
text
stringlengths 55
456k
| metadata
dict |
|---|---|
Changes by Version
==================
1.2.0 (2020-07-01)
-------------------
* Restore the ability to reset the current span in context to nil (#231) -- Yuri Shkuro
* Use error.object per OpenTracing Semantic Conventions (#179) -- Rahman Syed
* Convert nil pointer log field value to string "nil" (#230) -- Cyril Tovena
* Add Go module support (#215) -- Zaba505
* Make SetTag helper types in ext public (#229) -- Blake Edwards
* Add log/fields helpers for keys from specification (#226) -- Dmitry Monakhov
* Improve noop impementation (#223) -- chanxuehong
* Add an extension to Tracer interface for custom go context creation (#220) -- Krzesimir Nowak
* Fix typo in comments (#222) -- meteorlxy
* Improve documentation for log.Object() to emphasize the requirement to pass immutable arguments (#219) -- 疯狂的小企鹅
* [mock] Return ErrInvalidSpanContext if span context is not MockSpanContext (#216) -- Milad Irannejad
1.1.0 (2019-03-23)
-------------------
Notable changes:
- The library is now released under Apache 2.0 license
- Use Set() instead of Add() in HTTPHeadersCarrier is functionally a breaking change (fixes issue [#159](https://github.com/opentracing/opentracing-go/issues/159))
- 'golang.org/x/net/context' is replaced with 'context' from the standard library
List of all changes:
- Export StartSpanFromContextWithTracer (#214) <Aaron Delaney>
- Add IsGlobalTracerRegistered() to indicate if a tracer has been registered (#201) <Mike Goldsmith>
- Use Set() instead of Add() in HTTPHeadersCarrier (#191) <jeremyxu2010>
- Update license to Apache 2.0 (#181) <Andrea Kao>
- Replace 'golang.org/x/net/context' with 'context' (#176) <Tony Ghita>
- Port of Python opentracing/harness/api_check.py to Go (#146) <chris erway>
- Fix race condition in MockSpan.Context() (#170) <Brad>
- Add PeerHostIPv4.SetString() (#155) <NeoCN>
- Add a Noop log field type to log to allow for optional fields (#150) <Matt Ho>
1.0.2 (2017-04-26)
-------------------
- Add more semantic tags (#139) <Rustam Zagirov>
1.0.1 (2017-02-06)
-------------------
- Correct spelling in comments <Ben Sigelman>
- Address race in nextMockID() (#123) <bill fumerola>
- log: avoid panic marshaling nil error (#131) <Anthony Voutas>
- Deprecate InitGlobalTracer in favor of SetGlobalTracer (#128) <Yuri Shkuro>
- Drop Go 1.5 that fails in Travis (#129) <Yuri Shkuro>
- Add convenience methods Key() and Value() to log.Field <Ben Sigelman>
- Add convenience methods to log.Field (2 years, 6 months ago) <Radu Berinde>
1.0.0 (2016-09-26)
-------------------
- This release implements OpenTracing Specification 1.0 (https://opentracing.io/spec) | {
"source": "yandex/perforator",
"title": "vendor/github.com/opentracing/opentracing-go/CHANGELOG.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/opentracing/opentracing-go/CHANGELOG.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2630
} |
[](https://gitter.im/opentracing/public) [](https://travis-ci.org/opentracing/opentracing-go) [](http://godoc.org/github.com/opentracing/opentracing-go)
[](https://sourcegraph.com/github.com/opentracing/opentracing-go?badge)
# OpenTracing API for Go
This package is a Go platform API for OpenTracing.
## Required Reading
In order to understand the Go platform API, one must first be familiar with the
[OpenTracing project](https://opentracing.io) and
[terminology](https://opentracing.io/specification/) more specifically.
## API overview for those adding instrumentation
Everyday consumers of this `opentracing` package really only need to worry
about a couple of key abstractions: the `StartSpan` function, the `Span`
interface, and binding a `Tracer` at `main()`-time. Here are code snippets
demonstrating some important use cases.
#### Singleton initialization
The simplest starting point is `./default_tracer.go`. As early as possible, call
```go
import "github.com/opentracing/opentracing-go"
import ".../some_tracing_impl"
func main() {
opentracing.SetGlobalTracer(
// tracing impl specific:
some_tracing_impl.New(...),
)
...
}
```
#### Non-Singleton initialization
If you prefer direct control to singletons, manage ownership of the
`opentracing.Tracer` implementation explicitly.
#### Creating a Span given an existing Go `context.Context`
If you use `context.Context` in your application, OpenTracing's Go library will
happily rely on it for `Span` propagation. To start a new (blocking child)
`Span`, you can use `StartSpanFromContext`.
```go
func xyz(ctx context.Context, ...) {
...
span, ctx := opentracing.StartSpanFromContext(ctx, "operation_name")
defer span.Finish()
span.LogFields(
log.String("event", "soft error"),
log.String("type", "cache timeout"),
log.Int("waited.millis", 1500))
...
}
```
#### Starting an empty trace by creating a "root span"
It's always possible to create a "root" `Span` with no parent or other causal
reference.
```go
func xyz() {
...
sp := opentracing.StartSpan("operation_name")
defer sp.Finish()
...
}
```
#### Creating a (child) Span given an existing (parent) Span
```go
func xyz(parentSpan opentracing.Span, ...) {
...
sp := opentracing.StartSpan(
"operation_name",
opentracing.ChildOf(parentSpan.Context()))
defer sp.Finish()
...
}
```
#### Serializing to the wire
```go
func makeSomeRequest(ctx context.Context) ... {
if span := opentracing.SpanFromContext(ctx); span != nil {
httpClient := &http.Client{}
httpReq, _ := http.NewRequest("GET", "http://myservice/", nil)
// Transmit the span's TraceContext as HTTP headers on our
// outbound request.
opentracing.GlobalTracer().Inject(
span.Context(),
opentracing.HTTPHeaders,
opentracing.HTTPHeadersCarrier(httpReq.Header))
resp, err := httpClient.Do(httpReq)
...
}
...
}
```
#### Deserializing from the wire
```go
http.HandleFunc("/", func(w http.ResponseWriter, req *http.Request) {
var serverSpan opentracing.Span
appSpecificOperationName := ...
wireContext, err := opentracing.GlobalTracer().Extract(
opentracing.HTTPHeaders,
opentracing.HTTPHeadersCarrier(req.Header))
if err != nil {
// Optionally record something about err here
}
// Create the span referring to the RPC client if available.
// If wireContext == nil, a root span will be created.
serverSpan = opentracing.StartSpan(
appSpecificOperationName,
ext.RPCServerOption(wireContext))
defer serverSpan.Finish()
ctx := opentracing.ContextWithSpan(context.Background(), serverSpan)
...
}
```
#### Conditionally capture a field using `log.Noop`
In some situations, you may want to dynamically decide whether or not
to log a field. For example, you may want to capture additional data,
such as a customer ID, in non-production environments:
```go
func Customer(order *Order) log.Field {
if os.Getenv("ENVIRONMENT") == "dev" {
return log.String("customer", order.Customer.ID)
}
return log.Noop()
}
```
#### Goroutine-safety
The entire public API is goroutine-safe and does not require external
synchronization.
## API pointers for those implementing a tracing system
Tracing system implementors may be able to reuse or copy-paste-modify the `basictracer` package, found [here](https://github.com/opentracing/basictracer-go). In particular, see `basictracer.New(...)`.
## API compatibility
For the time being, "mild" backwards-incompatible changes may be made without changing the major version number. As OpenTracing and `opentracing-go` mature, backwards compatibility will become more of a priority.
## Tracer test suite
A test suite is available in the [harness](https://godoc.org/github.com/opentracing/opentracing-go/harness) package that can assist Tracer implementors to assert that their Tracer is working correctly.
## Licensing
[Apache 2.0 License](./LICENSE). | {
"source": "yandex/perforator",
"title": "vendor/github.com/opentracing/opentracing-go/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/opentracing/opentracing-go/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 5736
} |
# Changelog
All notable changes to this project will be documented in this file.
## [v0.11.1](https://github.com/paulmach/orb/compare/v0.11.0...v0.11.1) - 2024-01-29
### Fixed
- geojson: `null` json into non-pointer Feature/FeatureCollection will set them to empty by [@paulmach](https://github.com/paulmach)in https://github.com/paulmach/orb/pull/145
## [v0.11.0](https://github.com/paulmach/orb/compare/v0.10.0...v0.11.0) - 2024-01-11
### Fixed
- quadtree: InBoundMatching does not properly accept passed-in buffer by [@nirmal-vuppuluri](https://github.com/nirmal-vuppuluri) in https://github.com/paulmach/orb/pull/139
- mvt: Do not swallow error cause by [@m-pavel](https://github.com/m-pavel) in https://github.com/paulmach/orb/pull/137
### Changed
- simplify: Visvalingam, by default, keeps 3 points for "areas" by [@paulmach](https://github.com/paulmach) in https://github.com/paulmach/orb/pull/140
- encoding/mvt: skip encoding of features will nil geometry by [@paulmach](https://github.com/paulmach) in https://github.com/paulmach/orb/pull/141
- encoding/wkt: improve unmarshalling performance by [@paulmach](https://github.com/paulmach) in https://github.com/paulmach/orb/pull/142
## [v0.10.0](https://github.com/paulmach/orb/compare/v0.9.2...v0.10.0) - 2023-07-16
### Added
- add ChildrenInZoomRange method to maptile.Tile by [@peitili](https://github.com/peitili) in https://github.com/paulmach/orb/pull/133
## [v0.9.2](https://github.com/paulmach/orb/compare/v0.9.1...v0.9.2) - 2023-05-04
### Fixed
- encoding/wkt: better handling/validation of missing parens by [@paulmach](https://github.com/paulmach) in https://github.com/paulmach/orb/pull/131
## [v0.9.1](https://github.com/paulmach/orb/compare/v0.9.0...v0.9.1) - 2023-04-26
### Fixed
- Bump up mongo driver to 1.11.4 by [@m-pavel](https://github.com/m-pavel) in https://github.com/paulmach/orb/pull/129
- encoding/wkt: split strings with regexp by [@m-pavel](https://github.com/m-pavel) in https://github.com/paulmach/orb/pull/128
## [v0.9.0](https://github.com/paulmach/orb/compare/v0.8.0...v0.9.0) - 2023-02-19
### Added
- geojson: marshal/unmarshal BSON [@paulmach](https://github.com/paulmach) in https://github.com/paulmach/orb/pull/123
## [v0.8.0](https://github.com/paulmach/orb/compare/v0.7.1...v0.8.0) - 2023-01-05
### Fixed
- quadtree: fix bad sort due to pointer allocation issue by [@paulmach](https://github.com/paulmach) in https://github.com/paulmach/orb/pull/115
- geojson: ensure geometry unmarshal errors get returned by [@paulmach](https://github.com/paulmach) in https://github.com/paulmach/orb/pull/117
- encoding/mvt: remove use of crypto/md5 to compare marshalling in tests by [@paulmach](https://github.com/paulmach) in https://github.com/paulmach/orb/pull/118
- encoding/wkt: fix panic for some invalid wkt data by [@paulmach](https://github.com/paulmach) in https://github.com/paulmach/orb/pull/119
### Other
- fix typo by [@rubenpoppe](https://github.com/rubenpoppe) in https://github.com/paulmach/orb/pull/107
- Fixed a small twister in README.md by [@Timahawk](https://github.com/Timahawk) in https://github.com/paulmach/orb/pull/108
- update github ci to use go 1.19 by [@paulmach](https://github.com/paulmach) in https://github.com/paulmach/orb/pull/116
## [v0.7.1](https://github.com/paulmach/orb/compare/v0.7.0...v0.7.1) - 2022-05-16
No changes
The v0.7.0 tag was updated since it initially pointed to the wrong commit. This is causing caching issues.
## [v0.7.0](https://github.com/paulmach/orb/compare/v0.6.0...v0.7.0) - 2022-05-10
This tag is broken, please use v0.7.1 instead.
### Breaking Changes
- tilecover now returns an error (vs. panicing) on non-closed 2d geometry by [@paulmach](https://github.com/paulmach) in https://github.com/paulmach/orb/pull/87
This changes the signature of many of the methods in the [maptile/tilecover](https://github.com/paulmach/orb/tree/master/maptile/tilecover) package.
To emulate the old behavior replace:
tiles := tilecover.Geometry(poly, zoom)
with
tiles, err := tilecover.Geometry(poly, zoom)
if err != nil {
panic(err)
}
## [v0.6.0](https://github.com/paulmach/orb/compare/v0.5.0...v0.6.0) - 2022-05-04
### Added
- geo: add correctly spelled LengthHaversine by [@paulmach](https://github.com/paulmach) in https://github.com/paulmach/orb/pull/97
- geojson: add support for "external" json encoders/decoders by [@paulmach](https://github.com/paulmach) in https://github.com/paulmach/orb/pull/98
- Add ewkb encoding/decoding support by [@paulmach](https://github.com/paulmach) in https://github.com/paulmach/orb/pull/88
## [v0.5.0](https://github.com/paulmach/orb/compare/v0.4.0...v0.5.0) - 2022-04-06
### Added
- encoding/mvt: stable marshalling by [@travisgrigsby](https://github.com/travisgrigsby) in https://github.com/paulmach/orb/pull/93
- encoding/mvt: support mvt marshal for GeometryCollection by [@dadadamarine](https://github.com/dadadamarine) in https://github.com/paulmach/orb/pull/89
### Fixed
- quadtree: fix cleanup of nodes during removal by [@paulmach](https://github.com/paulmach) in https://github.com/paulmach/orb/pull/94
### Other
- encoding/wkt: various code improvements by [@paulmach](https://github.com/paulmach) in https://github.com/paulmach/orb/pull/95
- update protoscan to 0.2.1 by [@paulmach](https://github.com/paulmach) in https://github.com/paulmach/orb/pull/83
## [v0.4.0](https://github.com/paulmach/orb/compare/v0.3.0...v0.4.0) - 2021-11-11
### Added
- geo: Add functions to calculate points based on distance and bearing by [@thzinc](https://github.com/thzinc) in https://github.com/paulmach/orb/pull/76
### Fixed
- encoding/mvt: avoid reflect nil value by [@nicklasaven](https://github.com/nicklasaven) in https://github.com/paulmach/orb/pull/78
## [v0.3.0](https://github.com/paulmach/orb/compare/v0.2.2...v0.3.0) - 2021-10-16
### Changed
- quadtree: sort KNearest results closest first by [@paulmach](https://github.com/paulmach) in https://github.com/paulmach/orb/pull/75
- ring: require >=4 points to return true when calling Closed() by [@missinglink](https://github.com/missinglink) in https://github.com/paulmach/orb/pull/70
### Fixed
- encoding/mvt: verify tile coord does not overflow for z > 20 by [@paulmach](https://github.com/paulmach) in https://github.com/paulmach/orb/pull/74
- quadtree: Address panic-ing quadtree.Matching(…) method when finding no closest node by [@willsalz](https://github.com/willsalz) in https://github.com/paulmach/orb/pull/73
## [v0.2.2](https://github.com/paulmach/orb/compare/v0.2.1...v0.2.2) - 2021-06-05
### Fixed
- Dependency resolution problems in some cases, issue https://github.com/paulmach/orb/issues/65, pr https://github.com/paulmach/orb/pull/66
## [v0.2.1](https://github.com/paulmach/orb/compare/v0.2.0...v0.2.1) - 2021-01-16
### Changed
- encoding/mvt: upgrade protoscan v0.1 -> v0.2 [`ad31566`](https://github.com/paulmach/orb/commit/ad31566942027c1cd30dd341f35123fb54676599)
- encoding/mvt: remove github.com/pkg/errors as a dependency [`d2e235`](https://github.com/paulmach/orb/commit/d2e23529a295a0d973cc787ad2742cb6ccbd5306)
## v0.2.0 - 2021-01-16
### Breaking Changes
- Foreign Members in Feature Collections
Extra attributes in a feature collection object will now be put into `featureCollection.ExtraMembers`.
Similarly, stuff in `ExtraMembers will be marshalled into the feature collection base.
The break happens if you were decoding these foreign members using something like
```go
type MyFeatureCollection struct {
geojson.FeatureCollection
Title string `json:"title"`
}
```
**The above will no longer work** in this release and it never supported marshalling. See https://github.com/paulmach/orb/pull/56 for more details.
- Features with nil/missing geometry will no longer return an errors
Previously missing or invalid geometry in a feature collection would return a `ErrInvalidGeometry` error.
However missing geometry is compliant with [section 3.2](https://tools.ietf.org/html/rfc7946#section-3.2) of the spec.
See https://github.com/paulmach/orb/issues/38 and https://github.com/paulmach/orb/pull/58 for more details.
### Changed
- encoding/mvt: faster unmarshalling for Mapbox Vector Tiles (MVT) see https://github.com/paulmach/orb/pull/57 | {
"source": "yandex/perforator",
"title": "vendor/github.com/paulmach/orb/CHANGELOG.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/paulmach/orb/CHANGELOG.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 8464
} |
The MIT License (MIT)
Copyright (c) 2017 Paul Mach
Permission is hereby granted, free of charge, to any person obtaining a copy of
this software and associated documentation files (the "Software"), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
the Software, and to permit persons to whom the Software is furnished to do so,
subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. | {
"source": "yandex/perforator",
"title": "vendor/github.com/paulmach/orb/LICENSE.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/paulmach/orb/LICENSE.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1075
} |
# orb [](https://github.com/paulmach/orb/actions?query=workflow%3ACI+event%3Apush) [](https://codecov.io/gh/paulmach/orb) [](https://goreportcard.com/report/github.com/paulmach/orb) [](https://pkg.go.dev/github.com/paulmach/orb)
Package `orb` defines a set of types for working with 2d geo and planar/projected geometric data in Golang.
There are a set of sub-packages that use these types to do interesting things.
They each provide their own README with extra info.
## Interesting features
- **Simple types** - allow for natural operations using the `make`, `append`, `len`, `[s:e]` builtins.
- **GeoJSON** - support as part of the [`geojson`](geojson) sub-package.
- **Mapbox Vector Tile** - encoding and decoding as part of the [`encoding/mvt`](encoding/mvt) sub-package.
- **Direct to type from DB query results** - by scanning WKB data directly into types.
- **Rich set of sub-packages** - including [`clipping`](clip), [`simplifing`](simplify), [`quadtree`](quadtree) and more.
## Type definitions
```go
type Point [2]float64
type MultiPoint []Point
type LineString []Point
type MultiLineString []LineString
type Ring LineString
type Polygon []Ring
type MultiPolygon []Polygon
type Collection []Geometry
type Bound struct { Min, Max Point }
```
Defining the types as slices allows them to be accessed in an idiomatic way
using Go's built-in functions such at `make`, `append`, `len`
and with slice notation like `[s:e]`. For example:
```go
ls := make(orb.LineString, 0, 100)
ls = append(ls, orb.Point{1, 1})
point := ls[0]
```
### Shared `Geometry` interface
All of the base types implement the `orb.Geometry` interface defined as:
```go
type Geometry interface {
GeoJSONType() string
Dimensions() int // e.g. 0d, 1d, 2d
Bound() Bound
}
```
This interface is accepted by functions in the sub-packages which then act on the
base types correctly. For example:
```go
l := clip.Geometry(bound, geom)
```
will use the appropriate clipping algorithm depending on if the input is 1d or 2d,
e.g. a `orb.LineString` or a `orb.Polygon`.
Only a few methods are defined directly on these type, for example `Clone`, `Equal`, `GeoJSONType`.
Other operation that depend on geo vs. planar contexts are defined in the respective sub-package.
For example:
- Computing the geo distance between two point:
```go
p1 := orb.Point{-72.796408, -45.407131}
p2 := orb.Point{-72.688541, -45.384987}
geo.Distance(p1, p2)
```
- Compute the planar area and centroid of a polygon:
```go
poly := orb.Polygon{...}
centroid, area := planar.CentroidArea(poly)
```
## GeoJSON
The [geojson](geojson) sub-package implements Marshalling and Unmarshalling of GeoJSON data.
Features are defined as:
```go
type Feature struct {
ID interface{} `json:"id,omitempty"`
Type string `json:"type"`
Geometry orb.Geometry `json:"geometry"`
Properties Properties `json:"properties"`
}
```
Defining the geometry as an `orb.Geometry` interface along with sub-package functions
accepting geometries allows them to work together to create easy to follow code.
For example, clipping all the geometries in a collection:
```go
fc, err := geojson.UnmarshalFeatureCollection(data)
for _, f := range fc {
f.Geometry = clip.Geometry(bound, f.Geometry)
}
```
The library supports third party "encoding/json" replacements
such [github.com/json-iterator/go](https://github.com/json-iterator/go).
See the [geojson](geojson) readme for more details.
The types also support BSON so they can be used directly when working with MongoDB.
## Mapbox Vector Tiles
The [encoding/mvt](encoding/mvt) sub-package implements Marshalling and
Unmarshalling [MVT](https://www.mapbox.com/vector-tiles/) data.
This package uses sets of `geojson.FeatureCollection` to define the layers,
keyed by the layer name. For example:
```go
collections := map[string]*geojson.FeatureCollection{}
// Convert to a layers object and project to tile coordinates.
layers := mvt.NewLayers(collections)
layers.ProjectToTile(maptile.New(x, y, z))
// In order to be used as source for MapboxGL geometries need to be clipped
// to max allowed extent. (uncomment next line)
// layers.Clip(mvt.MapboxGLDefaultExtentBound)
// Simplify the geometry now that it's in tile coordinate space.
layers.Simplify(simplify.DouglasPeucker(1.0))
// Depending on use-case remove empty geometry, those too small to be
// represented in this tile space.
// In this case lines shorter than 1, and areas smaller than 2.
layers.RemoveEmpty(1.0, 2.0)
// encoding using the Mapbox Vector Tile protobuf encoding.
data, err := mvt.Marshal(layers) // this data is NOT gzipped.
// Sometimes MVT data is stored and transfered gzip compressed. In that case:
data, err := mvt.MarshalGzipped(layers)
```
## Decoding WKB/EWKB from a database query
Geometries are usually returned from databases in WKB or EWKB format. The [encoding/ewkb](encoding/ewkb)
sub-package offers helpers to "scan" the data into the base types directly.
For example:
```go
db.Exec(
"INSERT INTO postgis_table (point_column) VALUES (ST_GeomFromEWKB(?))",
ewkb.Value(orb.Point{1, 2}, 4326),
)
row := db.QueryRow("SELECT ST_AsBinary(point_column) FROM postgis_table")
var p orb.Point
err := row.Scan(ewkb.Scanner(&p))
```
For more information see the readme in the [encoding/ewkb](encoding/ewkb) package.
## List of sub-package utilities
- [`clip`](clip) - clipping geometry to a bounding box
- [`encoding/mvt`](encoding/mvt) - encoded and decoding from [Mapbox Vector Tiles](https://www.mapbox.com/vector-tiles/)
- [`encoding/wkb`](encoding/wkb) - well-known binary as well as helpers to decode from the database queries
- [`encoding/ewkb`](encoding/ewkb) - extended well-known binary format that includes the SRID
- [`encoding/wkt`](encoding/wkt) - well-known text encoding
- [`geojson`](geojson) - working with geojson and the types in this package
- [`maptile`](maptile) - working with mercator map tiles and quadkeys
- [`project`](project) - project geometries between geo and planar contexts
- [`quadtree`](quadtree) - quadtree implementation using the types in this package
- [`resample`](resample) - resample points in a line string geometry
- [`simplify`](simplify) - linear geometry simplifications like Douglas-Peucker | {
"source": "yandex/perforator",
"title": "vendor/github.com/paulmach/orb/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/paulmach/orb/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 6646
} |
The MIT License (MIT)
Copyright (c) 2020 Paul Mach
Permission is hereby granted, free of charge, to any person obtaining a copy of
this software and associated documentation files (the "Software"), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
the Software, and to permit persons to whom the Software is furnished to do so,
subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. | {
"source": "yandex/perforator",
"title": "vendor/github.com/paulmach/protoscan/LICENSE.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/paulmach/protoscan/LICENSE.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1075
} |
# protoscan [](https://github.com/paulmach/protoscan/actions?query=workflow%3ACI+event%3Apush) [](https://codecov.io/gh/paulmach/protoscan) [](https://goreportcard.com/report/github.com/paulmach/protoscan) [](https://godoc.org/github.com/paulmach/protoscan)
Package `protoscan` is a low-level reader for
[protocol buffers](https://developers.google.com/protocol-buffers) encoded data
in Golang. The main feature is the support for lazy/conditional decoding of fields.
This library can help decoding performance in two ways:
1. fields can be conditionally decoded, skipping over fields that are not needed
for a specific use-case,
2. decoding directly into specific types or perform other transformations, the extra state
can be skipped by manually decoding into the types directly.
Please be aware that to decode an entire message it is still faster to use
[gogoprotobuf](https://github.com/gogo/protobuf). After much testing I think this is due
to the generated code inlining almost all code to eliminate the function call overhead.
**Warning:** Writing code with this library is like writing the auto-generated protobuf
decoder and is very time-consuming. It should only be used for specific use cases and
for stable protobuf definitions.
## Usage
First, the encoded protobuf data is used to initialize a new Message. Then you
iterate over the fields, reading or skipping them.
```go
msg := protoscan.New(encodedData)
for msg.Next() {
switch msg.FieldNumber() {
case 1: // an int64 type
v, err := msg.Int64()
if err != nil {
// handle
}
case 3: // repeated number types can be returned as a slice
ids, err := msg.RepeatedInt64(nil)
if err != nil {
// handle
}
case 2: // for more control repeated+packed fields can be read using an iterator
iter, err := msg.Iterator(nil)
if err != nil {
// handle
}
userIDs := make([]UserID, 0, iter.Count(protoscan.WireTypeVarint))
for iter.HasNext() {
v, err := iter.Int64()
if err != nil {
// handle
}
userIDs = append(userIDs, UserID(v))
}
default:
msg.Skip() // required if value not needed.
}
}
if msg.Err() != nil {
// handle
}
```
After calling `Next()` you MUST call an accessor function (`Int64()`, `RepeatedInt64()`,
`Iterator()`, etc.) or `Skip()` to ignore the field. All these functions, including
`Next()` and `Skip()`, must not be called twice in a row.
### Value Accessor Functions
There is an accessor for each one the protobuf
[scalar value types](https://developers.google.com/protocol-buffers/docs/proto#scalar).
For repeated fields there is a corresponding set of functions like
`RepeatedInt64(buf []int64) ([]int64, error)`. Repeated fields may or may not be packed, so you
should pass in a pre-created buffer variable when calling. For example
```go
var ids []int64
msg := protoscan.New(encodedData)
for msg.Next() {
switch msg.FieldNumber() {
case 1: // repeated int64 field
var err error
ids, err = msg.RepeatedInt64(ids)
if err != nil {
// handle
}
default:
msg.Skip()
}
}
if msg.Err() != nil {
// handle
}
```
If the ids are 'packed', `RepeatedInt64()` will be called once. If the ids are simply repeated
`RepeatedInt64()` will be called N times, but the resulting array of ids will be the same.
For more control over the values in a packed, repeated field use an Iterator. See above for an example.
### Decoding Embedded Messages
Embedded messages can be handled recursively, or the raw data can be returned and decoded
using a standard/auto-generated `proto.Unmarshal` function.
```go
msg := protoscan.New(encodedData)
for msg.Next() {
fn := msg.FieldNumber()
// use protoscan recursively
if fn == 1 && needFieldNumber1 {
embeddedMsg, err := msg.Message()
for embeddedMsg.Next() {
switch embeddedMsg.FieldNumber() {
case 1:
// do something
default:
embeddedMsg.Skip()
}
}
}
// if you need the whole message decode the message in the standard way.
if fn == 2 && needFieldNumber2 {
data, err := msg.MessageData()
v := &ProtoBufThing()
err = proto.Unmarshal(data, v)
}
}
```
### Handling errors
For Errors can occure for two reason:
1. The field is being read as the incorrect type.
2. The data is corrupted or somehow invalid.
## Larger Example
Starting with a customer message with embedded orders and items and you only want
to count the number of items in open orders.
```protobuf
message Customer {
required int64 id = 1;
optional string username = 2;
repeated Order orders = 3;
repeated int64 favorite_ids = 4 [packed=true];
}
message Order {
required int64 id = 1;
required bool open = 2;
repeated Item items = 3;
}
message Item {
// a big object
}
```
Sample Code:
```go
openCount := 0
itemCount := 0
favoritesCount := 0
customer := protoscan.New(data)
for customer.Next() {
switch customer.FieldNumber() {
case 1: // id
id, err := customer.Int64()
if err != nil {
panic(err)
}
_ = id // do something or skip this case if not needed
case 2: // username
username, err := customer.String()
if err != nil {
panic(err)
}
_ = username // do something or skip this case if not needed
case 3: // orders
open := false
count := 0
orderData, _ := customer.MessageData()
order := protoscan.New(orderData)
for order.Next() {
switch order.FieldNumber() {
case 2: // open
v, _ := order.Bool()
open = v
case 3: // item
count++
// we're not reading the data but we still need to skip it.
order.Skip()
default:
// required to move past unneeded fields
order.Skip()
}
}
if open {
openCount++
itemCount += count
}
case 4: // favorite ids
iter, err := customer.Iterator(nil)
if err != nil {
panic(err)
}
// Typically this section would only be run once but it is valid
// protobuf to contain multiple sections of repeated fields that should
// be concatenated together.
favoritesCount += iter.Count(protoscan.WireTypeVarint)
default:
// unread fields must be skipped
customer.Skip()
}
}
fmt.Printf("Open Orders: %d\n", openCount)
fmt.Printf("Items: %d\n", itemCount)
fmt.Printf("Favorites: %d\n", favoritesCount)
// Output:
// Open Orders: 2
// Items: 4
// Favorites: 8
```
## Wire Type Start Group and End Group
Groups are an old protobuf wire type that has been deprecated for a long time.
They function as parentheses but with no "data length" information
so their content can not be effectively skipped.
Just the start and end group indicators can be read and skipped like any other field.
This would cause the data to be read without the parentheses, whatever that may mean in practice.
To get the raw protobuf data inside a group try something like:
```go
var (
groupFieldNum = 123
groupData []byte
)
msg := New(data)
for msg.Next() {
if msg.FieldNumber() == groupFieldNum && msg.WireType() == WireTypeStartGroup {
start, end := msg.Index, msg.Index
for msg.Next() {
msg.Skip()
if msg.FieldNumber() == groupFieldNum && msg.WireType() == WireTypeEndGroup {
break
}
end = msg.Index
}
// groupData would be the raw protobuf encoded bytes of the fields in the group.
groupData = msg.Data[start:end]
}
}
```
## Similar libraries in other languages
- [protozero](https://github.com/mapbox/protozero) - C++, the inspiration for this library
- [pbf](https://github.com/mapbox/pbf) - javascript | {
"source": "yandex/perforator",
"title": "vendor/github.com/paulmach/protoscan/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/paulmach/protoscan/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 8408
} |
<h1 align="center">
<br>
Pion Logging
<br>
</h1>
<h4 align="center">The Pion logging library</h4>
<p align="center">
<a href="https://pion.ly"><img src="https://img.shields.io/badge/pion-logging-gray.svg?longCache=true&colorB=brightgreen" alt="Pion transport"></a>
<a href="http://gophers.slack.com/messages/pion"><img src="https://img.shields.io/badge/join-us%20on%20slack-gray.svg?longCache=true&logo=slack&colorB=brightgreen" alt="Slack Widget"></a>
<br>
<a href="https://travis-ci.org/pion/logging"><img src="https://travis-ci.org/pion/logging.svg?branch=master" alt="Build Status"></a>
<a href="https://godoc.org/github.com/pion/logging"><img src="https://godoc.org/github.com/pion/logging?status.svg" alt="GoDoc"></a>
<a href="https://codecov.io/gh/pion/logging"><img src="https://codecov.io/gh/pion/logging/branch/master/graph/badge.svg" alt="Coverage Status"></a>
<a href="https://goreportcard.com/report/github.com/pion/logging"><img src="https://goreportcard.com/badge/github.com/pion/logging" alt="Go Report Card"></a>
<a href="LICENSE"><img src="https://img.shields.io/badge/License-MIT-yellow.svg" alt="License: MIT"></a>
</p>
<br>
### Roadmap
The library is used as a part of our WebRTC implementation. Please refer to that [roadmap](https://github.com/pion/webrtc/issues/9) to track our major milestones.
### Community
Pion has an active community on the [Golang Slack](https://invite.slack.golangbridge.org/). Sign up and join the **#pion** channel for discussions and support. You can also use [Pion mailing list](https://groups.google.com/forum/#!forum/pion).
We are always looking to support **your projects**. Please reach out if you have something to build!
If you need commercial support or don't want to use public methods you can contact us at [[email protected]](mailto:[email protected])
### Contributing
Check out the **[contributing wiki](https://github.com/pion/webrtc/wiki/Contributing)** to join the group of amazing people making this project possible:
* [John Bradley](https://github.com/kc5nra) - *Original Author*
* [Sean DuBois](https://github.com/Sean-Der) - *Original Author*
* [Michael MacDonald](https://github.com/mjmac) - *Original Author*
* [Woodrow Douglass](https://github.com/wdouglass) - *Test coverage*
* [Michiel De Backker](https://github.com/backkem) - *Docs*
* [Hugo Arregui](https://github.com/hugoArregui) - *Custom Logs*
* [Justin Okamoto](https://github.com/justinokamoto) - *Disabled Logs Update*
### License
MIT License - see [LICENSE](LICENSE) for full text | {
"source": "yandex/perforator",
"title": "vendor/github.com/pion/logging/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/pion/logging/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2535
} |
# errors [](https://travis-ci.org/pkg/errors) [](https://ci.appveyor.com/project/davecheney/errors/branch/master) [](http://godoc.org/github.com/pkg/errors) [](https://goreportcard.com/report/github.com/pkg/errors) [](https://sourcegraph.com/github.com/pkg/errors?badge)
Package errors provides simple error handling primitives.
`go get github.com/pkg/errors`
The traditional error handling idiom in Go is roughly akin to
```go
if err != nil {
return err
}
```
which applied recursively up the call stack results in error reports without context or debugging information. The errors package allows programmers to add context to the failure path in their code in a way that does not destroy the original value of the error.
## Adding context to an error
The errors.Wrap function returns a new error that adds context to the original error. For example
```go
_, err := ioutil.ReadAll(r)
if err != nil {
return errors.Wrap(err, "read failed")
}
```
## Retrieving the cause of an error
Using `errors.Wrap` constructs a stack of errors, adding context to the preceding error. Depending on the nature of the error it may be necessary to reverse the operation of errors.Wrap to retrieve the original error for inspection. Any error value which implements this interface can be inspected by `errors.Cause`.
```go
type causer interface {
Cause() error
}
```
`errors.Cause` will recursively retrieve the topmost error which does not implement `causer`, which is assumed to be the original cause. For example:
```go
switch err := errors.Cause(err).(type) {
case *MyError:
// handle specifically
default:
// unknown error
}
```
[Read the package documentation for more information](https://godoc.org/github.com/pkg/errors).
## Roadmap
With the upcoming [Go2 error proposals](https://go.googlesource.com/proposal/+/master/design/go2draft.md) this package is moving into maintenance mode. The roadmap for a 1.0 release is as follows:
- 0.9. Remove pre Go 1.9 and Go 1.10 support, address outstanding pull requests (if possible)
- 1.0. Final release.
## Contributing
Because of the Go2 errors changes, this package is not accepting proposals for new functionality. With that said, we welcome pull requests, bug fixes and issue reports.
Before sending a PR, please discuss your change by raising an issue.
## License
BSD-2-Clause | {
"source": "yandex/perforator",
"title": "vendor/github.com/pkg/errors/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/pkg/errors/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2716
} |
# Changelog
All notable changes to this project will be documented in this file.
The format is based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/),
and this project adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0.html).
## 1.1.0 - 2021-12-11
### Changed
- Use Go modules to track dependencies
## 1.0.0 - 2018-11-09
### Added
- Initial release with APIs to stub and reset values for testing.
- Supports stubbing Go variables, and environment variables. | {
"source": "yandex/perforator",
"title": "vendor/github.com/prashantv/gostub/CHANGELOG.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/prashantv/gostub/CHANGELOG.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 484
} |
The MIT License (MIT)
Copyright (c) 2015 Prashant Varanasi
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE. | {
"source": "yandex/perforator",
"title": "vendor/github.com/prashantv/gostub/LICENSE.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/prashantv/gostub/LICENSE.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1083
} |
# gostub
[](https://travis-ci.org/prashantv/gostub)
[](https://godoc.org/github.com/prashantv/gostub)
[](https://coveralls.io/github/prashantv/gostub?branch=master)
gostub is a library to make stubbing in unit tests easy.
## Getting started
Import the following package:
`github.com/prashantv/gostub`
Click [here](https://godoc.org/github.com/prashantv/gostub) to read the [API documentation](https://godoc.org/github.com/prashantv/gostub).
## Package overview
Package gostub is used for stubbing variables in tests, and resetting the
original value once the test has been run.
This can be used to stub static variables as well as static functions. To stub a
static variable, use the Stub function:
```go
var configFile = "config.json"
func GetConfig() ([]byte, error) {
return ioutil.ReadFile(configFile)
}
// Test code
stubs := gostub.Stub(&configFile, "/tmp/test.config")
data, err := GetConfig()
// data will now return contents of the /tmp/test.config file
```
gostub can also stub static functions in a test by using a variable to reference
the static function, and using that local variable to call the static function:
```go
var timeNow = time.Now
func GetDate() int {
return timeNow().Day()
}
```
You can test this by using gostub to stub the timeNow variable:
```go
stubs := gostub.Stub(&timeNow, func() time.Time {
return time.Date(2015, 6, 1, 0, 0, 0, 0, time.UTC)
})
defer stubs.Reset()
// Test can check that GetDate returns 6
```
If you are stubbing a function to return a constant value like in the above
test, you can use StubFunc instead:
```go
stubs := gostub.StubFunc(&timeNow, time.Date(2015, 6, 1, 0, 0, 0, 0, time.UTC))
defer stubs.Reset()
```
StubFunc can also be used to stub functions that return multiple values:
```go
var osHostname = osHostname
// [...] production code using osHostname to call it.
// Test code:
stubs := gostub.StubFunc(&osHostname, "fakehost", nil)
defer stubs.Reset()
```
StubEnv can be used to setup environment variables for tests, and the
environment values are reset to their original values upon Reset:
```go
stubs := gostub.New()
stubs.SetEnv("GOSTUB_VAR", "test_value")
defer stubs.Reset()
```
The Reset method should be deferred to run at the end of the test to reset all
stubbed variables back to their original values.
You can set up multiple stubs by calling Stub again:
```go
stubs := gostub.Stub(&v1, 1)
stubs.Stub(&v2, 2)
defer stubs.Reset()
```
For simple cases where you are only setting up simple stubs, you can condense
the setup and cleanup into a single line:
```go
defer gostub.Stub(&v1, 1).Stub(&v2, 2).Reset()
```
This sets up the stubs and then defers the Reset call.
You should keep the return argument from the Stub call if you need to change
stubs or add more stubs during test execution:
```go
stubs := gostub.Stub(&v1, 1)
defer stubs.Reset()
// Do some testing
stubs.Stub(&v1, 5)
// More testing
stubs.Stub(&b2, 6)
```
The Stub call must be passed a pointer to the variable that should be stubbed,
and a value which can be assigned to the variable. | {
"source": "yandex/perforator",
"title": "vendor/github.com/prashantv/gostub/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/prashantv/gostub/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 3306
} |
# Prometheus Community Code of Conduct
Prometheus follows the [CNCF Code of Conduct](https://github.com/cncf/foundation/blob/main/code-of-conduct.md). | {
"source": "yandex/perforator",
"title": "vendor/github.com/prometheus/procfs/CODE_OF_CONDUCT.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/prometheus/procfs/CODE_OF_CONDUCT.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 151
} |
# Contributing
Prometheus uses GitHub to manage reviews of pull requests.
* If you are a new contributor see: [Steps to Contribute](#steps-to-contribute)
* If you have a trivial fix or improvement, go ahead and create a pull request,
addressing (with `@...`) a suitable maintainer of this repository (see
[MAINTAINERS.md](MAINTAINERS.md)) in the description of the pull request.
* If you plan to do something more involved, first discuss your ideas
on our [mailing list](https://groups.google.com/forum/?fromgroups#!forum/prometheus-developers).
This will avoid unnecessary work and surely give you and us a good deal
of inspiration. Also please see our [non-goals issue](https://github.com/prometheus/docs/issues/149) on areas that the Prometheus community doesn't plan to work on.
* Relevant coding style guidelines are the [Go Code Review
Comments](https://code.google.com/p/go-wiki/wiki/CodeReviewComments)
and the _Formatting and style_ section of Peter Bourgon's [Go: Best
Practices for Production
Environments](https://peter.bourgon.org/go-in-production/#formatting-and-style).
* Be sure to sign off on the [DCO](https://github.com/probot/dco#how-it-works)
## Steps to Contribute
Should you wish to work on an issue, please claim it first by commenting on the GitHub issue that you want to work on it. This is to prevent duplicated efforts from contributors on the same issue.
Please check the [`help-wanted`](https://github.com/prometheus/procfs/issues?q=is%3Aissue+is%3Aopen+label%3A%22help+wanted%22) label to find issues that are good for getting started. If you have questions about one of the issues, with or without the tag, please comment on them and one of the maintainers will clarify it. For a quicker response, contact us over [IRC](https://prometheus.io/community).
For quickly compiling and testing your changes do:
```
make test # Make sure all the tests pass before you commit and push :)
```
We use [`golangci-lint`](https://github.com/golangci/golangci-lint) for linting the code. If it reports an issue and you think that the warning needs to be disregarded or is a false-positive, you can add a special comment `//nolint:linter1[,linter2,...]` before the offending line. Use this sparingly though, fixing the code to comply with the linter's recommendation is in general the preferred course of action.
## Pull Request Checklist
* Branch from the master branch and, if needed, rebase to the current master branch before submitting your pull request. If it doesn't merge cleanly with master you may be asked to rebase your changes.
* Commits should be as small as possible, while ensuring that each commit is correct independently (i.e., each commit should compile and pass tests).
* If your patch is not getting reviewed or you need a specific person to review it, you can @-reply a reviewer asking for a review in the pull request or a comment, or you can ask for a review on IRC channel [#prometheus](https://webchat.freenode.net/?channels=#prometheus) on irc.freenode.net (for the easiest start, [join via Riot](https://riot.im/app/#/room/#prometheus:matrix.org)).
* Add tests relevant to the fixed bug or new feature.
## Dependency management
The Prometheus project uses [Go modules](https://golang.org/cmd/go/#hdr-Modules__module_versions__and_more) to manage dependencies on external packages. This requires a working Go environment with version 1.12 or greater installed.
All dependencies are vendored in the `vendor/` directory.
To add or update a new dependency, use the `go get` command:
```bash
# Pick the latest tagged release.
go get example.com/some/module/pkg
# Pick a specific version.
go get example.com/some/module/[email protected]
```
Tidy up the `go.mod` and `go.sum` files and copy the new/updated dependency to the `vendor/` directory:
```bash
# The GO111MODULE variable can be omitted when the code isn't located in GOPATH.
GO111MODULE=on go mod tidy
GO111MODULE=on go mod vendor
```
You have to commit the changes to `go.mod`, `go.sum` and the `vendor/` directory before submitting the pull request.
## API Implementation Guidelines
### Naming and Documentation
Public functions and structs should normally be named according to the file(s) being read and parsed. For example,
the `fs.BuddyInfo()` function reads the file `/proc/buddyinfo`. In addition, the godoc for each public function
should contain the path to the file(s) being read and a URL of the linux kernel documentation describing the file(s).
### Reading vs. Parsing
Most functionality in this library consists of reading files and then parsing the text into structured data. In most
cases reading and parsing should be separated into different functions/methods with a public `fs.Thing()` method and
a private `parseThing(r Reader)` function. This provides a logical separation and allows parsing to be tested
directly without the need to read from the filesystem. Using a `Reader` argument is preferred over other data types
such as `string` or `*File` because it provides the most flexibility regarding the data source. When a set of files
in a directory needs to be parsed, then a `path` string parameter to the parse function can be used instead.
### /proc and /sys filesystem I/O
The `proc` and `sys` filesystems are pseudo file systems and work a bit differently from standard disk I/O.
Many of the files are changing continuously and the data being read can in some cases change between subsequent
reads in the same file. Also, most of the files are relatively small (less than a few KBs), and system calls
to the `stat` function will often return the wrong size. Therefore, for most files it's recommended to read the
full file in a single operation using an internal utility function called `util.ReadFileNoStat`.
This function is similar to `os.ReadFile`, but it avoids the system call to `stat` to get the current size of
the file.
Note that parsing the file's contents can still be performed one line at a time. This is done by first reading
the full file, and then using a scanner on the `[]byte` or `string` containing the data.
```
data, err := util.ReadFileNoStat("/proc/cpuinfo")
if err != nil {
return err
}
reader := bytes.NewReader(data)
scanner := bufio.NewScanner(reader)
```
The `/sys` filesystem contains many very small files which contain only a single numeric or text value. These files
can be read using an internal function called `util.SysReadFile` which is similar to `os.ReadFile` but does
not bother to check the size of the file before reading.
```
data, err := util.SysReadFile("/sys/class/power_supply/BAT0/capacity")
``` | {
"source": "yandex/perforator",
"title": "vendor/github.com/prometheus/procfs/CONTRIBUTING.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/prometheus/procfs/CONTRIBUTING.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 6682
} |
# procfs
This package provides functions to retrieve system, kernel, and process
metrics from the pseudo-filesystems /proc and /sys.
*WARNING*: This package is a work in progress. Its API may still break in
backwards-incompatible ways without warnings. Use it at your own risk.
[](https://pkg.go.dev/github.com/prometheus/procfs)
[](https://circleci.com/gh/prometheus/procfs/tree/master)
[](https://goreportcard.com/report/github.com/prometheus/procfs)
## Usage
The procfs library is organized by packages based on whether the gathered data is coming from
/proc, /sys, or both. Each package contains an `FS` type which represents the path to either /proc,
/sys, or both. For example, cpu statistics are gathered from
`/proc/stat` and are available via the root procfs package. First, the proc filesystem mount
point is initialized, and then the stat information is read.
```go
fs, err := procfs.NewFS("/proc")
stats, err := fs.Stat()
```
Some sub-packages such as `blockdevice`, require access to both the proc and sys filesystems.
```go
fs, err := blockdevice.NewFS("/proc", "/sys")
stats, err := fs.ProcDiskstats()
```
## Package Organization
The packages in this project are organized according to (1) whether the data comes from the `/proc` or
`/sys` filesystem and (2) the type of information being retrieved. For example, most process information
can be gathered from the functions in the root `procfs` package. Information about block devices such as disk drives
is available in the `blockdevices` sub-package.
## Building and Testing
The procfs library is intended to be built as part of another application, so there are no distributable binaries.
However, most of the API includes unit tests which can be run with `make test`.
### Updating Test Fixtures
The procfs library includes a set of test fixtures which include many example files from
the `/proc` and `/sys` filesystems. These fixtures are included as a [ttar](https://github.com/ideaship/ttar) file
which is extracted automatically during testing. To add/update the test fixtures, first
ensure the `fixtures` directory is up to date by removing the existing directory and then
extracting the ttar file using `make fixtures/.unpacked` or just `make test`.
```bash
rm -rf testdata/fixtures
make test
```
Next, make the required changes to the extracted files in the `fixtures` directory. When
the changes are complete, run `make update_fixtures` to create a new `fixtures.ttar` file
based on the updated `fixtures` directory. And finally, verify the changes using
`git diff testdata/fixtures.ttar`. | {
"source": "yandex/perforator",
"title": "vendor/github.com/prometheus/procfs/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/prometheus/procfs/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2833
} |
## Decimal v1.3.1
#### ENHANCEMENTS
- Reduce memory allocation in case of initialization from big.Int [#252](https://github.com/shopspring/decimal/pull/252)
#### BUGFIXES
- Fix binary marshalling of decimal zero value [#253](https://github.com/shopspring/decimal/pull/253)
## Decimal v1.3.0
#### FEATURES
- Add NewFromFormattedString initializer [#184](https://github.com/shopspring/decimal/pull/184)
- Add NewNullDecimal initializer [#234](https://github.com/shopspring/decimal/pull/234)
- Add implementation of natural exponent function (Taylor, Hull-Abraham) [#229](https://github.com/shopspring/decimal/pull/229)
- Add RoundUp, RoundDown, RoundCeil, RoundFloor methods [#196](https://github.com/shopspring/decimal/pull/196) [#202](https://github.com/shopspring/decimal/pull/202) [#220](https://github.com/shopspring/decimal/pull/220)
- Add XML support for NullDecimal [#192](https://github.com/shopspring/decimal/pull/192)
- Add IsInteger method [#179](https://github.com/shopspring/decimal/pull/179)
- Add Copy helper method [#123](https://github.com/shopspring/decimal/pull/123)
- Add InexactFloat64 helper method [#205](https://github.com/shopspring/decimal/pull/205)
- Add CoefficientInt64 helper method [#244](https://github.com/shopspring/decimal/pull/244)
#### ENHANCEMENTS
- Performance optimization of NewFromString init method [#198](https://github.com/shopspring/decimal/pull/198)
- Performance optimization of Abs and Round methods [#240](https://github.com/shopspring/decimal/pull/240)
- Additional tests (CI) for ppc64le architecture [#188](https://github.com/shopspring/decimal/pull/188)
#### BUGFIXES
- Fix rounding in FormatFloat fallback path (roundShortest method, fix taken from Go main repository) [#161](https://github.com/shopspring/decimal/pull/161)
- Add slice range checks to UnmarshalBinary method [#232](https://github.com/shopspring/decimal/pull/232)
## Decimal v1.2.0
#### BREAKING
- Drop support for Go version older than 1.7 [#172](https://github.com/shopspring/decimal/pull/172)
#### FEATURES
- Add NewFromInt and NewFromInt32 initializers [#72](https://github.com/shopspring/decimal/pull/72)
- Add support for Go modules [#157](https://github.com/shopspring/decimal/pull/157)
- Add BigInt, BigFloat helper methods [#171](https://github.com/shopspring/decimal/pull/171)
#### ENHANCEMENTS
- Memory usage optimization [#160](https://github.com/shopspring/decimal/pull/160)
- Updated travis CI golang versions [#156](https://github.com/shopspring/decimal/pull/156)
- Update documentation [#173](https://github.com/shopspring/decimal/pull/173)
- Improve code quality [#174](https://github.com/shopspring/decimal/pull/174)
#### BUGFIXES
- Revert remove insignificant digits [#159](https://github.com/shopspring/decimal/pull/159)
- Remove 15 interval for RoundCash [#166](https://github.com/shopspring/decimal/pull/166) | {
"source": "yandex/perforator",
"title": "vendor/github.com/shopspring/decimal/CHANGELOG.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/shopspring/decimal/CHANGELOG.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2862
} |
# decimal
[](https://app.travis-ci.com/shopspring/decimal) [](https://godoc.org/github.com/shopspring/decimal) [](https://goreportcard.com/report/github.com/shopspring/decimal)
Arbitrary-precision fixed-point decimal numbers in go.
_Note:_ Decimal library can "only" represent numbers with a maximum of 2^31 digits after the decimal point.
## Features
* The zero-value is 0, and is safe to use without initialization
* Addition, subtraction, multiplication with no loss of precision
* Division with specified precision
* Database/sql serialization/deserialization
* JSON and XML serialization/deserialization
## Install
Run `go get github.com/shopspring/decimal`
## Requirements
Decimal library requires Go version `>=1.7`
## Usage
```go
package main
import (
"fmt"
"github.com/shopspring/decimal"
)
func main() {
price, err := decimal.NewFromString("136.02")
if err != nil {
panic(err)
}
quantity := decimal.NewFromInt(3)
fee, _ := decimal.NewFromString(".035")
taxRate, _ := decimal.NewFromString(".08875")
subtotal := price.Mul(quantity)
preTax := subtotal.Mul(fee.Add(decimal.NewFromFloat(1)))
total := preTax.Mul(taxRate.Add(decimal.NewFromFloat(1)))
fmt.Println("Subtotal:", subtotal) // Subtotal: 408.06
fmt.Println("Pre-tax:", preTax) // Pre-tax: 422.3421
fmt.Println("Taxes:", total.Sub(preTax)) // Taxes: 37.482861375
fmt.Println("Total:", total) // Total: 459.824961375
fmt.Println("Tax rate:", total.Sub(preTax).Div(preTax)) // Tax rate: 0.08875
}
```
## Documentation
http://godoc.org/github.com/shopspring/decimal
## Production Usage
* [Spring](https://shopspring.com/), since August 14, 2014.
* If you are using this in production, please let us know!
## FAQ
#### Why don't you just use float64?
Because float64 (or any binary floating point type, actually) can't represent
numbers such as `0.1` exactly.
Consider this code: http://play.golang.org/p/TQBd4yJe6B You might expect that
it prints out `10`, but it actually prints `9.999999999999831`. Over time,
these small errors can really add up!
#### Why don't you just use big.Rat?
big.Rat is fine for representing rational numbers, but Decimal is better for
representing money. Why? Here's a (contrived) example:
Let's say you use big.Rat, and you have two numbers, x and y, both
representing 1/3, and you have `z = 1 - x - y = 1/3`. If you print each one
out, the string output has to stop somewhere (let's say it stops at 3 decimal
digits, for simplicity), so you'll get 0.333, 0.333, and 0.333. But where did
the other 0.001 go?
Here's the above example as code: http://play.golang.org/p/lCZZs0w9KE
With Decimal, the strings being printed out represent the number exactly. So,
if you have `x = y = 1/3` (with precision 3), they will actually be equal to
0.333, and when you do `z = 1 - x - y`, `z` will be equal to .334. No money is
unaccounted for!
You still have to be careful. If you want to split a number `N` 3 ways, you
can't just send `N/3` to three different people. You have to pick one to send
`N - (2/3*N)` to. That person will receive the fraction of a penny remainder.
But, it is much easier to be careful with Decimal than with big.Rat.
#### Why isn't the API similar to big.Int's?
big.Int's API is built to reduce the number of memory allocations for maximal
performance. This makes sense for its use-case, but the trade-off is that the
API is awkward and easy to misuse.
For example, to add two big.Ints, you do: `z := new(big.Int).Add(x, y)`. A
developer unfamiliar with this API might try to do `z := a.Add(a, b)`. This
modifies `a` and sets `z` as an alias for `a`, which they might not expect. It
also modifies any other aliases to `a`.
Here's an example of the subtle bugs you can introduce with big.Int's API:
https://play.golang.org/p/x2R_78pa8r
In contrast, it's difficult to make such mistakes with decimal. Decimals
behave like other go numbers types: even though `a = b` will not deep copy
`b` into `a`, it is impossible to modify a Decimal, since all Decimal methods
return new Decimals and do not modify the originals. The downside is that
this causes extra allocations, so Decimal is less performant. My assumption
is that if you're using Decimals, you probably care more about correctness
than performance.
## License
The MIT License (MIT)
This is a heavily modified fork of [fpd.Decimal](https://github.com/oguzbilgic/fpd), which was also released under the MIT License. | {
"source": "yandex/perforator",
"title": "vendor/github.com/shopspring/decimal/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/shopspring/decimal/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 4752
} |
# 1.8.1
Code quality:
* move magefile in its own subdir/submodule to remove magefile dependency on logrus consumer
* improve timestamp format documentation
Fixes:
* fix race condition on logger hooks
# 1.8.0
Correct versioning number replacing v1.7.1.
# 1.7.1
Beware this release has introduced a new public API and its semver is therefore incorrect.
Code quality:
* use go 1.15 in travis
* use magefile as task runner
Fixes:
* small fixes about new go 1.13 error formatting system
* Fix for long time race condiction with mutating data hooks
Features:
* build support for zos
# 1.7.0
Fixes:
* the dependency toward a windows terminal library has been removed
Features:
* a new buffer pool management API has been added
* a set of `<LogLevel>Fn()` functions have been added
# 1.6.0
Fixes:
* end of line cleanup
* revert the entry concurrency bug fix whic leads to deadlock under some circumstances
* update dependency on go-windows-terminal-sequences to fix a crash with go 1.14
Features:
* add an option to the `TextFormatter` to completely disable fields quoting
# 1.5.0
Code quality:
* add golangci linter run on travis
Fixes:
* add mutex for hooks concurrent access on `Entry` data
* caller function field for go1.14
* fix build issue for gopherjs target
Feature:
* add an hooks/writer sub-package whose goal is to split output on different stream depending on the trace level
* add a `DisableHTMLEscape` option in the `JSONFormatter`
* add `ForceQuote` and `PadLevelText` options in the `TextFormatter`
# 1.4.2
* Fixes build break for plan9, nacl, solaris
# 1.4.1
This new release introduces:
* Enhance TextFormatter to not print caller information when they are empty (#944)
* Remove dependency on golang.org/x/crypto (#932, #943)
Fixes:
* Fix Entry.WithContext method to return a copy of the initial entry (#941)
# 1.4.0
This new release introduces:
* Add `DeferExitHandler`, similar to `RegisterExitHandler` but prepending the handler to the list of handlers (semantically like `defer`) (#848).
* Add `CallerPrettyfier` to `JSONFormatter` and `TextFormatter` (#909, #911)
* Add `Entry.WithContext()` and `Entry.Context`, to set a context on entries to be used e.g. in hooks (#919).
Fixes:
* Fix wrong method calls `Logger.Print` and `Logger.Warningln` (#893).
* Update `Entry.Logf` to not do string formatting unless the log level is enabled (#903)
* Fix infinite recursion on unknown `Level.String()` (#907)
* Fix race condition in `getCaller` (#916).
# 1.3.0
This new release introduces:
* Log, Logf, Logln functions for Logger and Entry that take a Level
Fixes:
* Building prometheus node_exporter on AIX (#840)
* Race condition in TextFormatter (#468)
* Travis CI import path (#868)
* Remove coloured output on Windows (#862)
* Pointer to func as field in JSONFormatter (#870)
* Properly marshal Levels (#873)
# 1.2.0
This new release introduces:
* A new method `SetReportCaller` in the `Logger` to enable the file, line and calling function from which the trace has been issued
* A new trace level named `Trace` whose level is below `Debug`
* A configurable exit function to be called upon a Fatal trace
* The `Level` object now implements `encoding.TextUnmarshaler` interface
# 1.1.1
This is a bug fix release.
* fix the build break on Solaris
* don't drop a whole trace in JSONFormatter when a field param is a function pointer which can not be serialized
# 1.1.0
This new release introduces:
* several fixes:
* a fix for a race condition on entry formatting
* proper cleanup of previously used entries before putting them back in the pool
* the extra new line at the end of message in text formatter has been removed
* a new global public API to check if a level is activated: IsLevelEnabled
* the following methods have been added to the Logger object
* IsLevelEnabled
* SetFormatter
* SetOutput
* ReplaceHooks
* introduction of go module
* an indent configuration for the json formatter
* output colour support for windows
* the field sort function is now configurable for text formatter
* the CLICOLOR and CLICOLOR\_FORCE environment variable support in text formater
# 1.0.6
This new release introduces:
* a new api WithTime which allows to easily force the time of the log entry
which is mostly useful for logger wrapper
* a fix reverting the immutability of the entry given as parameter to the hooks
a new configuration field of the json formatter in order to put all the fields
in a nested dictionnary
* a new SetOutput method in the Logger
* a new configuration of the textformatter to configure the name of the default keys
* a new configuration of the text formatter to disable the level truncation
# 1.0.5
* Fix hooks race (#707)
* Fix panic deadlock (#695)
# 1.0.4
* Fix race when adding hooks (#612)
* Fix terminal check in AppEngine (#635)
# 1.0.3
* Replace example files with testable examples
# 1.0.2
* bug: quote non-string values in text formatter (#583)
* Make (*Logger) SetLevel a public method
# 1.0.1
* bug: fix escaping in text formatter (#575)
# 1.0.0
* Officially changed name to lower-case
* bug: colors on Windows 10 (#541)
* bug: fix race in accessing level (#512)
# 0.11.5
* feature: add writer and writerlevel to entry (#372)
# 0.11.4
* bug: fix undefined variable on solaris (#493)
# 0.11.3
* formatter: configure quoting of empty values (#484)
* formatter: configure quoting character (default is `"`) (#484)
* bug: fix not importing io correctly in non-linux environments (#481)
# 0.11.2
* bug: fix windows terminal detection (#476)
# 0.11.1
* bug: fix tty detection with custom out (#471)
# 0.11.0
* performance: Use bufferpool to allocate (#370)
* terminal: terminal detection for app-engine (#343)
* feature: exit handler (#375)
# 0.10.0
* feature: Add a test hook (#180)
* feature: `ParseLevel` is now case-insensitive (#326)
* feature: `FieldLogger` interface that generalizes `Logger` and `Entry` (#308)
* performance: avoid re-allocations on `WithFields` (#335)
# 0.9.0
* logrus/text_formatter: don't emit empty msg
* logrus/hooks/airbrake: move out of main repository
* logrus/hooks/sentry: move out of main repository
* logrus/hooks/papertrail: move out of main repository
* logrus/hooks/bugsnag: move out of main repository
* logrus/core: run tests with `-race`
* logrus/core: detect TTY based on `stderr`
* logrus/core: support `WithError` on logger
* logrus/core: Solaris support
# 0.8.7
* logrus/core: fix possible race (#216)
* logrus/doc: small typo fixes and doc improvements
# 0.8.6
* hooks/raven: allow passing an initialized client
# 0.8.5
* logrus/core: revert #208
# 0.8.4
* formatter/text: fix data race (#218)
# 0.8.3
* logrus/core: fix entry log level (#208)
* logrus/core: improve performance of text formatter by 40%
* logrus/core: expose `LevelHooks` type
* logrus/core: add support for DragonflyBSD and NetBSD
* formatter/text: print structs more verbosely
# 0.8.2
* logrus: fix more Fatal family functions
# 0.8.1
* logrus: fix not exiting on `Fatalf` and `Fatalln`
# 0.8.0
* logrus: defaults to stderr instead of stdout
* hooks/sentry: add special field for `*http.Request`
* formatter/text: ignore Windows for colors
# 0.7.3
* formatter/\*: allow configuration of timestamp layout
# 0.7.2
* formatter/text: Add configuration option for time format (#158) | {
"source": "yandex/perforator",
"title": "vendor/github.com/sirupsen/logrus/CHANGELOG.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/sirupsen/logrus/CHANGELOG.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 7469
} |
# Logrus <img src="http://i.imgur.com/hTeVwmJ.png" width="40" height="40" alt=":walrus:" class="emoji" title=":walrus:"/> [](https://github.com/sirupsen/logrus/actions?query=workflow%3ACI) [](https://travis-ci.org/sirupsen/logrus) [](https://pkg.go.dev/github.com/sirupsen/logrus)
Logrus is a structured logger for Go (golang), completely API compatible with
the standard library logger.
**Logrus is in maintenance-mode.** We will not be introducing new features. It's
simply too hard to do in a way that won't break many people's projects, which is
the last thing you want from your Logging library (again...).
This does not mean Logrus is dead. Logrus will continue to be maintained for
security, (backwards compatible) bug fixes, and performance (where we are
limited by the interface).
I believe Logrus' biggest contribution is to have played a part in today's
widespread use of structured logging in Golang. There doesn't seem to be a
reason to do a major, breaking iteration into Logrus V2, since the fantastic Go
community has built those independently. Many fantastic alternatives have sprung
up. Logrus would look like those, had it been re-designed with what we know
about structured logging in Go today. Check out, for example,
[Zerolog][zerolog], [Zap][zap], and [Apex][apex].
[zerolog]: https://github.com/rs/zerolog
[zap]: https://github.com/uber-go/zap
[apex]: https://github.com/apex/log
**Seeing weird case-sensitive problems?** It's in the past been possible to
import Logrus as both upper- and lower-case. Due to the Go package environment,
this caused issues in the community and we needed a standard. Some environments
experienced problems with the upper-case variant, so the lower-case was decided.
Everything using `logrus` will need to use the lower-case:
`github.com/sirupsen/logrus`. Any package that isn't, should be changed.
To fix Glide, see [these
comments](https://github.com/sirupsen/logrus/issues/553#issuecomment-306591437).
For an in-depth explanation of the casing issue, see [this
comment](https://github.com/sirupsen/logrus/issues/570#issuecomment-313933276).
Nicely color-coded in development (when a TTY is attached, otherwise just
plain text):

With `log.SetFormatter(&log.JSONFormatter{})`, for easy parsing by logstash
or Splunk:
```text
{"animal":"walrus","level":"info","msg":"A group of walrus emerges from the
ocean","size":10,"time":"2014-03-10 19:57:38.562264131 -0400 EDT"}
{"level":"warning","msg":"The group's number increased tremendously!",
"number":122,"omg":true,"time":"2014-03-10 19:57:38.562471297 -0400 EDT"}
{"animal":"walrus","level":"info","msg":"A giant walrus appears!",
"size":10,"time":"2014-03-10 19:57:38.562500591 -0400 EDT"}
{"animal":"walrus","level":"info","msg":"Tremendously sized cow enters the ocean.",
"size":9,"time":"2014-03-10 19:57:38.562527896 -0400 EDT"}
{"level":"fatal","msg":"The ice breaks!","number":100,"omg":true,
"time":"2014-03-10 19:57:38.562543128 -0400 EDT"}
```
With the default `log.SetFormatter(&log.TextFormatter{})` when a TTY is not
attached, the output is compatible with the
[logfmt](http://godoc.org/github.com/kr/logfmt) format:
```text
time="2015-03-26T01:27:38-04:00" level=debug msg="Started observing beach" animal=walrus number=8
time="2015-03-26T01:27:38-04:00" level=info msg="A group of walrus emerges from the ocean" animal=walrus size=10
time="2015-03-26T01:27:38-04:00" level=warning msg="The group's number increased tremendously!" number=122 omg=true
time="2015-03-26T01:27:38-04:00" level=debug msg="Temperature changes" temperature=-4
time="2015-03-26T01:27:38-04:00" level=panic msg="It's over 9000!" animal=orca size=9009
time="2015-03-26T01:27:38-04:00" level=fatal msg="The ice breaks!" err=&{0x2082280c0 map[animal:orca size:9009] 2015-03-26 01:27:38.441574009 -0400 EDT panic It's over 9000!} number=100 omg=true
```
To ensure this behaviour even if a TTY is attached, set your formatter as follows:
```go
log.SetFormatter(&log.TextFormatter{
DisableColors: true,
FullTimestamp: true,
})
```
#### Logging Method Name
If you wish to add the calling method as a field, instruct the logger via:
```go
log.SetReportCaller(true)
```
This adds the caller as 'method' like so:
```json
{"animal":"penguin","level":"fatal","method":"github.com/sirupsen/arcticcreatures.migrate","msg":"a penguin swims by",
"time":"2014-03-10 19:57:38.562543129 -0400 EDT"}
```
```text
time="2015-03-26T01:27:38-04:00" level=fatal method=github.com/sirupsen/arcticcreatures.migrate msg="a penguin swims by" animal=penguin
```
Note that this does add measurable overhead - the cost will depend on the version of Go, but is
between 20 and 40% in recent tests with 1.6 and 1.7. You can validate this in your
environment via benchmarks:
```
go test -bench=.*CallerTracing
```
#### Case-sensitivity
The organization's name was changed to lower-case--and this will not be changed
back. If you are getting import conflicts due to case sensitivity, please use
the lower-case import: `github.com/sirupsen/logrus`.
#### Example
The simplest way to use Logrus is simply the package-level exported logger:
```go
package main
import (
log "github.com/sirupsen/logrus"
)
func main() {
log.WithFields(log.Fields{
"animal": "walrus",
}).Info("A walrus appears")
}
```
Note that it's completely api-compatible with the stdlib logger, so you can
replace your `log` imports everywhere with `log "github.com/sirupsen/logrus"`
and you'll now have the flexibility of Logrus. You can customize it all you
want:
```go
package main
import (
"os"
log "github.com/sirupsen/logrus"
)
func init() {
// Log as JSON instead of the default ASCII formatter.
log.SetFormatter(&log.JSONFormatter{})
// Output to stdout instead of the default stderr
// Can be any io.Writer, see below for File example
log.SetOutput(os.Stdout)
// Only log the warning severity or above.
log.SetLevel(log.WarnLevel)
}
func main() {
log.WithFields(log.Fields{
"animal": "walrus",
"size": 10,
}).Info("A group of walrus emerges from the ocean")
log.WithFields(log.Fields{
"omg": true,
"number": 122,
}).Warn("The group's number increased tremendously!")
log.WithFields(log.Fields{
"omg": true,
"number": 100,
}).Fatal("The ice breaks!")
// A common pattern is to re-use fields between logging statements by re-using
// the logrus.Entry returned from WithFields()
contextLogger := log.WithFields(log.Fields{
"common": "this is a common field",
"other": "I also should be logged always",
})
contextLogger.Info("I'll be logged with common and other field")
contextLogger.Info("Me too")
}
```
For more advanced usage such as logging to multiple locations from the same
application, you can also create an instance of the `logrus` Logger:
```go
package main
import (
"os"
"github.com/sirupsen/logrus"
)
// Create a new instance of the logger. You can have any number of instances.
var log = logrus.New()
func main() {
// The API for setting attributes is a little different than the package level
// exported logger. See Godoc.
log.Out = os.Stdout
// You could set this to any `io.Writer` such as a file
// file, err := os.OpenFile("logrus.log", os.O_CREATE|os.O_WRONLY|os.O_APPEND, 0666)
// if err == nil {
// log.Out = file
// } else {
// log.Info("Failed to log to file, using default stderr")
// }
log.WithFields(logrus.Fields{
"animal": "walrus",
"size": 10,
}).Info("A group of walrus emerges from the ocean")
}
```
#### Fields
Logrus encourages careful, structured logging through logging fields instead of
long, unparseable error messages. For example, instead of: `log.Fatalf("Failed
to send event %s to topic %s with key %d")`, you should log the much more
discoverable:
```go
log.WithFields(log.Fields{
"event": event,
"topic": topic,
"key": key,
}).Fatal("Failed to send event")
```
We've found this API forces you to think about logging in a way that produces
much more useful logging messages. We've been in countless situations where just
a single added field to a log statement that was already there would've saved us
hours. The `WithFields` call is optional.
In general, with Logrus using any of the `printf`-family functions should be
seen as a hint you should add a field, however, you can still use the
`printf`-family functions with Logrus.
#### Default Fields
Often it's helpful to have fields _always_ attached to log statements in an
application or parts of one. For example, you may want to always log the
`request_id` and `user_ip` in the context of a request. Instead of writing
`log.WithFields(log.Fields{"request_id": request_id, "user_ip": user_ip})` on
every line, you can create a `logrus.Entry` to pass around instead:
```go
requestLogger := log.WithFields(log.Fields{"request_id": request_id, "user_ip": user_ip})
requestLogger.Info("something happened on that request") # will log request_id and user_ip
requestLogger.Warn("something not great happened")
```
#### Hooks
You can add hooks for logging levels. For example to send errors to an exception
tracking service on `Error`, `Fatal` and `Panic`, info to StatsD or log to
multiple places simultaneously, e.g. syslog.
Logrus comes with [built-in hooks](hooks/). Add those, or your custom hook, in
`init`:
```go
import (
log "github.com/sirupsen/logrus"
"gopkg.in/gemnasium/logrus-airbrake-hook.v2" // the package is named "airbrake"
logrus_syslog "github.com/sirupsen/logrus/hooks/syslog"
"log/syslog"
)
func init() {
// Use the Airbrake hook to report errors that have Error severity or above to
// an exception tracker. You can create custom hooks, see the Hooks section.
log.AddHook(airbrake.NewHook(123, "xyz", "production"))
hook, err := logrus_syslog.NewSyslogHook("udp", "localhost:514", syslog.LOG_INFO, "")
if err != nil {
log.Error("Unable to connect to local syslog daemon")
} else {
log.AddHook(hook)
}
}
```
Note: Syslog hook also support connecting to local syslog (Ex. "/dev/log" or "/var/run/syslog" or "/var/run/log"). For the detail, please check the [syslog hook README](hooks/syslog/README.md).
A list of currently known service hooks can be found in this wiki [page](https://github.com/sirupsen/logrus/wiki/Hooks)
#### Level logging
Logrus has seven logging levels: Trace, Debug, Info, Warning, Error, Fatal and Panic.
```go
log.Trace("Something very low level.")
log.Debug("Useful debugging information.")
log.Info("Something noteworthy happened!")
log.Warn("You should probably take a look at this.")
log.Error("Something failed but I'm not quitting.")
// Calls os.Exit(1) after logging
log.Fatal("Bye.")
// Calls panic() after logging
log.Panic("I'm bailing.")
```
You can set the logging level on a `Logger`, then it will only log entries with
that severity or anything above it:
```go
// Will log anything that is info or above (warn, error, fatal, panic). Default.
log.SetLevel(log.InfoLevel)
```
It may be useful to set `log.Level = logrus.DebugLevel` in a debug or verbose
environment if your application has that.
Note: If you want different log levels for global (`log.SetLevel(...)`) and syslog logging, please check the [syslog hook README](hooks/syslog/README.md#different-log-levels-for-local-and-remote-logging).
#### Entries
Besides the fields added with `WithField` or `WithFields` some fields are
automatically added to all logging events:
1. `time`. The timestamp when the entry was created.
2. `msg`. The logging message passed to `{Info,Warn,Error,Fatal,Panic}` after
the `AddFields` call. E.g. `Failed to send event.`
3. `level`. The logging level. E.g. `info`.
#### Environments
Logrus has no notion of environment.
If you wish for hooks and formatters to only be used in specific environments,
you should handle that yourself. For example, if your application has a global
variable `Environment`, which is a string representation of the environment you
could do:
```go
import (
log "github.com/sirupsen/logrus"
)
func init() {
// do something here to set environment depending on an environment variable
// or command-line flag
if Environment == "production" {
log.SetFormatter(&log.JSONFormatter{})
} else {
// The TextFormatter is default, you don't actually have to do this.
log.SetFormatter(&log.TextFormatter{})
}
}
```
This configuration is how `logrus` was intended to be used, but JSON in
production is mostly only useful if you do log aggregation with tools like
Splunk or Logstash.
#### Formatters
The built-in logging formatters are:
* `logrus.TextFormatter`. Logs the event in colors if stdout is a tty, otherwise
without colors.
* *Note:* to force colored output when there is no TTY, set the `ForceColors`
field to `true`. To force no colored output even if there is a TTY set the
`DisableColors` field to `true`. For Windows, see
[github.com/mattn/go-colorable](https://github.com/mattn/go-colorable).
* When colors are enabled, levels are truncated to 4 characters by default. To disable
truncation set the `DisableLevelTruncation` field to `true`.
* When outputting to a TTY, it's often helpful to visually scan down a column where all the levels are the same width. Setting the `PadLevelText` field to `true` enables this behavior, by adding padding to the level text.
* All options are listed in the [generated docs](https://godoc.org/github.com/sirupsen/logrus#TextFormatter).
* `logrus.JSONFormatter`. Logs fields as JSON.
* All options are listed in the [generated docs](https://godoc.org/github.com/sirupsen/logrus#JSONFormatter).
Third party logging formatters:
* [`FluentdFormatter`](https://github.com/joonix/log). Formats entries that can be parsed by Kubernetes and Google Container Engine.
* [`GELF`](https://github.com/fabienm/go-logrus-formatters). Formats entries so they comply to Graylog's [GELF 1.1 specification](http://docs.graylog.org/en/2.4/pages/gelf.html).
* [`logstash`](https://github.com/bshuster-repo/logrus-logstash-hook). Logs fields as [Logstash](http://logstash.net) Events.
* [`prefixed`](https://github.com/x-cray/logrus-prefixed-formatter). Displays log entry source along with alternative layout.
* [`zalgo`](https://github.com/aybabtme/logzalgo). Invoking the Power of Zalgo.
* [`nested-logrus-formatter`](https://github.com/antonfisher/nested-logrus-formatter). Converts logrus fields to a nested structure.
* [`powerful-logrus-formatter`](https://github.com/zput/zxcTool). get fileName, log's line number and the latest function's name when print log; Sava log to files.
* [`caption-json-formatter`](https://github.com/nolleh/caption_json_formatter). logrus's message json formatter with human-readable caption added.
You can define your formatter by implementing the `Formatter` interface,
requiring a `Format` method. `Format` takes an `*Entry`. `entry.Data` is a
`Fields` type (`map[string]interface{}`) with all your fields as well as the
default ones (see Entries section above):
```go
type MyJSONFormatter struct {
}
log.SetFormatter(new(MyJSONFormatter))
func (f *MyJSONFormatter) Format(entry *Entry) ([]byte, error) {
// Note this doesn't include Time, Level and Message which are available on
// the Entry. Consult `godoc` on information about those fields or read the
// source of the official loggers.
serialized, err := json.Marshal(entry.Data)
if err != nil {
return nil, fmt.Errorf("Failed to marshal fields to JSON, %w", err)
}
return append(serialized, '\n'), nil
}
```
#### Logger as an `io.Writer`
Logrus can be transformed into an `io.Writer`. That writer is the end of an `io.Pipe` and it is your responsibility to close it.
```go
w := logger.Writer()
defer w.Close()
srv := http.Server{
// create a stdlib log.Logger that writes to
// logrus.Logger.
ErrorLog: log.New(w, "", 0),
}
```
Each line written to that writer will be printed the usual way, using formatters
and hooks. The level for those entries is `info`.
This means that we can override the standard library logger easily:
```go
logger := logrus.New()
logger.Formatter = &logrus.JSONFormatter{}
// Use logrus for standard log output
// Note that `log` here references stdlib's log
// Not logrus imported under the name `log`.
log.SetOutput(logger.Writer())
```
#### Rotation
Log rotation is not provided with Logrus. Log rotation should be done by an
external program (like `logrotate(8)`) that can compress and delete old log
entries. It should not be a feature of the application-level logger.
#### Tools
| Tool | Description |
| ---- | ----------- |
|[Logrus Mate](https://github.com/gogap/logrus_mate)|Logrus mate is a tool for Logrus to manage loggers, you can initial logger's level, hook and formatter by config file, the logger will be generated with different configs in different environments.|
|[Logrus Viper Helper](https://github.com/heirko/go-contrib/tree/master/logrusHelper)|An Helper around Logrus to wrap with spf13/Viper to load configuration with fangs! And to simplify Logrus configuration use some behavior of [Logrus Mate](https://github.com/gogap/logrus_mate). [sample](https://github.com/heirko/iris-contrib/blob/master/middleware/logrus-logger/example) |
#### Testing
Logrus has a built in facility for asserting the presence of log messages. This is implemented through the `test` hook and provides:
* decorators for existing logger (`test.NewLocal` and `test.NewGlobal`) which basically just adds the `test` hook
* a test logger (`test.NewNullLogger`) that just records log messages (and does not output any):
```go
import(
"github.com/sirupsen/logrus"
"github.com/sirupsen/logrus/hooks/test"
"github.com/stretchr/testify/assert"
"testing"
)
func TestSomething(t*testing.T){
logger, hook := test.NewNullLogger()
logger.Error("Helloerror")
assert.Equal(t, 1, len(hook.Entries))
assert.Equal(t, logrus.ErrorLevel, hook.LastEntry().Level)
assert.Equal(t, "Helloerror", hook.LastEntry().Message)
hook.Reset()
assert.Nil(t, hook.LastEntry())
}
```
#### Fatal handlers
Logrus can register one or more functions that will be called when any `fatal`
level message is logged. The registered handlers will be executed before
logrus performs an `os.Exit(1)`. This behavior may be helpful if callers need
to gracefully shutdown. Unlike a `panic("Something went wrong...")` call which can be intercepted with a deferred `recover` a call to `os.Exit(1)` can not be intercepted.
```
...
handler := func() {
// gracefully shutdown something...
}
logrus.RegisterExitHandler(handler)
...
```
#### Thread safety
By default, Logger is protected by a mutex for concurrent writes. The mutex is held when calling hooks and writing logs.
If you are sure such locking is not needed, you can call logger.SetNoLock() to disable the locking.
Situation when locking is not needed includes:
* You have no hooks registered, or hooks calling is already thread-safe.
* Writing to logger.Out is already thread-safe, for example:
1) logger.Out is protected by locks.
2) logger.Out is an os.File handler opened with `O_APPEND` flag, and every write is smaller than 4k. (This allows multi-thread/multi-process writing)
(Refer to http://www.notthewizard.com/2014/06/17/are-files-appends-really-atomic/) | {
"source": "yandex/perforator",
"title": "vendor/github.com/sirupsen/logrus/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/sirupsen/logrus/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 19585
} |

A FileSystem Abstraction System for Go
[](https://github.com/spf13/afero/actions/workflows/test.yml) [](https://godoc.org/github.com/spf13/afero) [](https://gitter.im/spf13/afero?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
# Overview
Afero is a filesystem framework providing a simple, uniform and universal API
interacting with any filesystem, as an abstraction layer providing interfaces,
types and methods. Afero has an exceptionally clean interface and simple design
without needless constructors or initialization methods.
Afero is also a library providing a base set of interoperable backend
filesystems that make it easy to work with afero while retaining all the power
and benefit of the os and ioutil packages.
Afero provides significant improvements over using the os package alone, most
notably the ability to create mock and testing filesystems without relying on the disk.
It is suitable for use in any situation where you would consider using the OS
package as it provides an additional abstraction that makes it easy to use a
memory backed file system during testing. It also adds support for the http
filesystem for full interoperability.
## Afero Features
* A single consistent API for accessing a variety of filesystems
* Interoperation between a variety of file system types
* A set of interfaces to encourage and enforce interoperability between backends
* An atomic cross platform memory backed file system
* Support for compositional (union) file systems by combining multiple file systems acting as one
* Specialized backends which modify existing filesystems (Read Only, Regexp filtered)
* A set of utility functions ported from io, ioutil & hugo to be afero aware
* Wrapper for go 1.16 filesystem abstraction `io/fs.FS`
# Using Afero
Afero is easy to use and easier to adopt.
A few different ways you could use Afero:
* Use the interfaces alone to define your own file system.
* Wrapper for the OS packages.
* Define different filesystems for different parts of your application.
* Use Afero for mock filesystems while testing
## Step 1: Install Afero
First use go get to install the latest version of the library.
$ go get github.com/spf13/afero
Next include Afero in your application.
```go
import "github.com/spf13/afero"
```
## Step 2: Declare a backend
First define a package variable and set it to a pointer to a filesystem.
```go
var AppFs = afero.NewMemMapFs()
or
var AppFs = afero.NewOsFs()
```
It is important to note that if you repeat the composite literal you
will be using a completely new and isolated filesystem. In the case of
OsFs it will still use the same underlying filesystem but will reduce
the ability to drop in other filesystems as desired.
## Step 3: Use it like you would the OS package
Throughout your application use any function and method like you normally
would.
So if my application before had:
```go
os.Open("/tmp/foo")
```
We would replace it with:
```go
AppFs.Open("/tmp/foo")
```
`AppFs` being the variable we defined above.
## List of all available functions
File System Methods Available:
```go
Chmod(name string, mode os.FileMode) : error
Chown(name string, uid, gid int) : error
Chtimes(name string, atime time.Time, mtime time.Time) : error
Create(name string) : File, error
Mkdir(name string, perm os.FileMode) : error
MkdirAll(path string, perm os.FileMode) : error
Name() : string
Open(name string) : File, error
OpenFile(name string, flag int, perm os.FileMode) : File, error
Remove(name string) : error
RemoveAll(path string) : error
Rename(oldname, newname string) : error
Stat(name string) : os.FileInfo, error
```
File Interfaces and Methods Available:
```go
io.Closer
io.Reader
io.ReaderAt
io.Seeker
io.Writer
io.WriterAt
Name() : string
Readdir(count int) : []os.FileInfo, error
Readdirnames(n int) : []string, error
Stat() : os.FileInfo, error
Sync() : error
Truncate(size int64) : error
WriteString(s string) : ret int, err error
```
In some applications it may make sense to define a new package that
simply exports the file system variable for easy access from anywhere.
## Using Afero's utility functions
Afero provides a set of functions to make it easier to use the underlying file systems.
These functions have been primarily ported from io & ioutil with some developed for Hugo.
The afero utilities support all afero compatible backends.
The list of utilities includes:
```go
DirExists(path string) (bool, error)
Exists(path string) (bool, error)
FileContainsBytes(filename string, subslice []byte) (bool, error)
GetTempDir(subPath string) string
IsDir(path string) (bool, error)
IsEmpty(path string) (bool, error)
ReadDir(dirname string) ([]os.FileInfo, error)
ReadFile(filename string) ([]byte, error)
SafeWriteReader(path string, r io.Reader) (err error)
TempDir(dir, prefix string) (name string, err error)
TempFile(dir, prefix string) (f File, err error)
Walk(root string, walkFn filepath.WalkFunc) error
WriteFile(filename string, data []byte, perm os.FileMode) error
WriteReader(path string, r io.Reader) (err error)
```
For a complete list see [Afero's GoDoc](https://godoc.org/github.com/spf13/afero)
They are available under two different approaches to use. You can either call
them directly where the first parameter of each function will be the file
system, or you can declare a new `Afero`, a custom type used to bind these
functions as methods to a given filesystem.
### Calling utilities directly
```go
fs := new(afero.MemMapFs)
f, err := afero.TempFile(fs,"", "ioutil-test")
```
### Calling via Afero
```go
fs := afero.NewMemMapFs()
afs := &afero.Afero{Fs: fs}
f, err := afs.TempFile("", "ioutil-test")
```
## Using Afero for Testing
There is a large benefit to using a mock filesystem for testing. It has a
completely blank state every time it is initialized and can be easily
reproducible regardless of OS. You could create files to your heart’s content
and the file access would be fast while also saving you from all the annoying
issues with deleting temporary files, Windows file locking, etc. The MemMapFs
backend is perfect for testing.
* Much faster than performing I/O operations on disk
* Avoid security issues and permissions
* Far more control. 'rm -rf /' with confidence
* Test setup is far more easier to do
* No test cleanup needed
One way to accomplish this is to define a variable as mentioned above.
In your application this will be set to afero.NewOsFs() during testing you
can set it to afero.NewMemMapFs().
It wouldn't be uncommon to have each test initialize a blank slate memory
backend. To do this I would define my `appFS = afero.NewOsFs()` somewhere
appropriate in my application code. This approach ensures that Tests are order
independent, with no test relying on the state left by an earlier test.
Then in my tests I would initialize a new MemMapFs for each test:
```go
func TestExist(t *testing.T) {
appFS := afero.NewMemMapFs()
// create test files and directories
appFS.MkdirAll("src/a", 0755)
afero.WriteFile(appFS, "src/a/b", []byte("file b"), 0644)
afero.WriteFile(appFS, "src/c", []byte("file c"), 0644)
name := "src/c"
_, err := appFS.Stat(name)
if os.IsNotExist(err) {
t.Errorf("file \"%s\" does not exist.\n", name)
}
}
```
# Available Backends
## Operating System Native
### OsFs
The first is simply a wrapper around the native OS calls. This makes it
very easy to use as all of the calls are the same as the existing OS
calls. It also makes it trivial to have your code use the OS during
operation and a mock filesystem during testing or as needed.
```go
appfs := afero.NewOsFs()
appfs.MkdirAll("src/a", 0755)
```
## Memory Backed Storage
### MemMapFs
Afero also provides a fully atomic memory backed filesystem perfect for use in
mocking and to speed up unnecessary disk io when persistence isn’t
necessary. It is fully concurrent and will work within go routines
safely.
```go
mm := afero.NewMemMapFs()
mm.MkdirAll("src/a", 0755)
```
#### InMemoryFile
As part of MemMapFs, Afero also provides an atomic, fully concurrent memory
backed file implementation. This can be used in other memory backed file
systems with ease. Plans are to add a radix tree memory stored file
system using InMemoryFile.
## Network Interfaces
### SftpFs
Afero has experimental support for secure file transfer protocol (sftp). Which can
be used to perform file operations over a encrypted channel.
### GCSFs
Afero has experimental support for Google Cloud Storage (GCS). You can either set the
`GOOGLE_APPLICATION_CREDENTIALS_JSON` env variable to your JSON credentials or use `opts` in
`NewGcsFS` to configure access to your GCS bucket.
Some known limitations of the existing implementation:
* No Chmod support - The GCS ACL could probably be mapped to *nix style permissions but that would add another level of complexity and is ignored in this version.
* No Chtimes support - Could be simulated with attributes (gcs a/m-times are set implicitly) but that's is left for another version.
* Not thread safe - Also assumes all file operations are done through the same instance of the GcsFs. File operations between different GcsFs instances are not guaranteed to be consistent.
## Filtering Backends
### BasePathFs
The BasePathFs restricts all operations to a given path within an Fs.
The given file name to the operations on this Fs will be prepended with
the base path before calling the source Fs.
```go
bp := afero.NewBasePathFs(afero.NewOsFs(), "/base/path")
```
### ReadOnlyFs
A thin wrapper around the source Fs providing a read only view.
```go
fs := afero.NewReadOnlyFs(afero.NewOsFs())
_, err := fs.Create("/file.txt")
// err = syscall.EPERM
```
# RegexpFs
A filtered view on file names, any file NOT matching
the passed regexp will be treated as non-existing.
Files not matching the regexp provided will not be created.
Directories are not filtered.
```go
fs := afero.NewRegexpFs(afero.NewMemMapFs(), regexp.MustCompile(`\.txt$`))
_, err := fs.Create("/file.html")
// err = syscall.ENOENT
```
### HttpFs
Afero provides an http compatible backend which can wrap any of the existing
backends.
The Http package requires a slightly specific version of Open which
returns an http.File type.
Afero provides an httpFs file system which satisfies this requirement.
Any Afero FileSystem can be used as an httpFs.
```go
httpFs := afero.NewHttpFs(<ExistingFS>)
fileserver := http.FileServer(httpFs.Dir(<PATH>))
http.Handle("/", fileserver)
```
## Composite Backends
Afero provides the ability have two filesystems (or more) act as a single
file system.
### CacheOnReadFs
The CacheOnReadFs will lazily make copies of any accessed files from the base
layer into the overlay. Subsequent reads will be pulled from the overlay
directly permitting the request is within the cache duration of when it was
created in the overlay.
If the base filesystem is writeable, any changes to files will be
done first to the base, then to the overlay layer. Write calls to open file
handles like `Write()` or `Truncate()` to the overlay first.
To writing files to the overlay only, you can use the overlay Fs directly (not
via the union Fs).
Cache files in the layer for the given time.Duration, a cache duration of 0
means "forever" meaning the file will not be re-requested from the base ever.
A read-only base will make the overlay also read-only but still copy files
from the base to the overlay when they're not present (or outdated) in the
caching layer.
```go
base := afero.NewOsFs()
layer := afero.NewMemMapFs()
ufs := afero.NewCacheOnReadFs(base, layer, 100 * time.Second)
```
### CopyOnWriteFs()
The CopyOnWriteFs is a read only base file system with a potentially
writeable layer on top.
Read operations will first look in the overlay and if not found there, will
serve the file from the base.
Changes to the file system will only be made in the overlay.
Any attempt to modify a file found only in the base will copy the file to the
overlay layer before modification (including opening a file with a writable
handle).
Removing and Renaming files present only in the base layer is not currently
permitted. If a file is present in the base layer and the overlay, only the
overlay will be removed/renamed.
```go
base := afero.NewOsFs()
roBase := afero.NewReadOnlyFs(base)
ufs := afero.NewCopyOnWriteFs(roBase, afero.NewMemMapFs())
fh, _ = ufs.Create("/home/test/file2.txt")
fh.WriteString("This is a test")
fh.Close()
```
In this example all write operations will only occur in memory (MemMapFs)
leaving the base filesystem (OsFs) untouched.
## Desired/possible backends
The following is a short list of possible backends we hope someone will
implement:
* SSH
* S3
# About the project
## What's in the name
Afero comes from the latin roots Ad-Facere.
**"Ad"** is a prefix meaning "to".
**"Facere"** is a form of the root "faciō" making "make or do".
The literal meaning of afero is "to make" or "to do" which seems very fitting
for a library that allows one to make files and directories and do things with them.
The English word that shares the same roots as Afero is "affair". Affair shares
the same concept but as a noun it means "something that is made or done" or "an
object of a particular type".
It's also nice that unlike some of my other libraries (hugo, cobra, viper) it
Googles very well.
## Release Notes
See the [Releases Page](https://github.com/spf13/afero/releases).
## Contributing
1. Fork it
2. Create your feature branch (`git checkout -b my-new-feature`)
3. Commit your changes (`git commit -am 'Add some feature'`)
4. Push to the branch (`git push origin my-new-feature`)
5. Create new Pull Request
## Contributors
Names in no particular order:
* [spf13](https://github.com/spf13)
* [jaqx0r](https://github.com/jaqx0r)
* [mbertschler](https://github.com/mbertschler)
* [xor-gate](https://github.com/xor-gate)
## License
Afero is released under the Apache 2.0 license. See
[LICENSE.txt](https://github.com/spf13/afero/blob/master/LICENSE.txt) | {
"source": "yandex/perforator",
"title": "vendor/github.com/spf13/afero/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/spf13/afero/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 14388
} |
# Contributing to Cobra
Thank you so much for contributing to Cobra. We appreciate your time and help.
Here are some guidelines to help you get started.
## Code of Conduct
Be kind and respectful to the members of the community. Take time to educate
others who are seeking help. Harassment of any kind will not be tolerated.
## Questions
If you have questions regarding Cobra, feel free to ask it in the community
[#cobra Slack channel][cobra-slack]
## Filing a bug or feature
1. Before filing an issue, please check the existing issues to see if a
similar one was already opened. If there is one already opened, feel free
to comment on it.
1. If you believe you've found a bug, please provide detailed steps of
reproduction, the version of Cobra and anything else you believe will be
useful to help troubleshoot it (e.g. OS environment, environment variables,
etc...). Also state the current behavior vs. the expected behavior.
1. If you'd like to see a feature or an enhancement please open an issue with
a clear title and description of what the feature is and why it would be
beneficial to the project and its users.
## Submitting changes
1. CLA: Upon submitting a Pull Request (PR), contributors will be prompted to
sign a CLA. Please sign the CLA :slightly_smiling_face:
1. Tests: If you are submitting code, please ensure you have adequate tests
for the feature. Tests can be run via `go test ./...` or `make test`.
1. Since this is golang project, ensure the new code is properly formatted to
ensure code consistency. Run `make all`.
### Quick steps to contribute
1. Fork the project.
1. Download your fork to your PC (`git clone https://github.com/your_username/cobra && cd cobra`)
1. Create your feature branch (`git checkout -b my-new-feature`)
1. Make changes and run tests (`make test`)
1. Add them to staging (`git add .`)
1. Commit your changes (`git commit -m 'Add some feature'`)
1. Push to the branch (`git push origin my-new-feature`)
1. Create new pull request
<!-- Links -->
[cobra-slack]: https://gophers.slack.com/archives/CD3LP1199 | {
"source": "yandex/perforator",
"title": "vendor/github.com/spf13/cobra/CONTRIBUTING.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/spf13/cobra/CONTRIBUTING.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2096
} |

Cobra is a library for creating powerful modern CLI applications.
Cobra is used in many Go projects such as [Kubernetes](https://kubernetes.io/),
[Hugo](https://gohugo.io), and [GitHub CLI](https://github.com/cli/cli) to
name a few. [This list](site/content/projects_using_cobra.md) contains a more extensive list of projects using Cobra.
[](https://github.com/spf13/cobra/actions?query=workflow%3ATest)
[](https://pkg.go.dev/github.com/spf13/cobra)
[](https://goreportcard.com/report/github.com/spf13/cobra)
[](https://gophers.slack.com/archives/CD3LP1199)
# Overview
Cobra is a library providing a simple interface to create powerful modern CLI
interfaces similar to git & go tools.
Cobra provides:
* Easy subcommand-based CLIs: `app server`, `app fetch`, etc.
* Fully POSIX-compliant flags (including short & long versions)
* Nested subcommands
* Global, local and cascading flags
* Intelligent suggestions (`app srver`... did you mean `app server`?)
* Automatic help generation for commands and flags
* Grouping help for subcommands
* Automatic help flag recognition of `-h`, `--help`, etc.
* Automatically generated shell autocomplete for your application (bash, zsh, fish, powershell)
* Automatically generated man pages for your application
* Command aliases so you can change things without breaking them
* The flexibility to define your own help, usage, etc.
* Optional seamless integration with [viper](https://github.com/spf13/viper) for 12-factor apps
# Concepts
Cobra is built on a structure of commands, arguments & flags.
**Commands** represent actions, **Args** are things and **Flags** are modifiers for those actions.
The best applications read like sentences when used, and as a result, users
intuitively know how to interact with them.
The pattern to follow is
`APPNAME VERB NOUN --ADJECTIVE`
or
`APPNAME COMMAND ARG --FLAG`.
A few good real world examples may better illustrate this point.
In the following example, 'server' is a command, and 'port' is a flag:
hugo server --port=1313
In this command we are telling Git to clone the url bare.
git clone URL --bare
## Commands
Command is the central point of the application. Each interaction that
the application supports will be contained in a Command. A command can
have children commands and optionally run an action.
In the example above, 'server' is the command.
[More about cobra.Command](https://pkg.go.dev/github.com/spf13/cobra#Command)
## Flags
A flag is a way to modify the behavior of a command. Cobra supports
fully POSIX-compliant flags as well as the Go [flag package](https://golang.org/pkg/flag/).
A Cobra command can define flags that persist through to children commands
and flags that are only available to that command.
In the example above, 'port' is the flag.
Flag functionality is provided by the [pflag
library](https://github.com/spf13/pflag), a fork of the flag standard library
which maintains the same interface while adding POSIX compliance.
# Installing
Using Cobra is easy. First, use `go get` to install the latest version
of the library.
```
go get -u github.com/spf13/cobra@latest
```
Next, include Cobra in your application:
```go
import "github.com/spf13/cobra"
```
# Usage
`cobra-cli` is a command line program to generate cobra applications and command files.
It will bootstrap your application scaffolding to rapidly
develop a Cobra-based application. It is the easiest way to incorporate Cobra into your application.
It can be installed by running:
```
go install github.com/spf13/cobra-cli@latest
```
For complete details on using the Cobra-CLI generator, please read [The Cobra Generator README](https://github.com/spf13/cobra-cli/blob/main/README.md)
For complete details on using the Cobra library, please read the [The Cobra User Guide](site/content/user_guide.md).
# License
Cobra is released under the Apache 2.0 license. See [LICENSE.txt](LICENSE.txt) | {
"source": "yandex/perforator",
"title": "vendor/github.com/spf13/cobra/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/spf13/cobra/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 4309
} |
[](https://travis-ci.org/spf13/pflag)
[](https://goreportcard.com/report/github.com/spf13/pflag)
[](https://godoc.org/github.com/spf13/pflag)
## Description
pflag is a drop-in replacement for Go's flag package, implementing
POSIX/GNU-style --flags.
pflag is compatible with the [GNU extensions to the POSIX recommendations
for command-line options][1]. For a more precise description, see the
"Command-line flag syntax" section below.
[1]: http://www.gnu.org/software/libc/manual/html_node/Argument-Syntax.html
pflag is available under the same style of BSD license as the Go language,
which can be found in the LICENSE file.
## Installation
pflag is available using the standard `go get` command.
Install by running:
go get github.com/spf13/pflag
Run tests by running:
go test github.com/spf13/pflag
## Usage
pflag is a drop-in replacement of Go's native flag package. If you import
pflag under the name "flag" then all code should continue to function
with no changes.
``` go
import flag "github.com/spf13/pflag"
```
There is one exception to this: if you directly instantiate the Flag struct
there is one more field "Shorthand" that you will need to set.
Most code never instantiates this struct directly, and instead uses
functions such as String(), BoolVar(), and Var(), and is therefore
unaffected.
Define flags using flag.String(), Bool(), Int(), etc.
This declares an integer flag, -flagname, stored in the pointer ip, with type *int.
``` go
var ip *int = flag.Int("flagname", 1234, "help message for flagname")
```
If you like, you can bind the flag to a variable using the Var() functions.
``` go
var flagvar int
func init() {
flag.IntVar(&flagvar, "flagname", 1234, "help message for flagname")
}
```
Or you can create custom flags that satisfy the Value interface (with
pointer receivers) and couple them to flag parsing by
``` go
flag.Var(&flagVal, "name", "help message for flagname")
```
For such flags, the default value is just the initial value of the variable.
After all flags are defined, call
``` go
flag.Parse()
```
to parse the command line into the defined flags.
Flags may then be used directly. If you're using the flags themselves,
they are all pointers; if you bind to variables, they're values.
``` go
fmt.Println("ip has value ", *ip)
fmt.Println("flagvar has value ", flagvar)
```
There are helper functions available to get the value stored in a Flag if you have a FlagSet but find
it difficult to keep up with all of the pointers in your code.
If you have a pflag.FlagSet with a flag called 'flagname' of type int you
can use GetInt() to get the int value. But notice that 'flagname' must exist
and it must be an int. GetString("flagname") will fail.
``` go
i, err := flagset.GetInt("flagname")
```
After parsing, the arguments after the flag are available as the
slice flag.Args() or individually as flag.Arg(i).
The arguments are indexed from 0 through flag.NArg()-1.
The pflag package also defines some new functions that are not in flag,
that give one-letter shorthands for flags. You can use these by appending
'P' to the name of any function that defines a flag.
``` go
var ip = flag.IntP("flagname", "f", 1234, "help message")
var flagvar bool
func init() {
flag.BoolVarP(&flagvar, "boolname", "b", true, "help message")
}
flag.VarP(&flagVal, "varname", "v", "help message")
```
Shorthand letters can be used with single dashes on the command line.
Boolean shorthand flags can be combined with other shorthand flags.
The default set of command-line flags is controlled by
top-level functions. The FlagSet type allows one to define
independent sets of flags, such as to implement subcommands
in a command-line interface. The methods of FlagSet are
analogous to the top-level functions for the command-line
flag set.
## Setting no option default values for flags
After you create a flag it is possible to set the pflag.NoOptDefVal for
the given flag. Doing this changes the meaning of the flag slightly. If
a flag has a NoOptDefVal and the flag is set on the command line without
an option the flag will be set to the NoOptDefVal. For example given:
``` go
var ip = flag.IntP("flagname", "f", 1234, "help message")
flag.Lookup("flagname").NoOptDefVal = "4321"
```
Would result in something like
| Parsed Arguments | Resulting Value |
| ------------- | ------------- |
| --flagname=1357 | ip=1357 |
| --flagname | ip=4321 |
| [nothing] | ip=1234 |
## Command line flag syntax
```
--flag // boolean flags, or flags with no option default values
--flag x // only on flags without a default value
--flag=x
```
Unlike the flag package, a single dash before an option means something
different than a double dash. Single dashes signify a series of shorthand
letters for flags. All but the last shorthand letter must be boolean flags
or a flag with a default value
```
// boolean or flags where the 'no option default value' is set
-f
-f=true
-abc
but
-b true is INVALID
// non-boolean and flags without a 'no option default value'
-n 1234
-n=1234
-n1234
// mixed
-abcs "hello"
-absd="hello"
-abcs1234
```
Flag parsing stops after the terminator "--". Unlike the flag package,
flags can be interspersed with arguments anywhere on the command line
before this terminator.
Integer flags accept 1234, 0664, 0x1234 and may be negative.
Boolean flags (in their long form) accept 1, 0, t, f, true, false,
TRUE, FALSE, True, False.
Duration flags accept any input valid for time.ParseDuration.
## Mutating or "Normalizing" Flag names
It is possible to set a custom flag name 'normalization function.' It allows flag names to be mutated both when created in the code and when used on the command line to some 'normalized' form. The 'normalized' form is used for comparison. Two examples of using the custom normalization func follow.
**Example #1**: You want -, _, and . in flags to compare the same. aka --my-flag == --my_flag == --my.flag
``` go
func wordSepNormalizeFunc(f *pflag.FlagSet, name string) pflag.NormalizedName {
from := []string{"-", "_"}
to := "."
for _, sep := range from {
name = strings.Replace(name, sep, to, -1)
}
return pflag.NormalizedName(name)
}
myFlagSet.SetNormalizeFunc(wordSepNormalizeFunc)
```
**Example #2**: You want to alias two flags. aka --old-flag-name == --new-flag-name
``` go
func aliasNormalizeFunc(f *pflag.FlagSet, name string) pflag.NormalizedName {
switch name {
case "old-flag-name":
name = "new-flag-name"
break
}
return pflag.NormalizedName(name)
}
myFlagSet.SetNormalizeFunc(aliasNormalizeFunc)
```
## Deprecating a flag or its shorthand
It is possible to deprecate a flag, or just its shorthand. Deprecating a flag/shorthand hides it from help text and prints a usage message when the deprecated flag/shorthand is used.
**Example #1**: You want to deprecate a flag named "badflag" as well as inform the users what flag they should use instead.
```go
// deprecate a flag by specifying its name and a usage message
flags.MarkDeprecated("badflag", "please use --good-flag instead")
```
This hides "badflag" from help text, and prints `Flag --badflag has been deprecated, please use --good-flag instead` when "badflag" is used.
**Example #2**: You want to keep a flag name "noshorthandflag" but deprecate its shortname "n".
```go
// deprecate a flag shorthand by specifying its flag name and a usage message
flags.MarkShorthandDeprecated("noshorthandflag", "please use --noshorthandflag only")
```
This hides the shortname "n" from help text, and prints `Flag shorthand -n has been deprecated, please use --noshorthandflag only` when the shorthand "n" is used.
Note that usage message is essential here, and it should not be empty.
## Hidden flags
It is possible to mark a flag as hidden, meaning it will still function as normal, however will not show up in usage/help text.
**Example**: You have a flag named "secretFlag" that you need for internal use only and don't want it showing up in help text, or for its usage text to be available.
```go
// hide a flag by specifying its name
flags.MarkHidden("secretFlag")
```
## Disable sorting of flags
`pflag` allows you to disable sorting of flags for help and usage message.
**Example**:
```go
flags.BoolP("verbose", "v", false, "verbose output")
flags.String("coolflag", "yeaah", "it's really cool flag")
flags.Int("usefulflag", 777, "sometimes it's very useful")
flags.SortFlags = false
flags.PrintDefaults()
```
**Output**:
```
-v, --verbose verbose output
--coolflag string it's really cool flag (default "yeaah")
--usefulflag int sometimes it's very useful (default 777)
```
## Supporting Go flags when using pflag
In order to support flags defined using Go's `flag` package, they must be added to the `pflag` flagset. This is usually necessary
to support flags defined by third-party dependencies (e.g. `golang/glog`).
**Example**: You want to add the Go flags to the `CommandLine` flagset
```go
import (
goflag "flag"
flag "github.com/spf13/pflag"
)
var ip *int = flag.Int("flagname", 1234, "help message for flagname")
func main() {
flag.CommandLine.AddGoFlagSet(goflag.CommandLine)
flag.Parse()
}
```
## More info
You can see the full reference documentation of the pflag package
[at godoc.org][3], or through go's standard documentation system by
running `godoc -http=:6060` and browsing to
[http://localhost:6060/pkg/github.com/spf13/pflag][2] after
installation.
[2]: http://localhost:6060/pkg/github.com/spf13/pflag
[3]: http://godoc.org/github.com/spf13/pflag | {
"source": "yandex/perforator",
"title": "vendor/github.com/spf13/pflag/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/spf13/pflag/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 9773
} |
# Contributing to Testify
So you'd like to contribute to Testify? First of all, thank you! Testify is widely used, so each
contribution has a significant impact within the Golang community! Below you'll find everything you
need to know to get up to speed on the project.
## Philosophy
The Testify maintainers generally attempt to follow widely accepted practices within the Golang
community. That being said, the first priority is always to make sure that the package is useful to
the community. A few general guidelines are listed here:
*Keep it simple (whenever practical)* - Try not to expand the API unless the new surface area
provides meaningful benefits. For example, don't add functions because they might be useful to
someone, someday. Add what is useful to specific users, today.
*Ease of use is paramount* - This means good documentation and package organization. It also means
that we should try hard to use meaningful, descriptive function names, avoid breaking the API
unnecessarily, and try not to surprise the user.
*Quality isn't an afterthought* - Testify is a testing library, so it seems reasonable that we
should have a decent test suite. This is doubly important because a bug in Testify doesn't just mean
a bug in our users' code, it means a bug in our users' tests, which means a potentially unnoticed
and hard-to-find bug in our users' code.
## Pull Requests
We welcome pull requests! Please include the following in the description:
* Motivation, why your change is important or helpful
* Example usage (if applicable)
* Whether you intend to add / change behavior or fix a bug
Please be aware that the maintainers may ask for changes. This isn't a commentary on the quality of
your idea or your code. Testify is the result of many contributions from many individuals, so we
need to enforce certain practices and patterns to keep the package easy for others to understand.
Essentially, we recognize that there are often many good ways to do a given thing, but we have to
pick one and stick with it.
See `MAINTAINERS.md` for a list of users who can approve / merge your changes.
## Issues
If you find a bug or think of a useful feature you'd like to see added to Testify, the best thing
you can do is make the necessary changes and open a pull request (see above). If that isn't an
option, or if you'd like to discuss your change before you write the code, open an issue!
Please provide enough context in the issue description that other members of the community can
easily understand what it is that you'd like to see. | {
"source": "yandex/perforator",
"title": "vendor/github.com/stretchr/testify/CONTRIBUTING.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/stretchr/testify/CONTRIBUTING.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2564
} |
# Emeritus
We would like to acknowledge previous testify maintainers and their huge contributions to our collective success:
* @matryer
* @glesica
* @ernesto-jimenez
* @mvdkleijn
* @georgelesica-wf
* @bencampbell-wf
We thank these members for their service to this community. | {
"source": "yandex/perforator",
"title": "vendor/github.com/stretchr/testify/EMERITUS.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/stretchr/testify/EMERITUS.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 290
} |
# Testify Maintainers
The individuals listed below are active in the project and have the ability to approve and merge
pull requests.
* @boyan-soubachov
* @dolmen
* @MovieStoreGuy
* @arjunmahishi
* @brackendawson | {
"source": "yandex/perforator",
"title": "vendor/github.com/stretchr/testify/MAINTAINERS.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/stretchr/testify/MAINTAINERS.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 224
} |
Testify - Thou Shalt Write Tests
================================
> [!NOTE]
> Testify is being maintained at v1, no breaking changes will be accepted in this repo.
> [See discussion about v2](https://github.com/stretchr/testify/discussions/1560).
[](https://github.com/stretchr/testify/actions/workflows/main.yml) [](https://goreportcard.com/report/github.com/stretchr/testify) [](https://pkg.go.dev/github.com/stretchr/testify)
Go code (golang) set of packages that provide many tools for testifying that your code will behave as you intend.
Features include:
* [Easy assertions](#assert-package)
* [Mocking](#mock-package)
* [Testing suite interfaces and functions](#suite-package)
Get started:
* Install testify with [one line of code](#installation), or [update it with another](#staying-up-to-date)
* For an introduction to writing test code in Go, see https://go.dev/doc/code#Testing
* Check out the API Documentation https://pkg.go.dev/github.com/stretchr/testify
* Use [testifylint](https://github.com/Antonboom/testifylint) (via [golanci-lint](https://golangci-lint.run/)) to avoid common mistakes
* A little about [Test-Driven Development (TDD)](https://en.wikipedia.org/wiki/Test-driven_development)
[`assert`](https://pkg.go.dev/github.com/stretchr/testify/assert "API documentation") package
-------------------------------------------------------------------------------------------
The `assert` package provides some helpful methods that allow you to write better test code in Go.
* Prints friendly, easy to read failure descriptions
* Allows for very readable code
* Optionally annotate each assertion with a message
See it in action:
```go
package yours
import (
"testing"
"github.com/stretchr/testify/assert"
)
func TestSomething(t *testing.T) {
// assert equality
assert.Equal(t, 123, 123, "they should be equal")
// assert inequality
assert.NotEqual(t, 123, 456, "they should not be equal")
// assert for nil (good for errors)
assert.Nil(t, object)
// assert for not nil (good when you expect something)
if assert.NotNil(t, object) {
// now we know that object isn't nil, we are safe to make
// further assertions without causing any errors
assert.Equal(t, "Something", object.Value)
}
}
```
* Every assert func takes the `testing.T` object as the first argument. This is how it writes the errors out through the normal `go test` capabilities.
* Every assert func returns a bool indicating whether the assertion was successful or not, this is useful for if you want to go on making further assertions under certain conditions.
if you assert many times, use the below:
```go
package yours
import (
"testing"
"github.com/stretchr/testify/assert"
)
func TestSomething(t *testing.T) {
assert := assert.New(t)
// assert equality
assert.Equal(123, 123, "they should be equal")
// assert inequality
assert.NotEqual(123, 456, "they should not be equal")
// assert for nil (good for errors)
assert.Nil(object)
// assert for not nil (good when you expect something)
if assert.NotNil(object) {
// now we know that object isn't nil, we are safe to make
// further assertions without causing any errors
assert.Equal("Something", object.Value)
}
}
```
[`require`](https://pkg.go.dev/github.com/stretchr/testify/require "API documentation") package
---------------------------------------------------------------------------------------------
The `require` package provides same global functions as the `assert` package, but instead of returning a boolean result they terminate current test.
These functions must be called from the goroutine running the test or benchmark function, not from other goroutines created during the test.
Otherwise race conditions may occur.
See [t.FailNow](https://pkg.go.dev/testing#T.FailNow) for details.
[`mock`](https://pkg.go.dev/github.com/stretchr/testify/mock "API documentation") package
----------------------------------------------------------------------------------------
The `mock` package provides a mechanism for easily writing mock objects that can be used in place of real objects when writing test code.
An example test function that tests a piece of code that relies on an external object `testObj`, can set up expectations (testify) and assert that they indeed happened:
```go
package yours
import (
"testing"
"github.com/stretchr/testify/mock"
)
/*
Test objects
*/
// MyMockedObject is a mocked object that implements an interface
// that describes an object that the code I am testing relies on.
type MyMockedObject struct{
mock.Mock
}
// DoSomething is a method on MyMockedObject that implements some interface
// and just records the activity, and returns what the Mock object tells it to.
//
// In the real object, this method would do something useful, but since this
// is a mocked object - we're just going to stub it out.
//
// NOTE: This method is not being tested here, code that uses this object is.
func (m *MyMockedObject) DoSomething(number int) (bool, error) {
args := m.Called(number)
return args.Bool(0), args.Error(1)
}
/*
Actual test functions
*/
// TestSomething is an example of how to use our test object to
// make assertions about some target code we are testing.
func TestSomething(t *testing.T) {
// create an instance of our test object
testObj := new(MyMockedObject)
// set up expectations
testObj.On("DoSomething", 123).Return(true, nil)
// call the code we are testing
targetFuncThatDoesSomethingWithObj(testObj)
// assert that the expectations were met
testObj.AssertExpectations(t)
}
// TestSomethingWithPlaceholder is a second example of how to use our test object to
// make assertions about some target code we are testing.
// This time using a placeholder. Placeholders might be used when the
// data being passed in is normally dynamically generated and cannot be
// predicted beforehand (eg. containing hashes that are time sensitive)
func TestSomethingWithPlaceholder(t *testing.T) {
// create an instance of our test object
testObj := new(MyMockedObject)
// set up expectations with a placeholder in the argument list
testObj.On("DoSomething", mock.Anything).Return(true, nil)
// call the code we are testing
targetFuncThatDoesSomethingWithObj(testObj)
// assert that the expectations were met
testObj.AssertExpectations(t)
}
// TestSomethingElse2 is a third example that shows how you can use
// the Unset method to cleanup handlers and then add new ones.
func TestSomethingElse2(t *testing.T) {
// create an instance of our test object
testObj := new(MyMockedObject)
// set up expectations with a placeholder in the argument list
mockCall := testObj.On("DoSomething", mock.Anything).Return(true, nil)
// call the code we are testing
targetFuncThatDoesSomethingWithObj(testObj)
// assert that the expectations were met
testObj.AssertExpectations(t)
// remove the handler now so we can add another one that takes precedence
mockCall.Unset()
// return false now instead of true
testObj.On("DoSomething", mock.Anything).Return(false, nil)
testObj.AssertExpectations(t)
}
```
For more information on how to write mock code, check out the [API documentation for the `mock` package](https://pkg.go.dev/github.com/stretchr/testify/mock).
You can use the [mockery tool](https://vektra.github.io/mockery/latest/) to autogenerate the mock code against an interface as well, making using mocks much quicker.
[`suite`](https://pkg.go.dev/github.com/stretchr/testify/suite "API documentation") package
-----------------------------------------------------------------------------------------
> [!WARNING]
> The suite package does not support parallel tests. See [#934](https://github.com/stretchr/testify/issues/934).
The `suite` package provides functionality that you might be used to from more common object-oriented languages. With it, you can build a testing suite as a struct, build setup/teardown methods and testing methods on your struct, and run them with 'go test' as per normal.
An example suite is shown below:
```go
// Basic imports
import (
"testing"
"github.com/stretchr/testify/assert"
"github.com/stretchr/testify/suite"
)
// Define the suite, and absorb the built-in basic suite
// functionality from testify - including a T() method which
// returns the current testing context
type ExampleTestSuite struct {
suite.Suite
VariableThatShouldStartAtFive int
}
// Make sure that VariableThatShouldStartAtFive is set to five
// before each test
func (suite *ExampleTestSuite) SetupTest() {
suite.VariableThatShouldStartAtFive = 5
}
// All methods that begin with "Test" are run as tests within a
// suite.
func (suite *ExampleTestSuite) TestExample() {
assert.Equal(suite.T(), 5, suite.VariableThatShouldStartAtFive)
}
// In order for 'go test' to run this suite, we need to create
// a normal test function and pass our suite to suite.Run
func TestExampleTestSuite(t *testing.T) {
suite.Run(t, new(ExampleTestSuite))
}
```
For a more complete example, using all of the functionality provided by the suite package, look at our [example testing suite](https://github.com/stretchr/testify/blob/master/suite/suite_test.go)
For more information on writing suites, check out the [API documentation for the `suite` package](https://pkg.go.dev/github.com/stretchr/testify/suite).
`Suite` object has assertion methods:
```go
// Basic imports
import (
"testing"
"github.com/stretchr/testify/suite"
)
// Define the suite, and absorb the built-in basic suite
// functionality from testify - including assertion methods.
type ExampleTestSuite struct {
suite.Suite
VariableThatShouldStartAtFive int
}
// Make sure that VariableThatShouldStartAtFive is set to five
// before each test
func (suite *ExampleTestSuite) SetupTest() {
suite.VariableThatShouldStartAtFive = 5
}
// All methods that begin with "Test" are run as tests within a
// suite.
func (suite *ExampleTestSuite) TestExample() {
suite.Equal(suite.VariableThatShouldStartAtFive, 5)
}
// In order for 'go test' to run this suite, we need to create
// a normal test function and pass our suite to suite.Run
func TestExampleTestSuite(t *testing.T) {
suite.Run(t, new(ExampleTestSuite))
}
```
------
Installation
============
To install Testify, use `go get`:
go get github.com/stretchr/testify
This will then make the following packages available to you:
github.com/stretchr/testify/assert
github.com/stretchr/testify/require
github.com/stretchr/testify/mock
github.com/stretchr/testify/suite
github.com/stretchr/testify/http (deprecated)
Import the `testify/assert` package into your code using this template:
```go
package yours
import (
"testing"
"github.com/stretchr/testify/assert"
)
func TestSomething(t *testing.T) {
assert.True(t, true, "True is true!")
}
```
------
Staying up to date
==================
To update Testify to the latest version, use `go get -u github.com/stretchr/testify`.
------
Supported go versions
==================
We currently support the most recent major Go versions from 1.19 onward.
------
Contributing
============
Please feel free to submit issues, fork the repository and send pull requests!
When submitting an issue, we ask that you please include a complete test function that demonstrates the issue. Extra credit for those using Testify to write the test code that demonstrates it.
Code generation is used. [Look for `Code generated with`](https://github.com/search?q=repo%3Astretchr%2Ftestify%20%22Code%20generated%20with%22&type=code) at the top of some files. Run `go generate ./...` to update generated files.
We also chat on the [Gophers Slack](https://gophers.slack.com) group in the `#testify` and `#testify-dev` channels.
------
License
=======
This project is licensed under the terms of the MIT license. | {
"source": "yandex/perforator",
"title": "vendor/github.com/stretchr/testify/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/stretchr/testify/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 12222
} |
# Contributing
Please see the [main contributing guidelines](./docs/contributing.md).
There are additional docs describing [contributing documentation changes](./docs/contributing_docs.md).
### GitHub Sponsorship
Testcontainers is [in the GitHub Sponsors program](https://github.com/sponsors/testcontainers)!
This repository is supported by our sponsors, meaning that issues are eligible to have a 'bounty' attached to them by sponsors.
Please see [the bounty policy page](https://golang.testcontainers.org/bounty) if you are interested, either as a sponsor or as a contributor. | {
"source": "yandex/perforator",
"title": "vendor/github.com/testcontainers/testcontainers-go/CONTRIBUTING.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/testcontainers/testcontainers-go/CONTRIBUTING.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 584
} |
# Testcontainers
[](https://github.com/codespaces/new?hide_repo_select=true&ref=main&repo=141451032&machine=standardLinux32gb&devcontainer_path=.devcontainer%2Fdevcontainer.json&location=EastUs)
**Builds**
[](https://github.com/testcontainers/testcontainers-go/actions/workflows/ci.yml)
**Documentation**
[](https://pkg.go.dev/github.com/testcontainers/testcontainers-go)
**Social**
[](https://testcontainers.slack.com/)
**Code quality**
[](https://goreportcard.com/report/github.com/testcontainers/testcontainers-go)
[](https://sonarcloud.io/summary/new_code?id=testcontainers_testcontainers-go)
**License**
[](https://github.com/testcontainers/testcontainers-go/blob/main/LICENSE)
_Testcontainers for Go_ is a Go package that makes it simple to create and clean up container-based dependencies for
automated integration/smoke tests. The clean, easy-to-use API enables developers to programmatically define containers
that should be run as part of a test and clean up those resources when the test is done.
You can find more information about _Testcontainers for Go_ at [golang.testcontainers.org](https://golang.testcontainers.org), which is rendered from the [./docs](./docs) directory.
## Using _Testcontainers for Go_
Please visit [the quickstart guide](https://golang.testcontainers.org/quickstart) to understand how to add the dependency to your Go project. | {
"source": "yandex/perforator",
"title": "vendor/github.com/testcontainers/testcontainers-go/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/testcontainers/testcontainers-go/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2001
} |
# go-sysconf
[](https://pkg.go.dev/github.com/tklauser/go-sysconf)
[](https://github.com/tklauser/go-sysconf/actions?query=workflow%3ATests)
`sysconf` for Go, without using cgo or external binaries (e.g. getconf).
Supported operating systems: Linux, macOS, DragonflyBSD, FreeBSD, NetBSD, OpenBSD, Solaris/Illumos.
All POSIX.1 and POSIX.2 variables are supported, see [References](#references) for a complete list.
Additionally, the following non-standard variables are supported on some operating systems:
| Variable | Supported on |
|---|---|
| `SC_PHYS_PAGES` | Linux, macOS, FreeBSD, NetBSD, OpenBSD, Solaris/Illumos |
| `SC_AVPHYS_PAGES` | Linux, OpenBSD, Solaris/Illumos |
| `SC_NPROCESSORS_CONF` | Linux, macOS, FreeBSD, NetBSD, OpenBSD, Solaris/Illumos |
| `SC_NPROCESSORS_ONLN` | Linux, macOS, FreeBSD, NetBSD, OpenBSD, Solaris/Illumos |
| `SC_UIO_MAXIOV` | Linux |
## Usage
```Go
package main
import (
"fmt"
"github.com/tklauser/go-sysconf"
)
func main() {
// get clock ticks, this will return the same as C.sysconf(C._SC_CLK_TCK)
clktck, err := sysconf.Sysconf(sysconf.SC_CLK_TCK)
if err == nil {
fmt.Printf("SC_CLK_TCK: %v\n", clktck)
}
}
```
## References
* [POSIX documenation for `sysconf`](http://pubs.opengroup.org/onlinepubs/9699919799/functions/sysconf.html)
* [Linux manpage for `sysconf(3)`](http://man7.org/linux/man-pages/man3/sysconf.3.html)
* [glibc constants for `sysconf` parameters](https://www.gnu.org/software/libc/manual/html_node/Constants-for-Sysconf.html) | {
"source": "yandex/perforator",
"title": "vendor/github.com/tklauser/go-sysconf/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/tklauser/go-sysconf/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1690
} |
# numcpus
[](https://pkg.go.dev/github.com/tklauser/numcpus)
[](https://github.com/tklauser/numcpus/actions?query=workflow%3ATests)
Package numcpus provides information about the number of CPUs in the system.
It gets the number of CPUs (online, offline, present, possible, configured or
kernel maximum) on Linux, Darwin, FreeBSD, NetBSD, OpenBSD, DragonflyBSD or
Solaris/Illumos systems.
On Linux, the information is retrieved by reading the corresponding CPU
topology files in `/sys/devices/system/cpu`.
On BSD systems, the information is retrieved using the `hw.ncpu` and
`hw.ncpuonline` sysctls, if supported.
Not all functions are supported on Darwin, FreeBSD, NetBSD, OpenBSD,
DragonflyBSD and Solaris/Illumos. ErrNotSupported is returned in case a
function is not supported on a particular platform.
## Usage
```Go
package main
import (
"fmt"
"os"
"github.com/tklauser/numcpus"
)
func main() {
online, err := numcpus.GetOnline()
if err != nil {
fmt.Fprintf(os.Stderr, "GetOnline: %v\n", err)
}
fmt.Printf("online CPUs: %v\n", online)
possible, err := numcpus.GetPossible()
if err != nil {
fmt.Fprintf(os.Stderr, "GetPossible: %v\n", err)
}
fmt.Printf("possible CPUs: %v\n", possible)
}
```
## References
* [Linux kernel sysfs documentation for CPU attributes](https://www.kernel.org/doc/Documentation/ABI/testing/sysfs-devices-system-cpu)
* [Linux kernel CPU topology documentation](https://www.kernel.org/doc/Documentation/cputopology.txt) | {
"source": "yandex/perforator",
"title": "vendor/github.com/tklauser/numcpus/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/tklauser/numcpus/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1634
} |
[](https://pkg.go.dev/github.com/xdg-go/pbkdf2)
[](https://goreportcard.com/report/github.com/xdg-go/pbkdf2)
[](https://github.com/xdg-go/pbkdf2/actions/workflows/test.yml)
# pbkdf2 – Go implementation of PBKDF2
## Description
Package pbkdf2 provides password-based key derivation based on
[RFC 8018](https://tools.ietf.org/html/rfc8018).
## Copyright and License
Copyright 2021 by David A. Golden. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"). You may
obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 | {
"source": "yandex/perforator",
"title": "vendor/github.com/xdg-go/pbkdf2/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/xdg-go/pbkdf2/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 804
} |
# CHANGELOG
## v1.1.2 - 2022-12-07
- Bump stringprep dependency to v1.0.4 for upstream CVE fix.
## v1.1.1 - 2022-03-03
- Bump stringprep dependency to v1.0.3 for upstream CVE fix.
## v1.1.0 - 2022-01-16
- Add SHA-512 hash generator function for convenience.
## v1.0.2 - 2021-03-28
- Switch PBKDF2 dependency to github.com/xdg-go/pbkdf2 to
minimize transitive dependencies and support Go 1.9+.
## v1.0.1 - 2021-03-27
- Bump stringprep dependency to v1.0.2 for Go 1.11 support.
## v1.0.0 - 2021-03-27
- First release as a Go module | {
"source": "yandex/perforator",
"title": "vendor/github.com/xdg-go/scram/CHANGELOG.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/xdg-go/scram/CHANGELOG.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 543
} |
[](https://pkg.go.dev/github.com/xdg-go/scram)
[](https://goreportcard.com/report/github.com/xdg-go/scram)
[](https://github.com/xdg-go/scram/actions/workflows/test.yml)
# scram – Go implementation of RFC-5802
## Description
Package scram provides client and server implementations of the Salted
Challenge Response Authentication Mechanism (SCRAM) described in
[RFC-5802](https://tools.ietf.org/html/rfc5802) and
[RFC-7677](https://tools.ietf.org/html/rfc7677).
It includes both client and server side support.
Channel binding and extensions are not (yet) supported.
## Examples
### Client side
package main
import "github.com/xdg-go/scram"
func main() {
// Get Client with username, password and (optional) authorization ID.
clientSHA1, err := scram.SHA1.NewClient("mulder", "trustno1", "")
if err != nil {
panic(err)
}
// Prepare the authentication conversation. Use the empty string as the
// initial server message argument to start the conversation.
conv := clientSHA1.NewConversation()
var serverMsg string
// Get the first message, send it and read the response.
firstMsg, err := conv.Step(serverMsg)
if err != nil {
panic(err)
}
serverMsg = sendClientMsg(firstMsg)
// Get the second message, send it, and read the response.
secondMsg, err := conv.Step(serverMsg)
if err != nil {
panic(err)
}
serverMsg = sendClientMsg(secondMsg)
// Validate the server's final message. We have no further message to
// send so ignore that return value.
_, err = conv.Step(serverMsg)
if err != nil {
panic(err)
}
return
}
func sendClientMsg(s string) string {
// A real implementation would send this to a server and read a reply.
return ""
}
## Copyright and License
Copyright 2018 by David A. Golden. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"). You may
obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 | {
"source": "yandex/perforator",
"title": "vendor/github.com/xdg-go/scram/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/xdg-go/scram/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2389
} |
# CHANGELOG
<a name="v1.0.4"></a>
## [v1.0.4] - 2022-12-07
### Maintenance
- Bump golang.org/x/text to v0.3.8 due to CVE-2022-32149
<a name="v1.0.3"></a>
## [v1.0.3] - 2022-03-01
### Maintenance
- Bump golang.org/x/text to v0.3.7 due to CVE-2021-38561
<a name="v1.0.2"></a>
## [v1.0.2] - 2021-03-27
### Maintenance
- Change minimum Go version to 1.11
<a name="v1.0.1"></a>
## [v1.0.1] - 2021-03-24
### Bug Fixes
- Add go.mod file
<a name="v1.0.0"></a>
## [v1.0.0] - 2018-02-21
[v1.0.2]: https://github.com/xdg-go/stringprep/releases/tag/v1.0.2
[v1.0.1]: https://github.com/xdg-go/stringprep/releases/tag/v1.0.1
[v1.0.0]: https://github.com/xdg-go/stringprep/releases/tag/v1.0.0 | {
"source": "yandex/perforator",
"title": "vendor/github.com/xdg-go/stringprep/CHANGELOG.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/xdg-go/stringprep/CHANGELOG.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 691
} |
[](https://pkg.go.dev/github.com/xdg-go/stringprep)
[](https://goreportcard.com/report/github.com/xdg-go/stringprep)
[](https://github.com/xdg-go/stringprep/actions/workflows/test.yml)
# stringprep – Go implementation of RFC-3454 stringprep and RFC-4013 SASLprep
## Synopsis
```
import "github.com/xdg-go/stringprep"
prepped := stringprep.SASLprep.Prepare("TrustNô1")
```
## Description
This library provides an implementation of the stringprep algorithm
(RFC-3454) in Go, including all data tables.
A pre-built SASLprep (RFC-4013) profile is provided as well.
## Copyright and License
Copyright 2018 by David A. Golden. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"). You may
obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 | {
"source": "yandex/perforator",
"title": "vendor/github.com/xdg-go/stringprep/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/xdg-go/stringprep/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1051
} |
pkcs8
===
OpenSSL can generate private keys in both "traditional format" and PKCS#8 format. Newer applications are advised to use more secure PKCS#8 format. Go standard crypto package provides a [function](http://golang.org/pkg/crypto/x509/#ParsePKCS8PrivateKey) to parse private key in PKCS#8 format. There is a limitation to this function. It can only handle unencrypted PKCS#8 private keys. To use this function, the user has to save the private key in file without encryption, which is a bad practice to leave private keys unprotected on file systems. In addition, Go standard package lacks the functions to convert RSA/ECDSA private keys into PKCS#8 format.
pkcs8 package fills the gap here. It implements functions to process private keys in PKCS#8 format, as defined in [RFC5208](https://tools.ietf.org/html/rfc5208) and [RFC5958](https://tools.ietf.org/html/rfc5958). It can handle both unencrypted PKCS#8 PrivateKeyInfo format and EncryptedPrivateKeyInfo format with PKCS#5 (v2.0) algorithms.
[**Godoc**](http://godoc.org/github.com/youmark/pkcs8)
## Installation
Supports Go 1.10+. Release v1.1 is the last release supporting Go 1.9
```text
go get github.com/youmark/pkcs8
```
## dependency
This package depends on golang.org/x/crypto/pbkdf2 and golang.org/x/crypto/scrypt packages. Use the following command to retrieve them
```text
go get golang.org/x/crypto/pbkdf2
go get golang.org/x/crypto/scrypt
``` | {
"source": "yandex/perforator",
"title": "vendor/github.com/youmark/pkcs8/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/youmark/pkcs8/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1421
} |
# Contributing to go.opentelemetry.io/auto/sdk
The `go.opentelemetry.io/auto/sdk` module is a purpose built OpenTelemetry SDK.
It is designed to be:
0. An OpenTelemetry compliant SDK
1. Instrumented by auto-instrumentation (serializable into OTLP JSON)
2. Lightweight
3. User-friendly
These design choices are listed in the order of their importance.
The primary design goal of this module is to be an OpenTelemetry SDK.
This means that it needs to implement the Go APIs found in `go.opentelemetry.io/otel`.
Having met the requirement of SDK compliance, this module needs to provide code that the `go.opentelemetry.io/auto` module can instrument.
The chosen approach to meet this goal is to ensure the telemetry from the SDK is serializable into JSON encoded OTLP.
This ensures then that the serialized form is compatible with other OpenTelemetry systems, and the auto-instrumentation can use these systems to deserialize any telemetry it is sent.
Outside of these first two goals, the intended use becomes relevant.
This package is intended to be used in the `go.opentelemetry.io/otel` global API as a default when the auto-instrumentation is running.
Because of this, this package needs to not add unnecessary dependencies to that API.
Ideally, it adds none.
It also needs to operate efficiently.
Finally, this module is designed to be user-friendly to Go development.
It hides complexity in order to provide simpler APIs when the previous goals can all still be met. | {
"source": "yandex/perforator",
"title": "vendor/go.opentelemetry.io/auto/sdk/CONTRIBUTING.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/go.opentelemetry.io/auto/sdk/CONTRIBUTING.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1476
} |
# Attribute
[](https://pkg.go.dev/go.opentelemetry.io/otel/attribute) | {
"source": "yandex/perforator",
"title": "vendor/go.opentelemetry.io/otel/attribute/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/go.opentelemetry.io/otel/attribute/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 142
} |
# Baggage
[](https://pkg.go.dev/go.opentelemetry.io/otel/baggage) | {
"source": "yandex/perforator",
"title": "vendor/go.opentelemetry.io/otel/baggage/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/go.opentelemetry.io/otel/baggage/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 136
} |
# Codes
[](https://pkg.go.dev/go.opentelemetry.io/otel/codes) | {
"source": "yandex/perforator",
"title": "vendor/go.opentelemetry.io/otel/codes/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/go.opentelemetry.io/otel/codes/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 130
} |
# Metric API
[](https://pkg.go.dev/go.opentelemetry.io/otel/metric) | {
"source": "yandex/perforator",
"title": "vendor/go.opentelemetry.io/otel/metric/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/go.opentelemetry.io/otel/metric/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 137
} |
# Propagation
[](https://pkg.go.dev/go.opentelemetry.io/otel/propagation) | {
"source": "yandex/perforator",
"title": "vendor/go.opentelemetry.io/otel/propagation/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/go.opentelemetry.io/otel/propagation/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 148
} |
# SDK
[](https://pkg.go.dev/go.opentelemetry.io/otel/sdk) | {
"source": "yandex/perforator",
"title": "vendor/go.opentelemetry.io/otel/sdk/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/go.opentelemetry.io/otel/sdk/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 124
} |
# Trace API
[](https://pkg.go.dev/go.opentelemetry.io/otel/trace) | {
"source": "yandex/perforator",
"title": "vendor/go.opentelemetry.io/otel/trace/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/go.opentelemetry.io/otel/trace/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 134
} |
# Contributing to Go
Go is an open source project.
It is the work of hundreds of contributors. We appreciate your help!
## Filing issues
When [filing an issue](https://github.com/golang/oauth2/issues), make sure to answer these five questions:
1. What version of Go are you using (`go version`)?
2. What operating system and processor architecture are you using?
3. What did you do?
4. What did you expect to see?
5. What did you see instead?
General questions should go to the [golang-nuts mailing list](https://groups.google.com/group/golang-nuts) instead of the issue tracker.
The gophers there will answer or ask you to file an issue if you've tripped over a bug.
## Contributing code
Please read the [Contribution Guidelines](https://golang.org/doc/contribute.html)
before sending patches.
Unless otherwise noted, the Go source files are distributed under
the BSD-style license found in the LICENSE file. | {
"source": "yandex/perforator",
"title": "vendor/golang.org/x/oauth2/CONTRIBUTING.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/golang.org/x/oauth2/CONTRIBUTING.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 923
} |
# OAuth2 for Go
[](https://pkg.go.dev/golang.org/x/oauth2)
[](https://travis-ci.org/golang/oauth2)
oauth2 package contains a client implementation for OAuth 2.0 spec.
See pkg.go.dev for further documentation and examples.
* [pkg.go.dev/golang.org/x/oauth2](https://pkg.go.dev/golang.org/x/oauth2)
* [pkg.go.dev/golang.org/x/oauth2/google](https://pkg.go.dev/golang.org/x/oauth2/google)
## Policy for new endpoints
We no longer accept new provider-specific packages in this repo if all
they do is add a single endpoint variable. If you just want to add a
single endpoint, add it to the
[pkg.go.dev/golang.org/x/oauth2/endpoints](https://pkg.go.dev/golang.org/x/oauth2/endpoints)
package.
## Report Issues / Send Patches
The main issue tracker for the oauth2 repository is located at
https://github.com/golang/oauth2/issues.
This repository uses Gerrit for code changes. To learn how to submit changes to
this repository, see https://go.dev/doc/contribute.
The git repository is https://go.googlesource.com/oauth2.
Note:
* Excluding trivial changes, all contributions should be connected to an existing issue.
* API changes must go through the [change proposal process](https://go.dev/s/proposal-process) before they can be accepted.
* The code owners are listed at [dev.golang.org/owners](https://dev.golang.org/owners#:~:text=x/oauth2). | {
"source": "yandex/perforator",
"title": "vendor/golang.org/x/oauth2/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/golang.org/x/oauth2/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1483
} |
# Contributing to Go
Go is an open source project.
It is the work of hundreds of contributors. We appreciate your help!
## Filing issues
When [filing an issue](https://golang.org/issue/new), make sure to answer these five questions:
1. What version of Go are you using (`go version`)?
2. What operating system and processor architecture are you using?
3. What did you do?
4. What did you expect to see?
5. What did you see instead?
General questions should go to the [golang-nuts mailing list](https://groups.google.com/group/golang-nuts) instead of the issue tracker.
The gophers there will answer or ask you to file an issue if you've tripped over a bug.
## Contributing code
Please read the [Contribution Guidelines](https://golang.org/doc/contribute.html)
before sending patches.
Unless otherwise noted, the Go source files are distributed under
the BSD-style license found in the LICENSE file. | {
"source": "yandex/perforator",
"title": "vendor/golang.org/x/term/CONTRIBUTING.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/golang.org/x/term/CONTRIBUTING.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 912
} |
# Go terminal/console support
[](https://pkg.go.dev/golang.org/x/term)
This repository provides Go terminal and console support packages.
## Report Issues / Send Patches
This repository uses Gerrit for code changes. To learn how to submit changes to
this repository, see https://go.dev/doc/contribute.
The git repository is https://go.googlesource.com/term.
The main issue tracker for the term repository is located at
https://go.dev/issues. Prefix your issue with "x/term:" in the
subject line, so it is easy to find. | {
"source": "yandex/perforator",
"title": "vendor/golang.org/x/term/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/golang.org/x/term/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 587
} |
# Reflection
Package reflection implements server reflection service.
The service implemented is defined in: https://github.com/grpc/grpc/blob/master/src/proto/grpc/reflection/v1/reflection.proto.
To register server reflection on a gRPC server:
```go
import "google.golang.org/grpc/reflection"
s := grpc.NewServer()
pb.RegisterYourOwnServer(s, &server{})
// Register reflection service on gRPC server.
reflection.Register(s)
s.Serve(lis)
``` | {
"source": "yandex/perforator",
"title": "vendor/google.golang.org/grpc/reflection/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/google.golang.org/grpc/reflection/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 447
} |
This directory contains x509 certificates used in cloud-to-prod interop tests.
For tests within gRPC-Go repo, please use the files in testsdata/x509
directory. | {
"source": "yandex/perforator",
"title": "vendor/google.golang.org/grpc/testdata/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/google.golang.org/grpc/testdata/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 159
} |
# Contributing Guidelines
Welcome to Kubernetes. We are excited about the prospect of you joining our [community](https://github.com/kubernetes/community)! The Kubernetes community abides by the CNCF [code of conduct](code-of-conduct.md). Here is an excerpt:
_As contributors and maintainers of this project, and in the interest of fostering an open and welcoming community, we pledge to respect all people who contribute through reporting issues, posting feature requests, updating documentation, submitting pull requests or patches, and other activities._
## Getting Started
We have full documentation on how to get started contributing here:
- [Contributor License Agreement](https://git.k8s.io/community/CLA.md) Kubernetes projects require that you sign a Contributor License Agreement (CLA) before we can accept your pull requests
- [Kubernetes Contributor Guide](http://git.k8s.io/community/contributors/guide) - Main contributor documentation, or you can just jump directly to the [contributing section](http://git.k8s.io/community/contributors/guide#contributing)
- [Contributor Cheat Sheet](https://git.k8s.io/community/contributors/guide/contributor-cheatsheet) - Common resources for existing developers
## Mentorship
- [Mentoring Initiatives](https://git.k8s.io/community/mentoring) - We have a diverse set of mentorship programs available that are always looking for volunteers!
## Contact Information
- [Slack](https://kubernetes.slack.com/messages/sig-architecture)
- [Mailing List](https://groups.google.com/forum/#!forum/kubernetes-sig-architecture) | {
"source": "yandex/perforator",
"title": "vendor/k8s.io/klog/v2/CONTRIBUTING.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/k8s.io/klog/v2/CONTRIBUTING.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1575
} |
klog
====
klog is a permanent fork of https://github.com/golang/glog.
## Why was klog created?
The decision to create klog was one that wasn't made lightly, but it was necessary due to some
drawbacks that are present in [glog](https://github.com/golang/glog). Ultimately, the fork was created due to glog not being under active development; this can be seen in the glog README:
> The code in this repo [...] is not itself under development
This makes us unable to solve many use cases without a fork. The factors that contributed to needing feature development are listed below:
* `glog` [presents a lot "gotchas"](https://github.com/kubernetes/kubernetes/issues/61006) and introduces challenges in containerized environments, all of which aren't well documented.
* `glog` doesn't provide an easy way to test logs, which detracts from the stability of software using it
* A long term goal is to implement a logging interface that allows us to add context, change output format, etc.
Historical context is available here:
* https://github.com/kubernetes/kubernetes/issues/61006
* https://github.com/kubernetes/kubernetes/issues/70264
* https://groups.google.com/forum/#!msg/kubernetes-sig-architecture/wCWiWf3Juzs/hXRVBH90CgAJ
* https://groups.google.com/forum/#!msg/kubernetes-dev/7vnijOMhLS0/1oRiNtigBgAJ
## Release versioning
Semantic versioning is used in this repository. It contains several Go modules
with different levels of stability:
- `k8s.io/klog/v2` - stable API, `vX.Y.Z` tags
- `examples` - no stable API, no tags, no intention to ever stabilize
Exempt from the API stability guarantee are items (packages, functions, etc.)
which are marked explicitly as `EXPERIMENTAL` in their docs comment. Those
may still change in incompatible ways or get removed entirely. This can only
be used for code that is used in tests to avoid situations where non-test
code from two different Kubernetes dependencies depends on incompatible
releases of klog because an experimental API was changed.
----
How to use klog
===============
- Replace imports for `"github.com/golang/glog"` with `"k8s.io/klog/v2"`
- Use `klog.InitFlags(nil)` explicitly for initializing global flags as we no longer use `init()` method to register the flags
- You can now use `log_file` instead of `log_dir` for logging to a single file (See `examples/log_file/usage_log_file.go`)
- If you want to redirect everything logged using klog somewhere else (say syslog!), you can use `klog.SetOutput()` method and supply a `io.Writer`. (See `examples/set_output/usage_set_output.go`)
- For more logging conventions (See [Logging Conventions](https://github.com/kubernetes/community/blob/master/contributors/devel/sig-instrumentation/logging.md))
- See our documentation on [pkg.go.dev/k8s.io](https://pkg.go.dev/k8s.io/klog).
**NOTE**: please use the newer go versions that support semantic import versioning in modules, ideally go 1.11.4 or greater.
### Coexisting with klog/v2
See [this example](examples/coexist_klog_v1_and_v2/) to see how to coexist with both klog/v1 and klog/v2.
### Coexisting with glog
This package can be used side by side with glog. [This example](examples/coexist_glog/coexist_glog.go) shows how to initialize and synchronize flags from the global `flag.CommandLine` FlagSet. In addition, the example makes use of stderr as combined output by setting `alsologtostderr` (or `logtostderr`) to `true`.
## Community, discussion, contribution, and support
Learn how to engage with the Kubernetes community on the [community page](http://kubernetes.io/community/).
You can reach the maintainers of this project at:
- [Slack](https://kubernetes.slack.com/messages/klog)
- [Mailing List](https://groups.google.com/forum/#!forum/kubernetes-sig-architecture)
### Code of conduct
Participation in the Kubernetes community is governed by the [Kubernetes Code of Conduct](code-of-conduct.md).
----
glog
====
Leveled execution logs for Go.
This is an efficient pure Go implementation of leveled logs in the
manner of the open source C++ package
https://github.com/google/glog
By binding methods to booleans it is possible to use the log package
without paying the expense of evaluating the arguments to the log.
Through the -vmodule flag, the package also provides fine-grained
control over logging at the file level.
The comment from glog.go introduces the ideas:
Package glog implements logging analogous to the Google-internal
C++ INFO/ERROR/V setup. It provides functions Info, Warning,
Error, Fatal, plus formatting variants such as Infof. It
also provides V-style logging controlled by the -v and
-vmodule=file=2 flags.
Basic examples:
glog.Info("Prepare to repel boarders")
glog.Fatalf("Initialization failed: %s", err)
See the documentation of the V function for an explanation
of these examples:
if glog.V(2) {
glog.Info("Starting transaction...")
}
glog.V(2).Infoln("Processed", nItems, "elements")
The repository contains an open source version of the log package
used inside Google. The master copy of the source lives inside
Google, not here. The code in this repo is for export only and is not itself
under development. Feature requests will be ignored.
Send bug reports to [email protected]. | {
"source": "yandex/perforator",
"title": "vendor/k8s.io/klog/v2/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/k8s.io/klog/v2/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 5267
} |
# Clock
This package provides an interface for time-based operations. It allows
mocking time for testing. | {
"source": "yandex/perforator",
"title": "vendor/k8s.io/utils/clock/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/k8s.io/utils/clock/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 107
} |
# go-yaml fork
This package is a fork of the go-yaml library and is intended solely for consumption
by kubernetes projects. In this fork, we plan to support only critical changes required for
kubernetes, such as small bug fixes and regressions. Larger, general-purpose feature requests
should be made in the upstream go-yaml library, and we will reject such changes in this fork
unless we are pulling them from upstream.
This fork is based on v2.4.0: https://github.com/go-yaml/yaml/releases/tag/v2.4.0
# YAML support for the Go language
Introduction
------------
The yaml package enables Go programs to comfortably encode and decode YAML
values. It was developed within [Canonical](https://www.canonical.com) as
part of the [juju](https://juju.ubuntu.com) project, and is based on a
pure Go port of the well-known [libyaml](http://pyyaml.org/wiki/LibYAML)
C library to parse and generate YAML data quickly and reliably.
Compatibility
-------------
The yaml package supports most of YAML 1.1 and 1.2, including support for
anchors, tags, map merging, etc. Multi-document unmarshalling is not yet
implemented, and base-60 floats from YAML 1.1 are purposefully not
supported since they're a poor design and are gone in YAML 1.2.
Installation and usage
----------------------
The import path for the package is *gopkg.in/yaml.v2*.
To install it, run:
go get gopkg.in/yaml.v2
API documentation
-----------------
If opened in a browser, the import path itself leads to the API documentation:
* [https://gopkg.in/yaml.v2](https://gopkg.in/yaml.v2)
API stability
-------------
The package API for yaml v2 will remain stable as described in [gopkg.in](https://gopkg.in).
License
-------
The yaml package is licensed under the Apache License 2.0. Please see the LICENSE file for details.
Example
-------
```Go
package main
import (
"fmt"
"log"
"gopkg.in/yaml.v2"
)
var data = `
a: Easy!
b:
c: 2
d: [3, 4]
`
// Note: struct fields must be public in order for unmarshal to
// correctly populate the data.
type T struct {
A string
B struct {
RenamedC int `yaml:"c"`
D []int `yaml:",flow"`
}
}
func main() {
t := T{}
err := yaml.Unmarshal([]byte(data), &t)
if err != nil {
log.Fatalf("error: %v", err)
}
fmt.Printf("--- t:\n%v\n\n", t)
d, err := yaml.Marshal(&t)
if err != nil {
log.Fatalf("error: %v", err)
}
fmt.Printf("--- t dump:\n%s\n\n", string(d))
m := make(map[interface{}]interface{})
err = yaml.Unmarshal([]byte(data), &m)
if err != nil {
log.Fatalf("error: %v", err)
}
fmt.Printf("--- m:\n%v\n\n", m)
d, err = yaml.Marshal(&m)
if err != nil {
log.Fatalf("error: %v", err)
}
fmt.Printf("--- m dump:\n%s\n\n", string(d))
}
```
This example will generate the following output:
```
--- t:
{Easy! {2 [3 4]}}
--- t dump:
a: Easy!
b:
c: 2
d: [3, 4]
--- m:
map[a:Easy! b:map[c:2 d:[3 4]]]
--- m dump:
a: Easy!
b:
c: 2
d:
- 3
- 4
``` | {
"source": "yandex/perforator",
"title": "vendor/sigs.k8s.io/yaml/goyaml.v2/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/sigs.k8s.io/yaml/goyaml.v2/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 3199
} |
This is a living document and at times it will be out of date. It is
intended to articulate how programming in the Go runtime differs from
writing normal Go. It focuses on pervasive concepts rather than
details of particular interfaces.
Scheduler structures
====================
The scheduler manages three types of resources that pervade the
runtime: Gs, Ms, and Ps. It's important to understand these even if
you're not working on the scheduler.
Gs, Ms, Ps
----------
A "G" is simply a goroutine. It's represented by type `g`. When a
goroutine exits, its `g` object is returned to a pool of free `g`s and
can later be reused for some other goroutine.
An "M" is an OS thread that can be executing user Go code, runtime
code, a system call, or be idle. It's represented by type `m`. There
can be any number of Ms at a time since any number of threads may be
blocked in system calls.
Finally, a "P" represents the resources required to execute user Go
code, such as scheduler and memory allocator state. It's represented
by type `p`. There are exactly `GOMAXPROCS` Ps. A P can be thought of
like a CPU in the OS scheduler and the contents of the `p` type like
per-CPU state. This is a good place to put state that needs to be
sharded for efficiency, but doesn't need to be per-thread or
per-goroutine.
The scheduler's job is to match up a G (the code to execute), an M
(where to execute it), and a P (the rights and resources to execute
it). When an M stops executing user Go code, for example by entering a
system call, it returns its P to the idle P pool. In order to resume
executing user Go code, for example on return from a system call, it
must acquire a P from the idle pool.
All `g`, `m`, and `p` objects are heap allocated, but are never freed,
so their memory remains type stable. As a result, the runtime can
avoid write barriers in the depths of the scheduler.
`getg()` and `getg().m.curg`
----------------------------
To get the current user `g`, use `getg().m.curg`.
`getg()` alone returns the current `g`, but when executing on the
system or signal stacks, this will return the current M's "g0" or
"gsignal", respectively. This is usually not what you want.
To determine if you're running on the user stack or the system stack,
use `getg() == getg().m.curg`.
Stacks
======
Every non-dead G has a *user stack* associated with it, which is what
user Go code executes on. User stacks start small (e.g., 2K) and grow
or shrink dynamically.
Every M has a *system stack* associated with it (also known as the M's
"g0" stack because it's implemented as a stub G) and, on Unix
platforms, a *signal stack* (also known as the M's "gsignal" stack).
System and signal stacks cannot grow, but are large enough to execute
runtime and cgo code (8K in a pure Go binary; system-allocated in a
cgo binary).
Runtime code often temporarily switches to the system stack using
`systemstack`, `mcall`, or `asmcgocall` to perform tasks that must not
be preempted, that must not grow the user stack, or that switch user
goroutines. Code running on the system stack is implicitly
non-preemptible and the garbage collector does not scan system stacks.
While running on the system stack, the current user stack is not used
for execution.
nosplit functions
-----------------
Most functions start with a prologue that inspects the stack pointer
and the current G's stack bound and calls `morestack` if the stack
needs to grow.
Functions can be marked `//go:nosplit` (or `NOSPLIT` in assembly) to
indicate that they should not get this prologue. This has several
uses:
- Functions that must run on the user stack, but must not call into
stack growth, for example because this would cause a deadlock, or
because they have untyped words on the stack.
- Functions that must not be preempted on entry.
- Functions that may run without a valid G. For example, functions
that run in early runtime start-up, or that may be entered from C
code such as cgo callbacks or the signal handler.
Splittable functions ensure there's some amount of space on the stack
for nosplit functions to run in and the linker checks that any static
chain of nosplit function calls cannot exceed this bound.
Any function with a `//go:nosplit` annotation should explain why it is
nosplit in its documentation comment.
Error handling and reporting
============================
Errors that can reasonably be recovered from in user code should use
`panic` like usual. However, there are some situations where `panic`
will cause an immediate fatal error, such as when called on the system
stack or when called during `mallocgc`.
Most errors in the runtime are not recoverable. For these, use
`throw`, which dumps the traceback and immediately terminates the
process. In general, `throw` should be passed a string constant to
avoid allocating in perilous situations. By convention, additional
details are printed before `throw` using `print` or `println` and the
messages are prefixed with "runtime:".
For unrecoverable errors where user code is expected to be at fault for the
failure (such as racing map writes), use `fatal`.
For runtime error debugging, it may be useful to run with `GOTRACEBACK=system`
or `GOTRACEBACK=crash`. The output of `panic` and `fatal` is as described by
`GOTRACEBACK`. The output of `throw` always includes runtime frames, metadata
and all goroutines regardless of `GOTRACEBACK` (i.e., equivalent to
`GOTRACEBACK=system`). Whether `throw` crashes or not is still controlled by
`GOTRACEBACK`.
Synchronization
===============
The runtime has multiple synchronization mechanisms. They differ in
semantics and, in particular, in whether they interact with the
goroutine scheduler or the OS scheduler.
The simplest is `mutex`, which is manipulated using `lock` and
`unlock`. This should be used to protect shared structures for short
periods. Blocking on a `mutex` directly blocks the M, without
interacting with the Go scheduler. This means it is safe to use from
the lowest levels of the runtime, but also prevents any associated G
and P from being rescheduled. `rwmutex` is similar.
For one-shot notifications, use `note`, which provides `notesleep` and
`notewakeup`. Unlike traditional UNIX `sleep`/`wakeup`, `note`s are
race-free, so `notesleep` returns immediately if the `notewakeup` has
already happened. A `note` can be reset after use with `noteclear`,
which must not race with a sleep or wakeup. Like `mutex`, blocking on
a `note` blocks the M. However, there are different ways to sleep on a
`note`:`notesleep` also prevents rescheduling of any associated G and
P, while `notetsleepg` acts like a blocking system call that allows
the P to be reused to run another G. This is still less efficient than
blocking the G directly since it consumes an M.
To interact directly with the goroutine scheduler, use `gopark` and
`goready`. `gopark` parks the current goroutine—putting it in the
"waiting" state and removing it from the scheduler's run queue—and
schedules another goroutine on the current M/P. `goready` puts a
parked goroutine back in the "runnable" state and adds it to the run
queue.
In summary,
<table>
<tr><th></th><th colspan="3">Blocks</th></tr>
<tr><th>Interface</th><th>G</th><th>M</th><th>P</th></tr>
<tr><td>(rw)mutex</td><td>Y</td><td>Y</td><td>Y</td></tr>
<tr><td>note</td><td>Y</td><td>Y</td><td>Y/N</td></tr>
<tr><td>park</td><td>Y</td><td>N</td><td>N</td></tr>
</table>
Atomics
=======
The runtime uses its own atomics package at `runtime/internal/atomic`.
This corresponds to `sync/atomic`, but functions have different names
for historical reasons and there are a few additional functions needed
by the runtime.
In general, we think hard about the uses of atomics in the runtime and
try to avoid unnecessary atomic operations. If access to a variable is
sometimes protected by another synchronization mechanism, the
already-protected accesses generally don't need to be atomic. There
are several reasons for this:
1. Using non-atomic or atomic access where appropriate makes the code
more self-documenting. Atomic access to a variable implies there's
somewhere else that may concurrently access the variable.
2. Non-atomic access allows for automatic race detection. The runtime
doesn't currently have a race detector, but it may in the future.
Atomic access defeats the race detector, while non-atomic access
allows the race detector to check your assumptions.
3. Non-atomic access may improve performance.
Of course, any non-atomic access to a shared variable should be
documented to explain how that access is protected.
Some common patterns that mix atomic and non-atomic access are:
* Read-mostly variables where updates are protected by a lock. Within
the locked region, reads do not need to be atomic, but the write
does. Outside the locked region, reads need to be atomic.
* Reads that only happen during STW, where no writes can happen during
STW, do not need to be atomic.
That said, the advice from the Go memory model stands: "Don't be
[too] clever." The performance of the runtime matters, but its
robustness matters more.
Unmanaged memory
================
In general, the runtime tries to use regular heap allocation. However,
in some cases the runtime must allocate objects outside of the garbage
collected heap, in *unmanaged memory*. This is necessary if the
objects are part of the memory manager itself or if they must be
allocated in situations where the caller may not have a P.
There are three mechanisms for allocating unmanaged memory:
* sysAlloc obtains memory directly from the OS. This comes in whole
multiples of the system page size, but it can be freed with sysFree.
* persistentalloc combines multiple smaller allocations into a single
sysAlloc to avoid fragmentation. However, there is no way to free
persistentalloced objects (hence the name).
* fixalloc is a SLAB-style allocator that allocates objects of a fixed
size. fixalloced objects can be freed, but this memory can only be
reused by the same fixalloc pool, so it can only be reused for
objects of the same type.
In general, types that are allocated using any of these should be
marked as not in heap by embedding `runtime/internal/sys.NotInHeap`.
Objects that are allocated in unmanaged memory **must not** contain
heap pointers unless the following rules are also obeyed:
1. Any pointers from unmanaged memory to the heap must be garbage
collection roots. More specifically, any pointer must either be
accessible through a global variable or be added as an explicit
garbage collection root in `runtime.markroot`.
2. If the memory is reused, the heap pointers must be zero-initialized
before they become visible as GC roots. Otherwise, the GC may
observe stale heap pointers. See "Zero-initialization versus
zeroing".
Zero-initialization versus zeroing
==================================
There are two types of zeroing in the runtime, depending on whether
the memory is already initialized to a type-safe state.
If memory is not in a type-safe state, meaning it potentially contains
"garbage" because it was just allocated and it is being initialized
for first use, then it must be *zero-initialized* using
`memclrNoHeapPointers` or non-pointer writes. This does not perform
write barriers.
If memory is already in a type-safe state and is simply being set to
the zero value, this must be done using regular writes, `typedmemclr`,
or `memclrHasPointers`. This performs write barriers.
Runtime-only compiler directives
================================
In addition to the "//go:" directives documented in "go doc compile",
the compiler supports additional directives only in the runtime.
go:systemstack
--------------
`go:systemstack` indicates that a function must run on the system
stack. This is checked dynamically by a special function prologue.
go:nowritebarrier
-----------------
`go:nowritebarrier` directs the compiler to emit an error if the
following function contains any write barriers. (It *does not*
suppress the generation of write barriers; it is simply an assertion.)
Usually you want `go:nowritebarrierrec`. `go:nowritebarrier` is
primarily useful in situations where it's "nice" not to have write
barriers, but not required for correctness.
go:nowritebarrierrec and go:yeswritebarrierrec
----------------------------------------------
`go:nowritebarrierrec` directs the compiler to emit an error if the
following function or any function it calls recursively, up to a
`go:yeswritebarrierrec`, contains a write barrier.
Logically, the compiler floods the call graph starting from each
`go:nowritebarrierrec` function and produces an error if it encounters
a function containing a write barrier. This flood stops at
`go:yeswritebarrierrec` functions.
`go:nowritebarrierrec` is used in the implementation of the write
barrier to prevent infinite loops.
Both directives are used in the scheduler. The write barrier requires
an active P (`getg().m.p != nil`) and scheduler code often runs
without an active P. In this case, `go:nowritebarrierrec` is used on
functions that release the P or may run without a P and
`go:yeswritebarrierrec` is used when code re-acquires an active P.
Since these are function-level annotations, code that releases or
acquires a P may need to be split across two functions.
go:uintptrkeepalive
-------------------
The //go:uintptrkeepalive directive must be followed by a function declaration.
It specifies that the function's uintptr arguments may be pointer values that
have been converted to uintptr and must be kept alive for the duration of the
call, even though from the types alone it would appear that the object is no
longer needed during the call.
This directive is similar to //go:uintptrescapes, but it does not force
arguments to escape. Since stack growth does not understand these arguments,
this directive must be used with //go:nosplit (in the marked function and all
transitive calls) to prevent stack growth.
The conversion from pointer to uintptr must appear in the argument list of any
call to this function. This directive is used for some low-level system call
implementations. | {
"source": "yandex/perforator",
"title": "contrib/go/_std_1.22/src/runtime/HACKING.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/go/_std_1.22/src/runtime/HACKING.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 14178
} |
## API Protos
This folder contains the schema of the configuration model for Google's
internal API serving platform, which handles routing, quotas, monitoring,
logging, and the like.
Google refers to this configuration colloquially as the "service config",
and the `service.proto` file in this directory is the entry point for
understanding these.
## Using these protos
To be honest, we probably open sourced way too much of this (basically by
accident). There are a couple files in here you are most likely to be
interested in: `http.proto`, `documentation.proto`, `auth.proto`, and
`annotations.proto`.
### HTTP and REST
The `http.proto` file contains the `Http` message (which then is wrapped
in an annotation in `annotations.proto`), which provides a specification
for REST endpoints and verbs (`GET`, `POST`, etc.) on RPC methods.
We recommend use of this annotation for describing the relationship
between RPCs and REST endpoints.
### Documentation
The `documentation.proto` file contains a `Documentation` message which
provides a mechanism to fully describe an API, allowing a tool to build
structured documentation artifacts.
### Authentication
The `auth.proto` file contains descriptions of both authentication rules
and authenticaion providers, allowing you to describe what your services
expect and accept from clients.
## api-compiler
Google provides a tool called [api-compiler][], which is a tool that accepts
a protocol buffer descriptor and a YAML file specifying some of the
options described in `service.proto`, and outputs a much more thorough
`Service` descriptor based on the information it infers from the protos
themselves.
[api-compiler]: https://github.com/googleapis/api-compiler | {
"source": "yandex/perforator",
"title": "contrib/libs/googleapis-common-protos/google/api/README.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/libs/googleapis-common-protos/google/api/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1721
} |
## Long-running Operations API
This package contains the definition of an abstract interface that
manages long running operations with API services.
### Operation
The primary message to understand within LRO is the `Operation` message.
Operations have a unique name (in the context of a particular endpoint).
Additionally, a service (called `Operations` -- plural) defines the interface
for querying the state of any given operation.
APIs that implement a concept of long-running operations are encouraged
to follow this pattern: When a caller invokes an API backend to start a job...
* The API backend starts asychronous work to fulfill the caller's
request, and generates a unique name (the `Operation` name) to refer
to the ongoing asychronous work.
* The API backend immediately returns the `Operation` back to the caller.
* The caller can invoke the API methods defined in the `Operations` service
to get the current status of the asychronous work, and also to
discover the final result (success or error).
For Google APIs, the implementation of this pattern and the use of this
proto are part of our [design rules][operations-rules]. Additionally, our
[API client tooling][gapic-generator] seeks to be intelligent about these, to
improve the client API consumption experience. Therefore, APIs outside of
Google can also benefit by following this same pattern.
[operations-rules]: https://cloud.google.com/apis/design/design_patterns#long_running_operations
[gapic-generator]: https://github.com/googleapis/gapic-generator | {
"source": "yandex/perforator",
"title": "contrib/libs/googleapis-common-protos/google/longrunning/README.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/libs/googleapis-common-protos/google/longrunning/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1560
} |
## RPC (Remote Procedure Call) Types
This package contains [protocol buffer][protobuf] types that represent remote procedure
call concepts. While [gRPC](https://grpc.io) uses these types, we encourage their
use in any interested RPC implementation to promote compatibility and consistency.
### Key Concepts
- **Code**: An enum that represents an error code returned by an RPC. These error codes
map to HTTP codes, but are slightly finer-grained. Every gRPC code has exactly one
corresponding HTTP code; however, some HTTP codes have more than one corresponding
gRPC code.
- **Error details**: Any of the types contained in `error_details.proto` which provide
extra details about particular types of failures.
- **Status**: Combines a code, message, and error details to represent the success or
failure details of an RPC call.
[protobuf]: https://developers.google.com/protocol-buffers/ | {
"source": "yandex/perforator",
"title": "contrib/libs/googleapis-common-protos/google/rpc/README.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/libs/googleapis-common-protos/google/rpc/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 900
} |
## Google Common Types
This package contains definitions of common types for Google APIs.
All types defined in this package are suitable for different APIs to
exchange data, and will never break binary compatibility. They should
have design quality comparable to major programming languages like
Java and C#. | {
"source": "yandex/perforator",
"title": "contrib/libs/googleapis-common-protos/google/type/README.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/libs/googleapis-common-protos/google/type/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 309
} |
# include/grpc++
This was the original directory name for all C++ header files but it
conflicted with the naming scheme required for some build systems. It
is superseded by `include/grpcpp` but the old directory structure is
still present to avoid breaking code that used the old include files.
All new include files are only in `include/grpcpp`. | {
"source": "yandex/perforator",
"title": "contrib/libs/grpc/include/grpc++/README.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/libs/grpc/include/grpc++/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 347
} |
# Overview
This directory contains source code for gRPC protocol buffer compiler (*protoc*) plugins. Along with `protoc`,
these plugins are used to generate gRPC client and server stubs from `.proto` files. | {
"source": "yandex/perforator",
"title": "contrib/libs/grpc/src/compiler/README.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/libs/grpc/src/compiler/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 207
} |
# gRPC core library
This shared library provides all of gRPC's core functionality through a low
level API. gRPC libraries for the other languages supported in this repo, are
built on top of this shared core library. | {
"source": "yandex/perforator",
"title": "contrib/libs/grpc/src/core/README.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/libs/grpc/src/core/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 216
} |
# gRPC C++
This directory contains the C++ implementation of gRPC.
# To start using gRPC C++
This section describes how to add gRPC as a dependency to your C++ project.
In the C++ world, there's no universally accepted standard for managing project dependencies.
Therefore, gRPC supports several major build systems, which should satisfy most users.
## Supported Platforms
* Officially Supported: These platforms are officially supported. We follow
[the OSS Foundational C++ Support Policy](https://opensource.google/documentation/policies/cplusplus-support)
to choose platforms to support.
We test our code on these platform and have automated continuous integration tests for
them.
.
* Best Effort: We do not have continous integration tests for these, but we are
fairly confident that gRPC C++ would work on them. We will make our best
effort to support them, and we welcome patches for such platforms, but we
might need to declare bankruptcy on some issues.
* Community Supported: These platforms are supported by contributions from the
open source community, there is no official support for them. Breakages on
these platforms may go unnoticed, and the community is responsible for all
maintenance. Unmaintained code for these platforms may be deleted.
| Operating System | Architectures | Versions | Support Level |
|------------------|---------------|----------|---------------|
| Linux - Debian, Ubuntu, CentOS | x86, x64 | clang 6+, GCC 7.3+ | Officially Supported |
| Windows 10+ | x86, x64 | Visual Studio 2019+ | Officially Supported |
| MacOS | x86, x64 | XCode 12+ | Officially Supported |
| Linux - Others | x86, x64 | clang 6+, GCC 7.3+ | Best Effort |
| Linux | ARM | | Best Effort |
| iOS | | | Best Effort |
| Android | | | Best Effort |
| Asylo | | | Best Effort |
| FreeBSD | | | Community Supported |
| NetBSD | | | Community Supported |
| OpenBSD | | | Community Supported |
| AIX | | | Community Supported |
| Solaris | | | Community Supported |
| NaCL | | | Community Supported |
| Fuchsia | | | Community Supported |
## Bazel
Bazel is the primary build system used by the core gRPC development team. Bazel
provides fast builds and it easily handles dependencies that support bazel.
To add gRPC as a dependency in bazel:
1. determine commit SHA for the grpc release you want to use
2. Use the [http_archive](https://docs.bazel.build/versions/master/repo/http.html#http_archive) bazel rule to include gRPC source
```
http_archive(
name = "com_github_grpc_grpc",
urls = [
"https://github.com/grpc/grpc/archive/YOUR_GRPC_COMMIT_SHA.tar.gz",
],
strip_prefix = "grpc-YOUR_GRPC_COMMIT_SHA",
)
load("@com_github_grpc_grpc//bazel:grpc_deps.bzl", "grpc_deps")
grpc_deps()
load("@com_github_grpc_grpc//bazel:grpc_extra_deps.bzl", "grpc_extra_deps")
grpc_extra_deps()
```
## CMake
`cmake` is your best option if you cannot use bazel. It supports building on Linux,
MacOS and Windows (official support) but also has a good chance of working on
other platforms (no promises!). `cmake` has good support for crosscompiling and
can be used for targeting the Android platform.
To build gRPC C++ from source, follow the [BUILDING guide](../../BUILDING.md).
### find_package
The canonical way to discover dependencies in CMake is the
[`find_package` command](https://cmake.org/cmake/help/latest/command/find_package.html).
```cmake
find_package(gRPC CONFIG REQUIRED)
add_executable(my_exe my_exe.cc)
target_link_libraries(my_exe gRPC::grpc++)
```
[Full example](../../examples/cpp/helloworld/CMakeLists.txt)
`find_package` can only find software that has already been installed on your
system. In practice that means you'll need to install gRPC using cmake first.
gRPC's cmake support provides the option to install gRPC either system-wide
(not recommended) or under a directory prefix in a way that you can later
easily use it with the `find_package(gRPC CONFIG REQUIRED)` command.
The following sections describe strategies to automatically build gRPC
as part of your project.
### FetchContent
If you are using CMake v3.11 or newer you should use CMake's
[FetchContent module](https://cmake.org/cmake/help/latest/module/FetchContent.html).
The first time you run CMake in a given build directory, FetchContent will
clone the gRPC repository and its submodules. `FetchContent_MakeAvailable()`
also sets up an `add_subdirectory()` rule for you. This causes gRPC to be
built as part of your project.
```cmake
cmake_minimum_required(VERSION 3.15)
project(my_project)
include(FetchContent)
FetchContent_Declare(
gRPC
GIT_REPOSITORY https://github.com/grpc/grpc
GIT_TAG RELEASE_TAG_HERE # e.g v1.28.0
)
set(FETCHCONTENT_QUIET OFF)
FetchContent_MakeAvailable(gRPC)
add_executable(my_exe my_exe.cc)
target_link_libraries(my_exe grpc++)
```
Note that you need to
[install the prerequisites](../../BUILDING.md#pre-requisites)
before building gRPC.
### git submodule
If you cannot use FetchContent, another approach is to add the gRPC source tree
to your project as a
[git submodule](https://git-scm.com/book/en/v2/Git-Tools-Submodules).
You can then add it to your CMake project with `add_subdirectory()`.
[Example](../../examples/cpp/helloworld/CMakeLists.txt)
### Support system-installed gRPC
If your project builds gRPC you should still consider the case where a user
wants to build your software using a previously installed gRPC. Here's a
code snippet showing how this is typically done.
```cmake
option(USE_SYSTEM_GRPC "Use system installed gRPC" OFF)
if(USE_SYSTEM_GRPC)
# Find system-installed gRPC
find_package(gRPC CONFIG REQUIRED)
else()
# Build gRPC using FetchContent or add_subdirectory
endif()
```
[Full example](../../examples/cpp/helloworld/CMakeLists.txt)
## pkg-config
If your project does not use CMake (e.g. you're using `make` directly), you can
first install gRPC C++ using CMake, and have your non-CMake project rely on the
`pkgconfig` files which are provided by gRPC installation.
[Example](../../test/distrib/cpp/run_distrib_test_cmake_pkgconfig.sh)
**Note for CentOS 7 users**
CentOS-7 ships with `pkg-config` 0.27.1, which has a
[bug](https://bugs.freedesktop.org/show_bug.cgi?id=54716) that can make
invocations take extremely long to complete. If you plan to use `pkg-config`,
you'll want to upgrade it to something newer.
## make (deprecated)
The default choice for building on UNIX based systems used to be `make`, but we are no longer recommending it.
You should use `bazel` or `cmake` instead.
To install gRPC for C++ on your system using `make`, follow the [Building gRPC C++](../../BUILDING.md)
instructions to build from source and then install locally using `make install`.
This also installs the protocol buffer compiler `protoc` (if you don't have it already),
and the C++ gRPC plugin for `protoc`.
WARNING: After installing with `make install` there is no easy way to uninstall, which can cause issues
if you later want to remove the grpc and/or protobuf installation or upgrade to a newer version.
## Packaging systems
We do not officially support any packaging system for C++, but there are some community-maintained packages that are kept up-to-date
and are known to work well. More contributions and support for popular packaging systems are welcome!
### Install using vcpkg package
gRPC is available using the [vcpkg](https://github.com/Microsoft/vcpkg) dependency manager:
```
# install vcpkg package manager on your system using the official instructions
git clone https://github.com/Microsoft/vcpkg.git
cd vcpkg
# Bootstrap on Linux:
./bootstrap-vcpkg.sh
# Bootstrap on Windows instead:
# ./bootstrap-vcpkg.bat
./vcpkg integrate install
# install gRPC using vcpkg package manager
./vcpkg install grpc
```
The gRPC port in vcpkg is kept up to date by Microsoft team members and community contributors. If the version is out of date, please [create an issue or pull request](https://github.com/Microsoft/vcpkg) on the vcpkg repository.
## Examples & Additional Documentation
You can find out how to build and run our simplest gRPC C++ example in our
[C++ quick start](../../examples/cpp).
For more detailed documentation on using gRPC in C++ , see our main
documentation site at [grpc.io](https://grpc.io), specifically:
* [Overview](https://grpc.io/docs): An introduction to gRPC with a simple
Hello World example in all our supported languages, including C++.
* [gRPC Basics - C++](https://grpc.io/docs/languages/cpp/basics):
A tutorial that steps you through creating a simple gRPC C++ example
application.
* [Asynchronous Basics - C++](https://grpc.io/docs/languages/cpp/async):
A tutorial that shows you how to use gRPC C++'s asynchronous/non-blocking
APIs.
# To start developing gRPC C++
For instructions on how to build gRPC C++ from source, follow the [Building gRPC C++](../../BUILDING.md) instructions. | {
"source": "yandex/perforator",
"title": "contrib/libs/grpc/src/cpp/README.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/libs/grpc/src/cpp/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 9743
} |
# How to Contribute
We'd love to accept your patches and contributions to this project. There are
just a few small guidelines you need to follow.
## Get in touch
If your idea will take you more than, say, 30 minutes to
implement, please get in touch first via the issue tracker
to touch base about your plan. That will give an
opportunity for early feedback and help avoid wasting your
time.
## Contributor License Agreement
Contributions to this project must be accompanied by a Contributor License
Agreement. You (or your employer) retain the copyright to your contribution;
this simply gives us permission to use and redistribute your contributions as
part of the project. Head over to <https://cla.developers.google.com/> to see
your current agreements on file or to sign a new one.
You generally only need to submit a CLA once, so if you've already submitted one
(even if it was for a different project), you probably don't need to do it
again.
## Code Reviews
All submissions, including submissions by project members, require review. We
use GitHub pull requests for this purpose. Consult
[GitHub Help](https://help.github.com/articles/about-pull-requests/) for more
information on using pull requests.
## Community Guidelines
This project follows [Google's Open Source Community
Guidelines](https://opensource.google/conduct/). | {
"source": "yandex/perforator",
"title": "contrib/libs/grpc/third_party/upb/CONTRIBUTING.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/libs/grpc/third_party/upb/CONTRIBUTING.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1345
} |
# upb Design
upb aims to be a minimal C protobuf kernel. It has a C API, but its primary
goal is to be the core runtime for a higher-level API.
## Design goals
- Full protobuf conformance
- Small code size
- Fast performance (without compromising code size)
- Easy to wrap in language runtimes
- Easy to adapt to different memory management schemes (refcounting, GC, etc)
## Design parameters
- C99
- 32 or 64-bit CPU (assumes 4 or 8 byte pointers)
- Uses pointer tagging, but avoids other implementation-defined behavior
- Aims to never invoke undefined behavior (tests with ASAN, UBSAN, etc)
- No global state, fully re-entrant
## Overall Structure
The upb library is divided into two main parts:
- A core message representation, which supports binary format parsing
and serialization.
- `upb/upb.h`: arena allocator (`upb_arena`)
- `upb/msg_internal.h`: core message representation and parse tables
- `upb/msg.h`: accessing metadata common to all messages, like unknown fields
- `upb/decode.h`: binary format parsing
- `upb/encode.h`: binary format serialization
- `upb/table_internal.h`: hash table (used for maps)
- `upbc/protoc-gen-upbc.cc`: compiler that generates `.upb.h`/`.upb.c` APIs for
accessing messages without reflection.
- A reflection add-on library that supports JSON and text format.
- `upb/def.h`: schema representation and loading from descriptors
- `upb/reflection.h`: reflective access to message data.
- `upb/json_encode.h`: JSON encoding
- `upb/json_decode.h`: JSON decoding
- `upb/text_encode.h`: text format encoding
- `upbc/protoc-gen-upbdefs.cc`: compiler that generates `.upbdefs.h`/`.upbdefs.c`
APIs for loading reflection.
## Core Message Representation
The representation for each message consists of:
- One pointer (`upb_msg_internaldata*`) for unknown fields and extensions. This
pointer is `NULL` when no unknown fields or extensions are present.
- Hasbits for any optional/required fields.
- Case integers for each oneof.
- Data for each field.
For example, a layout for a message with two `optional int32` fields would end
up looking something like this:
```c
// For illustration only, upb does not actually generate structs.
typedef struct {
upb_msg_internaldata* internal; // Unknown fields and extensions.
uint32_t hasbits; // We are only using two hasbits.
int32_t field1;
int32_t field2;
} package_name_MessageName;
```
Note in particular that messages do *not* have:
- A pointer to reflection or a parse table (upb messages are not self-describing).
- A pointer to an arena (the arena must be explicitly passed into any function that
allocates).
The upb compiler computes a layout for each message, and determines the offset for
each field using normal alignment rules (each data member must be aligned to a
multiple of its size). This layout is then embedded into the generated `.upb.h`
and `.upb.c` headers in two different forms. First as inline accessors that expect
the data at a given offset:
```c
// Example of a generated accessor, from foo.upb.h
UPB_INLINE int32_t package_name_MessageName_field1(
const upb_test_MessageName *msg) {
return *UPB_PTR_AT(msg, UPB_SIZE(4, 4), int32_t);
}
```
Secondly, the layout is emitted as a table which is used by the parser and serializer.
We call these tables "mini-tables" to distinguish them from the larger and more
optimized "fast tables" used in `upb/decode_fast.c` (an experimental parser that is
2-3x the speed of the main parser, though the main parser is already quite fast).
```c
// Definition of mini-table structure, from upb/msg_internal.h
typedef struct {
uint32_t number;
uint16_t offset;
int16_t presence; /* If >0, hasbit_index. If <0, ~oneof_index. */
uint16_t submsg_index; /* undefined if descriptortype != MESSAGE or GROUP. */
uint8_t descriptortype;
int8_t mode; /* upb_fieldmode, with flags from upb_labelflags */
} upb_msglayout_field;
typedef enum {
_UPB_MODE_MAP = 0,
_UPB_MODE_ARRAY = 1,
_UPB_MODE_SCALAR = 2,
} upb_fieldmode;
typedef struct {
const struct upb_msglayout *const* submsgs;
const upb_msglayout_field *fields;
uint16_t size;
uint16_t field_count;
bool extendable;
uint8_t dense_below;
uint8_t table_mask;
} upb_msglayout;
// Example of a generated mini-table, from foo.upb.c
static const upb_msglayout_field upb_test_MessageName__fields[2] = {
{1, UPB_SIZE(4, 4), 1, 0, 5, _UPB_MODE_SCALAR},
{2, UPB_SIZE(8, 8), 2, 0, 5, _UPB_MODE_SCALAR},
};
const upb_msglayout upb_test_MessageName_msginit = {
NULL,
&upb_test_MessageName__fields[0],
UPB_SIZE(16, 16), 2, false, 2, 255,
};
```
The upb compiler computes separate layouts for 32 and 64 bit modes, since the
pointer size will be 4 or 8 bytes respectively. The upb compiler embeds both
sizes into the source code, using a `UPB_SIZE(size32, size64)` macro that can
choose the appropriate size at build time based on the size of `UINTPTR_MAX`.
Note that `.upb.c` files contain data tables only. There is no "generated code"
except for the inline accessors in the `.upb.h` files: the entire footprint
of `.upb.c` files is in `.rodata`, none in `.text` or `.data`.
## Memory Management Model
All memory management in upb is built around arenas. A message is never
considered to "own" the strings or sub-messages contained within it. Instead a
message and all of its sub-messages/strings/etc. are all owned by an arena and
are freed when the arena is freed. An entire message tree will probably be
owned by a single arena, but this is not required or enforced. As far as upb is
concerned, it is up to the client how to partition its arenas. upb only requires
that when you ask it to serialize a message, that all reachable messages are
still alive.
The arena supports both a user-supplied initial block and a custom allocation
callback, so there is a lot of flexibility in memory allocation strategy. The
allocation callback can even be `NULL` for heap-free operation. The main
constraint of the arena is that all of the memory in each arena must be freed
together.
`upb_arena` supports a novel operation called "fuse". When two arenas are fused
together, their lifetimes are irreversibly joined, such that none of the arena
blocks in either arena will be freed until *both* arenas are freed with
`upb_arena_free()`. This is useful when joining two messages from separate
arenas (making one a sub-message of the other). Fuse is a very cheap
operation, and an unlimited number of arenas can be fused together efficiently.
## Reflection and Descriptors
upb offers a fully-featured reflection library. There are two main ways of
using reflection:
1. You can load descriptors from strings using `upb_symtab_addfile()`.
The upb runtime will dynamically create mini-tables like what the upb compiler
would have created if you had compiled this type into a `.upb.c` file.
2. You can load descriptors using generated `.upbdefs.h` interfaces.
This will load reflection that references the corresponding `.upb.c`
mini-tables instead of building a new mini-table on the fly. This lets
you reflect on generated types that are linked into your program.
upb's design for descriptors is similar to protobuf C++ in many ways, with
the following correspondences:
| C++ Type | upb type |
| ---------| ---------|
| `google::protobuf::DescriptorPool` | `upb_symtab`
| `google::protobuf::Descriptor` | `upb_msgdef`
| `google::protobuf::FieldDescriptor` | `upb_fielddef`
| `google::protobuf::OneofDescriptor` | `upb_oneofdef`
| `google::protobuf::EnumDescriptor` | `upb_enumdef`
| `google::protobuf::FileDescriptor` | `upb_filedef`
| `google::protobuf::ServiceDescriptor` | `upb_servicedef`
| `google::protobuf::MethodDescriptor` | `upb_methoddef`
Like in C++ descriptors (defs) are created by loading a
`google_protobuf_FileDescriptorProto` into a `upb_symtab`. This creates and
links all of the def objects corresponding to that `.proto` file, and inserts
the names into a symbol table so they can be looked up by name.
Once you have loaded some descriptors into a `upb_symtab`, you can create and
manipulate messages using the interfaces defined in `upb/reflection.h`. If your
descriptors are linked to your generated layouts using option (2) above, you can
safely access the same messages using both reflection and generated interfaces. | {
"source": "yandex/perforator",
"title": "contrib/libs/grpc/third_party/upb/DESIGN.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/libs/grpc/third_party/upb/DESIGN.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 8387
} |
# μpb: small, fast C protos
μpb (often written 'upb') is a small
[protobuf](https://github.com/protocolbuffers/protobuf) implementation written
in C.
upb is the core runtime for protobuf languages extensions in
[Ruby](https://github.com/protocolbuffers/protobuf/tree/master/ruby),
[PHP](https://github.com/protocolbuffers/protobuf/tree/master/php), and (soon)
Python.
While upb offers a C API, the C API & ABI **are not stable**. For this reason,
upb is not generally offered as a C library for direct consumption, and there
are no releases.
## Features
upb has comparable speed to protobuf C++, but is an order of magnitude smaller
in code size.
Like the main protobuf implementation in C++, it supports:
- a generated API (in C)
- reflection
- binary & JSON wire formats
- text format serialization
- all standard features of protobufs (oneofs, maps, unknown fields, extensions,
etc.)
- full conformance with the protobuf conformance tests
upb also supports some features that C++ does not:
- **optional reflection:** generated messages are agnostic to whether
reflection will be linked in or not.
- **no global state:** no pre-main registration or other global state.
- **fast reflection-based parsing:** messages loaded at runtime parse
just as fast as compiled-in messages.
However there are a few features it does not support:
- text format parsing
- deep descriptor verification: upb's descriptor validation is not as exhaustive
as `protoc`.
## Install
For Ruby, use [RubyGems](https://rubygems.org/gems/google-protobuf):
```
$ gem install google-protobuf
```
For PHP, use [PECL](https://pecl.php.net/package/protobuf):
```
$ sudo pecl install protobuf
```
Alternatively, you can build and install upb using
[vcpkg](https://github.com/microsoft/vcpkg/) dependency manager:
git clone https://github.com/Microsoft/vcpkg.git
cd vcpkg
./bootstrap-vcpkg.sh
./vcpkg integrate install
./vcpkg install upb
The upb port in vcpkg is kept up to date by microsoft team members and community
contributors.
If the version is out of date, please
[create an issue or pull request](https://github.com/Microsoft/vcpkg) on the
vcpkg repository.
## Contributing
Please see [CONTRIBUTING.md](CONTRIBUTING.md). | {
"source": "yandex/perforator",
"title": "contrib/libs/grpc/third_party/upb/README.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/libs/grpc/third_party/upb/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2245
} |
# llvm-exegesis
`llvm-exegesis` is a benchmarking tool that accepts or assembles a snippet and
can measure characteristics of that snippet by executing it while keeping track
of performance counters.
### Currently Supported Platforms
`llvm-exegesis` is quite platform-dependent and currently only supports a couple
platform configurations for benchmarking. The limitations are listed below.
Analysis mode in `llvm-exegesis` is supported on all platforms on which LLVM is.
#### Currently Supported Operating Systems for Benchmarking
Currently, `llvm-exegesis` only supports benchmarking on Linux. This is mainly
due to a dependency on the Linux perf subsystem for reading performance
counters.
The subprocess execution mode and memory annotations currently only supports
Linux due to a heavy reliance on many Linux specific syscalls/syscall
implementations.
#### Currently Supported Architectures for Benchmarking
Currently, using `llvm-exegesis` for benchmarking is supported on the following
architectures:
* x86
* 64-bit only due to this being the only implemented calling convention
in `llvm-exegesis` currently.
* ARM
* AArch64 only
* MIPS
* PowerPC (PowerPC64LE only)
Note that not benchmarking functionality is guaranteed to work on all platforms.
Memory annotations are currently only supported on 64-bit X86. There is no
inherent limitations for porting memory annotations to other architectures, but
parts of the test harness are implemented as MCJITed assembly that is generated
in `./lib/X86/Target.cpp` that would need to be implemented on other architectures
to bring up support. | {
"source": "yandex/perforator",
"title": "contrib/libs/llvm18/tools/llvm-exegesis/README.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/libs/llvm18/tools/llvm-exegesis/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1611
} |
# LLVM TableGen
The purpose of TableGen is to generate complex output files based on information
from source files that are significantly easier to code than the output files would be, and also easier to maintain and modify over time.
The information is coded in a declarative style involving classes and records,
which are then processed by TableGen.
```
class Hello <string _msg> {
string msg = !strconcat("Hello ", _msg);
}
def HelloWorld: Hello<"world!"> {}
```
```
------------- Classes -----------------
class Hello<string Hello:_msg = ?> {
string msg = !strconcat("Hello ", Hello:_msg);
}
------------- Defs -----------------
def HelloWorld { // Hello
string msg = "Hello world!";
}
```
[Try this example on Compiler Explorer.](https://godbolt.org/z/13xo1P5oz)
The internalized records are passed on to various backends, which extract
information from a subset of the records and generate one or more output files.
These output files are typically .inc files for C++, but may be any type of file
that the backend developer needs.
Resources for learning the language:
* [TableGen Overview](https://llvm.org/docs/TableGen/index.html)
* [Programmer's reference guide](https://llvm.org/docs/TableGen/ProgRef.html)
* [Tutorial](jupyter/tablegen_tutorial_part_1.ipynb)
* [Tools for Learning LLVM TableGen](https://blog.llvm.org/posts/2023-12-07-tools-for-learning-llvm-tablegen/)
* [Lessons in TableGen](https://www.youtube.com/watch?v=45gmF77JFBY) (video),
[slides](https://archive.fosdem.org/2019/schedule/event/llvm_tablegen/attachments/slides/3304/export/events/attachments/llvm_tablegen/slides/3304/tablegen.pdf)
* [Improving Your TableGen Descriptions](https://www.youtube.com/watch?v=dIEVUlsiktQ)
(video), [slides](https://llvm.org/devmtg/2019-10/slides/Absar-ImprovingYourTableGenDescription.pdf)
Writing TableGen backends:
* [TableGen Backend Developer's Guide](https://llvm.org/docs/TableGen/BackGuide.html)
* [How to write a TableGen backend](https://www.youtube.com/watch?v=UP-LBRbvI_U)
(video), [slides](https://llvm.org/devmtg/2021-11/slides/2021-how-to-write-a-tablegen-backend.pdf), also available as a
[notebook](jupyter/sql_query_backend.ipynb).
TableGen in MLIR:
* [Operation Definition Specification](https://mlir.llvm.org/docs/DefiningDialects/Operations/)
* [Defining Dialect Attributes and Types](https://mlir.llvm.org/docs/DefiningDialects/AttributesAndTypes/)
Useful tools:
* [TableGen Jupyter Kernel](jupyter/)
* [TableGen LSP Language Server](https://mlir.llvm.org/docs/Tools/MLIRLSP/#tablegen-lsp-language-server--tblgen-lsp-server) | {
"source": "yandex/perforator",
"title": "contrib/libs/llvm18/utils/TableGen/README.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/libs/llvm18/utils/TableGen/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2591
} |
# How to Contribute
This repository is currently a read-only clone of internal Google code for use
in open-source projects. We don't currently have a mechanism to upstream
changes, but if you'd like to contribute, please reach out to us to discuss your
proposed changes.
## Contributor License Agreement
Contributions to this project must be accompanied by a Contributor License
Agreement (CLA). You (or your employer) retain the copyright to your
contribution; this simply gives us permission to use and redistribute your
contributions as part of the project. Head over to
<https://cla.developers.google.com/> to see your current agreements on file or
to sign a new one.
You generally only need to submit a CLA once, so if you've already submitted one
(even if it was for a different project), you probably don't need to do it
again.
## Code Reviews
All submissions, including submissions by project members, require review. We
use GitHub pull requests for this purpose. Consult
[GitHub Help](https://help.github.com/articles/about-pull-requests/) for more
information on using pull requests.
## Community Guidelines
This project follows
[Google's Open Source Community Guidelines](https://opensource.google/conduct/). | {
"source": "yandex/perforator",
"title": "contrib/libs/protobuf/third_party/utf8_range/CONTRIBUTING.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/libs/protobuf/third_party/utf8_range/CONTRIBUTING.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1228
} |
[](https://travis-ci.com/cyb70289/utf8)
# Fast UTF-8 validation with Range algorithm (NEON+SSE4+AVX2)
This is a brand new algorithm to leverage SIMD for fast UTF-8 string validation. Both **NEON**(armv8a) and **SSE4** versions are implemented. **AVX2** implementation contributed by [ioioioio](https://github.com/ioioioio).
Four UTF-8 validation methods are compared on both x86 and Arm platforms. Benchmark result shows range base algorithm is the best solution on Arm, and achieves same performance as [Lemire's approach](https://lemire.me/blog/2018/05/16/validating-utf-8-strings-using-as-little-as-0-7-cycles-per-byte/) on x86.
* Range based algorithm
* range-neon.c: NEON version
* range-sse.c: SSE4 version
* range-avx2.c: AVX2 version
* range2-neon.c, range2-sse.c: Process two blocks in one iteration
* [Lemire's SIMD implementation](https://github.com/lemire/fastvalidate-utf-8)
* lemire-sse.c: SSE4 version
* lemire-avx2.c: AVX2 version
* lemire-neon.c: NEON porting
* naive.c: Naive UTF-8 validation byte by byte
* lookup.c: [Lookup-table method](http://bjoern.hoehrmann.de/utf-8/decoder/dfa/)
## About the code
* Run "make" to build. Built and tested with gcc-7.3.
* Run "./utf8" to see all command line options.
* Benchmark
* Run "./utf8 bench" to bechmark all algorithms with [default test file](https://raw.githubusercontent.com/cyb70289/utf8/master/UTF-8-demo.txt).
* Run "./utf8 bench size NUM" to benchmark specified string size.
* Run "./utf8 test" to test all algorithms with positive and negative test cases.
* To benchmark or test specific algorithm, run something like "./utf8 bench range".
## Benchmark result (MB/s)
### Method
1. Generate UTF-8 test buffer per [test file](https://raw.githubusercontent.com/cyb70289/utf8/master/UTF-8-demo.txt) or buffer size.
1. Call validation sub-routines in a loop until 1G bytes are checked.
1. Calculate speed(MB/s) of validating UTF-8 strings.
### NEON(armv8a)
Test case | naive | lookup | lemire | range | range2
:-------- | :---- | :----- | :----- | :---- | :-----
[UTF-demo.txt](https://raw.githubusercontent.com/cyb70289/utf8/master/UTF-8-demo.txt) | 562.25 | 412.84 | 1198.50 | 1411.72 | **1579.85**
32 bytes | 651.55 | 441.70 | 891.38 | 1003.95 | **1043.58**
33 bytes | 660.00 | 446.78 | 588.77 | 1009.31 | **1048.12**
129 bytes | 771.89 | 402.55 | 938.07 | 1283.77 | **1401.76**
1K bytes | 811.92 | 411.58 | 1188.96 | 1398.15 | **1560.23**
8K bytes | 812.25 | 412.74 | 1198.90 | 1412.18 | **1580.65**
64K bytes | 817.35 | 412.24 | 1200.20 | 1415.11 | **1583.86**
1M bytes | 815.70 | 411.93 | 1200.93 | 1415.65 | **1585.40**
### SSE4(E5-2650)
Test case | naive | lookup | lemire | range | range2
:-------- | :---- | :----- | :----- | :---- | :-----
[UTF-demo.txt](https://raw.githubusercontent.com/cyb70289/utf8/master/UTF-8-demo.txt) | 753.70 | 310.41 | 3954.74 | 3945.60 | **3986.13**
32 bytes | 1135.76 | 364.07 | **2890.52** | 2351.81 | 2173.02
33 bytes | 1161.85 | 376.29 | 1352.95 | **2239.55** | 2041.43
129 bytes | 1161.22 | 322.47 | 2742.49 | **3315.33** | 3249.35
1K bytes | 1310.95 | 310.72 | 3755.88 | 3781.23 | **3874.17**
8K bytes | 1348.32 | 307.93 | 3860.71 | 3922.81 | **3968.93**
64K bytes | 1301.34 | 308.39 | 3935.15 | 3973.50 | **3983.44**
1M bytes | 1279.78 | 309.06 | 3923.51 | 3953.00 | **3960.49**
## Range algorithm analysis
Basic idea:
* Load 16 bytes
* Leverage SIMD to calculate value range for each byte efficiently
* Validate 16 bytes at once
### UTF-8 coding format
http://www.unicode.org/versions/Unicode6.0.0/ch03.pdf, page 94
Table 3-7. Well-Formed UTF-8 Byte Sequences
Code Points | First Byte | Second Byte | Third Byte | Fourth Byte |
:---------- | :--------- | :---------- | :--------- | :---------- |
U+0000..U+007F | 00..7F | | | |
U+0080..U+07FF | C2..DF | 80..BF | | |
U+0800..U+0FFF | E0 | ***A0***..BF| 80..BF | |
U+1000..U+CFFF | E1..EC | 80..BF | 80..BF | |
U+D000..U+D7FF | ED | 80..***9F***| 80..BF | |
U+E000..U+FFFF | EE..EF | 80..BF | 80..BF | |
U+10000..U+3FFFF | F0 | ***90***..BF| 80..BF | 80..BF |
U+40000..U+FFFFF | F1..F3 | 80..BF | 80..BF | 80..BF |
U+100000..U+10FFFF | F4 | 80..***8F***| 80..BF | 80..BF |
To summarise UTF-8 encoding:
* Depending on First Byte, one legal character can be 1, 2, 3, 4 bytes
* For First Byte within C0..DF, character length = 2
* For First Byte within E0..EF, character length = 3
* For First Byte within F0..F4, character length = 4
* C0, C1, F5..FF are not allowed
* Second,Third,Fourth Bytes must lie in 80..BF.
* There are four **special cases** for Second Byte, shown ***bold italic*** in above table.
### Range table
Range table maps range index 0 ~ 15 to minimal and maximum values allowed. Our task is to observe input string, find the pattern and set correct range index for each byte, then validate input string.
Index | Min | Max | Byte type
:---- | :-- | :-- | :--------
0 | 00 | 7F | First Byte, ASCII
1,2,3 | 80 | BF | Second, Third, Fourth Bytes
4 | A0 | BF | Second Byte after E0
5 | 80 | 9F | Second Byte after ED
6 | 90 | BF | Second Byte after F0
7 | 80 | 8F | Second Byte after F4
8 | C2 | F4 | First Byte, non-ASCII
9..15(NEON) | FF | 00 | Illegal: unsigned char >= 255 && unsigned char <= 0
9..15(SSE) | 7F | 80 | Illegal: signed char >= 127 && signed char <= -128
### Calculate byte ranges (ignore special cases)
Ignoring the four special cases(E0,ED,F0,F4), how should we set range index for each byte?
* Set range index to 0(00..7F) for all bytes by default
* Find non-ASCII First Byte (C0..FF), set their range index to 8(C2..F4)
* For First Byte within C0..DF, set next byte's range index to 1(80..BF)
* For First Byte within E0..EF, set next two byte's range index to 2,1(80..BF) in sequence
* For First Byte within F0..FF, set next three byte's range index to 3,2,1(80..BF) in sequence
To implement above operations efficiently with SIMD:
* For 16 input bytes, use lookup table to map C0..DF to 1, E0..EF to 2, F0..FF to 3, others to 0. Save to first_len.
* Map C0..FF to 8, we get range indices for First Byte.
* Shift first_len one byte, we get range indices for Second Byte.
* Saturate substract first_len by one(3->2, 2->1, 1->0, 0->0), then shift two bytes, we get range indices for Third Byte.
* Saturate substract first_len by two(3->1, 2->0, 1->0, 0->0), then shift three bytes, we get range indices for Fourth Byte.
Example(assume no previous data)
Input | F1 | 80 | 80 | 80 | 80 | C2 | 80 | 80 | ...
:---- | :- | :- | :- | :- | :- | :- | :- | :- | :--
*first_len* |*3* |*0* |*0* |*0* |*0* |*1* |*0* |*0* |*...*
First Byte | 8 | 0 | 0 | 0 | 0 | 8 | 0 | 0 | ...
Second Byte | 0 | 3 | 0 | 0 | 0 | 0 | 1 | 0 | ...
Third Byte | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | ...
Fourth Byte | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | ...
Range index | 8 | 3 | 2 | 1 | 0 | 8 | 1 | 0 | ...
```c
Range_index = First_Byte | Second_Byte | Third_Byte | Fourth_Byte
```
#### Error handling
* C0,C1,F5..FF are not included in range table and will always be detected.
* Illegal 80..BF will have range index 0(00..7F) and be detected.
* Based on First Byte, according Second, Third and Fourth Bytes will have range index 1/2/3, to make sure they must lie in 80..BF.
* If non-ASCII First Byte overlaps, above algorithm will set range index of the latter First Byte to 9,10,11, which are illegal ranges. E.g, Input = F1 80 C2 90 --> Range index = 8 3 10 1, where 10 indicates error. See table below.
Overlapped non-ASCII First Byte
Input | F1 | 80 | C2 | 90
:---- | :- | :- | :- | :-
*first_len* |*3* |*0* |*1* |*0*
First Byte | 8 | 0 | 8 | 0
Second Byte | 0 | 3 | 0 | 1
Third Byte | 0 | 0 | 2 | 0
Fourth Byte | 0 | 0 | 0 | 1
Range index | 8 | 3 |***10***| 1
### Adjust Second Byte range for special cases
Range index adjustment for four special cases
First Byte | Second Byte | Before adjustment | Correct index | Adjustment |
:--------- | :---------- | :---------------- | :------------ | :---------
E0 | A0..BF | 2 | 4 | **2**
ED | 80..9F | 2 | 5 | **3**
F0 | 90..BF | 3 | 6 | **3**
F4 | 80..8F | 3 | 7 | **4**
Range index adjustment can be reduced to below problem:
***Given 16 bytes, replace E0 with 2, ED with 3, F0 with 3, F4 with 4, others with 0.***
A naive SIMD approach:
1. Compare 16 bytes with E0, get the mask for eacy byte (FF if equal, 00 otherwise)
1. And the mask with 2 to get adjustment for E0
1. Repeat step 1,2 for ED,F0,F4
At least **eight** operations are required for naive approach.
Observing special bytes(E0,ED,F0,F4) are close to each other, we can do much better using lookup table.
#### NEON
NEON ```tbl``` instruction is very convenient for table lookup:
* Table can be up to 16x4 bytes in size
* Return zero if index is out of range
Leverage these features, we can solve the problem with as few as **two** operations:
* Precreate a 16x2 lookup table, where table[0]=2, table[13]=3, table[16]=3, table[20]=4, table[others]=0.
* Substract input bytes with E0 (E0 -> 0, ED -> 13, F0 -> 16, F4 -> 20).
* Use the substracted byte as index of lookup table and get range adjustment directly.
* For indices less than 32, we get zero or required adjustment value per input byte
* For out of bound indices, we get zero per ```tbl``` behaviour
#### SSE
SSE ```pshufb``` instruction is not as friendly as NEON ```tbl``` in this case:
* Table can only be 16 bytes in size
* Out of bound indices are handled this way:
* If 7-th bit of index is 0, least four bits are used as index (E.g, index 0x73 returns 3rd element)
* If 7-th bit of index is 1, return 0 (E.g, index 0x83 returns 0)
We can still leverage these features to solve the problem in **five** operations:
* Precreate two tables:
* table_df[1] = 2, table_df[14] = 3, table_df[others] = 0
* table_ef[1] = 3, table_ef[5] = 4, table_ef[others] = 0
* Substract input bytes with EF (E0 -> 241, ED -> 254, F0 -> 1, F4 -> 5) to get the temporary indices
* Get range index for E0,ED
* Saturate substract temporary indices with 240 (E0 -> 1, ED -> 14, all values below 240 becomes 0)
* Use substracted indices to look up table_df, get the correct adjustment
* Get range index for F0,F4
* Saturate add temporary indices with 112(0x70) (F0 -> 0x71, F4 -> 0x75, all values above 16 will be larger than 128(7-th bit set))
* Use added indices to look up table_ef, get the correct adjustment (index 0x71,0x75 returns 1st,5th elements, per ```pshufb``` behaviour)
#### Error handling
* For overlapped non-ASCII First Byte, range index before adjustment is 9,10,11. After adjustment (adds 2,3,4 or 0), the range index will be 9 to 15, which is still illegal in range table. So the error will be detected.
### Handling remaining bytes
For remaining input less than 16 bytes, we will fallback to naive byte by byte approach to validate them, which is actually faster than SIMD processing.
* Look back last 16 bytes buffer to find First Byte. At most three bytes need to look back. Otherwise we either happen to be at character boundray, or there are some errors we already detected.
* Validate string byte by byte starting from the First Byte.
## Tests
It's necessary to design test cases to cover corner cases as more as possible.
### Positive cases
1. Prepare correct characters
2. Validate correct characters
3. Validate long strings
* Round concatenate characters starting from first character to 1024 bytes
* Validate 1024 bytes string
* Shift 1 byte, validate 1025 bytes string
* Shift 2 bytes, Validate 1026 bytes string
* ...
* Shift 16 bytes, validate 1040 bytes string
4. Repeat step3, test buffer starting from second character
5. Repeat step3, test buffer starting from third character
6. ...
### Negative cases
1. Prepare bad characters and bad strings
* Bad character
* Bad character cross 16 bytes boundary
* Bad character cross last 16 bytes and remaining bytes boundary
2. Test long strings
* Prepare correct long strings same as positive cases
* Append bad characters
* Shift one byte for each iteration
* Validate each shift
## Code breakdown
Below table shows how 16 bytes input are processed step by step. See [range-neon.c](range-neon.c) for according code.
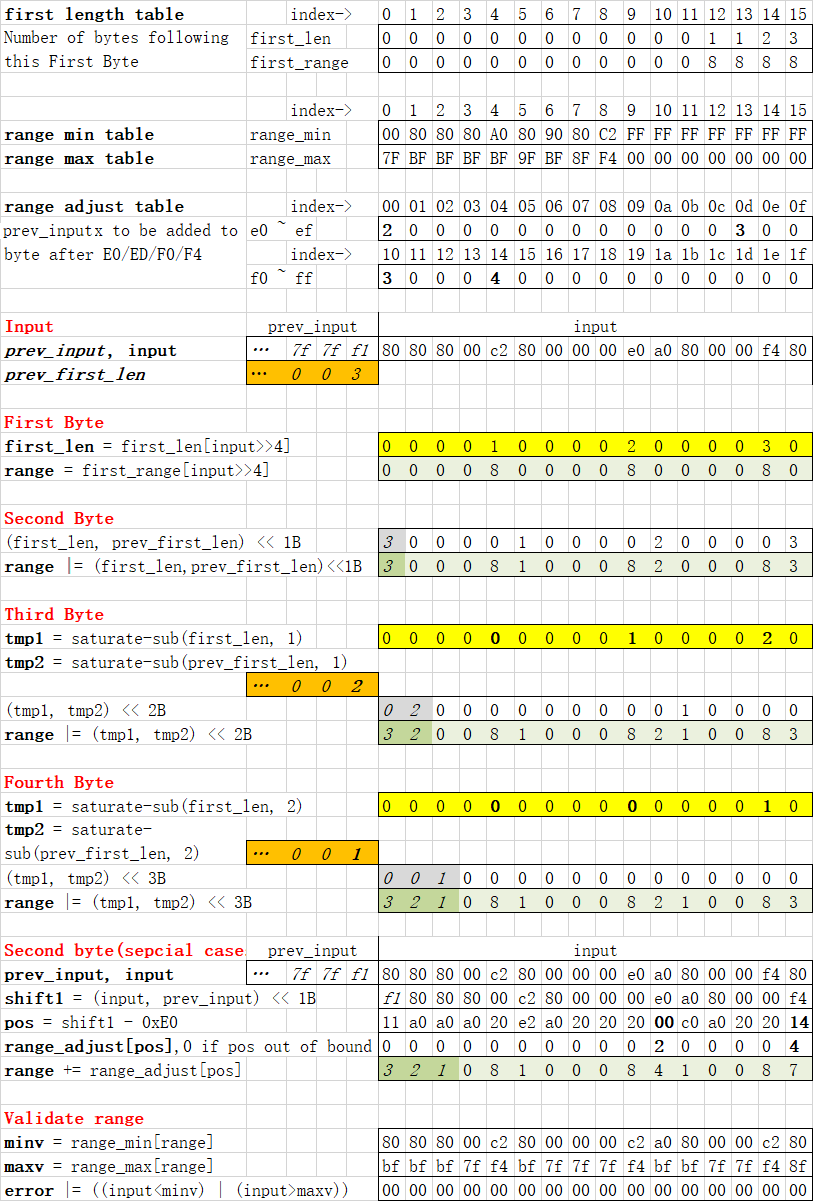 | {
"source": "yandex/perforator",
"title": "contrib/libs/protobuf/third_party/utf8_range/README.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/libs/protobuf/third_party/utf8_range/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 12920
} |
# Algorithm implementations used by the `hashlib` module.
This code comes from the
[HACL\*](https://github.com/hacl-star/hacl-star/) project.
HACL\* is a cryptographic library that has been formally verified for memory
safety, functional correctness, and secret independence.
## Updating HACL*
Use the `refresh.sh` script in this directory to pull in a new upstream code
version. The upstream git hash used for the most recent code pull is recorded
in the script. Modify the script as needed to bring in more if changes are
needed based on upstream code refactoring.
Never manually edit HACL\* files. Always add transformation shell code to the
`refresh.sh` script to perform any necessary edits. If there are serious code
changes needed, work with the upstream repository.
## Local files
1. `./include/python_hacl_namespaces.h`
1. `./README.md`
1. `./refresh.sh`
## ACKS
* Jonathan Protzenko aka [@msprotz on Github](https://github.com/msprotz)
contributed our HACL\* based builtin code. | {
"source": "yandex/perforator",
"title": "contrib/tools/python3/Modules/_hacl/README.md",
"url": "https://github.com/yandex/perforator/blob/main/contrib/tools/python3/Modules/_hacl/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 999
} |
Fuzz Tests for CPython
======================
These fuzz tests are designed to be included in Google's `oss-fuzz`_ project.
oss-fuzz works against a library exposing a function of the form
``int LLVMFuzzerTestOneInput(const uint8_t* data, size_t length)``. We provide
that library (``fuzzer.c``), and include a ``_fuzz`` module for testing with
some toy values -- no fuzzing occurs in Python's test suite.
oss-fuzz will regularly pull from CPython, discover all the tests in
``fuzz_tests.txt``, and run them -- so adding a new test here means it will
automatically be run in oss-fuzz, while also being smoke-tested as part of
CPython's test suite.
Adding a new fuzz test
----------------------
Add the test name on a new line in ``fuzz_tests.txt``.
In ``fuzzer.c``, add a function to be run::
static int $fuzz_test_name(const char* data, size_t size) {
...
return 0;
}
And invoke it from ``LLVMFuzzerTestOneInput``::
#if !defined(_Py_FUZZ_ONE) || defined(_Py_FUZZ_$fuzz_test_name)
rv |= _run_fuzz(data, size, $fuzz_test_name);
#endif
Don't forget to replace ``$fuzz_test_name`` with your actual test name.
``LLVMFuzzerTestOneInput`` will run in oss-fuzz, with each test in
``fuzz_tests.txt`` run separately.
Seed data (corpus) for the test can be provided in a subfolder called
``<test_name>_corpus`` such as ``fuzz_json_loads_corpus``. A wide variety
of good input samples allows the fuzzer to more easily explore a diverse
set of paths and provides a better base to find buggy input from.
Dictionaries of tokens (see oss-fuzz documentation for more details) can
be placed in the ``dictionaries`` folder with the name of the test.
For example, ``dictionaries/fuzz_json_loads.dict`` contains JSON tokens
to guide the fuzzer.
What makes a good fuzz test
---------------------------
Libraries written in C that might handle untrusted data are worthwhile. The
more complex the logic (e.g. parsing), the more likely this is to be a useful
fuzz test. See the existing examples for reference, and refer to the
`oss-fuzz`_ docs.
.. _oss-fuzz: https://github.com/google/oss-fuzz | {
"source": "yandex/perforator",
"title": "contrib/tools/python3/Modules/_xxtestfuzz/README.rst",
"url": "https://github.com/yandex/perforator/blob/main/contrib/tools/python3/Modules/_xxtestfuzz/README.rst",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2127
} |
# Рецепт extract_node_modules
Про рецепты читай в [документации](https://docs.yandex-team.ru/ya-make/manual/tests/recipe).
Используется в `TS_TEST_*_FOR` модулях для предварительной распаковки `node_modules.tar`. Рецепт автоматически добавляется плагином за счет использования внутреннего макроса `_SETUP_EXTRACT_NODE_MODULES_RECIPE`.
Время работы рецепта не учитывается во время выполнения теста, поэтому длительная распаковка не влечет timeout. | {
"source": "yandex/perforator",
"title": "devtools/frontend_build_platform/nots/recipes/extract_node_modules/readme.md",
"url": "https://github.com/yandex/perforator/blob/main/devtools/frontend_build_platform/nots/recipes/extract_node_modules/readme.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 449
} |
# Рецепт extract_output_tars
Про рецепты читай в [документации](https://docs.yandex-team.ru/ya-make/manual/tests/recipe).
Используется в `TS_TEST_*_FOR` модулях для предварительной распаковки `<module_name>.output.tar` во всём дереве зависимостей. Рецепт автоматически добавляется плагином за счет использования внутреннего макроса `_SETUP_EXTRACT_OUTPUT_TARS_RECIPE`.
Время работы рецепта не учитывается во время выполнения теста, поэтому длительная распаковка не влечет timeout. | {
"source": "yandex/perforator",
"title": "devtools/frontend_build_platform/nots/recipes/extract_output_tars/readme.md",
"url": "https://github.com/yandex/perforator/blob/main/devtools/frontend_build_platform/nots/recipes/extract_output_tars/readme.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 483
} |
# Рецепт extract_node_modules
Про рецепты читай в [документации](https://docs.yandex-team.ru/ya-make/manual/tests/recipe).
Используется в `TS_TEST_*_FOR` модулях для предварительной распаковки `node_modules.tar`. Рецепт автоматически добавляется плагином за счет использования внутреннего макроса `_SETUP_EXTRACT_NODE_MODULES_RECIPE`.
Время работы рецепта не учитывается во время выполнения теста, поэтому длительная распаковка не влечет timeout. | {
"source": "yandex/perforator",
"title": "devtools/frontend_build_platform/nots/recipes/install_node_modules/readme.md",
"url": "https://github.com/yandex/perforator/blob/main/devtools/frontend_build_platform/nots/recipes/install_node_modules/readme.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 449
} |
# Merging Python Stack with Native Stack
The native and Python stacks are collected separately for the same perf event. Afterwards these stacks are merged into a single stack for better visualization and analysis, because looking at two stacks simultaneously is not convenient.
## Stub Frames
When C code starts evaluating Python code through CPython API, it pushes a stub frame. Each `_PyInterpreterFrame` structure contains the `owner` field, which stores the `python_frame_owner` enum value.
```c
enum python_frame_owner : u8 {
FRAME_OWNED_BY_THREAD = 0,
FRAME_OWNED_BY_GENERATOR = 1,
FRAME_OWNED_BY_FRAME_OBJECT = 2,
FRAME_OWNED_BY_CSTACK = 3,
};
```
If the value is equal to `FRAME_OWNED_BY_CSTACK`, then the frame is a stub frame.
A stub frame is a delimiter between the native and Python stacks. This frame is pushed onto the native stack in the `_PyEval_EvalFrameDefault` function.
## Algorithm
The Python user stack is divided into segments each one starting with a stub frame. Also, segments of the native stack with CPython are extracted using `_PyEval_EvalFrameDefault` as a delimiter. The functions starting with the `_Py` or `Py` prefix are considered to be CPython internal implementation.

These stack segments should map one-to-one with each other, but there are some exceptions:
* `_PyEval_EvalFrameDefault` has started executing on top of the native stack but has not finished pushing the stub Python frame yet.
* The native stack contains entries like `PyImport_ImportModule`. Python importlib may drop its own frames from the native stack.
The first case is handled easily, while the second case is more complex and is ignored for now. | {
"source": "yandex/perforator",
"title": "docs/en/reference/language-support/python/merging.md",
"url": "https://github.com/yandex/perforator/blob/main/docs/en/reference/language-support/python/merging.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1749
} |
# ELF Parsing
## Requirements for ELF CPython binary:
* `.dynsym`, `.rodata`, `.text` sections
* `Py_Version` or `Py_GetVersion` symbol available in `.dynsym`
* `_PyThreadState_GetCurrent` or `_PyRuntime` symbol available in `.dynsym`
## Python Version
There are multiple ways to parse the Python version from an ELF file that we utilize in Perforator.
### `Py_Version` Symbol
There is a `Py_Version` symbol in the ELF file. This is a global variable that stores 4 bytes of the Python version: the first byte is the major version, the second byte is the minor version, the third byte is the micro version, and the fourth byte is the release level.
### Disassemble `Py_GetVersion` Function
For CPython versions earlier than 3.11, we can disassemble the `Py_GetVersion` function to get the version.
There is this line of code inside the `Py_GetVersion` function:
```
PyOS_snprintf(version, sizeof(version), buildinfo_format, PY_VERSION, Py_GetBuildInfo(), Py_GetCompiler());
```
Perforator extracts the 4th argument, which is a pointer to a constant global string with the Python version in the `.rodata` section.
Then, we can read the version as a string from this address in the binary.
## `_PyRuntime` Global Variable
There is a `_PyRuntime` symbol in the `.dynsym` section which can be used to obtain the address of the `_PyRuntime` global variable.
## Disassembling `PyThreadState_GetCurrent`
The `PyThreadState_GetCurrent` function can be disassembled to get the offset of `_PyThreadState_Current` in the Thread Local Image for [Python Thread State collection](./threadstate.md). | {
"source": "yandex/perforator",
"title": "docs/en/reference/language-support/python/parse_elf.md",
"url": "https://github.com/yandex/perforator/blob/main/docs/en/reference/language-support/python/parse_elf.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1599
} |
# Python Profiling
Perforator supports stack unwinding for the latest releases of Python - 3.12 and 3.13 executing with CPython.
Cython is not supported yet. Previous versions of CPython will be supported soon.
## Problem
The native stack unwinding algorithm allows to collect stacks of different compiled programming languages in an eBPF program. However, trying to collect a Python process stack with the same algorithm will result in only seeing CPython runtime frames that are called to execute the user's code. To collect the user's Python stack, a different algorithm is needed. It traverses Python's internal structures and extracts valuable information about the execution.
## Algorithm
Each native thread is mapped to one `PyThreadState` structure that contains information about the corresponding Python thread. From this structure, we can extract information about the current executing frame of user code - the `struct _PyInterpreterFrame *current_frame;` field is responsible for this. In Python 3.11 to 3.12 versions, there is a proxy field `_PyCFrame *cframe`. The `_PyCFrame` structure also contains the `struct _PyInterpreterFrame *current_frame` field.
Having the top executing user frame, which is represented by the `_PyInterpreterFrame` structure, the stack can be collected. `_PyInterpreterFrame` structure contains the `f_code` or `f_executable` field that stores a pointer to the `PyCodeObject` structure, which can be utilized to extract the symbol name and line number. Also, there is a field `struct _PyInterpreterFrame *previous` pointing to the previous frame.
With all this knowledge the eBPF algorithm can be divided into these phases:
1. [Extract the corresponding `*PyThreadState`](./threadstate.md)
2. [Retrieve `current_frame` from `*PyThreadState`](./stack-unwinding.md)
3. [Walk the stack frames collecting symbol names](./symbolization.md)
4. [Symbolize frames in user space](./merging.md)
To follow all the steps the hardcode of the offsets of certain fields in CPython internal structures is needed. These offsets are not exported by CPython until Python 3.13. [The necessary information is extracted from the CPython ELF file.](./parse_elf.md)
The phases of the algorithm are described in the following sections. | {
"source": "yandex/perforator",
"title": "docs/en/reference/language-support/python/profiling.md",
"url": "https://github.com/yandex/perforator/blob/main/docs/en/reference/language-support/python/profiling.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2264
} |
# Python Stack Unwinding
Having a current `*PyThreadState` pointer a top executing frame is retrieved using the `current_frame` field and the frame chain is traversed using the `previous` field.

The process of passing symbols from the eBPF context to the user space is not trivial. Copying symbol names on each frame processing is avoided as it is not efficient.
[Python Symbolization](./symbolization.md) section describes how python symbols are handled in the eBPF program. | {
"source": "yandex/perforator",
"title": "docs/en/reference/language-support/python/stack-unwinding.md",
"url": "https://github.com/yandex/perforator/blob/main/docs/en/reference/language-support/python/stack-unwinding.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 542
} |
# Python Symbolization
## eBPF symbol collection
Python symbols are stored in a `BPF_MAP_TYPE_LRU_HASH` map called `python_symbols`. The map is filled by an eBPF program during the stack unwinding process.
`python_symbols` contains function names and filenames for each symbol by ID. The symbol ID is a `(code_object_address, pid, co_firstlineno)` tuple which serves as a unique Python symbol identifier within the system.

The Python stack is passed as an array of Python symbol IDs to the user space.
## User space symbolization
Upon receiving a Python sample from the perf buffer, Python symbol IDs need to be converted to function names and filenames. For this, we can look up the `python_symbols` BPF map using another layer of userspace cache to avoid syscall map lookup overhead. | {
"source": "yandex/perforator",
"title": "docs/en/reference/language-support/python/symbolization.md",
"url": "https://github.com/yandex/perforator/blob/main/docs/en/reference/language-support/python/symbolization.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 856
} |
# Python Current Thread State Collection
Each native thread is mapped to one `PyThreadState` structure which contains information about the corresponding Python thread.

Perforator utilizes multiple ways to obtain current `*PyThreadState` in eBPF context - reading from Thread Local Storage (TLS) and extracting from global variables - such as `_PyRuntime` or others. The combination of these approaches and caching helps to improve the accuracy of the `*PyThreadState` collection.
## Reading `*PyThreadState` from TLS
In Python 3.12+, a pointer to current thread's `PyThreadState` is stored in a Thread Local Storage variable called `_PyThreadState_Current`.
In an eBPF program, the pointer to userspace thread structure can be retrieved by reading `thread.fsbase` from the `task_struct` structure. This structure can be obtained with the `bpf_get_current_task()` helper. The Thread Local Image will be to the left of the pointer stored in `thread.fsbase`.
The exact offset of thread local variable `_PyThreadState_Current` in Thread Local Image is unknown yet. Therefore, the disassembler is used to find the offset of `_PyThreadState_Current`.

### Parsing offset of `_PyThreadState_Current` in Thread Local Image
`_PyThreadState_GetCurrent` is a simple getter function which returns the pointer from `_PyThreadState_Current` thread local variable and looks somewhat like this:
**Optimized build**:
```
000000000028a0b0 <_PyThreadState_GetCurrent@@Base>:
28a0b0: f3 0f 1e fa endbr64
28a0b4: 64 48 8b 04 25 f8 ff mov %fs:0xfffffffffffffff8,%rax
28a0bb: ff ff
28a0bd: c3 ret
28a0be: 66 90 xchg %ax,%ax
```
**Debug build**:
```
0000000001dad910 <_PyThreadState_GetCurrent>:
1dad910: 55 push %rbp
1dad911: 48 89 e5 mov %rsp,%rbp
1dad914: 48 8d 3d 15 6e 65 00 lea 0x656e15(%rip),%rdi # 2404730 <_PyRuntime>
1dad91b: e8 10 00 00 00 callq 1dad930 <current_fast_get>
1dad920: 5d pop %rbp
...
...
...
0000000001db7c50 <current_fast_get>:
1db7c50: 55 push %rbp
1db7c51: 48 89 e5 mov %rsp,%rbp
1db7c54: 48 89 7d f8 mov %rdi,-0x8(%rbp)
1db7c58: 64 48 8b 04 25 00 00 mov %fs:0x0,%rax
1db7c5f: 00 00
1db7c61: 48 8d 80 f8 ff ff ff lea -0x8(%rax),%rax
1db7c68: 48 8b 00 mov (%rax),%rax
1db7c6b: 5d pop %rbp
1db7c6c: c3 retq
```
Looking at these functions, the offset relative to `%fs` register which is used to access `_PyThreadState_Current` variable in userspace can be extracted for later use in the eBPF program.
## Restoring the mapping `native_thread_id` -> `*PyThreadState` using `_PyRuntime` global state
Starting from Python 3.7, there is a global state for CPython runtime - `_PyRuntime`. The address of this global variable can be found in the `.dynsym` section. This structure contains the list of Python interpreter states represented by `_PyInterpreterState` structure.
From each `_PyInterpreterState`, the pointer to the head of `*PyThreadState` linked list can be extracted.

Each `PyThreadState` structure stores a field `native_thread_id` which can be checked against current TID to find the correct Python thread.
Using all this knowledge, the linked list of `*PyThreadState` structures can be traversed and the BPF map with the mapping `native_thread_id` -> `*PyThreadState` can be filled. This mapping can be further used.
## Combination of both approaches
By combining both approaches, we can improve the accuracy of the stack collection. `_PyThreadState_Current` is `NULL` if the current OS thread is not holding a GIL. In this case, the mapping `native_thread_id` -> `*PyThreadState` can be used to find the correct `*PyThreadState`. Also, occasionally we need to trigger the `PyThreadState` linked list traversal to fill the map.
Collecting the stack of threads which are not holding a GIL is crucial for a more accurate picture of what the program is doing. The OS thread may be blocked on I/O operations or executing compression/decompression off-GIL. | {
"source": "yandex/perforator",
"title": "docs/en/reference/language-support/python/threadstate.md",
"url": "https://github.com/yandex/perforator/blob/main/docs/en/reference/language-support/python/threadstate.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 4525
} |
Note: integration tests are located in */devtools/ya/test/tests/gtest_beta*. Launch them as well after changing this library. | {
"source": "yandex/perforator",
"title": "library/cpp/testing/gtest/ut/README.md",
"url": "https://github.com/yandex/perforator/blob/main/library/cpp/testing/gtest/ut/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 125
} |
Note: integration tests are located in */devtools/ya/test/tests/gtest_beta*. Launch them as well after changing this library. | {
"source": "yandex/perforator",
"title": "library/cpp/testing/gtest_extensions/ut/README.md",
"url": "https://github.com/yandex/perforator/blob/main/library/cpp/testing/gtest_extensions/ut/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 125
} |
# Changelog
## [0.2.2](https://github.com/googleapis/google-cloud-go/compare/auth/oauth2adapt/v0.2.1...auth/oauth2adapt/v0.2.2) (2024-04-23)
### Bug Fixes
* **auth/oauth2adapt:** Bump x/net to v0.24.0 ([ba31ed5](https://github.com/googleapis/google-cloud-go/commit/ba31ed5fda2c9664f2e1cf972469295e63deb5b4))
## [0.2.1](https://github.com/googleapis/google-cloud-go/compare/auth/oauth2adapt/v0.2.0...auth/oauth2adapt/v0.2.1) (2024-04-18)
### Bug Fixes
* **auth/oauth2adapt:** Adapt Token Types to be translated ([#9801](https://github.com/googleapis/google-cloud-go/issues/9801)) ([70f4115](https://github.com/googleapis/google-cloud-go/commit/70f411555ebbf2b71e6d425cc8d2030644c6b438)), refs [#9800](https://github.com/googleapis/google-cloud-go/issues/9800)
## [0.2.0](https://github.com/googleapis/google-cloud-go/compare/auth/oauth2adapt/v0.1.0...auth/oauth2adapt/v0.2.0) (2024-04-16)
### Features
* **auth/oauth2adapt:** Add helpers for working with credentials types ([#9694](https://github.com/googleapis/google-cloud-go/issues/9694)) ([cf33b55](https://github.com/googleapis/google-cloud-go/commit/cf33b5514423a2ac5c2a323a1cd99aac34fd4233))
### Bug Fixes
* **auth/oauth2adapt:** Update protobuf dep to v1.33.0 ([30b038d](https://github.com/googleapis/google-cloud-go/commit/30b038d8cac0b8cd5dd4761c87f3f298760dd33a))
## 0.1.0 (2023-10-19)
### Features
* **auth/oauth2adapt:** Adds a new module to translate types ([#8595](https://github.com/googleapis/google-cloud-go/issues/8595)) ([6933c5a](https://github.com/googleapis/google-cloud-go/commit/6933c5a0c1fc8e58cbfff8bbca439d671b94672f))
* **auth/oauth2adapt:** Fixup deps for release ([#8747](https://github.com/googleapis/google-cloud-go/issues/8747)) ([749d243](https://github.com/googleapis/google-cloud-go/commit/749d243862b025a6487a4d2d339219889b4cfe70))
### Bug Fixes
* **auth/oauth2adapt:** Update golang.org/x/net to v0.17.0 ([174da47](https://github.com/googleapis/google-cloud-go/commit/174da47254fefb12921bbfc65b7829a453af6f5d)) | {
"source": "yandex/perforator",
"title": "vendor/cloud.google.com/go/auth/oauth2adapt/CHANGES.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/cloud.google.com/go/auth/oauth2adapt/CHANGES.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2020
} |
# Changes
## [0.5.0](https://github.com/googleapis/google-cloud-go/compare/compute/metadata/v0.4.0...compute/metadata/v0.5.0) (2024-07-10)
### Features
* **compute/metadata:** Add sys check for windows OnGCE ([#10521](https://github.com/googleapis/google-cloud-go/issues/10521)) ([3b9a830](https://github.com/googleapis/google-cloud-go/commit/3b9a83063960d2a2ac20beb47cc15818a68bd302))
## [0.4.0](https://github.com/googleapis/google-cloud-go/compare/compute/metadata/v0.3.0...compute/metadata/v0.4.0) (2024-07-01)
### Features
* **compute/metadata:** Add context for all functions/methods ([#10370](https://github.com/googleapis/google-cloud-go/issues/10370)) ([66b8efe](https://github.com/googleapis/google-cloud-go/commit/66b8efe7ad877e052b2987bb4475477e38c67bb3))
### Documentation
* **compute/metadata:** Update OnGCE description ([#10408](https://github.com/googleapis/google-cloud-go/issues/10408)) ([6a46dca](https://github.com/googleapis/google-cloud-go/commit/6a46dca4eae4f88ec6f88822e01e5bf8aeca787f))
## [0.3.0](https://github.com/googleapis/google-cloud-go/compare/compute/metadata/v0.2.3...compute/metadata/v0.3.0) (2024-04-15)
### Features
* **compute/metadata:** Add context aware functions ([#9733](https://github.com/googleapis/google-cloud-go/issues/9733)) ([e4eb5b4](https://github.com/googleapis/google-cloud-go/commit/e4eb5b46ee2aec9d2fc18300bfd66015e25a0510))
## [0.2.3](https://github.com/googleapis/google-cloud-go/compare/compute/metadata/v0.2.2...compute/metadata/v0.2.3) (2022-12-15)
### Bug Fixes
* **compute/metadata:** Switch DNS lookup to an absolute lookup ([119b410](https://github.com/googleapis/google-cloud-go/commit/119b41060c7895e45e48aee5621ad35607c4d021)), refs [#7165](https://github.com/googleapis/google-cloud-go/issues/7165)
## [0.2.2](https://github.com/googleapis/google-cloud-go/compare/compute/metadata/v0.2.1...compute/metadata/v0.2.2) (2022-12-01)
### Bug Fixes
* **compute/metadata:** Set IdleConnTimeout for http.Client ([#7084](https://github.com/googleapis/google-cloud-go/issues/7084)) ([766516a](https://github.com/googleapis/google-cloud-go/commit/766516aaf3816bfb3159efeea65aa3d1d205a3e2)), refs [#5430](https://github.com/googleapis/google-cloud-go/issues/5430)
## [0.1.0] (2022-10-26)
Initial release of metadata being it's own module. | {
"source": "yandex/perforator",
"title": "vendor/cloud.google.com/go/compute/metadata/CHANGES.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/cloud.google.com/go/compute/metadata/CHANGES.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2322
} |
# Compute API
[](https://pkg.go.dev/cloud.google.com/go/compute/metadata)
This is a utility library for communicating with Google Cloud metadata service
on Google Cloud.
## Install
```bash
go get cloud.google.com/go/compute/metadata
```
## Go Version Support
See the [Go Versions Supported](https://github.com/googleapis/google-cloud-go#go-versions-supported)
section in the root directory's README.
## Contributing
Contributions are welcome. Please, see the [CONTRIBUTING](https://github.com/GoogleCloudPlatform/google-cloud-go/blob/main/CONTRIBUTING.md)
document for details.
Please note that this project is released with a Contributor Code of Conduct.
By participating in this project you agree to abide by its terms. See
[Contributor Code of Conduct](https://github.com/GoogleCloudPlatform/google-cloud-go/blob/main/CONTRIBUTING.md#contributor-code-of-conduct)
for more information. | {
"source": "yandex/perforator",
"title": "vendor/cloud.google.com/go/compute/metadata/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/cloud.google.com/go/compute/metadata/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 969
} |
# CUE Test Suite
This directory contains a test suite for testing the CUE language. This is only
intended to test language evaluation and exporting. Eventually it will also
contains tests for parsing and formatting. It is not intended to cover
testing of the API itself.
## Overview
### Work in progress
The tests are currently converted from various internal Go tests and the
grouping reflect properties of the current implementation. Once the transition
to the new implementation is completed, tests should be reordered along more
logical lines: such as literals, expressions, references, cycles, etc.
## Forseen Structure
The txtar format allows a collection of files to be defined. Any .cue file
is used as an input. The out/* files, which should not have an extension,
define outputs for various tests. A test definition is active for a certain test
if it contains output for this test.
The comments section of the txtar file may contain additional control inputs for
a test. Each line that starts with a `#` immediately followed by a letter or
digit is specially interpreted. These can be boolean tags (`#foo`) or a
key-value pair (`#key: value`), where the value can be a free-form string.
A line starting with `#` followed by a space is interpreted as a comment.
Lines not starting with a `#` are for interpretation by the testscript package.
This organization allows the same test sets to be used for the testing of
tooling as well as internal libraries.
## Common options
- `#skip`: skip this test case for all tests
- `#skip-{name}`: skip this test for the namesake test
- `#todo-{name}`: skip this test for the namesake test, but run it if the
`--todo` flag is specified.
## Tests
### cue/internal/compile
Compiles all *.cue files and prints the debug string of the internal
representation. This is not valid CUE. | {
"source": "yandex/perforator",
"title": "vendor/cuelang.org/go/cue/testdata/readme.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/cuelang.org/go/cue/testdata/readme.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1844
} |
# v2.18.0, 2024-02-01 <!-- Release notes generated using configuration in .github/release.yml at main -->
## What's Changed
### Enhancements 🎉
* Add WithAllocBufferColStrProvider string column allocator for batch insert performance boost by @hongker in https://github.com/ClickHouse/clickhouse-go/pull/1181
### Fixes 🐛
* Fix bind for seconds scale DateTime by @jkaflik in https://github.com/ClickHouse/clickhouse-go/pull/1184
### Other Changes 🛠
* resolves #1163 debugF function is not respected by @omurbekjk in https://github.com/ClickHouse/clickhouse-go/pull/1166
## New Contributors
* @omurbekjk made their first contribution in https://github.com/ClickHouse/clickhouse-go/pull/1166
* @hongker made their first contribution in https://github.com/ClickHouse/clickhouse-go/pull/1181
**Full Changelog**: https://github.com/ClickHouse/clickhouse-go/compare/v2.17.1...v2.18.0
# v2.17.1, 2023-12-27 <!-- Release notes generated using configuration in .github/release.yml at main -->
## What's Changed
### Fixes 🐛
* fix panic in contextWatchDog nil pointer check by @nityanandagohain in https://github.com/ClickHouse/clickhouse-go/pull/1168
## New Contributors
* @nityanandagohain made their first contribution in https://github.com/ClickHouse/clickhouse-go/pull/1168
**Full Changelog**: https://github.com/ClickHouse/clickhouse-go/compare/v2.17.0...v2.17.1
# v2.17.0, 2023-12-21 <!-- Release notes generated using configuration in .github/release.yml at main -->
## What's Changed
### Enhancements 🎉
* Iterable ordered map alternative with improved performance by @hanjm in https://github.com/ClickHouse/clickhouse-go/pull/1152
* Support bool alias type by @yogasw in https://github.com/ClickHouse/clickhouse-go/pull/1156
### Fixes 🐛
* Update README - mention HTTP protocol usable only with `database/sql` interface by @jkaflik in https://github.com/ClickHouse/clickhouse-go/pull/1160
* Fix README example for Debugf by @aramperes in https://github.com/ClickHouse/clickhouse-go/pull/1153
## New Contributors
* @yogasw made their first contribution in https://github.com/ClickHouse/clickhouse-go/pull/1156
* @aramperes made their first contribution in https://github.com/ClickHouse/clickhouse-go/pull/1153
**Full Changelog**: https://github.com/ClickHouse/clickhouse-go/compare/v2.16.0...v2.17.0
# v2.16.0, 2023-12-01 <!-- Release notes generated using configuration in .github/release.yml at main -->
## What's Changed
### Enhancements 🎉
* Add sql.Valuer support for all types by @deankarn in https://github.com/ClickHouse/clickhouse-go/pull/1144
### Fixes 🐛
* Fix DateTime64 range to actual supported range per ClickHouse documentation by @phil-schreiber in https://github.com/ClickHouse/clickhouse-go/pull/1148
## New Contributors
* @phil-schreiber made their first contribution in https://github.com/ClickHouse/clickhouse-go/pull/1148
* @deankarn made their first contribution in https://github.com/ClickHouse/clickhouse-go/pull/1144
**Full Changelog**: https://github.com/ClickHouse/clickhouse-go/compare/v2.15.0...v2.16.0
# v2.14.3, 2023-10-12 <!-- Release notes generated using configuration in .github/release.yml at main -->
## What's Changed
### Fixes 🐛
* Fix insertion of empty map into JSON column by using _dummy subcolumn by @leodido in https://github.com/ClickHouse/clickhouse-go/pull/1116
### Other Changes 🛠
* chore: specify method field on compression in example by @rdaniels6813 in https://github.com/ClickHouse/clickhouse-go/pull/1111
* chore: remove extra error checks by @rutaka-n in https://github.com/ClickHouse/clickhouse-go/pull/1095
## New Contributors
* @leodido made their first contribution in https://github.com/ClickHouse/clickhouse-go/pull/1116
* @rdaniels6813 made their first contribution in https://github.com/ClickHouse/clickhouse-go/pull/1111
* @rutaka-n made their first contribution in https://github.com/ClickHouse/clickhouse-go/pull/1095
**Full Changelog**: https://github.com/ClickHouse/clickhouse-go/compare/v2.14.2...v2.14.3
# v2.14.2, 2023-10-04 <!-- Release notes generated using configuration in .github/release.yml at main -->
## What's Changed
### Fixes 🐛
* Fix: Block stream read process would be terminated by empty block with zero rows by @crisismaple in https://github.com/ClickHouse/clickhouse-go/pull/1104
* Free compressor's buffer when FreeBufOnConnRelease enabled by @cergxx in https://github.com/ClickHouse/clickhouse-go/pull/1100
* Fix truncate ` for HTTP adapter by @beck917 in https://github.com/ClickHouse/clickhouse-go/pull/1103
### Other Changes 🛠
* docs: update readme.md by @rfyiamcool in https://github.com/ClickHouse/clickhouse-go/pull/1068
* Remove dependency on github.com/satori/go.uuid by @srikanthccv in https://github.com/ClickHouse/clickhouse-go/pull/1085
## New Contributors
* @rfyiamcool made their first contribution in https://github.com/ClickHouse/clickhouse-go/pull/1068
* @beck917 made their first contribution in https://github.com/ClickHouse/clickhouse-go/pull/1103
* @srikanthccv made their first contribution in https://github.com/ClickHouse/clickhouse-go/pull/1085
**Full Changelog**: https://github.com/ClickHouse/clickhouse-go/compare/v2.14.1...v2.14.2
# v2.14.1, 2023-09-14 <!-- Release notes generated using configuration in .github/release.yml at main -->
## What's Changed
### Enhancements 🎉
* parseDSN: support connection pool settings (#1082) by @hanjm in https://github.com/ClickHouse/clickhouse-go/pull/1084
## New Contributors
* @hanjm made their first contribution in https://github.com/ClickHouse/clickhouse-go/pull/1084
**Full Changelog**: https://github.com/ClickHouse/clickhouse-go/compare/v2.14.0...v2.14.1
# v2.14.0, 2023-09-12 <!-- Release notes generated using configuration in .github/release.yml at main -->
## What's Changed
### Enhancements 🎉
* Add FreeBufOnConnRelease to clickhouse.Options by @cergxx in https://github.com/ClickHouse/clickhouse-go/pull/1091
* Improving object allocation for (positional) parameter binding by @mdonkers in https://github.com/ClickHouse/clickhouse-go/pull/1092
### Fixes 🐛
* Fix escaping double quote in SQL statement in prepare batch by @jkaflik in https://github.com/ClickHouse/clickhouse-go/pull/1083
### Other Changes 🛠
* Update Go & ClickHouse versions by @jkaflik in https://github.com/ClickHouse/clickhouse-go/pull/1079
* Return status code from any http error by @RoryCrispin in https://github.com/ClickHouse/clickhouse-go/pull/1090
* tests: fix dropped error by @alrs in https://github.com/ClickHouse/clickhouse-go/pull/1081
* chore: unnecessary use of fmt.Sprintf by @testwill in https://github.com/ClickHouse/clickhouse-go/pull/1080
* Run CI on self hosted runner by @jkaflik in https://github.com/ClickHouse/clickhouse-go/pull/1094
## New Contributors
* @cergxx made their first contribution in https://github.com/ClickHouse/clickhouse-go/pull/1091
* @alrs made their first contribution in https://github.com/ClickHouse/clickhouse-go/pull/1081
* @testwill made their first contribution in https://github.com/ClickHouse/clickhouse-go/pull/1080
**Full Changelog**: https://github.com/ClickHouse/clickhouse-go/compare/v2.13.4...v2.14
# v2.13.4, 2023-08-30 <!-- Release notes generated using configuration in .github/release.yml at main -->
## What's Changed
### Fixes 🐛
* fix(proto): add TCP protocol version in query packet by @jkaflik in https://github.com/ClickHouse/clickhouse-go/pull/1077
**Full Changelog**: https://github.com/ClickHouse/clickhouse-go/compare/v2.13.3...v2.13.4
# v2.13.3, 2023-08-23 <!-- Release notes generated using configuration in .github/release.yml at main -->
## What's Changed
### Fixes 🐛
* fix(column.json): fix bool type handling by @jkaflik in https://github.com/ClickHouse/clickhouse-go/pull/1073
**Full Changelog**: https://github.com/ClickHouse/clickhouse-go/compare/v2.13.2...v2.13.3
# v2.13.2, 2023-08-18 <!-- Release notes generated using configuration in .github/release.yml at main -->
## What's Changed
### Fixes 🐛
* fix: update ch-go to remove string length limit by @jkaflik in https://github.com/ClickHouse/clickhouse-go/pull/1071
### Other Changes 🛠
* Test against latest and head CH by @jkaflik in https://github.com/ClickHouse/clickhouse-go/pull/1060
**Full Changelog**: https://github.com/ClickHouse/clickhouse-go/compare/v2.13.1...v2.13.2
# v2.13.1, 2023-08-17 <!-- Release notes generated using configuration in .github/release.yml at main -->
## What's Changed
### Fixes 🐛
* fix: native format Date32 representation by @jkaflik in https://github.com/ClickHouse/clickhouse-go/pull/1069
**Full Changelog**: https://github.com/ClickHouse/clickhouse-go/compare/v2.13.0...v2.13.1
# v2.13.0, 2023-08-10 <!-- Release notes generated using configuration in .github/release.yml at main -->
## What's Changed
### Enhancements 🎉
* Support scan from uint8 to bool by @ValManP in https://github.com/ClickHouse/clickhouse-go/pull/1051
* Binding arguments for AsyncInsert interface by @mdonkers in https://github.com/ClickHouse/clickhouse-go/pull/1052
* Batch rows count API by @EpicStep in https://github.com/ClickHouse/clickhouse-go/pull/1063
* Implement release connection in batch by @EpicStep in https://github.com/ClickHouse/clickhouse-go/pull/1062
### Other Changes 🛠
* Restore test against CH 23.7 by @jkaflik in https://github.com/ClickHouse/clickhouse-go/pull/1059
## New Contributors
* @ValManP made their first contribution in https://github.com/ClickHouse/clickhouse-go/pull/1051
**Full Changelog**: https://github.com/ClickHouse/clickhouse-go/compare/v2.12.1...v2.13.0
# v2.12.1, 2023-08-02 <!-- Release notes generated using configuration in .github/release.yml at main -->
## What's Changed
### Fixes 🐛
* Fix InsertAsync typo in docs by @et in https://github.com/ClickHouse/clickhouse-go/pull/1044
* Fix panic and releasing in batch column by @EpicStep in https://github.com/ClickHouse/clickhouse-go/pull/1055
* Docs/changelog fixes by @jmaicher in https://github.com/ClickHouse/clickhouse-go/pull/1046
* Clarify error message re custom serializaion support by @RoryCrispin in https://github.com/ClickHouse/clickhouse-go/pull/1056
* Fix send query on batch retry by @EpicStep in https://github.com/ClickHouse/clickhouse-go/pull/1045
### Other Changes 🛠
* Update ClickHouse versions by @jkaflik in https://github.com/ClickHouse/clickhouse-go/pull/1054
## New Contributors
* @et made their first contribution in https://github.com/ClickHouse/clickhouse-go/pull/1044
* @EpicStep made their first contribution in https://github.com/ClickHouse/clickhouse-go/pull/1055
* @jmaicher made their first contribution in https://github.com/ClickHouse/clickhouse-go/pull/1046
* @RoryCrispin made their first contribution in https://github.com/ClickHouse/clickhouse-go/pull/1056
**Full Changelog**: https://github.com/ClickHouse/clickhouse-go/compare/v2.12.0...v2.12.1
# v2.12.0, 2023-07-27 <!-- Release notes generated using configuration in .github/release.yml at main -->
## What's Changed
### Enhancements 🎉
* Implement elapsed time in query progress by @jkaflik in https://github.com/ClickHouse/clickhouse-go/pull/1039
### Fixes 🐛
* Release connection slot on connection acquire timeout by @sentanos in https://github.com/ClickHouse/clickhouse-go/pull/1042
## New Contributors
* @sentanos made their first contribution in https://github.com/ClickHouse/clickhouse-go/pull/1042
**Full Changelog**: https://github.com/ClickHouse/clickhouse-go/compare/v2.11.0...v2.12.0
# v2.11.0, 2023-07-20 <!-- Release notes generated using configuration in .github/release.yml at main -->
## What's Changed
### Enhancements 🎉
* Retry for batch API by @djosephsen in https://github.com/ClickHouse/clickhouse-go/pull/941
### Fixes 🐛
* Fix startAutoCloseIdleConnections cause goroutine leak by @YenchangChan in https://github.com/ClickHouse/clickhouse-go/pull/1011
* Fix netip.Addr pointer panic by @anjmao in https://github.com/ClickHouse/clickhouse-go/pull/1029
### Other Changes 🛠
* Git actions terraform by @gingerwizard in https://github.com/ClickHouse/clickhouse-go/pull/1023
## New Contributors
* @YenchangChan made their first contribution in https://github.com/ClickHouse/clickhouse-go/pull/1011
* @djosephsen made their first contribution in https://github.com/ClickHouse/clickhouse-go/pull/941
* @anjmao made their first contribution in https://github.com/ClickHouse/clickhouse-go/pull/1029
**Full Changelog**: https://github.com/ClickHouse/clickhouse-go/compare/v2.10.1...v2.11.0
# v2.10.1, 2023-06-06 <!-- Release notes generated using configuration in .github/release.yml at main -->
## What's Changed
### Other Changes 🛠
* Update outdated README.md by @kokizzu in https://github.com/ClickHouse/clickhouse-go/pull/1006
* Remove incorrect usage of KeepAlive in DialContext by @jkaflik in https://github.com/ClickHouse/clickhouse-go/pull/1009
## New Contributors
* @kokizzu made their first contribution in https://github.com/ClickHouse/clickhouse-go/pull/1006
**Full Changelog**: https://github.com/ClickHouse/clickhouse-go/compare/v2.10.0...v2.10.1
# v2.10.0, 2023-05-17 <!-- Release notes generated using configuration in .github/release.yml at main -->
## What's Changed
### Enhancements 🎉
* Support [16]byte/[]byte typed scan/append for IPv6 column by @crisismaple in https://github.com/ClickHouse/clickhouse-go/pull/996
* Add custom dialer option to http protocol by @stephaniehingtgen in https://github.com/ClickHouse/clickhouse-go/pull/998
### Fixes 🐛
* Tuple scan respects both value and pointer variable by @crisismaple in https://github.com/ClickHouse/clickhouse-go/pull/971
* Auto close idle connections in native protocol in respect of ConnMaxLifetime option by @jkaflik in https://github.com/ClickHouse/clickhouse-go/pull/999
## New Contributors
* @stephaniehingtgen made their first contribution in https://github.com/ClickHouse/clickhouse-go/pull/998
**Full Changelog**: https://github.com/ClickHouse/clickhouse-go/compare/v2.9.3...v2.10.0
# v2.9.2, 2023-05-08 <!-- Release notes generated using configuration in .github/release.yml at main -->
## What's Changed
### Fixes 🐛
* Pass http.ProxyFromEnvironment configuration to http.Transport by @slvrtrn in https://github.com/ClickHouse/clickhouse-go/pull/987
### Other Changes 🛠
* Use `any` instead of `interface{}` by @candiduslynx in https://github.com/ClickHouse/clickhouse-go/pull/984
## New Contributors
* @candiduslynx made their first contribution in https://github.com/ClickHouse/clickhouse-go/pull/984
* @slvrtrn made their first contribution in https://github.com/ClickHouse/clickhouse-go/pull/987
**Full Changelog**: https://github.com/ClickHouse/clickhouse-go/compare/v2.9.1...v2.9.2
# v2.9.1, 2023-04-24 <!-- Release notes generated using configuration in .github/release.yml at main -->
## What's Changed
### Enhancements 🎉
* Do not return hard error on unparsable version in HTTP proto by @hexchain in https://github.com/ClickHouse/clickhouse-go/pull/975
### Fixes 🐛
* Return ErrBadConn in stdDriver Prepare if connection is broken by @czubocha in https://github.com/ClickHouse/clickhouse-go/pull/977
## New Contributors
* @czubocha made their first contribution in https://github.com/ClickHouse/clickhouse-go/pull/977
* @hexchain made their first contribution in https://github.com/ClickHouse/clickhouse-go/pull/975
**Full Changelog**: https://github.com/ClickHouse/clickhouse-go/compare/v2.9.0...v2.9.1
# v2.9.0, 2023-04-13 <!-- Release notes generated using configuration in .github/release.yml at main -->
## What's Changed
### Enhancements 🎉
* External tables support for HTTP protocol by @crisismaple in https://github.com/ClickHouse/clickhouse-go/pull/942
* Support driver.Valuer in String and FixedString columns by @jkaflik in https://github.com/ClickHouse/clickhouse-go/pull/946
* Support boolean and pointer type parameter binding by @crisismaple in https://github.com/ClickHouse/clickhouse-go/pull/963
* Support insert/scan IPv4 using UInt32/*UInt32 types by @crisismaple in https://github.com/ClickHouse/clickhouse-go/pull/966
### Fixes 🐛
* Reset the pointer to the nullable field by @xiaochaoren1 in https://github.com/ClickHouse/clickhouse-go/pull/964
* Enable to use ternary operator with named arguments by @crisismaple in https://github.com/ClickHouse/clickhouse-go/pull/965
### Other Changes 🛠
* chore: explain async insert in docs by @jkaflik in https://github.com/ClickHouse/clickhouse-go/pull/969
## New Contributors
* @xiaochaoren1 made their first contribution in https://github.com/ClickHouse/clickhouse-go/pull/964
**Full Changelog**: https://github.com/ClickHouse/clickhouse-go/compare/v2.8.3...v2.9.0
## 2.8.3, 2023-04-03
### Bug fixes
- Revert: Expire idle connections no longer acquired during lifetime [#958](https://github.com/ClickHouse/clickhouse-go/pull/958) by @jkaflik
## 2.8.2, 2023-03-31
### Bug fixes
- Expire idle connections no longer acquired during lifetime [#945](https://github.com/ClickHouse/clickhouse-go/pull/945) by @jkaflik
## 2.8.1, 2023-03-29
### Bug fixes
- Fix idle connection check for TLS connections [#951](https://github.com/ClickHouse/clickhouse-go/pull/951) by @jkaflik & @alekar
## 2.8.0, 2023-03-27
### New features
- Support customized "url path" in http connection [#938](https://github.com/ClickHouse/clickhouse-go/pull/938) by @crisismaple
- Allow Auth.Database option to be empty [#926](https://github.com/ClickHouse/clickhouse-go/pull/938) by @v4run
### Chores
- Bump github.com/stretchr/testify from 1.8.1 to 1.8.2 [#933](https://github.com/ClickHouse/clickhouse-go/pull/933)
- fix: small typo in the text of an error [#936](https://github.com/ClickHouse/clickhouse-go/pull/936) by @lspgn
- Improved bug template [#916](https://github.com/ClickHouse/clickhouse-go/pull/916) by @mshustov
## 2.7.0, 2023-03-08
### New features
- Date type with user location [#923](https://github.com/ClickHouse/clickhouse-go/pull/923) by @jkaflik
- Add AppendRow function to BatchColumn [#927](https://github.com/ClickHouse/clickhouse-go/pull/927) by @pikot
### Bug fixes
- fix: fix connect.compression's format verb [#924](https://github.com/ClickHouse/clickhouse-go/pull/924) by @mind1949
- Add extra padding for strings shorter than FixedColumn length [#910](https://github.com/ClickHouse/clickhouse-go/pull/910) by @jkaflik
### Chore
- Bump github.com/andybalholm/brotli from 1.0.4 to 1.0.5 [#911](https://github.com/ClickHouse/clickhouse-go/pull/911)
- Bump github.com/paulmach/orb from 0.8.0 to 0.9.0 [#912](https://github.com/ClickHouse/clickhouse-go/pull/912)
- Bump golang.org/x/net from 0.0.0-20220722155237-a158d28d115b to 0.7.0 [#928](https://github.com/ClickHouse/clickhouse-go/pull/928)
## 2.6.5, 2023-02-28
### Bug fixes
- Fix array parameter formatting in binding mechanism [#921](https://github.com/ClickHouse/clickhouse-go/pull/921) by @genzgd
## 2.6.4, 2023-02-23
### Bug fixes
- Fixed concurrency issue in stdConnOpener [#918](https://github.com/ClickHouse/clickhouse-go/pull/918) by @jkaflik
## 2.6.3, 2023-02-22
### Bug fixes
- Fixed `lib/binary/string_safe.go` for non 64bit arch [#914](https://github.com/ClickHouse/clickhouse-go/pull/914) by @atoulme
## 2.6.2, 2023-02-20
### Bug fixes
- Fix decimal encoding with non-standard exponential representation [#909](https://github.com/ClickHouse/clickhouse-go/pull/909) by @vogrelord
- Add extra padding for strings shorter than FixedColumn length [#910](https://github.com/ClickHouse/clickhouse-go/pull/910) by @jkaflik
### Chore
- Remove Yandex ClickHouse image from Makefile [#895](https://github.com/ClickHouse/clickhouse-go/pull/895) by @alexey-milovidov
- Remove duplicate of error handling [#898](https://github.com/ClickHouse/clickhouse-go/pull/898) by @Astemirdum
- Bump github.com/ClickHouse/ch-go from 0.51.2 to 0.52.1 [#901](https://github.com/ClickHouse/clickhouse-go/pull/901)
## 2.6.1, 2023-02-13
### Bug fixes
- Do not reuse expired connections (`ConnMaxLifetime`) [#892](https://github.com/ClickHouse/clickhouse-go/pull/892) by @iamluc
- Extend default dial timeout value to 30s [#893](https://github.com/ClickHouse/clickhouse-go/pull/893) by @jkaflik
- Compression name fixed in sendQuery log [#884](https://github.com/ClickHouse/clickhouse-go/pull/884) by @fredngr
## 2.6.0, 2023-01-27
### New features
- Client info specification implementation [#876](https://github.com/ClickHouse/clickhouse-go/pull/876) by @jkaflik
### Bug fixes
- Better handling for broken connection errors in the std interface [#879](https://github.com/ClickHouse/clickhouse-go/pull/879) by @n-oden
### Chore
- Document way to provide table or database identifier with query parameters [#875](https://github.com/ClickHouse/clickhouse-go/pull/875) by @jkaflik
- Bump github.com/ClickHouse/ch-go from 0.51.0 to 0.51.2 [#881](https://github.com/ClickHouse/clickhouse-go/pull/881)
## 2.5.1, 2023-01-10
### Bug fixes
- Flag connection as closed on broken pipe [#871](https://github.com/ClickHouse/clickhouse-go/pull/871) by @n-oden
## 2.5.0, 2023-01-10
### New features
- Buffered compression column by column for a native protocol. Introduces the `MaxCompressionBuffer` option - max size (bytes) of compression buffer during column-by-column compression (default 10MiB) [#808](https://github.com/ClickHouse/clickhouse-go/pull/808) by @gingerwizard and @jkaflik
- Support custom types that implement `sql.Scanner` interface (e.g. `type customString string`) [#850](https://github.com/ClickHouse/clickhouse-go/pull/850) by @DarkDrim
- Append query options to the context instead of overwriting [#860](https://github.com/ClickHouse/clickhouse-go/pull/860) by @aaron276h
- Query parameters support [#854](https://github.com/ClickHouse/clickhouse-go/pull/854) by @jkaflik
- Expose `DialStrategy` function to the user for custom connection routing. [#855](https://github.com/ClickHouse/clickhouse-go/pull/855) by @jkaflik
### Bug fixes
- Close connection on `Cancel`. This is to make sure context timed out/canceled connection is not reused further [#764](https://github.com/ClickHouse/clickhouse-go/pull/764) by @gingerwizard
- Fully parse `secure` and `skip_verify` in DSN query parameters. [#862](https://github.com/ClickHouse/clickhouse-go/pull/862) by @n-oden
### Chore
- Added tests covering read-only user queries [#837](https://github.com/ClickHouse/clickhouse-go/pull/837) by @jkaflik
- Agreed on a batch append fail semantics [#853](https://github.com/ClickHouse/clickhouse-go/pull/853) by @jkaflik
## 2.4.3, 2022-11-30
### Bug Fixes
* Fix in batch concurrency - batch could panic if used in separate go routines. <br/>
The issue was originally detected due to the use of a batch in a go routine and Abort being called after the connection was released on the batch. This would invalidate the connection which had been subsequently reassigned. <br/>
This issue could occur as soon as the conn is released (this can happen in a number of places e.g. after Send or an Append error), and it potentially returns to the pool for use in another go routine. Subsequent releases could then occur e.g., the user calls Abort mainly but also Send would do it. The result is the connection being closed in the release function while another batch or query potentially used it. <br/>
This release includes a guard to prevent release from being called more than once on a batch. It assumes that batches are not thread-safe - they aren't (only connections are).
## 2.4.2, 2022-11-24
### Bug Fixes
- Don't panic on `Send()` on batch after invalid `Append`. [#830](https://github.com/ClickHouse/clickhouse-go/pull/830)
- Fix JSON issue with `nil` if column order is inconsisent. [#824](https://github.com/ClickHouse/clickhouse-go/pull/824)
## 2.4.1, 2022-11-23
### Bug Fixes
- Patch release to fix "Regression - escape character was not considered when comparing column names". [#828](https://github.com/ClickHouse/clickhouse-go/issues/828)
## 2.4.0, 2022-11-22
### New Features
- Support for Nullables in Tuples. [#821](https://github.com/ClickHouse/clickhouse-go/pull/821) [#817](https://github.com/ClickHouse/clickhouse-go/pull/817)
- Use headers for auth and not url if SSL. [#811](https://github.com/ClickHouse/clickhouse-go/pull/811)
- Support additional headers. [#811](https://github.com/ClickHouse/clickhouse-go/pull/811)
- Support int64 for DateTime. [#807](https://github.com/ClickHouse/clickhouse-go/pull/807)
- Support inserting Enums as int8/int16/int. [#802](https://github.com/ClickHouse/clickhouse-go/pull/802)
- Print error if unsupported server. [#792](https://github.com/ClickHouse/clickhouse-go/pull/792)
- Allow block buffer size to tuned for performance - see `BlockBufferSize`. [#776](https://github.com/ClickHouse/clickhouse-go/pull/776)
- Support custom datetime in Scan. [#767](https://github.com/ClickHouse/clickhouse-go/pull/767)
- Support insertion of an orderedmap. [#763](https://github.com/ClickHouse/clickhouse-go/pull/763)
### Bug Fixes
- Decompress errors over HTTP. [#792](https://github.com/ClickHouse/clickhouse-go/pull/792)
- Use `timezone` vs `timeZone` so we work on older versions. [#781](https://github.com/ClickHouse/clickhouse-go/pull/781)
- Ensure only columns specified in INSERT are required in batch. [#790](https://github.com/ClickHouse/clickhouse-go/pull/790)
- Respect order of columns in insert for batch. [#790](https://github.com/ClickHouse/clickhouse-go/pull/790)
- Handle double pointers for Nullable columns when batch inserting. [#774](https://github.com/ClickHouse/clickhouse-go/pull/774)
- Use nil for `LowCardinality(Nullable(X))`. [#768](https://github.com/ClickHouse/clickhouse-go/pull/768)
### Breaking Changes
- Align timezone handling with spec. [#776](https://github.com/ClickHouse/clickhouse-go/pull/766), specifically:
- If parsing strings for datetime, datetime64 or dates we assume the locale is Local (i.e. the client) if not specified in the string.
- The server (or column tz) is used for datetime and datetime64 rendering. For date/date32, these have no tz info in the server. For now, they will be rendered as UTC - consistent with the clickhouse-client
- Addresses bind when no location is set | {
"source": "yandex/perforator",
"title": "vendor/github.com/ClickHouse/clickhouse-go/v2/CHANGELOG.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/ClickHouse/clickhouse-go/v2/CHANGELOG.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 26358
} |
# Contributing notes
## Local setup
The easiest way to run tests is to use Docker Compose:
```
docker-compose up
make
``` | {
"source": "yandex/perforator",
"title": "vendor/github.com/ClickHouse/clickhouse-go/v2/CONTRIBUTING.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/ClickHouse/clickhouse-go/v2/CONTRIBUTING.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 124
} |
# ClickHouse [](https://github.com/ClickHouse/clickhouse-go/actions/workflows/run-tests.yml) [](https://pkg.go.dev/github.com/ClickHouse/clickhouse-go/v2)
Golang SQL database client for [ClickHouse](https://clickhouse.com/).
## Versions
There are two version of this client, v1 and v2, available as separate branches.
**v1 is now in a state of a maintenance - we will only accept PRs for bug and security fixes.**
Users should use v2 which is production ready and [significantly faster than v1](#benchmark).
v2 has breaking changes for users migrating from v1. These were not properly tracked prior to this client being officially supported. We endeavour to track known differences [here](https://github.com/ClickHouse/clickhouse-go/blob/main/v1_v2_CHANGES.md) and resolve where possible.
## Supported ClickHouse Versions
The client is tested against the currently [supported versions](https://github.com/ClickHouse/ClickHouse/blob/master/SECURITY.md) of ClickHouse
## Supported Golang Versions
| Client Version | Golang Versions |
|----------------|-----------------|
| => 2.0 <= 2.2 | 1.17, 1.18 |
| >= 2.3 | 1.18.4+, 1.19 |
| >= 2.14 | 1.20, 1.21 |
## Key features
* Uses ClickHouse native format for optimal performance. Utilises low level [ch-go](https://github.com/ClickHouse/ch-go) client for encoding/decoding and compression (versions >= 2.3.0).
* Supports native ClickHouse TCP client-server protocol
* Compatibility with [`database/sql`](#std-databasesql-interface) ([slower](#benchmark) than [native interface](#native-interface)!)
* [`database/sql`](#std-databasesql-interface) supports http protocol for transport. (Experimental)
* Marshal rows into structs ([ScanStruct](examples/clickhouse_api/scan_struct.go), [Select](examples/clickhouse_api/select_struct.go))
* Unmarshal struct to row ([AppendStruct](benchmark/v2/write-native-struct/main.go))
* Connection pool
* Failover and load balancing
* [Bulk write support](examples/clickhouse_api/batch.go) (for `database/sql` [use](examples/std/batch.go) `begin->prepare->(in loop exec)->commit`)
* [PrepareBatch options](#preparebatch-options)
* [AsyncInsert](benchmark/v2/write-async/main.go) (more details in [Async insert](#async-insert) section)
* Named and numeric placeholders support
* LZ4/ZSTD compression support
* External data
* [Query parameters](examples/std/query_parameters.go)
Support for the ClickHouse protocol advanced features using `Context`:
* Query ID
* Quota Key
* Settings
* [Query parameters](examples/clickhouse_api/query_parameters.go)
* OpenTelemetry
* Execution events:
* Logs
* Progress
* Profile info
* Profile events
## Documentation
[https://clickhouse.com/docs/en/integrations/go](https://clickhouse.com/docs/en/integrations/go)
# `clickhouse` interface (formally `native` interface)
```go
conn, err := clickhouse.Open(&clickhouse.Options{
Addr: []string{"127.0.0.1:9000"},
Auth: clickhouse.Auth{
Database: "default",
Username: "default",
Password: "",
},
DialContext: func(ctx context.Context, addr string) (net.Conn, error) {
dialCount++
var d net.Dialer
return d.DialContext(ctx, "tcp", addr)
},
Debug: true,
Debugf: func(format string, v ...any) {
fmt.Printf(format+"\n", v...)
},
Settings: clickhouse.Settings{
"max_execution_time": 60,
},
Compression: &clickhouse.Compression{
Method: clickhouse.CompressionLZ4,
},
DialTimeout: time.Second * 30,
MaxOpenConns: 5,
MaxIdleConns: 5,
ConnMaxLifetime: time.Duration(10) * time.Minute,
ConnOpenStrategy: clickhouse.ConnOpenInOrder,
BlockBufferSize: 10,
MaxCompressionBuffer: 10240,
ClientInfo: clickhouse.ClientInfo{ // optional, please see Client info section in the README.md
Products: []struct {
Name string
Version string
}{
{Name: "my-app", Version: "0.1"},
},
},
})
if err != nil {
return err
}
return conn.Ping(context.Background())
```
# `database/sql` interface
## OpenDB
```go
conn := clickhouse.OpenDB(&clickhouse.Options{
Addr: []string{"127.0.0.1:9999"},
Auth: clickhouse.Auth{
Database: "default",
Username: "default",
Password: "",
},
TLS: &tls.Config{
InsecureSkipVerify: true,
},
Settings: clickhouse.Settings{
"max_execution_time": 60,
},
DialTimeout: time.Second * 30,
Compression: &clickhouse.Compression{
Method: clickhouse.CompressionLZ4,
},
Debug: true,
BlockBufferSize: 10,
MaxCompressionBuffer: 10240,
ClientInfo: clickhouse.ClientInfo{ // optional, please see Client info section in the README.md
Products: []struct {
Name string
Version string
}{
{Name: "my-app", Version: "0.1"},
},
},
})
conn.SetMaxIdleConns(5)
conn.SetMaxOpenConns(10)
conn.SetConnMaxLifetime(time.Hour)
```
## DSN
* hosts - comma-separated list of single address hosts for load-balancing and failover
* username/password - auth credentials
* database - select the current default database
* dial_timeout - a duration string is a possibly signed sequence of decimal numbers, each with optional fraction and a unit suffix such as "300ms", "1s". Valid time units are "ms", "s", "m". (default 30s)
* connection_open_strategy - round_robin/in_order (default in_order).
* round_robin - choose a round-robin server from the set
* in_order - first live server is chosen in specified order
* debug - enable debug output (boolean value)
* compress - compress - specify the compression algorithm - “none” (default), `zstd`, `lz4`, `gzip`, `deflate`, `br`. If set to `true`, `lz4` will be used.
* compress_level - Level of compression (default is 0). This is algorithm specific:
- `gzip` - `-2` (Best Speed) to `9` (Best Compression)
- `deflate` - `-2` (Best Speed) to `9` (Best Compression)
- `br` - `0` (Best Speed) to `11` (Best Compression)
- `zstd`, `lz4` - ignored
* block_buffer_size - size of block buffer (default 2)
* read_timeout - a duration string is a possibly signed sequence of decimal numbers, each with optional fraction and a unit suffix such as "300ms", "1s". Valid time units are "ms", "s", "m" (default 5m).
* max_compression_buffer - max size (bytes) of compression buffer during column by column compression (default 10MiB)
* client_info_product - optional list (comma separated) of product name and version pair separated with `/`. This value will be pass a part of client info. e.g. `client_info_product=my_app/1.0,my_module/0.1` More details in [Client info](#client-info) section.
SSL/TLS parameters:
* secure - establish secure connection (default is false)
* skip_verify - skip certificate verification (default is false)
Example:
```sh
clickhouse://username:password@host1:9000,host2:9000/database?dial_timeout=200ms&max_execution_time=60
```
### HTTP Support (Experimental)
The native format can be used over the HTTP protocol. This is useful in scenarios where users need to proxy traffic e.g. using [ChProxy](https://www.chproxy.org/) or via load balancers.
This can be achieved by modifying the DSN to specify the HTTP protocol.
```sh
http://host1:8123,host2:8123/database?dial_timeout=200ms&max_execution_time=60
```
Alternatively, use `OpenDB` and specify the interface type.
```go
conn := clickhouse.OpenDB(&clickhouse.Options{
Addr: []string{"127.0.0.1:8123"},
Auth: clickhouse.Auth{
Database: "default",
Username: "default",
Password: "",
},
Settings: clickhouse.Settings{
"max_execution_time": 60,
},
DialTimeout: 30 * time.Second,
Compression: &clickhouse.Compression{
Method: clickhouse.CompressionLZ4,
},
Protocol: clickhouse.HTTP,
})
```
**Note**: using HTTP protocol is possible only with `database/sql` interface.
## Compression
ZSTD/LZ4 compression is supported over native and http protocols. This is performed column by column at a block level and is only used for inserts. Compression buffer size is set as `MaxCompressionBuffer` option.
If using `Open` via the std interface and specifying a DSN, compression can be enabled via the `compress` flag. Currently, this is a boolean flag which enables `LZ4` compression.
Other compression methods will be added in future PRs.
## TLS/SSL
At a low level all client connect methods (DSN/OpenDB/Open) will use the [Go tls package](https://pkg.go.dev/crypto/tls) to establish a secure connection. The client knows to use TLS if the Options struct contains a non-nil tls.Config pointer.
Setting secure in the DSN creates a minimal tls.Config struct with only the InsecureSkipVerify field set (either true or false). It is equivalent to this code:
```go
conn := clickhouse.OpenDB(&clickhouse.Options{
...
TLS: &tls.Config{
InsecureSkipVerify: false
}
...
})
```
This minimal tls.Config is normally all that is necessary to connect to the secure native port (normally 9440) on a ClickHouse server. If the ClickHouse server does not have a valid certificate (expired, wrong host name, not signed by a publicly recognized root Certificate Authority), InsecureSkipVerify can be to `true`, but that is strongly discouraged.
If additional TLS parameters are necessary the application code should set the desired fields in the tls.Config struct. That can include specific cipher suites, forcing a particular TLS version (like 1.2 or 1.3), adding an internal CA certificate chain, adding a client certificate (and private key) if required by the ClickHouse server, and most of the other options that come with a more specialized security setup.
### HTTPS (Experimental)
To connect using HTTPS either:
- Use `https` in your dsn string e.g.
```sh
https://host1:8443,host2:8443/database?dial_timeout=200ms&max_execution_time=60
```
- Specify the interface type as `HttpsInterface` e.g.
```go
conn := clickhouse.OpenDB(&clickhouse.Options{
Addr: []string{"127.0.0.1:8443"},
Auth: clickhouse.Auth{
Database: "default",
Username: "default",
Password: "",
},
Protocol: clickhouse.HTTP,
})
```
## Client info
Clickhouse-go implements [client info](https://docs.google.com/document/d/1924Dvy79KXIhfqKpi1EBVY3133pIdoMwgCQtZ-uhEKs/edit#heading=h.ah33hoz5xei2) as a part of language client specification. `client_name` for native protocol and HTTP `User-Agent` header values are provided with the exact client info string.
Users can extend client options with additional product information included in client info. This might be useful for analysis [on a server side](https://clickhouse.com/docs/en/operations/system-tables/query_log/).
Order is the highest abstraction to the lowest level implementation left to right.
Usage examples for [native API](examples/clickhouse_api/client_info.go) and [database/sql](examples/std/client_info.go) are provided.
## Async insert
[Asynchronous insert](https://clickhouse.com/docs/en/optimize/asynchronous-inserts#enabling-asynchronous-inserts) is supported via dedicated `AsyncInsert` method. This allows to insert data with a non-blocking call.
Effectively, it controls a `async_insert` setting for the query.
### Using with batch API
Using native protocol, asynchronous insert does not support batching. It means, only inline query data is supported. Please see an example [here](examples/std/async.go).
HTTP protocol supports batching. It can be enabled by setting `async_insert` when using standard `Prepare` method.
For more details please see [asynchronous inserts](https://clickhouse.com/docs/en/optimize/asynchronous-inserts#enabling-asynchronous-inserts) documentation.
## PrepareBatch options
Available options:
- [WithReleaseConnection](examples/clickhouse_api/batch_release_connection.go) - after PrepareBatch connection will be returned to the pool. It can help you make a long-lived batch.
## Benchmark
| [V1 (READ)](benchmark/v1/read/main.go) | [V2 (READ) std](benchmark/v2/read/main.go) | [V2 (READ) clickhouse API](benchmark/v2/read-native/main.go) |
| -------------------------------------- | ------------------------------------------ |--------------------------------------------------------------|
| 1.218s | 924.390ms | 675.721ms |
| [V1 (WRITE)](benchmark/v1/write/main.go) | [V2 (WRITE) std](benchmark/v2/write/main.go) | [V2 (WRITE) clickhouse API](benchmark/v2/write-native/main.go) | [V2 (WRITE) by column](benchmark/v2/write-native-columnar/main.go) |
| ---------------------------------------- | -------------------------------------------- | ------------------------------------------------------ | ------------------------------------------------------------------ |
| 1.899s | 1.177s | 699.203ms | 661.973ms |
## Install
```sh
go get -u github.com/ClickHouse/clickhouse-go/v2
```
## Examples
### native interface
* [batch](examples/clickhouse_api/batch.go)
* [batch with release connection](examples/clickhouse_api/batch_release_connection.go)
* [async insert](examples/clickhouse_api/async.go)
* [batch struct](examples/clickhouse_api/append_struct.go)
* [columnar](examples/clickhouse_api/columnar_insert.go)
* [scan struct](examples/clickhouse_api/scan_struct.go)
* [query parameters](examples/clickhouse_api/query_parameters.go) (deprecated in favour of native query parameters)
* [bind params](examples/clickhouse_api/bind.go) (deprecated in favour of native query parameters)
* [client info](examples/clickhouse_api/client_info.go)
### std `database/sql` interface
* [batch](examples/std/batch.go)
* [async insert](examples/std/async.go)
* [open db](examples/std/connect.go)
* [query parameters](examples/std/query_parameters.go)
* [bind params](examples/std/bind.go) (deprecated in favour of native query parameters)
* [client info](examples/std/client_info.go)
## ClickHouse alternatives - ch-go
Versions of this client >=2.3.x utilise [ch-go](https://github.com/ClickHouse/ch-go) for their low level encoding/decoding. This low lever client provides a high performance columnar interface and should be used in performance critical use cases. This client provides more familar row orientated and `database/sql` semantics at the cost of some performance.
Both clients are supported by ClickHouse.
## Third-party alternatives
* Database client/clients:
* [mailru/go-clickhouse](https://github.com/mailru/go-clickhouse) (uses the HTTP protocol)
* [uptrace/go-clickhouse](https://github.com/uptrace/go-clickhouse) (uses the native TCP protocol with `database/sql`-like API)
* Drivers with columnar interface:
* [vahid-sohrabloo/chconn](https://github.com/vahid-sohrabloo/chconn)
* Insert collectors:
* [KittenHouse](https://github.com/YuriyNasretdinov/kittenhouse)
* [nikepan/clickhouse-bulk](https://github.com/nikepan/clickhouse-bulk) | {
"source": "yandex/perforator",
"title": "vendor/github.com/ClickHouse/clickhouse-go/v2/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/ClickHouse/clickhouse-go/v2/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 15077
} |
# Breaking Changes v1 to v2
Known breaking changes for v1 to v2 are collated below. These are subject to change, if a fix is possible, and reflect the latest release only.
- v1 allowed precision loss when inserting types. For example, a sql.NullInt32 could be inserted to a UInt8 column and float64 and Decimals were interchangeable. Whilst v2 aims to be flexible, it will not transparently loose precision. Users must accept and explicitly perform this work outside the client.
- strings cannot be inserted in Date or DateTime columns in v2. [#574](https://github.com/ClickHouse/clickhouse-go/issues/574)
- Arrays must be strongly typed in v2 e.g. a `[]any` containing strings cannot be inserted into a string column. This conversion must be down outside the client, since it incurs a cost - the array must be iterated and converted. The client will not conceal this overhead in v2.
- v1 used a connection strategy of random. v2 uses in_order by default. | {
"source": "yandex/perforator",
"title": "vendor/github.com/ClickHouse/clickhouse-go/v2/v1_v2_CHANGES.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/ClickHouse/clickhouse-go/v2/v1_v2_CHANGES.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 957
} |
[](https://goreportcard.com/report/github.com/antlr4-go/antlr)
[](https://pkg.go.dev/github.com/antlr4-go/antlr)
[](https://github.com/antlr4-go/antlr/releases/latest)
[](https://github.com/antlr4-go/antlr/releases/latest)
[](https://github.com/antlr4-go/antlr/commit-activity)
[](https://opensource.org/licenses/BSD-3-Clause)
[](https://GitHub.com/Naereen/StrapDown.js/stargazers/)
# ANTLR4 Go Runtime Module Repo
IMPORTANT: Please submit PRs via a clone of the https://github.com/antlr/antlr4 repo, and not here.
- Do not submit PRs or any change requests to this repo
- This repo is read only and is updated by the ANTLR team to create a new release of the Go Runtime for ANTLR
- This repo contains the Go runtime that your generated projects should import
## Introduction
This repo contains the official modules for the Go Runtime for ANTLR. It is a copy of the runtime maintained
at: https://github.com/antlr/antlr4/tree/master/runtime/Go/antlr and is automatically updated by the ANTLR team to create
the official Go runtime release only. No development work is carried out in this repo and PRs are not accepted here.
The dev branch of this repo is kept in sync with the dev branch of the main ANTLR repo and is updated periodically.
### Why?
The `go get` command is unable to retrieve the Go runtime when it is embedded so
deeply in the main repo. A `go get` against the `antlr/antlr4` repo, while retrieving the correct source code for the runtime,
does not correctly resolve tags and will create a reference in your `go.mod` file that is unclear, will not upgrade smoothly and
causes confusion.
For instance, the current Go runtime release, which is tagged with v4.13.0 in `antlr/antlr4` is retrieved by go get as:
```sh
require (
github.com/antlr/antlr4/runtime/Go/antlr/v4 v4.0.0-20230219212500-1f9a474cc2dc
)
```
Where you would expect to see:
```sh
require (
github.com/antlr/antlr4/runtime/Go/antlr/v4 v4.13.0
)
```
The decision was taken to create a separate org in a separate repo to hold the official Go runtime for ANTLR and
from whence users can expect `go get` to behave as expected.
# Documentation
Please read the official documentation at: https://github.com/antlr/antlr4/blob/master/doc/index.md for tips on
migrating existing projects to use the new module location and for information on how to use the Go runtime in
general. | {
"source": "yandex/perforator",
"title": "vendor/github.com/antlr4-go/antlr/v4/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/antlr4-go/antlr/v4/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 3008
} |
## AWS SDK for Go awstesting packages ##
`awstesting` is a collection of packages used internally by the SDK, and is subject to have breaking changes. This package is not `internal` so that if you really need to use its functionality, and understand breaking changes will be made, you are able to.
These packages will be refactored in the future so that the API generator and model parsers are exposed cleanly on their own. | {
"source": "yandex/perforator",
"title": "vendor/github.com/aws/aws-sdk-go/awstesting/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/aws/aws-sdk-go/awstesting/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 424
} |
# Exponential Backoff [![GoDoc][godoc image]][godoc] [![Coverage Status][coveralls image]][coveralls]
This is a Go port of the exponential backoff algorithm from [Google's HTTP Client Library for Java][google-http-java-client].
[Exponential backoff][exponential backoff wiki]
is an algorithm that uses feedback to multiplicatively decrease the rate of some process,
in order to gradually find an acceptable rate.
The retries exponentially increase and stop increasing when a certain threshold is met.
## Usage
Import path is `github.com/cenkalti/backoff/v4`. Please note the version part at the end.
Use https://pkg.go.dev/github.com/cenkalti/backoff/v4 to view the documentation.
## Contributing
* I would like to keep this library as small as possible.
* Please don't send a PR without opening an issue and discussing it first.
* If proposed change is not a common use case, I will probably not accept it.
[godoc]: https://pkg.go.dev/github.com/cenkalti/backoff/v4
[godoc image]: https://godoc.org/github.com/cenkalti/backoff?status.png
[coveralls]: https://coveralls.io/github/cenkalti/backoff?branch=master
[coveralls image]: https://coveralls.io/repos/github/cenkalti/backoff/badge.svg?branch=master
[google-http-java-client]: https://github.com/google/google-http-java-client/blob/da1aa993e90285ec18579f1553339b00e19b3ab5/google-http-client/src/main/java/com/google/api/client/util/ExponentialBackOff.java
[exponential backoff wiki]: http://en.wikipedia.org/wiki/Exponential_backoff
[advanced example]: https://pkg.go.dev/github.com/cenkalti/backoff/v4?tab=doc#pkg-examples | {
"source": "yandex/perforator",
"title": "vendor/github.com/cenkalti/backoff/v4/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/cenkalti/backoff/v4/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 1589
} |
# xxhash
[](https://pkg.go.dev/github.com/cespare/xxhash/v2)
[](https://github.com/cespare/xxhash/actions/workflows/test.yml)
xxhash is a Go implementation of the 64-bit [xxHash] algorithm, XXH64. This is a
high-quality hashing algorithm that is much faster than anything in the Go
standard library.
This package provides a straightforward API:
```
func Sum64(b []byte) uint64
func Sum64String(s string) uint64
type Digest struct{ ... }
func New() *Digest
```
The `Digest` type implements hash.Hash64. Its key methods are:
```
func (*Digest) Write([]byte) (int, error)
func (*Digest) WriteString(string) (int, error)
func (*Digest) Sum64() uint64
```
The package is written with optimized pure Go and also contains even faster
assembly implementations for amd64 and arm64. If desired, the `purego` build tag
opts into using the Go code even on those architectures.
[xxHash]: http://cyan4973.github.io/xxHash/
## Compatibility
This package is in a module and the latest code is in version 2 of the module.
You need a version of Go with at least "minimal module compatibility" to use
github.com/cespare/xxhash/v2:
* 1.9.7+ for Go 1.9
* 1.10.3+ for Go 1.10
* Go 1.11 or later
I recommend using the latest release of Go.
## Benchmarks
Here are some quick benchmarks comparing the pure-Go and assembly
implementations of Sum64.
| input size | purego | asm |
| ---------- | --------- | --------- |
| 4 B | 1.3 GB/s | 1.2 GB/s |
| 16 B | 2.9 GB/s | 3.5 GB/s |
| 100 B | 6.9 GB/s | 8.1 GB/s |
| 4 KB | 11.7 GB/s | 16.7 GB/s |
| 10 MB | 12.0 GB/s | 17.3 GB/s |
These numbers were generated on Ubuntu 20.04 with an Intel Xeon Platinum 8252C
CPU using the following commands under Go 1.19.2:
```
benchstat <(go test -tags purego -benchtime 500ms -count 15 -bench 'Sum64$')
benchstat <(go test -benchtime 500ms -count 15 -bench 'Sum64$')
```
## Projects using this package
- [InfluxDB](https://github.com/influxdata/influxdb)
- [Prometheus](https://github.com/prometheus/prometheus)
- [VictoriaMetrics](https://github.com/VictoriaMetrics/VictoriaMetrics)
- [FreeCache](https://github.com/coocood/freecache)
- [FastCache](https://github.com/VictoriaMetrics/fastcache)
- [Ristretto](https://github.com/dgraph-io/ristretto)
- [Badger](https://github.com/dgraph-io/badger) | {
"source": "yandex/perforator",
"title": "vendor/github.com/cespare/xxhash/v2/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/cespare/xxhash/v2/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2476
} |
# apd
apd is an arbitrary-precision decimal package for Go.
`apd` implements much of the decimal specification from the [General Decimal Arithmetic](http://speleotrove.com/decimal/) description. This is the same specification implemented by [python’s decimal module](https://docs.python.org/2/library/decimal.html) and GCC’s decimal extension.
## Features
- **Panic-free operation**. The `math/big` types don’t return errors, and instead panic under some conditions that are documented. This requires users to validate the inputs before using them. Meanwhile, we’d like our decimal operations to have more failure modes and more input requirements than the `math/big` types, so using that API would be difficult. `apd` instead returns errors when needed.
- **Support for standard functions**. `sqrt`, `ln`, `pow`, etc.
- **Accurate and configurable precision**. Operations will use enough internal precision to produce a correct result at the requested precision. Precision is set by a "context" structure that accompanies the function arguments, as discussed in the next section.
- **Good performance**. Operations will either be fast enough or will produce an error if they will be slow. This prevents edge-case operations from consuming lots of CPU or memory.
- **Condition flags and traps**. All operations will report whether their result is exact, is rounded, is over- or under-flowed, is [subnormal](https://en.wikipedia.org/wiki/Denormal_number), or is some other condition. `apd` supports traps which will trigger an error on any of these conditions. This makes it possible to guarantee exactness in computations, if needed.
`apd` has two main types. The first is [`Decimal`](https://godoc.org/github.com/cockroachdb/apd#Decimal) which holds the values of decimals. It is simple and uses a `big.Int` with an exponent to describe values. Most operations on `Decimal`s can’t produce errors as they work directly on the underlying `big.Int`. Notably, however, there are no arithmetic operations on `Decimal`s.
The second main type is [`Context`](https://godoc.org/github.com/cockroachdb/apd#Context), which is where all arithmetic operations are defined. A `Context` describes the precision, range, and some other restrictions during operations. These operations can all produce failures, and so return errors.
`Context` operations, in addition to errors, return a [`Condition`](https://godoc.org/github.com/cockroachdb/apd#Condition), which is a bitfield of flags that occurred during an operation. These include overflow, underflow, inexact, rounded, and others. The `Traps` field of a `Context` can be set which will produce an error if the corresponding flag occurs. An example of this is given below.
See the [examples](https://godoc.org/github.com/cockroachdb/apd#pkg-examples) for some operations that were previously difficult to perform in Go.
## Documentation
https://godoc.org/github.com/cockroachdb/apd | {
"source": "yandex/perforator",
"title": "vendor/github.com/cockroachdb/apd/v2/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/cockroachdb/apd/v2/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2930
} |
# Working on the Engine API
The Engine API is an HTTP API used by the command-line client to communicate with the daemon. It can also be used by third-party software to control the daemon.
It consists of various components in this repository:
- `api/swagger.yaml` A Swagger definition of the API.
- `api/types/` Types shared by both the client and server, representing various objects, options, responses, etc. Most are written manually, but some are automatically generated from the Swagger definition. See [#27919](https://github.com/docker/docker/issues/27919) for progress on this.
- `cli/` The command-line client.
- `client/` The Go client used by the command-line client. It can also be used by third-party Go programs.
- `daemon/` The daemon, which serves the API.
## Swagger definition
The API is defined by the [Swagger](http://swagger.io/specification/) definition in `api/swagger.yaml`. This definition can be used to:
1. Automatically generate documentation.
2. Automatically generate the Go server and client. (A work-in-progress.)
3. Provide a machine readable version of the API for introspecting what it can do, automatically generating clients for other languages, etc.
## Updating the API documentation
The API documentation is generated entirely from `api/swagger.yaml`. If you make updates to the API, edit this file to represent the change in the documentation.
The file is split into two main sections:
- `definitions`, which defines re-usable objects used in requests and responses
- `paths`, which defines the API endpoints (and some inline objects which don't need to be reusable)
To make an edit, first look for the endpoint you want to edit under `paths`, then make the required edits. Endpoints may reference reusable objects with `$ref`, which can be found in the `definitions` section.
There is hopefully enough example material in the file for you to copy a similar pattern from elsewhere in the file (e.g. adding new fields or endpoints), but for the full reference, see the [Swagger specification](https://github.com/docker/docker/issues/27919).
`swagger.yaml` is validated by `hack/validate/swagger` to ensure it is a valid Swagger definition. This is useful when making edits to ensure you are doing the right thing.
## Viewing the API documentation
When you make edits to `swagger.yaml`, you may want to check the generated API documentation to ensure it renders correctly.
Run `make swagger-docs` and a preview will be running at `http://localhost:9000`. Some of the styling may be incorrect, but you'll be able to ensure that it is generating the correct documentation.
The production documentation is generated by vendoring `swagger.yaml` into [docker/docker.github.io](https://github.com/docker/docker.github.io). | {
"source": "yandex/perforator",
"title": "vendor/github.com/docker/docker/api/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/docker/docker/api/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 2771
} |
# Go client for the Docker Engine API
The `docker` command uses this package to communicate with the daemon. It can
also be used by your own Go applications to do anything the command-line
interface does – running containers, pulling images, managing swarms, etc.
For example, to list all containers (the equivalent of `docker ps --all`):
```go
package main
import (
"context"
"fmt"
"github.com/docker/docker/api/types/container"
"github.com/docker/docker/client"
)
func main() {
apiClient, err := client.NewClientWithOpts(client.FromEnv)
if err != nil {
panic(err)
}
defer apiClient.Close()
containers, err := apiClient.ContainerList(context.Background(), container.ListOptions{All: true})
if err != nil {
panic(err)
}
for _, ctr := range containers {
fmt.Printf("%s %s (status: %s)\n", ctr.ID, ctr.Image, ctr.Status)
}
}
```
[Full documentation is available on pkg.go.dev.](https://pkg.go.dev/github.com/docker/docker/client) | {
"source": "yandex/perforator",
"title": "vendor/github.com/docker/docker/client/README.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/docker/docker/client/README.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 955
} |
# Changelog
## v5.0.12 (2024-02-16)
- History of changes: see https://github.com/go-chi/chi/compare/v5.0.11...v5.0.12
## v5.0.11 (2023-12-19)
- History of changes: see https://github.com/go-chi/chi/compare/v5.0.10...v5.0.11
## v5.0.10 (2023-07-13)
- Fixed small edge case in tests of v5.0.9 for older Go versions
- History of changes: see https://github.com/go-chi/chi/compare/v5.0.9...v5.0.10
## v5.0.9 (2023-07-13)
- History of changes: see https://github.com/go-chi/chi/compare/v5.0.8...v5.0.9
## v5.0.8 (2022-12-07)
- History of changes: see https://github.com/go-chi/chi/compare/v5.0.7...v5.0.8
## v5.0.7 (2021-11-18)
- History of changes: see https://github.com/go-chi/chi/compare/v5.0.6...v5.0.7
## v5.0.6 (2021-11-15)
- History of changes: see https://github.com/go-chi/chi/compare/v5.0.5...v5.0.6
## v5.0.5 (2021-10-27)
- History of changes: see https://github.com/go-chi/chi/compare/v5.0.4...v5.0.5
## v5.0.4 (2021-08-29)
- History of changes: see https://github.com/go-chi/chi/compare/v5.0.3...v5.0.4
## v5.0.3 (2021-04-29)
- History of changes: see https://github.com/go-chi/chi/compare/v5.0.2...v5.0.3
## v5.0.2 (2021-03-25)
- History of changes: see https://github.com/go-chi/chi/compare/v5.0.1...v5.0.2
## v5.0.1 (2021-03-10)
- Small improvements
- History of changes: see https://github.com/go-chi/chi/compare/v5.0.0...v5.0.1
## v5.0.0 (2021-02-27)
- chi v5, `github.com/go-chi/chi/v5` introduces the adoption of Go's SIV to adhere to the current state-of-the-tools in Go.
- chi v1.5.x did not work out as planned, as the Go tooling is too powerful and chi's adoption is too wide.
The most responsible thing to do for everyone's benefit is to just release v5 with SIV, so I present to you all,
chi v5 at `github.com/go-chi/chi/v5`. I hope someday the developer experience and ergonomics I've been seeking
will still come to fruition in some form, see https://github.com/golang/go/issues/44550
- History of changes: see https://github.com/go-chi/chi/compare/v1.5.4...v5.0.0
## v1.5.4 (2021-02-27)
- Undo prior retraction in v1.5.3 as we prepare for v5.0.0 release
- History of changes: see https://github.com/go-chi/chi/compare/v1.5.3...v1.5.4
## v1.5.3 (2021-02-21)
- Update go.mod to go 1.16 with new retract directive marking all versions without prior go.mod support
- History of changes: see https://github.com/go-chi/chi/compare/v1.5.2...v1.5.3
## v1.5.2 (2021-02-10)
- Reverting allocation optimization as a precaution as go test -race fails.
- Minor improvements, see history below
- History of changes: see https://github.com/go-chi/chi/compare/v1.5.1...v1.5.2
## v1.5.1 (2020-12-06)
- Performance improvement: removing 1 allocation by foregoing context.WithValue, thank you @bouk for
your contribution (https://github.com/go-chi/chi/pull/555). Note: new benchmarks posted in README.
- `middleware.CleanPath`: new middleware that clean's request path of double slashes
- deprecate & remove `chi.ServerBaseContext` in favour of stdlib `http.Server#BaseContext`
- plus other tiny improvements, see full commit history below
- History of changes: see https://github.com/go-chi/chi/compare/v4.1.2...v1.5.1
## v1.5.0 (2020-11-12) - now with go.mod support
`chi` dates back to 2016 with it's original implementation as one of the first routers to adopt the newly introduced
context.Context api to the stdlib -- set out to design a router that is faster, more modular and simpler than anything
else out there -- while not introducing any custom handler types or dependencies. Today, `chi` still has zero dependencies,
and in many ways is future proofed from changes, given it's minimal nature. Between versions, chi's iterations have been very
incremental, with the architecture and api being the same today as it was originally designed in 2016. For this reason it
makes chi a pretty easy project to maintain, as well thanks to the many amazing community contributions over the years
to who all help make chi better (total of 86 contributors to date -- thanks all!).
Chi has been a labour of love, art and engineering, with the goals to offer beautiful ergonomics, flexibility, performance
and simplicity when building HTTP services with Go. I've strived to keep the router very minimal in surface area / code size,
and always improving the code wherever possible -- and as of today the `chi` package is just 1082 lines of code (not counting
middlewares, which are all optional). As well, I don't have the exact metrics, but from my analysis and email exchanges from
companies and developers, chi is used by thousands of projects around the world -- thank you all as there is no better form of
joy for me than to have art I had started be helpful and enjoyed by others. And of course I use chi in all of my own projects too :)
For me, the aesthetics of chi's code and usage are very important. With the introduction of Go's module support
(which I'm a big fan of), chi's past versioning scheme choice to v2, v3 and v4 would mean I'd require the import path
of "github.com/go-chi/chi/v4", leading to the lengthy discussion at https://github.com/go-chi/chi/issues/462.
Haha, to some, you may be scratching your head why I've spent > 1 year stalling to adopt "/vXX" convention in the import
path -- which isn't horrible in general -- but for chi, I'm unable to accept it as I strive for perfection in it's API design,
aesthetics and simplicity. It just doesn't feel good to me given chi's simple nature -- I do not foresee a "v5" or "v6",
and upgrading between versions in the future will also be just incremental.
I do understand versioning is a part of the API design as well, which is why the solution for a while has been to "do nothing",
as Go supports both old and new import paths with/out go.mod. However, now that Go module support has had time to iron out kinks and
is adopted everywhere, it's time for chi to get with the times. Luckily, I've discovered a path forward that will make me happy,
while also not breaking anyone's app who adopted a prior versioning from tags in v2/v3/v4. I've made an experimental release of
v1.5.0 with go.mod silently, and tested it with new and old projects, to ensure the developer experience is preserved, and it's
largely unnoticed. Fortunately, Go's toolchain will check the tags of a repo and consider the "latest" tag the one with go.mod.
However, you can still request a specific older tag such as v4.1.2, and everything will "just work". But new users can just
`go get github.com/go-chi/chi` or `go get github.com/go-chi/chi@latest` and they will get the latest version which contains
go.mod support, which is v1.5.0+. `chi` will not change very much over the years, just like it hasn't changed much from 4 years ago.
Therefore, we will stay on v1.x from here on, starting from v1.5.0. Any breaking changes will bump a "minor" release and
backwards-compatible improvements/fixes will bump a "tiny" release.
For existing projects who want to upgrade to the latest go.mod version, run: `go get -u github.com/go-chi/[email protected]`,
which will get you on the go.mod version line (as Go's mod cache may still remember v4.x). Brand new systems can run
`go get -u github.com/go-chi/chi` or `go get -u github.com/go-chi/chi@latest` to install chi, which will install v1.5.0+
built with go.mod support.
My apologies to the developers who will disagree with the decisions above, but, hope you'll try it and see it's a very
minor request which is backwards compatible and won't break your existing installations.
Cheers all, happy coding!
---
## v4.1.2 (2020-06-02)
- fix that handles MethodNotAllowed with path variables, thank you @caseyhadden for your contribution
- fix to replace nested wildcards correctly in RoutePattern, thank you @@unmultimedio for your contribution
- History of changes: see https://github.com/go-chi/chi/compare/v4.1.1...v4.1.2
## v4.1.1 (2020-04-16)
- fix for issue https://github.com/go-chi/chi/issues/411 which allows for overlapping regexp
route to the correct handler through a recursive tree search, thanks to @Jahaja for the PR/fix!
- new middleware.RouteHeaders as a simple router for request headers with wildcard support
- History of changes: see https://github.com/go-chi/chi/compare/v4.1.0...v4.1.1
## v4.1.0 (2020-04-1)
- middleware.LogEntry: Write method on interface now passes the response header
and an extra interface type useful for custom logger implementations.
- middleware.WrapResponseWriter: minor fix
- middleware.Recoverer: a bit prettier
- History of changes: see https://github.com/go-chi/chi/compare/v4.0.4...v4.1.0
## v4.0.4 (2020-03-24)
- middleware.Recoverer: new pretty stack trace printing (https://github.com/go-chi/chi/pull/496)
- a few minor improvements and fixes
- History of changes: see https://github.com/go-chi/chi/compare/v4.0.3...v4.0.4
## v4.0.3 (2020-01-09)
- core: fix regexp routing to include default value when param is not matched
- middleware: rewrite of middleware.Compress
- middleware: suppress http.ErrAbortHandler in middleware.Recoverer
- History of changes: see https://github.com/go-chi/chi/compare/v4.0.2...v4.0.3
## v4.0.2 (2019-02-26)
- Minor fixes
- History of changes: see https://github.com/go-chi/chi/compare/v4.0.1...v4.0.2
## v4.0.1 (2019-01-21)
- Fixes issue with compress middleware: #382 #385
- History of changes: see https://github.com/go-chi/chi/compare/v4.0.0...v4.0.1
## v4.0.0 (2019-01-10)
- chi v4 requires Go 1.10.3+ (or Go 1.9.7+) - we have deprecated support for Go 1.7 and 1.8
- router: respond with 404 on router with no routes (#362)
- router: additional check to ensure wildcard is at the end of a url pattern (#333)
- middleware: deprecate use of http.CloseNotifier (#347)
- middleware: fix RedirectSlashes to include query params on redirect (#334)
- History of changes: see https://github.com/go-chi/chi/compare/v3.3.4...v4.0.0
## v3.3.4 (2019-01-07)
- Minor middleware improvements. No changes to core library/router. Moving v3 into its
- own branch as a version of chi for Go 1.7, 1.8, 1.9, 1.10, 1.11
- History of changes: see https://github.com/go-chi/chi/compare/v3.3.3...v3.3.4
## v3.3.3 (2018-08-27)
- Minor release
- See https://github.com/go-chi/chi/compare/v3.3.2...v3.3.3
## v3.3.2 (2017-12-22)
- Support to route trailing slashes on mounted sub-routers (#281)
- middleware: new `ContentCharset` to check matching charsets. Thank you
@csucu for your community contribution!
## v3.3.1 (2017-11-20)
- middleware: new `AllowContentType` handler for explicit whitelist of accepted request Content-Types
- middleware: new `SetHeader` handler for short-hand middleware to set a response header key/value
- Minor bug fixes
## v3.3.0 (2017-10-10)
- New chi.RegisterMethod(method) to add support for custom HTTP methods, see _examples/custom-method for usage
- Deprecated LINK and UNLINK methods from the default list, please use `chi.RegisterMethod("LINK")` and `chi.RegisterMethod("UNLINK")` in an `init()` function
## v3.2.1 (2017-08-31)
- Add new `Match(rctx *Context, method, path string) bool` method to `Routes` interface
and `Mux`. Match searches the mux's routing tree for a handler that matches the method/path
- Add new `RouteMethod` to `*Context`
- Add new `Routes` pointer to `*Context`
- Add new `middleware.GetHead` to route missing HEAD requests to GET handler
- Updated benchmarks (see README)
## v3.1.5 (2017-08-02)
- Setup golint and go vet for the project
- As per golint, we've redefined `func ServerBaseContext(h http.Handler, baseCtx context.Context) http.Handler`
to `func ServerBaseContext(baseCtx context.Context, h http.Handler) http.Handler`
## v3.1.0 (2017-07-10)
- Fix a few minor issues after v3 release
- Move `docgen` sub-pkg to https://github.com/go-chi/docgen
- Move `render` sub-pkg to https://github.com/go-chi/render
- Add new `URLFormat` handler to chi/middleware sub-pkg to make working with url mime
suffixes easier, ie. parsing `/articles/1.json` and `/articles/1.xml`. See comments in
https://github.com/go-chi/chi/blob/master/middleware/url_format.go for example usage.
## v3.0.0 (2017-06-21)
- Major update to chi library with many exciting updates, but also some *breaking changes*
- URL parameter syntax changed from `/:id` to `/{id}` for even more flexible routing, such as
`/articles/{month}-{day}-{year}-{slug}`, `/articles/{id}`, and `/articles/{id}.{ext}` on the
same router
- Support for regexp for routing patterns, in the form of `/{paramKey:regExp}` for example:
`r.Get("/articles/{name:[a-z]+}", h)` and `chi.URLParam(r, "name")`
- Add `Method` and `MethodFunc` to `chi.Router` to allow routing definitions such as
`r.Method("GET", "/", h)` which provides a cleaner interface for custom handlers like
in `_examples/custom-handler`
- Deprecating `mux#FileServer` helper function. Instead, we encourage users to create their
own using file handler with the stdlib, see `_examples/fileserver` for an example
- Add support for LINK/UNLINK http methods via `r.Method()` and `r.MethodFunc()`
- Moved the chi project to its own organization, to allow chi-related community packages to
be easily discovered and supported, at: https://github.com/go-chi
- *NOTE:* please update your import paths to `"github.com/go-chi/chi"`
- *NOTE:* chi v2 is still available at https://github.com/go-chi/chi/tree/v2
## v2.1.0 (2017-03-30)
- Minor improvements and update to the chi core library
- Introduced a brand new `chi/render` sub-package to complete the story of building
APIs to offer a pattern for managing well-defined request / response payloads. Please
check out the updated `_examples/rest` example for how it works.
- Added `MethodNotAllowed(h http.HandlerFunc)` to chi.Router interface
## v2.0.0 (2017-01-06)
- After many months of v2 being in an RC state with many companies and users running it in
production, the inclusion of some improvements to the middlewares, we are very pleased to
announce v2.0.0 of chi.
## v2.0.0-rc1 (2016-07-26)
- Huge update! chi v2 is a large refactor targeting Go 1.7+. As of Go 1.7, the popular
community `"net/context"` package has been included in the standard library as `"context"` and
utilized by `"net/http"` and `http.Request` to managing deadlines, cancelation signals and other
request-scoped values. We're very excited about the new context addition and are proud to
introduce chi v2, a minimal and powerful routing package for building large HTTP services,
with zero external dependencies. Chi focuses on idiomatic design and encourages the use of
stdlib HTTP handlers and middlewares.
- chi v2 deprecates its `chi.Handler` interface and requires `http.Handler` or `http.HandlerFunc`
- chi v2 stores URL routing parameters and patterns in the standard request context: `r.Context()`
- chi v2 lower-level routing context is accessible by `chi.RouteContext(r.Context()) *chi.Context`,
which provides direct access to URL routing parameters, the routing path and the matching
routing patterns.
- Users upgrading from chi v1 to v2, need to:
1. Update the old chi.Handler signature, `func(ctx context.Context, w http.ResponseWriter, r *http.Request)` to
the standard http.Handler: `func(w http.ResponseWriter, r *http.Request)`
2. Use `chi.URLParam(r *http.Request, paramKey string) string`
or `URLParamFromCtx(ctx context.Context, paramKey string) string` to access a url parameter value
## v1.0.0 (2016-07-01)
- Released chi v1 stable https://github.com/go-chi/chi/tree/v1.0.0 for Go 1.6 and older.
## v0.9.0 (2016-03-31)
- Reuse context objects via sync.Pool for zero-allocation routing [#33](https://github.com/go-chi/chi/pull/33)
- BREAKING NOTE: due to subtle API changes, previously `chi.URLParams(ctx)["id"]` used to access url parameters
has changed to: `chi.URLParam(ctx, "id")` | {
"source": "yandex/perforator",
"title": "vendor/github.com/go-chi/chi/v5/CHANGELOG.md",
"url": "https://github.com/yandex/perforator/blob/main/vendor/github.com/go-chi/chi/v5/CHANGELOG.md",
"date": "2025-01-29T14:20:43",
"stars": 2926,
"description": "Perforator is a cluster-wide continuous profiling tool designed for large data centers",
"file_size": 15853
} |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.