
Id
int64 1.68k
75.6M
| PostTypeId
int64 1
2
| AcceptedAnswerId
int64 1.7k
75.6M
⌀ | ParentId
int64 1.68k
75.6M
⌀ | Score
int64 -60
3.16k
| ViewCount
int64 8
2.68M
⌀ | Body
stringlengths 1
41.1k
| Title
stringlengths 14
150
⌀ | ContentLicense
stringclasses 3
values | FavoriteCount
int64 0
1
⌀ | CreationDate
stringlengths 23
23
| LastActivityDate
stringlengths 23
23
| LastEditDate
stringlengths 23
23
⌀ | LastEditorUserId
int64 -1
21.3M
⌀ | OwnerUserId
int64 1
21.3M
⌀ | Tags
sequence |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
74,279,253 | 2 | null | 49,505,446 | 0 | null | This is completely stupid, but it happened to me, so I will mention it in case it happens to someone else:
This error occurred on because of a .
Changes to `package.json` were not pushed with the code using the newly added dependency. x)
True story. (facepalm)
Another instance:
.
| null | CC BY-SA 4.0 | null | 2022-11-01T16:54:03.220 | 2022-11-18T17:27:24.240 | 2022-11-18T17:27:24.240 | 12,322,350 | 12,322,350 | null |
74,279,569 | 2 | null | 73,987,290 | 1 | null | My guess is there's an issue with the default color space in PDFKit: RGB vs CMYK
Here's a workaround:
```
class func imageToPDF(_ image:UIImage) -> Data {
let data = NSMutableData()
let bounds = CGRect(origin: CGPoint.zero, size: image.size)
UIGraphicsBeginPDFContextToData(data, bounds, nil)
UIGraphicsBeginPDFPage()
image.draw(at: CGPoint.zero)
UIGraphicsEndPDFContext()
return data as Data
}
```
You'll have to alter it for multiple pages in your instance
| null | CC BY-SA 4.0 | null | 2022-11-01T17:20:46.390 | 2022-11-01T17:20:46.390 | null | null | 1,839,307 | null |
74,279,677 | 2 | null | 74,279,163 | 0 | null | I don't know why you have them scoped to the class instead of scoped to the listener.
I have cleaned up your code and added them as local variables to the listener.
```
shirtBTN.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
Chip chip = findViewById(colorCG.getCheckedChipId());
String color = chip.getText().toString();
int quantity = Integer.parseInt( quantityCOUNTER.getText().toString());
float cost = quantity * 150;
String type = "SHIRT";
checkoutSTRUCT.add(new listitem(quantity, color, type, cost));
shirtCOUNTER.setText( String.valueOf( getQuantity_Sum(checkoutSTRUCT, type)));
}
});
```
This creates new local variables for every click instead of using the same one every time.
Also please refer to the java naming conventions, standardized code is very important. For example: "quantityCOUNTER", "item_cost" "listitem" do not follow the convention.
| null | CC BY-SA 4.0 | null | 2022-11-01T17:30:41.543 | 2022-11-01T17:30:41.543 | null | null | 2,398,000 | null |
74,279,807 | 2 | null | 72,303,759 | 0 | null | I guess I have found one solution which fixes mine. I used to have the same error.
When you run this:
```
import tensorflow as tf
tf.test.gpu_device_name()
```
it will give you the GPU number, which in my case it was
```
/device:GPU:0
```
I realized that I was passing the code as:
```
parser.add_argument('--gpu', type=str, default="1", help='choose GPU')
```
so I replaced the "1" with "0", the number of GPU that Colab gave me, then it worked.
I hope this fixes your problem too.
| null | CC BY-SA 4.0 | null | 2022-11-01T17:44:26.860 | 2022-11-01T17:44:26.860 | null | null | 14,775,029 | null |
74,280,121 | 2 | null | 22,346,707 | 0 | null | ```
<?php
function TableFunc($Data)
{
$Table = "<table>" . PHP_EOL;
foreach ($Data as $tags => $array) {
$Table .= "<$tags>" . PHP_EOL;
foreach ($array as $thead) {
$tag=$tags==="tbody"?"td":"th";
$Table .= "<tr>" . PHP_EOL;
if (is_array($thead)) {
foreach ($thead as $theadItem) {
if (is_array($theadItem))
$Table .= "<$tag colspan='$theadItem[1]'>$theadItem[0]</$tag>" . PHP_EOL;
else
$Table .= "<$tag>$theadItem</$tag>" . PHP_EOL;
}
}
$Table .= "</tr>" . PHP_EOL;
}
$Table .= "</$tags>" . PHP_EOL;
}
$Table .= "</table>" . PHP_EOL;
return $Table;
}
$Data = array(
"thead" => [
[["GENEL BİLGİ", 2], ["KALORİMETRE (ISINMA)", 2], ["HESAPLAMA", 2]],
["NO", "AD SOYAD", "FARK", "TUTAR", "OKUMA", "ÖDENECEK"]
],
"tbody"=>array(
array("1","MURAT DURAN","100","100.00","10.00","110.00"),
array("1","MURAT DURAN","100","100.00","10.00","110.00"),
array("1","MURAT DURAN","100","100.00","10.00","110.00"),
array("1","MURAT DURAN","100","100.00","10.00","110.00"),
),
"tfoot" => [["NO", "AD SOYAD", "M2", "MAHSUP", "SAYAÇ", "15°", "FARK", "TUTAR", "ORTAK ALAN", "EKSTRA", "MUAFİYET", "OKUMA", "ÖDENECEK"]]
);
echo TableFunc($Data);
```
| null | CC BY-SA 4.0 | null | 2022-11-01T18:12:42.727 | 2022-11-01T18:12:42.727 | null | null | 19,576,029 | null |
74,280,209 | 2 | null | 69,709,251 | 0 | null | I ran into the same problem, but was able to resolve it in my environment.
Go to and add the following
```
-Dfile.encoding=UTF-8
```
Here is my environment:
```
Windows 11
PyCharm Community 2022.2.3 (installed from JetBrains ToolBox)
Python 3.11 (installed from microsoft store)
```
| null | CC BY-SA 4.0 | null | 2022-11-01T18:20:25.620 | 2022-11-05T21:48:49.803 | 2022-11-05T21:48:49.803 | 12,846,952 | 20,390,736 | null |
74,280,252 | 2 | null | 74,280,188 | 0 | null | You can use [getElementsByClassName](https://developer.mozilla.org/en-US/docs/Web/API/Document/getElementsByClassName):
```
document.getElementsByClassName('text-content');
```
But do notice this returns a [HTMLCollection](https://developer.mozilla.org/en-US/docs/Web/API/HTMLCollection). So you'll have to use accessors or iterate to get the elements contents:
```
const elements = document.getElementsByClassName('text-content');
// using acessor
console.log(elements[0].innerText);
console.log(elements[1].innerText);
// or iterating
for (const element of elements)
console.log(element.innerText);
```
```
<div class="something something text-content">aaa</div>
<div class="something something text-content">bbb</div>
```
| null | CC BY-SA 4.0 | null | 2022-11-01T18:25:14.150 | 2022-11-01T18:25:14.150 | null | null | 1,850,609 | null |
74,280,253 | 2 | null | 74,280,188 | 0 | null |
# Why your solution won't work
[Document.querySelectorAll](https://developer.mozilla.org/en-US/docs/Web/API/Document/querySelectorAll) will return an HTMLCollection (an array-like element) so accessing to [Node.textContent](https://developer.mozilla.org/en-US/docs/Web/API/Node/textContent) property will result in `undefined`, you should either use [Document.querySelector](https://developer.mozilla.org/en-US/docs/Web/API/Document/querySelector) or get the first index separately.
## Get individual element
Working example for demonstration:
```
document.querySelectorAll("[class$='text-content']")[0].textContent
```
```
const content = document.querySelector("[class$='text-content']").textContent;
console.log(content)
```
```
<div class="MuiBox-root jss1500 jss1169 js1499 text-content">This is the content</div>
```
or
```
document.querySelector("[class$='text-content']").textContent
```
```
const content = document.querySelectorAll("[class$='text-content']")[0].textContent;
console.log(content)
```
```
<div class="MuiBox-root jss1500 jss1169 js1499 text-content">This is the content</div>
```
## Get all the matching elements
Also if you want to get all of the you can do a loop over the elements provided by `querySelectorAll` and the with the help of [Array#forEach](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/forEach).
```
const elements = document.querySelectorAll("[class$='text-content']");
Array.from(elements).forEach(element => console.log(element.textContent))
```
```
<div class="MuiBox-root jss1500 jss1169 js1499 text-content">This is the content</div>
<div class="MuiBox-root jss1500 jss1169 js1499 text-content">This is the content 2</div>
<div class="MuiBox-root jss1500 jss1169 js1499 text-content">This is the content 3</div>
<div class="MuiBox-root jss1500 jss1169 js1499 text-content">This is the content 4</div>
<div class="MuiBox-root jss1500 jss1169 js1499 text-content">This is the content 5</div>
<div class="MuiBox-root jss1500 jss1169 js1499 text-content">This is the content 6</div>
```
| null | CC BY-SA 4.0 | null | 2022-11-01T18:25:20.563 | 2022-11-01T18:51:41.363 | 2022-11-01T18:51:41.363 | 11,908,502 | 11,908,502 | null |
74,280,357 | 2 | null | 74,280,188 | 0 | null | You are actually quite close.
The classes are denoted by the . and these can be strung together.
So those random values you stung together are dynamic classes.
For usage on that `querySelector` you can have a look here:
[https://developer.mozilla.org/en-US/docs/Web/API/Document/querySelector](https://developer.mozilla.org/en-US/docs/Web/API/Document/querySelector)
Armed with that knowledge you can easily pick up the elements you need.
```
// Since you need only the one class:
var elements = document.querySelectorAll(".text-content");
// Then you can get all of the elements matching.
for (let i = 0; i < elements. Length; i++) {
// And easily do what you want with each.
// Like getting or setting content.
elements[i].innerText = "updated content";
}
```
```
<div class="text-content other another">
dummy content
</div>
<div class="text-content other">
dummy content
</div>
<div class="other another">
dummy content
</div>
```
| null | CC BY-SA 4.0 | null | 2022-11-01T18:34:37.270 | 2022-11-01T18:40:13.667 | 2022-11-01T18:40:13.667 | 3,454,921 | 3,454,921 | null |
74,280,455 | 2 | null | 69,240,557 | 0 | null | You can now find all variables in a Jupyter Notebook in VS Code in the Output panel under
[](https://i.stack.imgur.com/LhtNg.png)
| null | CC BY-SA 4.0 | null | 2022-11-01T18:45:27.047 | 2022-11-01T18:45:27.047 | null | null | 5,494,562 | null |
74,281,304 | 2 | null | 74,279,245 | 0 | null | I have found out the issue by running `firebase deploy` in debug mode. The issue was in the resulting`firebase.json`:

After removing the `rewrites` attribute in `firebase.json` the issue was resolved. All requests go pass the ssr function now.
| null | CC BY-SA 4.0 | null | 2022-11-01T20:12:12.297 | 2022-11-01T20:12:12.297 | null | null | 2,876,105 | null |
74,281,308 | 2 | null | 71,673,147 | 0 | null | Taken from this [repo](https://github.com/pnp/sp-dev-fx-extensions/tree/main/samples/react-aadtokenprovider-bot) which has some of the official samples from the SPFx extensions model and depicts a pretty close use-case to the one that you are searching, there is an element in [Fluent UI called Panel](https://developer.microsoft.com/en-us/fluentui#/controls/web/panel).
As it is written in the documentation:
> Panels are overlays that contain supplementary content and are used for complex creation, edit, or management experiences. For example, viewing details about an item in a list or editing settings.
Furthermore, scouring the repo we can see that the panel is triggered:
```
...
import { Panel, PanelType } from "office-ui-fabric-react/lib/Panel";
...
class GraphBot extends React.Component<IGraphBotProps, IGraphBotState> {
....
public render() {
// Be careful, the user Id is mandatory to be able to use the bot state service (i.e privateConversationData)
return (
<div className={ styles.banner }>
<ActionButton onClick= { this._login } checked={ true } iconProps={ { iconName: "Robot", className: styles.banner__chatButtonIcon } } className={ styles.banner__chatButton}>
{ strings.GraphBotButtonLabel }
</ActionButton>
<Panel
isOpen={ this.state.showPanel }
type={ PanelType.medium}
isLightDismiss={ true }
onDismiss={ () => this.setState({ showPanel: false }) }
>
{ this.state.isBotInitializing ?
....
}
</Panel>
</div>
);
}
```
There is an `<ActionButton>` with an OnClick Eventhandler to execute the below function :
```
private async _login() {
this.setState({
isBotInitializing :true,
showPanel: true,
});
....
```
The above function sets the `showPanel` prop to `true` and this prop is used in the Panel Component, where it checks when set to true to open the Panel and move on with the Business Logic of the application extension.
The same can be seen in the Fluent UI Documentation [here](https://developer.microsoft.com/en-us/fluentui#/controls/web/panel#usage), in the basic example.
```
import * as React from 'react';
import { DefaultButton } from '@fluentui/react/lib/Button';
import { Panel } from '@fluentui/react/lib/Panel';
import { useBoolean } from '@fluentui/react-hooks';
export const PanelBasicExample: React.FunctionComponent = () => {
const [isOpen, { setTrue: openPanel, setFalse: dismissPanel }] = useBoolean(false);
return (
<div>
<DefaultButton text="Open panel" onClick={openPanel} />
<Panel
headerText="Sample panel"
isOpen={isOpen}
onDismiss={dismissPanel}
// You MUST provide this prop! Otherwise screen readers will just say "button" with no label.
closeButtonAriaLabel="Close"
>
<p>Content goes here.</p>
</Panel>
</div>
);
};
```
| null | CC BY-SA 4.0 | null | 2022-11-01T20:12:54.830 | 2022-11-01T20:12:54.830 | null | null | 8,894,067 | null |
74,281,388 | 2 | null | 12,095,135 | 0 | null | Reading uninitialized memory leads to undefined behavior. Bear in mind that what it means to be initialized depends on the invariant of a particular type. For example, it may be required for some pointer to be non-null, some `enum` to be from a valid range or a certain parameter to be a power of two. Situation complicates further with compound structures. . This is why zeroing memory is not enough. If the expected invariant is broken, some code path relying on it will behave in an undefined manner and may pose a security issue.
| null | CC BY-SA 4.0 | null | 2022-11-01T20:22:29.713 | 2022-11-01T20:28:43.947 | 2022-11-01T20:28:43.947 | 10,450,868 | 10,450,868 | null |
74,281,493 | 2 | null | 30,601,516 | -1 | null | One use case of controlling content editable in react js:
[](https://i.stack.imgur.com/ghX3L.png)
| null | CC BY-SA 4.0 | null | 2022-11-01T20:34:33.230 | 2022-11-06T14:21:46.343 | 2022-11-06T14:21:46.343 | 5,411,817 | 17,115,374 | null |
74,281,716 | 2 | null | 73,721,823 | 0 | null | I did it like this btw
```
async function handleSubmit(event: SyntheticEvent) {
event.preventDefault();
const username = event.target[0].value;
const plaintext = event.target[1].value;
const emailOpt = event.target[2].value;
const registerPayload = { username:username, password:plaintext, email:emailOpt}
const tempArr = [];
for (const key in registerPayload){
tempArr.push(encodeURIComponent(key)+'='+encodeURIComponent(registerPayload[key]))
}
// const content = tempArr.join('&');
// console.log(content)
try {
const res = fetch("/api/auth/register",{
method: 'POST',
body: JSON.stringify(registerPayload),
headers: {"Content-Type": "application/json"}
}).then((res) => {
if(res.ok) {
window.location.replace("/login");
}else{
console.log("There was an error registering");
setErrorMessage(res.statusText)
}
})
return res;
} catch (err) {
console.log(err);
}
}
```
The synthetic event exposes targets which are the form data (not sure if this is intended or correct but it gets the job done.)
| null | CC BY-SA 4.0 | null | 2022-11-01T20:57:38.527 | 2022-11-01T20:57:38.527 | null | null | 19,730,434 | null |
74,282,144 | 2 | null | 74,249,432 | 0 | null | try this:
```
import tkinter
import customtkinter as ctk
class App(ctk.CTk):
def __init__(self):
super().__init__()
self.geometry('500x500')
self.title('TestApp')
self.frame = Frame1(self)
class Frame1(ctk.CTkFrame):
def __init__(self, master):
super().__init__(master)
#if you remove this, the "red block" will stick to the upper left corner
master.grid_columnconfigure(0, weight=1)
master.grid_rowconfigure(0, weight=1)
self.frame_rot = ctk.CTkFrame(master=master, fg_color='red')
self.frame_rot.grid(row=0, column=0)
#sticky "ns" will centralize the label vertically
self.label = ctk.CTkLabel(master=self.frame_rot, text='hallo', height=130)
self.label.grid(row=0, column=0, sticky="ns")
if __name__ == "__main__":
app = App()
app.mainloop()
```
| null | CC BY-SA 4.0 | null | 2022-11-01T21:45:12.943 | 2022-11-01T21:45:12.943 | null | null | 20,176,486 | null |
74,282,253 | 2 | null | 66,358,200 | 0 | null | My Unity editor version: 2021.3.5f1
---
1. Go to Window > Package Manager > Packages: In Project
> make sure is imported and up to date.
[view example 1](https://i.stack.imgur.com/8ZjYo.png)
---
1. Go to Edit > Project Settings > XR Plug-in Management > Windows, Mac, Linux settings (monitor icon)
> tick the following:- -
[view example 2](https://i.stack.imgur.com/6yc4I.png)
---
1. Go to Edit > Project Settings > XR Plug-in Management > Android settings (android icon)
> tick the following:- -
[see example 3](https://i.stack.imgur.com/T2R1G.png)
---
1. Go to Edit > Project Settings > Player > Android settings (android icon) > Other Settings
> In the section do:- - - -
[see example 4](https://i.stack.imgur.com/PwpjL.png)
---
1. In the Project section search for OVRCameraRig prefab
> -
[see example 5](https://i.stack.imgur.com/N6XV9.png)
---
1. In the Project section search for OVRHandPrefab prefab
> In the section do:- - - -
[see example 6](https://i.stack.imgur.com/HkeQO.png)
---
1. Click on OVRHandPrefab prefab under LeftHandAnchor and ensure:
> In the section:- - -
[see example 7](https://i.stack.imgur.com/FdNdX.png)
---
1. Click on OVRHandPrefab prefab under RightHandAnchor and ensure:
> In the section:- - -
[see example 8](https://i.stack.imgur.com/APXFf.png)
---
1. Click on OVRCameraRig and select:
> In the section:-
---
1. To adjust the tracking origin click on OVRCameraRig and choose from:
> In the section:-
---
1. Go to File > Build Settings
> - - - -
---
I assume you have your Oculus device plugged in to your computer and it is in and you cannot test the hand tracking in play mode in Unity.
| null | CC BY-SA 4.0 | null | 2022-11-01T21:58:34.837 | 2022-11-01T22:01:27.293 | 2022-11-01T22:01:27.293 | 20,391,849 | 20,391,849 | null |
74,282,372 | 2 | null | 3,838,329 | 1 | null | if anybody wants to do a C-like speed look up for multiple lines intersections you could use this code done in `numba` and `python`
the epsilon argument should be proportional to your line distance. Also,
the imports are just `import numba` and `import numpy as np`
```
@numba.njit('float64[:,::1], float64[::1], float64', fastmath=True)
def nb_isBetween(line_ab, c, epsilon):
"""
:param line_ab: like --> np.array([[731362.47087528, 9746708.78767337], [731297.282, 9746727.286]])
:param c: point to check like --> np.array([731362.47087528, 9746708.78767337])
:param epsilon:
:return: check if points is on line or not netween point a and b
"""
a, b = line_ab
a_x, a_y = a
b_x, b_y = b
c_x, c_y = c
crossproduct = (c_y - a_y) * (b_x - a_x) - (c_x - a_x) * (b_y - a_y)
# compare versus epsilon for floating point values, or != 0 if using integers
if abs(crossproduct) > epsilon:
return False
dotproduct = (c_x - a_x) * (b_x - a_x) + (c_y - a_y) * (b_y - a_y)
if dotproduct < 0:
return False
squaredlengthba = (b_x - a_x) * (b_x - a_x) + (b_y - a_y) * (b_y - a_y)
if dotproduct > squaredlengthba:
return False
return True
@numba.njit('float64[:,::1], float64[:,::1]', fastmath=True)
def nb_get_line_intersect(line_ab, line_cd):
"""
:param line_ab: like --> np.array([[731362.47087528, 9746708.78767337], [731297.282, 9746727.286]])
:param line_cd: like --> np.array([[731362.47087528, 9746708.78767337], [731297.282, 9746727.286]])
:return: get point of intersection, if the points in on line ab or cd returns the point if not retunrs 0
"""
A, B = line_ab
C, D = line_cd
# a1x + b1y = c1
a1 = B[1] - A[1]
b1 = A[0] - B[0]
c1 = a1 * (A[0]) + b1 * (A[1])
# a2x + b2y = c2
a2 = D[1] - C[1]
b2 = C[0] - D[0]
c2 = a2 * (C[0]) + b2 * (C[1])
# determinant
det = a1 * b2 - a2 * b1
# parallel line
if det == 0:
return np.array([np.nan, np.nan])
# intersect point(x,y)
x = ((b2 * c1) - (b1 * c2)) / det
y = ((a1 * c2) - (a2 * c1)) / det
#check if x and y area in the line segment interval
if nb_isBetween(line_ab, np.array([x, y]), epsilon=0.001) and nb_isBetween(line_cd, np.array([x, y]), epsilon=0.001):
return np.array([x, y])
else:
return np.array([np.nan, np.nan])
@numba.njit('float64[:, :, ::1], float64[:, :, ::1]', parallel=True, fastmath=True)
def nb_get_line_intersect(m_ramales_lines, interference_lines):
"""
:param m_ramales_lines: like --> np.array([[[731362.47087528, 9746708.78767337], [731297.282, 9746727.286]] , [[731297.282, 9746727.286], [ 731290.048, 9746724.403]]])
:param interference_lines: like --> np.array([[[731362.47087528, 9746708.78767337], [731297.282, 9746727.286]] , [[731297.282, 9746727.286], [ 731290.048, 9746724.403]]])
:return: m_ramales_lines x interference_lines x 2
"""
#empty matrix to fill
m_ramales_interference = np.empty(shape=(len(m_ramales_lines), len(interference_lines), 2))
for pos1 in range(len(m_ramales_lines)):
line_ab = m_ramales_lines[pos1]
for pos2 in numba.prange(len(interference_lines)):
# interference line
line_cd = interference_lines[pos2].T
# get crossing point
cross_point = nb_get_line_intersect(line_ab.copy(), line_cd.copy())
#fill 2D array
m_ramales_interference[pos1, pos2] = cross_point
return m_ramales_interference
```
| null | CC BY-SA 4.0 | null | 2022-11-01T22:15:41.503 | 2022-11-01T22:21:29.560 | 2022-11-01T22:21:29.560 | 12,870,750 | 12,870,750 | null |
74,282,438 | 2 | null | 71,806,578 | 1 | null | Not in the shell itself, but in the , you should set the `Shell.NavBarIsVisible` attribute to false, like so:
```
<ContentPage
...
Shell.NavBarIsVisible="False" />
```
| null | CC BY-SA 4.0 | null | 2022-11-01T22:24:04.420 | 2022-11-01T22:24:04.420 | null | null | 1,602,039 | null |
74,282,760 | 2 | null | 74,279,875 | 1 | null | You are joining three tables. It is using two merge joins to do that, with the output of one merge join being one input of the other. The intermediate table is joined using two different columns, but it can't be ordered on two different columns simultaneously, so if you are only going to use merge joins, you need at least one sort.
This whole thing seems pointless, as the query is already very fast, and why do you care if it uses a hash join or not?
| null | CC BY-SA 4.0 | null | 2022-11-01T23:16:02.020 | 2022-11-01T23:16:02.020 | null | null | 1,721,239 | null |
74,282,903 | 2 | null | 74,281,964 | 0 | null | If you just want today's date, why do you need `cal`? Just use `date +%e`.
But for what ever reason, if you want to only print the matched date with `grep`, use `-o`.
```
$ cal | grep --color=never -o "\b$(date +%e | tr -d ' ' )\b"
2
```
Or maybe you just want to trim the leading whitespace, in that case just use the `date` & `tr` command:
```
$ date +%e | tr -d ' '
2
```
| null | CC BY-SA 4.0 | null | 2022-11-01T23:41:57.180 | 2022-11-02T06:29:46.307 | 2022-11-02T06:29:46.307 | 289,784 | 289,784 | null |
74,283,167 | 2 | null | 74,279,939 | 0 | null | ```
html,body,h1,h2,h3 {
padding:0;
margin:0;
}
.container {
width:100%;
max-width:80vw;
margin:0 auto;
display:flex;
align-items:center;
justify-content:center;
gap:4rem;
}
.left-col {
width:30%;
}
.left-col img {
width:100%;
height:auto;
}
.right-col {
display:flex;
flex-direction:column;
width:70%;
border:1px solid red;
padding:2rem;
}
```
```
<div class="container">
<div class="left-col">
<img src="https://everpath-course-content.s3-accelerate.amazonaws.com/instructor%2F3vkvwjz9hnng2dhlfwzj2a5lt%2Fpublic%2F1666809704%2F6527-q2retarget-hc.1666809704408.png" alt="" width="529" height="360" align="left" />
</div>
<div class="right-col">
<h1 class="break-word"><strong>Get started with Ally Lending basics</strong></h1>
<h2>Find and start conversations, collaborate effectively in channels, find information you need, keep work organized with channels and keep your sidebar organized in Slack.</h2>
<div id="purchase-button-wrapper-large" class="purchase-button-wrapper">
<a class="medium button purchase-button login-link free" href="/checkout/1ycnoni7kt1cn"><span class="purchase-button-full-text"> Get Started </span>
</a>
</div>
</div>
</div>
<div id="purchase-button-wrapper-large" class="purchase-button-wrapper">
<div id="purchase-button-wrapper-large" class="purchase-button-wrapper">
<!-- START Walkthrough developer center tile design,
add to page source code -->
</div>
</div>
```
| null | CC BY-SA 4.0 | null | 2022-11-02T00:30:29.163 | 2022-11-02T00:30:29.163 | null | null | 8,396,541 | null |
74,283,281 | 2 | null | 69,515,086 | 0 | null | You can uninstall the Python package `pyreadline` and install `pyreadline3`, which is an updated fork !
| null | CC BY-SA 4.0 | null | 2022-11-02T00:51:59.363 | 2022-11-02T00:51:59.363 | null | null | 12,778,808 | null |
74,283,432 | 2 | null | 74,226,456 | 0 | null | Ok I solved the issue. It seems the creator of the book added tabs in app.js in the Bottonnavigator class just in case you'd want to add and Update and Delete feature in detailview.js page.
All that is needed is to just add the navigation.navigate("Tabs") in a button in my detailview.js file.
```
<Button
style={styles.addButton}
title="Click for tabs"
onPress={() => navigation.navigate("Tabs")}
/>
```
| null | CC BY-SA 4.0 | null | 2022-11-02T01:22:17.137 | 2022-11-02T01:22:17.137 | null | null | 9,472,443 | null |
74,283,578 | 2 | null | 74,283,496 | 2 | null | Can't see any issues except of your code editor doesn't highlight the syntax.
```
<!DOCTYPE html>
<html lang="en" dir="ltr">
<head>
<meta charset="UTF-8">
<title>Personal Size</title>
<style>
body {
width:600px;
margin:0 auto;
background-color: #ff9500;
padding: 0 20px 20px 20px;
border: 5px solid black;
}
</style>
</head>
<body>
</body>
</html>
```
| null | CC BY-SA 4.0 | null | 2022-11-02T01:51:45.190 | 2022-11-02T01:51:45.190 | null | null | 8,396,541 | null |
74,283,594 | 2 | null | 74,283,496 | 1 | null | Works in jsbin, just try it in jsbin bro
[](https://i.stack.imgur.com/1rM95.png)
| null | CC BY-SA 4.0 | null | 2022-11-02T01:54:28.910 | 2022-11-02T01:54:28.910 | null | null | 20,039,428 | null |
74,283,846 | 2 | null | 16,770,049 | 0 | null | i use
```
plt.legend(loc='center').set_zorder(100)
```
| null | CC BY-SA 4.0 | null | 2022-11-02T02:45:53.967 | 2022-11-02T02:45:53.967 | null | null | 14,351,958 | null |
74,283,852 | 2 | null | 74,256,645 | 1 | null | http-proxy-middleware relies on a initial http request in order to listen to the http upgrade event by default. To proxy WebSockets without the initial http request, you can subscribe to the server's http upgrade event manually.
Add this listener to your http server
```
const wsProxy = createProxyMiddleware({ target: targetURL, onError, ...PROXY_DEFAULT_OPTIONS, ...addlProxyOptions });
httpsServer.on('upgrade', wsProxy.upgrade); // <-- subscribe to http 'upgrade'
```
| null | CC BY-SA 4.0 | null | 2022-11-02T02:47:08.650 | 2022-11-02T02:47:08.650 | null | null | 12,840,372 | null |
74,283,854 | 2 | null | 74,283,790 | 0 | null | You should check the code again, which code that called the CrewInfoAPI? if you havent solved the problem, you may have to update more details on the question.
[](https://i.stack.imgur.com/8TOA1.jpg)
| null | CC BY-SA 4.0 | null | 2022-11-02T02:47:34.170 | 2022-11-02T02:47:34.170 | null | null | 16,363,643 | null |
74,284,149 | 2 | null | 74,135,239 | 0 | null | Finally, I found the solution to my problem. Before I used the unity 2020.3.9. Now I changed the version to 2020.3.4. Now I can deploy and see the game objects in my hololens 2.
| null | CC BY-SA 4.0 | null | 2022-11-02T03:47:48.783 | 2022-11-02T03:47:48.783 | null | null | 20,288,672 | null |
74,285,084 | 2 | null | 20,351,728 | 0 | null | ```
req.files.forEach(function(value, key) {
console.log(value.filename)
})
```
| null | CC BY-SA 4.0 | null | 2022-11-02T06:20:18.923 | 2022-11-02T06:20:18.923 | null | null | 20,394,654 | null |
74,285,420 | 2 | null | 74,285,357 | 0 | null | ```
public static void main(String[] args){
List<byte[]> byteList = new ArrayList<>();
BigInteger encrypt = new BigInteger("434729217");
int value = encrypt.intValue();
byte[] byteArray = toHH(value);
byteList.add(byteArray)
}
public static byte[] toHH(int n) {
byte[] b = new byte[4];
b[3] = (byte) (n & 0xff);
b[2] = (byte) (n >> 8 & 0xff);
b[1] = (byte) (n >> 16 & 0xff);
b[0] = (byte) (n >> 24 & 0xff);
return b;
}
```
| null | CC BY-SA 4.0 | null | 2022-11-02T06:58:38.050 | 2022-11-02T07:24:46.150 | 2022-11-02T07:24:46.150 | 19,583,813 | 19,583,813 | null |
74,285,421 | 2 | null | 28,180,871 | 0 | null | Yes,it is possible to do grouped bar charts of this sort in chart.js and so easy
First of all add the script link of charts.js:-
```
<script src="https://cdnjs.cloudflare.com/ajax/libs/Chart.js/1.0.2/Chart.min.js"></script>
```
Add div in body of html'
```
<body>
<table>
<tr>
<td>
<div id="chart_div" style="width: 800px; height: 300px;">
</div>
</td>
</tr>
</table>
</body>
```
```
<script>
var densityCanvas = document.getElementById("densityChart");
var Data1 = {
label: 'A',
data: [3.7, 8.9, 9.8, 3.7, 23.1, 9.0, 8.7, 11.0],
backgroundColor: 'rgba(99, 132, 0, 0.6)',
borderColor: 'rgba(99, 132, 0, 1)',
yAxisID: "y-axis-gravity"
}
var Data2 = {
label: 'B',
data: [3.7, 8.9, 9.8, 3.7, 23.1, 9.0, 8.7, 11.0],
backgroundColor: 'rgba(99, 132, 0, 0.6)',
borderColor: 'rgba(99, 132, 0, 1)',
//yAxisID: "y-axis-gravity"
}
var Data3 = {
label: 'C',
data: [3.7, 8.9, 9.8, 3.7, 23.1, 9.0, 8.7, 11.0],
backgroundColor: 'rgba(99, 132, 0, 0.6)',
borderColor: 'rgba(99, 132, 0, 1)',
//yAxisID: "y-axis-gravity"
}
```
:You can make multiple Var data which you want to display and only give the yAxisID to one var Data which then display as one group yaxis
```
var planetData = {
labels: ["A", "B", "C"],
datasets: [Data1,Data2, Data3 ]
};
var chartOptions = {
scales: {
xAxes: [{
barPercentage: 1,
categoryPercentage: 0.4
}],
yAxes: [{
id: "y-axis-Registered"
}
]
}
};
var barChart = new Chart(densityCanvas, {
type: 'bar',
data: planetData,
options: chartOptions
});
</script>
```
When I am trying to use this offline Chart.js library and create chart for my case then this pretty solution helps me a lot :-
In picture Last Look:-
[In picture Last Look](https://i.stack.imgur.com/br9CI.png)
| null | CC BY-SA 4.0 | null | 2022-11-02T06:58:46.203 | 2022-11-02T06:58:46.203 | null | null | 14,981,083 | null |
74,287,015 | 2 | null | 50,674,827 | 0 | null | I just tried deleting the "panel" and creating it again and it worked.
The minimize button work again.
| null | CC BY-SA 4.0 | null | 2022-11-02T09:32:19.743 | 2022-11-02T09:32:19.743 | null | null | 20,311,218 | null |
74,287,145 | 2 | null | 74,282,343 | 0 | null | You can [customize your theme](https://code.visualstudio.com/docs/getstarted/themes#_customizing-a-color-theme). First open the [token inspector](https://code.visualstudio.com/api/language-extensions/syntax-highlight-guide#scope-inspector) by executing the `Developer: Inspect Editor Tokens and Scopes` command from the [command palette](https://code.visualstudio.com/docs/getstarted/userinterface#_command-palette):
[](https://i.stack.imgur.com/v5SFt.png)
It looks something like this:
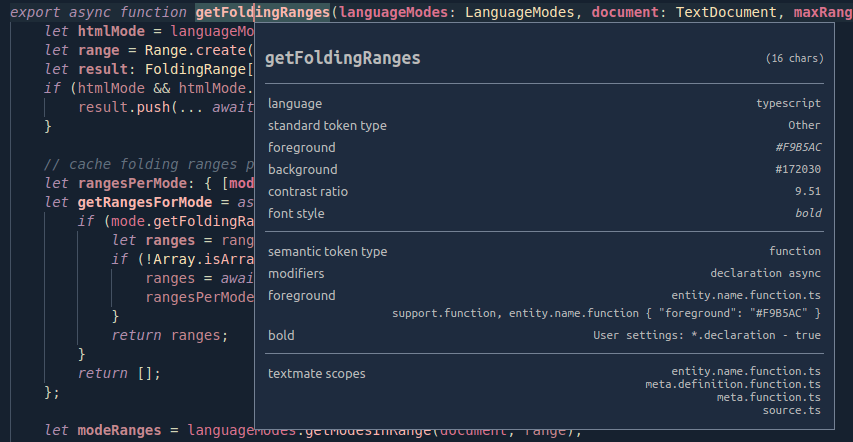
You can then use the textmate scopes at the bottom of the window to change their look in your [JSON configuration](https://code.visualstudio.com/docs/getstarted/settings#_settingsjson):
```
"editor.tokenColorCustomizations": {
"textMateRules": [
{
"scope": [
"entity.name.function.ts",
],
"settings": {
"foreground": "#FF0000",
}
},
],
}
```
The above code would change the color of typescript functions to red.
Use the scope inspector in your react file to find the token names for the type of word you want to change the style of. For each token add a `scope`/`settings` pair to the config.
| null | CC BY-SA 4.0 | null | 2022-11-02T09:42:06.550 | 2022-11-02T09:42:06.550 | null | null | 3,018,229 | null |
74,287,726 | 2 | null | 63,613,914 | 0 | null | Got mine working thanks to this question and Bryan's example that way:
[](https://i.stack.imgur.com/qfXIR.gif)
[HD mp4 Version](https://i.imgur.com/8fU16xh.mp4)
With Bryan's solution Script:
```
from tkinter import *
from random import sample
root = Tk()
root.title('Name Picker')
root.iconbitmap('c:/myguipython/table.ico')
root.geometry("400x400")
def pick():
entries = ["1st name","2nd name","3rd name","4th name","5th name"]
number_of_items = 2
string_data = [str(data) for data in entries]
rando = sample(string_data, number_of_items)
rando1 = sample(string_data, number_of_items)
my_text.delete(1.0, END)
my_text.insert(INSERT, " ".join(rando + rando1))
topLabel = Label(root, text="Picked Names", font=("Helvetica", 24))
topLabel.pack(pady=20)
winButton = Button(root, text="pick names", font=("Helvetica", 24), command=pick)
winButton.pack(pady=20)
my_text = Text(root, width=40, height=10, font=("Helvetica", 18))
my_text.pack(pady=10)
root.mainloop()
```
Solution Snippet:
```
string_data = [str(data) for data in entries]
rando = sample(string_data, number_of_items)
rando1 = sample(string_data, number_of_items)
my_text.delete(1.0, END)
my_text.insert(INSERT, " ".join(rando + rando1))
```
Original script:
```
from tkinter import *
from random import sample
root = Tk()
root.title('Name Picker')
root.iconbitmap('c:/myguipython/table.ico')
root.geometry("400x400")
def pick():
entries = ["1st name","2nd name","3rd name","4th name","5th name"]
number_of_items = 2
rando = sample(entries, number_of_items)
rando1 = sample(entries, number_of_items)
my_text.delete(1.0, END)
my_text.insert(INSERT, rando + rando1)
topLabel = Label(root, text="Picked Names", font=("Helvetica", 24))
topLabel.pack(pady=20)
winButton = Button(root, text="pick names", font=("Helvetica", 24), command=pick)
winButton.pack(pady=20)
my_text = Text(root, width=40, height=10, font=("Helvetica", 18))
my_text.pack(pady=10)
root.mainloop()
```
| null | CC BY-SA 4.0 | null | 2022-11-02T10:28:59.693 | 2022-11-02T11:02:04.783 | 2022-11-02T11:02:04.783 | 10,789,707 | 10,789,707 | null |
74,287,753 | 2 | null | 57,933,593 | 3 | null | with iOS 16 and above it is quite simple:
```
ScrollView {
...
}
.scrollDisabled(true)
```
but for iOS versions less it needs a view modifier:
```
struct DisableScrollingModifier: ViewModifier {
var disabled: Bool
func body(content: Content) -> some View {
if disabled {
content
.simultaneousGesture(DragGesture(minimumDistance: 0))
} else {
content
}
}
}
extension View {
func scrollingDisabled(_ disabled: Bool) -> some View {
modifier(DisableScrollingModifier(disabled: disabled))
}
}
```
Usage Example:
```
ScrollView {
...
}
.scrollingDisabled(true)
```
| null | CC BY-SA 4.0 | null | 2022-11-02T10:30:42.320 | 2022-11-02T10:30:42.320 | null | null | 3,013,992 | null |
74,288,292 | 2 | null | 74,288,271 | 2 | null | For big images you will always end up with this error.
You can either change you implementation to iterative DFS (which doesn't use recursion), or use BFS.
Implementation can be found [here (for iterative DFS)](https://stackoverflow.com/questions/73837517/recursive-dfs-into-iterative-dfs-with-global-state)
[BFS implementation](https://stackoverflow.com/questions/26152380/connected-components-using-breadth-first-search)
| null | CC BY-SA 4.0 | null | 2022-11-02T11:15:28.660 | 2022-11-02T13:46:21.093 | 2022-11-02T13:46:21.093 | 1,460,718 | 1,460,718 | null |
74,288,438 | 2 | null | 49,022,731 | 1 | null | This worked for me on windows pc. This one is for those are not seeing the port when you run this command `netstat -a -o -n` on your command prompt.
Open your command prompt in administrator mode and run this command
`net stop winnat`
you'll get this response:
`The Windows NAT Driver service was stopped successfully.`
Them you run this next:
`net start winnat`
then you will get this response:
`The Windows NAT Driver service was started successfully.`
once you do that. Start the react server and it would work. Same too if your backend server doesn't run on 3000
| null | CC BY-SA 4.0 | null | 2022-11-02T11:25:54.360 | 2022-11-02T11:25:54.360 | null | null | 13,592,987 | null |
74,288,688 | 2 | null | 39,715,412 | 0 | null | CFBundleShortVersionString CFBundleVersion Please check these two values in your info.plist file, you must have hard coded them sometime. It was the case with me. These values were hard codedly given
| null | CC BY-SA 4.0 | null | 2022-11-02T11:49:11.717 | 2022-11-02T11:49:11.717 | null | null | 7,570,861 | null |
74,289,008 | 2 | null | 74,288,808 | 2 | null | ```
import numpy as np
A = np.array([[ 0, 3, 6, 9, 12],
[ 1, 4, 7, 10, 13],
[ 2, 5, 8, 11, 14]])
mul = A[None, :, :] * A[:, None, :]
np.median(mul, axis=2)
# array([[36., 42., 48.],
# [42., 49., 56.],
# [48., 56., 64.]])
```
| null | CC BY-SA 4.0 | null | 2022-11-02T12:15:18.020 | 2022-11-20T23:30:41.417 | 2022-11-20T23:30:41.417 | 9,499,196 | 9,499,196 | null |
74,289,337 | 2 | null | 74,286,275 | 0 | null | Similar as the suggestion to use the `cycler`, you could also define a list with colors (e.g. from a [Colormap](https://matplotlib.org/stable/tutorials/colors/colormaps.html)), where each row corresponds to the color for each plot.
```
#list with 5 colors, e.g. from colormap 'tab10'
c = [plt.cm.tab10(i) for i in range(5)]
```
```
#list with 5 colors
c = [plt.cm.RdBu_r(i/5) for i in range(5)]
```
```
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#some random data
numLines = 5
df = pd.DataFrame(np.random.randint(0,100,size=(10, numLines)))
#list with colors
c = [plt.cm.RdBu_r(i/numLines) for i in range(numLines)]
#plot
ax = df.plot(color=c)
plt.show()
```
| null | CC BY-SA 4.0 | null | 2022-11-02T12:43:11.147 | 2022-11-02T12:43:11.147 | null | null | 17,326,889 | null |
74,289,720 | 2 | null | 74,288,015 | 1 | null | [df.colRegex](https://spark.apache.org/docs/latest/api/python/reference/pyspark.sql/api/pyspark.sql.DataFrame.colRegex.html#pyspark.sql.DataFrame.colRegex) may serve you well. If all the values in columns which match the regex are equal, you get 1. The script is efficient, as everything is done in one `select`.
Inputs:
```
from pyspark.sql import functions as F
df = spark.createDataFrame(
[('p', 1, 2, 'g', 'm'),
('a', 3, 3, 'g', 'g'),
('b', 4, 5, 'g', 'g'),
('r', 8, 8, 'm', 'm'),
('d', 2, 1, 'u', 'g')],
['Name', 'Marks_1', 'Marks_2', 'Qualification_1', 'Qualification_2'])
col_pairs = ['Marks', 'Qualification']
```
Script:
```
def equals(*cols):
return (F.size(F.array_distinct(F.array(*cols))) == 1).cast('int')
df = df.select(
'*',
*[equals(df.colRegex(f"`^{c}.*`")).alias(f'{c}_result') for c in col_pairs]
)
df.show()
# +----+-------+-------+---------------+---------------+------------+--------------------+
# |Name|Marks_1|Marks_2|Qualification_1|Qualification_2|Marks_result|Qualification_result|
# +----+-------+-------+---------------+---------------+------------+--------------------+
# | p| 1| 2| g| m| 0| 0|
# | a| 3| 3| g| g| 1| 1|
# | b| 4| 5| g| g| 0| 1|
# | r| 8| 8| m| m| 1| 1|
# | d| 2| 1| u| g| 0| 0|
# +----+-------+-------+---------------+---------------+------------+--------------------+
```
Proof of efficiency:
```
df.explain()
# == Physical Plan ==
# *(1) Project [Name#636, Marks_1#637L, Marks_2#638L, Qualification_1#639, Qualification_2#640, cast((size(array_distinct(array(Marks_1#637L, Marks_2#638L)), true) = 1) as int) AS Marks_result#646, cast((size(array_distinct(array(Qualification_1#639, Qualification_2#640)), true) = 1) as int) AS Qualification_result#647]
# +- Scan ExistingRDD[Name#636,Marks_1#637L,Marks_2#638L,Qualification_1#639,Qualification_2#640]
```
```
def equals(*cols):
return (F.size(F.array_distinct(F.array(*cols))) != 1).cast('int')
df = df.select(
'*',
*[equals(df.colRegex(f"`^{c}.*`")).alias(f'{c}_result') for c in col_pairs]
).agg(
*[F.sum(f'{c}_result').alias(f'rec_changed_{c}') for c in col_pairs],
*[(F.sum(f'{c}_result') / F.count(f'{c}_result')).alias(f'{c}_%_rec_changed') for c in col_pairs]
)
df.show()
# +-----------------+-------------------------+-------------------+---------------------------+
# |rec_changed_Marks|rec_changed_Qualification|Marks_%_rec_changed|Qualification_%_rec_changed|
# +-----------------+-------------------------+-------------------+---------------------------+
# | 3| 2| 0.6| 0.4|
# +-----------------+-------------------------+-------------------+---------------------------+
```
| null | CC BY-SA 4.0 | null | 2022-11-02T13:10:33.527 | 2022-11-03T07:21:16.530 | 2022-11-03T07:21:16.530 | 2,753,501 | 2,753,501 | null |
74,289,721 | 2 | null | 74,288,015 | 1 | null | i'm not sure what loop are you running, but here's an implementation with list comprehension within a `select`.
```
data_ls = [
(10, 11, 'foo', 'foo'),
(12, 12, 'bar', 'bar'),
(10, 12, 'foo', 'bar')
]
data_sdf = spark.sparkContext.parallelize(data_ls). \
toDF(['marks_1', 'marks_2', 'qualification_1', 'qualification_2'])
col_pairs = ['marks','qualification']
data_sdf. \
select('*',
*[(func.col(c+'_1') == func.col(c+'_2')).cast('int').alias(c+'_check') for c in col_pairs]
). \
show()
# +-------+-------+---------------+---------------+-----------+-------------------+
# |marks_1|marks_2|qualification_1|qualification_2|marks_check|qualification_check|
# +-------+-------+---------------+---------------+-----------+-------------------+
# | 10| 11| foo| foo| 0| 1|
# | 12| 12| bar| bar| 1| 1|
# | 10| 12| foo| bar| 0| 0|
# +-------+-------+---------------+---------------+-----------+-------------------+
```
where the list comprehension would yield the following
```
[(func.col(c+'_1') == func.col(c+'_2')).cast('int').alias(c+'_check') for c in col_pairs]
# [Column<'CAST((marks_1 = marks_2) AS INT) AS `marks_check`'>,
# Column<'CAST((qualification_1 = qualification_2) AS INT) AS `qualification_check`'>]
```
---
based on the additional (updated) info, you need the count of unmatched records for that pair and then you want to calculate the unmatched percentage.
reversing the aforementioned logic to count the unmatched records
```
col_pairs = ['marks','qualification']
data_sdf. \
agg(*[func.sum((func.col(c+'_1') != func.col(c+'_2')).cast('int')).alias(c+'_unmatch') for c in col_pairs],
func.count('*').alias('row_cnt')
). \
select('*',
*[(func.col(c+'_unmatch') / func.col('row_cnt')).alias(c+'_unmatch_perc') for c in col_pairs]
). \
show()
# +-------------+---------------------+-------+------------------+--------------------------+
# |marks_unmatch|qualification_unmatch|row_cnt|marks_unmatch_perc|qualification_unmatch_perc|
# +-------------+---------------------+-------+------------------+--------------------------+
# | 2| 1| 3|0.6666666666666666| 0.3333333333333333|
# +-------------+---------------------+-------+------------------+--------------------------+
```
the code flags (as 1) the records where the pair does not match and takes a sum of the flag - which gives us the pair's unmatched record count. dividing that with the total row count will give the percentage.
the list comprehension will yield the following
```
[func.sum((func.col(c+'_1') != func.col(c+'_2')).cast('int')).alias(c+'_unmatch') for c in col_pairs]
# [Column<'sum(CAST((NOT (marks_1 = marks_2)) AS INT)) AS `marks_unmatch`'>,
# Column<'sum(CAST((NOT (qualification_1 = qualification_2)) AS INT)) AS `qualification_unmatch`'>]
```
this is very much efficient as all of it happens in a single `select` statement which will only project once in the spark plan as opposed to your approach which will project every time you do a `withColumn` - and that is inefficient to spark.
| null | CC BY-SA 4.0 | null | 2022-11-02T13:10:42.033 | 2022-11-03T06:02:52.633 | 2022-11-03T06:02:52.633 | 8,279,585 | 8,279,585 | null |
74,290,062 | 2 | null | 74,287,664 | 1 | null | You can use relative paths . [By default](https://code.visualstudio.com/docs/languages/markdown#_path-completions), markdown paths starting with `/` resolve to the workspace root. Paths starting with `./` resolve relative to the file.
For example, lets say your markdown file is located in `C:/dev/Markdown` and your image(s) are located in `C:/dev`. If you try to do:
```

*My Test Image*
```
This won't work, because the markdown file will try to look for the image using relative pathing. You can see the path it is trying to resolve by trying to open the link of the image in the markdown by holding and left clicking it and then hover over the tab like so:
[](https://i.stack.imgur.com/EkyfB.png)
Notice how butchered that path is. Thus, you need to use relative paths to the file. In this example, you can do:
```

*My Test Image*
```
This will resolve to `C:/dev/MyImage.jpg`. Depending on how deep your file is in a folder structure, you may need to go further back (so maybe something like `../../..MyImage.jpg`).
Visual Studio Code will even try to autocomplete paths if it can like so:
[](https://i.stack.imgur.com/8HkgL.png)
| null | CC BY-SA 4.0 | null | 2022-11-02T13:35:04.473 | 2022-11-02T13:35:04.473 | null | null | 6,530,134 | null |
74,291,783 | 2 | null | 32,022,580 | 0 | null | On window, work for me.
1 - Open
2 - Search for
3 - Right Click on
Thank you!!!
[](https://i.stack.imgur.com/regm8.png)
| null | CC BY-SA 4.0 | null | 2022-11-02T15:33:28.020 | 2022-11-02T15:33:28.020 | null | null | 15,394,108 | null |
74,292,321 | 2 | null | 57,534,160 | 0 | null | You could try my library ([capped_progress_indicator](https://pub.dev/packages/capped_progress_indicator)) that does what you want and works exactly like Flutter's original `LinearProgressIndicator` and `CircularProgressIndicator`. It not only rounds the ends of the track/background but also the ends of the progress/indicator.
So its just a matter of installing the package and changing your code from
```
LinearProgressIndicator(
// ...
)
```
to
```
import 'package:capped_progress_indicator/capped_progress_indicator.dart';
LinearCappedProgressIndicator(
// ...
)
```
You can also change the corner radius to your liking
```
LinearCappedProgressIndicator(), // Circle end (default).
LinearCappedProgressIndicator(cornerRadius: 5), // Rounded end.
LinearCappedProgressIndicator(cornerRadius: 0), // Square end.
```
| null | CC BY-SA 4.0 | null | 2022-11-02T16:07:52.117 | 2022-11-02T16:07:52.117 | null | null | 11,979,688 | null |
74,292,409 | 2 | null | 74,292,286 | 0 | null | Using the `item` function you are adding another item to the scrollable content of the `LazyColumn`.
If you want that the `LazyColumn` occupies only the remaining height available, and the footer that doesn't scroll with the list, you can move the footer out of the `LazyColumn` and apply the `weight` modifier to the `LazyColumn`.
Something like:
```
Column(){
Header()
LazyColumn(Modifier.weight(1f)) {
//....
}
Footer() //your Box
}
```
In your case:
```
Column {
//Header
Box(Modifier.fillMaxWidth().height(30.dp).background(Red))
LazyColumn(Modifier.weight(1f)) {
items(itemsList){
Text("Item $it")
}
}
//Footer
OtherLayout()
}
```
With:
```
@Composable
fun OtherLayout(modifier: Modifier = Modifier) {
Box(modifier = modifier.fillMaxWidth()) {
//..
}
}
```
[](https://i.stack.imgur.com/SV3xJ.png)
| null | CC BY-SA 4.0 | null | 2022-11-02T16:13:10.210 | 2022-11-03T10:31:22.123 | 2022-11-03T10:31:22.123 | 2,016,562 | 2,016,562 | null |
74,292,534 | 2 | null | 74,284,250 | 0 | null | I'm not sure if I could exactly answer your question, but I suppose you have to apply your data using K-Means algorithm.
Based from your source code, I've noticed the following:
1. You are tokenizing your tokens by using .split(). Your code could save a lot of lines and list comprehensions by using libraries such as nltk's tokenizer. Since you are tokenizing tweets, you can from nltk.tokenize import TweetTokenizer. Similar steps could be done on lemmatization.
2. Your output files are unstructured, you need to structure it in a way that it could be easily understood. You can store it in CSV. An alternative way is to:
3. Store the processed data using Pandas' Dataframe. That way you'll have access to a table-like structure where you can modify the table they way you want.
4. Instead of coding your own K-Means algorithm, you can instead import the algorithm KMeans from sklearn.cluster.
5. Now you can obtain statistical treatments such as scores, cluster centers. You can also obtain treatments from numpy
6. (Addtnl) If you want to visualize your data, you can do so by using packages such as matplotlib or seaborn
I hope this answer would be helpful for your thesis. I just saw your Facebook post from a data science group.
| null | CC BY-SA 4.0 | null | 2022-11-02T16:22:28.667 | 2022-11-02T16:22:28.667 | null | null | 5,766,822 | null |
74,292,644 | 2 | null | 8,186,436 | 2 | null | A much simpler solution is to change the underlying function in `reorder`:
```
ggplot(data = md, aes(x = reorder(fullname, value, sum), y = value, fill = variable)) +
geom_col()
```

| null | CC BY-SA 4.0 | null | 2022-11-02T16:32:06.623 | 2022-11-02T16:32:06.623 | null | null | 7,941,188 | null |
74,293,647 | 2 | null | 14,751,461 | 0 | null | In my case, I had installed jenkins with snap. I brought everything down with docker-compose. Then I copied the downloaded jenkins.war to the snap directory. Next, brought things up with docker-compose, then latest version appeared in the jenkins ui.
| null | CC BY-SA 4.0 | null | 2022-11-02T17:51:12.417 | 2022-11-02T17:51:12.417 | null | null | 20,400,405 | null |
74,293,761 | 2 | null | 74,290,369 | 0 | null | There are no table design issues here, it's a normal one-to-many relationship. But just to ensure data integrity here you should use transactions in the DB.
To properly protect data integrity when inserting records into multiple tables, you have two options:
1. using transactions
2. write single query (one statement) to insert into both tables at the same time
In PostgreSQL, any functions are performed with transactions, so one function = one transaction. For example:
```
CREATE OR REPLACE FUNCTION inser_all_order_data(
)
RETURNS void
LANGUAGE plpgsql
AS $function$
declare
orderid integer;
begin -- begin transaction
insert into orders (created_at, type, status) values (now(), 'mytype', 'mystatus')
returning id into orderid;
insert into ordercontent (order_id, code, name, content) values (orderid, '001', 'myname', 'some text');
end; -- end transaction
$function$
;
```
In here, both insert statements are in the same transaction.
Example for writing single query:
```
with tb as (
insert into orders (created_at, type, status) values (now(), 'mytype', 'mystatus')
returning id
)
insert into ordercontent (order_id, code, name, content)
select id, '001', 'myname', 'some text' from tb;
```
When you write single query you needed using transactions, because one statement = one transaction.
| null | CC BY-SA 4.0 | null | 2022-11-02T17:59:09.323 | 2022-11-02T17:59:09.323 | null | null | 17,296,084 | null |
74,293,774 | 2 | null | 74,293,510 | 1 | null | One option would be to convert the labels to millions via the `labels` argument of `scale_y_continuous`.
Using some fake random example data:
```
set.seed(123)
sleeptocalories1 <- data.frame(
Id = 1:10,
TotalCalories = runif(10, 86, 12e6)
)
library(ggplot2)
ggplot(sleeptocalories1, aes(Id, TotalCalories)) +
geom_col(fill = "steelblue") +
scale_y_continuous(labels = ~ .x / 1e6) +
theme(axis.text.x = element_text(angle = 90)) +
theme(axis.text.y = element_text(angle = 45))
```

| null | CC BY-SA 4.0 | null | 2022-11-02T18:00:58.200 | 2022-11-02T18:00:58.200 | null | null | 12,993,861 | null |
74,293,783 | 2 | null | 74,293,510 | 0 | null | The `scales` library can help with formatting the scales of plots. Scientific notation is an abbreviation.
```
library(scales)
library(ggplot2)
```
```
demo_continuous(c(0, 1e9), labels = label_number_auto())
```
[](https://i.stack.imgur.com/Ah7Wt.png)
May not be appropriate for this application, but log breaks are also possible
```
demo_log10(c(1, 1e5), labels = label_log())
```
[](https://i.stack.imgur.com/u1Hov.png)
| null | CC BY-SA 4.0 | null | 2022-11-02T18:02:16.200 | 2022-11-02T18:02:16.200 | null | null | 13,110,995 | null |
74,293,977 | 2 | null | 10,879,361 | 0 | null | I would advise using plotly
Here's [a link] ([https://plotly.com/python/ternary-contour/](https://plotly.com/python/ternary-contour/))
```
import plotly.figure_factory as ff
import numpy as np
Al = np.array([0. , 0. , 0., 0., 1./3, 1./3, 1./3, 2./3, 2./3, 1.])
Cu = np.array([0., 1./3, 2./3, 1., 0., 1./3, 2./3, 0., 1./3, 0.])
Y = 1 - Al - Cu
# synthetic data for mixing enthalpy
# See https://pycalphad.org/docs/latest/examples/TernaryExamples.html
enthalpy = (Al - 0.01) * Cu * (Al - 0.52) * (Cu - 0.48) * (Y - 1)**2
fig = ff.create_ternary_contour(np.array([Al, Y, Cu]), enthalpy,
pole_labels=['Al', 'Y', 'Cu'],
interp_mode='cartesian')
fig.show()
```
[image description here](https://i.stack.imgur.com/h38vQ.png)
| null | CC BY-SA 4.0 | null | 2022-11-02T18:17:59.570 | 2022-11-02T18:22:07.780 | 2022-11-02T18:22:07.780 | 17,432,123 | 17,432,123 | null |
74,294,079 | 2 | null | 74,291,051 | 1 | null | There is no way to delete individual pipeline executions; it is an immutable history of executions, in the same way that Step Functions execution history cannot be deleted.
| null | CC BY-SA 4.0 | null | 2022-11-02T18:27:13.980 | 2022-11-02T18:27:13.980 | null | null | 895,615 | null |
74,294,160 | 2 | null | 74,293,510 | 1 | null | I like `scales::label_number_si()`:
```
ggplot(data.frame(x = 1:5, y = 10^(2:6)), aes(x, y)) +
geom_col() +
scale_y_continuous(labels = scales::label_number_si())
```
[](https://i.stack.imgur.com/TZ8gh.png)
On your data, it might be:
```
ggplot(sleeptocalories1, aes(Id,TotalCalories) +
geom_col(fill="steelblue") +
theme(axis.text.x = element_text(angle = 90)) +
theme(axis.text.y = element_text(angle = 45)) +
scale_y_continuous(labels = scales::label_number_si())
```
| null | CC BY-SA 4.0 | null | 2022-11-02T18:34:54.297 | 2022-11-03T15:57:32.960 | 2022-11-03T15:57:32.960 | 6,851,825 | 6,851,825 | null |
74,294,260 | 2 | null | 74,293,217 | 1 | null | @WaddleDee72
,
I suggest doing following:
1. Delete wxWidgets directory.
2. Unpack wxWidgets into i.e. ~/wxWidgets.
3. Open Terminal.
4. In the Terminal
4a. cd ~/wxWidgets
4b. mkdir buildOSX
4c. cd buildOSX
4d. ../configure --enable-debug
4e. make -j5
After successful build
1. wx-config --cxxflags
2. wx-config --libs
Use the output of 2 commands above and put the values where they belong in XCode project.
If you get any issues - let us know.
Thank you.
| null | CC BY-SA 4.0 | null | 2022-11-02T18:45:41.670 | 2022-11-02T20:21:13.387 | 2022-11-02T20:21:13.387 | 945,871 | 945,871 | null |
74,294,795 | 2 | null | 74,294,486 | 1 | null | Try adding `self.driver.implicitly_wait(10)` to the end of the `__init__` method.
Or add an explicit wait into query method:
```
def query(self):
WebDriverWait(self.driver, 10).until(EC.presence_of_element_located((By.ID, 'login-button'))).click()
```
| null | CC BY-SA 4.0 | null | 2022-11-02T19:38:01.823 | 2022-11-02T19:38:01.823 | null | null | 12,023,661 | null |
74,294,830 | 2 | null | 74,294,486 | 0 | null | problematic code:
```
self.driver.implicitly_wait(10)
# login_button = WebDriverWait(self.driver, 20).until(
# EC.frame_to_be_available_and_switch_to_it((By.CSS_SELECTOR, "iframe[id$='IFrame_htmIFrame']"))
# )
```
An explicit wait (similar to that which was commented out) seems to work better here.
I changed
```
login_button = WebDriverWait(self.driver, 20).until(
EC.frame_to_be_available_and_switch_to_it((By.CSS_SELECTOR, "iframe[id$='IFrame_htmIFrame']")))
```
to
```
login_button = WebDriverWait(self.driver, 20).until(
EC.element_to_be_clickable((By.ID, 'login-button')))
login_button.click()
```
and it has worked. Thanks all and hope this helps someone else.
| null | CC BY-SA 4.0 | null | 2022-11-02T19:41:06.323 | 2022-11-02T19:41:06.323 | null | null | 13,132,761 | null |
74,294,994 | 2 | null | 8,964,279 | 0 | null | I know this original post was for binary search trees, but I created a pretty print for red-black trees which looks pretty nice. The code basically gives creates a table with the same number of rows as the height of the tree, and a width the same as the number of nodes. Then as you recurse through each layer of the ree, you can put in the node in the proper index of the table, and eventually pretty print that.
[](https://i.stack.imgur.com/gsdrP.png)
Link to the full code for the red-black tree:
[https://github.com/spencermitton/rbTree](https://github.com/spencermitton/rbTree)
| null | CC BY-SA 4.0 | null | 2022-11-02T19:57:11.767 | 2022-11-06T09:44:27.333 | 2022-11-06T09:44:27.333 | 6,277,104 | 15,101,762 | null |
74,295,656 | 2 | null | 31,405,857 | 0 | null | Addition to the answer by Anton Bevza
Their library has some disadvantages that are fixed in the [fork](https://github.com/martipello/MultiImageView)
Add dependency in :
```
implementation 'com.github.martipello:MultiImageView:1.0.8.2'
```
Add MultiImageView to layout xml file
```
<com.sealstudios.multiimageview.MultiImageView
android:id="@+id/iv"
android:layout_width="100dp"
android:layout_height="100dp"
app:shape="circle" />
```
For setting shape of MultiImageView use attributes in layout xml file
```
app:shape="circle" //Circle
app:shape="rectangle" //Rectangle with round corners
app:shape="none" //Without shape
```
Also you can change shape by using method:
```
multiImageView.setShape(MultiImageView.Shape.RECTANGLE);//Rectangle with round corners
multiImageView.setShape(MultiImageView.Shape.CIRCLE);//Circle
multiImageView.setShape(MultiImageView.Shape.NONE);//Without shape
```
In java class find view by id:
```
final MultiImageView multiImageView = findViewById(R.id.iv);
```
For adding image to MultiImageView use method addImage(Bitmap bitmap). For example:
```
multiImageView.addImage(BitmapFactory.decodeResource(getResources(), R.drawable.avatar));
//or
Bitmap bitmap = MediaStore.Images.Media.getBitmap(getContentResolver(), ImageUri);
multiImageView.addImage(bitmap);
```
| null | CC BY-SA 4.0 | null | 2022-11-02T21:09:32.337 | 2022-11-02T21:17:41.560 | 2022-11-02T21:17:41.560 | 18,750,563 | 18,750,563 | null |
74,295,687 | 2 | null | 20,431,491 | 0 | null |
1. Install MySQL installer.
2. Select Add... from the right side and install the latest version of MySQL server.
I hope this will work. It worked for me. Thank You.
| null | CC BY-SA 4.0 | null | 2022-11-02T21:13:00.820 | 2022-11-02T21:13:35.277 | 2022-11-02T21:13:35.277 | 15,489,060 | 15,489,060 | null |
74,296,191 | 2 | null | 74,295,854 | 0 | null | ```
df.loc[df['action'].eq('visited') & df['target'].eq('pricing page'), 'type'] = 'free'
```
```
action target type
0 visited pricing page free
1 clicked homepage NaN
2 switched succeesed NaN
```
| null | CC BY-SA 4.0 | null | 2022-11-02T22:18:41.663 | 2022-11-02T22:18:41.663 | null | null | 3,494,754 | null |
74,296,289 | 2 | null | 74,296,110 | 2 | null | When you apply a `border-radius` the childs will still 'overflow' past the radius, it's only noticeable when a child has a background color.
you may resolve it by applying a `overflow:hidden` rule on the element that has the radius.
```
body {
height: 100vh;
display: flex;
justify-content: center;
align-items: center;
}
table {
border-collapse: collapse;
border: solid transparent 2px;
border-radius: 12px;
background-color: rgb(166, 89, 89);
color: rgb(248, 215, 215);
/*you need to hide overflows for the border-radius items*/
overflow: hidden;
}
table thead tr th {
text-align: left;
padding: 5px;
font-size: 1rem;
color: rgb(240, 240, 240);
}
table tbody tr td {
font-size: 0.9rem;
padding: 5px;
text-align: left;
}
table tbody tr:last-child {
background-color: rgba(0, 0, 255, 0.405);
}
```
```
<table>
<thead>
<tr>
<th>
head
</th>
</tr>
</thead>
<tbody>
<tr>
<td>cell</td>
</tr>
</tbody>
</table>
```
| null | CC BY-SA 4.0 | null | 2022-11-02T22:30:15.753 | 2022-11-02T22:30:15.753 | null | null | 1,203,738 | null |
74,296,563 | 2 | null | 73,222,147 | 0 | null | You might also have your firewall or selinux still up and blocking traffic.
Did your poller install complete or is it stuck at the part where you have to copy the gorgone config to the CLI?
Do you already have the gorgone config file `/etc/centreon-gorgone/config.d/40-gorgoned.yaml` on your poller?
| null | CC BY-SA 4.0 | null | 2022-11-02T23:11:59.733 | 2022-11-02T23:11:59.733 | null | null | 1,592,607 | null |
74,296,928 | 2 | null | 74,296,730 | 1 | null | I draw a traditional overlapping plot and (if i understood correctly) your desired plot below to compare results:
```
library(tidyverse)
set.seed(7)
df = tibble(
categories = rep(c("a", "b", "c"), each = 3) %>% factor(),
xaxis = rep(1:3, 3) %>% factor(),
yaxis = runif(9))
ggplot() +
geom_bar(aes(xaxis, yaxis, fill = categories, group=categories), df, alpha=0.8,
stat = "identity", position = position_dodge(width=0.3,preserve = "single"))
```

```
df<-df %>% group_by(xaxis) %>% mutate(rank=rank(-yaxis)) %>%
pivot_wider(values_from=yaxis, names_from = rank, values_fill = 0,
names_sort = T, names_prefix = "rank")
print(df)
#> # A tibble: 9 × 5
#> # Groups: xaxis [3]
#> categories xaxis rank1 rank2 rank3
#> <fct> <fct> <dbl> <dbl> <dbl>
#> 1 a 1 0.989 0 0
#> 2 a 2 0 0.398 0
#> 3 a 3 0 0 0.116
#> 4 b 1 0 0 0.0697
#> 5 b 2 0 0 0.244
#> 6 b 3 0.792 0 0
#> 7 c 1 0 0.340 0
#> 8 c 2 0.972 0 0
#> 9 c 3 0 0.166 0
g <- reduce(
map(paste0("rank",1:3),
~geom_bar(aes(xaxis, .data[[.x]], fill=categories), stat="identity", position="identity")),
`+`, .init = ggplot(df) )
g
```

[reprex v2.0.2](https://reprex.tidyverse.org)
It is easier, thanks to Park and [this](https://stackoverflow.com/questions/62078386/reorder-overlaid-bars-in-plot-so-longer-bars-are-in-back-r) post
```
set.seed(7)
df = tibble(
categories = rep(c("a", "b", "c"), each = 3) %>% factor(),
xaxis = rep(1:3, 3) %>% factor(),
yaxis = runif(9))
df %>% group_by(xaxis) %>% arrange(rank(-yaxis)) %>%
ggplot() + geom_bar(aes(xaxis, yaxis, fill=categories), stat="identity", position="identity")
```
| null | CC BY-SA 4.0 | null | 2022-11-03T00:19:06.667 | 2022-11-03T00:49:50.590 | 2022-11-03T00:49:50.590 | 6,912,817 | 6,912,817 | null |
74,296,950 | 2 | null | 74,296,730 | 1 | null | How about this?
```
df %>%
arrange(xaxis, yaxis) %>%
group_by(xaxis) %>%
mutate(yaxis = yaxis - lag(yaxis, default = 0)) %>%
ggplot() +
geom_bar(aes(xaxis, yaxis, fill = categories),
stat = "identity", position = "stack")
```
[](https://i.stack.imgur.com/mAWGQ.png)
| null | CC BY-SA 4.0 | null | 2022-11-03T00:23:40.150 | 2022-11-03T00:23:40.150 | null | null | 16,729,175 | null |
74,296,989 | 2 | null | 25,142,270 | 0 | null | Bootstrap's navbar has the Bootstrap sticky-top class by defualt. Which, has a z-index of 1020. To put your ribbon in front of the navbar, you need to make your ribbon's z-index larger than 1020. Add the following style to your ribbon class to put your ribbon in front of Bootstrap's navbar:
```
z-index: 1021;
```
| null | CC BY-SA 4.0 | null | 2022-11-03T00:32:54.593 | 2022-11-03T00:32:54.593 | null | null | 15,890,157 | null |
74,297,965 | 2 | null | 18,457,907 | 0 | null | By default duration is 5 seconds. You can set/change duration for SVProgressHUD like below:
```
SVProgressHUD.setMinimumDismissTimeInterval(20.0) // 20 seconds
```
| null | CC BY-SA 4.0 | null | 2022-11-03T03:48:16.463 | 2022-11-03T03:48:16.463 | null | null | 2,976,879 | null |
74,298,074 | 2 | null | 74,293,787 | 0 | null | Instead of only storing the player object in the `Path` script, store a collection of objects. That way, the path can keep track of more than one object.
```
//public GameObject m_PlayerObj; // Get rid of this
public List<GameObject> followers; // Add this
```
Then, in your `Update` loop, you can loop through all of them.
```
void Update()
{
for (var i = 0; i < followers.Length; ++i)
{
if (value < 1)
{
value += Time.deltaTime / 10;
}
iTween.PutOnPath(m_PlayerObj, positionPoint, value);
}
}
```
Of course, now, you need to make sure you pass your cube instance to the `Path` GameObject when you spawn it, so the path knows about the cube follower. That means your spawner also needs to know about the path.
```
public class SpawnerScript : MonoBehaviour
{
public GameObject cubeprefab;
public Path path; // Need to populate this in the Editor, or fetch it during Awake()
void Update()
{
if (Input.GetKeyDown(KeyCode.Space))
{
var cubeInst = Instantiate(cubeprefab, transform.position, Quaternion.identity);
path.followers.Add(cubeInst);
}
}
}
```
Now a new problem is going to be that each object is going to be at the same position on the path, because the path only stores one `value` - a better term might be `progress`. So if they're all the same, like the cube, you won't be able to tell because they'd overlap.
So you have to decide what you want to do instead. Evenly space them? You could do that with some math. Or have them all start from the beginning and keep track of their progress separately? Then you'd need to store progress for each of them. A better place to do that is probably on the cube object, which means you need to add a new script to your cube prefab:
```
public class PathFollower : MonoBehaviour
{
[Range(0, 1)]
public float pathProgress;
}
```
And, you need to start referring to the prefab by this script, instead of just `GameObject`:
```
public class SpawnerScript : MonoBehaviour
{
public PathFollower pathFollower;
public Path path; // Need to populate this in the Editor, or fetch it during Awake()
void Update()
{
if (Input.GetKeyDown(KeyCode.Space))
{
var followerInst = Instantiate(pathFollower, transform.position, Quaternion.identity);
path.followers.Add(followerInst);
}
}
}
```
```
public class Path : MonoBehaviour
{
//public GameObject m_PlayerObj; // Get rid of this
public List<PathFollower> followers; // Add this
//...
```
Finally, you need to make sure to use the individual progress for each path follower, rather than a single progress value like your old Path script did:
```
for (var i = 0; i < followers.Count; ++i)
{
if (followers[i].pathProgress < 1)
{
followers[i].pathProgress += Time.deltaTime / 10;
}
iTween.PutOnPath(followers[i].gameObject, positionPoint, followers[i].pathProgress);
}
```
Putting it all together (separate files of course, with their own `include`s!):
```
public class SpawnerScript : MonoBehaviour
{
public PathFollower pathFollower;
public Path path; // Need to populate this in the Editor, or fetch it during Awake()
void Update()
{
if (Input.GetKeyDown(KeyCode.Space))
{
var followerInst = Instantiate(pathFollower, transform.position, Quaternion.identity);
path.followers.Add(followerInst);
}
}
}
public class Path : MonoBehaviour
{
//public GameObject m_PlayerObj; // Get rid of this
public List<PathFollower> followers; // Add this
public Transform[] positionPoint;
//[Range(0, 1)]
//public float value; // Don't need this anymore either
// Start is called before the first frame update
void Start()
{
Debug.Log(iTween.PathLength(positionPoint));
}
// Update is called once per frame
void Update()
{
for (var i = 0; i < followers.Count; ++i)
{
if (followers[i].pathProgress < 1)
{
followers[i].pathProgress += Time.deltaTime / 10;
}
iTween.PutOnPath(followers[i].gameObject, positionPoint, followers[i].pathProgress);
}
}
private void OnDrawGizmos()
{
iTween.DrawPath(positionPoint,Color.green);
}
}
public class PathFollower : MonoBehaviour
{
[Range(0, 1)]
public float pathProgress;
}
```
| null | CC BY-SA 4.0 | null | 2022-11-03T04:12:28.047 | 2022-11-03T04:12:28.047 | null | null | 802,517 | null |
74,298,155 | 2 | null | 23,193,614 | 0 | null | go to the directory `C:\Users\username` and delete the npmrc file
this solved my issue
| null | CC BY-SA 4.0 | null | 2022-11-03T04:28:06.913 | 2022-11-03T04:28:06.913 | null | null | 20,175,263 | null |
74,299,018 | 2 | null | 70,001,982 | 0 | null | Is may help some one,
```
deleteNode(node:any) : void {
if (node.parent != null) {
console.log(node.buildingId)
console.log(node.parent.children.indexOf(node))
node.parent.children.splice(node.parent.children.indexOf(node), 1)
}}
```
| null | CC BY-SA 4.0 | null | 2022-11-03T06:51:09.133 | 2022-11-03T06:51:09.133 | null | null | 5,051,619 | null |
74,299,464 | 2 | null | 74,299,282 | 1 | null | You could simply loop through the two lists and check each number in the `dict_index` list with each number of `li` to find what indices match. In my code, I have followed your example of having the first spot of a list being 1, but depending on your use case, it might be better to have it start at 0. To do this just remove the `+1` in the `index_list.append(j+1)`. Here is the function I wrote:
```
li = [1,1,2,2,4,4,4,7,5,5]
dict_index = [1,2,3,4,5,6,7,8,9,10]
def make_dict(li,dict_index):
#make empty dictionary to store indices in
our_dict = {}
#loop through all numbers of the dict_index
for i in range(len(dict_index)):
current_number = dict_index[i]
#create empty index_list
index_list = []
#loop through list li to check what indices match our current number
for j in range(len(li)):
#If we have a match, we add the index to our index list
if li[j] == current_number:
index_list.append(j+1)
#when we are done looping through li we add result to our dictionary
if index_list:
#if not empty, we add our index list
our_dict[current_number] = index_list
else:
#otherwise, if we had no match, we just add None to the dictionary
our_dict[current_number] = None
#return our dictionary at the end
return our_dict
index_dict = make_dict(li,dict_index)
```
This will yield the following output for index_dict:
```
{1: [1, 2], 2: [3, 4], 3: None, 4: [5, 6, 7], 5: [9, 10], 6: None,
7: [8], 8: None, 9: None, 10: None}
```
| null | CC BY-SA 4.0 | null | 2022-11-03T07:39:15.050 | 2022-11-03T07:39:15.050 | null | null | 18,931,013 | null |
74,299,546 | 2 | null | 43,158,709 | 0 | null | use matplotlib.pyplot and from scipy.stats import norm
plt.plot(dataset,norm.pdf(dataset,mean of dataset,std of dataset)
| null | CC BY-SA 4.0 | null | 2022-11-03T07:45:40.040 | 2022-11-03T07:45:40.040 | null | null | 20,405,207 | null |
74,299,533 | 2 | null | 74,298,572 | 1 | null | > Can anyone help me with the code skeleton an API like this should
follow?
Based on the scenario, you should know how your frontend team sends request to your API. At the same time being an API developer you should deal with the country name as your API parameter, not how the radio button change event works -- as you said it should be front-end teams's concern. Therefore, I am providing you the complete example:
Let's assume you have following country and states:
```
public static List<Country> ListOfCountry = new List<Country>()
{
new Country() { CountryId =101, CountryName ="INDIA", },
new Country() { CountryId =102, CountryName ="UnitedStates", },
new Country() { CountryId =103, CountryName ="UK", },
new Country() { CountryId =104, CountryName ="Canada", },
};
```
```
public static List<State> ListOfState = new List<State>()
{
//INDIA
new State() { CountryId =101, StateId =1, StateName = "Delhi" },
new State() { CountryId =101, StateId =2, StateName = "Haydrabad" },
new State() { CountryId =101, StateId =3, StateName = "Pune" },
//USA
new State() { CountryId =102, StateId =4, StateName = "New York" },
new State() { CountryId =102, StateId =5, StateName = "Silicon Valley" },
new State() { CountryId =102, StateId =6, StateName = "Dallaus" },
//UK
new State() { CountryId =103, StateId =7, StateName = "London" },
new State() { CountryId =103, StateId =8, StateName = "Cardif" },
new State() { CountryId =103, StateId =9, StateName = "Sundarland" },
//Candada
new State() { CountryId =104, StateId =10, StateName = "Alberta" },
new State() { CountryId =104, StateId =11, StateName = "Ontario" },
new State() { CountryId =104, StateId =12, StateName = "Manitoba" },
};
```
Seeing the list I hope you have enough knowledge to write the POCO model class yourself.
```
public class CascadingDropdownController : Controller
{
[HttpGet]
public async Task<ActionResult> GetStateByCountryName(string countryName)
{
int getCountryId = ListOfCountry.Where(name => name.CountryName == countryName).Select(id => id.CountryId).FirstOrDefault();
var state = ListOfState.Where(cId => cId.CountryId == getCountryId).ToList();
return Ok(state);
}
public IActionResult Index() // This action is for the view
{
return View();
}
}
```
```
<div class="container">
<div class="form-group">
<input type="radio" name="country" value="UnitedStates" /><span><strong> United States</strong></span>
<input type="radio" name="country" value="Canada" /> <span><strong> Canada</strong></span>
<input type="radio" name="country" value="India" /> <span><strong> India</strong></span>
</div>
<br />
<table class="table table-sm table-bordered table-striped">
<tr>
<td> <span><strong>City</strong></span> <input class="form-control" placeholder="Enter City" /></td>
<td>
<span><strong>State/Province</strong></span>
<select class="form-control" id="ddlState"> </select>
</td>
<td><span><strong>Zip/Postal Code</strong></span><input id="zip" class="form-control" placeholder="Enter Zip/Postal Code" /> </td>
<td><input type="submit" style="margin-top:22px" value="Search" class="btn btn-primary" /></td>
</tr>
</table>
</div>
@section scripts {
<script src="https://ajax.aspnetcdn.com/ajax/jQuery/jquery-3.2.1.min.js"></script>
<script>
$(document).ready(function () {
var ddlState = $('#ddlState');
ddlState.empty();
ddlState.append($("<option></option>").val('').html('Choose State'));
$('input[type=radio][name=country]').change(function () {
var country = "";
if (this.value == 'UnitedStates') {
country = "UnitedStates"
}
else if (this.value == 'Canada') {
country = "Canada"
}
else if (this.value == 'India') {
country = "INDIA"
}
if (country != "") {
var ddlState = $('#ddlState');
ddlState.empty();
ddlState.append($("<option></option>").val('').html('Please wait ...'));
$.ajax({
url: 'http://localhost:5094/CascadingDropdown/GetStateByCountryName',
type: 'GET',
dataType: 'json',
data: { countryName: country },
success: function (d) {
ddlState.empty(); // Clear the please wait
ddlState.append($("<option></option>").val('').html('Choose State'));
$.each(d, function (i, states) {
ddlState.append($("<option></option>").val(states.stateId).html(states.stateName));
});
},
error: function () {
alert('Error!');
}
});
}
});
});
</script>
}
```
Here `'input[type=radio][name=country]').change` based on `radio button` change event you have to get the selected country name then need to call your API that is `GetStateByCountryName` which expecting a country name as parameter and base on that parameter search the list of state and return you are done.
[](https://i.stack.imgur.com/DHaQr.gif)
I have used a static list of country and states you all need to search from your database. In addition, I have set a submit button.n Nonetheless, it's doing nothing at this stage, hence it will required for any further submission.
| null | CC BY-SA 4.0 | null | 2022-11-03T07:44:46.083 | 2022-11-14T01:15:05.647 | 2022-11-14T01:15:05.647 | 9,663,070 | 9,663,070 | null |
74,299,576 | 2 | null | 74,299,282 | 2 | null | You can zip `li` and `dict_index`, iterate through the parent-child pairs, and append child to the sub-list under the parent key. Initialize non-existing keys with the `dict.setdefault` method:
```
tree = {}
for parent, child in zip(li, dict_index):
if parent != child:
tree.setdefault(parent, []).append(child)
tree.setdefault(child, [])
```
so that given the sample input, `tree` would become:
```
{1: [2], 2: [3, 4], 3: [], 4: [5, 6, 7], 5: [9, 10], 6: [], 7: [8], 8: [], 9: [], 10: []}
```
Demo: [https://replit.com/@blhsing/LikablePoshBundledsoftware](https://replit.com/@blhsing/LikablePoshBundledsoftware)
| null | CC BY-SA 4.0 | null | 2022-11-03T07:49:14.227 | 2022-11-03T07:49:14.227 | null | null | 6,890,912 | null |
74,299,646 | 2 | null | 74,299,487 | 0 | null | If you want to set your JSR223 Sampler execution time to the value of your JSR223 Sampler result text you need to use [JSR223 PostProcessor](https://jmeter.apache.org/usermanual/component_reference.html#JSR223_PostProcessor) and the following code:
```
prev.elapsedTime = prev.getResponseDataAsString() as long
```
where `prev` stands for the ious [SampleResult](https://jmeter.apache.org/api/org/apache/jmeter/samplers/SampleResult.html), see JavaDoc for all functions available with descriptions and [Top 8 JMeter Java Classes You Should Be Using with Groovy](https://www.blazemeter.com/blog/jmeter-java-classes) article for more information on this and other [JMeter API shorthands](https://jmeter.apache.org/api/index.html) available for the [JSR223 Test Elements](https://jmeter.apache.org/usermanual/best-practices.html#jsr223).
also remove this `/1000` bit from your JSR223 Sampler code as JMeter elapsed time is in , if you want it to be in seconds - round it up so it won't have any decimal points.
| null | CC BY-SA 4.0 | null | 2022-11-03T07:54:39.880 | 2022-11-03T07:54:39.880 | null | null | 2,897,748 | null |
74,300,624 | 2 | null | 74,300,002 | 0 | null | in your widget declare this
```
late GoogleMapController mapController;
```
In do this
```
GoogleMap(
initialCameraPosition: _initialLocation,
markers: markers,
myLocationEnabled: true,
myLocationButtonEnabled: true,
mapToolbarEnabled: true,
mapType: MapType.hybrid,
zoomGesturesEnabled: true,
zoomControlsEnabled: true,
onMapCreated: (GoogleMapController controller) {
mapController = controller;
},
),
```
When you initialize map add mapController in it
```
onTap: () {
setState(() {
mapController.animateCamera(
CameraUpdate.newLatLngZoom(LatLng(lat, long), 14));
});
},
```
| null | CC BY-SA 4.0 | null | 2022-11-03T09:20:08.620 | 2022-11-04T06:09:40.093 | 2022-11-04T06:09:40.093 | 16,453,584 | 16,453,584 | null |
74,301,451 | 2 | null | 18,770,447 | 0 | null | It's a bit late to answer this question now, but for those who now come across the similar issue, here is the explanation.
Each back press will reverse a single fragment transaction. So basically what you have in the example above is that you have 2 transactions on navigation click.
1st one is Hiding fragment and second is showing a new one. Once you press back, it will reverse showing new one but nobody will reveal the hidden one and you are left with the Blank/empty screen.
On the next back press you will reverse hide action, so fragment will now appear.
What you need to do is to execute both hiding and showing in a single transaction. In that way, a single back press will know that you want to reverse adding and hiding a fragment below.
```
fragmentManager.beginTransaction().hide(existingFragment).add(newFragment).addToBackStack(null).commit();
```
| null | CC BY-SA 4.0 | null | 2022-11-03T10:23:41.660 | 2022-11-03T10:23:41.660 | null | null | 16,366,395 | null |
74,301,546 | 2 | null | 73,113,484 | 0 | null | Download the Flutter SDK. We’ll have to download the Flutter SDK file in order to work with flutter. We can easily download it from the official website of Flutter.[click for preview](https://i.stack.imgur.com/Cqj1d.png)
Set Environment variable path. After downloading Flutter SDK, extract the file and copy the path of the bin folder.
[click for preview](https://i.stack.imgur.com/0IAKP.png)
Press WIN + R and paste the following: rundll32.exe sysdm.cpl,EditEnvironmentVariables
[click for preview](https://i.stack.imgur.com/kNyJF.png)
Now click on new and paste the path that was copied earlier and save.
[click for preview](https://i.stack.imgur.com/NEyPe.png)
Now We have to set up the Visual Studio Code for the Flutter. We have to install two extensions in order to use flutter. The very first extension is Flutter and 2nd is Dart. Note that Dart is the programming language that is used in flutter for the application development for both and android and iOS.
Installing Flutter in Visual Studio Code
[click for preview](https://i.stack.imgur.com/H4g93.png)
Now install Dart in Visual Studio Code
[click for preview](https://i.stack.imgur.com/bLd1q.png)
Now we have successfully added Flutter and Dart to the Visual studio code, now let’s check if flutter is installed or not. For this we will open a new terminal in Visual Studio Code and type the following “flutter –version”, if everything is fine then it will normally show the version of the installed flutter.
[click for preview](https://i.stack.imgur.com/pfrxw.png)
| null | CC BY-SA 4.0 | null | 2022-11-03T10:29:57.243 | 2022-11-03T10:34:05.777 | 2022-11-03T10:34:05.777 | 19,025,372 | 19,025,372 | null |
74,301,613 | 2 | null | 71,869,322 | 0 | null | Out of the information given it could be anything.
Neverless i had a similar issue maybe this helps somebody:
With , just an empty screen on IOS physical and emulator device.
on physical device
My issue is related to which seems not to be working as expected for IOS 16.1.
After in , my screens where getting loaded - currently trying to figure out what was wrong.
This is more a hint for people, maybe to check if they have same issue
My Issue was related to: [https://github.com/angular/angularfire/issues/3087](https://github.com/angular/angularfire/issues/3087)
Using dependencies provided by DeezCashews in Issue saved my day
```
"@angular/fire": "^7.2.0",
"firebase": "^9.6.4",
"rxfire": "^6.0.3"
```
Seems there is an issue with Angular Fire and ionic capacitor.
| null | CC BY-SA 4.0 | null | 2022-11-03T10:33:54.567 | 2022-11-15T12:59:12.637 | 2022-11-15T12:59:12.637 | 13,123,159 | 13,123,159 | null |
74,301,969 | 2 | null | 74,301,703 | 2 | null | You could do something like:
```
ggplot(data = within(my.df, SampleSize <- paste(SampleSize, 'Samples'))) +
geom_histogram(aes(x = control, fill = factor(SampleSize)),
color = 'gray70') +
geom_vline(data = . %>% group_by(SampleSize) %>%
summarize(mean = mean(control)), size = 5,
aes(xintercept = mean, color = factor(SampleSize))) +
facet_wrap(.~SampleSize, scales = "free_y") +
scale_fill_manual(values = c("#abb0b2", "#596160")) +
scale_color_manual(values = c("#00862a", "#00862a")) +
guides(fill = guide_none(), color = guide_none()) +
theme_minimal() +
theme(strip.text = element_text(size = 16, face = 'bold'))
```
[](https://i.stack.imgur.com/7GR7z.png)
| null | CC BY-SA 4.0 | null | 2022-11-03T10:58:16.273 | 2022-11-03T10:58:16.273 | null | null | 12,500,315 | null |
74,302,169 | 2 | null | 8,850,142 | 1 | null | Just thought I would provide an alternative solution that I just created [textalloc](https://i.stack.imgur.com/Arcgj.png) that makes sure that text-boxes avoids overlap with both each other and lines when possible, and is fast.
For this example you could use something like this:
```
import textalloc as ta
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(2017)
x_data = np.random.random_sample(100)
y_data = np.random.random_integers(10,50,(100))
f, ax = plt.subplots(dpi=200)
bars = ax.bar(x_data, y_data, width=0.002, facecolor='k')
ta.allocate_text(f,ax,x_data,y_data,
[str(yy) for yy in list(y_data)],
x_lines=[np.array([xx,xx]) for xx in list(x_data)],
y_lines=[np.array([0,yy]) for yy in list(y_data)],
textsize=8,
margin=0.004,
min_distance=0.005,
linewidth=0.7,
textcolor="b")
plt.show()
```
This results in this [](https://i.stack.imgur.com/Arcgj.png)
| null | CC BY-SA 4.0 | null | 2022-11-03T11:12:03.053 | 2022-11-04T11:43:00.437 | 2022-11-04T11:43:00.437 | 16,879,899 | 16,879,899 | null |
74,302,603 | 2 | null | 54,813,410 | 0 | null | Your image has been cached, rename the static file or add query string to dynamic file:
```
source={require('../../assets/images/background_new.png')}
source={{uri: "link/image.jpg?v=1.1" }}
```
| null | CC BY-SA 4.0 | null | 2022-11-03T11:51:27.573 | 2022-11-03T11:51:27.573 | null | null | 5,511,839 | null |
74,303,044 | 2 | null | 74,244,322 | 0 | null | You want your "listview to take up the rest of the screen", and at the same time, you are wrapping this grid in a ScrollView, removing the limitation.
Do not wrap your Vertical ListView in Vertical ScrollView. Or, if you do, make sure the height of you ListView is limited.
Otherwise you will be scrolling on fully expanded ListView.
| null | CC BY-SA 4.0 | null | 2022-11-03T12:24:23.650 | 2022-11-03T12:32:00.150 | 2022-11-03T12:32:00.150 | 6,643,940 | 6,643,940 | null |
74,303,800 | 2 | null | 30,219,807 | 0 | null | In my case the bundler/minifier did not seem to like template literals ending with a newline.
This works (no leading/trailing newlines):
```
var t = `<div>
...
</div>`;
```
This works (leading newline):
```
var t = `
<div>
...
</div>`;
```
This works (leading/trailing newlines indented with whitespace):
```
var t = `
<div>
...
</div>
`; // closing backtick with some whitespace in front
```
As soon as I do this the @Scripts.Render bombs out:
```
var t = `
<div>
...
</div>
`; // closing backtick at the start of the line
```
| null | CC BY-SA 4.0 | null | 2022-11-03T13:24:12.130 | 2022-11-03T13:24:12.130 | null | null | 1,075,062 | null |
74,304,611 | 2 | null | 74,304,454 | 0 | null | You can use a case expression in an UPDATE statements:
```
UPDATE courses
SET diff=CASE
WHEN faculty in ('bio', 'gum') THEN 'ez'
WHEN faculty in ('chem', 'geo') THEN 'mid'
WHEN faculty = 'math' THEN 'hard'
END;
```
| null | CC BY-SA 4.0 | null | 2022-11-03T14:19:43.857 | 2022-11-03T14:19:43.857 | null | null | 2,221,001 | null |
74,305,125 | 2 | null | 54,364,288 | 1 | null | I had the same issue on Android, after implementing my own grouping it worked fine.
```
public class MyGrouping<K, T> : ObservableCollection<T>
{
public K Key { get; private set; }
public MyGrouping(K key, IEnumerable<T> items)
{
Key = key;
foreach (var item in items)
this.Items.Add(item);
}
}
```
| null | CC BY-SA 4.0 | null | 2022-11-03T14:56:39.460 | 2022-11-03T14:56:39.460 | null | null | 17,350,254 | null |
74,305,202 | 2 | null | 14,153,657 | 0 | null | Worked for me...here ip will be remote sql server instance
```
insert into YourDatabaseName.dbo.TableName select * from [192.168.9.230,1434].[SourceDatabaseName].[dbo].[SourceTableName]
```
| null | CC BY-SA 4.0 | null | 2022-11-03T15:02:00.383 | 2022-11-03T15:02:00.383 | null | null | 11,169,272 | null |
74,306,332 | 2 | null | 74,148,599 | 2 | null | I think this comes down to taste, and you prefer the result of the rendering without anti-aliasing. It looks bolder and sharper because the cells that are partially activated are shown at full brightness, in contrast with fully black adjacent pixels. Mssr. Pederson argues that the anti-aliased version is in some respects a truer depiction of the underlying data, since it will perceptually give the dots more consistent weight and spacing that corresponds to their actual size and placement.
Two examples:
```
set.seed(42)
library(ggplot2)
df_rand <- data.frame(x = runif(1000), y = runif(1000))
ggplot(df_rand, aes(x,y)) +
geom_point(colour = "#fcfa53", size = 0.01, stroke = 0) +
theme_void() +
theme(plot.background = element_rect(fill = "black", colour = NA),
panel.background = element_rect(fill = "black", colour = NA))
ggsave("rand_no_anti-alias.png", device = png,
units = "px", width = 100, height = 100)
ggsave("rand_ragg_anti-alias.png", device = ragg::agg_png(),
units = "px", width = 100, height = 100)
```
[](https://i.stack.imgur.com/tVvcp.png)
[](https://i.stack.imgur.com/P0c26.png)
Of these two, you prefer the former for your use case and particular settings.
```
df_grid <- data.frame(expand.grid(x = 1:30, y = 1:30))
ggplot(df_grid, aes(x,y)) +
geom_point(colour = "#fcfa53", size = 0.01, stroke = 0) +
theme_void() +
theme(plot.background = element_rect(fill = "black", colour = NA),
panel.background = element_rect(fill = "black", colour = NA))
ggsave("grid_no_anti-alias.png", device = png,
units = "px", width = 100, height = 100)
ggsave("grid_ragg_anti-alias.png", device = ragg::agg_png(),
units = "px", width = 100, height = 100)
```
[](https://i.stack.imgur.com/96bnL.png)
[](https://i.stack.imgur.com/4aCGX.png)
Note here that the version without anti-aliasing creates phantom groupings out of a uniform grid. Its algorithm shows full intensity even when the point covers a tiny part of the pixel. The anti-aliased version reflects that the points cover a very small part of each pixel, and it attempts to even out the error by sometimes depicting a point in one pixel and sometimes using two adjacent pixels, but dimmer. While the uniform data creates some moire effect in this contrived example, in my view the perceptual distortion is smaller.
If I make the point size much larger (e.g. 0.3), it makes for a closer match in brightness with the non-anti-aliased version. This version avoids the phantom groupings that the non-anti-aliased version has, but at the cost of the pixels looking smudged at the pixel level. That's anti-aliasing for ya.
[](https://i.stack.imgur.com/7T53i.png)
Technical arguments aside, use the rendering method that gives you the output you want.
| null | CC BY-SA 4.0 | null | 2022-11-03T16:17:51.347 | 2022-11-03T16:37:06.640 | 2022-11-03T16:37:06.640 | 6,851,825 | 6,851,825 | null |
74,306,357 | 2 | null | 74,305,972 | 1 | null | You are expecting values between 0 and 1, which you multiply with 100 here:
```
item.spawnChance = (byte)(item.spawnChance / sum * 100);
```
but it snaps to 0 or 100. That's because `item.spawnChance / sum` will be 0 or 1.
spawnChance is a byte (whole number like int) and dividing that will not result in a fraction like 0.34. You need a float for this operation.
Simple fix, cast the spawnChance to float before dividing by sum:
```
item.spawnChance = (byte)((float)item.spawnChance / sum * 100);
```
| null | CC BY-SA 4.0 | null | 2022-11-03T16:19:44.613 | 2022-11-03T16:19:44.613 | null | null | 5,967,872 | null |
74,306,936 | 2 | null | 74,305,678 | 0 | null | Just by looking at this i see the number "c" goes way above the number of length of y_vals. Each iteration that starts with 7-6, 7-5, 7-4.. up to 6-7 where first FOR breaks increases "c" by one. Then you remove elements from y_vals with index of range(c) which makes the whole y_vals list empty. Then it would set PP and JJ to 0 but it would search indexes of an empty list y_vals[0] and there you get "list index out of range" error. Please correct me if im wrong
| null | CC BY-SA 4.0 | null | 2022-11-03T17:01:00.580 | 2022-11-03T17:01:00.580 | null | null | 19,034,851 | null |
74,307,099 | 2 | null | 60,981,109 | 0 | null | Try this:
```
reward = 0
newReward = 0
***// @ write here ur class/id/selector.***
cy.get('.col-1 sub-total-label').then(($el) => {
newReward = $el.text().trim();
expect(newReward).not.to.eq(reward);
})
***// @ write here ur class/id/selector.***
cy.get('.total-wrapper valid-amount')
.find('label').should('exist')
.then(($el) => {
reward = newReward;
newReward = $el.text().trim();
expect(newReward).not.to.eq(reward);
})
`
```
| null | CC BY-SA 4.0 | null | 2022-11-03T17:16:08.487 | 2022-12-28T22:58:36.057 | 2022-12-28T22:58:36.057 | 20,291,492 | 20,291,492 | null |
74,307,625 | 2 | null | 30,497,413 | -1 | null | As for me I spent half a day searching for a suitable solution for the Angular / MangoDB combination, but failed. So, I have found one workaround by using the Google extension CORS-Unblock (Unblock CORS error while developing or experimenting) and it worked like a charm. Hope it helps somebody.
| null | CC BY-SA 4.0 | null | 2022-11-03T18:00:27.510 | 2022-11-03T18:00:27.510 | null | null | 20,410,683 | null |
74,307,748 | 2 | null | 74,300,120 | 0 | null | You really don't need that table that lists out the month. I find that for booking systems, or whatever? All so often the developer cooks up a table of records to represent the month.
Don't do that. If a booking is from 10 am to 11:30 am, then add a booking records (don't add a tempalte table of reocrds for those slots).
If you do that, then you are forever writing a boatload of code to create that month of reocrds, and it not at all required.
You have
People/staff - a table of staff
Attendance - a table, People_ID and date and true/false for attend.
That is ALL you need.
Build the month UI with code, and then simply add, or remove child records to that one given person.
So, your two data tables are this:
[](https://i.stack.imgur.com/tAVxA.png)
Ok, so now lets build a UI that:
displays the data, and ALSO lets you check off/pick which days for attendance.
We could use a Gridview, but listview tends to be MUCH better.
So, our lisview will look like this:
```
<asp:ListView ID="LV1" runat="server" DataKeyNames="ID" >
<ItemTemplate>
<tr runat="server">
<td><asp:Label ID="FirstnameLabel" runat="server" Text='<%# Eval("Firstname") %>' /></td>
<td><asp:Label ID="LastNameLabel" runat="server" Text='<%# Eval("LastName") %>' /></td>
<td><asp:CheckBox ID="C1" runat="server" /></td>
<td><asp:CheckBox ID="C2" runat="server" /></td>
<td><asp:CheckBox ID="C3" runat="server" /></td>
<td><asp:CheckBox ID="C4" runat="server" /></td>
<td><asp:CheckBox ID="C5" runat="server" /></td>
all the way to c31
<td><asp:CheckBox ID="C31" runat="server" /></td>
</tr>
</ItemTemplate>
<LayoutTemplate>
<table id="itemPlaceholderContainer" runat="server" border="0" class="table" >
<tr runat="server" id="headerrow" style="">
<th runat="server">Firstname</th>
<th runat="server">LastName</th>
<th runat="server" id="H1">1</th>
<th runat="server" id="H2">2</th>
<th runat="server" id="H3">3</th>
<th runat="server" id="H4">4</th>
<th runat="server" id="H5">5</th>
all the way to 31
<th runat="server" id="H31">31</th>
</tr>
<tr id="itemPlaceholder" runat="server">
</tr>
</table>
</table>
</LayoutTemplate>
</asp:ListView>
<asp:Button ID="cmdSave" runat="server" Text="Save Edits" CssClass="btn" />
```
Ok, now our code to load becomes quite simple.
The code to load the list view is this:
```
Dim dtStart As Date
Dim dtEnd As Date
Dim Days As Integer
Protected Sub Page_Load(ByVal sender As Object, ByVal e As System.EventArgs) Handles Me.Load
dtStart = DateSerial(Year(DateTime.Now), Month(DateTime.Now), 1)
Days = DateTime.DaysInMonth(Year(dtStart), Month(dtStart))
dtEnd = DateAdd(DateInterval.Day, Days - 1, dtStart)
If Not IsPostBack Then
LoadData()
End If
End Sub
Sub LoadData()
Dim strSQL = "SELECT * FROM People ORDER BY FirstName"
Dim rstData As DataTable = Myrst(strSQL)
LV1.DataSource = rstData
LV1.DataBind()
' add day of week to the header
Dim dPtr As Date = dtStart
' add day of week to header
Dim MyHeader As HtmlTableRow = LV1.FindControl("headerrow")
For i = 1 To Days
Dim mytdH As HtmlTableCell = MyHeader.FindControl("H" & i)
Dim sDay As String = dPtr.ToString("ddd").Substring(0, 2)
mytdH.InnerHtml += "<br/>" + sDay
dPtr = DateAdd(DateInterval.Day, 1, dPtr)
Next
End Sub
```
And we now see this:
[](https://i.stack.imgur.com/lbJAe.png)
So, all we have to do is wire up the on data row bound, and that code looks like this:
(I added the shading for weekends)
```
Protected Sub LV1_ItemDataBound(sender As Object, e As ListViewItemEventArgs) Handles LV1.ItemDataBound
If e.Item.ItemType = ListViewItemType.DataItem Then
' format and load one row
Dim gRow As ListViewItem = e.Item
Dim PeoplePK As Integer = LV1.DataKeys(gRow.DataItemIndex).Item("ID")
Dim strSQL As String =
"SELECT * FROM Attendance
WHERE People_ID = @ID
AND ADate >= @dtStart AND ADate <= @dtEnd"
Dim cmdSQL As New SqlCommand(strSQL)
cmdSQL.Parameters.Add("@ID", SqlDbType.Int).Value = PeoplePK
cmdSQL.Parameters.Add("@dtStart", SqlDbType.Date).Value = dtStart
cmdSQL.Parameters.Add("@dtEnd", SqlDbType.Date).Value = dtEnd
Dim rstAttend As DataTable = MyrstP(cmdSQL)
Dim dPtr As Date = dtStart
For i = 1 To 31
Dim ck As CheckBox = gRow.FindControl("C" + i.ToString)
Dim mytd As HtmlTableCell = ck.Parent
If i <= Days Then
If Weekday(dPtr) = 1 Or Weekday(dPtr) = 7 Then
' week end - shade as blue
mytd.Style.Add("background-Color", "aliceblue")
End If
' check for record
Dim sFind As String = "ADate = '" & dPtr & "'"
Dim dView As DataRow() = rstAttend.Select(sFind)
If dView.Length > 0 Then
ck.Checked = dView(0).Item("Present")
End If
Else
' out of bounds for this month - hide
mytd.Style.Add("display", "none")
' hide the header row also
Dim MyHeader As HtmlTableRow = LV1.FindControl("headerrow")
Dim mytdH As HtmlTableCell = MyHeader.FindControl("H" & i)
mytdH.Style.Add("display", "none")
End If
'mytd.Style.Add("text-align", "center")
'ck.Style.Add("background-Color", "aliceblue")
dPtr = DateAdd(DateInterval.Day, 1, dPtr)
Next
End If
End Sub
```
So, now you can click away on the check boxes.
the save button to save all the edits/changes is thus this:
```
Protected Sub cmdSave_Click(sender As Object, e As EventArgs) Handles cmdSave.Click
For Each gRow As ListViewItem In LV1.Items
Dim PeoplePK As Integer = LV1.DataKeys(gRow.DisplayIndex).Item("ID")
Dim rstAttend As New DataTable
rstAttend = Myrst("SELECT * FROM Attendance WHERE People_ID = " & PeoplePK)
' Update the data
Dim dPtr As Date = dtStart
For i = 1 To Days
Dim ck As CheckBox = gRow.FindControl("C" + i.ToString)
Dim sFind As String = "ADate = '" & dPtr & "'"
Dim dView As DataRow() = rstAttend.Select(sFind)
If dView.Length > 0 Then
dView(0).Item("Present") = ck.Checked
' you could optonal delete records if un-checked - your choice
' If ck.Checked = False Then
' dView(0).Delete()
' End If
Else
If ck.Checked Then
' we have to add this record
Dim NewRow As DataRow = rstAttend.NewRow
NewRow("People_ID") = PeoplePK
NewRow("ADate") = dPtr
NewRow("Present") = True
rstAttend.Rows.Add(NewRow)
End If
End If
dPtr = DateAdd(DateInterval.Day, 1, dPtr)
Next
' save this one employee
MyRstSave(rstAttend, "Attendance")
Next
End Sub
```
So above works just fine. it not really a "huge" amount of code, and we thus get both display and edit.
I'm sure after you hit save, we jump to some other page to select another month or whatever, but the above quite much works rather well.
I also used 3 helper routines (but, I use these for most of my projects).
they are to get/return data as a table, and write the table back to database.
They are these 3
```
Public Function Myrst(strSQL As String) As DataTable
Dim rstData As New DataTable
Using mycon As New SqlConnection(GetConstr)
Using cmdSQL As New SqlCommand(strSQL, mycon)
mycon.Open()
rstData.Load(cmdSQL.ExecuteReader)
End Using
End Using
Return rstData
End Function
Public Function MyrstP(cmdSQL As SqlCommand) As DataTable
Dim rstData As New DataTable
Using mycon As New SqlConnection(GetConstr)
Using (cmdSQL)
cmdSQL.Connection = mycon
mycon.Open()
rstData.Load(cmdSQL.ExecuteReader)
End Using
End Using
Return rstData
End Function
Public Sub MyRstSave(rstData As DataTable, strTable As String)
Dim strSQL = "SELECT * FROM " & strTable
Using conn As New SqlConnection(GetConstr)
Using cmdSQL As New SqlCommand(strSQL, conn)
conn.Open()
Dim da As New SqlDataAdapter(cmdSQL)
Dim daU As New SqlCommandBuilder(da)
da.Update(rstData)
End Using
End Using
End Sub
```
Now I used check boxes, but it would be trivial to use a label or even a text box and show P or NP.
# Edit: User wants N or NP for display, not check box
Ok, so just do a search/replace on Checkbox to a label then right?
I mean, the meat and potatos here is the above layout and approach to the "problem", and things like changing a checkbox to a label is rather trivial. (changing a checkbox to a label is not much of a issue or problem - in fact, if that is too much of a challenge, then I think we have VAST MORE of a issue here!!!).
So, just change in my example markup to a label.
eg:
```
<td><asp:Label ID="C1" runat="server" /></td>
<td><asp:Label ID="C2" runat="server" /></td>
<td><asp:Label ID="C3" runat="server" /></td>
<td><asp:Label ID="C4" runat="server" /></td>
<td><asp:Label ID="C5" runat="server" /></td>
... all the way to 31
```
(as noted, we can use a search/replace on this).
Now, our code can be changed to use a label in place of a check box.
So, our code is still really the same, but now we use a label in place of a check box, so like this:
```
' check for record
Dim sFind As String = "ADate = '" & dPtr & "'"
Dim dView As DataRow() = rstAttend.Select(sFind)
If dView.Length > 0 Then
ck.Text = IIf(dView(0).Item("Present"), "P", "NP")
Else
ck.Text = "NP"
End If
```
And thus we now see/get this:
[](https://i.stack.imgur.com/MkHaG.png)
I'm not a whole lot sure why changing a check box to a label is all that of a difficult challenge here, but without question the above code solution is rather nice, and the cherry on top was me posting that save code.
But, just change the checkbox to a label, and tweak the code to use a label in place of check box, and you should be off to the races.
of course, one could play with formatting a bit, and change things.
so, say we add table bordered to the style class like this:
```
<table id="itemPlaceholderContainer" runat="server"
border="0" class="table table-bordered" >
```
And now we get this:
[](https://i.stack.imgur.com/Sl42V.png)
And we probably should center the text, but regardless, one thing at a time, right?
| null | CC BY-SA 4.0 | null | 2022-11-03T18:11:01.903 | 2022-11-06T08:17:01.583 | 2022-11-06T08:17:01.583 | 10,527 | 10,527 | null |
74,307,874 | 2 | null | 43,037,692 | 0 | null | I found all the answers above a bit too technical. Here is a way to do this in the simplest terms I could think of.
First we need to agree on what a branch point is. A branch point in a binary image (matrix of `0`'s and `1`s) is a `1` with at least three other `1`'s in its neighborhood.
We also need to agree on how to discern neighboring pixels (top/bottom/left/right only,
or with added diagonally adjacent pixels). This is up to us.
Having agreed on the above, we can now detect the branch points in the image.
1. Traverse the image skipping zero pixels (these can't be branch points)
2. At each 1 look around its neighborhood. How many 1s are there?
3. Let's use our definition to answer the question: If there are at least three 1s you've found a branch point!
| null | CC BY-SA 4.0 | null | 2022-11-03T18:22:11.967 | 2022-11-03T18:22:11.967 | null | null | 16,904,735 | null |
74,307,982 | 2 | null | 74,306,305 | 0 | null | You define `Partial View` in the wrong way. according to the Microsoft document, the `Partial View` is `.cshtml` file without an @page directive.
> Partial View is a Razor markup file (.cshtml) without an @page
directive that renders HTML output within another markup file's
rendered output.
Document link:
[https://learn.microsoft.com/en-us/aspnet/core/mvc/views/partial?view=aspnetcore-6.0](https://learn.microsoft.com/en-us/aspnet/core/mvc/views/partial?view=aspnetcore-6.0)
On the other hand, `PageModel` used for creating `Razor Page` code behind and is not suitable for creating a model for `Partial View` or any other type of view. a simple class do the job for you. apply these changes and your code will work like champ.
| null | CC BY-SA 4.0 | null | 2022-11-03T18:32:41.797 | 2022-11-03T18:32:41.797 | null | null | 17,797,258 | null |
74,308,027 | 2 | null | 23,490,320 | 0 | null | First of all you should add a class to your img tag:
```
<img src="/image.png" class="img-author">
```
Otherwise, it will change all images in your website.
You can fix this small gap using the "object-fit" css attribute.
```
img.img-author{
border: 3px solid #4CB7AC;
height: 46px;
width: 46px;
border-radius:50%;
object-fit: contain;
}
```
```
<img src="https://www.gravatar.com/avatar/a5c9fa2dbf60eb47b3c0e17eaa43d889?s=64&d=identicon&r=PG&f=1" class="img-author">
```
| null | CC BY-SA 4.0 | null | 2022-11-03T18:36:36.503 | 2022-12-24T00:06:16.980 | 2022-12-24T00:06:16.980 | 1,430,631 | 2,857,611 | null |
74,308,411 | 2 | null | 43,782,697 | 0 | null | , refers to a HTTP response status code. This means that the Powershell command is calling a URL and the URL is reporting a error.
You need to know the URL to really find out what the problem is. One way you can get the URL, is downloading Fiddler Classic. Once installed, you have to enable HTTPS decryption.
In my case the URL was...
```
https://<my-crm-domain>/XrmDeployment/2011/deployment.svc?wsdl
```
When I ran this URL on the server where CRM is installed, I got an exception stating...
```
Could not load file or assembly 'Microsoft.Crm.Application.Components.Application'
```
All this meant, I needed to copy a file, , from into folder .
Once this was done, the URL worked and therefor my PowerShell command as well.
| null | CC BY-SA 4.0 | null | 2022-11-03T19:10:47.197 | 2022-11-03T19:10:47.197 | null | null | 958,398 | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.