
text
stringlengths 55
456k
| metadata
dict |
|---|---|
# `pure_eval`
[](https://travis-ci.org/alexmojaki/pure_eval) [](https://coveralls.io/github/alexmojaki/pure_eval?branch=master) [](https://pypi.python.org/pypi/pure_eval)
This is a Python package that lets you safely evaluate certain AST nodes without triggering arbitrary code that may have unwanted side effects.
It can be installed from PyPI:
pip install pure_eval
To demonstrate usage, suppose we have an object defined as follows:
```python
class Rectangle:
def __init__(self, width, height):
self.width = width
self.height = height
@property
def area(self):
print("Calculating area...")
return self.width * self.height
rect = Rectangle(3, 5)
```
Given the `rect` object, we want to evaluate whatever expressions we can in this source code:
```python
source = "(rect.width, rect.height, rect.area)"
```
This library works with the AST, so let's parse the source code and peek inside:
```python
import ast
tree = ast.parse(source)
the_tuple = tree.body[0].value
for node in the_tuple.elts:
print(ast.dump(node))
```
Output:
```python
Attribute(value=Name(id='rect', ctx=Load()), attr='width', ctx=Load())
Attribute(value=Name(id='rect', ctx=Load()), attr='height', ctx=Load())
Attribute(value=Name(id='rect', ctx=Load()), attr='area', ctx=Load())
```
Now to actually use the library. First construct an Evaluator:
```python
from pure_eval import Evaluator
evaluator = Evaluator({"rect": rect})
```
The argument to `Evaluator` should be a mapping from variable names to their values. Or if you have access to the stack frame where `rect` is defined, you can instead use:
```python
evaluator = Evaluator.from_frame(frame)
```
Now to evaluate some nodes, using `evaluator[node]`:
```python
print("rect.width:", evaluator[the_tuple.elts[0]])
print("rect:", evaluator[the_tuple.elts[0].value])
```
Output:
```
rect.width: 3
rect: <__main__.Rectangle object at 0x105b0dd30>
```
OK, but you could have done the same thing with `eval`. The useful part is that it will refuse to evaluate the property `rect.area` because that would trigger unknown code. If we try, it'll raise a `CannotEval` exception.
```python
from pure_eval import CannotEval
try:
print("rect.area:", evaluator[the_tuple.elts[2]]) # fails
except CannotEval as e:
print(e) # prints CannotEval
```
To find all the expressions that can be evaluated in a tree:
```python
for node, value in evaluator.find_expressions(tree):
print(ast.dump(node), value)
```
Output:
```python
Attribute(value=Name(id='rect', ctx=Load()), attr='width', ctx=Load()) 3
Attribute(value=Name(id='rect', ctx=Load()), attr='height', ctx=Load()) 5
Name(id='rect', ctx=Load()) <__main__.Rectangle object at 0x105568d30>
Name(id='rect', ctx=Load()) <__main__.Rectangle object at 0x105568d30>
Name(id='rect', ctx=Load()) <__main__.Rectangle object at 0x105568d30>
```
Note that this includes `rect` three times, once for each appearance in the source code. Since all these nodes are equivalent, we can group them together:
```python
from pure_eval import group_expressions
for nodes, values in group_expressions(evaluator.find_expressions(tree)):
print(len(nodes), "nodes with value:", values)
```
Output:
```
1 nodes with value: 3
1 nodes with value: 5
3 nodes with value: <__main__.Rectangle object at 0x10d374d30>
```
If we want to list all the expressions in a tree, we may want to filter out certain expressions whose values are obvious. For example, suppose we have a function `foo`:
```python
def foo():
pass
```
If we refer to `foo` by its name as usual, then that's not interesting:
```python
from pure_eval import is_expression_interesting
node = ast.parse('foo').body[0].value
print(ast.dump(node))
print(is_expression_interesting(node, foo))
```
Output:
```python
Name(id='foo', ctx=Load())
False
```
But if we refer to it by a different name, then it's interesting:
```python
node = ast.parse('bar').body[0].value
print(ast.dump(node))
print(is_expression_interesting(node, foo))
```
Output:
```python
Name(id='bar', ctx=Load())
True
```
In general `is_expression_interesting` returns False for the following values:
- Literals (e.g. `123`, `'abc'`, `[1, 2, 3]`, `{'a': (), 'b': ([1, 2], [3])}`)
- Variables or attributes whose name is equal to the value's `__name__`, such as `foo` above or `self.foo` if it was a method.
- Builtins (e.g. `len`) referred to by their usual name.
To make things easier, you can combine finding expressions, grouping them, and filtering out the obvious ones with:
```python
evaluator.interesting_expressions_grouped(root)
```
To get the source code of an AST node, I recommend [asttokens](https://github.com/gristlabs/asttokens).
Here's a complete example that brings it all together:
```python
from asttokens import ASTTokens
from pure_eval import Evaluator
source = """
x = 1
d = {x: 2}
y = d[x]
"""
names = {}
exec(source, names)
atok = ASTTokens(source, parse=True)
for nodes, value in Evaluator(names).interesting_expressions_grouped(atok.tree):
print(atok.get_text(nodes[0]), "=", value)
```
Output:
```python
x = 1
d = {1: 2}
y = 2
d[x] = 2
``` | {
"source": "yandex/perforator",
"title": "contrib/python/pure-eval/README.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/python/pure-eval/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 5425
} |
.. -*- coding: utf-8 -*-
.. :Project: python-rapidjson -- Introduction
.. :Author: Ken Robbins <[email protected]>
.. :License: MIT License
.. :Copyright: © 2015 Ken Robbins
.. :Copyright: © 2016, 2017, 2018, 2020, 2022 Lele Gaifax
..
==================
python-rapidjson
==================
Python wrapper around RapidJSON
===============================
:Authors: Ken Robbins <[email protected]>; Lele Gaifax <[email protected]>
:License: `MIT License`__
:Status: |build| |doc|
__ https://raw.githubusercontent.com/python-rapidjson/python-rapidjson/master/LICENSE
.. |build| image:: https://travis-ci.org/python-rapidjson/python-rapidjson.svg?branch=master
:target: https://travis-ci.org/python-rapidjson/python-rapidjson
:alt: Build status
.. |doc| image:: https://readthedocs.org/projects/python-rapidjson/badge/?version=latest
:target: https://readthedocs.org/projects/python-rapidjson/builds/
:alt: Documentation status
RapidJSON_ is an extremely fast C++ JSON parser and serialization library: this module
wraps it into a Python 3 extension, exposing its serialization/deserialization (to/from
either ``bytes``, ``str`` or *file-like* instances) and `JSON Schema`__ validation
capabilities.
Latest version documentation is automatically rendered by `Read the Docs`__.
__ http://json-schema.org/documentation.html
__ https://python-rapidjson.readthedocs.io/en/latest/
Getting Started
---------------
First install ``python-rapidjson``:
.. code-block:: bash
$ pip install python-rapidjson
or, if you prefer `Conda`__:
.. code-block:: bash
$ conda install -c conda-forge python-rapidjson
__ https://conda.io/docs/
Basic usage looks like this:
.. code-block:: python
>>> import rapidjson
>>> data = {'foo': 100, 'bar': 'baz'}
>>> rapidjson.dumps(data)
'{"foo":100,"bar":"baz"}'
>>> rapidjson.loads('{"bar":"baz","foo":100}')
{'bar': 'baz', 'foo': 100}
>>>
>>> class Stream:
... def write(self, data):
... print("Chunk:", data)
...
>>> rapidjson.dump(data, Stream(), chunk_size=5)
Chunk: b'{"foo'
Chunk: b'":100'
Chunk: b',"bar'
Chunk: b'":"ba'
Chunk: b'z"}'
Development
-----------
If you want to install the development version (maybe to contribute fixes or
enhancements) you may clone the repository:
.. code-block:: bash
$ git clone --recursive https://github.com/python-rapidjson/python-rapidjson.git
.. note:: The ``--recursive`` option is needed because we use a *submodule* to
include RapidJSON_ sources. Alternatively you can do a plain
``clone`` immediately followed by a ``git submodule update --init``.
Alternatively, if you already have (a *compatible* version of)
RapidJSON includes around, you can compile the module specifying
their location with the option ``--rj-include-dir``, for example:
.. code-block:: shell
$ python3 setup.py build --rj-include-dir=/usr/include/rapidjson
A set of makefiles implement most common operations, such as *build*, *check*
and *release*; see ``make help`` output for a list of available targets.
Performance
-----------
``python-rapidjson`` tries to be as performant as possible while staying
compatible with the ``json`` module.
See the `this section`__ in the documentation for a comparison with other JSON libraries.
__ https://python-rapidjson.readthedocs.io/en/latest/benchmarks.html
Incompatibility
---------------
Although we tried to implement an API similar to the standard library ``json``, being a
strict *drop-in* replacement in not our goal and we have decided to depart from there in
some aspects. See `this section`__ in the documentation for further details.
__ https://python-rapidjson.readthedocs.io/en/latest/quickstart.html#incompatibilities
.. _RapidJSON: http://rapidjson.org/ | {
"source": "yandex/perforator",
"title": "contrib/python/python-rapidjson/README.rst",
"url": "https://github.com/yandex/perforator/blob/main/contrib/python/python-rapidjson/README.rst",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 3873
} |
# stack_data
[](https://github.com/alexmojaki/stack_data/actions/workflows/pytest.yml) [](https://coveralls.io/github/alexmojaki/stack_data?branch=master) [](https://pypi.python.org/pypi/stack_data)
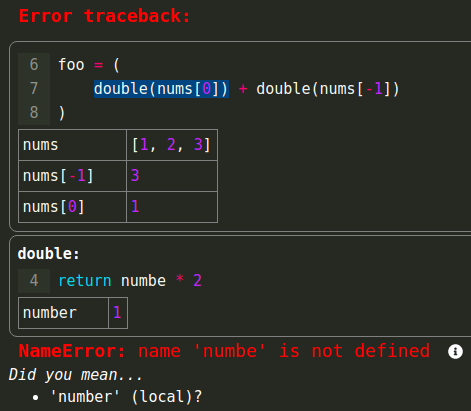
This is a library that extracts data from stack frames and tracebacks, particularly to display more useful tracebacks than the default. It powers the tracebacks in IPython and [futurecoder](https://futurecoder.io/):
You can install it from PyPI:
pip install stack_data
## Basic usage
Here's some code we'd like to inspect:
```python
def foo():
result = []
for i in range(5):
row = []
result.append(row)
print_stack()
for j in range(5):
row.append(i * j)
return result
```
Note that `foo` calls a function `print_stack()`. In reality we can imagine that an exception was raised at this line, or a debugger stopped there, but this is easy to play with directly. Here's a basic implementation:
```python
import inspect
import stack_data
def print_stack():
frame = inspect.currentframe().f_back
frame_info = stack_data.FrameInfo(frame)
print(f"{frame_info.code.co_name} at line {frame_info.lineno}")
print("-----------")
for line in frame_info.lines:
print(f"{'-->' if line.is_current else ' '} {line.lineno:4} | {line.render()}")
```
(Beware that this has a major bug - it doesn't account for line gaps, which we'll learn about later)
The output of one call to `print_stack()` looks like:
```
foo at line 9
-----------
6 | for i in range(5):
7 | row = []
8 | result.append(row)
--> 9 | print_stack()
10 | for j in range(5):
```
The code for `print_stack()` is fairly self-explanatory. If you want to learn more details about a particular class or method I suggest looking through some docstrings. `FrameInfo` is a class that accepts either a frame or a traceback object and provides a bunch of nice attributes and properties (which are cached so you don't need to worry about performance). In particular `frame_info.lines` is a list of `Line` objects. `line.render()` returns the source code of that line suitable for display. Without any arguments it simply strips any common leading indentation. Later on we'll see a more powerful use for it.
You can see that `frame_info.lines` includes some lines of surrounding context. By default it includes 3 pieces of context before the main line and 1 piece after. We can configure the amount of context by passing options:
```python
options = stack_data.Options(before=1, after=0)
frame_info = stack_data.FrameInfo(frame, options)
```
Then the output looks like:
```
foo at line 9
-----------
8 | result.append(row)
--> 9 | print_stack()
```
Note that these parameters are not the number of *lines* before and after to include, but the number of *pieces*. A piece is a range of one or more lines in a file that should logically be grouped together. A piece contains either a single simple statement or a part of a compound statement (loops, if, try/except, etc) that doesn't contain any other statements. Most pieces are a single line, but a multi-line statement or `if` condition is a single piece. In the example above, all pieces are one line, because nothing is spread across multiple lines. If we change our code to include some multiline bits:
```python
def foo():
result = []
for i in range(5):
row = []
result.append(
row
)
print_stack()
for j in range(
5
):
row.append(i * j)
return result
```
and then run the original code with the default options, then the output is:
```
foo at line 11
-----------
6 | for i in range(5):
7 | row = []
8 | result.append(
9 | row
10 | )
--> 11 | print_stack()
12 | for j in range(
13 | 5
14 | ):
```
Now lines 8-10 and lines 12-14 are each a single piece. Note that the output is essentially the same as the original in terms of the amount of code. The division of files into pieces means that the edge of the context is intuitive and doesn't crop out parts of statements or expressions. For example, if context was measured in lines instead of pieces, the last line of the above would be `for j in range(` which is much less useful.
However, if a piece is very long, including all of it could be cumbersome. For this, `Options` has a parameter `max_lines_per_piece`, which is 6 by default. Suppose we have a piece in our code that's longer than that:
```python
row = [
1,
2,
3,
4,
5,
]
```
`frame_info.lines` will truncate this piece so that instead of 7 `Line` objects it will produce 5 `Line` objects and one `LINE_GAP` in the middle, making 6 objects in total for the piece. Our code doesn't currently handle gaps, so it will raise an exception. We can modify it like so:
```python
for line in frame_info.lines:
if line is stack_data.LINE_GAP:
print(" (...)")
else:
print(f"{'-->' if line.is_current else ' '} {line.lineno:4} | {line.render()}")
```
Now the output looks like:
```
foo at line 15
-----------
6 | for i in range(5):
7 | row = [
8 | 1,
9 | 2,
(...)
12 | 5,
13 | ]
14 | result.append(row)
--> 15 | print_stack()
16 | for j in range(5):
```
Alternatively, you can flip the condition around and check `if isinstance(line, stack_data.Line):`. Either way, you should always check for line gaps, or your code may appear to work at first but fail when it encounters a long piece.
Note that the executing piece, i.e. the piece containing the current line being executed (line 15 in this case) is never truncated, no matter how long it is.
The lines of context never stray outside `frame_info.scope`, which is the innermost function or class definition containing the current line. For example, this is the output for a short function which has neither 3 lines before nor 1 line after the current line:
```
bar at line 6
-----------
4 | def bar():
5 | foo()
--> 6 | print_stack()
```
Sometimes it's nice to ensure that the function signature is always showing. This can be done with `Options(include_signature=True)`. The result looks like this:
```
foo at line 14
-----------
9 | def foo():
(...)
11 | for i in range(5):
12 | row = []
13 | result.append(row)
--> 14 | print_stack()
15 | for j in range(5):
```
To avoid wasting space, pieces never start or end with a blank line, and blank lines between pieces are excluded. So if our code looks like this:
```python
for i in range(5):
row = []
result.append(row)
print_stack()
for j in range(5):
```
The output doesn't change much, except you can see jumps in the line numbers:
```
11 | for i in range(5):
12 | row = []
14 | result.append(row)
--> 15 | print_stack()
17 | for j in range(5):
```
## Variables
You can also inspect variables and other expressions in a frame, e.g:
```python
for var in frame_info.variables:
print(f"{var.name} = {repr(var.value)}")
```
which may output:
```python
result = [[0, 0, 0, 0, 0], [0, 1, 2, 3, 4], [0, 2, 4, 6, 8], [0, 3, 6, 9, 12], []]
i = 4
row = []
j = 4
```
`frame_info.variables` returns a list of `Variable` objects, which have attributes `name`, `value`, and `nodes`, which is a list of all AST representing that expression.
A `Variable` may refer to an expression other than a simple variable name. It can be any expression evaluated by the library [`pure_eval`](https://github.com/alexmojaki/pure_eval) which it deems 'interesting' (see those docs for more info). This includes expressions like `foo.bar` or `foo[bar]`. In these cases `name` is the source code of that expression. `pure_eval` ensures that it only evaluates expressions that won't have any side effects, e.g. where `foo.bar` is a normal attribute rather than a descriptor such as a property.
`frame_info.variables` is a list of all the interesting expressions found in `frame_info.scope`, e.g. the current function, which may include expressions not visible in `frame_info.lines`. You can restrict the list by using `frame_info.variables_in_lines` or even `frame_info.variables_in_executing_piece`. For more control you can use `frame_info.variables_by_lineno`. See the docstrings for more information.
## Rendering lines with ranges and markers
Sometimes you may want to insert special characters into the text for display purposes, e.g. HTML or ANSI color codes. `stack_data` provides a few tools to make this easier.
Let's say we have a `Line` object where `line.text` (the original raw source code of that line) is `"foo = bar"`, so `line.text[6:9]` is `"bar"`, and we want to emphasise that part by inserting HTML at positions 6 and 9 in the text. Here's how we can do that directly:
```python
markers = [
stack_data.MarkerInLine(position=6, is_start=True, string="<b>"),
stack_data.MarkerInLine(position=9, is_start=False, string="</b>"),
]
line.render(markers) # returns "foo = <b>bar</b>"
```
Here `is_start=True` indicates that the marker is the first of a pair. This helps `line.render()` sort and insert the markers correctly so you don't end up with malformed HTML like `foo<b>.<i></b>bar</i>` where tags overlap.
Since we're inserting HTML, we should actually use `line.render(markers, escape_html=True)` which will escape special HTML characters in the Python source (but not the markers) so for example `foo = bar < spam` would be rendered as `foo = <b>bar</b> < spam`.
Usually though you wouldn't create markers directly yourself. Instead you would start with one or more ranges and then convert them, like so:
```python
ranges = [
stack_data.RangeInLine(start=0, end=3, data="foo"),
stack_data.RangeInLine(start=6, end=9, data="bar"),
]
def convert_ranges(r):
if r.data == "bar":
return "<b>", "</b>"
# This results in `markers` being the same as in the above example.
markers = stack_data.markers_from_ranges(ranges, convert_ranges)
```
`RangeInLine` has a `data` attribute which can be any object. `markers_from_ranges` accepts a converter function to which it passes all the `RangeInLine` objects. If the converter function returns a pair of strings, it creates two markers from them. Otherwise it should return `None` to indicate that the range should be ignored, as with the first range containing `"foo"` in this example.
The reason this is useful is because there are built in tools to create these ranges for you. For example, if we change our `print_stack()` function to contain this:
```python
def convert_variable_ranges(r):
variable, _node = r.data
return f'<span data-value="{repr(variable.value)}">', '</span>'
markers = stack_data.markers_from_ranges(line.variable_ranges, convert_variable_ranges)
print(f"{'-->' if line.is_current else ' '} {line.lineno:4} | {line.render(markers, escape_html=True)}")
```
Then the output becomes:
```
foo at line 15
-----------
9 | def foo():
(...)
11 | for <span data-value="4">i</span> in range(5):
12 | <span data-value="[]">row</span> = []
14 | <span data-value="[[0, 0, 0, 0, 0], [0, 1, 2, 3, 4], [0, 2, 4, 6, 8], [0, 3, 6, 9, 12], []]">result</span>.append(<span data-value="[]">row</span>)
--> 15 | print_stack()
17 | for <span data-value="4">j</span> in range(5):
```
`line.variable_ranges` is a list of RangeInLines for each Variable that appears at least partially in this line. The data attribute of the range is a pair `(variable, node)` where node is the particular AST node from the list `variable.nodes` that corresponds to this range.
You can also use `line.token_ranges` (e.g. if you want to do your own syntax highlighting) or `line.executing_node_ranges` if you want to highlight the currently executing node identified by the [`executing`](https://github.com/alexmojaki/executing) library. Or if you want to make your own range from an AST node, use `line.range_from_node(node, data)`. See the docstrings for more info.
### Syntax highlighting with Pygments
If you'd like pretty colored text without the work, you can let [Pygments](https://pygments.org/) do it for you. Just follow these steps:
1. `pip install pygments` separately as it's not a dependency of `stack_data`.
2. Create a pygments formatter object such as `HtmlFormatter` or `Terminal256Formatter`.
3. Pass the formatter to `Options` in the argument `pygments_formatter`.
4. Use `line.render(pygmented=True)` to get your formatted text. In this case you can't pass any markers to `render`.
If you want, you can also highlight the executing node in the frame in combination with the pygments syntax highlighting. For this you will need:
1. A pygments style - either a style class or a string that names it. See the [documentation on styles](https://pygments.org/docs/styles/) and the [styles gallery](https://blog.yjl.im/2015/08/pygments-styles-gallery.html).
2. A modification to make to the style for the executing node, which is a string such as `"bold"` or `"bg:#ffff00"` (yellow background). See the [documentation on style rules](https://pygments.org/docs/styles/#style-rules).
3. Pass these two things to `stack_data.style_with_executing_node(style, modifier)` to get a new style class.
4. Pass the new style to your formatter when you create it.
Note that this doesn't work with `TerminalFormatter` which just uses the basic ANSI colors and doesn't use the style passed to it in general.
## Getting the full stack
Currently `print_stack()` doesn't actually print the stack, it just prints one frame. Instead of `frame_info = FrameInfo(frame, options)`, let's do this:
```python
for frame_info in FrameInfo.stack_data(frame, options):
```
Now the output looks something like this:
```
<module> at line 18
-----------
14 | for j in range(5):
15 | row.append(i * j)
16 | return result
--> 18 | bar()
bar at line 5
-----------
4 | def bar():
--> 5 | foo()
foo at line 13
-----------
10 | for i in range(5):
11 | row = []
12 | result.append(row)
--> 13 | print_stack()
14 | for j in range(5):
```
However, just as `frame_info.lines` doesn't always yield `Line` objects, `FrameInfo.stack_data` doesn't always yield `FrameInfo` objects, and we must modify our code to handle that. Let's look at some different sample code:
```python
def factorial(x):
return x * factorial(x - 1)
try:
print(factorial(5))
except:
print_stack()
```
In this code we've forgotten to include a base case in our `factorial` function so it will fail with a `RecursionError` and there'll be many frames with similar information. Similar to the built in Python traceback, `stack_data` avoids showing all of these frames. Instead you will get a `RepeatedFrames` object which summarises the information. See its docstring for more details.
Here is our updated implementation:
```python
def print_stack():
for frame_info in FrameInfo.stack_data(sys.exc_info()[2]):
if isinstance(frame_info, FrameInfo):
print(f"{frame_info.code.co_name} at line {frame_info.lineno}")
print("-----------")
for line in frame_info.lines:
print(f"{'-->' if line.is_current else ' '} {line.lineno:4} | {line.render()}")
for var in frame_info.variables:
print(f"{var.name} = {repr(var.value)}")
print()
else:
print(f"... {frame_info.description} ...\n")
```
And the output:
```
<module> at line 9
-----------
4 | def factorial(x):
5 | return x * factorial(x - 1)
8 | try:
--> 9 | print(factorial(5))
10 | except:
factorial at line 5
-----------
4 | def factorial(x):
--> 5 | return x * factorial(x - 1)
x = 5
factorial at line 5
-----------
4 | def factorial(x):
--> 5 | return x * factorial(x - 1)
x = 4
... factorial at line 5 (996 times) ...
factorial at line 5
-----------
4 | def factorial(x):
--> 5 | return x * factorial(x - 1)
x = -993
```
In addition to handling repeated frames, we've passed a traceback object to `FrameInfo.stack_data` instead of a frame.
If you want, you can pass `collapse_repeated_frames=False` to `FrameInfo.stack_data` (not to `Options`) and it will just yield `FrameInfo` objects for the full stack. | {
"source": "yandex/perforator",
"title": "contrib/python/stack-data/README.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/python/stack-data/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 17185
} |
.. image:: https://travis-ci.com/agronholm/typeguard.svg?branch=master
:target: https://travis-ci.com/agronholm/typeguard
:alt: Build Status
.. image:: https://coveralls.io/repos/agronholm/typeguard/badge.svg?branch=master&service=github
:target: https://coveralls.io/github/agronholm/typeguard?branch=master
:alt: Code Coverage
.. image:: https://readthedocs.org/projects/typeguard/badge/?version=latest
:target: https://typeguard.readthedocs.io/en/latest/?badge=latest
This library provides run-time type checking for functions defined with
`PEP 484 <https://www.python.org/dev/peps/pep-0484/>`_ argument (and return) type annotations.
Four principal ways to do type checking are provided, each with its pros and cons:
#. the ``check_argument_types()`` and ``check_return_type()`` functions:
* debugger friendly (except when running with the pydev debugger with the C extension installed)
* does not work reliably with dynamically defined type hints (e.g. in nested functions)
#. the ``@typechecked`` decorator:
* automatically type checks yields and sends of returned generators (regular and async)
* adds an extra frame to the call stack for every call to a decorated function
#. the stack profiler hook (``with TypeChecker('packagename'):``) (deprecated):
* emits warnings instead of raising ``TypeError``
* requires very few modifications to the code
* multiple TypeCheckers can be stacked/nested
* does not work reliably with dynamically defined type hints (e.g. in nested functions)
* may cause problems with badly behaving debuggers or profilers
* cannot distinguish between an exception being raised and a ``None`` being returned
#. the import hook (``typeguard.importhook.install_import_hook()``):
* automatically annotates classes and functions with ``@typechecked`` on import
* no code changes required in target modules
* requires imports of modules you need to check to be deferred until after the import hook has
been installed
* may clash with other import hooks
See the documentation_ for further instructions.
.. _documentation: https://typeguard.readthedocs.io/en/latest/ | {
"source": "yandex/perforator",
"title": "contrib/python/typeguard/README.rst",
"url": "https://github.com/yandex/perforator/blob/main/contrib/python/typeguard/README.rst",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2157
} |
## Typing stubs for protobuf
This is a [PEP 561](https://peps.python.org/pep-0561/)
type stub package for the [`protobuf`](https://github.com/protocolbuffers/protobuf) package.
It can be used by type-checking tools like
[mypy](https://github.com/python/mypy/),
[pyright](https://github.com/microsoft/pyright),
[pytype](https://github.com/google/pytype/),
[Pyre](https://pyre-check.org/),
PyCharm, etc. to check code that uses `protobuf`. This version of
`types-protobuf` aims to provide accurate annotations for
`protobuf~=5.29.1`.
Partially generated using [mypy-protobuf==3.6.0](https://github.com/nipunn1313/mypy-protobuf/tree/v3.6.0) and libprotoc 28.1 on [protobuf v29.1](https://github.com/protocolbuffers/protobuf/releases/tag/v29.1) (python `protobuf==5.29.1`).
This stub package is marked as [partial](https://peps.python.org/pep-0561/#partial-stub-packages).
If you find that annotations are missing, feel free to contribute and help complete them.
This package is part of the [typeshed project](https://github.com/python/typeshed).
All fixes for types and metadata should be contributed there.
See [the README](https://github.com/python/typeshed/blob/main/README.md)
for more details. The source for this package can be found in the
[`stubs/protobuf`](https://github.com/python/typeshed/tree/main/stubs/protobuf)
directory.
This package was tested with
mypy 1.15.0,
pyright 1.1.389,
and pytype 2024.10.11.
It was generated from typeshed commit
[`73ebb9dfd7dfce93c5becde4dcdd51d5626853b8`](https://github.com/python/typeshed/commit/73ebb9dfd7dfce93c5becde4dcdd51d5626853b8). | {
"source": "yandex/perforator",
"title": "contrib/python/types-protobuf/README.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/python/types-protobuf/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1590
} |
wheel
=====
This is a command line tool for manipulating Python wheel files, as defined in
`PEP 427`_. It contains the following functionality:
* Convert ``.egg`` archives into ``.whl``
* Unpack wheel archives
* Repack wheel archives
* Add or remove tags in existing wheel archives
.. _PEP 427: https://www.python.org/dev/peps/pep-0427/
Historical note
---------------
This project used to contain the implementation of the setuptools_ ``bdist_wheel``
command, but as of setuptools v70.1, it no longer needs ``wheel`` installed for that to
work. Thus, you should install this **only** if you intend to use the ``wheel`` command
line tool!
.. _setuptools: https://pypi.org/project/setuptools/
Documentation
-------------
The documentation_ can be found on Read The Docs.
.. _documentation: https://wheel.readthedocs.io/
Code of Conduct
---------------
Everyone interacting in the wheel project's codebases, issue trackers, chat
rooms, and mailing lists is expected to follow the `PSF Code of Conduct`_.
.. _PSF Code of Conduct: https://github.com/pypa/.github/blob/main/CODE_OF_CONDUCT.md | {
"source": "yandex/perforator",
"title": "contrib/python/wheel/README.rst",
"url": "https://github.com/yandex/perforator/blob/main/contrib/python/wheel/README.rst",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1099
} |
Please submit a new Abseil Issue using the template below:
## [Short title of proposed API change(s)]
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
## Background
[Provide the background information that is required in order to evaluate the
proposed API changes. No controversial claims should be made here. If there are
design constraints that need to be considered, they should be presented here
**along with justification for those constraints**. Linking to other docs is
good, but please keep the **pertinent information as self contained** as
possible in this section.]
## Proposed API Change (s)
[Please clearly describe the API change(s) being proposed. If multiple changes,
please keep them clearly distinguished. When possible, **use example code
snippets to illustrate before-after API usages**. List pros-n-cons. Highlight
the main questions that you want to be answered. Given the Abseil project compatibility requirements, describe why the API change is safe.] | {
"source": "yandex/perforator",
"title": "contrib/restricted/abseil-cpp/ABSEIL_ISSUE_TEMPLATE.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/restricted/abseil-cpp/ABSEIL_ISSUE_TEMPLATE.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1094
} |
# How to Contribute to Abseil
We'd love to accept your patches and contributions to this project. There are
just a few small guidelines you need to follow.
NOTE: If you are new to GitHub, please start by reading [Pull Request
howto](https://help.github.com/articles/about-pull-requests/)
## Contributor License Agreement
Contributions to this project must be accompanied by a Contributor License
Agreement. You (or your employer) retain the copyright to your contribution,
this simply gives us permission to use and redistribute your contributions as
part of the project. Head over to <https://cla.developers.google.com/> to see
your current agreements on file or to sign a new one.
You generally only need to submit a CLA once, so if you've already submitted one
(even if it was for a different project), you probably don't need to do it
again.
## Contribution Guidelines
Potential contributors sometimes ask us if the Abseil project is the appropriate
home for their utility library code or for specific functions implementing
missing portions of the standard. Often, the answer to this question is "no".
We’d like to articulate our thinking on this issue so that our choices can be
understood by everyone and so that contributors can have a better intuition
about whether Abseil might be interested in adopting a new library.
### Priorities
Although our mission is to augment the C++ standard library, our goal is not to
provide a full forward-compatible implementation of the latest standard. For us
to consider a library for inclusion in Abseil, it is not enough that a library
is useful. We generally choose to release a library when it meets at least one
of the following criteria:
* **Widespread usage** - Using our internal codebase to help gauge usage, most
of the libraries we've released have tens of thousands of users.
* **Anticipated widespread usage** - Pre-adoption of some standard-compliant
APIs may not have broad adoption initially but can be expected to pick up
usage when it replaces legacy APIs. `absl::from_chars`, for example,
replaces existing code that converts strings to numbers and will therefore
likely see usage growth.
* **High impact** - APIs that provide a key solution to a specific problem,
such as `absl::FixedArray`, have higher impact than usage numbers may signal
and are released because of their importance.
* **Direct support for a library that falls under one of the above** - When we
want access to a smaller library as an implementation detail for a
higher-priority library we plan to release, we may release it, as we did
with portions of `absl/meta/type_traits.h`. One consequence of this is that
the presence of a library in Abseil does not necessarily mean that other
similar libraries would be a high priority.
### API Freeze Consequences
Via the
[Abseil Compatibility Guidelines](https://abseil.io/about/compatibility), we
have promised a large degree of API stability. In particular, we will not make
backward-incompatible changes to released APIs without also shipping a tool or
process that can upgrade our users' code. We are not yet at the point of easily
releasing such tools. Therefore, at this time, shipping a library establishes an
API contract which is borderline unchangeable. (We can add new functionality,
but we cannot easily change existing behavior.) This constraint forces us to
very carefully review all APIs that we ship.
## Coding Style
To keep the source consistent, readable, diffable and easy to merge, we use a
fairly rigid coding style, as defined by the
[google-styleguide](https://github.com/google/styleguide) project. All patches
will be expected to conform to the style outlined
[here](https://google.github.io/styleguide/cppguide.html).
## Guidelines for Pull Requests
* If you are a Googler, it is required that you send us a Piper CL instead of
using the GitHub pull-request process. The code propagation process will
deliver the change to GitHub.
* Create **small PRs** that are narrowly focused on **addressing a single
concern**. We often receive PRs that are trying to fix several things at a
time, but if only one fix is considered acceptable, nothing gets merged and
both author's & review's time is wasted. Create more PRs to address
different concerns and everyone will be happy.
* For speculative changes, consider opening an [Abseil
issue](https://github.com/abseil/abseil-cpp/issues) and discussing it first.
If you are suggesting a behavioral or API change, consider starting with an
[Abseil proposal template](ABSEIL_ISSUE_TEMPLATE.md).
* Provide a good **PR description** as a record of **what** change is being
made and **why** it was made. Link to a GitHub issue if it exists.
* Don't fix code style and formatting unless you are already changing that
line to address an issue. Formatting of modified lines may be done using
`git clang-format`. PRs with irrelevant changes won't be merged. If
you do want to fix formatting or style, do that in a separate PR.
* Unless your PR is trivial, you should expect there will be reviewer comments
that you'll need to address before merging. We expect you to be reasonably
responsive to those comments, otherwise the PR will be closed after 2-3
weeks of inactivity.
* Maintain **clean commit history** and use **meaningful commit messages**.
PRs with messy commit history are difficult to review and won't be merged.
Use `rebase -i upstream/master` to curate your commit history and/or to
bring in latest changes from master (but avoid rebasing in the middle of a
code review).
* Keep your PR up to date with upstream/master (if there are merge conflicts,
we can't really merge your change).
* **All tests need to be passing** before your change can be merged. We
recommend you **run tests locally** (see below)
* Exceptions to the rules can be made if there's a compelling reason for doing
so. That is - the rules are here to serve us, not the other way around, and
the rules need to be serving their intended purpose to be valuable.
* All submissions, including submissions by project members, require review.
## Running Tests
If you have [Bazel](https://bazel.build/) installed, use `bazel test
--test_tag_filters="-benchmark" ...` to run the unit tests.
If you are running the Linux operating system and have
[Docker](https://www.docker.com/) installed, you can also run the `linux_*.sh`
scripts under the `ci/`(https://github.com/abseil/abseil-cpp/tree/master/ci)
directory to test Abseil under a variety of conditions.
## Abseil Committers
The current members of the Abseil engineering team are the only committers at
present.
## Release Process
Abseil lives at head, where latest-and-greatest code can be found. | {
"source": "yandex/perforator",
"title": "contrib/restricted/abseil-cpp/CONTRIBUTING.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/restricted/abseil-cpp/CONTRIBUTING.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 6869
} |
# Abseil FAQ
## Is Abseil the right home for my utility library?
Most often the answer to the question is "no." As both the [About
Abseil](https://abseil.io/about/) page and our [contributing
guidelines](https://github.com/abseil/abseil-cpp/blob/master/CONTRIBUTING.md#contribution-guidelines)
explain, Abseil contains a variety of core C++ library code that is widely used
at [Google](https://www.google.com/). As such, Abseil's primary purpose is to be
used as a dependency by Google's open source C++ projects. While we do hope that
Abseil is also useful to the C++ community at large, this added constraint also
means that we are unlikely to accept a contribution of utility code that isn't
already widely used by Google.
## How to I set the C++ dialect used to build Abseil?
The short answer is that whatever mechanism you choose, you need to make sure
that you set this option consistently at the global level for your entire
project. If, for example, you want to set the C++ dialect to C++17, with
[Bazel](https://bazel/build/) as the build system and `gcc` or `clang` as the
compiler, there several ways to do this:
* Pass `--cxxopt=-std=c++17` on the command line (for example, `bazel build
--cxxopt=-std=c++17 ...`)
* Set the environment variable `BAZEL_CXXOPTS` (for example,
`BAZEL_CXXOPTS=-std=c++17`)
* Add `build --cxxopt=-std=c++17` to your [`.bazelrc`
file](https://docs.bazel.build/versions/master/guide.html#bazelrc)
If you are using CMake as the build system, you'll need to add a line like
`set(CMAKE_CXX_STANDARD 17)` to your top level `CMakeLists.txt` file. If you
are developing a library designed to be used by other clients, you should
instead leave `CMAKE_CXX_STANDARD` unset and configure the minimum C++ standard
required by each of your library targets via `target_compile_features`. See the
[CMake build
instructions](https://github.com/abseil/abseil-cpp/blob/master/CMake/README.md)
for more information.
For a longer answer to this question and to understand why some other approaches
don't work, see the answer to ["What is ABI and why don't you recommend using a
pre-compiled version of
Abseil?"](#what-is-abi-and-why-dont-you-recommend-using-a-pre-compiled-version-of-abseil)
## What is ABI and why don't you recommend using a pre-compiled version of Abseil?
For the purposes of this discussion, you can think of
[ABI](https://en.wikipedia.org/wiki/Application_binary_interface) as the
compiled representation of the interfaces in code. This is in contrast to
[API](https://en.wikipedia.org/wiki/Application_programming_interface), which
you can think of as the interfaces as defined by the code itself. [Abseil has a
strong promise of API compatibility, but does not make any promise of ABI
compatibility](https://abseil.io/about/compatibility). Let's take a look at what
this means in practice.
You might be tempted to do something like this in a
[Bazel](https://bazel.build/) `BUILD` file:
```
# DON'T DO THIS!!!
cc_library(
name = "my_library",
srcs = ["my_library.cc"],
copts = ["-std=c++17"], # May create a mixed-mode compile!
deps = ["@com_google_absl//absl/strings"],
)
```
Applying `-std=c++17` to an individual target in your `BUILD` file is going to
compile that specific target in C++17 mode, but it isn't going to ensure the
Abseil library is built in C++17 mode, since the Abseil library itself is a
different build target. If your code includes an Abseil header, then your
program may contain conflicting definitions of the same
class/function/variable/enum, etc. As a rule, all compile options that affect
the ABI of a program need to be applied to the entire build on a global basis.
C++ has something called the [One Definition
Rule](https://en.wikipedia.org/wiki/One_Definition_Rule) (ODR). C++ doesn't
allow multiple definitions of the same class/function/variable/enum, etc. ODR
violations sometimes result in linker errors, but linkers do not always catch
violations. Uncaught ODR violations can result in strange runtime behaviors or
crashes that can be hard to debug.
If you build the Abseil library and your code using different compile options
that affect ABI, there is a good chance you will run afoul of the One Definition
Rule. Examples of GCC compile options that affect ABI include (but aren't
limited to) language dialect (e.g. `-std=`), optimization level (e.g. `-O2`),
code generation flags (e.g. `-fexceptions`), and preprocessor defines
(e.g. `-DNDEBUG`).
If you use a pre-compiled version of Abseil, (for example, from your Linux
distribution package manager or from something like
[vcpkg](https://github.com/microsoft/vcpkg)) you have to be very careful to
ensure ABI compatibility across the components of your program. The only way you
can be sure your program is going to be correct regarding ABI is to ensure
you've used the exact same compile options as were used to build the
pre-compiled library. This does not mean that Abseil cannot work as part of a
Linux distribution since a knowledgeable binary packager will have ensured that
all packages have been built with consistent compile options. This is one of the
reasons we warn against - though do not outright reject - using Abseil as a
pre-compiled library.
Another possible way that you might afoul of ABI issues is if you accidentally
include two versions of Abseil in your program. Multiple versions of Abseil can
end up within the same binary if your program uses the Abseil library and
another library also transitively depends on Abseil (resulting in what is
sometimes called the diamond dependency problem). In cases such as this you must
structure your build so that all libraries use the same version of Abseil.
[Abseil's strong promise of API compatibility between
releases](https://abseil.io/about/compatibility) means the latest "HEAD" release
of Abseil is almost certainly the right choice if you are doing as we recommend
and building all of your code from source.
For these reasons we recommend you avoid pre-compiled code and build the Abseil
library yourself in a consistent manner with the rest of your code.
## What is "live at head" and how do I do it?
From Abseil's point-of-view, "live at head" means that every Abseil source
release (which happens on an almost daily basis) is either API compatible with
the previous release, or comes with an automated tool that you can run over code
to make it compatible. In practice, the need to use an automated tool is
extremely rare. This means that upgrading from one source release to another
should be a routine practice that can and should be performed often.
We recommend you update to the [latest commit in the `master` branch of
Abseil](https://github.com/abseil/abseil-cpp/commits/master) as often as
possible. Not only will you pick up bug fixes more quickly, but if you have good
automated testing, you will catch and be able to fix any [Hyrum's
Law](https://www.hyrumslaw.com/) dependency problems on an incremental basis
instead of being overwhelmed by them and having difficulty isolating them if you
wait longer between updates.
If you are using the [Bazel](https://bazel.build/) build system and its
[external dependencies](https://docs.bazel.build/versions/master/external.html)
feature, updating the
[`http_archive`](https://docs.bazel.build/versions/master/repo/http.html#http_archive)
rule in your
[`WORKSPACE`](https://docs.bazel.build/versions/master/be/workspace.html) for
`com_google_abseil` to point to the [latest commit in the `master` branch of
Abseil](https://github.com/abseil/abseil-cpp/commits/master) is all you need to
do. For example, on February 11, 2020, the latest commit to the master branch
was `98eb410c93ad059f9bba1bf43f5bb916fc92a5ea`. To update to this commit, you
would add the following snippet to your `WORKSPACE` file:
```
http_archive(
name = "com_google_absl",
urls = ["https://github.com/abseil/abseil-cpp/archive/98eb410c93ad059f9bba1bf43f5bb916fc92a5ea.zip"], # 2020-02-11T18:50:53Z
strip_prefix = "abseil-cpp-98eb410c93ad059f9bba1bf43f5bb916fc92a5ea",
sha256 = "aabf6c57e3834f8dc3873a927f37eaf69975d4b28117fc7427dfb1c661542a87",
)
```
To get the `sha256` of this URL, run `curl -sL --output -
https://github.com/abseil/abseil-cpp/archive/98eb410c93ad059f9bba1bf43f5bb916fc92a5ea.zip
| sha256sum -`.
You can commit the updated `WORKSPACE` file to your source control every time
you update, and if you have good automated testing, you might even consider
automating this.
One thing we don't recommend is using GitHub's `master.zip` files (for example
[https://github.com/abseil/abseil-cpp/archive/master.zip](https://github.com/abseil/abseil-cpp/archive/master.zip)),
which are always the latest commit in the `master` branch, to implement live at
head. Since these `master.zip` URLs are not versioned, you will lose build
reproducibility. In addition, some build systems, including Bazel, will simply
cache this file, which means you won't actually be updating to the latest
release until your cache is cleared or invalidated. | {
"source": "yandex/perforator",
"title": "contrib/restricted/abseil-cpp/FAQ.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/restricted/abseil-cpp/FAQ.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 9033
} |
# Abseil - C++ Common Libraries
The repository contains the Abseil C++ library code. Abseil is an open-source
collection of C++ code (compliant to C++14) designed to augment the C++
standard library.
## Table of Contents
- [About Abseil](#about)
- [Quickstart](#quickstart)
- [Building Abseil](#build)
- [Support](#support)
- [Codemap](#codemap)
- [Releases](#releases)
- [License](#license)
- [Links](#links)
<a name="about"></a>
## About Abseil
Abseil is an open-source collection of C++ library code designed to augment
the C++ standard library. The Abseil library code is collected from Google's
own C++ code base, has been extensively tested and used in production, and
is the same code we depend on in our daily coding lives.
In some cases, Abseil provides pieces missing from the C++ standard; in
others, Abseil provides alternatives to the standard for special needs
we've found through usage in the Google code base. We denote those cases
clearly within the library code we provide you.
Abseil is not meant to be a competitor to the standard library; we've
just found that many of these utilities serve a purpose within our code
base, and we now want to provide those resources to the C++ community as
a whole.
<a name="quickstart"></a>
## Quickstart
If you want to just get started, make sure you at least run through the
[Abseil Quickstart](https://abseil.io/docs/cpp/quickstart). The Quickstart
contains information about setting up your development environment, downloading
the Abseil code, running tests, and getting a simple binary working.
<a name="build"></a>
## Building Abseil
[Bazel](https://bazel.build) and [CMake](https://cmake.org/) are the official
build systems for Abseil.
See the [quickstart](https://abseil.io/docs/cpp/quickstart) for more information
on building Abseil using the Bazel build system.
If you require CMake support, please check the [CMake build
instructions](CMake/README.md) and [CMake
Quickstart](https://abseil.io/docs/cpp/quickstart-cmake).
<a name="support"></a>
## Support
Abseil follows Google's [Foundational C++ Support
Policy](https://opensource.google/documentation/policies/cplusplus-support). See
[this
table](https://github.com/google/oss-policies-info/blob/main/foundational-cxx-support-matrix.md)
for a list of currently supported versions compilers, platforms, and build
tools.
<a name="codemap"></a>
## Codemap
Abseil contains the following C++ library components:
* [`base`](absl/base/)
<br /> The `base` library contains initialization code and other code which
all other Abseil code depends on. Code within `base` may not depend on any
other code (other than the C++ standard library).
* [`algorithm`](absl/algorithm/)
<br /> The `algorithm` library contains additions to the C++ `<algorithm>`
library and container-based versions of such algorithms.
* [`cleanup`](absl/cleanup/)
<br /> The `cleanup` library contains the control-flow-construct-like type
`absl::Cleanup` which is used for executing a callback on scope exit.
* [`container`](absl/container/)
<br /> The `container` library contains additional STL-style containers,
including Abseil's unordered "Swiss table" containers.
* [`crc`](absl/crc/) The `crc` library contains code for
computing error-detecting cyclic redundancy checks on data.
* [`debugging`](absl/debugging/)
<br /> The `debugging` library contains code useful for enabling leak
checks, and stacktrace and symbolization utilities.
* [`flags`](absl/flags/)
<br /> The `flags` library contains code for handling command line flags for
libraries and binaries built with Abseil.
* [`hash`](absl/hash/)
<br /> The `hash` library contains the hashing framework and default hash
functor implementations for hashable types in Abseil.
* [`log`](absl/log/)
<br /> The `log` library contains `LOG` and `CHECK` macros and facilities
for writing logged messages out to disk, `stderr`, or user-extensible
destinations.
* [`memory`](absl/memory/)
<br /> The `memory` library contains memory management facilities that augment
C++'s `<memory>` library.
* [`meta`](absl/meta/)
<br /> The `meta` library contains compatible versions of type checks
available within C++14 and C++17 versions of the C++ `<type_traits>` library.
* [`numeric`](absl/numeric/)
<br /> The `numeric` library contains 128-bit integer types as well as
implementations of C++20's bitwise math functions.
* [`profiling`](absl/profiling/)
<br /> The `profiling` library contains utility code for profiling C++
entities. It is currently a private dependency of other Abseil libraries.
* [`random`](absl/random/)
<br /> The `random` library contains functions for generating psuedorandom
values.
* [`status`](absl/status/)
<br /> The `status` library contains abstractions for error handling,
specifically `absl::Status` and `absl::StatusOr<T>`.
* [`strings`](absl/strings/)
<br /> The `strings` library contains a variety of strings routines and
utilities, including a C++14-compatible version of the C++17
`std::string_view` type.
* [`synchronization`](absl/synchronization/)
<br /> The `synchronization` library contains concurrency primitives (Abseil's
`absl::Mutex` class, an alternative to `std::mutex`) and a variety of
synchronization abstractions.
* [`time`](absl/time/)
<br /> The `time` library contains abstractions for computing with absolute
points in time, durations of time, and formatting and parsing time within
time zones.
* [`types`](absl/types/)
<br /> The `types` library contains non-container utility types, like a
C++14-compatible version of the C++17 `std::optional` type.
* [`utility`](absl/utility/)
<br /> The `utility` library contains utility and helper code.
<a name="releases"></a>
## Releases
Abseil recommends users "live-at-head" (update to the latest commit from the
master branch as often as possible). However, we realize this philosophy doesn't
work for every project, so we also provide [Long Term Support
Releases](https://github.com/abseil/abseil-cpp/releases) to which we backport
fixes for severe bugs. See our [release
management](https://abseil.io/about/releases) document for more details.
<a name="license"></a>
## License
The Abseil C++ library is licensed under the terms of the Apache
license. See [LICENSE](LICENSE) for more information.
<a name="links"></a>
## Links
For more information about Abseil:
* Consult our [Abseil Introduction](https://abseil.io/about/intro)
* Read [Why Adopt Abseil](https://abseil.io/about/philosophy) to understand our
design philosophy.
* Peruse our
[Abseil Compatibility Guarantees](https://abseil.io/about/compatibility) to
understand both what we promise to you, and what we expect of you in return. | {
"source": "yandex/perforator",
"title": "contrib/restricted/abseil-cpp/README.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/restricted/abseil-cpp/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 6747
} |
# C++ Upgrade Tools
Abseil may occasionally release API-breaking changes. As noted in our
[Compatibility Guidelines][compatibility-guide], we will aim to provide a tool
to do the work of effecting such API-breaking changes, when absolutely
necessary.
These tools will be listed on the [C++ Upgrade Tools][upgrade-tools] guide on
https://abseil.io.
For more information, the [C++ Automated Upgrade Guide][api-upgrades-guide]
outlines this process.
[compatibility-guide]: https://abseil.io/about/compatibility
[api-upgrades-guide]: https://abseil.io/docs/cpp/tools/api-upgrades
[upgrade-tools]: https://abseil.io/docs/cpp/tools/upgrades/ | {
"source": "yandex/perforator",
"title": "contrib/restricted/abseil-cpp/UPGRADES.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/restricted/abseil-cpp/UPGRADES.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 639
} |
Status
======
[](https://travis-ci.org/libffi/libffi)
[](https://ci.appveyor.com/project/atgreen/libffi)
libffi-3.3 was released on November 23, 2019. Check the libffi web
page for updates: <URL:http://sourceware.org/libffi/>.
What is libffi?
===============
Compilers for high level languages generate code that follow certain
conventions. These conventions are necessary, in part, for separate
compilation to work. One such convention is the "calling
convention". The "calling convention" is essentially a set of
assumptions made by the compiler about where function arguments will
be found on entry to a function. A "calling convention" also specifies
where the return value for a function is found.
Some programs may not know at the time of compilation what arguments
are to be passed to a function. For instance, an interpreter may be
told at run-time about the number and types of arguments used to call
a given function. Libffi can be used in such programs to provide a
bridge from the interpreter program to compiled code.
The libffi library provides a portable, high level programming
interface to various calling conventions. This allows a programmer to
call any function specified by a call interface description at run
time.
FFI stands for Foreign Function Interface. A foreign function
interface is the popular name for the interface that allows code
written in one language to call code written in another language. The
libffi library really only provides the lowest, machine dependent
layer of a fully featured foreign function interface. A layer must
exist above libffi that handles type conversions for values passed
between the two languages.
Supported Platforms
===================
Libffi has been ported to many different platforms.
At the time of release, the following basic configurations have been
tested:
| Architecture | Operating System | Compiler |
| --------------- | ---------------- | ----------------------- |
| AArch64 (ARM64) | iOS | Clang |
| AArch64 | Linux | GCC |
| AArch64 | Windows | MSVC |
| Alpha | Linux | GCC |
| Alpha | Tru64 | GCC |
| ARC | Linux | GCC |
| ARM | Linux | GCC |
| ARM | iOS | GCC |
| ARM | Windows | MSVC |
| AVR32 | Linux | GCC |
| Blackfin | uClinux | GCC |
| HPPA | HPUX | GCC |
| IA-64 | Linux | GCC |
| M68K | FreeMiNT | GCC |
| M68K | Linux | GCC |
| M68K | RTEMS | GCC |
| M88K | OpenBSD/mvme88k | GCC |
| Meta | Linux | GCC |
| MicroBlaze | Linux | GCC |
| MIPS | IRIX | GCC |
| MIPS | Linux | GCC |
| MIPS | RTEMS | GCC |
| MIPS64 | Linux | GCC |
| Moxie | Bare metal | GCC |
| Nios II | Linux | GCC |
| OpenRISC | Linux | GCC |
| PowerPC 32-bit | AIX | IBM XL C |
| PowerPC 64-bit | AIX | IBM XL C |
| PowerPC | AMIGA | GCC |
| PowerPC | Linux | GCC |
| PowerPC | Mac OSX | GCC |
| PowerPC | FreeBSD | GCC |
| PowerPC 64-bit | FreeBSD | GCC |
| PowerPC 64-bit | Linux ELFv1 | GCC |
| PowerPC 64-bit | Linux ELFv2 | GCC |
| RISC-V 32-bit | Linux | GCC |
| RISC-V 64-bit | Linux | GCC |
| S390 | Linux | GCC |
| S390X | Linux | GCC |
| SPARC | Linux | GCC |
| SPARC | Solaris | GCC |
| SPARC | Solaris | Oracle Solaris Studio C |
| SPARC64 | Linux | GCC |
| SPARC64 | FreeBSD | GCC |
| SPARC64 | Solaris | Oracle Solaris Studio C |
| TILE-Gx/TILEPro | Linux | GCC |
| VAX | OpenBSD/vax | GCC |
| X86 | FreeBSD | GCC |
| X86 | GNU HURD | GCC |
| X86 | Interix | GCC |
| X86 | kFreeBSD | GCC |
| X86 | Linux | GCC |
| X86 | Mac OSX | GCC |
| X86 | OpenBSD | GCC |
| X86 | OS/2 | GCC |
| X86 | Solaris | GCC |
| X86 | Solaris | Oracle Solaris Studio C |
| X86 | Windows/Cygwin | GCC |
| X86 | Windows/MingW | GCC |
| X86-64 | FreeBSD | GCC |
| X86-64 | Linux | GCC |
| X86-64 | Linux/x32 | GCC |
| X86-64 | OpenBSD | GCC |
| X86-64 | Solaris | Oracle Solaris Studio C |
| X86-64 | Windows/Cygwin | GCC |
| X86-64 | Windows/MingW | GCC |
| X86-64 | Mac OSX | GCC |
| Xtensa | Linux | GCC |
Please send additional platform test results to
[email protected].
Installing libffi
=================
First you must configure the distribution for your particular
system. Go to the directory you wish to build libffi in and run the
"configure" program found in the root directory of the libffi source
distribution. Note that building libffi requires a C99 compatible
compiler.
If you're building libffi directly from git hosted sources, configure
won't exist yet; run ./autogen.sh first. This will require that you
install autoconf, automake and libtool.
You may want to tell configure where to install the libffi library and
header files. To do that, use the ``--prefix`` configure switch. Libffi
will install under /usr/local by default.
If you want to enable extra run-time debugging checks use the the
``--enable-debug`` configure switch. This is useful when your program dies
mysteriously while using libffi.
Another useful configure switch is ``--enable-purify-safety``. Using this
will add some extra code which will suppress certain warnings when you
are using Purify with libffi. Only use this switch when using
Purify, as it will slow down the library.
If you don't want to build documentation, use the ``--disable-docs``
configure switch.
It's also possible to build libffi on Windows platforms with
Microsoft's Visual C++ compiler. In this case, use the msvcc.sh
wrapper script during configuration like so:
path/to/configure CC=path/to/msvcc.sh CXX=path/to/msvcc.sh LD=link CPP="cl -nologo -EP" CPPFLAGS="-DFFI_BUILDING_DLL"
For 64-bit Windows builds, use ``CC="path/to/msvcc.sh -m64"`` and
``CXX="path/to/msvcc.sh -m64"``. You may also need to specify
``--build`` appropriately.
It is also possible to build libffi on Windows platforms with the LLVM
project's clang-cl compiler, like below:
path/to/configure CC="path/to/msvcc.sh -clang-cl" CXX="path/to/msvcc.sh -clang-cl" LD=link CPP="clang-cl -EP"
When building with MSVC under a MingW environment, you may need to
remove the line in configure that sets 'fix_srcfile_path' to a 'cygpath'
command. ('cygpath' is not present in MingW, and is not required when
using MingW-style paths.)
To build static library for ARM64 with MSVC using visual studio solution, msvc_build folder have
aarch64/Ffi_staticLib.sln
required header files in aarch64/aarch64_include/
SPARC Solaris builds require the use of the GNU assembler and linker.
Point ``AS`` and ``LD`` environment variables at those tool prior to
configuration.
For iOS builds, the ``libffi.xcodeproj`` Xcode project is available.
Configure has many other options. Use ``configure --help`` to see them all.
Once configure has finished, type "make". Note that you must be using
GNU make. You can ftp GNU make from ftp.gnu.org:/pub/gnu/make .
To ensure that libffi is working as advertised, type "make check".
This will require that you have DejaGNU installed.
To install the library and header files, type ``make install``.
History
=======
See the git log for details at http://github.com/libffi/libffi.
3.3 Nov-23-19
Add RISC-V support.
New API in support of GO closures.
Add IEEE754 binary128 long double support for 64-bit Power
Default to Microsoft's 64 bit long double ABI with Visual C++.
GNU compiler uses 80 bits (128 in memory) FFI_GNUW64 ABI.
Add Windows on ARM64 (WOA) support.
Add Windows 32-bit ARM support.
Raw java (gcj) API deprecated.
Add pre-built PDF documentation to source distribution.
Many new tests cases and bug fixes.
3.2.1 Nov-12-14
Build fix for non-iOS AArch64 targets.
3.2 Nov-11-14
Add C99 Complex Type support (currently only supported on
s390).
Add support for PASCAL and REGISTER calling conventions on x86
Windows/Linux.
Add OpenRISC and Cygwin-64 support.
Bug fixes.
3.1 May-19-14
Add AArch64 (ARM64) iOS support.
Add Nios II support.
Add m88k and DEC VAX support.
Add support for stdcall, thiscall, and fastcall on non-Windows
32-bit x86 targets such as Linux.
Various Android, MIPS N32, x86, FreeBSD and UltraSPARC IIi
fixes.
Make the testsuite more robust: eliminate several spurious
failures, and respect the $CC and $CXX environment variables.
Archive off the manually maintained ChangeLog in favor of git
log.
3.0.13 Mar-17-13
Add Meta support.
Add missing Moxie bits.
Fix stack alignment bug on 32-bit x86.
Build fix for m68000 targets.
Build fix for soft-float Power targets.
Fix the install dir location for some platforms when building
with GCC (OS X, Solaris).
Fix Cygwin regression.
3.0.12 Feb-11-13
Add Moxie support.
Add AArch64 support.
Add Blackfin support.
Add TILE-Gx/TILEPro support.
Add MicroBlaze support.
Add Xtensa support.
Add support for PaX enabled kernels with MPROTECT.
Add support for native vendor compilers on
Solaris and AIX.
Work around LLVM/GCC interoperability issue on x86_64.
3.0.11 Apr-11-12
Lots of build fixes.
Add support for variadic functions (ffi_prep_cif_var).
Add Linux/x32 support.
Add thiscall, fastcall and MSVC cdecl support on Windows.
Add Amiga and newer MacOS support.
Add m68k FreeMiNT support.
Integration with iOS' xcode build tools.
Fix Octeon and MC68881 support.
Fix code pessimizations.
3.0.10 Aug-23-11
Add support for Apple's iOS.
Add support for ARM VFP ABI.
Add RTEMS support for MIPS and M68K.
Fix instruction cache clearing problems on
ARM and SPARC.
Fix the N64 build on mips-sgi-irix6.5.
Enable builds with Microsoft's compiler.
Enable x86 builds with Oracle's Solaris compiler.
Fix support for calling code compiled with Oracle's Sparc
Solaris compiler.
Testsuite fixes for Tru64 Unix.
Additional platform support.
3.0.9 Dec-31-09
Add AVR32 and win64 ports. Add ARM softfp support.
Many fixes for AIX, Solaris, HP-UX, *BSD.
Several PowerPC and x86-64 bug fixes.
Build DLL for windows.
3.0.8 Dec-19-08
Add *BSD, BeOS, and PA-Linux support.
3.0.7 Nov-11-08
Fix for ppc FreeBSD.
(thanks to Andreas Tobler)
3.0.6 Jul-17-08
Fix for closures on sh.
Mark the sh/sh64 stack as non-executable.
(both thanks to Kaz Kojima)
3.0.5 Apr-3-08
Fix libffi.pc file.
Fix #define ARM for IcedTea users.
Fix x86 closure bug.
3.0.4 Feb-24-08
Fix x86 OpenBSD configury.
3.0.3 Feb-22-08
Enable x86 OpenBSD thanks to Thomas Heller, and
x86-64 FreeBSD thanks to Björn König and Andreas Tobler.
Clean up test instruction in README.
3.0.2 Feb-21-08
Improved x86 FreeBSD support.
Thanks to Björn König.
3.0.1 Feb-15-08
Fix instruction cache flushing bug on MIPS.
Thanks to David Daney.
3.0.0 Feb-15-08
Many changes, mostly thanks to the GCC project.
Cygnus Solutions is now Red Hat.
[10 years go by...]
1.20 Oct-5-98
Raffaele Sena produces ARM port.
1.19 Oct-5-98
Fixed x86 long double and long long return support.
m68k bug fixes from Andreas Schwab.
Patch for DU assembler compatibility for the Alpha from Richard
Henderson.
1.18 Apr-17-98
Bug fixes and MIPS configuration changes.
1.17 Feb-24-98
Bug fixes and m68k port from Andreas Schwab. PowerPC port from
Geoffrey Keating. Various bug x86, Sparc and MIPS bug fixes.
1.16 Feb-11-98
Richard Henderson produces Alpha port.
1.15 Dec-4-97
Fixed an n32 ABI bug. New libtool, auto* support.
1.14 May-13-97
libtool is now used to generate shared and static libraries.
Fixed a minor portability problem reported by Russ McManus
<[email protected]>.
1.13 Dec-2-96
Added --enable-purify-safety to keep Purify from complaining
about certain low level code.
Sparc fix for calling functions with < 6 args.
Linux x86 a.out fix.
1.12 Nov-22-96
Added missing ffi_type_void, needed for supporting void return
types. Fixed test case for non MIPS machines. Cygnus Support
is now Cygnus Solutions.
1.11 Oct-30-96
Added notes about GNU make.
1.10 Oct-29-96
Added configuration fix for non GNU compilers.
1.09 Oct-29-96
Added --enable-debug configure switch. Clean-ups based on LCLint
feedback. ffi_mips.h is always installed. Many configuration
fixes. Fixed ffitest.c for sparc builds.
1.08 Oct-15-96
Fixed n32 problem. Many clean-ups.
1.07 Oct-14-96
Gordon Irlam rewrites v8.S again. Bug fixes.
1.06 Oct-14-96
Gordon Irlam improved the sparc port.
1.05 Oct-14-96
Interface changes based on feedback.
1.04 Oct-11-96
Sparc port complete (modulo struct passing bug).
1.03 Oct-10-96
Passing struct args, and returning struct values works for
all architectures/calling conventions. Expanded tests.
1.02 Oct-9-96
Added SGI n32 support. Fixed bugs in both o32 and Linux support.
Added "make test".
1.01 Oct-8-96
Fixed float passing bug in mips version. Restructured some
of the code. Builds cleanly with SGI tools.
1.00 Oct-7-96
First release. No public announcement.
Authors & Credits
=================
libffi was originally written by Anthony Green <[email protected]>.
The developers of the GNU Compiler Collection project have made
innumerable valuable contributions. See the ChangeLog file for
details.
Some of the ideas behind libffi were inspired by Gianni Mariani's free
gencall library for Silicon Graphics machines.
The closure mechanism was designed and implemented by Kresten Krab
Thorup.
Major processor architecture ports were contributed by the following
developers:
aarch64 Marcus Shawcroft, James Greenhalgh
alpha Richard Henderson
arc Hackers at Synopsis
arm Raffaele Sena
avr32 Bradley Smith
blackfin Alexandre Keunecke I. de Mendonca
cris Simon Posnjak, Hans-Peter Nilsson
frv Anthony Green
ia64 Hans Boehm
m32r Kazuhiro Inaoka
m68k Andreas Schwab
m88k Miod Vallat
metag Hackers at Imagination Technologies
microblaze Nathan Rossi
mips Anthony Green, Casey Marshall
mips64 David Daney
moxie Anthony Green
nios ii Sandra Loosemore
openrisc Sebastian Macke
pa Randolph Chung, Dave Anglin, Andreas Tobler
powerpc Geoffrey Keating, Andreas Tobler,
David Edelsohn, John Hornkvist
powerpc64 Jakub Jelinek
riscv Michael Knyszek, Andrew Waterman, Stef O'Rear
s390 Gerhard Tonn, Ulrich Weigand
sh Kaz Kojima
sh64 Kaz Kojima
sparc Anthony Green, Gordon Irlam
tile-gx/tilepro Walter Lee
vax Miod Vallat
x86 Anthony Green, Jon Beniston
x86-64 Bo Thorsen
xtensa Chris Zankel
Jesper Skov and Andrew Haley both did more than their fair share of
stepping through the code and tracking down bugs.
Thanks also to Tom Tromey for bug fixes, documentation and
configuration help.
Thanks to Jim Blandy, who provided some useful feedback on the libffi
interface.
Andreas Tobler has done a tremendous amount of work on the testsuite.
Alex Oliva solved the executable page problem for SElinux.
The list above is almost certainly incomplete and inaccurate. I'm
happy to make corrections or additions upon request.
If you have a problem, or have found a bug, please send a note to the
author at [email protected], or the project mailing list at
[email protected]. | {
"source": "yandex/perforator",
"title": "contrib/restricted/libffi/README.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/restricted/libffi/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 19223
} |
================
Cython Changelog
================
0.29.37 (2023-12-18)
====================
Bugs fixed
----------
* Fix a potential crash while cleaning up subtypes of externally imported extension
types when terminating Python. This was introduced in Cython 0.29.35.
* Fix a ``complex`` related compile error on Windows.
(Github issue :issue:`5512`)
* Compiling fused types used in pxd files could crash Cython in Python 3.11+.
(Github issues :issue:`5894`, :issue:`5588`)
* ``cythonize`` failed to consider the ``CYTHON_FORCE_REGEN`` env variable.
Patch by Harmen Stoppels. (Github issue :issue:`5712`)
0.29.36 (2023-07-04)
====================
Bugs fixed
----------
* Async generators lost their return value in PyPy.
(Github issue :issue:`5465`)
* The outdated C macro ``_PyGC_FINALIZED()`` is no longer used in Py3.9+.
* The deprecated ``Py_OptimizeFlag`` is no longer used in Python 3.9+.
(Github issue :issue:`5343`)
* Using the global ``__debug__`` variable but not assertions could lead to compile errors.
* The broken HTML template support was removed from Tempita.
(Github issue :issue:`3309`)
0.29.35 (2023-05-24)
====================
Bugs fixed
----------
* A garbage collection enabled subtype of a non-GC extension type could call into the
deallocation function of the super type with GC tracking enabled. This could lead
to crashes during deallocation if GC was triggered on the type at the same time.
(Github issue :issue:`5432`)
* Some C compile failures and crashes in CPython 3.12 were resolved.
* ``except + nogil`` was syntactically not allowed.
``except +nogil`` (i.e. defining a C++ exception handling function called ``nogil``)
is now disallowed to prevent typos.
(Github issue :issue:`5430`)
* A C compile failure in PyPy 3.10 was resolved.
Patch by Matti Picus. (Github issue :issue:`5408`)
* Cython modules now use PEP-489 multi-phase init by default in PyPy 3.9 and later.
Original patch by Matti Picus. (Github issue :issue:`5413`)
* API header files generated by different Cython versions can now be included in the
same C file.
(Github issue :issue:`5383`)
* Function signatures containing a type like `tuple[()]` could not be printed.
Patch by Lisandro Dalcin. (Github issue :issue:`5355`)
0.29.34 (2023-04-02)
====================
Bugs fixed
----------
* A refence leak of the for-loop list/tuple iterable was resolved if the for-loop's
``else:`` branch executes a ``break`` for an outer loop.
(Github issue :issue:`5347`)
* Some C compile failures in CPython 3.12 were resolved.
* Some old usages of the deprecated Python ``imp`` module were replaced with ``importlib``.
Patch by Matúš Valo. (Github issue :issue:`5300`)
* Some issues with ``depfile`` generation were resolved.
Patches by Eli Schwartz. (Github issues :issue:`5279`, :issue:`5291`)
0.29.33 (2023-01-06)
====================
Features added
--------------
* The ``cythonize`` and ``cython`` commands have a new option ``-M`` / ``--depfile``
to generate ``.dep`` dependency files for the compilation unit. This can be used
by external build tools to track these dependencies.
The ``cythonize`` option was already available in Cython :ref:`0.29.27`.
Patches by Evgeni Burovski and Eli Schwartz. (Github issue :issue:`1214`)
Bugs fixed
----------
* ``const`` fused types could not be used with memory views.
Patch by Thomas Vincent. (Github issue :issue:`1772`)
* ``wstr`` usage was removed in Python 3.12 and later (PEP-623).
(Github issue :issue:`5145`)
* A type check assertion for Cython functions failed in debug Python builds.
(Github issue :issue:`5031`)
* Fixed various compiler warnings.
Patches by Lisandro Dalcin et al. (Github issues :issue:`4948`, :issue:`5086`)
* Fixed error when calculating complex powers of negative numbers.
(Github issue :issue:`5014`)
* Corrected a small mis-formatting of exception messages on Python 2.
(Github issue :issue:`5018`)
* The ``PyUnicode_AsUTF8AndSize()`` C-API function was missing from the CPython declarations.
(Github issue :issue:`5163`)
* A performance problem in the compiler was resolved when nesting conditional expressions.
(Github issue :issue:`5197`)
* Test suite problems with recent NumPy and CPython versions were resolved.
(Github issues :issue:`5183`, :issue:`5190`)
Other changes
-------------
* The undocumented, untested and apparently useless syntax
``from somemodule cimport class/struct/union somename`` was deprecated
in anticipation of its removal in Cython 3. The type
modifier is not needed here and a plain ``cimport`` of the name will do.
(Github issue :issue:`4905`)
* Properly disable generation of descriptor docstrings on PyPy since they cause crashes.
It was previously disabled, but only accidentally via a typo.
Patch by Matti Picus. (Github issue :issue:`5083`)
* The ``cpow`` directive of Cython 3.0 is available as a no-op.
(Github issue :issue:`5016`)
0.29.32 (2022-07-29)
====================
Bugs fixed
----------
* Revert "Using memoryview typed arguments in inner functions is now rejected as unsupported."
Patch by David Woods. (Github issue #4798)
* ``from module import *`` failed in 0.29.31 when using memoryviews.
Patch by David Woods. (Github issue #4927)
0.29.31 (2022-07-27)
====================
Features added
--------------
* A new argument ``--module-name`` was added to the ``cython`` command to
provide the (one) exact target module name from the command line.
Patch by Matthew Brett and h-vetinari. (Github issue #4906)
* A new keyword ``noexcept`` was added for forward compatibility with Cython 3.
Patch by David Woods. (Github issue #4903)
Bugs fixed
----------
* Use ``importlib.util.find_spec()`` instead of the deprecated ``importlib.find_loader()``
function when setting up the package path at import-time.
Patch by Matti Picus. (Github issue #4764)
* Require the C compiler to support the two-arg form of ``va_start``
on Python 3.10 and higher.
Patch by Thomas Caswell. (Github issue #4820)
* Make ``fused_type`` subscriptable in Shadow.py.
Patch by Pfebrer. (Github issue #4842)
* Fix the incorrect code generation of the target type in ``bytearray`` loops.
Patch by Kenrick Everett. (Github issue #4108)
* Atomic refcounts for memoryviews were not used on some GCC versions by accident.
Patch by Sam Gross. (Github issue #4915)
* Silence some GCC ``-Wconversion`` warnings in C utility code.
Patch by Lisandro Dalcin. (Github issue #4854)
* Tuple multiplication was ignored in expressions such as ``[*(1,) * 2]``.
Patch by David Woods. (Github issue #4864)
* Calling ``append`` methods on extension types could fail to find the method
in some cases.
Patch by David Woods. (Github issue #4828)
* Ensure that object buffers (e.g. ``ndarray[object, ndim=1]``) containing
``NULL`` pointers are safe to use, returning ``None`` instead of the ``NULL``
pointer.
Patch by Sebastian Berg. (Github issue #4859)
* Using memoryview typed arguments in inner functions is now rejected as unsupported.
Patch by David Woods. (Github issue #4798)
* Compilation could fail on systems (e.g. FIPS) that block MD5 checksums at runtime.
(Github issue #4909)
* Experimental adaptations for the CPython "nogil" fork was added.
Note that there is no official support for this in Cython 0.x.
Patch by Sam Gross. (Github issue #4912)
0.29.30 (2022-05-16)
====================
Bugs fixed
----------
* The GIL handling changes in 0.29.29 introduced a regression where
objects could be deallocated without holding the GIL.
(Github issue #4796)
0.29.29 (2022-05-16)
====================
Features added
--------------
* Avoid acquiring the GIL at the end of nogil functions.
This change was backported in order to avoid generating wrong C code
that would trigger C compiler warnings with tracing support enabled.
Backport by Oleksandr Pavlyk. (Github issue #4637)
Bugs fixed
----------
* Function definitions in ``finally:`` clauses were not correctly generated.
Patch by David Woods. (Github issue #4651)
* A case where C-API functions could be called with a live exception set was fixed.
Patch by Jakub Kulík. (Github issue #4722)
* Pickles can now be exchanged again with those generated from Cython 3.0 modules.
(Github issue #4680)
* Cython now correctly generates Python methods for both the provided regular and
reversed special numeric methods of extension types.
Patch by David Woods. (Github issue #4750)
* Calling unbound extension type methods without arguments could raise an
``IndexError`` instead of a ``TypeError``.
Patch by David Woods. (Github issue #4779)
* Calling unbound ``.__contains__()`` super class methods on some builtin base
types could trigger an infinite recursion.
Patch by David Woods. (Github issue #4785)
* The C union type in pure Python mode mishandled some field names.
Patch by Jordan Brière. (Github issue #4727)
* Allow users to overwrite the C macro ``_USE_MATH_DEFINES``.
Patch by Yuriy Chernyshov. (Github issue #4690)
* Improved compatibility with CPython 3.10/11.
Patches by Thomas Caswell, David Woods. (Github issues #4609, #4667, #4721, #4730, #4777)
* Docstrings of descriptors are now provided in PyPy 7.3.9.
Patch by Matti Picus. (Github issue #4701)
0.29.28 (2022-02-17)
====================
Bugs fixed
----------
* Due to backwards incompatible changes in CPython 3.11a4, the feature flags
``CYTHON_FAST_THREAD_STATE`` and ``CYTHON_USE_EXC_INFO_STACK`` are now disabled
in Python 3.11 and later. They are enabled again in Cython 3.0.
Patch by David Woods. (Github issue #4610)
* A C compiler warning in older PyPy versions was resolved.
Patch by Matti Picus. (Github issue #4236)
0.29.27 (2022-01-28)
====================
Features added
--------------
* The ``cythonize`` command has a new option ``-M`` to generate ``.dep`` dependency
files for the compilation unit. This can be used by external build tools to track
these dependencies.
Patch by Evgeni Burovski. (Github issue #1214)
Bugs fixed
----------
* Compilation failures on PyPy were resolved.
Patches by Matti Picus. (Github issues #4509, #4517)
* Calls to ``range()`` with more than three arguments did not fail.
Original patch by Max Bachmann. (Github issue #4550)
* Some C compiler warnings about missing type struct initialisers in Py3.10 were resolved.
* Cython no longer warns about using OpenMP 3.0 features since they are now
considered generally available.
0.29.26 (2021-12-16)
====================
Bugs fixed
----------
* An incompatibility with CPython 3.11.0a3 was resolved.
(Github issue #4499)
* The ``in`` operator failed on literal lists with starred expressions.
Patch by Arvind Natarajan. (Github issue #3938)
* A C compiler warning in PyPy about a missing struct field initialisation was resolved.
0.29.25 (2021-12-06)
====================
Bugs fixed
----------
* Several incompatibilities with CPython 3.11 were resolved.
Patches by David Woods, Victor Stinner, Thomas Caswell.
(Github issues #4411, #4414, #4415, #4416, #4420, #4428, #4473, #4479, #4480)
* Some C compiler warnings were resolved.
Patches by Lisandro Dalcin and others. (Github issue #4439)
* C++ ``std::move()`` should only be used automatically in MSVC versions that support it.
Patch by Max Bachmann. (Github issue #4191)
* The ``Py_hash_t`` type failed to accept arbitrary "index" values.
(Github issue #2752)
* Avoid copying unaligned 16-bit values since some platforms require them to be aligned.
Use memcpy() instead to let the C compiler decide how to do it.
(Github issue #4343)
* Cython crashed on invalid truthiness tests on C++ types without ``operator bool``.
Patch by David Woods. (Github issue #4348)
* The declaration of ``PyUnicode_CompareWithASCIIString()`` in ``cpython.unicode`` was incorrect.
Patch by Max Bachmann. (Github issue #4344)
0.29.24 (2021-07-14)
====================
Bugs fixed
----------
* Inline functions in pxd files that used memory views could lead to invalid
C code if the module that imported from them does not use memory views.
Patch by David Woods. (Github issue #1415)
* Several declarations in ``libcpp.string`` were added and corrected.
Patch by Janek Bevendorff. (Github issue #4268)
* Pickling unbound Cython compiled methods failed.
Patch by Pierre Glaser. (Github issue #2972)
* The tracing code was adapted to work with CPython 3.10.
* The optimised ``in`` operator failed on unicode strings in Py3.9 and later
that were constructed from an external ``wchar_t`` source.
Also, related C compiler warnings about deprecated C-API usage were resolved.
(Github issue #3925)
* Some compiler crashes were resolved.
Patch by David Woods. (Github issues #4214, #2811)
* An incorrect warning about 'unused' generator expressions was removed.
(GIthub issue #1699)
* The attributes ``gen.gi_frame`` and ``coro.cr_frame`` of Cython compiled
generators and coroutines now return an actual frame object for introspection,
instead of ``None``.
(Github issue #2306)
0.29.23 (2021-04-14)
====================
Bugs fixed
----------
* Some problems with Python 3.10 were resolved.
Patches by Victor Stinner and David Woods. (Github issues #4046, #4100)
* An incorrect "optimisation" was removed that allowed changes to a keyword
dict to leak into keyword arguments passed into a function.
Patch by Peng Weikang. (Github issue #3227)
* Multiplied str constants could end up as bytes constants with language_level=2.
Patch by Alphadelta14 and David Woods. (Github issue #3951)
* ``PY_SSIZE_T_CLEAN`` does not get defined any more if it is already defined.
Patch by Andrew Jones. (Github issue #4104)
0.29.22 (2021-02-20)
====================
Features added
--------------
* Some declarations were added to the provided pxd includes.
Patches by Zackery Spytz and John Kirkham.
(Github issues #3811, #3882, #3899, #3901)
Bugs fixed
----------
* A crash when calling certain functions in Py3.9 and later was resolved.
(Github issue #3917)
* ``const`` memory views of structs failed to compile.
(Github issue #2251)
* ``const`` template declarations could not be nested.
Patch by Ashwin Srinath. (Github issue #1355)
* The declarations in the ``cpython.pycapsule`` module were missing their
``const`` modifiers and generated incorrect C code.
Patch by Warren Weckesser. (Github issue #3964)
* Casts to memory views failed for fused dtypes.
Patch by David Woods. (Github issue #3881)
* ``repr()`` was assumed to return ``str`` instead of ``unicode`` with ``language_level=3``.
(Github issue #3736)
* Calling ``cpdef`` functions from cimported modules crashed the compiler.
Patch by David Woods. (Github issue #4000)
* Cython no longer validates the ABI size of the NumPy classes it compiled against.
See the discussion in https://github.com/numpy/numpy/pull/432
* A C compiler warning about enum value casting was resolved in GCC.
(Github issue #2749)
* Coverage reporting in the annotated HTML file failed in Py3.9.
Patch by Nick Pope. (Github issue #3865)
* The embedding code now reports Python errors as exit status.
* Long type declarations could lead to (harmless) random changes in the
C file when used in auto-generated Python wrappers or pickled classes.
Other changes
-------------
* Variables defined as ``cpdef`` now generate a warning since this
is currently useless and thus does not do what users would expect.
Patch by David Woods. (Github issue #3959)
0.29.21 (2020-07-09)
====================
Bugs fixed
----------
* Fix a regression in 0.29.20 where ``__div__`` failed to be found in extension types.
(Github issue #3688)
* Fix a regression in 0.29.20 where a call inside of a finally clause could fail to compile.
Patch by David Woods. (Github issue #3712)
* Zero-sized buffers could fail to validate as C/Fortran-contiguous.
Patch by Clemens Hofreither. (Github issue #2093)
* ``exec()`` did not allow recent Python syntax features in Py3.8+ due to
https://bugs.python.org/issue35975.
(Github issue #3695)
* Binding staticmethods of Cython functions were not behaving like Python methods in Py3.
Patch by Jeroen Demeyer and Michał Górny. (Github issue #3106)
* Pythran calls to NumPy methods no longer generate useless method lookup code.
* The ``PyUnicode_GET_LENGTH()`` macro was missing from the ``cpython.*`` declarations.
Patch by Thomas Caswell. (Github issue #3692)
* The deprecated ``PyUnicode_*()`` C-API functions are no longer used, except for Unicode
strings that contain lone surrogates. Unicode strings that contain non-BMP characters
or surrogate pairs now generate different C code on 16-bit Python 2.x Unicode deployments
(such as MS-Windows). Generating the C code on Python 3.x is recommended in this case.
Original patches by Inada Naoki and Victor Stinner. (Github issues #3677, #3721, #3697)
* Some template parameters were missing from the C++ ``std::unordered_map`` declaration.
Patch by will. (Github issue #3685)
* Several internal code generation issues regarding temporary variables were resolved.
(Github issue #3708)
0.29.20 (2020-06-10)
====================
Bugs fixed
----------
* Nested try-except statements with multiple ``return`` statements could crash
due to incorrect deletion of the ``except as`` target variable.
(Github issue #3666)
* The ``@classmethod`` decorator no longer rejects unknown input from other decorators.
Patch by David Woods. (Github issue #3660)
* Fused types could leak into unrelated usages.
Patch by David Woods. (Github issue #3642)
* Now uses ``Py_SET_SIZE()`` and ``Py_SET_REFCNT()`` in Py3.9+ to avoid low-level
write access to these object fields.
Patch by Victor Stinner. (Github issue #3639)
* The built-in ``abs()`` function could lead to undefined behaviour when used on
the negative-most value of a signed C integer type.
Patch by Serge Guelton. (Github issue #1911)
* Usages of ``sizeof()`` and ``typeid()`` on uninitialised variables no longer
produce a warning.
Patch by Celelibi. (Github issue #3575)
* The C++ ``typeid()`` function was allowed in C mode.
Patch by Celelibi. (Github issue #3637)
* The error position reported for errors found in f-strings was misleading.
(Github issue #3674)
* The new ``c_api_binop_methods`` directive was added for forward compatibility, but can
only be set to True (the current default value). It can be disabled in Cython 3.0.
0.29.19 (2020-05-20)
====================
Bugs fixed
----------
* A typo in Windows specific code in 0.29.18 was fixed that broke "libc.math".
(Github issue #3622)
* A platform specific test failure in 0.29.18 was fixed.
Patch by smutch. (Github issue #3620)
0.29.18 (2020-05-18)
====================
Bugs fixed
----------
* Exception position reporting could run into race conditions on threaded code.
It now uses function-local variables again.
* Error handling early in the module init code could lead to a crash.
* Error handling in ``cython.array`` creation was improved to avoid calling
C-API functions with an error held.
* A memory corruption was fixed when garbage collection was triggered during calls
to ``PyType_Ready()`` of extension type subclasses.
(Github issue #3603)
* Memory view slicing generated unused error handling code which could negatively
impact the C compiler optimisations for parallel OpenMP code etc. Also, it is
now helped by static branch hints.
(Github issue #2987)
* Cython's built-in OpenMP functions were not translated inside of call arguments.
Original patch by Celelibi and David Woods. (Github issue #3594)
* Complex buffer item types of structs of arrays could fail to validate.
Patch by Leo and smutch. (Github issue #1407)
* Decorators were not allowed on nested `async def` functions.
(Github issue #1462)
* C-tuples could use invalid C struct casting.
Patch by MegaIng. (Github issue #3038)
* Optimised ``%d`` string formatting into f-strings failed on float values.
(Github issue #3092)
* Optimised aligned string formatting (``%05s``, ``%-5s``) failed.
(Github issue #3476)
* When importing the old Cython ``build_ext`` integration with distutils, the
additional command line arguments leaked into the regular command.
Patch by Kamekameha. (Github issue #2209)
* When using the ``CYTHON_NO_PYINIT_EXPORT`` option in C++, the module init function
was not declared as ``extern "C"``.
(Github issue #3414)
* Three missing timedelta access macros were added in ``cpython.datetime``.
* The signature of the NumPy C-API function ``PyArray_SearchSorted()`` was fixed.
Patch by Brock Mendel. (Github issue #3606)
0.29.17 (2020-04-26)
====================
Features added
--------------
* ``std::move()`` is now available from ``libcpp.utility``.
Patch by Omer Ozarslan. (Github issue #2169)
* The ``@cython.binding`` decorator is available in Python code.
(Github issue #3505)
Bugs fixed
----------
* Creating an empty unicode slice with large bounds could crash.
Patch by Sam Sneddon. (Github issue #3531)
* Decoding an empty bytes/char* slice with large bounds could crash.
Patch by Sam Sneddon. (Github issue #3534)
* Re-importing a Cython extension no longer raises the error
"``__reduce_cython__ not found``".
(Github issue #3545)
* Unused C-tuples could generate incorrect code in 0.29.16.
Patch by Kirk Meyer. (Github issue #3543)
* Creating a fused function attached it to the garbage collector before it
was fully initialised, thus risking crashes in rare failure cases.
Original patch by achernomorov. (Github issue #3215)
* Temporary buffer indexing variables were not released and could show up in
C compiler warnings, e.g. in generators.
Patch by David Woods. (Github issues #3430, #3522)
* The compilation cache in ``cython.inline("…")`` failed to take the language
level into account.
Patch by will-ca. (Github issue #3419)
* The deprecated ``PyUnicode_GET_SIZE()`` function is no longer used in Py3.
0.29.16 (2020-03-24)
====================
Bugs fixed
----------
* Temporary internal variables in nested prange loops could leak into other
threads. Patch by Frank Schlimbach. (Github issue #3348)
* Default arguments on fused functions could crash.
Patch by David Woods. (Github issue #3370)
* C-tuples declared in ``.pxd`` files could generate incomplete C code.
Patch by Kirk Meyer. (Github issue #1427)
* Fused functions were not always detected and optimised as Cython
implemented functions.
Patch by David Woods. (Github issue #3384)
* Valid Python object concatenation of (iterable) strings to non-strings
could fail with an exception.
Patch by David Woods. (Github issue #3433)
* Using C functions as temporary values lead to invalid C code.
Original patch by David Woods. (Github issue #3418)
* Fix an unhandled C++ exception in comparisons.
Patch by David Woods. (Github issue #3361)
* Fix deprecated import of "imp" module.
Patch by Matti Picus. (Github issue #3350)
* Fix compatibility with Pythran 0.9.6 and later.
Patch by Serge Guelton. (Github issue #3308)
* The ``_Py_PyAtExit()`` function in ``cpython.pylifecycle`` was misdeclared.
Patch by Zackery Spytz. (Github issue #3382)
* Several missing declarations in ``cpython.*`` were added.
Patches by Zackery Spytz. (Github issue #3452, #3421, #3411, #3402)
* A declaration for ``libc.math.fpclassify()`` was added.
Patch by Zackery Spytz. (Github issue #2514)
* Avoid "undeclared" warning about automatically generated pickle methods.
Patch by David Woods. (Github issue #3353)
* Avoid C compiler warning about unreachable code in ``prange()``.
* Some C compiler warnings in PyPy were resolved.
Patch by Matti Picus. (Github issue #3437)
0.29.15 (2020-02-06)
====================
Bugs fixed
----------
* Crash when returning a temporary Python object from an async-def function.
(Github issue #3337)
* Crash when using ``**kwargs`` in generators.
Patch by David Woods. (Github issue #3265)
* Double reference free in ``__class__`` cell handling for ``super()`` calls.
(Github issue #3246)
* Compile error when using ``*args`` as Python class bases.
(Github issue #3338)
* Import failure in IPython 7.11.
(Github issue #3297)
* Fixed C name collision in the auto-pickle code.
Patch by ThePrez. (Github issue #3238)
* Deprecated import failed in Python 3.9.
(Github issue #3266)
0.29.14 (2019-11-01)
====================
Bugs fixed
----------
* The generated code failed to initialise the ``tp_print`` slot in CPython 3.8.
Patches by Pablo Galindo and Orivej Desh. (Github issues #3171, #3201)
* ``?`` for ``bool`` was missing from the supported NumPy dtypes.
Patch by Max Klein. (Github issue #2675)
* ``await`` was not allowed inside of f-strings.
Patch by Dmitro Getz. (Github issue #2877)
* Coverage analysis failed for projects where the code resides in separate
source sub-directories.
Patch by Antonio Valentino. (Github issue #1985)
* An incorrect compiler warning was fixed in automatic C++ string conversions.
Patch by Gerion Entrup. (Github issue #3108)
* Error reports in the Jupyter notebook showed unhelpful stack traces.
Patch by Matthew Edwards (Github issue #3196).
* ``Python.h`` is now also included explicitly from ``public`` header files.
(Github issue #3133).
* Distutils builds with ``--parallel`` did not work when using Cython's
deprecated ``build_ext`` command.
Patch by Alphadelta14 (Github issue #3187).
Other changes
-------------
* The ``PyMemoryView_*()`` C-API is available in ``cpython.memoryview``.
Patch by Nathan Manville. (Github issue #2541)
0.29.13 (2019-07-26)
====================
Bugs fixed
----------
* A reference leak for ``None`` was fixed when converting a memoryview
to a Python object. (Github issue #3023)
* The declaration of ``PyGILState_STATE`` in ``cpython.pystate`` was unusable.
Patch by Kirill Smelkov. (Github issue #2997)
Other changes
-------------
* The declarations in ``posix.mman`` were extended.
Patches by Kirill Smelkov. (Github issues #2893, #2894, #3012)
0.29.12 (2019-07-07)
====================
Bugs fixed
----------
* Fix compile error in CPython 3.8b2 regarding the ``PyCode_New()`` signature.
(Github issue #3031)
* Fix a C compiler warning about a missing ``int`` downcast.
(Github issue #3028)
* Fix reported error positions of undefined builtins and constants.
Patch by Orivej Desh. (Github issue #3030)
* A 32 bit issue in the Pythran support was resolved.
Patch by Serge Guelton. (Github issue #3032)
0.29.11 (2019-06-30)
====================
Bugs fixed
----------
* Fix compile error in CPython 3.8b2 regarding the ``PyCode_New()`` signature.
Patch by Nick Coghlan. (Github issue #3009)
* Invalid C code generated for lambda functions in cdef methods.
Patch by Josh Tobin. (Github issue #2967)
* Support slice handling in newer Pythran versions.
Patch by Serge Guelton. (Github issue #2989)
* A reference leak in power-of-2 calculation was fixed.
Patch by Sebastian Berg. (Github issue #3022)
* The search order for include files was changed. Previously it was
``include_directories``, ``Cython/Includes``, ``sys.path``. Now it is
``include_directories``, ``sys.path``, ``Cython/Includes``. This was done to
allow third-party ``*.pxd`` files to override the ones in Cython.
Original patch by Matti Picus. (Github issue #2905)
* Setting ``language_level=2`` in a file did not work if ``language_level=3``
was enabled globally before.
Patch by Jeroen Demeyer. (Github issue #2791)
0.29.10 (2019-06-02)
====================
Bugs fixed
----------
* Fix compile errors in CPython 3.8b1 due to the new "tp_vectorcall" slots.
(Github issue #2976)
0.29.9 (2019-05-29)
===================
Bugs fixed
----------
* Fix a crash regression in 0.29.8 when creating code objects fails.
* Remove an incorrect cast when using true-division in C++ operations.
(Github issue #1950)
0.29.8 (2019-05-28)
===================
Bugs fixed
----------
* C compile errors with CPython 3.8 were resolved.
Patch by Marcel Plch. (Github issue #2938)
* Python tuple constants that compare equal but have different item
types could incorrectly be merged into a single constant.
(Github issue #2919)
* Non-ASCII characters in unprefixed strings could crash the compiler when
used with language level ``3str``.
* Starred expressions in %-formatting tuples could fail to compile for
unicode strings. (Github issue #2939)
* Passing Python class references through ``cython.inline()`` was broken.
(Github issue #2936)
0.29.7 (2019-04-14)
===================
Bugs fixed
----------
* Crash when the shared Cython config module gets unloaded and another Cython
module reports an exceptions. Cython now makes sure it keeps an owned reference
to the module.
(Github issue #2885)
* Resolved a C89 compilation problem when enabling the fast-gil sharing feature.
* Coverage reporting did not include the signature line of ``cdef`` functions.
(Github issue #1461)
* Casting a GIL-requiring function into a nogil function now issues a warning.
(Github issue #2879)
* Generators and coroutines were missing their return type annotation.
(Github issue #2884)
0.29.6 (2019-02-27)
===================
Bugs fixed
----------
* Fix a crash when accessing the ``__kwdefaults__`` special attribute of
fused functions. (Github issue #1470)
* Fix the parsing of buffer format strings that contain numeric sizes, which
could lead to incorrect input rejections. (Github issue #2845)
* Avoid a C #pragma in old gcc versions that was only added in GCC 4.6.
Patch by Michael Anselmi. (Github issue #2838)
* Auto-encoding of Unicode strings to UTF-8 C/C++ strings failed in Python 3,
even though the default encoding there is UTF-8.
(Github issue #2819)
0.29.5 (2019-02-09)
===================
Bugs fixed
----------
* Crash when defining a Python subclass of an extension type and repeatedly calling
a cpdef method on it. (Github issue #2823)
* Compiler crash when ``prange()`` loops appear inside of with-statements.
(Github issue #2780)
* Some C compiler warnings were resolved.
Patches by Christoph Gohlke. (Github issues #2815, #2816, #2817, #2822)
* Python conversion of C++ enums failed in 0.29.
Patch by Orivej Desh. (Github issue #2767)
0.29.4 (2019-02-01)
===================
Bugs fixed
----------
* Division of numeric constants by a runtime value of 0 could fail to raise a
``ZeroDivisionError``. (Github issue #2820)
0.29.3 (2019-01-19)
===================
Bugs fixed
----------
* Some C code for memoryviews was generated in a non-deterministic order.
Patch by Martijn van Steenbergen. (Github issue #2779)
* C89 compatibility was accidentally lost since 0.28.
Patches by gastineau and true-pasky. (Github issues #2778, #2801)
* A C compiler cast warning was resolved.
Patch by Michael Buesch. (Github issue #2774)
* An compilation failure with complex numbers under MSVC++ was resolved.
(Github issue #2797)
* Coverage reporting could fail when modules were moved around after the build.
Patch by Wenjun Si. (Github issue #2776)
0.29.2 (2018-12-14)
===================
Bugs fixed
----------
* The code generated for deduplicated constants leaked some references.
(Github issue #2750)
* The declaration of ``sigismember()`` in ``libc.signal`` was corrected.
(Github issue #2756)
* Crashes in compiler and test runner were fixed.
(Github issue #2736, #2755)
* A C compiler warning about an invalid safety check was resolved.
(Github issue #2731)
0.29.1 (2018-11-24)
===================
Bugs fixed
----------
* Extensions compiled with MinGW-64 under Windows could misinterpret integer
objects larger than 15 bit and return incorrect results.
(Github issue #2670)
* Cython no longer requires the source to be writable when copying its data
into a memory view slice.
Patch by Andrey Paramonov. (Github issue #2644)
* Line tracing of ``try``-statements generated invalid C code.
(Github issue #2274)
* When using the ``warn.undeclared`` directive, Cython's own code generated
warnings that are now fixed.
Patch by Nicolas Pauss. (Github issue #2685)
* Cython's memoryviews no longer require strides for setting the shape field
but only the ``PyBUF_ND`` flag to be set.
Patch by John Kirkham. (Github issue #2716)
* Some C compiler warnings about unused memoryview code were fixed.
Patch by Ho Cheuk Ting. (Github issue #2588)
* A C compiler warning about implicit signed/unsigned conversion was fixed.
(Github issue #2729)
* Assignments to C++ references returned by ``operator[]`` could fail to compile.
(Github issue #2671)
* The power operator and the support for NumPy math functions were fixed
in Pythran expressions.
Patch by Serge Guelton. (Github issues #2702, #2709)
* Signatures with memory view arguments now show the expected type
when embedded in docstrings.
Patch by Matthew Chan and Benjamin Weigel. (Github issue #2634)
* Some ``from ... cimport ...`` constructs were not correctly considered
when searching modified dependencies in ``cythonize()`` to decide
whether to recompile a module.
Patch by Kryštof Pilnáček. (Github issue #2638)
* A struct field type in the ``cpython.array`` declarations was corrected.
Patch by John Kirkham. (Github issue #2712)
0.29 (2018-10-14)
=================
Features added
--------------
* PEP-489 multi-phase module initialisation has been enabled again. Module
reloads in other subinterpreters raise an exception to prevent corruption
of the static module state.
* A set of ``mypy`` compatible PEP-484 declarations were added for Cython's C data
types to integrate with static analysers in typed Python code. They are available
in the ``Cython/Shadow.pyi`` module and describe the types in the special ``cython``
module that can be used for typing in Python code.
Original patch by Julian Gethmann. (Github issue #1965)
* Memoryviews are supported in PEP-484/526 style type declarations.
(Github issue #2529)
* ``@cython.nogil`` is supported as a C-function decorator in Python code.
(Github issue #2557)
* Raising exceptions from nogil code will automatically acquire the GIL, instead
of requiring an explicit ``with gil`` block.
* C++ functions can now be declared as potentially raising both C++ and Python
exceptions, so that Cython can handle both correctly.
(Github issue #2615)
* ``cython.inline()`` supports a direct ``language_level`` keyword argument that
was previously only available via a directive.
* A new language level name ``3str`` was added that mostly corresponds to language
level 3, but keeps unprefixed string literals as type 'str' in both Py2 and Py3,
and the builtin 'str' type unchanged. This will become the default in the next
Cython release and is meant to help user code a) transition more easily to this
new default and b) migrate to Python 3 source code semantics without making support
for Python 2.x difficult.
* In CPython 3.6 and later, looking up globals in the module dict is almost
as fast as looking up C globals.
(Github issue #2313)
* For a Python subclass of an extension type, repeated method calls to non-overridden
cpdef methods can avoid the attribute lookup in Py3.6+, which makes them 4x faster.
(Github issue #2313)
* (In-)equality comparisons of objects to integer literals are faster.
(Github issue #2188)
* Some internal and 1-argument method calls are faster.
* Modules that cimport many external extension types from other Cython modules
execute less import requests during module initialisation.
* Constant tuples and slices are deduplicated and only created once per module.
(Github issue #2292)
* The coverage plugin considers more C file extensions such as ``.cc`` and ``.cxx``.
(Github issue #2266)
* The ``cythonize`` command accepts compile time variable values (as set by ``DEF``)
through the new ``-E`` option.
Patch by Jerome Kieffer. (Github issue #2315)
* ``pyximport`` can import from namespace packages.
Patch by Prakhar Goel. (Github issue #2294)
* Some missing numpy and CPython C-API declarations were added.
Patch by John Kirkham. (Github issues #2523, #2520, #2537)
* Declarations for the ``pylifecycle`` C-API functions were added in a new .pxd file
``cpython.pylifecycle``.
* The Pythran support was updated to work with the latest Pythran 0.8.7.
Original patch by Adrien Guinet. (Github issue #2600)
* ``%a`` is included in the string formatting types that are optimised into f-strings.
In this case, it is also automatically mapped to ``%r`` in Python 2.x.
* New C macro ``CYTHON_HEX_VERSION`` to access Cython's version in the same style as
``PY_VERSION_HEX``.
* Constants in ``libc.math`` are now declared as ``const`` to simplify their handling.
* An additional ``check_size`` clause was added to the ``ctypedef class`` name
specification to allow suppressing warnings when importing modules with
backwards-compatible ``PyTypeObject`` size changes.
Patch by Matti Picus. (Github issue #2627)
Bugs fixed
----------
* The exception handling in generators and coroutines under CPython 3.7 was adapted
to the newly introduced exception stack. Users of Cython 0.28 who want to support
Python 3.7 are encouraged to upgrade to 0.29 to avoid potentially incorrect error
reporting and tracebacks. (Github issue #1958)
* Crash when importing a module under Stackless Python that was built for CPython.
Patch by Anselm Kruis. (Github issue #2534)
* 2-value slicing of typed sequences failed if the start or stop index was None.
Patch by Christian Gibson. (Github issue #2508)
* Multiplied string literals lost their factor when they are part of another
constant expression (e.g. 'x' * 10 + 'y' => 'xy').
* String formatting with the '%' operator didn't call the special ``__rmod__()``
method if the right side is a string subclass that implements it.
(Python issue 28598)
* The directive ``language_level=3`` did not apply to the first token in the
source file. (Github issue #2230)
* Overriding cpdef methods did not work in Python subclasses with slots.
Note that this can have a performance impact on calls from Cython code.
(Github issue #1771)
* Fix declarations of builtin or C types using strings in pure python mode.
(Github issue #2046)
* Generator expressions and lambdas failed to compile in ``@cfunc`` functions.
(Github issue #459)
* Global names with ``const`` types were not excluded from star-import assignments
which could lead to invalid C code.
(Github issue #2621)
* Several internal function signatures were fixed that lead to warnings in gcc-8.
(Github issue #2363)
* The numpy helper functions ``set_array_base()`` and ``get_array_base()``
were adapted to the current numpy C-API recommendations.
Patch by Matti Picus. (Github issue #2528)
* Some NumPy related code was updated to avoid deprecated API usage.
Original patch by jbrockmendel. (Github issue #2559)
* Several C++ STL declarations were extended and corrected.
Patch by Valentin Valls. (Github issue #2207)
* C lines of the module init function were unconditionally not reported in
exception stack traces.
Patch by Jeroen Demeyer. (Github issue #2492)
* When PEP-489 support is enabled, reloading the module overwrote any static
module state. It now raises an exception instead, given that reloading is
not actually supported.
* Object-returning, C++ exception throwing functions were not checking that
the return value was non-null.
Original patch by Matt Wozniski (Github Issue #2603)
* The source file encoding detection could get confused if the
``c_string_encoding`` directive appeared within the first two lines.
(Github issue #2632)
* Cython generated modules no longer emit a warning during import when the
size of the NumPy array type is larger than what was found at compile time.
Instead, this is assumed to be a backwards compatible change on NumPy side.
Other changes
-------------
* Cython now emits a warning when no ``language_level`` (2, 3 or '3str') is set
explicitly, neither as a ``cythonize()`` option nor as a compiler directive.
This is meant to prepare the transition of the default language level from
currently Py2 to Py3, since that is what most new users will expect these days.
The future default will, however, not enforce unicode literals, because this
has proven a major obstacle in the support for both Python 2.x and 3.x. The
next major release is intended to make this change, so that it will parse all
code that does not request a specific language level as Python 3 code, but with
``str`` literals. The language level 2 will continue to be supported for an
indefinite time.
* The documentation was restructured, cleaned up and examples are now tested.
The NumPy tutorial was also rewritten to simplify the running example.
Contributed by Gabriel de Marmiesse. (Github issue #2245)
* Cython compiles less of its own modules at build time to reduce the installed
package size to about half of its previous size. This makes the compiler
slightly slower, by about 5-7%.
0.28.6 (2018-11-01)
===================
Bugs fixed
----------
* Extensions compiled with MinGW-64 under Windows could misinterpret integer
objects larger than 15 bit and return incorrect results.
(Github issue #2670)
* Multiplied string literals lost their factor when they are part of another
constant expression (e.g. 'x' * 10 + 'y' => 'xy').
0.28.5 (2018-08-03)
===================
Bugs fixed
----------
* The discouraged usage of GCC's attribute ``optimize("Os")`` was replaced by the
similar attribute ``cold`` to reduce the code impact of the module init functions.
(Github issue #2494)
* A reference leak in Py2.x was fixed when comparing str to unicode for equality.
0.28.4 (2018-07-08)
===================
Bugs fixed
----------
* Reallowing ``tp_clear()`` in a subtype of an ``@no_gc_clear`` extension type
generated an invalid C function call to the (non-existent) base type implementation.
(Github issue #2309)
* Exception catching based on a non-literal (runtime) tuple could fail to match the
exception. (Github issue #2425)
* Compile fix for CPython 3.7.0a2. (Github issue #2477)
0.28.3 (2018-05-27)
===================
Bugs fixed
----------
* Set iteration was broken in non-CPython since 0.28.
* ``UnicodeEncodeError`` in Py2 when ``%s`` formatting is optimised for
unicode strings. (Github issue #2276)
* Work around a crash bug in g++ 4.4.x by disabling the size reduction setting
of the module init function in this version. (Github issue #2235)
* Crash when exceptions occur early during module initialisation.
(Github issue #2199)
0.28.2 (2018-04-13)
===================
Features added
--------------
* ``abs()`` is faster for Python long objects.
* The C++11 methods ``front()`` and ``end()`` were added to the declaration of
``libcpp.string``. Patch by Alex Huszagh. (Github issue #2123)
* The C++11 methods ``reserve()`` and ``bucket_count()`` are declared for
``libcpp.unordered_map``. Patch by Valentin Valls. (Github issue #2168)
Bugs fixed
----------
* The copy of a read-only memoryview was considered read-only as well, whereas
a common reason to copy a read-only view is to make it writable. The result
of the copying is now a writable buffer by default.
(Github issue #2134)
* The ``switch`` statement generation failed to apply recursively to the body of
converted if-statements.
* ``NULL`` was sometimes rejected as exception return value when the returned
type is a fused pointer type.
Patch by Callie LeFave. (Github issue #2177)
* Fixed compatibility with PyPy 5.11.
Patch by Matti Picus. (Github issue #2165)
Other changes
-------------
* The NumPy tutorial was rewritten to use memoryviews instead of the older
buffer declaration syntax.
Contributed by Gabriel de Marmiesse. (Github issue #2162)
0.28.1 (2018-03-18)
===================
Bugs fixed
----------
* ``PyFrozenSet_New()`` was accidentally used in PyPy where it is missing
from the C-API.
* Assignment between some C++ templated types were incorrectly rejected
when the templates mix ``const`` with ``ctypedef``.
(Github issue #2148)
* Undeclared C++ no-args constructors in subclasses could make the compilation
fail if the base class constructor was declared without ``nogil``.
(Github issue #2157)
* Bytes %-formatting inferred ``basestring`` (bytes or unicode) as result type
in some cases where ``bytes`` would have been safe to infer.
(Github issue #2153)
* ``None`` was accidentally disallowed as typed return value of ``dict.pop()``.
(Github issue #2152)
0.28 (2018-03-13)
=================
Features added
--------------
* Cdef classes can now multiply inherit from ordinary Python classes.
(The primary base must still be a c class, possibly ``object``, and
the other bases must *not* be cdef classes.)
* Type inference is now supported for Pythran compiled NumPy expressions.
Patch by Nils Braun. (Github issue #1954)
* The ``const`` modifier can be applied to memoryview declarations to allow
read-only buffers as input. (Github issues #1605, #1869)
* C code in the docstring of a ``cdef extern`` block is copied verbatimly
into the generated file.
Patch by Jeroen Demeyer. (Github issue #1915)
* When compiling with gcc, the module init function is now tuned for small
code size instead of whatever compile flags were provided externally.
Cython now also disables some code intensive optimisations in that function
to further reduce the code size. (Github issue #2102)
* Decorating an async coroutine with ``@cython.iterable_coroutine`` changes its
type at compile time to make it iterable. While this is not strictly in line
with PEP-492, it improves the interoperability with old-style coroutines that
use ``yield from`` instead of ``await``.
* The IPython magic has preliminary support for JupyterLab.
(Github issue #1775)
* The new TSS C-API in CPython 3.7 is supported and has been backported.
Patch by Naotoshi Seo. (Github issue #1932)
* Cython knows the new ``Py_tss_t`` type defined in PEP-539 and automatically
initialises variables declared with that type to ``Py_tss_NEEDS_INIT``,
a value which cannot be used outside of static assignments.
* The set methods ``.remove()`` and ``.discard()`` are optimised.
Patch by Antoine Pitrou. (Github issue #2042)
* ``dict.pop()`` is optimised.
Original patch by Antoine Pitrou. (Github issue #2047)
* Iteration over sets and frozensets is optimised.
(Github issue #2048)
* Safe integer loops (< range(2^30)) are automatically optimised into C loops.
* ``alist.extend([a,b,c])`` is optimised into sequential ``list.append()`` calls
for short literal sequences.
* Calls to builtin methods that are not specifically optimised into C-API calls
now use a cache that avoids repeated lookups of the underlying C function.
(Github issue #2054)
* Single argument function calls can avoid the argument tuple creation in some cases.
* Some redundant extension type checks are avoided.
* Formatting C enum values in f-strings is faster, as well as some other special cases.
* String formatting with the '%' operator is optimised into f-strings in simple cases.
* Subscripting (item access) is faster in some cases.
* Some ``bytearray`` operations have been optimised similar to ``bytes``.
* Some PEP-484/526 container type declarations are now considered for
loop optimisations.
* Indexing into memoryview slices with ``view[i][j]`` is now optimised into
``view[i, j]``.
* Python compatible ``cython.*`` types can now be mixed with type declarations
in Cython syntax.
* Name lookups in the module and in classes are faster.
* Python attribute lookups on extension types without instance dict are faster.
* Some missing signals were added to ``libc/signal.pxd``.
Patch by Jeroen Demeyer. (Github issue #1914)
* The warning about repeated extern declarations is now visible by default.
(Github issue #1874)
* The exception handling of the function types used by CPython's type slot
functions was corrected to match the de-facto standard behaviour, so that
code that uses them directly benefits from automatic and correct exception
propagation. Patch by Jeroen Demeyer. (Github issue #1980)
* Defining the macro ``CYTHON_NO_PYINIT_EXPORT`` will prevent the module init
function from being exported as symbol, e.g. when linking modules statically
in an embedding setup. Patch by AraHaan. (Github issue #1944)
Bugs fixed
----------
* If a module name is explicitly provided for an ``Extension()`` that is compiled
via ``cythonize()``, it was previously ignored and replaced by the source file
name. It can now be used to override the target module name, e.g. for compiling
prefixed accelerator modules from Python files. (Github issue #2038)
* The arguments of the ``num_threads`` parameter of parallel sections
were not sufficiently validated and could lead to invalid C code.
(Github issue #1957)
* Catching exceptions with a non-trivial exception pattern could call into
CPython with a live exception set. This triggered incorrect behaviour
and crashes, especially in CPython 3.7.
* The signature of the special ``__richcmp__()`` method was corrected to recognise
the type of the first argument as ``self``. It was previously treated as plain
object, but CPython actually guarantees that it always has the correct type.
Note: this can change the semantics of user code that previously relied on
``self`` being untyped.
* Some Python 3 exceptions were not recognised as builtins when running Cython
under Python 2.
* Some async helper functions were not defined in the generated C code when
compiling simple async code. (Github issue #2075)
* Line tracing did not include generators and coroutines.
(Github issue #1949)
* C++ declarations for ``unordered_map`` were corrected.
Patch by Michael Schatzow. (Github issue #1484)
* Iterator declarations in C++ ``deque`` and ``vector`` were corrected.
Patch by Alex Huszagh. (Github issue #1870)
* The const modifiers in the C++ ``string`` declarations were corrected, together
with the coercion behaviour of string literals into C++ strings.
(Github issue #2132)
* Some declaration types in ``libc.limits`` were corrected.
Patch by Jeroen Demeyer. (Github issue #2016)
* ``@cython.final`` was not accepted on Python classes with an ``@cython.cclass``
decorator. (Github issue #2040)
* Cython no longer creates useless and incorrect ``PyInstanceMethod`` wrappers for
methods in Python 3. Patch by Jeroen Demeyer. (Github issue #2105)
* The builtin ``bytearray`` type could not be used as base type of cdef classes.
(Github issue #2106)
Other changes
-------------
0.27.3 (2017-11-03)
===================
Bugs fixed
----------
* String forward references to extension types like ``@cython.locals(x="ExtType")``
failed to find the named type. (Github issue #1962)
* NumPy slicing generated incorrect results when compiled with Pythran.
Original patch by Serge Guelton (Github issue #1946).
* Fix "undefined reference" linker error for generators on Windows in Py3.3-3.5.
(Github issue #1968)
* Adapt to recent C-API change of ``PyThreadState`` in CPython 3.7.
* Fix signature of ``PyWeakref_GetObject()`` API declaration.
Patch by Jeroen Demeyer (Github issue #1975).
0.27.2 (2017-10-22)
===================
Bugs fixed
----------
* Comprehensions could incorrectly be optimised away when they appeared in boolean
test contexts. (Github issue #1920)
* The special methods ``__eq__``, ``__lt__`` etc. in extension types did not type
their first argument as the type of the class but ``object``. (Github issue #1935)
* Crash on first lookup of "cline_in_traceback" option during exception handling.
(Github issue #1907)
* Some nested module level comprehensions failed to compile.
(Github issue #1906)
* Compiler crash on some complex type declarations in pure mode.
(Github issue #1908)
* ``std::unordered_map.erase()`` was declared with an incorrect ``void`` return
type in ``libcpp.unordered_map``. (Github issue #1484)
* Invalid use of C++ ``fallthrough`` attribute before C++11 and similar issue in clang.
(Github issue #1930)
* Compiler crash on misnamed properties. (Github issue #1905)
0.27.1 (2017-10-01)
===================
Features added
--------------
* The Jupyter magic has a new debug option ``--verbose`` that shows details about
the distutils invocation. Patch by Boris Filippov (Github issue #1881).
Bugs fixed
----------
* Py3 list comprehensions in class bodies resulted in invalid C code.
(Github issue #1889)
* Modules built for later CPython 3.5.x versions failed to import in 3.5.0/3.5.1.
(Github issue #1880)
* Deallocating fused types functions and methods kept their GC tracking enabled,
which could potentially lead to recursive deallocation attempts.
* Crash when compiling in C++ mode with old setuptools versions.
(Github issue #1879)
* C++ object arguments for the constructor of Cython implemented C++ are now
passed by reference and not by value to allow for non-copyable arguments, such
as ``unique_ptr``.
* API-exported C++ classes with Python object members failed to compile.
(Github issue #1866)
* Some issues with the new relaxed exception value handling were resolved.
* Python classes as annotation types could prevent compilation.
(Github issue #1887)
* Cython annotation types in Python files could lead to import failures
with a "cython undefined" error. Recognised types are now turned into strings.
* Coverage analysis could fail to report on extension modules on some platforms.
* Annotations could be parsed (and rejected) as types even with
``annotation_typing=False``.
Other changes
-------------
* PEP 489 support has been disabled by default to counter incompatibilities with
import setups that try to reload or reinitialise modules.
0.27 (2017-09-23)
=================
Features added
--------------
* Extension module initialisation follows
`PEP 489 <https://www.python.org/dev/peps/pep-0489/>`_ in CPython 3.5+, which
resolves several differences with regard to normal Python modules. This makes
the global names ``__file__`` and ``__path__`` correctly available to module
level code and improves the support for module-level relative imports.
(Github issues #1715, #1753, #1035)
* Asynchronous generators (`PEP 525 <https://www.python.org/dev/peps/pep-0525/>`_)
and asynchronous comprehensions (`PEP 530 <https://www.python.org/dev/peps/pep-0530/>`_)
have been implemented. Note that async generators require finalisation support
in order to allow for asynchronous operations during cleanup, which is only
available in CPython 3.6+. All other functionality has been backported as usual.
* Variable annotations are now parsed according to
`PEP 526 <https://www.python.org/dev/peps/pep-0526/>`_. Cython types (e.g.
``cython.int``) are evaluated as C type declarations and everything else as Python
types. This can be disabled with the directive ``annotation_typing=False``.
Note that most complex PEP-484 style annotations are currently ignored. This will
change in future releases. (Github issue #1850)
* Extension types (also in pure Python mode) can implement the normal special methods
``__eq__``, ``__lt__`` etc. for comparisons instead of the low-level ``__richcmp__``
method. (Github issue #690)
* New decorator ``@cython.exceptval(x=None, check=False)`` that makes the signature
declarations ``except x``, ``except? x`` and ``except *`` available to pure Python
code. Original patch by Antonio Cuni. (Github issue #1653)
* Signature annotations are now included in the signature docstring generated by
the ``embedsignature`` directive. Patch by Lisandro Dalcin (Github issue #1781).
* The gdb support for Python code (``libpython.py``) was updated to the latest
version in CPython 3.7 (git rev 5fe59f8).
* The compiler tries to find a usable exception return value for cdef functions
with ``except *`` if the returned type allows it. Note that this feature is subject
to safety limitations, so it is still better to provide an explicit declaration.
* C functions can be assigned to function pointers with a compatible exception
declaration, not only with exact matches. A side-effect is that certain compatible
signature overrides are now allowed and some more mismatches of exception signatures
are now detected and rejected as errors that were not detected before.
* The IPython/Jupyter magic integration has a new option ``%%cython --pgo`` for profile
guided optimisation. It compiles the cell with PGO settings for the C compiler,
executes it to generate a runtime profile, and then compiles it again using that
profile for C compiler optimisation. Currently only tested with gcc.
* ``len(memoryview)`` can be used in nogil sections to get the size of the
first dimension of a memory view (``shape[0]``). (Github issue #1733)
* C++ classes can now contain (properly refcounted) Python objects.
* NumPy dtype subarrays are now accessible through the C-API.
Patch by Gerald Dalley (Github issue #245).
* Resolves several issues with PyPy and uses faster async slots in PyPy3.
Patch by Ronan Lamy (Github issues #1871, #1878).
Bugs fixed
----------
* Extension types that were cimported from other Cython modules could disagree
about the order of fused cdef methods in their call table. This could lead
to wrong methods being called and potentially also crashes. The fix required
changes to the ordering of fused methods in the call table, which may break
existing compiled modules that call fused cdef methods across module boundaries,
if these methods were implemented in a different order than they were declared
in the corresponding .pxd file. (Github issue #1873)
* The exception state handling in generators and coroutines could lead to
exceptions in the caller being lost if an exception was raised and handled
inside of the coroutine when yielding. (Github issue #1731)
* Loops over ``range(enum)`` were not converted into C for-loops. Note that it
is still recommended to use an explicit cast to a C integer type in this case.
* Error positions of names (e.g. variables) were incorrectly reported after the
name and not at the beginning of the name.
* Compile time ``DEF`` assignments were evaluated even when they occur inside of
falsy ``IF`` blocks. (Github issue #1796)
* Disabling the line tracing from a trace function could fail.
Original patch by Dmitry Trofimov. (Github issue #1769)
* Several issues with the Pythran integration were resolved.
* abs(signed int) now returns a signed rather than unsigned int.
(Github issue #1837)
* Reading ``frame.f_locals`` of a Cython function (e.g. from a debugger or profiler
could modify the module globals. (Github issue #1836)
* Buffer type mismatches in the NumPy buffer support could leak a reference to the
buffer owner.
* Using the "is_f_contig" and "is_c_contig" memoryview methods together could leave
one of them undeclared. (Github issue #1872)
* Compilation failed if the for-in-range loop target was not a variable but a more
complex expression, e.g. an item assignment. (Github issue #1831)
* Compile time evaluations of (partially) constant f-strings could show incorrect
results.
* Escape sequences in raw f-strings (``fr'...'``) were resolved instead of passing
them through as expected.
* Some ref-counting issues in buffer error handling have been resolved.
Other changes
-------------
* Type declarations in signature annotations are now parsed according to
`PEP 484 <https://www.python.org/dev/peps/pep-0484/>`_
typing. Only Cython types (e.g. ``cython.int``) and Python builtin types are
currently considered as type declarations. Everything else is ignored, but this
will change in a future Cython release.
(Github issue #1672)
* The directive ``annotation_typing`` is now ``True`` by default, which enables
parsing type declarations from annotations.
* This release no longer supports Python 3.2.
0.26.1 (2017-08-29)
===================
Features added
--------------
Bugs fixed
----------
* ``cython.view.array`` was missing ``.__len__()``.
* Extension types with a ``.pxd`` override for their ``__releasebuffer__`` slot
(e.g. as provided by Cython for the Python ``array.array`` type) could leak
a reference to the buffer owner on release, thus not freeing the memory.
(Github issue #1638)
* Auto-decoding failed in 0.26 for strings inside of C++ containers.
(Github issue #1790)
* Compile error when inheriting from C++ container types.
(Github issue #1788)
* Invalid C code in generators (declaration after code).
(Github issue #1801)
* Arithmetic operations on ``const`` integer variables could generate invalid code.
(Github issue #1798)
* Local variables with names of special Python methods failed to compile inside of
closures. (Github issue #1797)
* Problem with indirect Emacs buffers in cython-mode.
Patch by Martin Albrecht (Github issue #1743).
* Extension types named ``result`` or ``PickleError`` generated invalid unpickling code.
Patch by Jason Madden (Github issue #1786).
* Bazel integration failed to compile ``.py`` files.
Patch by Guro Bokum (Github issue #1784).
* Some include directories and dependencies were referenced with their absolute paths
in the generated files despite lying within the project directory.
* Failure to compile in Py3.7 due to a modified signature of ``_PyCFunctionFast()``
0.26 (2017-07-19)
=================
Features added
--------------
* Pythran can be used as a backend for evaluating NumPy array expressions.
Patch by Adrien Guinet (Github issue #1607).
* cdef classes now support pickling by default when possible.
This can be disabled with the ``auto_pickle`` directive.
* Speed up comparisons of strings if their hash value is available.
Patch by Claudio Freire (Github issue #1571).
* Support pyximport from zip files.
Patch by Sergei Lebedev (Github issue #1485).
* IPython magic now respects the ``__all__`` variable and ignores
names with leading-underscore (like ``import *`` does).
Patch by Syrtis Major (Github issue #1625).
* ``abs()`` is optimised for C complex numbers.
Patch by da-woods (Github issue #1648).
* The display of C lines in Cython tracebacks can now be enabled at runtime
via ``import cython_runtime; cython_runtime.cline_in_traceback=True``.
The default has been changed to False.
* The overhead of calling fused types generic functions was reduced.
* "cdef extern" include files are now also searched relative to the current file.
Patch by Jeroen Demeyer (Github issue #1654).
* Optional optimization for re-aquiring the GIL, controlled by the
`fast_gil` directive.
Bugs fixed
----------
* Item lookup/assignment with a unicode character as index that is typed
(explicitly or implicitly) as ``Py_UCS4`` or ``Py_UNICODE`` used the
integer value instead of the Unicode string value. Code that relied on
the previous behaviour now triggers a warning that can be disabled by
applying an explicit cast. (Github issue #1602)
* f-string processing was adapted to changes in PEP 498 and CPython 3.6.
* Invalid C code when decoding from UTF-16(LE/BE) byte strings.
(Github issue #1696)
* Unicode escapes in 'ur' raw-unicode strings were not resolved in Py2 code.
Original patch by Aaron Gallagher (Github issue #1594).
* File paths of code objects are now relative.
Original patch by Jelmer Vernooij (Github issue #1565).
* Decorators of cdef class methods could be executed twice.
Patch by Jeroen Demeyer (Github issue #1724).
* Dict iteration using the Py2 ``iter*`` methods failed in PyPy3.
Patch by Armin Rigo (Github issue #1631).
* Several warnings in the generated code are now suppressed.
Other changes
-------------
* The ``unraisable_tracebacks`` option now defaults to ``True``.
* Coercion of C++ containers to Python is no longer automatic on attribute
access (Github issue #1521).
* Access to Python attributes of cimported modules without the corresponding
import is now a compile-time (rather than runtime) error.
* Do not use special dll linkage for "cdef public" functions.
Patch by Jeroen Demeyer (Github issue #1687).
* cdef/cpdef methods must match their declarations. See Github Issue #1732.
This is now a warning and will be an error in future releases.
0.25.2 (2016-12-08)
===================
Bugs fixed
----------
* Fixes several issues with C++ template deduction.
* Fixes a issue with bound method type inference (Github issue #551).
* Fixes a bug with cascaded tuple assignment (Github issue #1523).
* Fixed or silenced many Clang warnings.
* Fixes bug with powers of pure real complex numbers (Github issue #1538).
0.25.1 (2016-10-26)
===================
Bugs fixed
----------
* Fixes a bug with ``isinstance(o, Exception)`` (Github issue #1496).
* Fixes bug with ``cython.view.array`` missing utility code in some cases
(Github issue #1502).
Other changes
-------------
* The distutils extension ``Cython.Distutils.build_ext`` has been reverted,
temporarily, to be ``old_build_ext`` to give projects time to migrate.
The new build_ext is available as ``new_build_ext``.
0.25 (2016-10-25)
=================
Features added
--------------
* def/cpdef methods of cdef classes benefit from Cython's internal function
implementation, which enables introspection and line profiling for them.
Implementation sponsored by Turbostream (www.turbostream-cfd.com).
* Calls to Python functions are faster, following the recent "FastCall"
optimisations that Victor Stinner implemented for CPython 3.6.
See https://bugs.python.org/issue27128 and related issues.
* The new METH_FASTCALL calling convention for PyCFunctions is supported
in CPython 3.6. See https://bugs.python.org/issue27810
* Initial support for using Cython modules in Pyston.
Patch by Boxiang Sun.
* Dynamic Python attributes are allowed on cdef classes if an attribute
``cdef dict __dict__`` is declared in the class. Patch by empyrical.
* Cython implemented C++ classes can make direct calls to base class methods.
Patch by empyrical.
* C++ classes can now have typedef members. STL containers updated with
value_type.
* New directive ``cython.no_gc`` to fully disable GC for a cdef class.
Patch by Claudio Freire.
* Buffer variables are no longer excluded from ``locals()``.
Patch by da-woods.
* Building f-strings is faster, especially when formatting C integers.
* for-loop iteration over "std::string".
* ``libc/math.pxd`` provides ``e`` and ``pi`` as alias constants to simplify
usage as a drop-in replacement for Python's math module.
* Speed up cython.inline().
* Binary lshift operations with small constant Python integers are faster.
* Some integer operations on Python long objects are faster in Python 2.7.
* Support for the C++ ``typeid`` operator.
* Support for bazel using a the pyx_library rule in //Tools:rules.bzl.
Significant Bugs fixed
----------------------
* Division of complex numbers avoids overflow by using Smith's method.
* Some function signatures in ``libc.math`` and ``numpy.pxd`` were incorrect.
Patch by Michael Seifert.
Other changes
-------------
* The "%%cython" IPython/jupyter magic now defaults to the language level of
the current jupyter kernel. The language level can be set explicitly with
"%%cython -2" or "%%cython -3".
* The distutils extension ``Cython.Distutils.build_ext`` has now been updated
to use cythonize which properly handles dependencies. The old extension can
still be found in ``Cython.Distutils.old_build_ext`` and is now deprecated.
* ``directive_defaults`` is no longer available in ``Cython.Compiler.Options``,
use ``get_directive_defaults()`` instead.
0.24.1 (2016-07-15)
===================
Bugs fixed
----------
* IPython cell magic was lacking a good way to enable Python 3 code semantics.
It can now be used as "%%cython -3".
* Follow a recent change in `PEP 492 <https://www.python.org/dev/peps/pep-0492/>`_
and CPython 3.5.2 that now requires the ``__aiter__()`` method of asynchronous
iterators to be a simple ``def`` method instead of an ``async def`` method.
* Coroutines and generators were lacking the ``__module__`` special attribute.
* C++ ``std::complex`` values failed to auto-convert from and to Python complex
objects.
* Namespaced C++ types could not be used as memory view types due to lack of
name mangling. Patch by Ivan Smirnov.
* Assignments between identical C++ types that were declared with differently
typedefed template types could fail.
* Rebuilds could fail to evaluate dependency timestamps in C++ mode.
Patch by Ian Henriksen.
* Macros defined in the ``distutils`` compiler option do not require values
anymore. Patch by Ian Henriksen.
* Minor fixes for MSVC, Cygwin and PyPy.
0.24 (2016-04-04)
=================
Features added
--------------
* `PEP 498 <https://www.python.org/dev/peps/pep-0498/>`_:
Literal String Formatting (f-strings).
Original patch by Jelle Zijlstra.
* `PEP 515 <https://www.python.org/dev/peps/pep-0515/>`_:
Underscores as visual separators in number literals.
* Parser was adapted to some minor syntax changes in Py3.6, e.g.
https://bugs.python.org/issue9232
* The embedded C code comments that show the original source code
can be discarded with the new directive ``emit_code_comments=False``.
* Cpdef enums are now first-class iterable, callable types in Python.
* Ctuples can now be declared in pure Python code.
* Posix declarations for DLL loading and stdio extensions were added.
Patch by Lars Buitinck.
* The Py2-only builtins ``unicode()``, ``xrange()``, ``reduce()`` and
``long`` are now also available in compile time ``DEF`` expressions
when compiling with Py3.
* Exception type tests have slightly lower overhead.
This fixes ticket 868.
* @property syntax fully supported in cdef classes, old syntax deprecated.
* C++ classes can now be declared with default template parameters.
Bugs fixed
----------
* C++ exceptions raised by overloaded C++ operators were not always
handled. Patch by Ian Henriksen.
* C string literals were previously always stored as non-const global
variables in the module. They are now stored as global constants
when possible, and otherwise as non-const C string literals in the
generated code that uses them. This improves compatibility with
strict C compiler options and prevents non-const strings literals
with the same content from being incorrectly merged.
* Compile time evaluated ``str`` expressions (``DEF``) now behave in a
more useful way by turning into Unicode strings when compiling under
Python 3. This allows using them as intermediate values in expressions.
Previously, they always evaluated to bytes objects.
* ``isinf()`` declarations in ``libc/math.pxd`` and ``numpy/math.pxd`` now
reflect the actual tristate ``int`` return value instead of using ``bint``.
* Literal assignments to ctuples avoid Python tuple round-trips in some
more corner cases.
* Iteration over ``dict(...).items()`` failed to get optimised when dict
arguments included keyword arguments.
* cProfile now correctly profiles cpdef functions and methods.
0.23.5 (2016-03-26)
===================
* Compile errors and warnings in integer type conversion code. This fixes
ticket 877. Patches by Christian Neukirchen, Nikolaus Rath, Ian Henriksen.
* Reference leak when "*args" argument was reassigned in closures.
* Truth-testing Unicode strings could waste time and memory in Py3.3+.
* Return values of async functions could be ignored and replaced by ``None``.
* Compiler crash in CPython 3.6.
* Fix prange() to behave identically to range(). The end condition was
miscalculated when the range was not exactly divisible by the step.
* Optimised ``all(genexpr)``/``any(genexpr)`` calls could warn about unused
code. This fixes ticket 876.
0.23.4 (2015-10-10)
===================
Bugs fixed
----------
* Memory leak when calling Python functions in PyPy.
* Compilation problem with MSVC in C99-ish mode.
* Warning about unused values in a helper macro.
0.23.3 (2015-09-29)
===================
Bugs fixed
----------
* Invalid C code for some builtin methods. This fixes ticket 856 again.
* Incorrect C code in helper functions for PyLong conversion and string
decoding. This fixes ticket 863, ticket 864 and ticket 865.
Original patch by Nikolaus Rath.
* Large folded or inserted integer constants could use too small C
integer types and thus trigger a value wrap-around.
Other changes
-------------
* The coroutine and generator types of Cython now also register directly
with the ``Coroutine`` and ``Generator`` ABCs in the ``backports_abc``
module if it can be imported. This fixes ticket 870.
0.23.2 (2015-09-11)
===================
Bugs fixed
----------
* Compiler crash when analysing some optimised expressions.
* Coverage plugin was adapted to coverage.py 4.0 beta 2.
* C++ destructor calls could fail when '&' operator is overwritten.
* Incorrect C literal generation for large integers in compile-time
evaluated DEF expressions and constant folded expressions.
* Byte string constants could end up as Unicode strings when originating
from compile-time evaluated DEF expressions.
* Invalid C code when caching known builtin methods.
This fixes ticket 860.
* ``ino_t`` in ``posix.types`` was not declared as ``unsigned``.
* Declarations in ``libcpp/memory.pxd`` were missing ``operator!()``.
Patch by Leo Razoumov.
* Static cdef methods can now be declared in .pxd files.
0.23.1 (2015-08-22)
===================
Bugs fixed
----------
* Invalid C code for generators. This fixes ticket 858.
* Invalid C code for some builtin methods. This fixes ticket 856.
* Invalid C code for unused local buffer variables.
This fixes ticket 154.
* Test failures on 32bit systems. This fixes ticket 857.
* Code that uses ``from xyz import *`` and global C struct/union/array
variables could fail to compile due to missing helper functions.
This fixes ticket 851.
* Misnamed PEP 492 coroutine property ``cr_yieldfrom`` renamed to
``cr_await`` to match CPython.
* Missing deallocation code for C++ object attributes in certain
extension class hierarchies.
* Crash when async coroutine was not awaited.
* Compiler crash on ``yield`` in signature annotations and default
argument values. Both are forbidden now.
* Compiler crash on certain constructs in ``finally`` clauses.
* Cython failed to build when CPython's pgen is installed.
0.23 (2015-08-08)
=================
Features added
--------------
* `PEP 492 <https://www.python.org/dev/peps/pep-0492/>`_
(async/await) was implemented.
* `PEP 448 <https://www.python.org/dev/peps/pep-0448/>`_
(Additional Unpacking Generalizations) was implemented.
* Support for coverage.py 4.0+ can be enabled by adding the plugin
"Cython.Coverage" to the ".coveragerc" config file.
* Annotated HTML source pages can integrate (XML) coverage reports.
* Tracing is supported in ``nogil`` functions/sections and module init code.
* When generators are used in a Cython module and the module imports the
modules "inspect" and/or "asyncio", Cython enables interoperability by
patching these modules during the import to recognise Cython's internal
generator and coroutine types. This can be disabled by C compiling the
module with "-D CYTHON_PATCH_ASYNCIO=0" or "-D CYTHON_PATCH_INSPECT=0"
* When generators or coroutines are used in a Cython module, their types
are registered with the ``Generator`` and ``Coroutine`` ABCs in the
``collections`` or ``collections.abc`` stdlib module at import time to
enable interoperability with code that needs to detect and process Python
generators/coroutines. These ABCs were added in CPython 3.5 and are
available for older Python versions through the ``backports_abc`` module
on PyPI. See https://bugs.python.org/issue24018
* Adding/subtracting/dividing/modulus and equality comparisons with
constant Python floats and small integers are faster.
* Binary and/or/xor/rshift operations with small constant Python integers
are faster.
* When called on generator expressions, the builtins ``all()``, ``any()``,
``dict()``, ``list()``, ``set()``, ``sorted()`` and ``unicode.join()``
avoid the generator iteration overhead by inlining a part of their
functionality into the for-loop.
* Keyword argument dicts are no longer copied on function entry when they
are not being used or only passed through to other function calls (e.g.
in wrapper functions).
* The ``PyTypeObject`` declaration in ``cpython.object`` was extended.
* The builtin ``type`` type is now declared as PyTypeObject in source,
allowing for extern functions taking type parameters to have the correct
C signatures. Note that this might break code that uses ``type`` just
for passing around Python types in typed variables. Removing the type
declaration provides a backwards compatible fix.
* ``wraparound()`` and ``boundscheck()`` are available as no-ops in pure
Python mode.
* Const iterators were added to the provided C++ STL declarations.
* Smart pointers were added to the provided C++ STL declarations.
Patch by Daniel Filonik.
* ``NULL`` is allowed as default argument when embedding signatures.
This fixes ticket 843.
* When compiling with ``--embed``, the internal module name is changed to
``__main__`` to allow arbitrary program names, including those that would
be invalid for modules. Note that this prevents reuse of the generated
C code as an importable module.
* External C++ classes that overload the assignment operator can be used.
Patch by Ian Henriksen.
* Support operator bool() for C++ classes so they can be used in if statements.
Bugs fixed
----------
* Calling "yield from" from Python on a Cython generator that returned a
value triggered a crash in CPython. This is now being worked around.
See https://bugs.python.org/issue23996
* Language level 3 did not enable true division (a.k.a. float division)
for integer operands.
* Functions with fused argument types that included a generic 'object'
fallback could end up using that fallback also for other explicitly
listed object types.
* Relative cimports could accidentally fall back to trying an absolute
cimport on failure.
* The result of calling a C struct constructor no longer requires an
intermediate assignment when coercing to a Python dict.
* C++ exception declarations with mapping functions could fail to compile
when pre-declared in .pxd files.
* ``cpdef void`` methods are now permitted.
* ``abs(cint)`` could fail to compile in MSVC and used sub-optimal code
in C++. Patch by David Vierra, original patch by Michael Enßlin.
* Buffer index calculations using index variables with small C integer
types could overflow for large buffer sizes.
Original patch by David Vierra.
* C unions use a saner way to coerce from and to Python dicts.
* When compiling a module ``foo.pyx``, the directories in ``sys.path``
are no longer searched when looking for ``foo.pxd``.
Patch by Jeroen Demeyer.
* Memory leaks in the embedding main function were fixed.
Original patch by Michael Enßlin.
* Some complex Python expressions could fail to compile inside of finally
clauses.
* Unprefixed 'str' literals were not supported as C varargs arguments.
* Fixed type errors in conversion enum types to/from Python. Note that
this imposes stricter correctness requirements on enum declarations.
Other changes
-------------
* Changed mangling scheme in header files generated by ``cdef api``
declarations.
* Installation under CPython 3.3+ no longer requires a pass of the
2to3 tool. This also makes it possible to run Cython in Python
3.3+ from a source checkout without installing it first.
Patch by Petr Viktorin.
* ``jedi-typer.py`` (in ``Tools/``) was extended and renamed to
``jedityper.py`` (to make it importable) and now works with and
requires Jedi 0.9. Patch by Tzer-jen Wei.
0.22.1 (2015-06-20)
===================
Bugs fixed
----------
* Crash when returning values on generator termination.
* In some cases, exceptions raised during internal isinstance() checks were
not propagated.
* Runtime reported file paths of source files (e.g for profiling and tracing)
are now relative to the build root directory instead of the main source file.
* Tracing exception handling code could enter the trace function with an active
exception set.
* The internal generator function type was not shared across modules.
* Comparisons of (inferred) ctuples failed to compile.
* Closures inside of cdef functions returning ``void`` failed to compile.
* Using ``const`` C++ references in intermediate parts of longer expressions
could fail to compile.
* C++ exception declarations with mapping functions could fail to compile when
pre-declared in .pxd files.
* C++ compilation could fail with an ambiguity error in recent MacOS-X Xcode
versions.
* C compilation could fail in pypy3.
* Fixed a memory leak in the compiler when compiling multiple modules.
* When compiling multiple modules, external library dependencies could leak
into later compiler runs. Fix by Jeroen Demeyer. This fixes ticket 845.
0.22 (2015-02-11)
=================
Features added
--------------
* C functions can coerce to Python functions, which allows passing them
around as callable objects.
* C arrays can be assigned by value and auto-coerce from Python iterables
and to Python lists (and tuples).
* Extern C functions can now be declared as cpdef to export them to
the module's Python namespace. Extern C functions in pxd files export
their values to their own module, iff it exists.
* Anonymous C tuple types can be declared as (ctype1, ctype2, ...).
* `PEP 479 <https://www.python.org/dev/peps/pep-0479/>`_:
turn accidental StopIteration exceptions that exit generators
into a RuntimeError, activated with future import "generator_stop".
* Looping over ``reversed(range())`` is optimised in the same way as
``range()``. Patch by Favian Contreras.
Bugs fixed
----------
* Mismatching 'except' declarations on signatures in .pxd and .pyx files failed
to produce a compile error.
* Failure to find any files for the path pattern(s) passed into ``cythonize()``
is now an error to more easily detect accidental typos.
* The ``logaddexp`` family of functions in ``numpy.math`` now has correct
declarations.
* In Py2.6/7 and Py3.2, simple Cython memory views could accidentally be
interpreted as non-contiguous by CPython, which could trigger a CPython
bug when copying data from them, thus leading to data corruption.
See CPython issues 12834 and 23349.
Other changes
-------------
* Preliminary support for defining the Cython language with a formal grammar.
To try parsing your files against this grammar, use the --formal_grammar directive.
Experimental.
* ``_`` is no longer considered a cacheable builtin as it could interfere with
gettext.
* Cythonize-computed metadata now cached in the generated C files.
* Several corrections and extensions in numpy, cpython, and libcpp pxd files.
0.21.2 (2014-12-27)
===================
Bugs fixed
----------
* Crash when assigning a C value to both a Python and C target at the same time.
* Automatic coercion from C++ strings to ``str`` generated incomplete code that
failed to compile.
* Declaring a constructor in a C++ child class erroneously required a default
constructor declaration in the super class.
* ``resize_smart()`` in ``cpython.array`` was broken.
* Functions in ``libcpp.cast`` are now declared as ``nogil``.
* Some missing C-API declarations were added.
* Py3 main code in embedding program code was lacking casts.
* Exception related to distutils "Distribution" class type in pyximport under
latest CPython 2.7 and 3.4 releases when setuptools is being imported later.
0.21.1 (2014-10-18)
===================
Features added
--------------
* New ``cythonize`` option ``-a`` to generate the annotated HTML source view.
* Missing C-API declarations in ``cpython.unicode`` were added.
* Passing ``language='c++'`` into cythonize() globally enables C++ mode for
all modules that were not passed as Extension objects (i.e. only source
files and file patterns).
* ``Py_hash_t`` is a known type (used in CPython for hash values).
* ``PySlice_*()`` C-API functions are available from the ``cpython.slice``
module.
* Allow arrays of C++ classes.
Bugs fixed
----------
* Reference leak for non-simple Python expressions in boolean and/or expressions.
* To fix a name collision and to reflect availability on host platforms,
standard C declarations [ clock(), time(), struct tm and tm* functions ]
were moved from posix/time.pxd to a new libc/time.pxd. Patch by Charles
Blake.
* Rerunning unmodified modules in IPython's cython support failed.
Patch by Matthias Bussonier.
* Casting C++ ``std::string`` to Python byte strings failed when
auto-decoding was enabled.
* Fatal exceptions in global module init code could lead to crashes
if the already created module was used later on (e.g. through a
stale reference in sys.modules or elsewhere).
* ``cythonize.py`` script was not installed on MS-Windows.
Other changes
-------------
* Compilation no longer fails hard when unknown compilation options are
passed. Instead, it raises a warning and ignores them (as it did silently
before 0.21). This will be changed back to an error in a future release.
0.21 (2014-09-10)
=================
Features added
--------------
* C (cdef) functions allow inner Python functions.
* Enums can now be declared as cpdef to export their values to
the module's Python namespace. Cpdef enums in pxd files export
their values to their own module, iff it exists.
* Allow @staticmethod decorator to declare static cdef methods.
This is especially useful for declaring "constructors" for
cdef classes that can take non-Python arguments.
* Taking a ``char*`` from a temporary Python string object is safer
in more cases and can be done inside of non-trivial expressions,
including arguments of a function call. A compile time error
is raised only when such a pointer is assigned to a variable and
would thus exceed the lifetime of the string itself.
* Generators have new properties ``__name__`` and ``__qualname__``
that provide the plain/qualified name of the generator function
(following CPython 3.5). See http://bugs.python.org/issue21205
* The ``inline`` function modifier is available as a decorator
``@cython.inline`` in pure mode.
* When cygdb is run in a virtualenv, it enables the same virtualenv
inside of the debugger. Patch by Marc Abramowitz.
* PEP 465: dedicated infix operator for matrix multiplication (A @ B).
* HTML output of annotated code uses Pygments for code highlighting
and generally received a major overhaul by Matthias Bussonier.
* IPython magic support is now available directly from Cython with
the command "%load_ext cython". Cython code can directly be
executed in a cell when marked with "%%cython". Code analysis
is available with "%%cython -a". Patch by Martín Gaitán.
* Simple support for declaring Python object types in Python signature
annotations. Currently requires setting the compiler directive
``annotation_typing=True``.
* New directive ``use_switch`` (defaults to True) to optionally disable
the optimization of chained if statement to C switch statements.
* Defines dynamic_cast et al. in ``libcpp.cast`` and C++ heap data
structure operations in ``libcpp.algorithm``.
* Shipped header declarations in ``posix.*`` were extended to cover
more of the POSIX API. Patches by Lars Buitinck and Mark Peek.
Optimizations
-------------
* Simple calls to C implemented Python functions/methods are faster.
This also speeds up many operations on builtins that Cython cannot
otherwise optimise.
* The "and"/"or" operators try to avoid unnecessary coercions of their
arguments. They now evaluate the truth value of each argument
independently and only coerce the final result of the whole expression
to the target type (e.g. the type on the left side of an assignment).
This also avoids reference counting overhead for Python values during
evaluation and generally improves the code flow in the generated C code.
* The Python expression "2 ** N" is optimised into bit shifting.
See http://bugs.python.org/issue21420
* Cascaded assignments (a = b = ...) try to minimise the number of
type coercions.
* Calls to ``slice()`` are translated to a straight C-API call.
Bugs fixed
----------
* Crash when assigning memory views from ternary conditional expressions.
* Nested C++ templates could lead to unseparated ">>" characters being
generated into the C++ declarations, which older C++ compilers could
not parse.
* Sending SIGINT (Ctrl-C) during parallel cythonize() builds could
hang the child processes.
* No longer ignore local setup.cfg files for distutils in pyximport.
Patch by Martin Teichmann.
* Taking a ``char*`` from an indexed Python string generated unsafe
reference counting code.
* Set literals now create all of their items before trying to add them
to the set, following the behaviour in CPython. This makes a
difference in the rare case that the item creation has side effects
and some items are not hashable (or if hashing them has side effects,
too).
* Cython no longer generates the cross product of C functions for code
that uses memory views of fused types in function signatures (e.g.
``cdef func(floating[:] a, floating[:] b)``). This is considered the
expected behaviour by most users and was previously inconsistent with
other structured types like C arrays. Code that really wants all type
combinations can create the same fused memoryview type under different
names and use those in the signature to make it clear which types are
independent.
* Names that were unknown at compile time were looked up as builtins at
runtime but not as global module names. Trying both lookups helps with
globals() manipulation.
* Fixed stl container conversion for typedef element types.
* ``obj.pop(x)`` truncated large C integer values of x to ``Py_ssize_t``.
* ``__init__.pyc`` is recognised as marking a package directory
(in addition to .py, .pyx and .pxd).
* Syntax highlighting in ``cython-mode.el`` for Emacs no longer
incorrectly highlights keywords found as part of longer names.
* Correctly handle ``from cython.submodule cimport name``.
* Fix infinite recursion when using super with cpdef methods.
* No-args ``dir()`` was not guaranteed to return a sorted list.
Other changes
-------------
* The header line in the generated C files no longer contains the
timestamp but only the Cython version that wrote it. This was
changed to make builds more reproducible.
* Removed support for CPython 2.4, 2.5 and 3.1.
* The licensing implications on the generated code were clarified
to avoid legal constraints for users.
0.20.2 (2014-06-16)
===================
Features added
--------------
* Some optimisations for set/frozenset instantiation.
* Support for C++ unordered_set and unordered_map.
Bugs fixed
----------
* Access to attributes of optimised builtin methods (e.g.
``[].append.__name__``) could fail to compile.
* Memory leak when extension subtypes add a memory view as attribute
to those of the parent type without having Python object attributes
or a user provided dealloc method.
* Compiler crash on readonly properties in "binding" mode.
* Auto-encoding with ``c_string_encoding=ascii`` failed in Py3.3.
* Crash when subtyping freelist enabled Cython extension types with
Python classes that use ``__slots__``.
* Freelist usage is restricted to CPython to avoid problems with other
Python implementations.
* Memory leak in memory views when copying overlapping, contiguous slices.
* Format checking when requesting non-contiguous buffers from
``cython.array`` objects was accidentally omitted in Py3.
* C++ destructor calls in extension types could fail to compile in clang.
* Buffer format validation failed for sequences of strings in structs.
* Docstrings on extension type attributes in .pxd files were rejected.
0.20.1 (2014-02-11)
===================
Bugs fixed
----------
* Build error under recent MacOS-X versions where ``isspace()`` could not be
resolved by clang.
* List/Tuple literals multiplied by more than one factor were only multiplied
by the last factor instead of all.
* Lookups of special methods (specifically for context managers) could fail
in Python <= 2.6/3.1.
* Local variables were erroneously appended to the signature introspection
of Cython implemented functions with keyword-only arguments under Python 3.
* In-place assignments to variables with inferred Python builtin/extension
types could fail with type errors if the result value type was incompatible
with the type of the previous value.
* The C code generation order of cdef classes, closures, helper code,
etc. was not deterministic, thus leading to high code churn.
* Type inference could fail to deduce C enum types.
* Type inference could deduce unsafe or inefficient types from integer
assignments within a mix of inferred Python variables and integer
variables.
0.20 (2014-01-18)
=================
Features added
--------------
* Support for CPython 3.4.
* Support for calling C++ template functions.
* ``yield`` is supported in ``finally`` clauses.
* The C code generated for finally blocks is duplicated for each exit
case to allow for better optimisations by the C compiler.
* Cython tries to undo the Python optimisationism of assigning a bound
method to a local variable when it can generate better code for the
direct call.
* Constant Python float values are cached.
* String equality comparisons can use faster type specific code in
more cases than before.
* String/Unicode formatting using the '%' operator uses a faster
C-API call.
* ``bytearray`` has become a known type and supports coercion from and
to C strings. Indexing, slicing and decoding is optimised. Note that
this may have an impact on existing code due to type inference.
* Using ``cdef basestring stringvar`` and function arguments typed as
``basestring`` is now meaningful and allows assigning exactly
``str`` and ``unicode`` objects, but no subtypes of these types.
* Support for the ``__debug__`` builtin.
* Assertions in Cython compiled modules are disabled if the running
Python interpreter was started with the "-O" option.
* Some types that Cython provides internally, such as functions and
generators, are now shared across modules if more than one Cython
implemented module is imported.
* The type inference algorithm works more fine granular by taking the
results of the control flow analysis into account.
* A new script in ``bin/cythonize`` provides a command line frontend
to the cythonize() compilation function (including distutils build).
* The new extension type decorator ``@cython.no_gc_clear`` prevents
objects from being cleared during cyclic garbage collection, thus
making sure that object attributes are kept alive until deallocation.
* During cyclic garbage collection, attributes of extension types that
cannot create reference cycles due to their type (e.g. strings) are
no longer considered for traversal or clearing. This can reduce the
processing overhead when searching for or cleaning up reference cycles.
* Package compilation (i.e. ``__init__.py`` files) now works, starting
with Python 3.3.
* The cython-mode.el script for Emacs was updated. Patch by Ivan Andrus.
* An option common_utility_include_dir was added to cythonize() to save
oft-used utility code once in a separate directory rather than as
part of each generated file.
* ``unraisable_tracebacks`` directive added to control printing of
tracebacks of unraisable exceptions.
Bugs fixed
----------
* Abstract Python classes that subtyped a Cython extension type
failed to raise an exception on instantiation, and thus ended
up being instantiated.
* ``set.add(a_tuple)`` and ``set.discard(a_tuple)`` failed with a
TypeError in Py2.4.
* The PEP 3155 ``__qualname__`` was incorrect for nested classes and
inner classes/functions declared as ``global``.
* Several corner cases in the try-finally statement were fixed.
* The metaclass of a Python class was not inherited from its parent
class(es). It is now extracted from the list of base classes if not
provided explicitly using the Py3 ``metaclass`` keyword argument.
In Py2 compilation mode, a ``__metaclass__`` entry in the class
dict will still take precedence if not using Py3 metaclass syntax,
but only *after* creating the class dict (which may have been done
by a metaclass of a base class, see PEP 3115). It is generally
recommended to use the explicit Py3 syntax to define metaclasses
for Python types at compile time.
* The automatic C switch statement generation behaves more safely for
heterogeneous value types (e.g. mixing enum and char), allowing for
a slightly wider application and reducing corner cases. It now always
generates a 'default' clause to avoid C compiler warnings about
unmatched enum values.
* Fixed a bug where class hierarchies declared out-of-order could result
in broken generated code.
* Fixed a bug which prevented overriding const methods of C++ classes.
* Fixed a crash when converting Python objects to C++ strings fails.
Other changes
-------------
* In Py3 compilation mode, Python2-style metaclasses declared by a
``__metaclass__`` class dict entry are ignored.
* In Py3.4+, the Cython generator type uses ``tp_finalize()`` for safer
cleanup instead of ``tp_del()``.
0.19.2 (2013-10-13)
===================
Features added
--------------
Bugs fixed
----------
* Some standard declarations were fixed or updated, including the previously
incorrect declaration of ``PyBuffer_FillInfo()`` and some missing bits in
``libc.math``.
* Heap allocated subtypes of ``type`` used the wrong base type struct at the
C level.
* Calling the unbound method dict.keys/value/items() in dict subtypes could
call the bound object method instead of the unbound supertype method.
* "yield" wasn't supported in "return" value expressions.
* Using the "bint" type in memory views lead to unexpected results.
It is now an error.
* Assignments to global/closure variables could catch them in an illegal state
while deallocating the old value.
Other changes
-------------
0.19.1 (2013-05-11)
===================
Features added
--------------
* Completely empty C-API structs for extension type slots (protocols like
number/mapping/sequence) are no longer generated into the C code.
* Docstrings that directly follow a public/readonly attribute declaration
in a cdef class will be used as docstring of the auto-generated property.
This fixes ticket 206.
* The automatic signature documentation tries to preserve more semantics
of default arguments and argument types. Specifically, ``bint`` arguments
now appear as type ``bool``.
* A warning is emitted when negative literal indices are found inside of
a code section that disables ``wraparound`` handling. This helps with
fixing invalid code that might fail in the face of future compiler
optimisations.
* Constant folding for boolean expressions (and/or) was improved.
* Added a build_dir option to cythonize() which allows one to place
the generated .c files outside the source tree.
Bugs fixed
----------
* ``isinstance(X, type)`` failed to get optimised into a call to
``PyType_Check()``, as done for other builtin types.
* A spurious ``from datetime cimport *`` was removed from the "cpython"
declaration package. This means that the "datetime" declarations
(added in 0.19) are no longer available directly from the "cpython"
namespace, but only from "cpython.datetime". This is the correct
way of doing it because the declarations refer to a standard library
module, not the core CPython C-API itself.
* The C code for extension types is now generated in topological order
instead of source code order to avoid C compiler errors about missing
declarations for subtypes that are defined before their parent.
* The ``memoryview`` type name no longer shows up in the module dict of
modules that use memory views. This fixes trac ticket 775.
* Regression in 0.19 that rejected valid C expressions from being used
in C array size declarations.
* In C++ mode, the C99-only keyword ``restrict`` could accidentally be
seen by the GNU C++ compiler. It is now specially handled for both
GCC and MSVC.
* Testing large (> int) C integer values for their truth value could fail
due to integer wrap-around.
Other changes
-------------
0.19 (2013-04-19)
=================
Features added
--------------
* New directives ``c_string_type`` and ``c_string_encoding`` to more easily
and automatically convert between C strings and the different Python string
types.
* The extension type flag ``Py_TPFLAGS_HAVE_VERSION_TAG`` is enabled by default
on extension types and can be disabled using the ``type_version_tag`` compiler
directive.
* EXPERIMENTAL support for simple Cython code level line tracing. Enabled by
the "linetrace" compiler directive.
* Cython implemented functions make their argument and return type annotations
available through the ``__annotations__`` attribute (PEP 3107).
* Access to non-cdef module globals and Python object attributes is faster.
* ``Py_UNICODE*`` coerces from and to Python unicode strings. This is
helpful when talking to Windows APIs, which use compatible wchar_t
arrays for strings. Note that the ``Py_UNICODE`` type is otherwise
deprecated as of CPython 3.3.
* ``isinstance(obj, basestring)`` is optimised. In Python 3 it only tests
for instances of ``str`` (i.e. Py2 ``unicode``).
* The ``basestring`` builtin is mapped to ``str`` (i.e. Py2 ``unicode``) when
compiling the generated C code under Python 3.
* Closures use freelists, which can speed up their creation quite substantially.
This is also visible for short running generator expressions, for example.
* A new class decorator ``@cython.freelist(N)`` creates a static freelist of N
instances for an extension type, thus avoiding the costly allocation step if
possible. This can speed up object instantiation by 20-30% in suitable
scenarios. Note that freelists are currently only supported for base types,
not for types that inherit from others.
* Fast extension type instantiation using the ``Type.__new__(Type)`` idiom has
gained support for passing arguments. It is also a bit faster for types defined
inside of the module.
* The Python2-only dict methods ``.iter*()`` and ``.view*()`` (requires Python 2.7)
are automatically mapped to the equivalent keys/values/items methods in Python 3
for typed dictionaries.
* Slicing unicode strings, lists and tuples is faster.
* list.append() is faster on average.
* ``raise Exception() from None`` suppresses the exception context in Py3.3.
* Py3 compatible ``exec(tuple)`` syntax is supported in Py2 code.
* Keyword arguments are supported for cdef functions.
* External C++ classes can be declared nogil. Patch by John Stumpo. This fixes
trac ticket 805.
Bugs fixed
----------
* 2-value slicing of unknown objects passes the correct slice when the ``getitem``
protocol is used instead of the ``getslice`` protocol (especially in Python 3),
i.e. ``None`` values for missing bounds instead of ``[0,maxsize]``. It is also
a bit faster in some cases, e.g. for constant bounds. This fixes trac ticket 636.
* Cascaded assignments of None values to extension type variables failed with
a ``TypeError`` at runtime.
* The ``__defaults__`` attribute was not writable for Cython implemented
functions.
* Default values of keyword-only arguments showed up in ``__defaults__`` instead
of ``__kwdefaults__`` (which was not implemented). Both are available for
Cython implemented functions now, as specified in Python 3.x.
* ``yield`` works inside of ``with gil`` sections. It previously lead to a crash.
This fixes trac ticket 803.
* Static methods without explicitly named positional arguments (e.g. having only
``*args``) crashed when being called. This fixes trac ticket 804.
* ``dir()`` without arguments previously returned an unsorted list, which now
gets sorted as expected.
* ``dict.items()``, ``dict.keys()`` and ``dict.values()`` no longer return lists
in Python 3.
* Exiting from an ``except-as`` clause now deletes the exception in Python 3 mode.
* The declarations of ``frexp()`` and ``ldexp()`` in ``math.pxd`` were incorrect.
Other changes
-------------
0.18 (2013-01-28)
=================
Features added
--------------
* Named Unicode escapes ("\N{...}") are supported.
* Python functions/classes provide the special attribute "__qualname__"
as defined by PEP 3155.
* Added a directive ``overflowcheck`` which raises an OverflowException when
arithmetic with C ints overflow. This has a modest performance penalty, but
is much faster than using Python ints.
* Calls to nested Python functions are resolved at compile time.
* Type inference works across nested functions.
* ``py_bytes_string.decode(...)`` is optimised.
* C ``const`` declarations are supported in the language.
Bugs fixed
----------
* Automatic C++ exception mapping didn't work in nogil functions (only in
"with nogil" blocks).
Other changes
-------------
0.17.4 (2013-01-03)
===================
Bugs fixed
----------
* Garbage collection triggered during deallocation of container classes could lead to a double-deallocation.
0.17.3 (2012-12-14)
===================
Features added
--------------
Bugs fixed
----------
* During final interpreter cleanup (with types cleanup enabled at compile time), extension types that inherit from base types over more than one level that were cimported from other modules could lead to a crash.
* Weak-reference support in extension types (with a ``cdef __weakref__`` attribute) generated incorrect deallocation code.
* In CPython 3.3, converting a Unicode character to the Py_UNICODE type could fail to raise an overflow for non-BMP characters that do not fit into a wchar_t on the current platform.
* Negative C integer constants lost their longness suffix in the generated C code.
Other changes
-------------
0.17.2 (2012-11-20)
===================
Features added
--------------
* ``cythonize()`` gained a best effort compile mode that can be used to simply ignore .py files that fail to compile.
Bugs fixed
----------
* Replacing an object reference with the value of one of its cdef attributes could generate incorrect C code that accessed the object after deleting its last reference.
* C-to-Python type coercions during cascaded comparisons could generate invalid C code, specifically when using the 'in' operator.
* "obj[1,]" passed a single integer into the item getter instead of a tuple.
* Cyclic imports at module init time did not work in Py3.
* The names of C++ destructors for template classes were built incorrectly.
* In pure mode, type casts in Cython syntax and the C ampersand operator are now rejected. Use the pure mode replacements instead.
* In pure mode, C type names and the sizeof() function are no longer recognised as such and can be used as normal Python names.
* The extended C level support for the CPython array type was declared too late to be used by user defined classes.
* C++ class nesting was broken.
* Better checking for required nullary constructors for stack-allocated C++ instances.
* Remove module docstring in no-docstring mode.
* Fix specialization for varargs function signatures.
* Fix several compiler crashes.
Other changes
-------------
* An experimental distutils script for compiling the CPython standard library was added as Tools/cystdlib.py.
0.17.1 (2012-09-26)
===================
Features added
--------------
Bugs fixed
----------
* A reference leak was fixed in the new dict iteration code when the loop target was not a plain variable but an unpacked tuple.
* Memory views did not handle the special case of a NULL buffer strides value, as allowed by PEP3118.
Other changes
-------------
0.17 (2012-09-01)
=================
Features added
--------------
* Alpha quality support for compiling and running Cython generated extension modules in PyPy (through cpyext). Note that this requires at least PyPy 1.9 and in many cases also adaptations in user code, especially to avoid borrowed references when no owned reference is being held directly in C space (a reference in a Python list or dict is not enough, for example). See the documentation on porting Cython code to PyPy.
* "yield from" is supported (PEP 380) and a couple of minor problems with generators were fixed.
* C++ STL container classes automatically coerce from and to the equivalent Python container types on typed assignments and casts. Note that the data in the containers is copied during this conversion.
* C++ iterators can now be iterated over using "for x in cpp_container" whenever cpp_container has begin() and end() methods returning objects satisfying the iterator pattern (that is, it can be incremented, dereferenced, and compared (for non-equality)).
* cdef classes can now have C++ class members (provided a zero-argument constructor exists)
* A new cpython.array standard cimport file allows to efficiently talk to the stdlib array.array data type in Python 2. Since CPython does not export an official C-API for this module, it receives special casing by the compiler in order to avoid setup overhead on user side. In Python 3, both buffers and memory views on the array type already worked out of the box with earlier versions of Cython due to the native support for the buffer interface in the Py3 array module.
* Fast dict iteration is now enabled optimistically also for untyped variables when the common iteration methods are used.
* The unicode string processing code was adapted for the upcoming CPython 3.3 (PEP 393, new Unicode buffer layout).
* Buffer arguments and memory view arguments in Python functions can be declared "not None" to raise a TypeError on None input.
* c(p)def functions in pure mode can specify their return type with "@cython.returns()".
* Automatic dispatch for fused functions with memoryview arguments
* Support newaxis indexing for memoryviews
* Support decorators for fused functions
Bugs fixed
----------
* Old-style Py2 imports did not work reliably in Python 3.x and were broken in Python 3.3. Regardless of this fix, it's generally best to be explicit about relative and global imports in Cython code because old-style imports have a higher overhead. To this end, "from __future__ import absolute_import" is supported in Python/Cython 2.x code now (previous versions of Cython already used it when compiling Python 3 code).
* Stricter constraints on the "inline" and "final" modifiers. If your code does not compile due to this change, chances are these modifiers were previously being ignored by the compiler and can be removed without any performance regression.
* Exceptions are always instantiated while raising them (as in Python), instead of risking to instantiate them in potentially unsafe situations when they need to be handled or otherwise processed.
* locals() properly ignores names that do not have Python compatible types (including automatically inferred types).
* Some garbage collection issues of memory views were fixed.
* numpy.pxd compiles in Python 3 mode.
* Several C compiler warnings were fixed.
* Several bugs related to memoryviews and fused types were fixed.
* Several bug-fixes and improvements related to cythonize(), including ccache-style caching.
Other changes
-------------
* libc.string provides a convenience declaration for const uchar in addition to const char.
* User declared char* types are now recognised as such and auto-coerce to and from Python bytes strings.
* callable() and next() compile to more efficient C code.
* list.append() is faster on average.
* Modules generated by @cython.inline() are written into the directory pointed to by the environment variable CYTHON_CACHE_DIR if set.
0.16 (2012-04-21)
=================
Features added
--------------
* Enhancements to Cython's function type (support for weak references, default arguments, code objects, dynamic attributes, classmethods, staticmethods, and more)
* Fused Types - Template-like support for functions and methods CEP 522 (docs)
* Typed views on memory - Support for efficient direct and indirect buffers (indexing, slicing, transposing, ...) CEP 517 (docs)
* super() without arguments
* Final cdef methods (which translate into direct calls on known instances)
Bugs fixed
----------
* fix alignment handling for record types in buffer support
Other changes
-------------
* support default arguments for closures
* search sys.path for pxd files
* support C++ template casting
* faster traceback building and faster generator termination
* support inplace operators on indexed buffers
* allow nested prange sections
0.15.1 (2011-09-19)
===================
Features added
--------------
Bugs fixed
----------
Other changes
-------------
0.15 (2011-08-05)
=================
Features added
--------------
* Generators (yield) - Cython has full support for generators, generator expressions and PEP 342 coroutines.
* The nonlocal keyword is supported.
* Re-acquiring the gil: with gil - works as expected within a nogil context.
* OpenMP support: prange.
* Control flow analysis prunes dead code and emits warnings and errors about uninitialised variables.
* Debugger command cy set to assign values of expressions to Cython variables and cy exec counterpart $cy_eval().
* Exception chaining PEP 3134.
* Relative imports PEP 328.
* Improved pure syntax including cython.cclass, cython.cfunc, and cython.ccall.
* The with statement has its own dedicated and faster C implementation.
* Support for del.
* Boundschecking directives implemented for builtin Python sequence types.
* Several updates and additions to the shipped standard library .pxd files.
* Forward declaration of types is no longer required for circular references.
Bugs fixed
----------
Other changes
-------------
* Uninitialized variables are no longer initialized to None and accessing them has the same semantics as standard Python.
* globals() now returns a read-only dict of the Cython module's globals, rather than the globals of the first non-Cython module in the stack
* Many C++ exceptions are now special cased to give closer Python counterparts. This means that except+ functions that formerly raised generic RuntimeErrors may raise something else such as ArithmeticError.
* The inlined generator expressions (introduced in Cython 0.13) were disabled in favour of full generator expression support. This breaks code that previously used them inside of cdef functions (usage in def functions continues to work) and induces a performance regression for cases that continue to work but that were previously inlined. We hope to reinstate this feature in the near future.
0.14.1 (2011-02-04)
===================
Features added
--------------
* The gdb debugging support was extended to include all major Cython features, including closures.
* raise MemoryError() is now safe to use as Cython replaces it with the correct C-API call.
Bugs fixed
----------
Other changes
-------------
* Decorators on special methods of cdef classes now raise a compile time error rather than being ignored.
* In Python 3 language level mode (-3 option), the 'str' type is now mapped to 'unicode', so that cdef str s declares a Unicode string even when running in Python 2.
0.14 (2010-12-14)
=================
Features added
--------------
* Python classes can now be nested and receive a proper closure at definition time.
* Redefinition is supported for Python functions, even within the same scope.
* Lambda expressions are supported in class bodies and at the module level.
* Metaclasses are supported for Python classes, both in Python 2 and Python 3 syntax. The Python 3 syntax (using a keyword argument in the type declaration) is preferred and optimised at compile time.
* "final" extension classes prevent inheritance in Python space. This feature is available through the new "cython.final" decorator. In the future, these classes may receive further optimisations.
* "internal" extension classes do not show up in the module dictionary. This feature is available through the new "cython.internal" decorator.
* Extension type inheritance from builtin types, such as "cdef class MyUnicode(unicode)", now works without further external type redeclarations (which are also strongly discouraged now and continue to issue a warning).
* GDB support. http://docs.cython.org/src/userguide/debugging.html
* A new build system with support for inline distutils directives, correct dependency tracking, and parallel compilation. https://github.com/cython/cython/wiki/enhancements-distutils_preprocessing
* Support for dynamic compilation at runtime via the new cython.inline function and cython.compile decorator. https://github.com/cython/cython/wiki/enhancements-inline
* "nogil" blocks are supported when compiling pure Python code by writing "with cython.nogil".
* Iterating over arbitrary pointer types is now supported, as is an optimized version of the in operator, e.g. x in ptr[a:b].
Bugs fixed
----------
* In parallel assignments, the right side was evaluated in reverse order in 0.13. This could result in errors if it had side effects (e.g. function calls).
* In some cases, methods of builtin types would raise a SystemError instead of an AttributeError when called on None.
Other changes
-------------
* Constant tuples are now cached over the lifetime of an extension module, just like CPython does. Constant argument tuples of Python function calls are also cached.
* Closures have tightened to include exactly the names used in the inner functions and classes. Previously, they held the complete locals of the defining function.
* The builtin "next()" function in Python 2.6 and later is now implemented internally and therefore available in all Python versions. This makes it the preferred and portable way of manually advancing an iterator.
* In addition to the previously supported inlined generator expressions in 0.13, "sorted(genexpr)" can now be used as well. Typing issues were fixed in "sum(genexpr)" that could lead to invalid C code being generated. Other known issues with inlined generator expressions were also fixed that make upgrading to 0.14 a strong recommendation for code that uses them. Note that general generators and generator expressions continue to be not supported.
* Inplace arithmetic operators now respect the cdivision directive and are supported for complex types.
* Typing a variable as type "complex" previously gave it the Python object type. It now uses the appropriate C/C++ double complex type. A side-effect is that assignments and typed function parameters now accept anything that Python can coerce to a complex, including integers and floats, and not only complex instances.
* Large integer literals pass through the compiler in a safer way. To prevent truncation in C code, non 32-bit literals are turned into Python objects if not used in a C context. This context can either be given by a clear C literal suffix such as "UL" or "LL" (or "L" in Python 3 code), or it can be an assignment to a typed variable or a typed function argument, in which case it is up to the user to take care of a sufficiently large value space of the target.
* Python functions are declared in the order they appear in the file, rather than all being created at module creation time. This is consistent with Python and needed to support, for example, conditional or repeated declarations of functions. In the face of circular imports this may cause code to break, so a new --disable-function-redefinition flag was added to revert to the old behavior. This flag will be removed in a future release, so should only be used as a stopgap until old code can be fixed.
0.13 (2010-08-25)
=================
Features added
--------------
* Closures are fully supported for Python functions. Cython supports inner functions and lambda expressions. Generators and generator expressions are not supported in this release.
* Proper C++ support. Cython knows about C++ classes, templates and overloaded function signatures, so that Cython code can interact with them in a straight forward way.
* Type inference is enabled by default for safe C types (e.g. double, bint, C++ classes) and known extension types. This reduces the need for explicit type declarations and can improve the performance of untyped code in some cases. There is also a verbose compile mode for testing the impact on user code.
* Cython's for-in-loop can iterate over C arrays and sliced pointers. The type of the loop variable will be inferred automatically in this case.
* The Py_UNICODE integer type for Unicode code points is fully supported, including for-loops and 'in' tests on unicode strings. It coerces from and to single character unicode strings. Note that untyped for-loop variables will automatically be inferred as Py_UNICODE when iterating over a unicode string. In most cases, this will be much more efficient than yielding sliced string objects, but can also have a negative performance impact when the variable is used in a Python context multiple times, so that it needs to coerce to a unicode string object more than once. If this happens, typing the loop variable as unicode or object will help.
* The built-in functions any(), all(), sum(), list(), set() and dict() are inlined as plain for loops when called on generator expressions. Note that generator expressions are not generally supported apart from this feature. Also, tuple(genexpr) is not currently supported - use tuple([listcomp]) instead.
* More shipped standard library declarations. The python_* and stdlib/stdio .pxd files have been deprecated in favor of clib.* and cpython[.*] and may get removed in a future release.
* Pure Python mode no longer disallows non-Python keywords like 'cdef', 'include' or 'cimport'. It also no longer recognises syntax extensions like the for-from loop.
* Parsing has improved for Python 3 syntax in Python code, although not all features are correctly supported. The missing Python 3 features are being worked on for the next release.
* from __future__ import print_function is supported in Python 2.6 and later. Note that there is currently no emulation for earlier Python versions, so code that uses print() with this future import will require at least Python 2.6.
* New compiler directive language_level (valid values: 2 or 3) with corresponding command line options -2 and -3 requests source code compatibility with Python 2.x or Python 3.x respectively. Language level 3 currently enforces unicode literals for unprefixed string literals, enables the print function (requires Python 2.6 or later) and keeps loop variables in list comprehensions from leaking.
* Loop variables in set/dict comprehensions no longer leak into the surrounding scope (following Python 2.7). List comprehensions are unchanged in language level 2.
* print >> stream
Bugs fixed
----------
Other changes
-------------
* The availability of type inference by default means that Cython will also infer the type of pointers on assignments. Previously, code like this::
cdef char* s = ...
untyped_variable = s
would convert the char* to a Python bytes string and assign that. This is no longer the case and no coercion will happen in the example above. The correct way of doing this is through an explicit cast or by typing the target variable, i.e.
::
cdef char* s = ...
untyped_variable1 = <bytes>s
untyped_variable2 = <object>s
cdef object py_object = s
cdef bytes bytes_string = s
* bool is no longer a valid type name by default. The problem is that it's not clear whether bool should refer to the Python type or the C++ type, and expecting one and finding the other has already led to several hard-to-find bugs. Both types are available for importing: you can use from cpython cimport bool for the Python bool type, and from libcpp cimport bool for the C++ type. bool is still a valid object by default, so one can still write bool(x).
* ``__getsegcount__`` is now correctly typed to take a ``Py_size_t*`` rather than an ``int*``.
0.12.1 (2010-02-02)
===================
Features added
--------------
* Type inference improvements.
* There have been several bug fixes and improvements to the type inferencer.
* Notably, there is now a "safe" mode enabled by setting the infer_types directive to None. (The None here refers to the "default" mode, which will be the default in 0.13.) This safe mode limits inference to Python object types and C doubles, which should speed up execution without affecting any semantics such as integer overflow behavior like infer_types=True might. There is also an infer_types.verbose option which allows one to see what types are inferred.
* The boundscheck directive works for lists and tuples as well as buffers.
* len(s) and s.decode("encoding") are efficiently supported for char* s.
* Cython's INLINE macro has been renamed to CYTHON_INLINE to reduce conflict and has better support for the MSVC compiler on Windows. It is no longer clobbered if externally defined.
* Revision history is now omitted from the source package, resulting in a 85% size reduction. Running make repo will download the history and turn the directory into a complete Mercurial working repository.
* Cython modules don't need to be recompiled when the size of an external type grows. (A warning, rather than an error, is produced.) This should be helpful for binary distributions relying on NumPy.
Bugs fixed
----------
* Several other bugs and minor improvements have been made. This release should be fully backwards compatible with 0.12.
Other changes
-------------
0.12 (2009-11-23)
=================
Features added
--------------
* Type inference with the infer_types directive
* Seamless C++ complex support
* Fast extension type instantiation using the normal Python meme obj = MyType.__new__(MyType)
* Improved support for Py3.1
* Cython now runs under Python 3.x using the 2to3 tool
* unittest support for doctests in Cython modules
* Optimised handling of C strings (char*): for c in cstring[2:50] and cstring.decode()
* Looping over c pointers: for i in intptr[:50].
* pyximport improvements
* cython_freeze improvements
Bugs fixed
----------
* Many bug fixes
Other changes
-------------
* Many other optimisation, e.g. enumerate() loops, parallel swap assignments (a,b = b,a), and unicode.encode()
* More complete numpy.pxd
0.11.2 (2009-05-20)
===================
Features added
--------------
* There's now native complex floating point support! C99 complex will be used if complex.h is included, otherwise explicit complex arithmetic working on all C compilers is used. [Robert Bradshaw]
::
cdef double complex a = 1 + 0.3j
cdef np.ndarray[np.complex128_t, ndim=2] arr = \
np.zeros(10, np.complex128)
* Cython can now generate a main()-method for embedding of the Python interpreter into an executable (see #289) [Robert Bradshaw]
* @wraparound directive (another way to disable arr[idx] for negative idx) [Dag Sverre Seljebotn]
* Correct support for NumPy record dtypes with different alignments, and "cdef packed struct" support [Dag Sverre Seljebotn]
* @callspec directive, allowing custom calling convention macros [Lisandro Dalcin]
Bugs fixed
----------
Other changes
-------------
* Bug fixes and smaller improvements. For the full list, see [1]. | {
"source": "yandex/perforator",
"title": "contrib/tools/cython/CHANGES.rst",
"url": "https://github.com/yandex/perforator/blob/main/contrib/tools/cython/CHANGES.rst",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 129115
} |
Welcome to Cython!
==================
Cython is a language that makes writing C extensions for
Python as easy as Python itself. Cython is based on
Pyrex, but supports more cutting edge functionality and
optimizations.
The Cython language is very close to the Python language, but Cython
additionally supports calling C functions and declaring C types on variables
and class attributes. This allows the compiler to generate very efficient C
code from Cython code.
This makes Cython the ideal language for wrapping external C libraries, and
for fast C modules that speed up the execution of Python code.
* Official website: http://cython.org/
* Documentation: http://docs.cython.org/en/latest/
* Github repository: https://github.com/cython/cython
* Wiki: https://github.com/cython/cython/wiki
Installation:
-------------
If you already have a C compiler, just do::
pip install Cython
otherwise, see `the installation page <http://docs.cython.org/en/latest/src/quickstart/install.html>`_.
License:
--------
The original Pyrex program was licensed "free of restrictions" (see below).
Cython itself is licensed under the permissive **Apache License**.
See `LICENSE.txt <https://github.com/cython/cython/blob/master/LICENSE.txt>`_.
Contributing:
-------------
Want to contribute to the Cython project?
Here is some `help to get you started <https://github.com/cython/cython/blob/master/docs/CONTRIBUTING.rst>`_.
Get the full source history:
----------------------------
Note that Cython used to ship the full version control repository in its source
distribution, but no longer does so due to space constraints. To get the
full source history from a downloaded source archive, make sure you have git
installed, then step into the base directory of the Cython source distribution
and type::
make repo
The following is from Pyrex:
------------------------------------------------------
This is a development version of Pyrex, a language
for writing Python extension modules.
For more info, see:
* Doc/About.html for a description of the language
* INSTALL.txt for installation instructions
* USAGE.txt for usage instructions
* Demos for usage examples
Comments, suggestions, bug reports, etc. are
welcome!
Copyright stuff: Pyrex is free of restrictions. You
may use, redistribute, modify and distribute modified
versions.
The latest version of Pyrex can be found `here <http://www.cosc.canterbury.ac.nz/~greg/python/Pyrex/>`_.
| Greg Ewing, Computer Science Dept
| University of Canterbury
| Christchurch, New Zealand
A citizen of NewZealandCorp, a wholly-owned subsidiary of USA Inc. | {
"source": "yandex/perforator",
"title": "contrib/tools/cython/README.rst",
"url": "https://github.com/yandex/perforator/blob/main/contrib/tools/cython/README.rst",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2636
} |
This is Python version 3.12.9
=============================
.. image:: https://github.com/python/cpython/workflows/Tests/badge.svg
:alt: CPython build status on GitHub Actions
:target: https://github.com/python/cpython/actions
.. image:: https://dev.azure.com/python/cpython/_apis/build/status/Azure%20Pipelines%20CI?branchName=main
:alt: CPython build status on Azure DevOps
:target: https://dev.azure.com/python/cpython/_build/latest?definitionId=4&branchName=main
.. image:: https://img.shields.io/badge/discourse-join_chat-brightgreen.svg
:alt: Python Discourse chat
:target: https://discuss.python.org/
Copyright © 2001-2024 Python Software Foundation. All rights reserved.
See the end of this file for further copyright and license information.
.. contents::
General Information
-------------------
- Website: https://www.python.org
- Source code: https://github.com/python/cpython
- Issue tracker: https://github.com/python/cpython/issues
- Documentation: https://docs.python.org
- Developer's Guide: https://devguide.python.org/
Contributing to CPython
-----------------------
For more complete instructions on contributing to CPython development,
see the `Developer Guide`_.
.. _Developer Guide: https://devguide.python.org/
Using Python
------------
Installable Python kits, and information about using Python, are available at
`python.org`_.
.. _python.org: https://www.python.org/
Build Instructions
------------------
On Unix, Linux, BSD, macOS, and Cygwin::
./configure
make
make test
sudo make install
This will install Python as ``python3``.
You can pass many options to the configure script; run ``./configure --help``
to find out more. On macOS case-insensitive file systems and on Cygwin,
the executable is called ``python.exe``; elsewhere it's just ``python``.
Building a complete Python installation requires the use of various
additional third-party libraries, depending on your build platform and
configure options. Not all standard library modules are buildable or
usable on all platforms. Refer to the
`Install dependencies <https://devguide.python.org/getting-started/setup-building.html#build-dependencies>`_
section of the `Developer Guide`_ for current detailed information on
dependencies for various Linux distributions and macOS.
On macOS, there are additional configure and build options related
to macOS framework and universal builds. Refer to `Mac/README.rst
<https://github.com/python/cpython/blob/main/Mac/README.rst>`_.
On Windows, see `PCbuild/readme.txt
<https://github.com/python/cpython/blob/main/PCbuild/readme.txt>`_.
If you wish, you can create a subdirectory and invoke configure from there.
For example::
mkdir debug
cd debug
../configure --with-pydebug
make
make test
(This will fail if you *also* built at the top-level directory. You should do
a ``make clean`` at the top-level first.)
To get an optimized build of Python, ``configure --enable-optimizations``
before you run ``make``. This sets the default make targets up to enable
Profile Guided Optimization (PGO) and may be used to auto-enable Link Time
Optimization (LTO) on some platforms. For more details, see the sections
below.
Profile Guided Optimization
^^^^^^^^^^^^^^^^^^^^^^^^^^^
PGO takes advantage of recent versions of the GCC or Clang compilers. If used,
either via ``configure --enable-optimizations`` or by manually running
``make profile-opt`` regardless of configure flags, the optimized build
process will perform the following steps:
The entire Python directory is cleaned of temporary files that may have
resulted from a previous compilation.
An instrumented version of the interpreter is built, using suitable compiler
flags for each flavor. Note that this is just an intermediary step. The
binary resulting from this step is not good for real-life workloads as it has
profiling instructions embedded inside.
After the instrumented interpreter is built, the Makefile will run a training
workload. This is necessary in order to profile the interpreter's execution.
Note also that any output, both stdout and stderr, that may appear at this step
is suppressed.
The final step is to build the actual interpreter, using the information
collected from the instrumented one. The end result will be a Python binary
that is optimized; suitable for distribution or production installation.
Link Time Optimization
^^^^^^^^^^^^^^^^^^^^^^
Enabled via configure's ``--with-lto`` flag. LTO takes advantage of the
ability of recent compiler toolchains to optimize across the otherwise
arbitrary ``.o`` file boundary when building final executables or shared
libraries for additional performance gains.
What's New
----------
We have a comprehensive overview of the changes in the `What's New in Python
3.12 <https://docs.python.org/3.12/whatsnew/3.12.html>`_ document. For a more
detailed change log, read `Misc/NEWS
<https://github.com/python/cpython/tree/main/Misc/NEWS.d>`_, but a full
accounting of changes can only be gleaned from the `commit history
<https://github.com/python/cpython/commits/main>`_.
If you want to install multiple versions of Python, see the section below
entitled "Installing multiple versions".
Documentation
-------------
`Documentation for Python 3.12 <https://docs.python.org/3.12/>`_ is online,
updated daily.
It can also be downloaded in many formats for faster access. The documentation
is downloadable in HTML, PDF, and reStructuredText formats; the latter version
is primarily for documentation authors, translators, and people with special
formatting requirements.
For information about building Python's documentation, refer to `Doc/README.rst
<https://github.com/python/cpython/blob/main/Doc/README.rst>`_.
Testing
-------
To test the interpreter, type ``make test`` in the top-level directory. The
test set produces some output. You can generally ignore the messages about
skipped tests due to optional features which can't be imported. If a message
is printed about a failed test or a traceback or core dump is produced,
something is wrong.
By default, tests are prevented from overusing resources like disk space and
memory. To enable these tests, run ``make testall``.
If any tests fail, you can re-run the failing test(s) in verbose mode. For
example, if ``test_os`` and ``test_gdb`` failed, you can run::
make test TESTOPTS="-v test_os test_gdb"
If the failure persists and appears to be a problem with Python rather than
your environment, you can `file a bug report
<https://github.com/python/cpython/issues>`_ and include relevant output from
that command to show the issue.
See `Running & Writing Tests <https://devguide.python.org/testing/run-write-tests.html>`_
for more on running tests.
Installing multiple versions
----------------------------
On Unix and Mac systems if you intend to install multiple versions of Python
using the same installation prefix (``--prefix`` argument to the configure
script) you must take care that your primary python executable is not
overwritten by the installation of a different version. All files and
directories installed using ``make altinstall`` contain the major and minor
version and can thus live side-by-side. ``make install`` also creates
``${prefix}/bin/python3`` which refers to ``${prefix}/bin/python3.X``. If you
intend to install multiple versions using the same prefix you must decide which
version (if any) is your "primary" version. Install that version using ``make
install``. Install all other versions using ``make altinstall``.
For example, if you want to install Python 2.7, 3.6, and 3.12 with 3.12 being the
primary version, you would execute ``make install`` in your 3.12 build directory
and ``make altinstall`` in the others.
Release Schedule
----------------
See :pep:`693` for Python 3.12 release details.
Copyright and License Information
---------------------------------
Copyright © 2001-2024 Python Software Foundation. All rights reserved.
Copyright © 2000 BeOpen.com. All rights reserved.
Copyright © 1995-2001 Corporation for National Research Initiatives. All
rights reserved.
Copyright © 1991-1995 Stichting Mathematisch Centrum. All rights reserved.
See the `LICENSE <https://github.com/python/cpython/blob/main/LICENSE>`_ for
information on the history of this software, terms & conditions for usage, and a
DISCLAIMER OF ALL WARRANTIES.
This Python distribution contains *no* GNU General Public License (GPL) code,
so it may be used in proprietary projects. There are interfaces to some GNU
code but these are entirely optional.
All trademarks referenced herein are property of their respective holders. | {
"source": "yandex/perforator",
"title": "contrib/tools/python3/README.rst",
"url": "https://github.com/yandex/perforator/blob/main/contrib/tools/python3/README.rst",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 8696
} |
# How to use Perforator for continuous profile-guided optimization
Perforator supports generating sPGO (sampling Profile-guided optimization) profiles for subsequent use in the compilation pipeline. This guide shows how to use such profiles for performance gains and outlines the hardware/software prerequisites of deployment/toolchain for profiles generation to work.
## Toolchain prerequisites
* LLVM-based toolchain (clang/lld)
* Binary built with DWARF debug info (we recommend also using `-fdebug-info-for-profiling` clang flag for higher profile quality)
## Deployment prerequisites
* Intel CPU
* Linux Kernel >=5.7
* LBR (Last Branch Records) available for reading. Many cloud providers disable LBR by default.
## Acquiring the sPGO profile
Run the following command `./perforator/cmd/cli/perforator pgo <service-name>`, targeting your installation of Perforator.
In case of failure, recheck the deployment prerequisites and try again; in case of success, check the `TakenBranchesToExecutableBytesRatio` value in the command output: we recommend it to be at least 1.0 for higher profile quality. If the value is less than 1.0, one might either increase profile sampling rate or reschedule the deployment to have more Intel CPU + Kernel >=5.7 nodes.
If everything goes well, you now have a sPGO profile for use in subsequent compilation.
## Using the sPGO profile in the compilation pipeline
* Add the `-fprofile-sample-use=<path-to-spgo-profile>` flag to clang flags
* In case of LTO being used, add `-fprofile-sample-use=<path-to-spgo-profile>` flags to lld flags
{% note warning %}
Build caches don't necessarily play nicely with `-fprofile-sample-use`: if the path doesn't change, but the profile content changes, build cache system might consider a compilation invocation as a cache hit, even though it clearly is not, since the profile has changed.
At best, this would lead to linker errors, at worst to some kind of UB at runtime. To avoid such situations, we recommend always generating random paths to the profile.
{% endnote %} | {
"source": "yandex/perforator",
"title": "docs/en/guides/autofdo.md",
"url": "https://github.com/yandex/perforator/blob/main/docs/en/guides/autofdo.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2058
} |
# How to build
There are two primary ways to build Perforator:
1. Build inside Docker container. This method is more convenient if you simply want to obtain working binaries, because it has no host requirements besides Docker.
1. Build directly on host. This method is more convenient if you want to contribute to Perforator (i.e. if you need to quickly patch source code and iterate)
## Components
Perforator consists of several binaries, located in `perforator/cmd` directory.
Currently following components exist:
- `agent`
- `cli`
- `gc`
- `migrate`
- `offline_processing`
- `proxy`
- `storage`
- `web`
## Building inside a container {#container}
{% note info %}
While this guide assumes you are using Docker, any other BuildKit-compatible tool should work as well.
{% endnote %}
Example usage
```bash
# See above for possible ${COMPONENT} values
# Add flags such as `--tag` or `--push` as necessary
docker build -f Dockerfile.build --platform linux/amd64 --target ${COMPONENT} ../../..
```
This command will build the desired component and create an image.
To obtain a standalone `cli` binary, you can do this:
```bash
# Replace tmp with cli image name
id=$(docker create tmp -- /)
docker cp ${id}:/perforator/cli .
# Now ./cli is Perforator cli
./cli version
# Cleanup
docker rm ${id}
```
## Building directly on host {#host}
We use [yatool](https://github.com/yandex/yatool) to build Perforator. The only dependency is Python 3.12+.
To build any component, simply run from the repository root:
```bash
./ya make -r <relative path to binary>
```
It will build binary in the `<relative path to binary>` directory in the release mode. If you want to build fully static executable without dynamic linker, add flag `--musl` to the build command. Such executable can be safely transferred between different Linux machines.
There's also a convenient way to build all binaries in one command:
```bash
./ya make -r perforator/bundle
```
Binaries will be available in `perforator/bundle` directory.
To create a docker image for a component named `foo`:
1. Prepare a directory which will be a build context
1. Put `foo` binary in the directory root
1. Additionally, when building Perforator proxy, put `create_llvm_prof` binary in the directory root
1. Run `docker build -f perforator/deploy/docker/Dockerfile.prebuilt --target foo path/to/context` with other flags as necessary.
{% note info %}
Note that Ya has local caches to speed up subsequent builds. Default cache locations are `~/.ya/build` and `~/.ya/tools`. If you do not wish to leave these artifacts in your host system, please use [Docker](#container) with provided Dockerfiles.
{% endnote %}
All microservices required to run in full fledged environment are located in `perforator/cmd` directory. If you wish to record flamegraph locally you can build `perforator/cmd/cli` tool.
Note that initial building process can take a long time and consumes ~10GiB of disk space. Perforator uses LLVM extensively to analyze binaries and we love static builds, so unfortunately we need to compile a lot of LLVM internals. | {
"source": "yandex/perforator",
"title": "docs/en/guides/build.md",
"url": "https://github.com/yandex/perforator/blob/main/docs/en/guides/build.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 3093
} |
# How to find difference betweeen two flamegraphs
Perforator can help you find differences between two profiles. There can be multiple different situations where you might want to compare profiles.
It can help to answer different questions such as:
- did your optimization actually help?
- did the service performance degrade due to recent code changes?
- does the new runtime version make things faster or slower?
## Selectors
Fundamentally, a diff requires two selectors: baseline selector and a new one (diff) selector.
A baseline will probably be using data from the past, or be the old version on blue/green deployment.
## Building base selector
### Option 1: There is a flamegraph that might be used as a base
You have already built one profile and want to compare it.
Open the flamegraph and click the "Compare with" button, you will get redirected to a comparison page. It looks like two main pages side by side. The left hand side will be pre-filled with the selector from the profile you've been seeing just yet.

On the right hand side, enter the new selector for comparison.
### Option 2: Building base selector from scratch
This is the option you need if you only know the service name or the first option is not applicable for some other reason.

Go to diffs page marked on the toolbar with scales icon.
There you'll have to build a selector for baseline (on the left) and new (on the right).
### Fine-tuning the selectors
By this point, you should have both selectors and see two lists of profiles that match them.

Also note, that if you have used a small sample number for the base profile you might want to adjust it on both sides.
Selectors use the [perforator query language](../reference/querylang.md) format.
Configure selectors on the right and on the left.
Once you're happy with the selectors, click "Diff profiles" button.
# Interpreting diff flamegraph
Contrary to the standard flamegraph, the color carries additional information. The blue shades show decrease of the function cycles, while the shades of red show growth against baseline. The darker the color — the bigger the difference. If the difference is less than 0.1%, the color switches to white. | {
"source": "yandex/perforator",
"title": "docs/en/guides/diff.md",
"url": "https://github.com/yandex/perforator/blob/main/docs/en/guides/diff.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2414
} |
# Simple databases installation via docker compose
This document helps to deploy local databases for testing full fledged Perforator cluster. It deploys and setups local PostgreSQL, Clickhouse and MinIO (S3) databases via docker compose.
## Prerequisites
- docker
## Setup containers
From the repository root navigate to the docker compose directory.
```console
cd perforator/deploy/db/docker-compose/
```
Start containers
```console
docker compose up -d
```
After starting, you can verify which containers are running.
```console
docker ps
```
After deploying DBs, you should run migrations manually via [migrate tool](migrate-schema.md). | {
"source": "yandex/perforator",
"title": "docs/en/guides/docker-compose.md",
"url": "https://github.com/yandex/perforator/blob/main/docs/en/guides/docker-compose.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 649
} |
# Perforator Helm Chart
This guide provides instructions on how to deploy Perforator on a Kubernetes cluster via the Helm package manager.
## Prerequisites
- Kubernetes cluster
- Helm 3+
- PostgreSQL database
- ClickHouse database
- S3 storage
{% note warning %}
Make sure you have necessary [buckets](https://github.com/yandex/perforator/blob/be7ed14b5b875217984d3aab5d93ca10289cb134/perforator/deploy/db/docker-compose/compose.yaml#L86-L90) in your S3 storage.
{% endnote %}
{% note info %}
For testing purposes, you can set up databases using [docker compose](docker-compose.md).
{% endnote %}
## Adding Helm Repository
```
helm repo add perforator https://helm.perforator.tech
helm repo update
```
## Installing Helm Chart
Create file `my-values.yaml` and add necessary values:
my-values.yaml example
```yaml
databases:
postgresql:
endpoints:
- host: "<host>"
port: <port>
db: "<db>"
user: "<user>"
password: "<password>"
clickhouse:
replicas:
- "<host>:<port>"
db: "<db>"
user: "<user>"
password: "<password>"
s3:
buckets:
# If buckets were created with recommended names
profiles: "perforator-profile"
binaries: "perforator-binary"
taskResults: "perforator-task-results"
binariesGSYM: "perforator-binary-gsym"
endpoint: "<host>:<port>"
accessKey: "<accessKey>"
secretKey: "<secretKey>"
proxy:
url_prefix: https://<address>/static/results/
```
{% note warning %}
Suggested `proxy.url_prefix` value is based on the following assumptions:
- Your installation includes `web` component (i.e. you do not explicitly set `web.enabled` to false)
- `<address>` is a DNS name or IP address pointing to `web`
- TLS is enabled (use `http://` otherwise)
{% endnote %}
{% note info %}
Alternatively, you can use existing kubernetes secrets.
```yaml
databases:
secretName: "<kubernetes secret>"
secretKey: "<key>"
clickhouse:
secretName: "<kubernetes secret>"
secretKey: "<key>"
s3:
secretName: "<kubernetes secret>"
```
{% endnote %}
Use created values to install chart:
```console
helm install perforator-release -n perforator perforator/perforator -f my-values.yaml
```
## Connecting to Perforator UI
To access the Perforator UI, configure port forwarding to the local machine:
```console
kubectl port-forward svc/perforator-release-perforator-web-service -n perforator 8080:80
```
Then open `http://localhost:8080` in your browser
## Uninstalling Helm Chart
```console
helm uninstall perforator-release -n perforator
```
## Upgrading Helm Chart
```console
helm upgrade perforator-release -n perforator perforator/perforator -f my-values.yaml
``` | {
"source": "yandex/perforator",
"title": "docs/en/guides/helm-chart.md",
"url": "https://github.com/yandex/perforator/blob/main/docs/en/guides/helm-chart.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2698
} |
# How to configure profiling for JVM applications
Perforator is able to profile JVM application. This guide shows how to configure application to get meaningful profiles.
{% note warning %}
For now, JVM support is experimental and has known limitations. It will be improved in the future releases.
{% endnote %}
## Prerequisites
* Application runs on HotSpot JVM.
* JVM is 17 or newer.
## Configure JVM
Add the following flag to the JVM process
```
-XX:+PreserveFramePointer
```
Additionally, add the following environment variable to the JVM process
```
__PERFORATOR_ENABLE_PERFMAP=java=true,percentage=50
```
See [reference](../reference/perfmap.md#configuration) for configuration options. | {
"source": "yandex/perforator",
"title": "docs/en/guides/jvm.md",
"url": "https://github.com/yandex/perforator/blob/main/docs/en/guides/jvm.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 704
} |
# Migrating database schema
This guide shows how to upgrade database schema when upgrading Perforator.
{% note warning %}
To minimize disruption, apply migrations before updating binaries.
{% endnote %}
## Migrating PostgreSQL database
Run the following command from the source root:
```console
./ya run perforator/cmd/migrate postgres up --hosts HOST --user USER --pass PASSWORD
```
Where:
* `HOST` is the hostname of the PostgreSQL primary server.
* `USER` and `PASSWORD` are credentials to connect to the PostgreSQL server.
## Migrating ClickHouse database
Run the following command from the source root:
```console
./ya run perforator/cmd/migrate clickhouse up --hosts HOSTS --user USER --pass PASSWORD
```
Where:
* `HOSTS` is a comma-separated list of ClickHouse hosts.
* `USER` and `PASSWORD` are credentials to connect to the ClickHouse server. | {
"source": "yandex/perforator",
"title": "docs/en/guides/migrate-schema.md",
"url": "https://github.com/yandex/perforator/blob/main/docs/en/guides/migrate-schema.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 865
} |
# Databases
Perforator relies on several databases to store its persistent state.
## PostgreSQL
Perforator stores various metadata and configuration in a PostgreSQL database.
### Tables
Following tables are used:
* `tasks` - contains recent tasks (user-specified parameters as well as coordination state and task outcome).
* `binaries` - contains metadata for binaries, uploaded to [object storage](#object-storage).
* `banned_users` - contains users banned from interacting with API (i.e. they are unable to create new tasks).
* `binary_processing_queue` - queue-like table used in GSYM-based symbolization.
[//]: # (TODO: link to GSYM)
* `gsym` - contains metadata for the GSYM-based symbolization.
* `schema_migrations` - coordination state for the [database migration process](../howto/migrate-schema).
* `microscopes` - contains data for the microscopes.
[//]: # (TODO: link to microscopes)
## ClickHouse
Perforator stores profiles metadata in a ClickHouse table named `profiles`. Perforator uses it to find profiles matching filter.
[//]: # (Document projections?)
## Object storage {#object-storage}
Additionally, Perforator requires S3-compatible object storage buckets to store profiles, GSYM data and binaries.
## Compatibility
Perforator is tested to work with the following databases:
* PostgreSQL 15.
* ClickHouse 24.3 and 24.8. | {
"source": "yandex/perforator",
"title": "docs/en/reference/database.md",
"url": "https://github.com/yandex/perforator/blob/main/docs/en/reference/database.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1364
} |
# Microscope
Perforator storage can drop some profiles to save space. This feature is disabled by default but should be enabled for huge production installations. Microscope is a tool that forces Perforator storage to store all profiles satisfying the given selector. This is useful for more precise profiling for some period of time. Also, microscope requires user authorization to be enabled. Users can set up Microscope by running `perforator microscope` command.
Each microscope is saved in Postgres database. Each Perforator storage pod polls the database for new microscopes and saves profiles if they match the microscope selector. For now only concrete selectors are supported - by pod_id or node_id. This way storage can apply multiple microscopes at once by using node_id or pod_id maps. This approach allows constant complexity for microscope checks during `PushProfile` rpc calls. | {
"source": "yandex/perforator",
"title": "docs/en/reference/microscope.md",
"url": "https://github.com/yandex/perforator/blob/main/docs/en/reference/microscope.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 894
} |
# Perfmap-based symbolization
This page explains how Perforator uses perfmap.
## Motivation
Many applications employ runtime code generation. For example, this is true for all code written in JIT-compiled languages such as Java or JavaScript. `perf` tool established perfmap - a simple protocol which allows an application to report all dynamic symbols to a profiling tool. Perforator is capable of loading and using this information.
## Configuration {#configuration}
Perfmap usage is controlled by environment variable `__PERFORATOR_ENABLE_PERFMAP`. Its value consists of comma-separated key-value pairs specifying individual settings, e.g. `java=true,percentage=25`. Any value, including empty string, is a signal that perfmap should be used in addition to any other methods when profiling this process. Any unsupported settings are ignored.
### `java` {#configuration-java}
This setting enables [JVM-specific support](./language-support/java.md#jvm). The only supported value is `true`.
### `percentage`
Percentage option can be used to gradually rollout perfmap-based symbolization. Note that it is applied uniformly at random for each process, so overall share of affected processes may differ. Supported values are 0..100 inclusively, where 0 effectively disables feature. If not set, default value is 100.
## Loading perfmaps
Perforator agent follows convention that perfmap is written to `/tmp/perf-N.map`, where N is the process identifier (PID). If process is running in container, agent searches inside the container's root directory. Additionally, instead of the real PID agent uses namespaced pid, i.e. pid inside the container. This way, profiling containerized workloads just works.
Perforator supports both streaming (i.e. process appends new symbols to the end of the perfmap) and periodic (i.e. process periodically rewrites the perfmap with all active symbols) updates.
By default Perforator assumes that creating perfmap will be arranged by some external entity (i.e. application developer specifying certain flags). However, [special support](./language-support/java.md#jvm) is provided for Java. | {
"source": "yandex/perforator",
"title": "docs/en/reference/perfmap.md",
"url": "https://github.com/yandex/perforator/blob/main/docs/en/reference/perfmap.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2131
} |
# Query Language
When you're profiling an application, you almost always want to filter the profiles by some properties. For instance, you might need to select only samples from a specific pod that were collected at a specific time. The query language used in Perforator can help you with that.
## Selector
To make a query to the profile database, you need to build a *selector*. Here is a simple example of one:
```
{service="perforator.storage-production", timestamp>="now-30m"}
```
The result of this query would be a set of profiles collected in the last 30 minutes from the service called `perforator.storage-production`.
As you can see, a number of *labels* and their corresponding *values* are specified in a selector. A label is a property of a collected profile, e.g. `service`, `pod_id`, `cpu` (you can find a list of them further down on this page). And a value can be a string or a regex.
You can enter the selector in the input field in the UI. After that, you'll see the matching profiles in the table below it. If you click on the “Merge profiles” button, you'll get to the page with the rendered flamegraph of the merged profile.

Alternatively, you can set a selector to build a profile in [the CLI](../guides/cli/fetch.md).
## Supported fields
Here are the most useful labels that are supported in the query language. There are several others, but they are very internal and chances are you will never need them.
| Name | Description | Examples |
|--------------|---------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------|
| `service` | [Deployment](https://kubernetes.io/docs/concepts/workloads/controllers/deployment/) / service / a set of pods | `{service="perforator-agent"}` |
| `cluster` | [Availability zone](https://kubernetes.io/docs/setup/best-practices/multiple-zones/) / data center / cluster | `{cluster="nl-central1-a}"` |
| `pod_id` | [Pod](https://kubernetes.io/docs/concepts/workloads/pods/) | `{pod_id="perforator-agent-f00d"}` |
| `node_id` | [Node](https://kubernetes.io/docs/concepts/architecture/nodes/) | `{node_id="cl1e9f5mob6348aja6cc-beef"}` |
| `cpu` | Model of CPU used on the node | `{cpu=~"AMD EPYC .*"}` |
| `id` | Profile ID<br/>Can be useful if you know exactly which atomic profile you want to inspect | `{id="0194b346-e2d9-7dcc-b613-a222fbbc9682}"` |
| `timestamp` | Profile collection time | `{timestamp>"now-30m"}`<br/>`{timestamp<"2025-01-30T07:31:41.159Z"}` |
| `event_type` | Event used to collect a profile<br/>Possible values: `cpu.cycles`, `signal.count`, `wall.seconds` | `{event_type="cpu.cycles"}` |
| `build_ids` | ELF Build ID of an executable file used in a profile | `{build_ids="4b1d"}` |
| `tls.KEY` | TLS variable | `{tls.KEY="value"}` |
## Supported operators
The most common way to find profiles is by using exact matching. After all, in most cases you know the value of the property that you wish to find. But there are some other ways which are supported through different operators.
| Operator | Description | Examples |
|----------------------|--------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| `=`, `!=` | Exact matching operators | `{cluster="nl-central1-a"}`<br/>Profiles from the `nl-central1-a` zone<br/><br/>`{service!="mongodb"}`<br/>Profiles from everywhere except `mongodb` deployment<br/><br/>`{service="grafana\|mongo"}`<br/>Profiles from `grafana` and `mongo` deployments |
| `=~`, `!~` | Regex matching operators | `{cpu=~"Intel.*"}`<br/>Profiles from the pods with Intel processors<br/><br/>`{service!~"perforator-.*-testing"}`<br/>Profiles that are not from the testing deployments |
| `<`, `>`, `<=`, `>=` | Ordinal operators | `{timestamp<"now-1d"}`<br/>Profiles that are at least 24 hours old
## More complex examples
- `{service="perforator-agent", cpu=~"AMD.*"}`<br/>
Profiles collected from the pods of the `perforator-agent` deployment which are using AMD processors
- `{cluster="us-central-1b", timestamp>="now-3h", timestamp<"2h"}`<br/>
Profiles from the `us-central-1b` zone that were collected between 2 and 3 hours ago
- `{pod_id="perforator-agent-f00d", event_type="signal.count"}`<br/>
Profiles collected on fatal signals from the `perforator-agent-f00d` pod
- `{build_ids="4b1d|c0de", node_id="cl1e9f5mob6348aja6cc-beef"}`<br/>
Profiles for executable files with ELF build IDs `4b1d` or `c0de` that were collected from the `cl1e9f5mob6348aja6cc-beef` node | {
"source": "yandex/perforator",
"title": "docs/en/reference/querylang.md",
"url": "https://github.com/yandex/perforator/blob/main/docs/en/reference/querylang.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 6173
} |
# System requirements
This page describes the system requirements for running Perforator.
## Limitations
Perforator profiling core is based on eBPF which is a relatively new technology and evolving rapidly. So there are some requirements on the system you can run Perforator on.
### Architecture
The only supported architecture is x86-64. We plan to support aarch64 later though.
### Linux kernel version
We support Linux 5.4 or newer. Before Linux 5.4 there was a hard limit on the number of eBPF instructions analyzed by verifier (no more than 4096 instructions), so the profiler is required to run in a very constrained environment. In 5.4 this limit was raised to 1M instructions. Moreover, latest version of the Linux kernel may not work. Complex eBPF programs that read kernel structures by design rely on evolving definitions of the kernel types, so they sometimes should be adapted to the new kernel versions. We test Perforator on all LTS kernels after 5.4, so if you are using LTS kernel you should be fine. Otherwise there is a minor probability that your kernel becomes incompatible with compiled Perforator version. We try to fix such issues as fast as possible.
In addition, the kernel should be compiled with [BPF Type Format](https://docs.kernel.org/bpf/btf.html) (BTF). You can check presence of file `/sys/kernel/btf/vmlinux` to determine if your kernel has BTF. Most modern Linux distributions enable BTF by default. See [this page](https://github.com/libbpf/libbpf#bpf-co-re-compile-once--run-everywhere) for more info.
### Root privileges
Perforator agent should have `CAP_SYS_ADMIN` capability (in most cases this means the agent must run under root user). eBPF programs have access to raw kernel memory, so there is no way to run the agent in more restricted environments.
### LBR profiles
Perforator supports collecting LBR profiles and collects LBR profiles by default. There are two additional requirements on the LBR profiles though:
- The minimal supported kernel version is raised to 5.7. In Linux 5.7 the required eBPF helper which allows us to read last branch records was introduced.
- LBR is supported on Intel processors only.
Such requirements apply only if you are trying to collect and use LBR profiles (for example, for sPGO or BOLT). | {
"source": "yandex/perforator",
"title": "docs/en/reference/system-requirements.md",
"url": "https://github.com/yandex/perforator/blob/main/docs/en/reference/system-requirements.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2278
} |
# Setup Perforator test deployment in Kubernetes via Helm
In this tutorial we will deploy Perforator on a Kubernetes cluster via the Helm package manager without additional database setup.
{% note warning %}
This setup is intended solely for demonstration.
There is no guarantee for compatibility with older versions of the chart.
Please do not use it in production environments.
{% endnote %}
## Prerequisites
- Kubernetes cluster
- Helm 3+
{% note info %}
To run Kubernetes locally you can isntall kind (kubernetes in docker).
See official instalation instruction https://kind.sigs.k8s.io/docs/user/quick-start/#installation
{% endnote %}
## Adding Helm Repository
```
helm repo add perforator https://helm.perforator.tech
helm repo update
```
## Installing Helm Chart
Create file `my-values.yaml` with values:
my-values.yaml example
```yaml
databases:
postgresql:
migrations:
enabled: true
db: "perforator"
user: "perforator"
password: "perforator"
clickhouse:
migrations:
enabled: true
insecure: true
db: "perforator"
user: "perforator"
password: "perforator"
s3:
buckets:
profiles: "perforator-profile"
binaries: "perforator-binary"
taskResults: "perforator-task-results"
binariesGSYM: "perforator-binary-gsym"
insecure: true
force_path_style: true
accessKey: "perforator"
secretKey: "perforator"
proxy:
url_prefix: "http://localhost:8080/static/results/"
testing:
enableTestingDatabases: true
```
Use created values to install chart:
```console
helm install perforator-release -n perforator perforator/perforator -f my-values.yaml --create-namespace
```
## Connecting to Perforator UI
To access the Perforator UI, configure port forwarding to the local machine:
```console
kubectl port-forward svc/perforator-release-perforator-web-service -n perforator 8080:80
```
Then open `http://localhost:8080` in your browser
## Uninstalling Helm Chart
```console
helm uninstall perforator-release -n perforator
``` | {
"source": "yandex/perforator",
"title": "docs/en/tutorials/helm-chart.md",
"url": "https://github.com/yandex/perforator/blob/main/docs/en/tutorials/helm-chart.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2037
} |
# Optimizing Native Applications with Perforator
In this tutorial we will optimize a simple C++ application using Perforator. We will build an app, view its flamegraph and see how we can improve the performance.
## Prerequisites
- Any Linux amd64 OS with 5.4+ kernel;
- `python` 3.12+ interpreter for building Perforator CLI (or already downloaded Perforator CLI);
- `clang++` 14+ for building C++ app.
## Running the application
Let's optimize the following code:
```C++
#include <algorithm>
#include <cstdint>
#include <iostream>
#include <random>
#include <vector>
uint64_t inefficient_calc_sum() {
uint64_t result = 0;
for (int i = 1; i <= 1'000'000'000; ++i) {
result += i;
}
return result;
}
void shuffle_some_array() {
std::vector<int> vec;
for (int i = 0; i < 3'000'000; ++i) {
vec.push_back(std::rand());
}
for (int i = 0; i < 20; ++i) {
std::shuffle(vec.begin(), vec.end(), std::mt19937());
}
}
void my_function() {
shuffle_some_array();
std::cout << inefficient_calc_sum() << std::endl;
}
int main() {
for (int i = 0; i < 10; ++i) {
std::cout << "Iteration:" << i << " ";
my_function();
}
return 0;
}
```
Let's put this code in `~/optimize_with_perforator/main.cpp`, build it and run it with time:
```bash
mkdir -p ~/optimize_with_perforator && cd ~/optimize_with_perforator
clang++ -g main.cpp -o main && time ./main
Iteration:0 500000000500000000
Iteration:1 500000000500000000
Iteration:2 500000000500000000
Iteration:3 500000000500000000
Iteration:4 500000000500000000
./main 17.24s user 0.04s system 99% cpu 17.288 total
```
Notice we build with -g flag to add debug information to binary - with it the analysis will show us more.
17 seconds for executing a simple program is a bit too much.
We can see multiple optimization opportunities here, but it is not obvious where is the performance bottleneck.
Let's find and optimize it!
## Analyzing the performance using Perforator CLI
For analysis we need Perforator CLI. Either download it into `~/optimize_with_perforator` from [releases page](https://github.com/yandex/perforator/releases) or build it from Perforator repo using Ya:
```bash
git clone https://github.com/yandex/perforator.git
cd perforator
./ya make perforator/cmd/cli
cd ~/optimize_with_perforator
ln -s perforator/perforator/cmd/cli/perforator perforator
```
After build, we make symlink to CLI for convenience.
After getting the CLI, run Perforator CLI under sudo:
```bash
sudo ./perforator record --serve :1234 -- ./main
```
This command records stacks from running command you specified after `--`, and in the end it shows you a static page hosted at `localhost:1234`.
Let's type `localhost:1234` in browser in the new tab. We will see the _flamegraph_.

### A few words about flamegraph
Flamegraph is one way of viewing the details of CPU consumption by your apps. Given a number of processes' stacks, which were collected every small period of time (in Perforator it is 10ms), we draw each of them separately as a one-width rectangle stack with each rectangle equal to one stack callframe, like this:

The stack can be read from top to bottom, that is, `main` calls `my_function`, which in turn calls `shuffle_some_array` and so on.
And to draw them all together, we draw them by putting stacks with common prefix together, forming a wider common parts and thinner differing ones. From the construction process it can be seen that the order of columns in flamegraphs does not matter, what matters is the width of the specific rectangle - the wider the rectangle, the more portion of CPU it consumes.
The flamegraph is _interactive_ - you can click on the frame and it will show all stacks having this frame in their prefix. For example, let's click on `shuffle_some_array`:

You can return to the original flamegraph by clicking on the root frame (all).
We've played with flamegraph a bit, let's move to optimizing the app!
### Optimizing the app
Looking at the level under `my_function`, we see that the most CPU consuming functions are `inefficient_calc_sum` and `shuffle_some_array`. `shuffle_some_array` in turn has `std::shuffle` as the most consuming function, so we do not really hope to optimize it easily. Let's look at the `inefficient_calc_sum`. There is no children in it (except some blue small kernel interrupt-related code on the left), so it is the code inside this function which burns so much CPU! Obviously, it's the loop. We can notice that the function can be rewritten in much more efficient way:
```C++
uint64_t inefficient_calc_sum() {
// uint64_t result = 0;
// for (int i = 1; i <= 1'000'000'000; ++i) {
// result += i;
// }
// return result;
return 1ll * (1 + 1'000'000'000) * 1'000'000'000 / 2;
}
```
Let's recompile the code and see the flamegraph again:
```bash
clang++ -g main.cpp -o main
sudo ./perforator record --serve :1234 -- ./main
```

The `inefficient_calc_sum` became so efficient that Perforator's sampling period wasn't enough to record even one sample.
Let's measure the execution time of `main`:
```bash
time ./main
Iteration:0 500000000500000000
Iteration:1 500000000500000000
Iteration:2 500000000500000000
Iteration:3 500000000500000000
Iteration:4 500000000500000000
./main 11.81s user 0.06s system 99% cpu 11.885 total
```
We reduced execution time by 6 seconds, great! | {
"source": "yandex/perforator",
"title": "docs/en/tutorials/native-profiling.md",
"url": "https://github.com/yandex/perforator/blob/main/docs/en/tutorials/native-profiling.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 5558
} |
# Optimizing Python Applications with Perforator
In this tutorial we will optimize a simple Python application using Perforator. We will view the flamegraph of the application and see how we can improve the performance.
## Prerequisites
- `perforator` CLI
- `python` 3.12+ interpreter
- `curl` HTTP client
## Running the application
Let's say we have a simple Python HTTP server that has exactly one handler `UserIDSearchHandler`. This handler checks if the user exists.
```python
import http.server
import socketserver
import os
from urllib.parse import urlparse, parse_qs
PORT = 9007
# Create a large sorted array of user IDs (not necessarily consecutive)
user_ids = list(range(1, 1000000, 2)) # Example: [1, 3, 5, ..., 999999]
# Global variable to count the number of requests
request_count = 0
def increment_request_count():
global request_count
request_count += 1
def search_user(arr, target):
# Simple linear search
for value in arr:
if value == target:
return True
return False
class UserIDSearchHandler(http.server.SimpleHTTPRequestHandler):
def do_GET(self):
increment_request_count()
if self.path.startswith('/search_user'):
query_components = parse_qs(urlparse(self.path).query)
user_id = int(query_components.get("user_id", [0])[0])
exists = search_user(user_ids, user_id)
self.send_response(200)
self.send_header("Content-type", "text/plain")
self.end_headers()
if exists:
response = f"The user {user_id} exists. Request ID: {request_count}\n"
else:
response = f"The user {user_id} does not exist. Request ID: {request_count}\n"
self.wfile.write(response.encode())
else:
self.send_response(404)
self.end_headers()
def run(server_class=http.server.HTTPServer, handler_class=UserIDSearchHandler):
with server_class(("", PORT), handler_class) as httpd:
print(f"Serving on port {PORT}")
httpd.serve_forever()
if __name__ == "__main__":
print(f"My pid is {os.getpid()}")
run()
```
We can assume that `user_ids` is retrieved from a database, but for the sake of simplicity we will just use a sorted pre-generated list.
Copy this code to a file `server.py` and run it.
```bash
python server.py
```
You should see something like this:
```console
-$ python server.py
My pid is 3090163
Serving on port 9007
```
Let's send a request to the server and check if user with ID 13 exists.
```console
$ curl "http://localhost:9007/search_user?user_id=13"
The user 13 exists
```
Now we have a simple working Python application.
## Recording a flamegraph
We can collect a flamegraph which is a visual representation of the program's execution.
`perforator record` collects stacks from the desired process for some time and then generates a flamegraph. You can read more about it [here](../guides/cli/record.md).
Let's collect a flamegraph of the application. But do not forget to replace the `--pid` with the PID of your application.
```console
$ sudo perforator record --pid 3090163 --duration 1m --serve ":9006"
```
You should see the output with a lot of information about the system analysis. But the most important part is the URL of the flamegraph. Paste it in your browser and open it (e.g. `http://localhost:9006`).
You would see the flamegraph like this.

We can notice that there is no `UserIDSearchHandler` in the flamegraph. This is during the flamegraph collection the server handler was not executing.
{% note info %}
The program must be executing the code that we want to profile during the flamegraph collection.
{% endnote %}
So for this example we should be sending requests to the server during the flamegraph collection.
## Loading the application
Let's load the application handler with a simple python script.
```python
import requests
import random
while True:
user_id = random.randint(1, 1000000)
requests.get(f"http://localhost:9007/search_user?user_id={user_id}")
```
Run this in a separate terminal.
## Collect the meaningful flamegraph and find the bottleneck
```console
$ sudo perforator record --pid 3090163 --duration 1m --serve ":9006"
```
Now we can see the flamegraph which looks like this.

As we want to optimize the `UserIDSearchHandler` we should focus on the part of the flamegraph which corresponds to this handler.
Click "Search" in the top left corner and paste "UserIDSearchHandler" in the search bar. Then click on the `UserIDSearchHandler` in the flamegraph.

We can see that `search_user` block is really long, it means that it takes the majority of CPU time of the handler which is a parent block.
Let's notice that we can replace the linear search by a lookup into the precomputed dictionary.
## Optimizing the bottleneck
Now let's modify the code to use a dictionary instead of a linear search.
```python
import http.server
import socketserver
import os
from urllib.parse import urlparse, parse_qs
PORT = 9007
# Create a large sorted array of user IDs (not necessarily consecutive)
user_ids = list(range(1, 1000000, 2)) # Example: [1, 3, 5, ..., 999999]
# Build a dictionary for quick lookup
user_id_dict = {user_id: True for user_id in user_ids}
# Global variable to count the number of requests
request_count = 0
def increment_request_count():
global request_count
request_count += 1
def search_user(arr, target):
return user_id_dict.get(target, False)
class UserIDSearchHandler(http.server.SimpleHTTPRequestHandler):
def do_GET(self):
increment_request_count()
if self.path.startswith('/search_user'):
query_components = parse_qs(urlparse(self.path).query)
user_id = int(query_components.get("user_id", [0])[0])
exists = search_user(user_ids, user_id)
self.send_response(200)
self.send_header("Content-type", "text/plain")
self.end_headers()
if exists:
response = f"The user {user_id} exists. Request ID: {request_count}\n"
else:
response = f"The user {user_id} does not exist. Request ID: {request_count}\n"
self.wfile.write(response.encode())
else:
self.send_response(404)
self.end_headers()
def run(server_class=http.server.HTTPServer, handler_class=UserIDSearchHandler):
with server_class(("", PORT), handler_class) as httpd:
print(f"Serving on port {PORT}")
httpd.serve_forever()
if __name__ == "__main__":
print(f"My pid is {os.getpid()}")
run()
```
Run this server, run the load script and collect the flamegraph again.
We will see the flamegraph of `UserIDSearchHandler` with a significantly smaller `search_user` block.

Now the `UserIDSearchHandler` takes 26.30% of the CPU time of the program instead of 96.22% as before.
From this process we can see that the flamegraph is useful for comparing relative performance of different parts of the program by looking at the sizes of the blocks.
## Conclusion
In this tutorial we
* Used `perforator record` to profile the application
* Collected a meaningful flamegraph with the application loaded
* Navigated the flamegraph to find the bottleneck
* Optimized the application handler
We can see that the flamegraph is a useful tool for profiling and optimizing the performance of the application. | {
"source": "yandex/perforator",
"title": "docs/en/tutorials/python-profiling.md",
"url": "https://github.com/yandex/perforator/blob/main/docs/en/tutorials/python-profiling.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 7732
} |
# Building your first profile with Perforator UI
You've deployed perforator to your experimental kubernetes cluster and not sure what to do next?
This article will guide you through basic operations related to the UI. You will
- Create a flamegraph
- Inspect a flamegraph
- Find previously created flamegraphs
## Prerequisites
- App deployed into k8s cluster(for example, according to the [guide](../guides/helm-chart.md)) network access to Perforator
- some kind of a cpu-heavy workload that is being monitored by perforator agent, for example perforator `cpu_burner`
## Navigating the UI
### Merge profiles form page
Once you open the UI, you will see the start page with an empty field for a selector waiting for you to start typing.

To see the list of already-collected profiles that that can be used for a flamegraph type in `{service="your-service-name"}`. If you are unsure about the name of the service and what `service` means, you can rely on auto-complete.

See further instructions on perforator querylang [here](../reference/querylang.md). It can be used to switch the profile type from default (cycles) to wall time profiling and other perf events, and many other things.
Once you select a service, you will see a table with all the profiles collected for such a selector.
If you click the profile id link, a flamegraph will be built right away. It will come with the profile id inlined into the selector.
### Aggregation settings
The "Merge profiles" button starts aggregation of the profiles to build a flamegraph. You can configure the amount of profiles that will end up in that merged flamegraph with the "Sample size" selector. You can also change the time interval that is used to pick profiles for aggregation by changing the selected portion of the timeline, or by changing time intervals manually.
Note that the bigger the sample size the longer it will take to merge and build a flamegraph.
Once you click the "Merge profiles" button, you will be redirected to the flamegraph page. At first, you will see the progress bar while flamegraph is being prepared, and after a while you will see the flamegraph.
## Flamegraph

## History
Once the flamegraph has been built, it will be accessible via the history tab (button on the left with an arrow back and a clock).
 | {
"source": "yandex/perforator",
"title": "docs/en/tutorials/ui.md",
"url": "https://github.com/yandex/perforator/blob/main/docs/en/tutorials/ui.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2602
} |
This is a simple library for block data compression (this means data is compressed/uncompressed
by whole blocks in memory). It's a lite-version of the `library/cpp/codecs`. Lite here means that it
provide only well-known compression algorithms, without the possibility of learning.
There are two possible ways to work with it.
Codec by name
=============
Use `NBlockCodec::Codec` to obtain the codec by name. The codec can be asked to compress
or decompress something and in various ways.
To get a full list of codecs there is a function `NBlockCodecs::ListAllCodecs()`.
Streaming
=========
Use `stream.h` to obtain simple streams over block codecs (buffer data, compress them by blocks,
write to the resulting stream).
Using codec plugins
===================
If you don't want your code to bloat from unused codecs, you can use the small version of the
library: `library/cpp/blockcodecs/core`. In that case, you need to manually set `PEERDIR()`s to
needed codecs (i.e. `PEERDIR(library/cpp/blockcodecs/codecs/lzma)`). | {
"source": "yandex/perforator",
"title": "library/cpp/blockcodecs/README.md",
"url": "https://github.com/yandex/perforator/blob/main/library/cpp/blockcodecs/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1023
} |
A simple parser of C++ codes (only lexical analysis, no semantic checking)
It is similar to a sax-parser by its interface. | {
"source": "yandex/perforator",
"title": "library/cpp/cppparser/README.md",
"url": "https://github.com/yandex/perforator/blob/main/library/cpp/cppparser/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 123
} |
Simple utility to check base target x86 SIMD exensions at startup.
Program may be built with some SIMD extension enabled (e.g. `-msse4.2`). `PEERDIR` to this library adds statrup check that machine where the program is running supports SIMD extension the program is built for.
Currently supported check are: sse4.2, pclmul, aes, avx, avx2 and fma.
**Note:** the library depends on `util`.
**Note:** the library adds stratup code and so if `PEERDIR`-ed from `LIBRARY` will do so for all `PROGRAM`-s that (transitively) use the `LIBRARY`. Don't do this!
You normally don't need to `PEERDIR` this library at all. Since making sse4 in Arcadia default this library is used implicitly. It is `PEERDIR`-ed from all `PROGRAM`-s and derived modules (e.g. `PY2_PROGRAM`, but not `GO_PROGRAM` or `JAVA_PROGRAM`).
It is also not applied to `PROGRAM`-s where `NO_UTIL()`, `NO_PLATFORM()` or `ALLOCATOR(FAKE)` set to avoid undesired dependencied. To disable this implicit check use `NO_CPU_CHECK()` macro or `-DCPU_CHECK=no` ya make flag. | {
"source": "yandex/perforator",
"title": "library/cpp/cpuid_check/README.md",
"url": "https://github.com/yandex/perforator/blob/main/library/cpp/cpuid_check/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1030
} |
Note: underlying algorithm `library/cpp/lcs` has complexity of O(r log n) by time and O(r) of additional memory, where r is the number of pairs (i, j) for which S1[i] = S2[j]. When comparing file with itself (or with little modifications) it becomes quadratic on the number of occurences of the most frequent line. | {
"source": "yandex/perforator",
"title": "library/cpp/diff/README.md",
"url": "https://github.com/yandex/perforator/blob/main/library/cpp/diff/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 314
} |
Library to get access for individual struct members.
Library is inspired by [apolukhin/magic_get](https://github.com/apolukhin/magic_get)
#### Usage
```
struct TSample {
int field1;
int field2;
};
TSample sample{1, 2};
size_t membersCount = NIntrospection::MembersCount<TSample>(); // membersCount == 2
const auto members = NIntrospection::Members<TSample>(); // get const reference to all members as std::tuple<const int&, const int&>
const auto&& field1 = NIntrospection::Member<0>(sample); // const reference to TSample::field1
const auto&& field2 = NIntrospection::Member<1>(sample); // const reference to TSample::field2
```
#### Limitiations:
* Provides read-only access to members (cannot be used for modification)
* Supported only Only C-style structures w/o user-declared or inherited constructors (see https://en.cppreference.com/w/cpp/language/aggregate_initialization)
* C-style array members are not supported.
Example:
```
struct TSample {
int a[3];
}
```
the library determines that the structure has 3 members instead of 1.
As workarraund the std::array can be used:
```
struct TSample {
std::array<int, 3> a;
}
``` | {
"source": "yandex/perforator",
"title": "library/cpp/introspection/README.md",
"url": "https://github.com/yandex/perforator/blob/main/library/cpp/introspection/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1194
} |
# Functools library
Эта библиотека предоставляет функции `Enumerate`, `Zip`, `Map`, `Filter`, `Concatenate` и `CartesianProduct`.
`Enumerate`, `Zip`, `Map`, `Filter` повторяют логику одноименных функций из python.
Важный момент:
* Итераторы данных view почти во всех случаях (кроме Map, там зависит от маппера) возвращают `std::tuple` **по значению** (при этом шаблонные параметры всегда, когда это уместно, ссылки).
<br> Так что нет никакого смысла делать `for (const auto& [i, x] : Enumerate(c))`.
<br> Лучше всегда `for (auto [i, x] : Enumerate(c))` (`x` в этом случае будет ссылкой и работать с ним можно как со ссылкой) или `for (const auto [i, x] : Enumerate(c))`.
Предоставляемые гарантии:
* Работа для всех контейнеров, для которых работает range-based for (для `Enumerate`, `Zip`, `Concatenate`, `CartesianProduct`).
Для `Map` и `Filter` есть требование на то, что первый и последний итераторы контейнера имеют один тип
* В том числе работает для обычных массивов (`int a[] = {1, 2, 3}; Enumerate(a)`).
* Поддержка rvalue для контейнеров, предикатов и функций-мапперов (`Filter([](auto x){...}, TVector{1, 2, 3})`).
В этом случае объекты сохраняются внутри view.
* Проброс элементов контейнеров по неконстантной ссылке
* `TView::iterator` - можно полагаться, что этот тип есть и корректен
* `TIterator::iterator_category` - можно полагаться, что этот тип есть и определен.
На что гарантий нет:
* Любые изменения контейнеров, меняющие размер или инвалидирующие их итераторы, инвалидируют созданные view
* Не принимает списки инициализации (`Enumerate({1, 2, 3})`), так как неизвестен желаемый тип контейнера.
* В классах реализации оставлены публичные члены вида `.Field_`, чтобы не загромождать реализацию
Тем не менее эти поля не гарантированы, могут стать приватными или исчезнуть
* Для всех итераторов определены вложенные типы: `value_type`, `pointer`, `reference`.
Тем не менее не рекомендуется их использовать в связи с их неоднозначностью.
`value_type` может быть как обычным типом, так и ссылкой. Может быть `std::tuple<T1, T2>`,
а может `std::tuple<T1&, const T2&>`.
Если возникает необходимость в этих типах, то возможно, стоит упростить код и вообще не использовать эти view.
Если очень хочется можно использовать `delctype(*container.begin())`.
Производительность:
* Бенчмарки времени компиляции и скорости выполнения, а так же сравнение с range-v3 и другими существующими реализациями
доступны в [репозитории где ведется разработка](https://github.com/yuri-pechatnov/cpp_functools/tree/master "functools").
Q: Оверхед?
A: По выполнению: на Enumerate, Zip, Map - нулевой. Где-то x1.5 на Filter, и x3 на Concatenate и CartesianProduct. Но если в теле цикла происходит хоть что-то существенное, то это пренебрежимо мало.
По компиляции: сложно рассчитать как оно скажется в реальном большом проекте, но приблизительно не более x1.5 на один цикл.
Q: А зачем свой велосипед?
A: ((https://pechatnov.at.yandex-team.ru/67 Ответ в этом посте)).
Q: А почему вот здесь плохо написано, надо же по-другому?
A: Код несколько раз переписывался и согласовывался ((https://st.yandex-team.ru/IGNIETFERRO-973 более полугода)). А допиливать его внутреннюю реализацию после коммита никто не мешает и дальше.
Сигнатуры и эквиваленты:
```cpp
//! In all comments variables ending with '_'
//! are considered as invisible for {...} block.
//! Usage: for (auto [i, x] : Enumerate(container)) {...}
//! Equivalent: { std::size_t i_ = 0; for (auto& x : container) { const std::size_t i = i_; {...}; ++i_; }}
template <typename TContainerOrRef>
auto Enumerate(TContainerOrRef&& container);
//! Usage: for (auto x : Map(mapperFunc, container)) {...}
//! Equivalent: for (auto iter_ = std::begin(container); iter_ != std::end(container); ++iter_) {
//! auto x = mapperFunc(*iter_); {...}; }
template <typename TMapper, typename TContainerOrRef>
auto Map(TMapper&& mapper, TContainerOrRef&& container);
//! Usage: for (auto x : Filter(predicate, container)) {...}
//! Equivalent: for (auto x : container) { if (predicate(x)) {...}}
template <typename TPredicate, typename TContainerOrRef>
auto Filter(TPredicate&& predicate, TContainerOrRef&& container);
//! Usage: for (auto [ai, bi] : Zip(a, b)) {...}
//! Equivalent: { auto ia_ = std::begin(a); auto ib_ = std::begin(b);
//! for (; ia_ != std::end(a) && ib_ != std::end(b); ++ia_, ++ib_) {
//! auto&& ai = *ia_; auto&& bi = *ib_; {...}
//! }}
template <typename... TContainers>
auto Zip(TContainers&&... containers);
//! Usage: for (auto x : Reversed(container)) {...}
//! Equivalent: for (auto iter_ = std::rbegin(container); iter_ != std::rend(container); ++iter_) {
//! auto x = *iter_; {...}}
template <typename TContainerOrRef>
auto Reversed(TContainerOrRef&& container);
//! Usage: for (auto x : Concatenate(a, b)) {...}
//! Equivalent: { for (auto x : a) {...} for (auto x : b) {...} }
//! (if there is no static variables in {...})
template <typename TFirstContainer, typename... TContainers>
auto Concatenate(TFirstContainer&& container, TContainers&&... containers);
//! Usage: for (auto [ai, bi] : CartesianProduct(a, b)) {...}
//! Equivalent: for (auto& ai : a) { for (auto& bi : b) {...} }
template <typename... TContainers>
auto CartesianProduct(TContainers&&... containers);
``` | {
"source": "yandex/perforator",
"title": "library/cpp/iterator/README.md",
"url": "https://github.com/yandex/perforator/blob/main/library/cpp/iterator/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 5387
} |
A set of algorithms for approximate string matching.
====================================================
**Lcs_via_lis.h**
Combinatorial algorithm LCS (Longest common subsequence) through LIS (Longest increasing subsequence) for rows S1 and S2 of lengths n and m respectively (we assume that n < m).
Complexity is O(r log n) by time and O(r) of additional memory, where r is the number of pairs (i, j) for which S1[i] = S2[j]. Thus for the uniform distribution of letters of an alphabet of s elements the estimate is O(nm / s * log n).
Effective for large alphabets s = O(n) (like hashes of words in a text). If only the LCS length is needed, the LCS itself will not be built.
See Gusfield, Algorithms on Strings, Trees and Sequences, 1997, Chapt.12.5
Or here: http://www.cs.ucf.edu/courses/cap5937/fall2004/Longest%20common%20subsequence.pdf
#### Summary of the idea:
Let's suppose we have a sequence of numbers.
Denote by:
- IS is a subsequence strictly increasing from left to right.
- LIS is the largest IS of the original sequence.
- DS is a subsequence that does not decrease from left to right.
- C is a covering of disjoint DS of the original sequence.
- SC is the smallest such covering.
It is easy to prove the theorem that the dimensions of SC and LIS are the same, and it is possible to construct LIS from SC.
Next, let's suppose we have 2 strings of S1 and S2. It can be shown that if for each symbol in S1 we take the list of its appearances in S2 in the reverse order, and concatenate all such lists keeping order, then any IS in the resulting list will be equivalent to some common subsequence S1 and S2 of the same length. And, consequently, LIS will be equivalent to LCS.
The idea of the algorithm for constructing DS:
- Going along the original sequence, for the current member x in the list of its DS we find the leftmost, such that its last term is not less than x.
- If there is one, then add x to the end.
- If not, add a new DS consisting of x to the DS list.
It can be shown that the DS list constructed this way will be SC. | {
"source": "yandex/perforator",
"title": "library/cpp/lcs/README.md",
"url": "https://github.com/yandex/perforator/blob/main/library/cpp/lcs/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2059
} |
This library provides implementation to access a resource (data, file, image, etc.) by a key.
=============================================================================================
See ya make documentation, resources section for more details.
### Example - adding a resource file into build:
```
LIBRARY()
OWNER(user1)
RESOURCE(
path/to/file1 /key/in/program/1
path/to/file2 /key2
)
END()
```
### Example - access to a file content by a key:
```cpp
#include <library/cpp/resource/resource.h>
int main() {
Cout << NResource::Find("/key/in/program/1") << Endl;
Cout << NResource::Find("/key2") << Endl;
}
``` | {
"source": "yandex/perforator",
"title": "library/cpp/resource/README.md",
"url": "https://github.com/yandex/perforator/blob/main/library/cpp/resource/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 641
} |
Certifi
-------
Certifi is a collection of public and internal Root Certificates for validating the trustworthiness of SSL certificates while verifying the identity of TLS hosts.
Certifi use Arcadia Root Certificates for that: https://a.yandex-team.ru/arc/trunk/arcadia/certs | {
"source": "yandex/perforator",
"title": "library/go/certifi/README.md",
"url": "https://github.com/yandex/perforator/blob/main/library/go/certifi/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 277
} |
Расширение [termcolor](https://github.com/termcolor/termcolor/) дополнительными функциями.
Может быть использован для конвертации текстовых спецификаций цвета (например, из markup) в esc-последовательности для корректного отображения в терминале.
Пример использования:
```python
from library.python.color import tcolor
tcolor("some text", "green-bold-on_red") -> '\x1b[32m\x1b[41m\x1b[1msome text\x1b[0m'
``` | {
"source": "yandex/perforator",
"title": "library/python/color/README.md",
"url": "https://github.com/yandex/perforator/blob/main/library/python/color/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 411
} |
### Overview
Reservoir sampling is a family of randomized algorithms for choosing a simple random sample, without replacement, of k items from a population of unknown size n in a single pass over the items.
### Example
```jupyter
In [1]: from library.python import reservoir_sampling
In [2]: reservoir_sampling.reservoir_sampling(data=range(100), nsamples=10)
Out[2]: [27, 19, 81, 45, 89, 78, 13, 36, 29, 9]
``` | {
"source": "yandex/perforator",
"title": "library/python/reservoir_sampling/README.md",
"url": "https://github.com/yandex/perforator/blob/main/library/python/reservoir_sampling/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 414
} |
# Perforator Dockerfiles
See [docs](https://perforator.tech/docs/en/guides/build) for details. | {
"source": "yandex/perforator",
"title": "perforator/deploy/docker/README.md",
"url": "https://github.com/yandex/perforator/blob/main/perforator/deploy/docker/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 95
} |
A small tool to convert a lbr-stacks-profile into autofdo's text input format | {
"source": "yandex/perforator",
"title": "perforator/tools/lbr_to_autofdo/README.md",
"url": "https://github.com/yandex/perforator/blob/main/perforator/tools/lbr_to_autofdo/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 77
} |
# Enum serialization runtime support library
{% note warning %}
This library should not be used or referred directly.
Use `GENERATE_ENUM_SERIALIZATION_WITH_HEADER` and `GENERATE_ENUM_SERIALIZATION` macros instead.
{% endnote %}
## Implementation details
### Code bloat
Использование шаблонов вида `TVector<EEnum>`, `std::array<EEnum>` или `TMap<EEnum, TStringBuf>`, а также алгоритмов поверх них, приводит к значительному разбуханию коде. Так как компилятор для разных перечислений вынужден генерировать разные специализации, даже если они компилируются в идентичный машинный код.
Можно во многом выиграть если хранить не массив из `EEnum`, а массив из `std::underlying_type_t<EEnum>` (или из `TSelectEnumRepresentationType<EEnum>::TType`).
Ведь различных типов-перечислений намного больше, чем целочисленных типов, на которых они базируются (и тем более больше, чем различных `TSelectEnumRepresentationType::TType`, коих всего четыре).
И когда компилятор встречает вызов `std::lower_bound`, то для двух массивов из двух перечислений `enum A: int {}` и `enum B: int{}` он создаст две специализации, а если использовать целочисленные типы — то только одну.
Всё это позволяет вынести вызовы вроде `std::lower_bound` в универсальные и переиспользуемые функции, принимающие например `(TArrayRef<const int> values, int enumValue)` своими аргументами.
За счёт этого код
1) быстрее компилируется,
2) результат получается более компактным,
3) как следствие, он меньше засоряет во время исполнения кеш инструкций процессора одинаковыми или очень похожими специализациями функций.
Преобразование между `enum` и `int` выносится в пользовательский код (в шаблонные `inline` функции), и производится только в момент непосредственного использования (первым действием в семействе функций `ToString`, последним действием в семуйстве функций `FromString`), где оптимизирующий компилятор обычно может заменить их на no-op или на простые операции со значениями в регистрах.
А контейнеры вида `TVector<EEnum>` и `TMap<EEnum, ...>`, которые возвращаются из функций `util/generic/serialized_enum.h`, заменяются на специальные классы `TArrayView` и `TMappedDictView`. Они также поддерживают быстрое и преобразование из перечислений в целочисленные типы и обратно в момент использования, и не требуют создавать специализации для каждого из возможных типов-перечислений. | {
"source": "yandex/perforator",
"title": "tools/enum_parser/enum_serialization_runtime/README.md",
"url": "https://github.com/yandex/perforator/blob/main/tools/enum_parser/enum_serialization_runtime/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2357
} |
# Contributor Code of Conduct
## Version 0.1.1 (adapted from 0.3b-angular)
As contributors and maintainers of the Common Expression Language
(CEL) project, we pledge to respect everyone who contributes by
posting issues, updating documentation, submitting pull requests,
providing feedback in comments, and any other activities.
Communication through any of CEL's channels (GitHub, Gitter, IRC,
mailing lists, Google+, Twitter, etc.) must be constructive and never
resort to personal attacks, trolling, public or private harassment,
insults, or other unprofessional conduct.
We promise to extend courtesy and respect to everyone involved in this
project regardless of gender, gender identity, sexual orientation,
disability, age, race, ethnicity, religion, or level of experience. We
expect anyone contributing to the project to do the same.
If any member of the community violates this code of conduct, the
maintainers of the CEL project may take action, removing issues,
comments, and PRs or blocking accounts as deemed appropriate.
If you are subject to or witness unacceptable behavior, or have any
other concerns, please email us at
[[email protected]](mailto:[email protected]). | {
"source": "yandex/perforator",
"title": "vendor/cel.dev/expr/CODE_OF_CONDUCT.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/cel.dev/expr/CODE_OF_CONDUCT.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1199
} |
# How to Contribute
We'd love to accept your patches and contributions to this project. There are a
few guidelines you need to follow.
## Contributor License Agreement
Contributions to this project must be accompanied by a Contributor License
Agreement. You (or your employer) retain the copyright to your contribution,
this simply gives us permission to use and redistribute your contributions as
part of the project. Head over to <https://cla.developers.google.com/> to see
your current agreements on file or to sign a new one.
You generally only need to submit a CLA once, so if you've already submitted one
(even if it was for a different project), you probably don't need to do it
again.
## Code reviews
All submissions, including submissions by project members, require review. We
use GitHub pull requests for this purpose. Consult
[GitHub Help](https://help.github.com/articles/about-pull-requests/) for more
information on using pull requests.
## What to expect from maintainers
Expect maintainers to respond to new issues or pull requests within a week.
For outstanding and ongoing issues and particularly for long-running
pull requests, expect the maintainers to review within a week of a
contributor asking for a new review. There is no commitment to resolution --
merging or closing a pull request, or fixing or closing an issue -- because some
issues will require more discussion than others. | {
"source": "yandex/perforator",
"title": "vendor/cel.dev/expr/CONTRIBUTING.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/cel.dev/expr/CONTRIBUTING.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1413
} |
# Common Expression Language
The Common Expression Language (CEL) implements common semantics for expression
evaluation, enabling different applications to more easily interoperate.
Key Applications
* Security policy: organizations have complex infrastructure and need common
tooling to reason about the system as a whole
* Protocols: expressions are a useful data type and require interoperability
across programming languages and platforms.
Guiding philosophy:
1. Keep it small & fast.
* CEL evaluates in linear time, is mutation free, and not Turing-complete.
This limitation is a feature of the language design, which allows the
implementation to evaluate orders of magnitude faster than equivalently
sandboxed JavaScript.
2. Make it extensible.
* CEL is designed to be embedded in applications, and allows for
extensibility via its context which allows for functions and data to be
provided by the software that embeds it.
3. Developer-friendly.
* The language is approachable to developers. The initial spec was based
on the experience of developing Firebase Rules and usability testing
many prior iterations.
* The library itself and accompanying toolings should be easy to adopt by
teams that seek to integrate CEL into their platforms.
The required components of a system that supports CEL are:
* The textual representation of an expression as written by a developer. It is
of similar syntax to expressions in C/C++/Java/JavaScript
* A binary representation of an expression. It is an abstract syntax tree
(AST).
* A compiler library that converts the textual representation to the binary
representation. This can be done ahead of time (in the control plane) or
just before evaluation (in the data plane).
* A context containing one or more typed variables, often protobuf messages.
Most use-cases will use `attribute_context.proto`
* An evaluator library that takes the binary format in the context and
produces a result, usually a Boolean.
Example of boolean conditions and object construction:
``` c
// Condition
account.balance >= transaction.withdrawal
|| (account.overdraftProtection
&& account.overdraftLimit >= transaction.withdrawal - account.balance)
// Object construction
common.GeoPoint{ latitude: 10.0, longitude: -5.5 }
```
For more detail, see:
* [Introduction](doc/intro.md)
* [Language Definition](doc/langdef.md)
Released under the [Apache License](LICENSE).
Disclaimer: This is not an official Google product. | {
"source": "yandex/perforator",
"title": "vendor/cel.dev/expr/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/cel.dev/expr/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2603
} |
# Contributor Covenant Code of Conduct
## Our Pledge
In the interest of fostering an open and welcoming environment, we as contributors and maintainers pledge to making participation in our project and our community a harassment-free experience for everyone, regardless of age, body size, disability, ethnicity, gender identity and expression, level of experience, nationality, personal appearance, race, religion, or sexual identity and orientation.
## Our Standards
Examples of behavior that contributes to creating a positive environment include:
* Using welcoming and inclusive language
* Being respectful of differing viewpoints and experiences
* Gracefully accepting constructive criticism
* Focusing on what is best for the community
* Showing empathy towards other community members
Examples of unacceptable behavior by participants include:
* The use of sexualized language or imagery and unwelcome sexual attention or advances
* Trolling, insulting/derogatory comments, and personal or political attacks
* Public or private harassment
* Publishing others' private information, such as a physical or electronic address, without explicit permission
* Other conduct which could reasonably be considered inappropriate in a professional setting
## Our Responsibilities
Project maintainers are responsible for clarifying the standards of acceptable behavior and are expected to take appropriate and fair corrective action in response to any instances of unacceptable behavior.
Project maintainers have the right and responsibility to remove, edit, or reject comments, commits, code, wiki edits, issues, and other contributions that are not aligned to this Code of Conduct, or to ban temporarily or permanently any contributor for other behaviors that they deem inappropriate, threatening, offensive, or harmful.
## Scope
This Code of Conduct applies both within project spaces and in public spaces when an individual is representing the project or its community. Examples of representing a project or community include using an official project e-mail address, posting via an official social media account, or acting as an appointed representative at an online or offline event. Representation of a project may be further defined and clarified by project maintainers.
## Enforcement
Instances of abusive, harassing, or otherwise unacceptable behavior may be reported by contacting the project team at [email protected]. The project team will review and investigate all complaints, and will respond in a way that it deems appropriate to the circumstances. The project team is obligated to maintain confidentiality with regard to the reporter of an incident. Further details of specific enforcement policies may be posted separately.
Project maintainers who do not follow or enforce the Code of Conduct in good faith may face temporary or permanent repercussions as determined by other members of the project's leadership.
## Attribution
This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 1.4, available at [http://contributor-covenant.org/version/1/4][version]
[homepage]: http://contributor-covenant.org
[version]: http://contributor-covenant.org/version/1/4/ | {
"source": "yandex/perforator",
"title": "vendor/dario.cat/mergo/CODE_OF_CONDUCT.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/dario.cat/mergo/CODE_OF_CONDUCT.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 3206
} |
<!-- omit in toc -->
# Contributing to mergo
First off, thanks for taking the time to contribute! ❤️
All types of contributions are encouraged and valued. See the [Table of Contents](#table-of-contents) for different ways to help and details about how this project handles them. Please make sure to read the relevant section before making your contribution. It will make it a lot easier for us maintainers and smooth out the experience for all involved. The community looks forward to your contributions. 🎉
> And if you like the project, but just don't have time to contribute, that's fine. There are other easy ways to support the project and show your appreciation, which we would also be very happy about:
> - Star the project
> - Tweet about it
> - Refer this project in your project's readme
> - Mention the project at local meetups and tell your friends/colleagues
<!-- omit in toc -->
## Table of Contents
- [Code of Conduct](#code-of-conduct)
- [I Have a Question](#i-have-a-question)
- [I Want To Contribute](#i-want-to-contribute)
- [Reporting Bugs](#reporting-bugs)
- [Suggesting Enhancements](#suggesting-enhancements)
## Code of Conduct
This project and everyone participating in it is governed by the
[mergo Code of Conduct](https://github.com/imdario/mergoblob/master/CODE_OF_CONDUCT.md).
By participating, you are expected to uphold this code. Please report unacceptable behavior
to <>.
## I Have a Question
> If you want to ask a question, we assume that you have read the available [Documentation](https://pkg.go.dev/github.com/imdario/mergo).
Before you ask a question, it is best to search for existing [Issues](https://github.com/imdario/mergo/issues) that might help you. In case you have found a suitable issue and still need clarification, you can write your question in this issue. It is also advisable to search the internet for answers first.
If you then still feel the need to ask a question and need clarification, we recommend the following:
- Open an [Issue](https://github.com/imdario/mergo/issues/new).
- Provide as much context as you can about what you're running into.
- Provide project and platform versions (nodejs, npm, etc), depending on what seems relevant.
We will then take care of the issue as soon as possible.
## I Want To Contribute
> ### Legal Notice <!-- omit in toc -->
> When contributing to this project, you must agree that you have authored 100% of the content, that you have the necessary rights to the content and that the content you contribute may be provided under the project license.
### Reporting Bugs
<!-- omit in toc -->
#### Before Submitting a Bug Report
A good bug report shouldn't leave others needing to chase you up for more information. Therefore, we ask you to investigate carefully, collect information and describe the issue in detail in your report. Please complete the following steps in advance to help us fix any potential bug as fast as possible.
- Make sure that you are using the latest version.
- Determine if your bug is really a bug and not an error on your side e.g. using incompatible environment components/versions (Make sure that you have read the [documentation](). If you are looking for support, you might want to check [this section](#i-have-a-question)).
- To see if other users have experienced (and potentially already solved) the same issue you are having, check if there is not already a bug report existing for your bug or error in the [bug tracker](https://github.com/imdario/mergoissues?q=label%3Abug).
- Also make sure to search the internet (including Stack Overflow) to see if users outside of the GitHub community have discussed the issue.
- Collect information about the bug:
- Stack trace (Traceback)
- OS, Platform and Version (Windows, Linux, macOS, x86, ARM)
- Version of the interpreter, compiler, SDK, runtime environment, package manager, depending on what seems relevant.
- Possibly your input and the output
- Can you reliably reproduce the issue? And can you also reproduce it with older versions?
<!-- omit in toc -->
#### How Do I Submit a Good Bug Report?
> You must never report security related issues, vulnerabilities or bugs including sensitive information to the issue tracker, or elsewhere in public. Instead sensitive bugs must be sent by email to .
<!-- You may add a PGP key to allow the messages to be sent encrypted as well. -->
We use GitHub issues to track bugs and errors. If you run into an issue with the project:
- Open an [Issue](https://github.com/imdario/mergo/issues/new). (Since we can't be sure at this point whether it is a bug or not, we ask you not to talk about a bug yet and not to label the issue.)
- Explain the behavior you would expect and the actual behavior.
- Please provide as much context as possible and describe the *reproduction steps* that someone else can follow to recreate the issue on their own. This usually includes your code. For good bug reports you should isolate the problem and create a reduced test case.
- Provide the information you collected in the previous section.
Once it's filed:
- The project team will label the issue accordingly.
- A team member will try to reproduce the issue with your provided steps. If there are no reproduction steps or no obvious way to reproduce the issue, the team will ask you for those steps and mark the issue as `needs-repro`. Bugs with the `needs-repro` tag will not be addressed until they are reproduced.
- If the team is able to reproduce the issue, it will be marked `needs-fix`, as well as possibly other tags (such as `critical`), and the issue will be left to be implemented by someone.
### Suggesting Enhancements
This section guides you through submitting an enhancement suggestion for mergo, **including completely new features and minor improvements to existing functionality**. Following these guidelines will help maintainers and the community to understand your suggestion and find related suggestions.
<!-- omit in toc -->
#### Before Submitting an Enhancement
- Make sure that you are using the latest version.
- Read the [documentation]() carefully and find out if the functionality is already covered, maybe by an individual configuration.
- Perform a [search](https://github.com/imdario/mergo/issues) to see if the enhancement has already been suggested. If it has, add a comment to the existing issue instead of opening a new one.
- Find out whether your idea fits with the scope and aims of the project. It's up to you to make a strong case to convince the project's developers of the merits of this feature. Keep in mind that we want features that will be useful to the majority of our users and not just a small subset. If you're just targeting a minority of users, consider writing an add-on/plugin library.
<!-- omit in toc -->
#### How Do I Submit a Good Enhancement Suggestion?
Enhancement suggestions are tracked as [GitHub issues](https://github.com/imdario/mergo/issues).
- Use a **clear and descriptive title** for the issue to identify the suggestion.
- Provide a **step-by-step description of the suggested enhancement** in as many details as possible.
- **Describe the current behavior** and **explain which behavior you expected to see instead** and why. At this point you can also tell which alternatives do not work for you.
- You may want to **include screenshots and animated GIFs** which help you demonstrate the steps or point out the part which the suggestion is related to. You can use [this tool](https://www.cockos.com/licecap/) to record GIFs on macOS and Windows, and [this tool](https://github.com/colinkeenan/silentcast) or [this tool](https://github.com/GNOME/byzanz) on Linux. <!-- this should only be included if the project has a GUI -->
- **Explain why this enhancement would be useful** to most mergo users. You may also want to point out the other projects that solved it better and which could serve as inspiration.
<!-- omit in toc -->
## Attribution
This guide is based on the **contributing-gen**. [Make your own](https://github.com/bttger/contributing-gen)! | {
"source": "yandex/perforator",
"title": "vendor/dario.cat/mergo/CONTRIBUTING.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/dario.cat/mergo/CONTRIBUTING.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 8064
} |
# Mergo
[![GitHub release][5]][6]
[![GoCard][7]][8]
[![Test status][1]][2]
[![OpenSSF Scorecard][21]][22]
[![OpenSSF Best Practices][19]][20]
[![Coverage status][9]][10]
[![Sourcegraph][11]][12]
[![FOSSA status][13]][14]
[![GoDoc][3]][4]
[![Become my sponsor][15]][16]
[![Tidelift][17]][18]
[1]: https://github.com/imdario/mergo/workflows/tests/badge.svg?branch=master
[2]: https://github.com/imdario/mergo/actions/workflows/tests.yml
[3]: https://godoc.org/github.com/imdario/mergo?status.svg
[4]: https://godoc.org/github.com/imdario/mergo
[5]: https://img.shields.io/github/release/imdario/mergo.svg
[6]: https://github.com/imdario/mergo/releases
[7]: https://goreportcard.com/badge/imdario/mergo
[8]: https://goreportcard.com/report/github.com/imdario/mergo
[9]: https://coveralls.io/repos/github/imdario/mergo/badge.svg?branch=master
[10]: https://coveralls.io/github/imdario/mergo?branch=master
[11]: https://sourcegraph.com/github.com/imdario/mergo/-/badge.svg
[12]: https://sourcegraph.com/github.com/imdario/mergo?badge
[13]: https://app.fossa.io/api/projects/git%2Bgithub.com%2Fimdario%2Fmergo.svg?type=shield
[14]: https://app.fossa.io/projects/git%2Bgithub.com%2Fimdario%2Fmergo?ref=badge_shield
[15]: https://img.shields.io/github/sponsors/imdario
[16]: https://github.com/sponsors/imdario
[17]: https://tidelift.com/badges/package/go/github.com%2Fimdario%2Fmergo
[18]: https://tidelift.com/subscription/pkg/go-github.com-imdario-mergo
[19]: https://bestpractices.coreinfrastructure.org/projects/7177/badge
[20]: https://bestpractices.coreinfrastructure.org/projects/7177
[21]: https://api.securityscorecards.dev/projects/github.com/imdario/mergo/badge
[22]: https://api.securityscorecards.dev/projects/github.com/imdario/mergo
A helper to merge structs and maps in Golang. Useful for configuration default values, avoiding messy if-statements.
Mergo merges same-type structs and maps by setting default values in zero-value fields. Mergo won't merge unexported (private) fields. It will do recursively any exported one. It also won't merge structs inside maps (because they are not addressable using Go reflection).
Also a lovely [comune](http://en.wikipedia.org/wiki/Mergo) (municipality) in the Province of Ancona in the Italian region of Marche.
## Status
It is ready for production use. [It is used in several projects by Docker, Google, The Linux Foundation, VMWare, Shopify, Microsoft, etc](https://github.com/imdario/mergo#mergo-in-the-wild).
### Important notes
#### 1.0.0
In [1.0.0](//github.com/imdario/mergo/releases/tag/1.0.0) Mergo moves to a vanity URL `dario.cat/mergo`.
#### 0.3.9
Please keep in mind that a problematic PR broke [0.3.9](//github.com/imdario/mergo/releases/tag/0.3.9). I reverted it in [0.3.10](//github.com/imdario/mergo/releases/tag/0.3.10), and I consider it stable but not bug-free. Also, this version adds support for go modules.
Keep in mind that in [0.3.2](//github.com/imdario/mergo/releases/tag/0.3.2), Mergo changed `Merge()`and `Map()` signatures to support [transformers](#transformers). I added an optional/variadic argument so that it won't break the existing code.
If you were using Mergo before April 6th, 2015, please check your project works as intended after updating your local copy with ```go get -u dario.cat/mergo```. I apologize for any issue caused by its previous behavior and any future bug that Mergo could cause in existing projects after the change (release 0.2.0).
### Donations
If Mergo is useful to you, consider buying me a coffee, a beer, or making a monthly donation to allow me to keep building great free software. :heart_eyes:
<a href='https://ko-fi.com/B0B58839' target='_blank'><img height='36' style='border:0px;height:36px;' src='https://az743702.vo.msecnd.net/cdn/kofi1.png?v=0' border='0' alt='Buy Me a Coffee at ko-fi.com' /></a>
<a href="https://liberapay.com/dario/donate"><img alt="Donate using Liberapay" src="https://liberapay.com/assets/widgets/donate.svg"></a>
<a href='https://github.com/sponsors/imdario' target='_blank'><img alt="Become my sponsor" src="https://img.shields.io/github/sponsors/imdario?style=for-the-badge" /></a>
### Mergo in the wild
- [moby/moby](https://github.com/moby/moby)
- [kubernetes/kubernetes](https://github.com/kubernetes/kubernetes)
- [vmware/dispatch](https://github.com/vmware/dispatch)
- [Shopify/themekit](https://github.com/Shopify/themekit)
- [imdario/zas](https://github.com/imdario/zas)
- [matcornic/hermes](https://github.com/matcornic/hermes)
- [OpenBazaar/openbazaar-go](https://github.com/OpenBazaar/openbazaar-go)
- [kataras/iris](https://github.com/kataras/iris)
- [michaelsauter/crane](https://github.com/michaelsauter/crane)
- [go-task/task](https://github.com/go-task/task)
- [sensu/uchiwa](https://github.com/sensu/uchiwa)
- [ory/hydra](https://github.com/ory/hydra)
- [sisatech/vcli](https://github.com/sisatech/vcli)
- [dairycart/dairycart](https://github.com/dairycart/dairycart)
- [projectcalico/felix](https://github.com/projectcalico/felix)
- [resin-os/balena](https://github.com/resin-os/balena)
- [go-kivik/kivik](https://github.com/go-kivik/kivik)
- [Telefonica/govice](https://github.com/Telefonica/govice)
- [supergiant/supergiant](supergiant/supergiant)
- [SergeyTsalkov/brooce](https://github.com/SergeyTsalkov/brooce)
- [soniah/dnsmadeeasy](https://github.com/soniah/dnsmadeeasy)
- [ohsu-comp-bio/funnel](https://github.com/ohsu-comp-bio/funnel)
- [EagerIO/Stout](https://github.com/EagerIO/Stout)
- [lynndylanhurley/defsynth-api](https://github.com/lynndylanhurley/defsynth-api)
- [russross/canvasassignments](https://github.com/russross/canvasassignments)
- [rdegges/cryptly-api](https://github.com/rdegges/cryptly-api)
- [casualjim/exeggutor](https://github.com/casualjim/exeggutor)
- [divshot/gitling](https://github.com/divshot/gitling)
- [RWJMurphy/gorl](https://github.com/RWJMurphy/gorl)
- [andrerocker/deploy42](https://github.com/andrerocker/deploy42)
- [elwinar/rambler](https://github.com/elwinar/rambler)
- [tmaiaroto/gopartman](https://github.com/tmaiaroto/gopartman)
- [jfbus/impressionist](https://github.com/jfbus/impressionist)
- [Jmeyering/zealot](https://github.com/Jmeyering/zealot)
- [godep-migrator/rigger-host](https://github.com/godep-migrator/rigger-host)
- [Dronevery/MultiwaySwitch-Go](https://github.com/Dronevery/MultiwaySwitch-Go)
- [thoas/picfit](https://github.com/thoas/picfit)
- [mantasmatelis/whooplist-server](https://github.com/mantasmatelis/whooplist-server)
- [jnuthong/item_search](https://github.com/jnuthong/item_search)
- [bukalapak/snowboard](https://github.com/bukalapak/snowboard)
- [containerssh/containerssh](https://github.com/containerssh/containerssh)
- [goreleaser/goreleaser](https://github.com/goreleaser/goreleaser)
- [tjpnz/structbot](https://github.com/tjpnz/structbot)
## Install
go get dario.cat/mergo
// use in your .go code
import (
"dario.cat/mergo"
)
## Usage
You can only merge same-type structs with exported fields initialized as zero value of their type and same-types maps. Mergo won't merge unexported (private) fields but will do recursively any exported one. It won't merge empty structs value as [they are zero values](https://golang.org/ref/spec#The_zero_value) too. Also, maps will be merged recursively except for structs inside maps (because they are not addressable using Go reflection).
```go
if err := mergo.Merge(&dst, src); err != nil {
// ...
}
```
Also, you can merge overwriting values using the transformer `WithOverride`.
```go
if err := mergo.Merge(&dst, src, mergo.WithOverride); err != nil {
// ...
}
```
Additionally, you can map a `map[string]interface{}` to a struct (and otherwise, from struct to map), following the same restrictions as in `Merge()`. Keys are capitalized to find each corresponding exported field.
```go
if err := mergo.Map(&dst, srcMap); err != nil {
// ...
}
```
Warning: if you map a struct to map, it won't do it recursively. Don't expect Mergo to map struct members of your struct as `map[string]interface{}`. They will be just assigned as values.
Here is a nice example:
```go
package main
import (
"fmt"
"dario.cat/mergo"
)
type Foo struct {
A string
B int64
}
func main() {
src := Foo{
A: "one",
B: 2,
}
dest := Foo{
A: "two",
}
mergo.Merge(&dest, src)
fmt.Println(dest)
// Will print
// {two 2}
}
```
Note: if test are failing due missing package, please execute:
go get gopkg.in/yaml.v3
### Transformers
Transformers allow to merge specific types differently than in the default behavior. In other words, now you can customize how some types are merged. For example, `time.Time` is a struct; it doesn't have zero value but IsZero can return true because it has fields with zero value. How can we merge a non-zero `time.Time`?
```go
package main
import (
"fmt"
"dario.cat/mergo"
"reflect"
"time"
)
type timeTransformer struct {
}
func (t timeTransformer) Transformer(typ reflect.Type) func(dst, src reflect.Value) error {
if typ == reflect.TypeOf(time.Time{}) {
return func(dst, src reflect.Value) error {
if dst.CanSet() {
isZero := dst.MethodByName("IsZero")
result := isZero.Call([]reflect.Value{})
if result[0].Bool() {
dst.Set(src)
}
}
return nil
}
}
return nil
}
type Snapshot struct {
Time time.Time
// ...
}
func main() {
src := Snapshot{time.Now()}
dest := Snapshot{}
mergo.Merge(&dest, src, mergo.WithTransformers(timeTransformer{}))
fmt.Println(dest)
// Will print
// { 2018-01-12 01:15:00 +0000 UTC m=+0.000000001 }
}
```
## Contact me
If I can help you, you have an idea or you are using Mergo in your projects, don't hesitate to drop me a line (or a pull request): [@im_dario](https://twitter.com/im_dario)
## About
Written by [Dario Castañé](http://dario.im).
## License
[BSD 3-Clause](http://opensource.org/licenses/BSD-3-Clause) license, as [Go language](http://golang.org/LICENSE).
[](https://app.fossa.io/projects/git%2Bgithub.com%2Fimdario%2Fmergo?ref=badge_large) | {
"source": "yandex/perforator",
"title": "vendor/dario.cat/mergo/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/dario.cat/mergo/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 10135
} |
# Changelog
All notable changes to this project will be documented in this file.
The format is based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/).
This project adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0.html).
## [Unreleased]
## [1.33.0/0.55.0/0.9.0/0.0.12] 2024-12-12
### Added
- Add `Reset` method to `SpanRecorder` in `go.opentelemetry.io/otel/sdk/trace/tracetest`. (#5994)
- Add `EnabledInstrument` interface in `go.opentelemetry.io/otel/sdk/metric/internal/x`.
This is an experimental interface that is implemented by synchronous instruments provided by `go.opentelemetry.io/otel/sdk/metric`.
Users can use it to avoid performing computationally expensive operations when recording measurements.
It does not fall within the scope of the OpenTelemetry Go versioning and stability [policy](./VERSIONING.md) and it may be changed in backwards incompatible ways or removed in feature releases. (#6016)
### Changed
- The default global API now supports full auto-instrumentation from the `go.opentelemetry.io/auto` package.
See that package for more information. (#5920)
- Propagate non-retryable error messages to client in `go.opentelemetry.io/otel/exporters/otlp/otlplog/otlploghttp`. (#5929)
- Propagate non-retryable error messages to client in `go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracehttp`. (#5929)
- Propagate non-retryable error messages to client in `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetrichttp`. (#5929)
- Performance improvements for attribute value `AsStringSlice`, `AsFloat64Slice`, `AsInt64Slice`, `AsBoolSlice`. (#6011)
- Change `EnabledParameters` to have a `Severity` field instead of a getter and setter in `go.opentelemetry.io/otel/log`. (#6009)
### Fixed
- Fix inconsistent request body closing in `go.opentelemetry.io/otel/exporters/otlp/otlplog/otlploghttp`. (#5954)
- Fix inconsistent request body closing in `go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracehttp`. (#5954)
- Fix inconsistent request body closing in `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetrichttp`. (#5954)
- Fix invalid exemplar keys in `go.opentelemetry.io/otel/exporters/prometheus`. (#5995)
- Fix attribute value truncation in `go.opentelemetry.io/otel/sdk/trace`. (#5997)
- Fix attribute value truncation in `go.opentelemetry.io/otel/sdk/log`. (#6032)
<!-- Released section -->
<!-- Don't change this section unless doing release -->
## [1.32.0/0.54.0/0.8.0/0.0.11] 2024-11-08
### Added
- Add `go.opentelemetry.io/otel/sdk/metric/exemplar.AlwaysOffFilter`, which can be used to disable exemplar recording. (#5850)
- Add `go.opentelemetry.io/otel/sdk/metric.WithExemplarFilter`, which can be used to configure the exemplar filter used by the metrics SDK. (#5850)
- Add `ExemplarReservoirProviderSelector` and `DefaultExemplarReservoirProviderSelector` to `go.opentelemetry.io/otel/sdk/metric`, which defines the exemplar reservoir to use based on the aggregation of the metric. (#5861)
- Add `ExemplarReservoirProviderSelector` to `go.opentelemetry.io/otel/sdk/metric.Stream` to allow using views to configure the exemplar reservoir to use for a metric. (#5861)
- Add `ReservoirProvider`, `HistogramReservoirProvider` and `FixedSizeReservoirProvider` to `go.opentelemetry.io/otel/sdk/metric/exemplar` to make it convenient to use providers of Reservoirs. (#5861)
- The `go.opentelemetry.io/otel/semconv/v1.27.0` package.
The package contains semantic conventions from the `v1.27.0` version of the OpenTelemetry Semantic Conventions. (#5894)
- Add `Attributes attribute.Set` field to `Scope` in `go.opentelemetry.io/otel/sdk/instrumentation`. (#5903)
- Add `Attributes attribute.Set` field to `ScopeRecords` in `go.opentelemetry.io/otel/log/logtest`. (#5927)
- `go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracegrpc` adds instrumentation scope attributes. (#5934)
- `go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracehttp` adds instrumentation scope attributes. (#5934)
- `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetricgrpc` adds instrumentation scope attributes. (#5935)
- `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetrichttp` adds instrumentation scope attributes. (#5935)
- `go.opentelemetry.io/otel/exporters/otlp/otlplog/otlploggrpc` adds instrumentation scope attributes. (#5933)
- `go.opentelemetry.io/otel/exporters/otlp/otlplog/otlploghttp` adds instrumentation scope attributes. (#5933)
- `go.opentelemetry.io/otel/exporters/prometheus` adds instrumentation scope attributes in `otel_scope_info` metric as labels. (#5932)
### Changed
- Support scope attributes and make them as identifying for `Tracer` in `go.opentelemetry.io/otel` and `go.opentelemetry.io/otel/sdk/trace`. (#5924)
- Support scope attributes and make them as identifying for `Meter` in `go.opentelemetry.io/otel` and `go.opentelemetry.io/otel/sdk/metric`. (#5926)
- Support scope attributes and make them as identifying for `Logger` in `go.opentelemetry.io/otel` and `go.opentelemetry.io/otel/sdk/log`. (#5925)
- Make schema URL and scope attributes as identifying for `Tracer` in `go.opentelemetry.io/otel/bridge/opentracing`. (#5931)
- Clear unneeded slice elements to allow GC to collect the objects in `go.opentelemetry.io/otel/sdk/metric` and `go.opentelemetry.io/otel/sdk/trace`. (#5804)
### Fixed
- Global MeterProvider registration unwraps global instrument Observers, the undocumented Unwrap() methods are now private. (#5881)
- `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetricgrpc` now keeps the metadata already present in the context when `WithHeaders` is used. (#5892)
- `go.opentelemetry.io/otel/exporters/otlp/otlplog/otlploggrpc` now keeps the metadata already present in the context when `WithHeaders` is used. (#5911)
- `go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracegrpc` now keeps the metadata already present in the context when `WithHeaders` is used. (#5915)
- Fix `go.opentelemetry.io/otel/exporters/prometheus` trying to add exemplars to Gauge metrics, which is unsupported. (#5912)
- Fix `WithEndpointURL` to always use a secure connection when an https URL is passed in `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetricgrpc`. (#5944)
- Fix `WithEndpointURL` to always use a secure connection when an https URL is passed in `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetrichttp`. (#5944)
- Fix `WithEndpointURL` to always use a secure connection when an https URL is passed in `go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracegrpc`. (#5944)
- Fix `WithEndpointURL` to always use a secure connection when an https URL is passed in `go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracehttp`. (#5944)
- Fix incorrect metrics generated from callbacks when multiple readers are used in `go.opentelemetry.io/otel/sdk/metric`. (#5900)
### Removed
- Remove all examples under `go.opentelemetry.io/otel/example` as they are moved to [Contrib repository](https://github.com/open-telemetry/opentelemetry-go-contrib/tree/main/examples). (#5930)
## [1.31.0/0.53.0/0.7.0/0.0.10] 2024-10-11
### Added
- Add `go.opentelemetry.io/otel/sdk/metric/exemplar` package which includes `Exemplar`, `Filter`, `TraceBasedFilter`, `AlwaysOnFilter`, `HistogramReservoir`, `FixedSizeReservoir`, `Reservoir`, `Value` and `ValueType` types. These will be used for configuring the exemplar reservoir for the metrics sdk. (#5747, #5862)
- Add `WithExportBufferSize` option to log batch processor.(#5877)
### Changed
- Enable exemplars by default in `go.opentelemetry.io/otel/sdk/metric`. Exemplars can be disabled by setting `OTEL_METRICS_EXEMPLAR_FILTER=always_off` (#5778)
- `Logger.Enabled` in `go.opentelemetry.io/otel/log` now accepts a newly introduced `EnabledParameters` type instead of `Record`. (#5791)
- `FilterProcessor.Enabled` in `go.opentelemetry.io/otel/sdk/log/internal/x` now accepts `EnabledParameters` instead of `Record`. (#5791)
- The `Record` type in `go.opentelemetry.io/otel/log` is no longer comparable. (#5847)
- Performance improvements for the trace SDK `SetAttributes` method in `Span`. (#5864)
- Reduce memory allocations for the `Event` and `Link` lists in `Span`. (#5858)
- Performance improvements for the trace SDK `AddEvent`, `AddLink`, `RecordError` and `End` methods in `Span`. (#5874)
### Deprecated
- Deprecate all examples under `go.opentelemetry.io/otel/example` as they are moved to [Contrib repository](https://github.com/open-telemetry/opentelemetry-go-contrib/tree/main/examples). (#5854)
### Fixed
- The race condition for multiple `FixedSize` exemplar reservoirs identified in #5814 is resolved. (#5819)
- Fix log records duplication in case of heterogeneous resource attributes by correctly mapping each log record to it's resource and scope. (#5803)
- Fix timer channel drain to avoid hanging on Go 1.23. (#5868)
- Fix delegation for global meter providers, and panic when calling otel.SetMeterProvider. (#5827)
- Change the `reflect.TypeOf` to use a nil pointer to not allocate on the heap unless necessary. (#5827)
## [1.30.0/0.52.0/0.6.0/0.0.9] 2024-09-09
### Added
- Support `OTEL_EXPORTER_OTLP_LOGS_INSECURE` and `OTEL_EXPORTER_OTLP_INSECURE` environments in `go.opentelemetry.io/otel/exporters/otlp/otlplog/otlploggrpc`. (#5739)
- The `WithResource` option for `NewMeterProvider` now merges the provided resources with the ones from environment variables. (#5773)
- The `WithResource` option for `NewLoggerProvider` now merges the provided resources with the ones from environment variables. (#5773)
- Add UTF-8 support to `go.opentelemetry.io/otel/exporters/prometheus`. (#5755)
### Fixed
- Fix memory leak in the global `MeterProvider` when identical instruments are repeatedly created. (#5754)
- Fix panic on instruments creation when setting meter provider. (#5758)
- Fix an issue where `SetMeterProvider` in `go.opentelemetry.io/otel` might miss the delegation for instruments and registries. (#5780)
### Removed
- Drop support for [Go 1.21]. (#5736, #5740, #5800)
## [1.29.0/0.51.0/0.5.0] 2024-08-23
This release is the last to support [Go 1.21].
The next release will require at least [Go 1.22].
### Added
- Add MacOS ARM64 platform to the compatibility testing suite. (#5577)
- Add `InstrumentationScope` field to `SpanStub` in `go.opentelemetry.io/otel/sdk/trace/tracetest`, as a replacement for the deprecated `InstrumentationLibrary`. (#5627)
- Make the initial release of `go.opentelemetry.io/otel/exporters/otlp/otlplog/otlploggrpc`.
This new module contains an OTLP exporter that transmits log telemetry using gRPC.
This module is unstable and breaking changes may be introduced.
See our [versioning policy](VERSIONING.md) for more information about these stability guarantees. (#5629)
- Add `Walk` function to `TraceState` in `go.opentelemetry.io/otel/trace` to iterate all the key-value pairs. (#5651)
- Bridge the trace state in `go.opentelemetry.io/otel/bridge/opencensus`. (#5651)
- Zero value of `SimpleProcessor` in `go.opentelemetry.io/otel/sdk/log` no longer panics. (#5665)
- The `FilterProcessor` interface type is added in `go.opentelemetry.io/otel/sdk/log/internal/x`.
This is an optional and experimental interface that log `Processor`s can implement to instruct the `Logger` if a `Record` will be processed or not.
It replaces the existing `Enabled` method that is removed from the `Processor` interface itself.
It does not fall within the scope of the OpenTelemetry Go versioning and stability [policy](./VERSIONING.md) and it may be changed in backwards incompatible ways or removed in feature releases. (#5692)
- Support [Go 1.23]. (#5720)
### Changed
- `NewMemberRaw`, `NewKeyProperty` and `NewKeyValuePropertyRaw` in `go.opentelemetry.io/otel/baggage` allow UTF-8 string in key. (#5132)
- `Processor.OnEmit` in `go.opentelemetry.io/otel/sdk/log` now accepts a pointer to `Record` instead of a value so that the record modifications done in a processor are propagated to subsequent registered processors. (#5636)
- `SimpleProcessor.Enabled` in `go.opentelemetry.io/otel/sdk/log` now returns `false` if the exporter is `nil`. (#5665)
- Update the concurrency requirements of `Exporter` in `go.opentelemetry.io/otel/sdk/log`. (#5666)
- `SimpleProcessor` in `go.opentelemetry.io/otel/sdk/log` synchronizes `OnEmit` calls. (#5666)
- The `Processor` interface in `go.opentelemetry.io/otel/sdk/log` no longer includes the `Enabled` method.
See the `FilterProcessor` interface type added in `go.opentelemetry.io/otel/sdk/log/internal/x` to continue providing this functionality. (#5692)
- The `SimpleProcessor` type in `go.opentelemetry.io/otel/sdk/log` is no longer comparable. (#5693)
- The `BatchProcessor` type in `go.opentelemetry.io/otel/sdk/log` is no longer comparable. (#5693)
### Fixed
- Correct comments for the priority of the `WithEndpoint` and `WithEndpointURL` options and their corresponding environment variables in `go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracehttp`. (#5584)
- Pass the underlying error rather than a generic retry-able failure in `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetrichttp`, `go.opentelemetry.io/otel/exporters/otlp/otlplog/otlploghttp` and `go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracehttp`. (#5541)
- Correct the `Tracer`, `Meter`, and `Logger` names used in `go.opentelemetry.io/otel/example/dice`. (#5612)
- Correct the `Tracer` names used in `go.opentelemetry.io/otel/example/namedtracer`. (#5612)
- Correct the `Tracer` name used in `go.opentelemetry.io/otel/example/opencensus`. (#5612)
- Correct the `Tracer` and `Meter` names used in `go.opentelemetry.io/otel/example/otel-collector`. (#5612)
- Correct the `Tracer` names used in `go.opentelemetry.io/otel/example/passthrough`. (#5612)
- Correct the `Meter` name used in `go.opentelemetry.io/otel/example/prometheus`. (#5612)
- Correct the `Tracer` names used in `go.opentelemetry.io/otel/example/zipkin`. (#5612)
- Correct comments for the priority of the `WithEndpoint` and `WithEndpointURL` options and their corresponding environment variables in `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetricgrpc` and `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetrichttp`. (#5641)
- Correct comments for the priority of the `WithEndpoint` and `WithEndpointURL` options and their corresponding environment variables in `go.opentelemetry.io/otel/exporters/otlp/otlplog/otlploghttp`. (#5650)
- Stop percent encoding header environment variables in `go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracegrpc`, `go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracehttp`, `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetricgrpc` and `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetrichttp` (#5705)
- Remove invalid environment variable header keys in `go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracegrpc`, `go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracehttp`, `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetricgrpc` and `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetrichttp` (#5705)
### Removed
- The `Enabled` method of the `SimpleProcessor` in `go.opentelemetry.io/otel/sdk/log` is removed. (#5692)
- The `Enabled` method of the `BatchProcessor` in `go.opentelemetry.io/otel/sdk/log` is removed. (#5692)
## [1.28.0/0.50.0/0.4.0] 2024-07-02
### Added
- The `IsEmpty` method is added to the `Instrument` type in `go.opentelemetry.io/otel/sdk/metric`.
This method is used to check if an `Instrument` instance is a zero-value. (#5431)
- Store and provide the emitted `context.Context` in `ScopeRecords` of `go.opentelemetry.io/otel/sdk/log/logtest`. (#5468)
- The `go.opentelemetry.io/otel/semconv/v1.26.0` package.
The package contains semantic conventions from the `v1.26.0` version of the OpenTelemetry Semantic Conventions. (#5476)
- The `AssertRecordEqual` method to `go.opentelemetry.io/otel/log/logtest` to allow comparison of two log records in tests. (#5499)
- The `WithHeaders` option to `go.opentelemetry.io/otel/exporters/zipkin` to allow configuring custom http headers while exporting spans. (#5530)
### Changed
- `Tracer.Start` in `go.opentelemetry.io/otel/trace/noop` no longer allocates a span for empty span context. (#5457)
- Upgrade `go.opentelemetry.io/otel/semconv/v1.25.0` to `go.opentelemetry.io/otel/semconv/v1.26.0` in `go.opentelemetry.io/otel/example/otel-collector`. (#5490)
- Upgrade `go.opentelemetry.io/otel/semconv/v1.25.0` to `go.opentelemetry.io/otel/semconv/v1.26.0` in `go.opentelemetry.io/otel/example/zipkin`. (#5490)
- Upgrade `go.opentelemetry.io/otel/semconv/v1.25.0` to `go.opentelemetry.io/otel/semconv/v1.26.0` in `go.opentelemetry.io/otel/exporters/zipkin`. (#5490)
- The exporter no longer exports the deprecated "otel.library.name" or "otel.library.version" attributes.
- Upgrade `go.opentelemetry.io/otel/semconv/v1.25.0` to `go.opentelemetry.io/otel/semconv/v1.26.0` in `go.opentelemetry.io/otel/sdk/resource`. (#5490)
- Upgrade `go.opentelemetry.io/otel/semconv/v1.25.0` to `go.opentelemetry.io/otel/semconv/v1.26.0` in `go.opentelemetry.io/otel/sdk/trace`. (#5490)
- `SimpleProcessor.OnEmit` in `go.opentelemetry.io/otel/sdk/log` no longer allocates a slice which makes it possible to have a zero-allocation log processing using `SimpleProcessor`. (#5493)
- Use non-generic functions in the `Start` method of `"go.opentelemetry.io/otel/sdk/trace".Trace` to reduce memory allocation. (#5497)
- `service.instance.id` is populated for a `Resource` created with `"go.opentelemetry.io/otel/sdk/resource".Default` with a default value when `OTEL_GO_X_RESOURCE` is set. (#5520)
- Improve performance of metric instruments in `go.opentelemetry.io/otel/sdk/metric` by removing unnecessary calls to `time.Now`. (#5545)
### Fixed
- Log a warning to the OpenTelemetry internal logger when a `Record` in `go.opentelemetry.io/otel/sdk/log` drops an attribute due to a limit being reached. (#5376)
- Identify the `Tracer` returned from the global `TracerProvider` in `go.opentelemetry.io/otel/global` with its schema URL. (#5426)
- Identify the `Meter` returned from the global `MeterProvider` in `go.opentelemetry.io/otel/global` with its schema URL. (#5426)
- Log a warning to the OpenTelemetry internal logger when a `Span` in `go.opentelemetry.io/otel/sdk/trace` drops an attribute, event, or link due to a limit being reached. (#5434)
- Document instrument name requirements in `go.opentelemetry.io/otel/metric`. (#5435)
- Prevent random number generation data-race for experimental rand exemplars in `go.opentelemetry.io/otel/sdk/metric`. (#5456)
- Fix counting number of dropped attributes of `Record` in `go.opentelemetry.io/otel/sdk/log`. (#5464)
- Fix panic in baggage creation when a member contains `0x80` char in key or value. (#5494)
- Correct comments for the priority of the `WithEndpoint` and `WithEndpointURL` options and their corresponding environment variables in `go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracegrpc`. (#5508)
- Retry trace and span ID generation if it generated an invalid one in `go.opentelemetry.io/otel/sdk/trace`. (#5514)
- Fix stale timestamps reported by the last-value aggregation. (#5517)
- Indicate the `Exporter` in `go.opentelemetry.io/otel/exporters/otlp/otlplog/otlploghttp` must be created by the `New` method. (#5521)
- Improved performance in all `{Bool,Int64,Float64,String}SliceValue` functions of `go.opentelemetry.io/attributes` by reducing the number of allocations. (#5549)
- Replace invalid percent-encoded octet sequences with replacement char in `go.opentelemetry.io/otel/baggage`. (#5528)
## [1.27.0/0.49.0/0.3.0] 2024-05-21
### Added
- Add example for `go.opentelemetry.io/otel/exporters/stdout/stdoutlog`. (#5242)
- Add `RecordFactory` in `go.opentelemetry.io/otel/sdk/log/logtest` to facilitate testing exporter and processor implementations. (#5258)
- Add `RecordFactory` in `go.opentelemetry.io/otel/log/logtest` to facilitate testing bridge implementations. (#5263)
- The count of dropped records from the `BatchProcessor` in `go.opentelemetry.io/otel/sdk/log` is logged. (#5276)
- Add metrics in the `otel-collector` example. (#5283)
- Add the synchronous gauge instrument to `go.opentelemetry.io/otel/metric`. (#5304)
- An `int64` or `float64` synchronous gauge instrument can now be created from a `Meter`.
- All implementations of the API (`go.opentelemetry.io/otel/metric/noop`, `go.opentelemetry.io/otel/sdk/metric`) are updated to support this instrument.
- Add logs to `go.opentelemetry.io/otel/example/dice`. (#5349)
### Changed
- The `Shutdown` method of `Exporter` in `go.opentelemetry.io/otel/exporters/stdout/stdouttrace` ignores the context cancellation and always returns `nil`. (#5189)
- The `ForceFlush` and `Shutdown` methods of the exporter returned by `New` in `go.opentelemetry.io/otel/exporters/stdout/stdoutmetric` ignore the context cancellation and always return `nil`. (#5189)
- Apply the value length limits to `Record` attributes in `go.opentelemetry.io/otel/sdk/log`. (#5230)
- De-duplicate map attributes added to a `Record` in `go.opentelemetry.io/otel/sdk/log`. (#5230)
- `go.opentelemetry.io/otel/exporters/stdout/stdoutlog` won't print timestamps when `WithoutTimestamps` option is set. (#5241)
- The `go.opentelemetry.io/otel/exporters/stdout/stdoutlog` exporter won't print `AttributeValueLengthLimit` and `AttributeCountLimit` fields now, instead it prints the `DroppedAttributes` field. (#5272)
- Improved performance in the `Stringer` implementation of `go.opentelemetry.io/otel/baggage.Member` by reducing the number of allocations. (#5286)
- Set the start time for last-value aggregates in `go.opentelemetry.io/otel/sdk/metric`. (#5305)
- The `Span` in `go.opentelemetry.io/otel/sdk/trace` will record links without span context if either non-empty `TraceState` or attributes are provided. (#5315)
- Upgrade all dependencies of `go.opentelemetry.io/otel/semconv/v1.24.0` to `go.opentelemetry.io/otel/semconv/v1.25.0`. (#5374)
### Fixed
- Comparison of unordered maps for `go.opentelemetry.io/otel/log.KeyValue` and `go.opentelemetry.io/otel/log.Value`. (#5306)
- Fix the empty output of `go.opentelemetry.io/otel/log.Value` in `go.opentelemetry.io/otel/exporters/stdout/stdoutlog`. (#5311)
- Split the behavior of `Recorder` in `go.opentelemetry.io/otel/log/logtest` so it behaves as a `LoggerProvider` only. (#5365)
- Fix wrong package name of the error message when parsing endpoint URL in `go.opentelemetry.io/otel/exporters/otlp/otlplog/otlploghttp`. (#5371)
- Identify the `Logger` returned from the global `LoggerProvider` in `go.opentelemetry.io/otel/log/global` with its schema URL. (#5375)
## [1.26.0/0.48.0/0.2.0-alpha] 2024-04-24
### Added
- Add `Recorder` in `go.opentelemetry.io/otel/log/logtest` to facilitate testing the log bridge implementations. (#5134)
- Add span flags to OTLP spans and links exported by `go.opentelemetry.io/otel/exporters/otlp/otlptrace`. (#5194)
- Make the initial alpha release of `go.opentelemetry.io/otel/sdk/log`.
This new module contains the Go implementation of the OpenTelemetry Logs SDK.
This module is unstable and breaking changes may be introduced.
See our [versioning policy](VERSIONING.md) for more information about these stability guarantees. (#5240)
- Make the initial alpha release of `go.opentelemetry.io/otel/exporters/otlp/otlplog/otlploghttp`.
This new module contains an OTLP exporter that transmits log telemetry using HTTP.
This module is unstable and breaking changes may be introduced.
See our [versioning policy](VERSIONING.md) for more information about these stability guarantees. (#5240)
- Make the initial alpha release of `go.opentelemetry.io/otel/exporters/stdout/stdoutlog`.
This new module contains an exporter prints log records to STDOUT.
This module is unstable and breaking changes may be introduced.
See our [versioning policy](VERSIONING.md) for more information about these stability guarantees. (#5240)
- The `go.opentelemetry.io/otel/semconv/v1.25.0` package.
The package contains semantic conventions from the `v1.25.0` version of the OpenTelemetry Semantic Conventions. (#5254)
### Changed
- Update `go.opentelemetry.io/proto/otlp` from v1.1.0 to v1.2.0. (#5177)
- Improve performance of baggage member character validation in `go.opentelemetry.io/otel/baggage`. (#5214)
- The `otel-collector` example now uses docker compose to bring up services instead of kubernetes. (#5244)
### Fixed
- Slice attribute values in `go.opentelemetry.io/otel/attribute` are now emitted as their JSON representation. (#5159)
## [1.25.0/0.47.0/0.0.8/0.1.0-alpha] 2024-04-05
### Added
- Add `WithProxy` option in `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetrichttp`. (#4906)
- Add `WithProxy` option in `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlptracehttp`. (#4906)
- Add `AddLink` method to the `Span` interface in `go.opentelemetry.io/otel/trace`. (#5032)
- The `Enabled` method is added to the `Logger` interface in `go.opentelemetry.io/otel/log`.
This method is used to notify users if a log record will be emitted or not. (#5071)
- Add `SeverityUndefined` `const` to `go.opentelemetry.io/otel/log`.
This value represents an unset severity level. (#5072)
- Add `Empty` function in `go.opentelemetry.io/otel/log` to return a `KeyValue` for an empty value. (#5076)
- Add `go.opentelemetry.io/otel/log/global` to manage the global `LoggerProvider`.
This package is provided with the anticipation that all functionality will be migrate to `go.opentelemetry.io/otel` when `go.opentelemetry.io/otel/log` stabilizes.
At which point, users will be required to migrage their code, and this package will be deprecated then removed. (#5085)
- Add support for `Summary` metrics in the `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetrichttp` and `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetricgrpc` exporters. (#5100)
- Add `otel.scope.name` and `otel.scope.version` tags to spans exported by `go.opentelemetry.io/otel/exporters/zipkin`. (#5108)
- Add support for `AddLink` to `go.opentelemetry.io/otel/bridge/opencensus`. (#5116)
- Add `String` method to `Value` and `KeyValue` in `go.opentelemetry.io/otel/log`. (#5117)
- Add Exemplar support to `go.opentelemetry.io/otel/exporters/prometheus`. (#5111)
- Add metric semantic conventions to `go.opentelemetry.io/otel/semconv/v1.24.0`. Future `semconv` packages will include metric semantic conventions as well. (#4528)
### Changed
- `SpanFromContext` and `SpanContextFromContext` in `go.opentelemetry.io/otel/trace` no longer make a heap allocation when the passed context has no span. (#5049)
- `go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracegrpc` and `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetricgrpc` now create a gRPC client in idle mode and with "dns" as the default resolver using [`grpc.NewClient`](https://pkg.go.dev/google.golang.org/grpc#NewClient). (#5151)
Because of that `WithDialOption` ignores [`grpc.WithBlock`](https://pkg.go.dev/google.golang.org/grpc#WithBlock), [`grpc.WithTimeout`](https://pkg.go.dev/google.golang.org/grpc#WithTimeout), and [`grpc.WithReturnConnectionError`](https://pkg.go.dev/google.golang.org/grpc#WithReturnConnectionError).
Notice that [`grpc.DialContext`](https://pkg.go.dev/google.golang.org/grpc#DialContext) which was used before is now deprecated.
### Fixed
- Clarify the documentation about equivalence guarantees for the `Set` and `Distinct` types in `go.opentelemetry.io/otel/attribute`. (#5027)
- Prevent default `ErrorHandler` self-delegation. (#5137)
- Update all dependencies to address [GO-2024-2687]. (#5139)
### Removed
- Drop support for [Go 1.20]. (#4967)
### Deprecated
- Deprecate `go.opentelemetry.io/otel/attribute.Sortable` type. (#4734)
- Deprecate `go.opentelemetry.io/otel/attribute.NewSetWithSortable` function. (#4734)
- Deprecate `go.opentelemetry.io/otel/attribute.NewSetWithSortableFiltered` function. (#4734)
## [1.24.0/0.46.0/0.0.1-alpha] 2024-02-23
This release is the last to support [Go 1.20].
The next release will require at least [Go 1.21].
### Added
- Support [Go 1.22]. (#4890)
- Add exemplar support to `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetricgrpc`. (#4900)
- Add exemplar support to `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetrichttp`. (#4900)
- The `go.opentelemetry.io/otel/log` module is added.
This module includes OpenTelemetry Go's implementation of the Logs Bridge API.
This module is in an alpha state, it is subject to breaking changes.
See our [versioning policy](./VERSIONING.md) for more info. (#4961)
- Add ARM64 platform to the compatibility testing suite. (#4994)
### Fixed
- Fix registration of multiple callbacks when using the global meter provider from `go.opentelemetry.io/otel`. (#4945)
- Fix negative buckets in output of exponential histograms. (#4956)
## [1.23.1] 2024-02-07
### Fixed
- Register all callbacks passed during observable instrument creation instead of just the last one multiple times in `go.opentelemetry.io/otel/sdk/metric`. (#4888)
## [1.23.0] 2024-02-06
This release contains the first stable, `v1`, release of the following modules:
- `go.opentelemetry.io/otel/bridge/opencensus`
- `go.opentelemetry.io/otel/bridge/opencensus/test`
- `go.opentelemetry.io/otel/example/opencensus`
- `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetricgrpc`
- `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetrichttp`
- `go.opentelemetry.io/otel/exporters/stdout/stdoutmetric`
See our [versioning policy](VERSIONING.md) for more information about these stability guarantees.
### Added
- Add `WithEndpointURL` option to the `exporters/otlp/otlpmetric/otlpmetricgrpc`, `exporters/otlp/otlpmetric/otlpmetrichttp`, `exporters/otlp/otlptrace/otlptracegrpc` and `exporters/otlp/otlptrace/otlptracehttp` packages. (#4808)
- Experimental exemplar exporting is added to the metric SDK.
See [metric documentation](./sdk/metric/internal/x/README.md#exemplars) for more information about this feature and how to enable it. (#4871)
- `ErrSchemaURLConflict` is added to `go.opentelemetry.io/otel/sdk/resource`.
This error is returned when a merge of two `Resource`s with different (non-empty) schema URL is attempted. (#4876)
### Changed
- The `Merge` and `New` functions in `go.opentelemetry.io/otel/sdk/resource` now returns a partial result if there is a schema URL merge conflict.
Instead of returning `nil` when two `Resource`s with different (non-empty) schema URLs are merged the merged `Resource`, along with the new `ErrSchemaURLConflict` error, is returned.
It is up to the user to decide if they want to use the returned `Resource` or not.
It may have desired attributes overwritten or include stale semantic conventions. (#4876)
### Fixed
- Fix `ContainerID` resource detection on systemd when cgroup path has a colon. (#4449)
- Fix `go.opentelemetry.io/otel/sdk/metric` to cache instruments to avoid leaking memory when the same instrument is created multiple times. (#4820)
- Fix missing `Mix` and `Max` values for `go.opentelemetry.io/otel/exporters/stdout/stdoutmetric` by introducing `MarshalText` and `MarshalJSON` for the `Extrema` type in `go.opentelemetry.io/sdk/metric/metricdata`. (#4827)
## [1.23.0-rc.1] 2024-01-18
This is a release candidate for the v1.23.0 release.
That release is expected to include the `v1` release of the following modules:
- `go.opentelemetry.io/otel/bridge/opencensus`
- `go.opentelemetry.io/otel/bridge/opencensus/test`
- `go.opentelemetry.io/otel/example/opencensus`
- `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetricgrpc`
- `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetrichttp`
- `go.opentelemetry.io/otel/exporters/stdout/stdoutmetric`
See our [versioning policy](VERSIONING.md) for more information about these stability guarantees.
## [1.22.0/0.45.0] 2024-01-17
### Added
- The `go.opentelemetry.io/otel/semconv/v1.22.0` package.
The package contains semantic conventions from the `v1.22.0` version of the OpenTelemetry Semantic Conventions. (#4735)
- The `go.opentelemetry.io/otel/semconv/v1.23.0` package.
The package contains semantic conventions from the `v1.23.0` version of the OpenTelemetry Semantic Conventions. (#4746)
- The `go.opentelemetry.io/otel/semconv/v1.23.1` package.
The package contains semantic conventions from the `v1.23.1` version of the OpenTelemetry Semantic Conventions. (#4749)
- The `go.opentelemetry.io/otel/semconv/v1.24.0` package.
The package contains semantic conventions from the `v1.24.0` version of the OpenTelemetry Semantic Conventions. (#4770)
- Add `WithResourceAsConstantLabels` option to apply resource attributes for every metric emitted by the Prometheus exporter. (#4733)
- Experimental cardinality limiting is added to the metric SDK.
See [metric documentation](./sdk/metric/internal/x/README.md#cardinality-limit) for more information about this feature and how to enable it. (#4457)
- Add `NewMemberRaw` and `NewKeyValuePropertyRaw` in `go.opentelemetry.io/otel/baggage`. (#4804)
### Changed
- Upgrade all use of `go.opentelemetry.io/otel/semconv` to use `v1.24.0`. (#4754)
- Update transformations in `go.opentelemetry.io/otel/exporters/zipkin` to follow `v1.24.0` version of the OpenTelemetry specification. (#4754)
- Record synchronous measurements when the passed context is canceled instead of dropping in `go.opentelemetry.io/otel/sdk/metric`.
If you do not want to make a measurement when the context is cancelled, you need to handle it yourself (e.g `if ctx.Err() != nil`). (#4671)
- Improve `go.opentelemetry.io/otel/trace.TraceState`'s performance. (#4722)
- Improve `go.opentelemetry.io/otel/propagation.TraceContext`'s performance. (#4721)
- Improve `go.opentelemetry.io/otel/baggage` performance. (#4743)
- Improve performance of the `(*Set).Filter` method in `go.opentelemetry.io/otel/attribute` when the passed filter does not filter out any attributes from the set. (#4774)
- `Member.String` in `go.opentelemetry.io/otel/baggage` percent-encodes only when necessary. (#4775)
- Improve `go.opentelemetry.io/otel/trace.Span`'s performance when adding multiple attributes. (#4818)
- `Property.Value` in `go.opentelemetry.io/otel/baggage` now returns a raw string instead of a percent-encoded value. (#4804)
### Fixed
- Fix `Parse` in `go.opentelemetry.io/otel/baggage` to validate member value before percent-decoding. (#4755)
- Fix whitespace encoding of `Member.String` in `go.opentelemetry.io/otel/baggage`. (#4756)
- Fix observable not registered error when the asynchronous instrument has a drop aggregation in `go.opentelemetry.io/otel/sdk/metric`. (#4772)
- Fix baggage item key so that it is not canonicalized in `go.opentelemetry.io/otel/bridge/opentracing`. (#4776)
- Fix `go.opentelemetry.io/otel/bridge/opentracing` to properly handle baggage values that requires escaping during propagation. (#4804)
- Fix a bug where using multiple readers resulted in incorrect asynchronous counter values in `go.opentelemetry.io/otel/sdk/metric`. (#4742)
## [1.21.0/0.44.0] 2023-11-16
### Removed
- Remove the deprecated `go.opentelemetry.io/otel/bridge/opencensus.NewTracer`. (#4706)
- Remove the deprecated `go.opentelemetry.io/otel/exporters/otlp/otlpmetric` module. (#4707)
- Remove the deprecated `go.opentelemetry.io/otel/example/view` module. (#4708)
- Remove the deprecated `go.opentelemetry.io/otel/example/fib` module. (#4723)
### Fixed
- Do not parse non-protobuf responses in `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetrichttp`. (#4719)
- Do not parse non-protobuf responses in `go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracehttp`. (#4719)
## [1.20.0/0.43.0] 2023-11-10
This release brings a breaking change for custom trace API implementations. Some interfaces (`TracerProvider`, `Tracer`, `Span`) now embed the `go.opentelemetry.io/otel/trace/embedded` types. Implementers need to update their implementations based on what they want the default behavior to be. See the "API Implementations" section of the [trace API] package documentation for more information about how to accomplish this.
### Added
- Add `go.opentelemetry.io/otel/bridge/opencensus.InstallTraceBridge`, which installs the OpenCensus trace bridge, and replaces `opencensus.NewTracer`. (#4567)
- Add scope version to trace and metric bridges in `go.opentelemetry.io/otel/bridge/opencensus`. (#4584)
- Add the `go.opentelemetry.io/otel/trace/embedded` package to be embedded in the exported trace API interfaces. (#4620)
- Add the `go.opentelemetry.io/otel/trace/noop` package as a default no-op implementation of the trace API. (#4620)
- Add context propagation in `go.opentelemetry.io/otel/example/dice`. (#4644)
- Add view configuration to `go.opentelemetry.io/otel/example/prometheus`. (#4649)
- Add `go.opentelemetry.io/otel/metric.WithExplicitBucketBoundaries`, which allows defining default explicit bucket boundaries when creating histogram instruments. (#4603)
- Add `Version` function in `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetricgrpc`. (#4660)
- Add `Version` function in `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetrichttp`. (#4660)
- Add Summary, SummaryDataPoint, and QuantileValue to `go.opentelemetry.io/sdk/metric/metricdata`. (#4622)
- `go.opentelemetry.io/otel/bridge/opencensus.NewMetricProducer` now supports exemplars from OpenCensus. (#4585)
- Add support for `WithExplicitBucketBoundaries` in `go.opentelemetry.io/otel/sdk/metric`. (#4605)
- Add support for Summary metrics in `go.opentelemetry.io/otel/bridge/opencensus`. (#4668)
### Deprecated
- Deprecate `go.opentelemetry.io/otel/bridge/opencensus.NewTracer` in favor of `opencensus.InstallTraceBridge`. (#4567)
- Deprecate `go.opentelemetry.io/otel/example/fib` package is in favor of `go.opentelemetry.io/otel/example/dice`. (#4618)
- Deprecate `go.opentelemetry.io/otel/trace.NewNoopTracerProvider`.
Use the added `NewTracerProvider` function in `go.opentelemetry.io/otel/trace/noop` instead. (#4620)
- Deprecate `go.opentelemetry.io/otel/example/view` package in favor of `go.opentelemetry.io/otel/example/prometheus`. (#4649)
- Deprecate `go.opentelemetry.io/otel/exporters/otlp/otlpmetric`. (#4693)
### Changed
- `go.opentelemetry.io/otel/bridge/opencensus.NewMetricProducer` returns a `*MetricProducer` struct instead of the metric.Producer interface. (#4583)
- The `TracerProvider` in `go.opentelemetry.io/otel/trace` now embeds the `go.opentelemetry.io/otel/trace/embedded.TracerProvider` type.
This extends the `TracerProvider` interface and is is a breaking change for any existing implementation.
Implementers need to update their implementations based on what they want the default behavior of the interface to be.
See the "API Implementations" section of the `go.opentelemetry.io/otel/trace` package documentation for more information about how to accomplish this. (#4620)
- The `Tracer` in `go.opentelemetry.io/otel/trace` now embeds the `go.opentelemetry.io/otel/trace/embedded.Tracer` type.
This extends the `Tracer` interface and is is a breaking change for any existing implementation.
Implementers need to update their implementations based on what they want the default behavior of the interface to be.
See the "API Implementations" section of the `go.opentelemetry.io/otel/trace` package documentation for more information about how to accomplish this. (#4620)
- The `Span` in `go.opentelemetry.io/otel/trace` now embeds the `go.opentelemetry.io/otel/trace/embedded.Span` type.
This extends the `Span` interface and is is a breaking change for any existing implementation.
Implementers need to update their implementations based on what they want the default behavior of the interface to be.
See the "API Implementations" section of the `go.opentelemetry.io/otel/trace` package documentation for more information about how to accomplish this. (#4620)
- `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetricgrpc` does no longer depend on `go.opentelemetry.io/otel/exporters/otlp/otlpmetric`. (#4660)
- `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetrichttp` does no longer depend on `go.opentelemetry.io/otel/exporters/otlp/otlpmetric`. (#4660)
- Retry for `502 Bad Gateway` and `504 Gateway Timeout` HTTP statuses in `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetrichttp`. (#4670)
- Retry for `502 Bad Gateway` and `504 Gateway Timeout` HTTP statuses in `go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracehttp`. (#4670)
- Retry for `RESOURCE_EXHAUSTED` only if RetryInfo is returned in `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetricgrpc`. (#4669)
- Retry for `RESOURCE_EXHAUSTED` only if RetryInfo is returned in `go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracegrpc`. (#4669)
- Retry temporary HTTP request failures in `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetrichttp`. (#4679)
- Retry temporary HTTP request failures in `go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracehttp`. (#4679)
### Fixed
- Fix improper parsing of characters such us `+`, `/` by `Parse` in `go.opentelemetry.io/otel/baggage` as they were rendered as a whitespace. (#4667)
- Fix improper parsing of characters such us `+`, `/` passed via `OTEL_RESOURCE_ATTRIBUTES` in `go.opentelemetry.io/otel/sdk/resource` as they were rendered as a whitespace. (#4699)
- Fix improper parsing of characters such us `+`, `/` passed via `OTEL_EXPORTER_OTLP_HEADERS` and `OTEL_EXPORTER_OTLP_METRICS_HEADERS` in `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetricgrpc` as they were rendered as a whitespace. (#4699)
- Fix improper parsing of characters such us `+`, `/` passed via `OTEL_EXPORTER_OTLP_HEADERS` and `OTEL_EXPORTER_OTLP_METRICS_HEADERS` in `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetrichttp` as they were rendered as a whitespace. (#4699)
- Fix improper parsing of characters such us `+`, `/` passed via `OTEL_EXPORTER_OTLP_HEADERS` and `OTEL_EXPORTER_OTLP_TRACES_HEADERS` in `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlptracegrpc` as they were rendered as a whitespace. (#4699)
- Fix improper parsing of characters such us `+`, `/` passed via `OTEL_EXPORTER_OTLP_HEADERS` and `OTEL_EXPORTER_OTLP_TRACES_HEADERS` in `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlptracehttp` as they were rendered as a whitespace. (#4699)
- In `go.opentelemetry.op/otel/exporters/prometheus`, the exporter no longer `Collect`s metrics after `Shutdown` is invoked. (#4648)
- Fix documentation for `WithCompressor` in `go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracegrpc`. (#4695)
- Fix documentation for `WithCompressor` in `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetricgrpc`. (#4695)
## [1.19.0/0.42.0/0.0.7] 2023-09-28
This release contains the first stable release of the OpenTelemetry Go [metric SDK].
Our project stability guarantees now apply to the `go.opentelemetry.io/otel/sdk/metric` package.
See our [versioning policy](VERSIONING.md) for more information about these stability guarantees.
### Added
- Add the "Roll the dice" getting started application example in `go.opentelemetry.io/otel/example/dice`. (#4539)
- The `WithWriter` and `WithPrettyPrint` options to `go.opentelemetry.io/otel/exporters/stdout/stdoutmetric` to set a custom `io.Writer`, and allow displaying the output in human-readable JSON. (#4507)
### Changed
- Allow '/' characters in metric instrument names. (#4501)
- The exporter in `go.opentelemetry.io/otel/exporters/stdout/stdoutmetric` does not prettify its output by default anymore. (#4507)
- Upgrade `gopkg.io/yaml` from `v2` to `v3` in `go.opentelemetry.io/otel/schema`. (#4535)
### Fixed
- In `go.opentelemetry.op/otel/exporters/prometheus`, don't try to create the Prometheus metric on every `Collect` if we know the scope is invalid. (#4499)
### Removed
- Remove `"go.opentelemetry.io/otel/bridge/opencensus".NewMetricExporter`, which is replaced by `NewMetricProducer`. (#4566)
## [1.19.0-rc.1/0.42.0-rc.1] 2023-09-14
This is a release candidate for the v1.19.0/v0.42.0 release.
That release is expected to include the `v1` release of the OpenTelemetry Go metric SDK and will provide stability guarantees of that SDK.
See our [versioning policy](VERSIONING.md) for more information about these stability guarantees.
### Changed
- Allow '/' characters in metric instrument names. (#4501)
### Fixed
- In `go.opentelemetry.op/otel/exporters/prometheus`, don't try to create the prometheus metric on every `Collect` if we know the scope is invalid. (#4499)
## [1.18.0/0.41.0/0.0.6] 2023-09-12
This release drops the compatibility guarantee of [Go 1.19].
### Added
- Add `WithProducer` option in `go.opentelemetry.op/otel/exporters/prometheus` to restore the ability to register producers on the prometheus exporter's manual reader. (#4473)
- Add `IgnoreValue` option in `go.opentelemetry.io/otel/sdk/metric/metricdata/metricdatatest` to allow ignoring values when comparing metrics. (#4447)
### Changed
- Use a `TestingT` interface instead of `*testing.T` struct in `go.opentelemetry.io/otel/sdk/metric/metricdata/metricdatatest`. (#4483)
### Deprecated
- The `NewMetricExporter` in `go.opentelemetry.io/otel/bridge/opencensus` was deprecated in `v0.35.0` (#3541).
The deprecation notice format for the function has been corrected to trigger Go documentation and build tooling. (#4470)
### Removed
- Removed the deprecated `go.opentelemetry.io/otel/exporters/jaeger` package. (#4467)
- Removed the deprecated `go.opentelemetry.io/otel/example/jaeger` package. (#4467)
- Removed the deprecated `go.opentelemetry.io/otel/sdk/metric/aggregation` package. (#4468)
- Removed the deprecated internal packages in `go.opentelemetry.io/otel/exporters/otlp` and its sub-packages. (#4469)
- Dropped guaranteed support for versions of Go less than 1.20. (#4481)
## [1.17.0/0.40.0/0.0.5] 2023-08-28
### Added
- Export the `ManualReader` struct in `go.opentelemetry.io/otel/sdk/metric`. (#4244)
- Export the `PeriodicReader` struct in `go.opentelemetry.io/otel/sdk/metric`. (#4244)
- Add support for exponential histogram aggregations.
A histogram can be configured as an exponential histogram using a view with `"go.opentelemetry.io/otel/sdk/metric".ExponentialHistogram` as the aggregation. (#4245)
- Export the `Exporter` struct in `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetricgrpc`. (#4272)
- Export the `Exporter` struct in `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetrichttp`. (#4272)
- The exporters in `go.opentelemetry.io/otel/exporters/otlp/otlpmetric` now support the `OTEL_EXPORTER_OTLP_METRICS_TEMPORALITY_PREFERENCE` environment variable. (#4287)
- Add `WithoutCounterSuffixes` option in `go.opentelemetry.io/otel/exporters/prometheus` to disable addition of `_total` suffixes. (#4306)
- Add info and debug logging to the metric SDK in `go.opentelemetry.io/otel/sdk/metric`. (#4315)
- The `go.opentelemetry.io/otel/semconv/v1.21.0` package.
The package contains semantic conventions from the `v1.21.0` version of the OpenTelemetry Semantic Conventions. (#4362)
- Accept 201 to 299 HTTP status as success in `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetrichttp` and `go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracehttp`. (#4365)
- Document the `Temporality` and `Aggregation` methods of the `"go.opentelemetry.io/otel/sdk/metric".Exporter"` need to be concurrent safe. (#4381)
- Expand the set of units supported by the Prometheus exporter, and don't add unit suffixes if they are already present in `go.opentelemetry.op/otel/exporters/prometheus` (#4374)
- Move the `Aggregation` interface and its implementations from `go.opentelemetry.io/otel/sdk/metric/aggregation` to `go.opentelemetry.io/otel/sdk/metric`. (#4435)
- The exporters in `go.opentelemetry.io/otel/exporters/otlp/otlpmetric` now support the `OTEL_EXPORTER_OTLP_METRICS_DEFAULT_HISTOGRAM_AGGREGATION` environment variable. (#4437)
- Add the `NewAllowKeysFilter` and `NewDenyKeysFilter` functions to `go.opentelemetry.io/otel/attribute` to allow convenient creation of allow-keys and deny-keys filters. (#4444)
- Support Go 1.21. (#4463)
### Changed
- Starting from `v1.21.0` of semantic conventions, `go.opentelemetry.io/otel/semconv/{version}/httpconv` and `go.opentelemetry.io/otel/semconv/{version}/netconv` packages will no longer be published. (#4145)
- Log duplicate instrument conflict at a warning level instead of info in `go.opentelemetry.io/otel/sdk/metric`. (#4202)
- Return an error on the creation of new instruments in `go.opentelemetry.io/otel/sdk/metric` if their name doesn't pass regexp validation. (#4210)
- `NewManualReader` in `go.opentelemetry.io/otel/sdk/metric` returns `*ManualReader` instead of `Reader`. (#4244)
- `NewPeriodicReader` in `go.opentelemetry.io/otel/sdk/metric` returns `*PeriodicReader` instead of `Reader`. (#4244)
- Count the Collect time in the `PeriodicReader` timeout in `go.opentelemetry.io/otel/sdk/metric`. (#4221)
- The function `New` in `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetricgrpc` returns `*Exporter` instead of `"go.opentelemetry.io/otel/sdk/metric".Exporter`. (#4272)
- The function `New` in `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetrichttp` returns `*Exporter` instead of `"go.opentelemetry.io/otel/sdk/metric".Exporter`. (#4272)
- If an attribute set is omitted from an async callback, the previous value will no longer be exported in `go.opentelemetry.io/otel/sdk/metric`. (#4290)
- If an attribute set is observed multiple times in an async callback in `go.opentelemetry.io/otel/sdk/metric`, the values will be summed instead of the last observation winning. (#4289)
- Allow the explicit bucket histogram aggregation to be used for the up-down counter, observable counter, observable up-down counter, and observable gauge in the `go.opentelemetry.io/otel/sdk/metric` package. (#4332)
- Restrict `Meter`s in `go.opentelemetry.io/otel/sdk/metric` to only register and collect instruments it created. (#4333)
- `PeriodicReader.Shutdown` and `PeriodicReader.ForceFlush` in `go.opentelemetry.io/otel/sdk/metric` now apply the periodic reader's timeout to the operation if the user provided context does not contain a deadline. (#4356, #4377)
- Upgrade all use of `go.opentelemetry.io/otel/semconv` to use `v1.21.0`. (#4408)
- Increase instrument name maximum length from 63 to 255 characters in `go.opentelemetry.io/otel/sdk/metric`. (#4434)
- Add `go.opentelemetry.op/otel/sdk/metric.WithProducer` as an `Option` for `"go.opentelemetry.io/otel/sdk/metric".NewManualReader` and `"go.opentelemetry.io/otel/sdk/metric".NewPeriodicReader`. (#4346)
### Removed
- Remove `Reader.RegisterProducer` in `go.opentelemetry.io/otel/metric`.
Use the added `WithProducer` option instead. (#4346)
- Remove `Reader.ForceFlush` in `go.opentelemetry.io/otel/metric`.
Notice that `PeriodicReader.ForceFlush` is still available. (#4375)
### Fixed
- Correctly format log messages from the `go.opentelemetry.io/otel/exporters/zipkin` exporter. (#4143)
- Log an error for calls to `NewView` in `go.opentelemetry.io/otel/sdk/metric` that have empty criteria. (#4307)
- Fix `"go.opentelemetry.io/otel/sdk/resource".WithHostID()` to not set an empty `host.id`. (#4317)
- Use the instrument identifying fields to cache aggregators and determine duplicate instrument registrations in `go.opentelemetry.io/otel/sdk/metric`. (#4337)
- Detect duplicate instruments for case-insensitive names in `go.opentelemetry.io/otel/sdk/metric`. (#4338)
- The `ManualReader` will not panic if `AggregationSelector` returns `nil` in `go.opentelemetry.io/otel/sdk/metric`. (#4350)
- If a `Reader`'s `AggregationSelector` returns `nil` or `DefaultAggregation` the pipeline will use the default aggregation. (#4350)
- Log a suggested view that fixes instrument conflicts in `go.opentelemetry.io/otel/sdk/metric`. (#4349)
- Fix possible panic, deadlock and race condition in batch span processor in `go.opentelemetry.io/otel/sdk/trace`. (#4353)
- Improve context cancellation handling in batch span processor's `ForceFlush` in `go.opentelemetry.io/otel/sdk/trace`. (#4369)
- Decouple `go.opentelemetry.io/otel/exporters/otlp/otlptrace/internal` from `go.opentelemetry.io/otel/exporters/otlp/internal` using gotmpl. (#4397, #3846)
- Decouple `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetricgrpc/internal` from `go.opentelemetry.io/otel/exporters/otlp/internal` and `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/internal` using gotmpl. (#4404, #3846)
- Decouple `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetrichttp/internal` from `go.opentelemetry.io/otel/exporters/otlp/internal` and `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/internal` using gotmpl. (#4407, #3846)
- Decouple `go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracegrpc/internal` from `go.opentelemetry.io/otel/exporters/otlp/internal` and `go.opentelemetry.io/otel/exporters/otlp/otlptrace/internal` using gotmpl. (#4400, #3846)
- Decouple `go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracehttp/internal` from `go.opentelemetry.io/otel/exporters/otlp/internal` and `go.opentelemetry.io/otel/exporters/otlp/otlptrace/internal` using gotmpl. (#4401, #3846)
- Do not block the metric SDK when OTLP metric exports are blocked in `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetricgrpc` and `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetrichttp`. (#3925, #4395)
- Do not append `_total` if the counter already has that suffix for the Prometheus exproter in `go.opentelemetry.io/otel/exporter/prometheus`. (#4373)
- Fix resource detection data race in `go.opentelemetry.io/otel/sdk/resource`. (#4409)
- Use the first-seen instrument name during instrument name conflicts in `go.opentelemetry.io/otel/sdk/metric`. (#4428)
### Deprecated
- The `go.opentelemetry.io/otel/exporters/jaeger` package is deprecated.
OpenTelemetry dropped support for Jaeger exporter in July 2023.
Use `go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracehttp`
or `go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracegrpc` instead. (#4423)
- The `go.opentelemetry.io/otel/example/jaeger` package is deprecated. (#4423)
- The `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/internal` package is deprecated. (#4420)
- The `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/internal/oconf` package is deprecated. (#4420)
- The `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/internal/otest` package is deprecated. (#4420)
- The `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/internal/transform` package is deprecated. (#4420)
- The `go.opentelemetry.io/otel/exporters/otlp/internal` package is deprecated. (#4421)
- The `go.opentelemetry.io/otel/exporters/otlp/internal/envconfig` package is deprecated. (#4421)
- The `go.opentelemetry.io/otel/exporters/otlp/internal/retry` package is deprecated. (#4421)
- The `go.opentelemetry.io/otel/exporters/otlp/otlptrace/internal` package is deprecated. (#4425)
- The `go.opentelemetry.io/otel/exporters/otlp/otlptrace/internal/envconfig` package is deprecated. (#4425)
- The `go.opentelemetry.io/otel/exporters/otlp/otlptrace/internal/otlpconfig` package is deprecated. (#4425)
- The `go.opentelemetry.io/otel/exporters/otlp/otlptrace/internal/otlptracetest` package is deprecated. (#4425)
- The `go.opentelemetry.io/otel/exporters/otlp/otlptrace/internal/retry` package is deprecated. (#4425)
- The `go.opentelemetry.io/otel/sdk/metric/aggregation` package is deprecated.
Use the aggregation types added to `go.opentelemetry.io/otel/sdk/metric` instead. (#4435)
## [1.16.0/0.39.0] 2023-05-18
This release contains the first stable release of the OpenTelemetry Go [metric API].
Our project stability guarantees now apply to the `go.opentelemetry.io/otel/metric` package.
See our [versioning policy](VERSIONING.md) for more information about these stability guarantees.
### Added
- The `go.opentelemetry.io/otel/semconv/v1.19.0` package.
The package contains semantic conventions from the `v1.19.0` version of the OpenTelemetry specification. (#3848)
- The `go.opentelemetry.io/otel/semconv/v1.20.0` package.
The package contains semantic conventions from the `v1.20.0` version of the OpenTelemetry specification. (#4078)
- The Exponential Histogram data types in `go.opentelemetry.io/otel/sdk/metric/metricdata`. (#4165)
- OTLP metrics exporter now supports the Exponential Histogram Data Type. (#4222)
- Fix serialization of `time.Time` zero values in `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetricgrpc` and `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetrichttp` packages. (#4271)
### Changed
- Use `strings.Cut()` instead of `string.SplitN()` for better readability and memory use. (#4049)
- `MeterProvider` returns noop meters once it has been shutdown. (#4154)
### Removed
- The deprecated `go.opentelemetry.io/otel/metric/instrument` package is removed.
Use `go.opentelemetry.io/otel/metric` instead. (#4055)
### Fixed
- Fix build for BSD based systems in `go.opentelemetry.io/otel/sdk/resource`. (#4077)
## [1.16.0-rc.1/0.39.0-rc.1] 2023-05-03
This is a release candidate for the v1.16.0/v0.39.0 release.
That release is expected to include the `v1` release of the OpenTelemetry Go metric API and will provide stability guarantees of that API.
See our [versioning policy](VERSIONING.md) for more information about these stability guarantees.
### Added
- Support global `MeterProvider` in `go.opentelemetry.io/otel`. (#4039)
- Use `Meter` for a `metric.Meter` from the global `metric.MeterProvider`.
- Use `GetMeterProivder` for a global `metric.MeterProvider`.
- Use `SetMeterProivder` to set the global `metric.MeterProvider`.
### Changed
- Move the `go.opentelemetry.io/otel/metric` module to the `stable-v1` module set.
This stages the metric API to be released as a stable module. (#4038)
### Removed
- The `go.opentelemetry.io/otel/metric/global` package is removed.
Use `go.opentelemetry.io/otel` instead. (#4039)
## [1.15.1/0.38.1] 2023-05-02
### Fixed
- Remove unused imports from `sdk/resource/host_id_bsd.go` which caused build failures. (#4040, #4041)
## [1.15.0/0.38.0] 2023-04-27
### Added
- The `go.opentelemetry.io/otel/metric/embedded` package. (#3916)
- The `Version` function to `go.opentelemetry.io/otel/sdk` to return the SDK version. (#3949)
- Add a `WithNamespace` option to `go.opentelemetry.io/otel/exporters/prometheus` to allow users to prefix metrics with a namespace. (#3970)
- The following configuration types were added to `go.opentelemetry.io/otel/metric/instrument` to be used in the configuration of measurement methods. (#3971)
- The `AddConfig` used to hold configuration for addition measurements
- `NewAddConfig` used to create a new `AddConfig`
- `AddOption` used to configure an `AddConfig`
- The `RecordConfig` used to hold configuration for recorded measurements
- `NewRecordConfig` used to create a new `RecordConfig`
- `RecordOption` used to configure a `RecordConfig`
- The `ObserveConfig` used to hold configuration for observed measurements
- `NewObserveConfig` used to create a new `ObserveConfig`
- `ObserveOption` used to configure an `ObserveConfig`
- `WithAttributeSet` and `WithAttributes` are added to `go.opentelemetry.io/otel/metric/instrument`.
They return an option used during a measurement that defines the attribute Set associated with the measurement. (#3971)
- The `Version` function to `go.opentelemetry.io/otel/exporters/otlp/otlpmetric` to return the OTLP metrics client version. (#3956)
- The `Version` function to `go.opentelemetry.io/otel/exporters/otlp/otlptrace` to return the OTLP trace client version. (#3956)
### Changed
- The `Extrema` in `go.opentelemetry.io/otel/sdk/metric/metricdata` is redefined with a generic argument of `[N int64 | float64]`. (#3870)
- Update all exported interfaces from `go.opentelemetry.io/otel/metric` to embed their corresponding interface from `go.opentelemetry.io/otel/metric/embedded`.
This adds an implementation requirement to set the interface default behavior for unimplemented methods. (#3916)
- Move No-Op implementation from `go.opentelemetry.io/otel/metric` into its own package `go.opentelemetry.io/otel/metric/noop`. (#3941)
- `metric.NewNoopMeterProvider` is replaced with `noop.NewMeterProvider`
- Add all the methods from `"go.opentelemetry.io/otel/trace".SpanContext` to `bridgeSpanContext` by embedding `otel.SpanContext` in `bridgeSpanContext`. (#3966)
- Wrap `UploadMetrics` error in `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/` to improve error message when encountering generic grpc errors. (#3974)
- The measurement methods for all instruments in `go.opentelemetry.io/otel/metric/instrument` accept an option instead of the variadic `"go.opentelemetry.io/otel/attribute".KeyValue`. (#3971)
- The `Int64Counter.Add` method now accepts `...AddOption`
- The `Float64Counter.Add` method now accepts `...AddOption`
- The `Int64UpDownCounter.Add` method now accepts `...AddOption`
- The `Float64UpDownCounter.Add` method now accepts `...AddOption`
- The `Int64Histogram.Record` method now accepts `...RecordOption`
- The `Float64Histogram.Record` method now accepts `...RecordOption`
- The `Int64Observer.Observe` method now accepts `...ObserveOption`
- The `Float64Observer.Observe` method now accepts `...ObserveOption`
- The `Observer` methods in `go.opentelemetry.io/otel/metric` accept an option instead of the variadic `"go.opentelemetry.io/otel/attribute".KeyValue`. (#3971)
- The `Observer.ObserveInt64` method now accepts `...ObserveOption`
- The `Observer.ObserveFloat64` method now accepts `...ObserveOption`
- Move global metric back to `go.opentelemetry.io/otel/metric/global` from `go.opentelemetry.io/otel`. (#3986)
### Fixed
- `TracerProvider` allows calling `Tracer()` while it's shutting down.
It used to deadlock. (#3924)
- Use the SDK version for the Telemetry SDK resource detector in `go.opentelemetry.io/otel/sdk/resource`. (#3949)
- Fix a data race in `SpanProcessor` returned by `NewSimpleSpanProcessor` in `go.opentelemetry.io/otel/sdk/trace`. (#3951)
- Automatically figure out the default aggregation with `aggregation.Default`. (#3967)
### Deprecated
- The `go.opentelemetry.io/otel/metric/instrument` package is deprecated.
Use the equivalent types added to `go.opentelemetry.io/otel/metric` instead. (#4018)
## [1.15.0-rc.2/0.38.0-rc.2] 2023-03-23
This is a release candidate for the v1.15.0/v0.38.0 release.
That release will include the `v1` release of the OpenTelemetry Go metric API and will provide stability guarantees of that API.
See our [versioning policy](VERSIONING.md) for more information about these stability guarantees.
### Added
- The `WithHostID` option to `go.opentelemetry.io/otel/sdk/resource`. (#3812)
- The `WithoutTimestamps` option to `go.opentelemetry.io/otel/exporters/stdout/stdoutmetric` to sets all timestamps to zero. (#3828)
- The new `Exemplar` type is added to `go.opentelemetry.io/otel/sdk/metric/metricdata`.
Both the `DataPoint` and `HistogramDataPoint` types from that package have a new field of `Exemplars` containing the sampled exemplars for their timeseries. (#3849)
- Configuration for each metric instrument in `go.opentelemetry.io/otel/sdk/metric/instrument`. (#3895)
- The internal logging introduces a warning level verbosity equal to `V(1)`. (#3900)
- Added a log message warning about usage of `SimpleSpanProcessor` in production environments. (#3854)
### Changed
- Optimize memory allocation when creation a new `Set` using `NewSet` or `NewSetWithFiltered` in `go.opentelemetry.io/otel/attribute`. (#3832)
- Optimize memory allocation when creation new metric instruments in `go.opentelemetry.io/otel/sdk/metric`. (#3832)
- Avoid creating new objects on all calls to `WithDeferredSetup` and `SkipContextSetup` in OpenTracing bridge. (#3833)
- The `New` and `Detect` functions from `go.opentelemetry.io/otel/sdk/resource` return errors that wrap underlying errors instead of just containing the underlying error strings. (#3844)
- Both the `Histogram` and `HistogramDataPoint` are redefined with a generic argument of `[N int64 | float64]` in `go.opentelemetry.io/otel/sdk/metric/metricdata`. (#3849)
- The metric `Export` interface from `go.opentelemetry.io/otel/sdk/metric` accepts a `*ResourceMetrics` instead of `ResourceMetrics`. (#3853)
- Rename `Asynchronous` to `Observable` in `go.opentelemetry.io/otel/metric/instrument`. (#3892)
- Rename `Int64ObserverOption` to `Int64ObservableOption` in `go.opentelemetry.io/otel/metric/instrument`. (#3895)
- Rename `Float64ObserverOption` to `Float64ObservableOption` in `go.opentelemetry.io/otel/metric/instrument`. (#3895)
- The internal logging changes the verbosity level of info to `V(4)`, the verbosity level of debug to `V(8)`. (#3900)
### Fixed
- `TracerProvider` consistently doesn't allow to register a `SpanProcessor` after shutdown. (#3845)
### Removed
- The deprecated `go.opentelemetry.io/otel/metric/global` package is removed. (#3829)
- The unneeded `Synchronous` interface in `go.opentelemetry.io/otel/metric/instrument` was removed. (#3892)
- The `Float64ObserverConfig` and `NewFloat64ObserverConfig` in `go.opentelemetry.io/otel/sdk/metric/instrument`.
Use the added `float64` instrument configuration instead. (#3895)
- The `Int64ObserverConfig` and `NewInt64ObserverConfig` in `go.opentelemetry.io/otel/sdk/metric/instrument`.
Use the added `int64` instrument configuration instead. (#3895)
- The `NewNoopMeter` function in `go.opentelemetry.io/otel/metric`, use `NewMeterProvider().Meter("")` instead. (#3893)
## [1.15.0-rc.1/0.38.0-rc.1] 2023-03-01
This is a release candidate for the v1.15.0/v0.38.0 release.
That release will include the `v1` release of the OpenTelemetry Go metric API and will provide stability guarantees of that API.
See our [versioning policy](VERSIONING.md) for more information about these stability guarantees.
This release drops the compatibility guarantee of [Go 1.18].
### Added
- Support global `MeterProvider` in `go.opentelemetry.io/otel`. (#3818)
- Use `Meter` for a `metric.Meter` from the global `metric.MeterProvider`.
- Use `GetMeterProivder` for a global `metric.MeterProvider`.
- Use `SetMeterProivder` to set the global `metric.MeterProvider`.
### Changed
- Dropped compatibility testing for [Go 1.18].
The project no longer guarantees support for this version of Go. (#3813)
### Fixed
- Handle empty environment variable as it they were not set. (#3764)
- Clarify the `httpconv` and `netconv` packages in `go.opentelemetry.io/otel/semconv/*` provide tracing semantic conventions. (#3823)
- Fix race conditions in `go.opentelemetry.io/otel/exporters/metric/prometheus` that could cause a panic. (#3899)
- Fix sending nil `scopeInfo` to metrics channel in `go.opentelemetry.io/otel/exporters/metric/prometheus` that could cause a panic in `github.com/prometheus/client_golang/prometheus`. (#3899)
### Deprecated
- The `go.opentelemetry.io/otel/metric/global` package is deprecated.
Use `go.opentelemetry.io/otel` instead. (#3818)
### Removed
- The deprecated `go.opentelemetry.io/otel/metric/unit` package is removed. (#3814)
## [1.14.0/0.37.0/0.0.4] 2023-02-27
This release is the last to support [Go 1.18].
The next release will require at least [Go 1.19].
### Added
- The `event` type semantic conventions are added to `go.opentelemetry.io/otel/semconv/v1.17.0`. (#3697)
- Support [Go 1.20]. (#3693)
- The `go.opentelemetry.io/otel/semconv/v1.18.0` package.
The package contains semantic conventions from the `v1.18.0` version of the OpenTelemetry specification. (#3719)
- The following `const` renames from `go.opentelemetry.io/otel/semconv/v1.17.0` are included:
- `OtelScopeNameKey` -> `OTelScopeNameKey`
- `OtelScopeVersionKey` -> `OTelScopeVersionKey`
- `OtelLibraryNameKey` -> `OTelLibraryNameKey`
- `OtelLibraryVersionKey` -> `OTelLibraryVersionKey`
- `OtelStatusCodeKey` -> `OTelStatusCodeKey`
- `OtelStatusDescriptionKey` -> `OTelStatusDescriptionKey`
- `OtelStatusCodeOk` -> `OTelStatusCodeOk`
- `OtelStatusCodeError` -> `OTelStatusCodeError`
- The following `func` renames from `go.opentelemetry.io/otel/semconv/v1.17.0` are included:
- `OtelScopeName` -> `OTelScopeName`
- `OtelScopeVersion` -> `OTelScopeVersion`
- `OtelLibraryName` -> `OTelLibraryName`
- `OtelLibraryVersion` -> `OTelLibraryVersion`
- `OtelStatusDescription` -> `OTelStatusDescription`
- A `IsSampled` method is added to the `SpanContext` implementation in `go.opentelemetry.io/otel/bridge/opentracing` to expose the span sampled state.
See the [README](./bridge/opentracing/README.md) for more information. (#3570)
- The `WithInstrumentationAttributes` option to `go.opentelemetry.io/otel/metric`. (#3738)
- The `WithInstrumentationAttributes` option to `go.opentelemetry.io/otel/trace`. (#3739)
- The following environment variables are supported by the periodic `Reader` in `go.opentelemetry.io/otel/sdk/metric`. (#3763)
- `OTEL_METRIC_EXPORT_INTERVAL` sets the time between collections and exports.
- `OTEL_METRIC_EXPORT_TIMEOUT` sets the timeout an export is attempted.
### Changed
- Fall-back to `TextMapCarrier` when it's not `HttpHeader`s in `go.opentelemetry.io/otel/bridge/opentracing`. (#3679)
- The `Collect` method of the `"go.opentelemetry.io/otel/sdk/metric".Reader` interface is updated to accept the `metricdata.ResourceMetrics` value the collection will be made into.
This change is made to enable memory reuse by SDK users. (#3732)
- The `WithUnit` option in `go.opentelemetry.io/otel/sdk/metric/instrument` is updated to accept a `string` for the unit value. (#3776)
### Fixed
- Ensure `go.opentelemetry.io/otel` does not use generics. (#3723, #3725)
- Multi-reader `MeterProvider`s now export metrics for all readers, instead of just the first reader. (#3720, #3724)
- Remove use of deprecated `"math/rand".Seed` in `go.opentelemetry.io/otel/example/prometheus`. (#3733)
- Do not silently drop unknown schema data with `Parse` in `go.opentelemetry.io/otel/schema/v1.1`. (#3743)
- Data race issue in OTLP exporter retry mechanism. (#3755, #3756)
- Wrapping empty errors when exporting in `go.opentelemetry.io/otel/sdk/metric`. (#3698, #3772)
- Incorrect "all" and "resource" definition for schema files in `go.opentelemetry.io/otel/schema/v1.1`. (#3777)
### Deprecated
- The `go.opentelemetry.io/otel/metric/unit` package is deprecated.
Use the equivalent unit string instead. (#3776)
- Use `"1"` instead of `unit.Dimensionless`
- Use `"By"` instead of `unit.Bytes`
- Use `"ms"` instead of `unit.Milliseconds`
## [1.13.0/0.36.0] 2023-02-07
### Added
- Attribute `KeyValue` creations functions to `go.opentelemetry.io/otel/semconv/v1.17.0` for all non-enum semantic conventions.
These functions ensure semantic convention type correctness. (#3675)
### Fixed
- Removed the `http.target` attribute from being added by `ServerRequest` in the following packages. (#3687)
- `go.opentelemetry.io/otel/semconv/v1.13.0/httpconv`
- `go.opentelemetry.io/otel/semconv/v1.14.0/httpconv`
- `go.opentelemetry.io/otel/semconv/v1.15.0/httpconv`
- `go.opentelemetry.io/otel/semconv/v1.16.0/httpconv`
- `go.opentelemetry.io/otel/semconv/v1.17.0/httpconv`
### Removed
- The deprecated `go.opentelemetry.io/otel/metric/instrument/asyncfloat64` package is removed. (#3631)
- The deprecated `go.opentelemetry.io/otel/metric/instrument/asyncint64` package is removed. (#3631)
- The deprecated `go.opentelemetry.io/otel/metric/instrument/syncfloat64` package is removed. (#3631)
- The deprecated `go.opentelemetry.io/otel/metric/instrument/syncint64` package is removed. (#3631)
## [1.12.0/0.35.0] 2023-01-28
### Added
- The `WithInt64Callback` option to `go.opentelemetry.io/otel/metric/instrument`.
This options is used to configure `int64` Observer callbacks during their creation. (#3507)
- The `WithFloat64Callback` option to `go.opentelemetry.io/otel/metric/instrument`.
This options is used to configure `float64` Observer callbacks during their creation. (#3507)
- The `Producer` interface and `Reader.RegisterProducer(Producer)` to `go.opentelemetry.io/otel/sdk/metric`.
These additions are used to enable external metric Producers. (#3524)
- The `Callback` function type to `go.opentelemetry.io/otel/metric`.
This new named function type is registered with a `Meter`. (#3564)
- The `go.opentelemetry.io/otel/semconv/v1.13.0` package.
The package contains semantic conventions from the `v1.13.0` version of the OpenTelemetry specification. (#3499)
- The `EndUserAttributesFromHTTPRequest` function in `go.opentelemetry.io/otel/semconv/v1.12.0` is merged into `ClientRequest` and `ServerRequest` in `go.opentelemetry.io/otel/semconv/v1.13.0/httpconv`.
- The `HTTPAttributesFromHTTPStatusCode` function in `go.opentelemetry.io/otel/semconv/v1.12.0` is merged into `ClientResponse` in `go.opentelemetry.io/otel/semconv/v1.13.0/httpconv`.
- The `HTTPClientAttributesFromHTTPRequest` function in `go.opentelemetry.io/otel/semconv/v1.12.0` is replaced by `ClientRequest` in `go.opentelemetry.io/otel/semconv/v1.13.0/httpconv`.
- The `HTTPServerAttributesFromHTTPRequest` function in `go.opentelemetry.io/otel/semconv/v1.12.0` is replaced by `ServerRequest` in `go.opentelemetry.io/otel/semconv/v1.13.0/httpconv`.
- The `HTTPServerMetricAttributesFromHTTPRequest` function in `go.opentelemetry.io/otel/semconv/v1.12.0` is replaced by `ServerRequest` in `go.opentelemetry.io/otel/semconv/v1.13.0/httpconv`.
- The `NetAttributesFromHTTPRequest` function in `go.opentelemetry.io/otel/semconv/v1.12.0` is split into `Transport` in `go.opentelemetry.io/otel/semconv/v1.13.0/netconv` and `ClientRequest` or `ServerRequest` in `go.opentelemetry.io/otel/semconv/v1.13.0/httpconv`.
- The `SpanStatusFromHTTPStatusCode` function in `go.opentelemetry.io/otel/semconv/v1.12.0` is replaced by `ClientStatus` in `go.opentelemetry.io/otel/semconv/v1.13.0/httpconv`.
- The `SpanStatusFromHTTPStatusCodeAndSpanKind` function in `go.opentelemetry.io/otel/semconv/v1.12.0` is split into `ClientStatus` and `ServerStatus` in `go.opentelemetry.io/otel/semconv/v1.13.0/httpconv`.
- The `Client` function is included in `go.opentelemetry.io/otel/semconv/v1.13.0/netconv` to generate attributes for a `net.Conn`.
- The `Server` function is included in `go.opentelemetry.io/otel/semconv/v1.13.0/netconv` to generate attributes for a `net.Listener`.
- The `go.opentelemetry.io/otel/semconv/v1.14.0` package.
The package contains semantic conventions from the `v1.14.0` version of the OpenTelemetry specification. (#3566)
- The `go.opentelemetry.io/otel/semconv/v1.15.0` package.
The package contains semantic conventions from the `v1.15.0` version of the OpenTelemetry specification. (#3578)
- The `go.opentelemetry.io/otel/semconv/v1.16.0` package.
The package contains semantic conventions from the `v1.16.0` version of the OpenTelemetry specification. (#3579)
- Metric instruments to `go.opentelemetry.io/otel/metric/instrument`.
These instruments are use as replacements of the deprecated `go.opentelemetry.io/otel/metric/instrument/{asyncfloat64,asyncint64,syncfloat64,syncint64}` packages.(#3575, #3586)
- `Float64ObservableCounter` replaces the `asyncfloat64.Counter`
- `Float64ObservableUpDownCounter` replaces the `asyncfloat64.UpDownCounter`
- `Float64ObservableGauge` replaces the `asyncfloat64.Gauge`
- `Int64ObservableCounter` replaces the `asyncint64.Counter`
- `Int64ObservableUpDownCounter` replaces the `asyncint64.UpDownCounter`
- `Int64ObservableGauge` replaces the `asyncint64.Gauge`
- `Float64Counter` replaces the `syncfloat64.Counter`
- `Float64UpDownCounter` replaces the `syncfloat64.UpDownCounter`
- `Float64Histogram` replaces the `syncfloat64.Histogram`
- `Int64Counter` replaces the `syncint64.Counter`
- `Int64UpDownCounter` replaces the `syncint64.UpDownCounter`
- `Int64Histogram` replaces the `syncint64.Histogram`
- `NewTracerProvider` to `go.opentelemetry.io/otel/bridge/opentracing`.
This is used to create `WrapperTracer` instances from a `TracerProvider`. (#3116)
- The `Extrema` type to `go.opentelemetry.io/otel/sdk/metric/metricdata`.
This type is used to represent min/max values and still be able to distinguish unset and zero values. (#3487)
- The `go.opentelemetry.io/otel/semconv/v1.17.0` package.
The package contains semantic conventions from the `v1.17.0` version of the OpenTelemetry specification. (#3599)
### Changed
- Jaeger and Zipkin exporter use `github.com/go-logr/logr` as the logging interface, and add the `WithLogr` option. (#3497, #3500)
- Instrument configuration in `go.opentelemetry.io/otel/metric/instrument` is split into specific options and configuration based on the instrument type. (#3507)
- Use the added `Int64Option` type to configure instruments from `go.opentelemetry.io/otel/metric/instrument/syncint64`.
- Use the added `Float64Option` type to configure instruments from `go.opentelemetry.io/otel/metric/instrument/syncfloat64`.
- Use the added `Int64ObserverOption` type to configure instruments from `go.opentelemetry.io/otel/metric/instrument/asyncint64`.
- Use the added `Float64ObserverOption` type to configure instruments from `go.opentelemetry.io/otel/metric/instrument/asyncfloat64`.
- Return a `Registration` from the `RegisterCallback` method of a `Meter` in the `go.opentelemetry.io/otel/metric` package.
This `Registration` can be used to unregister callbacks. (#3522)
- Global error handler uses an atomic value instead of a mutex. (#3543)
- Add `NewMetricProducer` to `go.opentelemetry.io/otel/bridge/opencensus`, which can be used to pass OpenCensus metrics to an OpenTelemetry Reader. (#3541)
- Global logger uses an atomic value instead of a mutex. (#3545)
- The `Shutdown` method of the `"go.opentelemetry.io/otel/sdk/trace".TracerProvider` releases all computational resources when called the first time. (#3551)
- The `Sampler` returned from `TraceIDRatioBased` `go.opentelemetry.io/otel/sdk/trace` now uses the rightmost bits for sampling decisions.
This fixes random sampling when using ID generators like `xray.IDGenerator` and increasing parity with other language implementations. (#3557)
- Errors from `go.opentelemetry.io/otel/exporters/otlp/otlptrace` exporters are wrapped in errors identifying their signal name.
Existing users of the exporters attempting to identify specific errors will need to use `errors.Unwrap()` to get the underlying error. (#3516)
- Exporters from `go.opentelemetry.io/otel/exporters/otlp` will print the final retryable error message when attempts to retry time out. (#3514)
- The instrument kind names in `go.opentelemetry.io/otel/sdk/metric` are updated to match the API. (#3562)
- `InstrumentKindSyncCounter` is renamed to `InstrumentKindCounter`
- `InstrumentKindSyncUpDownCounter` is renamed to `InstrumentKindUpDownCounter`
- `InstrumentKindSyncHistogram` is renamed to `InstrumentKindHistogram`
- `InstrumentKindAsyncCounter` is renamed to `InstrumentKindObservableCounter`
- `InstrumentKindAsyncUpDownCounter` is renamed to `InstrumentKindObservableUpDownCounter`
- `InstrumentKindAsyncGauge` is renamed to `InstrumentKindObservableGauge`
- The `RegisterCallback` method of the `Meter` in `go.opentelemetry.io/otel/metric` changed.
- The named `Callback` replaces the inline function parameter. (#3564)
- `Callback` is required to return an error. (#3576)
- `Callback` accepts the added `Observer` parameter added.
This new parameter is used by `Callback` implementations to observe values for asynchronous instruments instead of calling the `Observe` method of the instrument directly. (#3584)
- The slice of `instrument.Asynchronous` is now passed as a variadic argument. (#3587)
- The exporter from `go.opentelemetry.io/otel/exporters/zipkin` is updated to use the `v1.16.0` version of semantic conventions.
This means it no longer uses the removed `net.peer.ip` or `http.host` attributes to determine the remote endpoint.
Instead it uses the `net.sock.peer` attributes. (#3581)
- The `Min` and `Max` fields of the `HistogramDataPoint` in `go.opentelemetry.io/otel/sdk/metric/metricdata` are now defined with the added `Extrema` type instead of a `*float64`. (#3487)
### Fixed
- Asynchronous instruments that use sum aggregators and attribute filters correctly add values from equivalent attribute sets that have been filtered. (#3439, #3549)
- The `RegisterCallback` method of the `Meter` from `go.opentelemetry.io/otel/sdk/metric` only registers a callback for instruments created by that meter.
Trying to register a callback with instruments from a different meter will result in an error being returned. (#3584)
### Deprecated
- The `NewMetricExporter` in `go.opentelemetry.io/otel/bridge/opencensus` is deprecated.
Use `NewMetricProducer` instead. (#3541)
- The `go.opentelemetry.io/otel/metric/instrument/asyncfloat64` package is deprecated.
Use the instruments from `go.opentelemetry.io/otel/metric/instrument` instead. (#3575)
- The `go.opentelemetry.io/otel/metric/instrument/asyncint64` package is deprecated.
Use the instruments from `go.opentelemetry.io/otel/metric/instrument` instead. (#3575)
- The `go.opentelemetry.io/otel/metric/instrument/syncfloat64` package is deprecated.
Use the instruments from `go.opentelemetry.io/otel/metric/instrument` instead. (#3575)
- The `go.opentelemetry.io/otel/metric/instrument/syncint64` package is deprecated.
Use the instruments from `go.opentelemetry.io/otel/metric/instrument` instead. (#3575)
- The `NewWrappedTracerProvider` in `go.opentelemetry.io/otel/bridge/opentracing` is now deprecated.
Use `NewTracerProvider` instead. (#3116)
### Removed
- The deprecated `go.opentelemetry.io/otel/sdk/metric/view` package is removed. (#3520)
- The `InstrumentProvider` from `go.opentelemetry.io/otel/sdk/metric/asyncint64` is removed.
Use the new creation methods of the `Meter` in `go.opentelemetry.io/otel/sdk/metric` instead. (#3530)
- The `Counter` method is replaced by `Meter.Int64ObservableCounter`
- The `UpDownCounter` method is replaced by `Meter.Int64ObservableUpDownCounter`
- The `Gauge` method is replaced by `Meter.Int64ObservableGauge`
- The `InstrumentProvider` from `go.opentelemetry.io/otel/sdk/metric/asyncfloat64` is removed.
Use the new creation methods of the `Meter` in `go.opentelemetry.io/otel/sdk/metric` instead. (#3530)
- The `Counter` method is replaced by `Meter.Float64ObservableCounter`
- The `UpDownCounter` method is replaced by `Meter.Float64ObservableUpDownCounter`
- The `Gauge` method is replaced by `Meter.Float64ObservableGauge`
- The `InstrumentProvider` from `go.opentelemetry.io/otel/sdk/metric/syncint64` is removed.
Use the new creation methods of the `Meter` in `go.opentelemetry.io/otel/sdk/metric` instead. (#3530)
- The `Counter` method is replaced by `Meter.Int64Counter`
- The `UpDownCounter` method is replaced by `Meter.Int64UpDownCounter`
- The `Histogram` method is replaced by `Meter.Int64Histogram`
- The `InstrumentProvider` from `go.opentelemetry.io/otel/sdk/metric/syncfloat64` is removed.
Use the new creation methods of the `Meter` in `go.opentelemetry.io/otel/sdk/metric` instead. (#3530)
- The `Counter` method is replaced by `Meter.Float64Counter`
- The `UpDownCounter` method is replaced by `Meter.Float64UpDownCounter`
- The `Histogram` method is replaced by `Meter.Float64Histogram`
## [1.11.2/0.34.0] 2022-12-05
### Added
- The `WithView` `Option` is added to the `go.opentelemetry.io/otel/sdk/metric` package.
This option is used to configure the view(s) a `MeterProvider` will use for all `Reader`s that are registered with it. (#3387)
- Add Instrumentation Scope and Version as info metric and label in Prometheus exporter.
This can be disabled using the `WithoutScopeInfo()` option added to that package.(#3273, #3357)
- OTLP exporters now recognize: (#3363)
- `OTEL_EXPORTER_OTLP_INSECURE`
- `OTEL_EXPORTER_OTLP_TRACES_INSECURE`
- `OTEL_EXPORTER_OTLP_METRICS_INSECURE`
- `OTEL_EXPORTER_OTLP_CLIENT_KEY`
- `OTEL_EXPORTER_OTLP_TRACES_CLIENT_KEY`
- `OTEL_EXPORTER_OTLP_METRICS_CLIENT_KEY`
- `OTEL_EXPORTER_OTLP_CLIENT_CERTIFICATE`
- `OTEL_EXPORTER_OTLP_TRACES_CLIENT_CERTIFICATE`
- `OTEL_EXPORTER_OTLP_METRICS_CLIENT_CERTIFICATE`
- The `View` type and related `NewView` function to create a view according to the OpenTelemetry specification are added to `go.opentelemetry.io/otel/sdk/metric`.
These additions are replacements for the `View` type and `New` function from `go.opentelemetry.io/otel/sdk/metric/view`. (#3459)
- The `Instrument` and `InstrumentKind` type are added to `go.opentelemetry.io/otel/sdk/metric`.
These additions are replacements for the `Instrument` and `InstrumentKind` types from `go.opentelemetry.io/otel/sdk/metric/view`. (#3459)
- The `Stream` type is added to `go.opentelemetry.io/otel/sdk/metric` to define a metric data stream a view will produce. (#3459)
- The `AssertHasAttributes` allows instrument authors to test that datapoints returned have appropriate attributes. (#3487)
### Changed
- The `"go.opentelemetry.io/otel/sdk/metric".WithReader` option no longer accepts views to associate with the `Reader`.
Instead, views are now registered directly with the `MeterProvider` via the new `WithView` option.
The views registered with the `MeterProvider` apply to all `Reader`s. (#3387)
- The `Temporality(view.InstrumentKind) metricdata.Temporality` and `Aggregation(view.InstrumentKind) aggregation.Aggregation` methods are added to the `"go.opentelemetry.io/otel/sdk/metric".Exporter` interface. (#3260)
- The `Temporality(view.InstrumentKind) metricdata.Temporality` and `Aggregation(view.InstrumentKind) aggregation.Aggregation` methods are added to the `"go.opentelemetry.io/otel/exporters/otlp/otlpmetric".Client` interface. (#3260)
- The `WithTemporalitySelector` and `WithAggregationSelector` `ReaderOption`s have been changed to `ManualReaderOption`s in the `go.opentelemetry.io/otel/sdk/metric` package. (#3260)
- The periodic reader in the `go.opentelemetry.io/otel/sdk/metric` package now uses the temporality and aggregation selectors from its configured exporter instead of accepting them as options. (#3260)
### Fixed
- The `go.opentelemetry.io/otel/exporters/prometheus` exporter fixes duplicated `_total` suffixes. (#3369)
- Remove comparable requirement for `Reader`s. (#3387)
- Cumulative metrics from the OpenCensus bridge (`go.opentelemetry.io/otel/bridge/opencensus`) are defined as monotonic sums, instead of non-monotonic. (#3389)
- Asynchronous counters (`Counter` and `UpDownCounter`) from the metric SDK now produce delta sums when configured with delta temporality. (#3398)
- Exported `Status` codes in the `go.opentelemetry.io/otel/exporters/zipkin` exporter are now exported as all upper case values. (#3340)
- `Aggregation`s from `go.opentelemetry.io/otel/sdk/metric` with no data are not exported. (#3394, #3436)
- Re-enabled Attribute Filters in the Metric SDK. (#3396)
- Asynchronous callbacks are only called if they are registered with at least one instrument that does not use drop aggregation. (#3408)
- Do not report empty partial-success responses in the `go.opentelemetry.io/otel/exporters/otlp` exporters. (#3438, #3432)
- Handle partial success responses in `go.opentelemetry.io/otel/exporters/otlp/otlpmetric` exporters. (#3162, #3440)
- Prevent duplicate Prometheus description, unit, and type. (#3469)
- Prevents panic when using incorrect `attribute.Value.As[Type]Slice()`. (#3489)
### Removed
- The `go.opentelemetry.io/otel/exporters/otlp/otlpmetric.Client` interface is removed. (#3486)
- The `go.opentelemetry.io/otel/exporters/otlp/otlpmetric.New` function is removed. Use the `otlpmetric[http|grpc].New` directly. (#3486)
### Deprecated
- The `go.opentelemetry.io/otel/sdk/metric/view` package is deprecated.
Use `Instrument`, `InstrumentKind`, `View`, and `NewView` in `go.opentelemetry.io/otel/sdk/metric` instead. (#3476)
## [1.11.1/0.33.0] 2022-10-19
### Added
- The Prometheus exporter in `go.opentelemetry.io/otel/exporters/prometheus` registers with a Prometheus registerer on creation.
By default, it will register with the default Prometheus registerer.
A non-default registerer can be used by passing the `WithRegisterer` option. (#3239)
- Added the `WithAggregationSelector` option to the `go.opentelemetry.io/otel/exporters/prometheus` package to change the default `AggregationSelector` used. (#3341)
- The Prometheus exporter in `go.opentelemetry.io/otel/exporters/prometheus` converts the `Resource` associated with metric exports into a `target_info` metric. (#3285)
### Changed
- The `"go.opentelemetry.io/otel/exporters/prometheus".New` function is updated to return an error.
It will return an error if the exporter fails to register with Prometheus. (#3239)
### Fixed
- The URL-encoded values from the `OTEL_RESOURCE_ATTRIBUTES` environment variable are decoded. (#2963)
- The `baggage.NewMember` function decodes the `value` parameter instead of directly using it.
This fixes the implementation to be compliant with the W3C specification. (#3226)
- Slice attributes of the `attribute` package are now comparable based on their value, not instance. (#3108 #3252)
- The `Shutdown` and `ForceFlush` methods of the `"go.opentelemetry.io/otel/sdk/trace".TraceProvider` no longer return an error when no processor is registered. (#3268)
- The Prometheus exporter in `go.opentelemetry.io/otel/exporters/prometheus` cumulatively sums histogram buckets. (#3281)
- The sum of each histogram data point is now uniquely exported by the `go.opentelemetry.io/otel/exporters/otlpmetric` exporters. (#3284, #3293)
- Recorded values for asynchronous counters (`Counter` and `UpDownCounter`) are interpreted as exact, not incremental, sum values by the metric SDK. (#3350, #3278)
- `UpDownCounters` are now correctly output as Prometheus gauges in the `go.opentelemetry.io/otel/exporters/prometheus` exporter. (#3358)
- The Prometheus exporter in `go.opentelemetry.io/otel/exporters/prometheus` no longer describes the metrics it will send to Prometheus on startup.
Instead the exporter is defined as an "unchecked" collector for Prometheus.
This fixes the `reader is not registered` warning currently emitted on startup. (#3291 #3342)
- The `go.opentelemetry.io/otel/exporters/prometheus` exporter now correctly adds `_total` suffixes to counter metrics. (#3360)
- The `go.opentelemetry.io/otel/exporters/prometheus` exporter now adds a unit suffix to metric names.
This can be disabled using the `WithoutUnits()` option added to that package. (#3352)
## [1.11.0/0.32.3] 2022-10-12
### Added
- Add default User-Agent header to OTLP exporter requests (`go.opentelemetry.io/otel/exporters/otlptrace/otlptracegrpc` and `go.opentelemetry.io/otel/exporters/otlptrace/otlptracehttp`). (#3261)
### Changed
- `span.SetStatus` has been updated such that calls that lower the status are now no-ops. (#3214)
- Upgrade `golang.org/x/sys/unix` from `v0.0.0-20210423185535-09eb48e85fd7` to `v0.0.0-20220919091848-fb04ddd9f9c8`.
This addresses [GO-2022-0493](https://pkg.go.dev/vuln/GO-2022-0493). (#3235)
## [0.32.2] Metric SDK (Alpha) - 2022-10-11
### Added
- Added an example of using metric views to customize instruments. (#3177)
- Add default User-Agent header to OTLP exporter requests (`go.opentelemetry.io/otel/exporters/otlpmetric/otlpmetricgrpc` and `go.opentelemetry.io/otel/exporters/otlpmetric/otlpmetrichttp`). (#3261)
### Changed
- Flush pending measurements with the `PeriodicReader` in the `go.opentelemetry.io/otel/sdk/metric` when `ForceFlush` or `Shutdown` are called. (#3220)
- Update histogram default bounds to match the requirements of the latest specification. (#3222)
- Encode the HTTP status code in the OpenTracing bridge (`go.opentelemetry.io/otel/bridge/opentracing`) as an integer. (#3265)
### Fixed
- Use default view if instrument does not match any registered view of a reader. (#3224, #3237)
- Return the same instrument every time a user makes the exact same instrument creation call. (#3229, #3251)
- Return the existing instrument when a view transforms a creation call to match an existing instrument. (#3240, #3251)
- Log a warning when a conflicting instrument (e.g. description, unit, data-type) is created instead of returning an error. (#3251)
- The OpenCensus bridge no longer sends empty batches of metrics. (#3263)
## [0.32.1] Metric SDK (Alpha) - 2022-09-22
### Changed
- The Prometheus exporter sanitizes OpenTelemetry instrument names when exporting.
Invalid characters are replaced with `_`. (#3212)
### Added
- The metric portion of the OpenCensus bridge (`go.opentelemetry.io/otel/bridge/opencensus`) has been reintroduced. (#3192)
- The OpenCensus bridge example (`go.opentelemetry.io/otel/example/opencensus`) has been reintroduced. (#3206)
### Fixed
- Updated go.mods to point to valid versions of the sdk. (#3216)
- Set the `MeterProvider` resource on all exported metric data. (#3218)
## [0.32.0] Revised Metric SDK (Alpha) - 2022-09-18
### Changed
- The metric SDK in `go.opentelemetry.io/otel/sdk/metric` is completely refactored to comply with the OpenTelemetry specification.
Please see the package documentation for how the new SDK is initialized and configured. (#3175)
- Update the minimum supported go version to go1.18. Removes support for go1.17 (#3179)
### Removed
- The metric portion of the OpenCensus bridge (`go.opentelemetry.io/otel/bridge/opencensus`) has been removed.
A new bridge compliant with the revised metric SDK will be added back in a future release. (#3175)
- The `go.opentelemetry.io/otel/sdk/metric/aggregator/aggregatortest` package is removed, see the new metric SDK. (#3175)
- The `go.opentelemetry.io/otel/sdk/metric/aggregator/histogram` package is removed, see the new metric SDK. (#3175)
- The `go.opentelemetry.io/otel/sdk/metric/aggregator/lastvalue` package is removed, see the new metric SDK. (#3175)
- The `go.opentelemetry.io/otel/sdk/metric/aggregator/sum` package is removed, see the new metric SDK. (#3175)
- The `go.opentelemetry.io/otel/sdk/metric/aggregator` package is removed, see the new metric SDK. (#3175)
- The `go.opentelemetry.io/otel/sdk/metric/controller/basic` package is removed, see the new metric SDK. (#3175)
- The `go.opentelemetry.io/otel/sdk/metric/controller/controllertest` package is removed, see the new metric SDK. (#3175)
- The `go.opentelemetry.io/otel/sdk/metric/controller/time` package is removed, see the new metric SDK. (#3175)
- The `go.opentelemetry.io/otel/sdk/metric/export/aggregation` package is removed, see the new metric SDK. (#3175)
- The `go.opentelemetry.io/otel/sdk/metric/export` package is removed, see the new metric SDK. (#3175)
- The `go.opentelemetry.io/otel/sdk/metric/metrictest` package is removed.
A replacement package that supports the new metric SDK will be added back in a future release. (#3175)
- The `go.opentelemetry.io/otel/sdk/metric/number` package is removed, see the new metric SDK. (#3175)
- The `go.opentelemetry.io/otel/sdk/metric/processor/basic` package is removed, see the new metric SDK. (#3175)
- The `go.opentelemetry.io/otel/sdk/metric/processor/processortest` package is removed, see the new metric SDK. (#3175)
- The `go.opentelemetry.io/otel/sdk/metric/processor/reducer` package is removed, see the new metric SDK. (#3175)
- The `go.opentelemetry.io/otel/sdk/metric/registry` package is removed, see the new metric SDK. (#3175)
- The `go.opentelemetry.io/otel/sdk/metric/sdkapi` package is removed, see the new metric SDK. (#3175)
- The `go.opentelemetry.io/otel/sdk/metric/selector/simple` package is removed, see the new metric SDK. (#3175)
- The `"go.opentelemetry.io/otel/sdk/metric".ErrUninitializedInstrument` variable was removed. (#3175)
- The `"go.opentelemetry.io/otel/sdk/metric".ErrBadInstrument` variable was removed. (#3175)
- The `"go.opentelemetry.io/otel/sdk/metric".Accumulator` type was removed, see the `MeterProvider`in the new metric SDK. (#3175)
- The `"go.opentelemetry.io/otel/sdk/metric".NewAccumulator` function was removed, see `NewMeterProvider`in the new metric SDK. (#3175)
- The deprecated `"go.opentelemetry.io/otel/sdk/metric".AtomicFieldOffsets` function was removed. (#3175)
## [1.10.0] - 2022-09-09
### Added
- Support Go 1.19. (#3077)
Include compatibility testing and document support. (#3077)
- Support the OTLP ExportTracePartialSuccess response; these are passed to the registered error handler. (#3106)
- Upgrade go.opentelemetry.io/proto/otlp from v0.18.0 to v0.19.0 (#3107)
### Changed
- Fix misidentification of OpenTelemetry `SpanKind` in OpenTracing bridge (`go.opentelemetry.io/otel/bridge/opentracing`). (#3096)
- Attempting to start a span with a nil `context` will no longer cause a panic. (#3110)
- All exporters will be shutdown even if one reports an error (#3091)
- Ensure valid UTF-8 when truncating over-length attribute values. (#3156)
## [1.9.0/0.0.3] - 2022-08-01
### Added
- Add support for Schema Files format 1.1.x (metric "split" transform) with the new `go.opentelemetry.io/otel/schema/v1.1` package. (#2999)
- Add the `go.opentelemetry.io/otel/semconv/v1.11.0` package.
The package contains semantic conventions from the `v1.11.0` version of the OpenTelemetry specification. (#3009)
- Add the `go.opentelemetry.io/otel/semconv/v1.12.0` package.
The package contains semantic conventions from the `v1.12.0` version of the OpenTelemetry specification. (#3010)
- Add the `http.method` attribute to HTTP server metric from all `go.opentelemetry.io/otel/semconv/*` packages. (#3018)
### Fixed
- Invalid warning for context setup being deferred in `go.opentelemetry.io/otel/bridge/opentracing` package. (#3029)
## [1.8.0/0.31.0] - 2022-07-08
### Added
- Add support for `opentracing.TextMap` format in the `Inject` and `Extract` methods
of the `"go.opentelemetry.io/otel/bridge/opentracing".BridgeTracer` type. (#2911)
### Changed
- The `crosslink` make target has been updated to use the `go.opentelemetry.io/build-tools/crosslink` package. (#2886)
- In the `go.opentelemetry.io/otel/sdk/instrumentation` package rename `Library` to `Scope` and alias `Library` as `Scope` (#2976)
- Move metric no-op implementation form `nonrecording` to `metric` package. (#2866)
### Removed
- Support for go1.16. Support is now only for go1.17 and go1.18 (#2917)
### Deprecated
- The `Library` struct in the `go.opentelemetry.io/otel/sdk/instrumentation` package is deprecated.
Use the equivalent `Scope` struct instead. (#2977)
- The `ReadOnlySpan.InstrumentationLibrary` method from the `go.opentelemetry.io/otel/sdk/trace` package is deprecated.
Use the equivalent `ReadOnlySpan.InstrumentationScope` method instead. (#2977)
## [1.7.0/0.30.0] - 2022-04-28
### Added
- Add the `go.opentelemetry.io/otel/semconv/v1.8.0` package.
The package contains semantic conventions from the `v1.8.0` version of the OpenTelemetry specification. (#2763)
- Add the `go.opentelemetry.io/otel/semconv/v1.9.0` package.
The package contains semantic conventions from the `v1.9.0` version of the OpenTelemetry specification. (#2792)
- Add the `go.opentelemetry.io/otel/semconv/v1.10.0` package.
The package contains semantic conventions from the `v1.10.0` version of the OpenTelemetry specification. (#2842)
- Added an in-memory exporter to metrictest to aid testing with a full SDK. (#2776)
### Fixed
- Globally delegated instruments are unwrapped before delegating asynchronous callbacks. (#2784)
- Remove import of `testing` package in non-tests builds of the `go.opentelemetry.io/otel` package. (#2786)
### Changed
- The `WithLabelEncoder` option from the `go.opentelemetry.io/otel/exporters/stdout/stdoutmetric` package is renamed to `WithAttributeEncoder`. (#2790)
- The `LabelFilterSelector` interface from `go.opentelemetry.io/otel/sdk/metric/processor/reducer` is renamed to `AttributeFilterSelector`.
The method included in the renamed interface also changed from `LabelFilterFor` to `AttributeFilterFor`. (#2790)
- The `Metadata.Labels` method from the `go.opentelemetry.io/otel/sdk/metric/export` package is renamed to `Metadata.Attributes`.
Consequentially, the `Record` type from the same package also has had the embedded method renamed. (#2790)
### Deprecated
- The `Iterator.Label` method in the `go.opentelemetry.io/otel/attribute` package is deprecated.
Use the equivalent `Iterator.Attribute` method instead. (#2790)
- The `Iterator.IndexedLabel` method in the `go.opentelemetry.io/otel/attribute` package is deprecated.
Use the equivalent `Iterator.IndexedAttribute` method instead. (#2790)
- The `MergeIterator.Label` method in the `go.opentelemetry.io/otel/attribute` package is deprecated.
Use the equivalent `MergeIterator.Attribute` method instead. (#2790)
### Removed
- Removed the `Batch` type from the `go.opentelemetry.io/otel/sdk/metric/metrictest` package. (#2864)
- Removed the `Measurement` type from the `go.opentelemetry.io/otel/sdk/metric/metrictest` package. (#2864)
## [0.29.0] - 2022-04-11
### Added
- The metrics global package was added back into several test files. (#2764)
- The `Meter` function is added back to the `go.opentelemetry.io/otel/metric/global` package.
This function is a convenience function equivalent to calling `global.MeterProvider().Meter(...)`. (#2750)
### Removed
- Removed module the `go.opentelemetry.io/otel/sdk/export/metric`.
Use the `go.opentelemetry.io/otel/sdk/metric` module instead. (#2720)
### Changed
- Don't panic anymore when setting a global MeterProvider to itself. (#2749)
- Upgrade `go.opentelemetry.io/proto/otlp` in `go.opentelemetry.io/otel/exporters/otlp/otlpmetric` from `v0.12.1` to `v0.15.0`.
This replaces the use of the now deprecated `InstrumentationLibrary` and `InstrumentationLibraryMetrics` types and fields in the proto library with the equivalent `InstrumentationScope` and `ScopeMetrics`. (#2748)
## [1.6.3] - 2022-04-07
### Fixed
- Allow non-comparable global `MeterProvider`, `TracerProvider`, and `TextMapPropagator` types to be set. (#2772, #2773)
## [1.6.2] - 2022-04-06
### Changed
- Don't panic anymore when setting a global TracerProvider or TextMapPropagator to itself. (#2749)
- Upgrade `go.opentelemetry.io/proto/otlp` in `go.opentelemetry.io/otel/exporters/otlp/otlptrace` from `v0.12.1` to `v0.15.0`.
This replaces the use of the now deprecated `InstrumentationLibrary` and `InstrumentationLibrarySpans` types and fields in the proto library with the equivalent `InstrumentationScope` and `ScopeSpans`. (#2748)
## [1.6.1] - 2022-03-28
### Fixed
- The `go.opentelemetry.io/otel/schema/*` packages now use the correct schema URL for their `SchemaURL` constant.
Instead of using `"https://opentelemetry.io/schemas/v<version>"` they now use the correct URL without a `v` prefix, `"https://opentelemetry.io/schemas/<version>"`. (#2743, #2744)
### Security
- Upgrade `go.opentelemetry.io/proto/otlp` from `v0.12.0` to `v0.12.1`.
This includes an indirect upgrade of `github.com/grpc-ecosystem/grpc-gateway` which resolves [a vulnerability](https://nvd.nist.gov/vuln/detail/CVE-2019-11254) from `gopkg.in/yaml.v2` in version `v2.2.3`. (#2724, #2728)
## [1.6.0/0.28.0] - 2022-03-23
### ⚠️ Notice ⚠️
This update is a breaking change of the unstable Metrics API.
Code instrumented with the `go.opentelemetry.io/otel/metric` will need to be modified.
### Added
- Add metrics exponential histogram support.
New mapping functions have been made available in `sdk/metric/aggregator/exponential/mapping` for other OpenTelemetry projects to take dependencies on. (#2502)
- Add Go 1.18 to our compatibility tests. (#2679)
- Allow configuring the Sampler with the `OTEL_TRACES_SAMPLER` and `OTEL_TRACES_SAMPLER_ARG` environment variables. (#2305, #2517)
- Add the `metric/global` for obtaining and setting the global `MeterProvider`. (#2660)
### Changed
- The metrics API has been significantly changed to match the revised OpenTelemetry specification.
High-level changes include:
- Synchronous and asynchronous instruments are now handled by independent `InstrumentProvider`s.
These `InstrumentProvider`s are managed with a `Meter`.
- Synchronous and asynchronous instruments are grouped into their own packages based on value types.
- Asynchronous callbacks can now be registered with a `Meter`.
Be sure to check out the metric module documentation for more information on how to use the revised API. (#2587, #2660)
### Fixed
- Fallback to general attribute limits when span specific ones are not set in the environment. (#2675, #2677)
## [1.5.0] - 2022-03-16
### Added
- Log the Exporters configuration in the TracerProviders message. (#2578)
- Added support to configure the span limits with environment variables.
The following environment variables are supported. (#2606, #2637)
- `OTEL_SPAN_ATTRIBUTE_VALUE_LENGTH_LIMIT`
- `OTEL_SPAN_ATTRIBUTE_COUNT_LIMIT`
- `OTEL_SPAN_EVENT_COUNT_LIMIT`
- `OTEL_EVENT_ATTRIBUTE_COUNT_LIMIT`
- `OTEL_SPAN_LINK_COUNT_LIMIT`
- `OTEL_LINK_ATTRIBUTE_COUNT_LIMIT`
If the provided environment variables are invalid (negative), the default values would be used.
- Rename the `gc` runtime name to `go` (#2560)
- Add resource container ID detection. (#2418)
- Add span attribute value length limit.
The new `AttributeValueLengthLimit` field is added to the `"go.opentelemetry.io/otel/sdk/trace".SpanLimits` type to configure this limit for a `TracerProvider`.
The default limit for this resource is "unlimited". (#2637)
- Add the `WithRawSpanLimits` option to `go.opentelemetry.io/otel/sdk/trace`.
This option replaces the `WithSpanLimits` option.
Zero or negative values will not be changed to the default value like `WithSpanLimits` does.
Setting a limit to zero will effectively disable the related resource it limits and setting to a negative value will mean that resource is unlimited.
Consequentially, limits should be constructed using `NewSpanLimits` and updated accordingly. (#2637)
### Changed
- Drop oldest tracestate `Member` when capacity is reached. (#2592)
- Add event and link drop counts to the exported data from the `oltptrace` exporter. (#2601)
- Unify path cleaning functionally in the `otlpmetric` and `otlptrace` configuration. (#2639)
- Change the debug message from the `sdk/trace.BatchSpanProcessor` to reflect the count is cumulative. (#2640)
- Introduce new internal `envconfig` package for OTLP exporters. (#2608)
- If `http.Request.Host` is empty, fall back to use `URL.Host` when populating `http.host` in the `semconv` packages. (#2661)
### Fixed
- Remove the OTLP trace exporter limit of SpanEvents when exporting. (#2616)
- Default to port `4318` instead of `4317` for the `otlpmetrichttp` and `otlptracehttp` client. (#2614, #2625)
- Unlimited span limits are now supported (negative values). (#2636, #2637)
### Deprecated
- Deprecated `"go.opentelemetry.io/otel/sdk/trace".WithSpanLimits`.
Use `WithRawSpanLimits` instead.
That option allows setting unlimited and zero limits, this option does not.
This option will be kept until the next major version incremented release. (#2637)
## [1.4.1] - 2022-02-16
### Fixed
- Fix race condition in reading the dropped spans number for the `BatchSpanProcessor`. (#2615)
## [1.4.0] - 2022-02-11
### Added
- Use `OTEL_EXPORTER_ZIPKIN_ENDPOINT` environment variable to specify zipkin collector endpoint. (#2490)
- Log the configuration of `TracerProvider`s, and `Tracer`s for debugging.
To enable use a logger with Verbosity (V level) `>=1`. (#2500)
- Added support to configure the batch span-processor with environment variables.
The following environment variables are used. (#2515)
- `OTEL_BSP_SCHEDULE_DELAY`
- `OTEL_BSP_EXPORT_TIMEOUT`
- `OTEL_BSP_MAX_QUEUE_SIZE`.
- `OTEL_BSP_MAX_EXPORT_BATCH_SIZE`
### Changed
- Zipkin exporter exports `Resource` attributes in the `Tags` field. (#2589)
### Deprecated
- Deprecate module the `go.opentelemetry.io/otel/sdk/export/metric`.
Use the `go.opentelemetry.io/otel/sdk/metric` module instead. (#2382)
- Deprecate `"go.opentelemetry.io/otel/sdk/metric".AtomicFieldOffsets`. (#2445)
### Fixed
- Fixed the instrument kind for noop async instruments to correctly report an implementation. (#2461)
- Fix UDP packets overflowing with Jaeger payloads. (#2489, #2512)
- Change the `otlpmetric.Client` interface's `UploadMetrics` method to accept a single `ResourceMetrics` instead of a slice of them. (#2491)
- Specify explicit buckets in Prometheus example, fixing issue where example only has `+inf` bucket. (#2419, #2493)
- W3C baggage will now decode urlescaped values. (#2529)
- Baggage members are now only validated once, when calling `NewMember` and not also when adding it to the baggage itself. (#2522)
- The order attributes are dropped from spans in the `go.opentelemetry.io/otel/sdk/trace` package when capacity is reached is fixed to be in compliance with the OpenTelemetry specification.
Instead of dropping the least-recently-used attribute, the last added attribute is dropped.
This drop order still only applies to attributes with unique keys not already contained in the span.
If an attribute is added with a key already contained in the span, that attribute is updated to the new value being added. (#2576)
### Removed
- Updated `go.opentelemetry.io/proto/otlp` from `v0.11.0` to `v0.12.0`. This version removes a number of deprecated methods. (#2546)
- [`Metric.GetIntGauge()`](https://pkg.go.dev/go.opentelemetry.io/proto/[email protected]/metrics/v1#Metric.GetIntGauge)
- [`Metric.GetIntHistogram()`](https://pkg.go.dev/go.opentelemetry.io/proto/[email protected]/metrics/v1#Metric.GetIntHistogram)
- [`Metric.GetIntSum()`](https://pkg.go.dev/go.opentelemetry.io/proto/[email protected]/metrics/v1#Metric.GetIntSum)
## [1.3.0] - 2021-12-10
### ⚠️ Notice ⚠️
We have updated the project minimum supported Go version to 1.16
### Added
- Added an internal Logger.
This can be used by the SDK and API to provide users with feedback of the internal state.
To enable verbose logs configure the logger which will print V(1) logs. For debugging information configure to print V(5) logs. (#2343)
- Add the `WithRetry` `Option` and the `RetryConfig` type to the `go.opentelemetry.io/otel/exporter/otel/otlpmetric/otlpmetrichttp` package to specify retry behavior consistently. (#2425)
- Add `SpanStatusFromHTTPStatusCodeAndSpanKind` to all `semconv` packages to return a span status code similar to `SpanStatusFromHTTPStatusCode`, but exclude `4XX` HTTP errors as span errors if the span is of server kind. (#2296)
### Changed
- The `"go.opentelemetry.io/otel/exporter/otel/otlptrace/otlptracegrpc".Client` now uses the underlying gRPC `ClientConn` to handle name resolution, TCP connection establishment (with retries and backoff) and TLS handshakes, and handling errors on established connections by re-resolving the name and reconnecting. (#2329)
- The `"go.opentelemetry.io/otel/exporter/otel/otlpmetric/otlpmetricgrpc".Client` now uses the underlying gRPC `ClientConn` to handle name resolution, TCP connection establishment (with retries and backoff) and TLS handshakes, and handling errors on established connections by re-resolving the name and reconnecting. (#2425)
- The `"go.opentelemetry.io/otel/exporter/otel/otlpmetric/otlpmetricgrpc".RetrySettings` type is renamed to `RetryConfig`. (#2425)
- The `go.opentelemetry.io/otel/exporter/otel/*` gRPC exporters now default to using the host's root CA set if none are provided by the user and `WithInsecure` is not specified. (#2432)
- Change `resource.Default` to be evaluated the first time it is called, rather than on import. This allows the caller the option to update `OTEL_RESOURCE_ATTRIBUTES` first, such as with `os.Setenv`. (#2371)
### Fixed
- The `go.opentelemetry.io/otel/exporter/otel/*` exporters are updated to handle per-signal and universal endpoints according to the OpenTelemetry specification.
Any per-signal endpoint set via an `OTEL_EXPORTER_OTLP_<signal>_ENDPOINT` environment variable is now used without modification of the path.
When `OTEL_EXPORTER_OTLP_ENDPOINT` is set, if it contains a path, that path is used as a base path which per-signal paths are appended to. (#2433)
- Basic metric controller updated to use sync.Map to avoid blocking calls (#2381)
- The `go.opentelemetry.io/otel/exporter/jaeger` correctly sets the `otel.status_code` value to be a string of `ERROR` or `OK` instead of an integer code. (#2439, #2440)
### Deprecated
- Deprecated the `"go.opentelemetry.io/otel/exporter/otel/otlpmetric/otlpmetrichttp".WithMaxAttempts` `Option`, use the new `WithRetry` `Option` instead. (#2425)
- Deprecated the `"go.opentelemetry.io/otel/exporter/otel/otlpmetric/otlpmetrichttp".WithBackoff` `Option`, use the new `WithRetry` `Option` instead. (#2425)
### Removed
- Remove the metric Processor's ability to convert cumulative to delta aggregation temporality. (#2350)
- Remove the metric Bound Instruments interface and implementations. (#2399)
- Remove the metric MinMaxSumCount kind aggregation and the corresponding OTLP export path. (#2423)
- Metric SDK removes the "exact" aggregator for histogram instruments, as it performed a non-standard aggregation for OTLP export (creating repeated Gauge points) and worked its way into a number of confusing examples. (#2348)
## [1.2.0] - 2021-11-12
### Changed
- Metric SDK `export.ExportKind`, `export.ExportKindSelector` types have been renamed to `aggregation.Temporality` and `aggregation.TemporalitySelector` respectively to keep in line with current specification and protocol along with built-in selectors (e.g., `aggregation.CumulativeTemporalitySelector`, ...). (#2274)
- The Metric `Exporter` interface now requires a `TemporalitySelector` method instead of an `ExportKindSelector`. (#2274)
- Metrics API cleanup. The `metric/sdkapi` package has been created to relocate the API-to-SDK interface:
- The following interface types simply moved from `metric` to `metric/sdkapi`: `Descriptor`, `MeterImpl`, `InstrumentImpl`, `SyncImpl`, `BoundSyncImpl`, `AsyncImpl`, `AsyncRunner`, `AsyncSingleRunner`, and `AsyncBatchRunner`
- The following struct types moved and are replaced with type aliases, since they are exposed to the user: `Observation`, `Measurement`.
- The No-op implementations of sync and async instruments are no longer exported, new functions `sdkapi.NewNoopAsyncInstrument()` and `sdkapi.NewNoopSyncInstrument()` are provided instead. (#2271)
- Update the SDK `BatchSpanProcessor` to export all queued spans when `ForceFlush` is called. (#2080, #2335)
### Added
- Add the `"go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetricgrpc".WithGRPCConn` option so the exporter can reuse an existing gRPC connection. (#2002)
- Added a new `schema` module to help parse Schema Files in OTEP 0152 format. (#2267)
- Added a new `MapCarrier` to the `go.opentelemetry.io/otel/propagation` package to hold propagated cross-cutting concerns as a `map[string]string` held in memory. (#2334)
## [1.1.0] - 2021-10-27
### Added
- Add the `"go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracegrpc".WithGRPCConn` option so the exporter can reuse an existing gRPC connection. (#2002)
- Add the `go.opentelemetry.io/otel/semconv/v1.7.0` package.
The package contains semantic conventions from the `v1.7.0` version of the OpenTelemetry specification. (#2320)
- Add the `go.opentelemetry.io/otel/semconv/v1.6.1` package.
The package contains semantic conventions from the `v1.6.1` version of the OpenTelemetry specification. (#2321)
- Add the `go.opentelemetry.io/otel/semconv/v1.5.0` package.
The package contains semantic conventions from the `v1.5.0` version of the OpenTelemetry specification. (#2322)
- When upgrading from the `semconv/v1.4.0` package note the following name changes:
- `K8SReplicasetUIDKey` -> `K8SReplicaSetUIDKey`
- `K8SReplicasetNameKey` -> `K8SReplicaSetNameKey`
- `K8SStatefulsetUIDKey` -> `K8SStatefulSetUIDKey`
- `k8SStatefulsetNameKey` -> `K8SStatefulSetNameKey`
- `K8SDaemonsetUIDKey` -> `K8SDaemonSetUIDKey`
- `K8SDaemonsetNameKey` -> `K8SDaemonSetNameKey`
### Changed
- Links added to a span will be dropped by the SDK if they contain an invalid span context (#2275).
### Fixed
- The `"go.opentelemetry.io/otel/semconv/v1.4.0".HTTPServerAttributesFromHTTPRequest` now correctly only sets the HTTP client IP attribute even if the connection was routed with proxies and there are multiple addresses in the `X-Forwarded-For` header. (#2282, #2284)
- The `"go.opentelemetry.io/otel/semconv/v1.4.0".NetAttributesFromHTTPRequest` function correctly handles IPv6 addresses as IP addresses and sets the correct net peer IP instead of the net peer hostname attribute. (#2283, #2285)
- The simple span processor shutdown method deterministically returns the exporter error status if it simultaneously finishes when the deadline is reached. (#2290, #2289)
## [1.0.1] - 2021-10-01
### Fixed
- json stdout exporter no longer crashes due to concurrency bug. (#2265)
## [Metrics 0.24.0] - 2021-10-01
### Changed
- NoopMeterProvider is now private and NewNoopMeterProvider must be used to obtain a noopMeterProvider. (#2237)
- The Metric SDK `Export()` function takes a new two-level reader interface for iterating over results one instrumentation library at a time. (#2197)
- The former `"go.opentelemetry.io/otel/sdk/export/metric".CheckpointSet` is renamed `Reader`.
- The new interface is named `"go.opentelemetry.io/otel/sdk/export/metric".InstrumentationLibraryReader`.
## [1.0.0] - 2021-09-20
This is the first stable release for the project.
This release includes an API and SDK for the tracing signal that will comply with the stability guarantees defined by the projects [versioning policy](./VERSIONING.md).
### Added
- OTLP trace exporter now sets the `SchemaURL` field in the exported telemetry if the Tracer has `WithSchemaURL` option. (#2242)
### Fixed
- Slice-valued attributes can correctly be used as map keys. (#2223)
### Removed
- Removed the `"go.opentelemetry.io/otel/exporters/zipkin".WithSDKOptions` function. (#2248)
- Removed the deprecated package `go.opentelemetry.io/otel/oteltest`. (#2234)
- Removed the deprecated package `go.opentelemetry.io/otel/bridge/opencensus/utils`. (#2233)
- Removed deprecated functions, types, and methods from `go.opentelemetry.io/otel/attribute` package.
Use the typed functions and methods added to the package instead. (#2235)
- The `Key.Array` method is removed.
- The `Array` function is removed.
- The `Any` function is removed.
- The `ArrayValue` function is removed.
- The `AsArray` function is removed.
## [1.0.0-RC3] - 2021-09-02
### Added
- Added `ErrorHandlerFunc` to use a function as an `"go.opentelemetry.io/otel".ErrorHandler`. (#2149)
- Added `"go.opentelemetry.io/otel/trace".WithStackTrace` option to add a stack trace when using `span.RecordError` or when panic is handled in `span.End`. (#2163)
- Added typed slice attribute types and functionality to the `go.opentelemetry.io/otel/attribute` package to replace the existing array type and functions. (#2162)
- `BoolSlice`, `IntSlice`, `Int64Slice`, `Float64Slice`, and `StringSlice` replace the use of the `Array` function in the package.
- Added the `go.opentelemetry.io/otel/example/fib` example package.
Included is an example application that computes Fibonacci numbers. (#2203)
### Changed
- Metric instruments have been renamed to match the (feature-frozen) metric API specification:
- ValueRecorder becomes Histogram
- ValueObserver becomes Gauge
- SumObserver becomes CounterObserver
- UpDownSumObserver becomes UpDownCounterObserver
The API exported from this project is still considered experimental. (#2202)
- Metric SDK/API implementation type `InstrumentKind` moves into `sdkapi` sub-package. (#2091)
- The Metrics SDK export record no longer contains a Resource pointer, the SDK `"go.opentelemetry.io/otel/sdk/trace/export/metric".Exporter.Export()` function for push-based exporters now takes a single Resource argument, pull-based exporters use `"go.opentelemetry.io/otel/sdk/metric/controller/basic".Controller.Resource()`. (#2120)
- The JSON output of the `go.opentelemetry.io/otel/exporters/stdout/stdouttrace` is harmonized now such that the output is "plain" JSON objects after each other of the form `{ ... } { ... } { ... }`. Earlier the JSON objects describing a span were wrapped in a slice for each `Exporter.ExportSpans` call, like `[ { ... } ][ { ... } { ... } ]`. Outputting JSON object directly after each other is consistent with JSON loggers, and a bit easier to parse and read. (#2196)
- Update the `NewTracerConfig`, `NewSpanStartConfig`, `NewSpanEndConfig`, and `NewEventConfig` function in the `go.opentelemetry.io/otel/trace` package to return their respective configurations as structs instead of pointers to the struct. (#2212)
### Deprecated
- The `go.opentelemetry.io/otel/bridge/opencensus/utils` package is deprecated.
All functionality from this package now exists in the `go.opentelemetry.io/otel/bridge/opencensus` package.
The functions from that package should be used instead. (#2166)
- The `"go.opentelemetry.io/otel/attribute".Array` function and the related `ARRAY` value type is deprecated.
Use the typed `*Slice` functions and types added to the package instead. (#2162)
- The `"go.opentelemetry.io/otel/attribute".Any` function is deprecated.
Use the typed functions instead. (#2181)
- The `go.opentelemetry.io/otel/oteltest` package is deprecated.
The `"go.opentelemetry.io/otel/sdk/trace/tracetest".SpanRecorder` can be registered with the default SDK (`go.opentelemetry.io/otel/sdk/trace`) as a `SpanProcessor` and used as a replacement for this deprecated package. (#2188)
### Removed
- Removed metrics test package `go.opentelemetry.io/otel/sdk/export/metric/metrictest`. (#2105)
### Fixed
- The `fromEnv` detector no longer throws an error when `OTEL_RESOURCE_ATTRIBUTES` environment variable is not set or empty. (#2138)
- Setting the global `ErrorHandler` with `"go.opentelemetry.io/otel".SetErrorHandler` multiple times is now supported. (#2160, #2140)
- The `"go.opentelemetry.io/otel/attribute".Any` function now supports `int32` values. (#2169)
- Multiple calls to `"go.opentelemetry.io/otel/sdk/metric/controller/basic".WithResource()` are handled correctly, and when no resources are provided `"go.opentelemetry.io/otel/sdk/resource".Default()` is used. (#2120)
- The `WithoutTimestamps` option for the `go.opentelemetry.io/otel/exporters/stdout/stdouttrace` exporter causes the exporter to correctly omit timestamps. (#2195)
- Fixed typos in resources.go. (#2201)
## [1.0.0-RC2] - 2021-07-26
### Added
- Added `WithOSDescription` resource configuration option to set OS (Operating System) description resource attribute (`os.description`). (#1840)
- Added `WithOS` resource configuration option to set all OS (Operating System) resource attributes at once. (#1840)
- Added the `WithRetry` option to the `go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracehttp` package.
This option is a replacement for the removed `WithMaxAttempts` and `WithBackoff` options. (#2095)
- Added API `LinkFromContext` to return Link which encapsulates SpanContext from provided context and also encapsulates attributes. (#2115)
- Added a new `Link` type under the SDK `otel/sdk/trace` package that counts the number of attributes that were dropped for surpassing the `AttributePerLinkCountLimit` configured in the Span's `SpanLimits`.
This new type replaces the equal-named API `Link` type found in the `otel/trace` package for most usages within the SDK.
For example, instances of this type are now returned by the `Links()` function of `ReadOnlySpan`s provided in places like the `OnEnd` function of `SpanProcessor` implementations. (#2118)
- Added the `SpanRecorder` type to the `go.opentelemetry.io/otel/skd/trace/tracetest` package.
This type can be used with the default SDK as a `SpanProcessor` during testing. (#2132)
### Changed
- The `SpanModels` function is now exported from the `go.opentelemetry.io/otel/exporters/zipkin` package to convert OpenTelemetry spans into Zipkin model spans. (#2027)
- Rename the `"go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracegrpc".RetrySettings` to `RetryConfig`. (#2095)
### Deprecated
- The `TextMapCarrier` and `TextMapPropagator` from the `go.opentelemetry.io/otel/oteltest` package and their associated creation functions (`TextMapCarrier`, `NewTextMapPropagator`) are deprecated. (#2114)
- The `Harness` type from the `go.opentelemetry.io/otel/oteltest` package and its associated creation function, `NewHarness` are deprecated and will be removed in the next release. (#2123)
- The `TraceStateFromKeyValues` function from the `go.opentelemetry.io/otel/oteltest` package is deprecated.
Use the `trace.ParseTraceState` function instead. (#2122)
### Removed
- Removed the deprecated package `go.opentelemetry.io/otel/exporters/trace/jaeger`. (#2020)
- Removed the deprecated package `go.opentelemetry.io/otel/exporters/trace/zipkin`. (#2020)
- Removed the `"go.opentelemetry.io/otel/sdk/resource".WithBuiltinDetectors` function.
The explicit `With*` options for every built-in detector should be used instead. (#2026 #2097)
- Removed the `WithMaxAttempts` and `WithBackoff` options from the `go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracehttp` package.
The retry logic of the package has been updated to match the `otlptracegrpc` package and accordingly a `WithRetry` option is added that should be used instead. (#2095)
- Removed `DroppedAttributeCount` field from `otel/trace.Link` struct. (#2118)
### Fixed
- When using WithNewRoot, don't use the parent context for making sampling decisions. (#2032)
- `oteltest.Tracer` now creates a valid `SpanContext` when using `WithNewRoot`. (#2073)
- OS type detector now sets the correct `dragonflybsd` value for DragonFly BSD. (#2092)
- The OTel span status is correctly transformed into the OTLP status in the `go.opentelemetry.io/otel/exporters/otlp/otlptrace` package.
This fix will by default set the status to `Unset` if it is not explicitly set to `Ok` or `Error`. (#2099 #2102)
- The `Inject` method for the `"go.opentelemetry.io/otel/propagation".TraceContext` type no longer injects empty `tracestate` values. (#2108)
- Use `6831` as default Jaeger agent port instead of `6832`. (#2131)
## [Experimental Metrics v0.22.0] - 2021-07-19
### Added
- Adds HTTP support for OTLP metrics exporter. (#2022)
### Removed
- Removed the deprecated package `go.opentelemetry.io/otel/exporters/metric/prometheus`. (#2020)
## [1.0.0-RC1] / 0.21.0 - 2021-06-18
With this release we are introducing a split in module versions. The tracing API and SDK are entering the `v1.0.0` Release Candidate phase with `v1.0.0-RC1`
while the experimental metrics API and SDK continue with `v0.x` releases at `v0.21.0`. Modules at major version 1 or greater will not depend on modules
with major version 0.
### Added
- Adds `otlpgrpc.WithRetry`option for configuring the retry policy for transient errors on the otlp/gRPC exporter. (#1832)
- The following status codes are defined as transient errors:
| gRPC Status Code | Description |
| ---------------- | ----------- |
| 1 | Cancelled |
| 4 | Deadline Exceeded |
| 8 | Resource Exhausted |
| 10 | Aborted |
| 10 | Out of Range |
| 14 | Unavailable |
| 15 | Data Loss |
- Added `Status` type to the `go.opentelemetry.io/otel/sdk/trace` package to represent the status of a span. (#1874)
- Added `SpanStub` type and its associated functions to the `go.opentelemetry.io/otel/sdk/trace/tracetest` package.
This type can be used as a testing replacement for the `SpanSnapshot` that was removed from the `go.opentelemetry.io/otel/sdk/trace` package. (#1873)
- Adds support for scheme in `OTEL_EXPORTER_OTLP_ENDPOINT` according to the spec. (#1886)
- Adds `trace.WithSchemaURL` option for configuring the tracer with a Schema URL. (#1889)
- Added an example of using OpenTelemetry Go as a trace context forwarder. (#1912)
- `ParseTraceState` is added to the `go.opentelemetry.io/otel/trace` package.
It can be used to decode a `TraceState` from a `tracestate` header string value. (#1937)
- Added `Len` method to the `TraceState` type in the `go.opentelemetry.io/otel/trace` package.
This method returns the number of list-members the `TraceState` holds. (#1937)
- Creates package `go.opentelemetry.io/otel/exporters/otlp/otlptrace` that defines a trace exporter that uses a `otlptrace.Client` to send data.
Creates package `go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracegrpc` implementing a gRPC `otlptrace.Client` and offers convenience functions, `NewExportPipeline` and `InstallNewPipeline`, to setup and install a `otlptrace.Exporter` in tracing .(#1922)
- Added `Baggage`, `Member`, and `Property` types to the `go.opentelemetry.io/otel/baggage` package along with their related functions. (#1967)
- Added `ContextWithBaggage`, `ContextWithoutBaggage`, and `FromContext` functions to the `go.opentelemetry.io/otel/baggage` package.
These functions replace the `Set`, `Value`, `ContextWithValue`, `ContextWithoutValue`, and `ContextWithEmpty` functions from that package and directly work with the new `Baggage` type. (#1967)
- The `OTEL_SERVICE_NAME` environment variable is the preferred source for `service.name`, used by the environment resource detector if a service name is present both there and in `OTEL_RESOURCE_ATTRIBUTES`. (#1969)
- Creates package `go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracehttp` implementing an HTTP `otlptrace.Client` and offers convenience functions, `NewExportPipeline` and `InstallNewPipeline`, to setup and install a `otlptrace.Exporter` in tracing. (#1963)
- Changes `go.opentelemetry.io/otel/sdk/resource.NewWithAttributes` to require a schema URL. The old function is still available as `resource.NewSchemaless`. This is a breaking change. (#1938)
- Several builtin resource detectors now correctly populate the schema URL. (#1938)
- Creates package `go.opentelemetry.io/otel/exporters/otlp/otlpmetric` that defines a metrics exporter that uses a `otlpmetric.Client` to send data.
- Creates package `go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetricgrpc` implementing a gRPC `otlpmetric.Client` and offers convenience functions, `New` and `NewUnstarted`, to create an `otlpmetric.Exporter`.(#1991)
- Added `go.opentelemetry.io/otel/exporters/stdout/stdouttrace` exporter. (#2005)
- Added `go.opentelemetry.io/otel/exporters/stdout/stdoutmetric` exporter. (#2005)
- Added a `TracerProvider()` method to the `"go.opentelemetry.io/otel/trace".Span` interface. This can be used to obtain a `TracerProvider` from a given span that utilizes the same trace processing pipeline. (#2009)
### Changed
- Make `NewSplitDriver` from `go.opentelemetry.io/otel/exporters/otlp` take variadic arguments instead of a `SplitConfig` item.
`NewSplitDriver` now automatically implements an internal `noopDriver` for `SplitConfig` fields that are not initialized. (#1798)
- `resource.New()` now creates a Resource without builtin detectors. Previous behavior is now achieved by using `WithBuiltinDetectors` Option. (#1810)
- Move the `Event` type from the `go.opentelemetry.io/otel` package to the `go.opentelemetry.io/otel/sdk/trace` package. (#1846)
- CI builds validate against last two versions of Go, dropping 1.14 and adding 1.16. (#1865)
- BatchSpanProcessor now report export failures when calling `ForceFlush()` method. (#1860)
- `Set.Encoded(Encoder)` no longer caches the result of an encoding. (#1855)
- Renamed `CloudZoneKey` to `CloudAvailabilityZoneKey` in Resource semantic conventions according to spec. (#1871)
- The `StatusCode` and `StatusMessage` methods of the `ReadOnlySpan` interface and the `Span` produced by the `go.opentelemetry.io/otel/sdk/trace` package have been replaced with a single `Status` method.
This method returns the status of a span using the new `Status` type. (#1874)
- Updated `ExportSpans` method of the`SpanExporter` interface type to accept `ReadOnlySpan`s instead of the removed `SpanSnapshot`.
This brings the export interface into compliance with the specification in that it now accepts an explicitly immutable type instead of just an implied one. (#1873)
- Unembed `SpanContext` in `Link`. (#1877)
- Generate Semantic conventions from the specification YAML. (#1891)
- Spans created by the global `Tracer` obtained from `go.opentelemetry.io/otel`, prior to a functioning `TracerProvider` being set, now propagate the span context from their parent if one exists. (#1901)
- The `"go.opentelemetry.io/otel".Tracer` function now accepts tracer options. (#1902)
- Move the `go.opentelemetry.io/otel/unit` package to `go.opentelemetry.io/otel/metric/unit`. (#1903)
- Changed `go.opentelemetry.io/otel/trace.TracerConfig` to conform to the [Contributing guidelines](CONTRIBUTING.md#config.) (#1921)
- Changed `go.opentelemetry.io/otel/trace.SpanConfig` to conform to the [Contributing guidelines](CONTRIBUTING.md#config). (#1921)
- Changed `span.End()` now only accepts Options that are allowed at `End()`. (#1921)
- Changed `go.opentelemetry.io/otel/metric.InstrumentConfig` to conform to the [Contributing guidelines](CONTRIBUTING.md#config). (#1921)
- Changed `go.opentelemetry.io/otel/metric.MeterConfig` to conform to the [Contributing guidelines](CONTRIBUTING.md#config). (#1921)
- Refactored option types according to the contribution style guide. (#1882)
- Move the `go.opentelemetry.io/otel/trace.TraceStateFromKeyValues` function to the `go.opentelemetry.io/otel/oteltest` package.
This function is preserved for testing purposes where it may be useful to create a `TraceState` from `attribute.KeyValue`s, but it is not intended for production use.
The new `ParseTraceState` function should be used to create a `TraceState`. (#1931)
- Updated `MarshalJSON` method of the `go.opentelemetry.io/otel/trace.TraceState` type to marshal the type into the string representation of the `TraceState`. (#1931)
- The `TraceState.Delete` method from the `go.opentelemetry.io/otel/trace` package no longer returns an error in addition to a `TraceState`. (#1931)
- Updated `Get` method of the `TraceState` type from the `go.opentelemetry.io/otel/trace` package to accept a `string` instead of an `attribute.Key` type. (#1931)
- Updated `Insert` method of the `TraceState` type from the `go.opentelemetry.io/otel/trace` package to accept a pair of `string`s instead of an `attribute.KeyValue` type. (#1931)
- Updated `Delete` method of the `TraceState` type from the `go.opentelemetry.io/otel/trace` package to accept a `string` instead of an `attribute.Key` type. (#1931)
- Renamed `NewExporter` to `New` in the `go.opentelemetry.io/otel/exporters/stdout` package. (#1985)
- Renamed `NewExporter` to `New` in the `go.opentelemetry.io/otel/exporters/metric/prometheus` package. (#1985)
- Renamed `NewExporter` to `New` in the `go.opentelemetry.io/otel/exporters/trace/jaeger` package. (#1985)
- Renamed `NewExporter` to `New` in the `go.opentelemetry.io/otel/exporters/trace/zipkin` package. (#1985)
- Renamed `NewExporter` to `New` in the `go.opentelemetry.io/otel/exporters/otlp` package. (#1985)
- Renamed `NewUnstartedExporter` to `NewUnstarted` in the `go.opentelemetry.io/otel/exporters/otlp` package. (#1985)
- The `go.opentelemetry.io/otel/semconv` package has been moved to `go.opentelemetry.io/otel/semconv/v1.4.0` to allow for multiple [telemetry schema](https://github.com/open-telemetry/oteps/blob/main/text/0152-telemetry-schemas.md) versions to be used concurrently. (#1987)
- Metrics test helpers in `go.opentelemetry.io/otel/oteltest` have been moved to `go.opentelemetry.io/otel/metric/metrictest`. (#1988)
### Deprecated
- The `go.opentelemetry.io/otel/exporters/metric/prometheus` is deprecated, use `go.opentelemetry.io/otel/exporters/prometheus` instead. (#1993)
- The `go.opentelemetry.io/otel/exporters/trace/jaeger` is deprecated, use `go.opentelemetry.io/otel/exporters/jaeger` instead. (#1993)
- The `go.opentelemetry.io/otel/exporters/trace/zipkin` is deprecated, use `go.opentelemetry.io/otel/exporters/zipkin` instead. (#1993)
### Removed
- Removed `resource.WithoutBuiltin()`. Use `resource.New()`. (#1810)
- Unexported types `resource.FromEnv`, `resource.Host`, and `resource.TelemetrySDK`, Use the corresponding `With*()` to use individually. (#1810)
- Removed the `Tracer` and `IsRecording` method from the `ReadOnlySpan` in the `go.opentelemetry.io/otel/sdk/trace`.
The `Tracer` method is not a required to be included in this interface and given the mutable nature of the tracer that is associated with a span, this method is not appropriate.
The `IsRecording` method returns if the span is recording or not.
A read-only span value does not need to know if updates to it will be recorded or not.
By definition, it cannot be updated so there is no point in communicating if an update is recorded. (#1873)
- Removed the `SpanSnapshot` type from the `go.opentelemetry.io/otel/sdk/trace` package.
The use of this type has been replaced with the use of the explicitly immutable `ReadOnlySpan` type.
When a concrete representation of a read-only span is needed for testing, the newly added `SpanStub` in the `go.opentelemetry.io/otel/sdk/trace/tracetest` package should be used. (#1873)
- Removed the `Tracer` method from the `Span` interface in the `go.opentelemetry.io/otel/trace` package.
Using the same tracer that created a span introduces the error where an instrumentation library's `Tracer` is used by other code instead of their own.
The `"go.opentelemetry.io/otel".Tracer` function or a `TracerProvider` should be used to acquire a library specific `Tracer` instead. (#1900)
- The `TracerProvider()` method on the `Span` interface may also be used to obtain a `TracerProvider` using the same trace processing pipeline. (#2009)
- The `http.url` attribute generated by `HTTPClientAttributesFromHTTPRequest` will no longer include username or password information. (#1919)
- Removed `IsEmpty` method of the `TraceState` type in the `go.opentelemetry.io/otel/trace` package in favor of using the added `TraceState.Len` method. (#1931)
- Removed `Set`, `Value`, `ContextWithValue`, `ContextWithoutValue`, and `ContextWithEmpty` functions in the `go.opentelemetry.io/otel/baggage` package.
Handling of baggage is now done using the added `Baggage` type and related context functions (`ContextWithBaggage`, `ContextWithoutBaggage`, and `FromContext`) in that package. (#1967)
- The `InstallNewPipeline` and `NewExportPipeline` creation functions in all the exporters (prometheus, otlp, stdout, jaeger, and zipkin) have been removed.
These functions were deemed premature attempts to provide convenience that did not achieve this aim. (#1985)
- The `go.opentelemetry.io/otel/exporters/otlp` exporter has been removed. Use `go.opentelemetry.io/otel/exporters/otlp/otlptrace` instead. (#1990)
- The `go.opentelemetry.io/otel/exporters/stdout` exporter has been removed. Use `go.opentelemetry.io/otel/exporters/stdout/stdouttrace` or `go.opentelemetry.io/otel/exporters/stdout/stdoutmetric` instead. (#2005)
### Fixed
- Only report errors from the `"go.opentelemetry.io/otel/sdk/resource".Environment` function when they are not `nil`. (#1850, #1851)
- The `Shutdown` method of the simple `SpanProcessor` in the `go.opentelemetry.io/otel/sdk/trace` package now honors the context deadline or cancellation. (#1616, #1856)
- BatchSpanProcessor now drops span batches that failed to be exported. (#1860)
- Use `http://localhost:14268/api/traces` as default Jaeger collector endpoint instead of `http://localhost:14250`. (#1898)
- Allow trailing and leading whitespace in the parsing of a `tracestate` header. (#1931)
- Add logic to determine if the channel is closed to fix Jaeger exporter test panic with close closed channel. (#1870, #1973)
- Avoid transport security when OTLP endpoint is a Unix socket. (#2001)
### Security
## [0.20.0] - 2021-04-23
### Added
- The OTLP exporter now has two new convenience functions, `NewExportPipeline` and `InstallNewPipeline`, setup and install the exporter in tracing and metrics pipelines. (#1373)
- Adds semantic conventions for exceptions. (#1492)
- Added Jaeger Environment variables: `OTEL_EXPORTER_JAEGER_AGENT_HOST`, `OTEL_EXPORTER_JAEGER_AGENT_PORT`
These environment variables can be used to override Jaeger agent hostname and port (#1752)
- Option `ExportTimeout` was added to batch span processor. (#1755)
- `trace.TraceFlags` is now a defined type over `byte` and `WithSampled(bool) TraceFlags` and `IsSampled() bool` methods have been added to it. (#1770)
- The `Event` and `Link` struct types from the `go.opentelemetry.io/otel` package now include a `DroppedAttributeCount` field to record the number of attributes that were not recorded due to configured limits being reached. (#1771)
- The Jaeger exporter now reports dropped attributes for a Span event in the exported log. (#1771)
- Adds test to check BatchSpanProcessor ignores `OnEnd` and `ForceFlush` post `Shutdown`. (#1772)
- Extract resource attributes from the `OTEL_RESOURCE_ATTRIBUTES` environment variable and merge them with the `resource.Default` resource as well as resources provided to the `TracerProvider` and metric `Controller`. (#1785)
- Added `WithOSType` resource configuration option to set OS (Operating System) type resource attribute (`os.type`). (#1788)
- Added `WithProcess*` resource configuration options to set Process resource attributes. (#1788)
- `process.pid`
- `process.executable.name`
- `process.executable.path`
- `process.command_args`
- `process.owner`
- `process.runtime.name`
- `process.runtime.version`
- `process.runtime.description`
- Adds `k8s.node.name` and `k8s.node.uid` attribute keys to the `semconv` package. (#1789)
- Added support for configuring OTLP/HTTP and OTLP/gRPC Endpoints, TLS Certificates, Headers, Compression and Timeout via Environment Variables. (#1758, #1769 and #1811)
- `OTEL_EXPORTER_OTLP_ENDPOINT`
- `OTEL_EXPORTER_OTLP_TRACES_ENDPOINT`
- `OTEL_EXPORTER_OTLP_METRICS_ENDPOINT`
- `OTEL_EXPORTER_OTLP_HEADERS`
- `OTEL_EXPORTER_OTLP_TRACES_HEADERS`
- `OTEL_EXPORTER_OTLP_METRICS_HEADERS`
- `OTEL_EXPORTER_OTLP_COMPRESSION`
- `OTEL_EXPORTER_OTLP_TRACES_COMPRESSION`
- `OTEL_EXPORTER_OTLP_METRICS_COMPRESSION`
- `OTEL_EXPORTER_OTLP_TIMEOUT`
- `OTEL_EXPORTER_OTLP_TRACES_TIMEOUT`
- `OTEL_EXPORTER_OTLP_METRICS_TIMEOUT`
- `OTEL_EXPORTER_OTLP_CERTIFICATE`
- `OTEL_EXPORTER_OTLP_TRACES_CERTIFICATE`
- `OTEL_EXPORTER_OTLP_METRICS_CERTIFICATE`
- Adds `otlpgrpc.WithTimeout` option for configuring timeout to the otlp/gRPC exporter. (#1821)
- Adds `jaeger.WithMaxPacketSize` option for configuring maximum UDP packet size used when connecting to the Jaeger agent. (#1853)
### Fixed
- The `Span.IsRecording` implementation from `go.opentelemetry.io/otel/sdk/trace` always returns false when not being sampled. (#1750)
- The Jaeger exporter now correctly sets tags for the Span status code and message.
This means it uses the correct tag keys (`"otel.status_code"`, `"otel.status_description"`) and does not set the status message as a tag unless it is set on the span. (#1761)
- The Jaeger exporter now correctly records Span event's names using the `"event"` key for a tag.
Additionally, this tag is overridden, as specified in the OTel specification, if the event contains an attribute with that key. (#1768)
- Zipkin Exporter: Ensure mapping between OTel and Zipkin span data complies with the specification. (#1688)
- Fixed typo for default service name in Jaeger Exporter. (#1797)
- Fix flaky OTLP for the reconnnection of the client connection. (#1527, #1814)
- Fix Jaeger exporter dropping of span batches that exceed the UDP packet size limit.
Instead, the exporter now splits the batch into smaller sendable batches. (#1828)
### Changed
- Span `RecordError` now records an `exception` event to comply with the semantic convention specification. (#1492)
- Jaeger exporter was updated to use thrift v0.14.1. (#1712)
- Migrate from using internally built and maintained version of the OTLP to the one hosted at `go.opentelemetry.io/proto/otlp`. (#1713)
- Migrate from using `github.com/gogo/protobuf` to `google.golang.org/protobuf` to match `go.opentelemetry.io/proto/otlp`. (#1713)
- The storage of a local or remote Span in a `context.Context` using its SpanContext is unified to store just the current Span.
The Span's SpanContext can now self-identify as being remote or not.
This means that `"go.opentelemetry.io/otel/trace".ContextWithRemoteSpanContext` will now overwrite any existing current Span, not just existing remote Spans, and make it the current Span in a `context.Context`. (#1731)
- Improve OTLP/gRPC exporter connection errors. (#1737)
- Information about a parent span context in a `"go.opentelemetry.io/otel/export/trace".SpanSnapshot` is unified in a new `Parent` field.
The existing `ParentSpanID` and `HasRemoteParent` fields are removed in favor of this. (#1748)
- The `ParentContext` field of the `"go.opentelemetry.io/otel/sdk/trace".SamplingParameters` is updated to hold a `context.Context` containing the parent span.
This changes it to make `SamplingParameters` conform with the OpenTelemetry specification. (#1749)
- Updated Jaeger Environment Variables: `JAEGER_ENDPOINT`, `JAEGER_USER`, `JAEGER_PASSWORD`
to `OTEL_EXPORTER_JAEGER_ENDPOINT`, `OTEL_EXPORTER_JAEGER_USER`, `OTEL_EXPORTER_JAEGER_PASSWORD` in compliance with OTel specification. (#1752)
- Modify `BatchSpanProcessor.ForceFlush` to abort after timeout/cancellation. (#1757)
- The `DroppedAttributeCount` field of the `Span` in the `go.opentelemetry.io/otel` package now only represents the number of attributes dropped for the span itself.
It no longer is a conglomerate of itself, events, and link attributes that have been dropped. (#1771)
- Make `ExportSpans` in Jaeger Exporter honor context deadline. (#1773)
- Modify Zipkin Exporter default service name, use default resource's serviceName instead of empty. (#1777)
- The `go.opentelemetry.io/otel/sdk/export/trace` package is merged into the `go.opentelemetry.io/otel/sdk/trace` package. (#1778)
- The prometheus.InstallNewPipeline example is moved from comment to example test (#1796)
- The convenience functions for the stdout exporter have been updated to return the `TracerProvider` implementation and enable the shutdown of the exporter. (#1800)
- Replace the flush function returned from the Jaeger exporter's convenience creation functions (`InstallNewPipeline` and `NewExportPipeline`) with the `TracerProvider` implementation they create.
This enables the caller to shutdown and flush using the related `TracerProvider` methods. (#1822)
- Updated the Jaeger exporter to have a default endpoint, `http://localhost:14250`, for the collector. (#1824)
- Changed the function `WithCollectorEndpoint` in the Jaeger exporter to no longer accept an endpoint as an argument.
The endpoint can be passed with the `CollectorEndpointOption` using the `WithEndpoint` function or by setting the `OTEL_EXPORTER_JAEGER_ENDPOINT` environment variable value appropriately. (#1824)
- The Jaeger exporter no longer batches exported spans itself, instead it relies on the SDK's `BatchSpanProcessor` for this functionality. (#1830)
- The Jaeger exporter creation functions (`NewRawExporter`, `NewExportPipeline`, and `InstallNewPipeline`) no longer accept the removed `Option` type as a variadic argument. (#1830)
### Removed
- Removed Jaeger Environment variables: `JAEGER_SERVICE_NAME`, `JAEGER_DISABLED`, `JAEGER_TAGS`
These environment variables will no longer be used to override values of the Jaeger exporter (#1752)
- No longer set the links for a `Span` in `go.opentelemetry.io/otel/sdk/trace` that is configured to be a new root.
This is unspecified behavior that the OpenTelemetry community plans to standardize in the future.
To prevent backwards incompatible changes when it is specified, these links are removed. (#1726)
- Setting error status while recording error with Span from oteltest package. (#1729)
- The concept of a remote and local Span stored in a context is unified to just the current Span.
Because of this `"go.opentelemetry.io/otel/trace".RemoteSpanContextFromContext` is removed as it is no longer needed.
Instead, `"go.opentelemetry.io/otel/trace".SpanContextFromContext` can be used to return the current Span.
If needed, that Span's `SpanContext.IsRemote()` can then be used to determine if it is remote or not. (#1731)
- The `HasRemoteParent` field of the `"go.opentelemetry.io/otel/sdk/trace".SamplingParameters` is removed.
This field is redundant to the information returned from the `Remote` method of the `SpanContext` held in the `ParentContext` field. (#1749)
- The `trace.FlagsDebug` and `trace.FlagsDeferred` constants have been removed and will be localized to the B3 propagator. (#1770)
- Remove `Process` configuration, `WithProcessFromEnv` and `ProcessFromEnv`, and type from the Jaeger exporter package.
The information that could be configured in the `Process` struct should be configured in a `Resource` instead. (#1776, #1804)
- Remove the `WithDisabled` option from the Jaeger exporter.
To disable the exporter unregister it from the `TracerProvider` or use a no-operation `TracerProvider`. (#1806)
- Removed the functions `CollectorEndpointFromEnv` and `WithCollectorEndpointOptionFromEnv` from the Jaeger exporter.
These functions for retrieving specific environment variable values are redundant of other internal functions and
are not intended for end user use. (#1824)
- Removed the Jaeger exporter `WithSDKOptions` `Option`.
This option was used to set SDK options for the exporter creation convenience functions.
These functions are provided as a way to easily setup or install the exporter with what are deemed reasonable SDK settings for common use cases.
If the SDK needs to be configured differently, the `NewRawExporter` function and direct setup of the SDK with the desired settings should be used. (#1825)
- The `WithBufferMaxCount` and `WithBatchMaxCount` `Option`s from the Jaeger exporter are removed.
The exporter no longer batches exports, instead relying on the SDK's `BatchSpanProcessor` for this functionality. (#1830)
- The Jaeger exporter `Option` type is removed.
The type is no longer used by the exporter to configure anything.
All the previous configurations these options provided were duplicates of SDK configuration.
They have been removed in favor of using the SDK configuration and focuses the exporter configuration to be only about the endpoints it will send telemetry to. (#1830)
## [0.19.0] - 2021-03-18
### Added
- Added `Marshaler` config option to `otlphttp` to enable otlp over json or protobufs. (#1586)
- A `ForceFlush` method to the `"go.opentelemetry.io/otel/sdk/trace".TracerProvider` to flush all registered `SpanProcessor`s. (#1608)
- Added `WithSampler` and `WithSpanLimits` to tracer provider. (#1633, #1702)
- `"go.opentelemetry.io/otel/trace".SpanContext` now has a `remote` property, and `IsRemote()` predicate, that is true when the `SpanContext` has been extracted from remote context data. (#1701)
- A `Valid` method to the `"go.opentelemetry.io/otel/attribute".KeyValue` type. (#1703)
### Changed
- `trace.SpanContext` is now immutable and has no exported fields. (#1573)
- `trace.NewSpanContext()` can be used in conjunction with the `trace.SpanContextConfig` struct to initialize a new `SpanContext` where all values are known.
- Update the `ForceFlush` method signature to the `"go.opentelemetry.io/otel/sdk/trace".SpanProcessor` to accept a `context.Context` and return an error. (#1608)
- Update the `Shutdown` method to the `"go.opentelemetry.io/otel/sdk/trace".TracerProvider` return an error on shutdown failure. (#1608)
- The SimpleSpanProcessor will now shut down the enclosed `SpanExporter` and gracefully ignore subsequent calls to `OnEnd` after `Shutdown` is called. (#1612)
- `"go.opentelemetry.io/sdk/metric/controller.basic".WithPusher` is replaced with `WithExporter` to provide consistent naming across project. (#1656)
- Added non-empty string check for trace `Attribute` keys. (#1659)
- Add `description` to SpanStatus only when `StatusCode` is set to error. (#1662)
- Jaeger exporter falls back to `resource.Default`'s `service.name` if the exported Span does not have one. (#1673)
- Jaeger exporter populates Jaeger's Span Process from Resource. (#1673)
- Renamed the `LabelSet` method of `"go.opentelemetry.io/otel/sdk/resource".Resource` to `Set`. (#1692)
- Changed `WithSDK` to `WithSDKOptions` to accept variadic arguments of `TracerProviderOption` type in `go.opentelemetry.io/otel/exporters/trace/jaeger` package. (#1693)
- Changed `WithSDK` to `WithSDKOptions` to accept variadic arguments of `TracerProviderOption` type in `go.opentelemetry.io/otel/exporters/trace/zipkin` package. (#1693)
### Removed
- Removed `serviceName` parameter from Zipkin exporter and uses resource instead. (#1549)
- Removed `WithConfig` from tracer provider to avoid overriding configuration. (#1633)
- Removed the exported `SimpleSpanProcessor` and `BatchSpanProcessor` structs.
These are now returned as a SpanProcessor interface from their respective constructors. (#1638)
- Removed `WithRecord()` from `trace.SpanOption` when creating a span. (#1660)
- Removed setting status to `Error` while recording an error as a span event in `RecordError`. (#1663)
- Removed `jaeger.WithProcess` configuration option. (#1673)
- Removed `ApplyConfig` method from `"go.opentelemetry.io/otel/sdk/trace".TracerProvider` and the now unneeded `Config` struct. (#1693)
### Fixed
- Jaeger Exporter: Ensure mapping between OTEL and Jaeger span data complies with the specification. (#1626)
- `SamplingResult.TraceState` is correctly propagated to a newly created span's `SpanContext`. (#1655)
- The `otel-collector` example now correctly flushes metric events prior to shutting down the exporter. (#1678)
- Do not set span status message in `SpanStatusFromHTTPStatusCode` if it can be inferred from `http.status_code`. (#1681)
- Synchronization issues in global trace delegate implementation. (#1686)
- Reduced excess memory usage by global `TracerProvider`. (#1687)
## [0.18.0] - 2021-03-03
### Added
- Added `resource.Default()` for use with meter and tracer providers. (#1507)
- `AttributePerEventCountLimit` and `AttributePerLinkCountLimit` for `SpanLimits`. (#1535)
- Added `Keys()` method to `propagation.TextMapCarrier` and `propagation.HeaderCarrier` to adapt `http.Header` to this interface. (#1544)
- Added `code` attributes to `go.opentelemetry.io/otel/semconv` package. (#1558)
- Compatibility testing suite in the CI system for the following systems. (#1567)
| OS | Go Version | Architecture |
| ------- | ---------- | ------------ |
| Ubuntu | 1.15 | amd64 |
| Ubuntu | 1.14 | amd64 |
| Ubuntu | 1.15 | 386 |
| Ubuntu | 1.14 | 386 |
| MacOS | 1.15 | amd64 |
| MacOS | 1.14 | amd64 |
| Windows | 1.15 | amd64 |
| Windows | 1.14 | amd64 |
| Windows | 1.15 | 386 |
| Windows | 1.14 | 386 |
### Changed
- Replaced interface `oteltest.SpanRecorder` with its existing implementation
`StandardSpanRecorder`. (#1542)
- Default span limit values to 128. (#1535)
- Rename `MaxEventsPerSpan`, `MaxAttributesPerSpan` and `MaxLinksPerSpan` to `EventCountLimit`, `AttributeCountLimit` and `LinkCountLimit`, and move these fields into `SpanLimits`. (#1535)
- Renamed the `otel/label` package to `otel/attribute`. (#1541)
- Vendor the Jaeger exporter's dependency on Apache Thrift. (#1551)
- Parallelize the CI linting and testing. (#1567)
- Stagger timestamps in exact aggregator tests. (#1569)
- Changed all examples to use `WithBatchTimeout(5 * time.Second)` rather than `WithBatchTimeout(5)`. (#1621)
- Prevent end-users from implementing some interfaces (#1575)
```
"otel/exporters/otlp/otlphttp".Option
"otel/exporters/stdout".Option
"otel/oteltest".Option
"otel/trace".TracerOption
"otel/trace".SpanOption
"otel/trace".EventOption
"otel/trace".LifeCycleOption
"otel/trace".InstrumentationOption
"otel/sdk/resource".Option
"otel/sdk/trace".ParentBasedSamplerOption
"otel/sdk/trace".ReadOnlySpan
"otel/sdk/trace".ReadWriteSpan
```
### Removed
- Removed attempt to resample spans upon changing the span name with `span.SetName()`. (#1545)
- The `test-benchmark` is no longer a dependency of the `precommit` make target. (#1567)
- Removed the `test-386` make target.
This was replaced with a full compatibility testing suite (i.e. multi OS/arch) in the CI system. (#1567)
### Fixed
- The sequential timing check of timestamps in the stdout exporter are now setup explicitly to be sequential (#1571). (#1572)
- Windows build of Jaeger tests now compiles with OS specific functions (#1576). (#1577)
- The sequential timing check of timestamps of go.opentelemetry.io/otel/sdk/metric/aggregator/lastvalue are now setup explicitly to be sequential (#1578). (#1579)
- Validate tracestate header keys with vendors according to the W3C TraceContext specification (#1475). (#1581)
- The OTLP exporter includes related labels for translations of a GaugeArray (#1563). (#1570)
## [0.17.0] - 2021-02-12
### Changed
- Rename project default branch from `master` to `main`. (#1505)
- Reverse order in which `Resource` attributes are merged, per change in spec. (#1501)
- Add tooling to maintain "replace" directives in go.mod files automatically. (#1528)
- Create new modules: otel/metric, otel/trace, otel/oteltest, otel/sdk/export/metric, otel/sdk/metric (#1528)
- Move metric-related public global APIs from otel to otel/metric/global. (#1528)
## Fixed
- Fixed otlpgrpc reconnection issue.
- The example code in the README.md of `go.opentelemetry.io/otel/exporters/otlp` is moved to a compiled example test and used the new `WithAddress` instead of `WithEndpoint`. (#1513)
- The otel-collector example now uses the default OTLP receiver port of the collector.
## [0.16.0] - 2021-01-13
### Added
- Add the `ReadOnlySpan` and `ReadWriteSpan` interfaces to provide better control for accessing span data. (#1360)
- `NewGRPCDriver` function returns a `ProtocolDriver` that maintains a single gRPC connection to the collector. (#1369)
- Added documentation about the project's versioning policy. (#1388)
- Added `NewSplitDriver` for OTLP exporter that allows sending traces and metrics to different endpoints. (#1418)
- Added codeql workflow to GitHub Actions (#1428)
- Added Gosec workflow to GitHub Actions (#1429)
- Add new HTTP driver for OTLP exporter in `exporters/otlp/otlphttp`. Currently it only supports the binary protobuf payloads. (#1420)
- Add an OpenCensus exporter bridge. (#1444)
### Changed
- Rename `internal/testing` to `internal/internaltest`. (#1449)
- Rename `export.SpanData` to `export.SpanSnapshot` and use it only for exporting spans. (#1360)
- Store the parent's full `SpanContext` rather than just its span ID in the `span` struct. (#1360)
- Improve span duration accuracy. (#1360)
- Migrated CI/CD from CircleCI to GitHub Actions (#1382)
- Remove duplicate checkout from GitHub Actions workflow (#1407)
- Metric `array` aggregator renamed `exact` to match its `aggregation.Kind` (#1412)
- Metric `exact` aggregator includes per-point timestamps (#1412)
- Metric stdout exporter uses MinMaxSumCount aggregator for ValueRecorder instruments (#1412)
- `NewExporter` from `exporters/otlp` now takes a `ProtocolDriver` as a parameter. (#1369)
- Many OTLP Exporter options became gRPC ProtocolDriver options. (#1369)
- Unify endpoint API that related to OTel exporter. (#1401)
- Optimize metric histogram aggregator to reuse its slice of buckets. (#1435)
- Metric aggregator Count() and histogram Bucket.Counts are consistently `uint64`. (1430)
- Histogram aggregator accepts functional options, uses default boundaries if none given. (#1434)
- `SamplingResult` now passed a `Tracestate` from the parent `SpanContext` (#1432)
- Moved gRPC driver for OTLP exporter to `exporters/otlp/otlpgrpc`. (#1420)
- The `TraceContext` propagator now correctly propagates `TraceState` through the `SpanContext`. (#1447)
- Metric Push and Pull Controller components are combined into a single "basic" Controller:
- `WithExporter()` and `Start()` to configure Push behavior
- `Start()` is optional; use `Collect()` and `ForEach()` for Pull behavior
- `Start()` and `Stop()` accept Context. (#1378)
- The `Event` type is moved from the `otel/sdk/export/trace` package to the `otel/trace` API package. (#1452)
### Removed
- Remove `errUninitializedSpan` as its only usage is now obsolete. (#1360)
- Remove Metric export functionality related to quantiles and summary data points: this is not specified (#1412)
- Remove DDSketch metric aggregator; our intention is to re-introduce this as an option of the histogram aggregator after [new OTLP histogram data types](https://github.com/open-telemetry/opentelemetry-proto/pull/226) are released (#1412)
### Fixed
- `BatchSpanProcessor.Shutdown()` will now shutdown underlying `export.SpanExporter`. (#1443)
## [0.15.0] - 2020-12-10
### Added
- The `WithIDGenerator` `TracerProviderOption` is added to the `go.opentelemetry.io/otel/trace` package to configure an `IDGenerator` for the `TracerProvider`. (#1363)
### Changed
- The Zipkin exporter now uses the Span status code to determine. (#1328)
- `NewExporter` and `Start` functions in `go.opentelemetry.io/otel/exporters/otlp` now receive `context.Context` as a first parameter. (#1357)
- Move the OpenCensus example into `example` directory. (#1359)
- Moved the SDK's `internal.IDGenerator` interface in to the `sdk/trace` package to enable support for externally-defined ID generators. (#1363)
- Bump `github.com/google/go-cmp` from 0.5.3 to 0.5.4 (#1374)
- Bump `github.com/golangci/golangci-lint` in `/internal/tools` (#1375)
### Fixed
- Metric SDK `SumObserver` and `UpDownSumObserver` instruments correctness fixes. (#1381)
## [0.14.0] - 2020-11-19
### Added
- An `EventOption` and the related `NewEventConfig` function are added to the `go.opentelemetry.io/otel` package to configure Span events. (#1254)
- A `TextMapPropagator` and associated `TextMapCarrier` are added to the `go.opentelemetry.io/otel/oteltest` package to test `TextMap` type propagators and their use. (#1259)
- `SpanContextFromContext` returns `SpanContext` from context. (#1255)
- `TraceState` has been added to `SpanContext`. (#1340)
- `DeploymentEnvironmentKey` added to `go.opentelemetry.io/otel/semconv` package. (#1323)
- Add an OpenCensus to OpenTelemetry tracing bridge. (#1305)
- Add a parent context argument to `SpanProcessor.OnStart` to follow the specification. (#1333)
- Add missing tests for `sdk/trace/attributes_map.go`. (#1337)
### Changed
- Move the `go.opentelemetry.io/otel/api/trace` package into `go.opentelemetry.io/otel/trace` with the following changes. (#1229) (#1307)
- `ID` has been renamed to `TraceID`.
- `IDFromHex` has been renamed to `TraceIDFromHex`.
- `EmptySpanContext` is removed.
- Move the `go.opentelemetry.io/otel/api/trace/tracetest` package into `go.opentelemetry.io/otel/oteltest`. (#1229)
- OTLP Exporter updates:
- supports OTLP v0.6.0 (#1230, #1354)
- supports configurable aggregation temporality (default: Cumulative, optional: Stateless). (#1296)
- The Sampler is now called on local child spans. (#1233)
- The `Kind` type from the `go.opentelemetry.io/otel/api/metric` package was renamed to `InstrumentKind` to more specifically describe what it is and avoid semantic ambiguity. (#1240)
- The `MetricKind` method of the `Descriptor` type in the `go.opentelemetry.io/otel/api/metric` package was renamed to `Descriptor.InstrumentKind`.
This matches the returned type and fixes misuse of the term metric. (#1240)
- Move test harness from the `go.opentelemetry.io/otel/api/apitest` package into `go.opentelemetry.io/otel/oteltest`. (#1241)
- Move the `go.opentelemetry.io/otel/api/metric/metrictest` package into `go.opentelemetry.io/oteltest` as part of #964. (#1252)
- Move the `go.opentelemetry.io/otel/api/metric` package into `go.opentelemetry.io/otel/metric` as part of #1303. (#1321)
- Move the `go.opentelemetry.io/otel/api/metric/registry` package into `go.opentelemetry.io/otel/metric/registry` as a part of #1303. (#1316)
- Move the `Number` type (together with related functions) from `go.opentelemetry.io/otel/api/metric` package into `go.opentelemetry.io/otel/metric/number` as a part of #1303. (#1316)
- The function signature of the Span `AddEvent` method in `go.opentelemetry.io/otel` is updated to no longer take an unused context and instead take a required name and a variable number of `EventOption`s. (#1254)
- The function signature of the Span `RecordError` method in `go.opentelemetry.io/otel` is updated to no longer take an unused context and instead take a required error value and a variable number of `EventOption`s. (#1254)
- Move the `go.opentelemetry.io/otel/api/global` package to `go.opentelemetry.io/otel`. (#1262) (#1330)
- Move the `Version` function from `go.opentelemetry.io/otel/sdk` to `go.opentelemetry.io/otel`. (#1330)
- Rename correlation context header from `"otcorrelations"` to `"baggage"` to match the OpenTelemetry specification. (#1267)
- Fix `Code.UnmarshalJSON` to work with valid JSON only. (#1276)
- The `resource.New()` method changes signature to support builtin attributes and functional options, including `telemetry.sdk.*` and
`host.name` semantic conventions; the former method is renamed `resource.NewWithAttributes`. (#1235)
- The Prometheus exporter now exports non-monotonic counters (i.e. `UpDownCounter`s) as gauges. (#1210)
- Correct the `Span.End` method documentation in the `otel` API to state updates are not allowed on a span after it has ended. (#1310)
- Updated span collection limits for attribute, event and link counts to 1000 (#1318)
- Renamed `semconv.HTTPUrlKey` to `semconv.HTTPURLKey`. (#1338)
### Removed
- The `ErrInvalidHexID`, `ErrInvalidTraceIDLength`, `ErrInvalidSpanIDLength`, `ErrInvalidSpanIDLength`, or `ErrNilSpanID` from the `go.opentelemetry.io/otel` package are unexported now. (#1243)
- The `AddEventWithTimestamp` method on the `Span` interface in `go.opentelemetry.io/otel` is removed due to its redundancy.
It is replaced by using the `AddEvent` method with a `WithTimestamp` option. (#1254)
- The `MockSpan` and `MockTracer` types are removed from `go.opentelemetry.io/otel/oteltest`.
`Tracer` and `Span` from the same module should be used in their place instead. (#1306)
- `WorkerCount` option is removed from `go.opentelemetry.io/otel/exporters/otlp`. (#1350)
- Remove the following labels types: INT32, UINT32, UINT64 and FLOAT32. (#1314)
### Fixed
- Rename `MergeItererator` to `MergeIterator` in the `go.opentelemetry.io/otel/label` package. (#1244)
- The `go.opentelemetry.io/otel/api/global` packages global TextMapPropagator now delegates functionality to a globally set delegate for all previously returned propagators. (#1258)
- Fix condition in `label.Any`. (#1299)
- Fix global `TracerProvider` to pass options to its configured provider. (#1329)
- Fix missing handler for `ExactKind` aggregator in OTLP metrics transformer (#1309)
## [0.13.0] - 2020-10-08
### Added
- OTLP Metric exporter supports Histogram aggregation. (#1209)
- The `Code` struct from the `go.opentelemetry.io/otel/codes` package now supports JSON marshaling and unmarshaling as well as implements the `Stringer` interface. (#1214)
- A Baggage API to implement the OpenTelemetry specification. (#1217)
- Add Shutdown method to sdk/trace/provider, shutdown processors in the order they were registered. (#1227)
### Changed
- Set default propagator to no-op propagator. (#1184)
- The `HTTPSupplier`, `HTTPExtractor`, `HTTPInjector`, and `HTTPPropagator` from the `go.opentelemetry.io/otel/api/propagation` package were replaced with unified `TextMapCarrier` and `TextMapPropagator` in the `go.opentelemetry.io/otel/propagation` package. (#1212) (#1325)
- The `New` function from the `go.opentelemetry.io/otel/api/propagation` package was replaced with `NewCompositeTextMapPropagator` in the `go.opentelemetry.io/otel` package. (#1212)
- The status codes of the `go.opentelemetry.io/otel/codes` package have been updated to match the latest OpenTelemetry specification.
They now are `Unset`, `Error`, and `Ok`.
They no longer track the gRPC codes. (#1214)
- The `StatusCode` field of the `SpanData` struct in the `go.opentelemetry.io/otel/sdk/export/trace` package now uses the codes package from this package instead of the gRPC project. (#1214)
- Move the `go.opentelemetry.io/otel/api/baggage` package into `go.opentelemetry.io/otel/baggage`. (#1217) (#1325)
- A `Shutdown` method of `SpanProcessor` and all its implementations receives a context and returns an error. (#1264)
### Fixed
- Copies of data from arrays and slices passed to `go.opentelemetry.io/otel/label.ArrayValue()` are now used in the returned `Value` instead of using the mutable data itself. (#1226)
### Removed
- The `ExtractHTTP` and `InjectHTTP` functions from the `go.opentelemetry.io/otel/api/propagation` package were removed. (#1212)
- The `Propagators` interface from the `go.opentelemetry.io/otel/api/propagation` package was removed to conform to the OpenTelemetry specification.
The explicit `TextMapPropagator` type can be used in its place as this is the `Propagator` type the specification defines. (#1212)
- The `SetAttribute` method of the `Span` from the `go.opentelemetry.io/otel/api/trace` package was removed given its redundancy with the `SetAttributes` method. (#1216)
- The internal implementation of Baggage storage is removed in favor of using the new Baggage API functionality. (#1217)
- Remove duplicate hostname key `HostHostNameKey` in Resource semantic conventions. (#1219)
- Nested array/slice support has been removed. (#1226)
## [0.12.0] - 2020-09-24
### Added
- A `SpanConfigure` function in `go.opentelemetry.io/otel/api/trace` to create a new `SpanConfig` from `SpanOption`s. (#1108)
- In the `go.opentelemetry.io/otel/api/trace` package, `NewTracerConfig` was added to construct new `TracerConfig`s.
This addition was made to conform with our project option conventions. (#1155)
- Instrumentation library information was added to the Zipkin exporter. (#1119)
- The `SpanProcessor` interface now has a `ForceFlush()` method. (#1166)
- More semantic conventions for k8s as resource attributes. (#1167)
### Changed
- Add reconnecting udp connection type to Jaeger exporter.
This change adds a new optional implementation of the udp conn interface used to detect changes to an agent's host dns record.
It then adopts the new destination address to ensure the exporter doesn't get stuck. This change was ported from jaegertracing/jaeger-client-go#520. (#1063)
- Replace `StartOption` and `EndOption` in `go.opentelemetry.io/otel/api/trace` with `SpanOption`.
This change is matched by replacing the `StartConfig` and `EndConfig` with a unified `SpanConfig`. (#1108)
- Replace the `LinkedTo` span option in `go.opentelemetry.io/otel/api/trace` with `WithLinks`.
This is be more consistent with our other option patterns, i.e. passing the item to be configured directly instead of its component parts, and provides a cleaner function signature. (#1108)
- The `go.opentelemetry.io/otel/api/trace` `TracerOption` was changed to an interface to conform to project option conventions. (#1109)
- Move the `B3` and `TraceContext` from within the `go.opentelemetry.io/otel/api/trace` package to their own `go.opentelemetry.io/otel/propagators` package.
This removal of the propagators is reflective of the OpenTelemetry specification for these propagators as well as cleans up the `go.opentelemetry.io/otel/api/trace` API. (#1118)
- Rename Jaeger tags used for instrumentation library information to reflect changes in OpenTelemetry specification. (#1119)
- Rename `ProbabilitySampler` to `TraceIDRatioBased` and change semantics to ignore parent span sampling status. (#1115)
- Move `tools` package under `internal`. (#1141)
- Move `go.opentelemetry.io/otel/api/correlation` package to `go.opentelemetry.io/otel/api/baggage`. (#1142)
The `correlation.CorrelationContext` propagator has been renamed `baggage.Baggage`. Other exported functions and types are unchanged.
- Rename `ParentOrElse` sampler to `ParentBased` and allow setting samplers depending on parent span. (#1153)
- In the `go.opentelemetry.io/otel/api/trace` package, `SpanConfigure` was renamed to `NewSpanConfig`. (#1155)
- Change `dependabot.yml` to add a `Skip Changelog` label to dependabot-sourced PRs. (#1161)
- The [configuration style guide](https://github.com/open-telemetry/opentelemetry-go/blob/master/CONTRIBUTING.md#config) has been updated to
recommend the use of `newConfig()` instead of `configure()`. (#1163)
- The `otlp.Config` type has been unexported and changed to `otlp.config`, along with its initializer. (#1163)
- Ensure exported interface types include parameter names and update the
Style Guide to reflect this styling rule. (#1172)
- Don't consider unset environment variable for resource detection to be an error. (#1170)
- Rename `go.opentelemetry.io/otel/api/metric.ConfigureInstrument` to `NewInstrumentConfig` and
`go.opentelemetry.io/otel/api/metric.ConfigureMeter` to `NewMeterConfig`.
- ValueObserver instruments use LastValue aggregator by default. (#1165)
- OTLP Metric exporter supports LastValue aggregation. (#1165)
- Move the `go.opentelemetry.io/otel/api/unit` package to `go.opentelemetry.io/otel/unit`. (#1185)
- Rename `Provider` to `MeterProvider` in the `go.opentelemetry.io/otel/api/metric` package. (#1190)
- Rename `NoopProvider` to `NoopMeterProvider` in the `go.opentelemetry.io/otel/api/metric` package. (#1190)
- Rename `NewProvider` to `NewMeterProvider` in the `go.opentelemetry.io/otel/api/metric/metrictest` package. (#1190)
- Rename `Provider` to `MeterProvider` in the `go.opentelemetry.io/otel/api/metric/registry` package. (#1190)
- Rename `NewProvider` to `NewMeterProvider` in the `go.opentelemetry.io/otel/api/metri/registryc` package. (#1190)
- Rename `Provider` to `TracerProvider` in the `go.opentelemetry.io/otel/api/trace` package. (#1190)
- Rename `NoopProvider` to `NoopTracerProvider` in the `go.opentelemetry.io/otel/api/trace` package. (#1190)
- Rename `Provider` to `TracerProvider` in the `go.opentelemetry.io/otel/api/trace/tracetest` package. (#1190)
- Rename `NewProvider` to `NewTracerProvider` in the `go.opentelemetry.io/otel/api/trace/tracetest` package. (#1190)
- Rename `WrapperProvider` to `WrapperTracerProvider` in the `go.opentelemetry.io/otel/bridge/opentracing` package. (#1190)
- Rename `NewWrapperProvider` to `NewWrapperTracerProvider` in the `go.opentelemetry.io/otel/bridge/opentracing` package. (#1190)
- Rename `Provider` method of the pull controller to `MeterProvider` in the `go.opentelemetry.io/otel/sdk/metric/controller/pull` package. (#1190)
- Rename `Provider` method of the push controller to `MeterProvider` in the `go.opentelemetry.io/otel/sdk/metric/controller/push` package. (#1190)
- Rename `ProviderOptions` to `TracerProviderConfig` in the `go.opentelemetry.io/otel/sdk/trace` package. (#1190)
- Rename `ProviderOption` to `TracerProviderOption` in the `go.opentelemetry.io/otel/sdk/trace` package. (#1190)
- Rename `Provider` to `TracerProvider` in the `go.opentelemetry.io/otel/sdk/trace` package. (#1190)
- Rename `NewProvider` to `NewTracerProvider` in the `go.opentelemetry.io/otel/sdk/trace` package. (#1190)
- Renamed `SamplingDecision` values to comply with OpenTelemetry specification change. (#1192)
- Renamed Zipkin attribute names from `ot.status_code & ot.status_description` to `otel.status_code & otel.status_description`. (#1201)
- The default SDK now invokes registered `SpanProcessor`s in the order they were registered with the `TracerProvider`. (#1195)
- Add test of spans being processed by the `SpanProcessor`s in the order they were registered. (#1203)
### Removed
- Remove the B3 propagator from `go.opentelemetry.io/otel/propagators`. It is now located in the
`go.opentelemetry.io/contrib/propagators/` module. (#1191)
- Remove the semantic convention for HTTP status text, `HTTPStatusTextKey` from package `go.opentelemetry.io/otel/semconv`. (#1194)
### Fixed
- Zipkin example no longer mentions `ParentSampler`, corrected to `ParentBased`. (#1171)
- Fix missing shutdown processor in otel-collector example. (#1186)
- Fix missing shutdown processor in basic and namedtracer examples. (#1197)
## [0.11.0] - 2020-08-24
### Added
- Support for exporting array-valued attributes via OTLP. (#992)
- `Noop` and `InMemory` `SpanBatcher` implementations to help with testing integrations. (#994)
- Support for filtering metric label sets. (#1047)
- A dimensionality-reducing metric Processor. (#1057)
- Integration tests for more OTel Collector Attribute types. (#1062)
- A new `WithSpanProcessor` `ProviderOption` is added to the `go.opentelemetry.io/otel/sdk/trace` package to create a `Provider` and automatically register the `SpanProcessor`. (#1078)
### Changed
- Rename `sdk/metric/processor/test` to `sdk/metric/processor/processortest`. (#1049)
- Rename `sdk/metric/controller/test` to `sdk/metric/controller/controllertest`. (#1049)
- Rename `api/testharness` to `api/apitest`. (#1049)
- Rename `api/trace/testtrace` to `api/trace/tracetest`. (#1049)
- Change Metric Processor to merge multiple observations. (#1024)
- The `go.opentelemetry.io/otel/bridge/opentracing` bridge package has been made into its own module.
This removes the package dependencies of this bridge from the rest of the OpenTelemetry based project. (#1038)
- Renamed `go.opentelemetry.io/otel/api/standard` package to `go.opentelemetry.io/otel/semconv` to avoid the ambiguous and generic name `standard` and better describe the package as containing OpenTelemetry semantic conventions. (#1016)
- The environment variable used for resource detection has been changed from `OTEL_RESOURCE_LABELS` to `OTEL_RESOURCE_ATTRIBUTES` (#1042)
- Replace `WithSyncer` with `WithBatcher` in examples. (#1044)
- Replace the `google.golang.org/grpc/codes` dependency in the API with an equivalent `go.opentelemetry.io/otel/codes` package. (#1046)
- Merge the `go.opentelemetry.io/otel/api/label` and `go.opentelemetry.io/otel/api/kv` into the new `go.opentelemetry.io/otel/label` package. (#1060)
- Unify Callback Function Naming.
Rename `*Callback` with `*Func`. (#1061)
- CI builds validate against last two versions of Go, dropping 1.13 and adding 1.15. (#1064)
- The `go.opentelemetry.io/otel/sdk/export/trace` interfaces `SpanSyncer` and `SpanBatcher` have been replaced with a specification compliant `Exporter` interface.
This interface still supports the export of `SpanData`, but only as a slice.
Implementation are also required now to return any error from `ExportSpans` if one occurs as well as implement a `Shutdown` method for exporter clean-up. (#1078)
- The `go.opentelemetry.io/otel/sdk/trace` `NewBatchSpanProcessor` function no longer returns an error.
If a `nil` exporter is passed as an argument to this function, instead of it returning an error, it now returns a `BatchSpanProcessor` that handles the export of `SpanData` by not taking any action. (#1078)
- The `go.opentelemetry.io/otel/sdk/trace` `NewProvider` function to create a `Provider` no longer returns an error, instead only a `*Provider`.
This change is related to `NewBatchSpanProcessor` not returning an error which was the only error this function would return. (#1078)
### Removed
- Duplicate, unused API sampler interface. (#999)
Use the [`Sampler` interface](https://github.com/open-telemetry/opentelemetry-go/blob/v0.11.0/sdk/trace/sampling.go) provided by the SDK instead.
- The `grpctrace` instrumentation was moved to the `go.opentelemetry.io/contrib` repository and out of this repository.
This move includes moving the `grpc` example to the `go.opentelemetry.io/contrib` as well. (#1027)
- The `WithSpan` method of the `Tracer` interface.
The functionality this method provided was limited compared to what a user can provide themselves.
It was removed with the understanding that if there is sufficient user need it can be added back based on actual user usage. (#1043)
- The `RegisterSpanProcessor` and `UnregisterSpanProcessor` functions.
These were holdovers from an approach prior to the TracerProvider design. They were not used anymore. (#1077)
- The `oterror` package. (#1026)
- The `othttp` and `httptrace` instrumentations were moved to `go.opentelemetry.io/contrib`. (#1032)
### Fixed
- The `semconv.HTTPServerMetricAttributesFromHTTPRequest()` function no longer generates the high-cardinality `http.request.content.length` label. (#1031)
- Correct instrumentation version tag in Jaeger exporter. (#1037)
- The SDK span will now set an error event if the `End` method is called during a panic (i.e. it was deferred). (#1043)
- Move internally generated protobuf code from the `go.opentelemetry.io/otel` to the OTLP exporter to reduce dependency overhead. (#1050)
- The `otel-collector` example referenced outdated collector processors. (#1006)
## [0.10.0] - 2020-07-29
This release migrates the default OpenTelemetry SDK into its own Go module, decoupling the SDK from the API and reducing dependencies for instrumentation packages.
### Added
- The Zipkin exporter now has `NewExportPipeline` and `InstallNewPipeline` constructor functions to match the common pattern.
These function build a new exporter with default SDK options and register the exporter with the `global` package respectively. (#944)
- Add propagator option for gRPC instrumentation. (#986)
- The `testtrace` package now tracks the `trace.SpanKind` for each span. (#987)
### Changed
- Replace the `RegisterGlobal` `Option` in the Jaeger exporter with an `InstallNewPipeline` constructor function.
This matches the other exporter constructor patterns and will register a new exporter after building it with default configuration. (#944)
- The trace (`go.opentelemetry.io/otel/exporters/trace/stdout`) and metric (`go.opentelemetry.io/otel/exporters/metric/stdout`) `stdout` exporters are now merged into a single exporter at `go.opentelemetry.io/otel/exporters/stdout`.
This new exporter was made into its own Go module to follow the pattern of all exporters and decouple it from the `go.opentelemetry.io/otel` module. (#956, #963)
- Move the `go.opentelemetry.io/otel/exporters/test` test package to `go.opentelemetry.io/otel/sdk/export/metric/metrictest`. (#962)
- The `go.opentelemetry.io/otel/api/kv/value` package was merged into the parent `go.opentelemetry.io/otel/api/kv` package. (#968)
- `value.Bool` was replaced with `kv.BoolValue`.
- `value.Int64` was replaced with `kv.Int64Value`.
- `value.Uint64` was replaced with `kv.Uint64Value`.
- `value.Float64` was replaced with `kv.Float64Value`.
- `value.Int32` was replaced with `kv.Int32Value`.
- `value.Uint32` was replaced with `kv.Uint32Value`.
- `value.Float32` was replaced with `kv.Float32Value`.
- `value.String` was replaced with `kv.StringValue`.
- `value.Int` was replaced with `kv.IntValue`.
- `value.Uint` was replaced with `kv.UintValue`.
- `value.Array` was replaced with `kv.ArrayValue`.
- Rename `Infer` to `Any` in the `go.opentelemetry.io/otel/api/kv` package. (#972)
- Change `othttp` to use the `httpsnoop` package to wrap the `ResponseWriter` so that optional interfaces (`http.Hijacker`, `http.Flusher`, etc.) that are implemented by the original `ResponseWriter`are also implemented by the wrapped `ResponseWriter`. (#979)
- Rename `go.opentelemetry.io/otel/sdk/metric/aggregator/test` package to `go.opentelemetry.io/otel/sdk/metric/aggregator/aggregatortest`. (#980)
- Make the SDK into its own Go module called `go.opentelemetry.io/otel/sdk`. (#985)
- Changed the default trace `Sampler` from `AlwaysOn` to `ParentOrElse(AlwaysOn)`. (#989)
### Removed
- The `IndexedAttribute` function from the `go.opentelemetry.io/otel/api/label` package was removed in favor of `IndexedLabel` which it was synonymous with. (#970)
### Fixed
- Bump github.com/golangci/golangci-lint from 1.28.3 to 1.29.0 in /tools. (#953)
- Bump github.com/google/go-cmp from 0.5.0 to 0.5.1. (#957)
- Use `global.Handle` for span export errors in the OTLP exporter. (#946)
- Correct Go language formatting in the README documentation. (#961)
- Remove default SDK dependencies from the `go.opentelemetry.io/otel/api` package. (#977)
- Remove default SDK dependencies from the `go.opentelemetry.io/otel/instrumentation` package. (#983)
- Move documented examples for `go.opentelemetry.io/otel/instrumentation/grpctrace` interceptors into Go example tests. (#984)
## [0.9.0] - 2020-07-20
### Added
- A new Resource Detector interface is included to allow resources to be automatically detected and included. (#939)
- A Detector to automatically detect resources from an environment variable. (#939)
- Github action to generate protobuf Go bindings locally in `internal/opentelemetry-proto-gen`. (#938)
- OTLP .proto files from `open-telemetry/opentelemetry-proto` imported as a git submodule under `internal/opentelemetry-proto`.
References to `github.com/open-telemetry/opentelemetry-proto` changed to `go.opentelemetry.io/otel/internal/opentelemetry-proto-gen`. (#942)
### Changed
- Non-nil value `struct`s for key-value pairs will be marshalled using JSON rather than `Sprintf`. (#948)
### Removed
- Removed dependency on `github.com/open-telemetry/opentelemetry-collector`. (#943)
## [0.8.0] - 2020-07-09
### Added
- The `B3Encoding` type to represent the B3 encoding(s) the B3 propagator can inject.
A value for HTTP supported encodings (Multiple Header: `MultipleHeader`, Single Header: `SingleHeader`) are included. (#882)
- The `FlagsDeferred` trace flag to indicate if the trace sampling decision has been deferred. (#882)
- The `FlagsDebug` trace flag to indicate if the trace is a debug trace. (#882)
- Add `peer.service` semantic attribute. (#898)
- Add database-specific semantic attributes. (#899)
- Add semantic convention for `faas.coldstart` and `container.id`. (#909)
- Add http content size semantic conventions. (#905)
- Include `http.request_content_length` in HTTP request basic attributes. (#905)
- Add semantic conventions for operating system process resource attribute keys. (#919)
- The Jaeger exporter now has a `WithBatchMaxCount` option to specify the maximum number of spans sent in a batch. (#931)
### Changed
- Update `CONTRIBUTING.md` to ask for updates to `CHANGELOG.md` with each pull request. (#879)
- Use lowercase header names for B3 Multiple Headers. (#881)
- The B3 propagator `SingleHeader` field has been replaced with `InjectEncoding`.
This new field can be set to combinations of the `B3Encoding` bitmasks and will inject trace information in these encodings.
If no encoding is set, the propagator will default to `MultipleHeader` encoding. (#882)
- The B3 propagator now extracts from either HTTP encoding of B3 (Single Header or Multiple Header) based on what is contained in the header.
Preference is given to Single Header encoding with Multiple Header being the fallback if Single Header is not found or is invalid.
This behavior change is made to dynamically support all correctly encoded traces received instead of having to guess the expected encoding prior to receiving. (#882)
- Extend semantic conventions for RPC. (#900)
- To match constant naming conventions in the `api/standard` package, the `FaaS*` key names are appended with a suffix of `Key`. (#920)
- `"api/standard".FaaSName` -> `FaaSNameKey`
- `"api/standard".FaaSID` -> `FaaSIDKey`
- `"api/standard".FaaSVersion` -> `FaaSVersionKey`
- `"api/standard".FaaSInstance` -> `FaaSInstanceKey`
### Removed
- The `FlagsUnused` trace flag is removed.
The purpose of this flag was to act as the inverse of `FlagsSampled`, the inverse of `FlagsSampled` is used instead. (#882)
- The B3 header constants (`B3SingleHeader`, `B3DebugFlagHeader`, `B3TraceIDHeader`, `B3SpanIDHeader`, `B3SampledHeader`, `B3ParentSpanIDHeader`) are removed.
If B3 header keys are needed [the authoritative OpenZipkin package constants](https://pkg.go.dev/github.com/openzipkin/[email protected]/propagation/b3?tab=doc#pkg-constants) should be used instead. (#882)
### Fixed
- The B3 Single Header name is now correctly `b3` instead of the previous `X-B3`. (#881)
- The B3 propagator now correctly supports sampling only values (`b3: 0`, `b3: 1`, or `b3: d`) for a Single B3 Header. (#882)
- The B3 propagator now propagates the debug flag.
This removes the behavior of changing the debug flag into a set sampling bit.
Instead, this now follow the B3 specification and omits the `X-B3-Sampling` header. (#882)
- The B3 propagator now tracks "unset" sampling state (meaning "defer the decision") and does not set the `X-B3-Sampling` header when injecting. (#882)
- Bump github.com/itchyny/gojq from 0.10.3 to 0.10.4 in /tools. (#883)
- Bump github.com/opentracing/opentracing-go from v1.1.1-0.20190913142402-a7454ce5950e to v1.2.0. (#885)
- The tracing time conversion for OTLP spans is now correctly set to `UnixNano`. (#896)
- Ensure span status is not set to `Unknown` when no HTTP status code is provided as it is assumed to be `200 OK`. (#908)
- Ensure `httptrace.clientTracer` closes `http.headers` span. (#912)
- Prometheus exporter will not apply stale updates or forget inactive metrics. (#903)
- Add test for api.standard `HTTPClientAttributesFromHTTPRequest`. (#905)
- Bump github.com/golangci/golangci-lint from 1.27.0 to 1.28.1 in /tools. (#901, #913)
- Update otel-collector example to use the v0.5.0 collector. (#915)
- The `grpctrace` instrumentation uses a span name conforming to the OpenTelemetry semantic conventions (does not contain a leading slash (`/`)). (#922)
- The `grpctrace` instrumentation includes an `rpc.method` attribute now set to the gRPC method name. (#900, #922)
- The `grpctrace` instrumentation `rpc.service` attribute now contains the package name if one exists.
This is in accordance with OpenTelemetry semantic conventions. (#922)
- Correlation Context extractor will no longer insert an empty map into the returned context when no valid values are extracted. (#923)
- Bump google.golang.org/api from 0.28.0 to 0.29.0 in /exporters/trace/jaeger. (#925)
- Bump github.com/itchyny/gojq from 0.10.4 to 0.11.0 in /tools. (#926)
- Bump github.com/golangci/golangci-lint from 1.28.1 to 1.28.2 in /tools. (#930)
## [0.7.0] - 2020-06-26
This release implements the v0.5.0 version of the OpenTelemetry specification.
### Added
- The othttp instrumentation now includes default metrics. (#861)
- This CHANGELOG file to track all changes in the project going forward.
- Support for array type attributes. (#798)
- Apply transitive dependabot go.mod dependency updates as part of a new automatic Github workflow. (#844)
- Timestamps are now passed to exporters for each export. (#835)
- Add new `Accumulation` type to metric SDK to transport telemetry from `Accumulator`s to `Processor`s.
This replaces the prior `Record` `struct` use for this purpose. (#835)
- New dependabot integration to automate package upgrades. (#814)
- `Meter` and `Tracer` implementations accept instrumentation version version as an optional argument.
This instrumentation version is passed on to exporters. (#811) (#805) (#802)
- The OTLP exporter includes the instrumentation version in telemetry it exports. (#811)
- Environment variables for Jaeger exporter are supported. (#796)
- New `aggregation.Kind` in the export metric API. (#808)
- New example that uses OTLP and the collector. (#790)
- Handle errors in the span `SetName` during span initialization. (#791)
- Default service config to enable retries for retry-able failed requests in the OTLP exporter and an option to override this default. (#777)
- New `go.opentelemetry.io/otel/api/oterror` package to uniformly support error handling and definitions for the project. (#778)
- New `global` default implementation of the `go.opentelemetry.io/otel/api/oterror.Handler` interface to be used to handle errors prior to an user defined `Handler`.
There is also functionality for the user to register their `Handler` as well as a convenience function `Handle` to handle an error with this global `Handler`(#778)
- Options to specify propagators for httptrace and grpctrace instrumentation. (#784)
- The required `application/json` header for the Zipkin exporter is included in all exports. (#774)
- Integrate HTTP semantics helpers from the contrib repository into the `api/standard` package. #769
### Changed
- Rename `Integrator` to `Processor` in the metric SDK. (#863)
- Rename `AggregationSelector` to `AggregatorSelector`. (#859)
- Rename `SynchronizedCopy` to `SynchronizedMove`. (#858)
- Rename `simple` integrator to `basic` integrator. (#857)
- Merge otlp collector examples. (#841)
- Change the metric SDK to support cumulative, delta, and pass-through exporters directly.
With these changes, cumulative and delta specific exporters are able to request the correct kind of aggregation from the SDK. (#840)
- The `Aggregator.Checkpoint` API is renamed to `SynchronizedCopy` and adds an argument, a different `Aggregator` into which the copy is stored. (#812)
- The `export.Aggregator` contract is that `Update()` and `SynchronizedCopy()` are synchronized with each other.
All the aggregation interfaces (`Sum`, `LastValue`, ...) are not meant to be synchronized, as the caller is expected to synchronize aggregators at a higher level after the `Accumulator`.
Some of the `Aggregators` used unnecessary locking and that has been cleaned up. (#812)
- Use of `metric.Number` was replaced by `int64` now that we use `sync.Mutex` in the `MinMaxSumCount` and `Histogram` `Aggregators`. (#812)
- Replace `AlwaysParentSample` with `ParentSample(fallback)` to match the OpenTelemetry v0.5.0 specification. (#810)
- Rename `sdk/export/metric/aggregator` to `sdk/export/metric/aggregation`. #808
- Send configured headers with every request in the OTLP exporter, instead of just on connection creation. (#806)
- Update error handling for any one off error handlers, replacing, instead, with the `global.Handle` function. (#791)
- Rename `plugin` directory to `instrumentation` to match the OpenTelemetry specification. (#779)
- Makes the argument order to Histogram and DDSketch `New()` consistent. (#781)
### Removed
- `Uint64NumberKind` and related functions from the API. (#864)
- Context arguments from `Aggregator.Checkpoint` and `Integrator.Process` as they were unused. (#803)
- `SpanID` is no longer included in parameters for sampling decision to match the OpenTelemetry specification. (#775)
### Fixed
- Upgrade OTLP exporter to opentelemetry-proto matching the opentelemetry-collector v0.4.0 release. (#866)
- Allow changes to `go.sum` and `go.mod` when running dependabot tidy-up. (#871)
- Bump github.com/stretchr/testify from 1.4.0 to 1.6.1. (#824)
- Bump github.com/prometheus/client_golang from 1.7.0 to 1.7.1 in /exporters/metric/prometheus. (#867)
- Bump google.golang.org/grpc from 1.29.1 to 1.30.0 in /exporters/trace/jaeger. (#853)
- Bump google.golang.org/grpc from 1.29.1 to 1.30.0 in /exporters/trace/zipkin. (#854)
- Bumps github.com/golang/protobuf from 1.3.2 to 1.4.2 (#848)
- Bump github.com/stretchr/testify from 1.4.0 to 1.6.1 in /exporters/otlp (#817)
- Bump github.com/golangci/golangci-lint from 1.25.1 to 1.27.0 in /tools (#828)
- Bump github.com/prometheus/client_golang from 1.5.0 to 1.7.0 in /exporters/metric/prometheus (#838)
- Bump github.com/stretchr/testify from 1.4.0 to 1.6.1 in /exporters/trace/jaeger (#829)
- Bump github.com/benbjohnson/clock from 1.0.0 to 1.0.3 (#815)
- Bump github.com/stretchr/testify from 1.4.0 to 1.6.1 in /exporters/trace/zipkin (#823)
- Bump github.com/itchyny/gojq from 0.10.1 to 0.10.3 in /tools (#830)
- Bump github.com/stretchr/testify from 1.4.0 to 1.6.1 in /exporters/metric/prometheus (#822)
- Bump google.golang.org/grpc from 1.27.1 to 1.29.1 in /exporters/trace/zipkin (#820)
- Bump google.golang.org/grpc from 1.27.1 to 1.29.1 in /exporters/trace/jaeger (#831)
- Bump github.com/google/go-cmp from 0.4.0 to 0.5.0 (#836)
- Bump github.com/google/go-cmp from 0.4.0 to 0.5.0 in /exporters/trace/jaeger (#837)
- Bump github.com/google/go-cmp from 0.4.0 to 0.5.0 in /exporters/otlp (#839)
- Bump google.golang.org/api from 0.20.0 to 0.28.0 in /exporters/trace/jaeger (#843)
- Set span status from HTTP status code in the othttp instrumentation. (#832)
- Fixed typo in push controller comment. (#834)
- The `Aggregator` testing has been updated and cleaned. (#812)
- `metric.Number(0)` expressions are replaced by `0` where possible. (#812)
- Fixed `global` `handler_test.go` test failure. #804
- Fixed `BatchSpanProcessor.Shutdown` to wait until all spans are processed. (#766)
- Fixed OTLP example's accidental early close of exporter. (#807)
- Ensure zipkin exporter reads and closes response body. (#788)
- Update instrumentation to use `api/standard` keys instead of custom keys. (#782)
- Clean up tools and RELEASING documentation. (#762)
## [0.6.0] - 2020-05-21
### Added
- Support for `Resource`s in the prometheus exporter. (#757)
- New pull controller. (#751)
- New `UpDownSumObserver` instrument. (#750)
- OpenTelemetry collector demo. (#711)
- New `SumObserver` instrument. (#747)
- New `UpDownCounter` instrument. (#745)
- New timeout `Option` and configuration function `WithTimeout` to the push controller. (#742)
- New `api/standards` package to implement semantic conventions and standard key-value generation. (#731)
### Changed
- Rename `Register*` functions in the metric API to `New*` for all `Observer` instruments. (#761)
- Use `[]float64` for histogram boundaries, not `[]metric.Number`. (#758)
- Change OTLP example to use exporter as a trace `Syncer` instead of as an unneeded `Batcher`. (#756)
- Replace `WithResourceAttributes()` with `WithResource()` in the trace SDK. (#754)
- The prometheus exporter now uses the new pull controller. (#751)
- Rename `ScheduleDelayMillis` to `BatchTimeout` in the trace `BatchSpanProcessor`.(#752)
- Support use of synchronous instruments in asynchronous callbacks (#725)
- Move `Resource` from the `Export` method parameter into the metric export `Record`. (#739)
- Rename `Observer` instrument to `ValueObserver`. (#734)
- The push controller now has a method (`Provider()`) to return a `metric.Provider` instead of the old `Meter` method that acted as a `metric.Provider`. (#738)
- Replace `Measure` instrument by `ValueRecorder` instrument. (#732)
- Rename correlation context header from `"Correlation-Context"` to `"otcorrelations"` to match the OpenTelemetry specification. (#727)
### Fixed
- Ensure gRPC `ClientStream` override methods do not panic in grpctrace package. (#755)
- Disable parts of `BatchSpanProcessor` test until a fix is found. (#743)
- Fix `string` case in `kv` `Infer` function. (#746)
- Fix panic in grpctrace client interceptors. (#740)
- Refactor the `api/metrics` push controller and add `CheckpointSet` synchronization. (#737)
- Rewrite span batch process queue batching logic. (#719)
- Remove the push controller named Meter map. (#738)
- Fix Histogram aggregator initial state (fix #735). (#736)
- Ensure golang alpine image is running `golang-1.14` for examples. (#733)
- Added test for grpctrace `UnaryInterceptorClient`. (#695)
- Rearrange `api/metric` code layout. (#724)
## [0.5.0] - 2020-05-13
### Added
- Batch `Observer` callback support. (#717)
- Alias `api` types to root package of project. (#696)
- Create basic `othttp.Transport` for simple client instrumentation. (#678)
- `SetAttribute(string, interface{})` to the trace API. (#674)
- Jaeger exporter option that allows user to specify custom http client. (#671)
- `Stringer` and `Infer` methods to `key`s. (#662)
### Changed
- Rename `NewKey` in the `kv` package to just `Key`. (#721)
- Move `core` and `key` to `kv` package. (#720)
- Make the metric API `Meter` a `struct` so the abstract `MeterImpl` can be passed and simplify implementation. (#709)
- Rename SDK `Batcher` to `Integrator` to match draft OpenTelemetry SDK specification. (#710)
- Rename SDK `Ungrouped` integrator to `simple.Integrator` to match draft OpenTelemetry SDK specification. (#710)
- Rename SDK `SDK` `struct` to `Accumulator` to match draft OpenTelemetry SDK specification. (#710)
- Move `Number` from `core` to `api/metric` package. (#706)
- Move `SpanContext` from `core` to `trace` package. (#692)
- Change traceparent header from `Traceparent` to `traceparent` to implement the W3C specification. (#681)
### Fixed
- Update tooling to run generators in all submodules. (#705)
- gRPC interceptor regexp to match methods without a service name. (#683)
- Use a `const` for padding 64-bit B3 trace IDs. (#701)
- Update `mockZipkin` listen address from `:0` to `127.0.0.1:0`. (#700)
- Left-pad 64-bit B3 trace IDs with zero. (#698)
- Propagate at least the first W3C tracestate header. (#694)
- Remove internal `StateLocker` implementation. (#688)
- Increase instance size CI system uses. (#690)
- Add a `key` benchmark and use reflection in `key.Infer()`. (#679)
- Fix internal `global` test by using `global.Meter` with `RecordBatch()`. (#680)
- Reimplement histogram using mutex instead of `StateLocker`. (#669)
- Switch `MinMaxSumCount` to a mutex lock implementation instead of `StateLocker`. (#667)
- Update documentation to not include any references to `WithKeys`. (#672)
- Correct misspelling. (#668)
- Fix clobbering of the span context if extraction fails. (#656)
- Bump `golangci-lint` and work around the corrupting bug. (#666) (#670)
## [0.4.3] - 2020-04-24
### Added
- `Dockerfile` and `docker-compose.yml` to run example code. (#635)
- New `grpctrace` package that provides gRPC client and server interceptors for both unary and stream connections. (#621)
- New `api/label` package, providing common label set implementation. (#651)
- Support for JSON marshaling of `Resources`. (#654)
- `TraceID` and `SpanID` implementations for `Stringer` interface. (#642)
- `RemoteAddrKey` in the othttp plugin to include the HTTP client address in top-level spans. (#627)
- `WithSpanFormatter` option to the othttp plugin. (#617)
- Updated README to include section for compatible libraries and include reference to the contrib repository. (#612)
- The prometheus exporter now supports exporting histograms. (#601)
- A `String` method to the `Resource` to return a hashable identifier for a now unique resource. (#613)
- An `Iter` method to the `Resource` to return an array `AttributeIterator`. (#613)
- An `Equal` method to the `Resource` test the equivalence of resources. (#613)
- An iterable structure (`AttributeIterator`) for `Resource` attributes.
### Changed
- zipkin export's `NewExporter` now requires a `serviceName` argument to ensure this needed values is provided. (#644)
- Pass `Resources` through the metrics export pipeline. (#659)
### Removed
- `WithKeys` option from the metric API. (#639)
### Fixed
- Use the `label.Set.Equivalent` value instead of an encoding in the batcher. (#658)
- Correct typo `trace.Exporter` to `trace.SpanSyncer` in comments. (#653)
- Use type names for return values in jaeger exporter. (#648)
- Increase the visibility of the `api/key` package by updating comments and fixing usages locally. (#650)
- `Checkpoint` only after `Update`; Keep records in the `sync.Map` longer. (#647)
- Do not cache `reflect.ValueOf()` in metric Labels. (#649)
- Batch metrics exported from the OTLP exporter based on `Resource` and labels. (#626)
- Add error wrapping to the prometheus exporter. (#631)
- Update the OTLP exporter batching of traces to use a unique `string` representation of an associated `Resource` as the batching key. (#623)
- Update OTLP `SpanData` transform to only include the `ParentSpanID` if one exists. (#614)
- Update `Resource` internal representation to uniquely and reliably identify resources. (#613)
- Check return value from `CheckpointSet.ForEach` in prometheus exporter. (#622)
- Ensure spans created by httptrace client tracer reflect operation structure. (#618)
- Create a new recorder rather than reuse when multiple observations in same epoch for asynchronous instruments. #610
- The default port the OTLP exporter uses to connect to the OpenTelemetry collector is updated to match the one the collector listens on by default. (#611)
## [0.4.2] - 2020-03-31
### Fixed
- Fix `pre_release.sh` to update version in `sdk/opentelemetry.go`. (#607)
- Fix time conversion from internal to OTLP in OTLP exporter. (#606)
## [0.4.1] - 2020-03-31
### Fixed
- Update `tag.sh` to create signed tags. (#604)
## [0.4.0] - 2020-03-30
### Added
- New API package `api/metric/registry` that exposes a `MeterImpl` wrapper for use by SDKs to generate unique instruments. (#580)
- Script to verify examples after a new release. (#579)
### Removed
- The dogstatsd exporter due to lack of support.
This additionally removes support for statsd. (#591)
- `LabelSet` from the metric API.
This is replaced by a `[]core.KeyValue` slice. (#595)
- `Labels` from the metric API's `Meter` interface. (#595)
### Changed
- The metric `export.Labels` became an interface which the SDK implements and the `export` package provides a simple, immutable implementation of this interface intended for testing purposes. (#574)
- Renamed `internal/metric.Meter` to `MeterImpl`. (#580)
- Renamed `api/global/internal.obsImpl` to `asyncImpl`. (#580)
### Fixed
- Corrected missing return in mock span. (#582)
- Update License header for all source files to match CNCF guidelines and include a test to ensure it is present. (#586) (#596)
- Update to v0.3.0 of the OTLP in the OTLP exporter. (#588)
- Update pre-release script to be compatible between GNU and BSD based systems. (#592)
- Add a `RecordBatch` benchmark. (#594)
- Moved span transforms of the OTLP exporter to the internal package. (#593)
- Build both go-1.13 and go-1.14 in circleci to test for all supported versions of Go. (#569)
- Removed unneeded allocation on empty labels in OLTP exporter. (#597)
- Update `BatchedSpanProcessor` to process the queue until no data but respect max batch size. (#599)
- Update project documentation godoc.org links to pkg.go.dev. (#602)
## [0.3.0] - 2020-03-21
This is a first official beta release, which provides almost fully complete metrics, tracing, and context propagation functionality.
There is still a possibility of breaking changes.
### Added
- Add `Observer` metric instrument. (#474)
- Add global `Propagators` functionality to enable deferred initialization for propagators registered before the first Meter SDK is installed. (#494)
- Simplified export setup pipeline for the jaeger exporter to match other exporters. (#459)
- The zipkin trace exporter. (#495)
- The OTLP exporter to export metric and trace telemetry to the OpenTelemetry collector. (#497) (#544) (#545)
- Add `StatusMessage` field to the trace `Span`. (#524)
- Context propagation in OpenTracing bridge in terms of OpenTelemetry context propagation. (#525)
- The `Resource` type was added to the SDK. (#528)
- The global API now supports a `Tracer` and `Meter` function as shortcuts to getting a global `*Provider` and calling these methods directly. (#538)
- The metric API now defines a generic `MeterImpl` interface to support general purpose `Meter` construction.
Additionally, `SyncImpl` and `AsyncImpl` are added to support general purpose instrument construction. (#560)
- A metric `Kind` is added to represent the `MeasureKind`, `ObserverKind`, and `CounterKind`. (#560)
- Scripts to better automate the release process. (#576)
### Changed
- Default to to use `AlwaysSampler` instead of `ProbabilitySampler` to match OpenTelemetry specification. (#506)
- Renamed `AlwaysSampleSampler` to `AlwaysOnSampler` in the trace API. (#511)
- Renamed `NeverSampleSampler` to `AlwaysOffSampler` in the trace API. (#511)
- The `Status` field of the `Span` was changed to `StatusCode` to disambiguate with the added `StatusMessage`. (#524)
- Updated the trace `Sampler` interface conform to the OpenTelemetry specification. (#531)
- Rename metric API `Options` to `Config`. (#541)
- Rename metric `Counter` aggregator to be `Sum`. (#541)
- Unify metric options into `Option` from instrument specific options. (#541)
- The trace API's `TraceProvider` now support `Resource`s. (#545)
- Correct error in zipkin module name. (#548)
- The jaeger trace exporter now supports `Resource`s. (#551)
- Metric SDK now supports `Resource`s.
The `WithResource` option was added to configure a `Resource` on creation and the `Resource` method was added to the metric `Descriptor` to return the associated `Resource`. (#552)
- Replace `ErrNoLastValue` and `ErrEmptyDataSet` by `ErrNoData` in the metric SDK. (#557)
- The stdout trace exporter now supports `Resource`s. (#558)
- The metric `Descriptor` is now included at the API instead of the SDK. (#560)
- Replace `Ordered` with an iterator in `export.Labels`. (#567)
### Removed
- The vendor specific Stackdriver. It is now hosted on 3rd party vendor infrastructure. (#452)
- The `Unregister` method for metric observers as it is not in the OpenTelemetry specification. (#560)
- `GetDescriptor` from the metric SDK. (#575)
- The `Gauge` instrument from the metric API. (#537)
### Fixed
- Make histogram aggregator checkpoint consistent. (#438)
- Update README with import instructions and how to build and test. (#505)
- The default label encoding was updated to be unique. (#508)
- Use `NewRoot` in the othttp plugin for public endpoints. (#513)
- Fix data race in `BatchedSpanProcessor`. (#518)
- Skip test-386 for Mac OS 10.15.x (Catalina and upwards). #521
- Use a variable-size array to represent ordered labels in maps. (#523)
- Update the OTLP protobuf and update changed import path. (#532)
- Use `StateLocker` implementation in `MinMaxSumCount`. (#546)
- Eliminate goroutine leak in histogram stress test. (#547)
- Update OTLP exporter with latest protobuf. (#550)
- Add filters to the othttp plugin. (#556)
- Provide an implementation of the `Header*` filters that do not depend on Go 1.14. (#565)
- Encode labels once during checkpoint.
The checkpoint function is executed in a single thread so we can do the encoding lazily before passing the encoded version of labels to the exporter.
This is a cheap and quick way to avoid encoding the labels on every collection interval. (#572)
- Run coverage over all packages in `COVERAGE_MOD_DIR`. (#573)
## [0.2.3] - 2020-03-04
### Added
- `RecordError` method on `Span`s in the trace API to Simplify adding error events to spans. (#473)
- Configurable push frequency for exporters setup pipeline. (#504)
### Changed
- Rename the `exporter` directory to `exporters`.
The `go.opentelemetry.io/otel/exporter/trace/jaeger` package was mistakenly released with a `v1.0.0` tag instead of `v0.1.0`.
This resulted in all subsequent releases not becoming the default latest.
A consequence of this was that all `go get`s pulled in the incompatible `v0.1.0` release of that package when pulling in more recent packages from other otel packages.
Renaming the `exporter` directory to `exporters` fixes this issue by renaming the package and therefore clearing any existing dependency tags.
Consequentially, this action also renames *all* exporter packages. (#502)
### Removed
- The `CorrelationContextHeader` constant in the `correlation` package is no longer exported. (#503)
## [0.2.2] - 2020-02-27
### Added
- `HTTPSupplier` interface in the propagation API to specify methods to retrieve and store a single value for a key to be associated with a carrier. (#467)
- `HTTPExtractor` interface in the propagation API to extract information from an `HTTPSupplier` into a context. (#467)
- `HTTPInjector` interface in the propagation API to inject information into an `HTTPSupplier.` (#467)
- `Config` and configuring `Option` to the propagator API. (#467)
- `Propagators` interface in the propagation API to contain the set of injectors and extractors for all supported carrier formats. (#467)
- `HTTPPropagator` interface in the propagation API to inject and extract from an `HTTPSupplier.` (#467)
- `WithInjectors` and `WithExtractors` functions to the propagator API to configure injectors and extractors to use. (#467)
- `ExtractHTTP` and `InjectHTTP` functions to apply configured HTTP extractors and injectors to a passed context. (#467)
- Histogram aggregator. (#433)
- `DefaultPropagator` function and have it return `trace.TraceContext` as the default context propagator. (#456)
- `AlwaysParentSample` sampler to the trace API. (#455)
- `WithNewRoot` option function to the trace API to specify the created span should be considered a root span. (#451)
### Changed
- Renamed `WithMap` to `ContextWithMap` in the correlation package. (#481)
- Renamed `FromContext` to `MapFromContext` in the correlation package. (#481)
- Move correlation context propagation to correlation package. (#479)
- Do not default to putting remote span context into links. (#480)
- `Tracer.WithSpan` updated to accept `StartOptions`. (#472)
- Renamed `MetricKind` to `Kind` to not stutter in the type usage. (#432)
- Renamed the `export` package to `metric` to match directory structure. (#432)
- Rename the `api/distributedcontext` package to `api/correlation`. (#444)
- Rename the `api/propagators` package to `api/propagation`. (#444)
- Move the propagators from the `propagators` package into the `trace` API package. (#444)
- Update `Float64Gauge`, `Int64Gauge`, `Float64Counter`, `Int64Counter`, `Float64Measure`, and `Int64Measure` metric methods to use value receivers instead of pointers. (#462)
- Moved all dependencies of tools package to a tools directory. (#466)
### Removed
- Binary propagators. (#467)
- NOOP propagator. (#467)
### Fixed
- Upgraded `github.com/golangci/golangci-lint` from `v1.21.0` to `v1.23.6` in `tools/`. (#492)
- Fix a possible nil-dereference crash (#478)
- Correct comments for `InstallNewPipeline` in the stdout exporter. (#483)
- Correct comments for `InstallNewPipeline` in the dogstatsd exporter. (#484)
- Correct comments for `InstallNewPipeline` in the prometheus exporter. (#482)
- Initialize `onError` based on `Config` in prometheus exporter. (#486)
- Correct module name in prometheus exporter README. (#475)
- Removed tracer name prefix from span names. (#430)
- Fix `aggregator_test.go` import package comment. (#431)
- Improved detail in stdout exporter. (#436)
- Fix a dependency issue (generate target should depend on stringer, not lint target) in Makefile. (#442)
- Reorders the Makefile targets within `precommit` target so we generate files and build the code before doing linting, so we can get much nicer errors about syntax errors from the compiler. (#442)
- Reword function documentation in gRPC plugin. (#446)
- Send the `span.kind` tag to Jaeger from the jaeger exporter. (#441)
- Fix `metadataSupplier` in the jaeger exporter to overwrite the header if existing instead of appending to it. (#441)
- Upgraded to Go 1.13 in CI. (#465)
- Correct opentelemetry.io URL in trace SDK documentation. (#464)
- Refactored reference counting logic in SDK determination of stale records. (#468)
- Add call to `runtime.Gosched` in instrument `acquireHandle` logic to not block the collector. (#469)
## [0.2.1.1] - 2020-01-13
### Fixed
- Use stateful batcher on Prometheus exporter fixing regression introduced in #395. (#428)
## [0.2.1] - 2020-01-08
### Added
- Global meter forwarding implementation.
This enables deferred initialization for metric instruments registered before the first Meter SDK is installed. (#392)
- Global trace forwarding implementation.
This enables deferred initialization for tracers registered before the first Trace SDK is installed. (#406)
- Standardize export pipeline creation in all exporters. (#395)
- A testing, organization, and comments for 64-bit field alignment. (#418)
- Script to tag all modules in the project. (#414)
### Changed
- Renamed `propagation` package to `propagators`. (#362)
- Renamed `B3Propagator` propagator to `B3`. (#362)
- Renamed `TextFormatPropagator` propagator to `TextFormat`. (#362)
- Renamed `BinaryPropagator` propagator to `Binary`. (#362)
- Renamed `BinaryFormatPropagator` propagator to `BinaryFormat`. (#362)
- Renamed `NoopTextFormatPropagator` propagator to `NoopTextFormat`. (#362)
- Renamed `TraceContextPropagator` propagator to `TraceContext`. (#362)
- Renamed `SpanOption` to `StartOption` in the trace API. (#369)
- Renamed `StartOptions` to `StartConfig` in the trace API. (#369)
- Renamed `EndOptions` to `EndConfig` in the trace API. (#369)
- `Number` now has a pointer receiver for its methods. (#375)
- Renamed `CurrentSpan` to `SpanFromContext` in the trace API. (#379)
- Renamed `SetCurrentSpan` to `ContextWithSpan` in the trace API. (#379)
- Renamed `Message` in Event to `Name` in the trace API. (#389)
- Prometheus exporter no longer aggregates metrics, instead it only exports them. (#385)
- Renamed `HandleImpl` to `BoundInstrumentImpl` in the metric API. (#400)
- Renamed `Float64CounterHandle` to `Float64CounterBoundInstrument` in the metric API. (#400)
- Renamed `Int64CounterHandle` to `Int64CounterBoundInstrument` in the metric API. (#400)
- Renamed `Float64GaugeHandle` to `Float64GaugeBoundInstrument` in the metric API. (#400)
- Renamed `Int64GaugeHandle` to `Int64GaugeBoundInstrument` in the metric API. (#400)
- Renamed `Float64MeasureHandle` to `Float64MeasureBoundInstrument` in the metric API. (#400)
- Renamed `Int64MeasureHandle` to `Int64MeasureBoundInstrument` in the metric API. (#400)
- Renamed `Release` method for bound instruments in the metric API to `Unbind`. (#400)
- Renamed `AcquireHandle` method for bound instruments in the metric API to `Bind`. (#400)
- Renamed the `File` option in the stdout exporter to `Writer`. (#404)
- Renamed all `Options` to `Config` for all metric exports where this wasn't already the case.
### Fixed
- Aggregator import path corrected. (#421)
- Correct links in README. (#368)
- The README was updated to match latest code changes in its examples. (#374)
- Don't capitalize error statements. (#375)
- Fix ignored errors. (#375)
- Fix ambiguous variable naming. (#375)
- Removed unnecessary type casting. (#375)
- Use named parameters. (#375)
- Updated release schedule. (#378)
- Correct http-stackdriver example module name. (#394)
- Removed the `http.request` span in `httptrace` package. (#397)
- Add comments in the metrics SDK (#399)
- Initialize checkpoint when creating ddsketch aggregator to prevent panic when merging into a empty one. (#402) (#403)
- Add documentation of compatible exporters in the README. (#405)
- Typo fix. (#408)
- Simplify span check logic in SDK tracer implementation. (#419)
## [0.2.0] - 2019-12-03
### Added
- Unary gRPC tracing example. (#351)
- Prometheus exporter. (#334)
- Dogstatsd metrics exporter. (#326)
### Changed
- Rename `MaxSumCount` aggregation to `MinMaxSumCount` and add the `Min` interface for this aggregation. (#352)
- Rename `GetMeter` to `Meter`. (#357)
- Rename `HTTPTraceContextPropagator` to `TraceContextPropagator`. (#355)
- Rename `HTTPB3Propagator` to `B3Propagator`. (#355)
- Rename `HTTPTraceContextPropagator` to `TraceContextPropagator`. (#355)
- Move `/global` package to `/api/global`. (#356)
- Rename `GetTracer` to `Tracer`. (#347)
### Removed
- `SetAttribute` from the `Span` interface in the trace API. (#361)
- `AddLink` from the `Span` interface in the trace API. (#349)
- `Link` from the `Span` interface in the trace API. (#349)
### Fixed
- Exclude example directories from coverage report. (#365)
- Lint make target now implements automatic fixes with `golangci-lint` before a second run to report the remaining issues. (#360)
- Drop `GO111MODULE` environment variable in Makefile as Go 1.13 is the project specified minimum version and this is environment variable is not needed for that version of Go. (#359)
- Run the race checker for all test. (#354)
- Redundant commands in the Makefile are removed. (#354)
- Split the `generate` and `lint` targets of the Makefile. (#354)
- Renames `circle-ci` target to more generic `ci` in Makefile. (#354)
- Add example Prometheus binary to gitignore. (#358)
- Support negative numbers with the `MaxSumCount`. (#335)
- Resolve race conditions in `push_test.go` identified in #339. (#340)
- Use `/usr/bin/env bash` as a shebang in scripts rather than `/bin/bash`. (#336)
- Trace benchmark now tests both `AlwaysSample` and `NeverSample`.
Previously it was testing `AlwaysSample` twice. (#325)
- Trace benchmark now uses a `[]byte` for `TraceID` to fix failing test. (#325)
- Added a trace benchmark to test variadic functions in `setAttribute` vs `setAttributes` (#325)
- The `defaultkeys` batcher was only using the encoded label set as its map key while building a checkpoint.
This allowed distinct label sets through, but any metrics sharing a label set could be overwritten or merged incorrectly.
This was corrected. (#333)
## [0.1.2] - 2019-11-18
### Fixed
- Optimized the `simplelru` map for attributes to reduce the number of allocations. (#328)
- Removed unnecessary unslicing of parameters that are already a slice. (#324)
## [0.1.1] - 2019-11-18
This release contains a Metrics SDK with stdout exporter and supports basic aggregations such as counter, gauges, array, maxsumcount, and ddsketch.
### Added
- Metrics stdout export pipeline. (#265)
- Array aggregation for raw measure metrics. (#282)
- The core.Value now have a `MarshalJSON` method. (#281)
### Removed
- `WithService`, `WithResources`, and `WithComponent` methods of tracers. (#314)
- Prefix slash in `Tracer.Start()` for the Jaeger example. (#292)
### Changed
- Allocation in LabelSet construction to reduce GC overhead. (#318)
- `trace.WithAttributes` to append values instead of replacing (#315)
- Use a formula for tolerance in sampling tests. (#298)
- Move export types into trace and metric-specific sub-directories. (#289)
- `SpanKind` back to being based on an `int` type. (#288)
### Fixed
- URL to OpenTelemetry website in README. (#323)
- Name of othttp default tracer. (#321)
- `ExportSpans` for the stackdriver exporter now handles `nil` context. (#294)
- CI modules cache to correctly restore/save from/to the cache. (#316)
- Fix metric SDK race condition between `LoadOrStore` and the assignment `rec.recorder = i.meter.exporter.AggregatorFor(rec)`. (#293)
- README now reflects the new code structure introduced with these changes. (#291)
- Make the basic example work. (#279)
## [0.1.0] - 2019-11-04
This is the first release of open-telemetry go library.
It contains api and sdk for trace and meter.
### Added
- Initial OpenTelemetry trace and metric API prototypes.
- Initial OpenTelemetry trace, metric, and export SDK packages.
- A wireframe bridge to support compatibility with OpenTracing.
- Example code for a basic, http-stackdriver, http, jaeger, and named tracer setup.
- Exporters for Jaeger, Stackdriver, and stdout.
- Propagators for binary, B3, and trace-context protocols.
- Project information and guidelines in the form of a README and CONTRIBUTING.
- Tools to build the project and a Makefile to automate the process.
- Apache-2.0 license.
- CircleCI build CI manifest files.
- CODEOWNERS file to track owners of this project.
[Unreleased]: https://github.com/open-telemetry/opentelemetry-go/compare/v1.33.0...HEAD
[1.33.0/0.55.0/0.9.0/0.0.12]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.33.0
[1.32.0/0.54.0/0.8.0/0.0.11]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.32.0
[1.31.0/0.53.0/0.7.0/0.0.10]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.31.0
[1.30.0/0.52.0/0.6.0/0.0.9]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.30.0
[1.29.0/0.51.0/0.5.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.29.0
[1.28.0/0.50.0/0.4.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.28.0
[1.27.0/0.49.0/0.3.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.27.0
[1.26.0/0.48.0/0.2.0-alpha]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.26.0
[1.25.0/0.47.0/0.0.8/0.1.0-alpha]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.25.0
[1.24.0/0.46.0/0.0.1-alpha]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.24.0
[1.23.1]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.23.1
[1.23.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.23.0
[1.23.0-rc.1]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.23.0-rc.1
[1.22.0/0.45.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.22.0
[1.21.0/0.44.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.21.0
[1.20.0/0.43.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.20.0
[1.19.0/0.42.0/0.0.7]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.19.0
[1.19.0-rc.1/0.42.0-rc.1]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.19.0-rc.1
[1.18.0/0.41.0/0.0.6]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.18.0
[1.17.0/0.40.0/0.0.5]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.17.0
[1.16.0/0.39.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.16.0
[1.16.0-rc.1/0.39.0-rc.1]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.16.0-rc.1
[1.15.1/0.38.1]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.15.1
[1.15.0/0.38.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.15.0
[1.15.0-rc.2/0.38.0-rc.2]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.15.0-rc.2
[1.15.0-rc.1/0.38.0-rc.1]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.15.0-rc.1
[1.14.0/0.37.0/0.0.4]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.14.0
[1.13.0/0.36.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.13.0
[1.12.0/0.35.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.12.0
[1.11.2/0.34.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.11.2
[1.11.1/0.33.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.11.1
[1.11.0/0.32.3]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.11.0
[0.32.2]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/sdk/metric/v0.32.2
[0.32.1]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/sdk/metric/v0.32.1
[0.32.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/sdk/metric/v0.32.0
[1.10.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.10.0
[1.9.0/0.0.3]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.9.0
[1.8.0/0.31.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.8.0
[1.7.0/0.30.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.7.0
[0.29.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/metric/v0.29.0
[1.6.3]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.6.3
[1.6.2]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.6.2
[1.6.1]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.6.1
[1.6.0/0.28.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.6.0
[1.5.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.5.0
[1.4.1]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.4.1
[1.4.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.4.0
[1.3.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.3.0
[1.2.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.2.0
[1.1.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.1.0
[1.0.1]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.0.1
[Metrics 0.24.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/metric/v0.24.0
[1.0.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.0.0
[1.0.0-RC3]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.0.0-RC3
[1.0.0-RC2]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.0.0-RC2
[Experimental Metrics v0.22.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/metric/v0.22.0
[1.0.0-RC1]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.0.0-RC1
[0.20.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v0.20.0
[0.19.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v0.19.0
[0.18.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v0.18.0
[0.17.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v0.17.0
[0.16.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v0.16.0
[0.15.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v0.15.0
[0.14.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v0.14.0
[0.13.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v0.13.0
[0.12.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v0.12.0
[0.11.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v0.11.0
[0.10.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v0.10.0
[0.9.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v0.9.0
[0.8.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v0.8.0
[0.7.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v0.7.0
[0.6.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v0.6.0
[0.5.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v0.5.0
[0.4.3]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v0.4.3
[0.4.2]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v0.4.2
[0.4.1]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v0.4.1
[0.4.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v0.4.0
[0.3.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v0.3.0
[0.2.3]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v0.2.3
[0.2.2]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v0.2.2
[0.2.1.1]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v0.2.1.1
[0.2.1]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v0.2.1
[0.2.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v0.2.0
[0.1.2]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v0.1.2
[0.1.1]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v0.1.1
[0.1.0]: https://github.com/open-telemetry/opentelemetry-go/releases/tag/v0.1.0
<!-- Released section ended -->
[Go 1.23]: https://go.dev/doc/go1.23
[Go 1.22]: https://go.dev/doc/go1.22
[Go 1.21]: https://go.dev/doc/go1.21
[Go 1.20]: https://go.dev/doc/go1.20
[Go 1.19]: https://go.dev/doc/go1.19
[Go 1.18]: https://go.dev/doc/go1.18
[metric API]:https://pkg.go.dev/go.opentelemetry.io/otel/metric
[metric SDK]:https://pkg.go.dev/go.opentelemetry.io/otel/sdk/metric
[trace API]:https://pkg.go.dev/go.opentelemetry.io/otel/trace
[GO-2024-2687]: https://pkg.go.dev/vuln/GO-2024-2687 | {
"source": "yandex/perforator",
"title": "vendor/go.opentelemetry.io/otel/CHANGELOG.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/go.opentelemetry.io/otel/CHANGELOG.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 233057
} |
# Contributing to opentelemetry-go
The Go special interest group (SIG) meets regularly. See the
OpenTelemetry
[community](https://github.com/open-telemetry/community#golang-sdk)
repo for information on this and other language SIGs.
See the [public meeting
notes](https://docs.google.com/document/d/1E5e7Ld0NuU1iVvf-42tOBpu2VBBLYnh73GJuITGJTTU/edit)
for a summary description of past meetings. To request edit access,
join the meeting or get in touch on
[Slack](https://cloud-native.slack.com/archives/C01NPAXACKT).
## Development
You can view and edit the source code by cloning this repository:
```sh
git clone https://github.com/open-telemetry/opentelemetry-go.git
```
Run `make test` to run the tests instead of `go test`.
There are some generated files checked into the repo. To make sure
that the generated files are up-to-date, run `make` (or `make
precommit` - the `precommit` target is the default).
The `precommit` target also fixes the formatting of the code and
checks the status of the go module files.
Additionally, there is a `codespell` target that checks for common
typos in the code. It is not run by default, but you can run it
manually with `make codespell`. It will set up a virtual environment
in `venv` and install `codespell` there.
If after running `make precommit` the output of `git status` contains
`nothing to commit, working tree clean` then it means that everything
is up-to-date and properly formatted.
## Pull Requests
### How to Send Pull Requests
Everyone is welcome to contribute code to `opentelemetry-go` via
GitHub pull requests (PRs).
To create a new PR, fork the project in GitHub and clone the upstream
repo:
```sh
go get -d go.opentelemetry.io/otel
```
(This may print some warning about "build constraints exclude all Go
files", just ignore it.)
This will put the project in `${GOPATH}/src/go.opentelemetry.io/otel`. You
can alternatively use `git` directly with:
```sh
git clone https://github.com/open-telemetry/opentelemetry-go
```
(Note that `git clone` is *not* using the `go.opentelemetry.io/otel` name -
that name is a kind of a redirector to GitHub that `go get` can
understand, but `git` does not.)
This would put the project in the `opentelemetry-go` directory in
current working directory.
Enter the newly created directory and add your fork as a new remote:
```sh
git remote add <YOUR_FORK> [email protected]:<YOUR_GITHUB_USERNAME>/opentelemetry-go
```
Check out a new branch, make modifications, run linters and tests, update
`CHANGELOG.md`, and push the branch to your fork:
```sh
git checkout -b <YOUR_BRANCH_NAME>
# edit files
# update changelog
make precommit
git add -p
git commit
git push <YOUR_FORK> <YOUR_BRANCH_NAME>
```
Open a pull request against the main `opentelemetry-go` repo. Be sure to add the pull
request ID to the entry you added to `CHANGELOG.md`.
Avoid rebasing and force-pushing to your branch to facilitate reviewing the pull request.
Rewriting Git history makes it difficult to keep track of iterations during code review.
All pull requests are squashed to a single commit upon merge to `main`.
### How to Receive Comments
* If the PR is not ready for review, please put `[WIP]` in the title,
tag it as `work-in-progress`, or mark it as
[`draft`](https://github.blog/2019-02-14-introducing-draft-pull-requests/).
* Make sure CLA is signed and CI is clear.
### How to Get PRs Merged
A PR is considered **ready to merge** when:
* It has received two qualified approvals[^1].
This is not enforced through automation, but needs to be validated by the
maintainer merging.
* The qualified approvals need to be from [Approver]s/[Maintainer]s
affiliated with different companies. Two qualified approvals from
[Approver]s or [Maintainer]s affiliated with the same company counts as a
single qualified approval.
* PRs introducing changes that have already been discussed and consensus
reached only need one qualified approval. The discussion and resolution
needs to be linked to the PR.
* Trivial changes[^2] only need one qualified approval.
* All feedback has been addressed.
* All PR comments and suggestions are resolved.
* All GitHub Pull Request reviews with a status of "Request changes" have
been addressed. Another review by the objecting reviewer with a different
status can be submitted to clear the original review, or the review can be
dismissed by a [Maintainer] when the issues from the original review have
been addressed.
* Any comments or reviews that cannot be resolved between the PR author and
reviewers can be submitted to the community [Approver]s and [Maintainer]s
during the weekly SIG meeting. If consensus is reached among the
[Approver]s and [Maintainer]s during the SIG meeting the objections to the
PR may be dismissed or resolved or the PR closed by a [Maintainer].
* Any substantive changes to the PR require existing Approval reviews be
cleared unless the approver explicitly states that their approval persists
across changes. This includes changes resulting from other feedback.
[Approver]s and [Maintainer]s can help in clearing reviews and they should
be consulted if there are any questions.
* The PR branch is up to date with the base branch it is merging into.
* To ensure this does not block the PR, it should be configured to allow
maintainers to update it.
* It has been open for review for at least one working day. This gives people
reasonable time to review.
* Trivial changes[^2] do not have to wait for one day and may be merged with
a single [Maintainer]'s approval.
* All required GitHub workflows have succeeded.
* Urgent fix can take exception as long as it has been actively communicated
among [Maintainer]s.
Any [Maintainer] can merge the PR once the above criteria have been met.
[^1]: A qualified approval is a GitHub Pull Request review with "Approve"
status from an OpenTelemetry Go [Approver] or [Maintainer].
[^2]: Trivial changes include: typo corrections, cosmetic non-substantive
changes, documentation corrections or updates, dependency updates, etc.
## Design Choices
As with other OpenTelemetry clients, opentelemetry-go follows the
[OpenTelemetry Specification](https://opentelemetry.io/docs/specs/otel).
It's especially valuable to read through the [library
guidelines](https://opentelemetry.io/docs/specs/otel/library-guidelines).
### Focus on Capabilities, Not Structure Compliance
OpenTelemetry is an evolving specification, one where the desires and
use cases are clear, but the method to satisfy those uses cases are
not.
As such, Contributions should provide functionality and behavior that
conforms to the specification, but the interface and structure is
flexible.
It is preferable to have contributions follow the idioms of the
language rather than conform to specific API names or argument
patterns in the spec.
For a deeper discussion, see
[this](https://github.com/open-telemetry/opentelemetry-specification/issues/165).
## Documentation
Each (non-internal, non-test) package must be documented using
[Go Doc Comments](https://go.dev/doc/comment),
preferably in a `doc.go` file.
Prefer using [Examples](https://pkg.go.dev/testing#hdr-Examples)
instead of putting code snippets in Go doc comments.
In some cases, you can even create [Testable Examples](https://go.dev/blog/examples).
You can install and run a "local Go Doc site" in the following way:
```sh
go install golang.org/x/pkgsite/cmd/pkgsite@latest
pkgsite
```
[`go.opentelemetry.io/otel/metric`](https://pkg.go.dev/go.opentelemetry.io/otel/metric)
is an example of a very well-documented package.
### README files
Each (non-internal, non-test, non-documentation) package must contain a
`README.md` file containing at least a title, and a `pkg.go.dev` badge.
The README should not be a repetition of Go doc comments.
You can verify the presence of all README files with the `make verify-readmes`
command.
## Style Guide
One of the primary goals of this project is that it is actually used by
developers. With this goal in mind the project strives to build
user-friendly and idiomatic Go code adhering to the Go community's best
practices.
For a non-comprehensive but foundational overview of these best practices
the [Effective Go](https://golang.org/doc/effective_go.html) documentation
is an excellent starting place.
As a convenience for developers building this project the `make precommit`
will format, lint, validate, and in some cases fix the changes you plan to
submit. This check will need to pass for your changes to be able to be
merged.
In addition to idiomatic Go, the project has adopted certain standards for
implementations of common patterns. These standards should be followed as a
default, and if they are not followed documentation needs to be included as
to the reasons why.
### Configuration
When creating an instantiation function for a complex `type T struct`, it is
useful to allow variable number of options to be applied. However, the strong
type system of Go restricts the function design options. There are a few ways
to solve this problem, but we have landed on the following design.
#### `config`
Configuration should be held in a `struct` named `config`, or prefixed with
specific type name this Configuration applies to if there are multiple
`config` in the package. This type must contain configuration options.
```go
// config contains configuration options for a thing.
type config struct {
// options ...
}
```
In general the `config` type will not need to be used externally to the
package and should be unexported. If, however, it is expected that the user
will likely want to build custom options for the configuration, the `config`
should be exported. Please, include in the documentation for the `config`
how the user can extend the configuration.
It is important that internal `config` are not shared across package boundaries.
Meaning a `config` from one package should not be directly used by another. The
one exception is the API packages. The configs from the base API, eg.
`go.opentelemetry.io/otel/trace.TracerConfig` and
`go.opentelemetry.io/otel/metric.InstrumentConfig`, are intended to be consumed
by the SDK therefore it is expected that these are exported.
When a config is exported we want to maintain forward and backward
compatibility, to achieve this no fields should be exported but should
instead be accessed by methods.
Optionally, it is common to include a `newConfig` function (with the same
naming scheme). This function wraps any defaults setting and looping over
all options to create a configured `config`.
```go
// newConfig returns an appropriately configured config.
func newConfig(options ...Option) config {
// Set default values for config.
config := config{/* […] */}
for _, option := range options {
config = option.apply(config)
}
// Perform any validation here.
return config
}
```
If validation of the `config` options is also performed this can return an
error as well that is expected to be handled by the instantiation function
or propagated to the user.
Given the design goal of not having the user need to work with the `config`,
the `newConfig` function should also be unexported.
#### `Option`
To set the value of the options a `config` contains, a corresponding
`Option` interface type should be used.
```go
type Option interface {
apply(config) config
}
```
Having `apply` unexported makes sure that it will not be used externally.
Moreover, the interface becomes sealed so the user cannot easily implement
the interface on its own.
The `apply` method should return a modified version of the passed config.
This approach, instead of passing a pointer, is used to prevent the config from being allocated to the heap.
The name of the interface should be prefixed in the same way the
corresponding `config` is (if at all).
#### Options
All user configurable options for a `config` must have a related unexported
implementation of the `Option` interface and an exported configuration
function that wraps this implementation.
The wrapping function name should be prefixed with `With*` (or in the
special case of a boolean options `Without*`) and should have the following
function signature.
```go
func With*(…) Option { … }
```
##### `bool` Options
```go
type defaultFalseOption bool
func (o defaultFalseOption) apply(c config) config {
c.Bool = bool(o)
return c
}
// WithOption sets a T to have an option included.
func WithOption() Option {
return defaultFalseOption(true)
}
```
```go
type defaultTrueOption bool
func (o defaultTrueOption) apply(c config) config {
c.Bool = bool(o)
return c
}
// WithoutOption sets a T to have Bool option excluded.
func WithoutOption() Option {
return defaultTrueOption(false)
}
```
##### Declared Type Options
```go
type myTypeOption struct {
MyType MyType
}
func (o myTypeOption) apply(c config) config {
c.MyType = o.MyType
return c
}
// WithMyType sets T to have include MyType.
func WithMyType(t MyType) Option {
return myTypeOption{t}
}
```
##### Functional Options
```go
type optionFunc func(config) config
func (fn optionFunc) apply(c config) config {
return fn(c)
}
// WithMyType sets t as MyType.
func WithMyType(t MyType) Option {
return optionFunc(func(c config) config {
c.MyType = t
return c
})
}
```
#### Instantiation
Using this configuration pattern to configure instantiation with a `NewT`
function.
```go
func NewT(options ...Option) T {…}
```
Any required parameters can be declared before the variadic `options`.
#### Dealing with Overlap
Sometimes there are multiple complex `struct` that share common
configuration and also have distinct configuration. To avoid repeated
portions of `config`s, a common `config` can be used with the union of
options being handled with the `Option` interface.
For example.
```go
// config holds options for all animals.
type config struct {
Weight float64
Color string
MaxAltitude float64
}
// DogOption apply Dog specific options.
type DogOption interface {
applyDog(config) config
}
// BirdOption apply Bird specific options.
type BirdOption interface {
applyBird(config) config
}
// Option apply options for all animals.
type Option interface {
BirdOption
DogOption
}
type weightOption float64
func (o weightOption) applyDog(c config) config {
c.Weight = float64(o)
return c
}
func (o weightOption) applyBird(c config) config {
c.Weight = float64(o)
return c
}
func WithWeight(w float64) Option { return weightOption(w) }
type furColorOption string
func (o furColorOption) applyDog(c config) config {
c.Color = string(o)
return c
}
func WithFurColor(c string) DogOption { return furColorOption(c) }
type maxAltitudeOption float64
func (o maxAltitudeOption) applyBird(c config) config {
c.MaxAltitude = float64(o)
return c
}
func WithMaxAltitude(a float64) BirdOption { return maxAltitudeOption(a) }
func NewDog(name string, o ...DogOption) Dog {…}
func NewBird(name string, o ...BirdOption) Bird {…}
```
### Interfaces
To allow other developers to better comprehend the code, it is important
to ensure it is sufficiently documented. One simple measure that contributes
to this aim is self-documenting by naming method parameters. Therefore,
where appropriate, methods of every exported interface type should have
their parameters appropriately named.
#### Interface Stability
All exported stable interfaces that include the following warning in their
documentation are allowed to be extended with additional methods.
> Warning: methods may be added to this interface in minor releases.
These interfaces are defined by the OpenTelemetry specification and will be
updated as the specification evolves.
Otherwise, stable interfaces MUST NOT be modified.
#### How to Change Specification Interfaces
When an API change must be made, we will update the SDK with the new method one
release before the API change. This will allow the SDK one version before the
API change to work seamlessly with the new API.
If an incompatible version of the SDK is used with the new API the application
will fail to compile.
#### How Not to Change Specification Interfaces
We have explored using a v2 of the API to change interfaces and found that there
was no way to introduce a v2 and have it work seamlessly with the v1 of the API.
Problems happened with libraries that upgraded to v2 when an application did not,
and would not produce any telemetry.
More detail of the approaches considered and their limitations can be found in
the [Use a V2 API to evolve interfaces](https://github.com/open-telemetry/opentelemetry-go/issues/3920)
issue.
#### How to Change Other Interfaces
If new functionality is needed for an interface that cannot be changed it MUST
be added by including an additional interface. That added interface can be a
simple interface for the specific functionality that you want to add or it can
be a super-set of the original interface. For example, if you wanted to a
`Close` method to the `Exporter` interface:
```go
type Exporter interface {
Export()
}
```
A new interface, `Closer`, can be added:
```go
type Closer interface {
Close()
}
```
Code that is passed the `Exporter` interface can now check to see if the passed
value also satisfies the new interface. E.g.
```go
func caller(e Exporter) {
/* ... */
if c, ok := e.(Closer); ok {
c.Close()
}
/* ... */
}
```
Alternatively, a new type that is the super-set of an `Exporter` can be created.
```go
type ClosingExporter struct {
Exporter
Close()
}
```
This new type can be used similar to the simple interface above in that a
passed `Exporter` type can be asserted to satisfy the `ClosingExporter` type
and the `Close` method called.
This super-set approach can be useful if there is explicit behavior that needs
to be coupled with the original type and passed as a unified type to a new
function, but, because of this coupling, it also limits the applicability of
the added functionality. If there exist other interfaces where this
functionality should be added, each one will need their own super-set
interfaces and will duplicate the pattern. For this reason, the simple targeted
interface that defines the specific functionality should be preferred.
See also:
[Keeping Your Modules Compatible: Working with interfaces](https://go.dev/blog/module-compatibility#working-with-interfaces).
### Testing
The tests should never leak goroutines.
Use the term `ConcurrentSafe` in the test name when it aims to verify the
absence of race conditions. The top-level tests with this term will be run
many times in the `test-concurrent-safe` CI job to increase the chance of
catching concurrency issues. This does not apply to subtests when this term
is not in their root name.
### Internal packages
The use of internal packages should be scoped to a single module. A sub-module
should never import from a parent internal package. This creates a coupling
between the two modules where a user can upgrade the parent without the child
and if the internal package API has changed it will fail to upgrade[^3].
There are two known exceptions to this rule:
- `go.opentelemetry.io/otel/internal/global`
- This package manages global state for all of opentelemetry-go. It needs to
be a single package in order to ensure the uniqueness of the global state.
- `go.opentelemetry.io/otel/internal/baggage`
- This package provides values in a `context.Context` that need to be
recognized by `go.opentelemetry.io/otel/baggage` and
`go.opentelemetry.io/otel/bridge/opentracing` but remain private.
If you have duplicate code in multiple modules, make that code into a Go
template stored in `go.opentelemetry.io/otel/internal/shared` and use [gotmpl]
to render the templates in the desired locations. See [#4404] for an example of
this.
[^3]: https://github.com/open-telemetry/opentelemetry-go/issues/3548
### Ignoring context cancellation
OpenTelemetry API implementations need to ignore the cancellation of the context that are
passed when recording a value (e.g. starting a span, recording a measurement, emitting a log).
Recording methods should not return an error describing the cancellation state of the context
when they complete, nor should they abort any work.
This rule may not apply if the OpenTelemetry specification defines a timeout mechanism for
the method. In that case the context cancellation can be used for the timeout with the
restriction that this behavior is documented for the method. Otherwise, timeouts
are expected to be handled by the user calling the API, not the implementation.
Stoppage of the telemetry pipeline is handled by calling the appropriate `Shutdown` method
of a provider. It is assumed the context passed from a user is not used for this purpose.
Outside of the direct recording of telemetry from the API (e.g. exporting telemetry,
force flushing telemetry, shutting down a signal provider) the context cancellation
should be honored. This means all work done on behalf of the user provided context
should be canceled.
## Approvers and Maintainers
### Triagers
- [Cheng-Zhen Yang](https://github.com/scorpionknifes), Independent
### Approvers
### Maintainers
- [Damien Mathieu](https://github.com/dmathieu), Elastic
- [David Ashpole](https://github.com/dashpole), Google
- [Robert Pająk](https://github.com/pellared), Splunk
- [Sam Xie](https://github.com/XSAM), Cisco/AppDynamics
- [Tyler Yahn](https://github.com/MrAlias), Splunk
### Emeritus
- [Aaron Clawson](https://github.com/MadVikingGod)
- [Anthony Mirabella](https://github.com/Aneurysm9)
- [Chester Cheung](https://github.com/hanyuancheung)
- [Evan Torrie](https://github.com/evantorrie)
- [Gustavo Silva Paiva](https://github.com/paivagustavo)
- [Josh MacDonald](https://github.com/jmacd)
- [Liz Fong-Jones](https://github.com/lizthegrey)
### Become an Approver or a Maintainer
See the [community membership document in OpenTelemetry community
repo](https://github.com/open-telemetry/community/blob/main/guides/contributor/membership.md).
[Approver]: #approvers
[Maintainer]: #maintainers
[gotmpl]: https://pkg.go.dev/go.opentelemetry.io/build-tools/gotmpl
[#4404]: https://github.com/open-telemetry/opentelemetry-go/pull/4404 | {
"source": "yandex/perforator",
"title": "vendor/go.opentelemetry.io/otel/CONTRIBUTING.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/go.opentelemetry.io/otel/CONTRIBUTING.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 22325
} |
# OpenTelemetry-Go
[](https://github.com/open-telemetry/opentelemetry-go/actions?query=workflow%3Aci+branch%3Amain)
[](https://app.codecov.io/gh/open-telemetry/opentelemetry-go?branch=main)
[](https://pkg.go.dev/go.opentelemetry.io/otel)
[](https://goreportcard.com/report/go.opentelemetry.io/otel)
[](https://cloud-native.slack.com/archives/C01NPAXACKT)
OpenTelemetry-Go is the [Go](https://golang.org/) implementation of [OpenTelemetry](https://opentelemetry.io/).
It provides a set of APIs to directly measure performance and behavior of your software and send this data to observability platforms.
## Project Status
| Signal | Status |
|---------|--------------------|
| Traces | Stable |
| Metrics | Stable |
| Logs | Beta[^1] |
Progress and status specific to this repository is tracked in our
[project boards](https://github.com/open-telemetry/opentelemetry-go/projects)
and
[milestones](https://github.com/open-telemetry/opentelemetry-go/milestones).
Project versioning information and stability guarantees can be found in the
[versioning documentation](VERSIONING.md).
[^1]: https://github.com/orgs/open-telemetry/projects/43
### Compatibility
OpenTelemetry-Go ensures compatibility with the current supported versions of
the [Go language](https://golang.org/doc/devel/release#policy):
> Each major Go release is supported until there are two newer major releases.
> For example, Go 1.5 was supported until the Go 1.7 release, and Go 1.6 was supported until the Go 1.8 release.
For versions of Go that are no longer supported upstream, opentelemetry-go will
stop ensuring compatibility with these versions in the following manner:
- A minor release of opentelemetry-go will be made to add support for the new
supported release of Go.
- The following minor release of opentelemetry-go will remove compatibility
testing for the oldest (now archived upstream) version of Go. This, and
future, releases of opentelemetry-go may include features only supported by
the currently supported versions of Go.
Currently, this project supports the following environments.
| OS | Go Version | Architecture |
|----------|------------|--------------|
| Ubuntu | 1.23 | amd64 |
| Ubuntu | 1.22 | amd64 |
| Ubuntu | 1.23 | 386 |
| Ubuntu | 1.22 | 386 |
| Linux | 1.23 | arm64 |
| Linux | 1.22 | arm64 |
| macOS 13 | 1.23 | amd64 |
| macOS 13 | 1.22 | amd64 |
| macOS | 1.23 | arm64 |
| macOS | 1.22 | arm64 |
| Windows | 1.23 | amd64 |
| Windows | 1.22 | amd64 |
| Windows | 1.23 | 386 |
| Windows | 1.22 | 386 |
While this project should work for other systems, no compatibility guarantees
are made for those systems currently.
## Getting Started
You can find a getting started guide on [opentelemetry.io](https://opentelemetry.io/docs/languages/go/getting-started/).
OpenTelemetry's goal is to provide a single set of APIs to capture distributed
traces and metrics from your application and send them to an observability
platform. This project allows you to do just that for applications written in
Go. There are two steps to this process: instrument your application, and
configure an exporter.
### Instrumentation
To start capturing distributed traces and metric events from your application
it first needs to be instrumented. The easiest way to do this is by using an
instrumentation library for your code. Be sure to check out [the officially
supported instrumentation
libraries](https://github.com/open-telemetry/opentelemetry-go-contrib/tree/main/instrumentation).
If you need to extend the telemetry an instrumentation library provides or want
to build your own instrumentation for your application directly you will need
to use the
[Go otel](https://pkg.go.dev/go.opentelemetry.io/otel)
package. The [examples](https://github.com/open-telemetry/opentelemetry-go-contrib/tree/main/examples)
are a good way to see some practical uses of this process.
### Export
Now that your application is instrumented to collect telemetry, it needs an
export pipeline to send that telemetry to an observability platform.
All officially supported exporters for the OpenTelemetry project are contained in the [exporters directory](./exporters).
| Exporter | Logs | Metrics | Traces |
|---------------------------------------|:----:|:-------:|:------:|
| [OTLP](./exporters/otlp/) | ✓ | ✓ | ✓ |
| [Prometheus](./exporters/prometheus/) | | ✓ | |
| [stdout](./exporters/stdout/) | ✓ | ✓ | ✓ |
| [Zipkin](./exporters/zipkin/) | | | ✓ |
## Contributing
See the [contributing documentation](CONTRIBUTING.md). | {
"source": "yandex/perforator",
"title": "vendor/go.opentelemetry.io/otel/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/go.opentelemetry.io/otel/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 5307
} |
# Changelog
All notable changes to this project will be documented in this file.
The format is based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/),
and this project adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0.html).
## [1.11.0] - 2023-05-02
### Fixed
- Fix initialization of `Value` wrappers.
### Added
- Add `String` method to `atomic.Pointer[T]` type allowing users to safely print
underlying values of pointers.
[1.11.0]: https://github.com/uber-go/atomic/compare/v1.10.0...v1.11.0
## [1.10.0] - 2022-08-11
### Added
- Add `atomic.Float32` type for atomic operations on `float32`.
- Add `CompareAndSwap` and `Swap` methods to `atomic.String`, `atomic.Error`,
and `atomic.Value`.
- Add generic `atomic.Pointer[T]` type for atomic operations on pointers of any
type. This is present only for Go 1.18 or higher, and is a drop-in for
replacement for the standard library's `sync/atomic.Pointer` type.
### Changed
- Deprecate `CAS` methods on all types in favor of corresponding
`CompareAndSwap` methods.
Thanks to @eNV25 and @icpd for their contributions to this release.
[1.10.0]: https://github.com/uber-go/atomic/compare/v1.9.0...v1.10.0
## [1.9.0] - 2021-07-15
### Added
- Add `Float64.Swap` to match int atomic operations.
- Add `atomic.Time` type for atomic operations on `time.Time` values.
[1.9.0]: https://github.com/uber-go/atomic/compare/v1.8.0...v1.9.0
## [1.8.0] - 2021-06-09
### Added
- Add `atomic.Uintptr` type for atomic operations on `uintptr` values.
- Add `atomic.UnsafePointer` type for atomic operations on `unsafe.Pointer` values.
[1.8.0]: https://github.com/uber-go/atomic/compare/v1.7.0...v1.8.0
## [1.7.0] - 2020-09-14
### Added
- Support JSON serialization and deserialization of primitive atomic types.
- Support Text marshalling and unmarshalling for string atomics.
### Changed
- Disallow incorrect comparison of atomic values in a non-atomic way.
### Removed
- Remove dependency on `golang.org/x/{lint, tools}`.
[1.7.0]: https://github.com/uber-go/atomic/compare/v1.6.0...v1.7.0
## [1.6.0] - 2020-02-24
### Changed
- Drop library dependency on `golang.org/x/{lint, tools}`.
[1.6.0]: https://github.com/uber-go/atomic/compare/v1.5.1...v1.6.0
## [1.5.1] - 2019-11-19
- Fix bug where `Bool.CAS` and `Bool.Toggle` do work correctly together
causing `CAS` to fail even though the old value matches.
[1.5.1]: https://github.com/uber-go/atomic/compare/v1.5.0...v1.5.1
## [1.5.0] - 2019-10-29
### Changed
- With Go modules, only the `go.uber.org/atomic` import path is supported now.
If you need to use the old import path, please add a `replace` directive to
your `go.mod`.
[1.5.0]: https://github.com/uber-go/atomic/compare/v1.4.0...v1.5.0
## [1.4.0] - 2019-05-01
### Added
- Add `atomic.Error` type for atomic operations on `error` values.
[1.4.0]: https://github.com/uber-go/atomic/compare/v1.3.2...v1.4.0
## [1.3.2] - 2018-05-02
### Added
- Add `atomic.Duration` type for atomic operations on `time.Duration` values.
[1.3.2]: https://github.com/uber-go/atomic/compare/v1.3.1...v1.3.2
## [1.3.1] - 2017-11-14
### Fixed
- Revert optimization for `atomic.String.Store("")` which caused data races.
[1.3.1]: https://github.com/uber-go/atomic/compare/v1.3.0...v1.3.1
## [1.3.0] - 2017-11-13
### Added
- Add `atomic.Bool.CAS` for compare-and-swap semantics on bools.
### Changed
- Optimize `atomic.String.Store("")` by avoiding an allocation.
[1.3.0]: https://github.com/uber-go/atomic/compare/v1.2.0...v1.3.0
## [1.2.0] - 2017-04-12
### Added
- Shadow `atomic.Value` from `sync/atomic`.
[1.2.0]: https://github.com/uber-go/atomic/compare/v1.1.0...v1.2.0
## [1.1.0] - 2017-03-10
### Added
- Add atomic `Float64` type.
### Changed
- Support new `go.uber.org/atomic` import path.
[1.1.0]: https://github.com/uber-go/atomic/compare/v1.0.0...v1.1.0
## [1.0.0] - 2016-07-18
- Initial release.
[1.0.0]: https://github.com/uber-go/atomic/releases/tag/v1.0.0 | {
"source": "yandex/perforator",
"title": "vendor/go.uber.org/atomic/CHANGELOG.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/go.uber.org/atomic/CHANGELOG.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 3959
} |
# atomic [![GoDoc][doc-img]][doc] [![Build Status][ci-img]][ci] [![Coverage Status][cov-img]][cov] [![Go Report Card][reportcard-img]][reportcard]
Simple wrappers for primitive types to enforce atomic access.
## Installation
```shell
$ go get -u go.uber.org/atomic@v1
```
### Legacy Import Path
As of v1.5.0, the import path `go.uber.org/atomic` is the only supported way
of using this package. If you are using Go modules, this package will fail to
compile with the legacy import path path `github.com/uber-go/atomic`.
We recommend migrating your code to the new import path but if you're unable
to do so, or if your dependencies are still using the old import path, you
will have to add a `replace` directive to your `go.mod` file downgrading the
legacy import path to an older version.
```
replace github.com/uber-go/atomic => github.com/uber-go/atomic v1.4.0
```
You can do so automatically by running the following command.
```shell
$ go mod edit -replace github.com/uber-go/atomic=github.com/uber-go/[email protected]
```
## Usage
The standard library's `sync/atomic` is powerful, but it's easy to forget which
variables must be accessed atomically. `go.uber.org/atomic` preserves all the
functionality of the standard library, but wraps the primitive types to
provide a safer, more convenient API.
```go
var atom atomic.Uint32
atom.Store(42)
atom.Sub(2)
atom.CAS(40, 11)
```
See the [documentation][doc] for a complete API specification.
## Development Status
Stable.
---
Released under the [MIT License](LICENSE.txt).
[doc-img]: https://godoc.org/github.com/uber-go/atomic?status.svg
[doc]: https://godoc.org/go.uber.org/atomic
[ci-img]: https://github.com/uber-go/atomic/actions/workflows/go.yml/badge.svg
[ci]: https://github.com/uber-go/atomic/actions/workflows/go.yml
[cov-img]: https://codecov.io/gh/uber-go/atomic/branch/master/graph/badge.svg
[cov]: https://codecov.io/gh/uber-go/atomic
[reportcard-img]: https://goreportcard.com/badge/go.uber.org/atomic
[reportcard]: https://goreportcard.com/report/go.uber.org/atomic | {
"source": "yandex/perforator",
"title": "vendor/go.uber.org/atomic/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/go.uber.org/atomic/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2048
} |
# Changelog
All notable changes to this project will be documented in this file.
The format is based on [Keep a Changelog](http://keepachangelog.com/en/1.0.0/)
and this project adheres to [Semantic Versioning](http://semver.org/spec/v2.0.0.html).
## [1.3.0]
### Fixed
- Built-in ignores now match function names more accurately.
They will no longer ignore stacks because of file names
that look similar to function names. (#112)
### Added
- Add an `IgnoreAnyFunction` option to ignore stack traces
that have the provided function anywhere in the stack. (#113)
- Ignore `testing.runFuzzing` and `testing.runFuzzTests` alongside
other already-ignored test functions (`testing.RunTests`, etc). (#105)
### Changed
- Miscellaneous CI-related fixes. (#103, #108, #114)
[1.3.0]: https://github.com/uber-go/goleak/compare/v1.2.1...v1.3.0
## [1.2.1]
### Changed
- Drop golang/x/lint dependency.
[1.2.1]: https://github.com/uber-go/goleak/compare/v1.2.0...v1.2.1
## [1.2.0]
### Added
- Add Cleanup option that can be used for registering cleanup callbacks. (#78)
### Changed
- Mark VerifyNone as a test helper. (#75)
Thanks to @tallclair for their contribution to this release.
[1.2.0]: https://github.com/uber-go/goleak/compare/v1.1.12...v1.2.0
## [1.1.12]
### Fixed
- Fixed logic for ignoring trace related goroutines on Go versions 1.16 and above.
[1.1.12]: https://github.com/uber-go/goleak/compare/v1.1.11...v1.1.12
## [1.1.11]
### Fixed
- Documentation fix on how to test.
- Update dependency on stretchr/testify to v1.7.0. (#59)
- Update dependency on golang.org/x/tools to address CVE-2020-14040. (#62)
[1.1.11]: https://github.com/uber-go/goleak/compare/v1.1.10...v1.1.11
## [1.1.10]
### Added
- [#49]: Add option to ignore current goroutines, which checks for any additional leaks and allows for incremental adoption of goleak in larger projects.
Thanks to @denis-tingajkin for their contributions to this release.
[#49]: https://github.com/uber-go/goleak/pull/49
[1.1.10]: https://github.com/uber-go/goleak/compare/v1.0.0...v1.1.10
## [1.0.0]
### Changed
- Migrate to Go modules.
### Fixed
- Ignore trace related goroutines that cause false positives with -trace.
[1.0.0]: https://github.com/uber-go/goleak/compare/v0.10.0...v1.0.0
## [0.10.0]
- Initial release.
[0.10.0]: https://github.com/uber-go/goleak/compare/v0.10.0...HEAD | {
"source": "yandex/perforator",
"title": "vendor/go.uber.org/goleak/CHANGELOG.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/go.uber.org/goleak/CHANGELOG.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2359
} |
# goleak [![GoDoc][doc-img]][doc] [![Build Status][ci-img]][ci] [![Coverage Status][cov-img]][cov]
Goroutine leak detector to help avoid Goroutine leaks.
## Installation
You can use `go get` to get the latest version:
`go get -u go.uber.org/goleak`
`goleak` also supports semver releases.
Note that go-leak only [supports][release] the two most recent minor versions of Go.
## Quick Start
To verify that there are no unexpected goroutines running at the end of a test:
```go
func TestA(t *testing.T) {
defer goleak.VerifyNone(t)
// test logic here.
}
```
Instead of checking for leaks at the end of every test, `goleak` can also be run
at the end of every test package by creating a `TestMain` function for your
package:
```go
func TestMain(m *testing.M) {
goleak.VerifyTestMain(m)
}
```
## Determine Source of Package Leaks
When verifying leaks using `TestMain`, the leak test is only run once after all tests
have been run. This is typically enough to ensure there's no goroutines leaked from
tests, but when there are leaks, it's hard to determine which test is causing them.
You can use the following bash script to determine the source of the failing test:
```sh
# Create a test binary which will be used to run each test individually
$ go test -c -o tests
# Run each test individually, printing "." for successful tests, or the test name
# for failing tests.
$ for test in $(go test -list . | grep -E "^(Test|Example)"); do ./tests -test.run "^$test\$" &>/dev/null && echo -n "." || echo -e "\n$test failed"; done
```
This will only print names of failing tests which can be investigated individually. E.g.,
```
.....
TestLeakyTest failed
.......
```
## Stability
goleak is v1 and follows [SemVer](http://semver.org/) strictly.
No breaking changes will be made to exported APIs before 2.0.
[doc-img]: https://godoc.org/go.uber.org/goleak?status.svg
[doc]: https://godoc.org/go.uber.org/goleak
[ci-img]: https://github.com/uber-go/goleak/actions/workflows/ci.yml/badge.svg
[ci]: https://github.com/uber-go/goleak/actions/workflows/ci.yml
[cov-img]: https://codecov.io/gh/uber-go/goleak/branch/master/graph/badge.svg
[cov]: https://codecov.io/gh/uber-go/goleak
[release]: https://go.dev/doc/devel/release#policy | {
"source": "yandex/perforator",
"title": "vendor/go.uber.org/goleak/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/go.uber.org/goleak/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2241
} |
Releases
========
v1.11.0 (2023-03-28)
====================
- `Errors` now supports any error that implements multiple-error
interface.
- Add `Every` function to allow checking if all errors in the chain
satisfies `errors.Is` against the target error.
v1.10.0 (2023-03-08)
====================
- Comply with Go 1.20's multiple-error interface.
- Drop Go 1.18 support.
Per the support policy, only Go 1.19 and 1.20 are supported now.
- Drop all non-test external dependencies.
v1.9.0 (2022-12-12)
===================
- Add `AppendFunc` that allow passsing functions to similar to
`AppendInvoke`.
- Bump up yaml.v3 dependency to 3.0.1.
v1.8.0 (2022-02-28)
===================
- `Combine`: perform zero allocations when there are no errors.
v1.7.0 (2021-05-06)
===================
- Add `AppendInvoke` to append into errors from `defer` blocks.
v1.6.0 (2020-09-14)
===================
- Actually drop library dependency on development-time tooling.
v1.5.0 (2020-02-24)
===================
- Drop library dependency on development-time tooling.
v1.4.0 (2019-11-04)
===================
- Add `AppendInto` function to more ergonomically build errors inside a
loop.
v1.3.0 (2019-10-29)
===================
- Switch to Go modules.
v1.2.0 (2019-09-26)
===================
- Support extracting and matching against wrapped errors with `errors.As`
and `errors.Is`.
v1.1.0 (2017-06-30)
===================
- Added an `Errors(error) []error` function to extract the underlying list of
errors for a multierr error.
v1.0.0 (2017-05-31)
===================
No changes since v0.2.0. This release is committing to making no breaking
changes to the current API in the 1.X series.
v0.2.0 (2017-04-11)
===================
- Repeatedly appending to the same error is now faster due to fewer
allocations.
v0.1.0 (2017-31-03)
===================
- Initial release | {
"source": "yandex/perforator",
"title": "vendor/go.uber.org/multierr/CHANGELOG.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/go.uber.org/multierr/CHANGELOG.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1943
} |
# multierr [![GoDoc][doc-img]][doc] [![Build Status][ci-img]][ci] [![Coverage Status][cov-img]][cov]
`multierr` allows combining one or more Go `error`s together.
## Features
- **Idiomatic**:
multierr follows best practices in Go, and keeps your code idiomatic.
- It keeps the underlying error type hidden,
allowing you to deal in `error` values exclusively.
- It provides APIs to safely append into an error from a `defer` statement.
- **Performant**:
multierr is optimized for performance:
- It avoids allocations where possible.
- It utilizes slice resizing semantics to optimize common cases
like appending into the same error object from a loop.
- **Interoperable**:
multierr interoperates with the Go standard library's error APIs seamlessly:
- The `errors.Is` and `errors.As` functions *just work*.
- **Lightweight**:
multierr comes with virtually no dependencies.
## Installation
```bash
go get -u go.uber.org/multierr@latest
```
## Status
Stable: No breaking changes will be made before 2.0.
-------------------------------------------------------------------------------
Released under the [MIT License].
[MIT License]: LICENSE.txt
[doc-img]: https://pkg.go.dev/badge/go.uber.org/multierr
[doc]: https://pkg.go.dev/go.uber.org/multierr
[ci-img]: https://github.com/uber-go/multierr/actions/workflows/go.yml/badge.svg
[cov-img]: https://codecov.io/gh/uber-go/multierr/branch/master/graph/badge.svg
[ci]: https://github.com/uber-go/multierr/actions/workflows/go.yml
[cov]: https://codecov.io/gh/uber-go/multierr | {
"source": "yandex/perforator",
"title": "vendor/go.uber.org/multierr/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/go.uber.org/multierr/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1569
} |
# Changelog
All notable changes to this project will be documented in this file.
This project adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0.html).
## 1.27.0 (20 Feb 2024)
Enhancements:
* [#1378][]: Add `WithLazy` method for `SugaredLogger`.
* [#1399][]: zaptest: Add `NewTestingWriter` for customizing TestingWriter with more flexibility than `NewLogger`.
* [#1406][]: Add `Log`, `Logw`, `Logln` methods for `SugaredLogger`.
* [#1416][]: Add `WithPanicHook` option for testing panic logs.
Thanks to @defval, @dimmo, @arxeiss, and @MKrupauskas for their contributions to this release.
[#1378]: https://github.com/uber-go/zap/pull/1378
[#1399]: https://github.com/uber-go/zap/pull/1399
[#1406]: https://github.com/uber-go/zap/pull/1406
[#1416]: https://github.com/uber-go/zap/pull/1416
## 1.26.0 (14 Sep 2023)
Enhancements:
* [#1297][]: Add Dict as a Field.
* [#1319][]: Add `WithLazy` method to `Logger` which lazily evaluates the structured
context.
* [#1350][]: String encoding is much (~50%) faster now.
Thanks to @hhk7734, @jquirke, and @cdvr1993 for their contributions to this release.
[#1297]: https://github.com/uber-go/zap/pull/1297
[#1319]: https://github.com/uber-go/zap/pull/1319
[#1350]: https://github.com/uber-go/zap/pull/1350
## 1.25.0 (1 Aug 2023)
This release contains several improvements including performance, API additions,
and two new experimental packages whose APIs are unstable and may change in the
future.
Enhancements:
* [#1246][]: Add `zap/exp/zapslog` package for integration with slog.
* [#1273][]: Add `Name` to `Logger` which returns the Logger's name if one is set.
* [#1281][]: Add `zap/exp/expfield` package which contains helper methods
`Str` and `Strs` for constructing String-like zap.Fields.
* [#1310][]: Reduce stack size on `Any`.
Thanks to @knight42, @dzakaammar, @bcspragu, and @rexywork for their contributions
to this release.
[#1246]: https://github.com/uber-go/zap/pull/1246
[#1273]: https://github.com/uber-go/zap/pull/1273
[#1281]: https://github.com/uber-go/zap/pull/1281
[#1310]: https://github.com/uber-go/zap/pull/1310
## 1.24.0 (30 Nov 2022)
Enhancements:
* [#1148][]: Add `Level` to both `Logger` and `SugaredLogger` that reports the
current minimum enabled log level.
* [#1185][]: `SugaredLogger` turns errors to zap.Error automatically.
Thanks to @Abirdcfly, @craigpastro, @nnnkkk7, and @sashamelentyev for their
contributions to this release.
[#1148]: https://github.coml/uber-go/zap/pull/1148
[#1185]: https://github.coml/uber-go/zap/pull/1185
## 1.23.0 (24 Aug 2022)
Enhancements:
* [#1147][]: Add a `zapcore.LevelOf` function to determine the level of a
`LevelEnabler` or `Core`.
* [#1155][]: Add `zap.Stringers` field constructor to log arrays of objects
that implement `String() string`.
[#1147]: https://github.com/uber-go/zap/pull/1147
[#1155]: https://github.com/uber-go/zap/pull/1155
## 1.22.0 (8 Aug 2022)
Enhancements:
* [#1071][]: Add `zap.Objects` and `zap.ObjectValues` field constructors to log
arrays of objects. With these two constructors, you don't need to implement
`zapcore.ArrayMarshaler` for use with `zap.Array` if those objects implement
`zapcore.ObjectMarshaler`.
* [#1079][]: Add `SugaredLogger.WithOptions` to build a copy of an existing
`SugaredLogger` with the provided options applied.
* [#1080][]: Add `*ln` variants to `SugaredLogger` for each log level.
These functions provide a string joining behavior similar to `fmt.Println`.
* [#1088][]: Add `zap.WithFatalHook` option to control the behavior of the
logger for `Fatal`-level log entries. This defaults to exiting the program.
* [#1108][]: Add a `zap.Must` function that you can use with `NewProduction` or
`NewDevelopment` to panic if the system was unable to build the logger.
* [#1118][]: Add a `Logger.Log` method that allows specifying the log level for
a statement dynamically.
Thanks to @cardil, @craigpastro, @sashamelentyev, @shota3506, and @zhupeijun
for their contributions to this release.
[#1071]: https://github.com/uber-go/zap/pull/1071
[#1079]: https://github.com/uber-go/zap/pull/1079
[#1080]: https://github.com/uber-go/zap/pull/1080
[#1088]: https://github.com/uber-go/zap/pull/1088
[#1108]: https://github.com/uber-go/zap/pull/1108
[#1118]: https://github.com/uber-go/zap/pull/1118
## 1.21.0 (7 Feb 2022)
Enhancements:
* [#1047][]: Add `zapcore.ParseLevel` to parse a `Level` from a string.
* [#1048][]: Add `zap.ParseAtomicLevel` to parse an `AtomicLevel` from a
string.
Bugfixes:
* [#1058][]: Fix panic in JSON encoder when `EncodeLevel` is unset.
Other changes:
* [#1052][]: Improve encoding performance when the `AddCaller` and
`AddStacktrace` options are used together.
[#1047]: https://github.com/uber-go/zap/pull/1047
[#1048]: https://github.com/uber-go/zap/pull/1048
[#1052]: https://github.com/uber-go/zap/pull/1052
[#1058]: https://github.com/uber-go/zap/pull/1058
Thanks to @aerosol and @Techassi for their contributions to this release.
## 1.20.0 (4 Jan 2022)
Enhancements:
* [#989][]: Add `EncoderConfig.SkipLineEnding` flag to disable adding newline
characters between log statements.
* [#1039][]: Add `EncoderConfig.NewReflectedEncoder` field to customize JSON
encoding of reflected log fields.
Bugfixes:
* [#1011][]: Fix inaccurate precision when encoding complex64 as JSON.
* [#554][], [#1017][]: Close JSON namespaces opened in `MarshalLogObject`
methods when the methods return.
* [#1033][]: Avoid panicking in Sampler core if `thereafter` is zero.
Other changes:
* [#1028][]: Drop support for Go < 1.15.
[#554]: https://github.com/uber-go/zap/pull/554
[#989]: https://github.com/uber-go/zap/pull/989
[#1011]: https://github.com/uber-go/zap/pull/1011
[#1017]: https://github.com/uber-go/zap/pull/1017
[#1028]: https://github.com/uber-go/zap/pull/1028
[#1033]: https://github.com/uber-go/zap/pull/1033
[#1039]: https://github.com/uber-go/zap/pull/1039
Thanks to @psrajat, @lruggieri, @sammyrnycreal for their contributions to this release.
## 1.19.1 (8 Sep 2021)
Bugfixes:
* [#1001][]: JSON: Fix complex number encoding with negative imaginary part. Thanks to @hemantjadon.
* [#1003][]: JSON: Fix inaccurate precision when encoding float32.
[#1001]: https://github.com/uber-go/zap/pull/1001
[#1003]: https://github.com/uber-go/zap/pull/1003
## 1.19.0 (9 Aug 2021)
Enhancements:
* [#975][]: Avoid panicking in Sampler core if the level is out of bounds.
* [#984][]: Reduce the size of BufferedWriteSyncer by aligning the fields
better.
[#975]: https://github.com/uber-go/zap/pull/975
[#984]: https://github.com/uber-go/zap/pull/984
Thanks to @lancoLiu and @thockin for their contributions to this release.
## 1.18.1 (28 Jun 2021)
Bugfixes:
* [#974][]: Fix nil dereference in logger constructed by `zap.NewNop`.
[#974]: https://github.com/uber-go/zap/pull/974
## 1.18.0 (28 Jun 2021)
Enhancements:
* [#961][]: Add `zapcore.BufferedWriteSyncer`, a new `WriteSyncer` that buffers
messages in-memory and flushes them periodically.
* [#971][]: Add `zapio.Writer` to use a Zap logger as an `io.Writer`.
* [#897][]: Add `zap.WithClock` option to control the source of time via the
new `zapcore.Clock` interface.
* [#949][]: Avoid panicking in `zap.SugaredLogger` when arguments of `*w`
methods don't match expectations.
* [#943][]: Add support for filtering by level or arbitrary matcher function to
`zaptest/observer`.
* [#691][]: Comply with `io.StringWriter` and `io.ByteWriter` in Zap's
`buffer.Buffer`.
Thanks to @atrn0, @ernado, @heyanfu, @hnlq715, @zchee
for their contributions to this release.
[#691]: https://github.com/uber-go/zap/pull/691
[#897]: https://github.com/uber-go/zap/pull/897
[#943]: https://github.com/uber-go/zap/pull/943
[#949]: https://github.com/uber-go/zap/pull/949
[#961]: https://github.com/uber-go/zap/pull/961
[#971]: https://github.com/uber-go/zap/pull/971
## 1.17.0 (25 May 2021)
Bugfixes:
* [#867][]: Encode `<nil>` for nil `error` instead of a panic.
* [#931][], [#936][]: Update minimum version constraints to address
vulnerabilities in dependencies.
Enhancements:
* [#865][]: Improve alignment of fields of the Logger struct, reducing its
size from 96 to 80 bytes.
* [#881][]: Support `grpclog.LoggerV2` in zapgrpc.
* [#903][]: Support URL-encoded POST requests to the AtomicLevel HTTP handler
with the `application/x-www-form-urlencoded` content type.
* [#912][]: Support multi-field encoding with `zap.Inline`.
* [#913][]: Speed up SugaredLogger for calls with a single string.
* [#928][]: Add support for filtering by field name to `zaptest/observer`.
Thanks to @ash2k, @FMLS, @jimmystewpot, @Oncilla, @tsoslow, @tylitianrui, @withshubh, and @wziww for their contributions to this release.
[#865]: https://github.com/uber-go/zap/pull/865
[#867]: https://github.com/uber-go/zap/pull/867
[#881]: https://github.com/uber-go/zap/pull/881
[#903]: https://github.com/uber-go/zap/pull/903
[#912]: https://github.com/uber-go/zap/pull/912
[#913]: https://github.com/uber-go/zap/pull/913
[#928]: https://github.com/uber-go/zap/pull/928
[#931]: https://github.com/uber-go/zap/pull/931
[#936]: https://github.com/uber-go/zap/pull/936
## 1.16.0 (1 Sep 2020)
Bugfixes:
* [#828][]: Fix missing newline in IncreaseLevel error messages.
* [#835][]: Fix panic in JSON encoder when encoding times or durations
without specifying a time or duration encoder.
* [#843][]: Honor CallerSkip when taking stack traces.
* [#862][]: Fix the default file permissions to use `0666` and rely on the umask instead.
* [#854][]: Encode `<nil>` for nil `Stringer` instead of a panic error log.
Enhancements:
* [#629][]: Added `zapcore.TimeEncoderOfLayout` to easily create time encoders
for custom layouts.
* [#697][]: Added support for a configurable delimiter in the console encoder.
* [#852][]: Optimize console encoder by pooling the underlying JSON encoder.
* [#844][]: Add ability to include the calling function as part of logs.
* [#843][]: Add `StackSkip` for including truncated stacks as a field.
* [#861][]: Add options to customize Fatal behaviour for better testability.
Thanks to @SteelPhase, @tmshn, @lixingwang, @wyxloading, @moul, @segevfiner, @andy-retailnext and @jcorbin for their contributions to this release.
[#629]: https://github.com/uber-go/zap/pull/629
[#697]: https://github.com/uber-go/zap/pull/697
[#828]: https://github.com/uber-go/zap/pull/828
[#835]: https://github.com/uber-go/zap/pull/835
[#843]: https://github.com/uber-go/zap/pull/843
[#844]: https://github.com/uber-go/zap/pull/844
[#852]: https://github.com/uber-go/zap/pull/852
[#854]: https://github.com/uber-go/zap/pull/854
[#861]: https://github.com/uber-go/zap/pull/861
[#862]: https://github.com/uber-go/zap/pull/862
## 1.15.0 (23 Apr 2020)
Bugfixes:
* [#804][]: Fix handling of `Time` values out of `UnixNano` range.
* [#812][]: Fix `IncreaseLevel` being reset after a call to `With`.
Enhancements:
* [#806][]: Add `WithCaller` option to supersede the `AddCaller` option. This
allows disabling annotation of log entries with caller information if
previously enabled with `AddCaller`.
* [#813][]: Deprecate `NewSampler` constructor in favor of
`NewSamplerWithOptions` which supports a `SamplerHook` option. This option
adds support for monitoring sampling decisions through a hook.
Thanks to @danielbprice for their contributions to this release.
[#804]: https://github.com/uber-go/zap/pull/804
[#812]: https://github.com/uber-go/zap/pull/812
[#806]: https://github.com/uber-go/zap/pull/806
[#813]: https://github.com/uber-go/zap/pull/813
## 1.14.1 (14 Mar 2020)
Bugfixes:
* [#791][]: Fix panic on attempting to build a logger with an invalid Config.
* [#795][]: Vendoring Zap with `go mod vendor` no longer includes Zap's
development-time dependencies.
* [#799][]: Fix issue introduced in 1.14.0 that caused invalid JSON output to
be generated for arrays of `time.Time` objects when using string-based time
formats.
Thanks to @YashishDua for their contributions to this release.
[#791]: https://github.com/uber-go/zap/pull/791
[#795]: https://github.com/uber-go/zap/pull/795
[#799]: https://github.com/uber-go/zap/pull/799
## 1.14.0 (20 Feb 2020)
Enhancements:
* [#771][]: Optimize calls for disabled log levels.
* [#773][]: Add millisecond duration encoder.
* [#775][]: Add option to increase the level of a logger.
* [#786][]: Optimize time formatters using `Time.AppendFormat` where possible.
Thanks to @caibirdme for their contributions to this release.
[#771]: https://github.com/uber-go/zap/pull/771
[#773]: https://github.com/uber-go/zap/pull/773
[#775]: https://github.com/uber-go/zap/pull/775
[#786]: https://github.com/uber-go/zap/pull/786
## 1.13.0 (13 Nov 2019)
Enhancements:
* [#758][]: Add `Intp`, `Stringp`, and other similar `*p` field constructors
to log pointers to primitives with support for `nil` values.
Thanks to @jbizzle for their contributions to this release.
[#758]: https://github.com/uber-go/zap/pull/758
## 1.12.0 (29 Oct 2019)
Enhancements:
* [#751][]: Migrate to Go modules.
[#751]: https://github.com/uber-go/zap/pull/751
## 1.11.0 (21 Oct 2019)
Enhancements:
* [#725][]: Add `zapcore.OmitKey` to omit keys in an `EncoderConfig`.
* [#736][]: Add `RFC3339` and `RFC3339Nano` time encoders.
Thanks to @juicemia, @uhthomas for their contributions to this release.
[#725]: https://github.com/uber-go/zap/pull/725
[#736]: https://github.com/uber-go/zap/pull/736
## 1.10.0 (29 Apr 2019)
Bugfixes:
* [#657][]: Fix `MapObjectEncoder.AppendByteString` not adding value as a
string.
* [#706][]: Fix incorrect call depth to determine caller in Go 1.12.
Enhancements:
* [#610][]: Add `zaptest.WrapOptions` to wrap `zap.Option` for creating test
loggers.
* [#675][]: Don't panic when encoding a String field.
* [#704][]: Disable HTML escaping for JSON objects encoded using the
reflect-based encoder.
Thanks to @iaroslav-ciupin, @lelenanam, @joa, @NWilson for their contributions
to this release.
[#657]: https://github.com/uber-go/zap/pull/657
[#706]: https://github.com/uber-go/zap/pull/706
[#610]: https://github.com/uber-go/zap/pull/610
[#675]: https://github.com/uber-go/zap/pull/675
[#704]: https://github.com/uber-go/zap/pull/704
## 1.9.1 (06 Aug 2018)
Bugfixes:
* [#614][]: MapObjectEncoder should not ignore empty slices.
[#614]: https://github.com/uber-go/zap/pull/614
## 1.9.0 (19 Jul 2018)
Enhancements:
* [#602][]: Reduce number of allocations when logging with reflection.
* [#572][], [#606][]: Expose a registry for third-party logging sinks.
Thanks to @nfarah86, @AlekSi, @JeanMertz, @philippgille, @etsangsplk, and
@dimroc for their contributions to this release.
[#602]: https://github.com/uber-go/zap/pull/602
[#572]: https://github.com/uber-go/zap/pull/572
[#606]: https://github.com/uber-go/zap/pull/606
## 1.8.0 (13 Apr 2018)
Enhancements:
* [#508][]: Make log level configurable when redirecting the standard
library's logger.
* [#518][]: Add a logger that writes to a `*testing.TB`.
* [#577][]: Add a top-level alias for `zapcore.Field` to clean up GoDoc.
Bugfixes:
* [#574][]: Add a missing import comment to `go.uber.org/zap/buffer`.
Thanks to @DiSiqueira and @djui for their contributions to this release.
[#508]: https://github.com/uber-go/zap/pull/508
[#518]: https://github.com/uber-go/zap/pull/518
[#577]: https://github.com/uber-go/zap/pull/577
[#574]: https://github.com/uber-go/zap/pull/574
## 1.7.1 (25 Sep 2017)
Bugfixes:
* [#504][]: Store strings when using AddByteString with the map encoder.
[#504]: https://github.com/uber-go/zap/pull/504
## 1.7.0 (21 Sep 2017)
Enhancements:
* [#487][]: Add `NewStdLogAt`, which extends `NewStdLog` by allowing the user
to specify the level of the logged messages.
[#487]: https://github.com/uber-go/zap/pull/487
## 1.6.0 (30 Aug 2017)
Enhancements:
* [#491][]: Omit zap stack frames from stacktraces.
* [#490][]: Add a `ContextMap` method to observer logs for simpler
field validation in tests.
[#490]: https://github.com/uber-go/zap/pull/490
[#491]: https://github.com/uber-go/zap/pull/491
## 1.5.0 (22 Jul 2017)
Enhancements:
* [#460][] and [#470][]: Support errors produced by `go.uber.org/multierr`.
* [#465][]: Support user-supplied encoders for logger names.
Bugfixes:
* [#477][]: Fix a bug that incorrectly truncated deep stacktraces.
Thanks to @richard-tunein and @pavius for their contributions to this release.
[#477]: https://github.com/uber-go/zap/pull/477
[#465]: https://github.com/uber-go/zap/pull/465
[#460]: https://github.com/uber-go/zap/pull/460
[#470]: https://github.com/uber-go/zap/pull/470
## 1.4.1 (08 Jun 2017)
This release fixes two bugs.
Bugfixes:
* [#435][]: Support a variety of case conventions when unmarshaling levels.
* [#444][]: Fix a panic in the observer.
[#435]: https://github.com/uber-go/zap/pull/435
[#444]: https://github.com/uber-go/zap/pull/444
## 1.4.0 (12 May 2017)
This release adds a few small features and is fully backward-compatible.
Enhancements:
* [#424][]: Add a `LineEnding` field to `EncoderConfig`, allowing users to
override the Unix-style default.
* [#425][]: Preserve time zones when logging times.
* [#431][]: Make `zap.AtomicLevel` implement `fmt.Stringer`, which makes a
variety of operations a bit simpler.
[#424]: https://github.com/uber-go/zap/pull/424
[#425]: https://github.com/uber-go/zap/pull/425
[#431]: https://github.com/uber-go/zap/pull/431
## 1.3.0 (25 Apr 2017)
This release adds an enhancement to zap's testing helpers as well as the
ability to marshal an AtomicLevel. It is fully backward-compatible.
Enhancements:
* [#415][]: Add a substring-filtering helper to zap's observer. This is
particularly useful when testing the `SugaredLogger`.
* [#416][]: Make `AtomicLevel` implement `encoding.TextMarshaler`.
[#415]: https://github.com/uber-go/zap/pull/415
[#416]: https://github.com/uber-go/zap/pull/416
## 1.2.0 (13 Apr 2017)
This release adds a gRPC compatibility wrapper. It is fully backward-compatible.
Enhancements:
* [#402][]: Add a `zapgrpc` package that wraps zap's Logger and implements
`grpclog.Logger`.
[#402]: https://github.com/uber-go/zap/pull/402
## 1.1.0 (31 Mar 2017)
This release fixes two bugs and adds some enhancements to zap's testing helpers.
It is fully backward-compatible.
Bugfixes:
* [#385][]: Fix caller path trimming on Windows.
* [#396][]: Fix a panic when attempting to use non-existent directories with
zap's configuration struct.
Enhancements:
* [#386][]: Add filtering helpers to zaptest's observing logger.
Thanks to @moitias for contributing to this release.
[#385]: https://github.com/uber-go/zap/pull/385
[#396]: https://github.com/uber-go/zap/pull/396
[#386]: https://github.com/uber-go/zap/pull/386
## 1.0.0 (14 Mar 2017)
This is zap's first stable release. All exported APIs are now final, and no
further breaking changes will be made in the 1.x release series. Anyone using a
semver-aware dependency manager should now pin to `^1`.
Breaking changes:
* [#366][]: Add byte-oriented APIs to encoders to log UTF-8 encoded text without
casting from `[]byte` to `string`.
* [#364][]: To support buffering outputs, add `Sync` methods to `zapcore.Core`,
`zap.Logger`, and `zap.SugaredLogger`.
* [#371][]: Rename the `testutils` package to `zaptest`, which is less likely to
clash with other testing helpers.
Bugfixes:
* [#362][]: Make the ISO8601 time formatters fixed-width, which is friendlier
for tab-separated console output.
* [#369][]: Remove the automatic locks in `zapcore.NewCore`, which allows zap to
work with concurrency-safe `WriteSyncer` implementations.
* [#347][]: Stop reporting errors when trying to `fsync` standard out on Linux
systems.
* [#373][]: Report the correct caller from zap's standard library
interoperability wrappers.
Enhancements:
* [#348][]: Add a registry allowing third-party encodings to work with zap's
built-in `Config`.
* [#327][]: Make the representation of logger callers configurable (like times,
levels, and durations).
* [#376][]: Allow third-party encoders to use their own buffer pools, which
removes the last performance advantage that zap's encoders have over plugins.
* [#346][]: Add `CombineWriteSyncers`, a convenience function to tee multiple
`WriteSyncer`s and lock the result.
* [#365][]: Make zap's stacktraces compatible with mid-stack inlining (coming in
Go 1.9).
* [#372][]: Export zap's observing logger as `zaptest/observer`. This makes it
easier for particularly punctilious users to unit test their application's
logging.
Thanks to @suyash, @htrendev, @flisky, @Ulexus, and @skipor for their
contributions to this release.
[#366]: https://github.com/uber-go/zap/pull/366
[#364]: https://github.com/uber-go/zap/pull/364
[#371]: https://github.com/uber-go/zap/pull/371
[#362]: https://github.com/uber-go/zap/pull/362
[#369]: https://github.com/uber-go/zap/pull/369
[#347]: https://github.com/uber-go/zap/pull/347
[#373]: https://github.com/uber-go/zap/pull/373
[#348]: https://github.com/uber-go/zap/pull/348
[#327]: https://github.com/uber-go/zap/pull/327
[#376]: https://github.com/uber-go/zap/pull/376
[#346]: https://github.com/uber-go/zap/pull/346
[#365]: https://github.com/uber-go/zap/pull/365
[#372]: https://github.com/uber-go/zap/pull/372
## 1.0.0-rc.3 (7 Mar 2017)
This is the third release candidate for zap's stable release. There are no
breaking changes.
Bugfixes:
* [#339][]: Byte slices passed to `zap.Any` are now correctly treated as binary blobs
rather than `[]uint8`.
Enhancements:
* [#307][]: Users can opt into colored output for log levels.
* [#353][]: In addition to hijacking the output of the standard library's
package-global logging functions, users can now construct a zap-backed
`log.Logger` instance.
* [#311][]: Frames from common runtime functions and some of zap's internal
machinery are now omitted from stacktraces.
Thanks to @ansel1 and @suyash for their contributions to this release.
[#339]: https://github.com/uber-go/zap/pull/339
[#307]: https://github.com/uber-go/zap/pull/307
[#353]: https://github.com/uber-go/zap/pull/353
[#311]: https://github.com/uber-go/zap/pull/311
## 1.0.0-rc.2 (21 Feb 2017)
This is the second release candidate for zap's stable release. It includes two
breaking changes.
Breaking changes:
* [#316][]: Zap's global loggers are now fully concurrency-safe
(previously, users had to ensure that `ReplaceGlobals` was called before the
loggers were in use). However, they must now be accessed via the `L()` and
`S()` functions. Users can update their projects with
```
gofmt -r "zap.L -> zap.L()" -w .
gofmt -r "zap.S -> zap.S()" -w .
```
* [#309][] and [#317][]: RC1 was mistakenly shipped with invalid
JSON and YAML struct tags on all config structs. This release fixes the tags
and adds static analysis to prevent similar bugs in the future.
Bugfixes:
* [#321][]: Redirecting the standard library's `log` output now
correctly reports the logger's caller.
Enhancements:
* [#325][] and [#333][]: Zap now transparently supports non-standard, rich
errors like those produced by `github.com/pkg/errors`.
* [#326][]: Though `New(nil)` continues to return a no-op logger, `NewNop()` is
now preferred. Users can update their projects with `gofmt -r 'zap.New(nil) ->
zap.NewNop()' -w .`.
* [#300][]: Incorrectly importing zap as `github.com/uber-go/zap` now returns a
more informative error.
Thanks to @skipor and @chapsuk for their contributions to this release.
[#316]: https://github.com/uber-go/zap/pull/316
[#309]: https://github.com/uber-go/zap/pull/309
[#317]: https://github.com/uber-go/zap/pull/317
[#321]: https://github.com/uber-go/zap/pull/321
[#325]: https://github.com/uber-go/zap/pull/325
[#333]: https://github.com/uber-go/zap/pull/333
[#326]: https://github.com/uber-go/zap/pull/326
[#300]: https://github.com/uber-go/zap/pull/300
## 1.0.0-rc.1 (14 Feb 2017)
This is the first release candidate for zap's stable release. There are multiple
breaking changes and improvements from the pre-release version. Most notably:
* **Zap's import path is now "go.uber.org/zap"** — all users will
need to update their code.
* User-facing types and functions remain in the `zap` package. Code relevant
largely to extension authors is now in the `zapcore` package.
* The `zapcore.Core` type makes it easy for third-party packages to use zap's
internals but provide a different user-facing API.
* `Logger` is now a concrete type instead of an interface.
* A less verbose (though slower) logging API is included by default.
* Package-global loggers `L` and `S` are included.
* A human-friendly console encoder is included.
* A declarative config struct allows common logger configurations to be managed
as configuration instead of code.
* Sampling is more accurate, and doesn't depend on the standard library's shared
timer heap.
## 0.1.0-beta.1 (6 Feb 2017)
This is a minor version, tagged to allow users to pin to the pre-1.0 APIs and
upgrade at their leisure. Since this is the first tagged release, there are no
backward compatibility concerns and all functionality is new.
Early zap adopters should pin to the 0.1.x minor version until they're ready to
upgrade to the upcoming stable release. | {
"source": "yandex/perforator",
"title": "vendor/go.uber.org/zap/CHANGELOG.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/go.uber.org/zap/CHANGELOG.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 25278
} |
# Contributor Covenant Code of Conduct
## Our Pledge
In the interest of fostering an open and welcoming environment, we as
contributors and maintainers pledge to making participation in our project and
our community a harassment-free experience for everyone, regardless of age,
body size, disability, ethnicity, gender identity and expression, level of
experience, nationality, personal appearance, race, religion, or sexual
identity and orientation.
## Our Standards
Examples of behavior that contributes to creating a positive environment
include:
* Using welcoming and inclusive language
* Being respectful of differing viewpoints and experiences
* Gracefully accepting constructive criticism
* Focusing on what is best for the community
* Showing empathy towards other community members
Examples of unacceptable behavior by participants include:
* The use of sexualized language or imagery and unwelcome sexual attention or
advances
* Trolling, insulting/derogatory comments, and personal or political attacks
* Public or private harassment
* Publishing others' private information, such as a physical or electronic
address, without explicit permission
* Other conduct which could reasonably be considered inappropriate in a
professional setting
## Our Responsibilities
Project maintainers are responsible for clarifying the standards of acceptable
behavior and are expected to take appropriate and fair corrective action in
response to any instances of unacceptable behavior.
Project maintainers have the right and responsibility to remove, edit, or
reject comments, commits, code, wiki edits, issues, and other contributions
that are not aligned to this Code of Conduct, or to ban temporarily or
permanently any contributor for other behaviors that they deem inappropriate,
threatening, offensive, or harmful.
## Scope
This Code of Conduct applies both within project spaces and in public spaces
when an individual is representing the project or its community. Examples of
representing a project or community include using an official project e-mail
address, posting via an official social media account, or acting as an
appointed representative at an online or offline event. Representation of a
project may be further defined and clarified by project maintainers.
## Enforcement
Instances of abusive, harassing, or otherwise unacceptable behavior may be
reported by contacting the project team at [email protected]. The project
team will review and investigate all complaints, and will respond in a way
that it deems appropriate to the circumstances. The project team is obligated
to maintain confidentiality with regard to the reporter of an incident.
Further details of specific enforcement policies may be posted separately.
Project maintainers who do not follow or enforce the Code of Conduct in good
faith may face temporary or permanent repercussions as determined by other
members of the project's leadership.
## Attribution
This Code of Conduct is adapted from the [Contributor Covenant][homepage],
version 1.4, available at
[http://contributor-covenant.org/version/1/4][version].
[homepage]: http://contributor-covenant.org
[version]: http://contributor-covenant.org/version/1/4/ | {
"source": "yandex/perforator",
"title": "vendor/go.uber.org/zap/CODE_OF_CONDUCT.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/go.uber.org/zap/CODE_OF_CONDUCT.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 3223
} |
# Contributing
We'd love your help making zap the very best structured logging library in Go!
If you'd like to add new exported APIs, please [open an issue][open-issue]
describing your proposal — discussing API changes ahead of time makes
pull request review much smoother. In your issue, pull request, and any other
communications, please remember to treat your fellow contributors with
respect! We take our [code of conduct](CODE_OF_CONDUCT.md) seriously.
Note that you'll need to sign [Uber's Contributor License Agreement][cla]
before we can accept any of your contributions. If necessary, a bot will remind
you to accept the CLA when you open your pull request.
## Setup
[Fork][fork], then clone the repository:
```bash
mkdir -p $GOPATH/src/go.uber.org
cd $GOPATH/src/go.uber.org
git clone [email protected]:your_github_username/zap.git
cd zap
git remote add upstream https://github.com/uber-go/zap.git
git fetch upstream
```
Make sure that the tests and the linters pass:
```bash
make test
make lint
```
## Making Changes
Start by creating a new branch for your changes:
```bash
cd $GOPATH/src/go.uber.org/zap
git checkout master
git fetch upstream
git rebase upstream/master
git checkout -b cool_new_feature
```
Make your changes, then ensure that `make lint` and `make test` still pass. If
you're satisfied with your changes, push them to your fork.
```bash
git push origin cool_new_feature
```
Then use the GitHub UI to open a pull request.
At this point, you're waiting on us to review your changes. We _try_ to respond
to issues and pull requests within a few business days, and we may suggest some
improvements or alternatives. Once your changes are approved, one of the
project maintainers will merge them.
We're much more likely to approve your changes if you:
- Add tests for new functionality.
- Write a [good commit message][commit-message].
- Maintain backward compatibility.
[fork]: https://github.com/uber-go/zap/fork
[open-issue]: https://github.com/uber-go/zap/issues/new
[cla]: https://cla-assistant.io/uber-go/zap
[commit-message]: http://tbaggery.com/2008/04/19/a-note-about-git-commit-messages.html | {
"source": "yandex/perforator",
"title": "vendor/go.uber.org/zap/CONTRIBUTING.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/go.uber.org/zap/CONTRIBUTING.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2145
} |
# :zap: zap
<div align="center">
Blazing fast, structured, leveled logging in Go.

[![GoDoc][doc-img]][doc] [![Build Status][ci-img]][ci] [![Coverage Status][cov-img]][cov]
</div>
## Installation
`go get -u go.uber.org/zap`
Note that zap only supports the two most recent minor versions of Go.
## Quick Start
In contexts where performance is nice, but not critical, use the
`SugaredLogger`. It's 4-10x faster than other structured logging
packages and includes both structured and `printf`-style APIs.
```go
logger, _ := zap.NewProduction()
defer logger.Sync() // flushes buffer, if any
sugar := logger.Sugar()
sugar.Infow("failed to fetch URL",
// Structured context as loosely typed key-value pairs.
"url", url,
"attempt", 3,
"backoff", time.Second,
)
sugar.Infof("Failed to fetch URL: %s", url)
```
When performance and type safety are critical, use the `Logger`. It's even
faster than the `SugaredLogger` and allocates far less, but it only supports
structured logging.
```go
logger, _ := zap.NewProduction()
defer logger.Sync()
logger.Info("failed to fetch URL",
// Structured context as strongly typed Field values.
zap.String("url", url),
zap.Int("attempt", 3),
zap.Duration("backoff", time.Second),
)
```
See the [documentation][doc] and [FAQ](FAQ.md) for more details.
## Performance
For applications that log in the hot path, reflection-based serialization and
string formatting are prohibitively expensive — they're CPU-intensive
and make many small allocations. Put differently, using `encoding/json` and
`fmt.Fprintf` to log tons of `interface{}`s makes your application slow.
Zap takes a different approach. It includes a reflection-free, zero-allocation
JSON encoder, and the base `Logger` strives to avoid serialization overhead
and allocations wherever possible. By building the high-level `SugaredLogger`
on that foundation, zap lets users *choose* when they need to count every
allocation and when they'd prefer a more familiar, loosely typed API.
As measured by its own [benchmarking suite][], not only is zap more performant
than comparable structured logging packages — it's also faster than the
standard library. Like all benchmarks, take these with a grain of salt.<sup
id="anchor-versions">[1](#footnote-versions)</sup>
Log a message and 10 fields:
| Package | Time | Time % to zap | Objects Allocated |
| :------ | :--: | :-----------: | :---------------: |
| :zap: zap | 656 ns/op | +0% | 5 allocs/op
| :zap: zap (sugared) | 935 ns/op | +43% | 10 allocs/op
| zerolog | 380 ns/op | -42% | 1 allocs/op
| go-kit | 2249 ns/op | +243% | 57 allocs/op
| slog (LogAttrs) | 2479 ns/op | +278% | 40 allocs/op
| slog | 2481 ns/op | +278% | 42 allocs/op
| apex/log | 9591 ns/op | +1362% | 63 allocs/op
| log15 | 11393 ns/op | +1637% | 75 allocs/op
| logrus | 11654 ns/op | +1677% | 79 allocs/op
Log a message with a logger that already has 10 fields of context:
| Package | Time | Time % to zap | Objects Allocated |
| :------ | :--: | :-----------: | :---------------: |
| :zap: zap | 67 ns/op | +0% | 0 allocs/op
| :zap: zap (sugared) | 84 ns/op | +25% | 1 allocs/op
| zerolog | 35 ns/op | -48% | 0 allocs/op
| slog | 193 ns/op | +188% | 0 allocs/op
| slog (LogAttrs) | 200 ns/op | +199% | 0 allocs/op
| go-kit | 2460 ns/op | +3572% | 56 allocs/op
| log15 | 9038 ns/op | +13390% | 70 allocs/op
| apex/log | 9068 ns/op | +13434% | 53 allocs/op
| logrus | 10521 ns/op | +15603% | 68 allocs/op
Log a static string, without any context or `printf`-style templating:
| Package | Time | Time % to zap | Objects Allocated |
| :------ | :--: | :-----------: | :---------------: |
| :zap: zap | 63 ns/op | +0% | 0 allocs/op
| :zap: zap (sugared) | 81 ns/op | +29% | 1 allocs/op
| zerolog | 32 ns/op | -49% | 0 allocs/op
| standard library | 124 ns/op | +97% | 1 allocs/op
| slog | 196 ns/op | +211% | 0 allocs/op
| slog (LogAttrs) | 200 ns/op | +217% | 0 allocs/op
| go-kit | 213 ns/op | +238% | 9 allocs/op
| apex/log | 771 ns/op | +1124% | 5 allocs/op
| logrus | 1439 ns/op | +2184% | 23 allocs/op
| log15 | 2069 ns/op | +3184% | 20 allocs/op
## Development Status: Stable
All APIs are finalized, and no breaking changes will be made in the 1.x series
of releases. Users of semver-aware dependency management systems should pin
zap to `^1`.
## Contributing
We encourage and support an active, healthy community of contributors —
including you! Details are in the [contribution guide](CONTRIBUTING.md) and
the [code of conduct](CODE_OF_CONDUCT.md). The zap maintainers keep an eye on
issues and pull requests, but you can also report any negative conduct to
[email protected]. That email list is a private, safe space; even the zap
maintainers don't have access, so don't hesitate to hold us to a high
standard.
<hr>
Released under the [MIT License](LICENSE).
<sup id="footnote-versions">1</sup> In particular, keep in mind that we may be
benchmarking against slightly older versions of other packages. Versions are
pinned in the [benchmarks/go.mod][] file. [↩](#anchor-versions)
[doc-img]: https://pkg.go.dev/badge/go.uber.org/zap
[doc]: https://pkg.go.dev/go.uber.org/zap
[ci-img]: https://github.com/uber-go/zap/actions/workflows/go.yml/badge.svg
[ci]: https://github.com/uber-go/zap/actions/workflows/go.yml
[cov-img]: https://codecov.io/gh/uber-go/zap/branch/master/graph/badge.svg
[cov]: https://codecov.io/gh/uber-go/zap
[benchmarking suite]: https://github.com/uber-go/zap/tree/master/benchmarks
[benchmarks/go.mod]: https://github.com/uber-go/zap/blob/master/benchmarks/go.mod | {
"source": "yandex/perforator",
"title": "vendor/go.uber.org/zap/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/go.uber.org/zap/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 5592
} |
# hasql
[](https://pkg.go.dev/golang.yandex/hasql)
[](https://godoc.org/golang.yandex/hasql)


[](https://goreportcard.com/report/golang.yandex/hasql)
[](https://codecov.io/gh/yandex/go-hasql)
`hasql` provides simple and reliable way to access high-availability database setups with multiple hosts.
## Status
`hasql` is production-ready and is actively used inside Yandex' production environment.
## Prerequisites
- **[Go](https://golang.org)**: any one of the **two latest major** [releases](https://golang.org/doc/devel/release.html).
## Installation
With [Go module](https://github.com/golang/go/wiki/Modules) support, simply add the following import
```go
import "golang.yandex/hasql"
```
to your code, and then `go [build|run|test]` will automatically fetch the
necessary dependencies.
Otherwise, to install the `hasql` package, run the following command:
```console
$ go get -u golang.yandex/hasql
```
## How does it work
`hasql` operates using standard `database/sql` connection pool objects. User creates `*sql.DB` objects for each node of database cluster and passes them to constructor. Library keeps up to date information on state of each node by 'pinging' them periodically. User is provided with a set of interfaces to retrieve `*sql.DB` object suitable for required operation.
```go
dbFoo, _ := sql.Open("pgx", "host=foo")
dbBar, _ := sql.Open("pgx", "host=bar")
cl, err := hasql.NewCluster(
[]hasql.Node{hasql.NewNode("foo", dbFoo), hasql.NewNode("bar", dbBar) },
checkers.PostgreSQL,
)
if err != nil { ... }
node := cl.Primary()
if node == nil {
err := cl.Err() // most recent errors for all nodes in the cluster
}
// Do anything you like
fmt.Println("Node address", node.Addr)
ctx, cancel := context.WithTimeout(context.Background(), time.Second)
defer cancel()
if err = node.DB().PingContext(ctx); err != nil { ... }
```
`hasql` does not configure provided connection pools in any way. It is user's job to set them up properly. Library does handle their lifetime though - pools are closed when `Cluster` object is closed.
### Supported criteria
_Alive primary_|_Alive standby_|_Any alive_ node, or _none_ otherwise
```go
node := c.Primary()
if node == nil { ... }
```
_Alive primary_|_Alive standby_, or _any alive_ node, or _none_ otherwise
```go
node := c.PreferPrimary()
if node == nil { ... }
```
### Ways of accessing nodes
Any of _currently alive_ nodes _satisfying criteria_, or _none_ otherwise
```go
node := c.Primary()
if node == nil { ... }
```
Any of _currently alive_ nodes _satisfying criteria_, or _wait_ for one to become _alive_
```go
ctx, cancel := context.WithTimeout(context.Background(), time.Second)
defer cancel()
node, err := c.WaitForPrimary(ctx)
if err == nil { ... }
```
### Node pickers
When user asks `Cluster` object for a node a random one from a list of suitable nodes is returned. User can override this behavior by providing a custom node picker.
Library provides a couple of predefined pickers. For example if user wants 'closest' node (with lowest latency) `PickNodeClosest` picker should be used.
```go
cl, err := hasql.NewCluster(
[]hasql.Node{hasql.NewNode("foo", dbFoo), hasql.NewNode("bar", dbBar) },
checkers.PostgreSQL,
hasql.WithNodePicker(hasql.PickNodeClosest()),
)
if err != nil { ... }
```
## Supported databases
Since library works over standard `database/sql` it supports any database that has a `database/sql` driver. All it requires is a database-specific checker function that can tell if node is primary or standby.
Check out `golang.yandex/hasql/checkers` package for more information.
### Caveats
Node's state is transient at any given time. If `Primary()` returns a node it does not mean that node is still primary when you execute statement on it. All it means is that it was primary when it was last checked. Nodes can change their state at a whim or even go offline and `hasql` can't control it in any manner.
This is one of the reasons why nodes do not expose their perceived state to user.
## Extensions
### Instrumentation
You can add instrumentation via `Tracer` object similar to [httptrace](https://godoc.org/net/http/httptrace) in standard library.
### sqlx
`hasql` can operate over `database/sql` pools wrapped with [sqlx](https://github.com/jmoiron/sqlx). It works the same as with standard library but requires user to import `golang.yandex/hasql/sqlx` instead.
Refer to `golang.yandex/hasql/sqlx` package for more information. | {
"source": "yandex/perforator",
"title": "vendor/golang.yandex/hasql/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/golang.yandex/hasql/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 4900
} |
# How to contribute
We definitely welcome your patches and contributions to gRPC! Please read the gRPC
organization's [governance rules](https://github.com/grpc/grpc-community/blob/master/governance.md)
and [contribution guidelines](https://github.com/grpc/grpc-community/blob/master/CONTRIBUTING.md) before proceeding.
If you are new to github, please start by reading [Pull Request howto](https://help.github.com/articles/about-pull-requests/)
## Legal requirements
In order to protect both you and ourselves, you will need to sign the
[Contributor License Agreement](https://identity.linuxfoundation.org/projects/cncf).
## Guidelines for Pull Requests
How to get your contributions merged smoothly and quickly.
- Create **small PRs** that are narrowly focused on **addressing a single
concern**. We often times receive PRs that are trying to fix several things at
a time, but only one fix is considered acceptable, nothing gets merged and
both author's & review's time is wasted. Create more PRs to address different
concerns and everyone will be happy.
- If you are searching for features to work on, issues labeled [Status: Help
Wanted](https://github.com/grpc/grpc-go/issues?q=is%3Aissue+is%3Aopen+sort%3Aupdated-desc+label%3A%22Status%3A+Help+Wanted%22)
is a great place to start. These issues are well-documented and usually can be
resolved with a single pull request.
- If you are adding a new file, make sure it has the copyright message template
at the top as a comment. You can copy over the message from an existing file
and update the year.
- The grpc package should only depend on standard Go packages and a small number
of exceptions. If your contribution introduces new dependencies which are NOT
in the [list](https://godoc.org/google.golang.org/grpc?imports), you need a
discussion with gRPC-Go authors and consultants.
- For speculative changes, consider opening an issue and discussing it first. If
you are suggesting a behavioral or API change, consider starting with a [gRFC
proposal](https://github.com/grpc/proposal).
- Provide a good **PR description** as a record of **what** change is being made
and **why** it was made. Link to a github issue if it exists.
- If you want to fix formatting or style, consider whether your changes are an
obvious improvement or might be considered a personal preference. If a style
change is based on preference, it likely will not be accepted. If it corrects
widely agreed-upon anti-patterns, then please do create a PR and explain the
benefits of the change.
- Unless your PR is trivial, you should expect there will be reviewer comments
that you'll need to address before merging. We'll mark it as `Status: Requires
Reporter Clarification` if we expect you to respond to these comments in a
timely manner. If the PR remains inactive for 6 days, it will be marked as
`stale` and automatically close 7 days after that if we don't hear back from
you.
- Maintain **clean commit history** and use **meaningful commit messages**. PRs
with messy commit history are difficult to review and won't be merged. Use
`rebase -i upstream/master` to curate your commit history and/or to bring in
latest changes from master (but avoid rebasing in the middle of a code
review).
- Keep your PR up to date with upstream/master (if there are merge conflicts, we
can't really merge your change).
- **All tests need to be passing** before your change can be merged. We
recommend you **run tests locally** before creating your PR to catch breakages
early on.
- `VET_SKIP_PROTO=1 ./vet.sh` to catch vet errors
- `go test -cpu 1,4 -timeout 7m ./...` to run the tests
- `go test -race -cpu 1,4 -timeout 7m ./...` to run tests in race mode
- Exceptions to the rules can be made if there's a compelling reason for doing so. | {
"source": "yandex/perforator",
"title": "vendor/google.golang.org/grpc/CONTRIBUTING.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/google.golang.org/grpc/CONTRIBUTING.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 3848
} |
# gRPC-Go
[][API]
[](https://goreportcard.com/report/github.com/grpc/grpc-go)
[](https://codecov.io/gh/grpc/grpc-go)
The [Go][] implementation of [gRPC][]: A high performance, open source, general
RPC framework that puts mobile and HTTP/2 first. For more information see the
[Go gRPC docs][], or jump directly into the [quick start][].
## Prerequisites
- **[Go][]**: any one of the **three latest major** [releases][go-releases].
## Installation
Simply add the following import to your code, and then `go [build|run|test]`
will automatically fetch the necessary dependencies:
```go
import "google.golang.org/grpc"
```
> **Note:** If you are trying to access `grpc-go` from **China**, see the
> [FAQ](#FAQ) below.
## Learn more
- [Go gRPC docs][], which include a [quick start][] and [API
reference][API] among other resources
- [Low-level technical docs](Documentation) from this repository
- [Performance benchmark][]
- [Examples](examples)
## FAQ
### I/O Timeout Errors
The `golang.org` domain may be blocked from some countries. `go get` usually
produces an error like the following when this happens:
```console
$ go get -u google.golang.org/grpc
package google.golang.org/grpc: unrecognized import path "google.golang.org/grpc" (https fetch: Get https://google.golang.org/grpc?go-get=1: dial tcp 216.239.37.1:443: i/o timeout)
```
To build Go code, there are several options:
- Set up a VPN and access google.golang.org through that.
- With Go module support: it is possible to use the `replace` feature of `go
mod` to create aliases for golang.org packages. In your project's directory:
```sh
go mod edit -replace=google.golang.org/grpc=github.com/grpc/grpc-go@latest
go mod tidy
go mod vendor
go build -mod=vendor
```
Again, this will need to be done for all transitive dependencies hosted on
golang.org as well. For details, refer to [golang/go issue
#28652](https://github.com/golang/go/issues/28652).
### Compiling error, undefined: grpc.SupportPackageIsVersion
Please update to the latest version of gRPC-Go using
`go get google.golang.org/grpc`.
### How to turn on logging
The default logger is controlled by environment variables. Turn everything on
like this:
```console
$ export GRPC_GO_LOG_VERBOSITY_LEVEL=99
$ export GRPC_GO_LOG_SEVERITY_LEVEL=info
```
### The RPC failed with error `"code = Unavailable desc = transport is closing"`
This error means the connection the RPC is using was closed, and there are many
possible reasons, including:
1. mis-configured transport credentials, connection failed on handshaking
1. bytes disrupted, possibly by a proxy in between
1. server shutdown
1. Keepalive parameters caused connection shutdown, for example if you have
configured your server to terminate connections regularly to [trigger DNS
lookups](https://github.com/grpc/grpc-go/issues/3170#issuecomment-552517779).
If this is the case, you may want to increase your
[MaxConnectionAgeGrace](https://pkg.go.dev/google.golang.org/grpc/keepalive?tab=doc#ServerParameters),
to allow longer RPC calls to finish.
It can be tricky to debug this because the error happens on the client side but
the root cause of the connection being closed is on the server side. Turn on
logging on __both client and server__, and see if there are any transport
errors.
[API]: https://pkg.go.dev/google.golang.org/grpc
[Go]: https://golang.org
[Go module]: https://github.com/golang/go/wiki/Modules
[gRPC]: https://grpc.io
[Go gRPC docs]: https://grpc.io/docs/languages/go
[Performance benchmark]: https://performance-dot-grpc-testing.appspot.com/explore?dashboard=5180705743044608
[quick start]: https://grpc.io/docs/languages/go/quickstart
[go-releases]: https://golang.org/doc/devel/release.html | {
"source": "yandex/perforator",
"title": "vendor/google.golang.org/grpc/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/google.golang.org/grpc/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 3945
} |
Instructions
============
Install the package with:
go get gopkg.in/check.v1
Import it with:
import "gopkg.in/check.v1"
and use _check_ as the package name inside the code.
For more details, visit the project page:
* http://labix.org/gocheck
and the API documentation:
* https://gopkg.in/check.v1 | {
"source": "yandex/perforator",
"title": "vendor/gopkg.in/check.v1/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/gopkg.in/check.v1/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 317
} |
# YAML support for the Go language
Introduction
------------
The yaml package enables Go programs to comfortably encode and decode YAML
values. It was developed within [Canonical](https://www.canonical.com) as
part of the [juju](https://juju.ubuntu.com) project, and is based on a
pure Go port of the well-known [libyaml](http://pyyaml.org/wiki/LibYAML)
C library to parse and generate YAML data quickly and reliably.
Compatibility
-------------
The yaml package supports most of YAML 1.1 and 1.2, including support for
anchors, tags, map merging, etc. Multi-document unmarshalling is not yet
implemented, and base-60 floats from YAML 1.1 are purposefully not
supported since they're a poor design and are gone in YAML 1.2.
Installation and usage
----------------------
The import path for the package is *gopkg.in/yaml.v2*.
To install it, run:
go get gopkg.in/yaml.v2
API documentation
-----------------
If opened in a browser, the import path itself leads to the API documentation:
* [https://gopkg.in/yaml.v2](https://gopkg.in/yaml.v2)
API stability
-------------
The package API for yaml v2 will remain stable as described in [gopkg.in](https://gopkg.in).
License
-------
The yaml package is licensed under the Apache License 2.0. Please see the LICENSE file for details.
Example
-------
```Go
package main
import (
"fmt"
"log"
"gopkg.in/yaml.v2"
)
var data = `
a: Easy!
b:
c: 2
d: [3, 4]
`
// Note: struct fields must be public in order for unmarshal to
// correctly populate the data.
type T struct {
A string
B struct {
RenamedC int `yaml:"c"`
D []int `yaml:",flow"`
}
}
func main() {
t := T{}
err := yaml.Unmarshal([]byte(data), &t)
if err != nil {
log.Fatalf("error: %v", err)
}
fmt.Printf("--- t:\n%v\n\n", t)
d, err := yaml.Marshal(&t)
if err != nil {
log.Fatalf("error: %v", err)
}
fmt.Printf("--- t dump:\n%s\n\n", string(d))
m := make(map[interface{}]interface{})
err = yaml.Unmarshal([]byte(data), &m)
if err != nil {
log.Fatalf("error: %v", err)
}
fmt.Printf("--- m:\n%v\n\n", m)
d, err = yaml.Marshal(&m)
if err != nil {
log.Fatalf("error: %v", err)
}
fmt.Printf("--- m dump:\n%s\n\n", string(d))
}
```
This example will generate the following output:
```
--- t:
{Easy! {2 [3 4]}}
--- t dump:
a: Easy!
b:
c: 2
d: [3, 4]
--- m:
map[a:Easy! b:map[c:2 d:[3 4]]]
--- m dump:
a: Easy!
b:
c: 2
d:
- 3
- 4
``` | {
"source": "yandex/perforator",
"title": "vendor/gopkg.in/yaml.v2/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/gopkg.in/yaml.v2/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2693
} |
# YAML support for the Go language
Introduction
------------
The yaml package enables Go programs to comfortably encode and decode YAML
values. It was developed within [Canonical](https://www.canonical.com) as
part of the [juju](https://juju.ubuntu.com) project, and is based on a
pure Go port of the well-known [libyaml](http://pyyaml.org/wiki/LibYAML)
C library to parse and generate YAML data quickly and reliably.
Compatibility
-------------
The yaml package supports most of YAML 1.2, but preserves some behavior
from 1.1 for backwards compatibility.
Specifically, as of v3 of the yaml package:
- YAML 1.1 bools (_yes/no, on/off_) are supported as long as they are being
decoded into a typed bool value. Otherwise they behave as a string. Booleans
in YAML 1.2 are _true/false_ only.
- Octals encode and decode as _0777_ per YAML 1.1, rather than _0o777_
as specified in YAML 1.2, because most parsers still use the old format.
Octals in the _0o777_ format are supported though, so new files work.
- Does not support base-60 floats. These are gone from YAML 1.2, and were
actually never supported by this package as it's clearly a poor choice.
and offers backwards
compatibility with YAML 1.1 in some cases.
1.2, including support for
anchors, tags, map merging, etc. Multi-document unmarshalling is not yet
implemented, and base-60 floats from YAML 1.1 are purposefully not
supported since they're a poor design and are gone in YAML 1.2.
Installation and usage
----------------------
The import path for the package is *gopkg.in/yaml.v3*.
To install it, run:
go get gopkg.in/yaml.v3
API documentation
-----------------
If opened in a browser, the import path itself leads to the API documentation:
- [https://gopkg.in/yaml.v3](https://gopkg.in/yaml.v3)
API stability
-------------
The package API for yaml v3 will remain stable as described in [gopkg.in](https://gopkg.in).
License
-------
The yaml package is licensed under the MIT and Apache License 2.0 licenses.
Please see the LICENSE file for details.
Example
-------
```Go
package main
import (
"fmt"
"log"
"gopkg.in/yaml.v3"
)
var data = `
a: Easy!
b:
c: 2
d: [3, 4]
`
// Note: struct fields must be public in order for unmarshal to
// correctly populate the data.
type T struct {
A string
B struct {
RenamedC int `yaml:"c"`
D []int `yaml:",flow"`
}
}
func main() {
t := T{}
err := yaml.Unmarshal([]byte(data), &t)
if err != nil {
log.Fatalf("error: %v", err)
}
fmt.Printf("--- t:\n%v\n\n", t)
d, err := yaml.Marshal(&t)
if err != nil {
log.Fatalf("error: %v", err)
}
fmt.Printf("--- t dump:\n%s\n\n", string(d))
m := make(map[interface{}]interface{})
err = yaml.Unmarshal([]byte(data), &m)
if err != nil {
log.Fatalf("error: %v", err)
}
fmt.Printf("--- m:\n%v\n\n", m)
d, err = yaml.Marshal(&m)
if err != nil {
log.Fatalf("error: %v", err)
}
fmt.Printf("--- m dump:\n%s\n\n", string(d))
}
```
This example will generate the following output:
```
--- t:
{Easy! {2 [3 4]}}
--- t dump:
a: Easy!
b:
c: 2
d: [3, 4]
--- m:
map[a:Easy! b:map[c:2 d:[3 4]]]
--- m dump:
a: Easy!
b:
c: 2
d:
- 3
- 4
``` | {
"source": "yandex/perforator",
"title": "vendor/gopkg.in/yaml.v3/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/gopkg.in/yaml.v3/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 3451
} |
# libc
Package libc provides C-runtime services. Work in progress.
This package is a continuation of the Crt package in modernc.org/crt/v3.
Installation
$ go get [-u] modernc.org/libc
Documentation: [godoc.org/modernc.org/libc](http://godoc.org/modernc.org/libc)
Building with `make` requires the following Go packages
* github.com/golang/lint/golint
* github.com/mdempsky/maligned
* github.com/mdempsky/unconvert
* honnef.co/go/tools/cmd/unused
* honnef.co/go/tools/cmd/gosimple
* github.com/client9/misspell/cmd/misspell | {
"source": "yandex/perforator",
"title": "vendor/modernc.org/libc/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/modernc.org/libc/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 533
} |
# memory
Package memory implements a memory allocator.
## Build status
available at https://modern-c.appspot.com/-/builder/?importpath=modernc.org%2fmemory
Installation
$ go get modernc.org/memory
Documentation: [godoc.org/modernc.org/memory](http://godoc.org/modernc.org/memory) | {
"source": "yandex/perforator",
"title": "vendor/modernc.org/memory/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/modernc.org/memory/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 289
} |
# sqlite
Package sqlite is a cgo-free port of SQLite. Although you could see mattn's driver (`github.com/mattn/go-sqlite3`) in go.mod file, we import it for tests only.
SQLite is an in-process implementation of a self-contained, serverless,
zero-configuration, transactional SQL database engine.
## Thanks
This project is sponsored by Schleibinger Geräte Teubert u. Greim GmbH by
allowing one of the maintainers to work on it also in office hours.
## Installation
$ go get modernc.org/sqlite
## Documentation
[pkg.go.dev/modernc.org/sqlite](https://pkg.go.dev/modernc.org/sqlite)
## Builders
[modern-c.appspot.com/-/builder/?importpath=modernc.org%2fsqlite](https://modern-c.appspot.com/-/builder/?importpath=modernc.org%2fsqlite)
## Speedtest1
Numbers for the pure Go version were produced by
~/src/modernc.org/sqlite/speedtest1$ go build && ./speedtest1
Numbers for the pure C version were produced by
~/src/modernc.org/sqlite/testdata/sqlite-src-3410200/test$ gcc speedtest1.c ../../sqlite-amalgamation-3410200/sqlite3.c -lpthread -ldl && ./a.out
The results are from Go version 1.20.4 and GCC version 10.2.1 on a
Linux/amd64 machine, CPU: AMD Ryzen 9 3900X 12-Core Processor × 24, 128GB
RAM. Shown are the best of 3 runs.
Go C
-- Speedtest1 for SQLite 3.41.2 2023-03-22 11:56:21 0d1fc92f94cb6b76bffe3ec34d69 -- Speedtest1 for SQLite 3.41.2 2023-03-22 11:56:21 0d1fc92f94cb6b76bffe3ec34d69
100 - 50000 INSERTs into table with no index...................... 0.071s 100 - 50000 INSERTs into table with no index...................... 0.077s
110 - 50000 ordered INSERTS with one index/PK..................... 0.114s 110 - 50000 ordered INSERTS with one index/PK..................... 0.082s
120 - 50000 unordered INSERTS with one index/PK................... 0.137s 120 - 50000 unordered INSERTS with one index/PK................... 0.099s
130 - 25 SELECTS, numeric BETWEEN, unindexed...................... 0.083s 130 - 25 SELECTS, numeric BETWEEN, unindexed...................... 0.091s
140 - 10 SELECTS, LIKE, unindexed................................. 0.210s 140 - 10 SELECTS, LIKE, unindexed................................. 0.120s
142 - 10 SELECTS w/ORDER BY, unindexed............................ 0.276s 142 - 10 SELECTS w/ORDER BY, unindexed............................ 0.182s
145 - 10 SELECTS w/ORDER BY and LIMIT, unindexed.................. 0.183s 145 - 10 SELECTS w/ORDER BY and LIMIT, unindexed.................. 0.099s
150 - CREATE INDEX five times..................................... 0.172s 150 - CREATE INDEX five times..................................... 0.127s
160 - 10000 SELECTS, numeric BETWEEN, indexed..................... 0.080s 160 - 10000 SELECTS, numeric BETWEEN, indexed..................... 0.078s
161 - 10000 SELECTS, numeric BETWEEN, PK.......................... 0.080s 161 - 10000 SELECTS, numeric BETWEEN, PK.......................... 0.078s
170 - 10000 SELECTS, text BETWEEN, indexed........................ 0.187s 170 - 10000 SELECTS, text BETWEEN, indexed........................ 0.169s
180 - 50000 INSERTS with three indexes............................ 0.196s 180 - 50000 INSERTS with three indexes............................ 0.154s
190 - DELETE and REFILL one table................................. 0.200s 190 - DELETE and REFILL one table................................. 0.155s
200 - VACUUM...................................................... 0.180s 200 - VACUUM...................................................... 0.142s
210 - ALTER TABLE ADD COLUMN, and query........................... 0.004s 210 - ALTER TABLE ADD COLUMN, and query........................... 0.005s
230 - 10000 UPDATES, numeric BETWEEN, indexed..................... 0.093s 230 - 10000 UPDATES, numeric BETWEEN, indexed..................... 0.080s
240 - 50000 UPDATES of individual rows............................ 0.153s 240 - 50000 UPDATES of individual rows............................ 0.137s
250 - One big UPDATE of the whole 50000-row table................. 0.024s 250 - One big UPDATE of the whole 50000-row table................. 0.019s
260 - Query added column after filling............................ 0.004s 260 - Query added column after filling............................ 0.005s
270 - 10000 DELETEs, numeric BETWEEN, indexed..................... 0.278s 270 - 10000 DELETEs, numeric BETWEEN, indexed..................... 0.263s
280 - 50000 DELETEs of individual rows............................ 0.188s 280 - 50000 DELETEs of individual rows............................ 0.180s
290 - Refill two 50000-row tables using REPLACE................... 0.411s 290 - Refill two 50000-row tables using REPLACE................... 0.359s
300 - Refill a 50000-row table using (b&1)==(a&1)................. 0.175s 300 - Refill a 50000-row table using (b&1)==(a&1)................. 0.151s
310 - 10000 four-ways joins....................................... 0.427s 310 - 10000 four-ways joins....................................... 0.365s
320 - subquery in result set...................................... 0.440s 320 - subquery in result set...................................... 0.521s
400 - 70000 REPLACE ops on an IPK................................. 0.125s 400 - 70000 REPLACE ops on an IPK................................. 0.106s
410 - 70000 SELECTS on an IPK..................................... 0.081s 410 - 70000 SELECTS on an IPK..................................... 0.078s
500 - 70000 REPLACE on TEXT PK.................................... 0.174s 500 - 70000 REPLACE on TEXT PK.................................... 0.116s
510 - 70000 SELECTS on a TEXT PK.................................. 0.153s 510 - 70000 SELECTS on a TEXT PK.................................. 0.117s
520 - 70000 SELECT DISTINCT....................................... 0.083s 520 - 70000 SELECT DISTINCT....................................... 0.067s
980 - PRAGMA integrity_check...................................... 0.436s 980 - PRAGMA integrity_check...................................... 0.377s
990 - ANALYZE..................................................... 0.107s 990 - ANALYZE..................................................... 0.038s
TOTAL....................................................... 5.525s TOTAL....................................................... 4.637s
This particular test executes 16.1% faster in the C version.
## Troubleshooting
* Q: **How can I write to a database concurrently without getting the `database is locked` error (or `SQLITE_BUSY`)?**
* A: You can't. The C sqlite implementation does not allow concurrent writes, and this libary does not modify that behaviour. You can, however, use [DB.SetMaxOpenConns(1)](https://pkg.go.dev/database/sql#DB.SetMaxOpenConns) so that only 1 connection is ever used by the `DB`, allowing concurrent access to DB without making the writes concurrent. More information on issues [#65](https://gitlab.com/cznic/sqlite/-/issues/65) and [#106](https://gitlab.com/cznic/sqlite/-/issues/106). | {
"source": "yandex/perforator",
"title": "vendor/modernc.org/sqlite/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/modernc.org/sqlite/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 7777
} |
# Contributing Guidelines
Welcome to Kubernetes. We are excited about the prospect of you joining our [community](https://git.k8s.io/community)! The Kubernetes community abides by the CNCF [code of conduct](code-of-conduct.md). Here is an excerpt:
_As contributors and maintainers of this project, and in the interest of fostering an open and welcoming community, we pledge to respect all people who contribute through reporting issues, posting feature requests, updating documentation, submitting pull requests or patches, and other activities._
## Criteria for adding code here
This library adapts the stdlib `encoding/json` decoder to be compatible with
Kubernetes JSON decoding, and is not expected to actively add new features.
It may be updated with changes from the stdlib `encoding/json` decoder.
Any code that is added must:
* Have full unit test and benchmark coverage
* Be backward compatible with the existing exposed go API
* Have zero external dependencies
* Preserve existing benchmark performance
* Preserve compatibility with existing decoding behavior of `UnmarshalCaseSensitivePreserveInts()` or `UnmarshalStrict()`
* Avoid use of `unsafe`
## Getting Started
We have full documentation on how to get started contributing here:
<!---
If your repo has certain guidelines for contribution, put them here ahead of the general k8s resources
-->
- [Contributor License Agreement](https://git.k8s.io/community/CLA.md) Kubernetes projects require that you sign a Contributor License Agreement (CLA) before we can accept your pull requests
- [Kubernetes Contributor Guide](https://git.k8s.io/community/contributors/guide) - Main contributor documentation, or you can just jump directly to the [contributing section](https://git.k8s.io/community/contributors/guide#contributing)
- [Contributor Cheat Sheet](https://git.k8s.io/community/contributors/guide/contributor-cheatsheet) - Common resources for existing developers
## Community, discussion, contribution, and support
You can reach the maintainers of this project via the
[sig-api-machinery mailing list / channels](https://github.com/kubernetes/community/tree/master/sig-api-machinery#contact).
## Mentorship
- [Mentoring Initiatives](https://git.k8s.io/community/mentoring) - We have a diverse set of mentorship programs available that are always looking for volunteers! | {
"source": "yandex/perforator",
"title": "vendor/sigs.k8s.io/json/CONTRIBUTING.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/sigs.k8s.io/json/CONTRIBUTING.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2353
} |
# sigs.k8s.io/json
[](https://pkg.go.dev/sigs.k8s.io/json)
## Introduction
This library is a subproject of [sig-api-machinery](https://github.com/kubernetes/community/tree/master/sig-api-machinery#json).
It provides case-sensitive, integer-preserving JSON unmarshaling functions based on `encoding/json` `Unmarshal()`.
## Compatibility
The `UnmarshalCaseSensitivePreserveInts()` function behaves like `encoding/json#Unmarshal()` with the following differences:
- JSON object keys are treated case-sensitively.
Object keys must exactly match json tag names (for tagged struct fields)
or struct field names (for untagged struct fields).
- JSON integers are unmarshaled into `interface{}` fields as an `int64` instead of a
`float64` when possible, falling back to `float64` on any parse or overflow error.
- Syntax errors do not return an `encoding/json` `*SyntaxError` error.
Instead, they return an error which can be passed to `SyntaxErrorOffset()` to obtain an offset.
## Additional capabilities
The `UnmarshalStrict()` function decodes identically to `UnmarshalCaseSensitivePreserveInts()`,
and also returns non-fatal strict errors encountered while decoding:
- Duplicate fields encountered
- Unknown fields encountered
### Community, discussion, contribution, and support
You can reach the maintainers of this project via the
[sig-api-machinery mailing list / channels](https://github.com/kubernetes/community/tree/master/sig-api-machinery#contact).
### Code of conduct
Participation in the Kubernetes community is governed by the [Kubernetes Code of Conduct](code-of-conduct.md).
[owners]: https://git.k8s.io/community/contributors/guide/owners.md
[Creative Commons 4.0]: https://git.k8s.io/website/LICENSE | {
"source": "yandex/perforator",
"title": "vendor/sigs.k8s.io/json/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/sigs.k8s.io/json/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1796
} |
# Contributing Guidelines
Welcome to Kubernetes. We are excited about the prospect of you joining our [community](https://github.com/kubernetes/community)! The Kubernetes community abides by the CNCF [code of conduct](code-of-conduct.md). Here is an excerpt:
_As contributors and maintainers of this project, and in the interest of fostering an open and welcoming community, we pledge to respect all people who contribute through reporting issues, posting feature requests, updating documentation, submitting pull requests or patches, and other activities._
## Getting Started
We have full documentation on how to get started contributing here:
<!---
If your repo has certain guidelines for contribution, put them here ahead of the general k8s resources
-->
- [Contributor License Agreement](https://git.k8s.io/community/CLA.md) Kubernetes projects require that you sign a Contributor License Agreement (CLA) before we can accept your pull requests
- [Kubernetes Contributor Guide](http://git.k8s.io/community/contributors/guide) - Main contributor documentation, or you can just jump directly to the [contributing section](http://git.k8s.io/community/contributors/guide#contributing)
- [Contributor Cheat Sheet](https://git.k8s.io/community/contributors/guide/contributor-cheatsheet.md) - Common resources for existing developers
## Mentorship
- [Mentoring Initiatives](https://git.k8s.io/community/mentoring) - We have a diverse set of mentorship programs available that are always looking for volunteers!
<!---
Custom Information - if you're copying this template for the first time you can add custom content here, for example:
## Contact Information
- [Slack channel](https://kubernetes.slack.com/messages/kubernetes-users) - Replace `kubernetes-users` with your slack channel string, this will send users directly to your channel.
- [Mailing list](URL)
--> | {
"source": "yandex/perforator",
"title": "vendor/sigs.k8s.io/yaml/CONTRIBUTING.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/sigs.k8s.io/yaml/CONTRIBUTING.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1875
} |
# YAML marshaling and unmarshaling support for Go
[](https://travis-ci.org/kubernetes-sigs/yaml)
kubernetes-sigs/yaml is a permanent fork of [ghodss/yaml](https://github.com/ghodss/yaml).
## Introduction
A wrapper around [go-yaml](https://github.com/go-yaml/yaml) designed to enable a better way of handling YAML when marshaling to and from structs.
In short, this library first converts YAML to JSON using go-yaml and then uses `json.Marshal` and `json.Unmarshal` to convert to or from the struct. This means that it effectively reuses the JSON struct tags as well as the custom JSON methods `MarshalJSON` and `UnmarshalJSON` unlike go-yaml. For a detailed overview of the rationale behind this method, [see this blog post](http://web.archive.org/web/20190603050330/http://ghodss.com/2014/the-right-way-to-handle-yaml-in-golang/).
## Compatibility
This package uses [go-yaml](https://github.com/go-yaml/yaml) and therefore supports [everything go-yaml supports](https://github.com/go-yaml/yaml#compatibility).
## Caveats
**Caveat #1:** When using `yaml.Marshal` and `yaml.Unmarshal`, binary data should NOT be preceded with the `!!binary` YAML tag. If you do, go-yaml will convert the binary data from base64 to native binary data, which is not compatible with JSON. You can still use binary in your YAML files though - just store them without the `!!binary` tag and decode the base64 in your code (e.g. in the custom JSON methods `MarshalJSON` and `UnmarshalJSON`). This also has the benefit that your YAML and your JSON binary data will be decoded exactly the same way. As an example:
```
BAD:
exampleKey: !!binary gIGC
GOOD:
exampleKey: gIGC
... and decode the base64 data in your code.
```
**Caveat #2:** When using `YAMLToJSON` directly, maps with keys that are maps will result in an error since this is not supported by JSON. This error will occur in `Unmarshal` as well since you can't unmarshal map keys anyways since struct fields can't be keys.
## Installation and usage
To install, run:
```
$ go get sigs.k8s.io/yaml
```
And import using:
```
import "sigs.k8s.io/yaml"
```
Usage is very similar to the JSON library:
```go
package main
import (
"fmt"
"sigs.k8s.io/yaml"
)
type Person struct {
Name string `json:"name"` // Affects YAML field names too.
Age int `json:"age"`
}
func main() {
// Marshal a Person struct to YAML.
p := Person{"John", 30}
y, err := yaml.Marshal(p)
if err != nil {
fmt.Printf("err: %v\n", err)
return
}
fmt.Println(string(y))
/* Output:
age: 30
name: John
*/
// Unmarshal the YAML back into a Person struct.
var p2 Person
err = yaml.Unmarshal(y, &p2)
if err != nil {
fmt.Printf("err: %v\n", err)
return
}
fmt.Println(p2)
/* Output:
{John 30}
*/
}
```
`yaml.YAMLToJSON` and `yaml.JSONToYAML` methods are also available:
```go
package main
import (
"fmt"
"sigs.k8s.io/yaml"
)
func main() {
j := []byte(`{"name": "John", "age": 30}`)
y, err := yaml.JSONToYAML(j)
if err != nil {
fmt.Printf("err: %v\n", err)
return
}
fmt.Println(string(y))
/* Output:
age: 30
name: John
*/
j2, err := yaml.YAMLToJSON(y)
if err != nil {
fmt.Printf("err: %v\n", err)
return
}
fmt.Println(string(j2))
/* Output:
{"age":30,"name":"John"}
*/
}
``` | {
"source": "yandex/perforator",
"title": "vendor/sigs.k8s.io/yaml/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/sigs.k8s.io/yaml/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 3315
} |
.. image:: https://img.shields.io/pypi/v/backports.functools_lru_cache.svg
:target: https://pypi.org/project/backports.functools_lru_cache
.. image:: https://img.shields.io/pypi/pyversions/backports.functools_lru_cache.svg
.. image:: https://github.com/jaraco/backports.functools_lru_cache/workflows/tests/badge.svg
:target: https://github.com/jaraco/backports.functools_lru_cache/actions?query=workflow%3A%22tests%22
:alt: tests
.. image:: https://img.shields.io/endpoint?url=https://raw.githubusercontent.com/charliermarsh/ruff/main/assets/badge/v2.json
:target: https://github.com/astral-sh/ruff
:alt: Ruff
.. image:: https://img.shields.io/badge/code%20style-black-000000.svg
:target: https://github.com/psf/black
:alt: Code style: Black
.. image:: https://readthedocs.org/projects/backportsfunctools_lru_cache/badge/?version=latest
:target: https://backportsfunctools_lru_cache.readthedocs.io/en/latest/?badge=latest
.. image:: https://img.shields.io/badge/skeleton-2023-informational
:target: https://blog.jaraco.com/skeleton
.. image:: https://tidelift.com/badges/package/pypi/backports.functools_lru_cache
:target: https://tidelift.com/subscription/pkg/pypi-backports.functools_lru_cache?utm_source=pypi-backports.functools_lru_cache&utm_medium=readme
Backport of functools.lru_cache from Python 3.3 as published at `ActiveState
<http://code.activestate.com/recipes/578078/>`_.
Usage
=====
Consider using this technique for importing the 'lru_cache' function::
try:
from functools import lru_cache
except ImportError:
from backports.functools_lru_cache import lru_cache
For Enterprise
==============
Available as part of the Tidelift Subscription.
This project and the maintainers of thousands of other packages are working with Tidelift to deliver one enterprise subscription that covers all of the open source you use.
`Learn more <https://tidelift.com/subscription/pkg/pypi-backports.functools_lru_cache?utm_source=pypi-backports.functools_lru_cache&utm_medium=referral&utm_campaign=github>`_. | {
"source": "yandex/perforator",
"title": "contrib/deprecated/python/backports.functools-lru-cache/README.rst",
"url": "https://github.com/yandex/perforator/blob/main/contrib/deprecated/python/backports.functools-lru-cache/README.rst",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2076
} |
backports.shutil_get_terminal_size
==================================
A backport of the `get_terminal_size`_ function from Python 3.3's shutil.
Unlike the original version it is written in pure Python rather than C,
so it might be a tiny bit slower.
.. _get_terminal_size: https://docs.python.org/3/library/shutil.html#shutil.get_terminal_size
Example usage
-------------
>>> from backports.shutil_get_terminal_size import get_terminal_size
>>> get_terminal_size()
terminal_size(columns=105, lines=33) | {
"source": "yandex/perforator",
"title": "contrib/deprecated/python/backports.shutil-get-terminal-size/README.rst",
"url": "https://github.com/yandex/perforator/blob/main/contrib/deprecated/python/backports.shutil-get-terminal-size/README.rst",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 519
} |
.. image:: https://img.shields.io/pypi/v/configparser.svg
:target: https://pypi.org/project/configparser
.. image:: https://img.shields.io/pypi/pyversions/configparser.svg
.. image:: https://img.shields.io/travis/jaraco/configparser/master.svg
:target: https://travis-ci.org/jaraco/configparser
.. image:: https://img.shields.io/badge/code%20style-black-000000.svg
:target: https://github.com/ambv/black
:alt: Code style: Black
.. .. image:: https://img.shields.io/appveyor/ci/jaraco/configparser/master.svg
.. :target: https://ci.appveyor.com/project/jaraco/configparser/branch/master
.. image:: https://readthedocs.org/projects/configparser/badge/?version=latest
:target: https://configparser.readthedocs.io/en/latest/?badge=latest
.. image:: https://tidelift.com/badges/package/pypi/configparser
:target: https://tidelift.com/subscription/pkg/pypi-configparser?utm_source=pypi-configparser&utm_medium=readme
The ancient ``ConfigParser`` module available in the standard library 2.x has
seen a major update in Python 3.2. This is a backport of those changes so that
they can be used directly in Python 2.6 - 3.5.
To use the ``configparser`` backport instead of the built-in version on both
Python 2 and Python 3, simply import it explicitly as a backport::
from backports import configparser
If you'd like to use the backport on Python 2 and the built-in version on
Python 3, use that invocation instead::
import configparser
For detailed documentation consult the vanilla version at
http://docs.python.org/3/library/configparser.html.
Why you'll love ``configparser``
--------------------------------
Whereas almost completely compatible with its older brother, ``configparser``
sports a bunch of interesting new features:
* full mapping protocol access (`more info
<http://docs.python.org/3/library/configparser.html#mapping-protocol-access>`_)::
>>> parser = ConfigParser()
>>> parser.read_string("""
[DEFAULT]
location = upper left
visible = yes
editable = no
color = blue
[main]
title = Main Menu
color = green
[options]
title = Options
""")
>>> parser['main']['color']
'green'
>>> parser['main']['editable']
'no'
>>> section = parser['options']
>>> section['title']
'Options'
>>> section['title'] = 'Options (editable: %(editable)s)'
>>> section['title']
'Options (editable: no)'
* there's now one default ``ConfigParser`` class, which basically is the old
``SafeConfigParser`` with a bunch of tweaks which make it more predictable for
users. Don't need interpolation? Simply use
``ConfigParser(interpolation=None)``, no need to use a distinct
``RawConfigParser`` anymore.
* the parser is highly `customizable upon instantiation
<http://docs.python.org/3/library/configparser.html#customizing-parser-behaviour>`__
supporting things like changing option delimiters, comment characters, the
name of the DEFAULT section, the interpolation syntax, etc.
* you can easily create your own interpolation syntax but there are two powerful
implementations built-in (`more info
<http://docs.python.org/3/library/configparser.html#interpolation-of-values>`__):
* the classic ``%(string-like)s`` syntax (called ``BasicInterpolation``)
* a new ``${buildout:like}`` syntax (called ``ExtendedInterpolation``)
* fallback values may be specified in getters (`more info
<http://docs.python.org/3/library/configparser.html#fallback-values>`__)::
>>> config.get('closet', 'monster',
... fallback='No such things as monsters')
'No such things as monsters'
* ``ConfigParser`` objects can now read data directly `from strings
<http://docs.python.org/3/library/configparser.html#configparser.ConfigParser.read_string>`__
and `from dictionaries
<http://docs.python.org/3/library/configparser.html#configparser.ConfigParser.read_dict>`__.
That means importing configuration from JSON or specifying default values for
the whole configuration (multiple sections) is now a single line of code. Same
goes for copying data from another ``ConfigParser`` instance, thanks to its
mapping protocol support.
* many smaller tweaks, updates and fixes
A few words about Unicode
-------------------------
``configparser`` comes from Python 3 and as such it works well with Unicode.
The library is generally cleaned up in terms of internal data storage and
reading/writing files. There are a couple of incompatibilities with the old
``ConfigParser`` due to that. However, the work required to migrate is well
worth it as it shows the issues that would likely come up during migration of
your project to Python 3.
The design assumes that Unicode strings are used whenever possible [1]_. That
gives you the certainty that what's stored in a configuration object is text.
Once your configuration is read, the rest of your application doesn't have to
deal with encoding issues. All you have is text [2]_. The only two phases when
you should explicitly state encoding is when you either read from an external
source (e.g. a file) or write back.
Versioning
----------
This project uses `semver <https://semver.org/spec/v2.0.0.html>`_ to
communicate the impact of various releases while periodically syncing
with the upstream implementation in CPython.
`The changelog <https://github.com/jaraco/configparser/blob/master/CHANGES.rst>`_
serves as a reference indicating which versions incorporate
which upstream functionality.
Prior to the ``4.0.0`` release, `another scheme
<https://github.com/jaraco/configparser/blob/3.8.1/README.rst#versioning>`_
was used to associate the CPython and backports releases.
Maintenance
-----------
This backport was originally authored by Łukasz Langa, the current vanilla
``configparser`` maintainer for CPython and is currently maintained by
Jason R. Coombs:
* `configparser repository <https://github.com/jaraco/configparser>`_
* `configparser issue tracker <https://github.com/jaraco/configparser/issues>`_
Security Contact
----------------
To report a security vulnerability, please use the
`Tidelift security contact <https://tidelift.com/security>`_.
Tidelift will coordinate the fix and disclosure.
Conversion Process
------------------
This section is technical and should bother you only if you are wondering how
this backport is produced. If the implementation details of this backport are
not important for you, feel free to ignore the following content.
``configparser`` is converted using `python-future
<http://python-future.org>`_. The project takes the following
branching approach:
* the ``3.x`` branch holds unchanged files synchronized from the upstream
CPython repository. The synchronization is currently done by manually copying
the required files and stating from which CPython changeset they come from.
* the ``master`` branch holds a version of the ``3.x`` code with some tweaks
that make it independent from libraries and constructions unavailable on 2.x.
Code on this branch still *must* work on the corresponding Python 3.x but
will also work on Python 2.6 and 2.7 (including PyPy). You can check this
running the supplied unit tests with ``tox``.
The process works like this:
1. In the ``3.x`` branch, run ``pip-run -- sync-upstream.py``, which
downloads the latest stable release of Python and copies the relevant
files from there into their new locations here and then commits those
changes with a nice reference to the relevant upstream commit hash.
2. I check for new names in ``__all__`` and update imports in
``configparser.py`` accordingly. I run the tests on Python 3. Commit.
3. I merge the new commit to ``master``. I run ``tox``. Commit.
4. If there are necessary changes, I do them now (on ``master``). Note that
the changes should be written in the syntax subset supported by Python
2.6.
5. I run ``tox``. If it works, I update the docs and release the new version.
Otherwise, I go back to point 3. I might use ``pasteurize`` to suggest me
required changes but usually I do them manually to keep resulting code in
a nicer form.
Footnotes
---------
.. [1] To somewhat ease migration, passing bytestrings is still supported but
they are converted to Unicode for internal storage anyway. This means
that for the vast majority of strings used in configuration files, it
won't matter if you pass them as bytestrings or Unicode. However, if you
pass a bytestring that cannot be converted to Unicode using the naive
ASCII codec, a ``UnicodeDecodeError`` will be raised. This is purposeful
and helps you manage proper encoding for all content you store in
memory, read from various sources and write back.
.. [2] Life gets much easier when you understand that you basically manage
**text** in your application. You don't care about bytes but about
letters. In that regard the concept of content encoding is meaningless.
The only time when you deal with raw bytes is when you write the data to
a file. Then you have to specify how your text should be encoded. On
the other end, to get meaningful text from a file, the application
reading it has to know which encoding was used during its creation. But
once the bytes are read and properly decoded, all you have is text. This
is especially powerful when you start interacting with multiple data
sources. Even if each of them uses a different encoding, inside your
application data is held in abstract text form. You can program your
business logic without worrying about which data came from which source.
You can freely exchange the data you store between sources. Only
reading/writing files requires encoding your text to bytes. | {
"source": "yandex/perforator",
"title": "contrib/deprecated/python/configparser/README.rst",
"url": "https://github.com/yandex/perforator/blob/main/contrib/deprecated/python/configparser/README.rst",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 9831
} |
+++++++++++++
Fault handler
+++++++++++++
.. image:: https://img.shields.io/pypi/v/faulthandler.svg
:alt: Latest release on the Python Cheeseshop (PyPI)
:target: https://pypi.python.org/pypi/faulthandler
.. image:: https://travis-ci.org/vstinner/faulthandler.svg?branch=master
:alt: Build status of faulthandler on Travis CI
:target: https://travis-ci.org/vstinner/faulthandler
.. image:: http://unmaintained.tech/badge.svg
:target: http://unmaintained.tech/
:alt: No Maintenance Intended
Fault handler for SIGSEGV, SIGFPE, SIGABRT, SIGBUS and SIGILL signals: display
the Python traceback and restore the previous handler. Allocate an alternate
stack for this handler, if sigaltstack() is available, to be able to allocate
memory on the stack, even on stack overflow (not available on Windows).
Import the module and call faulthandler.enable() to enable the fault handler.
Alternatively you can set the PYTHONFAULTHANDLER environment variable to a
non-empty value.
The fault handler is called on catastrophic cases and so it can only use
signal-safe functions (eg. it doesn't allocate memory on the heap). That's why
the traceback is limited: it only supports ASCII encoding (use the
backslashreplace error handler for non-ASCII characters) and limits each string
to 100 characters, doesn't print the source code in the traceback (only the
filename, the function name and the line number), is limited to 100 frames and
100 threads.
By default, the Python traceback is written to the standard error stream. Start
your graphical applications in a terminal and run your server in foreground to
see the traceback, or pass a file to faulthandler.enable().
faulthandler is implemented in C using signal handlers to be able to dump a
traceback on a crash or when Python is blocked (eg. deadlock).
This module is the backport for CPython 2.7. faulthandler is part of CPython
standard library since CPython 3.3: `faulthandler
<http://docs.python.org/dev/library/faulthandler.html>`_. For PyPy,
faulthandler is builtin since PyPy 5.5: use ``pypy -X faulthandler``.
Website:
https://faulthandler.readthedocs.io/
faulthandler 3.2 is the last version released by Victor Stinner. I maintained
it for 10 years in my free time for the great pleasure of Python 2 users, but
Python 2 is no longer supported upstream since 2020-01-01. Each faulthandler
release requires me to start my Windows VM, install Python 2.7 in 32-bit and
64-bit, install an old C compiler just for Python 2.7, and type manually some
commands to upload Windows binaries. Moreover, I have to fix some issues on
Travis CI and many small boring tasks. The maintenance is far from being free.
In 10 years, I got zero "thank you" (and 0€), only bug reports :-) | {
"source": "yandex/perforator",
"title": "contrib/deprecated/python/faulthandler/README.rst",
"url": "https://github.com/yandex/perforator/blob/main/contrib/deprecated/python/faulthandler/README.rst",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2740
} |
scandir, a better directory iterator and faster os.walk()
=========================================================
.. image:: https://img.shields.io/pypi/v/scandir.svg
:target: https://pypi.python.org/pypi/scandir
:alt: scandir on PyPI (Python Package Index)
.. image:: https://travis-ci.org/benhoyt/scandir.svg?branch=master
:target: https://travis-ci.org/benhoyt/scandir
:alt: Travis CI tests (Linux)
.. image:: https://ci.appveyor.com/api/projects/status/github/benhoyt/scandir?branch=master&svg=true
:target: https://ci.appveyor.com/project/benhoyt/scandir
:alt: Appveyor tests (Windows)
``scandir()`` is a directory iteration function like ``os.listdir()``,
except that instead of returning a list of bare filenames, it yields
``DirEntry`` objects that include file type and stat information along
with the name. Using ``scandir()`` increases the speed of ``os.walk()``
by 2-20 times (depending on the platform and file system) by avoiding
unnecessary calls to ``os.stat()`` in most cases.
Now included in a Python near you!
----------------------------------
``scandir`` has been included in the Python 3.5 standard library as
``os.scandir()``, and the related performance improvements to
``os.walk()`` have also been included. So if you're lucky enough to be
using Python 3.5 (release date September 13, 2015) you get the benefit
immediately, otherwise just
`download this module from PyPI <https://pypi.python.org/pypi/scandir>`_,
install it with ``pip install scandir``, and then do something like
this in your code:
.. code-block:: python
# Use the built-in version of scandir/walk if possible, otherwise
# use the scandir module version
try:
from os import scandir, walk
except ImportError:
from scandir import scandir, walk
`PEP 471 <https://www.python.org/dev/peps/pep-0471/>`_, which is the
PEP that proposes including ``scandir`` in the Python standard library,
was `accepted <https://mail.python.org/pipermail/python-dev/2014-July/135561.html>`_
in July 2014 by Victor Stinner, the BDFL-delegate for the PEP.
This ``scandir`` module is intended to work on Python 2.7+ and Python
3.4+ (and it has been tested on those versions).
Background
----------
Python's built-in ``os.walk()`` is significantly slower than it needs to be,
because -- in addition to calling ``listdir()`` on each directory -- it calls
``stat()`` on each file to determine whether the filename is a directory or not.
But both ``FindFirstFile`` / ``FindNextFile`` on Windows and ``readdir`` on Linux/OS
X already tell you whether the files returned are directories or not, so
no further ``stat`` system calls are needed. In short, you can reduce the number
of system calls from about 2N to N, where N is the total number of files and
directories in the tree.
In practice, removing all those extra system calls makes ``os.walk()`` about
**7-50 times as fast on Windows, and about 3-10 times as fast on Linux and Mac OS
X.** So we're not talking about micro-optimizations. See more benchmarks
in the "Benchmarks" section below.
Somewhat relatedly, many people have also asked for a version of
``os.listdir()`` that yields filenames as it iterates instead of returning them
as one big list. This improves memory efficiency for iterating very large
directories.
So as well as a faster ``walk()``, scandir adds a new ``scandir()`` function.
They're pretty easy to use, but see "The API" below for the full docs.
Benchmarks
----------
Below are results showing how many times as fast ``scandir.walk()`` is than
``os.walk()`` on various systems, found by running ``benchmark.py`` with no
arguments:
==================== ============== =============
System version Python version Times as fast
==================== ============== =============
Windows 7 64-bit 2.7.7 64-bit 10.4
Windows 7 64-bit SSD 2.7.7 64-bit 10.3
Windows 7 64-bit NFS 2.7.6 64-bit 36.8
Windows 7 64-bit SSD 3.4.1 64-bit 9.9
Windows 7 64-bit SSD 3.5.0 64-bit 9.5
Ubuntu 14.04 64-bit 2.7.6 64-bit 5.8
Mac OS X 10.9.3 2.7.5 64-bit 3.8
==================== ============== =============
All of the above tests were done using the fast C version of scandir
(source code in ``_scandir.c``).
Note that the gains are less than the above on smaller directories and greater
on larger directories. This is why ``benchmark.py`` creates a test directory
tree with a standardized size.
The API
-------
walk()
~~~~~~
The API for ``scandir.walk()`` is exactly the same as ``os.walk()``, so just
`read the Python docs <https://docs.python.org/3.5/library/os.html#os.walk>`_.
scandir()
~~~~~~~~~
The full docs for ``scandir()`` and the ``DirEntry`` objects it yields are
available in the `Python documentation here <https://docs.python.org/3.5/library/os.html#os.scandir>`_.
But below is a brief summary as well.
scandir(path='.') -> iterator of DirEntry objects for given path
Like ``listdir``, ``scandir`` calls the operating system's directory
iteration system calls to get the names of the files in the given
``path``, but it's different from ``listdir`` in two ways:
* Instead of returning bare filename strings, it returns lightweight
``DirEntry`` objects that hold the filename string and provide
simple methods that allow access to the additional data the
operating system may have returned.
* It returns a generator instead of a list, so that ``scandir`` acts
as a true iterator instead of returning the full list immediately.
``scandir()`` yields a ``DirEntry`` object for each file and
sub-directory in ``path``. Just like ``listdir``, the ``'.'``
and ``'..'`` pseudo-directories are skipped, and the entries are
yielded in system-dependent order. Each ``DirEntry`` object has the
following attributes and methods:
* ``name``: the entry's filename, relative to the scandir ``path``
argument (corresponds to the return values of ``os.listdir``)
* ``path``: the entry's full path name (not necessarily an absolute
path) -- the equivalent of ``os.path.join(scandir_path, entry.name)``
* ``is_dir(*, follow_symlinks=True)``: similar to
``pathlib.Path.is_dir()``, but the return value is cached on the
``DirEntry`` object; doesn't require a system call in most cases;
don't follow symbolic links if ``follow_symlinks`` is False
* ``is_file(*, follow_symlinks=True)``: similar to
``pathlib.Path.is_file()``, but the return value is cached on the
``DirEntry`` object; doesn't require a system call in most cases;
don't follow symbolic links if ``follow_symlinks`` is False
* ``is_symlink()``: similar to ``pathlib.Path.is_symlink()``, but the
return value is cached on the ``DirEntry`` object; doesn't require a
system call in most cases
* ``stat(*, follow_symlinks=True)``: like ``os.stat()``, but the
return value is cached on the ``DirEntry`` object; does not require a
system call on Windows (except for symlinks); don't follow symbolic links
(like ``os.lstat()``) if ``follow_symlinks`` is False
* ``inode()``: return the inode number of the entry; the return value
is cached on the ``DirEntry`` object
Here's a very simple example of ``scandir()`` showing use of the
``DirEntry.name`` attribute and the ``DirEntry.is_dir()`` method:
.. code-block:: python
def subdirs(path):
"""Yield directory names not starting with '.' under given path."""
for entry in os.scandir(path):
if not entry.name.startswith('.') and entry.is_dir():
yield entry.name
This ``subdirs()`` function will be significantly faster with scandir
than ``os.listdir()`` and ``os.path.isdir()`` on both Windows and POSIX
systems, especially on medium-sized or large directories.
Further reading
---------------
* `The Python docs for scandir <https://docs.python.org/3.5/library/os.html#os.scandir>`_
* `PEP 471 <https://www.python.org/dev/peps/pep-0471/>`_, the
(now-accepted) Python Enhancement Proposal that proposed adding
``scandir`` to the standard library -- a lot of details here,
including rejected ideas and previous discussion
Flames, comments, bug reports
-----------------------------
Please send flames, comments, and questions about scandir to Ben Hoyt:
http://benhoyt.com/
File bug reports for the version in the Python 3.5 standard library
`here <https://docs.python.org/3.5/bugs.html>`_, or file bug reports
or feature requests for this module at the GitHub project page:
https://github.com/benhoyt/scandir | {
"source": "yandex/perforator",
"title": "contrib/deprecated/python/scandir/README.rst",
"url": "https://github.com/yandex/perforator/blob/main/contrib/deprecated/python/scandir/README.rst",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 8504
} |
subprocess32
------------
[](https://badge.fury.io/py/subprocess32)
[](https://travis-ci.org/google/python-subprocess32)
[](https://ci.appveyor.com/project/gpshead/python-subprocess32)
This is a backport of the Python 3 subprocess module for use on Python 2.
This code has not been tested on Windows or other non-POSIX platforms.
subprocess32 includes many important reliability bug fixes relevant on
POSIX platforms. The most important of which is a C extension module
used internally to handle the code path between fork() and exec().
This module is reliable when an application is using threads.
Refer to the
[Python 3.5 subprocess documentation](https://docs.python.org/3.5/library/subprocess.html)
for usage information.
* Timeout support backported from Python 3.3 is included.
* The run() API from Python 3.5 was backported in subprocess32 3.5.0.
* Otherwise features are frozen at the 3.2 level.
Usage
-----
The recommend pattern for cross platform code is to use the following:
```python
if os.name == 'posix' and sys.version_info[0] < 3:
import subprocess32 as subprocess
else:
import subprocess
```
Or if you fully control your POSIX Python 2.7 installation, this can serve
as a replacement for its subprocess module. Users will thank you by not
filing concurrency bugs.
Got Bugs?
---------
Try to reproduce them on the latest Python 3.x itself and file bug
reports on [bugs.python.org](https://bugs.python.org/).
Add gregory.p.smith to the Nosy list.
If you have reason to believe the issue is specifically with this backport
and not a problem in Python 3 itself, use the github issue tracker.
-- Gregory P. Smith [email protected]_ | {
"source": "yandex/perforator",
"title": "contrib/deprecated/python/subprocess32/README.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/deprecated/python/subprocess32/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1908
} |
========================================
How to Build the LLVM* OpenMP* Libraries
========================================
This repository requires `CMake <http://www.cmake.org/>`_ v2.8.0 or later. LLVM
and Clang need a more recent version which also applies for in-tree builds. For
more information than available in this document please see
`LLVM's CMake documentation <https://llvm.org/docs/CMake.html>`_ and the
`official documentation <https://cmake.org/cmake/help/v2.8.0/cmake.html>`_.
.. contents::
:local:
How to Call CMake Initially, then Repeatedly
============================================
- When calling CMake for the first time, all needed compiler options must be
specified on the command line. After this initial call to CMake, the compiler
definitions must not be included for further calls to CMake. Other options
can be specified on the command line multiple times including all definitions
in the build options section below.
- Example of configuring, building, reconfiguring, rebuilding:
.. code-block:: console
$ mkdir build
$ cd build
$ cmake -DCMAKE_C_COMPILER=clang -DCMAKE_CXX_COMPILER=clang++ .. # Initial configuration
$ make
...
$ make clean
$ cmake -DCMAKE_BUILD_TYPE=Debug .. # Second configuration
$ make
...
$ rm -rf *
$ cmake -DCMAKE_C_COMPILER=gcc -DCMAKE_CXX_COMPILER=g++ .. # Third configuration
$ make
- Notice in the example how the compiler definitions are only specified for an
empty build directory, but other build options are used at any time.
- The file ``CMakeCache.txt`` which is created after the first call to CMake is
a configuration file which holds all values for the build options. These
values can be changed using a text editor to modify ``CMakeCache.txt`` as
opposed to using definitions on the command line.
- To have CMake create a particular type of build generator file simply include
the ``-G <Generator name>`` option:
.. code-block:: console
$ cmake -G "Unix Makefiles" ...
You can see a list of generators CMake supports by executing the cmake command
with no arguments.
Instructions to Build
=====================
.. code-block:: console
$ cd openmp_top_level/ [ this directory with libomptarget/, runtime/, etc. ]
$ mkdir build
$ cd build
[ Unix* Libraries ]
$ cmake -DCMAKE_C_COMPILER=<C Compiler> -DCMAKE_CXX_COMPILER=<C++ Compiler> ..
[ Windows* Libraries ]
$ cmake -G <Generator Type> -DCMAKE_C_COMPILER=<C Compiler> -DCMAKE_CXX_COMPILER=<C++ Compiler> -DCMAKE_ASM_MASM_COMPILER=[ml | ml64] -DCMAKE_BUILD_TYPE=Release ..
$ make
$ make install
CMake Options
=============
Builds with CMake can be customized by means of options as already seen above.
One possibility is to pass them via the command line:
.. code-block:: console
$ cmake -DOPTION=<value> path/to/source
.. note:: The first value listed is the respective default for that option.
Generic Options
---------------
For full documentation consult the CMake manual or execute
``cmake --help-variable VARIABLE_NAME`` to get information about a specific
variable.
**CMAKE_BUILD_TYPE** = ``Release|Debug|RelWithDebInfo``
Build type can be ``Release``, ``Debug``, or ``RelWithDebInfo`` which chooses
the optimization level and presence of debugging symbols.
**CMAKE_C_COMPILER** = <C compiler name>
Specify the C compiler.
**CMAKE_CXX_COMPILER** = <C++ compiler name>
Specify the C++ compiler.
**CMAKE_Fortran_COMPILER** = <Fortran compiler name>
Specify the Fortran compiler. This option is only needed when
**LIBOMP_FORTRAN_MODULES** is ``ON`` (see below). So typically, a Fortran
compiler is not needed during the build.
**CMAKE_ASM_MASM_COMPILER** = ``ml|ml64``
This option is only relevant for Windows*.
Options for all Libraries
-------------------------
**OPENMP_ENABLE_WERROR** = ``OFF|ON``
Treat warnings as errors and fail, if a compiler warning is triggered.
**OPENMP_LIBDIR_SUFFIX** = ``""``
Extra suffix to append to the directory where libraries are to be installed.
**OPENMP_TEST_C_COMPILER** = ``${CMAKE_C_COMPILER}``
Compiler to use for testing. Defaults to the compiler that was also used for
building.
**OPENMP_TEST_CXX_COMPILER** = ``${CMAKE_CXX_COMPILER}``
Compiler to use for testing. Defaults to the compiler that was also used for
building.
**OPENMP_LLVM_TOOLS_DIR** = ``/path/to/built/llvm/tools``
Additional path to search for LLVM tools needed by tests.
**OPENMP_LLVM_LIT_EXECUTABLE** = ``/path/to/llvm-lit``
Specify full path to ``llvm-lit`` executable for running tests. The default
is to search the ``PATH`` and the directory in **OPENMP_LLVM_TOOLS_DIR**.
**OPENMP_FILECHECK_EXECUTABLE** = ``/path/to/FileCheck``
Specify full path to ``FileCheck`` executable for running tests. The default
is to search the ``PATH`` and the directory in **OPENMP_LLVM_TOOLS_DIR**.
**OPENMP_NOT_EXECUTABLE** = ``/path/to/not``
Specify full path to ``not`` executable for running tests. The default
is to search the ``PATH`` and the directory in **OPENMP_LLVM_TOOLS_DIR**.
Options for ``libomp``
----------------------
**LIBOMP_ARCH** = ``aarch64|arm|i386|mic|mips|mips64|ppc64|ppc64le|x86_64|riscv64``
The default value for this option is chosen based on probing the compiler for
architecture macros (e.g., is ``__x86_64__`` predefined by compiler?).
**LIBOMP_MIC_ARCH** = ``knc|knf``
Intel(R) Many Integrated Core Architecture (Intel(R) MIC Architecture) to
build for. This value is ignored if **LIBOMP_ARCH** does not equal ``mic``.
**LIBOMP_LIB_TYPE** = ``normal|profile|stubs``
Library type can be ``normal``, ``profile``, or ``stubs``.
**LIBOMP_USE_VERSION_SYMBOLS** = ``ON|OFF``
Use versioned symbols for building the library. This option only makes sense
for ELF based libraries where version symbols are supported (Linux*, some BSD*
variants). It is ``OFF`` by default for Windows* and macOS*, but ``ON`` for
other Unix based operating systems.
**LIBOMP_ENABLE_SHARED** = ``ON|OFF``
Build a shared library. If this option is ``OFF``, static OpenMP libraries
will be built instead of dynamic ones.
.. note::
Static libraries are not supported on Windows*.
**LIBOMP_FORTRAN_MODULES** = ``OFF|ON``
Create the Fortran modules (requires Fortran compiler).
macOS* Fat Libraries
""""""""""""""""""""
On macOS* machines, it is possible to build universal (or fat) libraries which
include both i386 and x86_64 architecture objects in a single archive.
.. code-block:: console
$ cmake -DCMAKE_C_COMPILER=clang -DCMAKE_CXX_COMPILER=clang++ -DCMAKE_OSX_ARCHITECTURES='i386;x86_64' ..
$ make
There is also an option **LIBOMP_OSX_ARCHITECTURES** which can be set in case
this is an LLVM source tree build. It will only apply for the ``libomp`` library
avoids having the entire LLVM/Clang build produce universal binaries.
Optional Features
"""""""""""""""""
**LIBOMP_USE_ADAPTIVE_LOCKS** = ``ON|OFF``
Include adaptive locks, based on Intel(R) Transactional Synchronization
Extensions (Intel(R) TSX). This feature is x86 specific and turned ``ON``
by default for IA-32 architecture and Intel(R) 64 architecture.
**LIBOMP_USE_INTERNODE_ALIGNMENT** = ``OFF|ON``
Align certain data structures on 4096-byte. This option is useful on
multi-node systems where a small ``CACHE_LINE`` setting leads to false sharing.
**LIBOMP_OMPT_SUPPORT** = ``ON|OFF``
Include support for the OpenMP Tools Interface (OMPT).
This option is supported and ``ON`` by default for x86, x86_64, AArch64,
PPC64 and RISCV64 on Linux* and macOS*.
This option is ``OFF`` if this feature is not supported for the platform.
**LIBOMP_OMPT_OPTIONAL** = ``ON|OFF``
Include support for optional OMPT functionality. This option is ignored if
**LIBOMP_OMPT_SUPPORT** is ``OFF``.
**LIBOMP_STATS** = ``OFF|ON``
Include stats-gathering code.
**LIBOMP_USE_DEBUGGER** = ``OFF|ON``
Include the friendly debugger interface.
**LIBOMP_USE_HWLOC** = ``OFF|ON``
Use `OpenMPI's hwloc library <https://www.open-mpi.org/projects/hwloc/>`_ for
topology detection and affinity.
**LIBOMP_HWLOC_INSTALL_DIR** = ``/path/to/hwloc/install/dir``
Specify install location of hwloc. The configuration system will look for
``hwloc.h`` in ``${LIBOMP_HWLOC_INSTALL_DIR}/include`` and the library in
``${LIBOMP_HWLOC_INSTALL_DIR}/lib``. The default is ``/usr/local``.
This option is only used if **LIBOMP_USE_HWLOC** is ``ON``.
Additional Compiler Flags
"""""""""""""""""""""""""
These flags are **appended**, they do not overwrite any of the preset flags.
**LIBOMP_CPPFLAGS** = <space-separated flags>
Additional C preprocessor flags.
**LIBOMP_CXXFLAGS** = <space-separated flags>
Additional C++ compiler flags.
**LIBOMP_ASMFLAGS** = <space-separated flags>
Additional assembler flags.
**LIBOMP_LDFLAGS** = <space-separated flags>
Additional linker flags.
**LIBOMP_LIBFLAGS** = <space-separated flags>
Additional libraries to link.
**LIBOMP_FFLAGS** = <space-separated flags>
Additional Fortran compiler flags.
Options for ``libomptarget``
----------------------------
An installed LLVM package is a prerequisite for building ``libomptarget``
library. So ``libomptarget`` may only be built in two cases:
- As a project of a regular LLVM build via **LLVM_ENABLE_PROJECTS**,
**LLVM_EXTERNAL_PROJECTS**, or **LLVM_ENABLE_RUNTIMES** or
- as a standalone project build that uses a pre-installed LLVM package.
In this mode one has to make sure that the default CMake
``find_package(LLVM)`` call `succeeds <https://cmake.org/cmake/help/latest/command/find_package.html#search-procedure>`_.
**LIBOMPTARGET_OPENMP_HEADER_FOLDER** = ``""``
Path of the folder that contains ``omp.h``. This is required for testing
out-of-tree builds.
**LIBOMPTARGET_OPENMP_HOST_RTL_FOLDER** = ``""``
Path of the folder that contains ``libomp.so``, and ``libLLVMSupport.so``
when profiling is enabled. This is required for testing.
Options for ``NVPTX device RTL``
--------------------------------
**LIBOMPTARGET_NVPTX_ENABLE_BCLIB** = ``ON|OFF``
Enable CUDA LLVM bitcode offloading device RTL. This is used for link time
optimization of the OMP runtime and application code. This option is enabled
by default if the build system determines that `CMAKE_C_COMPILER` is able to
compile and link the library.
**LIBOMPTARGET_NVPTX_CUDA_COMPILER** = ``""``
Location of a CUDA compiler capable of emitting LLVM bitcode. Currently only
the Clang compiler is supported. This is only used when building the CUDA LLVM
bitcode offloading device RTL. If unspecified, either the Clang from the build
itself is used (i.e. an in-tree build with LLVM_ENABLE_PROJECTS including
clang), or the Clang compiler that the build uses as C compiler
(CMAKE_C_COMPILER; only if it is Clang). The latter is common for a
stage2-build or when using -DLLVM_ENABLE_RUNTIMES=openmp.
**LIBOMPTARGET_NVPTX_BC_LINKER** = ``""``
Location of a linker capable of linking LLVM bitcode objects. This is only
used when building the CUDA LLVM bitcode offloading device RTL. If
unspecified, either the llvm-link in that same directory as
LIBOMPTARGET_NVPTX_CUDA_COMPILER is used, or the llvm-link from the
same build (available in an in-tree build).
**LIBOMPTARGET_NVPTX_ALTERNATE_HOST_COMPILER** = ``""``
Host compiler to use with NVCC. This compiler is not going to be used to
produce any binary. Instead, this is used to overcome the input compiler
checks done by NVCC. E.g. if using a default host compiler that is not
compatible with NVCC, this option can be use to pass to NVCC a valid compiler
to avoid the error.
**LIBOMPTARGET_NVPTX_COMPUTE_CAPABILITIES** = ``35``
List of CUDA compute capabilities that should be supported by the NVPTX
device RTL. E.g. for compute capabilities 6.0 and 7.0, the option "60;70"
should be used. Compute capability 3.5 is the minimum required.
**LIBOMPTARGET_NVPTX_DEBUG** = ``OFF|ON``
Enable printing of debug messages from the NVPTX device RTL.
**LIBOMPTARGET_LIT_ARGS** = ``""``
Arguments given to lit. ``make check-libomptarget`` and
``make check-libomptarget-*`` are affected. For example, use
``LIBOMPTARGET_LIT_ARGS="-j4"`` to force ``lit`` to start only four parallel
jobs instead of by default the number of threads in the system.
Example Usages of CMake
=======================
Typical Invocations
-------------------
.. code-block:: console
$ cmake -DCMAKE_C_COMPILER=clang -DCMAKE_CXX_COMPILER=clang++ ..
$ cmake -DCMAKE_C_COMPILER=gcc -DCMAKE_CXX_COMPILER=g++ ..
$ cmake -DCMAKE_C_COMPILER=icc -DCMAKE_CXX_COMPILER=icpc ..
Advanced Builds with Various Options
------------------------------------
- Build the i386 Linux* library using GCC*
.. code-block:: console
$ cmake -DCMAKE_C_COMPILER=gcc -DCMAKE_CXX_COMPILER=g++ -DLIBOMP_ARCH=i386 ..
- Build the x86_64 debug Mac library using Clang*
.. code-block:: console
$ cmake -DCMAKE_C_COMPILER=clang -DCMAKE_CXX_COMPILER=clang++ -DLIBOMP_ARCH=x86_64 -DCMAKE_BUILD_TYPE=Debug ..
- Build the library (architecture determined by probing compiler) using the
Intel(R) C Compiler and the Intel(R) C++ Compiler. Also, create Fortran
modules with the Intel(R) Fortran Compiler.
.. code-block:: console
$ cmake -DCMAKE_C_COMPILER=icc -DCMAKE_CXX_COMPILER=icpc -DCMAKE_Fortran_COMPILER=ifort -DLIBOMP_FORTRAN_MODULES=on ..
- Have CMake find the C/C++ compiler and specify additional flags for the
preprocessor and C++ compiler.
.. code-blocks:: console
$ cmake -DLIBOMP_CPPFLAGS='-DNEW_FEATURE=1 -DOLD_FEATURE=0' -DLIBOMP_CXXFLAGS='--one-specific-flag --two-specific-flag' ..
- Build the stubs library
.. code-blocks:: console
$ cmake -DCMAKE_C_COMPILER=gcc -DCMAKE_CXX_COMPILER=g++ -DLIBOMP_LIB_TYPE=stubs ..
**Footnotes**
.. [*] Other names and brands may be claimed as the property of others. | {
"source": "yandex/perforator",
"title": "contrib/libs/cxxsupp/openmp/README.rst",
"url": "https://github.com/yandex/perforator/blob/main/contrib/libs/cxxsupp/openmp/README.rst",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 13968
} |
# Abseil in gRPC
This document explains how to use Abseil throughout gRPC. Note that this isn't
supposed to explain general usage of Abseil.
## The version of Abseil
gRPC intends to use the LTS versions of Abseil only because it simplifies
dependency management. Abseil is being distributed via package distribution
systems such as vcpkg and cocoapods. If gRPC depends on the certain version
that aren't registered, gRPC in that system cannot get the right version of
Abseil when being built, resulting in a build failure.
Therefore, gRPC will use the LTS version only, preferably the latest one.
## Libraries that are not ready to use
Most of Abseil libraries are okay to use but there are some exceptions
because they're not going well yet on some of our test machinaries or
platforms it supports. The following is a list of targets that are NOT
ready to use.
- `y_absl/synchronization:*`: Blocked by b/186685878.
- `y_absl/random`: [WIP](https://github.com/grpc/grpc/pull/23346).
## Implemetation only
You can use Abseil in gRPC Core and gRPC C++. But you cannot use it in
the public interface of gRPC C++ because i) it doesn't gurantee no breaking
API changes like gRPC C++ does and ii) it may make users change their build
system to address Abseil. | {
"source": "yandex/perforator",
"title": "contrib/libs/grpc/third_party/ABSEIL_MANUAL.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/libs/grpc/third_party/ABSEIL_MANUAL.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1261
} |
# Third-party libraries
gRPC depends on several third-party libraries, their source code is available
(usually as a git submodule) in this directory.
## Guidelines on updating submodules
- IMPORTANT: whenever possible, try to only update to a stable release of a library (= not to master / random commit). Depending on unreleased revisions
makes gRPC installation harder for users, as it forces them to always build the dependency from source and prevents them from using more
convenient installation channels (linux packages, package managers etc.)
- bazel BUILD uses a different dependency model - whenever updating a submodule, also update the revision in `grpc_deps.bzl` so that bazel and
non-bazel builds stay in sync (this is actually enforced by a sanity check in some cases)
## Considerations when adding a new third-party dependency
- gRPC C++ needs to stay buildable/installable even if the submodules are not present (e.g. the tar.gz archive with gRPC doesn't contain the submodules),
assuming that the dependencies are already installed. This is a requirement for being able to provide a reasonable install process (e.g. using cmake)
and to support package managers for gRPC C++.
- Adding a new dependency is a lot of work (both for us and for the users).
We currently support multiple build systems (BAZEL, cmake, make, ...) so adding a new dependency usually requires updates in multiple build systems
(often not trivial). The installation process also needs to continue to work (we do have distrib tests to test many of the possible installation scenarios,
but they are not perfect). Adding a new dependency also usually affects the installation instructions that need to be updated.
Also keep in mind that adding a new dependency can be quite disruptive
for the users and community - it means that all users will need to update their projects accordingly (for C++ projects often non-trivial) and
the community-provided C++ packages (e.g. vcpkg) will need to be updated as well.
## Checklist for adding a new third-party dependency
**READ THIS BEFORE YOU ADD A NEW DEPENDENCY**
- [ ] Make sure you understand the hidden costs of adding a dependency (see section above) and that you understand the complexities of updating the build files. Maintenance of the build files isn't for free, so expect to be involved in maintenance tasks, cleanup and support (e.g resolving user bugs) of the build files in the future.
- [ ] Once your change is ready, start an [adhoc run of artifact - packages - distribtests flow](https://fusion.corp.google.com/projectanalysis/summary/KOKORO/prod%3Agrpc%2Fcore%2Fexperimental%2Fgrpc_build_artifacts_multiplatform) and make sure everything passes (for technical reasons, not all the distribtests can run on each PR automatically).
- [ ] Check the impact of the new dependency on the size of our distribution packages (compare BEFORE and AFTER) and post the comparison on your PR (it should not be approved without checking the impact sizes of packages first). The package sizes AFTER can be obtained from the adhoc package build from bullet point above.
## Instructions for updating dependencies
Usually the process is
1. update the submodule to selected commit (see guidance above)
2. update the dependency in `grpc_deps.bzl` to the same commit
3. update `tools/run_tests/sanity/check_submodules.sh` to make the sanity test pass
4. (when needed) run `tools/buildgen/generate_projects.sh` to regenerate the generated files
5. populate the bazel download mirror by running `bazel/update_mirror.sh`
Updating some dependencies requires extra care.
### Updating third_party/abseil-cpp
- Two additional steps should be done before running `generate_projects.sh` above.
- Running `src/abseil-cpp/preprocessed_builds.yaml.gen.py`.
- Updating `abseil_version =` scripts in `templates/gRPC-C++.podspec.template` and
`templates/gRPC-Core.podspec.template`.
- You can see an example of previous [upgrade](https://github.com/grpc/grpc/pull/24270).
### Updating third_party/boringssl-with-bazel
NOTE: updating the boringssl dependency is now part of the internal grpc release tooling (see [go/grpc-release](http://go/grpc-release)).
Prefer using the release tooling when possible. The instructions below are provided as a reference and aren't guaranteed to be up-to-date.
- Update the `third_party/boringssl-with-bazel` submodule to the latest [`master-with-bazel`](https://github.com/google/boringssl/tree/master-with-bazel) branch
```
git submodule update --init # just to start in a clean state
cd third_party/boringssl-with-bazel
git fetch origin # fetch what's new in the boringssl repository
git checkout origin/master-with-bazel # checkout the current state of master-with-bazel branch in the boringssl repo
# Note the latest commit SHA on master-with-bazel branch
cd ../.. # go back to grpc repo root
git status # will show that there are new commits in third_party/boringssl-with-bazel
git add third_party/boringssl-with-bazel # we actually want to update the changes to the submodule
git commit -m "update submodule boringssl-with-bazel with origin/master-with-bazel" # commit
```
- Update boringssl dependency in `bazel/grpc_deps.bzl` to the same commit SHA as master-with-bazel branch
- Update `http_archive(name = "boringssl",` section by updating the sha in `strip_prefix` and `urls` fields.
- Also, set `sha256` field to "" as the existing value is not valid. This will be added later once we know what that value is.
- Update `tools/run_tests/sanity/check_submodules.sh` with the same commit
- Commit these changes `git commit -m "update boringssl dependency to master-with-bazel commit SHA"`
- Run `tools/buildgen/generate_projects.sh` to regenerate the generated files
- Because `sha256` in `bazel/grpc_deps.bzl` was left empty, you will get a DEBUG msg like this one:
```
Rule 'boringssl' indicated that a canonical reproducible form can be obtained by modifying arguments sha256 = "SHA value"
```
- Commit the regenrated files `git commit -m "regenerate files"`
- Update `bazel/grpc_deps.bzl` with the SHA value shown in the above debug msg. Commit again `git commit -m "Updated sha256"`
- Run `tools/distrib/generate_boringssl_prefix_header.sh`
- Commit again `git commit -m "generate boringssl prefix headers"`
- Increment the boringssl podspec version number in
`templates/src/objective-c/BoringSSL-GRPC.podspec.template` and `templates/gRPC-Core.podspec.template`.
[example](https://github.com/grpc/grpc/pull/21527/commits/9d4411842f02f167209887f1f3d2b9ab5d14931a)
- Commit again `git commit -m "Increment podspec version"`
- Run `tools/buildgen/generate_projects.sh` (yes, again)
- Commit again `git commit -m "Second regeneration"`
- Create a PR with all the above commits.
- Run `bazel/update_mirror.sh` to update GCS mirror.
### Updating third_party/protobuf
Updating the protobuf dependency is now part of the internal release process (see [go/grpc-release](http://go/grpc-release)).
### Updating third_party/envoy-api
Apart from the above steps, please perform the following two steps to generate the Python `xds-protos` package:
1. Bump the version in the `tools/distrib/python/xds_protos/setup.py`;
2. Run `tools/distrib/python/xds_protos/build_validate_upload.sh` to upload the built wheel.
### Updating third_party/upb
Since upb is vendored in the gRPC repo, you cannot use submodule to update it. Please follow the steps below.
1. Update third_party/upb directory by running
- `export GRPC_ROOT=~/git/grpc`
- `wget https://github.com/protocolbuffers/upb/archive/refs/heads/main.zip`
- `rm -rf $GRPC_ROOT/third_party/upb`
- `unzip main.zip -d $GRPC_ROOT/third_party`
- `mv $GRPC_ROOT/third_party/upb-main $GRPC_ROOT/third_party/upb`
2. Update the dependency in `grpc_deps.bzl` to the same commit
3. Populate the bazel download mirror by running `bazel/update_mirror.sh`
4. Update `src/upb/gen_build_yaml.py` for newly added or removed upb files
- Running `bazel query "deps(upb) union deps(json) union deps(textformat)"`
under third_party/upb would give some idea on what needs to be included.
5. Run `tools/buildgen/generate_projects.sh` to regenerate the generated files
6. Run `tools/codegen/core/gen_upb_api.sh` to regenerate upb files.
### Updating third_party/xxhash
TODO(https://github.com/Cyan4973/xxHash/issues/548): revisit LICENSE
instructions if upstream splits library and CLI.
The upstream xxhash repository contains a bunch of files that we don't want, so
we employ a rather manual update flow to pick up just the bits we care about:
```
git remote add xxhash https://github.com/Cyan4973/xxHash.git
git fetch xxhash
git show xxhash/dev:xxhash.h > third_party/xxhash/xxhash.h
git show xxhash/dev:LICENSE | sed -nE '/^-+$/q;p' > third_party/xxhash/LICENSE
``` | {
"source": "yandex/perforator",
"title": "contrib/libs/grpc/third_party/README.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/libs/grpc/third_party/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 8917
} |
## Общие соображения
В библиотеку добавлены реализации символов, появившихся в `libc.so.6` Ubuntu
14.04 с момента Ubuntu 12.04.
Если какой-либо объектный файл ссылается на один из таких символов, то при
компоновке этот символ будет взят из нашей библиотеки. В противном случае,
компоновщик сослался бы на такой символ из `libc.so.6`, добавив к исполняемому
файлу зависимость от новой версии динамической библиотеки (`GLIBC_2.16`,
`GLIBC_2.17` или `GLIBC_2.18`). Такой исполняемый файл не может быть запущен на
Ubuntu 12.04, даже если ни один из новых символов не используется в runtime.
На Ubuntu 14.04 или более новых, в случае если процесс загружает `libc.so.6`, мы
будем в runtime иметь две реализации символов, нашу и libc. Но все добавленные
функции не имеют какого-либо состояния и никакими деталями внутренней реализации
не связаны с другими. Нет разницы, какую из реализаций использовать, и даже
попеременное использование различных реализаций в одном и том же контексте не
должно приводить к некорректной работе.
В какой-то момент этот слой совместимости будет отключен: https://st.yandex-team.ru/DEVTOOLS-7436
### Разделяемая реализация
Была идея оформить новые реализации так, чтобы в случае их наличия и в
загруженной libc динамический компоновщик выбирал для всех ссылок одну
реализацию.
По всей видимости, для этого требуется собирать исполняемый файл как PIE. Только
в этом случае для наших реализаций будут сгенерированы дополнительные PLT
прослойки и вызовы наших реализаций будут проходить через них.
Но в этом случае вообще все вызовы будут происходить таким образом и это
повлияет на производительность. Ухудшения производительности, наверное, можно
избежать, явно указав, какие символы в исполняемом файле должны быть публичными,
но сейчас нет способа сделать это в одном месте, учитывая, что в некоторых
случаях этот список должен дополняться.
## `getauxval` и `secure_getenv`
Функция `getauxval` требует загрузки и хранения «Auxiliary Vector» (см.
[здесь](https://refspecs.linuxfoundation.org/LSB_1.3.0/IA64/spec/auxiliaryvector.html)).
Эти данные доступны в момент запуска процесса. libc из новых Ubuntu сохраняет
эти данные и предоставляет реализацию `getauxval`. В этом случае наша реализация
перенаправляет вызовы `getauxval` в libc, получив при старте исполняемого файла
соответствующий указатель.
Если реализация libc недоступна (на старых Ubuntu или если libc не загружена),
то эти данные можно получить, прочитав `/proc/self/auxv`. Это также делается
один раз при старте.
В обоих случаях, статически инициализируется синглтон `NUbuntuCompat::TGlibc`,
который производит эти действия в конструкторе.
`secure_getenv` использует одно из значений `getauxval`, поэтому к нему всё это
также относится.
Каждый метод новой libc реализован в отдельном объектом файле. `TGlibc` также
находится в отдельном файле, и ссылки на неё стоят только в местах использования.
Если при компоновке не понадобились ни `getauxval`, ни `secure_getenv`, то
объектный файл с `TGlibc` тоже не будет выбран компоновщиком, и в этом случае
никакой лишней статической инициализации выполняться не будет.
## Патч libc.so
Чтобы иметь возможность использовать `getauxval` (точнее его реализацию
`__getauxval`) из новой libc, если таковая уже используется процессом,
библиотека совместимости объявляет этот символ у себя как внешний и слабый. При
загрузке динамический компоновщик устанавливает значение этого символа из libc
или `nullptr`, если его там нет. Наша реализация `getauxval` проверяет
доступность реализации libc, просто сравнивая указатель с `nullptr`.
В Аркадии также есть код, который подобным образом работает с символом
`__cxa_thread_atexit_impl`.
Однако, если компоновать такую программу с использованием новой libc, то к таким
символам и самой программе будет приписано требование соответствующей (новой)
версии libc. Чтобы этого не произошло, при сборке с этой библиотекой
совместимости используется патченный вариант `libc.so.6`, где у таких символов
удалена версия.
Также, файлы, проверяющие, что доступна реализация из libc, должны быть собраны
как PIC. В противном случае вместо значения, заполненного динамическим
компоновщиком, компилятор ещё на стадии компиляции использует `nullptr` и
проверка никогда не срабатывает.
## Упоминания
Идея о возможности добавить слой совместимости была взята из ClickHouse.
* [https://clickhouse.tech/](https://clickhouse.tech/)
* [https://wiki.yandex-team.ru/clickhouse/](https://wiki.yandex-team.ru/clickhouse/) | {
"source": "yandex/perforator",
"title": "contrib/libs/libc_compat/ubuntu_14/README.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/libs/libc_compat/ubuntu_14/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 4489
} |
Protocol Buffers - Google's data interchange format
===================================================
Copyright 2008 Google Inc.
https://developers.google.com/protocol-buffers/
CMake Installation
-----------------------
To compile or install protobuf from source using CMake, see
[cmake/README.md](../cmake/README.md).
C++ Protobuf - Unix
-----------------------
To build protobuf from source, the following tools are needed:
* bazel
* git
* g++
On Ubuntu/Debian, for example, you can install them with:
sudo apt-get install g++ git bazel
On other platforms, please use the corresponding package managing tool to
install them before proceeding. See https://bazel.build/install for further
instructions on installing Bazel, or to build from source using CMake, see
[cmake/README.md](../cmake/README.md).
To get the source, download the release .tar.gz or .zip package in the
release page:
https://github.com/protocolbuffers/protobuf/releases/latest
For example: if you only need C++, download `protobuf-cpp-[VERSION].tar.gz`; if
you need C++ and Java, download `protobuf-java-[VERSION].tar.gz` (every package
contains C++ source already); if you need C++ and multiple other languages,
download `protobuf-all-[VERSION].tar.gz`.
You can also get the source by "git clone" our git repository. Make sure you
have also cloned the submodules and generated the configure script (skip this
if you are using a release .tar.gz or .zip package):
git clone https://github.com/protocolbuffers/protobuf.git
cd protobuf
git submodule update --init --recursive
To build the C++ Protocol Buffer runtime and the Protocol Buffer compiler
(protoc) execute the following:
bazel build :protoc :protobuf
The compiler can then be installed, for example on Linux:
cp bazel-bin/protoc /usr/local/bin
For more usage information on Bazel, please refer to http://bazel.build.
**Compiling dependent packages**
To compile a package that uses Protocol Buffers, you need to setup a Bazel
WORKSPACE that's hooked up to the protobuf repository and loads its
dependencies. For an example, see [WORKSPACE](../examples/WORKSPACE).
**Note for Mac users**
For a Mac system, Unix tools are not available by default. You will first need
to install Xcode from the Mac AppStore and then run the following command from
a terminal:
sudo xcode-select --install
To install Unix tools, you can install "port" following the instructions at
https://www.macports.org . This will reside in /opt/local/bin/port for most
Mac installations.
sudo /opt/local/bin/port install bazel
Alternative for Homebrew users:
brew install bazel
Then follow the Unix instructions above.
C++ Protobuf - Windows
--------------------------
If you only need the protoc binary, you can download it from the release
page:
https://github.com/protocolbuffers/protobuf/releases/latest
In the downloads section, download the zip file protoc-$VERSION-win32.zip.
It contains the protoc binary as well as public proto files of protobuf
library.
Protobuf and its dependencies can be installed directly by using `vcpkg`:
>vcpkg install protobuf protobuf:x64-windows
If zlib support is desired, you'll also need to install the zlib feature:
>vcpkg install protobuf[zlib] protobuf[zlib]:x64-windows
See https://github.com/Microsoft/vcpkg for more information.
To build from source using Microsoft Visual C++, see [cmake/README.md](../cmake/README.md).
To build from source using Cygwin or MinGW, follow the Unix installation
instructions, above.
Binary Compatibility Warning
----------------------------
Due to the nature of C++, it is unlikely that any two versions of the
Protocol Buffers C++ runtime libraries will have compatible ABIs.
That is, if you linked an executable against an older version of
libprotobuf, it is unlikely to work with a newer version without
re-compiling. This problem, when it occurs, will normally be detected
immediately on startup of your app. Still, you may want to consider
using static linkage. You can configure this in your `cc_binary` Bazel rules
by specifying:
linkstatic=True
Usage
-----
The complete documentation for Protocol Buffers is available via the
web at:
https://protobuf.dev/ | {
"source": "yandex/perforator",
"title": "contrib/libs/protobuf/src/README.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/libs/protobuf/src/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 4254
} |
Protocol Buffers - Google's data interchange format
===================================================
Copyright 2008 Google Inc.
https://developers.google.com/protocol-buffers/
C++ Installation - Unix
-----------------------
To build protobuf from source, the following tools are needed:
* autoconf
* automake
* libtool
* make
* g++
* unzip
On Ubuntu/Debian, you can install them with:
sudo apt-get install autoconf automake libtool curl make g++ unzip
On other platforms, please use the corresponding package managing tool to
install them before proceeding.
To get the source, download one of the release .tar.gz or .zip packages in the
release page:
https://github.com/protocolbuffers/protobuf/releases/latest
For example: if you only need C++, download `protobuf-cpp-[VERSION].tar.gz`; if
you need C++ and Java, download `protobuf-java-[VERSION].tar.gz` (every package
contains C++ source already); if you need C++ and multiple other languages,
download `protobuf-all-[VERSION].tar.gz`.
You can also get the source by "git clone" our git repository. Make sure you
have also cloned the submodules and generated the configure script (skip this
if you are using a release .tar.gz or .zip package):
git clone https://github.com/protocolbuffers/protobuf.git
cd protobuf
git submodule update --init --recursive
./autogen.sh
To build and install the C++ Protocol Buffer runtime and the Protocol
Buffer compiler (protoc) execute the following:
./configure
make
make check
sudo make install
sudo ldconfig # refresh shared library cache.
If "make check" fails, you can still install, but it is likely that
some features of this library will not work correctly on your system.
Proceed at your own risk.
For advanced usage information on configure and make, please refer to the
autoconf documentation:
http://www.gnu.org/software/autoconf/manual/autoconf.html#Running-configure-Scripts
**Hint on install location**
By default, the package will be installed to /usr/local. However,
on many platforms, /usr/local/lib is not part of LD_LIBRARY_PATH.
You can add it, but it may be easier to just install to /usr
instead. To do this, invoke configure as follows:
./configure --prefix=/usr
If you already built the package with a different prefix, make sure
to run "make clean" before building again.
**Compiling dependent packages**
To compile a package that uses Protocol Buffers, you need to pass
various flags to your compiler and linker. As of version 2.2.0,
Protocol Buffers integrates with pkg-config to manage this. If you
have pkg-config installed, then you can invoke it to get a list of
flags like so:
pkg-config --cflags protobuf # print compiler flags
pkg-config --libs protobuf # print linker flags
pkg-config --cflags --libs protobuf # print both
For example:
c++ my_program.cc my_proto.pb.cc `pkg-config --cflags --libs protobuf`
Note that packages written prior to the 2.2.0 release of Protocol
Buffers may not yet integrate with pkg-config to get flags, and may
not pass the correct set of flags to correctly link against
libprotobuf. If the package in question uses autoconf, you can
often fix the problem by invoking its configure script like:
configure CXXFLAGS="$(pkg-config --cflags protobuf)" \
LIBS="$(pkg-config --libs protobuf)"
This will force it to use the correct flags.
If you are writing an autoconf-based package that uses Protocol
Buffers, you should probably use the PKG_CHECK_MODULES macro in your
configure script like:
PKG_CHECK_MODULES([protobuf], [protobuf])
See the pkg-config man page for more info.
If you only want protobuf-lite, substitute "protobuf-lite" in place
of "protobuf" in these examples.
**Note for Mac users**
For a Mac system, Unix tools are not available by default. You will first need
to install Xcode from the Mac AppStore and then run the following command from
a terminal:
sudo xcode-select --install
To install Unix tools, you can install "port" following the instructions at
https://www.macports.org . This will reside in /opt/local/bin/port for most
Mac installations.
sudo /opt/local/bin/port install autoconf automake libtool
Then follow the Unix instructions above.
**Note for cross-compiling**
The makefiles normally invoke the protoc executable that they just
built in order to build tests. When cross-compiling, the protoc
executable may not be executable on the host machine. In this case,
you must build a copy of protoc for the host machine first, then use
the --with-protoc option to tell configure to use it instead. For
example:
./configure --with-protoc=protoc
This will use the installed protoc (found in your $PATH) instead of
trying to execute the one built during the build process. You can
also use an executable that hasn't been installed. For example, if
you built the protobuf package for your host machine in ../host,
you might do:
./configure --with-protoc=../host/src/protoc
Either way, you must make sure that the protoc executable you use
has the same version as the protobuf source code you are trying to
use it with.
**Note for Solaris users**
Solaris 10 x86 has a bug that will make linking fail, complaining
about libstdc++.la being invalid. We have included a work-around
in this package. To use the work-around, run configure as follows:
./configure LDFLAGS=-L$PWD/src/solaris
See src/solaris/libstdc++.la for more info on this bug.
**Note for HP C++ Tru64 users**
To compile invoke configure as follows:
./configure CXXFLAGS="-O -std ansi -ieee -D__USE_STD_IOSTREAM"
Also, you will need to use gmake instead of make.
**Note for AIX users**
Compile using the IBM xlC C++ compiler as follows:
./configure CXX=xlC
Also, you will need to use GNU `make` (`gmake`) instead of AIX `make`.
C++ Installation - Windows
--------------------------
If you only need the protoc binary, you can download it from the release
page:
https://github.com/protocolbuffers/protobuf/releases/latest
In the downloads section, download the zip file protoc-$VERSION-win32.zip.
It contains the protoc binary as well as public proto files of protobuf
library.
Protobuf and its dependencies can be installed directly by using `vcpkg`:
>vcpkg install protobuf protobuf:x64-windows
If zlib support is desired, you'll also need to install the zlib feature:
>vcpkg install protobuf[zlib] protobuf[zlib]:x64-windows
See https://github.com/Microsoft/vcpkg for more information.
To build from source using Microsoft Visual C++, see [cmake/README.md](../cmake/README.md).
To build from source using Cygwin or MinGW, follow the Unix installation
instructions, above.
Binary Compatibility Warning
----------------------------
Due to the nature of C++, it is unlikely that any two versions of the
Protocol Buffers C++ runtime libraries will have compatible ABIs.
That is, if you linked an executable against an older version of
libprotobuf, it is unlikely to work with a newer version without
re-compiling. This problem, when it occurs, will normally be detected
immediately on startup of your app. Still, you may want to consider
using static linkage. You can configure this package to install
static libraries only using:
./configure --disable-shared
Usage
-----
The complete documentation for Protocol Buffers is available via the
web at:
https://developers.google.com/protocol-buffers/ | {
"source": "yandex/perforator",
"title": "contrib/libs/protobuf_old/src/README.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/libs/protobuf_old/src/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 7498
} |
Zstandard library files
================================
The __lib__ directory is split into several sub-directories,
in order to make it easier to select or exclude features.
#### Building
`Makefile` script is provided, supporting [Makefile conventions](https://www.gnu.org/prep/standards/html_node/Makefile-Conventions.html#Makefile-Conventions),
including commands variables, staged install, directory variables and standard targets.
- `make` : generates both static and dynamic libraries
- `make install` : install libraries and headers in target system directories
`libzstd` default scope is pretty large, including compression, decompression, dictionary builder,
and support for decoding legacy formats >= v0.5.0.
The scope can be reduced on demand (see paragraph _modular build_).
#### Multithreading support
When building with `make`, by default the dynamic library is multithreaded and static library is single-threaded (for compatibility reasons).
Enabling multithreading requires 2 conditions :
- set build macro `ZSTD_MULTITHREAD` (`-DZSTD_MULTITHREAD` for `gcc`)
- for POSIX systems : compile with pthread (`-pthread` compilation flag for `gcc`)
For convenience, we provide a build target to generate multi and single threaded libraries:
- Force enable multithreading on both dynamic and static libraries by appending `-mt` to the target, e.g. `make lib-mt`.
Note that the `.pc` generated on calling `make lib-mt` will already include the require Libs and Cflags.
- Force disable multithreading on both dynamic and static libraries by appending `-nomt` to the target, e.g. `make lib-nomt`.
- By default, as mentioned before, dynamic library is multithreaded, and static library is single-threaded, e.g. `make lib`.
When linking a POSIX program with a multithreaded version of `libzstd`,
note that it's necessary to invoke the `-pthread` flag during link stage.
The `.pc` generated from `make install` or `make install-pc` always assume a single-threaded static library
is compiled. To correctly generate a `.pc` for the multi-threaded static library, set `MT=1` as ENV variable.
Multithreading capabilities are exposed
via the [advanced API defined in `lib/zstd.h`](https://github.com/facebook/zstd/blob/v1.4.3/lib/zstd.h#L351).
#### API
Zstandard's stable API is exposed within [lib/zstd.h](zstd.h).
#### Advanced API
Optional advanced features are exposed via :
- `lib/zstd_errors.h` : translates `size_t` function results
into a `ZSTD_ErrorCode`, for accurate error handling.
- `ZSTD_STATIC_LINKING_ONLY` : if this macro is defined _before_ including `zstd.h`,
it unlocks access to the experimental API,
exposed in the second part of `zstd.h`.
All definitions in the experimental APIs are unstable,
they may still change in the future, or even be removed.
As a consequence, experimental definitions shall ___never be used with dynamic library___ !
Only static linking is allowed.
#### Modular build
It's possible to compile only a limited set of features within `libzstd`.
The file structure is designed to make this selection manually achievable for any build system :
- Directory `lib/common` is always required, for all variants.
- Compression source code lies in `lib/compress`
- Decompression source code lies in `lib/decompress`
- It's possible to include only `compress` or only `decompress`, they don't depend on each other.
- `lib/dictBuilder` : makes it possible to generate dictionaries from a set of samples.
The API is exposed in `lib/dictBuilder/zdict.h`.
This module depends on both `lib/common` and `lib/compress` .
- `lib/legacy` : makes it possible to decompress legacy zstd formats, starting from `v0.1.0`.
This module depends on `lib/common` and `lib/decompress`.
To enable this feature, define `ZSTD_LEGACY_SUPPORT` during compilation.
Specifying a number limits versions supported to that version onward.
For example, `ZSTD_LEGACY_SUPPORT=2` means : "support legacy formats >= v0.2.0".
Conversely, `ZSTD_LEGACY_SUPPORT=0` means "do __not__ support legacy formats".
By default, this build macro is set as `ZSTD_LEGACY_SUPPORT=5`.
Decoding supported legacy format is a transparent capability triggered within decompression functions.
It's also allowed to invoke legacy API directly, exposed in `lib/legacy/zstd_legacy.h`.
Each version does also provide its own set of advanced API.
For example, advanced API for version `v0.4` is exposed in `lib/legacy/zstd_v04.h` .
- While invoking `make libzstd`, it's possible to define build macros
`ZSTD_LIB_COMPRESSION`, `ZSTD_LIB_DECOMPRESSION`, `ZSTD_LIB_DICTBUILDER`,
and `ZSTD_LIB_DEPRECATED` as `0` to forgo compilation of the
corresponding features. This will also disable compilation of all
dependencies (e.g. `ZSTD_LIB_COMPRESSION=0` will also disable
dictBuilder).
- There are a number of options that can help minimize the binary size of
`libzstd`.
The first step is to select the components needed (using the above-described
`ZSTD_LIB_COMPRESSION` etc.).
The next step is to set `ZSTD_LIB_MINIFY` to `1` when invoking `make`. This
disables various optional components and changes the compilation flags to
prioritize space-saving.
Detailed options: Zstandard's code and build environment is set up by default
to optimize above all else for performance. In pursuit of this goal, Zstandard
makes significant trade-offs in code size. For example, Zstandard often has
more than one implementation of a particular component, with each
implementation optimized for different scenarios. For example, the Huffman
decoder has complementary implementations that decode the stream one symbol at
a time or two symbols at a time. Zstd normally includes both (and dispatches
between them at runtime), but by defining `HUF_FORCE_DECOMPRESS_X1` or
`HUF_FORCE_DECOMPRESS_X2`, you can force the use of one or the other, avoiding
compilation of the other. Similarly, `ZSTD_FORCE_DECOMPRESS_SEQUENCES_SHORT`
and `ZSTD_FORCE_DECOMPRESS_SEQUENCES_LONG` force the compilation and use of
only one or the other of two decompression implementations. The smallest
binary is achieved by using `HUF_FORCE_DECOMPRESS_X1` and
`ZSTD_FORCE_DECOMPRESS_SEQUENCES_SHORT` (implied by `ZSTD_LIB_MINIFY`).
On the compressor side, Zstd's compression levels map to several internal
strategies. In environments where the higher compression levels aren't used,
it is possible to exclude all but the fastest strategy with
`ZSTD_LIB_EXCLUDE_COMPRESSORS_DFAST_AND_UP=1`. (Note that this will change
the behavior of the default compression level.) Or if you want to retain the
default compressor as well, you can set
`ZSTD_LIB_EXCLUDE_COMPRESSORS_GREEDY_AND_UP=1`, at the cost of an additional
~20KB or so.
For squeezing the last ounce of size out, you can also define
`ZSTD_NO_INLINE`, which disables inlining, and `ZSTD_STRIP_ERROR_STRINGS`,
which removes the error messages that are otherwise returned by
`ZSTD_getErrorName` (implied by `ZSTD_LIB_MINIFY`).
Finally, when integrating into your application, make sure you're doing link-
time optimization and unused symbol garbage collection (via some combination of,
e.g., `-flto`, `-ffat-lto-objects`, `-fuse-linker-plugin`,
`-ffunction-sections`, `-fdata-sections`, `-fmerge-all-constants`,
`-Wl,--gc-sections`, `-Wl,-z,norelro`, and an archiver that understands
the compiler's intermediate representation, e.g., `AR=gcc-ar`). Consult your
compiler's documentation.
- While invoking `make libzstd`, the build macro `ZSTD_LEGACY_MULTITHREADED_API=1`
will expose the deprecated `ZSTDMT` API exposed by `zstdmt_compress.h` in
the shared library, which is now hidden by default.
- The build macro `STATIC_BMI2` can be set to 1 to force usage of `bmi2` instructions.
It is generally not necessary to set this build macro,
because `STATIC_BMI2` will be automatically set to 1
on detecting the presence of the corresponding instruction set in the compilation target.
It's nonetheless available as an optional manual toggle for better control,
and can also be used to forcefully disable `bmi2` instructions by setting it to 0.
- The build macro `DYNAMIC_BMI2` can be set to 1 or 0 in order to generate binaries
which can detect at runtime the presence of BMI2 instructions, and use them only if present.
These instructions contribute to better performance, notably on the decoder side.
By default, this feature is automatically enabled on detecting
the right instruction set (x64) and compiler (clang or gcc >= 5).
It's obviously disabled for different cpus,
or when BMI2 instruction set is _required_ by the compiler command line
(in this case, only the BMI2 code path is generated).
Setting this macro will either force to generate the BMI2 dispatcher (1)
or prevent it (0). It overrides automatic detection.
- The build macro `ZSTD_NO_UNUSED_FUNCTIONS` can be defined to hide the definitions of functions
that zstd does not use. Not all unused functions are hidden, but they can be if needed.
Currently, this macro will hide function definitions in FSE and HUF that use an excessive
amount of stack space.
- The build macro `ZSTD_NO_INTRINSICS` can be defined to disable all explicit intrinsics.
Compiler builtins are still used.
- The build macro `ZSTD_DECODER_INTERNAL_BUFFER` can be set to control
the amount of extra memory used during decompression to store literals.
This defaults to 64kB. Reducing this value reduces the memory footprint of
`ZSTD_DCtx` decompression contexts,
but might also result in a small decompression speed cost.
- The C compiler macros `ZSTDLIB_VISIBLE`, `ZSTDERRORLIB_VISIBLE` and `ZDICTLIB_VISIBLE`
can be overridden to control the visibility of zstd's API. Additionally,
`ZSTDLIB_STATIC_API` and `ZDICTLIB_STATIC_API` can be overridden to control the visibility
of zstd's static API. Specifically, it can be set to `ZSTDLIB_HIDDEN` to hide the symbols
from the shared library. These macros default to `ZSTDLIB_VISIBILITY`,
`ZSTDERRORLIB_VSIBILITY`, and `ZDICTLIB_VISIBILITY` if unset, for backwards compatibility
with the old macro names.
- The C compiler macro `HUF_DISABLE_FAST_DECODE` disables the newer Huffman fast C
and assembly decoding loops. You may want to use this macro if these loops are
slower on your platform.
#### Windows : using MinGW+MSYS to create DLL
DLL can be created using MinGW+MSYS with the `make libzstd` command.
This command creates `dll\libzstd.dll` and the import library `dll\libzstd.lib`.
The import library is only required with Visual C++.
The header file `zstd.h` and the dynamic library `dll\libzstd.dll` are required to
compile a project using gcc/MinGW.
The dynamic library has to be added to linking options.
It means that if a project that uses ZSTD consists of a single `test-dll.c`
file it should be linked with `dll\libzstd.dll`. For example:
```
gcc $(CFLAGS) -Iinclude/ test-dll.c -o test-dll dll\libzstd.dll
```
The compiled executable will require ZSTD DLL which is available at `dll\libzstd.dll`.
#### Advanced Build options
The build system requires a hash function in order to
separate object files created with different compilation flags.
By default, it tries to use `md5sum` or equivalent.
The hash function can be manually switched by setting the `HASH` variable.
For example : `make HASH=xxhsum`
The hash function needs to generate at least 64-bit using hexadecimal format.
When no hash function is found,
the Makefile just generates all object files into the same default directory,
irrespective of compilation flags.
This functionality only matters if `libzstd` is compiled multiple times
with different build flags.
The build directory, where object files are stored
can also be manually controlled using variable `BUILD_DIR`,
for example `make BUILD_DIR=objectDir/v1`.
In which case, the hash function doesn't matter.
#### Deprecated API
Obsolete API on their way out are stored in directory `lib/deprecated`.
At this stage, it contains older streaming prototypes, in `lib/deprecated/zbuff.h`.
These prototypes will be removed in some future version.
Consider migrating code towards supported streaming API exposed in `zstd.h`.
#### Miscellaneous
The other files are not source code. There are :
- `BUCK` : support for `buck` build system (https://buckbuild.com/)
- `Makefile` : `make` script to build and install zstd library (static and dynamic)
- `README.md` : this file
- `dll/` : resources directory for Windows compilation
- `libzstd.pc.in` : script for `pkg-config` (used in `make install`) | {
"source": "yandex/perforator",
"title": "contrib/libs/zstd/lib/README.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/libs/zstd/lib/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 12908
} |
Command Line Interface for Zstandard library
============================================
Command Line Interface (CLI) can be created using the `make` command without any additional parameters.
There are however other Makefile targets that create different variations of CLI:
- `zstd` : default CLI supporting gzip-like arguments; includes dictionary builder, benchmark, and supports decompression of legacy zstd formats
- `zstd_nolegacy` : Same as `zstd` but without support for legacy zstd formats
- `zstd-small` : CLI optimized for minimal size; no dictionary builder, no benchmark, and no support for legacy zstd formats
- `zstd-compress` : version of CLI which can only compress into zstd format
- `zstd-decompress` : version of CLI which can only decompress zstd format
### Compilation variables
`zstd` scope can be altered by modifying the following `make` variables :
- __HAVE_THREAD__ : multithreading is automatically enabled when `pthread` is detected.
It's possible to disable multithread support, by setting `HAVE_THREAD=0`.
Example : `make zstd HAVE_THREAD=0`
It's also possible to force multithread support, using `HAVE_THREAD=1`.
In which case, linking stage will fail if neither `pthread` nor `windows.h` library can be found.
This is useful to ensure this feature is not silently disabled.
- __ZSTD_LEGACY_SUPPORT__ : `zstd` can decompress files compressed by older versions of `zstd`.
Starting v0.8.0, all versions of `zstd` produce frames compliant with the [specification](../doc/zstd_compression_format.md), and are therefore compatible.
But older versions (< v0.8.0) produced different, incompatible, frames.
By default, `zstd` supports decoding legacy formats >= v0.4.0 (`ZSTD_LEGACY_SUPPORT=4`).
This can be altered by modifying this compilation variable.
`ZSTD_LEGACY_SUPPORT=1` means "support all formats >= v0.1.0".
`ZSTD_LEGACY_SUPPORT=2` means "support all formats >= v0.2.0", and so on.
`ZSTD_LEGACY_SUPPORT=0` means _DO NOT_ support any legacy format.
if `ZSTD_LEGACY_SUPPORT >= 8`, it's the same as `0`, since there is no legacy format after `7`.
Note : `zstd` only supports decoding older formats, and cannot generate any legacy format.
- __HAVE_ZLIB__ : `zstd` can compress and decompress files in `.gz` format.
This is ordered through command `--format=gzip`.
Alternatively, symlinks named `gzip` or `gunzip` will mimic intended behavior.
`.gz` support is automatically enabled when `zlib` library is detected at build time.
It's possible to disable `.gz` support, by setting `HAVE_ZLIB=0`.
Example : `make zstd HAVE_ZLIB=0`
It's also possible to force compilation with zlib support, using `HAVE_ZLIB=1`.
In which case, linking stage will fail if `zlib` library cannot be found.
This is useful to prevent silent feature disabling.
- __HAVE_LZMA__ : `zstd` can compress and decompress files in `.xz` and `.lzma` formats.
This is ordered through commands `--format=xz` and `--format=lzma` respectively.
Alternatively, symlinks named `xz`, `unxz`, `lzma`, or `unlzma` will mimic intended behavior.
`.xz` and `.lzma` support is automatically enabled when `lzma` library is detected at build time.
It's possible to disable `.xz` and `.lzma` support, by setting `HAVE_LZMA=0`.
Example : `make zstd HAVE_LZMA=0`
It's also possible to force compilation with lzma support, using `HAVE_LZMA=1`.
In which case, linking stage will fail if `lzma` library cannot be found.
This is useful to prevent silent feature disabling.
- __HAVE_LZ4__ : `zstd` can compress and decompress files in `.lz4` formats.
This is ordered through commands `--format=lz4`.
Alternatively, symlinks named `lz4`, or `unlz4` will mimic intended behavior.
`.lz4` support is automatically enabled when `lz4` library is detected at build time.
It's possible to disable `.lz4` support, by setting `HAVE_LZ4=0` .
Example : `make zstd HAVE_LZ4=0`
It's also possible to force compilation with lz4 support, using `HAVE_LZ4=1`.
In which case, linking stage will fail if `lz4` library cannot be found.
This is useful to prevent silent feature disabling.
- __ZSTD_NOBENCH__ : `zstd` cli will be compiled without its integrated benchmark module.
This can be useful to produce smaller binaries.
In this case, the corresponding unit can also be excluded from compilation target.
- __ZSTD_NODICT__ : `zstd` cli will be compiled without support for the integrated dictionary builder.
This can be useful to produce smaller binaries.
In this case, the corresponding unit can also be excluded from compilation target.
- __ZSTD_NOCOMPRESS__ : `zstd` cli will be compiled without support for compression.
The resulting binary will only be able to decompress files.
This can be useful to produce smaller binaries.
A corresponding `Makefile` target using this ability is `zstd-decompress`.
- __ZSTD_NODECOMPRESS__ : `zstd` cli will be compiled without support for decompression.
The resulting binary will only be able to compress files.
This can be useful to produce smaller binaries.
A corresponding `Makefile` target using this ability is `zstd-compress`.
- __BACKTRACE__ : `zstd` can display a stack backtrace when execution
generates a runtime exception. By default, this feature may be
degraded/disabled on some platforms unless additional compiler directives are
applied. When triaging a runtime issue, enabling this feature can provide
more context to determine the location of the fault.
Example : `make zstd BACKTRACE=1`
### Aggregation of parameters
CLI supports aggregation of parameters i.e. `-b1`, `-e18`, and `-i1` can be joined into `-b1e18i1`.
### Symlink shortcuts
It's possible to invoke `zstd` through a symlink.
When the name of the symlink has a specific value, it triggers an associated behavior.
- `zstdmt` : compress using all cores available on local system.
- `zcat` : will decompress and output target file using any of the supported formats. `gzcat` and `zstdcat` are also equivalent.
- `gzip` : if zlib support is enabled, will mimic `gzip` by compressing file using `.gz` format, removing source file by default (use `--keep` to preserve). If zlib is not supported, triggers an error.
- `xz` : if lzma support is enabled, will mimic `xz` by compressing file using `.xz` format, removing source file by default (use `--keep` to preserve). If xz is not supported, triggers an error.
- `lzma` : if lzma support is enabled, will mimic `lzma` by compressing file using `.lzma` format, removing source file by default (use `--keep` to preserve). If lzma is not supported, triggers an error.
- `lz4` : if lz4 support is enabled, will mimic `lz4` by compressing file using `.lz4` format. If lz4 is not supported, triggers an error.
- `unzstd` and `unlz4` will decompress any of the supported format.
- `ungz`, `unxz` and `unlzma` will do the same, and will also remove source file by default (use `--keep` to preserve).
### Dictionary builder in Command Line Interface
Zstd offers a training mode, which can be used to tune the algorithm for a selected
type of data, by providing it with a few samples. The result of the training is stored
in a file selected with the `-o` option (default name is `dictionary`),
which can be loaded before compression and decompression.
Using a dictionary, the compression ratio achievable on small data improves dramatically.
These compression gains are achieved while simultaneously providing faster compression and decompression speeds.
Dictionary work if there is some correlation in a family of small data (there is no universal dictionary).
Hence, deploying one dictionary per type of data will provide the greater benefits.
Dictionary gains are mostly effective in the first few KB. Then, the compression algorithm
will rely more and more on previously decoded content to compress the rest of the file.
Usage of the dictionary builder and created dictionaries with CLI:
1. Create the dictionary : `zstd --train PathToTrainingSet/* -o dictionaryName`
2. Compress with the dictionary: `zstd FILE -D dictionaryName`
3. Decompress with the dictionary: `zstd --decompress FILE.zst -D dictionaryName`
### Benchmark in Command Line Interface
CLI includes in-memory compression benchmark module for zstd.
The benchmark is conducted using given filenames. The files are read into memory and joined together.
It makes benchmark more precise as it eliminates I/O overhead.
Multiple filenames can be supplied, as multiple parameters, with wildcards,
or directory names can be used with `-r` option.
If no file is provided, the benchmark will use a procedurally generated "lorem ipsum" content.
The benchmark measures ratio, compressed size, compression and decompression speed.
One can select compression levels starting from `-b` and ending with `-e`.
The `-i` parameter selects minimal time used for each of tested levels.
The benchmark can also be used to test specific parameters,
such as number of threads (`-T#`), or advanced parameters (`--zstd=#`), or dictionary compression (`-D DICTIONARY`),
and many others available on command for regular compression and decompression.
### Usage of Command Line Interface
The full list of options can be obtained with `-h` or `-H` parameter:
```
*** Zstandard CLI (64-bit) v1.5.6, by Yann Collet ***
Compress or decompress the INPUT file(s); reads from STDIN if INPUT is `-` or not provided.
Usage: zstd [OPTIONS...] [INPUT... | -] [-o OUTPUT]
Options:
-o OUTPUT Write output to a single file, OUTPUT.
-k, --keep Preserve INPUT file(s). [Default]
--rm Remove INPUT file(s) after successful (de)compression.
-# Desired compression level, where `#` is a number between 1 and 19;
lower numbers provide faster compression, higher numbers yield
better compression ratios. [Default: 3]
-d, --decompress Perform decompression.
-D DICT Use DICT as the dictionary for compression or decompression.
-f, --force Disable input and output checks. Allows overwriting existing files,
receiving input from the console, printing output to STDOUT, and
operating on links, block devices, etc. Unrecognized formats will be
passed-through through as-is.
-h Display short usage and exit.
-H, --help Display full help and exit.
-V, --version Display the program version and exit.
Advanced options:
-c, --stdout Write to STDOUT (even if it is a console) and keep the INPUT file(s).
-v, --verbose Enable verbose output; pass multiple times to increase verbosity.
-q, --quiet Suppress warnings; pass twice to suppress errors.
--trace LOG Log tracing information to LOG.
--[no-]progress Forcibly show/hide the progress counter. NOTE: Any (de)compressed
output to terminal will mix with progress counter text.
-r Operate recursively on directories.
--filelist LIST Read a list of files to operate on from LIST.
--output-dir-flat DIR Store processed files in DIR.
--output-dir-mirror DIR Store processed files in DIR, respecting original directory structure.
--[no-]asyncio Use asynchronous IO. [Default: Enabled]
--[no-]check Add XXH64 integrity checksums during compression. [Default: Add, Validate]
If `-d` is present, ignore/validate checksums during decompression.
-- Treat remaining arguments after `--` as files.
Advanced compression options:
--ultra Enable levels beyond 19, up to 22; requires more memory.
--fast[=#] Use to very fast compression levels. [Default: 1]
--adapt Dynamically adapt compression level to I/O conditions.
--long[=#] Enable long distance matching with window log #. [Default: 27]
--patch-from=REF Use REF as the reference point for Zstandard's diff engine.
-T# Spawn # compression threads. [Default: 1; pass 0 for core count.]
--single-thread Share a single thread for I/O and compression (slightly different than `-T1`).
--auto-threads={physical|logical}
Use physical/logical cores when using `-T0`. [Default: Physical]
-B# Set job size to #. [Default: 0 (automatic)]
--rsyncable Compress using a rsync-friendly method (`-B` sets block size).
--exclude-compressed Only compress files that are not already compressed.
--stream-size=# Specify size of streaming input from STDIN.
--size-hint=# Optimize compression parameters for streaming input of approximately size #.
--target-compressed-block-size=#
Generate compressed blocks of approximately # size.
--no-dictID Don't write `dictID` into the header (dictionary compression only).
--[no-]compress-literals Force (un)compressed literals.
--[no-]row-match-finder Explicitly enable/disable the fast, row-based matchfinder for
the 'greedy', 'lazy', and 'lazy2' strategies.
--format=zstd Compress files to the `.zst` format. [Default]
--[no-]mmap-dict Memory-map dictionary file rather than mallocing and loading all at once
--format=gzip Compress files to the `.gz` format.
--format=xz Compress files to the `.xz` format.
--format=lzma Compress files to the `.lzma` format.
--format=lz4 Compress files to the `.lz4` format.
Advanced decompression options:
-l Print information about Zstandard-compressed files.
--test Test compressed file integrity.
-M# Set the memory usage limit to # megabytes.
--[no-]sparse Enable sparse mode. [Default: Enabled for files, disabled for STDOUT.]
--[no-]pass-through Pass through uncompressed files as-is. [Default: Disabled]
Dictionary builder:
--train Create a dictionary from a training set of files.
--train-cover[=k=#,d=#,steps=#,split=#,shrink[=#]]
Use the cover algorithm (with optional arguments).
--train-fastcover[=k=#,d=#,f=#,steps=#,split=#,accel=#,shrink[=#]]
Use the fast cover algorithm (with optional arguments).
--train-legacy[=s=#] Use the legacy algorithm with selectivity #. [Default: 9]
-o NAME Use NAME as dictionary name. [Default: dictionary]
--maxdict=# Limit dictionary to specified size #. [Default: 112640]
--dictID=# Force dictionary ID to #. [Default: Random]
Benchmark options:
-b# Perform benchmarking with compression level #. [Default: 3]
-e# Test all compression levels up to #; starting level is `-b#`. [Default: 1]
-i# Set the minimum evaluation to time # seconds. [Default: 3]
-B# Cut file into independent chunks of size #. [Default: No chunking]
-S Output one benchmark result per input file. [Default: Consolidated result]
-D dictionary Benchmark using dictionary
--priority=rt Set process priority to real-time.
```
### Passing parameters through Environment Variables
There is no "generic" way to pass "any kind of parameter" to `zstd` in a pass-through manner.
Using environment variables for this purpose has security implications.
Therefore, this avenue is intentionally restricted and only supports `ZSTD_CLEVEL` and `ZSTD_NBTHREADS`.
`ZSTD_CLEVEL` can be used to modify the default compression level of `zstd`
(usually set to `3`) to another value between 1 and 19 (the "normal" range).
`ZSTD_NBTHREADS` can be used to specify a number of threads
that `zstd` will use for compression, which by default is `1`.
This functionality only exists when `zstd` is compiled with multithread support.
`0` means "use as many threads as detected cpu cores on local system".
The max # of threads is capped at `ZSTDMT_NBWORKERS_MAX`,
which is either 64 in 32-bit mode, or 256 for 64-bit environments.
This functionality can be useful when `zstd` CLI is invoked in a way that doesn't allow passing arguments.
One such scenario is `tar --zstd`.
As `ZSTD_CLEVEL` and `ZSTD_NBTHREADS` only replace the default compression level
and number of threads respectively, they can both be overridden by corresponding command line arguments:
`-#` for compression level and `-T#` for number of threads.
### Long distance matching mode
The long distance matching mode, enabled with `--long`, is designed to improve
the compression ratio for files with long matches at a large distance (up to the
maximum window size, `128 MiB`) while still maintaining compression speed.
Enabling this mode sets the window size to `128 MiB` and thus increases the memory
usage for both the compressor and decompressor. Performance in terms of speed is
dependent on long matches being found. Compression speed may degrade if few long
matches are found. Decompression speed usually improves when there are many long
distance matches.
Below are graphs comparing the compression speed, compression ratio, and
decompression speed with and without long distance matching on an ideal use
case: a tar of four versions of clang (versions `3.4.1`, `3.4.2`, `3.5.0`,
`3.5.1`) with a total size of `244889600 B`. This is an ideal use case as there
are many long distance matches within the maximum window size of `128 MiB` (each
version is less than `128 MiB`).
Compression Speed vs Ratio | Decompression Speed
---------------------------|---------------------
 | 
| Method | Compression ratio | Compression speed | Decompression speed |
|:-------|------------------:|-------------------------:|---------------------------:|
| `zstd -1` | `5.065` | `284.8 MB/s` | `759.3 MB/s` |
| `zstd -5` | `5.826` | `124.9 MB/s` | `674.0 MB/s` |
| `zstd -10` | `6.504` | `29.5 MB/s` | `771.3 MB/s` |
| `zstd -1 --long` | `17.426` | `220.6 MB/s` | `1638.4 MB/s` |
| `zstd -5 --long` | `19.661` | `165.5 MB/s` | `1530.6 MB/s` |
| `zstd -10 --long`| `21.949` | `75.6 MB/s` | `1632.6 MB/s` |
On this file, the compression ratio improves significantly with minimal impact
on compression speed, and the decompression speed doubles.
On the other extreme, compressing a file with few long distance matches (such as
the [Silesia compression corpus]) will likely lead to a deterioration in
compression speed (for lower levels) with minimal change in compression ratio.
The below table illustrates this on the [Silesia compression corpus].
[Silesia compression corpus]: https://sun.aei.polsl.pl//~sdeor/index.php?page=silesia
| Method | Compression ratio | Compression speed | Decompression speed |
|:-------|------------------:|------------------:|---------------------:|
| `zstd -1` | `2.878` | `231.7 MB/s` | `594.4 MB/s` |
| `zstd -1 --long` | `2.929` | `106.5 MB/s` | `517.9 MB/s` |
| `zstd -5` | `3.274` | `77.1 MB/s` | `464.2 MB/s` |
| `zstd -5 --long` | `3.319` | `51.7 MB/s` | `371.9 MB/s` |
| `zstd -10` | `3.523` | `16.4 MB/s` | `489.2 MB/s` |
| `zstd -10 --long`| `3.566` | `16.2 MB/s` | `415.7 MB/s` |
### zstdgrep
`zstdgrep` is a utility which makes it possible to `grep` directly a `.zst` compressed file.
It's used the same way as normal `grep`, for example :
`zstdgrep pattern file.zst`
`zstdgrep` is _not_ compatible with dictionary compression.
To search into a file compressed with a dictionary,
it's necessary to decompress it using `zstd` or `zstdcat`,
and then pipe the result to `grep`. For example :
`zstdcat -D dictionary -qc -- file.zst | grep pattern` | {
"source": "yandex/perforator",
"title": "contrib/libs/zstd/programs/README.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/libs/zstd/programs/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 20645
} |
PyYAML
======
A full-featured YAML processing framework for Python
## Installation
To install, type `python setup.py install`.
By default, the `setup.py` script checks whether LibYAML is installed and if
so, builds and installs LibYAML bindings.
To skip the check and force installation of LibYAML bindings, use the option
`--with-libyaml`: `python setup.py --with-libyaml install`.
To disable the check and skip building and installing LibYAML bindings, use
`--without-libyaml`: `python setup.py --without-libyaml install`.
When LibYAML bindings are installed, you may use fast LibYAML-based parser and
emitter as follows:
>>> yaml.load(stream, Loader=yaml.CLoader)
>>> yaml.dump(data, Dumper=yaml.CDumper)
If you don't trust the input YAML stream, you should use:
>>> yaml.safe_load(stream)
## Testing
PyYAML includes a comprehensive test suite.
To run the tests, type `python setup.py test`.
## Further Information
* For more information, check the
[PyYAML homepage](https://github.com/yaml/pyyaml).
* [PyYAML tutorial and reference](http://pyyaml.org/wiki/PyYAMLDocumentation).
* Discuss PyYAML with the maintainers on
Matrix at https://matrix.to/#/#pyyaml:yaml.io or
IRC #pyyaml irc.libera.chat
* Submit bug reports and feature requests to the
[PyYAML bug tracker](https://github.com/yaml/pyyaml/issues).
## License
The PyYAML module was written by Kirill Simonov <[email protected]>.
It is currently maintained by the YAML and Python communities.
PyYAML is released under the MIT license.
See the file LICENSE for more details. | {
"source": "yandex/perforator",
"title": "contrib/python/PyYAML/py3/README.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/python/PyYAML/py3/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1571
} |
Welcome to Pygments
===================
This is the source of Pygments. It is a **generic syntax highlighter** written
in Python that supports over 300 languages and text formats, for use in code
hosting, forums, wikis or other applications that need to prettify source code.
Installing
----------
... works as usual, use ``pip install Pygments`` to get published versions,
or ``python setup.py install`` to install from a checkout.
Documentation
-------------
... can be found online at http://pygments.org/ or created with Sphinx by ::
cd doc
make html
Development
-----------
... takes place on `GitHub <https://github.com/pygments/pygments>`_, where the
Git repository, tickets and pull requests can be viewed.
Continuous testing runs on GitHub workflows:
.. image:: https://github.com/pygments/pygments/workflows/Pygments/badge.svg
:target: https://github.com/pygments/pygments/actions?query=workflow%3APygments
The authors
-----------
Pygments is maintained by **Georg Brandl**, e-mail address *georg*\ *@*\ *python.org*
and **Matthäus Chajdas**.
Many lexers and fixes have been contributed by **Armin Ronacher**, the rest of
the `Pocoo <http://dev.pocoo.org/>`_ team and **Tim Hatch**.
The code is distributed under the BSD 2-clause license. Contributors making pull
requests must agree that they are able and willing to put their contributions
under that license. | {
"source": "yandex/perforator",
"title": "contrib/python/Pygments/py2/README.rst",
"url": "https://github.com/yandex/perforator/blob/main/contrib/python/Pygments/py2/README.rst",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1396
} |
Welcome to Pygments
===================
This is the source of Pygments. It is a **generic syntax highlighter** written
in Python that supports over 500 languages and text formats, for use in code
hosting, forums, wikis or other applications that need to prettify source code.
Installing
----------
... works as usual, use ``pip install Pygments`` to get published versions,
or ``pip install -e .`` to install from a checkout in editable mode.
Documentation
-------------
... can be found online at https://pygments.org/ or created with Sphinx by ::
tox -e doc
By default, the documentation does not include the demo page, as it requires
having Docker installed for building Pyodide. To build the documentation with
the demo page, use ::
tox -e web-doc
The initial build might take some time, but subsequent ones should be instant
because of Docker caching.
To view the generated documentation, serve it using Python's ``http.server``
module (this step is required for the demo to work) ::
python3 -m http.server --directory doc/_build/html
Development
-----------
... takes place on `GitHub <https://github.com/pygments/pygments>`_, where the
Git repository, tickets and pull requests can be viewed.
Continuous testing runs on GitHub workflows:
.. image:: https://github.com/pygments/pygments/workflows/Pygments/badge.svg
:target: https://github.com/pygments/pygments/actions?query=workflow%3APygments
Please read our `Contributing instructions <https://pygments.org/docs/contributing>`_.
Security considerations
-----------------------
Pygments provides no guarantees on execution time, which needs to be taken
into consideration when using Pygments to process arbitrary user inputs. For
example, if you have a web service which uses Pygments for highlighting, there
may be inputs which will cause the Pygments process to run "forever" and/or use
significant amounts of memory. This can subsequently be used to perform a
remote denial-of-service attack on the server if the processes are not
terminated quickly.
Unfortunately, it's practically impossible to harden Pygments itself against
those issues: Some regular expressions can result in "catastrophic
backtracking", but other bugs like incorrect matchers can also
cause similar problems, and there is no way to find them in an automated fashion
(short of solving the halting problem.) Pygments has extensive unit tests,
automated randomized testing, and is also tested by `OSS-Fuzz <https://github.com/google/oss-fuzz/tree/master/projects/pygments>`_,
but we will never be able to eliminate all bugs in this area.
Our recommendations are:
* Ensure that the Pygments process is *terminated* after a reasonably short
timeout. In general Pygments should take seconds at most for reasonably-sized
input.
* *Limit* the number of concurrent Pygments processes to avoid oversubscription
of resources.
The Pygments authors will treat any bug resulting in long processing times with
high priority -- it's one of those things that will be fixed in a patch release.
When reporting a bug where you suspect super-linear execution times, please make
sure to attach an input to reproduce it.
The authors
-----------
Pygments is maintained by **Georg Brandl**, e-mail address *georg*\ *@*\ *python.org*, **Matthäus Chajdas** and **Jean Abou-Samra**.
Many lexers and fixes have been contributed by **Armin Ronacher**, the rest of
the `Pocoo <https://www.pocoo.org/>`_ team and **Tim Hatch**.
The code is distributed under the BSD 2-clause license. Contributors making pull
requests must agree that they are able and willing to put their contributions
under that license. | {
"source": "yandex/perforator",
"title": "contrib/python/Pygments/py3/README.rst",
"url": "https://github.com/yandex/perforator/blob/main/contrib/python/Pygments/py3/README.rst",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 3656
} |
===================
python-atomicwrites
===================
.. image:: https://travis-ci.com/untitaker/python-atomicwrites.svg?branch=master
:target: https://travis-ci.com/untitaker/python-atomicwrites
.. image:: https://ci.appveyor.com/api/projects/status/vadc4le3c27to59x/branch/master?svg=true
:target: https://ci.appveyor.com/project/untitaker/python-atomicwrites/branch/master
.. image:: https://readthedocs.org/projects/python-atomicwrites/badge/?version=latest
:target: https://python-atomicwrites.readthedocs.io/en/latest/?badge=latest
:alt: Documentation Status
**Atomic file writes.**
.. code-block:: python
from atomicwrites import atomic_write
with atomic_write('foo.txt', overwrite=True) as f:
f.write('Hello world.')
# "foo.txt" doesn't exist yet.
# Now it does.
See `API documentation <https://python-atomicwrites.readthedocs.io/en/latest/#api>`_ for more
low-level interfaces.
Features that distinguish it from other similar libraries (see `Alternatives and Credit`_):
- Race-free assertion that the target file doesn't yet exist. This can be
controlled with the ``overwrite`` parameter.
- Windows support, although not well-tested. The MSDN resources are not very
explicit about which operations are atomic. I'm basing my assumptions off `a
comment
<https://social.msdn.microsoft.com/Forums/windowsdesktop/en-US/449bb49d-8acc-48dc-a46f-0760ceddbfc3/movefileexmovefilereplaceexisting-ntfs-same-volume-atomic?forum=windowssdk#a239bc26-eaf0-4920-9f21-440bd2be9cc8>`_
by `Doug Cook
<https://social.msdn.microsoft.com/Profile/doug%20e.%20cook>`_, who appears
to be a Microsoft employee:
Question: Is MoveFileEx atomic if the existing and new
files are both on the same drive?
The simple answer is "usually, but in some cases it will silently fall-back
to a non-atomic method, so don't count on it".
The implementation of MoveFileEx looks something like this: [...]
The problem is if the rename fails, you might end up with a CopyFile, which
is definitely not atomic.
If you really need atomic-or-nothing, you can try calling
NtSetInformationFile, which is unsupported but is much more likely to be
atomic.
- Simple high-level API that wraps a very flexible class-based API.
- Consistent error handling across platforms.
How it works
============
It uses a temporary file in the same directory as the given path. This ensures
that the temporary file resides on the same filesystem.
The temporary file will then be atomically moved to the target location: On
POSIX, it will use ``rename`` if files should be overwritten, otherwise a
combination of ``link`` and ``unlink``. On Windows, it uses MoveFileEx_ through
stdlib's ``ctypes`` with the appropriate flags.
Note that with ``link`` and ``unlink``, there's a timewindow where the file
might be available under two entries in the filesystem: The name of the
temporary file, and the name of the target file.
Also note that the permissions of the target file may change this way. In some
situations a ``chmod`` can be issued without any concurrency problems, but
since that is not always the case, this library doesn't do it by itself.
.. _MoveFileEx: https://msdn.microsoft.com/en-us/library/windows/desktop/aa365240%28v=vs.85%29.aspx
fsync
-----
On POSIX, ``fsync`` is invoked on the temporary file after it is written (to
flush file content and metadata), and on the parent directory after the file is
moved (to flush filename).
``fsync`` does not take care of disks' internal buffers, but there don't seem
to be any standard POSIX APIs for that. On OS X, ``fcntl`` is used with
``F_FULLFSYNC`` instead of ``fsync`` for that reason.
On Windows, `_commit <https://msdn.microsoft.com/en-us/library/17618685.aspx>`_
is used, but there are no guarantees about disk internal buffers.
Alternatives and Credit
=======================
Atomicwrites is directly inspired by the following libraries (and shares a
minimal amount of code):
- The Trac project's `utility functions
<http://www.edgewall.org/docs/tags-trac-0.11.7/epydoc/trac.util-pysrc.html>`_,
also used in `Werkzeug <http://werkzeug.pocoo.org/>`_ and
`mitsuhiko/python-atomicfile
<https://github.com/mitsuhiko/python-atomicfile>`_. The idea to use
``ctypes`` instead of ``PyWin32`` originated there.
- `abarnert/fatomic <https://github.com/abarnert/fatomic>`_. Windows support
(based on ``PyWin32``) was originally taken from there.
Other alternatives to atomicwrites include:
- `sashka/atomicfile <https://github.com/sashka/atomicfile>`_. Originally I
considered using that, but at the time it was lacking a lot of features I
needed (Windows support, overwrite-parameter, overriding behavior through
subclassing).
- The `Boltons library collection <https://github.com/mahmoud/boltons>`_
features a class for atomic file writes, which seems to have a very similar
``overwrite`` parameter. It is lacking Windows support though.
License
=======
Licensed under the MIT, see ``LICENSE``. | {
"source": "yandex/perforator",
"title": "contrib/python/atomicwrites/py2/README.rst",
"url": "https://github.com/yandex/perforator/blob/main/contrib/python/atomicwrites/py2/README.rst",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 5077
} |
===================
python-atomicwrites
===================
.. image:: https://travis-ci.com/untitaker/python-atomicwrites.svg?branch=master
:target: https://travis-ci.com/untitaker/python-atomicwrites
.. image:: https://ci.appveyor.com/api/projects/status/vadc4le3c27to59x/branch/master?svg=true
:target: https://ci.appveyor.com/project/untitaker/python-atomicwrites/branch/master
.. image:: https://readthedocs.org/projects/python-atomicwrites/badge/?version=latest
:target: https://python-atomicwrites.readthedocs.io/en/latest/?badge=latest
:alt: Documentation Status
**Atomic file writes.**
.. code-block:: python
from atomicwrites import atomic_write
with atomic_write('foo.txt', overwrite=True) as f:
f.write('Hello world.')
# "foo.txt" doesn't exist yet.
# Now it does.
See `API documentation <https://python-atomicwrites.readthedocs.io/en/latest/#api>`_ for more
low-level interfaces.
Features that distinguish it from other similar libraries (see `Alternatives and Credit`_):
- Race-free assertion that the target file doesn't yet exist. This can be
controlled with the ``overwrite`` parameter.
- Windows support, although not well-tested. The MSDN resources are not very
explicit about which operations are atomic. I'm basing my assumptions off `a
comment
<https://social.msdn.microsoft.com/Forums/windowsdesktop/en-US/449bb49d-8acc-48dc-a46f-0760ceddbfc3/movefileexmovefilereplaceexisting-ntfs-same-volume-atomic?forum=windowssdk#a239bc26-eaf0-4920-9f21-440bd2be9cc8>`_
by `Doug Cook
<https://social.msdn.microsoft.com/Profile/doug%20e.%20cook>`_, who appears
to be a Microsoft employee:
Question: Is MoveFileEx atomic if the existing and new
files are both on the same drive?
The simple answer is "usually, but in some cases it will silently fall-back
to a non-atomic method, so don't count on it".
The implementation of MoveFileEx looks something like this: [...]
The problem is if the rename fails, you might end up with a CopyFile, which
is definitely not atomic.
If you really need atomic-or-nothing, you can try calling
NtSetInformationFile, which is unsupported but is much more likely to be
atomic.
- Simple high-level API that wraps a very flexible class-based API.
- Consistent error handling across platforms.
How it works
============
It uses a temporary file in the same directory as the given path. This ensures
that the temporary file resides on the same filesystem.
The temporary file will then be atomically moved to the target location: On
POSIX, it will use ``rename`` if files should be overwritten, otherwise a
combination of ``link`` and ``unlink``. On Windows, it uses MoveFileEx_ through
stdlib's ``ctypes`` with the appropriate flags.
Note that with ``link`` and ``unlink``, there's a timewindow where the file
might be available under two entries in the filesystem: The name of the
temporary file, and the name of the target file.
Also note that the permissions of the target file may change this way. In some
situations a ``chmod`` can be issued without any concurrency problems, but
since that is not always the case, this library doesn't do it by itself.
.. _MoveFileEx: https://msdn.microsoft.com/en-us/library/windows/desktop/aa365240%28v=vs.85%29.aspx
fsync
-----
On POSIX, ``fsync`` is invoked on the temporary file after it is written (to
flush file content and metadata), and on the parent directory after the file is
moved (to flush filename).
``fsync`` does not take care of disks' internal buffers, but there don't seem
to be any standard POSIX APIs for that. On OS X, ``fcntl`` is used with
``F_FULLFSYNC`` instead of ``fsync`` for that reason.
On Windows, `_commit <https://msdn.microsoft.com/en-us/library/17618685.aspx>`_
is used, but there are no guarantees about disk internal buffers.
Alternatives and Credit
=======================
Atomicwrites is directly inspired by the following libraries (and shares a
minimal amount of code):
- The Trac project's `utility functions
<http://www.edgewall.org/docs/tags-trac-0.11.7/epydoc/trac.util-pysrc.html>`_,
also used in `Werkzeug <http://werkzeug.pocoo.org/>`_ and
`mitsuhiko/python-atomicfile
<https://github.com/mitsuhiko/python-atomicfile>`_. The idea to use
``ctypes`` instead of ``PyWin32`` originated there.
- `abarnert/fatomic <https://github.com/abarnert/fatomic>`_. Windows support
(based on ``PyWin32``) was originally taken from there.
Other alternatives to atomicwrites include:
- `sashka/atomicfile <https://github.com/sashka/atomicfile>`_. Originally I
considered using that, but at the time it was lacking a lot of features I
needed (Windows support, overwrite-parameter, overriding behavior through
subclassing).
- The `Boltons library collection <https://github.com/mahmoud/boltons>`_
features a class for atomic file writes, which seems to have a very similar
``overwrite`` parameter. It is lacking Windows support though.
License
=======
Licensed under the MIT, see ``LICENSE``. | {
"source": "yandex/perforator",
"title": "contrib/python/atomicwrites/py3/README.rst",
"url": "https://github.com/yandex/perforator/blob/main/contrib/python/atomicwrites/py3/README.rst",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 5077
} |
Credits
=======
``attrs`` is written and maintained by `Hynek Schlawack <https://hynek.me/>`_.
The development is kindly supported by `Variomedia AG <https://www.variomedia.de/>`_.
A full list of contributors can be found in `GitHub's overview <https://github.com/python-attrs/attrs/graphs/contributors>`_.
It’s the spiritual successor of `characteristic <https://characteristic.readthedocs.io/>`_ and aspires to fix some of it clunkiness and unfortunate decisions.
Both were inspired by Twisted’s `FancyEqMixin <https://twistedmatrix.com/documents/current/api/twisted.python.util.FancyEqMixin.html>`_ but both are implemented using class decorators because `subclassing is bad for you <https://www.youtube.com/watch?v=3MNVP9-hglc>`_, m’kay? | {
"source": "yandex/perforator",
"title": "contrib/python/attrs/py2/AUTHORS.rst",
"url": "https://github.com/yandex/perforator/blob/main/contrib/python/attrs/py2/AUTHORS.rst",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 745
} |
.. raw:: html
<p align="center">
<a href="https://www.attrs.org/">
<img src="./docs/_static/attrs_logo.svg" width="35%" alt="attrs" />
</a>
</p>
<p align="center">
<a href="https://www.attrs.org/en/stable/?badge=stable">
<img src="https://readthedocs.org/projects/attrs/badge/?version=stable" alt="Documentation Status" />
</a>
<a href="https://github.com/python-attrs/attrs/actions?workflow=CI">
<img src="https://github.com/python-attrs/attrs/workflows/CI/badge.svg?branch=main" alt="CI Status" />
</a>
<a href="https://codecov.io/github/python-attrs/attrs">
<img src="https://codecov.io/github/python-attrs/attrs/branch/main/graph/badge.svg" alt="Test Coverage" />
</a>
<a href="https://github.com/psf/black">
<img src="https://img.shields.io/badge/code%20style-black-000000.svg" alt="Code style: black" />
</a>
</p>
.. teaser-begin
``attrs`` is the Python package that will bring back the **joy** of **writing classes** by relieving you from the drudgery of implementing object protocols (aka `dunder <https://nedbatchelder.com/blog/200605/dunder.html>`_ methods).
`Trusted by NASA <https://docs.github.com/en/github/setting-up-and-managing-your-github-profile/personalizing-your-profile#list-of-qualifying-repositories-for-mars-2020-helicopter-contributor-badge>`_ for Mars missions since 2020!
Its main goal is to help you to write **concise** and **correct** software without slowing down your code.
.. teaser-end
For that, it gives you a class decorator and a way to declaratively define the attributes on that class:
.. -code-begin-
.. code-block:: pycon
>>> import attr
>>> @attr.s
... class SomeClass(object):
... a_number = attr.ib(default=42)
... list_of_numbers = attr.ib(factory=list)
...
... def hard_math(self, another_number):
... return self.a_number + sum(self.list_of_numbers) * another_number
>>> sc = SomeClass(1, [1, 2, 3])
>>> sc
SomeClass(a_number=1, list_of_numbers=[1, 2, 3])
>>> sc.hard_math(3)
19
>>> sc == SomeClass(1, [1, 2, 3])
True
>>> sc != SomeClass(2, [3, 2, 1])
True
>>> attr.asdict(sc)
{'a_number': 1, 'list_of_numbers': [1, 2, 3]}
>>> SomeClass()
SomeClass(a_number=42, list_of_numbers=[])
>>> C = attr.make_class("C", ["a", "b"])
>>> C("foo", "bar")
C(a='foo', b='bar')
After *declaring* your attributes ``attrs`` gives you:
- a concise and explicit overview of the class's attributes,
- a nice human-readable ``__repr__``,
- a complete set of comparison methods (equality and ordering),
- an initializer,
- and much more,
*without* writing dull boilerplate code again and again and *without* runtime performance penalties.
On Python 3.6 and later, you can often even drop the calls to ``attr.ib()`` by using `type annotations <https://www.attrs.org/en/latest/types.html>`_.
This gives you the power to use actual classes with actual types in your code instead of confusing ``tuple``\ s or `confusingly behaving <https://www.attrs.org/en/stable/why.html#namedtuples>`_ ``namedtuple``\ s.
Which in turn encourages you to write *small classes* that do `one thing well <https://www.destroyallsoftware.com/talks/boundaries>`_.
Never again violate the `single responsibility principle <https://en.wikipedia.org/wiki/Single_responsibility_principle>`_ just because implementing ``__init__`` et al is a painful drag.
.. -getting-help-
Getting Help
============
Please use the ``python-attrs`` tag on `StackOverflow <https://stackoverflow.com/questions/tagged/python-attrs>`_ to get help.
Answering questions of your fellow developers is also a great way to help the project!
.. -project-information-
Project Information
===================
``attrs`` is released under the `MIT <https://choosealicense.com/licenses/mit/>`_ license,
its documentation lives at `Read the Docs <https://www.attrs.org/>`_,
the code on `GitHub <https://github.com/python-attrs/attrs>`_,
and the latest release on `PyPI <https://pypi.org/project/attrs/>`_.
It’s rigorously tested on Python 2.7, 3.5+, and PyPy.
We collect information on **third-party extensions** in our `wiki <https://github.com/python-attrs/attrs/wiki/Extensions-to-attrs>`_.
Feel free to browse and add your own!
If you'd like to contribute to ``attrs`` you're most welcome and we've written `a little guide <https://www.attrs.org/en/latest/contributing.html>`_ to get you started!
``attrs`` for Enterprise
------------------------
Available as part of the Tidelift Subscription.
The maintainers of ``attrs`` and thousands of other packages are working with Tidelift to deliver commercial support and maintenance for the open source packages you use to build your applications.
Save time, reduce risk, and improve code health, while paying the maintainers of the exact packages you use.
`Learn more. <https://tidelift.com/subscription/pkg/pypi-attrs?utm_source=pypi-attrs&utm_medium=referral&utm_campaign=enterprise&utm_term=repo>`_ | {
"source": "yandex/perforator",
"title": "contrib/python/attrs/py2/README.rst",
"url": "https://github.com/yandex/perforator/blob/main/contrib/python/attrs/py2/README.rst",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 5062
} |
<p align="center">
<a href="https://www.attrs.org/">
<picture>
<source srcset="https://raw.githubusercontent.com/python-attrs/attrs/main/docs/_static/attrs_logo_white.svg" media="(prefers-color-scheme: dark)">
<img src="https://raw.githubusercontent.com/python-attrs/attrs/main/docs/_static/attrs_logo.svg" width="35%" alt="attrs" />
</picture>
</a>
</p>
<p align="center">
<a href="https://www.attrs.org/en/stable/"><img src="https://img.shields.io/badge/Docs-RTD-black" alt="Documentation" /></a>
<a href="https://github.com/python-attrs/attrs/blob/main/LICENSE"><img src="https://img.shields.io/badge/license-MIT-C06524" alt="License: MIT" /></a>
<a href="https://bestpractices.coreinfrastructure.org/projects/6482"><img src="https://bestpractices.coreinfrastructure.org/projects/6482/badge"></a>
<a href="https://pypi.org/project/attrs/"><img src="https://img.shields.io/pypi/v/attrs" /></a>
<a href="https://pepy.tech/project/attrs"><img src="https://static.pepy.tech/personalized-badge/attrs?period=month&units=international_system&left_color=grey&right_color=blue&left_text=Downloads%20/%20Month" alt="Downloads per month" /></a>
<a href="https://zenodo.org/badge/latestdoi/29918975"><img src="https://zenodo.org/badge/29918975.svg" alt="DOI"></a>
</p>
<!-- teaser-begin -->
*attrs* is the Python package that will bring back the **joy** of **writing classes** by relieving you from the drudgery of implementing object protocols (aka [dunder methods](https://www.attrs.org/en/latest/glossary.html#term-dunder-methods)).
[Trusted by NASA](https://docs.github.com/en/account-and-profile/setting-up-and-managing-your-github-profile/customizing-your-profile/personalizing-your-profile#list-of-qualifying-repositories-for-mars-2020-helicopter-contributor-achievement) for Mars missions since 2020!
Its main goal is to help you to write **concise** and **correct** software without slowing down your code.
## Sponsors
*attrs* would not be possible without our [amazing sponsors](https://github.com/sponsors/hynek).
Especially those generously supporting us at the *The Organization* tier and higher:
<p align="center">
<a href="https://www.variomedia.de/"><img src="https://www.attrs.org/en/latest/_static/sponsors/Variomedia.svg" width="200" height="60" /></a>
<a href="https://tidelift.com/subscription/pkg/pypi-attrs?utm_source=pypi-attrs&utm_medium=referral&utm_campaign=enterprise&utm_term=repo"><img src="https://www.attrs.org/en/latest/_static/sponsors/Tidelift.svg" width="200" height="60" /></a>
<a href="https://filepreviews.io/"><img src="https://www.attrs.org/en/latest/_static/sponsors/FilePreviews.svg" width="200" height="60"/></a>
</p>
<p align="center">
<strong>Please consider <a href="https://github.com/sponsors/hynek">joining them</a> to help make <em>attrs</em>’s maintenance more sustainable!</strong>
</p>
<!-- teaser-end -->
## Example
*attrs* gives you a class decorator and a way to declaratively define the attributes on that class:
<!-- code-begin -->
```pycon
>>> from attrs import asdict, define, make_class, Factory
>>> @define
... class SomeClass:
... a_number: int = 42
... list_of_numbers: list[int] = Factory(list)
...
... def hard_math(self, another_number):
... return self.a_number + sum(self.list_of_numbers) * another_number
>>> sc = SomeClass(1, [1, 2, 3])
>>> sc
SomeClass(a_number=1, list_of_numbers=[1, 2, 3])
>>> sc.hard_math(3)
19
>>> sc == SomeClass(1, [1, 2, 3])
True
>>> sc != SomeClass(2, [3, 2, 1])
True
>>> asdict(sc)
{'a_number': 1, 'list_of_numbers': [1, 2, 3]}
>>> SomeClass()
SomeClass(a_number=42, list_of_numbers=[])
>>> C = make_class("C", ["a", "b"])
>>> C("foo", "bar")
C(a='foo', b='bar')
```
After *declaring* your attributes, *attrs* gives you:
- a concise and explicit overview of the class's attributes,
- a nice human-readable `__repr__`,
- equality-checking methods,
- an initializer,
- and much more,
*without* writing dull boilerplate code again and again and *without* runtime performance penalties.
**Hate type annotations**!?
No problem!
Types are entirely **optional** with *attrs*.
Simply assign `attrs.field()` to the attributes instead of annotating them with types.
---
This example uses *attrs*'s modern APIs that have been introduced in version 20.1.0, and the *attrs* package import name that has been added in version 21.3.0.
The classic APIs (`@attr.s`, `attr.ib`, plus their serious-business aliases) and the `attr` package import name will remain **indefinitely**.
Please check out [*On The Core API Names*](https://www.attrs.org/en/latest/names.html) for a more in-depth explanation.
## Data Classes
On the tin, *attrs* might remind you of `dataclasses` (and indeed, `dataclasses` [are a descendant](https://hynek.me/articles/import-attrs/) of *attrs*).
In practice it does a lot more and is more flexible.
For instance it allows you to define [special handling of NumPy arrays for equality checks](https://www.attrs.org/en/stable/comparison.html#customization), allows more ways to [plug into the initialization process](https://www.attrs.org/en/stable/init.html#hooking-yourself-into-initialization), and allows for stepping through the generated methods using a debugger.
For more details, please refer to our [comparison page](https://www.attrs.org/en/stable/why.html#data-classes).
## Project Information
- [**Changelog**](https://www.attrs.org/en/stable/changelog.html)
- [**Documentation**](https://www.attrs.org/)
- [**PyPI**](https://pypi.org/project/attrs/)
- [**Source Code**](https://github.com/python-attrs/attrs)
- [**Contributing**](https://github.com/python-attrs/attrs/blob/main/.github/CONTRIBUTING.md)
- [**Third-party Extensions**](https://github.com/python-attrs/attrs/wiki/Extensions-to-attrs)
- **Get Help**: please use the `python-attrs` tag on [StackOverflow](https://stackoverflow.com/questions/tagged/python-attrs)
### *attrs* for Enterprise
Available as part of the Tidelift Subscription.
The maintainers of *attrs* and thousands of other packages are working with Tidelift to deliver commercial support and maintenance for the open source packages you use to build your applications.
Save time, reduce risk, and improve code health, while paying the maintainers of the exact packages you use.
[Learn more.](https://tidelift.com/subscription/pkg/pypi-attrs?utm_source=pypi-attrs&utm_medium=referral&utm_campaign=enterprise&utm_term=repo) | {
"source": "yandex/perforator",
"title": "contrib/python/attrs/py3/README.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/python/attrs/py3/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 6478
} |
Copyright 2014 Pallets
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are
met:
1. Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or other materials provided with the distribution.
3. Neither the name of the copyright holder nor the names of its
contributors may be used to endorse or promote products derived from
this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
"AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A
PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED
TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR
PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF
LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING
NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. | {
"source": "yandex/perforator",
"title": "contrib/python/click/py2/LICENSE.rst",
"url": "https://github.com/yandex/perforator/blob/main/contrib/python/click/py2/LICENSE.rst",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1474
} |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.