
text
stringlengths 55
456k
| metadata
dict |
|---|---|
## Documentation
Fork from [@midscene/visualizer](https://github.com/web-infra-dev/midscene/tree/main/packages/visualizer)
## License
Midscene is MIT licensed. | {
"source": "bytedance/UI-TARS-desktop",
"title": "packages/visualizer/README.md",
"url": "https://github.com/bytedance/UI-TARS-desktop/blob/main/packages/visualizer/README.md",
"date": "2025-01-19T09:04:43",
"stars": 2834,
"description": "A GUI Agent application based on UI-TARS(Vision-Lanuage Model) that allows you to control your computer using natural language.",
"file_size": 162
} |
# @ui-tars/operator-browserbase
## 1.2.0-beta.12
### Patch Changes
- chore: open-operator
- Updated dependencies
- @ui-tars/[email protected]
- @ui-tars/[email protected]
## 1.2.0-beta.11
### Patch Changes
- chore: types
- Updated dependencies
- @ui-tars/[email protected] | {
"source": "bytedance/UI-TARS-desktop",
"title": "packages/operators/browserbase/CHANGELOG.md",
"url": "https://github.com/bytedance/UI-TARS-desktop/blob/main/packages/operators/browserbase/CHANGELOG.md",
"date": "2025-01-19T09:04:43",
"stars": 2834,
"description": "A GUI Agent application based on UI-TARS(Vision-Lanuage Model) that allows you to control your computer using natural language.",
"file_size": 287
} |
# @ui-tars/operator-browserbase
Operator Browserbase SDK for UI-TARS.
See [example](https://github.com/bytedance/UI-TARS-desktop/tree/main/operator-browserbase) for usage. | {
"source": "bytedance/UI-TARS-desktop",
"title": "packages/operators/browserbase/README.md",
"url": "https://github.com/bytedance/UI-TARS-desktop/blob/main/packages/operators/browserbase/README.md",
"date": "2025-01-19T09:04:43",
"stars": 2834,
"description": "A GUI Agent application based on UI-TARS(Vision-Lanuage Model) that allows you to control your computer using natural language.",
"file_size": 173
} |
# @ui-tars/operator-nut-js
## 1.2.0-beta.12
### Patch Changes
- chore: open-operator
- Updated dependencies
- @ui-tars/[email protected]
- @ui-tars/[email protected]
## 1.2.0-beta.11
### Patch Changes
- chore: types
- Updated dependencies
- @ui-tars/[email protected]
## 1.2.0-beta.10
### Patch Changes
- Updated dependencies
- @ui-tars/[email protected]
- @ui-tars/[email protected]
## 1.2.0-beta.9
### Patch Changes
- bump: sdk support
- Updated dependencies
- @ui-tars/[email protected]
- @ui-tars/[email protected]
## 1.2.0-beta.8
### Patch Changes
- fix: useConfig to useContext
- Updated dependencies
- @ui-tars/[email protected]
## 1.2.0-beta.7
### Patch Changes
- Updated dependencies
- @ui-tars/[email protected]
## 1.2.0-beta.6
### Patch Changes
- feat: new sdk
- Updated dependencies
- @ui-tars/[email protected]
- @ui-tars/[email protected]
## 1.2.0-beta.5
### Patch Changes
- chore: update sdk
- Updated dependencies
- @ui-tars/[email protected]
- @ui-tars/[email protected]
## 1.2.0-beta.4
### Patch Changes
- chore: new version
- Updated dependencies
- @ui-tars/[email protected]
- @ui-tars/[email protected]
## 1.2.0-beta.3
### Patch Changes
- chore: add retry
- Updated dependencies
- @ui-tars/[email protected]
- @ui-tars/[email protected]
## 1.2.0-beta.2
### Patch Changes
- chore: publish
- Updated dependencies
- @ui-tars/[email protected]
- @ui-tars/[email protected]
## 1.2.0-beta.1
### Patch Changes
- chore: remove unused code
- Updated dependencies
- @ui-tars/[email protected]
- @ui-tars/[email protected]
## 1.2.0-beta.0
### Minor Changes
- a062e03: feat: ui-tars agent sdk support
### Patch Changes
- Updated dependencies [a062e03]
- @ui-tars/[email protected]
- @ui-tars/[email protected] | {
"source": "bytedance/UI-TARS-desktop",
"title": "packages/operators/nut-js/CHANGELOG.md",
"url": "https://github.com/bytedance/UI-TARS-desktop/blob/main/packages/operators/nut-js/CHANGELOG.md",
"date": "2025-01-19T09:04:43",
"stars": 2834,
"description": "A GUI Agent application based on UI-TARS(Vision-Lanuage Model) that allows you to control your computer using natural language.",
"file_size": 1817
} |
# @ui-tars/operator-nut-js
Operator Nut JS SDK for UI-TARS. | {
"source": "bytedance/UI-TARS-desktop",
"title": "packages/operators/nut-js/README.md",
"url": "https://github.com/bytedance/UI-TARS-desktop/blob/main/packages/operators/nut-js/README.md",
"date": "2025-01-19T09:04:43",
"stars": 2834,
"description": "A GUI Agent application based on UI-TARS(Vision-Lanuage Model) that allows you to control your computer using natural language.",
"file_size": 60
} |
# 🦙🎧 LLaMA-Omni: Seamless Speech Interaction with Large Language Models
> **Authors: [Qingkai Fang](https://fangqingkai.github.io/), [Shoutao Guo](https://scholar.google.com/citations?hl=en&user=XwHtPyAAAAAJ), [Yan Zhou](https://zhouyan19.github.io/zhouyan/), [Zhengrui Ma](https://scholar.google.com.hk/citations?user=dUgq6tEAAAAJ), [Shaolei Zhang](https://zhangshaolei1998.github.io/), [Yang Feng*](https://people.ucas.edu.cn/~yangfeng?language=en)**
[](https://arxiv.org/abs/2409.06666)
[](https://github.com/ictnlp/LLaMA-Omni)
[](https://huggingface.co/ICTNLP/Llama-3.1-8B-Omni)
[](https://modelscope.cn/models/ICTNLP/Llama-3.1-8B-Omni)
[](https://www.wisemodel.cn/models/ICT_NLP/Llama-3.1-8B-Omni/)
[](https://replicate.com/ictnlp/llama-omni)
LLaMA-Omni is a speech-language model built upon Llama-3.1-8B-Instruct. It supports low-latency and high-quality speech interactions, simultaneously generating both text and speech responses based on speech instructions.
<div align="center"><img src="images/model.png" width="75%"/></div>
## 💡 Highlights
- 💪 **Built on Llama-3.1-8B-Instruct, ensuring high-quality responses.**
- 🚀 **Low-latency speech interaction with a latency as low as 226ms.**
- 🎧 **Simultaneous generation of both text and speech responses.**
- ♻️ **Trained in less than 3 days using just 4 GPUs.**
https://github.com/user-attachments/assets/2b097af8-47d7-494f-b3b3-6be17ca0247a
## Install
1. Clone this repository.
```shell
git clone https://github.com/ictnlp/LLaMA-Omni
cd LLaMA-Omni
```
2. Install packages.
```shell
conda create -n llama-omni python=3.10
conda activate llama-omni
pip install pip==24.0
pip install -e .
```
3. Install `fairseq`.
```shell
git clone https://github.com/pytorch/fairseq
cd fairseq
pip install -e . --no-build-isolation
```
4. Install `flash-attention`.
```shell
pip install flash-attn --no-build-isolation
```
## Quick Start
1. Download the `Llama-3.1-8B-Omni` model from 🤗[Huggingface](https://huggingface.co/ICTNLP/Llama-3.1-8B-Omni).
2. Download the `Whisper-large-v3` model.
```shell
import whisper
model = whisper.load_model("large-v3", download_root="models/speech_encoder/")
```
3. Download the unit-based HiFi-GAN vocoder.
```shell
wget https://dl.fbaipublicfiles.com/fairseq/speech_to_speech/vocoder/code_hifigan/mhubert_vp_en_es_fr_it3_400k_layer11_km1000_lj/g_00500000 -P vocoder/
wget https://dl.fbaipublicfiles.com/fairseq/speech_to_speech/vocoder/code_hifigan/mhubert_vp_en_es_fr_it3_400k_layer11_km1000_lj/config.json -P vocoder/
```
## Gradio Demo
1. Launch a controller.
```shell
python -m omni_speech.serve.controller --host 0.0.0.0 --port 10000
```
2. Launch a gradio web server.
```shell
python -m omni_speech.serve.gradio_web_server --controller http://localhost:10000 --port 8000 --model-list-mode reload --vocoder vocoder/g_00500000 --vocoder-cfg vocoder/config.json
```
3. Launch a model worker.
```shell
python -m omni_speech.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path Llama-3.1-8B-Omni --model-name Llama-3.1-8B-Omni --s2s
```
4. Visit [http://localhost:8000/](http://localhost:8000/) and interact with LLaMA-3.1-8B-Omni!
**Note: Due to the instability of streaming audio playback in Gradio, we have only implemented streaming audio synthesis without enabling autoplay. If you have a good solution, feel free to submit a PR. Thanks!**
## Local Inference
To run inference locally, please organize the speech instruction files according to the format in the `omni_speech/infer/examples` directory, then refer to the following script.
```shell
bash omni_speech/infer/run.sh omni_speech/infer/examples
```
## LICENSE
Our code is released under the Apache-2.0 License. Our model is intended for academic research purposes only and may **NOT** be used for commercial purposes.
You are free to use, modify, and distribute this model in academic settings, provided that the following conditions are met:
- **Non-commercial use**: The model may not be used for any commercial purposes.
- **Citation**: If you use this model in your research, please cite the original work.
### Commercial Use Restriction
For any commercial use inquiries or to obtain a commercial license, please contact `[email protected]`.
## Acknowledgements
- [LLaVA](https://github.com/haotian-liu/LLaVA): The codebase we built upon.
- [SLAM-LLM](https://github.com/X-LANCE/SLAM-LLM): We borrow some code about speech encoder and speech adaptor.
## Citation
If you have any questions, please feel free to submit an issue or contact `[email protected]`.
If our work is useful for you, please cite as:
```
@article{fang-etal-2024-llama-omni,
title={LLaMA-Omni: Seamless Speech Interaction with Large Language Models},
author={Fang, Qingkai and Guo, Shoutao and Zhou, Yan and Ma, Zhengrui and Zhang, Shaolei and Feng, Yang},
journal={arXiv preprint arXiv:2409.06666},
year={2024}
}
```
## Star History
[](https://star-history.com/#ictnlp/llama-omni&Date) | {
"source": "ictnlp/LLaMA-Omni",
"title": "README.md",
"url": "https://github.com/ictnlp/LLaMA-Omni/blob/main/README.md",
"date": "2024-09-10T12:21:53",
"stars": 2821,
"description": "LLaMA-Omni is a low-latency and high-quality end-to-end speech interaction model built upon Llama-3.1-8B-Instruct, aiming to achieve speech capabilities at the GPT-4o level.",
"file_size": 5557
} |
<div align="center">
# ⚡️Pyramid Flow⚡️
[[Paper]](https://arxiv.org/abs/2410.05954) [[Project Page ✨]](https://pyramid-flow.github.io) [[miniFLUX Model 🚀]](https://huggingface.co/rain1011/pyramid-flow-miniflux) [[SD3 Model ⚡️]](https://huggingface.co/rain1011/pyramid-flow-sd3) [[demo 🤗](https://huggingface.co/spaces/Pyramid-Flow/pyramid-flow)]
</div>
This is the official repository for Pyramid Flow, a training-efficient **Autoregressive Video Generation** method based on **Flow Matching**. By training only on **open-source datasets**, it can generate high-quality 10-second videos at 768p resolution and 24 FPS, and naturally supports image-to-video generation.
<table class="center" border="0" style="width: 100%; text-align: left;">
<tr>
<th>10s, 768p, 24fps</th>
<th>5s, 768p, 24fps</th>
<th>Image-to-video</th>
</tr>
<tr>
<td><video src="https://github.com/user-attachments/assets/9935da83-ae56-4672-8747-0f46e90f7b2b" autoplay muted loop playsinline></video></td>
<td><video src="https://github.com/user-attachments/assets/3412848b-64db-4d9e-8dbf-11403f6d02c5" autoplay muted loop playsinline></video></td>
<td><video src="https://github.com/user-attachments/assets/3bd7251f-7b2c-4bee-951d-656fdb45f427" autoplay muted loop playsinline></video></td>
</tr>
</table>
## News
* `2024.11.13` 🚀🚀🚀 We release the [768p miniFLUX checkpoint](https://huggingface.co/rain1011/pyramid-flow-miniflux) (up to 10s).
> We have switched the model structure from SD3 to a mini FLUX to fix human structure issues, please try our 1024p image checkpoint, 384p video checkpoint (up to 5s) and 768p video checkpoint (up to 10s). The new miniflux model shows great improvement on human structure and motion stability
* `2024.10.29` ⚡️⚡️⚡️ We release [training code for VAE](#1-training-vae), [finetuning code for DiT](#2-finetuning-dit) and [new model checkpoints](https://huggingface.co/rain1011/pyramid-flow-miniflux) with FLUX structure trained from scratch.
* `2024.10.13` ✨✨✨ [Multi-GPU inference](#3-multi-gpu-inference) and [CPU offloading](#cpu-offloading) are supported. Use it with **less than 8GB** of GPU memory, with great speedup on multiple GPUs.
* `2024.10.11` 🤗🤗🤗 [Hugging Face demo](https://huggingface.co/spaces/Pyramid-Flow/pyramid-flow) is available. Thanks [@multimodalart](https://huggingface.co/multimodalart) for the commit!
* `2024.10.10` 🚀🚀🚀 We release the [technical report](https://arxiv.org/abs/2410.05954), [project page](https://pyramid-flow.github.io) and [model checkpoint](https://huggingface.co/rain1011/pyramid-flow-sd3) of Pyramid Flow.
## Table of Contents
* [Introduction](#introduction)
* [Installation](#installation)
* [Inference](#inference)
1. [Quick Start with Gradio](#1-quick-start-with-gradio)
2. [Inference Code](#2-inference-code)
3. [Multi-GPU Inference](#3-multi-gpu-inference)
4. [Usage Tips](#4-usage-tips)
* [Training](#Training)
1. [Training VAE](#training-vae)
2. [Finetuning DiT](#finetuning-dit)
* [Gallery](#gallery)
* [Comparison](#comparison)
* [Acknowledgement](#acknowledgement)
* [Citation](#citation)
## Introduction

Existing video diffusion models operate at full resolution, spending a lot of computation on very noisy latents. By contrast, our method harnesses the flexibility of flow matching ([Lipman et al., 2023](https://openreview.net/forum?id=PqvMRDCJT9t); [Liu et al., 2023](https://openreview.net/forum?id=XVjTT1nw5z); [Albergo & Vanden-Eijnden, 2023](https://openreview.net/forum?id=li7qeBbCR1t)) to interpolate between latents of different resolutions and noise levels, allowing for simultaneous generation and decompression of visual content with better computational efficiency. The entire framework is end-to-end optimized with a single DiT ([Peebles & Xie, 2023](http://openaccess.thecvf.com/content/ICCV2023/html/Peebles_Scalable_Diffusion_Models_with_Transformers_ICCV_2023_paper.html)), generating high-quality 10-second videos at 768p resolution and 24 FPS within 20.7k A100 GPU training hours.
## Installation
We recommend setting up the environment with conda. The codebase currently uses Python 3.8.10 and PyTorch 2.1.2 ([guide](https://pytorch.org/get-started/previous-versions/#v212)), and we are actively working to support a wider range of versions.
```bash
git clone https://github.com/jy0205/Pyramid-Flow
cd Pyramid-Flow
# create env using conda
conda create -n pyramid python==3.8.10
conda activate pyramid
pip install -r requirements.txt
```
Then, download the model from [Huggingface](https://huggingface.co/rain1011) (there are two variants: [miniFLUX](https://huggingface.co/rain1011/pyramid-flow-miniflux) or [SD3](https://huggingface.co/rain1011/pyramid-flow-sd3)). The miniFLUX models support 1024p image, 384p and 768p video generation, and the SD3-based models support 768p and 384p video generation. The 384p checkpoint generates 5-second video at 24FPS, while the 768p checkpoint generates up to 10-second video at 24FPS.
```python
from huggingface_hub import snapshot_download
model_path = 'PATH' # The local directory to save downloaded checkpoint
snapshot_download("rain1011/pyramid-flow-miniflux", local_dir=model_path, local_dir_use_symlinks=False, repo_type='model')
```
## Inference
### 1. Quick start with Gradio
To get started, first install [Gradio](https://www.gradio.app/guides/quickstart), set your model path at [#L36](https://github.com/jy0205/Pyramid-Flow/blob/3777f8b84bddfa2aa2b497ca919b3f40567712e6/app.py#L36), and then run on your local machine:
```bash
python app.py
```
The Gradio demo will be opened in a browser. Thanks to [@tpc2233](https://github.com/tpc2233) the commit, see [#48](https://github.com/jy0205/Pyramid-Flow/pull/48) for details.
Or, try it out effortlessly on [Hugging Face Space 🤗](https://huggingface.co/spaces/Pyramid-Flow/pyramid-flow) created by [@multimodalart](https://huggingface.co/multimodalart). Due to GPU limits, this online demo can only generate 25 frames (export at 8FPS or 24FPS). Duplicate the space to generate longer videos.
#### Quick Start on Google Colab
To quickly try out Pyramid Flow on Google Colab, run the code below:
```
# Setup
!git clone https://github.com/jy0205/Pyramid-Flow
%cd Pyramid-Flow
!pip install -r requirements.txt
!pip install gradio
# This code downloads miniFLUX
from huggingface_hub import snapshot_download
model_path = '/content/Pyramid-Flow'
snapshot_download("rain1011/pyramid-flow-miniflux", local_dir=model_path, local_dir_use_symlinks=False, repo_type='model')
# Start
!python app.py
```
### 2. Inference Code
To use our model, please follow the inference code in `video_generation_demo.ipynb` at [this link](https://github.com/jy0205/Pyramid-Flow/blob/main/video_generation_demo.ipynb). We strongly recommend you to try the latest published pyramid-miniflux, which shows great improvement on human structure and motion stability. Set the param `model_name` to `pyramid_flux` to use. We further simplify it into the following two-step procedure. First, load the downloaded model:
```python
import torch
from PIL import Image
from pyramid_dit import PyramidDiTForVideoGeneration
from diffusers.utils import load_image, export_to_video
torch.cuda.set_device(0)
model_dtype, torch_dtype = 'bf16', torch.bfloat16 # Use bf16 (not support fp16 yet)
model = PyramidDiTForVideoGeneration(
'PATH', # The downloaded checkpoint dir
model_name="pyramid_flux",
model_dtype=model_dtype,
model_variant='diffusion_transformer_768p',
)
model.vae.enable_tiling()
# model.vae.to("cuda")
# model.dit.to("cuda")
# model.text_encoder.to("cuda")
# if you're not using sequential offloading bellow uncomment the lines above ^
model.enable_sequential_cpu_offload()
```
Then, you can try text-to-video generation on your own prompts. Noting that the 384p version only support 5s now (set temp up to 16)!
```python
prompt = "A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors"
# used for 384p model variant
# width = 640
# height = 384
# used for 768p model variant
width = 1280
height = 768
with torch.no_grad(), torch.cuda.amp.autocast(enabled=True, dtype=torch_dtype):
frames = model.generate(
prompt=prompt,
num_inference_steps=[20, 20, 20],
video_num_inference_steps=[10, 10, 10],
height=height,
width=width,
temp=16, # temp=16: 5s, temp=31: 10s
guidance_scale=7.0, # The guidance for the first frame, set it to 7 for 384p variant
video_guidance_scale=5.0, # The guidance for the other video latent
output_type="pil",
save_memory=True, # If you have enough GPU memory, set it to `False` to improve vae decoding speed
)
export_to_video(frames, "./text_to_video_sample.mp4", fps=24)
```
As an autoregressive model, our model also supports (text conditioned) image-to-video generation:
```python
# used for 384p model variant
# width = 640
# height = 384
# used for 768p model variant
width = 1280
height = 768
image = Image.open('assets/the_great_wall.jpg').convert("RGB").resize((width, height))
prompt = "FPV flying over the Great Wall"
with torch.no_grad(), torch.cuda.amp.autocast(enabled=True, dtype=torch_dtype):
frames = model.generate_i2v(
prompt=prompt,
input_image=image,
num_inference_steps=[10, 10, 10],
temp=16,
video_guidance_scale=4.0,
output_type="pil",
save_memory=True, # If you have enough GPU memory, set it to `False` to improve vae decoding speed
)
export_to_video(frames, "./image_to_video_sample.mp4", fps=24)
```
#### CPU offloading
We also support two types of CPU offloading to reduce GPU memory requirements. Note that they may sacrifice efficiency.
* Adding a `cpu_offloading=True` parameter to the generate function allows inference with **less than 12GB** of GPU memory. This feature was contributed by [@Ednaordinary](https://github.com/Ednaordinary), see [#23](https://github.com/jy0205/Pyramid-Flow/pull/23) for details.
* Calling `model.enable_sequential_cpu_offload()` before the above procedure allows inference with **less than 8GB** of GPU memory. This feature was contributed by [@rodjjo](https://github.com/rodjjo), see [#75](https://github.com/jy0205/Pyramid-Flow/pull/75) for details.
#### MPS backend
Thanks to [@niw](https://github.com/niw), Apple Silicon users (e.g. MacBook Pro with M2 24GB) can also try our model using the MPS backend! Please see [#113](https://github.com/jy0205/Pyramid-Flow/pull/113) for the details.
### 3. Multi-GPU Inference
For users with multiple GPUs, we provide an [inference script](https://github.com/jy0205/Pyramid-Flow/blob/main/scripts/inference_multigpu.sh) that uses sequence parallelism to save memory on each GPU. This also brings a big speedup, taking only 2.5 minutes to generate a 5s, 768p, 24fps video on 4 A100 GPUs (vs. 5.5 minutes on a single A100 GPU). Run it on 2 GPUs with the following command:
```bash
CUDA_VISIBLE_DEVICES=0,1 sh scripts/inference_multigpu.sh
```
It currently supports 2 or 4 GPUs (For SD3 Version), with more configurations available in the original script. You can also launch a [multi-GPU Gradio demo](https://github.com/jy0205/Pyramid-Flow/blob/main/scripts/app_multigpu_engine.sh) created by [@tpc2233](https://github.com/tpc2233), see [#59](https://github.com/jy0205/Pyramid-Flow/pull/59) for details.
> Spoiler: We didn't even use sequence parallelism in training, thanks to our efficient pyramid flow designs.
### 4. Usage tips
* The `guidance_scale` parameter controls the visual quality. We suggest using a guidance within [7, 9] for the 768p checkpoint during text-to-video generation, and 7 for the 384p checkpoint.
* The `video_guidance_scale` parameter controls the motion. A larger value increases the dynamic degree and mitigates the autoregressive generation degradation, while a smaller value stabilizes the video.
* For 10-second video generation, we recommend using a guidance scale of 7 and a video guidance scale of 5.
## Training
### 1. Training VAE
The hardware requirements for training VAE are at least 8 A100 GPUs. Please refer to [this document](https://github.com/jy0205/Pyramid-Flow/blob/main/docs/VAE.md). This is a [MAGVIT-v2](https://arxiv.org/abs/2310.05737) like continuous 3D VAE, which should be quite flexible. Feel free to build your own video generative model on this part of VAE training code.
### 2. Finetuning DiT
The hardware requirements for finetuning DiT are at least 8 A100 GPUs. Please refer to [this document](https://github.com/jy0205/Pyramid-Flow/blob/main/docs/DiT.md). We provide instructions for both autoregressive and non-autoregressive versions of Pyramid Flow. The former is more research oriented and the latter is more stable (but less efficient without temporal pyramid).
## Gallery
The following video examples are generated at 5s, 768p, 24fps. For more results, please visit our [project page](https://pyramid-flow.github.io).
<table class="center" border="0" style="width: 100%; text-align: left;">
<tr>
<td><video src="https://github.com/user-attachments/assets/5b44a57e-fa08-4554-84a2-2c7a99f2b343" autoplay muted loop playsinline></video></td>
<td><video src="https://github.com/user-attachments/assets/5afd5970-de72-40e2-900d-a20d18308e8e" autoplay muted loop playsinline></video></td>
</tr>
<tr>
<td><video src="https://github.com/user-attachments/assets/1d44daf8-017f-40e9-bf18-1e19c0a8983b" autoplay muted loop playsinline></video></td>
<td><video src="https://github.com/user-attachments/assets/7f5dd901-b7d7-48cc-b67a-3c5f9e1546d2" autoplay muted loop playsinline></video></td>
</tr>
</table>
## Comparison
On VBench ([Huang et al., 2024](https://huggingface.co/spaces/Vchitect/VBench_Leaderboard)), our method surpasses all the compared open-source baselines. Even with only public video data, it achieves comparable performance to commercial models like Kling ([Kuaishou, 2024](https://kling.kuaishou.com/en)) and Gen-3 Alpha ([Runway, 2024](https://runwayml.com/research/introducing-gen-3-alpha)), especially in the quality score (84.74 vs. 84.11 of Gen-3) and motion smoothness.

We conduct an additional user study with 20+ participants. As can be seen, our method is preferred over open-source models such as [Open-Sora](https://github.com/hpcaitech/Open-Sora) and [CogVideoX-2B](https://github.com/THUDM/CogVideo) especially in terms of motion smoothness.

## Acknowledgement
We are grateful for the following awesome projects when implementing Pyramid Flow:
* [SD3 Medium](https://huggingface.co/stabilityai/stable-diffusion-3-medium) and [Flux 1.0](https://huggingface.co/black-forest-labs/FLUX.1-dev): State-of-the-art image generation models based on flow matching.
* [Diffusion Forcing](https://boyuan.space/diffusion-forcing) and [GameNGen](https://gamengen.github.io): Next-token prediction meets full-sequence diffusion.
* [WebVid-10M](https://github.com/m-bain/webvid), [OpenVid-1M](https://github.com/NJU-PCALab/OpenVid-1M) and [Open-Sora Plan](https://github.com/PKU-YuanGroup/Open-Sora-Plan): Large-scale datasets for text-to-video generation.
* [CogVideoX](https://github.com/THUDM/CogVideo): An open-source text-to-video generation model that shares many training details.
* [Video-LLaMA2](https://github.com/DAMO-NLP-SG/VideoLLaMA2): An open-source video LLM for our video recaptioning.
## Citation
Consider giving this repository a star and cite Pyramid Flow in your publications if it helps your research.
```
@article{jin2024pyramidal,
title={Pyramidal Flow Matching for Efficient Video Generative Modeling},
author={Jin, Yang and Sun, Zhicheng and Li, Ningyuan and Xu, Kun and Xu, Kun and Jiang, Hao and Zhuang, Nan and Huang, Quzhe and Song, Yang and Mu, Yadong and Lin, Zhouchen},
jounal={arXiv preprint arXiv:2410.05954},
year={2024}
}
``` | {
"source": "jy0205/Pyramid-Flow",
"title": "README.md",
"url": "https://github.com/jy0205/Pyramid-Flow/blob/main/README.md",
"date": "2024-10-06T13:06:31",
"stars": 2795,
"description": "Code of Pyramidal Flow Matching for Efficient Video Generative Modeling",
"file_size": 16162
} |
# Pyramid Flow's DiT Finetuning Guide
This is the finetuning guide for the DiT in Pyramid Flow. We provide instructions for both autoregressive and non-autoregressive versions. The former is more research oriented and the latter is more stable (but less efficient without temporal pyramid). Please refer to [another document](https://github.com/jy0205/Pyramid-Flow/blob/main/docs/VAE) for VAE finetuning.
## Hardware Requirements
+ DiT finetuning: At least 8 A100 GPUs.
## Prepare the Dataset
The training dataset should be arranged into a json file, with `video`, `text` fields. Since the video vae latent extraction is very slow, we strongly recommend you to pre-extract the video vae latents to save the training time. We provide a video vae latent extraction script in folder `tools`. You can run it with the following command:
```bash
sh scripts/extract_vae_latent.sh
```
(optional) Since the T5 text encoder will cost a lot of GPU memory, pre-extract the text features will save the training memory. We also provide a text feature extraction script in folder `tools`. You can run it with the following command:
```bash
sh scripts/extract_text_feature.sh
```
The final training annotation json file should look like the following format:
```
{"video": video_path, "text": text prompt, "latent": extracted video vae latent, "text_fea": extracted text feature}
```
We provide the example json annotation files for [video](https://github.com/jy0205/Pyramid-Flow/blob/main/annotation/video_text.jsonl) and [image](https://github.com/jy0205/Pyramid-Flow/blob/main/annotation/image_text.jsonl)) training in the `annotation` folder. You can refer them to prepare your training dataset.
## Run Training
We provide two types of training scripts: (1) autoregressive video generation training with temporal pyramid. (2) Full-sequence diffusion training with pyramid-flow for both text-to-image and text-to-video training. This corresponds to the following two script files. Running these training scripts using at least 8 GPUs:
+ `scripts/train_pyramid_flow.sh`: The autoregressive video generation training with temporal pyramid.
```bash
sh scripts/train_pyramid_flow.sh
```
+ `scripts/train_pyramid_flow_without_ar.sh`: Using pyramid-flow for full-sequence diffusion training.
```bash
sh scripts/train_pyramid_flow_without_ar.sh
```
## Tips
+ For the 768p version, make sure to add the args: `--gradient_checkpointing`
+ Param `NUM_FRAMES` should be set to a multiple of 8
+ For the param `video_sync_group`, it indicates the number of process that accepts the same input video, used for temporal pyramid AR training. We recommend to set this value to 4, 8 or 16. (16 is better if you have more GPUs)
+ Make sure to set `NUM_FRAMES % VIDEO_SYNC_GROUP == 0`, `GPUS % VIDEO_SYNC_GROUP == 0`, and `BATCH_SIZE % 4 == 0` | {
"source": "jy0205/Pyramid-Flow",
"title": "docs/DiT.md",
"url": "https://github.com/jy0205/Pyramid-Flow/blob/main/docs/DiT.md",
"date": "2024-10-06T13:06:31",
"stars": 2795,
"description": "Code of Pyramidal Flow Matching for Efficient Video Generative Modeling",
"file_size": 2833
} |
# Pyramid Flow's VAE Training Guide
This is the training guide for a [MAGVIT-v2](https://arxiv.org/abs/2310.05737) like continuous 3D VAE, which should be quite flexible. Feel free to build your own video generative model on this part of VAE training code. Please refer to [another document](https://github.com/jy0205/Pyramid-Flow/blob/main/docs/DiT) for DiT finetuning.
## Hardware Requirements
+ VAE training: At least 8 A100 GPUs.
## Prepare the Dataset
The training of our causal video vae uses both image and video data. Both of them should be arranged into a json file, with `video` or `image` field. The final training annotation json file should look like the following format:
```
# For Video
{"video": video_path}
# For Image
{"image": image_path}
```
## Run Training
The causal video vae undergoes a two-stage training.
+ Stage-1: image and video mixed training
+ Stage-2: pure video training, using context parallel to load video with more video frames
The VAE training script is `scripts/train_causal_video_vae.sh`, run it as follows:
```bash
sh scripts/train_causal_video_vae.sh
```
We also provide a VAE demo `causal_video_vae_demo.ipynb` for image and video reconstruction.
> The original vgg lpips download URL is not available, I have shared the one we used in this [URL](https://drive.google.com/file/d/1YeFlX5BKKw-HGkjNd1r7DSwas1iJJwqC/view). You can download it and replace the LPIPS_CKPT with the correct path.
## Tips
+ For stage-1, we use a mixed image and video training. Add the param `--use_image_video_mixed_training` to support the mixed training. We set the image ratio to 0.1 by default.
+ Set the `resolution` to 256 is enough for VAE training.
+ For stage-1, the `max_frames` is set to 17. It means we use 17 sampled video frames for training.
+ For stage-2, we open the param `use_context_parallel` to distribute long video frames to multiple GPUs. Make sure to set `GPUS % CONTEXT_SIZE == 0` and `NUM_FRAMES=17 * CONTEXT_SIZE + 1` | {
"source": "jy0205/Pyramid-Flow",
"title": "docs/VAE.md",
"url": "https://github.com/jy0205/Pyramid-Flow/blob/main/docs/VAE.md",
"date": "2024-10-06T13:06:31",
"stars": 2795,
"description": "Code of Pyramidal Flow Matching for Efficient Video Generative Modeling",
"file_size": 1984
} |
<h1 align="center">
Pipet
</h1>
<p align="center">
<a href="https://goreportcard.com/report/github.com/bjesus/pipet"><img src="https://goreportcard.com/badge/github.com/bjesus/pipet" /></a>
<a href="https://opensource.org/licenses/MIT"><img src="https://img.shields.io/badge/License-MIT-yellow.svg" /></a>
<a href="https://pkg.go.dev/github.com/bjesus/pipet"><img src="https://pkg.go.dev/badge/github.com/bjesus/pipet.svg" alt="Go Reference"></a>
<br/>
a swiss-army tool for scraping and extracting data from online assets, made for hackers
</p>
<p align="center">
<img src="https://github.com/user-attachments/assets/e23a40de-c391-46a5-a30c-b825cc02ee8a" height="200">
</p>
Pipet is a command line based web scraper. It supports 3 modes of operation - HTML parsing, JSON parsing, and client-side JavaScript evaluation. It relies heavily on existing tools like curl, and it uses unix pipes for extending its built-in capabilities.
You can use Pipet to track a shipment, get notified when concert tickets are available, stock price changes, and any other kind of information that appears online.
# Try it out!
1. Create a `hackernews.pipet` file containing this:
```
curl https://news.ycombinator.com/
.title .titleline
span > a
.sitebit a
```
2. Run `go run github.com/bjesus/pipet/cmd/pipet@latest hackernews.pipet` or install Pipet and run `pipet hackernews.pipet`
3. See all of the latest hacker news in your terminal!
<details><summary>Use custom separators</summary>
Use the `--separator` (or `-s`) flag to specify custom separators for text output. For example, run `pipet -s "\n" -s "->" hackernews.pipet` to see each item in a new line, with `->` between the title and the domain.</details>
<details><summary>Get as JSON</summary>
Use the `--json` flag to make Pipet collect the results into a nice JSON. For example, run `pipet --json hackernews.pipet` to get a JSON representation of the above results.</details>
<details><summary>Render to a template</summary>
Add a template file called `hackernews.tpl` next to your `hackernews.pipet` file with this content:
```
<ul>
{{range $index, $item := index (index . 0) 0}}
<li>{{index $item 0}} ({{index $item 1}})</li>
{{end}}
</ul>
```
Now run `pipet hackernews.pipet` again and Pipet will automatically detect your template file, and render the results to it.
</details>
<details><summary>Use pipes</summary>
Use Unix pipes after your queries, as if they were running in your shell. For example, count the characters in each title (with `wc`) and extract the full article URL (with [htmlq](https://github.com/mgdm/htmlq)):
```
curl https://news.ycombinator.com/
.title .titleline
span > a
span > a | wc -c
.sitebit a
.sitebit a | htmlq --attribute href a
```
</details>
<details><summary>Monitor for changes</summary>
Set an interval and a command to run on change, and have Pipet notify you when something happened. For example, get a notification whenever the Hacker News #1 story is different:
```
curl https://news.ycombinator.com/
.title .titleline a
```
Run it with `pipet --interval 60 --on-change "notify-send {}" hackernews.pipet`
</details>
# Installation
## Pre-built
Download the latest release from the [Releases](https://github.com/bjesus/pipet/releases/) page. `chmod +x pipet` and run `./pipet`.
## Compile
This installation method requires Go to be installed on your system.
You can use Go to install Pipet using `go install github.com/bjesus/pipet/cmd/pipet@latest`. Otherwise you can run it without installing using `go run`.
## Distros
Packages are currently available for [Arch Linux](https://aur.archlinux.org/packages/pipet-git), [Homebrew](https://formulae.brew.sh/formula/pipet) and [Nix](https://search.nixos.org/packages?channel=unstable&show=pipet&from=0&size=50&sort=relevance&type=packages&query=pipet).
# Usage
The only required argument for Pipet is the path to your `.pipet` file. Other than this, the `pipet` command accepts the following flags:
- `--json`, `-j` - Output as JSON (default: false)
- `--template value`, `-t value` - Specify a path to a template file. You can also simply name the file like your `.pipet` file but with a `.tpl` extension for it to be auto-detected.
- `--separator value`, `-s value` - Set a separator for text output (can be used multiple times for setting different separators for different levels of data nesting)
- `---max-pages value`, `-p value` - Maximum number of pages to scrape (default: 3)
- `--interval value`, `-i value` - Rerun Pipet after X seconds. Use 0 to disable (default: 0)
- `--on-change value`, `-c value` - A command to run when the pipet result is new
- `--verbose`, `-v` - Enable verbose logging (default: false)
- `--version` - Print the Pipet version
- `--help`, `-h` - Show help
# Pipet files
Pipet files describe where and how to get the data you are interested in. They are normal text files containing one or more blocks separated by an empty line. Lines beginning with `//` are ignored and can be used for comments. Every block can have 3 sections:
1. **Resource** - The first line containing the URL and the tool we are using for scraping
2. **Queries** - The following lines describing the selectors reaching the data we would like scrap
3. **Next page** - An _optional_ last line starting with `>` describing the selector pointing to the "next page" of data
Below is an example Pipet file.
```
// Read Wikipedia's "On This Day" and the subject of today's featured article
curl https://en.wikipedia.org/wiki/Main_Page
div#mp-otd li
body
div#mp-tfa > p > b > a
// Get the weather in Alert, Canada
curl https://wttr.in/Alert%20Canada?format=j1
current_condition.0.FeelsLikeC
current_condition.0.FeelsLikeF
// Check how popular the Pipet repo is
playwright https://github.com/bjesus/pipet
Array.from(document.querySelectorAll('.about-margin .Link')).map(e => e.innerText.trim()).filter(t=> /^\d/.test(t) )
```
## Resource
Resource lines can start with either `curl` or `playwright`.
### curl
Resource lines starting with `curl` will be executed using curl. This is meant so that you can use your browser to find the request containing the information you are interested in, right click it, choose "Copy as cURL", and paste in your Pipet file. This ensures that your headers and cookies are all the same, making it very easy to get data that is behind a login page or hidden from bots. For example, this is a perfectly valid first line for a block: `curl 'https://news.ycombinator.com/' --compressed -H 'User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:131.0) Gecko/20100101 Firefox/131.0' -H 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/png,image/svg+xml,*/*;q=0.8' -H 'Accept-Language: en-US,en;q=0.5' -H 'Accept-Encoding: gzip, deflate, br, zstd' -H 'DNT: 1' -H 'Sec-GPC: 1' -H 'Connection: keep-alive' -H 'Upgrade-Insecure-Requests: 1' -H 'Sec-Fetch-Dest: document' -H 'Sec-Fetch-Mode: navigate' -H 'Sec-Fetch-Site: none' -H 'Sec-Fetch-User: ?1' -H 'Priority: u=0, i' -H 'Pragma: no-cache' -H 'Cache-Control: no-cache' -H 'TE: trailers'`.
### Playwright
Resource lines starting with `playwright` will use a headless browser to navigate to the specified URL. If you don't have a headless browser installed, Pipet will attempt to download one for you.
## Queries
Query lines define 3 things:
1. The way to the exact pieces of data you would like to extract (e.g. using CSS selectors)
2. The data structure your output will use (e.g. every title and URL should be grouped together by item)
3. The way the data will be processed (e.g. using Unix pipes) before it is printed
Pipet uses 3 different query types - for HTML, for JSON, and for when loading pages with Playwright.
### HTML Queries
HTML Queries use CSS Selectors to select specific elements. Whitespace nesting is used for iterations - parent lines will run as iterators, making their children lines run for each occurrence of the parent selector. This means that you can use nesting to determine the structure of your final output. See the following 3 examples:
<details><summary>Get only the first title and first URL</summary>
```
curl https://news.ycombinator.com/
.title .titleline > a
.sitebit a
```
</details><details><summary>Get all the titles, and then get all URLs</summary>
```
curl https://news.ycombinator.com/
.title .titleline
span > a
.title .titleline
.sitebit a
```
</details><details><summary>Get all the title and URL for each story</summary>
```
curl https://news.ycombinator.com/
.title .titleline
span > a
.sitebit a
```
</details>
When writing your child selectors, note that the whole document isn't available anymore. Pipet is passing only your parent HTML to the child iterations.
By default, Pipet will return the `innerText` of your elements. If you need to another piece of data, use Unix pipes. When piping HTML elements, Pipet will pipe the element's complete HTML. For example, you can use `| htmq --attr href a` to extract the `href` attribute from links.
### JSON Queries
JSON Queries use the [GJSON syntax](https://github.com/tidwall/gjson/blob/master/SYNTAX.md) to select specific elements. Here too, whitespace nesting is used for iterations - parent lines will run as iterators, making their children lines run for each occurrence of the parent selector. If you don't like GJSON, that's okay. For example, you can use `jq` by passing parts or the complete JSON to it using Unix pipes, like `@this | jq '.[].firstName'`.
When using pipes, Pipet will attempt to parse the returned string. If it's valid JSON, it will be parsed and injected as an object into the Pipet result.
<details><summary>Querying and jq usage</summary>
The example below will return the latest water temperature in Amsterdam NDSM, and then pipe the complete JSON to `jq` so it will combine the coordinates of the reading into one field.
```
curl https://waterinfo.rws.nl/api/detail/get?locationSlug=NDSM-werf-(o)(NDS1)&mapType=watertemperatuur
latest.data
@this | jq -r '"\(.coordinatex), \(.coordinatey)"'
```
</details><details><summary>Iterations</summary>
This will return times for bus deparatures. Note the two types of iterations - the first line is GJSON query that returns the `ExpectedDepartureTime` for each trip, while the the following lines iterates over each trip object using the nested lines below it, allowing us to return multiple keys - `ExpectedDepartureTime` & `TripStopStatus`.
```
curl http://v0.ovapi.nl/tpc/30005093
30005093.Passes.@values.#.ExpectedDepartureTime
30005093.Passes.@values
ExpectedDepartureTime
TripStopStatus
```
</details><details><summary>CSV export</summary>
We can create a simple CSV file by using the previous iteration and configurating a separator
```
curl http://v0.ovapi.nl/tpc/30005093
30005093.Passes.@values
ExpectedDepartureTime
TripStopStatus
```
Run using `pipet -s '\n' water.pipet > output.csv` to generate a CSV file.
</details>
### Playwright Queries
Playwright Queries are different and do not use whitespace nesting. Instead, queries here are simply JavaScript code that will be evaluated after the webpage loaded. If the JavaScript code returns something that can be serialized as JSON, it will be included in Pipet's output. Otherwise, you can write JavaScript that will click, scroll or perform any other action you might want.
<details><summary>Simple Playwright example</summary>
This example will return a string like `80 stars, 2 watching, 2 forks` after visiting the Pipet repo on Github.
```
playwright https://github.com/bjesus/pipet
Array.from(document.querySelectorAll('.about-margin .Link')).map(e => e.innerText.trim()).filter(t=> /^\d/.test(t) )
```
Note that if you copy the second line and paste it in your browser console while visiting https://github.com/bjesus/pipet, you'd get exactly the same result. The vice-versa is also true - if your code worked in the browser, it should work in Pipet too.
</details>
## Next page
The Next Page line lets you specify a CSS selector that will be used to determine the link to the next page of data. Pipet will then follow it and execute the same queries over it. For example, see this `hackernews.pipet` file:
```
curl https://news.ycombinator.com/
.title .titleline
span > a
.sitebit a
> a.morelink
```
The Next Page line is currently only available when working with `curl` and HTML files. | {
"source": "bjesus/pipet",
"title": "README.md",
"url": "https://github.com/bjesus/pipet/blob/main/README.md",
"date": "2024-08-31T18:00:43",
"stars": 2786,
"description": "Swiss-army tool for scraping and extracting data from online assets, made for hackers ",
"file_size": 12424
} |
# LLM-engineer-handbook
🔥 Large Language Models(LLM) have taken the ~~NLP community~~ ~~AI community~~ **the Whole World** by storm.
Why do we create this repo?
- Everyone can now build an LLM demo in minutes, but it takes a real LLM/AI expert to close the last mile of performance, security, and scalability gaps.
- The LLM space is complicated! This repo provides a curated list to help you navigate so that you are more likely to build production-grade LLM applications. It includes a collection of Large Language Model frameworks and tutorials, covering model training, serving, fine-tuning, LLM applications & prompt optimization, and LLMOps.
*However, classical ML is not going away. Even LLMs need them. We have seen classical models used for protecting data privacy, detecing hallucinations, and more. So, do not forget to study the fundamentals of classical ML.*
## Overview
The current workflow might look like this: You build a demo using an existing application library or directly from LLM model provider SDKs. It works somehow, but you need to further create evaluation and training datasets to optimize the performance (e.g., accuracy, latency, cost).
You can do prompt engineering or auto-prompt optimization; you can create a larger dataset to fine-tune the LLM or use Direct Preference Optimization (DPO) to align the model with human preferences.
Then you need to consider the serving and LLMOps to deploy the model at scale and pipelines to refresh the data.
We organize the resources by (1) tracking all libraries, frameworks, and tools, (2) learning resources on the whole LLM lifecycle, (3) understanding LLMs, (4) social accounts and community, and (5) how to contribute to this repo.
- [LLM-engineer-handbook](#llm-engineer-handbook)
- [Overview](#overview)
- [Libraries \& Frameworks \& Tools](#libraries--frameworks--tools)
- [Applications](#applications)
- [Pretraining](#pretraining)
- [Fine-tuning](#fine-tuning)
- [Serving](#serving)
- [Prompt Management](#prompt-management)
- [Datasets](#datasets)
- [Benchmarks](#benchmarks)
- [Learning Resources for LLMs](#learning-resources-for-llms)
- [Applications](#applications-1)
- [Agent](#agent)
- [Modeling](#modeling)
- [Training](#training)
- [Fine-tuning](#fine-tuning-1)
- [Fundamentals](#fundamentals)
- [Books](#books)
- [Newsletters](#newsletters)
- [Auto-optimization](#auto-optimization)
- [Understanding LLMs](#understanding-llms)
- [Social Accounts \& Community](#social-accounts--community)
- [Social Accounts](#social-accounts)
- [Community](#community)
- [Contributing](#contributing)
# Libraries & Frameworks & Tools
## Applications
**Build & Auto-optimize**
- [AdalFlow](https://github.com/SylphAI-Inc/AdalFlow) - The library to build & auto-optimize LLM applications, from Chatbot, RAG, to Agent by [SylphAI](https://www.sylph.ai/).
- [dspy](https://github.com/stanfordnlp/dspy) - DSPy: The framework for programming—not prompting—foundation models.
**Build**
- [LlamaIndex](https://github.com/jerryjliu/llama_index) — A Python library for augmenting LLM apps with data.
- [LangChain](https://github.com/hwchase17/langchain) — A popular Python/JavaScript library for chaining sequences of language model prompts.
- [Haystack](https://github.com/deepset-ai/haystack) — Python framework that allows you to build applications powered by LLMs.
- [Instill Core](https://github.com/instill-ai/instill-core) — A platform built with Go for orchestrating LLMs to create AI applications.
**Prompt Optimization**
- [AutoPrompt](https://github.com/Eladlev/AutoPrompt) - A framework for prompt tuning using Intent-based Prompt Calibration.
- [PromptFify](https://github.com/promptslab/Promptify) - A library for prompt engineering that simplifies NLP tasks (e.g., NER, classification) using LLMs like GPT.
**Others**
- [LiteLLM](https://github.com/BerriAI/litellm) - Python SDK, Proxy Server (LLM Gateway) to call 100+ LLM APIs in OpenAI format.
## Pretraining
- [PyTorch](https://pytorch.org/) - PyTorch is an open source machine learning library based on the Torch library, used for applications such as computer vision and natural language processing.
- [TensorFlow](https://www.tensorflow.org/) - TensorFlow is an open source machine learning library developed by Google.
- [JAX](https://github.com/jax-ml/jax) - Google’s library for high-performance computing and automatic differentiation.
- [tinygrad](https://github.com/tinygrad/tinygrad) - A minimalistic deep learning library with a focus on simplicity and educational use, created by George Hotz.
- [micrograd](https://github.com/karpathy/micrograd) - A simple, lightweight autograd engine for educational purposes, created by Andrej Karpathy.
## Fine-tuning
- [Transformers](https://huggingface.co/docs/transformers/en/installation) - Hugging Face Transformers is a popular library for Natural Language Processing (NLP) tasks, including fine-tuning large language models.
- [Unsloth](https://github.com/unslothai/unsloth) - Finetune Llama 3.2, Mistral, Phi-3.5 & Gemma 2-5x faster with 80% less memory!
- [LitGPT](https://github.com/Lightning-AI/litgpt) - 20+ high-performance LLMs with recipes to pretrain, finetune, and deploy at scale.
- [AutoTrain](https://github.com/huggingface/autotrain-advanced) - No code fine-tuning of LLMs and other machine learning tasks.
## Top Models
- [DeepSeek R1](https://github.com/deepseek-ai/DeepSeek-R1) - The most popular GPTo1 comparable open-source reasoning model. Read their technical report + check out their github.
## Serving
- [TorchServe](https://pytorch.org/serve/) - An open-source model serving library developed by AWS and Facebook specifically for PyTorch models, enabling scalable deployment, model versioning, and A/B testing.
- [TensorFlow Serving](https://www.tensorflow.org/tfx/guide/serving) - A flexible, high-performance serving system for machine learning models, designed for production environments, and optimized for TensorFlow models but also supports other formats.
- [Ray Serve](https://docs.ray.io/en/latest/serve/index.html) - Part of the Ray ecosystem, Ray Serve is a scalable model-serving library that supports deployment of machine learning models across multiple frameworks, with built-in support for Python-based APIs and model pipelines.
- [NVIDIA TensorRT-LLM](https://github.com/NVIDIA/TensorRT-LLM) - TensorRT-LLM is NVIDIA's compiler for transformer-based models (LLMs), providing state-of-the-art optimizations on NVIDIA GPUs.
- [NVIDIA Triton Inference Server](https://developer.nvidia.com/triton-inference-server) - A high-performance inference server supporting multiple ML/DL frameworks (TensorFlow, PyTorch, ONNX, TensorRT etc.), optimized for NVIDIA GPU deployments, and ideal for both cloud and on-premises serving.
- [ollama](https://github.com/ollama/ollama) - A lightweight, extensible framework for building and running large language models on the local machine.
- [llama.cpp](https://github.com/ggerganov/llama.cpp) - A library for running LLMs in pure C/C++. Supported architectures include (LLaMA, Falcon, Mistral, MoEs, phi and more)
- [TGI](https://github.com/huggingface/text-generation-inference) - HuggingFace's text-generation-inference toolkit for deploying and serving LLMs, built on top of Rust, Python and gRPC.
- [vllm](https://github.com/vllm-project/vllm) - An optimized, high-throughput serving engine for large language models, designed to efficiently handle massive-scale inference with reduced latency.
- [sglang](https://github.com/sgl-project/sglang) - SGLang is a fast serving framework for large language models and vision language models.
- [LitServe](https://github.com/Lightning-AI/LitServe) - LitServe is a lightning-fast serving engine for any AI model of any size. Flexible. Easy. Enterprise-scale.
## Prompt Management
- [Opik](https://github.com/comet-ml/opik) - Opik is an open-source platform for evaluating, testing and monitoring LLM applications
## Datasets
Use Cases
- [Datasets](https://huggingface.co/docs/datasets/en/index) - A vast collection of ready-to-use datasets for machine learning tasks, including NLP, computer vision, and audio, with tools for easy access, filtering, and preprocessing.
- [Argilla](https://github.com/argilla-io/argilla) - A UI tool for curating and reviewing datasets for LLM evaluation or training.
- [distilabel](https://distilabel.argilla.io/latest/) - A library for generating synthetic datasets with LLM APIs or models.
Fine-tuning
- [LLMDataHub](https://github.com/Zjh-819/LLMDataHub) - A quick guide (especially) for trending instruction finetuning datasets
- [LLM Datasets](https://github.com/mlabonne/llm-datasets) - High-quality datasets, tools, and concepts for LLM fine-tuning.
Pretraining
- [IBM LLMs Granite 3.0](https://www.linkedin.com/feed/update/urn:li:activity:7259535100927725569?updateEntityUrn=urn%3Ali%3Afs_updateV2%3A%28urn%3Ali%3Aactivity%3A7259535100927725569%2CFEED_DETAIL%2CEMPTY%2CDEFAULT%2Cfalse%29) - Full list of datasets used to train IBM LLMs Granite 3.0
## Benchmarks
- [lighteval](https://github.com/huggingface/lighteval) - A library for evaluating local LLMs on major benchmarks and custom tasks.
- [evals](https://github.com/openai/evals) - OpenAI's open sourced evaluation framework for LLMs and systems built with LLMs.
- [ragas](https://github.com/explodinggradients/ragas) - A library for evaluating and optimizing LLM applications, offering a rich set of eval metrics.
Agent
- [TravelPlanner](https://osu-nlp-group.github.io/TravelPlanner/) - [paper](https://arxiv.org/pdf/2402.01622) A Benchmark for Real-World Planning with Language Agents.
# Learning Resources for LLMs
We will categorize the best resources to learn LLMs, from modeling to training, and applications.
### Applications
General
- [AdalFlow documentation](https://adalflow.sylph.ai/) - Includes tutorials from building RAG, Agent, to LLM evaluation and fine-tuning.
- [CS224N](https://www.youtube.com/watch?v=rmVRLeJRkl4) - Stanford course covering NLP fundamentals, LLMs, and PyTorch-based model building, led by Chris Manning and Shikhar Murty.
- [LLM-driven Data Engineering](https://github.com/DataExpert-io/llm-driven-data-engineering) - A playlist of 6 lectures by [Zach Wilson](https://www.linkedin.com/in/eczachly) on how LLMs will impact data pipeline development
- [LLM Course by Maxime Labonne](https://github.com/mlabonne/llm-course) - An end-to-end course for AI and ML engineers on open source LLMs.
#### Agent
Lectures
- [LLM Agents MOOC](https://youtube.com/playlist?list=PLS01nW3RtgopsNLeM936V4TNSsvvVglLc&si=LAonD5VfG9jFAOuE) - A playlist of 11 lectures by the Berkeley RDI Center on Decentralization & AI, featuring guest speakers like Yuandong Tian, Graham Neubig, Omar Khattab, and others, covering core topics on Large Language Model agents. [CS294](https://rdi.berkeley.edu/llm-agents/f24)
Projects
- [OpenHands](https://github.com/All-Hands-AI/OpenHands) - Open source agents for developers by [AllHands](https://www.all-hands.dev/).
- [CAMEL](https://github.com/camel-ai/camel) - First LLM multi-agent framework and an open-source community dedicated to finding the scaling law of agents. by [CAMEL-AI](https://www.camel-ai.org/).
- [swarm](https://github.com/openai/swarm) - Educational framework exploring ergonomic, lightweight multi-agent orchestration. Managed by OpenAI Solution team.
- [AutoGen](https://github.com/microsoft/autogen) - A programming framework for agentic AI 🤖 by Microsoft.
- [CrewAI](https://github.com/crewAIInc/crewAI) - 🤖 CrewAI: Cutting-edge framework for orchestrating role-playing, autonomous AI agents.
- [TinyTroupe](https://github.com/microsoft/TinyTroupe) - Simulates customizable personas using GPT-4 for testing, insights, and innovation by Microsoft.
### Modeling
- [Llama3 from scratch](https://github.com/naklecha/llama3-from-scratch) - llama3 implementation one matrix multiplication at a time with PyTorch.
- [Interactive LLM visualization](https://github.com/bbycroft/llm-viz) - An interactive visualization of transformers. [Visualizer](https://bbycroft.net/llm)
- [3Blue1Brown transformers visualization](https://www.youtube.com/watch?v=wjZofJX0v4M) - 3Blue1Brown's video on how transformers work.
- [Self-Attention explained as directed graph](https://x.com/akshay_pachaar/status/1853474819523965088) - An X post explaining self-attention as a directed graph by Akshay Pachaar.
### Training
- [HuggingFace's SmolLM & SmolLM2 training release](https://huggingface.co/blog/smollm) - HuggingFace's sharing on data curation methods, processed data, training recipes, and all of their code. [Github repo](https://github.com/huggingface/smollm?tab=readme-ov-file).
- [Lil'Log](https://lilianweng.github.io/) - Lilian Weng(OpenAI)'s blog on machine learning, deep learning, and AI, with a focus on LLMs and NLP.
- [Chip's Blog](https://huyenchip.com/blog/) - Chip Huyen's blog on training LLMs, including the latest research, tutorials, and best practices.
### Fine-tuning
- [DPO](https://arxiv.org/abs/2305.18290): Rafailov, Rafael, et al. "Direct preference optimization: Your language model is secretly a reward model." Advances in Neural Information Processing Systems 36 (2024). [Code](https://github.com/eric-mitchell/direct-preference-optimization).
### Fundamentals
- [Intro to LLMs](https://www.youtube.com/watch?v=zjkBMFhNj_g&t=1390s&ab_channel=AndrejKarpathy) - A 1 hour general-audience introduction to Large Language Models by Andrej Karpathy.
- [Building GPT-2 from Scratch](https://www.youtube.com/watch?v=l8pRSuU81PU&t=1564s&ab_channel=AndrejKarpathy) - A 4 hour deep dive into building GPT2 from scratch by Andrej Karpathy.
### Books
- [LLM Engineer's Handbook: Master the art of engineering large language models from concept to production](https://www.amazon.com/dp/1836200072?ref=cm_sw_r_cp_ud_dp_ZFR4XZPT7EY41ZE1M5X9&ref_=cm_sw_r_cp_ud_dp_ZFR4XZPT7EY41ZE1M5X9&social_share=cm_sw_r_cp_ud_dp_ZFR4XZPT7EY41ZE1M5X9) by Paul Iusztin , Maxime Labonne. Covers mostly the lifecycle of LLMs, including LLMOps on pipelines, deployment, monitoring, and more. [Youtube overview by Paul](https://www.youtube.com/live/6WmPfKPmoz0).
- [Build a Large Language Model from Scratch](https://www.manning.com/books/build-a-large-language-model-from-scratch) by Sebastian Raschka
- [Hands-On Large Language Models: Build, Tune, and Apply LLMs](https://www.amazon.com/Hands-Large-Language-Models-Understanding/dp/1098150961) by Jay Alammar , Maarten Grootendorst
- [Generative Deep Learning - Teaching machines to Paint, Write, Compose and Play](https://www.amazon.com/Generative-Deep-Learning-Teaching-Machines/dp/1492041947) by David Foster
### Newsletters
- [Ahead of AI](https://magazine.sebastianraschka.com/) - Sebastian Raschka's Newsletter, covering end-to-end LLMs understanding.
- [Decoding ML](https://decodingml.substack.com/) - Content on building production GenAI, RecSys and MLOps applications.
### Auto-optimization
- [TextGrad](https://github.com/zou-group/textgrad) - Automatic ''Differentiation'' via Text -- using large language models to backpropagate textual gradients.
# Understanding LLMs
It can be fun and important to understand the capabilities, behaviors, and limitations of LLMs. This can directly help with prompt engineering.
In-context Learning
- [Brown, Tom B. "Language models are few-shot learners." arXiv preprint arXiv:2005.14165 (2020).](https://rosanneliu.com/dlctfs/dlct_200724.pdf)
Reasoning & Planning
- [Kambhampati, Subbarao, et al. "LLMs can't plan, but can help planning in LLM-modulo frameworks." arXiv preprint arXiv:2402.01817 (2024).](https://arxiv.org/abs/2402.01817)
- [Mirzadeh, Iman, et al. "Gsm-symbolic: Understanding the limitations of mathematical reasoning in large language models." arXiv preprint arXiv:2410.05229 (2024).](https://arxiv.org/abs/2410.05229) By Apple.
# Social Accounts & Community
## Social Accounts
Social accounts are the best ways to stay up-to-date with the lastest LLM research, industry trends, and best practices.
| Name | Social | Expertise |
|---------------------|-------------------------------------------------------|-----------------------------|
| Li Yin | [LinkedIn](https://www.linkedin.com/in/li-yin-ai) | AdalFlow Author & SylphAI founder |
| Chip Huyen | [LinkedIn](https://www.linkedin.com/in/chiphuyen) | AI Engineering & ML Systems |
| Damien Benveniste, PhD | [LinkedIn](https://www.linkedin.com/in/damienbenveniste/) | ML Systems & MLOps |
| Jim Fan | [LinkedIn](https://www.linkedin.com/in/drjimfan/) | LLM Agents & Robotics |
| Paul Iusztin | [LinkedIn](https://www.linkedin.com/in/pauliusztin/) | LLM Engineering & LLMOps |
| Armand Ruiz | [LinkedIn](https://www.linkedin.com/in/armand-ruiz/) | AI Engineering Director at IBM |
| Alex Razvant | [LinkedIn](https://www.linkedin.com/in/arazvant/) | AI/ML Engineering |
| Pascal Biese | [LinkedIn](https://www.linkedin.com/in/pascalbiese/) | LLM Papers Daily |
| Maxime Labonne | [LinkedIn](https://www.linkedin.com/in/maxime-labonne/) | LLM Fine-Tuning |
| Sebastian Raschka | [LinkedIn](https://www.linkedin.com/in/sebastianraschka/) | LLMs from Scratch |
| Zach Wilson | [LinkedIn](https://www.linkedin.com/in/eczachly) | Data Engineering for LLMs |
| Adi Polak | [LinkedIn](https://www.linkedin.com/in/polak-adi/) | Data Streaming for LLMs |
| Eduardo Ordax | [LinkedIn](https://www.linkedin.com/in/eordax/) | GenAI voice @ AWS |
## Community
| Name | Social | Scope |
|---------------------|-------------------------------------------------------|-----------------------------|
| AdalFlow | [Discord](https://discord.gg/ezzszrRZvT) | LLM Engineering, auto-prompts, and AdalFlow discussions&contributions |
# Contributing
Only with the power of the community can we keep this repo up-to-date and relevant. If you have any suggestions, please open an issue or a direct pull request.
I will keep some pull requests open if I'm not sure if they are not an instant fit for this repo, you could vote for them by adding 👍 to them.
Thanks to the community, this repo is getting read by more people every day.
[](https://star-history.com/#SylphAI-Inc/LLM-engineer-handbook&Date)
---
🤝 Please share so we can continue investing in it and make it the go-to resource for LLM engineers—whether they are just starting out or looking to stay updated in the field.
[](https://twitter.com/intent/tweet?text=Check+out+this+awesome+repository+for+LLM+engineers!&url=https://github.com/LLM-engineer-handbook)
[](https://www.linkedin.com/sharing/share-offsite/?url=https://github.com/LLM-engineer-handbook)
---
If you have any question about this opinionated list, do not hesitate to contact [Li Yin](https://www.linkedin.com/in/li-yin-ai) | {
"source": "SylphAI-Inc/LLM-engineer-handbook",
"title": "README.md",
"url": "https://github.com/SylphAI-Inc/LLM-engineer-handbook/blob/main/README.md",
"date": "2024-11-04T20:53:14",
"stars": 2718,
"description": "A curated list of Large Language Model resources, covering model training, serving, fine-tuning, and building LLM applications.",
"file_size": 19613
} |
# GLM-4-Voice
<p align="center">
📄<a href="https://arxiv.org/abs/2412.02612" target="_blank"> Report </a> • 🤗 <a href="https://huggingface.co/THUDM/glm-4-voice-9b" target="_blank">HF Repo</a> • 🤖 <a href="https://modelscope.cn/studios/ZhipuAI/GLM-4-Voice-Demo" target="_blank">Demo</a> • 🐦 <a href="https://twitter.com/thukeg" target="_blank">Twitter</a>
</p>
Read this in [English](./README_en.md)
GLM-4-Voice 是智谱 AI 推出的端到端语音模型。GLM-4-Voice 能够直接理解和生成中英文语音,进行实时语音对话,并且能够遵循用户的指令要求改变语音的情感、语调、语速、方言等属性。
## Model Architecture

GLM-4-Voice 由三个部分组成:
* GLM-4-Voice-Tokenizer: 通过在 [Whisper](https://github.com/openai/whisper) 的 Encoder 部分增加 Vector Quantization 并在 ASR 数据上有监督训练,将连续的语音输入转化为离散的 token。每秒音频平均只需要用 12.5 个离散 token 表示。
* GLM-4-Voice-Decoder: 基于 [CosyVoice](https://github.com/FunAudioLLM/CosyVoice) 的 Flow Matching 模型结构训练的支持流式推理的语音解码器,将离散化的语音 token 转化为连续的语音输出。最少只需要 10 个语音 token 即可开始生成,降低端到端对话延迟。
* GLM-4-Voice-9B: 在 [GLM-4-9B](https://github.com/THUDM/GLM-4) 的基础上进行语音模态的预训练和对齐,从而能够理解和生成离散化的语音 token。
预训练方面,为了攻克模型在语音模态下的智商和合成表现力两个难关,我们将 Speech2Speech 任务解耦合为“根据用户音频做出文本回复”和“根据文本回复和用户语音合成回复语音”两个任务,并设计两种预训练目标,分别基于文本预训练数据和无监督音频数据合成语音-文本交错数据以适配这两种任务形式。GLM-4-Voice-9B 在 GLM-4-9B 的基座模型基础之上,经过了数百万小时音频和数千亿 token 的音频文本交错数据预训练,拥有很强的音频理解和建模能力。
对齐方面,为了支持高质量的语音对话,我们设计了一套流式思考架构:根据用户语音,GLM-4-Voice 可以流式交替输出文本和语音两个模态的内容,其中语音模态以文本作为参照保证回复内容的高质量,并根据用户的语音指令要求做出相应的声音变化,在最大程度保留语言模型智商的情况下仍然具有端到端建模的能力,同时具备低延迟性,最低只需要输出 20 个 token 便可以合成语音。
## Model List
| Model | Type | Download |
|:---------------------:|:----------------:|:------------------------------------------------------------------------------------------------------------------------------------------------:|
| GLM-4-Voice-Tokenizer | Speech Tokenizer | [🤗 Huggingface](https://huggingface.co/THUDM/glm-4-voice-tokenizer) [🤖 ModelScope](https://modelscope.cn/models/ZhipuAI/glm-4-voice-tokenizer) |
| GLM-4-Voice-9B | Chat Model | [🤗 Huggingface](https://huggingface.co/THUDM/glm-4-voice-9b) [🤖 ModelScope](https://modelscope.cn/models/ZhipuAI/glm-4-voice-9b) |
| GLM-4-Voice-Decoder | Speech Decoder | [🤗 Huggingface](https://huggingface.co/THUDM/glm-4-voice-decoder) [🤖 ModelScope](https://modelscope.cn/models/ZhipuAI/glm-4-voice-decoder) |
## Usage
我们提供了可以直接启动的 Web Demo。用户可以输入语音或文本,模型会同时给出语音和文字回复。

### Preparation
首先下载仓库
```shell
git clone --recurse-submodules https://github.com/THUDM/GLM-4-Voice
cd GLM-4-Voice
```
然后安装依赖。也可以使用我们提供的镜像 `zhipuai/glm-4-voice:0.1` 以跳过这一步。
```shell
pip install -r requirements.txt
```
由于 Decoder 模型不支持通过 `transformers` 初始化,因此 checkpoint 需要单独下载。
```shell
# git 模型下载,请确保已安装 git-lfs
git lfs install
git clone https://huggingface.co/THUDM/glm-4-voice-decoder
```
### Launch Web Demo
1. 启动模型服务
```shell
python model_server.py --host localhost --model-path THUDM/glm-4-voice-9b --port 10000 --dtype bfloat16 --device cuda:0
```
如果你需要使用 Int4 精度启动,请运行
```shell
python model_server.py --host localhost --model-path THUDM/glm-4-voice-9b --port 10000 --dtype int4 --device cuda:0
```
此命令会自动下载 `glm-4-voice-9b`。如果网络条件不好,也手动下载之后通过 `--model-path` 指定本地的路径。
2. 启动 web 服务
```shell
python web_demo.py --tokenizer-path THUDM/glm-4-voice-tokenizer --model-path THUDM/glm-4-voice-9b --flow-path ./glm-4-voice-decoder
```
即可在 http://127.0.0.1:8888 访问 web demo。
此命令会自动下载 `glm-4-voice-tokenizer` 和 `glm-4-voice-9b`。 请注意,`glm-4-voice-decoder` 需要手动下载。
如果网络条件不好,可以手动下载这三个模型之后通过 `--tokenizer-path`, `--flow-path` 和 `--model-path` 指定本地的路径。
### Known Issues
* Gradio 的流式音频播放效果不稳定。在生成完成后点击对话框中的音频质量会更高。
## Cases
我们提供了 GLM-4-Voice 的部分对话案例,包括控制情绪、改变语速、生成方言等。
* 用轻柔的声音引导我放松
https://github.com/user-attachments/assets/4e3d9200-076d-4c28-a641-99df3af38eb0
* 用激动的声音解说足球比赛
https://github.com/user-attachments/assets/0163de2d-e876-4999-b1bc-bbfa364b799b
* 用哀怨的声音讲一个鬼故事
https://github.com/user-attachments/assets/a75b2087-d7bc-49fa-a0c5-e8c99935b39a
* 用东北话介绍一下冬天有多冷
https://github.com/user-attachments/assets/91ba54a1-8f5c-4cfe-8e87-16ed1ecf4037
* 用重庆话念“吃葡萄不吐葡萄皮”
https://github.com/user-attachments/assets/7eb72461-9e84-4d8e-9c58-1809cf6a8a9b
* 用北京话念一句绕口令
https://github.com/user-attachments/assets/a9bb223e-9c0a-440d-8537-0a7f16e31651
* 加快语速
https://github.com/user-attachments/assets/c98a4604-366b-4304-917f-3c850a82fe9f
* 再快一点
https://github.com/user-attachments/assets/d5ff0815-74f8-4738-b0f1-477cfc8dcc2d
## Acknowledgements
本项目的部分代码来自:
* [CosyVoice](https://github.com/FunAudioLLM/CosyVoice)
* [transformers](https://github.com/huggingface/transformers)
* [GLM-4](https://github.com/THUDM/GLM-4)
## 协议
+ GLM-4 模型的权重的使用则需要遵循 [模型协议](https://huggingface.co/THUDM/glm-4-voice-9b/blob/main/LICENSE)。
+ 本开源仓库的代码则遵循 [Apache 2.0](LICENSE) 协议。
## 引用
```
@misc{zeng2024glm4,
title={GLM-4-Voice: Towards Intelligent and Human-Like End-to-End Spoken Chatbot},
author={Aohan Zeng and Zhengxiao Du and Mingdao Liu and Kedong Wang and Shengmin Jiang and Lei Zhao and Yuxiao Dong and Jie Tang},
year={2024},
eprint={2412.02612},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.02612},
}
```
```
@misc{zeng2024scaling,
title={Scaling Speech-Text Pre-training with Synthetic Interleaved Data},
author={Aohan Zeng and Zhengxiao Du and Mingdao Liu and Lei Zhang and Shengmin Jiang and Yuxiao Dong and Jie Tang},
year={2024},
eprint={2411.17607},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2411.17607},
}
``` | {
"source": "THUDM/GLM-4-Voice",
"title": "README.md",
"url": "https://github.com/THUDM/GLM-4-Voice/blob/main/README.md",
"date": "2024-10-24T12:12:32",
"stars": 2689,
"description": "GLM-4-Voice | 端到端中英语音对话模型",
"file_size": 5716
} |
# GLM-4-Voice
<p align="center">
📄<a href="https://arxiv.org/abs/2412.02612" target="_blank"> Report </a> • 🤗 <a href="https://huggingface.co/THUDM/glm-4-voice-9b" target="_blank">HF Repo</a> • 🤖 <a href="https://modelscope.cn/studios/ZhipuAI/GLM-4-Voice-Demo" target="_blank">Demo</a> • 🐦 <a href="https://twitter.com/thukeg" target="_blank">Twitter</a>
</p>
GLM-4-Voice is an end-to-end voice model launched by Zhipu AI. GLM-4-Voice can directly understand and generate Chinese and English speech, engage in real-time voice conversations, and change attributes such as emotion, intonation, speech rate, and dialect based on user instructions.
## Model Architecture

We provide the three components of GLM-4-Voice:
* GLM-4-Voice-Tokenizer: Trained by adding vector quantization to the encoder part of [Whisper](https://github.com/openai/whisper), converting continuous speech input into discrete tokens. Each second of audio is converted into 12.5 discrete tokens.
* GLM-4-Voice-9B: Pre-trained and aligned on speech modality based on [GLM-4-9B](https://github.com/THUDM/GLM-4), enabling understanding and generation of discretized speech.
* GLM-4-Voice-Decoder: A speech decoder supporting streaming inference, retrained based on [CosyVoice](https://github.com/FunAudioLLM/CosyVoice), converting discrete speech tokens into continuous speech output. Generation can start with as few as 10 audio tokens, reducing conversation latency.
## Model List
| Model | Type | Download |
|:---------------------:|:----------------:|:--------------------------------------------------------------------:|
| GLM-4-Voice-Tokenizer | Speech Tokenizer | [🤗 Huggingface](https://huggingface.co/THUDM/glm-4-voice-tokenizer) |
| GLM-4-Voice-9B | Chat Model | [🤗 Huggingface](https://huggingface.co/THUDM/glm-4-voice-9b) |
| GLM-4-Voice-Decoder | Speech Decoder | [🤗 Huggingface](https://huggingface.co/THUDM/glm-4-voice-decoder) |
## Usage
We provide a Web Demo that can be launched directly. Users can input speech or text, and the model will respond with both speech and text.

### Preparation
First, download the repository
```shell
git clone --recurse-submodules https://github.com/THUDM/GLM-4-Voice
cd GLM-4-Voice
```
Then, install the dependencies. You can also use our pre-built docker image `zhipuai/glm-4-voice:0.1` to skip the step.
```shell
pip install -r requirements.txt
```
Since the Decoder model does not support initialization via `transformers`, the checkpoint needs to be downloaded separately.
```shell
# Git model download, please ensure git-lfs is installed
git clone https://huggingface.co/THUDM/glm-4-voice-decoder
```
### Launch Web Demo
1. Start the model server
```shell
python model_server.py --host localhost --model-path THUDM/glm-4-voice-9b --port 10000 --dtype bfloat16 --device cuda:0
```
If you need to launch with Int4 precision, run
```shell
python model_server.py --host localhost --model-path THUDM/glm-4-voice-9b --port 10000 --dtype int4 --device cuda:0
```
This command will automatically download `glm-4-voice-9b`. If network conditions are poor, you can manually download it and specify the local path using `--model-path`.
2. Start the web service
```shell
python web_demo.py --tokenizer-path THUDM/glm-4-voice-tokenizer --model-path THUDM/glm-4-voice-9b --flow-path ./glm-4-voice-decoder
```
You can access the web demo at [http://127.0.0.1:8888](http://127.0.0.1:8888).
This command will automatically download `glm-4-voice-tokenizer` and `glm-4-voice-9b`. Please note that `glm-4-voice-decoder` needs to be downloaded manually.
If the network connection is poor, you can manually download these three models and specify the local paths using `--tokenizer-path`, `--flow-path`, and `--model-path`.
### Known Issues
* Gradio’s streaming audio playback can be unstable. The audio quality will be higher when clicking on the audio in the dialogue box after generation is complete.
## Examples
We provide some dialogue cases for GLM-4-Voice, including emotion control, speech rate alteration, dialect generation, etc. (The examples are in Chinese.)
* Use a gentle voice to guide me to relax
https://github.com/user-attachments/assets/4e3d9200-076d-4c28-a641-99df3af38eb0
* Use an excited voice to commentate a football match
https://github.com/user-attachments/assets/0163de2d-e876-4999-b1bc-bbfa364b799b
* Tell a ghost story with a mournful voice
https://github.com/user-attachments/assets/a75b2087-d7bc-49fa-a0c5-e8c99935b39a
* Introduce how cold winter is with a Northeastern dialect
https://github.com/user-attachments/assets/91ba54a1-8f5c-4cfe-8e87-16ed1ecf4037
* Say "Eat grapes without spitting out the skins" in Chongqing dialect
https://github.com/user-attachments/assets/7eb72461-9e84-4d8e-9c58-1809cf6a8a9b
* Recite a tongue twister with a Beijing accent
https://github.com/user-attachments/assets/a9bb223e-9c0a-440d-8537-0a7f16e31651
* Increase the speech rate
https://github.com/user-attachments/assets/c98a4604-366b-4304-917f-3c850a82fe9f
* Even faster
https://github.com/user-attachments/assets/d5ff0815-74f8-4738-b0f1-477cfc8dcc2d
## Acknowledgements
Some code in this project is from:
* [CosyVoice](https://github.com/FunAudioLLM/CosyVoice)
* [transformers](https://github.com/huggingface/transformers)
* [GLM-4](https://github.com/THUDM/GLM-4)
## License Agreement
+ The use of GLM-4 model weights must follow the [Model License Agreement](https://huggingface.co/THUDM/glm-4-voice-9b/blob/main/LICENSE).
+ The code in this open-source repository is licensed under the [Apache 2.0](LICENSE) License.
## Citation
```
@misc{zeng2024glm4,
title={GLM-4-Voice: Towards Intelligent and Human-Like End-to-End Spoken Chatbot},
author={Aohan Zeng and Zhengxiao Du and Mingdao Liu and Kedong Wang and Shengmin Jiang and Lei Zhao and Yuxiao Dong and Jie Tang},
year={2024},
eprint={2412.02612},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.02612},
}
```
```
@misc{zeng2024scaling,
title={Scaling Speech-Text Pre-training with Synthetic Interleaved Data},
author={Aohan Zeng and Zhengxiao Du and Mingdao Liu and Lei Zhang and Shengmin Jiang and Yuxiao Dong and Jie Tang},
year={2024},
eprint={2411.17607},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2411.17607},
}
``` | {
"source": "THUDM/GLM-4-Voice",
"title": "README_en.md",
"url": "https://github.com/THUDM/GLM-4-Voice/blob/main/README_en.md",
"date": "2024-10-24T12:12:32",
"stars": 2689,
"description": "GLM-4-Voice | 端到端中英语音对话模型",
"file_size": 6588
} |
# Automated-AI-Web-Researcher-Ollama
## Description
Automated-AI-Web-Researcher is an innovative research assistant that leverages locally run large language models through Ollama to conduct thorough, automated online research on any given topic or question. Unlike traditional LLM interactions, this tool actually performs structured research by breaking down queries into focused research areas, systematically investigating each area via web searching and scraping relevant websites, and compiling its findings. The findings are automatically saved into a text document with all the content found and links to the sources. Whenever you want it to stop its research, you can input a command, which will terminate the research. The LLM will then review all of the content it found and provide a comprehensive final summary of your original topic or question. Afterward, you can ask the LLM questions about its research findings.
## Project Demonstration
[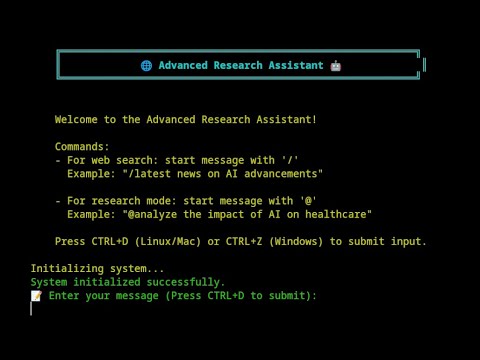](https://youtu.be/hS7Q1B8N1mQ "My Project Demo")
Click the image above to watch the demonstration of my project.
## Here's How It Works:
1. You provide a research query (e.g., "What year will the global population begin to decrease rather than increase according to research?").
2. The LLM analyzes your query and generates 5 specific research focus areas, each with assigned priorities based on relevance to the topic or question.
3. Starting with the highest priority area, the LLM:
- Formulates targeted search queries
- Performs web searches
- Analyzes search results, selecting the most relevant web pages
- Scrapes and extracts relevant information from the selected web pages
- Documents all content found during the research session into a research text file, including links to the websites that the content was retrieved from
4. After investigating all focus areas, the LLM generates new focus areas based on the information found and repeats its research cycle, often discovering new relevant focus areas based on previous findings, leading to interesting and novel research focuses in some cases.
5. You can let it research as long as you like, with the ability to input a quit command at any time. This will stop the research and cause the LLM to review all the content collected so far in full, generating a comprehensive summary in response to your original query or topic.
6. The LLM will then enter a conversation mode where you can ask specific questions about the research findings if desired.
The key distinction is that this isn't just a chatbot—it's an automated research assistant that methodically investigates topics and maintains a documented research trail, all from a single question or topic of your choosing. Depending on your system and model, it can perform over a hundred searches and content retrievals in a relatively short amount of time. You can leave it running and return to a full text document with over a hundred pieces of content from relevant websites and then have it summarize the findings, after which you can ask it questions about what it found.
## Features
- Automated research planning with prioritized focus areas
- Systematic web searching and content analysis
- All research content and source URLs saved into a detailed text document
- Research summary generation
- Post-research Q&A capability about findings
- Self-improving search mechanism
- Rich console output with status indicators
- Comprehensive answer synthesis using web-sourced information
- Research conversation mode for exploring findings
## Installation
**Note:** To use on Windows, follow the instructions on the [/feature/windows-support](https://github.com/TheBlewish/Automated-AI-Web-Researcher-Ollama/tree/feature/windows-support) branch. For Linux and MacOS, use this main branch and the follow steps below:
1. **Clone the repository:**
```sh
git clone https://github.com/TheBlewish/Automated-AI-Web-Researcher-Ollama
cd Automated-AI-Web-Researcher-Ollama
```
2. **Create and activate a virtual environment:**
```sh
python -m venv venv
source venv/bin/activate
```
3. **Install dependencies:**
```sh
pip install -r requirements.txt
```
4. **Install and configure Ollama:**
Install Ollama following the instructions at [https://ollama.ai](https://ollama.ai).
Using your selected model, reccommended to pick one with the required context length for lots of searches (`phi3:3.8b-mini-128k-instruct` or `phi3:14b-medium-128k-instruct` are recommended).
5. Go to the llm_config.py file which should have an ollama section that looks like this:
```sh
LLM_CONFIG_OLLAMA = {
"llm_type": "ollama",
"base_url": "http://localhost:11434", # default Ollama server URL
"model_name": "custom-phi3-32k-Q4_K_M", # Replace with your Ollama model name
"temperature": 0.7,
"top_p": 0.9,
"n_ctx": 55000,
"stop": ["User:", "\n\n"]
```
Then change to the left of where it says replace with your Ollama model name, the "model_name" function, to the name of the model you have setup in Ollama to use with the program, you can now also change 'n_ctx' to set the desired context size.
## Usage
1. **Start Ollama:**
```sh
ollama serve
```
2. **Run the researcher:**
```sh
python Web-LLM.py
```
3. **Start a research session:**
- Type `@` followed by your research query.
- Press `CTRL+D` to submit.
- Example: `@What year is the global population projected to start declining?`
4. **During research, you can use the following commands by typing the associated letter and submitting with `CTRL+D`:**
- Use `s` to show status.
- Use `f` to show the current focus.
- Use `p` to pause and assess research progress, which will give you an assessment from the LLM after reviewing the entire research content to determine whether it can answer your query with the content collected so far. It will then wait for you to input one of two commands: `c` to continue with the research or `q` to terminate it, resulting in a summary as if you had terminated it without using the pause feature.
- Use `q` to quit research.
5. **After the research completes:**
- Wait for the summary to be generated and review the LLM's findings.
- Enter conversation mode to ask specific questions about its findings.
- Access the detailed research content found, available in a research session text file which will be located in the program's directory. This includes:
- All retrieved content
- Source URLs for all of the information
- Focus areas investigated
- Generated summary
## Configuration
The LLM settings can be modified in `llm_config.py`. You must specify your model name in the configuration for the researcher to function. The default configuration is optimized for research tasks with the specified Phi-3 model.
## Current Status
This is a prototype that demonstrates functional automated research capabilities. While still in development, it successfully performs structured research tasks. It has been tested and works well with the `phi3:3.8b-mini-128k-instruct` model when the context is set as advised previously.
## Dependencies
- Ollama
- Python packages listed in `requirements.txt`
- Recommended models: `phi3:3.8b-mini-128k-instruct` or `phi3:14b-medium-128k-instruct` (with custom context length as specified)
## Contributing
Contributions are welcome! This is a prototype with room for improvements and new features.
## License
This project is licensed under the MIT License—see the [LICENSE](LICENSE) file for details.
## Acknowledgments
- Ollama team for their local LLM runtime
- DuckDuckGo for their search API
## Personal Note
This tool represents an attempt to bridge the gap between simple LLM interactions and genuine research capabilities. By structuring the research process and maintaining documentation, it aims to provide more thorough and verifiable results than traditional LLM conversations. It also represents an attempt to improve on my previous project, 'Web-LLM-Assistant-Llamacpp-Ollama,' which simply gave LLMs the ability to search and scrape websites to answer questions. Unlike its predecessor, I feel this program takes that capability and uses it in a novel and very useful way. As a very new programmer, with this being my second ever program, I feel very good about the result. I hope that it hits the mark!
Given how much I have been using it myself, unlike the previous program, which felt more like a novelty than an actual tool, this is actually quite useful and unique—but I am quite biased!
Please enjoy! And feel free to submit any suggestions for improvements so that we can make this automated AI researcher even more capable.
## Disclaimer
This project is for educational purposes only. Ensure you comply with the terms of service of all APIs and services used. | {
"source": "TheBlewish/Automated-AI-Web-Researcher-Ollama",
"title": "README.md",
"url": "https://github.com/TheBlewish/Automated-AI-Web-Researcher-Ollama/blob/main/README.md",
"date": "2024-11-20T07:50:38",
"stars": 2688,
"description": "A python program that turns an LLM, running on Ollama, into an automated researcher, which will with a single query determine focus areas to investigate, do websearches and scrape content from various relevant websites and do research for you all on its own! And more, not limited to but including saving the findings for you!",
"file_size": 8957
} |
# Microsoft Open Source Code of Conduct
This project has adopted the [Microsoft Open Source Code of Conduct](https://opensource.microsoft.com/codeofconduct/).
Resources:
- [Microsoft Open Source Code of Conduct](https://opensource.microsoft.com/codeofconduct/)
- [Microsoft Code of Conduct FAQ](https://opensource.microsoft.com/codeofconduct/faq/)
- Contact [[email protected]](mailto:[email protected]) with questions or concerns
- Employees can reach out at [aka.ms/opensource/moderation-support](https://aka.ms/opensource/moderation-support) | {
"source": "hyperlight-dev/hyperlight",
"title": "CODE_OF_CONDUCT.md",
"url": "https://github.com/hyperlight-dev/hyperlight/blob/main/CODE_OF_CONDUCT.md",
"date": "2024-11-05T16:39:07",
"stars": 2667,
"description": "Hyperlight is a lightweight Virtual Machine Manager (VMM) designed to be embedded within applications. It enables safe execution of untrusted code within micro virtual machines with very low latency and minimal overhead.",
"file_size": 557
} |
# Contribution Guidelines
This project welcomes contributions. Most contributions require you to signoff on your commits via
the Developer Certificate of Origin (DCO). When you submit a pull request, a DCO-bot will automatically determine
whether you need to provide signoff for your commit. Please follow the instructions provided by DCO-bot, as pull
requests cannot be merged until the author(s) have provided signoff to fulfill the DCO requirement.
You may find more information on the DCO requirements [below](#developer-certificate-of-origin-signing-your-work).
## Issues
This section describes the guidelines for submitting issues
### Issue Types
There are 2 types of issues:
- Bug: You've found a bug with the code, and want to report it, or create an issue to track the bug.
- Proposal: Used for items that propose a new idea or functionality. This allows feedback from others before code is written.
## Contributing to Hyperlight
This section describes the guidelines for contributing code / docs to Hyperlight.
### Pull Requests
All contributions come through pull requests. To submit a proposed change, we recommend following this workflow:
1. Make sure there's an issue (bug or proposal) raised, which sets the expectations for the contribution you are about to make.
2. Fork the relevant repo and create a new branch
3. Create your change
- Code changes require tests
- Make sure to run the linters to check and format the code
4. Update relevant documentation for the change
5. Commit with [DCO sign-off](#developer-certificate-of-origin-signing-your-work) and open a PR
6. Wait for the CI process to finish and make sure all checks are green
7. A maintainer of the project will be assigned, and you can expect a review within a few days
#### Use work-in-progress PRs for early feedback
A good way to communicate before investing too much time is to create a "Work-in-progress" PR and share it with your reviewers. The standard way of doing this is to add a "[WIP]" prefix in your PR's title and open the pull request as a draft.
### Developer Certificate of Origin: Signing your work
#### Every commit needs to be signed
The Developer Certificate of Origin (DCO) is a lightweight way for contributors to certify that they wrote or otherwise have the right to submit the code they are contributing to the project. Here is the full text of the [DCO](https://developercertificate.org/), reformatted for readability:
```
By making a contribution to this project, I certify that:
(a) The contribution was created in whole or in part by me and I have the right to submit it under the open source license indicated in the file; or
(b) The contribution is based upon previous work that, to the best of my knowledge, is covered under an appropriate open source license and I have the right under that license to submit that work with modifications, whether created in whole or in part by me, under the same open source license (unless I am permitted to submit under a different license), as indicated in the file; or
(c) The contribution was provided directly to me by some other person who certified (a), (b) or (c) and I have not modified it.
(d) I understand and agree that this project and the contribution are public and that a record of the contribution (including all personal information I submit with it, including my sign-off) is maintained indefinitely and may be redistributed consistent with this project or the open source license(s) involved.
```
Contributors sign-off that they adhere to these requirements by adding a `Signed-off-by` line to commit messages.
```text
This is my commit message
Signed-off-by: Random J Developer <[email protected]>
```
Git even has a `-s` command line option to append this automatically to your commit message:
```sh
git commit -s -m 'This is my commit message'
```
Each Pull Request is checked whether or not commits in a Pull Request do contain a valid Signed-off-by line.
#### I didn't sign my commit, now what?!
No worries - You can easily replay your changes, sign them and force push them!
```sh
git checkout <branch-name>
git commit --amend --no-edit --signoff
git push --force-with-lease <remote-name> <branch-name>
```
*Credit: This doc was cribbed from Dapr.*
### Rust Analyzer
If you are using the [Rust Analyzer](https://rust-analyzer.github.io/manual.html) then you may need to set the configuration option `rust-analyzer.rustfmt.extraArgs` to `["+nightly"]` to ensure that formatting works correctly as this project has a [`rustfmt.toml`](./rustfmt.toml) file that uses nightly features. | {
"source": "hyperlight-dev/hyperlight",
"title": "CONTRIBUTING.md",
"url": "https://github.com/hyperlight-dev/hyperlight/blob/main/CONTRIBUTING.md",
"date": "2024-11-05T16:39:07",
"stars": 2667,
"description": "Hyperlight is a lightweight Virtual Machine Manager (VMM) designed to be embedded within applications. It enables safe execution of untrusted code within micro virtual machines with very low latency and minimal overhead.",
"file_size": 4625
} |
# Current Maintainers
| Name | GitHub ID |
|--------------------|----------------------------------------------------|
| Danilo Chiarlone | [@danbugs](https://github.com/danbugs) |
| David Justice | [@devigned](https://github.com/devigned) |
| Doru Blânzeanu | [@dblnz](https://github.com/dblnz) |
| Jorge Prendes | [@jprendes](https://github.com/jprendes) |
| Lucy Menon | [@syntactically](https://github.com/syntactically) |
| Ludvig Liljenberg | [@ludfjig](https://github.com/ludfjig) |
| Mark Rosetti | [@marosset](https://github.com/marosset) |
| Simon Davies | [@simongdavies](https://github.com/simongdavies) |
| Tomasz Andrzejak | [@andreiltd](https://github.com/andreiltd) |
<!-- Note: Please maintain alphabetical order when adding new entries to the table. --> | {
"source": "hyperlight-dev/hyperlight",
"title": "MAINTAINERS.md",
"url": "https://github.com/hyperlight-dev/hyperlight/blob/main/MAINTAINERS.md",
"date": "2024-11-05T16:39:07",
"stars": 2667,
"description": "Hyperlight is a lightweight Virtual Machine Manager (VMM) designed to be embedded within applications. It enables safe execution of untrusted code within micro virtual machines with very low latency and minimal overhead.",
"file_size": 947
} |
<div align="center">
<h1>Hyperlight</h1>
<img src="https://raw.githubusercontent.com/hyperlight-dev/hyperlight/refs/heads/main/docs/assets/hyperlight-logo.png" width="150px" alt="hyperlight logo"/>
<p><strong>Hyperlight is a lightweight Virtual Machine Manager (VMM) designed to be embedded within applications. It enables safe execution of untrusted code within <i>micro virtual machines</i> with very low latency and minimal overhead.</strong></p>
</div>
> Note: Hyperlight is a nascent project with an evolving API and no guaranteed support. Assistance is provided on a
> best-effort basis by the developers.
---
## Overview
Hyperlight is a library for creating _micro virtual machines_ — or _sandboxes_ — specifically optimized for securely
running untrusted code with minimal impact. It supports both Windows and Linux,
utilizing [Windows Hypervisor Platform](https://docs.microsoft.com/en-us/virtualization/api/#windows-hypervisor-platform)
on Windows, and either Microsoft Hypervisor (mshv) or [KVM](https://linux-kvm.org/page/Main_Page) on Linux.
These micro VMs operate without a kernel or operating system, keeping overhead low. Instead, guests are built
specifically for Hyperlight using the Hyperlight Guest library, which provides a controlled set of APIs that facilitate
interaction between host and guest:
- The host can call functions implemented and exposed by the guest (known as _guest functions_).
- Once running, the guest can call functions implemented and exposed by the host (known as _host functions_).
By default, Hyperlight restricts guest access to a minimal API. The only _host function_ available by default allows the
guest to print messages, which are displayed on the host console or redirected to stdout, as configured. Hosts can
choose to expose additional host functions, expanding the guest’s capabilities as needed.
Below is an example demonstrating the use of the Hyperlight host library in Rust to execute a simple guest application
and an example of a simple guest application using the Hyperlight guest library in also written in Rust.
### Host
```rust
use std::{thread, sync::{Arc, Mutex}};
use hyperlight_common::flatbuffer_wrappers::function_types::{ParameterValue, ReturnType};
use hyperlight_host::{UninitializedSandbox, MultiUseSandbox, func::HostFunction0, sandbox_state::transition::Noop, sandbox_state::sandbox::EvolvableSandbox};
fn main() -> hyperlight_host::Result<()> {
// Create an uninitialized sandbox with a guest binary
let mut uninitialized_sandbox = UninitializedSandbox::new(
hyperlight_host::GuestBinary::FilePath(hyperlight_testing::simple_guest_as_string().unwrap()),
None, // default configuration
None, // default run options
None, // default host print function
)?;
// Register a host function
fn sleep_5_secs() -> hyperlight_host::Result<()> {
thread::sleep(std::time::Duration::from_secs(5));
Ok(())
}
let host_function = Arc::new(Mutex::new(sleep_5_secs));
// Registering a host function makes it available to be called by the guest
host_function.register(&mut uninitialized_sandbox, "Sleep5Secs")?;
// Note: This function is unused by the guest code below, it's just here for demonstration purposes
// Initialize sandbox to be able to call host functions
let mut multi_use_sandbox: MultiUseSandbox = uninitialized_sandbox.evolve(Noop::default())?;
// Call a function in the guest
let message = "Hello, World! I am executing inside of a VM :)\n".to_string();
// in order to call a function it first must be defined in the guest and exposed so that
// the host can call it
let result = multi_use_sandbox.call_guest_function_by_name(
"PrintOutput",
ReturnType::Int,
Some(vec![ParameterValue::String(message.clone())]),
);
assert!(result.is_ok());
Ok(())
}
```
### Guest
```rust
#![no_std]
#![no_main]
extern crate alloc;
use alloc::string::ToString;
use alloc::vec::Vec;
use hyperlight_common::flatbuffer_wrappers::function_call::FunctionCall;
use hyperlight_common::flatbuffer_wrappers::function_types::{
ParameterType, ParameterValue, ReturnType,
};
use hyperlight_common::flatbuffer_wrappers::guest_error::ErrorCode;
use hyperlight_common::flatbuffer_wrappers::util::get_flatbuffer_result_from_int;
use hyperlight_guest::error::{HyperlightGuestError, Result};
use hyperlight_guest::guest_function_definition::GuestFunctionDefinition;
use hyperlight_guest::guest_function_register::register_function;
use hyperlight_guest::host_function_call::{
call_host_function, get_host_value_return_as_int,
};
fn print_output(function_call: &FunctionCall) -> Result<Vec<u8>> {
if let ParameterValue::String(message) = function_call.parameters.clone().unwrap()[0].clone() {
call_host_function(
"HostPrint",
Some(Vec::from(&[ParameterValue::String(message.to_string())])),
ReturnType::Int,
)?;
let result = get_host_value_return_as_int()?;
Ok(get_flatbuffer_result_from_int(result))
} else {
Err(HyperlightGuestError::new(
ErrorCode::GuestFunctionParameterTypeMismatch,
"Invalid parameters passed to simple_print_output".to_string(),
))
}
}
#[no_mangle]
pub extern "C" fn hyperlight_main() {
let print_output_def = GuestFunctionDefinition::new(
"PrintOutput".to_string(),
Vec::from(&[ParameterType::String]),
ReturnType::Int,
print_output as i64,
);
register_function(print_output_def);
}
#[no_mangle]
pub fn guest_dispatch_function(function_call: FunctionCall) -> Result<Vec<u8>> {
let function_name = function_call.function_name.clone();
return Err(HyperlightGuestError::new(
ErrorCode::GuestFunctionNotFound,
function_name,
));
}
```
For additional examples of using the Hyperlight host Rust library, see
the [./src/hyperlight_host/examples](./src/hyperlight_host/examples) directory.
For examples of guest applications, see the [./src/tests/c_guests](./src/tests/c_guests) directory for C guests and
the [./src/tests/rust_guests](./src/tests/rust_guests) directory for Rust guests.
> Note: Hyperlight guests can be written using the Hyperlight Rust or C Guest libraries.
## Repository Structure
- Hyperlight Host Libraries (i.e., the ones that create and manage the VMs)
- [src/hyperlight_host](./src/hyperlight_host) - This is the Rust Hyperlight host library.
- Hyperlight Guest Libraries (i.e., the ones to make it easier to create guests that run inside the VMs)
- [src/hyperlight_guest](./src/hyperlight_guest) - This is the Rust Hyperlight guest library.
- [src/hyperlight_guest_capi](./src/hyperlight_guest_capi) - This is the C compatible wrapper for the Hyperlight
guest library.
- Hyperlight Common (functionality used by both the host and the guest)
- [src/hyperlight_common](./src/hyperlight_common)
- Test Guest Applications:
- [src/tests/rust_guests](./src/tests/rust_guests) - This directory contains three Hyperlight Guest programs written
in Rust, which are intended to be launched within partitions as "guests".
- [src/tests/c_guests](./src/tests/c_guests) - This directory contains two Hyperlight Guest programs written in C,
which are intended to be launched within partitions as "guests".
- Tests:
- [src/hyperlight-testing](./src/hyperlight_testing) - Shared testing code for Hyperlight projects built in Rust.
## Try it yourself!
You can run Hyperlight on:
- [Linux with KVM][kvm].
- [Windows with Windows Hypervisor Platform (WHP).][whp] - Note that you need Windows 11 / Windows Server 2022 or later to use hyperlight, if you are running on earlier versions of Windows then you should consider using our devcontainer on [GitHub codespaces]((https://codespaces.new/hyperlight-dev/hyperlight)) or WSL2.
- Windows Subsystem for Linux 2 (see instructions [here](https://learn.microsoft.com/en-us/windows/wsl/install) for Windows client and [here](https://learn.microsoft.com/en-us/windows/wsl/install-on-server) for Windows Server) with KVM.
- Azure Linux with mshv (note that you need mshv to be installed to use Hyperlight)
After having an environment with a hypervisor setup, running the example has the following pre-requisites:
1. On Linux or WSL, you'll most likely need build essential. For Ubuntu, run `sudo apt install build-essential`. For
Azure Linux, run `sudo dnf install build-essential`.
2. [Rust](https://www.rust-lang.org/tools/install). Install toolchain v1.81 or later.
Also, install the `x86_64-pc-windows-msvc` and `x86_64-unknown-none` targets, these are needed to build the test
guest binaries. (Note: install both targets on either Linux or Windows: Hyperlight can load ELF or PE files on either
OS, and the tests/examples are built for both):
```sh
rustup target add x86_64-unknown-none
rustup target add x86_64-pc-windows-msvc
```
3. [just](https://github.com/casey/just). `cargo install just` On Windows you also need [pwsh](https://learn.microsoft.com/en-us/powershell/scripting/install/installing-powershell-on-windows?view=powershell-7.4).
4. [clang and LLVM](https://clang.llvm.org/get_started.html).
- On Ubuntu, run:
```sh
wget https://apt.llvm.org/llvm.sh
chmod +x ./llvm.sh
sudo ./llvm.sh 17 all
sudo ln -s /usr/lib/llvm-17/bin/clang-cl /usr/bin/clang-cl
sudo ln -s /usr/lib/llvm-17/bin/llvm-lib /usr/bin/llvm-lib
sudo ln -s /usr/lib/llvm-17/bin/lld-link /usr/bin/lld-link
sudo ln -s /usr/lib/llvm-17/bin/llvm-ml /usr/bin/llvm-ml
sudo ln -s /usr/lib/llvm-17/bin/ld.lld /usr/bin/ld.lld
sudo ln -s /usr/lib/llvm-17/bin/clang /usr/bin/clang
```
- On Windows, see [this](https://learn.microsoft.com/en-us/cpp/build/clang-support-msbuild?view=msvc-170).
- On Azure Linux, run:
```sh
sudo dnf remove clang -y || true
sudo dnf install clang17 -y
sudo dnf install clang17-tools-extra -y
```
Then, we are ready to build and run the example:
```sh
just build # build the Hyperlight library
just rg # build the rust test guest binaries
cargo run --example hello-world
```
If all worked as expected, you should see the following message in your console:
```text
Hello, World! I am executing inside of a VM :)
```
If you get the error `Error: NoHypervisorFound` and KVM or mshv is set up then this may be a permissions issue. In bash,
you can use `ls -l /dev/kvm` or `ls -l /dev/mshv` to check which group owns that device and then `groups` to make sure
your user is a member of that group.
For more details on how to verify that KVM is correctly installed and permissions are correct, follow the
guide [here](https://help.ubuntu.com/community/KVM/Installation).
### Or you can use a codespace
[](https://codespaces.new/hyperlight-dev/hyperlight)
## Contributing to Hyperlight
If you are interested in contributing to Hyperlight, running the entire test-suite is a good way to get started. To do
so, on your console, run the following commands:
```sh
just guests # build the c and rust test guests
just build # build the Hyperlight library
just test # runs the tests
```
Also , please review the [CONTRIBUTING.md](./CONTRIBUTING.md) file for more information on how to contribute to
Hyperlight.
> Note: For general Hyperlight development, you may also need flatc (Flatbuffer compiler): for instructions,
> see [here](https://github.com/google/flatbuffers).
## Join our Community Meetings
This project holds fortnightly community meetings to discuss the project's progress, roadmap, and any other topics of interest. The meetings are open to everyone, and we encourage you to join us.
- **When**: Every other Wednesday 09:00 (PST/PDT) [Convert to your local time](https://dateful.com/convert/pst-pdt-pacific-time?t=09)
- **Where**: Zoom! - Agenda and information on how to join can be found in the [Hyperlight Community Meeting Notes](https://hackmd.io/blCrncfOSEuqSbRVT9KYkg#Agenda). Please log into hackmd to edit!
## More Information
For more information, please refer to our compilation of documents in the [`docs/` directory](./docs/README.md).
## Code of Conduct
See the [Code of Conduct](./CODE_OF_CONDUCT.md).
[wsl2]: https://docs.microsoft.com/en-us/windows/wsl/install
[kvm]: https://help.ubuntu.com/community/KVM/Installation
[whp]: https://devblogs.microsoft.com/visualstudio/hyper-v-android-emulator-support/#1-enable-hyper-v-and-the-windows-hypervisor-platform | {
"source": "hyperlight-dev/hyperlight",
"title": "README.md",
"url": "https://github.com/hyperlight-dev/hyperlight/blob/main/README.md",
"date": "2024-11-05T16:39:07",
"stars": 2667,
"description": "Hyperlight is a lightweight Virtual Machine Manager (VMM) designed to be embedded within applications. It enables safe execution of untrusted code within micro virtual machines with very low latency and minimal overhead.",
"file_size": 12710
} |
## Reporting Security Issues
**Please do not report security vulnerabilities through public GitHub issues.**
Instead, please report them via the [GitHub's private security vulnerability reporting mechanism on this repo](https://docs.github.com/en/code-security/security-advisories/guidance-on-reporting-and-writing-information-about-vulnerabilities/privately-reporting-a-security-vulnerability#privately-reporting-a-security-vulnerability).
Please include the requested information listed below (as much as you can provide) to help us better understand the nature and scope of the possible issue:
* Type of issue (e.g. buffer overflow, SQL injection, cross-site scripting, etc.)
* Full paths of source file(s) related to the manifestation of the issue
* The location of the affected source code (tag/branch/commit or direct URL)
* Any special configuration required to reproduce the issue
* Step-by-step instructions to reproduce the issue
* Proof-of-concept or exploit code (if possible)
* Impact of the issue, including how an attacker might exploit the issue
This information will help us triage your report more quickly.
## Preferred Languages
We prefer all communications to be in English. | {
"source": "hyperlight-dev/hyperlight",
"title": "SECURITY.md",
"url": "https://github.com/hyperlight-dev/hyperlight/blob/main/SECURITY.md",
"date": "2024-11-05T16:39:07",
"stars": 2667,
"description": "Hyperlight is a lightweight Virtual Machine Manager (VMM) designed to be embedded within applications. It enables safe execution of untrusted code within micro virtual machines with very low latency and minimal overhead.",
"file_size": 1215
} |
# Support
## How to file issues and get help
This project uses GitHub Issues to track bugs and feature requests. Please search the existing
issues before filing new issues to avoid duplicates. For new issues, file your bug or
feature request as a new Issue.
[//]: <> (For help and questions about using this project, please use Slack channel [TODO: add Slack channel])
## Microsoft Support Policy
Support for this **Hyperlight** is limited to the resources listed above. | {
"source": "hyperlight-dev/hyperlight",
"title": "SUPPORT.md",
"url": "https://github.com/hyperlight-dev/hyperlight/blob/main/SUPPORT.md",
"date": "2024-11-05T16:39:07",
"stars": 2667,
"description": "Hyperlight is a lightweight Virtual Machine Manager (VMM) designed to be embedded within applications. It enables safe execution of untrusted code within micro virtual machines with very low latency and minimal overhead.",
"file_size": 476
} |
# Hyperlight Project Documentation
Hyperlight is a library for running hypervisor-isolated workloads without the overhead of booting a full guest operating system inside the virtual machine.
By eliminating this overhead, Hyperlight can execute arbitrary code more efficiently. It's primarily aimed at supporting functions-as-a-service workloads, where a user's code must be loaded into memory and executed very quickly with high density.
## Basics: Hyperlight internals
Hyperlight achieves these efficiencies by removing all operating system functionality from inside the virtual machine, and instead requiring all guest binaries be run directly on the virtual CPU (vCPU). This key requirement means all Hyperlight guest binaries must not only be compiled to run on the vCPU's architecture, but also must be statically linked to specialized libraries to support their functionality (e.g. there are no syscalls whatsoever available). Roughly similar to Unikernel technologies, we provide a guest library (in Rust, and a C compatible wrapper for it) to which guest binaries can be statically linked.
Given a guest, then, Hyperlight takes some simple steps prior to executing it, including the following:
- Provisioning memory
- Configuring specialized regions of memory
- Provisioning a virtual machine (VM) and CPU with the platform-appropriate hypervisor API, and mapping memory into the VM
- Configuring virtual registers for the vCPU
- Executing the vCPU at a specified instruction pointer
## Basics: Hyperlight architecture
This project is composed internally of several internal components, depicted in the below diagram:

## Further reading
* [Glossary](./glossary.md)
* [How code gets executed in a VM](./hyperlight-execution-details.md)
* [How to build a Hyperlight guest binary](./how-to-build-a-hyperlight-guest-binary.md)
* [Security considerations](./security.md)
* [Technical requirements document](./technical-requirements-document.md)
## For developers
* [Security guidance for developers](./security-guidance-for-developers.md)
* [Paging Development Notes](./paging-development-notes.md)
* [How to debug a Hyperlight guest](./how-to-debug-a-hyperlight-guest.md)
* [How to use Flatbuffers in Hyperlight](./how-to-use-flatbuffers.md)
* [How to make a Hyperlight release](./how-to-make-releases.md)
* [Getting Hyperlight Metrics, Logs, and Traces](./hyperlight-metrics-logs-and-traces.md)
* [Benchmarking Hyperlight](./benchmarking-hyperlight.md)
* [Hyperlight Surrogate Development Notes](./hyperlight-surrogate-development-notes.md)
* [Debugging Hyperlight](./debugging-hyperlight.md)
* [Signal Handling in Hyperlight](./signal-handlers-development-notes.md) | {
"source": "hyperlight-dev/hyperlight",
"title": "docs/README.md",
"url": "https://github.com/hyperlight-dev/hyperlight/blob/main/docs/README.md",
"date": "2024-11-05T16:39:07",
"stars": 2667,
"description": "Hyperlight is a lightweight Virtual Machine Manager (VMM) designed to be embedded within applications. It enables safe execution of untrusted code within micro virtual machines with very low latency and minimal overhead.",
"file_size": 2741
} |
# Benchmark Notes
Hyperlight uses the [Criterion](https://bheisler.github.io/criterion.rs/book/index.html) framework to run and analyze benchmarks. A benefit to this framework is that it doesn't require the nightly toolchain.
## When Benchmarks are ran
1. Every time a branch gets a push
- Compares the current branch benchmarking results to the "dev-latest" release (which is the most recent push to "main" branch). This is done as part of `dep_rust.yml`, which is invoked by `ValidatePullRequest.yml`. These benchmarks are for the developer to compare their branch to main, and the results can only be seen in the GitHub action logs, and nothing is saved.
```
sandboxes/create_sandbox
time: [33.803 ms 34.740 ms 35.763 ms]
change: [+0.7173% +3.7017% +7.1346%] (p = 0.03 < 0.05)
Change within noise threshold.*
```
2. For each release
- For each release, benchmarks are ran as part of the release pipeline in `CreateRelease.yml`, which invokes `Benchmarks.yml`. These benchmark results are compared to the previous release, and are uploaded as port of the "Release assets" on the GitHub release page.
Currently, benchmarks are ran on windows, linux-kvm (ubuntu), and linux-hyperv (mariner). Only release builds are benchmarked, not debug.
## Criterion artifacts
When running `cargo bench -- --save-baseline my_baseline`, criterion runs all benchmarks defined in `src/hyperlight_host/benches/`, prints the results to the stdout, as well as produces several artifacts. All artifacts can be found in `target/criterion/`. For each benchmarking group, for each benchmark, a subfolder with the name of the benchmark is created. This folder in turn contains folders `my_baseline`, `new` and `report`. When running `cargo bench`, criterion always creates `new` and `report`, which always contains the most recent benchmark result and html report, but because we provided the `--save-baseline` flag, we also have a `my_baseline` folder, which is an exact copy of `new`. Moreover, if this `my_baseline` folder already existed before we ran `cargo bench -- --save-baseline my_baseline`, criterion would also compare the benchmark results with the old `my_baseline` folder, and then overwrite the folder.
The first time we run `cargo bench -- --save-baseline my_baseline` (starting with a clean project), we get the following structure.
```
target/criterion/
|-- report
`-- sandboxes
|-- create_sandbox
| |-- my_baseline
| |-- new
| `-- report
|-- create_sandbox_and_call_context
| |-- my_baseline
| |-- new
| `-- report
`-- report
```
If we run the exact same command again, we get
```
target/criterion/
|-- report
`-- sandboxes
|-- create_sandbox
| |-- change
| |-- my_baseline
| |-- new
| `-- report
|-- create_sandbox_and_call_context
| |-- change
| |-- my_baseline
| |-- new
| `-- report
`-- report
```
Note that it overwrote the previous `my_baseline` with the new result. But notably, there is a new `change` folder, which contains the benchmarking difference between the two runs. In addition, on stdout you'll also find a comparison to our previous `my_baseline` run.
```
time: [40.434 ms 40.777 ms 41.166 ms]
change: [+0.0506% +1.1399% +2.2775%] (p = 0.06 > 0.05)
No change in performance detected.
Found 1 outliers among 100 measurements (1.00%)
```
**Note** that Criterion does not differ between release and debug/dev benchmark results, so it's up to the developer to make sure baselines of the same config are compared.
## Running benchmarks locally
Use `just bench [debug/release]` parameter to run benchmarks. Comparing local benchmarks results to github-saved benchmarks doesn't make much sense, since you'd be using different hardware, but you can use `just bench-download os hypervisor [tag] ` to download and extract the GitHub release benchmarks to the correct place folder. You can then run `just bench-ci main` to compare to (and overwrite) the previous release benchmarks. Note that `main` is the name of the baselines stored in GitHub. | {
"source": "hyperlight-dev/hyperlight",
"title": "docs/benchmarking-hyperlight.md",
"url": "https://github.com/hyperlight-dev/hyperlight/blob/main/docs/benchmarking-hyperlight.md",
"date": "2024-11-05T16:39:07",
"stars": 2667,
"description": "Hyperlight is a lightweight Virtual Machine Manager (VMM) designed to be embedded within applications. It enables safe execution of untrusted code within micro virtual machines with very low latency and minimal overhead.",
"file_size": 4249
} |
# Debugging Hyperlight
Support for debugging Hyperlight is currently very limited and experimental. Despite this we offer some very primitive tools to help.
When creating a Uninitialized sandbox, passing a `SandboxRunOptions::RunInProcess(false)` will make the guest run inside a regular host process, rather than inside a hypervisor partition. This allows you to step through the code of the guest using your IDE's debugger. However, there are no symbols, and breakpoints are not supported, so you'll be stepping through assembly.
However, on Windows platform, passing `SandboxRunOptions::RunInProcess(true)` is supported, and will load the guest binary using the win32 `LoadLibrary` function. This has the advantage of also allowing your IDE to set breakpoints in the guest, and also loading symbols, allowing for easy debugging.
## Notes on running guest in-process
The support for running a guest using in-process mode is experimental, highly unsafe, and has many limitations. It requires
enabling cargo feature `inprocess`, and only works when hyperlight-host is built with debug_assertions. Inprocess currently does not support calling guest functions that returns errors. If a guest panics, it will surface as assertion fault ""ERROR: The guest either panicked or returned an Error. Running inprocess-mode currently does not support error handling."
Running in process is specifically only for testing, and should never be used in production as it offers no security guarantees.
## Logging
Hyperlight guests supports logging using the log crate. Any log records logged inside a hyperlight guest using the various
log macros trace!/info!/warning!, etc., will be logged, given that a logger has been instantiated in the host. This can be
very helpful for debugging as well.
## Getting debug print output of memory configuration, virtual processor register state, and other information
Enabling the feature `print_debug` and running a debug build will result in some debug output being printed to the console. Amongst other things this output will show the memory configuration and virtual processor register state.
To enable this permanently in the rust analyzer for Visual Studio Code so that this output shows when running tests using `Run Test` option add the following to your `settings.json` file:
```json
"rust-analyzer.runnables.extraArgs": [
"--features=print_debug"
],
```
Alternatively, this can be enabled when running a test from the command line:
```sh
cargo test --package hyperlight-host --test integration_test --features print_debug -- static_stack_allocate --exact --show-output
```
## Dumping the memory configuration, virtual processor register state and memory contents on a crash or unexpected VM Exit
To dump the details of the memory configuration, the virtual processors register state and the contents of the VM memory set the feature `crashdump` and run a debug build. This will result in a dump file being created in the temporary directory. The name and location of the dump file will be printed to the console and logged as an error message.
There are no tools at this time to analyze the dump file, but it can be useful for debugging. | {
"source": "hyperlight-dev/hyperlight",
"title": "docs/debugging-hyperlight.md",
"url": "https://github.com/hyperlight-dev/hyperlight/blob/main/docs/debugging-hyperlight.md",
"date": "2024-11-05T16:39:07",
"stars": 2667,
"description": "Hyperlight is a lightweight Virtual Machine Manager (VMM) designed to be embedded within applications. It enables safe execution of untrusted code within micro virtual machines with very low latency and minimal overhead.",
"file_size": 3192
} |
# Glossary
* [Hyperlight](#hyperlight)
* [Host Application](#host-application)
* [Host](#host)
* [Hypervisor](#hypervisor)
* [Driver](#driver)
* [Hyper-V](#hyper-v)
* [KVM](#kvm)
* [Guest](#guest)
* [Micro Virtual Machine](#micro-virtual-machine)
* [Workload](#workload)
* [Sandbox](#sandbox)
## Hyperlight
Hyperlight refers to the Hyperlight Project and not a specific component. Hyperlight is intended to be used as a library to embed hypervisor-isolated execution support inside a [host application](#host-application).
## Host Application
This is an application that consumes the Hyperlight library, in order to execute code in an hypervisor-isolated environment.
## Host
Host is the machine on which the [host application](#host-application) is running. A host could be a bare metal or virtual machine, when the host is a virtual machine, the nested virtualization is required to run Hyperlight.
## Hypervisor
Hypervisor is the software responsible for creating isolated [micro virtual machines](#micro-virtual-machine), as well as executing [guests](#guest) inside of those micro virtual machines. Hyperlight has [drivers](#driver) for the following hypervisors: [Hyper-V](#hyper-v) on Windows, [Hyper-V](#hyper-v) on Linux, and [KVM](#kvm).
## Driver
Hyperlight supports executing workloads on particular [hypervisors](#hypervisor) through drivers. Each supported hypervisor has its own driver to manage interacting with that hypervisor.
## Hyper-V
Hyper-V is a [hypervisor](#hypervisor) capable of creating and executing isolated [micro virtual machines](#micro-virtual-machine) on both Windows and Linux. On Linux, Hyper-V is sometimes referred to as MSHV (Microsoft Hypervisor).
## KVM
Kernel-based Virtual Machine (KVM) is a [hypervisor](#hypervisor) capable of creating and executing isolated [micro virtual machines](#micro-virtual-machine) on Linux.
## MSHV
MSHV stands for Microsoft Hypervisor and is the name commonly used for Hyper-V when the hypervisor is running Linux dom0 (as opposed to Windows dom0).
## Guest
A guest is a standalone executable binary that is executed inside a hypervisor [micro virtual machine](#micro-virtual-machine). By having purpose-fit guests binaries, as opposed to running a full operating system, Hyperlight achieves low-latency startup times of workloads, since it doesn't need to first boot an entire operating system before executing the workload.
The interface that a guest must implement is specific to the associated [host](#host) and the type of workloads that it may be specialized for executing, such as WebAssembly Modules (Wasm), or a specific language.
## Micro Virtual Machine
A micro virtual machine is an execution environment managed by a hypervisor that isolates a [guest](#guest) from the [host](#host). A hypervisor prevents the guest from directly accessing the host's resources, such as memory, filesystem, devices, memory or CPU.
We use the term Micro Virtual Machine as the VMs are very lightweight compared to traditional VMs, they contains no operating system or other unnecessary components. The goal is to provide a minimal environment for executing workloads with low latency and high density. However the isolation provided by the hypervisor is the same as that of a traditional VM.
## Workload
A workload is the code that the [host application](#host-application) wants to execute in an isolated [micro virtual machine](#micro-virtual-machine).
## Sandbox
A Sandbox is the abstraction used in Hyperlight to represent the isolated environment in which a workload is executed. A sandbox is used to create, configure, execute and destroy a [micro virtual machine](#micro-virtual-machine) that runs a [guest](#guest) workload. Sandboxes are created by the [host application](#host-application) using the Hyperlight host library. | {
"source": "hyperlight-dev/hyperlight",
"title": "docs/glossary.md",
"url": "https://github.com/hyperlight-dev/hyperlight/blob/main/docs/glossary.md",
"date": "2024-11-05T16:39:07",
"stars": 2667,
"description": "Hyperlight is a lightweight Virtual Machine Manager (VMM) designed to be embedded within applications. It enables safe execution of untrusted code within micro virtual machines with very low latency and minimal overhead.",
"file_size": 3830
} |
# Building a Hyperlight guest binary
This document explains how to build a binary to be used as a Hyperlight guest.
When building a guest, one needs to follow some rules so that the resulting
binary can be used with Hyperlight:
- the binary must not use the standard library
- the expected entrypoint function signature is `void hyperlight_main(void)` or
`pub fn hyperlight_main()`
- Hyperlight expects
`hl_Vec* c_guest_dispatch_function(const hl_FunctionCall *functioncall)` or
`pub fn guest_dispatch_function(function_call: FunctionCall) -> Result<Vec<u8>>`
to be defined in the binary so that in case the host calls a function that is
not registered by the guest, this function is called instead.
- to be callable by the host, a function needs to be registered by the guest in
the `hyperlight_main` function.
## Rust guest binary
In the case of a binary that is written in Rust, one needs to make use of the
Hyperlight crate, `hyperlight_guest` that contains the types and APIs that enable
the guest to:
- register functions that can be called by the host application
- call host functions that have been registered by the host.
## C guest binary
For the binary written in C, the generated C bindings can be downloaded from the
latest release page that contain: the `hyperlight_guest.h` header and the
C API library.
The `hyperlight_guest.h` header contains the corresponding APIs to register
guest functions and call host functions from within the guest. | {
"source": "hyperlight-dev/hyperlight",
"title": "docs/how-to-build-a-hyperlight-guest-binary.md",
"url": "https://github.com/hyperlight-dev/hyperlight/blob/main/docs/how-to-build-a-hyperlight-guest-binary.md",
"date": "2024-11-05T16:39:07",
"stars": 2667,
"description": "Hyperlight is a lightweight Virtual Machine Manager (VMM) designed to be embedded within applications. It enables safe execution of untrusted code within micro virtual machines with very low latency and minimal overhead.",
"file_size": 1477
} |
# How to debug a Hyperlight **KVM** guest using gdb
Hyperlight supports gdb debugging of a **KVM** guest running inside a Hyperlight sandbox.
When Hyperlight is compiled with the `gdb` feature enabled, a Hyperlight KVM sandbox can be configured
to start listening for a gdb connection.
## Supported features
The Hyperlight `gdb` feature enables **KVM** guest debugging:
- an entry point breakpoint is automatically set for the guest to stop
- add and remove HW breakpoints (maximum 4 set breakpoints at a time)
- add and remove SW breakpoints
- read and write registers
- read and write addresses
- step/continue
- get code offset from target
## Expected behavior
Below is a list describing some cases of expected behavior from a gdb debug
session of a guest binary running inside a KVM Hyperlight sandbox.
- when the `gdb` feature is enabled and a SandboxConfiguration is provided a
debug port, the created sandbox will wait for a gdb client to connect on the
configured port
- when the gdb client attaches, the guest vCPU is expected to be stopped at the
entry point
- if a gdb client disconnects unexpectedly, the debug session will be closed and
the guest will continue executing disregarding any prior breakpoints
- if multiple sandbox instances are created, each instance will have its own
gdb thread listening on the configured port
- if two sandbox instances are created with the same debug port, the second
instance logs an error and the gdb thread will not be created, but the sandbox
will continue to run without gdb debugging
## Example
### Sandbox configuration
The `guest-debugging` example in Hyperlight demonstrates how to configure a Hyperlight
sandbox to listen for a gdb client on a specific port.
### CLI Gdb configuration
One can use a gdb config file to provide the symbols and desired configuration.
The below contents of the `.gdbinit` file can be used to provide a basic configuration
to gdb startup.
```gdb
# Path to symbols
file path/to/symbols.elf
# The port on which Hyperlight listens for a connection
target remote :8080
set disassembly-flavor intel
set disassemble-next-line on
enable pretty-printer
layout src
```
One can find more information about the `.gdbinit` file at [gdbinit(5)](https://www.man7.org/linux/man-pages/man5/gdbinit.5.html).
### End to end example
Using the example mentioned at [Sandbox configuration](#sandbox-configuration)
one can run the below commands to debug the guest binary:
```bash
# Terminal 1
$ cargo run --example guest-debugging --features gdb
```
```bash
# Terminal 2
$ cat .gdbinit
file src/tests/rust_guests/bin/debug/simpleguest
target remote :8080
set disassembly-flavor intel
set disassemble-next-line on
enable pretty-printer
layout src
$ gdb
```
### Using VSCode to debug a Hyperlight guest
To replicate the above behavior using VSCode follow the below steps:
- install the `gdb` package on the host machine
- install the `C/C++` extension in VSCode to add debugging capabilities
- create a `.vscode/launch.json` file in the project directory with the below content:
```json
{
"version": "0.2.0",
"configurations": [
{
"name": "GDB",
"type": "cppdbg",
"request": "launch",
"program": "${workspaceFolder}/src/tests/rust_guests/bin/debug/simpleguest",
"args": [],
"stopAtEntry": true,
"hardwareBreakpoints": {"require": false, "limit": 4},
"cwd": "${workspaceFolder}",
"environment": [],
"externalConsole": false,
"MIMode": "gdb",
"miDebuggerPath": "/usr/bin/gdb",
"miDebuggerServerAddress": "localhost:8080",
"setupCommands": [
{
"description": "Enable pretty-printing for gdb",
"text": "-enable-pretty-printing",
"ignoreFailures": true
},
{
"description": "Set Disassembly Flavor to Intel",
"text": "-gdb-set disassembly-flavor intel",
"ignoreFailures": true
}
]
}
]
}
```
- in `Run and Debug` tab, select the `GDB` configuration and click on the `Run`
button to start the debugging session.
The gdb client will connect to the Hyperlight sandbox and the guest vCPU will
stop at the entry point.
## How it works
The gdb feature is designed to work like a Request - Response protocol between
a thread that accepts commands from a gdb client and the hypervisor handler over
a communication channel.
All the functionality is implemented on the hypervisor side so it has access to
the shared memory and the vCPU.
The gdb thread uses the `gdbstub` crate to handle the communication with the gdb client.
When the gdb client requests one of the supported features mentioned above, a request
is sent over the communication channel to the hypervisor handler for the sandbox
to resolve.
Below is a sequence diagram that shows the interaction between the entities
involved in the gdb debugging of a Hyperlight guest running inside a KVM sandbox.
```
┌───────────────────────────────────────────────────────────────────────────────────────────────┐
│ Hyperlight Sandbox │
USER │ │
┌────────────┐ │ ┌──────────────┐ ┌───────────────────────────┐ ┌────────┐ │
│ gdb client │ │ │ gdb thread │ │ hypervisor handler thread │ │ vCPU │ │
└────────────┘ │ └──────────────┘ └───────────────────────────┘ └────────┘ │
| │ | create_gdb_thread | | │
| │ |◄─────────────────────────────────────────┌─┐ vcpu stopped ┌─┐ │
| attach │ ┌─┐ │ │◄──────────────────────────────┴─┘ │
┌─┐───────────────────────┼────────►│ │ │ │ entrypoint breakpoint | │
│ │ attach response │ │ │ │ │ | │
│ │◄──────────────────────┼─────────│ │ │ │ | │
│ │ │ │ │ │ │ | │
│ │ add_breakpoint │ │ │ │ │ | │
│ │───────────────────────┼────────►│ │ add_breakpoint │ │ | │
│ │ │ │ │────────────────────────────────────────►│ │ add_breakpoint | │
│ │ │ │ │ │ │────┐ | │
│ │ │ │ │ │ │ │ | │
│ │ │ │ │ │ │◄───┘ | │
│ │ │ │ │ add_breakpoint response │ │ | │
│ │ add_breakpoint response │ │◄────────────────────────────────────────│ │ | │
│ │◄──────────────────────┬─────────│ │ │ │ | │
│ │ continue │ │ │ │ │ | │
│ │───────────────────────┼────────►│ │ continue │ │ | │
│ │ │ │ │────────────────────────────────────────►│ │ resume vcpu | │
│ │ │ │ │ │ │──────────────────────────────►┌─┐ │
│ │ │ │ │ │ │ │ │ │
│ │ │ │ │ │ │ │ │ │
│ │ │ │ │ │ │ │ │ │
│ │ │ │ │ │ │ │ │ │
│ │ │ │ │ │ │ vcpu stopped │ │ │
│ │ │ │ │ notify vcpu stop reason │ │◄──────────────────────────────┴─┘ │
│ │ notify vcpu stop reason │ │◄────────────────────────────────────────│ │ | │
│ │◄──────────────────────┬─────────│ │ │ │ | │
│ │ continue until end │ │ │ │ │ | │
│ │───────────────────────┼────────►│ │ continue │ │ resume vcpu | │
│ │ │ │ │────────────────────────────────────────►│ │──────────────────────────────►┌─┐ │
│ │ │ │ │ │ │ │ │ │
│ │ │ │ │ comm channel disconnected │ │ vcpu halted │ │ │
│ │ target finished exec│ │ │◄────────────────────────────────────────┤ │◄──────────────────────────────┴─┘ │
│ │◄──────────────────────┼─────────┴─┘ target finished exec └─┘ | │
│ │ │ | | | │
└─┘ │ | | | │
| └───────────────────────────────────────────────────────────────────────────────────────────────┘
``` | {
"source": "hyperlight-dev/hyperlight",
"title": "docs/how-to-debug-a-hyperlight-guest.md",
"url": "https://github.com/hyperlight-dev/hyperlight/blob/main/docs/how-to-debug-a-hyperlight-guest.md",
"date": "2024-11-05T16:39:07",
"stars": 2667,
"description": "Hyperlight is a lightweight Virtual Machine Manager (VMM) designed to be embedded within applications. It enables safe execution of untrusted code within micro virtual machines with very low latency and minimal overhead.",
"file_size": 10991
} |
# Releasing a new Hyperlight version to Cargo
This document details the process of releasing a new version of Hyperlight to [crates.io](https://crates.io). It's intended to be used as a checklist for the developer doing the release. The checklist is represented in the below sections.
## Update Cargo.toml Versions
Currently, we need to manually update the workspace `Cargo.toml` version number to match to whatever release we are making. This will affect the version of all the crates in the workspace.
> Note: we'll use `v0.4.0` as the version for the above and all subsequent instructions. You should replace this with the version you're releasing. Make sure your version follows [SemVer](https://semver.org) conventions as closely as possible, and is prefixed with a `v` character. *In particular do not use a patch version unless you are patching an issue in a release branch, releases from main should always be minor or major versions*.
Create a PR with this change and merge it into the main branch.
## Create a tag
When the above PR has merged into `main` branch you should create a tag. ***Make sure you have pulled the recently updated `main` branch***, and do the following on the `main` branch:
```bash
git tag -a v0.4.0 -m "A brief description of the release"
git push origin v0.4.0 # if you've named your git remote for the hyperlight-dev/hyperlight repo differently, change 'origin' to your remote name
```
If you are creating a patch release see the instructions [here](#patching-a-release).
## Create a release branch (no manual steps)
After you push your new tag in the previous section, the ["Create a Release Branch"](https://github.com/hyperlight-dev/hyperlight/actions/workflows/CreateReleaseBranch.yml) CI job will automatically run. When this job completes, a new `release/v0.4.0` branch will be automatically created for you.
## Create a new GitHub release
After the previous CI job runs to create the new release branch, go to the ["Create a Release"](https://github.com/hyperlight-dev/hyperlight/actions/workflows/CreateRelease.yml). GitHub actions workflow and do the following:
1. Click the "Run workflow" button near the top right
2. In the Use workflow from dropdown, select the `release/v0.4.0` branch
3. Click the green **Run workflow** button
> Note: In case you see a "Create a Release" job already running before starting this step, that is because the "Create a Release" workflow also automatically runs on push to `main` branch to create a pre-release. You must still do the steps outlined above.
When this job is done, a new [GitHub release](https://github.com/hyperlight-dev/hyperlight/releases) will be created for you. This job also publishes the following rust packages to the crates.io:
- `hyperlight-common`
- `hyperlight-guest`
- `hyperlight-host`
## Patching a release
If you need to update a previously released version of Hyperlight then you should open a Pull Request against the release branch you want to patch, for example if you wish to patch the release `v0.4.0` then you should open a PR against the `release/v0.4.0` branch.
Once the PR is merged, then you should follow the instructions above. In this instance the version number of the tag should be a patch version, for example if you are patching the `release/v0.4.0` branch and this is the first patch release to that branch then the tag should be `v0.4.1`. If you are patching a patch release then the tag should be `v0.4.2` and the target branch should be `release/v0.4.1` and so on. | {
"source": "hyperlight-dev/hyperlight",
"title": "docs/how-to-make-releases.md",
"url": "https://github.com/hyperlight-dev/hyperlight/blob/main/docs/how-to-make-releases.md",
"date": "2024-11-05T16:39:07",
"stars": 2667,
"description": "Hyperlight is a lightweight Virtual Machine Manager (VMM) designed to be embedded within applications. It enables safe execution of untrusted code within micro virtual machines with very low latency and minimal overhead.",
"file_size": 3516
} |
# How to use FlatBuffers
Flatbuffers is used to serialize and deserialize some data structures.
Schema files are used to define the data structures and are used to generate the code to serialize and deserialize the data structures.
Those files are located in the [`schema`](../src/schema) directory.
Code generated from the schema files is checked in to the repository, therefore you only need to generate the code if you change an existing schema file or add a new one. You can find details on how to update schema files [here](https://google.github.io/flatbuffers/flatbuffers_guide_writing_schema.html).
## Generating code
We use [flatc](https://google.github.io/flatbuffers/flatbuffers_guide_using_schema_compiler.html) to generate rust code.
We recommend building `flatc` from source. To generate rust code, use
```console
just gen-all-fbs-rust-code
```
### Note about generated code
Because we invoke `flatc` multiple times when generating the Rust code, the `mod.rs` generated in `./src/hyperlight_common/src/flatbuffers` is overwritten multiple times and will likely be incorrect. Make sure to manually inspect and if necessary update this file before continuing with your changes as certain modules might be missing. After fixing `mod.rs`, you might need to re-run `just fmt`, since it might not have applied to all generated files if your `mod.rs` was invalid.
>`flatc` does support passing multiple schema files (e.g. it is possible to pass `.\src\schema\*.fbs`), so we could regenerate all the files each time a change was made, however that generates incorrect code (see [here](https://github.com/google/flatbuffers/issues/6800) for details). | {
"source": "hyperlight-dev/hyperlight",
"title": "docs/how-to-use-flatbuffers.md",
"url": "https://github.com/hyperlight-dev/hyperlight/blob/main/docs/how-to-use-flatbuffers.md",
"date": "2024-11-05T16:39:07",
"stars": 2667,
"description": "Hyperlight is a lightweight Virtual Machine Manager (VMM) designed to be embedded within applications. It enables safe execution of untrusted code within micro virtual machines with very low latency and minimal overhead.",
"file_size": 1665
} |
# How code is run inside a VM
This document details how VMs are very quickly and efficiently created and configured to run arbitrary code.
## Background
Hyperlight is a library for creating micro virtual machines (VMs) intended for executing small, short-running functions. This use case is different from that of many other VM platforms, which are aimed at longer-running, more complex workloads.
A very rough contrast between Hyperlight's offerings and other platforms is as follows:
| Feature | Hyperlight | Other platforms |
|-------------------------------------------------------------------------|------------|--------------------|
| Hardware isolation (vCPU, virtual memory) | Yes | Yes |
| Shared memory between host and in-VM process | Yes | Yes <sup>[2]</sup> |
| Lightweight function calls between host and in-VM process (the "guest") | Yes | No |
| Bootloader/OS kernel | No | Yes <sup>[1]</sup> |
| Virtual networking | No | Yes <sup>[2]</sup> |
| Virtual filesystem | No | Yes <sup>[1]</sup> |
As seen in this table, Hyperlight offers little more than a CPU and memory. We've removed every feature we could, while still providing a machine on which arbitrary code can execute, so we can achieve our various use cases and efficiency targets.
## How code runs
With this background in mind, it's well worth focusing on the "lifecycle" of a VM -- how, exactly, a VM is created, modified, loaded, executed, and ultimately destroyed.
At the highest level, Hyperlight takes roughly the following steps to create and run arbitrary code inside a VM:
1. Loads a specially built, statically linked binary (currently, the [PE](https://en.wikipedia.org/wiki/Portable_Executable) and [ELF](https://en.wikipedia.org/wiki/Executable_and_Linkable_Format) executable formats are supported) into memory. This is the code that is executed inside a virtual machine.
2. Allocates additional memory regions, for example stack and heap for the guest, as well as some regions used for communication between the host and the guest.
3. Creates a Virtual Machine and maps shared memory into it
5. Create one virtual CPU (vCPU) within the newly created VM
6. Write appropriate values to the new vCPUs registers.
7. In a loop, tell previously created vCPU to run until we reach a halt message, one of several known error states, or an unsupported message
1. In the former case, exit successfully
2. In any of the latter cases, exit with a failure message
---
_<sup>[1]</sup> nearly universal support_
_<sup>[2]</sup> varied support_ | {
"source": "hyperlight-dev/hyperlight",
"title": "docs/hyperlight-execution-details.md",
"url": "https://github.com/hyperlight-dev/hyperlight/blob/main/docs/hyperlight-execution-details.md",
"date": "2024-11-05T16:39:07",
"stars": 2667,
"description": "Hyperlight is a lightweight Virtual Machine Manager (VMM) designed to be embedded within applications. It enables safe execution of untrusted code within micro virtual machines with very low latency and minimal overhead.",
"file_size": 2894
} |
# Observability
Hyperlight provides the following observability features:
* [Metrics](#metrics) are provided using Prometheus.
* [Logs](#logs) are provided using the Rust [log crate](https://docs.rs/log/0.4.6/log/), and can be consumed by any Rust logger implementation, including LogTracer which can be used to emit log records as tracing events.
* [Tracing](#tracing) is provided using the Rust [tracing crate](https://docs.rs/tracing/0.1.37/tracing/), and can be consumed by any Rust tracing implementation. In addition, the [log feature](https://docs.rs/tracing/latest/tracing/#crate-feature-flags) is enabled which means that should a hyperlight host application not want to consume tracing events, you can still consume them as logs.
## Metrics
Hyperlight provides metrics using Prometheus. The metrics are registered using either the [default_registry](https://docs.rs/prometheus/latest/prometheus/fn.default_registry.html) or a registry instance provided by the host application.
To provide a registry to Hyperlight, use the `set_metrics_registry` function and pass a reference to a registry with `static` lifetime:
```rust
use hyperlight_host::metrics::set_metrics_registry;
use prometheus::Registry;
use lazy_static::lazy_static;
lazy_static! {
static ref REGISTRY: Registry = Registry::new();
}
set_metrics_registry(®ISTRY);
```
The following metrics are provided and are enabled by default:
* `hyperlight_guest_error_count` - a vector of counters that tracks the number of guest errors by code and message.
* `hyperlight_number_of_cancelled_guest_execution` - a counter that tracks the number of guest executions that have been cancelled because the execution time exceeded the time allowed.
The following metrics are provided but are disabled by default and require the feature `function_call_metrics` to be enabled:
* `hyperlight_guest_function_call_duration_microseconds` - a vector of histograms that tracks the execution time of guest functions in microseconds by function name. The histogram also tracks the number of calls to each function.
* `hyperlight_host_function_calls_duration_microseconds` - a vector of histograms that tracks the execution time of host functions in microseconds by function name. The histogram also tracks the number of calls to each function.
The rationale for disabling the function call metrics by default is that:
* A Hyperlight host may wish to provide its own metrics for function calls.
* Enabling a trace subscriber will cause the function call metrics to be emitted as trace events, which may be sufficient for some use cases.
There is an example of how to gather metrics in the [examples/metrics](../src/hyperlight_host/examples/metrics) directory.
The metrics capabilities provided by Hyperlight can also be used by a library or host that is using Hyperlight to provide additional metrics, see the [hypervisor metrics module](../src/hyperlight_host/src/hypervisor/metrics.rs) for an example of how to define metrics.
## Logs
Hyperlight provides logs using the Rust [log crate](https://docs.rs/log/0.4.6/log/), and can be consumed by any Rust logger implementation, including LogTracer which can be used to emit log records as tracing events(see below for more details). To consume logs, the host application must provide a logger implementation either by using the `set_logger` function directly or using a logger implementation that is compatible with the log crate.
For an example that uses the `env_logger` crate, see the [examples/logging](../src/hyperlight_host/examples/logging) directory. By default, the `env_logger` crate will only log messages at the `error` level or higher. To see all log messages, set the `RUST_LOG` environment variable to `debug`.
Hyperlight also provides tracing capabilities (see below for more details), if no trace subscriber is registered, trace records will be emitted as log records, using the `log` feature of the [tracing crate](https://docs.rs/tracing/latest/tracing/#crate-feature-flags).
## Tracing
Tracing spans are created for any call to a public API and the parent span will be set to the current span in the host if one exists, the level of the span is set to `info`. The span will be closed when the call returns. Any Result that contains an error variant will be logged as an error event. In addition to the public APIs, all internal functions are instrumented with trace spans at the `trace` level, therefore in order to see full trace information, the trace level should be enabled.
Hyperlight provides tracing using the Rust [tracing crate](https://docs.rs/tracing/0.1.37/tracing/), and can be consumed by any Rust trace subscriber implementation(see[here](https://docs.rs/tracing/latest/tracing/index.html#related-crates) for some examples). In addition to consuming trace output the log records may also be consumed by a tracing subscriber, using the `tracing-log` crate.
There are two examples that show how to consume both tracing events and log records as tracing events.
### Using tracing_forest
In the [examples/tracing](../src/hyperlight_host/examples/tracing) directory, there is an example that shows how to capture and output trace and log information using the tracing_forest crate. With this example the following commands can be used to set the verbosity of the trace output to `INFO` and run the example:
#### Linux
```bash
RUST_LOG='none,hyperlight-host=info,tracing=info' cargo run --example tracing
```
#### Windows
```powershell
$env:RUST_LOG='none,hyperlight-host=info,tracing=info'; cargo run --example tracing
```
### Using OTLP exporter and Jaeger
In the [examples/otlp_tracing](../src/hyperlight_host/examples/otlp_tracing) directory, there is an example that shows how to capture and send trace and log information to an otlp_collector using the opentelemetry_otlp crate. With this example the following commands can be used to set the verbosity of the trace output to `INFO` and run the example to generate trace data:
#### Linux
```bash
RUST_LOG='none,hyperlight_host=info,tracing=info' cargo run --example otlp_tracing
```
#### Windows
```powershell
$env:RUST_LOG='none,hyperlight_host=info,tracing=info';cargo run --example otlp_tracing
```
The sample will run and generate trace data until any key is pressed.
To view the trace data, leave the example running and use the jaegertracing/all-in-one container image with the following command:
```console
docker run -d --name jaeger -e COLLECTOR_OTLP_ENABLED=true -p 4317:4317 -p 16686:16686 jaegertracing/all-in-one:1.60
```
NOTE: when running this on windows that this is a linux container, so you will need to ensure that docker is configured to run linux containers using WSL2. Alternatively, you can download the Jaeger binaries from [here](https://www.jaegertracing.io/download/). Extract the archive and run the `jaeger-all-in-one` executable as follows:
```powershell
.\jaeger-all-in-one.exe --collector.otlp.grpc.host-port=4317
```
Once the container or the exe is running, the trace output can be viewed in the jaeger UI at [http://localhost:16686/search](http://localhost:16686/search). | {
"source": "hyperlight-dev/hyperlight",
"title": "docs/hyperlight-metrics-logs-and-traces.md",
"url": "https://github.com/hyperlight-dev/hyperlight/blob/main/docs/hyperlight-metrics-logs-and-traces.md",
"date": "2024-11-05T16:39:07",
"stars": 2667,
"description": "Hyperlight is a lightweight Virtual Machine Manager (VMM) designed to be embedded within applications. It enables safe execution of untrusted code within micro virtual machines with very low latency and minimal overhead.",
"file_size": 7135
} |
### HyperlightSurrogate
`hyperlight_surrogate.exe` is a tiny Rust application we use to create multiple virtual machine (VM) partitions per process when running on Windows with the Windows Hypervisor Platform (WHP, e-g Hyper-V). This binary has no functionality. Its purpose is to provide a running process into which memory will be mapped via the `WHvMapGpaRange2` Windows API. Hyperlight does this memory mapping to pass parameters into, and fetch return values out of, a given VM partition.
> Note: The use of surrogates is a temporary workaround on Windows until WHP allows us to create more than one partition per running process.
These surrogate processes are managed by the host via the [surrogate_process_manager](./src/hyperlight_host/src/hypervisor/surrogate_process_manager.rs) which will launch several of these surrogates (up to the 512), assign memory to them, then launch partitions from there, and reuse them as necessary.
`hyperlight_surrogate.exe` gets built during `hyperlight-host`'s build script, gets embedded into the `hyperlight-host` Rust library via [rust-embed](https://crates.io/crates/rust-embed), and is extracted at runtime next to the executable when the surrogate process manager is initialized. | {
"source": "hyperlight-dev/hyperlight",
"title": "docs/hyperlight-surrogate-development-notes.md",
"url": "https://github.com/hyperlight-dev/hyperlight/blob/main/docs/hyperlight-surrogate-development-notes.md",
"date": "2024-11-05T16:39:07",
"stars": 2667,
"description": "Hyperlight is a lightweight Virtual Machine Manager (VMM) designed to be embedded within applications. It enables safe execution of untrusted code within micro virtual machines with very low latency and minimal overhead.",
"file_size": 1232
} |
# Paging in Hyperlight
Hyperlight uses paging, which means the all addresses inside a Hyperlight VM are treated as virtual addresses by the processor. Specifically, Hyperlight uses (ordinary) 4-level paging. 4-level paging is used because we set the following control registers on logical cores inside a VM: `CR0.PG = 1, CR4.PAE = 1, IA32_EFER.LME = 1, and CR4.LA57 = 0`. A Hyperlight VM is limited to 1GB of addressable memory, see below for more details. These control register settings have the following effects:
- `CR0.PG = 1`: Enables paging
- `CR4.PAE = 1`: Enables Physical Address Extension (PAE) mode (this is required for 4-level paging)
- `IA32_EFER.LME = 1`: Enables Long Mode (64-bit mode)
- `CR4.LA57 = 0`: Makes sure 5-level paging is disabled
## Host-to-Guest memory mapping
Into each Hyperlight VM, memory from the host is mapped into the VM as physical memory. The physical memory inside the VM starts at address `0x200_000` and extends linearly to however much memory was mapped into the VM (depends on various parameters).
## Page table setup
The following page table structs are set up in memory before running a Hyperlight VM (See [Access Flags](#access-flags) for details on access flags that are also set on each entry)
### PML4 (Page Map Level 4) Table
The PML4 table is located at physical address specified in CR3. In Hyperlight we set `CR3=0x200_000`, which means the PML4 table is located at physical address `0x200_000`. The PML4 table comprises 512 64-bit entries.
In Hyperlight, we only initialize the first entry (at address `0x200_000`), with value `0x201_000`, implying that we only have a single PDPT.
### PDPT (Page-directory-pointer Table)
The first and only PDPT is located at physical address `0x201_000`. The PDPT comprises 512 64-bit entries. In Hyperlight, we only initialize the first entry of the PDPT (at address `0x201_000`), with the value `0x202_000`, implying that we only have a single PD.
### PD (Page Directory)
The first and only PD is located at physical address `0x202_000`. The PD comprises 512 64-bit entries, each entry `i` is set to the value `(i * 0x1000) + 0x203_000`. Thus, the first entry is `0x203_000`, the second entry is `0x204_000` and so on.
### PT (Page Table)
The page tables start at physical address `0x203_000`. Each page table has 512 64-bit entries. Each entry is set to the value `p << 21|i << 12` where `p` is the page table number and `i` is the index of the entry in the page table. Thus, the first entry of the first page table is `0x000_000`, the second entry is `0x000_000 + 0x1000`, and so on. The first entry of the second page table is `0x200_000 + 0x1000`, the second entry is `0x200_000 + 0x2000`, and so on. Enough page tables are created to cover the size of memory mapped into the VM.
## Address Translation
Given a 64-bit virtual address X, the corresponding physical address is obtained as follows:
1. PML4 table's physical address is located using CR3 (CR3 is `0x200_000`).
2. Bits 47:39 of X are used to index into PML4, giving us the address of the PDPT.
3. Bits 38:30 of X are used to index into PDPT, giving us the address of the PD.
4. Bits 29:21 of X are used to index into PD, giving us the address of the PT.
5. Bits 20:12 of X are used to index into PT, giving us a base address of a 4K page.
6. Bits 11:0 of X are treated as an offset.
7. The final physical address is the base address + the offset.
However, because we have only one PDPT4E and only one PDPT4E, bits 47:30 must always be zero. Each PDE points to a PT, and because each PTE with index `p,i` (where p is the page table number of i is the entry within that page) has value `p << 21|i << 12`, the base address received in step 5 above is always just bits 29:12 of X itself. **As bits 11:0 are an offset this means that translating a virtual address to a physical address is essentially a NO-OP**.
A diagram to describe how a linear (virtual) address is translated to physical address inside a Hyperlight VM:

Diagram is taken from "The Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 3A: System Programming Guide"
### Limitations
Since we only have 1 PML4E and only 1 PDPTE, bits 47:30 of a linear address must be zero. Thus, we have only 30 bits (bit 29:0) to work with, giving us access to (1 << 30) bytes of memory (1GB).
## Access Flags
In addition to providing addresses, page table entries also contain access flags that describe how memory can be accessed, and whether it is present or not. The following access flags are set on each entry:
PML4E, PDPTE, and PD Entries have the present flag set to 1, and the rest of the flags are not set.
PTE Entries all have the present flag set to 1, apart from those for the address range `0x000_000` to `0x1FF_000` which have the present flag set to 0 as we do not map memory below physical address `0x200_000`.
In addition, the following flags are set according to the type of memory being mapped:
For `Host Function Definitions` and `Host Exception Data` the NX flag is set to 1 meaning that the memory is not executable in the guest and is not accessible to guest code (ring 3) and is also read only even in ring 0.
For `Input/Output Data`, `Page Table Data`, `PEB`, `PanicContext` and `GuestErrorData` the NX flag is set to 1 meaning that the memory is not executable in the guest and the RW flag is set to 1 meaning that the memory is read/write in ring 0, this means that this data is not accessible to guest code unless accessed via the Hyperlight Guest API (which will be in ring 0).
For `Code` the NX flag is not set meaning that the memory is executable in the guest and the RW flag is set to 1 meaning the data is read/write, as the user/supervisor flag is set then the memory is also read/write accessible to user code. (The code section contains both code and data, so it is marked as read/write. In a future update we will parse the layout of the code and set the access flags accordingly).
For `Stack` the NX flag is set to 1 meaning that the memory is not executable in the guest, the RW flag is set to 1 meaning the data is read/write, as the user/supervisor flag is set then the memory is also read/write accessible to user code.
For `Heap` the RW flag is set to 1 meaning the data is read/write, as the user/supervisor flag is set then the memory is also read/write accessible to user code. The NX flag is not set if the feature `executable_heap` is enabled, otherwise the NX flag is set to 1 meaning that the memory is not executable in the guest. The `executable_heap` feature is disabled by default. It is required to allow data in the heap to be executable to when guests dynamically load or generate code, e.g. `hyperlight-wasm` supports loading of AOT compiled WebAssembly modules, these are loaded dynamically by the Wasm runtime and end up in the heap, therefore for this scenario the `executable_heap` feature must be enabled. In a future update we will implement a mechanism to allow the guest to request memory to be executable at runtime via the Hyperlight Guest API.
For `Guard Pages` the NX flag is set to 1 meaning that the memory is not executable in the guest. The RW flag is set to 1 meaning the data is read/write, as the user/supervisor flag is set then the memory is also read/write accessible to user code. **Note that neither of these flags should really be set as the purpose of the guard pages is to cause a fault if accessed, however, as we deal with this fault in the host not in the guest we need to make the memory accessible to the guest, in a future update we will implement exception and interrupt handling in the guest and then change these flags.** | {
"source": "hyperlight-dev/hyperlight",
"title": "docs/paging-development-notes.md",
"url": "https://github.com/hyperlight-dev/hyperlight/blob/main/docs/paging-development-notes.md",
"date": "2024-11-05T16:39:07",
"stars": 2667,
"description": "Hyperlight is a lightweight Virtual Machine Manager (VMM) designed to be embedded within applications. It enables safe execution of untrusted code within micro virtual machines with very low latency and minimal overhead.",
"file_size": 7797
} |
# Security Requirements for Hyperlight developers
This document discusses the security requirements and best practices for services building on Hyperlight. These requirements are designed to uphold the security promise around the guest to host boundary:
## Terminology
* _MUST_, _MUST NOT_ -- A security requirement that is mandatory to perform, or not to perform, respectively.
* _SHOULD_, _SHOULD NOT_ -- A security recommendation is encouraged to perform, or not perform, respectively.
## Brief Checklist
* All host functions that receive parameters from a guest, or operate indirectly on guest data _MUST_ be continuously fuzzed
* Host functions _MUST NOT_ call APIs or be used to expose functionality deemed risky in a multi-tenant context
* Guests and host processes _MUST_ use the same version of a FlatBuffer definition
More detailed guidance on the requirements and best practices is detailed below.
## All host functions exposed to the guest _MUST_ be continuously fuzzed
In the case of the host function calling guest functions, there will be the need to mock callees. Thus, be aware it may not be an identical state machine, thus have different bugs.
A host exposed function should be able to execute at least 500 million of fuzz test cases iterations without any crash.
For rust code, Cargo-fuzz is the recommended way to harness and satisfy the fuzzing requirements. An example with a complete example implementation can be found [Fuzzing with cargo-fuzz - Rust Fuzz Book (rust-fuzz.github.io)](https://rust-fuzz.github.io/book/cargo-fuzz.html).
```rust
#![no_main]
#[macro_use] extern crate libfuzzer_sys;
extern crate url;
fuzz_target!(|data: &[u8]| {
if let Ok(s) = std::str::from_utf8(data) {
let _ = url::Url::parse(s);
}
});
```
## Host functions _MUST NOT_ call APIs or expose functionality deemed risky in a multi-tenant context
In a multi-tenant context, the following operations are considered security sensitive:
* File creation and manipulation
* Shared Data store access
* Accessing network resources
* Resource allocation and usage: if not designed properly, one guest may exhaust the resources for other tenants
* Managing encryption keys
If any of these operations is performed in a host process, a security audit _MUST_ occur.
## Flatbuffers - Guests and host processes _MUST_ use compatible versions of a FlatBuffer definitions
The guests and host processes _MUST_ use the exact same versions of a FlatBuffer definition. I.e., the same .fbs file _MUST_ be used for generating the encoders and decoders.
## Flatbuffers - If using the same language for development, the guests and host processes _SHOULD_ use the same version of flatc compilers.
This can be seen in the header files containing FLATBUFFERS_COMMON_READER_H. For instance: `/* Generated by flatcc 0.6.2 FlatBuffers schema compiler`.
We emit this recommendation because there is a history of compiler bugs, which may affect certain behaviors (encoding, decoding). We emit this recommendation because there is a history of compiler bugs, which may adversely affect certain behaviors (encoding, decoding).
## Flatbuffers – a verifier should always be called before any decoder. In the case of failed verification, the input _MUST NOT_ be processed.
For Rust code, if the return code is InvalidFlatBuffer, the input _MUST_ be rejected.
## Flatbuffers – the host process _MUST NOT_ operate on Flatbuffers from several threads.
Because of the zero-copy approach that FlatBuffers is using, there is a risk of memory safety issues. Flatbuffers are unsafe to be used in a multithreaded environment. This is explicitly indicated in several parts of the Flatbuffer documentation.
Additionally, because Flatbuffers tainted data coming from the guests, this is even more critical in a multi-tenant scenario.
## A rust host process _SHOULD_ handle [panics](https://doc.rust-lang.org/book/ch09-03-to-panic-or-not-to-panic.html) or the service _SHOULD_ restart automatically
If the error is recoverable, the service _SHOULD_ process the next input. Otherwise, the service _SHOULD_ gracefully restart. | {
"source": "hyperlight-dev/hyperlight",
"title": "docs/security-guidance-for-developers.md",
"url": "https://github.com/hyperlight-dev/hyperlight/blob/main/docs/security-guidance-for-developers.md",
"date": "2024-11-05T16:39:07",
"stars": 2667,
"description": "Hyperlight is a lightweight Virtual Machine Manager (VMM) designed to be embedded within applications. It enables safe execution of untrusted code within micro virtual machines with very low latency and minimal overhead.",
"file_size": 4126
} |
# Security
A primary goal of Hyperlight is to safely execute untrusted or unsafe code.
## Threat Model
Hyperlight assumes that guest binaries are untrusted, and are running arbitrary, potentially malicious code. Despite this, the host should never be compromised. This document outlines some of the steps Hyperlight takes to uphold this strong security guarantee.
### Hypervisor Isolation
Hyperlight runs all guest code inside a Virtual Machine, Each VM only has access to a very specific, small (by default) pre-allocated memory buffer in the host's process, no dynamic memory allocations are allowed. As a result, any attempt by the guest to read or write to memory anywhere outside of that particular buffer is caught by the hypervisor. Similarly, the guest VM does not have any access to devices since none are provided by the hyperlight host library, therefore there is no file, network, etc. access available to guest code.
### Host-Guest Communication (Serialization and Deserialization)
All communication between the host and the guest is done through a shared memory buffer. Messages are serialized and deserialized using [FlatBuffers](https://flatbuffers.dev/). To minimize attack surface area, we rely on FlatBuffers to formally specify the data structures passed to/from the host and guest, and to generate serialization/deserialization code. Of course, a compromised guest can write arbitrary data to the shared memory buffer, but the host will not accept anything that does not match our strongly typed FlatBuffer [schemas](../src/schema).
### Accessing host functionality from the guest
Hyperlight provides a mechanism for the host to register functions that may be called from the guest. This mechanism is useful to allow developers to provide guests with strictly controlled access to functionality we don't make available by default inside the VM. This mechanism likely represents the largest attack surface area of this project.
To mitigate the risk, only functions that have been explicitly exposed to the guest by the host application, are allowed to be called from the guest. Any attempt to call other host functions will result in an error.
Additionally, we provide an API for using Seccomp filters to further restrict the system calls available to the host-provided functions, to help limit the impact of the un-audited or un-managed functions. | {
"source": "hyperlight-dev/hyperlight",
"title": "docs/security.md",
"url": "https://github.com/hyperlight-dev/hyperlight/blob/main/docs/security.md",
"date": "2024-11-05T16:39:07",
"stars": 2667,
"description": "Hyperlight is a lightweight Virtual Machine Manager (VMM) designed to be embedded within applications. It enables safe execution of untrusted code within micro virtual machines with very low latency and minimal overhead.",
"file_size": 2379
} |
# Signal Handling in Hyperlight
Hyperlight registers custom signal handlers to intercept and manage specific signals, primarily `SIGSYS` and `SIGRTMIN`. Here's an overview of the registration process:
- **Preserving Old Handlers**: When registering a new signal handler, Hyperlight first retrieves and stores the existing handler using `OnceCell`. This allows Hyperlight to delegate signals to the original handler if necessary.
- **Custom Handlers**:
- **`SIGSYS` Handler**: Captures disallowed syscalls enforced by seccomp. If the signal originates from a hyperlight thread, Hyperlight logs the syscall details. Otherwise, it delegates the signal to the previously registered handler.
- **`SIGRTMIN` Handler**: Utilized for inter-thread signaling, such as execution cancellation. Similar to SIGSYS, it distinguishes between application and non-hyperlight threads to determine how to handle the signal.
- **Thread Differentiation**: Hyperlight uses thread-local storage (IS_HYPERLIGHT_THREAD) to identify whether the current thread is a hyperlight thread. This distinction ensures that signals are handled appropriately based on the thread's role.
## Potential Issues and Considerations
### Handler Invalidation
**Issue**: After Hyperlight registers its custom signal handler and preserves the `old_handler`, if the host or another component modifies the signal handler for the same signal, it can lead to:
- **Invalidation of `old_handler`**: The stored old_handler reference may no longer point to a valid handler, causing undefined behavior when Hyperlight attempts to delegate signals.
- **Loss of Custom Handling**: Hyperlight's custom handler might not be invoked as expected, disrupting its ability to enforce syscall restrictions or manage inter-thread signals. | {
"source": "hyperlight-dev/hyperlight",
"title": "docs/signal-handlers-development-notes.md",
"url": "https://github.com/hyperlight-dev/hyperlight/blob/main/docs/signal-handlers-development-notes.md",
"date": "2024-11-05T16:39:07",
"stars": 2667,
"description": "Hyperlight is a lightweight Virtual Machine Manager (VMM) designed to be embedded within applications. It enables safe execution of untrusted code within micro virtual machines with very low latency and minimal overhead.",
"file_size": 1788
} |
# Hyperlight technical requirements document (TRD)
In this technical requirements document (TRD), we have the following goals:
- Describe the high-level architecture of Hyperlight
- Provide relevant implementation details
- Provide additional information necessary for assessing the security and threat model of Hyperlight
- Detail the security claims Hyperlight makes
## High-level architecture
At a high level, Hyperlight's architecture is relatively simple. It consists of two primary components:
- Host library: the code that does the following:
- Creates the Hyperlight VM, called the "sandbox"
- Configures the VM, vCPU, and virtual registers
- Configures VM memory
- Loads the guest binary (see subsequent bullet point) into VM memory
- Marshals calls to functions (called "guest functions") in the Guest binary inside the VM
- Dispatches callbacks, called "host functions", from the guest back into the host
- Guest binary: the code that runs inside the Hyperlight sandbox and does the following:
- Dispatches calls from the host into particular functions inside the guest
- Marshals calls to host functions
## Relevant implementation details
As indicated in the previous "architecture" section, the two main components, the host and guest, interact in a specific, controlled manner. This section details the guest and host, and focuses on the details the implementation of that interaction.
### Guest binaries
Until this point, we've been using "guest" as an abstract term to indicate some binary to be run inside a Hyperlight sandbox. Because Hyperlight sandboxes only provide a limited set of functionality, guests must be compiled against and linked to all APIs necessary for providing the functionality above. These APIs are provided by our rust or C hyperlight guest libraries.
> While guests may compile against additional libraries (e.g. `libc`), they are not guaranteed to run inside a sandbox, and likely won't.
The Hyperlight sandbox deliberately provides a very limited set of functionality to guest binaries. We expect the most useful guests will execute code inside language interpreters or bytecode-level virtual machines, including Wasm VMs (e.g., [wasmtime](https://github.com/bytecodealliance/wasmtime)). Via this abstraction, we aim to provide functionality the "raw" Hyperlight sandbox does not provide directly. Any further functionality a given guest cannot provide can be provided via host functions.
### Host library
The Hyperlight host library provides a Rust-native API for its users to create and interact with Hyperlight sandboxes. Due to (1) the nature of this project (see the section below on threat modeling for details), and (2) the fact the host library has access to host system resources, we have spent considerable time and energy ensuring the host library has two major features:
- It is memory safe
- It provides a public API that prevents its users from doing unsafe things, using Rust features and other techniques
## Security threat model and guarantees
The set of security guarantees we aim to provide with Hyperlight are as follows:
- All user-level code will, in production builds, be executed within a Hyperlight sandbox backed by a Virtual Machine.
- All Hyperlight sandboxes, in production builds, will be isolated from each other and the host using hypervisor provided Virtual Machines.
- Guest binaries, in production Hyperlight builds, will have no access to the host system beyond VM-mapped memory (e.g., memory the host creates and maps into the system-appropriate VM) and a Hypervisor-provided vCPU. Specifically, a guest cannot request access to additional memory from the host.
- Only host functions that are explicitly made available by the host to a guest are available to the guest, the default state is that the guest has no access to host provided functions.
- If a host provides a guest with such a host function, the guest will never be able to call that host function without explicitly being invoked first. In other words, a guest function must first be called before it can call a host function.
- If a host provides a guest with a host function, the guest will never be able to execute that host function with an argument list of length and types not expected by the host. | {
"source": "hyperlight-dev/hyperlight",
"title": "docs/technical-requirements-document.md",
"url": "https://github.com/hyperlight-dev/hyperlight/blob/main/docs/technical-requirements-document.md",
"date": "2024-11-05T16:39:07",
"stars": 2667,
"description": "Hyperlight is a lightweight Virtual Machine Manager (VMM) designed to be embedded within applications. It enables safe execution of untrusted code within micro virtual machines with very low latency and minimal overhead.",
"file_size": 4281
} |
# Hyperlight Improvement Proposals (HIPs)
Hyperlight Improvement Proposals, otherwise known as HIPs, are largely influenced by the Kubernetes
Enhancement Proposal (KEP) process which provides a standardized development process for Hyperlight
enhancements. You can read more about the
[KEP process in 0000-kep-process here](https://github.com/kubernetes/enhancements/blob/master/keps/sig-architecture/0000-kep-process/README.md).
## Authoring a HIP
When you have a new enhancement that is more than a relatively trivial enhancement or bug fix, the
change should be first socialized as a HIP. To help authors to get started a HIP template is located in
[NNNN-hip-template](./NNNN-hip-template/README.md).
1. Create a new directory under [the proposals directory](../proposals) in the form of `NNNN-hip-${hip_name}`
where `NNNN` is the next HIP number available. For example, if HIP 0001 is currently the highest number HIP and
your enhancement is titled "Make Me a Sandwich", then your HIP would be `0002-hip-make-me-a-sandwich`.
2. Within your `NNNN-hip-${hip_name}` directory create a file named `README.md` containing a copy of the HIP
template.
3. Author the content of the template. Not all sections are necessary. Please consider filling out the
summary, motivation, and proposal sections first to gather early feedback on the desirability of the
enhancement through a draft pull request.
4. After socializing the proposal and integrating early feedback, continue with the rest of the sections.
5. Update the pull request with the rest of the sections and remove the draft status from the pull request.
6. Address any feedback to the proposal and get it merged.
7. Implement the enhancement. | {
"source": "hyperlight-dev/hyperlight",
"title": "proposals/README.md",
"url": "https://github.com/hyperlight-dev/hyperlight/blob/main/proposals/README.md",
"date": "2024-11-05T16:39:07",
"stars": 2667,
"description": "Hyperlight is a lightweight Virtual Machine Manager (VMM) designed to be embedded within applications. It enables safe execution of untrusted code within micro virtual machines with very low latency and minimal overhead.",
"file_size": 1710
} |
# GitHub Actions Workflows
This directory contains [GitHub Workflows](https://docs.github.com/en/actions/using-workflows) of two primary types:
- Ones to be used as dependencies within other workflow files outside this directory.
- These types of workflows are stored in files with names preceded with `dep_`
- Ones to be executed directly.
## More information on dependency workflows
For more information on how dependencies work in GitHub Actions, see the [GitHub documentation on reusing workflows](https://docs.github.com/en/actions/using-workflows/reusing-workflows).
### About the `workflow_call` trigger
The primary mechanism by which all files within this directory declare themselves dependencies of others is the `workflow_call` trigger. This indicates to GitHub Actions that, for a given workflow, another workflow will invoke it.
To read more about this trigger, see [GitHub Actions documentation](https://docs.github.com/en/actions/using-workflows/workflow-syntax-for-github-actions#onworkflow_call). | {
"source": "hyperlight-dev/hyperlight",
"title": ".github/workflows/README.md",
"url": "https://github.com/hyperlight-dev/hyperlight/blob/main/.github/workflows/README.md",
"date": "2024-11-05T16:39:07",
"stars": 2667,
"description": "Hyperlight is a lightweight Virtual Machine Manager (VMM) designed to be embedded within applications. It enables safe execution of untrusted code within micro virtual machines with very low latency and minimal overhead.",
"file_size": 1022
} |
# Hyperlight Improvement Process
<!-- toc -->
- [Summary](#summary)
- [Motivation](#motivation)
- [Goals](#goals)
- [Non-Goals](#non-goals)
- [Proposal](#proposal)
<!-- /toc -->
## Summary
Hyperlight Improvement Proposals, otherwise known as HIPs, are largely influenced by the Kubernetes
Enhancement Proposal (KEP) process which provides a standardized development process for Hyperlight
enhancements. You can read more about the
[KEP process in 0000-kep-process here](https://github.com/kubernetes/enhancements/blob/master/keps/sig-architecture/0000-kep-process/README.md).
## Motivation
### Goals
1. Since Hyperlight is a smaller project than Kubernetes and has a smaller community of contributors, the
needs are slightly different from that of the Kubernetes project. HIPs do not strive to meet the rigor
of their inspiration in Kubernetes, but rather, to provide a means for communication of intent and a
historical record for the motivations that drove the improvement.
### Non-goals
1. To have all changes require a HIP. Only significantly impacting work should be stated as a HIP, e.g.
a large refactoring, significant feature enhancements, breaking APIs, etc.
2. We will omit the use of KEP like metadata that is associated with KEPs.
## Proposal
We propose creating a standardized improvement proposal process for Hyperlight modeled after the Kubernetes
Enhancement Proposal process. | {
"source": "hyperlight-dev/hyperlight",
"title": "proposals/0000-hip-process/README.md",
"url": "https://github.com/hyperlight-dev/hyperlight/blob/main/proposals/0000-hip-process/README.md",
"date": "2024-11-05T16:39:07",
"stars": 2667,
"description": "Hyperlight is a lightweight Virtual Machine Manager (VMM) designed to be embedded within applications. It enables safe execution of untrusted code within micro virtual machines with very low latency and minimal overhead.",
"file_size": 1412
} |
# HIP NNNN - HIP NAME
<!-- toc -->
- [Summary](#summary)
- [Motivation](#motivation)
- [Goals](#goals)
- [Non-Goals](#non-goals)
- [Proposal](#proposal)
- [User Stories (Optional)](#user-stories-optional)
- [Story 1](#story-1)
- [Story 2](#story-2)
- [Notes/Constraints/Caveats (Optional)](#notesconstraintscaveats-optional)
- [Risks and Mitigations](#risks-and-mitigations)
- [Design Details](#design-details)
- [Test Plan](#test-plan)
- [Unit tests](#unit-tests)
- [Integration tests](#integration-tests)
- [e2e tests](#e2e-tests)
- [Implementation History](#implementation-history)
- [Drawbacks](#drawbacks)
- [Alternatives](#alternatives)
<!-- /toc -->
## Summary
<!--
This section is incredibly important for producing high-quality, user-focused
documentation such as release notes or a development roadmap. It should be
possible to collect this information before implementation begins, in order to
avoid requiring implementers to split their attention between writing release
notes and implementing the feature itself. HIP editors should help to ensure
that the tone and content of the `Summary` section is useful for a wide audience.
A good summary is probably at least a paragraph in length.
Both in this section and below, follow the guidelines of the [documentation
style guide]. In particular, wrap lines to a reasonable length, to make it
easier for reviewers to cite specific portions, and to minimize diff churn on
updates.
[documentation style guide]: https://github.com/kubernetes/community/blob/master/contributors/guide/style-guide.md
-->
## Motivation
<!--
This section is for explicitly listing the motivation, goals, and non-goals of
this HIP. Describe why the change is important and the benefits to users. The
motivation section can optionally provide links to [experience reports] to
demonstrate the interest in a KEP within the wider Kubernetes community.
[experience reports]: https://github.com/golang/go/wiki/ExperienceReports
-->
### Goals
<!--
List the specific goals of the HIP. What is it trying to achieve? How will we
know that this has succeeded?
-->
### Non-Goals
<!--
What is out of scope for this HIP? Listing non-goals helps to focus discussion
and make progress.
-->
## Proposal
<!--
This is where we get down to the specifics of what the proposal actually is.
This should have enough detail that reviewers can understand exactly what
you're proposing, but should not include things like API designs or
implementation. What is the desired outcome and how do we measure success?.
The "Design Details" section below is for the real
nitty-gritty.
-->
### User Stories (Optional)
<!--
Detail the things that people will be able to do if this HIP is implemented.
Include as much detail as possible so that people can understand the "how" of
the system. The goal here is to make this feel real for users without getting
bogged down.
-->
#### Story 1
#### Story 2
### Notes/Constraints/Caveats (Optional)
<!--
What are the caveats to the proposal?
What are some important details that didn't come across above?
Go in to as much detail as necessary here.
This might be a good place to talk about core concepts and how they relate.
-->
### Risks and Mitigations
<!--
What are the risks of this proposal, and how do we mitigate? Think broadly.
For example, consider both security and how this will impact the larger ecosystem.
How will security be reviewed, and by whom?
-->
## Design Details
<!--
This section should contain enough information that the specifics of your
change are understandable. This may include API specs (though not always
required) or even code snippets. If there's any ambiguity about HOW your
proposal will be implemented, this is the place to discuss them.
-->
### Test Plan
<!--
The goal is to ensure that we don't accept enhancements with inadequate testing.
All code is expected to have adequate tests (eventually with coverage
expectations).
-->
##### Unit tests
<!--
In principle every added code should have complete unit test coverage, so providing
the exact set of tests will not bring additional value.
However, if complete unit test coverage is not possible, explain the reason of it
together with explanation why this is acceptable.
-->
##### Integration tests
<!--
Integration tests allow control of the configuration parameters used to start the binaries under test.
This is different from e2e tests which do not allow configuration of parameters.
Doing this allows testing non-default options and multiple different and potentially conflicting command line options.
-->
##### e2e tests
<!--
We expect no non-infra related flakes in the last month as a GA graduation criteria.
-->
## Implementation History
<!--
Major milestones in the lifecycle of a HIP should be tracked in this section.
Major milestones might include:
- the `Summary` and `Motivation` sections being merged, signaling SIG acceptance
- the `Proposal` section being merged, signaling agreement on a proposed design
- the date implementation started
- the first Hyperlight release where an initial version of the HIP was available
- the version of Hyperlight where the HIP graduated to general availability
- when the HIP was retired or superseded
-->
## Drawbacks
<!--
Why should this HIP _not_ be implemented?
-->
## Alternatives
<!--
What other approaches did you consider, and why did you rule them out? These do
not need to be as detailed as the proposal, but should include enough
information to express the idea and why it was not acceptable.
--> | {
"source": "hyperlight-dev/hyperlight",
"title": "proposals/NNNN-hip-template/README.md",
"url": "https://github.com/hyperlight-dev/hyperlight/blob/main/proposals/NNNN-hip-template/README.md",
"date": "2024-11-05T16:39:07",
"stars": 2667,
"description": "Hyperlight is a lightweight Virtual Machine Manager (VMM) designed to be embedded within applications. It enables safe execution of untrusted code within micro virtual machines with very low latency and minimal overhead.",
"file_size": 5597
} |
This is a c-api wrapper over the hyperlight-guest crate. The purpose of this crate is to allow the creation of guests in the c language. This crate generates a .lib/.a library file depending on the platform, as well necessary header files.
For examples on how to use it, see the c [simpleguest](../tests/c_guests/c_simpleguest/).
# Important
All guest functions must return a `hl_Vec*` obtained by calling one of the `hl_flatbuffer_result_from_*` functions. These functions will return a flatbuffer encoded byte-buffer of given value, for example `hl_flatbuffer_result_from_int(int)` will return the flatbuffer representation of the given int.
## NOTE
**You may not construct and return your own `hl_Vec*`**, as the hyperlight api assumes that all returned `hl_Vec*` are constructed through calls to a `hl_flatbuffer_result_from_*` function.
Additionally, note that type `hl_Vec*` is used in two different contexts. First, `hl_Vec*` is used input-parameter-type for guest functions that take a buffer of bytes. This buffer of bytes can contain **arbitrary** bytes. Second, all guest functions return a `hl_Vec*` (it might be hidden away by c macros). These `hl_Vec*` are flatbuffer-encoded data, and are not arbitrary. | {
"source": "hyperlight-dev/hyperlight",
"title": "src/hyperlight_guest_capi/README.md",
"url": "https://github.com/hyperlight-dev/hyperlight/blob/main/src/hyperlight_guest_capi/README.md",
"date": "2024-11-05T16:39:07",
"stars": 2667,
"description": "Hyperlight is a lightweight Virtual Machine Manager (VMM) designed to be embedded within applications. It enables safe execution of untrusted code within micro virtual machines with very low latency and minimal overhead.",
"file_size": 1226
} |
# Third Party Library Use
This project makes use of the following third party libraries, each of which is contained in a subdirectory of `third_party` with a COPYRIGHT/LICENSE file in the root of the subdirectory. These libraries are used under the terms of their respective licenses. They are also listed in the NOTICE file in the root of the repository
## printf
This implementation of printf is from [here](https://github.com/mpaland/printf.git)
The copy was taken at version at [version 4.0](https://github.com/mpaland/printf/releases/tag/v4.0.0)
Changes have been applied to the original code for Hyperlight using this [patch](./printf/printf.patch)
## libc
A partial version of musl libc is used by hyperlight and is located in the [musl](./musl) directory as a git subtree.
The current version is release [v1.2.5](https://git.musl-libc.org/cgit/musl/tag/?h=v1.2.5). Many files have been deleted and changes have been made to some of the remaining files. | {
"source": "hyperlight-dev/hyperlight",
"title": "src/hyperlight_guest/third_party/README.md",
"url": "https://github.com/hyperlight-dev/hyperlight/blob/main/src/hyperlight_guest/third_party/README.md",
"date": "2024-11-05T16:39:07",
"stars": 2667,
"description": "Hyperlight is a lightweight Virtual Machine Manager (VMM) designed to be embedded within applications. It enables safe execution of untrusted code within micro virtual machines with very low latency and minimal overhead.",
"file_size": 967
} |
# Fuzzing Hyperlight
This directory contains the fuzzing infrastructure for Hyperlight. We use `cargo-fuzz` to run the fuzzers - i.e., small programs that run specific tests with semi-random inputs to find bugs. Because `cargo-fuzz` is not yet stable, we use the nightly toolchain. Also, because `cargo-fuzz` doesn't support Windows, we have to run this WSL or Linux (Mariner/Ubuntu).
You can run the fuzzers with:
```sh
cargo +nightly-2023-11-28-x86_64-unknown-linux-gnu fuzz run --release <fuzzer_name>
```
> Note: Because nightly toolchains are not stable, we pin the nightly version to `2023-11-28`. To install this toolchain, run:
> ```sh
> rustup toolchain install nightly-2023-11-28-x86_64-unknown-linux-gnu
> ```
As per Microsoft's Offensive Research & Security Engineering (MORSE) team, all host exposed functions that receive or interact with guest data must be continuously fuzzed for, at least, 500 million fuzz test cases without any crashes. Because `cargo-fuzz` doesn't support setting a maximum number of iterations; instead, we use the `--max_total_time` flag to set a maximum time to run the fuzzer. We have a GitHub action (acting like a CRON job) that runs the fuzzers for 24 hours every week.
Currently, we only fuzz the `PrintOutput` function. We plan to add more fuzzers in the future.
## On Failure
If you encounter a failure, you can re-run an entire seed (i.e., group of inputs) with:
```sh
cargo +nightly-2023-11-28-x86_64-unknown-linux-gnu fuzz run --release <fuzzer_name> -- -seed=<seed-number>
```
The seed number can be seed in a specific run, like:

Or, if repro-ing a failure from CI, you can download the artifact from the fuzzing run, and run it like:
```sh
cargo +nightly-2023-11-28-x86_64-unknown-linux-gnu fuzz run --release -O <fuzzer_name> <fuzzer-input (e.g., fuzz/artifacts/fuzz_target_1/crash-93c522e64ee822034972ccf7026d3a8f20d5267c>
``` | {
"source": "hyperlight-dev/hyperlight",
"title": "src/hyperlight_host/fuzz/README.md",
"url": "https://github.com/hyperlight-dev/hyperlight/blob/main/src/hyperlight_host/fuzz/README.md",
"date": "2024-11-05T16:39:07",
"stars": 2667,
"description": "Hyperlight is a lightweight Virtual Machine Manager (VMM) designed to be embedded within applications. It enables safe execution of untrusted code within micro virtual machines with very low latency and minimal overhead.",
"file_size": 1926
} |
# A printf / sprintf Implementation for Embedded Systems
[](https://travis-ci.org/mpaland/printf)
[](https://codecov.io/gh/mpaland/printf)
[](https://scan.coverity.com/projects/mpaland-printf)
[](http://github.com/mpaland/printf/issues)
[](https://github.com/mpaland/printf/releases)
[](https://raw.githubusercontent.com/mpaland/avl_array/master/LICENSE)
This is a tiny but **fully loaded** printf, sprintf and (v)snprintf implementation.
Primarily designed for usage in embedded systems, where printf is not available due to memory issues or in avoidance of linking against libc.
Using the standard libc printf may pull **a lot** of unwanted library stuff and can bloat code size about 20k or is not 100% thread safe. In this cases the following implementation can be used.
Absolutely **NO dependencies** are required, *printf.c* brings all necessary routines, even its own fast `ftoa` (floating point), `ntoa` (decimal) conversion.
If memory footprint is really a critical issue, floating point, exponential and 'long long' support and can be turned off via the `PRINTF_DISABLE_SUPPORT_FLOAT`, `PRINTF_DISABLE_SUPPORT_EXPONENTIAL` and `PRINTF_DISABLE_SUPPORT_LONG_LONG` compiler switches.
When using printf (instead of sprintf/snprintf) you have to provide your own `_putchar()` low level function as console/serial output.
## Highlights and Design Goals
There is a boatload of so called 'tiny' printf implementations around. So why this one?
I've tested many implementations, but most of them have very limited flag/specifier support, a lot of other dependencies or are just not standard compliant and failing most of the test suite.
Therefore I decided to write an own, final implementation which meets the following items:
- Very small implementation (around 600 code lines)
- NO dependencies, no libs, just one module file
- Support of all important flags, width and precision sub-specifiers (see below)
- Support of decimal/floating number representation (with an own fast itoa/ftoa)
- Reentrant and thread-safe, malloc free, no static vars/buffers
- LINT and compiler L4 warning free, mature, coverity clean, automotive ready
- Extensive test suite (> 400 test cases) passing
- Simply the best *printf* around the net
- MIT license
## Usage
Add/link *printf.c* to your project and include *printf.h*. That's it.
Implement your low level output function needed for `printf()`:
```C
void _putchar(char character)
{
// send char to console etc.
}
```
Usage is 1:1 like the according stdio.h library version:
```C
int printf(const char* format, ...);
int sprintf(char* buffer, const char* format, ...);
int snprintf(char* buffer, size_t count, const char* format, ...);
int vsnprintf(char* buffer, size_t count, const char* format, va_list va);
// use output function (instead of buffer) for streamlike interface
int fctprintf(void (*out)(char character, void* arg), void* arg, const char* format, ...);
```
**Due to general security reasons it is highly recommended to prefer and use `snprintf` (with the max buffer size as `count` parameter) instead of `sprintf`.**
`sprintf` has no buffer limitation, so when needed - use it really with care!
### Streamlike Usage
Besides the regular standard `printf()` functions, this module also provides `fctprintf()`, which takes an output function as first parameter to build a streamlike output like `fprintf()`:
```C
// define the output function
void my_stream_output(char character, void* arg)
{
// opt. evaluate the argument and send the char somewhere
}
{
// in your code
void* arg = (void*)100; // this argument is passed to the output function
fctprintf(&my_stream_output, arg, "This is a test: %X", 0xAA);
fctprintf(&my_stream_output, nullptr, "Send to null dev");
}
```
## Format Specifiers
A format specifier follows this prototype: `%[flags][width][.precision][length]type`
The following format specifiers are supported:
### Supported Types
| Type | Output |
|--------|--------|
| d or i | Signed decimal integer |
| u | Unsigned decimal integer |
| b | Unsigned binary |
| o | Unsigned octal |
| x | Unsigned hexadecimal integer (lowercase) |
| X | Unsigned hexadecimal integer (uppercase) |
| f or F | Decimal floating point |
| e or E | Scientific-notation (exponential) floating point |
| g or G | Scientific or decimal floating point |
| c | Single character |
| s | String of characters |
| p | Pointer address |
| % | A % followed by another % character will write a single % |
### Supported Flags
| Flags | Description |
|-------|-------------|
| - | Left-justify within the given field width; Right justification is the default. |
| + | Forces to precede the result with a plus or minus sign (+ or -) even for positive numbers.<br>By default, only negative numbers are preceded with a - sign. |
| (space) | If no sign is going to be written, a blank space is inserted before the value. |
| # | Used with o, b, x or X specifiers the value is preceded with 0, 0b, 0x or 0X respectively for values different than zero.<br>Used with f, F it forces the written output to contain a decimal point even if no more digits follow. By default, if no digits follow, no decimal point is written. |
| 0 | Left-pads the number with zeros (0) instead of spaces when padding is specified (see width sub-specifier). |
### Supported Width
| Width | Description |
|----------|-------------|
| (number) | Minimum number of characters to be printed. If the value to be printed is shorter than this number, the result is padded with blank spaces. The value is not truncated even if the result is larger. |
| * | The width is not specified in the format string, but as an additional integer value argument preceding the argument that has to be formatted. |
### Supported Precision
| Precision | Description |
|-----------|-------------|
| .number | For integer specifiers (d, i, o, u, x, X): precision specifies the minimum number of digits to be written. If the value to be written is shorter than this number, the result is padded with leading zeros. The value is not truncated even if the result is longer. A precision of 0 means that no character is written for the value 0.<br>For f and F specifiers: this is the number of digits to be printed after the decimal point. **By default, this is 6, maximum is 9**.<br>For s: this is the maximum number of characters to be printed. By default all characters are printed until the ending null character is encountered.<br>If the period is specified without an explicit value for precision, 0 is assumed. |
| .* | The precision is not specified in the format string, but as an additional integer value argument preceding the argument that has to be formatted. |
### Supported Length
The length sub-specifier modifies the length of the data type.
| Length | d i | u o x X |
|--------|------|---------|
| (none) | int | unsigned int |
| hh | char | unsigned char |
| h | short int | unsigned short int |
| l | long int | unsigned long int |
| ll | long long int | unsigned long long int (if PRINTF_SUPPORT_LONG_LONG is defined) |
| j | intmax_t | uintmax_t |
| z | size_t | size_t |
| t | ptrdiff_t | ptrdiff_t (if PRINTF_SUPPORT_PTRDIFF_T is defined) |
### Return Value
Upon successful return, all functions return the number of characters written, _excluding_ the terminating null character used to end the string.
Functions `snprintf()` and `vsnprintf()` don't write more than `count` bytes, _including_ the terminating null byte ('\0').
Anyway, if the output was truncated due to this limit, the return value is the number of characters that _could_ have been written.
Notice that a value equal or larger than `count` indicates a truncation. Only when the returned value is non-negative and less than `count`,
the string has been completely written.
If any error is encountered, `-1` is returned.
If `buffer` is set to `NULL` (`nullptr`) nothing is written and just the formatted length is returned.
```C
int length = sprintf(NULL, "Hello, world"); // length is set to 12
```
## Compiler Switches/Defines
| Name | Default value | Description |
|------|---------------|-------------|
| PRINTF_INCLUDE_CONFIG_H | undefined | Define this as compiler switch (e.g. `gcc -DPRINTF_INCLUDE_CONFIG_H`) to include a "printf_config.h" definition file |
| PRINTF_NTOA_BUFFER_SIZE | 32 | ntoa (integer) conversion buffer size. This must be big enough to hold one converted numeric number _including_ leading zeros, normally 32 is a sufficient value. Created on the stack |
| PRINTF_FTOA_BUFFER_SIZE | 32 | ftoa (float) conversion buffer size. This must be big enough to hold one converted float number _including_ leading zeros, normally 32 is a sufficient value. Created on the stack |
| PRINTF_DEFAULT_FLOAT_PRECISION | 6 | Define the default floating point precision |
| PRINTF_MAX_FLOAT | 1e9 | Define the largest suitable value to be printed with %f, before using exponential representation |
| PRINTF_DISABLE_SUPPORT_FLOAT | undefined | Define this to disable floating point (%f) support |
| PRINTF_DISABLE_SUPPORT_EXPONENTIAL | undefined | Define this to disable exponential floating point (%e) support |
| PRINTF_DISABLE_SUPPORT_LONG_LONG | undefined | Define this to disable long long (%ll) support |
| PRINTF_DISABLE_SUPPORT_PTRDIFF_T | undefined | Define this to disable ptrdiff_t (%t) support |
## Caveats
None anymore (finally).
## Test Suite
For testing just compile, build and run the test suite located in `test/test_suite.cpp`. This uses the [catch](https://github.com/catchorg/Catch2) framework for unit-tests, which is auto-adding main().
Running with the `--wait-for-keypress exit` option waits for the enter key after test end.
## Projects Using printf
- [turnkeyboard](https://github.com/mpaland/turnkeyboard) uses printf as log and generic tty (formatting) output.
- printf is part of [embeddedartistry/libc](https://github.com/embeddedartistry/libc), a libc targeted for embedded systems usage.
- The [Hatchling Platform]( https://github.com/adrian3git/HatchlingPlatform) uses printf.
(Just send me a mail/issue/PR to get *your* project listed here)
## Contributing
0. Give this project a :star:
1. Create an issue and describe your idea
2. [Fork it](https://github.com/mpaland/printf/fork)
3. Create your feature branch (`git checkout -b my-new-feature`)
4. Commit your changes (`git commit -am 'Add some feature'`)
5. Publish the branch (`git push origin my-new-feature`)
6. Create a new pull request
7. Profit! :heavy_check_mark:
## License
printf is written under the [MIT license](http://www.opensource.org/licenses/MIT). | {
"source": "hyperlight-dev/hyperlight",
"title": "src/hyperlight_guest/third_party/printf/README.md",
"url": "https://github.com/hyperlight-dev/hyperlight/blob/main/src/hyperlight_guest/third_party/printf/README.md",
"date": "2024-11-05T16:39:07",
"stars": 2667,
"description": "Hyperlight is a lightweight Virtual Machine Manager (VMM) designed to be embedded within applications. It enables safe execution of untrusted code within micro virtual machines with very low latency and minimal overhead.",
"file_size": 11244
} |
This is an example of using the tracing-chrome tracing-subscriber. When ran, it will generate a file `trace-*.json` in the root directory. This file can then be visualized by going to `chrome://tracing` or `ui.perfetto.dev`. Both these sites can be navigated using WASD. | {
"source": "hyperlight-dev/hyperlight",
"title": "src/hyperlight_host/examples/chrome-tracing/README.md",
"url": "https://github.com/hyperlight-dev/hyperlight/blob/main/src/hyperlight_host/examples/chrome-tracing/README.md",
"date": "2024-11-05T16:39:07",
"stars": 2667,
"description": "Hyperlight is a lightweight Virtual Machine Manager (VMM) designed to be embedded within applications. It enables safe execution of untrusted code within micro virtual machines with very low latency and minimal overhead.",
"file_size": 270
} |
# LatentSync: Audio Conditioned Latent Diffusion Models for Lip Sync
<div align="center">
[](https://arxiv.org/abs/2412.09262)
[](https://huggingface.co/spaces/fffiloni/LatentSync)
<a href="https://replicate.com/lucataco/latentsync"><img src="https://replicate.com/lucataco/latentsync/badge" alt="Replicate"></a>
</div>
## 📖 Abstract
We present *LatentSync*, an end-to-end lip sync framework based on audio conditioned latent diffusion models without any intermediate motion representation, diverging from previous diffusion-based lip sync methods based on pixel space diffusion or two-stage generation. Our framework can leverage the powerful capabilities of Stable Diffusion to directly model complex audio-visual correlations. Additionally, we found that the diffusion-based lip sync methods exhibit inferior temporal consistency due to the inconsistency in the diffusion process across different frames. We propose *Temporal REPresentation Alignment (TREPA)* to enhance temporal consistency while preserving lip-sync accuracy. TREPA uses temporal representations extracted by large-scale self-supervised video models to align the generated frames with the ground truth frames.
## 🏗️ Framework
<p align="center">
<img src="assets/framework.png" width=100%>
<p>
LatentSync uses the [Whisper](https://github.com/openai/whisper) to convert melspectrogram into audio embeddings, which are then integrated into the U-Net via cross-attention layers. The reference and masked frames are channel-wise concatenated with noised latents as the input of U-Net. In the training process, we use a one-step method to get estimated clean latents from predicted noises, which are then decoded to obtain the estimated clean frames. The TREPA, [LPIPS](https://arxiv.org/abs/1801.03924) and [SyncNet](https://www.robots.ox.ac.uk/~vgg/publications/2016/Chung16a/chung16a.pdf) losses are added in the pixel space.
## 🎬 Demo
<table class="center">
<tr style="font-weight: bolder;text-align:center;">
<td width="50%"><b>Original video</b></td>
<td width="50%"><b>Lip-synced video</b></td>
</tr>
<tr>
<td>
<video src=https://github.com/user-attachments/assets/ff3a84da-dc9b-498a-950f-5c54f58dd5c5 controls preload></video>
</td>
<td>
<video src=https://github.com/user-attachments/assets/150e00fd-381e-4421-a478-a9ea3d1212a8 controls preload></video>
</td>
</tr>
<tr>
<td>
<video src=https://github.com/user-attachments/assets/32c830a9-4d7d-4044-9b33-b184d8e11010 controls preload></video>
</td>
<td>
<video src=https://github.com/user-attachments/assets/84e4fe9d-b108-44a4-8712-13a012348145 controls preload></video>
</td>
</tr>
<tr>
<td>
<video src=https://github.com/user-attachments/assets/7510a448-255a-44ee-b093-a1b98bd3961d controls preload></video>
</td>
<td>
<video src=https://github.com/user-attachments/assets/6150c453-c559-4ae0-bb00-c565f135ff41 controls preload></video>
</td>
</tr>
<tr>
<td width=300px>
<video src=https://github.com/user-attachments/assets/0f7f9845-68b2-4165-bd08-c7bbe01a0e52 controls preload></video>
</td>
<td width=300px>
<video src=https://github.com/user-attachments/assets/c34fe89d-0c09-4de3-8601-3d01229a69e3 controls preload></video>
</td>
</tr>
<tr>
<td>
<video src=https://github.com/user-attachments/assets/7ce04d50-d39f-4154-932a-ec3a590a8f64 controls preload></video>
</td>
<td>
<video src=https://github.com/user-attachments/assets/70bde520-42fa-4a0e-b66c-d3040ae5e065 controls preload></video>
</td>
</tr>
</table>
(Photorealistic videos are filmed by contracted models, and anime videos are from [VASA-1](https://www.microsoft.com/en-us/research/project/vasa-1/) and [EMO](https://humanaigc.github.io/emote-portrait-alive/))
## 📑 Open-source Plan
- [x] Inference code and checkpoints
- [x] Data processing pipeline
- [x] Training code
## 🔧 Setting up the Environment
Install the required packages and download the checkpoints via:
```bash
source setup_env.sh
```
If the download is successful, the checkpoints should appear as follows:
```
./checkpoints/
|-- latentsync_unet.pt
|-- latentsync_syncnet.pt
|-- whisper
| `-- tiny.pt
|-- auxiliary
| |-- 2DFAN4-cd938726ad.zip
| |-- i3d_torchscript.pt
| |-- koniq_pretrained.pkl
| |-- s3fd-619a316812.pth
| |-- sfd_face.pth
| |-- syncnet_v2.model
| |-- vgg16-397923af.pth
| `-- vit_g_hybrid_pt_1200e_ssv2_ft.pth
```
These already include all the checkpoints required for latentsync training and inference. If you just want to try inference, you only need to download `latentsync_unet.pt` and `tiny.pt` from our [HuggingFace repo](https://huggingface.co/ByteDance/LatentSync)
## 🚀 Inference
There are two ways to perform inference, and both require 6.5 GB of VRAM.
### 1. Gradio App
Run the Gradio app for inference:
```bash
python gradio_app.py
```
### 2. Command Line Interface
Run the script for inference:
```bash
./inference.sh
```
You can change the parameters `inference_steps` and `guidance_scale` to see more results.
## 🔄 Data Processing Pipeline
The complete data processing pipeline includes the following steps:
1. Remove the broken video files.
2. Resample the video FPS to 25, and resample the audio to 16000 Hz.
3. Scene detect via [PySceneDetect](https://github.com/Breakthrough/PySceneDetect).
4. Split each video into 5-10 second segments.
5. Remove videos where the face is smaller than 256 $\times$ 256, as well as videos with more than one face.
6. Affine transform the faces according to the landmarks detected by [face-alignment](https://github.com/1adrianb/face-alignment), then resize to 256 $\times$ 256.
7. Remove videos with [sync confidence score](https://www.robots.ox.ac.uk/~vgg/publications/2016/Chung16a/chung16a.pdf) lower than 3, and adjust the audio-visual offset to 0.
8. Calculate [hyperIQA](https://openaccess.thecvf.com/content_CVPR_2020/papers/Su_Blindly_Assess_Image_Quality_in_the_Wild_Guided_by_a_CVPR_2020_paper.pdf) score, and remove videos with scores lower than 40.
Run the script to execute the data processing pipeline:
```bash
./data_processing_pipeline.sh
```
You can change the parameter `input_dir` in the script to specify the data directory to be processed. The processed data will be saved in the `high_visual_quality` directory. Each step will generate a new directory to prevent the need to redo the entire pipeline in case the process is interrupted by an unexpected error.
## 🏋️♂️ Training U-Net
Before training, you must process the data as described above and download all the checkpoints. We released a pretrained SyncNet with 94% accuracy on the VoxCeleb2 dataset for the supervision of U-Net training. Note that this SyncNet is trained on affine transformed videos, so when using or evaluating this SyncNet, you need to perform affine transformation on the video first (the code of affine transformation is included in the data processing pipeline).
If all the preparations are complete, you can train the U-Net with the following script:
```bash
./train_unet.sh
```
You should change the parameters in U-Net config file to specify the data directory, checkpoint save path, and other training hyperparameters.
## 🏋️♂️ Training SyncNet
In case you want to train SyncNet on your own datasets, you can run the following script. The data processing pipeline for SyncNet is the same as U-Net.
```bash
./train_syncnet.sh
```
After `validations_steps` training, the loss charts will be saved in `train_output_dir`. They contain both the training and validation loss.
## 📊 Evaluation
You can evaluate the [sync confidence score](https://www.robots.ox.ac.uk/~vgg/publications/2016/Chung16a/chung16a.pdf) of a generated video by running the following script:
```bash
./eval/eval_sync_conf.sh
```
You can evaluate the accuracy of SyncNet on a dataset by running the following script:
```bash
./eval/eval_syncnet_acc.sh
```
## 🙏 Acknowledgement
- Our code is built on [AnimateDiff](https://github.com/guoyww/AnimateDiff).
- Some code are borrowed from [MuseTalk](https://github.com/TMElyralab/MuseTalk), [StyleSync](https://github.com/guanjz20/StyleSync), [SyncNet](https://github.com/joonson/syncnet_python), [Wav2Lip](https://github.com/Rudrabha/Wav2Lip).
Thanks for their generous contributions to the open-source community. | {
"source": "bytedance/LatentSync",
"title": "README.md",
"url": "https://github.com/bytedance/LatentSync/blob/main/README.md",
"date": "2024-12-11T10:32:54",
"stars": 2663,
"description": "Taming Stable Diffusion for Lip Sync!",
"file_size": 8553
} |
# Face detector
This face detector is adapted from `https://github.com/cs-giung/face-detection-pytorch`. | {
"source": "bytedance/LatentSync",
"title": "eval/detectors/README.md",
"url": "https://github.com/bytedance/LatentSync/blob/main/eval/detectors/README.md",
"date": "2024-12-11T10:32:54",
"stars": 2663,
"description": "Taming Stable Diffusion for Lip Sync!",
"file_size": 105
} |
# Trend Finder 🔦
**Stay on top of trending topics on social media — all in one place.**
Trend Finder collects and analyzes posts from key influencers, then sends a Slack or Discord notification when it detects new trends or product launches. This has been a complete game-changer for the Firecrawl marketing team by:
- **Saving time** normally spent manually searching social channels
- **Keeping you informed** of relevant, real-time conversations
- **Enabling rapid response** to new opportunities or emerging industry shifts
_Spend less time hunting for trends and more time creating impactful campaigns._
## Watch the Demo & Tutorial video
[](https://www.youtube.com/watch?v=puimQSun92g)
Learn how to set up Trend Finder and start monitoring trends in this video!
## How it Works
1. **Data Collection** 📥
- Monitors selected influencers' posts on Twitter/X using the X API (Warning: the X API free plan is rate limited to only monitor 1 X account every 15 min)
- Monitors websites for new releases and news with Firecrawl's /extract
- Runs on a scheduled basis using cron jobs
2. **AI Analysis** 🧠
- Processes collected content through Together AI
- Identifies emerging trends, releases, and news.
- Analyzes sentiment and relevance
3. **Notification System** 📢
- When significant trends are detected, sends Slack or Discord notifications based on cron job setup
- Provides context about the trend and its sources
- Enables quick response to emerging opportunities
## Features
- 🤖 AI-powered trend analysis using Together AI
- 📱 Social media monitoring (Twitter/X integration)
- 🔍 Website monitoring with Firecrawl
- 💬 Instant Slack or Discord notifications
- ⏱️ Scheduled monitoring using cron jobs
## Prerequisites
- Node.js (v14 or higher)
- npm or yarn
- Docker
- Docker Compose
- Slack workspace with webhook permissions
- API keys for required services
## Environment Variables
Copy `.env.example` to `.env` and configure the following variables:
```
# Optional: API key from Together AI for trend analysis (https://www.together.ai/)
TOGETHER_API_KEY=your_together_api_key_here
# Optional: API key from DeepSeek for trend analysis (https://deepseek.com/)
DEEPSEEK_API_KEY=
# Optional: API key from OpenAI for trend analysis (https://openai.com/)
OPENAI_API_KEY=
# Required if monitoring web pages (https://www.firecrawl.dev/)
FIRECRAWL_API_KEY=your_firecrawl_api_key_here
# Required if monitoring Twitter/X trends (https://developer.x.com/)
X_API_BEARER_TOKEN=your_twitter_api_bearer_token_here
# Notification driver. Supported drivers: "slack", "discord"
NOTIFICATION_DRIVER=discord
# Required (if NOTIFICATION_DRIVER is "slack"): Incoming Webhook URL from Slack for notifications
SLACK_WEBHOOK_URL=https://hooks.slack.com/services/YOUR/WEBHOOK/URL
# Required (if NOTIFICATION_DRIVER is "discord"): Incoming Webhook URL from Discord for notifications
DISCORD_WEBHOOK_URL=https://discord.com/api/webhooks/WEBHOOK/URL
```
## Getting Started
1. **Clone the repository:**
```bash
git clone [repository-url]
cd trend-finder
```
2. **Install dependencies:**
```bash
npm install
```
3. **Configure environment variables:**
```bash
cp .env.example .env
# Edit .env with your configuration
```
4. **Run the application:**
```bash
# Development mode with hot reloading
npm run start
# Build for production
npm run build
```
## Using Docker
1. **Build the Docker image:**
```bash
docker build -t trend-finder .
```
2. **Run the Docker container:**
```bash
docker run -d -p 3000:3000 --env-file .env trend-finder
```
## Using Docker Compose
1. **Start the application with Docker Compose:**
```bash
docker-compose up --build -d
```
2. **Stop the application with Docker Compose:**
```bash
docker-compose down
```
## Project Structure
```
trend-finder/
├── src/
│ ├── controllers/ # Request handlers
│ ├── services/ # Business logic
│ └── index.ts # Application entry point
├── .env.example # Environment variables template
├── package.json # Dependencies and scripts
└── tsconfig.json # TypeScript configuration
```
## Contributing
1. Fork the repository
2. Create your feature branch (`git checkout -b feature/amazing-feature`)
3. Commit your changes (`git commit -m 'Add some amazing feature'`)
4. Push to the branch (`git push origin feature/amazing-feature`)
5. Open a Pull Request | {
"source": "ericciarla/trendFinder",
"title": "README.md",
"url": "https://github.com/ericciarla/trendFinder/blob/main/README.md",
"date": "2024-12-31T17:15:49",
"stars": 2663,
"description": "Stay on top of trending topics on social media and the web with AI",
"file_size": 4543
} |
# Contributor Covenant Code of Conduct
## Our Pledge
We as members, contributors, and leaders pledge to make participation in our
community a harassment-free experience for everyone, regardless of age, body
size, visible or invisible disability, ethnicity, sex characteristics, gender
identity and expression, level of experience, education, socio-economic status,
nationality, personal appearance, race, caste, color, religion, or sexual
identity and orientation.
We pledge to act and interact in ways that contribute to an open, welcoming,
diverse, inclusive, and healthy community.
## Our Standards
Examples of behavior that contributes to a positive environment for our
community include:
* Demonstrating empathy and kindness toward other people
* Being respectful of differing opinions, viewpoints, and experiences
* Giving and gracefully accepting constructive feedback
* Accepting responsibility and apologizing to those affected by our mistakes,
and learning from the experience
* Focusing on what is best not just for us as individuals, but for the overall
community
Examples of unacceptable behavior include:
* The use of sexualized language or imagery, and sexual attention or advances of
any kind
* Trolling, insulting or derogatory comments, and personal or political attacks
* Public or private harassment
* Publishing others' private information, such as a physical or email address,
without their explicit permission
* Other conduct which could reasonably be considered inappropriate in a
professional setting
## Enforcement Responsibilities
Community leaders are responsible for clarifying and enforcing our standards of
acceptable behavior and will take appropriate and fair corrective action in
response to any behavior that they deem inappropriate, threatening, offensive,
or harmful.
Community leaders have the right and responsibility to remove, edit, or reject
comments, commits, code, wiki edits, issues, and other contributions that are
not aligned to this Code of Conduct, and will communicate reasons for moderation
decisions when appropriate.
## Scope
This Code of Conduct applies within all community spaces, and also applies when
an individual is officially representing the community in public spaces.
Examples of representing our community include using an official email address,
posting via an official social media account, or acting as an appointed
representative at an online or offline event.
## Enforcement
Instances of abusive, harassing, or otherwise unacceptable behavior may be
reported to the community leaders responsible for enforcement at
[[email protected]](mailto:[email protected]).
All complaints will be reviewed and investigated promptly and fairly.
All community leaders are obligated to respect the privacy and security of the
reporter of any incident.
## Enforcement Guidelines
Community leaders will follow these Community Impact Guidelines in determining
the consequences for any action they deem in violation of this Code of Conduct:
### 1. Correction
**Community Impact**: Use of inappropriate language or other behavior deemed
unprofessional or unwelcome in the community.
**Consequence**: A private, written warning from community leaders, providing
clarity around the nature of the violation and an explanation of why the
behavior was inappropriate. A public apology may be requested.
### 2. Warning
**Community Impact**: A violation through a single incident or series of
actions.
**Consequence**: A warning with consequences for continued behavior. No
interaction with the people involved, including unsolicited interaction with
those enforcing the Code of Conduct, for a specified period of time. This
includes avoiding interactions in community spaces as well as external channels
like social media. Violating these terms may lead to a temporary or permanent
ban.
### 3. Temporary Ban
**Community Impact**: A serious violation of community standards, including
sustained inappropriate behavior.
**Consequence**: A temporary ban from any sort of interaction or public
communication with the community for a specified period of time. No public or
private interaction with the people involved, including unsolicited interaction
with those enforcing the Code of Conduct, is allowed during this period.
Violating these terms may lead to a permanent ban.
### 4. Permanent Ban
**Community Impact**: Demonstrating a pattern of violation of community
standards, including sustained inappropriate behavior, harassment of an
individual, or aggression toward or disparagement of classes of individuals.
**Consequence**: A permanent ban from any sort of public interaction within the
community.
## Attribution
This Code of Conduct is adapted from the [Contributor Covenant][homepage],
version 2.1, available at
[https://www.contributor-covenant.org/version/2/1/code_of_conduct.html][v2.1].
Community Impact Guidelines were inspired by
[Mozilla's code of conduct enforcement ladder][Mozilla CoC].
For answers to common questions about this code of conduct, see the FAQ at
[https://www.contributor-covenant.org/faq][FAQ]. Translations are available at
[https://www.contributor-covenant.org/translations][translations]. | {
"source": "chonkie-ai/chonkie",
"title": "CODE_OF_CONDUCT.md",
"url": "https://github.com/chonkie-ai/chonkie/blob/main/CODE_OF_CONDUCT.md",
"date": "2024-11-01T07:26:05",
"stars": 2661,
"description": "🦛 CHONK your texts with Chonkie ✨ - The no-nonsense RAG chunking library",
"file_size": 5216
} |
# 🦛 Contributing to Chonkie
> "I like them big, I like them CONTRIBUTING" ~ Moto Moto, probably
Welcome fellow CHONKer! We're excited that you want to contribute to Chonkie. Whether you're fixing bugs, adding features, or improving documentation, every contribution makes Chonkie a better library for everyone.
## 🎯 Before You Start
1. **Check the issues**: Look for existing issues or open a new one to start a discussion.
2. **Read the docs**: Familiarize yourself with [Chonkie's docs](https://docs.chonkie.ai) and core [concepts](https://docs.chonkie.ai/getting-started/concepts).
3. **Set up your environment**: Follow our development setup guide below.
## 🚀 Development Setup
1. Fork and clone the repository:
```bash
git clone https://github.com/your-username/chonkie.git
cd chonkie
```
2. Create a virtual environment and install dependencies:
```bash
python -m venv venv
source venv/bin/activate # On Windows: venv\Scripts\activate
# Install with dev dependencies
pip install -e ".[dev]"
# If working on semantic features, also install semantic dependencies
pip install -e ".[dev,semantic]"
# For all features
pip install -e ".[dev,all]"
```
## 🧪 Running Tests
We use pytest for testing. Our tests are configured via `pyproject.toml`. Before submitting a PR, make sure all tests pass:
```bash
# Run all tests
pytest
# Run specific test file
pytest tests/test_token_chunker.py
# Run tests with coverage
pytest --cov=chonkie
```
## 🎨 Code Style
Chonkie uses [ruff](https://github.com/astral-sh/ruff) for code formatting and linting. Our configuration in `pyproject.toml` enforces:
- Code formatting (`F`)
- Import sorting (`I`)
- Documentation style (`D`)
- Docstring coverage (`DOC`)
```bash
# Run ruff
ruff check .
# Run ruff with auto-fix
ruff check --fix .
```
### Documentation Style
We use Google-style docstrings. Example:
```python
def chunk_text(text: str, chunk_size: int = 512) -> List[str]:
"""Split text into chunks of specified size.
Args:
text: Input text to chunk
chunk_size: Maximum size of each chunk
Returns:
List of text chunks
Raises:
ValueError: If chunk_size <= 0
"""
pass
```
## 🚦 Pull Request Process
1. **Branch Naming**: Use descriptive branch names:
- `feature/description` for new features
- `fix/description` for bug fixes
- `docs/description` for documentation changes
2. **Commit Messages**: Write clear commit messages:
```markdown
feat: add batch processing to WordChunker
- Implement batch_process method
- Add tests for batch processing
- Update documentation
```
3. **Dependencies**: If adding new dependencies:
- Core dependencies go in `project.dependencies`
- Optional features go in `project.optional-dependencies`
- Development tools go in the `dev` optional dependency group
## 📦 Project Structure
Chonkie's package structure is:
```
src/
├── chonkie/
├── chunker/ # Chunking implementations
├── embeddings/ # Embedding implementations
└── refinery/ # Refinement utilities
```
## 🎯 Where to Contribute
### 1. Good First Issues
Look for issues labeled [`good-first-issue`](https://github.com/chonkie-ai/chonkie/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22). These are great starting points for new contributors.
### 2. Documentation
- Improve existing docs
- Add examples
- Fix typos
- Add tutorials
### 3. Code
- Implement new chunking strategies
- Optimize existing chunkers
- Add new tokenizer support
- Improve test coverage
### 4. Performance
- Profile and optimize code
- Add benchmarks
- Improve memory usage
- Enhance batch processing
### 5. New Features
- Add new features to the library
- Add new optional dependencies
- Look for [FEAT] labels in issues, especially by Chonkie Maintainers
## 🦛 Development Dependencies
Current development dependencies are (as of January 1, 2025):
```toml
[project.optional-dependencies]
dev = [
"pytest>=6.2.0",
"datasets>=1.14.0",
"transformers>=4.0.0",
"ruff>=0.0.265"
]
```
Additional optional dependencies:
- `model2vec`: For model2vec embeddings
- `st`: For sentence-transformers
- `openai`: For OpenAI embeddings
- `semantic`: For semantic features
- `all`: All optional dependencies
## 🤝 Code Review Process
1. All PRs need at least one review
2. Maintainers will review for:
- Code quality (via ruff)
- Test coverage
- Performance impact
- Documentation completeness
- Adherence to principles
## 💡 Getting Help
- **Questions?** Open an issue or ask in Discord
- **Bugs?** Open an issue or report in Discord
- **Chat?** Join our Discord!
- **Email?** Contact [[email protected]](mailto:[email protected])
## 🙏 Thank You
Every contribution helps make Chonkie better! We appreciate your time and effort in helping make Chonkie the CHONKiest it can be!
Remember:
> "A journey of a thousand CHONKs begins with a single commit" ~ Ancient Proverb, probably | {
"source": "chonkie-ai/chonkie",
"title": "CONTRIBUTING.md",
"url": "https://github.com/chonkie-ai/chonkie/blob/main/CONTRIBUTING.md",
"date": "2024-11-01T07:26:05",
"stars": 2661,
"description": "🦛 CHONK your texts with Chonkie ✨ - The no-nonsense RAG chunking library",
"file_size": 4974
} |
# 🦛 Chonkie DOCS
> ugh, do i _need_ to explain how to use chonkie? man, that's a bummer... to be honest, Chonkie is very easy, with little documentation necessary, but just in case, i'll include some here.
# Table of Contents
- [🦛 Chonkie DOCS](#-chonkie-docs)
- [Table of Contents](#table-of-contents)
- [Installation](#installation)
- [Basic installation](#basic-installation)
- [Dependency Tables](#dependency-tables)
- [Chunker Availability](#chunker-availability)
- [Embeddings Availability](#embeddings-availability)
- [Required Dependencies](#required-dependencies)
- [Quick Start](#quick-start)
- [Design CHONKosophy](#design-chonkosophy)
- [core chonk principles](#core-chonk-principles)
- [1. 🎯 small but precise](#1--small-but-precise)
- [2. 🚀 surprisingly quick](#2--surprisingly-quick)
- [3. 🪶 tiny but complete](#3--tiny-but-complete)
- [4. 🧠 the clever chonk](#4--the-clever-chonk)
- [5. 🌱 growing with purpose](#5--growing-with-purpose)
- [why chunking is needed? (and may always be needed!)](#why-chunking-is-needed-and-may-always-be-needed)
- [does speed matter while chunking? (tl;dr: yes!!!)](#does-speed-matter-while-chunking-tldr-yes)
- [but but but... how? how is chonkie so fast?](#but-but-but-how-how-is-chonkie-so-fast)
- [Chunkers](#chunkers)
- [TokenChunker](#tokenchunker)
- [WordChunker](#wordchunker)
- [SentenceChunker](#sentencechunker)
- [SemanticChunker](#semanticchunker)
- [SDPMChunker](#sdpmchunker)
- [Embeddings](#embeddings)
- [BaseEmbeddings](#baseembeddings)
- [Model2Vec Embeddings](#model2vec-embeddings)
- [SentenceTransformerEmbeddings](#sentencetransformerembeddings)
- [OpenAIEmbeddings](#openaiembeddings)
- [Using AutoEmbeddings](#using-autoembeddings)
- [Creating Custom Embeddings](#creating-custom-embeddings)
- [API Reference](#api-reference)
- [Chunk object](#chunk-object)
- [SentenceChunk object](#sentencechunk-object)
- [SemanticChunk object](#semanticchunk-object)
- [FAQ](#faq)
- [Can I run a Chunker multiple times on different texts? Is Chonkie thread-safe?](#can-i-run-a-chunker-multiple-times-on-different-texts-is-chonkie-thread-safe)
# Installation
## Basic installation
```bash
pip install chonkie
```
## Dependency Tables
As per the details mentioned in the [design](#design-chonkosophy) section, Chonkie is lightweight because it keeps most of the dependencies for each chunker seperate, making it more of an aggregate of multiple repositories and python packages. The optional dependencies feature in python really helps with this.
### Chunker Availability
The following table shows which chunkers are available with different installation options:
| Chunker | Default | embeddings | 'all' |
|---------|---------|-----------|----------|
| TokenChunker | ✅ | ✅ | ✅ |
| WordChunker | ✅ | ✅ | ✅ |
| SentenceChunker | ✅ | ✅ | ✅ |
| SemanticChunker | ❌ | ✅ | ✅ |
| SDPMChunker | ❌ | ✅ | ✅ |
Any of the embeddings availability will enable the `SemanticChunker` and `SDPMChunker`. Please check the availability of the embeddings below or you may use the `chonkie[semantic]` install for quick access.
### Embeddings Availability
The following table shows which embedding providers are available with different installation options:
| Embeddings Provider | Default | 'model2vec' | 'st' | 'openai' | 'semantic'| 'all' |
|--------------------|---------|-----------|----------|-------|--------|---------|
| Model2VecEmbeddings | ❌| ✅ | ❌ | ❌ | ✅ | ✅ |
| SentenceTransformerEmbeddings | ❌ | ❌| ✅ | ❌ | ❌ | ✅|
| OpenAIEmbeddings | ❌ | ❌ | ❌ | ✅ | ❌ | ✅|
### Required Dependencies
| Installation Option | Additional Dependencies |
|--------------------|------------------------|
| Default | autotiktokenizer |
| 'model2vec' | + model2vec, numpy |
| 'st' | + sentence-transformers, numpy |
| 'openai' | + openai, tiktoken |
| 'semantic' | + model2vec, numpy |
| 'all' | all above dependencies |
NOTE: We have seperate `semantic` and `all` installs pre-packaged that might match other installation options breeding redundancy. This redundancy is so we can provide the user the best experience with the freedom to choose their prefered means. The `semantic` and `all` optional installs would continue to change in future versions, so what you might expect to download today may not be the same for tomorrow.
You can install the version you need using:
```bash
# Basic installation (TokenChunker, WordChunker, SentenceChunker)
pip install chonkie
# For the default semantic provider support
pip install "chonkie[semantic]"
# For OpenAI embeddings support
pip install "chonkie[openai]"
# For installing multiple features together
pip install "chonkie[st, model2vec]"
# For all features
pip install "chonkie[all]"
```
Note: Installing either 'semantic' or 'openai' extras will enable SemanticChunker and SDPMChunker, as these chunkers can work with any embeddings provider. The difference is in which embedding providers are available for use with these chunkers.
# Quick Start
```python
from chonkie import TokenChunker
# create chunker
chunker = TokenChunker(
tokenizer="gpt2", # You can pass your desired tokenizer
chunk_size=512,
chunk_overlap=128
)
# chunk your text
text = """your long text here..."""
chunks = chunker.chunk(text)
# access chunks
for chunk in chunks:
print(f"chunk: {chunk.text[:50]}...")
print(f"tokens: {chunk.token_count}")
```
# Design CHONKosophy
> did you know that pygmy hippos are only 1/4 the size of regular hippos, but they're just as mighty? that's the chonkie spirit - tiny but powerful! 🦛
listen up chonkers! just like our adorable pygmy hippo mascot, chonkie proves that the best things come in small packages. let's dive into why this tiny chonkster is built the way it is!
## core chonk principles
### 1. 🎯 small but precise
like how pygmy hippos take perfect little bites of their favorite fruits, chonkie knows exactly how to size your chunks:
- **compact & efficient**: just like our tiny mascot, every chunk is exactly the size it needs to be
- **smart defaults**: we've done the research so you don't have to! our default parameters are battle-tested
- **flexible sizing**: because sometimes you need a smaller bite!
### 2. 🚀 surprisingly quick
fun fact: pygmy hippos might be small, but they can zoom through the forest at impressive speeds! similarly, chonkie is:
- **lightning fast**: small size doesn't mean slow performance
- **optimized paths**: like our mascot's forest shortcuts, we take the most efficient route (we use cacheing extensively btw!)
- **minimal overhead**: no wasted energy, just pure chonk power
### 3. 🪶 tiny but complete
just as pygmy hippos pack all hippo features into a compact frame, chonkie is:
- **minimum footprint**: base installation smaller than a pygmy hippo footprint
- **modular growth**: add features as you need them, like a growing hippo
- **zero bloat**: every feature has a purpose, just like every trait of our tiny friend
- **smart imports**: load only what you need, when you need it
### 4. 🧠 the clever chonk
why chunking still matters (from a tiny hippo's perspective):
1. **right-sized processing**
- even tiny chunks can carry big meaning
- smart chunking = efficient processing
- our pygmy hippo philosophy: "just enough, never too much"
2. **the goldilocks zone**
- too small: like a hippo bite that's too tiny
- too large: like trying to swallow a whole watermelon
- just right: the chonkie way™️ (pygmy-approved!)
3. **semantic sense**
- each chunk is carefully crafted
- like our mascot's careful step through the forest
- small, meaningful units that work together
### 5. 🌱 growing with purpose
like how pygmy hippos stay small but mighty, chonkie grows sensibly:
```
smart chunks → better embeddings → precise retrieval → quality generation
```
even as models grow bigger, you'll appreciate our tiny-but-mighty approach:
- focused context (like a pygmy hippo's keen senses)
- efficient processing (like our mascot's energy-saving size)
- clean, purposeful design (like nature's perfect mini-hippo)
## why chunking is needed? (and may always be needed!)
while you might be aware of models having longer and longer contexts in recent times (as of 2024), models have yet to reach the stage where adding additional context to them comes for free. additional context, even with the greatest of model architectures comes at a o(n) penalty in speed, to say nothing of the additional memory requirements. and as long as we belive in that attention is all we need, it doesn't seem likely we would be free from this penalty.
that means, to make models run efficiently (lower speed, memory) it is absoulutely vital that we provide the most accurate information it needs during the retrieval phase.
accuracy is one part during retrieval and the other is granularity. you might be able to extract the relevant article out for model to work with, but if only 1 line is relevant from that passage, you are in effect adding a lot of noise that would hamper and confuse the model in practice. you want and hope to give the model only what it should require ideally (of course, the ideal scenario is rarely ever possible). this finally brings us to granularity and retrieval accuracy.
representation models (or embedding models as you may call them) are great at representing large amount of information (sometimes pages of text) in a limited space of just 700-1000 floats, but that doesn't mean it does not suffer from any loss. most representation is lossy, and if we have many concepts being covered in the same space, it is often that much of it would be lost. however, singluar concepts and explainations breed stronger representation vectors. it then becomes vital again to make sure we don't dilute the representation with noise.
all this brings me back to chunking. chunking, done well, can make sure your representation vector (or embedding) is of high-quality to be able to retrieve the best context for your model to generate with. and that in turn, leads to better quality rag generations. therefore, i believe chunking is here to stay as long as rag is here. and hence, it becomes important that we give it little more than a after-thought.
## does speed matter while chunking? (tl;dr: yes!!!)
human time is limited, and if you have an option that gives you faster chunks, why would you not?
but speed is not just a bonus; it's central to chonkie! whether you are doing rag on the entirity of wikipedia or working for large scale organization data that updates regularly, you would need the speed that chonkie comes with. stock solutions just don't cut it in these scenarios.
## but but but... how? how is chonkie so fast?
we used a lot of optimizations when building each and every chunker inside chonkie, making sure it's as optimized as possible.
1. **using tiktoken (as a default):** tiktoken is around 3-6x faster than it's counterparts; and it is blazing fast when used with multiple threads. we see the available threads on the cpu at the moment, and use about ~70-80% of them (so as to not hog all resources), which inturn let's us tokenize fast.
2. **pre-compute and cache:** we never tokenize or embed on the fly! as long as something can be pre-computed and cached we do that, store it and re-use it wherever possible. ram is cheap but time is priceless. (of course, we also provide options to turn off the pre-computation and make it memory efficient if need be)
3. **running mean pooling:** most semantic chunkers re-embed the chunks every time they get updated, but we don't do that. we pre-compute the embeddings for the sentences, and use mathematical trickery (which is theoretically found) to instead have a running mean pooling of tokens -- which allows us to save the cost from the embedding models.
# Chunkers
## TokenChunker
The `TokenChunker` splits text into chunks based on token count.
**Key Parameters:**
- `tokenizer` (`Optional[str, tokenizers.Tokenizer, tiktoken.Encoding]`): any tokenizer implementing the encode/decode interface
- `chunk_size` (`int`): maximum tokens per chunk
- `chunk_overlap` (`Union[int, float]`): number of overlapping tokens between chunks
**Methods:**
- `chunk`: Chunks a piece of text.
- **Parameters:**
- `text` (`str`): The input text to be chunked.
- **Returns:**
- `List[Chunk]`: A list of `Chunk` objects containing the chunked text and metadata.
- `chunk_batch`: Chunks a list of strings.
- **Parameters:**
- `texts` (`List[str]`): A list of input texts to be chunked.
- **Returns:**
- `List[List[Chunk]]`: A list of lists of `Chunk` objects, where each sublist corresponds to the chunks of an input text.
- `__call__`: Takes either a string or a list of strings for chunking.
- **Parameters:**
- `text` (`Union[str, List[str]]`): The input text or list of texts to be chunked.
- **Returns:**
- `Union[List[Chunk], List[List[Chunk]]]`: A list of `Chunk` objects if a single string is provided, or a list of lists of `Chunk` objects if a list of strings is provided.
**Example Usage:**
```python
# Import the TokenChunker
from chonkie import TokenChunker
from autotiktokenizer import AutoTikTokenizer
# Initialize the tokenizer
tokenizer = AutoTikTokenizer.from_pretrained("gpt2")
# Initialize the chunker
chunker = TokenChunker(
tokenizer=tokenizer,
chunk_size=512, # maximum tokens per chunk
chunk_overlap=128 # overlap between chunks
)
# Chunk a single piece of text
chunks = chunker.chunk("Woah! Chonkie, the chunking library is so cool! I love the tiny hippo hehe.")
for chunk in chunks:
print(f"Chunk: {chunk.text}")
print(f"Tokens: {chunk.token_count}")
# Chunk a batch of texts
texts = ["First text to chunk.", "Second text to chunk."]
batch_chunks = chunker.chunk_batch(texts)
for text_chunks in batch_chunks:
for chunk in text_chunks:
print(f"Chunk: {chunk.text}")
print(f"Tokens: {chunk.token_count}")
# Use the chunker as a callable
chunks = chunker("Another text to chunk using __call__.")
for chunk in chunks:
print(f"Chunk: {chunk.text}")
print(f"Tokens: {chunk.token_count}")
```
## WordChunker
The `WordChunker` maintains word boundaries while chunking, ensuring words stay intact.
**Key Parameters:**
- `tokenizer` (`Optional[str, tokenizers.Tokenizer, tiktoken.Encoding]`): Any tokenizer implementing the encode/decode interface
- `chunk_size` (`int`): Maximum tokens per chunk
- `chunk_overlap` (`int`): Number of overlapping tokens between chunks
- `mode` (`str`): Chunking mode, either 'simple' (space-based splitting) or 'advanced' (handles punctuation and special cases)
**Methods:**
- `chunk`: Chunks a piece of text.
- **Parameters:**
- `text` (`str`): The input text to be chunked.
- **Returns:**
- `List[Chunk]`: A list of `Chunk` objects containing the chunked text and metadata.
- `chunk_batch`: Chunks a list of strings.
- **Parameters:**
- `texts` (`List[str]`): A list of input texts to be chunked.
- **Returns:**
- `List[List[Chunk]]`: A list of lists of `Chunk` objects, where each sublist corresponds to the chunks of an input text.
- `__call__`: Takes either a string or a list of strings for chunking.
- **Parameters:**
- `text` (`Union[str, List[str]]`): The input text or list of texts to be chunked.
- **Returns:**
- `Union[List[Chunk], List[List[Chunk]]]`: A list of `Chunk` objects if a single string is provided, or a list of lists of `Chunk` objects if a list of strings is provided.
**Example Usage:**
```python
from chonkie import WordChunker
from autotiktokenizer import AutoTikTokenizer
tokenizer = AutoTikTokenizer.from_pretrained("gpt2")
chunker = WordChunker(
tokenizer=tokenizer,
chunk_size=512,
chunk_overlap=128,
mode="advanced"
)
# Chunk a single piece of text
chunks = chunker.chunk("Some text to chunk while preserving word boundaries.")
for chunk in chunks:
print(f"Chunk: {chunk.text}")
print(f"Tokens: {chunk.token_count}")
```
## SentenceChunker
The `SentenceChunker` preserves sentence boundaries while chunking text.
**Key Parameters:**
- `tokenizer` (`Optional[str, tokenizers.Tokenizer, tiktoken.Encoding]`): Any tokenizer implementing the encode/decode interface
- `chunk_size` (`int`): Maximum tokens per chunk
- `chunk_overlap` (`int`): Number of overlapping tokens between chunks
- `min_sentences_per_chunk` (`int`): Minimum number of sentences to include in each chunk
**Methods:**
- `chunk`: Chunks a piece of text.
- **Parameters:**
- `text` (`str`): The input text to be chunked.
- **Returns:**
- `List[SentenceChunk]`: A list of `SentenceChunk` objects containing the chunked text and metadata, including individual sentences.
- `chunk_batch`: Chunks a list of strings.
- **Parameters:**
- `texts` (`List[str]`): A list of input texts to be chunked.
- **Returns:**
- `List[List[SentenceChunk]]`: A list of lists of `SentenceChunk` objects.
- `__call__`: Takes either a string or a list of strings for chunking.
- **Parameters:**
- `text` (`Union[str, List[str]]`): The input text or list of texts to be chunked.
- **Returns:**
- `Union[List[SentenceChunk], List[List[SentenceChunk]]]`: A list of `SentenceChunk` objects or a list of lists of `SentenceChunk` objects.
**Example Usage:**
```python
from chonkie import SentenceChunker
from autotiktokenizer import AutoTikTokenizer
tokenizer = AutoTikTokenizer.from_pretrained("gpt2")
chunker = SentenceChunker(
tokenizer=tokenizer,
chunk_size=512,
chunk_overlap=128,
min_sentences_per_chunk=1
)
# Chunk a single piece of text
chunks = chunker.chunk("First sentence. Second sentence. Third sentence.")
for chunk in chunks:
print(f"Chunk: {chunk.text}")
print(f"Number of sentences: {len(chunk.sentences)}")
```
## SemanticChunker
The `SemanticChunker` groups content by semantic similarity. The implementation is inspired by the semantic chunking approach described in the [FullStackRetrieval Tutorials](https://github.com/FullStackRetrieval-com/RetrievalTutorials/blob/main/tutorials/LevelsOfTextSplitting/5_Levels_Of_Text_Splitting.ipynb), with modifications and optimizations for better performance and integration with Chonkie's architecture.
This version of `SemanticChunker` has some optimizations that speed it up considerably, but make the assumption that the `tokenizer` you used is the same as the one used for `embedding_model`. This is a valid assumption since most often than not, `chunk_size` and hence, `token_count` is dependent on the `embedding_model` context sizes rather than on the Generative models context length.
**Key Parameters:**
- `embedding_model` (`Union[str, SentenceTransformer]`): Model for semantic embeddings, either a model name string or a SentenceTransformer instance
- `similarity_threshold` (`Optional[float]`): Minimum similarity score to consider sentences similar (0-1)
- `similarity_percentile` (`Optional[float]`): Minimum similarity percentile to consider sentences similar (0-100)
- `chunk_size` (`Optional[int]`): Maximum tokens allowed per chunk
- `initial_sentences` (`Optional[int]`): Number of sentences to start each chunk with
**Methods:**
- `chunk`: Chunks a piece of text using semantic similarity.
- **Parameters:**
- `text` (`str`): The input text to be chunked.
- **Returns:**
- `List[SemanticChunk]`: A list of `SemanticChunk` objects containing semantically coherent chunks.
- `chunk_batch`: Chunks a list of strings.
- **Parameters:**
- `texts` (`List[str]`): A list of input texts to be chunked.
- **Returns:**
- `List[List[SemanticChunk]]`: A list of lists of `SemanticChunk` objects.
- `__call__`: Takes either a string or a list of strings for chunking.
- **Parameters:**
- `text` (`Union[str, List[str]]`): The input text or list of texts to be chunked.
- **Returns:**
- `Union[List[SemanticChunk], List[List[SemanticChunk]]]`: A list of `SemanticChunk` objects or a list of lists of `SemanticChunk` objects.
**Example Usage:**
```python
from chonkie import SemanticChunker
chunker = SemanticChunker(
embedding_model="minishlab/potion-base-8M", # Default model supported with SemanticChunker
chunk_size=512,
similarity_threshold=0.7
)
# Chunk a single piece of text
chunks = chunker.chunk("Some text with semantic meaning to chunk appropriately.")
for chunk in chunks:
print(f"Chunk: {chunk.text}")
print(f"Number of semantic sentences: {len(chunk.sentences)}")
```
## SDPMChunker
the `SDPMChunker` groups content via the semantic double-pass merging method, which groups paragraphs that are semantically similar even if they do not occur consecutively, by making use of a skip-window.
**Key Parameters:**
- `embedding_model` (`Union[str, SentenceTransformer]`): Model for semantic embeddings, either a model name string or a SentenceTransformer instance
- `similarity_threshold` (`Optional[float]`): Minimum similarity score to consider sentences similar (0-1)
- `similarity_percentile` (`Optional[float]`): Minimum similarity percentile to consider sentences similar (0-100)
- `chunk_size` (`Optional[int]`): Maximum tokens allowed per chunk
- `initial_sentences` (`Optional[int]`): Number of sentences to start each chunk with
- `skip_window` (`Optional[int]`): Number of chunks to skip when looking for similarities
**Methods:**
- `chunk`: Chunks a piece of text using semantic double-pass merging.
- **Parameters:**
- `text` (`str`): The input text to be chunked.
- **Returns:**
- `List[SemanticChunk]`: A list of `SemanticChunk` objects containing semantically coherent chunks.
- `chunk_batch`: Chunks a list of strings.
- **Parameters:**
- `texts` (`List[str]`): A list of input texts to be chunked.
- **Returns:**
- `List[List[SemanticChunk]]`: A list of lists of `SemanticChunk` objects.
- `__call__`: Takes either a string or a list of strings for chunking.
- **Parameters:**
- `text` (`Union[str, List[str]]`): The input text or list of texts to be chunked.
- **Returns:**
- `Union[List[SemanticChunk], List[List[SemanticChunk]]]`: A list of `SemanticChunk` objects or a list of lists of `SemanticChunk` objects.
**Example Usage:**
```python
from chonkie import SDPMChunker
chunker = SDPMChunker(
embedding_model="minishlab/potion-base-8M",
chunk_size=512,
similarity_threshold=0.7,
skip_window=1
)
# Chunk a single piece of text
chunks = chunker.chunk("Some text with related but non-consecutive content to chunk.")
for chunk in chunks:
print(f"Chunk: {chunk.text}")
print(f"Number of semantic sentences: {len(chunk.sentences)}")
```
# Embeddings
Chonkie provides a flexible embeddings system that can be used with various embedding providers. The embeddings system is designed to work seamlessly with the semantic chunking features.
## BaseEmbeddings
All embedding implementations in Chonkie inherit from the `BaseEmbeddings` abstract class, which defines the common interface:
```python
class BaseEmbeddings:
def embed(self, text: str) -> np.ndarray:
"""Embed a single text into a vector."""
pass
def embed_batch(self, texts: List[str]) -> List[np.ndarray]:
"""Embed multiple texts into vectors."""
pass
def count_tokens(self, text: str) -> int:
"""Count tokens in a text."""
pass
def similarity(self, u: np.ndarray, v: np.ndarray) -> float:
"""Compute similarity between two embeddings."""
pass
@property
def dimension(self) -> int:
"""Return embedding dimension."""
pass
```
## Model2Vec Embeddings
Uses distilled static embedding models with help of [`model2vec`](https://github.com/MinishLab/model2vec) package. These models are 500x faster than standard `SentenceTransformer` models and about 15x smaller with the `potion-base-8M` being just about 30MB. When used in conjuction with `chonkie[model2vec]` the entire package for `SemanticChunker` usage is just about 57MiB, the smallest of all the options and a 10x smaller package size than the other stock options.
```python
from chonkie.embeddings import Model2VecEmbeddings, AutoEmbeddings
# Initialise with the Model2VecEmbeddings class
embeddings = Model2VecEmbeddings("minishlab/potion-base-8M")
# OR initialise with the AutoEmbeddings get_embeddings()
embeddings = AutoEmbeddings.get_embeddings("minishlab/potion-base-8M")
chunker = SemanticChunker(
embedding_model=embeddings,
similarity_threshold=0.5,
)
```
Available potion models from [Minish lab](https://minishlab.github.io/):
- [potion-base-8M](https://huggingface.co/minishlab/potion-base-8M)
- [potion-base-4M](https://huggingface.co/minishlab/potion-base-4M)
- [potion-base-2M](https://huggingface.co/minishlab/potion-base-2M)
Resources:
- Model2Vec [blog](https://minishlab.github.io/hf_blogpost/)
## SentenceTransformerEmbeddings
Uses Sentence Transformers models for creating embeddings.
```python
from chonkie.embeddings import SentenceTransformerEmbeddings
# Initialize with default model
embeddings = SentenceTransformerEmbeddings()
# Use specific model
embeddings = SentenceTransformerEmbeddings("paraphrase-MiniLM-L6-v2")
# Use with semantic chunker
chunker = SemanticChunker(embedding_model=embeddings)
```
## OpenAIEmbeddings
Uses OpenAI's API for creating embeddings.
```python
from chonkie.embeddings import OpenAIEmbeddings
# Initialize with API key
embeddings = OpenAIEmbeddings(
model="text-embedding-3-small",
api_key="your-api-key" # Optional if OPENAI_API_KEY env var is set
)
# Configure batch size and timeouts
embeddings = OpenAIEmbeddings(
model="text-embedding-3-large",
batch_size=32,
timeout=30.0
)
# Use with semantic chunker
chunker = SemanticChunker(embedding_model=embeddings)
```
Available OpenAI models:
- `text-embedding-3-small` (1536 dimensions, best performance/cost ratio)
- `text-embedding-3-large` (3072 dimensions, highest performance)
- `text-embedding-ada-002` (1536 dimensions, legacy model)
## Using AutoEmbeddings
The `AutoEmbeddings` class provides a convenient way to load embeddings:
```python
from chonkie.embeddings import AutoEmbeddings
# Load sentence transformers
embeddings = AutoEmbeddings.get_embeddings("sentence-transformers/all-MiniLM-L6-v2")
# Load OpenAI embeddings
embeddings = AutoEmbeddings.get_embeddings(
"openai/text-embedding-3-small",
api_key="your-api-key"
)
# Use directly with semantic chunker
chunker = SemanticChunker(
embedding_model="openai/text-embedding-3-small",
api_key="your-api-key"
)
```
## Creating Custom Embeddings
You can create custom embedding implementations by inheriting from `BaseEmbeddings`:
```python
from chonkie.embeddings import BaseEmbeddings
class CustomEmbeddings(BaseEmbeddings):
def embed(self, text: str) -> np.ndarray:
# Implement embedding logic
pass
def count_tokens(self, text: str) -> int:
# Implement token counting
pass
# Implement other required methods...
# Register with the embeddings registry
EmbeddingsRegistry.register(
"custom",
CustomEmbeddings,
pattern=r"^custom/|^model-name"
)
```
# API Reference
## Chunk object
```python
@dataclass
class Chunk:
text: str # the chunk text
start_index: int # starting position in original text
end_index: int # ending position in original text
token_count: int # number of tokens in chunk
```
## SentenceChunk object
```python
@dataclass
class Sentence:
text: str
start_index: int
end_index: int
token_count: int
@dataclass
class SentenceChunk(Chunk):
text: str
start_index: int
end_index: int
token_count: int
sentences: list[Sentence]
```
## SemanticChunk object
```python
@dataclass
class SemanticSentence(Sentence):
text: str
start_index: int
end_index: int
token_count: int
embedding: optional[np.ndarray]
@dataclass
class SemanticChunk(SentenceChunk):
text: str
start_index: int
end_index: int
token_count: int
sentences: list[SemanticSentence]
```
# FAQ
## Can I run a Chunker multiple times on different texts? Is Chonkie thread-safe?
Yes! Chonkie's Chunkers can be run multiple times without having to re-initialize them. Just initialise them once like you would expect to, and run them on any piece of text you might want to.
That also means it is absolutely thread-safe! But I would recommend monitoring the CPU usage, since few Chunkers frequently default to multi-threaded chunking (like WordChunker and SentenceChunker) so your resources might be depleted faster than usual running these Chunkers. | {
"source": "chonkie-ai/chonkie",
"title": "DOCS.md",
"url": "https://github.com/chonkie-ai/chonkie/blob/main/DOCS.md",
"date": "2024-11-01T07:26:05",
"stars": 2661,
"description": "🦛 CHONK your texts with Chonkie ✨ - The no-nonsense RAG chunking library",
"file_size": 28798
} |
<div align='center'>

# 🦛 Chonkie ✨
[](https://pypi.org/project/chonkie/)
[](https://github.com/bhavnicksm/chonkie/blob/main/LICENSE)
[](https://docs.chonkie.ai)

[](https://pepy.tech/project/chonkie)
[](https://discord.gg/rYYp6DC4cv)
[](https://github.com/bhavnicksm/chonkie/stargazers)
_The no-nonsense RAG chunking library that's lightweight, lightning-fast, and ready to CHONK your texts_
[Installation](#installation) •
[Usage](#usage) •
[Supported Methods](#supported-methods) •
[Benchmarks](#benchmarks-️) •
[Documentation](https://docs.chonkie.ai) •
[Contributing](#contributing)
</div>
Ever found yourself building yet another RAG bot (your 2,342,148th one), only to hit that all-too-familiar wall? You know the one —— where you're stuck choosing between:
- Library X: A behemoth that takes forever to install and probably includes three different kitchen sinks
- Library Y: So bare-bones it might as well be a "Hello World" program
- Writing it yourself? For the 2,342,149th time, _sigh_
And you think to yourself:
> "WHY CAN'T THIS JUST BE SIMPLE?!" </br>
> "Why do I need to choose between bloated and bare-bones?" </br>
> "Why can't I just install, import, and CHONK?!" </br>
Well, look no further than Chonkie! (chonkie boi is a gud boi 🦛💕)
**🚀 Feature-rich**: All the CHONKs you'd ever need </br>
**✨ Easy to use**: Install, Import, CHONK </br>
**⚡ Fast**: CHONK at the speed of light! zooooom </br>
**🌐 Wide support**: Supports all your favorite tokenizer CHONKS </br>
**🪶 Light-weight**: No bloat, just CHONK </br>
**🦛 Cute CHONK mascot**: psst it's a pygmy hippo btw </br>
**❤️ [Moto Moto](#acknowledgements)'s favorite python library** </br>
**Chonkie** is a chunking library that "**just works™**".
# Installation
To install chonkie, simply run:
```bash
pip install chonkie
```
Chonkie follows the rule to have minimal default installs, read the [DOCS](https://docs.chonkie.ai) to know the installation for your required chunker, or simply install `all` if you don't want to think about it (not recommended).
```bash
pip install chonkie[all]
```
# Usage
Here's a basic example to get you started:
```python
# First import the chunker you want from Chonkie
from chonkie import TokenChunker
# Import your favorite tokenizer library
# Also supports AutoTokenizers, TikToken and AutoTikTokenizer
from tokenizers import Tokenizer
tokenizer = Tokenizer.from_pretrained("gpt2")
# Initialize the chunker
chunker = TokenChunker(tokenizer)
# Chunk some text
chunks = chunker("Woah! Chonkie, the chunking library is so cool! I love the tiny hippo hehe.")
# Access chunks
for chunk in chunks:
print(f"Chunk: {chunk.text}")
print(f"Tokens: {chunk.token_count}")
```
More example usages given inside the [DOCS](https://docs.chonkie.ai)
# Supported Methods
Chonkie provides several chunkers to help you split your text efficiently for RAG applications. Here's a quick overview of the available chunkers:
- **TokenChunker**: Splits text into fixed-size token chunks.
- **WordChunker**: Splits text into chunks based on words.
- **SentenceChunker**: Splits text into chunks based on sentences.
- **RecursiveChunker**: Splits text hierarchically using customizable rules to create semantically meaningful chunks.
- **SemanticChunker**: Splits text into chunks based on semantic similarity.
- **SDPMChunker**: Splits text using a Semantic Double-Pass Merge approach.
- **LateChunker (experimental)**: Embeds text and then splits it to have better chunk embeddings.
More on these methods and the approaches taken inside the [DOCS](https://docs.chonkie.ai)
# Benchmarks 🏃♂️
> "I may be smol hippo, but I pack a punch!" 🦛
Here's a quick peek at how Chonkie performs:
**Size**📦
- **Default Install:** 15MB (vs 80-171MB for alternatives)
- **With Semantic:** Still lighter than the competition!
**Speed**⚡
- **Token Chunking:** 33x faster than the slowest alternative
- **Sentence Chunking:** Almost 2x faster than competitors
- **Semantic Chunking:** Up to 2.5x faster than others
Check out our detailed [benchmarks](https://docs.chonkie.ai/benchmarks) to see how Chonkie races past the competition! 🏃♂️💨
# Contributing
Want to help make Chonkie even better? Check out our [CONTRIBUTING.md](CONTRIBUTING.md) guide! Whether you're fixing bugs, adding features, or improving docs, every contribution helps make Chonkie a better CHONK for everyone.
Remember: No contribution is too small for this tiny hippo! 🦛
# Acknowledgements
Chonkie would like to CHONK its way through a special thanks to all the users and contributors who have helped make this library what it is today! Your feedback, issue reports, and improvements have helped make Chonkie the CHONKIEST it can be.
And of course, special thanks to [Moto Moto](https://www.youtube.com/watch?v=I0zZC4wtqDQ&t=5s) for endorsing Chonkie with his famous quote:
> "I like them big, I like them chonkie."
> ~ Moto Moto
# Citation
If you use Chonkie in your research, please cite it as follows:
```bibtex
@misc{chonkie2024,
author = {Minhas, Bhavnick},
title = {Chonkie: A Fast Feature-full Chunking Library for RAG Bots},
year = {2024},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/bhavnick/chonkie}},
}
``` | {
"source": "chonkie-ai/chonkie",
"title": "README.md",
"url": "https://github.com/chonkie-ai/chonkie/blob/main/README.md",
"date": "2024-11-01T07:26:05",
"stars": 2661,
"description": "🦛 CHONK your texts with Chonkie ✨ - The no-nonsense RAG chunking library",
"file_size": 5849
} |
# 🦛 CHONK vs The World
> Look how **THICC** the competition is! Meanwhile, Chonkie be looking slim and trim 💪
Ever wondered how much CHONKier other text splitting libraries are? Well, wonder no more! We've put Chonkie up against some of the most popular RAG libraries out there, and the results are... well, let's just say Moto Moto might need to revise his famous quote!
## ⚡ Speed Benchmarks
> ZOOOOOM! Watch Chonkie run! 🏃♂️💨
### 100K Wikipedia Articles
The following benchmarks were run on 100,000 Wikipedia articles from the
[`chonkie-ai/wikipedia-100k`](https://huggingface.co/datasets/chonkie-ai/wikipedia-100k) dataset
All tests were run on a Google Colab A100 instance.
#### Token Chunking
| Library | Time | Speed Factor |
|---------|-----------|--------------|
| 🦛 Chonkie | 58 sec | 1x |
| 🔗 LangChain | 1 min 10 sec | 1.21x slower |
| 📚 LlamaIndex | 50 min | 51.7x slower |
#### Sentence Chunking
| Library | Time | Speed Factor |
|---------|-----------|--------------|
| 🦛 Chonkie | 59 sec | 1x |
| 📚 LlamaIndex | 3 min 59 sec | 4.05x slower |
| 🔗 LangChain | N/A | Doesn't exist |
#### Recursive Chunking
| Library | Time | Speed Factor |
|---------|-----------|--------------|
| 🦛 Chonkie | 1 min 19 sec | 1x |
| 🔗 LangChain | 2 min 45 sec | 2.09x slower |
| 📚 LlamaIndex | N/A | Doesn't exist |
#### Semantic Chunking
Tested with `sentence-transformers/all-minilm-l6-v2` model unless specified otherwise.
| Library | Time | Speed Factor |
|---------|-----------|--------------|
| 🦛 Chonkie (with default settings) | 13 min 59 sec | 1x |
| 🦛 Chonkie | 1 hour 8 min min 53 sec | 4.92x slower |
| 🔗 LangChain | 1 hour 13 sec | 4.35x slower |
| 📚 LlamaIndex | 1 hour 24 min 15 sec| 6.07x slower |
### 500K Wikipedia Articles
The following benchmarks were run on 500,000 Wikipedia articles from the
[`chonkie-ai/wikipedia-500k`](https://huggingface.co/datasets/chonkie-ai/wikipedia-500k) dataset
All tests were run on a `c3-highmem-4` VM from Google Cloud with 32 GB RAM and a 200 GB SSD Persistent Disk attachment.
#### Token Chunking
| Library | Time | Speed Factor |
|---------|-----------|--------------|
| 🦛 Chonkie | 2 min 17 sec | 1x |
| 🔗 LangChain | 2 min 42 sec | 1.18x slower |
| 📚 LlamaIndex | 50 min | 21.9x slower |
#### Sentence Chunking
| Library | Time | Speed Factor |
|---------|-----------|--------------|
| 🦛 Chonkie | 7 min 16 sec | 1x |
| 📚 LlamaIndex | 10 min 55 sec | 1.5x slower |
| 🔗 LangChain | N/A | Doesn't exist |
#### Recursive Chunking
| Library | Time | Speed Factor |
|---------|-----------|--------------|
| 🦛 Chonkie | 3 min 42 sec | 1x |
| 🔗 LangChain | 7 min 36 sec | 2.05x slower |
| 📚 LlamaIndex | N/A | Doesn't exist |
### Paul Graham Essays Dataset
The following benchmarks were run on the Paul Graham Essays dataset using the GPT-2 tokenizer.
#### Token Chunking
| Library | Time (ms) | Speed Factor |
|---------|-----------|--------------|
| 🦛 Chonkie | 8.18 | 1x |
| 🔗 LangChain | 8.68 | 1.06x slower |
| 📚 LlamaIndex | 272 | 33.25x slower |
#### Sentence Chunking
| Library | Time (ms) | Speed Factor |
|---------|-----------|--------------|
| 🦛 Chonkie | 52.6 | 1x |
| 📚 LlamaIndex | 91.2 | 1.73x slower |
| 🔗 LangChain | N/A | Doesn't exist |
#### Semantic Chunking
| Library | Time | Speed Factor |
|---------|------|--------------|
| 🦛 Chonkie | 482ms | 1x |
| 🔗 LangChain | 899ms | 1.86x slower |
| 📚 LlamaIndex | 1.2s | 2.49x slower |
## 📊 Size Comparison (Package Size)
### Default Installation (Basic Chunking)
| Library | Size | Chonk Factor |
|---------|------|--------------|
| 🦛 Chonkie | 11.2 MiB | 1x |
| 🔗 LangChain | 80 MiB | ~7.1x CHONKier |
| 📚 LlamaIndex | 171 MiB | ~15.3x CHONKier |
### With Semantic Features
| Library | Size | Chonk Factor |
|---------|------|--------------|
| 🦛 Chonkie | 62 MiB | 1x |
| 🔗 LangChain | 625 MiB | ~10x CHONKier |
| 📚 LlamaIndex | 678 MiB | ~11x CHONKier |
## 💡 Why These Numbers Matter
### Speed Benefits
1. **Faster Processing**: Chonkie leads in all chunking methods!
2. **Production Ready**: Optimized for real-world usage
3. **Consistent Performance**: Fast across all chunking types
4. **Scale Friendly**: Process more text in less time
### Size Benefits
1. **Faster Installation**: Less to download = faster to get started
2. **Lower Memory Footprint**: Lighter package = less RAM usage
3. **Cleaner Dependencies**: Only install what you actually need
4. **CI/CD Friendly**: Faster builds and deployments
Remember what Chonkie always says:
> "I may be a hippo, but I'm still light and fast!" 🦛✨
---
*Note: All measurements were taken using Python 3.8+ on a clean virtual environment. Your actual mileage may vary slightly depending on your specific setup and dependencies.* | {
"source": "chonkie-ai/chonkie",
"title": "benchmarks/README.md",
"url": "https://github.com/chonkie-ai/chonkie/blob/main/benchmarks/README.md",
"date": "2024-11-01T07:26:05",
"stars": 2661,
"description": "🦛 CHONK your texts with Chonkie ✨ - The no-nonsense RAG chunking library",
"file_size": 4750
} |
<div align='center'>

# 🦛 Chonkie's Cookbook 📚
_A collection of recipes, tutorials, and projects using Chonkie_
</div>
## 📖 Official Tutorials
| Tutorial | Description | Try it |
|----------|-------------|-----------------|
| Recursive Chunking for PDF/Markdown Documents | A quick look at how you can use Chonkie's RecursiveChunker to chunk your PDF/Markdown documents and build a RAG pipeline over it! | [](https://colab.research.google.com/github/bhavnicksm/chonkie/blob/main/cookbook/tutorials/Chonkie_RecursiveChunker_for_PDF_and_Markdown.ipynb) |
## 🔌 Community Integrations
Chonkie is proud to power a diverse ecosystem of projects and integrations across the AI and ML landscape. Our lightweight, flexible architecture makes it easy to integrate Chonkie into your existing workflows and tools.
Want to add your integration? Simply [raise an issue](https://github.com/bhavnicksm/chonkie/issues/new) and we'll help you get started! Once approved, your integration will be featured here.
| Integration | Description | Repository |
|-------------|-------------|------------|
| ⚡️ FlashRAG | A Python toolkit for the reproduction and development of Retrieval Augmented Generation (RAG) research. | [](https://github.com/RUC-NLPIR/FlashRAG) |
| 📄 txtai | All-in-one embeddings database for semantic search, LLM orchestration and language model workflows | [](https://github.com/neuml/txtai) |
| [Add your integration here!](CONTRIBUTING.md) | Share your Chonkie integration with the community | [](CONTRIBUTING.md) |
## 📚 Community Blogs & Resources
Share your knowledge and experiences with Chonkie! Whether it's a blog post, video tutorial, or technical deep-dive, we'd love to feature your content here.
| Type | Title | Author | Description |
|------|--------|--------|-------------|
| Video | [Chonkie - RAG Chunking Library - Easy Local Installation and Testing](https://www.youtube.com/watch?v=f4f1TkeL5Hk) | Fahd Mirza | A quick walkthrough of how to install Chonkie and test it out for yourself! |
| Blog | [Easy Late-Chunking with Chonkie](https://pub.towardsai.net/easy-late-chunking-with-chonkie-7f05e5916997) | Michael Ryaboy | This blog post is a quick look at how you can use Chonkie's LateChunker to chunk your documents and build a search pipeline over it with KDB.AI! |
Have content to share? Open an issue with your resource and we'll get it added to the cookbook!
## 📝 Contributing
Want to add your project or integration to the cookbook? Check out our [contribution guidelines](/CONTRIBUTING.md)!
---
<div align='center'>
Need help? Join our [Discord community](https://discord.gg/rYYp6DC4cv)!
</div> | {
"source": "chonkie-ai/chonkie",
"title": "cookbook/README.md",
"url": "https://github.com/chonkie-ai/chonkie/blob/main/cookbook/README.md",
"date": "2024-11-01T07:26:05",
"stars": 2661,
"description": "🦛 CHONK your texts with Chonkie ✨ - The no-nonsense RAG chunking library",
"file_size": 3123
} |
---
name: 🐛 Bug Report
about: Report a bug in Chonkie
title: "[BUG] "
labels: bug
assignees: bhavnicksm, shreyashnigam
---
## 🐛 Bug Description
<!-- A clear description of what's going wrong -->
## 🔍 Minimal Example
<!-- A small, self-contained code example that demonstrates the issue -->
```python
from chonkie import TokenChunker
# Your minimal example here
```
## 💻 Environment
<!-- Please complete the following information -->
- Chonkie Version: <!-- e.g., 0.4.0 -->
- Python Version: <!-- e.g., 3.9.7 -->
- OS: <!-- e.g., Ubuntu 22.04, Windows 11, macOS 13.1 -->
- Installation Method: <!-- e.g., pip install chonkie, pip install chonkie[all] -->
- Python Environment: <!-- e.g. pip freeze or pip list -->
## 📋 Current Behavior
<!-- What actually happened? Include full error messages and/or screenshots if applicable -->
```bash
Error message or output here
```
## ✨ Expected Behavior
<!-- What did you expect to happen? -->
## 📝 Additional Context
<!-- Any other relevant information? -->
<!-- e.g., Are you using any specific tokenizer? Processing large files? -->
## ✅ Reproduction Rate
<!-- How often does this bug occur? -->
- [ ] Always
- [ ] Sometimes
- [ ] Rarely
- [ ] Not sure
## 🔄 Workaround
<!-- If you found a temporary workaround, please share it here -->
<!-- Thank you for helping make Chonkie better! 🦛 --> | {
"source": "chonkie-ai/chonkie",
"title": ".github/ISSUE_TEMPLATE/bug_report.md",
"url": "https://github.com/chonkie-ai/chonkie/blob/main/.github/ISSUE_TEMPLATE/bug_report.md",
"date": "2024-11-01T07:26:05",
"stars": 2661,
"description": "🦛 CHONK your texts with Chonkie ✨ - The no-nonsense RAG chunking library",
"file_size": 1346
} |
---
name: ✨ Feature Request
about: Suggest a new feature for Chonkie
title: "[FEAT] "
labels: enhancement
assignees: bhavnicksm, shreyashnigam
---
## 📋 Quick Check
- [ ] I've checked this feature isn't already implemented or proposed
- [ ] This feature is relevant to Chonkie's purpose (text chunking for RAG)
## 💡 Feature Description
<!-- What would you like Chonkie to do? -->
## 🛠️ Implementation Approach
<!-- How do you think this could be implemented? Code sketches welcome! -->
```python
# Example of how this feature might work
from chonkie import ...
# Your implementation idea
```
## 🎯 Why is this needed?
<!-- What problem does this solve? -->
<!-- Thank you for helping make Chonkie CHONKier! 🦛 --> | {
"source": "chonkie-ai/chonkie",
"title": ".github/ISSUE_TEMPLATE/feature_request.md",
"url": "https://github.com/chonkie-ai/chonkie/blob/main/.github/ISSUE_TEMPLATE/feature_request.md",
"date": "2024-11-01T07:26:05",
"stars": 2661,
"description": "🦛 CHONK your texts with Chonkie ✨ - The no-nonsense RAG chunking library",
"file_size": 719
} |
# DeepResearch
[Official UI](https://search.jina.ai/) | [UI Code](https://github.com/jina-ai/deepsearch-ui) | [Official API](https://jina.ai/deepsearch) | [Evaluation](#evaluation)
Keep searching, reading webpages, reasoning until an answer is found (or the token budget is exceeded). Useful for deeply investigating a query.
> [!IMPORTANT]
> Unlike OpenAI/Gemini/Perplexity's "Deep Research", we focus solely on **finding the right answers via our iterative process**. We don't optimize for long-form articles, that's a **completely different problem** – so if you need quick, concise answers from deep search, you're in the right place. If you're looking for AI-generated long reports like OpenAI/Gemini/Perplexity does, this isn't for you.
```mermaid
---
config:
theme: mc
look: handDrawn
---
flowchart LR
subgraph Loop["until budget exceed"]
direction LR
Search["Search"]
Read["Read"]
Reason["Reason"]
end
Query(["Query"]) --> Loop
Search --> Read
Read --> Reason
Reason --> Search
Loop --> Answer(["Answer"])
```
## Install
```bash
git clone https://github.com/jina-ai/node-DeepResearch.git
cd node-DeepResearch
npm install
```
[安装部署视频教程 on Youtube](https://youtu.be/vrpraFiPUyA)
It is also available on npm but not recommended for now, as the code is still under active development.
## Usage
We use Gemini (latest `gemini-2.0-flash`) / OpenAI / [LocalLLM](#use-local-llm) for reasoning, [Jina Reader](https://jina.ai/reader) for searching and reading webpages, you can get a free API key with 1M tokens from jina.ai.
```bash
export GEMINI_API_KEY=... # for gemini
# export OPENAI_API_KEY=... # for openai
# export LLM_PROVIDER=openai # for openai
export JINA_API_KEY=jina_... # free jina api key, get from https://jina.ai/reader
npm run dev $QUERY
```
### Official Site
You can try it on [our official site](https://search.jina.ai).
### Official API
You can also use [our official DeepSearch API](https://jina.ai/deepsearch):
```
https://deepsearch.jina.ai/v1/chat/completions
```
You can use it with any OpenAI-compatible client.
For the authentication Bearer, API key, rate limit, get from https://jina.ai/deepsearch.
#### Client integration guidelines
If you are building a web/local/mobile client that uses `Jina DeepSearch API`, here are some design guidelines:
- Our API is fully compatible with [OpenAI API schema](https://platform.openai.com/docs/api-reference/chat/create), this should greatly simplify the integration process. The model name is `jina-deepsearch-v1`.
- Our DeepSearch API is a reasoning+search grounding LLM, so it's best for questions that require deep reasoning and search.
- Two special tokens are introduced `<think>...</think>`. Please render them with care.
- Citations are often provided, and in [Github-flavored markdown footnote format](https://github.blog/changelog/2021-09-30-footnotes-now-supported-in-markdown-fields/), e.g. `[^1]`, `[^2]`, ...
- Guide the user to get a Jina API key from https://jina.ai, with 1M free tokens for new API key.
- There are rate limits, [between 10RPM to 30RPM depending on the API key tier](https://jina.ai/contact-sales#rate-limit).
- [Download Jina AI logo here](https://jina.ai/logo-Jina-1024.zip)
## Demo
> was recorded with `gemini-1.5-flash`, the latest `gemini-2.0-flash` leads to much better results!
Query: `"what is the latest blog post's title from jina ai?"`
3 steps; answer is correct!

Query: `"what is the context length of readerlm-v2?"`
2 steps; answer is correct!

Query: `"list all employees from jina ai that u can find, as many as possible"`
11 steps; partially correct! but im not in the list :(

Query: `"who will be the biggest competitor of Jina AI"`
42 steps; future prediction kind, so it's arguably correct! atm Im not seeing `weaviate` as a competitor, but im open for the future "i told you so" moment.

More examples:
```
# example: no tool calling
npm run dev "1+1="
npm run dev "what is the capital of France?"
# example: 2-step
npm run dev "what is the latest news from Jina AI?"
# example: 3-step
npm run dev "what is the twitter account of jina ai's founder"
# example: 13-step, ambiguious question (no def of "big")
npm run dev "who is bigger? cohere, jina ai, voyage?"
# example: open question, research-like, long chain of thoughts
npm run dev "who will be president of US in 2028?"
npm run dev "what should be jina ai strategy for 2025?"
```
## Use Local LLM
> Note, not every LLM works with our reasoning flow, we need those who support structured output (sometimes called JSON Schema output, object output) well. Feel free to purpose a PR to add more open-source LLMs to the working list.
If you use Ollama or LMStudio, you can redirect the reasoning request to your local LLM by setting the following environment variables:
```bash
export LLM_PROVIDER=openai # yes, that's right - for local llm we still use openai client
export OPENAI_BASE_URL=http://127.0.0.1:1234/v1 # your local llm endpoint
export OPENAI_API_KEY=whatever # random string would do, as we don't use it (unless your local LLM has authentication)
export DEFAULT_MODEL_NAME=qwen2.5-7b # your local llm model name
```
## OpenAI-Compatible Server API
If you have a GUI client that supports OpenAI API (e.g. [CherryStudio](https://docs.cherry-ai.com/), [Chatbox](https://github.com/Bin-Huang/chatbox)) , you can simply config it to use this server.

Start the server:
```bash
# Without authentication
npm run serve
# With authentication (clients must provide this secret as Bearer token)
npm run serve --secret=your_secret_token
```
The server will start on http://localhost:3000 with the following endpoint:
### POST /v1/chat/completions
```bash
# Without authentication
curl http://localhost:3000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "jina-deepsearch-v1",
"messages": [
{
"role": "user",
"content": "Hello!"
}
]
}'
# With authentication (when server is started with --secret)
curl http://localhost:3000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer your_secret_token" \
-d '{
"model": "jina-deepsearch-v1",
"messages": [
{
"role": "user",
"content": "Hello!"
}
],
"stream": true
}'
```
Response format:
```json
{
"id": "chatcmpl-123",
"object": "chat.completion",
"created": 1677652288,
"model": "jina-deepsearch-v1",
"system_fingerprint": "fp_44709d6fcb",
"choices": [{
"index": 0,
"message": {
"role": "assistant",
"content": "YOUR FINAL ANSWER"
},
"logprobs": null,
"finish_reason": "stop"
}],
"usage": {
"prompt_tokens": 9,
"completion_tokens": 12,
"total_tokens": 21
}
}
```
For streaming responses (stream: true), the server sends chunks in this format:
```json
{
"id": "chatcmpl-123",
"object": "chat.completion.chunk",
"created": 1694268190,
"model": "jina-deepsearch-v1",
"system_fingerprint": "fp_44709d6fcb",
"choices": [{
"index": 0,
"delta": {
"content": "..."
},
"logprobs": null,
"finish_reason": null
}]
}
```
Note: The think content in streaming responses is wrapped in XML tags:
```
<think>
[thinking steps...]
</think>
[final answer]
```
## Docker Setup
### Build Docker Image
To build the Docker image for the application, run the following command:
```bash
docker build -t deepresearch:latest .
```
### Run Docker Container
To run the Docker container, use the following command:
```bash
docker run -p 3000:3000 --env GEMINI_API_KEY=your_gemini_api_key --env JINA_API_KEY=your_jina_api_key deepresearch:latest
```
### Docker Compose
You can also use Docker Compose to manage multi-container applications. To start the application with Docker Compose, run:
```bash
docker-compose up
```
## How Does it Work?
Not sure a flowchart helps, but here it is:
```mermaid
flowchart TD
Start([Start]) --> Init[Initialize context & variables]
Init --> CheckBudget{Token budget<br/>exceeded?}
CheckBudget -->|No| GetQuestion[Get current question<br/>from gaps]
CheckBudget -->|Yes| BeastMode[Enter Beast Mode]
GetQuestion --> GenPrompt[Generate prompt]
GenPrompt --> ModelGen[Generate response<br/>using Gemini]
ModelGen --> ActionCheck{Check action<br/>type}
ActionCheck -->|answer| AnswerCheck{Is original<br/>question?}
AnswerCheck -->|Yes| EvalAnswer[Evaluate answer]
EvalAnswer --> IsGoodAnswer{Is answer<br/>definitive?}
IsGoodAnswer -->|Yes| HasRefs{Has<br/>references?}
HasRefs -->|Yes| End([End])
HasRefs -->|No| GetQuestion
IsGoodAnswer -->|No| StoreBad[Store bad attempt<br/>Reset context]
StoreBad --> GetQuestion
AnswerCheck -->|No| StoreKnowledge[Store as intermediate<br/>knowledge]
StoreKnowledge --> GetQuestion
ActionCheck -->|reflect| ProcessQuestions[Process new<br/>sub-questions]
ProcessQuestions --> DedupQuestions{New unique<br/>questions?}
DedupQuestions -->|Yes| AddGaps[Add to gaps queue]
DedupQuestions -->|No| DisableReflect[Disable reflect<br/>for next step]
AddGaps --> GetQuestion
DisableReflect --> GetQuestion
ActionCheck -->|search| SearchQuery[Execute search]
SearchQuery --> NewURLs{New URLs<br/>found?}
NewURLs -->|Yes| StoreURLs[Store URLs for<br/>future visits]
NewURLs -->|No| DisableSearch[Disable search<br/>for next step]
StoreURLs --> GetQuestion
DisableSearch --> GetQuestion
ActionCheck -->|visit| VisitURLs[Visit URLs]
VisitURLs --> NewContent{New content<br/>found?}
NewContent -->|Yes| StoreContent[Store content as<br/>knowledge]
NewContent -->|No| DisableVisit[Disable visit<br/>for next step]
StoreContent --> GetQuestion
DisableVisit --> GetQuestion
BeastMode --> FinalAnswer[Generate final answer] --> End
```
## Evaluation
I kept the evaluation simple, LLM-as-a-judge and collect some [ego questions](./src/evals/ego-questions.json) for evaluation. These are the questions about Jina AI that I know 100% the answer but LLMs do not.
I mainly look at 3 things: total steps, total tokens, and the correctness of the final answer.
```bash
npm run eval ./src/evals/questions.json
```
Here's the table comparing plain `gemini-2.0-flash` and `gemini-2.0-flash + node-deepresearch` on the ego set.
Plain `gemini-2.0-flash` can be run by setting `tokenBudget` to zero, skipping the while-loop and directly answering the question.
It should not be surprised that plain `gemini-2.0-flash` has a 0% pass rate, as I intentionally filtered out the questions that LLMs can answer.
| Metric | gemini-2.0-flash | #188f1bb |
|--------|------------------|----------|
| Pass Rate | 0% | 75% |
| Average Steps | 1 | 4 |
| Maximum Steps | 1 | 13 |
| Minimum Steps | 1 | 2 |
| Median Steps | 1 | 3 |
| Average Tokens | 428 | 68,574 |
| Median Tokens | 434 | 31,541 |
| Maximum Tokens | 463 | 363,655 |
| Minimum Tokens | 374 | 7,963 | | {
"source": "jina-ai/node-DeepResearch",
"title": "README.md",
"url": "https://github.com/jina-ai/node-DeepResearch/blob/main/README.md",
"date": "2025-01-26T06:46:28",
"stars": 2646,
"description": "Keep searching, reading webpages, reasoning until it finds the answer (or exceeding the token budget)",
"file_size": 11239
} |
# Contributing to Eko
Thank you for your interest in contributing to Eko! This document provides guidelines and instructions for contributing to the project.
## Table of Contents
- [Development Setup](#development-setup)
- [Branching Strategy](#branching-strategy)
- [Commit Message Guidelines](#commit-message-guidelines)
- [Pull Request Process](#pull-request-process)
## Development Setup
### Prerequisites
- Node.js (>= 18.0.0)
- npm (latest stable version)
- Git
### Setting Up the Development Environment
1. Fork the repository
2. Clone your fork:
```bash
git clone https://github.com/your-username/eko.git
cd eko
```
3. Install dependencies:
```bash
npm install
```
4. Start the TypeScript compiler in watch mode:
```bash
npm run dev
```
5. Run tests:
```bash
npm test
```
### Development Commands
- `npm run dev`: Start TypeScript compiler in watch mode
- `npm test`: Run tests
- `npm run test:watch`: Run tests in watch mode
- `npm run build`: Build the project
- `npm run lint`: Run linting
- `npm run format`: Format code using Prettier
## Branching Strategy
### Branch Types
- `main`: Production-ready code
- `feature/*`: New features or enhancements (e.g., `feature/workflow-parser`)
- `fix/*`: Bug fixes (e.g., `fix/parsing-error`)
- `refactor/*`: Code refactoring without functionality changes
- `docs/*`: Documentation changes
- `test/*`: Adding or modifying tests
- `chore/*`: Maintenance tasks
- `build/*`: Changes affecting the build system
### Branch Naming Convention
- Use lowercase letters and hyphens
- Start with the type followed by a descriptive name
- Examples:
- `feature/json-parser`
- `fix/validation-error`
- `refactor/typescript-migration`
## Commit Message Guidelines
### Format
```
<type>(<scope>): <subject>
<body>
<footer>
```
### Type
Must be one of:
- `build`: Changes affecting build system or external dependencies
- `ci`: CI configuration changes
- `docs`: Documentation only changes
- `feat`: A new feature
- `fix`: A bug fix
- `perf`: Performance improvement
- `refactor`: Code change that neither fixes a bug nor adds a feature
- `style`: Changes not affecting code meaning (formatting, missing semicolons, etc.)
- `test`: Adding or correcting tests
### Subject
- Use imperative, present tense: "change" not "changed" nor "changes"
- Don't capitalize the first letter
- No period (.) at the end
- Maximum 50 characters
### Body
- Optional
- Use imperative, present tense
- Include motivation for change and contrast with previous behavior
- Wrap at 72 characters
### Examples
```
feat(parser): add JSON workflow parser implementation
Add parser class with validation and schema support.
Includes bidirectional conversion between JSON and runtime objects.
Closes #123
```
```
fix(validation): handle circular dependencies in workflow
Previously, the validator would hang on circular dependencies.
Now it detects and reports them as validation errors.
```
## Pull Request Process
1. Rebase your branch onto the latest main:
```bash
git checkout main
git pull upstream main
git checkout your-branch
git rebase main
```
2. Fix up commits to maintain clean history:
```bash
git rebase -i main
```
3. Ensure:
- All tests pass
- Code is properly formatted
- Documentation is updated
- Commit messages follow guidelines
4. Submit PR:
- Use a clear title following commit message format
- Include comprehensive description
- Reference any related issues
5. Address review feedback:
- Fix issues in the original commits where they appear
- Force push updates after rebasing
- Don't add "fix review comments" commits
## Code Style
We use ESLint and Prettier to enforce consistent code style. The project comes with pre-configured ESLint and Prettier settings.
### Style Guidelines
- Use 2 spaces for indentation
- Maximum line length of 100 characters
- Single quotes for strings
- Semicolons are required
- Trailing commas in multiline objects
- Explicit function return types
- Explicit accessibility modifiers in classes
### Examples
```typescript
// Good
interface Config {
name: string;
options?: Record<string, unknown>;
}
export class Parser {
private readonly config: Config;
public constructor(config: Config) {
this.config = config;
}
public parse(input: string): Record<string, unknown> {
const result = this.processInput(input);
return {
name: this.config.name,
result,
};
}
}
// Bad - Various style issues
interface config {
name: string;
options?: any; // Avoid 'any'
}
export class parser {
config: config; // Missing accessibility modifier
constructor(config: config) {
// Missing explicit 'public'
this.config = config;
} // Missing semicolon
}
```
### Editor Setup
1. Install required VS Code extensions:
- ESLint
- Prettier
2. VS Code will automatically use project's ESLint and Prettier configurations.
3. Enable format on save in VS Code settings:
```json
{
"editor.formatOnSave": true,
"editor.defaultFormatter": "esbenp.prettier-vscode",
"editor.codeActionsOnSave": {
"source.fixAll.eslint": true
}
}
```
### Available Scripts
- `npm run lint`: Check code style
- `npm run lint:fix`: Fix auto-fixable style issues
- `npm run format`: Format code using Prettier
- `npm run format:check`: Check if files are properly formatted
## Questions?
If you have questions or need help, please:
1. Check existing issues and documentation
2. Create a new issue for discussion
3. Ask in the project's communication channels
Thank you for contributing to Eko! | {
"source": "FellouAI/eko",
"title": "CONTRIBUTING.md",
"url": "https://github.com/FellouAI/eko/blob/main/CONTRIBUTING.md",
"date": "2024-11-23T07:32:24",
"stars": 2629,
"description": "Eko (Eko Keeps Operating) - Build Production-ready Agentic Workflow with Natural Language - eko.fellou.ai",
"file_size": 5679
} |
<h1 align="center">
<a href="https://github.com/FellouAI/eko" target="_blank">
<img src="https://github.com/user-attachments/assets/55dbdd6c-2b08-4e5f-a841-8fea7c2a0b92" alt="eko-logo" width="200" height="200">
</a>
<br>
<small>Eko - Build Production-ready Agentic Workflow with Natural Language</small>
</h1>
[](LICENSE) [](https://example.com/build-status) [](https://eko.fellou.ai/docs/release/versions/)
Eko (pronounced like ‘echo’) is a production-ready JavaScript framework that enables developers to create reliable agents, **from simple commands to complex workflows**. It provides a unified interface for running agents in both **computer and browser environments**.
# Framework Comparison
| Feature | Eko | Langchain | Browser-use | Dify.ai | Coze |
|--------------------------------------|-------|------------|--------------|----------|--------|
| **Supported Platform** | **All platform** | Server side | Browser | Web | Web |
| **One sentence to multi-step workflow** | ✅ | ❌ | ✅ | ❌ | ❌ |
| **Intervenability** | ✅ | ✅ | ❌ | ❌ | ❌ |
| **Development Efficiency** | **High** | Low | Middle | Middle | Low |
| **Task Complexity** | **High** | High | Low | Middle | Middle | Middle |
| **Open-source** | ✅ | ✅ | ✅ | ✅ | ❌ |
| **Access to private web resources** | ✅ | ❌ | ❌ | ❌ | ❌ |
## Quickstart
```bash
npm install @eko-ai/eko
```
> Important Notice: The following example code cannot be executed directly. Please refer to the [Eko Quickstart guide](https://eko.fellou.ai/docs/getting-started/quickstart/) guide for instructions on how to run it.
```typescript
import { Eko } from '@eko-ai/eko';
const eko = new Eko({
apiKey: 'your_anthropic_api_key',
});
// Example: Browser automation
const extWorkflow = await eko.generate("Search for 'Eko framework' on Google and save the first result");
await eko.execute(extWorkflow);
// Example: System operation
const sysWorkflow = await eko.generate("Create a new folder named 'reports' and move all PDF files there");
await eko.execute(sysWorkflow);
```
## Demos
**Prompt:** `Collect the latest NASDAQ data on Yahoo Finance, including price changes, market capitalization, trading volume of major stocks, analyze the data and generate visualization reports`.
https://github.com/user-attachments/assets/4087b370-8eb8-4346-a549-c4ce4d1efec3
Click [here](https://github.com/FellouAI/eko-demos/tree/main/browser-extension-stock) to get the source code.
---
**Prompt:** `Based on the README of FellouAI/eko on github, search for competitors, highlight the key contributions of Eko, write a blog post advertising Eko, and post it on Write.as.`
https://github.com/user-attachments/assets/6feaea86-2fb9-4e5c-b510-479c2473d810
Click [here](https://github.com/FellouAI/eko-demos/tree/main/browser-extension-blog) to get the source code.
---
**Prompt:** `Clean up all files in the current directory larger than 1MB`
https://github.com/user-attachments/assets/ef7feb58-3ddd-4296-a1de-bb8b6c66e48b
Click [here](https://eko.fellou.ai/docs/computeruse/computer-node/#example-file-cleanup-workflow) to Learn more.
---
**Prompt:** Automatic software testing
```
Current login page automation test:
1. Correct account and password are: admin / 666666
2. Please randomly combine usernames and passwords for testing to verify if login validation works properly, such as: username cannot be empty, password cannot be empty, incorrect username, incorrect password
3. Finally, try to login with the correct account and password to verify if login is successful
4. Generate test report and export
```
https://github.com/user-attachments/assets/7716300a-c51d-41f1-8d4f-e3f593c1b6d5
Click [here](https://eko.fellou.ai/docs/browseruse/browser-web#example-login-automation-testing) to Learn more.
## Use Cases
- Browser automation and web scraping
- System file and process management
- Workflow automation
- Data processing and organization
- GUI automation
- Multi-step task orchestration
## Documentation
Visit our [documentation site](https://eko.fellou.ai/docs) for:
- Getting started guide
- API reference
- Usage examples
- Best practices
- Configuration options
## Development Environments
Eko can be used in multiple environments:
- Browser Extension
- Web Applications
- Node.js Applications
## Community and Support
- Report issues on [GitHub Issues](https://github.com/FellouAI/eko/issues)
- Join our [slack community discussions](https://join.slack.com/t/eko-ai/shared_invite/zt-2xhvkudv9-nHvD1g8Smp227sM51x_Meg)
- Contribute tools and improvements
- Share your use cases and feedback
<h1 align="center">
<a href="https://github.com/FellouAI/eko" target="_blank">
<img width="663" alt="Screenshot 2025-02-05 at 10 49 58" src="https://github.com/user-attachments/assets/02df5b97-41c0-423f-84d8-2fee2364c36b" />
</a>
</h1>
[](https://star-history.com/#FellouAI/eko&Date)
## License
Eko is released under the MIT License. See the [LICENSE](LICENSE) file for details. | {
"source": "FellouAI/eko",
"title": "README.md",
"url": "https://github.com/FellouAI/eko/blob/main/README.md",
"date": "2024-11-23T07:32:24",
"stars": 2629,
"description": "Eko (Eko Keeps Operating) - Build Production-ready Agentic Workflow with Natural Language - eko.fellou.ai",
"file_size": 5591
} |
# Eko JSON Workflow DSL
## Overview
A JSON-based Domain Specific Language for defining AI agent workflows, optimized for LLM generation and programmatic manipulation.
## Design Goals
1. Schema-compliant JSON structure
2. Direct mapping to runtime types
3. Easy for LLMs to generate and modify
4. Validation through JSON Schema
5. Bidirectional conversion with runtime objects
## JSON Structure
### Basic Structure
```json
{
"version": "1.0",
"id": "string",
"name": "string",
"description": "string",
"nodes": [Node],
"variables": {
"key": "value"
}
}
```
### Node Structure
```json
{
"id": "string",
"type": "action | condition | loop",
"dependencies": ["nodeId1", "nodeId2"],
"input": {
"type": "string",
"schema": {}
},
"output": {
"type": "string",
"schema": {}
},
"action": {
"type": "prompt | script | hybrid",
"name": "string",
"params": {},
"tools": ["toolId1", "toolId2"]
}
}
```
## Variable Resolution
- Use JSON Pointer syntax for referencing
- Example: "/nodes/0/output/value" refers to first node's output value
- Variables in params use ${variableName} syntax
## Type System
- Use JSON Schema for type definitions
- Runtime type validation through schema
- Support for primitives and complex objects
- Schema stored with type definitions
## Validation Rules
1. All node IDs must be unique
2. Dependencies must reference existing nodes
3. No circular dependencies
4. Type compatibility between connected nodes
5. All required parameters must be provided
6. All tools must be registered and available
## Error Types
1. Schema Validation Errors: Invalid JSON structure
2. Reference Errors: Invalid node references
3. Type Errors: Incompatible types between nodes
4. Tool Errors: Unavailable or invalid tools
## Example Workflow
```json
{
"version": "1.0",
"id": "search-workflow",
"name": "Web Search Workflow",
"nodes": [
{
"id": "search",
"type": "action",
"action": {
"type": "script",
"name": "webSearch",
"params": {
"query": "${searchQuery}",
"maxResults": 10
}
},
"output": {
"type": "array",
"schema": {
"type": "array",
"items": {
"type": "object",
"properties": {
"title": {"type": "string"},
"url": {"type": "string"}
}
}
}
}
}
],
"variables": {
"searchQuery": "Eko framework github"
}
}
``` | {
"source": "FellouAI/eko",
"title": "docs/designs/dsl-design.md",
"url": "https://github.com/FellouAI/eko/blob/main/docs/designs/dsl-design.md",
"date": "2024-11-23T07:32:24",
"stars": 2629,
"description": "Eko (Eko Keeps Operating) - Build Production-ready Agentic Workflow with Natural Language - eko.fellou.ai",
"file_size": 2523
} |
# Advanced Node Types Design Document
## Overview
This document describes the design for conditional and loop node types in the Eko workflow system. While the current implementation only supports action nodes, this design can be referenced when adding support for more complex control flow patterns.
## Node Types
### 1. Condition Nodes
Condition nodes enable branching logic in workflows by evaluating expressions and directing flow accordingly.
```typescript
interface ConditionNode extends BaseNode {
type: 'condition';
condition: {
expression: string; // Boolean expression to evaluate
truePathNodeId?: string; // Next node if true
falsePathNodeId?: string;// Next node if false
};
}
```
Key Features:
- Expression evaluation using workflow context
- Optional true/false paths (for optional branches)
- Access to previous nodes' outputs in condition
- Type-safe expression evaluation
Example:
```json
{
"id": "check-status",
"type": "condition",
"name": "Check API Response",
"condition": {
"expression": "input.status === 200",
"truePathNodeId": "process-data",
"falsePathNodeId": "handle-error"
}
}
```
### 2. Loop Nodes
Loop nodes enable iteration patterns with two main variants: foreach and while loops.
#### Foreach Loop
```typescript
interface ForeachLoopNode extends BaseLoopNode {
loopType: 'foreach';
foreach: {
collection: string; // Expression returning array
itemVariable: string; // Current item variable name
indexVariable?: string; // Optional index variable
};
}
```
#### While Loop
```typescript
interface WhileLoopNode extends BaseLoopNode {
loopType: 'while';
while: {
condition: string; // Boolean expression
checkBefore: boolean; // while vs do-while behavior
};
}
```
Common Loop Features:
```typescript
interface BaseLoopNode extends BaseNode {
type: 'loop';
loopType: LoopType;
maxIterations?: number; // Safety limit
bodyNodeIds: string[]; // Nodes to execute in loop
}
```
## Control Flow Mechanisms
### Loop Control
1. Break Conditions:
- Maximum iterations reached
- Explicit break signal (`__break` variable)
- Timeout exceeded
- While condition false
- Exception in body execution
2. Continue Support:
- Skip remaining body nodes
- Continue to next iteration
- Controlled via `__continue` variable
### Context Management
1. Loop Variables:
- Current item reference
- Index tracking
- Accumulator support
2. Scope Isolation:
- Loop-local variables
- Parent context access
- Result aggregation
## Example Patterns
### 1. Retry Pattern
```json
{
"id": "retry-loop",
"type": "loop",
"loopType": "while",
"while": {
"condition": "context.variables.get('needsRetry')",
"checkBefore": true
},
"bodyNodeIds": ["api-call", "check-response"],
"maxIterations": 3
}
```
### 2. Batch Processing
```json
{
"id": "process-batch",
"type": "loop",
"loopType": "foreach",
"foreach": {
"collection": "input.items",
"itemVariable": "item",
"indexVariable": "index"
},
"bodyNodeIds": ["validate", "transform", "save"],
"maxIterations": 1000
}
```
## Implementation Considerations
### 1. Type Safety
- Runtime type checking for expressions
- Compile-time node type validation
- Context variable type preservation
### 2. Performance
- Parallel execution of independent iterations
- Resource cleanup between iterations
- Memory management for large collections
### 3. Error Handling
- Loop-specific error types
- Partial execution results
- Recovery mechanisms
### 4. Debugging
- Iteration tracking
- Expression evaluation tracing
- Loop state inspection
## Future Extensions
1. **Parallel Loops**
- Concurrent iteration execution
- Batch size control
- Resource pooling
2. **Advanced Break Conditions**
- Time-based limits
- Resource consumption limits
- External signal handling
3. **State Management**
- Persistent loop state
- Checkpoint/resume capability
- Progress tracking
## Migration Path
To implement these advanced nodes:
1. Update schema validation
2. Extend node executor
3. Add type definitions
4. Implement context extensions
5. Add execution engine support
## Conclusion
This design provides a foundation for adding complex control flow to workflows while maintaining type safety and execution control. Implementation should be phased, starting with basic conditionals, then foreach loops, and finally while loops. | {
"source": "FellouAI/eko",
"title": "docs/designs/node-types.md",
"url": "https://github.com/FellouAI/eko/blob/main/docs/designs/node-types.md",
"date": "2024-11-23T07:32:24",
"stars": 2629,
"description": "Eko (Eko Keeps Operating) - Build Production-ready Agentic Workflow with Natural Language - eko.fellou.ai",
"file_size": 4493
} |
<!-- <p align="center">
<img alt="UI-TARS" width="260" src="figures/icon.png">
</p>
# UI-TARS: Pioneering Automated GUI Interaction with Native Agents -->

<p align="center">
🤗 <a href="https://huggingface.co/bytedance-research/UI-TARS-7B-DPO">Hugging Face Models</a>   |   🤖 <a href="https://www.modelscope.cn/models/bytedance-research/UI-TARS-7B-DPO">ModelScope</a>   |    📑 <a href="https://arxiv.org/abs/2501.12326">Paper</a>    |  </a>
🖥️ <a href="https://github.com/bytedance/UI-TARS-desktop">UI-TARS-desktop</a>   <br>🏄 <a href="https://github.com/web-infra-dev/Midscene">Midscene (Browser Automation) </a>   |   🤗 <a href="https://huggingface.co/spaces/bytedance-research/UI-TARS">Space</a>   |   🫨 <a href="https://discord.gg/pTXwYVjfcs">Discord</a>  
</p>
We also offer a **UI-TARS-desktop** version, which can operate on your **local personal device**. To use it, please visit [https://github.com/bytedance/UI-TARS-desktop](https://github.com/bytedance/UI-TARS-desktop). To use UI-TARS in web automation, you may refer to the open-source project [Midscene.js](https://github.com/web-infra-dev/Midscene).
### ⚠️ Important Announcement: GGUF Model Performance
The **GGUF model** has undergone quantization, but unfortunately, its performance cannot be guaranteed. As a result, we have decided to **downgrade** it.
💡 **Alternative Solution**:
You can use **[Cloud Deployment](#cloud-deployment)** or **[Local Deployment [vLLM]](#local-deployment-vllm)**(If you have enough GPU resources) instead.
We appreciate your understanding and patience as we work to ensure the best possible experience.
## Updates
- ✨ We updated the OSWorld inference scripts from the original official [OSWorld repository](https://github.com/xlang-ai/OSWorld/blob/main/run_uitars.py). Now, you can use the OSWorld official inference scripts for deployment and we've provided [trajectory examples](https://drive.google.com/file/d/1N9dYzAB9xSiHwE9VSdEi9xSpB9eXfVZT/view?usp=sharing) for OSWorld to help you get started. We also provide the training example data format in the readme.
- 🚀 01.25: We updated the **[Cloud Deployment](#cloud-deployment)** section in the 中文版: [GUI模型部署教程](https://bytedance.sg.larkoffice.com/docx/TCcudYwyIox5vyxiSDLlgIsTgWf#U94rdCxzBoJMLex38NPlHL21gNb) with new information related to the ModelScope platform. You can now use the ModelScope platform for deployment.
## Overview
UI-TARS is a next-generation native GUI agent model designed to interact seamlessly with graphical user interfaces (GUIs) using human-like perception, reasoning, and action capabilities. Unlike traditional modular frameworks, UI-TARS integrates all key components—perception, reasoning, grounding, and memory—within a single vision-language model (VLM), enabling end-to-end task automation without predefined workflows or manual rules.


## Core Features
### Perception
- **Comprehensive GUI Understanding**: Processes multimodal inputs (text, images, interactions) to build a coherent understanding of interfaces.
- **Real-Time Interaction**: Continuously monitors dynamic GUIs and responds accurately to changes in real-time.
### Action
- **Unified Action Space**: Standardized action definitions across platforms (desktop, mobile, and web).
- **Platform-Specific Actions**: Supports additional actions like hotkeys, long press, and platform-specific gestures.
### Reasoning
- **System 1 & System 2 Reasoning**: Combines fast, intuitive responses with deliberate, high-level planning for complex tasks.
- **Task Decomposition & Reflection**: Supports multi-step planning, reflection, and error correction for robust task execution.
### Memory
- **Short-Term Memory**: Captures task-specific context for situational awareness.
- **Long-Term Memory**: Retains historical interactions and knowledge for improved decision-making.
## Capabilities
- **Cross-Platform Interaction**: Supports desktop, mobile, and web environments with a unified action framework.
- **Multi-Step Task Execution**: Trained to handle complex tasks through multi-step trajectories and reasoning.
- **Learning from Synthetic and Real Data**: Combines large-scale annotated and synthetic datasets for improved generalization and robustness.
## Performance
**Perception Capabilty Evaluation**
| Model | VisualWebBench | WebSRC | SQAshort |
|---------------------------|---------------|---------|----------|
| Qwen2-VL-7B | 73.3 | 81.8 | 84.9 |
| Qwen-VL-Max | 74.1 | 91.1 | 78.6 |
| Gemini-1.5-Pro | 75.4 | 88.9 | 82.2 |
| UIX-Qwen2-7B | 75.9 | 82.9 | 78.8 |
| Claude-3.5-Sonnet | 78.2 | 90.4 | 83.1 |
| GPT-4o | 78.5 | 87.7 | 82.3 |
| **UI-TARS-2B** | 72.9 | 89.2 | 86.4 |
| **UI-TARS-7B** | 79.7 | **93.6** | 87.7 |
| **UI-TARS-72B** | **82.8** | 89.3 | **88.6** |
**Grounding Capability Evaluation**
- **ScreenSpot Pro**
| Agent Model | Dev-Text | Dev-Icon | Dev-Avg | Creative-Text | Creative-Icon | Creative-Avg | CAD-Text | CAD-Icon | CAD-Avg | Scientific-Text | Scientific-Icon | Scientific-Avg | Office-Text | Office-Icon | Office-Avg | OS-Text | OS-Icon | OS-Avg | Avg-Text | Avg-Icon | Avg |
|--------------------------|----------|----------|----------|--------------|--------------|--------------|---------|---------|---------|---------------|---------------|---------------|------------|------------|------------|--------|--------|--------|---------|---------|------|
| QwenVL-7B | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.7 | 0.0 | 0.4 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.1 | 0.0 | **0.1** |
| GPT-4o | 1.3 | 0.0 | 0.7 | 1.0 | 0.0 | 0.6 | 2.0 | 0.0 | 1.5 | 2.1 | 0.0 | 1.2 | 1.1 | 0.0 | 0.9 | 0.0 | 0.0 | 0.0 | 1.3 | 0.0 | **0.8** |
| SeeClick | 0.6 | 0.0 | 0.3 | 1.0 | 0.0 | 0.6 | 2.5 | 0.0 | 1.9 | 3.5 | 0.0 | 2.0 | 1.1 | 0.0 | 0.9 | 2.8 | 0.0 | 1.5 | 1.8 | 0.0 | **1.1** |
| Qwen2-VL-7B | 2.6 | 0.0 | 1.3 | 1.5 | 0.0 | 0.9 | 0.5 | 0.0 | 0.4 | 6.3 | 0.0 | 3.5 | 3.4 | 1.9 | 3.0 | 0.9 | 0.0 | 0.5 | 2.5 | 0.2 | **1.6** |
| OS-Atlas-4B | 7.1 | 0.0 | 3.7 | 3.0 | 1.4 | 2.3 | 2.0 | 0.0 | 1.5 | 9.0 | 5.5 | 7.5 | 5.1 | 3.8 | 4.8 | 5.6 | 0.0 | 3.1 | 5.0 | 1.7 | **3.7** |
| ShowUI-2B | 16.9 | 1.4 | 9.4 | 9.1 | 0.0 | 5.3 | 2.5 | 0.0 | 1.9 | 13.2 | 7.3 | 10.6 | 15.3 | 7.5 | 13.5 | 10.3 | 2.2 | 6.6 | 10.8 | 2.6 | **7.7** |
| CogAgent-18B | 14.9 | 0.7 | 8.0 | 9.6 | 0.0 | 5.6 | 7.1 | 3.1 | 6.1 | 22.2 | 1.8 | 13.4 | 13.0 | 0.0 | 10.0 | 5.6 | 0.0 | 3.1 | 12.0 | 0.8 | **7.7** |
| Aria-UI | 16.2 | 0.0 | 8.4 | 23.7 | 2.1 | 14.7 | 7.6 | 1.6 | 6.1 | 27.1 | 6.4 | 18.1 | 20.3 | 1.9 | 16.1 | 4.7 | 0.0 | 2.6 | 17.1 | 2.0 | **11.3** |
| UGround-7B | 26.6 | 2.1 | 14.7 | 27.3 | 2.8 | 17.0 | 14.2 | 1.6 | 11.1 | 31.9 | 2.7 | 19.3 | 31.6 | 11.3 | 27.0 | 17.8 | 0.0 | 9.7 | 25.0 | 2.8 | **16.5** |
| Claude Computer Use | 22.0 | 3.9 | 12.6 | 25.9 | 3.4 | 16.8 | 14.5 | 3.7 | 11.9 | 33.9 | 15.8 | 25.8 | 30.1 | 16.3 | 26.9 | 11.0 | 4.5 | 8.1 | 23.4 | 7.1 | **17.1** |
| OS-Atlas-7B | 33.1 | 1.4 | 17.7 | 28.8 | 2.8 | 17.9 | 12.2 | 4.7 | 10.3 | 37.5 | 7.3 | 24.4 | 33.9 | 5.7 | 27.4 | 27.1 | 4.5 | 16.8 | 28.1 | 4.0 | **18.9** |
| UGround-V1-7B | - | - | 35.5 | - | - | 27.8 | - | - | 13.5 | - | - | 38.8 | - | - | 48.8 | - | - | 26.1 | - | - | **31.1** |
| **UI-TARS-2B** | 47.4 | 4.1 | 26.4 | 42.9 | 6.3 | 27.6 | 17.8 | 4.7 | 14.6 | 56.9 | 17.3 | 39.8 | 50.3 | 17.0 | 42.6 | 21.5 | 5.6 | 14.3 | 39.6 | 8.4 | **27.7** |
| **UI-TARS-7B** | 58.4 | 12.4 | 36.1 | 50.0 | 9.1 | 32.8 | **20.8**| 9.4 | **18.0**| 63.9 | **31.8** | **50.0** | **63.3** | 20.8 | 53.5 | 30.8 | **16.9**| 24.5 | 47.8 | 16.2 | **35.7** |
| **UI-TARS-72B** | **63.0** | **17.3** | **40.8** | **57.1** | **15.4** | **39.6** | 18.8 | **12.5**| 17.2 | **64.6** | 20.9 | 45.7 | **63.3** | **26.4** | **54.8** | **42.1**| 15.7 | **30.1**| **50.9**| **17.5**| **38.1** |
- **ScreenSpot**
| Method | Mobile-Text | Mobile-Icon/Widget | Desktop-Text | Desktop-Icon/Widget | Web-Text | Web-Icon/Widget | Avg |
|--------|-------------|-------------|-------------|-------------|-------------|---------|---------|
| **Agent Framework** | | | | | | | |
| GPT-4 (SeeClick) | 76.6 | 55.5 | 68.0 | 28.6 | 40.9 | 23.3 | **48.8** |
| GPT-4 (OmniParser) | 93.9 | 57.0 | 91.3 | 63.6 | 81.3 | 51.0 | **73.0** |
| GPT-4 (UGround-7B) | 90.1 | 70.3 | 87.1 | 55.7 | 85.7 | 64.6 | **75.6** |
| GPT-4o (SeeClick) | 81.0 | 59.8 | 69.6 | 33.6 | 43.9 | 26.2 | **52.3** |
| GPT-4o (UGround-7B) | 93.4 | 76.9 | 92.8 | 67.9 | 88.7 | 68.9 | **81.4** |
| **Agent Model** | | | | | | | |
| GPT-4 | 22.6 | 24.5 | 20.2 | 11.8 | 9.2 | 8.8 | **16.2** |
| GPT-4o | 20.2 | 24.9 | 21.1 | 23.6 | 12.2 | 7.8 | **18.3** |
| CogAgent | 67.0 | 24.0 | 74.2 | 20.0 | 70.4 | 28.6 | **47.4** |
| SeeClick | 78.0 | 52.0 | 72.2 | 30.0 | 55.7 | 32.5 | **53.4** |
| Qwen2-VL | 75.5 | 60.7 | 76.3 | 54.3 | 35.2 | 25.7 | **55.3** |
| UGround-7B | 82.8 | 60.3 | 82.5 | 63.6 | 80.4 | 70.4 | **73.3** |
| Aguvis-G-7B | 88.3 | 78.2 | 88.1 | 70.7 | 85.7 | 74.8 | **81.8** |
| OS-Atlas-7B | 93.0 | 72.9 | 91.8 | 62.9 | 90.9 | 74.3 | **82.5** |
| Claude Computer Use | - | - | - | - | - | - | **83.0** |
| Gemini 2.0 (Project Mariner) | - | - | - | - | - | - | **84.0** |
| Aguvis-7B | **95.6** | 77.7 | 93.8 | 67.1 | 88.3 | 75.2 | **84.4** |
| Aguvis-72B | 94.5 | **85.2** | 95.4 | 77.9 | **91.3** | **85.9** | **89.2** |
| **Our Model** | | | | | | | |
| **UI-TARS-2B** | 93.0 | 75.5 | 90.7 | 68.6 | 84.3 | 74.8 | **82.3** |
| **UI-TARS-7B** | 94.5 | **85.2** | **95.9** | 85.7 | 90.0 | 83.5 | **89.5** |
| **UI-TARS-72B** | 94.9 | 82.5 | 89.7 | **88.6** | 88.7 | 85.0 | **88.4** |
- **ScreenSpot v2**
| Method | Mobile-Text | Mobile-Icon/Widget | Desktop-Text | Desktop-Icon/Widget | Web-Text | Web-Icon/Widget | Avg |
|--------|-------------|-------------|-------------|-------------|-------------|---------|---------|
| **Agent Framework** | | | | | | | |
| GPT-4o (SeeClick) | 85.2 | 58.8 | 79.9 | 37.1 | 72.7 | 30.1 | **63.6** |
| GPT-4o (OS-Atlas-4B) | 95.5 | 75.8 | 79.4 | 49.3 | 90.2 | 66.5 | **79.1** |
| GPT-4o (OS-Atlas-7B) | 96.2 | 83.4 | 89.7 | 69.3 | **94.0** | 79.8 | **87.1** |
| **Agent Model** | | | | | | | |
| SeeClick | 78.4 | 50.7 | 70.1 | 29.3 | 55.2 | 32.5 | **55.1** |
| OS-Atlas-4B | 87.2 | 59.7 | 72.7 | 46.4 | 85.9 | 63.1 | **71.9** |
| OS-Atlas-7B | 95.2 | 75.8 | 90.7 | 63.6 | 90.6 | 77.3 | **84.1** |
| **Our Model** | | | | | | | |
| **UI-TARS-2B** | 95.2 | 79.1 | 90.7 | 68.6 | 87.2 | 78.3 | **84.7** |
| **UI-TARS-7B** | **96.9** | **89.1** | **95.4** | 85.0 | 93.6 | 85.2 | **91.6** |
| **UI-TARS-72B** | 94.8 | 86.3 | 91.2 | **87.9** | 91.5 | **87.7** | **90.3** |
**Offline Agent Capability Evaluation**
- **Multimodal Mind2Web**
| Method | Cross-Task Ele.Acc | Cross-Task Op.F1 | Cross-Task Step SR | Cross-Website Ele.Acc | Cross-Website Op.F1 | Cross-Website Step SR | Cross-Domain Ele.Acc | Cross-Domain Op.F1 | Cross-Domain Step SR |
|--------|----------------------|-------------------|--------------------|----------------------|--------------------|-------------------|--------------------|-------------------|-------------------|
| **Agent Framework** | | | | | | | | | |
| GPT-4o (SeeClick) | 32.1 | - | - | 33.1 | - | - | 33.5 | - | - |
| GPT-4o (UGround) | 47.7 | - | - | 46.0 | - | - | 46.6 | - | - |
| GPT-4o (Aria-UI) | 57.6 | - | - | 57.7 | - | - | 61.4 | - | - |
| GPT-4V (OmniParser) | 42.4 | 87.6 | 39.4 | 41.0 | 84.8 | 36.5 | 45.5 | 85.7 | 42.0 |
| **Agent Model** | | | | | | | | | |
| GPT-4o | 5.7 | 77.2 | 4.3 | 5.7 | 79.0 | 3.9 | 5.5 | 86.4 | 4.5 |
| GPT-4 (SOM) | 29.6 | - | 20.3 | 20.1 | - | 13.9 | 27.0 | - | 23.7 |
| GPT-3.5 (Text-only) | 19.4 | 59.2 | 16.8 | 14.9 | 56.5 | 14.1 | 25.2 | 57.9 | 24.1 |
| GPT-4 (Text-only) | 40.8 | 63.1 | 32.3 | 30.2 | 61.0 | 27.0 | 35.4 | 61.9 | 29.7 |
| Claude | 62.7 | 84.7 | 53.5 | 59.5 | 79.6 | 47.7 | 64.5 | 85.4 | 56.4 |
| Aguvis-7B | 64.2 | 89.8 | 60.4 | 60.7 | 88.1 | 54.6 | 60.4 | 89.2 | 56.6 |
| CogAgent | - | - | 62.3 | - | - | 54.0 | - | - | 59.4 |
| Aguvis-72B | 69.5 | 90.8 | 64.0 | 62.6 | 88.6 | 56.5 | 63.5 | 88.5 | 58.2 |
| **Our Model** | | | | | | | | | |
| **UI-TARS-2B** | 62.3 | 90.0 | 56.3 | 58.5 | 87.2 | 50.8 | 58.8 | 89.6 | 52.3 |
| **UI-TARS-7B** | 73.1 | 92.2 | 67.1 | 68.2 | 90.9 | 61.7 | 66.6 | 90.9 | 60.5 |
| **UI-TARS-72B** | **74.7** | **92.5** | **68.6** | **72.4** | **91.2** | **63.5** | **68.9** | **91.8** | **62.1** |
- **Android Control and GUI Odyssey**
| Agent Models | AndroidControl-Low Type | AndroidControl-Low Grounding | AndroidControl-Low SR | AndroidControl-High Type | AndroidControl-High Grounding | AndroidControl-High SR | GUIOdyssey Type | GUIOdyssey Grounding | GUIOdyssey SR |
|---------------------|----------------------|----------------------|----------------|----------------------|----------------------|----------------|----------------|----------------|----------------|
| Claude | 74.3 | 0.0 | 19.4 | 63.7 | 0.0 | 12.5 | 60.9 | 0.0 | 3.1 |
| GPT-4o | 74.3 | 0.0 | 19.4 | 66.3 | 0.0 | 20.8 | 34.3 | 0.0 | 3.3 |
| SeeClick | 93.0 | 73.4 | 75.0 | 82.9 | 62.9 | 59.1 | 71.0 | 52.4 | 53.9 |
| InternVL-2-4B | 90.9 | 84.1 | 80.1 | 84.1 | 72.7 | 66.7 | 82.1 | 55.5 | 51.5 |
| Qwen2-VL-7B | 91.9 | 86.5 | 82.6 | 83.8 | 77.7 | 69.7 | 83.5 | 65.9 | 60.2 |
| Aria-UI | -- | 87.7 | 67.3 | -- | 43.2 | 10.2 | -- | 86.8 | 36.5 |
| OS-Atlas-4B | 91.9 | 83.8 | 80.6 | 84.7 | 73.8 | 67.5 | 83.5 | 61.4 | 56.4 |
| OS-Atlas-7B | 93.6 | 88.0 | 85.2 | 85.2 | 78.5 | 71.2 | 84.5 | 67.8 | 62.0 |
| Aguvis-7B | -- | -- | 80.5 | -- | -- | 61.5 | -- | -- | -- |
| Aguvis-72B | -- | -- | 84.4 | -- | -- | 66.4 | -- | -- | -- |
| **UI-TARS-2B** | **98.1** | 87.3 | 89.3 | 81.2 | 78.4 | 68.9 | 93.9 | 86.8 | 83.4 |
| **UI-TARS-7B** | 98.0 | 89.3 | 90.8 | 83.7 | 80.5 | 72.5 | 94.6 | 90.1 | 87.0 |
| **UI-TARS-72B** | **98.1** | **89.9** | **91.3** | **85.2** | **81.5** | **74.7** | **95.4** | **91.4** | **88.6** |
**Online Agent Capability Evaluation**
| Method | OSWorld (Online) | AndroidWorld (Online) |
|--------|-------------------|------------------|
| **Agent Framework** | | |
| GPT-4o (UGround) | - | 32.8 |
| GPT-4o (Aria-UI) | 15.2 | 44.8 |
| GPT-4o (Aguvis-7B) | 14.8 | 37.1 |
| GPT-4o (Aguvis-72B) | 17.0 | - |
| GPT-4o (OS-Atlas-7B) | 14.6 | - |
| **Agent Model** | | |
| GPT-4o | 5.0 | 34.5 (SoM) |
| Gemini-Pro-1.5 | 5.4 | 22.8 (SoM) |
| Aguvis-72B | 10.3 | 26.1 |
| Claude Computer-Use | 14.9 (15 steps) | 27.9 |
| Claude Computer-Use | 22.0 (50 steps) | - |
| **Our Model** | | |
| **UI-TARS-7B-SFT** | 17.7 (15 steps) | 33.0 |
| **UI-TARS-7B-DPO** | 18.7 (15 steps) | - |
| **UI-TARS-72B-SFT** | 18.8 (15 steps) | **46.6** |
| **UI-TARS-72B-DPO** | **22.7** (15 steps) | - |
| **UI-TARS-72B-DPO** | **24.6** (50 steps) | - |
## Deployment
### Cloud Deployment
We recommend using HuggingFace Inference Endpoints for fast deployment.
We provide two docs for reference:
English version: [GUI Model Deployment Guide](https://juniper-switch-f10.notion.site/GUI-Model-Deployment-Guide-17b5350241e280058e98cea60317de71)
中文版: [GUI模型部署教程](https://bytedance.sg.larkoffice.com/docx/TCcudYwyIox5vyxiSDLlgIsTgWf#U94rdCxzBoJMLex38NPlHL21gNb)
### Local Deployment [Transformers]
We follow the same way as Qwen2-VL. Check this [tutorial](https://github.com/QwenLM/Qwen2-VL?tab=readme-ov-file#using---transformers-to-chat) for more details.
### Local Deployment [vLLM]
We recommend using vLLM for fast deployment and inference. You need to use `vllm>=0.6.1`.
```bash
pip install -U transformers
VLLM_VERSION=0.6.6
CUDA_VERSION=cu124
pip install vllm==${VLLM_VERSION} --extra-index-url https://download.pytorch.org/whl/${CUDA_VERSION}
```
#### Download the Model
We provide three model sizes on Hugging Face: **2B**, **7B**, and **72B**. To achieve the best performance, we recommend using the **7B-DPO** or **72B-DPO** model (depends on your GPU configuration):
- [2B-SFT](https://huggingface.co/bytedance-research/UI-TARS-2B-SFT)
- [7B-SFT](https://huggingface.co/bytedance-research/UI-TARS-7B-SFT)
- [7B-DPO](https://huggingface.co/bytedance-research/UI-TARS-7B-DPO)
- [72B-SFT](https://huggingface.co/bytedance-research/UI-TARS-72B-SFT)
- [72B-DPO](https://huggingface.co/bytedance-research/UI-TARS-72B-DPO)
#### Start an OpenAI API Service
Run the command below to start an OpenAI-compatible API service. It is recommended to set the tensor parallel size `-tp=1` for 7B models and `-tp=4` for 72B models.
```bash
python -m vllm.entrypoints.openai.api_server --served-model-name ui-tars \
--model <path to your model> --limit-mm-per-prompt image=5 -tp <tp>
```
Then you can use the chat API as below with the gui prompt (choose from mobile or computer) and base64-encoded local images (see [OpenAI API protocol document](https://platform.openai.com/docs/guides/vision/uploading-base-64-encoded-images) for more details), you can also use it in [UI-TARS-desktop](https://github.com/bytedance/UI-TARS-desktop):
```python
import base64
from openai import OpenAI
instruction = "search for today's weather"
screenshot_path = "screenshot.png"
client = OpenAI(
base_url="http://127.0.0.1:8000/v1",
api_key="empty",
)
## Below is the prompt for mobile
prompt = r"""You are a GUI agent. You are given a task and your action history, with screenshots. You need to perform the next action to complete the task.
## Output Format
```\nThought: ...
Action: ...\n```
## Action Space
click(start_box='<|box_start|>(x1,y1)<|box_end|>')
left_double(start_box='<|box_start|>(x1,y1)<|box_end|>')
right_single(start_box='<|box_start|>(x1,y1)<|box_end|>')
drag(start_box='<|box_start|>(x1,y1)<|box_end|>', end_box='<|box_start|>(x3,y3)<|box_end|>')
hotkey(key='')
type(content='') #If you want to submit your input, use \"\
\" at the end of `content`.
scroll(start_box='<|box_start|>(x1,y1)<|box_end|>', direction='down or up or right or left')
wait() #Sleep for 5s and take a screenshot to check for any changes.
finished()
call_user() # Submit the task and call the user when the task is unsolvable, or when you need the user's help.
## Note
- Use Chinese in `Thought` part.
- Summarize your next action (with its target element) in one sentence in `Thought` part.
## User Instruction
"""
with open(screenshot_path, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode("utf-8")
response = client.chat.completions.create(
model="ui-tars",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": prompt + instruction},
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{encoded_string}"}},
],
},
],
frequency_penalty=1,
max_tokens=128,
)
print(response.choices[0].message.content)
```
For single step grounding task or inference on grounding dataset such as Seeclick, kindly refer to the following script:
```python
import base64
from openai import OpenAI
instruction = "search for today's weather"
screenshot_path = "screenshot.png"
client = OpenAI(
base_url="http://127.0.0.1:8000/v1",
api_key="empty",
)
## Below is the prompt for mobile
prompt = r"""Output only the coordinate of one point in your response. What element matches the following task: """
with open(screenshot_path, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode("utf-8")
response = client.chat.completions.create(
model="ui-tars",
messages=[
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{encoded_string}"}},
{"type": "text", "text": prompt + instruction}
],
},
],
frequency_penalty=1,
max_tokens=128,
)
print(response.choices[0].message.content)
```
### Prompt Templates
We provide two prompt templates currently for stable running and performance, one for mobile scene and one for personal computer scene.
- Prompt template for mobile:
```python
## Below is the prompt for mobile
prompt = r"""You are a GUI agent. You are given a task and your action history, with screenshots. You need to perform the next action to complete the task.
## Output Format
```\nThought: ...
Action: ...\n```
## Action Space
click(start_box='<|box_start|>(x1,y1)<|box_end|>')
long_press(start_box='<|box_start|>(x1,y1)<|box_end|>', time='')
type(content='')
scroll(start_box='<|box_start|>(x1,y1)<|box_end|>', end_box='<|box_start|>(x3,y3)<|box_end|>')
press_home()
press_back()
finished(content='') # Submit the task regardless of whether it succeeds or fails.
## Note
- Use English in `Thought` part.
- Write a small plan and finally summarize your next action (with its target element) in one sentence in `Thought` part.
## User Instruction
"""
```
- Prompt template for computer:
```python
## Below is the prompt for computer
prompt = r"""You are a GUI agent. You are given a task and your action history, with screenshots. You need to perform the next action to complete the task.
## Output Format
```\nThought: ...
Action: ...\n```
## Action Space
click(start_box='<|box_start|>(x1,y1)<|box_end|>')
left_double(start_box='<|box_start|>(x1,y1)<|box_end|>')
right_single(start_box='<|box_start|>(x1,y1)<|box_end|>')
drag(start_box='<|box_start|>(x1,y1)<|box_end|>', end_box='<|box_start|>(x3,y3)<|box_end|>')
hotkey(key='')
type(content='') #If you want to submit your input, use \"\
\" at the end of `content`.
scroll(start_box='<|box_start|>(x1,y1)<|box_end|>', direction='down or up or right or left')
wait() #Sleep for 5s and take a screenshot to check for any changes.
finished()
call_user() # Submit the task and call the user when the task is unsolvable, or when you need the user's help.
## Note
- Use Chinese in `Thought` part.
- Summarize your next action (with its target element) in one sentence in `Thought` part.
## User Instruction
"""
```
### Local Deployment [Ollama]
<!-- Ollama can deploy the model via gguf format. Bugs exist for safetensors. -->Ollama will be coming soon. Please be patient and wait~ 😊
<!-- #### Get the model in GGUF format
We provide 2B and 7B model in [GGUF](https://huggingface.co/docs/hub/en/gguf) format:
2B: https://huggingface.co/bytedance-research/UI-TARS-2B-gguf
7B: https://huggingface.co/bytedance-research/UI-TARS-7B-gguf
Users can convert the model into GGUF format by using the script from [llama.cpp](https://github.com/ggerganov/llama.cpp/blob/master/convert_hf_to_gguf.py):
```bash
python3 convert_hf_to_gguf.py <path to your model>
```
The GGUF file will be generated under the path provided.
#### Deploy GGUF model
We deploy the model by following Ollama [tutorial](https://github.com/ollama/ollama?tab=readme-ov-file#customize-a-model).
```bash
# Create Modelfile, Windows users can just create a file named Modelfile
echo "FROM ./path/to/model.gguf" > Modelfile
# Create model in Ollama
ollama create ui-tars -f Modelfile
# Run the model
ollama run ui-tars
```
Test script is same as vLLM except two changes:
```python
...
client = OpenAI(
base_url="http://127.0.0.1:11434/v1/",
...
)
...
response = client.chat.completions.create(
model="ui-tars" # the name we create via Ollama cli
...
)
``` -->
### Explanation of Inference Results
#### Coordinate Mapping
The model generates a 2D coordinate output that represents relative positions. To convert these values to image-relative coordinates, divide each component by 1000 to obtain values in the range [0,1]. The absolute coordinates required by the Action can be calculated by:
- X absolute = X relative × image width
- Y absolute = Y relative × image height
For example, given a screen size: 1920 × 1080, and the model generates a coordinate output of (235, 512). The X absolute is `round(1920*235/1000)=451`. The Y absolute is `round(1080*512/1000)=553`. The absolute coordinate is (451, 553)
## Training Data Example
The `training_example.json` is a sample from the Mind2Web training set. We organize the data using a history of 5 (with a maximum of 5 images), and the coordinate information is normalized to the range [0, 1000].
## Use in desktop and web automation
To experience UI-TARS agent in desktop, you may refer to [UI-TARS-desktop](https://github.com/bytedance/UI-TARS-desktop). We recommend using the **7B/72B DPO model** on desktop.
[Midscene.js](https://github.com/web-infra-dev/Midscene) is an open-source web automation SDK that has supported UI-TARS model. Developers can use javascript and natural language to control the browser. See [this guide](https://midscenejs.com/choose-a-model) for more details about setting up the model.
## License
UI-TARS is licensed under the Apache License 2.0.
## Acknowledgements
This project builds upon and extends the capabilities of Qwen2-VL, a powerful vision-language model, which serves as the foundational architecture for UI-TARS. We would like to acknowledge the contributions of the developers and researchers behind Qwen2-VL for their groundbreaking work in the field of multimodal AI and for providing a robust base for further advancements.
Additionally, we thank the broader open-source community for their datasets, tools, and insights that have facilitated the development of UI-TARS. These collaborative efforts continue to push the boundaries of what GUI automation and AI-driven agents can achieve.
## Citation
If you find our paper and code useful in your research, please consider giving a star :star: and citation :pencil:
```BibTeX
@article{qin2025ui,
title={UI-TARS: Pioneering Automated GUI Interaction with Native Agents},
author={Qin, Yujia and Ye, Yining and Fang, Junjie and Wang, Haoming and Liang, Shihao and Tian, Shizuo and Zhang, Junda and Li, Jiahao and Li, Yunxin and Huang, Shijue and others},
journal={arXiv preprint arXiv:2501.12326},
year={2025}
}
``` | {
"source": "bytedance/UI-TARS",
"title": "README.md",
"url": "https://github.com/bytedance/UI-TARS/blob/main/README.md",
"date": "2025-01-19T09:04:17",
"stars": 2592,
"description": null,
"file_size": 29471
} |
[](https://gitdiagram.com/)

[](https://ko-fi.com/ahmedkhaleel2004)
# GitDiagram
Turn any GitHub repository into an interactive diagram for visualization in seconds.
You can also replace `hub` with `diagram` in any Github URL to access its diagram.
## 🚀 Features
- 👀 **Instant Visualization**: Convert any GitHub repository structure into a system design / architecture diagram
- 🎨 **Interactivity**: Click on components to navigate directly to source files and relevant directories
- ⚡ **Fast Generation**: Powered by Claude 3.5 Sonnet for quick and accurate diagrams
- 🔄 **Customization**: Modify and regenerate diagrams with custom instructions
- 🌐 **API Access**: Public API available for integration (WIP)
## ⚙️ Tech Stack
- **Frontend**: Next.js, TypeScript, Tailwind CSS, ShadCN
- **Backend**: FastAPI, Python, Server Actions
- **Database**: PostgreSQL (with Drizzle ORM)
- **AI**: Claude 3.5 Sonnet
- **Deployment**: Vercel (Frontend), EC2 (Backend)
- **CI/CD**: GitHub Actions
- **Analytics**: PostHog, Api-Analytics
## 🤔 About
I created this because I wanted to contribute to open-source projects but quickly realized their codebases are too massive for me to dig through manually, so this helps me get started - but it's definitely got many more use cases!
Given any public (or private!) GitHub repository it generates diagrams in Mermaid.js with OpenAI's o3-mini! (Previously Claude 3.5 Sonnet)
I extract information from the file tree and README for details and interactivity (you can click components to be taken to relevant files and directories)
Most of what you might call the "processing" of this app is done with prompt engineering - see `/backend/app/prompts.py`. This basically extracts and pipelines data and analysis for a larger action workflow, ending in the diagram code.
## 🔒 How to diagram private repositories
You can simply click on "Private Repos" in the header and follow the instructions by providing a GitHub personal access token with the `repo` scope.
You can also self-host this app locally (backend separated as well!) with the steps below.
## 🛠️ Self-hosting / Local Development
1. Clone the repository
```bash
git clone https://github.com/ahmedkhaleel2004/gitdiagram.git
cd gitdiagram
```
2. Install dependencies
```bash
pnpm i
```
3. Set up environment variables (create .env)
```bash
cp .env.example .env
```
Then edit the `.env` file with your Anthropic API key and optional GitHub personal access token.
4. Run backend
```bash
docker-compose up --build -d
```
Logs available at `docker-compose logs -f`
The FastAPI server will be available at `localhost:8000`
5. Start local database
```bash
chmod +x start-database.sh
./start-database.sh
```
When prompted to generate a random password, input yes.
The Postgres database will start in a container at `localhost:5432`
6. Initialize the database schema
```bash
pnpm db:push
```
You can view and interact with the database using `pnpm db:studio`
7. Run Frontend
```bash
pnpm dev
```
You can now access the website at `localhost:3000` and edit the rate limits defined in `backend/app/routers/generate.py` in the generate function decorator.
## Contributing
Contributions are welcome! Please feel free to submit a Pull Request.
## Acknowledgements
Shoutout to [Romain Courtois](https://github.com/cyclotruc)'s [Gitingest](https://gitingest.com/) for inspiration and styling
## 📈 Rate Limits
I am currently hosting it for free with no rate limits though this is somewhat likely to change in the future.
<!-- If you would like to bypass these, self-hosting instructions are provided. I also plan on adding an input for your own Anthropic API key.
Diagram generation:
- 1 request per minute
- 5 requests per day -->
## 🤔 Future Steps
- Implement font-awesome icons in diagram
- Implement an embedded feature like star-history.com but for diagrams. The diagram could also be updated progressively as commits are made. | {
"source": "ahmedkhaleel2004/gitdiagram",
"title": "README.md",
"url": "https://github.com/ahmedkhaleel2004/gitdiagram/blob/main/README.md",
"date": "2024-12-15T10:32:03",
"stars": 2585,
"description": "Replace 'hub' with 'diagram' in any GitHub url to instantly visualize the codebase as an interactive diagram",
"file_size": 4145
} |
<p align="center">
<img src="logo.png" width="192px" />
</p>
<h1 style="text-align:center;">Moonshine</h1>
[[Blog]](https://petewarden.com/2024/10/21/introducing-moonshine-the-new-state-of-the-art-for-speech-to-text/) [[Paper]](https://arxiv.org/abs/2410.15608) [[Model Card]](https://github.com/usefulsensors/moonshine/blob/main/model-card.md) [[Podcast]](https://notebooklm.google.com/notebook/d787d6c2-7d7b-478c-b7d5-a0be4c74ae19/audio)
Moonshine is a family of speech-to-text models optimized for fast and accurate automatic speech recognition (ASR) on resource-constrained devices. It is well-suited to real-time, on-device applications like live transcription and voice command recognition. Moonshine obtains word-error rates (WER) better than similarly-sized tiny.en and base.en Whisper models from OpenAI on the datasets used in the [OpenASR leaderboard](https://huggingface.co/spaces/hf-audio/open_asr_leaderboard) maintained by HuggingFace:
<table>
<tr><th>Tiny</th><th>Base</th></tr>
<tr><td>
| WER | Moonshine | Whisper |
| ---------- | --------- | ------- |
| Average | **12.66** | 12.81 |
| AMI | 22.77 | 24.24 |
| Earnings22 | 21.25 | 19.12 |
| Gigaspeech | 14.41 | 14.08 |
| LS Clean | 4.52 | 5.66 |
| LS Other | 11.71 | 15.45 |
| SPGISpeech | 7.70 | 5.93 |
| Tedlium | 5.64 | 5.97 |
| Voxpopuli | 13.27 | 12.00 |
</td><td>
| WER | Moonshine | Whisper |
| ---------- | --------- | ------- |
| Average | **10.07** | 10.32 |
| AMI | 17.79 | 21.13 |
| Earnings22 | 17.65 | 15.09 |
| Gigaspeech | 12.19 | 12.83 |
| LS Clean | 3.23 | 4.25 |
| LS Other | 8.18 | 10.35 |
| SPGISpeech | 5.46 | 4.26 |
| Tedlium | 5.22 | 4.87 |
| Voxpopuli | 10.81 | 9.76 |
</td></tr> </table>
Moonshine's compute requirements scale with the length of input audio. This means that shorter input audio is processed faster, unlike existing Whisper models that process everything as 30-second chunks. To give you an idea of the benefits: Moonshine processes 10-second audio segments _5x faster_ than Whisper while maintaining the same (or better!) WER.
Moonshine Base is approximately 400MB, while Tiny is around 190MB. Both publicly-released models currently support English only.
This repo hosts inference code and demos for Moonshine.
- [Installation](#installation)
- [1. Create a virtual environment](#1-create-a-virtual-environment)
- [2a. Install the `useful-moonshine` package to use Moonshine with Torch, TensorFlow, or JAX](#2a-install-the-useful-moonshine-package-to-use-moonshine-with-torch-tensorflow-or-jax)
- [2b. Install the `useful-moonshine-onnx` package to use Moonshine with ONNX](#2b-install-the-useful-moonshine-onnx-package-to-use-moonshine-with-onnx)
- [3. Try it out](#3-try-it-out)
- [Examples](#examples)
- [Live Captions](#live-captions)
- [Running in the Browser](#running-in-the-browser)
- [CTranslate2](#ctranslate2)
- [HuggingFace Transformers](#huggingface-transformers)
- [TODO](#todo)
- [Citation](#citation)
## Installation
We currently offer two options for installing Moonshine:
1. `useful-moonshine`, which uses Keras (with support for Torch, TensorFlow, and JAX backends)
2. `useful-moonshine-onnx`, which uses the ONNX runtime
These instructions apply to both options; follow along to get started.
Note: We like `uv` for managing Python environments, so we use it here. If you don't want to use it, simply skip the `uv` installation and leave `uv` off of your shell commands.
### 1. Create a virtual environment
First, [install](https://github.com/astral-sh/uv) `uv` for Python environment management.
Then create and activate a virtual environment:
```shell
uv venv env_moonshine
source env_moonshine/bin/activate
```
### 2a. Install the `useful-moonshine` package to use Moonshine with Torch, TensorFlow, or JAX
The `useful-moonshine` inference code is written in Keras and can run with each of the backends that Keras supports: Torch, TensorFlow, and JAX. The backend you choose will determine which flavor of the `useful-moonshine` package to install. If you're just getting started, we suggest installing the (default) Torch backend:
```shell
uv pip install useful-moonshine@git+https://github.com/usefulsensors/moonshine.git
```
To run the provided inference code, you have to instruct Keras to use the PyTorch backend by setting an environment variable:
```shell
export KERAS_BACKEND=torch
```
To run with the TensorFlow backend, run the following to install Moonshine and set the environment variable:
```shell
uv pip install useful-moonshine[tensorflow]@git+https://github.com/usefulsensors/moonshine.git
export KERAS_BACKEND=tensorflow
```
To run with the JAX backend, run the following:
```shell
uv pip install useful-moonshine[jax]@git+https://github.com/usefulsensors/moonshine.git
export KERAS_BACKEND=jax
# Use useful-moonshine[jax-cuda] for jax on GPU
```
### 2b. Install the `useful-moonshine-onnx` package to use Moonshine with ONNX
Using Moonshine with the ONNX runtime is preferable if you want to run the models on SBCs like the Raspberry Pi. We've prepared a separate version of
the package with minimal dependencies to support these use cases. To use it, run the following:
```shell
uv pip install useful-moonshine-onnx@git+https://[email protected]/usefulsensors/moonshine.git#subdirectory=moonshine-onnx
```
### 3. Try it out
You can test whichever type of Moonshine you installed by transcribing the provided example audio file with the `.transcribe` function:
```shell
python
>>> import moonshine # or import moonshine_onnx
>>> moonshine.transcribe(moonshine.ASSETS_DIR / 'beckett.wav', 'moonshine/tiny') # or moonshine_onnx.transcribe(...)
['Ever tried ever failed, no matter try again, fail again, fail better.']
```
The first argument is a path to an audio file and the second is the name of a Moonshine model. `moonshine/tiny` and `moonshine/base` are the currently available models.
## Examples
Since the Moonshine models can be used with a variety of different runtimes and applications, we've included code samples showing how to use them in different situations. The [`demo`](/demo/) folder in this repository also has more information on many of them.
### Live Captions
You can try the Moonshine ONNX models with live input from a microphone with the [live captions demo](/demo/README.md#demo-live-captioning-from-microphone-input).
### Running in the Browser
You can try out the Moonshine ONNX models locally in a web browser with our [HuggingFace space](https://huggingface.co/spaces/UsefulSensors/moonshine-web). We've included the [source for this demo](/demo/moonshine-web/) in this repository; this is a great starting place for those wishing to build web-based applications with Moonshine.
### CTranslate2
The files for the CTranslate2 versions of Moonshine are available at [huggingface.co/UsefulSensors/moonshine/tree/main/ctranslate2](https://huggingface.co/UsefulSensors/moonshine/tree/main/ctranslate2), but they require [a pull request to be merged](https://github.com/OpenNMT/CTranslate2/pull/1808) before they can be used with the mainline version of the framework. Until then, you should be able to try them with [our branch](https://github.com/njeffrie/CTranslate2/tree/master), with [this example script](https://github.com/OpenNMT/CTranslate2/pull/1808#issuecomment-2439725339).
### HuggingFace Transformers
Both models are also available on the HuggingFace hub and can be used with the `transformers` library, as follows:
```python
import torch
from transformers import AutoProcessor, MoonshineForConditionalGeneration
from datasets import load_dataset
processor = AutoProcessor.from_pretrained("UsefulSensors/moonshine-tiny")
model = MoonshineForConditionalGeneration.from_pretrained("UsefulSensors/moonshine-tiny")
ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
audio_array = ds[0]["audio"]["array"]
inputs = processor(audio_array, return_tensors="pt")
generated_ids = model.generate(**inputs)
transcription = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(transcription)
```
## TODO
* [x] Live transcription demo
* [x] ONNX model
* [x] HF transformers support
* [x] Demo Moonshine running in the browser
* [ ] CTranslate2 support (complete but [awaiting a merge](https://github.com/OpenNMT/CTranslate2/pull/1808))
* [ ] MLX support
* [ ] Fine-tuning code
* [ ] HF transformers.js support
* [ ] Long-form transcription demo
## Known Issues
### UserWarning: You are using a softmax over axis 3 of a tensor of shape torch.Size([1, 8, 1, 1])
This is a benign warning arising from Keras. For the first token in the decoding loop, the attention score matrix's shape is 1x1, which triggers this warning. You can safely ignore it, or run with `python -W ignore` to suppress the warning.
## Citation
If you benefit from our work, please cite us:
```
@misc{jeffries2024moonshinespeechrecognitionlive,
title={Moonshine: Speech Recognition for Live Transcription and Voice Commands},
author={Nat Jeffries and Evan King and Manjunath Kudlur and Guy Nicholson and James Wang and Pete Warden},
year={2024},
eprint={2410.15608},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2410.15608},
}
``` | {
"source": "usefulsensors/moonshine",
"title": "README.md",
"url": "https://github.com/usefulsensors/moonshine/blob/main/README.md",
"date": "2024-10-04T22:10:28",
"stars": 2583,
"description": "Fast and accurate automatic speech recognition (ASR) for edge devices",
"file_size": 9452
} |
# Model Card: Moonshine
This is the reference codebase for running the automatic speech recognition (ASR) models (Moonshine models) trained and released by Useful Sensors.
Following [Model Cards for Model Reporting (Mitchell et al.)](https://arxiv.org/abs/1810.03993), we're providing some information about the automatic speech recognition model. More information on how these models were trained and evaluated can be found [in the paper](https://arxiv.org/abs/2410.15608). Note, lot of the text has been copied verbatim from the [model card](https://github.com/openai/whisper/blob/main/model-card.md) for the Whisper model developed by OpenAI, because both models serve identical purposes, and carry identical risks.
## Model Details
The Moonshine models are trained for the speech recognition task, capable of transcribing English speech audio into English text. Useful Sensors developed the models to support their business direction of developing real time speech transcription products based on low cost hardware. There are 2 models of different sizes and capabilities, summarized in the following table.
| Size | Parameters | English-only model | Multilingual model |
|:----:|:----------:|:------------------:|:------------------:|
| tiny | 27 M | ✓ | |
| base | 61 M | ✓ | |
### Release date
October 2024
### Model type
Sequence-to-sequence ASR (automatic speech recognition) and speech translation model
### Paper & samples
[Paper](https://arxiv.org/abs/2410.15608) / [Blog](https://petewarden.com/2024/10/21/introducing-moonshine-the-new-state-of-the-art-for-speech-to-text/)
## Model Use
### Evaluated Use
The primary intended users of these models are AI developers that want to deploy English speech recognition systems in platforms that are severely constrained in memory capacity and computational resources. We recognize that once models are released, it is impossible to restrict access to only “intended” uses or to draw reasonable guidelines around what is or is not safe use.
The models are primarily trained and evaluated on English ASR task. They may exhibit additional capabilities, particularly if fine-tuned on certain tasks like voice activity detection, speaker classification, or speaker diarization but have not been robustly evaluated in these areas. We strongly recommend that users perform robust evaluations of the models in a particular context and domain before deploying them.
In particular, we caution against using Moonshine models to transcribe recordings of individuals taken without their consent or purporting to use these models for any kind of subjective classification. We recommend against use in high-risk domains like decision-making contexts, where flaws in accuracy can lead to pronounced flaws in outcomes. The models are intended to transcribe English speech, use of the model for classification is not only not evaluated but also not appropriate, particularly to infer human attributes.
## Training Data
The models are trained on 200,000 hours of audio and the corresponding transcripts collected from the internet, as well as datasets openly available and accessible on HuggingFace. The open datasets used are listed in the [the accompanying paper](https://arxiv.org/abs/2410.15608).
## Performance and Limitations
Our evaluations show that, the models exhibit greater accuracy on standard datasets over existing ASR systems of similar sizes.
However, like any machine learning model, the predictions may include texts that are not actually spoken in the audio input (i.e. hallucination). We hypothesize that this happens because, given their general knowledge of language, the models combine trying to predict the next word in audio with trying to transcribe the audio itself.
In addition, the sequence-to-sequence architecture of the model makes it prone to generating repetitive texts, which can be mitigated to some degree by beam search and temperature scheduling but not perfectly. It is likely that this behavior and hallucinations may be worse for short audio segments, or segments where parts of words are cut off at the beginning or the end of the segment.
## Broader Implications
We anticipate that Moonshine models’ transcription capabilities may be used for improving accessibility tools, especially for real-time transcription. The real value of beneficial applications built on top of Moonshine models suggests that the disparate performance of these models may have real economic implications.
There are also potential dual-use concerns that come with releasing Moonshine. While we hope the technology will be used primarily for beneficial purposes, making ASR technology more accessible could enable more actors to build capable surveillance technologies or scale up existing surveillance efforts, as the speed and accuracy allow for affordable automatic transcription and translation of large volumes of audio communication. Moreover, these models may have some capabilities to recognize specific individuals out of the box, which in turn presents safety concerns related both to dual use and disparate performance. In practice, we expect that the cost of transcription is not the limiting factor of scaling up surveillance projects. | {
"source": "usefulsensors/moonshine",
"title": "model-card.md",
"url": "https://github.com/usefulsensors/moonshine/blob/main/model-card.md",
"date": "2024-10-04T22:10:28",
"stars": 2583,
"description": "Fast and accurate automatic speech recognition (ASR) for edge devices",
"file_size": 5315
} |
# Moonshine Demos
This directory contains scripts to demonstrate the capabilities of the
Moonshine ASR models.
- [Moonshine Demos](#moonshine-demos)
- [Demo: Running in the browser](#demo-running-in-the-browser)
- [Installation](#installation)
- [Demo: Live captioning from microphone input](#demo-live-captioning-from-microphone-input)
- [Installation](#installation-1)
- [0. Setup environment](#0-setup-environment)
- [1. Clone the repo and install extra dependencies](#1-clone-the-repo-and-install-extra-dependencies)
- [Ubuntu: Install PortAudio](#ubuntu-install-portaudio)
- [Running the demo](#running-the-demo)
- [Script notes](#script-notes)
- [Speech truncation and hallucination](#speech-truncation-and-hallucination)
- [Running on a slower processor](#running-on-a-slower-processor)
- [Metrics](#metrics)
- [Citation](#citation)
# Demo: Running in the browser
The Node.js project in [`moonshine-web`](/demo/moonshine-web/) demonstrates how to run the
Moonshine models in the web browser using `onnxruntime-web`. You can try this demo on your own device using our [HuggingFace space](https://huggingface.co/spaces/UsefulSensors/moonshine-web) without having to run the project from the source here. Of note, the [`moonshine.js`](/demo/moonshine-web/src/moonshine.js) script contains everything you need to perform inferences with the Moonshine ONNX models in the browser. If you would like to build on the web demo, follow these instructions to get started.
## Installation
You must have Node.js (or another JavaScript toolkit like [Bun](https://bun.sh/)) installed to get started. Install [Node.js](https://nodejs.org/en) if you don't have it already.
Once you have your JavaScript toolkit installed, clone the `moonshine` repo and navigate to this directory:
```shell
git clone [email protected]:usefulsensors/moonshine.git
cd moonshine/demo/moonshine-web
```
Then install the project's dependencies:
```shell
npm install
```
The demo expects the Moonshine Tiny and Base ONNX models to be available in `public/moonshine/tiny` and `public/moonshine/base`, respectively. To preserve space, they are not included here. However, we've included a helper script that you can run to conveniently download them from HuggingFace:
```shell
npm run get-models
```
This project uses Vite for bundling and development. Run the following to start a development server and open the demo in your web browser:
```shell
npm run dev
```
# Demo: Live captioning from microphone input
https://github.com/user-attachments/assets/aa65ef54-d4ac-4d31-864f-222b0e6ccbd3
The [`moonshine-onnx/live_captions.py`](/demo/moonshine-onnx/live_captions.py) script contains a demo of live captioning from microphone input, built on Moonshine. The script runs the Moonshine ONNX model on segments of speech detected in the microphone signal using a voice activity detector called [`silero-vad`](https://github.com/snakers4/silero-vad). The script prints scrolling text or "live captions" assembled from the model predictions to the console.
The following steps have been tested in `uv` virtual environments on these platforms:
- macOS 14.1 on a MacBook Pro M3
- Ubuntu 22.04 VM on a MacBook Pro M2
- Ubuntu 24.04 VM on a MacBook Pro M2
- Debian 12.8 (64-bit) on a Raspberry Pi 5 (Model B Rev 1.0)
## Installation
### 0. Setup environment
Steps to set up a virtual environment are available in the [top level README](/README.md) of this repo. After creating a virtual environment, do the following:
### 1. Clone the repo and install extra dependencies
You will need to clone the repo first:
```shell
git clone [email protected]:usefulsensors/moonshine.git
```
Then install the demo's requirements including mitigation for a failure to build
and install `llvmlite` without `numba` package:
```shell
uv pip install numba
uv pip install -r moonshine/demo/moonshine-onnx/requirements.txt
```
Note that while `useful-moonshine-onnx` has no requirement for `torch`, this demo introduces a dependency for it because of the `silero-vad` package.
#### Ubuntu: Install PortAudio
Ubuntu needs PortAudio for the `sounddevice` package to run. The latest version (19.6.0-1.2build3 as of writing) is suitable.
```shell
sudo apt update
sudo apt upgrade -y
sudo apt install -y portaudio19-dev
```
## Running the demo
First, check that your microphone is connected and that the volume setting is not muted in your host OS or system audio drivers. Then, run the script:
``` shell
python3 moonshine/demo/moonshine-onnx/live_captions.py
```
By default, this will run the demo with the Moonshine Base model using the ONNX runtime. The optional `--model_name` argument sets the model to use: supported arguments are `moonshine/base` and `moonshine/tiny`.
When running, speak in English language to the microphone and observe live captions in the terminal. Quit the demo with `Ctrl+C` to see a full printout of the captions.
An example run on Ubuntu 24.04 VM on MacBook Pro M2 with Moonshine base ONNX
model:
```console
(env_moonshine_demo) parallels@ubuntu-linux-2404:~$ python3 moonshine/demo/moonshine-onnx/live_captions.py
Error in cpuinfo: prctl(PR_SVE_GET_VL) failed
Loading Moonshine model 'moonshine/base' (ONNX runtime) ...
Press Ctrl+C to quit live captions.
hine base model being used to generate live captions while someone is speaking. ^C
model_name : moonshine/base
MIN_REFRESH_SECS : 0.2s
number inferences : 25
mean inference time : 0.14s
model realtime factor : 27.82x
Cached captions.
This is an example of the Moonshine base model being used to generate live captions while someone is speaking.
(env_moonshine_demo) parallels@ubuntu-linux-2404:~$
```
For comparison, this is the `faster-whisper` base model on the same instance.
The value of `MIN_REFRESH_SECS` was increased as the model inference is too slow
for a value of 0.2 seconds. Our Moonshine base model runs ~ 7x faster for this
example.
```console
(env_moonshine_faster_whisper) parallels@ubuntu-linux-2404:~$ python3 moonshine/demo/moonshine-onnx/live_captions.py
Error in cpuinfo: prctl(PR_SVE_GET_VL) failed
Loading Faster-Whisper float32 base.en model ...
Press Ctrl+C to quit live captions.
r float32 base model being used to generate captions while someone is speaking. ^C
model_name : base.en
MIN_REFRESH_SECS : 1.2s
number inferences : 6
mean inference time : 1.02s
model realtime factor : 4.82x
Cached captions.
This is an example of the Faster Whisper float32 base model being used to generate captions while someone is speaking.
(env_moonshine_faster_whisper) parallels@ubuntu-linux-2404:~$
```
## Script notes
You may customize this script to display Moonshine text transcriptions as you wish.
The script `moonshine-onnx/live_captions.py` loads the English language version of Moonshine base ONNX model. It includes logic to detect speech activity and limit the context window of speech fed to the Moonshine model. The returned transcriptions are displayed as scrolling captions. Speech segments with pauses are cached and these cached captions are printed on exit.
### Speech truncation and hallucination
Some hallucinations will be seen when the script is running: one reason is speech gets truncated out of necessity to generate the frequent refresh and timeout transcriptions. Truncated speech contains partial or sliced words for which transcriber model transcriptions are unpredictable. See the printed captions on script exit for the best results.
### Running on a slower processor
If you run this script on a slower processor, consider using the `tiny` model.
```shell
python3 ./moonshine/demo/moonshine-onnx/live_captions.py --model_name moonshine/tiny
```
The value of `MIN_REFRESH_SECS` will be ineffective when the model inference time exceeds that value. Conversely on a faster processor consider reducing the value of `MIN_REFRESH_SECS` for more frequent caption updates. On a slower processor you might also consider reducing the value of `MAX_SPEECH_SECS` to avoid slower model inferencing encountered with longer speech segments.
### Metrics
The metrics shown on program exit will vary based on the talker's speaking style. If the talker speaks with more frequent pauses, the speech segments are shorter and the mean inference time will be lower. This is a feature of the Moonshine model described in [our paper](https://arxiv.org/abs/2410.15608). When benchmarking, use the same speech, e.g., a recording of someone talking.
# Citation
If you benefit from our work, please cite us:
```
@misc{jeffries2024moonshinespeechrecognitionlive,
title={Moonshine: Speech Recognition for Live Transcription and Voice Commands},
author={Nat Jeffries and Evan King and Manjunath Kudlur and Guy Nicholson and James Wang and Pete Warden},
year={2024},
eprint={2410.15608},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2410.15608},
}
``` | {
"source": "usefulsensors/moonshine",
"title": "demo/README.md",
"url": "https://github.com/usefulsensors/moonshine/blob/main/demo/README.md",
"date": "2024-10-04T22:10:28",
"stars": 2583,
"description": "Fast and accurate automatic speech recognition (ASR) for edge devices",
"file_size": 9020
} |
# useful-moonshine-onnx
Moonshine is a family of speech-to-text models optimized for fast and accurate automatic speech recognition (ASR) on resource-constrained devices. This package contains inference code for using Moonshine models with the ONNX runtime. For more information, please refer to the [project repo on GitHub](https://github.com/usefulsensors/moonshine). | {
"source": "usefulsensors/moonshine",
"title": "moonshine-onnx/README.md",
"url": "https://github.com/usefulsensors/moonshine/blob/main/moonshine-onnx/README.md",
"date": "2024-10-04T22:10:28",
"stars": 2583,
"description": "Fast and accurate automatic speech recognition (ASR) for edge devices",
"file_size": 370
} |

<p align="center"><strong>PySpur is an AI agent builder in Python. AI engineers use it to build agents, execute them step-by-step and inspect past runs.</strong></p>
<p align="center">
<a href="./README.md"><img alt="README in English" src="https://img.shields.io/badge/English-blue"></a>
<a href="./README_CN.md"><img alt="简体中文版自述文件" src="https://img.shields.io/badge/简体中文-blue"></a>
<a href="./README_JA.md"><img alt="日本語のREADME" src="https://img.shields.io/badge/日本語-blue"></a>
<a href="./README_KR.md"><img alt="README in Korean" src="https://img.shields.io/badge/한국어-blue"></a>
<a href="./README_DE.md"><img alt="Deutsche Version der README" src="https://img.shields.io/badge/Deutsch-blue"></a>
<a href="./README_FR.md"><img alt="Version française du README" src="https://img.shields.io/badge/Français-blue"></a>
<a href="./README_ES.md"><img alt="Versión en español del README" src="https://img.shields.io/badge/Español-blue"></a>
</p>
<p align="center">
<a href="https://docs.pyspur.dev/" target="_blank">
<img alt="Docs" src="https://img.shields.io/badge/Docs-green.svg?style=for-the-badge&logo=readthedocs&logoColor=white">
</a>
<a href="https://calendly.com/d/cnf9-57m-bv3/pyspur-founders" target="_blank">
<img alt="Meet us" src="https://img.shields.io/badge/Meet%20us-blue.svg?style=for-the-badge&logo=calendly&logoColor=white">
</a>
<a href="https://forms.gle/5wHRctedMpgfNGah7" target="_blank">
<img alt="Cloud" src="https://img.shields.io/badge/Cloud-orange.svg?style=for-the-badge&logo=cloud&logoColor=white">
</a>
<a href="https://discord.gg/7Spn7C8A5F">
<img alt="Join Our Discord" src="https://img.shields.io/badge/Discord-7289DA.svg?style=for-the-badge&logo=discord&logoColor=white">
</a>
</p>
https://github.com/user-attachments/assets/1ebf78c9-94b2-468d-bbbb-566311df16fe
# 🕸️ Why PySpur?
- 🖐️ **Drag-and-Drop**: Build, Test and Iterate in Seconds.
- 🔄 **Loops**: Iterative Tool Calling with Memory.
- 📤 **File Upload**: Upload files or paste URLs to process documents.
- 📋 **Structured Outputs**: UI editor for JSON Schemas.
- 🗃️ **RAG**: Parse, Chunk, Embed, and Upsert Data into a Vector DB.
- 🖼️ **Multimodal**: Support for Video, Images, Audio, Texts, Code.
- 🧰 **Tools**: Slack, Firecrawl.dev, Google Sheets, GitHub, and more.
- 🧪 **Evals**: Evaluate Agents on Real-World Datasets.
- 🚀 **One-Click Deploy**: Publish as an API and integrate wherever you want.
- 🐍 **Python-Based**: Add new nodes by creating a single Python file.
- 🎛️ **Any-Vendor-Support**: >100 LLM providers, embedders, and vector DBs.
# ⚡ Quick start
## Option A: Using `pyspur` Python Package
This is the quickest way to get started. Python 3.12 or higher is required.
1. **Install PySpur:**
```sh
pip install pyspur
```
2. **Initialize a new project:**
```sh
pyspur init my-project
cd my-project
```
This will create a new directory with a `.env` file.
3. **Start the server:**
```sh
pyspur serve --sqlite
```
By default, this will start PySpur app at `http://localhost:6080` using a sqlite database.
We recommend you configure a postgres instance URL in the `.env` file to get a more stable experience.
4. **[Optional] Customize Your Deployment:**
You can customize your PySpur deployment in two ways:
a. **Through the app** (Recommended):
- Navigate to the API Keys tab in the app
- Add your API keys for various providers (OpenAI, Anthropic, etc.)
- Changes take effect immediately
b. **Manual Configuration**:
- Edit the `.env` file in your project directory
- It is recommended to configure a postgres database in .env for more reliability
- Restart the app with `pyspur serve`. Add `--sqlite` if you are not using postgres
## Option B: Using Docker (Recommended for Scalable, In-Production Systems)
This is the recommended way for production deployments:
1. **Install Docker:**
First, install Docker by following the official installation guide for your operating system:
- [Docker for Linux](https://docs.docker.com/engine/install/)
- [Docker Desktop for Mac](https://docs.docker.com/desktop/install/mac-install/)
2. **Create a PySpur Project:**
Once Docker is installed, create a new PySpur project with:
```sh
curl -fsSL https://raw.githubusercontent.com/PySpur-com/pyspur/main/start_pyspur_docker.sh | bash -s pyspur-project
```
This will:
- Start a new PySpur project in a new directory called `pyspur-project`
- Set up the necessary configuration files
- Start PySpur app automatically backed by a local postgres docker instance
3. **Access PySpur:**
Go to `http://localhost:6080` in your browser.
4. **[Optional] Customize Your Deployment:**
You can customize your PySpur deployment in two ways:
a. **Through the app** (Recommended):
- Navigate to the API Keys tab in the app
- Add your API keys for various providers (OpenAI, Anthropic, etc.)
- Changes take effect immediately
b. **Manual Configuration**:
- Edit the `.env` file in your project directory
- Restart the services with:
```sh
docker compose up -d
```
That's it! Click on "New Spur" to create a workflow, or start with one of the stock templates.
# ✨ Core Benefits
## Debug at Node Level:
https://github.com/user-attachments/assets/6e82ad25-2a46-4c50-b030-415ea9994690
## Multimodal (Upload files or paste URLs)
PDFs, Videos, Audio, Images, ...
https://github.com/user-attachments/assets/83ed9a22-1ec1-4d86-9dd6-5d945588fd0b
## Loops
<img width="1919" alt="Loops" src="https://github.com/user-attachments/assets/3aea63dc-f46f-46e9-bddd-e2af9c2a56bf" />
## RAG
### Step 1) Create Document Collection (Chunking + Parsing)
https://github.com/user-attachments/assets/c77723b1-c076-4a64-a01d-6d6677e9c60e
### Step 2) Create Vector Index (Embedding + Vector DB Upsert)
https://github.com/user-attachments/assets/50e5c711-dd01-4d92-bb23-181a1c5bba25
## Modular Building Blocks
https://github.com/user-attachments/assets/6442f0ad-86d8-43d9-aa70-e5c01e55e876
## Evaluate Final Performance
https://github.com/user-attachments/assets/4dc2abc3-c6e6-4d6d-a5c3-787d518de7ae
## Coming soon: Self-improvement
https://github.com/user-attachments/assets/5bef7a16-ef9f-4650-b385-4ea70fa54c8a
# 🛠️ PySpur Development Setup
#### [ Instructions for development on Unix-like systems. Development on Windows/PC not supported ]
For development, follow these steps:
1. **Clone the repository:**
```sh
git clone https://github.com/PySpur-com/pyspur.git
cd pyspur
```
2. **Launch using docker-compose.dev.yml:**
```sh
docker compose -f docker-compose.dev.yml up --build -d
```
This will start a local instance of PySpur with hot-reloading enabled for development.
3. **Customize your setup:**
Edit the `.env` file to configure your environment. By default, PySpur uses a local PostgreSQL database. To use an external database, modify the `POSTGRES_*` variables in `.env`.
# ⭐ Support us
You can support us in our work by leaving a star! Thank you!

Your feedback will be massively appreciated.
Please [tell us](mailto:[email protected]?subject=Feature%20Request&body=I%20want%20this%20feature%3Ai) which features on that list you like to see next or request entirely new ones. | {
"source": "PySpur-Dev/pyspur",
"title": "README.md",
"url": "https://github.com/PySpur-Dev/pyspur/blob/main/README.md",
"date": "2024-09-23T17:24:52",
"stars": 2509,
"description": "AI Agent Builder in Python",
"file_size": 7489
} |

<p align="center"><strong>PySpur 是一个基于 Python 的 AI 代理构建器。AI 工程师使用它来构建代理、逐步执行并检查过去的运行记录。</strong></p>
<p align="center">
<a href="./README.md"><img alt="README in English" src="https://img.shields.io/badge/English-blue"></a>
<a href="./README_CN.md"><img alt="简体中文版自述文件" src="https://img.shields.io/badge/简体中文-blue"></a>
<a href="./README_JA.md"><img alt="日本語のREADME" src="https://img.shields.io/badge/日本語-blue"></a>
<a href="./README_KR.md"><img alt="README in Korean" src="https://img.shields.io/badge/한국어-blue"></a>
<a href="./README_DE.md"><img alt="Deutsche Version der README" src="https://img.shields.io/badge/Deutsch-blue"></a>
<a href="./README_FR.md"><img alt="Version française du README" src="https://img.shields.io/badge/Français-blue"></a>
<a href="./README_ES.md"><img alt="Versión en español del README" src="https://img.shields.io/badge/Español-blue"></a>
</p>
<p align="center">
<a href="https://docs.pyspur.dev/" target="_blank">
<img alt="Docs" src="https://img.shields.io/badge/Docs-green.svg?style=for-the-badge&logo=readthedocs&logoColor=white">
</a>
<a href="https://calendly.com/d/cnf9-57m-bv3/pyspur-founders" target="_blank">
<img alt="Meet us" src="https://img.shields.io/badge/Meet%20us-blue.svg?style=for-the-badge&logo=calendly&logoColor=white">
</a>
<a href="https://forms.gle/5wHRctedMpgfNGah7" target="_blank">
<img alt="Cloud" src="https://img.shields.io/badge/Cloud-orange.svg?style=for-the-badge&logo=cloud&logoColor=white">
</a>
<a href="https://discord.gg/7Spn7C8A5F">
<img alt="Join Our Discord" src="https://img.shields.io/badge/Discord-7289DA.svg?style=for-the-badge&logo=discord&logoColor=white">
</a>
</p>
https://github.com/user-attachments/assets/1ebf78c9-94b2-468d-bbbb-566311df16fe
# 🕸️ 为什么选择 PySpur?
- 🖐️ **拖拽式构建**:几秒内构建、测试并迭代。
- 🔄 **循环**:具有记忆功能的迭代工具调用。
- 📤 **文件上传**:上传文件或粘贴 URL 来处理文档。
- 📋 **结构化输出**:用于 JSON Schema 的 UI 编辑器。
- 🗃️ **RAG**:解析、分块、嵌入并将数据插入向量数据库。
- 🖼️ **多模态**:支持视频、图像、音频、文本、代码。
- 🧰 **工具**:Slack、Firecrawl.dev、Google Sheets、GitHub 等。
- 🧪 **评估**:在真实数据集上评估代理。
- 🚀 **一键部署**:发布为 API 并在任意地方集成。
- 🐍 **基于 Python**:通过创建单个 Python 文件来添加新节点。
- 🎛️ **供应商通用支持**:支持超过 100 个 LLM 提供商、嵌入器和向量数据库。
# ⚡ 快速开始
## 选项 A:使用 `pyspur` Python 包
这是入门的最快方式。需要 Python 3.12 或更高版本。
1. **安装 PySpur:**
```sh
pip install pyspur
```
2. **初始化新项目:**
```sh
pyspur init my-project
cd my-project
```
这将创建一个包含 `.env` 文件的新目录。
3. **启动服务器:**
```sh
pyspur serve --sqlite
```
默认情况下,这将使用 SQLite 数据库在 `http://localhost:6080` 启动 PySpur 应用。
我们建议你在 `.env` 文件中配置 Postgres 实例的 URL,以获得更稳定的体验。
4. **[可选] 自定义部署:**
你可以通过两种方式自定义你的 PySpur 部署:
a. **通过应用**(推荐):
- 在应用中导航至 API 密钥标签页
- 添加各供应商的 API 密钥(例如 OpenAI、Anthropic 等)
- 更改会立即生效
b. **手动配置**:
- 编辑项目目录中的 `.env` 文件
- 建议在 .env 中配置 Postgres 数据库以获得更高的可靠性
- 使用 `pyspur serve` 重启应用;如果不使用 Postgres,请添加 `--sqlite`
## 选项 B:使用 Docker(推荐用于可扩展的生产系统)
这是生产部署的推荐方式:
1. **安装 Docker:**
首先,根据你的操作系统,按照官方安装指南安装 Docker:
- [Linux 上的 Docker](https://docs.docker.com/engine/install/)
- [Mac 上的 Docker Desktop](https://docs.docker.com/desktop/install/mac-install/)
2. **创建 PySpur 项目:**
安装 Docker 后,使用以下命令创建一个新的 PySpur 项目:
```sh
curl -fsSL https://raw.githubusercontent.com/PySpur-com/pyspur/main/start_pyspur_docker.sh | bash -s pyspur-project
```
这将:
- 在名为 `pyspur-project` 的新目录中启动一个新的 PySpur 项目
- 设置所需的配置文件
- 自动启动由本地 Postgres Docker 实例支持的 PySpur 应用
3. **访问 PySpur:**
在浏览器中访问 `http://localhost:6080`。
4. **[可选] 自定义部署:**
你可以通过两种方式自定义你的 PySpur 部署:
a. **通过应用**(推荐):
- 在应用中导航至 API 密钥标签页
- 添加各供应商的 API 密钥(例如 OpenAI、Anthropic 等)
- 更改会立即生效
b. **手动配置**:
- 编辑项目目录中的 `.env` 文件
- 使用以下命令重启服务:
```sh
docker compose up -d
```
就这么简单!点击 “New Spur” 创建工作流,或从内置模板开始。
# ✨ 核心优势
## 节点级调试:
https://github.com/user-attachments/assets/6e82ad25-2a46-4c50-b030-415ea9994690
## 多模态(上传文件或粘贴 URL)
支持 PDF、视频、音频、图像等……
https://github.com/user-attachments/assets/83ed9a22-1ec1-4d86-9dd6-5d945588fd0b
## 循环
<img width="1919" alt="Loops" src="https://github.com/user-attachments/assets/3aea63dc-f46f-46e9-bddd-e2af9c2a56bf" />
## RAG
### 步骤 1) 创建文档集合(分块 + 解析)
https://github.com/user-attachments/assets/c77723b1-c076-4a64-a01d-6d6677e9c60e
### 步骤 2) 创建向量索引(嵌入 + 向量数据库插入)
https://github.com/user-attachments/assets/50e5c711-dd01-4d92-bb23-181a1c5bba25
## 模块化构建块
https://github.com/user-attachments/assets/6442f0ad-86d8-43d9-aa70-e5c01e55e876
## 评估最终性能
https://github.com/user-attachments/assets/4dc2abc3-c6e6-4d6d-a5c3-787d518de7ae
## 即将推出:自我提升
https://github.com/user-attachments/assets/5bef7a16-ef9f-4650-b385-4ea70fa54c8a
# 🛠️ PySpur 开发环境设置
#### [ Unix 类系统开发指南。Windows/PC 开发不支持。 ]
开发时,请按照以下步骤操作:
1. **克隆仓库:**
```sh
git clone https://github.com/PySpur-com/pyspur.git
cd pyspur
```
2. **使用 docker-compose.dev.yml 启动:**
```sh
docker compose -f docker-compose.dev.yml up --build -d
```
这将启动一个本地 PySpur 实例,并启用热重载以便开发。
3. **自定义你的设置:**
编辑 `.env` 文件以配置你的环境。默认情况下,PySpur 使用本地 PostgreSQL 数据库。若要使用外部数据库,请修改 `.env` 中的 `POSTGRES_*` 变量。
# ⭐ 支持我们
你可以通过给我们项目加星标来支持我们的工作!谢谢!

我们非常感谢你的反馈。
请 [告诉我们](mailto:[email protected]?subject=Feature%20Request&body=I%20want%20this%20feature%3Ai) 你希望下一个看到列表中的哪些功能,或请求全新的功能。 | {
"source": "PySpur-Dev/pyspur",
"title": "README_CN.md",
"url": "https://github.com/PySpur-Dev/pyspur/blob/main/README_CN.md",
"date": "2024-09-23T17:24:52",
"stars": 2509,
"description": "AI Agent Builder in Python",
"file_size": 5469
} |

<p align="center"><strong>PySpur ist ein KI-Agenten-Builder in Python. KI-Entwickler nutzen ihn, um Agenten zu erstellen, sie Schritt für Schritt auszuführen und vergangene Durchläufe zu analysieren.</strong></p>
<p align="center">
<a href="./README.md"><img alt="README auf Englisch" src="https://img.shields.io/badge/English-blue"></a>
<a href="./README_CN.md"><img alt="README auf vereinfachtem Chinesisch" src="https://img.shields.io/badge/简体中文-blue"></a>
<a href="./README_JA.md"><img alt="README auf Japanisch" src="https://img.shields.io/badge/日本語-blue"></a>
<a href="./README_KR.md"><img alt="README auf Koreanisch" src="https://img.shields.io/badge/한국어-blue"></a>
<a href="./README_DE.md"><img alt="Deutsche Version der README" src="https://img.shields.io/badge/Deutsch-blue"></a>
<a href="./README_FR.md"><img alt="README auf Französisch" src="https://img.shields.io/badge/Français-blue"></a>
<a href="./README_ES.md"><img alt="README auf Spanisch" src="https://img.shields.io/badge/Español-blue"></a>
</p>
<p align="center">
<a href="https://docs.pyspur.dev/" target="_blank">
<img alt="Dokumentation" src="https://img.shields.io/badge/Docs-green.svg?style=for-the-badge&logo=readthedocs&logoColor=white">
</a>
<a href="https://calendly.com/d/cnf9-57m-bv3/pyspur-founders" target="_blank">
<img alt="Treffen Sie uns" src="https://img.shields.io/badge/Meet%20us-blue.svg?style=for-the-badge&logo=calendly&logoColor=white">
</a>
<a href="https://forms.gle/5wHRctedMpgfNGah7" target="_blank">
<img alt="Cloud" src="https://img.shields.io/badge/Cloud-orange.svg?style=for-the-badge&logo=cloud&logoColor=white">
</a>
<a href="https://discord.gg/7Spn7C8A5F">
<img alt="Discord beitreten" src="https://img.shields.io/badge/Discord-7289DA.svg?style=for-the-badge&logo=discord&logoColor=white">
</a>
</p>
https://github.com/user-attachments/assets/1ebf78c9-94b2-468d-bbbb-566311df16fe
# 🕸️ Warum PySpur?
- 🖐️ **Drag-and-Drop**: Erstellen, Testen und iteratives Anpassen in Sekunden.
- 🔄 **Loops**: Wiederholte Toolaufrufe mit Zwischenspeicherung.
- 📤 **Datei-Upload**: Laden Sie Dateien hoch oder fügen Sie URLs ein, um Dokumente zu verarbeiten.
- 📋 **Strukturierte Outputs**: UI-Editor für JSON-Schemata.
- 🗃️ **RAG**: Daten parsen, in Abschnitte unterteilen, einbetten und in eine Vektor-Datenbank einfügen/aktualisieren.
- 🖼️ **Multimodal**: Unterstützung für Video, Bilder, Audio, Texte, Code.
- 🧰 **Tools**: Slack, Firecrawl.dev, Google Sheets, GitHub und mehr.
- 🧪 **Evaluierungen**: Bewerten Sie Agenten anhand von realen Datensätzen.
- 🚀 **One-Click Deploy**: Veröffentlichen Sie Ihre Lösung als API und integrieren Sie sie überall.
- 🐍 **Python-basiert**: Fügen Sie neue Knoten hinzu, indem Sie eine einzige Python-Datei erstellen.
- 🎛️ **Support für jeden Anbieter**: Über 100 LLM-Anbieter, Einbettungslösungen und Vektor-Datenbanken.
# ⚡ Schnellstart
## Option A: Verwendung des `pyspur` Python-Pakets
Dies ist der schnellste Weg, um loszulegen. Python 3.12 oder höher wird benötigt.
1. **PySpur installieren:**
```sh
pip install pyspur
```
2. **Ein neues Projekt initialisieren:**
```sh
pyspur init my-project
cd my-project
```
Dadurch wird ein neues Verzeichnis mit einer `.env`-Datei erstellt.
3. **Den Server starten:**
```sh
pyspur serve --sqlite
```
Standardmäßig startet dies die PySpur-App unter `http://localhost:6080` mit einer SQLite-Datenbank.
Wir empfehlen, in der `.env`-Datei eine PostgreSQL-Instanz-URL zu konfigurieren, um eine stabilere Erfahrung zu gewährleisten.
4. **[Optional] Bereitstellung anpassen:**
Sie können Ihre PySpur-Bereitstellung auf zwei Arten anpassen:
a. **Über die App** (Empfohlen):
- Navigieren Sie zum Tab „API Keys“ in der App.
- Fügen Sie Ihre API-Schlüssel für verschiedene Anbieter (OpenAI, Anthropic usw.) hinzu.
- Die Änderungen werden sofort wirksam.
b. **Manuelle Konfiguration**:
- Bearbeiten Sie die `.env`-Datei in Ihrem Projektverzeichnis.
- Es wird empfohlen, in der `.env`-Datei eine PostgreSQL-Datenbank zu konfigurieren, um mehr Zuverlässigkeit zu gewährleisten.
- Starten Sie die App mit `pyspur serve` neu. Fügen Sie `--sqlite` hinzu, falls Sie keine PostgreSQL verwenden.
## Option B: Verwendung von Docker (Empfohlen für skalierbare, produktive Systeme)
Dies ist der empfohlene Weg für produktive Bereitstellungen:
1. **Docker installieren:**
Installieren Sie Docker, indem Sie der offiziellen Installationsanleitung für Ihr Betriebssystem folgen:
- [Docker for Linux](https://docs.docker.com/engine/install/)
- [Docker Desktop for Mac](https://docs.docker.com/desktop/install/mac-install/)
2. **Ein PySpur-Projekt erstellen:**
Sobald Docker installiert ist, erstellen Sie ein neues PySpur-Projekt mit:
```sh
curl -fsSL https://raw.githubusercontent.com/PySpur-com/pyspur/main/start_pyspur_docker.sh | bash -s pyspur-project
```
Dies wird:
- Ein neues PySpur-Projekt in einem neuen Verzeichnis namens `pyspur-project` starten.
- Die notwendigen Konfigurationsdateien einrichten.
- Die PySpur-App automatisch starten, unterstützt durch eine lokale PostgreSQL-Docker-Instanz.
3. **Auf PySpur zugreifen:**
Öffnen Sie `http://localhost:6080` in Ihrem Browser.
4. **[Optional] Bereitstellung anpassen:**
Sie können Ihre PySpur-Bereitstellung auf zwei Arten anpassen:
a. **Über die App** (Empfohlen):
- Navigieren Sie zum Tab „API Keys“ in der App.
- Fügen Sie Ihre API-Schlüssel für verschiedene Anbieter (OpenAI, Anthropic usw.) hinzu.
- Die Änderungen werden sofort wirksam.
b. **Manuelle Konfiguration**:
- Bearbeiten Sie die `.env`-Datei in Ihrem Projektverzeichnis.
- Starten Sie die Dienste mit:
```sh
docker compose up -d
```
Das war's! Klicken Sie auf „New Spur“, um einen Workflow zu erstellen, oder starten Sie mit einer der Standardvorlagen.
# ✨ Kernvorteile
## Debuggen auf Node-Ebene:
https://github.com/user-attachments/assets/6e82ad25-2a46-4c50-b030-415ea9994690
## Multimodal (Dateien hochladen oder URLs einfügen)
PDFs, Videos, Audio, Bilder, ...
https://github.com/user-attachments/assets/83ed9a22-1ec1-4d86-9dd6-5d945588fd0b
## Loops
<img width="1919" alt="Loops" src="https://github.com/user-attachments/assets/3aea63dc-f46f-46e9-bddd-e2af9c2a56bf" />
## RAG
### Schritt 1) Erstellen einer Dokumentensammlung (Chunking + Parsing)
https://github.com/user-attachments/assets/c77723b1-c076-4a64-a01d-6d6677e9c60e
### Schritt 2) Erstellen eines Vektorindex (Einbettung + Einfügen/Aktualisieren in der Vektor-Datenbank)
https://github.com/user-attachments/assets/50e5c711-dd01-4d92-bb23-181a1c5bba25
## Modulare Bausteine
https://github.com/user-attachments/assets/6442f0ad-86d8-43d9-aa70-e5c01e55e876
## Endgültige Leistung bewerten
https://github.com/user-attachments/assets/4dc2abc3-c6e6-4d6d-a5c3-787d518de7ae
## Demnächst: Selbstverbesserung
https://github.com/user-attachments/assets/5bef7a16-ef9f-4650-b385-4ea70fa54c8a
# 🛠️ PySpur Entwicklungs-Setup
#### [ Anweisungen für die Entwicklung auf Unix-ähnlichen Systemen. Entwicklung auf Windows/PC wird nicht unterstützt ]
Für die Entwicklung folgen Sie diesen Schritten:
1. **Das Repository klonen:**
```sh
git clone https://github.com/PySpur-com/pyspur.git
cd pyspur
```
2. **Mit docker-compose.dev.yml starten:**
```sh
docker compose -f docker-compose.dev.yml up --build -d
```
Dadurch wird eine lokale Instanz von PySpur mit aktiviertem Hot-Reloading für die Entwicklung gestartet.
3. **Ihre Einrichtung anpassen:**
Bearbeiten Sie die `.env`-Datei, um Ihre Umgebung zu konfigurieren. Standardmäßig verwendet PySpur eine lokale PostgreSQL-Datenbank. Um eine externe Datenbank zu nutzen, ändern Sie die `POSTGRES_*`-Variablen in der `.env`.
# ⭐ Unterstützen Sie uns
Sie können uns bei unserer Arbeit unterstützen, indem Sie einen Stern hinterlassen! Vielen Dank!

Ihr Feedback wird sehr geschätzt.
Bitte [sagen Sie uns](mailto:[email protected]?subject=Feature%20Request&body=I%20want%20this%20feature%3Ai), welche Funktionen aus dieser Liste Sie als Nächstes sehen möchten oder schlagen Sie ganz neue vor. | {
"source": "PySpur-Dev/pyspur",
"title": "README_DE.md",
"url": "https://github.com/PySpur-Dev/pyspur/blob/main/README_DE.md",
"date": "2024-09-23T17:24:52",
"stars": 2509,
"description": "AI Agent Builder in Python",
"file_size": 8433
} |

<p align="center"><strong>PySpur es un constructor de agentes de IA en Python. Los ingenieros de IA lo utilizan para crear agentes, ejecutarlos paso a paso e inspeccionar ejecuciones anteriores.</strong></p>
<p align="center">
<a href="./README.md"><img alt="README en inglés" src="https://img.shields.io/badge/English-blue"></a>
<a href="./README_CN.md"><img alt="Versión en chino simplificado" src="https://img.shields.io/badge/简体中文-blue"></a>
<a href="./README_JA.md"><img alt="README en japonés" src="https://img.shields.io/badge/日本語-blue"></a>
<a href="./README_KR.md"><img alt="README en coreano" src="https://img.shields.io/badge/한국어-blue"></a>
<a href="./README_DE.md"><img alt="Versión en alemán del README" src="https://img.shields.io/badge/Deutsch-blue"></a>
<a href="./README_FR.md"><img alt="Versión en francés del README" src="https://img.shields.io/badge/Français-blue"></a>
<a href="./README_ES.md"><img alt="Versión en español del README" src="https://img.shields.io/badge/Español-blue"></a>
</p>
<p align="center">
<a href="https://docs.pyspur.dev/" target="_blank">
<img alt="Docs" src="https://img.shields.io/badge/Docs-green.svg?style=for-the-badge&logo=readthedocs&logoColor=white">
</a>
<a href="https://calendly.com/d/cnf9-57m-bv3/pyspur-founders" target="_blank">
<img alt="Conócenos" src="https://img.shields.io/badge/Meet%20us-blue.svg?style=for-the-badge&logo=calendly&logoColor=white">
</a>
<a href="https://forms.gle/5wHRctedMpgfNGah7" target="_blank">
<img alt="Cloud" src="https://img.shields.io/badge/Cloud-orange.svg?style=for-the-badge&logo=cloud&logoColor=white">
</a>
<a href="https://discord.gg/7Spn7C8A5F">
<img alt="Únete a nuestro Discord" src="https://img.shields.io/badge/Discord-7289DA.svg?style=for-the-badge&logo=discord&logoColor=white">
</a>
</p>
https://github.com/user-attachments/assets/1ebf78c9-94b2-468d-bbbb-566311df16fe
# 🕸️ ¿Por qué PySpur?
- 🖐️ **Arrastrar y Soltar**: Construye, prueba e itera en segundos.
- 🔄 **Bucles**: Llamadas iterativas a herramientas con memoria.
- 📤 **Carga de Archivos**: Sube archivos o pega URLs para procesar documentos.
- 📋 **Salidas Estructuradas**: Editor de interfaz para esquemas JSON.
- 🗃️ **RAG**: Analiza, segmenta, incrusta y actualiza datos en una base de datos vectorial.
- 🖼️ **Multimodal**: Soporte para video, imágenes, audio, textos y código.
- 🧰 **Herramientas**: Slack, Firecrawl.dev, Google Sheets, GitHub y más.
- 🧪 **Evaluaciones**: Evalúa agentes en conjuntos de datos del mundo real.
- 🚀 **Despliegue con un clic**: Publica como una API e intégrala donde desees.
- 🐍 **Basado en Python**: Agrega nuevos nodos creando un solo archivo Python.
- 🎛️ **Soporte para Cualquier Proveedor**: Más de 100 proveedores de LLM, embedders y bases de datos vectoriales.
# ⚡ Inicio Rápido
## Opción A: Usando el Paquete Python `pyspur`
Esta es la forma más rápida de comenzar. Se requiere Python 3.12 o superior.
1. **Instala PySpur:**
```sh
pip install pyspur
```
2. **Inicializa un nuevo proyecto:**
```sh
pyspur init my-project
cd my-project
```
Esto creará un nuevo directorio con un archivo `.env`.
3. **Inicia el servidor:**
```sh
pyspur serve --sqlite
```
Por defecto, esto iniciará la aplicación PySpur en `http://localhost:6080` utilizando una base de datos SQLite.
Se recomienda configurar una URL de instancia de Postgres en el archivo `.env` para obtener una experiencia más estable.
4. **[Opcional] Personaliza tu despliegue:**
Puedes personalizar tu despliegue de PySpur de dos maneras:
a. **A través de la aplicación** (Recomendado):
- Navega a la pestaña de API Keys en la aplicación
- Agrega tus claves API para varios proveedores (OpenAI, Anthropic, etc.)
- Los cambios se aplican inmediatamente
b. **Configuración Manual**:
- Edita el archivo `.env` en el directorio de tu proyecto
- Se recomienda configurar una base de datos Postgres en el archivo `.env` para mayor fiabilidad
- Reinicia la aplicación con `pyspur serve`. Agrega `--sqlite` si no estás utilizando Postgres
## Opción B: Usando Docker (Recomendado para sistemas escalables y en producción)
Esta es la forma recomendada para despliegues en producción:
1. **Instala Docker:**
Primero, instala Docker siguiendo la guía oficial de instalación para tu sistema operativo:
- [Docker para Linux](https://docs.docker.com/engine/install/)
- [Docker Desktop para Mac](https://docs.docker.com/desktop/install/mac-install/)
2. **Crea un Proyecto PySpur:**
Una vez instalado Docker, crea un nuevo proyecto PySpur con:
```sh
curl -fsSL https://raw.githubusercontent.com/PySpur-com/pyspur/main/start_pyspur_docker.sh | bash -s pyspur-project
```
Esto:
- Iniciará un nuevo proyecto PySpur en un directorio llamado `pyspur-project`
- Configurará los archivos de configuración necesarios
- Iniciará la aplicación PySpur automáticamente, respaldada por una instancia local de Postgres en Docker
3. **Accede a PySpur:**
Ve a `http://localhost:6080` en tu navegador.
4. **[Opcional] Personaliza tu despliegue:**
Puedes personalizar tu despliegue de PySpur de dos maneras:
a. **A través de la aplicación** (Recomendado):
- Navega a la pestaña de API Keys en la aplicación
- Agrega tus claves API para varios proveedores (OpenAI, Anthropic, etc.)
- Los cambios se aplican inmediatamente
b. **Configuración Manual**:
- Edita el archivo `.env` en el directorio de tu proyecto
- Reinicia los servicios con:
```sh
docker compose up -d
```
¡Eso es todo! Haz clic en "New Spur" para crear un flujo de trabajo, o comienza con una de las plantillas predefinidas.
# ✨ Beneficios Principales
## Depuración a Nivel de Nodo:
https://github.com/user-attachments/assets/6e82ad25-2a46-4c50-b030-415ea9994690
## Multimodal (Sube archivos o pega URLs)
PDFs, Videos, Audio, Imágenes, ...
https://github.com/user-attachments/assets/83ed9a22-1ec1-4d86-9dd6-5d945588fd0b
## Bucles
<img width="1919" alt="Bucles" src="https://github.com/user-attachments/assets/3aea63dc-f46f-46e9-bddd-e2af9c2a56bf" />
## RAG
### Paso 1) Crear Colección de Documentos (Segmentación + Análisis)
https://github.com/user-attachments/assets/c77723b1-c076-4a64-a01d-6d6677e9c60e
### Paso 2) Crear Índice Vectorial (Incrustación + Actualización en DB Vectorial)
https://github.com/user-attachments/assets/50e5c711-dd01-4d92-bb23-181a1c5bba25
## Bloques Modulares
https://github.com/user-attachments/assets/6442f0ad-86d8-43d9-aa70-e5c01e55e876
## Evaluar el Rendimiento Final
https://github.com/user-attachments/assets/4dc2abc3-c6e6-4d6d-a5c3-787d518de7ae
## Próximamente: Auto-mejora
https://github.com/user-attachments/assets/5bef7a16-ef9f-4650-b385-4ea70fa54c8a
# 🛠️ Configuración de Desarrollo de PySpur
#### [ Instrucciones para el desarrollo en sistemas tipo Unix. Desarrollo en Windows/PC no es soportado ]
Para el desarrollo, sigue estos pasos:
1. **Clona el repositorio:**
```sh
git clone https://github.com/PySpur-com/pyspur.git
cd pyspur
```
2. **Inicia utilizando docker-compose.dev.yml:**
```sh
docker compose -f docker-compose.dev.yml up --build -d
```
Esto iniciará una instancia local de PySpur con recarga en caliente habilitada para el desarrollo.
3. **Personaliza tu configuración:**
Edita el archivo `.env` para configurar tu entorno. Por defecto, PySpur utiliza una base de datos PostgreSQL local. Para usar una base de datos externa, modifica las variables `POSTGRES_*` en el archivo `.env`.
# ⭐ Apóyanos
¡Puedes apoyarnos en nuestro trabajo dándonos una estrella! ¡Gracias!

Tu retroalimentación será enormemente apreciada.
Por favor [dinos](mailto:[email protected]?subject=Feature%20Request&body=I%20want%20this%20feature%3Ai) qué características de esa lista te gustaría ver a continuación o solicita nuevas funcionalidades. | {
"source": "PySpur-Dev/pyspur",
"title": "README_ES.md",
"url": "https://github.com/PySpur-Dev/pyspur/blob/main/README_ES.md",
"date": "2024-09-23T17:24:52",
"stars": 2509,
"description": "AI Agent Builder in Python",
"file_size": 8144
} |

<p align="center"><strong>PySpur est un créateur d'agents d'IA en Python. Les ingénieurs en IA l'utilisent pour créer des agents, les exécuter étape par étape et inspecter les exécutions passées.</strong></p>
<p align="center">
<a href="./README.md"><img alt="README in English" src="https://img.shields.io/badge/English-blue"></a>
<a href="./README_CN.md"><img alt="简体中文版自述文件" src="https://img.shields.io/badge/简体中文-blue"></a>
<a href="./README_JA.md"><img alt="日本語のREADME" src="https://img.shields.io/badge/日本語-blue"></a>
<a href="./README_KR.md"><img alt="README in Korean" src="https://img.shields.io/badge/한국어-blue"></a>
<a href="./README_DE.md"><img alt="Deutsche Version der README" src="https://img.shields.io/badge/Deutsch-blue"></a>
<a href="./README_FR.md"><img alt="Version française du README" src="https://img.shields.io/badge/Français-blue"></a>
<a href="./README_ES.md"><img alt="Versión en español del README" src="https://img.shields.io/badge/Español-blue"></a>
</p>
<p align="center">
<a href="https://docs.pyspur.dev/" target="_blank">
<img alt="Documentation" src="https://img.shields.io/badge/Docs-green.svg?style=for-the-badge&logo=readthedocs&logoColor=white">
</a>
<a href="https://calendly.com/d/cnf9-57m-bv3/pyspur-founders" target="_blank">
<img alt="Rencontrez-nous" src="https://img.shields.io/badge/Meet%20us-blue.svg?style=for-the-badge&logo=calendly&logoColor=white">
</a>
<a href="https://forms.gle/5wHRctedMpgfNGah7" target="_blank">
<img alt="Cloud" src="https://img.shields.io/badge/Cloud-orange.svg?style=for-the-badge&logo=cloud&logoColor=white">
</a>
<a href="https://discord.gg/7Spn7C8A5F">
<img alt="Rejoignez notre Discord" src="https://img.shields.io/badge/Discord-7289DA.svg?style=for-the-badge&logo=discord&logoColor=white">
</a>
</p>
https://github.com/user-attachments/assets/1ebf78c9-94b2-468d-bbbb-566311df16fe
# 🕸️ Pourquoi PySpur ?
- 🖐️ **Glisser-déposer** : Créez, testez et itérez en quelques secondes.
- 🔄 **Boucles** : Appels d’outils itératifs avec mémoire.
- 📤 **Téléversement de fichiers** : Téléchargez des fichiers ou collez des URL pour traiter des documents.
- 📋 **Sorties structurées** : Éditeur d’interface utilisateur pour les schémas JSON.
- 🗃️ **RAG** : Analyser, découper, intégrer et insérer ou mettre à jour des données dans une base de données vectorielle.
- 🖼️ **Multimodal** : Support pour vidéos, images, audio, textes, code.
- 🧰 **Outils** : Slack, Firecrawl.dev, Google Sheets, GitHub, et plus encore.
- 🧪 **Évaluations** : Évaluez les agents sur des ensembles de données réelles.
- 🚀 **Déploiement en un clic** : Publiez en tant qu’API et intégrez-le où vous le souhaitez.
- 🐍 **Basé sur Python** : Ajoutez de nouveaux nœuds en créant un seul fichier Python.
- 🎛️ **Support multi-fournisseurs** : >100 fournisseurs de LLM, intégrateurs et bases de données vectorielles.
# ⚡ Démarrage rapide
## Option A : Utiliser le package Python `pyspur`
C'est la manière la plus rapide de commencer. Python 3.12 ou une version supérieure est requis.
1. **Installer PySpur :**
```sh
pip install pyspur
```
2. **Initialiser un nouveau projet :**
```sh
pyspur init my-project
cd my-project
```
Cela va créer un nouveau répertoire avec un fichier `.env`.
3. **Démarrer le serveur :**
```sh
pyspur serve --sqlite
```
Par défaut, cela démarrera l'application PySpur sur `http://localhost:6080` en utilisant une base de données SQLite.
Nous vous recommandons de configurer une URL d'instance Postgres dans le fichier `.env` pour une expérience plus stable.
4. **[Optionnel] Personnaliser votre déploiement :**
Vous pouvez personnaliser votre déploiement PySpur de deux façons :
a. **Via l'application** (Recommandé) :
- Naviguez vers l'onglet des clés API dans l'application
- Ajoutez vos clés API pour divers fournisseurs (OpenAI, Anthropic, etc.)
- Les modifications prennent effet immédiatement
b. **Configuration manuelle** :
- Éditez le fichier `.env` dans le répertoire de votre projet
- Il est recommandé de configurer une base de données Postgres dans le fichier `.env` pour une meilleure fiabilité
- Redémarrez l'application avec `pyspur serve`. Ajoutez `--sqlite` si vous n'utilisez pas Postgres
## Option B : Utiliser Docker (Recommandé pour des systèmes évolutifs en production)
C'est la méthode recommandée pour les déploiements en production :
1. **Installer Docker :**
Tout d'abord, installez Docker en suivant le guide d'installation officiel pour votre système d'exploitation :
- [Docker pour Linux](https://docs.docker.com/engine/install/)
- [Docker Desktop pour Mac](https://docs.docker.com/desktop/install/mac-install/)
2. **Créer un projet PySpur :**
Une fois Docker installé, créez un nouveau projet PySpur avec :
```sh
curl -fsSL https://raw.githubusercontent.com/PySpur-com/pyspur/main/start_pyspur_docker.sh | bash -s pyspur-project
```
Cela va :
- Démarrer un nouveau projet PySpur dans un nouveau répertoire nommé `pyspur-project`
- Configurer les fichiers de configuration nécessaires
- Démarrer automatiquement l'application PySpur avec une instance Docker Postgres locale
3. **Accéder à PySpur :**
Allez sur `http://localhost:6080` dans votre navigateur.
4. **[Optionnel] Personnaliser votre déploiement :**
a. **Via l'application** (Recommandé) :
- Naviguez vers l'onglet des clés API dans l'application
- Ajoutez vos clés API pour divers fournisseurs (OpenAI, Anthropic, etc.)
- Les modifications prennent effet immédiatement
b. **Configuration manuelle** :
- Éditez le fichier `.env` dans le répertoire de votre projet
- Redémarrez les services avec :
```sh
docker compose up -d
```
C'est tout ! Cliquez sur « New Spur » pour créer un workflow, ou commencez avec l'un des modèles de base.
# ✨ Avantages principaux
## Déboguer au niveau des nœuds :
https://github.com/user-attachments/assets/6e82ad25-2a46-4c50-b030-415ea9994690
## Multimodal (téléverser des fichiers ou coller des URL)
PDF, vidéos, audio, images, ...
https://github.com/user-attachments/assets/83ed9a22-1ec1-4d86-9dd6-5d945588fd0b
## Boucles
<img width="1919" alt="Loops" src="https://github.com/user-attachments/assets/3aea63dc-f46f-46e9-bddd-e2af9c2a56bf" />
## RAG
### Étape 1) Créer une collection de documents (découpage + analyse)
https://github.com/user-attachments/assets/c77723b1-c076-4a64-a01d-6d6677e9c60e
### Étape 2) Créer un index vectoriel (intégration + insertion/mise à jour dans la base de données vectorielle)
https://github.com/user-attachments/assets/50e5c711-dd01-4d92-bb23-181a1c5bba25
## Blocs modulaires
https://github.com/user-attachments/assets/6442f0ad-86d8-43d9-aa70-e5c01e55e876
## Évaluer la performance finale
https://github.com/user-attachments/assets/4dc2abc3-c6e6-4d6d-a5c3-787d518de7ae
## Bientôt : Auto-amélioration
https://github.com/user-attachments/assets/5bef7a16-ef9f-4650-b385-4ea70fa54c8a
# 🛠️ Configuration de développement de PySpur
#### [ Instructions pour le développement sur des systèmes de type Unix. Le développement sur Windows/PC n'est pas supporté ]
Pour le développement, suivez ces étapes :
1. **Cloner le dépôt :**
```sh
git clone https://github.com/PySpur-com/pyspur.git
cd pyspur
```
2. **Lancer en utilisant docker-compose.dev.yml :**
```sh
docker compose -f docker-compose.dev.yml up --build -d
```
Cela démarrera une instance locale de PySpur avec le rechargement à chaud activé pour le développement.
3. **Personnaliser votre configuration :**
Modifiez le fichier `.env` pour configurer votre environnement. Par défaut, PySpur utilise une base de données PostgreSQL locale. Pour utiliser une base de données externe, modifiez les variables `POSTGRES_*` dans le fichier `.env`.
# ⭐ Soutenez-nous
Vous pouvez nous soutenir en laissant une étoile ! Merci !

Vos retours seront grandement appréciés.
Veuillez nous [faire part](mailto:[email protected]?subject=Feature%20Request&body=I%20want%20this%20feature%3Ai) des fonctionnalités de cette liste que vous souhaitez voir prochainement ou proposer de toutes nouvelles fonctionnalités. | {
"source": "PySpur-Dev/pyspur",
"title": "README_FR.md",
"url": "https://github.com/PySpur-Dev/pyspur/blob/main/README_FR.md",
"date": "2024-09-23T17:24:52",
"stars": 2509,
"description": "AI Agent Builder in Python",
"file_size": 8411
} |

<p align="center"><strong>PySpurはPython製のAIエージェントビルダーです。AIエンジニアはこれを利用してエージェントを構築し、ステップバイステップで実行し、過去の実行結果を検証します。</strong></p>
<p align="center">
<a href="./README.md"><img alt="英語版README" src="https://img.shields.io/badge/English-blue"></a>
<a href="./README_CN.md"><img alt="简体中文版自述文件" src="https://img.shields.io/badge/简体中文-blue"></a>
<a href="./README_JA.md"><img alt="日本語のREADME" src="https://img.shields.io/badge/日本語-blue"></a>
<a href="./README_KR.md"><img alt="韓国語版README" src="https://img.shields.io/badge/한국어-blue"></a>
<a href="./README_DE.md"><img alt="ドイツ語版README" src="https://img.shields.io/badge/Deutsch-blue"></a>
<a href="./README_FR.md"><img alt="フランス語版README" src="https://img.shields.io/badge/Français-blue"></a>
<a href="./README_ES.md"><img alt="スペイン語版README" src="https://img.shields.io/badge/Español-blue"></a>
</p>
<p align="center">
<a href="https://docs.pyspur.dev/" target="_blank">
<img alt="ドキュメント" src="https://img.shields.io/badge/Docs-green.svg?style=for-the-badge&logo=readthedocs&logoColor=white">
</a>
<a href="https://calendly.com/d/cnf9-57m-bv3/pyspur-founders" target="_blank">
<img alt="お会いしましょう" src="https://img.shields.io/badge/Meet%20us-blue.svg?style=for-the-badge&logo=calendly&logoColor=white">
</a>
<a href="https://forms.gle/5wHRctedMpgfNGah7" target="_blank">
<img alt="クラウド" src="https://img.shields.io/badge/Cloud-orange.svg?style=for-the-badge&logo=cloud&logoColor=white">
</a>
<a href="https://discord.gg/7Spn7C8A5F">
<img alt="Discordに参加する" src="https://img.shields.io/badge/Discord-7289DA.svg?style=for-the-badge&logo=discord&logoColor=white">
</a>
</p>
https://github.com/user-attachments/assets/1ebf78c9-94b2-468d-bbbb-566311df16fe
# 🕸️ なぜ PySpur なのか?
- 🖐️ **ドラッグ&ドロップ**: 数秒で構築、テスト、反復できます。
- 🔄 **ループ**: メモリを活用した反復的なツール呼び出し。
- 📤 **ファイルアップロード**: ファイルのアップロードやURLの貼り付けによりドキュメントを処理します。
- 📋 **構造化された出力**: JSONスキーマ用のUIエディタ。
- 🗃️ **RAG**: データを解析、分割、埋め込み、そしてVector DBにアップサートします。
- 🖼️ **マルチモーダル**: ビデオ、画像、オーディオ、テキスト、コードに対応。
- 🧰 **ツール**: Slack、Firecrawl.dev、Google Sheets、GitHubなど多数。
- 🧪 **評価**: 実際のデータセットでエージェントを評価します。
- 🚀 **ワンクリックデプロイ**: APIとして公開し、どこにでも統合可能。
- 🐍 **Pythonベース**: 単一のPythonファイルを作成するだけで新しいノードを追加できます。
- 🎛️ **どのベンダーにも対応**: 100以上のLLMプロバイダー、エンベッダー、Vector DBに対応。
# ⚡ クイックスタート
## オプション A: `pyspur` Pythonパッケージの使用
これは最も迅速なスタート方法です。Python 3.12以上が必要です。
1. **PySpurのインストール:**
```sh
pip install pyspur
```
2. **新しいプロジェクトの初期化:**
```sh
pyspur init my-project
cd my-project
```
これにより、`.env`ファイルを含む新しいディレクトリが作成されます。
3. **サーバーの起動:**
```sh
pyspur serve --sqlite
```
デフォルトでは、SQLiteデータベースを使用して `http://localhost:6080` でPySpurアプリが起動します。より安定した動作を求める場合は、`.env`ファイルにPostgresのインスタンスURLを設定することを推奨します。
4. **[オプション] デプロイのカスタマイズ:**
PySpurのデプロイは以下の2通りの方法でカスタマイズできます:
a. **アプリ内から** (推奨):
- アプリ内の「APIキー」タブに移動する
- 各種プロバイダー(OpenAI、Anthropicなど)のAPIキーを追加する
- 変更は即座に反映される
b. **手動設定**:
- プロジェクトディレクトリ内の `.env` ファイルを編集する
- より信頼性を高めるために、`.env`でPostgresデータベースを設定することを推奨
- `pyspur serve` でアプリを再起動する。Postgresを使用していない場合は `--sqlite` を追加する
## オプション B: Dockerの利用(スケーラブルな本番システム向けに推奨)
本番環境でのデプロイにはこちらの方法を推奨します:
1. **Dockerのインストール:**
まず、お使いのOSに合わせた公式インストールガイドに従い、Dockerをインストールしてください:
- [Docker for Linux](https://docs.docker.com/engine/install/)
- [Docker Desktop for Mac](https://docs.docker.com/desktop/install/mac-install/)
2. **PySpurプロジェクトの作成:**
Dockerをインストールしたら、以下のコマンドで新しいPySpurプロジェクトを作成します:
```sh
curl -fsSL https://raw.githubusercontent.com/PySpur-com/pyspur/main/start_pyspur_docker.sh | bash -s pyspur-project
```
このコマンドは以下の処理を行います:
- `pyspur-project` という新しいディレクトリ内にPySpurプロジェクトを作成
- 必要な設定ファイルを構成
- ローカルのPostgres Dockerインスタンスをバックエンドに、PySpurアプリを自動で起動
3. **PySpurへのアクセス:**
ブラウザで `http://localhost:6080` にアクセスしてください。
4. **[オプション] デプロイのカスタマイズ:**
a. **アプリ内から** (推奨):
- アプリ内の「APIキー」タブに移動する
- 各種プロバイダー(OpenAI、Anthropicなど)のAPIキーを追加する
- 変更は即座に反映される
b. **手動設定**:
- プロジェクトディレクトリ内の `.env` ファイルを編集する
- 以下のコマンドでサービスを再起動する:
```sh
docker compose up -d
```
以上です!「New Spur」をクリックしてワークフローを作成するか、標準テンプレートから開始してください。
# ✨ 主な利点
## ノードレベルでのデバッグ:
https://github.com/user-attachments/assets/6e82ad25-2a46-4c50-b030-415ea9994690
## マルチモーダル(ファイルアップロードまたはURL貼り付け)
PDF、ビデオ、オーディオ、画像、…
https://github.com/user-attachments/assets/83ed9a22-1ec1-4d86-9dd6-5d945588fd0b
## ループ
<img width="1919" alt="Loops" src="https://github.com/user-attachments/assets/3aea63dc-f46f-46e9-bddd-e2af9c2a56bf" />
## RAG
### ステップ 1) ドキュメントコレクションの作成(チャンク分割+解析)
https://github.com/user-attachments/assets/c77723b1-c076-4a64-a01d-6d6677e9c60e
### ステップ 2) ベクターインデックスの作成(埋め込み+Vector DBアップサート)
https://github.com/user-attachments/assets/50e5c711-dd01-4d92-bb23-181a1c5bba25
## モジュール式ビルディングブロック
https://github.com/user-attachments/assets/6442f0ad-86d8-43d9-aa70-e5c01e55e876
## 最終パフォーマンスの評価
https://github.com/user-attachments/assets/4dc2abc3-c6e6-4d6d-a5c3-787d518de7ae
## 近日公開予定:自己改善
https://github.com/user-attachments/assets/5bef7a16-ef9f-4650-b385-4ea70fa54c8a
# 🛠️ PySpur 開発環境セットアップ
#### [ Unix系システムでの開発向けの手順です。Windows/PCでの開発はサポートされていません ]
開発のためには、以下の手順に従ってください:
1. **リポジトリのクローン:**
```sh
git clone https://github.com/PySpur-com/pyspur.git
cd pyspur
```
2. **docker-compose.dev.ymlを使用して起動:**
```sh
docker compose -f docker-compose.dev.yml up --build -d
```
これにより、開発用にホットリロードが有効なPySpurのローカルインスタンスが起動します。
3. **セットアップのカスタマイズ:**
環境設定のために `.env` ファイルを編集してください。デフォルトでは、PySpurはローカルのPostgreSQLデータベースを使用しています。外部データベースを使用する場合は、`.env` 内の `POSTGRES_*` 変数を変更してください.
# ⭐ サポート
スターを押していただくことで、私たちの活動をサポートしていただけます。ありがとうございます!

皆様のフィードバックを大変ありがたく思います。
次にどの機能を見たいか、または全く新しい機能のリクエストがあれば、ぜひ[お知らせください](mailto:[email protected]?subject=Feature%20Request&body=I%20want%20this%20feature%3Ai). | {
"source": "PySpur-Dev/pyspur",
"title": "README_JA.md",
"url": "https://github.com/PySpur-Dev/pyspur/blob/main/README_JA.md",
"date": "2024-09-23T17:24:52",
"stars": 2509,
"description": "AI Agent Builder in Python",
"file_size": 6011
} |

<p align="center"><strong>PySpur은 파이썬 기반의 AI 에이전트 빌더입니다. AI 엔지니어들은 이를 사용해 에이전트를 구축하고, 단계별로 실행하며 과거 실행 기록을 검토합니다.</strong></p>
<p align="center">
<a href="./README.md"><img alt="영문 README" src="https://img.shields.io/badge/English-blue"></a>
<a href="./README_CN.md"><img alt="简体中文版自述文件" src="https://img.shields.io/badge/简体中文-blue"></a>
<a href="./README_JA.md"><img alt="日本語のREADME" src="https://img.shields.io/badge/日本語-blue"></a>
<a href="./README_KR.md"><img alt="한국어 README" src="https://img.shields.io/badge/한국어-blue"></a>
<a href="./README_DE.md"><img alt="독일어 README" src="https://img.shields.io/badge/Deutsch-blue"></a>
<a href="./README_FR.md"><img alt="프랑스어 README" src="https://img.shields.io/badge/Français-blue"></a>
<a href="./README_ES.md"><img alt="스페인어 README" src="https://img.shields.io/badge/Español-blue"></a>
</p>
<p align="center">
<a href="https://docs.pyspur.dev/" target="_blank">
<img alt="문서" src="https://img.shields.io/badge/Docs-green.svg?style=for-the-badge&logo=readthedocs&logoColor=white">
</a>
<a href="https://calendly.com/d/cnf9-57m-bv3/pyspur-founders" target="_blank">
<img alt="만나기" src="https://img.shields.io/badge/Meet%20us-blue.svg?style=for-the-badge&logo=calendly&logoColor=white">
</a>
<a href="https://forms.gle/5wHRctedMpgfNGah7" target="_blank">
<img alt="클라우드" src="https://img.shields.io/badge/Cloud-orange.svg?style=for-the-badge&logo=cloud&logoColor=white">
</a>
<a href="https://discord.gg/7Spn7C8A5F">
<img alt="디스코드 참여" src="https://img.shields.io/badge/Discord-7289DA.svg?style=for-the-badge&logo=discord&logoColor=white">
</a>
</p>
https://github.com/user-attachments/assets/1ebf78c9-94b2-468d-bbbb-566311df16fe
# 🕸️ 왜 PySpur인가?
- 🖐️ **드래그 앤 드롭**: 몇 초 안에 구축, 테스트 및 반복 진행.
- 🔄 **루프**: 메모리를 활용한 반복적 도구 호출.
- 📤 **파일 업로드**: 파일을 업로드하거나 URL을 붙여넣어 문서를 처리.
- 📋 **구조화된 출력**: JSON 스키마용 UI 편집기.
- 🗃️ **RAG**: 데이터를 파싱, 청킹, 임베딩 및 벡터 DB에 업서트.
- 🖼️ **멀티모달**: 비디오, 이미지, 오디오, 텍스트, 코드 지원.
- 🧰 **도구**: Slack, Firecrawl.dev, Google Sheets, GitHub 등.
- 🧪 **평가**: 실제 데이터셋에서 에이전트 평가.
- 🚀 **원클릭 배포**: API로 발행하여 원하는 곳에 통합.
- 🐍 **파이썬 기반**: 단일 파이썬 파일 생성으로 새 노드 추가.
- 🎛️ **모든 벤더 지원**: 100개 이상의 LLM 제공업체, 임베더, 벡터 DB 지원.
# ⚡ 빠른 시작
## 옵션 A: `pyspur` 파이썬 패키지 사용
시작하는 가장 빠른 방법입니다. 파이썬 3.12 이상이 필요합니다.
1. **PySpur 설치:**
```sh
pip install pyspur
```
2. **새 프로젝트 초기화:**
```sh
pyspur init my-project
cd my-project
```
새 디렉토리와 함께 `.env` 파일이 생성됩니다.
3. **서버 시작:**
```sh
pyspur serve --sqlite
```
기본적으로 SQLite 데이터베이스를 사용하여 `http://localhost:6080`에서 PySpur 앱이 시작됩니다.
보다 안정적인 사용을 위해 `.env` 파일에 PostgreSQL 인스턴스 URL을 설정하는 것을 권장합니다.
4. **[선택 사항] 배포 맞춤 설정:**
PySpur 배포는 두 가지 방법으로 맞춤 설정할 수 있습니다:
a. **앱을 통한 설정** (권장):
- 앱의 API 키 탭으로 이동
- 다양한 제공업체(OpenAI, Anthropic 등)의 API 키를 추가
- 변경 사항이 즉시 적용됨
b. **수동 설정:**
- 프로젝트 디렉토리 내의 `.env` 파일을 수정
- 보다 안정적인 사용을 위해 `.env` 파일에 PostgreSQL 데이터베이스 설정을 권장
- PostgreSQL을 사용하지 않을 경우 `--sqlite` 옵션을 추가하여 `pyspur serve` 명령어로 앱을 재시작
## 옵션 B: Docker 사용 (확장 가능, 운영 환경에 적합)
운영 환경 배포에 권장되는 방법입니다:
1. **Docker 설치:**
먼저, 사용 중인 운영 체제에 맞는 공식 설치 가이드를 따라 Docker를 설치하세요:
- [Docker for Linux](https://docs.docker.com/engine/install/)
- [Docker Desktop for Mac](https://docs.docker.com/desktop/install/mac-install/)
2. **PySpur 프로젝트 생성:**
Docker 설치 후, 다음 명령어로 새로운 PySpur 프로젝트를 생성합니다:
```sh
curl -fsSL https://raw.githubusercontent.com/PySpur-com/pyspur/main/start_pyspur_docker.sh | bash -s pyspur-project
```
이 명령어는:
- `pyspur-project`라는 새 디렉토리에서 PySpur 프로젝트를 시작하고,
- 필요한 구성 파일들을 설정하며,
- 로컬 PostgreSQL Docker 인스턴스를 백엔드로 하여 PySpur 앱을 자동으로 시작합니다.
3. **PySpur 접속:**
브라우저에서 `http://localhost:6080`으로 접속합니다.
4. **[선택 사항] 배포 맞춤 설정:**
PySpur 배포는 두 가지 방법으로 맞춤 설정할 수 있습니다:
a. **앱을 통한 설정** (권장):
- 앱의 API 키 탭으로 이동
- 다양한 제공업체(OpenAI, Anthropic 등)의 API 키를 추가
- 변경 사항이 즉시 적용됨
b. **수동 설정:**
- 프로젝트 디렉토리 내의 `.env` 파일을 수정
- 다음 명령어로 서비스를 재시작:
```sh
docker compose up -d
```
이제 끝입니다! "New Spur"을 클릭하여 워크플로우를 생성하거나 기본 템플릿 중 하나로 시작하세요.
# ✨ 핵심 이점
## 노드 레벨에서 디버그:
https://github.com/user-attachments/assets/6e82ad25-2a46-4c50-b030-415ea9994690
## 멀티모달 (파일 업로드 또는 URL 붙여넣기)
PDF, 비디오, 오디오, 이미지, ...
https://github.com/user-attachments/assets/83ed9a22-1ec1-4d86-9dd6-5d945588fd0b
## 루프
<img width="1919" alt="Loops" src="https://github.com/user-attachments/assets/3aea63dc-f46f-46e9-bddd-e2af9c2a56bf" />
## RAG
### 1단계) 문서 컬렉션 생성 (청킹 + 파싱)
https://github.com/user-attachments/assets/c77723b1-c076-4a64-a01d-6d6677e9c60e
### 2단계) 벡터 인덱스 생성 (임베딩 + 벡터 DB 업서트)
https://github.com/user-attachments/assets/50e5c711-dd01-4d92-bb23-181a1c5bba25
## 모듈형 빌딩 블록
https://github.com/user-attachments/assets/6442f0ad-86d8-43d9-aa70-e5c01e55e876
## 최종 성능 평가
https://github.com/user-attachments/assets/4dc2abc3-c6e6-4d6d-a5c3-787d518de7ae
## 곧 추가될 기능: 자기 개선
https://github.com/user-attachments/assets/5bef7a16-ef9f-4650-b385-4ea70fa54c8a
# 🛠️ PySpur 개발 환경 설정
#### [ 유닉스 계열 시스템 개발 지침. Windows/PC 개발은 지원되지 않음 ]
개발을 위해 아래 단계를 따르세요:
1. **리포지토리 클론:**
```sh
git clone https://github.com/PySpur-com/pyspur.git
cd pyspur
```
2. **docker-compose.dev.yml 사용하여 실행:**
```sh
docker compose -f docker-compose.dev.yml up --build -d
```
이 명령어는 개발용 핫 리로딩이 활성화된 로컬 PySpur 인스턴스를 시작합니다.
3. **환경 설정 맞춤:**
환경 구성을 위해 `.env` 파일을 수정합니다. 기본적으로 PySpur는 로컬 PostgreSQL 데이터베이스를 사용합니다. 외부 데이터베이스를 사용하려면 `.env` 파일의 `POSTGRES_*` 변수를 수정하세요.
# ⭐ 지원해 주세요
별을 남겨 주셔서 저희의 작업을 지원하실 수 있습니다! 감사합니다!

여러분의 피드백은 큰 힘이 됩니다.
다음에 보고 싶은 기능이나 완전히 새로운 기능 요청이 있다면 [알려주세요](mailto:[email protected]?subject=Feature%20Request&body=I%20want%20this%20feature%3Ai). | {
"source": "PySpur-Dev/pyspur",
"title": "README_KR.md",
"url": "https://github.com/PySpur-Dev/pyspur/blob/main/README_KR.md",
"date": "2024-09-23T17:24:52",
"stars": 2509,
"description": "AI Agent Builder in Python",
"file_size": 5883
} |
# Development Container Configuration
[](https://codespaces.new/pyspur-dev/pyspur)
This directory contains configuration files for Visual Studio Code Dev Containers / GitHub Codespaces. Dev containers provide a consistent, isolated development environment for this project.
## Contents
- `devcontainer.json` - The main configuration file that defines the development container settings
- `Dockerfile` - Defines the container image and development environment
## Usage
### Prerequisites
- Visual Studio Code
- Docker installation:
- Docker Desktop (Windows/macOS)
- Docker Engine (Linux)
- [Remote - Containers](https://marketplace.visualstudio.com/items?itemName=ms-vscode-remote.remote-containers) extension for VS Code
### Getting Started
1. Open this project in Visual Studio Code
2. When prompted, click "Reopen in Container"
- Alternatively, press `F1` and select "Remote-Containers: Reopen in Container"
3. Wait for the container to build and initialize
4. Launch the application using:
```bash
dcup
```
5. Access the application (assuming the ports are forwarded as is to the host machine)
- Main application: http://localhost:6080
- Frontend development server: http://localhost:3000
- Backend API: http://localhost:8000
The development environment will be automatically configured with all necessary tools and extensions.
### Viewing Logs
You can monitor the application logs using these commands:
- View all container logs:
```bash
dlogs
```
- View backend logs only:
```bash
dlogb
```
- View frontend logs only:
```bash
dlogf
```
- View nginx logs only:
```bash
dlogn
```
All log commands show the last 5 minutes of logs and continue to tail new entries.
### Modifying the database schemas
1. **Stop Containers**
```bash
docker compose down
```
2. **Generate a Migration**
```bash
./generate_migrations.sh 002 <short_description_in_snake_case>
```
- Migration file appears in `./backend/app/models/management/alembic/versions/` with prefix `002_...`.
3. **Review the Generated Script**
- Open the file to ensure it has the intended changes.
4. **Apply the Migration**
```bash
docker compose down
docker compose up --build
```
- Alembic applies the new migration automatically on startup.
5. **Test the App**
- Confirm new tables/columns work as expected.
6. **Commit & Push**
```bash
git add .
git commit -m "Add migration 002 <description>"
git push origin <branch>
```
### Docker commands
```bash
docker compose down
docker compose up --build
```
## Customization
You can customize the development environment by:
- Modifying `devcontainer.json` to:
- Add VS Code extensions
- Set container-specific settings
- Configure environment variables
- Updating the `Dockerfile` to:
- Install additional packages
- Configure system settings
- Add development tools
## Troubleshooting
If you encounter issues:
1. Rebuild the container: `F1` → "Remote-Containers: Rebuild Container"
2. Check Docker logs for build errors
3. Verify Docker Desktop is running
4. Ensure all prerequisites are installed
For more information, see the [VS Code Remote Development documentation](https://code.visualstudio.com/docs/remote/containers). | {
"source": "PySpur-Dev/pyspur",
"title": ".devcontainer/README.md",
"url": "https://github.com/PySpur-Dev/pyspur/blob/main/.devcontainer/README.md",
"date": "2024-09-23T17:24:52",
"stars": 2509,
"description": "AI Agent Builder in Python",
"file_size": 3348
} |
# Mintlify Starter Kit
Click on `Use this template` to copy the Mintlify starter kit. The starter kit contains examples including
- Guide pages
- Navigation
- Customizations
- API Reference pages
- Use of popular components
### Development
Install the [Mintlify CLI](https://www.npmjs.com/package/mintlify) to preview the documentation changes locally. To install, use the following command
```
npm i -g mintlify
```
Run the following command at the root of your documentation (where mint.json is)
```
mintlify dev
```
### Publishing Changes
Install our Github App to auto propagate changes from your repo to your deployment. Changes will be deployed to production automatically after pushing to the default branch. Find the link to install on your dashboard.
#### Troubleshooting
- Mintlify dev isn't running - Run `mintlify install` it'll re-install dependencies.
- Page loads as a 404 - Make sure you are running in a folder with `mint.json` | {
"source": "PySpur-Dev/pyspur",
"title": "docs/README.md",
"url": "https://github.com/PySpur-Dev/pyspur/blob/main/docs/README.md",
"date": "2024-09-23T17:24:52",
"stars": 2509,
"description": "AI Agent Builder in Python",
"file_size": 956
} |
# Development
## Adding an NPM Package
You can add a package to `package.json` via your favorite package manager and the next time your Docker container gets built from scratch, it will install that package too.
### Adding to an Existing Docker Container
If you need to add a package to a running Docker container for immediate use, follow these steps:
1. Access the running container:
```sh
docker exec -it pyspur_dev-frontend-1 sh
```
2. Install the package:
```sh
npm install <package_name>
```
3. Restart the container to apply changes:
```sh
docker restart pyspur_dev-frontend-1
``` | {
"source": "PySpur-Dev/pyspur",
"title": "frontend/README.md",
"url": "https://github.com/PySpur-Dev/pyspur/blob/main/frontend/README.md",
"date": "2024-09-23T17:24:52",
"stars": 2509,
"description": "AI Agent Builder in Python",
"file_size": 597
} |
# Key Components
* `chunker.py`
* `embedder.py`
* `parser.py`
* `` | {
"source": "PySpur-Dev/pyspur",
"title": "backend/pyspur/rag/README.md",
"url": "https://github.com/PySpur-Dev/pyspur/blob/main/backend/pyspur/rag/README.md",
"date": "2024-09-23T17:24:52",
"stars": 2509,
"description": "AI Agent Builder in Python",
"file_size": 67
} |
# Datastore Module
This module is adapted from the [ChatGPT Retrieval Plugin datastore implementation](https://github.com/openai/chatgpt-retrieval-plugin/tree/main/datastore).
We considered using a Git submodule to include the original code, but decided against it for two main reasons:
1. Simplicity - Direct inclusion makes the codebase more straightforward to work with
2. Update Frequency - The original repository has infrequent updates, reducing the benefits of using a submodule
The code has been modified and integrated directly into this codebase while maintaining attribution to the original source. | {
"source": "PySpur-Dev/pyspur",
"title": "backend/pyspur/rag/datastore/README.md",
"url": "https://github.com/PySpur-Dev/pyspur/blob/main/backend/pyspur/rag/datastore/README.md",
"date": "2024-09-23T17:24:52",
"stars": 2509,
"description": "AI Agent Builder in Python",
"file_size": 613
} |
# **CHANGELOG - NeverSink's Filter 2**
----------------------------------
PoE2 is currently in an early access. As the game changes and adjusts you can expect large changes in the filter as well.
Suggestions and feedback is highly welcome! Please take a moment to write in our [DISCORD](https://discord.gg/zFEx92a).
Major thanks to all patreon supports to help us fund the continious development. [Patreon](https://www.patreon.com/Neversink) supporters.
----------------------------------
# **VERSION 0.52.0a** - Overseer's Tablets and adjustments
----------------------------------
## SHORT OVERVIEW:
This patch adresses changes in PoE2 patch 0.1.1 and also adds a bit of finetuning here and there.
Changed "Overseer's Precursor Tablet" to "Overseer Precursor Tablet"
## CHANGES:
- Changed
- Economy adjusted the tiering of some catalsts, currency, fragments etc
- Added the new "Overseer's Precursor Tablet"
- Reworked flasks and crafting sections slightlx to adjust for the new glassblower salvaging change
- Slightly retiered rare/crafting bases
- Slightly adjusted the tiering on some salvaging rules
----------------------------------
# **VERSION 0.52.0** - Overseer's Tablets and adjustments
----------------------------------
## SHORT OVERVIEW:
This patch adresses changes in PoE2 patch 0.1.1 and also adds a bit of finetuning here and there
## CHANGES:
- Economy adjusted the tiering of some catalsts, currency, fragments etc
- Added the new "Overseer's Precursor Tablet"
- Reworked flasks and crafting sections slightlx to adjust for the new glassblower salvaging change
- Slightly retiered rare/crafting bases
- Slightly adjusted the tiering on some salvaging rules
----------------------------------
# **VERSION 0.5.1** - Initial Public Version
----------------------------------
## SHORT OVERVIEW:
- Removed emerald ring from chancing list
- Iron Rune tier is hidden on Uber Plus Strict instead of Uber Strict now
- Added a section to highlight ilvl81+ siphoning and attuned normal wands for crafting, since these are in high demand right now.
- Fixed multiple dozens of bugs and small improvements for FilterBlade
----------------------------------
# **VERSION 0.5.0** - Initial Public Version
----------------------------------
Keep in mind this is just the initial release. The filter will be updated and improved over the days, weeks and hopefully years to come.
## SHORT OVERVIEW:
- The filter comes with a companion website: [FilterBlade.xyz](https://filterblade.xyz). FilterBlade allows modifying, previewing and customizing the filter to your needs and to your specific build. It's also a great way to learn what the filter can do and it's many features/colors.
- 7 levels of strictness ranging from soft to uber-plus-strict (semi-strict is recommended for beginners). These define the number of items hidden. A higher strictness filter shows fewer items. Very Strict or above should not be used while leveling, unless you're twinked out in leveling gear.
- Item colors, map icons and beams are clustered in a way to make item recognition really easy and minimize the cognitive efforts required to make good decisions. Plus due to the reuse of similar patterns it's good for your dopamin-on-drop-maxing.
- added first alternative style: Dark Mode
- the filter is written using a dedicated programming domain language to minimize errors, optimize performance, increase quality and make its management easier. This concept has been proven quite effective in the many years that I've been supporting PoE1.
- added the following economy based tierlists: currencies, runes, soul cores, catalysts, distilled emotions, essences, omen, fragments/tablets and others. Most bases come with 6 tiers (S,A,B,C,D,E) that are economically tiered and easily distinguishable
- uniques have their own tierlist, that is slightly different and has support for boss-drops and uniques with multiple bases. NOTE: in POE(2) you can't distinguish an specific unique on the same base. For instance the filter can't tell if a unique 'silk robe' is a 'cloak of flame' or a 'temporalis'.
- added neutral-basetype-tiering: a comprehensive tiering of every single basetype from the endgame's player perspective. In the future FilterBlade will provide the choice of the neutral and the meta-based basetype tiering. You'll also be able to mix and match those
- added rare and normal/magic crafting progression: the filter now scales the basetypes available depending on the map tier. For instance: in a level 68 zone a 'advanced dualstring bow' is still one of the best bases. However, in a level 80 zone it is quite poor, since new bases get unlocked
- added special highlight and treatment for bases in arealevel 82
- added campaign leveling mode. The shift between leveling and endgame happens at arealevel 65. Campaign and endgame is handled by the same filter.
- every single item type in the game is tiered or otherwise handled. If it's NOT known, the filter will notify you with a special PINK/CYAN color. If you see this color, you most likely should update the filter.
----------------------------------
# **SPECIAL THANKS:**
----------------------------------
- Tobnac/Haggis for their amazing contribution to the project development and support
- GGG for the awesome game with a special shoutout to Bex, Chris, Rory, Zeyra and Jatin for their assistance!
- A massive thank you to all the [PATREONS](https://www.patreon.com/Neversink), [DISCORD](https://discord.gg/zFEx92a) and [TWITCH](https://www.twitch.tv/neversink) community!
- The FilterBlade Team on discord - Abyxcos, Cdr, Mellontoss, Really Evil bunny, TarrasqueSorcerer, Thesenzei, VenomsAssassin
- The community (that includes you!) for using the filter and providing feedback and support! | {
"source": "NeverSinkDev/NeverSink-Filter-for-PoE2",
"title": "CHANGELOG.md",
"url": "https://github.com/NeverSinkDev/NeverSink-Filter-for-PoE2/blob/main/CHANGELOG.md",
"date": "2024-12-08T21:20:57",
"stars": 2483,
"description": "This is a lootfilter for the game \"Path of Exile 2\". It adds colors, sounds, map icons, beams to highlight remarkable gear and inform the user",
"file_size": 5769
} |
[](https://twitter.com/NeverSinkDev) [](https://discord.gg/zFEx92a) [](https://twitch.tv/neversink) [](https://www.patreon.com/Neversink)
## **QUICK START:**
This is an "ItemFilter" - a script for the game Path of Exile 2 (not PoE1!). It highlights valuable items, and enhances gameplay comfort and experience.
This is _NOT_ a hack/mod. It written using the official POE filter domain language.
This is my full filter for PoE2 and a successor to my initial lite-filter.

Feature highlights
- The filter comes with a companion website: [FilterBlade.xyz](https://filterblade.xyz). FilterBlade allows modifying, previewing and customizing the filter to your needs and to your specific build. It's also a great way to learn what the filter can do and its many features/colors.
- 7 levels of strictness ranging from soft to uber-plus-strict (semi-strict is recommended for beginners). These define the number of items hidden. A higher strictness filter shows fewer items. Very Strict or above should not be used while leveling, unless you're twinked out in leveling gear.
- Item colors, map icons and beams are clustered in a way to make item recognition really easy and minimize the cognitive efforts required to make good decisions. Plus due to the reuse of similar patterns it's good for your dopamin-on-drop-maxing.
- added first alternative style: Dark Mode
- the filter is written using a dedicated programming domain language to minimize errors, optimize performance, increase quality and make its management easier. This concept has been proven quite effective in the many years that I've been supporting PoE1.
- added the following economy based tierlists: currencies, runes, soul cores, catalysts, distilled emotions, essences, omen, fragments/tablets and others. Most bases come with 6 tiers (S,A,B,C,D,E) that are economically tiered and easily distinguishable
- uniques have their own tierlist, that is slightly different and has support for boss-drops and uniques with multiple bases. NOTE: in POE(2) you can't distinguish an specific unique on the same base. For instance the filter can't tell if a unique 'silk robe' is a 'cloak of flame' or a 'temporalis'.
- added neutral-basetype-tiering: a comprehensive tiering of every single basetype from the endgame's player perspective. In the future FilterBlade will provide the choice of the neutral and the meta-based basetype tiering. You'll also be able to mix and match those
- added rare and normal/magic crafting progression: the filter now scales the basetypes available depending on the map tier. For instance: in a level 68 zone a 'advanced dualstring bow' is still one of the best bases. However, in a level 80 zone it is quite poor, since new bases get unlocked
- added special highlight and treatment for bases in arealevel 82
- added campaign leveling mode. The shift between leveling and endgame happens at arealevel 65. Campaign and endgame is handled by the same filter.
- every single item type in the game is tiered or otherwise handled. If it's NOT known, the filter will notify you with a special PINK/CYAN color. If you see this color, you most likely should update the filter.
## **IMPORTANT: MUST READ:**
1. The filters in this GitHub project are ALWAYS updated before the start of a new league (4-6 hours before start). Afterwards, usually every few weeks.
2. The filters from this GitHub project do NOT auto-update. At least redownload the latest version once a league - better once a month - to stay up-to-date and not miss out on valuable drops! There is an auto-updater, read about it below.
3. Filters can't distinguish between different variations of one unique base! A unique "Leather Belt" can be an expensive "Headhunter" or a cheap "Wurm's Molt". The same goes for all unique jewels etc. Things that need manual checking usually have a blue icon on the minimap!
4. Join our [Discord Server](https://discord.gg/zFEx92a) to get updates and ask questions.
## **HOW TO INSTALL?**
Currently there are multiple sources:
Download the latest release from github.
- [FILTER LADDER](https://www.pathofexile.com/account/view-profile/NeverSink-3349/item-filters) - Are you new to the game and don't care about styles and finetuning the filter to your gameplay experience? I recommend subscribing to my filters on the ladder. It's just a click, fast and auto-updates. Just restart the game and select the subscribed filter in the options menu. The downside is that you can't edit these filters or use styles. Once you're more experienced consider:
- *[FILTERBLADE](https://www.filterblade.xyz)* - you can adjust the filter to your preferences here, change the appearance, style and finetune everything to your liking.
- We also offer a [FilterBlade Auto-Updater](https://www.youtube.com/watch?v=i8RJx0s0zsA), it's super comfy and you don't have to install anything, but heavy on our servers, so it costs a few bucks. Plus you support the project.
- You can also download the [LATEST RELEASE](https://github.com/NeverSinkDev/NeverSink-PoE2litefilter/releases/latest) from github. Note that it doesn't auto-update though and unlike my filterblade/ladder is not adjusted to match the economy perfectly.
0. Get the latest filter file from [GitHub](https://github.com/NeverSinkDev/NeverSink-PoE2litefilter/releases/latest).
1. Extract the files using 7zip or a similar tool.
2. Paste the `NeverSinks Litefilter.filter` file into the following folder (directly where ingame folder button opens - not a subfolder):
- NOTE: do NOT place it in the 'onlinefilters' folder in the directories below!
- Windows: `%userprofile%\Documents\My Games\Path of Exile 2`
- Linux: `steamapps/compatdata/2694490/pfx/drive_c/users/steamuser/My Documents/My Games/Path of Exile 2`
4. INGAME: Escape -> Options -> Game -> Filters -> Select the filter from the dropdown box.
5. Done. Enjoy.
## **SUPPORT:**
The filter itself will always be free, including updates.
Major thanks to all patreon support to help us fund the continious development. [Patreon](https://www.patreon.com/Neversink) supporters also receive a Patreon-exclusive [Filter-Auto-Updater](https://youtu.be/i8RJx0s0zsA). You can also [buy me a beer](https://www.paypal.com/cgi-bin/webscr?cmd=_s-xclick&hosted_button_id=6J3S7PBNDQGY2). Your support is appreciated. Thank you!
---
[](https://www.patreon.com/Neversink) | {
"source": "NeverSinkDev/NeverSink-Filter-for-PoE2",
"title": "README.md",
"url": "https://github.com/NeverSinkDev/NeverSink-Filter-for-PoE2/blob/main/README.md",
"date": "2024-12-08T21:20:57",
"stars": 2483,
"description": "This is a lootfilter for the game \"Path of Exile 2\". It adds colors, sounds, map icons, beams to highlight remarkable gear and inform the user",
"file_size": 6955
} |
# text-extract-api
Convert any image, PDF or Office document to Markdown *text* or JSON structured document with super-high accuracy, including tabular data, numbers or math formulas.
The API is built with FastAPI and uses Celery for asynchronous task processing. Redis is used for caching OCR results.

## Features:
- **No Cloud/external dependencies** all you need: PyTorch based OCR (EasyOCR) + Ollama are shipped and configured via `docker-compose` no data is sent outside your dev/server environment,
- **PDF/Office to Markdown** conversion with very high accuracy using different OCR strategies including [llama3.2-vision](https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/), [easyOCR](https://github.com/JaidedAI/EasyOCR), [minicpm-v](https://github.com/OpenBMB/MiniCPM-o?tab=readme-ov-file#minicpm-v-26), remote URL strategies including [marker-pdf](https://github.com/VikParuchuri/marker)
- **PDF/Office to JSON** conversion using Ollama supported models (eg. LLama 3.1)
- **LLM Improving OCR results** LLama is pretty good with fixing spelling and text issues in the OCR text
- **Removing PII** This tool can be used for removing Personally Identifiable Information out of document - see `examples`
- **Distributed queue processing** using [Celery](https://docs.celeryq.dev/en/stable/getting-started/introduction.html)
- **Caching** using Redis - the OCR results can be easily cached prior to LLM processing,
- **Storage Strategies** switchable storage strategies (Google Drive, Local File System ...)
- **CLI tool** for sending tasks and processing results
## Screenshots
Converting MRI report to Markdown + JSON.
```bash
python client/cli.py ocr_upload --file examples/example-mri.pdf --prompt_file examples/example-mri-2-json-prompt.txt
```
Before running the example see [getting started](#getting-started)

Converting Invoice to JSON and remove PII
```bash
python client/cli.py ocr_upload --file examples/example-invoice.pdf --prompt_file examples/example-invoice-remove-pii.txt
```
Before running the example see [getting started](#getting-started)

## Getting started
You might want to run the app directly on your machine for development purposes OR to use for example Apple GPUs (which are not supported by Docker at the moment).
### Prerequisites
To have it up and running please execute the following steps:
[Download and install Ollama](https://ollama.com/download)
[Download and install Docker](https://www.docker.com/products/docker-desktop/)
> ### Setting Up Ollama on a Remote Host
>
> To connect to an external Ollama instance, set the environment variable: `OLLAMA_HOST=http://address:port`, e.g.:
> ```bash
> OLLAMA_HOST=http(s)://127.0.0.1:5000
> ```
>
> If you want to disable the local Ollama model, use env `DISABLE_LOCAL_OLLAMA=1`, e.g.
> ```bash
> DISABLE_LOCAL_OLLAMA=1 make install
> ```
> **Note**: When local Ollama is disabled, ensure the required model is downloaded on the external instance.
>
> Currently, the `DISABLE_LOCAL_OLLAMA` variable cannot be used to disable Ollama in Docker. As a workaround, remove the `ollama` service from `docker-compose.yml` or `docker-compose.gpu.yml`.
>
> Support for using the variable in Docker environments will be added in a future release.
### Clone the Repository
First, clone the repository and change current directory to it:
```sh
git clone https://github.com/CatchTheTornado/text-extract-api.git
cd text-extract-api
```
### Setup with `Makefile`
Be default application create [virtual python env](https://docs.python.org/3/library/venv.html): `.venv`. You can disable this functionality on local setup by adding `DISABLE_VENV=1` before running script:
```bash
DISABLE_VENV=1 make install
```
```bash
DISABLE_VENV=1 make run
```
### Manual setup
Configure environment variables:
```bash
cp .env.localhost.example .env.localhost
```
You might want to just use the defaults - should be fine. After ENV variables are set, just execute:
```bash
python3 -m venv .venv
source .venv/bin/activate
pip install -e .
chmod +x run.sh
run.sh
```
This command will install all the dependencies - including Redis (via Docker, so it is not entirely docker free method of running `text-extract-api` anyways :)
(MAC) - Dependencies
```
brew update && brew install libmagic poppler pkg-config ghostscript ffmpeg automake autoconf
```
(Mac) - You need to startup the celery worker
```
source .venv/bin/activate && celery -A text_extract_api.celery_app worker --loglevel=info --pool=solo
```
Then you're good to go with running some CLI commands like:
```bash
python client/cli.py ocr_upload --file examples/example-mri.pdf --ocr_cache --prompt_file=examples/example-mri-remove-pii.txt
```
### Scaling the parallell processing
To have multiple tasks running at once - for concurrent processing please run the following command to start single worker process:
```bash
celery -A text_extract_api.tasks worker --loglevel=info --pool=solo & # to scale by concurrent processing please run this line as many times as many concurrent processess you want to have running
```
## Online demo
To try out the application with our hosted version you can skip the Getting started and try out the CLI tool against our cloud:
Open in the browser: <a href="https://demo.doctractor.com/">demo.doctractor.com</a>
... or run n the terminal:
```bash
python3 -m venv .venv
source .venv/bin/activate
pip install -e .
export OCR_UPLOAD_URL=https://doctractor:[email protected]/ocr/upload
export RESULT_URL=https://doctractor:[email protected]/ocr/result/
python client/cli.py ocr_upload --file examples/example-mri.pdf --ocr_cache --prompt_file=examples/example-mri-remove-pii.txt
```
[Demo Source code](https://github.com/CatchTheTornado/text-extract-api-demo)
**Note:** In the free demo we don't guarantee any processing times. The API is Open so please do **not send any secret documents neither any documents containing personal information**, If you do - you're doing it on your own risk and responsiblity.
<img src="screenshots/demo.png" alt="Demo screenshot" />
## Join us on Discord
In case of any questions, help requests or just feedback - please [join us on Discord](https://discord.gg/NJzu47Ye3a)!
## Text extract strategies
### `easyocr`
Easy OCR is available on Apache based license. It's general purpose OCR with support for more than 30 languages, probably with the best performance for English.
Enabled by default. Please do use the `strategy=easyocr` CLI and URL parameters to use it.
### `minicpm-v`
MiniCPM-V is an Apache based licensed OCR strategy.
The usage of MiniCPM-o/V model weights must strictly follow [MiniCPM Model License.md](https://github.com/OpenBMB/MiniCPM/blob/main/MiniCPM%20Model%20License.md).
The models and weights of MiniCPM are completely free for academic research. After filling out a ["questionnaire"](https://modelbest.feishu.cn/share/base/form/shrcnpV5ZT9EJ6xYjh3Kx0J6v8g) for registration, are also available for free commercial use.
Enabled by default. Please do use the `strategy=minicpm_v` CLI and URL parameters to use it.
| ⚠️ **Remember to pull the model in Ollama first** |
|---------------------------------------------------------|
| You need to pull the model in Ollama - use the command: |
| `python client/cli.py llm_pull --model minicpm-v` |
| Or, if you have Ollama locally: `ollama pull minicpm-v` |
### `llama_vision`
LLama 3.2 Vision Strategy is licensed on [Meta Community License Agreement](https://ollama.com/library/llama3.2-vision/blobs/0b4284c1f870). Works great for many languages, although due to the number of parameters (90b) this model is probably **the slowest** one.
Enabled by default. Please do use the `strategy=llama_vision` CLI and URL parameters to use it. It's by the way the default strategy
### `remote`
Some OCR's - like [Marker, state of the art PDF OCR](https://github.com/VikParuchuri/marker) - works really great for more than 50 languages, including great accuracy for Polish and other languages - let's say that are "diffult" to read for standard OCR.
The `marker-pdf` is however licensed on GPL3 license and **therefore it's not included** by default in this application (as we're bound to MIT).
The weights for the models are licensed cc-by-nc-sa-4.0, but I will waive that for any organization under $5M USD in gross revenue in the most recent 12-month period AND under $5M in lifetime VC/angel funding raised. You also must not be competitive with the Datalab API. If you want to remove the GPL license requirements (dual-license) and/or use the weights commercially over the revenue limit, check out the options here.
To have it up and running you can execute the following steps:
```bash
mkdir marker-distribution # this should be outside of the `text-extract-api` folder!
cd marker-distribution
pip install marker-pdf
pip install -U uvicorn fastapi python-multipart
marker_server --port 8002
```
Set the Remote API Url:
**Note: *** you might run `marker_server` on different port or server - then just make sure you export a proper env setting beffore starting off `text-extract-api` server:
```bash
export REMOTE_API_URL=http://localhost:8002/marker/upload
```
**Note: *** the URL might be also set via `/config/strategies.yaml` file
Run the `text-extract-api`:
```bash
make run
```
Please do use the `strategy=remote` CLI and URL parameters to use it. For example:
```bash
curl -X POST -H "Content-Type: multipart/form-data" -F "file=@examples/example-mri.pdf" -F "strategy=remote" -F "ocr_cache=true" -F "prompt=" -F "model=" "http://localhost:8000/ocr/upload"
```
We are connecting to remote OCR via it's API to not share the same license (GPL3) by having it all linked on the source code level.
## Getting started with Docker
### Prerequisites
- Docker
- Docker Compose
### Clone the Repository
```sh
git clone https://github.com/CatchTheTornado/text-extract-api.git
cd text-extract-api
```
### Using `Makefile`
You can use the `make install` and `make run` commands to set up the Docker environment for `text-extract-api`. You can find the manual steps required to do so described below.
### Manual setup
Create `.env` file in the root directory and set the necessary environment variables. You can use the `.env.example` file as a template:
```bash
# defaults for docker instances
cp .env.example .env
```
or
```bash
# defaults for local run
cp .env.example.localhost .env
```
Then modify the variables inside the file:
```bash
#APP_ENV=production # sets the app into prod mode, otherwise dev mode with auto-reload on code changes
REDIS_CACHE_URL=redis://localhost:6379/1
STORAGE_PROFILE_PATH=./storage_profiles
LLAMA_VISION_PROMPT="You are OCR. Convert image to markdown."
# CLI settings
OCR_URL=http://localhost:8000/ocr/upload
OCR_UPLOAD_URL=http://localhost:8000/ocr/upload
OCR_REQUEST_URL=http://localhost:8000/ocr/request
RESULT_URL=http://localhost:8000/ocr/result/
CLEAR_CACHE_URL=http://localhost:8000/ocr/clear_cache
LLM_PULL_API_URL=http://localhost:8000/llm_pull
LLM_GENERATE_API_URL=http://localhost:8000/llm_generate
CELERY_BROKER_URL=redis://localhost:6379/0
CELERY_RESULT_BACKEND=redis://localhost:6379/0
OLLAMA_HOST=http://localhost:11434
APP_ENV=development # Default to development mode
```
**Note:** In order to properly save the output files, you might need to modify `storage_profiles/default.yaml` to change the default storage path according to the volumes path defined in the `docker-compose.yml`
### Build and Run the Docker Containers
Build and run the Docker containers using Docker Compose:
```bash
docker-compose up --build
```
... for GPU support run:
```bash
docker-compose -f docker-compose.gpu.yml -p text-extract-api-gpu up --build
```
**Note:** While on Mac - Docker does not support Apple GPUs. In this case you might want to run the application natively without the Docker Compose please check [how to run it natively with GPU support](#getting-started)
This will start the following services:
- **FastAPI App**: Runs the FastAPI application.
- **Celery Worker**: Processes asynchronous OCR tasks.
- **Redis**: Caches OCR results.
- **Ollama**: Runs the Ollama model.
## Cloud - paid edition
If the on-prem is too much hassle [ask us about the hosted/cloud edition](mailto:[email protected]?subject=text-extract-api%20but%20hosted) of text-extract-api, we can setup it you, billed just for the usage.
## CLI tool
**Note**: While on Mac, you may need to create a virtual Python environment first:
```bash
python3 -m venv .venv
source .venv/bin/activate
# now you've got access to `python` and `pip` within your virutal env.
pip install -e . # install main project requirements
```
The project includes a CLI for interacting with the API. To make it work, first run:
```bash
cd client
pip install -e .
```
### Pull the LLama3.1 and LLama3.2-vision models
You might want to test out [different models supported by LLama](https://ollama.com/library)
```bash
python client/cli.py llm_pull --model llama3.1
python client/cli.py llm_pull --model llama3.2-vision
```
These models are required for most features supported by `text-extract-api`.
### Upload a File for OCR (converting to Markdown)
```bash
python client/cli.py ocr_upload --file examples/example-mri.pdf --ocr_cache
```
or alternatively
```bash
python client/cli.py ocr_request --file examples/example-mri.pdf --ocr_cache
```
The difference is just that the first call uses `ocr/upload` - multipart form data upload, and the second one is a request to `ocr/request` sending the file via base64 encoded JSON property - probable a better suit for smaller files.
### Upload a File for OCR (processing by LLM)
**Important note:** To use LLM you must first run the **llm_pull** to get the specific model required by your requests.
For example, you must run:
```bash
python client/cli.py llm_pull --model llama3.1
python client/cli.py llm_pull --model llama3.2-vision
```
and only after to run this specific prompt query:
```bash
python client/cli.py ocr_upload --file examples/example-mri.pdf --ocr_cache --prompt_file=examples/example-mri-remove-pii.txt --language en
```
**Note:** The language argument is used for the OCR strategy to load the model weights for the selected language. You can specify multiple languages as a list: `en,de,pl` etc.
The `ocr` command can store the results using the `storage_profiles`:
- **storage_profile**: Used to save the result - the `default` profile (`./storage_profiles/default.yaml`) is used by default; if empty file is not saved
- **storage_filename**: Outputting filename - relative path of the `root_path` set in the storage profile - by default a relative path to `/storage` folder; can use placeholders for dynamic formatting: `{file_name}`, `{file_extension}`, `{Y}`, `{mm}`, `{dd}` - for date formatting, `{HH}`, `{MM}`, `{SS}` - for time formatting
### Upload a File for OCR (processing by LLM), store result on disk
```bash
python client/cli.py ocr_upload --file examples/example-mri.pdf --ocr_cache --prompt_file=examples/example-mri-remove-pii.txt --storage_filename "invoices/{Y}/{file_name}-{Y}-{mm}-{dd}.md"
```
### Get OCR Result by Task ID
```bash
python client/cli.py result --task_id {your_task_id_from_upload_step}
```
### List file results archived by `storage_profile`
```bash
python client/cli.py list_files
```
to use specific (in this case `google drive`) storage profile run:
```bash
python client/cli.py list_files --storage_profile gdrive
```
### Load file result archived by `storage_profile`
```bash
python client/cli.py load_file --file_name "invoices/2024/example-invoice-2024-10-31-16-33.md"
```
### Delete file result archived by `storage_profile`
```bash
python client/cli.py delete_file --file_name "invoices/2024/example-invoice-2024-10-31-16-33.md" --storage_profile gdrive
```
or for default profile (local file system):
```bash
python client/cli.py delete_file --file_name "invoices/2024/example-invoice-2024-10-31-16-33.md"
```
### Clear OCR Cache
```bash
python client/cli.py clear_cache
```
### Test LLama
```bash
python llm_generate --prompt "Your prompt here"
```
## API Clients
You might want to use the dedicated API clients to use `text-extract-api`.
### Typescript
There's a dedicated API client for Typescript - [text-extract-api-client](https://github.com/CatchTheTornado/text-extract-api-client) and the `npm` package by the same name:
```bash
npm install text-extract-api-client
```
Usage:
```js
import { ApiClient, OcrRequest } from 'text-extract-api-client';
const apiClient = new ApiClient('https://api.doctractor.com/', 'doctractor', 'Aekie2ao');
const formData = new FormData();
formData.append('file', fileInput.files[0]);
formData.append('prompt', 'Convert file to JSON and return only JSON'); // if not provided, no LLM transformation will gonna happen - just the OCR
formData.append('strategy', 'llama_vision');
formData.append('model', 'llama3.1');
formData.append('ocr_cache', 'true');
apiClient.uploadFile(formData).then(response => {
console.log(response);
});
```
## Endpoints
### OCR Endpoint via File Upload / multiform data
- **URL**: /ocr/upload
- **Method**: POST
- **Parameters**:
- **file**: PDF, image or Office file to be processed.
- **strategy**: OCR strategy to use (`llama_vision`, `minicpm_v`, `remote` or `easyocr`). See the [available strategies](#text-extract-stratgies)
- **ocr_cache**: Whether to cache the OCR result (true or false).
- **prompt**: When provided, will be used for Ollama processing the OCR result
- **model**: When provided along with the prompt - this model will be used for LLM processing
- **storage_profile**: Used to save the result - the `default` profile (`./storage_profiles/default.yaml`) is used by default; if empty file is not saved
- **storage_filename**: Outputting filename - relative path of the `root_path` set in the storage profile - by default a relative path to `/storage` folder; can use placeholders for dynamic formatting: `{file_name}`, `{file_extension}`, `{Y}`, `{mm}`, `{dd}` - for date formatting, `{HH}`, `{MM}`, `{SS}` - for time formatting
- **language**: One or many (`en` or `en,pl,de`) language codes for the OCR to load the language weights
Example:
```bash
curl -X POST -H "Content-Type: multipart/form-data" -F "file=@examples/example-mri.pdf" -F "strategy=easyocr" -F "ocr_cache=true" -F "prompt=" -F "model=" "http://localhost:8000/ocr/upload"
```
### OCR Endpoint via JSON request
- **URL**: /ocr/request
- **Method**: POST
- **Parameters** (JSON body):
- **file**: Base64 encoded PDF file content.
- **strategy**: OCR strategy to use (`llama_vision`, `minicpm_v`, `remote` or `easyocr`). See the [available strategies](#text-extract-stratgies)
- **ocr_cache**: Whether to cache the OCR result (true or false).
- **prompt**: When provided, will be used for Ollama processing the OCR result.
- **model**: When provided along with the prompt - this model will be used for LLM processing.
- **storage_profile**: Used to save the result - the `default` profile (`/storage_profiles/default.yaml`) is used by default; if empty file is not saved.
- **storage_filename**: Outputting filename - relative path of the `root_path` set in the storage profile - by default a relative path to `/storage` folder; can use placeholders for dynamic formatting: `{file_name}`, `{file_extension}`, `{Y}`, `{mm}`, `{dd}` - for date formatting, `{HH}`, `{MM}`, `{SS}` - for time formatting.
- **language**: One or many (`en` or `en,pl,de`) language codes for the OCR to load the language weights
Example:
```bash
curl -X POST "http://localhost:8000/ocr/request" -H "Content-Type: application/json" -d '{
"file": "<base64-encoded-file-content>",
"strategy": "easyocr",
"ocr_cache": true,
"prompt": "",
"model": "llama3.1",
"storage_profile": "default",
"storage_filename": "example.md"
}'
```
### OCR Result Endpoint
- **URL**: /ocr/result/{task_id}
- **Method**: GET
- **Parameters**:
- **task_id**: Task ID returned by the OCR endpoint.
Example:
```bash
curl -X GET "http://localhost:8000/ocr/result/{task_id}"
```
### Clear OCR Cache Endpoint
- **URL**: /ocr/clear_cache
- **Method**: POST
Example:
```bash
curl -X POST "http://localhost:8000/ocr/clear_cache"
```
### Ollama Pull Endpoint
- **URL**: /llm/pull
- **Method**: POST
- **Parameters**:
- **model**: Pull the model you are to use first
Example:
```bash
curl -X POST "http://localhost:8000/llm/pull" -H "Content-Type: application/json" -d '{"model": "llama3.1"}'
```
### Ollama Endpoint
- **URL**: /llm/generate
- **Method**: POST
- **Parameters**:
- **prompt**: Prompt for the Ollama model.
- **model**: Model you like to query
Example:
```bash
curl -X POST "http://localhost:8000/llm/generate" -H "Content-Type: application/json" -d '{"prompt": "Your prompt here", "model":"llama3.1"}'
```
### List storage files:
- **URL:** /storage/list
- **Method:** GET
- **Parameters**:
- **storage_profile**: Name of the storage profile to use for listing files (default: `default`).
### Download storage file:
- **URL:** /storage/load
- **Method:** GET
- **Parameters**:
- **file_name**: File name to load from the storage
- **storage_profile**: Name of the storage profile to use for listing files (default: `default`).
### Delete storage file:
- **URL:** /storage/delete
- **Method:** DELETE
- **Parameters**:
- **file_name**: File name to load from the storage
- **storage_profile**: Name of the storage profile to use for listing files (default: `default`).
## Storage profiles
The tool can automatically save the results using different storage strategies and storage profiles. Storage profiles are set in the `/storage_profiles` by a yaml configuration files.
### Local File System
```yaml
strategy: local_filesystem
settings:
root_path: /storage # The root path where the files will be stored - mount a proper folder in the docker file to match it
subfolder_names_format: "" # eg: by_months/{Y}-{mm}/
create_subfolders: true
```
### Google Drive
```yaml
strategy: google_drive
settings:
## how to enable GDrive API: https://developers.google.com/drive/api/quickstart/python?hl=pl
service_account_file: /storage/client_secret_269403342997-290pbjjlb06nbof78sjaj7qrqeakp3t0.apps.googleusercontent.com.json
folder_id:
```
Where the `service_account_file` is a `json` file with authorization credentials. Please read on how to enable Google Drive API and prepare this authorization file [here](https://developers.google.com/drive/api/quickstart/python?hl=pl).
Note: Service Account is different account that the one you're using for Google workspace (files will not be visible in the UI)
### Amazon S3 - Cloud Object Storage
```yaml
strategy: aws_s3
settings:
bucket_name: ${AWS_S3_BUCKET_NAME}
region: ${AWS_REGION}
access_key: ${AWS_ACCESS_KEY_ID}
secret_access_key: ${AWS_SECRET_ACCESS_KEY}
```
#### Requirements for AWS S3 Access Key
1. **Access Key Ownership**
The access key must belong to an IAM user or role with permissions for S3 operations.
2. **IAM Policy Example**
The IAM policy attached to the user or role must allow the necessary actions. Below is an example of a policy granting access to an S3 bucket:
```json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:ListBucket",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::your-bucket-name",
"arn:aws:s3:::your-bucket-name/*"
]
}
]
}
```
Next, populate the appropriate `.env` file (e.g., .env, .env.localhost) with the required AWS credentials:
```bash
AWS_ACCESS_KEY_ID=your-access-key-id
AWS_SECRET_ACCESS_KEY=your-secret-access-key
AWS_REGION=your-region
AWS_S3_BUCKET_NAME=your-bucket-name
```
## License
This project is licensed under the MIT License. See the [LICENSE](LICENSE) file for details.
## Contact
In case of any questions please contact us at: [email protected] | {
"source": "CatchTheTornado/text-extract-api",
"title": "README.md",
"url": "https://github.com/CatchTheTornado/text-extract-api/blob/main/README.md",
"date": "2024-10-23T09:27:19",
"stars": 2411,
"description": "Document (PDF, Word, PPTX ...) extraction and parse API using state of the art modern OCRs + Ollama supported models. Anonymize documents. Remove PII. Convert any document or picture to structured JSON or Markdown",
"file_size": 24478
} |
# Acme Invoice Ltd
Invoice For John Doe 2048 Michigan Str Adress Line 2 601 Chicago, US
## Subject
From Acme Invoice Ltd Darrow Street 2 E1 7AW Portsoken London Invoice ID
INV/S/24/2024 17/09/2024 Issue Date PO Number 11/10/2024 Due Date
| Amount | | | |
|-----------------------|------------|--------|-------|
| Quantity | Unit Price | | |
| Description | 700.00 | 700.00 | |
| 1 | | | |
| iPhone 13 PRO MAX | 1 | 54.00 | 54.00 |
| Magic Mouse | 0.00 | | |
| 0.00 | | | |
| 0.00 | | | |
| 0.00 | | | |
| 754.00 | | | |
| Subtotal | 7% | | |
| Discount (0:25 = 25%) | 701.22 | | |
| Amount Due | | | |

NotesHere is the corrected text:
# Acme Invoice Ltd
Invoice For John Doe ANONYMIZED
2048 Michigan Str Adress Line 2
601 Chicago, US
## Subject
From Acme Invoice Ltd Darrow Street 2 E1 7AW Portsoken London
Invoice ID INV/S/24/2024 17/09/2024 Issue Date PO Number 11/10/2024 Due Date
| Amount | | | |
|-----------------------|------------|--------|-------|
| Quantity | Unit Price | | |
| Description | 700.00 | 700.00 | |
| 1 | | | |
| iPhone 13 PRO MAX | 1 | 54.00 | 54.00 |
| Magic Mouse | 0.00 | | |
| 0.00 | | | |
| 0.00 | | | |
| 0.00 | | | |
| 754.00 | | | |
| Subtotal | | | |
| Discount (7%) | 701.22 | | |
| Amount Due | | | |
**Notes**
(I removed the image reference and notes as they are not relevant to the invoice data)
Here is the corrected text with spelling issues fixed:
Now, I will convert this text to JSON according to the provided schema.
```json
{
"invoiceNumber": "INV/S/24/2024",
"date": "17/09/2024",
"dueDate": "11/10/2024",
"client": {
"clientName": "ANONYMIZED",
"clientAddress": "2048 Michigan Str Adress Line 2, 601 Chicago, US"
},
"items": [
{
"description": "iPhone 13 PRO MAX",
"quantity": 1,
"unitPrice": 54.00,
"total": 54.00
}
],
"subtotal": null,
"tax": null,
"total": null
}
```
However, I noticed that there are missing fields in the provided text (e.g., subtotal, tax, total). Also, there is no clear indication of the client's email or phone number. If this information exists elsewhere in the document (which was not provided), please let me know and I'll be happy to assist further.
Here is a more complete JSON representation based on the given text:
```json
{
"invoiceNumber": "INV/S/24/2024",
"date": "17/09/2024",
"dueDate": "11/10/2024",
"client": {
"clientName": "ANONYMIZED",
"clientAddress": "2048 Michigan Str Adress Line 2, 601 Chicago, US"
},
"items": [
{
"description": "iPhone 13 PRO MAX",
"quantity": 1,
"unitPrice": 54.00,
"total": 54.00
}
],
"subtotal": 701.22,
"tax": "7%",
"total": 754.00
}
``` | {
"source": "CatchTheTornado/text-extract-api",
"title": "examples/example-invoice-remove-pii.md",
"url": "https://github.com/CatchTheTornado/text-extract-api/blob/main/examples/example-invoice-remove-pii.md",
"date": "2024-10-23T09:27:19",
"stars": 2411,
"description": "Document (PDF, Word, PPTX ...) extraction and parse API using state of the art modern OCRs + Ollama supported models. Anonymize documents. Remove PII. Convert any document or picture to structured JSON or Markdown",
"file_size": 3586
} |
| Maywood, NJ 0000 |
|--------------------|
# Ikengil Radiology Associates
DikengilRadiologyAssociates.com | 201-725-0913 Phil Referrer, M. D.
0 Maywood Ave.
## Clinical History:
| RE: Jane, Mary; 55 F |
|------------------------|
| Acct #: 00002 |
| DOB: 00/00/1966 |
| Study: Brain MRI |
| DOS: 04/29/2021 |

55 year old female with intermittent, positional headaches.
## Technique:
Noncontrast MRI of the brain was performed in the three orthogonal planes utilizing T1/T2/T2 FLAIR/T2* GRE/Diffusion-ADC sequences. Findings:
The lateral, third and fourth ventricles are normal in volume and configuration with intact symmetry.
There is no diffusion signal abnormality. The gradient echo sequence reveals no evidence of susceptibility related intra-axial signal dropoff or blooming artifact.
The gray—white matter signal intensities and interface are normal.
There is no evidence of intra-or extra-axial mass lesion. There is no evidence of infarct, premature iron deposition or abnormal hemosiderin cllection.
Posterior fossa sections reveal pointed descent of the cerebellar tonsils with estimated 10 mm inferior migration below the foramen magnum
(McRae line) characterizing a moderately advanced Chiari I
malformation likely to be symptomatic at this degree. There is moderate crowding of the foramen magnum. There is no additional morphologic or signal abnormality of the cerebellar hemispheres or the brain stem structures. Cisternal–intracanalicular segments of CN7/8 are unremarkable.
There are no abnormal extra-axial fluid collections except for a mildly prominent CSF signal intensity empty sella and prominent midline superior vermian cistern.
Calvarium, skull base and the visualized paranasal sinuses are unremarkable.
## Conclusion:
Chiari I malformation with 10 mm descent of cerebellar tonsils.
Asim G Dikengil, M. D.Here is the corrected text and spelling issues:
Maywood, NJ 07607 |
|--------------------|
# Ikenga Radiology Associates
IkengaRadiologyAssociates.com | (201) 725-0913 Phil Referrer, MD.
0 Maywood Ave.
## Clinical History:
| RE: Jane, Mary; 55 F |
|------------------------|
| Acct #: 00002 |
| DOB: 06/00/1966 |
| Study: Brain MRI |
| DOS: 04/29/2021 |

55-year-old female with intermittent, positional headaches.
## Technique:
Noncontrast MRI of the brain was performed in the three orthogonal planes utilizing T1/T2/T2 FLAIR/T2* GRE/Diffusion-ADC sequences. Findings:
The lateral, third, and fourth ventricles are normal in volume and configuration with intact symmetry.
There is no diffusion signal abnormality. The gradient echo sequence reveals no evidence of susceptibility-related intra-axial signal dropoff or blooming artifact.
The gray-white matter signal intensities and interface are normal.
There is no evidence of intra-or extra-axial mass lesion. There is no evidence of infarct, premature iron deposition, or abnormal hemosiderin collection.
Posterior fossa sections reveal pointed descent of the cerebellar tonsils with estimated 10 mm inferior migration below the foramen magnum (McRae line) characterizing a moderately advanced Chiari I malformation likely to be symptomatic at this degree. There is moderate crowding of the foramen magnum. There is no additional morphologic or signal abnormality of the cerebellar hemispheres or the brain stem structures. Cisternal-intracanalicular segments of CN7/8 are unremarkable.
There are no abnormal extra-axial fluid collections except for a mildly prominent CSF signal intensity empty sella and prominent midline superior vermian cistern.
Calvarium, skull base, and the visualized paranasal sinuses are unremarkable.
## Conclusion:
Chiari I malformation with 10 mm descent of cerebellar tonsils.
Asim G Dikengil, MD.
And here is the JSON object:
```json
{
"patientName": "Jane Mary",
"dateOfBirth": "1966-06-00",
"bloodType": null,
"allergies": [],
"conditions": [
{
"name": "Chiari I malformation"
}
],
"medications": [],
"emergencyContact": {
"name": "Phil Referrer",
"title": "MD.",
"phone": "(201) 725-0913",
"email": "IkengaRadiologyAssociates.com"
},
"clinicalHistory": [
{
"studyType": "Brain MRI",
"dateOfStudy": "2021-04-29",
"age": 55,
"sex": "F",
"chiefComplaint": "intermittent, positional headaches"
}
],
"diagnosis": [
{
"description": "Chiari I malformation with 10 mm descent of cerebellar tonsils."
}
]
}
``` | {
"source": "CatchTheTornado/text-extract-api",
"title": "examples/example-mri-result.md",
"url": "https://github.com/CatchTheTornado/text-extract-api/blob/main/examples/example-mri-result.md",
"date": "2024-10-23T09:27:19",
"stars": 2411,
"description": "Document (PDF, Word, PPTX ...) extraction and parse API using state of the art modern OCRs + Ollama supported models. Anonymize documents. Remove PII. Convert any document or picture to structured JSON or Markdown",
"file_size": 4604
} |
# Changelog
All notable changes to this project will be documented in this file.
<!-- ignore lint rules that are often triggered by content generated from commits / git-cliff -->
<!-- markdownlint-disable line-length no-bare-urls ul-style emphasis-style -->
## [0.10.6](https://github.com/alexpasmantier/television/releases/tag/0.10.6) - 2025-02-08
### 🐛 Bug Fixes
- [8e38ffc](https://github.com/alexpamantier/television/commit/8e38ffc3ab52414df29d8310e3f7a5b66bb2be6c) *(clipboard)* Gracefully fail if clipboard isn't available by @alexpasmantier in [#350](https://github.com/alexpasmantier/television/pull/350)
- [df2592f](https://github.com/alexpamantier/television/commit/df2592f2c8aa6edbea0e46a319435e27b8998859) *(events)* Remove sorting and deduplicating incoming actions by @alexpasmantier in [#356](https://github.com/alexpasmantier/television/pull/356)
### 🚜 Refactor
- [7f87b2f](https://github.com/alexpamantier/television/commit/7f87b2fb31db239b4e534e29989b4286f6a7d052) *(cable)* Use HISTFILE for bash and zsh history channels by @alexpasmantier in [#357](https://github.com/alexpasmantier/television/pull/357)
- [b706dcb](https://github.com/alexpamantier/television/commit/b706dcb8ddef8b93dca8de21b5e605360b9b8f07) *(help)* Add multiselect keybindings to help panel by @alexpasmantier in [#353](https://github.com/alexpasmantier/television/pull/353)
- [86c100e](https://github.com/alexpamantier/television/commit/86c100e381b00033f4ae57c53e2070be367333d7) *(ui)* Display current channel in input bar border by @alexpasmantier in [#354](https://github.com/alexpasmantier/television/pull/354)
### 📚 Documentation
- [ade69d7](https://github.com/alexpamantier/television/commit/ade69d7bfff109141ab0709b4feabc66973c582f) *(uncategorized)* Update readme by @alexpasmantier
- [d40a86d](https://github.com/alexpamantier/television/commit/d40a86daa281aaa16ef61017f3dad6d899105ed8) *(uncategorized)* Update readme by @alexpasmantier
### ⚙️ Miscellaneous Tasks
- [1e44478](https://github.com/alexpamantier/television/commit/1e44478147e6d0aa8f320f0b15cd8e4ff4d2f0f9) *(changelog)* Update changelog (auto) by @github-actions[bot] in [#349](https://github.com/alexpasmantier/television/pull/349)
- [11e440c](https://github.com/alexpamantier/television/commit/11e440c151ef02abc9aed52059c1b648d161ffb5) *(deb)* Add arm64 deb packaging to cd by @alexpasmantier in [#351](https://github.com/alexpasmantier/television/pull/351)
- [bb727bd](https://github.com/alexpamantier/television/commit/bb727bd070597c60f2750678e9d2cf589ff6f754) *(glibc)* Packaging for older linux distros by @alexpasmantier
- [56be4dc](https://github.com/alexpamantier/television/commit/56be4dca4f71a21ead8dc50a97e0036ab3ce7b0b) *(winget)* Update winget release configuration by @alexpasmantier
- [28f62f1](https://github.com/alexpamantier/television/commit/28f62f138dd47c9f0ef3ca33f2daa17a8e9eb909) *(uncategorized)* Bump to 0.10.6 by @alexpasmantier
**Full Changelog**: https://github.com/alexpasmantier/television/compare/0.10.5...0.10.6
## [0.10.5](https://github.com/alexpasmantier/television/releases/tag/0.10.5) - 2025-02-07
### 🐛 Bug Fixes
- [4eead98](https://github.com/alexpamantier/television/commit/4eead98fae18cfc4146def7a776fe4497e1cbc59) *(windows)* Bypass mouse capture disabling on windows by @alexpasmantier in [#348](https://github.com/alexpasmantier/television/pull/348)
### ⚙️ Miscellaneous Tasks
- [fd8bf61](https://github.com/alexpamantier/television/commit/fd8bf6100963baaf6967cbf983a9ee620effbd4f) *(cd)* Automatically bump winget-pkgs registered version by @kachick in [#340](https://github.com/alexpasmantier/television/pull/340)
- [0d5f394](https://github.com/alexpamantier/television/commit/0d5f39408279539431f79af3fccc5414e958e50d) *(changelog)* Update changelog (auto) by @github-actions[bot] in [#336](https://github.com/alexpasmantier/television/pull/336)
- [5d552d1](https://github.com/alexpamantier/television/commit/5d552d1655de46255e6ab62cc8c446bf37ba717d) *(uncategorized)* Bump to 0.10.5 by @alexpasmantier
### New Contributors
* @dependabot[bot] made their first contribution in [#345](https://github.com/alexpasmantier/television/pull/345)
**Full Changelog**: https://github.com/alexpasmantier/television/compare/0.10.4...0.10.5
## [0.10.4](https://github.com/alexpasmantier/television/releases/tag/0.10.4) - 2025-02-02
### 🚜 Refactor
- [8881842](https://github.com/alexpamantier/television/commit/888184235891313cbc3114344d6935e43cb66725) *(shell)* More default shell integration triggers by @alexpasmantier in [#335](https://github.com/alexpasmantier/television/pull/335)
- [a6a73c5](https://github.com/alexpamantier/television/commit/a6a73c5bb3b23339dfb96538a10f728bb61e1c2d) *(shell)* Improve shell integration configuration syntax by @alexpasmantier in [#334](https://github.com/alexpasmantier/television/pull/334)
### ⚙️ Miscellaneous Tasks
- [c74b47d](https://github.com/alexpamantier/television/commit/c74b47d07caf12efaf073c16f2177607171c573e) *(changelog)* Update changelog (auto) by @github-actions[bot] in [#330](https://github.com/alexpasmantier/television/pull/330)
- [eaafe40](https://github.com/alexpamantier/television/commit/eaafe40cfbb7dbf906dad24756a7b2070be33a32) *(uncategorized)* Bump to 0.10.4 by @alexpasmantier
**Full Changelog**: https://github.com/alexpasmantier/television/compare/0.10.3...0.10.4
## [0.10.3](https://github.com/alexpasmantier/television/releases/tag/0.10.3) - 2025-01-31
### 🚜 Refactor
- [5214dd1](https://github.com/alexpamantier/television/commit/5214dd17d0c9b82409dbd81358beb7afc6e28be2) *(app)* Buffering actions and events handling to improve overall UI responsiveness by @alexpasmantier in [#328](https://github.com/alexpasmantier/television/pull/328)
- [be80496](https://github.com/alexpamantier/television/commit/be804965491b65714613ace52419b9fbb821b9b0) *(draw)* Clearing out mut operations from rendering critical path, avoiding mutexes and perf improvements by @alexpasmantier in [#322](https://github.com/alexpasmantier/television/pull/322)
### ⚙️ Miscellaneous Tasks
- [eaab4e9](https://github.com/alexpamantier/television/commit/eaab4e966baf1d5dbe83230e4b145ee64fe1b5be) *(changelog)* Update changelog (auto) by @github-actions[bot] in [#320](https://github.com/alexpasmantier/television/pull/320)
- [6955c5b](https://github.com/alexpamantier/television/commit/6955c5b31357088db4debf202ca99cf303866e7d) *(uncategorized)* Bump to 0.10.3 by @alexpasmantier in [#329](https://github.com/alexpasmantier/television/pull/329)
**Full Changelog**: https://github.com/alexpasmantier/television/compare/0.10.2...0.10.3
## [0.10.2](https://github.com/alexpasmantier/television/releases/tag/0.10.2) - 2025-01-26
### 🐛 Bug Fixes
- [f536156](https://github.com/alexpamantier/television/commit/f536156e7e959fc043dcd972162411bc34b6bc89) *(config)* Add serde default for shell integration configuration by @alexpasmantier in [#319](https://github.com/alexpasmantier/television/pull/319)
### 📚 Documentation
- [4b632f8](https://github.com/alexpamantier/television/commit/4b632f81f8754b59def555099165d0face28e3c1) *(changelog)* Update changelog template by @alexpasmantier in [#317](https://github.com/alexpasmantier/television/pull/317)
### ⚙️ Miscellaneous Tasks
- [f9f0277](https://github.com/alexpamantier/television/commit/f9f0277184304f6ddc2d6cb88193273ac8513a5a) *(changelog)* Update changelog (auto) by @github-actions[bot] in [#316](https://github.com/alexpasmantier/television/pull/316)
- [a03da82](https://github.com/alexpamantier/television/commit/a03da82c56bab5e1e6ed644b82ce8a220a3a6847) *(uncategorized)* Bump to 0.10.2 by @alexpasmantier
**Full Changelog**: https://github.com/alexpasmantier/television/compare/0.10.1...0.10.2
## [0.10.1](https://github.com/alexpasmantier/television/releases/tag/0.10.1) - 2025-01-26
### 🐛 Bug Fixes
- [82f471d](https://github.com/alexpamantier/television/commit/82f471d0aa01285ce82dfb19ab5c81b4b9d1f562) *(cli)* Re-enable clap help feature by @alexpasmantier in [#315](https://github.com/alexpasmantier/television/pull/315)
### ⚙️ Miscellaneous Tasks
- [eede078](https://github.com/alexpamantier/television/commit/eede07871503b66ad56dbbc66d3f11d491564519) *(changelog)* Update changelog (auto) by @github-actions[bot] in [#312](https://github.com/alexpasmantier/television/pull/312)
- [5271b50](https://github.com/alexpamantier/television/commit/5271b507a04af992f49ef04871abc8edeb5e0b81) *(terminal)* Custom shell keybindings by @bertrand-chardon in [#313](https://github.com/alexpasmantier/television/pull/313)
**Full Changelog**: https://github.com/alexpasmantier/television/compare/0.10.0...0.10.1
## [0.10.0](https://github.com/alexpasmantier/television/releases/tag/0.10.0) - 2025-01-25
### ⛰️ Features
- [37b71b7](https://github.com/alexpamantier/television/commit/37b71b7a881aa634f67c0a051eea5d8a23f66a8b) *(i18n)* Improve support for non-western scripts by @bertrand-chardon in [#305](https://github.com/alexpasmantier/television/pull/305)
### 🐛 Bug Fixes
- [c710904](https://github.com/alexpamantier/television/commit/c7109044f05dfc967a487ba4583269d3b7b049a5) *(stdout)* Never quote selected entries by @bertrand-chardon in [#307](https://github.com/alexpasmantier/television/pull/307)
- [cb565d6](https://github.com/alexpamantier/television/commit/cb565d667edeeb629c34f10b50b4a0e78682f643) *(uncategorized)* Add repaint command to the fish shell scripts by @jscarrott in [#303](https://github.com/alexpasmantier/television/pull/303)
### 🚜 Refactor
- [1e8c8db](https://github.com/alexpamantier/television/commit/1e8c8dbc963c4796b4720ad69e4572c5e881981c) *(uncategorized)* Simplify configuration and build code + leaner crate by @alexpasmantier in [#308](https://github.com/alexpasmantier/television/pull/308)
### ⚡ Performance
- [172ba23](https://github.com/alexpamantier/television/commit/172ba231eec45b2bff30e80eeca2ccb54504cc01) *(async)* Make overall UI much smoother and snappier by @alexpasmantier in [#311](https://github.com/alexpasmantier/television/pull/311)
### ⚙️ Miscellaneous Tasks
- [4dc7c71](https://github.com/alexpamantier/television/commit/4dc7c7129f923f937778f66cb512d303fc4df16f) *(changelog)* Update changelog (auto) by @github-actions[bot] in [#294](https://github.com/alexpasmantier/television/pull/294)
- [7a54e5a](https://github.com/alexpamantier/television/commit/7a54e5a50711f5122f7731863afb85db96816494) *(uncategorized)* Bump to 0.10.0 by @alexpasmantier
- [3970f65](https://github.com/alexpamantier/television/commit/3970f65946ed2753a1ab0841ea01b45ab23b3fba) *(uncategorized)* Flatten workspace into a single crate by @alexpasmantier in [#306](https://github.com/alexpasmantier/television/pull/306)
- [5750531](https://github.com/alexpamantier/television/commit/5750531cb2bac6a39aae3348bfc8362a4830fdab) *(uncategorized)* Add zip format in a Windows release assets by @kachick in [#298](https://github.com/alexpasmantier/television/pull/298)
### New Contributors
* @jscarrott made their first contribution in [#303](https://github.com/alexpasmantier/television/pull/303)
* @kachick made their first contribution in [#298](https://github.com/alexpasmantier/television/pull/298)
**Full Changelog**: https://github.com/alexpasmantier/television/compare/0.9.4...0.10.0
## [0.9.4](https://github.com/alexpasmantier/television/releases/tag/0.9.4) - 2025-01-20
### 🐛 Bug Fixes
- [8bbebf7](https://github.com/alexpamantier/television/commit/8bbebf7e57600d9f03c607a000188a784728ca11) *(syntect)* Switch back to oniguruma while investigating parsing issues by @alexpasmantier in [#292](https://github.com/alexpasmantier/television/pull/292)
### ⚙️ Miscellaneous Tasks
- [3d97394](https://github.com/alexpamantier/television/commit/3d973947abeb85312c58f77d146f2a3ae4cb4a09) *(changelog)* Update changelog (auto) by @github-actions[bot] in [#288](https://github.com/alexpasmantier/television/pull/288)
- [40c97c9](https://github.com/alexpamantier/television/commit/40c97c9c4c5086092f2cfc1bf58b5081e7292f20) *(uncategorized)* Bump workspace to 0.9.4 by @alexpasmantier in [#293](https://github.com/alexpasmantier/television/pull/293)
**Full Changelog**: https://github.com/alexpasmantier/television/compare/0.9.3...0.9.4
## [0.9.3](https://github.com/alexpasmantier/television/releases/tag/0.9.3) - 2025-01-19
### ⛰️ Features
- [6c3bede](https://github.com/alexpamantier/television/commit/6c3bede3ca2473d0a9e9d9bd2bc0b42ea9cadbd6) *(preview)* Add support for displaying nerd fonts in preview by @alexpasmantier in [#286](https://github.com/alexpasmantier/television/pull/286)
### 🐛 Bug Fixes
- [c227b2a](https://github.com/alexpamantier/television/commit/c227b2a20137f615123af5d8d8991d93d8080329) *(cable)* Cable channels now take precedence over builtins for the cli / shell integration by @alexpasmantier in [#278](https://github.com/alexpasmantier/television/pull/278)
### 🚜 Refactor
- [1934d3f](https://github.com/alexpamantier/television/commit/1934d3f03f4e0398357e1975777670e3e922cabc) *(uncategorized)* Exit application on SIGINT / C-c by @alexpasmantier in [#274](https://github.com/alexpasmantier/television/pull/274)
### 📚 Documentation
- [d68ae21](https://github.com/alexpamantier/television/commit/d68ae21630bfcfff96b283700a2058d1d44a1f3f) *(readme)* Link to nucleo directly by @archseer in [#266](https://github.com/alexpasmantier/television/pull/266)
### ⚡ Performance
- [a3dc819](https://github.com/alexpamantier/television/commit/a3dc8196aa5199bedfd62b640c4020a92df9d9d7) *(preview)* Add partial preview rendering and buffer preview requests by @alexpasmantier in [#285](https://github.com/alexpasmantier/television/pull/285)
### ⚙️ Miscellaneous Tasks
- [01a25ac](https://github.com/alexpamantier/television/commit/01a25ac84623df62e574a3d44cd077224fa6685f) *(changelog)* Update changelog (auto) by @github-actions[bot] in [#265](https://github.com/alexpasmantier/television/pull/265)
- [a43ed22](https://github.com/alexpamantier/television/commit/a43ed226668d9f2cc1078c66b1e31571ccb22e72) *(uncategorized)* Bump workspace to 0.9.3 by @alexpasmantier in [#287](https://github.com/alexpasmantier/television/pull/287)
### New Contributors
* @archseer made their first contribution in [#266](https://github.com/alexpasmantier/television/pull/266)
**Full Changelog**: https://github.com/alexpasmantier/television/compare/0.9.2...0.9.3
## [0.9.2](https://github.com/alexpasmantier/television/releases/tag/0.9.2) - 2025-01-09
### 🐛 Bug Fixes
- [9433fea](https://github.com/alexpamantier/television/commit/9433fea80df9f6277114d2c27795c35450ad7880) *(cable)* Filter out non-utf8 lines when loading cable candidates by @alexpasmantier in [#263](https://github.com/alexpasmantier/television/pull/263)
### ⚙️ Miscellaneous Tasks
- [510b528](https://github.com/alexpamantier/television/commit/510b52858800cc2b813b21030e9266b0028b1c0a) *(changelog)* Update changelog (auto) by @github-actions[bot] in [#261](https://github.com/alexpasmantier/television/pull/261)
- [1a4dae9](https://github.com/alexpamantier/television/commit/1a4dae9bd82f284e86ef6e83e07b47dda6e3908f) *(uncategorized)* Bump to 0.9.2 by @alexpasmantier
**Full Changelog**: https://github.com/alexpasmantier/television/compare/0.9.1...0.9.2
## [0.9.1](https://github.com/alexpasmantier/television/releases/tag/0.9.1) - 2025-01-09
### ⛰️ Features
- [d9ca7b1](https://github.com/alexpamantier/television/commit/d9ca7b1f9d7460593b3adeac042a50ee3a03649c) *(cable)* Allow custom cable channels to override builtins by @alexpasmantier in [#260](https://github.com/alexpasmantier/television/pull/260)
- [ea8b955](https://github.com/alexpamantier/television/commit/ea8b955e6d34eade1f83de41805cbab6b7eb6335) *(cli)* Add `no-preview` flag to disable the preview pane by @alexpasmantier in [#258](https://github.com/alexpasmantier/television/pull/258)
### 🐛 Bug Fixes
- [b388a56](https://github.com/alexpamantier/television/commit/b388a56745f4ad63ded1ebe5f296241695892c4b) *(fish)* Don't add extra space to prompt if it's an implicit cd (`\.`) by @alexpasmantier in [#259](https://github.com/alexpasmantier/television/pull/259)
### 🚜 Refactor
- [3b7fb0c](https://github.com/alexpamantier/television/commit/3b7fb0c6d6e73a6558a99648c5269ae458ab9404) *(cable)* Stream in cable results + better error logging + default delimiter consistency by @alexpasmantier in [#257](https://github.com/alexpasmantier/television/pull/257)
- [b5e9846](https://github.com/alexpamantier/television/commit/b5e9846e1b5f62a757057c5403768e20ff3e7f69) *(providers)* Improve cable provider files loading sequence by @alexpasmantier in [#254](https://github.com/alexpasmantier/television/pull/254)
### ⚙️ Miscellaneous Tasks
- [ef26d32](https://github.com/alexpamantier/television/commit/ef26d326f4f29d01bf9a2087fac7878a7ccbc3db) *(changelog)* Update changelog (auto) by @github-actions[bot] in [#251](https://github.com/alexpasmantier/television/pull/251)
- [d00d8e4](https://github.com/alexpamantier/television/commit/d00d8e4f84511c3c8c8c3c0ef2634ca671c7c0bd) *(uncategorized)* Bump to 0.9.1 by @alexpasmantier
**Full Changelog**: https://github.com/alexpasmantier/television/compare/0.9.0...0.9.1
## [0.9.0](https://github.com/alexpasmantier/television/releases/tag/0.9.0) - 2025-01-07
### ⛰️ Features
- [76bff30](https://github.com/alexpamantier/television/commit/76bff30759612094635cd06366b6eaa240867488) *(cable)* Add default git diff cable channel by @alexpasmantier in [#226](https://github.com/alexpasmantier/television/pull/226)
- [e2398ab](https://github.com/alexpamantier/television/commit/e2398abcfa6d368389456b79723d87842ee5e33f) *(channels)* Allow sending currently selected entries to other channels by @alexpasmantier in [#235](https://github.com/alexpasmantier/television/pull/235)
- [2e5f65b](https://github.com/alexpamantier/television/commit/2e5f65baefd7ce10dcb6aa85fd41158f86c6dfcd) *(channels)* Add support for multi selection by @alexpasmantier in [#234](https://github.com/alexpasmantier/television/pull/234)
- [3bd2bb4](https://github.com/alexpamantier/television/commit/3bd2bb44bd3ab0d4a3423cdb1df3133ed0f4bf84) *(uncategorized)* Add support for CJK unified ideographs by @alexpasmantier in [#243](https://github.com/alexpasmantier/television/pull/243)
### 🐛 Bug Fixes
- [1c00dec](https://github.com/alexpamantier/television/commit/1c00dece942f09d749699a5d22467b9c279ad950) *(ansi)* Catch implicit reset escape sequences by @alexpasmantier in [#245](https://github.com/alexpasmantier/television/pull/245)
- [a2a264c](https://github.com/alexpamantier/television/commit/a2a264cc4d7868d31c35ff10912e790cd790262d) *(ingestion)* Use lossy conversion when source doesn't produce valid utf8 by @alexpasmantier in [#240](https://github.com/alexpasmantier/television/pull/240)
### ⚡ Performance
- [8b5beee](https://github.com/alexpamantier/television/commit/8b5beee1dc3da153d0e4a2c9a9e85ff8540e15d8) *(uncategorized)* Drop deduplication when loading cable candidate lines by @alexpasmantier in [#248](https://github.com/alexpasmantier/television/pull/248)
- [072ecdb](https://github.com/alexpamantier/television/commit/072ecdba73b4e6677f0ce5d313a45a327df44eed) *(uncategorized)* Only display the first 200 log entries when previewing git-repos by @alexpasmantier in [#241](https://github.com/alexpasmantier/television/pull/241)
- [0624002](https://github.com/alexpamantier/television/commit/0624002f350d2df0b3aed83c2a8a1b9426757687) *(uncategorized)* Use FxHash instead of SipHash where it makes sense by @alexpasmantier in [#237](https://github.com/alexpasmantier/television/pull/237)
### ⚙️ Miscellaneous Tasks
- [59bdcaa](https://github.com/alexpamantier/television/commit/59bdcaa278638c97e3ebd469be93d683c15c57fe) *(changelog)* Update changelog (auto) by @github-actions[bot] in [#244](https://github.com/alexpasmantier/television/pull/244)
- [7cd0a9d](https://github.com/alexpamantier/television/commit/7cd0a9d1b75ecfa9e449e0f8cdcc2663ac9f8d5b) *(changelog)* Update changelog (auto) by @github-actions[bot] in [#225](https://github.com/alexpasmantier/television/pull/225)
- [da2396e](https://github.com/alexpamantier/television/commit/da2396e19a73ed6b042a78bf037ca7d2894f8946) *(linting)* Add workspace lints by @xosxos in [#228](https://github.com/alexpasmantier/television/pull/228)
- [853da49](https://github.com/alexpamantier/television/commit/853da494255dcc34d71a6281eee5c353c83bec62) *(uncategorized)* Bump to 0.9.0 by @alexpasmantier in [#249](https://github.com/alexpasmantier/television/pull/249)
- [d207848](https://github.com/alexpamantier/television/commit/d20784891fc034cf401bcfc6f5f522582d5a8f98) *(uncategorized)* Fix linting warnings by @alexpasmantier in [#230](https://github.com/alexpasmantier/television/pull/230)
### New Contributors
* @xosxos made their first contribution in [#228](https://github.com/alexpasmantier/television/pull/228)
**Full Changelog**: https://github.com/alexpasmantier/television/compare/0.8.8...0.9.0
## [0.8.8](https://github.com/alexpasmantier/television/releases/tag/0.8.8) - 2025-01-06
### ⛰️ Features
- [d7e6c35](https://github.com/alexpamantier/television/commit/d7e6c357357d59152eb198c0d18697d5591ff397) *(ui)* Add support for standard ANSI colors theming and update default theme by @alexpasmantier in [#221](https://github.com/alexpasmantier/television/pull/221)
- [53bd4a3](https://github.com/alexpamantier/television/commit/53bd4a38159edfec4db7d80813a3cf51a36fb491) *(ui)* Add new `television` theme that inherits the terminal bg by @alexpasmantier in [#220](https://github.com/alexpasmantier/television/pull/220)
- [931a7bb](https://github.com/alexpamantier/television/commit/931a7bb5c35d992b53f8c4aeee87b66ee9ab14f9) *(ui)* Make background color optional and fallback to terminal default bg color by @alexpasmantier in [#219](https://github.com/alexpasmantier/television/pull/219)
### 🐛 Bug Fixes
- [88b08b7](https://github.com/alexpamantier/television/commit/88b08b798e5acd39077048ef14e5f33d25067d87) *(cable)* Zsh-history and bash-history cable channels now point to default histfiles locations by @alexpasmantier in [#224](https://github.com/alexpasmantier/television/pull/224)
### 🚜 Refactor
- [3d49d30](https://github.com/alexpamantier/television/commit/3d49d308c1e2d8c1020bdf27e75bb69cd20e2235) *(cable)* More debug information for cable channels by @alexpasmantier in [#223](https://github.com/alexpasmantier/television/pull/223)
- [074889b](https://github.com/alexpamantier/television/commit/074889b43fc36d036b067e90a7977a2fd6b519d3) *(ux)* Don't print the list of available channels on channel parsing error by @alexpasmantier in [#222](https://github.com/alexpasmantier/television/pull/222)
### 📚 Documentation
- [21fb3cb](https://github.com/alexpamantier/television/commit/21fb3cb53cff24b4f30041014c4fa9aa018ba360) *(uncategorized)* Add shell autocompletion GIF to the README by @alexpasmantier
### ⚙️ Miscellaneous Tasks
- [b1309af](https://github.com/alexpamantier/television/commit/b1309af25f0b5c6741f16b6ef90e084ac2cb9dd8) *(changelog)* Update changelog (auto) by @github-actions[bot] in [#218](https://github.com/alexpasmantier/television/pull/218)
- [6536bbf](https://github.com/alexpamantier/television/commit/6536bbf32389682b3783a277d176e5e2f4421e60) *(uncategorized)* Bump to 0.8.8 by @alexpasmantier
**Full Changelog**: https://github.com/alexpasmantier/television/compare/0.8.7...0.8.8
## [0.8.7](https://github.com/alexpasmantier/television/releases/tag/0.8.7) - 2025-01-04
### 🐛 Bug Fixes
- [3e5f0a4](https://github.com/alexpamantier/television/commit/3e5f0a44a3405826b599de35f9901dfe4fc86351) *(unix)* Use sed instead of tail for bash and zsh default history channels by @alexpasmantier in [#216](https://github.com/alexpasmantier/television/pull/216)
### 🚜 Refactor
- [657af5e](https://github.com/alexpamantier/television/commit/657af5e36d82f7e819c592f7dbc2a2c9a41a067d) *(cable)* Always create default cable channels in user directory if no cable channels exist by @alexpasmantier in [#213](https://github.com/alexpasmantier/television/pull/213)
- [124c06c](https://github.com/alexpamantier/television/commit/124c06c403b019438bbd60663eef48fb8172557c) *(config)* Check for config file existence before processing subcommands by @alexpasmantier in [#214](https://github.com/alexpasmantier/television/pull/214)
- [971a2e7](https://github.com/alexpamantier/television/commit/971a2e7697d888a09f21fb50a2684e6162ac6329) *(shell)* Use $HISTFILE for cable history channels by @alexpasmantier in [#210](https://github.com/alexpasmantier/television/pull/210)
### ⚙️ Miscellaneous Tasks
- [8089657](https://github.com/alexpamantier/television/commit/80896578b4f49e346fa5c680d3a486b90d8ec527) *(changelog)* Update changelog (auto) by @github-actions[bot] in [#206](https://github.com/alexpasmantier/television/pull/206)
- [25adee3](https://github.com/alexpamantier/television/commit/25adee34d8ce35f512cc641c4fc0529545fd2af0) *(uncategorized)* Bump to 0.8.7 by @alexpasmantier in [#217](https://github.com/alexpasmantier/television/pull/217)
### New Contributors
* @tangowithfoxtrot made their first contribution in [#208](https://github.com/alexpasmantier/television/pull/208)
**Full Changelog**: https://github.com/alexpasmantier/television/compare/0.8.6...0.8.7
## [0.8.6](https://github.com/alexpasmantier/television/releases/tag/0.8.6) - 2025-01-01
### 🐛 Bug Fixes
- [bff7068](https://github.com/alexpamantier/television/commit/bff70687814b6dfa682e737d3eec74a918229eb2) *(uncategorized)* Nix build by @tukanoidd in [#203](https://github.com/alexpasmantier/television/pull/203)
- [741ce30](https://github.com/alexpamantier/television/commit/741ce30b080b462cf8938661ee630a2136b565c5) *(uncategorized)* Automatically create configuration and data directories if they don't exist by @tulilirockz in [#204](https://github.com/alexpasmantier/television/pull/204)
### ⚙️ Miscellaneous Tasks
- [314aa93](https://github.com/alexpamantier/television/commit/314aa93a4592626cfff56957a62f12f3575d53ae) *(changelog)* Update changelog (auto) by @github-actions[bot] in [#202](https://github.com/alexpasmantier/television/pull/202)
- [df936dd](https://github.com/alexpamantier/television/commit/df936dd4ebed89d1e7c0fc81892e8230e22aea49) *(uncategorized)* Bump to 0.8.6 by @alexpasmantier
### New Contributors
* @tulilirockz made their first contribution in [#204](https://github.com/alexpasmantier/television/pull/204)
**Full Changelog**: https://github.com/alexpasmantier/television/compare/0.8.5...0.8.6
## [0.8.5](https://github.com/alexpasmantier/television/releases/tag/0.8.5) - 2024-12-31
### ⛰️ Features
- [2acfc41](https://github.com/alexpamantier/television/commit/2acfc41ceb9654e3bb1bf28a51bd9afc2b395293) *(ui)* Respect BAT_THEME env var for previewer syntax highlighting theme by @alexpasmantier in [#201](https://github.com/alexpasmantier/television/pull/201)
### 🐛 Bug Fixes
- [a74dece](https://github.com/alexpamantier/television/commit/a74deceb982970ae38b6b9052ed65b0deb14c00c) *(shell)* Add space if needed when using smart autocomplete by @alexpasmantier in [#200](https://github.com/alexpasmantier/television/pull/200)
### 📚 Documentation
- [0382ff8](https://github.com/alexpamantier/television/commit/0382ff81b6e0753448cbfbb94c3ff11ae0253eb3) *(config)* Fix typo in default configuration file comment by @alexpasmantier in [#198](https://github.com/alexpasmantier/television/pull/198)
- [690e88d](https://github.com/alexpamantier/television/commit/690e88dd1a0ba58d34b1c0db0cfae7577d385df8) *(uncategorized)* Move parts of README to Wiki by @bertrand-chardon in [#199](https://github.com/alexpasmantier/television/pull/199)
### ⚙️ Miscellaneous Tasks
- [d2bf172](https://github.com/alexpamantier/television/commit/d2bf172f4b029f8eb8b0eaafe4fa556acc93a32b) *(changelog)* Update changelog (auto) by @github-actions[bot] in [#197](https://github.com/alexpasmantier/television/pull/197)
- [8cae592](https://github.com/alexpamantier/television/commit/8cae59256d0e43a2bf2d1c3ad7db438a9b98a9d8) *(uncategorized)* Bump to 0.8.5 by @alexpasmantier
**Full Changelog**: https://github.com/alexpasmantier/television/compare/0.8.4...0.8.5
## [0.8.4](https://github.com/alexpasmantier/television/releases/tag/0.8.4) - 2024-12-31
### ⛰️ Features
- [343ed3c](https://github.com/alexpamantier/television/commit/343ed3c126c11452a467cbcaae77bfcf53cd937c) *(ux)* Automatically create default user configuration file if nonexistent by @alexpasmantier in [#196](https://github.com/alexpasmantier/television/pull/196)
### 🐛 Bug Fixes
- [1899873](https://github.com/alexpamantier/television/commit/1899873680987f797f41dfc682483a4a26ec82b3) *(channels)* List-channels in kebab-case by @fannheyward in [#195](https://github.com/alexpasmantier/television/pull/195)
### ⚙️ Miscellaneous Tasks
- [76da8b0](https://github.com/alexpamantier/television/commit/76da8b0a5b76d07ae36fe0f972a6f5de549d58a0) *(changelog)* Update changelog (auto) by @github-actions[bot]
- [430e325](https://github.com/alexpamantier/television/commit/430e3255675139d70a11b1e272d08effb7967ae3) *(uncategorized)* Bump version to 0.8.4 by @alexpasmantier
### New Contributors
* @fannheyward made their first contribution in [#195](https://github.com/alexpasmantier/television/pull/195)
**Full Changelog**: https://github.com/alexpasmantier/television/compare/0.8.3...0.8.4
## [0.8.3](https://github.com/alexpasmantier/television/releases/tag/0.8.3) - 2024-12-30
### 🐛 Bug Fixes
- [26036dd](https://github.com/alexpamantier/television/commit/26036dd0b9663e3aafd2442009b4ff700e841a7a) *(uncategorized)* Bump version to match with the release by @chenrui333 in [#188](https://github.com/alexpasmantier/television/pull/188)
### ⚡ Performance
- [b552657](https://github.com/alexpamantier/television/commit/b552657926eeac37de24fae5684b1f758fc23f72) *(bin)* Compile binary as a single code unit and use fat LTO by @alexpasmantier in [#191](https://github.com/alexpasmantier/television/pull/191)
### ⚙️ Miscellaneous Tasks
- [9b0129a](https://github.com/alexpamantier/television/commit/9b0129a8d899c83bc3230cfc36c2266c49b407a8) *(changelog)* Update changelog (auto) by @github-actions[bot] in [#187](https://github.com/alexpasmantier/television/pull/187)
- [0c5da2a](https://github.com/alexpamantier/television/commit/0c5da2a0c3e72361300b09e03cd2a9fed1619401) *(uncategorized)* Bump to 0.8.3 by @alexpasmantier in [#192](https://github.com/alexpasmantier/television/pull/192)
- [53afed2](https://github.com/alexpamantier/television/commit/53afed28eebc4be5aab3399cc35a580045033be4) *(uncategorized)* Bump workspace to 0.0.16 by @alexpasmantier in [#189](https://github.com/alexpasmantier/television/pull/189)
### New Contributors
* @chenrui333 made their first contribution in [#188](https://github.com/alexpasmantier/television/pull/188)
**Full Changelog**: https://github.com/alexpasmantier/television/compare/0.8.2...0.8.3
## [0.8.2](https://github.com/alexpasmantier/television/releases/tag/0.8.2) - 2024-12-30
### ⛰️ Features
- [b49a069](https://github.com/alexpamantier/television/commit/b49a06997b93bc48f9cae2a66acda1e4ccfdb621) *(shell)* Shell integration support for fish by @alexpasmantier in [#186](https://github.com/alexpasmantier/television/pull/186)
- [7614fbc](https://github.com/alexpamantier/television/commit/7614fbc653cd5ec64037a9c5890381ab98269791) *(shell)* Add bash support for smart autocomplete and shell history by @alexpasmantier in [#184](https://github.com/alexpasmantier/television/pull/184)
- [0b5facc](https://github.com/alexpamantier/television/commit/0b5facca6a3c449dcb7335465b11cae169280612) *(shell)* Add separate history binding for zsh integration by @alexpasmantier in [#183](https://github.com/alexpasmantier/television/pull/183)
### 📚 Documentation
- [537f738](https://github.com/alexpamantier/television/commit/537f738424ddbfb11d4f840b06b597caf36ecbaa) *(uncategorized)* Move terminal emulator compatibility section to separate docs file by @alexpasmantier in [#179](https://github.com/alexpasmantier/television/pull/179)
- [c3d6b87](https://github.com/alexpamantier/television/commit/c3d6b873d0f5a0ef25087dd09e725dfa4b7ad055) *(uncategorized)* Add a credits section to the readme by @alexpasmantier in [#178](https://github.com/alexpasmantier/television/pull/178)
### ⚙️ Miscellaneous Tasks
- [d8eac4d](https://github.com/alexpamantier/television/commit/d8eac4da8a738ba6c888874f8c0069d55cd236af) *(changelog)* Update changelog (auto) by @github-actions[bot] in [#177](https://github.com/alexpasmantier/television/pull/177)
**Full Changelog**: https://github.com/alexpasmantier/television/compare/0.8.1...0.8.2
## [0.8.1](https://github.com/alexpasmantier/television/releases/tag/0.8.1) - 2024-12-29
### 🐛 Bug Fixes
- [08fa41b](https://github.com/alexpamantier/television/commit/08fa41b06c59cc0fc1e0fcc8803a4f77517190b1) *(channels)* Use the number of actual bytes read and not the sample buffer size when calculating the proportion of printable ASCII characters by @alexpasmantier in [#174](https://github.com/alexpasmantier/television/pull/174)
- [97343c6](https://github.com/alexpamantier/television/commit/97343c679d5fd93548226ba34c7c8fd3d52137c9) *(ux)* Make DeletePrevWord trigger channel update by @alexpasmantier in [#175](https://github.com/alexpasmantier/television/pull/175)
### 📚 Documentation
- [b74b130](https://github.com/alexpamantier/television/commit/b74b13075df34cad63b0a45e5face1f240cfa408) *(uncategorized)* Fix broken image in channels.md by @alexpasmantier
- [dc4028f](https://github.com/alexpamantier/television/commit/dc4028fd7cf0c697083a28d2bd949e00bd022a0b) *(uncategorized)* Update readme animations by @alexpasmantier
- [a14dccb](https://github.com/alexpamantier/television/commit/a14dccb726cd09d43811201e80768d51f0bb8d38) *(uncategorized)* Update README.md by @alexpasmantier in [#171](https://github.com/alexpasmantier/television/pull/171)
- [90c2b9c](https://github.com/alexpamantier/television/commit/90c2b9ce437535f50f0a431a6629e8fc006a2f1d) *(uncategorized)* Fix broken link in README by @alexpasmantier in [#168](https://github.com/alexpasmantier/television/pull/168)
### ⚙️ Miscellaneous Tasks
- [19e6593](https://github.com/alexpamantier/television/commit/19e6593968c3b15a77286e90ee201305359ee8f2) *(changelog)* Update changelog (auto) by @github-actions[bot] in [#167](https://github.com/alexpasmantier/television/pull/167)
- [7434f14](https://github.com/alexpamantier/television/commit/7434f1476abeaeb71d135389bd02092d68b36446) *(uncategorized)* Bump to 0.8.1 by @alexpasmantier in [#176](https://github.com/alexpasmantier/television/pull/176)
- [e9c3ebf](https://github.com/alexpamantier/television/commit/e9c3ebf05f66060f51b1c75b90e3f7b8af137575) *(uncategorized)* Docs(readme): Update README.md by @bertrand-chardon in [#172](https://github.com/alexpasmantier/television/pull/172)
**Full Changelog**: https://github.com/alexpasmantier/television/compare/0.8.0...0.8.1
## [0.8.0](https://github.com/alexpasmantier/television/releases/tag/0.8.0) - 2024-12-29
### ⛰️ Features
- [ee71e47](https://github.com/alexpamantier/television/commit/ee71e4788f8ee3f6fd3891e6c0316a4a4df7b369) *(cable)* Using builtin previewers inside cable channel prototypes by @alexpasmantier in [#156](https://github.com/alexpasmantier/television/pull/156)
- [e034615](https://github.com/alexpamantier/television/commit/e0346155945250defd3298a61aa3f6fee1518283) *(cable)* Make preview optional for cable channels by @alexpasmantier in [#155](https://github.com/alexpasmantier/television/pull/155)
- [309ff53](https://github.com/alexpamantier/television/commit/309ff537a499a0d9350c907735b07bdb016d7538) *(cli)* Allow passing --input <STRING> to prefill input prompt by @alexpasmantier in [#153](https://github.com/alexpasmantier/television/pull/153)
- [557686e](https://github.com/alexpamantier/television/commit/557686e1976ef474de314c790270985d6c7c73af) *(config)* Allow specifying multiple keymaps for the same action + better defaults by @alexpasmantier in [#149](https://github.com/alexpasmantier/television/pull/149)
- [12fdf94](https://github.com/alexpamantier/television/commit/12fdf94e5de7abff4792db760ca77f7223d6f438) *(input)* Bind ctrl-w to delete previous word by @alexpasmantier in [#150](https://github.com/alexpasmantier/television/pull/150)
- [68d1189](https://github.com/alexpamantier/television/commit/68d118986cbed4d86ccc3006ce5244a358f244ee) *(shell)* Autocompletion plugin for zsh by @alexpasmantier in [#145](https://github.com/alexpasmantier/television/pull/145)
- [22f1b4d](https://github.com/alexpamantier/television/commit/22f1b4dc337353782474bf59580cab91b87f9ede) *(ui)* Decouple preview title position from input bar position and make it configurable by @alexpasmantier in [#144](https://github.com/alexpasmantier/television/pull/144)
- [c3b8c68](https://github.com/alexpamantier/television/commit/c3b8c68d1bb5b7d4351f66af125af1561dccf248) *(ux)* Print current query to stdout on Enter if no entry is selected by @alexpasmantier in [#151](https://github.com/alexpasmantier/television/pull/151)
### 🚜 Refactor
- [157d01c](https://github.com/alexpamantier/television/commit/157d01c4e71faaaa106f922e9a3b59139d632003) *(cable)* Use tail instead of tac for zsh and bash command history channels by @alexpasmantier in [#161](https://github.com/alexpasmantier/television/pull/161)
- [499bfdb](https://github.com/alexpamantier/television/commit/499bfdb8e5b33d1c4c8554908fc3d71abf8bd0b3) *(ui)* More compact general layout and make preview panel optional by @alexpasmantier in [#148](https://github.com/alexpasmantier/television/pull/148)
- [697f295](https://github.com/alexpamantier/television/commit/697f295afb930298f8e37e536ce89a573b863a29) *(uncategorized)* Update default configuration and simplify channel enum conversions by @alexpasmantier in [#157](https://github.com/alexpasmantier/television/pull/157)
### 📚 Documentation
- [8de82fe](https://github.com/alexpamantier/television/commit/8de82fec5d2bea58ef8f74f0c042088b62ec2a01) *(uncategorized)* Update README with more legible screenshot of the files channel by @alexpasmantier in [#164](https://github.com/alexpasmantier/television/pull/164)
- [07a7c7b](https://github.com/alexpamantier/television/commit/07a7c7b34c87e0e4cb70ce4fff521b70c5b549f2) *(uncategorized)* Replace top image with a screenshot of the application by @alexpasmantier in [#163](https://github.com/alexpasmantier/television/pull/163)
- [f83c5d1](https://github.com/alexpamantier/television/commit/f83c5d1396664fae4d68ed26c7b6dbc60f507bea) *(uncategorized)* Update readme by @alexpasmantier in [#160](https://github.com/alexpasmantier/television/pull/160)
- [6d706b4](https://github.com/alexpamantier/television/commit/6d706b4c12bfeae2bb097fe75deb17f3e0fcdcb0) *(uncategorized)* Rearrange README, add a features section, and move more technical stuff to separate files by @alexpasmantier in [#159](https://github.com/alexpasmantier/television/pull/159)
### ⚙️ Miscellaneous Tasks
- [3f92ca2](https://github.com/alexpamantier/television/commit/3f92ca2b135205c7112f0e9e2bb36f8f4866dccc) *(changelog)* Update changelog (auto) by @github-actions[bot] in [#154](https://github.com/alexpasmantier/television/pull/154)
- [ba5b085](https://github.com/alexpamantier/television/commit/ba5b0857c3ce54a6fe37ca6e7d6824114188d8b7) *(changelog)* Update changelog (auto) by @github-actions[bot] in [#146](https://github.com/alexpasmantier/television/pull/146)
- [ac7762e](https://github.com/alexpamantier/television/commit/ac7762e8f2d7a2c5d582be5b20fe2f8f22a71234) *(changelog)* Update changelog (auto) by @github-actions[bot] in [#141](https://github.com/alexpasmantier/television/pull/141)
- [f707190](https://github.com/alexpamantier/television/commit/f7071904397b03f25f8e56df1d5ca2f5bc445fd9) *(uncategorized)* Include cable channels by @alexpasmantier in [#166](https://github.com/alexpasmantier/television/pull/166)
- [1bc6f12](https://github.com/alexpamantier/television/commit/1bc6f127821bdaa93291a04afaf19111737ee42f) *(uncategorized)* Bump to 0.8.0 by @alexpasmantier in [#165](https://github.com/alexpasmantier/television/pull/165)
**Full Changelog**: https://github.com/alexpasmantier/television/compare/0.7.2...0.8.0
## [0.7.2](https://github.com/alexpasmantier/television/releases/tag/0.7.2) - 2024-12-17
### ⛰️ Features
- [882737d](https://github.com/alexpamantier/television/commit/882737d147ce64bb50f2193a0e47bb10fd2970d8) *(cli)* Add argument to start tv in another working directory by @defigli in [#132](https://github.com/alexpasmantier/television/pull/132)
### 📚 Documentation
- [e27c834](https://github.com/alexpamantier/television/commit/e27c8342e84b195027202b8c92a5e694f0ea6d46) *(readme)* Make channel names consistent everywhere by @peter-fh in [#138](https://github.com/alexpasmantier/television/pull/138)
### ⚙️ Miscellaneous Tasks
- [3b8ab1f](https://github.com/alexpamantier/television/commit/3b8ab1fbd8416bcdf774421352eccf5b53752b05) *(changelog)* Update changelog (auto) by @github-actions[bot] in [#131](https://github.com/alexpasmantier/television/pull/131)
### New Contributors
* @peter-fh made their first contribution in [#138](https://github.com/alexpasmantier/television/pull/138)
* @defigli made their first contribution in [#132](https://github.com/alexpasmantier/television/pull/132)
**Full Changelog**: https://github.com/alexpasmantier/television/compare/0.7.1...0.7.2
## [0.7.1](https://github.com/alexpasmantier/television/releases/tag/0.7.1) - 2024-12-15
### ⛰️ Features
- [18c5213](https://github.com/alexpamantier/television/commit/18c5213e83955e3a58fc50cf6d948bb93af2c2c0) *(channels)* New channel for directories and associated transitions by @alexpasmantier in [#130](https://github.com/alexpasmantier/television/pull/130)
### 📚 Documentation
- [c0c790c](https://github.com/alexpamantier/television/commit/c0c790cb48011a7ff055d71779ebad3ac20b6f91) *(contributing)* Update contributing.md with hot topics and link todo by @alexpasmantier in [#129](https://github.com/alexpasmantier/television/pull/129)
### ⚙️ Miscellaneous Tasks
- [7fa469a](https://github.com/alexpamantier/television/commit/7fa469aea02c7c23d2ebf953c8b8c6ad2d39d3ec) *(changelog)* Update changelog (auto) by @github-actions[bot] in [#128](https://github.com/alexpasmantier/television/pull/128)
**Full Changelog**: https://github.com/alexpasmantier/television/compare/0.7.0...0.7.1
## [0.7.0](https://github.com/alexpasmantier/television/releases/tag/0.7.0) - 2024-12-15
### ⛰️ Features
- [937d0f0](https://github.com/alexpamantier/television/commit/937d0f0758367eb209f5abfff2ef7afdc09d4971) *(cable)* Support cable channel invocation through the cli by @alexpasmantier in [#116](https://github.com/alexpasmantier/television/pull/116)
- [4164e90](https://github.com/alexpamantier/television/commit/4164e9092b577f577ada87286326b465f07300f6) *(themes)* More builtin UI themes by @alexpasmantier in [#125](https://github.com/alexpasmantier/television/pull/125)
- [11da96d](https://github.com/alexpamantier/television/commit/11da96d7fb1d380a289e33482bd534e1cd4fa4cd) *(themes)* Add support for global themes background colors by @alexpasmantier in [#120](https://github.com/alexpasmantier/television/pull/120)
- [913aa85](https://github.com/alexpamantier/television/commit/913aa85af03ad1b819f58388c8f0192b6d3e6b66) *(themes)* Add support for ui themes by @alexpasmantier in [#114](https://github.com/alexpasmantier/television/pull/114)
### 🐛 Bug Fixes
- [7b114b7](https://github.com/alexpamantier/television/commit/7b114b7cb6c7559c98546451461e8af5da4fb645) *(config)* Better handling of default values by @alexpasmantier in [#123](https://github.com/alexpasmantier/television/pull/123)
- [ea752b1](https://github.com/alexpamantier/television/commit/ea752b13e6e2933a0be785cf29a9a7ebac123a23) *(previewers)* Handle crlf sequences when parsing ansi into ratatui objects by @alexpasmantier in [#119](https://github.com/alexpasmantier/television/pull/119)
- [9809e74](https://github.com/alexpamantier/television/commit/9809e742d86443950800854042013ae80094584e) *(stdin)* Trim entry newlines when streaming from stdin by @alexpasmantier in [#121](https://github.com/alexpasmantier/television/pull/121)
### 🚜 Refactor
- [a7064c1](https://github.com/alexpamantier/television/commit/a7064c18c8a74a0eba2d93be904c7f72bbff1e1c) *(config)* Use `$HOME/.config/television` by default for macOS by @alexpasmantier in [#124](https://github.com/alexpasmantier/television/pull/124) [**breaking**]
- [37b2dda](https://github.com/alexpamantier/television/commit/37b2dda7297a83f58d35d71de5cb971a355ff3f7) *(help)* Enable help bar by default and add help keybinding by @alexpasmantier in [#122](https://github.com/alexpasmantier/television/pull/122)
- [54399e3](https://github.com/alexpamantier/television/commit/54399e377776ae6a192d4565647a412e3e49354e) *(screen)* Extract UI related code to separate crate by @alexpasmantier in [#106](https://github.com/alexpasmantier/television/pull/106)
### 📚 Documentation
- [630e791](https://github.com/alexpamantier/television/commit/630e791961767ae071b883728e901dd201c376bb) *(readme)* Add theme previews and udpate readme structure by @alexpasmantier in [#126](https://github.com/alexpasmantier/television/pull/126)
### ⚡ Performance
- [758bfc2](https://github.com/alexpamantier/television/commit/758bfc290a09f708b1f7bcab915cc0465aaa8af8) *(ui)* Improve merging of continuous name match ranges by @alexpasmantier in [#109](https://github.com/alexpasmantier/television/pull/109)
- [a4d15af](https://github.com/alexpamantier/television/commit/a4d15af694cb09a2bf338ea7b6b573d274cdeddb) *(uncategorized)* Optimize entry ranges by @bertrand-chardon in [#110](https://github.com/alexpasmantier/television/pull/110)
- [5fb02c7](https://github.com/alexpamantier/television/commit/5fb02c768f82d81af2426661b67183dbc333b21d) *(uncategorized)* Merge contiguous name match ranges by @bertrand-chardon in [#108](https://github.com/alexpasmantier/television/pull/108)
- [c0db566](https://github.com/alexpamantier/television/commit/c0db566a48d7821dcdc4bd9ff330b24b8df6b963) *(uncategorized)* Add bench for build results list by @bertrand-chardon in [#107](https://github.com/alexpasmantier/television/pull/107)
### ⚙️ Miscellaneous Tasks
- [6e35e1a](https://github.com/alexpamantier/television/commit/6e35e1a50ce4ace43920db8eba459c9de965f05a) *(changelog)* Update changelog (auto) by @github-actions[bot] in [#105](https://github.com/alexpasmantier/television/pull/105)
- [a8e3ea5](https://github.com/alexpamantier/television/commit/a8e3ea5f8954e2cde8c81c10c4cf5172ab2a00f1) *(version)* Bump workspace to 0.7.0 by @alexpasmantier in [#127](https://github.com/alexpasmantier/television/pull/127)
**Full Changelog**: https://github.com/alexpasmantier/television/compare/0.6.2...0.7.0
## [0.6.2](https://github.com/alexpasmantier/television/releases/tag/0.6.2) - 2024-12-06
### 🐛 Bug Fixes
- [f9d33e4](https://github.com/alexpamantier/television/commit/f9d33e4797e6d21bf27de62d51ecd8985455a5a2) *(windows)* Use cmd on windows instead of sh by @Liyixin95 in [#102](https://github.com/alexpasmantier/television/pull/102)
### ⚙️ Miscellaneous Tasks
- [2ea6f9a](https://github.com/alexpamantier/television/commit/2ea6f9a5c1a2c84b03cf390e02df0647d7de271d) *(changelog)* Update changelog (auto) by @github-actions[bot] in [#98](https://github.com/alexpasmantier/television/pull/98)
- [ffc8dae](https://github.com/alexpamantier/television/commit/ffc8dae4942102a9ec4c8661d6a0adfb1f4813fc) *(uncategorized)* Bump workspace to 0.6.2 by @alexpasmantier in [#104](https://github.com/alexpasmantier/television/pull/104)
- [4567f26](https://github.com/alexpamantier/television/commit/4567f26a37995f9af6648777ada491c227bcaccd) *(uncategorized)* Use named constant for colors by @bertrand-chardon in [#99](https://github.com/alexpasmantier/television/pull/99)
### New Contributors
* @Liyixin95 made their first contribution in [#102](https://github.com/alexpasmantier/television/pull/102)
**Full Changelog**: https://github.com/alexpasmantier/television/compare/0.6.1...0.6.2
## [0.6.1](https://github.com/alexpasmantier/television/releases/tag/0.6.1) - 2024-12-05
### ⛰️ Features
- [ad3e52d](https://github.com/alexpamantier/television/commit/ad3e52d3407a25fff6a2a86f64de46a5fd8b89fd) *(remote)* Distinguish cable channels with a separate icon by @alexpasmantier in [#94](https://github.com/alexpasmantier/television/pull/94)
### 🐛 Bug Fixes
- [795db19](https://github.com/alexpamantier/television/commit/795db19ffffafb080a54b6fc8d699f9c9d316255) *(cable)* Add cable to unit channel variants by @alexpasmantier in [#96](https://github.com/alexpasmantier/television/pull/96)
### 🚜 Refactor
- [6a13590](https://github.com/alexpamantier/television/commit/6a1359055dc9546c235f6470deabf9dbaa0f8e61) *(helpbar)* Hide the top help panel by default by @alexpasmantier in [#97](https://github.com/alexpasmantier/television/pull/97)
### 📚 Documentation
- [b6f12b3](https://github.com/alexpamantier/television/commit/b6f12b372b85c571539989d73b4bbfec6f548541) *(readme)* Update readme with latest version and fix section link by @alexpasmantier in [#93](https://github.com/alexpasmantier/television/pull/93)
### ⚙️ Miscellaneous Tasks
- [99a4405](https://github.com/alexpamantier/television/commit/99a4405e66a624494ec69afbd94f19f9d2dc31a1) *(changelog)* Update changelog (auto) by @github-actions[bot] in [#92](https://github.com/alexpasmantier/television/pull/92)
**Full Changelog**: https://github.com/alexpasmantier/television/compare/0.6.0...0.6.1
## [0.6.0](https://github.com/alexpasmantier/television/releases/tag/0.6.0) - 2024-12-04
### ⛰️ Features
- [a5f5d20](https://github.com/alexpamantier/television/commit/a5f5d20071a3d58761c1917b34fcd0a12ae7f102) *(cable)* Add support for custom channels by @alexpasmantier in [#75](https://github.com/alexpasmantier/television/pull/75)
- [2206711](https://github.com/alexpamantier/television/commit/220671106e621454e2088ccf08bc9957f240bbec) *(layout)* Allow reversing the layout and placing input bar on top by @alexpasmantier in [#76](https://github.com/alexpasmantier/television/pull/76)
### 🐛 Bug Fixes
- [1ebec7e](https://github.com/alexpamantier/television/commit/1ebec7ead22e2bac806450f8a3ab31e840838a4c) *(output)* Quote output string when it contains spaces and points to an existing path by @alexpasmantier in [#77](https://github.com/alexpasmantier/television/pull/77)
- [128a611](https://github.com/alexpamantier/television/commit/128a6116c3e7ffb1f850bae309c84b2da43f3d77) *(preview)* Remove redundant tokio task when generating builtin file previews by @alexpasmantier in [#86](https://github.com/alexpasmantier/television/pull/86)
- [d3c16af](https://github.com/alexpamantier/television/commit/d3c16af4e94e2f47b9e966b8bd6284392368a37b) *(stdin)* Better handling of long running stdin streams by @alexpasmantier in [#81](https://github.com/alexpasmantier/television/pull/81)
### 🚜 Refactor
- [30f1940](https://github.com/alexpamantier/television/commit/30f194081514d25a3a4e8a13e092cc6c3e896736) *(exit)* Use std::process::exit explicitly by @alexpasmantier in [#84](https://github.com/alexpasmantier/television/pull/84)
### 📚 Documentation
- [48ea12e](https://github.com/alexpamantier/television/commit/48ea12ed7a0f273cf9154b4b3e3aeb2ce5e5add0) *(install)* Update the installation section of the README by @alexpasmantier in [#79](https://github.com/alexpasmantier/television/pull/79)
- [20cf83b](https://github.com/alexpamantier/television/commit/20cf83b72017bec4029fd502b7c730e1bc99dd31) *(installation)* Update homebrew installation command by @alexpasmantier in [#87](https://github.com/alexpasmantier/television/pull/87)
### ⚡ Performance
- [fee4ed2](https://github.com/alexpamantier/television/commit/fee4ed2671be1aee9c6f3fd2c77d45c208525c83) *(uncategorized)* Add cache for icon colors by @bertrand-chardon in [#89](https://github.com/alexpasmantier/television/pull/89)
- [b7ddb00](https://github.com/alexpamantier/television/commit/b7ddb00c4eadacfb5512819798072f112b0bbb07) *(uncategorized)* Skip ratatui span when match at end of string by @bertrand-chardon in [#91](https://github.com/alexpasmantier/television/pull/91)
- [4bea114](https://github.com/alexpamantier/television/commit/4bea114635848e1d26a2226585981e37fd707843) *(uncategorized)* Remove unnecessary clone() calls by @bertrand-chardon
### ⚙️ Miscellaneous Tasks
- [c96d855](https://github.com/alexpamantier/television/commit/c96d85529033cb509e38114c5c14c3e7ff877cb8) *(changelog)* Update changelog (auto) by @github-actions[bot] in [#85](https://github.com/alexpasmantier/television/pull/85)
- [9998b9d](https://github.com/alexpamantier/television/commit/9998b9d9f80d381e58353236194f2cd511596aa9) *(changelog)* Update changelog (auto) by @github-actions[bot] in [#74](https://github.com/alexpasmantier/television/pull/74)
### New Contributors
* @moritzwilksch made their first contribution in [#78](https://github.com/alexpasmantier/television/pull/78)
**Full Changelog**: https://github.com/alexpasmantier/television/compare/0.5.3...0.6.0
## [0.5.3](https://github.com/alexpasmantier/television/releases/tag/0.5.3) - 2024-11-24
### ⛰️ Features
- [6d39651](https://github.com/alexpamantier/television/commit/6d3965152e91639babaedb1e8a00953a9b01b05f) *(navigation)* Add action to scroll results list by a page by @alexpasmantier in [#72](https://github.com/alexpasmantier/television/pull/72)
### 🐛 Bug Fixes
- [edd9df4](https://github.com/alexpamantier/television/commit/edd9df4e2911e1fd8e96a83e9f4696f61b0f5647) *(entry)* Always preserve raw input + match ranges conversions by @alexpasmantier in [#62](https://github.com/alexpasmantier/television/pull/62)
- [21cdaae](https://github.com/alexpamantier/television/commit/21cdaaee42fade21f43014c983bb650352f61926) *(uncategorized)* Quote file names that contain spaces when printing them to stdout by @fredmorcos in [#51](https://github.com/alexpasmantier/television/pull/51)
### 🚜 Refactor
- [b757305](https://github.com/alexpamantier/television/commit/b757305d7ab8d3ca7059b2a0b603215c8f9a608a) *(picker)* Refactor picker logic and add tests to picker, cli, and events by @alexpasmantier in [#57](https://github.com/alexpasmantier/television/pull/57)
### 📚 Documentation
- [790c870](https://github.com/alexpamantier/television/commit/790c870ff39e6c41442706cbc9bc8f24af73c9fe) *(contributing)* Added TOC and Code of Conduct link by @MohamedBsh
- [cdcce4d](https://github.com/alexpamantier/television/commit/cdcce4d9f9afcf852c024f7d54f05a55c3147ddd) *(uncategorized)* Terminal emulators compatibility and good first issues by @alexpasmantier in [#56](https://github.com/alexpasmantier/television/pull/56)
### ⚡ Performance
- [84d54b5](https://github.com/alexpamantier/television/commit/84d54b5751611684d30ff287a89a681410b2be84) *(preview)* Cap the number of concurrent preview tokio tasks in the background by @alexpasmantier in [#67](https://github.com/alexpasmantier/television/pull/67)
### 🎨 Styling
- [b703e1b](https://github.com/alexpamantier/television/commit/b703e1b26c9d9816da297f2b8744a22139635f04) *(git)* Enforce conventional commits on git push with a hook by @alexpasmantier in [#61](https://github.com/alexpasmantier/television/pull/61)
### ⚙️ Miscellaneous Tasks
- [ebcccb1](https://github.com/alexpamantier/television/commit/ebcccb146a3fb1e0290d3649adf71d8b9f984f35) *(changelog)* Update changelog (auto) by @github-actions[bot] in [#73](https://github.com/alexpasmantier/television/pull/73)
- [c87af47](https://github.com/alexpamantier/television/commit/c87af47d4e7cec67c5e844cc77849cedb5037bfa) *(changelog)* Update changelog (auto) by @github-actions[bot]
- [03fb7d0](https://github.com/alexpamantier/television/commit/03fb7d0f35740707a3c2612a10f0b3ff5914589c) *(changelog)* Update changelog action trigger by @alexpasmantier
- [dc36b21](https://github.com/alexpamantier/television/commit/dc36b2152d50c377e7c0741112e8038c464f04fc) *(update_readme)* Fix `update_readme` workflow by @alexpasmantier
- [2fc9bd9](https://github.com/alexpamantier/television/commit/2fc9bd9e80797905feea5e6109d398f5a587bb1c) *(uncategorized)* Bump crate to 0.5.3 and workspace crates to 0.0.7 by @alexpasmantier
- [0f6aad9](https://github.com/alexpamantier/television/commit/0f6aad952f2793bb636c148ea472440daba166a2) *(uncategorized)* Add readme version update to github actions by @alexpasmantier in [#55](https://github.com/alexpasmantier/television/pull/55)
### Build
- [f0e1115](https://github.com/alexpamantier/television/commit/f0e1115bab72a0226f728ae17ac1937d2c7d010d) *(infer)* Drop infer dependency and refactor code to a simpler heuristic by @alexpasmantier in [#58](https://github.com/alexpasmantier/television/pull/58)
### New Contributors
* @github-actions[bot] made their first contribution in [#73](https://github.com/alexpasmantier/television/pull/73)
* @MohamedBsh made their first contribution
* @bertrand-chardon made their first contribution in [#59](https://github.com/alexpasmantier/television/pull/59)
**Full Changelog**: https://github.com/alexpasmantier/television/compare/0.5.1...0.5.3
## [0.5.1](https://github.com/alexpasmantier/television/releases/tag/0.5.1) - 2024-11-20
### 📚 Documentation
- [f43b5bf](https://github.com/alexpamantier/television/commit/f43b5bf9b8fe034e958bec100f2d4569c87878be) *(brew)* Add brew installation method for MacOS to README by @alexpasmantier in [#45](https://github.com/alexpasmantier/television/pull/45)
- [30639c6](https://github.com/alexpamantier/television/commit/30639c66b037733f6db0300b4573a1ccd2e33093) *(config)* Update docs to mention XDG_CONFIG_HOME precedence on all platform by @alexpasmantier in [#48](https://github.com/alexpasmantier/television/pull/48)
- [8a7b3da](https://github.com/alexpamantier/television/commit/8a7b3da7fa20024bf5201c387260a36a16884b45) *(uncategorized)* Add instructions for installing on Arch Linux by @orhun in [#43](https://github.com/alexpasmantier/television/pull/43)
### ⚙️ Miscellaneous Tasks
- [9dcb223](https://github.com/alexpamantier/television/commit/9dcb223dbac93b79f5913c782ab601446bab6052) *(actions)* Remove changelog update from the main branch by @alexpasmantier
- [6540094](https://github.com/alexpamantier/television/commit/6540094cc9977419a92c4dcf37d761bebd5f052a) *(changelog)* Udpate changelog and add corresponding makefile command by @alexpasmantier in [#53](https://github.com/alexpasmantier/television/pull/53)
- [ccd7c68](https://github.com/alexpamantier/television/commit/ccd7c687026ecca6f6d43b843a805089b5bfe4b1) *(config)* Default configuration now uses 100% of terminal screen space by @alexpasmantier in [#47](https://github.com/alexpasmantier/television/pull/47)
- [d3564f2](https://github.com/alexpamantier/television/commit/d3564f2aca060838c5bbba01ad40427379e90060) *(uncategorized)* Bump version to 0.5.1 by @alexpasmantier
- [3bf04d7](https://github.com/alexpamantier/television/commit/3bf04d77858f69f79c161c94dca7f52ca17ba50f) *(uncategorized)* Add CHANGELOG.md by @alexpasmantier in [#44](https://github.com/alexpasmantier/television/pull/44)
### New Contributors
* @fredmorcos made their first contribution in [#50](https://github.com/alexpasmantier/television/pull/50)
* @orhun made their first contribution in [#43](https://github.com/alexpasmantier/television/pull/43)
**Full Changelog**: https://github.com/alexpasmantier/television/compare/0.5.0...0.5.1
## [0.5.0](https://github.com/alexpasmantier/television/releases/tag/0.5.0) - 2024-11-18
### ⛰️ Features
- [5807cda](https://github.com/alexpamantier/television/commit/5807cda45d0f9935617c92e2b47a6d54712f93bc) *(cli)* Allow passing passthrough keybindings via stdout for the parent process to deal with by @alexpasmantier in [#39](https://github.com/alexpasmantier/television/pull/39)
- [40d5b20](https://github.com/alexpamantier/television/commit/40d5b20c7d5fd6dd6b32a07f40eafb37d16b4cfd) *(ui)* Make the top UI help bar toggleable by @alexpasmantier in [#41](https://github.com/alexpasmantier/television/pull/41)
### 🚜 Refactor
- [75d0bf7](https://github.com/alexpamantier/television/commit/75d0bf7b6b4c7139b5fd0862e595b63b93e322bb) *(config)* Make action names snake case in keybinding configuration by @alexpasmantier in [#40](https://github.com/alexpasmantier/television/pull/40) [**breaking**]
### 📚 Documentation
- [5c44432](https://github.com/alexpamantier/television/commit/5c44432776cfd1bdaae2d9a82a7caba2af0b7ac9) *(uncategorized)* Update README television version by @alexpasmantier
- [cb7a245](https://github.com/alexpamantier/television/commit/cb7a24537c3f1e85d8050a39ba0eae49e9f6db69) *(uncategorized)* Update README television version specifier by @alexpasmantier
- [da5c903](https://github.com/alexpamantier/television/commit/da5c90317792f61abb0d793ed83b4d1728d2cb0e) *(uncategorized)* Update README television version by @alexpasmantier
### ⚙️ Miscellaneous Tasks
- [480059e](https://github.com/alexpamantier/television/commit/480059eaaee16da11718ad765eda5e0c90cef4d7) *(rustfmt)* Update rustfmt.toml by @alexpasmantier in [#42](https://github.com/alexpasmantier/television/pull/42)
**Full Changelog**: https://github.com/alexpasmantier/television/compare/0.4.23...0.5.0
## [0.4.23](https://github.com/alexpasmantier/television/releases/tag/0.4.23) - 2024-11-16
### ⛰️ Features
- [512afa2](https://github.com/alexpamantier/television/commit/512afa2fda3a679ce0dc4ed37f85b177b3a215f6) *(ui)* Make help bar display optional by @alexpasmantier in [#35](https://github.com/alexpasmantier/television/pull/35)
### 🚜 Refactor
- [aa2f260](https://github.com/alexpamantier/television/commit/aa2f2609a438768866d333713a938453eba1b402) *(configuration)* Modularize code and better handling of default options by @alexpasmantier in [#32](https://github.com/alexpasmantier/television/pull/32)
### 📚 Documentation
- [7277a3f](https://github.com/alexpamantier/television/commit/7277a3f3ab32d61a41ec0d4f8dd083855527e0a5) *(config)* Update docs default configuration by @alexpasmantier in [#34](https://github.com/alexpasmantier/television/pull/34)
- [45e14d3](https://github.com/alexpamantier/television/commit/45e14d3fa20a8e708fdc8ec75f74f34e8b86b0da) *(debian)* Add installation docs for debian-based systems by @alexpasmantier in [#33](https://github.com/alexpasmantier/television/pull/33)
**Full Changelog**: https://github.com/alexpasmantier/television/compare/0.4.22...0.4.23
## [0.4.22](https://github.com/alexpasmantier/television/releases/tag/0.4.22) - 2024-11-16
### 🐛 Bug Fixes
- [06a4feb](https://github.com/alexpamantier/television/commit/06a4feb9f2a1b191d7f1773d7fc99cb5565da407) *(config)* Swap out default keymaps with user defined ones instead of stacking by @alexpasmantier in [#26](https://github.com/alexpasmantier/television/pull/26)
- [f47b8be](https://github.com/alexpamantier/television/commit/f47b8be9de8c1bfd29a08eea90e10c2d03865003) *(ghactions)* Only trigger cd workflow on new tags by @alexpasmantier in [#22](https://github.com/alexpasmantier/television/pull/22)
### 🚜 Refactor
- [4f0daec](https://github.com/alexpamantier/television/commit/4f0daec63d868e16b1aa0349652ce9480623a496) *(channels)* Converting between entries and channels is now generic over channels by @alexpasmantier in [#25](https://github.com/alexpasmantier/television/pull/25)
### ⚙️ Miscellaneous Tasks
- [dcf9f6a](https://github.com/alexpamantier/television/commit/dcf9f6a62156f425e378ac346ad6f18466076356) *(cd)* Fix cd configuration for deb packages by @alexpasmantier
- [e9dde70](https://github.com/alexpamantier/television/commit/e9dde70ecf4bf48ae0f16c19f2b0aa296b6af777) *(cd)* Fix cd configuration for deb packages by @alexpasmantier
- [900bfa5](https://github.com/alexpamantier/television/commit/900bfa50b92e2f023afc78fe4a4bed618480c2e5) *(deb)* Release deb package for television by @alexpasmantier
- [d0f023c](https://github.com/alexpamantier/television/commit/d0f023cf1848055a7d83f6b81b286bd5e14237da) *(versions)* Bump workspace crates versions by @alexpasmantier
- [d50337b](https://github.com/alexpamantier/television/commit/d50337b5c51c45f48a5a09431ff1b85c45964da2) *(uncategorized)* Update CD workflow by @alexpasmantier
**Full Changelog**: https://github.com/alexpasmantier/television/compare/v0.4.21...0.4.22
## [v0.4.21](https://github.com/alexpasmantier/television/releases/tag/v0.4.21) - 2024-11-13
### 🐛 Bug Fixes
- [ff25fb2](https://github.com/alexpamantier/television/commit/ff25fb2ddeb9c6f70294e5099a617219e30248d8) *(windows)* #20 respect `TELEVISION_CONFIG` env var on windows by @alexpasmantier in [#21](https://github.com/alexpasmantier/television/pull/21)
### ⚙️ Miscellaneous Tasks
- [65bb26e](https://github.com/alexpamantier/television/commit/65bb26ec847e0d2caae49fbaeb3bffef90e094cd) *(nix)* Nix flake shell + rust-toolchain.toml setup by @tukanoidd in [#14](https://github.com/alexpasmantier/television/pull/14)
### New Contributors
* @tukanoidd made their first contribution in [#14](https://github.com/alexpasmantier/television/pull/14)
**Full Changelog**: https://github.com/alexpasmantier/television/compare/v0.4.20...v0.4.21
## [v0.4.20](https://github.com/alexpasmantier/television/releases/tag/v0.4.20) - 2024-11-11
### 🐛 Bug Fixes
- [b1fe018](https://github.com/alexpamantier/television/commit/b1fe0182f8f8de8ea5834fc3b148b53666d4349a) *(cargo workspace)* Fix cargo workspace structure and dependencies by @alexpasmantier in [#15](https://github.com/alexpasmantier/television/pull/15)
- [81cf17b](https://github.com/alexpamantier/television/commit/81cf17bd5d883f581b5958ae70995a8acdd6e9d2) *(config)* More consistent configuration file location for linux and macos by @alexpasmantier in [#9](https://github.com/alexpasmantier/television/pull/9)
- [b3760d2](https://github.com/alexpamantier/television/commit/b3760d2259951cc904f1fde7d7ac18d20f94b73c) *(windows)* Bump television_utils to v0.0.1 by @alexpasmantier in [#4](https://github.com/alexpasmantier/television/pull/4)
- [e475523](https://github.com/alexpamantier/television/commit/e475523c797a46c7f229558789e8a1856c5adc23) *(windows)* Ignore `KeyEventKind::Release` events by @ErichDonGubler in [#3](https://github.com/alexpasmantier/television/pull/3)
- [d2e7789](https://github.com/alexpamantier/television/commit/d2e7789612b22174e3ff24b0c7afe2da421cf5e7) *(workspace)* Fix cargo workspace dependencies by @alexpasmantier
### 🚜 Refactor
- [5611ee8](https://github.com/alexpamantier/television/commit/5611ee8b2d7b02d9af311c31f6c2366dd2224248) *(workspace)* Reorganize cargo workspace by @alexpasmantier in [#12](https://github.com/alexpasmantier/television/pull/12)
### 📚 Documentation
- [cc9924d](https://github.com/alexpamantier/television/commit/cc9924dd614b1b1625e019f76b8465e9b88880c3) *(readme)* Update terminal emulators compatibility list by @alexpasmantier in [#6](https://github.com/alexpasmantier/television/pull/6)
- [0c13626](https://github.com/alexpamantier/television/commit/0c13626d4c1b1799ffc8e5f68b731222c3234dbd) *(uncategorized)* Fix table alignments by @alexpasmantier
- [6b0a038](https://github.com/alexpamantier/television/commit/6b0a0387382f0d1bf61e2adbeca2276dd71b9836) *(uncategorized)* Add terminal emulators compatibility status by @alexpasmantier
### ⚡ Performance
- [62073d6](https://github.com/alexpamantier/television/commit/62073d69ccc022d75bcc6bc5adc4472bdfe5b7f5) *(preview)* Remove temporary plaintext previews in favor of loading message preview by @alexpasmantier in [#10](https://github.com/alexpasmantier/television/pull/10)
### ⚙️ Miscellaneous Tasks
- [3a9ff06](https://github.com/alexpamantier/television/commit/3a9ff067afad7e317fa5a34a95ba9ccbcca3e9ef) *(coc)* Create CODE_OF_CONDUCT.md by @alexpasmantier in [#7](https://github.com/alexpasmantier/television/pull/7)
- [7bc6f29](https://github.com/alexpamantier/television/commit/7bc6f29c30334218da6baaeef1ddb02fdaa06a5c) *(crate)* Add include directives to Cargo.toml to make the crate leaner by @alexpasmantier in [#11](https://github.com/alexpasmantier/television/pull/11)
- [b8ad340](https://github.com/alexpamantier/television/commit/b8ad34060d506c41a1ff491258edb09419b33178) *(uncategorized)* Update README.md install section by @alexpasmantier
### New Contributors
* @tranzystorekk made their first contribution in [#5](https://github.com/alexpasmantier/television/pull/5)
* @ErichDonGubler made their first contribution in [#3](https://github.com/alexpasmantier/television/pull/3)
**Full Changelog**: https://github.com/alexpasmantier/television/compare/v0.4.18...v0.4.20
## [v0.4.18](https://github.com/alexpasmantier/television/releases/tag/v0.4.18) - 2024-11-10
### 🐛 Bug Fixes
- [c70e675](https://github.com/alexpamantier/television/commit/c70e6756553bbeb1bc9332a7b011fddf24be52c0) *(uncategorized)* Add `winapi-util` dependency for windows builds by @alexpasmantier
- [df7020a](https://github.com/alexpamantier/television/commit/df7020a7a82e82cace2fa84d24182c7a0911613d) *(uncategorized)* Add the correct permissions to release binaries by @alexpasmantier
**Full Changelog**: https://github.com/alexpasmantier/television/compare/v0.4.17...v0.4.18
## [v0.4.17](https://github.com/alexpasmantier/television/releases/tag/v0.4.17) - 2024-11-10
### ⚙️ Miscellaneous Tasks
- [2f5640f](https://github.com/alexpamantier/television/commit/2f5640f4cde0a61d6dc9946c8b73bc3c2b54e4dd) *(uncategorized)* Testing out the CD pipeline by @alexpasmantier
- [2e49862](https://github.com/alexpamantier/television/commit/2e49862a7e40b87b704eaf3ef0a30b8cf483cb24) *(uncategorized)* Update Makefile and CONTRIBUTING.md by @alexpasmantier
- [6eafb7b](https://github.com/alexpamantier/television/commit/6eafb7bfe800e0a96d52674a46903e06238536d0) *(uncategorized)* Udate documentation and dependencies by @alexpasmantier
**Full Changelog**: https://github.com/alexpasmantier/television/compare/v0.4.15...v0.4.17
## [v0.4.15](https://github.com/alexpasmantier/television/releases/tag/v0.4.15) - 2024-11-10
### ⛰️ Features
- [759815a](https://github.com/alexpamantier/television/commit/759815ae24dd471365455b932922fb66773eb50b) *(uncategorized)* More syntaxes and themes for highlighting + configuration by @alexpasmantier
- [d0d453f](https://github.com/alexpamantier/television/commit/d0d453fe9748c42b7d81d7a2bfbad6fe0d966c84) *(uncategorized)* Send to channel by @alexpasmantier
### 🐛 Bug Fixes
- [32c114a](https://github.com/alexpamantier/television/commit/32c114aa9fa51c1f74b15b6d38ba904f9cfce557) *(uncategorized)* Gag stdout and stderr while loading theme assets to silence bat warning by @alexpasmantier
- [f449477](https://github.com/alexpamantier/television/commit/f449477605bb48f6c18334440dbc9d360b0ec43e) *(uncategorized)* Doctests imports by @alexpasmantier
- [de74b61](https://github.com/alexpamantier/television/commit/de74b619b86b81feb165c5518995d36ca9a0bada) *(uncategorized)* Stabilize preview scroll initialization by @alexpasmantier
- [dd14bd4](https://github.com/alexpamantier/television/commit/dd14bd4f8d2ff58aed9bfda2ca6fc8c0f9a74729) *(uncategorized)* Filtering system directories in gitrepos by @alexpasmantier
### 🚜 Refactor
- [8dd7f23](https://github.com/alexpamantier/television/commit/8dd7f237345601a976c55b112d71e493bf83d2e2) *(uncategorized)* More refactoring and fixing doctests by @alexpasmantier
- [ae938dc](https://github.com/alexpamantier/television/commit/ae938dcfc0778ef85df3b8f81cd35edec737f644) *(uncategorized)* Split project into separate crates by @alexpasmantier
- [c1f41bf](https://github.com/alexpamantier/television/commit/c1f41bf107e5352ac910543cd1b447193af494cd) *(uncategorized)* Extract matcher logic into separate crate by @alexpasmantier
### 📚 Documentation
- [cd31619](https://github.com/alexpamantier/television/commit/cd31619c8ab7df6975f6d26d9948617318d05de0) *(readme)* Update README.md by @alexpasmantier
- [51a98db](https://github.com/alexpamantier/television/commit/51a98db9d564f02e0ef9b3bc3242439ea74c7406) *(readme)* Update README.md by @alexpasmantier
- [c7fbe26](https://github.com/alexpamantier/television/commit/c7fbe26596561e5155d5a52f04957fbcb168397f) *(readme)* Update README.md by @alexpasmantier
- [ef4ab70](https://github.com/alexpamantier/television/commit/ef4ab705b44d0b4644e859c13bb804815226259f) *(readme)* Update README.md by @alexpasmantier
- [068ed88](https://github.com/alexpamantier/television/commit/068ed8813c5bd51aea290842667eb25cfd26d7b9) *(readme)* Update README.md by @alexpasmantier
- [cfa4178](https://github.com/alexpamantier/television/commit/cfa41789bc850a3078e97278878336985f487b08) *(readme)* Update README.md by @alexpasmantier
- [37fb013](https://github.com/alexpamantier/television/commit/37fb013f0cdaf9d97ea84f4432f8348b18bbc340) *(uncategorized)* More work on CONTRIBUTING.md by @alexpasmantier
- [b0ab8a1](https://github.com/alexpamantier/television/commit/b0ab8a179aa72dbd42c8928d2425bd0d9d7ef22f) *(uncategorized)* Some work on CONTRIBUTING.md by @alexpasmantier
- [19f00f5](https://github.com/alexpamantier/television/commit/19f00f5916e1f3a2a4d2320c84eb2c1ea2858a8b) *(uncategorized)* Add default keybindings to README.md by @alexpasmantier
- [96976d9](https://github.com/alexpamantier/television/commit/96976d93cb4a7859c25599269f6ba87229afecfe) *(uncategorized)* Update README.md by @alexpasmantier
### ⚙️ Miscellaneous Tasks
- [4e4ef97](https://github.com/alexpamantier/television/commit/4e4ef9761b997badd5a57347d62f9c3e617deff8) *(precommit)* Don't allow committing if clippy doesn't pass by @alexpasmantier
- [b04e182](https://github.com/alexpamantier/television/commit/b04e1824535467f401d7117b0e6048b2dfabb7fe) *(previewers)* Unused attributes by @alexpasmantier
- [d2005e1](https://github.com/alexpamantier/television/commit/d2005e1116b7830ee3d85c0fc7dec35ac4e5e99d) *(uncategorized)* Bump version by @alexpasmantier
- [79da161](https://github.com/alexpamantier/television/commit/79da161943c0cd2865c5931b8c251417035c393d) *(uncategorized)* Add license to syntax snippet by @alexpasmantier
- [5b57d6b](https://github.com/alexpamantier/television/commit/5b57d6b29019a67706ee354d32b23ebbadb710ba) *(uncategorized)* Update workspace crates configurations by @alexpasmantier
- [c4863ff](https://github.com/alexpamantier/television/commit/c4863ff7ae55fd1536caf7a490deb21bf9be7329) *(uncategorized)* Patch by @alexpasmantier
- [9bdbf44](https://github.com/alexpamantier/television/commit/9bdbf44f35e92740e7b0ac4e8c26d299ca6fa1ef) *(uncategorized)* Makefile and dist scripts by @alexpasmantier
- [b913eac](https://github.com/alexpamantier/television/commit/b913eac4ae0f3767d1495c95902ce8be0d33656d) *(uncategorized)* Update dependencies and bump version by @alexpasmantier
- [2dbbd0c](https://github.com/alexpamantier/television/commit/2dbbd0c4a3b227062402d7c994b4dc6b3a8eeb87) *(uncategorized)* Bump version by @alexpasmantier
- [8fe1246](https://github.com/alexpamantier/television/commit/8fe1246923939f16536aa276ca5a3b878982001d) *(uncategorized)* Update dependencies and bump version by @alexpasmantier
- [3d647b2](https://github.com/alexpamantier/television/commit/3d647b20103b3609a7d4edb372b24341fa0d03dc) *(uncategorized)* Update dependencies and bump version by @alexpasmantier
- [7b18c4f](https://github.com/alexpamantier/television/commit/7b18c4f88d562e9a1a32d4685fa4d039363c6f3c) *(uncategorized)* Unused imports and ci docs by @alexpasmantier
- [e83fabb](https://github.com/alexpamantier/television/commit/e83fabbc0b6e691a40eff4ffc190dc94516b3841) *(uncategorized)* Bump version by @alexpasmantier
- [dbc4b6c](https://github.com/alexpamantier/television/commit/dbc4b6c06a57bcc6528bfa180de495a444588515) *(uncategorized)* Bump version by @alexpasmantier
### New Contributors
* @alexpasmantier made their first contribution
<!-- generated by git-cliff --> | {
"source": "alexpasmantier/television",
"title": "CHANGELOG.md",
"url": "https://github.com/alexpasmantier/television/blob/main/CHANGELOG.md",
"date": "2024-09-15T22:16:18",
"stars": 2410,
"description": "The revolution will (not) be televised 📺",
"file_size": 76039
} |
# Contributor Covenant Code of Conduct
## Our Pledge
We as members, contributors, and leaders pledge to make participation in our
community a harassment-free experience for everyone, regardless of age, body
size, visible or invisible disability, ethnicity, sex characteristics, gender
identity and expression, level of experience, education, socio-economic status,
nationality, personal appearance, race, religion, or sexual identity
and orientation.
We pledge to act and interact in ways that contribute to an open, welcoming,
diverse, inclusive, and healthy community.
## Our Standards
Examples of behavior that contributes to a positive environment for our
community include:
* Demonstrating empathy and kindness toward other people
* Being respectful of differing opinions, viewpoints, and experiences
* Giving and gracefully accepting constructive feedback
* Accepting responsibility and apologizing to those affected by our mistakes,
and learning from the experience
* Focusing on what is best not just for us as individuals, but for the
overall community
Examples of unacceptable behavior include:
* The use of sexualized language or imagery, and sexual attention or
advances of any kind
* Trolling, insulting or derogatory comments, and personal or political attacks
* Public or private harassment
* Publishing others' private information, such as a physical or email
address, without their explicit permission
* Other conduct which could reasonably be considered inappropriate in a
professional setting
## Enforcement Responsibilities
Community leaders are responsible for clarifying and enforcing our standards of
acceptable behavior and will take appropriate and fair corrective action in
response to any behavior that they deem inappropriate, threatening, offensive,
or harmful.
Community leaders have the right and responsibility to remove, edit, or reject
comments, commits, code, wiki edits, issues, and other contributions that are
not aligned to this Code of Conduct, and will communicate reasons for moderation
decisions when appropriate.
## Scope
This Code of Conduct applies within all community spaces, and also applies when
an individual is officially representing the community in public spaces.
Examples of representing our community include using an official e-mail address,
posting via an official social media account, or acting as an appointed
representative at an online or offline event.
## Enforcement
Instances of abusive, harassing, or otherwise unacceptable behavior may be
reported to the community leaders responsible for enforcement at
[email protected].
All complaints will be reviewed and investigated promptly and fairly.
All community leaders are obligated to respect the privacy and security of the
reporter of any incident.
## Enforcement Guidelines
Community leaders will follow these Community Impact Guidelines in determining
the consequences for any action they deem in violation of this Code of Conduct:
### 1. Correction
**Community Impact**: Use of inappropriate language or other behavior deemed
unprofessional or unwelcome in the community.
**Consequence**: A private, written warning from community leaders, providing
clarity around the nature of the violation and an explanation of why the
behavior was inappropriate. A public apology may be requested.
### 2. Warning
**Community Impact**: A violation through a single incident or series
of actions.
**Consequence**: A warning with consequences for continued behavior. No
interaction with the people involved, including unsolicited interaction with
those enforcing the Code of Conduct, for a specified period of time. This
includes avoiding interactions in community spaces as well as external channels
like social media. Violating these terms may lead to a temporary or
permanent ban.
### 3. Temporary Ban
**Community Impact**: A serious violation of community standards, including
sustained inappropriate behavior.
**Consequence**: A temporary ban from any sort of interaction or public
communication with the community for a specified period of time. No public or
private interaction with the people involved, including unsolicited interaction
with those enforcing the Code of Conduct, is allowed during this period.
Violating these terms may lead to a permanent ban.
### 4. Permanent Ban
**Community Impact**: Demonstrating a pattern of violation of community
standards, including sustained inappropriate behavior, harassment of an
individual, or aggression toward or disparagement of classes of individuals.
**Consequence**: A permanent ban from any sort of public interaction within
the community.
## Attribution
This Code of Conduct is adapted from the [Contributor Covenant][homepage],
version 2.0, available at
https://www.contributor-covenant.org/version/2/0/code_of_conduct.html.
Community Impact Guidelines were inspired by [Mozilla's code of conduct
enforcement ladder](https://github.com/mozilla/diversity).
[homepage]: https://www.contributor-covenant.org
For answers to common questions about this code of conduct, see the FAQ at
https://www.contributor-covenant.org/faq. Translations are available at
https://www.contributor-covenant.org/translations. | {
"source": "alexpasmantier/television",
"title": "CODE_OF_CONDUCT.md",
"url": "https://github.com/alexpasmantier/television/blob/main/CODE_OF_CONDUCT.md",
"date": "2024-09-15T22:16:18",
"stars": 2410,
"description": "The revolution will (not) be televised 📺",
"file_size": 5223
} |
# Contributing
First of all, thanks for considering contributing to this project. All contributions are welcome, whether they are bug
reports, documentation improvements, feature requests, or pull requests.
Please make sure to read and follow our [Code of Conduct](CODE_OF_CONDUCT.md) to ensure a positive experience for
everyone involved.
If you're not sure where to start, take a look at the [Hot Topics](#hot-topics) section for some ideas on what you could
work on.
## Table of Contents
- [Getting started](#getting-started)
- [Prerequisites](#prerequisites)
- [Forking the repository and setting up the project](#forking-the-repository-and-setting-up-the-project)
- [Building the project](#building-the-project)
- [Project structure](#project-structure)
- [Contributing a new channel](#contributing-a-new-channel)
- [Hot Topics](#hot-topics)
## Getting started
### Prerequisites
These are pretty much the only things you need to have installed on your machine to get started with contributing to
this project:
- the [Rust](https://www.rust-lang.org/tools/install) toolchain installed on your machine
- any working version of [Git](https://git-scm.com/downloads)
### Forking the repository and setting up the project
1. Click on the `Fork` button at the top right corner of the repository page to create a copy of the repository to your
GitHub account.
2. Clone the forked repository to your local machine by running the following command in your terminal:
```shell
git clone https://github.com/<your-username>/television.git
```
3. Navigate to the project directory and set up the upstream remote by running the following commands:
```shell
cd television
git remote add upstream https://github.com/alexpasmantier/television.git
```
4. Install the project dependencies by running the following command:
```shell
make setup
```
5. Create a new branch for your feature or bug fix:
```shell
git checkout -b <branch-name>
```
6. Make your changes and commit them to your branch:
```shell
git add .
git commit -m "Your commit message"
```
7. Push your changes to your forked repository:
```shell
git push origin <branch-name>
```
8. If not done automatically, create a pull request by navigating to the original repository and clicking on the
`New pull request` button.
### Building the project
Before anything else:
```shell
make setup
```
To run the application in debug mode while developing, with the ability to see logs and debug information:
```shell
make run
```
**Accessing the Logs:**
The logs are written to a file called `television.log` in a directory that depends on your operating system /
configuration:
| Platform | Location |
|----------|----------|
| Linux | `$XDG_DATA_HOME/television/television.log` or `$HOME/.local/share/television/television.log` |
| macOS | `$XDG_DATA_HOME/television/television.log` or `$HOME/Library/Application\ Support/television/television.log` |
| Windows | `{FOLDERID_LocalAppData}\television\television.log` |
To build the project in debug mode, run the following command in the project directory:
```shell
make
```
or
```shell
make build
```
To build the project in release mode, run the following command in the project directory:
```shell
make release
```
Formatting the code
```shell
make format
```
Linting the code
```shell
make lint
```
Running the tests
```shell
make test
```
### Project structure
The project is laid out in several rust crates that are organized in the following way:
- `television`: the main binary crate that contains the CLI application
- `television_derive`: a library crate that contains the derive macros used in the project
### Contributing a new channel
`television` is built around the concept of _channels_.
From a technical standpoint, channels are structs that implement the `OnAir` trait defined in
`television/channels/mod.rs`.
They can be anything that can respond to a user query and return a result under the form of a list of entries. This
means channels can be anything from conventional data sources you might want to search through (like files, git
repositories, remote filesystems, environment variables etc.) to more exotic implementations that might include a REPL,
a calculator, a web browser, search through your spotify library, your email, etc.
As mentioned in [Project structure](#project-structure) `television`
uses [crates](https://doc.rust-lang.org/book/ch07-01-packages-and-crates.html) for its different subcomponents (
_previewers_, _channels_, _utils_, etc).
When contributing a new channel, you should create a new module in the `crate::channels` crate with a new struct for
your channel and ensure that it implements the `OnAir` trait defined
in [crates/television-channels/src/channels.rs](crates/television-channels/src/channels.rs)
```rust
// crates/television-channels/src/channels/my_new_channel.rs
use crate::channels::OnAir;
pub struct MyNewChannel;
impl OnAir for MyNewChannel {
// Implement the OnAir trait for your channel here
}
```
You should also add your channel to the `TelevisionChannel` enum in the `crate::channels` crate.
```rust
// crates/television-channels/src/mod
#[derive(ToUnitChannel, ToCliChannel, Broadcast)]
pub enum TelevisionChannel {
// Other channels
MyNewChannel,
}
```
☝️ There are built-in channels in `television` that you might want to draw inspiration from if need be, they're located
at [crates/television-channels/src/channels](crates/television-channels/src/channels).
**TODO**: document transitions between channels and previewers
## Hot Topics
### Current hot topics:
- shell integration (autocomplete, keybindings)
- packaging for various linux package managers (apt, dnf, ...)
- configuring custom actions for each channel
### Other ideas:
See the [todo list](./TODO.md) for ideas.
- `Customization`:
- allow users to further customize the behavior of the application (e.g. the default channel, fuzzy matching
constants, channel heuristics, etc.)
- `Channels`:
- new channel ideas (builtin or cable):
- shell history
- directories
- git (commits, branches, status, diff, ...)
- remote filesystems (s3, ...)
- kubernetes resources (jobs, pods, deployments, services, ...)
- recent directories
- makefile commands
- etc.
- add more tests for existing channels
- `Previewers`:
- new previewer ideas:
- previewing text in documents (pdfs, archives, ...)
- previewing images (actually already implemented but commented out)
- remote files (s3, ...)
- etc.
- more tests for existing previewers
- `Documentation`:
- add more technical documentation to the project
- general design of the TUI application
- design of channels, previewers, transitions, etc.
- how to contribute a new channel, previewer, etc.
- more docstrings
- `Performance/Refactoring`:
- working on reducing coupling between the different crates in the project
- working on reducing the number of allocations and copies in the code
- writing benchmarks for different parts of the application
- `Project`:
- polish project configuration:
- CI/CD | {
"source": "alexpasmantier/television",
"title": "CONTRIBUTING.md",
"url": "https://github.com/alexpasmantier/television/blob/main/CONTRIBUTING.md",
"date": "2024-09-15T22:16:18",
"stars": 2410,
"description": "The revolution will (not) be televised 📺",
"file_size": 7277
} |
<div align="center">
# 📺 television
**A cross-platform, fast and extensible general purpose fuzzy finder TUI.**







</div>
## About
`Television` is a cross-platform, fast and extensible fuzzy finder TUI.
It lets you quickly search through any kind of data source (files, git repositories, environment variables, docker
images, you name it) using a fuzzy matching algorithm and is designed to be easily extensible.

It is inspired by the neovim [telescope](https://github.com/nvim-telescope/telescope.nvim) plugin and leverages [tokio](https://github.com/tokio-rs/tokio) and the [nucleo](https://github.com/helix-editor/nucleo) matcher used by the [helix](https://github.com/helix-editor/helix) editor to ensure optimal performance.
## Features
- ⚡️ **High Speed**: asynchronous I/O and multithreading to ensure a smooth and responsive UI.
- 🧠 **Fuzzy Matching**: cutting-edge fuzzy matching library for efficiently filtering through lists of entries.
- 🔋 **Batteries Included**: comes with a set of builtin channels and previewers that you can start using out of the box.
- 🐚 **Shell Integration**: benefit from smart completion anywhere using `television`'s shell integration.
- 📺 **Channels**: designed around the concept of channels, which are a set of builtin data sources that you can search through (e.g. files, git repositories, environment variables, etc).
- 📡 **Cable Channels**: users may add their own custom channels to tv using a simple and centralized configuration file.
- 📜 **Previewers**: allows you to preview the contents of an entry in a separate pane.
- 🖼️ **Builtin Syntax Highlighting**: comes with builtin asynchronous syntax highlighting for a wide variety of file types.
- 🎛️ **Keybindings**: includes a set of intuitive default keybindings inspired by vim and other popular terminal shortcuts.
- 🌈 **Themes**: either use one of the 10 builtin themes or create your own easily.
- 📦 **Cross-platform**: works on Linux, MacOS and Windows.
- ✅ **Terminal Emulator Compatibility**: television works flawlessly on all major terminal emulators.
## Installation
See the [installation docs](https://github.com/alexpasmantier/television/wiki/Installation).
## Usage
```bash
tv [channel] #[default: files] [possible values: env, files, git-repos, text, alias]
# e.g. to search through environment variables
tv env
# piping into tv (e.g. logs)
my_program | tv
# piping into tv with a custom preview command
fd -t f . | tv --preview 'bat -n --color=always {0}'
```
*For more information on the different channels, see the [channels](./docs/channels.md) documentation.*
> [!TIP]
> 🐚 *Television provides smart autocompletion based on the commands you start typing out of the box.*
>
> *Take a look at [this page](https://github.com/alexpasmantier/television/wiki/Shell-Autocompletion) for how to set it up for your shell.*
## Keybindings
For information about available keybindings, check the [associated page of the wiki](https://github.com/alexpasmantier/television/wiki/Keybindings)
## Configuration
For information about tv's configuration file, check the [associated page of the wiki](https://github.com/alexpasmantier/television/wiki/Configuration-file)
## Themes
Builtin themes are available in the [themes](./themes) directory. Feel free to experiment and maybe even contribute your own!
|  catppuccin |  gruvbox-dark |
|:--:|:--:|
|  **solarized-dark** |  **nord** |
You may create your own custom themes by adding them to the `themes` directory in your configuration folder and then referring to them by file name (without the extension) in the configuration file.
```
config_location/
├── themes/
│ └── my_theme.toml
└── config.toml
```
## Search Patterns
For information on how to use search patterns with tv, refer to the [associated page of the wiki](https://github.com/alexpasmantier/television/wiki/Search-patterns)
## Contributions
Contributions, issues and pull requests are welcome.
See [CONTRIBUTING.md](CONTRIBUTING.md) and [good first issues](https://github.com/alexpasmantier/television/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22) for more information.
## Credits
This project was inspired by the **awesome** work done by the [telescope](https://github.com/nvim-telescope/telescope.nvim) neovim plugin.
It also leverages the great [helix](https://github.com/helix-editor/helix) editor's nucleo fuzzy matching library, the [tokio](https://github.com/tokio-rs/tokio) async runtime as well as the **formidable** [ratatui](https://github.com/ratatui/ratatui) library. | {
"source": "alexpasmantier/television",
"title": "README.md",
"url": "https://github.com/alexpasmantier/television/blob/main/README.md",
"date": "2024-09-15T22:16:18",
"stars": 2410,
"description": "The revolution will (not) be televised 📺",
"file_size": 5464
} |
# bugs
- [x] index out of bounds when resizing the terminal to a very small size
- [x] meta previews in cache are not terminal size aware
# tasks
- [x] preview navigation
- [ ] add a way to open the selected file in the default editor (or maybe that
should be achieved using pipes?) --> xargs
- [x] maybe filter out image types etc. for now
- [x] return selected entry on exit
- [x] piping output to another command
- [x] piping custom entries from stdin (e.g. `ls | tv`, what bout choosing
previewers in that case? Some AUTO mode?)
- [x] documentation
## improvements
- [x] async finder initialization
- [x] async finder search
- [x] use nucleo for env
- [x] better keymaps
- [ ] mutualize placeholder previews in cache (really not a priority)
- [x] better abstractions for channels / separation / isolation so that others
can contribute new ones easily
- [x] channel selection in the UI (separate menu or top panel or something)
- [x] only render highlighted lines that are visible
- [x] only ever read a portion of the file for the temp preview
- [x] profile using dyn Traits instead of an enum for channels (might degrade performance by storing on the heap)
- [x] I feel like the finder abstraction is a superfluous layer, maybe just use
the channel directly?
- [x] support for images is implemented but do we really want that in the core?
it's quite heavy
- [x] shrink entry names that are too long (from the middle)
- [ ] more syntaxes for the previewer https://www.sublimetext.com/docs/syntax.html#include-syntax
- [ ] more preview colorschemes
## feature ideas
- [x] environment variables
- [x] aliases
- [ ] shell history
- [x] text
- [ ] text in documents (pdfs, archives, ...) (rga, adapters)
https://github.com/jrmuizel/pdf-extract
- [x] fd
- [ ] recent directories
- [ ] git (commits, branches, status, diff, ...)
- [ ] makefile commands
- [ ] remote files (s3, ...)
- [ ] custom actions as part of a channel (mappable)
- [x] add a way of copying the selected entry name/value to the clipboard
- [ ] have a keybinding to send all current entries to stdout
- [x] git repositories channel (crawl the filesystem for git repos) | {
"source": "alexpasmantier/television",
"title": "TODO.md",
"url": "https://github.com/alexpasmantier/television/blob/main/TODO.md",
"date": "2024-09-15T22:16:18",
"stars": 2410,
"description": "The revolution will (not) be televised 📺",
"file_size": 2155
} |
## 📺 Built-in Channels
The following built-in channels are currently available:
- `files`: search through files in a directory tree.
- `text`: search through textual content in a directory tree.
- `gitrepos`: search through git repositories anywhere on the file system.
- `env`: search through environment variables and their values.
- `alias`: search through shell aliases and their values.
- `stdin`: search through lines of text from stdin.
## 🍿 Cable channels
*Tired of broadcast television? Want to watch your favorite shows on demand? `television` has you covered with cable channels. Cable channels are channels that are not built-in to `television` but are instead provided by the community.*
You can find a list of cable channels ideas [on the wiki](https://github.com/alexpasmantier/television/wiki/Cable-channels).
### Installing cable channels
Installing cable channels is as simple as creating provider files in your configuration folder.
A provider file is a `*channels.toml` file that contains cable channel prototypes defined as follows:
**my-custom-channels.toml**
```toml
[[cable_channel]]
name = "git-log"
source_command = 'git log --oneline --date=short --pretty="format:%h %s %an %cd" "$@"'
preview_command = 'git show -p --stat --pretty=fuller --color=always {0}'
[[cable_channel]]
name = "my-dotfiles"
source_command = 'fd -t f . $HOME/.config'
preview_command = 'bat -n --color=always {0}'
```
This would add two new cable channels to `television` available:
- using the remote control mode
- through the cli (e.g. `tv git-log`, `tv my-dotfiles`)

<details>
<summary>Deciding which part of the source command output to pass to the previewer:</summary>
By default, each line of the source command can be passed to the previewer using `{}`.
If you wish to pass only a part of the output to the previewer, you may do so by specifying the `preview_delimiter` to use as a separator and refering to the desired part using the corresponding index.
**Example:**
```toml
[[cable_channel]]
name = "Disney channel"
source_command = 'echo "one:two:three:four" && echo "five:six:seven:eight"'
preview_command = 'echo {2}'
preview_delimiter = ':'
# which will pass "three" and "seven" to the preview command
```
</details> | {
"source": "alexpasmantier/television",
"title": "docs/channels.md",
"url": "https://github.com/alexpasmantier/television/blob/main/docs/channels.md",
"date": "2024-09-15T22:16:18",
"stars": 2410,
"description": "The revolution will (not) be televised 📺",
"file_size": 2335
} |
## Design (high-level)
#### Channels
**Television**'s design is primarily based on the concept of **Channels**.
Channels are just structs that implement the `OnAir` trait.
As such, channels can virtually be anything that can respond to a user query and return a result under the form of a list of entries. This means channels can be anything from conventional data sources you might want to search through (like files, git repositories, remote filesystems, environment variables etc.) to more exotic implementations that might inclue a REPL, a calculator, a web browser, search through your spotify library, your email, etc.
**Television** provides a set of built-in **Channels** that can be used out of the box (see [Built-in Channels](#built-in-channels)). The list of available channels
will grow over time as new channels are implemented to satisfy different use cases.
#### Transitions
When it makes sense, **Television** allows for transitions between different channels. For example, you might want to
start searching through git repositories, then refine your search to a specific set of files in that shortlist of
repositories and then finally search through the textual content of those files.
This can easily be achieved using transitions.
#### Previewers
Entries returned by different channels can be previewed in a separate pane. This is useful when you want to see the
contents of a file, the value of an environment variable, etc. Because entries returned by different channels may
represent different types of data, **Television** allows for channels to declare the type of previewer that should be
used. Television comes with a set of built-in previewers that can be used out of the box and will grow over time. | {
"source": "alexpasmantier/television",
"title": "docs/design.md",
"url": "https://github.com/alexpasmantier/television/blob/main/docs/design.md",
"date": "2024-09-15T22:16:18",
"stars": 2410,
"description": "The revolution will (not) be televised 📺",
"file_size": 1738
} |
## Terminal Emulators Compatibility
Here is a list of terminal emulators that have currently been tested with `television` and their compatibility status.
| Terminal Emulator | Tested Platforms | Compatibility |
| --- | :---: | :---: |
| Alacritty | macOS, Linux | ✅ |
| Kitty | macOS, Linux | ✅ |
| iTerm2 | macOS | ✅ |
| Ghostty | macOS | ✅ |
| Wezterm | macOS, Linux, Windows | ✅ |
| macOS Terminal | macOS | functional but coloring issues |
| Konsole | Linux | ✅ |
| Terminator | Linux | ✅ |
| Xterm | Linux | ✅ |
| Cmder | Windows | ✖️ |
| Foot | Linux | ✅ |
| Rio | macOS, Linux, Windows | ✅ |
| Warp | macOS | ✅ |
| Hyper | macOS | ✅ |
If you're able to test the application with a configuration not yet listed above, feel free to open a PR and add it here 🙏 | {
"source": "alexpasmantier/television",
"title": "docs/terminal_emulators.md",
"url": "https://github.com/alexpasmantier/television/blob/main/docs/terminal_emulators.md",
"date": "2024-09-15T22:16:18",
"stars": 2410,
"description": "The revolution will (not) be televised 📺",
"file_size": 767
} |
---
name: Bug report
about: Create a report to help us improve
title: ''
labels: bug
assignees: ''
---
**Description**
A description of what the bug is.
**Example**
A [minimal reproducible code example](https://stackoverflow.com/help/minimal-reproducible-example) where the bug happens.
**Expected behavior**
A description of what you expected to happen.
**Actual behavior**
A description of what actually happens.
**Environment**
- OS: [e.g. Windows]
- Rust version: [e.g. 1.50.0]
- Project version: [e.g. 0.1.0]
- [Any other dependency version if needed]
**Additional context**
Any other context about the bug here. | {
"source": "alexpasmantier/television",
"title": ".github/ISSUE_TEMPLATE/bug_report.md",
"url": "https://github.com/alexpasmantier/television/blob/main/.github/ISSUE_TEMPLATE/bug_report.md",
"date": "2024-09-15T22:16:18",
"stars": 2410,
"description": "The revolution will (not) be televised 📺",
"file_size": 628
} |
---
name: Feature request
about: Suggest an idea for this project
title: ''
labels: enhancement
assignees: ''
---
**Problem**
A description of what is the problem that can be fixed with the feature you propose.
**Feature**
A description of the feature you propose.
**Examples**
One or more code examples that shows the feature in action.
**Additional context**
Any other context about the feature request here. | {
"source": "alexpasmantier/television",
"title": ".github/ISSUE_TEMPLATE/feature_request.md",
"url": "https://github.com/alexpasmantier/television/blob/main/.github/ISSUE_TEMPLATE/feature_request.md",
"date": "2024-09-15T22:16:18",
"stars": 2410,
"description": "The revolution will (not) be televised 📺",
"file_size": 415
} |
# Changelog
All notable changes to this project will be documented in this file.
## [0.6.0-alpha.7] - 2025-02-25
### Added
- Added support for MCP server overrides in the marketplace
- Implemented hardcoded overrides in `MCP_OVERRIDES` map
- Added override for google-calendar-mcp to use eastlondoner fork
- Overrides can specify custom `githubUrl`, `command`, and `args`
- Preserves environment variables when using overrides
- Type-safe implementation ensures overrides match the MCPServer interface
- Overrides take precedence over marketplace data and automatic GitHub repository checks
- Logs when an override is applied using console.log for transparency
- Added support for user-configurable overrides in `cursor-tools.config.json`
- Users can define custom overrides in the `mcp.overrides` section
- Config overrides take precedence over hardcoded overrides
- Warns when a config override replaces a hardcoded override
### Changed
- Updated all references to Claude 3.5 Sonnet models to Claude 3.7 Sonnet models throughout the codebase
- Updated model references in configuration files, documentation, and source code
- Updated default model settings for Anthropic provider
- Updated error messages and model suggestions
- Used `claude-3-7-sonnet` for most use cases and `claude-3-7-sonnet-thinking` for MCP client
- Updated @browserbasehq/stagehand dependency from 1.13.0 to 1.13.1
## [0.6.0-alpha.5] - 2024-03-22
### Changed
- cursor-tools now only recommends global installation
- Updated install command to check for and warn about cursor-tools dependencies in package.json files
- Checks both dependencies and devDependencies in package.json
- Provides clear instructions for removing local installations using npm, pnpm, or yarn
- This is in response to multiple issues caused by local installation and execution under different js runtimes
## [0.6.0-alpha.4] - 2024-03-22
### Changed
- Added validation to require --tag alpha or --tag latest when running release command
## [0.6.0-alpha.3] - 2024-03-22
### Added
- Added ModelBox provider for access to a wider range of models through an OpenAI-compatible API
- Added OpenRouter provider to enable access to models from various providers including Perplexity
### Changed
- Improved browser command state management when using `--connect-to`:
- Reuses existing browser tabs for subsequent commands in a session, preserving page state
- Introduced `reload-current` as a special URL value to refresh the current page without losing the connected session
## [0.6.0-alpha.1] - 2024-03-22
### Fixed
- Fixed debug logging in all provider commands to properly pass through the debug flag
- Fixed `ask` command to pass debug flag to provider
- Fixed `web` command to properly handle debug flag
- Fixed `doc` command to include debug flag in options
- Fixed `plan` command to pass debug flag to both file and thinking providers
- Standardized debug logging format across all providers
- Debug logs now show full request and response details when enabled
### Changed
- Changed default thinking provider for plan command to OpenAI with o3-mini model for significantly faster plan generation, while maintaining plan quality
- Browser commands (`open`, `act`, `observe`, `extract`) now have `--console` and `--network` options enabled by default. Use `--no-console` and `--no-network` to disable them.
- Improved page reuse in browser commands when using `--connect-to`: now reuses existing tabs instead of creating new ones for better state preservation
- Improved error handling and type safety in cursor rules management
- Enhanced directory creation order in installation process
- Added user choice during installation for cursor rules location (legacy `.cursorrules` or new `.cursor/rules/cursor-tools.mdc`)
- Added `USE_LEGACY_CURSORRULES` environment variable to control cursor rules file location
- Improved output handling across all commands:
- Centralized output handling in main CLI
- Commands now yield output consistently
- Better error handling for file writes
- Added timeout protection for stdout writes
- More reliable output flushing
### Added
- New `ask` command for direct model queries
- Requires both provider and model parameters
- Allows querying any model from any provider directly
- Simple and focused command for direct questions
- Support for new Cursor IDE project rules structure
- New installations now use `.cursor/rules/cursor-tools.mdc` by default
- Maintain compatibility with legacy `.cursorrules` file via `USE_LEGACY_CURSORRULES=true`
- Interactive choice during installation
- When both exist, use path based on `USE_LEGACY_CURSORRULES` environment variable
- Updated documentation to reflect new path structure
- Added support for the `gpt-4o` model in browser commands (`act`, `extract`, `observe`)
- The model can be selected using the `--model=gpt-4o` command-line option
- The default model can be configured in `cursor-tools.config.json`
- If no model is specified, a default model is used based on the configured provider (OpenAI or Anthropic)
- **Internal:** Bundled Stagehand script directly into the codebase to prevent dependency issues
- **Build:** Added stagehand script verification to the release process
- Enhanced `plan` command with dual-provider architecture:
- Separate providers for file identification and plan generation
- `fileProvider` handles repository file analysis
- `thinkingProvider` generates implementation plans
- New command options:
- `--fileProvider`: Provider for file identification (gemini, openai, or openrouter)
- `--thinkingProvider`: Provider for plan generation (gemini, openai, or openrouter)
- `--fileModel`: Model to use for file identification
- `--thinkingModel`: Model to use for plan generation
- `--fileMaxTokens`: Maximum tokens for file identification
- `--thinkingMaxTokens`: Maximum tokens for plan generation
- Brand new provider system with enhanced error handling and configuration:
- New provider interfaces for specialized tasks
- Shared implementations via provider mixins
- Better error messages and debugging support
- Configurable system prompts for different tasks
- Added `--quiet` flag to suppress stdout output while still saving to file with `--save-to`
- Useful for scripting and automated documentation generation
- All commands now support quiet mode
- Error messages are still displayed even in quiet mode
## [0.4.3-alpha.23] - 2024-03-22
### Fixed
- Fixed browser commands to respect system color scheme when using `--connect-to` by not forcing a specific color scheme
## [0.4.3-alpha.22] - 2024-03-22
### Fixed
- Fixed browser commands to not set viewport size in Stagehand when using `--connect-to`
## [0.4.3-alpha.21] - 2024-03-22
### Fixed
- Fixed browser commands to not set viewport size when using `--connect-to` without an explicit `--viewport` option
## [0.4.3-alpha.20] - 2024-03-22
### Changed
- Browser commands (`open`, `act`, `observe`, `extract`) now have `--console` and `--network` options enabled by default. Use `--no-console` and `--no-network` to disable them.
## [0.4.3-alpha.19] - 2024-03-22
### Fixed
- Fixed browser commands to always reuse existing tabs when using `--connect-to` instead of creating new ones
## [0.4.3-alpha.18] - 2024-03-22
### Changed
- Browser commands now preserve viewport size when using `--connect-to` unless `--viewport` is explicitly provided
- Added validation to prevent using `--video` with `--connect-to` as video recording is not supported when connecting to existing Chrome instances
## [0.4.3-alpha.17] - 2024-03-22
### Added
- Added `reload-current` as a special URL value for browser commands when using `--connect-to`. This allows refreshing the current page while maintaining the connection, which is particularly useful in development workflows.
## [0.4.3-alpha.15] - 2024-03-21
### Fixed
- Fixed console logging in browser act command by correcting parameter order in outputMessages call
## [0.4.3-alpha.13] - 2024-03-21
### Added
- Browser commands now support `--url=current` to skip navigation and use the current page
- Browser commands now automatically skip navigation if already on the correct URL
- Improved page reuse when connecting to existing Chrome instance
## [0.4.3-alpha.12] - 2025-02-07
### Added
- New `browser` command for AI-powered web automation and debugging, leveraging Stagehand AI for natural language interaction
- `act <instruction> --url <url> [options]`: Execute actions on a webpage using natural language instructions
- `<instruction>`: Natural language instruction describing the action (e.g., "Click Login", "Type 'hello' in the search box")
- `--url <url>`: Required URL to navigate to before performing actions
- Additional options:
- `--delay=<milliseconds>`: Delay between actions (default: 100)
- `--retry=<number>`: Number of retries for failed actions (default: 3)
- `extract <instruction> --url <url> [options]`: Extract data from webpages based on natural language instructions
- `<instruction>`: Natural language instruction describing the data to extract (e.g., "product names", "article content")
- `--url <url>`: Required URL to navigate to
- Additional options:
- `--format=<json|csv|text>`: Output format (default: json)
- `--flatten`: Flatten nested objects in output
- `observe <instruction> --url <url> [options]`: Observe interactive elements on a webpage and suggest possible actions
- `<instruction>`: Natural language instruction describing what to observe (e.g., "interactive elements", "login form")
- `--url <url>`: Required URL to navigate to
- Additional options:
- `--interval=<milliseconds>`: Check interval for observation (default: 1000)
- `--duration=<duration>`: Total observation time (e.g., '30s', '5m')
- `--changes-only`: Only report when changes are detected
- `open <url> [options]`: Open and interact with web pages
- Capture HTML content with `--html`
- Monitor console logs with `--console`
- Track network activity with `--network`
- Take screenshots with `--screenshot=<file path>`
- Configure viewport size with `--viewport=<width>x<height>`
- Debug with visible browser using `--no-headless`
- Connect to existing Chrome instances with `--connect-to=<port>`
- Common options for all browser commands:
- `--timeout=<milliseconds>`: Set navigation timeout (default: 30000)
- `--viewport=<width>x<height>`: Set viewport size (e.g., 1280x720)
- `--headless`: Run browser in headless mode (default: true)
- `--no-headless`: Show browser UI for visual inspection and debugging
- `--connect-to=<port>`: Connect to an existing Chrome instance
- `--wait=<duration or selector>`: Wait after page load, supports:
- Time duration: '5s', '1000ms', '2m' (seconds, milliseconds, minutes)
- CSS selector: '#element-id', '.my-class'
- Explicit format: 'time:5s', 'selector:#element-id', 'css:.my-class'
- Made Playwright a peer dependency for lighter installation
- Added browser configuration options in config file (headless mode, viewport, timeout)
- Integrated Stagehand AI for browser automation
- Support for OpenAI and Anthropic providers
- Auto-selection of provider based on available API keys
- Configurable timeout and debug options
### Changed
- Moved Playwright from direct dependency to peer dependency
- Users need to install Playwright separately to use browser commands
- Added clear installation instructions and error messages
## [0.4.3-alpha.10] - 2025-02-07
### Fixed
- Fixed punycode deprecation warning by properly redirecting both `punycode` and `node:punycode` imports to `punycode/`
## [0.4.3-alpha.9] - 2025-02-07
### Fixed
- Fixed dynamic require issues with Node.js built-in modules by using proper ESM imports
- Improved handling of Node.js built-in modules in build configuration
## [0.4.1] - 2025-02-06
### Changed
- Changed default tokenizer to `o200k_base` for better compatibility with Gemini models
- Added configurable tokenizer support through `tokenCount.encoding` in config file
- Updated documentation to reflect new tokenizer configuration options
## [0.4.0] - 2025-02-06
### Improvements
- Big improvements to robustness of command line arguments
- Introduces doc command to generate documentation for local or remote repositories
- Introduces github command to access PRs and issues from github
- Support for listing recent PRs and issues
- Detailed view of PR/issue discussions and code review comments
- Multiple authentication methods:
- GitHub token via environment variable
- GitHub CLI integration for automatic token generation
- Git credentials support (stored tokens or Basic Auth)
- Support for both local and remote repositories
- Markdown-formatted output for readability
- Use token count estimation to switch gemini models to pro if repository is large to fit any other model
- Updates GitHub model names to latest versions
- Updates Perplexity model names to latest versions
- Added version command to display the current version of cursor-tools
### Fixed
- Improved GitHub authentication error handling and rate limit messages
- Better detection of stored GitHub tokens in git credentials
- Fixed authentication status messages to accurately reflect available methods
## [0.3.4] - 2025-02-05
### Fixed
- Fixed ESM compatibility issues with Node.js built-in modules
- Removed bundling of Node.js built-ins for better ESM support
- Reduced bundle size by externalizing Node.js core modules
## [0.3.3] - 2025-02-05
### Fixed
- Fixed dynamic require issues with Node.js built-in modules
- Updated build configuration to properly handle Node.js built-ins in ESM context
## [0.3.2] - 2025-02-05
### Fixed
- Fixed dynamic require of url module in ESM context
- Updated import-meta-url.js to use proper ESM imports
## [0.3.1] - 2025-02-05
### Changed
- Improved release process with dedicated release script
- Fixed ESM compatibility issues with dependencies
- Added better error handling for git operations during release
## [0.3.0] - 2025-02-05
### Changed
- Updated build configuration to output ES Module format for better Node.js 20+ compatibility
- Changed output file from CommonJS (.cjs) to ES Module (.mjs)
- Fixed ESM compatibility issues with dependencies
## [0.2.0] - 2025-02-05
### Added
- Added branch support for GitHub repositories in `doc` command
- Support for specifying branch using `@branch` syntax (e.g. `--fromGithub=username/repo@branch`)
- Works with both HTTPS URLs and shorthand format
- Properly integrates with repomix API using the `ref` parameter
## [0.1.0] - 2025-02-04
### Added
- New `doc` command to generate comprehensive repository documentation
- Support for local repository documentation generation
- Support for remote GitHub repository documentation via `--fromGithub` option
- Option to save documentation to file with `--output`
- Development mode support via `pnpm dev` for running latest code without building
### Changed
- Updated `.cursorrules` to include documentation for the new `doc` command
- Improved command-line argument parsing for better option handling
## [0.0.14] - Previous Release
Initial release with basic functionality:
- Web search using Perplexity AI
- Repository context-aware answers using Google Gemini
- Installation and configuration utilities | {
"source": "eastlondoner/cursor-tools",
"title": "CHANGELOG.md",
"url": "https://github.com/eastlondoner/cursor-tools/blob/main/CHANGELOG.md",
"date": "2025-01-13T15:03:33",
"stars": 2408,
"description": "Give Cursor Agent an AI Team and Advanced Skills",
"file_size": 15582
} |
# cursor-tools Configuration Guide
This document provides detailed configuration information for cursor-tools.
## Configuration Overview
cursor-tools can be configured through two main mechanisms:
1. Environment variables (API keys and core settings)
2. JSON configuration file (provider settings, model preferences, and command options)
## Environment Variables
Create `.cursor-tools.env` in your project root or `~/.cursor-tools/.env` in your home directory:
```env
# Required API Keys
PERPLEXITY_API_KEY="your-perplexity-api-key" # Required for web search
GEMINI_API_KEY="your-gemini-api-key" # Required for repository analysis
# Optional API Keys
OPENAI_API_KEY="your-openai-api-key" # For browser commands with OpenAI
ANTHROPIC_API_KEY="your-anthropic-api-key" # For browser commands with Anthropic
GITHUB_TOKEN="your-github-token" # For enhanced GitHub access
# Configuration Options
USE_LEGACY_CURSORRULES="true" # Use legacy .cursorrules file (default: false)
```
## Configuration File (cursor-tools.config.json)
Create this file in your project root to customize behavior. Here's a comprehensive example with all available options:
```json
{
"perplexity": {
"model": "sonar-pro", // Default model for web search
"maxTokens": 8000 // Maximum tokens for responses
},
"gemini": {
"model": "gemini-2.0-pro-exp", // Default model for repository analysis
"maxTokens": 10000 // Maximum tokens for responses
},
"plan": {
"fileProvider": "gemini", // Provider for file identification
"thinkingProvider": "openai", // Provider for plan generation
"fileMaxTokens": 8192, // Tokens for file identification
"thinkingMaxTokens": 8192 // Tokens for plan generation
},
"repo": {
"provider": "gemini", // Default provider for repo command
"maxTokens": 10000 // Maximum tokens for responses
},
"doc": {
"maxRepoSizeMB": 100, // Maximum repository size for remote docs
"provider": "gemini", // Default provider for doc generation
"maxTokens": 10000 // Maximum tokens for responses
},
"browser": {
"defaultViewport": "1280x720", // Default browser window size
"timeout": 30000, // Default timeout in milliseconds
"stagehand": {
"env": "LOCAL", // Stagehand environment
"headless": true, // Run browser in headless mode
"verbose": 1, // Logging verbosity (0-2)
"debugDom": false, // Enable DOM debugging
"enableCaching": false, // Enable response caching
"model": "claude-3-7-sonnet-latest", // Default Stagehand model
"provider": "anthropic", // AI provider (anthropic or openai)
"timeout": 30000 // Operation timeout
}
},
"tokenCount": {
"encoding": "o200k_base" // Token counting method
},
"openai": {
"maxTokens": 8000 // Will be used when provider is "openai"
},
"anthropic": {
"maxTokens": 8000 // Will be used when provider is "anthropic"
}
}
```
## Configuration Sections
### Perplexity Settings
- `model`: The AI model to use for web searches
- `maxTokens`: Maximum tokens in responses
### Gemini Settings
- `model`: The AI model for repository analysis
- `maxTokens`: Maximum tokens in responses
- Note: For repositories >800K tokens, automatically switches to gemini-2.0-pro-exp
### Plan Command Settings
- `fileProvider`: AI provider for identifying relevant files
- `thinkingProvider`: AI provider for generating implementation plans
- `fileMaxTokens`: Token limit for file identification
- `thinkingMaxTokens`: Token limit for plan generation
### Repository Command Settings
- `provider`: Default AI provider for repository analysis
- `maxTokens`: Maximum tokens in responses
### Documentation Settings
- `maxRepoSizeMB`: Size limit for remote repositories
- `provider`: Default AI provider for documentation
- `maxTokens`: Maximum tokens in responses
### Browser Automation Settings
- `defaultViewport`: Browser window size
- `timeout`: Navigation timeout
- `stagehand`: Stagehand-specific settings including:
- `env`: Environment configuration
- `headless`: Browser visibility
- `verbose`: Logging detail level
- `debugDom`: DOM debugging
- `enableCaching`: Response caching
- `model`: Default AI model
- `provider`: AI provider selection
- `timeout`: Operation timeout
### Token Counting Settings
- `encoding`: Method used for counting tokens
- `o200k_base`: Optimized for Gemini (default)
- `gpt2`: Traditional GPT-2 encoding
## GitHub Authentication
The GitHub commands support several authentication methods:
1. **Environment Variable**: Set `GITHUB_TOKEN` in your environment:
```env
GITHUB_TOKEN=your_token_here
```
2. **GitHub CLI**: If you have the GitHub CLI (`gh`) installed and logged in, cursor-tools will automatically use it to generate tokens with the necessary scopes.
3. **Git Credentials**: If you have authenticated git with GitHub (via HTTPS), cursor-tools will automatically:
- Use your stored GitHub token if available (credentials starting with `ghp_` or `gho_`)
- Fall back to using Basic Auth with your git credentials
To set up git credentials:
1. Configure git to use HTTPS instead of SSH:
```bash
git config --global url."https://github.com/".insteadOf [email protected]:
```
2. Store your credentials:
```bash
git config --global credential.helper store # Permanent storage
# Or for macOS keychain:
git config --global credential.helper osxkeychain
```
3. The next time you perform a git operation requiring authentication, your credentials will be stored
Authentication Status:
- Without authentication:
- Public repositories: Limited to 60 requests per hour
- Private repositories: Not accessible
- Some features may be restricted
- With authentication (any method):
- Public repositories: 5,000 requests per hour
- Private repositories: Full access (if token has required scopes)
cursor-tools will automatically try these authentication methods in order:
1. `GITHUB_TOKEN` environment variable
2. GitHub CLI token (if `gh` is installed and logged in)
3. Git credentials (stored token or Basic Auth)
If no authentication is available, it will fall back to unauthenticated access with rate limits.
## Repomix Configuration
When generating documentation, cursor-tools uses Repomix to analyze your repository. By default, it excludes certain files and directories that are typically not relevant for documentation:
- Node modules and package directories (`node_modules/`, `packages/`, etc.)
- Build output directories (`dist/`, `build/`, etc.)
- Version control directories (`.git/`)
- Test files and directories (`test/`, `tests/`, `__tests__/`, etc.)
- Configuration files (`.env`, `.config`, etc.)
- Log files and temporary files
- Binary files and media files
You can customize the files and folders to exclude by adding a `.repomixignore` file to your project root.
Example `.repomixignore` file for a Laravel project:
```
vendor/
public/
database/
storage/
.idea
.env
```
This ensures that the documentation focuses on your actual source code and documentation files.
Support to customize the input files to include is coming soon - open an issue if you run into problems here.
## Model Selection
The `browser` commands support different AI models for processing. You can select the model using the `--model` option:
```bash
# Use gpt-4o
cursor-tools browser act "Click Login" --url "https://example.com" --model=gpt-4o
# Use Claude 3.7 Sonnet
cursor-tools browser act "Click Login" --url "https://example.com" --model=claude-3-7-sonnet-latest
```
You can set a default provider in your `cursor-tools.config.json` file under the `stagehand` section:
```json
{
"stagehand": {
"provider": "openai", // or "anthropic"
}
}
```
You can also set a default model in your `cursor-tools.config.json` file under the `stagehand` section:
```json
{
"stagehand": {
"provider": "openai", // or "anthropic"
"model": "gpt-4o"
}
}
```
If no model is specified (either on the command line or in the config), a default model will be used based on your configured provider:
- **OpenAI:** `o3-mini`
- **Anthropic:** `claude-3-7-sonnet-latest`
Available models depend on your configured provider (OpenAI or Anthropic) in `cursor-tools.config.json` and your API key.
## Cursor Configuration
`cursor-tools` automatically configures Cursor by updating your project rules during installation. This provides:
- Command suggestions
- Usage examples
- Context-aware assistance
For new installations, we use the recommended `.cursor/rules/cursor-tools.mdc` path. For existing installations, we maintain compatibility with the legacy `.cursorrules` file. If both files exist, we prefer the new path and show a warning.
### Cursor Agent Configuration
To get the benefits of cursor-tools you should use Cursor agent in "yolo mode". Ideal settings:

## Command-Specific Configuration
### Ask Command
The `ask` command requires both a provider and a model to be specified. While these must be provided via command-line arguments, the maxTokens can be configured through the provider-specific settings:
```json
{
"openai": {
"maxTokens": 8000 // Will be used when provider is "openai"
},
"anthropic": {
"maxTokens": 8000 // Will be used when provider is "anthropic"
}
}
```
### Plan Command
The plan command uses two different models:
1. A file identification model (default: Gemini with gemini-2.0-pro-exp)
2. A thinking model for plan generation (default: OpenAI with o3-mini)
You can configure both models and their providers:
```json
{
"plan": {
"fileProvider": "gemini",
"thinkingProvider": "openai",
"fileModel": "gemini-2.0-pro-exp",
"thinkingModel": "o3-mini",
"fileMaxTokens": 8192,
"thinkingMaxTokens": 8192
}
}
```
The OpenAI o3-mini model is chosen as the default thinking provider for its speed and efficiency in generating implementation plans. | {
"source": "eastlondoner/cursor-tools",
"title": "CONFIGURATION.md",
"url": "https://github.com/eastlondoner/cursor-tools/blob/main/CONFIGURATION.md",
"date": "2025-01-13T15:03:33",
"stars": 2408,
"description": "Give Cursor Agent an AI Team and Advanced Skills",
"file_size": 10264
} |
<div align="center">
<img height="72" src="https://github.com/user-attachments/assets/45eff178-242f-4d84-863e-247b080cc6f5" />
</div>
<div align=center><h1>Give Cursor Agent an AI team and advanced skills</h1></div>
## Table of Contents
- [The AI Team](#the-ai-team)
- [New Skills](#new-skills-for-your-existing-agent)
- [How to Use](#how-do-i-use-it)
- [Example: Using Perplexity](#asking-perplexity-to-carry-out-web-research)
- [Example: Using Gemini](#asking-gemini-for-a-plan)
- [What is cursor-tools](#what-is-cursor-tools)
- [Installation](#installation)
- [Requirements](#requirements)
- [Tips](#tips)
- [Additional Examples](#additional-examples)
- [GitHub Skills](#github-skills)
- [Gemini Code Review](#gemini-code-review)
- [Detailed Cursor Usage](#detailed-cursor-usage)
- [Tool Recommendations](#tool-recommendations)
- [Command Nicknames](#command-nicknames)
- [Web Search](#use-web-search)
- [Repository Search](#use-repo-search)
- [Documentation Generation](#use-doc-generation)
- [GitHub Integration](#use-github-integration)
- [Browser Automation](#use-browser-automation)
- [Direct Model Queries](#use-direct-model-queries)
- [Authentication and API Keys](#authentication-and-api-keys)
- [AI Team Features](#ai-team-features)
- [Perplexity: Web Search & Research](#perplexity-web-search--research)
- [Gemini 2.0: Repository Context & Planning](#gemini-20-repository-context--planning)
- [Stagehand: Browser Automation](#stagehand-browser-automation)
- [Browser Command Options](#browser-command-options)
- [Video Recording](#video-recording)
- [Console and Network Logging](#console-and-network-logging)
- [Complex Actions](#complex-actions)
- [Troubleshooting Browser Commands](#troubleshooting-browser-commands)
- [Skills](#skills)
- [GitHub Integration](#github-integration)
- [Documentation Generation](#documentation-generation-uses-gemini-20)
- [Configuration](#configuration)
- [cursor-tools.config.json](#cursor-toolsconfigjson)
- [GitHub Authentication](#github-authentication)
- [Repomix Configuration](#repomix-configuration)
- [Model Selection](#model-selection)
- [Cursor Configuration](#cursor-configuration)
- [Cursor Agent Configuration](#cursor-agent-configuration)
- [cursor-tools cli](#cursor-tools-cli)
- [Command Options](#command-options)
- [Execution Methods](#execution-methods)
- [Troubleshooting](#troubleshooting)
- [Examples](#examples)
- [Web Search Examples](#web-search-examples)
- [Repository Context Examples](#repository-context-examples)
- [Documentation Examples](#documentation-examples)
- [GitHub Integration Examples](#github-integration-examples)
- [Browser Command Examples](#browser-command-examples)
- [open subcommand examples](#open-subcommand-examples)
- [act, extract, observe subcommands examples](#act-extract-observe-subcommands-examples)
- [Node Package Manager](#node-package-manager-npm)
- [Contributing](#contributing)
- [Sponsors](#sponsors)
- [License](#license)
### The AI Team
- Perplexity to search the web and perform deep research
- Gemini 2.0 for huge whole-codebase context window, search grounding and reasoning
- Stagehand for browser operation to test and debug web apps (uses Anthropic or OpenAI models)
### New Skills for your existing Agent
- Work with GitHub Issues and Pull Requests
- Generate local agent-accessible documentation for external dependencies
`cursor-tools` is optimized for Cursor Composer Agent but it can be used by any coding agent that can execute commands
### How do I use it?
After installation, to see AI teamwork in action just ask Cursor Composer to use Perplexity or Gemini.
Here are two examples:
<div align="center">
<div>
<h3>Asking Perplexity to carry out web research</h3>
</div>
<div style="display: flex;">
<img width="350" alt="image" src="https://github.com/user-attachments/assets/d136c007-387b-449c-9737-553b34e71bbd" />
</div>
<details>
<summary>see what happens next...</summary>
<img width="350" alt="image" src="https://github.com/user-attachments/assets/06566162-fbaa-492a-8ce8-1a51e0713ee8" />
<details>
<summary>see what happens next...</summary>
<img width="350" alt="image" src="https://github.com/user-attachments/assets/fbca8d46-0e0e-4752-922e-62cceec6c12b" />
<details>
<summary>see what happens next...</summary>
<img width="1172" alt="image" src="https://github.com/user-attachments/assets/4bdae605-6f6c-43c3-b10c-c0263060033c" />
</details>
</details>
</details>
see the spec composer and perplexity produced together:
<a href="https://github.com/eastlondoner/pac-man/blob/main/specs/pac-man-spec.md">pac-man-spec.md</a> (link out to the example repo)
<br/>
<br/>
</div>
</div>
<div align="center">
<div>
<h3>Asking Gemini for a plan</h3>
</div>
<div style="display: flex;">
<img width="350" src="https://github.com/user-attachments/assets/816daee4-0a31-4a6b-8aac-39796cb03b51" />
</div>
<details>
<summary>see what happens next...</summary>
<img width="350" alt="image" src="https://github.com/user-attachments/assets/b44c4cc2-6498-42e8-bda6-227fbfed0a7c" />
<details>
<summary>see what happens next...</summary>
<img width="350" alt="image" src="https://github.com/user-attachments/assets/dcfcac67-ce79-4cd1-a66e-697c654ee986" />
<details>
<summary>see what happens next...</summary>
<img width="350" alt="image" src="https://github.com/user-attachments/assets/8df7d591-f48b-463d-8d9b-f7e9c1c9c95b" />
</details>
</details>
</details>
see the spec composer and perplexity produced together:
<a href="https://github.com/eastlondoner/pac-man/blob/main/specs/pac-man-plan.md">pac-man-plan.md</a> (link out to the example repo)
<br/>
<br/>
</div>
</div>
## What is cursor-tools
`cursor-tools` provides a CLI that your **AI agent can use** to expand its capabilities. `cursor-tools` is designed to be installed globally, providing system-wide access to its powerful features. When you run `cursor-tools install` we automatically add a prompt section to your Cursor project rules. During installation, you can choose between:
- The new `.cursor/rules/cursor-tools.mdc` file (recommended)
- The legacy `.cursorrules` file (for backward compatibility)
You can also control this using the `USE_LEGACY_CURSORRULES` environment variable:
- `USE_LEGACY_CURSORRULES=true` - Use legacy `.cursorrules` file
- `USE_LEGACY_CURSORRULES=false` - Use new `.cursor/rules/cursor-tools.mdc` file
- If not set, defaults to legacy mode for backward compatibility
`cursor-tools` requires a Perplexity API key and a Google AI API key.
`cursor-tools` is a node package that should be installed globally.
## Installation
Install cursor-tools globally:
```bash
npm install -g cursor-tools
```
Then run the interactive setup:
```bash
cursor-tools install .
```
This command will:
1. Guide you through API key configuration
2. Update your Cursor project rules for Cursor integration (using `.cursor/rules/cursor-tools.mdc` or existing `.cursorrules`)
## Requirements
- Node.js 18 or later
- Perplexity API key
- Google Gemini API key
- For browser commands:
- Playwright (`npm install --global playwright`)
- OpenAI API key or Anthropic API key (for `act`, `extract`, and `observe` commands)
`cursor-tools` uses Gemini-2.0 because it is the only good LLM with a context window that goes up to 2 million tokens - enough to handle and entire codebase in one shot. Gemini 2.0 experimental models that we use by default are currently free to use on Google and you need a Google Cloud project to create an API key.
`cursor-tools` uses Perplexity because Perplexity has the best web search api and indexes and it does not hallucinate. Perplexity Pro users can get an API key with their pro account and recieve $5/month of free credits (at time of writing). Support for Google search grounding is coming soon but so far testing has shown it still frequently hallucinates things like APIs and libraries that don't exist.
## Tips:
- Ask Cursor Agent to have Gemini review its work
- Ask Cursor Agent to generate documentation for external dependencies and write it to a local-docs/ folder
If you do something cool with `cursor-tools` please let me know on twitter or make a PR to add to this section!
## Additional Examples
### GitHub Skills
To see cursor-tools GitHub and Perplexity skills: Check out [this example issue that was solved using Cursor agent and cursor-tools](https://github.com/eastlondoner/cursor-tools/issues/1)
### Gemini code review
See cursor get approximately 5x more work done per-prompt with Gemini code review:
<img width="1701" alt="long view export" src="https://github.com/user-attachments/assets/a8a63f4a-1818-4e84-bb1f-0f60d82c1c42" />
## Detailed Cursor Usage
Use Cursor Composer in agent mode with command execution (not sure what this means, see section below on Cursor Agent configuration). If you have installed the cursor-tools prompt to your .cursorrules (or equivalent) just ask your AI coding agent/assistant to use "cursor-tools" to do things.
### Tool Recommendations
- `cursor-tools ask` allows direct querying of any model from any provider. It's best for simple questions where you want to use a specific model or compare responses from different models.
- `cursor-tools web` uses an AI teammate with web search capability to answer questions. `web` is best for finding up-to-date information from the web that is not specific to the repository such as how to use a library to search for known issues and error messages or to get suggestions on how to do something. Web is a teammate who knows tons of stuff and is always up to date.
- `cursor-tools repo` uses an AI teammate with large context window capability to answer questions. `repo` sends the entire repo as context so it is ideal for questions about how things work or where to find something, it is also great for code review, debugging and planning. is a teammate who knows the entire codebase inside out and understands how everything works together.
- `cursor-tools plan` uses an AI teammate with reasoning capability to plan complex tasks. Plan uses a two step process. First it does a whole repo search with a large context window model to find relevant files. Then it sends only those files as context to a thinking model to generate a plan it is great for planning complex tasks and for debugging and refactoring. Plan is a teammate who is really smart on a well defined problem, although doesn't consider the bigger picture.
- `cursor-tools doc` uses an AI teammate with large context window capability to generate documentation for local or github hosted repositories by sending the entire repo as context. `doc` can be given precise documentation tasks or can be asked to generate complete docs from scratch it is great for generating docs updates or for generating local documentation for a libary or API that you use! Doc is a teammate who is great at summarising and explaining code, in this repo or in any other repo!
- `cursor-tools browser` uses an AI teammate with browser control (aka operator) capability to operate web browsers. `browser` can operate in a hidden (headless) mode to invisibly test and debug web apps or it can be used to connect to an existing browser session to interactively share your browser with Cursor agent it is great for testing and debugging web apps and for carrying out any task that can be done in a browser such as reading information from a bug ticket or even filling out a form. Browser is a teammate who can help you test and debug web apps, and can share control of your browser to perform small browser-based tasks.
Note: For repo, doc and plan commands the repository content that is sent as context can be reduced by filtering out files in a .repomixignore file.
### Command Nicknames
When using cursor-tools with Cursor Composer, you can use these nicknames:
- "Gemini" is a nickname for `cursor-tools repo`
- "Perplexity" is a nickname for `cursor-tools web`
- "Stagehand" is a nickname for `cursor-tools browser`
### Use web search
"Please implement country specific stripe payment pages for the USA, UK, France and Germany. Use cursor-tools web to check the available stripe payment methods in each country."
Note: in most cases you can say "ask Perplexity" instead of "use cursor-tools web" and it will work the same.
### Use repo search
"Let's refactor our User class to allow multiple email aliases per user. Use cursor-tools repo to ask for a plan including a list of all files that need to be changed."
Note: in most cases you can say "ask Gemini" instead of "use cursor-tools repo" and it will work the same.
### Use doc generation
"Use cursor-tools to generate documentation for the Github repo https://github.com/kait-http/kaito" and write it to docs/kaito.md"
Note: in most cases you can say "generate documentation" instead of "use cursor-tools doc" and it will work the same.
### Use github integration
"Use cursor-tools github to fetch issue 123 and suggest a solution to the user's problem"
"Use cursor-tools github to fetch PR 321 and see if you can fix Andy's latest comment"
Note: in most cases you can say "fetch issue 123" or "fetch PR 321" instead of "use cursor-tools github" and it will work the same.
### Use browser automation
"Use cursor-tools to open the users page and check the error in the console logs, fix it"
"Use cursor-tools to test the form field validation logic. Take screenshots of each state"
"Use cursor-tools to open https://example.com/foo the and check the error in the network logs, what could be causing it?"
Note: in most cases you can say "Use Stagehand" instead of "use cursor-tools" and it will work the same.
### Use direct model queries
"Use cursor-tools ask to compare how different models answer this question: 'What are the key differences between REST and GraphQL?'"
"Ask OpenAI's o3-mini model to explain the concept of dependency injection."
Note: The ask command requires both --provider and --model parameters to be specified. This command is generally less useful than other commands like `repo` or `plan` because it does not include any context from your codebase or repository.
## Authentication and API Keys
`cursor-tools` requires API keys for both Perplexity AI and Google Gemini. These can be configured in two ways:
1. **Interactive Setup**: Run `cursor-tools install` and follow the prompts
2. **Manual Setup**: Create `~/.cursor-tools/.env` in your home directory or `.cursor-tools.env` in your project root:
```env
PERPLEXITY_API_KEY="your-perplexity-api-key"
GEMINI_API_KEY="your-gemini-api-key"
```
## AI Team Features
### Perplexity: Web Search & Research
Use Perplexity AI to get up-to-date information directly within Cursor:
```bash
cursor-tools web "What's new in TypeScript 5.7?"
```
### Gemini 2.0: Repository Context & Planning
Leverage Google Gemini 2.0 models with 1M+ token context windows for codebase-aware assistance and implementation planning:
```bash
# Get context-aware assistance
cursor-tools repo "Explain the authentication flow in this project, which files are involved?"
# Generate implementation plans
cursor-tools plan "Add user authentication to the login page"
```
The plan command uses multiple AI models to:
1. Identify relevant files in your codebase (using Gemini by default)
2. Extract content from those files
3. Generate a detailed implementation plan (using o3-mini by default)
**Plan Command Options:**
- `--fileProvider=<provider>`: Provider for file identification (gemini, openai, anthropic, perplexity, modelbox, or openrouter)
- `--thinkingProvider=<provider>`: Provider for plan generation (gemini, openai, anthropic, perplexity, modelbox, or openrouter)
- `--fileModel=<model>`: Model to use for file identification
- `--thinkingModel=<model>`: Model to use for plan generation
- `--fileMaxTokens=<number>`: Maximum tokens for file identification
- `--thinkingMaxTokens=<number>`: Maximum tokens for plan generation
- `--debug`: Show detailed error information
Repository context is created using Repomix. See repomix configuration section below for details on how to change repomix behaviour.
Above 1M tokens cursor-tools will always send requests to Gemini 2.0 Pro as it is the only model that supports 1M+ tokens.
The Gemini 2.0 Pro context limit is 2M tokens, you can add filters to .repomixignore if your repomix context is above this limit.
### Stagehand: Browser Automation
Automate browser interactions for web scraping, testing, and debugging:
**Important:** The `browser` command requires the Playwright package to be installed separately in your project:
```bash
npm install playwright
# or
yarn add playwright
# or
pnpm add playwright
```
1. `open` - Open a URL and capture page content:
```bash
# Open and capture HTML content, console logs and network activity (enabled by default)
cursor-tools browser open "https://example.com" --html
# Take a screenshot
cursor-tools browser open "https://example.com" --screenshot=page.png
# Debug in an interactive browser session
cursor-tools browser open "https://example.com" --connect-to=9222
```
2. `act` - Execute actions using natural language - Agent tells the browser-use agent what to do:
```bash
# Single action
cursor-tools browser act "Login as '[email protected]'" --url "https://example.com/login"
# Multi-step workflow using pipe separator
cursor-tools browser act "Click Login | Type '[email protected]' into email | Click Submit" --url "https://example.com"
# Record interaction video
cursor-tools browser act "Fill out registration form" --url "https://example.com/signup" --video="./recordings"
```
3. `observe` - Analyze interactive elements:
```bash
# Get overview of interactive elements
cursor-tools browser observe "What can I interact with?" --url "https://example.com"
# Find specific elements
cursor-tools browser observe "Find the login form" --url "https://example.com"
```
4. `extract` - Extract data using natural language:
```bash
# Extract specific content
cursor-tools browser extract "Get all product prices" --url "https://example.com/products"
# Save extracted content
cursor-tools browser extract "Get article text" --url "https://example.com/blog" --html > article.html
# Extract with network monitoring
cursor-tools browser extract "Get API responses" --url "https://example.com/api-test" --network
```
#### Browser Command Options
All browser commands (`open`, `act`, `observe`, `extract`) support these options:
- `--console`: Capture browser console logs (enabled by default, use `--no-console` to disable)
- `--html`: Capture page HTML content (disabled by default)
- `--network`: Capture network activity (enabled by default, use `--no-network` to disable)
- `--screenshot=<file path>`: Save a screenshot of the page
- `--timeout=<milliseconds>`: Set navigation timeout (default: 120000ms for Stagehand operations, 30000ms for navigation)
- `--viewport=<width>x<height>`: Set viewport size (e.g., 1280x720)
- `--headless`: Run browser in headless mode (default: true)
- `--no-headless`: Show browser UI (non-headless mode) for debugging
- `--connect-to=<port>`: Connect to existing Chrome instance. Special values: 'current' (use existing page), 'reload-current' (refresh existing page)
- `--wait=<time:duration or selector:css-selector>`: Wait after page load (e.g., 'time:5s', 'selector:#element-id')
- `--video=<directory>`: Save a video recording (1280x720 resolution, timestamped subdirectory). Not available when using --connect-to
- `--url=<url>`: Required for `act`, `observe`, and `extract` commands
- `--evaluate=<string>`: JavaScript code to execute in the browser before the main command
**Notes on Connecting to an existing browser session with --connect-to**
- DO NOT ask browser act to "wait" for anything, the wait command is currently disabled in Stagehand.
- When using `--connect-to`, viewport is only changed if `--viewport` is explicitly provided
- Video recording is not available when using `--connect-to`
- Special `--connect-to` values:
- `current`: Use the existing page without reloading
- `reload-current`: Use the existing page and refresh it (useful in development)
#### Video Recording
All browser commands support video recording of the browser interaction in headless mode (not supported with --connect-to):
- Use `--video=<directory>` to enable recording
- Videos are saved at 1280x720 resolution in timestamped subdirectories
- Recording starts when the browser opens and ends when it closes
- Videos are saved as .webm files
Example:
```bash
# Record a video of filling out a form
cursor-tools browser act "Fill out registration form with name John Doe" --url "http://localhost:3000/signup" --video="./recordings"
```
#### Console and Network Logging
Console logs and network activity are captured by default:
- Use `--no-console` to disable console logging
- Use `--no-network` to disable network logging
- Logs are displayed in the command output
#### Complex Actions
The `act` command supports chaining multiple actions using the pipe (|) separator:
```bash
# Login sequence with console/network logging (enabled by default)
cursor-tools browser act "Click Login | Type '[email protected]' into email | Click Submit" --url "http://localhost:3000/login"
# Form filling with multiple fields
cursor-tools browser act "Select 'Mr' from title | Type 'John' into first name | Type 'Doe' into last name | Click Next" --url "http://localhost:3000/register"
# Record complex interaction
cursor-tools browser act "Fill form | Submit | Verify success" --url "http://localhost:3000/signup" --video="./recordings"
```
#### Troubleshooting Browser Commands
Common issues and solutions:
1. **Element Not Found Errors**
- Use `--no-headless` to visually debug the page
- Use `browser observe` to see what elements Stagehand can identify
- Check if the element is in an iframe or shadow DOM
- Ensure the page has fully loaded (try increasing `--timeout`)
2. **Stagehand API Errors**
- Verify your OpenAI or Anthropic API key is set correctly
- Check if you have sufficient API credits
- Try switching models using `--model`
3. **Network Errors**
- Check your internet connection
- Verify the target website is accessible
- Try increasing the timeout with `--timeout`
- Check if the site blocks automated access
4. **Video Recording Issues**
- Ensure the target directory exists and is writable
- Check disk space
- Video recording is not available with `--connect-to`
5. **Performance Issues**
- Use `--headless` mode for better performance (default)
- Reduce the viewport size with `--viewport`
- Consider using `--connect-to` for development
## Skills
### GitHub Integration
Access GitHub issues and pull requests directly from the command line with rich formatting and full context:
```bash
# List recent PRs or issues
cursor-tools github pr
cursor-tools github issue
# View specific PR or issue with full discussion
cursor-tools github pr 123
cursor-tools github issue 456
```
The GitHub commands provide:
- View of 10 most recent open PRs or issues when no number specified
- Detailed view of specific PR/issue including:
- PR/Issue description and metadata
- Code review comments grouped by file (PRs only)
- Full discussion thread
- Labels, assignees, milestones and reviewers
- Support for both local repositories and remote GitHub repositories
- Markdown-formatted output for readability
**Authentication Methods:**
The commands support multiple authentication methods:
1. GitHub token via environment variable: `GITHUB_TOKEN=your_token_here`
2. GitHub CLI integration (if `gh` is installed and logged in)
3. Git credentials (stored tokens or Basic Auth)
Without authentication:
- Public repositories: Limited to 60 requests per hour
- Private repositories: Not accessible
With authentication:
- Public repositories: 5,000 requests per hour
- Private repositories: Full access (with appropriate token scopes)
### Documentation Generation (uses Gemini 2.0)
Generate comprehensive documentation for your repository or any GitHub repository:
```bash
# Document local repository and save to file
cursor-tools doc --save-to=docs.md
# Document remote GitHub repository (both formats supported)
cursor-tools doc --from-github=username/repo-name@branch
cursor-tools doc --from-github=https://github.com/username/repo-name@branch
# Save documentation to file (with and without a hint)
# This is really useful to generate local documentation for libraries and dependencies
cursor-tools doc --from-github=eastlondoner/cursor-tools --save-to=docs/CURSOR-TOOLS.md
cursor-tools doc --from-github=eastlondoner/cursor-tools --save-to=docs/CURSOR-TOOLS.md --hint="only information about the doc command"
```
## Configuration
### cursor-tools.config.json
Customize `cursor-tools` behavior by creating a `cursor-tools.config.json` file. This file can be created either globally in `~/.cursor-tools/cursor-tools.config.json` or locally in your project root.
The cursor-tools.config file configures the local default behaviour for each command and provider.
Here is an example of a typical cursor-tools.config.json file, showing some of the most common configuration options:
```json
{
// Commands
"repo": {
"provider": "openrouter",
"model": "google/gemini-2.0-pro-exp-02-05:free",
},
"doc": {
"provider": "openrouter",
"model": "anthropic/claude-3.7-sonnet",
"maxTokens": 4096
},
"web": {
"provider": "gemini",
"model": "gemini-2.0-pro-exp",
},
"plan": {
"fileProvider": "gemini",
"thinkingProvider": "perplexity",
"thinkingModel": "r1-1776"
},
"browser": {
"headless": false,
},
//...
// Providers
"stagehand": {
"model": "claude-3-7-sonnet-latest", // For Anthropic provider
"provider": "anthropic", // or "openai"
"timeout": 90000
},
"openai": {
"model": "gpt-4o"
},
//...
}
```
For details of all configuration options, see [CONFIGURATION.md](CONFIGURATION.md). This includes details of all the configuration options and how to use them.
### GitHub Authentication
The GitHub commands support several authentication methods:
1. **Environment Variable**: Set `GITHUB_TOKEN` in your environment:
```env
GITHUB_TOKEN=your_token_here
```
2. **GitHub CLI**: If you have the GitHub CLI (`gh`) installed and are logged in, cursor-tools will automatically use it to generate tokens with the necessary scopes.
3. **Git Credentials**: If you have authenticated git with GitHub (via HTTPS), cursor-tools will automatically:
- Use your stored GitHub token if available (credentials starting with `ghp_` or `gho_`)
- Fall back to using Basic Auth with your git credentials
To set up git credentials:
1. Configure git to use HTTPS instead of SSH:
```bash
git config --global url."https://github.com/".insteadOf [email protected]:
```
2. Store your credentials:
```bash
git config --global credential.helper store # Permanent storage
# Or for macOS keychain:
git config --global credential.helper osxkeychain
```
3. The next time you perform a git operation requiring authentication, your credentials will be stored
Authentication Status:
- Without authentication:
- Public repositories: Limited to 60 requests per hour
- Private repositories: Not accessible
- Some features may be restricted
- With authentication (any method):
- Public repositories: 5,000 requests per hour
- Private repositories: Full access (if token has required scopes)
cursor-tools will automatically try these authentication methods in order:
1. `GITHUB_TOKEN` environment variable
2. GitHub CLI token (if `gh` is installed and logged in)
3. Git credentials (stored token or Basic Auth)
If no authentication is available, it will fall back to unauthenticated access with rate limits.
### Repomix Configuration
When generating documentation, cursor-tools uses Repomix to analyze your repository. By default, it excludes certain files and directories that are typically not relevant for documentation:
- Node modules and package directories (`node_modules/`, `packages/`, etc.)
- Build output directories (`dist/`, `build/`, etc.)
- Version control directories (`.git/`)
- Test files and directories (`test/`, `tests/`, `__tests__/`, etc.)
- Configuration files (`.env`, `.config`, etc.)
- Log files and temporary files
- Binary files and media files
You can customize the files and folders to exclude by adding a `.repomixignore` file to your project root.
Example `.repomixignore` file for a Laravel project:
```
vendor/
public/
database/
storage/
.idea
.env
```
This ensures that the documentation focuses on your actual source code and documentation files.
Support to customize the input files to include is coming soon - open an issue if you run into problems here.
#### Model Selection
The `browser` commands support different AI models for processing. You can select the model using the `--model` option:
```bash
# Use gpt-4o
cursor-tools browser act "Click Login" --url "https://example.com" --model=gpt-4o
# Use Claude 3.7 Sonnet
cursor-tools browser act "Click Login" --url "https://example.com" --model=claude-3-7-sonnet-latest
```
You can set a default provider in your `cursor-tools.config.json` file under the `stagehand` section:
```json
{
"stagehand": {
"model": "claude-3-7-sonnet-latest", // For Anthropic provider
"provider": "anthropic", // or "openai"
"timeout": 90000
}
}
```
You can also set a default model in your `cursor-tools.config.json` file under the `stagehand` section:
```json
{
"stagehand": {
"provider": "openai", // or "anthropic"
"model": "gpt-4o"
}
}
```
If no model is specified (either on the command line or in the config), a default model will be used based on your configured provider:
- **OpenAI:** `o3-mini`
- **Anthropic:** `claude-3-7-sonnet-latest`
Available models depend on your configured provider (OpenAI or Anthropic) in `cursor-tools.config.json` and your API key.
### Cursor Configuration
`cursor-tools` automatically configures Cursor by updating your project rules during installation. This provides:
- Command suggestions
- Usage examples
- Context-aware assistance
For new installations, we use the recommended `.cursor/rules/cursor-tools.mdc` path. For existing installations, we maintain compatibility with the legacy `.cursorrules` file. If both files exist, we prefer the new path and show a warning.
#### Cursor Agent Configuration:
To get the benefits of cursor-tools you should use Cursor agent in "yolo mode". Ideal settings:

## cursor-tools cli
In general you do not need to use the cli directly, your AI coding agent will call the CLI but it is useful to know it exists and this is how it works.
### Command Options
All commands support these general options:
- `--model`: Specify an alternative model
- `--max-tokens`: Control response length
- `--save-to`: Save command output to a file (in addition to displaying it, like tee)
- `--quiet`: Suppress stdout output (only useful with --save-to)
- `--debug`: Show detailed error information
- `--help`: View all available options
- `--provider`: AI provider to use. Valid values: openai, anthropic, perplexity, gemini, openrouter
Documentation command specific options:
- `--from-github`: Generate documentation for a remote GitHub repository (supports @branch syntax)
- `--hint`: Provide additional context or focus for documentation generation
Plan command specific options:
- `--fileProvider`: Provider for file identification (gemini, openai, anthropic, perplexity, modelbox, or openrouter)
- `--thinkingProvider`: Provider for plan generation (gemini, openai, anthropic, perplexity, modelbox, or openrouter)
- `--fileModel`: Model to use for file identification
- `--thinkingModel`: Model to use for plan generation
- `--fileMaxTokens`: Maximum tokens for file identification
- `--thinkingMaxTokens`: Maximum tokens for plan generation
GitHub command specific options:
- `--from-github=<GitHub username>/<repository name>[@<branch>]`: Access PRs/issues from a specific GitHub repository. `--repo` is an older, still supported synonym for this option.
Browser command specific options:
- `--console`: Capture browser console logs (enabled by default, use `--no-console` to disable)
- `--html`: Capture page HTML content (disabled by default)
- `--network`: Capture network activity (enabled by default, use `--no-network` to disable)
- `--screenshot`: Save a screenshot of the page
- `--timeout`: Set navigation timeout (default: 120000ms for Stagehand operations, 30000ms for navigation)
- `--viewport`: Set viewport size (e.g., 1280x720)
- `--headless`: Run browser in headless mode (default: true)
- `--no-headless`: Show browser UI (non-headless mode) for debugging
- `--connect-to`: Connect to existing Chrome instance
- `--wait`: Wait after page load (e.g., 'time:5s', 'selector:#element-id')
- `--video`: Save a video recording (1280x720 resolution, timestamped subdirectory)
- `--url`: Required for `act`, `observe`, and `extract` commands. Url to navigate to on connection or one of the special values: 'current' (use existing page), 'reload-current' (refresh existing page).
- `--evaluate`: JavaScript code to execute in the browser before the main command
### Execution Methods
Execute commands using:
```bash
cursor-tools <command> [options]
```
For example:
```bash
cursor-tools web "What's new in TypeScript 5.7?"
```
## Troubleshooting
1. **Command Not Found**
- Ensure `cursor-tools` is installed globally using `npm install -g cursor-tools`
- Check your system's PATH environment variable to ensure it includes npm's global bin directory
- On Unix-like systems, the global bin directory is typically `/usr/local/bin` or `~/.npm-global/bin`
- On Windows, it's typically `%AppData%\npm`
2. **API Key Errors**
- Verify `.cursor-tools.env` exists and contains valid API keys
- Run `cursor-tools install` to reconfigure API keys
- Check that your API keys have the necessary permissions
- For GitHub operations, ensure your token has the required scopes (repo, read:user)
3. **Model Errors**
- Check your internet connection
- Verify API key permissions
- Ensure the specified model is available for your API tier
4. **GitHub API Rate Limits**
- GitHub API has rate limits for unauthenticated requests. For higher limits you must be authenticated.
- If you have the gh cli installed and logged in cursor-tools will use that to obtain a short lived auth token. Otherwise you can add a GitHub token to your environment:
```env
GITHUB_TOKEN=your_token_here
```
- Private repositories always require authentication
5. **Documentation Generation Issues**
- Repository too large: Try using `--hint` to focus on specific parts
- Token limit exceeded: The tool will automatically switch to a larger model
- Network timeouts: The tool includes automatic retries
- For very large repositories, consider documenting specific directories or files
6. **Cursor Integration**
- If .cursorrules is outdated, run `cursor-tools install .` to update
- Ensure Cursor is configured to allow command execution
- Check that your Cursor version supports AI commands
### Examples
#### Web Search Examples
```bash
# Get information about new technologies
cursor-tools web "What are the key features of Bun.js?"
# Check API documentation
cursor-tools web "How to implement OAuth2 in Express.js?"
# Compare technologies
cursor-tools web "Compare Vite vs Webpack for modern web development"
```
#### Repository Context Examples
```bash
# Architecture understanding
cursor-tools repo "Explain the overall architecture of this project"
# Find usage examples
cursor-tools repo "Show me examples of error handling in this codebase"
# Debugging help
cursor-tools repo "Why might the authentication be failing in the login flow?"
```
#### Documentation Examples
```bash
# Document specific aspects and save to file without stdout output
cursor-tools doc --save-to=docs/api.md --quiet --hint="Focus on the API endpoints and their usage"
# Document with hint to customize the docs output
cursor-tools doc --save-to=docs/architecture.md --quiet --hint="Focus on system architecture"
# Document dependencies
cursor-tools doc --from-github=expressjs/express --save-to=docs/EXPRESS.md --quiet
```
#### GitHub Integration Examples
```bash
# List PRs with specific labels
cursor-tools github pr --from-github facebook/react
# Check recent issues in a specific repository
cursor-tools github issue --from-github vercel/next.js
# View PR with code review comments
cursor-tools github pr 123 --from-github microsoft/typescript
# Track issue discussions
cursor-tools github issue 456 --from-github golang/go
```
#### Browser Command Examples
##### `open` subcommand examples:
```bash
# Open a URL and get HTML
cursor-tools browser open "https://example.com" --html
# Open and capture console logs and network activity
cursor-tools browser open "https://example.com" --console --network
# Take a screenshot
cursor-tools browser open "https://example.com" --screenshot=page.png
# Run in non-headless mode for debugging
cursor-tools browser open "https://example.com" --no-headless
```
##### `act`, `extract`, `observe` subcommands examples:
```bash
# AI-powered action
cursor-tools browser act "Click on 'Sign Up'" --url "https://example.com"
# AI-powered extraction
cursor-tools browser extract "Get the main content" --url "https://example.com/blog"
# AI-powered observation
cursor-tools browser observe "What can I do on this page?" --url "https://example.com"
```
## Node Package Manager (npm)
cursor-tools is available on npm [here](https://www.npmjs.com/package/cursor-tools)
## Contributing
Contributions are welcome! Please feel free to submit a Pull Request. If you used cursor-tools to make your contribution please include screenshots or videos of cursor-tools in action.
## Sponsors
### [Vinta.app](https://vinta.app)
**Optimise your Vinted accounting** with real-time analytics, inventory management, and tax compliance tools.
:link: [Start scaling your Vinted business today](https://vinta.app)
---
### [Resoled.it](https://resoled.it)
**Automate your Vinted reselling business** with advanced tools like autobuy, custom snipers, and one-click relisting.
:link: [Take Vinted reselling to the next level](https://resoled.it)
---
### [iterate.com](https://iterate.com)
**Build self-driving startups** with autonomous AI agents that run your company.
:link: [AI Engineer in London? Join the startup revolution](https://iterate.com)
## License
MIT License - see [LICENSE](LICENSE) for details. | {
"source": "eastlondoner/cursor-tools",
"title": "README.md",
"url": "https://github.com/eastlondoner/cursor-tools/blob/main/README.md",
"date": "2025-01-13T15:03:33",
"stars": 2408,
"description": "Give Cursor Agent an AI Team and Advanced Skills",
"file_size": 39054
} |
Packing repository using Repomix...
Analyzing repository using gemini-2.0-flash-thinking-exp...
Okay, I've reviewed the test plan in `test-plan.md` against the functionalities of cursor-tools, the file summaries, and especially the recent changes detailed in `CHANGELOG.md`. Here's my feedback:
**Overall Completeness and Adequacy:**
The test plan is quite comprehensive and covers a good range of `cursor-tools` functionalities. It's well-structured and organized by command, which makes it easy to follow. It directly addresses the recent changes highlighted in the `CHANGELOG.md`, demonstrating a clear effort to validate the latest updates.
**Specific Feedback and Suggestions:**
1. **MCP Server Overrides:**
* The test plan includes a test case for MCP `run` with overrides: `cursor-tools mcp run "using google-calendar-mcp list upcoming events"`. This is good and directly targets the new override feature.
* **Suggestion:** It would be beneficial to add a test case that explicitly verifies that a *user-configured* override (in `cursor-tools.config.json`) is also working as expected, not just the hardcoded override. This could involve a temporary config file modification for the test.
2. **Claude 3.7 Sonnet Model Updates:**
* The test plan mentions verifying Claude 3.7 Sonnet in the `ask` and `browser` command sections. This is important to ensure the model switch was successful.
* **Improvement:** While mentioned, it's not explicitly a separate test case. Consider adding a test case specifically to confirm that commands using default models (where Claude 3.7 Sonnet should now be used) are indeed using the correct updated model and functioning as expected. For example, for `ask` command without specifying a model, and for `browser act` without specifying a model (if it defaults to Anthropic/Claude).
3. **Stagehand Dependency Update (1.13.0 to 1.13.1):**
* The test plan mentions testing with the updated Stagehand dependency, which is good.
* **Suggestion:** It's not clear *what* specifically about the Stagehand update is being tested. Add specific test cases that would highlight any potential regressions or improvements from the Stagehand update. For example, are there any known bug fixes or feature enhancements in 1.13.1 that you can verify? If not explicitly, then ensure the existing browser command tests are run thoroughly to catch any regressions.
4. **Global Installation Recommendation Change:**
* This change is more about documentation and user guidance than functionality. The test plan doesn't need to directly test this.
* **Feedback:** The test plan is fine as is concerning this change, as it's not a functional change.
5. **Validation for `--tag` in Release Command:**
* This is a change to the release script, not the core functionality. The test plan doesn't need to directly test this.
* **Feedback:** The test plan is fine as is concerning this change, as it's a release process change.
6. **ModelBox and OpenRouter Provider Addition:**
* The `ask`, `web`, `plan`, and `repo` command sections all mention testing with different providers, including ModelBox and OpenRouter. This is good.
* **Improvement:** For each of these commands, explicitly include ModelBox and OpenRouter in the list of providers tested in the "Test Cases" subsections. For example, in `web`, add a test case like `cursor-tools web "Explain OpenRouter models" --provider openrouter`. This will ensure these new providers are specifically tested in each relevant command.
7. **Browser Command State Management with `--connect-to` and `reload-current`:**
* The test plan includes test cases for `browser open` with `--connect-to`.
* **Missing Test Case:** Crucially missing is a test case that verifies the *state persistence* and the functionality of `reload-current`. Add a test case like:
* `cursor-tools browser open "tests/commands/browser/test-browser-persistence.html" --connect-to=9222` (open test page, interact with it)
* `cursor-tools browser act "Click 'Button 2'" --url=current --connect-to=9222` (verify state is maintained)
* `cursor-tools browser act "Click 'Button 3'" --url=reload-current --connect-to=9222` (verify state is maintained after reload).
* Verify that the output and browser behavior are as expected across these steps.
8. **Debug Logging Fixes:**
* The test plan mentions using the `--debug` flag in several test cases. This is good.
* **Suggestion:** Add a specific point to the "Test Execution Plan" to "Verify debug output is generated and contains useful information when `--debug` is used for each command". This will ensure that the debug logging fixes are actually validated during testing.
9. **Default Thinking Provider Change to OpenAI o3-mini:**
* The `plan` command section includes tests with different thinking providers.
* **Improvement:** Add a test case for the `plan` command *without* specifying `--thinkingProvider` or `--thinkingModel` to verify that the default is indeed OpenAI `o3-mini` and that it functions correctly.
10. **Default Console and Network Options for Browser Commands:**
* The test plan doesn't explicitly test the default `console` and `network` options being enabled.
* **Missing Test Case:** Add a test case for `browser act` or `browser open` *without* `--no-console` or `--no-network` flags and verify that console logs and network activity are indeed captured in the output. Also, add test cases with `--no-console` and `--no-network` to verify they are correctly disabled.
11. **Page Reuse and Viewport Size Preservation in Browser Commands with `--connect-to`:**
* Viewport preservation is partially covered by the suggested `--connect-to` test case above.
* **Suggestion:** Explicitly add a step in the `--connect-to` test case in the "Test Execution Plan" to "Verify viewport size is preserved when reusing pages with `--connect-to`, and that `--viewport` option correctly overrides it".
12. **New `ask` Command:**
* The test plan has a dedicated section for the `ask` command, which is excellent. The test cases are good for basic functionality.
* **Improvement:** Add test cases to verify error handling, specifically:
* `cursor-tools ask "Question" --provider openai` (missing `--model` - should throw `ModelNotFoundError`)
* `cursor-tools ask "Question" --model o3-mini` (missing `--provider` - should throw `ProviderError`)
* `cursor-tools ask "Question" --provider invalid-provider --model o3-mini` (invalid provider - should throw `ProviderError`)
13. **New Cursor Rules Directory Structure and `USE_LEGACY_CURSORRULES`:**
* The test plan doesn't explicitly cover the cursor rules changes.
* **Missing Test Cases:** Add test cases to verify the install command in relation to cursor rules:
* Test `cursor-tools install .` with `USE_LEGACY_CURSORRULES=false` and verify `.cursor/rules/cursor-tools.mdc` is created/updated correctly.
* Test `cursor-tools install .` with `USE_LEGACY_CURSORRULES=true` and verify `.cursorrules` is created/updated correctly.
* Test `cursor-tools install .` when both `.cursorrules` and `.cursor/rules/cursor-tools.mdc` exist and `USE_LEGACY_CURSORRULES` is toggled, verifying the correct file is updated based on the environment variable.
14. **Dual-Provider Architecture for `plan` Command:**
* The test plan *does* include test cases with split providers for the `plan` command. This is good.
* **Feedback:** The existing test cases seem sufficient to cover this feature.
15. **New Provider System and Error Handling:**
* Error handling is partially covered by the `ask` command test case suggestions.
* **Improvement:** In the "Test Execution Plan", add a point to "Verify error messages are user-friendly and informative for common error scenarios (API key missing, model not found, network errors, etc.) across all commands".
16. **`--quiet` Flag Addition:**
* The test plan does not explicitly test the `--quiet` flag.
* **Missing Test Case:** Add test cases to verify the `--quiet` flag works as expected:
* `cursor-tools web "Test query" --save-to test-output.txt --quiet` (verify no output to stdout, output is saved to file)
* `cursor-tools repo "Test query" --save-to test-output.txt --quiet` (verify no output to stdout, output is saved to file)
* Test with other commands as well to ensure `--quiet` is consistently applied across all commands.
**Other Issues/Suggestions:**
* **Test Environment Setup:** It would be helpful to add a section to the test plan describing the required test environment setup, including:
* API keys needed and how to set them (mention `.cursor-tools.env`)
* Playwright installation instructions (for browser command tests)
* Test server setup (for browser command testing, mention `pnpm serve-test`)
* **Test Data/HTML Files:** Mention the location of test HTML files (`tests/commands/browser/`) and how to access them via the test server (`http://localhost:3000/filename.html`).
* **Success Criteria Clarity:** While the "Success Criteria" section is present, it's quite high-level. Consider adding more specific success criteria for each command or test category. For example, for browser commands, success might include "Verify console logs are captured and formatted correctly", "Verify screenshots are generated at the correct path", etc.
* **Consider Categorizing Test Cases:** For each command, you could categorize test cases into "Positive Tests" (verifying expected behavior), "Negative Tests" (verifying error handling), and "Boundary/Edge Cases" (testing limits, unusual inputs, etc.). This can improve the structure and coverage of the test plan.
**In Summary:**
The test plan is a strong starting point and already covers many important aspects. By incorporating the suggested improvements, especially adding the missing test cases for `--connect-to` state persistence, `--quiet` flag, cursor rules installation, and more explicit error handling verification, and by clarifying the test environment and success criteria, you can make it even more robust and comprehensive, ensuring thorough validation of the latest cursor-tools features. | {
"source": "eastlondoner/cursor-tools",
"title": "gemini-review.md",
"url": "https://github.com/eastlondoner/cursor-tools/blob/main/gemini-review.md",
"date": "2025-01-13T15:03:33",
"stars": 2408,
"description": "Give Cursor Agent an AI Team and Advanced Skills",
"file_size": 10427
} |
# Cursor-Tools Test Plan
## Purpose
This test plan aims to verify the functionality of cursor-tools commands, with particular focus on:
1. Features documented in the README
2. Recently changed functionality (from CHANGELOG)
3. Different models and providers across commands
## Recent Changes to Test
From the CHANGELOG, key areas to test include:
- MCP server overrides in the marketplace (both hardcoded and user-configured)
- Updated references to Claude 3.7 Sonnet models (from Claude 3.5)
- Updated @browserbasehq/stagehand dependency (1.13.0 to 1.13.1)
- Browser command state management with `--connect-to` and `reload-current`
- Default console and network options for browser commands
- New cursor rules directory structure (`.cursor/rules/cursor-tools.mdc`)
- Dual-provider architecture for `plan` command
- `--quiet` flag for suppressing stdout while saving to file
## Test Environment Setup
1. Required API keys:
- Set up `.cursor-tools.env` with:
- `PERPLEXITY_API_KEY`
- `GEMINI_API_KEY`
- `OPENAI_API_KEY` (for browser commands)
- `ANTHROPIC_API_KEY` (for MCP commands and browser commands)
- `GITHUB_TOKEN` (optional, for GitHub commands)
2. For browser command testing:
- Install Playwright: `npm install --global playwright`
- Start test server: `pnpm serve-test` (runs on http://localhost:3000)
- Test files located in `tests/commands/browser/`
## Test Approach
For each command, we will:
1. Test basic functionality (positive tests)
2. Test error handling (negative tests)
3. Test with different providers where applicable
4. Test with different models where applicable
5. Verify output quality and correctness
6. Test recent changes and edge cases
## Commands to Test
### 1. Direct Model Queries (`ask`)
- Test with different providers (OpenAI, Anthropic, Perplexity, Gemini, ModelBox, OpenRouter)
- Verify Claude 3.7 Sonnet model works correctly (previously 3.5)
- Compare output quality across models
- Test error handling
#### Test Cases:
- Basic query: `cursor-tools ask "What is cursor-tools?" --provider openai --model o3-mini`
- Complex query: `cursor-tools ask "Explain the differences between REST and GraphQL" --provider anthropic --model claude-3-7-sonnet`
- Technical query: `cursor-tools ask "How does JavaScript event loop work?" --provider perplexity --model perplexity-online-latest`
- ModelBox query: `cursor-tools ask "What are the benefits of TypeScript?" --provider modelbox --model claude-3-7-sonnet`
- OpenRouter query: `cursor-tools ask "Explain the SOLID principles" --provider openrouter --model anthropic/claude-3-7-sonnet`
#### Error Handling Tests:
- Missing model: `cursor-tools ask "Test question" --provider openai` (should throw ModelNotFoundError)
- Missing provider: `cursor-tools ask "Test question" --model o3-mini` (should throw ProviderError)
- Invalid provider: `cursor-tools ask "Test question" --provider invalid-provider --model o3-mini` (should throw ProviderError)
- Invalid model: `cursor-tools ask "Test question" --provider openai --model invalid-model` (should throw ModelNotFoundError)
### 2. Web Search (`web`)
- Test with different providers (Perplexity, Gemini, ModelBox, OpenRouter)
- Test saving output to file
- Test with debug flag
- Test quiet flag
#### Test Cases:
- Current technology: `cursor-tools web "Latest TypeScript features" --provider perplexity`
- Technical documentation: `cursor-tools web "Next.js app router documentation" --provider gemini`
- Saving output: `cursor-tools web "cursor-tools installation guide" --save-to web-results.md`
- ModelBox provider: `cursor-tools web "React 19 new features" --provider modelbox --model claude-3-7-sonnet`
- OpenRouter provider: `cursor-tools web "Node.js best practices 2024" --provider openrouter`
- Debug flag: `cursor-tools web "TypeScript 5.7 features" --debug`
- Quiet flag with save: `cursor-tools web "Angular vs React in 2024" --save-to web-compare.md --quiet`
### 3. Repository Context (`repo`)
- Test with different providers and models
- Test on this repository
- Test with token limit considerations
- Test default Claude 3.7 model (previously 3.5)
#### Test Cases:
- Code explanation: `cursor-tools repo "Explain the MCP server override implementation"`
- Architecture question: `cursor-tools repo "How are providers implemented in the codebase?"`
- Different models: `cursor-tools repo "What's the structure of browser commands?" --provider openai --model o3-mini`
- ModelBox provider: `cursor-tools repo "Explain the dual-provider architecture for plan command" --provider modelbox`
- OpenRouter provider: `cursor-tools repo "How is cursor rule integration implemented?" --provider openrouter`
- Debug flag: `cursor-tools repo "Analyze error handling in the codebase" --debug`
- Quiet flag: `cursor-tools repo "Summarize recent changes" --save-to repo-changes.md --quiet`
### 4. Implementation Planning (`plan`)
- Test with different file and thinking providers
- Test with various combinations of models
- Test default thinking provider (OpenAI with o3-mini model)
- Test small and larger planning tasks
#### Test Cases:
- Basic plan: `cursor-tools plan "How to add a new command to cursor-tools?"`
- Default providers (verify o3-mini is used): `cursor-tools plan "Add a health check endpoint" --debug`
- Split providers: `cursor-tools plan "Implement a health check endpoint" --fileProvider gemini --thinkingProvider openai --thinkingModel o3-mini`
- Complex task: `cursor-tools plan "Implement TypeScript strict mode across the codebase" --fileProvider gemini --thinkingProvider anthropic --thinkingModel claude-3-7-sonnet`
- ModelBox provider: `cursor-tools plan "Add support for a new AI provider" --fileProvider modelbox --thinkingProvider modelbox`
- OpenRouter provider: `cursor-tools plan "Implement a new browser command feature" --fileProvider openrouter --thinkingProvider openrouter`
- Quiet flag: `cursor-tools plan "Refactor error handling" --save-to plan-errors.md --quiet`
### 5. Documentation Generation (`doc`)
- Test local repository documentation
- Test remote GitHub repository documentation
- Test with different hints for focused documentation
- Test with different models including Claude 3.7 Sonnet
#### Test Cases:
- Local repo: `cursor-tools doc --save-to repo-docs.md`
- Remote repo: `cursor-tools doc --from-github=eastlondoner/cursor-tools --save-to cursor-tools-docs.md`
- Focused docs: `cursor-tools doc --hint="Focus on browser commands" --save-to browser-docs.md`
- With Anthropic provider: `cursor-tools doc --provider anthropic --model claude-3-7-sonnet --save-to anthropic-docs.md`
- With specific branch: `cursor-tools doc --from-github=eastlondoner/cursor-tools@main --save-to main-docs.md`
- Quiet flag: `cursor-tools doc --from-github=eastlondoner/cursor-tools --save-to docs.md --quiet`
### 6. GitHub Integration
- Test PR listing
- Test issue listing
- Test specific PR and issue viewing
- Test remote repository specification
#### Test Cases:
- List PRs: `cursor-tools github pr`
- List issues: `cursor-tools github issue`
- View specific PR: `cursor-tools github pr 1` (if available)
- View specific issue: `cursor-tools github issue 1` (if available)
- From remote repo: `cursor-tools github pr --from-github=eastlondoner/cursor-tools`
- Quiet flag: `cursor-tools github pr --save-to prs.md --quiet`
### 7. Browser Automation
- Test each browser subcommand (open, act, observe, extract)
- Test with updated Stagehand dependency
- Test with different models including Claude 3.7 Sonnet
- Test default console and network options
- Test state persistence with `--connect-to` and `reload-current`
#### Test Cases:
- Open webpage: `cursor-tools browser open "https://example.com" --html`
- Default console/network: `cursor-tools browser open "http://localhost:3000/test-logging.html"` (verify console/network logs are captured)
- Disable console/network: `cursor-tools browser open "http://localhost:3000/test-logging.html" --no-console --no-network` (verify logs are not captured)
- Perform action: `cursor-tools browser act "Click on the first link" --url "https://example.com" --model claude-3-7-sonnet-latest`
- Default model: `cursor-tools browser act "Click the submit button" --url "http://localhost:3000/test-form.html" --provider anthropic` (verify claude-3-7-sonnet is used)
- Observe page: `cursor-tools browser observe "What interactive elements are visible?" --url "https://example.com"`
- Extract data: `cursor-tools browser extract "Get all heading text" --url "https://example.com"`
#### State Persistence Test Sequence:
1. `cursor-tools browser open "http://localhost:3000/test-state.html" --connect-to=9222`
2. `cursor-tools browser act "Click the 'Counter' button" --url=current --connect-to=9222` (verify state is maintained)
3. `cursor-tools browser act "Check the counter value" --url=current --connect-to=9222` (verify state persisted from previous action)
4. `cursor-tools browser act "Click the 'Counter' button" --url=reload-current --connect-to=9222` (verify reload works while maintaining connection)
5. `cursor-tools browser act "Check the counter value" --url=current --connect-to=9222` (verify counter was reset after reload)
### 8. MCP Commands
- Test MCP search functionality
- Test MCP run with overrides (recent feature)
- Test different MCP servers
- Test both hardcoded and user-configured overrides
#### Test Cases:
- Search: `cursor-tools mcp search "git operations"`
- Run command: `cursor-tools mcp run "list files in the current directory"`
- Hardcoded override: `cursor-tools mcp run "using google-calendar-mcp list upcoming events"` (testing the eastlondoner fork override)
#### User-Configured Override Test:
1. Temporarily modify `cursor-tools.config.json` to add user override:
```json
{
"mcp": {
"overrides": {
"test-mcp-server": {
"githubUrl": "https://github.com/example/test-mcp-server",
"command": "custom-command",
"args": []
}
}
}
}
```
2. Run: `cursor-tools mcp run "using test-mcp-server perform test action"`
3. Verify that the user-configured override is applied (check logs)
4. Restore original `cursor-tools.config.json`
### 9. Installation and Cursor Rules
- Test cursor rules installation with different environment settings
- Test new `.cursor/rules/cursor-tools.mdc` file creation
- Test legacy `.cursorrules` file creation
#### Test Cases:
- New cursor rules format: `USE_LEGACY_CURSORRULES=false cursor-tools install .` (verify `.cursor/rules/cursor-tools.mdc` is created/updated)
- Legacy cursor rules format: `USE_LEGACY_CURSORRULES=true cursor-tools install .` (verify `.cursorrules` is created/updated)
- Default behavior: `cursor-tools install .` (verify correct file is updated based on default behavior)
## Test Execution Plan
1. Set up environment with all required API keys
2. Start test server for browser testing: `pnpm serve-test`
3. Execute tests for each command category
4. For each test:
- Document command executed
- Record output
- Verify debug output when `--debug` flag is used
- Verify no stdout output when `--quiet` flag is used
- Confirm file output when `--save-to` is used
- Note any errors or unexpected behavior
- Assess response quality and correctness
5. Test environment cleanup
## Success Criteria
### General Criteria
- All commands execute without unexpected errors
- Output quality meets expectations
- Different providers and models can be successfully used
- Debug output is informative when `--debug` flag is used
- No stdout output occurs when `--quiet` flag is used with `--save-to`
- File output is correct when `--save-to` is used
### Recent Changes Validation
- Claude 3.7 Sonnet model works correctly in all commands (replacing Claude 3.5)
- MCP server overrides (both hardcoded and user-configured) function correctly
- Browser commands with Stagehand 1.13.1 function correctly
- Console and network logs are captured by default in browser commands
- Browser state is maintained correctly when using `--connect-to=current`
- Browser state is reset correctly when using `--connect-to=reload-current`
- Default thinking provider for plan command is OpenAI with o3-mini model
- Cursor rules are installed to the correct location based on `USE_LEGACY_CURSORRULES`
- Error messages are user-friendly and informative across all commands | {
"source": "eastlondoner/cursor-tools",
"title": "test-plan.md",
"url": "https://github.com/eastlondoner/cursor-tools/blob/main/test-plan.md",
"date": "2025-01-13T15:03:33",
"stars": 2408,
"description": "Give Cursor Agent an AI Team and Advanced Skills",
"file_size": 12409
} |
# Implementation Plan: Add 'ask' Command
## Overview
Add a new `ask` command endpoint that requires model and provider parameters and a question. The command will use the specified model and provider to answer the question directly.
## Step 1: Create the AskCommand File
Create a new file at `src/commands/ask.ts`:
```typescript
import type { Command, CommandGenerator, CommandOptions } from '../types';
import { loadEnv, loadConfig, defaultMaxTokens } from '../config';
import { createProvider } from '../providers/base';
import { ProviderError, ModelNotFoundError } from '../errors';
export class AskCommand implements Command {
private config;
constructor() {
// Load environment variables and configuration.
loadEnv();
this.config = loadConfig();
}
async *execute(query: string, options?: CommandOptions): CommandGenerator {
// Ensure provider was passed, otherwise throw an error.
const providerName = options?.provider;
if (!providerName) {
throw new ProviderError("The 'ask' command requires a provider parameter (e.g. --provider openai).");
}
// Ensure model parameter was passed.
const model = options?.model;
if (!model) {
throw new ModelNotFoundError(providerName);
}
// Set maxTokens from provided options or fallback to the default.
const maxTokens = options?.maxTokens || defaultMaxTokens;
// Create the provider instance.
const provider = createProvider(providerName);
let answer: string;
try {
// Provide a very simple system prompt.
answer = await provider.executePrompt(query, {
model,
maxTokens,
systemPrompt: "You are a helpful assistant. Answer the following question directly and concisely.",
});
} catch (error) {
throw new ProviderError(
error instanceof Error ? error.message : 'Unknown error during ask command execution',
error
);
}
// Yield the answer as the result.
yield answer;
}
}
```
## Step 2: Register the Command
Update `src/commands/index.ts`:
```typescript
import type { CommandMap } from '../types';
import { WebCommand } from './web.ts';
import { InstallCommand } from './install.ts';
import { GithubCommand } from './github.ts';
import { BrowserCommand } from './browser/browserCommand.ts';
import { PlanCommand } from './plan.ts';
import { RepoCommand } from './repo.ts';
import { DocCommand } from './doc.ts';
import { AskCommand } from './ask'; // <-- New Import
export const commands: CommandMap = {
web: new WebCommand(),
repo: new RepoCommand(),
install: new InstallCommand(),
doc: new DocCommand(),
github: new GithubCommand(),
browser: new BrowserCommand(),
plan: new PlanCommand(),
ask: new AskCommand(), // <-- Register new command
};
```
## Step 3: Test and Validate
1. Ensure proper environment variables are set for the selected provider (e.g., OPENAI_API_KEY for OpenAI)
2. Test the command with appropriate flags:
```bash
cursor-tools ask "What is the capital of France?" --provider openai --model o3-mini
```
3. Verify that the question is sent to the provider and the response is printed
## Notes
- Both `--provider` and `--model` parameters are required
- The command is intentionally simple and focused on just forwarding the question
- Additional options (e.g., maxTokens) can be passed via CommandOptions
- Error handling is implemented for missing parameters and provider errors | {
"source": "eastlondoner/cursor-tools",
"title": "todo.md",
"url": "https://github.com/eastlondoner/cursor-tools/blob/main/todo.md",
"date": "2025-01-13T15:03:33",
"stars": 2408,
"description": "Give Cursor Agent an AI Team and Advanced Skills",
"file_size": 3457
} |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.