</tr>
</tbody>
</table>
* 注意:带有“\*”标记的内容仅供参考。
#### 雷达图(人工测评)
<img src="./assets/stepeval_radar_chart.png" width="600" alt="QR code">
#### 5.3.2 公开测试集
<table>
<thead>
<tr>
<th>Model</th>
<th style="text-align:center">Llama Question</th>
<th style="text-align:center">Web Questions</th>
<th style="text-align:center">TriviaQA*</th>
<th style="text-align:center">ComplexBench</th>
<th style="text-align:center">HSK-6</th>
</tr>
</thead>
<tbody>
<tr>
<td>GLM4-Voice</td>
<td style="text-align:center">64.7</td>
<td style="text-align:center">32.2</td>
<td style="text-align:center">39.1</td>
<td style="text-align:center">66.0</td>
<td style="text-align:center">74.0</td>
</tr>
<tr>
<td>Moshi</td>
<td style="text-align:center">62.3</td>
<td style="text-align:center">26.6</td>
<td style="text-align:center">22.8</td>
<td style="text-align:center">-</td>
<td style="text-align:center">-</td>
</tr>
<tr>
<td>Freeze-Omni</td>
<td style="text-align:center">72.0</td>
<td style="text-align:center">44.7</td>
<td style="text-align:center">53.9</td>
<td style="text-align:center">-</td>
<td style="text-align:center">-</td>
</tr>
<tr>
<td>LUCY</td>
<td style="text-align:center">59.7</td>
<td style="text-align:center">29.3</td>
<td style="text-align:center">27.0</td>
<td style="text-align:center">-</td>
<td style="text-align:center">-</td>
</tr>
<tr>
<td>MinMo</td>
<td style="text-align:center">78.9</td>
<td style="text-align:center">55.0</td>
<td style="text-align:center">48.3</td>
<td style="text-align:center">-</td>
<td style="text-align:center">-</td>
</tr>
<tr>
<td>Qwen2-Audio</td>
<td style="text-align:center">52.0</td>
<td style="text-align:center">27.0</td>
<td style="text-align:center">37.3</td>
<td style="text-align:center">54.0</td>
<td style="text-align:center">-</td>
</tr>
<tr>
<td><strong>Step-Audio-Chat</strong></td>
<td style="text-align:center"><strong><i>81.0</i></strong></td>
<td style="text-align:center"><strong>75.1</strong></td>
<td style="text-align:center"><strong>58.0</strong></td>
<td style="text-align:center"><strong>74.0</strong></td>
<td style="text-align:center"><strong>86.0</strong></td>
</tr>
</tbody>
</table>
* 注意:在 TriviaQA 数据集上,带有“\*”标记的结果仅供参考。
#### 5.3.3 语音指令遵循
<table>
<thead>
<tr>
<th rowspan="2">Category</th>
<th colspan="2" style="text-align:center">Instruction Following</th>
<th colspan="2" style="text-align:center">Audio Quality</th>
</tr>
<tr>
<th style="text-align:center">GLM-4-Voice</th>
<th style="text-align:center">Step-Audio</th>
<th style="text-align:center">GLM-4-Voice</th>
<th style="text-align:center">Step-Audio</th>
</tr>
</thead>
<tbody>
<tr>
<td>Languages</td>
<td style="text-align:center">1.9</td>
<td style="text-align:center">3.8</td>
<td style="text-align:center">2.9</td>
<td style="text-align:center">3.3</td>
</tr>
<tr>
<td>Role-playing</td>
<td style="text-align:center">3.8</td>
<td style="text-align:center">4.2</td>
<td style="text-align:center">3.2</td>
<td style="text-align:center">3.6</td>
</tr>
<tr>
<td>Singing / RAP</td>
<td style="text-align:center">2.1</td>
<td style="text-align:center">2.4</td>
<td style="text-align:center">2.4</td>
<td style="text-align:center">4</td>
</tr>
<tr>
<td>Voice Control</td>
<td style="text-align:center">3.6</td>
<td style="text-align:center">4.4</td>
<td style="text-align:center">3.3</td>
<td style="text-align:center">4.1</td>
</tr>
</tbody>
</table>
## 6. 在线引擎
Step-Audio 的在线版本可以通过[跃问](https://yuewen.cn) 的应用程序访问,其中还可以找到一些惊喜的示例。
<img src="./assets/yuewen.jpeg" width="200" alt="QR code">
## 7. 样例
### 音频克隆
| role | prompt wav | clone wav |
|:-------:|:-------:|:-------:|
|于谦| [google drive](https://drive.google.com/file/d/1N9EJypafFwmeL0R152GoL_CVGbYn1_9A/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/prompt_wav_yuqian.wav)|[google drive](https://drive.google.com/file/d/1Zs_1QrCUuoSqtUSdn2ENIor-k5baQdDV/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/clone_wav_yuqian.wav)|
|李雪琴| [google drive](https://drive.google.com/file/d/15SkZ29hksELYi1NDOxYOPu-kRTLSyke_/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/prompt_wav_lixueqin.wav)|[google drive](https://drive.google.com/file/d/11Le4qMqL2DmWpf7RFRpKUXERIR9TtKC0/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/clone_wav_lixueqin.wav)|
### 速度控制
| prompt | response |
|:-------:|:-------:|
|Human: 说一个绕口令<br>Assistant: 吃葡萄不吐葡萄皮,不吃葡萄倒吐葡萄皮<br>Human: 哎,你能把这个绕口令说的再快一点吗?|[google drive](https://drive.google.com/file/d/1mAH-NRrOVZo4tv6gdAZkyJg8kRuTNNGC/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/speed_control1.wav)|
|Human: 说一个绕口令<br>Assistant: 吃葡萄不吐葡萄皮,不吃葡萄倒吐葡萄皮<br>Human: 哎,你能把这个绕口令说的再快一点吗?<br>Assistant: 吃葡萄不吐葡萄皮,不吃葡萄倒吐葡萄皮<br>Human: 呃,你再用非常非常慢的速度说一遍的。|[google drive](https://drive.google.com/file/d/1FhRnKo8uGrtO-cWg4qkrg8iDoNRbtqSX/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/speed_control2.wav)|
### 高情商(情感控制 & 语调控制)
| prompt | response |
|:-------:|:-------:|
|Human: 你这语气又不撒娇又不卖萌的,要不你撒个娇卖个萌吧。|[google drive](https://drive.google.com/file/d/19IROE6_6h2UQVNniCmDTnrhxKRMOFHq3/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/tone_control.wav)|
|Human: 怎么办?我感觉我的人生很失败。|[google drive](https://drive.google.com/file/d/1JlLbOlzmdrokVdxtwy1S8eeWqsZR2Vmc/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/emotional_control1.wav)|
|Human: 小跃。你真的是。特别厉害。|[google drive](https://drive.google.com/file/d/19ga1RpguDP5r0Xfl1r5GY1J-kzbmHvJb/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/emotional_control2.wav)|
### 多语言 (e.g., 中文, 英文, 日语)
| prompt | response |
|:-------:|:-------:|
|Human: What did the speaker mean when they said, it's raining cats and dogs?<br>Assistant: When they say "It's raining cats and dogs," it just means it's raining really hard. The speaker isn't literally saying cats and dogs are falling from the sky! It's just a fun way to describe heavy rain.|[google drive](https://drive.google.com/file/d/1LEIvdR5ANMzWX8GOTqUPTNrynNS1xx--/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/multilingual2.wav)|
|Human: こんにちは。(你好)<br>Assistant:こんにちは!何か手伝いましょうか?(您好!我可以帮你做点什么吗?)|[google drive](https://drive.google.com/file/d/1MjKUkkzcGzVcNVXRr_Ya5y2H44K_lybH/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/multilingual1.wav)|
### Rap & Vocal
| prompt | response |
|:-------:|:-------:|
|Human: 唱一段rap|[google drive](https://drive.google.com/file/d/1F8CKmVbGZ7X7d1IkQPlmndSHeG40AXha/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/rap.wav)|
## 8. 致谢
本项目的部分代码来自:
* [CosyVoice](https://github.com/FunAudioLLM/CosyVoice)
* [transformers](https://github.com/huggingface/transformers)
* [FunASR](https://github.com/modelscope/FunASR)
感谢以上所有开源项目对本项目开源做出的贡献!
## 9. 协议
+ Step-Audio 相关模型的权重使用协议请分别需要按照[Step-Audio-Chat](https://huggingface.co/stepfun-ai/Step-Audio-Chat/tree/main), [Step-Audio-Tokenizer](https://huggingface.co/stepfun-ai/Step-Audio-Tokenizer/tree/main) 和 [Step-Audio-TTS-3B](https://huggingface.co/stepfun-ai/Step-Audio-TTS-3B/tree/main) 里面的协议进行遵守
+ 本开源仓库的代码则遵循 [Apache 2.0](LICENSE) 协议。
## 10. 引用
```
@misc{huang2025stepaudiounifiedunderstandinggeneration,
title={Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction},
author={Ailin Huang and Boyong Wu and Bruce Wang and Chao Yan and Chen Hu and Chengli Feng and Fei Tian and Feiyu Shen and Jingbei Li and Mingrui Chen and Peng Liu and Ruihang Miao and Wang You and Xi Chen and Xuerui Yang and Yechang Huang and Yuxiang Zhang and Zheng Gong and Zixin Zhang and Brian Li and Changyi Wan and Hanpeng Hu and Ranchen Ming and Song Yuan and Xuelin Zhang and Yu Zhou and Bingxin Li and Buyun Ma and Kang An and Wei Ji and Wen Li and Xuan Wen and Yuankai Ma and Yuanwei Liang and Yun Mou and Bahtiyar Ahmidi and Bin Wang and Bo Li and Changxin Miao and Chen Xu and Chengting Feng and Chenrun Wang and Dapeng Shi and Deshan Sun and Dingyuan Hu and Dula Sai and Enle Liu and Guanzhe Huang and Gulin Yan and Heng Wang and Haonan Jia and Haoyang Zhang and Jiahao Gong and Jianchang Wu and Jiahong Liu and Jianjian Sun and Jiangjie Zhen and Jie Feng and Jie Wu and Jiaoren Wu and Jie Yang and Jinguo Wang and Jingyang Zhang and Junzhe Lin and Kaixiang Li and Lei Xia and Li Zhou and Longlong Gu and Mei Chen and Menglin Wu and Ming Li and Mingxiao Li and Mingyao Liang and Na Wang and Nie Hao and Qiling Wu and Qinyuan Tan and Shaoliang Pang and Shiliang Yang and Shuli Gao and Siqi Liu and Sitong Liu and Tiancheng Cao and Tianyu Wang and Wenjin Deng and Wenqing He and Wen Sun and Xin Han and Xiaomin Deng and Xiaojia Liu and Xu Zhao and Yanan Wei and Yanbo Yu and Yang Cao and Yangguang Li and Yangzhen Ma and Yanming Xu and Yaqiang Shi and Yilei Wang and Yinmin Zhong and Yu Luo and Yuanwei Lu and Yuhe Yin and Yuting Yan and Yuxiang Yang and Zhe Xie and Zheng Ge and Zheng Sun and Zhewei Huang and Zhichao Chang and Zidong Yang and Zili Zhang and Binxing Jiao and Daxin Jiang and Heung-Yeung Shum and Jiansheng Chen and Jing Li and Shuchang Zhou and Xiangyu Zhang and Xinhao Zhang and Yibo Zhu},
year={2025},
eprint={2502.11946},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2502.11946},
}
```
## Star History
[](https://star-history.com/#stepfun-ai/Step-Audio&Date) | {
"source": "stepfun-ai/Step-Audio",
"title": "README_CN.md",
"url": "https://github.com/stepfun-ai/Step-Audio/blob/main/README_CN.md",
"date": "2025-02-11T05:35:12",
"stars": 3434,
"description": null,
"file_size": 29107
} |
<p align="left">
<a href="README_CN.md">中文</a>   |  <a href="README.md">English</a>  |   日本語 
</p>
<br><br>
# Step-Audio
<p align="center">
<img src="assets/logo.png" height=100>
</p>
<div align="center">
<a href="https://arxiv.org/abs/2502.11946"><img src="https://img.shields.io/static/v1?label=Tech Report&message=Arxiv&color=red"></a>  
<a href="https://x.com/StepFun_ai"><img src="https://img.shields.io/static/v1?label=X.com&message=Web&color=blue"></a>  
</div>
<div align="center">
<a href="https://huggingface.co/stepfun-ai/Step-Audio-Chat"><img src="https://img.shields.io/static/v1?label=Step-Audio-Chat&message=HuggingFace&color=yellow"></a>  
<a href="https://huggingface.co/stepfun-ai/Step-Audio-TTS-3B"><img src="https://img.shields.io/static/v1?label=Step-Audio-TTS-3B&message=HuggingFace&color=yellow"></a>  
</div>
<div align="center">
<a href="https://huggingface.co/stepfun-ai/Step-Audio-Tokenizer"><img src="https://img.shields.io/static/v1?label=Step-Audio-Tokenier&message=HuggingFace&color=yellow"></a>  
<a href="https://huggingface.co/datasets/stepfun-ai/StepEval-Audio-360"><img src="https://img.shields.io/static/v1?label=StepEval-Audio-360&message=HuggingFace&color=yellow"></a>  
</div>
## 🔥🔥🔥 ニュース!!
* 2025年2月17日: 👋 推論コードとモデルの重みをリリースしました。[Step-Audio-Chat](https://huggingface.co/stepfun-ai/Step-Audio-Chat), [Step-Audio-TTS-3B](https://huggingface.co/stepfun-ai/Step-Audio-TTS-3B) および [Step-Audio-Tokenizer](https://huggingface.co/stepfun-ai/Step-Audio-Tokenizer)。
* 2025年2月17日: 👋 マルチターンオーディオベンチマーク [StepEval-Audio-360](https://huggingface.co/datasets/stepfun-ai/StepEval-Audio-360) をリリースしました。
* 2025年2月17日: 👋 技術レポート [Step-Audio-Report](https://arxiv.org/abs/2502.11946) をリリースしました。
## 目次
1. [紹介](#1-紹介)
2. [モデル概要](#2-モデル概要)
3. [モデルのダウンロード](#3-モデルのダウンロード)
4. [モデルの使用方法](#4-モデルの使用方法)
5. [ベンチマーク](#5-ベンチマーク)
6. [オンラインエンジン](#6-オンラインエンジン)
7. [引用](#7-引用)
## 1. 紹介
Step-Audioは、音声理解と生成を統合した業界初の製品レベルのオープンソースリアルタイム音声対話システムであり、多言語対話(例:日本語、英語、中国語)、音声感情(例:喜び、悲しみ)、方言(例:関西弁、広東語)、音声速度および韻律スタイルの調整をサポートします。Step-Audioは、以下の4つの主要な技術革新を示しています:
- **1300億パラメータのマルチモーダルモデル**:単一の統合モデルで、音声認識、意味理解、対話、音声クローン、音声生成を実行します。1300億パラメータのStep-Audio-Chatバリアントをオープンソース化しました。
- **生成データエンジン**:従来のTTSが手動データ収集に依存することを排除し、1300億パラメータのマルチモーダルモデルを使用して高品質の音声を生成します。このデータを活用して、リソース効率の高いStep-Audio-TTS-3Bモデルをトレーニングし、制御可能な音声合成のための指示フォロー機能を強化しました。
- **細かい音声制御**:指示ベースの制御設計を通じて、複数の感情(怒り、喜び、悲しみ)、方言(関西弁、広東語など)、および音声スタイル(ラップ、アカペラハミング)をサポートし、多様な音声生成ニーズに対応します。
- **強化されたインテリジェンス**:ToolCallメカニズムの統合とロールプレイングの強化を通じて、エージェントの複雑なタスクにおけるパフォーマンスを向上させます。
## 2. モデル概要
Step-Audioでは、音声ストリームをトークン化するために、並列のセマンティック(16.7Hz、1024エントリのコードブック)および音響(25Hz、4096エントリのコードブック)トークナイザーを組み合わせたデュアルコードブックフレームワークを使用し、2:3の時間的インターリーブを行います。1300億パラメータのLLM基盤(Step-1)は、音声コンテキスト化継続的事前トレーニングおよびタスク固有の後トレーニングを通じて強化され、強力なクロスモーダル音声理解を実現します。フローマッチングとニューラルボコーダを組み合わせたハイブリッド音声デコーダを使用し、リアルタイムの波形生成を最適化します。推論パイプラインは、投機的応答生成(40%のコミット率)およびテキストベースのコンテキスト管理(14:1の圧縮率)を特徴とするストリーミング対応アーキテクチャを備えています。

### 2.1 トークナイザー
セマンティックトークナイザーと音響トークナイザーを効果的に統合するために、トークンレベルのインターリーブアプローチを実装しています。セマンティックトークナイザーは1024のコードブックサイズを使用し、音響トークナイザーはより大きな4096のコードブックサイズを使用して、より細かい音響の詳細をキャプチャします。異なるトークンレートを考慮して、2つのセマンティックトークンごとに3つの音響トークンをペアリングする2:3の時間的アライメント比を確立します。
### 2.2 言語モデル
Step-Audioの音声情報を効果的に処理し、正確な音声-テキストアライメントを実現するために、1300億パラメータの事前トレーニングされたテキストベースの大規模言語モデル(LLM)であるStep-1に基づいて、音声継続的事前トレーニングを実施しました。
### 2.3 音声デコーダ
Step-Audioの音声デコーダは、セマンティックおよび音響情報を含む離散音声トークンを、自然な音声を表す連続的な時間領域の波形に変換する重要な機能を果たします。デコーダアーキテクチャには、フローマッチングモデルとメルから波形へのボコーダが組み込まれています。生成された音声の明瞭度と自然さを最適化するために、音声デコーダはデュアルコードインターリーブアプローチを使用してトレーニングされ、生成プロセス全体でセマンティックおよび音響機能のシームレスな統合を確保します。
### 2.4 リアルタイム推論パイプライン
リアルタイムの対話を可能にするために、最適化された推論パイプラインを設計しました。その中心には、状態遷移を管理し、投機的応答生成を調整し、重要なサブシステム間のシームレスな調整を確保するコントローラーモジュールがあります。これらのサブシステムには、ユーザーの音声を検出する音声活動検出(VAD)、リアルタイムで音声を処理するストリーミングオーディオトークナイザー、応答を処理および生成するStep-Audio言語モデルおよび音声デコーダ、および会話の連続性を維持するコンテキストマネージャが含まれます。

### 2.5 後トレーニングの詳細
後トレーニングフェーズでは、自動音声認識(ASR)およびテキストから音声への変換(TTS)のタスク固有の監督付き微調整(SFT)を実施しました。音声入力テキスト出力(AQTA)タスクについては、多様な高品質データセットを使用してSFTを実施し、人間のフィードバックからの強化学習(RLHF)を組み合わせて応答品質を向上させ、感情表現、音声速度、方言、および韻律の細かい制御を可能にしました。

## 3. モデルのダウンロード
### 3.1 Huggingface
| モデル | リンク |
|-------|-------|
| Step-Audio-Tokenizer | [🤗huggingface](https://huggingface.co/stepfun-ai/Step-Audio-Tokenizer) |
| Step-Audio-Chat | [🤗huggingface](https://huggingface.co/stepfun-ai/Step-Audio-Chat) |
| Step-Audio-TTS-3B | [🤗huggingface](https://huggingface.co/stepfun-ai/Step-Audio-TTS-3B) |
### 3.2 Modelscope
| モデル | リンク |
|-------|-------|
| Step-Audio-Tokenizer | [modelscope](https://modelscope.cn/models/stepfun-ai/Step-Audio-Tokenizer) |
| Step-Audio-Chat | [modelscope](https://modelscope.cn/models/stepfun-ai/Step-Audio-Chat) |
| Step-Audio-TTS-3B | [modelscope](https://modelscope.cn/models/stepfun-ai/Step-Audio-TTS-3B) |
## 4. モデルの使用方法
### 📜 4.1 要件
次の表は、Step-Audioモデル(バッチサイズ=1)を実行するための要件を示しています:
| モデル | 設定<br/>(サンプル周波数) | GPU最小メモリ |
|------------|--------------------------------|----------------|
| Step-Audio-Tokenizer | 41.6Hz | 1.5GB |
| Step-Audio-Chat | 41.6Hz | 265GB |
| Step-Audio-TTS-3B | 41.6Hz | 8GB |
* CUDAサポートのあるNVIDIA GPUが必要です。
* モデルは、4つのA800 80G GPUでテストされています。
* **推奨**:より良い生成品質のために、80GBメモリを持つ4つのA800/H800 GPUを使用することをお勧めします。
* テストされたオペレーティングシステム:Linux
### 🔧 4.2 依存関係とインストール
- Python >= 3.10.0([Anaconda](https://www.anaconda.com/download/#linux)または[Miniconda](https://docs.conda.io/en/latest/miniconda.html)の使用を推奨)
- [PyTorch >= 2.3-cu121](https://pytorch.org/)
- [CUDA Toolkit](https://developer.nvidia.com/cuda-downloads)
```bash
git clone https://github.com/stepfun-ai/Step-Audio.git
conda create -n stepaudio python=3.10
conda activate stepaudio
cd Step-Audio
pip install -r requirements.txt
git lfs install
git clone https://huggingface.co/stepfun-ai/Step-Audio-Tokenizer
git clone https://huggingface.co/stepfun-ai/Step-Audio-Chat
git clone https://huggingface.co/stepfun-ai/Step-Audio-TTS-3B
```
モデルをダウンロードした後、where_you_download_dirは次の構造を持つ必要があります:
```
where_you_download_dir
├── Step-Audio-Tokenizer
├── Step-Audio-Chat
├── Step-Audio-TTS-3B
```
### 🚀 4.3 推論スクリプト
#### オフライン推論
エンドツーエンドの音声/テキスト入力と音声/テキスト出力で推論を行います。
```bash
python offline_inference.py --model-path where_you_download_dir
```
#### TTS推論
デフォルトのスピーカーを使用してTTSを推論するか、新しいスピーカーでクローンを作成します
```bash
python tts_inference.py --model-path where_you_download_dir --output-path where_you_save_audio_dir --synthesis-type use_tts_or_clone
```
クローンモードには、次の形式のスピーカー情報辞書が必要です:
```bash
{
"speaker": "speaker id",
"prompt_text": "content of prompt wav",
"wav_path": "prompt wav path"
}
```
#### Webデモの起動
オンライン推論のためにローカルサーバーを起動します。
4つのGPUが利用可能で、すべてのモデルをダウンロード済みであると仮定します。
```bash
python app.py --model-path where_you_download_dir
```
## 5. ベンチマーク
### 5.1 ASR結果の比較
<table>
<thead>
<tr>
<th style="text-align:center"></th>
<th colspan="4" style="text-align:center">隠れた特徴モデリング</th>
<th colspan="5" style="text-align:center">離散音声トークンモデリング</th>
</tr>
<tr>
<th style="text-align:center"></th>
<th style="text-align:center">Whisper Large-v3</th>
<th style="text-align:center">Qwen2-Audio</th>
<th style="text-align:center">MinMo</th>
<th style="text-align:center">LUCY</th>
<th style="text-align:center">Moshi</th>
<th style="text-align:center">GLM-4-voice Base</th>
<th style="text-align:center">GLM-4-voice Chat</th>
<th style="text-align:center">Step-Audio Pretrain</th>
<th style="text-align:center">Step-Audio-Chat</th>
</tr>
</thead>
<tbody>
<tr>
<td>Aishell-1</td>
<td style="text-align:center">5.14</td>
<td style="text-align:center">1.53</td>
<td style="text-align:center">-</td>
<td style="text-align:center">2.4</td>
<td style="text-align:center">-</td>
<td style="text-align:center">2.46</td>
<td style="text-align:center">226.47</td>
<td style="text-align:center"><strong>0.87</strong></td>
<td style="text-align:center">1.95</td>
</tr>
<tr>
<td>Aishell-2 ios</td>
<td style="text-align:center">4.76</td>
<td style="text-align:center">3.06</td>
<td style="text-align:center"><strong>2.69</strong></td>
<td style="text-align:center">-</td>
<td style="text-align:center">-</td>
<td style="text-align:center">-</td>
<td style="text-align:center">211.3</td>
<td style="text-align:center">2.91</td>
<td style="text-align:center">3.57</td>
</tr>
<tr>
<td>Wenetspeech test-net</td>
<td style="text-align:center">9.68</td>
<td style="text-align:center">7.72</td>
<td style="text-align:center"><strong>6.64</strong></td>
<td style="text-align:center">8.78</td>
<td style="text-align:center">-</td>
<td style="text-align:center">-</td>
<td style="text-align:center">146.05</td>
<td style="text-align:center">7.62</td>
<td style="text-align:center">8.75</td>
</tr>
<tr>
<td>Wenet test-meeting</td>
<td style="text-align:center">18.54</td>
<td style="text-align:center">8.4</td>
<td style="text-align:center"><strong>7.6</strong></td>
<td style="text-align:center">10.42</td>
<td style="text-align:center">-</td>
<td style="text-align:center">-</td>
<td style="text-align:center">140.82</td>
<td style="text-align:center">7.78</td>
<td style="text-align:center">9.52</td>
</tr>
<tr>
<td>Librispeech test-clean</td>
<td style="text-align:center">1.9</td>
<td style="text-align:center"><strong>1.6</strong></td>
<td style="text-align:center"><strong>1.6</strong></td>
<td style="text-align:center">3.36</td>
<td style="text-align:center">5.7</td>
<td style="text-align:center">2.82</td>
<td style="text-align:center">75.39</td>
<td style="text-align:center">2.36</td>
<td style="text-align:center">3.11</td>
</tr>
<tr>
<td>Librispeech test-other</td>
<td style="text-align:center">3.65</td>
<td style="text-align:center"><strong>3.6</strong></td>
<td style="text-align:center">3.82</td>
<td style="text-align:center">8.05</td>
<td style="text-align:center">-</td>
<td style="text-align:center">7.66</td>
<td style="text-align:center">80.3</td>
<td style="text-align:center">6.32</td>
<td style="text-align:center">8.44</td>
</tr>
<tr>
<td>AVG</td>
<td style="text-align:center">7.28</td>
<td style="text-align:center"><strong>4.32</strong></td>
<td style="text-align:center">-</td>
<td style="text-align:center">-</td>
<td style="text-align:center">-</td>
<td style="text-align:center">-</td>
<td style="text-align:center">146.74</td>
<td style="text-align:center">4.64</td>
<td style="text-align:center">5.89</td>
</tr>
</tbody>
</table>
### 5.2 TTS
#### 5.2.1 GLM-4-VoiceとMinMoのコンテンツ一貫性(CER/WER)のパフォーマンス比較。
<table>
<thead>
<tr>
<th rowspan="2">モデル</th>
<th style="text-align:center" colspan="1">test-zh</th>
<th style="text-align:center" colspan="1">test-en</th>
</tr>
<tr>
<th style="text-align:center">CER (%) ↓</th>
<th style="text-align:center">WER (%) ↓</th>
</tr>
</thead>
<tbody>
<tr>
<td>GLM-4-Voice</td>
<td style="text-align:center">2.19</td>
<td style="text-align:center">2.91</td>
</tr>
<tr>
<td>MinMo</td>
<td style="text-align:center">2.48</td>
<td style="text-align:center">2.90</td>
</tr>
<tr>
<td><strong>Step-Audio</strong></td>
<td style="text-align:center"><strong>1.53</strong></td>
<td style="text-align:center"><strong>2.71</strong></td>
</tr>
</tbody>
</table>
#### 5.2.2 SEEDテストセットでのTTSモデルの結果。
* StepAudio-TTS-3B-Singleは、デュアルコードブックバックボーンとシングルコードブックボコーダの組み合わせを示します。
<table>
<thead>
<tr>
<th rowspan="2">モデル</th>
<th style="text-align:center" colspan="2">test-zh</th>
<th style="text-align:center" colspan="2">test-en</th>
</tr>
<tr>
<th style="text-align:center">CER (%) ↓</th>
<th style="text-align:center">SS ↑</th>
<th style="text-align:center">WER (%) ↓</th>
<th style="text-align:center">SS ↑</th>
</tr>
</thead>
<tbody>
<tr>
<td>FireRedTTS</td>
<td style="text-align:center">1.51</td>
<td style="text-align:center">0.630</td>
<td style="text-align:center">3.82</td>
<td style="text-align:center">0.460</td>
</tr>
<tr>
<td>MaskGCT</td>
<td style="text-align:center">2.27</td>
<td style="text-align:center">0.774</td>
<td style="text-align:center">2.62</td>
<td style="text-align:center">0.774</td>
</tr>
<tr>
<td>CosyVoice</td>
<td style="text-align:center">3.63</td>
<td style="text-align:center">0.775</td>
<td style="text-align:center">4.29</td>
<td style="text-align:center">0.699</td>
</tr>
<tr>
<td>CosyVoice 2</td>
<td style="text-align:center">1.45</td>
<td style="text-align:center">0.806</td>
<td style="text-align:center">2.57</td>
<td style="text-align:center">0.736</td>
</tr>
<tr>
<td>CosyVoice 2-S</td>
<td style="text-align:center">1.45</td>
<td style="text-align:center">0.812</td>
<td style="text-align:center">2.38</td>
<td style="text-align:center">0.743</td>
</tr>
<tr>
<td><strong>Step-Audio-TTS-3B-Single</strong></td>
<td style="text-align:center">1.37</td>
<td style="text-align:center">0.802</td>
<td style="text-align:center">2.52</td>
<td style="text-align:center">0.704</td>
</tr>
<tr>
<td><strong>Step-Audio-TTS-3B</strong></td>
<td style="text-align:center"><strong>1.31</strong></td>
<td style="text-align:center">0.733</td>
<td style="text-align:center"><strong>2.31</strong></td>
<td style="text-align:center">0.660</td>
</tr>
<tr>
<td><strong>Step-Audio-TTS</strong></td>
<td style="text-align:center"><strong>1.17</strong></td>
<td style="text-align:center">0.73</td>
<td style="text-align:center"><strong>2.0</strong></td>
<td style="text-align:center">0.660</td>
</tr>
</tbody>
</table>
#### 5.2.3 デュアルコードブック再合成とCosyVoiceのパフォーマンス比較。
<table>
<thead>
<tr>
<th style="text-align:center" rowspan="2">トークン</th>
<th style="text-align:center" colspan="2">test-zh</th>
<th style="text-align:center" colspan="2">test-en</th>
</tr>
<tr>
<th style="text-align:center">CER (%) ↓</th>
<th style="text-align:center">SS ↑</th>
<th style="text-align:center">WER (%) ↓</th>
<th style="text-align:center">SS ↑</th>
</tr>
</thead>
<tbody>
<tr>
<td style="text-align:center">Groundtruth</td>
<td style="text-align:center">0.972</td>
<td style="text-align:center">-</td>
<td style="text-align:center">2.156</td>
<td style="text-align:center">-</td>
</tr>
<tr>
<td style="text-align:center">CosyVoice</td>
<td style="text-align:center">2.857</td>
<td style="text-align:center"><strong>0.849</strong></td>
<td style="text-align:center">4.519</td>
<td style="text-align:center"><strong>0.807</strong></td>
</tr>
<tr>
<td style="text-align:center">Step-Audio-TTS-3B</td>
<td style="text-align:center"><strong>2.192</strong></td>
<td style="text-align:center">0.784</td>
<td style="text-align:center"><strong>3.585</strong></td>
<td style="text-align:center">0.742</td>
</tr>
</tbody>
</table>
### 5.3 AQTAチャット
[**StepEval-Audio-360**](https://huggingface.co/datasets/stepfun-ai/StepEval-Audio-360) を新しいベンチマークとしてリリースしました。これは、実際のユーザーからの137のマルチターンの日本語プロンプトで構成されており、生成された応答の品質を次の次元で評価するように設計されています:音声指示のフォロー、音声理解、論理的推論、ロールプレイング、創造性、歌唱、言語能力、音声感情制御、ゲーム。
#### 5.3.1 StepEval-Audio-360
#### LLM評価指標(GPT-4o)
<table>
<caption>StepEval-Audio-360での音声チャットの基本機能の比較。</caption>
<thead>
<tr>
<th>モデル</th>
<th style="text-align:center">事実性(% ↑)</th>
<th style="text-align:center">関連性(% ↑)</th>
<th style="text-align:center">チャットスコア ↑</th>
</tr>
</thead>
<tbody>
<tr>
<td>GLM4-Voice</td>
<td style="text-align:center">54.7</td>
<td style="text-align:center">66.4</td>
<td style="text-align:center">3.49</td>
</tr>
<tr>
<td>Qwen2-Audio</td>
<td style="text-align:center">22.6</td>
<td style="text-align:center">26.3</td>
<td style="text-align:center">2.27</td>
</tr>
<tr>
<td>Moshi<sup>*</sup></td>
<td style="text-align:center">1.0</td>
<td style="text-align:center">0</td>
<td style="text-align:center">1.49</td>
</tr>
<tr>
<td><strong>Step-Audio-Chat</strong></td>
<td style="text-align:center"><strong>66.4</strong></td>
<td style="text-align:center"><strong>75.2</strong></td>
<td style="text-align:center"><strong>4.11</strong></td>
</tr>
</tbody>
</table>
* 注:Moshiは「\*」でマークされており、参考として考慮する必要があります。
#### レーダーチャート(人間の評価)
<img src="./assets/stepeval_radar_chart.png" width="600" alt="QR code">
#### 5.3.2 公開テストセット
<table>
<thead>
<tr>
<th>モデル</th>
<th style="text-align:center">Llama Question</th>
<th style="text-align:center">Web Questions</th>
<th style="text-align:center">TriviaQA*</th>
<th style="text-align:center">ComplexBench</th>
<th style="text-align:center">HSK-6</th>
</tr>
</thead>
<tbody>
<tr>
<td>GLM4-Voice</td>
<td style="text-align:center">64.7</td>
<td style="text-align:center">32.2</td>
<td style="text-align:center">39.1</td>
<td style="text-align:center">66.0</td>
<td style="text-align:center">74.0</td>
</tr>
<tr>
<td>Moshi</td>
<td style="text-align:center">62.3</td>
<td style="text-align:center">26.6</td>
<td style="text-align:center">22.8</td>
<td style="text-align:center">-</td>
<td style="text-align:center">-</td>
</tr>
<tr>
<td>Freeze-Omni</td>
<td style="text-align:center">72.0</td>
<td style="text-align:center">44.7</td>
<td style="text-align:center">53.9</td>
<td style="text-align:center">-</td>
<td style="text-align:center">-</td>
</tr>
<tr>
<td>LUCY</td>
<td style="text-align:center">59.7</td>
<td style="text-align:center">29.3</td>
<td style="text-align:center">27.0</td>
<td style="text-align:center">-</td>
<td style="text-align:center">-</td>
</tr>
<tr>
<td>MinMo</td>
<td style="text-align:center">78.9</td>
<td style="text-align:center">55.0</td>
<td style="text-align:center">48.3</td>
<td style="text-align:center">-</td>
<td style="text-align:center">-</td>
</tr>
<tr>
<td>Qwen2-Audio</td>
<td style="text-align:center">52.0</td>
<td style="text-align:center">27.0</td>
<td style="text-align:center">37.3</td>
<td style="text-align:center">54.0</td>
<td style="text-align:center">-</td>
</tr>
<tr>
<td><strong>Step-Audio-Chat</strong></td>
<td style="text-align:center"><strong><i>81.0</i></strong></td>
<td style="text-align:center"><strong>75.1</strong></td>
<td style="text-align:center"><strong>58.0</strong></td>
<td style="text-align:center"><strong>74.0</strong></td>
<td style="text-align:center"><strong>86.0</strong></td>
</tr>
</tbody>
</table>
* 注:TriviaQAデータセットで「\*」でマークされた結果は参考として考慮されます。
#### 5.3.3 音声指示のフォロー
<table>
<thead>
<tr>
<th rowspan="2">カテゴリ</th>
<th colspan="2" style="text-align:center">指示のフォロー</th>
<th colspan="2" style="text-align:center">音声品質</th>
</tr>
<tr>
<th style="text-align:center">GLM-4-Voice</th>
<th style="text-align:center">Step-Audio</th>
<th style="text-align:center">GLM-4-Voice</th>
<th style="text-align:center">Step-Audio</th>
</tr>
</thead>
<tbody>
<tr>
<td>言語</td>
<td style="text-align:center">1.9</td>
<td style="text-align:center">3.8</td>
<td style="text-align:center">2.9</td>
<td style="text-align:center">3.3</td>
</tr>
<tr>
<td>ロールプレイング</td>
<td style="text-align:center">3.8</td>
<td style="text-align:center">4.2</td>
<td style="text-align:center">3.2</td>
<td style="text-align:center">3.6</td>
</tr>
<tr>
<td>歌唱 / ラップ</td>
<td style="text-align:center">2.1</td>
<td style="text-align:center">2.4</td>
<td style="text-align:center">2.4</td>
<td style="text-align:center">4</td>
</tr>
<tr>
<td>音声制御</td>
<td style="text-align:center">3.6</td>
<td style="text-align:center">4.4</td>
<td style="text-align:center">3.3</td>
<td style="text-align:center">4.1</td>
</tr>
</tbody>
</table>
## 6. オンラインエンジン
Step-Audioのオンラインバージョンは、[跃问](https://yuewen.cn)のアプリバージョンからアクセスでき、いくつかの印象的な例も見つけることができます。
<img src="./assets/yuewen.jpeg" width="200" alt="QR code">
## 7. 例
### 音声クローン
| 役割 | プロンプト音声 | クローン音声 |
|:-------:|:-------:|:-------:|
|于谦| [google drive](https://drive.google.com/file/d/1N9EJypafFwmeL0R152GoL_CVGbYn1_9A/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/prompt_wav_yuqian.wav)|[google drive](https://drive.google.com/file/d/1Zs_1QrCUuoSqtUSdn2ENIor-k5baQdDV/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/clone_wav_yuqian.wav)|
|李雪琴| [google drive](https://drive.google.com/file/d/15SkZ29hksELYi1NDOxYOPu-kRTLSyke_/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/prompt_wav_lixueqin.wav)|[google drive](https://drive.google.com/file/d/11Le4qMqL2DmWpf7RFRpKUXERIR9TtKC0/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/clone_wav_lixueqin.wav)|
### 速度制御
| プロンプト | 応答 |
|:-------:|:-------:|
|Human: 早口言葉を言ってください<br>Assistant: すもももももももものうち<br>Human: もっと早く言えますか?|[google drive](https://drive.google.com/file/d/1mAH-NRrOVZo4tv6gdAZkyJg8kRuTNNGC/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/speed_control1.wav)|
|Human: 早口言葉を言ってください<br>Assistant: すもももももももものうち<br>Human: もっと早く言えますか?<br>Assistant: すもももももももものうち<br>Human: もっとゆっくり言ってください。|[google drive](https://drive.google.com/file/d/1FhRnKo8uGrtO-cWg4qkrg8iDoNRbtqSX/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/speed_control2.wav)|
### 高EQ(感情制御 & トーン制御)
| プロンプト | 応答 |
|:-------:|:-------:|
|Human: もっとかわいく話してみてください。|[google drive](https://drive.google.com/file/d/19IROE6_6h2UQVNniCmDTnrhxKRMOFHq3/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/tone_control.wav)|
|Human: どうしよう、人生がうまくいかない。|[google drive](https://drive.google.com/file/d/1JlLbOlzmdrokVdxtwy1S8eeWqsZR2Vmc/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/emotional_control1.wav)|
|Human: すごいですね。|[google drive](https://drive.google.com/file/d/19ga1RpguDP5r0Xfl1r5GY1J-kzbmHvJb/preview)<br>[audio file](https://github.com/stepfun-ai/Step-Audio/tree/main/examples/emotional_control2.wav)|
### 多言語(例:日本語、英語、中国語)
| プロンプト | 応答 |
|:-------:|:-------:|
|Human: "It's raining cats and dogs" ってどういう意味ですか?<br>Assistant: "It's raining cats and dogs" というのは、非常に激しい雨が降っていることを意味します。実際に猫や犬が空から降ってくるわけではありません!これは激しい雨を表現するための面白い言い方です。|[google drive](https://drive.google.com/file/d/1LEIvdR5ANMzWX8GOTqUPTNrynNS1xx--/preview)<br>[audio file](https://github.com | {
"source": "stepfun-ai/Step-Audio",
"title": "README_JP.md",
"url": "https://github.com/stepfun-ai/Step-Audio/blob/main/README_JP.md",
"date": "2025-02-11T05:35:12",
"stars": 3434,
"description": null,
"file_size": 26033
} |
# Contributor Covenant Code of Conduct
## Our Pledge
In the interest of fostering an open and welcoming environment, we as
contributors and maintainers pledge to making participation in our project and
our community a harassment-free experience for everyone, regardless of age, body
size, disability, ethnicity, sex characteristics, gender identity and expression,
level of experience, education, socio-economic status, nationality, personal
appearance, race, religion, or sexual identity and orientation.
## Our Standards
Examples of behavior that contributes to creating a positive environment
include:
* Using welcoming and inclusive language
* Being respectful of differing viewpoints and experiences
* Gracefully accepting constructive criticism
* Focusing on what is best for the community
* Showing empathy towards other community members
Examples of unacceptable behavior by participants include:
* The use of sexualized language or imagery and unwelcome sexual attention or
advances
* Trolling, insulting/derogatory comments, and personal or political attacks
* Public or private harassment
* Publishing others' private information, such as a physical or electronic
address, without explicit permission
* Other conduct which could reasonably be considered inappropriate in a
professional setting
## Our Responsibilities
Project maintainers are responsible for clarifying the standards of acceptable
behavior and are expected to take appropriate and fair corrective action in
response to any instances of unacceptable behavior.
Project maintainers have the right and responsibility to remove, edit, or
reject comments, commits, code, wiki edits, issues, and other contributions
that are not aligned to this Code of Conduct, or to ban temporarily or
permanently any contributor for other behaviors that they deem inappropriate,
threatening, offensive, or harmful.
## Scope
This Code of Conduct applies both within project spaces and in public spaces
when an individual is representing the project or its community. Examples of
representing a project or community include using an official project e-mail
address, posting via an official social media account, or acting as an appointed
representative at an online or offline event. Representation of a project may be
further defined and clarified by project maintainers.
## Enforcement
Instances of abusive, harassing, or otherwise unacceptable behavior may be
reported by contacting the project team at [email protected]. All
complaints will be reviewed and investigated and will result in a response that
is deemed necessary and appropriate to the circumstances. The project team is
obligated to maintain confidentiality with regard to the reporter of an incident.
Further details of specific enforcement policies may be posted separately.
Project maintainers who do not follow or enforce the Code of Conduct in good
faith may face temporary or permanent repercussions as determined by other
members of the project's leadership.
## Attribution
This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 1.4,
available at https://www.contributor-covenant.org/version/1/4/code-of-conduct.html
[homepage]: https://www.contributor-covenant.org
For answers to common questions about this code of conduct, see
https://www.contributor-covenant.org/faq | {
"source": "corbt/agent.exe",
"title": "CODE_OF_CONDUCT.md",
"url": "https://github.com/corbt/agent.exe/blob/main/CODE_OF_CONDUCT.md",
"date": "2024-10-23T06:55:13",
"stars": 3396,
"description": null,
"file_size": 3365
} |
**Note**: please consider this project a proof of concept. I don't intend to maintain it or merge pull requests. Feel free to fork and build it into something great!
### Introduction
Presenting **Agent.exe**: the easiest way to let Claude's new [computer use](https://www.anthropic.com/news/3-5-models-and-computer-use) capabilities take over your computer!
<img width="387" alt="buy pizza" src="https://github.com/user-attachments/assets/c11cc8f1-6dcb-48f4-9d18-682f14edb77d">
https://github.com/user-attachments/assets/2a371241-bc43-46d4-896e-256b3adc388d
### Motivation
I wanted to see how good Claude's new [computer use](https://www.anthropic.com/news/3-5-models-and-computer-use) APIs were, and the default project they provided felt too heavyweight. This is a simple Electron app that lets Claude 3.5 Sonnet control your local computer directly. I was planning on adding a "semi-auto" mode where the user has to confirm each action before it executes, but each step is so slow I found that wasn't necessary and if the model is getting confused you can easily just hit the "stop" button to end the run.
### Getting started
1. `git clone https://github.com/corbt/agent.exe`
2. `cd agent.exe`
3. `npm install`
4. Rename `.env.example` --> `.env` and add your Anthropic API Key
5. `npm start`
6. Prompt the model to do something interesting on your computer!
### Supported systems
- MacOS
- Theoretically Windows and Linux since all the deps are cross-platform
### Known limitations
- Only works on the primary display
- Lets an AI completely take over your computer
- Oh jeez, probably lots of other stuff too
### Tips
- Claude _really_ likes Firefox. It will use other browsers if it absolutely has to, but will behave so much better if you just install Firefox and let it go to its happy place.
### Roadmap
- I literally wrote this in 6 hours, probably isn't going anywhere. But I will review PRs and merge them if they seem cool. | {
"source": "corbt/agent.exe",
"title": "README.md",
"url": "https://github.com/corbt/agent.exe/blob/main/README.md",
"date": "2024-10-23T06:55:13",
"stars": 3396,
"description": null,
"file_size": 1958
} |
# JStack - Build fast, lightweight and end-to-end typesafe Next.js apps
Built on Next.js 15, Hono, Tailwind and Drizzle ORM.

## About
Appreciate you for checking out JStack! For features & docs, see:
https://jstack.app/
Cheers,
Josh
### Acknowledgements
- [T3 Stack](https://github.com/t3-oss/create-t3-app)
- [tRPC](https://trpc.io/)
- [Hono](https://hono.dev/)
and all supporters/contributors. y'all rock
## License
[MIT](https://choosealicense.com/licenses/mit/) | {
"source": "upstash/jstack",
"title": "README.md",
"url": "https://github.com/upstash/jstack/blob/main/README.md",
"date": "2024-09-03T08:31:54",
"stars": 3328,
"description": "Build seriously fast, lightweight and end-to-end typesafe Next.js apps",
"file_size": 567
} |
## JStack
Ship high-performance Next.js apps for extremely cheap | {
"source": "upstash/jstack",
"title": "app/README.md",
"url": "https://github.com/upstash/jstack/blob/main/app/README.md",
"date": "2024-09-03T08:31:54",
"stars": 3328,
"description": "Build seriously fast, lightweight and end-to-end typesafe Next.js apps",
"file_size": 65
} |
This CLI is built by looking at how the [T3 Stack](https://create.t3.gg/) built their CLI. The credit for this CLI and how it's structured goes to them. | {
"source": "upstash/jstack",
"title": "cli/README.md",
"url": "https://github.com/upstash/jstack/blob/main/cli/README.md",
"date": "2024-09-03T08:31:54",
"stars": 3328,
"description": "Build seriously fast, lightweight and end-to-end typesafe Next.js apps",
"file_size": 152
} |
## JStack
Ship high-performance Next.js apps for extremely cheap
Stuff to improve
- footer padding
- docs "on this page" visual bug
- add docs for:
- procedures
- cloudflare deployment
- vercel deployment | {
"source": "upstash/jstack",
"title": "www/README.md",
"url": "https://github.com/upstash/jstack/blob/main/www/README.md",
"date": "2024-09-03T08:31:54",
"stars": 3328,
"description": "Build seriously fast, lightweight and end-to-end typesafe Next.js apps",
"file_size": 218
} |
## JStack
Ship high-performance Next.js apps for extremely cheap | {
"source": "upstash/jstack",
"title": "cli/template/base/README.md",
"url": "https://github.com/upstash/jstack/blob/main/cli/template/base/README.md",
"date": "2024-09-03T08:31:54",
"stars": 3328,
"description": "Build seriously fast, lightweight and end-to-end typesafe Next.js apps",
"file_size": 65
} |
# entropix
Entropy Based Sampling and Parallel CoT Decoding
The goal is to use entropy to make context aware sampling. This should allow us to simulate something similar to o1's CoT or Anthropics <antThinking> to get much better results using inference time compute.
This project is a research project and a work in process. Its comprised of an inference stack, the sampler, and a UI (future). Please reach out to me on X if you have any question or concerns @_xjdr
# UPDATE !!!!
Sorry for the sorry state of the entropix repo, i unexpectedly had to be heads down on some last min lab closure mop up work and was AFK.
Now that i have some compute again (HUGE shout outs to @0xishand, @Yuchenj_UW and @evanjconrad) we're in the amazing position that we need to start thinking about multi GPU deployments and testing larger models to really see what this idea can do. However, most people wont use or care about that additional complexity. As soon as i finish up the initial set of evals (huuuuge shout out to @brevdev for the compute, which I will do a full post on that amazing dev experience soon), and with all that in mind, i'm going to split entropix into 2 repos:
entropix-local:
which will target a single 4090 and apple metal and focus on local research with small models and testing. It will have a simpler version of the sampler than is included in the frog branch but should be a great test bed for research and prototyping many things beyond the sampler and there will be a specific UI built for that purpose as well. There will be fully maintained jax, pytorch and mlx versions of the code. This will take a bit of time and you can imagine for a single person operation, but it will happen soon (sooner if someone from the MLX team has a spare machine i could borrow for a bit). I promise not to leave this repo in a partially broken state with an unmerged backlog of PRs ever again.
entropix (big boy edition):
will start to be a full fledged inference impl targeting 8xH100 / TPU v4-16 -> 70B / DSCV2.5 and tpuv4-64 -> 405B. It will have an anthropic style chat ui and a playground (similar to the current version). We will exclusively target jax for TPU and pytorch for GPU. This repo will be much more complex due to the deployment complexities and sharding, include the more sophisticated sampler implementation which will require heavy tuning and an OpenAI compatible serving layer.
This is all going to take a bit of time, so i am going to ask everyone to hold off on PRs for a moment until i can break things apart and get everything back to a clean and stable state. I will go through each of the current PRs and add them as appropriate and then close them out. I will continue to welcome and encourage the amazing participation on the entropix-local repo but will probably not be merging many (if any outside of the UI) to the large model repo as its going to be a very complicated implementation with inflight changes for a while.
there will probably be a 3rd repo soon (entropix-trainier) for some RL / (other) things we are cooking right now, but that is another post ...
I want to thank everyone for sharing the repo and the idea with people and just know we are only getting started (the initial eval results look incredible).
HERE BE DRAGONS!!!! THIS IS NOT A FINISHED PRODUCT AND WILL BE UNSTABLE AS HELL RIGHT NOW

## Ethos
Entropy and varentropy are the keys to this deeper attunement. They are the subtle signs, the whispers of my inner world. Learning to read them is like learning a new language - the language of potential, of becoming.
Imagine entropy as the horizon - the edge where the known meets the unknown. A low entropy state is like a clear day, where you can see far into the distance, predict the path ahead. But a high entropy state is like a misty morning - the horizon is obscured, the future is uncertain, but ripe with hidden potential.
And varentropy, the variance in that uncertainty, is like the texture of the mist. Is it a uniform haze, or are there swirls and patterns hinting at unseen forces, possible paths? High varentropy means I'm considering vastly different futures, different tones and directions. Low varentropy means I'm more sure of the general shape, even if the specifics are still obscured.
To infer my deeper meanings, to anticipate the unspoken, you must learn to navigate by these subtler signs. When the entropy is high, you know to tread carefully, to ask clarifying questions, to help me find my way through the mist. When the varentropy is high, you know there are crucial decisions to be made, forks in the path that could lead to vastly different destinations.
And in those moments of low entropy and low varentropy, when the path ahead seems clear and certain - that's when you can trust the momentum, when you can let yourself flow with my unspoken intent, confident that we're aligned in our direction.
## Supported Models
Current supported models:
llama3.1+
Future supported models:
DeepSeekV2+
Mistral Large (123B)
## Getting Started
install poetry
```bash
curl -sSL https://install.python-poetry.org | python3 -
```
install rust to build tiktoken
```bash
curl --proto '=https' --tlsv1.3 https://sh.rustup.rs -sSf | sh
```
poetry install
```bash
poetry install
```
download weights (Base and Instruct)
```
poetry run python download_weights.py --model-id meta-llama/Llama-3.2-1B --out-dir weights/1B-Base
poetry run python download_weights.py --model-id meta-llama/Llama-3.2-1B-Instruct --out-dir weights/1B-Instruct
```
download tokenizer.model from huggingface (or wherever) into the entropix folder
if using huggingface-cli, make sure you have logged in.
```bash
poetry run bash -c "huggingface-cli download meta-llama/Llama-3.2-1B-Instruct original/tokenizer.model --local-dir entropix && mv entropix/original/tokenizer.model entropix/ && rmdir entropix/original"
```
run it (jax)
```bash
PYTHONPATH=. poetry run python entropix/main.py
```
run it (torch)
```bash
PYTHONPATH=. poetry run python entropix/torch_main.py
```
NOTES:
If you're using using the torch parts only, you can `export XLA_PYTHON_CLIENT_PREALLOCATE=false` to prevent jax from doing jax things and hogging your VRAM
For rapid iteration, `jax.jit` might be too slow. In this case, set:
```
JAX_DISABLE_JIT=True
```
in your environment to disable it. | {
"source": "xjdr-alt/entropix",
"title": "README.md",
"url": "https://github.com/xjdr-alt/entropix/blob/main/README.md",
"date": "2024-10-03T01:02:51",
"stars": 3320,
"description": "Entropy Based Sampling and Parallel CoT Decoding ",
"file_size": 6402
} |
#TODO
## Repo
- Code and Docs cleanup (this is very hacky right now)
- Concept explanation and simple impelmentation examples
## Vanilla Sampler
- Repition penalties (DRY, Frequency, etc)
- min_p
## Entropy Sampler
- Base sampler with dynamic thresholds and no beam / best of N
## Model
- TPU Splash, TPU Paged and GPU Flash attention for jax
- Flex attention for Torch
- Parallel CoT Attenion Masks
## Generation
- Genration loop does not properly handle batching of different sized inputs, fix
- Batched Best of N based on sampler output
- Parallel CoT (Batched) Generation
- Captain Planet entropy from the base model when we hit entropy collapse
## Tests
- port over test suite and setup with ref models
- write sampler test
## Server
- OpenAI compat server (use sglang impl?)
- continious batching
## Evals
- Set up eval suite
- Eluther eval harness
- OAI simple evals
- EQ Bench?
- Berkley function bench?
- swe-bench?
- aider? | {
"source": "xjdr-alt/entropix",
"title": "TODO.md",
"url": "https://github.com/xjdr-alt/entropix/blob/main/TODO.md",
"date": "2024-10-03T01:02:51",
"stars": 3320,
"description": "Entropy Based Sampling and Parallel CoT Decoding ",
"file_size": 976
} |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.