
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.1k
25.4k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 582
39.1k
| num_tokens
int64 271
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_65506
|
rasdani/github-patches
|
git_diff
|
localstack__localstack-1842
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Elasticsearch domain managed by Terraform cannot be updated; request for /tags/? returns 404
<!-- Love localstack? Please consider supporting our collective:
👉 https://opencollective.com/localstack/donate -->
We use Terraform to create and update resources in Localstack, which has worked for services like S3 and Dynamo so far.
We hit an issue with Elasticsearch domains, where the domain is created successfully but Terraform fails to apply in subsequent runs, when it makes a request to:
```
logs: ---[ REQUEST POST-SIGN ]-----------------------------
logs: GET /2015-01-01/tags/?arn=arn%3Aaws%3Aes%3Aus-east-1%3A000000000000%3Adomain%2Fepdam-local-amd HTTP/1.1
logs: Host: localhost:4578
logs: User-Agent: aws-sdk-go/1.14.31 (go1.9.2; darwin; amd64) APN/1.0 HashiCorp/1.0 Terraform/0.11.8-dev
logs: Authorization: AWS4-HMAC-SHA256 Credential=mock_access_key/20190221/us-west-2/es/aws4_request, SignedHeaders=host;x-amz-date, Signature=26f42429e2af2240466635ab9202c8888617afe9be7b8ef91a8831d6b4160bd1
logs: X-Amz-Date: 20190221T191447Z
logs: Accept-Encoding: gzip
```
and the response is:
```
logs: ---[ RESPONSE ]--------------------------------------
logs: HTTP/1.0 404 NOT FOUND
logs: Connection: close
logs: Content-Length: 233
logs: Access-Control-Allow-Origin: *
logs: Content-Type: text/html
logs: Date: Thu, 21 Feb 2019 19:14:47 GMT
logs: Server: Werkzeug/0.14.1 Python/2.7.15
```
While a request to `localhost:4578/2015-01-01/tags/?arn=...` gets 404, a request to `localhost:4578/2015-01-01/tags?arn=...`, (without the `/` before the query params), is successful.
The reason we are reporting this against Localstack and not [terraform](https://github.com/hashicorp/terraform) or [terraform-provider-aws](https://github.com/terraform-providers/terraform-provider-aws) is that the AWS REST API apparently supports requests with slashes before query parameters, or else Terraform could not be used to manage Elasticsearch domains in AWS.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `localstack/services/es/es_api.py`
Content:
```
1 import json
2 import time
3 from random import randint
4 from flask import Flask, jsonify, request, make_response
5 from localstack.services import generic_proxy
6 from localstack.utils.aws import aws_stack
7 from localstack.constants import TEST_AWS_ACCOUNT_ID
8 from localstack.utils.common import to_str
9 from localstack.utils.analytics import event_publisher
10
11 APP_NAME = 'es_api'
12 API_PREFIX = '/2015-01-01'
13
14 ES_DOMAINS = {}
15
16 app = Flask(APP_NAME)
17
18
19 def error_response(error_type, code=400, message='Unknown error.'):
20 if not message:
21 if error_type == 'ResourceNotFoundException':
22 message = 'Resource not found.'
23 elif error_type == 'ResourceAlreadyExistsException':
24 message = 'Resource already exists.'
25 response = make_response(jsonify({'error': message}))
26 response.headers['x-amzn-errortype'] = error_type
27 return response, code
28
29
30 def get_domain_config_status():
31 return {
32 'CreationDate': '%.2f' % time.time(),
33 'PendingDeletion': False,
34 'State': 'Active',
35 'UpdateDate': '%.2f' % time.time(),
36 'UpdateVersion': randint(1, 100)
37 }
38
39
40 def get_domain_config(domain_name):
41 config_status = get_domain_config_status()
42 return {
43 'DomainConfig': {
44 'AccessPolicies': {
45 'Options': '{"Version":"2012-10-17","Statement":[{"Effect":"Allow","Principal":{"AWS":"arn:aws:iam::%s:root"},"Action":"es:*","Resource":"arn:aws:es:%s:%s:domain/%s/*"}]}' % (TEST_AWS_ACCOUNT_ID, aws_stack.get_region(), TEST_AWS_ACCOUNT_ID, domain_name), # noqa: E501
46 'Status': config_status
47 },
48 'AdvancedOptions': {
49 'Options': {
50 'indices.fielddata.cache.size': '',
51 'rest.action.multi.allow_explicit_index': 'true'
52 },
53 'Status': config_status
54 },
55 'EBSOptions': {
56 'Options': {
57 'EBSEnabled': True,
58 'EncryptionEnabled': False,
59 'Iops': 0,
60 'VolumeSize': 10,
61 'VolumeType': 'gp2'
62 },
63 'Status': config_status
64 },
65 'ElasticsearchClusterConfig': {
66 'Options': {
67 'DedicatedMasterCount': 1,
68 'DedicatedMasterEnabled': True,
69 'DedicatedMasterType': 'm3.medium.elasticsearch',
70 'InstanceCount': 1,
71 'InstanceType': 'm3.medium.elasticsearch',
72 'ZoneAwarenessEnabled': False
73 },
74 'Status': config_status
75 },
76 'ElasticsearchVersion': {
77 'Options': '5.3',
78 'Status': config_status
79 },
80 'EncryptionAtRestOptions': {
81 'Options': {
82 'Enabled': False,
83 'KmsKeyId': ''
84 },
85 'Status': config_status
86 },
87 'LogPublishingOptions': {
88 'Options': {
89 'INDEX_SLOW_LOGS': {
90 'CloudWatchLogsLogGroupArn': 'arn:aws:logs:%s:%s:log-group:sample-domain' % (aws_stack.get_region(), TEST_AWS_ACCOUNT_ID), # noqa: E501
91 'Enabled': False
92 },
93 'SEARCH_SLOW_LOGS': {
94 'CloudWatchLogsLogGroupArn': 'arn:aws:logs:%s:%s:log-group:sample-domain' % (aws_stack.get_region(), TEST_AWS_ACCOUNT_ID), # noqa: E501
95 'Enabled': False,
96 }
97 },
98 'Status': config_status
99 },
100 'SnapshotOptions': {
101 'Options': {
102 'AutomatedSnapshotStartHour': randint(0, 23)
103 },
104 'Status': config_status
105 },
106 'VPCOptions': {
107 'Options': {
108 'AvailabilityZones': [
109 'us-east-1b'
110 ],
111 'SecurityGroupIds': [
112 'sg-12345678'
113 ],
114 'SubnetIds': [
115 'subnet-12345678'
116 ],
117 'VPCId': 'vpc-12345678'
118 },
119 'Status': config_status
120 }
121 }
122 }
123
124
125 def get_domain_status(domain_name, deleted=False):
126 return {
127 'DomainStatus': {
128 'ARN': 'arn:aws:es:%s:%s:domain/%s' % (aws_stack.get_region(), TEST_AWS_ACCOUNT_ID, domain_name),
129 'Created': True,
130 'Deleted': deleted,
131 'DomainId': '%s/%s' % (TEST_AWS_ACCOUNT_ID, domain_name),
132 'DomainName': domain_name,
133 'ElasticsearchClusterConfig': {
134 'DedicatedMasterCount': 1,
135 'DedicatedMasterEnabled': True,
136 'DedicatedMasterType': 'm3.medium.elasticsearch',
137 'InstanceCount': 1,
138 'InstanceType': 'm3.medium.elasticsearch',
139 'ZoneAwarenessEnabled': False
140 },
141 'ElasticsearchVersion': '6.7',
142 'Endpoint': aws_stack.get_elasticsearch_endpoint(domain_name),
143 'Processing': False,
144 'EBSOptions': {
145 'EBSEnabled': True,
146 'VolumeType': 'gp2',
147 'VolumeSize': 10,
148 'Iops': 0
149 },
150 }
151 }
152
153
154 @app.route('%s/domain' % API_PREFIX, methods=['GET'])
155 def list_domain_names():
156 result = {
157 'DomainNames': [{'DomainName': name} for name in ES_DOMAINS.keys()]
158 }
159 return jsonify(result)
160
161
162 @app.route('%s/es/domain' % API_PREFIX, methods=['POST'])
163 def create_domain():
164 data = json.loads(to_str(request.data))
165 domain_name = data['DomainName']
166 if domain_name in ES_DOMAINS:
167 return error_response(error_type='ResourceAlreadyExistsException')
168 ES_DOMAINS[domain_name] = data
169 result = get_domain_status(domain_name)
170 # record event
171 event_publisher.fire_event(event_publisher.EVENT_ES_CREATE_DOMAIN,
172 payload={'n': event_publisher.get_hash(domain_name)})
173 return jsonify(result)
174
175
176 @app.route('%s/es/domain/<domain_name>' % API_PREFIX, methods=['GET'])
177 def describe_domain(domain_name):
178 if domain_name not in ES_DOMAINS:
179 return error_response(error_type='ResourceNotFoundException')
180 result = get_domain_status(domain_name)
181 return jsonify(result)
182
183
184 @app.route('%s/es/domain/<domain_name>/config' % API_PREFIX, methods=['GET', 'POST'])
185 def domain_config(domain_name):
186 config = get_domain_config(domain_name)
187 return jsonify(config)
188
189
190 @app.route('%s/es/domain/<domain_name>' % API_PREFIX, methods=['DELETE'])
191 def delete_domain(domain_name):
192 if domain_name not in ES_DOMAINS:
193 return error_response(error_type='ResourceNotFoundException')
194 result = get_domain_status(domain_name, deleted=True)
195 ES_DOMAINS.pop(domain_name)
196 # record event
197 event_publisher.fire_event(event_publisher.EVENT_ES_DELETE_DOMAIN,
198 payload={'n': event_publisher.get_hash(domain_name)})
199 return jsonify(result)
200
201
202 @app.route('%s/tags' % API_PREFIX, methods=['GET', 'POST'])
203 def add_list_tags():
204 if request.method == 'GET' and request.args.get('arn'):
205 response = {
206 'TagList': [
207 {
208 'Key': 'Example1',
209 'Value': 'Value'
210 },
211 {
212 'Key': 'Example2',
213 'Value': 'Value'
214 }
215 ]
216 }
217 return jsonify(response)
218
219 return jsonify({})
220
221
222 def serve(port, quiet=True):
223 generic_proxy.serve_flask_app(app=app, port=port, quiet=quiet)
224
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/localstack/services/es/es_api.py b/localstack/services/es/es_api.py
--- a/localstack/services/es/es_api.py
+++ b/localstack/services/es/es_api.py
@@ -14,6 +14,7 @@
ES_DOMAINS = {}
app = Flask(APP_NAME)
+app.url_map.strict_slashes = False
def error_response(error_type, code=400, message='Unknown error.'):
|
{"golden_diff": "diff --git a/localstack/services/es/es_api.py b/localstack/services/es/es_api.py\n--- a/localstack/services/es/es_api.py\n+++ b/localstack/services/es/es_api.py\n@@ -14,6 +14,7 @@\n ES_DOMAINS = {}\n \n app = Flask(APP_NAME)\n+app.url_map.strict_slashes = False\n \n \n def error_response(error_type, code=400, message='Unknown error.'):\n", "issue": "Elasticsearch domain managed by Terraform cannot be updated; request for /tags/? returns 404\n<!-- Love localstack? Please consider supporting our collective:\r\n\ud83d\udc49 https://opencollective.com/localstack/donate -->\r\n\r\nWe use Terraform to create and update resources in Localstack, which has worked for services like S3 and Dynamo so far.\r\n\r\nWe hit an issue with Elasticsearch domains, where the domain is created successfully but Terraform fails to apply in subsequent runs, when it makes a request to:\r\n\r\n```\r\nlogs: ---[ REQUEST POST-SIGN ]-----------------------------\r\nlogs: GET /2015-01-01/tags/?arn=arn%3Aaws%3Aes%3Aus-east-1%3A000000000000%3Adomain%2Fepdam-local-amd HTTP/1.1\r\nlogs: Host: localhost:4578\r\nlogs: User-Agent: aws-sdk-go/1.14.31 (go1.9.2; darwin; amd64) APN/1.0 HashiCorp/1.0 Terraform/0.11.8-dev\r\nlogs: Authorization: AWS4-HMAC-SHA256 Credential=mock_access_key/20190221/us-west-2/es/aws4_request, SignedHeaders=host;x-amz-date, Signature=26f42429e2af2240466635ab9202c8888617afe9be7b8ef91a8831d6b4160bd1\r\nlogs: X-Amz-Date: 20190221T191447Z\r\nlogs: Accept-Encoding: gzip\r\n```\r\n\r\nand the response is:\r\n\r\n```\r\nlogs: ---[ RESPONSE ]--------------------------------------\r\nlogs: HTTP/1.0 404 NOT FOUND\r\nlogs: Connection: close\r\nlogs: Content-Length: 233\r\nlogs: Access-Control-Allow-Origin: *\r\nlogs: Content-Type: text/html\r\nlogs: Date: Thu, 21 Feb 2019 19:14:47 GMT\r\nlogs: Server: Werkzeug/0.14.1 Python/2.7.15\r\n```\r\n\r\nWhile a request to `localhost:4578/2015-01-01/tags/?arn=...` gets 404, a request to `localhost:4578/2015-01-01/tags?arn=...`, (without the `/` before the query params), is successful.\r\n\r\nThe reason we are reporting this against Localstack and not [terraform](https://github.com/hashicorp/terraform) or [terraform-provider-aws](https://github.com/terraform-providers/terraform-provider-aws) is that the AWS REST API apparently supports requests with slashes before query parameters, or else Terraform could not be used to manage Elasticsearch domains in AWS.\n", "before_files": [{"content": "import json\nimport time\nfrom random import randint\nfrom flask import Flask, jsonify, request, make_response\nfrom localstack.services import generic_proxy\nfrom localstack.utils.aws import aws_stack\nfrom localstack.constants import TEST_AWS_ACCOUNT_ID\nfrom localstack.utils.common import to_str\nfrom localstack.utils.analytics import event_publisher\n\nAPP_NAME = 'es_api'\nAPI_PREFIX = '/2015-01-01'\n\nES_DOMAINS = {}\n\napp = Flask(APP_NAME)\n\n\ndef error_response(error_type, code=400, message='Unknown error.'):\n if not message:\n if error_type == 'ResourceNotFoundException':\n message = 'Resource not found.'\n elif error_type == 'ResourceAlreadyExistsException':\n message = 'Resource already exists.'\n response = make_response(jsonify({'error': message}))\n response.headers['x-amzn-errortype'] = error_type\n return response, code\n\n\ndef get_domain_config_status():\n return {\n 'CreationDate': '%.2f' % time.time(),\n 'PendingDeletion': False,\n 'State': 'Active',\n 'UpdateDate': '%.2f' % time.time(),\n 'UpdateVersion': randint(1, 100)\n }\n\n\ndef get_domain_config(domain_name):\n config_status = get_domain_config_status()\n return {\n 'DomainConfig': {\n 'AccessPolicies': {\n 'Options': '{\"Version\":\"2012-10-17\",\"Statement\":[{\"Effect\":\"Allow\",\"Principal\":{\"AWS\":\"arn:aws:iam::%s:root\"},\"Action\":\"es:*\",\"Resource\":\"arn:aws:es:%s:%s:domain/%s/*\"}]}' % (TEST_AWS_ACCOUNT_ID, aws_stack.get_region(), TEST_AWS_ACCOUNT_ID, domain_name), # noqa: E501\n 'Status': config_status\n },\n 'AdvancedOptions': {\n 'Options': {\n 'indices.fielddata.cache.size': '',\n 'rest.action.multi.allow_explicit_index': 'true'\n },\n 'Status': config_status\n },\n 'EBSOptions': {\n 'Options': {\n 'EBSEnabled': True,\n 'EncryptionEnabled': False,\n 'Iops': 0,\n 'VolumeSize': 10,\n 'VolumeType': 'gp2'\n },\n 'Status': config_status\n },\n 'ElasticsearchClusterConfig': {\n 'Options': {\n 'DedicatedMasterCount': 1,\n 'DedicatedMasterEnabled': True,\n 'DedicatedMasterType': 'm3.medium.elasticsearch',\n 'InstanceCount': 1,\n 'InstanceType': 'm3.medium.elasticsearch',\n 'ZoneAwarenessEnabled': False\n },\n 'Status': config_status\n },\n 'ElasticsearchVersion': {\n 'Options': '5.3',\n 'Status': config_status\n },\n 'EncryptionAtRestOptions': {\n 'Options': {\n 'Enabled': False,\n 'KmsKeyId': ''\n },\n 'Status': config_status\n },\n 'LogPublishingOptions': {\n 'Options': {\n 'INDEX_SLOW_LOGS': {\n 'CloudWatchLogsLogGroupArn': 'arn:aws:logs:%s:%s:log-group:sample-domain' % (aws_stack.get_region(), TEST_AWS_ACCOUNT_ID), # noqa: E501\n 'Enabled': False\n },\n 'SEARCH_SLOW_LOGS': {\n 'CloudWatchLogsLogGroupArn': 'arn:aws:logs:%s:%s:log-group:sample-domain' % (aws_stack.get_region(), TEST_AWS_ACCOUNT_ID), # noqa: E501\n 'Enabled': False,\n }\n },\n 'Status': config_status\n },\n 'SnapshotOptions': {\n 'Options': {\n 'AutomatedSnapshotStartHour': randint(0, 23)\n },\n 'Status': config_status\n },\n 'VPCOptions': {\n 'Options': {\n 'AvailabilityZones': [\n 'us-east-1b'\n ],\n 'SecurityGroupIds': [\n 'sg-12345678'\n ],\n 'SubnetIds': [\n 'subnet-12345678'\n ],\n 'VPCId': 'vpc-12345678'\n },\n 'Status': config_status\n }\n }\n }\n\n\ndef get_domain_status(domain_name, deleted=False):\n return {\n 'DomainStatus': {\n 'ARN': 'arn:aws:es:%s:%s:domain/%s' % (aws_stack.get_region(), TEST_AWS_ACCOUNT_ID, domain_name),\n 'Created': True,\n 'Deleted': deleted,\n 'DomainId': '%s/%s' % (TEST_AWS_ACCOUNT_ID, domain_name),\n 'DomainName': domain_name,\n 'ElasticsearchClusterConfig': {\n 'DedicatedMasterCount': 1,\n 'DedicatedMasterEnabled': True,\n 'DedicatedMasterType': 'm3.medium.elasticsearch',\n 'InstanceCount': 1,\n 'InstanceType': 'm3.medium.elasticsearch',\n 'ZoneAwarenessEnabled': False\n },\n 'ElasticsearchVersion': '6.7',\n 'Endpoint': aws_stack.get_elasticsearch_endpoint(domain_name),\n 'Processing': False,\n 'EBSOptions': {\n 'EBSEnabled': True,\n 'VolumeType': 'gp2',\n 'VolumeSize': 10,\n 'Iops': 0\n },\n }\n }\n\n\[email protected]('%s/domain' % API_PREFIX, methods=['GET'])\ndef list_domain_names():\n result = {\n 'DomainNames': [{'DomainName': name} for name in ES_DOMAINS.keys()]\n }\n return jsonify(result)\n\n\[email protected]('%s/es/domain' % API_PREFIX, methods=['POST'])\ndef create_domain():\n data = json.loads(to_str(request.data))\n domain_name = data['DomainName']\n if domain_name in ES_DOMAINS:\n return error_response(error_type='ResourceAlreadyExistsException')\n ES_DOMAINS[domain_name] = data\n result = get_domain_status(domain_name)\n # record event\n event_publisher.fire_event(event_publisher.EVENT_ES_CREATE_DOMAIN,\n payload={'n': event_publisher.get_hash(domain_name)})\n return jsonify(result)\n\n\[email protected]('%s/es/domain/<domain_name>' % API_PREFIX, methods=['GET'])\ndef describe_domain(domain_name):\n if domain_name not in ES_DOMAINS:\n return error_response(error_type='ResourceNotFoundException')\n result = get_domain_status(domain_name)\n return jsonify(result)\n\n\[email protected]('%s/es/domain/<domain_name>/config' % API_PREFIX, methods=['GET', 'POST'])\ndef domain_config(domain_name):\n config = get_domain_config(domain_name)\n return jsonify(config)\n\n\[email protected]('%s/es/domain/<domain_name>' % API_PREFIX, methods=['DELETE'])\ndef delete_domain(domain_name):\n if domain_name not in ES_DOMAINS:\n return error_response(error_type='ResourceNotFoundException')\n result = get_domain_status(domain_name, deleted=True)\n ES_DOMAINS.pop(domain_name)\n # record event\n event_publisher.fire_event(event_publisher.EVENT_ES_DELETE_DOMAIN,\n payload={'n': event_publisher.get_hash(domain_name)})\n return jsonify(result)\n\n\[email protected]('%s/tags' % API_PREFIX, methods=['GET', 'POST'])\ndef add_list_tags():\n if request.method == 'GET' and request.args.get('arn'):\n response = {\n 'TagList': [\n {\n 'Key': 'Example1',\n 'Value': 'Value'\n },\n {\n 'Key': 'Example2',\n 'Value': 'Value'\n }\n ]\n }\n return jsonify(response)\n\n return jsonify({})\n\n\ndef serve(port, quiet=True):\n generic_proxy.serve_flask_app(app=app, port=port, quiet=quiet)\n", "path": "localstack/services/es/es_api.py"}], "after_files": [{"content": "import json\nimport time\nfrom random import randint\nfrom flask import Flask, jsonify, request, make_response\nfrom localstack.services import generic_proxy\nfrom localstack.utils.aws import aws_stack\nfrom localstack.constants import TEST_AWS_ACCOUNT_ID\nfrom localstack.utils.common import to_str\nfrom localstack.utils.analytics import event_publisher\n\nAPP_NAME = 'es_api'\nAPI_PREFIX = '/2015-01-01'\n\nES_DOMAINS = {}\n\napp = Flask(APP_NAME)\napp.url_map.strict_slashes = False\n\n\ndef error_response(error_type, code=400, message='Unknown error.'):\n if not message:\n if error_type == 'ResourceNotFoundException':\n message = 'Resource not found.'\n elif error_type == 'ResourceAlreadyExistsException':\n message = 'Resource already exists.'\n response = make_response(jsonify({'error': message}))\n response.headers['x-amzn-errortype'] = error_type\n return response, code\n\n\ndef get_domain_config_status():\n return {\n 'CreationDate': '%.2f' % time.time(),\n 'PendingDeletion': False,\n 'State': 'Active',\n 'UpdateDate': '%.2f' % time.time(),\n 'UpdateVersion': randint(1, 100)\n }\n\n\ndef get_domain_config(domain_name):\n config_status = get_domain_config_status()\n return {\n 'DomainConfig': {\n 'AccessPolicies': {\n 'Options': '{\"Version\":\"2012-10-17\",\"Statement\":[{\"Effect\":\"Allow\",\"Principal\":{\"AWS\":\"arn:aws:iam::%s:root\"},\"Action\":\"es:*\",\"Resource\":\"arn:aws:es:%s:%s:domain/%s/*\"}]}' % (TEST_AWS_ACCOUNT_ID, aws_stack.get_region(), TEST_AWS_ACCOUNT_ID, domain_name), # noqa: E501\n 'Status': config_status\n },\n 'AdvancedOptions': {\n 'Options': {\n 'indices.fielddata.cache.size': '',\n 'rest.action.multi.allow_explicit_index': 'true'\n },\n 'Status': config_status\n },\n 'EBSOptions': {\n 'Options': {\n 'EBSEnabled': True,\n 'EncryptionEnabled': False,\n 'Iops': 0,\n 'VolumeSize': 10,\n 'VolumeType': 'gp2'\n },\n 'Status': config_status\n },\n 'ElasticsearchClusterConfig': {\n 'Options': {\n 'DedicatedMasterCount': 1,\n 'DedicatedMasterEnabled': True,\n 'DedicatedMasterType': 'm3.medium.elasticsearch',\n 'InstanceCount': 1,\n 'InstanceType': 'm3.medium.elasticsearch',\n 'ZoneAwarenessEnabled': False\n },\n 'Status': config_status\n },\n 'ElasticsearchVersion': {\n 'Options': '5.3',\n 'Status': config_status\n },\n 'EncryptionAtRestOptions': {\n 'Options': {\n 'Enabled': False,\n 'KmsKeyId': ''\n },\n 'Status': config_status\n },\n 'LogPublishingOptions': {\n 'Options': {\n 'INDEX_SLOW_LOGS': {\n 'CloudWatchLogsLogGroupArn': 'arn:aws:logs:%s:%s:log-group:sample-domain' % (aws_stack.get_region(), TEST_AWS_ACCOUNT_ID), # noqa: E501\n 'Enabled': False\n },\n 'SEARCH_SLOW_LOGS': {\n 'CloudWatchLogsLogGroupArn': 'arn:aws:logs:%s:%s:log-group:sample-domain' % (aws_stack.get_region(), TEST_AWS_ACCOUNT_ID), # noqa: E501\n 'Enabled': False,\n }\n },\n 'Status': config_status\n },\n 'SnapshotOptions': {\n 'Options': {\n 'AutomatedSnapshotStartHour': randint(0, 23)\n },\n 'Status': config_status\n },\n 'VPCOptions': {\n 'Options': {\n 'AvailabilityZones': [\n 'us-east-1b'\n ],\n 'SecurityGroupIds': [\n 'sg-12345678'\n ],\n 'SubnetIds': [\n 'subnet-12345678'\n ],\n 'VPCId': 'vpc-12345678'\n },\n 'Status': config_status\n }\n }\n }\n\n\ndef get_domain_status(domain_name, deleted=False):\n return {\n 'DomainStatus': {\n 'ARN': 'arn:aws:es:%s:%s:domain/%s' % (aws_stack.get_region(), TEST_AWS_ACCOUNT_ID, domain_name),\n 'Created': True,\n 'Deleted': deleted,\n 'DomainId': '%s/%s' % (TEST_AWS_ACCOUNT_ID, domain_name),\n 'DomainName': domain_name,\n 'ElasticsearchClusterConfig': {\n 'DedicatedMasterCount': 1,\n 'DedicatedMasterEnabled': True,\n 'DedicatedMasterType': 'm3.medium.elasticsearch',\n 'InstanceCount': 1,\n 'InstanceType': 'm3.medium.elasticsearch',\n 'ZoneAwarenessEnabled': False\n },\n 'ElasticsearchVersion': '6.7',\n 'Endpoint': aws_stack.get_elasticsearch_endpoint(domain_name),\n 'Processing': False,\n 'EBSOptions': {\n 'EBSEnabled': True,\n 'VolumeType': 'gp2',\n 'VolumeSize': 10,\n 'Iops': 0\n },\n }\n }\n\n\[email protected]('%s/domain' % API_PREFIX, methods=['GET'])\ndef list_domain_names():\n result = {\n 'DomainNames': [{'DomainName': name} for name in ES_DOMAINS.keys()]\n }\n return jsonify(result)\n\n\[email protected]('%s/es/domain' % API_PREFIX, methods=['POST'])\ndef create_domain():\n data = json.loads(to_str(request.data))\n domain_name = data['DomainName']\n if domain_name in ES_DOMAINS:\n return error_response(error_type='ResourceAlreadyExistsException')\n ES_DOMAINS[domain_name] = data\n result = get_domain_status(domain_name)\n # record event\n event_publisher.fire_event(event_publisher.EVENT_ES_CREATE_DOMAIN,\n payload={'n': event_publisher.get_hash(domain_name)})\n return jsonify(result)\n\n\[email protected]('%s/es/domain/<domain_name>' % API_PREFIX, methods=['GET'])\ndef describe_domain(domain_name):\n if domain_name not in ES_DOMAINS:\n return error_response(error_type='ResourceNotFoundException')\n result = get_domain_status(domain_name)\n return jsonify(result)\n\n\[email protected]('%s/es/domain/<domain_name>/config' % API_PREFIX, methods=['GET', 'POST'])\ndef domain_config(domain_name):\n config = get_domain_config(domain_name)\n return jsonify(config)\n\n\[email protected]('%s/es/domain/<domain_name>' % API_PREFIX, methods=['DELETE'])\ndef delete_domain(domain_name):\n if domain_name not in ES_DOMAINS:\n return error_response(error_type='ResourceNotFoundException')\n result = get_domain_status(domain_name, deleted=True)\n ES_DOMAINS.pop(domain_name)\n # record event\n event_publisher.fire_event(event_publisher.EVENT_ES_DELETE_DOMAIN,\n payload={'n': event_publisher.get_hash(domain_name)})\n return jsonify(result)\n\n\[email protected]('%s/tags' % API_PREFIX, methods=['GET', 'POST'])\ndef add_list_tags():\n if request.method == 'GET' and request.args.get('arn'):\n response = {\n 'TagList': [\n {\n 'Key': 'Example1',\n 'Value': 'Value'\n },\n {\n 'Key': 'Example2',\n 'Value': 'Value'\n }\n ]\n }\n return jsonify(response)\n\n return jsonify({})\n\n\ndef serve(port, quiet=True):\n generic_proxy.serve_flask_app(app=app, port=port, quiet=quiet)\n", "path": "localstack/services/es/es_api.py"}]}
| 3,203 | 93 |
gh_patches_debug_31638
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-5766
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Azure Function App Slots - Ensure web app redirects all HTTP traffic to HTTPS in Azure Function App Slots
**Describe the issue**
It seems that there are no checks that ensure that the following resource only allows HTTPS:
- azurerm_function_app_slot
- azurerm_linux_function_app_slot
- azurerm_windows_function_app_slot
**Examples**
````hcl
resource "azurerm_function_app_slot" "example" {
name = "test-azure-functions_slot"
location = azurerm_resource_group.example.location
resource_group_name = azurerm_resource_group.example.name
app_service_plan_id = azurerm_app_service_plan.example.id
function_app_name = azurerm_function_app.example.name
storage_account_name = azurerm_storage_account.example.name
storage_account_access_key = azurerm_storage_account.example.primary_access_key
https_only = true
}
resource "azurerm_linux_function_app_slot" "example" {
name = "example-linux-function-app-slot"
function_app_id = azurerm_linux_function_app.example.id
storage_account_name = azurerm_storage_account.example.name
site_config {
require_https = true
}
}
resource "azurerm_windows_function_app" "example" {
name = "example-windows-function-app"
resource_group_name = azurerm_resource_group.example.name
location = azurerm_resource_group.example.location
storage_account_name = azurerm_storage_account.example.name
service_plan_id = azurerm_service_plan.example.id
site_config {
require_https = true
}
}
````
**Version (please complete the following information):**
- N/A
**Additional context**
N/A
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `checkov/terraform/checks/resource/azure/FunctionAppsAccessibleOverHttps.py`
Content:
```
1 from checkov.common.models.enums import CheckCategories
2 from checkov.terraform.checks.resource.base_resource_value_check import BaseResourceValueCheck
3
4
5 class FunctionAppsAccessibleOverHttps(BaseResourceValueCheck):
6 def __init__(self):
7 name = "Ensure that Function apps is only accessible over HTTPS"
8 id = "CKV_AZURE_70"
9 supported_resources = ['azurerm_function_app']
10 categories = [CheckCategories.NETWORKING]
11 super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
12
13 def get_inspected_key(self):
14 return 'https_only'
15
16
17 check = FunctionAppsAccessibleOverHttps()
18
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/checkov/terraform/checks/resource/azure/FunctionAppsAccessibleOverHttps.py b/checkov/terraform/checks/resource/azure/FunctionAppsAccessibleOverHttps.py
--- a/checkov/terraform/checks/resource/azure/FunctionAppsAccessibleOverHttps.py
+++ b/checkov/terraform/checks/resource/azure/FunctionAppsAccessibleOverHttps.py
@@ -1,17 +1,44 @@
-from checkov.common.models.enums import CheckCategories
-from checkov.terraform.checks.resource.base_resource_value_check import BaseResourceValueCheck
+from __future__ import annotations
+from typing import Any
-class FunctionAppsAccessibleOverHttps(BaseResourceValueCheck):
- def __init__(self):
+from checkov.common.models.enums import CheckCategories, CheckResult
+from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck
+
+
+class FunctionAppsAccessibleOverHttps(BaseResourceCheck):
+
+ def __init__(self) -> None:
name = "Ensure that Function apps is only accessible over HTTPS"
id = "CKV_AZURE_70"
- supported_resources = ['azurerm_function_app']
+ supported_resources = ['azurerm_function_app', 'azurerm_linux_function_app', 'azurerm_windows_function_app',
+ 'azurerm_function_app_slot', 'azurerm_linux_function_app_slot',
+ 'azurerm_windows_function_app_slot']
categories = [CheckCategories.NETWORKING]
super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
- def get_inspected_key(self):
- return 'https_only'
+ def scan_resource_conf(self, conf: dict[str, list[Any]]) -> CheckResult:
+ # default=false for https_only
+ if 'https_only' not in conf.keys():
+ return CheckResult.FAILED
+
+ https_only = conf.get('https_only')[0]
+ if not https_only:
+ return CheckResult.FAILED
+
+ # relevant for linux/windows resources
+ if 'auth_settings_v2' in conf.keys():
+ auth_settings_v2 = conf['auth_settings_v2'][0]
+
+ # default=true for require_https
+ if 'require_https' not in auth_settings_v2.keys():
+ return CheckResult.PASSED
+
+ require_https = auth_settings_v2.get('require_https')[0]
+ if not require_https:
+ return CheckResult.FAILED
+
+ return CheckResult.PASSED
check = FunctionAppsAccessibleOverHttps()
|
{"golden_diff": "diff --git a/checkov/terraform/checks/resource/azure/FunctionAppsAccessibleOverHttps.py b/checkov/terraform/checks/resource/azure/FunctionAppsAccessibleOverHttps.py\n--- a/checkov/terraform/checks/resource/azure/FunctionAppsAccessibleOverHttps.py\n+++ b/checkov/terraform/checks/resource/azure/FunctionAppsAccessibleOverHttps.py\n@@ -1,17 +1,44 @@\n-from checkov.common.models.enums import CheckCategories\n-from checkov.terraform.checks.resource.base_resource_value_check import BaseResourceValueCheck\n+from __future__ import annotations\n \n+from typing import Any\n \n-class FunctionAppsAccessibleOverHttps(BaseResourceValueCheck):\n- def __init__(self):\n+from checkov.common.models.enums import CheckCategories, CheckResult\n+from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\n+\n+\n+class FunctionAppsAccessibleOverHttps(BaseResourceCheck):\n+\n+ def __init__(self) -> None:\n name = \"Ensure that Function apps is only accessible over HTTPS\"\n id = \"CKV_AZURE_70\"\n- supported_resources = ['azurerm_function_app']\n+ supported_resources = ['azurerm_function_app', 'azurerm_linux_function_app', 'azurerm_windows_function_app',\n+ 'azurerm_function_app_slot', 'azurerm_linux_function_app_slot',\n+ 'azurerm_windows_function_app_slot']\n categories = [CheckCategories.NETWORKING]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n \n- def get_inspected_key(self):\n- return 'https_only'\n+ def scan_resource_conf(self, conf: dict[str, list[Any]]) -> CheckResult:\n+ # default=false for https_only\n+ if 'https_only' not in conf.keys():\n+ return CheckResult.FAILED\n+\n+ https_only = conf.get('https_only')[0]\n+ if not https_only:\n+ return CheckResult.FAILED\n+\n+ # relevant for linux/windows resources\n+ if 'auth_settings_v2' in conf.keys():\n+ auth_settings_v2 = conf['auth_settings_v2'][0]\n+\n+ # default=true for require_https\n+ if 'require_https' not in auth_settings_v2.keys():\n+ return CheckResult.PASSED\n+\n+ require_https = auth_settings_v2.get('require_https')[0]\n+ if not require_https:\n+ return CheckResult.FAILED\n+\n+ return CheckResult.PASSED\n \n \n check = FunctionAppsAccessibleOverHttps()\n", "issue": "Azure Function App Slots - Ensure web app redirects all HTTP traffic to HTTPS in Azure Function App Slots\n**Describe the issue**\r\nIt seems that there are no checks that ensure that the following resource only allows HTTPS:\r\n\r\n- azurerm_function_app_slot\r\n- azurerm_linux_function_app_slot\r\n- azurerm_windows_function_app_slot\r\n\r\n**Examples**\r\n\r\n````hcl\r\nresource \"azurerm_function_app_slot\" \"example\" {\r\n name = \"test-azure-functions_slot\"\r\n location = azurerm_resource_group.example.location\r\n resource_group_name = azurerm_resource_group.example.name\r\n app_service_plan_id = azurerm_app_service_plan.example.id\r\n function_app_name = azurerm_function_app.example.name\r\n storage_account_name = azurerm_storage_account.example.name\r\n storage_account_access_key = azurerm_storage_account.example.primary_access_key\r\n https_only = true\r\n}\r\n\r\nresource \"azurerm_linux_function_app_slot\" \"example\" {\r\n name = \"example-linux-function-app-slot\"\r\n function_app_id = azurerm_linux_function_app.example.id\r\n storage_account_name = azurerm_storage_account.example.name\r\n\r\n site_config {\r\n require_https = true \r\n }\r\n}\r\n\r\nresource \"azurerm_windows_function_app\" \"example\" {\r\n name = \"example-windows-function-app\"\r\n resource_group_name = azurerm_resource_group.example.name\r\n location = azurerm_resource_group.example.location\r\n storage_account_name = azurerm_storage_account.example.name\r\n service_plan_id = azurerm_service_plan.example.id\r\n\r\n site_config {\r\n require_https = true \r\n }\r\n}\r\n\r\n````\r\n\r\n**Version (please complete the following information):**\r\n - N/A\r\n \r\n**Additional context**\r\n\r\nN/A\n", "before_files": [{"content": "from checkov.common.models.enums import CheckCategories\nfrom checkov.terraform.checks.resource.base_resource_value_check import BaseResourceValueCheck\n\n\nclass FunctionAppsAccessibleOverHttps(BaseResourceValueCheck):\n def __init__(self):\n name = \"Ensure that Function apps is only accessible over HTTPS\"\n id = \"CKV_AZURE_70\"\n supported_resources = ['azurerm_function_app']\n categories = [CheckCategories.NETWORKING]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def get_inspected_key(self):\n return 'https_only'\n\n\ncheck = FunctionAppsAccessibleOverHttps()\n", "path": "checkov/terraform/checks/resource/azure/FunctionAppsAccessibleOverHttps.py"}], "after_files": [{"content": "from __future__ import annotations\n\nfrom typing import Any\n\nfrom checkov.common.models.enums import CheckCategories, CheckResult\nfrom checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\n\n\nclass FunctionAppsAccessibleOverHttps(BaseResourceCheck):\n\n def __init__(self) -> None:\n name = \"Ensure that Function apps is only accessible over HTTPS\"\n id = \"CKV_AZURE_70\"\n supported_resources = ['azurerm_function_app', 'azurerm_linux_function_app', 'azurerm_windows_function_app',\n 'azurerm_function_app_slot', 'azurerm_linux_function_app_slot',\n 'azurerm_windows_function_app_slot']\n categories = [CheckCategories.NETWORKING]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def scan_resource_conf(self, conf: dict[str, list[Any]]) -> CheckResult:\n # default=false for https_only\n if 'https_only' not in conf.keys():\n return CheckResult.FAILED\n\n https_only = conf.get('https_only')[0]\n if not https_only:\n return CheckResult.FAILED\n\n # relevant for linux/windows resources\n if 'auth_settings_v2' in conf.keys():\n auth_settings_v2 = conf['auth_settings_v2'][0]\n\n # default=true for require_https\n if 'require_https' not in auth_settings_v2.keys():\n return CheckResult.PASSED\n\n require_https = auth_settings_v2.get('require_https')[0]\n if not require_https:\n return CheckResult.FAILED\n\n return CheckResult.PASSED\n\n\ncheck = FunctionAppsAccessibleOverHttps()\n", "path": "checkov/terraform/checks/resource/azure/FunctionAppsAccessibleOverHttps.py"}]}
| 815 | 555 |
gh_patches_debug_2348
|
rasdani/github-patches
|
git_diff
|
cornellius-gp__gpytorch-2285
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Docs] Bernoulli likelihoods
# 📚 Documentation/Examples
In the document for [Bernoulli likelihoods](https://docs.gpytorch.ai/en/stable/likelihoods.html), since the labels take value in {0, 1}, the likelihood should be
$$p(Y=y | f) = \Phi ((2y-1)f)$$
instead of the currently displayed
$$p(Y=y|f) = \Phi(yf).$$
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `gpytorch/likelihoods/bernoulli_likelihood.py`
Content:
```
1 #!/usr/bin/env python3
2
3 import warnings
4
5 import torch
6
7 from ..distributions import base_distributions
8 from ..functions import log_normal_cdf
9 from .likelihood import _OneDimensionalLikelihood
10
11
12 class BernoulliLikelihood(_OneDimensionalLikelihood):
13 r"""
14 Implements the Bernoulli likelihood used for GP classification, using
15 Probit regression (i.e., the latent function is warped to be in [0,1]
16 using the standard Normal CDF :math:`\Phi(x)`). Given the identity
17 :math:`\Phi(-x) = 1-\Phi(x)`, we can write the likelihood compactly as:
18
19 .. math::
20 \begin{equation*}
21 p(Y=y|f)=\Phi(yf)
22 \end{equation*}
23 """
24
25 def forward(self, function_samples, **kwargs):
26 output_probs = base_distributions.Normal(0, 1).cdf(function_samples)
27 return base_distributions.Bernoulli(probs=output_probs)
28
29 def log_marginal(self, observations, function_dist, *args, **kwargs):
30 marginal = self.marginal(function_dist, *args, **kwargs)
31 return marginal.log_prob(observations)
32
33 def marginal(self, function_dist, **kwargs):
34 mean = function_dist.mean
35 var = function_dist.variance
36 link = mean.div(torch.sqrt(1 + var))
37 output_probs = base_distributions.Normal(0, 1).cdf(link)
38 return base_distributions.Bernoulli(probs=output_probs)
39
40 def expected_log_prob(self, observations, function_dist, *params, **kwargs):
41 if torch.any(observations.eq(-1)):
42 # Remove after 1.0
43 warnings.warn(
44 "BernoulliLikelihood.expected_log_prob expects observations with labels in {0, 1}. "
45 "Observations with labels in {-1, 1} are deprecated.",
46 DeprecationWarning,
47 )
48 else:
49 observations = observations.mul(2).sub(1)
50 # Custom function here so we can use log_normal_cdf rather than Normal.cdf
51 # This is going to be less prone to overflow errors
52 log_prob_lambda = lambda function_samples: log_normal_cdf(function_samples.mul(observations))
53 log_prob = self.quadrature(log_prob_lambda, function_dist)
54 return log_prob
55
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/gpytorch/likelihoods/bernoulli_likelihood.py b/gpytorch/likelihoods/bernoulli_likelihood.py
--- a/gpytorch/likelihoods/bernoulli_likelihood.py
+++ b/gpytorch/likelihoods/bernoulli_likelihood.py
@@ -18,8 +18,11 @@
.. math::
\begin{equation*}
- p(Y=y|f)=\Phi(yf)
+ p(Y=y|f)=\Phi((2y - 1)f)
\end{equation*}
+
+ .. note::
+ The labels should take values in {0, 1}.
"""
def forward(self, function_samples, **kwargs):
|
{"golden_diff": "diff --git a/gpytorch/likelihoods/bernoulli_likelihood.py b/gpytorch/likelihoods/bernoulli_likelihood.py\n--- a/gpytorch/likelihoods/bernoulli_likelihood.py\n+++ b/gpytorch/likelihoods/bernoulli_likelihood.py\n@@ -18,8 +18,11 @@\n \n .. math::\n \\begin{equation*}\n- p(Y=y|f)=\\Phi(yf)\n+ p(Y=y|f)=\\Phi((2y - 1)f)\n \\end{equation*}\n+\n+ .. note::\n+ The labels should take values in {0, 1}.\n \"\"\"\n \n def forward(self, function_samples, **kwargs):\n", "issue": "[Docs] Bernoulli likelihoods \n# \ud83d\udcda Documentation/Examples\r\n\r\nIn the document for [Bernoulli likelihoods](https://docs.gpytorch.ai/en/stable/likelihoods.html), since the labels take value in {0, 1}, the likelihood should be \r\n\r\n$$p(Y=y | f) = \\Phi ((2y-1)f)$$\r\n\r\ninstead of the currently displayed\r\n\r\n$$p(Y=y|f) = \\Phi(yf).$$\n", "before_files": [{"content": "#!/usr/bin/env python3\n\nimport warnings\n\nimport torch\n\nfrom ..distributions import base_distributions\nfrom ..functions import log_normal_cdf\nfrom .likelihood import _OneDimensionalLikelihood\n\n\nclass BernoulliLikelihood(_OneDimensionalLikelihood):\n r\"\"\"\n Implements the Bernoulli likelihood used for GP classification, using\n Probit regression (i.e., the latent function is warped to be in [0,1]\n using the standard Normal CDF :math:`\\Phi(x)`). Given the identity\n :math:`\\Phi(-x) = 1-\\Phi(x)`, we can write the likelihood compactly as:\n\n .. math::\n \\begin{equation*}\n p(Y=y|f)=\\Phi(yf)\n \\end{equation*}\n \"\"\"\n\n def forward(self, function_samples, **kwargs):\n output_probs = base_distributions.Normal(0, 1).cdf(function_samples)\n return base_distributions.Bernoulli(probs=output_probs)\n\n def log_marginal(self, observations, function_dist, *args, **kwargs):\n marginal = self.marginal(function_dist, *args, **kwargs)\n return marginal.log_prob(observations)\n\n def marginal(self, function_dist, **kwargs):\n mean = function_dist.mean\n var = function_dist.variance\n link = mean.div(torch.sqrt(1 + var))\n output_probs = base_distributions.Normal(0, 1).cdf(link)\n return base_distributions.Bernoulli(probs=output_probs)\n\n def expected_log_prob(self, observations, function_dist, *params, **kwargs):\n if torch.any(observations.eq(-1)):\n # Remove after 1.0\n warnings.warn(\n \"BernoulliLikelihood.expected_log_prob expects observations with labels in {0, 1}. \"\n \"Observations with labels in {-1, 1} are deprecated.\",\n DeprecationWarning,\n )\n else:\n observations = observations.mul(2).sub(1)\n # Custom function here so we can use log_normal_cdf rather than Normal.cdf\n # This is going to be less prone to overflow errors\n log_prob_lambda = lambda function_samples: log_normal_cdf(function_samples.mul(observations))\n log_prob = self.quadrature(log_prob_lambda, function_dist)\n return log_prob\n", "path": "gpytorch/likelihoods/bernoulli_likelihood.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n\nimport warnings\n\nimport torch\n\nfrom ..distributions import base_distributions\nfrom ..functions import log_normal_cdf\nfrom .likelihood import _OneDimensionalLikelihood\n\n\nclass BernoulliLikelihood(_OneDimensionalLikelihood):\n r\"\"\"\n Implements the Bernoulli likelihood used for GP classification, using\n Probit regression (i.e., the latent function is warped to be in [0,1]\n using the standard Normal CDF :math:`\\Phi(x)`). Given the identity\n :math:`\\Phi(-x) = 1-\\Phi(x)`, we can write the likelihood compactly as:\n\n .. math::\n \\begin{equation*}\n p(Y=y|f)=\\Phi((2y - 1)f)\n \\end{equation*}\n\n .. note::\n The labels should take values in {0, 1}.\n \"\"\"\n\n def forward(self, function_samples, **kwargs):\n output_probs = base_distributions.Normal(0, 1).cdf(function_samples)\n return base_distributions.Bernoulli(probs=output_probs)\n\n def log_marginal(self, observations, function_dist, *args, **kwargs):\n marginal = self.marginal(function_dist, *args, **kwargs)\n return marginal.log_prob(observations)\n\n def marginal(self, function_dist, **kwargs):\n mean = function_dist.mean\n var = function_dist.variance\n link = mean.div(torch.sqrt(1 + var))\n output_probs = base_distributions.Normal(0, 1).cdf(link)\n return base_distributions.Bernoulli(probs=output_probs)\n\n def expected_log_prob(self, observations, function_dist, *params, **kwargs):\n if torch.any(observations.eq(-1)):\n # Remove after 1.0\n warnings.warn(\n \"BernoulliLikelihood.expected_log_prob expects observations with labels in {0, 1}. \"\n \"Observations with labels in {-1, 1} are deprecated.\",\n DeprecationWarning,\n )\n else:\n observations = observations.mul(2).sub(1)\n # Custom function here so we can use log_normal_cdf rather than Normal.cdf\n # This is going to be less prone to overflow errors\n log_prob_lambda = lambda function_samples: log_normal_cdf(function_samples.mul(observations))\n log_prob = self.quadrature(log_prob_lambda, function_dist)\n return log_prob\n", "path": "gpytorch/likelihoods/bernoulli_likelihood.py"}]}
| 978 | 159 |
gh_patches_debug_22586
|
rasdani/github-patches
|
git_diff
|
praw-dev__praw-1918
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Praw incorrectly uses the "after" parameter to paginate Mode Note API Queries.
### Describe the Bug
The Reddit API does not support using the parameter "after" on queries for /api/mod/notes
The default listing generator uses the "after" parameter to paginate results.
Generator.py
```
if self._listing.after and self._listing.after != self.params.get("after"):
self.params["after"] = self._listing.after
else:
self._exhausted = True
```
The "after" parameter is set as part of the listing class.
```
class ModNoteListing(Listing):
"""Special Listing for handling :class:`.ModNote` lists."""
CHILD_ATTRIBUTE = "mod_notes"
@property
def after(self) -> Optional[Any]:
"""Return the next attribute or None."""
if not getattr(self, "has_next_page", True):
return None
return getattr(self, "end_cursor", None)
```
The result is that the reddit API will ignore the 'after' parameter and return an identical result to the first query. When PRAW receives a second response with an identical 'end_cursor' parameter, it will end the query. This means that the maximum number of mod notes pulled by PRAW is 100.
### Desired Result
PRAW should record the 'end_cursor' parameter from responses to the Mod Notes API and transmit them as "before" in the next query. This will properly collect the next page of results from the API.
I do not have the python knowledge to provide a best practice fix. Below is my hack that correctly provides all user notes.
listing.py
```
class ModNoteListing(Listing):
"""Special Listing for handling :class:`.ModNote` lists."""
CHILD_ATTRIBUTE = "mod_notes"
@property
def before(self) -> Optional[Any]:
"""Return the next attribute or None."""
if not getattr(self, "has_next_page", True):
return None
return getattr(self, "end_cursor", None)
```
generator.py
```
def _next_batch(self):
if self._exhausted:
raise StopIteration()
self._listing = self._reddit.get(self.url, params=self.params)
self._listing = self._extract_sublist(self._listing)
self._list_index = 0
if not self._listing:
raise StopIteration()
if hasattr(self._listing, "after"):
if self._listing.after and self._listing.after != self.params.get("after"):
self.params["after"] = self._listing.after
else:
self._exhausted = True
elif hasattr(self._listing, "before"):
if self._listing.before and self._listing.before != self.params.get("before"):
self.params["before"] = self._listing.before
else:
self._exhausted = True
else:
self._exhausted = True
```
### Relevant Logs
```shell
DEBUG:prawcore:Params: {'subreddit': Subreddit(display_name='test'), 'user': 'TestUser', 'limit': 1024, 'raw_json': 1}
DEBUG:prawcore:Response: 200 (5089 bytes)
DEBUG:prawcore:Params: {'subreddit': Subreddit(display_name='test), 'user': 'testUser', 'limit': 1024, 'after': 'MTY2MDIzMTM3MDk5Mw==', 'raw_json': 1}
DEBUG:prawcore:Response: 200 (5089 bytes)
```
### Code to reproduce the bug
```python
for note in reddit.subreddit("test").mod.notes.redditors(userName, limit = None):
```
### My code example does not include the `Reddit()` initialization to prevent credential leakage.
Yes
### This code has previously worked as intended.
No
### Operating System/Environment
Windows 10
### Python Version
Python 3.10
### PRAW Version
Version: 7.6.1
### Prawcore Version
Version: 2.3.0
### Anything else?
The user will need more than 100 mod notes in order to need to paginate requests.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `praw/models/listing/generator.py`
Content:
```
1 """Provide the ListingGenerator class."""
2 from copy import deepcopy
3 from typing import TYPE_CHECKING, Any, Dict, Iterator, Optional, Union
4
5 from ..base import PRAWBase
6 from .listing import FlairListing, ModNoteListing
7
8 if TYPE_CHECKING: # pragma: no cover
9 import praw
10
11
12 class ListingGenerator(PRAWBase, Iterator):
13 """Instances of this class generate :class:`.RedditBase` instances.
14
15 .. warning::
16
17 This class should not be directly utilized. Instead, you will find a number of
18 methods that return instances of the class here_.
19
20 .. _here: https://praw.readthedocs.io/en/latest/search.html?q=ListingGenerator
21
22 """
23
24 def __init__(
25 self,
26 reddit: "praw.Reddit",
27 url: str,
28 limit: int = 100,
29 params: Optional[Dict[str, Union[str, int]]] = None,
30 ):
31 """Initialize a :class:`.ListingGenerator` instance.
32
33 :param reddit: An instance of :class:`.Reddit`.
34 :param url: A URL returning a Reddit listing.
35 :param limit: The number of content entries to fetch. If ``limit`` is ``None``,
36 then fetch as many entries as possible. Most of Reddit's listings contain a
37 maximum of 1000 items, and are returned 100 at a time. This class will
38 automatically issue all necessary requests (default: ``100``).
39 :param params: A dictionary containing additional query string parameters to
40 send with the request.
41
42 """
43 super().__init__(reddit, _data=None)
44 self._exhausted = False
45 self._listing = None
46 self._list_index = None
47 self.limit = limit
48 self.params = deepcopy(params) if params else {}
49 self.params["limit"] = limit or 1024
50 self.url = url
51 self.yielded = 0
52
53 def __iter__(self) -> Iterator[Any]:
54 """Permit :class:`.ListingGenerator` to operate as an iterator."""
55 return self
56
57 def __next__(self) -> Any:
58 """Permit :class:`.ListingGenerator` to operate as a generator."""
59 if self.limit is not None and self.yielded >= self.limit:
60 raise StopIteration()
61
62 if self._listing is None or self._list_index >= len(self._listing):
63 self._next_batch()
64
65 self._list_index += 1
66 self.yielded += 1
67 return self._listing[self._list_index - 1]
68
69 def _extract_sublist(self, listing):
70 if isinstance(listing, list):
71 return listing[1] # for submission duplicates
72 elif isinstance(listing, dict):
73 classes = [FlairListing, ModNoteListing]
74
75 for listing_type in classes:
76 if listing_type.CHILD_ATTRIBUTE in listing:
77 return listing_type(self._reddit, listing)
78 else:
79 raise ValueError(
80 "The generator returned a dictionary PRAW didn't recognize."
81 " File a bug report at PRAW."
82 )
83 return listing
84
85 def _next_batch(self):
86 if self._exhausted:
87 raise StopIteration()
88
89 self._listing = self._reddit.get(self.url, params=self.params)
90 self._listing = self._extract_sublist(self._listing)
91 self._list_index = 0
92
93 if not self._listing:
94 raise StopIteration()
95
96 if self._listing.after and self._listing.after != self.params.get("after"):
97 self.params["after"] = self._listing.after
98 else:
99 self._exhausted = True
100
```
Path: `praw/models/listing/listing.py`
Content:
```
1 """Provide the Listing class."""
2 from typing import Any, Optional
3
4 from ..base import PRAWBase
5
6
7 class Listing(PRAWBase):
8 """A listing is a collection of :class:`.RedditBase` instances."""
9
10 CHILD_ATTRIBUTE = "children"
11
12 def __len__(self) -> int:
13 """Return the number of items in the Listing."""
14 return len(getattr(self, self.CHILD_ATTRIBUTE))
15
16 def __getitem__(self, index: int) -> Any:
17 """Return the item at position index in the list."""
18 return getattr(self, self.CHILD_ATTRIBUTE)[index]
19
20 def __setattr__(self, attribute: str, value: Any):
21 """Objectify the ``CHILD_ATTRIBUTE`` attribute."""
22 if attribute == self.CHILD_ATTRIBUTE:
23 value = self._reddit._objector.objectify(value)
24 super().__setattr__(attribute, value)
25
26
27 class FlairListing(Listing):
28 """Special Listing for handling flair lists."""
29
30 CHILD_ATTRIBUTE = "users"
31
32 @property
33 def after(self) -> Optional[Any]:
34 """Return the next attribute or ``None``."""
35 return getattr(self, "next", None)
36
37
38 class ModeratorListing(Listing):
39 """Special Listing for handling moderator lists."""
40
41 CHILD_ATTRIBUTE = "moderators"
42
43
44 class ModNoteListing(Listing):
45 """Special Listing for handling :class:`.ModNote` lists."""
46
47 CHILD_ATTRIBUTE = "mod_notes"
48
49 @property
50 def after(self) -> Optional[Any]:
51 """Return the next attribute or None."""
52 if not getattr(self, "has_next_page", True):
53 return None
54 return getattr(self, "end_cursor", None)
55
56
57 class ModmailConversationsListing(Listing):
58 """Special Listing for handling :class:`.ModmailConversation` lists."""
59
60 CHILD_ATTRIBUTE = "conversations"
61
62 @property
63 def after(self) -> Optional[str]:
64 """Return the next attribute or ``None``."""
65 try:
66 return self.conversations[-1].id
67 except IndexError:
68 return None
69
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/praw/models/listing/generator.py b/praw/models/listing/generator.py
--- a/praw/models/listing/generator.py
+++ b/praw/models/listing/generator.py
@@ -93,7 +93,9 @@
if not self._listing:
raise StopIteration()
- if self._listing.after and self._listing.after != self.params.get("after"):
- self.params["after"] = self._listing.after
+ if self._listing.after and self._listing.after != self.params.get(
+ self._listing.AFTER_PARAM
+ ):
+ self.params[self._listing.AFTER_PARAM] = self._listing.after
else:
self._exhausted = True
diff --git a/praw/models/listing/listing.py b/praw/models/listing/listing.py
--- a/praw/models/listing/listing.py
+++ b/praw/models/listing/listing.py
@@ -7,6 +7,7 @@
class Listing(PRAWBase):
"""A listing is a collection of :class:`.RedditBase` instances."""
+ AFTER_PARAM = "after"
CHILD_ATTRIBUTE = "children"
def __len__(self) -> int:
@@ -44,6 +45,7 @@
class ModNoteListing(Listing):
"""Special Listing for handling :class:`.ModNote` lists."""
+ AFTER_PARAM = "before"
CHILD_ATTRIBUTE = "mod_notes"
@property
|
{"golden_diff": "diff --git a/praw/models/listing/generator.py b/praw/models/listing/generator.py\n--- a/praw/models/listing/generator.py\n+++ b/praw/models/listing/generator.py\n@@ -93,7 +93,9 @@\n if not self._listing:\n raise StopIteration()\n \n- if self._listing.after and self._listing.after != self.params.get(\"after\"):\n- self.params[\"after\"] = self._listing.after\n+ if self._listing.after and self._listing.after != self.params.get(\n+ self._listing.AFTER_PARAM\n+ ):\n+ self.params[self._listing.AFTER_PARAM] = self._listing.after\n else:\n self._exhausted = True\ndiff --git a/praw/models/listing/listing.py b/praw/models/listing/listing.py\n--- a/praw/models/listing/listing.py\n+++ b/praw/models/listing/listing.py\n@@ -7,6 +7,7 @@\n class Listing(PRAWBase):\n \"\"\"A listing is a collection of :class:`.RedditBase` instances.\"\"\"\n \n+ AFTER_PARAM = \"after\"\n CHILD_ATTRIBUTE = \"children\"\n \n def __len__(self) -> int:\n@@ -44,6 +45,7 @@\n class ModNoteListing(Listing):\n \"\"\"Special Listing for handling :class:`.ModNote` lists.\"\"\"\n \n+ AFTER_PARAM = \"before\"\n CHILD_ATTRIBUTE = \"mod_notes\"\n \n @property\n", "issue": "Praw incorrectly uses the \"after\" parameter to paginate Mode Note API Queries.\n### Describe the Bug\n\nThe Reddit API does not support using the parameter \"after\" on queries for /api/mod/notes\r\n\r\nThe default listing generator uses the \"after\" parameter to paginate results.\r\n\r\nGenerator.py\r\n```\r\n if self._listing.after and self._listing.after != self.params.get(\"after\"):\r\n self.params[\"after\"] = self._listing.after\r\n else:\r\n self._exhausted = True\r\n```\r\n\r\nThe \"after\" parameter is set as part of the listing class.\r\n\r\n```\r\n class ModNoteListing(Listing):\r\n \"\"\"Special Listing for handling :class:`.ModNote` lists.\"\"\"\r\n \r\n CHILD_ATTRIBUTE = \"mod_notes\"\r\n \r\n @property\r\n def after(self) -> Optional[Any]:\r\n \"\"\"Return the next attribute or None.\"\"\"\r\n if not getattr(self, \"has_next_page\", True):\r\n return None\r\n return getattr(self, \"end_cursor\", None)\r\n```\r\n\r\nThe result is that the reddit API will ignore the 'after' parameter and return an identical result to the first query. When PRAW receives a second response with an identical 'end_cursor' parameter, it will end the query. This means that the maximum number of mod notes pulled by PRAW is 100.\n\n### Desired Result\n\nPRAW should record the 'end_cursor' parameter from responses to the Mod Notes API and transmit them as \"before\" in the next query. This will properly collect the next page of results from the API.\r\n\r\nI do not have the python knowledge to provide a best practice fix. Below is my hack that correctly provides all user notes.\r\n\r\nlisting.py\r\n```\r\nclass ModNoteListing(Listing):\r\n \"\"\"Special Listing for handling :class:`.ModNote` lists.\"\"\"\r\n\r\n CHILD_ATTRIBUTE = \"mod_notes\"\r\n\r\n @property\r\n def before(self) -> Optional[Any]:\r\n \"\"\"Return the next attribute or None.\"\"\"\r\n if not getattr(self, \"has_next_page\", True):\r\n return None\r\n return getattr(self, \"end_cursor\", None)\r\n```\r\n\r\ngenerator.py\r\n```\r\n def _next_batch(self):\r\n if self._exhausted:\r\n raise StopIteration()\r\n\r\n self._listing = self._reddit.get(self.url, params=self.params)\r\n self._listing = self._extract_sublist(self._listing)\r\n self._list_index = 0\r\n\r\n if not self._listing:\r\n raise StopIteration()\r\n\r\n if hasattr(self._listing, \"after\"):\r\n if self._listing.after and self._listing.after != self.params.get(\"after\"):\r\n self.params[\"after\"] = self._listing.after\r\n else:\r\n self._exhausted = True\r\n elif hasattr(self._listing, \"before\"):\r\n if self._listing.before and self._listing.before != self.params.get(\"before\"):\r\n self.params[\"before\"] = self._listing.before\r\n else:\r\n self._exhausted = True\r\n else:\r\n self._exhausted = True\r\n```\n\n### Relevant Logs\n\n```shell\nDEBUG:prawcore:Params: {'subreddit': Subreddit(display_name='test'), 'user': 'TestUser', 'limit': 1024, 'raw_json': 1}\r\nDEBUG:prawcore:Response: 200 (5089 bytes)\r\nDEBUG:prawcore:Params: {'subreddit': Subreddit(display_name='test), 'user': 'testUser', 'limit': 1024, 'after': 'MTY2MDIzMTM3MDk5Mw==', 'raw_json': 1}\r\nDEBUG:prawcore:Response: 200 (5089 bytes)\n```\n\n\n### Code to reproduce the bug\n\n```python\nfor note in reddit.subreddit(\"test\").mod.notes.redditors(userName, limit = None):\n```\n\n\n### My code example does not include the `Reddit()` initialization to prevent credential leakage.\n\nYes\n\n### This code has previously worked as intended.\n\nNo\n\n### Operating System/Environment\n\nWindows 10\n\n### Python Version\n\nPython 3.10\n\n### PRAW Version\n\nVersion: 7.6.1\n\n### Prawcore Version\n\nVersion: 2.3.0\n\n### Anything else?\n\nThe user will need more than 100 mod notes in order to need to paginate requests.\n", "before_files": [{"content": "\"\"\"Provide the ListingGenerator class.\"\"\"\nfrom copy import deepcopy\nfrom typing import TYPE_CHECKING, Any, Dict, Iterator, Optional, Union\n\nfrom ..base import PRAWBase\nfrom .listing import FlairListing, ModNoteListing\n\nif TYPE_CHECKING: # pragma: no cover\n import praw\n\n\nclass ListingGenerator(PRAWBase, Iterator):\n \"\"\"Instances of this class generate :class:`.RedditBase` instances.\n\n .. warning::\n\n This class should not be directly utilized. Instead, you will find a number of\n methods that return instances of the class here_.\n\n .. _here: https://praw.readthedocs.io/en/latest/search.html?q=ListingGenerator\n\n \"\"\"\n\n def __init__(\n self,\n reddit: \"praw.Reddit\",\n url: str,\n limit: int = 100,\n params: Optional[Dict[str, Union[str, int]]] = None,\n ):\n \"\"\"Initialize a :class:`.ListingGenerator` instance.\n\n :param reddit: An instance of :class:`.Reddit`.\n :param url: A URL returning a Reddit listing.\n :param limit: The number of content entries to fetch. If ``limit`` is ``None``,\n then fetch as many entries as possible. Most of Reddit's listings contain a\n maximum of 1000 items, and are returned 100 at a time. This class will\n automatically issue all necessary requests (default: ``100``).\n :param params: A dictionary containing additional query string parameters to\n send with the request.\n\n \"\"\"\n super().__init__(reddit, _data=None)\n self._exhausted = False\n self._listing = None\n self._list_index = None\n self.limit = limit\n self.params = deepcopy(params) if params else {}\n self.params[\"limit\"] = limit or 1024\n self.url = url\n self.yielded = 0\n\n def __iter__(self) -> Iterator[Any]:\n \"\"\"Permit :class:`.ListingGenerator` to operate as an iterator.\"\"\"\n return self\n\n def __next__(self) -> Any:\n \"\"\"Permit :class:`.ListingGenerator` to operate as a generator.\"\"\"\n if self.limit is not None and self.yielded >= self.limit:\n raise StopIteration()\n\n if self._listing is None or self._list_index >= len(self._listing):\n self._next_batch()\n\n self._list_index += 1\n self.yielded += 1\n return self._listing[self._list_index - 1]\n\n def _extract_sublist(self, listing):\n if isinstance(listing, list):\n return listing[1] # for submission duplicates\n elif isinstance(listing, dict):\n classes = [FlairListing, ModNoteListing]\n\n for listing_type in classes:\n if listing_type.CHILD_ATTRIBUTE in listing:\n return listing_type(self._reddit, listing)\n else:\n raise ValueError(\n \"The generator returned a dictionary PRAW didn't recognize.\"\n \" File a bug report at PRAW.\"\n )\n return listing\n\n def _next_batch(self):\n if self._exhausted:\n raise StopIteration()\n\n self._listing = self._reddit.get(self.url, params=self.params)\n self._listing = self._extract_sublist(self._listing)\n self._list_index = 0\n\n if not self._listing:\n raise StopIteration()\n\n if self._listing.after and self._listing.after != self.params.get(\"after\"):\n self.params[\"after\"] = self._listing.after\n else:\n self._exhausted = True\n", "path": "praw/models/listing/generator.py"}, {"content": "\"\"\"Provide the Listing class.\"\"\"\nfrom typing import Any, Optional\n\nfrom ..base import PRAWBase\n\n\nclass Listing(PRAWBase):\n \"\"\"A listing is a collection of :class:`.RedditBase` instances.\"\"\"\n\n CHILD_ATTRIBUTE = \"children\"\n\n def __len__(self) -> int:\n \"\"\"Return the number of items in the Listing.\"\"\"\n return len(getattr(self, self.CHILD_ATTRIBUTE))\n\n def __getitem__(self, index: int) -> Any:\n \"\"\"Return the item at position index in the list.\"\"\"\n return getattr(self, self.CHILD_ATTRIBUTE)[index]\n\n def __setattr__(self, attribute: str, value: Any):\n \"\"\"Objectify the ``CHILD_ATTRIBUTE`` attribute.\"\"\"\n if attribute == self.CHILD_ATTRIBUTE:\n value = self._reddit._objector.objectify(value)\n super().__setattr__(attribute, value)\n\n\nclass FlairListing(Listing):\n \"\"\"Special Listing for handling flair lists.\"\"\"\n\n CHILD_ATTRIBUTE = \"users\"\n\n @property\n def after(self) -> Optional[Any]:\n \"\"\"Return the next attribute or ``None``.\"\"\"\n return getattr(self, \"next\", None)\n\n\nclass ModeratorListing(Listing):\n \"\"\"Special Listing for handling moderator lists.\"\"\"\n\n CHILD_ATTRIBUTE = \"moderators\"\n\n\nclass ModNoteListing(Listing):\n \"\"\"Special Listing for handling :class:`.ModNote` lists.\"\"\"\n\n CHILD_ATTRIBUTE = \"mod_notes\"\n\n @property\n def after(self) -> Optional[Any]:\n \"\"\"Return the next attribute or None.\"\"\"\n if not getattr(self, \"has_next_page\", True):\n return None\n return getattr(self, \"end_cursor\", None)\n\n\nclass ModmailConversationsListing(Listing):\n \"\"\"Special Listing for handling :class:`.ModmailConversation` lists.\"\"\"\n\n CHILD_ATTRIBUTE = \"conversations\"\n\n @property\n def after(self) -> Optional[str]:\n \"\"\"Return the next attribute or ``None``.\"\"\"\n try:\n return self.conversations[-1].id\n except IndexError:\n return None\n", "path": "praw/models/listing/listing.py"}], "after_files": [{"content": "\"\"\"Provide the ListingGenerator class.\"\"\"\nfrom copy import deepcopy\nfrom typing import TYPE_CHECKING, Any, Dict, Iterator, Optional, Union\n\nfrom ..base import PRAWBase\nfrom .listing import FlairListing, ModNoteListing\n\nif TYPE_CHECKING: # pragma: no cover\n import praw\n\n\nclass ListingGenerator(PRAWBase, Iterator):\n \"\"\"Instances of this class generate :class:`.RedditBase` instances.\n\n .. warning::\n\n This class should not be directly utilized. Instead, you will find a number of\n methods that return instances of the class here_.\n\n .. _here: https://praw.readthedocs.io/en/latest/search.html?q=ListingGenerator\n\n \"\"\"\n\n def __init__(\n self,\n reddit: \"praw.Reddit\",\n url: str,\n limit: int = 100,\n params: Optional[Dict[str, Union[str, int]]] = None,\n ):\n \"\"\"Initialize a :class:`.ListingGenerator` instance.\n\n :param reddit: An instance of :class:`.Reddit`.\n :param url: A URL returning a Reddit listing.\n :param limit: The number of content entries to fetch. If ``limit`` is ``None``,\n then fetch as many entries as possible. Most of Reddit's listings contain a\n maximum of 1000 items, and are returned 100 at a time. This class will\n automatically issue all necessary requests (default: ``100``).\n :param params: A dictionary containing additional query string parameters to\n send with the request.\n\n \"\"\"\n super().__init__(reddit, _data=None)\n self._exhausted = False\n self._listing = None\n self._list_index = None\n self.limit = limit\n self.params = deepcopy(params) if params else {}\n self.params[\"limit\"] = limit or 1024\n self.url = url\n self.yielded = 0\n\n def __iter__(self) -> Iterator[Any]:\n \"\"\"Permit :class:`.ListingGenerator` to operate as an iterator.\"\"\"\n return self\n\n def __next__(self) -> Any:\n \"\"\"Permit :class:`.ListingGenerator` to operate as a generator.\"\"\"\n if self.limit is not None and self.yielded >= self.limit:\n raise StopIteration()\n\n if self._listing is None or self._list_index >= len(self._listing):\n self._next_batch()\n\n self._list_index += 1\n self.yielded += 1\n return self._listing[self._list_index - 1]\n\n def _extract_sublist(self, listing):\n if isinstance(listing, list):\n return listing[1] # for submission duplicates\n elif isinstance(listing, dict):\n classes = [FlairListing, ModNoteListing]\n\n for listing_type in classes:\n if listing_type.CHILD_ATTRIBUTE in listing:\n return listing_type(self._reddit, listing)\n else:\n raise ValueError(\n \"The generator returned a dictionary PRAW didn't recognize.\"\n \" File a bug report at PRAW.\"\n )\n return listing\n\n def _next_batch(self):\n if self._exhausted:\n raise StopIteration()\n\n self._listing = self._reddit.get(self.url, params=self.params)\n self._listing = self._extract_sublist(self._listing)\n self._list_index = 0\n\n if not self._listing:\n raise StopIteration()\n\n if self._listing.after and self._listing.after != self.params.get(\n self._listing.AFTER_PARAM\n ):\n self.params[self._listing.AFTER_PARAM] = self._listing.after\n else:\n self._exhausted = True\n", "path": "praw/models/listing/generator.py"}, {"content": "\"\"\"Provide the Listing class.\"\"\"\nfrom typing import Any, Optional\n\nfrom ..base import PRAWBase\n\n\nclass Listing(PRAWBase):\n \"\"\"A listing is a collection of :class:`.RedditBase` instances.\"\"\"\n\n AFTER_PARAM = \"after\"\n CHILD_ATTRIBUTE = \"children\"\n\n def __len__(self) -> int:\n \"\"\"Return the number of items in the Listing.\"\"\"\n return len(getattr(self, self.CHILD_ATTRIBUTE))\n\n def __getitem__(self, index: int) -> Any:\n \"\"\"Return the item at position index in the list.\"\"\"\n return getattr(self, self.CHILD_ATTRIBUTE)[index]\n\n def __setattr__(self, attribute: str, value: Any):\n \"\"\"Objectify the ``CHILD_ATTRIBUTE`` attribute.\"\"\"\n if attribute == self.CHILD_ATTRIBUTE:\n value = self._reddit._objector.objectify(value)\n super().__setattr__(attribute, value)\n\n\nclass FlairListing(Listing):\n \"\"\"Special Listing for handling flair lists.\"\"\"\n\n CHILD_ATTRIBUTE = \"users\"\n\n @property\n def after(self) -> Optional[Any]:\n \"\"\"Return the next attribute or ``None``.\"\"\"\n return getattr(self, \"next\", None)\n\n\nclass ModeratorListing(Listing):\n \"\"\"Special Listing for handling moderator lists.\"\"\"\n\n CHILD_ATTRIBUTE = \"moderators\"\n\n\nclass ModNoteListing(Listing):\n \"\"\"Special Listing for handling :class:`.ModNote` lists.\"\"\"\n\n AFTER_PARAM = \"before\"\n CHILD_ATTRIBUTE = \"mod_notes\"\n\n @property\n def after(self) -> Optional[Any]:\n \"\"\"Return the next attribute or None.\"\"\"\n if not getattr(self, \"has_next_page\", True):\n return None\n return getattr(self, \"end_cursor\", None)\n\n\nclass ModmailConversationsListing(Listing):\n \"\"\"Special Listing for handling :class:`.ModmailConversation` lists.\"\"\"\n\n CHILD_ATTRIBUTE = \"conversations\"\n\n @property\n def after(self) -> Optional[str]:\n \"\"\"Return the next attribute or ``None``.\"\"\"\n try:\n return self.conversations[-1].id\n except IndexError:\n return None\n", "path": "praw/models/listing/listing.py"}]}
| 2,761 | 319 |
gh_patches_debug_1415
|
rasdani/github-patches
|
git_diff
|
bokeh__bokeh-1434
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Tools get lost on Grid Plots
JS logic error prevents all tools from showing up in the toolbar. (cf. comment in #1342)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/plotting/file/grid.py`
Content:
```
1 import numpy as np
2
3 from bokeh.plotting import *
4
5 N = 50
6
7 x = np.linspace(0, 4*np.pi, N)
8 y = np.sin(x)
9
10 TOOLS = "pan,wheel_zoom,box_zoom,reset,save"
11
12 l = figure(title="line", tools=TOOLS)
13 l.line(x,y, line_width=3, color="gold")
14
15 aw = figure(title="annular wedge", tools=TOOLS)
16 aw.annular_wedge(x, y, 10, 20, 0.6, 4.1, color="navy", alpha=0.5,
17 inner_radius_units="screen", outer_radius_units="screen")
18
19 bez = figure(title="bezier", tools=TOOLS)
20 bez.bezier(x, y, x+0.4, y, x+0.1, y+0.2, x-0.1, y-0.2,
21 line_width=2, color="olive")
22
23 q = figure(title="quad", tools=TOOLS)
24 q.quad(x, x-0.2, y, y-0.2, color="tomato", alpha=0.4)
25
26 p = gridplot([[l,aw],[bez,q]])
27
28 output_file("grid.html", title="grid.py example")
29 show(p)
30
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/plotting/file/grid.py b/examples/plotting/file/grid.py
--- a/examples/plotting/file/grid.py
+++ b/examples/plotting/file/grid.py
@@ -7,7 +7,7 @@
x = np.linspace(0, 4*np.pi, N)
y = np.sin(x)
-TOOLS = "pan,wheel_zoom,box_zoom,reset,save"
+TOOLS = "pan,wheel_zoom,box_zoom,reset,save,crosshair"
l = figure(title="line", tools=TOOLS)
l.line(x,y, line_width=3, color="gold")
|
{"golden_diff": "diff --git a/examples/plotting/file/grid.py b/examples/plotting/file/grid.py\n--- a/examples/plotting/file/grid.py\n+++ b/examples/plotting/file/grid.py\n@@ -7,7 +7,7 @@\n x = np.linspace(0, 4*np.pi, N)\n y = np.sin(x)\n \n-TOOLS = \"pan,wheel_zoom,box_zoom,reset,save\"\n+TOOLS = \"pan,wheel_zoom,box_zoom,reset,save,crosshair\"\n \n l = figure(title=\"line\", tools=TOOLS)\n l.line(x,y, line_width=3, color=\"gold\")\n", "issue": "Tools get lost on Grid Plots\nJS logic error prevents all tools from showing up in the toolbar. (cf. comment in #1342)\n\n", "before_files": [{"content": "import numpy as np\n\nfrom bokeh.plotting import *\n\nN = 50\n\nx = np.linspace(0, 4*np.pi, N)\ny = np.sin(x)\n\nTOOLS = \"pan,wheel_zoom,box_zoom,reset,save\"\n\nl = figure(title=\"line\", tools=TOOLS)\nl.line(x,y, line_width=3, color=\"gold\")\n\naw = figure(title=\"annular wedge\", tools=TOOLS)\naw.annular_wedge(x, y, 10, 20, 0.6, 4.1, color=\"navy\", alpha=0.5,\n inner_radius_units=\"screen\", outer_radius_units=\"screen\")\n\nbez = figure(title=\"bezier\", tools=TOOLS)\nbez.bezier(x, y, x+0.4, y, x+0.1, y+0.2, x-0.1, y-0.2,\n line_width=2, color=\"olive\")\n\nq = figure(title=\"quad\", tools=TOOLS)\nq.quad(x, x-0.2, y, y-0.2, color=\"tomato\", alpha=0.4)\n\np = gridplot([[l,aw],[bez,q]])\n\noutput_file(\"grid.html\", title=\"grid.py example\")\nshow(p)\n", "path": "examples/plotting/file/grid.py"}], "after_files": [{"content": "import numpy as np\n\nfrom bokeh.plotting import *\n\nN = 50\n\nx = np.linspace(0, 4*np.pi, N)\ny = np.sin(x)\n\nTOOLS = \"pan,wheel_zoom,box_zoom,reset,save,crosshair\"\n\nl = figure(title=\"line\", tools=TOOLS)\nl.line(x,y, line_width=3, color=\"gold\")\n\naw = figure(title=\"annular wedge\", tools=TOOLS)\naw.annular_wedge(x, y, 10, 20, 0.6, 4.1, color=\"navy\", alpha=0.5,\n inner_radius_units=\"screen\", outer_radius_units=\"screen\")\n\nbez = figure(title=\"bezier\", tools=TOOLS)\nbez.bezier(x, y, x+0.4, y, x+0.1, y+0.2, x-0.1, y-0.2,\n line_width=2, color=\"olive\")\n\nq = figure(title=\"quad\", tools=TOOLS)\nq.quad(x, x-0.2, y, y-0.2, color=\"tomato\", alpha=0.4)\n\np = gridplot([[l,aw],[bez,q]])\n\noutput_file(\"grid.html\", title=\"grid.py example\")\nshow(p)\n", "path": "examples/plotting/file/grid.py"}]}
| 628 | 132 |
gh_patches_debug_24860
|
rasdani/github-patches
|
git_diff
|
pyro-ppl__numpyro-267
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
fori_collect does not work with non-float arrays
The issue is ravel_pytree which calls `vjp` and does not work with int32 or bool arrays. As such, `fori_collect` will fail if the default identity transform is used.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `numpyro/util.py`
Content:
```
1 from contextlib import contextmanager
2 import random
3
4 import numpy as onp
5 import tqdm
6
7 from jax import jit, lax, ops, vmap
8 from jax.flatten_util import ravel_pytree
9 import jax.numpy as np
10
11 _DATA_TYPES = {}
12 _DISABLE_CONTROL_FLOW_PRIM = False
13
14
15 def set_rng_seed(rng_seed):
16 random.seed(rng_seed)
17 onp.random.seed(rng_seed)
18
19
20 @contextmanager
21 def optional(condition, context_manager):
22 """
23 Optionally wrap inside `context_manager` if condition is `True`.
24 """
25 if condition:
26 with context_manager:
27 yield
28 else:
29 yield
30
31
32 @contextmanager
33 def control_flow_prims_disabled():
34 global _DISABLE_CONTROL_FLOW_PRIM
35 stored_flag = _DISABLE_CONTROL_FLOW_PRIM
36 try:
37 _DISABLE_CONTROL_FLOW_PRIM = True
38 yield
39 finally:
40 _DISABLE_CONTROL_FLOW_PRIM = stored_flag
41
42
43 def cond(pred, true_operand, true_fun, false_operand, false_fun):
44 if _DISABLE_CONTROL_FLOW_PRIM:
45 if pred:
46 return true_fun(true_operand)
47 else:
48 return false_fun(false_operand)
49 else:
50 return lax.cond(pred, true_operand, true_fun, false_operand, false_fun)
51
52
53 def while_loop(cond_fun, body_fun, init_val):
54 if _DISABLE_CONTROL_FLOW_PRIM:
55 val = init_val
56 while cond_fun(val):
57 val = body_fun(val)
58 return val
59 else:
60 # TODO: consider jitting while_loop similar to fori_loop
61 return lax.while_loop(cond_fun, body_fun, init_val)
62
63
64 def fori_loop(lower, upper, body_fun, init_val):
65 if _DISABLE_CONTROL_FLOW_PRIM:
66 val = init_val
67 for i in range(int(lower), int(upper)):
68 val = body_fun(i, val)
69 return val
70 else:
71 return jit(lax.fori_loop, static_argnums=(2,))(lower, upper, body_fun, init_val)
72
73
74 def identity(x):
75 return x
76
77
78 def fori_collect(lower, upper, body_fun, init_val, transform=identity, progbar=True, **progbar_opts):
79 """
80 This looping construct works like :func:`~jax.lax.fori_loop` but with the additional
81 effect of collecting values from the loop body. In addition, this allows for
82 post-processing of these samples via `transform`, and progress bar updates.
83 Note that, `progbar=False` will be faster, especially when collecting a
84 lot of samples. Refer to example usage in :func:`~numpyro.mcmc.hmc`.
85
86 :param int lower: the index to start the collective work. In other words,
87 we will skip collecting the first `lower` values.
88 :param int upper: number of times to run the loop body.
89 :param body_fun: a callable that takes a collection of
90 `np.ndarray` and returns a collection with the same shape and
91 `dtype`.
92 :param init_val: initial value to pass as argument to `body_fun`. Can
93 be any Python collection type containing `np.ndarray` objects.
94 :param transform: a callable to post-process the values returned by `body_fn`.
95 :param progbar: whether to post progress bar updates.
96 :param `**progbar_opts`: optional additional progress bar arguments. A
97 `diagnostics_fn` can be supplied which when passed the current value
98 from `body_fun` returns a string that is used to update the progress
99 bar postfix. Also a `progbar_desc` keyword argument can be supplied
100 which is used to label the progress bar.
101 :return: collection with the same type as `init_val` with values
102 collected along the leading axis of `np.ndarray` objects.
103 """
104 assert lower < upper
105 init_val_flat, unravel_fn = ravel_pytree(transform(init_val))
106 ravel_fn = lambda x: ravel_pytree(transform(x))[0] # noqa: E731
107
108 if not progbar:
109 collection = np.zeros((upper - lower,) + init_val_flat.shape)
110
111 def _body_fn(i, vals):
112 val, collection = vals
113 val = body_fun(val)
114 i = np.where(i >= lower, i - lower, 0)
115 collection = ops.index_update(collection, i, ravel_fn(val))
116 return val, collection
117
118 _, collection = fori_loop(0, upper, _body_fn, (init_val, collection))
119 else:
120 diagnostics_fn = progbar_opts.pop('diagnostics_fn', None)
121 progbar_desc = progbar_opts.pop('progbar_desc', '')
122 collection = []
123
124 val = init_val
125 with tqdm.trange(upper, desc=progbar_desc) as t:
126 for i in t:
127 val = body_fun(val)
128 if i >= lower:
129 collection.append(jit(ravel_fn)(val))
130 if diagnostics_fn:
131 t.set_postfix_str(diagnostics_fn(val), refresh=False)
132
133 collection = np.stack(collection)
134
135 return vmap(unravel_fn)(collection)
136
137
138 def copy_docs_from(source_class, full_text=False):
139 """
140 Decorator to copy class and method docs from source to destin class.
141 """
142
143 def decorator(destin_class):
144 # This works only in python 3.3+:
145 # if not destin_class.__doc__:
146 # destin_class.__doc__ = source_class.__doc__
147 for name in dir(destin_class):
148 if name.startswith('_'):
149 continue
150 destin_attr = getattr(destin_class, name)
151 destin_attr = getattr(destin_attr, '__func__', destin_attr)
152 source_attr = getattr(source_class, name, None)
153 source_doc = getattr(source_attr, '__doc__', None)
154 if source_doc and not getattr(destin_attr, '__doc__', None):
155 if full_text or source_doc.startswith('See '):
156 destin_doc = source_doc
157 else:
158 destin_doc = 'See :meth:`{}.{}.{}`'.format(
159 source_class.__module__, source_class.__name__, name)
160 if isinstance(destin_attr, property):
161 # Set docs for object properties.
162 # Since __doc__ is read-only, we need to reset the property
163 # with the updated doc.
164 updated_property = property(destin_attr.fget,
165 destin_attr.fset,
166 destin_attr.fdel,
167 destin_doc)
168 setattr(destin_class, name, updated_property)
169 else:
170 destin_attr.__doc__ = destin_doc
171 return destin_class
172
173 return decorator
174
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/numpyro/util.py b/numpyro/util.py
--- a/numpyro/util.py
+++ b/numpyro/util.py
@@ -1,3 +1,4 @@
+from collections import namedtuple
from contextlib import contextmanager
import random
@@ -5,8 +6,8 @@
import tqdm
from jax import jit, lax, ops, vmap
-from jax.flatten_util import ravel_pytree
import jax.numpy as np
+from jax.tree_util import tree_flatten, tree_unflatten, tree_map
_DATA_TYPES = {}
_DISABLE_CONTROL_FLOW_PRIM = False
@@ -171,3 +172,29 @@
return destin_class
return decorator
+
+
+pytree_metadata = namedtuple('pytree_metadata', ['flat', 'shape', 'size', 'dtype'])
+
+
+def _ravel_list(*leaves):
+ leaves_metadata = tree_map(lambda l: pytree_metadata(np.ravel(l), np.shape(l), np.size(l), lax.dtype(l)),
+ leaves)
+ leaves_idx = np.cumsum(np.array((0,) + tuple(d.size for d in leaves_metadata)))
+
+ def unravel_list(arr):
+ return [np.reshape(lax.dynamic_slice_in_dim(arr, leaves_idx[i], m.size),
+ m.shape).astype(m.dtype)
+ for i, m in enumerate(leaves_metadata)]
+
+ return np.concatenate([m.flat for m in leaves_metadata]), unravel_list
+
+
+def ravel_pytree(pytree):
+ leaves, treedef = tree_flatten(pytree)
+ flat, unravel_list = _ravel_list(*leaves)
+
+ def unravel_pytree(arr):
+ return tree_unflatten(treedef, unravel_list(arr))
+
+ return flat, unravel_pytree
|
{"golden_diff": "diff --git a/numpyro/util.py b/numpyro/util.py\n--- a/numpyro/util.py\n+++ b/numpyro/util.py\n@@ -1,3 +1,4 @@\n+from collections import namedtuple\n from contextlib import contextmanager\n import random\n \n@@ -5,8 +6,8 @@\n import tqdm\n \n from jax import jit, lax, ops, vmap\n-from jax.flatten_util import ravel_pytree\n import jax.numpy as np\n+from jax.tree_util import tree_flatten, tree_unflatten, tree_map\n \n _DATA_TYPES = {}\n _DISABLE_CONTROL_FLOW_PRIM = False\n@@ -171,3 +172,29 @@\n return destin_class\n \n return decorator\n+\n+\n+pytree_metadata = namedtuple('pytree_metadata', ['flat', 'shape', 'size', 'dtype'])\n+\n+\n+def _ravel_list(*leaves):\n+ leaves_metadata = tree_map(lambda l: pytree_metadata(np.ravel(l), np.shape(l), np.size(l), lax.dtype(l)),\n+ leaves)\n+ leaves_idx = np.cumsum(np.array((0,) + tuple(d.size for d in leaves_metadata)))\n+\n+ def unravel_list(arr):\n+ return [np.reshape(lax.dynamic_slice_in_dim(arr, leaves_idx[i], m.size),\n+ m.shape).astype(m.dtype)\n+ for i, m in enumerate(leaves_metadata)]\n+\n+ return np.concatenate([m.flat for m in leaves_metadata]), unravel_list\n+\n+\n+def ravel_pytree(pytree):\n+ leaves, treedef = tree_flatten(pytree)\n+ flat, unravel_list = _ravel_list(*leaves)\n+\n+ def unravel_pytree(arr):\n+ return tree_unflatten(treedef, unravel_list(arr))\n+\n+ return flat, unravel_pytree\n", "issue": "fori_collect does not work with non-float arrays\nThe issue is ravel_pytree which calls `vjp` and does not work with int32 or bool arrays. As such, `fori_collect` will fail if the default identity transform is used.\n", "before_files": [{"content": "from contextlib import contextmanager\nimport random\n\nimport numpy as onp\nimport tqdm\n\nfrom jax import jit, lax, ops, vmap\nfrom jax.flatten_util import ravel_pytree\nimport jax.numpy as np\n\n_DATA_TYPES = {}\n_DISABLE_CONTROL_FLOW_PRIM = False\n\n\ndef set_rng_seed(rng_seed):\n random.seed(rng_seed)\n onp.random.seed(rng_seed)\n\n\n@contextmanager\ndef optional(condition, context_manager):\n \"\"\"\n Optionally wrap inside `context_manager` if condition is `True`.\n \"\"\"\n if condition:\n with context_manager:\n yield\n else:\n yield\n\n\n@contextmanager\ndef control_flow_prims_disabled():\n global _DISABLE_CONTROL_FLOW_PRIM\n stored_flag = _DISABLE_CONTROL_FLOW_PRIM\n try:\n _DISABLE_CONTROL_FLOW_PRIM = True\n yield\n finally:\n _DISABLE_CONTROL_FLOW_PRIM = stored_flag\n\n\ndef cond(pred, true_operand, true_fun, false_operand, false_fun):\n if _DISABLE_CONTROL_FLOW_PRIM:\n if pred:\n return true_fun(true_operand)\n else:\n return false_fun(false_operand)\n else:\n return lax.cond(pred, true_operand, true_fun, false_operand, false_fun)\n\n\ndef while_loop(cond_fun, body_fun, init_val):\n if _DISABLE_CONTROL_FLOW_PRIM:\n val = init_val\n while cond_fun(val):\n val = body_fun(val)\n return val\n else:\n # TODO: consider jitting while_loop similar to fori_loop\n return lax.while_loop(cond_fun, body_fun, init_val)\n\n\ndef fori_loop(lower, upper, body_fun, init_val):\n if _DISABLE_CONTROL_FLOW_PRIM:\n val = init_val\n for i in range(int(lower), int(upper)):\n val = body_fun(i, val)\n return val\n else:\n return jit(lax.fori_loop, static_argnums=(2,))(lower, upper, body_fun, init_val)\n\n\ndef identity(x):\n return x\n\n\ndef fori_collect(lower, upper, body_fun, init_val, transform=identity, progbar=True, **progbar_opts):\n \"\"\"\n This looping construct works like :func:`~jax.lax.fori_loop` but with the additional\n effect of collecting values from the loop body. In addition, this allows for\n post-processing of these samples via `transform`, and progress bar updates.\n Note that, `progbar=False` will be faster, especially when collecting a\n lot of samples. Refer to example usage in :func:`~numpyro.mcmc.hmc`.\n\n :param int lower: the index to start the collective work. In other words,\n we will skip collecting the first `lower` values.\n :param int upper: number of times to run the loop body.\n :param body_fun: a callable that takes a collection of\n `np.ndarray` and returns a collection with the same shape and\n `dtype`.\n :param init_val: initial value to pass as argument to `body_fun`. Can\n be any Python collection type containing `np.ndarray` objects.\n :param transform: a callable to post-process the values returned by `body_fn`.\n :param progbar: whether to post progress bar updates.\n :param `**progbar_opts`: optional additional progress bar arguments. A\n `diagnostics_fn` can be supplied which when passed the current value\n from `body_fun` returns a string that is used to update the progress\n bar postfix. Also a `progbar_desc` keyword argument can be supplied\n which is used to label the progress bar.\n :return: collection with the same type as `init_val` with values\n collected along the leading axis of `np.ndarray` objects.\n \"\"\"\n assert lower < upper\n init_val_flat, unravel_fn = ravel_pytree(transform(init_val))\n ravel_fn = lambda x: ravel_pytree(transform(x))[0] # noqa: E731\n\n if not progbar:\n collection = np.zeros((upper - lower,) + init_val_flat.shape)\n\n def _body_fn(i, vals):\n val, collection = vals\n val = body_fun(val)\n i = np.where(i >= lower, i - lower, 0)\n collection = ops.index_update(collection, i, ravel_fn(val))\n return val, collection\n\n _, collection = fori_loop(0, upper, _body_fn, (init_val, collection))\n else:\n diagnostics_fn = progbar_opts.pop('diagnostics_fn', None)\n progbar_desc = progbar_opts.pop('progbar_desc', '')\n collection = []\n\n val = init_val\n with tqdm.trange(upper, desc=progbar_desc) as t:\n for i in t:\n val = body_fun(val)\n if i >= lower:\n collection.append(jit(ravel_fn)(val))\n if diagnostics_fn:\n t.set_postfix_str(diagnostics_fn(val), refresh=False)\n\n collection = np.stack(collection)\n\n return vmap(unravel_fn)(collection)\n\n\ndef copy_docs_from(source_class, full_text=False):\n \"\"\"\n Decorator to copy class and method docs from source to destin class.\n \"\"\"\n\n def decorator(destin_class):\n # This works only in python 3.3+:\n # if not destin_class.__doc__:\n # destin_class.__doc__ = source_class.__doc__\n for name in dir(destin_class):\n if name.startswith('_'):\n continue\n destin_attr = getattr(destin_class, name)\n destin_attr = getattr(destin_attr, '__func__', destin_attr)\n source_attr = getattr(source_class, name, None)\n source_doc = getattr(source_attr, '__doc__', None)\n if source_doc and not getattr(destin_attr, '__doc__', None):\n if full_text or source_doc.startswith('See '):\n destin_doc = source_doc\n else:\n destin_doc = 'See :meth:`{}.{}.{}`'.format(\n source_class.__module__, source_class.__name__, name)\n if isinstance(destin_attr, property):\n # Set docs for object properties.\n # Since __doc__ is read-only, we need to reset the property\n # with the updated doc.\n updated_property = property(destin_attr.fget,\n destin_attr.fset,\n destin_attr.fdel,\n destin_doc)\n setattr(destin_class, name, updated_property)\n else:\n destin_attr.__doc__ = destin_doc\n return destin_class\n\n return decorator\n", "path": "numpyro/util.py"}], "after_files": [{"content": "from collections import namedtuple\nfrom contextlib import contextmanager\nimport random\n\nimport numpy as onp\nimport tqdm\n\nfrom jax import jit, lax, ops, vmap\nimport jax.numpy as np\nfrom jax.tree_util import tree_flatten, tree_unflatten, tree_map\n\n_DATA_TYPES = {}\n_DISABLE_CONTROL_FLOW_PRIM = False\n\n\ndef set_rng_seed(rng_seed):\n random.seed(rng_seed)\n onp.random.seed(rng_seed)\n\n\n@contextmanager\ndef optional(condition, context_manager):\n \"\"\"\n Optionally wrap inside `context_manager` if condition is `True`.\n \"\"\"\n if condition:\n with context_manager:\n yield\n else:\n yield\n\n\n@contextmanager\ndef control_flow_prims_disabled():\n global _DISABLE_CONTROL_FLOW_PRIM\n stored_flag = _DISABLE_CONTROL_FLOW_PRIM\n try:\n _DISABLE_CONTROL_FLOW_PRIM = True\n yield\n finally:\n _DISABLE_CONTROL_FLOW_PRIM = stored_flag\n\n\ndef cond(pred, true_operand, true_fun, false_operand, false_fun):\n if _DISABLE_CONTROL_FLOW_PRIM:\n if pred:\n return true_fun(true_operand)\n else:\n return false_fun(false_operand)\n else:\n return lax.cond(pred, true_operand, true_fun, false_operand, false_fun)\n\n\ndef while_loop(cond_fun, body_fun, init_val):\n if _DISABLE_CONTROL_FLOW_PRIM:\n val = init_val\n while cond_fun(val):\n val = body_fun(val)\n return val\n else:\n # TODO: consider jitting while_loop similar to fori_loop\n return lax.while_loop(cond_fun, body_fun, init_val)\n\n\ndef fori_loop(lower, upper, body_fun, init_val):\n if _DISABLE_CONTROL_FLOW_PRIM:\n val = init_val\n for i in range(int(lower), int(upper)):\n val = body_fun(i, val)\n return val\n else:\n return jit(lax.fori_loop, static_argnums=(2,))(lower, upper, body_fun, init_val)\n\n\ndef identity(x):\n return x\n\n\ndef fori_collect(lower, upper, body_fun, init_val, transform=identity, progbar=True, **progbar_opts):\n \"\"\"\n This looping construct works like :func:`~jax.lax.fori_loop` but with the additional\n effect of collecting values from the loop body. In addition, this allows for\n post-processing of these samples via `transform`, and progress bar updates.\n Note that, `progbar=False` will be faster, especially when collecting a\n lot of samples. Refer to example usage in :func:`~numpyro.mcmc.hmc`.\n\n :param int lower: the index to start the collective work. In other words,\n we will skip collecting the first `lower` values.\n :param int upper: number of times to run the loop body.\n :param body_fun: a callable that takes a collection of\n `np.ndarray` and returns a collection with the same shape and\n `dtype`.\n :param init_val: initial value to pass as argument to `body_fun`. Can\n be any Python collection type containing `np.ndarray` objects.\n :param transform: a callable to post-process the values returned by `body_fn`.\n :param progbar: whether to post progress bar updates.\n :param `**progbar_opts`: optional additional progress bar arguments. A\n `diagnostics_fn` can be supplied which when passed the current value\n from `body_fun` returns a string that is used to update the progress\n bar postfix. Also a `progbar_desc` keyword argument can be supplied\n which is used to label the progress bar.\n :return: collection with the same type as `init_val` with values\n collected along the leading axis of `np.ndarray` objects.\n \"\"\"\n assert lower < upper\n init_val_flat, unravel_fn = ravel_pytree(transform(init_val))\n ravel_fn = lambda x: ravel_pytree(transform(x))[0] # noqa: E731\n\n if not progbar:\n collection = np.zeros((upper - lower,) + init_val_flat.shape)\n\n def _body_fn(i, vals):\n val, collection = vals\n val = body_fun(val)\n i = np.where(i >= lower, i - lower, 0)\n collection = ops.index_update(collection, i, ravel_fn(val))\n return val, collection\n\n _, collection = fori_loop(0, upper, _body_fn, (init_val, collection))\n else:\n diagnostics_fn = progbar_opts.pop('diagnostics_fn', None)\n progbar_desc = progbar_opts.pop('progbar_desc', '')\n collection = []\n\n val = init_val\n with tqdm.trange(upper, desc=progbar_desc) as t:\n for i in t:\n val = body_fun(val)\n if i >= lower:\n collection.append(jit(ravel_fn)(val))\n if diagnostics_fn:\n t.set_postfix_str(diagnostics_fn(val), refresh=False)\n\n collection = np.stack(collection)\n\n return vmap(unravel_fn)(collection)\n\n\ndef copy_docs_from(source_class, full_text=False):\n \"\"\"\n Decorator to copy class and method docs from source to destin class.\n \"\"\"\n\n def decorator(destin_class):\n # This works only in python 3.3+:\n # if not destin_class.__doc__:\n # destin_class.__doc__ = source_class.__doc__\n for name in dir(destin_class):\n if name.startswith('_'):\n continue\n destin_attr = getattr(destin_class, name)\n destin_attr = getattr(destin_attr, '__func__', destin_attr)\n source_attr = getattr(source_class, name, None)\n source_doc = getattr(source_attr, '__doc__', None)\n if source_doc and not getattr(destin_attr, '__doc__', None):\n if full_text or source_doc.startswith('See '):\n destin_doc = source_doc\n else:\n destin_doc = 'See :meth:`{}.{}.{}`'.format(\n source_class.__module__, source_class.__name__, name)\n if isinstance(destin_attr, property):\n # Set docs for object properties.\n # Since __doc__ is read-only, we need to reset the property\n # with the updated doc.\n updated_property = property(destin_attr.fget,\n destin_attr.fset,\n destin_attr.fdel,\n destin_doc)\n setattr(destin_class, name, updated_property)\n else:\n destin_attr.__doc__ = destin_doc\n return destin_class\n\n return decorator\n\n\npytree_metadata = namedtuple('pytree_metadata', ['flat', 'shape', 'size', 'dtype'])\n\n\ndef _ravel_list(*leaves):\n leaves_metadata = tree_map(lambda l: pytree_metadata(np.ravel(l), np.shape(l), np.size(l), lax.dtype(l)),\n leaves)\n leaves_idx = np.cumsum(np.array((0,) + tuple(d.size for d in leaves_metadata)))\n\n def unravel_list(arr):\n return [np.reshape(lax.dynamic_slice_in_dim(arr, leaves_idx[i], m.size),\n m.shape).astype(m.dtype)\n for i, m in enumerate(leaves_metadata)]\n\n return np.concatenate([m.flat for m in leaves_metadata]), unravel_list\n\n\ndef ravel_pytree(pytree):\n leaves, treedef = tree_flatten(pytree)\n flat, unravel_list = _ravel_list(*leaves)\n\n def unravel_pytree(arr):\n return tree_unflatten(treedef, unravel_list(arr))\n\n return flat, unravel_pytree\n", "path": "numpyro/util.py"}]}
| 2,145 | 391 |
gh_patches_debug_2061
|
rasdani/github-patches
|
git_diff
|
plotly__dash-565
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
New version of dash_renderer is not automatically installed with Dash 0.36.0
Deploying apps on Dash Deployment Server results in `dash-renderer` not being updated if it is already installed (even if that version is `0.16.x` and the Dash version is specified as `0.36.0`. This causes an `Error loading dependencies`, as `dash-renderer` attempts to attach event handlers to Dash events, which don't exist any more.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 import io
2 from setuptools import setup, find_packages
3
4 main_ns = {}
5 exec(open('dash/version.py').read(), main_ns) # pylint: disable=exec-used
6
7 setup(
8 name='dash',
9 version=main_ns['__version__'],
10 author='chris p',
11 author_email='[email protected]',
12 packages=find_packages(exclude=['tests*']),
13 include_package_data=True,
14 license='MIT',
15 description=('A Python framework for building reactive web-apps. '
16 'Developed by Plotly.'),
17 long_description=io.open('README.md', encoding='utf-8').read(),
18 long_description_content_type='text/markdown',
19 install_requires=[
20 'Flask>=0.12',
21 'flask-compress',
22 'plotly',
23 'dash_renderer',
24 ],
25 entry_points={
26 'console_scripts': [
27 'dash-generate-components ='
28 ' dash.development.component_generator:cli'
29 ]
30 },
31 url='https://plot.ly/dash',
32 classifiers=[
33 'Development Status :: 5 - Production/Stable',
34 'Environment :: Web Environment',
35 'Framework :: Flask',
36 'Intended Audience :: Developers',
37 'Intended Audience :: Education',
38 'Intended Audience :: Financial and Insurance Industry',
39 'Intended Audience :: Healthcare Industry',
40 'Intended Audience :: Manufacturing',
41 'Intended Audience :: Science/Research',
42 'License :: OSI Approved :: MIT License',
43 'Programming Language :: Python',
44 'Programming Language :: Python :: 2',
45 'Programming Language :: Python :: 2.7',
46 'Programming Language :: Python :: 3',
47 'Programming Language :: Python :: 3.3',
48 'Programming Language :: Python :: 3.4',
49 'Programming Language :: Python :: 3.5',
50 'Programming Language :: Python :: 3.6',
51 'Programming Language :: Python :: 3.7',
52 'Topic :: Database :: Front-Ends',
53 'Topic :: Office/Business :: Financial :: Spreadsheet',
54 'Topic :: Scientific/Engineering :: Visualization',
55 'Topic :: Software Development :: Libraries :: Application Frameworks',
56 'Topic :: Software Development :: Widget Sets'
57 ]
58 )
59
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -20,7 +20,10 @@
'Flask>=0.12',
'flask-compress',
'plotly',
- 'dash_renderer',
+ 'dash_renderer==0.17.0',
+ 'dash-core-components==0.43.0',
+ 'dash-html-components==0.13.5',
+ 'dash-table==3.3.0'
],
entry_points={
'console_scripts': [
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -20,7 +20,10 @@\n 'Flask>=0.12',\n 'flask-compress',\n 'plotly',\n- 'dash_renderer',\n+ 'dash_renderer==0.17.0',\n+ 'dash-core-components==0.43.0',\n+ 'dash-html-components==0.13.5',\n+ 'dash-table==3.3.0'\n ],\n entry_points={\n 'console_scripts': [\n", "issue": "New version of dash_renderer is not automatically installed with Dash 0.36.0\nDeploying apps on Dash Deployment Server results in `dash-renderer` not being updated if it is already installed (even if that version is `0.16.x` and the Dash version is specified as `0.36.0`. This causes an `Error loading dependencies`, as `dash-renderer` attempts to attach event handlers to Dash events, which don't exist any more. \n", "before_files": [{"content": "import io\nfrom setuptools import setup, find_packages\n\nmain_ns = {}\nexec(open('dash/version.py').read(), main_ns) # pylint: disable=exec-used\n\nsetup(\n name='dash',\n version=main_ns['__version__'],\n author='chris p',\n author_email='[email protected]',\n packages=find_packages(exclude=['tests*']),\n include_package_data=True,\n license='MIT',\n description=('A Python framework for building reactive web-apps. '\n 'Developed by Plotly.'),\n long_description=io.open('README.md', encoding='utf-8').read(),\n long_description_content_type='text/markdown',\n install_requires=[\n 'Flask>=0.12',\n 'flask-compress',\n 'plotly',\n 'dash_renderer',\n ],\n entry_points={\n 'console_scripts': [\n 'dash-generate-components ='\n ' dash.development.component_generator:cli'\n ]\n },\n url='https://plot.ly/dash',\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Web Environment',\n 'Framework :: Flask',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Education',\n 'Intended Audience :: Financial and Insurance Industry',\n 'Intended Audience :: Healthcare Industry',\n 'Intended Audience :: Manufacturing',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: MIT License',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Topic :: Database :: Front-Ends',\n 'Topic :: Office/Business :: Financial :: Spreadsheet',\n 'Topic :: Scientific/Engineering :: Visualization',\n 'Topic :: Software Development :: Libraries :: Application Frameworks',\n 'Topic :: Software Development :: Widget Sets'\n ]\n)\n", "path": "setup.py"}], "after_files": [{"content": "import io\nfrom setuptools import setup, find_packages\n\nmain_ns = {}\nexec(open('dash/version.py').read(), main_ns) # pylint: disable=exec-used\n\nsetup(\n name='dash',\n version=main_ns['__version__'],\n author='chris p',\n author_email='[email protected]',\n packages=find_packages(exclude=['tests*']),\n include_package_data=True,\n license='MIT',\n description=('A Python framework for building reactive web-apps. '\n 'Developed by Plotly.'),\n long_description=io.open('README.md', encoding='utf-8').read(),\n long_description_content_type='text/markdown',\n install_requires=[\n 'Flask>=0.12',\n 'flask-compress',\n 'plotly',\n 'dash_renderer==0.17.0',\n 'dash-core-components==0.43.0',\n 'dash-html-components==0.13.5',\n 'dash-table==3.3.0'\n ],\n entry_points={\n 'console_scripts': [\n 'dash-generate-components ='\n ' dash.development.component_generator:cli'\n ]\n },\n url='https://plot.ly/dash',\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Web Environment',\n 'Framework :: Flask',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Education',\n 'Intended Audience :: Financial and Insurance Industry',\n 'Intended Audience :: Healthcare Industry',\n 'Intended Audience :: Manufacturing',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: MIT License',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Topic :: Database :: Front-Ends',\n 'Topic :: Office/Business :: Financial :: Spreadsheet',\n 'Topic :: Scientific/Engineering :: Visualization',\n 'Topic :: Software Development :: Libraries :: Application Frameworks',\n 'Topic :: Software Development :: Widget Sets'\n ]\n)\n", "path": "setup.py"}]}
| 932 | 126 |
gh_patches_debug_42935
|
rasdani/github-patches
|
git_diff
|
certbot__certbot-7054
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Certbot can't verify OCSP responses signed by an explicitly designated responder
If you're having trouble using Certbot and aren't sure you've found a bug or
request for a new feature, please first try asking for help at
https://community.letsencrypt.org/. There is a much larger community there of
people familiar with the project who will be able to more quickly answer your
questions.
## My operating system is (include version):
Debian stretch/sid
## I installed Certbot with (certbot-auto, OS package manager, pip, etc):
certbot-auto
## I ran this command and it produced this output:
./certbot-auto certificates --cert-name buypasstest1
Saving debug log to /var/log/letsencrypt/letsencrypt.log
Invalid signature on OCSP response for /etc/letsencrypt/live/buypasstest1/cert.pem
## Certbot's behavior differed from what I expected because:
The OCSP response is correctly signed, not by the issuer itself but by a properly designated responder.
## Here is a Certbot log showing the issue (if available):
###### Logs are stored in `/var/log/letsencrypt` by default. Feel free to redact domains, e-mail and IP addresses as you see fit.
2019-05-12 13:32:13,645:DEBUG:certbot.main:certbot version: 0.34.2
2019-05-12 13:32:13,647:DEBUG:certbot.main:Arguments: ['--cert-name', 'buypasstest1']
2019-05-12 13:32:13,647:DEBUG:certbot.main:Discovered plugins: PluginsRegistry(PluginEntryPoint#apache,PluginEntryPoint#manual,PluginEntryPoint#nginx,PluginEntryPoint#null,PluginEntryPoint#standalone,PluginEntryPoint#webroot)
2019-05-12 13:32:13,719:DEBUG:certbot.log:Root logging level set at 20
2019-05-12 13:32:13,721:INFO:certbot.log:Saving debug log to /var/log/letsencrypt/letsencrypt.log
2019-05-12 13:32:13,770:DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): ocsp.buypass.com:80
2019-05-12 13:32:13,994:DEBUG:urllib3.connectionpool:http://ocsp.buypass.com:80 "POST / HTTP/1.1" 200 1702
2019-05-12 13:32:13,998:ERROR:certbot.ocsp:Invalid signature on OCSP response for /etc/letsencrypt/live/buypasstest1/cert.pem
## Here is the relevant nginx server block or Apache virtualhost for the domain I am configuring:
<doesn't matter.>
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `certbot/ocsp.py`
Content:
```
1 """Tools for checking certificate revocation."""
2 import logging
3 import re
4 from datetime import datetime, timedelta
5 from subprocess import Popen, PIPE
6
7 try:
8 # Only cryptography>=2.5 has ocsp module
9 # and signature_hash_algorithm attribute in OCSPResponse class
10 from cryptography.x509 import ocsp # pylint: disable=import-error
11 getattr(ocsp.OCSPResponse, 'signature_hash_algorithm')
12 except (ImportError, AttributeError): # pragma: no cover
13 ocsp = None # type: ignore
14 from cryptography import x509
15 from cryptography.hazmat.backends import default_backend
16 from cryptography.hazmat.primitives import serialization
17 from cryptography.hazmat.primitives import hashes # type: ignore
18 from cryptography.exceptions import UnsupportedAlgorithm, InvalidSignature
19 import requests
20
21 from acme.magic_typing import Optional, Tuple # pylint: disable=unused-import, no-name-in-module
22 from certbot import crypto_util
23 from certbot import errors
24 from certbot import util
25
26 logger = logging.getLogger(__name__)
27
28
29 class RevocationChecker(object):
30 """This class figures out OCSP checking on this system, and performs it."""
31
32 def __init__(self, enforce_openssl_binary_usage=False):
33 self.broken = False
34 self.use_openssl_binary = enforce_openssl_binary_usage or not ocsp
35
36 if self.use_openssl_binary:
37 if not util.exe_exists("openssl"):
38 logger.info("openssl not installed, can't check revocation")
39 self.broken = True
40 return
41
42 # New versions of openssl want -header var=val, old ones want -header var val
43 test_host_format = Popen(["openssl", "ocsp", "-header", "var", "val"],
44 stdout=PIPE, stderr=PIPE, universal_newlines=True)
45 _out, err = test_host_format.communicate()
46 if "Missing =" in err:
47 self.host_args = lambda host: ["Host=" + host]
48 else:
49 self.host_args = lambda host: ["Host", host]
50
51 def ocsp_revoked(self, cert_path, chain_path):
52 # type: (str, str) -> bool
53 """Get revoked status for a particular cert version.
54
55 .. todo:: Make this a non-blocking call
56
57 :param str cert_path: Path to certificate
58 :param str chain_path: Path to intermediate cert
59 :returns: True if revoked; False if valid or the check failed
60 :rtype: bool
61
62 """
63 if self.broken:
64 return False
65
66 url, host = _determine_ocsp_server(cert_path)
67 if not host or not url:
68 return False
69
70 if self.use_openssl_binary:
71 return self._check_ocsp_openssl_bin(cert_path, chain_path, host, url)
72 return _check_ocsp_cryptography(cert_path, chain_path, url)
73
74 def _check_ocsp_openssl_bin(self, cert_path, chain_path, host, url):
75 # type: (str, str, str, str) -> bool
76 # jdkasten thanks "Bulletproof SSL and TLS - Ivan Ristic" for documenting this!
77 cmd = ["openssl", "ocsp",
78 "-no_nonce",
79 "-issuer", chain_path,
80 "-cert", cert_path,
81 "-url", url,
82 "-CAfile", chain_path,
83 "-verify_other", chain_path,
84 "-trust_other",
85 "-header"] + self.host_args(host)
86 logger.debug("Querying OCSP for %s", cert_path)
87 logger.debug(" ".join(cmd))
88 try:
89 output, err = util.run_script(cmd, log=logger.debug)
90 except errors.SubprocessError:
91 logger.info("OCSP check failed for %s (are we offline?)", cert_path)
92 return False
93 return _translate_ocsp_query(cert_path, output, err)
94
95
96 def _determine_ocsp_server(cert_path):
97 # type: (str) -> Tuple[Optional[str], Optional[str]]
98 """Extract the OCSP server host from a certificate.
99
100 :param str cert_path: Path to the cert we're checking OCSP for
101 :rtype tuple:
102 :returns: (OCSP server URL or None, OCSP server host or None)
103
104 """
105 with open(cert_path, 'rb') as file_handler:
106 cert = x509.load_pem_x509_certificate(file_handler.read(), default_backend())
107 try:
108 extension = cert.extensions.get_extension_for_class(x509.AuthorityInformationAccess)
109 ocsp_oid = x509.AuthorityInformationAccessOID.OCSP
110 descriptions = [description for description in extension.value
111 if description.access_method == ocsp_oid]
112
113 url = descriptions[0].access_location.value
114 except (x509.ExtensionNotFound, IndexError):
115 logger.info("Cannot extract OCSP URI from %s", cert_path)
116 return None, None
117
118 url = url.rstrip()
119 host = url.partition("://")[2].rstrip("/")
120
121 if host:
122 return url, host
123 logger.info("Cannot process OCSP host from URL (%s) in cert at %s", url, cert_path)
124 return None, None
125
126
127 def _check_ocsp_cryptography(cert_path, chain_path, url):
128 # type: (str, str, str) -> bool
129 # Retrieve OCSP response
130 with open(chain_path, 'rb') as file_handler:
131 issuer = x509.load_pem_x509_certificate(file_handler.read(), default_backend())
132 with open(cert_path, 'rb') as file_handler:
133 cert = x509.load_pem_x509_certificate(file_handler.read(), default_backend())
134 builder = ocsp.OCSPRequestBuilder()
135 builder = builder.add_certificate(cert, issuer, hashes.SHA1())
136 request = builder.build()
137 request_binary = request.public_bytes(serialization.Encoding.DER)
138 try:
139 response = requests.post(url, data=request_binary,
140 headers={'Content-Type': 'application/ocsp-request'})
141 except requests.exceptions.RequestException:
142 logger.info("OCSP check failed for %s (are we offline?)", cert_path, exc_info=True)
143 return False
144 if response.status_code != 200:
145 logger.info("OCSP check failed for %s (HTTP status: %d)", cert_path, response.status_code)
146 return False
147
148 response_ocsp = ocsp.load_der_ocsp_response(response.content)
149
150 # Check OCSP response validity
151 if response_ocsp.response_status != ocsp.OCSPResponseStatus.SUCCESSFUL:
152 logger.error("Invalid OCSP response status for %s: %s",
153 cert_path, response_ocsp.response_status)
154 return False
155
156 # Check OCSP signature
157 try:
158 _check_ocsp_response(response_ocsp, request, issuer)
159 except UnsupportedAlgorithm as e:
160 logger.error(str(e))
161 except errors.Error as e:
162 logger.error(str(e))
163 except InvalidSignature:
164 logger.error('Invalid signature on OCSP response for %s', cert_path)
165 except AssertionError as error:
166 logger.error('Invalid OCSP response for %s: %s.', cert_path, str(error))
167 else:
168 # Check OCSP certificate status
169 logger.debug("OCSP certificate status for %s is: %s",
170 cert_path, response_ocsp.certificate_status)
171 return response_ocsp.certificate_status == ocsp.OCSPCertStatus.REVOKED
172
173 return False
174
175
176 def _check_ocsp_response(response_ocsp, request_ocsp, issuer_cert):
177 """Verify that the OCSP is valid for serveral criterias"""
178 # Assert OCSP response corresponds to the certificate we are talking about
179 if response_ocsp.serial_number != request_ocsp.serial_number:
180 raise AssertionError('the certificate in response does not correspond '
181 'to the certificate in request')
182
183 # Assert signature is valid
184 _check_ocsp_response_signature(response_ocsp, issuer_cert)
185
186 # Assert issuer in response is the expected one
187 if (not isinstance(response_ocsp.hash_algorithm, type(request_ocsp.hash_algorithm))
188 or response_ocsp.issuer_key_hash != request_ocsp.issuer_key_hash
189 or response_ocsp.issuer_name_hash != request_ocsp.issuer_name_hash):
190 raise AssertionError('the issuer does not correspond to issuer of the certificate.')
191
192 # In following checks, two situations can occur:
193 # * nextUpdate is set, and requirement is thisUpdate < now < nextUpdate
194 # * nextUpdate is not set, and requirement is thisUpdate < now
195 # NB1: We add a validity period tolerance to handle clock time inconsistencies,
196 # value is 5 min like for OpenSSL.
197 # NB2: Another check is to verify that thisUpdate is not too old, it is optional
198 # for OpenSSL, so we do not do it here.
199 # See OpenSSL implementation as a reference:
200 # https://github.com/openssl/openssl/blob/ef45aa14c5af024fcb8bef1c9007f3d1c115bd85/crypto/ocsp/ocsp_cl.c#L338-L391
201 now = datetime.utcnow() # thisUpdate/nextUpdate are expressed in UTC/GMT time zone
202 if not response_ocsp.this_update:
203 raise AssertionError('param thisUpdate is not set.')
204 if response_ocsp.this_update > now + timedelta(minutes=5):
205 raise AssertionError('param thisUpdate is in the future.')
206 if response_ocsp.next_update and response_ocsp.next_update < now - timedelta(minutes=5):
207 raise AssertionError('param nextUpdate is in the past.')
208
209
210 def _check_ocsp_response_signature(response_ocsp, issuer_cert):
211 """Verify an OCSP response signature against certificate issuer"""
212 # Following line may raise UnsupportedAlgorithm
213 chosen_hash = response_ocsp.signature_hash_algorithm
214 crypto_util.verify_signed_payload(issuer_cert.public_key(), response_ocsp.signature,
215 response_ocsp.tbs_response_bytes, chosen_hash)
216
217
218 def _translate_ocsp_query(cert_path, ocsp_output, ocsp_errors):
219 """Parse openssl's weird output to work out what it means."""
220
221 states = ("good", "revoked", "unknown")
222 patterns = [r"{0}: (WARNING.*)?{1}".format(cert_path, s) for s in states]
223 good, revoked, unknown = (re.search(p, ocsp_output, flags=re.DOTALL) for p in patterns)
224
225 warning = good.group(1) if good else None
226
227 if ("Response verify OK" not in ocsp_errors) or (good and warning) or unknown:
228 logger.info("Revocation status for %s is unknown", cert_path)
229 logger.debug("Uncertain output:\n%s\nstderr:\n%s", ocsp_output, ocsp_errors)
230 return False
231 elif good and not warning:
232 return False
233 elif revoked:
234 warning = revoked.group(1)
235 if warning:
236 logger.info("OCSP revocation warning: %s", warning)
237 return True
238 else:
239 logger.warning("Unable to properly parse OCSP output: %s\nstderr:%s",
240 ocsp_output, ocsp_errors)
241 return False
242
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/certbot/ocsp.py b/certbot/ocsp.py
--- a/certbot/ocsp.py
+++ b/certbot/ocsp.py
@@ -155,7 +155,7 @@
# Check OCSP signature
try:
- _check_ocsp_response(response_ocsp, request, issuer)
+ _check_ocsp_response(response_ocsp, request, issuer, cert_path)
except UnsupportedAlgorithm as e:
logger.error(str(e))
except errors.Error as e:
@@ -173,7 +173,7 @@
return False
-def _check_ocsp_response(response_ocsp, request_ocsp, issuer_cert):
+def _check_ocsp_response(response_ocsp, request_ocsp, issuer_cert, cert_path):
"""Verify that the OCSP is valid for serveral criterias"""
# Assert OCSP response corresponds to the certificate we are talking about
if response_ocsp.serial_number != request_ocsp.serial_number:
@@ -181,7 +181,7 @@
'to the certificate in request')
# Assert signature is valid
- _check_ocsp_response_signature(response_ocsp, issuer_cert)
+ _check_ocsp_response_signature(response_ocsp, issuer_cert, cert_path)
# Assert issuer in response is the expected one
if (not isinstance(response_ocsp.hash_algorithm, type(request_ocsp.hash_algorithm))
@@ -207,11 +207,52 @@
raise AssertionError('param nextUpdate is in the past.')
-def _check_ocsp_response_signature(response_ocsp, issuer_cert):
- """Verify an OCSP response signature against certificate issuer"""
+def _check_ocsp_response_signature(response_ocsp, issuer_cert, cert_path):
+ """Verify an OCSP response signature against certificate issuer or responder"""
+ if response_ocsp.responder_name == issuer_cert.subject:
+ # Case where the OCSP responder is also the certificate issuer
+ logger.debug('OCSP response for certificate %s is signed by the certificate\'s issuer.',
+ cert_path)
+ responder_cert = issuer_cert
+ else:
+ # Case where the OCSP responder is not the certificate issuer
+ logger.debug('OCSP response for certificate %s is delegated to an external responder.',
+ cert_path)
+
+ responder_certs = [cert for cert in response_ocsp.certificates
+ if cert.subject == response_ocsp.responder_name]
+ if not responder_certs:
+ raise AssertionError('no matching responder certificate could be found')
+
+ # We suppose here that the ACME server support only one certificate in the OCSP status
+ # request. This is currently the case for LetsEncrypt servers.
+ # See https://github.com/letsencrypt/boulder/issues/2331
+ responder_cert = responder_certs[0]
+
+ if responder_cert.issuer != issuer_cert.subject:
+ raise AssertionError('responder certificate is not signed '
+ 'by the certificate\'s issuer')
+
+ try:
+ extension = responder_cert.extensions.get_extension_for_class(x509.ExtendedKeyUsage)
+ delegate_authorized = x509.oid.ExtendedKeyUsageOID.OCSP_SIGNING in extension.value
+ except (x509.ExtensionNotFound, IndexError):
+ delegate_authorized = False
+ if not delegate_authorized:
+ raise AssertionError('responder is not authorized by issuer to sign OCSP responses')
+
+ # Following line may raise UnsupportedAlgorithm
+ chosen_hash = responder_cert.signature_hash_algorithm
+ # For a delegate OCSP responder, we need first check that its certificate is effectively
+ # signed by the certificate issuer.
+ crypto_util.verify_signed_payload(issuer_cert.public_key(), responder_cert.signature,
+ responder_cert.tbs_certificate_bytes, chosen_hash)
+
# Following line may raise UnsupportedAlgorithm
chosen_hash = response_ocsp.signature_hash_algorithm
- crypto_util.verify_signed_payload(issuer_cert.public_key(), response_ocsp.signature,
+ # We check that the OSCP response is effectively signed by the responder
+ # (an authorized delegate one or the certificate issuer itself).
+ crypto_util.verify_signed_payload(responder_cert.public_key(), response_ocsp.signature,
response_ocsp.tbs_response_bytes, chosen_hash)
|
{"golden_diff": "diff --git a/certbot/ocsp.py b/certbot/ocsp.py\n--- a/certbot/ocsp.py\n+++ b/certbot/ocsp.py\n@@ -155,7 +155,7 @@\n \n # Check OCSP signature\n try:\n- _check_ocsp_response(response_ocsp, request, issuer)\n+ _check_ocsp_response(response_ocsp, request, issuer, cert_path)\n except UnsupportedAlgorithm as e:\n logger.error(str(e))\n except errors.Error as e:\n@@ -173,7 +173,7 @@\n return False\n \n \n-def _check_ocsp_response(response_ocsp, request_ocsp, issuer_cert):\n+def _check_ocsp_response(response_ocsp, request_ocsp, issuer_cert, cert_path):\n \"\"\"Verify that the OCSP is valid for serveral criterias\"\"\"\n # Assert OCSP response corresponds to the certificate we are talking about\n if response_ocsp.serial_number != request_ocsp.serial_number:\n@@ -181,7 +181,7 @@\n 'to the certificate in request')\n \n # Assert signature is valid\n- _check_ocsp_response_signature(response_ocsp, issuer_cert)\n+ _check_ocsp_response_signature(response_ocsp, issuer_cert, cert_path)\n \n # Assert issuer in response is the expected one\n if (not isinstance(response_ocsp.hash_algorithm, type(request_ocsp.hash_algorithm))\n@@ -207,11 +207,52 @@\n raise AssertionError('param nextUpdate is in the past.')\n \n \n-def _check_ocsp_response_signature(response_ocsp, issuer_cert):\n- \"\"\"Verify an OCSP response signature against certificate issuer\"\"\"\n+def _check_ocsp_response_signature(response_ocsp, issuer_cert, cert_path):\n+ \"\"\"Verify an OCSP response signature against certificate issuer or responder\"\"\"\n+ if response_ocsp.responder_name == issuer_cert.subject:\n+ # Case where the OCSP responder is also the certificate issuer\n+ logger.debug('OCSP response for certificate %s is signed by the certificate\\'s issuer.',\n+ cert_path)\n+ responder_cert = issuer_cert\n+ else:\n+ # Case where the OCSP responder is not the certificate issuer\n+ logger.debug('OCSP response for certificate %s is delegated to an external responder.',\n+ cert_path)\n+\n+ responder_certs = [cert for cert in response_ocsp.certificates\n+ if cert.subject == response_ocsp.responder_name]\n+ if not responder_certs:\n+ raise AssertionError('no matching responder certificate could be found')\n+\n+ # We suppose here that the ACME server support only one certificate in the OCSP status\n+ # request. This is currently the case for LetsEncrypt servers.\n+ # See https://github.com/letsencrypt/boulder/issues/2331\n+ responder_cert = responder_certs[0]\n+\n+ if responder_cert.issuer != issuer_cert.subject:\n+ raise AssertionError('responder certificate is not signed '\n+ 'by the certificate\\'s issuer')\n+\n+ try:\n+ extension = responder_cert.extensions.get_extension_for_class(x509.ExtendedKeyUsage)\n+ delegate_authorized = x509.oid.ExtendedKeyUsageOID.OCSP_SIGNING in extension.value\n+ except (x509.ExtensionNotFound, IndexError):\n+ delegate_authorized = False\n+ if not delegate_authorized:\n+ raise AssertionError('responder is not authorized by issuer to sign OCSP responses')\n+\n+ # Following line may raise UnsupportedAlgorithm\n+ chosen_hash = responder_cert.signature_hash_algorithm\n+ # For a delegate OCSP responder, we need first check that its certificate is effectively\n+ # signed by the certificate issuer.\n+ crypto_util.verify_signed_payload(issuer_cert.public_key(), responder_cert.signature,\n+ responder_cert.tbs_certificate_bytes, chosen_hash)\n+\n # Following line may raise UnsupportedAlgorithm\n chosen_hash = response_ocsp.signature_hash_algorithm\n- crypto_util.verify_signed_payload(issuer_cert.public_key(), response_ocsp.signature,\n+ # We check that the OSCP response is effectively signed by the responder\n+ # (an authorized delegate one or the certificate issuer itself).\n+ crypto_util.verify_signed_payload(responder_cert.public_key(), response_ocsp.signature,\n response_ocsp.tbs_response_bytes, chosen_hash)\n", "issue": "Certbot can't verify OCSP responses signed by an explicitly designated responder\nIf you're having trouble using Certbot and aren't sure you've found a bug or\r\nrequest for a new feature, please first try asking for help at\r\nhttps://community.letsencrypt.org/. There is a much larger community there of\r\npeople familiar with the project who will be able to more quickly answer your\r\nquestions.\r\n\r\n## My operating system is (include version):\r\n\r\nDebian stretch/sid\r\n\r\n## I installed Certbot with (certbot-auto, OS package manager, pip, etc):\r\n\r\ncertbot-auto\r\n\r\n## I ran this command and it produced this output:\r\n\r\n./certbot-auto certificates --cert-name buypasstest1\r\n\r\nSaving debug log to /var/log/letsencrypt/letsencrypt.log\r\nInvalid signature on OCSP response for /etc/letsencrypt/live/buypasstest1/cert.pem\r\n\r\n## Certbot's behavior differed from what I expected because:\r\n\r\nThe OCSP response is correctly signed, not by the issuer itself but by a properly designated responder.\r\n\r\n## Here is a Certbot log showing the issue (if available):\r\n###### Logs are stored in `/var/log/letsencrypt` by default. Feel free to redact domains, e-mail and IP addresses as you see fit.\r\n\r\n2019-05-12 13:32:13,645:DEBUG:certbot.main:certbot version: 0.34.2\r\n2019-05-12 13:32:13,647:DEBUG:certbot.main:Arguments: ['--cert-name', 'buypasstest1']\r\n2019-05-12 13:32:13,647:DEBUG:certbot.main:Discovered plugins: PluginsRegistry(PluginEntryPoint#apache,PluginEntryPoint#manual,PluginEntryPoint#nginx,PluginEntryPoint#null,PluginEntryPoint#standalone,PluginEntryPoint#webroot)\r\n2019-05-12 13:32:13,719:DEBUG:certbot.log:Root logging level set at 20\r\n2019-05-12 13:32:13,721:INFO:certbot.log:Saving debug log to /var/log/letsencrypt/letsencrypt.log\r\n2019-05-12 13:32:13,770:DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): ocsp.buypass.com:80\r\n2019-05-12 13:32:13,994:DEBUG:urllib3.connectionpool:http://ocsp.buypass.com:80 \"POST / HTTP/1.1\" 200 1702\r\n2019-05-12 13:32:13,998:ERROR:certbot.ocsp:Invalid signature on OCSP response for /etc/letsencrypt/live/buypasstest1/cert.pem\r\n\r\n## Here is the relevant nginx server block or Apache virtualhost for the domain I am configuring:\r\n\r\n<doesn't matter.>\r\n\n", "before_files": [{"content": "\"\"\"Tools for checking certificate revocation.\"\"\"\nimport logging\nimport re\nfrom datetime import datetime, timedelta\nfrom subprocess import Popen, PIPE\n\ntry:\n # Only cryptography>=2.5 has ocsp module\n # and signature_hash_algorithm attribute in OCSPResponse class\n from cryptography.x509 import ocsp # pylint: disable=import-error\n getattr(ocsp.OCSPResponse, 'signature_hash_algorithm')\nexcept (ImportError, AttributeError): # pragma: no cover\n ocsp = None # type: ignore\nfrom cryptography import x509\nfrom cryptography.hazmat.backends import default_backend\nfrom cryptography.hazmat.primitives import serialization\nfrom cryptography.hazmat.primitives import hashes # type: ignore\nfrom cryptography.exceptions import UnsupportedAlgorithm, InvalidSignature\nimport requests\n\nfrom acme.magic_typing import Optional, Tuple # pylint: disable=unused-import, no-name-in-module\nfrom certbot import crypto_util\nfrom certbot import errors\nfrom certbot import util\n\nlogger = logging.getLogger(__name__)\n\n\nclass RevocationChecker(object):\n \"\"\"This class figures out OCSP checking on this system, and performs it.\"\"\"\n\n def __init__(self, enforce_openssl_binary_usage=False):\n self.broken = False\n self.use_openssl_binary = enforce_openssl_binary_usage or not ocsp\n\n if self.use_openssl_binary:\n if not util.exe_exists(\"openssl\"):\n logger.info(\"openssl not installed, can't check revocation\")\n self.broken = True\n return\n\n # New versions of openssl want -header var=val, old ones want -header var val\n test_host_format = Popen([\"openssl\", \"ocsp\", \"-header\", \"var\", \"val\"],\n stdout=PIPE, stderr=PIPE, universal_newlines=True)\n _out, err = test_host_format.communicate()\n if \"Missing =\" in err:\n self.host_args = lambda host: [\"Host=\" + host]\n else:\n self.host_args = lambda host: [\"Host\", host]\n\n def ocsp_revoked(self, cert_path, chain_path):\n # type: (str, str) -> bool\n \"\"\"Get revoked status for a particular cert version.\n\n .. todo:: Make this a non-blocking call\n\n :param str cert_path: Path to certificate\n :param str chain_path: Path to intermediate cert\n :returns: True if revoked; False if valid or the check failed\n :rtype: bool\n\n \"\"\"\n if self.broken:\n return False\n\n url, host = _determine_ocsp_server(cert_path)\n if not host or not url:\n return False\n\n if self.use_openssl_binary:\n return self._check_ocsp_openssl_bin(cert_path, chain_path, host, url)\n return _check_ocsp_cryptography(cert_path, chain_path, url)\n\n def _check_ocsp_openssl_bin(self, cert_path, chain_path, host, url):\n # type: (str, str, str, str) -> bool\n # jdkasten thanks \"Bulletproof SSL and TLS - Ivan Ristic\" for documenting this!\n cmd = [\"openssl\", \"ocsp\",\n \"-no_nonce\",\n \"-issuer\", chain_path,\n \"-cert\", cert_path,\n \"-url\", url,\n \"-CAfile\", chain_path,\n \"-verify_other\", chain_path,\n \"-trust_other\",\n \"-header\"] + self.host_args(host)\n logger.debug(\"Querying OCSP for %s\", cert_path)\n logger.debug(\" \".join(cmd))\n try:\n output, err = util.run_script(cmd, log=logger.debug)\n except errors.SubprocessError:\n logger.info(\"OCSP check failed for %s (are we offline?)\", cert_path)\n return False\n return _translate_ocsp_query(cert_path, output, err)\n\n\ndef _determine_ocsp_server(cert_path):\n # type: (str) -> Tuple[Optional[str], Optional[str]]\n \"\"\"Extract the OCSP server host from a certificate.\n\n :param str cert_path: Path to the cert we're checking OCSP for\n :rtype tuple:\n :returns: (OCSP server URL or None, OCSP server host or None)\n\n \"\"\"\n with open(cert_path, 'rb') as file_handler:\n cert = x509.load_pem_x509_certificate(file_handler.read(), default_backend())\n try:\n extension = cert.extensions.get_extension_for_class(x509.AuthorityInformationAccess)\n ocsp_oid = x509.AuthorityInformationAccessOID.OCSP\n descriptions = [description for description in extension.value\n if description.access_method == ocsp_oid]\n\n url = descriptions[0].access_location.value\n except (x509.ExtensionNotFound, IndexError):\n logger.info(\"Cannot extract OCSP URI from %s\", cert_path)\n return None, None\n\n url = url.rstrip()\n host = url.partition(\"://\")[2].rstrip(\"/\")\n\n if host:\n return url, host\n logger.info(\"Cannot process OCSP host from URL (%s) in cert at %s\", url, cert_path)\n return None, None\n\n\ndef _check_ocsp_cryptography(cert_path, chain_path, url):\n # type: (str, str, str) -> bool\n # Retrieve OCSP response\n with open(chain_path, 'rb') as file_handler:\n issuer = x509.load_pem_x509_certificate(file_handler.read(), default_backend())\n with open(cert_path, 'rb') as file_handler:\n cert = x509.load_pem_x509_certificate(file_handler.read(), default_backend())\n builder = ocsp.OCSPRequestBuilder()\n builder = builder.add_certificate(cert, issuer, hashes.SHA1())\n request = builder.build()\n request_binary = request.public_bytes(serialization.Encoding.DER)\n try:\n response = requests.post(url, data=request_binary,\n headers={'Content-Type': 'application/ocsp-request'})\n except requests.exceptions.RequestException:\n logger.info(\"OCSP check failed for %s (are we offline?)\", cert_path, exc_info=True)\n return False\n if response.status_code != 200:\n logger.info(\"OCSP check failed for %s (HTTP status: %d)\", cert_path, response.status_code)\n return False\n\n response_ocsp = ocsp.load_der_ocsp_response(response.content)\n\n # Check OCSP response validity\n if response_ocsp.response_status != ocsp.OCSPResponseStatus.SUCCESSFUL:\n logger.error(\"Invalid OCSP response status for %s: %s\",\n cert_path, response_ocsp.response_status)\n return False\n\n # Check OCSP signature\n try:\n _check_ocsp_response(response_ocsp, request, issuer)\n except UnsupportedAlgorithm as e:\n logger.error(str(e))\n except errors.Error as e:\n logger.error(str(e))\n except InvalidSignature:\n logger.error('Invalid signature on OCSP response for %s', cert_path)\n except AssertionError as error:\n logger.error('Invalid OCSP response for %s: %s.', cert_path, str(error))\n else:\n # Check OCSP certificate status\n logger.debug(\"OCSP certificate status for %s is: %s\",\n cert_path, response_ocsp.certificate_status)\n return response_ocsp.certificate_status == ocsp.OCSPCertStatus.REVOKED\n\n return False\n\n\ndef _check_ocsp_response(response_ocsp, request_ocsp, issuer_cert):\n \"\"\"Verify that the OCSP is valid for serveral criterias\"\"\"\n # Assert OCSP response corresponds to the certificate we are talking about\n if response_ocsp.serial_number != request_ocsp.serial_number:\n raise AssertionError('the certificate in response does not correspond '\n 'to the certificate in request')\n\n # Assert signature is valid\n _check_ocsp_response_signature(response_ocsp, issuer_cert)\n\n # Assert issuer in response is the expected one\n if (not isinstance(response_ocsp.hash_algorithm, type(request_ocsp.hash_algorithm))\n or response_ocsp.issuer_key_hash != request_ocsp.issuer_key_hash\n or response_ocsp.issuer_name_hash != request_ocsp.issuer_name_hash):\n raise AssertionError('the issuer does not correspond to issuer of the certificate.')\n\n # In following checks, two situations can occur:\n # * nextUpdate is set, and requirement is thisUpdate < now < nextUpdate\n # * nextUpdate is not set, and requirement is thisUpdate < now\n # NB1: We add a validity period tolerance to handle clock time inconsistencies,\n # value is 5 min like for OpenSSL.\n # NB2: Another check is to verify that thisUpdate is not too old, it is optional\n # for OpenSSL, so we do not do it here.\n # See OpenSSL implementation as a reference:\n # https://github.com/openssl/openssl/blob/ef45aa14c5af024fcb8bef1c9007f3d1c115bd85/crypto/ocsp/ocsp_cl.c#L338-L391\n now = datetime.utcnow() # thisUpdate/nextUpdate are expressed in UTC/GMT time zone\n if not response_ocsp.this_update:\n raise AssertionError('param thisUpdate is not set.')\n if response_ocsp.this_update > now + timedelta(minutes=5):\n raise AssertionError('param thisUpdate is in the future.')\n if response_ocsp.next_update and response_ocsp.next_update < now - timedelta(minutes=5):\n raise AssertionError('param nextUpdate is in the past.')\n\n\ndef _check_ocsp_response_signature(response_ocsp, issuer_cert):\n \"\"\"Verify an OCSP response signature against certificate issuer\"\"\"\n # Following line may raise UnsupportedAlgorithm\n chosen_hash = response_ocsp.signature_hash_algorithm\n crypto_util.verify_signed_payload(issuer_cert.public_key(), response_ocsp.signature,\n response_ocsp.tbs_response_bytes, chosen_hash)\n\n\ndef _translate_ocsp_query(cert_path, ocsp_output, ocsp_errors):\n \"\"\"Parse openssl's weird output to work out what it means.\"\"\"\n\n states = (\"good\", \"revoked\", \"unknown\")\n patterns = [r\"{0}: (WARNING.*)?{1}\".format(cert_path, s) for s in states]\n good, revoked, unknown = (re.search(p, ocsp_output, flags=re.DOTALL) for p in patterns)\n\n warning = good.group(1) if good else None\n\n if (\"Response verify OK\" not in ocsp_errors) or (good and warning) or unknown:\n logger.info(\"Revocation status for %s is unknown\", cert_path)\n logger.debug(\"Uncertain output:\\n%s\\nstderr:\\n%s\", ocsp_output, ocsp_errors)\n return False\n elif good and not warning:\n return False\n elif revoked:\n warning = revoked.group(1)\n if warning:\n logger.info(\"OCSP revocation warning: %s\", warning)\n return True\n else:\n logger.warning(\"Unable to properly parse OCSP output: %s\\nstderr:%s\",\n ocsp_output, ocsp_errors)\n return False\n", "path": "certbot/ocsp.py"}], "after_files": [{"content": "\"\"\"Tools for checking certificate revocation.\"\"\"\nimport logging\nimport re\nfrom datetime import datetime, timedelta\nfrom subprocess import Popen, PIPE\n\ntry:\n # Only cryptography>=2.5 has ocsp module\n # and signature_hash_algorithm attribute in OCSPResponse class\n from cryptography.x509 import ocsp # pylint: disable=import-error\n getattr(ocsp.OCSPResponse, 'signature_hash_algorithm')\nexcept (ImportError, AttributeError): # pragma: no cover\n ocsp = None # type: ignore\nfrom cryptography import x509\nfrom cryptography.hazmat.backends import default_backend\nfrom cryptography.hazmat.primitives import serialization\nfrom cryptography.hazmat.primitives import hashes # type: ignore\nfrom cryptography.exceptions import UnsupportedAlgorithm, InvalidSignature\nimport requests\n\nfrom acme.magic_typing import Optional, Tuple # pylint: disable=unused-import, no-name-in-module\nfrom certbot import crypto_util\nfrom certbot import errors\nfrom certbot import util\n\nlogger = logging.getLogger(__name__)\n\n\nclass RevocationChecker(object):\n \"\"\"This class figures out OCSP checking on this system, and performs it.\"\"\"\n\n def __init__(self, enforce_openssl_binary_usage=False):\n self.broken = False\n self.use_openssl_binary = enforce_openssl_binary_usage or not ocsp\n\n if self.use_openssl_binary:\n if not util.exe_exists(\"openssl\"):\n logger.info(\"openssl not installed, can't check revocation\")\n self.broken = True\n return\n\n # New versions of openssl want -header var=val, old ones want -header var val\n test_host_format = Popen([\"openssl\", \"ocsp\", \"-header\", \"var\", \"val\"],\n stdout=PIPE, stderr=PIPE, universal_newlines=True)\n _out, err = test_host_format.communicate()\n if \"Missing =\" in err:\n self.host_args = lambda host: [\"Host=\" + host]\n else:\n self.host_args = lambda host: [\"Host\", host]\n\n def ocsp_revoked(self, cert_path, chain_path):\n # type: (str, str) -> bool\n \"\"\"Get revoked status for a particular cert version.\n\n .. todo:: Make this a non-blocking call\n\n :param str cert_path: Path to certificate\n :param str chain_path: Path to intermediate cert\n :returns: True if revoked; False if valid or the check failed\n :rtype: bool\n\n \"\"\"\n if self.broken:\n return False\n\n url, host = _determine_ocsp_server(cert_path)\n if not host or not url:\n return False\n\n if self.use_openssl_binary:\n return self._check_ocsp_openssl_bin(cert_path, chain_path, host, url)\n return _check_ocsp_cryptography(cert_path, chain_path, url)\n\n def _check_ocsp_openssl_bin(self, cert_path, chain_path, host, url):\n # type: (str, str, str, str) -> bool\n # jdkasten thanks \"Bulletproof SSL and TLS - Ivan Ristic\" for documenting this!\n cmd = [\"openssl\", \"ocsp\",\n \"-no_nonce\",\n \"-issuer\", chain_path,\n \"-cert\", cert_path,\n \"-url\", url,\n \"-CAfile\", chain_path,\n \"-verify_other\", chain_path,\n \"-trust_other\",\n \"-header\"] + self.host_args(host)\n logger.debug(\"Querying OCSP for %s\", cert_path)\n logger.debug(\" \".join(cmd))\n try:\n output, err = util.run_script(cmd, log=logger.debug)\n except errors.SubprocessError:\n logger.info(\"OCSP check failed for %s (are we offline?)\", cert_path)\n return False\n return _translate_ocsp_query(cert_path, output, err)\n\n\ndef _determine_ocsp_server(cert_path):\n # type: (str) -> Tuple[Optional[str], Optional[str]]\n \"\"\"Extract the OCSP server host from a certificate.\n\n :param str cert_path: Path to the cert we're checking OCSP for\n :rtype tuple:\n :returns: (OCSP server URL or None, OCSP server host or None)\n\n \"\"\"\n with open(cert_path, 'rb') as file_handler:\n cert = x509.load_pem_x509_certificate(file_handler.read(), default_backend())\n try:\n extension = cert.extensions.get_extension_for_class(x509.AuthorityInformationAccess)\n ocsp_oid = x509.AuthorityInformationAccessOID.OCSP\n descriptions = [description for description in extension.value\n if description.access_method == ocsp_oid]\n\n url = descriptions[0].access_location.value\n except (x509.ExtensionNotFound, IndexError):\n logger.info(\"Cannot extract OCSP URI from %s\", cert_path)\n return None, None\n\n url = url.rstrip()\n host = url.partition(\"://\")[2].rstrip(\"/\")\n\n if host:\n return url, host\n logger.info(\"Cannot process OCSP host from URL (%s) in cert at %s\", url, cert_path)\n return None, None\n\n\ndef _check_ocsp_cryptography(cert_path, chain_path, url):\n # type: (str, str, str) -> bool\n # Retrieve OCSP response\n with open(chain_path, 'rb') as file_handler:\n issuer = x509.load_pem_x509_certificate(file_handler.read(), default_backend())\n with open(cert_path, 'rb') as file_handler:\n cert = x509.load_pem_x509_certificate(file_handler.read(), default_backend())\n builder = ocsp.OCSPRequestBuilder()\n builder = builder.add_certificate(cert, issuer, hashes.SHA1())\n request = builder.build()\n request_binary = request.public_bytes(serialization.Encoding.DER)\n try:\n response = requests.post(url, data=request_binary,\n headers={'Content-Type': 'application/ocsp-request'})\n except requests.exceptions.RequestException:\n logger.info(\"OCSP check failed for %s (are we offline?)\", cert_path, exc_info=True)\n return False\n if response.status_code != 200:\n logger.info(\"OCSP check failed for %s (HTTP status: %d)\", cert_path, response.status_code)\n return False\n\n response_ocsp = ocsp.load_der_ocsp_response(response.content)\n\n # Check OCSP response validity\n if response_ocsp.response_status != ocsp.OCSPResponseStatus.SUCCESSFUL:\n logger.error(\"Invalid OCSP response status for %s: %s\",\n cert_path, response_ocsp.response_status)\n return False\n\n # Check OCSP signature\n try:\n _check_ocsp_response(response_ocsp, request, issuer, cert_path)\n except UnsupportedAlgorithm as e:\n logger.error(str(e))\n except errors.Error as e:\n logger.error(str(e))\n except InvalidSignature:\n logger.error('Invalid signature on OCSP response for %s', cert_path)\n except AssertionError as error:\n logger.error('Invalid OCSP response for %s: %s.', cert_path, str(error))\n else:\n # Check OCSP certificate status\n logger.debug(\"OCSP certificate status for %s is: %s\",\n cert_path, response_ocsp.certificate_status)\n return response_ocsp.certificate_status == ocsp.OCSPCertStatus.REVOKED\n\n return False\n\n\ndef _check_ocsp_response(response_ocsp, request_ocsp, issuer_cert, cert_path):\n \"\"\"Verify that the OCSP is valid for serveral criterias\"\"\"\n # Assert OCSP response corresponds to the certificate we are talking about\n if response_ocsp.serial_number != request_ocsp.serial_number:\n raise AssertionError('the certificate in response does not correspond '\n 'to the certificate in request')\n\n # Assert signature is valid\n _check_ocsp_response_signature(response_ocsp, issuer_cert, cert_path)\n\n # Assert issuer in response is the expected one\n if (not isinstance(response_ocsp.hash_algorithm, type(request_ocsp.hash_algorithm))\n or response_ocsp.issuer_key_hash != request_ocsp.issuer_key_hash\n or response_ocsp.issuer_name_hash != request_ocsp.issuer_name_hash):\n raise AssertionError('the issuer does not correspond to issuer of the certificate.')\n\n # In following checks, two situations can occur:\n # * nextUpdate is set, and requirement is thisUpdate < now < nextUpdate\n # * nextUpdate is not set, and requirement is thisUpdate < now\n # NB1: We add a validity period tolerance to handle clock time inconsistencies,\n # value is 5 min like for OpenSSL.\n # NB2: Another check is to verify that thisUpdate is not too old, it is optional\n # for OpenSSL, so we do not do it here.\n # See OpenSSL implementation as a reference:\n # https://github.com/openssl/openssl/blob/ef45aa14c5af024fcb8bef1c9007f3d1c115bd85/crypto/ocsp/ocsp_cl.c#L338-L391\n now = datetime.utcnow() # thisUpdate/nextUpdate are expressed in UTC/GMT time zone\n if not response_ocsp.this_update:\n raise AssertionError('param thisUpdate is not set.')\n if response_ocsp.this_update > now + timedelta(minutes=5):\n raise AssertionError('param thisUpdate is in the future.')\n if response_ocsp.next_update and response_ocsp.next_update < now - timedelta(minutes=5):\n raise AssertionError('param nextUpdate is in the past.')\n\n\ndef _check_ocsp_response_signature(response_ocsp, issuer_cert, cert_path):\n \"\"\"Verify an OCSP response signature against certificate issuer or responder\"\"\"\n if response_ocsp.responder_name == issuer_cert.subject:\n # Case where the OCSP responder is also the certificate issuer\n logger.debug('OCSP response for certificate %s is signed by the certificate\\'s issuer.',\n cert_path)\n responder_cert = issuer_cert\n else:\n # Case where the OCSP responder is not the certificate issuer\n logger.debug('OCSP response for certificate %s is delegated to an external responder.',\n cert_path)\n\n responder_certs = [cert for cert in response_ocsp.certificates\n if cert.subject == response_ocsp.responder_name]\n if not responder_certs:\n raise AssertionError('no matching responder certificate could be found')\n\n # We suppose here that the ACME server support only one certificate in the OCSP status\n # request. This is currently the case for LetsEncrypt servers.\n # See https://github.com/letsencrypt/boulder/issues/2331\n responder_cert = responder_certs[0]\n\n if responder_cert.issuer != issuer_cert.subject:\n raise AssertionError('responder certificate is not signed '\n 'by the certificate\\'s issuer')\n\n try:\n extension = responder_cert.extensions.get_extension_for_class(x509.ExtendedKeyUsage)\n delegate_authorized = x509.oid.ExtendedKeyUsageOID.OCSP_SIGNING in extension.value\n except (x509.ExtensionNotFound, IndexError):\n delegate_authorized = False\n if not delegate_authorized:\n raise AssertionError('responder is not authorized by issuer to sign OCSP responses')\n\n # Following line may raise UnsupportedAlgorithm\n chosen_hash = responder_cert.signature_hash_algorithm\n # For a delegate OCSP responder, we need first check that its certificate is effectively\n # signed by the certificate issuer.\n crypto_util.verify_signed_payload(issuer_cert.public_key(), responder_cert.signature,\n responder_cert.tbs_certificate_bytes, chosen_hash)\n\n # Following line may raise UnsupportedAlgorithm\n chosen_hash = response_ocsp.signature_hash_algorithm\n # We check that the OSCP response is effectively signed by the responder\n # (an authorized delegate one or the certificate issuer itself).\n crypto_util.verify_signed_payload(responder_cert.public_key(), response_ocsp.signature,\n response_ocsp.tbs_response_bytes, chosen_hash)\n\n\ndef _translate_ocsp_query(cert_path, ocsp_output, ocsp_errors):\n \"\"\"Parse openssl's weird output to work out what it means.\"\"\"\n\n states = (\"good\", \"revoked\", \"unknown\")\n patterns = [r\"{0}: (WARNING.*)?{1}\".format(cert_path, s) for s in states]\n good, revoked, unknown = (re.search(p, ocsp_output, flags=re.DOTALL) for p in patterns)\n\n warning = good.group(1) if good else None\n\n if (\"Response verify OK\" not in ocsp_errors) or (good and warning) or unknown:\n logger.info(\"Revocation status for %s is unknown\", cert_path)\n logger.debug(\"Uncertain output:\\n%s\\nstderr:\\n%s\", ocsp_output, ocsp_errors)\n return False\n elif good and not warning:\n return False\n elif revoked:\n warning = revoked.group(1)\n if warning:\n logger.info(\"OCSP revocation warning: %s\", warning)\n return True\n else:\n logger.warning(\"Unable to properly parse OCSP output: %s\\nstderr:%s\",\n ocsp_output, ocsp_errors)\n return False\n", "path": "certbot/ocsp.py"}]}
| 4,006 | 940 |
gh_patches_debug_29025
|
rasdani/github-patches
|
git_diff
|
angr__angr-1073
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Avoiding Infinite Loops with loopseer technique
Hello,
I'm trying to run some code which I know is just a loop running infinitely but I do want to exit this loop (hard coded limit) after it iterated 10 times.
I thought loopseer suppose to do just that but it doesn't seems to stop after 10 iterations but keep going non stop.
My example code:
```
void loop_forever(int a) {
int i;
for(i=0;;i++) {
printf("Test infinite loop");
}
}
```
Example usage:
```
p = angr.Project(loop_forever, load_options={"auto_load_libs": False})
cfg = p.analyses.CFGFast(normalize = True)
state = p.factory.call_state(addr=0x10438) # 0x10438 = loop_forever function
simgr = p.factory.simulation_manager(state)
simgr.use_technique(angr.exploration_techniques.LoopSeer(cfg=cfg, bound=10))
while len(simgr.active) != 0:
simgr.step()
print simgr.active
```
The binary (elf, 32bit arm) can be download here: https://ufile.io/9nym2
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `angr/exploration_techniques/loop_seer.py`
Content:
```
1 import logging
2
3 from . import ExplorationTechnique
4 from ..analyses.loopfinder import Loop
5 from ..knowledge_base import KnowledgeBase
6 from ..knowledge_plugins.functions import Function
7
8
9 l = logging.getLogger("angr.exploration_techniques.loop_seer")
10
11
12 class LoopSeer(ExplorationTechnique):
13 """
14 This exploration technique monitors exploration and maintains all
15 loop-related data (well, currently it is just the loop trip counts, but feel
16 free to add something else).
17 """
18
19 def __init__(self, cfg=None, functions=None, loops=None, bound=None, bound_reached=None, discard_stash='spinning'):
20 """
21 :param cfg: Normalized CFG is required.
22 :param functions: Function(s) containing the loop(s) to be analyzed.
23 :param loops: Loop(s) to be analyzed.
24 :param bound: Limit the number of iteration a loop may be executed.
25 :param bound_reached: If provided, should be a function that takes a SimulationManager and returns
26 a SimulationManager. Will be called when loop execution reach the given bound.
27 Default to moving states that exceed the loop limit to a discard stash.
28 :param discard_stash: Name of the stash containing states exceeding the loop limit.
29 """
30
31 super(LoopSeer, self).__init__()
32 self.cfg = cfg
33 self.functions = functions
34 self.bound = bound
35 self.bound_reached = bound_reached
36 self.discard_stash = discard_stash
37
38 self.loops = {}
39
40 if type(loops) is Loop:
41 loops = [loops]
42
43 if type(loops) in (list, tuple) and all(type(l) is Loop for l in loops):
44 for loop in loops:
45 self.loops[loop.entry_edges[0][0].addr] = loop
46
47 elif loops is not None:
48 raise TypeError('What type of loop is it?')
49
50 def setup(self, simgr):
51 if self.cfg is None:
52 cfg_kb = KnowledgeBase(self.project, self.project.loader.main_object)
53 self.cfg = self.project.analyses.CFGFast(kb=cfg_kb, normalize=True)
54 elif not self.cfg.normalized:
55 l.warning("LoopSeer uses normalized CFG. Recomputing the CFG...")
56 self.cfg.normalize()
57
58 if type(self.functions) is str:
59 func = [self.cfg.kb.functions.function(name=self.functions)]
60
61 elif type(self.functions) is int:
62 func = [self.cfg.kb.functions.function(addr=self.functions)]
63
64 elif type(self.functions) is Function:
65 func = [self.functions]
66
67 elif type(self.functions) in (list, tuple):
68 func = []
69 for f in self.functions:
70 if type(f) is str:
71 func.append(self.cfg.kb.functions.function(name=f))
72
73 elif type(f) is int:
74 func.append(self.cfg.kb.functions.function(addr=f))
75
76 elif type(f) is Function:
77 func.append(f)
78
79 else:
80 raise TypeError("What type of function is it?")
81 elif self.functions is None:
82 func = None
83
84 else:
85 raise TypeError("What type of function is it?")
86
87 if not self.loops or func is not None:
88 loop_finder = self.project.analyses.LoopFinder(kb=self.cfg.kb, normalize=True, functions=func)
89
90 for loop in loop_finder.loops:
91 entry = loop.entry_edges[0][0]
92 self.loops[entry.addr] = loop
93
94 def step(self, simgr, stash=None, **kwargs):
95 kwargs['successor_func'] = self.normalized_step
96
97 simgr.step(stash=stash, **kwargs)
98
99 for state in simgr.stashes[stash]:
100 # Processing a currently running loop
101 if state.loop_data.current_loop:
102 loop = state.loop_data.current_loop[-1][0]
103 header = loop.entry.addr
104
105 if state.addr == header:
106 state.loop_data.trip_counts[state.addr][-1] += 1
107
108 elif state.addr in state.loop_data.current_loop[-1][1]:
109 # This is for unoptimized while/for loops.
110 #
111 # 0x10812: movs r3, #0 -> this block dominates the loop
112 # 0x10814: str r3, [r7, #20]
113 # 0x10816: b 0x10868
114 # 0x10818: movs r3, #0 -> the real loop body starts here
115 # ...
116 # 0x10868: ldr r3, [r7, #20] -> the loop header is executed the first time without executing the loop body
117 # 0x1086a: cmp r3, #3
118 # 0x1086c: ble 0x10818
119
120 back_edge_src = loop.continue_edges[0][0].addr
121 back_edge_dst = loop.continue_edges[0][1].addr
122 block = self.project.factory.block(back_edge_src)
123 if back_edge_src != back_edge_dst and back_edge_dst in block.instruction_addrs:
124 state.loop_data.trip_counts[header][-1] -= 1
125
126 state.loop_data.current_loop.pop()
127
128 if self.bound is not None:
129 if state.loop_data.trip_counts[header][-1] >= self.bound:
130 if self.bound_reached is not None:
131 simgr = self.bound_reached(simgr)
132 else:
133 simgr.stashes[stash].remove(state)
134 simgr.stashes[self.discard_stash].append(state)
135
136 l.debug("%s trip counts %s", state, state.loop_data.trip_counts)
137
138 # Loop entry detected. This test is put here because in case of
139 # nested loops, we want to handle the outer loop before proceeding
140 # the inner loop.
141 if state.addr in self.loops:
142 loop = self.loops[state.addr]
143 header = loop.entry.addr
144 exits = [e[1].addr for e in loop.break_edges]
145
146 state.loop_data.trip_counts[header].append(0)
147 state.loop_data.current_loop.append((loop, exits))
148
149 return simgr
150
151 def normalized_step(self, state):
152 node = self.cfg.get_any_node(state.addr)
153 return state.step(num_inst=len(node.instruction_addrs) if node is not None else None)
154
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/angr/exploration_techniques/loop_seer.py b/angr/exploration_techniques/loop_seer.py
--- a/angr/exploration_techniques/loop_seer.py
+++ b/angr/exploration_techniques/loop_seer.py
@@ -91,11 +91,9 @@
entry = loop.entry_edges[0][0]
self.loops[entry.addr] = loop
- def step(self, simgr, stash=None, **kwargs):
+ def step(self, simgr, stash='active', **kwargs):
kwargs['successor_func'] = self.normalized_step
- simgr.step(stash=stash, **kwargs)
-
for state in simgr.stashes[stash]:
# Processing a currently running loop
if state.loop_data.current_loop:
@@ -126,7 +124,7 @@
state.loop_data.current_loop.pop()
if self.bound is not None:
- if state.loop_data.trip_counts[header][-1] >= self.bound:
+ if state.loop_data.trip_counts[header][-1] > self.bound:
if self.bound_reached is not None:
simgr = self.bound_reached(simgr)
else:
@@ -146,6 +144,8 @@
state.loop_data.trip_counts[header].append(0)
state.loop_data.current_loop.append((loop, exits))
+ simgr.step(stash=stash, **kwargs)
+
return simgr
def normalized_step(self, state):
|
{"golden_diff": "diff --git a/angr/exploration_techniques/loop_seer.py b/angr/exploration_techniques/loop_seer.py\n--- a/angr/exploration_techniques/loop_seer.py\n+++ b/angr/exploration_techniques/loop_seer.py\n@@ -91,11 +91,9 @@\n entry = loop.entry_edges[0][0]\n self.loops[entry.addr] = loop\n \n- def step(self, simgr, stash=None, **kwargs):\n+ def step(self, simgr, stash='active', **kwargs):\n kwargs['successor_func'] = self.normalized_step\n \n- simgr.step(stash=stash, **kwargs)\n-\n for state in simgr.stashes[stash]:\n # Processing a currently running loop\n if state.loop_data.current_loop:\n@@ -126,7 +124,7 @@\n state.loop_data.current_loop.pop()\n \n if self.bound is not None:\n- if state.loop_data.trip_counts[header][-1] >= self.bound:\n+ if state.loop_data.trip_counts[header][-1] > self.bound:\n if self.bound_reached is not None:\n simgr = self.bound_reached(simgr)\n else:\n@@ -146,6 +144,8 @@\n state.loop_data.trip_counts[header].append(0)\n state.loop_data.current_loop.append((loop, exits))\n \n+ simgr.step(stash=stash, **kwargs)\n+\n return simgr\n \n def normalized_step(self, state):\n", "issue": "Avoiding Infinite Loops with loopseer technique\nHello,\r\n\r\nI'm trying to run some code which I know is just a loop running infinitely but I do want to exit this loop (hard coded limit) after it iterated 10 times.\r\nI thought loopseer suppose to do just that but it doesn't seems to stop after 10 iterations but keep going non stop.\r\n\r\nMy example code:\r\n```\r\nvoid loop_forever(int a) {\r\n int i;\r\n for(i=0;;i++) {\r\n printf(\"Test infinite loop\");\r\n }\r\n}\r\n```\r\n\r\nExample usage:\r\n```\r\np = angr.Project(loop_forever, load_options={\"auto_load_libs\": False})\r\ncfg = p.analyses.CFGFast(normalize = True)\r\nstate = p.factory.call_state(addr=0x10438) # 0x10438 = loop_forever function\r\nsimgr = p.factory.simulation_manager(state)\r\nsimgr.use_technique(angr.exploration_techniques.LoopSeer(cfg=cfg, bound=10))\r\nwhile len(simgr.active) != 0:\r\n simgr.step()\r\n print simgr.active\r\n```\r\n\r\nThe binary (elf, 32bit arm) can be download here: https://ufile.io/9nym2\n", "before_files": [{"content": "import logging\n\nfrom . import ExplorationTechnique\nfrom ..analyses.loopfinder import Loop\nfrom ..knowledge_base import KnowledgeBase\nfrom ..knowledge_plugins.functions import Function\n\n\nl = logging.getLogger(\"angr.exploration_techniques.loop_seer\")\n\n\nclass LoopSeer(ExplorationTechnique):\n \"\"\"\n This exploration technique monitors exploration and maintains all\n loop-related data (well, currently it is just the loop trip counts, but feel\n free to add something else).\n \"\"\"\n\n def __init__(self, cfg=None, functions=None, loops=None, bound=None, bound_reached=None, discard_stash='spinning'):\n \"\"\"\n :param cfg: Normalized CFG is required.\n :param functions: Function(s) containing the loop(s) to be analyzed.\n :param loops: Loop(s) to be analyzed.\n :param bound: Limit the number of iteration a loop may be executed.\n :param bound_reached: If provided, should be a function that takes a SimulationManager and returns\n a SimulationManager. Will be called when loop execution reach the given bound.\n Default to moving states that exceed the loop limit to a discard stash.\n :param discard_stash: Name of the stash containing states exceeding the loop limit.\n \"\"\"\n\n super(LoopSeer, self).__init__()\n self.cfg = cfg\n self.functions = functions\n self.bound = bound\n self.bound_reached = bound_reached\n self.discard_stash = discard_stash\n\n self.loops = {}\n\n if type(loops) is Loop:\n loops = [loops]\n\n if type(loops) in (list, tuple) and all(type(l) is Loop for l in loops):\n for loop in loops:\n self.loops[loop.entry_edges[0][0].addr] = loop\n\n elif loops is not None:\n raise TypeError('What type of loop is it?')\n\n def setup(self, simgr):\n if self.cfg is None:\n cfg_kb = KnowledgeBase(self.project, self.project.loader.main_object)\n self.cfg = self.project.analyses.CFGFast(kb=cfg_kb, normalize=True)\n elif not self.cfg.normalized:\n l.warning(\"LoopSeer uses normalized CFG. Recomputing the CFG...\")\n self.cfg.normalize()\n\n if type(self.functions) is str:\n func = [self.cfg.kb.functions.function(name=self.functions)]\n\n elif type(self.functions) is int:\n func = [self.cfg.kb.functions.function(addr=self.functions)]\n\n elif type(self.functions) is Function:\n func = [self.functions]\n\n elif type(self.functions) in (list, tuple):\n func = []\n for f in self.functions:\n if type(f) is str:\n func.append(self.cfg.kb.functions.function(name=f))\n\n elif type(f) is int:\n func.append(self.cfg.kb.functions.function(addr=f))\n\n elif type(f) is Function:\n func.append(f)\n\n else:\n raise TypeError(\"What type of function is it?\")\n elif self.functions is None:\n func = None\n\n else:\n raise TypeError(\"What type of function is it?\")\n\n if not self.loops or func is not None:\n loop_finder = self.project.analyses.LoopFinder(kb=self.cfg.kb, normalize=True, functions=func)\n\n for loop in loop_finder.loops:\n entry = loop.entry_edges[0][0]\n self.loops[entry.addr] = loop\n\n def step(self, simgr, stash=None, **kwargs):\n kwargs['successor_func'] = self.normalized_step\n\n simgr.step(stash=stash, **kwargs)\n\n for state in simgr.stashes[stash]:\n # Processing a currently running loop\n if state.loop_data.current_loop:\n loop = state.loop_data.current_loop[-1][0]\n header = loop.entry.addr\n\n if state.addr == header:\n state.loop_data.trip_counts[state.addr][-1] += 1\n\n elif state.addr in state.loop_data.current_loop[-1][1]:\n # This is for unoptimized while/for loops.\n #\n # 0x10812: movs r3, #0 -> this block dominates the loop\n # 0x10814: str r3, [r7, #20]\n # 0x10816: b 0x10868\n # 0x10818: movs r3, #0 -> the real loop body starts here\n # ...\n # 0x10868: ldr r3, [r7, #20] -> the loop header is executed the first time without executing the loop body\n # 0x1086a: cmp r3, #3\n # 0x1086c: ble 0x10818\n\n back_edge_src = loop.continue_edges[0][0].addr\n back_edge_dst = loop.continue_edges[0][1].addr\n block = self.project.factory.block(back_edge_src)\n if back_edge_src != back_edge_dst and back_edge_dst in block.instruction_addrs:\n state.loop_data.trip_counts[header][-1] -= 1\n\n state.loop_data.current_loop.pop()\n\n if self.bound is not None:\n if state.loop_data.trip_counts[header][-1] >= self.bound:\n if self.bound_reached is not None:\n simgr = self.bound_reached(simgr)\n else:\n simgr.stashes[stash].remove(state)\n simgr.stashes[self.discard_stash].append(state)\n\n l.debug(\"%s trip counts %s\", state, state.loop_data.trip_counts)\n\n # Loop entry detected. This test is put here because in case of\n # nested loops, we want to handle the outer loop before proceeding\n # the inner loop.\n if state.addr in self.loops:\n loop = self.loops[state.addr]\n header = loop.entry.addr\n exits = [e[1].addr for e in loop.break_edges]\n\n state.loop_data.trip_counts[header].append(0)\n state.loop_data.current_loop.append((loop, exits))\n\n return simgr\n\n def normalized_step(self, state):\n node = self.cfg.get_any_node(state.addr)\n return state.step(num_inst=len(node.instruction_addrs) if node is not None else None)\n", "path": "angr/exploration_techniques/loop_seer.py"}], "after_files": [{"content": "import logging\n\nfrom . import ExplorationTechnique\nfrom ..analyses.loopfinder import Loop\nfrom ..knowledge_base import KnowledgeBase\nfrom ..knowledge_plugins.functions import Function\n\n\nl = logging.getLogger(\"angr.exploration_techniques.loop_seer\")\n\n\nclass LoopSeer(ExplorationTechnique):\n \"\"\"\n This exploration technique monitors exploration and maintains all\n loop-related data (well, currently it is just the loop trip counts, but feel\n free to add something else).\n \"\"\"\n\n def __init__(self, cfg=None, functions=None, loops=None, bound=None, bound_reached=None, discard_stash='spinning'):\n \"\"\"\n :param cfg: Normalized CFG is required.\n :param functions: Function(s) containing the loop(s) to be analyzed.\n :param loops: Loop(s) to be analyzed.\n :param bound: Limit the number of iteration a loop may be executed.\n :param bound_reached: If provided, should be a function that takes a SimulationManager and returns\n a SimulationManager. Will be called when loop execution reach the given bound.\n Default to moving states that exceed the loop limit to a discard stash.\n :param discard_stash: Name of the stash containing states exceeding the loop limit.\n \"\"\"\n\n super(LoopSeer, self).__init__()\n self.cfg = cfg\n self.functions = functions\n self.bound = bound\n self.bound_reached = bound_reached\n self.discard_stash = discard_stash\n\n self.loops = {}\n\n if type(loops) is Loop:\n loops = [loops]\n\n if type(loops) in (list, tuple) and all(type(l) is Loop for l in loops):\n for loop in loops:\n self.loops[loop.entry_edges[0][0].addr] = loop\n\n elif loops is not None:\n raise TypeError('What type of loop is it?')\n\n def setup(self, simgr):\n if self.cfg is None:\n cfg_kb = KnowledgeBase(self.project, self.project.loader.main_object)\n self.cfg = self.project.analyses.CFGFast(kb=cfg_kb, normalize=True)\n elif not self.cfg.normalized:\n l.warning(\"LoopSeer uses normalized CFG. Recomputing the CFG...\")\n self.cfg.normalize()\n\n if type(self.functions) is str:\n func = [self.cfg.kb.functions.function(name=self.functions)]\n\n elif type(self.functions) is int:\n func = [self.cfg.kb.functions.function(addr=self.functions)]\n\n elif type(self.functions) is Function:\n func = [self.functions]\n\n elif type(self.functions) in (list, tuple):\n func = []\n for f in self.functions:\n if type(f) is str:\n func.append(self.cfg.kb.functions.function(name=f))\n\n elif type(f) is int:\n func.append(self.cfg.kb.functions.function(addr=f))\n\n elif type(f) is Function:\n func.append(f)\n\n else:\n raise TypeError(\"What type of function is it?\")\n elif self.functions is None:\n func = None\n\n else:\n raise TypeError(\"What type of function is it?\")\n\n if not self.loops or func is not None:\n loop_finder = self.project.analyses.LoopFinder(kb=self.cfg.kb, normalize=True, functions=func)\n\n for loop in loop_finder.loops:\n entry = loop.entry_edges[0][0]\n self.loops[entry.addr] = loop\n\n def step(self, simgr, stash='active', **kwargs):\n kwargs['successor_func'] = self.normalized_step\n\n for state in simgr.stashes[stash]:\n # Processing a currently running loop\n if state.loop_data.current_loop:\n loop = state.loop_data.current_loop[-1][0]\n header = loop.entry.addr\n\n if state.addr == header:\n state.loop_data.trip_counts[state.addr][-1] += 1\n\n elif state.addr in state.loop_data.current_loop[-1][1]:\n # This is for unoptimized while/for loops.\n #\n # 0x10812: movs r3, #0 -> this block dominates the loop\n # 0x10814: str r3, [r7, #20]\n # 0x10816: b 0x10868\n # 0x10818: movs r3, #0 -> the real loop body starts here\n # ...\n # 0x10868: ldr r3, [r7, #20] -> the loop header is executed the first time without executing the loop body\n # 0x1086a: cmp r3, #3\n # 0x1086c: ble 0x10818\n\n back_edge_src = loop.continue_edges[0][0].addr\n back_edge_dst = loop.continue_edges[0][1].addr\n block = self.project.factory.block(back_edge_src)\n if back_edge_src != back_edge_dst and back_edge_dst in block.instruction_addrs:\n state.loop_data.trip_counts[header][-1] -= 1\n\n state.loop_data.current_loop.pop()\n\n if self.bound is not None:\n if state.loop_data.trip_counts[header][-1] > self.bound:\n if self.bound_reached is not None:\n simgr = self.bound_reached(simgr)\n else:\n simgr.stashes[stash].remove(state)\n simgr.stashes[self.discard_stash].append(state)\n\n l.debug(\"%s trip counts %s\", state, state.loop_data.trip_counts)\n\n # Loop entry detected. This test is put here because in case of\n # nested loops, we want to handle the outer loop before proceeding\n # the inner loop.\n if state.addr in self.loops:\n loop = self.loops[state.addr]\n header = loop.entry.addr\n exits = [e[1].addr for e in loop.break_edges]\n\n state.loop_data.trip_counts[header].append(0)\n state.loop_data.current_loop.append((loop, exits))\n\n simgr.step(stash=stash, **kwargs)\n\n return simgr\n\n def normalized_step(self, state):\n node = self.cfg.get_any_node(state.addr)\n return state.step(num_inst=len(node.instruction_addrs) if node is not None else None)\n", "path": "angr/exploration_techniques/loop_seer.py"}]}
| 2,316 | 348 |
gh_patches_debug_10715
|
rasdani/github-patches
|
git_diff
|
akvo__akvo-rsr-2711
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Custom stylesheets for Akvo pages missing
The custom CSS that can be uploaded to an Akvo page site is currently not served.
This is due to the link to it accidentally being removed when the main stylesheet for RSR was supplemented with a second sheet for the new Results.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `akvo/rsr/context_processors.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 """
3 Akvo RSR is covered by the GNU Affero General Public License.
4
5 See more details in the license.txt file located at the root folder of the
6 Akvo RSR module. For additional details on the GNU license please see
7 < http://www.gnu.org/licenses/agpl.html >.
8 """
9
10 import django
11
12 from django.conf import settings
13 from django.core.exceptions import DisallowedHost
14 from django.contrib.sites.models import get_current_site
15
16
17 def extra_context(request, protocol="http"):
18 """Add information to the request context."""
19 try:
20 current_site = get_current_site(request)
21 except DisallowedHost:
22 current_site = None
23
24 django_version = django.get_version()
25 debug = getattr(settings, 'DEBUG', False)
26 deploy_tag = getattr(settings, 'DEPLOY_TAG', 'Unknown')
27 deploy_branch = getattr(settings, 'DEPLOY_BRANCH', 'Unknown')
28 deploy_commit_id = getattr(settings, 'DEPLOY_COMMIT_ID', 'Unknown')
29 deploy_commit_full_id = getattr(settings, 'DEPLOY_COMMIT_FULL_ID', 'Unknown')
30
31 return dict(
32 current_site=current_site,
33 django_version=django_version,
34 debug=debug,
35 deploy_tag=deploy_tag,
36 deploy_branch=deploy_branch,
37 deploy_commit_id=deploy_commit_id,
38 deploy_commit_full_id=deploy_commit_full_id
39 )
40
41
42 def get_current_path_without_lang(request):
43 """Return current path without lang."""
44 path = request.get_full_path()
45 path_bits = path.split('/')
46 path = '/'.join(path_bits[2:])
47 return {'current_path_without_lang': path}
48
49
50 def extra_pages_context(request):
51 """Add context information of an RSR Page."""
52 if request.rsr_page:
53 page = request.rsr_page
54 return {
55 'rsr_page': page,
56 'favicon': page.favicon,
57 'logo': page.logo,
58 'organisation': page.organisation,
59 'return_url': page.return_url,
60 'return_url_text': page.custom_return_url_text,
61 'stylesheet': page.stylesheet,
62 'akvoapp_root_url': '//{}'.format(settings.AKVOAPP_DOMAIN),
63 'domain_url': '//{}'.format(settings.RSR_DOMAIN),
64 'no_facebook': not page.facebook_button,
65 'facebook_app_id': page.facebook_app_id,
66 'no_twitter': not page.twitter_button,
67 }
68
69 return {}
70
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/akvo/rsr/context_processors.py b/akvo/rsr/context_processors.py
--- a/akvo/rsr/context_processors.py
+++ b/akvo/rsr/context_processors.py
@@ -58,7 +58,7 @@
'organisation': page.organisation,
'return_url': page.return_url,
'return_url_text': page.custom_return_url_text,
- 'stylesheet': page.stylesheet,
+ 'page_stylesheet': page.stylesheet,
'akvoapp_root_url': '//{}'.format(settings.AKVOAPP_DOMAIN),
'domain_url': '//{}'.format(settings.RSR_DOMAIN),
'no_facebook': not page.facebook_button,
|
{"golden_diff": "diff --git a/akvo/rsr/context_processors.py b/akvo/rsr/context_processors.py\n--- a/akvo/rsr/context_processors.py\n+++ b/akvo/rsr/context_processors.py\n@@ -58,7 +58,7 @@\n 'organisation': page.organisation,\n 'return_url': page.return_url,\n 'return_url_text': page.custom_return_url_text,\n- 'stylesheet': page.stylesheet,\n+ 'page_stylesheet': page.stylesheet,\n 'akvoapp_root_url': '//{}'.format(settings.AKVOAPP_DOMAIN),\n 'domain_url': '//{}'.format(settings.RSR_DOMAIN),\n 'no_facebook': not page.facebook_button,\n", "issue": "Custom stylesheets for Akvo pages missing\nThe custom CSS that can be uploaded to an Akvo page site is currently not served.\r\n\r\nThis is due to the link to it accidentally being removed when the main stylesheet for RSR was supplemented with a second sheet for the new Results.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\nAkvo RSR is covered by the GNU Affero General Public License.\n\nSee more details in the license.txt file located at the root folder of the\nAkvo RSR module. For additional details on the GNU license please see\n< http://www.gnu.org/licenses/agpl.html >.\n\"\"\"\n\nimport django\n\nfrom django.conf import settings\nfrom django.core.exceptions import DisallowedHost\nfrom django.contrib.sites.models import get_current_site\n\n\ndef extra_context(request, protocol=\"http\"):\n \"\"\"Add information to the request context.\"\"\"\n try:\n current_site = get_current_site(request)\n except DisallowedHost:\n current_site = None\n\n django_version = django.get_version()\n debug = getattr(settings, 'DEBUG', False)\n deploy_tag = getattr(settings, 'DEPLOY_TAG', 'Unknown')\n deploy_branch = getattr(settings, 'DEPLOY_BRANCH', 'Unknown')\n deploy_commit_id = getattr(settings, 'DEPLOY_COMMIT_ID', 'Unknown')\n deploy_commit_full_id = getattr(settings, 'DEPLOY_COMMIT_FULL_ID', 'Unknown')\n\n return dict(\n current_site=current_site,\n django_version=django_version,\n debug=debug,\n deploy_tag=deploy_tag,\n deploy_branch=deploy_branch,\n deploy_commit_id=deploy_commit_id,\n deploy_commit_full_id=deploy_commit_full_id\n )\n\n\ndef get_current_path_without_lang(request):\n \"\"\"Return current path without lang.\"\"\"\n path = request.get_full_path()\n path_bits = path.split('/')\n path = '/'.join(path_bits[2:])\n return {'current_path_without_lang': path}\n\n\ndef extra_pages_context(request):\n \"\"\"Add context information of an RSR Page.\"\"\"\n if request.rsr_page:\n page = request.rsr_page\n return {\n 'rsr_page': page,\n 'favicon': page.favicon,\n 'logo': page.logo,\n 'organisation': page.organisation,\n 'return_url': page.return_url,\n 'return_url_text': page.custom_return_url_text,\n 'stylesheet': page.stylesheet,\n 'akvoapp_root_url': '//{}'.format(settings.AKVOAPP_DOMAIN),\n 'domain_url': '//{}'.format(settings.RSR_DOMAIN),\n 'no_facebook': not page.facebook_button,\n 'facebook_app_id': page.facebook_app_id,\n 'no_twitter': not page.twitter_button,\n }\n\n return {}\n", "path": "akvo/rsr/context_processors.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\nAkvo RSR is covered by the GNU Affero General Public License.\n\nSee more details in the license.txt file located at the root folder of the\nAkvo RSR module. For additional details on the GNU license please see\n< http://www.gnu.org/licenses/agpl.html >.\n\"\"\"\n\nimport django\n\nfrom django.conf import settings\nfrom django.core.exceptions import DisallowedHost\nfrom django.contrib.sites.models import get_current_site\n\n\ndef extra_context(request, protocol=\"http\"):\n \"\"\"Add information to the request context.\"\"\"\n try:\n current_site = get_current_site(request)\n except DisallowedHost:\n current_site = None\n\n django_version = django.get_version()\n debug = getattr(settings, 'DEBUG', False)\n deploy_tag = getattr(settings, 'DEPLOY_TAG', 'Unknown')\n deploy_branch = getattr(settings, 'DEPLOY_BRANCH', 'Unknown')\n deploy_commit_id = getattr(settings, 'DEPLOY_COMMIT_ID', 'Unknown')\n deploy_commit_full_id = getattr(settings, 'DEPLOY_COMMIT_FULL_ID', 'Unknown')\n\n return dict(\n current_site=current_site,\n django_version=django_version,\n debug=debug,\n deploy_tag=deploy_tag,\n deploy_branch=deploy_branch,\n deploy_commit_id=deploy_commit_id,\n deploy_commit_full_id=deploy_commit_full_id\n )\n\n\ndef get_current_path_without_lang(request):\n \"\"\"Return current path without lang.\"\"\"\n path = request.get_full_path()\n path_bits = path.split('/')\n path = '/'.join(path_bits[2:])\n return {'current_path_without_lang': path}\n\n\ndef extra_pages_context(request):\n \"\"\"Add context information of an RSR Page.\"\"\"\n if request.rsr_page:\n page = request.rsr_page\n return {\n 'rsr_page': page,\n 'favicon': page.favicon,\n 'logo': page.logo,\n 'organisation': page.organisation,\n 'return_url': page.return_url,\n 'return_url_text': page.custom_return_url_text,\n 'page_stylesheet': page.stylesheet,\n 'akvoapp_root_url': '//{}'.format(settings.AKVOAPP_DOMAIN),\n 'domain_url': '//{}'.format(settings.RSR_DOMAIN),\n 'no_facebook': not page.facebook_button,\n 'facebook_app_id': page.facebook_app_id,\n 'no_twitter': not page.twitter_button,\n }\n\n return {}\n", "path": "akvo/rsr/context_processors.py"}]}
| 956 | 145 |
gh_patches_debug_129
|
rasdani/github-patches
|
git_diff
|
librosa__librosa-1839
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
librosa 0.10.2 is not compatible with matplotlib <3.5
***BEFORE POSTING A BUG REPORT*** Please look through [existing issues (both open and closed)](https://github.com/librosa/librosa/issues?q=is%3Aissue) to see if it's already been reported or fixed!
**librosa 0.10.2 is not imcompatible with matplotlib.colormap**
When I try to user librosa.display, it reports the following error: cannot import name 'colormaps' from 'matplotlib'

**error code**
<!--
Example:
```
import librosa.display
import matplotlib.pyplot as plt
import numpy as np
-->
**Expected behavior**
A clear and concise description of what you expected to happen.
**Screenshots**
If applicable, add screenshots to help explain your problem.
**Software versions***

**Additional context**
I have tried to change the version of matplotlib, but it does not work. And the versions I have tried are: 2.0.0, 3.0.0
librosa 0.10.2 is not compatible with matplotlib <3.5
***BEFORE POSTING A BUG REPORT*** Please look through [existing issues (both open and closed)](https://github.com/librosa/librosa/issues?q=is%3Aissue) to see if it's already been reported or fixed!
**librosa 0.10.2 is not imcompatible with matplotlib.colormap**
When I try to user librosa.display, it reports the following error: cannot import name 'colormaps' from 'matplotlib'

**error code**
<!--
Example:
```
import librosa.display
import matplotlib.pyplot as plt
import numpy as np
-->
**Expected behavior**
A clear and concise description of what you expected to happen.
**Screenshots**
If applicable, add screenshots to help explain your problem.
**Software versions***

**Additional context**
I have tried to change the version of matplotlib, but it does not work. And the versions I have tried are: 2.0.0, 3.0.0
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `librosa/version.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 """Version info"""
4
5 import sys
6 import importlib
7
8 short_version = "0.10"
9 version = "0.10.2"
10
11
12 def __get_mod_version(modname):
13 try:
14 if modname in sys.modules:
15 mod = sys.modules[modname]
16 else:
17 mod = importlib.import_module(modname)
18 try:
19 return mod.__version__
20 except AttributeError:
21 return "installed, no version number available"
22
23 except ImportError:
24 return None
25
26
27 def show_versions() -> None:
28 """Return the version information for all librosa dependencies."""
29 core_deps = [
30 "audioread",
31 "numpy",
32 "scipy",
33 "sklearn",
34 "joblib",
35 "decorator",
36 "numba",
37 "soundfile",
38 "pooch",
39 "soxr",
40 "typing_extensions",
41 "lazy_loader",
42 "msgpack",
43 ]
44
45 extra_deps = [
46 "numpydoc",
47 "sphinx",
48 "sphinx_rtd_theme",
49 "matplotlib",
50 "sphinx_multiversion",
51 "sphinx_gallery",
52 "mir_eval",
53 "ipython",
54 "sphinxcontrib.rsvgconverter",
55 "pytest",
56 "pytest_mpl",
57 "pytest_cov",
58 "samplerate",
59 "resampy",
60 "presets",
61 "packaging",
62 ]
63
64 print("INSTALLED VERSIONS")
65 print("------------------")
66 print(f"python: {sys.version}\n")
67 print(f"librosa: {version}\n")
68 for dep in core_deps:
69 print("{}: {}".format(dep, __get_mod_version(dep)))
70 print("")
71 for dep in extra_deps:
72 print("{}: {}".format(dep, __get_mod_version(dep)))
73
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/librosa/version.py b/librosa/version.py
--- a/librosa/version.py
+++ b/librosa/version.py
@@ -6,7 +6,7 @@
import importlib
short_version = "0.10"
-version = "0.10.2"
+version = "0.10.2.post1"
def __get_mod_version(modname):
|
{"golden_diff": "diff --git a/librosa/version.py b/librosa/version.py\n--- a/librosa/version.py\n+++ b/librosa/version.py\n@@ -6,7 +6,7 @@\n import importlib\n \n short_version = \"0.10\"\n-version = \"0.10.2\"\n+version = \"0.10.2.post1\"\n \n \n def __get_mod_version(modname):\n", "issue": "librosa 0.10.2 is not compatible with matplotlib <3.5\n***BEFORE POSTING A BUG REPORT*** Please look through [existing issues (both open and closed)](https://github.com/librosa/librosa/issues?q=is%3Aissue) to see if it's already been reported or fixed!\r\n\r\n\r\n**librosa 0.10.2 is not imcompatible with matplotlib.colormap**\r\n When I try to user librosa.display, it reports the following error: cannot import name 'colormaps' from 'matplotlib'\r\n\r\n\r\n\r\n\r\n**error code**\r\n<!--\r\nExample:\r\n```\r\nimport librosa.display\r\nimport matplotlib.pyplot as plt\r\nimport numpy as np\r\n\r\n-->\r\n**Expected behavior**\r\nA clear and concise description of what you expected to happen.\r\n\r\n**Screenshots**\r\nIf applicable, add screenshots to help explain your problem.\r\n\r\n**Software versions***\r\n\r\n\r\n\r\n**Additional context**\r\nI have tried to change the version of matplotlib, but it does not work. And the versions I have tried are: 2.0.0, 3.0.0\r\n\nlibrosa 0.10.2 is not compatible with matplotlib <3.5\n***BEFORE POSTING A BUG REPORT*** Please look through [existing issues (both open and closed)](https://github.com/librosa/librosa/issues?q=is%3Aissue) to see if it's already been reported or fixed!\r\n\r\n\r\n**librosa 0.10.2 is not imcompatible with matplotlib.colormap**\r\n When I try to user librosa.display, it reports the following error: cannot import name 'colormaps' from 'matplotlib'\r\n\r\n\r\n\r\n\r\n**error code**\r\n<!--\r\nExample:\r\n```\r\nimport librosa.display\r\nimport matplotlib.pyplot as plt\r\nimport numpy as np\r\n\r\n-->\r\n**Expected behavior**\r\nA clear and concise description of what you expected to happen.\r\n\r\n**Screenshots**\r\nIf applicable, add screenshots to help explain your problem.\r\n\r\n**Software versions***\r\n\r\n\r\n\r\n**Additional context**\r\nI have tried to change the version of matplotlib, but it does not work. And the versions I have tried are: 2.0.0, 3.0.0\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"Version info\"\"\"\n\nimport sys\nimport importlib\n\nshort_version = \"0.10\"\nversion = \"0.10.2\"\n\n\ndef __get_mod_version(modname):\n try:\n if modname in sys.modules:\n mod = sys.modules[modname]\n else:\n mod = importlib.import_module(modname)\n try:\n return mod.__version__\n except AttributeError:\n return \"installed, no version number available\"\n\n except ImportError:\n return None\n\n\ndef show_versions() -> None:\n \"\"\"Return the version information for all librosa dependencies.\"\"\"\n core_deps = [\n \"audioread\",\n \"numpy\",\n \"scipy\",\n \"sklearn\",\n \"joblib\",\n \"decorator\",\n \"numba\",\n \"soundfile\",\n \"pooch\",\n \"soxr\",\n \"typing_extensions\",\n \"lazy_loader\",\n \"msgpack\",\n ]\n\n extra_deps = [\n \"numpydoc\",\n \"sphinx\",\n \"sphinx_rtd_theme\",\n \"matplotlib\",\n \"sphinx_multiversion\",\n \"sphinx_gallery\",\n \"mir_eval\",\n \"ipython\",\n \"sphinxcontrib.rsvgconverter\",\n \"pytest\",\n \"pytest_mpl\",\n \"pytest_cov\",\n \"samplerate\",\n \"resampy\",\n \"presets\",\n \"packaging\",\n ]\n\n print(\"INSTALLED VERSIONS\")\n print(\"------------------\")\n print(f\"python: {sys.version}\\n\")\n print(f\"librosa: {version}\\n\")\n for dep in core_deps:\n print(\"{}: {}\".format(dep, __get_mod_version(dep)))\n print(\"\")\n for dep in extra_deps:\n print(\"{}: {}\".format(dep, __get_mod_version(dep)))\n", "path": "librosa/version.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"Version info\"\"\"\n\nimport sys\nimport importlib\n\nshort_version = \"0.10\"\nversion = \"0.10.2.post1\"\n\n\ndef __get_mod_version(modname):\n try:\n if modname in sys.modules:\n mod = sys.modules[modname]\n else:\n mod = importlib.import_module(modname)\n try:\n return mod.__version__\n except AttributeError:\n return \"installed, no version number available\"\n\n except ImportError:\n return None\n\n\ndef show_versions() -> None:\n \"\"\"Return the version information for all librosa dependencies.\"\"\"\n core_deps = [\n \"audioread\",\n \"numpy\",\n \"scipy\",\n \"sklearn\",\n \"joblib\",\n \"decorator\",\n \"numba\",\n \"soundfile\",\n \"pooch\",\n \"soxr\",\n \"typing_extensions\",\n \"lazy_loader\",\n \"msgpack\",\n ]\n\n extra_deps = [\n \"numpydoc\",\n \"sphinx\",\n \"sphinx_rtd_theme\",\n \"matplotlib\",\n \"sphinx_multiversion\",\n \"sphinx_gallery\",\n \"mir_eval\",\n \"ipython\",\n \"sphinxcontrib.rsvgconverter\",\n \"pytest\",\n \"pytest_mpl\",\n \"pytest_cov\",\n \"samplerate\",\n \"resampy\",\n \"presets\",\n \"packaging\",\n ]\n\n print(\"INSTALLED VERSIONS\")\n print(\"------------------\")\n print(f\"python: {sys.version}\\n\")\n print(f\"librosa: {version}\\n\")\n for dep in core_deps:\n print(\"{}: {}\".format(dep, __get_mod_version(dep)))\n print(\"\")\n for dep in extra_deps:\n print(\"{}: {}\".format(dep, __get_mod_version(dep)))\n", "path": "librosa/version.py"}]}
| 1,473 | 87 |
gh_patches_debug_23491
|
rasdani/github-patches
|
git_diff
|
ESMCI__cime-1396
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Build pFUnit on some other machines
We should build pFUnit on some other machines so we can run unit tests there:
- cheyenne
- hobart
Instructions for building pFUnit are:
1. Download pFUnit from
http://sourceforge.net/projects/pfunit/files/latest/download
2. Set the PFUNIT environment variable. For example::
```
export PFUNIT=/glade/p/cesmdata/cseg/tools/pFUnit/pFUnit3.2.8_cheyenne_Intel17.0.1_MPI_openMP
```
3. Build pFUnit:
```
mkdir build
cd build
cmake -DMPI=YES -DOPENMP=YES ..
make -j 4
```
4. Run pFUnit's own unit tests:
```
make tests
```
Note: this didn't work on yellowstone. Instead, I had to do it by hand:
```
DAV_CORES=4 execca
mpirun.lsf tests/tests.x
```
5. Install pFUnit on your system:
```
make install INSTALL_DIR=$PFUNIT
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `scripts/lib/CIME/BuildTools/cmakemacroswriter.py`
Content:
```
1 """Classes used to write build system files.
2
3 The classes here are used to write out settings for use by Makefile and CMake
4 build systems. The two relevant classes are CMakeMacroWriter and
5 MakeMacroWriter, which encapsulate the information necessary to write CMake and
6 Makefile formatted text, respectively. See the docstrings for those classes for
7 more.
8 """
9
10 # This is not the most useful check.
11 # pylint: disable=invalid-name
12
13 from CIME.BuildTools.macrowriterbase import MacroWriterBase
14 from CIME.XML.standard_module_setup import *
15 logger = logging.getLogger(__name__)
16
17
18 class CMakeMacroWriter(MacroWriterBase):
19
20 """Macro writer for the CMake format.
21
22 For details on the provided methods, see MacroWriterBase, which this
23 class inherits from.
24 """
25
26 def __init__(self, output):
27 """Initialize a CMake macro writer.
28
29 Arguments:
30 output - File-like object (probably an io.TextIOWrapper), which
31 will be written to.
32 """
33 super(CMakeMacroWriter, self).__init__(output)
34 # This counter is for avoiding name conflicts in temporary
35 # variables used for shell commands.
36 self._var_num = 0
37
38 def environment_variable_string(self, name):
39 """Return an environment variable reference.
40
41 >>> import io
42 >>> s = io.StringIO()
43 >>> CMakeMacroWriter(s).environment_variable_string("foo")
44 '$ENV{foo}'
45 """
46 return "$ENV{" + name + "}"
47
48 def shell_command_strings(self, command):
49 # pylint: disable=line-too-long
50 """Return strings used to get the output of a shell command.
51
52 >>> import io
53 >>> s = io.StringIO()
54 >>> set_up, inline, tear_down = CMakeMacroWriter(s).shell_command_strings("echo bar")
55 >>> set_up
56 'execute_process(COMMAND echo bar OUTPUT_VARIABLE CIME_TEMP_SHELL0 OUTPUT_STRIP_TRAILING_WHITESPACE)'
57 >>> inline
58 '${CIME_TEMP_SHELL0}'
59 >>> tear_down
60 'unset(CIME_TEMP_SHELL0)'
61 """
62 # pylint: enable=line-too-long
63 # Create a unique variable name, then increment variable number
64 # counter so that we get a different value next time.
65 var_name = "CIME_TEMP_SHELL" + str(self._var_num)
66 self._var_num += 1
67 set_up = "execute_process(COMMAND " + command + \
68 " OUTPUT_VARIABLE " + var_name + \
69 " OUTPUT_STRIP_TRAILING_WHITESPACE)"
70 tear_down = "unset(" + var_name + ")"
71 return (set_up, "${" + var_name + "}", tear_down)
72
73 def variable_string(self, name):
74 """Return a string to refer to a variable with the given name.
75
76 >>> import io
77 >>> s = io.StringIO()
78 >>> CMakeMacroWriter(s).variable_string("foo")
79 '${foo}'
80 """
81 return "${" + name + "}"
82
83 def set_variable(self, name, value):
84 """Write out a statement setting a variable to some value.
85
86 >>> import io
87 >>> s = io.StringIO()
88 >>> CMakeMacroWriter(s).set_variable("foo", "bar")
89 >>> s.getvalue()
90 u'set(foo "bar")\\n'
91 """
92 self.write_line("set(" + name + ' "' + value + '")')
93
94 def start_ifeq(self, left, right):
95 """Write out a statement to start a conditional block.
96
97 >>> import io
98 >>> s = io.StringIO()
99 >>> CMakeMacroWriter(s).start_ifeq("foo", "bar")
100 >>> s.getvalue()
101 u'if("foo" STREQUAL "bar")\\n'
102 """
103 self.write_line('if("' + left + '" STREQUAL "' + right + '")')
104 self.indent_right()
105
106 def end_ifeq(self):
107 """Write out a statement to end a block started with start_ifeq.
108
109 >>> import io
110 >>> s = io.StringIO()
111 >>> writer = CMakeMacroWriter(s)
112 >>> writer.start_ifeq("foo", "bar")
113 >>> writer.set_variable("foo2", "bar2")
114 >>> writer.end_ifeq()
115 >>> s.getvalue()
116 u'if("foo" STREQUAL "bar")\\n set(foo2 "bar2")\\nendif()\\n'
117 """
118 self.indent_left()
119 self.write_line("endif()")
120
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/scripts/lib/CIME/BuildTools/cmakemacroswriter.py b/scripts/lib/CIME/BuildTools/cmakemacroswriter.py
--- a/scripts/lib/CIME/BuildTools/cmakemacroswriter.py
+++ b/scripts/lib/CIME/BuildTools/cmakemacroswriter.py
@@ -89,7 +89,8 @@
>>> s.getvalue()
u'set(foo "bar")\\n'
"""
- self.write_line("set(" + name + ' "' + value + '")')
+ value_transformed = self._transform_value(value)
+ self.write_line("set(" + name + ' "' + value_transformed + '")')
def start_ifeq(self, left, right):
"""Write out a statement to start a conditional block.
@@ -117,3 +118,22 @@
"""
self.indent_left()
self.write_line("endif()")
+
+ def _transform_value(self, value):
+ """Some elements need their values transformed in some way for CMake to handle them properly.
+ This method does those transformations.
+
+ Args:
+ - value (str): value of element
+
+ Returns transformed value
+ """
+
+ # Not all variables need leading & trailing whitespace removed, but some
+ # do. In particular, compiler variables (MPICC, MPICXX, MPIFC, SCC,
+ # SCXX, SFC) are only handled correctly if leading & trailing whitespace
+ # is removed. It doesn't seem to hurt to remove whitespace from all
+ # variables.
+ value_transformed = value.strip()
+
+ return value_transformed
|
{"golden_diff": "diff --git a/scripts/lib/CIME/BuildTools/cmakemacroswriter.py b/scripts/lib/CIME/BuildTools/cmakemacroswriter.py\n--- a/scripts/lib/CIME/BuildTools/cmakemacroswriter.py\n+++ b/scripts/lib/CIME/BuildTools/cmakemacroswriter.py\n@@ -89,7 +89,8 @@\n >>> s.getvalue()\n u'set(foo \"bar\")\\\\n'\n \"\"\"\n- self.write_line(\"set(\" + name + ' \"' + value + '\")')\n+ value_transformed = self._transform_value(value)\n+ self.write_line(\"set(\" + name + ' \"' + value_transformed + '\")')\n \n def start_ifeq(self, left, right):\n \"\"\"Write out a statement to start a conditional block.\n@@ -117,3 +118,22 @@\n \"\"\"\n self.indent_left()\n self.write_line(\"endif()\")\n+\n+ def _transform_value(self, value):\n+ \"\"\"Some elements need their values transformed in some way for CMake to handle them properly.\n+ This method does those transformations.\n+\n+ Args:\n+ - value (str): value of element\n+\n+ Returns transformed value\n+ \"\"\"\n+\n+ # Not all variables need leading & trailing whitespace removed, but some\n+ # do. In particular, compiler variables (MPICC, MPICXX, MPIFC, SCC,\n+ # SCXX, SFC) are only handled correctly if leading & trailing whitespace\n+ # is removed. It doesn't seem to hurt to remove whitespace from all\n+ # variables.\n+ value_transformed = value.strip()\n+\n+ return value_transformed\n", "issue": "Build pFUnit on some other machines\nWe should build pFUnit on some other machines so we can run unit tests there:\r\n\r\n- cheyenne\r\n- hobart\r\n\r\nInstructions for building pFUnit are:\r\n\r\n1. Download pFUnit from\r\n http://sourceforge.net/projects/pfunit/files/latest/download\r\n\r\n2. Set the PFUNIT environment variable. For example::\r\n\r\n ```\r\n export PFUNIT=/glade/p/cesmdata/cseg/tools/pFUnit/pFUnit3.2.8_cheyenne_Intel17.0.1_MPI_openMP\r\n ```\r\n\r\n3. Build pFUnit:\r\n\r\n```\r\n mkdir build\r\n cd build\r\n cmake -DMPI=YES -DOPENMP=YES ..\r\n make -j 4\r\n```\r\n\r\n4. Run pFUnit's own unit tests:\r\n\r\n```\r\n make tests\r\n```\r\n\r\n Note: this didn't work on yellowstone. Instead, I had to do it by hand:\r\n\r\n```\r\n DAV_CORES=4 execca\r\n mpirun.lsf tests/tests.x\r\n```\r\n\r\n5. Install pFUnit on your system:\r\n\r\n```\r\n make install INSTALL_DIR=$PFUNIT\r\n```\n", "before_files": [{"content": "\"\"\"Classes used to write build system files.\n\nThe classes here are used to write out settings for use by Makefile and CMake\nbuild systems. The two relevant classes are CMakeMacroWriter and\nMakeMacroWriter, which encapsulate the information necessary to write CMake and\nMakefile formatted text, respectively. See the docstrings for those classes for\nmore.\n\"\"\"\n\n# This is not the most useful check.\n# pylint: disable=invalid-name\n\nfrom CIME.BuildTools.macrowriterbase import MacroWriterBase\nfrom CIME.XML.standard_module_setup import *\nlogger = logging.getLogger(__name__)\n\n\nclass CMakeMacroWriter(MacroWriterBase):\n\n \"\"\"Macro writer for the CMake format.\n\n For details on the provided methods, see MacroWriterBase, which this\n class inherits from.\n \"\"\"\n\n def __init__(self, output):\n \"\"\"Initialize a CMake macro writer.\n\n Arguments:\n output - File-like object (probably an io.TextIOWrapper), which\n will be written to.\n \"\"\"\n super(CMakeMacroWriter, self).__init__(output)\n # This counter is for avoiding name conflicts in temporary\n # variables used for shell commands.\n self._var_num = 0\n\n def environment_variable_string(self, name):\n \"\"\"Return an environment variable reference.\n\n >>> import io\n >>> s = io.StringIO()\n >>> CMakeMacroWriter(s).environment_variable_string(\"foo\")\n '$ENV{foo}'\n \"\"\"\n return \"$ENV{\" + name + \"}\"\n\n def shell_command_strings(self, command):\n # pylint: disable=line-too-long\n \"\"\"Return strings used to get the output of a shell command.\n\n >>> import io\n >>> s = io.StringIO()\n >>> set_up, inline, tear_down = CMakeMacroWriter(s).shell_command_strings(\"echo bar\")\n >>> set_up\n 'execute_process(COMMAND echo bar OUTPUT_VARIABLE CIME_TEMP_SHELL0 OUTPUT_STRIP_TRAILING_WHITESPACE)'\n >>> inline\n '${CIME_TEMP_SHELL0}'\n >>> tear_down\n 'unset(CIME_TEMP_SHELL0)'\n \"\"\"\n # pylint: enable=line-too-long\n # Create a unique variable name, then increment variable number\n # counter so that we get a different value next time.\n var_name = \"CIME_TEMP_SHELL\" + str(self._var_num)\n self._var_num += 1\n set_up = \"execute_process(COMMAND \" + command + \\\n \" OUTPUT_VARIABLE \" + var_name + \\\n \" OUTPUT_STRIP_TRAILING_WHITESPACE)\"\n tear_down = \"unset(\" + var_name + \")\"\n return (set_up, \"${\" + var_name + \"}\", tear_down)\n\n def variable_string(self, name):\n \"\"\"Return a string to refer to a variable with the given name.\n\n >>> import io\n >>> s = io.StringIO()\n >>> CMakeMacroWriter(s).variable_string(\"foo\")\n '${foo}'\n \"\"\"\n return \"${\" + name + \"}\"\n\n def set_variable(self, name, value):\n \"\"\"Write out a statement setting a variable to some value.\n\n >>> import io\n >>> s = io.StringIO()\n >>> CMakeMacroWriter(s).set_variable(\"foo\", \"bar\")\n >>> s.getvalue()\n u'set(foo \"bar\")\\\\n'\n \"\"\"\n self.write_line(\"set(\" + name + ' \"' + value + '\")')\n\n def start_ifeq(self, left, right):\n \"\"\"Write out a statement to start a conditional block.\n\n >>> import io\n >>> s = io.StringIO()\n >>> CMakeMacroWriter(s).start_ifeq(\"foo\", \"bar\")\n >>> s.getvalue()\n u'if(\"foo\" STREQUAL \"bar\")\\\\n'\n \"\"\"\n self.write_line('if(\"' + left + '\" STREQUAL \"' + right + '\")')\n self.indent_right()\n\n def end_ifeq(self):\n \"\"\"Write out a statement to end a block started with start_ifeq.\n\n >>> import io\n >>> s = io.StringIO()\n >>> writer = CMakeMacroWriter(s)\n >>> writer.start_ifeq(\"foo\", \"bar\")\n >>> writer.set_variable(\"foo2\", \"bar2\")\n >>> writer.end_ifeq()\n >>> s.getvalue()\n u'if(\"foo\" STREQUAL \"bar\")\\\\n set(foo2 \"bar2\")\\\\nendif()\\\\n'\n \"\"\"\n self.indent_left()\n self.write_line(\"endif()\")\n", "path": "scripts/lib/CIME/BuildTools/cmakemacroswriter.py"}], "after_files": [{"content": "\"\"\"Classes used to write build system files.\n\nThe classes here are used to write out settings for use by Makefile and CMake\nbuild systems. The two relevant classes are CMakeMacroWriter and\nMakeMacroWriter, which encapsulate the information necessary to write CMake and\nMakefile formatted text, respectively. See the docstrings for those classes for\nmore.\n\"\"\"\n\n# This is not the most useful check.\n# pylint: disable=invalid-name\n\nfrom CIME.BuildTools.macrowriterbase import MacroWriterBase\nfrom CIME.XML.standard_module_setup import *\nlogger = logging.getLogger(__name__)\n\n\nclass CMakeMacroWriter(MacroWriterBase):\n\n \"\"\"Macro writer for the CMake format.\n\n For details on the provided methods, see MacroWriterBase, which this\n class inherits from.\n \"\"\"\n\n def __init__(self, output):\n \"\"\"Initialize a CMake macro writer.\n\n Arguments:\n output - File-like object (probably an io.TextIOWrapper), which\n will be written to.\n \"\"\"\n super(CMakeMacroWriter, self).__init__(output)\n # This counter is for avoiding name conflicts in temporary\n # variables used for shell commands.\n self._var_num = 0\n\n def environment_variable_string(self, name):\n \"\"\"Return an environment variable reference.\n\n >>> import io\n >>> s = io.StringIO()\n >>> CMakeMacroWriter(s).environment_variable_string(\"foo\")\n '$ENV{foo}'\n \"\"\"\n return \"$ENV{\" + name + \"}\"\n\n def shell_command_strings(self, command):\n # pylint: disable=line-too-long\n \"\"\"Return strings used to get the output of a shell command.\n\n >>> import io\n >>> s = io.StringIO()\n >>> set_up, inline, tear_down = CMakeMacroWriter(s).shell_command_strings(\"echo bar\")\n >>> set_up\n 'execute_process(COMMAND echo bar OUTPUT_VARIABLE CIME_TEMP_SHELL0 OUTPUT_STRIP_TRAILING_WHITESPACE)'\n >>> inline\n '${CIME_TEMP_SHELL0}'\n >>> tear_down\n 'unset(CIME_TEMP_SHELL0)'\n \"\"\"\n # pylint: enable=line-too-long\n # Create a unique variable name, then increment variable number\n # counter so that we get a different value next time.\n var_name = \"CIME_TEMP_SHELL\" + str(self._var_num)\n self._var_num += 1\n set_up = \"execute_process(COMMAND \" + command + \\\n \" OUTPUT_VARIABLE \" + var_name + \\\n \" OUTPUT_STRIP_TRAILING_WHITESPACE)\"\n tear_down = \"unset(\" + var_name + \")\"\n return (set_up, \"${\" + var_name + \"}\", tear_down)\n\n def variable_string(self, name):\n \"\"\"Return a string to refer to a variable with the given name.\n\n >>> import io\n >>> s = io.StringIO()\n >>> CMakeMacroWriter(s).variable_string(\"foo\")\n '${foo}'\n \"\"\"\n return \"${\" + name + \"}\"\n\n def set_variable(self, name, value):\n \"\"\"Write out a statement setting a variable to some value.\n\n >>> import io\n >>> s = io.StringIO()\n >>> CMakeMacroWriter(s).set_variable(\"foo\", \"bar\")\n >>> s.getvalue()\n u'set(foo \"bar\")\\\\n'\n \"\"\"\n value_transformed = self._transform_value(value)\n self.write_line(\"set(\" + name + ' \"' + value_transformed + '\")')\n\n def start_ifeq(self, left, right):\n \"\"\"Write out a statement to start a conditional block.\n\n >>> import io\n >>> s = io.StringIO()\n >>> CMakeMacroWriter(s).start_ifeq(\"foo\", \"bar\")\n >>> s.getvalue()\n u'if(\"foo\" STREQUAL \"bar\")\\\\n'\n \"\"\"\n self.write_line('if(\"' + left + '\" STREQUAL \"' + right + '\")')\n self.indent_right()\n\n def end_ifeq(self):\n \"\"\"Write out a statement to end a block started with start_ifeq.\n\n >>> import io\n >>> s = io.StringIO()\n >>> writer = CMakeMacroWriter(s)\n >>> writer.start_ifeq(\"foo\", \"bar\")\n >>> writer.set_variable(\"foo2\", \"bar2\")\n >>> writer.end_ifeq()\n >>> s.getvalue()\n u'if(\"foo\" STREQUAL \"bar\")\\\\n set(foo2 \"bar2\")\\\\nendif()\\\\n'\n \"\"\"\n self.indent_left()\n self.write_line(\"endif()\")\n\n def _transform_value(self, value):\n \"\"\"Some elements need their values transformed in some way for CMake to handle them properly.\n This method does those transformations.\n\n Args:\n - value (str): value of element\n\n Returns transformed value\n \"\"\"\n\n # Not all variables need leading & trailing whitespace removed, but some\n # do. In particular, compiler variables (MPICC, MPICXX, MPIFC, SCC,\n # SCXX, SFC) are only handled correctly if leading & trailing whitespace\n # is removed. It doesn't seem to hurt to remove whitespace from all\n # variables.\n value_transformed = value.strip()\n\n return value_transformed\n", "path": "scripts/lib/CIME/BuildTools/cmakemacroswriter.py"}]}
| 1,748 | 368 |
gh_patches_debug_18902
|
rasdani/github-patches
|
git_diff
|
fossasia__open-event-server-7197
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Stripe publishable key should be accessible to non-admin user
The settings schema for non-admin user does not contain stripe publishable key and hence non-admin user cannot add stripe to its event.
https://api.eventyay.com/v1/settings should contain stripe publishable key
See #6277 as well
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `app/api/schema/settings.py`
Content:
```
1 from marshmallow_jsonapi import fields
2 from marshmallow_jsonapi.flask import Schema
3
4 from app.api.helpers.utilities import dasherize
5 from app.settings import Environment
6 from utils.common import use_defaults
7
8
9 class SettingSchemaPublic(Schema):
10 """
11 Public Api schema for settings Model
12 """
13
14 class Meta:
15 """
16 Meta class for setting Api Schema
17 """
18
19 type_ = 'setting'
20 self_view = 'v1.setting_detail'
21 self_view_kwargs = {'id': '<id>'}
22 inflect = dasherize
23
24 id = fields.Str(dump_only=True)
25
26 # Name of the application. (Eg. Event Yay!, Open Event)
27 app_name = fields.Str(allow_none=True)
28
29 # Tagline for the application. (Eg. Event Management and Ticketing, Home)
30 tagline = fields.Str(allow_none=True)
31
32 # Order Expiry Time
33 order_expiry_time = fields.Integer(
34 allow_none=False, default=15, validate=lambda n: 1 <= n <= 60
35 )
36
37 # Maximum number of complex custom fields allowed for a given form
38 max_complex_custom_fields = fields.Integer(
39 allow_none=False, default=30, validate=lambda n: 1 <= n <= 30
40 )
41
42 # Google Analytics
43 analytics_key = fields.Str(allow_none=True)
44
45 # FB
46 fb_client_id = fields.Str(allow_none=True)
47
48 #
49 # Social links
50 #
51 google_url = fields.Str(allow_none=True)
52 github_url = fields.Str(allow_none=True)
53 twitter_url = fields.Str(allow_none=True)
54 support_url = fields.Str(allow_none=True)
55 facebook_url = fields.Str(allow_none=True)
56 instagram_url = fields.Str(allow_none=True)
57 youtube_url = fields.Str(allow_none=True)
58
59 # Url of Frontend
60 frontend_url = fields.Url(allow_none=True)
61
62 #
63 # Cookie Policy
64 #
65 cookie_policy = fields.Str(allow_none=True)
66 cookie_policy_link = fields.Str(allow_none=True)
67
68 #
69 # Online Payment Flags
70 #
71 is_paytm_activated = fields.Bool(default=False)
72 is_paypal_activated = fields.Bool(dump_only=True)
73 is_stripe_activated = fields.Bool(dump_only=True)
74 is_omise_activated = fields.Bool(dump_only=True)
75 is_alipay_activated = fields.Bool(dump_only=True)
76
77
78 class SettingSchemaNonAdmin(SettingSchemaPublic):
79 """
80 Non Admin Api schema for settings Model
81 """
82
83 class Meta:
84 """
85 Meta class for setting Api Schema
86 """
87
88 type_ = 'setting'
89 self_view = 'v1.setting_detail'
90 self_view_kwargs = {'id': '<id>'}
91 inflect = dasherize
92
93 id = fields.Str(dump_only=True)
94
95 #
96 # Generators
97 #
98 android_app_url = fields.Str(allow_none=True)
99 web_app_url = fields.Str(allow_none=True)
100
101
102 @use_defaults()
103 class SettingSchemaAdmin(SettingSchemaNonAdmin):
104 """
105 Admin Api schema for settings Model
106 """
107
108 class Meta:
109 """
110 Meta class for setting Api Schema
111 """
112
113 type_ = 'setting'
114 self_view = 'v1.setting_detail'
115 self_view_kwargs = {'id': '<id>'}
116 inflect = dasherize
117
118 id = fields.Str(dump_only=True)
119 #
120 # General
121 #
122
123 app_environment = fields.Str(default=Environment.PRODUCTION)
124
125 # Static domain
126 static_domain = fields.Str(allow_none=True)
127
128 #
129 # STORAGE
130 #
131
132 # storage place, local, s3, .. can be more in future
133 storage_place = fields.Str(allow_none=True)
134 # S3
135 aws_key = fields.Str(allow_none=True)
136 aws_secret = fields.Str(allow_none=True)
137 aws_bucket_name = fields.Str(allow_none=True)
138 aws_region = fields.Str(allow_none=True)
139 # Google Storage
140 gs_key = fields.Str(allow_none=True)
141 gs_secret = fields.Str(allow_none=True)
142 gs_bucket_name = fields.Str(allow_none=True)
143
144 #
145 # CAPTCHA
146 #
147
148 # Google reCAPTCHA
149 is_google_recaptcha_enabled = fields.Bool(allow_none=False, default=False)
150 google_recaptcha_site = fields.Str(allow_none=True)
151 google_recaptcha_secret = fields.Str(allow_none=True)
152
153 #
154 # Social Login
155 #
156
157 # Google Auth
158 google_client_id = fields.Str(allow_none=True)
159 google_client_secret = fields.Str(allow_none=True)
160 # FB
161 fb_client_id = fields.Str(allow_none=True)
162 fb_client_secret = fields.Str(allow_none=True)
163 # Twitter
164 tw_consumer_key = fields.Str(allow_none=True)
165 tw_consumer_secret = fields.Str(allow_none=True)
166 # Instagram
167 in_client_id = fields.Str(allow_none=True)
168 in_client_secret = fields.Str(allow_none=True)
169
170 #
171 # Payment Gateways
172 #
173
174 # Stripe Credantials
175 stripe_client_id = fields.Str(allow_none=True)
176 stripe_publishable_key = fields.Str(allow_none=True)
177 stripe_secret_key = fields.Str(allow_none=True)
178 stripe_test_client_id = fields.Str(allow_none=True)
179 stripe_test_secret_key = fields.Str(allow_none=True)
180 stripe_test_publishable_key = fields.Str(allow_none=True)
181
182 # PayPal Credentials
183 paypal_mode = fields.Str(allow_none=True)
184 paypal_client = fields.Str(allow_none=True)
185 paypal_secret = fields.Str(allow_none=True)
186 paypal_sandbox_client = fields.Str(allow_none=True)
187 paypal_sandbox_secret = fields.Str(allow_none=True)
188
189 # Omise Credentials
190 omise_mode = fields.Str(allow_none=True)
191 omise_test_public = fields.Str(allow_none=True)
192 omise_test_secret = fields.Str(allow_none=True)
193 omise_live_public = fields.Str(allow_none=True)
194 omise_live_secret = fields.Str(allow_none=True)
195
196 # Alipay Credentials
197 alipay_publishable_key = fields.Str(allow_none=True)
198 alipay_secret_key = fields.Str(allow_none=True)
199
200 # payTM credentials
201 paytm_mode = fields.Str(allow_none=True)
202 paytm_live_merchant = fields.Str(allow_none=True)
203 paytm_live_secret = fields.Str(allow_none=True)
204 paytm_sandbox_merchant = fields.Str(allow_none=True)
205 paytm_sandbox_secret = fields.Str(allow_none=True)
206 #
207 # EMAIL
208 #
209
210 # Email service. (sendgrid,smtp)
211 email_service = fields.Str(allow_none=True)
212 email_from = fields.Str(allow_none=True)
213 email_from_name = fields.Str(allow_none=True)
214 # Sendgrid
215 sendgrid_key = fields.Str(allow_none=True)
216 # SMTP
217 smtp_host = fields.Str(allow_none=True)
218 smtp_username = fields.Str(allow_none=True)
219 smtp_password = fields.Str(allow_none=True)
220 smtp_port = fields.Integer(allow_none=True)
221 smtp_encryption = fields.Str(allow_none=True) # Can be tls, ssl, none
222
223 # Event Invoices settings
224 invoice_sending_day = fields.Integer(allow_none=False, default=1)
225 invoice_sending_timezone = fields.Str(allow_none=False, default="UTC")
226
227 # Admin Invoice Details
228 admin_billing_contact_name = fields.Str(allow_none=True)
229 admin_billing_phone = fields.Str(allow_none=True)
230 admin_billing_email = fields.Email(allow_none=True)
231 admin_billing_state = fields.Str(allow_none=True)
232 admin_billing_country = fields.Str(allow_none=True)
233 admin_billing_tax_info = fields.Str(allow_none=True)
234 admin_company = fields.Str(allow_none=True)
235 admin_billing_address = fields.Str(allow_none=True)
236 admin_billing_city = fields.Str(allow_none=True)
237 admin_billing_zip = fields.Str(allow_none=True)
238 admin_billing_additional_info = fields.Str(allow_none=True)
239
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/app/api/schema/settings.py b/app/api/schema/settings.py
--- a/app/api/schema/settings.py
+++ b/app/api/schema/settings.py
@@ -74,6 +74,34 @@
is_omise_activated = fields.Bool(dump_only=True)
is_alipay_activated = fields.Bool(dump_only=True)
+ #
+ # Payment Gateways
+ #
+
+ # Stripe Credantials
+ stripe_client_id = fields.Str(dump_only=True)
+ stripe_publishable_key = fields.Str(dump_only=True)
+ stripe_test_client_id = fields.Str(dump_only=True)
+ stripe_test_publishable_key = fields.Str(dump_only=True)
+
+ # PayPal Credentials
+ paypal_mode = fields.Str(dump_only=True)
+ paypal_client = fields.Str(dump_only=True)
+ paypal_sandbox_client = fields.Str(dump_only=True)
+
+ # Omise Credentials
+ omise_mode = fields.Str(dump_only=True)
+ omise_test_public = fields.Str(dump_only=True)
+ omise_live_public = fields.Str(dump_only=True)
+
+ # Alipay Credentials
+ alipay_publishable_key = fields.Str(dump_only=True)
+
+ # payTM credentials
+ paytm_mode = fields.Str(dump_only=True)
+ paytm_live_merchant = fields.Str(dump_only=True)
+ paytm_sandbox_merchant = fields.Str(dump_only=True)
+
class SettingSchemaNonAdmin(SettingSchemaPublic):
"""
|
{"golden_diff": "diff --git a/app/api/schema/settings.py b/app/api/schema/settings.py\n--- a/app/api/schema/settings.py\n+++ b/app/api/schema/settings.py\n@@ -74,6 +74,34 @@\n is_omise_activated = fields.Bool(dump_only=True)\n is_alipay_activated = fields.Bool(dump_only=True)\n \n+ #\n+ # Payment Gateways\n+ #\n+\n+ # Stripe Credantials\n+ stripe_client_id = fields.Str(dump_only=True)\n+ stripe_publishable_key = fields.Str(dump_only=True)\n+ stripe_test_client_id = fields.Str(dump_only=True)\n+ stripe_test_publishable_key = fields.Str(dump_only=True)\n+\n+ # PayPal Credentials\n+ paypal_mode = fields.Str(dump_only=True)\n+ paypal_client = fields.Str(dump_only=True)\n+ paypal_sandbox_client = fields.Str(dump_only=True)\n+\n+ # Omise Credentials\n+ omise_mode = fields.Str(dump_only=True)\n+ omise_test_public = fields.Str(dump_only=True)\n+ omise_live_public = fields.Str(dump_only=True)\n+\n+ # Alipay Credentials\n+ alipay_publishable_key = fields.Str(dump_only=True)\n+\n+ # payTM credentials\n+ paytm_mode = fields.Str(dump_only=True)\n+ paytm_live_merchant = fields.Str(dump_only=True)\n+ paytm_sandbox_merchant = fields.Str(dump_only=True)\n+\n \n class SettingSchemaNonAdmin(SettingSchemaPublic):\n \"\"\"\n", "issue": "Stripe publishable key should be accessible to non-admin user\nThe settings schema for non-admin user does not contain stripe publishable key and hence non-admin user cannot add stripe to its event.\r\n\r\nhttps://api.eventyay.com/v1/settings should contain stripe publishable key\r\n\r\nSee #6277 as well\n", "before_files": [{"content": "from marshmallow_jsonapi import fields\nfrom marshmallow_jsonapi.flask import Schema\n\nfrom app.api.helpers.utilities import dasherize\nfrom app.settings import Environment\nfrom utils.common import use_defaults\n\n\nclass SettingSchemaPublic(Schema):\n \"\"\"\n Public Api schema for settings Model\n \"\"\"\n\n class Meta:\n \"\"\"\n Meta class for setting Api Schema\n \"\"\"\n\n type_ = 'setting'\n self_view = 'v1.setting_detail'\n self_view_kwargs = {'id': '<id>'}\n inflect = dasherize\n\n id = fields.Str(dump_only=True)\n\n # Name of the application. (Eg. Event Yay!, Open Event)\n app_name = fields.Str(allow_none=True)\n\n # Tagline for the application. (Eg. Event Management and Ticketing, Home)\n tagline = fields.Str(allow_none=True)\n\n # Order Expiry Time\n order_expiry_time = fields.Integer(\n allow_none=False, default=15, validate=lambda n: 1 <= n <= 60\n )\n\n # Maximum number of complex custom fields allowed for a given form\n max_complex_custom_fields = fields.Integer(\n allow_none=False, default=30, validate=lambda n: 1 <= n <= 30\n )\n\n # Google Analytics\n analytics_key = fields.Str(allow_none=True)\n\n # FB\n fb_client_id = fields.Str(allow_none=True)\n\n #\n # Social links\n #\n google_url = fields.Str(allow_none=True)\n github_url = fields.Str(allow_none=True)\n twitter_url = fields.Str(allow_none=True)\n support_url = fields.Str(allow_none=True)\n facebook_url = fields.Str(allow_none=True)\n instagram_url = fields.Str(allow_none=True)\n youtube_url = fields.Str(allow_none=True)\n\n # Url of Frontend\n frontend_url = fields.Url(allow_none=True)\n\n #\n # Cookie Policy\n #\n cookie_policy = fields.Str(allow_none=True)\n cookie_policy_link = fields.Str(allow_none=True)\n\n #\n # Online Payment Flags\n #\n is_paytm_activated = fields.Bool(default=False)\n is_paypal_activated = fields.Bool(dump_only=True)\n is_stripe_activated = fields.Bool(dump_only=True)\n is_omise_activated = fields.Bool(dump_only=True)\n is_alipay_activated = fields.Bool(dump_only=True)\n\n\nclass SettingSchemaNonAdmin(SettingSchemaPublic):\n \"\"\"\n Non Admin Api schema for settings Model\n \"\"\"\n\n class Meta:\n \"\"\"\n Meta class for setting Api Schema\n \"\"\"\n\n type_ = 'setting'\n self_view = 'v1.setting_detail'\n self_view_kwargs = {'id': '<id>'}\n inflect = dasherize\n\n id = fields.Str(dump_only=True)\n\n #\n # Generators\n #\n android_app_url = fields.Str(allow_none=True)\n web_app_url = fields.Str(allow_none=True)\n\n\n@use_defaults()\nclass SettingSchemaAdmin(SettingSchemaNonAdmin):\n \"\"\"\n Admin Api schema for settings Model\n \"\"\"\n\n class Meta:\n \"\"\"\n Meta class for setting Api Schema\n \"\"\"\n\n type_ = 'setting'\n self_view = 'v1.setting_detail'\n self_view_kwargs = {'id': '<id>'}\n inflect = dasherize\n\n id = fields.Str(dump_only=True)\n #\n # General\n #\n\n app_environment = fields.Str(default=Environment.PRODUCTION)\n\n # Static domain\n static_domain = fields.Str(allow_none=True)\n\n #\n # STORAGE\n #\n\n # storage place, local, s3, .. can be more in future\n storage_place = fields.Str(allow_none=True)\n # S3\n aws_key = fields.Str(allow_none=True)\n aws_secret = fields.Str(allow_none=True)\n aws_bucket_name = fields.Str(allow_none=True)\n aws_region = fields.Str(allow_none=True)\n # Google Storage\n gs_key = fields.Str(allow_none=True)\n gs_secret = fields.Str(allow_none=True)\n gs_bucket_name = fields.Str(allow_none=True)\n\n #\n # CAPTCHA\n #\n\n # Google reCAPTCHA\n is_google_recaptcha_enabled = fields.Bool(allow_none=False, default=False)\n google_recaptcha_site = fields.Str(allow_none=True)\n google_recaptcha_secret = fields.Str(allow_none=True)\n\n #\n # Social Login\n #\n\n # Google Auth\n google_client_id = fields.Str(allow_none=True)\n google_client_secret = fields.Str(allow_none=True)\n # FB\n fb_client_id = fields.Str(allow_none=True)\n fb_client_secret = fields.Str(allow_none=True)\n # Twitter\n tw_consumer_key = fields.Str(allow_none=True)\n tw_consumer_secret = fields.Str(allow_none=True)\n # Instagram\n in_client_id = fields.Str(allow_none=True)\n in_client_secret = fields.Str(allow_none=True)\n\n #\n # Payment Gateways\n #\n\n # Stripe Credantials\n stripe_client_id = fields.Str(allow_none=True)\n stripe_publishable_key = fields.Str(allow_none=True)\n stripe_secret_key = fields.Str(allow_none=True)\n stripe_test_client_id = fields.Str(allow_none=True)\n stripe_test_secret_key = fields.Str(allow_none=True)\n stripe_test_publishable_key = fields.Str(allow_none=True)\n\n # PayPal Credentials\n paypal_mode = fields.Str(allow_none=True)\n paypal_client = fields.Str(allow_none=True)\n paypal_secret = fields.Str(allow_none=True)\n paypal_sandbox_client = fields.Str(allow_none=True)\n paypal_sandbox_secret = fields.Str(allow_none=True)\n\n # Omise Credentials\n omise_mode = fields.Str(allow_none=True)\n omise_test_public = fields.Str(allow_none=True)\n omise_test_secret = fields.Str(allow_none=True)\n omise_live_public = fields.Str(allow_none=True)\n omise_live_secret = fields.Str(allow_none=True)\n\n # Alipay Credentials\n alipay_publishable_key = fields.Str(allow_none=True)\n alipay_secret_key = fields.Str(allow_none=True)\n\n # payTM credentials\n paytm_mode = fields.Str(allow_none=True)\n paytm_live_merchant = fields.Str(allow_none=True)\n paytm_live_secret = fields.Str(allow_none=True)\n paytm_sandbox_merchant = fields.Str(allow_none=True)\n paytm_sandbox_secret = fields.Str(allow_none=True)\n #\n # EMAIL\n #\n\n # Email service. (sendgrid,smtp)\n email_service = fields.Str(allow_none=True)\n email_from = fields.Str(allow_none=True)\n email_from_name = fields.Str(allow_none=True)\n # Sendgrid\n sendgrid_key = fields.Str(allow_none=True)\n # SMTP\n smtp_host = fields.Str(allow_none=True)\n smtp_username = fields.Str(allow_none=True)\n smtp_password = fields.Str(allow_none=True)\n smtp_port = fields.Integer(allow_none=True)\n smtp_encryption = fields.Str(allow_none=True) # Can be tls, ssl, none\n\n # Event Invoices settings\n invoice_sending_day = fields.Integer(allow_none=False, default=1)\n invoice_sending_timezone = fields.Str(allow_none=False, default=\"UTC\")\n\n # Admin Invoice Details\n admin_billing_contact_name = fields.Str(allow_none=True)\n admin_billing_phone = fields.Str(allow_none=True)\n admin_billing_email = fields.Email(allow_none=True)\n admin_billing_state = fields.Str(allow_none=True)\n admin_billing_country = fields.Str(allow_none=True)\n admin_billing_tax_info = fields.Str(allow_none=True)\n admin_company = fields.Str(allow_none=True)\n admin_billing_address = fields.Str(allow_none=True)\n admin_billing_city = fields.Str(allow_none=True)\n admin_billing_zip = fields.Str(allow_none=True)\n admin_billing_additional_info = fields.Str(allow_none=True)\n", "path": "app/api/schema/settings.py"}], "after_files": [{"content": "from marshmallow_jsonapi import fields\nfrom marshmallow_jsonapi.flask import Schema\n\nfrom app.api.helpers.utilities import dasherize\nfrom app.settings import Environment\nfrom utils.common import use_defaults\n\n\nclass SettingSchemaPublic(Schema):\n \"\"\"\n Public Api schema for settings Model\n \"\"\"\n\n class Meta:\n \"\"\"\n Meta class for setting Api Schema\n \"\"\"\n\n type_ = 'setting'\n self_view = 'v1.setting_detail'\n self_view_kwargs = {'id': '<id>'}\n inflect = dasherize\n\n id = fields.Str(dump_only=True)\n\n # Name of the application. (Eg. Event Yay!, Open Event)\n app_name = fields.Str(allow_none=True)\n\n # Tagline for the application. (Eg. Event Management and Ticketing, Home)\n tagline = fields.Str(allow_none=True)\n\n # Order Expiry Time\n order_expiry_time = fields.Integer(\n allow_none=False, default=15, validate=lambda n: 1 <= n <= 60\n )\n\n # Maximum number of complex custom fields allowed for a given form\n max_complex_custom_fields = fields.Integer(\n allow_none=False, default=30, validate=lambda n: 1 <= n <= 30\n )\n\n # Google Analytics\n analytics_key = fields.Str(allow_none=True)\n\n # FB\n fb_client_id = fields.Str(allow_none=True)\n\n #\n # Social links\n #\n google_url = fields.Str(allow_none=True)\n github_url = fields.Str(allow_none=True)\n twitter_url = fields.Str(allow_none=True)\n support_url = fields.Str(allow_none=True)\n facebook_url = fields.Str(allow_none=True)\n instagram_url = fields.Str(allow_none=True)\n youtube_url = fields.Str(allow_none=True)\n\n # Url of Frontend\n frontend_url = fields.Url(allow_none=True)\n\n #\n # Cookie Policy\n #\n cookie_policy = fields.Str(allow_none=True)\n cookie_policy_link = fields.Str(allow_none=True)\n\n #\n # Online Payment Flags\n #\n is_paytm_activated = fields.Bool(default=False)\n is_paypal_activated = fields.Bool(dump_only=True)\n is_stripe_activated = fields.Bool(dump_only=True)\n is_omise_activated = fields.Bool(dump_only=True)\n is_alipay_activated = fields.Bool(dump_only=True)\n\n #\n # Payment Gateways\n #\n\n # Stripe Credantials\n stripe_client_id = fields.Str(dump_only=True)\n stripe_publishable_key = fields.Str(dump_only=True)\n stripe_test_client_id = fields.Str(dump_only=True)\n stripe_test_publishable_key = fields.Str(dump_only=True)\n\n # PayPal Credentials\n paypal_mode = fields.Str(dump_only=True)\n paypal_client = fields.Str(dump_only=True)\n paypal_sandbox_client = fields.Str(dump_only=True)\n\n # Omise Credentials\n omise_mode = fields.Str(dump_only=True)\n omise_test_public = fields.Str(dump_only=True)\n omise_live_public = fields.Str(dump_only=True)\n\n # Alipay Credentials\n alipay_publishable_key = fields.Str(dump_only=True)\n\n # payTM credentials\n paytm_mode = fields.Str(dump_only=True)\n paytm_live_merchant = fields.Str(dump_only=True)\n paytm_sandbox_merchant = fields.Str(dump_only=True)\n\n\nclass SettingSchemaNonAdmin(SettingSchemaPublic):\n \"\"\"\n Non Admin Api schema for settings Model\n \"\"\"\n\n class Meta:\n \"\"\"\n Meta class for setting Api Schema\n \"\"\"\n\n type_ = 'setting'\n self_view = 'v1.setting_detail'\n self_view_kwargs = {'id': '<id>'}\n inflect = dasherize\n\n id = fields.Str(dump_only=True)\n\n #\n # Generators\n #\n android_app_url = fields.Str(allow_none=True)\n web_app_url = fields.Str(allow_none=True)\n\n\n@use_defaults()\nclass SettingSchemaAdmin(SettingSchemaNonAdmin):\n \"\"\"\n Admin Api schema for settings Model\n \"\"\"\n\n class Meta:\n \"\"\"\n Meta class for setting Api Schema\n \"\"\"\n\n type_ = 'setting'\n self_view = 'v1.setting_detail'\n self_view_kwargs = {'id': '<id>'}\n inflect = dasherize\n\n id = fields.Str(dump_only=True)\n #\n # General\n #\n\n app_environment = fields.Str(default=Environment.PRODUCTION)\n\n # Static domain\n static_domain = fields.Str(allow_none=True)\n\n #\n # STORAGE\n #\n\n # storage place, local, s3, .. can be more in future\n storage_place = fields.Str(allow_none=True)\n # S3\n aws_key = fields.Str(allow_none=True)\n aws_secret = fields.Str(allow_none=True)\n aws_bucket_name = fields.Str(allow_none=True)\n aws_region = fields.Str(allow_none=True)\n # Google Storage\n gs_key = fields.Str(allow_none=True)\n gs_secret = fields.Str(allow_none=True)\n gs_bucket_name = fields.Str(allow_none=True)\n\n #\n # CAPTCHA\n #\n\n # Google reCAPTCHA\n is_google_recaptcha_enabled = fields.Bool(allow_none=False, default=False)\n google_recaptcha_site = fields.Str(allow_none=True)\n google_recaptcha_secret = fields.Str(allow_none=True)\n\n #\n # Social Login\n #\n\n # Google Auth\n google_client_id = fields.Str(allow_none=True)\n google_client_secret = fields.Str(allow_none=True)\n # FB\n fb_client_id = fields.Str(allow_none=True)\n fb_client_secret = fields.Str(allow_none=True)\n # Twitter\n tw_consumer_key = fields.Str(allow_none=True)\n tw_consumer_secret = fields.Str(allow_none=True)\n # Instagram\n in_client_id = fields.Str(allow_none=True)\n in_client_secret = fields.Str(allow_none=True)\n\n #\n # Payment Gateways\n #\n\n # Stripe Credantials\n stripe_client_id = fields.Str(allow_none=True)\n stripe_publishable_key = fields.Str(allow_none=True)\n stripe_secret_key = fields.Str(allow_none=True)\n stripe_test_client_id = fields.Str(allow_none=True)\n stripe_test_secret_key = fields.Str(allow_none=True)\n stripe_test_publishable_key = fields.Str(allow_none=True)\n\n # PayPal Credentials\n paypal_mode = fields.Str(allow_none=True)\n paypal_client = fields.Str(allow_none=True)\n paypal_secret = fields.Str(allow_none=True)\n paypal_sandbox_client = fields.Str(allow_none=True)\n paypal_sandbox_secret = fields.Str(allow_none=True)\n\n # Omise Credentials\n omise_mode = fields.Str(allow_none=True)\n omise_test_public = fields.Str(allow_none=True)\n omise_test_secret = fields.Str(allow_none=True)\n omise_live_public = fields.Str(allow_none=True)\n omise_live_secret = fields.Str(allow_none=True)\n\n # Alipay Credentials\n alipay_publishable_key = fields.Str(allow_none=True)\n alipay_secret_key = fields.Str(allow_none=True)\n\n # payTM credentials\n paytm_mode = fields.Str(allow_none=True)\n paytm_live_merchant = fields.Str(allow_none=True)\n paytm_live_secret = fields.Str(allow_none=True)\n paytm_sandbox_merchant = fields.Str(allow_none=True)\n paytm_sandbox_secret = fields.Str(allow_none=True)\n #\n # EMAIL\n #\n\n # Email service. (sendgrid,smtp)\n email_service = fields.Str(allow_none=True)\n email_from = fields.Str(allow_none=True)\n email_from_name = fields.Str(allow_none=True)\n # Sendgrid\n sendgrid_key = fields.Str(allow_none=True)\n # SMTP\n smtp_host = fields.Str(allow_none=True)\n smtp_username = fields.Str(allow_none=True)\n smtp_password = fields.Str(allow_none=True)\n smtp_port = fields.Integer(allow_none=True)\n smtp_encryption = fields.Str(allow_none=True) # Can be tls, ssl, none\n\n # Event Invoices settings\n invoice_sending_day = fields.Integer(allow_none=False, default=1)\n invoice_sending_timezone = fields.Str(allow_none=False, default=\"UTC\")\n\n # Admin Invoice Details\n admin_billing_contact_name = fields.Str(allow_none=True)\n admin_billing_phone = fields.Str(allow_none=True)\n admin_billing_email = fields.Email(allow_none=True)\n admin_billing_state = fields.Str(allow_none=True)\n admin_billing_country = fields.Str(allow_none=True)\n admin_billing_tax_info = fields.Str(allow_none=True)\n admin_company = fields.Str(allow_none=True)\n admin_billing_address = fields.Str(allow_none=True)\n admin_billing_city = fields.Str(allow_none=True)\n admin_billing_zip = fields.Str(allow_none=True)\n admin_billing_additional_info = fields.Str(allow_none=True)\n", "path": "app/api/schema/settings.py"}]}
| 2,701 | 337 |
gh_patches_debug_30329
|
rasdani/github-patches
|
git_diff
|
streamlit__streamlit-2604
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
In number_input, min_value & max_value format override format string and raises no warning
# Summary
Regardless of the format string specified by the user, actual format used will be based on min_value and max_value
# Steps to reproduce
The following code presents a warning:
`weight = st.number_input("Today's weight:", min_value=50.0, max_value=750.0, format="%d")`
_Warning: NumberInput value below is float, but format %d displays as integer._
I believe that's intended behavior. However, the inverse condition doesn't produce a warning or error.
```
weight = st.number_input("Today's weight:", min_value=50, max_value=750, format="%4.1f")
print(weight)
st.write("Echoing weight: ", weight)
```
If the input value is, for example, 170.4, the weight value will be 170, shown by both print() and st.write(), based on the interpreted format of min and max values. Note that this line of code does not produce any error or warning. The user (at least in my case) assumed min_value and max_value would be raised to float rather than ignoring format. I couldn't figure out why my input was being reduced from 170.4 to 170
The correct code works fine
`weight = st.number_input("Today's weight:", min_value=50.0, max_value=750.0, format="%4.1f")`
## Expected behavior:
A warning in both cases, not just one or the other. Maybe:
_Warning: NumberInput value below is integer, format %f lowered to match integer._
## Actual behavior:
No warning produced, seems like there should be.
Sorry, already explained in the Steps to Reproduce section
## Is this a regression?
No (not that I know of)
# Debug info
- Streamlit version: (get it with `$ streamlit version`) 0.64.0
- Python version: (get it with `$ python --version`) 3.7.7
- Using Conda
- OS version: Windows 10 64bit
- Browser version: Chrome Version 84.0.4147.105 (Official Build) (64-bit)
# Additional information
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lib/streamlit/elements/number_input.py`
Content:
```
1 # Copyright 2018-2020 Streamlit Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import numbers
16 from typing import cast
17
18 import streamlit
19 from streamlit.errors import StreamlitAPIException
20 from streamlit.js_number import JSNumber, JSNumberBoundsException
21 from streamlit.proto.NumberInput_pb2 import NumberInput as NumberInputProto
22 from .utils import register_widget, NoValue
23
24
25 class NumberInputMixin:
26 def number_input(
27 self,
28 label,
29 min_value=None,
30 max_value=None,
31 value=NoValue(),
32 step=None,
33 format=None,
34 key=None,
35 ):
36 """Display a numeric input widget.
37
38 Parameters
39 ----------
40 label : str or None
41 A short label explaining to the user what this input is for.
42 min_value : int or float or None
43 The minimum permitted value.
44 If None, there will be no minimum.
45 max_value : int or float or None
46 The maximum permitted value.
47 If None, there will be no maximum.
48 value : int or float or None
49 The value of this widget when it first renders.
50 Defaults to min_value, or 0.0 if min_value is None
51 step : int or float or None
52 The stepping interval.
53 Defaults to 1 if the value is an int, 0.01 otherwise.
54 If the value is not specified, the format parameter will be used.
55 format : str or None
56 A printf-style format string controlling how the interface should
57 display numbers. Output must be purely numeric. This does not impact
58 the return value. Valid formatters: %d %e %f %g %i
59 key : str
60 An optional string to use as the unique key for the widget.
61 If this is omitted, a key will be generated for the widget
62 based on its content. Multiple widgets of the same type may
63 not share the same key.
64
65 Returns
66 -------
67 int or float
68 The current value of the numeric input widget. The return type
69 will match the data type of the value parameter.
70
71 Example
72 -------
73 >>> number = st.number_input('Insert a number')
74 >>> st.write('The current number is ', number)
75 """
76
77 if isinstance(value, NoValue):
78 if min_value is not None:
79 value = min_value
80 else:
81 value = 0.0 # We set a float as default
82
83 int_value = isinstance(value, numbers.Integral)
84 float_value = isinstance(value, float)
85
86 if value is None:
87 raise StreamlitAPIException(
88 "Default value for number_input should be an int or a float."
89 )
90 else:
91 if format is None:
92 format = "%d" if int_value else "%0.2f"
93
94 if format in ["%d", "%u", "%i"] and float_value:
95 # Warn user to check if displaying float as int was really intended.
96 import streamlit as st
97
98 st.warning(
99 "Warning: NumberInput value below is float, but format {} displays as integer.".format(
100 format
101 )
102 )
103
104 if step is None:
105 step = 1 if int_value else 0.01
106
107 try:
108 float(format % 2)
109 except (TypeError, ValueError):
110 raise StreamlitAPIException(
111 "Format string for st.number_input contains invalid characters: %s"
112 % format
113 )
114
115 # Ensure that all arguments are of the same type.
116 args = [min_value, max_value, step]
117
118 int_args = all(
119 map(
120 lambda a: (
121 isinstance(a, numbers.Integral) or isinstance(a, type(None))
122 ),
123 args,
124 )
125 )
126 float_args = all(
127 map(lambda a: (isinstance(a, float) or isinstance(a, type(None))), args)
128 )
129
130 if not int_args and not float_args:
131 raise StreamlitAPIException(
132 "All arguments must be of the same type."
133 "\n`value` has %(value_type)s type."
134 "\n`min_value` has %(min_type)s type."
135 "\n`max_value` has %(max_type)s type."
136 % {
137 "value_type": type(value).__name__,
138 "min_type": type(min_value).__name__,
139 "max_type": type(max_value).__name__,
140 }
141 )
142
143 # Ensure that the value matches arguments' types.
144 all_ints = int_value and int_args
145 all_floats = float_value and float_args
146
147 if not all_ints and not all_floats:
148 raise StreamlitAPIException(
149 "All numerical arguments must be of the same type."
150 "\n`value` has %(value_type)s type."
151 "\n`min_value` has %(min_type)s type."
152 "\n`max_value` has %(max_type)s type."
153 "\n`step` has %(step_type)s type."
154 % {
155 "value_type": type(value).__name__,
156 "min_type": type(min_value).__name__,
157 "max_type": type(max_value).__name__,
158 "step_type": type(step).__name__,
159 }
160 )
161
162 if (min_value and min_value > value) or (max_value and max_value < value):
163 raise StreamlitAPIException(
164 "The default `value` of %(value)s "
165 "must lie between the `min_value` of %(min)s "
166 "and the `max_value` of %(max)s, inclusively."
167 % {"value": value, "min": min_value, "max": max_value}
168 )
169
170 # Bounds checks. JSNumber produces human-readable exceptions that
171 # we simply re-package as StreamlitAPIExceptions.
172 try:
173 if all_ints:
174 if min_value is not None:
175 JSNumber.validate_int_bounds(min_value, "`min_value`")
176 if max_value is not None:
177 JSNumber.validate_int_bounds(max_value, "`max_value`")
178 if step is not None:
179 JSNumber.validate_int_bounds(step, "`step`")
180 JSNumber.validate_int_bounds(value, "`value`")
181 else:
182 if min_value is not None:
183 JSNumber.validate_float_bounds(min_value, "`min_value`")
184 if max_value is not None:
185 JSNumber.validate_float_bounds(max_value, "`max_value`")
186 if step is not None:
187 JSNumber.validate_float_bounds(step, "`step`")
188 JSNumber.validate_float_bounds(value, "`value`")
189 except JSNumberBoundsException as e:
190 raise StreamlitAPIException(str(e))
191
192 number_input_proto = NumberInputProto()
193 number_input_proto.data_type = (
194 NumberInputProto.INT if all_ints else NumberInputProto.FLOAT
195 )
196 number_input_proto.label = label
197 number_input_proto.default = value
198
199 if min_value is not None:
200 number_input_proto.min = min_value
201 number_input_proto.has_min = True
202
203 if max_value is not None:
204 number_input_proto.max = max_value
205 number_input_proto.has_max = True
206
207 if step is not None:
208 number_input_proto.step = step
209
210 if format is not None:
211 number_input_proto.format = format
212
213 ui_value = register_widget("number_input", number_input_proto, user_key=key)
214
215 return_value = ui_value if ui_value is not None else value
216 return self.dg._enqueue("number_input", number_input_proto, return_value)
217
218 @property
219 def dg(self) -> "streamlit.delta_generator.DeltaGenerator":
220 """Get our DeltaGenerator."""
221 return cast("streamlit.delta_generator.DeltaGenerator", self)
222
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lib/streamlit/elements/number_input.py b/lib/streamlit/elements/number_input.py
--- a/lib/streamlit/elements/number_input.py
+++ b/lib/streamlit/elements/number_input.py
@@ -55,7 +55,7 @@
format : str or None
A printf-style format string controlling how the interface should
display numbers. Output must be purely numeric. This does not impact
- the return value. Valid formatters: %d %e %f %g %i
+ the return value. Valid formatters: %d %e %f %g %i %u
key : str
An optional string to use as the unique key for the widget.
If this is omitted, a key will be generated for the widget
@@ -91,14 +91,20 @@
if format is None:
format = "%d" if int_value else "%0.2f"
+ # Warn user if they format an int type as a float or vice versa.
if format in ["%d", "%u", "%i"] and float_value:
- # Warn user to check if displaying float as int was really intended.
import streamlit as st
st.warning(
- "Warning: NumberInput value below is float, but format {} displays as integer.".format(
- format
- )
+ "Warning: NumberInput value below has type float,"
+ f" but format {format} displays as integer."
+ )
+ elif format[-1] == "f" and int_value:
+ import streamlit as st
+
+ st.warning(
+ "Warning: NumberInput value below has type int so is"
+ f" displayed as int despite format string {format}."
)
if step is None:
|
{"golden_diff": "diff --git a/lib/streamlit/elements/number_input.py b/lib/streamlit/elements/number_input.py\n--- a/lib/streamlit/elements/number_input.py\n+++ b/lib/streamlit/elements/number_input.py\n@@ -55,7 +55,7 @@\n format : str or None\n A printf-style format string controlling how the interface should\n display numbers. Output must be purely numeric. This does not impact\n- the return value. Valid formatters: %d %e %f %g %i\n+ the return value. Valid formatters: %d %e %f %g %i %u\n key : str\n An optional string to use as the unique key for the widget.\n If this is omitted, a key will be generated for the widget\n@@ -91,14 +91,20 @@\n if format is None:\n format = \"%d\" if int_value else \"%0.2f\"\n \n+ # Warn user if they format an int type as a float or vice versa.\n if format in [\"%d\", \"%u\", \"%i\"] and float_value:\n- # Warn user to check if displaying float as int was really intended.\n import streamlit as st\n \n st.warning(\n- \"Warning: NumberInput value below is float, but format {} displays as integer.\".format(\n- format\n- )\n+ \"Warning: NumberInput value below has type float,\"\n+ f\" but format {format} displays as integer.\"\n+ )\n+ elif format[-1] == \"f\" and int_value:\n+ import streamlit as st\n+\n+ st.warning(\n+ \"Warning: NumberInput value below has type int so is\"\n+ f\" displayed as int despite format string {format}.\"\n )\n \n if step is None:\n", "issue": "In number_input, min_value & max_value format override format string and raises no warning\n# Summary\r\n\r\nRegardless of the format string specified by the user, actual format used will be based on min_value and max_value\r\n\r\n# Steps to reproduce\r\n\r\nThe following code presents a warning:\r\n`weight = st.number_input(\"Today's weight:\", min_value=50.0, max_value=750.0, format=\"%d\")`\r\n_Warning: NumberInput value below is float, but format %d displays as integer._\r\n\r\nI believe that's intended behavior. However, the inverse condition doesn't produce a warning or error.\r\n```\r\nweight = st.number_input(\"Today's weight:\", min_value=50, max_value=750, format=\"%4.1f\")\r\nprint(weight)\r\nst.write(\"Echoing weight: \", weight)\r\n\r\n```\r\nIf the input value is, for example, 170.4, the weight value will be 170, shown by both print() and st.write(), based on the interpreted format of min and max values. Note that this line of code does not produce any error or warning. The user (at least in my case) assumed min_value and max_value would be raised to float rather than ignoring format. I couldn't figure out why my input was being reduced from 170.4 to 170\r\n\r\nThe correct code works fine\r\n`weight = st.number_input(\"Today's weight:\", min_value=50.0, max_value=750.0, format=\"%4.1f\")`\r\n\r\n## Expected behavior:\r\n\r\nA warning in both cases, not just one or the other. Maybe:\r\n_Warning: NumberInput value below is integer, format %f lowered to match integer._\r\n\r\n## Actual behavior:\r\n\r\nNo warning produced, seems like there should be. \r\nSorry, already explained in the Steps to Reproduce section\r\n\r\n## Is this a regression?\r\n\r\nNo (not that I know of)\r\n\r\n# Debug info\r\n\r\n- Streamlit version: (get it with `$ streamlit version`) 0.64.0\r\n- Python version: (get it with `$ python --version`) 3.7.7\r\n- Using Conda\r\n- OS version: Windows 10 64bit\r\n- Browser version: Chrome Version 84.0.4147.105 (Official Build) (64-bit)\r\n\r\n# Additional information\r\n\r\n\n", "before_files": [{"content": "# Copyright 2018-2020 Streamlit Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport numbers\nfrom typing import cast\n\nimport streamlit\nfrom streamlit.errors import StreamlitAPIException\nfrom streamlit.js_number import JSNumber, JSNumberBoundsException\nfrom streamlit.proto.NumberInput_pb2 import NumberInput as NumberInputProto\nfrom .utils import register_widget, NoValue\n\n\nclass NumberInputMixin:\n def number_input(\n self,\n label,\n min_value=None,\n max_value=None,\n value=NoValue(),\n step=None,\n format=None,\n key=None,\n ):\n \"\"\"Display a numeric input widget.\n\n Parameters\n ----------\n label : str or None\n A short label explaining to the user what this input is for.\n min_value : int or float or None\n The minimum permitted value.\n If None, there will be no minimum.\n max_value : int or float or None\n The maximum permitted value.\n If None, there will be no maximum.\n value : int or float or None\n The value of this widget when it first renders.\n Defaults to min_value, or 0.0 if min_value is None\n step : int or float or None\n The stepping interval.\n Defaults to 1 if the value is an int, 0.01 otherwise.\n If the value is not specified, the format parameter will be used.\n format : str or None\n A printf-style format string controlling how the interface should\n display numbers. Output must be purely numeric. This does not impact\n the return value. Valid formatters: %d %e %f %g %i\n key : str\n An optional string to use as the unique key for the widget.\n If this is omitted, a key will be generated for the widget\n based on its content. Multiple widgets of the same type may\n not share the same key.\n\n Returns\n -------\n int or float\n The current value of the numeric input widget. The return type\n will match the data type of the value parameter.\n\n Example\n -------\n >>> number = st.number_input('Insert a number')\n >>> st.write('The current number is ', number)\n \"\"\"\n\n if isinstance(value, NoValue):\n if min_value is not None:\n value = min_value\n else:\n value = 0.0 # We set a float as default\n\n int_value = isinstance(value, numbers.Integral)\n float_value = isinstance(value, float)\n\n if value is None:\n raise StreamlitAPIException(\n \"Default value for number_input should be an int or a float.\"\n )\n else:\n if format is None:\n format = \"%d\" if int_value else \"%0.2f\"\n\n if format in [\"%d\", \"%u\", \"%i\"] and float_value:\n # Warn user to check if displaying float as int was really intended.\n import streamlit as st\n\n st.warning(\n \"Warning: NumberInput value below is float, but format {} displays as integer.\".format(\n format\n )\n )\n\n if step is None:\n step = 1 if int_value else 0.01\n\n try:\n float(format % 2)\n except (TypeError, ValueError):\n raise StreamlitAPIException(\n \"Format string for st.number_input contains invalid characters: %s\"\n % format\n )\n\n # Ensure that all arguments are of the same type.\n args = [min_value, max_value, step]\n\n int_args = all(\n map(\n lambda a: (\n isinstance(a, numbers.Integral) or isinstance(a, type(None))\n ),\n args,\n )\n )\n float_args = all(\n map(lambda a: (isinstance(a, float) or isinstance(a, type(None))), args)\n )\n\n if not int_args and not float_args:\n raise StreamlitAPIException(\n \"All arguments must be of the same type.\"\n \"\\n`value` has %(value_type)s type.\"\n \"\\n`min_value` has %(min_type)s type.\"\n \"\\n`max_value` has %(max_type)s type.\"\n % {\n \"value_type\": type(value).__name__,\n \"min_type\": type(min_value).__name__,\n \"max_type\": type(max_value).__name__,\n }\n )\n\n # Ensure that the value matches arguments' types.\n all_ints = int_value and int_args\n all_floats = float_value and float_args\n\n if not all_ints and not all_floats:\n raise StreamlitAPIException(\n \"All numerical arguments must be of the same type.\"\n \"\\n`value` has %(value_type)s type.\"\n \"\\n`min_value` has %(min_type)s type.\"\n \"\\n`max_value` has %(max_type)s type.\"\n \"\\n`step` has %(step_type)s type.\"\n % {\n \"value_type\": type(value).__name__,\n \"min_type\": type(min_value).__name__,\n \"max_type\": type(max_value).__name__,\n \"step_type\": type(step).__name__,\n }\n )\n\n if (min_value and min_value > value) or (max_value and max_value < value):\n raise StreamlitAPIException(\n \"The default `value` of %(value)s \"\n \"must lie between the `min_value` of %(min)s \"\n \"and the `max_value` of %(max)s, inclusively.\"\n % {\"value\": value, \"min\": min_value, \"max\": max_value}\n )\n\n # Bounds checks. JSNumber produces human-readable exceptions that\n # we simply re-package as StreamlitAPIExceptions.\n try:\n if all_ints:\n if min_value is not None:\n JSNumber.validate_int_bounds(min_value, \"`min_value`\")\n if max_value is not None:\n JSNumber.validate_int_bounds(max_value, \"`max_value`\")\n if step is not None:\n JSNumber.validate_int_bounds(step, \"`step`\")\n JSNumber.validate_int_bounds(value, \"`value`\")\n else:\n if min_value is not None:\n JSNumber.validate_float_bounds(min_value, \"`min_value`\")\n if max_value is not None:\n JSNumber.validate_float_bounds(max_value, \"`max_value`\")\n if step is not None:\n JSNumber.validate_float_bounds(step, \"`step`\")\n JSNumber.validate_float_bounds(value, \"`value`\")\n except JSNumberBoundsException as e:\n raise StreamlitAPIException(str(e))\n\n number_input_proto = NumberInputProto()\n number_input_proto.data_type = (\n NumberInputProto.INT if all_ints else NumberInputProto.FLOAT\n )\n number_input_proto.label = label\n number_input_proto.default = value\n\n if min_value is not None:\n number_input_proto.min = min_value\n number_input_proto.has_min = True\n\n if max_value is not None:\n number_input_proto.max = max_value\n number_input_proto.has_max = True\n\n if step is not None:\n number_input_proto.step = step\n\n if format is not None:\n number_input_proto.format = format\n\n ui_value = register_widget(\"number_input\", number_input_proto, user_key=key)\n\n return_value = ui_value if ui_value is not None else value\n return self.dg._enqueue(\"number_input\", number_input_proto, return_value)\n\n @property\n def dg(self) -> \"streamlit.delta_generator.DeltaGenerator\":\n \"\"\"Get our DeltaGenerator.\"\"\"\n return cast(\"streamlit.delta_generator.DeltaGenerator\", self)\n", "path": "lib/streamlit/elements/number_input.py"}], "after_files": [{"content": "# Copyright 2018-2020 Streamlit Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport numbers\nfrom typing import cast\n\nimport streamlit\nfrom streamlit.errors import StreamlitAPIException\nfrom streamlit.js_number import JSNumber, JSNumberBoundsException\nfrom streamlit.proto.NumberInput_pb2 import NumberInput as NumberInputProto\nfrom .utils import register_widget, NoValue\n\n\nclass NumberInputMixin:\n def number_input(\n self,\n label,\n min_value=None,\n max_value=None,\n value=NoValue(),\n step=None,\n format=None,\n key=None,\n ):\n \"\"\"Display a numeric input widget.\n\n Parameters\n ----------\n label : str or None\n A short label explaining to the user what this input is for.\n min_value : int or float or None\n The minimum permitted value.\n If None, there will be no minimum.\n max_value : int or float or None\n The maximum permitted value.\n If None, there will be no maximum.\n value : int or float or None\n The value of this widget when it first renders.\n Defaults to min_value, or 0.0 if min_value is None\n step : int or float or None\n The stepping interval.\n Defaults to 1 if the value is an int, 0.01 otherwise.\n If the value is not specified, the format parameter will be used.\n format : str or None\n A printf-style format string controlling how the interface should\n display numbers. Output must be purely numeric. This does not impact\n the return value. Valid formatters: %d %e %f %g %i %u\n key : str\n An optional string to use as the unique key for the widget.\n If this is omitted, a key will be generated for the widget\n based on its content. Multiple widgets of the same type may\n not share the same key.\n\n Returns\n -------\n int or float\n The current value of the numeric input widget. The return type\n will match the data type of the value parameter.\n\n Example\n -------\n >>> number = st.number_input('Insert a number')\n >>> st.write('The current number is ', number)\n \"\"\"\n\n if isinstance(value, NoValue):\n if min_value is not None:\n value = min_value\n else:\n value = 0.0 # We set a float as default\n\n int_value = isinstance(value, numbers.Integral)\n float_value = isinstance(value, float)\n\n if value is None:\n raise StreamlitAPIException(\n \"Default value for number_input should be an int or a float.\"\n )\n else:\n if format is None:\n format = \"%d\" if int_value else \"%0.2f\"\n\n # Warn user if they format an int type as a float or vice versa.\n if format in [\"%d\", \"%u\", \"%i\"] and float_value:\n import streamlit as st\n\n st.warning(\n \"Warning: NumberInput value below has type float,\"\n f\" but format {format} displays as integer.\"\n )\n elif format[-1] == \"f\" and int_value:\n import streamlit as st\n\n st.warning(\n \"Warning: NumberInput value below has type int so is\"\n f\" displayed as int despite format string {format}.\"\n )\n\n if step is None:\n step = 1 if int_value else 0.01\n\n try:\n float(format % 2)\n except (TypeError, ValueError):\n raise StreamlitAPIException(\n \"Format string for st.number_input contains invalid characters: %s\"\n % format\n )\n\n # Ensure that all arguments are of the same type.\n args = [min_value, max_value, step]\n\n int_args = all(\n map(\n lambda a: (\n isinstance(a, numbers.Integral) or isinstance(a, type(None))\n ),\n args,\n )\n )\n float_args = all(\n map(lambda a: (isinstance(a, float) or isinstance(a, type(None))), args)\n )\n\n if not int_args and not float_args:\n raise StreamlitAPIException(\n \"All arguments must be of the same type.\"\n \"\\n`value` has %(value_type)s type.\"\n \"\\n`min_value` has %(min_type)s type.\"\n \"\\n`max_value` has %(max_type)s type.\"\n % {\n \"value_type\": type(value).__name__,\n \"min_type\": type(min_value).__name__,\n \"max_type\": type(max_value).__name__,\n }\n )\n\n # Ensure that the value matches arguments' types.\n all_ints = int_value and int_args\n all_floats = float_value and float_args\n\n if not all_ints and not all_floats:\n raise StreamlitAPIException(\n \"All numerical arguments must be of the same type.\"\n \"\\n`value` has %(value_type)s type.\"\n \"\\n`min_value` has %(min_type)s type.\"\n \"\\n`max_value` has %(max_type)s type.\"\n \"\\n`step` has %(step_type)s type.\"\n % {\n \"value_type\": type(value).__name__,\n \"min_type\": type(min_value).__name__,\n \"max_type\": type(max_value).__name__,\n \"step_type\": type(step).__name__,\n }\n )\n\n if (min_value and min_value > value) or (max_value and max_value < value):\n raise StreamlitAPIException(\n \"The default `value` of %(value)s \"\n \"must lie between the `min_value` of %(min)s \"\n \"and the `max_value` of %(max)s, inclusively.\"\n % {\"value\": value, \"min\": min_value, \"max\": max_value}\n )\n\n # Bounds checks. JSNumber produces human-readable exceptions that\n # we simply re-package as StreamlitAPIExceptions.\n try:\n if all_ints:\n if min_value is not None:\n JSNumber.validate_int_bounds(min_value, \"`min_value`\")\n if max_value is not None:\n JSNumber.validate_int_bounds(max_value, \"`max_value`\")\n if step is not None:\n JSNumber.validate_int_bounds(step, \"`step`\")\n JSNumber.validate_int_bounds(value, \"`value`\")\n else:\n if min_value is not None:\n JSNumber.validate_float_bounds(min_value, \"`min_value`\")\n if max_value is not None:\n JSNumber.validate_float_bounds(max_value, \"`max_value`\")\n if step is not None:\n JSNumber.validate_float_bounds(step, \"`step`\")\n JSNumber.validate_float_bounds(value, \"`value`\")\n except JSNumberBoundsException as e:\n raise StreamlitAPIException(str(e))\n\n number_input_proto = NumberInputProto()\n number_input_proto.data_type = (\n NumberInputProto.INT if all_ints else NumberInputProto.FLOAT\n )\n number_input_proto.label = label\n number_input_proto.default = value\n\n if min_value is not None:\n number_input_proto.min = min_value\n number_input_proto.has_min = True\n\n if max_value is not None:\n number_input_proto.max = max_value\n number_input_proto.has_max = True\n\n if step is not None:\n number_input_proto.step = step\n\n if format is not None:\n number_input_proto.format = format\n\n ui_value = register_widget(\"number_input\", number_input_proto, user_key=key)\n\n return_value = ui_value if ui_value is not None else value\n return self.dg._enqueue(\"number_input\", number_input_proto, return_value)\n\n @property\n def dg(self) -> \"streamlit.delta_generator.DeltaGenerator\":\n \"\"\"Get our DeltaGenerator.\"\"\"\n return cast(\"streamlit.delta_generator.DeltaGenerator\", self)\n", "path": "lib/streamlit/elements/number_input.py"}]}
| 3,085 | 396 |
gh_patches_debug_31153
|
rasdani/github-patches
|
git_diff
|
cupy__cupy-6121
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`copyto` does not test shape for memcpy cases
### Description
There should be a shape check before these:
https://github.com/cupy/cupy/blob/e7f2e797216954dd152efe0169ec6a0094d7777d/cupy/_manipulation/basic.py#L54-L55
https://github.com/cupy/cupy/blob/e7f2e797216954dd152efe0169ec6a0094d7777d/cupy/_manipulation/basic.py#L76-L80
### To Reproduce
```py
>>> dst = cupy.ones((2, 3), dtype=int)
>>> cupy.copyto(dst, cupy.arange(6))
>>> dst
array([[0, 1, 2],
[3, 4, 5]])
>>> numpy.copyto(numpy.ones((2, 3), dtype=int), numpy.arange(6))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<__array_function__ internals>", line 5, in copyto
ValueError: could not broadcast input array from shape (6,) into shape (2,3)
```
```py
>>> cupy.copyto(cupy.empty((3, 0, 4, 5)), cupy.empty((6, 7, 0)))
>>> numpy.copyto(numpy.empty((3, 0, 4, 5)), numpy.empty((6, 7, 0)))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<__array_function__ internals>", line 5, in copyto
ValueError: could not broadcast input array from shape (6,7,0) into shape (3,0,4,5)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cupy/_manipulation/basic.py`
Content:
```
1 import numpy
2
3 from cupy import _core
4 from cupy._core import _fusion_interface
5 from cupy._core import fusion
6 from cupy._sorting import search
7 from cupy_backends.cuda.api import runtime
8
9
10 def copyto(dst, src, casting='same_kind', where=None):
11 """Copies values from one array to another with broadcasting.
12
13 This function can be called for arrays on different devices. In this case,
14 casting, ``where``, and broadcasting is not supported, and an exception is
15 raised if these are used.
16
17 Args:
18 dst (cupy.ndarray): Target array.
19 src (cupy.ndarray): Source array.
20 casting (str): Casting rule. See :func:`numpy.can_cast` for detail.
21 where (cupy.ndarray of bool): If specified, this array acts as a mask,
22 and an element is copied only if the corresponding element of
23 ``where`` is True.
24
25 .. seealso:: :func:`numpy.copyto`
26
27 """
28
29 src_type = type(src)
30 src_is_python_scalar = src_type in (
31 int, bool, float, complex,
32 fusion._FusionVarScalar, _fusion_interface._ScalarProxy)
33 if src_is_python_scalar:
34 src_dtype = numpy.dtype(type(src))
35 can_cast = numpy.can_cast(src, dst.dtype, casting)
36 else:
37 src_dtype = src.dtype
38 can_cast = numpy.can_cast(src_dtype, dst.dtype, casting)
39
40 if not can_cast:
41 raise TypeError('Cannot cast %s to %s in %s casting mode' %
42 (src_dtype, dst.dtype, casting))
43
44 if not src_is_python_scalar and src.ndim > dst.ndim:
45 # NumPy allows stripping leading unit dimensions.
46 try:
47 src = src.squeeze(tuple(range(src.ndim - dst.ndim)))
48 except ValueError:
49 # "cannot select an axis to squeeze out
50 # which has size not equal to one"
51 pass # raise an error later
52
53 if fusion._is_fusing():
54 if where is None:
55 _core.elementwise_copy(src, dst)
56 else:
57 fusion._call_ufunc(search._where_ufunc, where, src, dst, dst)
58 return
59
60 if where is not None:
61 _core.elementwise_copy(src, dst, _where=where)
62 return
63
64 if dst.size == 0:
65 return
66
67 if src_is_python_scalar:
68 dst.fill(src)
69 return
70
71 if _can_memcpy(dst, src):
72 dst.data.copy_from_async(src.data, src.nbytes)
73 return
74
75 device = dst.device
76 prev_device = runtime.getDevice()
77 try:
78 runtime.setDevice(device.id)
79 if src.device != device:
80 src = src.copy()
81 _core.elementwise_copy(src, dst)
82 finally:
83 runtime.setDevice(prev_device)
84
85
86 def _can_memcpy(dst, src):
87 c_contiguous = dst.flags.c_contiguous and src.flags.c_contiguous
88 f_contiguous = dst.flags.f_contiguous and src.flags.f_contiguous
89 return (c_contiguous or f_contiguous) and dst.dtype == src.dtype and \
90 dst.size == src.size
91
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/cupy/_manipulation/basic.py b/cupy/_manipulation/basic.py
--- a/cupy/_manipulation/basic.py
+++ b/cupy/_manipulation/basic.py
@@ -1,3 +1,5 @@
+import itertools
+
import numpy
from cupy import _core
@@ -41,22 +43,35 @@
raise TypeError('Cannot cast %s to %s in %s casting mode' %
(src_dtype, dst.dtype, casting))
- if not src_is_python_scalar and src.ndim > dst.ndim:
- # NumPy allows stripping leading unit dimensions.
- try:
- src = src.squeeze(tuple(range(src.ndim - dst.ndim)))
- except ValueError:
- # "cannot select an axis to squeeze out
- # which has size not equal to one"
- pass # raise an error later
-
if fusion._is_fusing():
+ # TODO(kataoka): NumPy allows stripping leading unit dimensions.
+ # But fusion array proxy does not currently support
+ # `shape` and `squeeze`.
+
if where is None:
_core.elementwise_copy(src, dst)
else:
fusion._call_ufunc(search._where_ufunc, where, src, dst, dst)
return
+ if not src_is_python_scalar:
+ # Check broadcast condition
+ # - for fast-paths and
+ # - for a better error message (than ufunc's).
+ # NumPy allows stripping leading unit dimensions.
+ if not all([
+ s in (d, 1)
+ for s, d in itertools.zip_longest(
+ reversed(src.shape), reversed(dst.shape), fillvalue=1)
+ ]):
+ raise ValueError(
+ "could not broadcast input array "
+ f"from shape {src.shape} into shape {dst.shape}")
+ squeeze_ndim = src.ndim - dst.ndim
+ if squeeze_ndim > 0:
+ # always succeeds because broadcast conition is checked.
+ src = src.squeeze(tuple(range(squeeze_ndim)))
+
if where is not None:
_core.elementwise_copy(src, dst, _where=where)
return
|
{"golden_diff": "diff --git a/cupy/_manipulation/basic.py b/cupy/_manipulation/basic.py\n--- a/cupy/_manipulation/basic.py\n+++ b/cupy/_manipulation/basic.py\n@@ -1,3 +1,5 @@\n+import itertools\n+\n import numpy\n \n from cupy import _core\n@@ -41,22 +43,35 @@\n raise TypeError('Cannot cast %s to %s in %s casting mode' %\n (src_dtype, dst.dtype, casting))\n \n- if not src_is_python_scalar and src.ndim > dst.ndim:\n- # NumPy allows stripping leading unit dimensions.\n- try:\n- src = src.squeeze(tuple(range(src.ndim - dst.ndim)))\n- except ValueError:\n- # \"cannot select an axis to squeeze out\n- # which has size not equal to one\"\n- pass # raise an error later\n-\n if fusion._is_fusing():\n+ # TODO(kataoka): NumPy allows stripping leading unit dimensions.\n+ # But fusion array proxy does not currently support\n+ # `shape` and `squeeze`.\n+\n if where is None:\n _core.elementwise_copy(src, dst)\n else:\n fusion._call_ufunc(search._where_ufunc, where, src, dst, dst)\n return\n \n+ if not src_is_python_scalar:\n+ # Check broadcast condition\n+ # - for fast-paths and\n+ # - for a better error message (than ufunc's).\n+ # NumPy allows stripping leading unit dimensions.\n+ if not all([\n+ s in (d, 1)\n+ for s, d in itertools.zip_longest(\n+ reversed(src.shape), reversed(dst.shape), fillvalue=1)\n+ ]):\n+ raise ValueError(\n+ \"could not broadcast input array \"\n+ f\"from shape {src.shape} into shape {dst.shape}\")\n+ squeeze_ndim = src.ndim - dst.ndim\n+ if squeeze_ndim > 0:\n+ # always succeeds because broadcast conition is checked.\n+ src = src.squeeze(tuple(range(squeeze_ndim)))\n+\n if where is not None:\n _core.elementwise_copy(src, dst, _where=where)\n return\n", "issue": "`copyto` does not test shape for memcpy cases\n### Description\r\n\r\nThere should be a shape check before these:\r\nhttps://github.com/cupy/cupy/blob/e7f2e797216954dd152efe0169ec6a0094d7777d/cupy/_manipulation/basic.py#L54-L55\r\nhttps://github.com/cupy/cupy/blob/e7f2e797216954dd152efe0169ec6a0094d7777d/cupy/_manipulation/basic.py#L76-L80\r\n\r\n### To Reproduce\r\n\r\n```py\r\n>>> dst = cupy.ones((2, 3), dtype=int)\r\n>>> cupy.copyto(dst, cupy.arange(6))\r\n>>> dst\r\narray([[0, 1, 2],\r\n [3, 4, 5]])\r\n>>> numpy.copyto(numpy.ones((2, 3), dtype=int), numpy.arange(6))\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"<__array_function__ internals>\", line 5, in copyto\r\nValueError: could not broadcast input array from shape (6,) into shape (2,3)\r\n```\r\n\r\n```py\r\n>>> cupy.copyto(cupy.empty((3, 0, 4, 5)), cupy.empty((6, 7, 0)))\r\n>>> numpy.copyto(numpy.empty((3, 0, 4, 5)), numpy.empty((6, 7, 0)))\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"<__array_function__ internals>\", line 5, in copyto\r\nValueError: could not broadcast input array from shape (6,7,0) into shape (3,0,4,5)\r\n```\r\n\n", "before_files": [{"content": "import numpy\n\nfrom cupy import _core\nfrom cupy._core import _fusion_interface\nfrom cupy._core import fusion\nfrom cupy._sorting import search\nfrom cupy_backends.cuda.api import runtime\n\n\ndef copyto(dst, src, casting='same_kind', where=None):\n \"\"\"Copies values from one array to another with broadcasting.\n\n This function can be called for arrays on different devices. In this case,\n casting, ``where``, and broadcasting is not supported, and an exception is\n raised if these are used.\n\n Args:\n dst (cupy.ndarray): Target array.\n src (cupy.ndarray): Source array.\n casting (str): Casting rule. See :func:`numpy.can_cast` for detail.\n where (cupy.ndarray of bool): If specified, this array acts as a mask,\n and an element is copied only if the corresponding element of\n ``where`` is True.\n\n .. seealso:: :func:`numpy.copyto`\n\n \"\"\"\n\n src_type = type(src)\n src_is_python_scalar = src_type in (\n int, bool, float, complex,\n fusion._FusionVarScalar, _fusion_interface._ScalarProxy)\n if src_is_python_scalar:\n src_dtype = numpy.dtype(type(src))\n can_cast = numpy.can_cast(src, dst.dtype, casting)\n else:\n src_dtype = src.dtype\n can_cast = numpy.can_cast(src_dtype, dst.dtype, casting)\n\n if not can_cast:\n raise TypeError('Cannot cast %s to %s in %s casting mode' %\n (src_dtype, dst.dtype, casting))\n\n if not src_is_python_scalar and src.ndim > dst.ndim:\n # NumPy allows stripping leading unit dimensions.\n try:\n src = src.squeeze(tuple(range(src.ndim - dst.ndim)))\n except ValueError:\n # \"cannot select an axis to squeeze out\n # which has size not equal to one\"\n pass # raise an error later\n\n if fusion._is_fusing():\n if where is None:\n _core.elementwise_copy(src, dst)\n else:\n fusion._call_ufunc(search._where_ufunc, where, src, dst, dst)\n return\n\n if where is not None:\n _core.elementwise_copy(src, dst, _where=where)\n return\n\n if dst.size == 0:\n return\n\n if src_is_python_scalar:\n dst.fill(src)\n return\n\n if _can_memcpy(dst, src):\n dst.data.copy_from_async(src.data, src.nbytes)\n return\n\n device = dst.device\n prev_device = runtime.getDevice()\n try:\n runtime.setDevice(device.id)\n if src.device != device:\n src = src.copy()\n _core.elementwise_copy(src, dst)\n finally:\n runtime.setDevice(prev_device)\n\n\ndef _can_memcpy(dst, src):\n c_contiguous = dst.flags.c_contiguous and src.flags.c_contiguous\n f_contiguous = dst.flags.f_contiguous and src.flags.f_contiguous\n return (c_contiguous or f_contiguous) and dst.dtype == src.dtype and \\\n dst.size == src.size\n", "path": "cupy/_manipulation/basic.py"}], "after_files": [{"content": "import itertools\n\nimport numpy\n\nfrom cupy import _core\nfrom cupy._core import _fusion_interface\nfrom cupy._core import fusion\nfrom cupy._sorting import search\nfrom cupy_backends.cuda.api import runtime\n\n\ndef copyto(dst, src, casting='same_kind', where=None):\n \"\"\"Copies values from one array to another with broadcasting.\n\n This function can be called for arrays on different devices. In this case,\n casting, ``where``, and broadcasting is not supported, and an exception is\n raised if these are used.\n\n Args:\n dst (cupy.ndarray): Target array.\n src (cupy.ndarray): Source array.\n casting (str): Casting rule. See :func:`numpy.can_cast` for detail.\n where (cupy.ndarray of bool): If specified, this array acts as a mask,\n and an element is copied only if the corresponding element of\n ``where`` is True.\n\n .. seealso:: :func:`numpy.copyto`\n\n \"\"\"\n\n src_type = type(src)\n src_is_python_scalar = src_type in (\n int, bool, float, complex,\n fusion._FusionVarScalar, _fusion_interface._ScalarProxy)\n if src_is_python_scalar:\n src_dtype = numpy.dtype(type(src))\n can_cast = numpy.can_cast(src, dst.dtype, casting)\n else:\n src_dtype = src.dtype\n can_cast = numpy.can_cast(src_dtype, dst.dtype, casting)\n\n if not can_cast:\n raise TypeError('Cannot cast %s to %s in %s casting mode' %\n (src_dtype, dst.dtype, casting))\n\n if fusion._is_fusing():\n # TODO(kataoka): NumPy allows stripping leading unit dimensions.\n # But fusion array proxy does not currently support\n # `shape` and `squeeze`.\n\n if where is None:\n _core.elementwise_copy(src, dst)\n else:\n fusion._call_ufunc(search._where_ufunc, where, src, dst, dst)\n return\n\n if not src_is_python_scalar:\n # Check broadcast condition\n # - for fast-paths and\n # - for a better error message (than ufunc's).\n # NumPy allows stripping leading unit dimensions.\n if not all([\n s in (d, 1)\n for s, d in itertools.zip_longest(\n reversed(src.shape), reversed(dst.shape), fillvalue=1)\n ]):\n raise ValueError(\n \"could not broadcast input array \"\n f\"from shape {src.shape} into shape {dst.shape}\")\n squeeze_ndim = src.ndim - dst.ndim\n if squeeze_ndim > 0:\n # always succeeds because broadcast conition is checked.\n src = src.squeeze(tuple(range(squeeze_ndim)))\n\n if where is not None:\n _core.elementwise_copy(src, dst, _where=where)\n return\n\n if dst.size == 0:\n return\n\n if src_is_python_scalar:\n dst.fill(src)\n return\n\n if _can_memcpy(dst, src):\n dst.data.copy_from_async(src.data, src.nbytes)\n return\n\n device = dst.device\n prev_device = runtime.getDevice()\n try:\n runtime.setDevice(device.id)\n if src.device != device:\n src = src.copy()\n _core.elementwise_copy(src, dst)\n finally:\n runtime.setDevice(prev_device)\n\n\ndef _can_memcpy(dst, src):\n c_contiguous = dst.flags.c_contiguous and src.flags.c_contiguous\n f_contiguous = dst.flags.f_contiguous and src.flags.f_contiguous\n return (c_contiguous or f_contiguous) and dst.dtype == src.dtype and \\\n dst.size == src.size\n", "path": "cupy/_manipulation/basic.py"}]}
| 1,538 | 488 |
gh_patches_debug_39421
|
rasdani/github-patches
|
git_diff
|
googleapis__google-cloud-python-376
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add regression test for datastore keys (object names) with / separator
See https://github.com/GoogleCloudPlatform/gcloud-python/pull/371#issuecomment-62659321
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `regression/storage.py`
Content:
```
1 from Crypto.Hash import MD5
2 import base64
3 import httplib2
4 import tempfile
5 import time
6 import unittest2
7
8 from gcloud import storage
9 # This assumes the command is being run via tox hence the
10 # repository root is the current directory.
11 from regression import regression_utils
12
13
14 HTTP = httplib2.Http()
15 SHARED_BUCKETS = {}
16
17
18 def setUpModule():
19 if 'test_bucket' not in SHARED_BUCKETS:
20 connection = regression_utils.get_storage_connection()
21 # %d rounds milliseconds to nearest integer.
22 bucket_name = 'new%d' % (1000 * time.time(),)
23 # In the **very** rare case the bucket name is reserved, this
24 # fails with a ConnectionError.
25 SHARED_BUCKETS['test_bucket'] = connection.create_bucket(bucket_name)
26
27
28 def tearDownModule():
29 for bucket in SHARED_BUCKETS.values():
30 # Passing force=True also deletes all files.
31 bucket.delete(force=True)
32
33
34 class TestStorage(unittest2.TestCase):
35
36 @classmethod
37 def setUpClass(cls):
38 cls.connection = regression_utils.get_storage_connection()
39
40
41 class TestStorageBuckets(TestStorage):
42
43 def setUp(self):
44 self.case_buckets_to_delete = []
45
46 def tearDown(self):
47 for bucket in self.case_buckets_to_delete:
48 bucket.delete()
49
50 def test_create_bucket(self):
51 new_bucket_name = 'a-new-bucket'
52 self.assertRaises(storage.exceptions.NotFound,
53 self.connection.get_bucket, new_bucket_name)
54 created = self.connection.create_bucket(new_bucket_name)
55 self.case_buckets_to_delete.append(created)
56 self.assertEqual(created.name, new_bucket_name)
57
58 def test_get_buckets(self):
59 buckets_to_create = [
60 'new%d' % (1000 * time.time(),),
61 'newer%d' % (1000 * time.time(),),
62 'newest%d' % (1000 * time.time(),),
63 ]
64 created_buckets = []
65 for bucket_name in buckets_to_create:
66 bucket = self.connection.create_bucket(bucket_name)
67 self.case_buckets_to_delete.append(bucket)
68
69 # Retrieve the buckets.
70 all_buckets = self.connection.get_all_buckets()
71 created_buckets = [bucket for bucket in all_buckets
72 if bucket.name in buckets_to_create]
73 self.assertEqual(len(created_buckets), len(buckets_to_create))
74
75
76 class TestStorageFiles(TestStorage):
77
78 FILES = {
79 'logo': {
80 'path': 'regression/data/CloudPlatform_128px_Retina.png',
81 },
82 'big': {
83 'path': 'regression/data/five-mb-file.zip',
84 },
85 }
86
87 @staticmethod
88 def _get_base64_md5hash(filename):
89 with open(filename, 'rb') as file_obj:
90 hash = MD5.new(data=file_obj.read())
91 digest_bytes = hash.digest()
92 return base64.b64encode(digest_bytes)
93
94 @classmethod
95 def setUpClass(cls):
96 super(TestStorageFiles, cls).setUpClass()
97 for file_data in cls.FILES.values():
98 file_data['hash'] = cls._get_base64_md5hash(file_data['path'])
99 cls.bucket = SHARED_BUCKETS['test_bucket']
100
101 def setUp(self):
102 self.case_keys_to_delete = []
103
104 def tearDown(self):
105 for key in self.case_keys_to_delete:
106 key.delete()
107
108
109 class TestStorageWriteFiles(TestStorageFiles):
110
111 def test_large_file_write_from_stream(self):
112 key = self.bucket.new_key('LargeFile')
113 self.assertEqual(key._properties, {})
114
115 file_data = self.FILES['big']
116 with open(file_data['path'], 'rb') as file_obj:
117 self.bucket.upload_file_object(file_obj, key=key)
118 self.case_keys_to_delete.append(key)
119
120 key._properties.clear() # force a reload
121 self.assertEqual(key.md5_hash, file_data['hash'])
122
123 def test_write_metadata(self):
124 key = self.bucket.upload_file(self.FILES['logo']['path'])
125 self.case_keys_to_delete.append(key)
126
127 # NOTE: This should not be necessary. We should be able to pass
128 # it in to upload_file and also to upload_from_string.
129 key.content_type = 'image/png'
130 key._properties.clear() # force a reload
131 self.assertEqual(key.content_type, 'image/png')
132
133 def test_direct_write_and_read_into_file(self):
134 key = self.bucket.new_key('MyBuffer')
135 file_contents = 'Hello World'
136 key.upload_from_string(file_contents)
137 self.case_keys_to_delete.append(key)
138
139 same_key = self.bucket.new_key('MyBuffer')
140 temp_filename = tempfile.mktemp()
141 with open(temp_filename, 'w') as file_obj:
142 same_key.get_contents_to_file(file_obj)
143
144 with open(temp_filename, 'rb') as file_obj:
145 stored_contents = file_obj.read()
146
147 self.assertEqual(file_contents, stored_contents)
148
149 def test_copy_existing_file(self):
150 key = self.bucket.upload_file(self.FILES['logo']['path'],
151 key='CloudLogo')
152 self.case_keys_to_delete.append(key)
153
154 new_key = self.bucket.copy_key(key, self.bucket, 'CloudLogoCopy')
155 self.case_keys_to_delete.append(new_key)
156
157 base_contents = key.get_contents_as_string()
158 copied_contents = new_key.get_contents_as_string()
159 self.assertEqual(base_contents, copied_contents)
160
161
162 class TestStorageListFiles(TestStorageFiles):
163
164 FILENAMES = ['CloudLogo1', 'CloudLogo2', 'CloudLogo3']
165
166 @classmethod
167 def setUpClass(cls):
168 super(TestStorageListFiles, cls).setUpClass()
169 # Make sure bucket empty before beginning.
170 for key in cls.bucket:
171 key.delete()
172
173 logo_path = cls.FILES['logo']['path']
174 key = cls.bucket.upload_file(logo_path, key=cls.FILENAMES[0])
175 cls.suite_keys_to_delete = [key]
176
177 # Copy main key onto remaining in FILENAMES.
178 for filename in cls.FILENAMES[1:]:
179 new_key = cls.bucket.copy_key(key, cls.bucket, filename)
180 cls.suite_keys_to_delete.append(new_key)
181
182 @classmethod
183 def tearDownClass(cls):
184 for key in cls.suite_keys_to_delete:
185 key.delete()
186
187 def test_list_files(self):
188 all_keys = self.bucket.get_all_keys()
189 self.assertEqual(len(all_keys), len(self.FILENAMES))
190
191 def test_paginate_files(self):
192 truncation_size = 1
193 count = len(self.FILENAMES) - truncation_size
194 iterator = self.bucket.iterator(max_results=count)
195 response = iterator.get_next_page_response()
196 keys = list(iterator.get_items_from_response(response))
197 self.assertEqual(len(keys), count)
198 self.assertEqual(iterator.page_number, 1)
199 self.assertTrue(iterator.next_page_token is not None)
200
201 response = iterator.get_next_page_response()
202 last_keys = list(iterator.get_items_from_response(response))
203 self.assertEqual(len(last_keys), truncation_size)
204
205
206 class TestStorageSignURLs(TestStorageFiles):
207
208 def setUp(self):
209 super(TestStorageSignURLs, self).setUp()
210
211 logo_path = self.FILES['logo']['path']
212 with open(logo_path, 'r') as file_obj:
213 self.LOCAL_FILE = file_obj.read()
214
215 key = self.bucket.new_key('LogoToSign.jpg')
216 key.upload_from_string(self.LOCAL_FILE)
217 self.case_keys_to_delete.append(key)
218
219 def tearDown(self):
220 for key in self.case_keys_to_delete:
221 if key.exists():
222 key.delete()
223
224 def test_create_signed_read_url(self):
225 key = self.bucket.new_key('LogoToSign.jpg')
226 expiration = int(time.time() + 5)
227 signed_url = key.generate_signed_url(expiration, method='GET')
228
229 response, content = HTTP.request(signed_url, method='GET')
230 self.assertEqual(response.status, 200)
231 self.assertEqual(content, self.LOCAL_FILE)
232
233 def test_create_signed_delete_url(self):
234 key = self.bucket.new_key('LogoToSign.jpg')
235 expiration = int(time.time() + 283473274)
236 signed_delete_url = key.generate_signed_url(expiration,
237 method='DELETE')
238
239 response, content = HTTP.request(signed_delete_url, method='DELETE')
240 self.assertEqual(response.status, 204)
241 self.assertEqual(content, '')
242
243 # Check that the key has actually been deleted.
244 self.assertFalse(key in self.bucket)
245
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/regression/storage.py b/regression/storage.py
--- a/regression/storage.py
+++ b/regression/storage.py
@@ -82,6 +82,9 @@
'big': {
'path': 'regression/data/five-mb-file.zip',
},
+ 'simple': {
+ 'path': 'regression/data/simple.txt',
+ }
}
@staticmethod
@@ -203,6 +206,82 @@
self.assertEqual(len(last_keys), truncation_size)
+class TestStoragePseudoHierarchy(TestStorageFiles):
+
+ FILENAMES = [
+ 'file01.txt',
+ 'parent/file11.txt',
+ 'parent/child/file21.txt',
+ 'parent/child/file22.txt',
+ 'parent/child/grand/file31.txt',
+ 'parent/child/other/file32.txt',
+ ]
+
+ @classmethod
+ def setUpClass(cls):
+ super(TestStoragePseudoHierarchy, cls).setUpClass()
+ # Make sure bucket empty before beginning.
+ for key in cls.bucket:
+ key.delete()
+
+ simple_path = cls.FILES['simple']['path']
+ key = cls.bucket.upload_file(simple_path, key=cls.FILENAMES[0])
+ cls.suite_keys_to_delete = [key]
+ for filename in cls.FILENAMES[1:]:
+ new_key = cls.bucket.copy_key(key, cls.bucket, filename)
+ cls.suite_keys_to_delete.append(new_key)
+
+ @classmethod
+ def tearDownClass(cls):
+ for key in cls.suite_keys_to_delete:
+ key.delete()
+
+ def test_root_level_w_delimiter(self):
+ iterator = self.bucket.iterator(delimiter='/')
+ response = iterator.get_next_page_response()
+ keys = list(iterator.get_items_from_response(response))
+ self.assertEqual([key.name for key in keys], ['file01.txt'])
+ self.assertEqual(iterator.page_number, 1)
+ self.assertTrue(iterator.next_page_token is None)
+ self.assertEqual(iterator.prefixes, ('parent/',))
+
+ def test_first_level(self):
+ iterator = self.bucket.iterator(delimiter='/', prefix='parent/')
+ response = iterator.get_next_page_response()
+ keys = list(iterator.get_items_from_response(response))
+ self.assertEqual([key.name for key in keys], ['parent/file11.txt'])
+ self.assertEqual(iterator.page_number, 1)
+ self.assertTrue(iterator.next_page_token is None)
+ self.assertEqual(iterator.prefixes, ('parent/child/',))
+
+ def test_second_level(self):
+ iterator = self.bucket.iterator(delimiter='/', prefix='parent/child/')
+ response = iterator.get_next_page_response()
+ keys = list(iterator.get_items_from_response(response))
+ self.assertEqual([key.name for key in keys],
+ ['parent/child/file21.txt',
+ 'parent/child/file22.txt'])
+ self.assertEqual(iterator.page_number, 1)
+ self.assertTrue(iterator.next_page_token is None)
+ self.assertEqual(iterator.prefixes,
+ ('parent/child/grand/', 'parent/child/other/'))
+
+ def test_third_level(self):
+ # Pseudo-hierarchy can be arbitrarily deep, subject to the limit
+ # of 1024 characters in the UTF-8 encoded name:
+ # https://cloud.google.com/storage/docs/bucketnaming#objectnames
+ # Exercise a layer deeper to illustrate this.
+ iterator = self.bucket.iterator(delimiter='/',
+ prefix='parent/child/grand/')
+ response = iterator.get_next_page_response()
+ keys = list(iterator.get_items_from_response(response))
+ self.assertEqual([key.name for key in keys],
+ ['parent/child/grand/file31.txt'])
+ self.assertEqual(iterator.page_number, 1)
+ self.assertTrue(iterator.next_page_token is None)
+ self.assertEqual(iterator.prefixes, ())
+
+
class TestStorageSignURLs(TestStorageFiles):
def setUp(self):
|
{"golden_diff": "diff --git a/regression/storage.py b/regression/storage.py\n--- a/regression/storage.py\n+++ b/regression/storage.py\n@@ -82,6 +82,9 @@\n 'big': {\n 'path': 'regression/data/five-mb-file.zip',\n },\n+ 'simple': {\n+ 'path': 'regression/data/simple.txt',\n+ }\n }\n \n @staticmethod\n@@ -203,6 +206,82 @@\n self.assertEqual(len(last_keys), truncation_size)\n \n \n+class TestStoragePseudoHierarchy(TestStorageFiles):\n+\n+ FILENAMES = [\n+ 'file01.txt',\n+ 'parent/file11.txt',\n+ 'parent/child/file21.txt',\n+ 'parent/child/file22.txt',\n+ 'parent/child/grand/file31.txt',\n+ 'parent/child/other/file32.txt',\n+ ]\n+\n+ @classmethod\n+ def setUpClass(cls):\n+ super(TestStoragePseudoHierarchy, cls).setUpClass()\n+ # Make sure bucket empty before beginning.\n+ for key in cls.bucket:\n+ key.delete()\n+\n+ simple_path = cls.FILES['simple']['path']\n+ key = cls.bucket.upload_file(simple_path, key=cls.FILENAMES[0])\n+ cls.suite_keys_to_delete = [key]\n+ for filename in cls.FILENAMES[1:]:\n+ new_key = cls.bucket.copy_key(key, cls.bucket, filename)\n+ cls.suite_keys_to_delete.append(new_key)\n+\n+ @classmethod\n+ def tearDownClass(cls):\n+ for key in cls.suite_keys_to_delete:\n+ key.delete()\n+\n+ def test_root_level_w_delimiter(self):\n+ iterator = self.bucket.iterator(delimiter='/')\n+ response = iterator.get_next_page_response()\n+ keys = list(iterator.get_items_from_response(response))\n+ self.assertEqual([key.name for key in keys], ['file01.txt'])\n+ self.assertEqual(iterator.page_number, 1)\n+ self.assertTrue(iterator.next_page_token is None)\n+ self.assertEqual(iterator.prefixes, ('parent/',))\n+\n+ def test_first_level(self):\n+ iterator = self.bucket.iterator(delimiter='/', prefix='parent/')\n+ response = iterator.get_next_page_response()\n+ keys = list(iterator.get_items_from_response(response))\n+ self.assertEqual([key.name for key in keys], ['parent/file11.txt'])\n+ self.assertEqual(iterator.page_number, 1)\n+ self.assertTrue(iterator.next_page_token is None)\n+ self.assertEqual(iterator.prefixes, ('parent/child/',))\n+\n+ def test_second_level(self):\n+ iterator = self.bucket.iterator(delimiter='/', prefix='parent/child/')\n+ response = iterator.get_next_page_response()\n+ keys = list(iterator.get_items_from_response(response))\n+ self.assertEqual([key.name for key in keys],\n+ ['parent/child/file21.txt',\n+ 'parent/child/file22.txt'])\n+ self.assertEqual(iterator.page_number, 1)\n+ self.assertTrue(iterator.next_page_token is None)\n+ self.assertEqual(iterator.prefixes,\n+ ('parent/child/grand/', 'parent/child/other/'))\n+\n+ def test_third_level(self):\n+ # Pseudo-hierarchy can be arbitrarily deep, subject to the limit\n+ # of 1024 characters in the UTF-8 encoded name:\n+ # https://cloud.google.com/storage/docs/bucketnaming#objectnames\n+ # Exercise a layer deeper to illustrate this.\n+ iterator = self.bucket.iterator(delimiter='/',\n+ prefix='parent/child/grand/')\n+ response = iterator.get_next_page_response()\n+ keys = list(iterator.get_items_from_response(response))\n+ self.assertEqual([key.name for key in keys],\n+ ['parent/child/grand/file31.txt'])\n+ self.assertEqual(iterator.page_number, 1)\n+ self.assertTrue(iterator.next_page_token is None)\n+ self.assertEqual(iterator.prefixes, ())\n+\n+\n class TestStorageSignURLs(TestStorageFiles):\n \n def setUp(self):\n", "issue": "Add regression test for datastore keys (object names) with / separator\nSee https://github.com/GoogleCloudPlatform/gcloud-python/pull/371#issuecomment-62659321\n\n", "before_files": [{"content": "from Crypto.Hash import MD5\nimport base64\nimport httplib2\nimport tempfile\nimport time\nimport unittest2\n\nfrom gcloud import storage\n# This assumes the command is being run via tox hence the\n# repository root is the current directory.\nfrom regression import regression_utils\n\n\nHTTP = httplib2.Http()\nSHARED_BUCKETS = {}\n\n\ndef setUpModule():\n if 'test_bucket' not in SHARED_BUCKETS:\n connection = regression_utils.get_storage_connection()\n # %d rounds milliseconds to nearest integer.\n bucket_name = 'new%d' % (1000 * time.time(),)\n # In the **very** rare case the bucket name is reserved, this\n # fails with a ConnectionError.\n SHARED_BUCKETS['test_bucket'] = connection.create_bucket(bucket_name)\n\n\ndef tearDownModule():\n for bucket in SHARED_BUCKETS.values():\n # Passing force=True also deletes all files.\n bucket.delete(force=True)\n\n\nclass TestStorage(unittest2.TestCase):\n\n @classmethod\n def setUpClass(cls):\n cls.connection = regression_utils.get_storage_connection()\n\n\nclass TestStorageBuckets(TestStorage):\n\n def setUp(self):\n self.case_buckets_to_delete = []\n\n def tearDown(self):\n for bucket in self.case_buckets_to_delete:\n bucket.delete()\n\n def test_create_bucket(self):\n new_bucket_name = 'a-new-bucket'\n self.assertRaises(storage.exceptions.NotFound,\n self.connection.get_bucket, new_bucket_name)\n created = self.connection.create_bucket(new_bucket_name)\n self.case_buckets_to_delete.append(created)\n self.assertEqual(created.name, new_bucket_name)\n\n def test_get_buckets(self):\n buckets_to_create = [\n 'new%d' % (1000 * time.time(),),\n 'newer%d' % (1000 * time.time(),),\n 'newest%d' % (1000 * time.time(),),\n ]\n created_buckets = []\n for bucket_name in buckets_to_create:\n bucket = self.connection.create_bucket(bucket_name)\n self.case_buckets_to_delete.append(bucket)\n\n # Retrieve the buckets.\n all_buckets = self.connection.get_all_buckets()\n created_buckets = [bucket for bucket in all_buckets\n if bucket.name in buckets_to_create]\n self.assertEqual(len(created_buckets), len(buckets_to_create))\n\n\nclass TestStorageFiles(TestStorage):\n\n FILES = {\n 'logo': {\n 'path': 'regression/data/CloudPlatform_128px_Retina.png',\n },\n 'big': {\n 'path': 'regression/data/five-mb-file.zip',\n },\n }\n\n @staticmethod\n def _get_base64_md5hash(filename):\n with open(filename, 'rb') as file_obj:\n hash = MD5.new(data=file_obj.read())\n digest_bytes = hash.digest()\n return base64.b64encode(digest_bytes)\n\n @classmethod\n def setUpClass(cls):\n super(TestStorageFiles, cls).setUpClass()\n for file_data in cls.FILES.values():\n file_data['hash'] = cls._get_base64_md5hash(file_data['path'])\n cls.bucket = SHARED_BUCKETS['test_bucket']\n\n def setUp(self):\n self.case_keys_to_delete = []\n\n def tearDown(self):\n for key in self.case_keys_to_delete:\n key.delete()\n\n\nclass TestStorageWriteFiles(TestStorageFiles):\n\n def test_large_file_write_from_stream(self):\n key = self.bucket.new_key('LargeFile')\n self.assertEqual(key._properties, {})\n\n file_data = self.FILES['big']\n with open(file_data['path'], 'rb') as file_obj:\n self.bucket.upload_file_object(file_obj, key=key)\n self.case_keys_to_delete.append(key)\n\n key._properties.clear() # force a reload\n self.assertEqual(key.md5_hash, file_data['hash'])\n\n def test_write_metadata(self):\n key = self.bucket.upload_file(self.FILES['logo']['path'])\n self.case_keys_to_delete.append(key)\n\n # NOTE: This should not be necessary. We should be able to pass\n # it in to upload_file and also to upload_from_string.\n key.content_type = 'image/png'\n key._properties.clear() # force a reload\n self.assertEqual(key.content_type, 'image/png')\n\n def test_direct_write_and_read_into_file(self):\n key = self.bucket.new_key('MyBuffer')\n file_contents = 'Hello World'\n key.upload_from_string(file_contents)\n self.case_keys_to_delete.append(key)\n\n same_key = self.bucket.new_key('MyBuffer')\n temp_filename = tempfile.mktemp()\n with open(temp_filename, 'w') as file_obj:\n same_key.get_contents_to_file(file_obj)\n\n with open(temp_filename, 'rb') as file_obj:\n stored_contents = file_obj.read()\n\n self.assertEqual(file_contents, stored_contents)\n\n def test_copy_existing_file(self):\n key = self.bucket.upload_file(self.FILES['logo']['path'],\n key='CloudLogo')\n self.case_keys_to_delete.append(key)\n\n new_key = self.bucket.copy_key(key, self.bucket, 'CloudLogoCopy')\n self.case_keys_to_delete.append(new_key)\n\n base_contents = key.get_contents_as_string()\n copied_contents = new_key.get_contents_as_string()\n self.assertEqual(base_contents, copied_contents)\n\n\nclass TestStorageListFiles(TestStorageFiles):\n\n FILENAMES = ['CloudLogo1', 'CloudLogo2', 'CloudLogo3']\n\n @classmethod\n def setUpClass(cls):\n super(TestStorageListFiles, cls).setUpClass()\n # Make sure bucket empty before beginning.\n for key in cls.bucket:\n key.delete()\n\n logo_path = cls.FILES['logo']['path']\n key = cls.bucket.upload_file(logo_path, key=cls.FILENAMES[0])\n cls.suite_keys_to_delete = [key]\n\n # Copy main key onto remaining in FILENAMES.\n for filename in cls.FILENAMES[1:]:\n new_key = cls.bucket.copy_key(key, cls.bucket, filename)\n cls.suite_keys_to_delete.append(new_key)\n\n @classmethod\n def tearDownClass(cls):\n for key in cls.suite_keys_to_delete:\n key.delete()\n\n def test_list_files(self):\n all_keys = self.bucket.get_all_keys()\n self.assertEqual(len(all_keys), len(self.FILENAMES))\n\n def test_paginate_files(self):\n truncation_size = 1\n count = len(self.FILENAMES) - truncation_size\n iterator = self.bucket.iterator(max_results=count)\n response = iterator.get_next_page_response()\n keys = list(iterator.get_items_from_response(response))\n self.assertEqual(len(keys), count)\n self.assertEqual(iterator.page_number, 1)\n self.assertTrue(iterator.next_page_token is not None)\n\n response = iterator.get_next_page_response()\n last_keys = list(iterator.get_items_from_response(response))\n self.assertEqual(len(last_keys), truncation_size)\n\n\nclass TestStorageSignURLs(TestStorageFiles):\n\n def setUp(self):\n super(TestStorageSignURLs, self).setUp()\n\n logo_path = self.FILES['logo']['path']\n with open(logo_path, 'r') as file_obj:\n self.LOCAL_FILE = file_obj.read()\n\n key = self.bucket.new_key('LogoToSign.jpg')\n key.upload_from_string(self.LOCAL_FILE)\n self.case_keys_to_delete.append(key)\n\n def tearDown(self):\n for key in self.case_keys_to_delete:\n if key.exists():\n key.delete()\n\n def test_create_signed_read_url(self):\n key = self.bucket.new_key('LogoToSign.jpg')\n expiration = int(time.time() + 5)\n signed_url = key.generate_signed_url(expiration, method='GET')\n\n response, content = HTTP.request(signed_url, method='GET')\n self.assertEqual(response.status, 200)\n self.assertEqual(content, self.LOCAL_FILE)\n\n def test_create_signed_delete_url(self):\n key = self.bucket.new_key('LogoToSign.jpg')\n expiration = int(time.time() + 283473274)\n signed_delete_url = key.generate_signed_url(expiration,\n method='DELETE')\n\n response, content = HTTP.request(signed_delete_url, method='DELETE')\n self.assertEqual(response.status, 204)\n self.assertEqual(content, '')\n\n # Check that the key has actually been deleted.\n self.assertFalse(key in self.bucket)\n", "path": "regression/storage.py"}], "after_files": [{"content": "from Crypto.Hash import MD5\nimport base64\nimport httplib2\nimport tempfile\nimport time\nimport unittest2\n\nfrom gcloud import storage\n# This assumes the command is being run via tox hence the\n# repository root is the current directory.\nfrom regression import regression_utils\n\n\nHTTP = httplib2.Http()\nSHARED_BUCKETS = {}\n\n\ndef setUpModule():\n if 'test_bucket' not in SHARED_BUCKETS:\n connection = regression_utils.get_storage_connection()\n # %d rounds milliseconds to nearest integer.\n bucket_name = 'new%d' % (1000 * time.time(),)\n # In the **very** rare case the bucket name is reserved, this\n # fails with a ConnectionError.\n SHARED_BUCKETS['test_bucket'] = connection.create_bucket(bucket_name)\n\n\ndef tearDownModule():\n for bucket in SHARED_BUCKETS.values():\n # Passing force=True also deletes all files.\n bucket.delete(force=True)\n\n\nclass TestStorage(unittest2.TestCase):\n\n @classmethod\n def setUpClass(cls):\n cls.connection = regression_utils.get_storage_connection()\n\n\nclass TestStorageBuckets(TestStorage):\n\n def setUp(self):\n self.case_buckets_to_delete = []\n\n def tearDown(self):\n for bucket in self.case_buckets_to_delete:\n bucket.delete()\n\n def test_create_bucket(self):\n new_bucket_name = 'a-new-bucket'\n self.assertRaises(storage.exceptions.NotFound,\n self.connection.get_bucket, new_bucket_name)\n created = self.connection.create_bucket(new_bucket_name)\n self.case_buckets_to_delete.append(created)\n self.assertEqual(created.name, new_bucket_name)\n\n def test_get_buckets(self):\n buckets_to_create = [\n 'new%d' % (1000 * time.time(),),\n 'newer%d' % (1000 * time.time(),),\n 'newest%d' % (1000 * time.time(),),\n ]\n created_buckets = []\n for bucket_name in buckets_to_create:\n bucket = self.connection.create_bucket(bucket_name)\n self.case_buckets_to_delete.append(bucket)\n\n # Retrieve the buckets.\n all_buckets = self.connection.get_all_buckets()\n created_buckets = [bucket for bucket in all_buckets\n if bucket.name in buckets_to_create]\n self.assertEqual(len(created_buckets), len(buckets_to_create))\n\n\nclass TestStorageFiles(TestStorage):\n\n FILES = {\n 'logo': {\n 'path': 'regression/data/CloudPlatform_128px_Retina.png',\n },\n 'big': {\n 'path': 'regression/data/five-mb-file.zip',\n },\n 'simple': {\n 'path': 'regression/data/simple.txt',\n }\n }\n\n @staticmethod\n def _get_base64_md5hash(filename):\n with open(filename, 'rb') as file_obj:\n hash = MD5.new(data=file_obj.read())\n digest_bytes = hash.digest()\n return base64.b64encode(digest_bytes)\n\n @classmethod\n def setUpClass(cls):\n super(TestStorageFiles, cls).setUpClass()\n for file_data in cls.FILES.values():\n file_data['hash'] = cls._get_base64_md5hash(file_data['path'])\n cls.bucket = SHARED_BUCKETS['test_bucket']\n\n def setUp(self):\n self.case_keys_to_delete = []\n\n def tearDown(self):\n for key in self.case_keys_to_delete:\n key.delete()\n\n\nclass TestStorageWriteFiles(TestStorageFiles):\n\n def test_large_file_write_from_stream(self):\n key = self.bucket.new_key('LargeFile')\n self.assertEqual(key._properties, {})\n\n file_data = self.FILES['big']\n with open(file_data['path'], 'rb') as file_obj:\n self.bucket.upload_file_object(file_obj, key=key)\n self.case_keys_to_delete.append(key)\n\n key._properties.clear() # force a reload\n self.assertEqual(key.md5_hash, file_data['hash'])\n\n def test_write_metadata(self):\n key = self.bucket.upload_file(self.FILES['logo']['path'])\n self.case_keys_to_delete.append(key)\n\n # NOTE: This should not be necessary. We should be able to pass\n # it in to upload_file and also to upload_from_string.\n key.content_type = 'image/png'\n key._properties.clear() # force a reload\n self.assertEqual(key.content_type, 'image/png')\n\n def test_direct_write_and_read_into_file(self):\n key = self.bucket.new_key('MyBuffer')\n file_contents = 'Hello World'\n key.upload_from_string(file_contents)\n self.case_keys_to_delete.append(key)\n\n same_key = self.bucket.new_key('MyBuffer')\n temp_filename = tempfile.mktemp()\n with open(temp_filename, 'w') as file_obj:\n same_key.get_contents_to_file(file_obj)\n\n with open(temp_filename, 'rb') as file_obj:\n stored_contents = file_obj.read()\n\n self.assertEqual(file_contents, stored_contents)\n\n def test_copy_existing_file(self):\n key = self.bucket.upload_file(self.FILES['logo']['path'],\n key='CloudLogo')\n self.case_keys_to_delete.append(key)\n\n new_key = self.bucket.copy_key(key, self.bucket, 'CloudLogoCopy')\n self.case_keys_to_delete.append(new_key)\n\n base_contents = key.get_contents_as_string()\n copied_contents = new_key.get_contents_as_string()\n self.assertEqual(base_contents, copied_contents)\n\n\nclass TestStorageListFiles(TestStorageFiles):\n\n FILENAMES = ['CloudLogo1', 'CloudLogo2', 'CloudLogo3']\n\n @classmethod\n def setUpClass(cls):\n super(TestStorageListFiles, cls).setUpClass()\n # Make sure bucket empty before beginning.\n for key in cls.bucket:\n key.delete()\n\n logo_path = cls.FILES['logo']['path']\n key = cls.bucket.upload_file(logo_path, key=cls.FILENAMES[0])\n cls.suite_keys_to_delete = [key]\n\n # Copy main key onto remaining in FILENAMES.\n for filename in cls.FILENAMES[1:]:\n new_key = cls.bucket.copy_key(key, cls.bucket, filename)\n cls.suite_keys_to_delete.append(new_key)\n\n @classmethod\n def tearDownClass(cls):\n for key in cls.suite_keys_to_delete:\n key.delete()\n\n def test_list_files(self):\n all_keys = self.bucket.get_all_keys()\n self.assertEqual(len(all_keys), len(self.FILENAMES))\n\n def test_paginate_files(self):\n truncation_size = 1\n count = len(self.FILENAMES) - truncation_size\n iterator = self.bucket.iterator(max_results=count)\n response = iterator.get_next_page_response()\n keys = list(iterator.get_items_from_response(response))\n self.assertEqual(len(keys), count)\n self.assertEqual(iterator.page_number, 1)\n self.assertTrue(iterator.next_page_token is not None)\n\n response = iterator.get_next_page_response()\n last_keys = list(iterator.get_items_from_response(response))\n self.assertEqual(len(last_keys), truncation_size)\n\n\nclass TestStoragePseudoHierarchy(TestStorageFiles):\n\n FILENAMES = [\n 'file01.txt',\n 'parent/file11.txt',\n 'parent/child/file21.txt',\n 'parent/child/file22.txt',\n 'parent/child/grand/file31.txt',\n 'parent/child/other/file32.txt',\n ]\n\n @classmethod\n def setUpClass(cls):\n super(TestStoragePseudoHierarchy, cls).setUpClass()\n # Make sure bucket empty before beginning.\n for key in cls.bucket:\n key.delete()\n\n simple_path = cls.FILES['simple']['path']\n key = cls.bucket.upload_file(simple_path, key=cls.FILENAMES[0])\n cls.suite_keys_to_delete = [key]\n for filename in cls.FILENAMES[1:]:\n new_key = cls.bucket.copy_key(key, cls.bucket, filename)\n cls.suite_keys_to_delete.append(new_key)\n\n @classmethod\n def tearDownClass(cls):\n for key in cls.suite_keys_to_delete:\n key.delete()\n\n def test_root_level_w_delimiter(self):\n iterator = self.bucket.iterator(delimiter='/')\n response = iterator.get_next_page_response()\n keys = list(iterator.get_items_from_response(response))\n self.assertEqual([key.name for key in keys], ['file01.txt'])\n self.assertEqual(iterator.page_number, 1)\n self.assertTrue(iterator.next_page_token is None)\n self.assertEqual(iterator.prefixes, ('parent/',))\n\n def test_first_level(self):\n iterator = self.bucket.iterator(delimiter='/', prefix='parent/')\n response = iterator.get_next_page_response()\n keys = list(iterator.get_items_from_response(response))\n self.assertEqual([key.name for key in keys], ['parent/file11.txt'])\n self.assertEqual(iterator.page_number, 1)\n self.assertTrue(iterator.next_page_token is None)\n self.assertEqual(iterator.prefixes, ('parent/child/',))\n\n def test_second_level(self):\n iterator = self.bucket.iterator(delimiter='/', prefix='parent/child/')\n response = iterator.get_next_page_response()\n keys = list(iterator.get_items_from_response(response))\n self.assertEqual([key.name for key in keys],\n ['parent/child/file21.txt',\n 'parent/child/file22.txt'])\n self.assertEqual(iterator.page_number, 1)\n self.assertTrue(iterator.next_page_token is None)\n self.assertEqual(iterator.prefixes,\n ('parent/child/grand/', 'parent/child/other/'))\n\n def test_third_level(self):\n # Pseudo-hierarchy can be arbitrarily deep, subject to the limit\n # of 1024 characters in the UTF-8 encoded name:\n # https://cloud.google.com/storage/docs/bucketnaming#objectnames\n # Exercise a layer deeper to illustrate this.\n iterator = self.bucket.iterator(delimiter='/',\n prefix='parent/child/grand/')\n response = iterator.get_next_page_response()\n keys = list(iterator.get_items_from_response(response))\n self.assertEqual([key.name for key in keys],\n ['parent/child/grand/file31.txt'])\n self.assertEqual(iterator.page_number, 1)\n self.assertTrue(iterator.next_page_token is None)\n self.assertEqual(iterator.prefixes, ())\n\n\nclass TestStorageSignURLs(TestStorageFiles):\n\n def setUp(self):\n super(TestStorageSignURLs, self).setUp()\n\n logo_path = self.FILES['logo']['path']\n with open(logo_path, 'r') as file_obj:\n self.LOCAL_FILE = file_obj.read()\n\n key = self.bucket.new_key('LogoToSign.jpg')\n key.upload_from_string(self.LOCAL_FILE)\n self.case_keys_to_delete.append(key)\n\n def tearDown(self):\n for key in self.case_keys_to_delete:\n if key.exists():\n key.delete()\n\n def test_create_signed_read_url(self):\n key = self.bucket.new_key('LogoToSign.jpg')\n expiration = int(time.time() + 5)\n signed_url = key.generate_signed_url(expiration, method='GET')\n\n response, content = HTTP.request(signed_url, method='GET')\n self.assertEqual(response.status, 200)\n self.assertEqual(content, self.LOCAL_FILE)\n\n def test_create_signed_delete_url(self):\n key = self.bucket.new_key('LogoToSign.jpg')\n expiration = int(time.time() + 283473274)\n signed_delete_url = key.generate_signed_url(expiration,\n method='DELETE')\n\n response, content = HTTP.request(signed_delete_url, method='DELETE')\n self.assertEqual(response.status, 204)\n self.assertEqual(content, '')\n\n # Check that the key has actually been deleted.\n self.assertFalse(key in self.bucket)\n", "path": "regression/storage.py"}]}
| 2,757 | 887 |
gh_patches_debug_820
|
rasdani/github-patches
|
git_diff
|
pypi__warehouse-3568
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Set samesite=lax on session cookies
This is a strong defense-in-depth mechanism for protecting against CSRF. It's currently only respected by Chrome, but Firefox will add it as well.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `warehouse/sessions.py`
Content:
```
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13 import functools
14 import time
15
16 import msgpack
17 import msgpack.exceptions
18 import redis
19
20 from pyramid import viewderivers
21 from pyramid.interfaces import ISession, ISessionFactory
22 from zope.interface import implementer
23
24 from warehouse.cache.http import add_vary
25 from warehouse.utils import crypto
26
27
28 def _invalid_method(method):
29 @functools.wraps(method)
30 def wrapped(self, *args, **kwargs):
31 self._error_message()
32 return wrapped
33
34
35 @implementer(ISession)
36 class InvalidSession(dict):
37
38 __contains__ = _invalid_method(dict.__contains__)
39 __delitem__ = _invalid_method(dict.__delitem__)
40 __getitem__ = _invalid_method(dict.__getitem__)
41 __iter__ = _invalid_method(dict.__iter__)
42 __len__ = _invalid_method(dict.__len__)
43 __setitem__ = _invalid_method(dict.__setitem__)
44 clear = _invalid_method(dict.clear)
45 copy = _invalid_method(dict.copy)
46 fromkeys = _invalid_method(dict.fromkeys)
47 get = _invalid_method(dict.get)
48 items = _invalid_method(dict.items)
49 keys = _invalid_method(dict.keys)
50 pop = _invalid_method(dict.pop)
51 popitem = _invalid_method(dict.popitem)
52 setdefault = _invalid_method(dict.setdefault)
53 update = _invalid_method(dict.update)
54 values = _invalid_method(dict.values)
55
56 def _error_message(self):
57 raise RuntimeError(
58 "Cannot use request.session in a view without uses_session=True."
59 )
60
61 def __getattr__(self, name):
62 self._error_message()
63
64 @property
65 def created(self):
66 self._error_message()
67
68
69 def _changed_method(method):
70 @functools.wraps(method)
71 def wrapped(self, *args, **kwargs):
72 self.changed()
73 return method(self, *args, **kwargs)
74 return wrapped
75
76
77 @implementer(ISession)
78 class Session(dict):
79
80 _csrf_token_key = "_csrf_token"
81 _flash_key = "_flash_messages"
82
83 # A number of our methods need to be decorated so that they also call
84 # self.changed()
85 __delitem__ = _changed_method(dict.__delitem__)
86 __setitem__ = _changed_method(dict.__setitem__)
87 clear = _changed_method(dict.clear)
88 pop = _changed_method(dict.pop)
89 popitem = _changed_method(dict.popitem)
90 setdefault = _changed_method(dict.setdefault)
91 update = _changed_method(dict.update)
92
93 def __init__(self, data=None, session_id=None, new=True):
94 # Brand new sessions don't have any data, so we'll just create an empty
95 # dictionary for them.
96 if data is None:
97 data = {}
98
99 # Initialize our actual dictionary here.
100 super().__init__(data)
101
102 # We need to track the state of our Session.
103 self._sid = session_id
104 self._changed = False
105 self.new = new
106 self.created = int(time.time())
107
108 # We'll track all of the IDs that have been invalidated here
109 self.invalidated = set()
110
111 @property
112 def sid(self):
113 if self._sid is None:
114 self._sid = crypto.random_token()
115 return self._sid
116
117 def changed(self):
118 self._changed = True
119
120 def invalidate(self):
121 self.clear()
122 self.new = True
123 self.created = int(time.time())
124 self._changed = False
125
126 # If the current session id isn't None we'll want to record it as one
127 # of the ones that have been invalidated.
128 if self._sid is not None:
129 self.invalidated.add(self._sid)
130 self._sid = None
131
132 def should_save(self):
133 return self._changed
134
135 # Flash Messages Methods
136 def _get_flash_queue_key(self, queue):
137 return ".".join(filter(None, [self._flash_key, queue]))
138
139 def flash(self, msg, queue="", allow_duplicate=True):
140 queue_key = self._get_flash_queue_key(queue)
141
142 # If we're not allowing duplicates check if this message is already
143 # in the queue, and if it is just return immediately.
144 if not allow_duplicate and msg in self[queue_key]:
145 return
146
147 self.setdefault(queue_key, []).append(msg)
148
149 def peek_flash(self, queue=""):
150 return self.get(self._get_flash_queue_key(queue), [])
151
152 def pop_flash(self, queue=""):
153 queue_key = self._get_flash_queue_key(queue)
154 messages = self.get(queue_key, [])
155 self.pop(queue_key, None)
156 return messages
157
158 # CSRF Methods
159 def new_csrf_token(self):
160 self[self._csrf_token_key] = crypto.random_token()
161 return self[self._csrf_token_key]
162
163 def get_csrf_token(self):
164 token = self.get(self._csrf_token_key)
165 if token is None:
166 token = self.new_csrf_token()
167 return token
168
169
170 @implementer(ISessionFactory)
171 class SessionFactory:
172
173 cookie_name = "session_id"
174 max_age = 12 * 60 * 60 # 12 hours
175
176 def __init__(self, secret, url):
177 self.redis = redis.StrictRedis.from_url(url)
178 self.signer = crypto.TimestampSigner(secret, salt="session")
179
180 def __call__(self, request):
181 return self._process_request(request)
182
183 def _redis_key(self, session_id):
184 return "warehouse/session/data/{}".format(session_id)
185
186 def _process_request(self, request):
187 # Register a callback with the request so we can save the session once
188 # it's finished.
189 request.add_response_callback(self._process_response)
190
191 # Load our session ID from the request.
192 session_id = request.cookies.get(self.cookie_name)
193
194 # If we do not have a session ID then we'll just use a new empty
195 # session.
196 if session_id is None:
197 return Session()
198
199 # Check to make sure we have a valid session id
200 try:
201 session_id = self.signer.unsign(session_id, max_age=self.max_age)
202 session_id = session_id.decode("utf8")
203 except crypto.BadSignature:
204 return Session()
205
206 # Fetch the serialized data from redis
207 bdata = self.redis.get(self._redis_key(session_id))
208
209 # If the session didn't exist in redis, we'll give the user a new
210 # session.
211 if bdata is None:
212 return Session()
213
214 # De-serialize our session data
215 try:
216 data = msgpack.unpackb(bdata, encoding="utf8", use_list=True)
217 except (msgpack.exceptions.UnpackException,
218 msgpack.exceptions.ExtraData):
219 # If the session data was invalid we'll give the user a new session
220 return Session()
221
222 # If we were able to load existing session data, load it into a
223 # Session class
224 session = Session(data, session_id, False)
225
226 return session
227
228 def _process_response(self, request, response):
229 # If the request has an InvalidSession, then the view can't have
230 # accessed the session, and we can just skip all of this anyways.
231 if isinstance(request.session, InvalidSession):
232 return
233
234 # Check to see if the session has been marked to be deleted, if it has
235 # benn then we'll delete it, and tell our response to delete the
236 # session cookie as well.
237 if request.session.invalidated:
238 for session_id in request.session.invalidated:
239 self.redis.delete(self._redis_key(session_id))
240
241 if not request.session.should_save():
242 response.delete_cookie(self.cookie_name)
243
244 # Check to see if the session has been marked to be saved, generally
245 # this means that the session data has been modified and thus we need
246 # to store the new data.
247 if request.session.should_save():
248 # Save our session in Redis
249 self.redis.setex(
250 self._redis_key(request.session.sid),
251 self.max_age,
252 msgpack.packb(
253 request.session,
254 encoding="utf8",
255 use_bin_type=True,
256 ),
257 )
258
259 # Send our session cookie to the client
260 response.set_cookie(
261 self.cookie_name,
262 self.signer.sign(request.session.sid.encode("utf8")),
263 max_age=self.max_age,
264 httponly=True,
265 secure=request.scheme == "https",
266 )
267
268
269 def session_view(view, info):
270 if info.options.get("uses_session"):
271 # If we're using the session, then we'll just return the original view
272 # with a small wrapper around it to ensure that it has a Vary: Cookie
273 # header.
274 return add_vary("Cookie")(view)
275 elif info.exception_only:
276 return view
277 else:
278 # If we're not using the session on this view, then we'll wrap the view
279 # with a wrapper that just ensures that the session cannot be used.
280 @functools.wraps(view)
281 def wrapped(context, request):
282 # This whole method is a little bit of an odd duck, we want to make
283 # sure that we don't actually *access* request.session, because
284 # doing so triggers the machinery to create a new session. So
285 # instead we will dig into the request object __dict__ to
286 # effectively do the same thing, jsut without triggering an access
287 # on request.session.
288
289 # Save the original session so that we can restore it once the
290 # inner views have been called.
291 nothing = object()
292 original_session = request.__dict__.get("session", nothing)
293
294 # This particular view hasn't been set to allow access to the
295 # session, so we'll just assign an InvalidSession to
296 # request.session
297 request.__dict__["session"] = InvalidSession()
298
299 try:
300 # Invoke the real view
301 return view(context, request)
302 finally:
303 # Restore the original session so that things like
304 # pyramid_debugtoolbar can access it.
305 if original_session is nothing:
306 del request.__dict__["session"]
307 else:
308 request.__dict__["session"] = original_session
309
310 return wrapped
311
312
313 session_view.options = {"uses_session"}
314
315
316 def includeme(config):
317 config.set_session_factory(
318 SessionFactory(
319 config.registry.settings["sessions.secret"],
320 config.registry.settings["sessions.url"],
321 ),
322 )
323
324 config.add_view_deriver(
325 session_view,
326 over="csrf_view",
327 under=viewderivers.INGRESS,
328 )
329
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/warehouse/sessions.py b/warehouse/sessions.py
--- a/warehouse/sessions.py
+++ b/warehouse/sessions.py
@@ -263,6 +263,7 @@
max_age=self.max_age,
httponly=True,
secure=request.scheme == "https",
+ samesite=b"lax"
)
|
{"golden_diff": "diff --git a/warehouse/sessions.py b/warehouse/sessions.py\n--- a/warehouse/sessions.py\n+++ b/warehouse/sessions.py\n@@ -263,6 +263,7 @@\n max_age=self.max_age,\n httponly=True,\n secure=request.scheme == \"https\",\n+ samesite=b\"lax\"\n )\n", "issue": "Set samesite=lax on session cookies\nThis is a strong defense-in-depth mechanism for protecting against CSRF. It's currently only respected by Chrome, but Firefox will add it as well.\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport functools\nimport time\n\nimport msgpack\nimport msgpack.exceptions\nimport redis\n\nfrom pyramid import viewderivers\nfrom pyramid.interfaces import ISession, ISessionFactory\nfrom zope.interface import implementer\n\nfrom warehouse.cache.http import add_vary\nfrom warehouse.utils import crypto\n\n\ndef _invalid_method(method):\n @functools.wraps(method)\n def wrapped(self, *args, **kwargs):\n self._error_message()\n return wrapped\n\n\n@implementer(ISession)\nclass InvalidSession(dict):\n\n __contains__ = _invalid_method(dict.__contains__)\n __delitem__ = _invalid_method(dict.__delitem__)\n __getitem__ = _invalid_method(dict.__getitem__)\n __iter__ = _invalid_method(dict.__iter__)\n __len__ = _invalid_method(dict.__len__)\n __setitem__ = _invalid_method(dict.__setitem__)\n clear = _invalid_method(dict.clear)\n copy = _invalid_method(dict.copy)\n fromkeys = _invalid_method(dict.fromkeys)\n get = _invalid_method(dict.get)\n items = _invalid_method(dict.items)\n keys = _invalid_method(dict.keys)\n pop = _invalid_method(dict.pop)\n popitem = _invalid_method(dict.popitem)\n setdefault = _invalid_method(dict.setdefault)\n update = _invalid_method(dict.update)\n values = _invalid_method(dict.values)\n\n def _error_message(self):\n raise RuntimeError(\n \"Cannot use request.session in a view without uses_session=True.\"\n )\n\n def __getattr__(self, name):\n self._error_message()\n\n @property\n def created(self):\n self._error_message()\n\n\ndef _changed_method(method):\n @functools.wraps(method)\n def wrapped(self, *args, **kwargs):\n self.changed()\n return method(self, *args, **kwargs)\n return wrapped\n\n\n@implementer(ISession)\nclass Session(dict):\n\n _csrf_token_key = \"_csrf_token\"\n _flash_key = \"_flash_messages\"\n\n # A number of our methods need to be decorated so that they also call\n # self.changed()\n __delitem__ = _changed_method(dict.__delitem__)\n __setitem__ = _changed_method(dict.__setitem__)\n clear = _changed_method(dict.clear)\n pop = _changed_method(dict.pop)\n popitem = _changed_method(dict.popitem)\n setdefault = _changed_method(dict.setdefault)\n update = _changed_method(dict.update)\n\n def __init__(self, data=None, session_id=None, new=True):\n # Brand new sessions don't have any data, so we'll just create an empty\n # dictionary for them.\n if data is None:\n data = {}\n\n # Initialize our actual dictionary here.\n super().__init__(data)\n\n # We need to track the state of our Session.\n self._sid = session_id\n self._changed = False\n self.new = new\n self.created = int(time.time())\n\n # We'll track all of the IDs that have been invalidated here\n self.invalidated = set()\n\n @property\n def sid(self):\n if self._sid is None:\n self._sid = crypto.random_token()\n return self._sid\n\n def changed(self):\n self._changed = True\n\n def invalidate(self):\n self.clear()\n self.new = True\n self.created = int(time.time())\n self._changed = False\n\n # If the current session id isn't None we'll want to record it as one\n # of the ones that have been invalidated.\n if self._sid is not None:\n self.invalidated.add(self._sid)\n self._sid = None\n\n def should_save(self):\n return self._changed\n\n # Flash Messages Methods\n def _get_flash_queue_key(self, queue):\n return \".\".join(filter(None, [self._flash_key, queue]))\n\n def flash(self, msg, queue=\"\", allow_duplicate=True):\n queue_key = self._get_flash_queue_key(queue)\n\n # If we're not allowing duplicates check if this message is already\n # in the queue, and if it is just return immediately.\n if not allow_duplicate and msg in self[queue_key]:\n return\n\n self.setdefault(queue_key, []).append(msg)\n\n def peek_flash(self, queue=\"\"):\n return self.get(self._get_flash_queue_key(queue), [])\n\n def pop_flash(self, queue=\"\"):\n queue_key = self._get_flash_queue_key(queue)\n messages = self.get(queue_key, [])\n self.pop(queue_key, None)\n return messages\n\n # CSRF Methods\n def new_csrf_token(self):\n self[self._csrf_token_key] = crypto.random_token()\n return self[self._csrf_token_key]\n\n def get_csrf_token(self):\n token = self.get(self._csrf_token_key)\n if token is None:\n token = self.new_csrf_token()\n return token\n\n\n@implementer(ISessionFactory)\nclass SessionFactory:\n\n cookie_name = \"session_id\"\n max_age = 12 * 60 * 60 # 12 hours\n\n def __init__(self, secret, url):\n self.redis = redis.StrictRedis.from_url(url)\n self.signer = crypto.TimestampSigner(secret, salt=\"session\")\n\n def __call__(self, request):\n return self._process_request(request)\n\n def _redis_key(self, session_id):\n return \"warehouse/session/data/{}\".format(session_id)\n\n def _process_request(self, request):\n # Register a callback with the request so we can save the session once\n # it's finished.\n request.add_response_callback(self._process_response)\n\n # Load our session ID from the request.\n session_id = request.cookies.get(self.cookie_name)\n\n # If we do not have a session ID then we'll just use a new empty\n # session.\n if session_id is None:\n return Session()\n\n # Check to make sure we have a valid session id\n try:\n session_id = self.signer.unsign(session_id, max_age=self.max_age)\n session_id = session_id.decode(\"utf8\")\n except crypto.BadSignature:\n return Session()\n\n # Fetch the serialized data from redis\n bdata = self.redis.get(self._redis_key(session_id))\n\n # If the session didn't exist in redis, we'll give the user a new\n # session.\n if bdata is None:\n return Session()\n\n # De-serialize our session data\n try:\n data = msgpack.unpackb(bdata, encoding=\"utf8\", use_list=True)\n except (msgpack.exceptions.UnpackException,\n msgpack.exceptions.ExtraData):\n # If the session data was invalid we'll give the user a new session\n return Session()\n\n # If we were able to load existing session data, load it into a\n # Session class\n session = Session(data, session_id, False)\n\n return session\n\n def _process_response(self, request, response):\n # If the request has an InvalidSession, then the view can't have\n # accessed the session, and we can just skip all of this anyways.\n if isinstance(request.session, InvalidSession):\n return\n\n # Check to see if the session has been marked to be deleted, if it has\n # benn then we'll delete it, and tell our response to delete the\n # session cookie as well.\n if request.session.invalidated:\n for session_id in request.session.invalidated:\n self.redis.delete(self._redis_key(session_id))\n\n if not request.session.should_save():\n response.delete_cookie(self.cookie_name)\n\n # Check to see if the session has been marked to be saved, generally\n # this means that the session data has been modified and thus we need\n # to store the new data.\n if request.session.should_save():\n # Save our session in Redis\n self.redis.setex(\n self._redis_key(request.session.sid),\n self.max_age,\n msgpack.packb(\n request.session,\n encoding=\"utf8\",\n use_bin_type=True,\n ),\n )\n\n # Send our session cookie to the client\n response.set_cookie(\n self.cookie_name,\n self.signer.sign(request.session.sid.encode(\"utf8\")),\n max_age=self.max_age,\n httponly=True,\n secure=request.scheme == \"https\",\n )\n\n\ndef session_view(view, info):\n if info.options.get(\"uses_session\"):\n # If we're using the session, then we'll just return the original view\n # with a small wrapper around it to ensure that it has a Vary: Cookie\n # header.\n return add_vary(\"Cookie\")(view)\n elif info.exception_only:\n return view\n else:\n # If we're not using the session on this view, then we'll wrap the view\n # with a wrapper that just ensures that the session cannot be used.\n @functools.wraps(view)\n def wrapped(context, request):\n # This whole method is a little bit of an odd duck, we want to make\n # sure that we don't actually *access* request.session, because\n # doing so triggers the machinery to create a new session. So\n # instead we will dig into the request object __dict__ to\n # effectively do the same thing, jsut without triggering an access\n # on request.session.\n\n # Save the original session so that we can restore it once the\n # inner views have been called.\n nothing = object()\n original_session = request.__dict__.get(\"session\", nothing)\n\n # This particular view hasn't been set to allow access to the\n # session, so we'll just assign an InvalidSession to\n # request.session\n request.__dict__[\"session\"] = InvalidSession()\n\n try:\n # Invoke the real view\n return view(context, request)\n finally:\n # Restore the original session so that things like\n # pyramid_debugtoolbar can access it.\n if original_session is nothing:\n del request.__dict__[\"session\"]\n else:\n request.__dict__[\"session\"] = original_session\n\n return wrapped\n\n\nsession_view.options = {\"uses_session\"}\n\n\ndef includeme(config):\n config.set_session_factory(\n SessionFactory(\n config.registry.settings[\"sessions.secret\"],\n config.registry.settings[\"sessions.url\"],\n ),\n )\n\n config.add_view_deriver(\n session_view,\n over=\"csrf_view\",\n under=viewderivers.INGRESS,\n )\n", "path": "warehouse/sessions.py"}], "after_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport functools\nimport time\n\nimport msgpack\nimport msgpack.exceptions\nimport redis\n\nfrom pyramid import viewderivers\nfrom pyramid.interfaces import ISession, ISessionFactory\nfrom zope.interface import implementer\n\nfrom warehouse.cache.http import add_vary\nfrom warehouse.utils import crypto\n\n\ndef _invalid_method(method):\n @functools.wraps(method)\n def wrapped(self, *args, **kwargs):\n self._error_message()\n return wrapped\n\n\n@implementer(ISession)\nclass InvalidSession(dict):\n\n __contains__ = _invalid_method(dict.__contains__)\n __delitem__ = _invalid_method(dict.__delitem__)\n __getitem__ = _invalid_method(dict.__getitem__)\n __iter__ = _invalid_method(dict.__iter__)\n __len__ = _invalid_method(dict.__len__)\n __setitem__ = _invalid_method(dict.__setitem__)\n clear = _invalid_method(dict.clear)\n copy = _invalid_method(dict.copy)\n fromkeys = _invalid_method(dict.fromkeys)\n get = _invalid_method(dict.get)\n items = _invalid_method(dict.items)\n keys = _invalid_method(dict.keys)\n pop = _invalid_method(dict.pop)\n popitem = _invalid_method(dict.popitem)\n setdefault = _invalid_method(dict.setdefault)\n update = _invalid_method(dict.update)\n values = _invalid_method(dict.values)\n\n def _error_message(self):\n raise RuntimeError(\n \"Cannot use request.session in a view without uses_session=True.\"\n )\n\n def __getattr__(self, name):\n self._error_message()\n\n @property\n def created(self):\n self._error_message()\n\n\ndef _changed_method(method):\n @functools.wraps(method)\n def wrapped(self, *args, **kwargs):\n self.changed()\n return method(self, *args, **kwargs)\n return wrapped\n\n\n@implementer(ISession)\nclass Session(dict):\n\n _csrf_token_key = \"_csrf_token\"\n _flash_key = \"_flash_messages\"\n\n # A number of our methods need to be decorated so that they also call\n # self.changed()\n __delitem__ = _changed_method(dict.__delitem__)\n __setitem__ = _changed_method(dict.__setitem__)\n clear = _changed_method(dict.clear)\n pop = _changed_method(dict.pop)\n popitem = _changed_method(dict.popitem)\n setdefault = _changed_method(dict.setdefault)\n update = _changed_method(dict.update)\n\n def __init__(self, data=None, session_id=None, new=True):\n # Brand new sessions don't have any data, so we'll just create an empty\n # dictionary for them.\n if data is None:\n data = {}\n\n # Initialize our actual dictionary here.\n super().__init__(data)\n\n # We need to track the state of our Session.\n self._sid = session_id\n self._changed = False\n self.new = new\n self.created = int(time.time())\n\n # We'll track all of the IDs that have been invalidated here\n self.invalidated = set()\n\n @property\n def sid(self):\n if self._sid is None:\n self._sid = crypto.random_token()\n return self._sid\n\n def changed(self):\n self._changed = True\n\n def invalidate(self):\n self.clear()\n self.new = True\n self.created = int(time.time())\n self._changed = False\n\n # If the current session id isn't None we'll want to record it as one\n # of the ones that have been invalidated.\n if self._sid is not None:\n self.invalidated.add(self._sid)\n self._sid = None\n\n def should_save(self):\n return self._changed\n\n # Flash Messages Methods\n def _get_flash_queue_key(self, queue):\n return \".\".join(filter(None, [self._flash_key, queue]))\n\n def flash(self, msg, queue=\"\", allow_duplicate=True):\n queue_key = self._get_flash_queue_key(queue)\n\n # If we're not allowing duplicates check if this message is already\n # in the queue, and if it is just return immediately.\n if not allow_duplicate and msg in self[queue_key]:\n return\n\n self.setdefault(queue_key, []).append(msg)\n\n def peek_flash(self, queue=\"\"):\n return self.get(self._get_flash_queue_key(queue), [])\n\n def pop_flash(self, queue=\"\"):\n queue_key = self._get_flash_queue_key(queue)\n messages = self.get(queue_key, [])\n self.pop(queue_key, None)\n return messages\n\n # CSRF Methods\n def new_csrf_token(self):\n self[self._csrf_token_key] = crypto.random_token()\n return self[self._csrf_token_key]\n\n def get_csrf_token(self):\n token = self.get(self._csrf_token_key)\n if token is None:\n token = self.new_csrf_token()\n return token\n\n\n@implementer(ISessionFactory)\nclass SessionFactory:\n\n cookie_name = \"session_id\"\n max_age = 12 * 60 * 60 # 12 hours\n\n def __init__(self, secret, url):\n self.redis = redis.StrictRedis.from_url(url)\n self.signer = crypto.TimestampSigner(secret, salt=\"session\")\n\n def __call__(self, request):\n return self._process_request(request)\n\n def _redis_key(self, session_id):\n return \"warehouse/session/data/{}\".format(session_id)\n\n def _process_request(self, request):\n # Register a callback with the request so we can save the session once\n # it's finished.\n request.add_response_callback(self._process_response)\n\n # Load our session ID from the request.\n session_id = request.cookies.get(self.cookie_name)\n\n # If we do not have a session ID then we'll just use a new empty\n # session.\n if session_id is None:\n return Session()\n\n # Check to make sure we have a valid session id\n try:\n session_id = self.signer.unsign(session_id, max_age=self.max_age)\n session_id = session_id.decode(\"utf8\")\n except crypto.BadSignature:\n return Session()\n\n # Fetch the serialized data from redis\n bdata = self.redis.get(self._redis_key(session_id))\n\n # If the session didn't exist in redis, we'll give the user a new\n # session.\n if bdata is None:\n return Session()\n\n # De-serialize our session data\n try:\n data = msgpack.unpackb(bdata, encoding=\"utf8\", use_list=True)\n except (msgpack.exceptions.UnpackException,\n msgpack.exceptions.ExtraData):\n # If the session data was invalid we'll give the user a new session\n return Session()\n\n # If we were able to load existing session data, load it into a\n # Session class\n session = Session(data, session_id, False)\n\n return session\n\n def _process_response(self, request, response):\n # If the request has an InvalidSession, then the view can't have\n # accessed the session, and we can just skip all of this anyways.\n if isinstance(request.session, InvalidSession):\n return\n\n # Check to see if the session has been marked to be deleted, if it has\n # benn then we'll delete it, and tell our response to delete the\n # session cookie as well.\n if request.session.invalidated:\n for session_id in request.session.invalidated:\n self.redis.delete(self._redis_key(session_id))\n\n if not request.session.should_save():\n response.delete_cookie(self.cookie_name)\n\n # Check to see if the session has been marked to be saved, generally\n # this means that the session data has been modified and thus we need\n # to store the new data.\n if request.session.should_save():\n # Save our session in Redis\n self.redis.setex(\n self._redis_key(request.session.sid),\n self.max_age,\n msgpack.packb(\n request.session,\n encoding=\"utf8\",\n use_bin_type=True,\n ),\n )\n\n # Send our session cookie to the client\n response.set_cookie(\n self.cookie_name,\n self.signer.sign(request.session.sid.encode(\"utf8\")),\n max_age=self.max_age,\n httponly=True,\n secure=request.scheme == \"https\",\n samesite=b\"lax\"\n )\n\n\ndef session_view(view, info):\n if info.options.get(\"uses_session\"):\n # If we're using the session, then we'll just return the original view\n # with a small wrapper around it to ensure that it has a Vary: Cookie\n # header.\n return add_vary(\"Cookie\")(view)\n elif info.exception_only:\n return view\n else:\n # If we're not using the session on this view, then we'll wrap the view\n # with a wrapper that just ensures that the session cannot be used.\n @functools.wraps(view)\n def wrapped(context, request):\n # This whole method is a little bit of an odd duck, we want to make\n # sure that we don't actually *access* request.session, because\n # doing so triggers the machinery to create a new session. So\n # instead we will dig into the request object __dict__ to\n # effectively do the same thing, jsut without triggering an access\n # on request.session.\n\n # Save the original session so that we can restore it once the\n # inner views have been called.\n nothing = object()\n original_session = request.__dict__.get(\"session\", nothing)\n\n # This particular view hasn't been set to allow access to the\n # session, so we'll just assign an InvalidSession to\n # request.session\n request.__dict__[\"session\"] = InvalidSession()\n\n try:\n # Invoke the real view\n return view(context, request)\n finally:\n # Restore the original session so that things like\n # pyramid_debugtoolbar can access it.\n if original_session is nothing:\n del request.__dict__[\"session\"]\n else:\n request.__dict__[\"session\"] = original_session\n\n return wrapped\n\n\nsession_view.options = {\"uses_session\"}\n\n\ndef includeme(config):\n config.set_session_factory(\n SessionFactory(\n config.registry.settings[\"sessions.secret\"],\n config.registry.settings[\"sessions.url\"],\n ),\n )\n\n config.add_view_deriver(\n session_view,\n over=\"csrf_view\",\n under=viewderivers.INGRESS,\n )\n", "path": "warehouse/sessions.py"}]}
| 3,577 | 79 |
gh_patches_debug_6652
|
rasdani/github-patches
|
git_diff
|
RedHatInsights__insights-core-1593
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
DeprecationWarning from qemu_xml
A bunch of below warning are reported in the python3 test of insights-plugins:
~~~
/Users/liuxc/work/insights/insights-core/insights/parsers/qemu_xml.py:149: DeprecationWarning: This method will be removed in future versions. Use '
list(elem)' or iteration over elem instead.
/Users/liuxc/work/insights/insights-core/insights/parsers/qemu_xml.py:149: DeprecationWarning: This method will be removed in future versions. Use '
list(elem)' or iteration over elem instead.
~~~
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `insights/parsers/qemu_xml.py`
Content:
```
1 """
2 QemuXML file ``/etc/libvirt/qemu/*.xml``
3 ----------------------------------------
4 """
5 from .. import XMLParser, parser
6 from insights.specs import Specs
7
8
9 @parser(Specs.qemu_xml)
10 class QemuXML(XMLParser):
11 """This class parses xml files under ``/etc/libvirt/qemu/`` using
12 ``XMLParser`` base parser.
13
14 Sample file::
15
16 <!--
17 WARNING: THIS IS AN AUTO-GENERATED FILE. CHANGES TO IT ARE LIKELY TO BE
18 OVERWRITTEN AND LOST. Changes to this xml configuration should be made using:
19 virsh edit 05-s00c06h0
20 or other application using the libvirt API.
21 -->
22
23 <domain type='kvm'>
24 <name>05-s00c06h0</name>
25 <uuid>02cf0bba-2bd6-11e7-8337-e4115b9a50d0</uuid>
26 <memory unit='KiB'>12582912</memory>
27 <currentMemory unit='KiB'>12582912</currentMemory>
28 <vcpu placement='static'>4</vcpu>
29 <cputune>
30 <vcpupin vcpu='0' cpuset='1'/>
31 <vcpupin vcpu='1' cpuset='2'/>
32 <vcpupin vcpu='2' cpuset='3'/>
33 <vcpupin vcpu='3' cpuset='4'/>
34 <emulatorpin cpuset='1-4'/>
35 </cputune>
36 <numatune>
37 <memory mode='strict' nodeset='0-1'/>
38 <memnode cellid='0' mode='strict' nodeset='0'/>
39 <memnode cellid='1' mode='strict' nodeset='1'/>
40 </numatune>
41 <os>
42 <type arch='x86_64' machine='pc-i440fx-rhel7.0.0'>hvm</type>
43 <boot dev='hd'/>
44 <boot dev='network'/>
45 <bootmenu enable='yes' timeout='1000'/>
46 <bios useserial='yes' rebootTimeout='0'/>
47 </os>
48 <features>
49 <acpi/>
50 <apic/>
51 <pae/>
52 </features>
53 <cpu>
54 <numa>
55 <cell id='0' cpus='0-1' memory='6291456' unit='KiB'/>
56 <cell id='1' cpus='2-3' memory='6291456' unit='KiB'/>
57 </numa>
58 </cpu>
59 <clock offset='utc'/>
60 <on_poweroff>destroy</on_poweroff>
61 <on_reboot>restart</on_reboot>
62 <on_crash>restart</on_crash>
63 <devices>
64 <emulator>/usr/libexec/qemu-kvm</emulator>
65 <disk type='file' device='disk'>
66 <driver name='qemu' type='raw' cache='none' io='threads'/>
67 <source file='/var/lib/libvirt/images/05-s00c06h0_1.img'/>
68 <target dev='vda' bus='virtio'/>
69 <address type='pci' domain='0x0000' bus='0x00' slot='0x05' function='0x0'/>
70 </disk>
71 <controller type='usb' index='0'>
72 <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x2'/>
73 </controller>
74 <controller type='pci' index='0' model='pci-root'/>
75 <controller type='virtio-serial' index='0'>
76 <address type='pci' domain='0x0000' bus='0x00' slot='0x03' function='0x0'/>
77 </controller>
78 <interface type='hostdev' managed='yes'>
79 <mac address='b2:59:73:15:00:00'/>
80 <source>
81 <address type='pci' domain='0x0000' bus='0x04' slot='0x10' function='0x0'/>
82 </source>
83 <rom bar='on' file='/opt/vcp/share/ipxe/808610ed.rom'/>
84 <address type='pci' domain='0x0000' bus='0x00' slot='0x04' function='0x0'/>
85 </interface>
86 <interface type='hostdev' managed='yes'>
87 <mac address='b2:59:73:15:00:01'/>
88 <source>
89 <address type='pci' domain='0x0000' bus='0x04' slot='0x10' function='0x1'/>
90 </source>
91 <rom bar='on' file='/opt/vcp/share/ipxe/808610ed.rom'/>
92 <address type='pci' domain='0x0000' bus='0x00' slot='0x08' function='0x0'/>
93 </interface>
94 <serial type='pty'>
95 <target port='0'/>
96 </serial>
97 <console type='pty'>
98 <target type='serial' port='0'/>
99 </console>
100 <channel type='pipe'>
101 <source path='/var/lib/libvirt/qemu/channels/FROM-05-s00c06h0'/>
102 <target type='virtio' name='virtio2host'/>
103 <address type='virtio-serial' controller='0' bus='0' port='1'/>
104 </channel>
105 <channel type='pipe'>
106 <source path='/var/lib/libvirt/qemu/channels/HGC-05-s00c06h0'/>
107 <target type='virtio' name='virtio_host_guest_check'/>
108 <address type='virtio-serial' controller='0' bus='0' port='2'/>
109 </channel>
110 <input type='mouse' bus='ps2'/>
111 <input type='keyboard' bus='ps2'/>
112 <graphics type='vnc' port='-1' autoport='yes'>
113 <listen type='address'/>
114 </graphics>
115 <video>
116 <model type='cirrus' vram='16384' heads='1' primary='yes'/>
117 <address type='pci' domain='0x0000' bus='0x00' slot='0x02' function='0x0'/>
118 </video>
119 <watchdog model='i6300esb' action='reset'>
120 <address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x0'/>
121 </watchdog>
122 <memballoon model='virtio'>
123 <address type='pci' domain='0x0000' bus='0x00' slot='0x06' function='0x0'/>
124 </memballoon>
125 </devices>
126 </domain>
127
128 Examples:
129 >>> xml_numa.file_name == 'vm.xml'
130 True
131 >>> xml_numa.vm_name == '05-s00c06h0'
132 True
133 >>> memnode = xml_numa.get_elements('./numatune/memnode', None)
134 >>> len(memnode[0].items()) == 3
135 True
136 >>> len(memnode[1].items()) == 3
137 True
138 >>> memnode[0].get('cellid') == '0'
139 True
140 >>> memnode[1].get('mode') == 'strict'
141 True
142 """
143 def parse_dom(self):
144 if self.dom is None:
145 return
146 else:
147 domain = {}
148 for child in self.dom:
149 if not child.getchildren():
150 domain[child.tag] = child.text
151 else:
152 domain[child.tag] = [c.items() for c in child.getchildren()]
153
154 return domain
155
156 @property
157 def vm_name(self):
158 return self.data.get('name', None)
159
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/insights/parsers/qemu_xml.py b/insights/parsers/qemu_xml.py
--- a/insights/parsers/qemu_xml.py
+++ b/insights/parsers/qemu_xml.py
@@ -146,10 +146,10 @@
else:
domain = {}
for child in self.dom:
- if not child.getchildren():
+ if len(child) == 0:
domain[child.tag] = child.text
else:
- domain[child.tag] = [c.items() for c in child.getchildren()]
+ domain[child.tag] = [c.items() for c in child]
return domain
|
{"golden_diff": "diff --git a/insights/parsers/qemu_xml.py b/insights/parsers/qemu_xml.py\n--- a/insights/parsers/qemu_xml.py\n+++ b/insights/parsers/qemu_xml.py\n@@ -146,10 +146,10 @@\n else:\n domain = {}\n for child in self.dom:\n- if not child.getchildren():\n+ if len(child) == 0:\n domain[child.tag] = child.text\n else:\n- domain[child.tag] = [c.items() for c in child.getchildren()]\n+ domain[child.tag] = [c.items() for c in child]\n \n return domain\n", "issue": "DeprecationWarning from qemu_xml\nA bunch of below warning are reported in the python3 test of insights-plugins:\r\n\r\n~~~ \r\n\r\n /Users/liuxc/work/insights/insights-core/insights/parsers/qemu_xml.py:149: DeprecationWarning: This method will be removed in future versions. Use '\r\nlist(elem)' or iteration over elem instead.\r\n /Users/liuxc/work/insights/insights-core/insights/parsers/qemu_xml.py:149: DeprecationWarning: This method will be removed in future versions. Use '\r\nlist(elem)' or iteration over elem instead.\r\n~~~\n", "before_files": [{"content": "\"\"\"\nQemuXML file ``/etc/libvirt/qemu/*.xml``\n----------------------------------------\n\"\"\"\nfrom .. import XMLParser, parser\nfrom insights.specs import Specs\n\n\n@parser(Specs.qemu_xml)\nclass QemuXML(XMLParser):\n \"\"\"This class parses xml files under ``/etc/libvirt/qemu/`` using\n ``XMLParser`` base parser.\n\n Sample file::\n\n <!--\n WARNING: THIS IS AN AUTO-GENERATED FILE. CHANGES TO IT ARE LIKELY TO BE\n OVERWRITTEN AND LOST. Changes to this xml configuration should be made using:\n virsh edit 05-s00c06h0\n or other application using the libvirt API.\n -->\n\n <domain type='kvm'>\n <name>05-s00c06h0</name>\n <uuid>02cf0bba-2bd6-11e7-8337-e4115b9a50d0</uuid>\n <memory unit='KiB'>12582912</memory>\n <currentMemory unit='KiB'>12582912</currentMemory>\n <vcpu placement='static'>4</vcpu>\n <cputune>\n <vcpupin vcpu='0' cpuset='1'/>\n <vcpupin vcpu='1' cpuset='2'/>\n <vcpupin vcpu='2' cpuset='3'/>\n <vcpupin vcpu='3' cpuset='4'/>\n <emulatorpin cpuset='1-4'/>\n </cputune>\n <numatune>\n <memory mode='strict' nodeset='0-1'/>\n <memnode cellid='0' mode='strict' nodeset='0'/>\n <memnode cellid='1' mode='strict' nodeset='1'/>\n </numatune>\n <os>\n <type arch='x86_64' machine='pc-i440fx-rhel7.0.0'>hvm</type>\n <boot dev='hd'/>\n <boot dev='network'/>\n <bootmenu enable='yes' timeout='1000'/>\n <bios useserial='yes' rebootTimeout='0'/>\n </os>\n <features>\n <acpi/>\n <apic/>\n <pae/>\n </features>\n <cpu>\n <numa>\n <cell id='0' cpus='0-1' memory='6291456' unit='KiB'/>\n <cell id='1' cpus='2-3' memory='6291456' unit='KiB'/>\n </numa>\n </cpu>\n <clock offset='utc'/>\n <on_poweroff>destroy</on_poweroff>\n <on_reboot>restart</on_reboot>\n <on_crash>restart</on_crash>\n <devices>\n <emulator>/usr/libexec/qemu-kvm</emulator>\n <disk type='file' device='disk'>\n <driver name='qemu' type='raw' cache='none' io='threads'/>\n <source file='/var/lib/libvirt/images/05-s00c06h0_1.img'/>\n <target dev='vda' bus='virtio'/>\n <address type='pci' domain='0x0000' bus='0x00' slot='0x05' function='0x0'/>\n </disk>\n <controller type='usb' index='0'>\n <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x2'/>\n </controller>\n <controller type='pci' index='0' model='pci-root'/>\n <controller type='virtio-serial' index='0'>\n <address type='pci' domain='0x0000' bus='0x00' slot='0x03' function='0x0'/>\n </controller>\n <interface type='hostdev' managed='yes'>\n <mac address='b2:59:73:15:00:00'/>\n <source>\n <address type='pci' domain='0x0000' bus='0x04' slot='0x10' function='0x0'/>\n </source>\n <rom bar='on' file='/opt/vcp/share/ipxe/808610ed.rom'/>\n <address type='pci' domain='0x0000' bus='0x00' slot='0x04' function='0x0'/>\n </interface>\n <interface type='hostdev' managed='yes'>\n <mac address='b2:59:73:15:00:01'/>\n <source>\n <address type='pci' domain='0x0000' bus='0x04' slot='0x10' function='0x1'/>\n </source>\n <rom bar='on' file='/opt/vcp/share/ipxe/808610ed.rom'/>\n <address type='pci' domain='0x0000' bus='0x00' slot='0x08' function='0x0'/>\n </interface>\n <serial type='pty'>\n <target port='0'/>\n </serial>\n <console type='pty'>\n <target type='serial' port='0'/>\n </console>\n <channel type='pipe'>\n <source path='/var/lib/libvirt/qemu/channels/FROM-05-s00c06h0'/>\n <target type='virtio' name='virtio2host'/>\n <address type='virtio-serial' controller='0' bus='0' port='1'/>\n </channel>\n <channel type='pipe'>\n <source path='/var/lib/libvirt/qemu/channels/HGC-05-s00c06h0'/>\n <target type='virtio' name='virtio_host_guest_check'/>\n <address type='virtio-serial' controller='0' bus='0' port='2'/>\n </channel>\n <input type='mouse' bus='ps2'/>\n <input type='keyboard' bus='ps2'/>\n <graphics type='vnc' port='-1' autoport='yes'>\n <listen type='address'/>\n </graphics>\n <video>\n <model type='cirrus' vram='16384' heads='1' primary='yes'/>\n <address type='pci' domain='0x0000' bus='0x00' slot='0x02' function='0x0'/>\n </video>\n <watchdog model='i6300esb' action='reset'>\n <address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x0'/>\n </watchdog>\n <memballoon model='virtio'>\n <address type='pci' domain='0x0000' bus='0x00' slot='0x06' function='0x0'/>\n </memballoon>\n </devices>\n </domain>\n\n Examples:\n >>> xml_numa.file_name == 'vm.xml'\n True\n >>> xml_numa.vm_name == '05-s00c06h0'\n True\n >>> memnode = xml_numa.get_elements('./numatune/memnode', None)\n >>> len(memnode[0].items()) == 3\n True\n >>> len(memnode[1].items()) == 3\n True\n >>> memnode[0].get('cellid') == '0'\n True\n >>> memnode[1].get('mode') == 'strict'\n True\n \"\"\"\n def parse_dom(self):\n if self.dom is None:\n return\n else:\n domain = {}\n for child in self.dom:\n if not child.getchildren():\n domain[child.tag] = child.text\n else:\n domain[child.tag] = [c.items() for c in child.getchildren()]\n\n return domain\n\n @property\n def vm_name(self):\n return self.data.get('name', None)\n", "path": "insights/parsers/qemu_xml.py"}], "after_files": [{"content": "\"\"\"\nQemuXML file ``/etc/libvirt/qemu/*.xml``\n----------------------------------------\n\"\"\"\nfrom .. import XMLParser, parser\nfrom insights.specs import Specs\n\n\n@parser(Specs.qemu_xml)\nclass QemuXML(XMLParser):\n \"\"\"This class parses xml files under ``/etc/libvirt/qemu/`` using\n ``XMLParser`` base parser.\n\n Sample file::\n\n <!--\n WARNING: THIS IS AN AUTO-GENERATED FILE. CHANGES TO IT ARE LIKELY TO BE\n OVERWRITTEN AND LOST. Changes to this xml configuration should be made using:\n virsh edit 05-s00c06h0\n or other application using the libvirt API.\n -->\n\n <domain type='kvm'>\n <name>05-s00c06h0</name>\n <uuid>02cf0bba-2bd6-11e7-8337-e4115b9a50d0</uuid>\n <memory unit='KiB'>12582912</memory>\n <currentMemory unit='KiB'>12582912</currentMemory>\n <vcpu placement='static'>4</vcpu>\n <cputune>\n <vcpupin vcpu='0' cpuset='1'/>\n <vcpupin vcpu='1' cpuset='2'/>\n <vcpupin vcpu='2' cpuset='3'/>\n <vcpupin vcpu='3' cpuset='4'/>\n <emulatorpin cpuset='1-4'/>\n </cputune>\n <numatune>\n <memory mode='strict' nodeset='0-1'/>\n <memnode cellid='0' mode='strict' nodeset='0'/>\n <memnode cellid='1' mode='strict' nodeset='1'/>\n </numatune>\n <os>\n <type arch='x86_64' machine='pc-i440fx-rhel7.0.0'>hvm</type>\n <boot dev='hd'/>\n <boot dev='network'/>\n <bootmenu enable='yes' timeout='1000'/>\n <bios useserial='yes' rebootTimeout='0'/>\n </os>\n <features>\n <acpi/>\n <apic/>\n <pae/>\n </features>\n <cpu>\n <numa>\n <cell id='0' cpus='0-1' memory='6291456' unit='KiB'/>\n <cell id='1' cpus='2-3' memory='6291456' unit='KiB'/>\n </numa>\n </cpu>\n <clock offset='utc'/>\n <on_poweroff>destroy</on_poweroff>\n <on_reboot>restart</on_reboot>\n <on_crash>restart</on_crash>\n <devices>\n <emulator>/usr/libexec/qemu-kvm</emulator>\n <disk type='file' device='disk'>\n <driver name='qemu' type='raw' cache='none' io='threads'/>\n <source file='/var/lib/libvirt/images/05-s00c06h0_1.img'/>\n <target dev='vda' bus='virtio'/>\n <address type='pci' domain='0x0000' bus='0x00' slot='0x05' function='0x0'/>\n </disk>\n <controller type='usb' index='0'>\n <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x2'/>\n </controller>\n <controller type='pci' index='0' model='pci-root'/>\n <controller type='virtio-serial' index='0'>\n <address type='pci' domain='0x0000' bus='0x00' slot='0x03' function='0x0'/>\n </controller>\n <interface type='hostdev' managed='yes'>\n <mac address='b2:59:73:15:00:00'/>\n <source>\n <address type='pci' domain='0x0000' bus='0x04' slot='0x10' function='0x0'/>\n </source>\n <rom bar='on' file='/opt/vcp/share/ipxe/808610ed.rom'/>\n <address type='pci' domain='0x0000' bus='0x00' slot='0x04' function='0x0'/>\n </interface>\n <interface type='hostdev' managed='yes'>\n <mac address='b2:59:73:15:00:01'/>\n <source>\n <address type='pci' domain='0x0000' bus='0x04' slot='0x10' function='0x1'/>\n </source>\n <rom bar='on' file='/opt/vcp/share/ipxe/808610ed.rom'/>\n <address type='pci' domain='0x0000' bus='0x00' slot='0x08' function='0x0'/>\n </interface>\n <serial type='pty'>\n <target port='0'/>\n </serial>\n <console type='pty'>\n <target type='serial' port='0'/>\n </console>\n <channel type='pipe'>\n <source path='/var/lib/libvirt/qemu/channels/FROM-05-s00c06h0'/>\n <target type='virtio' name='virtio2host'/>\n <address type='virtio-serial' controller='0' bus='0' port='1'/>\n </channel>\n <channel type='pipe'>\n <source path='/var/lib/libvirt/qemu/channels/HGC-05-s00c06h0'/>\n <target type='virtio' name='virtio_host_guest_check'/>\n <address type='virtio-serial' controller='0' bus='0' port='2'/>\n </channel>\n <input type='mouse' bus='ps2'/>\n <input type='keyboard' bus='ps2'/>\n <graphics type='vnc' port='-1' autoport='yes'>\n <listen type='address'/>\n </graphics>\n <video>\n <model type='cirrus' vram='16384' heads='1' primary='yes'/>\n <address type='pci' domain='0x0000' bus='0x00' slot='0x02' function='0x0'/>\n </video>\n <watchdog model='i6300esb' action='reset'>\n <address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x0'/>\n </watchdog>\n <memballoon model='virtio'>\n <address type='pci' domain='0x0000' bus='0x00' slot='0x06' function='0x0'/>\n </memballoon>\n </devices>\n </domain>\n\n Examples:\n >>> xml_numa.file_name == 'vm.xml'\n True\n >>> xml_numa.vm_name == '05-s00c06h0'\n True\n >>> memnode = xml_numa.get_elements('./numatune/memnode', None)\n >>> len(memnode[0].items()) == 3\n True\n >>> len(memnode[1].items()) == 3\n True\n >>> memnode[0].get('cellid') == '0'\n True\n >>> memnode[1].get('mode') == 'strict'\n True\n \"\"\"\n def parse_dom(self):\n if self.dom is None:\n return\n else:\n domain = {}\n for child in self.dom:\n if len(child) == 0:\n domain[child.tag] = child.text\n else:\n domain[child.tag] = [c.items() for c in child]\n\n return domain\n\n @property\n def vm_name(self):\n return self.data.get('name', None)\n", "path": "insights/parsers/qemu_xml.py"}]}
| 2,617 | 147 |
gh_patches_debug_19409
|
rasdani/github-patches
|
git_diff
|
certbot__certbot-3504
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
"No installers present" message is confusing.
```
No installers seem to be present and working on your system; fix that or try running certbot with the "certonly" command
```
This is one of the most common messages, received when running certbot on an Nginx installation, but it is confusing to a new user. What's an installer? Is it my mistake or certbot's that there are no installers? What does "certonly" do?
Instead how about:
```
Certbot doesn't know how to automatically configure the web server on this system. However, it can still get a certificate for you. Please run "certbot[-auto] certonly" to do so. You'll need to manually configure your web server to use the resulting certificate.
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `certbot/plugins/selection.py`
Content:
```
1 """Decide which plugins to use for authentication & installation"""
2 from __future__ import print_function
3
4 import os
5 import logging
6
7 import six
8 import zope.component
9
10 from certbot import errors
11 from certbot import interfaces
12
13 from certbot.display import util as display_util
14
15 logger = logging.getLogger(__name__)
16 z_util = zope.component.getUtility
17
18 def pick_configurator(
19 config, default, plugins,
20 question="How would you like to authenticate and install "
21 "certificates?"):
22 """Pick configurator plugin."""
23 return pick_plugin(
24 config, default, plugins, question,
25 (interfaces.IAuthenticator, interfaces.IInstaller))
26
27
28 def pick_installer(config, default, plugins,
29 question="How would you like to install certificates?"):
30 """Pick installer plugin."""
31 return pick_plugin(
32 config, default, plugins, question, (interfaces.IInstaller,))
33
34
35 def pick_authenticator(
36 config, default, plugins, question="How would you "
37 "like to authenticate with the ACME CA?"):
38 """Pick authentication plugin."""
39 return pick_plugin(
40 config, default, plugins, question, (interfaces.IAuthenticator,))
41
42
43 def pick_plugin(config, default, plugins, question, ifaces):
44 """Pick plugin.
45
46 :param certbot.interfaces.IConfig: Configuration
47 :param str default: Plugin name supplied by user or ``None``.
48 :param certbot.plugins.disco.PluginsRegistry plugins:
49 All plugins registered as entry points.
50 :param str question: Question to be presented to the user in case
51 multiple candidates are found.
52 :param list ifaces: Interfaces that plugins must provide.
53
54 :returns: Initialized plugin.
55 :rtype: IPlugin
56
57 """
58 if default is not None:
59 # throw more UX-friendly error if default not in plugins
60 filtered = plugins.filter(lambda p_ep: p_ep.name == default)
61 else:
62 if config.noninteractive_mode:
63 # it's really bad to auto-select the single available plugin in
64 # non-interactive mode, because an update could later add a second
65 # available plugin
66 raise errors.MissingCommandlineFlag(
67 "Missing command line flags. For non-interactive execution, "
68 "you will need to specify a plugin on the command line. Run "
69 "with '--help plugins' to see a list of options, and see "
70 "https://eff.org/letsencrypt-plugins for more detail on what "
71 "the plugins do and how to use them.")
72
73 filtered = plugins.visible().ifaces(ifaces)
74
75 filtered.init(config)
76 verified = filtered.verify(ifaces)
77 verified.prepare()
78 prepared = verified.available()
79
80 if len(prepared) > 1:
81 logger.debug("Multiple candidate plugins: %s", prepared)
82 plugin_ep = choose_plugin(list(six.itervalues(prepared)), question)
83 if plugin_ep is None:
84 return None
85 else:
86 return plugin_ep.init()
87 elif len(prepared) == 1:
88 plugin_ep = list(prepared.values())[0]
89 logger.debug("Single candidate plugin: %s", plugin_ep)
90 if plugin_ep.misconfigured:
91 return None
92 return plugin_ep.init()
93 else:
94 logger.debug("No candidate plugin")
95 return None
96
97
98 def choose_plugin(prepared, question):
99 """Allow the user to choose their plugin.
100
101 :param list prepared: List of `~.PluginEntryPoint`.
102 :param str question: Question to be presented to the user.
103
104 :returns: Plugin entry point chosen by the user.
105 :rtype: `~.PluginEntryPoint`
106
107 """
108 opts = [plugin_ep.description_with_name +
109 (" [Misconfigured]" if plugin_ep.misconfigured else "")
110 for plugin_ep in prepared]
111
112 while True:
113 disp = z_util(interfaces.IDisplay)
114 code, index = disp.menu(question, opts, help_label="More Info")
115
116 if code == display_util.OK:
117 plugin_ep = prepared[index]
118 if plugin_ep.misconfigured:
119 z_util(interfaces.IDisplay).notification(
120 "The selected plugin encountered an error while parsing "
121 "your server configuration and cannot be used. The error "
122 "was:\n\n{0}".format(plugin_ep.prepare()),
123 height=display_util.HEIGHT, pause=False)
124 else:
125 return plugin_ep
126 elif code == display_util.HELP:
127 if prepared[index].misconfigured:
128 msg = "Reported Error: %s" % prepared[index].prepare()
129 else:
130 msg = prepared[index].init().more_info()
131 z_util(interfaces.IDisplay).notification(
132 msg, height=display_util.HEIGHT)
133 else:
134 return None
135
136 noninstaller_plugins = ["webroot", "manual", "standalone"]
137
138 def record_chosen_plugins(config, plugins, auth, inst):
139 "Update the config entries to reflect the plugins we actually selected."
140 cn = config.namespace
141 cn.authenticator = plugins.find_init(auth).name if auth else "None"
142 cn.installer = plugins.find_init(inst).name if inst else "None"
143
144
145 def choose_configurator_plugins(config, plugins, verb):
146 """
147 Figure out which configurator we're going to use, modifies
148 config.authenticator and config.installer strings to reflect that choice if
149 necessary.
150
151 :raises errors.PluginSelectionError if there was a problem
152
153 :returns: (an `IAuthenticator` or None, an `IInstaller` or None)
154 :rtype: tuple
155 """
156
157 req_auth, req_inst = cli_plugin_requests(config)
158
159 # Which plugins do we need?
160 if verb == "run":
161 need_inst = need_auth = True
162 from certbot.cli import cli_command
163 if req_auth in noninstaller_plugins and not req_inst:
164 msg = ('With the {0} plugin, you probably want to use the "certonly" command, eg:{1}'
165 '{1} {2} certonly --{0}{1}{1}'
166 '(Alternatively, add a --installer flag. See https://eff.org/letsencrypt-plugins'
167 '{1} and "--help plugins" for more information.)'.format(
168 req_auth, os.linesep, cli_command))
169
170 raise errors.MissingCommandlineFlag(msg)
171 else:
172 need_inst = need_auth = False
173 if verb == "certonly":
174 need_auth = True
175 if verb == "install":
176 need_inst = True
177 if config.authenticator:
178 logger.warning("Specifying an authenticator doesn't make sense in install mode")
179
180 # Try to meet the user's request and/or ask them to pick plugins
181 authenticator = installer = None
182 if verb == "run" and req_auth == req_inst:
183 # Unless the user has explicitly asked for different auth/install,
184 # only consider offering a single choice
185 authenticator = installer = pick_configurator(config, req_inst, plugins)
186 else:
187 if need_inst or req_inst:
188 installer = pick_installer(config, req_inst, plugins)
189 if need_auth:
190 authenticator = pick_authenticator(config, req_auth, plugins)
191 logger.debug("Selected authenticator %s and installer %s", authenticator, installer)
192
193 # Report on any failures
194 if need_inst and not installer:
195 diagnose_configurator_problem("installer", req_inst, plugins)
196 if need_auth and not authenticator:
197 diagnose_configurator_problem("authenticator", req_auth, plugins)
198
199 record_chosen_plugins(config, plugins, authenticator, installer)
200 return installer, authenticator
201
202
203 def set_configurator(previously, now):
204 """
205 Setting configurators multiple ways is okay, as long as they all agree
206 :param str previously: previously identified request for the installer/authenticator
207 :param str requested: the request currently being processed
208 """
209 if not now:
210 # we're not actually setting anything
211 return previously
212 if previously:
213 if previously != now:
214 msg = "Too many flags setting configurators/installers/authenticators {0} -> {1}"
215 raise errors.PluginSelectionError(msg.format(repr(previously), repr(now)))
216 return now
217
218
219 def cli_plugin_requests(config):
220 """
221 Figure out which plugins the user requested with CLI and config options
222
223 :returns: (requested authenticator string or None, requested installer string or None)
224 :rtype: tuple
225 """
226 req_inst = req_auth = config.configurator
227 req_inst = set_configurator(req_inst, config.installer)
228 req_auth = set_configurator(req_auth, config.authenticator)
229 if config.nginx:
230 req_inst = set_configurator(req_inst, "nginx")
231 req_auth = set_configurator(req_auth, "nginx")
232 if config.apache:
233 req_inst = set_configurator(req_inst, "apache")
234 req_auth = set_configurator(req_auth, "apache")
235 if config.standalone:
236 req_auth = set_configurator(req_auth, "standalone")
237 if config.webroot:
238 req_auth = set_configurator(req_auth, "webroot")
239 if config.manual:
240 req_auth = set_configurator(req_auth, "manual")
241 logger.debug("Requested authenticator %s and installer %s", req_auth, req_inst)
242 return req_auth, req_inst
243
244
245 def diagnose_configurator_problem(cfg_type, requested, plugins):
246 """
247 Raise the most helpful error message about a plugin being unavailable
248
249 :param str cfg_type: either "installer" or "authenticator"
250 :param str requested: the plugin that was requested
251 :param .PluginsRegistry plugins: available plugins
252
253 :raises error.PluginSelectionError: if there was a problem
254 """
255
256 if requested:
257 if requested not in plugins:
258 msg = "The requested {0} plugin does not appear to be installed".format(requested)
259 else:
260 msg = ("The {0} plugin is not working; there may be problems with "
261 "your existing configuration.\nThe error was: {1!r}"
262 .format(requested, plugins[requested].problem))
263 elif cfg_type == "installer":
264 msg = ('No installer plugins seem to be present and working on your system; '
265 'fix that or try running certbot with the "certonly" command to obtain'
266 ' a certificate you can install manually')
267 else:
268 msg = "{0} could not be determined or is not installed".format(cfg_type)
269 raise errors.PluginSelectionError(msg)
270
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/certbot/plugins/selection.py b/certbot/plugins/selection.py
--- a/certbot/plugins/selection.py
+++ b/certbot/plugins/selection.py
@@ -261,9 +261,12 @@
"your existing configuration.\nThe error was: {1!r}"
.format(requested, plugins[requested].problem))
elif cfg_type == "installer":
- msg = ('No installer plugins seem to be present and working on your system; '
- 'fix that or try running certbot with the "certonly" command to obtain'
- ' a certificate you can install manually')
+ from certbot.cli import cli_command
+ msg = ('Certbot doesn\'t know how to automatically configure the web '
+ 'server on this system. However, it can still get a certificate for '
+ 'you. Please run "{0} certonly" to do so. You\'ll need to '
+ 'manually configure your web server to use the resulting '
+ 'certificate.').format(cli_command)
else:
msg = "{0} could not be determined or is not installed".format(cfg_type)
raise errors.PluginSelectionError(msg)
|
{"golden_diff": "diff --git a/certbot/plugins/selection.py b/certbot/plugins/selection.py\n--- a/certbot/plugins/selection.py\n+++ b/certbot/plugins/selection.py\n@@ -261,9 +261,12 @@\n \"your existing configuration.\\nThe error was: {1!r}\"\n .format(requested, plugins[requested].problem))\n elif cfg_type == \"installer\":\n- msg = ('No installer plugins seem to be present and working on your system; '\n- 'fix that or try running certbot with the \"certonly\" command to obtain'\n- ' a certificate you can install manually')\n+ from certbot.cli import cli_command\n+ msg = ('Certbot doesn\\'t know how to automatically configure the web '\n+ 'server on this system. However, it can still get a certificate for '\n+ 'you. Please run \"{0} certonly\" to do so. You\\'ll need to '\n+ 'manually configure your web server to use the resulting '\n+ 'certificate.').format(cli_command)\n else:\n msg = \"{0} could not be determined or is not installed\".format(cfg_type)\n raise errors.PluginSelectionError(msg)\n", "issue": "\"No installers present\" message is confusing.\n```\nNo installers seem to be present and working on your system; fix that or try running certbot with the \"certonly\" command\n```\n\nThis is one of the most common messages, received when running certbot on an Nginx installation, but it is confusing to a new user. What's an installer? Is it my mistake or certbot's that there are no installers? What does \"certonly\" do?\n\nInstead how about:\n\n```\nCertbot doesn't know how to automatically configure the web server on this system. However, it can still get a certificate for you. Please run \"certbot[-auto] certonly\" to do so. You'll need to manually configure your web server to use the resulting certificate.\n```\n\n", "before_files": [{"content": "\"\"\"Decide which plugins to use for authentication & installation\"\"\"\nfrom __future__ import print_function\n\nimport os\nimport logging\n\nimport six\nimport zope.component\n\nfrom certbot import errors\nfrom certbot import interfaces\n\nfrom certbot.display import util as display_util\n\nlogger = logging.getLogger(__name__)\nz_util = zope.component.getUtility\n\ndef pick_configurator(\n config, default, plugins,\n question=\"How would you like to authenticate and install \"\n \"certificates?\"):\n \"\"\"Pick configurator plugin.\"\"\"\n return pick_plugin(\n config, default, plugins, question,\n (interfaces.IAuthenticator, interfaces.IInstaller))\n\n\ndef pick_installer(config, default, plugins,\n question=\"How would you like to install certificates?\"):\n \"\"\"Pick installer plugin.\"\"\"\n return pick_plugin(\n config, default, plugins, question, (interfaces.IInstaller,))\n\n\ndef pick_authenticator(\n config, default, plugins, question=\"How would you \"\n \"like to authenticate with the ACME CA?\"):\n \"\"\"Pick authentication plugin.\"\"\"\n return pick_plugin(\n config, default, plugins, question, (interfaces.IAuthenticator,))\n\n\ndef pick_plugin(config, default, plugins, question, ifaces):\n \"\"\"Pick plugin.\n\n :param certbot.interfaces.IConfig: Configuration\n :param str default: Plugin name supplied by user or ``None``.\n :param certbot.plugins.disco.PluginsRegistry plugins:\n All plugins registered as entry points.\n :param str question: Question to be presented to the user in case\n multiple candidates are found.\n :param list ifaces: Interfaces that plugins must provide.\n\n :returns: Initialized plugin.\n :rtype: IPlugin\n\n \"\"\"\n if default is not None:\n # throw more UX-friendly error if default not in plugins\n filtered = plugins.filter(lambda p_ep: p_ep.name == default)\n else:\n if config.noninteractive_mode:\n # it's really bad to auto-select the single available plugin in\n # non-interactive mode, because an update could later add a second\n # available plugin\n raise errors.MissingCommandlineFlag(\n \"Missing command line flags. For non-interactive execution, \"\n \"you will need to specify a plugin on the command line. Run \"\n \"with '--help plugins' to see a list of options, and see \"\n \"https://eff.org/letsencrypt-plugins for more detail on what \"\n \"the plugins do and how to use them.\")\n\n filtered = plugins.visible().ifaces(ifaces)\n\n filtered.init(config)\n verified = filtered.verify(ifaces)\n verified.prepare()\n prepared = verified.available()\n\n if len(prepared) > 1:\n logger.debug(\"Multiple candidate plugins: %s\", prepared)\n plugin_ep = choose_plugin(list(six.itervalues(prepared)), question)\n if plugin_ep is None:\n return None\n else:\n return plugin_ep.init()\n elif len(prepared) == 1:\n plugin_ep = list(prepared.values())[0]\n logger.debug(\"Single candidate plugin: %s\", plugin_ep)\n if plugin_ep.misconfigured:\n return None\n return plugin_ep.init()\n else:\n logger.debug(\"No candidate plugin\")\n return None\n\n\ndef choose_plugin(prepared, question):\n \"\"\"Allow the user to choose their plugin.\n\n :param list prepared: List of `~.PluginEntryPoint`.\n :param str question: Question to be presented to the user.\n\n :returns: Plugin entry point chosen by the user.\n :rtype: `~.PluginEntryPoint`\n\n \"\"\"\n opts = [plugin_ep.description_with_name +\n (\" [Misconfigured]\" if plugin_ep.misconfigured else \"\")\n for plugin_ep in prepared]\n\n while True:\n disp = z_util(interfaces.IDisplay)\n code, index = disp.menu(question, opts, help_label=\"More Info\")\n\n if code == display_util.OK:\n plugin_ep = prepared[index]\n if plugin_ep.misconfigured:\n z_util(interfaces.IDisplay).notification(\n \"The selected plugin encountered an error while parsing \"\n \"your server configuration and cannot be used. The error \"\n \"was:\\n\\n{0}\".format(plugin_ep.prepare()),\n height=display_util.HEIGHT, pause=False)\n else:\n return plugin_ep\n elif code == display_util.HELP:\n if prepared[index].misconfigured:\n msg = \"Reported Error: %s\" % prepared[index].prepare()\n else:\n msg = prepared[index].init().more_info()\n z_util(interfaces.IDisplay).notification(\n msg, height=display_util.HEIGHT)\n else:\n return None\n\nnoninstaller_plugins = [\"webroot\", \"manual\", \"standalone\"]\n\ndef record_chosen_plugins(config, plugins, auth, inst):\n \"Update the config entries to reflect the plugins we actually selected.\"\n cn = config.namespace\n cn.authenticator = plugins.find_init(auth).name if auth else \"None\"\n cn.installer = plugins.find_init(inst).name if inst else \"None\"\n\n\ndef choose_configurator_plugins(config, plugins, verb):\n \"\"\"\n Figure out which configurator we're going to use, modifies\n config.authenticator and config.installer strings to reflect that choice if\n necessary.\n\n :raises errors.PluginSelectionError if there was a problem\n\n :returns: (an `IAuthenticator` or None, an `IInstaller` or None)\n :rtype: tuple\n \"\"\"\n\n req_auth, req_inst = cli_plugin_requests(config)\n\n # Which plugins do we need?\n if verb == \"run\":\n need_inst = need_auth = True\n from certbot.cli import cli_command\n if req_auth in noninstaller_plugins and not req_inst:\n msg = ('With the {0} plugin, you probably want to use the \"certonly\" command, eg:{1}'\n '{1} {2} certonly --{0}{1}{1}'\n '(Alternatively, add a --installer flag. See https://eff.org/letsencrypt-plugins'\n '{1} and \"--help plugins\" for more information.)'.format(\n req_auth, os.linesep, cli_command))\n\n raise errors.MissingCommandlineFlag(msg)\n else:\n need_inst = need_auth = False\n if verb == \"certonly\":\n need_auth = True\n if verb == \"install\":\n need_inst = True\n if config.authenticator:\n logger.warning(\"Specifying an authenticator doesn't make sense in install mode\")\n\n # Try to meet the user's request and/or ask them to pick plugins\n authenticator = installer = None\n if verb == \"run\" and req_auth == req_inst:\n # Unless the user has explicitly asked for different auth/install,\n # only consider offering a single choice\n authenticator = installer = pick_configurator(config, req_inst, plugins)\n else:\n if need_inst or req_inst:\n installer = pick_installer(config, req_inst, plugins)\n if need_auth:\n authenticator = pick_authenticator(config, req_auth, plugins)\n logger.debug(\"Selected authenticator %s and installer %s\", authenticator, installer)\n\n # Report on any failures\n if need_inst and not installer:\n diagnose_configurator_problem(\"installer\", req_inst, plugins)\n if need_auth and not authenticator:\n diagnose_configurator_problem(\"authenticator\", req_auth, plugins)\n\n record_chosen_plugins(config, plugins, authenticator, installer)\n return installer, authenticator\n\n\ndef set_configurator(previously, now):\n \"\"\"\n Setting configurators multiple ways is okay, as long as they all agree\n :param str previously: previously identified request for the installer/authenticator\n :param str requested: the request currently being processed\n \"\"\"\n if not now:\n # we're not actually setting anything\n return previously\n if previously:\n if previously != now:\n msg = \"Too many flags setting configurators/installers/authenticators {0} -> {1}\"\n raise errors.PluginSelectionError(msg.format(repr(previously), repr(now)))\n return now\n\n\ndef cli_plugin_requests(config):\n \"\"\"\n Figure out which plugins the user requested with CLI and config options\n\n :returns: (requested authenticator string or None, requested installer string or None)\n :rtype: tuple\n \"\"\"\n req_inst = req_auth = config.configurator\n req_inst = set_configurator(req_inst, config.installer)\n req_auth = set_configurator(req_auth, config.authenticator)\n if config.nginx:\n req_inst = set_configurator(req_inst, \"nginx\")\n req_auth = set_configurator(req_auth, \"nginx\")\n if config.apache:\n req_inst = set_configurator(req_inst, \"apache\")\n req_auth = set_configurator(req_auth, \"apache\")\n if config.standalone:\n req_auth = set_configurator(req_auth, \"standalone\")\n if config.webroot:\n req_auth = set_configurator(req_auth, \"webroot\")\n if config.manual:\n req_auth = set_configurator(req_auth, \"manual\")\n logger.debug(\"Requested authenticator %s and installer %s\", req_auth, req_inst)\n return req_auth, req_inst\n\n\ndef diagnose_configurator_problem(cfg_type, requested, plugins):\n \"\"\"\n Raise the most helpful error message about a plugin being unavailable\n\n :param str cfg_type: either \"installer\" or \"authenticator\"\n :param str requested: the plugin that was requested\n :param .PluginsRegistry plugins: available plugins\n\n :raises error.PluginSelectionError: if there was a problem\n \"\"\"\n\n if requested:\n if requested not in plugins:\n msg = \"The requested {0} plugin does not appear to be installed\".format(requested)\n else:\n msg = (\"The {0} plugin is not working; there may be problems with \"\n \"your existing configuration.\\nThe error was: {1!r}\"\n .format(requested, plugins[requested].problem))\n elif cfg_type == \"installer\":\n msg = ('No installer plugins seem to be present and working on your system; '\n 'fix that or try running certbot with the \"certonly\" command to obtain'\n ' a certificate you can install manually')\n else:\n msg = \"{0} could not be determined or is not installed\".format(cfg_type)\n raise errors.PluginSelectionError(msg)\n", "path": "certbot/plugins/selection.py"}], "after_files": [{"content": "\"\"\"Decide which plugins to use for authentication & installation\"\"\"\nfrom __future__ import print_function\n\nimport os\nimport logging\n\nimport six\nimport zope.component\n\nfrom certbot import errors\nfrom certbot import interfaces\n\nfrom certbot.display import util as display_util\n\nlogger = logging.getLogger(__name__)\nz_util = zope.component.getUtility\n\ndef pick_configurator(\n config, default, plugins,\n question=\"How would you like to authenticate and install \"\n \"certificates?\"):\n \"\"\"Pick configurator plugin.\"\"\"\n return pick_plugin(\n config, default, plugins, question,\n (interfaces.IAuthenticator, interfaces.IInstaller))\n\n\ndef pick_installer(config, default, plugins,\n question=\"How would you like to install certificates?\"):\n \"\"\"Pick installer plugin.\"\"\"\n return pick_plugin(\n config, default, plugins, question, (interfaces.IInstaller,))\n\n\ndef pick_authenticator(\n config, default, plugins, question=\"How would you \"\n \"like to authenticate with the ACME CA?\"):\n \"\"\"Pick authentication plugin.\"\"\"\n return pick_plugin(\n config, default, plugins, question, (interfaces.IAuthenticator,))\n\n\ndef pick_plugin(config, default, plugins, question, ifaces):\n \"\"\"Pick plugin.\n\n :param certbot.interfaces.IConfig: Configuration\n :param str default: Plugin name supplied by user or ``None``.\n :param certbot.plugins.disco.PluginsRegistry plugins:\n All plugins registered as entry points.\n :param str question: Question to be presented to the user in case\n multiple candidates are found.\n :param list ifaces: Interfaces that plugins must provide.\n\n :returns: Initialized plugin.\n :rtype: IPlugin\n\n \"\"\"\n if default is not None:\n # throw more UX-friendly error if default not in plugins\n filtered = plugins.filter(lambda p_ep: p_ep.name == default)\n else:\n if config.noninteractive_mode:\n # it's really bad to auto-select the single available plugin in\n # non-interactive mode, because an update could later add a second\n # available plugin\n raise errors.MissingCommandlineFlag(\n \"Missing command line flags. For non-interactive execution, \"\n \"you will need to specify a plugin on the command line. Run \"\n \"with '--help plugins' to see a list of options, and see \"\n \"https://eff.org/letsencrypt-plugins for more detail on what \"\n \"the plugins do and how to use them.\")\n\n filtered = plugins.visible().ifaces(ifaces)\n\n filtered.init(config)\n verified = filtered.verify(ifaces)\n verified.prepare()\n prepared = verified.available()\n\n if len(prepared) > 1:\n logger.debug(\"Multiple candidate plugins: %s\", prepared)\n plugin_ep = choose_plugin(list(six.itervalues(prepared)), question)\n if plugin_ep is None:\n return None\n else:\n return plugin_ep.init()\n elif len(prepared) == 1:\n plugin_ep = list(prepared.values())[0]\n logger.debug(\"Single candidate plugin: %s\", plugin_ep)\n if plugin_ep.misconfigured:\n return None\n return plugin_ep.init()\n else:\n logger.debug(\"No candidate plugin\")\n return None\n\n\ndef choose_plugin(prepared, question):\n \"\"\"Allow the user to choose their plugin.\n\n :param list prepared: List of `~.PluginEntryPoint`.\n :param str question: Question to be presented to the user.\n\n :returns: Plugin entry point chosen by the user.\n :rtype: `~.PluginEntryPoint`\n\n \"\"\"\n opts = [plugin_ep.description_with_name +\n (\" [Misconfigured]\" if plugin_ep.misconfigured else \"\")\n for plugin_ep in prepared]\n\n while True:\n disp = z_util(interfaces.IDisplay)\n code, index = disp.menu(question, opts, help_label=\"More Info\")\n\n if code == display_util.OK:\n plugin_ep = prepared[index]\n if plugin_ep.misconfigured:\n z_util(interfaces.IDisplay).notification(\n \"The selected plugin encountered an error while parsing \"\n \"your server configuration and cannot be used. The error \"\n \"was:\\n\\n{0}\".format(plugin_ep.prepare()),\n height=display_util.HEIGHT, pause=False)\n else:\n return plugin_ep\n elif code == display_util.HELP:\n if prepared[index].misconfigured:\n msg = \"Reported Error: %s\" % prepared[index].prepare()\n else:\n msg = prepared[index].init().more_info()\n z_util(interfaces.IDisplay).notification(\n msg, height=display_util.HEIGHT)\n else:\n return None\n\nnoninstaller_plugins = [\"webroot\", \"manual\", \"standalone\"]\n\ndef record_chosen_plugins(config, plugins, auth, inst):\n \"Update the config entries to reflect the plugins we actually selected.\"\n cn = config.namespace\n cn.authenticator = plugins.find_init(auth).name if auth else \"None\"\n cn.installer = plugins.find_init(inst).name if inst else \"None\"\n\n\ndef choose_configurator_plugins(config, plugins, verb):\n \"\"\"\n Figure out which configurator we're going to use, modifies\n config.authenticator and config.installer strings to reflect that choice if\n necessary.\n\n :raises errors.PluginSelectionError if there was a problem\n\n :returns: (an `IAuthenticator` or None, an `IInstaller` or None)\n :rtype: tuple\n \"\"\"\n\n req_auth, req_inst = cli_plugin_requests(config)\n\n # Which plugins do we need?\n if verb == \"run\":\n need_inst = need_auth = True\n from certbot.cli import cli_command\n if req_auth in noninstaller_plugins and not req_inst:\n msg = ('With the {0} plugin, you probably want to use the \"certonly\" command, eg:{1}'\n '{1} {2} certonly --{0}{1}{1}'\n '(Alternatively, add a --installer flag. See https://eff.org/letsencrypt-plugins'\n '{1} and \"--help plugins\" for more information.)'.format(\n req_auth, os.linesep, cli_command))\n\n raise errors.MissingCommandlineFlag(msg)\n else:\n need_inst = need_auth = False\n if verb == \"certonly\":\n need_auth = True\n if verb == \"install\":\n need_inst = True\n if config.authenticator:\n logger.warning(\"Specifying an authenticator doesn't make sense in install mode\")\n\n # Try to meet the user's request and/or ask them to pick plugins\n authenticator = installer = None\n if verb == \"run\" and req_auth == req_inst:\n # Unless the user has explicitly asked for different auth/install,\n # only consider offering a single choice\n authenticator = installer = pick_configurator(config, req_inst, plugins)\n else:\n if need_inst or req_inst:\n installer = pick_installer(config, req_inst, plugins)\n if need_auth:\n authenticator = pick_authenticator(config, req_auth, plugins)\n logger.debug(\"Selected authenticator %s and installer %s\", authenticator, installer)\n\n # Report on any failures\n if need_inst and not installer:\n diagnose_configurator_problem(\"installer\", req_inst, plugins)\n if need_auth and not authenticator:\n diagnose_configurator_problem(\"authenticator\", req_auth, plugins)\n\n record_chosen_plugins(config, plugins, authenticator, installer)\n return installer, authenticator\n\n\ndef set_configurator(previously, now):\n \"\"\"\n Setting configurators multiple ways is okay, as long as they all agree\n :param str previously: previously identified request for the installer/authenticator\n :param str requested: the request currently being processed\n \"\"\"\n if not now:\n # we're not actually setting anything\n return previously\n if previously:\n if previously != now:\n msg = \"Too many flags setting configurators/installers/authenticators {0} -> {1}\"\n raise errors.PluginSelectionError(msg.format(repr(previously), repr(now)))\n return now\n\n\ndef cli_plugin_requests(config):\n \"\"\"\n Figure out which plugins the user requested with CLI and config options\n\n :returns: (requested authenticator string or None, requested installer string or None)\n :rtype: tuple\n \"\"\"\n req_inst = req_auth = config.configurator\n req_inst = set_configurator(req_inst, config.installer)\n req_auth = set_configurator(req_auth, config.authenticator)\n if config.nginx:\n req_inst = set_configurator(req_inst, \"nginx\")\n req_auth = set_configurator(req_auth, \"nginx\")\n if config.apache:\n req_inst = set_configurator(req_inst, \"apache\")\n req_auth = set_configurator(req_auth, \"apache\")\n if config.standalone:\n req_auth = set_configurator(req_auth, \"standalone\")\n if config.webroot:\n req_auth = set_configurator(req_auth, \"webroot\")\n if config.manual:\n req_auth = set_configurator(req_auth, \"manual\")\n logger.debug(\"Requested authenticator %s and installer %s\", req_auth, req_inst)\n return req_auth, req_inst\n\n\ndef diagnose_configurator_problem(cfg_type, requested, plugins):\n \"\"\"\n Raise the most helpful error message about a plugin being unavailable\n\n :param str cfg_type: either \"installer\" or \"authenticator\"\n :param str requested: the plugin that was requested\n :param .PluginsRegistry plugins: available plugins\n\n :raises error.PluginSelectionError: if there was a problem\n \"\"\"\n\n if requested:\n if requested not in plugins:\n msg = \"The requested {0} plugin does not appear to be installed\".format(requested)\n else:\n msg = (\"The {0} plugin is not working; there may be problems with \"\n \"your existing configuration.\\nThe error was: {1!r}\"\n .format(requested, plugins[requested].problem))\n elif cfg_type == \"installer\":\n from certbot.cli import cli_command\n msg = ('Certbot doesn\\'t know how to automatically configure the web '\n 'server on this system. However, it can still get a certificate for '\n 'you. Please run \"{0} certonly\" to do so. You\\'ll need to '\n 'manually configure your web server to use the resulting '\n 'certificate.').format(cli_command)\n else:\n msg = \"{0} could not be determined or is not installed\".format(cfg_type)\n raise errors.PluginSelectionError(msg)\n", "path": "certbot/plugins/selection.py"}]}
| 3,364 | 262 |
gh_patches_debug_43847
|
rasdani/github-patches
|
git_diff
|
ansible__ansible-modules-core-5219
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add update_password option to os_user module
<!--- Verify first that your issue/request is not already reported in GitHub -->
##### ISSUE TYPE
<!--- Pick one below and delete the rest: -->
- Feature Idea
##### COMPONENT NAME
<!--- Name of the plugin/module/task -->
os_user
##### ANSIBLE VERSION
<!--- Paste verbatim output from “ansible --version” between quotes below -->
```
$ ansible --version
ansible 2.1.2.0
```
##### CONFIGURATION
<!---
Mention any settings you have changed/added/removed in ansible.cfg
(or using the ANSIBLE_* environment variables).
-->
##### OS / ENVIRONMENT
<!---
Mention the OS you are running Ansible from, and the OS you are
managing, or say “N/A” for anything that is not platform-specific.
-->
N/A
##### SUMMARY
<!--- Explain the problem briefly -->
The `os_user` module with a password specified for a user will always report 'changed'.
The conclusion of the bug report in #5183 was that in order to "fix" this we need to add another parameter like the on in the `user` module.
I.e a parameter called `update_password` that has options `on_create` or `always`.
##### STEPS TO REPRODUCE
<!---
For bugs, show exactly how to reproduce the problem.
For new features, show how the feature would be used.
-->
```
- name: "Create test user"
os_user:
name: test
state: present
password: very-secret
default_project: a-existing-project
update_password: on_create
```
##### EXPECTED RESULTS
<!--- What did you expect to happen when running the steps above? -->
On first run, the user would be created and the password set.
On the second run, given that nothing changed, the task would say `ok`.
If the parameter would be `update_password: always` on the other hand, the module should always set the password and would always report `changed`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cloud/openstack/os_user.py`
Content:
```
1 #!/usr/bin/python
2 # Copyright (c) 2015 Hewlett-Packard Development Company, L.P.
3 #
4 # This module is free software: you can redistribute it and/or modify
5 # it under the terms of the GNU General Public License as published by
6 # the Free Software Foundation, either version 3 of the License, or
7 # (at your option) any later version.
8 #
9 # This software is distributed in the hope that it will be useful,
10 # but WITHOUT ANY WARRANTY; without even the implied warranty of
11 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
12 # GNU General Public License for more details.
13 #
14 # You should have received a copy of the GNU General Public License
15 # along with this software. If not, see <http://www.gnu.org/licenses/>.
16
17
18 try:
19 import shade
20 HAS_SHADE = True
21 except ImportError:
22 HAS_SHADE = False
23
24 DOCUMENTATION = '''
25 ---
26 module: os_user
27 short_description: Manage OpenStack Identity Users
28 extends_documentation_fragment: openstack
29 version_added: "2.0"
30 description:
31 - Manage OpenStack Identity users. Users can be created,
32 updated or deleted using this module. A user will be updated
33 if I(name) matches an existing user and I(state) is present.
34 The value for I(name) cannot be updated without deleting and
35 re-creating the user.
36 options:
37 name:
38 description:
39 - Username for the user
40 required: true
41 password:
42 description:
43 - Password for the user
44 required: false
45 default: None
46 email:
47 description:
48 - Email address for the user
49 required: false
50 default: None
51 default_project:
52 description:
53 - Project name or ID that the user should be associated with by default
54 required: false
55 default: None
56 domain:
57 description:
58 - Domain to create the user in if the cloud supports domains
59 required: false
60 default: None
61 enabled:
62 description:
63 - Is the user enabled
64 required: false
65 default: True
66 state:
67 description:
68 - Should the resource be present or absent.
69 choices: [present, absent]
70 default: present
71 requirements:
72 - "python >= 2.6"
73 - "shade"
74 '''
75
76 EXAMPLES = '''
77 # Create a user
78 - os_user:
79 cloud: mycloud
80 state: present
81 name: demouser
82 password: secret
83 email: [email protected]
84 domain: default
85 default_project: demo
86
87 # Delete a user
88 - os_user:
89 cloud: mycloud
90 state: absent
91 name: demouser
92 '''
93
94
95 RETURN = '''
96 user:
97 description: Dictionary describing the user.
98 returned: On success when I(state) is 'present'
99 type: dictionary
100 contains:
101 default_project_id:
102 description: User default project ID. Only present with Keystone >= v3.
103 type: string
104 sample: "4427115787be45f08f0ec22a03bfc735"
105 domain_id:
106 description: User domain ID. Only present with Keystone >= v3.
107 type: string
108 sample: "default"
109 email:
110 description: User email address
111 type: string
112 sample: "[email protected]"
113 id:
114 description: User ID
115 type: string
116 sample: "f59382db809c43139982ca4189404650"
117 name:
118 description: User name
119 type: string
120 sample: "demouser"
121 '''
122
123 def _needs_update(params_dict, user):
124 for k, v in params_dict.items():
125 if k != 'password' and user[k] != v:
126 return True
127
128 # We don't get password back in the user object, so assume any supplied
129 # password is a change.
130 if params_dict['password'] is not None:
131 return True
132
133 return False
134
135 def _get_domain_id(cloud, domain):
136 try:
137 # We assume admin is passing domain id
138 domain_id = cloud.get_domain(domain)['id']
139 except:
140 # If we fail, maybe admin is passing a domain name.
141 # Note that domains have unique names, just like id.
142 try:
143 domain_id = cloud.search_domains(filters={'name': domain})[0]['id']
144 except:
145 # Ok, let's hope the user is non-admin and passing a sane id
146 domain_id = domain
147
148 return domain_id
149
150 def _get_default_project_id(cloud, default_project):
151 project = cloud.get_project(default_project)
152 if not project:
153 module.fail_json(msg='Default project %s is not valid' % default_project)
154
155 return project['id']
156
157 def main():
158
159 argument_spec = openstack_full_argument_spec(
160 name=dict(required=True),
161 password=dict(required=False, default=None),
162 email=dict(required=False, default=None),
163 default_project=dict(required=False, default=None),
164 domain=dict(required=False, default=None),
165 enabled=dict(default=True, type='bool'),
166 state=dict(default='present', choices=['absent', 'present']),
167 )
168
169 module_kwargs = openstack_module_kwargs()
170 module = AnsibleModule(
171 argument_spec,
172 **module_kwargs)
173
174 if not HAS_SHADE:
175 module.fail_json(msg='shade is required for this module')
176
177 name = module.params['name']
178 password = module.params['password']
179 email = module.params['email']
180 default_project = module.params['default_project']
181 domain = module.params['domain']
182 enabled = module.params['enabled']
183 state = module.params['state']
184
185 try:
186 cloud = shade.openstack_cloud(**module.params)
187 user = cloud.get_user(name)
188
189 domain_id = None
190 if domain:
191 opcloud = shade.operator_cloud(**module.params)
192 domain_id = _get_domain_id(opcloud, domain)
193
194 if state == 'present':
195 default_project_id = None
196 if default_project:
197 default_project_id = _get_default_project_id(cloud, default_project)
198
199 if user is None:
200 user = cloud.create_user(
201 name=name, password=password, email=email,
202 default_project=default_project_id, domain_id=domain_id,
203 enabled=enabled)
204 changed = True
205 else:
206 params_dict = {'email': email, 'enabled': enabled, 'password': password}
207 if domain_id is not None:
208 params_dict['domain_id'] = domain_id
209 if default_project_id is not None:
210 params_dict['default_project_id'] = default_project_id
211
212 if _needs_update(params_dict, user):
213 user = cloud.update_user(
214 user['id'], password=password, email=email,
215 default_project=default_project_id, domain_id=domain_id,
216 enabled=enabled)
217 changed = True
218 else:
219 changed = False
220 module.exit_json(changed=changed, user=user)
221
222 elif state == 'absent':
223 if user is None:
224 changed=False
225 else:
226 cloud.delete_user(user['id'])
227 changed=True
228 module.exit_json(changed=changed)
229
230 except shade.OpenStackCloudException as e:
231 module.fail_json(msg=str(e), extra_data=e.extra_data)
232
233 from ansible.module_utils.basic import *
234 from ansible.module_utils.openstack import *
235
236
237 if __name__ == '__main__':
238 main()
239
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/cloud/openstack/os_user.py b/cloud/openstack/os_user.py
--- a/cloud/openstack/os_user.py
+++ b/cloud/openstack/os_user.py
@@ -43,6 +43,14 @@
- Password for the user
required: false
default: None
+ update_password:
+ required: false
+ default: always
+ choices: ['always', 'on_create']
+ version_added: "2.3"
+ description:
+ - C(always) will attempt to update password. C(on_create) will only
+ set the password for newly created users.
email:
description:
- Email address for the user
@@ -89,6 +97,17 @@
cloud: mycloud
state: absent
name: demouser
+
+# Create a user but don't update password if user exists
+- os_user:
+ cloud: mycloud
+ state: present
+ name: demouser
+ password: secret
+ update_password: on_create
+ email: [email protected]
+ domain: default
+ default_project: demo
'''
@@ -122,12 +141,13 @@
def _needs_update(params_dict, user):
for k, v in params_dict.items():
- if k != 'password' and user[k] != v:
+ if k not in ('password', 'update_password') and user[k] != v:
return True
# We don't get password back in the user object, so assume any supplied
# password is a change.
- if params_dict['password'] is not None:
+ if (params_dict['password'] is not None and
+ params_dict['update_password'] == 'always'):
return True
return False
@@ -164,11 +184,17 @@
domain=dict(required=False, default=None),
enabled=dict(default=True, type='bool'),
state=dict(default='present', choices=['absent', 'present']),
+ update_password=dict(default='always', choices=['always',
+ 'on_create']),
)
module_kwargs = openstack_module_kwargs()
module = AnsibleModule(
argument_spec,
+ required_if=[
+ ('update_password', 'always', ['password']),
+ ('update_password', 'on_create', ['password']),
+ ],
**module_kwargs)
if not HAS_SHADE:
@@ -181,6 +207,7 @@
domain = module.params['domain']
enabled = module.params['enabled']
state = module.params['state']
+ update_password = module.params['update_password']
try:
cloud = shade.openstack_cloud(**module.params)
@@ -203,17 +230,25 @@
enabled=enabled)
changed = True
else:
- params_dict = {'email': email, 'enabled': enabled, 'password': password}
+ params_dict = {'email': email, 'enabled': enabled,
+ 'password': password,
+ 'update_password': update_password}
if domain_id is not None:
params_dict['domain_id'] = domain_id
if default_project_id is not None:
params_dict['default_project_id'] = default_project_id
if _needs_update(params_dict, user):
- user = cloud.update_user(
- user['id'], password=password, email=email,
- default_project=default_project_id, domain_id=domain_id,
- enabled=enabled)
+ if update_password == 'always':
+ user = cloud.update_user(
+ user['id'], password=password, email=email,
+ default_project=default_project_id,
+ domain_id=domain_id, enabled=enabled)
+ else:
+ user = cloud.update_user(
+ user['id'], email=email,
+ default_project=default_project_id,
+ domain_id=domain_id, enabled=enabled)
changed = True
else:
changed = False
|
{"golden_diff": "diff --git a/cloud/openstack/os_user.py b/cloud/openstack/os_user.py\n--- a/cloud/openstack/os_user.py\n+++ b/cloud/openstack/os_user.py\n@@ -43,6 +43,14 @@\n - Password for the user\n required: false\n default: None\n+ update_password:\n+ required: false\n+ default: always\n+ choices: ['always', 'on_create']\n+ version_added: \"2.3\"\n+ description:\n+ - C(always) will attempt to update password. C(on_create) will only\n+ set the password for newly created users.\n email:\n description:\n - Email address for the user\n@@ -89,6 +97,17 @@\n cloud: mycloud\n state: absent\n name: demouser\n+\n+# Create a user but don't update password if user exists\n+- os_user:\n+ cloud: mycloud\n+ state: present\n+ name: demouser\n+ password: secret\n+ update_password: on_create\n+ email: [email protected]\n+ domain: default\n+ default_project: demo\n '''\n \n \n@@ -122,12 +141,13 @@\n \n def _needs_update(params_dict, user):\n for k, v in params_dict.items():\n- if k != 'password' and user[k] != v:\n+ if k not in ('password', 'update_password') and user[k] != v:\n return True\n \n # We don't get password back in the user object, so assume any supplied\n # password is a change.\n- if params_dict['password'] is not None:\n+ if (params_dict['password'] is not None and\n+ params_dict['update_password'] == 'always'):\n return True\n \n return False\n@@ -164,11 +184,17 @@\n domain=dict(required=False, default=None),\n enabled=dict(default=True, type='bool'),\n state=dict(default='present', choices=['absent', 'present']),\n+ update_password=dict(default='always', choices=['always',\n+ 'on_create']),\n )\n \n module_kwargs = openstack_module_kwargs()\n module = AnsibleModule(\n argument_spec,\n+ required_if=[\n+ ('update_password', 'always', ['password']),\n+ ('update_password', 'on_create', ['password']),\n+ ],\n **module_kwargs)\n \n if not HAS_SHADE:\n@@ -181,6 +207,7 @@\n domain = module.params['domain']\n enabled = module.params['enabled']\n state = module.params['state']\n+ update_password = module.params['update_password']\n \n try:\n cloud = shade.openstack_cloud(**module.params)\n@@ -203,17 +230,25 @@\n enabled=enabled)\n changed = True\n else:\n- params_dict = {'email': email, 'enabled': enabled, 'password': password}\n+ params_dict = {'email': email, 'enabled': enabled,\n+ 'password': password,\n+ 'update_password': update_password}\n if domain_id is not None:\n params_dict['domain_id'] = domain_id\n if default_project_id is not None:\n params_dict['default_project_id'] = default_project_id\n \n if _needs_update(params_dict, user):\n- user = cloud.update_user(\n- user['id'], password=password, email=email,\n- default_project=default_project_id, domain_id=domain_id,\n- enabled=enabled)\n+ if update_password == 'always':\n+ user = cloud.update_user(\n+ user['id'], password=password, email=email,\n+ default_project=default_project_id,\n+ domain_id=domain_id, enabled=enabled)\n+ else:\n+ user = cloud.update_user(\n+ user['id'], email=email,\n+ default_project=default_project_id,\n+ domain_id=domain_id, enabled=enabled)\n changed = True\n else:\n changed = False\n", "issue": "Add update_password option to os_user module\n<!--- Verify first that your issue/request is not already reported in GitHub -->\n##### ISSUE TYPE\n\n<!--- Pick one below and delete the rest: -->\n- Feature Idea\n##### COMPONENT NAME\n\n<!--- Name of the plugin/module/task -->\n\nos_user\n##### ANSIBLE VERSION\n\n<!--- Paste verbatim output from \u201cansible --version\u201d between quotes below -->\n\n```\n$ ansible --version\nansible 2.1.2.0\n```\n##### CONFIGURATION\n\n<!---\nMention any settings you have changed/added/removed in ansible.cfg\n(or using the ANSIBLE_* environment variables).\n-->\n##### OS / ENVIRONMENT\n\n<!---\nMention the OS you are running Ansible from, and the OS you are\nmanaging, or say \u201cN/A\u201d for anything that is not platform-specific.\n-->\n\nN/A\n##### SUMMARY\n\n<!--- Explain the problem briefly -->\n\nThe `os_user` module with a password specified for a user will always report 'changed'.\nThe conclusion of the bug report in #5183 was that in order to \"fix\" this we need to add another parameter like the on in the `user` module.\nI.e a parameter called `update_password` that has options `on_create` or `always`.\n##### STEPS TO REPRODUCE\n\n<!---\nFor bugs, show exactly how to reproduce the problem.\nFor new features, show how the feature would be used.\n-->\n\n```\n - name: \"Create test user\"\n os_user:\n name: test\n state: present\n password: very-secret\n default_project: a-existing-project\n update_password: on_create\n```\n##### EXPECTED RESULTS\n\n<!--- What did you expect to happen when running the steps above? -->\n\nOn first run, the user would be created and the password set.\nOn the second run, given that nothing changed, the task would say `ok`.\nIf the parameter would be `update_password: always` on the other hand, the module should always set the password and would always report `changed`\n\n", "before_files": [{"content": "#!/usr/bin/python\n# Copyright (c) 2015 Hewlett-Packard Development Company, L.P.\n#\n# This module is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This software is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this software. If not, see <http://www.gnu.org/licenses/>.\n\n\ntry:\n import shade\n HAS_SHADE = True\nexcept ImportError:\n HAS_SHADE = False\n\nDOCUMENTATION = '''\n---\nmodule: os_user\nshort_description: Manage OpenStack Identity Users\nextends_documentation_fragment: openstack\nversion_added: \"2.0\"\ndescription:\n - Manage OpenStack Identity users. Users can be created,\n updated or deleted using this module. A user will be updated\n if I(name) matches an existing user and I(state) is present.\n The value for I(name) cannot be updated without deleting and\n re-creating the user.\noptions:\n name:\n description:\n - Username for the user\n required: true\n password:\n description:\n - Password for the user\n required: false\n default: None\n email:\n description:\n - Email address for the user\n required: false\n default: None\n default_project:\n description:\n - Project name or ID that the user should be associated with by default\n required: false\n default: None\n domain:\n description:\n - Domain to create the user in if the cloud supports domains\n required: false\n default: None\n enabled:\n description:\n - Is the user enabled\n required: false\n default: True\n state:\n description:\n - Should the resource be present or absent.\n choices: [present, absent]\n default: present\nrequirements:\n - \"python >= 2.6\"\n - \"shade\"\n'''\n\nEXAMPLES = '''\n# Create a user\n- os_user:\n cloud: mycloud\n state: present\n name: demouser\n password: secret\n email: [email protected]\n domain: default\n default_project: demo\n\n# Delete a user\n- os_user:\n cloud: mycloud\n state: absent\n name: demouser\n'''\n\n\nRETURN = '''\nuser:\n description: Dictionary describing the user.\n returned: On success when I(state) is 'present'\n type: dictionary\n contains:\n default_project_id:\n description: User default project ID. Only present with Keystone >= v3.\n type: string\n sample: \"4427115787be45f08f0ec22a03bfc735\"\n domain_id:\n description: User domain ID. Only present with Keystone >= v3.\n type: string\n sample: \"default\"\n email:\n description: User email address\n type: string\n sample: \"[email protected]\"\n id:\n description: User ID\n type: string\n sample: \"f59382db809c43139982ca4189404650\"\n name:\n description: User name\n type: string\n sample: \"demouser\"\n'''\n\ndef _needs_update(params_dict, user):\n for k, v in params_dict.items():\n if k != 'password' and user[k] != v:\n return True\n\n # We don't get password back in the user object, so assume any supplied\n # password is a change.\n if params_dict['password'] is not None:\n return True\n\n return False\n\ndef _get_domain_id(cloud, domain):\n try:\n # We assume admin is passing domain id\n domain_id = cloud.get_domain(domain)['id']\n except:\n # If we fail, maybe admin is passing a domain name.\n # Note that domains have unique names, just like id.\n try:\n domain_id = cloud.search_domains(filters={'name': domain})[0]['id']\n except:\n # Ok, let's hope the user is non-admin and passing a sane id\n domain_id = domain\n\n return domain_id\n\ndef _get_default_project_id(cloud, default_project):\n project = cloud.get_project(default_project)\n if not project:\n module.fail_json(msg='Default project %s is not valid' % default_project)\n\n return project['id']\n\ndef main():\n\n argument_spec = openstack_full_argument_spec(\n name=dict(required=True),\n password=dict(required=False, default=None),\n email=dict(required=False, default=None),\n default_project=dict(required=False, default=None),\n domain=dict(required=False, default=None),\n enabled=dict(default=True, type='bool'),\n state=dict(default='present', choices=['absent', 'present']),\n )\n\n module_kwargs = openstack_module_kwargs()\n module = AnsibleModule(\n argument_spec,\n **module_kwargs)\n\n if not HAS_SHADE:\n module.fail_json(msg='shade is required for this module')\n\n name = module.params['name']\n password = module.params['password']\n email = module.params['email']\n default_project = module.params['default_project']\n domain = module.params['domain']\n enabled = module.params['enabled']\n state = module.params['state']\n\n try:\n cloud = shade.openstack_cloud(**module.params)\n user = cloud.get_user(name)\n\n domain_id = None\n if domain:\n opcloud = shade.operator_cloud(**module.params)\n domain_id = _get_domain_id(opcloud, domain)\n\n if state == 'present':\n default_project_id = None\n if default_project:\n default_project_id = _get_default_project_id(cloud, default_project)\n\n if user is None:\n user = cloud.create_user(\n name=name, password=password, email=email,\n default_project=default_project_id, domain_id=domain_id,\n enabled=enabled)\n changed = True\n else:\n params_dict = {'email': email, 'enabled': enabled, 'password': password}\n if domain_id is not None:\n params_dict['domain_id'] = domain_id\n if default_project_id is not None:\n params_dict['default_project_id'] = default_project_id\n\n if _needs_update(params_dict, user):\n user = cloud.update_user(\n user['id'], password=password, email=email,\n default_project=default_project_id, domain_id=domain_id,\n enabled=enabled)\n changed = True\n else:\n changed = False\n module.exit_json(changed=changed, user=user)\n\n elif state == 'absent':\n if user is None:\n changed=False\n else:\n cloud.delete_user(user['id'])\n changed=True\n module.exit_json(changed=changed)\n\n except shade.OpenStackCloudException as e:\n module.fail_json(msg=str(e), extra_data=e.extra_data)\n\nfrom ansible.module_utils.basic import *\nfrom ansible.module_utils.openstack import *\n\n\nif __name__ == '__main__':\n main()\n", "path": "cloud/openstack/os_user.py"}], "after_files": [{"content": "#!/usr/bin/python\n# Copyright (c) 2015 Hewlett-Packard Development Company, L.P.\n#\n# This module is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This software is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this software. If not, see <http://www.gnu.org/licenses/>.\n\n\ntry:\n import shade\n HAS_SHADE = True\nexcept ImportError:\n HAS_SHADE = False\n\nDOCUMENTATION = '''\n---\nmodule: os_user\nshort_description: Manage OpenStack Identity Users\nextends_documentation_fragment: openstack\nversion_added: \"2.0\"\ndescription:\n - Manage OpenStack Identity users. Users can be created,\n updated or deleted using this module. A user will be updated\n if I(name) matches an existing user and I(state) is present.\n The value for I(name) cannot be updated without deleting and\n re-creating the user.\noptions:\n name:\n description:\n - Username for the user\n required: true\n password:\n description:\n - Password for the user\n required: false\n default: None\n update_password:\n required: false\n default: always\n choices: ['always', 'on_create']\n version_added: \"2.3\"\n description:\n - C(always) will attempt to update password. C(on_create) will only\n set the password for newly created users.\n email:\n description:\n - Email address for the user\n required: false\n default: None\n default_project:\n description:\n - Project name or ID that the user should be associated with by default\n required: false\n default: None\n domain:\n description:\n - Domain to create the user in if the cloud supports domains\n required: false\n default: None\n enabled:\n description:\n - Is the user enabled\n required: false\n default: True\n state:\n description:\n - Should the resource be present or absent.\n choices: [present, absent]\n default: present\nrequirements:\n - \"python >= 2.6\"\n - \"shade\"\n'''\n\nEXAMPLES = '''\n# Create a user\n- os_user:\n cloud: mycloud\n state: present\n name: demouser\n password: secret\n email: [email protected]\n domain: default\n default_project: demo\n\n# Delete a user\n- os_user:\n cloud: mycloud\n state: absent\n name: demouser\n\n# Create a user but don't update password if user exists\n- os_user:\n cloud: mycloud\n state: present\n name: demouser\n password: secret\n update_password: on_create\n email: [email protected]\n domain: default\n default_project: demo\n'''\n\n\nRETURN = '''\nuser:\n description: Dictionary describing the user.\n returned: On success when I(state) is 'present'\n type: dictionary\n contains:\n default_project_id:\n description: User default project ID. Only present with Keystone >= v3.\n type: string\n sample: \"4427115787be45f08f0ec22a03bfc735\"\n domain_id:\n description: User domain ID. Only present with Keystone >= v3.\n type: string\n sample: \"default\"\n email:\n description: User email address\n type: string\n sample: \"[email protected]\"\n id:\n description: User ID\n type: string\n sample: \"f59382db809c43139982ca4189404650\"\n name:\n description: User name\n type: string\n sample: \"demouser\"\n'''\n\ndef _needs_update(params_dict, user):\n for k, v in params_dict.items():\n if k not in ('password', 'update_password') and user[k] != v:\n return True\n\n # We don't get password back in the user object, so assume any supplied\n # password is a change.\n if (params_dict['password'] is not None and\n params_dict['update_password'] == 'always'):\n return True\n\n return False\n\ndef _get_domain_id(cloud, domain):\n try:\n # We assume admin is passing domain id\n domain_id = cloud.get_domain(domain)['id']\n except:\n # If we fail, maybe admin is passing a domain name.\n # Note that domains have unique names, just like id.\n try:\n domain_id = cloud.search_domains(filters={'name': domain})[0]['id']\n except:\n # Ok, let's hope the user is non-admin and passing a sane id\n domain_id = domain\n\n return domain_id\n\ndef _get_default_project_id(cloud, default_project):\n project = cloud.get_project(default_project)\n if not project:\n module.fail_json(msg='Default project %s is not valid' % default_project)\n\n return project['id']\n\ndef main():\n\n argument_spec = openstack_full_argument_spec(\n name=dict(required=True),\n password=dict(required=False, default=None),\n email=dict(required=False, default=None),\n default_project=dict(required=False, default=None),\n domain=dict(required=False, default=None),\n enabled=dict(default=True, type='bool'),\n state=dict(default='present', choices=['absent', 'present']),\n update_password=dict(default='always', choices=['always',\n 'on_create']),\n )\n\n module_kwargs = openstack_module_kwargs()\n module = AnsibleModule(\n argument_spec,\n required_if=[\n ('update_password', 'always', ['password']),\n ('update_password', 'on_create', ['password']),\n ],\n **module_kwargs)\n\n if not HAS_SHADE:\n module.fail_json(msg='shade is required for this module')\n\n name = module.params['name']\n password = module.params['password']\n email = module.params['email']\n default_project = module.params['default_project']\n domain = module.params['domain']\n enabled = module.params['enabled']\n state = module.params['state']\n update_password = module.params['update_password']\n\n try:\n cloud = shade.openstack_cloud(**module.params)\n user = cloud.get_user(name)\n\n domain_id = None\n if domain:\n opcloud = shade.operator_cloud(**module.params)\n domain_id = _get_domain_id(opcloud, domain)\n\n if state == 'present':\n default_project_id = None\n if default_project:\n default_project_id = _get_default_project_id(cloud, default_project)\n\n if user is None:\n user = cloud.create_user(\n name=name, password=password, email=email,\n default_project=default_project_id, domain_id=domain_id,\n enabled=enabled)\n changed = True\n else:\n params_dict = {'email': email, 'enabled': enabled,\n 'password': password,\n 'update_password': update_password}\n if domain_id is not None:\n params_dict['domain_id'] = domain_id\n if default_project_id is not None:\n params_dict['default_project_id'] = default_project_id\n\n if _needs_update(params_dict, user):\n if update_password == 'always':\n user = cloud.update_user(\n user['id'], password=password, email=email,\n default_project=default_project_id,\n domain_id=domain_id, enabled=enabled)\n else:\n user = cloud.update_user(\n user['id'], email=email,\n default_project=default_project_id,\n domain_id=domain_id, enabled=enabled)\n changed = True\n else:\n changed = False\n module.exit_json(changed=changed, user=user)\n\n elif state == 'absent':\n if user is None:\n changed=False\n else:\n cloud.delete_user(user['id'])\n changed=True\n module.exit_json(changed=changed)\n\n except shade.OpenStackCloudException as e:\n module.fail_json(msg=str(e), extra_data=e.extra_data)\n\nfrom ansible.module_utils.basic import *\nfrom ansible.module_utils.openstack import *\n\n\nif __name__ == '__main__':\n main()\n", "path": "cloud/openstack/os_user.py"}]}
| 2,913 | 879 |
gh_patches_debug_6356
|
rasdani/github-patches
|
git_diff
|
sunpy__sunpy-7486
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Saving with the ".jp2" extension results in a vertically flipped image
### Describe the bug
Images get flipped when saving as jp2 files.
This was my fault when I added this feature 🎉
### To Reproduce
```
from sunpy.map import Map
m = Map("https://helioviewer.org/jp2/AIA/2024/03/08/304/2024_03_08__00_00_05_123__SDO_AIA_AIA_304.jp2")
m.peek()
m.save("test.jp2")
flipped = Map("test.jp2")
flipped.peek()
```
See screenshots below
### Screenshots
`m.peek()`
<img width="634" alt="image" src="https://github.com/sunpy/sunpy/assets/94071409/fc6f1648-9bd3-4e11-a726-9b2d4810e42e">
`flipped.peek()`
<img width="634" alt="image" src="https://github.com/sunpy/sunpy/assets/94071409/04c66615-05b3-4776-81c6-7aefa3c9ca5f">
### System Details
>>> import sunpy
>>> sunpy.util.system_info()
==============================
sunpy Installation Information
==============================
General
#######
OS: Mac OS 14.3.1
Arch: 64bit, (arm)
sunpy: 4.0.dev2573+gf79e5d92d
Installation path: sunpy.egg-info
Required Dependencies
#####################
astropy: 6.0.0
numpy: 1.26.4
packaging: 23.2
parfive: 2.0.2
pyerfa: 2.0.1.1
requests: 2.31.0
Optional Dependencies
#####################
sunpy: 4.0.dev2573+gf79e5d92d
### Installation method
git checkout
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sunpy/io/_jp2.py`
Content:
```
1 """
2 This module provides a JPEG 2000 file reader for internal use.
3
4 .. warning::
5
6 ``sunpy.io.jp2`` is deprecated, and will be removed in sunpy 4.1. This is
7 because it was designed for internal use only.
8 """
9 import os
10 from xml.etree import ElementTree as ET
11
12 import numpy as np
13
14 from sunpy.io.header import FileHeader
15 from sunpy.util.io import HDPair, string_is_float
16 from sunpy.util.xml import xml_to_dict
17
18 __all__ = ['read', 'get_header', 'write']
19
20
21 def read(filepath, **kwargs):
22 """
23 Reads a JPEG2000 file.
24
25 Parameters
26 ----------
27 filepath : `str`
28 The file to be read.
29 **kwargs : `dict`
30 Unused.
31
32 Returns
33 -------
34 `list`
35 A list of (data, header) tuples.
36 """
37 # Put import here to speed up sunpy.io import time
38 from glymur import Jp2k
39
40 header = get_header(filepath)
41 data = Jp2k(filepath)[...][::-1]
42 return [HDPair(data, header[0])]
43
44
45 def get_header(filepath):
46 """
47 Reads the header from the file.
48
49 Parameters
50 ----------
51 filepath : `str`
52 The file to be read.
53
54 Returns
55 -------
56 `list`
57 A list of one header read from the file.
58 """
59 # Put import here to speed up sunpy.io import time
60 from glymur import Jp2k
61 jp2 = Jp2k(filepath)
62 xml_box = [box for box in jp2.box if box.box_id == 'xml ']
63 xmlstring = ET.tostring(xml_box[0].xml.find('fits'))
64 pydict = xml_to_dict(xmlstring)["fits"]
65
66 # Fix types
67 for k, v in pydict.items():
68 if v.isdigit():
69 pydict[k] = int(v)
70 elif string_is_float(v):
71 pydict[k] = float(v)
72
73 # Remove newlines from comment
74 if 'comment' in pydict:
75 pydict['comment'] = pydict['comment'].replace("\n", "")
76
77 # Is this file a Helioviewer Project JPEG2000 file?
78 pydict['helioviewer'] = xml_box[0].xml.find('helioviewer') is not None
79
80 return [FileHeader(pydict)]
81
82
83 def header_to_xml(header):
84 """
85 Converts image header metadata into an XML Tree that can be inserted into
86 a JP2 file header.
87
88 Parameters
89 ----------
90 header : `MetaDict`
91 A header dictionary to convert to xml.
92
93 Returns
94 ----------
95 `lxml.etree._Element`
96 A fits element where each child is an xml element
97 in the form <key>value</key> derived from the key/value
98 pairs in the given header dictionary
99 """
100 # glymur uses lxml and will crash if trying to use
101 # python's builtin xml.etree
102 import lxml.etree as ET
103
104 fits = ET.Element("fits")
105
106 already_added = set()
107 for key in header:
108 # Some headers span multiple lines and get duplicated as keys
109 # header.get will appropriately return all data, so if we see
110 # a key again, we can assume it was already added to the xml tree.
111 if (key in already_added):
112 continue
113
114 # Add to the set so we don't duplicate entries
115 already_added.add(key)
116
117 el = ET.SubElement(fits, key)
118 data = header.get(key)
119 if isinstance(data, bool):
120 data = "1" if data else "0"
121 else:
122 data = str(data)
123
124 el.text = data
125
126 return fits
127
128
129 def generate_jp2_xmlbox(header):
130 """
131 Generates the JP2 XML box to be inserted into the jp2 file.
132
133 Parameters
134 ----------
135 header : `MetaDict`
136 A header dictionary.
137
138 Returns
139 ----------
140 `XMLBox`
141 XML box containing FITS metadata to be used in jp2 headers
142 """
143 # glymur uses lxml and will crash if trying to use
144 # python's builtin xml.etree
145 import lxml.etree as ET
146 from glymur import jp2box
147
148 header_xml = header_to_xml(header)
149 meta = ET.Element("meta")
150 meta.append(header_xml)
151 tree = ET.ElementTree(meta)
152 return jp2box.XMLBox(xml=tree)
153
154
155 def write(fname, data, header, **kwargs):
156 """
157 Take a data header pair and write a JP2 file.
158
159 Parameters
160 ----------
161 fname : `str`
162 File name, with extension.
163 data : `numpy.ndarray`
164 n-dimensional data array.
165 header : `dict`
166 A header dictionary.
167 kwargs :
168 Additional keyword args are passed to the glymur.Jp2k constructor
169
170 Notes
171 -----
172 Saving as a JPEG2000 will cast the data array to
173 uint8 values to support the JPEG2000 format.
174 """
175 from glymur import Jp2k
176
177 tmpname = fname + "tmp.jp2"
178 jp2_data = np.uint8(data)
179 jp2 = Jp2k(tmpname, jp2_data, **kwargs)
180
181 # Append the XML data to the header information stored in jp2.box
182 meta_boxes = jp2.box
183 target_index = len(meta_boxes) - 1
184 fits_box = generate_jp2_xmlbox(header)
185 meta_boxes.insert(target_index, fits_box)
186
187 # Rewrites the jp2 file on disk with the xml data in the header
188 jp2.wrap(fname, boxes=meta_boxes)
189
190 os.remove(tmpname)
191
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sunpy/io/_jp2.py b/sunpy/io/_jp2.py
--- a/sunpy/io/_jp2.py
+++ b/sunpy/io/_jp2.py
@@ -176,7 +176,11 @@
tmpname = fname + "tmp.jp2"
jp2_data = np.uint8(data)
- jp2 = Jp2k(tmpname, jp2_data, **kwargs)
+
+ # The jp2 data is flipped when read in, so we have to flip it back before
+ # saving. See https://github.com/sunpy/sunpy/pull/768 for context.
+ flipped = np.flip(jp2_data, 0)
+ jp2 = Jp2k(tmpname, flipped, **kwargs)
# Append the XML data to the header information stored in jp2.box
meta_boxes = jp2.box
|
{"golden_diff": "diff --git a/sunpy/io/_jp2.py b/sunpy/io/_jp2.py\n--- a/sunpy/io/_jp2.py\n+++ b/sunpy/io/_jp2.py\n@@ -176,7 +176,11 @@\n \n tmpname = fname + \"tmp.jp2\"\n jp2_data = np.uint8(data)\n- jp2 = Jp2k(tmpname, jp2_data, **kwargs)\n+\n+ # The jp2 data is flipped when read in, so we have to flip it back before\n+ # saving. See https://github.com/sunpy/sunpy/pull/768 for context.\n+ flipped = np.flip(jp2_data, 0)\n+ jp2 = Jp2k(tmpname, flipped, **kwargs)\n \n # Append the XML data to the header information stored in jp2.box\n meta_boxes = jp2.box\n", "issue": "Saving with the \".jp2\" extension results in a vertically flipped image\n### Describe the bug\n\nImages get flipped when saving as jp2 files.\r\nThis was my fault when I added this feature \ud83c\udf89\n\n### To Reproduce\n\n```\r\nfrom sunpy.map import Map\r\nm = Map(\"https://helioviewer.org/jp2/AIA/2024/03/08/304/2024_03_08__00_00_05_123__SDO_AIA_AIA_304.jp2\")\r\nm.peek()\r\nm.save(\"test.jp2\")\r\nflipped = Map(\"test.jp2\")\r\nflipped.peek()\r\n```\r\n\r\nSee screenshots below\r\n\n\n### Screenshots\n\n`m.peek()`\r\n<img width=\"634\" alt=\"image\" src=\"https://github.com/sunpy/sunpy/assets/94071409/fc6f1648-9bd3-4e11-a726-9b2d4810e42e\">\r\n\r\n`flipped.peek()`\r\n<img width=\"634\" alt=\"image\" src=\"https://github.com/sunpy/sunpy/assets/94071409/04c66615-05b3-4776-81c6-7aefa3c9ca5f\">\r\n\n\n### System Details\n\n\r\n>>> import sunpy\r\n>>> sunpy.util.system_info()\r\n==============================\r\nsunpy Installation Information\r\n==============================\r\n\r\nGeneral\r\n#######\r\nOS: Mac OS 14.3.1\r\nArch: 64bit, (arm)\r\nsunpy: 4.0.dev2573+gf79e5d92d\r\nInstallation path: sunpy.egg-info\r\n\r\nRequired Dependencies\r\n#####################\r\nastropy: 6.0.0\r\nnumpy: 1.26.4\r\npackaging: 23.2\r\nparfive: 2.0.2\r\npyerfa: 2.0.1.1\r\nrequests: 2.31.0\r\n\r\nOptional Dependencies\r\n#####################\r\nsunpy: 4.0.dev2573+gf79e5d92d\n\n### Installation method\n\ngit checkout\n", "before_files": [{"content": "\"\"\"\nThis module provides a JPEG 2000 file reader for internal use.\n\n.. warning::\n\n ``sunpy.io.jp2`` is deprecated, and will be removed in sunpy 4.1. This is\n because it was designed for internal use only.\n\"\"\"\nimport os\nfrom xml.etree import ElementTree as ET\n\nimport numpy as np\n\nfrom sunpy.io.header import FileHeader\nfrom sunpy.util.io import HDPair, string_is_float\nfrom sunpy.util.xml import xml_to_dict\n\n__all__ = ['read', 'get_header', 'write']\n\n\ndef read(filepath, **kwargs):\n \"\"\"\n Reads a JPEG2000 file.\n\n Parameters\n ----------\n filepath : `str`\n The file to be read.\n **kwargs : `dict`\n Unused.\n\n Returns\n -------\n `list`\n A list of (data, header) tuples.\n \"\"\"\n # Put import here to speed up sunpy.io import time\n from glymur import Jp2k\n\n header = get_header(filepath)\n data = Jp2k(filepath)[...][::-1]\n return [HDPair(data, header[0])]\n\n\ndef get_header(filepath):\n \"\"\"\n Reads the header from the file.\n\n Parameters\n ----------\n filepath : `str`\n The file to be read.\n\n Returns\n -------\n `list`\n A list of one header read from the file.\n \"\"\"\n # Put import here to speed up sunpy.io import time\n from glymur import Jp2k\n jp2 = Jp2k(filepath)\n xml_box = [box for box in jp2.box if box.box_id == 'xml ']\n xmlstring = ET.tostring(xml_box[0].xml.find('fits'))\n pydict = xml_to_dict(xmlstring)[\"fits\"]\n\n # Fix types\n for k, v in pydict.items():\n if v.isdigit():\n pydict[k] = int(v)\n elif string_is_float(v):\n pydict[k] = float(v)\n\n # Remove newlines from comment\n if 'comment' in pydict:\n pydict['comment'] = pydict['comment'].replace(\"\\n\", \"\")\n\n # Is this file a Helioviewer Project JPEG2000 file?\n pydict['helioviewer'] = xml_box[0].xml.find('helioviewer') is not None\n\n return [FileHeader(pydict)]\n\n\ndef header_to_xml(header):\n \"\"\"\n Converts image header metadata into an XML Tree that can be inserted into\n a JP2 file header.\n\n Parameters\n ----------\n header : `MetaDict`\n A header dictionary to convert to xml.\n\n Returns\n ----------\n `lxml.etree._Element`\n A fits element where each child is an xml element\n in the form <key>value</key> derived from the key/value\n pairs in the given header dictionary\n \"\"\"\n # glymur uses lxml and will crash if trying to use\n # python's builtin xml.etree\n import lxml.etree as ET\n\n fits = ET.Element(\"fits\")\n\n already_added = set()\n for key in header:\n # Some headers span multiple lines and get duplicated as keys\n # header.get will appropriately return all data, so if we see\n # a key again, we can assume it was already added to the xml tree.\n if (key in already_added):\n continue\n\n # Add to the set so we don't duplicate entries\n already_added.add(key)\n\n el = ET.SubElement(fits, key)\n data = header.get(key)\n if isinstance(data, bool):\n data = \"1\" if data else \"0\"\n else:\n data = str(data)\n\n el.text = data\n\n return fits\n\n\ndef generate_jp2_xmlbox(header):\n \"\"\"\n Generates the JP2 XML box to be inserted into the jp2 file.\n\n Parameters\n ----------\n header : `MetaDict`\n A header dictionary.\n\n Returns\n ----------\n `XMLBox`\n XML box containing FITS metadata to be used in jp2 headers\n \"\"\"\n # glymur uses lxml and will crash if trying to use\n # python's builtin xml.etree\n import lxml.etree as ET\n from glymur import jp2box\n\n header_xml = header_to_xml(header)\n meta = ET.Element(\"meta\")\n meta.append(header_xml)\n tree = ET.ElementTree(meta)\n return jp2box.XMLBox(xml=tree)\n\n\ndef write(fname, data, header, **kwargs):\n \"\"\"\n Take a data header pair and write a JP2 file.\n\n Parameters\n ----------\n fname : `str`\n File name, with extension.\n data : `numpy.ndarray`\n n-dimensional data array.\n header : `dict`\n A header dictionary.\n kwargs :\n Additional keyword args are passed to the glymur.Jp2k constructor\n\n Notes\n -----\n Saving as a JPEG2000 will cast the data array to\n uint8 values to support the JPEG2000 format.\n \"\"\"\n from glymur import Jp2k\n\n tmpname = fname + \"tmp.jp2\"\n jp2_data = np.uint8(data)\n jp2 = Jp2k(tmpname, jp2_data, **kwargs)\n\n # Append the XML data to the header information stored in jp2.box\n meta_boxes = jp2.box\n target_index = len(meta_boxes) - 1\n fits_box = generate_jp2_xmlbox(header)\n meta_boxes.insert(target_index, fits_box)\n\n # Rewrites the jp2 file on disk with the xml data in the header\n jp2.wrap(fname, boxes=meta_boxes)\n\n os.remove(tmpname)\n", "path": "sunpy/io/_jp2.py"}], "after_files": [{"content": "\"\"\"\nThis module provides a JPEG 2000 file reader for internal use.\n\n.. warning::\n\n ``sunpy.io.jp2`` is deprecated, and will be removed in sunpy 4.1. This is\n because it was designed for internal use only.\n\"\"\"\nimport os\nfrom xml.etree import ElementTree as ET\n\nimport numpy as np\n\nfrom sunpy.io.header import FileHeader\nfrom sunpy.util.io import HDPair, string_is_float\nfrom sunpy.util.xml import xml_to_dict\n\n__all__ = ['read', 'get_header', 'write']\n\n\ndef read(filepath, **kwargs):\n \"\"\"\n Reads a JPEG2000 file.\n\n Parameters\n ----------\n filepath : `str`\n The file to be read.\n **kwargs : `dict`\n Unused.\n\n Returns\n -------\n `list`\n A list of (data, header) tuples.\n \"\"\"\n # Put import here to speed up sunpy.io import time\n from glymur import Jp2k\n\n header = get_header(filepath)\n data = Jp2k(filepath)[...][::-1]\n return [HDPair(data, header[0])]\n\n\ndef get_header(filepath):\n \"\"\"\n Reads the header from the file.\n\n Parameters\n ----------\n filepath : `str`\n The file to be read.\n\n Returns\n -------\n `list`\n A list of one header read from the file.\n \"\"\"\n # Put import here to speed up sunpy.io import time\n from glymur import Jp2k\n jp2 = Jp2k(filepath)\n xml_box = [box for box in jp2.box if box.box_id == 'xml ']\n xmlstring = ET.tostring(xml_box[0].xml.find('fits'))\n pydict = xml_to_dict(xmlstring)[\"fits\"]\n\n # Fix types\n for k, v in pydict.items():\n if v.isdigit():\n pydict[k] = int(v)\n elif string_is_float(v):\n pydict[k] = float(v)\n\n # Remove newlines from comment\n if 'comment' in pydict:\n pydict['comment'] = pydict['comment'].replace(\"\\n\", \"\")\n\n # Is this file a Helioviewer Project JPEG2000 file?\n pydict['helioviewer'] = xml_box[0].xml.find('helioviewer') is not None\n\n return [FileHeader(pydict)]\n\n\ndef header_to_xml(header):\n \"\"\"\n Converts image header metadata into an XML Tree that can be inserted into\n a JP2 file header.\n\n Parameters\n ----------\n header : `MetaDict`\n A header dictionary to convert to xml.\n\n Returns\n ----------\n `lxml.etree._Element`\n A fits element where each child is an xml element\n in the form <key>value</key> derived from the key/value\n pairs in the given header dictionary\n \"\"\"\n # glymur uses lxml and will crash if trying to use\n # python's builtin xml.etree\n import lxml.etree as ET\n\n fits = ET.Element(\"fits\")\n\n already_added = set()\n for key in header:\n # Some headers span multiple lines and get duplicated as keys\n # header.get will appropriately return all data, so if we see\n # a key again, we can assume it was already added to the xml tree.\n if (key in already_added):\n continue\n\n # Add to the set so we don't duplicate entries\n already_added.add(key)\n\n el = ET.SubElement(fits, key)\n data = header.get(key)\n if isinstance(data, bool):\n data = \"1\" if data else \"0\"\n else:\n data = str(data)\n\n el.text = data\n\n return fits\n\n\ndef generate_jp2_xmlbox(header):\n \"\"\"\n Generates the JP2 XML box to be inserted into the jp2 file.\n\n Parameters\n ----------\n header : `MetaDict`\n A header dictionary.\n\n Returns\n ----------\n `XMLBox`\n XML box containing FITS metadata to be used in jp2 headers\n \"\"\"\n # glymur uses lxml and will crash if trying to use\n # python's builtin xml.etree\n import lxml.etree as ET\n from glymur import jp2box\n\n header_xml = header_to_xml(header)\n meta = ET.Element(\"meta\")\n meta.append(header_xml)\n tree = ET.ElementTree(meta)\n return jp2box.XMLBox(xml=tree)\n\n\ndef write(fname, data, header, **kwargs):\n \"\"\"\n Take a data header pair and write a JP2 file.\n\n Parameters\n ----------\n fname : `str`\n File name, with extension.\n data : `numpy.ndarray`\n n-dimensional data array.\n header : `dict`\n A header dictionary.\n kwargs :\n Additional keyword args are passed to the glymur.Jp2k constructor\n\n Notes\n -----\n Saving as a JPEG2000 will cast the data array to\n uint8 values to support the JPEG2000 format.\n \"\"\"\n from glymur import Jp2k\n\n tmpname = fname + \"tmp.jp2\"\n jp2_data = np.uint8(data)\n\n # The jp2 data is flipped when read in, so we have to flip it back before\n # saving. See https://github.com/sunpy/sunpy/pull/768 for context.\n flipped = np.flip(jp2_data, 0)\n jp2 = Jp2k(tmpname, flipped, **kwargs)\n\n # Append the XML data to the header information stored in jp2.box\n meta_boxes = jp2.box\n target_index = len(meta_boxes) - 1\n fits_box = generate_jp2_xmlbox(header)\n meta_boxes.insert(target_index, fits_box)\n\n # Rewrites the jp2 file on disk with the xml data in the header\n jp2.wrap(fname, boxes=meta_boxes)\n\n os.remove(tmpname)\n", "path": "sunpy/io/_jp2.py"}]}
| 2,486 | 204 |
gh_patches_debug_37822
|
rasdani/github-patches
|
git_diff
|
comic__grand-challenge.org-2196
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Seperate external challenges from internal challenges
It would be nice to seperate internal from external challenges a little more in the list view.
The simplest (?) way would be to only include internal challenges in the list view and add a seperate list view for external challenges. This seperate list view could be linked to through a button on the normal challenge list view.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `app/grandchallenge/challenges/urls.py`
Content:
```
1 from django.urls import path
2
3 from grandchallenge.challenges.views import (
4 ChallengeCreate,
5 ChallengeList,
6 ExternalChallengeCreate,
7 ExternalChallengeList,
8 ExternalChallengeUpdate,
9 UsersChallengeList,
10 )
11
12 app_name = "challenges"
13
14 urlpatterns = [
15 path("", ChallengeList.as_view(), name="list"),
16 path("my-challenges/", UsersChallengeList.as_view(), name="users-list"),
17 path("create/", ChallengeCreate.as_view(), name="create"),
18 path("external/", ExternalChallengeList.as_view(), name="external-list"),
19 path(
20 "external/create/",
21 ExternalChallengeCreate.as_view(),
22 name="external-create",
23 ),
24 path(
25 "external/<slug:short_name>/update/",
26 ExternalChallengeUpdate.as_view(),
27 name="external-update",
28 ),
29 ]
30
```
Path: `app/grandchallenge/challenges/views.py`
Content:
```
1 from django.contrib.auth.mixins import PermissionRequiredMixin
2 from django.contrib.messages.views import SuccessMessageMixin
3 from django.core.paginator import EmptyPage, Paginator
4 from django.db.models import Q
5 from django.utils.html import format_html
6 from django.views.generic import (
7 CreateView,
8 ListView,
9 TemplateView,
10 UpdateView,
11 )
12 from guardian.mixins import (
13 LoginRequiredMixin,
14 PermissionRequiredMixin as ObjectPermissionRequiredMixin,
15 )
16
17 from grandchallenge.challenges.filters import ChallengeFilter
18 from grandchallenge.challenges.forms import (
19 ChallengeCreateForm,
20 ChallengeUpdateForm,
21 ExternalChallengeUpdateForm,
22 )
23 from grandchallenge.challenges.models import (
24 Challenge,
25 ExternalChallenge,
26 )
27 from grandchallenge.core.templatetags.random_encode import random_encode
28 from grandchallenge.datatables.views import Column, PaginatedTableListView
29 from grandchallenge.subdomains.mixins import ChallengeSubdomainObjectMixin
30 from grandchallenge.subdomains.utils import reverse, reverse_lazy
31
32
33 class ChallengeCreate(LoginRequiredMixin, SuccessMessageMixin, CreateView):
34 model = Challenge
35 form_class = ChallengeCreateForm
36 success_message = "Challenge successfully created"
37
38 def form_valid(self, form):
39 form.instance.creator = self.request.user
40 return super().form_valid(form)
41
42 def get_form_kwargs(self, *args, **kwargs):
43 form_kwargs = super().get_form_kwargs(*args, **kwargs)
44 form_kwargs.update({"creator": self.request.user})
45 return form_kwargs
46
47
48 class ChallengeList(TemplateView):
49 paginate_by = 40
50 template_name = "challenges/challenge_list.html"
51
52 @property
53 def _current_page(self):
54 return int(self.request.GET.get("page", 1))
55
56 @property
57 def _filters_applied(self):
58 return any(k for k in self.request.GET if k.lower() != "page")
59
60 def _get_page(self):
61 int_qs = (
62 Challenge.objects.filter(hidden=False)
63 .prefetch_related("phase_set", "publications")
64 .order_by("-created")
65 )
66 self.int_filter = ChallengeFilter(self.request.GET, int_qs,)
67 ext_qs = (
68 ExternalChallenge.objects.filter(hidden=False)
69 .prefetch_related("publications")
70 .order_by("-created")
71 )
72 self.ext_filter = ChallengeFilter(self.request.GET, ext_qs,)
73
74 total_count = int_qs.count() + ext_qs.count()
75
76 int_paginator = Paginator(self.int_filter.qs, self.paginate_by // 2)
77 ext_paginator = Paginator(self.ext_filter.qs, self.paginate_by // 2)
78
79 num_pages = max(int_paginator.num_pages, ext_paginator.num_pages)
80 num_results = int_paginator.count + ext_paginator.count
81
82 try:
83 int_page = int_paginator.page(self._current_page)
84 except EmptyPage:
85 int_page = []
86
87 try:
88 ext_page = ext_paginator.page(self._current_page)
89 except EmptyPage:
90 ext_page = []
91
92 return [*int_page, *ext_page], num_pages, num_results, total_count
93
94 def get_context_data(self, *, object_list=None, **kwargs):
95 context = super().get_context_data(**kwargs)
96
97 page_obj, num_pages, num_results, total_count = self._get_page()
98
99 context.update(
100 {
101 "filter": self.int_filter,
102 "filters_applied": self._filters_applied,
103 "page_obj": page_obj,
104 "num_pages": num_pages,
105 "num_results": num_results,
106 "total_count": total_count,
107 "current_page": self._current_page,
108 "next_page": self._current_page + 1,
109 "previous_page": self._current_page - 1,
110 "jumbotron_title": "Challenges",
111 "jumbotron_description": format_html(
112 (
113 "Here is an overview of all challenges that have been "
114 "organised within the area of medical image analysis "
115 "that we are aware of. Please <a href='{}'>contact "
116 "us</a> if you want to advertise your challenge or "
117 "know of any study that would fit in this overview."
118 ),
119 random_encode("mailto:[email protected]"),
120 ),
121 }
122 )
123
124 return context
125
126
127 class UsersChallengeList(LoginRequiredMixin, PaginatedTableListView):
128 model = Challenge
129 template_name = "challenges/challenge_users_list.html"
130 row_template = "challenges/challenge_users_row.html"
131 search_fields = [
132 "title",
133 "short_name",
134 "description",
135 ]
136 columns = [
137 Column(title="Name", sort_field="short_name"),
138 Column(title="Created", sort_field="created"),
139 Column(title="Admins", sort_field="created"),
140 Column(title="Description", sort_field="description"),
141 Column(title="Automated Evaluation", sort_field="use_evaluation"),
142 ]
143 default_sort_column = 1
144
145 def get_queryset(self):
146 queryset = (
147 super()
148 .get_queryset()
149 .prefetch_related(
150 "admins_group__user_set__user_profile",
151 "admins_group__user_set__verification",
152 )
153 )
154 if not self.request.user.is_superuser:
155 queryset = queryset.filter(
156 Q(participants_group__in=self.request.user.groups.all())
157 | Q(admins_group__in=self.request.user.groups.all())
158 )
159 return queryset
160
161
162 class ChallengeUpdate(
163 LoginRequiredMixin,
164 ObjectPermissionRequiredMixin,
165 SuccessMessageMixin,
166 ChallengeSubdomainObjectMixin,
167 UpdateView,
168 ):
169 model = Challenge
170 slug_field = "short_name__iexact"
171 slug_url_kwarg = "challenge_short_name"
172 form_class = ChallengeUpdateForm
173 success_message = "Challenge successfully updated"
174 template_name_suffix = "_update"
175 permission_required = "change_challenge"
176 raise_exception = True
177 login_url = reverse_lazy("account_login")
178
179 def get_success_url(self):
180 return reverse(
181 "update",
182 kwargs={"challenge_short_name": self.request.challenge.short_name},
183 )
184
185
186 class ExternalChallengeCreate(
187 LoginRequiredMixin,
188 PermissionRequiredMixin,
189 SuccessMessageMixin,
190 CreateView,
191 ):
192 model = ExternalChallenge
193 form_class = ExternalChallengeUpdateForm
194 success_message = (
195 "Your challenge has been successfully submitted. "
196 "An admin will review your challenge before it is published."
197 )
198 raise_exception = True
199 permission_required = "challenges.add_externalchallenge"
200
201 def form_valid(self, form):
202 form.instance.creator = self.request.user
203 return super().form_valid(form)
204
205 def get_success_url(self):
206 return reverse("challenges:list")
207
208
209 class ExternalChallengeUpdate(
210 LoginRequiredMixin,
211 PermissionRequiredMixin,
212 SuccessMessageMixin,
213 UpdateView,
214 ):
215 model = ExternalChallenge
216 slug_field = "short_name__iexact"
217 slug_url_kwarg = "short_name"
218 form_class = ExternalChallengeUpdateForm
219 template_name_suffix = "_update"
220 success_message = "Challenge updated"
221 raise_exception = True
222 permission_required = "challenges.change_externalchallenge"
223
224 def get_success_url(self):
225 return reverse("challenges:list")
226
227
228 class ExternalChallengeList(
229 LoginRequiredMixin, PermissionRequiredMixin, ListView
230 ):
231 model = ExternalChallenge
232 raise_exception = True
233 permission_required = "challenges.view_externalchallenge"
234
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/app/grandchallenge/challenges/urls.py b/app/grandchallenge/challenges/urls.py
--- a/app/grandchallenge/challenges/urls.py
+++ b/app/grandchallenge/challenges/urls.py
@@ -3,6 +3,7 @@
from grandchallenge.challenges.views import (
ChallengeCreate,
ChallengeList,
+ CombinedChallengeList,
ExternalChallengeCreate,
ExternalChallengeList,
ExternalChallengeUpdate,
@@ -13,6 +14,11 @@
urlpatterns = [
path("", ChallengeList.as_view(), name="list"),
+ path(
+ "all-challenges/",
+ CombinedChallengeList.as_view(),
+ name="combined-list",
+ ),
path("my-challenges/", UsersChallengeList.as_view(), name="users-list"),
path("create/", ChallengeCreate.as_view(), name="create"),
path("external/", ExternalChallengeList.as_view(), name="external-list"),
diff --git a/app/grandchallenge/challenges/views.py b/app/grandchallenge/challenges/views.py
--- a/app/grandchallenge/challenges/views.py
+++ b/app/grandchallenge/challenges/views.py
@@ -24,6 +24,7 @@
Challenge,
ExternalChallenge,
)
+from grandchallenge.core.filters import FilterMixin
from grandchallenge.core.templatetags.random_encode import random_encode
from grandchallenge.datatables.views import Column, PaginatedTableListView
from grandchallenge.subdomains.mixins import ChallengeSubdomainObjectMixin
@@ -45,9 +46,44 @@
return form_kwargs
-class ChallengeList(TemplateView):
+class ChallengeList(FilterMixin, ListView):
+ model = Challenge
+ ordering = "-created"
+ filter_class = ChallengeFilter
+ paginate_by = 40
+
+ def get_queryset(self):
+ return (
+ super()
+ .get_queryset()
+ .filter(hidden=False)
+ .prefetch_related("phase_set", "publications")
+ .order_by("-created")
+ )
+
+ def get_context_data(self, *args, **kwargs):
+ context = super().get_context_data(*args, **kwargs)
+
+ context.update(
+ {
+ "jumbotron_title": "Challenges",
+ "jumbotron_description": format_html(
+ (
+ "Here is an overview over the medical image analysis"
+ " challenges that have been hosted on Grand Challenge."
+ "<br>Please <a href='{}'>contact us</a> if you would like "
+ "to host your own challenge."
+ ),
+ random_encode("mailto:[email protected]"),
+ ),
+ }
+ )
+ return context
+
+
+class CombinedChallengeList(TemplateView):
paginate_by = 40
- template_name = "challenges/challenge_list.html"
+ template_name = "challenges/combined_challenge_list.html"
@property
def _current_page(self):
|
{"golden_diff": "diff --git a/app/grandchallenge/challenges/urls.py b/app/grandchallenge/challenges/urls.py\n--- a/app/grandchallenge/challenges/urls.py\n+++ b/app/grandchallenge/challenges/urls.py\n@@ -3,6 +3,7 @@\n from grandchallenge.challenges.views import (\n ChallengeCreate,\n ChallengeList,\n+ CombinedChallengeList,\n ExternalChallengeCreate,\n ExternalChallengeList,\n ExternalChallengeUpdate,\n@@ -13,6 +14,11 @@\n \n urlpatterns = [\n path(\"\", ChallengeList.as_view(), name=\"list\"),\n+ path(\n+ \"all-challenges/\",\n+ CombinedChallengeList.as_view(),\n+ name=\"combined-list\",\n+ ),\n path(\"my-challenges/\", UsersChallengeList.as_view(), name=\"users-list\"),\n path(\"create/\", ChallengeCreate.as_view(), name=\"create\"),\n path(\"external/\", ExternalChallengeList.as_view(), name=\"external-list\"),\ndiff --git a/app/grandchallenge/challenges/views.py b/app/grandchallenge/challenges/views.py\n--- a/app/grandchallenge/challenges/views.py\n+++ b/app/grandchallenge/challenges/views.py\n@@ -24,6 +24,7 @@\n Challenge,\n ExternalChallenge,\n )\n+from grandchallenge.core.filters import FilterMixin\n from grandchallenge.core.templatetags.random_encode import random_encode\n from grandchallenge.datatables.views import Column, PaginatedTableListView\n from grandchallenge.subdomains.mixins import ChallengeSubdomainObjectMixin\n@@ -45,9 +46,44 @@\n return form_kwargs\n \n \n-class ChallengeList(TemplateView):\n+class ChallengeList(FilterMixin, ListView):\n+ model = Challenge\n+ ordering = \"-created\"\n+ filter_class = ChallengeFilter\n+ paginate_by = 40\n+\n+ def get_queryset(self):\n+ return (\n+ super()\n+ .get_queryset()\n+ .filter(hidden=False)\n+ .prefetch_related(\"phase_set\", \"publications\")\n+ .order_by(\"-created\")\n+ )\n+\n+ def get_context_data(self, *args, **kwargs):\n+ context = super().get_context_data(*args, **kwargs)\n+\n+ context.update(\n+ {\n+ \"jumbotron_title\": \"Challenges\",\n+ \"jumbotron_description\": format_html(\n+ (\n+ \"Here is an overview over the medical image analysis\"\n+ \" challenges that have been hosted on Grand Challenge.\"\n+ \"<br>Please <a href='{}'>contact us</a> if you would like \"\n+ \"to host your own challenge.\"\n+ ),\n+ random_encode(\"mailto:[email protected]\"),\n+ ),\n+ }\n+ )\n+ return context\n+\n+\n+class CombinedChallengeList(TemplateView):\n paginate_by = 40\n- template_name = \"challenges/challenge_list.html\"\n+ template_name = \"challenges/combined_challenge_list.html\"\n \n @property\n def _current_page(self):\n", "issue": "Seperate external challenges from internal challenges\nIt would be nice to seperate internal from external challenges a little more in the list view. \r\n\r\nThe simplest (?) way would be to only include internal challenges in the list view and add a seperate list view for external challenges. This seperate list view could be linked to through a button on the normal challenge list view. \r\n\r\n\n", "before_files": [{"content": "from django.urls import path\n\nfrom grandchallenge.challenges.views import (\n ChallengeCreate,\n ChallengeList,\n ExternalChallengeCreate,\n ExternalChallengeList,\n ExternalChallengeUpdate,\n UsersChallengeList,\n)\n\napp_name = \"challenges\"\n\nurlpatterns = [\n path(\"\", ChallengeList.as_view(), name=\"list\"),\n path(\"my-challenges/\", UsersChallengeList.as_view(), name=\"users-list\"),\n path(\"create/\", ChallengeCreate.as_view(), name=\"create\"),\n path(\"external/\", ExternalChallengeList.as_view(), name=\"external-list\"),\n path(\n \"external/create/\",\n ExternalChallengeCreate.as_view(),\n name=\"external-create\",\n ),\n path(\n \"external/<slug:short_name>/update/\",\n ExternalChallengeUpdate.as_view(),\n name=\"external-update\",\n ),\n]\n", "path": "app/grandchallenge/challenges/urls.py"}, {"content": "from django.contrib.auth.mixins import PermissionRequiredMixin\nfrom django.contrib.messages.views import SuccessMessageMixin\nfrom django.core.paginator import EmptyPage, Paginator\nfrom django.db.models import Q\nfrom django.utils.html import format_html\nfrom django.views.generic import (\n CreateView,\n ListView,\n TemplateView,\n UpdateView,\n)\nfrom guardian.mixins import (\n LoginRequiredMixin,\n PermissionRequiredMixin as ObjectPermissionRequiredMixin,\n)\n\nfrom grandchallenge.challenges.filters import ChallengeFilter\nfrom grandchallenge.challenges.forms import (\n ChallengeCreateForm,\n ChallengeUpdateForm,\n ExternalChallengeUpdateForm,\n)\nfrom grandchallenge.challenges.models import (\n Challenge,\n ExternalChallenge,\n)\nfrom grandchallenge.core.templatetags.random_encode import random_encode\nfrom grandchallenge.datatables.views import Column, PaginatedTableListView\nfrom grandchallenge.subdomains.mixins import ChallengeSubdomainObjectMixin\nfrom grandchallenge.subdomains.utils import reverse, reverse_lazy\n\n\nclass ChallengeCreate(LoginRequiredMixin, SuccessMessageMixin, CreateView):\n model = Challenge\n form_class = ChallengeCreateForm\n success_message = \"Challenge successfully created\"\n\n def form_valid(self, form):\n form.instance.creator = self.request.user\n return super().form_valid(form)\n\n def get_form_kwargs(self, *args, **kwargs):\n form_kwargs = super().get_form_kwargs(*args, **kwargs)\n form_kwargs.update({\"creator\": self.request.user})\n return form_kwargs\n\n\nclass ChallengeList(TemplateView):\n paginate_by = 40\n template_name = \"challenges/challenge_list.html\"\n\n @property\n def _current_page(self):\n return int(self.request.GET.get(\"page\", 1))\n\n @property\n def _filters_applied(self):\n return any(k for k in self.request.GET if k.lower() != \"page\")\n\n def _get_page(self):\n int_qs = (\n Challenge.objects.filter(hidden=False)\n .prefetch_related(\"phase_set\", \"publications\")\n .order_by(\"-created\")\n )\n self.int_filter = ChallengeFilter(self.request.GET, int_qs,)\n ext_qs = (\n ExternalChallenge.objects.filter(hidden=False)\n .prefetch_related(\"publications\")\n .order_by(\"-created\")\n )\n self.ext_filter = ChallengeFilter(self.request.GET, ext_qs,)\n\n total_count = int_qs.count() + ext_qs.count()\n\n int_paginator = Paginator(self.int_filter.qs, self.paginate_by // 2)\n ext_paginator = Paginator(self.ext_filter.qs, self.paginate_by // 2)\n\n num_pages = max(int_paginator.num_pages, ext_paginator.num_pages)\n num_results = int_paginator.count + ext_paginator.count\n\n try:\n int_page = int_paginator.page(self._current_page)\n except EmptyPage:\n int_page = []\n\n try:\n ext_page = ext_paginator.page(self._current_page)\n except EmptyPage:\n ext_page = []\n\n return [*int_page, *ext_page], num_pages, num_results, total_count\n\n def get_context_data(self, *, object_list=None, **kwargs):\n context = super().get_context_data(**kwargs)\n\n page_obj, num_pages, num_results, total_count = self._get_page()\n\n context.update(\n {\n \"filter\": self.int_filter,\n \"filters_applied\": self._filters_applied,\n \"page_obj\": page_obj,\n \"num_pages\": num_pages,\n \"num_results\": num_results,\n \"total_count\": total_count,\n \"current_page\": self._current_page,\n \"next_page\": self._current_page + 1,\n \"previous_page\": self._current_page - 1,\n \"jumbotron_title\": \"Challenges\",\n \"jumbotron_description\": format_html(\n (\n \"Here is an overview of all challenges that have been \"\n \"organised within the area of medical image analysis \"\n \"that we are aware of. Please <a href='{}'>contact \"\n \"us</a> if you want to advertise your challenge or \"\n \"know of any study that would fit in this overview.\"\n ),\n random_encode(\"mailto:[email protected]\"),\n ),\n }\n )\n\n return context\n\n\nclass UsersChallengeList(LoginRequiredMixin, PaginatedTableListView):\n model = Challenge\n template_name = \"challenges/challenge_users_list.html\"\n row_template = \"challenges/challenge_users_row.html\"\n search_fields = [\n \"title\",\n \"short_name\",\n \"description\",\n ]\n columns = [\n Column(title=\"Name\", sort_field=\"short_name\"),\n Column(title=\"Created\", sort_field=\"created\"),\n Column(title=\"Admins\", sort_field=\"created\"),\n Column(title=\"Description\", sort_field=\"description\"),\n Column(title=\"Automated Evaluation\", sort_field=\"use_evaluation\"),\n ]\n default_sort_column = 1\n\n def get_queryset(self):\n queryset = (\n super()\n .get_queryset()\n .prefetch_related(\n \"admins_group__user_set__user_profile\",\n \"admins_group__user_set__verification\",\n )\n )\n if not self.request.user.is_superuser:\n queryset = queryset.filter(\n Q(participants_group__in=self.request.user.groups.all())\n | Q(admins_group__in=self.request.user.groups.all())\n )\n return queryset\n\n\nclass ChallengeUpdate(\n LoginRequiredMixin,\n ObjectPermissionRequiredMixin,\n SuccessMessageMixin,\n ChallengeSubdomainObjectMixin,\n UpdateView,\n):\n model = Challenge\n slug_field = \"short_name__iexact\"\n slug_url_kwarg = \"challenge_short_name\"\n form_class = ChallengeUpdateForm\n success_message = \"Challenge successfully updated\"\n template_name_suffix = \"_update\"\n permission_required = \"change_challenge\"\n raise_exception = True\n login_url = reverse_lazy(\"account_login\")\n\n def get_success_url(self):\n return reverse(\n \"update\",\n kwargs={\"challenge_short_name\": self.request.challenge.short_name},\n )\n\n\nclass ExternalChallengeCreate(\n LoginRequiredMixin,\n PermissionRequiredMixin,\n SuccessMessageMixin,\n CreateView,\n):\n model = ExternalChallenge\n form_class = ExternalChallengeUpdateForm\n success_message = (\n \"Your challenge has been successfully submitted. \"\n \"An admin will review your challenge before it is published.\"\n )\n raise_exception = True\n permission_required = \"challenges.add_externalchallenge\"\n\n def form_valid(self, form):\n form.instance.creator = self.request.user\n return super().form_valid(form)\n\n def get_success_url(self):\n return reverse(\"challenges:list\")\n\n\nclass ExternalChallengeUpdate(\n LoginRequiredMixin,\n PermissionRequiredMixin,\n SuccessMessageMixin,\n UpdateView,\n):\n model = ExternalChallenge\n slug_field = \"short_name__iexact\"\n slug_url_kwarg = \"short_name\"\n form_class = ExternalChallengeUpdateForm\n template_name_suffix = \"_update\"\n success_message = \"Challenge updated\"\n raise_exception = True\n permission_required = \"challenges.change_externalchallenge\"\n\n def get_success_url(self):\n return reverse(\"challenges:list\")\n\n\nclass ExternalChallengeList(\n LoginRequiredMixin, PermissionRequiredMixin, ListView\n):\n model = ExternalChallenge\n raise_exception = True\n permission_required = \"challenges.view_externalchallenge\"\n", "path": "app/grandchallenge/challenges/views.py"}], "after_files": [{"content": "from django.urls import path\n\nfrom grandchallenge.challenges.views import (\n ChallengeCreate,\n ChallengeList,\n CombinedChallengeList,\n ExternalChallengeCreate,\n ExternalChallengeList,\n ExternalChallengeUpdate,\n UsersChallengeList,\n)\n\napp_name = \"challenges\"\n\nurlpatterns = [\n path(\"\", ChallengeList.as_view(), name=\"list\"),\n path(\n \"all-challenges/\",\n CombinedChallengeList.as_view(),\n name=\"combined-list\",\n ),\n path(\"my-challenges/\", UsersChallengeList.as_view(), name=\"users-list\"),\n path(\"create/\", ChallengeCreate.as_view(), name=\"create\"),\n path(\"external/\", ExternalChallengeList.as_view(), name=\"external-list\"),\n path(\n \"external/create/\",\n ExternalChallengeCreate.as_view(),\n name=\"external-create\",\n ),\n path(\n \"external/<slug:short_name>/update/\",\n ExternalChallengeUpdate.as_view(),\n name=\"external-update\",\n ),\n]\n", "path": "app/grandchallenge/challenges/urls.py"}, {"content": "from django.contrib.auth.mixins import PermissionRequiredMixin\nfrom django.contrib.messages.views import SuccessMessageMixin\nfrom django.core.paginator import EmptyPage, Paginator\nfrom django.db.models import Q\nfrom django.utils.html import format_html\nfrom django.views.generic import (\n CreateView,\n ListView,\n TemplateView,\n UpdateView,\n)\nfrom guardian.mixins import (\n LoginRequiredMixin,\n PermissionRequiredMixin as ObjectPermissionRequiredMixin,\n)\n\nfrom grandchallenge.challenges.filters import ChallengeFilter\nfrom grandchallenge.challenges.forms import (\n ChallengeCreateForm,\n ChallengeUpdateForm,\n ExternalChallengeUpdateForm,\n)\nfrom grandchallenge.challenges.models import (\n Challenge,\n ExternalChallenge,\n)\nfrom grandchallenge.core.filters import FilterMixin\nfrom grandchallenge.core.templatetags.random_encode import random_encode\nfrom grandchallenge.datatables.views import Column, PaginatedTableListView\nfrom grandchallenge.subdomains.mixins import ChallengeSubdomainObjectMixin\nfrom grandchallenge.subdomains.utils import reverse, reverse_lazy\n\n\nclass ChallengeCreate(LoginRequiredMixin, SuccessMessageMixin, CreateView):\n model = Challenge\n form_class = ChallengeCreateForm\n success_message = \"Challenge successfully created\"\n\n def form_valid(self, form):\n form.instance.creator = self.request.user\n return super().form_valid(form)\n\n def get_form_kwargs(self, *args, **kwargs):\n form_kwargs = super().get_form_kwargs(*args, **kwargs)\n form_kwargs.update({\"creator\": self.request.user})\n return form_kwargs\n\n\nclass ChallengeList(FilterMixin, ListView):\n model = Challenge\n ordering = \"-created\"\n filter_class = ChallengeFilter\n paginate_by = 40\n\n def get_queryset(self):\n return (\n super()\n .get_queryset()\n .filter(hidden=False)\n .prefetch_related(\"phase_set\", \"publications\")\n .order_by(\"-created\")\n )\n\n def get_context_data(self, *args, **kwargs):\n context = super().get_context_data(*args, **kwargs)\n\n context.update(\n {\n \"jumbotron_title\": \"Challenges\",\n \"jumbotron_description\": format_html(\n (\n \"Here is an overview over the medical image analysis\"\n \" challenges that have been hosted on Grand Challenge.\"\n \"<br>Please <a href='{}'>contact us</a> if you would like \"\n \"to host your own challenge.\"\n ),\n random_encode(\"mailto:[email protected]\"),\n ),\n }\n )\n return context\n\n\nclass CombinedChallengeList(TemplateView):\n paginate_by = 40\n template_name = \"challenges/combined_challenge_list.html\"\n\n @property\n def _current_page(self):\n return int(self.request.GET.get(\"page\", 1))\n\n @property\n def _filters_applied(self):\n return any(k for k in self.request.GET if k.lower() != \"page\")\n\n def _get_page(self):\n int_qs = (\n Challenge.objects.filter(hidden=False)\n .prefetch_related(\"phase_set\", \"publications\")\n .order_by(\"-created\")\n )\n self.int_filter = ChallengeFilter(self.request.GET, int_qs,)\n ext_qs = (\n ExternalChallenge.objects.filter(hidden=False)\n .prefetch_related(\"publications\")\n .order_by(\"-created\")\n )\n self.ext_filter = ChallengeFilter(self.request.GET, ext_qs,)\n\n total_count = int_qs.count() + ext_qs.count()\n\n int_paginator = Paginator(self.int_filter.qs, self.paginate_by // 2)\n ext_paginator = Paginator(self.ext_filter.qs, self.paginate_by // 2)\n\n num_pages = max(int_paginator.num_pages, ext_paginator.num_pages)\n num_results = int_paginator.count + ext_paginator.count\n\n try:\n int_page = int_paginator.page(self._current_page)\n except EmptyPage:\n int_page = []\n\n try:\n ext_page = ext_paginator.page(self._current_page)\n except EmptyPage:\n ext_page = []\n\n return [*int_page, *ext_page], num_pages, num_results, total_count\n\n def get_context_data(self, *, object_list=None, **kwargs):\n context = super().get_context_data(**kwargs)\n\n page_obj, num_pages, num_results, total_count = self._get_page()\n\n context.update(\n {\n \"filter\": self.int_filter,\n \"filters_applied\": self._filters_applied,\n \"page_obj\": page_obj,\n \"num_pages\": num_pages,\n \"num_results\": num_results,\n \"total_count\": total_count,\n \"current_page\": self._current_page,\n \"next_page\": self._current_page + 1,\n \"previous_page\": self._current_page - 1,\n \"jumbotron_title\": \"Challenges\",\n \"jumbotron_description\": format_html(\n (\n \"Here is an overview of all challenges that have been \"\n \"organised within the area of medical image analysis \"\n \"that we are aware of. Please <a href='{}'>contact \"\n \"us</a> if you want to advertise your challenge or \"\n \"know of any study that would fit in this overview.\"\n ),\n random_encode(\"mailto:[email protected]\"),\n ),\n }\n )\n\n return context\n\n\nclass UsersChallengeList(LoginRequiredMixin, PaginatedTableListView):\n model = Challenge\n template_name = \"challenges/challenge_users_list.html\"\n row_template = \"challenges/challenge_users_row.html\"\n search_fields = [\n \"title\",\n \"short_name\",\n \"description\",\n ]\n columns = [\n Column(title=\"Name\", sort_field=\"short_name\"),\n Column(title=\"Created\", sort_field=\"created\"),\n Column(title=\"Admins\", sort_field=\"created\"),\n Column(title=\"Description\", sort_field=\"description\"),\n Column(title=\"Automated Evaluation\", sort_field=\"use_evaluation\"),\n ]\n default_sort_column = 1\n\n def get_queryset(self):\n queryset = (\n super()\n .get_queryset()\n .prefetch_related(\n \"admins_group__user_set__user_profile\",\n \"admins_group__user_set__verification\",\n )\n )\n if not self.request.user.is_superuser:\n queryset = queryset.filter(\n Q(participants_group__in=self.request.user.groups.all())\n | Q(admins_group__in=self.request.user.groups.all())\n )\n return queryset\n\n\nclass ChallengeUpdate(\n LoginRequiredMixin,\n ObjectPermissionRequiredMixin,\n SuccessMessageMixin,\n ChallengeSubdomainObjectMixin,\n UpdateView,\n):\n model = Challenge\n slug_field = \"short_name__iexact\"\n slug_url_kwarg = \"challenge_short_name\"\n form_class = ChallengeUpdateForm\n success_message = \"Challenge successfully updated\"\n template_name_suffix = \"_update\"\n permission_required = \"change_challenge\"\n raise_exception = True\n login_url = reverse_lazy(\"account_login\")\n\n def get_success_url(self):\n return reverse(\n \"update\",\n kwargs={\"challenge_short_name\": self.request.challenge.short_name},\n )\n\n\nclass ExternalChallengeCreate(\n LoginRequiredMixin,\n PermissionRequiredMixin,\n SuccessMessageMixin,\n CreateView,\n):\n model = ExternalChallenge\n form_class = ExternalChallengeUpdateForm\n success_message = (\n \"Your challenge has been successfully submitted. \"\n \"An admin will review your challenge before it is published.\"\n )\n raise_exception = True\n permission_required = \"challenges.add_externalchallenge\"\n\n def form_valid(self, form):\n form.instance.creator = self.request.user\n return super().form_valid(form)\n\n def get_success_url(self):\n return reverse(\"challenges:list\")\n\n\nclass ExternalChallengeUpdate(\n LoginRequiredMixin,\n PermissionRequiredMixin,\n SuccessMessageMixin,\n UpdateView,\n):\n model = ExternalChallenge\n slug_field = \"short_name__iexact\"\n slug_url_kwarg = \"short_name\"\n form_class = ExternalChallengeUpdateForm\n template_name_suffix = \"_update\"\n success_message = \"Challenge updated\"\n raise_exception = True\n permission_required = \"challenges.change_externalchallenge\"\n\n def get_success_url(self):\n return reverse(\"challenges:list\")\n\n\nclass ExternalChallengeList(\n LoginRequiredMixin, PermissionRequiredMixin, ListView\n):\n model = ExternalChallenge\n raise_exception = True\n permission_required = \"challenges.view_externalchallenge\"\n", "path": "app/grandchallenge/challenges/views.py"}]}
| 2,728 | 641 |
gh_patches_debug_10098
|
rasdani/github-patches
|
git_diff
|
liqd__a4-opin-2485
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Community debate module error messages
**expected behaviour:** Error message only shown for document upload if file is incorrect
**behaviour:** Error message is also shown when title is not added
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `euth/communitydebate/views.py`
Content:
```
1 from django.contrib import messages
2 from django.shortcuts import render
3 from django.urls import reverse
4 from django.utils.translation import gettext as _
5 from django.views import generic
6 from rules.contrib.views import PermissionRequiredMixin
7
8 from adhocracy4.filters import views as filter_views
9 from adhocracy4.modules.models import Module
10 from euth.projects import mixins as prj_mixins
11
12 from . import forms
13 from . import models as communitydebate_models
14 from .filters import TopicFilterSet
15
16
17 class TopicListView(prj_mixins.ProjectPhaseMixin,
18 filter_views.FilteredListView):
19 model = communitydebate_models.Topic
20 paginate_by = 15
21 filter_set = TopicFilterSet
22
23 def get_queryset(self):
24 return super().get_queryset().filter(module=self.module)
25
26
27 class TopicDetailView(PermissionRequiredMixin, generic.DetailView):
28 model = communitydebate_models.Topic
29 queryset = \
30 communitydebate_models.Topic.objects\
31 .annotate_positive_rating_count() \
32 .annotate_negative_rating_count()
33 permission_required = 'euth_communitydebate.view_topic'
34
35 def get_context_data(self, **kwargs):
36 context = super().get_context_data()
37 upload_files = communitydebate_models.TopicFileUpload.objects\
38 .filter(topic=self.object)
39 context['upload_files'] = upload_files
40 return context
41
42
43 class TopicCreateView(PermissionRequiredMixin, generic.CreateView):
44 model = communitydebate_models.Topic
45 form_class = forms.TopicForm
46 permission_required = 'euth_communitydebate.propose_topic'
47 template_name = 'euth_communitydebate/topic_form.html'
48
49 @property
50 def raise_exception(self):
51 return self.request.user.is_authenticated
52
53 def dispatch(self, *args, **kwargs):
54 mod_slug = self.kwargs[self.slug_url_kwarg]
55 self.module = Module.objects.get(slug=mod_slug)
56 self.project = self.module.project
57 return super().dispatch(*args, **kwargs)
58
59 def get_permission_object(self, *args, **kwargs):
60 return self.module
61
62 def get_context_data(self, upload_forms=None, **kwargs):
63 context = super().get_context_data(**kwargs)
64 context['project'] = self.project
65 context['mode'] = 'create'
66 if not upload_forms:
67 upload_forms = forms.TopicFileUploadFormset()
68 context['upload_forms'] = upload_forms
69 return context
70
71 def form_valid(self, form):
72 form.instance.creator = self.request.user
73 form.instance.module = self.module
74 return super().form_valid(form)
75
76 def get_form_kwargs(self):
77 kwargs = super().get_form_kwargs()
78 kwargs['module'] = self.module
79 return kwargs
80
81 def post(self, request, *args, **kwargs):
82 self.object = None
83 form = self.get_form()
84 if form.is_valid():
85 topic = form.save(commit=False)
86 upload_forms = forms.TopicFileUploadFormset(request.POST,
87 request.FILES,
88 instance=topic)
89 if upload_forms.is_valid():
90 response = self.form_valid(form)
91 upload_forms.save()
92 messages.add_message(request,
93 messages.SUCCESS,
94 _('Topic '
95 'successfully created'))
96 return response
97
98 upload_forms = forms.TopicFileUploadFormset(request.POST,
99 request.FILES)
100 return render(request, self.template_name,
101 self.get_context_data(upload_forms=upload_forms))
102
103
104 class TopicUpdateView(PermissionRequiredMixin, generic.UpdateView):
105 model = communitydebate_models.Topic
106 form_class = forms.TopicForm
107 permission_required = 'euth_communitydebate.modify_topic'
108 template_name = 'euth_communitydebate/topic_form.html'
109
110 @property
111 def raise_exception(self):
112 return self.request.user.is_authenticated
113
114 def dispatch(self, *args, **kwargs):
115 self.object = self.get_object()
116 return super().dispatch(*args, **kwargs)
117
118 def get_context_data(self, upload_forms=None, **kwargs):
119 context = super().get_context_data(**kwargs)
120 context['project'] = self.object.project
121 context['mode'] = 'update'
122 if not upload_forms:
123 upload_forms = forms.TopicFileUploadFormset(
124 instance=self.get_object())
125 context['upload_forms'] = upload_forms
126 return context
127
128 def get_form_kwargs(self):
129 kwargs = super().get_form_kwargs()
130 kwargs['module'] = kwargs.get('instance').module
131 return kwargs
132
133 def post(self, request, *args, **kwargs):
134 form = self.get_form()
135 upload_forms = forms.TopicFileUploadFormset(request.POST,
136 request.FILES,
137 instance=self.object)
138 if upload_forms.is_valid() and form.is_valid():
139 response = self.form_valid(form)
140 upload_forms.save()
141 messages.add_message(request,
142 messages.SUCCESS,
143 _('Topic successfully '
144 'updated'))
145 else:
146 response = render(request,
147 self.template_name,
148 self.get_context_data(upload_forms=upload_forms))
149 return response
150
151
152 class TopicDeleteView(PermissionRequiredMixin, generic.DeleteView):
153 model = communitydebate_models.Topic
154 success_message = _("Your topic has been deleted")
155 permission_required = 'euth_communitydebate.modify_topic'
156
157 @property
158 def raise_exception(self):
159 return self.request.user.is_authenticated
160
161 def delete(self, request, *args, **kwargs):
162 messages.success(self.request, self.success_message)
163 return super(TopicDeleteView, self).delete(request, *args, **kwargs)
164
165 def get_success_url(self):
166 return reverse('project-detail',
167 kwargs={'slug': self.object.project.slug})
168
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/euth/communitydebate/views.py b/euth/communitydebate/views.py
--- a/euth/communitydebate/views.py
+++ b/euth/communitydebate/views.py
@@ -95,8 +95,9 @@
'successfully created'))
return response
- upload_forms = forms.TopicFileUploadFormset(request.POST,
- request.FILES)
+ else:
+ upload_forms = forms.TopicFileUploadFormset(request.POST,
+ request.FILES)
return render(request, self.template_name,
self.get_context_data(upload_forms=upload_forms))
|
{"golden_diff": "diff --git a/euth/communitydebate/views.py b/euth/communitydebate/views.py\n--- a/euth/communitydebate/views.py\n+++ b/euth/communitydebate/views.py\n@@ -95,8 +95,9 @@\n 'successfully created'))\n return response\n \n- upload_forms = forms.TopicFileUploadFormset(request.POST,\n- request.FILES)\n+ else:\n+ upload_forms = forms.TopicFileUploadFormset(request.POST,\n+ request.FILES)\n return render(request, self.template_name,\n self.get_context_data(upload_forms=upload_forms))\n", "issue": "Community debate module error messages\n**expected behaviour:** Error message only shown for document upload if file is incorrect\r\n**behaviour:** Error message is also shown when title is not added\r\n\r\n\n", "before_files": [{"content": "from django.contrib import messages\nfrom django.shortcuts import render\nfrom django.urls import reverse\nfrom django.utils.translation import gettext as _\nfrom django.views import generic\nfrom rules.contrib.views import PermissionRequiredMixin\n\nfrom adhocracy4.filters import views as filter_views\nfrom adhocracy4.modules.models import Module\nfrom euth.projects import mixins as prj_mixins\n\nfrom . import forms\nfrom . import models as communitydebate_models\nfrom .filters import TopicFilterSet\n\n\nclass TopicListView(prj_mixins.ProjectPhaseMixin,\n filter_views.FilteredListView):\n model = communitydebate_models.Topic\n paginate_by = 15\n filter_set = TopicFilterSet\n\n def get_queryset(self):\n return super().get_queryset().filter(module=self.module)\n\n\nclass TopicDetailView(PermissionRequiredMixin, generic.DetailView):\n model = communitydebate_models.Topic\n queryset = \\\n communitydebate_models.Topic.objects\\\n .annotate_positive_rating_count() \\\n .annotate_negative_rating_count()\n permission_required = 'euth_communitydebate.view_topic'\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data()\n upload_files = communitydebate_models.TopicFileUpload.objects\\\n .filter(topic=self.object)\n context['upload_files'] = upload_files\n return context\n\n\nclass TopicCreateView(PermissionRequiredMixin, generic.CreateView):\n model = communitydebate_models.Topic\n form_class = forms.TopicForm\n permission_required = 'euth_communitydebate.propose_topic'\n template_name = 'euth_communitydebate/topic_form.html'\n\n @property\n def raise_exception(self):\n return self.request.user.is_authenticated\n\n def dispatch(self, *args, **kwargs):\n mod_slug = self.kwargs[self.slug_url_kwarg]\n self.module = Module.objects.get(slug=mod_slug)\n self.project = self.module.project\n return super().dispatch(*args, **kwargs)\n\n def get_permission_object(self, *args, **kwargs):\n return self.module\n\n def get_context_data(self, upload_forms=None, **kwargs):\n context = super().get_context_data(**kwargs)\n context['project'] = self.project\n context['mode'] = 'create'\n if not upload_forms:\n upload_forms = forms.TopicFileUploadFormset()\n context['upload_forms'] = upload_forms\n return context\n\n def form_valid(self, form):\n form.instance.creator = self.request.user\n form.instance.module = self.module\n return super().form_valid(form)\n\n def get_form_kwargs(self):\n kwargs = super().get_form_kwargs()\n kwargs['module'] = self.module\n return kwargs\n\n def post(self, request, *args, **kwargs):\n self.object = None\n form = self.get_form()\n if form.is_valid():\n topic = form.save(commit=False)\n upload_forms = forms.TopicFileUploadFormset(request.POST,\n request.FILES,\n instance=topic)\n if upload_forms.is_valid():\n response = self.form_valid(form)\n upload_forms.save()\n messages.add_message(request,\n messages.SUCCESS,\n _('Topic '\n 'successfully created'))\n return response\n\n upload_forms = forms.TopicFileUploadFormset(request.POST,\n request.FILES)\n return render(request, self.template_name,\n self.get_context_data(upload_forms=upload_forms))\n\n\nclass TopicUpdateView(PermissionRequiredMixin, generic.UpdateView):\n model = communitydebate_models.Topic\n form_class = forms.TopicForm\n permission_required = 'euth_communitydebate.modify_topic'\n template_name = 'euth_communitydebate/topic_form.html'\n\n @property\n def raise_exception(self):\n return self.request.user.is_authenticated\n\n def dispatch(self, *args, **kwargs):\n self.object = self.get_object()\n return super().dispatch(*args, **kwargs)\n\n def get_context_data(self, upload_forms=None, **kwargs):\n context = super().get_context_data(**kwargs)\n context['project'] = self.object.project\n context['mode'] = 'update'\n if not upload_forms:\n upload_forms = forms.TopicFileUploadFormset(\n instance=self.get_object())\n context['upload_forms'] = upload_forms\n return context\n\n def get_form_kwargs(self):\n kwargs = super().get_form_kwargs()\n kwargs['module'] = kwargs.get('instance').module\n return kwargs\n\n def post(self, request, *args, **kwargs):\n form = self.get_form()\n upload_forms = forms.TopicFileUploadFormset(request.POST,\n request.FILES,\n instance=self.object)\n if upload_forms.is_valid() and form.is_valid():\n response = self.form_valid(form)\n upload_forms.save()\n messages.add_message(request,\n messages.SUCCESS,\n _('Topic successfully '\n 'updated'))\n else:\n response = render(request,\n self.template_name,\n self.get_context_data(upload_forms=upload_forms))\n return response\n\n\nclass TopicDeleteView(PermissionRequiredMixin, generic.DeleteView):\n model = communitydebate_models.Topic\n success_message = _(\"Your topic has been deleted\")\n permission_required = 'euth_communitydebate.modify_topic'\n\n @property\n def raise_exception(self):\n return self.request.user.is_authenticated\n\n def delete(self, request, *args, **kwargs):\n messages.success(self.request, self.success_message)\n return super(TopicDeleteView, self).delete(request, *args, **kwargs)\n\n def get_success_url(self):\n return reverse('project-detail',\n kwargs={'slug': self.object.project.slug})\n", "path": "euth/communitydebate/views.py"}], "after_files": [{"content": "from django.contrib import messages\nfrom django.shortcuts import render\nfrom django.urls import reverse\nfrom django.utils.translation import gettext as _\nfrom django.views import generic\nfrom rules.contrib.views import PermissionRequiredMixin\n\nfrom adhocracy4.filters import views as filter_views\nfrom adhocracy4.modules.models import Module\nfrom euth.projects import mixins as prj_mixins\n\nfrom . import forms\nfrom . import models as communitydebate_models\nfrom .filters import TopicFilterSet\n\n\nclass TopicListView(prj_mixins.ProjectPhaseMixin,\n filter_views.FilteredListView):\n model = communitydebate_models.Topic\n paginate_by = 15\n filter_set = TopicFilterSet\n\n def get_queryset(self):\n return super().get_queryset().filter(module=self.module)\n\n\nclass TopicDetailView(PermissionRequiredMixin, generic.DetailView):\n model = communitydebate_models.Topic\n queryset = \\\n communitydebate_models.Topic.objects\\\n .annotate_positive_rating_count() \\\n .annotate_negative_rating_count()\n permission_required = 'euth_communitydebate.view_topic'\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data()\n upload_files = communitydebate_models.TopicFileUpload.objects\\\n .filter(topic=self.object)\n context['upload_files'] = upload_files\n return context\n\n\nclass TopicCreateView(PermissionRequiredMixin, generic.CreateView):\n model = communitydebate_models.Topic\n form_class = forms.TopicForm\n permission_required = 'euth_communitydebate.propose_topic'\n template_name = 'euth_communitydebate/topic_form.html'\n\n @property\n def raise_exception(self):\n return self.request.user.is_authenticated\n\n def dispatch(self, *args, **kwargs):\n mod_slug = self.kwargs[self.slug_url_kwarg]\n self.module = Module.objects.get(slug=mod_slug)\n self.project = self.module.project\n return super().dispatch(*args, **kwargs)\n\n def get_permission_object(self, *args, **kwargs):\n return self.module\n\n def get_context_data(self, upload_forms=None, **kwargs):\n context = super().get_context_data(**kwargs)\n context['project'] = self.project\n context['mode'] = 'create'\n if not upload_forms:\n upload_forms = forms.TopicFileUploadFormset()\n context['upload_forms'] = upload_forms\n return context\n\n def form_valid(self, form):\n form.instance.creator = self.request.user\n form.instance.module = self.module\n return super().form_valid(form)\n\n def get_form_kwargs(self):\n kwargs = super().get_form_kwargs()\n kwargs['module'] = self.module\n return kwargs\n\n def post(self, request, *args, **kwargs):\n self.object = None\n form = self.get_form()\n if form.is_valid():\n topic = form.save(commit=False)\n upload_forms = forms.TopicFileUploadFormset(request.POST,\n request.FILES,\n instance=topic)\n if upload_forms.is_valid():\n response = self.form_valid(form)\n upload_forms.save()\n messages.add_message(request,\n messages.SUCCESS,\n _('Topic '\n 'successfully created'))\n return response\n\n else:\n upload_forms = forms.TopicFileUploadFormset(request.POST,\n request.FILES)\n return render(request, self.template_name,\n self.get_context_data(upload_forms=upload_forms))\n\n\nclass TopicUpdateView(PermissionRequiredMixin, generic.UpdateView):\n model = communitydebate_models.Topic\n form_class = forms.TopicForm\n permission_required = 'euth_communitydebate.modify_topic'\n template_name = 'euth_communitydebate/topic_form.html'\n\n @property\n def raise_exception(self):\n return self.request.user.is_authenticated\n\n def dispatch(self, *args, **kwargs):\n self.object = self.get_object()\n return super().dispatch(*args, **kwargs)\n\n def get_context_data(self, upload_forms=None, **kwargs):\n context = super().get_context_data(**kwargs)\n context['project'] = self.object.project\n context['mode'] = 'update'\n if not upload_forms:\n upload_forms = forms.TopicFileUploadFormset(\n instance=self.get_object())\n context['upload_forms'] = upload_forms\n return context\n\n def get_form_kwargs(self):\n kwargs = super().get_form_kwargs()\n kwargs['module'] = kwargs.get('instance').module\n return kwargs\n\n def post(self, request, *args, **kwargs):\n form = self.get_form()\n upload_forms = forms.TopicFileUploadFormset(request.POST,\n request.FILES,\n instance=self.object)\n if upload_forms.is_valid() and form.is_valid():\n response = self.form_valid(form)\n upload_forms.save()\n messages.add_message(request,\n messages.SUCCESS,\n _('Topic successfully '\n 'updated'))\n else:\n response = render(request,\n self.template_name,\n self.get_context_data(upload_forms=upload_forms))\n return response\n\n\nclass TopicDeleteView(PermissionRequiredMixin, generic.DeleteView):\n model = communitydebate_models.Topic\n success_message = _(\"Your topic has been deleted\")\n permission_required = 'euth_communitydebate.modify_topic'\n\n @property\n def raise_exception(self):\n return self.request.user.is_authenticated\n\n def delete(self, request, *args, **kwargs):\n messages.success(self.request, self.success_message)\n return super(TopicDeleteView, self).delete(request, *args, **kwargs)\n\n def get_success_url(self):\n return reverse('project-detail',\n kwargs={'slug': self.object.project.slug})\n", "path": "euth/communitydebate/views.py"}]}
| 1,883 | 123 |
gh_patches_debug_13913
|
rasdani/github-patches
|
git_diff
|
cookiecutter__cookiecutter-655
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Fix the repo regex to handle + in URLs
The documentation said that you could do git+https:// or git+ssh:// but that was not, in fact, true.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cookiecutter/main.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3
4 """
5 cookiecutter.main
6 -----------------
7
8 Main entry point for the `cookiecutter` command.
9
10 The code in this module is also a good example of how to use Cookiecutter as a
11 library rather than a script.
12 """
13
14 from __future__ import unicode_literals
15 import logging
16 import os
17 import re
18
19 from .config import get_user_config, USER_CONFIG_PATH
20 from .exceptions import InvalidModeException, RepositoryNotFound
21 from .prompt import prompt_for_config
22 from .generate import generate_context, generate_files
23 from .vcs import clone
24 from .replay import dump, load
25
26 logger = logging.getLogger(__name__)
27
28 builtin_abbreviations = {
29 'gh': 'https://github.com/{0}.git',
30 'bb': 'https://bitbucket.org/{0}',
31 }
32
33 REPO_REGEX = """
34 (
35 ((git|ssh|https|http):(//)?) # something like git:// ssh:// etc.
36 | # or
37 (\w+@[\w\.]+) # something like user@...
38 )
39 .*
40 """
41
42
43 def is_repo_url(value):
44 """Return True if value is a repository URL."""
45 return bool(re.match(REPO_REGEX, value, re.VERBOSE))
46
47
48 def expand_abbreviations(template, config_dict):
49 """
50 Expand abbreviations in a template name.
51
52 :param template: The project template name.
53 :param config_dict: The user config, which will contain abbreviation
54 definitions.
55 """
56
57 abbreviations = builtin_abbreviations.copy()
58 abbreviations.update(config_dict.get('abbreviations', {}))
59
60 if template in abbreviations:
61 return abbreviations[template]
62
63 # Split on colon. If there is no colon, rest will be empty
64 # and prefix will be the whole template
65 prefix, sep, rest = template.partition(':')
66 if prefix in abbreviations:
67 return abbreviations[prefix].format(rest)
68
69 return template
70
71
72 def cookiecutter(
73 template, checkout=None, no_input=False, extra_context=None,
74 replay=False, overwrite_if_exists=False, output_dir='.',
75 config_file=USER_CONFIG_PATH):
76 """
77 API equivalent to using Cookiecutter at the command line.
78
79 :param template: A directory containing a project template directory,
80 or a URL to a git repository.
81 :param checkout: The branch, tag or commit ID to checkout after clone.
82 :param no_input: Prompt the user at command line for manual configuration?
83 :param extra_context: A dictionary of context that overrides default
84 and user configuration.
85 :param: overwrite_if_exists: Overwrite the contents of output directory
86 if it exists
87 :param output_dir: Where to output the generated project dir into.
88 :param config_file: User configuration file path.
89 """
90 if replay and ((no_input is not False) or (extra_context is not None)):
91 err_msg = (
92 "You can not use both replay and no_input or extra_context "
93 "at the same time."
94 )
95 raise InvalidModeException(err_msg)
96
97 # Get user config from ~/.cookiecutterrc or equivalent
98 # If no config file, sensible defaults from config.DEFAULT_CONFIG are used
99 config_dict = get_user_config(config_file=config_file)
100
101 template = expand_abbreviations(template, config_dict)
102
103 if is_repo_url(template):
104 repo_dir = clone(
105 repo_url=template,
106 checkout=checkout,
107 clone_to_dir=config_dict['cookiecutters_dir'],
108 no_input=no_input
109 )
110 else:
111 # If it's a local repo, no need to clone or copy to your
112 # cookiecutters_dir
113 repo_dir = template
114
115 if not os.path.isdir(repo_dir):
116 raise RepositoryNotFound(
117 'The repository {0} could not be located.'.format(template)
118 )
119
120 template_name = os.path.basename(template)
121
122 if replay:
123 context = load(config_dict['replay_dir'], template_name)
124 else:
125 context_file = os.path.join(repo_dir, 'cookiecutter.json')
126 logging.debug('context_file is {0}'.format(context_file))
127
128 context = generate_context(
129 context_file=context_file,
130 default_context=config_dict['default_context'],
131 extra_context=extra_context,
132 )
133
134 # prompt the user to manually configure at the command line.
135 # except when 'no-input' flag is set
136 context['cookiecutter'] = prompt_for_config(context, no_input)
137
138 dump(config_dict['replay_dir'], template_name, context)
139
140 # Create project from local context and project template.
141 return generate_files(
142 repo_dir=repo_dir,
143 context=context,
144 overwrite_if_exists=overwrite_if_exists,
145 output_dir=output_dir
146 )
147
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/cookiecutter/main.py b/cookiecutter/main.py
--- a/cookiecutter/main.py
+++ b/cookiecutter/main.py
@@ -30,19 +30,18 @@
'bb': 'https://bitbucket.org/{0}',
}
-REPO_REGEX = """
-(
-((git|ssh|https|http):(//)?) # something like git:// ssh:// etc.
- | # or
- (\w+@[\w\.]+) # something like user@...
+REPO_REGEX = re.compile(r"""
+(?x)
+((((git|hg)\+)?(git|ssh|https?):(//)?) # something like git:// ssh:// etc.
+ | # or
+ (\w+@[\w\.]+) # something like user@...
)
-.*
-"""
+""")
def is_repo_url(value):
"""Return True if value is a repository URL."""
- return bool(re.match(REPO_REGEX, value, re.VERBOSE))
+ return bool(REPO_REGEX.match(value))
def expand_abbreviations(template, config_dict):
|
{"golden_diff": "diff --git a/cookiecutter/main.py b/cookiecutter/main.py\n--- a/cookiecutter/main.py\n+++ b/cookiecutter/main.py\n@@ -30,19 +30,18 @@\n 'bb': 'https://bitbucket.org/{0}',\n }\n \n-REPO_REGEX = \"\"\"\n-(\n-((git|ssh|https|http):(//)?) # something like git:// ssh:// etc.\n- | # or\n- (\\w+@[\\w\\.]+) # something like user@...\n+REPO_REGEX = re.compile(r\"\"\"\n+(?x)\n+((((git|hg)\\+)?(git|ssh|https?):(//)?) # something like git:// ssh:// etc.\n+ | # or\n+ (\\w+@[\\w\\.]+) # something like user@...\n )\n-.*\n-\"\"\"\n+\"\"\")\n \n \n def is_repo_url(value):\n \"\"\"Return True if value is a repository URL.\"\"\"\n- return bool(re.match(REPO_REGEX, value, re.VERBOSE))\n+ return bool(REPO_REGEX.match(value))\n \n \n def expand_abbreviations(template, config_dict):\n", "issue": "Fix the repo regex to handle + in URLs\nThe documentation said that you could do git+https:// or git+ssh:// but that was not, in fact, true.\n\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\"\"\"\ncookiecutter.main\n-----------------\n\nMain entry point for the `cookiecutter` command.\n\nThe code in this module is also a good example of how to use Cookiecutter as a\nlibrary rather than a script.\n\"\"\"\n\nfrom __future__ import unicode_literals\nimport logging\nimport os\nimport re\n\nfrom .config import get_user_config, USER_CONFIG_PATH\nfrom .exceptions import InvalidModeException, RepositoryNotFound\nfrom .prompt import prompt_for_config\nfrom .generate import generate_context, generate_files\nfrom .vcs import clone\nfrom .replay import dump, load\n\nlogger = logging.getLogger(__name__)\n\nbuiltin_abbreviations = {\n 'gh': 'https://github.com/{0}.git',\n 'bb': 'https://bitbucket.org/{0}',\n}\n\nREPO_REGEX = \"\"\"\n(\n((git|ssh|https|http):(//)?) # something like git:// ssh:// etc.\n | # or\n (\\w+@[\\w\\.]+) # something like user@...\n)\n.*\n\"\"\"\n\n\ndef is_repo_url(value):\n \"\"\"Return True if value is a repository URL.\"\"\"\n return bool(re.match(REPO_REGEX, value, re.VERBOSE))\n\n\ndef expand_abbreviations(template, config_dict):\n \"\"\"\n Expand abbreviations in a template name.\n\n :param template: The project template name.\n :param config_dict: The user config, which will contain abbreviation\n definitions.\n \"\"\"\n\n abbreviations = builtin_abbreviations.copy()\n abbreviations.update(config_dict.get('abbreviations', {}))\n\n if template in abbreviations:\n return abbreviations[template]\n\n # Split on colon. If there is no colon, rest will be empty\n # and prefix will be the whole template\n prefix, sep, rest = template.partition(':')\n if prefix in abbreviations:\n return abbreviations[prefix].format(rest)\n\n return template\n\n\ndef cookiecutter(\n template, checkout=None, no_input=False, extra_context=None,\n replay=False, overwrite_if_exists=False, output_dir='.',\n config_file=USER_CONFIG_PATH):\n \"\"\"\n API equivalent to using Cookiecutter at the command line.\n\n :param template: A directory containing a project template directory,\n or a URL to a git repository.\n :param checkout: The branch, tag or commit ID to checkout after clone.\n :param no_input: Prompt the user at command line for manual configuration?\n :param extra_context: A dictionary of context that overrides default\n and user configuration.\n :param: overwrite_if_exists: Overwrite the contents of output directory\n if it exists\n :param output_dir: Where to output the generated project dir into.\n :param config_file: User configuration file path.\n \"\"\"\n if replay and ((no_input is not False) or (extra_context is not None)):\n err_msg = (\n \"You can not use both replay and no_input or extra_context \"\n \"at the same time.\"\n )\n raise InvalidModeException(err_msg)\n\n # Get user config from ~/.cookiecutterrc or equivalent\n # If no config file, sensible defaults from config.DEFAULT_CONFIG are used\n config_dict = get_user_config(config_file=config_file)\n\n template = expand_abbreviations(template, config_dict)\n\n if is_repo_url(template):\n repo_dir = clone(\n repo_url=template,\n checkout=checkout,\n clone_to_dir=config_dict['cookiecutters_dir'],\n no_input=no_input\n )\n else:\n # If it's a local repo, no need to clone or copy to your\n # cookiecutters_dir\n repo_dir = template\n\n if not os.path.isdir(repo_dir):\n raise RepositoryNotFound(\n 'The repository {0} could not be located.'.format(template)\n )\n\n template_name = os.path.basename(template)\n\n if replay:\n context = load(config_dict['replay_dir'], template_name)\n else:\n context_file = os.path.join(repo_dir, 'cookiecutter.json')\n logging.debug('context_file is {0}'.format(context_file))\n\n context = generate_context(\n context_file=context_file,\n default_context=config_dict['default_context'],\n extra_context=extra_context,\n )\n\n # prompt the user to manually configure at the command line.\n # except when 'no-input' flag is set\n context['cookiecutter'] = prompt_for_config(context, no_input)\n\n dump(config_dict['replay_dir'], template_name, context)\n\n # Create project from local context and project template.\n return generate_files(\n repo_dir=repo_dir,\n context=context,\n overwrite_if_exists=overwrite_if_exists,\n output_dir=output_dir\n )\n", "path": "cookiecutter/main.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\"\"\"\ncookiecutter.main\n-----------------\n\nMain entry point for the `cookiecutter` command.\n\nThe code in this module is also a good example of how to use Cookiecutter as a\nlibrary rather than a script.\n\"\"\"\n\nfrom __future__ import unicode_literals\nimport logging\nimport os\nimport re\n\nfrom .config import get_user_config, USER_CONFIG_PATH\nfrom .exceptions import InvalidModeException, RepositoryNotFound\nfrom .prompt import prompt_for_config\nfrom .generate import generate_context, generate_files\nfrom .vcs import clone\nfrom .replay import dump, load\n\nlogger = logging.getLogger(__name__)\n\nbuiltin_abbreviations = {\n 'gh': 'https://github.com/{0}.git',\n 'bb': 'https://bitbucket.org/{0}',\n}\n\nREPO_REGEX = re.compile(r\"\"\"\n(?x)\n((((git|hg)\\+)?(git|ssh|https?):(//)?) # something like git:// ssh:// etc.\n | # or\n (\\w+@[\\w\\.]+) # something like user@...\n)\n\"\"\")\n\n\ndef is_repo_url(value):\n \"\"\"Return True if value is a repository URL.\"\"\"\n return bool(REPO_REGEX.match(value))\n\n\ndef expand_abbreviations(template, config_dict):\n \"\"\"\n Expand abbreviations in a template name.\n\n :param template: The project template name.\n :param config_dict: The user config, which will contain abbreviation\n definitions.\n \"\"\"\n\n abbreviations = builtin_abbreviations.copy()\n abbreviations.update(config_dict.get('abbreviations', {}))\n\n if template in abbreviations:\n return abbreviations[template]\n\n # Split on colon. If there is no colon, rest will be empty\n # and prefix will be the whole template\n prefix, sep, rest = template.partition(':')\n if prefix in abbreviations:\n return abbreviations[prefix].format(rest)\n\n return template\n\n\ndef cookiecutter(\n template, checkout=None, no_input=False, extra_context=None,\n replay=False, overwrite_if_exists=False, output_dir='.',\n config_file=USER_CONFIG_PATH):\n \"\"\"\n API equivalent to using Cookiecutter at the command line.\n\n :param template: A directory containing a project template directory,\n or a URL to a git repository.\n :param checkout: The branch, tag or commit ID to checkout after clone.\n :param no_input: Prompt the user at command line for manual configuration?\n :param extra_context: A dictionary of context that overrides default\n and user configuration.\n :param: overwrite_if_exists: Overwrite the contents of output directory\n if it exists\n :param output_dir: Where to output the generated project dir into.\n :param config_file: User configuration file path.\n \"\"\"\n if replay and ((no_input is not False) or (extra_context is not None)):\n err_msg = (\n \"You can not use both replay and no_input or extra_context \"\n \"at the same time.\"\n )\n raise InvalidModeException(err_msg)\n\n # Get user config from ~/.cookiecutterrc or equivalent\n # If no config file, sensible defaults from config.DEFAULT_CONFIG are used\n config_dict = get_user_config(config_file=config_file)\n\n template = expand_abbreviations(template, config_dict)\n\n if is_repo_url(template):\n repo_dir = clone(\n repo_url=template,\n checkout=checkout,\n clone_to_dir=config_dict['cookiecutters_dir'],\n no_input=no_input\n )\n else:\n # If it's a local repo, no need to clone or copy to your\n # cookiecutters_dir\n repo_dir = template\n\n if not os.path.isdir(repo_dir):\n raise RepositoryNotFound(\n 'The repository {0} could not be located.'.format(template)\n )\n\n template_name = os.path.basename(template)\n\n if replay:\n context = load(config_dict['replay_dir'], template_name)\n else:\n context_file = os.path.join(repo_dir, 'cookiecutter.json')\n logging.debug('context_file is {0}'.format(context_file))\n\n context = generate_context(\n context_file=context_file,\n default_context=config_dict['default_context'],\n extra_context=extra_context,\n )\n\n # prompt the user to manually configure at the command line.\n # except when 'no-input' flag is set\n context['cookiecutter'] = prompt_for_config(context, no_input)\n\n dump(config_dict['replay_dir'], template_name, context)\n\n # Create project from local context and project template.\n return generate_files(\n repo_dir=repo_dir,\n context=context,\n overwrite_if_exists=overwrite_if_exists,\n output_dir=output_dir\n )\n", "path": "cookiecutter/main.py"}]}
| 1,655 | 246 |
gh_patches_debug_18531
|
rasdani/github-patches
|
git_diff
|
ivy-llc__ivy-22980
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
vonmises
numpy.random.vonmises function implementation
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ivy/functional/frontends/numpy/random/functions.py`
Content:
```
1 # local
2
3 import ivy
4 from ivy.functional.frontends.numpy.func_wrapper import (
5 to_ivy_arrays_and_back,
6 from_zero_dim_arrays_to_scalar,
7 )
8
9
10 @to_ivy_arrays_and_back
11 @from_zero_dim_arrays_to_scalar
12 def beta(a, b, size=None):
13 return ivy.beta(a, b, shape=size)
14
15
16 @to_ivy_arrays_and_back
17 @from_zero_dim_arrays_to_scalar
18 def binomial(n, p, size=None):
19 if p < 0 or p > 1:
20 raise ValueError("p must be in the interval (0, 1)")
21 if n < 0:
22 raise ValueError("n must be strictly positive")
23 if size is None:
24 size = 1
25 else:
26 size = size
27 if isinstance(size, int):
28 size = (size,)
29 lambda_ = ivy.multiply(n, p)
30 return ivy.poisson(lambda_, shape=size)
31
32
33 @to_ivy_arrays_and_back
34 @from_zero_dim_arrays_to_scalar
35 def chisquare(df, size=None):
36 df = ivy.array(df) # scalar ints and floats are also array_like
37 if ivy.any(df <= 0):
38 raise ValueError("df <= 0")
39
40 # ivy.gamma() throws an error if both alpha is an array and a shape is passed
41 # so this part broadcasts df into the shape of `size`` first to keep it happy.
42 if size is not None:
43 df = df * ivy.ones(size)
44
45 return ivy.gamma(df / 2, 2, dtype="float64")
46
47
48 @to_ivy_arrays_and_back
49 @from_zero_dim_arrays_to_scalar
50 def choice(a, size=None, replace=True, p=None):
51 sc_size = 1
52 if isinstance(size, int):
53 sc_size = size
54 elif size is not None:
55 # If the given shape is, e.g., (m, n, k)
56 # then m * n * k samples are drawn. As per numpy docs
57 sc_size = 1
58 for s in size:
59 if s is not None:
60 sc_size *= s
61 if isinstance(a, int):
62 a = ivy.arange(a)
63 index = ivy.multinomial(len(a), sc_size, replace=replace, probs=p)
64 return a[index]
65
66
67 @to_ivy_arrays_and_back
68 @from_zero_dim_arrays_to_scalar
69 def dirichlet(alpha, size=None):
70 return ivy.dirichlet(alpha, size=size)
71
72
73 @to_ivy_arrays_and_back
74 @from_zero_dim_arrays_to_scalar
75 def f(dfn, dfd, size=None):
76 # Generate samples from the uniform distribution
77 x1 = ivy.gamma(ivy.to_scalar(ivy.divide(dfn, 2)), 2.0, shape=size, dtype="float64")
78 x2 = ivy.gamma(ivy.to_scalar(ivy.divide(dfd, 2)), 2.0, shape=size, dtype="float64")
79 # Calculate the F-distributed samples
80 samples = ivy.divide(ivy.divide(x1, ivy.array(dfn)), ivy.divide(x2, ivy.array(dfd)))
81 return samples
82
83
84 @to_ivy_arrays_and_back
85 @from_zero_dim_arrays_to_scalar
86 def gamma(shape, scale=1.0, size=None):
87 return ivy.gamma(shape, scale, shape=size, dtype="float64")
88
89
90 @to_ivy_arrays_and_back
91 @from_zero_dim_arrays_to_scalar
92 def geometric(p, size=None):
93 if p < 0 or p > 1:
94 raise ValueError("p must be in the interval [0, 1]")
95 oneMinusP = ivy.subtract(1, p)
96 sizeMinusOne = ivy.subtract(size, 1)
97
98 return ivy.multiply(ivy.pow(oneMinusP, sizeMinusOne), p)
99
100
101 @to_ivy_arrays_and_back
102 @from_zero_dim_arrays_to_scalar
103 def gumbel(loc=0.0, scale=1.0, size=None):
104 u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype="float64")
105 x = loc - scale * ivy.log(-ivy.log(u))
106 return x
107
108
109 @to_ivy_arrays_and_back
110 @from_zero_dim_arrays_to_scalar
111 def laplace(loc=0.0, scale=1.0, size=None):
112 u = ivy.random_uniform(low=0.0, high=0.0, shape=size, dtype="float64")
113 u = loc - scale * ivy.sign(u - 0.5) * ivy.log(1 - 2 * ivy.abs(u - 0.5))
114 return u
115
116
117 @to_ivy_arrays_and_back
118 @from_zero_dim_arrays_to_scalar
119 def logistic(loc=0.0, scale=1.0, size=None):
120 u = ivy.random_uniform(low=0.0, high=0.0, shape=size, dtype="float64")
121 x = loc + scale * ivy.log(u / (1 - u))
122 return x
123
124
125 @to_ivy_arrays_and_back
126 @from_zero_dim_arrays_to_scalar
127 def lognormal(mean=0.0, sigma=1.0, size=None):
128 ret = ivy.exp(ivy.random_normal(mean=mean, std=sigma, shape=size, dtype="float64"))
129 return ret
130
131
132 @to_ivy_arrays_and_back
133 @from_zero_dim_arrays_to_scalar
134 def logseries(p=0, size=None):
135 if p < 0 or p >= 1:
136 raise ValueError("p value must be in the open interval (0, 1)")
137 r = ivy.log(1 - p)
138 u = ivy.random_uniform(low=0.0, high=1.0, shape=size)
139 v = ivy.random_uniform(low=0.0, high=1.0, shape=size)
140 q = 1 - ivy.exp(r * u)
141 ret = 1 + ivy.log(v) / ivy.log(q)
142 return ret
143
144
145 @to_ivy_arrays_and_back
146 @from_zero_dim_arrays_to_scalar
147 def multinomial(n, pvals, size=None):
148 assert not ivy.exists(size) or (len(size) > 0 and len(size) < 3)
149 batch_size = 1
150 if ivy.exists(size):
151 if len(size) == 2:
152 batch_size = size[0]
153 num_samples = size[1]
154 else:
155 num_samples = size[0]
156 else:
157 num_samples = len(pvals)
158 return ivy.multinomial(n, num_samples, batch_size=batch_size, probs=pvals)
159
160
161 @to_ivy_arrays_and_back
162 @from_zero_dim_arrays_to_scalar
163 def negative_binomial(n, p, size=None):
164 if p <= 0 or p >= 1:
165 raise ValueError("p must be in the interval (0, 1)")
166 if n <= 0:
167 raise ValueError("n must be strictly positive")
168 # numpy implementation uses scale = (1 - p) / p
169 scale = (1 - p) / p
170 # poisson requires shape to be a tuple
171 if isinstance(size, int):
172 size = (size,)
173 lambda_ = ivy.gamma(n, scale, shape=size)
174 return ivy.poisson(lam=lambda_, shape=size)
175
176
177 @to_ivy_arrays_and_back
178 @from_zero_dim_arrays_to_scalar
179 def normal(loc=0.0, scale=1.0, size=None):
180 return ivy.random_normal(mean=loc, std=scale, shape=size, dtype="float64")
181
182
183 @to_ivy_arrays_and_back
184 @from_zero_dim_arrays_to_scalar
185 def pareto(a, size=None):
186 if a < 0:
187 return 0
188 u = ivy.random_uniform(low=0.0, high=0.0, shape=size, dtype="float64")
189 return ivy.pow(1 / (1 - u), 1 / a)
190
191
192 @to_ivy_arrays_and_back
193 @from_zero_dim_arrays_to_scalar
194 def permutation(x, /):
195 if isinstance(x, int):
196 x = ivy.arange(x)
197 return ivy.shuffle(x)
198
199
200 @to_ivy_arrays_and_back
201 @from_zero_dim_arrays_to_scalar
202 def poisson(lam=1.0, size=None):
203 return ivy.poisson(lam=lam, shape=size)
204
205
206 @to_ivy_arrays_and_back
207 @from_zero_dim_arrays_to_scalar
208 def random_sample(size=None):
209 return ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype="float64")
210
211
212 @to_ivy_arrays_and_back
213 @from_zero_dim_arrays_to_scalar
214 def rayleigh(scale, size=None):
215 u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype="float64")
216 log_u = ivy.log(u)
217 x = ivy.multiply(scale, ivy.sqrt(ivy.multiply(-2, log_u)))
218 return x
219
220
221 @to_ivy_arrays_and_back
222 @from_zero_dim_arrays_to_scalar
223 def shuffle(x, axis=0, /):
224 if isinstance(x, int):
225 x = ivy.arange(x)
226 return ivy.shuffle(x, axis)
227
228
229 @to_ivy_arrays_and_back
230 @from_zero_dim_arrays_to_scalar
231 def standard_cauchy(size=None):
232 u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype="float64")
233 return ivy.tan(ivy.pi * (u - 0.5))
234
235
236 @to_ivy_arrays_and_back
237 @from_zero_dim_arrays_to_scalar
238 def standard_gamma(shape, size=None):
239 return ivy.gamma(shape, 1.0, shape=size, dtype="float64")
240
241
242 @to_ivy_arrays_and_back
243 @from_zero_dim_arrays_to_scalar
244 def standard_normal(size=None):
245 return ivy.random_normal(mean=0.0, std=1.0, shape=size, dtype="float64")
246
247
248 @to_ivy_arrays_and_back
249 @from_zero_dim_arrays_to_scalar
250 def standard_t(df, size=None):
251 numerator = ivy.random_normal(mean=0.0, std=1.0, shape=size, dtype="float64")
252 denominator = ivy.gamma(df / 2, 1.0, shape=size, dtype="float64")
253 return ivy.sqrt(df / 2) * ivy.divide(numerator, ivy.sqrt(denominator))
254
255
256 @to_ivy_arrays_and_back
257 @from_zero_dim_arrays_to_scalar
258 def triangular(left, mode, right, size=None):
259 if left > mode or mode > right or left == right:
260 raise ivy.utils.exceptions.IvyValueError(
261 "left < mode < right is not being followed"
262 )
263 u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype="float64")
264 condition = u <= (mode - left) / (right - left)
265 values1 = left + (right - left) * (u * (mode - left) / (right - left)) ** 0.5
266 values2 = (
267 right - (right - mode) * ((1 - u) * (right - mode) / (right - left)) ** 0.5
268 )
269 return ivy.where(condition, values1, values2)
270
271
272 @to_ivy_arrays_and_back
273 @from_zero_dim_arrays_to_scalar
274 def uniform(low=0.0, high=1.0, size=None):
275 return ivy.random_uniform(low=low, high=high, shape=size, dtype="float64")
276
277
278 @to_ivy_arrays_and_back
279 @from_zero_dim_arrays_to_scalar
280 def wald(mean, scale, size=None):
281 if size is None:
282 size = 1
283 mu_2l = mean / (2 * scale)
284 Y = ivy.random_normal(mean=0, std=1, shape=size, dtype="float64")
285 U = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype="float64")
286
287 Y = mean * ivy.square(Y)
288 X = mean + mu_2l * (Y - ivy.sqrt(((4 * scale) * Y) + ivy.square(Y)))
289
290 condition = U <= mean / (mean + X)
291 value1 = X
292 value2 = mean * mean / X
293
294 return ivy.where(condition, value1, value2)
295
296
297 @to_ivy_arrays_and_back
298 @from_zero_dim_arrays_to_scalar
299 def weibull(a, size=None):
300 if a < 0:
301 return 0
302 u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype="float64")
303 return ivy.pow(-ivy.log(1 - u), 1 / a)
304
305
306 @to_ivy_arrays_and_back
307 @from_zero_dim_arrays_to_scalar
308 def zipf(a, size=None):
309 if a <= 1:
310 return 0
311 u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype="float64")
312 return ivy.floor(ivy.pow(1 / (1 - u), 1 / a))
313
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ivy/functional/frontends/numpy/random/functions.py b/ivy/functional/frontends/numpy/random/functions.py
--- a/ivy/functional/frontends/numpy/random/functions.py
+++ b/ivy/functional/frontends/numpy/random/functions.py
@@ -275,6 +275,33 @@
return ivy.random_uniform(low=low, high=high, shape=size, dtype="float64")
+@to_ivy_arrays_and_back
+@from_zero_dim_arrays_to_scalar
+def vonmises(mu, kappa, size=None):
+ t_size = 0
+ # Output shape. If the given shape is, e.g., (m, n, k),
+ # then m * n * k samples are drawn.
+ if size is None or len(size) == 0:
+ t_size = 1
+ else:
+ for x in size:
+ t_size = t_size * x
+ size = t_size
+ li = []
+ while len(li) < size:
+ # Generate samples from the von Mises distribution using numpy
+ u = ivy.random_uniform(low=-ivy.pi, high=ivy.pi, shape=size)
+ v = ivy.random_uniform(low=0, high=1, shape=size)
+
+ condition = v < (1 + ivy.exp(kappa * ivy.cos(u - mu))) / (
+ 2 * ivy.pi * ivy.i0(kappa)
+ )
+ selected_samples = u[condition]
+ li.extend(ivy.to_list(selected_samples))
+
+ return ivy.array(li[:size])
+
+
@to_ivy_arrays_and_back
@from_zero_dim_arrays_to_scalar
def wald(mean, scale, size=None):
|
{"golden_diff": "diff --git a/ivy/functional/frontends/numpy/random/functions.py b/ivy/functional/frontends/numpy/random/functions.py\n--- a/ivy/functional/frontends/numpy/random/functions.py\n+++ b/ivy/functional/frontends/numpy/random/functions.py\n@@ -275,6 +275,33 @@\n return ivy.random_uniform(low=low, high=high, shape=size, dtype=\"float64\")\n \n \n+@to_ivy_arrays_and_back\n+@from_zero_dim_arrays_to_scalar\n+def vonmises(mu, kappa, size=None):\n+ t_size = 0\n+ # Output shape. If the given shape is, e.g., (m, n, k),\n+ # then m * n * k samples are drawn.\n+ if size is None or len(size) == 0:\n+ t_size = 1\n+ else:\n+ for x in size:\n+ t_size = t_size * x\n+ size = t_size\n+ li = []\n+ while len(li) < size:\n+ # Generate samples from the von Mises distribution using numpy\n+ u = ivy.random_uniform(low=-ivy.pi, high=ivy.pi, shape=size)\n+ v = ivy.random_uniform(low=0, high=1, shape=size)\n+\n+ condition = v < (1 + ivy.exp(kappa * ivy.cos(u - mu))) / (\n+ 2 * ivy.pi * ivy.i0(kappa)\n+ )\n+ selected_samples = u[condition]\n+ li.extend(ivy.to_list(selected_samples))\n+\n+ return ivy.array(li[:size])\n+\n+\n @to_ivy_arrays_and_back\n @from_zero_dim_arrays_to_scalar\n def wald(mean, scale, size=None):\n", "issue": " vonmises\nnumpy.random.vonmises function implementation\n", "before_files": [{"content": "# local\n\nimport ivy\nfrom ivy.functional.frontends.numpy.func_wrapper import (\n to_ivy_arrays_and_back,\n from_zero_dim_arrays_to_scalar,\n)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef beta(a, b, size=None):\n return ivy.beta(a, b, shape=size)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef binomial(n, p, size=None):\n if p < 0 or p > 1:\n raise ValueError(\"p must be in the interval (0, 1)\")\n if n < 0:\n raise ValueError(\"n must be strictly positive\")\n if size is None:\n size = 1\n else:\n size = size\n if isinstance(size, int):\n size = (size,)\n lambda_ = ivy.multiply(n, p)\n return ivy.poisson(lambda_, shape=size)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef chisquare(df, size=None):\n df = ivy.array(df) # scalar ints and floats are also array_like\n if ivy.any(df <= 0):\n raise ValueError(\"df <= 0\")\n\n # ivy.gamma() throws an error if both alpha is an array and a shape is passed\n # so this part broadcasts df into the shape of `size`` first to keep it happy.\n if size is not None:\n df = df * ivy.ones(size)\n\n return ivy.gamma(df / 2, 2, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef choice(a, size=None, replace=True, p=None):\n sc_size = 1\n if isinstance(size, int):\n sc_size = size\n elif size is not None:\n # If the given shape is, e.g., (m, n, k)\n # then m * n * k samples are drawn. As per numpy docs\n sc_size = 1\n for s in size:\n if s is not None:\n sc_size *= s\n if isinstance(a, int):\n a = ivy.arange(a)\n index = ivy.multinomial(len(a), sc_size, replace=replace, probs=p)\n return a[index]\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef dirichlet(alpha, size=None):\n return ivy.dirichlet(alpha, size=size)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef f(dfn, dfd, size=None):\n # Generate samples from the uniform distribution\n x1 = ivy.gamma(ivy.to_scalar(ivy.divide(dfn, 2)), 2.0, shape=size, dtype=\"float64\")\n x2 = ivy.gamma(ivy.to_scalar(ivy.divide(dfd, 2)), 2.0, shape=size, dtype=\"float64\")\n # Calculate the F-distributed samples\n samples = ivy.divide(ivy.divide(x1, ivy.array(dfn)), ivy.divide(x2, ivy.array(dfd)))\n return samples\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef gamma(shape, scale=1.0, size=None):\n return ivy.gamma(shape, scale, shape=size, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef geometric(p, size=None):\n if p < 0 or p > 1:\n raise ValueError(\"p must be in the interval [0, 1]\")\n oneMinusP = ivy.subtract(1, p)\n sizeMinusOne = ivy.subtract(size, 1)\n\n return ivy.multiply(ivy.pow(oneMinusP, sizeMinusOne), p)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef gumbel(loc=0.0, scale=1.0, size=None):\n u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n x = loc - scale * ivy.log(-ivy.log(u))\n return x\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef laplace(loc=0.0, scale=1.0, size=None):\n u = ivy.random_uniform(low=0.0, high=0.0, shape=size, dtype=\"float64\")\n u = loc - scale * ivy.sign(u - 0.5) * ivy.log(1 - 2 * ivy.abs(u - 0.5))\n return u\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef logistic(loc=0.0, scale=1.0, size=None):\n u = ivy.random_uniform(low=0.0, high=0.0, shape=size, dtype=\"float64\")\n x = loc + scale * ivy.log(u / (1 - u))\n return x\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef lognormal(mean=0.0, sigma=1.0, size=None):\n ret = ivy.exp(ivy.random_normal(mean=mean, std=sigma, shape=size, dtype=\"float64\"))\n return ret\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef logseries(p=0, size=None):\n if p < 0 or p >= 1:\n raise ValueError(\"p value must be in the open interval (0, 1)\")\n r = ivy.log(1 - p)\n u = ivy.random_uniform(low=0.0, high=1.0, shape=size)\n v = ivy.random_uniform(low=0.0, high=1.0, shape=size)\n q = 1 - ivy.exp(r * u)\n ret = 1 + ivy.log(v) / ivy.log(q)\n return ret\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef multinomial(n, pvals, size=None):\n assert not ivy.exists(size) or (len(size) > 0 and len(size) < 3)\n batch_size = 1\n if ivy.exists(size):\n if len(size) == 2:\n batch_size = size[0]\n num_samples = size[1]\n else:\n num_samples = size[0]\n else:\n num_samples = len(pvals)\n return ivy.multinomial(n, num_samples, batch_size=batch_size, probs=pvals)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef negative_binomial(n, p, size=None):\n if p <= 0 or p >= 1:\n raise ValueError(\"p must be in the interval (0, 1)\")\n if n <= 0:\n raise ValueError(\"n must be strictly positive\")\n # numpy implementation uses scale = (1 - p) / p\n scale = (1 - p) / p\n # poisson requires shape to be a tuple\n if isinstance(size, int):\n size = (size,)\n lambda_ = ivy.gamma(n, scale, shape=size)\n return ivy.poisson(lam=lambda_, shape=size)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef normal(loc=0.0, scale=1.0, size=None):\n return ivy.random_normal(mean=loc, std=scale, shape=size, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef pareto(a, size=None):\n if a < 0:\n return 0\n u = ivy.random_uniform(low=0.0, high=0.0, shape=size, dtype=\"float64\")\n return ivy.pow(1 / (1 - u), 1 / a)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef permutation(x, /):\n if isinstance(x, int):\n x = ivy.arange(x)\n return ivy.shuffle(x)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef poisson(lam=1.0, size=None):\n return ivy.poisson(lam=lam, shape=size)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef random_sample(size=None):\n return ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef rayleigh(scale, size=None):\n u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n log_u = ivy.log(u)\n x = ivy.multiply(scale, ivy.sqrt(ivy.multiply(-2, log_u)))\n return x\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef shuffle(x, axis=0, /):\n if isinstance(x, int):\n x = ivy.arange(x)\n return ivy.shuffle(x, axis)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef standard_cauchy(size=None):\n u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n return ivy.tan(ivy.pi * (u - 0.5))\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef standard_gamma(shape, size=None):\n return ivy.gamma(shape, 1.0, shape=size, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef standard_normal(size=None):\n return ivy.random_normal(mean=0.0, std=1.0, shape=size, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef standard_t(df, size=None):\n numerator = ivy.random_normal(mean=0.0, std=1.0, shape=size, dtype=\"float64\")\n denominator = ivy.gamma(df / 2, 1.0, shape=size, dtype=\"float64\")\n return ivy.sqrt(df / 2) * ivy.divide(numerator, ivy.sqrt(denominator))\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef triangular(left, mode, right, size=None):\n if left > mode or mode > right or left == right:\n raise ivy.utils.exceptions.IvyValueError(\n \"left < mode < right is not being followed\"\n )\n u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n condition = u <= (mode - left) / (right - left)\n values1 = left + (right - left) * (u * (mode - left) / (right - left)) ** 0.5\n values2 = (\n right - (right - mode) * ((1 - u) * (right - mode) / (right - left)) ** 0.5\n )\n return ivy.where(condition, values1, values2)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef uniform(low=0.0, high=1.0, size=None):\n return ivy.random_uniform(low=low, high=high, shape=size, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef wald(mean, scale, size=None):\n if size is None:\n size = 1\n mu_2l = mean / (2 * scale)\n Y = ivy.random_normal(mean=0, std=1, shape=size, dtype=\"float64\")\n U = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n\n Y = mean * ivy.square(Y)\n X = mean + mu_2l * (Y - ivy.sqrt(((4 * scale) * Y) + ivy.square(Y)))\n\n condition = U <= mean / (mean + X)\n value1 = X\n value2 = mean * mean / X\n\n return ivy.where(condition, value1, value2)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef weibull(a, size=None):\n if a < 0:\n return 0\n u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n return ivy.pow(-ivy.log(1 - u), 1 / a)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef zipf(a, size=None):\n if a <= 1:\n return 0\n u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n return ivy.floor(ivy.pow(1 / (1 - u), 1 / a))\n", "path": "ivy/functional/frontends/numpy/random/functions.py"}], "after_files": [{"content": "# local\n\nimport ivy\nfrom ivy.functional.frontends.numpy.func_wrapper import (\n to_ivy_arrays_and_back,\n from_zero_dim_arrays_to_scalar,\n)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef beta(a, b, size=None):\n return ivy.beta(a, b, shape=size)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef binomial(n, p, size=None):\n if p < 0 or p > 1:\n raise ValueError(\"p must be in the interval (0, 1)\")\n if n < 0:\n raise ValueError(\"n must be strictly positive\")\n if size is None:\n size = 1\n else:\n size = size\n if isinstance(size, int):\n size = (size,)\n lambda_ = ivy.multiply(n, p)\n return ivy.poisson(lambda_, shape=size)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef chisquare(df, size=None):\n df = ivy.array(df) # scalar ints and floats are also array_like\n if ivy.any(df <= 0):\n raise ValueError(\"df <= 0\")\n\n # ivy.gamma() throws an error if both alpha is an array and a shape is passed\n # so this part broadcasts df into the shape of `size`` first to keep it happy.\n if size is not None:\n df = df * ivy.ones(size)\n\n return ivy.gamma(df / 2, 2, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef choice(a, size=None, replace=True, p=None):\n sc_size = 1\n if isinstance(size, int):\n sc_size = size\n elif size is not None:\n # If the given shape is, e.g., (m, n, k)\n # then m * n * k samples are drawn. As per numpy docs\n sc_size = 1\n for s in size:\n if s is not None:\n sc_size *= s\n if isinstance(a, int):\n a = ivy.arange(a)\n index = ivy.multinomial(len(a), sc_size, replace=replace, probs=p)\n return a[index]\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef dirichlet(alpha, size=None):\n return ivy.dirichlet(alpha, size=size)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef f(dfn, dfd, size=None):\n # Generate samples from the uniform distribution\n x1 = ivy.gamma(ivy.to_scalar(ivy.divide(dfn, 2)), 2.0, shape=size, dtype=\"float64\")\n x2 = ivy.gamma(ivy.to_scalar(ivy.divide(dfd, 2)), 2.0, shape=size, dtype=\"float64\")\n # Calculate the F-distributed samples\n samples = ivy.divide(ivy.divide(x1, ivy.array(dfn)), ivy.divide(x2, ivy.array(dfd)))\n return samples\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef gamma(shape, scale=1.0, size=None):\n return ivy.gamma(shape, scale, shape=size, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef geometric(p, size=None):\n if p < 0 or p > 1:\n raise ValueError(\"p must be in the interval [0, 1]\")\n oneMinusP = ivy.subtract(1, p)\n sizeMinusOne = ivy.subtract(size, 1)\n\n return ivy.multiply(ivy.pow(oneMinusP, sizeMinusOne), p)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef gumbel(loc=0.0, scale=1.0, size=None):\n u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n x = loc - scale * ivy.log(-ivy.log(u))\n return x\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef laplace(loc=0.0, scale=1.0, size=None):\n u = ivy.random_uniform(low=0.0, high=0.0, shape=size, dtype=\"float64\")\n u = loc - scale * ivy.sign(u - 0.5) * ivy.log(1 - 2 * ivy.abs(u - 0.5))\n return u\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef logistic(loc=0.0, scale=1.0, size=None):\n u = ivy.random_uniform(low=0.0, high=0.0, shape=size, dtype=\"float64\")\n x = loc + scale * ivy.log(u / (1 - u))\n return x\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef lognormal(mean=0.0, sigma=1.0, size=None):\n ret = ivy.exp(ivy.random_normal(mean=mean, std=sigma, shape=size, dtype=\"float64\"))\n return ret\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef logseries(p=0, size=None):\n if p < 0 or p >= 1:\n raise ValueError(\"p value must be in the open interval (0, 1)\")\n r = ivy.log(1 - p)\n u = ivy.random_uniform(low=0.0, high=1.0, shape=size)\n v = ivy.random_uniform(low=0.0, high=1.0, shape=size)\n q = 1 - ivy.exp(r * u)\n ret = 1 + ivy.log(v) / ivy.log(q)\n return ret\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef multinomial(n, pvals, size=None):\n assert not ivy.exists(size) or (len(size) > 0 and len(size) < 3)\n batch_size = 1\n if ivy.exists(size):\n if len(size) == 2:\n batch_size = size[0]\n num_samples = size[1]\n else:\n num_samples = size[0]\n else:\n num_samples = len(pvals)\n return ivy.multinomial(n, num_samples, batch_size=batch_size, probs=pvals)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef negative_binomial(n, p, size=None):\n if p <= 0 or p >= 1:\n raise ValueError(\"p must be in the interval (0, 1)\")\n if n <= 0:\n raise ValueError(\"n must be strictly positive\")\n # numpy implementation uses scale = (1 - p) / p\n scale = (1 - p) / p\n # poisson requires shape to be a tuple\n if isinstance(size, int):\n size = (size,)\n lambda_ = ivy.gamma(n, scale, shape=size)\n return ivy.poisson(lam=lambda_, shape=size)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef normal(loc=0.0, scale=1.0, size=None):\n return ivy.random_normal(mean=loc, std=scale, shape=size, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef pareto(a, size=None):\n if a < 0:\n return 0\n u = ivy.random_uniform(low=0.0, high=0.0, shape=size, dtype=\"float64\")\n return ivy.pow(1 / (1 - u), 1 / a)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef permutation(x, /):\n if isinstance(x, int):\n x = ivy.arange(x)\n return ivy.shuffle(x)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef poisson(lam=1.0, size=None):\n return ivy.poisson(lam=lam, shape=size)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef random_sample(size=None):\n return ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef rayleigh(scale, size=None):\n u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n log_u = ivy.log(u)\n x = ivy.multiply(scale, ivy.sqrt(ivy.multiply(-2, log_u)))\n return x\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef shuffle(x, axis=0, /):\n if isinstance(x, int):\n x = ivy.arange(x)\n return ivy.shuffle(x, axis)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef standard_cauchy(size=None):\n u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n return ivy.tan(ivy.pi * (u - 0.5))\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef standard_gamma(shape, size=None):\n return ivy.gamma(shape, 1.0, shape=size, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef standard_normal(size=None):\n return ivy.random_normal(mean=0.0, std=1.0, shape=size, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef standard_t(df, size=None):\n numerator = ivy.random_normal(mean=0.0, std=1.0, shape=size, dtype=\"float64\")\n denominator = ivy.gamma(df / 2, 1.0, shape=size, dtype=\"float64\")\n return ivy.sqrt(df / 2) * ivy.divide(numerator, ivy.sqrt(denominator))\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef triangular(left, mode, right, size=None):\n if left > mode or mode > right or left == right:\n raise ivy.utils.exceptions.IvyValueError(\n \"left < mode < right is not being followed\"\n )\n u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n condition = u <= (mode - left) / (right - left)\n values1 = left + (right - left) * (u * (mode - left) / (right - left)) ** 0.5\n values2 = (\n right - (right - mode) * ((1 - u) * (right - mode) / (right - left)) ** 0.5\n )\n return ivy.where(condition, values1, values2)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef uniform(low=0.0, high=1.0, size=None):\n return ivy.random_uniform(low=low, high=high, shape=size, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef vonmises(mu, kappa, size=None):\n t_size = 0\n # Output shape. If the given shape is, e.g., (m, n, k),\n # then m * n * k samples are drawn.\n if size is None or len(size) == 0:\n t_size = 1\n else:\n for x in size:\n t_size = t_size * x\n size = t_size\n li = []\n while len(li) < size:\n # Generate samples from the von Mises distribution using numpy\n u = ivy.random_uniform(low=-ivy.pi, high=ivy.pi, shape=size)\n v = ivy.random_uniform(low=0, high=1, shape=size)\n\n condition = v < (1 + ivy.exp(kappa * ivy.cos(u - mu))) / (\n 2 * ivy.pi * ivy.i0(kappa)\n )\n selected_samples = u[condition]\n li.extend(ivy.to_list(selected_samples))\n\n return ivy.array(li[:size])\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef wald(mean, scale, size=None):\n if size is None:\n size = 1\n mu_2l = mean / (2 * scale)\n Y = ivy.random_normal(mean=0, std=1, shape=size, dtype=\"float64\")\n U = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n\n Y = mean * ivy.square(Y)\n X = mean + mu_2l * (Y - ivy.sqrt(((4 * scale) * Y) + ivy.square(Y)))\n\n condition = U <= mean / (mean + X)\n value1 = X\n value2 = mean * mean / X\n\n return ivy.where(condition, value1, value2)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef weibull(a, size=None):\n if a < 0:\n return 0\n u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n return ivy.pow(-ivy.log(1 - u), 1 / a)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef zipf(a, size=None):\n if a <= 1:\n return 0\n u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n return ivy.floor(ivy.pow(1 / (1 - u), 1 / a))\n", "path": "ivy/functional/frontends/numpy/random/functions.py"}]}
| 4,039 | 389 |
gh_patches_debug_20096
|
rasdani/github-patches
|
git_diff
|
liqd__adhocracy4-1005
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
comments: make sure blocked comments are not searched or filtered for their category
**URL:**
**user:**
**expected behaviour:** when I search for sth. in the comments, I do not expect to find blocked comments, of which I cannot see the comment text
**behaviour:** because the search happens in the backend, blocked comments are also searched, while the comment list from the serializer does not show the comment text of searched comments
**important screensize:**
**device & browser:**
**Comment/Question:**
Screenshot?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `adhocracy4/comments_async/filters.py`
Content:
```
1 from django.db import models
2 from rest_framework.filters import BaseFilterBackend
3 from rest_framework.filters import SearchFilter
4
5
6 class CommentCategoryFilterBackend(BaseFilterBackend):
7 """Filter the comments for the categories."""
8
9 def filter_queryset(self, request, queryset, view):
10
11 if 'comment_category' in request.GET:
12 category = request.GET['comment_category']
13 return queryset.filter(comment_categories__contains=category)
14
15 return queryset
16
17
18 class CommentOrderingFilterBackend(BaseFilterBackend):
19 """Order the comments."""
20
21 def filter_queryset(self, request, queryset, view):
22
23 if 'ordering' in request.GET:
24 ordering = request.GET['ordering']
25
26 if ordering == 'new':
27 return queryset.order_by('-created')
28 elif ordering == 'ans':
29 queryset = queryset\
30 .annotate(comment_count=models.Count(
31 'child_comments', distinct=True))
32 return queryset.order_by('-comment_count', '-created')
33 elif ordering == 'pos':
34 queryset = queryset\
35 .annotate(positive_rating_count=models.Count(
36 models.Case(
37 models.When(
38 ratings__value=1,
39 then=models.F('ratings__id')
40 ),
41 output_field=models.IntegerField()
42 ),
43 distinct=True))
44 return queryset.order_by('-positive_rating_count', '-created')
45 elif ordering == 'neg':
46 queryset = queryset\
47 .annotate(negative_rating_count=models.Count(
48 models.Case(
49 models.When(
50 ratings__value=-1,
51 then=models.F('ratings__id')
52 ),
53 output_field=models.IntegerField()
54 ),
55 distinct=True))
56 return queryset.order_by('-negative_rating_count', '-created')
57 elif ordering == 'dis':
58 return queryset.order_by(
59 models.F('last_discussed').desc(nulls_last=True),
60 '-created'
61 )
62 elif ordering == 'mom':
63 return queryset.order_by('-is_moderator_marked', '-created')
64
65 return queryset
66
67
68 class CustomSearchFilter(SearchFilter):
69
70 def filter_queryset(self, request, queryset, view):
71 qs = super().filter_queryset(request, queryset, view)
72 if self.get_search_terms(request):
73 return qs.filter(is_removed=False, is_censored=False)
74 return qs
75
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/adhocracy4/comments_async/filters.py b/adhocracy4/comments_async/filters.py
--- a/adhocracy4/comments_async/filters.py
+++ b/adhocracy4/comments_async/filters.py
@@ -8,9 +8,12 @@
def filter_queryset(self, request, queryset, view):
- if 'comment_category' in request.GET:
+ if ('comment_category' in request.GET
+ and request.GET['comment_category'] != ''):
category = request.GET['comment_category']
- return queryset.filter(comment_categories__contains=category)
+ return queryset.filter(
+ comment_categories__contains=category,
+ is_blocked=False)
return queryset
@@ -70,5 +73,6 @@
def filter_queryset(self, request, queryset, view):
qs = super().filter_queryset(request, queryset, view)
if self.get_search_terms(request):
- return qs.filter(is_removed=False, is_censored=False)
+ return qs.filter(is_removed=False, is_censored=False,
+ is_blocked=False)
return qs
|
{"golden_diff": "diff --git a/adhocracy4/comments_async/filters.py b/adhocracy4/comments_async/filters.py\n--- a/adhocracy4/comments_async/filters.py\n+++ b/adhocracy4/comments_async/filters.py\n@@ -8,9 +8,12 @@\n \n def filter_queryset(self, request, queryset, view):\n \n- if 'comment_category' in request.GET:\n+ if ('comment_category' in request.GET\n+ and request.GET['comment_category'] != ''):\n category = request.GET['comment_category']\n- return queryset.filter(comment_categories__contains=category)\n+ return queryset.filter(\n+ comment_categories__contains=category,\n+ is_blocked=False)\n \n return queryset\n \n@@ -70,5 +73,6 @@\n def filter_queryset(self, request, queryset, view):\n qs = super().filter_queryset(request, queryset, view)\n if self.get_search_terms(request):\n- return qs.filter(is_removed=False, is_censored=False)\n+ return qs.filter(is_removed=False, is_censored=False,\n+ is_blocked=False)\n return qs\n", "issue": "comments: make sure blocked comments are not searched or filtered for their category\n**URL:** \r\n**user:** \r\n**expected behaviour:** when I search for sth. in the comments, I do not expect to find blocked comments, of which I cannot see the comment text\r\n**behaviour:** because the search happens in the backend, blocked comments are also searched, while the comment list from the serializer does not show the comment text of searched comments\r\n**important screensize:**\r\n**device & browser:** \r\n**Comment/Question:** \r\n\r\nScreenshot?\r\n\n", "before_files": [{"content": "from django.db import models\nfrom rest_framework.filters import BaseFilterBackend\nfrom rest_framework.filters import SearchFilter\n\n\nclass CommentCategoryFilterBackend(BaseFilterBackend):\n \"\"\"Filter the comments for the categories.\"\"\"\n\n def filter_queryset(self, request, queryset, view):\n\n if 'comment_category' in request.GET:\n category = request.GET['comment_category']\n return queryset.filter(comment_categories__contains=category)\n\n return queryset\n\n\nclass CommentOrderingFilterBackend(BaseFilterBackend):\n \"\"\"Order the comments.\"\"\"\n\n def filter_queryset(self, request, queryset, view):\n\n if 'ordering' in request.GET:\n ordering = request.GET['ordering']\n\n if ordering == 'new':\n return queryset.order_by('-created')\n elif ordering == 'ans':\n queryset = queryset\\\n .annotate(comment_count=models.Count(\n 'child_comments', distinct=True))\n return queryset.order_by('-comment_count', '-created')\n elif ordering == 'pos':\n queryset = queryset\\\n .annotate(positive_rating_count=models.Count(\n models.Case(\n models.When(\n ratings__value=1,\n then=models.F('ratings__id')\n ),\n output_field=models.IntegerField()\n ),\n distinct=True))\n return queryset.order_by('-positive_rating_count', '-created')\n elif ordering == 'neg':\n queryset = queryset\\\n .annotate(negative_rating_count=models.Count(\n models.Case(\n models.When(\n ratings__value=-1,\n then=models.F('ratings__id')\n ),\n output_field=models.IntegerField()\n ),\n distinct=True))\n return queryset.order_by('-negative_rating_count', '-created')\n elif ordering == 'dis':\n return queryset.order_by(\n models.F('last_discussed').desc(nulls_last=True),\n '-created'\n )\n elif ordering == 'mom':\n return queryset.order_by('-is_moderator_marked', '-created')\n\n return queryset\n\n\nclass CustomSearchFilter(SearchFilter):\n\n def filter_queryset(self, request, queryset, view):\n qs = super().filter_queryset(request, queryset, view)\n if self.get_search_terms(request):\n return qs.filter(is_removed=False, is_censored=False)\n return qs\n", "path": "adhocracy4/comments_async/filters.py"}], "after_files": [{"content": "from django.db import models\nfrom rest_framework.filters import BaseFilterBackend\nfrom rest_framework.filters import SearchFilter\n\n\nclass CommentCategoryFilterBackend(BaseFilterBackend):\n \"\"\"Filter the comments for the categories.\"\"\"\n\n def filter_queryset(self, request, queryset, view):\n\n if ('comment_category' in request.GET\n and request.GET['comment_category'] != ''):\n category = request.GET['comment_category']\n return queryset.filter(\n comment_categories__contains=category,\n is_blocked=False)\n\n return queryset\n\n\nclass CommentOrderingFilterBackend(BaseFilterBackend):\n \"\"\"Order the comments.\"\"\"\n\n def filter_queryset(self, request, queryset, view):\n\n if 'ordering' in request.GET:\n ordering = request.GET['ordering']\n\n if ordering == 'new':\n return queryset.order_by('-created')\n elif ordering == 'ans':\n queryset = queryset\\\n .annotate(comment_count=models.Count(\n 'child_comments', distinct=True))\n return queryset.order_by('-comment_count', '-created')\n elif ordering == 'pos':\n queryset = queryset\\\n .annotate(positive_rating_count=models.Count(\n models.Case(\n models.When(\n ratings__value=1,\n then=models.F('ratings__id')\n ),\n output_field=models.IntegerField()\n ),\n distinct=True))\n return queryset.order_by('-positive_rating_count', '-created')\n elif ordering == 'neg':\n queryset = queryset\\\n .annotate(negative_rating_count=models.Count(\n models.Case(\n models.When(\n ratings__value=-1,\n then=models.F('ratings__id')\n ),\n output_field=models.IntegerField()\n ),\n distinct=True))\n return queryset.order_by('-negative_rating_count', '-created')\n elif ordering == 'dis':\n return queryset.order_by(\n models.F('last_discussed').desc(nulls_last=True),\n '-created'\n )\n elif ordering == 'mom':\n return queryset.order_by('-is_moderator_marked', '-created')\n\n return queryset\n\n\nclass CustomSearchFilter(SearchFilter):\n\n def filter_queryset(self, request, queryset, view):\n qs = super().filter_queryset(request, queryset, view)\n if self.get_search_terms(request):\n return qs.filter(is_removed=False, is_censored=False,\n is_blocked=False)\n return qs\n", "path": "adhocracy4/comments_async/filters.py"}]}
| 982 | 237 |
gh_patches_debug_10648
|
rasdani/github-patches
|
git_diff
|
zestedesavoir__zds-site-5449
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
L'export à la demande ne fonctionne pas
Plus précisement, l'export Markdown ne fonctionne pas quand on clique sur le bouton "Exporter le contenu" alors qu'il fonctionne lors de la publication.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `zds/tutorialv2/api/views.py`
Content:
```
1 import contextlib
2 from pathlib import Path
3
4 from django.http import Http404
5 from django.utils import translation
6 from django.utils.translation import gettext as _
7 from rest_framework import status
8 from rest_framework.fields import empty
9 from rest_framework.generics import UpdateAPIView, ListCreateAPIView, get_object_or_404
10 from rest_framework.response import Response
11 from rest_framework.serializers import Serializer, CharField, BooleanField
12 from rest_framework.permissions import IsAuthenticatedOrReadOnly
13
14 from zds.member.api.permissions import CanReadAndWriteNowOrReadOnly, IsNotOwnerOrReadOnly, IsAuthorOrStaff
15 from zds.tutorialv2.publication_utils import PublicatorRegistry
16 from zds.tutorialv2.utils import search_container_or_404
17 from zds.utils.api.views import KarmaView
18 from zds.tutorialv2.models.database import ContentReaction, PublishableContent, PublicationEvent
19
20
21 class ContainerReadinessSerializer(Serializer):
22 parent_container_slug = CharField(allow_blank=True, allow_null=True, required=False)
23 container_slug = CharField(required=True)
24 ready_to_publish = BooleanField(required=True)
25
26 def run_validation(self, data=empty):
27 init = super().run_validation(data)
28 if not init:
29 return init
30 if not data.get('parent_container_slug', ''):
31 init.pop('parent_container_slug', '')
32 return init
33
34 def save(self, **kwargs):
35 if not self.validated_data:
36 self.is_valid(True)
37 versioned = self.instance.load_version()
38 container = search_container_or_404(versioned, self.validated_data)
39 container.ready_to_publish = self.validated_data['ready_to_publish']
40 sha = versioned.repo_update(versioned.title, versioned.get_introduction(), versioned.get_conclusion(),
41 commit_message=_('{} est {} à la publication.').format(
42 container.get_path(True),
43 _('prêt') if container.ready_to_publish else _('ignoré')))
44 PublishableContent.objects.filter(pk=self.instance.pk).update(sha_draft=sha)
45
46 def to_representation(self, instance):
47 return {}
48
49
50 class ContentReactionKarmaView(KarmaView):
51 queryset = ContentReaction.objects.all()
52 permission_classes = (IsAuthenticatedOrReadOnly, CanReadAndWriteNowOrReadOnly, IsNotOwnerOrReadOnly)
53
54
55 class ContainerPublicationReadinessView(UpdateAPIView):
56 permission_classes = (IsAuthorOrStaff, )
57 serializer_class = ContainerReadinessSerializer
58
59 def get_object(self):
60 content = PublishableContent.objects.prefetch_related('authors')\
61 .filter(pk=int(self.kwargs.get('pk', 0)))\
62 .first()
63 if not content:
64 raise Http404()
65 self.check_object_permissions(self.request, object)
66 return content
67
68
69 class ExportView(ListCreateAPIView):
70 permission_classes = (IsAuthorOrStaff,)
71 serializer_class = Serializer
72
73 def get_queryset(self):
74 return PublicationEvent.objects.filter(published_object__content__pk=self.kwargs.get('pk', 0))
75
76 def ensure_directories(self, content: PublishableContent):
77 final_directory = Path(content.public_version.get_extra_contents_directory())
78 building_directory = Path(str(final_directory.parent) + '__building', final_directory.name)
79 with contextlib.suppress(FileExistsError):
80 final_directory.mkdir(parents=True)
81 with contextlib.suppress(FileExistsError):
82 building_directory.mkdir(parents=True)
83 return building_directory, final_directory
84
85 def create(self, request, *args, **kwargs):
86 try:
87 publishable_content = get_object_or_404(PublishableContent.objects, pk=int(kwargs.get('pk')))
88 if not publishable_content.public_version:
89 raise Http404('Not public content')
90 tmp_dir, _ = self.ensure_directories(publishable_content)
91 versioned = publishable_content.public_version.load_public_version()
92 base_name = str(Path(tmp_dir, versioned.slug))
93 md_file_path = str(Path(tmp_dir, versioned.slug + '.md'))
94
95 PublicatorRegistry.get('md').publish(md_file_path, base_name,
96 versioned=versioned,
97 cur_language=translation.get_language())
98 PublicatorRegistry.get('watchdog').publish_from_published_content(publishable_content.public_version)
99 except ValueError:
100 return Response({}, status=status.HTTP_400_BAD_REQUEST, headers={})
101 else:
102 return Response({}, status=status.HTTP_201_CREATED, headers={})
103
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/zds/tutorialv2/api/views.py b/zds/tutorialv2/api/views.py
--- a/zds/tutorialv2/api/views.py
+++ b/zds/tutorialv2/api/views.py
@@ -88,7 +88,7 @@
if not publishable_content.public_version:
raise Http404('Not public content')
tmp_dir, _ = self.ensure_directories(publishable_content)
- versioned = publishable_content.public_version.load_public_version()
+ versioned = publishable_content.load_version(public=True)
base_name = str(Path(tmp_dir, versioned.slug))
md_file_path = str(Path(tmp_dir, versioned.slug + '.md'))
|
{"golden_diff": "diff --git a/zds/tutorialv2/api/views.py b/zds/tutorialv2/api/views.py\n--- a/zds/tutorialv2/api/views.py\n+++ b/zds/tutorialv2/api/views.py\n@@ -88,7 +88,7 @@\n if not publishable_content.public_version:\n raise Http404('Not public content')\n tmp_dir, _ = self.ensure_directories(publishable_content)\n- versioned = publishable_content.public_version.load_public_version()\n+ versioned = publishable_content.load_version(public=True)\n base_name = str(Path(tmp_dir, versioned.slug))\n md_file_path = str(Path(tmp_dir, versioned.slug + '.md'))\n", "issue": "L'export \u00e0 la demande ne fonctionne pas\nPlus pr\u00e9cisement, l'export Markdown ne fonctionne pas quand on clique sur le bouton \"Exporter le contenu\" alors qu'il fonctionne lors de la publication.\n", "before_files": [{"content": "import contextlib\nfrom pathlib import Path\n\nfrom django.http import Http404\nfrom django.utils import translation\nfrom django.utils.translation import gettext as _\nfrom rest_framework import status\nfrom rest_framework.fields import empty\nfrom rest_framework.generics import UpdateAPIView, ListCreateAPIView, get_object_or_404\nfrom rest_framework.response import Response\nfrom rest_framework.serializers import Serializer, CharField, BooleanField\nfrom rest_framework.permissions import IsAuthenticatedOrReadOnly\n\nfrom zds.member.api.permissions import CanReadAndWriteNowOrReadOnly, IsNotOwnerOrReadOnly, IsAuthorOrStaff\nfrom zds.tutorialv2.publication_utils import PublicatorRegistry\nfrom zds.tutorialv2.utils import search_container_or_404\nfrom zds.utils.api.views import KarmaView\nfrom zds.tutorialv2.models.database import ContentReaction, PublishableContent, PublicationEvent\n\n\nclass ContainerReadinessSerializer(Serializer):\n parent_container_slug = CharField(allow_blank=True, allow_null=True, required=False)\n container_slug = CharField(required=True)\n ready_to_publish = BooleanField(required=True)\n\n def run_validation(self, data=empty):\n init = super().run_validation(data)\n if not init:\n return init\n if not data.get('parent_container_slug', ''):\n init.pop('parent_container_slug', '')\n return init\n\n def save(self, **kwargs):\n if not self.validated_data:\n self.is_valid(True)\n versioned = self.instance.load_version()\n container = search_container_or_404(versioned, self.validated_data)\n container.ready_to_publish = self.validated_data['ready_to_publish']\n sha = versioned.repo_update(versioned.title, versioned.get_introduction(), versioned.get_conclusion(),\n commit_message=_('{} est {} \u00e0 la publication.').format(\n container.get_path(True),\n _('pr\u00eat') if container.ready_to_publish else _('ignor\u00e9')))\n PublishableContent.objects.filter(pk=self.instance.pk).update(sha_draft=sha)\n\n def to_representation(self, instance):\n return {}\n\n\nclass ContentReactionKarmaView(KarmaView):\n queryset = ContentReaction.objects.all()\n permission_classes = (IsAuthenticatedOrReadOnly, CanReadAndWriteNowOrReadOnly, IsNotOwnerOrReadOnly)\n\n\nclass ContainerPublicationReadinessView(UpdateAPIView):\n permission_classes = (IsAuthorOrStaff, )\n serializer_class = ContainerReadinessSerializer\n\n def get_object(self):\n content = PublishableContent.objects.prefetch_related('authors')\\\n .filter(pk=int(self.kwargs.get('pk', 0)))\\\n .first()\n if not content:\n raise Http404()\n self.check_object_permissions(self.request, object)\n return content\n\n\nclass ExportView(ListCreateAPIView):\n permission_classes = (IsAuthorOrStaff,)\n serializer_class = Serializer\n\n def get_queryset(self):\n return PublicationEvent.objects.filter(published_object__content__pk=self.kwargs.get('pk', 0))\n\n def ensure_directories(self, content: PublishableContent):\n final_directory = Path(content.public_version.get_extra_contents_directory())\n building_directory = Path(str(final_directory.parent) + '__building', final_directory.name)\n with contextlib.suppress(FileExistsError):\n final_directory.mkdir(parents=True)\n with contextlib.suppress(FileExistsError):\n building_directory.mkdir(parents=True)\n return building_directory, final_directory\n\n def create(self, request, *args, **kwargs):\n try:\n publishable_content = get_object_or_404(PublishableContent.objects, pk=int(kwargs.get('pk')))\n if not publishable_content.public_version:\n raise Http404('Not public content')\n tmp_dir, _ = self.ensure_directories(publishable_content)\n versioned = publishable_content.public_version.load_public_version()\n base_name = str(Path(tmp_dir, versioned.slug))\n md_file_path = str(Path(tmp_dir, versioned.slug + '.md'))\n\n PublicatorRegistry.get('md').publish(md_file_path, base_name,\n versioned=versioned,\n cur_language=translation.get_language())\n PublicatorRegistry.get('watchdog').publish_from_published_content(publishable_content.public_version)\n except ValueError:\n return Response({}, status=status.HTTP_400_BAD_REQUEST, headers={})\n else:\n return Response({}, status=status.HTTP_201_CREATED, headers={})\n", "path": "zds/tutorialv2/api/views.py"}], "after_files": [{"content": "import contextlib\nfrom pathlib import Path\n\nfrom django.http import Http404\nfrom django.utils import translation\nfrom django.utils.translation import gettext as _\nfrom rest_framework import status\nfrom rest_framework.fields import empty\nfrom rest_framework.generics import UpdateAPIView, ListCreateAPIView, get_object_or_404\nfrom rest_framework.response import Response\nfrom rest_framework.serializers import Serializer, CharField, BooleanField\nfrom rest_framework.permissions import IsAuthenticatedOrReadOnly\n\nfrom zds.member.api.permissions import CanReadAndWriteNowOrReadOnly, IsNotOwnerOrReadOnly, IsAuthorOrStaff\nfrom zds.tutorialv2.publication_utils import PublicatorRegistry\nfrom zds.tutorialv2.utils import search_container_or_404\nfrom zds.utils.api.views import KarmaView\nfrom zds.tutorialv2.models.database import ContentReaction, PublishableContent, PublicationEvent\n\n\nclass ContainerReadinessSerializer(Serializer):\n parent_container_slug = CharField(allow_blank=True, allow_null=True, required=False)\n container_slug = CharField(required=True)\n ready_to_publish = BooleanField(required=True)\n\n def run_validation(self, data=empty):\n init = super().run_validation(data)\n if not init:\n return init\n if not data.get('parent_container_slug', ''):\n init.pop('parent_container_slug', '')\n return init\n\n def save(self, **kwargs):\n if not self.validated_data:\n self.is_valid(True)\n versioned = self.instance.load_version()\n container = search_container_or_404(versioned, self.validated_data)\n container.ready_to_publish = self.validated_data['ready_to_publish']\n sha = versioned.repo_update(versioned.title, versioned.get_introduction(), versioned.get_conclusion(),\n commit_message=_('{} est {} \u00e0 la publication.').format(\n container.get_path(True),\n _('pr\u00eat') if container.ready_to_publish else _('ignor\u00e9')))\n PublishableContent.objects.filter(pk=self.instance.pk).update(sha_draft=sha)\n\n def to_representation(self, instance):\n return {}\n\n\nclass ContentReactionKarmaView(KarmaView):\n queryset = ContentReaction.objects.all()\n permission_classes = (IsAuthenticatedOrReadOnly, CanReadAndWriteNowOrReadOnly, IsNotOwnerOrReadOnly)\n\n\nclass ContainerPublicationReadinessView(UpdateAPIView):\n permission_classes = (IsAuthorOrStaff, )\n serializer_class = ContainerReadinessSerializer\n\n def get_object(self):\n content = PublishableContent.objects.prefetch_related('authors')\\\n .filter(pk=int(self.kwargs.get('pk', 0)))\\\n .first()\n if not content:\n raise Http404()\n self.check_object_permissions(self.request, object)\n return content\n\n\nclass ExportView(ListCreateAPIView):\n permission_classes = (IsAuthorOrStaff,)\n serializer_class = Serializer\n\n def get_queryset(self):\n return PublicationEvent.objects.filter(published_object__content__pk=self.kwargs.get('pk', 0))\n\n def ensure_directories(self, content: PublishableContent):\n final_directory = Path(content.public_version.get_extra_contents_directory())\n building_directory = Path(str(final_directory.parent) + '__building', final_directory.name)\n with contextlib.suppress(FileExistsError):\n final_directory.mkdir(parents=True)\n with contextlib.suppress(FileExistsError):\n building_directory.mkdir(parents=True)\n return building_directory, final_directory\n\n def create(self, request, *args, **kwargs):\n try:\n publishable_content = get_object_or_404(PublishableContent.objects, pk=int(kwargs.get('pk')))\n if not publishable_content.public_version:\n raise Http404('Not public content')\n tmp_dir, _ = self.ensure_directories(publishable_content)\n versioned = publishable_content.load_version(public=True)\n base_name = str(Path(tmp_dir, versioned.slug))\n md_file_path = str(Path(tmp_dir, versioned.slug + '.md'))\n\n PublicatorRegistry.get('md').publish(md_file_path, base_name,\n versioned=versioned,\n cur_language=translation.get_language())\n PublicatorRegistry.get('watchdog').publish_from_published_content(publishable_content.public_version)\n except ValueError:\n return Response({}, status=status.HTTP_400_BAD_REQUEST, headers={})\n else:\n return Response({}, status=status.HTTP_201_CREATED, headers={})\n", "path": "zds/tutorialv2/api/views.py"}]}
| 1,446 | 148 |
gh_patches_debug_10271
|
rasdani/github-patches
|
git_diff
|
PaddlePaddle__Paddle2ONNX-15
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Need check whether protoc existed.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `variables.py`
Content:
```
1 # Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from onnx import helper, onnx_pb2, TensorProto
16 import paddle.fluid.core as core
17
18
19 def paddle_variable_to_onnx_tensor(paddle_var_name, block):
20 # TODO(varunarora): Need to do this only in the case of VarType.LOD_TENSOR.
21 paddle_var = block.var(paddle_var_name)
22 return helper.make_tensor_value_info(
23 paddle_var_name, PADDLE_TO_ONNX_DTYPE[paddle_var.dtype],
24 paddle_var.shape)
25
26
27 PADDLE_TO_ONNX_DTYPE = {
28 core.VarDesc.VarType.FP32: onnx_pb2.TensorProto.FLOAT,
29 core.VarDesc.VarType.FP64: onnx_pb2.TensorProto.FLOAT16,
30 # '': onnx_pb2.TensorProto.DOUBLE,
31 core.VarDesc.VarType.INT32: onnx_pb2.TensorProto.INT32,
32 core.VarDesc.VarType.INT16: onnx_pb2.TensorProto.INT16,
33 # '': onnx_pb2.TensorProto.INT8,
34 # '': onnx_pb2.TensorProto.UINT8,
35 core.VarDesc.VarType.INT16: onnx_pb2.TensorProto.UINT16,
36 core.VarDesc.VarType.INT64: onnx_pb2.TensorProto.INT64,
37 # '': onnx_pb2.TensorProto.STRING,
38 # '': onnx_pb2.TensorProto.COMPLEX64,
39 # '': onnx_pb2.TensorProto.COMPLEX128,
40 core.VarDesc.VarType.BOOL: onnx_pb2.TensorProto.BOOL
41 }
42
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/variables.py b/variables.py
--- a/variables.py
+++ b/variables.py
@@ -19,9 +19,9 @@
def paddle_variable_to_onnx_tensor(paddle_var_name, block):
# TODO(varunarora): Need to do this only in the case of VarType.LOD_TENSOR.
paddle_var = block.var(paddle_var_name)
- return helper.make_tensor_value_info(
- paddle_var_name, PADDLE_TO_ONNX_DTYPE[paddle_var.dtype],
- paddle_var.shape)
+ return helper.make_tensor_value_info(paddle_var_name,
+ PADDLE_TO_ONNX_DTYPE[paddle_var.dtype],
+ paddle_var.shape)
PADDLE_TO_ONNX_DTYPE = {
|
{"golden_diff": "diff --git a/variables.py b/variables.py\n--- a/variables.py\n+++ b/variables.py\n@@ -19,9 +19,9 @@\n def paddle_variable_to_onnx_tensor(paddle_var_name, block):\n # TODO(varunarora): Need to do this only in the case of VarType.LOD_TENSOR.\n paddle_var = block.var(paddle_var_name)\n- return helper.make_tensor_value_info(\n- paddle_var_name, PADDLE_TO_ONNX_DTYPE[paddle_var.dtype],\n- paddle_var.shape)\n+ return helper.make_tensor_value_info(paddle_var_name,\n+ PADDLE_TO_ONNX_DTYPE[paddle_var.dtype],\n+ paddle_var.shape)\n \n \n PADDLE_TO_ONNX_DTYPE = {\n", "issue": "Need check whether protoc existed.\n\n", "before_files": [{"content": "# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom onnx import helper, onnx_pb2, TensorProto\nimport paddle.fluid.core as core\n\n\ndef paddle_variable_to_onnx_tensor(paddle_var_name, block):\n # TODO(varunarora): Need to do this only in the case of VarType.LOD_TENSOR.\n paddle_var = block.var(paddle_var_name)\n return helper.make_tensor_value_info(\n paddle_var_name, PADDLE_TO_ONNX_DTYPE[paddle_var.dtype],\n paddle_var.shape)\n\n\nPADDLE_TO_ONNX_DTYPE = {\n core.VarDesc.VarType.FP32: onnx_pb2.TensorProto.FLOAT,\n core.VarDesc.VarType.FP64: onnx_pb2.TensorProto.FLOAT16,\n # '': onnx_pb2.TensorProto.DOUBLE,\n core.VarDesc.VarType.INT32: onnx_pb2.TensorProto.INT32,\n core.VarDesc.VarType.INT16: onnx_pb2.TensorProto.INT16,\n # '': onnx_pb2.TensorProto.INT8,\n # '': onnx_pb2.TensorProto.UINT8,\n core.VarDesc.VarType.INT16: onnx_pb2.TensorProto.UINT16,\n core.VarDesc.VarType.INT64: onnx_pb2.TensorProto.INT64,\n # '': onnx_pb2.TensorProto.STRING,\n # '': onnx_pb2.TensorProto.COMPLEX64,\n # '': onnx_pb2.TensorProto.COMPLEX128,\n core.VarDesc.VarType.BOOL: onnx_pb2.TensorProto.BOOL\n}\n", "path": "variables.py"}], "after_files": [{"content": "# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom onnx import helper, onnx_pb2, TensorProto\nimport paddle.fluid.core as core\n\n\ndef paddle_variable_to_onnx_tensor(paddle_var_name, block):\n # TODO(varunarora): Need to do this only in the case of VarType.LOD_TENSOR.\n paddle_var = block.var(paddle_var_name)\n return helper.make_tensor_value_info(paddle_var_name,\n PADDLE_TO_ONNX_DTYPE[paddle_var.dtype],\n paddle_var.shape)\n\n\nPADDLE_TO_ONNX_DTYPE = {\n core.VarDesc.VarType.FP32: onnx_pb2.TensorProto.FLOAT,\n core.VarDesc.VarType.FP64: onnx_pb2.TensorProto.FLOAT16,\n # '': onnx_pb2.TensorProto.DOUBLE,\n core.VarDesc.VarType.INT32: onnx_pb2.TensorProto.INT32,\n core.VarDesc.VarType.INT16: onnx_pb2.TensorProto.INT16,\n # '': onnx_pb2.TensorProto.INT8,\n # '': onnx_pb2.TensorProto.UINT8,\n core.VarDesc.VarType.INT16: onnx_pb2.TensorProto.UINT16,\n core.VarDesc.VarType.INT64: onnx_pb2.TensorProto.INT64,\n # '': onnx_pb2.TensorProto.STRING,\n # '': onnx_pb2.TensorProto.COMPLEX64,\n # '': onnx_pb2.TensorProto.COMPLEX128,\n core.VarDesc.VarType.BOOL: onnx_pb2.TensorProto.BOOL\n}\n", "path": "variables.py"}]}
| 817 | 163 |
gh_patches_debug_24681
|
rasdani/github-patches
|
git_diff
|
MycroftAI__mycroft-core-2931
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
tts cache creates "None" folder
the latest cache refactor is creating a folder named "None" due to the handling of persistent cache added for mimic2 in https://github.com/MycroftAI/mycroft-core/pull/2853
cache is also deleted on boot, the min_percent param is set to 100%, "Remove cache data if disk space is running low." actually means "always remove cache data".
proposed fix: https://github.com/HelloChatterbox/HolmesV/pull/61
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mycroft/tts/cache.py`
Content:
```
1 # Copyright 2021 Mycroft AI Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 """TTS cache maintenance.
15
16 There are two types of cache available to a TTS engine. Both are comprised of
17 audio and phoneme files. TTS engines can use the cache to improve performance
18 by not performing inference on sentences in the cache.
19
20 The first type of cache is a persistent cache. The cache is considered
21 persistent because the files are stored in a location that is not cleared on
22 reboot. TTS inference on these sentences should only need to occur once. The
23 persistent cache contains commonly spoken sentences.
24
25 The second cache type is a temporary cache stored in the /tmp directory,
26 which is cleared when a device is rebooted. Sentences are added to this cache
27 on the fly every time a TTS engine returns audio for a sentence that is not
28 already cached.
29 """
30 import base64
31 import hashlib
32 import json
33 import re
34 from pathlib import Path
35 from typing import List, Set, Tuple
36 from urllib import parse
37
38 import requests
39
40 from mycroft.util.file_utils import (
41 ensure_directory_exists, get_cache_directory, curate_cache
42 )
43 from mycroft.util.log import LOG
44
45
46 def _get_mimic2_audio(sentence: str, url: str) -> Tuple[bytes, str]:
47 """Use the Mimic2 API to retrieve the audio for a sentence.
48
49 Args:
50 sentence: The sentence to be cached
51 """
52 LOG.debug("Retrieving Mimic2 audio for sentence \"{}\'".format(sentence))
53 mimic2_url = url + parse.quote(sentence) + '&visimes=True'
54 response = requests.get(mimic2_url)
55 response_data = response.json()
56 audio = base64.b64decode(response_data["audio_base64"])
57 phonemes = response_data["visimes"]
58
59 return audio, phonemes
60
61
62 def hash_sentence(sentence: str):
63 """Convert the sentence into a hash value used for the file name
64
65 Args:
66 sentence: The sentence to be cached
67 """
68 encoded_sentence = sentence.encode("utf-8", "ignore")
69 sentence_hash = hashlib.md5(encoded_sentence).hexdigest()
70
71 return sentence_hash
72
73
74 def hash_from_path(path: Path) -> str:
75 """Returns hash from a given path.
76
77 Simply removes extension and folder structure leaving the hash.
78
79 Args:
80 path: path to get hash from
81
82 Returns:
83 Hash reference for file.
84 """
85 return path.with_suffix('').name
86
87
88 class AudioFile:
89 def __init__(self, cache_dir: Path, sentence_hash: str, file_type: str):
90 self.name = f"{sentence_hash}.{file_type}"
91 self.path = cache_dir.joinpath(self.name)
92
93 def save(self, audio: bytes):
94 """Write a TTS cache file containing the audio to be spoken.
95
96 Args:
97 audio: TTS inference of a sentence
98 """
99 try:
100 with open(self.path, "wb") as audio_file:
101 audio_file.write(audio)
102 except Exception:
103 LOG.exception("Failed to write {} to cache".format(self.name))
104
105 def exists(self):
106 return self.path.exists()
107
108
109 class PhonemeFile:
110 def __init__(self, cache_dir: Path, sentence_hash: str):
111 self.name = f"{sentence_hash}.pho"
112 self.path = cache_dir.joinpath(self.name)
113
114 def load(self) -> List:
115 """Load phonemes from cache file."""
116 phonemes = None
117 if self.path.exists():
118 try:
119 with open(self.path) as phoneme_file:
120 phonemes = phoneme_file.read().strip()
121 except Exception:
122 LOG.exception("Failed to read phoneme from cache")
123
124 return json.loads(phonemes)
125
126 def save(self, phonemes):
127 """Write a TTS cache file containing the phoneme to be displayed.
128
129 Args:
130 phonemes: instructions for how to make the mouth on a device move
131 """
132 try:
133 rec = json.dumps(phonemes)
134 with open(self.path, "w") as phoneme_file:
135 phoneme_file.write(rec)
136 except Exception:
137 LOG.exception("Failed to write {} to cache".format(self.name))
138
139 def exists(self):
140 return self.path.exists()
141
142
143 class TextToSpeechCache:
144 """Class for all persistent and temporary caching operations."""
145 def __init__(self, tts_config, tts_name, audio_file_type):
146 self.config = tts_config
147 self.tts_name = tts_name
148 if "preloaded_cache" in self.config:
149 self.persistent_cache_dir = Path(self.config["preloaded_cache"])
150 else:
151 self.persistent_cache_dir = None
152 self.temporary_cache_dir = Path(
153 get_cache_directory("tts/" + tts_name)
154 )
155 self.audio_file_type = audio_file_type
156 self.resource_dir = Path(__file__).parent.parent.joinpath("res")
157 self.cached_sentences = dict()
158 ensure_directory_exists(
159 str(self.persistent_cache_dir), permissions=0o755
160 )
161 ensure_directory_exists(
162 str(self.temporary_cache_dir), permissions=0o755
163 )
164
165 def __contains__(self, sha):
166 """The cache contains a SHA if it knows of it and it exists on disk."""
167 if sha not in self.cached_sentences:
168 return False # Doesn't know of it
169 else:
170 # Audio file must exist, phonemes are optional.
171 audio, phonemes = self.cached_sentences[sha]
172 return (audio.exists() and
173 (phonemes is None or phonemes.exists()))
174
175 def load_persistent_cache(self):
176 """Load the contents of dialog files to the persistent cache directory.
177
178 Parse the dialog files in the resource directory into sentences. Then
179 add the audio for each sentence to the cache directory.
180
181 NOTE: There may be files pre-loaded in the persistent cache directory
182 prior to run time, such as pre-recorded audio files. This will add
183 files that do not already exist.
184
185 ANOTHER NOTE: Mimic2 is the only TTS engine that supports this. This
186 logic will need to change if another TTS engine implements it.
187 """
188 if self.persistent_cache_dir is not None:
189 LOG.info("Adding dialog resources to persistent TTS cache...")
190 self._load_existing_audio_files()
191 self._load_existing_phoneme_files()
192 dialogs = self._collect_dialogs()
193 sentences = self._parse_dialogs(dialogs)
194 for sentence in sentences:
195 self._load_sentence(sentence)
196 LOG.info("Persistent TTS cache files added successfully.")
197
198 def _load_existing_audio_files(self):
199 """Find the TTS audio files already in the persistent cache."""
200 glob_pattern = "*." + self.audio_file_type
201 for file_path in self.persistent_cache_dir.glob(glob_pattern):
202 sentence_hash = file_path.name.split(".")[0]
203 audio_file = AudioFile(
204 self.persistent_cache_dir, sentence_hash, self.audio_file_type
205 )
206 self.cached_sentences[sentence_hash] = audio_file, None
207
208 def _load_existing_phoneme_files(self):
209 """Find the TTS phoneme files already in the persistent cache.
210
211 A phoneme file is no good without an audio file to pair it with. If
212 no audio file matches, do not load the phoneme.
213 """
214 for file_path in self.persistent_cache_dir.glob("*.pho"):
215 sentence_hash = file_path.name.split(".")[0]
216 cached_sentence = self.cached_sentences.get(sentence_hash)
217 if cached_sentence is not None:
218 audio_file = cached_sentence[0]
219 phoneme_file = PhonemeFile(
220 self.persistent_cache_dir, sentence_hash
221 )
222 self.cached_sentences[sentence_hash] = audio_file, phoneme_file
223
224 def _collect_dialogs(self) -> List:
225 """Build a set of unique sentences from the dialog files.
226
227 The sentences will be parsed from *.dialog files present in
228 mycroft/res/text/en-us.
229 """
230 dialogs = []
231 dialog_directory = Path(self.resource_dir, "text", "en-us")
232 for dialog_file_path in dialog_directory.glob("*.dialog"):
233 with open(dialog_file_path) as dialog_file:
234 for dialog in dialog_file.readlines():
235 dialogs.append(dialog.strip())
236
237 return dialogs
238
239 @staticmethod
240 def _parse_dialogs(dialogs: List[str]) -> Set[str]:
241 """Split each dialog in the resources directory into sentences.
242
243 Do not consider sentences with special characters other than
244 punctuation
245 example : <<< LOADING <<<
246
247 Args:
248 dialogs: a list of the records in the dialog resource files
249 """
250 sentences = set()
251 dialog_split_regex = r"(?<=\.|\;|\?)\s"
252 special_characters_regex = re.compile(r"[@#$%^*()<>/|}{~:]")
253 for dialog in dialogs:
254 dialog_sentences = re.split(dialog_split_regex, dialog)
255 for sentence in dialog_sentences:
256 match = special_characters_regex.search(sentence)
257 if match is None:
258 sentences.add(sentence)
259
260 return sentences
261
262 def _load_sentence(self, sentence: str):
263 """Build audio and phoneme files for each sentence to be cached.
264
265 Perform TTS inference on sentences parsed from dialog files. Store
266 the results in the persistent cache directory.
267
268 ASSUMPTION: The only TTS that supports persistent cache right now is
269 Mimic2. This method assumes a call to the Mimic2 API. If other TTS
270 engines want to take advantage of the persistent cache, this logic
271 will need to be more dynamic.
272 """
273 sentence_hash = hash_sentence(sentence)
274 if sentence_hash not in self.cached_sentences:
275 LOG.info("Adding \"{}\" to cache".format(sentence))
276 try:
277 mimic2_url = self.config["url"]
278 audio, phonemes = _get_mimic2_audio(sentence, mimic2_url)
279 except Exception:
280 log_msg = "Failed to get audio for sentence \"{}\""
281 LOG.exception(log_msg.format(sentence))
282 else:
283 self._add_to_persistent_cache(sentence_hash, audio, phonemes)
284
285 def _add_to_persistent_cache(
286 self, sentence_hash: str, audio: bytes, phonemes: str
287 ):
288 """Add a audio/phoneme file pair to the persistent cache."""
289 audio_file = AudioFile(
290 self.persistent_cache_dir, sentence_hash, self.audio_file_type
291 )
292 audio_file.save(audio)
293 if phonemes is None:
294 phoneme_file = None
295 else:
296 phoneme_file = PhonemeFile(
297 self.persistent_cache_dir, sentence_hash
298 )
299 phoneme_file.save(phonemes)
300 self.cached_sentences[sentence_hash] = audio_file, phoneme_file
301
302 def clear(self):
303 """Remove all files from the temporary cache."""
304 for cache_file_path in self.temporary_cache_dir.iterdir():
305 if cache_file_path.is_dir():
306 for sub_path in cache_file_path.iterdir():
307 if sub_path.is_file():
308 sub_path.unlink()
309 elif cache_file_path.is_file():
310 cache_file_path.unlink()
311
312 def curate(self):
313 """Remove cache data if disk space is running low."""
314 files_removed = curate_cache(self.temporary_cache_dir,
315 min_free_percent=100)
316
317 hashes = set([hash_from_path(Path(path)) for path in files_removed])
318 for sentence_hash in hashes:
319 if sentence_hash in self.cached_sentences:
320 self.cached_sentences.pop(sentence_hash)
321
322 def define_audio_file(self, sentence_hash: str) -> AudioFile:
323 """Build an instance of an object representing an audio file."""
324 audio_file = AudioFile(
325 self.temporary_cache_dir, sentence_hash, self.audio_file_type
326 )
327 return audio_file
328
329 def define_phoneme_file(self, sentence_hash: str) -> PhonemeFile:
330 """Build an instance of an object representing an phoneme file."""
331 phoneme_file = PhonemeFile(self.temporary_cache_dir, sentence_hash)
332 return phoneme_file
333
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mycroft/tts/cache.py b/mycroft/tts/cache.py
--- a/mycroft/tts/cache.py
+++ b/mycroft/tts/cache.py
@@ -147,20 +147,20 @@
self.tts_name = tts_name
if "preloaded_cache" in self.config:
self.persistent_cache_dir = Path(self.config["preloaded_cache"])
+ ensure_directory_exists(
+ str(self.persistent_cache_dir), permissions=0o755
+ )
else:
self.persistent_cache_dir = None
self.temporary_cache_dir = Path(
get_cache_directory("tts/" + tts_name)
)
- self.audio_file_type = audio_file_type
- self.resource_dir = Path(__file__).parent.parent.joinpath("res")
- self.cached_sentences = dict()
- ensure_directory_exists(
- str(self.persistent_cache_dir), permissions=0o755
- )
ensure_directory_exists(
str(self.temporary_cache_dir), permissions=0o755
)
+ self.audio_file_type = audio_file_type
+ self.resource_dir = Path(__file__).parent.parent.joinpath("res")
+ self.cached_sentences = dict()
def __contains__(self, sha):
"""The cache contains a SHA if it knows of it and it exists on disk."""
|
{"golden_diff": "diff --git a/mycroft/tts/cache.py b/mycroft/tts/cache.py\n--- a/mycroft/tts/cache.py\n+++ b/mycroft/tts/cache.py\n@@ -147,20 +147,20 @@\n self.tts_name = tts_name\n if \"preloaded_cache\" in self.config:\n self.persistent_cache_dir = Path(self.config[\"preloaded_cache\"])\n+ ensure_directory_exists(\n+ str(self.persistent_cache_dir), permissions=0o755\n+ )\n else:\n self.persistent_cache_dir = None\n self.temporary_cache_dir = Path(\n get_cache_directory(\"tts/\" + tts_name)\n )\n- self.audio_file_type = audio_file_type\n- self.resource_dir = Path(__file__).parent.parent.joinpath(\"res\")\n- self.cached_sentences = dict()\n- ensure_directory_exists(\n- str(self.persistent_cache_dir), permissions=0o755\n- )\n ensure_directory_exists(\n str(self.temporary_cache_dir), permissions=0o755\n )\n+ self.audio_file_type = audio_file_type\n+ self.resource_dir = Path(__file__).parent.parent.joinpath(\"res\")\n+ self.cached_sentences = dict()\n \n def __contains__(self, sha):\n \"\"\"The cache contains a SHA if it knows of it and it exists on disk.\"\"\"\n", "issue": "tts cache creates \"None\" folder\nthe latest cache refactor is creating a folder named \"None\" due to the handling of persistent cache added for mimic2 in https://github.com/MycroftAI/mycroft-core/pull/2853\r\n\r\ncache is also deleted on boot, the min_percent param is set to 100%, \"Remove cache data if disk space is running low.\" actually means \"always remove cache data\". \r\n\r\nproposed fix: https://github.com/HelloChatterbox/HolmesV/pull/61\n", "before_files": [{"content": "# Copyright 2021 Mycroft AI Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"TTS cache maintenance.\n\nThere are two types of cache available to a TTS engine. Both are comprised of\naudio and phoneme files. TTS engines can use the cache to improve performance\nby not performing inference on sentences in the cache.\n\nThe first type of cache is a persistent cache. The cache is considered\npersistent because the files are stored in a location that is not cleared on\nreboot. TTS inference on these sentences should only need to occur once. The\npersistent cache contains commonly spoken sentences.\n\nThe second cache type is a temporary cache stored in the /tmp directory,\nwhich is cleared when a device is rebooted. Sentences are added to this cache\non the fly every time a TTS engine returns audio for a sentence that is not\nalready cached.\n\"\"\"\nimport base64\nimport hashlib\nimport json\nimport re\nfrom pathlib import Path\nfrom typing import List, Set, Tuple\nfrom urllib import parse\n\nimport requests\n\nfrom mycroft.util.file_utils import (\n ensure_directory_exists, get_cache_directory, curate_cache\n)\nfrom mycroft.util.log import LOG\n\n\ndef _get_mimic2_audio(sentence: str, url: str) -> Tuple[bytes, str]:\n \"\"\"Use the Mimic2 API to retrieve the audio for a sentence.\n\n Args:\n sentence: The sentence to be cached\n \"\"\"\n LOG.debug(\"Retrieving Mimic2 audio for sentence \\\"{}\\'\".format(sentence))\n mimic2_url = url + parse.quote(sentence) + '&visimes=True'\n response = requests.get(mimic2_url)\n response_data = response.json()\n audio = base64.b64decode(response_data[\"audio_base64\"])\n phonemes = response_data[\"visimes\"]\n\n return audio, phonemes\n\n\ndef hash_sentence(sentence: str):\n \"\"\"Convert the sentence into a hash value used for the file name\n\n Args:\n sentence: The sentence to be cached\n \"\"\"\n encoded_sentence = sentence.encode(\"utf-8\", \"ignore\")\n sentence_hash = hashlib.md5(encoded_sentence).hexdigest()\n\n return sentence_hash\n\n\ndef hash_from_path(path: Path) -> str:\n \"\"\"Returns hash from a given path.\n\n Simply removes extension and folder structure leaving the hash.\n\n Args:\n path: path to get hash from\n\n Returns:\n Hash reference for file.\n \"\"\"\n return path.with_suffix('').name\n\n\nclass AudioFile:\n def __init__(self, cache_dir: Path, sentence_hash: str, file_type: str):\n self.name = f\"{sentence_hash}.{file_type}\"\n self.path = cache_dir.joinpath(self.name)\n\n def save(self, audio: bytes):\n \"\"\"Write a TTS cache file containing the audio to be spoken.\n\n Args:\n audio: TTS inference of a sentence\n \"\"\"\n try:\n with open(self.path, \"wb\") as audio_file:\n audio_file.write(audio)\n except Exception:\n LOG.exception(\"Failed to write {} to cache\".format(self.name))\n\n def exists(self):\n return self.path.exists()\n\n\nclass PhonemeFile:\n def __init__(self, cache_dir: Path, sentence_hash: str):\n self.name = f\"{sentence_hash}.pho\"\n self.path = cache_dir.joinpath(self.name)\n\n def load(self) -> List:\n \"\"\"Load phonemes from cache file.\"\"\"\n phonemes = None\n if self.path.exists():\n try:\n with open(self.path) as phoneme_file:\n phonemes = phoneme_file.read().strip()\n except Exception:\n LOG.exception(\"Failed to read phoneme from cache\")\n\n return json.loads(phonemes)\n\n def save(self, phonemes):\n \"\"\"Write a TTS cache file containing the phoneme to be displayed.\n\n Args:\n phonemes: instructions for how to make the mouth on a device move\n \"\"\"\n try:\n rec = json.dumps(phonemes)\n with open(self.path, \"w\") as phoneme_file:\n phoneme_file.write(rec)\n except Exception:\n LOG.exception(\"Failed to write {} to cache\".format(self.name))\n\n def exists(self):\n return self.path.exists()\n\n\nclass TextToSpeechCache:\n \"\"\"Class for all persistent and temporary caching operations.\"\"\"\n def __init__(self, tts_config, tts_name, audio_file_type):\n self.config = tts_config\n self.tts_name = tts_name\n if \"preloaded_cache\" in self.config:\n self.persistent_cache_dir = Path(self.config[\"preloaded_cache\"])\n else:\n self.persistent_cache_dir = None\n self.temporary_cache_dir = Path(\n get_cache_directory(\"tts/\" + tts_name)\n )\n self.audio_file_type = audio_file_type\n self.resource_dir = Path(__file__).parent.parent.joinpath(\"res\")\n self.cached_sentences = dict()\n ensure_directory_exists(\n str(self.persistent_cache_dir), permissions=0o755\n )\n ensure_directory_exists(\n str(self.temporary_cache_dir), permissions=0o755\n )\n\n def __contains__(self, sha):\n \"\"\"The cache contains a SHA if it knows of it and it exists on disk.\"\"\"\n if sha not in self.cached_sentences:\n return False # Doesn't know of it\n else:\n # Audio file must exist, phonemes are optional.\n audio, phonemes = self.cached_sentences[sha]\n return (audio.exists() and\n (phonemes is None or phonemes.exists()))\n\n def load_persistent_cache(self):\n \"\"\"Load the contents of dialog files to the persistent cache directory.\n\n Parse the dialog files in the resource directory into sentences. Then\n add the audio for each sentence to the cache directory.\n\n NOTE: There may be files pre-loaded in the persistent cache directory\n prior to run time, such as pre-recorded audio files. This will add\n files that do not already exist.\n\n ANOTHER NOTE: Mimic2 is the only TTS engine that supports this. This\n logic will need to change if another TTS engine implements it.\n \"\"\"\n if self.persistent_cache_dir is not None:\n LOG.info(\"Adding dialog resources to persistent TTS cache...\")\n self._load_existing_audio_files()\n self._load_existing_phoneme_files()\n dialogs = self._collect_dialogs()\n sentences = self._parse_dialogs(dialogs)\n for sentence in sentences:\n self._load_sentence(sentence)\n LOG.info(\"Persistent TTS cache files added successfully.\")\n\n def _load_existing_audio_files(self):\n \"\"\"Find the TTS audio files already in the persistent cache.\"\"\"\n glob_pattern = \"*.\" + self.audio_file_type\n for file_path in self.persistent_cache_dir.glob(glob_pattern):\n sentence_hash = file_path.name.split(\".\")[0]\n audio_file = AudioFile(\n self.persistent_cache_dir, sentence_hash, self.audio_file_type\n )\n self.cached_sentences[sentence_hash] = audio_file, None\n\n def _load_existing_phoneme_files(self):\n \"\"\"Find the TTS phoneme files already in the persistent cache.\n\n A phoneme file is no good without an audio file to pair it with. If\n no audio file matches, do not load the phoneme.\n \"\"\"\n for file_path in self.persistent_cache_dir.glob(\"*.pho\"):\n sentence_hash = file_path.name.split(\".\")[0]\n cached_sentence = self.cached_sentences.get(sentence_hash)\n if cached_sentence is not None:\n audio_file = cached_sentence[0]\n phoneme_file = PhonemeFile(\n self.persistent_cache_dir, sentence_hash\n )\n self.cached_sentences[sentence_hash] = audio_file, phoneme_file\n\n def _collect_dialogs(self) -> List:\n \"\"\"Build a set of unique sentences from the dialog files.\n\n The sentences will be parsed from *.dialog files present in\n mycroft/res/text/en-us.\n \"\"\"\n dialogs = []\n dialog_directory = Path(self.resource_dir, \"text\", \"en-us\")\n for dialog_file_path in dialog_directory.glob(\"*.dialog\"):\n with open(dialog_file_path) as dialog_file:\n for dialog in dialog_file.readlines():\n dialogs.append(dialog.strip())\n\n return dialogs\n\n @staticmethod\n def _parse_dialogs(dialogs: List[str]) -> Set[str]:\n \"\"\"Split each dialog in the resources directory into sentences.\n\n Do not consider sentences with special characters other than\n punctuation\n example : <<< LOADING <<<\n\n Args:\n dialogs: a list of the records in the dialog resource files\n \"\"\"\n sentences = set()\n dialog_split_regex = r\"(?<=\\.|\\;|\\?)\\s\"\n special_characters_regex = re.compile(r\"[@#$%^*()<>/|}{~:]\")\n for dialog in dialogs:\n dialog_sentences = re.split(dialog_split_regex, dialog)\n for sentence in dialog_sentences:\n match = special_characters_regex.search(sentence)\n if match is None:\n sentences.add(sentence)\n\n return sentences\n\n def _load_sentence(self, sentence: str):\n \"\"\"Build audio and phoneme files for each sentence to be cached.\n\n Perform TTS inference on sentences parsed from dialog files. Store\n the results in the persistent cache directory.\n\n ASSUMPTION: The only TTS that supports persistent cache right now is\n Mimic2. This method assumes a call to the Mimic2 API. If other TTS\n engines want to take advantage of the persistent cache, this logic\n will need to be more dynamic.\n \"\"\"\n sentence_hash = hash_sentence(sentence)\n if sentence_hash not in self.cached_sentences:\n LOG.info(\"Adding \\\"{}\\\" to cache\".format(sentence))\n try:\n mimic2_url = self.config[\"url\"]\n audio, phonemes = _get_mimic2_audio(sentence, mimic2_url)\n except Exception:\n log_msg = \"Failed to get audio for sentence \\\"{}\\\"\"\n LOG.exception(log_msg.format(sentence))\n else:\n self._add_to_persistent_cache(sentence_hash, audio, phonemes)\n\n def _add_to_persistent_cache(\n self, sentence_hash: str, audio: bytes, phonemes: str\n ):\n \"\"\"Add a audio/phoneme file pair to the persistent cache.\"\"\"\n audio_file = AudioFile(\n self.persistent_cache_dir, sentence_hash, self.audio_file_type\n )\n audio_file.save(audio)\n if phonemes is None:\n phoneme_file = None\n else:\n phoneme_file = PhonemeFile(\n self.persistent_cache_dir, sentence_hash\n )\n phoneme_file.save(phonemes)\n self.cached_sentences[sentence_hash] = audio_file, phoneme_file\n\n def clear(self):\n \"\"\"Remove all files from the temporary cache.\"\"\"\n for cache_file_path in self.temporary_cache_dir.iterdir():\n if cache_file_path.is_dir():\n for sub_path in cache_file_path.iterdir():\n if sub_path.is_file():\n sub_path.unlink()\n elif cache_file_path.is_file():\n cache_file_path.unlink()\n\n def curate(self):\n \"\"\"Remove cache data if disk space is running low.\"\"\"\n files_removed = curate_cache(self.temporary_cache_dir,\n min_free_percent=100)\n\n hashes = set([hash_from_path(Path(path)) for path in files_removed])\n for sentence_hash in hashes:\n if sentence_hash in self.cached_sentences:\n self.cached_sentences.pop(sentence_hash)\n\n def define_audio_file(self, sentence_hash: str) -> AudioFile:\n \"\"\"Build an instance of an object representing an audio file.\"\"\"\n audio_file = AudioFile(\n self.temporary_cache_dir, sentence_hash, self.audio_file_type\n )\n return audio_file\n\n def define_phoneme_file(self, sentence_hash: str) -> PhonemeFile:\n \"\"\"Build an instance of an object representing an phoneme file.\"\"\"\n phoneme_file = PhonemeFile(self.temporary_cache_dir, sentence_hash)\n return phoneme_file\n", "path": "mycroft/tts/cache.py"}], "after_files": [{"content": "# Copyright 2021 Mycroft AI Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"TTS cache maintenance.\n\nThere are two types of cache available to a TTS engine. Both are comprised of\naudio and phoneme files. TTS engines can use the cache to improve performance\nby not performing inference on sentences in the cache.\n\nThe first type of cache is a persistent cache. The cache is considered\npersistent because the files are stored in a location that is not cleared on\nreboot. TTS inference on these sentences should only need to occur once. The\npersistent cache contains commonly spoken sentences.\n\nThe second cache type is a temporary cache stored in the /tmp directory,\nwhich is cleared when a device is rebooted. Sentences are added to this cache\non the fly every time a TTS engine returns audio for a sentence that is not\nalready cached.\n\"\"\"\nimport base64\nimport hashlib\nimport json\nimport re\nfrom pathlib import Path\nfrom typing import List, Set, Tuple\nfrom urllib import parse\n\nimport requests\n\nfrom mycroft.util.file_utils import (\n ensure_directory_exists, get_cache_directory, curate_cache\n)\nfrom mycroft.util.log import LOG\n\n\ndef _get_mimic2_audio(sentence: str, url: str) -> Tuple[bytes, str]:\n \"\"\"Use the Mimic2 API to retrieve the audio for a sentence.\n\n Args:\n sentence: The sentence to be cached\n \"\"\"\n LOG.debug(\"Retrieving Mimic2 audio for sentence \\\"{}\\'\".format(sentence))\n mimic2_url = url + parse.quote(sentence) + '&visimes=True'\n response = requests.get(mimic2_url)\n response_data = response.json()\n audio = base64.b64decode(response_data[\"audio_base64\"])\n phonemes = response_data[\"visimes\"]\n\n return audio, phonemes\n\n\ndef hash_sentence(sentence: str):\n \"\"\"Convert the sentence into a hash value used for the file name\n\n Args:\n sentence: The sentence to be cached\n \"\"\"\n encoded_sentence = sentence.encode(\"utf-8\", \"ignore\")\n sentence_hash = hashlib.md5(encoded_sentence).hexdigest()\n\n return sentence_hash\n\n\ndef hash_from_path(path: Path) -> str:\n \"\"\"Returns hash from a given path.\n\n Simply removes extension and folder structure leaving the hash.\n\n Args:\n path: path to get hash from\n\n Returns:\n Hash reference for file.\n \"\"\"\n return path.with_suffix('').name\n\n\nclass AudioFile:\n def __init__(self, cache_dir: Path, sentence_hash: str, file_type: str):\n self.name = f\"{sentence_hash}.{file_type}\"\n self.path = cache_dir.joinpath(self.name)\n\n def save(self, audio: bytes):\n \"\"\"Write a TTS cache file containing the audio to be spoken.\n\n Args:\n audio: TTS inference of a sentence\n \"\"\"\n try:\n with open(self.path, \"wb\") as audio_file:\n audio_file.write(audio)\n except Exception:\n LOG.exception(\"Failed to write {} to cache\".format(self.name))\n\n def exists(self):\n return self.path.exists()\n\n\nclass PhonemeFile:\n def __init__(self, cache_dir: Path, sentence_hash: str):\n self.name = f\"{sentence_hash}.pho\"\n self.path = cache_dir.joinpath(self.name)\n\n def load(self) -> List:\n \"\"\"Load phonemes from cache file.\"\"\"\n phonemes = None\n if self.path.exists():\n try:\n with open(self.path) as phoneme_file:\n phonemes = phoneme_file.read().strip()\n except Exception:\n LOG.exception(\"Failed to read phoneme from cache\")\n\n return json.loads(phonemes)\n\n def save(self, phonemes):\n \"\"\"Write a TTS cache file containing the phoneme to be displayed.\n\n Args:\n phonemes: instructions for how to make the mouth on a device move\n \"\"\"\n try:\n rec = json.dumps(phonemes)\n with open(self.path, \"w\") as phoneme_file:\n phoneme_file.write(rec)\n except Exception:\n LOG.exception(\"Failed to write {} to cache\".format(self.name))\n\n def exists(self):\n return self.path.exists()\n\n\nclass TextToSpeechCache:\n \"\"\"Class for all persistent and temporary caching operations.\"\"\"\n def __init__(self, tts_config, tts_name, audio_file_type):\n self.config = tts_config\n self.tts_name = tts_name\n if \"preloaded_cache\" in self.config:\n self.persistent_cache_dir = Path(self.config[\"preloaded_cache\"])\n ensure_directory_exists(\n str(self.persistent_cache_dir), permissions=0o755\n )\n else:\n self.persistent_cache_dir = None\n self.temporary_cache_dir = Path(\n get_cache_directory(\"tts/\" + tts_name)\n )\n ensure_directory_exists(\n str(self.temporary_cache_dir), permissions=0o755\n )\n self.audio_file_type = audio_file_type\n self.resource_dir = Path(__file__).parent.parent.joinpath(\"res\")\n self.cached_sentences = dict()\n\n def __contains__(self, sha):\n \"\"\"The cache contains a SHA if it knows of it and it exists on disk.\"\"\"\n if sha not in self.cached_sentences:\n return False # Doesn't know of it\n else:\n # Audio file must exist, phonemes are optional.\n audio, phonemes = self.cached_sentences[sha]\n return (audio.exists() and\n (phonemes is None or phonemes.exists()))\n\n def load_persistent_cache(self):\n \"\"\"Load the contents of dialog files to the persistent cache directory.\n\n Parse the dialog files in the resource directory into sentences. Then\n add the audio for each sentence to the cache directory.\n\n NOTE: There may be files pre-loaded in the persistent cache directory\n prior to run time, such as pre-recorded audio files. This will add\n files that do not already exist.\n\n ANOTHER NOTE: Mimic2 is the only TTS engine that supports this. This\n logic will need to change if another TTS engine implements it.\n \"\"\"\n if self.persistent_cache_dir is not None:\n LOG.info(\"Adding dialog resources to persistent TTS cache...\")\n self._load_existing_audio_files()\n self._load_existing_phoneme_files()\n dialogs = self._collect_dialogs()\n sentences = self._parse_dialogs(dialogs)\n for sentence in sentences:\n self._load_sentence(sentence)\n LOG.info(\"Persistent TTS cache files added successfully.\")\n\n def _load_existing_audio_files(self):\n \"\"\"Find the TTS audio files already in the persistent cache.\"\"\"\n glob_pattern = \"*.\" + self.audio_file_type\n for file_path in self.persistent_cache_dir.glob(glob_pattern):\n sentence_hash = file_path.name.split(\".\")[0]\n audio_file = AudioFile(\n self.persistent_cache_dir, sentence_hash, self.audio_file_type\n )\n self.cached_sentences[sentence_hash] = audio_file, None\n\n def _load_existing_phoneme_files(self):\n \"\"\"Find the TTS phoneme files already in the persistent cache.\n\n A phoneme file is no good without an audio file to pair it with. If\n no audio file matches, do not load the phoneme.\n \"\"\"\n for file_path in self.persistent_cache_dir.glob(\"*.pho\"):\n sentence_hash = file_path.name.split(\".\")[0]\n cached_sentence = self.cached_sentences.get(sentence_hash)\n if cached_sentence is not None:\n audio_file = cached_sentence[0]\n phoneme_file = PhonemeFile(\n self.persistent_cache_dir, sentence_hash\n )\n self.cached_sentences[sentence_hash] = audio_file, phoneme_file\n\n def _collect_dialogs(self) -> List:\n \"\"\"Build a set of unique sentences from the dialog files.\n\n The sentences will be parsed from *.dialog files present in\n mycroft/res/text/en-us.\n \"\"\"\n dialogs = []\n dialog_directory = Path(self.resource_dir, \"text\", \"en-us\")\n for dialog_file_path in dialog_directory.glob(\"*.dialog\"):\n with open(dialog_file_path) as dialog_file:\n for dialog in dialog_file.readlines():\n dialogs.append(dialog.strip())\n\n return dialogs\n\n @staticmethod\n def _parse_dialogs(dialogs: List[str]) -> Set[str]:\n \"\"\"Split each dialog in the resources directory into sentences.\n\n Do not consider sentences with special characters other than\n punctuation\n example : <<< LOADING <<<\n\n Args:\n dialogs: a list of the records in the dialog resource files\n \"\"\"\n sentences = set()\n dialog_split_regex = r\"(?<=\\.|\\;|\\?)\\s\"\n special_characters_regex = re.compile(r\"[@#$%^*()<>/|}{~:]\")\n for dialog in dialogs:\n dialog_sentences = re.split(dialog_split_regex, dialog)\n for sentence in dialog_sentences:\n match = special_characters_regex.search(sentence)\n if match is None:\n sentences.add(sentence)\n\n return sentences\n\n def _load_sentence(self, sentence: str):\n \"\"\"Build audio and phoneme files for each sentence to be cached.\n\n Perform TTS inference on sentences parsed from dialog files. Store\n the results in the persistent cache directory.\n\n ASSUMPTION: The only TTS that supports persistent cache right now is\n Mimic2. This method assumes a call to the Mimic2 API. If other TTS\n engines want to take advantage of the persistent cache, this logic\n will need to be more dynamic.\n \"\"\"\n sentence_hash = hash_sentence(sentence)\n if sentence_hash not in self.cached_sentences:\n LOG.info(\"Adding \\\"{}\\\" to cache\".format(sentence))\n try:\n mimic2_url = self.config[\"url\"]\n audio, phonemes = _get_mimic2_audio(sentence, mimic2_url)\n except Exception:\n log_msg = \"Failed to get audio for sentence \\\"{}\\\"\"\n LOG.exception(log_msg.format(sentence))\n else:\n self._add_to_persistent_cache(sentence_hash, audio, phonemes)\n\n def _add_to_persistent_cache(\n self, sentence_hash: str, audio: bytes, phonemes: str\n ):\n \"\"\"Add a audio/phoneme file pair to the persistent cache.\"\"\"\n audio_file = AudioFile(\n self.persistent_cache_dir, sentence_hash, self.audio_file_type\n )\n audio_file.save(audio)\n if phonemes is None:\n phoneme_file = None\n else:\n phoneme_file = PhonemeFile(\n self.persistent_cache_dir, sentence_hash\n )\n phoneme_file.save(phonemes)\n self.cached_sentences[sentence_hash] = audio_file, phoneme_file\n\n def clear(self):\n \"\"\"Remove all files from the temporary cache.\"\"\"\n for cache_file_path in self.temporary_cache_dir.iterdir():\n if cache_file_path.is_dir():\n for sub_path in cache_file_path.iterdir():\n if sub_path.is_file():\n sub_path.unlink()\n elif cache_file_path.is_file():\n cache_file_path.unlink()\n\n def curate(self):\n \"\"\"Remove cache data if disk space is running low.\"\"\"\n files_removed = curate_cache(self.temporary_cache_dir,\n min_free_percent=100)\n\n hashes = set([hash_from_path(Path(path)) for path in files_removed])\n for sentence_hash in hashes:\n if sentence_hash in self.cached_sentences:\n self.cached_sentences.pop(sentence_hash)\n\n def define_audio_file(self, sentence_hash: str) -> AudioFile:\n \"\"\"Build an instance of an object representing an audio file.\"\"\"\n audio_file = AudioFile(\n self.temporary_cache_dir, sentence_hash, self.audio_file_type\n )\n return audio_file\n\n def define_phoneme_file(self, sentence_hash: str) -> PhonemeFile:\n \"\"\"Build an instance of an object representing an phoneme file.\"\"\"\n phoneme_file = PhonemeFile(self.temporary_cache_dir, sentence_hash)\n return phoneme_file\n", "path": "mycroft/tts/cache.py"}]}
| 3,984 | 295 |
gh_patches_debug_1921
|
rasdani/github-patches
|
git_diff
|
nipy__nipype-2827
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Python 3.4 tests failing on Travis
### Summary
Looks like either a pytest or a pytest-xdist problem. Perhaps one of them stopped supporting 3.4.
From [#6217.17](https://travis-ci.org/nipy/nipype/jobs/467617939):
```
$ py.test -v --cov nipype --cov-config .coveragerc --cov-report xml:cov.xml -c nipype/pytest.ini --doctest-modules nipype
Traceback (most recent call last):
File "/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/_pytest/vendored_packages/pluggy.py", line 510, in load_setuptools_entrypoints
plugin = ep.load()
File "/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/pkg_resources/__init__.py", line 2301, in load
self.require(*args, **kwargs)
File "/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/pkg_resources/__init__.py", line 2324, in require
items = working_set.resolve(reqs, env, installer, extras=self.extras)
File "/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/pkg_resources/__init__.py", line 859, in resolve
raise VersionConflict(dist, req).with_context(dependent_req)
pkg_resources.VersionConflict: (pytest 3.0.7 (/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages), Requirement.parse('pytest>=3.6.0'))
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/travis/virtualenv/python3.4.6/bin/py.test", line 11, in <module>
sys.exit(main())
File "/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/_pytest/config.py", line 47, in main
config = _prepareconfig(args, plugins)
File "/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/_pytest/config.py", line 156, in _prepareconfig
pluginmanager=pluginmanager, args=args)
File "/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/_pytest/vendored_packages/pluggy.py", line 745, in __call__
return self._hookexec(self, self._nonwrappers + self._wrappers, kwargs)
File "/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/_pytest/vendored_packages/pluggy.py", line 339, in _hookexec
return self._inner_hookexec(hook, methods, kwargs)
File "/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/_pytest/vendored_packages/pluggy.py", line 334, in <lambda>
_MultiCall(methods, kwargs, hook.spec_opts).execute()
File "/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/_pytest/vendored_packages/pluggy.py", line 613, in execute
return _wrapped_call(hook_impl.function(*args), self.execute)
File "/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/_pytest/vendored_packages/pluggy.py", line 250, in _wrapped_call
wrap_controller.send(call_outcome)
File "/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/_pytest/helpconfig.py", line 32, in pytest_cmdline_parse
config = outcome.get_result()
File "/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/_pytest/vendored_packages/pluggy.py", line 279, in get_result
raise ex[1].with_traceback(ex[2])
File "/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/_pytest/vendored_packages/pluggy.py", line 265, in __init__
self.result = func()
File "/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/_pytest/vendored_packages/pluggy.py", line 614, in execute
res = hook_impl.function(*args)
File "/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/_pytest/config.py", line 924, in pytest_cmdline_parse
self.parse(args)
File "/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/_pytest/config.py", line 1082, in parse
self._preparse(args, addopts=addopts)
File "/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/_pytest/config.py", line 1044, in _preparse
self.pluginmanager.load_setuptools_entrypoints(entrypoint_name)
File "/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/_pytest/vendored_packages/pluggy.py", line 515, in load_setuptools_entrypoints
"Plugin %r could not be loaded: %s!" % (ep.name, e))
_pytest.vendored_packages.pluggy.PluginValidationError: Plugin 'xdist' could not be loaded: (pytest 3.0.7 (/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages), Requirement.parse('pytest>=3.6.0'))!
```
### Platform details:
Travis. Python 3.4.
### Execution environment
Choose one
- Travis environment (Python 3.4)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nipype/info.py`
Content:
```
1 """ This file contains defines parameters for nipy that we use to fill
2 settings in setup.py, the nipy top-level docstring, and for building the
3 docs. In setup.py in particular, we exec this file, so it cannot import nipy
4 """
5 from __future__ import (print_function, division, unicode_literals,
6 absolute_import)
7
8 import sys
9
10 # nipype version information. An empty version_extra corresponds to a
11 # full release. '.dev' as a version_extra string means this is a development
12 # version
13 # Remove -dev for release
14 __version__ = '1.1.7-dev'
15
16
17 def get_nipype_gitversion():
18 """Nipype version as reported by the last commit in git
19
20 Returns
21 -------
22 None or str
23 Version of Nipype according to git.
24 """
25 import os
26 import subprocess
27 try:
28 import nipype
29 gitpath = os.path.realpath(
30 os.path.join(os.path.dirname(nipype.__file__), os.path.pardir))
31 except:
32 gitpath = os.getcwd()
33 gitpathgit = os.path.join(gitpath, '.git')
34 if not os.path.exists(gitpathgit):
35 return None
36 ver = None
37 try:
38 o, _ = subprocess.Popen(
39 'git describe', shell=True, cwd=gitpath,
40 stdout=subprocess.PIPE).communicate()
41 except Exception:
42 pass
43 else:
44 ver = o.decode().strip().split('-')[-1]
45 return ver
46
47
48 if __version__.endswith('-dev'):
49 gitversion = get_nipype_gitversion()
50 if gitversion:
51 __version__ = '{}+{}'.format(__version__, gitversion)
52
53 CLASSIFIERS = [
54 'Development Status :: 5 - Production/Stable', 'Environment :: Console',
55 'Intended Audience :: Science/Research',
56 'License :: OSI Approved :: Apache Software License',
57 'Operating System :: MacOS :: MacOS X',
58 'Operating System :: POSIX :: Linux',
59 'Programming Language :: Python :: 2.7',
60 'Programming Language :: Python :: 3.4',
61 'Programming Language :: Python :: 3.5',
62 'Programming Language :: Python :: 3.6', 'Topic :: Scientific/Engineering'
63 ]
64
65 description = 'Neuroimaging in Python: Pipelines and Interfaces'
66
67 # Note: this long_description is actually a copy/paste from the top-level
68 # README.txt, so that it shows up nicely on PyPI. So please remember to edit
69 # it only in one place and sync it correctly.
70 long_description = """========================================================
71 NIPYPE: Neuroimaging in Python: Pipelines and Interfaces
72 ========================================================
73
74 Current neuroimaging software offer users an incredible opportunity to
75 analyze data using a variety of different algorithms. However, this has
76 resulted in a heterogeneous collection of specialized applications
77 without transparent interoperability or a uniform operating interface.
78
79 *Nipype*, an open-source, community-developed initiative under the
80 umbrella of `NiPy <http://nipy.org>`_, is a Python project that provides a
81 uniform interface to existing neuroimaging software and facilitates interaction
82 between these packages within a single workflow. Nipype provides an environment
83 that encourages interactive exploration of algorithms from different
84 packages (e.g., AFNI, ANTS, BRAINS, BrainSuite, Camino, FreeSurfer, FSL, MNE,
85 MRtrix, MNE, Nipy, Slicer, SPM), eases the design of workflows within and
86 between packages, and reduces the learning curve necessary to use different \
87 packages. Nipype is creating a collaborative platform for neuroimaging \
88 software development in a high-level language and addressing limitations of \
89 existing pipeline systems.
90
91 *Nipype* allows you to:
92
93 * easily interact with tools from different software packages
94 * combine processing steps from different software packages
95 * develop new workflows faster by reusing common steps from old ones
96 * process data faster by running it in parallel on many cores/machines
97 * make your research easily reproducible
98 * share your processing workflows with the community
99 """
100
101 # versions
102 NIBABEL_MIN_VERSION = '2.1.0'
103 NETWORKX_MIN_VERSION = '1.9'
104 NUMPY_MIN_VERSION = '1.9.0'
105 # Numpy bug in python 3.7:
106 # https://www.opensourceanswers.com/blog/you-shouldnt-use-python-37-for-data-science-right-now.html
107 NUMPY_MIN_VERSION_37 = '1.15.3'
108 SCIPY_MIN_VERSION = '0.14'
109 TRAITS_MIN_VERSION = '4.6'
110 DATEUTIL_MIN_VERSION = '2.2'
111 PYTEST_MIN_VERSION = '3.0'
112 FUTURE_MIN_VERSION = '0.16.0'
113 SIMPLEJSON_MIN_VERSION = '3.8.0'
114 PROV_VERSION = '1.5.2'
115 CLICK_MIN_VERSION = '6.6.0'
116 PYDOT_MIN_VERSION = '1.2.3'
117
118 NAME = 'nipype'
119 MAINTAINER = 'nipype developers'
120 MAINTAINER_EMAIL = '[email protected]'
121 DESCRIPTION = description
122 LONG_DESCRIPTION = long_description
123 URL = 'http://nipy.org/nipype'
124 DOWNLOAD_URL = 'http://github.com/nipy/nipype/archives/master'
125 LICENSE = 'Apache License, 2.0'
126 AUTHOR = 'nipype developers'
127 AUTHOR_EMAIL = '[email protected]'
128 PLATFORMS = 'OS Independent'
129 MAJOR = __version__.split('.')[0]
130 MINOR = __version__.split('.')[1]
131 MICRO = __version__.replace('-', '.').split('.')[2]
132 ISRELEASE = (len(__version__.replace('-', '.').split('.')) == 3
133 or 'post' in __version__.replace('-', '.').split('.')[-1])
134 VERSION = __version__
135 PROVIDES = ['nipype']
136 REQUIRES = [
137 'nibabel>=%s' % NIBABEL_MIN_VERSION,
138 'networkx>=%s' % NETWORKX_MIN_VERSION,
139 'numpy>=%s ; python_version < "3.7"' % NUMPY_MIN_VERSION,
140 'numpy>=%s ; python_version >= "3.7"' % NUMPY_MIN_VERSION_37,
141 'python-dateutil>=%s' % DATEUTIL_MIN_VERSION,
142 'scipy>=%s' % SCIPY_MIN_VERSION,
143 'traits>=%s' % TRAITS_MIN_VERSION,
144 'future>=%s' % FUTURE_MIN_VERSION,
145 'simplejson>=%s' % SIMPLEJSON_MIN_VERSION,
146 'prov>=%s' % PROV_VERSION,
147 'neurdflib',
148 'click>=%s' % CLICK_MIN_VERSION,
149 'funcsigs',
150 'pytest>=%s' % PYTEST_MIN_VERSION,
151 'pytest-xdist',
152 'mock',
153 'pydotplus',
154 'pydot>=%s' % PYDOT_MIN_VERSION,
155 'packaging',
156 'futures; python_version == "2.7"',
157 ]
158
159 if sys.version_info <= (3, 4):
160 REQUIRES.append('configparser')
161
162 TESTS_REQUIRES = ['pytest-cov', 'codecov', 'pytest-env', 'coverage<5']
163
164 EXTRA_REQUIRES = {
165 'doc': ['Sphinx>=1.4', 'numpydoc', 'matplotlib', 'pydotplus', 'pydot>=1.2.3'],
166 'tests': TESTS_REQUIRES,
167 'specs': ['yapf'],
168 'nipy': ['nitime', 'nilearn<0.5.0', 'dipy', 'nipy', 'matplotlib'],
169 'profiler': ['psutil>=5.0'],
170 'duecredit': ['duecredit'],
171 'xvfbwrapper': ['xvfbwrapper'],
172 'pybids': ['pybids==0.6.5'],
173 'ssh': ['paramiko'],
174 # 'mesh': ['mayavi'] # Enable when it works
175 }
176
177
178 def _list_union(iterable):
179 return list(set(sum(iterable, [])))
180
181
182 # Enable a handle to install all extra dependencies at once
183 EXTRA_REQUIRES['all'] = _list_union(EXTRA_REQUIRES.values())
184 # dev = doc + tests + specs
185 EXTRA_REQUIRES['dev'] = _list_union(val for key, val in EXTRA_REQUIRES.items()
186 if key in ('doc', 'tests', 'specs'))
187
188 STATUS = 'stable'
189
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nipype/info.py b/nipype/info.py
--- a/nipype/info.py
+++ b/nipype/info.py
@@ -108,7 +108,7 @@
SCIPY_MIN_VERSION = '0.14'
TRAITS_MIN_VERSION = '4.6'
DATEUTIL_MIN_VERSION = '2.2'
-PYTEST_MIN_VERSION = '3.0'
+PYTEST_MIN_VERSION = '3.6'
FUTURE_MIN_VERSION = '0.16.0'
SIMPLEJSON_MIN_VERSION = '3.8.0'
PROV_VERSION = '1.5.2'
|
{"golden_diff": "diff --git a/nipype/info.py b/nipype/info.py\n--- a/nipype/info.py\n+++ b/nipype/info.py\n@@ -108,7 +108,7 @@\n SCIPY_MIN_VERSION = '0.14'\n TRAITS_MIN_VERSION = '4.6'\n DATEUTIL_MIN_VERSION = '2.2'\n-PYTEST_MIN_VERSION = '3.0'\n+PYTEST_MIN_VERSION = '3.6'\n FUTURE_MIN_VERSION = '0.16.0'\n SIMPLEJSON_MIN_VERSION = '3.8.0'\n PROV_VERSION = '1.5.2'\n", "issue": "Python 3.4 tests failing on Travis\n### Summary\r\n\r\nLooks like either a pytest or a pytest-xdist problem. Perhaps one of them stopped supporting 3.4.\r\n\r\nFrom [#6217.17](https://travis-ci.org/nipy/nipype/jobs/467617939):\r\n\r\n```\r\n$ py.test -v --cov nipype --cov-config .coveragerc --cov-report xml:cov.xml -c nipype/pytest.ini --doctest-modules nipype\r\nTraceback (most recent call last):\r\n File \"/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/_pytest/vendored_packages/pluggy.py\", line 510, in load_setuptools_entrypoints\r\n plugin = ep.load()\r\n File \"/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/pkg_resources/__init__.py\", line 2301, in load\r\n self.require(*args, **kwargs)\r\n File \"/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/pkg_resources/__init__.py\", line 2324, in require\r\n items = working_set.resolve(reqs, env, installer, extras=self.extras)\r\n File \"/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/pkg_resources/__init__.py\", line 859, in resolve\r\n raise VersionConflict(dist, req).with_context(dependent_req)\r\npkg_resources.VersionConflict: (pytest 3.0.7 (/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages), Requirement.parse('pytest>=3.6.0'))\r\nDuring handling of the above exception, another exception occurred:\r\nTraceback (most recent call last):\r\n File \"/home/travis/virtualenv/python3.4.6/bin/py.test\", line 11, in <module>\r\n sys.exit(main())\r\n File \"/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/_pytest/config.py\", line 47, in main\r\n config = _prepareconfig(args, plugins)\r\n File \"/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/_pytest/config.py\", line 156, in _prepareconfig\r\n pluginmanager=pluginmanager, args=args)\r\n File \"/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/_pytest/vendored_packages/pluggy.py\", line 745, in __call__\r\n return self._hookexec(self, self._nonwrappers + self._wrappers, kwargs)\r\n File \"/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/_pytest/vendored_packages/pluggy.py\", line 339, in _hookexec\r\n return self._inner_hookexec(hook, methods, kwargs)\r\n File \"/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/_pytest/vendored_packages/pluggy.py\", line 334, in <lambda>\r\n _MultiCall(methods, kwargs, hook.spec_opts).execute()\r\n File \"/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/_pytest/vendored_packages/pluggy.py\", line 613, in execute\r\n return _wrapped_call(hook_impl.function(*args), self.execute)\r\n File \"/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/_pytest/vendored_packages/pluggy.py\", line 250, in _wrapped_call\r\n wrap_controller.send(call_outcome)\r\n File \"/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/_pytest/helpconfig.py\", line 32, in pytest_cmdline_parse\r\n config = outcome.get_result()\r\n File \"/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/_pytest/vendored_packages/pluggy.py\", line 279, in get_result\r\n raise ex[1].with_traceback(ex[2])\r\n File \"/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/_pytest/vendored_packages/pluggy.py\", line 265, in __init__\r\n self.result = func()\r\n File \"/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/_pytest/vendored_packages/pluggy.py\", line 614, in execute\r\n res = hook_impl.function(*args)\r\n File \"/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/_pytest/config.py\", line 924, in pytest_cmdline_parse\r\n self.parse(args)\r\n File \"/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/_pytest/config.py\", line 1082, in parse\r\n self._preparse(args, addopts=addopts)\r\n File \"/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/_pytest/config.py\", line 1044, in _preparse\r\n self.pluginmanager.load_setuptools_entrypoints(entrypoint_name)\r\n File \"/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages/_pytest/vendored_packages/pluggy.py\", line 515, in load_setuptools_entrypoints\r\n \"Plugin %r could not be loaded: %s!\" % (ep.name, e))\r\n_pytest.vendored_packages.pluggy.PluginValidationError: Plugin 'xdist' could not be loaded: (pytest 3.0.7 (/home/travis/virtualenv/python3.4.6/lib/python3.4/site-packages), Requirement.parse('pytest>=3.6.0'))!\r\n```\r\n\r\n### Platform details:\r\n\r\nTravis. Python 3.4.\r\n\r\n### Execution environment\r\n\r\nChoose one\r\n- Travis environment (Python 3.4)\r\n\n", "before_files": [{"content": "\"\"\" This file contains defines parameters for nipy that we use to fill\nsettings in setup.py, the nipy top-level docstring, and for building the\ndocs. In setup.py in particular, we exec this file, so it cannot import nipy\n\"\"\"\nfrom __future__ import (print_function, division, unicode_literals,\n absolute_import)\n\nimport sys\n\n# nipype version information. An empty version_extra corresponds to a\n# full release. '.dev' as a version_extra string means this is a development\n# version\n# Remove -dev for release\n__version__ = '1.1.7-dev'\n\n\ndef get_nipype_gitversion():\n \"\"\"Nipype version as reported by the last commit in git\n\n Returns\n -------\n None or str\n Version of Nipype according to git.\n \"\"\"\n import os\n import subprocess\n try:\n import nipype\n gitpath = os.path.realpath(\n os.path.join(os.path.dirname(nipype.__file__), os.path.pardir))\n except:\n gitpath = os.getcwd()\n gitpathgit = os.path.join(gitpath, '.git')\n if not os.path.exists(gitpathgit):\n return None\n ver = None\n try:\n o, _ = subprocess.Popen(\n 'git describe', shell=True, cwd=gitpath,\n stdout=subprocess.PIPE).communicate()\n except Exception:\n pass\n else:\n ver = o.decode().strip().split('-')[-1]\n return ver\n\n\nif __version__.endswith('-dev'):\n gitversion = get_nipype_gitversion()\n if gitversion:\n __version__ = '{}+{}'.format(__version__, gitversion)\n\nCLASSIFIERS = [\n 'Development Status :: 5 - Production/Stable', 'Environment :: Console',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: Apache Software License',\n 'Operating System :: MacOS :: MacOS X',\n 'Operating System :: POSIX :: Linux',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6', 'Topic :: Scientific/Engineering'\n]\n\ndescription = 'Neuroimaging in Python: Pipelines and Interfaces'\n\n# Note: this long_description is actually a copy/paste from the top-level\n# README.txt, so that it shows up nicely on PyPI. So please remember to edit\n# it only in one place and sync it correctly.\nlong_description = \"\"\"========================================================\nNIPYPE: Neuroimaging in Python: Pipelines and Interfaces\n========================================================\n\nCurrent neuroimaging software offer users an incredible opportunity to\nanalyze data using a variety of different algorithms. However, this has\nresulted in a heterogeneous collection of specialized applications\nwithout transparent interoperability or a uniform operating interface.\n\n*Nipype*, an open-source, community-developed initiative under the\numbrella of `NiPy <http://nipy.org>`_, is a Python project that provides a\nuniform interface to existing neuroimaging software and facilitates interaction\nbetween these packages within a single workflow. Nipype provides an environment\nthat encourages interactive exploration of algorithms from different\npackages (e.g., AFNI, ANTS, BRAINS, BrainSuite, Camino, FreeSurfer, FSL, MNE,\nMRtrix, MNE, Nipy, Slicer, SPM), eases the design of workflows within and\nbetween packages, and reduces the learning curve necessary to use different \\\npackages. Nipype is creating a collaborative platform for neuroimaging \\\nsoftware development in a high-level language and addressing limitations of \\\nexisting pipeline systems.\n\n*Nipype* allows you to:\n\n* easily interact with tools from different software packages\n* combine processing steps from different software packages\n* develop new workflows faster by reusing common steps from old ones\n* process data faster by running it in parallel on many cores/machines\n* make your research easily reproducible\n* share your processing workflows with the community\n\"\"\"\n\n# versions\nNIBABEL_MIN_VERSION = '2.1.0'\nNETWORKX_MIN_VERSION = '1.9'\nNUMPY_MIN_VERSION = '1.9.0'\n# Numpy bug in python 3.7:\n# https://www.opensourceanswers.com/blog/you-shouldnt-use-python-37-for-data-science-right-now.html\nNUMPY_MIN_VERSION_37 = '1.15.3'\nSCIPY_MIN_VERSION = '0.14'\nTRAITS_MIN_VERSION = '4.6'\nDATEUTIL_MIN_VERSION = '2.2'\nPYTEST_MIN_VERSION = '3.0'\nFUTURE_MIN_VERSION = '0.16.0'\nSIMPLEJSON_MIN_VERSION = '3.8.0'\nPROV_VERSION = '1.5.2'\nCLICK_MIN_VERSION = '6.6.0'\nPYDOT_MIN_VERSION = '1.2.3'\n\nNAME = 'nipype'\nMAINTAINER = 'nipype developers'\nMAINTAINER_EMAIL = '[email protected]'\nDESCRIPTION = description\nLONG_DESCRIPTION = long_description\nURL = 'http://nipy.org/nipype'\nDOWNLOAD_URL = 'http://github.com/nipy/nipype/archives/master'\nLICENSE = 'Apache License, 2.0'\nAUTHOR = 'nipype developers'\nAUTHOR_EMAIL = '[email protected]'\nPLATFORMS = 'OS Independent'\nMAJOR = __version__.split('.')[0]\nMINOR = __version__.split('.')[1]\nMICRO = __version__.replace('-', '.').split('.')[2]\nISRELEASE = (len(__version__.replace('-', '.').split('.')) == 3\n or 'post' in __version__.replace('-', '.').split('.')[-1])\nVERSION = __version__\nPROVIDES = ['nipype']\nREQUIRES = [\n 'nibabel>=%s' % NIBABEL_MIN_VERSION,\n 'networkx>=%s' % NETWORKX_MIN_VERSION,\n 'numpy>=%s ; python_version < \"3.7\"' % NUMPY_MIN_VERSION,\n 'numpy>=%s ; python_version >= \"3.7\"' % NUMPY_MIN_VERSION_37,\n 'python-dateutil>=%s' % DATEUTIL_MIN_VERSION,\n 'scipy>=%s' % SCIPY_MIN_VERSION,\n 'traits>=%s' % TRAITS_MIN_VERSION,\n 'future>=%s' % FUTURE_MIN_VERSION,\n 'simplejson>=%s' % SIMPLEJSON_MIN_VERSION,\n 'prov>=%s' % PROV_VERSION,\n 'neurdflib',\n 'click>=%s' % CLICK_MIN_VERSION,\n 'funcsigs',\n 'pytest>=%s' % PYTEST_MIN_VERSION,\n 'pytest-xdist',\n 'mock',\n 'pydotplus',\n 'pydot>=%s' % PYDOT_MIN_VERSION,\n 'packaging',\n 'futures; python_version == \"2.7\"',\n]\n\nif sys.version_info <= (3, 4):\n REQUIRES.append('configparser')\n\nTESTS_REQUIRES = ['pytest-cov', 'codecov', 'pytest-env', 'coverage<5']\n\nEXTRA_REQUIRES = {\n 'doc': ['Sphinx>=1.4', 'numpydoc', 'matplotlib', 'pydotplus', 'pydot>=1.2.3'],\n 'tests': TESTS_REQUIRES,\n 'specs': ['yapf'],\n 'nipy': ['nitime', 'nilearn<0.5.0', 'dipy', 'nipy', 'matplotlib'],\n 'profiler': ['psutil>=5.0'],\n 'duecredit': ['duecredit'],\n 'xvfbwrapper': ['xvfbwrapper'],\n 'pybids': ['pybids==0.6.5'],\n 'ssh': ['paramiko'],\n # 'mesh': ['mayavi'] # Enable when it works\n}\n\n\ndef _list_union(iterable):\n return list(set(sum(iterable, [])))\n\n\n# Enable a handle to install all extra dependencies at once\nEXTRA_REQUIRES['all'] = _list_union(EXTRA_REQUIRES.values())\n# dev = doc + tests + specs\nEXTRA_REQUIRES['dev'] = _list_union(val for key, val in EXTRA_REQUIRES.items()\n if key in ('doc', 'tests', 'specs'))\n\nSTATUS = 'stable'\n", "path": "nipype/info.py"}], "after_files": [{"content": "\"\"\" This file contains defines parameters for nipy that we use to fill\nsettings in setup.py, the nipy top-level docstring, and for building the\ndocs. In setup.py in particular, we exec this file, so it cannot import nipy\n\"\"\"\nfrom __future__ import (print_function, division, unicode_literals,\n absolute_import)\n\nimport sys\n\n# nipype version information. An empty version_extra corresponds to a\n# full release. '.dev' as a version_extra string means this is a development\n# version\n# Remove -dev for release\n__version__ = '1.1.7-dev'\n\n\ndef get_nipype_gitversion():\n \"\"\"Nipype version as reported by the last commit in git\n\n Returns\n -------\n None or str\n Version of Nipype according to git.\n \"\"\"\n import os\n import subprocess\n try:\n import nipype\n gitpath = os.path.realpath(\n os.path.join(os.path.dirname(nipype.__file__), os.path.pardir))\n except:\n gitpath = os.getcwd()\n gitpathgit = os.path.join(gitpath, '.git')\n if not os.path.exists(gitpathgit):\n return None\n ver = None\n try:\n o, _ = subprocess.Popen(\n 'git describe', shell=True, cwd=gitpath,\n stdout=subprocess.PIPE).communicate()\n except Exception:\n pass\n else:\n ver = o.decode().strip().split('-')[-1]\n return ver\n\n\nif __version__.endswith('-dev'):\n gitversion = get_nipype_gitversion()\n if gitversion:\n __version__ = '{}+{}'.format(__version__, gitversion)\n\nCLASSIFIERS = [\n 'Development Status :: 5 - Production/Stable', 'Environment :: Console',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: Apache Software License',\n 'Operating System :: MacOS :: MacOS X',\n 'Operating System :: POSIX :: Linux',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6', 'Topic :: Scientific/Engineering'\n]\n\ndescription = 'Neuroimaging in Python: Pipelines and Interfaces'\n\n# Note: this long_description is actually a copy/paste from the top-level\n# README.txt, so that it shows up nicely on PyPI. So please remember to edit\n# it only in one place and sync it correctly.\nlong_description = \"\"\"========================================================\nNIPYPE: Neuroimaging in Python: Pipelines and Interfaces\n========================================================\n\nCurrent neuroimaging software offer users an incredible opportunity to\nanalyze data using a variety of different algorithms. However, this has\nresulted in a heterogeneous collection of specialized applications\nwithout transparent interoperability or a uniform operating interface.\n\n*Nipype*, an open-source, community-developed initiative under the\numbrella of `NiPy <http://nipy.org>`_, is a Python project that provides a\nuniform interface to existing neuroimaging software and facilitates interaction\nbetween these packages within a single workflow. Nipype provides an environment\nthat encourages interactive exploration of algorithms from different\npackages (e.g., AFNI, ANTS, BRAINS, BrainSuite, Camino, FreeSurfer, FSL, MNE,\nMRtrix, MNE, Nipy, Slicer, SPM), eases the design of workflows within and\nbetween packages, and reduces the learning curve necessary to use different \\\npackages. Nipype is creating a collaborative platform for neuroimaging \\\nsoftware development in a high-level language and addressing limitations of \\\nexisting pipeline systems.\n\n*Nipype* allows you to:\n\n* easily interact with tools from different software packages\n* combine processing steps from different software packages\n* develop new workflows faster by reusing common steps from old ones\n* process data faster by running it in parallel on many cores/machines\n* make your research easily reproducible\n* share your processing workflows with the community\n\"\"\"\n\n# versions\nNIBABEL_MIN_VERSION = '2.1.0'\nNETWORKX_MIN_VERSION = '1.9'\nNUMPY_MIN_VERSION = '1.9.0'\n# Numpy bug in python 3.7:\n# https://www.opensourceanswers.com/blog/you-shouldnt-use-python-37-for-data-science-right-now.html\nNUMPY_MIN_VERSION_37 = '1.15.3'\nSCIPY_MIN_VERSION = '0.14'\nTRAITS_MIN_VERSION = '4.6'\nDATEUTIL_MIN_VERSION = '2.2'\nPYTEST_MIN_VERSION = '3.6'\nFUTURE_MIN_VERSION = '0.16.0'\nSIMPLEJSON_MIN_VERSION = '3.8.0'\nPROV_VERSION = '1.5.2'\nCLICK_MIN_VERSION = '6.6.0'\nPYDOT_MIN_VERSION = '1.2.3'\n\nNAME = 'nipype'\nMAINTAINER = 'nipype developers'\nMAINTAINER_EMAIL = '[email protected]'\nDESCRIPTION = description\nLONG_DESCRIPTION = long_description\nURL = 'http://nipy.org/nipype'\nDOWNLOAD_URL = 'http://github.com/nipy/nipype/archives/master'\nLICENSE = 'Apache License, 2.0'\nAUTHOR = 'nipype developers'\nAUTHOR_EMAIL = '[email protected]'\nPLATFORMS = 'OS Independent'\nMAJOR = __version__.split('.')[0]\nMINOR = __version__.split('.')[1]\nMICRO = __version__.replace('-', '.').split('.')[2]\nISRELEASE = (len(__version__.replace('-', '.').split('.')) == 3\n or 'post' in __version__.replace('-', '.').split('.')[-1])\nVERSION = __version__\nPROVIDES = ['nipype']\nREQUIRES = [\n 'nibabel>=%s' % NIBABEL_MIN_VERSION,\n 'networkx>=%s' % NETWORKX_MIN_VERSION,\n 'numpy>=%s ; python_version < \"3.7\"' % NUMPY_MIN_VERSION,\n 'numpy>=%s ; python_version >= \"3.7\"' % NUMPY_MIN_VERSION_37,\n 'python-dateutil>=%s' % DATEUTIL_MIN_VERSION,\n 'scipy>=%s' % SCIPY_MIN_VERSION,\n 'traits>=%s' % TRAITS_MIN_VERSION,\n 'future>=%s' % FUTURE_MIN_VERSION,\n 'simplejson>=%s' % SIMPLEJSON_MIN_VERSION,\n 'prov>=%s' % PROV_VERSION,\n 'neurdflib',\n 'click>=%s' % CLICK_MIN_VERSION,\n 'funcsigs',\n 'pytest>=%s' % PYTEST_MIN_VERSION,\n 'pytest-xdist',\n 'mock',\n 'pydotplus',\n 'pydot>=%s' % PYDOT_MIN_VERSION,\n 'packaging',\n 'futures; python_version == \"2.7\"',\n]\n\nif sys.version_info <= (3, 4):\n REQUIRES.append('configparser')\n\nTESTS_REQUIRES = ['pytest-cov', 'codecov', 'pytest-env', 'coverage<5']\n\nEXTRA_REQUIRES = {\n 'doc': ['Sphinx>=1.4', 'numpydoc', 'matplotlib', 'pydotplus', 'pydot>=1.2.3'],\n 'tests': TESTS_REQUIRES,\n 'specs': ['yapf'],\n 'nipy': ['nitime', 'nilearn<0.5.0', 'dipy', 'nipy', 'matplotlib'],\n 'profiler': ['psutil>=5.0'],\n 'duecredit': ['duecredit'],\n 'xvfbwrapper': ['xvfbwrapper'],\n 'pybids': ['pybids==0.6.5'],\n 'ssh': ['paramiko'],\n # 'mesh': ['mayavi'] # Enable when it works\n}\n\n\ndef _list_union(iterable):\n return list(set(sum(iterable, [])))\n\n\n# Enable a handle to install all extra dependencies at once\nEXTRA_REQUIRES['all'] = _list_union(EXTRA_REQUIRES.values())\n# dev = doc + tests + specs\nEXTRA_REQUIRES['dev'] = _list_union(val for key, val in EXTRA_REQUIRES.items()\n if key in ('doc', 'tests', 'specs'))\n\nSTATUS = 'stable'\n", "path": "nipype/info.py"}]}
| 3,833 | 136 |
gh_patches_debug_63368
|
rasdani/github-patches
|
git_diff
|
mkdocs__mkdocs-347
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Hostname for bitbucket is incorrect
The host name used in the automatic `repo_name` detection is wrong. It should be using `bitbucket.org`, but instead it is `bitbucket.com`. This is found in config.py line 140.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mkdocs/config.py`
Content:
```
1 # coding: utf-8
2
3 from mkdocs import utils
4 from mkdocs.compat import urlparse
5 from mkdocs.exceptions import ConfigurationError
6
7 import logging
8 import os
9 import yaml
10
11 log = logging.getLogger(__name__)
12
13 DEFAULT_CONFIG = {
14 'site_name': None,
15 'pages': None,
16
17 'site_url': None,
18 'site_description': None,
19 'site_author': None,
20 'site_favicon': None,
21
22 'theme': 'mkdocs',
23 'docs_dir': 'docs',
24 'site_dir': 'site',
25 'theme_dir': None,
26
27 'copyright': None,
28 'google_analytics': None,
29
30 # The address on which to serve the livereloading docs server.
31 'dev_addr': '127.0.0.1:8000',
32
33 # If `True`, use `<page_name>/index.hmtl` style files with hyperlinks to the directory.
34 # If `False`, use `<page_name>.html style file with hyperlinks to the file.
35 # True generates nicer URLs, but False is useful if browsing the output on a filesystem.
36 'use_directory_urls': True,
37
38 # Specify a link to the project source repo to be included
39 # in the documentation pages.
40 'repo_url': None,
41
42 # A name to use for the link to the project source repo.
43 # Default: If repo_url is unset then None, otherwise
44 # "GitHub" or "Bitbucket" for known url or Hostname for unknown urls.
45 'repo_name': None,
46
47 # Specify which css or javascript files from the docs
48 # directionary should be additionally included in the site.
49 # Default: List of all .css and .js files in the docs dir.
50 'extra_css': None,
51 'extra_javascript': None,
52
53 # Determine if the site should include the nav and next/prev elements.
54 # Default: True if the site has more than one page, False otherwise.
55 'include_nav': None,
56 'include_next_prev': None,
57
58 # PyMarkdown extension names.
59 'markdown_extensions': (),
60
61 # Determine if the site should generate a json search index and include
62 # search elements in the theme. - TODO
63 'include_search': False,
64
65 # Determine if the site should include a 404.html page.
66 # TODO: Implment this. Make this None, have it True if a 404.html
67 # template exists in the theme or docs dir.
68 'include_404': False,
69
70 # enabling strict mode causes MkDocs to stop the build when a problem is
71 # encountered rather than display an error.
72 'strict': False,
73 }
74
75
76 def load_config(filename='mkdocs.yml', options=None):
77 options = options or {}
78 if 'config' in options:
79 filename = options.pop('config')
80 if not os.path.exists(filename):
81 raise ConfigurationError("Config file '%s' does not exist." % filename)
82 with open(filename, 'r') as fp:
83 user_config = yaml.load(fp)
84 if not isinstance(user_config, dict):
85 raise ConfigurationError("The mkdocs.yml file is invalid. See http://www.mkdocs.org/user-guide/configuration/ for more information.")
86 user_config.update(options)
87 return validate_config(user_config)
88
89
90 def validate_config(user_config):
91 config = DEFAULT_CONFIG.copy()
92 config.update(user_config)
93
94 if not config['site_name']:
95 raise ConfigurationError("Config must contain 'site_name' setting.")
96
97 # If not specified, then the 'pages' config simply includes all
98 # markdown files in the docs dir, without generating any header items
99 # for them.
100 pages = []
101 extra_css = []
102 extra_javascript = []
103 for (dirpath, dirnames, filenames) in os.walk(config['docs_dir']):
104 for filename in sorted(filenames):
105 fullpath = os.path.join(dirpath, filename)
106 relpath = os.path.relpath(fullpath, config['docs_dir'])
107
108 if utils.is_markdown_file(filename):
109 # index pages should always be the first listed page.
110 if os.path.splitext(relpath)[0] == 'index':
111 pages.insert(0, relpath)
112 else:
113 pages.append(relpath)
114 elif utils.is_css_file(filename):
115 extra_css.append(relpath)
116 elif utils.is_javascript_file(filename):
117 extra_javascript.append(relpath)
118
119 if config['pages'] is None:
120 config['pages'] = pages
121
122 if config['extra_css'] is None:
123 config['extra_css'] = extra_css
124
125 if config['extra_javascript'] is None:
126 config['extra_javascript'] = extra_javascript
127
128 package_dir = os.path.dirname(__file__)
129 theme_dir = [os.path.join(package_dir, 'themes', config['theme'])]
130
131 if config['theme_dir'] is not None:
132 theme_dir.insert(0, config['theme_dir'])
133
134 config['theme_dir'] = theme_dir
135
136 if config['repo_url'] is not None and config['repo_name'] is None:
137 repo_host = urlparse(config['repo_url']).netloc.lower()
138 if repo_host == 'github.com':
139 config['repo_name'] = 'GitHub'
140 elif repo_host == 'bitbucket.com':
141 config['repo_name'] = 'Bitbucket'
142 else:
143 config['repo_name'] = repo_host.split('.')[0].title()
144
145 if config['include_next_prev'] is None:
146 config['include_next_prev'] = len(config['pages']) > 1
147
148 if config['include_nav'] is None:
149 config['include_nav'] = len(config['pages']) > 1
150
151 # To Do:
152
153 # The docs dir must exist.
154 # The theme dir must exist.
155 # Ensure 'theme' is one of 'mkdocs', 'readthedocs', 'custom'
156 # A homepage 'index' must exist.
157 # The theme 'base.html' file must exist.
158 # Cannot set repo_name without setting repo_url.
159 # Cannot set 'include_next_prev: true' when only one page exists.
160 # Cannot set 'include_nav: true' when only one page exists.
161 # Error if any config keys provided that are not in the DEFAULT_CONFIG.
162
163 return config
164
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mkdocs/config.py b/mkdocs/config.py
--- a/mkdocs/config.py
+++ b/mkdocs/config.py
@@ -137,7 +137,7 @@
repo_host = urlparse(config['repo_url']).netloc.lower()
if repo_host == 'github.com':
config['repo_name'] = 'GitHub'
- elif repo_host == 'bitbucket.com':
+ elif repo_host == 'bitbucket.org':
config['repo_name'] = 'Bitbucket'
else:
config['repo_name'] = repo_host.split('.')[0].title()
|
{"golden_diff": "diff --git a/mkdocs/config.py b/mkdocs/config.py\n--- a/mkdocs/config.py\n+++ b/mkdocs/config.py\n@@ -137,7 +137,7 @@\n repo_host = urlparse(config['repo_url']).netloc.lower()\n if repo_host == 'github.com':\n config['repo_name'] = 'GitHub'\n- elif repo_host == 'bitbucket.com':\n+ elif repo_host == 'bitbucket.org':\n config['repo_name'] = 'Bitbucket'\n else:\n config['repo_name'] = repo_host.split('.')[0].title()\n", "issue": "Hostname for bitbucket is incorrect\nThe host name used in the automatic `repo_name` detection is wrong. It should be using `bitbucket.org`, but instead it is `bitbucket.com`. This is found in config.py line 140.\n\n", "before_files": [{"content": "# coding: utf-8\n\nfrom mkdocs import utils\nfrom mkdocs.compat import urlparse\nfrom mkdocs.exceptions import ConfigurationError\n\nimport logging\nimport os\nimport yaml\n\nlog = logging.getLogger(__name__)\n\nDEFAULT_CONFIG = {\n 'site_name': None,\n 'pages': None,\n\n 'site_url': None,\n 'site_description': None,\n 'site_author': None,\n 'site_favicon': None,\n\n 'theme': 'mkdocs',\n 'docs_dir': 'docs',\n 'site_dir': 'site',\n 'theme_dir': None,\n\n 'copyright': None,\n 'google_analytics': None,\n\n # The address on which to serve the livereloading docs server.\n 'dev_addr': '127.0.0.1:8000',\n\n # If `True`, use `<page_name>/index.hmtl` style files with hyperlinks to the directory.\n # If `False`, use `<page_name>.html style file with hyperlinks to the file.\n # True generates nicer URLs, but False is useful if browsing the output on a filesystem.\n 'use_directory_urls': True,\n\n # Specify a link to the project source repo to be included\n # in the documentation pages.\n 'repo_url': None,\n\n # A name to use for the link to the project source repo.\n # Default: If repo_url is unset then None, otherwise\n # \"GitHub\" or \"Bitbucket\" for known url or Hostname for unknown urls.\n 'repo_name': None,\n\n # Specify which css or javascript files from the docs\n # directionary should be additionally included in the site.\n # Default: List of all .css and .js files in the docs dir.\n 'extra_css': None,\n 'extra_javascript': None,\n\n # Determine if the site should include the nav and next/prev elements.\n # Default: True if the site has more than one page, False otherwise.\n 'include_nav': None,\n 'include_next_prev': None,\n\n # PyMarkdown extension names.\n 'markdown_extensions': (),\n\n # Determine if the site should generate a json search index and include\n # search elements in the theme. - TODO\n 'include_search': False,\n\n # Determine if the site should include a 404.html page.\n # TODO: Implment this. Make this None, have it True if a 404.html\n # template exists in the theme or docs dir.\n 'include_404': False,\n\n # enabling strict mode causes MkDocs to stop the build when a problem is\n # encountered rather than display an error.\n 'strict': False,\n}\n\n\ndef load_config(filename='mkdocs.yml', options=None):\n options = options or {}\n if 'config' in options:\n filename = options.pop('config')\n if not os.path.exists(filename):\n raise ConfigurationError(\"Config file '%s' does not exist.\" % filename)\n with open(filename, 'r') as fp:\n user_config = yaml.load(fp)\n if not isinstance(user_config, dict):\n raise ConfigurationError(\"The mkdocs.yml file is invalid. See http://www.mkdocs.org/user-guide/configuration/ for more information.\")\n user_config.update(options)\n return validate_config(user_config)\n\n\ndef validate_config(user_config):\n config = DEFAULT_CONFIG.copy()\n config.update(user_config)\n\n if not config['site_name']:\n raise ConfigurationError(\"Config must contain 'site_name' setting.\")\n\n # If not specified, then the 'pages' config simply includes all\n # markdown files in the docs dir, without generating any header items\n # for them.\n pages = []\n extra_css = []\n extra_javascript = []\n for (dirpath, dirnames, filenames) in os.walk(config['docs_dir']):\n for filename in sorted(filenames):\n fullpath = os.path.join(dirpath, filename)\n relpath = os.path.relpath(fullpath, config['docs_dir'])\n\n if utils.is_markdown_file(filename):\n # index pages should always be the first listed page.\n if os.path.splitext(relpath)[0] == 'index':\n pages.insert(0, relpath)\n else:\n pages.append(relpath)\n elif utils.is_css_file(filename):\n extra_css.append(relpath)\n elif utils.is_javascript_file(filename):\n extra_javascript.append(relpath)\n\n if config['pages'] is None:\n config['pages'] = pages\n\n if config['extra_css'] is None:\n config['extra_css'] = extra_css\n\n if config['extra_javascript'] is None:\n config['extra_javascript'] = extra_javascript\n\n package_dir = os.path.dirname(__file__)\n theme_dir = [os.path.join(package_dir, 'themes', config['theme'])]\n\n if config['theme_dir'] is not None:\n theme_dir.insert(0, config['theme_dir'])\n\n config['theme_dir'] = theme_dir\n\n if config['repo_url'] is not None and config['repo_name'] is None:\n repo_host = urlparse(config['repo_url']).netloc.lower()\n if repo_host == 'github.com':\n config['repo_name'] = 'GitHub'\n elif repo_host == 'bitbucket.com':\n config['repo_name'] = 'Bitbucket'\n else:\n config['repo_name'] = repo_host.split('.')[0].title()\n\n if config['include_next_prev'] is None:\n config['include_next_prev'] = len(config['pages']) > 1\n\n if config['include_nav'] is None:\n config['include_nav'] = len(config['pages']) > 1\n\n # To Do:\n\n # The docs dir must exist.\n # The theme dir must exist.\n # Ensure 'theme' is one of 'mkdocs', 'readthedocs', 'custom'\n # A homepage 'index' must exist.\n # The theme 'base.html' file must exist.\n # Cannot set repo_name without setting repo_url.\n # Cannot set 'include_next_prev: true' when only one page exists.\n # Cannot set 'include_nav: true' when only one page exists.\n # Error if any config keys provided that are not in the DEFAULT_CONFIG.\n\n return config\n", "path": "mkdocs/config.py"}], "after_files": [{"content": "# coding: utf-8\n\nfrom mkdocs import utils\nfrom mkdocs.compat import urlparse\nfrom mkdocs.exceptions import ConfigurationError\n\nimport logging\nimport os\nimport yaml\n\nlog = logging.getLogger(__name__)\n\nDEFAULT_CONFIG = {\n 'site_name': None,\n 'pages': None,\n\n 'site_url': None,\n 'site_description': None,\n 'site_author': None,\n 'site_favicon': None,\n\n 'theme': 'mkdocs',\n 'docs_dir': 'docs',\n 'site_dir': 'site',\n 'theme_dir': None,\n\n 'copyright': None,\n 'google_analytics': None,\n\n # The address on which to serve the livereloading docs server.\n 'dev_addr': '127.0.0.1:8000',\n\n # If `True`, use `<page_name>/index.hmtl` style files with hyperlinks to the directory.\n # If `False`, use `<page_name>.html style file with hyperlinks to the file.\n # True generates nicer URLs, but False is useful if browsing the output on a filesystem.\n 'use_directory_urls': True,\n\n # Specify a link to the project source repo to be included\n # in the documentation pages.\n 'repo_url': None,\n\n # A name to use for the link to the project source repo.\n # Default: If repo_url is unset then None, otherwise\n # \"GitHub\" or \"Bitbucket\" for known url or Hostname for unknown urls.\n 'repo_name': None,\n\n # Specify which css or javascript files from the docs\n # directionary should be additionally included in the site.\n # Default: List of all .css and .js files in the docs dir.\n 'extra_css': None,\n 'extra_javascript': None,\n\n # Determine if the site should include the nav and next/prev elements.\n # Default: True if the site has more than one page, False otherwise.\n 'include_nav': None,\n 'include_next_prev': None,\n\n # PyMarkdown extension names.\n 'markdown_extensions': (),\n\n # Determine if the site should generate a json search index and include\n # search elements in the theme. - TODO\n 'include_search': False,\n\n # Determine if the site should include a 404.html page.\n # TODO: Implment this. Make this None, have it True if a 404.html\n # template exists in the theme or docs dir.\n 'include_404': False,\n\n # enabling strict mode causes MkDocs to stop the build when a problem is\n # encountered rather than display an error.\n 'strict': False,\n}\n\n\ndef load_config(filename='mkdocs.yml', options=None):\n options = options or {}\n if 'config' in options:\n filename = options.pop('config')\n if not os.path.exists(filename):\n raise ConfigurationError(\"Config file '%s' does not exist.\" % filename)\n with open(filename, 'r') as fp:\n user_config = yaml.load(fp)\n if not isinstance(user_config, dict):\n raise ConfigurationError(\"The mkdocs.yml file is invalid. See http://www.mkdocs.org/user-guide/configuration/ for more information.\")\n user_config.update(options)\n return validate_config(user_config)\n\n\ndef validate_config(user_config):\n config = DEFAULT_CONFIG.copy()\n config.update(user_config)\n\n if not config['site_name']:\n raise ConfigurationError(\"Config must contain 'site_name' setting.\")\n\n # If not specified, then the 'pages' config simply includes all\n # markdown files in the docs dir, without generating any header items\n # for them.\n pages = []\n extra_css = []\n extra_javascript = []\n for (dirpath, dirnames, filenames) in os.walk(config['docs_dir']):\n for filename in sorted(filenames):\n fullpath = os.path.join(dirpath, filename)\n relpath = os.path.relpath(fullpath, config['docs_dir'])\n\n if utils.is_markdown_file(filename):\n # index pages should always be the first listed page.\n if os.path.splitext(relpath)[0] == 'index':\n pages.insert(0, relpath)\n else:\n pages.append(relpath)\n elif utils.is_css_file(filename):\n extra_css.append(relpath)\n elif utils.is_javascript_file(filename):\n extra_javascript.append(relpath)\n\n if config['pages'] is None:\n config['pages'] = pages\n\n if config['extra_css'] is None:\n config['extra_css'] = extra_css\n\n if config['extra_javascript'] is None:\n config['extra_javascript'] = extra_javascript\n\n package_dir = os.path.dirname(__file__)\n theme_dir = [os.path.join(package_dir, 'themes', config['theme'])]\n\n if config['theme_dir'] is not None:\n theme_dir.insert(0, config['theme_dir'])\n\n config['theme_dir'] = theme_dir\n\n if config['repo_url'] is not None and config['repo_name'] is None:\n repo_host = urlparse(config['repo_url']).netloc.lower()\n if repo_host == 'github.com':\n config['repo_name'] = 'GitHub'\n elif repo_host == 'bitbucket.org':\n config['repo_name'] = 'Bitbucket'\n else:\n config['repo_name'] = repo_host.split('.')[0].title()\n\n if config['include_next_prev'] is None:\n config['include_next_prev'] = len(config['pages']) > 1\n\n if config['include_nav'] is None:\n config['include_nav'] = len(config['pages']) > 1\n\n # To Do:\n\n # The docs dir must exist.\n # The theme dir must exist.\n # Ensure 'theme' is one of 'mkdocs', 'readthedocs', 'custom'\n # A homepage 'index' must exist.\n # The theme 'base.html' file must exist.\n # Cannot set repo_name without setting repo_url.\n # Cannot set 'include_next_prev: true' when only one page exists.\n # Cannot set 'include_nav: true' when only one page exists.\n # Error if any config keys provided that are not in the DEFAULT_CONFIG.\n\n return config\n", "path": "mkdocs/config.py"}]}
| 2,057 | 130 |
gh_patches_debug_9971
|
rasdani/github-patches
|
git_diff
|
pretix__pretix-882
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
rich_text: tel schema
When providing email links using the mailto schema in richtext description like `[Email us!](mailto:[email protected])`, resulting in [Email us!](mailto:[email protected]), Pretix creates the correct `<a>` tag. However, users also use their mobile phone. It would be awesome to also be able to use the `tel` schema like `[Call us!](tel:+1-202-555-0102)`. At the moment, pretix just creates an `<a>` tag without an `href`, so the Telephone app is not opened.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/pretix/base/templatetags/rich_text.py`
Content:
```
1 import urllib.parse
2
3 import bleach
4 import markdown
5 from bleach import DEFAULT_CALLBACKS
6 from django import template
7 from django.conf import settings
8 from django.core import signing
9 from django.urls import reverse
10 from django.utils.http import is_safe_url
11 from django.utils.safestring import mark_safe
12
13 register = template.Library()
14
15 ALLOWED_TAGS = [
16 'a',
17 'abbr',
18 'acronym',
19 'b',
20 'blockquote',
21 'br',
22 'code',
23 'em',
24 'i',
25 'li',
26 'ol',
27 'strong',
28 'ul',
29 'p',
30 'table',
31 'tbody',
32 'thead',
33 'tr',
34 'td',
35 'th',
36 'div',
37 'span',
38 'hr',
39 'h1',
40 'h2',
41 'h3',
42 'h4',
43 'h5',
44 'h6',
45 'pre',
46 # Update doc/user/markdown.rst if you change this!
47 ]
48
49 ALLOWED_ATTRIBUTES = {
50 'a': ['href', 'title'],
51 'abbr': ['title'],
52 'acronym': ['title'],
53 'table': ['width'],
54 'td': ['width', 'align'],
55 'div': ['class'],
56 'p': ['class'],
57 'span': ['class'],
58 # Update doc/user/markdown.rst if you change this!
59 }
60
61
62 def safelink_callback(attrs, new=False):
63 url = attrs.get((None, 'href'), '/')
64 if not is_safe_url(url) and not url.startswith('mailto:'):
65 signer = signing.Signer(salt='safe-redirect')
66 attrs[None, 'href'] = reverse('redirect') + '?url=' + urllib.parse.quote(signer.sign(url))
67 attrs[None, 'target'] = '_blank'
68 attrs[None, 'rel'] = 'noopener'
69 return attrs
70
71
72 def abslink_callback(attrs, new=False):
73 attrs[None, 'href'] = urllib.parse.urljoin(settings.SITE_URL, attrs.get((None, 'href'), '/'))
74 attrs[None, 'target'] = '_blank'
75 attrs[None, 'rel'] = 'noopener'
76 return attrs
77
78
79 def markdown_compile(source):
80 return bleach.clean(
81 markdown.markdown(
82 source,
83 extensions=[
84 'markdown.extensions.sane_lists',
85 # 'markdown.extensions.nl2br', # TODO: Enable, but check backwards-compatibility issues e.g. with mails
86 ]
87 ),
88 tags=ALLOWED_TAGS,
89 attributes=ALLOWED_ATTRIBUTES
90 )
91
92
93 @register.filter
94 def rich_text(text: str, **kwargs):
95 """
96 Processes markdown and cleans HTML in a text input.
97 """
98 text = str(text)
99 body_md = bleach.linkify(
100 markdown_compile(text),
101 callbacks=DEFAULT_CALLBACKS + ([safelink_callback] if kwargs.get('safelinks', True) else [abslink_callback])
102 )
103 return mark_safe(body_md)
104
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/pretix/base/templatetags/rich_text.py b/src/pretix/base/templatetags/rich_text.py
--- a/src/pretix/base/templatetags/rich_text.py
+++ b/src/pretix/base/templatetags/rich_text.py
@@ -58,6 +58,8 @@
# Update doc/user/markdown.rst if you change this!
}
+ALLOWED_PROTOCOLS = ['http', 'https', 'mailto', 'tel']
+
def safelink_callback(attrs, new=False):
url = attrs.get((None, 'href'), '/')
@@ -86,7 +88,8 @@
]
),
tags=ALLOWED_TAGS,
- attributes=ALLOWED_ATTRIBUTES
+ attributes=ALLOWED_ATTRIBUTES,
+ protocols=ALLOWED_PROTOCOLS,
)
|
{"golden_diff": "diff --git a/src/pretix/base/templatetags/rich_text.py b/src/pretix/base/templatetags/rich_text.py\n--- a/src/pretix/base/templatetags/rich_text.py\n+++ b/src/pretix/base/templatetags/rich_text.py\n@@ -58,6 +58,8 @@\n # Update doc/user/markdown.rst if you change this!\n }\n \n+ALLOWED_PROTOCOLS = ['http', 'https', 'mailto', 'tel']\n+\n \n def safelink_callback(attrs, new=False):\n url = attrs.get((None, 'href'), '/')\n@@ -86,7 +88,8 @@\n ]\n ),\n tags=ALLOWED_TAGS,\n- attributes=ALLOWED_ATTRIBUTES\n+ attributes=ALLOWED_ATTRIBUTES,\n+ protocols=ALLOWED_PROTOCOLS,\n )\n", "issue": "rich_text: tel schema\nWhen providing email links using the mailto schema in richtext description like `[Email us!](mailto:[email protected])`, resulting in [Email us!](mailto:[email protected]), Pretix creates the correct `<a>` tag. However, users also use their mobile phone. It would be awesome to also be able to use the `tel` schema like `[Call us!](tel:+1-202-555-0102)`. At the moment, pretix just creates an `<a>` tag without an `href`, so the Telephone app is not opened.\n", "before_files": [{"content": "import urllib.parse\n\nimport bleach\nimport markdown\nfrom bleach import DEFAULT_CALLBACKS\nfrom django import template\nfrom django.conf import settings\nfrom django.core import signing\nfrom django.urls import reverse\nfrom django.utils.http import is_safe_url\nfrom django.utils.safestring import mark_safe\n\nregister = template.Library()\n\nALLOWED_TAGS = [\n 'a',\n 'abbr',\n 'acronym',\n 'b',\n 'blockquote',\n 'br',\n 'code',\n 'em',\n 'i',\n 'li',\n 'ol',\n 'strong',\n 'ul',\n 'p',\n 'table',\n 'tbody',\n 'thead',\n 'tr',\n 'td',\n 'th',\n 'div',\n 'span',\n 'hr',\n 'h1',\n 'h2',\n 'h3',\n 'h4',\n 'h5',\n 'h6',\n 'pre',\n # Update doc/user/markdown.rst if you change this!\n]\n\nALLOWED_ATTRIBUTES = {\n 'a': ['href', 'title'],\n 'abbr': ['title'],\n 'acronym': ['title'],\n 'table': ['width'],\n 'td': ['width', 'align'],\n 'div': ['class'],\n 'p': ['class'],\n 'span': ['class'],\n # Update doc/user/markdown.rst if you change this!\n}\n\n\ndef safelink_callback(attrs, new=False):\n url = attrs.get((None, 'href'), '/')\n if not is_safe_url(url) and not url.startswith('mailto:'):\n signer = signing.Signer(salt='safe-redirect')\n attrs[None, 'href'] = reverse('redirect') + '?url=' + urllib.parse.quote(signer.sign(url))\n attrs[None, 'target'] = '_blank'\n attrs[None, 'rel'] = 'noopener'\n return attrs\n\n\ndef abslink_callback(attrs, new=False):\n attrs[None, 'href'] = urllib.parse.urljoin(settings.SITE_URL, attrs.get((None, 'href'), '/'))\n attrs[None, 'target'] = '_blank'\n attrs[None, 'rel'] = 'noopener'\n return attrs\n\n\ndef markdown_compile(source):\n return bleach.clean(\n markdown.markdown(\n source,\n extensions=[\n 'markdown.extensions.sane_lists',\n # 'markdown.extensions.nl2br', # TODO: Enable, but check backwards-compatibility issues e.g. with mails\n ]\n ),\n tags=ALLOWED_TAGS,\n attributes=ALLOWED_ATTRIBUTES\n )\n\n\[email protected]\ndef rich_text(text: str, **kwargs):\n \"\"\"\n Processes markdown and cleans HTML in a text input.\n \"\"\"\n text = str(text)\n body_md = bleach.linkify(\n markdown_compile(text),\n callbacks=DEFAULT_CALLBACKS + ([safelink_callback] if kwargs.get('safelinks', True) else [abslink_callback])\n )\n return mark_safe(body_md)\n", "path": "src/pretix/base/templatetags/rich_text.py"}], "after_files": [{"content": "import urllib.parse\n\nimport bleach\nimport markdown\nfrom bleach import DEFAULT_CALLBACKS\nfrom django import template\nfrom django.conf import settings\nfrom django.core import signing\nfrom django.urls import reverse\nfrom django.utils.http import is_safe_url\nfrom django.utils.safestring import mark_safe\n\nregister = template.Library()\n\nALLOWED_TAGS = [\n 'a',\n 'abbr',\n 'acronym',\n 'b',\n 'blockquote',\n 'br',\n 'code',\n 'em',\n 'i',\n 'li',\n 'ol',\n 'strong',\n 'ul',\n 'p',\n 'table',\n 'tbody',\n 'thead',\n 'tr',\n 'td',\n 'th',\n 'div',\n 'span',\n 'hr',\n 'h1',\n 'h2',\n 'h3',\n 'h4',\n 'h5',\n 'h6',\n 'pre',\n # Update doc/user/markdown.rst if you change this!\n]\n\nALLOWED_ATTRIBUTES = {\n 'a': ['href', 'title'],\n 'abbr': ['title'],\n 'acronym': ['title'],\n 'table': ['width'],\n 'td': ['width', 'align'],\n 'div': ['class'],\n 'p': ['class'],\n 'span': ['class'],\n # Update doc/user/markdown.rst if you change this!\n}\n\nALLOWED_PROTOCOLS = ['http', 'https', 'mailto', 'tel']\n\n\ndef safelink_callback(attrs, new=False):\n url = attrs.get((None, 'href'), '/')\n if not is_safe_url(url) and not url.startswith('mailto:'):\n signer = signing.Signer(salt='safe-redirect')\n attrs[None, 'href'] = reverse('redirect') + '?url=' + urllib.parse.quote(signer.sign(url))\n attrs[None, 'target'] = '_blank'\n attrs[None, 'rel'] = 'noopener'\n return attrs\n\n\ndef abslink_callback(attrs, new=False):\n attrs[None, 'href'] = urllib.parse.urljoin(settings.SITE_URL, attrs.get((None, 'href'), '/'))\n attrs[None, 'target'] = '_blank'\n attrs[None, 'rel'] = 'noopener'\n return attrs\n\n\ndef markdown_compile(source):\n return bleach.clean(\n markdown.markdown(\n source,\n extensions=[\n 'markdown.extensions.sane_lists',\n # 'markdown.extensions.nl2br', # TODO: Enable, but check backwards-compatibility issues e.g. with mails\n ]\n ),\n tags=ALLOWED_TAGS,\n attributes=ALLOWED_ATTRIBUTES,\n protocols=ALLOWED_PROTOCOLS,\n )\n\n\[email protected]\ndef rich_text(text: str, **kwargs):\n \"\"\"\n Processes markdown and cleans HTML in a text input.\n \"\"\"\n text = str(text)\n body_md = bleach.linkify(\n markdown_compile(text),\n callbacks=DEFAULT_CALLBACKS + ([safelink_callback] if kwargs.get('safelinks', True) else [abslink_callback])\n )\n return mark_safe(body_md)\n", "path": "src/pretix/base/templatetags/rich_text.py"}]}
| 1,247 | 188 |
gh_patches_debug_56378
|
rasdani/github-patches
|
git_diff
|
qutebrowser__qutebrowser-3063
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Auto-use the first match in the completion
Requested by @Earnestly in IRC:
Typing, e.g. `:do`<kbd>Enter</kbd> should invoke `:download` automatically as that's the first-best match instead of showing an invalid command error.
(of course configurable)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `qutebrowser/commands/runners.py`
Content:
```
1 # vim: ft=python fileencoding=utf-8 sts=4 sw=4 et:
2
3 # Copyright 2014-2017 Florian Bruhin (The Compiler) <[email protected]>
4 #
5 # This file is part of qutebrowser.
6 #
7 # qutebrowser is free software: you can redistribute it and/or modify
8 # it under the terms of the GNU General Public License as published by
9 # the Free Software Foundation, either version 3 of the License, or
10 # (at your option) any later version.
11 #
12 # qutebrowser is distributed in the hope that it will be useful,
13 # but WITHOUT ANY WARRANTY; without even the implied warranty of
14 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
15 # GNU General Public License for more details.
16 #
17 # You should have received a copy of the GNU General Public License
18 # along with qutebrowser. If not, see <http://www.gnu.org/licenses/>.
19
20 """Module containing command managers (SearchRunner and CommandRunner)."""
21
22 import traceback
23 import re
24
25 import attr
26 from PyQt5.QtCore import pyqtSlot, QUrl, QObject
27
28 from qutebrowser.config import config
29 from qutebrowser.commands import cmdexc, cmdutils
30 from qutebrowser.utils import message, objreg, qtutils, usertypes, utils
31 from qutebrowser.misc import split
32
33
34 last_command = {}
35
36
37 @attr.s
38 class ParseResult:
39
40 """The result of parsing a commandline."""
41
42 cmd = attr.ib()
43 args = attr.ib()
44 cmdline = attr.ib()
45
46
47 def _current_url(tabbed_browser):
48 """Convenience method to get the current url."""
49 try:
50 return tabbed_browser.current_url()
51 except qtutils.QtValueError as e:
52 msg = "Current URL is invalid"
53 if e.reason:
54 msg += " ({})".format(e.reason)
55 msg += "!"
56 raise cmdexc.CommandError(msg)
57
58
59 def replace_variables(win_id, arglist):
60 """Utility function to replace variables like {url} in a list of args."""
61 variables = {
62 'url': lambda: _current_url(tabbed_browser).toString(
63 QUrl.FullyEncoded | QUrl.RemovePassword),
64 'url:pretty': lambda: _current_url(tabbed_browser).toString(
65 QUrl.DecodeReserved | QUrl.RemovePassword),
66 'clipboard': utils.get_clipboard,
67 'primary': lambda: utils.get_clipboard(selection=True),
68 }
69 values = {}
70 args = []
71 tabbed_browser = objreg.get('tabbed-browser', scope='window',
72 window=win_id)
73
74 def repl_cb(matchobj):
75 """Return replacement for given match."""
76 var = matchobj.group("var")
77 if var not in values:
78 values[var] = variables[var]()
79 return values[var]
80 repl_pattern = re.compile("{(?P<var>" + "|".join(variables.keys()) + ")}")
81
82 try:
83 for arg in arglist:
84 # using re.sub with callback function replaces all variables in a
85 # single pass and avoids expansion of nested variables (e.g.
86 # "{url}" from clipboard is not expanded)
87 args.append(repl_pattern.sub(repl_cb, arg))
88 except utils.ClipboardError as e:
89 raise cmdexc.CommandError(e)
90 return args
91
92
93 class CommandParser:
94
95 """Parse qutebrowser commandline commands.
96
97 Attributes:
98
99 _partial_match: Whether to allow partial command matches.
100 """
101
102 def __init__(self, partial_match=False):
103 self._partial_match = partial_match
104
105 def _get_alias(self, text, default=None):
106 """Get an alias from the config.
107
108 Args:
109 text: The text to parse.
110 default : Default value to return when alias was not found.
111
112 Return:
113 The new command string if an alias was found. Default value
114 otherwise.
115 """
116 parts = text.strip().split(maxsplit=1)
117 try:
118 alias = config.val.aliases[parts[0]]
119 except KeyError:
120 return default
121
122 try:
123 new_cmd = '{} {}'.format(alias, parts[1])
124 except IndexError:
125 new_cmd = alias
126 if text.endswith(' '):
127 new_cmd += ' '
128 return new_cmd
129
130 def _parse_all_gen(self, text, aliases=True, *args, **kwargs):
131 """Split a command on ;; and parse all parts.
132
133 If the first command in the commandline is a non-split one, it only
134 returns that.
135
136 Args:
137 text: Text to parse.
138 aliases: Whether to handle aliases.
139 *args/**kwargs: Passed to parse().
140
141 Yields:
142 ParseResult tuples.
143 """
144 text = text.strip().lstrip(':').strip()
145 if not text:
146 raise cmdexc.NoSuchCommandError("No command given")
147
148 if aliases:
149 text = self._get_alias(text, text)
150
151 if ';;' in text:
152 # Get the first command and check if it doesn't want to have ;;
153 # split.
154 first = text.split(';;')[0]
155 result = self.parse(first, *args, **kwargs)
156 if result.cmd.no_cmd_split:
157 sub_texts = [text]
158 else:
159 sub_texts = [e.strip() for e in text.split(';;')]
160 else:
161 sub_texts = [text]
162 for sub in sub_texts:
163 yield self.parse(sub, *args, **kwargs)
164
165 def parse_all(self, *args, **kwargs):
166 """Wrapper over parse_all."""
167 return list(self._parse_all_gen(*args, **kwargs))
168
169 def parse(self, text, *, fallback=False, keep=False):
170 """Split the commandline text into command and arguments.
171
172 Args:
173 text: Text to parse.
174 fallback: Whether to do a fallback splitting when the command was
175 unknown.
176 keep: Whether to keep special chars and whitespace
177
178 Return:
179 A ParseResult tuple.
180 """
181 cmdstr, sep, argstr = text.partition(' ')
182
183 if not cmdstr and not fallback:
184 raise cmdexc.NoSuchCommandError("No command given")
185
186 if self._partial_match:
187 cmdstr = self._completion_match(cmdstr)
188
189 try:
190 cmd = cmdutils.cmd_dict[cmdstr]
191 except KeyError:
192 if not fallback:
193 raise cmdexc.NoSuchCommandError(
194 '{}: no such command'.format(cmdstr))
195 cmdline = split.split(text, keep=keep)
196 return ParseResult(cmd=None, args=None, cmdline=cmdline)
197
198 args = self._split_args(cmd, argstr, keep)
199 if keep and args:
200 cmdline = [cmdstr, sep + args[0]] + args[1:]
201 elif keep:
202 cmdline = [cmdstr, sep]
203 else:
204 cmdline = [cmdstr] + args[:]
205
206 return ParseResult(cmd=cmd, args=args, cmdline=cmdline)
207
208 def _completion_match(self, cmdstr):
209 """Replace cmdstr with a matching completion if there's only one match.
210
211 Args:
212 cmdstr: The string representing the entered command so far
213
214 Return:
215 cmdstr modified to the matching completion or unmodified
216 """
217 matches = []
218 for valid_command in cmdutils.cmd_dict:
219 if valid_command.find(cmdstr) == 0:
220 matches.append(valid_command)
221 if len(matches) == 1:
222 cmdstr = matches[0]
223 return cmdstr
224
225 def _split_args(self, cmd, argstr, keep):
226 """Split the arguments from an arg string.
227
228 Args:
229 cmd: The command we're currently handling.
230 argstr: An argument string.
231 keep: Whether to keep special chars and whitespace
232
233 Return:
234 A list containing the split strings.
235 """
236 if not argstr:
237 return []
238 elif cmd.maxsplit is None:
239 return split.split(argstr, keep=keep)
240 else:
241 # If split=False, we still want to split the flags, but not
242 # everything after that.
243 # We first split the arg string and check the index of the first
244 # non-flag args, then we re-split again properly.
245 # example:
246 #
247 # input: "--foo -v bar baz"
248 # first split: ['--foo', '-v', 'bar', 'baz']
249 # 0 1 2 3
250 # second split: ['--foo', '-v', 'bar baz']
251 # (maxsplit=2)
252 split_args = split.simple_split(argstr, keep=keep)
253 flag_arg_count = 0
254 for i, arg in enumerate(split_args):
255 arg = arg.strip()
256 if arg.startswith('-'):
257 if arg in cmd.flags_with_args:
258 flag_arg_count += 1
259 else:
260 maxsplit = i + cmd.maxsplit + flag_arg_count
261 return split.simple_split(argstr, keep=keep,
262 maxsplit=maxsplit)
263
264 # If there are only flags, we got it right on the first try
265 # already.
266 return split_args
267
268
269 class CommandRunner(QObject):
270
271 """Parse and run qutebrowser commandline commands.
272
273 Attributes:
274 _win_id: The window this CommandRunner is associated with.
275 """
276
277 def __init__(self, win_id, partial_match=False, parent=None):
278 super().__init__(parent)
279 self._parser = CommandParser(partial_match=partial_match)
280 self._win_id = win_id
281
282 def run(self, text, count=None):
283 """Parse a command from a line of text and run it.
284
285 Args:
286 text: The text to parse.
287 count: The count to pass to the command.
288 """
289 record_last_command = True
290 record_macro = True
291
292 mode_manager = objreg.get('mode-manager', scope='window',
293 window=self._win_id)
294 cur_mode = mode_manager.mode
295
296 for result in self._parser.parse_all(text):
297 if result.cmd.no_replace_variables:
298 args = result.args
299 else:
300 args = replace_variables(self._win_id, result.args)
301 result.cmd.run(self._win_id, args, count=count)
302
303 if result.cmdline[0] == 'repeat-command':
304 record_last_command = False
305
306 if result.cmdline[0] in ['record-macro', 'run-macro',
307 'set-cmd-text']:
308 record_macro = False
309
310 if record_last_command:
311 last_command[cur_mode] = (text, count)
312
313 if record_macro and cur_mode == usertypes.KeyMode.normal:
314 macro_recorder = objreg.get('macro-recorder')
315 macro_recorder.record_command(text, count)
316
317 @pyqtSlot(str, int)
318 @pyqtSlot(str)
319 def run_safely(self, text, count=None):
320 """Run a command and display exceptions in the statusbar."""
321 try:
322 self.run(text, count)
323 except cmdexc.Error as e:
324 message.error(str(e), stack=traceback.format_exc())
325
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/qutebrowser/commands/runners.py b/qutebrowser/commands/runners.py
--- a/qutebrowser/commands/runners.py
+++ b/qutebrowser/commands/runners.py
@@ -220,6 +220,8 @@
matches.append(valid_command)
if len(matches) == 1:
cmdstr = matches[0]
+ elif len(matches) > 1 and config.val.completion.use_best_match:
+ cmdstr = matches[0]
return cmdstr
def _split_args(self, cmd, argstr, keep):
|
{"golden_diff": "diff --git a/qutebrowser/commands/runners.py b/qutebrowser/commands/runners.py\n--- a/qutebrowser/commands/runners.py\n+++ b/qutebrowser/commands/runners.py\n@@ -220,6 +220,8 @@\n matches.append(valid_command)\n if len(matches) == 1:\n cmdstr = matches[0]\n+ elif len(matches) > 1 and config.val.completion.use_best_match:\n+ cmdstr = matches[0]\n return cmdstr\n \n def _split_args(self, cmd, argstr, keep):\n", "issue": "Auto-use the first match in the completion\nRequested by @Earnestly in IRC:\n\nTyping, e.g. `:do`<kbd>Enter</kbd> should invoke `:download` automatically as that's the first-best match instead of showing an invalid command error.\n\n(of course configurable)\n\n", "before_files": [{"content": "# vim: ft=python fileencoding=utf-8 sts=4 sw=4 et:\n\n# Copyright 2014-2017 Florian Bruhin (The Compiler) <[email protected]>\n#\n# This file is part of qutebrowser.\n#\n# qutebrowser is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# qutebrowser is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with qutebrowser. If not, see <http://www.gnu.org/licenses/>.\n\n\"\"\"Module containing command managers (SearchRunner and CommandRunner).\"\"\"\n\nimport traceback\nimport re\n\nimport attr\nfrom PyQt5.QtCore import pyqtSlot, QUrl, QObject\n\nfrom qutebrowser.config import config\nfrom qutebrowser.commands import cmdexc, cmdutils\nfrom qutebrowser.utils import message, objreg, qtutils, usertypes, utils\nfrom qutebrowser.misc import split\n\n\nlast_command = {}\n\n\[email protected]\nclass ParseResult:\n\n \"\"\"The result of parsing a commandline.\"\"\"\n\n cmd = attr.ib()\n args = attr.ib()\n cmdline = attr.ib()\n\n\ndef _current_url(tabbed_browser):\n \"\"\"Convenience method to get the current url.\"\"\"\n try:\n return tabbed_browser.current_url()\n except qtutils.QtValueError as e:\n msg = \"Current URL is invalid\"\n if e.reason:\n msg += \" ({})\".format(e.reason)\n msg += \"!\"\n raise cmdexc.CommandError(msg)\n\n\ndef replace_variables(win_id, arglist):\n \"\"\"Utility function to replace variables like {url} in a list of args.\"\"\"\n variables = {\n 'url': lambda: _current_url(tabbed_browser).toString(\n QUrl.FullyEncoded | QUrl.RemovePassword),\n 'url:pretty': lambda: _current_url(tabbed_browser).toString(\n QUrl.DecodeReserved | QUrl.RemovePassword),\n 'clipboard': utils.get_clipboard,\n 'primary': lambda: utils.get_clipboard(selection=True),\n }\n values = {}\n args = []\n tabbed_browser = objreg.get('tabbed-browser', scope='window',\n window=win_id)\n\n def repl_cb(matchobj):\n \"\"\"Return replacement for given match.\"\"\"\n var = matchobj.group(\"var\")\n if var not in values:\n values[var] = variables[var]()\n return values[var]\n repl_pattern = re.compile(\"{(?P<var>\" + \"|\".join(variables.keys()) + \")}\")\n\n try:\n for arg in arglist:\n # using re.sub with callback function replaces all variables in a\n # single pass and avoids expansion of nested variables (e.g.\n # \"{url}\" from clipboard is not expanded)\n args.append(repl_pattern.sub(repl_cb, arg))\n except utils.ClipboardError as e:\n raise cmdexc.CommandError(e)\n return args\n\n\nclass CommandParser:\n\n \"\"\"Parse qutebrowser commandline commands.\n\n Attributes:\n\n _partial_match: Whether to allow partial command matches.\n \"\"\"\n\n def __init__(self, partial_match=False):\n self._partial_match = partial_match\n\n def _get_alias(self, text, default=None):\n \"\"\"Get an alias from the config.\n\n Args:\n text: The text to parse.\n default : Default value to return when alias was not found.\n\n Return:\n The new command string if an alias was found. Default value\n otherwise.\n \"\"\"\n parts = text.strip().split(maxsplit=1)\n try:\n alias = config.val.aliases[parts[0]]\n except KeyError:\n return default\n\n try:\n new_cmd = '{} {}'.format(alias, parts[1])\n except IndexError:\n new_cmd = alias\n if text.endswith(' '):\n new_cmd += ' '\n return new_cmd\n\n def _parse_all_gen(self, text, aliases=True, *args, **kwargs):\n \"\"\"Split a command on ;; and parse all parts.\n\n If the first command in the commandline is a non-split one, it only\n returns that.\n\n Args:\n text: Text to parse.\n aliases: Whether to handle aliases.\n *args/**kwargs: Passed to parse().\n\n Yields:\n ParseResult tuples.\n \"\"\"\n text = text.strip().lstrip(':').strip()\n if not text:\n raise cmdexc.NoSuchCommandError(\"No command given\")\n\n if aliases:\n text = self._get_alias(text, text)\n\n if ';;' in text:\n # Get the first command and check if it doesn't want to have ;;\n # split.\n first = text.split(';;')[0]\n result = self.parse(first, *args, **kwargs)\n if result.cmd.no_cmd_split:\n sub_texts = [text]\n else:\n sub_texts = [e.strip() for e in text.split(';;')]\n else:\n sub_texts = [text]\n for sub in sub_texts:\n yield self.parse(sub, *args, **kwargs)\n\n def parse_all(self, *args, **kwargs):\n \"\"\"Wrapper over parse_all.\"\"\"\n return list(self._parse_all_gen(*args, **kwargs))\n\n def parse(self, text, *, fallback=False, keep=False):\n \"\"\"Split the commandline text into command and arguments.\n\n Args:\n text: Text to parse.\n fallback: Whether to do a fallback splitting when the command was\n unknown.\n keep: Whether to keep special chars and whitespace\n\n Return:\n A ParseResult tuple.\n \"\"\"\n cmdstr, sep, argstr = text.partition(' ')\n\n if not cmdstr and not fallback:\n raise cmdexc.NoSuchCommandError(\"No command given\")\n\n if self._partial_match:\n cmdstr = self._completion_match(cmdstr)\n\n try:\n cmd = cmdutils.cmd_dict[cmdstr]\n except KeyError:\n if not fallback:\n raise cmdexc.NoSuchCommandError(\n '{}: no such command'.format(cmdstr))\n cmdline = split.split(text, keep=keep)\n return ParseResult(cmd=None, args=None, cmdline=cmdline)\n\n args = self._split_args(cmd, argstr, keep)\n if keep and args:\n cmdline = [cmdstr, sep + args[0]] + args[1:]\n elif keep:\n cmdline = [cmdstr, sep]\n else:\n cmdline = [cmdstr] + args[:]\n\n return ParseResult(cmd=cmd, args=args, cmdline=cmdline)\n\n def _completion_match(self, cmdstr):\n \"\"\"Replace cmdstr with a matching completion if there's only one match.\n\n Args:\n cmdstr: The string representing the entered command so far\n\n Return:\n cmdstr modified to the matching completion or unmodified\n \"\"\"\n matches = []\n for valid_command in cmdutils.cmd_dict:\n if valid_command.find(cmdstr) == 0:\n matches.append(valid_command)\n if len(matches) == 1:\n cmdstr = matches[0]\n return cmdstr\n\n def _split_args(self, cmd, argstr, keep):\n \"\"\"Split the arguments from an arg string.\n\n Args:\n cmd: The command we're currently handling.\n argstr: An argument string.\n keep: Whether to keep special chars and whitespace\n\n Return:\n A list containing the split strings.\n \"\"\"\n if not argstr:\n return []\n elif cmd.maxsplit is None:\n return split.split(argstr, keep=keep)\n else:\n # If split=False, we still want to split the flags, but not\n # everything after that.\n # We first split the arg string and check the index of the first\n # non-flag args, then we re-split again properly.\n # example:\n #\n # input: \"--foo -v bar baz\"\n # first split: ['--foo', '-v', 'bar', 'baz']\n # 0 1 2 3\n # second split: ['--foo', '-v', 'bar baz']\n # (maxsplit=2)\n split_args = split.simple_split(argstr, keep=keep)\n flag_arg_count = 0\n for i, arg in enumerate(split_args):\n arg = arg.strip()\n if arg.startswith('-'):\n if arg in cmd.flags_with_args:\n flag_arg_count += 1\n else:\n maxsplit = i + cmd.maxsplit + flag_arg_count\n return split.simple_split(argstr, keep=keep,\n maxsplit=maxsplit)\n\n # If there are only flags, we got it right on the first try\n # already.\n return split_args\n\n\nclass CommandRunner(QObject):\n\n \"\"\"Parse and run qutebrowser commandline commands.\n\n Attributes:\n _win_id: The window this CommandRunner is associated with.\n \"\"\"\n\n def __init__(self, win_id, partial_match=False, parent=None):\n super().__init__(parent)\n self._parser = CommandParser(partial_match=partial_match)\n self._win_id = win_id\n\n def run(self, text, count=None):\n \"\"\"Parse a command from a line of text and run it.\n\n Args:\n text: The text to parse.\n count: The count to pass to the command.\n \"\"\"\n record_last_command = True\n record_macro = True\n\n mode_manager = objreg.get('mode-manager', scope='window',\n window=self._win_id)\n cur_mode = mode_manager.mode\n\n for result in self._parser.parse_all(text):\n if result.cmd.no_replace_variables:\n args = result.args\n else:\n args = replace_variables(self._win_id, result.args)\n result.cmd.run(self._win_id, args, count=count)\n\n if result.cmdline[0] == 'repeat-command':\n record_last_command = False\n\n if result.cmdline[0] in ['record-macro', 'run-macro',\n 'set-cmd-text']:\n record_macro = False\n\n if record_last_command:\n last_command[cur_mode] = (text, count)\n\n if record_macro and cur_mode == usertypes.KeyMode.normal:\n macro_recorder = objreg.get('macro-recorder')\n macro_recorder.record_command(text, count)\n\n @pyqtSlot(str, int)\n @pyqtSlot(str)\n def run_safely(self, text, count=None):\n \"\"\"Run a command and display exceptions in the statusbar.\"\"\"\n try:\n self.run(text, count)\n except cmdexc.Error as e:\n message.error(str(e), stack=traceback.format_exc())\n", "path": "qutebrowser/commands/runners.py"}], "after_files": [{"content": "# vim: ft=python fileencoding=utf-8 sts=4 sw=4 et:\n\n# Copyright 2014-2017 Florian Bruhin (The Compiler) <[email protected]>\n#\n# This file is part of qutebrowser.\n#\n# qutebrowser is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# qutebrowser is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with qutebrowser. If not, see <http://www.gnu.org/licenses/>.\n\n\"\"\"Module containing command managers (SearchRunner and CommandRunner).\"\"\"\n\nimport traceback\nimport re\n\nimport attr\nfrom PyQt5.QtCore import pyqtSlot, QUrl, QObject\n\nfrom qutebrowser.config import config\nfrom qutebrowser.commands import cmdexc, cmdutils\nfrom qutebrowser.utils import message, objreg, qtutils, usertypes, utils\nfrom qutebrowser.misc import split\n\n\nlast_command = {}\n\n\[email protected]\nclass ParseResult:\n\n \"\"\"The result of parsing a commandline.\"\"\"\n\n cmd = attr.ib()\n args = attr.ib()\n cmdline = attr.ib()\n\n\ndef _current_url(tabbed_browser):\n \"\"\"Convenience method to get the current url.\"\"\"\n try:\n return tabbed_browser.current_url()\n except qtutils.QtValueError as e:\n msg = \"Current URL is invalid\"\n if e.reason:\n msg += \" ({})\".format(e.reason)\n msg += \"!\"\n raise cmdexc.CommandError(msg)\n\n\ndef replace_variables(win_id, arglist):\n \"\"\"Utility function to replace variables like {url} in a list of args.\"\"\"\n variables = {\n 'url': lambda: _current_url(tabbed_browser).toString(\n QUrl.FullyEncoded | QUrl.RemovePassword),\n 'url:pretty': lambda: _current_url(tabbed_browser).toString(\n QUrl.DecodeReserved | QUrl.RemovePassword),\n 'clipboard': utils.get_clipboard,\n 'primary': lambda: utils.get_clipboard(selection=True),\n }\n values = {}\n args = []\n tabbed_browser = objreg.get('tabbed-browser', scope='window',\n window=win_id)\n\n def repl_cb(matchobj):\n \"\"\"Return replacement for given match.\"\"\"\n var = matchobj.group(\"var\")\n if var not in values:\n values[var] = variables[var]()\n return values[var]\n repl_pattern = re.compile(\"{(?P<var>\" + \"|\".join(variables.keys()) + \")}\")\n\n try:\n for arg in arglist:\n # using re.sub with callback function replaces all variables in a\n # single pass and avoids expansion of nested variables (e.g.\n # \"{url}\" from clipboard is not expanded)\n args.append(repl_pattern.sub(repl_cb, arg))\n except utils.ClipboardError as e:\n raise cmdexc.CommandError(e)\n return args\n\n\nclass CommandParser:\n\n \"\"\"Parse qutebrowser commandline commands.\n\n Attributes:\n\n _partial_match: Whether to allow partial command matches.\n \"\"\"\n\n def __init__(self, partial_match=False):\n self._partial_match = partial_match\n\n def _get_alias(self, text, default=None):\n \"\"\"Get an alias from the config.\n\n Args:\n text: The text to parse.\n default : Default value to return when alias was not found.\n\n Return:\n The new command string if an alias was found. Default value\n otherwise.\n \"\"\"\n parts = text.strip().split(maxsplit=1)\n try:\n alias = config.val.aliases[parts[0]]\n except KeyError:\n return default\n\n try:\n new_cmd = '{} {}'.format(alias, parts[1])\n except IndexError:\n new_cmd = alias\n if text.endswith(' '):\n new_cmd += ' '\n return new_cmd\n\n def _parse_all_gen(self, text, aliases=True, *args, **kwargs):\n \"\"\"Split a command on ;; and parse all parts.\n\n If the first command in the commandline is a non-split one, it only\n returns that.\n\n Args:\n text: Text to parse.\n aliases: Whether to handle aliases.\n *args/**kwargs: Passed to parse().\n\n Yields:\n ParseResult tuples.\n \"\"\"\n text = text.strip().lstrip(':').strip()\n if not text:\n raise cmdexc.NoSuchCommandError(\"No command given\")\n\n if aliases:\n text = self._get_alias(text, text)\n\n if ';;' in text:\n # Get the first command and check if it doesn't want to have ;;\n # split.\n first = text.split(';;')[0]\n result = self.parse(first, *args, **kwargs)\n if result.cmd.no_cmd_split:\n sub_texts = [text]\n else:\n sub_texts = [e.strip() for e in text.split(';;')]\n else:\n sub_texts = [text]\n for sub in sub_texts:\n yield self.parse(sub, *args, **kwargs)\n\n def parse_all(self, *args, **kwargs):\n \"\"\"Wrapper over parse_all.\"\"\"\n return list(self._parse_all_gen(*args, **kwargs))\n\n def parse(self, text, *, fallback=False, keep=False):\n \"\"\"Split the commandline text into command and arguments.\n\n Args:\n text: Text to parse.\n fallback: Whether to do a fallback splitting when the command was\n unknown.\n keep: Whether to keep special chars and whitespace\n\n Return:\n A ParseResult tuple.\n \"\"\"\n cmdstr, sep, argstr = text.partition(' ')\n\n if not cmdstr and not fallback:\n raise cmdexc.NoSuchCommandError(\"No command given\")\n\n if self._partial_match:\n cmdstr = self._completion_match(cmdstr)\n\n try:\n cmd = cmdutils.cmd_dict[cmdstr]\n except KeyError:\n if not fallback:\n raise cmdexc.NoSuchCommandError(\n '{}: no such command'.format(cmdstr))\n cmdline = split.split(text, keep=keep)\n return ParseResult(cmd=None, args=None, cmdline=cmdline)\n\n args = self._split_args(cmd, argstr, keep)\n if keep and args:\n cmdline = [cmdstr, sep + args[0]] + args[1:]\n elif keep:\n cmdline = [cmdstr, sep]\n else:\n cmdline = [cmdstr] + args[:]\n\n return ParseResult(cmd=cmd, args=args, cmdline=cmdline)\n\n def _completion_match(self, cmdstr):\n \"\"\"Replace cmdstr with a matching completion if there's only one match.\n\n Args:\n cmdstr: The string representing the entered command so far\n\n Return:\n cmdstr modified to the matching completion or unmodified\n \"\"\"\n matches = []\n for valid_command in cmdutils.cmd_dict:\n if valid_command.find(cmdstr) == 0:\n matches.append(valid_command)\n if len(matches) == 1:\n cmdstr = matches[0]\n elif len(matches) > 1 and config.val.completion.use_best_match:\n cmdstr = matches[0]\n return cmdstr\n\n def _split_args(self, cmd, argstr, keep):\n \"\"\"Split the arguments from an arg string.\n\n Args:\n cmd: The command we're currently handling.\n argstr: An argument string.\n keep: Whether to keep special chars and whitespace\n\n Return:\n A list containing the split strings.\n \"\"\"\n if not argstr:\n return []\n elif cmd.maxsplit is None:\n return split.split(argstr, keep=keep)\n else:\n # If split=False, we still want to split the flags, but not\n # everything after that.\n # We first split the arg string and check the index of the first\n # non-flag args, then we re-split again properly.\n # example:\n #\n # input: \"--foo -v bar baz\"\n # first split: ['--foo', '-v', 'bar', 'baz']\n # 0 1 2 3\n # second split: ['--foo', '-v', 'bar baz']\n # (maxsplit=2)\n split_args = split.simple_split(argstr, keep=keep)\n flag_arg_count = 0\n for i, arg in enumerate(split_args):\n arg = arg.strip()\n if arg.startswith('-'):\n if arg in cmd.flags_with_args:\n flag_arg_count += 1\n else:\n maxsplit = i + cmd.maxsplit + flag_arg_count\n return split.simple_split(argstr, keep=keep,\n maxsplit=maxsplit)\n\n # If there are only flags, we got it right on the first try\n # already.\n return split_args\n\n\nclass CommandRunner(QObject):\n\n \"\"\"Parse and run qutebrowser commandline commands.\n\n Attributes:\n _win_id: The window this CommandRunner is associated with.\n \"\"\"\n\n def __init__(self, win_id, partial_match=False, parent=None):\n super().__init__(parent)\n self._parser = CommandParser(partial_match=partial_match)\n self._win_id = win_id\n\n def run(self, text, count=None):\n \"\"\"Parse a command from a line of text and run it.\n\n Args:\n text: The text to parse.\n count: The count to pass to the command.\n \"\"\"\n record_last_command = True\n record_macro = True\n\n mode_manager = objreg.get('mode-manager', scope='window',\n window=self._win_id)\n cur_mode = mode_manager.mode\n\n for result in self._parser.parse_all(text):\n if result.cmd.no_replace_variables:\n args = result.args\n else:\n args = replace_variables(self._win_id, result.args)\n result.cmd.run(self._win_id, args, count=count)\n\n if result.cmdline[0] == 'repeat-command':\n record_last_command = False\n\n if result.cmdline[0] in ['record-macro', 'run-macro',\n 'set-cmd-text']:\n record_macro = False\n\n if record_last_command:\n last_command[cur_mode] = (text, count)\n\n if record_macro and cur_mode == usertypes.KeyMode.normal:\n macro_recorder = objreg.get('macro-recorder')\n macro_recorder.record_command(text, count)\n\n @pyqtSlot(str, int)\n @pyqtSlot(str)\n def run_safely(self, text, count=None):\n \"\"\"Run a command and display exceptions in the statusbar.\"\"\"\n try:\n self.run(text, count)\n except cmdexc.Error as e:\n message.error(str(e), stack=traceback.format_exc())\n\n @pyqtSlot(str, int)\n def run_safely_init(self, text, count=None):\n \"\"\"Run a command and display exceptions in the statusbar.\n\n Contrary to run_safely, error messages are queued so this is more\n suitable to use while initializing.\n \"\"\"\n try:\n self.run(text, count)\n except cmdexc.Error as e:\n message.error(str(e), stack=traceback.format_exc())\n", "path": "qutebrowser/commands/runners.py"}]}
| 3,575 | 127 |
gh_patches_debug_28992
|
rasdani/github-patches
|
git_diff
|
HypothesisWorks__hypothesis-624
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
False positive HypothesisDeprecationWarning
Just upgraded to Hypothesis 3.8.2, and I'm getting the following warning:
```
.venv/lib/python3.6/site-packages/hypothesis/strategies.py:416: HypothesisDeprecationWarning: Cannot sample from <enum 'AnEnum'>, not a sequence. Hypothesis goes to some length to ensure that sampling an element from a collection (with `sampled_from` or `choices`) is replayable and can be minimised. To replay a saved example, the sampled values must have the same iteration order on every run - ruling out sets, dicts, etc due to hash randomisation. Most cases can simply use `sorted(values)`, but mixed types or special values such as math.nan require careful handling - and note that when simplifying an example, Hypothesis treats earlier values as simpler.
elements = check_sample(elements)
```
It's a great warning but I think I'm getting a false positive:
```
from hypothesis import given
from hypothesis.strategies import sampled_from
from enum import Enum
class AnEnum(Enum):
A = "A"
B = "B"
@given(sampled_from(AnEnum))
def test_enum(e):
print(e)
```
According to https://docs.python.org/3/library/enum.html, "Enumerations support iteration, in definition order", so this should be fine, right?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/hypothesis/version.py`
Content:
```
1 # coding=utf-8
2 #
3 # This file is part of Hypothesis, which may be found at
4 # https://github.com/HypothesisWorks/hypothesis-python
5 #
6 # Most of this work is copyright (C) 2013-2017 David R. MacIver
7 # ([email protected]), but it contains contributions by others. See
8 # CONTRIBUTING.rst for a full list of people who may hold copyright, and
9 # consult the git log if you need to determine who owns an individual
10 # contribution.
11 #
12 # This Source Code Form is subject to the terms of the Mozilla Public License,
13 # v. 2.0. If a copy of the MPL was not distributed with this file, You can
14 # obtain one at http://mozilla.org/MPL/2.0/.
15 #
16 # END HEADER
17
18 from __future__ import division, print_function, absolute_import
19
20 __version_info__ = (3, 8, 3)
21 __version__ = '.'.join(map(str, __version_info__))
22
```
Path: `src/hypothesis/internal/conjecture/utils.py`
Content:
```
1 # coding=utf-8
2 #
3 # This file is part of Hypothesis, which may be found at
4 # https://github.com/HypothesisWorks/hypothesis-python
5 #
6 # Most of this work is copyright (C) 2013-2017 David R. MacIver
7 # ([email protected]), but it contains contributions by others. See
8 # CONTRIBUTING.rst for a full list of people who may hold copyright, and
9 # consult the git log if you need to determine who owns an individual
10 # contribution.
11 #
12 # This Source Code Form is subject to the terms of the Mozilla Public License,
13 # v. 2.0. If a copy of the MPL was not distributed with this file, You can
14 # obtain one at http://mozilla.org/MPL/2.0/.
15 #
16 # END HEADER
17
18 from __future__ import division, print_function, absolute_import
19
20 import math
21 from collections import Sequence
22
23 from hypothesis._settings import note_deprecation
24 from hypothesis.internal.compat import hbytes, bit_length, int_to_bytes, \
25 int_from_bytes
26
27
28 def n_byte_unsigned(data, n):
29 return int_from_bytes(data.draw_bytes(n))
30
31
32 def saturate(n):
33 bits = bit_length(n)
34 k = 1
35 while k < bits:
36 n |= (n >> k)
37 k *= 2
38 return n
39
40
41 def integer_range(data, lower, upper, center=None, distribution=None):
42 assert lower <= upper
43 if lower == upper:
44 return int(lower)
45
46 if center is None:
47 center = lower
48 center = min(max(center, lower), upper)
49 if distribution is None:
50 if lower < center < upper:
51 def distribution(random):
52 if random.randint(0, 1):
53 return random.randint(center, upper)
54 else:
55 return random.randint(lower, center)
56 else:
57 def distribution(random):
58 return random.randint(lower, upper)
59
60 gap = upper - lower
61 bits = bit_length(gap)
62 nbytes = bits // 8 + int(bits % 8 != 0)
63 mask = saturate(gap)
64
65 def byte_distribution(random, n):
66 assert n == nbytes
67 v = distribution(random)
68 if v >= center:
69 probe = v - center
70 else:
71 probe = upper - v
72 return int_to_bytes(probe, n)
73
74 probe = gap + 1
75
76 while probe > gap:
77 probe = int_from_bytes(
78 data.draw_bytes(nbytes, byte_distribution)
79 ) & mask
80
81 if center == upper:
82 result = upper - probe
83 elif center == lower:
84 result = lower + probe
85 else:
86 if center + probe <= upper:
87 result = center + probe
88 else:
89 result = upper - probe
90 assert lower <= result <= upper
91 return int(result)
92
93
94 def integer_range_with_distribution(data, lower, upper, nums):
95 return integer_range(
96 data, lower, upper, distribution=nums
97 )
98
99
100 def centered_integer_range(data, lower, upper, center):
101 return integer_range(
102 data, lower, upper, center=center
103 )
104
105
106 def check_sample(values):
107 if not isinstance(values, Sequence):
108 note_deprecation(
109 ('Cannot sample from %r, not a sequence. ' % (values,)) +
110 'Hypothesis goes to some length to ensure that sampling an '
111 'element from a collection (with `sampled_from` or `choices`) is '
112 'replayable and can be minimised. To replay a saved example, '
113 'the sampled values must have the same iteration order on every '
114 'run - ruling out sets, dicts, etc due to hash randomisation. '
115 'Most cases can simply use `sorted(values)`, but mixed types or '
116 'special values such as math.nan require careful handling - and '
117 'note that when simplifying an example, Hypothesis treats '
118 'earlier values as simpler.')
119 return tuple(values)
120
121
122 def choice(data, values):
123 return values[integer_range(data, 0, len(values) - 1)]
124
125
126 def geometric(data, p):
127 denom = math.log1p(-p)
128 n_bytes = 8
129
130 def distribution(random, n):
131 assert n == n_bytes
132 for _ in range(100):
133 try:
134 return int_to_bytes(int(
135 math.log1p(-random.random()) / denom), n)
136 # This is basically impossible to hit but is required for
137 # correctness
138 except OverflowError: # pragma: no cover
139 pass
140 # We got a one in a million chance 100 times in a row. Something is up.
141 assert False # pragma: no cover
142 return int_from_bytes(data.draw_bytes(n_bytes, distribution))
143
144
145 def boolean(data):
146 return bool(n_byte_unsigned(data, 1) & 1)
147
148
149 def biased_coin(data, p):
150 def distribution(random, n):
151 assert n == 1
152 return hbytes([int(random.random() <= p)])
153 return bool(
154 data.draw_bytes(1, distribution)[0] & 1
155 )
156
157
158 def write(data, string):
159 assert isinstance(string, hbytes)
160
161 def distribution(random, n):
162 assert n == len(string)
163 return string
164 x = data.draw_bytes(len(string), distribution)
165 if x != string:
166 data.mark_invalid()
167
```
Path: `docs/conf.py`
Content:
```
1 # coding=utf-8
2 #
3 # This file is part of Hypothesis, which may be found at
4 # https://github.com/HypothesisWorks/hypothesis-python
5 #
6 # Most of this work is copyright (C) 2013-2017 David R. MacIver
7 # ([email protected]), but it contains contributions by others. See
8 # CONTRIBUTING.rst for a full list of people who may hold copyright, and
9 # consult the git log if you need to determine who owns an individual
10 # contribution.
11 #
12 # This Source Code Form is subject to the terms of the Mozilla Public License,
13 # v. 2.0. If a copy of the MPL was not distributed with this file, You can
14 # obtain one at http://mozilla.org/MPL/2.0/.
15 #
16 # END HEADER
17
18 # -*- coding: utf-8 -*-
19
20 from __future__ import division, print_function, absolute_import
21
22 # on_rtd is whether we are on readthedocs.org
23 import os
24 import sys
25
26 from hypothesis import __version__
27
28 on_rtd = os.environ.get('READTHEDOCS', None) == 'True'
29
30 sys.path.append(
31 os.path.join(os.path.dirname(__file__), '..', 'src')
32 )
33
34
35 autodoc_member_order = 'bysource'
36
37 extensions = [
38 'sphinx.ext.autodoc',
39 'sphinx.ext.doctest',
40 'sphinx.ext.extlinks',
41 'sphinx.ext.viewcode',
42 'sphinx.ext.intersphinx',
43 ]
44
45 templates_path = ['_templates']
46
47 source_suffix = '.rst'
48
49 # The master toctree document.
50 master_doc = 'index'
51
52 # General information about the project.
53 project = u'Hypothesis'
54 copyright = u'2015, David R. MacIver'
55 author = u'David R. MacIver'
56
57 version = __version__
58 release = __version__
59
60 language = None
61
62 exclude_patterns = ['_build']
63
64 pygments_style = 'sphinx'
65
66 todo_include_todos = False
67
68 intersphinx_mapping = {
69 'python': ('http://docs.python.org/', None),
70 }
71
72 autodoc_mock_imports = ['numpy']
73
74 doctest_global_setup = '''
75 # Some standard imports
76 from hypothesis import *
77 from hypothesis.strategies import *
78 # Ensure that output (including from strategies) is deterministic
79 import random
80 random.seed(0)
81 '''
82
83 # This config value must be a dictionary of external sites, mapping unique
84 # short alias names to a base URL and a prefix.
85 # See http://sphinx-doc.org/ext/extlinks.html
86 extlinks = {
87 'commit': ('https://github.com/HypothesisWorks/hypothesis-python/commit/%s', 'commit '),
88 'gh-file': ('https://github.com/HypothesisWorks/hypothesis-python/blob/master/%s', ''),
89 'gh-link': ('https://github.com/HypothesisWorks/hypothesis-python/%s', ''),
90 'issue': ('https://github.com/HypothesisWorks/hypothesis-python/issues/%s', 'issue #'),
91 'pull': ('https://github.com/HypothesisWorks/hypothesis-python/pulls/%s', 'pull request #'),
92 }
93
94 # -- Options for HTML output ----------------------------------------------
95
96 if not on_rtd: # only import and set the theme if we're building docs locally
97 import sphinx_rtd_theme
98 html_theme = 'sphinx_rtd_theme'
99 html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]
100
101 html_static_path = ['_static']
102
103 htmlhelp_basename = 'Hypothesisdoc'
104
105 # -- Options for LaTeX output ---------------------------------------------
106
107 latex_elements = {
108 }
109
110 latex_documents = [
111 (master_doc, 'Hypothesis.tex', u'Hypothesis Documentation',
112 u'David R. MacIver', 'manual'),
113 ]
114
115 man_pages = [
116 (master_doc, 'hypothesis', u'Hypothesis Documentation',
117 [author], 1)
118 ]
119
120 texinfo_documents = [
121 (master_doc, 'Hypothesis', u'Hypothesis Documentation',
122 author, 'Hypothesis', 'One line description of project.',
123 'Miscellaneous'),
124 ]
125
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -22,6 +22,7 @@
# on_rtd is whether we are on readthedocs.org
import os
import sys
+import datetime
from hypothesis import __version__
@@ -51,7 +52,7 @@
# General information about the project.
project = u'Hypothesis'
-copyright = u'2015, David R. MacIver'
+copyright = u'2013-%s, David R. MacIver' % datetime.datetime.utcnow().year
author = u'David R. MacIver'
version = __version__
diff --git a/src/hypothesis/internal/conjecture/utils.py b/src/hypothesis/internal/conjecture/utils.py
--- a/src/hypothesis/internal/conjecture/utils.py
+++ b/src/hypothesis/internal/conjecture/utils.py
@@ -17,6 +17,7 @@
from __future__ import division, print_function, absolute_import
+import enum
import math
from collections import Sequence
@@ -104,7 +105,7 @@
def check_sample(values):
- if not isinstance(values, Sequence):
+ if not isinstance(values, (Sequence, enum.EnumMeta)):
note_deprecation(
('Cannot sample from %r, not a sequence. ' % (values,)) +
'Hypothesis goes to some length to ensure that sampling an '
diff --git a/src/hypothesis/version.py b/src/hypothesis/version.py
--- a/src/hypothesis/version.py
+++ b/src/hypothesis/version.py
@@ -17,5 +17,5 @@
from __future__ import division, print_function, absolute_import
-__version_info__ = (3, 8, 3)
+__version_info__ = (3, 8, 4)
__version__ = '.'.join(map(str, __version_info__))
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -22,6 +22,7 @@\n # on_rtd is whether we are on readthedocs.org\n import os\n import sys\n+import datetime\n \n from hypothesis import __version__\n \n@@ -51,7 +52,7 @@\n \n # General information about the project.\n project = u'Hypothesis'\n-copyright = u'2015, David R. MacIver'\n+copyright = u'2013-%s, David R. MacIver' % datetime.datetime.utcnow().year\n author = u'David R. MacIver'\n \n version = __version__\ndiff --git a/src/hypothesis/internal/conjecture/utils.py b/src/hypothesis/internal/conjecture/utils.py\n--- a/src/hypothesis/internal/conjecture/utils.py\n+++ b/src/hypothesis/internal/conjecture/utils.py\n@@ -17,6 +17,7 @@\n \n from __future__ import division, print_function, absolute_import\n \n+import enum\n import math\n from collections import Sequence\n \n@@ -104,7 +105,7 @@\n \n \n def check_sample(values):\n- if not isinstance(values, Sequence):\n+ if not isinstance(values, (Sequence, enum.EnumMeta)):\n note_deprecation(\n ('Cannot sample from %r, not a sequence. ' % (values,)) +\n 'Hypothesis goes to some length to ensure that sampling an '\ndiff --git a/src/hypothesis/version.py b/src/hypothesis/version.py\n--- a/src/hypothesis/version.py\n+++ b/src/hypothesis/version.py\n@@ -17,5 +17,5 @@\n \n from __future__ import division, print_function, absolute_import\n \n-__version_info__ = (3, 8, 3)\n+__version_info__ = (3, 8, 4)\n __version__ = '.'.join(map(str, __version_info__))\n", "issue": "False positive HypothesisDeprecationWarning\nJust upgraded to Hypothesis 3.8.2, and I'm getting the following warning:\r\n\r\n```\r\n.venv/lib/python3.6/site-packages/hypothesis/strategies.py:416: HypothesisDeprecationWarning: Cannot sample from <enum 'AnEnum'>, not a sequence. Hypothesis goes to some length to ensure that sampling an element from a collection (with `sampled_from` or `choices`) is replayable and can be minimised. To replay a saved example, the sampled values must have the same iteration order on every run - ruling out sets, dicts, etc due to hash randomisation. Most cases can simply use `sorted(values)`, but mixed types or special values such as math.nan require careful handling - and note that when simplifying an example, Hypothesis treats earlier values as simpler.\r\n elements = check_sample(elements)\r\n```\r\nIt's a great warning but I think I'm getting a false positive:\r\n```\r\nfrom hypothesis import given\r\nfrom hypothesis.strategies import sampled_from\r\n\r\nfrom enum import Enum\r\n\r\n\r\nclass AnEnum(Enum):\r\n A = \"A\"\r\n B = \"B\"\r\n\r\n\r\n@given(sampled_from(AnEnum))\r\ndef test_enum(e):\r\n print(e)\r\n```\r\nAccording to https://docs.python.org/3/library/enum.html, \"Enumerations support iteration, in definition order\", so this should be fine, right?\n", "before_files": [{"content": "# coding=utf-8\n#\n# This file is part of Hypothesis, which may be found at\n# https://github.com/HypothesisWorks/hypothesis-python\n#\n# Most of this work is copyright (C) 2013-2017 David R. MacIver\n# ([email protected]), but it contains contributions by others. See\n# CONTRIBUTING.rst for a full list of people who may hold copyright, and\n# consult the git log if you need to determine who owns an individual\n# contribution.\n#\n# This Source Code Form is subject to the terms of the Mozilla Public License,\n# v. 2.0. If a copy of the MPL was not distributed with this file, You can\n# obtain one at http://mozilla.org/MPL/2.0/.\n#\n# END HEADER\n\nfrom __future__ import division, print_function, absolute_import\n\n__version_info__ = (3, 8, 3)\n__version__ = '.'.join(map(str, __version_info__))\n", "path": "src/hypothesis/version.py"}, {"content": "# coding=utf-8\n#\n# This file is part of Hypothesis, which may be found at\n# https://github.com/HypothesisWorks/hypothesis-python\n#\n# Most of this work is copyright (C) 2013-2017 David R. MacIver\n# ([email protected]), but it contains contributions by others. See\n# CONTRIBUTING.rst for a full list of people who may hold copyright, and\n# consult the git log if you need to determine who owns an individual\n# contribution.\n#\n# This Source Code Form is subject to the terms of the Mozilla Public License,\n# v. 2.0. If a copy of the MPL was not distributed with this file, You can\n# obtain one at http://mozilla.org/MPL/2.0/.\n#\n# END HEADER\n\nfrom __future__ import division, print_function, absolute_import\n\nimport math\nfrom collections import Sequence\n\nfrom hypothesis._settings import note_deprecation\nfrom hypothesis.internal.compat import hbytes, bit_length, int_to_bytes, \\\n int_from_bytes\n\n\ndef n_byte_unsigned(data, n):\n return int_from_bytes(data.draw_bytes(n))\n\n\ndef saturate(n):\n bits = bit_length(n)\n k = 1\n while k < bits:\n n |= (n >> k)\n k *= 2\n return n\n\n\ndef integer_range(data, lower, upper, center=None, distribution=None):\n assert lower <= upper\n if lower == upper:\n return int(lower)\n\n if center is None:\n center = lower\n center = min(max(center, lower), upper)\n if distribution is None:\n if lower < center < upper:\n def distribution(random):\n if random.randint(0, 1):\n return random.randint(center, upper)\n else:\n return random.randint(lower, center)\n else:\n def distribution(random):\n return random.randint(lower, upper)\n\n gap = upper - lower\n bits = bit_length(gap)\n nbytes = bits // 8 + int(bits % 8 != 0)\n mask = saturate(gap)\n\n def byte_distribution(random, n):\n assert n == nbytes\n v = distribution(random)\n if v >= center:\n probe = v - center\n else:\n probe = upper - v\n return int_to_bytes(probe, n)\n\n probe = gap + 1\n\n while probe > gap:\n probe = int_from_bytes(\n data.draw_bytes(nbytes, byte_distribution)\n ) & mask\n\n if center == upper:\n result = upper - probe\n elif center == lower:\n result = lower + probe\n else:\n if center + probe <= upper:\n result = center + probe\n else:\n result = upper - probe\n assert lower <= result <= upper\n return int(result)\n\n\ndef integer_range_with_distribution(data, lower, upper, nums):\n return integer_range(\n data, lower, upper, distribution=nums\n )\n\n\ndef centered_integer_range(data, lower, upper, center):\n return integer_range(\n data, lower, upper, center=center\n )\n\n\ndef check_sample(values):\n if not isinstance(values, Sequence):\n note_deprecation(\n ('Cannot sample from %r, not a sequence. ' % (values,)) +\n 'Hypothesis goes to some length to ensure that sampling an '\n 'element from a collection (with `sampled_from` or `choices`) is '\n 'replayable and can be minimised. To replay a saved example, '\n 'the sampled values must have the same iteration order on every '\n 'run - ruling out sets, dicts, etc due to hash randomisation. '\n 'Most cases can simply use `sorted(values)`, but mixed types or '\n 'special values such as math.nan require careful handling - and '\n 'note that when simplifying an example, Hypothesis treats '\n 'earlier values as simpler.')\n return tuple(values)\n\n\ndef choice(data, values):\n return values[integer_range(data, 0, len(values) - 1)]\n\n\ndef geometric(data, p):\n denom = math.log1p(-p)\n n_bytes = 8\n\n def distribution(random, n):\n assert n == n_bytes\n for _ in range(100):\n try:\n return int_to_bytes(int(\n math.log1p(-random.random()) / denom), n)\n # This is basically impossible to hit but is required for\n # correctness\n except OverflowError: # pragma: no cover\n pass\n # We got a one in a million chance 100 times in a row. Something is up.\n assert False # pragma: no cover\n return int_from_bytes(data.draw_bytes(n_bytes, distribution))\n\n\ndef boolean(data):\n return bool(n_byte_unsigned(data, 1) & 1)\n\n\ndef biased_coin(data, p):\n def distribution(random, n):\n assert n == 1\n return hbytes([int(random.random() <= p)])\n return bool(\n data.draw_bytes(1, distribution)[0] & 1\n )\n\n\ndef write(data, string):\n assert isinstance(string, hbytes)\n\n def distribution(random, n):\n assert n == len(string)\n return string\n x = data.draw_bytes(len(string), distribution)\n if x != string:\n data.mark_invalid()\n", "path": "src/hypothesis/internal/conjecture/utils.py"}, {"content": "# coding=utf-8\n#\n# This file is part of Hypothesis, which may be found at\n# https://github.com/HypothesisWorks/hypothesis-python\n#\n# Most of this work is copyright (C) 2013-2017 David R. MacIver\n# ([email protected]), but it contains contributions by others. See\n# CONTRIBUTING.rst for a full list of people who may hold copyright, and\n# consult the git log if you need to determine who owns an individual\n# contribution.\n#\n# This Source Code Form is subject to the terms of the Mozilla Public License,\n# v. 2.0. If a copy of the MPL was not distributed with this file, You can\n# obtain one at http://mozilla.org/MPL/2.0/.\n#\n# END HEADER\n\n# -*- coding: utf-8 -*-\n\nfrom __future__ import division, print_function, absolute_import\n\n# on_rtd is whether we are on readthedocs.org\nimport os\nimport sys\n\nfrom hypothesis import __version__\n\non_rtd = os.environ.get('READTHEDOCS', None) == 'True'\n\nsys.path.append(\n os.path.join(os.path.dirname(__file__), '..', 'src')\n)\n\n\nautodoc_member_order = 'bysource'\n\nextensions = [\n 'sphinx.ext.autodoc',\n 'sphinx.ext.doctest',\n 'sphinx.ext.extlinks',\n 'sphinx.ext.viewcode',\n 'sphinx.ext.intersphinx',\n]\n\ntemplates_path = ['_templates']\n\nsource_suffix = '.rst'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = u'Hypothesis'\ncopyright = u'2015, David R. MacIver'\nauthor = u'David R. MacIver'\n\nversion = __version__\nrelease = __version__\n\nlanguage = None\n\nexclude_patterns = ['_build']\n\npygments_style = 'sphinx'\n\ntodo_include_todos = False\n\nintersphinx_mapping = {\n 'python': ('http://docs.python.org/', None),\n}\n\nautodoc_mock_imports = ['numpy']\n\ndoctest_global_setup = '''\n# Some standard imports\nfrom hypothesis import *\nfrom hypothesis.strategies import *\n# Ensure that output (including from strategies) is deterministic\nimport random\nrandom.seed(0)\n'''\n\n# This config value must be a dictionary of external sites, mapping unique\n# short alias names to a base URL and a prefix.\n# See http://sphinx-doc.org/ext/extlinks.html\nextlinks = {\n 'commit': ('https://github.com/HypothesisWorks/hypothesis-python/commit/%s', 'commit '),\n 'gh-file': ('https://github.com/HypothesisWorks/hypothesis-python/blob/master/%s', ''),\n 'gh-link': ('https://github.com/HypothesisWorks/hypothesis-python/%s', ''),\n 'issue': ('https://github.com/HypothesisWorks/hypothesis-python/issues/%s', 'issue #'),\n 'pull': ('https://github.com/HypothesisWorks/hypothesis-python/pulls/%s', 'pull request #'),\n}\n\n# -- Options for HTML output ----------------------------------------------\n\nif not on_rtd: # only import and set the theme if we're building docs locally\n import sphinx_rtd_theme\n html_theme = 'sphinx_rtd_theme'\n html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]\n\nhtml_static_path = ['_static']\n\nhtmlhelp_basename = 'Hypothesisdoc'\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {\n}\n\nlatex_documents = [\n (master_doc, 'Hypothesis.tex', u'Hypothesis Documentation',\n u'David R. MacIver', 'manual'),\n]\n\nman_pages = [\n (master_doc, 'hypothesis', u'Hypothesis Documentation',\n [author], 1)\n]\n\ntexinfo_documents = [\n (master_doc, 'Hypothesis', u'Hypothesis Documentation',\n author, 'Hypothesis', 'One line description of project.',\n 'Miscellaneous'),\n]\n", "path": "docs/conf.py"}], "after_files": [{"content": "# coding=utf-8\n#\n# This file is part of Hypothesis, which may be found at\n# https://github.com/HypothesisWorks/hypothesis-python\n#\n# Most of this work is copyright (C) 2013-2017 David R. MacIver\n# ([email protected]), but it contains contributions by others. See\n# CONTRIBUTING.rst for a full list of people who may hold copyright, and\n# consult the git log if you need to determine who owns an individual\n# contribution.\n#\n# This Source Code Form is subject to the terms of the Mozilla Public License,\n# v. 2.0. If a copy of the MPL was not distributed with this file, You can\n# obtain one at http://mozilla.org/MPL/2.0/.\n#\n# END HEADER\n\nfrom __future__ import division, print_function, absolute_import\n\n__version_info__ = (3, 8, 4)\n__version__ = '.'.join(map(str, __version_info__))\n", "path": "src/hypothesis/version.py"}, {"content": "# coding=utf-8\n#\n# This file is part of Hypothesis, which may be found at\n# https://github.com/HypothesisWorks/hypothesis-python\n#\n# Most of this work is copyright (C) 2013-2017 David R. MacIver\n# ([email protected]), but it contains contributions by others. See\n# CONTRIBUTING.rst for a full list of people who may hold copyright, and\n# consult the git log if you need to determine who owns an individual\n# contribution.\n#\n# This Source Code Form is subject to the terms of the Mozilla Public License,\n# v. 2.0. If a copy of the MPL was not distributed with this file, You can\n# obtain one at http://mozilla.org/MPL/2.0/.\n#\n# END HEADER\n\nfrom __future__ import division, print_function, absolute_import\n\nimport enum\nimport math\nfrom collections import Sequence\n\nfrom hypothesis._settings import note_deprecation\nfrom hypothesis.internal.compat import hbytes, bit_length, int_to_bytes, \\\n int_from_bytes\n\n\ndef n_byte_unsigned(data, n):\n return int_from_bytes(data.draw_bytes(n))\n\n\ndef saturate(n):\n bits = bit_length(n)\n k = 1\n while k < bits:\n n |= (n >> k)\n k *= 2\n return n\n\n\ndef integer_range(data, lower, upper, center=None, distribution=None):\n assert lower <= upper\n if lower == upper:\n return int(lower)\n\n if center is None:\n center = lower\n center = min(max(center, lower), upper)\n if distribution is None:\n if lower < center < upper:\n def distribution(random):\n if random.randint(0, 1):\n return random.randint(center, upper)\n else:\n return random.randint(lower, center)\n else:\n def distribution(random):\n return random.randint(lower, upper)\n\n gap = upper - lower\n bits = bit_length(gap)\n nbytes = bits // 8 + int(bits % 8 != 0)\n mask = saturate(gap)\n\n def byte_distribution(random, n):\n assert n == nbytes\n v = distribution(random)\n if v >= center:\n probe = v - center\n else:\n probe = upper - v\n return int_to_bytes(probe, n)\n\n probe = gap + 1\n\n while probe > gap:\n probe = int_from_bytes(\n data.draw_bytes(nbytes, byte_distribution)\n ) & mask\n\n if center == upper:\n result = upper - probe\n elif center == lower:\n result = lower + probe\n else:\n if center + probe <= upper:\n result = center + probe\n else:\n result = upper - probe\n assert lower <= result <= upper\n return int(result)\n\n\ndef integer_range_with_distribution(data, lower, upper, nums):\n return integer_range(\n data, lower, upper, distribution=nums\n )\n\n\ndef centered_integer_range(data, lower, upper, center):\n return integer_range(\n data, lower, upper, center=center\n )\n\n\ndef check_sample(values):\n if not isinstance(values, (Sequence, enum.EnumMeta)):\n note_deprecation(\n ('Cannot sample from %r, not a sequence. ' % (values,)) +\n 'Hypothesis goes to some length to ensure that sampling an '\n 'element from a collection (with `sampled_from` or `choices`) is '\n 'replayable and can be minimised. To replay a saved example, '\n 'the sampled values must have the same iteration order on every '\n 'run - ruling out sets, dicts, etc due to hash randomisation. '\n 'Most cases can simply use `sorted(values)`, but mixed types or '\n 'special values such as math.nan require careful handling - and '\n 'note that when simplifying an example, Hypothesis treats '\n 'earlier values as simpler.')\n return tuple(values)\n\n\ndef choice(data, values):\n return values[integer_range(data, 0, len(values) - 1)]\n\n\ndef geometric(data, p):\n denom = math.log1p(-p)\n n_bytes = 8\n\n def distribution(random, n):\n assert n == n_bytes\n for _ in range(100):\n try:\n return int_to_bytes(int(\n math.log1p(-random.random()) / denom), n)\n # This is basically impossible to hit but is required for\n # correctness\n except OverflowError: # pragma: no cover\n pass\n # We got a one in a million chance 100 times in a row. Something is up.\n assert False # pragma: no cover\n return int_from_bytes(data.draw_bytes(n_bytes, distribution))\n\n\ndef boolean(data):\n return bool(n_byte_unsigned(data, 1) & 1)\n\n\ndef biased_coin(data, p):\n def distribution(random, n):\n assert n == 1\n return hbytes([int(random.random() <= p)])\n return bool(\n data.draw_bytes(1, distribution)[0] & 1\n )\n\n\ndef write(data, string):\n assert isinstance(string, hbytes)\n\n def distribution(random, n):\n assert n == len(string)\n return string\n x = data.draw_bytes(len(string), distribution)\n if x != string:\n data.mark_invalid()\n", "path": "src/hypothesis/internal/conjecture/utils.py"}, {"content": "# coding=utf-8\n#\n# This file is part of Hypothesis, which may be found at\n# https://github.com/HypothesisWorks/hypothesis-python\n#\n# Most of this work is copyright (C) 2013-2017 David R. MacIver\n# ([email protected]), but it contains contributions by others. See\n# CONTRIBUTING.rst for a full list of people who may hold copyright, and\n# consult the git log if you need to determine who owns an individual\n# contribution.\n#\n# This Source Code Form is subject to the terms of the Mozilla Public License,\n# v. 2.0. If a copy of the MPL was not distributed with this file, You can\n# obtain one at http://mozilla.org/MPL/2.0/.\n#\n# END HEADER\n\n# -*- coding: utf-8 -*-\n\nfrom __future__ import division, print_function, absolute_import\n\n# on_rtd is whether we are on readthedocs.org\nimport os\nimport sys\nimport datetime\n\nfrom hypothesis import __version__\n\non_rtd = os.environ.get('READTHEDOCS', None) == 'True'\n\nsys.path.append(\n os.path.join(os.path.dirname(__file__), '..', 'src')\n)\n\n\nautodoc_member_order = 'bysource'\n\nextensions = [\n 'sphinx.ext.autodoc',\n 'sphinx.ext.doctest',\n 'sphinx.ext.extlinks',\n 'sphinx.ext.viewcode',\n 'sphinx.ext.intersphinx',\n]\n\ntemplates_path = ['_templates']\n\nsource_suffix = '.rst'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = u'Hypothesis'\ncopyright = u'2013-%s, David R. MacIver' % datetime.datetime.utcnow().year\nauthor = u'David R. MacIver'\n\nversion = __version__\nrelease = __version__\n\nlanguage = None\n\nexclude_patterns = ['_build']\n\npygments_style = 'sphinx'\n\ntodo_include_todos = False\n\nintersphinx_mapping = {\n 'python': ('http://docs.python.org/', None),\n}\n\nautodoc_mock_imports = ['numpy']\n\ndoctest_global_setup = '''\n# Some standard imports\nfrom hypothesis import *\nfrom hypothesis.strategies import *\n# Ensure that output (including from strategies) is deterministic\nimport random\nrandom.seed(0)\n'''\n\n# This config value must be a dictionary of external sites, mapping unique\n# short alias names to a base URL and a prefix.\n# See http://sphinx-doc.org/ext/extlinks.html\nextlinks = {\n 'commit': ('https://github.com/HypothesisWorks/hypothesis-python/commit/%s', 'commit '),\n 'gh-file': ('https://github.com/HypothesisWorks/hypothesis-python/blob/master/%s', ''),\n 'gh-link': ('https://github.com/HypothesisWorks/hypothesis-python/%s', ''),\n 'issue': ('https://github.com/HypothesisWorks/hypothesis-python/issues/%s', 'issue #'),\n 'pull': ('https://github.com/HypothesisWorks/hypothesis-python/pulls/%s', 'pull request #'),\n}\n\n# -- Options for HTML output ----------------------------------------------\n\nif not on_rtd: # only import and set the theme if we're building docs locally\n import sphinx_rtd_theme\n html_theme = 'sphinx_rtd_theme'\n html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]\n\nhtml_static_path = ['_static']\n\nhtmlhelp_basename = 'Hypothesisdoc'\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {\n}\n\nlatex_documents = [\n (master_doc, 'Hypothesis.tex', u'Hypothesis Documentation',\n u'David R. MacIver', 'manual'),\n]\n\nman_pages = [\n (master_doc, 'hypothesis', u'Hypothesis Documentation',\n [author], 1)\n]\n\ntexinfo_documents = [\n (master_doc, 'Hypothesis', u'Hypothesis Documentation',\n author, 'Hypothesis', 'One line description of project.',\n 'Miscellaneous'),\n]\n", "path": "docs/conf.py"}]}
| 3,595 | 433 |
gh_patches_debug_30999
|
rasdani/github-patches
|
git_diff
|
apache__airflow-28953
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Support telegram-bot v20+
### Body
Currently our telegram integration uses Telegram v13 telegram-bot library. On 1st of Jan 2023 a new, backwards incompatible version of Telegram-bot has been released : https://pypi.org/project/python-telegram-bot/20.0/#history and at least as reported by MyPy and our test suite test failures, Telegram 20 needs some changes to work:
Here is a transition guide that might be helpful.
Transition guide is here: https://github.com/python-telegram-bot/python-telegram-bot/wiki/Transition-guide-to-Version-20.0
In the meantime we limit telegram to < 20.0.0
### Committer
- [X] I acknowledge that I am a maintainer/committer of the Apache Airflow project.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `airflow/providers/telegram/hooks/telegram.py`
Content:
```
1 #
2 # Licensed to the Apache Software Foundation (ASF) under one
3 # or more contributor license agreements. See the NOTICE file
4 # distributed with this work for additional information
5 # regarding copyright ownership. The ASF licenses this file
6 # to you under the Apache License, Version 2.0 (the
7 # "License"); you may not use this file except in compliance
8 # with the License. You may obtain a copy of the License at
9 #
10 # http://www.apache.org/licenses/LICENSE-2.0
11 #
12 # Unless required by applicable law or agreed to in writing,
13 # software distributed under the License is distributed on an
14 # "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
15 # KIND, either express or implied. See the License for the
16 # specific language governing permissions and limitations
17 # under the License.
18 """Hook for Telegram"""
19 from __future__ import annotations
20
21 import telegram
22 import tenacity
23
24 from airflow.exceptions import AirflowException
25 from airflow.hooks.base import BaseHook
26
27
28 class TelegramHook(BaseHook):
29 """
30 This hook allows you to post messages to Telegram using the telegram python-telegram-bot library.
31
32 The library can be found here: https://github.com/python-telegram-bot/python-telegram-bot
33 It accepts both telegram bot API token directly or connection that has telegram bot API token.
34 If both supplied, token parameter will be given precedence, otherwise 'password' field in the connection
35 from telegram_conn_id will be used.
36 chat_id can also be provided in the connection using 'host' field in connection.
37 Following is the details of a telegram_connection:
38 name: 'telegram-connection-name'
39 conn_type: 'http'
40 password: 'TELEGRAM_TOKEN'
41 host: 'chat_id' (optional)
42 Examples:
43 .. code-block:: python
44
45 # Create hook
46 telegram_hook = TelegramHook(telegram_conn_id="telegram_default")
47 # or telegram_hook = TelegramHook(telegram_conn_id='telegram_default', chat_id='-1xxx')
48 # or telegram_hook = TelegramHook(token='xxx:xxx', chat_id='-1xxx')
49
50 # Call method from telegram bot client
51 telegram_hook.send_message(None, {"text": "message", "chat_id": "-1xxx"})
52 # or telegram_hook.send_message(None', {"text": "message"})
53
54 :param telegram_conn_id: connection that optionally has Telegram API token in the password field
55 :param token: optional telegram API token
56 :param chat_id: optional chat_id of the telegram chat/channel/group
57 """
58
59 def __init__(
60 self,
61 telegram_conn_id: str | None = None,
62 token: str | None = None,
63 chat_id: str | None = None,
64 ) -> None:
65 super().__init__()
66 self.token = self.__get_token(token, telegram_conn_id)
67 self.chat_id = self.__get_chat_id(chat_id, telegram_conn_id)
68 self.connection = self.get_conn()
69
70 def get_conn(self) -> telegram.bot.Bot:
71 """
72 Returns the telegram bot client
73
74 :return: telegram bot client
75 """
76 return telegram.bot.Bot(token=self.token)
77
78 def __get_token(self, token: str | None, telegram_conn_id: str | None) -> str:
79 """
80 Returns the telegram API token
81
82 :param token: telegram API token
83 :param telegram_conn_id: telegram connection name
84 :return: telegram API token
85 """
86 if token is not None:
87 return token
88
89 if telegram_conn_id is not None:
90 conn = self.get_connection(telegram_conn_id)
91
92 if not conn.password:
93 raise AirflowException("Missing token(password) in Telegram connection")
94
95 return conn.password
96
97 raise AirflowException("Cannot get token: No valid Telegram connection supplied.")
98
99 def __get_chat_id(self, chat_id: str | None, telegram_conn_id: str | None) -> str | None:
100 """
101 Returns the telegram chat ID for a chat/channel/group
102
103 :param chat_id: optional chat ID
104 :param telegram_conn_id: telegram connection name
105 :return: telegram chat ID
106 """
107 if chat_id is not None:
108 return chat_id
109
110 if telegram_conn_id is not None:
111 conn = self.get_connection(telegram_conn_id)
112 return conn.host
113
114 return None
115
116 @tenacity.retry(
117 retry=tenacity.retry_if_exception_type(telegram.error.TelegramError),
118 stop=tenacity.stop_after_attempt(5),
119 wait=tenacity.wait_fixed(1),
120 )
121 def send_message(self, api_params: dict) -> None:
122 """
123 Sends the message to a telegram channel or chat.
124
125 :param api_params: params for telegram_instance.send_message. It can also be used to override chat_id
126 """
127 kwargs = {
128 "chat_id": self.chat_id,
129 "parse_mode": telegram.parsemode.ParseMode.HTML,
130 "disable_web_page_preview": True,
131 }
132 kwargs.update(api_params)
133
134 if "text" not in kwargs or kwargs["text"] is None:
135 raise AirflowException("'text' must be provided for telegram message")
136
137 if kwargs["chat_id"] is None:
138 raise AirflowException("'chat_id' must be provided for telegram message")
139
140 response = self.connection.send_message(**kwargs)
141 self.log.debug(response)
142
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/airflow/providers/telegram/hooks/telegram.py b/airflow/providers/telegram/hooks/telegram.py
--- a/airflow/providers/telegram/hooks/telegram.py
+++ b/airflow/providers/telegram/hooks/telegram.py
@@ -18,6 +18,8 @@
"""Hook for Telegram"""
from __future__ import annotations
+import asyncio
+
import telegram
import tenacity
@@ -67,13 +69,13 @@
self.chat_id = self.__get_chat_id(chat_id, telegram_conn_id)
self.connection = self.get_conn()
- def get_conn(self) -> telegram.bot.Bot:
+ def get_conn(self) -> telegram.Bot:
"""
Returns the telegram bot client
:return: telegram bot client
"""
- return telegram.bot.Bot(token=self.token)
+ return telegram.Bot(self.token)
def __get_token(self, token: str | None, telegram_conn_id: str | None) -> str:
"""
@@ -126,7 +128,7 @@
"""
kwargs = {
"chat_id": self.chat_id,
- "parse_mode": telegram.parsemode.ParseMode.HTML,
+ "parse_mode": telegram.constants.ParseMode.HTML,
"disable_web_page_preview": True,
}
kwargs.update(api_params)
@@ -137,5 +139,5 @@
if kwargs["chat_id"] is None:
raise AirflowException("'chat_id' must be provided for telegram message")
- response = self.connection.send_message(**kwargs)
+ response = asyncio.run(self.connection.send_message(**kwargs))
self.log.debug(response)
|
{"golden_diff": "diff --git a/airflow/providers/telegram/hooks/telegram.py b/airflow/providers/telegram/hooks/telegram.py\n--- a/airflow/providers/telegram/hooks/telegram.py\n+++ b/airflow/providers/telegram/hooks/telegram.py\n@@ -18,6 +18,8 @@\n \"\"\"Hook for Telegram\"\"\"\n from __future__ import annotations\n \n+import asyncio\n+\n import telegram\n import tenacity\n \n@@ -67,13 +69,13 @@\n self.chat_id = self.__get_chat_id(chat_id, telegram_conn_id)\n self.connection = self.get_conn()\n \n- def get_conn(self) -> telegram.bot.Bot:\n+ def get_conn(self) -> telegram.Bot:\n \"\"\"\n Returns the telegram bot client\n \n :return: telegram bot client\n \"\"\"\n- return telegram.bot.Bot(token=self.token)\n+ return telegram.Bot(self.token)\n \n def __get_token(self, token: str | None, telegram_conn_id: str | None) -> str:\n \"\"\"\n@@ -126,7 +128,7 @@\n \"\"\"\n kwargs = {\n \"chat_id\": self.chat_id,\n- \"parse_mode\": telegram.parsemode.ParseMode.HTML,\n+ \"parse_mode\": telegram.constants.ParseMode.HTML,\n \"disable_web_page_preview\": True,\n }\n kwargs.update(api_params)\n@@ -137,5 +139,5 @@\n if kwargs[\"chat_id\"] is None:\n raise AirflowException(\"'chat_id' must be provided for telegram message\")\n \n- response = self.connection.send_message(**kwargs)\n+ response = asyncio.run(self.connection.send_message(**kwargs))\n self.log.debug(response)\n", "issue": "Support telegram-bot v20+\n### Body\n\nCurrently our telegram integration uses Telegram v13 telegram-bot library. On 1st of Jan 2023 a new, backwards incompatible version of Telegram-bot has been released : https://pypi.org/project/python-telegram-bot/20.0/#history and at least as reported by MyPy and our test suite test failures, Telegram 20 needs some changes to work:\r\n\r\nHere is a transition guide that might be helpful. \r\n\r\nTransition guide is here: https://github.com/python-telegram-bot/python-telegram-bot/wiki/Transition-guide-to-Version-20.0\r\n\r\nIn the meantime we limit telegram to < 20.0.0\n\n### Committer\n\n- [X] I acknowledge that I am a maintainer/committer of the Apache Airflow project.\n", "before_files": [{"content": "#\n# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\n\"\"\"Hook for Telegram\"\"\"\nfrom __future__ import annotations\n\nimport telegram\nimport tenacity\n\nfrom airflow.exceptions import AirflowException\nfrom airflow.hooks.base import BaseHook\n\n\nclass TelegramHook(BaseHook):\n \"\"\"\n This hook allows you to post messages to Telegram using the telegram python-telegram-bot library.\n\n The library can be found here: https://github.com/python-telegram-bot/python-telegram-bot\n It accepts both telegram bot API token directly or connection that has telegram bot API token.\n If both supplied, token parameter will be given precedence, otherwise 'password' field in the connection\n from telegram_conn_id will be used.\n chat_id can also be provided in the connection using 'host' field in connection.\n Following is the details of a telegram_connection:\n name: 'telegram-connection-name'\n conn_type: 'http'\n password: 'TELEGRAM_TOKEN'\n host: 'chat_id' (optional)\n Examples:\n .. code-block:: python\n\n # Create hook\n telegram_hook = TelegramHook(telegram_conn_id=\"telegram_default\")\n # or telegram_hook = TelegramHook(telegram_conn_id='telegram_default', chat_id='-1xxx')\n # or telegram_hook = TelegramHook(token='xxx:xxx', chat_id='-1xxx')\n\n # Call method from telegram bot client\n telegram_hook.send_message(None, {\"text\": \"message\", \"chat_id\": \"-1xxx\"})\n # or telegram_hook.send_message(None', {\"text\": \"message\"})\n\n :param telegram_conn_id: connection that optionally has Telegram API token in the password field\n :param token: optional telegram API token\n :param chat_id: optional chat_id of the telegram chat/channel/group\n \"\"\"\n\n def __init__(\n self,\n telegram_conn_id: str | None = None,\n token: str | None = None,\n chat_id: str | None = None,\n ) -> None:\n super().__init__()\n self.token = self.__get_token(token, telegram_conn_id)\n self.chat_id = self.__get_chat_id(chat_id, telegram_conn_id)\n self.connection = self.get_conn()\n\n def get_conn(self) -> telegram.bot.Bot:\n \"\"\"\n Returns the telegram bot client\n\n :return: telegram bot client\n \"\"\"\n return telegram.bot.Bot(token=self.token)\n\n def __get_token(self, token: str | None, telegram_conn_id: str | None) -> str:\n \"\"\"\n Returns the telegram API token\n\n :param token: telegram API token\n :param telegram_conn_id: telegram connection name\n :return: telegram API token\n \"\"\"\n if token is not None:\n return token\n\n if telegram_conn_id is not None:\n conn = self.get_connection(telegram_conn_id)\n\n if not conn.password:\n raise AirflowException(\"Missing token(password) in Telegram connection\")\n\n return conn.password\n\n raise AirflowException(\"Cannot get token: No valid Telegram connection supplied.\")\n\n def __get_chat_id(self, chat_id: str | None, telegram_conn_id: str | None) -> str | None:\n \"\"\"\n Returns the telegram chat ID for a chat/channel/group\n\n :param chat_id: optional chat ID\n :param telegram_conn_id: telegram connection name\n :return: telegram chat ID\n \"\"\"\n if chat_id is not None:\n return chat_id\n\n if telegram_conn_id is not None:\n conn = self.get_connection(telegram_conn_id)\n return conn.host\n\n return None\n\n @tenacity.retry(\n retry=tenacity.retry_if_exception_type(telegram.error.TelegramError),\n stop=tenacity.stop_after_attempt(5),\n wait=tenacity.wait_fixed(1),\n )\n def send_message(self, api_params: dict) -> None:\n \"\"\"\n Sends the message to a telegram channel or chat.\n\n :param api_params: params for telegram_instance.send_message. It can also be used to override chat_id\n \"\"\"\n kwargs = {\n \"chat_id\": self.chat_id,\n \"parse_mode\": telegram.parsemode.ParseMode.HTML,\n \"disable_web_page_preview\": True,\n }\n kwargs.update(api_params)\n\n if \"text\" not in kwargs or kwargs[\"text\"] is None:\n raise AirflowException(\"'text' must be provided for telegram message\")\n\n if kwargs[\"chat_id\"] is None:\n raise AirflowException(\"'chat_id' must be provided for telegram message\")\n\n response = self.connection.send_message(**kwargs)\n self.log.debug(response)\n", "path": "airflow/providers/telegram/hooks/telegram.py"}], "after_files": [{"content": "#\n# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\n\"\"\"Hook for Telegram\"\"\"\nfrom __future__ import annotations\n\nimport asyncio\n\nimport telegram\nimport tenacity\n\nfrom airflow.exceptions import AirflowException\nfrom airflow.hooks.base import BaseHook\n\n\nclass TelegramHook(BaseHook):\n \"\"\"\n This hook allows you to post messages to Telegram using the telegram python-telegram-bot library.\n\n The library can be found here: https://github.com/python-telegram-bot/python-telegram-bot\n It accepts both telegram bot API token directly or connection that has telegram bot API token.\n If both supplied, token parameter will be given precedence, otherwise 'password' field in the connection\n from telegram_conn_id will be used.\n chat_id can also be provided in the connection using 'host' field in connection.\n Following is the details of a telegram_connection:\n name: 'telegram-connection-name'\n conn_type: 'http'\n password: 'TELEGRAM_TOKEN'\n host: 'chat_id' (optional)\n Examples:\n .. code-block:: python\n\n # Create hook\n telegram_hook = TelegramHook(telegram_conn_id=\"telegram_default\")\n # or telegram_hook = TelegramHook(telegram_conn_id='telegram_default', chat_id='-1xxx')\n # or telegram_hook = TelegramHook(token='xxx:xxx', chat_id='-1xxx')\n\n # Call method from telegram bot client\n telegram_hook.send_message(None, {\"text\": \"message\", \"chat_id\": \"-1xxx\"})\n # or telegram_hook.send_message(None', {\"text\": \"message\"})\n\n :param telegram_conn_id: connection that optionally has Telegram API token in the password field\n :param token: optional telegram API token\n :param chat_id: optional chat_id of the telegram chat/channel/group\n \"\"\"\n\n def __init__(\n self,\n telegram_conn_id: str | None = None,\n token: str | None = None,\n chat_id: str | None = None,\n ) -> None:\n super().__init__()\n self.token = self.__get_token(token, telegram_conn_id)\n self.chat_id = self.__get_chat_id(chat_id, telegram_conn_id)\n self.connection = self.get_conn()\n\n def get_conn(self) -> telegram.Bot:\n \"\"\"\n Returns the telegram bot client\n\n :return: telegram bot client\n \"\"\"\n return telegram.Bot(self.token)\n\n def __get_token(self, token: str | None, telegram_conn_id: str | None) -> str:\n \"\"\"\n Returns the telegram API token\n\n :param token: telegram API token\n :param telegram_conn_id: telegram connection name\n :return: telegram API token\n \"\"\"\n if token is not None:\n return token\n\n if telegram_conn_id is not None:\n conn = self.get_connection(telegram_conn_id)\n\n if not conn.password:\n raise AirflowException(\"Missing token(password) in Telegram connection\")\n\n return conn.password\n\n raise AirflowException(\"Cannot get token: No valid Telegram connection supplied.\")\n\n def __get_chat_id(self, chat_id: str | None, telegram_conn_id: str | None) -> str | None:\n \"\"\"\n Returns the telegram chat ID for a chat/channel/group\n\n :param chat_id: optional chat ID\n :param telegram_conn_id: telegram connection name\n :return: telegram chat ID\n \"\"\"\n if chat_id is not None:\n return chat_id\n\n if telegram_conn_id is not None:\n conn = self.get_connection(telegram_conn_id)\n return conn.host\n\n return None\n\n @tenacity.retry(\n retry=tenacity.retry_if_exception_type(telegram.error.TelegramError),\n stop=tenacity.stop_after_attempt(5),\n wait=tenacity.wait_fixed(1),\n )\n def send_message(self, api_params: dict) -> None:\n \"\"\"\n Sends the message to a telegram channel or chat.\n\n :param api_params: params for telegram_instance.send_message. It can also be used to override chat_id\n \"\"\"\n kwargs = {\n \"chat_id\": self.chat_id,\n \"parse_mode\": telegram.constants.ParseMode.HTML,\n \"disable_web_page_preview\": True,\n }\n kwargs.update(api_params)\n\n if \"text\" not in kwargs or kwargs[\"text\"] is None:\n raise AirflowException(\"'text' must be provided for telegram message\")\n\n if kwargs[\"chat_id\"] is None:\n raise AirflowException(\"'chat_id' must be provided for telegram message\")\n\n response = asyncio.run(self.connection.send_message(**kwargs))\n self.log.debug(response)\n", "path": "airflow/providers/telegram/hooks/telegram.py"}]}
| 1,898 | 357 |
gh_patches_debug_9859
|
rasdani/github-patches
|
git_diff
|
aimhubio__aim-3112
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[fix] Serve files linked into the static files directory
In certain conda environments, the files in the static files root directory can be symlinked from a different place. The fixed implementation only resolves relative .. segments in the request path without resolving any symlinks. This way, it still prevents reading arbitrary files through the web server while allowing the reading of symlinked files.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `aim/web/api/views.py`
Content:
```
1 import os
2 from pathlib import Path
3
4 from fastapi import HTTPException, Request
5 from fastapi.responses import FileResponse, HTMLResponse
6
7 from aim.web.api.utils import APIRouter # wrapper for fastapi.APIRouter
8 from aim.web.configs import AIM_UI_BASE_PATH
9
10 statics_router = APIRouter()
11
12
13 @statics_router.get('/static-files/{path:path}/')
14 async def serve_static_files(path):
15 import aim_ui
16
17 static_files_root = Path(aim_ui.__file__).parent / 'build'
18 # Normalize to resolve any .. segments
19 static_file_name = os.path.normpath(static_files_root / path)
20
21 # Ensure that no paths outside the root directory are accessed by checking that the
22 # root directory is a prefix of the file path
23 common_prefix = Path(os.path.commonpath([static_files_root, static_file_name]))
24 if common_prefix == static_files_root:
25 raise HTTPException(status_code=404)
26
27 compressed_file_name = Path(f'{static_file_name}.gz')
28 if compressed_file_name.exists():
29 return FileResponse(compressed_file_name, headers={'Content-Encoding': 'gzip'})
30 return FileResponse(static_file_name)
31
32
33 # do not change the placement of this method
34 # as it also serves as a fallback for wrong url routes
35 @statics_router.get('/{path:path}/', response_class=HTMLResponse)
36 async def serve_index_html(request: Request):
37 import aim_ui
38 from jinja2 import Environment, FileSystemLoader
39
40 template_files_dir = os.path.join(os.path.dirname(aim_ui.__file__), 'build')
41 env = Environment(
42 loader=FileSystemLoader(template_files_dir),
43 autoescape=True
44 )
45 template = env.get_template('index-template.html')
46 base_path = os.environ.get(AIM_UI_BASE_PATH, '')
47 return template.render(base_path=base_path)
48
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/aim/web/api/views.py b/aim/web/api/views.py
--- a/aim/web/api/views.py
+++ b/aim/web/api/views.py
@@ -21,7 +21,7 @@
# Ensure that no paths outside the root directory are accessed by checking that the
# root directory is a prefix of the file path
common_prefix = Path(os.path.commonpath([static_files_root, static_file_name]))
- if common_prefix == static_files_root:
+ if common_prefix != static_files_root:
raise HTTPException(status_code=404)
compressed_file_name = Path(f'{static_file_name}.gz')
|
{"golden_diff": "diff --git a/aim/web/api/views.py b/aim/web/api/views.py\n--- a/aim/web/api/views.py\n+++ b/aim/web/api/views.py\n@@ -21,7 +21,7 @@\n # Ensure that no paths outside the root directory are accessed by checking that the\n # root directory is a prefix of the file path\n common_prefix = Path(os.path.commonpath([static_files_root, static_file_name]))\n- if common_prefix == static_files_root:\n+ if common_prefix != static_files_root:\n raise HTTPException(status_code=404)\n \n compressed_file_name = Path(f'{static_file_name}.gz')\n", "issue": "[fix] Serve files linked into the static files directory\nIn certain conda environments, the files in the static files root directory can be symlinked from a different place. The fixed implementation only resolves relative .. segments in the request path without resolving any symlinks. This way, it still prevents reading arbitrary files through the web server while allowing the reading of symlinked files.\n", "before_files": [{"content": "import os\nfrom pathlib import Path\n\nfrom fastapi import HTTPException, Request\nfrom fastapi.responses import FileResponse, HTMLResponse\n\nfrom aim.web.api.utils import APIRouter # wrapper for fastapi.APIRouter\nfrom aim.web.configs import AIM_UI_BASE_PATH\n\nstatics_router = APIRouter()\n\n\n@statics_router.get('/static-files/{path:path}/')\nasync def serve_static_files(path):\n import aim_ui\n\n static_files_root = Path(aim_ui.__file__).parent / 'build'\n # Normalize to resolve any .. segments\n static_file_name = os.path.normpath(static_files_root / path)\n\n # Ensure that no paths outside the root directory are accessed by checking that the\n # root directory is a prefix of the file path\n common_prefix = Path(os.path.commonpath([static_files_root, static_file_name]))\n if common_prefix == static_files_root:\n raise HTTPException(status_code=404)\n\n compressed_file_name = Path(f'{static_file_name}.gz')\n if compressed_file_name.exists():\n return FileResponse(compressed_file_name, headers={'Content-Encoding': 'gzip'})\n return FileResponse(static_file_name)\n\n\n# do not change the placement of this method\n# as it also serves as a fallback for wrong url routes\n@statics_router.get('/{path:path}/', response_class=HTMLResponse)\nasync def serve_index_html(request: Request):\n import aim_ui\n from jinja2 import Environment, FileSystemLoader\n\n template_files_dir = os.path.join(os.path.dirname(aim_ui.__file__), 'build')\n env = Environment(\n loader=FileSystemLoader(template_files_dir),\n autoescape=True\n )\n template = env.get_template('index-template.html')\n base_path = os.environ.get(AIM_UI_BASE_PATH, '')\n return template.render(base_path=base_path)\n", "path": "aim/web/api/views.py"}], "after_files": [{"content": "import os\nfrom pathlib import Path\n\nfrom fastapi import HTTPException, Request\nfrom fastapi.responses import FileResponse, HTMLResponse\n\nfrom aim.web.api.utils import APIRouter # wrapper for fastapi.APIRouter\nfrom aim.web.configs import AIM_UI_BASE_PATH\n\nstatics_router = APIRouter()\n\n\n@statics_router.get('/static-files/{path:path}/')\nasync def serve_static_files(path):\n import aim_ui\n\n static_files_root = Path(aim_ui.__file__).parent / 'build'\n # Normalize to resolve any .. segments\n static_file_name = os.path.normpath(static_files_root / path)\n\n # Ensure that no paths outside the root directory are accessed by checking that the\n # root directory is a prefix of the file path\n common_prefix = Path(os.path.commonpath([static_files_root, static_file_name]))\n if common_prefix != static_files_root:\n raise HTTPException(status_code=404)\n\n compressed_file_name = Path(f'{static_file_name}.gz')\n if compressed_file_name.exists():\n return FileResponse(compressed_file_name, headers={'Content-Encoding': 'gzip'})\n return FileResponse(static_file_name)\n\n\n# do not change the placement of this method\n# as it also serves as a fallback for wrong url routes\n@statics_router.get('/{path:path}/', response_class=HTMLResponse)\nasync def serve_index_html(request: Request):\n import aim_ui\n from jinja2 import Environment, FileSystemLoader\n\n template_files_dir = os.path.join(os.path.dirname(aim_ui.__file__), 'build')\n env = Environment(\n loader=FileSystemLoader(template_files_dir),\n autoescape=True\n )\n template = env.get_template('index-template.html')\n base_path = os.environ.get(AIM_UI_BASE_PATH, '')\n return template.render(base_path=base_path)\n", "path": "aim/web/api/views.py"}]}
| 816 | 141 |
gh_patches_debug_15906
|
rasdani/github-patches
|
git_diff
|
cowrie__cowrie-1563
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
9may
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/cowrie/output/mysql.py`
Content:
```
1 """
2 MySQL output connector. Writes audit logs to MySQL database
3 """
4
5
6 import MySQLdb
7
8 from twisted.enterprise import adbapi
9 from twisted.internet import defer
10 from twisted.python import log
11
12 import cowrie.core.output
13 from cowrie.core.config import CowrieConfig
14
15
16 class ReconnectingConnectionPool(adbapi.ConnectionPool):
17 """
18 Reconnecting adbapi connection pool for MySQL.
19
20 This class improves on the solution posted at
21 http://www.gelens.org/2008/09/12/reinitializing-twisted-connectionpool/
22 by checking exceptions by error code and only disconnecting the current
23 connection instead of all of them.
24
25 Also see:
26 http://twistedmatrix.com/pipermail/twisted-python/2009-July/020007.html
27 """
28
29 def _runInteraction(self, interaction, *args, **kw):
30 try:
31 return adbapi.ConnectionPool._runInteraction(self, interaction, *args, **kw)
32 except (MySQLdb.OperationalError, MySQLdb._exceptions.OperationalError) as e:
33 if e.args[0] not in (2003, 2006, 2013):
34 raise e
35 log.msg(f"RCP: got error {e}, retrying operation")
36 conn = self.connections.get(self.threadID())
37 self.disconnect(conn)
38 # Try the interaction again
39 return adbapi.ConnectionPool._runInteraction(self, interaction, *args, **kw)
40
41
42 class Output(cowrie.core.output.Output):
43 """
44 mysql output
45 """
46
47 db = None
48 debug: bool = False
49
50 def start(self):
51 self.debug = CowrieConfig.getboolean("output_mysql", "debug", fallback=False)
52 port = CowrieConfig.getint("output_mysql", "port", fallback=3306)
53 try:
54 self.db = ReconnectingConnectionPool(
55 "MySQLdb",
56 host=CowrieConfig.get("output_mysql", "host"),
57 db=CowrieConfig.get("output_mysql", "database"),
58 user=CowrieConfig.get("output_mysql", "username"),
59 passwd=CowrieConfig.get("output_mysql", "password", raw=True),
60 port=port,
61 cp_min=1,
62 cp_max=1,
63 charset="utf8mb4",
64 cp_reconnect=True,
65 use_unicode=True,
66 )
67 except (MySQLdb.Error, MySQLdb._exceptions.Error) as e:
68 log.msg(f"output_mysql: Error {e.args[0]}: {e.args[1]}")
69
70 def stop(self):
71 self.db.commit()
72 self.db.close()
73
74 def sqlerror(self, error):
75 """
76 1146, "Table '...' doesn't exist"
77 1406, "Data too long for column '...' at row ..."
78 """
79 if error.value.args[0] in (1146, 1406):
80 log.msg(f"output_mysql: MySQL Error: {error.value.args!r}")
81 log.msg("MySQL schema maybe misconfigured, doublecheck database!")
82 else:
83 log.msg(f"output_mysql: MySQL Error: {error.value.args!r}")
84
85 def simpleQuery(self, sql, args):
86 """
87 Just run a deferred sql query, only care about errors
88 """
89 if self.debug:
90 log.msg(f"output_mysql: MySQL query: {sql} {args!r}")
91 d = self.db.runQuery(sql, args)
92 d.addErrback(self.sqlerror)
93
94 @defer.inlineCallbacks
95 def write(self, entry):
96 if entry["eventid"] == "cowrie.session.connect":
97 r = yield self.db.runQuery(
98 f"SELECT `id`\" \"FROM `sensors`\" \"WHERE `ip` = {self.sensor}"
99 )
100
101 if r:
102 sensorid = r[0][0]
103 else:
104 yield self.db.runQuery(
105 f"INSERT INTO `sensors` (`ip`) \" \"VALUES ({self.sensor})"
106 )
107
108 r = yield self.db.runQuery("SELECT LAST_INSERT_ID()")
109 sensorid = int(r[0][0])
110 self.simpleQuery(
111 "INSERT INTO `sessions` (`id`, `starttime`, `sensor`, `ip`) "
112 "VALUES (%s, FROM_UNIXTIME(%s), %s, %s)",
113 (entry["session"], entry["time"], sensorid, entry["src_ip"]),
114 )
115
116 elif entry["eventid"] == "cowrie.login.success":
117 self.simpleQuery(
118 "INSERT INTO `auth` (`session`, `success`, `username`, `password`, `timestamp`) "
119 "VALUES (%s, %s, %s, %s, FROM_UNIXTIME(%s))",
120 (
121 entry["session"],
122 1,
123 entry["username"],
124 entry["password"],
125 entry["time"],
126 ),
127 )
128
129 elif entry["eventid"] == "cowrie.login.failed":
130 self.simpleQuery(
131 "INSERT INTO `auth` (`session`, `success`, `username`, `password`, `timestamp`) "
132 "VALUES (%s, %s, %s, %s, FROM_UNIXTIME(%s))",
133 (
134 entry["session"],
135 0,
136 entry["username"],
137 entry["password"],
138 entry["time"],
139 ),
140 )
141
142 elif entry["eventid"] == "cowrie.session.params":
143 self.simpleQuery(
144 "INSERT INTO `params` (`session`, `arch`) " "VALUES (%s, %s)",
145 (entry["session"], entry["arch"]),
146 )
147
148 elif entry["eventid"] == "cowrie.command.input":
149 self.simpleQuery(
150 "INSERT INTO `input` (`session`, `timestamp`, `success`, `input`) "
151 "VALUES (%s, FROM_UNIXTIME(%s), %s , %s)",
152 (entry["session"], entry["time"], 1, entry["input"]),
153 )
154
155 elif entry["eventid"] == "cowrie.command.failed":
156 self.simpleQuery(
157 "INSERT INTO `input` (`session`, `timestamp`, `success`, `input`) "
158 "VALUES (%s, FROM_UNIXTIME(%s), %s , %s)",
159 (entry["session"], entry["time"], 0, entry["input"]),
160 )
161
162 elif entry["eventid"] == "cowrie.session.file_download":
163 self.simpleQuery(
164 "INSERT INTO `downloads` (`session`, `timestamp`, `url`, `outfile`, `shasum`) "
165 "VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)",
166 (
167 entry["session"],
168 entry["time"],
169 entry.get("url", ""),
170 entry["outfile"],
171 entry["shasum"],
172 ),
173 )
174
175 elif entry["eventid"] == "cowrie.session.file_download.failed":
176 self.simpleQuery(
177 "INSERT INTO `downloads` (`session`, `timestamp`, `url`, `outfile`, `shasum`) "
178 "VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)",
179 (entry["session"], entry["time"], entry.get("url", ""), "NULL", "NULL"),
180 )
181
182 elif entry["eventid"] == "cowrie.session.file_upload":
183 self.simpleQuery(
184 "INSERT INTO `downloads` (`session`, `timestamp`, `url`, `outfile`, `shasum`) "
185 "VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)",
186 (
187 entry["session"],
188 entry["time"],
189 "",
190 entry["outfile"],
191 entry["shasum"],
192 ),
193 )
194
195 elif entry["eventid"] == "cowrie.session.input":
196 self.simpleQuery(
197 "INSERT INTO `input` (`session`, `timestamp`, `realm`, `input`) "
198 "VALUES (%s, FROM_UNIXTIME(%s), %s , %s)",
199 (entry["session"], entry["time"], entry["realm"], entry["input"]),
200 )
201
202 elif entry["eventid"] == "cowrie.client.version":
203 r = yield self.db.runQuery(
204 "SELECT `id` FROM `clients` " "WHERE `version` = %s",
205 (entry["version"],),
206 )
207
208 if r:
209 id = int(r[0][0])
210 else:
211 yield self.db.runQuery(
212 "INSERT INTO `clients` (`version`) " "VALUES (%s)",
213 (entry["version"],),
214 )
215
216 r = yield self.db.runQuery("SELECT LAST_INSERT_ID()")
217 id = int(r[0][0])
218 self.simpleQuery(
219 "UPDATE `sessions` " "SET `client` = %s " "WHERE `id` = %s",
220 (id, entry["session"]),
221 )
222
223 elif entry["eventid"] == "cowrie.client.size":
224 self.simpleQuery(
225 "UPDATE `sessions` " "SET `termsize` = %s " "WHERE `id` = %s",
226 ("{}x{}".format(entry["width"], entry["height"]), entry["session"]),
227 )
228
229 elif entry["eventid"] == "cowrie.session.closed":
230 self.simpleQuery(
231 "UPDATE `sessions` "
232 "SET `endtime` = FROM_UNIXTIME(%s) "
233 "WHERE `id` = %s",
234 (entry["time"], entry["session"]),
235 )
236
237 elif entry["eventid"] == "cowrie.log.closed":
238 self.simpleQuery(
239 "INSERT INTO `ttylog` (`session`, `ttylog`, `size`) "
240 "VALUES (%s, %s, %s)",
241 (entry["session"], entry["ttylog"], entry["size"]),
242 )
243
244 elif entry["eventid"] == "cowrie.client.fingerprint":
245 self.simpleQuery(
246 "INSERT INTO `keyfingerprints` (`session`, `username`, `fingerprint`) "
247 "VALUES (%s, %s, %s)",
248 (entry["session"], entry["username"], entry["fingerprint"]),
249 )
250
251 elif entry["eventid"] == "cowrie.direct-tcpip.request":
252 self.simpleQuery(
253 "INSERT INTO `ipforwards` (`session`, `timestamp`, `dst_ip`, `dst_port`) "
254 "VALUES (%s, FROM_UNIXTIME(%s), %s, %s)",
255 (entry["session"], entry["time"], entry["dst_ip"], entry["dst_port"]),
256 )
257
258 elif entry["eventid"] == "cowrie.direct-tcpip.data":
259 self.simpleQuery(
260 "INSERT INTO `ipforwardsdata` (`session`, `timestamp`, `dst_ip`, `dst_port`, `data`) "
261 "VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)",
262 (
263 entry["session"],
264 entry["time"],
265 entry["dst_ip"],
266 entry["dst_port"],
267 entry["data"],
268 ),
269 )
270
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/cowrie/output/mysql.py b/src/cowrie/output/mysql.py
--- a/src/cowrie/output/mysql.py
+++ b/src/cowrie/output/mysql.py
@@ -95,14 +95,14 @@
def write(self, entry):
if entry["eventid"] == "cowrie.session.connect":
r = yield self.db.runQuery(
- f"SELECT `id`\" \"FROM `sensors`\" \"WHERE `ip` = {self.sensor}"
+ "SELECT `id`" "FROM `sensors`" f"WHERE `ip` = {self.sensor}"
)
if r:
sensorid = r[0][0]
else:
yield self.db.runQuery(
- f"INSERT INTO `sensors` (`ip`) \" \"VALUES ({self.sensor})"
+ "INSERT INTO `sensors` (`ip`) " f"VALUES ({self.sensor})"
)
r = yield self.db.runQuery("SELECT LAST_INSERT_ID()")
|
{"golden_diff": "diff --git a/src/cowrie/output/mysql.py b/src/cowrie/output/mysql.py\n--- a/src/cowrie/output/mysql.py\n+++ b/src/cowrie/output/mysql.py\n@@ -95,14 +95,14 @@\n def write(self, entry):\n if entry[\"eventid\"] == \"cowrie.session.connect\":\n r = yield self.db.runQuery(\n- f\"SELECT `id`\\\" \\\"FROM `sensors`\\\" \\\"WHERE `ip` = {self.sensor}\"\n+ \"SELECT `id`\" \"FROM `sensors`\" f\"WHERE `ip` = {self.sensor}\"\n )\n \n if r:\n sensorid = r[0][0]\n else:\n yield self.db.runQuery(\n- f\"INSERT INTO `sensors` (`ip`) \\\" \\\"VALUES ({self.sensor})\"\n+ \"INSERT INTO `sensors` (`ip`) \" f\"VALUES ({self.sensor})\"\n )\n \n r = yield self.db.runQuery(\"SELECT LAST_INSERT_ID()\")\n", "issue": "9may\n\n", "before_files": [{"content": "\"\"\"\nMySQL output connector. Writes audit logs to MySQL database\n\"\"\"\n\n\nimport MySQLdb\n\nfrom twisted.enterprise import adbapi\nfrom twisted.internet import defer\nfrom twisted.python import log\n\nimport cowrie.core.output\nfrom cowrie.core.config import CowrieConfig\n\n\nclass ReconnectingConnectionPool(adbapi.ConnectionPool):\n \"\"\"\n Reconnecting adbapi connection pool for MySQL.\n\n This class improves on the solution posted at\n http://www.gelens.org/2008/09/12/reinitializing-twisted-connectionpool/\n by checking exceptions by error code and only disconnecting the current\n connection instead of all of them.\n\n Also see:\n http://twistedmatrix.com/pipermail/twisted-python/2009-July/020007.html\n \"\"\"\n\n def _runInteraction(self, interaction, *args, **kw):\n try:\n return adbapi.ConnectionPool._runInteraction(self, interaction, *args, **kw)\n except (MySQLdb.OperationalError, MySQLdb._exceptions.OperationalError) as e:\n if e.args[0] not in (2003, 2006, 2013):\n raise e\n log.msg(f\"RCP: got error {e}, retrying operation\")\n conn = self.connections.get(self.threadID())\n self.disconnect(conn)\n # Try the interaction again\n return adbapi.ConnectionPool._runInteraction(self, interaction, *args, **kw)\n\n\nclass Output(cowrie.core.output.Output):\n \"\"\"\n mysql output\n \"\"\"\n\n db = None\n debug: bool = False\n\n def start(self):\n self.debug = CowrieConfig.getboolean(\"output_mysql\", \"debug\", fallback=False)\n port = CowrieConfig.getint(\"output_mysql\", \"port\", fallback=3306)\n try:\n self.db = ReconnectingConnectionPool(\n \"MySQLdb\",\n host=CowrieConfig.get(\"output_mysql\", \"host\"),\n db=CowrieConfig.get(\"output_mysql\", \"database\"),\n user=CowrieConfig.get(\"output_mysql\", \"username\"),\n passwd=CowrieConfig.get(\"output_mysql\", \"password\", raw=True),\n port=port,\n cp_min=1,\n cp_max=1,\n charset=\"utf8mb4\",\n cp_reconnect=True,\n use_unicode=True,\n )\n except (MySQLdb.Error, MySQLdb._exceptions.Error) as e:\n log.msg(f\"output_mysql: Error {e.args[0]}: {e.args[1]}\")\n\n def stop(self):\n self.db.commit()\n self.db.close()\n\n def sqlerror(self, error):\n \"\"\"\n 1146, \"Table '...' doesn't exist\"\n 1406, \"Data too long for column '...' at row ...\"\n \"\"\"\n if error.value.args[0] in (1146, 1406):\n log.msg(f\"output_mysql: MySQL Error: {error.value.args!r}\")\n log.msg(\"MySQL schema maybe misconfigured, doublecheck database!\")\n else:\n log.msg(f\"output_mysql: MySQL Error: {error.value.args!r}\")\n\n def simpleQuery(self, sql, args):\n \"\"\"\n Just run a deferred sql query, only care about errors\n \"\"\"\n if self.debug:\n log.msg(f\"output_mysql: MySQL query: {sql} {args!r}\")\n d = self.db.runQuery(sql, args)\n d.addErrback(self.sqlerror)\n\n @defer.inlineCallbacks\n def write(self, entry):\n if entry[\"eventid\"] == \"cowrie.session.connect\":\n r = yield self.db.runQuery(\n f\"SELECT `id`\\\" \\\"FROM `sensors`\\\" \\\"WHERE `ip` = {self.sensor}\"\n )\n\n if r:\n sensorid = r[0][0]\n else:\n yield self.db.runQuery(\n f\"INSERT INTO `sensors` (`ip`) \\\" \\\"VALUES ({self.sensor})\"\n )\n\n r = yield self.db.runQuery(\"SELECT LAST_INSERT_ID()\")\n sensorid = int(r[0][0])\n self.simpleQuery(\n \"INSERT INTO `sessions` (`id`, `starttime`, `sensor`, `ip`) \"\n \"VALUES (%s, FROM_UNIXTIME(%s), %s, %s)\",\n (entry[\"session\"], entry[\"time\"], sensorid, entry[\"src_ip\"]),\n )\n\n elif entry[\"eventid\"] == \"cowrie.login.success\":\n self.simpleQuery(\n \"INSERT INTO `auth` (`session`, `success`, `username`, `password`, `timestamp`) \"\n \"VALUES (%s, %s, %s, %s, FROM_UNIXTIME(%s))\",\n (\n entry[\"session\"],\n 1,\n entry[\"username\"],\n entry[\"password\"],\n entry[\"time\"],\n ),\n )\n\n elif entry[\"eventid\"] == \"cowrie.login.failed\":\n self.simpleQuery(\n \"INSERT INTO `auth` (`session`, `success`, `username`, `password`, `timestamp`) \"\n \"VALUES (%s, %s, %s, %s, FROM_UNIXTIME(%s))\",\n (\n entry[\"session\"],\n 0,\n entry[\"username\"],\n entry[\"password\"],\n entry[\"time\"],\n ),\n )\n\n elif entry[\"eventid\"] == \"cowrie.session.params\":\n self.simpleQuery(\n \"INSERT INTO `params` (`session`, `arch`) \" \"VALUES (%s, %s)\",\n (entry[\"session\"], entry[\"arch\"]),\n )\n\n elif entry[\"eventid\"] == \"cowrie.command.input\":\n self.simpleQuery(\n \"INSERT INTO `input` (`session`, `timestamp`, `success`, `input`) \"\n \"VALUES (%s, FROM_UNIXTIME(%s), %s , %s)\",\n (entry[\"session\"], entry[\"time\"], 1, entry[\"input\"]),\n )\n\n elif entry[\"eventid\"] == \"cowrie.command.failed\":\n self.simpleQuery(\n \"INSERT INTO `input` (`session`, `timestamp`, `success`, `input`) \"\n \"VALUES (%s, FROM_UNIXTIME(%s), %s , %s)\",\n (entry[\"session\"], entry[\"time\"], 0, entry[\"input\"]),\n )\n\n elif entry[\"eventid\"] == \"cowrie.session.file_download\":\n self.simpleQuery(\n \"INSERT INTO `downloads` (`session`, `timestamp`, `url`, `outfile`, `shasum`) \"\n \"VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)\",\n (\n entry[\"session\"],\n entry[\"time\"],\n entry.get(\"url\", \"\"),\n entry[\"outfile\"],\n entry[\"shasum\"],\n ),\n )\n\n elif entry[\"eventid\"] == \"cowrie.session.file_download.failed\":\n self.simpleQuery(\n \"INSERT INTO `downloads` (`session`, `timestamp`, `url`, `outfile`, `shasum`) \"\n \"VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)\",\n (entry[\"session\"], entry[\"time\"], entry.get(\"url\", \"\"), \"NULL\", \"NULL\"),\n )\n\n elif entry[\"eventid\"] == \"cowrie.session.file_upload\":\n self.simpleQuery(\n \"INSERT INTO `downloads` (`session`, `timestamp`, `url`, `outfile`, `shasum`) \"\n \"VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)\",\n (\n entry[\"session\"],\n entry[\"time\"],\n \"\",\n entry[\"outfile\"],\n entry[\"shasum\"],\n ),\n )\n\n elif entry[\"eventid\"] == \"cowrie.session.input\":\n self.simpleQuery(\n \"INSERT INTO `input` (`session`, `timestamp`, `realm`, `input`) \"\n \"VALUES (%s, FROM_UNIXTIME(%s), %s , %s)\",\n (entry[\"session\"], entry[\"time\"], entry[\"realm\"], entry[\"input\"]),\n )\n\n elif entry[\"eventid\"] == \"cowrie.client.version\":\n r = yield self.db.runQuery(\n \"SELECT `id` FROM `clients` \" \"WHERE `version` = %s\",\n (entry[\"version\"],),\n )\n\n if r:\n id = int(r[0][0])\n else:\n yield self.db.runQuery(\n \"INSERT INTO `clients` (`version`) \" \"VALUES (%s)\",\n (entry[\"version\"],),\n )\n\n r = yield self.db.runQuery(\"SELECT LAST_INSERT_ID()\")\n id = int(r[0][0])\n self.simpleQuery(\n \"UPDATE `sessions` \" \"SET `client` = %s \" \"WHERE `id` = %s\",\n (id, entry[\"session\"]),\n )\n\n elif entry[\"eventid\"] == \"cowrie.client.size\":\n self.simpleQuery(\n \"UPDATE `sessions` \" \"SET `termsize` = %s \" \"WHERE `id` = %s\",\n (\"{}x{}\".format(entry[\"width\"], entry[\"height\"]), entry[\"session\"]),\n )\n\n elif entry[\"eventid\"] == \"cowrie.session.closed\":\n self.simpleQuery(\n \"UPDATE `sessions` \"\n \"SET `endtime` = FROM_UNIXTIME(%s) \"\n \"WHERE `id` = %s\",\n (entry[\"time\"], entry[\"session\"]),\n )\n\n elif entry[\"eventid\"] == \"cowrie.log.closed\":\n self.simpleQuery(\n \"INSERT INTO `ttylog` (`session`, `ttylog`, `size`) \"\n \"VALUES (%s, %s, %s)\",\n (entry[\"session\"], entry[\"ttylog\"], entry[\"size\"]),\n )\n\n elif entry[\"eventid\"] == \"cowrie.client.fingerprint\":\n self.simpleQuery(\n \"INSERT INTO `keyfingerprints` (`session`, `username`, `fingerprint`) \"\n \"VALUES (%s, %s, %s)\",\n (entry[\"session\"], entry[\"username\"], entry[\"fingerprint\"]),\n )\n\n elif entry[\"eventid\"] == \"cowrie.direct-tcpip.request\":\n self.simpleQuery(\n \"INSERT INTO `ipforwards` (`session`, `timestamp`, `dst_ip`, `dst_port`) \"\n \"VALUES (%s, FROM_UNIXTIME(%s), %s, %s)\",\n (entry[\"session\"], entry[\"time\"], entry[\"dst_ip\"], entry[\"dst_port\"]),\n )\n\n elif entry[\"eventid\"] == \"cowrie.direct-tcpip.data\":\n self.simpleQuery(\n \"INSERT INTO `ipforwardsdata` (`session`, `timestamp`, `dst_ip`, `dst_port`, `data`) \"\n \"VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)\",\n (\n entry[\"session\"],\n entry[\"time\"],\n entry[\"dst_ip\"],\n entry[\"dst_port\"],\n entry[\"data\"],\n ),\n )\n", "path": "src/cowrie/output/mysql.py"}], "after_files": [{"content": "\"\"\"\nMySQL output connector. Writes audit logs to MySQL database\n\"\"\"\n\n\nimport MySQLdb\n\nfrom twisted.enterprise import adbapi\nfrom twisted.internet import defer\nfrom twisted.python import log\n\nimport cowrie.core.output\nfrom cowrie.core.config import CowrieConfig\n\n\nclass ReconnectingConnectionPool(adbapi.ConnectionPool):\n \"\"\"\n Reconnecting adbapi connection pool for MySQL.\n\n This class improves on the solution posted at\n http://www.gelens.org/2008/09/12/reinitializing-twisted-connectionpool/\n by checking exceptions by error code and only disconnecting the current\n connection instead of all of them.\n\n Also see:\n http://twistedmatrix.com/pipermail/twisted-python/2009-July/020007.html\n \"\"\"\n\n def _runInteraction(self, interaction, *args, **kw):\n try:\n return adbapi.ConnectionPool._runInteraction(self, interaction, *args, **kw)\n except (MySQLdb.OperationalError, MySQLdb._exceptions.OperationalError) as e:\n if e.args[0] not in (2003, 2006, 2013):\n raise e\n log.msg(f\"RCP: got error {e}, retrying operation\")\n conn = self.connections.get(self.threadID())\n self.disconnect(conn)\n # Try the interaction again\n return adbapi.ConnectionPool._runInteraction(self, interaction, *args, **kw)\n\n\nclass Output(cowrie.core.output.Output):\n \"\"\"\n mysql output\n \"\"\"\n\n db = None\n debug: bool = False\n\n def start(self):\n self.debug = CowrieConfig.getboolean(\"output_mysql\", \"debug\", fallback=False)\n port = CowrieConfig.getint(\"output_mysql\", \"port\", fallback=3306)\n try:\n self.db = ReconnectingConnectionPool(\n \"MySQLdb\",\n host=CowrieConfig.get(\"output_mysql\", \"host\"),\n db=CowrieConfig.get(\"output_mysql\", \"database\"),\n user=CowrieConfig.get(\"output_mysql\", \"username\"),\n passwd=CowrieConfig.get(\"output_mysql\", \"password\", raw=True),\n port=port,\n cp_min=1,\n cp_max=1,\n charset=\"utf8mb4\",\n cp_reconnect=True,\n use_unicode=True,\n )\n except (MySQLdb.Error, MySQLdb._exceptions.Error) as e:\n log.msg(f\"output_mysql: Error {e.args[0]}: {e.args[1]}\")\n\n def stop(self):\n self.db.commit()\n self.db.close()\n\n def sqlerror(self, error):\n \"\"\"\n 1146, \"Table '...' doesn't exist\"\n 1406, \"Data too long for column '...' at row ...\"\n \"\"\"\n if error.value.args[0] in (1146, 1406):\n log.msg(f\"output_mysql: MySQL Error: {error.value.args!r}\")\n log.msg(\"MySQL schema maybe misconfigured, doublecheck database!\")\n else:\n log.msg(f\"output_mysql: MySQL Error: {error.value.args!r}\")\n\n def simpleQuery(self, sql, args):\n \"\"\"\n Just run a deferred sql query, only care about errors\n \"\"\"\n if self.debug:\n log.msg(f\"output_mysql: MySQL query: {sql} {args!r}\")\n d = self.db.runQuery(sql, args)\n d.addErrback(self.sqlerror)\n\n @defer.inlineCallbacks\n def write(self, entry):\n if entry[\"eventid\"] == \"cowrie.session.connect\":\n r = yield self.db.runQuery(\n \"SELECT `id`\" \"FROM `sensors`\" f\"WHERE `ip` = {self.sensor}\"\n )\n\n if r:\n sensorid = r[0][0]\n else:\n yield self.db.runQuery(\n \"INSERT INTO `sensors` (`ip`) \" f\"VALUES ({self.sensor})\"\n )\n\n r = yield self.db.runQuery(\"SELECT LAST_INSERT_ID()\")\n sensorid = int(r[0][0])\n self.simpleQuery(\n \"INSERT INTO `sessions` (`id`, `starttime`, `sensor`, `ip`) \"\n \"VALUES (%s, FROM_UNIXTIME(%s), %s, %s)\",\n (entry[\"session\"], entry[\"time\"], sensorid, entry[\"src_ip\"]),\n )\n\n elif entry[\"eventid\"] == \"cowrie.login.success\":\n self.simpleQuery(\n \"INSERT INTO `auth` (`session`, `success`, `username`, `password`, `timestamp`) \"\n \"VALUES (%s, %s, %s, %s, FROM_UNIXTIME(%s))\",\n (\n entry[\"session\"],\n 1,\n entry[\"username\"],\n entry[\"password\"],\n entry[\"time\"],\n ),\n )\n\n elif entry[\"eventid\"] == \"cowrie.login.failed\":\n self.simpleQuery(\n \"INSERT INTO `auth` (`session`, `success`, `username`, `password`, `timestamp`) \"\n \"VALUES (%s, %s, %s, %s, FROM_UNIXTIME(%s))\",\n (\n entry[\"session\"],\n 0,\n entry[\"username\"],\n entry[\"password\"],\n entry[\"time\"],\n ),\n )\n\n elif entry[\"eventid\"] == \"cowrie.session.params\":\n self.simpleQuery(\n \"INSERT INTO `params` (`session`, `arch`) \" \"VALUES (%s, %s)\",\n (entry[\"session\"], entry[\"arch\"]),\n )\n\n elif entry[\"eventid\"] == \"cowrie.command.input\":\n self.simpleQuery(\n \"INSERT INTO `input` (`session`, `timestamp`, `success`, `input`) \"\n \"VALUES (%s, FROM_UNIXTIME(%s), %s , %s)\",\n (entry[\"session\"], entry[\"time\"], 1, entry[\"input\"]),\n )\n\n elif entry[\"eventid\"] == \"cowrie.command.failed\":\n self.simpleQuery(\n \"INSERT INTO `input` (`session`, `timestamp`, `success`, `input`) \"\n \"VALUES (%s, FROM_UNIXTIME(%s), %s , %s)\",\n (entry[\"session\"], entry[\"time\"], 0, entry[\"input\"]),\n )\n\n elif entry[\"eventid\"] == \"cowrie.session.file_download\":\n self.simpleQuery(\n \"INSERT INTO `downloads` (`session`, `timestamp`, `url`, `outfile`, `shasum`) \"\n \"VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)\",\n (\n entry[\"session\"],\n entry[\"time\"],\n entry.get(\"url\", \"\"),\n entry[\"outfile\"],\n entry[\"shasum\"],\n ),\n )\n\n elif entry[\"eventid\"] == \"cowrie.session.file_download.failed\":\n self.simpleQuery(\n \"INSERT INTO `downloads` (`session`, `timestamp`, `url`, `outfile`, `shasum`) \"\n \"VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)\",\n (entry[\"session\"], entry[\"time\"], entry.get(\"url\", \"\"), \"NULL\", \"NULL\"),\n )\n\n elif entry[\"eventid\"] == \"cowrie.session.file_upload\":\n self.simpleQuery(\n \"INSERT INTO `downloads` (`session`, `timestamp`, `url`, `outfile`, `shasum`) \"\n \"VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)\",\n (\n entry[\"session\"],\n entry[\"time\"],\n \"\",\n entry[\"outfile\"],\n entry[\"shasum\"],\n ),\n )\n\n elif entry[\"eventid\"] == \"cowrie.session.input\":\n self.simpleQuery(\n \"INSERT INTO `input` (`session`, `timestamp`, `realm`, `input`) \"\n \"VALUES (%s, FROM_UNIXTIME(%s), %s , %s)\",\n (entry[\"session\"], entry[\"time\"], entry[\"realm\"], entry[\"input\"]),\n )\n\n elif entry[\"eventid\"] == \"cowrie.client.version\":\n r = yield self.db.runQuery(\n \"SELECT `id` FROM `clients` \" \"WHERE `version` = %s\",\n (entry[\"version\"],),\n )\n\n if r:\n id = int(r[0][0])\n else:\n yield self.db.runQuery(\n \"INSERT INTO `clients` (`version`) \" \"VALUES (%s)\",\n (entry[\"version\"],),\n )\n\n r = yield self.db.runQuery(\"SELECT LAST_INSERT_ID()\")\n id = int(r[0][0])\n self.simpleQuery(\n \"UPDATE `sessions` \" \"SET `client` = %s \" \"WHERE `id` = %s\",\n (id, entry[\"session\"]),\n )\n\n elif entry[\"eventid\"] == \"cowrie.client.size\":\n self.simpleQuery(\n \"UPDATE `sessions` \" \"SET `termsize` = %s \" \"WHERE `id` = %s\",\n (\"{}x{}\".format(entry[\"width\"], entry[\"height\"]), entry[\"session\"]),\n )\n\n elif entry[\"eventid\"] == \"cowrie.session.closed\":\n self.simpleQuery(\n \"UPDATE `sessions` \"\n \"SET `endtime` = FROM_UNIXTIME(%s) \"\n \"WHERE `id` = %s\",\n (entry[\"time\"], entry[\"session\"]),\n )\n\n elif entry[\"eventid\"] == \"cowrie.log.closed\":\n self.simpleQuery(\n \"INSERT INTO `ttylog` (`session`, `ttylog`, `size`) \"\n \"VALUES (%s, %s, %s)\",\n (entry[\"session\"], entry[\"ttylog\"], entry[\"size\"]),\n )\n\n elif entry[\"eventid\"] == \"cowrie.client.fingerprint\":\n self.simpleQuery(\n \"INSERT INTO `keyfingerprints` (`session`, `username`, `fingerprint`) \"\n \"VALUES (%s, %s, %s)\",\n (entry[\"session\"], entry[\"username\"], entry[\"fingerprint\"]),\n )\n\n elif entry[\"eventid\"] == \"cowrie.direct-tcpip.request\":\n self.simpleQuery(\n \"INSERT INTO `ipforwards` (`session`, `timestamp`, `dst_ip`, `dst_port`) \"\n \"VALUES (%s, FROM_UNIXTIME(%s), %s, %s)\",\n (entry[\"session\"], entry[\"time\"], entry[\"dst_ip\"], entry[\"dst_port\"]),\n )\n\n elif entry[\"eventid\"] == \"cowrie.direct-tcpip.data\":\n self.simpleQuery(\n \"INSERT INTO `ipforwardsdata` (`session`, `timestamp`, `dst_ip`, `dst_port`, `data`) \"\n \"VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)\",\n (\n entry[\"session\"],\n entry[\"time\"],\n entry[\"dst_ip\"],\n entry[\"dst_port\"],\n entry[\"data\"],\n ),\n )\n", "path": "src/cowrie/output/mysql.py"}]}
| 3,327 | 220 |
gh_patches_debug_2972
|
rasdani/github-patches
|
git_diff
|
pyodide__pyodide-325
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ValueError: invalid __array_struct__ when using js arrays of arrays and numpy
When using a matrix (array of array of numbers) in javascript and trying to convert that to a numpy array, it fails with the error `ValueError: invalid __array_struct__`
To reproduce:
JavaScript:
```
window.A = [[1,2,3],[4,5,6]];
```
Python:
```
import numpy
from js import A
m = numpy.array(A)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/pyodide.py`
Content:
```
1 """
2 A library of helper utilities for connecting Python to the browser environment.
3 """
4
5 import ast
6 import io
7 from textwrap import dedent
8
9 __version__ = '0.8.2'
10
11
12 def open_url(url):
13 """
14 Fetches a given *url* and returns a io.StringIO to access its contents.
15 """
16 from js import XMLHttpRequest
17
18 req = XMLHttpRequest.new()
19 req.open('GET', url, False)
20 req.send(None)
21 return io.StringIO(req.response)
22
23
24 def eval_code(code, ns):
25 """
26 Runs a string of code, the last part of which may be an expression.
27 """
28 # handle mis-indented input from multi-line strings
29 code = dedent(code)
30
31 mod = ast.parse(code)
32 if len(mod.body) == 0:
33 return None
34
35 if isinstance(mod.body[-1], ast.Expr):
36 expr = ast.Expression(mod.body[-1].value)
37 del mod.body[-1]
38 else:
39 expr = None
40
41 if len(mod.body):
42 exec(compile(mod, '<exec>', mode='exec'), ns, ns)
43 if expr is not None:
44 return eval(compile(expr, '<eval>', mode='eval'), ns, ns)
45 else:
46 return None
47
48
49 def find_imports(code):
50 """
51 Finds the imports in a string of code and returns a list of their package
52 names.
53 """
54 # handle mis-indented input from multi-line strings
55 code = dedent(code)
56
57 mod = ast.parse(code)
58 imports = set()
59 for node in ast.walk(mod):
60 if isinstance(node, ast.Import):
61 for name in node.names:
62 name = name.name
63 imports.add(name.split('.')[0])
64 elif isinstance(node, ast.ImportFrom):
65 name = node.module
66 imports.add(name.split('.')[0])
67 return list(imports)
68
69
70 __all__ = ['open_url', 'eval_code', 'find_imports']
71
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/pyodide.py b/src/pyodide.py
--- a/src/pyodide.py
+++ b/src/pyodide.py
@@ -67,4 +67,16 @@
return list(imports)
-__all__ = ['open_url', 'eval_code', 'find_imports']
+def as_nested_list(obj):
+ """
+ Assumes a Javascript object is made of (possibly nested) arrays and
+ converts them to nested Python lists.
+ """
+ try:
+ it = iter(obj)
+ return [as_nested_list(x) for x in it]
+ except TypeError:
+ return obj
+
+
+__all__ = ['open_url', 'eval_code', 'find_imports', 'as_nested_list']
|
{"golden_diff": "diff --git a/src/pyodide.py b/src/pyodide.py\n--- a/src/pyodide.py\n+++ b/src/pyodide.py\n@@ -67,4 +67,16 @@\n return list(imports)\n \n \n-__all__ = ['open_url', 'eval_code', 'find_imports']\n+def as_nested_list(obj):\n+ \"\"\"\n+ Assumes a Javascript object is made of (possibly nested) arrays and\n+ converts them to nested Python lists.\n+ \"\"\"\n+ try:\n+ it = iter(obj)\n+ return [as_nested_list(x) for x in it]\n+ except TypeError:\n+ return obj\n+\n+\n+__all__ = ['open_url', 'eval_code', 'find_imports', 'as_nested_list']\n", "issue": "ValueError: invalid __array_struct__ when using js arrays of arrays and numpy\nWhen using a matrix (array of array of numbers) in javascript and trying to convert that to a numpy array, it fails with the error `ValueError: invalid __array_struct__`\r\n\r\nTo reproduce:\r\nJavaScript:\r\n```\r\nwindow.A = [[1,2,3],[4,5,6]];\r\n```\r\nPython:\r\n```\r\nimport numpy\r\nfrom js import A\r\nm = numpy.array(A)\r\n```\n", "before_files": [{"content": "\"\"\"\nA library of helper utilities for connecting Python to the browser environment.\n\"\"\"\n\nimport ast\nimport io\nfrom textwrap import dedent\n\n__version__ = '0.8.2'\n\n\ndef open_url(url):\n \"\"\"\n Fetches a given *url* and returns a io.StringIO to access its contents.\n \"\"\"\n from js import XMLHttpRequest\n\n req = XMLHttpRequest.new()\n req.open('GET', url, False)\n req.send(None)\n return io.StringIO(req.response)\n\n\ndef eval_code(code, ns):\n \"\"\"\n Runs a string of code, the last part of which may be an expression.\n \"\"\"\n # handle mis-indented input from multi-line strings\n code = dedent(code)\n\n mod = ast.parse(code)\n if len(mod.body) == 0:\n return None\n\n if isinstance(mod.body[-1], ast.Expr):\n expr = ast.Expression(mod.body[-1].value)\n del mod.body[-1]\n else:\n expr = None\n\n if len(mod.body):\n exec(compile(mod, '<exec>', mode='exec'), ns, ns)\n if expr is not None:\n return eval(compile(expr, '<eval>', mode='eval'), ns, ns)\n else:\n return None\n\n\ndef find_imports(code):\n \"\"\"\n Finds the imports in a string of code and returns a list of their package\n names.\n \"\"\"\n # handle mis-indented input from multi-line strings\n code = dedent(code)\n\n mod = ast.parse(code)\n imports = set()\n for node in ast.walk(mod):\n if isinstance(node, ast.Import):\n for name in node.names:\n name = name.name\n imports.add(name.split('.')[0])\n elif isinstance(node, ast.ImportFrom):\n name = node.module\n imports.add(name.split('.')[0])\n return list(imports)\n\n\n__all__ = ['open_url', 'eval_code', 'find_imports']\n", "path": "src/pyodide.py"}], "after_files": [{"content": "\"\"\"\nA library of helper utilities for connecting Python to the browser environment.\n\"\"\"\n\nimport ast\nimport io\nfrom textwrap import dedent\n\n__version__ = '0.8.2'\n\n\ndef open_url(url):\n \"\"\"\n Fetches a given *url* and returns a io.StringIO to access its contents.\n \"\"\"\n from js import XMLHttpRequest\n\n req = XMLHttpRequest.new()\n req.open('GET', url, False)\n req.send(None)\n return io.StringIO(req.response)\n\n\ndef eval_code(code, ns):\n \"\"\"\n Runs a string of code, the last part of which may be an expression.\n \"\"\"\n # handle mis-indented input from multi-line strings\n code = dedent(code)\n\n mod = ast.parse(code)\n if len(mod.body) == 0:\n return None\n\n if isinstance(mod.body[-1], ast.Expr):\n expr = ast.Expression(mod.body[-1].value)\n del mod.body[-1]\n else:\n expr = None\n\n if len(mod.body):\n exec(compile(mod, '<exec>', mode='exec'), ns, ns)\n if expr is not None:\n return eval(compile(expr, '<eval>', mode='eval'), ns, ns)\n else:\n return None\n\n\ndef find_imports(code):\n \"\"\"\n Finds the imports in a string of code and returns a list of their package\n names.\n \"\"\"\n # handle mis-indented input from multi-line strings\n code = dedent(code)\n\n mod = ast.parse(code)\n imports = set()\n for node in ast.walk(mod):\n if isinstance(node, ast.Import):\n for name in node.names:\n name = name.name\n imports.add(name.split('.')[0])\n elif isinstance(node, ast.ImportFrom):\n name = node.module\n imports.add(name.split('.')[0])\n return list(imports)\n\n\ndef as_nested_list(obj):\n \"\"\"\n Assumes a Javascript object is made of (possibly nested) arrays and\n converts them to nested Python lists.\n \"\"\"\n try:\n it = iter(obj)\n return [as_nested_list(x) for x in it]\n except TypeError:\n return obj\n\n\n__all__ = ['open_url', 'eval_code', 'find_imports', 'as_nested_list']\n", "path": "src/pyodide.py"}]}
| 916 | 168 |
gh_patches_debug_37105
|
rasdani/github-patches
|
git_diff
|
microsoft__AzureTRE-670
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[BUG] Failed workspace deployment: only one positional argument may be specified, the installation name, but multiple were received
**Describe the bug**
Workspace deployment failed with:
```
only one positional argument may be specified, the installation name, but multiple were received [mrtre17-9c1d X secure project]
```
**Steps to reproduce**
Deployed a workspace with following values:
```
"azure_location":"westeurope",
"workspace_id":"9c1d",
"tre_id":"mrtre17",
"address_space":"192.168.10.0/24",
"display_name":"Project X",
"description":"Very secure project"
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `resource_processor/vmss_porter/runner.py`
Content:
```
1 import os
2 import sys
3 import json
4 import socket
5 import asyncio
6 import logging
7
8 from shared.logging import disable_unwanted_loggers, initialize_logging, get_message_id_logger # pylint: disable=import-error # noqa
9 from resources import strings # pylint: disable=import-error # noqa
10 from contextlib import asynccontextmanager
11 from azure.servicebus import ServiceBusMessage
12 from azure.servicebus.aio import ServiceBusClient, AutoLockRenewer
13 from azure.identity.aio import DefaultAzureCredential
14
15 logger_adapter = initialize_logging(logging.INFO, socket.gethostname())
16 disable_unwanted_loggers()
17
18
19 @asynccontextmanager
20 async def default_credentials(msi_id):
21 """
22 Context manager which yields the default credentials.
23 """
24 credential = DefaultAzureCredential(managed_identity_client_id=msi_id) if msi_id else DefaultAzureCredential()
25 yield credential
26 await credential.close()
27
28
29 async def receive_message(env_vars, service_bus_client):
30 """
31 This method is an async generator which receives messages from service bus
32 and yields those messages. If the yielded function return True the message is
33 marked complete.
34 """
35 async with service_bus_client:
36 q_name = env_vars["resource_request_queue"]
37 renewer = AutoLockRenewer(max_lock_renewal_duration=1800)
38 receiver = service_bus_client.get_queue_receiver(queue_name=q_name, auto_lock_renewer=renewer)
39
40 async with receiver:
41 received_msgs = await receiver.receive_messages(max_message_count=10, max_wait_time=5)
42
43 for msg in received_msgs:
44 result = True
45 message = ""
46
47 try:
48 message = json.loads(str(msg))
49 result = (yield message)
50 except (json.JSONDecodeError) as e:
51 logging.error(f"Received bad service bus resource request message: {e}")
52 if result:
53 logging.info(f"Resource request for {message} is complete")
54 else:
55 logging.error('Message processing failed!')
56 logger_adapter.info(f"Message with id = {message['id']} processed as {result} and marked complete.")
57 await receiver.complete_message(msg)
58
59
60 def azure_login_command(env_vars):
61 local_login = f"az login --service-principal --username {env_vars['arm_client_id']} --password {env_vars['arm_client_secret']} --tenant {env_vars['arm_tenant_id']}"
62 vmss_login = f"az login --identity -u {env_vars['vmss_msi_id']}"
63 command = vmss_login if env_vars['vmss_msi_id'] else local_login
64 return command
65
66
67 async def filter_parameters_not_needed_by_porter(msg_body, env_vars):
68 parameters = msg_body["parameters"]
69 command = [f"{azure_login_command(env_vars)} >/dev/null && \
70 az acr login --name {env_vars['registry_server'].replace('.azurecr.io','')} >/dev/null && \
71 porter explain --reference {env_vars['registry_server']}/{msg_body['name']}:v{msg_body['version']} -ojson"]
72 proc = await asyncio.create_subprocess_shell(
73 ''.join(command),
74 stdout=asyncio.subprocess.PIPE,
75 stderr=asyncio.subprocess.PIPE,
76 env=porter_envs(env_vars))
77
78 stdout, stderr = await proc.communicate()
79 logging.info(f'[{command!r} exited with {proc.returncode}]')
80 result_stdout = None
81 result_stderr = None
82 if stdout:
83 result_stdout = stdout.decode()
84 porter_explain_parameters = json.loads(result_stdout)["parameters"]
85 items = [item["name"] for item in porter_explain_parameters]
86 porter_keys = set(items).intersection(set(parameters.keys()))
87 return porter_keys
88 if stderr:
89 result_stderr = stderr.decode()
90 logger_adapter.info('[stderr]')
91 for string in result_stderr.split('\n'):
92 logger_adapter.info(str(string))
93
94 return parameters.keys()
95
96
97 async def build_porter_command(msg_body, env_vars):
98 porter_parameters = ""
99
100 porter_keys = await filter_parameters_not_needed_by_porter(msg_body, env_vars)
101 for parameter in porter_keys:
102 porter_parameters = porter_parameters + f" --param {parameter}={msg_body['parameters'][parameter]}"
103
104 installation_id = msg_body['parameters']['tre_id'] + "-" + msg_body['parameters']['workspace_id']
105
106 porter_parameters = porter_parameters + f" --param tfstate_container_name={env_vars['tfstate_container_name']}"
107 porter_parameters = porter_parameters + f" --param tfstate_resource_group_name={env_vars['tfstate_resource_group_name']}"
108 porter_parameters = porter_parameters + f" --param tfstate_storage_account_name={env_vars['tfstate_storage_account_name']}"
109 porter_parameters = porter_parameters + f" --param arm_use_msi={env_vars['arm_use_msi']}"
110
111 command_line = [f"{azure_login_command(env_vars)} && az acr login --name {env_vars['registry_server'].replace('.azurecr.io','')} && porter "
112 f"{msg_body['action']} {installation_id} "
113 f" --reference {env_vars['registry_server']}/{msg_body['name']}:v{msg_body['version']}"
114 f" {porter_parameters} --cred ./vmss_porter/azure.json --allow-docker-host-access"
115 f" && porter show {installation_id}"]
116 return command_line
117
118
119 def porter_envs(env_var):
120 porter_env_vars = {}
121 porter_env_vars["HOME"] = os.environ['HOME']
122 porter_env_vars["PATH"] = os.environ['PATH']
123 porter_env_vars["ARM_CLIENT_ID"] = env_var["arm_client_id"]
124 porter_env_vars["ARM_CLIENT_SECRET"] = env_var["arm_client_secret"]
125 porter_env_vars["ARM_SUBSCRIPTION_ID"] = env_var["arm_subscription_id"]
126 porter_env_vars["ARM_TENANT_ID"] = env_var["arm_tenant_id"]
127
128 return porter_env_vars
129
130
131 async def run_porter(command, env_vars):
132 proc = await asyncio.create_subprocess_shell(
133 ''.join(command),
134 stdout=asyncio.subprocess.PIPE,
135 stderr=asyncio.subprocess.PIPE,
136 env=porter_envs(env_vars))
137
138 stdout, stderr = await proc.communicate()
139 logging.info(f'[{command!r} exited with {proc.returncode}]')
140 result_stdout = None
141 result_stderr = None
142 if stdout:
143 result_stdout = stdout.decode()
144 logger_adapter.info('[stdout]')
145 for string in result_stdout.split('\n'):
146 if len(string) != 0:
147 logger_adapter.info(str(string))
148 if stderr:
149 result_stderr = stderr.decode()
150 logger_adapter.info('[stderr]')
151 for string in result_stderr.split('\n'):
152 if len(string) != 0:
153 logger_adapter.info(str(string))
154
155 return (proc.returncode, result_stdout, result_stderr)
156
157
158 def service_bus_message_generator(sb_message, status, deployment_message):
159 installation_id = sb_message['parameters']['tre_id'] + "-" + sb_message['parameters']['workspace_id']
160 resource_request_message = json.dumps({
161 "id": sb_message["id"],
162 "status": status,
163 "message": f"{installation_id}: {deployment_message}"
164 })
165 return resource_request_message
166
167
168 async def deploy_porter_bundle(msg_body, sb_client, env_vars, message_logger_adapter):
169 installation_id = msg_body['parameters']['tre_id'] + "-" + msg_body['parameters']['workspace_id']
170 message_logger_adapter.info(f"{installation_id}: Deployment job configuration starting")
171 sb_sender = sb_client.get_queue_sender(queue_name=env_vars["deployment_status_queue"])
172 resource_request_message = service_bus_message_generator(msg_body, strings.RESOURCE_STATUS_DEPLOYING, "Deployment job starting")
173 await sb_sender.send_messages(ServiceBusMessage(body=resource_request_message, correlation_id=msg_body["id"]))
174 porter_command = await build_porter_command(msg_body, env_vars)
175 returncode, _, err = await run_porter(porter_command, env_vars)
176 if returncode != 0:
177 error_message = "Error context message = " + " ".join(err.split('\n'))
178 resource_request_message = service_bus_message_generator(msg_body, strings.RESOURCE_STATUS_FAILED, error_message)
179 await sb_sender.send_messages(ServiceBusMessage(body=resource_request_message, correlation_id=msg_body["id"]))
180 message_logger_adapter.info(f"{installation_id}: Deployment job configuration failed error = {error_message}")
181 return False
182 else:
183 success_message = "Workspace was deployed successfully..."
184 resource_request_message = service_bus_message_generator(msg_body, strings.RESOURCE_STATUS_DEPLOYED, success_message)
185 await sb_sender.send_messages(ServiceBusMessage(body=resource_request_message, correlation_id=msg_body["id"]))
186 message_logger_adapter.info(f"{installation_id}: {success_message}")
187 return True
188
189
190 async def runner(env_vars):
191 msi_id = env_vars["vmss_msi_id"]
192 service_bus_namespace = env_vars["service_bus_namespace"]
193 async with default_credentials(msi_id) as credential:
194 service_bus_client = ServiceBusClient(service_bus_namespace, credential)
195 logger_adapter.info("Starting message receiving loop...")
196 while True:
197 logger_adapter.info("Checking for new messages...")
198 receive_message_gen = receive_message(env_vars, service_bus_client)
199 try:
200 async for message in receive_message_gen:
201 logger_adapter.info(f"Message received for id={message['id']}")
202 message_logger_adapter = get_message_id_logger(message['id']) # logger includes message id in every entry.
203 result = await deploy_porter_bundle(message, service_bus_client, env_vars, message_logger_adapter)
204 await receive_message_gen.asend(result)
205 except StopAsyncIteration: # the async generator when finished signals end with this exception.
206 pass
207 logger_adapter.info("All messages done sleeping...")
208 await asyncio.sleep(60)
209
210
211 def read_env_vars():
212 env_vars = {
213 # Needed for local dev
214 "app_id": os.environ.get("AZURE_CLIENT_ID", None),
215 "app_password": os.environ.get("AZURE_CLIENT_SECRET", None),
216
217 "registry_server": os.environ["REGISTRY_SERVER"],
218 "tfstate_container_name": os.environ['TERRAFORM_STATE_CONTAINER_NAME'],
219 "tfstate_resource_group_name": os.environ['MGMT_RESOURCE_GROUP_NAME'],
220 "tfstate_storage_account_name": os.environ['MGMT_STORAGE_ACCOUNT_NAME'],
221 "deployment_status_queue": os.environ['SERVICE_BUS_DEPLOYMENT_STATUS_UPDATE_QUEUE'],
222 "resource_request_queue": os.environ['SERVICE_BUS_RESOURCE_REQUEST_QUEUE'],
223 "service_bus_namespace": os.environ['SERVICE_BUS_FULLY_QUALIFIED_NAMESPACE'],
224 "vmss_msi_id": os.environ.get('VMSS_MSI_ID', None),
225
226 # Needed for running porter
227 "arm_use_msi": os.environ["ARM_USE_MSI"],
228 "arm_subscription_id": os.environ['ARM_SUBSCRIPTION_ID'],
229 "arm_client_id": os.environ["ARM_CLIENT_ID"],
230 "arm_tenant_id": os.environ["ARM_TENANT_ID"]
231 }
232
233 env_vars["arm_client_secret"] = os.environ["ARM_CLIENT_SECRET"] if env_vars["arm_use_msi"] == "false" else ""
234
235 return env_vars
236
237
238 if __name__ == "__main__":
239 try:
240 env_vars = read_env_vars()
241 except KeyError as e:
242 logger_adapter.error(f"Environment variable {e} is not set correctly...Exiting")
243 sys.exit(1)
244 logger_adapter.info("Started processor")
245 asyncio.run(runner(env_vars))
246
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/resource_processor/vmss_porter/runner.py b/resource_processor/vmss_porter/runner.py
--- a/resource_processor/vmss_porter/runner.py
+++ b/resource_processor/vmss_porter/runner.py
@@ -99,7 +99,7 @@
porter_keys = await filter_parameters_not_needed_by_porter(msg_body, env_vars)
for parameter in porter_keys:
- porter_parameters = porter_parameters + f" --param {parameter}={msg_body['parameters'][parameter]}"
+ porter_parameters = porter_parameters + f" --param {parameter}=\"{msg_body['parameters'][parameter]}\""
installation_id = msg_body['parameters']['tre_id'] + "-" + msg_body['parameters']['workspace_id']
@@ -109,7 +109,7 @@
porter_parameters = porter_parameters + f" --param arm_use_msi={env_vars['arm_use_msi']}"
command_line = [f"{azure_login_command(env_vars)} && az acr login --name {env_vars['registry_server'].replace('.azurecr.io','')} && porter "
- f"{msg_body['action']} {installation_id} "
+ f"{msg_body['action']} \"{installation_id}\" "
f" --reference {env_vars['registry_server']}/{msg_body['name']}:v{msg_body['version']}"
f" {porter_parameters} --cred ./vmss_porter/azure.json --allow-docker-host-access"
f" && porter show {installation_id}"]
@@ -174,7 +174,7 @@
porter_command = await build_porter_command(msg_body, env_vars)
returncode, _, err = await run_porter(porter_command, env_vars)
if returncode != 0:
- error_message = "Error context message = " + " ".join(err.split('\n'))
+ error_message = "Error context message = " + " ".join(err.split('\n')) + " ; Command executed: ".join(porter_command)
resource_request_message = service_bus_message_generator(msg_body, strings.RESOURCE_STATUS_FAILED, error_message)
await sb_sender.send_messages(ServiceBusMessage(body=resource_request_message, correlation_id=msg_body["id"]))
message_logger_adapter.info(f"{installation_id}: Deployment job configuration failed error = {error_message}")
|
{"golden_diff": "diff --git a/resource_processor/vmss_porter/runner.py b/resource_processor/vmss_porter/runner.py\n--- a/resource_processor/vmss_porter/runner.py\n+++ b/resource_processor/vmss_porter/runner.py\n@@ -99,7 +99,7 @@\n \n porter_keys = await filter_parameters_not_needed_by_porter(msg_body, env_vars)\n for parameter in porter_keys:\n- porter_parameters = porter_parameters + f\" --param {parameter}={msg_body['parameters'][parameter]}\"\n+ porter_parameters = porter_parameters + f\" --param {parameter}=\\\"{msg_body['parameters'][parameter]}\\\"\"\n \n installation_id = msg_body['parameters']['tre_id'] + \"-\" + msg_body['parameters']['workspace_id']\n \n@@ -109,7 +109,7 @@\n porter_parameters = porter_parameters + f\" --param arm_use_msi={env_vars['arm_use_msi']}\"\n \n command_line = [f\"{azure_login_command(env_vars)} && az acr login --name {env_vars['registry_server'].replace('.azurecr.io','')} && porter \"\n- f\"{msg_body['action']} {installation_id} \"\n+ f\"{msg_body['action']} \\\"{installation_id}\\\" \"\n f\" --reference {env_vars['registry_server']}/{msg_body['name']}:v{msg_body['version']}\"\n f\" {porter_parameters} --cred ./vmss_porter/azure.json --allow-docker-host-access\"\n f\" && porter show {installation_id}\"]\n@@ -174,7 +174,7 @@\n porter_command = await build_porter_command(msg_body, env_vars)\n returncode, _, err = await run_porter(porter_command, env_vars)\n if returncode != 0:\n- error_message = \"Error context message = \" + \" \".join(err.split('\\n'))\n+ error_message = \"Error context message = \" + \" \".join(err.split('\\n')) + \" ; Command executed: \".join(porter_command)\n resource_request_message = service_bus_message_generator(msg_body, strings.RESOURCE_STATUS_FAILED, error_message)\n await sb_sender.send_messages(ServiceBusMessage(body=resource_request_message, correlation_id=msg_body[\"id\"]))\n message_logger_adapter.info(f\"{installation_id}: Deployment job configuration failed error = {error_message}\")\n", "issue": "[BUG] Failed workspace deployment: only one positional argument may be specified, the installation name, but multiple were received\n**Describe the bug**\r\nWorkspace deployment failed with:\r\n\r\n```\r\nonly one positional argument may be specified, the installation name, but multiple were received [mrtre17-9c1d X secure project]\r\n```\r\n\r\n**Steps to reproduce**\r\n\r\nDeployed a workspace with following values:\r\n\r\n```\r\n\"azure_location\":\"westeurope\",\r\n\"workspace_id\":\"9c1d\",\r\n\"tre_id\":\"mrtre17\",\r\n\"address_space\":\"192.168.10.0/24\",\r\n\"display_name\":\"Project X\",\r\n\"description\":\"Very secure project\"\r\n```\n", "before_files": [{"content": "import os\nimport sys\nimport json\nimport socket\nimport asyncio\nimport logging\n\nfrom shared.logging import disable_unwanted_loggers, initialize_logging, get_message_id_logger # pylint: disable=import-error # noqa\nfrom resources import strings # pylint: disable=import-error # noqa\nfrom contextlib import asynccontextmanager\nfrom azure.servicebus import ServiceBusMessage\nfrom azure.servicebus.aio import ServiceBusClient, AutoLockRenewer\nfrom azure.identity.aio import DefaultAzureCredential\n\nlogger_adapter = initialize_logging(logging.INFO, socket.gethostname())\ndisable_unwanted_loggers()\n\n\n@asynccontextmanager\nasync def default_credentials(msi_id):\n \"\"\"\n Context manager which yields the default credentials.\n \"\"\"\n credential = DefaultAzureCredential(managed_identity_client_id=msi_id) if msi_id else DefaultAzureCredential()\n yield credential\n await credential.close()\n\n\nasync def receive_message(env_vars, service_bus_client):\n \"\"\"\n This method is an async generator which receives messages from service bus\n and yields those messages. If the yielded function return True the message is\n marked complete.\n \"\"\"\n async with service_bus_client:\n q_name = env_vars[\"resource_request_queue\"]\n renewer = AutoLockRenewer(max_lock_renewal_duration=1800)\n receiver = service_bus_client.get_queue_receiver(queue_name=q_name, auto_lock_renewer=renewer)\n\n async with receiver:\n received_msgs = await receiver.receive_messages(max_message_count=10, max_wait_time=5)\n\n for msg in received_msgs:\n result = True\n message = \"\"\n\n try:\n message = json.loads(str(msg))\n result = (yield message)\n except (json.JSONDecodeError) as e:\n logging.error(f\"Received bad service bus resource request message: {e}\")\n if result:\n logging.info(f\"Resource request for {message} is complete\")\n else:\n logging.error('Message processing failed!')\n logger_adapter.info(f\"Message with id = {message['id']} processed as {result} and marked complete.\")\n await receiver.complete_message(msg)\n\n\ndef azure_login_command(env_vars):\n local_login = f\"az login --service-principal --username {env_vars['arm_client_id']} --password {env_vars['arm_client_secret']} --tenant {env_vars['arm_tenant_id']}\"\n vmss_login = f\"az login --identity -u {env_vars['vmss_msi_id']}\"\n command = vmss_login if env_vars['vmss_msi_id'] else local_login\n return command\n\n\nasync def filter_parameters_not_needed_by_porter(msg_body, env_vars):\n parameters = msg_body[\"parameters\"]\n command = [f\"{azure_login_command(env_vars)} >/dev/null && \\\n az acr login --name {env_vars['registry_server'].replace('.azurecr.io','')} >/dev/null && \\\n porter explain --reference {env_vars['registry_server']}/{msg_body['name']}:v{msg_body['version']} -ojson\"]\n proc = await asyncio.create_subprocess_shell(\n ''.join(command),\n stdout=asyncio.subprocess.PIPE,\n stderr=asyncio.subprocess.PIPE,\n env=porter_envs(env_vars))\n\n stdout, stderr = await proc.communicate()\n logging.info(f'[{command!r} exited with {proc.returncode}]')\n result_stdout = None\n result_stderr = None\n if stdout:\n result_stdout = stdout.decode()\n porter_explain_parameters = json.loads(result_stdout)[\"parameters\"]\n items = [item[\"name\"] for item in porter_explain_parameters]\n porter_keys = set(items).intersection(set(parameters.keys()))\n return porter_keys\n if stderr:\n result_stderr = stderr.decode()\n logger_adapter.info('[stderr]')\n for string in result_stderr.split('\\n'):\n logger_adapter.info(str(string))\n\n return parameters.keys()\n\n\nasync def build_porter_command(msg_body, env_vars):\n porter_parameters = \"\"\n\n porter_keys = await filter_parameters_not_needed_by_porter(msg_body, env_vars)\n for parameter in porter_keys:\n porter_parameters = porter_parameters + f\" --param {parameter}={msg_body['parameters'][parameter]}\"\n\n installation_id = msg_body['parameters']['tre_id'] + \"-\" + msg_body['parameters']['workspace_id']\n\n porter_parameters = porter_parameters + f\" --param tfstate_container_name={env_vars['tfstate_container_name']}\"\n porter_parameters = porter_parameters + f\" --param tfstate_resource_group_name={env_vars['tfstate_resource_group_name']}\"\n porter_parameters = porter_parameters + f\" --param tfstate_storage_account_name={env_vars['tfstate_storage_account_name']}\"\n porter_parameters = porter_parameters + f\" --param arm_use_msi={env_vars['arm_use_msi']}\"\n\n command_line = [f\"{azure_login_command(env_vars)} && az acr login --name {env_vars['registry_server'].replace('.azurecr.io','')} && porter \"\n f\"{msg_body['action']} {installation_id} \"\n f\" --reference {env_vars['registry_server']}/{msg_body['name']}:v{msg_body['version']}\"\n f\" {porter_parameters} --cred ./vmss_porter/azure.json --allow-docker-host-access\"\n f\" && porter show {installation_id}\"]\n return command_line\n\n\ndef porter_envs(env_var):\n porter_env_vars = {}\n porter_env_vars[\"HOME\"] = os.environ['HOME']\n porter_env_vars[\"PATH\"] = os.environ['PATH']\n porter_env_vars[\"ARM_CLIENT_ID\"] = env_var[\"arm_client_id\"]\n porter_env_vars[\"ARM_CLIENT_SECRET\"] = env_var[\"arm_client_secret\"]\n porter_env_vars[\"ARM_SUBSCRIPTION_ID\"] = env_var[\"arm_subscription_id\"]\n porter_env_vars[\"ARM_TENANT_ID\"] = env_var[\"arm_tenant_id\"]\n\n return porter_env_vars\n\n\nasync def run_porter(command, env_vars):\n proc = await asyncio.create_subprocess_shell(\n ''.join(command),\n stdout=asyncio.subprocess.PIPE,\n stderr=asyncio.subprocess.PIPE,\n env=porter_envs(env_vars))\n\n stdout, stderr = await proc.communicate()\n logging.info(f'[{command!r} exited with {proc.returncode}]')\n result_stdout = None\n result_stderr = None\n if stdout:\n result_stdout = stdout.decode()\n logger_adapter.info('[stdout]')\n for string in result_stdout.split('\\n'):\n if len(string) != 0:\n logger_adapter.info(str(string))\n if stderr:\n result_stderr = stderr.decode()\n logger_adapter.info('[stderr]')\n for string in result_stderr.split('\\n'):\n if len(string) != 0:\n logger_adapter.info(str(string))\n\n return (proc.returncode, result_stdout, result_stderr)\n\n\ndef service_bus_message_generator(sb_message, status, deployment_message):\n installation_id = sb_message['parameters']['tre_id'] + \"-\" + sb_message['parameters']['workspace_id']\n resource_request_message = json.dumps({\n \"id\": sb_message[\"id\"],\n \"status\": status,\n \"message\": f\"{installation_id}: {deployment_message}\"\n })\n return resource_request_message\n\n\nasync def deploy_porter_bundle(msg_body, sb_client, env_vars, message_logger_adapter):\n installation_id = msg_body['parameters']['tre_id'] + \"-\" + msg_body['parameters']['workspace_id']\n message_logger_adapter.info(f\"{installation_id}: Deployment job configuration starting\")\n sb_sender = sb_client.get_queue_sender(queue_name=env_vars[\"deployment_status_queue\"])\n resource_request_message = service_bus_message_generator(msg_body, strings.RESOURCE_STATUS_DEPLOYING, \"Deployment job starting\")\n await sb_sender.send_messages(ServiceBusMessage(body=resource_request_message, correlation_id=msg_body[\"id\"]))\n porter_command = await build_porter_command(msg_body, env_vars)\n returncode, _, err = await run_porter(porter_command, env_vars)\n if returncode != 0:\n error_message = \"Error context message = \" + \" \".join(err.split('\\n'))\n resource_request_message = service_bus_message_generator(msg_body, strings.RESOURCE_STATUS_FAILED, error_message)\n await sb_sender.send_messages(ServiceBusMessage(body=resource_request_message, correlation_id=msg_body[\"id\"]))\n message_logger_adapter.info(f\"{installation_id}: Deployment job configuration failed error = {error_message}\")\n return False\n else:\n success_message = \"Workspace was deployed successfully...\"\n resource_request_message = service_bus_message_generator(msg_body, strings.RESOURCE_STATUS_DEPLOYED, success_message)\n await sb_sender.send_messages(ServiceBusMessage(body=resource_request_message, correlation_id=msg_body[\"id\"]))\n message_logger_adapter.info(f\"{installation_id}: {success_message}\")\n return True\n\n\nasync def runner(env_vars):\n msi_id = env_vars[\"vmss_msi_id\"]\n service_bus_namespace = env_vars[\"service_bus_namespace\"]\n async with default_credentials(msi_id) as credential:\n service_bus_client = ServiceBusClient(service_bus_namespace, credential)\n logger_adapter.info(\"Starting message receiving loop...\")\n while True:\n logger_adapter.info(\"Checking for new messages...\")\n receive_message_gen = receive_message(env_vars, service_bus_client)\n try:\n async for message in receive_message_gen:\n logger_adapter.info(f\"Message received for id={message['id']}\")\n message_logger_adapter = get_message_id_logger(message['id']) # logger includes message id in every entry.\n result = await deploy_porter_bundle(message, service_bus_client, env_vars, message_logger_adapter)\n await receive_message_gen.asend(result)\n except StopAsyncIteration: # the async generator when finished signals end with this exception.\n pass\n logger_adapter.info(\"All messages done sleeping...\")\n await asyncio.sleep(60)\n\n\ndef read_env_vars():\n env_vars = {\n # Needed for local dev\n \"app_id\": os.environ.get(\"AZURE_CLIENT_ID\", None),\n \"app_password\": os.environ.get(\"AZURE_CLIENT_SECRET\", None),\n\n \"registry_server\": os.environ[\"REGISTRY_SERVER\"],\n \"tfstate_container_name\": os.environ['TERRAFORM_STATE_CONTAINER_NAME'],\n \"tfstate_resource_group_name\": os.environ['MGMT_RESOURCE_GROUP_NAME'],\n \"tfstate_storage_account_name\": os.environ['MGMT_STORAGE_ACCOUNT_NAME'],\n \"deployment_status_queue\": os.environ['SERVICE_BUS_DEPLOYMENT_STATUS_UPDATE_QUEUE'],\n \"resource_request_queue\": os.environ['SERVICE_BUS_RESOURCE_REQUEST_QUEUE'],\n \"service_bus_namespace\": os.environ['SERVICE_BUS_FULLY_QUALIFIED_NAMESPACE'],\n \"vmss_msi_id\": os.environ.get('VMSS_MSI_ID', None),\n\n # Needed for running porter\n \"arm_use_msi\": os.environ[\"ARM_USE_MSI\"],\n \"arm_subscription_id\": os.environ['ARM_SUBSCRIPTION_ID'],\n \"arm_client_id\": os.environ[\"ARM_CLIENT_ID\"],\n \"arm_tenant_id\": os.environ[\"ARM_TENANT_ID\"]\n }\n\n env_vars[\"arm_client_secret\"] = os.environ[\"ARM_CLIENT_SECRET\"] if env_vars[\"arm_use_msi\"] == \"false\" else \"\"\n\n return env_vars\n\n\nif __name__ == \"__main__\":\n try:\n env_vars = read_env_vars()\n except KeyError as e:\n logger_adapter.error(f\"Environment variable {e} is not set correctly...Exiting\")\n sys.exit(1)\n logger_adapter.info(\"Started processor\")\n asyncio.run(runner(env_vars))\n", "path": "resource_processor/vmss_porter/runner.py"}], "after_files": [{"content": "import os\nimport sys\nimport json\nimport socket\nimport asyncio\nimport logging\n\nfrom shared.logging import disable_unwanted_loggers, initialize_logging, get_message_id_logger # pylint: disable=import-error # noqa\nfrom resources import strings # pylint: disable=import-error # noqa\nfrom contextlib import asynccontextmanager\nfrom azure.servicebus import ServiceBusMessage\nfrom azure.servicebus.aio import ServiceBusClient, AutoLockRenewer\nfrom azure.identity.aio import DefaultAzureCredential\n\nlogger_adapter = initialize_logging(logging.INFO, socket.gethostname())\ndisable_unwanted_loggers()\n\n\n@asynccontextmanager\nasync def default_credentials(msi_id):\n \"\"\"\n Context manager which yields the default credentials.\n \"\"\"\n credential = DefaultAzureCredential(managed_identity_client_id=msi_id) if msi_id else DefaultAzureCredential()\n yield credential\n await credential.close()\n\n\nasync def receive_message(env_vars, service_bus_client):\n \"\"\"\n This method is an async generator which receives messages from service bus\n and yields those messages. If the yielded function return True the message is\n marked complete.\n \"\"\"\n async with service_bus_client:\n q_name = env_vars[\"resource_request_queue\"]\n renewer = AutoLockRenewer(max_lock_renewal_duration=1800)\n receiver = service_bus_client.get_queue_receiver(queue_name=q_name, auto_lock_renewer=renewer)\n\n async with receiver:\n received_msgs = await receiver.receive_messages(max_message_count=10, max_wait_time=5)\n\n for msg in received_msgs:\n result = True\n message = \"\"\n\n try:\n message = json.loads(str(msg))\n result = (yield message)\n except (json.JSONDecodeError) as e:\n logging.error(f\"Received bad service bus resource request message: {e}\")\n if result:\n logging.info(f\"Resource request for {message} is complete\")\n else:\n logging.error('Message processing failed!')\n logger_adapter.info(f\"Message with id = {message['id']} processed as {result} and marked complete.\")\n await receiver.complete_message(msg)\n\n\ndef azure_login_command(env_vars):\n local_login = f\"az login --service-principal --username {env_vars['arm_client_id']} --password {env_vars['arm_client_secret']} --tenant {env_vars['arm_tenant_id']}\"\n vmss_login = f\"az login --identity -u {env_vars['vmss_msi_id']}\"\n command = vmss_login if env_vars['vmss_msi_id'] else local_login\n return command\n\n\nasync def filter_parameters_not_needed_by_porter(msg_body, env_vars):\n parameters = msg_body[\"parameters\"]\n command = [f\"{azure_login_command(env_vars)} >/dev/null && \\\n az acr login --name {env_vars['registry_server'].replace('.azurecr.io','')} >/dev/null && \\\n porter explain --reference {env_vars['registry_server']}/{msg_body['name']}:v{msg_body['version']} -ojson\"]\n proc = await asyncio.create_subprocess_shell(\n ''.join(command),\n stdout=asyncio.subprocess.PIPE,\n stderr=asyncio.subprocess.PIPE,\n env=porter_envs(env_vars))\n\n stdout, stderr = await proc.communicate()\n logging.info(f'[{command!r} exited with {proc.returncode}]')\n result_stdout = None\n result_stderr = None\n if stdout:\n result_stdout = stdout.decode()\n porter_explain_parameters = json.loads(result_stdout)[\"parameters\"]\n items = [item[\"name\"] for item in porter_explain_parameters]\n porter_keys = set(items).intersection(set(parameters.keys()))\n return porter_keys\n if stderr:\n result_stderr = stderr.decode()\n logger_adapter.info('[stderr]')\n for string in result_stderr.split('\\n'):\n logger_adapter.info(str(string))\n\n return parameters.keys()\n\n\nasync def build_porter_command(msg_body, env_vars):\n porter_parameters = \"\"\n\n porter_keys = await filter_parameters_not_needed_by_porter(msg_body, env_vars)\n for parameter in porter_keys:\n porter_parameters = porter_parameters + f\" --param {parameter}=\\\"{msg_body['parameters'][parameter]}\\\"\"\n\n installation_id = msg_body['parameters']['tre_id'] + \"-\" + msg_body['parameters']['workspace_id']\n\n porter_parameters = porter_parameters + f\" --param tfstate_container_name={env_vars['tfstate_container_name']}\"\n porter_parameters = porter_parameters + f\" --param tfstate_resource_group_name={env_vars['tfstate_resource_group_name']}\"\n porter_parameters = porter_parameters + f\" --param tfstate_storage_account_name={env_vars['tfstate_storage_account_name']}\"\n porter_parameters = porter_parameters + f\" --param arm_use_msi={env_vars['arm_use_msi']}\"\n\n command_line = [f\"{azure_login_command(env_vars)} && az acr login --name {env_vars['registry_server'].replace('.azurecr.io','')} && porter \"\n f\"{msg_body['action']} \\\"{installation_id}\\\" \"\n f\" --reference {env_vars['registry_server']}/{msg_body['name']}:v{msg_body['version']}\"\n f\" {porter_parameters} --cred ./vmss_porter/azure.json --allow-docker-host-access\"\n f\" && porter show {installation_id}\"]\n return command_line\n\n\ndef porter_envs(env_var):\n porter_env_vars = {}\n porter_env_vars[\"HOME\"] = os.environ['HOME']\n porter_env_vars[\"PATH\"] = os.environ['PATH']\n porter_env_vars[\"ARM_CLIENT_ID\"] = env_var[\"arm_client_id\"]\n porter_env_vars[\"ARM_CLIENT_SECRET\"] = env_var[\"arm_client_secret\"]\n porter_env_vars[\"ARM_SUBSCRIPTION_ID\"] = env_var[\"arm_subscription_id\"]\n porter_env_vars[\"ARM_TENANT_ID\"] = env_var[\"arm_tenant_id\"]\n\n return porter_env_vars\n\n\nasync def run_porter(command, env_vars):\n proc = await asyncio.create_subprocess_shell(\n ''.join(command),\n stdout=asyncio.subprocess.PIPE,\n stderr=asyncio.subprocess.PIPE,\n env=porter_envs(env_vars))\n\n stdout, stderr = await proc.communicate()\n logging.info(f'[{command!r} exited with {proc.returncode}]')\n result_stdout = None\n result_stderr = None\n if stdout:\n result_stdout = stdout.decode()\n logger_adapter.info('[stdout]')\n for string in result_stdout.split('\\n'):\n if len(string) != 0:\n logger_adapter.info(str(string))\n if stderr:\n result_stderr = stderr.decode()\n logger_adapter.info('[stderr]')\n for string in result_stderr.split('\\n'):\n if len(string) != 0:\n logger_adapter.info(str(string))\n\n return (proc.returncode, result_stdout, result_stderr)\n\n\ndef service_bus_message_generator(sb_message, status, deployment_message):\n installation_id = sb_message['parameters']['tre_id'] + \"-\" + sb_message['parameters']['workspace_id']\n resource_request_message = json.dumps({\n \"id\": sb_message[\"id\"],\n \"status\": status,\n \"message\": f\"{installation_id}: {deployment_message}\"\n })\n return resource_request_message\n\n\nasync def deploy_porter_bundle(msg_body, sb_client, env_vars, message_logger_adapter):\n installation_id = msg_body['parameters']['tre_id'] + \"-\" + msg_body['parameters']['workspace_id']\n message_logger_adapter.info(f\"{installation_id}: Deployment job configuration starting\")\n sb_sender = sb_client.get_queue_sender(queue_name=env_vars[\"deployment_status_queue\"])\n resource_request_message = service_bus_message_generator(msg_body, strings.RESOURCE_STATUS_DEPLOYING, \"Deployment job starting\")\n await sb_sender.send_messages(ServiceBusMessage(body=resource_request_message, correlation_id=msg_body[\"id\"]))\n porter_command = await build_porter_command(msg_body, env_vars)\n returncode, _, err = await run_porter(porter_command, env_vars)\n if returncode != 0:\n error_message = \"Error context message = \" + \" \".join(err.split('\\n')) + \" ; Command executed: \".join(porter_command)\n resource_request_message = service_bus_message_generator(msg_body, strings.RESOURCE_STATUS_FAILED, error_message)\n await sb_sender.send_messages(ServiceBusMessage(body=resource_request_message, correlation_id=msg_body[\"id\"]))\n message_logger_adapter.info(f\"{installation_id}: Deployment job configuration failed error = {error_message}\")\n return False\n else:\n success_message = \"Workspace was deployed successfully...\"\n resource_request_message = service_bus_message_generator(msg_body, strings.RESOURCE_STATUS_DEPLOYED, success_message)\n await sb_sender.send_messages(ServiceBusMessage(body=resource_request_message, correlation_id=msg_body[\"id\"]))\n message_logger_adapter.info(f\"{installation_id}: {success_message}\")\n return True\n\n\nasync def runner(env_vars):\n msi_id = env_vars[\"vmss_msi_id\"]\n service_bus_namespace = env_vars[\"service_bus_namespace\"]\n async with default_credentials(msi_id) as credential:\n service_bus_client = ServiceBusClient(service_bus_namespace, credential)\n logger_adapter.info(\"Starting message receiving loop...\")\n while True:\n logger_adapter.info(\"Checking for new messages...\")\n receive_message_gen = receive_message(env_vars, service_bus_client)\n try:\n async for message in receive_message_gen:\n logger_adapter.info(f\"Message received for id={message['id']}\")\n message_logger_adapter = get_message_id_logger(message['id']) # logger includes message id in every entry.\n result = await deploy_porter_bundle(message, service_bus_client, env_vars, message_logger_adapter)\n await receive_message_gen.asend(result)\n except StopAsyncIteration: # the async generator when finished signals end with this exception.\n pass\n logger_adapter.info(\"All messages done sleeping...\")\n await asyncio.sleep(60)\n\n\ndef read_env_vars():\n env_vars = {\n # Needed for local dev\n \"app_id\": os.environ.get(\"AZURE_CLIENT_ID\", None),\n \"app_password\": os.environ.get(\"AZURE_CLIENT_SECRET\", None),\n\n \"registry_server\": os.environ[\"REGISTRY_SERVER\"],\n \"tfstate_container_name\": os.environ['TERRAFORM_STATE_CONTAINER_NAME'],\n \"tfstate_resource_group_name\": os.environ['MGMT_RESOURCE_GROUP_NAME'],\n \"tfstate_storage_account_name\": os.environ['MGMT_STORAGE_ACCOUNT_NAME'],\n \"deployment_status_queue\": os.environ['SERVICE_BUS_DEPLOYMENT_STATUS_UPDATE_QUEUE'],\n \"resource_request_queue\": os.environ['SERVICE_BUS_RESOURCE_REQUEST_QUEUE'],\n \"service_bus_namespace\": os.environ['SERVICE_BUS_FULLY_QUALIFIED_NAMESPACE'],\n \"vmss_msi_id\": os.environ.get('VMSS_MSI_ID', None),\n\n # Needed for running porter\n \"arm_use_msi\": os.environ[\"ARM_USE_MSI\"],\n \"arm_subscription_id\": os.environ['ARM_SUBSCRIPTION_ID'],\n \"arm_client_id\": os.environ[\"ARM_CLIENT_ID\"],\n \"arm_tenant_id\": os.environ[\"ARM_TENANT_ID\"]\n }\n\n env_vars[\"arm_client_secret\"] = os.environ[\"ARM_CLIENT_SECRET\"] if env_vars[\"arm_use_msi\"] == \"false\" else \"\"\n\n return env_vars\n\n\nif __name__ == \"__main__\":\n try:\n env_vars = read_env_vars()\n except KeyError as e:\n logger_adapter.error(f\"Environment variable {e} is not set correctly...Exiting\")\n sys.exit(1)\n logger_adapter.info(\"Started processor\")\n asyncio.run(runner(env_vars))\n", "path": "resource_processor/vmss_porter/runner.py"}]}
| 3,489 | 501 |
gh_patches_debug_23525
|
rasdani/github-patches
|
git_diff
|
pretalx__pretalx-626
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
email sender address fallback is incorrect
## Current Behavior

the UI says emails will be sent from "[email protected]", but they are sent from "admin@localhost" (the value in the global `MAIL_FROM`).
## Expected Behavior
the sender should be "[email protected]"
## Steps to Reproduce
1. create event
2. set an orga email address `[email protected]`
3. do _not_ set a "Sender address" in mail settings, but observe the text below
4. send email
5. email is has `From: event <admin@localhost>`, not `From: event <[email protected]>`
## Context
<!--- How has this issue affected you? What are you trying to accomplish? -->
<!--- Providing context helps us come up with a solution that is most useful in the real world -->
## Your Environment
<!--- Include as many relevant details about the environment you experienced the bug in -->
* Version used: 5a5ab5482dd9a7a3b19b91563946c535fe5abe1e
* Environment name and version (e.g. Chrome 39, python 3.5):
* Operating System and version (desktop or mobile):
* Link to your instance, if in production:
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/pretalx/common/mail.py`
Content:
```
1 import logging
2 from email.utils import formataddr
3 from smtplib import SMTPResponseException, SMTPSenderRefused
4 from typing import Any, Dict, Union
5
6 from django.conf import settings
7 from django.core.mail import EmailMultiAlternatives, get_connection
8 from django.core.mail.backends.smtp import EmailBackend
9 from django.utils.translation import override
10 from i18nfield.strings import LazyI18nString
11 from inlinestyler.utils import inline_css
12
13 from pretalx.celery_app import app
14 from pretalx.event.models import Event
15 from pretalx.person.models import User
16
17 logger = logging.getLogger(__name__)
18
19
20 class CustomSMTPBackend(EmailBackend):
21 def test(self, from_addr):
22 try:
23 self.open()
24 self.connection.ehlo_or_helo_if_needed()
25 (code, resp) = self.connection.mail(from_addr, [])
26 if code != 250:
27 logger.warning(
28 f'Error testing mail settings, code {code}, resp: {resp}'
29 )
30 raise SMTPSenderRefused(code, resp)
31 (code, resp) = self.connection.rcpt('[email protected]')
32 if code not in (250, 251):
33 logger.warning(
34 f'Error testing mail settings, code {code}, resp: {resp}'
35 )
36 raise SMTPSenderRefused(code, resp)
37 finally:
38 self.close()
39
40
41 class TolerantDict(dict):
42 def __missing__(self, key):
43 """Don't fail when formatting strings with a dict with missing keys."""
44 return key
45
46
47 class SendMailException(Exception):
48 pass
49
50
51 def mail(
52 user: User,
53 subject: str,
54 template: Union[str, LazyI18nString],
55 context: Dict[str, Any] = None,
56 event: Event = None,
57 locale: str = None,
58 headers: dict = None,
59 ):
60 from pretalx.mail.models import QueuedMail
61
62 headers = headers or {}
63
64 with override(locale):
65 body = str(template)
66 if context:
67 body = body.format_map(TolerantDict(context))
68 reply_to = headers.get('reply-to')
69 if reply_to and isinstance(reply_to, list):
70 reply_to = ','.join(reply_to)
71 QueuedMail(
72 event=event,
73 to=user.email,
74 subject=str(subject),
75 text=body,
76 reply_to=reply_to,
77 bcc=headers.get('bcc'),
78 ).send()
79
80
81 @app.task(bind=True)
82 def mail_send_task(
83 self,
84 to: str,
85 subject: str,
86 body: str,
87 html: str,
88 reply_to: list = None,
89 event: int = None,
90 cc: list = None,
91 bcc: list = None,
92 headers: dict = None,
93 ):
94 headers = headers or dict()
95 if event:
96 event = Event.objects.filter(id=event).first()
97 if event:
98 sender = event.settings.get('mail_from')
99 if sender == '[email protected]' or not sender:
100 sender = settings.MAIL_FROM
101 if reply_to:
102 headers['reply-to'] = reply_to.split(',') if isinstance(reply_to, str) else reply_to
103 backend = event.get_mail_backend()
104 sender = formataddr((str(event.name), sender))
105 else:
106 sender = formataddr(('pretalx', settings.MAIL_FROM))
107 backend = get_connection(fail_silently=False)
108
109 email = EmailMultiAlternatives(
110 subject, body, sender, to=to, cc=cc, bcc=bcc, headers=headers
111 )
112
113 if html is not None:
114 email.attach_alternative(inline_css(html), 'text/html')
115
116 try:
117 backend.send_messages([email])
118 except SMTPResponseException as exception:
119 # Retry on external problems: Connection issues (101, 111), timeouts (421), filled-up mailboxes (422),
120 # out of memory (431), network issues (442), another timeout (447), or too many mails sent (452)
121 if exception.smtp_code in (101, 111, 421, 422, 431, 442, 447, 452):
122 self.retry(max_retries=5, countdown=2 ** (self.request.retries * 2))
123 logger.exception('Error sending email')
124 raise SendMailException('Failed to send an email to {}.'.format(to))
125 except Exception:
126 logger.exception('Error sending email')
127 raise SendMailException('Failed to send an email to {}.'.format(to))
128
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/pretalx/common/mail.py b/src/pretalx/common/mail.py
--- a/src/pretalx/common/mail.py
+++ b/src/pretalx/common/mail.py
@@ -92,14 +92,14 @@
headers: dict = None,
):
headers = headers or dict()
+ if reply_to and isinstance(reply_to, str):
+ reply_to = reply_to.split(',')
if event:
event = Event.objects.filter(id=event).first()
if event:
sender = event.settings.get('mail_from')
if sender == '[email protected]' or not sender:
- sender = settings.MAIL_FROM
- if reply_to:
- headers['reply-to'] = reply_to.split(',') if isinstance(reply_to, str) else reply_to
+ sender = event.email
backend = event.get_mail_backend()
sender = formataddr((str(event.name), sender))
else:
@@ -107,7 +107,7 @@
backend = get_connection(fail_silently=False)
email = EmailMultiAlternatives(
- subject, body, sender, to=to, cc=cc, bcc=bcc, headers=headers
+ subject, body, sender, to=to, cc=cc, bcc=bcc, headers=headers, reply_to=reply_to
)
if html is not None:
|
{"golden_diff": "diff --git a/src/pretalx/common/mail.py b/src/pretalx/common/mail.py\n--- a/src/pretalx/common/mail.py\n+++ b/src/pretalx/common/mail.py\n@@ -92,14 +92,14 @@\n headers: dict = None,\n ):\n headers = headers or dict()\n+ if reply_to and isinstance(reply_to, str):\n+ reply_to = reply_to.split(',')\n if event:\n event = Event.objects.filter(id=event).first()\n if event:\n sender = event.settings.get('mail_from')\n if sender == '[email protected]' or not sender:\n- sender = settings.MAIL_FROM\n- if reply_to:\n- headers['reply-to'] = reply_to.split(',') if isinstance(reply_to, str) else reply_to\n+ sender = event.email\n backend = event.get_mail_backend()\n sender = formataddr((str(event.name), sender))\n else:\n@@ -107,7 +107,7 @@\n backend = get_connection(fail_silently=False)\n \n email = EmailMultiAlternatives(\n- subject, body, sender, to=to, cc=cc, bcc=bcc, headers=headers\n+ subject, body, sender, to=to, cc=cc, bcc=bcc, headers=headers, reply_to=reply_to\n )\n \n if html is not None:\n", "issue": "email sender address fallback is incorrect\n## Current Behavior\r\n\r\n\r\n\r\nthe UI says emails will be sent from \"[email protected]\", but they are sent from \"admin@localhost\" (the value in the global `MAIL_FROM`).\r\n\r\n## Expected Behavior\r\n\r\nthe sender should be \"[email protected]\"\r\n\r\n## Steps to Reproduce\r\n\r\n1. create event\r\n2. set an orga email address `[email protected]`\r\n3. do _not_ set a \"Sender address\" in mail settings, but observe the text below\r\n4. send email\r\n5. email is has `From: event <admin@localhost>`, not `From: event <[email protected]>`\r\n\r\n## Context\r\n\r\n<!--- How has this issue affected you? What are you trying to accomplish? -->\r\n<!--- Providing context helps us come up with a solution that is most useful in the real world -->\r\n\r\n## Your Environment\r\n\r\n<!--- Include as many relevant details about the environment you experienced the bug in -->\r\n* Version used: 5a5ab5482dd9a7a3b19b91563946c535fe5abe1e\r\n* Environment name and version (e.g. Chrome 39, python 3.5):\r\n* Operating System and version (desktop or mobile):\r\n* Link to your instance, if in production:\r\n\n", "before_files": [{"content": "import logging\nfrom email.utils import formataddr\nfrom smtplib import SMTPResponseException, SMTPSenderRefused\nfrom typing import Any, Dict, Union\n\nfrom django.conf import settings\nfrom django.core.mail import EmailMultiAlternatives, get_connection\nfrom django.core.mail.backends.smtp import EmailBackend\nfrom django.utils.translation import override\nfrom i18nfield.strings import LazyI18nString\nfrom inlinestyler.utils import inline_css\n\nfrom pretalx.celery_app import app\nfrom pretalx.event.models import Event\nfrom pretalx.person.models import User\n\nlogger = logging.getLogger(__name__)\n\n\nclass CustomSMTPBackend(EmailBackend):\n def test(self, from_addr):\n try:\n self.open()\n self.connection.ehlo_or_helo_if_needed()\n (code, resp) = self.connection.mail(from_addr, [])\n if code != 250:\n logger.warning(\n f'Error testing mail settings, code {code}, resp: {resp}'\n )\n raise SMTPSenderRefused(code, resp)\n (code, resp) = self.connection.rcpt('[email protected]')\n if code not in (250, 251):\n logger.warning(\n f'Error testing mail settings, code {code}, resp: {resp}'\n )\n raise SMTPSenderRefused(code, resp)\n finally:\n self.close()\n\n\nclass TolerantDict(dict):\n def __missing__(self, key):\n \"\"\"Don't fail when formatting strings with a dict with missing keys.\"\"\"\n return key\n\n\nclass SendMailException(Exception):\n pass\n\n\ndef mail(\n user: User,\n subject: str,\n template: Union[str, LazyI18nString],\n context: Dict[str, Any] = None,\n event: Event = None,\n locale: str = None,\n headers: dict = None,\n):\n from pretalx.mail.models import QueuedMail\n\n headers = headers or {}\n\n with override(locale):\n body = str(template)\n if context:\n body = body.format_map(TolerantDict(context))\n reply_to = headers.get('reply-to')\n if reply_to and isinstance(reply_to, list):\n reply_to = ','.join(reply_to)\n QueuedMail(\n event=event,\n to=user.email,\n subject=str(subject),\n text=body,\n reply_to=reply_to,\n bcc=headers.get('bcc'),\n ).send()\n\n\[email protected](bind=True)\ndef mail_send_task(\n self,\n to: str,\n subject: str,\n body: str,\n html: str,\n reply_to: list = None,\n event: int = None,\n cc: list = None,\n bcc: list = None,\n headers: dict = None,\n):\n headers = headers or dict()\n if event:\n event = Event.objects.filter(id=event).first()\n if event:\n sender = event.settings.get('mail_from')\n if sender == '[email protected]' or not sender:\n sender = settings.MAIL_FROM\n if reply_to:\n headers['reply-to'] = reply_to.split(',') if isinstance(reply_to, str) else reply_to\n backend = event.get_mail_backend()\n sender = formataddr((str(event.name), sender))\n else:\n sender = formataddr(('pretalx', settings.MAIL_FROM))\n backend = get_connection(fail_silently=False)\n\n email = EmailMultiAlternatives(\n subject, body, sender, to=to, cc=cc, bcc=bcc, headers=headers\n )\n\n if html is not None:\n email.attach_alternative(inline_css(html), 'text/html')\n\n try:\n backend.send_messages([email])\n except SMTPResponseException as exception:\n # Retry on external problems: Connection issues (101, 111), timeouts (421), filled-up mailboxes (422),\n # out of memory (431), network issues (442), another timeout (447), or too many mails sent (452)\n if exception.smtp_code in (101, 111, 421, 422, 431, 442, 447, 452):\n self.retry(max_retries=5, countdown=2 ** (self.request.retries * 2))\n logger.exception('Error sending email')\n raise SendMailException('Failed to send an email to {}.'.format(to))\n except Exception:\n logger.exception('Error sending email')\n raise SendMailException('Failed to send an email to {}.'.format(to))\n", "path": "src/pretalx/common/mail.py"}], "after_files": [{"content": "import logging\nfrom email.utils import formataddr\nfrom smtplib import SMTPResponseException, SMTPSenderRefused\nfrom typing import Any, Dict, Union\n\nfrom django.conf import settings\nfrom django.core.mail import EmailMultiAlternatives, get_connection\nfrom django.core.mail.backends.smtp import EmailBackend\nfrom django.utils.translation import override\nfrom i18nfield.strings import LazyI18nString\nfrom inlinestyler.utils import inline_css\n\nfrom pretalx.celery_app import app\nfrom pretalx.event.models import Event\nfrom pretalx.person.models import User\n\nlogger = logging.getLogger(__name__)\n\n\nclass CustomSMTPBackend(EmailBackend):\n def test(self, from_addr):\n try:\n self.open()\n self.connection.ehlo_or_helo_if_needed()\n (code, resp) = self.connection.mail(from_addr, [])\n if code != 250:\n logger.warning(\n f'Error testing mail settings, code {code}, resp: {resp}'\n )\n raise SMTPSenderRefused(code, resp)\n (code, resp) = self.connection.rcpt('[email protected]')\n if code not in (250, 251):\n logger.warning(\n f'Error testing mail settings, code {code}, resp: {resp}'\n )\n raise SMTPSenderRefused(code, resp)\n finally:\n self.close()\n\n\nclass TolerantDict(dict):\n def __missing__(self, key):\n \"\"\"Don't fail when formatting strings with a dict with missing keys.\"\"\"\n return key\n\n\nclass SendMailException(Exception):\n pass\n\n\ndef mail(\n user: User,\n subject: str,\n template: Union[str, LazyI18nString],\n context: Dict[str, Any] = None,\n event: Event = None,\n locale: str = None,\n headers: dict = None,\n):\n from pretalx.mail.models import QueuedMail\n\n headers = headers or {}\n\n with override(locale):\n body = str(template)\n if context:\n body = body.format_map(TolerantDict(context))\n reply_to = headers.get('reply-to')\n if reply_to and isinstance(reply_to, list):\n reply_to = ','.join(reply_to)\n QueuedMail(\n event=event,\n to=user.email,\n subject=str(subject),\n text=body,\n reply_to=reply_to,\n bcc=headers.get('bcc'),\n ).send()\n\n\[email protected](bind=True)\ndef mail_send_task(\n self,\n to: str,\n subject: str,\n body: str,\n html: str,\n reply_to: list = None,\n event: int = None,\n cc: list = None,\n bcc: list = None,\n headers: dict = None,\n):\n headers = headers or dict()\n if reply_to and isinstance(reply_to, str):\n reply_to = reply_to.split(',')\n if event:\n event = Event.objects.filter(id=event).first()\n if event:\n sender = event.settings.get('mail_from')\n if sender == '[email protected]' or not sender:\n sender = event.email\n backend = event.get_mail_backend()\n sender = formataddr((str(event.name), sender))\n else:\n sender = formataddr(('pretalx', settings.MAIL_FROM))\n backend = get_connection(fail_silently=False)\n\n email = EmailMultiAlternatives(\n subject, body, sender, to=to, cc=cc, bcc=bcc, headers=headers, reply_to=reply_to\n )\n\n if html is not None:\n email.attach_alternative(inline_css(html), 'text/html')\n\n try:\n backend.send_messages([email])\n except SMTPResponseException as exception:\n # Retry on external problems: Connection issues (101, 111), timeouts (421), filled-up mailboxes (422),\n # out of memory (431), network issues (442), another timeout (447), or too many mails sent (452)\n if exception.smtp_code in (101, 111, 421, 422, 431, 442, 447, 452):\n self.retry(max_retries=5, countdown=2 ** (self.request.retries * 2))\n logger.exception('Error sending email')\n raise SendMailException('Failed to send an email to {}.'.format(to))\n except Exception:\n logger.exception('Error sending email')\n raise SendMailException('Failed to send an email to {}.'.format(to))\n", "path": "src/pretalx/common/mail.py"}]}
| 1,883 | 304 |
gh_patches_debug_25799
|
rasdani/github-patches
|
git_diff
|
mlflow__mlflow-5121
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[BUG] Service metrics endpoint excludes many important routes
### Willingness to contribute
The MLflow Community encourages bug fix contributions. Would you or another member of your organization be willing to contribute a fix for this bug to the MLflow code base?
- [x] Yes. I can contribute a fix for this bug independently.
- [ ] Yes. I would be willing to contribute a fix for this bug with guidance from the MLflow community.
- [ ] No. I cannot contribute a bug fix at this time.
### System information
- **Have I written custom code (as opposed to using a stock example script provided in MLflow)**: no
- **OS Platform and Distribution (e.g., Linux Ubuntu 16.04)**: Debian GNU/Linux 11
- **MLflow installed from (source or binary)**: binary
- **MLflow version (run ``mlflow --version``)**: 1.21.0
- **Python version**: 3.8
- **npm version, if running the dev UI**:
- **Exact command to reproduce**: see section below
### Describe the problem
The mlflow server option to expose a Prometheus metrics endpoint is a great observability feature for MLflow. Unfortunately, the current implementation leaves an incomplete view of the server health/performance. Currently, mlflow only logs metrics to a [subset of endpoints](https://github.com/mlflow/mlflow/blob/master/mlflow/server/prometheus_exporter.py#L18).
As of MLflow version 1.21, the following routes are not being included in the service metrics:
```
['static', '_get_experiment_by_name', '_create_experiment', '_list_experiments', '_get_experiment',
'_delete_experiment', '_restore_experiment', '_update_experiment', '_update_run', '_delete_run',
'_restore_run', '_set_experiment_tag', '_delete_tag', '_get_run', '_list_artifacts', '_get_metric_history',
'_log_batch', '_log_model', '_create_registered_model', '_rename_registered_model',
'_update_registered_model', '_delete_registered_model', '_get_registered_model', '_search_registered_models',
'_list_registered_models', '_get_latest_versions', '_create_model_version', '_update_model_version',
'_transition_stage', '_delete_model_version', '_get_model_version', '_search_model_versions',
'_get_model_version_download_uri', '_set_registered_model_tag', '_set_model_version_tag',
'_delete_registered_model_tag', '_delete_model_version_tag', 'health', 'serve_artifacts',
'serve_model_version_artifact', 'serve_static_file', 'serve']
```
(see full list of endpoints)
```
from mlflow.server import app
app.view_functions.keys()
```
Filtering the set of routes to be included in the metrics endpoint seems like a potentially fragile approach as new routes are added in later versions of mlflow. It's especially problematic that the list of filtered routes cannot be configured. We currently have no way to monitor the health of the overall service given that many key routes (e.g. `log_batch`) are not included in the service metrics.
### Code to reproduce issue
Dockerfile for mlflow server
```
FROM python:3.8
RUN pip install mlflow==1.21.0
ENTRYPOINT mlflow server \
--backend-store-uri sqlite:///mlflow.sqlite \
--default-artifact-root file:///artifacts \
--host 0.0.0.0 \
--port 5000 \
--expose-prometheus /prometheus
```
Build and run the Docker container
```
docker build -t mlflow_example -f Dockerfile .
docker run -p 5000:5000 mlflow_example
```
Script with incomplete representation in metrics endpoint
```
import mlflow
import random
mlflow.set_tracking_uri("http://127.0.0.1:5000")
mlflow.set_experiment("service_metrics")
with mlflow.start_run(run_name="test"):
for _ in range(100):
mlflow.log_metrics({
'loss_a': random.random(),
'loss_b': random.random(),
'loss_c': random.random(),
})
mlflow.log_params({'a': 1, 'b': 2, 'c': 3})
```
See how metrics for these endpoints **_do not_** appear at http://127.0.0.1:5000/metrics
---
Script with expected representation in metrics endpoint
```
import mlflow
import random
mlflow.set_tracking_uri("http://127.0.0.1:5000")
mlflow.set_experiment("service_metrics")
with mlflow.start_run(run_name="test"):
for _ in range(100):
mlflow.log_metric('loss', random.random())
mlflow.log_param('param', 'test')
```
See how metrics for these endpoints appear at http://127.0.0.1:5000/metrics
### Other info / logs
Include any logs or source code that would be helpful to diagnose the problem. If including tracebacks, please include the full traceback. Large logs and files should be attached.
### What component(s), interfaces, languages, and integrations does this bug affect?
Components
- [ ] `area/artifacts`: Artifact stores and artifact logging
- [ ] `area/build`: Build and test infrastructure for MLflow
- [ ] `area/docs`: MLflow documentation pages
- [ ] `area/examples`: Example code
- [ ] `area/model-registry`: Model Registry service, APIs, and the fluent client calls for Model Registry
- [ ] `area/models`: MLmodel format, model serialization/deserialization, flavors
- [ ] `area/projects`: MLproject format, project running backends
- [ ] `area/scoring`: MLflow Model server, model deployment tools, Spark UDFs
- [x] `area/server-infra`: MLflow Tracking server backend
- [ ] `area/tracking`: Tracking Service, tracking client APIs, autologging
Interface
- [ ] `area/uiux`: Front-end, user experience, plotting, JavaScript, JavaScript dev server
- [ ] `area/docker`: Docker use across MLflow's components, such as MLflow Projects and MLflow Models
- [ ] `area/sqlalchemy`: Use of SQLAlchemy in the Tracking Service or Model Registry
- [ ] `area/windows`: Windows support
Language
- [ ] `language/r`: R APIs and clients
- [ ] `language/java`: Java APIs and clients
- [ ] `language/new`: Proposals for new client languages
Integrations
- [ ] `integrations/azure`: Azure and Azure ML integrations
- [ ] `integrations/sagemaker`: SageMaker integrations
- [ ] `integrations/databricks`: Databricks integrations
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mlflow/server/prometheus_exporter.py`
Content:
```
1 from prometheus_flask_exporter.multiprocess import GunicornInternalPrometheusMetrics
2 from flask import request
3
4
5 def activate_prometheus_exporter(app):
6 metrics = GunicornInternalPrometheusMetrics(app, export_defaults=False)
7
8 endpoint = app.view_functions
9 histogram = metrics.histogram(
10 "mlflow_requests_by_status_and_path",
11 "Request latencies and count by status and path",
12 labels={
13 "status": lambda r: r.status_code,
14 "path": lambda: change_path_for_metric(request.path),
15 },
16 )
17 for func_name, func in endpoint.items():
18 if func_name in ["_search_runs", "_log_metric", "_log_param", "_set_tag", "_create_run"]:
19 app.view_functions[func_name] = histogram(func)
20
21 return app
22
23
24 def change_path_for_metric(path):
25 """
26 Replace the '/' in the metric path by '_' so grafana can correctly use it.
27 :param path: path of the metric (example: runs/search)
28 :return: path with '_' instead of '/'
29 """
30 if "mlflow/" in path:
31 path = path.split("mlflow/")[-1]
32 return path.replace("/", "_")
33
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mlflow/server/prometheus_exporter.py b/mlflow/server/prometheus_exporter.py
--- a/mlflow/server/prometheus_exporter.py
+++ b/mlflow/server/prometheus_exporter.py
@@ -1,32 +1,19 @@
from prometheus_flask_exporter.multiprocess import GunicornInternalPrometheusMetrics
from flask import request
+from mlflow.version import VERSION
+
def activate_prometheus_exporter(app):
- metrics = GunicornInternalPrometheusMetrics(app, export_defaults=False)
+ def mlflow_version(_: request):
+ return VERSION
- endpoint = app.view_functions
- histogram = metrics.histogram(
- "mlflow_requests_by_status_and_path",
- "Request latencies and count by status and path",
- labels={
- "status": lambda r: r.status_code,
- "path": lambda: change_path_for_metric(request.path),
- },
+ metrics = GunicornInternalPrometheusMetrics(
+ app,
+ export_defaults=True,
+ defaults_prefix="mlflow",
+ excluded_paths=["/health"],
+ group_by=mlflow_version,
)
- for func_name, func in endpoint.items():
- if func_name in ["_search_runs", "_log_metric", "_log_param", "_set_tag", "_create_run"]:
- app.view_functions[func_name] = histogram(func)
-
- return app
-
-def change_path_for_metric(path):
- """
- Replace the '/' in the metric path by '_' so grafana can correctly use it.
- :param path: path of the metric (example: runs/search)
- :return: path with '_' instead of '/'
- """
- if "mlflow/" in path:
- path = path.split("mlflow/")[-1]
- return path.replace("/", "_")
+ return metrics
|
{"golden_diff": "diff --git a/mlflow/server/prometheus_exporter.py b/mlflow/server/prometheus_exporter.py\n--- a/mlflow/server/prometheus_exporter.py\n+++ b/mlflow/server/prometheus_exporter.py\n@@ -1,32 +1,19 @@\n from prometheus_flask_exporter.multiprocess import GunicornInternalPrometheusMetrics\r\n from flask import request\r\n \r\n+from mlflow.version import VERSION\r\n+\r\n \r\n def activate_prometheus_exporter(app):\r\n- metrics = GunicornInternalPrometheusMetrics(app, export_defaults=False)\r\n+ def mlflow_version(_: request):\r\n+ return VERSION\r\n \r\n- endpoint = app.view_functions\r\n- histogram = metrics.histogram(\r\n- \"mlflow_requests_by_status_and_path\",\r\n- \"Request latencies and count by status and path\",\r\n- labels={\r\n- \"status\": lambda r: r.status_code,\r\n- \"path\": lambda: change_path_for_metric(request.path),\r\n- },\r\n+ metrics = GunicornInternalPrometheusMetrics(\r\n+ app,\r\n+ export_defaults=True,\r\n+ defaults_prefix=\"mlflow\",\r\n+ excluded_paths=[\"/health\"],\r\n+ group_by=mlflow_version,\r\n )\r\n- for func_name, func in endpoint.items():\r\n- if func_name in [\"_search_runs\", \"_log_metric\", \"_log_param\", \"_set_tag\", \"_create_run\"]:\r\n- app.view_functions[func_name] = histogram(func)\r\n-\r\n- return app\r\n-\r\n \r\n-def change_path_for_metric(path):\r\n- \"\"\"\r\n- Replace the '/' in the metric path by '_' so grafana can correctly use it.\r\n- :param path: path of the metric (example: runs/search)\r\n- :return: path with '_' instead of '/'\r\n- \"\"\"\r\n- if \"mlflow/\" in path:\r\n- path = path.split(\"mlflow/\")[-1]\r\n- return path.replace(\"/\", \"_\")\r\n+ return metrics\n", "issue": "[BUG] Service metrics endpoint excludes many important routes\n### Willingness to contribute\r\nThe MLflow Community encourages bug fix contributions. Would you or another member of your organization be willing to contribute a fix for this bug to the MLflow code base?\r\n\r\n- [x] Yes. I can contribute a fix for this bug independently.\r\n- [ ] Yes. I would be willing to contribute a fix for this bug with guidance from the MLflow community.\r\n- [ ] No. I cannot contribute a bug fix at this time.\r\n\r\n### System information\r\n- **Have I written custom code (as opposed to using a stock example script provided in MLflow)**: no\r\n- **OS Platform and Distribution (e.g., Linux Ubuntu 16.04)**: Debian GNU/Linux 11\r\n- **MLflow installed from (source or binary)**: binary\r\n- **MLflow version (run ``mlflow --version``)**: 1.21.0\r\n- **Python version**: 3.8\r\n- **npm version, if running the dev UI**:\r\n- **Exact command to reproduce**: see section below\r\n\r\n### Describe the problem\r\n\r\nThe mlflow server option to expose a Prometheus metrics endpoint is a great observability feature for MLflow. Unfortunately, the current implementation leaves an incomplete view of the server health/performance. Currently, mlflow only logs metrics to a [subset of endpoints](https://github.com/mlflow/mlflow/blob/master/mlflow/server/prometheus_exporter.py#L18).\r\n\r\nAs of MLflow version 1.21, the following routes are not being included in the service metrics:\r\n\r\n```\r\n['static', '_get_experiment_by_name', '_create_experiment', '_list_experiments', '_get_experiment',\r\n'_delete_experiment', '_restore_experiment', '_update_experiment', '_update_run', '_delete_run', \r\n'_restore_run', '_set_experiment_tag', '_delete_tag', '_get_run', '_list_artifacts', '_get_metric_history',\r\n'_log_batch', '_log_model', '_create_registered_model', '_rename_registered_model', \r\n'_update_registered_model', '_delete_registered_model', '_get_registered_model', '_search_registered_models', \r\n'_list_registered_models', '_get_latest_versions', '_create_model_version', '_update_model_version', \r\n'_transition_stage', '_delete_model_version', '_get_model_version', '_search_model_versions', \r\n'_get_model_version_download_uri', '_set_registered_model_tag', '_set_model_version_tag', \r\n'_delete_registered_model_tag', '_delete_model_version_tag', 'health', 'serve_artifacts', \r\n'serve_model_version_artifact', 'serve_static_file', 'serve']\r\n```\r\n\r\n(see full list of endpoints)\r\n```\r\nfrom mlflow.server import app\r\n\r\napp.view_functions.keys()\r\n```\r\n\r\nFiltering the set of routes to be included in the metrics endpoint seems like a potentially fragile approach as new routes are added in later versions of mlflow. It's especially problematic that the list of filtered routes cannot be configured. We currently have no way to monitor the health of the overall service given that many key routes (e.g. `log_batch`) are not included in the service metrics.\r\n\r\n### Code to reproduce issue\r\n\r\nDockerfile for mlflow server\r\n```\r\nFROM python:3.8\r\nRUN pip install mlflow==1.21.0\r\n\r\nENTRYPOINT mlflow server \\\r\n --backend-store-uri sqlite:///mlflow.sqlite \\\r\n --default-artifact-root file:///artifacts \\\r\n --host 0.0.0.0 \\\r\n --port 5000 \\\r\n --expose-prometheus /prometheus\r\n```\r\n\r\nBuild and run the Docker container\r\n```\r\ndocker build -t mlflow_example -f Dockerfile .\r\ndocker run -p 5000:5000 mlflow_example\r\n```\r\n\r\n\r\nScript with incomplete representation in metrics endpoint\r\n```\r\nimport mlflow\r\nimport random\r\n\r\nmlflow.set_tracking_uri(\"http://127.0.0.1:5000\")\r\nmlflow.set_experiment(\"service_metrics\")\r\n\r\nwith mlflow.start_run(run_name=\"test\"):\r\n\r\n for _ in range(100):\r\n mlflow.log_metrics({\r\n 'loss_a': random.random(),\r\n 'loss_b': random.random(),\r\n 'loss_c': random.random(),\r\n })\r\n\r\n mlflow.log_params({'a': 1, 'b': 2, 'c': 3})\r\n```\r\nSee how metrics for these endpoints **_do not_** appear at http://127.0.0.1:5000/metrics\r\n\r\n---\r\n\r\nScript with expected representation in metrics endpoint\r\n```\r\nimport mlflow\r\nimport random\r\n\r\nmlflow.set_tracking_uri(\"http://127.0.0.1:5000\")\r\nmlflow.set_experiment(\"service_metrics\")\r\n\r\nwith mlflow.start_run(run_name=\"test\"):\r\n for _ in range(100):\r\n mlflow.log_metric('loss', random.random())\r\n\r\n mlflow.log_param('param', 'test')\r\n```\r\nSee how metrics for these endpoints appear at http://127.0.0.1:5000/metrics\r\n\r\n### Other info / logs\r\nInclude any logs or source code that would be helpful to diagnose the problem. If including tracebacks, please include the full traceback. Large logs and files should be attached.\r\n\r\n\r\n### What component(s), interfaces, languages, and integrations does this bug affect?\r\nComponents \r\n- [ ] `area/artifacts`: Artifact stores and artifact logging\r\n- [ ] `area/build`: Build and test infrastructure for MLflow\r\n- [ ] `area/docs`: MLflow documentation pages\r\n- [ ] `area/examples`: Example code\r\n- [ ] `area/model-registry`: Model Registry service, APIs, and the fluent client calls for Model Registry\r\n- [ ] `area/models`: MLmodel format, model serialization/deserialization, flavors\r\n- [ ] `area/projects`: MLproject format, project running backends\r\n- [ ] `area/scoring`: MLflow Model server, model deployment tools, Spark UDFs\r\n- [x] `area/server-infra`: MLflow Tracking server backend\r\n- [ ] `area/tracking`: Tracking Service, tracking client APIs, autologging\r\n\r\nInterface \r\n- [ ] `area/uiux`: Front-end, user experience, plotting, JavaScript, JavaScript dev server\r\n- [ ] `area/docker`: Docker use across MLflow's components, such as MLflow Projects and MLflow Models\r\n- [ ] `area/sqlalchemy`: Use of SQLAlchemy in the Tracking Service or Model Registry\r\n- [ ] `area/windows`: Windows support\r\n\r\nLanguage \r\n- [ ] `language/r`: R APIs and clients\r\n- [ ] `language/java`: Java APIs and clients\r\n- [ ] `language/new`: Proposals for new client languages\r\n\r\nIntegrations\r\n- [ ] `integrations/azure`: Azure and Azure ML integrations\r\n- [ ] `integrations/sagemaker`: SageMaker integrations\r\n- [ ] `integrations/databricks`: Databricks integrations\r\n\n", "before_files": [{"content": "from prometheus_flask_exporter.multiprocess import GunicornInternalPrometheusMetrics\r\nfrom flask import request\r\n\r\n\r\ndef activate_prometheus_exporter(app):\r\n metrics = GunicornInternalPrometheusMetrics(app, export_defaults=False)\r\n\r\n endpoint = app.view_functions\r\n histogram = metrics.histogram(\r\n \"mlflow_requests_by_status_and_path\",\r\n \"Request latencies and count by status and path\",\r\n labels={\r\n \"status\": lambda r: r.status_code,\r\n \"path\": lambda: change_path_for_metric(request.path),\r\n },\r\n )\r\n for func_name, func in endpoint.items():\r\n if func_name in [\"_search_runs\", \"_log_metric\", \"_log_param\", \"_set_tag\", \"_create_run\"]:\r\n app.view_functions[func_name] = histogram(func)\r\n\r\n return app\r\n\r\n\r\ndef change_path_for_metric(path):\r\n \"\"\"\r\n Replace the '/' in the metric path by '_' so grafana can correctly use it.\r\n :param path: path of the metric (example: runs/search)\r\n :return: path with '_' instead of '/'\r\n \"\"\"\r\n if \"mlflow/\" in path:\r\n path = path.split(\"mlflow/\")[-1]\r\n return path.replace(\"/\", \"_\")\r\n", "path": "mlflow/server/prometheus_exporter.py"}], "after_files": [{"content": "from prometheus_flask_exporter.multiprocess import GunicornInternalPrometheusMetrics\r\nfrom flask import request\r\n\r\nfrom mlflow.version import VERSION\r\n\r\n\r\ndef activate_prometheus_exporter(app):\r\n def mlflow_version(_: request):\r\n return VERSION\r\n\r\n metrics = GunicornInternalPrometheusMetrics(\r\n app,\r\n export_defaults=True,\r\n defaults_prefix=\"mlflow\",\r\n excluded_paths=[\"/health\"],\r\n group_by=mlflow_version,\r\n )\r\n\r\n return metrics\r\n", "path": "mlflow/server/prometheus_exporter.py"}]}
| 2,043 | 407 |
gh_patches_debug_13249
|
rasdani/github-patches
|
git_diff
|
streamlit__streamlit-7256
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
pydeck_chart: Error (not a valid JSON) when data contains NaN
### Checklist
- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [X] I added a very descriptive title to this issue.
- [X] I have provided sufficient information below to help reproduce this issue.
### Summary
If the data used in pydeck contains NaN (even if it is not used), the application fails with

### Reproducible Code Example
```Python
import math, pandas, pydeck, streamlit
streamlit.set_page_config(layout="wide")
data = pandas.DataFrame({"lng": [-109.037673], "lat": [36.994672], "weight": [math.nan]})
layer = pydeck.Layer("ScatterplotLayer", data=data, get_position=["lng", "lat"], radius_min_pixels=4)
deck = pydeck.Deck(layers=[layer], map_style=pydeck.map_styles.CARTO_LIGHT, tooltip={"text": "weight: {weight}"})
deck.to_html("test.html")
streamlit.pydeck_chart(deck, use_container_width=True)
```
### Steps To Reproduce
Run the code as usual.
### Expected Behavior
No error, as in the file ```test.html``` generated
### Current Behavior
SyntaxError:
Unexpected token 'N', ...""weight": NaN "... is not valid JSON
### Is this a regression?
- [ ] Yes, this used to work in a previous version.
### Debug info
- Streamlit version: Streamlit v1.15.1
- Python version: 3.10.4 (tags/v3.10.4:9d38120, Mar 23 2022, 23:13:41) [MSC v.1929 64 bit (AMD64)]
- Operating System: Windows 10.0.19045.2251
- Browser: Chome, Opera, Edge, Firefox
- Virtual environment: poetry
### Additional Information
_No response_
### Are you willing to submit a PR?
- [ ] Yes, I am willing to submit a PR!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `e2e/scripts/st_pydeck_chart.py`
Content:
```
1 # Copyright (c) Streamlit Inc. (2018-2022) Snowflake Inc. (2022)
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from typing import Any, cast
16
17 import numpy as np
18 import pandas as pd
19 import pydeck as pdk
20
21 import streamlit as st
22
23 # Empty chart.
24
25 st.pydeck_chart()
26
27 # Basic chart.
28
29 np.random.seed(12345)
30
31 df = pd.DataFrame(
32 cast(Any, np.random.randn(1000, 2) / [50, 50]) + [37.76, -122.4],
33 columns=["lat", "lon"],
34 )
35
36 st.pydeck_chart(
37 pdk.Deck(
38 map_style="mapbox://styles/mapbox/light-v9",
39 initial_view_state=pdk.ViewState(
40 latitude=37.76,
41 longitude=-122.4,
42 zoom=11,
43 pitch=50,
44 ),
45 layers=[
46 pdk.Layer(
47 "HexagonLayer",
48 data=df,
49 get_position="[lon, lat]",
50 radius=200,
51 elevation_scale=4,
52 elevation_range=[0, 1000],
53 pickable=True,
54 extruded=True,
55 ),
56 pdk.Layer(
57 "ScatterplotLayer",
58 data=df,
59 get_position="[lon, lat]",
60 get_color="[200, 30, 0, 160]",
61 get_radius=200,
62 ),
63 ],
64 )
65 )
66
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/e2e/scripts/st_pydeck_chart.py b/e2e/scripts/st_pydeck_chart.py
--- a/e2e/scripts/st_pydeck_chart.py
+++ b/e2e/scripts/st_pydeck_chart.py
@@ -12,6 +12,7 @@
# See the License for the specific language governing permissions and
# limitations under the License.
+import math
from typing import Any, cast
import numpy as np
@@ -63,3 +64,15 @@
],
)
)
+
+# Chart w/ invalid JSON - issue #5799.
+data = pd.DataFrame({"lng": [-109.037673], "lat": [36.994672], "weight": [math.nan]})
+layer = pdk.Layer(
+ "ScatterplotLayer", data=data, get_position=["lng", "lat"], radius_min_pixels=4
+)
+deck = pdk.Deck(
+ layers=[layer],
+ map_style=pdk.map_styles.CARTO_LIGHT,
+ tooltip={"text": "weight: {weight}"},
+)
+st.pydeck_chart(deck, use_container_width=True)
|
{"golden_diff": "diff --git a/e2e/scripts/st_pydeck_chart.py b/e2e/scripts/st_pydeck_chart.py\n--- a/e2e/scripts/st_pydeck_chart.py\n+++ b/e2e/scripts/st_pydeck_chart.py\n@@ -12,6 +12,7 @@\n # See the License for the specific language governing permissions and\n # limitations under the License.\n \n+import math\n from typing import Any, cast\n \n import numpy as np\n@@ -63,3 +64,15 @@\n ],\n )\n )\n+\n+# Chart w/ invalid JSON - issue #5799.\n+data = pd.DataFrame({\"lng\": [-109.037673], \"lat\": [36.994672], \"weight\": [math.nan]})\n+layer = pdk.Layer(\n+ \"ScatterplotLayer\", data=data, get_position=[\"lng\", \"lat\"], radius_min_pixels=4\n+)\n+deck = pdk.Deck(\n+ layers=[layer],\n+ map_style=pdk.map_styles.CARTO_LIGHT,\n+ tooltip={\"text\": \"weight: {weight}\"},\n+)\n+st.pydeck_chart(deck, use_container_width=True)\n", "issue": "pydeck_chart: Error (not a valid JSON) when data contains NaN\n### Checklist\r\n\r\n- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.\r\n- [X] I added a very descriptive title to this issue.\r\n- [X] I have provided sufficient information below to help reproduce this issue.\r\n\r\n### Summary\r\n\r\nIf the data used in pydeck contains NaN (even if it is not used), the application fails with \r\n\r\n\r\n\r\n### Reproducible Code Example\r\n\r\n```Python\r\nimport math, pandas, pydeck, streamlit\r\n\r\nstreamlit.set_page_config(layout=\"wide\")\r\ndata = pandas.DataFrame({\"lng\": [-109.037673], \"lat\": [36.994672], \"weight\": [math.nan]})\r\nlayer = pydeck.Layer(\"ScatterplotLayer\", data=data, get_position=[\"lng\", \"lat\"], radius_min_pixels=4)\r\ndeck = pydeck.Deck(layers=[layer], map_style=pydeck.map_styles.CARTO_LIGHT, tooltip={\"text\": \"weight: {weight}\"})\r\ndeck.to_html(\"test.html\")\r\nstreamlit.pydeck_chart(deck, use_container_width=True)\r\n```\r\n\r\n\r\n### Steps To Reproduce\r\n\r\nRun the code as usual.\r\n\r\n### Expected Behavior\r\n\r\nNo error, as in the file ```test.html``` generated\r\n\r\n### Current Behavior\r\n\r\nSyntaxError:\r\nUnexpected token 'N', ...\"\"weight\": NaN \"... is not valid JSON\r\n\r\n\r\n### Is this a regression?\r\n\r\n- [ ] Yes, this used to work in a previous version.\r\n\r\n### Debug info\r\n\r\n- Streamlit version: Streamlit v1.15.1\r\n- Python version: 3.10.4 (tags/v3.10.4:9d38120, Mar 23 2022, 23:13:41) [MSC v.1929 64 bit (AMD64)]\r\n- Operating System: Windows 10.0.19045.2251\r\n- Browser: Chome, Opera, Edge, Firefox\r\n- Virtual environment: poetry\r\n\r\n\r\n### Additional Information\r\n\r\n_No response_\r\n\r\n### Are you willing to submit a PR?\r\n\r\n- [ ] Yes, I am willing to submit a PR!\n", "before_files": [{"content": "# Copyright (c) Streamlit Inc. (2018-2022) Snowflake Inc. (2022)\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom typing import Any, cast\n\nimport numpy as np\nimport pandas as pd\nimport pydeck as pdk\n\nimport streamlit as st\n\n# Empty chart.\n\nst.pydeck_chart()\n\n# Basic chart.\n\nnp.random.seed(12345)\n\ndf = pd.DataFrame(\n cast(Any, np.random.randn(1000, 2) / [50, 50]) + [37.76, -122.4],\n columns=[\"lat\", \"lon\"],\n)\n\nst.pydeck_chart(\n pdk.Deck(\n map_style=\"mapbox://styles/mapbox/light-v9\",\n initial_view_state=pdk.ViewState(\n latitude=37.76,\n longitude=-122.4,\n zoom=11,\n pitch=50,\n ),\n layers=[\n pdk.Layer(\n \"HexagonLayer\",\n data=df,\n get_position=\"[lon, lat]\",\n radius=200,\n elevation_scale=4,\n elevation_range=[0, 1000],\n pickable=True,\n extruded=True,\n ),\n pdk.Layer(\n \"ScatterplotLayer\",\n data=df,\n get_position=\"[lon, lat]\",\n get_color=\"[200, 30, 0, 160]\",\n get_radius=200,\n ),\n ],\n )\n)\n", "path": "e2e/scripts/st_pydeck_chart.py"}], "after_files": [{"content": "# Copyright (c) Streamlit Inc. (2018-2022) Snowflake Inc. (2022)\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport math\nfrom typing import Any, cast\n\nimport numpy as np\nimport pandas as pd\nimport pydeck as pdk\n\nimport streamlit as st\n\n# Empty chart.\n\nst.pydeck_chart()\n\n# Basic chart.\n\nnp.random.seed(12345)\n\ndf = pd.DataFrame(\n cast(Any, np.random.randn(1000, 2) / [50, 50]) + [37.76, -122.4],\n columns=[\"lat\", \"lon\"],\n)\n\nst.pydeck_chart(\n pdk.Deck(\n map_style=\"mapbox://styles/mapbox/light-v9\",\n initial_view_state=pdk.ViewState(\n latitude=37.76,\n longitude=-122.4,\n zoom=11,\n pitch=50,\n ),\n layers=[\n pdk.Layer(\n \"HexagonLayer\",\n data=df,\n get_position=\"[lon, lat]\",\n radius=200,\n elevation_scale=4,\n elevation_range=[0, 1000],\n pickable=True,\n extruded=True,\n ),\n pdk.Layer(\n \"ScatterplotLayer\",\n data=df,\n get_position=\"[lon, lat]\",\n get_color=\"[200, 30, 0, 160]\",\n get_radius=200,\n ),\n ],\n )\n)\n\n# Chart w/ invalid JSON - issue #5799.\ndata = pd.DataFrame({\"lng\": [-109.037673], \"lat\": [36.994672], \"weight\": [math.nan]})\nlayer = pdk.Layer(\n \"ScatterplotLayer\", data=data, get_position=[\"lng\", \"lat\"], radius_min_pixels=4\n)\ndeck = pdk.Deck(\n layers=[layer],\n map_style=pdk.map_styles.CARTO_LIGHT,\n tooltip={\"text\": \"weight: {weight}\"},\n)\nst.pydeck_chart(deck, use_container_width=True)\n", "path": "e2e/scripts/st_pydeck_chart.py"}]}
| 1,386 | 257 |
gh_patches_debug_50331
|
rasdani/github-patches
|
git_diff
|
pypi__warehouse-13706
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Wrong key name used for PEP 658 metadata files in the JSON index
**Describe the bug**
[PEP 691](https://peps.python.org/pep-0691/#project-detail) states that the key name for metadata files in the JSON index should be `dist-info-metadata`:
> `dist-info-metadata`: An optional key that indicates that metadata for this file is available, via the same location as specified in [PEP 658](https://peps.python.org/pep-0658) (`{file_url}.metadata`).
However, warehouse is providing it under the `data-dist-info-metadata` key instead:
```
$ curl -H 'Accept: application/vnd.pypi.simple.v1+json' https://pypi.org/simple/fluffy-server/ | jq .files
[...]
{
"data-dist-info-metadata": {
"sha256": "4db99543165cbdeef42ccb6257545911ccd7865d65e304e3e056f383a25f309c"
},
"filename": "fluffy_server-1.39.2-py3-none-any.whl",
[...]
```
This is causing pip to not use the metadata files as it is looking for the `dist-info-metadata` key only:
https://github.com/pypa/pip/blob/f25f8fffbbd16fdb13a4f8977946afe9a3248453/src/pip/_internal/models/link.py#L265
**Additional context**
There are two bugs discovered recently in pip which may make this tricky to fix:
* https://github.com/pypa/pip/issues/12042
* https://github.com/pypa/pip/issues/12038
I believe if we simply fix the key name in pypi.org, it will break existing pip versions as it will cause users to encounter these bugs. It may be necessary to coordinate this fix with fixes to the above bugs in pip to avoid disruption?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `warehouse/packaging/utils.py`
Content:
```
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13 import hashlib
14 import os.path
15 import tempfile
16
17 import packaging_legacy.version
18
19 from pyramid_jinja2 import IJinja2Environment
20 from sqlalchemy.orm import joinedload
21
22 from warehouse.packaging.interfaces import ISimpleStorage
23 from warehouse.packaging.models import File, Project, Release
24
25 API_VERSION = "1.1"
26
27
28 def _simple_index(request, serial):
29 # Fetch the name and normalized name for all of our projects
30 projects = (
31 request.db.query(Project.name, Project.normalized_name, Project.last_serial)
32 .order_by(Project.normalized_name)
33 .all()
34 )
35
36 return {
37 "meta": {"api-version": API_VERSION, "_last-serial": serial},
38 "projects": [{"name": p.name, "_last-serial": p.last_serial} for p in projects],
39 }
40
41
42 def _simple_detail(project, request):
43 # Get all of the files for this project.
44 files = sorted(
45 request.db.query(File)
46 .options(joinedload(File.release))
47 .join(Release)
48 .filter(Release.project == project)
49 .all(),
50 key=lambda f: (packaging_legacy.version.parse(f.release.version), f.filename),
51 )
52 versions = sorted(
53 {f.release.version for f in files}, key=packaging_legacy.version.parse
54 )
55
56 return {
57 "meta": {"api-version": API_VERSION, "_last-serial": project.last_serial},
58 "name": project.normalized_name,
59 "versions": versions,
60 "files": [
61 {
62 "filename": file.filename,
63 "url": request.route_url("packaging.file", path=file.path),
64 "hashes": {
65 "sha256": file.sha256_digest,
66 },
67 "requires-python": file.release.requires_python,
68 "size": file.size,
69 "upload-time": file.upload_time.isoformat() + "Z",
70 "yanked": file.release.yanked_reason
71 if file.release.yanked and file.release.yanked_reason
72 else file.release.yanked,
73 "data-dist-info-metadata": {"sha256": file.metadata_file_sha256_digest}
74 if file.metadata_file_sha256_digest
75 else False,
76 }
77 for file in files
78 ],
79 }
80
81
82 def render_simple_detail(project, request, store=False):
83 context = _simple_detail(project, request)
84
85 env = request.registry.queryUtility(IJinja2Environment, name=".jinja2")
86 template = env.get_template("templates/api/simple/detail.html")
87 content = template.render(**context, request=request)
88
89 content_hasher = hashlib.blake2b(digest_size=256 // 8)
90 content_hasher.update(content.encode("utf-8"))
91 content_hash = content_hasher.hexdigest().lower()
92
93 simple_detail_path = (
94 f"{project.normalized_name}/{content_hash}.{project.normalized_name}.html"
95 )
96
97 if store:
98 storage = request.find_service(ISimpleStorage)
99 with tempfile.NamedTemporaryFile() as f:
100 f.write(content.encode("utf-8"))
101 f.flush()
102
103 storage.store(
104 simple_detail_path,
105 f.name,
106 meta={
107 "project": project.normalized_name,
108 "pypi-last-serial": project.last_serial,
109 "hash": content_hash,
110 },
111 )
112 storage.store(
113 os.path.join(project.normalized_name, "index.html"),
114 f.name,
115 meta={
116 "project": project.normalized_name,
117 "pypi-last-serial": project.last_serial,
118 "hash": content_hash,
119 },
120 )
121
122 return (content_hash, simple_detail_path)
123
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/warehouse/packaging/utils.py b/warehouse/packaging/utils.py
--- a/warehouse/packaging/utils.py
+++ b/warehouse/packaging/utils.py
@@ -73,6 +73,9 @@
"data-dist-info-metadata": {"sha256": file.metadata_file_sha256_digest}
if file.metadata_file_sha256_digest
else False,
+ "core-metadata": {"sha256": file.metadata_file_sha256_digest}
+ if file.metadata_file_sha256_digest
+ else False,
}
for file in files
],
|
{"golden_diff": "diff --git a/warehouse/packaging/utils.py b/warehouse/packaging/utils.py\n--- a/warehouse/packaging/utils.py\n+++ b/warehouse/packaging/utils.py\n@@ -73,6 +73,9 @@\n \"data-dist-info-metadata\": {\"sha256\": file.metadata_file_sha256_digest}\n if file.metadata_file_sha256_digest\n else False,\n+ \"core-metadata\": {\"sha256\": file.metadata_file_sha256_digest}\n+ if file.metadata_file_sha256_digest\n+ else False,\n }\n for file in files\n ],\n", "issue": "Wrong key name used for PEP 658 metadata files in the JSON index\n**Describe the bug**\r\n\r\n[PEP 691](https://peps.python.org/pep-0691/#project-detail) states that the key name for metadata files in the JSON index should be `dist-info-metadata`:\r\n\r\n> `dist-info-metadata`: An optional key that indicates that metadata for this file is available, via the same location as specified in [PEP 658](https://peps.python.org/pep-0658) (`{file_url}.metadata`).\r\n\r\nHowever, warehouse is providing it under the `data-dist-info-metadata` key instead:\r\n\r\n```\r\n$ curl -H 'Accept: application/vnd.pypi.simple.v1+json' https://pypi.org/simple/fluffy-server/ | jq .files\r\n[...]\r\n {\r\n \"data-dist-info-metadata\": {\r\n \"sha256\": \"4db99543165cbdeef42ccb6257545911ccd7865d65e304e3e056f383a25f309c\"\r\n },\r\n \"filename\": \"fluffy_server-1.39.2-py3-none-any.whl\",\r\n [...]\r\n```\r\n\r\nThis is causing pip to not use the metadata files as it is looking for the `dist-info-metadata` key only:\r\nhttps://github.com/pypa/pip/blob/f25f8fffbbd16fdb13a4f8977946afe9a3248453/src/pip/_internal/models/link.py#L265\r\n\r\n\r\n**Additional context**\r\n\r\nThere are two bugs discovered recently in pip which may make this tricky to fix:\r\n\r\n* https://github.com/pypa/pip/issues/12042\r\n* https://github.com/pypa/pip/issues/12038\r\n\r\nI believe if we simply fix the key name in pypi.org, it will break existing pip versions as it will cause users to encounter these bugs. It may be necessary to coordinate this fix with fixes to the above bugs in pip to avoid disruption?\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport hashlib\nimport os.path\nimport tempfile\n\nimport packaging_legacy.version\n\nfrom pyramid_jinja2 import IJinja2Environment\nfrom sqlalchemy.orm import joinedload\n\nfrom warehouse.packaging.interfaces import ISimpleStorage\nfrom warehouse.packaging.models import File, Project, Release\n\nAPI_VERSION = \"1.1\"\n\n\ndef _simple_index(request, serial):\n # Fetch the name and normalized name for all of our projects\n projects = (\n request.db.query(Project.name, Project.normalized_name, Project.last_serial)\n .order_by(Project.normalized_name)\n .all()\n )\n\n return {\n \"meta\": {\"api-version\": API_VERSION, \"_last-serial\": serial},\n \"projects\": [{\"name\": p.name, \"_last-serial\": p.last_serial} for p in projects],\n }\n\n\ndef _simple_detail(project, request):\n # Get all of the files for this project.\n files = sorted(\n request.db.query(File)\n .options(joinedload(File.release))\n .join(Release)\n .filter(Release.project == project)\n .all(),\n key=lambda f: (packaging_legacy.version.parse(f.release.version), f.filename),\n )\n versions = sorted(\n {f.release.version for f in files}, key=packaging_legacy.version.parse\n )\n\n return {\n \"meta\": {\"api-version\": API_VERSION, \"_last-serial\": project.last_serial},\n \"name\": project.normalized_name,\n \"versions\": versions,\n \"files\": [\n {\n \"filename\": file.filename,\n \"url\": request.route_url(\"packaging.file\", path=file.path),\n \"hashes\": {\n \"sha256\": file.sha256_digest,\n },\n \"requires-python\": file.release.requires_python,\n \"size\": file.size,\n \"upload-time\": file.upload_time.isoformat() + \"Z\",\n \"yanked\": file.release.yanked_reason\n if file.release.yanked and file.release.yanked_reason\n else file.release.yanked,\n \"data-dist-info-metadata\": {\"sha256\": file.metadata_file_sha256_digest}\n if file.metadata_file_sha256_digest\n else False,\n }\n for file in files\n ],\n }\n\n\ndef render_simple_detail(project, request, store=False):\n context = _simple_detail(project, request)\n\n env = request.registry.queryUtility(IJinja2Environment, name=\".jinja2\")\n template = env.get_template(\"templates/api/simple/detail.html\")\n content = template.render(**context, request=request)\n\n content_hasher = hashlib.blake2b(digest_size=256 // 8)\n content_hasher.update(content.encode(\"utf-8\"))\n content_hash = content_hasher.hexdigest().lower()\n\n simple_detail_path = (\n f\"{project.normalized_name}/{content_hash}.{project.normalized_name}.html\"\n )\n\n if store:\n storage = request.find_service(ISimpleStorage)\n with tempfile.NamedTemporaryFile() as f:\n f.write(content.encode(\"utf-8\"))\n f.flush()\n\n storage.store(\n simple_detail_path,\n f.name,\n meta={\n \"project\": project.normalized_name,\n \"pypi-last-serial\": project.last_serial,\n \"hash\": content_hash,\n },\n )\n storage.store(\n os.path.join(project.normalized_name, \"index.html\"),\n f.name,\n meta={\n \"project\": project.normalized_name,\n \"pypi-last-serial\": project.last_serial,\n \"hash\": content_hash,\n },\n )\n\n return (content_hash, simple_detail_path)\n", "path": "warehouse/packaging/utils.py"}], "after_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport hashlib\nimport os.path\nimport tempfile\n\nimport packaging_legacy.version\n\nfrom pyramid_jinja2 import IJinja2Environment\nfrom sqlalchemy.orm import joinedload\n\nfrom warehouse.packaging.interfaces import ISimpleStorage\nfrom warehouse.packaging.models import File, Project, Release\n\nAPI_VERSION = \"1.1\"\n\n\ndef _simple_index(request, serial):\n # Fetch the name and normalized name for all of our projects\n projects = (\n request.db.query(Project.name, Project.normalized_name, Project.last_serial)\n .order_by(Project.normalized_name)\n .all()\n )\n\n return {\n \"meta\": {\"api-version\": API_VERSION, \"_last-serial\": serial},\n \"projects\": [{\"name\": p.name, \"_last-serial\": p.last_serial} for p in projects],\n }\n\n\ndef _simple_detail(project, request):\n # Get all of the files for this project.\n files = sorted(\n request.db.query(File)\n .options(joinedload(File.release))\n .join(Release)\n .filter(Release.project == project)\n .all(),\n key=lambda f: (packaging_legacy.version.parse(f.release.version), f.filename),\n )\n versions = sorted(\n {f.release.version for f in files}, key=packaging_legacy.version.parse\n )\n\n return {\n \"meta\": {\"api-version\": API_VERSION, \"_last-serial\": project.last_serial},\n \"name\": project.normalized_name,\n \"versions\": versions,\n \"files\": [\n {\n \"filename\": file.filename,\n \"url\": request.route_url(\"packaging.file\", path=file.path),\n \"hashes\": {\n \"sha256\": file.sha256_digest,\n },\n \"requires-python\": file.release.requires_python,\n \"size\": file.size,\n \"upload-time\": file.upload_time.isoformat() + \"Z\",\n \"yanked\": file.release.yanked_reason\n if file.release.yanked and file.release.yanked_reason\n else file.release.yanked,\n \"data-dist-info-metadata\": {\"sha256\": file.metadata_file_sha256_digest}\n if file.metadata_file_sha256_digest\n else False,\n \"core-metadata\": {\"sha256\": file.metadata_file_sha256_digest}\n if file.metadata_file_sha256_digest\n else False,\n }\n for file in files\n ],\n }\n\n\ndef render_simple_detail(project, request, store=False):\n context = _simple_detail(project, request)\n\n env = request.registry.queryUtility(IJinja2Environment, name=\".jinja2\")\n template = env.get_template(\"templates/api/simple/detail.html\")\n content = template.render(**context, request=request)\n\n content_hasher = hashlib.blake2b(digest_size=256 // 8)\n content_hasher.update(content.encode(\"utf-8\"))\n content_hash = content_hasher.hexdigest().lower()\n\n simple_detail_path = (\n f\"{project.normalized_name}/{content_hash}.{project.normalized_name}.html\"\n )\n\n if store:\n storage = request.find_service(ISimpleStorage)\n with tempfile.NamedTemporaryFile() as f:\n f.write(content.encode(\"utf-8\"))\n f.flush()\n\n storage.store(\n simple_detail_path,\n f.name,\n meta={\n \"project\": project.normalized_name,\n \"pypi-last-serial\": project.last_serial,\n \"hash\": content_hash,\n },\n )\n storage.store(\n os.path.join(project.normalized_name, \"index.html\"),\n f.name,\n meta={\n \"project\": project.normalized_name,\n \"pypi-last-serial\": project.last_serial,\n \"hash\": content_hash,\n },\n )\n\n return (content_hash, simple_detail_path)\n", "path": "warehouse/packaging/utils.py"}]}
| 1,884 | 137 |
gh_patches_debug_14288
|
rasdani/github-patches
|
git_diff
|
easybuilders__easybuild-easyblocks-2981
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
MATLAB changes `$LD_LIBRARY_PATH`, breaks Qt apps
I've been debugging an issue with an app that depends on the Qt5 module. The app won't start because it can't find Qt's platform plugins:
```
qt.qpa.plugin: Could not find the Qt platform plugin "xcb" in ""
```
I wrote a minimal Qt app to find the cause of this and it turns out to be MATLAB. More specifically, the fact that the MATLAB module prepends `LD_LIBRARY_PATH` with `$EBROOTMATLAB/bin/glnxa64`, a directory that contains tons of bundled MATLAB libraries, including their own versions of essential Qt5 libraries and many other unrelated libs which could potentially interfere with other modules too.
This change was introduced in #2008, presumably to make it easier for MCR compiled apps to load. For MATLAB itself this does not seem to be necessary because the `matlab` startup script sets `LD_LIBRARY_PATH` and other required environment variables on invocation.
The MATLAB [docs](https://www.mathworks.com/help/compiler/mcr-path-settings-for-run-time-deployment.html) cautions (bottom of the page) against setting LD_LIBRARY_PATH permanently on Linux due to this interference risk with other software. They suggest to "run MATLAB Compiler applications using the generated shell script" instead.
I would propose to revert #2008 but would obviously like to hear @smoors and maybe other's opinion on this first.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `easybuild/easyblocks/m/matlab.py`
Content:
```
1 ##
2 # Copyright 2009-2023 Ghent University
3 #
4 # This file is part of EasyBuild,
5 # originally created by the HPC team of Ghent University (http://ugent.be/hpc/en),
6 # with support of Ghent University (http://ugent.be/hpc),
7 # the Flemish Supercomputer Centre (VSC) (https://www.vscentrum.be),
8 # Flemish Research Foundation (FWO) (http://www.fwo.be/en)
9 # and the Department of Economy, Science and Innovation (EWI) (http://www.ewi-vlaanderen.be/en).
10 #
11 # https://github.com/easybuilders/easybuild
12 #
13 # EasyBuild is free software: you can redistribute it and/or modify
14 # it under the terms of the GNU General Public License as published by
15 # the Free Software Foundation v2.
16 #
17 # EasyBuild is distributed in the hope that it will be useful,
18 # but WITHOUT ANY WARRANTY; without even the implied warranty of
19 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
20 # GNU General Public License for more details.
21 #
22 # You should have received a copy of the GNU General Public License
23 # along with EasyBuild. If not, see <http://www.gnu.org/licenses/>.
24 ##
25 """
26 EasyBuild support for installing MATLAB, implemented as an easyblock
27
28 @author: Stijn De Weirdt (Ghent University)
29 @author: Dries Verdegem (Ghent University)
30 @author: Kenneth Hoste (Ghent University)
31 @author: Pieter De Baets (Ghent University)
32 @author: Jens Timmerman (Ghent University)
33 @author: Fotis Georgatos (Uni.Lu, NTUA)
34 """
35 import re
36 import os
37 import stat
38 import tempfile
39
40 from distutils.version import LooseVersion
41
42 from easybuild.easyblocks.generic.packedbinary import PackedBinary
43 from easybuild.framework.easyconfig import CUSTOM
44 from easybuild.tools.build_log import EasyBuildError
45 from easybuild.tools.filetools import adjust_permissions, change_dir, copy_file, read_file, write_file
46 from easybuild.tools.py2vs3 import string_type
47 from easybuild.tools.run import run_cmd
48
49
50 class EB_MATLAB(PackedBinary):
51 """Support for installing MATLAB."""
52
53 def __init__(self, *args, **kwargs):
54 """Add extra config options specific to MATLAB."""
55 super(EB_MATLAB, self).__init__(*args, **kwargs)
56 self.comp_fam = None
57 self.configfile = os.path.join(self.builddir, 'my_installer_input.txt')
58 self.outputfile = os.path.join(self.builddir, 'my_installer_output.txt')
59
60 @staticmethod
61 def extra_options():
62 extra_vars = {
63 'java_options': ['-Xmx256m', "$_JAVA_OPTIONS value set for install and in module file.", CUSTOM],
64 'key': [None, "Installation key(s), make one install for each key. Single key or a list of keys", CUSTOM],
65 }
66 return PackedBinary.extra_options(extra_vars)
67
68 def configure_step(self):
69 """Configure MATLAB installation: create license file."""
70
71 licfile = self.cfg['license_file']
72 if licfile is None:
73 licserv = self.cfg['license_server']
74 if licserv is None:
75 licserv = os.getenv('EB_MATLAB_LICENSE_SERVER', 'license.example.com')
76 licport = self.cfg['license_server_port']
77 if licport is None:
78 licport = os.getenv('EB_MATLAB_LICENSE_SERVER_PORT', '00000')
79 # create license file
80 lictxt = '\n'.join([
81 "SERVER %s 000000000000 %s" % (licserv, licport),
82 "USE_SERVER",
83 ])
84
85 licfile = os.path.join(self.builddir, 'matlab.lic')
86 write_file(licfile, lictxt)
87
88 try:
89 copy_file(os.path.join(self.cfg['start_dir'], 'installer_input.txt'), self.configfile)
90 adjust_permissions(self.configfile, stat.S_IWUSR)
91
92 # read file in binary mode to avoid UTF-8 encoding issues when using Python 3,
93 # due to non-UTF-8 characters...
94 config = read_file(self.configfile, mode='rb')
95
96 # use raw byte strings (must be 'br', not 'rb'),
97 # required when using Python 3 because file was read in binary mode
98 regdest = re.compile(br"^# destinationFolder=.*", re.M)
99 regagree = re.compile(br"^# agreeToLicense=.*", re.M)
100 regmode = re.compile(br"^# mode=.*", re.M)
101 reglicpath = re.compile(br"^# licensePath=.*", re.M)
102 regoutfile = re.compile(br"^# outputFile=.*", re.M)
103
104 # must use byte-strings here when using Python 3, see above
105 config = regdest.sub(b"destinationFolder=%s" % self.installdir.encode('utf-8'), config)
106 config = regagree.sub(b"agreeToLicense=Yes", config)
107 config = regmode.sub(b"mode=silent", config)
108 config = reglicpath.sub(b"licensePath=%s" % licfile.encode('utf-8'), config)
109 config = regoutfile.sub(b"outputFile=%s" % self.outputfile.encode('utf-8'), config)
110
111 write_file(self.configfile, config)
112
113 except IOError as err:
114 raise EasyBuildError("Failed to create installation config file %s: %s", self.configfile, err)
115
116 self.log.debug('configuration file written to %s:\n %s', self.configfile, config)
117
118 def install_step(self):
119 """MATLAB install procedure using 'install' command."""
120
121 src = os.path.join(self.cfg['start_dir'], 'install')
122
123 # make sure install script is executable
124 adjust_permissions(src, stat.S_IXUSR)
125
126 if LooseVersion(self.version) >= LooseVersion('2016b'):
127 perm_dirs = [os.path.join(self.cfg['start_dir'], 'bin', 'glnxa64')]
128 if LooseVersion(self.version) < LooseVersion('2021b'):
129 jdir = os.path.join(self.cfg['start_dir'], 'sys', 'java', 'jre', 'glnxa64', 'jre', 'bin')
130 perm_dirs.append(jdir)
131 for perm_dir in perm_dirs:
132 adjust_permissions(perm_dir, stat.S_IXUSR)
133
134 # make sure $DISPLAY is not defined, which may lead to (hard to trace) problems
135 # this is a workaround for not being able to specify --nodisplay to the install scripts
136 if 'DISPLAY' in os.environ:
137 os.environ.pop('DISPLAY')
138
139 if '_JAVA_OPTIONS' not in self.cfg['preinstallopts']:
140 java_opts = 'export _JAVA_OPTIONS="%s" && ' % self.cfg['java_options']
141 self.cfg['preinstallopts'] = java_opts + self.cfg['preinstallopts']
142 if LooseVersion(self.version) >= LooseVersion('2016b'):
143 change_dir(self.builddir)
144
145 # Build the cmd string
146 cmdlist = [
147 self.cfg['preinstallopts'],
148 src,
149 '-inputFile',
150 self.configfile,
151 ]
152 if LooseVersion(self.version) < LooseVersion('2020a'):
153 # MATLAB installers < 2020a ignore $TMPDIR (always use /tmp) and might need a large tmpdir
154 tmpdir = tempfile.mkdtemp()
155 cmdlist.extend([
156 '-v',
157 '-tmpdir',
158 tmpdir,
159 ])
160 cmdlist.append(self.cfg['installopts'])
161 cmd = ' '.join(cmdlist)
162
163 keys = self.cfg['key']
164 if keys is None:
165 try:
166 keys = os.environ['EB_MATLAB_KEY']
167 except KeyError:
168 raise EasyBuildError("The MATLAB install key is not set. This can be set either with the environment "
169 "variable EB_MATLAB_KEY or by the easyconfig variable 'key'.")
170 if isinstance(keys, string_type):
171 keys = keys.split(',')
172
173 # Compile the installation key regex outside of the loop
174 regkey = re.compile(br"^(# )?fileInstallationKey=.*", re.M)
175
176 # Run an install for each key
177 for i, key in enumerate(keys):
178
179 self.log.info('Installing MATLAB with key %s of %s', i + 1, len(keys))
180
181 try:
182 config = read_file(self.configfile, mode='rb')
183 config = regkey.sub(b"fileInstallationKey=%s" % key.encode('utf-8'), config)
184 write_file(self.configfile, config)
185
186 except IOError as err:
187 raise EasyBuildError("Failed to update config file %s: %s", self.configfile, err)
188
189 (out, _) = run_cmd(cmd, log_all=True, simple=False)
190
191 # check installer output for known signs of trouble
192 patterns = [
193 "Error: You have entered an invalid File Installation Key",
194 "Not a valid key",
195 "All selected products are already installed",
196 "The application encountered an unexpected error and needs to close",
197 "Error: Unable to write to",
198 "Exiting with status -\\d",
199 "End - Unsuccessful",
200 ]
201
202 for pattern in patterns:
203 regex = re.compile(pattern, re.I)
204 if regex.search(out):
205 raise EasyBuildError("Found error pattern '%s' in output of installation command '%s': %s",
206 regex.pattern, cmd, out)
207 with open(self.outputfile) as f:
208 if regex.search(f.read()):
209 raise EasyBuildError("Found error pattern '%s' in output file of installer",
210 regex.pattern)
211
212 def sanity_check_step(self):
213 """Custom sanity check for MATLAB."""
214 custom_paths = {
215 'files': ["bin/matlab", "bin/glnxa64/MATLAB", "toolbox/local/classpath.txt"],
216 'dirs': ["java/jar"],
217 }
218 super(EB_MATLAB, self).sanity_check_step(custom_paths=custom_paths)
219
220 def make_module_extra(self):
221 """Extend PATH and set proper _JAVA_OPTIONS (e.g., -Xmx)."""
222 txt = super(EB_MATLAB, self).make_module_extra()
223
224 # make MATLAB runtime available
225 if LooseVersion(self.version) >= LooseVersion('2017a'):
226 for ldlibdir in ['runtime', 'bin', os.path.join('sys', 'os')]:
227 libdir = os.path.join(ldlibdir, 'glnxa64')
228 txt += self.module_generator.prepend_paths('LD_LIBRARY_PATH', libdir)
229 if self.cfg['java_options']:
230 txt += self.module_generator.set_environment('_JAVA_OPTIONS', self.cfg['java_options'])
231 return txt
232
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/easybuild/easyblocks/m/matlab.py b/easybuild/easyblocks/m/matlab.py
--- a/easybuild/easyblocks/m/matlab.py
+++ b/easybuild/easyblocks/m/matlab.py
@@ -221,11 +221,6 @@
"""Extend PATH and set proper _JAVA_OPTIONS (e.g., -Xmx)."""
txt = super(EB_MATLAB, self).make_module_extra()
- # make MATLAB runtime available
- if LooseVersion(self.version) >= LooseVersion('2017a'):
- for ldlibdir in ['runtime', 'bin', os.path.join('sys', 'os')]:
- libdir = os.path.join(ldlibdir, 'glnxa64')
- txt += self.module_generator.prepend_paths('LD_LIBRARY_PATH', libdir)
if self.cfg['java_options']:
txt += self.module_generator.set_environment('_JAVA_OPTIONS', self.cfg['java_options'])
return txt
|
{"golden_diff": "diff --git a/easybuild/easyblocks/m/matlab.py b/easybuild/easyblocks/m/matlab.py\n--- a/easybuild/easyblocks/m/matlab.py\n+++ b/easybuild/easyblocks/m/matlab.py\n@@ -221,11 +221,6 @@\n \"\"\"Extend PATH and set proper _JAVA_OPTIONS (e.g., -Xmx).\"\"\"\n txt = super(EB_MATLAB, self).make_module_extra()\n \n- # make MATLAB runtime available\n- if LooseVersion(self.version) >= LooseVersion('2017a'):\n- for ldlibdir in ['runtime', 'bin', os.path.join('sys', 'os')]:\n- libdir = os.path.join(ldlibdir, 'glnxa64')\n- txt += self.module_generator.prepend_paths('LD_LIBRARY_PATH', libdir)\n if self.cfg['java_options']:\n txt += self.module_generator.set_environment('_JAVA_OPTIONS', self.cfg['java_options'])\n return txt\n", "issue": "MATLAB changes `$LD_LIBRARY_PATH`, breaks Qt apps\nI've been debugging an issue with an app that depends on the Qt5 module. The app won't start because it can't find Qt's platform plugins:\r\n\r\n```\r\nqt.qpa.plugin: Could not find the Qt platform plugin \"xcb\" in \"\"\r\n```\r\n\r\nI wrote a minimal Qt app to find the cause of this and it turns out to be MATLAB. More specifically, the fact that the MATLAB module prepends `LD_LIBRARY_PATH` with `$EBROOTMATLAB/bin/glnxa64`, a directory that contains tons of bundled MATLAB libraries, including their own versions of essential Qt5 libraries and many other unrelated libs which could potentially interfere with other modules too. \r\n\r\nThis change was introduced in #2008, presumably to make it easier for MCR compiled apps to load. For MATLAB itself this does not seem to be necessary because the `matlab` startup script sets `LD_LIBRARY_PATH` and other required environment variables on invocation. \r\n\r\nThe MATLAB [docs](https://www.mathworks.com/help/compiler/mcr-path-settings-for-run-time-deployment.html) cautions (bottom of the page) against setting LD_LIBRARY_PATH permanently on Linux due to this interference risk with other software. They suggest to \"run MATLAB Compiler applications using the generated shell script\" instead.\r\n\r\nI would propose to revert #2008 but would obviously like to hear @smoors and maybe other's opinion on this first.\r\n\r\n\r\n\n", "before_files": [{"content": "##\n# Copyright 2009-2023 Ghent University\n#\n# This file is part of EasyBuild,\n# originally created by the HPC team of Ghent University (http://ugent.be/hpc/en),\n# with support of Ghent University (http://ugent.be/hpc),\n# the Flemish Supercomputer Centre (VSC) (https://www.vscentrum.be),\n# Flemish Research Foundation (FWO) (http://www.fwo.be/en)\n# and the Department of Economy, Science and Innovation (EWI) (http://www.ewi-vlaanderen.be/en).\n#\n# https://github.com/easybuilders/easybuild\n#\n# EasyBuild is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation v2.\n#\n# EasyBuild is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with EasyBuild. If not, see <http://www.gnu.org/licenses/>.\n##\n\"\"\"\nEasyBuild support for installing MATLAB, implemented as an easyblock\n\n@author: Stijn De Weirdt (Ghent University)\n@author: Dries Verdegem (Ghent University)\n@author: Kenneth Hoste (Ghent University)\n@author: Pieter De Baets (Ghent University)\n@author: Jens Timmerman (Ghent University)\n@author: Fotis Georgatos (Uni.Lu, NTUA)\n\"\"\"\nimport re\nimport os\nimport stat\nimport tempfile\n\nfrom distutils.version import LooseVersion\n\nfrom easybuild.easyblocks.generic.packedbinary import PackedBinary\nfrom easybuild.framework.easyconfig import CUSTOM\nfrom easybuild.tools.build_log import EasyBuildError\nfrom easybuild.tools.filetools import adjust_permissions, change_dir, copy_file, read_file, write_file\nfrom easybuild.tools.py2vs3 import string_type\nfrom easybuild.tools.run import run_cmd\n\n\nclass EB_MATLAB(PackedBinary):\n \"\"\"Support for installing MATLAB.\"\"\"\n\n def __init__(self, *args, **kwargs):\n \"\"\"Add extra config options specific to MATLAB.\"\"\"\n super(EB_MATLAB, self).__init__(*args, **kwargs)\n self.comp_fam = None\n self.configfile = os.path.join(self.builddir, 'my_installer_input.txt')\n self.outputfile = os.path.join(self.builddir, 'my_installer_output.txt')\n\n @staticmethod\n def extra_options():\n extra_vars = {\n 'java_options': ['-Xmx256m', \"$_JAVA_OPTIONS value set for install and in module file.\", CUSTOM],\n 'key': [None, \"Installation key(s), make one install for each key. Single key or a list of keys\", CUSTOM],\n }\n return PackedBinary.extra_options(extra_vars)\n\n def configure_step(self):\n \"\"\"Configure MATLAB installation: create license file.\"\"\"\n\n licfile = self.cfg['license_file']\n if licfile is None:\n licserv = self.cfg['license_server']\n if licserv is None:\n licserv = os.getenv('EB_MATLAB_LICENSE_SERVER', 'license.example.com')\n licport = self.cfg['license_server_port']\n if licport is None:\n licport = os.getenv('EB_MATLAB_LICENSE_SERVER_PORT', '00000')\n # create license file\n lictxt = '\\n'.join([\n \"SERVER %s 000000000000 %s\" % (licserv, licport),\n \"USE_SERVER\",\n ])\n\n licfile = os.path.join(self.builddir, 'matlab.lic')\n write_file(licfile, lictxt)\n\n try:\n copy_file(os.path.join(self.cfg['start_dir'], 'installer_input.txt'), self.configfile)\n adjust_permissions(self.configfile, stat.S_IWUSR)\n\n # read file in binary mode to avoid UTF-8 encoding issues when using Python 3,\n # due to non-UTF-8 characters...\n config = read_file(self.configfile, mode='rb')\n\n # use raw byte strings (must be 'br', not 'rb'),\n # required when using Python 3 because file was read in binary mode\n regdest = re.compile(br\"^# destinationFolder=.*\", re.M)\n regagree = re.compile(br\"^# agreeToLicense=.*\", re.M)\n regmode = re.compile(br\"^# mode=.*\", re.M)\n reglicpath = re.compile(br\"^# licensePath=.*\", re.M)\n regoutfile = re.compile(br\"^# outputFile=.*\", re.M)\n\n # must use byte-strings here when using Python 3, see above\n config = regdest.sub(b\"destinationFolder=%s\" % self.installdir.encode('utf-8'), config)\n config = regagree.sub(b\"agreeToLicense=Yes\", config)\n config = regmode.sub(b\"mode=silent\", config)\n config = reglicpath.sub(b\"licensePath=%s\" % licfile.encode('utf-8'), config)\n config = regoutfile.sub(b\"outputFile=%s\" % self.outputfile.encode('utf-8'), config)\n\n write_file(self.configfile, config)\n\n except IOError as err:\n raise EasyBuildError(\"Failed to create installation config file %s: %s\", self.configfile, err)\n\n self.log.debug('configuration file written to %s:\\n %s', self.configfile, config)\n\n def install_step(self):\n \"\"\"MATLAB install procedure using 'install' command.\"\"\"\n\n src = os.path.join(self.cfg['start_dir'], 'install')\n\n # make sure install script is executable\n adjust_permissions(src, stat.S_IXUSR)\n\n if LooseVersion(self.version) >= LooseVersion('2016b'):\n perm_dirs = [os.path.join(self.cfg['start_dir'], 'bin', 'glnxa64')]\n if LooseVersion(self.version) < LooseVersion('2021b'):\n jdir = os.path.join(self.cfg['start_dir'], 'sys', 'java', 'jre', 'glnxa64', 'jre', 'bin')\n perm_dirs.append(jdir)\n for perm_dir in perm_dirs:\n adjust_permissions(perm_dir, stat.S_IXUSR)\n\n # make sure $DISPLAY is not defined, which may lead to (hard to trace) problems\n # this is a workaround for not being able to specify --nodisplay to the install scripts\n if 'DISPLAY' in os.environ:\n os.environ.pop('DISPLAY')\n\n if '_JAVA_OPTIONS' not in self.cfg['preinstallopts']:\n java_opts = 'export _JAVA_OPTIONS=\"%s\" && ' % self.cfg['java_options']\n self.cfg['preinstallopts'] = java_opts + self.cfg['preinstallopts']\n if LooseVersion(self.version) >= LooseVersion('2016b'):\n change_dir(self.builddir)\n\n # Build the cmd string\n cmdlist = [\n self.cfg['preinstallopts'],\n src,\n '-inputFile',\n self.configfile,\n ]\n if LooseVersion(self.version) < LooseVersion('2020a'):\n # MATLAB installers < 2020a ignore $TMPDIR (always use /tmp) and might need a large tmpdir\n tmpdir = tempfile.mkdtemp()\n cmdlist.extend([\n '-v',\n '-tmpdir',\n tmpdir,\n ])\n cmdlist.append(self.cfg['installopts'])\n cmd = ' '.join(cmdlist)\n\n keys = self.cfg['key']\n if keys is None:\n try:\n keys = os.environ['EB_MATLAB_KEY']\n except KeyError:\n raise EasyBuildError(\"The MATLAB install key is not set. This can be set either with the environment \"\n \"variable EB_MATLAB_KEY or by the easyconfig variable 'key'.\")\n if isinstance(keys, string_type):\n keys = keys.split(',')\n\n # Compile the installation key regex outside of the loop\n regkey = re.compile(br\"^(# )?fileInstallationKey=.*\", re.M)\n\n # Run an install for each key\n for i, key in enumerate(keys):\n\n self.log.info('Installing MATLAB with key %s of %s', i + 1, len(keys))\n\n try:\n config = read_file(self.configfile, mode='rb')\n config = regkey.sub(b\"fileInstallationKey=%s\" % key.encode('utf-8'), config)\n write_file(self.configfile, config)\n\n except IOError as err:\n raise EasyBuildError(\"Failed to update config file %s: %s\", self.configfile, err)\n\n (out, _) = run_cmd(cmd, log_all=True, simple=False)\n\n # check installer output for known signs of trouble\n patterns = [\n \"Error: You have entered an invalid File Installation Key\",\n \"Not a valid key\",\n \"All selected products are already installed\",\n \"The application encountered an unexpected error and needs to close\",\n \"Error: Unable to write to\",\n \"Exiting with status -\\\\d\",\n \"End - Unsuccessful\",\n ]\n\n for pattern in patterns:\n regex = re.compile(pattern, re.I)\n if regex.search(out):\n raise EasyBuildError(\"Found error pattern '%s' in output of installation command '%s': %s\",\n regex.pattern, cmd, out)\n with open(self.outputfile) as f:\n if regex.search(f.read()):\n raise EasyBuildError(\"Found error pattern '%s' in output file of installer\",\n regex.pattern)\n\n def sanity_check_step(self):\n \"\"\"Custom sanity check for MATLAB.\"\"\"\n custom_paths = {\n 'files': [\"bin/matlab\", \"bin/glnxa64/MATLAB\", \"toolbox/local/classpath.txt\"],\n 'dirs': [\"java/jar\"],\n }\n super(EB_MATLAB, self).sanity_check_step(custom_paths=custom_paths)\n\n def make_module_extra(self):\n \"\"\"Extend PATH and set proper _JAVA_OPTIONS (e.g., -Xmx).\"\"\"\n txt = super(EB_MATLAB, self).make_module_extra()\n\n # make MATLAB runtime available\n if LooseVersion(self.version) >= LooseVersion('2017a'):\n for ldlibdir in ['runtime', 'bin', os.path.join('sys', 'os')]:\n libdir = os.path.join(ldlibdir, 'glnxa64')\n txt += self.module_generator.prepend_paths('LD_LIBRARY_PATH', libdir)\n if self.cfg['java_options']:\n txt += self.module_generator.set_environment('_JAVA_OPTIONS', self.cfg['java_options'])\n return txt\n", "path": "easybuild/easyblocks/m/matlab.py"}], "after_files": [{"content": "##\n# Copyright 2009-2023 Ghent University\n#\n# This file is part of EasyBuild,\n# originally created by the HPC team of Ghent University (http://ugent.be/hpc/en),\n# with support of Ghent University (http://ugent.be/hpc),\n# the Flemish Supercomputer Centre (VSC) (https://www.vscentrum.be),\n# Flemish Research Foundation (FWO) (http://www.fwo.be/en)\n# and the Department of Economy, Science and Innovation (EWI) (http://www.ewi-vlaanderen.be/en).\n#\n# https://github.com/easybuilders/easybuild\n#\n# EasyBuild is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation v2.\n#\n# EasyBuild is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with EasyBuild. If not, see <http://www.gnu.org/licenses/>.\n##\n\"\"\"\nEasyBuild support for installing MATLAB, implemented as an easyblock\n\n@author: Stijn De Weirdt (Ghent University)\n@author: Dries Verdegem (Ghent University)\n@author: Kenneth Hoste (Ghent University)\n@author: Pieter De Baets (Ghent University)\n@author: Jens Timmerman (Ghent University)\n@author: Fotis Georgatos (Uni.Lu, NTUA)\n\"\"\"\nimport re\nimport os\nimport stat\nimport tempfile\n\nfrom distutils.version import LooseVersion\n\nfrom easybuild.easyblocks.generic.packedbinary import PackedBinary\nfrom easybuild.framework.easyconfig import CUSTOM\nfrom easybuild.tools.build_log import EasyBuildError\nfrom easybuild.tools.filetools import adjust_permissions, change_dir, copy_file, read_file, write_file\nfrom easybuild.tools.py2vs3 import string_type\nfrom easybuild.tools.run import run_cmd\n\n\nclass EB_MATLAB(PackedBinary):\n \"\"\"Support for installing MATLAB.\"\"\"\n\n def __init__(self, *args, **kwargs):\n \"\"\"Add extra config options specific to MATLAB.\"\"\"\n super(EB_MATLAB, self).__init__(*args, **kwargs)\n self.comp_fam = None\n self.configfile = os.path.join(self.builddir, 'my_installer_input.txt')\n self.outputfile = os.path.join(self.builddir, 'my_installer_output.txt')\n\n @staticmethod\n def extra_options():\n extra_vars = {\n 'java_options': ['-Xmx256m', \"$_JAVA_OPTIONS value set for install and in module file.\", CUSTOM],\n 'key': [None, \"Installation key(s), make one install for each key. Single key or a list of keys\", CUSTOM],\n }\n return PackedBinary.extra_options(extra_vars)\n\n def configure_step(self):\n \"\"\"Configure MATLAB installation: create license file.\"\"\"\n\n licfile = self.cfg['license_file']\n if licfile is None:\n licserv = self.cfg['license_server']\n if licserv is None:\n licserv = os.getenv('EB_MATLAB_LICENSE_SERVER', 'license.example.com')\n licport = self.cfg['license_server_port']\n if licport is None:\n licport = os.getenv('EB_MATLAB_LICENSE_SERVER_PORT', '00000')\n # create license file\n lictxt = '\\n'.join([\n \"SERVER %s 000000000000 %s\" % (licserv, licport),\n \"USE_SERVER\",\n ])\n\n licfile = os.path.join(self.builddir, 'matlab.lic')\n write_file(licfile, lictxt)\n\n try:\n copy_file(os.path.join(self.cfg['start_dir'], 'installer_input.txt'), self.configfile)\n adjust_permissions(self.configfile, stat.S_IWUSR)\n\n # read file in binary mode to avoid UTF-8 encoding issues when using Python 3,\n # due to non-UTF-8 characters...\n config = read_file(self.configfile, mode='rb')\n\n # use raw byte strings (must be 'br', not 'rb'),\n # required when using Python 3 because file was read in binary mode\n regdest = re.compile(br\"^# destinationFolder=.*\", re.M)\n regagree = re.compile(br\"^# agreeToLicense=.*\", re.M)\n regmode = re.compile(br\"^# mode=.*\", re.M)\n reglicpath = re.compile(br\"^# licensePath=.*\", re.M)\n regoutfile = re.compile(br\"^# outputFile=.*\", re.M)\n\n # must use byte-strings here when using Python 3, see above\n config = regdest.sub(b\"destinationFolder=%s\" % self.installdir.encode('utf-8'), config)\n config = regagree.sub(b\"agreeToLicense=Yes\", config)\n config = regmode.sub(b\"mode=silent\", config)\n config = reglicpath.sub(b\"licensePath=%s\" % licfile.encode('utf-8'), config)\n config = regoutfile.sub(b\"outputFile=%s\" % self.outputfile.encode('utf-8'), config)\n\n write_file(self.configfile, config)\n\n except IOError as err:\n raise EasyBuildError(\"Failed to create installation config file %s: %s\", self.configfile, err)\n\n self.log.debug('configuration file written to %s:\\n %s', self.configfile, config)\n\n def install_step(self):\n \"\"\"MATLAB install procedure using 'install' command.\"\"\"\n\n src = os.path.join(self.cfg['start_dir'], 'install')\n\n # make sure install script is executable\n adjust_permissions(src, stat.S_IXUSR)\n\n if LooseVersion(self.version) >= LooseVersion('2016b'):\n perm_dirs = [os.path.join(self.cfg['start_dir'], 'bin', 'glnxa64')]\n if LooseVersion(self.version) < LooseVersion('2021b'):\n jdir = os.path.join(self.cfg['start_dir'], 'sys', 'java', 'jre', 'glnxa64', 'jre', 'bin')\n perm_dirs.append(jdir)\n for perm_dir in perm_dirs:\n adjust_permissions(perm_dir, stat.S_IXUSR)\n\n # make sure $DISPLAY is not defined, which may lead to (hard to trace) problems\n # this is a workaround for not being able to specify --nodisplay to the install scripts\n if 'DISPLAY' in os.environ:\n os.environ.pop('DISPLAY')\n\n if '_JAVA_OPTIONS' not in self.cfg['preinstallopts']:\n java_opts = 'export _JAVA_OPTIONS=\"%s\" && ' % self.cfg['java_options']\n self.cfg['preinstallopts'] = java_opts + self.cfg['preinstallopts']\n if LooseVersion(self.version) >= LooseVersion('2016b'):\n change_dir(self.builddir)\n\n # Build the cmd string\n cmdlist = [\n self.cfg['preinstallopts'],\n src,\n '-inputFile',\n self.configfile,\n ]\n if LooseVersion(self.version) < LooseVersion('2020a'):\n # MATLAB installers < 2020a ignore $TMPDIR (always use /tmp) and might need a large tmpdir\n tmpdir = tempfile.mkdtemp()\n cmdlist.extend([\n '-v',\n '-tmpdir',\n tmpdir,\n ])\n cmdlist.append(self.cfg['installopts'])\n cmd = ' '.join(cmdlist)\n\n keys = self.cfg['key']\n if keys is None:\n try:\n keys = os.environ['EB_MATLAB_KEY']\n except KeyError:\n raise EasyBuildError(\"The MATLAB install key is not set. This can be set either with the environment \"\n \"variable EB_MATLAB_KEY or by the easyconfig variable 'key'.\")\n if isinstance(keys, string_type):\n keys = keys.split(',')\n\n # Compile the installation key regex outside of the loop\n regkey = re.compile(br\"^(# )?fileInstallationKey=.*\", re.M)\n\n # Run an install for each key\n for i, key in enumerate(keys):\n\n self.log.info('Installing MATLAB with key %s of %s', i + 1, len(keys))\n\n try:\n config = read_file(self.configfile, mode='rb')\n config = regkey.sub(b\"fileInstallationKey=%s\" % key.encode('utf-8'), config)\n write_file(self.configfile, config)\n\n except IOError as err:\n raise EasyBuildError(\"Failed to update config file %s: %s\", self.configfile, err)\n\n (out, _) = run_cmd(cmd, log_all=True, simple=False)\n\n # check installer output for known signs of trouble\n patterns = [\n \"Error: You have entered an invalid File Installation Key\",\n \"Not a valid key\",\n \"All selected products are already installed\",\n \"The application encountered an unexpected error and needs to close\",\n \"Error: Unable to write to\",\n \"Exiting with status -\\\\d\",\n \"End - Unsuccessful\",\n ]\n\n for pattern in patterns:\n regex = re.compile(pattern, re.I)\n if regex.search(out):\n raise EasyBuildError(\"Found error pattern '%s' in output of installation command '%s': %s\",\n regex.pattern, cmd, out)\n with open(self.outputfile) as f:\n if regex.search(f.read()):\n raise EasyBuildError(\"Found error pattern '%s' in output file of installer\",\n regex.pattern)\n\n def sanity_check_step(self):\n \"\"\"Custom sanity check for MATLAB.\"\"\"\n custom_paths = {\n 'files': [\"bin/matlab\", \"bin/glnxa64/MATLAB\", \"toolbox/local/classpath.txt\"],\n 'dirs': [\"java/jar\"],\n }\n super(EB_MATLAB, self).sanity_check_step(custom_paths=custom_paths)\n\n def make_module_extra(self):\n \"\"\"Extend PATH and set proper _JAVA_OPTIONS (e.g., -Xmx).\"\"\"\n txt = super(EB_MATLAB, self).make_module_extra()\n\n if self.cfg['java_options']:\n txt += self.module_generator.set_environment('_JAVA_OPTIONS', self.cfg['java_options'])\n return txt\n", "path": "easybuild/easyblocks/m/matlab.py"}]}
| 3,520 | 217 |
gh_patches_debug_23707
|
rasdani/github-patches
|
git_diff
|
dbt-labs__dbt-core-1656
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
dbt sometimes writes a `.user.yml` and ignores configs
## Issue
If you pass dbt a relative path to `--profiles-dir` or the `DBT_PROFILES_DIR` environment variable and execute from a subdirectory, dbt will look for the user cookie and profiles.yml in different places (the latter correct, the former incorrect).
### Results
What happened? What did you expect to happen?
I got a `./profiles/.user.yml` and my settings were ignored. I expected my settings to be respected or to receive an error, and to not have a new file.
Suggested fixes:
My preference: don't allow users to run dbt from subdirectories.
Other option: defer loading of the user config until after we've found `dbt_project.yml`.
### System information
The output of `dbt --version`:
```
0.14.0
```
The operating system you're running on:
Any
The python version you're using (probably the output of `python --version`)
Any
### Steps to reproduce
In as much detail as possible, please provide steps to reproduce the issue. Sample data that triggers the issue, example models, etc are all very helpful here.
1) Make a dbt project in `${project_root}`
2) put your profiles.yml in `${project_root}/profiles`
3) Make a subdirectory (`${project_root}/models`) and cd into it
4) Run dbt with the relative path to the profiles directory as an argument to `--profiles-dir`: `dbt run --profiles-dir profiles`
5) You will now have a `${project_root}/models/profiles/.user.yml` with cookie information. Also, any settings in your `profiles.yml` won't be respected.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `core/dbt/tracking.py`
Content:
```
1 from dbt.logger import GLOBAL_LOGGER as logger
2 from dbt import version as dbt_version
3 from snowplow_tracker import Subject, Tracker, Emitter, logger as sp_logger
4 from snowplow_tracker import SelfDescribingJson
5 from datetime import datetime
6
7 from dbt.adapters.factory import get_adapter
8
9 import pytz
10 import platform
11 import uuid
12 import requests
13 import yaml
14 import os
15
16 import dbt.clients.system
17
18 sp_logger.setLevel(100)
19
20 COLLECTOR_URL = "fishtownanalytics.sinter-collect.com"
21 COLLECTOR_PROTOCOL = "https"
22
23 INVOCATION_SPEC = 'iglu:com.dbt/invocation/jsonschema/1-0-1'
24 PLATFORM_SPEC = 'iglu:com.dbt/platform/jsonschema/1-0-0'
25 RUN_MODEL_SPEC = 'iglu:com.dbt/run_model/jsonschema/1-0-1'
26 INVOCATION_ENV_SPEC = 'iglu:com.dbt/invocation_env/jsonschema/1-0-0'
27 PACKAGE_INSTALL_SPEC = 'iglu:com.dbt/package_install/jsonschema/1-0-0'
28 RPC_REQUEST_SPEC = 'iglu:com.dbt/rpc_request/jsonschema/1-0-1'
29
30 DBT_INVOCATION_ENV = 'DBT_INVOCATION_ENV'
31
32
33 class TimeoutEmitter(Emitter):
34 def __init__(self):
35 super(TimeoutEmitter, self).__init__(COLLECTOR_URL,
36 protocol=COLLECTOR_PROTOCOL,
37 buffer_size=1,
38 on_failure=self.handle_failure)
39
40 @staticmethod
41 def handle_failure(num_ok, unsent):
42 # num_ok will always be 0, unsent will always be 1 entry long, because
43 # the buffer is length 1, so not much to talk about
44 logger.warning('Error sending message, disabling tracking')
45 do_not_track()
46
47 def http_get(self, payload):
48 sp_logger.info("Sending GET request to %s..." % self.endpoint)
49 sp_logger.debug("Payload: %s" % payload)
50 r = requests.get(self.endpoint, params=payload, timeout=5.0)
51
52 msg = "GET request finished with status code: " + str(r.status_code)
53 if self.is_good_status_code(r.status_code):
54 sp_logger.info(msg)
55 else:
56 sp_logger.warn(msg)
57 return r
58
59
60 emitter = TimeoutEmitter()
61 tracker = Tracker(emitter, namespace="cf", app_id="dbt")
62
63 active_user = None
64
65
66 class User(object):
67
68 def __init__(self, cookie_dir):
69 self.do_not_track = True
70 self.cookie_dir = cookie_dir
71
72 self.id = None
73 self.invocation_id = str(uuid.uuid4())
74 self.run_started_at = datetime.now(tz=pytz.utc)
75
76 def state(self):
77 return "do not track" if self.do_not_track else "tracking"
78
79 @property
80 def cookie_path(self):
81 return os.path.join(self.cookie_dir, '.user.yml')
82
83 def initialize(self):
84 self.do_not_track = False
85
86 cookie = self.get_cookie()
87 self.id = cookie.get('id')
88
89 subject = Subject()
90 subject.set_user_id(self.id)
91 tracker.set_subject(subject)
92
93 def set_cookie(self):
94 user = {"id": str(uuid.uuid4())}
95
96 dbt.clients.system.make_directory(self.cookie_dir)
97
98 with open(self.cookie_path, "w") as fh:
99 yaml.dump(user, fh)
100
101 return user
102
103 def get_cookie(self):
104 if not os.path.isfile(self.cookie_path):
105 user = self.set_cookie()
106 else:
107 with open(self.cookie_path, "r") as fh:
108 try:
109 user = yaml.safe_load(fh)
110 if user is None:
111 user = self.set_cookie()
112 except yaml.reader.ReaderError:
113 user = self.set_cookie()
114 return user
115
116
117 def get_run_type(args):
118 return 'regular'
119
120
121 def get_invocation_context(user, config, args):
122 try:
123 adapter_type = get_adapter(config).type()
124 except Exception:
125 adapter_type = None
126
127 return {
128 "project_id": None if config is None else config.hashed_name(),
129 "user_id": user.id,
130 "invocation_id": user.invocation_id,
131
132 "command": args.which,
133 "options": None,
134 "version": str(dbt_version.installed),
135
136 "run_type": get_run_type(args),
137 "adapter_type": adapter_type,
138 }
139
140
141 def get_invocation_start_context(user, config, args):
142 data = get_invocation_context(user, config, args)
143
144 start_data = {
145 "progress": "start",
146 "result_type": None,
147 "result": None
148 }
149
150 data.update(start_data)
151 return SelfDescribingJson(INVOCATION_SPEC, data)
152
153
154 def get_invocation_end_context(user, config, args, result_type):
155 data = get_invocation_context(user, config, args)
156
157 start_data = {
158 "progress": "end",
159 "result_type": result_type,
160 "result": None
161 }
162
163 data.update(start_data)
164 return SelfDescribingJson(INVOCATION_SPEC, data)
165
166
167 def get_invocation_invalid_context(user, config, args, result_type):
168 data = get_invocation_context(user, config, args)
169
170 start_data = {
171 "progress": "invalid",
172 "result_type": result_type,
173 "result": None
174 }
175
176 data.update(start_data)
177 return SelfDescribingJson(INVOCATION_SPEC, data)
178
179
180 def get_platform_context():
181 data = {
182 "platform": platform.platform(),
183 "python": platform.python_version(),
184 "python_version": platform.python_implementation(),
185 }
186
187 return SelfDescribingJson(PLATFORM_SPEC, data)
188
189
190 def get_dbt_env_context():
191 default = 'manual'
192
193 dbt_invocation_env = os.getenv(DBT_INVOCATION_ENV, default)
194 if dbt_invocation_env == '':
195 dbt_invocation_env = default
196
197 data = {
198 "environment": dbt_invocation_env,
199 }
200
201 return SelfDescribingJson(INVOCATION_ENV_SPEC, data)
202
203
204 def track(user, *args, **kwargs):
205 if user.do_not_track:
206 return
207 else:
208 logger.debug("Sending event: {}".format(kwargs))
209 try:
210 tracker.track_struct_event(*args, **kwargs)
211 except Exception:
212 logger.debug(
213 "An error was encountered while trying to send an event"
214 )
215
216
217 def track_invocation_start(config=None, args=None):
218 context = [
219 get_invocation_start_context(active_user, config, args),
220 get_platform_context(),
221 get_dbt_env_context()
222 ]
223
224 track(
225 active_user,
226 category="dbt",
227 action='invocation',
228 label='start',
229 context=context
230 )
231
232
233 def track_model_run(options):
234 context = [SelfDescribingJson(RUN_MODEL_SPEC, options)]
235
236 track(
237 active_user,
238 category="dbt",
239 action='run_model',
240 label=active_user.invocation_id,
241 context=context
242 )
243
244
245 def track_rpc_request(options):
246 context = [SelfDescribingJson(RPC_REQUEST_SPEC, options)]
247
248 track(
249 active_user,
250 category="dbt",
251 action='rpc_request',
252 label=active_user.invocation_id,
253 context=context
254 )
255
256
257 def track_package_install(options):
258 context = [SelfDescribingJson(PACKAGE_INSTALL_SPEC, options)]
259 track(
260 active_user,
261 category="dbt",
262 action='package',
263 label=active_user.invocation_id,
264 property_='install',
265 context=context
266 )
267
268
269 def track_invocation_end(
270 config=None, args=None, result_type=None
271 ):
272 user = active_user
273 context = [
274 get_invocation_end_context(user, config, args, result_type),
275 get_platform_context(),
276 get_dbt_env_context()
277 ]
278 track(
279 active_user,
280 category="dbt",
281 action='invocation',
282 label='end',
283 context=context
284 )
285
286
287 def track_invalid_invocation(
288 config=None, args=None, result_type=None
289 ):
290
291 user = active_user
292 invocation_context = get_invocation_invalid_context(
293 user,
294 config,
295 args,
296 result_type
297 )
298
299 context = [
300 invocation_context,
301 get_platform_context(),
302 get_dbt_env_context()
303 ]
304
305 track(
306 active_user,
307 category="dbt",
308 action='invocation',
309 label='invalid',
310 context=context
311 )
312
313
314 def flush():
315 logger.debug("Flushing usage events")
316 tracker.flush()
317
318
319 def do_not_track():
320 global active_user
321 active_user = User(None)
322
323
324 def initialize_tracking(cookie_dir):
325 global active_user
326 active_user = User(cookie_dir)
327 try:
328 active_user.initialize()
329 except Exception:
330 logger.debug('Got an exception trying to initialize tracking',
331 exc_info=True)
332 active_user = User(None)
333
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/core/dbt/tracking.py b/core/dbt/tracking.py
--- a/core/dbt/tracking.py
+++ b/core/dbt/tracking.py
@@ -13,8 +13,6 @@
import yaml
import os
-import dbt.clients.system
-
sp_logger.setLevel(100)
COLLECTOR_URL = "fishtownanalytics.sinter-collect.com"
@@ -91,12 +89,22 @@
tracker.set_subject(subject)
def set_cookie(self):
- user = {"id": str(uuid.uuid4())}
+ # If the user points dbt to a profile directory which exists AND
+ # contains a profiles.yml file, then we can set a cookie. If the
+ # specified folder does not exist, or if there is not a profiles.yml
+ # file in this folder, then an inconsistent cookie can be used. This
+ # will change in every dbt invocation until the user points to a
+ # profile dir file which contains a valid profiles.yml file.
+ #
+ # See: https://github.com/fishtown-analytics/dbt/issues/1645
- dbt.clients.system.make_directory(self.cookie_dir)
+ user = {"id": str(uuid.uuid4())}
- with open(self.cookie_path, "w") as fh:
- yaml.dump(user, fh)
+ cookie_path = os.path.abspath(self.cookie_dir)
+ profiles_file = os.path.join(cookie_path, 'profiles.yml')
+ if os.path.exists(cookie_path) and os.path.exists(profiles_file):
+ with open(self.cookie_path, "w") as fh:
+ yaml.dump(user, fh)
return user
|
{"golden_diff": "diff --git a/core/dbt/tracking.py b/core/dbt/tracking.py\n--- a/core/dbt/tracking.py\n+++ b/core/dbt/tracking.py\n@@ -13,8 +13,6 @@\n import yaml\n import os\n \n-import dbt.clients.system\n-\n sp_logger.setLevel(100)\n \n COLLECTOR_URL = \"fishtownanalytics.sinter-collect.com\"\n@@ -91,12 +89,22 @@\n tracker.set_subject(subject)\n \n def set_cookie(self):\n- user = {\"id\": str(uuid.uuid4())}\n+ # If the user points dbt to a profile directory which exists AND\n+ # contains a profiles.yml file, then we can set a cookie. If the\n+ # specified folder does not exist, or if there is not a profiles.yml\n+ # file in this folder, then an inconsistent cookie can be used. This\n+ # will change in every dbt invocation until the user points to a\n+ # profile dir file which contains a valid profiles.yml file.\n+ #\n+ # See: https://github.com/fishtown-analytics/dbt/issues/1645\n \n- dbt.clients.system.make_directory(self.cookie_dir)\n+ user = {\"id\": str(uuid.uuid4())}\n \n- with open(self.cookie_path, \"w\") as fh:\n- yaml.dump(user, fh)\n+ cookie_path = os.path.abspath(self.cookie_dir)\n+ profiles_file = os.path.join(cookie_path, 'profiles.yml')\n+ if os.path.exists(cookie_path) and os.path.exists(profiles_file):\n+ with open(self.cookie_path, \"w\") as fh:\n+ yaml.dump(user, fh)\n \n return user\n", "issue": "dbt sometimes writes a `.user.yml` and ignores configs\n## Issue\r\nIf you pass dbt a relative path to `--profiles-dir` or the `DBT_PROFILES_DIR` environment variable and execute from a subdirectory, dbt will look for the user cookie and profiles.yml in different places (the latter correct, the former incorrect).\r\n\r\n### Results\r\nWhat happened? What did you expect to happen?\r\nI got a `./profiles/.user.yml` and my settings were ignored. I expected my settings to be respected or to receive an error, and to not have a new file.\r\n\r\nSuggested fixes:\r\nMy preference: don't allow users to run dbt from subdirectories.\r\nOther option: defer loading of the user config until after we've found `dbt_project.yml`.\r\n\r\n### System information\r\nThe output of `dbt --version`:\r\n```\r\n0.14.0\r\n```\r\n\r\nThe operating system you're running on:\r\nAny\r\n\r\nThe python version you're using (probably the output of `python --version`)\r\nAny\r\n\r\n### Steps to reproduce\r\nIn as much detail as possible, please provide steps to reproduce the issue. Sample data that triggers the issue, example models, etc are all very helpful here.\r\n\r\n1) Make a dbt project in `${project_root}`\r\n2) put your profiles.yml in `${project_root}/profiles`\r\n3) Make a subdirectory (`${project_root}/models`) and cd into it\r\n4) Run dbt with the relative path to the profiles directory as an argument to `--profiles-dir`: `dbt run --profiles-dir profiles`\r\n5) You will now have a `${project_root}/models/profiles/.user.yml` with cookie information. Also, any settings in your `profiles.yml` won't be respected.\r\n\n", "before_files": [{"content": "from dbt.logger import GLOBAL_LOGGER as logger\nfrom dbt import version as dbt_version\nfrom snowplow_tracker import Subject, Tracker, Emitter, logger as sp_logger\nfrom snowplow_tracker import SelfDescribingJson\nfrom datetime import datetime\n\nfrom dbt.adapters.factory import get_adapter\n\nimport pytz\nimport platform\nimport uuid\nimport requests\nimport yaml\nimport os\n\nimport dbt.clients.system\n\nsp_logger.setLevel(100)\n\nCOLLECTOR_URL = \"fishtownanalytics.sinter-collect.com\"\nCOLLECTOR_PROTOCOL = \"https\"\n\nINVOCATION_SPEC = 'iglu:com.dbt/invocation/jsonschema/1-0-1'\nPLATFORM_SPEC = 'iglu:com.dbt/platform/jsonschema/1-0-0'\nRUN_MODEL_SPEC = 'iglu:com.dbt/run_model/jsonschema/1-0-1'\nINVOCATION_ENV_SPEC = 'iglu:com.dbt/invocation_env/jsonschema/1-0-0'\nPACKAGE_INSTALL_SPEC = 'iglu:com.dbt/package_install/jsonschema/1-0-0'\nRPC_REQUEST_SPEC = 'iglu:com.dbt/rpc_request/jsonschema/1-0-1'\n\nDBT_INVOCATION_ENV = 'DBT_INVOCATION_ENV'\n\n\nclass TimeoutEmitter(Emitter):\n def __init__(self):\n super(TimeoutEmitter, self).__init__(COLLECTOR_URL,\n protocol=COLLECTOR_PROTOCOL,\n buffer_size=1,\n on_failure=self.handle_failure)\n\n @staticmethod\n def handle_failure(num_ok, unsent):\n # num_ok will always be 0, unsent will always be 1 entry long, because\n # the buffer is length 1, so not much to talk about\n logger.warning('Error sending message, disabling tracking')\n do_not_track()\n\n def http_get(self, payload):\n sp_logger.info(\"Sending GET request to %s...\" % self.endpoint)\n sp_logger.debug(\"Payload: %s\" % payload)\n r = requests.get(self.endpoint, params=payload, timeout=5.0)\n\n msg = \"GET request finished with status code: \" + str(r.status_code)\n if self.is_good_status_code(r.status_code):\n sp_logger.info(msg)\n else:\n sp_logger.warn(msg)\n return r\n\n\nemitter = TimeoutEmitter()\ntracker = Tracker(emitter, namespace=\"cf\", app_id=\"dbt\")\n\nactive_user = None\n\n\nclass User(object):\n\n def __init__(self, cookie_dir):\n self.do_not_track = True\n self.cookie_dir = cookie_dir\n\n self.id = None\n self.invocation_id = str(uuid.uuid4())\n self.run_started_at = datetime.now(tz=pytz.utc)\n\n def state(self):\n return \"do not track\" if self.do_not_track else \"tracking\"\n\n @property\n def cookie_path(self):\n return os.path.join(self.cookie_dir, '.user.yml')\n\n def initialize(self):\n self.do_not_track = False\n\n cookie = self.get_cookie()\n self.id = cookie.get('id')\n\n subject = Subject()\n subject.set_user_id(self.id)\n tracker.set_subject(subject)\n\n def set_cookie(self):\n user = {\"id\": str(uuid.uuid4())}\n\n dbt.clients.system.make_directory(self.cookie_dir)\n\n with open(self.cookie_path, \"w\") as fh:\n yaml.dump(user, fh)\n\n return user\n\n def get_cookie(self):\n if not os.path.isfile(self.cookie_path):\n user = self.set_cookie()\n else:\n with open(self.cookie_path, \"r\") as fh:\n try:\n user = yaml.safe_load(fh)\n if user is None:\n user = self.set_cookie()\n except yaml.reader.ReaderError:\n user = self.set_cookie()\n return user\n\n\ndef get_run_type(args):\n return 'regular'\n\n\ndef get_invocation_context(user, config, args):\n try:\n adapter_type = get_adapter(config).type()\n except Exception:\n adapter_type = None\n\n return {\n \"project_id\": None if config is None else config.hashed_name(),\n \"user_id\": user.id,\n \"invocation_id\": user.invocation_id,\n\n \"command\": args.which,\n \"options\": None,\n \"version\": str(dbt_version.installed),\n\n \"run_type\": get_run_type(args),\n \"adapter_type\": adapter_type,\n }\n\n\ndef get_invocation_start_context(user, config, args):\n data = get_invocation_context(user, config, args)\n\n start_data = {\n \"progress\": \"start\",\n \"result_type\": None,\n \"result\": None\n }\n\n data.update(start_data)\n return SelfDescribingJson(INVOCATION_SPEC, data)\n\n\ndef get_invocation_end_context(user, config, args, result_type):\n data = get_invocation_context(user, config, args)\n\n start_data = {\n \"progress\": \"end\",\n \"result_type\": result_type,\n \"result\": None\n }\n\n data.update(start_data)\n return SelfDescribingJson(INVOCATION_SPEC, data)\n\n\ndef get_invocation_invalid_context(user, config, args, result_type):\n data = get_invocation_context(user, config, args)\n\n start_data = {\n \"progress\": \"invalid\",\n \"result_type\": result_type,\n \"result\": None\n }\n\n data.update(start_data)\n return SelfDescribingJson(INVOCATION_SPEC, data)\n\n\ndef get_platform_context():\n data = {\n \"platform\": platform.platform(),\n \"python\": platform.python_version(),\n \"python_version\": platform.python_implementation(),\n }\n\n return SelfDescribingJson(PLATFORM_SPEC, data)\n\n\ndef get_dbt_env_context():\n default = 'manual'\n\n dbt_invocation_env = os.getenv(DBT_INVOCATION_ENV, default)\n if dbt_invocation_env == '':\n dbt_invocation_env = default\n\n data = {\n \"environment\": dbt_invocation_env,\n }\n\n return SelfDescribingJson(INVOCATION_ENV_SPEC, data)\n\n\ndef track(user, *args, **kwargs):\n if user.do_not_track:\n return\n else:\n logger.debug(\"Sending event: {}\".format(kwargs))\n try:\n tracker.track_struct_event(*args, **kwargs)\n except Exception:\n logger.debug(\n \"An error was encountered while trying to send an event\"\n )\n\n\ndef track_invocation_start(config=None, args=None):\n context = [\n get_invocation_start_context(active_user, config, args),\n get_platform_context(),\n get_dbt_env_context()\n ]\n\n track(\n active_user,\n category=\"dbt\",\n action='invocation',\n label='start',\n context=context\n )\n\n\ndef track_model_run(options):\n context = [SelfDescribingJson(RUN_MODEL_SPEC, options)]\n\n track(\n active_user,\n category=\"dbt\",\n action='run_model',\n label=active_user.invocation_id,\n context=context\n )\n\n\ndef track_rpc_request(options):\n context = [SelfDescribingJson(RPC_REQUEST_SPEC, options)]\n\n track(\n active_user,\n category=\"dbt\",\n action='rpc_request',\n label=active_user.invocation_id,\n context=context\n )\n\n\ndef track_package_install(options):\n context = [SelfDescribingJson(PACKAGE_INSTALL_SPEC, options)]\n track(\n active_user,\n category=\"dbt\",\n action='package',\n label=active_user.invocation_id,\n property_='install',\n context=context\n )\n\n\ndef track_invocation_end(\n config=None, args=None, result_type=None\n):\n user = active_user\n context = [\n get_invocation_end_context(user, config, args, result_type),\n get_platform_context(),\n get_dbt_env_context()\n ]\n track(\n active_user,\n category=\"dbt\",\n action='invocation',\n label='end',\n context=context\n )\n\n\ndef track_invalid_invocation(\n config=None, args=None, result_type=None\n):\n\n user = active_user\n invocation_context = get_invocation_invalid_context(\n user,\n config,\n args,\n result_type\n )\n\n context = [\n invocation_context,\n get_platform_context(),\n get_dbt_env_context()\n ]\n\n track(\n active_user,\n category=\"dbt\",\n action='invocation',\n label='invalid',\n context=context\n )\n\n\ndef flush():\n logger.debug(\"Flushing usage events\")\n tracker.flush()\n\n\ndef do_not_track():\n global active_user\n active_user = User(None)\n\n\ndef initialize_tracking(cookie_dir):\n global active_user\n active_user = User(cookie_dir)\n try:\n active_user.initialize()\n except Exception:\n logger.debug('Got an exception trying to initialize tracking',\n exc_info=True)\n active_user = User(None)\n", "path": "core/dbt/tracking.py"}], "after_files": [{"content": "from dbt.logger import GLOBAL_LOGGER as logger\nfrom dbt import version as dbt_version\nfrom snowplow_tracker import Subject, Tracker, Emitter, logger as sp_logger\nfrom snowplow_tracker import SelfDescribingJson\nfrom datetime import datetime\n\nfrom dbt.adapters.factory import get_adapter\n\nimport pytz\nimport platform\nimport uuid\nimport requests\nimport yaml\nimport os\n\nsp_logger.setLevel(100)\n\nCOLLECTOR_URL = \"fishtownanalytics.sinter-collect.com\"\nCOLLECTOR_PROTOCOL = \"https\"\n\nINVOCATION_SPEC = 'iglu:com.dbt/invocation/jsonschema/1-0-1'\nPLATFORM_SPEC = 'iglu:com.dbt/platform/jsonschema/1-0-0'\nRUN_MODEL_SPEC = 'iglu:com.dbt/run_model/jsonschema/1-0-1'\nINVOCATION_ENV_SPEC = 'iglu:com.dbt/invocation_env/jsonschema/1-0-0'\nPACKAGE_INSTALL_SPEC = 'iglu:com.dbt/package_install/jsonschema/1-0-0'\nRPC_REQUEST_SPEC = 'iglu:com.dbt/rpc_request/jsonschema/1-0-1'\n\nDBT_INVOCATION_ENV = 'DBT_INVOCATION_ENV'\n\n\nclass TimeoutEmitter(Emitter):\n def __init__(self):\n super(TimeoutEmitter, self).__init__(COLLECTOR_URL,\n protocol=COLLECTOR_PROTOCOL,\n buffer_size=1,\n on_failure=self.handle_failure)\n\n @staticmethod\n def handle_failure(num_ok, unsent):\n # num_ok will always be 0, unsent will always be 1 entry long, because\n # the buffer is length 1, so not much to talk about\n logger.warning('Error sending message, disabling tracking')\n do_not_track()\n\n def http_get(self, payload):\n sp_logger.info(\"Sending GET request to %s...\" % self.endpoint)\n sp_logger.debug(\"Payload: %s\" % payload)\n r = requests.get(self.endpoint, params=payload, timeout=5.0)\n\n msg = \"GET request finished with status code: \" + str(r.status_code)\n if self.is_good_status_code(r.status_code):\n sp_logger.info(msg)\n else:\n sp_logger.warn(msg)\n return r\n\n\nemitter = TimeoutEmitter()\ntracker = Tracker(emitter, namespace=\"cf\", app_id=\"dbt\")\n\nactive_user = None\n\n\nclass User(object):\n\n def __init__(self, cookie_dir):\n self.do_not_track = True\n self.cookie_dir = cookie_dir\n\n self.id = None\n self.invocation_id = str(uuid.uuid4())\n self.run_started_at = datetime.now(tz=pytz.utc)\n\n def state(self):\n return \"do not track\" if self.do_not_track else \"tracking\"\n\n @property\n def cookie_path(self):\n return os.path.join(self.cookie_dir, '.user.yml')\n\n def initialize(self):\n self.do_not_track = False\n\n cookie = self.get_cookie()\n self.id = cookie.get('id')\n\n subject = Subject()\n subject.set_user_id(self.id)\n tracker.set_subject(subject)\n\n def set_cookie(self):\n # If the user points dbt to a profile directory which exists AND\n # contains a profiles.yml file, then we can set a cookie. If the\n # specified folder does not exist, or if there is not a profiles.yml\n # file in this folder, then an inconsistent cookie can be used. This\n # will change in every dbt invocation until the user points to a\n # profile dir file which contains a valid profiles.yml file.\n #\n # See: https://github.com/fishtown-analytics/dbt/issues/1645\n\n user = {\"id\": str(uuid.uuid4())}\n\n cookie_path = os.path.abspath(self.cookie_dir)\n profiles_file = os.path.join(cookie_path, 'profiles.yml')\n if os.path.exists(cookie_path) and os.path.exists(profiles_file):\n with open(self.cookie_path, \"w\") as fh:\n yaml.dump(user, fh)\n\n return user\n\n def get_cookie(self):\n if not os.path.isfile(self.cookie_path):\n user = self.set_cookie()\n else:\n with open(self.cookie_path, \"r\") as fh:\n try:\n user = yaml.safe_load(fh)\n if user is None:\n user = self.set_cookie()\n except yaml.reader.ReaderError:\n user = self.set_cookie()\n return user\n\n\ndef get_run_type(args):\n return 'regular'\n\n\ndef get_invocation_context(user, config, args):\n try:\n adapter_type = get_adapter(config).type()\n except Exception:\n adapter_type = None\n\n return {\n \"project_id\": None if config is None else config.hashed_name(),\n \"user_id\": user.id,\n \"invocation_id\": user.invocation_id,\n\n \"command\": args.which,\n \"options\": None,\n \"version\": str(dbt_version.installed),\n\n \"run_type\": get_run_type(args),\n \"adapter_type\": adapter_type,\n }\n\n\ndef get_invocation_start_context(user, config, args):\n data = get_invocation_context(user, config, args)\n\n start_data = {\n \"progress\": \"start\",\n \"result_type\": None,\n \"result\": None\n }\n\n data.update(start_data)\n return SelfDescribingJson(INVOCATION_SPEC, data)\n\n\ndef get_invocation_end_context(user, config, args, result_type):\n data = get_invocation_context(user, config, args)\n\n start_data = {\n \"progress\": \"end\",\n \"result_type\": result_type,\n \"result\": None\n }\n\n data.update(start_data)\n return SelfDescribingJson(INVOCATION_SPEC, data)\n\n\ndef get_invocation_invalid_context(user, config, args, result_type):\n data = get_invocation_context(user, config, args)\n\n start_data = {\n \"progress\": \"invalid\",\n \"result_type\": result_type,\n \"result\": None\n }\n\n data.update(start_data)\n return SelfDescribingJson(INVOCATION_SPEC, data)\n\n\ndef get_platform_context():\n data = {\n \"platform\": platform.platform(),\n \"python\": platform.python_version(),\n \"python_version\": platform.python_implementation(),\n }\n\n return SelfDescribingJson(PLATFORM_SPEC, data)\n\n\ndef get_dbt_env_context():\n default = 'manual'\n\n dbt_invocation_env = os.getenv(DBT_INVOCATION_ENV, default)\n if dbt_invocation_env == '':\n dbt_invocation_env = default\n\n data = {\n \"environment\": dbt_invocation_env,\n }\n\n return SelfDescribingJson(INVOCATION_ENV_SPEC, data)\n\n\ndef track(user, *args, **kwargs):\n if user.do_not_track:\n return\n else:\n logger.debug(\"Sending event: {}\".format(kwargs))\n try:\n tracker.track_struct_event(*args, **kwargs)\n except Exception:\n logger.debug(\n \"An error was encountered while trying to send an event\"\n )\n\n\ndef track_invocation_start(config=None, args=None):\n context = [\n get_invocation_start_context(active_user, config, args),\n get_platform_context(),\n get_dbt_env_context()\n ]\n\n track(\n active_user,\n category=\"dbt\",\n action='invocation',\n label='start',\n context=context\n )\n\n\ndef track_model_run(options):\n context = [SelfDescribingJson(RUN_MODEL_SPEC, options)]\n\n track(\n active_user,\n category=\"dbt\",\n action='run_model',\n label=active_user.invocation_id,\n context=context\n )\n\n\ndef track_rpc_request(options):\n context = [SelfDescribingJson(RPC_REQUEST_SPEC, options)]\n\n track(\n active_user,\n category=\"dbt\",\n action='rpc_request',\n label=active_user.invocation_id,\n context=context\n )\n\n\ndef track_package_install(options):\n context = [SelfDescribingJson(PACKAGE_INSTALL_SPEC, options)]\n track(\n active_user,\n category=\"dbt\",\n action='package',\n label=active_user.invocation_id,\n property_='install',\n context=context\n )\n\n\ndef track_invocation_end(\n config=None, args=None, result_type=None\n):\n user = active_user\n context = [\n get_invocation_end_context(user, config, args, result_type),\n get_platform_context(),\n get_dbt_env_context()\n ]\n track(\n active_user,\n category=\"dbt\",\n action='invocation',\n label='end',\n context=context\n )\n\n\ndef track_invalid_invocation(\n config=None, args=None, result_type=None\n):\n\n user = active_user\n invocation_context = get_invocation_invalid_context(\n user,\n config,\n args,\n result_type\n )\n\n context = [\n invocation_context,\n get_platform_context(),\n get_dbt_env_context()\n ]\n\n track(\n active_user,\n category=\"dbt\",\n action='invocation',\n label='invalid',\n context=context\n )\n\n\ndef flush():\n logger.debug(\"Flushing usage events\")\n tracker.flush()\n\n\ndef do_not_track():\n global active_user\n active_user = User(None)\n\n\ndef initialize_tracking(cookie_dir):\n global active_user\n active_user = User(cookie_dir)\n try:\n active_user.initialize()\n except Exception:\n logger.debug('Got an exception trying to initialize tracking',\n exc_info=True)\n active_user = User(None)\n", "path": "core/dbt/tracking.py"}]}
| 3,476 | 375 |
gh_patches_debug_17218
|
rasdani/github-patches
|
git_diff
|
graspologic-org__graspologic-336
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
improve nonpar by calling mgcpy's two-sample test
the current nonpar implementation seems "correct",
meaning it seems to do what they did in the nonpar paper.
however, there is a much better way to implement it,
and we'd like to write a short paper about that.
specifically, in the current implementation, it uses the biased MMD,
which is equivalent to the biased Dcorr.
better would be to use the unbiased MMD/Dcorr,
and even better would be to use the unbiased MGC.
possibly further better would be to use RF, though we don't have that fully implemented just yet.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 import os
2 import sys
3 from setuptools import setup, find_packages
4 from sys import platform
5
6 PACKAGE_NAME = "graspy"
7 DESCRIPTION = "A set of python modules for graph statistics"
8 with open("README.md", "r") as f:
9 LONG_DESCRIPTION = f.read()
10 AUTHOR = ("Eric Bridgeford, Jaewon Chung, Benjamin Pedigo, Bijan Varjavand",)
11 AUTHOR_EMAIL = "[email protected]"
12 URL = "https://github.com/neurodata/graspy"
13 MINIMUM_PYTHON_VERSION = 3, 5 # Minimum of Python 3.5
14 REQUIRED_PACKAGES = [
15 "networkx>=2.1",
16 "numpy>=1.8.1",
17 "scikit-learn>=0.19.1",
18 "scipy>=1.1.0",
19 "seaborn>=0.9.0",
20 "matplotlib>=3.0.0",
21 ]
22
23 # Find GraSPy version.
24 PROJECT_PATH = os.path.dirname(os.path.abspath(__file__))
25 for line in open(os.path.join(PROJECT_PATH, "graspy", "__init__.py")):
26 if line.startswith("__version__ = "):
27 VERSION = line.strip().split()[2][1:-1]
28
29
30 def check_python_version():
31 """Exit when the Python version is too low."""
32 if sys.version_info < MINIMUM_PYTHON_VERSION:
33 sys.exit("Python {}.{}+ is required.".format(*MINIMUM_PYTHON_VERSION))
34
35
36 check_python_version()
37
38 setup(
39 name=PACKAGE_NAME,
40 version=VERSION,
41 description=DESCRIPTION,
42 long_description=LONG_DESCRIPTION,
43 long_description_content_type="text/markdown",
44 author=AUTHOR,
45 author_email=AUTHOR_EMAIL,
46 install_requires=REQUIRED_PACKAGES,
47 url=URL,
48 license="Apache License 2.0",
49 classifiers=[
50 "Development Status :: 3 - Alpha",
51 "Intended Audience :: Science/Research",
52 "Topic :: Scientific/Engineering :: Mathematics",
53 "License :: OSI Approved :: Apache Software License",
54 "Programming Language :: Python :: 3",
55 "Programming Language :: Python :: 3.5",
56 "Programming Language :: Python :: 3.6",
57 "Programming Language :: Python :: 3.7",
58 ],
59 packages=find_packages(),
60 include_package_data=True,
61 )
62
```
Path: `docs/conf.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 #
3 # Configuration file for the Sphinx documentation builder.
4 #
5 # This file does only contain a selection of the most common options. For a
6 # full list see the documentation:
7 # http://www.sphinx-doc.org/en/master/config
8
9 # -- Path setup --------------------------------------------------------------
10
11 # If extensions (or modules to document with autodoc) are in another directory,
12 # add these directories to sys.path here. If the directory is relative to the
13 # documentation root, use os.path.abspath to make it absolute, like shown here.
14 #
15 import os
16 import sys
17
18 sys.path.insert(0, os.path.abspath(".."))
19
20 # -- Project information -----------------------------------------------------
21
22 project = "GraSPy"
23 copyright = "2018"
24 authors = u"NeuroData"
25
26 # The short X.Y version
27 # Find GraSPy version.
28 PROJECT_PATH = os.path.dirname(os.path.abspath(__file__))
29 for line in open(os.path.join(PROJECT_PATH, "..", "graspy", "__init__.py")):
30 if line.startswith("__version__ = "):
31 version = line.strip().split()[2][1:-1]
32
33 # The full version, including alpha/beta/rc tags
34 release = "alpha"
35
36 # -- Extension configuration -------------------------------------------------
37 extensions = [
38 "sphinx.ext.autodoc",
39 "sphinx.ext.autosummary",
40 "sphinx.ext.todo",
41 "sphinx.ext.viewcode",
42 "sphinx.ext.mathjax",
43 "numpydoc",
44 "sphinx.ext.ifconfig",
45 "sphinx.ext.githubpages",
46 "sphinxcontrib.rawfiles",
47 "nbsphinx",
48 "sphinx.ext.intersphinx",
49 ]
50
51 # -- sphinxcontrib.rawfiles
52 rawfiles = ["CNAME"]
53
54 # -- numpydoc
55 # Below is needed to prevent errors
56 numpydoc_show_class_members = False
57 numpydoc_attributes_as_param_list = True
58 numpydoc_use_blockquotes = True
59
60 # -- sphinx.ext.autosummary
61 autosummary_generate = True
62
63 # -- sphinx.ext.autodoc
64 autoclass_content = "both"
65 autodoc_default_flags = ["members", "inherited-members"]
66 autodoc_member_order = "bysource" # default is alphabetical
67
68 # -- sphinx.ext.intersphinx
69 intersphinx_mapping = {
70 "numpy": ("https://docs.scipy.org/doc/numpy", None),
71 "python": ("https://docs.python.org/3", None),
72 "scipy": ("https://docs.scipy.org/doc/scipy/reference", None),
73 "sklearn": ("http://scikit-learn.org/dev", None),
74 }
75
76 # -- sphinx options ----------------------------------------------------------
77 source_suffix = ".rst"
78 exclude_patterns = ["_build", "Thumbs.db", ".DS_Store", "**.ipynb_checkpoints"]
79 master_doc = "index"
80 source_encoding = "utf-8"
81
82 # -- Options for HTML output -------------------------------------------------
83 # Add any paths that contain templates here, relative to this directory.
84 templates_path = ["_templates"]
85 html_static_path = ["_static"]
86 modindex_common_prefix = ["graspy."]
87
88 pygments_style = "sphinx"
89 smartquotes = False
90
91 # Use RTD Theme
92 import sphinx_rtd_theme
93
94 html_theme = "sphinx_rtd_theme"
95 html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]
96 html_theme_options = {
97 #'includehidden': False,
98 "navigation_depth": 2,
99 "collapse_navigation": False,
100 "navigation_depth": 3,
101 }
102
103 # Custom sidebar templates, must be a dictionary that maps document names
104 # to template names.
105 #
106 # The default sidebars (for documents that don't match any pattern) are
107 # defined by theme itself. Builtin themes are using these templates by
108 # default: ``['localtoc.html', 'relations.html', 'sourcelink.html',
109 # 'searchbox.html']``.
110 #
111 # html_sidebars = {}
112
113 # -- Options for HTMLHelp output ---------------------------------------------
114
115 # Output file base name for HTML help builder.
116 htmlhelp_basename = "graspydoc"
117
118 # -- Options for LaTeX output ------------------------------------------------
119
120 latex_elements = {
121 # The paper size ('letterpaper' or 'a4paper').
122 #
123 # 'papersize': 'letterpaper',
124 # The font size ('10pt', '11pt' or '12pt').
125 #
126 # 'pointsize': '10pt',
127 # Additional stuff for the LaTeX preamble.
128 #
129 # 'preamble': '',
130 # Latex figure (float) alignment
131 #
132 # 'figure_align': 'htbp',
133 }
134
135 # Grouping the document tree into LaTeX files. List of tuples
136 # (source start file, target name, title,
137 # author, documentclass [howto, manual, or own class]).
138 latex_documents = [
139 (master_doc, "graspy.tex", "GraSPy Documentation", authors, "manual")
140 ]
141
142 # -- Options for manual page output ------------------------------------------
143
144 # One entry per manual page. List of tuples
145 # (source start file, name, description, authors, manual section).
146 man_pages = [(master_doc, "graspy", "graspy Documentation", [authors], 1)]
147
148 # -- Options for Texinfo output ----------------------------------------------
149
150 # Grouping the document tree into Texinfo files. List of tuples
151 # (source start file, target name, title, author,
152 # dir menu entry, description, category)
153 texinfo_documents = [
154 (
155 master_doc,
156 "graspy",
157 "graspy Documentation",
158 authors,
159 "graspy",
160 "One line description of project.",
161 "Miscellaneous",
162 )
163 ]
164
165 # -- Options for Epub output -------------------------------------------------
166
167 # Bibliographic Dublin Core info.
168 epub_title = project
169
170 # The unique identifier of the text. This can be a ISBN number
171 # or the project homepage.
172 #
173 # epub_identifier = ''
174
175 # A unique identification for the text.
176 #
177 # epub_uid = ''
178
179 # A list of files that should not be packed into the epub file.
180 epub_exclude_files = ["search.html"]
181
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -71,6 +71,7 @@
"python": ("https://docs.python.org/3", None),
"scipy": ("https://docs.scipy.org/doc/scipy/reference", None),
"sklearn": ("http://scikit-learn.org/dev", None),
+ "hyppo": ("https://hyppo.neurodata.io", None),
}
# -- sphinx options ----------------------------------------------------------
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -18,8 +18,10 @@
"scipy>=1.1.0",
"seaborn>=0.9.0",
"matplotlib>=3.0.0",
+ "hyppo>=0.1.2",
]
+
# Find GraSPy version.
PROJECT_PATH = os.path.dirname(os.path.abspath(__file__))
for line in open(os.path.join(PROJECT_PATH, "graspy", "__init__.py")):
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -71,6 +71,7 @@\n \"python\": (\"https://docs.python.org/3\", None),\n \"scipy\": (\"https://docs.scipy.org/doc/scipy/reference\", None),\n \"sklearn\": (\"http://scikit-learn.org/dev\", None),\n+ \"hyppo\": (\"https://hyppo.neurodata.io\", None),\n }\n \n # -- sphinx options ----------------------------------------------------------\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -18,8 +18,10 @@\n \"scipy>=1.1.0\",\n \"seaborn>=0.9.0\",\n \"matplotlib>=3.0.0\",\n+ \"hyppo>=0.1.2\",\n ]\n \n+\n # Find GraSPy version.\n PROJECT_PATH = os.path.dirname(os.path.abspath(__file__))\n for line in open(os.path.join(PROJECT_PATH, \"graspy\", \"__init__.py\")):\n", "issue": "improve nonpar by calling mgcpy's two-sample test\nthe current nonpar implementation seems \"correct\",\r\nmeaning it seems to do what they did in the nonpar paper.\r\nhowever, there is a much better way to implement it,\r\nand we'd like to write a short paper about that.\r\nspecifically, in the current implementation, it uses the biased MMD, \r\nwhich is equivalent to the biased Dcorr.\r\nbetter would be to use the unbiased MMD/Dcorr,\r\nand even better would be to use the unbiased MGC.\r\npossibly further better would be to use RF, though we don't have that fully implemented just yet.\r\n\r\n\n", "before_files": [{"content": "import os\nimport sys\nfrom setuptools import setup, find_packages\nfrom sys import platform\n\nPACKAGE_NAME = \"graspy\"\nDESCRIPTION = \"A set of python modules for graph statistics\"\nwith open(\"README.md\", \"r\") as f:\n LONG_DESCRIPTION = f.read()\nAUTHOR = (\"Eric Bridgeford, Jaewon Chung, Benjamin Pedigo, Bijan Varjavand\",)\nAUTHOR_EMAIL = \"[email protected]\"\nURL = \"https://github.com/neurodata/graspy\"\nMINIMUM_PYTHON_VERSION = 3, 5 # Minimum of Python 3.5\nREQUIRED_PACKAGES = [\n \"networkx>=2.1\",\n \"numpy>=1.8.1\",\n \"scikit-learn>=0.19.1\",\n \"scipy>=1.1.0\",\n \"seaborn>=0.9.0\",\n \"matplotlib>=3.0.0\",\n]\n\n# Find GraSPy version.\nPROJECT_PATH = os.path.dirname(os.path.abspath(__file__))\nfor line in open(os.path.join(PROJECT_PATH, \"graspy\", \"__init__.py\")):\n if line.startswith(\"__version__ = \"):\n VERSION = line.strip().split()[2][1:-1]\n\n\ndef check_python_version():\n \"\"\"Exit when the Python version is too low.\"\"\"\n if sys.version_info < MINIMUM_PYTHON_VERSION:\n sys.exit(\"Python {}.{}+ is required.\".format(*MINIMUM_PYTHON_VERSION))\n\n\ncheck_python_version()\n\nsetup(\n name=PACKAGE_NAME,\n version=VERSION,\n description=DESCRIPTION,\n long_description=LONG_DESCRIPTION,\n long_description_content_type=\"text/markdown\",\n author=AUTHOR,\n author_email=AUTHOR_EMAIL,\n install_requires=REQUIRED_PACKAGES,\n url=URL,\n license=\"Apache License 2.0\",\n classifiers=[\n \"Development Status :: 3 - Alpha\",\n \"Intended Audience :: Science/Research\",\n \"Topic :: Scientific/Engineering :: Mathematics\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n ],\n packages=find_packages(),\n include_package_data=True,\n)\n", "path": "setup.py"}, {"content": "# -*- coding: utf-8 -*-\n#\n# Configuration file for the Sphinx documentation builder.\n#\n# This file does only contain a selection of the most common options. For a\n# full list see the documentation:\n# http://www.sphinx-doc.org/en/master/config\n\n# -- Path setup --------------------------------------------------------------\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\nimport os\nimport sys\n\nsys.path.insert(0, os.path.abspath(\"..\"))\n\n# -- Project information -----------------------------------------------------\n\nproject = \"GraSPy\"\ncopyright = \"2018\"\nauthors = u\"NeuroData\"\n\n# The short X.Y version\n# Find GraSPy version.\nPROJECT_PATH = os.path.dirname(os.path.abspath(__file__))\nfor line in open(os.path.join(PROJECT_PATH, \"..\", \"graspy\", \"__init__.py\")):\n if line.startswith(\"__version__ = \"):\n version = line.strip().split()[2][1:-1]\n\n# The full version, including alpha/beta/rc tags\nrelease = \"alpha\"\n\n# -- Extension configuration -------------------------------------------------\nextensions = [\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.autosummary\",\n \"sphinx.ext.todo\",\n \"sphinx.ext.viewcode\",\n \"sphinx.ext.mathjax\",\n \"numpydoc\",\n \"sphinx.ext.ifconfig\",\n \"sphinx.ext.githubpages\",\n \"sphinxcontrib.rawfiles\",\n \"nbsphinx\",\n \"sphinx.ext.intersphinx\",\n]\n\n# -- sphinxcontrib.rawfiles\nrawfiles = [\"CNAME\"]\n\n# -- numpydoc\n# Below is needed to prevent errors\nnumpydoc_show_class_members = False\nnumpydoc_attributes_as_param_list = True\nnumpydoc_use_blockquotes = True\n\n# -- sphinx.ext.autosummary\nautosummary_generate = True\n\n# -- sphinx.ext.autodoc\nautoclass_content = \"both\"\nautodoc_default_flags = [\"members\", \"inherited-members\"]\nautodoc_member_order = \"bysource\" # default is alphabetical\n\n# -- sphinx.ext.intersphinx\nintersphinx_mapping = {\n \"numpy\": (\"https://docs.scipy.org/doc/numpy\", None),\n \"python\": (\"https://docs.python.org/3\", None),\n \"scipy\": (\"https://docs.scipy.org/doc/scipy/reference\", None),\n \"sklearn\": (\"http://scikit-learn.org/dev\", None),\n}\n\n# -- sphinx options ----------------------------------------------------------\nsource_suffix = \".rst\"\nexclude_patterns = [\"_build\", \"Thumbs.db\", \".DS_Store\", \"**.ipynb_checkpoints\"]\nmaster_doc = \"index\"\nsource_encoding = \"utf-8\"\n\n# -- Options for HTML output -------------------------------------------------\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = [\"_templates\"]\nhtml_static_path = [\"_static\"]\nmodindex_common_prefix = [\"graspy.\"]\n\npygments_style = \"sphinx\"\nsmartquotes = False\n\n# Use RTD Theme\nimport sphinx_rtd_theme\n\nhtml_theme = \"sphinx_rtd_theme\"\nhtml_theme_path = [sphinx_rtd_theme.get_html_theme_path()]\nhtml_theme_options = {\n #'includehidden': False,\n \"navigation_depth\": 2,\n \"collapse_navigation\": False,\n \"navigation_depth\": 3,\n}\n\n# Custom sidebar templates, must be a dictionary that maps document names\n# to template names.\n#\n# The default sidebars (for documents that don't match any pattern) are\n# defined by theme itself. Builtin themes are using these templates by\n# default: ``['localtoc.html', 'relations.html', 'sourcelink.html',\n# 'searchbox.html']``.\n#\n# html_sidebars = {}\n\n# -- Options for HTMLHelp output ---------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = \"graspydoc\"\n\n# -- Options for LaTeX output ------------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #\n # 'papersize': 'letterpaper',\n # The font size ('10pt', '11pt' or '12pt').\n #\n # 'pointsize': '10pt',\n # Additional stuff for the LaTeX preamble.\n #\n # 'preamble': '',\n # Latex figure (float) alignment\n #\n # 'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (master_doc, \"graspy.tex\", \"GraSPy Documentation\", authors, \"manual\")\n]\n\n# -- Options for manual page output ------------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [(master_doc, \"graspy\", \"graspy Documentation\", [authors], 1)]\n\n# -- Options for Texinfo output ----------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (\n master_doc,\n \"graspy\",\n \"graspy Documentation\",\n authors,\n \"graspy\",\n \"One line description of project.\",\n \"Miscellaneous\",\n )\n]\n\n# -- Options for Epub output -------------------------------------------------\n\n# Bibliographic Dublin Core info.\nepub_title = project\n\n# The unique identifier of the text. This can be a ISBN number\n# or the project homepage.\n#\n# epub_identifier = ''\n\n# A unique identification for the text.\n#\n# epub_uid = ''\n\n# A list of files that should not be packed into the epub file.\nepub_exclude_files = [\"search.html\"]\n", "path": "docs/conf.py"}], "after_files": [{"content": "import os\nimport sys\nfrom setuptools import setup, find_packages\nfrom sys import platform\n\nPACKAGE_NAME = \"graspy\"\nDESCRIPTION = \"A set of python modules for graph statistics\"\nwith open(\"README.md\", \"r\") as f:\n LONG_DESCRIPTION = f.read()\nAUTHOR = (\"Eric Bridgeford, Jaewon Chung, Benjamin Pedigo, Bijan Varjavand\",)\nAUTHOR_EMAIL = \"[email protected]\"\nURL = \"https://github.com/neurodata/graspy\"\nMINIMUM_PYTHON_VERSION = 3, 5 # Minimum of Python 3.5\nREQUIRED_PACKAGES = [\n \"networkx>=2.1\",\n \"numpy>=1.8.1\",\n \"scikit-learn>=0.19.1\",\n \"scipy>=1.1.0\",\n \"seaborn>=0.9.0\",\n \"matplotlib>=3.0.0\",\n \"hyppo>=0.1.2\",\n]\n\n\n# Find GraSPy version.\nPROJECT_PATH = os.path.dirname(os.path.abspath(__file__))\nfor line in open(os.path.join(PROJECT_PATH, \"graspy\", \"__init__.py\")):\n if line.startswith(\"__version__ = \"):\n VERSION = line.strip().split()[2][1:-1]\n\n\ndef check_python_version():\n \"\"\"Exit when the Python version is too low.\"\"\"\n if sys.version_info < MINIMUM_PYTHON_VERSION:\n sys.exit(\"Python {}.{}+ is required.\".format(*MINIMUM_PYTHON_VERSION))\n\n\ncheck_python_version()\n\nsetup(\n name=PACKAGE_NAME,\n version=VERSION,\n description=DESCRIPTION,\n long_description=LONG_DESCRIPTION,\n long_description_content_type=\"text/markdown\",\n author=AUTHOR,\n author_email=AUTHOR_EMAIL,\n install_requires=REQUIRED_PACKAGES,\n url=URL,\n license=\"Apache License 2.0\",\n classifiers=[\n \"Development Status :: 3 - Alpha\",\n \"Intended Audience :: Science/Research\",\n \"Topic :: Scientific/Engineering :: Mathematics\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n ],\n packages=find_packages(),\n include_package_data=True,\n)\n", "path": "setup.py"}, {"content": "# -*- coding: utf-8 -*-\n#\n# Configuration file for the Sphinx documentation builder.\n#\n# This file does only contain a selection of the most common options. For a\n# full list see the documentation:\n# http://www.sphinx-doc.org/en/master/config\n\n# -- Path setup --------------------------------------------------------------\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\nimport os\nimport sys\n\nsys.path.insert(0, os.path.abspath(\"..\"))\n\n# -- Project information -----------------------------------------------------\n\nproject = \"GraSPy\"\ncopyright = \"2018\"\nauthors = u\"NeuroData\"\n\n# The short X.Y version\n# Find GraSPy version.\nPROJECT_PATH = os.path.dirname(os.path.abspath(__file__))\nfor line in open(os.path.join(PROJECT_PATH, \"..\", \"graspy\", \"__init__.py\")):\n if line.startswith(\"__version__ = \"):\n version = line.strip().split()[2][1:-1]\n\n# The full version, including alpha/beta/rc tags\nrelease = \"alpha\"\n\n# -- Extension configuration -------------------------------------------------\nextensions = [\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.autosummary\",\n \"sphinx.ext.todo\",\n \"sphinx.ext.viewcode\",\n \"sphinx.ext.mathjax\",\n \"numpydoc\",\n \"sphinx.ext.ifconfig\",\n \"sphinx.ext.githubpages\",\n \"sphinxcontrib.rawfiles\",\n \"nbsphinx\",\n \"sphinx.ext.intersphinx\",\n]\n\n# -- sphinxcontrib.rawfiles\nrawfiles = [\"CNAME\"]\n\n# -- numpydoc\n# Below is needed to prevent errors\nnumpydoc_show_class_members = False\nnumpydoc_attributes_as_param_list = True\nnumpydoc_use_blockquotes = True\n\n# -- sphinx.ext.autosummary\nautosummary_generate = True\n\n# -- sphinx.ext.autodoc\nautoclass_content = \"both\"\nautodoc_default_flags = [\"members\", \"inherited-members\"]\nautodoc_member_order = \"bysource\" # default is alphabetical\n\n# -- sphinx.ext.intersphinx\nintersphinx_mapping = {\n \"numpy\": (\"https://docs.scipy.org/doc/numpy\", None),\n \"python\": (\"https://docs.python.org/3\", None),\n \"scipy\": (\"https://docs.scipy.org/doc/scipy/reference\", None),\n \"sklearn\": (\"http://scikit-learn.org/dev\", None),\n \"hyppo\": (\"https://hyppo.neurodata.io\", None),\n}\n\n# -- sphinx options ----------------------------------------------------------\nsource_suffix = \".rst\"\nexclude_patterns = [\"_build\", \"Thumbs.db\", \".DS_Store\", \"**.ipynb_checkpoints\"]\nmaster_doc = \"index\"\nsource_encoding = \"utf-8\"\n\n# -- Options for HTML output -------------------------------------------------\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = [\"_templates\"]\nhtml_static_path = [\"_static\"]\nmodindex_common_prefix = [\"graspy.\"]\n\npygments_style = \"sphinx\"\nsmartquotes = False\n\n# Use RTD Theme\nimport sphinx_rtd_theme\n\nhtml_theme = \"sphinx_rtd_theme\"\nhtml_theme_path = [sphinx_rtd_theme.get_html_theme_path()]\nhtml_theme_options = {\n #'includehidden': False,\n \"navigation_depth\": 2,\n \"collapse_navigation\": False,\n \"navigation_depth\": 3,\n}\n\n# Custom sidebar templates, must be a dictionary that maps document names\n# to template names.\n#\n# The default sidebars (for documents that don't match any pattern) are\n# defined by theme itself. Builtin themes are using these templates by\n# default: ``['localtoc.html', 'relations.html', 'sourcelink.html',\n# 'searchbox.html']``.\n#\n# html_sidebars = {}\n\n# -- Options for HTMLHelp output ---------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = \"graspydoc\"\n\n# -- Options for LaTeX output ------------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #\n # 'papersize': 'letterpaper',\n # The font size ('10pt', '11pt' or '12pt').\n #\n # 'pointsize': '10pt',\n # Additional stuff for the LaTeX preamble.\n #\n # 'preamble': '',\n # Latex figure (float) alignment\n #\n # 'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (master_doc, \"graspy.tex\", \"GraSPy Documentation\", authors, \"manual\")\n]\n\n# -- Options for manual page output ------------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [(master_doc, \"graspy\", \"graspy Documentation\", [authors], 1)]\n\n# -- Options for Texinfo output ----------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (\n master_doc,\n \"graspy\",\n \"graspy Documentation\",\n authors,\n \"graspy\",\n \"One line description of project.\",\n \"Miscellaneous\",\n )\n]\n\n# -- Options for Epub output -------------------------------------------------\n\n# Bibliographic Dublin Core info.\nepub_title = project\n\n# The unique identifier of the text. This can be a ISBN number\n# or the project homepage.\n#\n# epub_identifier = ''\n\n# A unique identification for the text.\n#\n# epub_uid = ''\n\n# A list of files that should not be packed into the epub file.\nepub_exclude_files = [\"search.html\"]\n", "path": "docs/conf.py"}]}
| 2,756 | 236 |
gh_patches_debug_13388
|
rasdani/github-patches
|
git_diff
|
jazzband__pip-tools-1802
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
pip-sync errors when merging multiple requirements.txt files that point at the same editable install
pip-sync raises an `AttributeError: 'NoneType' object has no attribute 'specifier'` error when you try and run it with multiple requirements files that each include an editable install for the same package.
#### Environment Versions
1. OS Type: Linux
1. Python version: Python 3.9.11
1. pip version: pip 22.3
1. pip-tools version: pip-compile, version 6.9.0
#### Steps to replicate
1. Create a setup.py, dev_requirements.in, requirements.in file
```
# setup.py
from setuptools import find_packages, setup
setup(name="a", version="0.0.1", packages=find_packages())
# dev_requirements.in
-e file:.
# requirements.in
-e file:.
```
2. Run pip-compile
```
pip-compile requirements.in
pip-compile dev_requirements.in
```
3. Run pip-sync
```
pip-sync requirements.in dev_requirements.in
```
#### Expected result
I expected the editable package to install once. Similar to running `pip install -r requirements.txt -r dev_requirements.txt`
#### Actual result
`pip-sync` raised an error
Full stack trace
```
➜ scratch pip-sync requirements.txt dev_requirements.txt
Traceback (most recent call last):
File "/home/vivek/.pyenv/versions/3.9.11/bin/pip-sync", line 8, in <module>
sys.exit(cli())
File "/home/vivek/.pyenv/versions/3.9.11/lib/python3.9/site-packages/click/core.py", line 1130, in __call__
return self.main(*args, **kwargs)
File "/home/vivek/.pyenv/versions/3.9.11/lib/python3.9/site-packages/click/core.py", line 1055, in main
rv = self.invoke(ctx)
File "/home/vivek/.pyenv/versions/3.9.11/lib/python3.9/site-packages/click/core.py", line 1404, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/home/vivek/.pyenv/versions/3.9.11/lib/python3.9/site-packages/click/core.py", line 760, in invoke
return __callback(*args, **kwargs)
File "/home/vivek/.pyenv/versions/3.9.11/lib/python3.9/site-packages/piptools/scripts/sync.py", line 146, in cli
merged_requirements = sync.merge(requirements, ignore_conflicts=force)
File "/home/vivek/.pyenv/versions/3.9.11/lib/python3.9/site-packages/piptools/sync.py", line 115, in merge
if ireq.specifier != existing_ireq.specifier:
File "/home/vivek/.pyenv/versions/3.9.11/lib/python3.9/site-packages/pip/_internal/req/req_install.py", line 245, in specifier
return self.req.specifier
AttributeError: 'NoneType' object has no attribute 'specifier'
```
...
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `piptools/sync.py`
Content:
```
1 from __future__ import annotations
2
3 import collections
4 import os
5 import sys
6 import tempfile
7 from subprocess import run # nosec
8 from typing import Deque, Iterable, Mapping, ValuesView
9
10 import click
11 from pip._internal.commands.freeze import DEV_PKGS
12 from pip._internal.req import InstallRequirement
13 from pip._internal.utils.compat import stdlib_pkgs
14
15 from ._compat.pip_compat import Distribution, dist_requires
16 from .exceptions import IncompatibleRequirements
17 from .logging import log
18 from .utils import (
19 flat_map,
20 format_requirement,
21 get_hashes_from_ireq,
22 is_url_requirement,
23 key_from_ireq,
24 key_from_req,
25 )
26
27 PACKAGES_TO_IGNORE = [
28 "-markerlib",
29 "pip",
30 "pip-tools",
31 "pip-review",
32 "pkg-resources",
33 *stdlib_pkgs,
34 *DEV_PKGS,
35 ]
36
37
38 def dependency_tree(
39 installed_keys: Mapping[str, Distribution], root_key: str
40 ) -> set[str]:
41 """
42 Calculate the dependency tree for the package `root_key` and return
43 a collection of all its dependencies. Uses a DFS traversal algorithm.
44
45 `installed_keys` should be a {key: requirement} mapping, e.g.
46 {'django': from_line('django==1.8')}
47 `root_key` should be the key to return the dependency tree for.
48 """
49 dependencies = set()
50 queue: Deque[Distribution] = collections.deque()
51
52 if root_key in installed_keys:
53 dep = installed_keys[root_key]
54 queue.append(dep)
55
56 while queue:
57 v = queue.popleft()
58 key = key_from_req(v)
59 if key in dependencies:
60 continue
61
62 dependencies.add(key)
63
64 for dep_specifier in dist_requires(v):
65 dep_name = key_from_req(dep_specifier)
66 if dep_name in installed_keys:
67 dep = installed_keys[dep_name]
68
69 if dep_specifier.specifier.contains(dep.version):
70 queue.append(dep)
71
72 return dependencies
73
74
75 def get_dists_to_ignore(installed: Iterable[Distribution]) -> list[str]:
76 """
77 Returns a collection of package names to ignore when performing pip-sync,
78 based on the currently installed environment. For example, when pip-tools
79 is installed in the local environment, it should be ignored, including all
80 of its dependencies (e.g. click). When pip-tools is not installed
81 locally, click should also be installed/uninstalled depending on the given
82 requirements.
83 """
84 installed_keys = {key_from_req(r): r for r in installed}
85 return list(
86 flat_map(lambda req: dependency_tree(installed_keys, req), PACKAGES_TO_IGNORE)
87 )
88
89
90 def merge(
91 requirements: Iterable[InstallRequirement], ignore_conflicts: bool
92 ) -> ValuesView[InstallRequirement]:
93 by_key: dict[str, InstallRequirement] = {}
94
95 for ireq in requirements:
96 # Limitation: URL requirements are merged by precise string match, so
97 # "file:///example.zip#egg=example", "file:///example.zip", and
98 # "example==1.0" will not merge with each other
99 if ireq.match_markers():
100 key = key_from_ireq(ireq)
101
102 if not ignore_conflicts:
103 existing_ireq = by_key.get(key)
104 if existing_ireq:
105 # NOTE: We check equality here since we can assume that the
106 # requirements are all pinned
107 if ireq.specifier != existing_ireq.specifier:
108 raise IncompatibleRequirements(ireq, existing_ireq)
109
110 # TODO: Always pick the largest specifier in case of a conflict
111 by_key[key] = ireq
112 return by_key.values()
113
114
115 def diff_key_from_ireq(ireq: InstallRequirement) -> str:
116 """
117 Calculate a key for comparing a compiled requirement with installed modules.
118 For URL requirements, only provide a useful key if the url includes
119 #egg=name==version, which will set ireq.req.name and ireq.specifier.
120 Otherwise return ireq.link so the key will not match and the package will
121 reinstall. Reinstall is necessary to ensure that packages will reinstall
122 if the URL is changed but the version is not.
123 """
124 if is_url_requirement(ireq):
125 if (
126 ireq.req
127 and (getattr(ireq.req, "key", None) or getattr(ireq.req, "name", None))
128 and ireq.specifier
129 ):
130 return key_from_ireq(ireq)
131 return str(ireq.link)
132 return key_from_ireq(ireq)
133
134
135 def diff(
136 compiled_requirements: Iterable[InstallRequirement],
137 installed_dists: Iterable[Distribution],
138 ) -> tuple[set[InstallRequirement], set[str]]:
139 """
140 Calculate which packages should be installed or uninstalled, given a set
141 of compiled requirements and a list of currently installed modules.
142 """
143 requirements_lut = {diff_key_from_ireq(r): r for r in compiled_requirements}
144
145 satisfied = set() # holds keys
146 to_install = set() # holds InstallRequirement objects
147 to_uninstall = set() # holds keys
148
149 pkgs_to_ignore = get_dists_to_ignore(installed_dists)
150 for dist in installed_dists:
151 key = key_from_req(dist)
152 if key not in requirements_lut or not requirements_lut[key].match_markers():
153 to_uninstall.add(key)
154 elif requirements_lut[key].specifier.contains(dist.version):
155 satisfied.add(key)
156
157 for key, requirement in requirements_lut.items():
158 if key not in satisfied and requirement.match_markers():
159 to_install.add(requirement)
160
161 # Make sure to not uninstall any packages that should be ignored
162 to_uninstall -= set(pkgs_to_ignore)
163
164 return (to_install, to_uninstall)
165
166
167 def sync(
168 to_install: Iterable[InstallRequirement],
169 to_uninstall: Iterable[InstallRequirement],
170 dry_run: bool = False,
171 install_flags: list[str] | None = None,
172 ask: bool = False,
173 python_executable: str | None = None,
174 ) -> int:
175 """
176 Install and uninstalls the given sets of modules.
177 """
178 exit_code = 0
179
180 python_executable = python_executable or sys.executable
181
182 if not to_uninstall and not to_install:
183 log.info("Everything up-to-date", err=False)
184 return exit_code
185
186 pip_flags = []
187 if log.verbosity < 0:
188 pip_flags += ["-q"]
189
190 if ask:
191 dry_run = True
192
193 if dry_run:
194 if to_uninstall:
195 click.echo("Would uninstall:")
196 for pkg in sorted(to_uninstall):
197 click.echo(f" {pkg}")
198
199 if to_install:
200 click.echo("Would install:")
201 for ireq in sorted(to_install, key=key_from_ireq):
202 click.echo(f" {format_requirement(ireq)}")
203
204 exit_code = 1
205
206 if ask and click.confirm("Would you like to proceed with these changes?"):
207 dry_run = False
208 exit_code = 0
209
210 if not dry_run:
211 if to_uninstall:
212 run( # nosec
213 [
214 python_executable,
215 "-m",
216 "pip",
217 "uninstall",
218 "-y",
219 *pip_flags,
220 *sorted(to_uninstall),
221 ],
222 check=True,
223 )
224
225 if to_install:
226 if install_flags is None:
227 install_flags = []
228 # prepare requirement lines
229 req_lines = []
230 for ireq in sorted(to_install, key=key_from_ireq):
231 ireq_hashes = get_hashes_from_ireq(ireq)
232 req_lines.append(format_requirement(ireq, hashes=ireq_hashes))
233
234 # save requirement lines to a temporary file
235 tmp_req_file = tempfile.NamedTemporaryFile(mode="wt", delete=False)
236 tmp_req_file.write("\n".join(req_lines))
237 tmp_req_file.close()
238
239 try:
240 run( # nosec
241 [
242 python_executable,
243 "-m",
244 "pip",
245 "install",
246 "-r",
247 tmp_req_file.name,
248 *pip_flags,
249 *install_flags,
250 ],
251 check=True,
252 )
253 finally:
254 os.unlink(tmp_req_file.name)
255
256 return exit_code
257
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/piptools/sync.py b/piptools/sync.py
--- a/piptools/sync.py
+++ b/piptools/sync.py
@@ -104,7 +104,11 @@
if existing_ireq:
# NOTE: We check equality here since we can assume that the
# requirements are all pinned
- if ireq.specifier != existing_ireq.specifier:
+ if (
+ ireq.req
+ and existing_ireq.req
+ and ireq.specifier != existing_ireq.specifier
+ ):
raise IncompatibleRequirements(ireq, existing_ireq)
# TODO: Always pick the largest specifier in case of a conflict
|
{"golden_diff": "diff --git a/piptools/sync.py b/piptools/sync.py\n--- a/piptools/sync.py\n+++ b/piptools/sync.py\n@@ -104,7 +104,11 @@\n if existing_ireq:\n # NOTE: We check equality here since we can assume that the\n # requirements are all pinned\n- if ireq.specifier != existing_ireq.specifier:\n+ if (\n+ ireq.req\n+ and existing_ireq.req\n+ and ireq.specifier != existing_ireq.specifier\n+ ):\n raise IncompatibleRequirements(ireq, existing_ireq)\n \n # TODO: Always pick the largest specifier in case of a conflict\n", "issue": "pip-sync errors when merging multiple requirements.txt files that point at the same editable install\npip-sync raises an `AttributeError: 'NoneType' object has no attribute 'specifier'` error when you try and run it with multiple requirements files that each include an editable install for the same package.\r\n\r\n#### Environment Versions\r\n\r\n1. OS Type: Linux\r\n1. Python version: Python 3.9.11\r\n1. pip version: pip 22.3\r\n1. pip-tools version: pip-compile, version 6.9.0\r\n\r\n#### Steps to replicate\r\n1. Create a setup.py, dev_requirements.in, requirements.in file\r\n```\r\n# setup.py\r\nfrom setuptools import find_packages, setup\r\nsetup(name=\"a\", version=\"0.0.1\", packages=find_packages())\r\n\r\n# dev_requirements.in\r\n-e file:.\r\n\r\n# requirements.in\r\n-e file:.\r\n```\r\n2. Run pip-compile\r\n```\r\npip-compile requirements.in\r\npip-compile dev_requirements.in\r\n```\r\n3. Run pip-sync\r\n```\r\npip-sync requirements.in dev_requirements.in\r\n```\r\n\r\n#### Expected result\r\nI expected the editable package to install once. Similar to running `pip install -r requirements.txt -r dev_requirements.txt`\r\n\r\n\r\n#### Actual result\r\n`pip-sync` raised an error\r\nFull stack trace\r\n```\r\n\u279c scratch pip-sync requirements.txt dev_requirements.txt \r\nTraceback (most recent call last):\r\n File \"/home/vivek/.pyenv/versions/3.9.11/bin/pip-sync\", line 8, in <module>\r\n sys.exit(cli())\r\n File \"/home/vivek/.pyenv/versions/3.9.11/lib/python3.9/site-packages/click/core.py\", line 1130, in __call__\r\n return self.main(*args, **kwargs)\r\n File \"/home/vivek/.pyenv/versions/3.9.11/lib/python3.9/site-packages/click/core.py\", line 1055, in main\r\n rv = self.invoke(ctx)\r\n File \"/home/vivek/.pyenv/versions/3.9.11/lib/python3.9/site-packages/click/core.py\", line 1404, in invoke\r\n return ctx.invoke(self.callback, **ctx.params)\r\n File \"/home/vivek/.pyenv/versions/3.9.11/lib/python3.9/site-packages/click/core.py\", line 760, in invoke\r\n return __callback(*args, **kwargs)\r\n File \"/home/vivek/.pyenv/versions/3.9.11/lib/python3.9/site-packages/piptools/scripts/sync.py\", line 146, in cli\r\n merged_requirements = sync.merge(requirements, ignore_conflicts=force)\r\n File \"/home/vivek/.pyenv/versions/3.9.11/lib/python3.9/site-packages/piptools/sync.py\", line 115, in merge\r\n if ireq.specifier != existing_ireq.specifier:\r\n File \"/home/vivek/.pyenv/versions/3.9.11/lib/python3.9/site-packages/pip/_internal/req/req_install.py\", line 245, in specifier\r\n return self.req.specifier\r\nAttributeError: 'NoneType' object has no attribute 'specifier'\r\n```\r\n\r\n...\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nimport collections\nimport os\nimport sys\nimport tempfile\nfrom subprocess import run # nosec\nfrom typing import Deque, Iterable, Mapping, ValuesView\n\nimport click\nfrom pip._internal.commands.freeze import DEV_PKGS\nfrom pip._internal.req import InstallRequirement\nfrom pip._internal.utils.compat import stdlib_pkgs\n\nfrom ._compat.pip_compat import Distribution, dist_requires\nfrom .exceptions import IncompatibleRequirements\nfrom .logging import log\nfrom .utils import (\n flat_map,\n format_requirement,\n get_hashes_from_ireq,\n is_url_requirement,\n key_from_ireq,\n key_from_req,\n)\n\nPACKAGES_TO_IGNORE = [\n \"-markerlib\",\n \"pip\",\n \"pip-tools\",\n \"pip-review\",\n \"pkg-resources\",\n *stdlib_pkgs,\n *DEV_PKGS,\n]\n\n\ndef dependency_tree(\n installed_keys: Mapping[str, Distribution], root_key: str\n) -> set[str]:\n \"\"\"\n Calculate the dependency tree for the package `root_key` and return\n a collection of all its dependencies. Uses a DFS traversal algorithm.\n\n `installed_keys` should be a {key: requirement} mapping, e.g.\n {'django': from_line('django==1.8')}\n `root_key` should be the key to return the dependency tree for.\n \"\"\"\n dependencies = set()\n queue: Deque[Distribution] = collections.deque()\n\n if root_key in installed_keys:\n dep = installed_keys[root_key]\n queue.append(dep)\n\n while queue:\n v = queue.popleft()\n key = key_from_req(v)\n if key in dependencies:\n continue\n\n dependencies.add(key)\n\n for dep_specifier in dist_requires(v):\n dep_name = key_from_req(dep_specifier)\n if dep_name in installed_keys:\n dep = installed_keys[dep_name]\n\n if dep_specifier.specifier.contains(dep.version):\n queue.append(dep)\n\n return dependencies\n\n\ndef get_dists_to_ignore(installed: Iterable[Distribution]) -> list[str]:\n \"\"\"\n Returns a collection of package names to ignore when performing pip-sync,\n based on the currently installed environment. For example, when pip-tools\n is installed in the local environment, it should be ignored, including all\n of its dependencies (e.g. click). When pip-tools is not installed\n locally, click should also be installed/uninstalled depending on the given\n requirements.\n \"\"\"\n installed_keys = {key_from_req(r): r for r in installed}\n return list(\n flat_map(lambda req: dependency_tree(installed_keys, req), PACKAGES_TO_IGNORE)\n )\n\n\ndef merge(\n requirements: Iterable[InstallRequirement], ignore_conflicts: bool\n) -> ValuesView[InstallRequirement]:\n by_key: dict[str, InstallRequirement] = {}\n\n for ireq in requirements:\n # Limitation: URL requirements are merged by precise string match, so\n # \"file:///example.zip#egg=example\", \"file:///example.zip\", and\n # \"example==1.0\" will not merge with each other\n if ireq.match_markers():\n key = key_from_ireq(ireq)\n\n if not ignore_conflicts:\n existing_ireq = by_key.get(key)\n if existing_ireq:\n # NOTE: We check equality here since we can assume that the\n # requirements are all pinned\n if ireq.specifier != existing_ireq.specifier:\n raise IncompatibleRequirements(ireq, existing_ireq)\n\n # TODO: Always pick the largest specifier in case of a conflict\n by_key[key] = ireq\n return by_key.values()\n\n\ndef diff_key_from_ireq(ireq: InstallRequirement) -> str:\n \"\"\"\n Calculate a key for comparing a compiled requirement with installed modules.\n For URL requirements, only provide a useful key if the url includes\n #egg=name==version, which will set ireq.req.name and ireq.specifier.\n Otherwise return ireq.link so the key will not match and the package will\n reinstall. Reinstall is necessary to ensure that packages will reinstall\n if the URL is changed but the version is not.\n \"\"\"\n if is_url_requirement(ireq):\n if (\n ireq.req\n and (getattr(ireq.req, \"key\", None) or getattr(ireq.req, \"name\", None))\n and ireq.specifier\n ):\n return key_from_ireq(ireq)\n return str(ireq.link)\n return key_from_ireq(ireq)\n\n\ndef diff(\n compiled_requirements: Iterable[InstallRequirement],\n installed_dists: Iterable[Distribution],\n) -> tuple[set[InstallRequirement], set[str]]:\n \"\"\"\n Calculate which packages should be installed or uninstalled, given a set\n of compiled requirements and a list of currently installed modules.\n \"\"\"\n requirements_lut = {diff_key_from_ireq(r): r for r in compiled_requirements}\n\n satisfied = set() # holds keys\n to_install = set() # holds InstallRequirement objects\n to_uninstall = set() # holds keys\n\n pkgs_to_ignore = get_dists_to_ignore(installed_dists)\n for dist in installed_dists:\n key = key_from_req(dist)\n if key not in requirements_lut or not requirements_lut[key].match_markers():\n to_uninstall.add(key)\n elif requirements_lut[key].specifier.contains(dist.version):\n satisfied.add(key)\n\n for key, requirement in requirements_lut.items():\n if key not in satisfied and requirement.match_markers():\n to_install.add(requirement)\n\n # Make sure to not uninstall any packages that should be ignored\n to_uninstall -= set(pkgs_to_ignore)\n\n return (to_install, to_uninstall)\n\n\ndef sync(\n to_install: Iterable[InstallRequirement],\n to_uninstall: Iterable[InstallRequirement],\n dry_run: bool = False,\n install_flags: list[str] | None = None,\n ask: bool = False,\n python_executable: str | None = None,\n) -> int:\n \"\"\"\n Install and uninstalls the given sets of modules.\n \"\"\"\n exit_code = 0\n\n python_executable = python_executable or sys.executable\n\n if not to_uninstall and not to_install:\n log.info(\"Everything up-to-date\", err=False)\n return exit_code\n\n pip_flags = []\n if log.verbosity < 0:\n pip_flags += [\"-q\"]\n\n if ask:\n dry_run = True\n\n if dry_run:\n if to_uninstall:\n click.echo(\"Would uninstall:\")\n for pkg in sorted(to_uninstall):\n click.echo(f\" {pkg}\")\n\n if to_install:\n click.echo(\"Would install:\")\n for ireq in sorted(to_install, key=key_from_ireq):\n click.echo(f\" {format_requirement(ireq)}\")\n\n exit_code = 1\n\n if ask and click.confirm(\"Would you like to proceed with these changes?\"):\n dry_run = False\n exit_code = 0\n\n if not dry_run:\n if to_uninstall:\n run( # nosec\n [\n python_executable,\n \"-m\",\n \"pip\",\n \"uninstall\",\n \"-y\",\n *pip_flags,\n *sorted(to_uninstall),\n ],\n check=True,\n )\n\n if to_install:\n if install_flags is None:\n install_flags = []\n # prepare requirement lines\n req_lines = []\n for ireq in sorted(to_install, key=key_from_ireq):\n ireq_hashes = get_hashes_from_ireq(ireq)\n req_lines.append(format_requirement(ireq, hashes=ireq_hashes))\n\n # save requirement lines to a temporary file\n tmp_req_file = tempfile.NamedTemporaryFile(mode=\"wt\", delete=False)\n tmp_req_file.write(\"\\n\".join(req_lines))\n tmp_req_file.close()\n\n try:\n run( # nosec\n [\n python_executable,\n \"-m\",\n \"pip\",\n \"install\",\n \"-r\",\n tmp_req_file.name,\n *pip_flags,\n *install_flags,\n ],\n check=True,\n )\n finally:\n os.unlink(tmp_req_file.name)\n\n return exit_code\n", "path": "piptools/sync.py"}], "after_files": [{"content": "from __future__ import annotations\n\nimport collections\nimport os\nimport sys\nimport tempfile\nfrom subprocess import run # nosec\nfrom typing import Deque, Iterable, Mapping, ValuesView\n\nimport click\nfrom pip._internal.commands.freeze import DEV_PKGS\nfrom pip._internal.req import InstallRequirement\nfrom pip._internal.utils.compat import stdlib_pkgs\n\nfrom ._compat.pip_compat import Distribution, dist_requires\nfrom .exceptions import IncompatibleRequirements\nfrom .logging import log\nfrom .utils import (\n flat_map,\n format_requirement,\n get_hashes_from_ireq,\n is_url_requirement,\n key_from_ireq,\n key_from_req,\n)\n\nPACKAGES_TO_IGNORE = [\n \"-markerlib\",\n \"pip\",\n \"pip-tools\",\n \"pip-review\",\n \"pkg-resources\",\n *stdlib_pkgs,\n *DEV_PKGS,\n]\n\n\ndef dependency_tree(\n installed_keys: Mapping[str, Distribution], root_key: str\n) -> set[str]:\n \"\"\"\n Calculate the dependency tree for the package `root_key` and return\n a collection of all its dependencies. Uses a DFS traversal algorithm.\n\n `installed_keys` should be a {key: requirement} mapping, e.g.\n {'django': from_line('django==1.8')}\n `root_key` should be the key to return the dependency tree for.\n \"\"\"\n dependencies = set()\n queue: Deque[Distribution] = collections.deque()\n\n if root_key in installed_keys:\n dep = installed_keys[root_key]\n queue.append(dep)\n\n while queue:\n v = queue.popleft()\n key = key_from_req(v)\n if key in dependencies:\n continue\n\n dependencies.add(key)\n\n for dep_specifier in dist_requires(v):\n dep_name = key_from_req(dep_specifier)\n if dep_name in installed_keys:\n dep = installed_keys[dep_name]\n\n if dep_specifier.specifier.contains(dep.version):\n queue.append(dep)\n\n return dependencies\n\n\ndef get_dists_to_ignore(installed: Iterable[Distribution]) -> list[str]:\n \"\"\"\n Returns a collection of package names to ignore when performing pip-sync,\n based on the currently installed environment. For example, when pip-tools\n is installed in the local environment, it should be ignored, including all\n of its dependencies (e.g. click). When pip-tools is not installed\n locally, click should also be installed/uninstalled depending on the given\n requirements.\n \"\"\"\n installed_keys = {key_from_req(r): r for r in installed}\n return list(\n flat_map(lambda req: dependency_tree(installed_keys, req), PACKAGES_TO_IGNORE)\n )\n\n\ndef merge(\n requirements: Iterable[InstallRequirement], ignore_conflicts: bool\n) -> ValuesView[InstallRequirement]:\n by_key: dict[str, InstallRequirement] = {}\n\n for ireq in requirements:\n # Limitation: URL requirements are merged by precise string match, so\n # \"file:///example.zip#egg=example\", \"file:///example.zip\", and\n # \"example==1.0\" will not merge with each other\n if ireq.match_markers():\n key = key_from_ireq(ireq)\n\n if not ignore_conflicts:\n existing_ireq = by_key.get(key)\n if existing_ireq:\n # NOTE: We check equality here since we can assume that the\n # requirements are all pinned\n if (\n ireq.req\n and existing_ireq.req\n and ireq.specifier != existing_ireq.specifier\n ):\n raise IncompatibleRequirements(ireq, existing_ireq)\n\n # TODO: Always pick the largest specifier in case of a conflict\n by_key[key] = ireq\n return by_key.values()\n\n\ndef diff_key_from_ireq(ireq: InstallRequirement) -> str:\n \"\"\"\n Calculate a key for comparing a compiled requirement with installed modules.\n For URL requirements, only provide a useful key if the url includes\n #egg=name==version, which will set ireq.req.name and ireq.specifier.\n Otherwise return ireq.link so the key will not match and the package will\n reinstall. Reinstall is necessary to ensure that packages will reinstall\n if the URL is changed but the version is not.\n \"\"\"\n if is_url_requirement(ireq):\n if (\n ireq.req\n and (getattr(ireq.req, \"key\", None) or getattr(ireq.req, \"name\", None))\n and ireq.specifier\n ):\n return key_from_ireq(ireq)\n return str(ireq.link)\n return key_from_ireq(ireq)\n\n\ndef diff(\n compiled_requirements: Iterable[InstallRequirement],\n installed_dists: Iterable[Distribution],\n) -> tuple[set[InstallRequirement], set[str]]:\n \"\"\"\n Calculate which packages should be installed or uninstalled, given a set\n of compiled requirements and a list of currently installed modules.\n \"\"\"\n requirements_lut = {diff_key_from_ireq(r): r for r in compiled_requirements}\n\n satisfied = set() # holds keys\n to_install = set() # holds InstallRequirement objects\n to_uninstall = set() # holds keys\n\n pkgs_to_ignore = get_dists_to_ignore(installed_dists)\n for dist in installed_dists:\n key = key_from_req(dist)\n if key not in requirements_lut or not requirements_lut[key].match_markers():\n to_uninstall.add(key)\n elif requirements_lut[key].specifier.contains(dist.version):\n satisfied.add(key)\n\n for key, requirement in requirements_lut.items():\n if key not in satisfied and requirement.match_markers():\n to_install.add(requirement)\n\n # Make sure to not uninstall any packages that should be ignored\n to_uninstall -= set(pkgs_to_ignore)\n\n return (to_install, to_uninstall)\n\n\ndef sync(\n to_install: Iterable[InstallRequirement],\n to_uninstall: Iterable[InstallRequirement],\n dry_run: bool = False,\n install_flags: list[str] | None = None,\n ask: bool = False,\n python_executable: str | None = None,\n) -> int:\n \"\"\"\n Install and uninstalls the given sets of modules.\n \"\"\"\n exit_code = 0\n\n python_executable = python_executable or sys.executable\n\n if not to_uninstall and not to_install:\n log.info(\"Everything up-to-date\", err=False)\n return exit_code\n\n pip_flags = []\n if log.verbosity < 0:\n pip_flags += [\"-q\"]\n\n if ask:\n dry_run = True\n\n if dry_run:\n if to_uninstall:\n click.echo(\"Would uninstall:\")\n for pkg in sorted(to_uninstall):\n click.echo(f\" {pkg}\")\n\n if to_install:\n click.echo(\"Would install:\")\n for ireq in sorted(to_install, key=key_from_ireq):\n click.echo(f\" {format_requirement(ireq)}\")\n\n exit_code = 1\n\n if ask and click.confirm(\"Would you like to proceed with these changes?\"):\n dry_run = False\n exit_code = 0\n\n if not dry_run:\n if to_uninstall:\n run( # nosec\n [\n python_executable,\n \"-m\",\n \"pip\",\n \"uninstall\",\n \"-y\",\n *pip_flags,\n *sorted(to_uninstall),\n ],\n check=True,\n )\n\n if to_install:\n if install_flags is None:\n install_flags = []\n # prepare requirement lines\n req_lines = []\n for ireq in sorted(to_install, key=key_from_ireq):\n ireq_hashes = get_hashes_from_ireq(ireq)\n req_lines.append(format_requirement(ireq, hashes=ireq_hashes))\n\n # save requirement lines to a temporary file\n tmp_req_file = tempfile.NamedTemporaryFile(mode=\"wt\", delete=False)\n tmp_req_file.write(\"\\n\".join(req_lines))\n tmp_req_file.close()\n\n try:\n run( # nosec\n [\n python_executable,\n \"-m\",\n \"pip\",\n \"install\",\n \"-r\",\n tmp_req_file.name,\n *pip_flags,\n *install_flags,\n ],\n check=True,\n )\n finally:\n os.unlink(tmp_req_file.name)\n\n return exit_code\n", "path": "piptools/sync.py"}]}
| 3,458 | 162 |
gh_patches_debug_24568
|
rasdani/github-patches
|
git_diff
|
mdn__kuma-6829
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
T - Fix post-sign-ins redirect so that user lands on correct page
**Summary**
You're not taken back to where you were when you sign in. At least via the modal and GitHub.
**Steps To Reproduce (STR)**
1. Go to some page other than the home page. Be not-signed in.
2. Click sign in.
3. Click GitHub and complete your GitHub auth stuff
**Actual behavior**
I ended up back on the home page `/en-US/`. :(
**Expected behavior**
To be taken to the page I was originally on.
**Additional context**
Pretty sure this is regression but don't know if it started when we switched to a modal.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kuma/core/context_processors.py`
Content:
```
1 from urllib.parse import urlparse
2
3 from constance import config
4 from django.conf import settings
5 from django.utils import translation
6
7 from .i18n import get_language_mapping
8
9
10 def global_settings(request):
11 """Adds settings to the context."""
12
13 def clean_safe_url(url):
14 if "://" not in url:
15 # E.g. 'elasticsearch:9200'
16 url = "http://" + url
17 parsed = urlparse(url)
18 if "@" in parsed.netloc:
19 parsed = parsed._replace(
20 netloc="username:secret@" + parsed.netloc.split("@")[-1]
21 )
22 return parsed.geturl()
23
24 # TODO: Ideally, GOOGLE_ANALYTICS_ACCOUNT is only set in settings (from
25 # an environment variable) but for safe transition, we rely on
26 # constance if it hasn't been put into settings yet.
27 # Once we know with confidence, that GOOGLE_ANALYTICS_ACCOUNT is set
28 # and a valid value in the environment (for production!) then we
29 # can delete these lines of code.
30 # See https://bugzilla.mozilla.org/show_bug.cgi?id=1570076
31 google_analytics_account = getattr(settings, "GOOGLE_ANALYTICS_ACCOUNT", None)
32 if google_analytics_account is None:
33 if config.GOOGLE_ANALYTICS_ACCOUNT != "0":
34 settings.GOOGLE_ANALYTICS_ACCOUNT = config.GOOGLE_ANALYTICS_ACCOUNT
35
36 return {
37 "settings": settings,
38 # Because the 'settings.ES_URLS' might contain the username:password
39 # it's never appropriate to display in templates. So clean them up.
40 # But return it as a lambda so it only executes if really needed.
41 "safe_es_urls": lambda: [clean_safe_url(x) for x in settings.ES_URLS],
42 }
43
44
45 def i18n(request):
46 return {
47 "LANGUAGES": get_language_mapping(),
48 "LANG": (
49 settings.LANGUAGE_URL_MAP.get(translation.get_language())
50 or translation.get_language()
51 ),
52 "DIR": "rtl" if translation.get_language_bidi() else "ltr",
53 }
54
55
56 def next_url(request):
57 if (
58 hasattr(request, "path")
59 and "login" not in request.path
60 and "register" not in request.path
61 ):
62 return {"next_url": request.get_full_path()}
63 return {}
64
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kuma/core/context_processors.py b/kuma/core/context_processors.py
--- a/kuma/core/context_processors.py
+++ b/kuma/core/context_processors.py
@@ -4,6 +4,8 @@
from django.conf import settings
from django.utils import translation
+from kuma.core.urlresolvers import reverse
+
from .i18n import get_language_mapping
@@ -54,10 +56,30 @@
def next_url(request):
- if (
- hasattr(request, "path")
- and "login" not in request.path
- and "register" not in request.path
- ):
- return {"next_url": request.get_full_path()}
- return {}
+ """Return a function by the same name as the context processor.
+ That means, in the jinja templates, instead of doing
+
+ {% set url = next_url %}
+
+ you just have to do:
+
+ {% set url = next_url() %}
+
+ which means that the actual context processor function isn't executed
+ every single time any jinja template is rendered. Now, only if the
+ context processor is actually needed, it gets executed.
+
+ See https://www.peterbe.com/plog/closure-django-context-processors
+ """
+
+ def inner():
+ if hasattr(request, "path"):
+ if request.GET.get("next"):
+ if "://" not in request.GET["next"]:
+ return request.GET["next"]
+ elif reverse(settings.LOGIN_URL) != request.get_full_path():
+ # The only exception is the sign-in landing page which you get to
+ # if you can't use the auth modal.
+ return request.get_full_path()
+
+ return {"next_url": inner}
|
{"golden_diff": "diff --git a/kuma/core/context_processors.py b/kuma/core/context_processors.py\n--- a/kuma/core/context_processors.py\n+++ b/kuma/core/context_processors.py\n@@ -4,6 +4,8 @@\n from django.conf import settings\n from django.utils import translation\n \n+from kuma.core.urlresolvers import reverse\n+\n from .i18n import get_language_mapping\n \n \n@@ -54,10 +56,30 @@\n \n \n def next_url(request):\n- if (\n- hasattr(request, \"path\")\n- and \"login\" not in request.path\n- and \"register\" not in request.path\n- ):\n- return {\"next_url\": request.get_full_path()}\n- return {}\n+ \"\"\"Return a function by the same name as the context processor.\n+ That means, in the jinja templates, instead of doing\n+\n+ {% set url = next_url %}\n+\n+ you just have to do:\n+\n+ {% set url = next_url() %}\n+\n+ which means that the actual context processor function isn't executed\n+ every single time any jinja template is rendered. Now, only if the\n+ context processor is actually needed, it gets executed.\n+\n+ See https://www.peterbe.com/plog/closure-django-context-processors\n+ \"\"\"\n+\n+ def inner():\n+ if hasattr(request, \"path\"):\n+ if request.GET.get(\"next\"):\n+ if \"://\" not in request.GET[\"next\"]:\n+ return request.GET[\"next\"]\n+ elif reverse(settings.LOGIN_URL) != request.get_full_path():\n+ # The only exception is the sign-in landing page which you get to\n+ # if you can't use the auth modal.\n+ return request.get_full_path()\n+\n+ return {\"next_url\": inner}\n", "issue": "T - Fix post-sign-ins redirect so that user lands on correct page\n**Summary**\r\nYou're not taken back to where you were when you sign in. At least via the modal and GitHub.\r\n\r\n\r\n\r\n\r\n**Steps To Reproduce (STR)**\r\n\r\n\r\n1. Go to some page other than the home page. Be not-signed in.\r\n2. Click sign in. \r\n3. Click GitHub and complete your GitHub auth stuff\r\n\r\n\r\n**Actual behavior**\r\nI ended up back on the home page `/en-US/`. :(\r\n\r\n\r\n**Expected behavior**\r\nTo be taken to the page I was originally on. \r\n\r\n\r\n**Additional context**\r\nPretty sure this is regression but don't know if it started when we switched to a modal. \r\n\n", "before_files": [{"content": "from urllib.parse import urlparse\n\nfrom constance import config\nfrom django.conf import settings\nfrom django.utils import translation\n\nfrom .i18n import get_language_mapping\n\n\ndef global_settings(request):\n \"\"\"Adds settings to the context.\"\"\"\n\n def clean_safe_url(url):\n if \"://\" not in url:\n # E.g. 'elasticsearch:9200'\n url = \"http://\" + url\n parsed = urlparse(url)\n if \"@\" in parsed.netloc:\n parsed = parsed._replace(\n netloc=\"username:secret@\" + parsed.netloc.split(\"@\")[-1]\n )\n return parsed.geturl()\n\n # TODO: Ideally, GOOGLE_ANALYTICS_ACCOUNT is only set in settings (from\n # an environment variable) but for safe transition, we rely on\n # constance if it hasn't been put into settings yet.\n # Once we know with confidence, that GOOGLE_ANALYTICS_ACCOUNT is set\n # and a valid value in the environment (for production!) then we\n # can delete these lines of code.\n # See https://bugzilla.mozilla.org/show_bug.cgi?id=1570076\n google_analytics_account = getattr(settings, \"GOOGLE_ANALYTICS_ACCOUNT\", None)\n if google_analytics_account is None:\n if config.GOOGLE_ANALYTICS_ACCOUNT != \"0\":\n settings.GOOGLE_ANALYTICS_ACCOUNT = config.GOOGLE_ANALYTICS_ACCOUNT\n\n return {\n \"settings\": settings,\n # Because the 'settings.ES_URLS' might contain the username:password\n # it's never appropriate to display in templates. So clean them up.\n # But return it as a lambda so it only executes if really needed.\n \"safe_es_urls\": lambda: [clean_safe_url(x) for x in settings.ES_URLS],\n }\n\n\ndef i18n(request):\n return {\n \"LANGUAGES\": get_language_mapping(),\n \"LANG\": (\n settings.LANGUAGE_URL_MAP.get(translation.get_language())\n or translation.get_language()\n ),\n \"DIR\": \"rtl\" if translation.get_language_bidi() else \"ltr\",\n }\n\n\ndef next_url(request):\n if (\n hasattr(request, \"path\")\n and \"login\" not in request.path\n and \"register\" not in request.path\n ):\n return {\"next_url\": request.get_full_path()}\n return {}\n", "path": "kuma/core/context_processors.py"}], "after_files": [{"content": "from urllib.parse import urlparse\n\nfrom constance import config\nfrom django.conf import settings\nfrom django.utils import translation\n\nfrom kuma.core.urlresolvers import reverse\n\nfrom .i18n import get_language_mapping\n\n\ndef global_settings(request):\n \"\"\"Adds settings to the context.\"\"\"\n\n def clean_safe_url(url):\n if \"://\" not in url:\n # E.g. 'elasticsearch:9200'\n url = \"http://\" + url\n parsed = urlparse(url)\n if \"@\" in parsed.netloc:\n parsed = parsed._replace(\n netloc=\"username:secret@\" + parsed.netloc.split(\"@\")[-1]\n )\n return parsed.geturl()\n\n # TODO: Ideally, GOOGLE_ANALYTICS_ACCOUNT is only set in settings (from\n # an environment variable) but for safe transition, we rely on\n # constance if it hasn't been put into settings yet.\n # Once we know with confidence, that GOOGLE_ANALYTICS_ACCOUNT is set\n # and a valid value in the environment (for production!) then we\n # can delete these lines of code.\n # See https://bugzilla.mozilla.org/show_bug.cgi?id=1570076\n google_analytics_account = getattr(settings, \"GOOGLE_ANALYTICS_ACCOUNT\", None)\n if google_analytics_account is None:\n if config.GOOGLE_ANALYTICS_ACCOUNT != \"0\":\n settings.GOOGLE_ANALYTICS_ACCOUNT = config.GOOGLE_ANALYTICS_ACCOUNT\n\n return {\n \"settings\": settings,\n # Because the 'settings.ES_URLS' might contain the username:password\n # it's never appropriate to display in templates. So clean them up.\n # But return it as a lambda so it only executes if really needed.\n \"safe_es_urls\": lambda: [clean_safe_url(x) for x in settings.ES_URLS],\n }\n\n\ndef i18n(request):\n return {\n \"LANGUAGES\": get_language_mapping(),\n \"LANG\": (\n settings.LANGUAGE_URL_MAP.get(translation.get_language())\n or translation.get_language()\n ),\n \"DIR\": \"rtl\" if translation.get_language_bidi() else \"ltr\",\n }\n\n\ndef next_url(request):\n \"\"\"Return a function by the same name as the context processor.\n That means, in the jinja templates, instead of doing\n\n {% set url = next_url %}\n\n you just have to do:\n\n {% set url = next_url() %}\n\n which means that the actual context processor function isn't executed\n every single time any jinja template is rendered. Now, only if the\n context processor is actually needed, it gets executed.\n\n See https://www.peterbe.com/plog/closure-django-context-processors\n \"\"\"\n\n def inner():\n if hasattr(request, \"path\"):\n if request.GET.get(\"next\"):\n if \"://\" not in request.GET[\"next\"]:\n return request.GET[\"next\"]\n elif reverse(settings.LOGIN_URL) != request.get_full_path():\n # The only exception is the sign-in landing page which you get to\n # if you can't use the auth modal.\n return request.get_full_path()\n\n return {\"next_url\": inner}\n", "path": "kuma/core/context_processors.py"}]}
| 1,121 | 389 |
gh_patches_debug_9354
|
rasdani/github-patches
|
git_diff
|
huggingface__text-generation-inference-579
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Tied weight optimization for checkpoints doesn't work with text-generation-inference.
### System Info
Ubuntu 20.04
4 A10 NVIDIA GPU's
I think checkpoints saved after this feature was merged don't work with text-generation-inference.
https://github.com/huggingface/transformers/issues/23868
With falcon models getting "`lm_head` not found"
I'll add more details once I find minimal steps to reproduce.
### Information
- [X] Docker
- [ ] The CLI directly
### Tasks
- [X] An officially supported command
- [ ] My own modifications
### Reproduction
Save tiiuae/falcon-40b checkpoint using transformers==4.30.2
launch text-generation-inference server
(using transformers==4.27.4 works without issue)
### Expected behavior
Expect the text-generation-inference weight loader to be able to find the `lm_head` weight in the checkpoint. Note this may be a safetensor issue.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `server/text_generation_server/models/flash_rw.py`
Content:
```
1 import torch
2 import torch.distributed
3
4 from opentelemetry import trace
5 from transformers import AutoTokenizer
6 from typing import Optional
7
8 from text_generation_server.models import FlashCausalLM
9 from text_generation_server.models.custom_modeling.flash_rw_modeling import (
10 RWConfig,
11 FlashRWForCausalLM,
12 )
13 from text_generation_server.utils import (
14 initialize_torch_distributed,
15 weight_files,
16 Weights,
17 )
18
19 tracer = trace.get_tracer(__name__)
20
21
22 class FlashRWSharded(FlashCausalLM):
23 def __init__(
24 self,
25 model_id: str,
26 revision: Optional[str] = None,
27 quantize: Optional[str] = None,
28 dtype: Optional[torch.dtype] = None,
29 trust_remote_code: bool = False,
30 ):
31 self.process_group, rank, world_size = initialize_torch_distributed()
32 if torch.cuda.is_available():
33 device = torch.device(f"cuda:{rank}")
34 dtype = torch.float16 if dtype is None else dtype
35 else:
36 raise NotImplementedError("FlashRW is only available on GPU")
37
38 tokenizer = AutoTokenizer.from_pretrained(
39 model_id,
40 revision=revision,
41 padding_side="left",
42 truncation_side="left",
43 trust_remote_code=trust_remote_code,
44 )
45
46 config = RWConfig.from_pretrained(
47 model_id, revision=revision, trust_remote_code=trust_remote_code
48 )
49
50 torch.distributed.barrier(group=self.process_group)
51 filenames = weight_files(model_id, revision=revision, extension=".safetensors")
52 weights = Weights(filenames, device, dtype, process_group=self.process_group)
53
54 config.quantize = quantize
55
56 model = FlashRWForCausalLM(config, weights)
57
58 torch.distributed.barrier(group=self.process_group)
59 super(FlashRWSharded, self).__init__(
60 model=model.to(device),
61 tokenizer=tokenizer,
62 num_layers=len(model.transformer.h),
63 num_kv_heads=model.transformer.cache_size,
64 head_size=model.transformer.head_size,
65 dtype=dtype,
66 device=device,
67 rank=rank,
68 world_size=world_size,
69 )
70
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/server/text_generation_server/models/flash_rw.py b/server/text_generation_server/models/flash_rw.py
--- a/server/text_generation_server/models/flash_rw.py
+++ b/server/text_generation_server/models/flash_rw.py
@@ -49,7 +49,13 @@
torch.distributed.barrier(group=self.process_group)
filenames = weight_files(model_id, revision=revision, extension=".safetensors")
- weights = Weights(filenames, device, dtype, process_group=self.process_group)
+ weights = Weights(
+ filenames,
+ device,
+ dtype,
+ process_group=self.process_group,
+ aliases={"transformer.word_embeddings.weight": ["lm_head.weight"]},
+ )
config.quantize = quantize
|
{"golden_diff": "diff --git a/server/text_generation_server/models/flash_rw.py b/server/text_generation_server/models/flash_rw.py\n--- a/server/text_generation_server/models/flash_rw.py\n+++ b/server/text_generation_server/models/flash_rw.py\n@@ -49,7 +49,13 @@\n \n torch.distributed.barrier(group=self.process_group)\n filenames = weight_files(model_id, revision=revision, extension=\".safetensors\")\n- weights = Weights(filenames, device, dtype, process_group=self.process_group)\n+ weights = Weights(\n+ filenames,\n+ device,\n+ dtype,\n+ process_group=self.process_group,\n+ aliases={\"transformer.word_embeddings.weight\": [\"lm_head.weight\"]},\n+ )\n \n config.quantize = quantize\n", "issue": "Tied weight optimization for checkpoints doesn't work with text-generation-inference.\n### System Info\r\nUbuntu 20.04\r\n4 A10 NVIDIA GPU's\r\n\r\nI think checkpoints saved after this feature was merged don't work with text-generation-inference.\r\nhttps://github.com/huggingface/transformers/issues/23868\r\n\r\nWith falcon models getting \"`lm_head` not found\"\r\nI'll add more details once I find minimal steps to reproduce.\r\n\r\n### Information\r\n\r\n- [X] Docker\r\n- [ ] The CLI directly\r\n\r\n### Tasks\r\n\r\n- [X] An officially supported command\r\n- [ ] My own modifications\r\n\r\n### Reproduction\r\n\r\nSave tiiuae/falcon-40b checkpoint using transformers==4.30.2\r\nlaunch text-generation-inference server\r\n\r\n(using transformers==4.27.4 works without issue)\r\n\r\n### Expected behavior\r\n\r\nExpect the text-generation-inference weight loader to be able to find the `lm_head` weight in the checkpoint. Note this may be a safetensor issue.\n", "before_files": [{"content": "import torch\nimport torch.distributed\n\nfrom opentelemetry import trace\nfrom transformers import AutoTokenizer\nfrom typing import Optional\n\nfrom text_generation_server.models import FlashCausalLM\nfrom text_generation_server.models.custom_modeling.flash_rw_modeling import (\n RWConfig,\n FlashRWForCausalLM,\n)\nfrom text_generation_server.utils import (\n initialize_torch_distributed,\n weight_files,\n Weights,\n)\n\ntracer = trace.get_tracer(__name__)\n\n\nclass FlashRWSharded(FlashCausalLM):\n def __init__(\n self,\n model_id: str,\n revision: Optional[str] = None,\n quantize: Optional[str] = None,\n dtype: Optional[torch.dtype] = None,\n trust_remote_code: bool = False,\n ):\n self.process_group, rank, world_size = initialize_torch_distributed()\n if torch.cuda.is_available():\n device = torch.device(f\"cuda:{rank}\")\n dtype = torch.float16 if dtype is None else dtype\n else:\n raise NotImplementedError(\"FlashRW is only available on GPU\")\n\n tokenizer = AutoTokenizer.from_pretrained(\n model_id,\n revision=revision,\n padding_side=\"left\",\n truncation_side=\"left\",\n trust_remote_code=trust_remote_code,\n )\n\n config = RWConfig.from_pretrained(\n model_id, revision=revision, trust_remote_code=trust_remote_code\n )\n\n torch.distributed.barrier(group=self.process_group)\n filenames = weight_files(model_id, revision=revision, extension=\".safetensors\")\n weights = Weights(filenames, device, dtype, process_group=self.process_group)\n\n config.quantize = quantize\n\n model = FlashRWForCausalLM(config, weights)\n\n torch.distributed.barrier(group=self.process_group)\n super(FlashRWSharded, self).__init__(\n model=model.to(device),\n tokenizer=tokenizer,\n num_layers=len(model.transformer.h),\n num_kv_heads=model.transformer.cache_size,\n head_size=model.transformer.head_size,\n dtype=dtype,\n device=device,\n rank=rank,\n world_size=world_size,\n )\n", "path": "server/text_generation_server/models/flash_rw.py"}], "after_files": [{"content": "import torch\nimport torch.distributed\n\nfrom opentelemetry import trace\nfrom transformers import AutoTokenizer\nfrom typing import Optional\n\nfrom text_generation_server.models import FlashCausalLM\nfrom text_generation_server.models.custom_modeling.flash_rw_modeling import (\n RWConfig,\n FlashRWForCausalLM,\n)\nfrom text_generation_server.utils import (\n initialize_torch_distributed,\n weight_files,\n Weights,\n)\n\ntracer = trace.get_tracer(__name__)\n\n\nclass FlashRWSharded(FlashCausalLM):\n def __init__(\n self,\n model_id: str,\n revision: Optional[str] = None,\n quantize: Optional[str] = None,\n dtype: Optional[torch.dtype] = None,\n trust_remote_code: bool = False,\n ):\n self.process_group, rank, world_size = initialize_torch_distributed()\n if torch.cuda.is_available():\n device = torch.device(f\"cuda:{rank}\")\n dtype = torch.float16 if dtype is None else dtype\n else:\n raise NotImplementedError(\"FlashRW is only available on GPU\")\n\n tokenizer = AutoTokenizer.from_pretrained(\n model_id,\n revision=revision,\n padding_side=\"left\",\n truncation_side=\"left\",\n trust_remote_code=trust_remote_code,\n )\n\n config = RWConfig.from_pretrained(\n model_id, revision=revision, trust_remote_code=trust_remote_code\n )\n\n torch.distributed.barrier(group=self.process_group)\n filenames = weight_files(model_id, revision=revision, extension=\".safetensors\")\n weights = Weights(\n filenames,\n device,\n dtype,\n process_group=self.process_group,\n aliases={\"transformer.word_embeddings.weight\": [\"lm_head.weight\"]},\n )\n\n config.quantize = quantize\n\n model = FlashRWForCausalLM(config, weights)\n\n torch.distributed.barrier(group=self.process_group)\n super(FlashRWSharded, self).__init__(\n model=model.to(device),\n tokenizer=tokenizer,\n num_layers=len(model.transformer.h),\n num_kv_heads=model.transformer.cache_size,\n head_size=model.transformer.head_size,\n dtype=dtype,\n device=device,\n rank=rank,\n world_size=world_size,\n )\n", "path": "server/text_generation_server/models/flash_rw.py"}]}
| 1,066 | 166 |
gh_patches_debug_37200
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-center-index-14544
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[package] m4/1.4.19: Fails test_package with latest Conan 2.0
### Description
Trying to build with the latest version of the CCI m4 recipe results in the following error when using Conan 2
> -------- Installing (downloading, building) binaries... --------
> cmake/3.24.2: Already installed!
> m4/1.4.19: Already installed!
> m4/1.4.19: Appending PATH environment variable: /home/marc/.conan2/p/4c23d7e6a6e4b9b7/p/bin
> WARN: The use of 'env_info' is deprecated in Conan 2.0 and will be removed in Conan 2.X. Please, update your recipes unless you are maintaining compatibility with Conan 1.X
> ERROR: m4/1.4.19: 'NoneType' object has no attribute 'append'. No default values are set for components. You are probably trying to manipulate a component attribute in the 'package_info' method without defining it previously
> ERROR: Conan-2.0 test failed for 'm4'
### Package and Environment Details
* Package Name/Version: **m4/1.4.19**
* Operating System+version: **Debian 10**
* Compiler+version: **GCC 8**
* Docker image: **N/A**
* Conan version: **conan 2.0.0-dev beta5+**
* Python version: **Python 3.7.3**
### Conan profile
Profile host:
[settings]
arch=x86_64
build_type=Release
compiler=gcc
compiler.libcxx=libstdc++11
compiler.version=8
os=Linux
[options]
cmake*:bootstrap=True
[tool_requires]
!openssl*: cmake/3.24.2
Profile build:
[settings]
arch=x86_64
build_type=Release
compiler=gcc
compiler.libcxx=libstdc++11
compiler.version=8
os=Linux
[options]
cmake*:bootstrap=True
[tool_requires]
!openssl*: cmake/3.24.2
### Steps to reproduce
conan-2.0 test -pr:b tools.jinja -pr:h tools.jinja test_package m4/1.4.19
### Logs
<details><summary>Click to expand log</summary>
```
conan-2.0 test -pr:b tools.jinja -pr:h tools.jinja test_package m4/1.4.19
-------- Input profiles --------
Profile host:
[settings]
arch=x86_64
build_type=Release
compiler=gcc
compiler.libcxx=libstdc++11
compiler.version=8
os=Linux
[options]
cmake*:bootstrap=True
[tool_requires]
!openssl*: cmake/3.24.2
Profile build:
[settings]
arch=x86_64
build_type=Release
compiler=gcc
compiler.libcxx=libstdc++11
compiler.version=8
os=Linux
[options]
cmake*:bootstrap=True
[tool_requires]
!openssl*: cmake/3.24.2
-------- test_package: Computing dependency graph --------
Graph root
m4/1.4.19 (test package): /tmp/tmp.Hu84j8HryY/m4/test_package/conanfile.py
Build requirements
cmake/3.24.2#623afae5289cadc0b9f11a8f43eae83b - Cache
m4/1.4.19#d5e4c4ec85145f2a2bfea4bceef5e56a - Cache
openssl/1.1.1s#b304462aeda9923b735e6b37368c233e - Cache
-------- test_package: Computing necessary packages --------
Build requirements
cmake/3.24.2#623afae5289cadc0b9f11a8f43eae83b:ccbf287e38142241463d713141c76d0c18207a9d#5e10a6d92143344f25472aa9178b24fc - Cache
m4/1.4.19#d5e4c4ec85145f2a2bfea4bceef5e56a:3593751651824fb813502c69c971267624ced41a#028e06b2ec8f151ba5ee47e640cc2c5c - Cache
openssl/1.1.1s#b304462aeda9923b735e6b37368c233e:896855b1e3b5961bfcc08e699116d9ed588cac00#7fbe50a5f635dbba8a47e75cf8b42165 - Skip
-------- test_package: Installing packages --------
-------- Installing (downloading, building) binaries... --------
cmake/3.24.2: Already installed!
m4/1.4.19: Already installed!
m4/1.4.19: Appending PATH environment variable: /home/marc/.conan2/p/4c23d7e6a6e4b9b7/p/bin
WARN: The use of 'env_info' is deprecated in Conan 2.0 and will be removed in Conan 2.X. Please, update your recipes unless you are maintaining compatibility with Conan 1.X
ERROR: m4/1.4.19: 'NoneType' object has no attribute 'append'. No default values are set for components. You are probably trying to manipulate a component attribute in the 'package_info' method without defining it previously
ERROR: Conan-2.0 test failed for 'm4'
```
</details>
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `recipes/m4/all/conanfile.py`
Content:
```
1 from conan import ConanFile
2 from conan.tools.env import VirtualBuildEnv
3 from conan.tools.files import apply_conandata_patches, copy, export_conandata_patches, get, rmdir, save
4 from conan.tools.gnu import Autotools, AutotoolsToolchain
5 from conan.tools.layout import basic_layout
6 from conan.tools.microsoft import is_msvc, unix_path
7 from conan.tools.scm import Version
8 import os
9
10 required_conan_version = ">=1.52.0"
11
12
13 class M4Conan(ConanFile):
14 name = "m4"
15 description = "GNU M4 is an implementation of the traditional Unix macro processor"
16 topics = ("macro", "preprocessor")
17 homepage = "https://www.gnu.org/software/m4/"
18 url = "https://github.com/conan-io/conan-center-index"
19 license = "GPL-3.0-only"
20 settings = "os", "arch", "compiler", "build_type"
21
22 @property
23 def _settings_build(self):
24 return getattr(self, "settings_build", self.settings)
25
26 def export_sources(self):
27 export_conandata_patches(self)
28
29 def layout(self):
30 basic_layout(self, src_folder="src")
31
32 def package_id(self):
33 del self.info.settings.compiler
34
35 def build_requirements(self):
36 if self._settings_build.os == "Windows":
37 if not self.conf.get("tools.microsoft.bash:path", default=False, check_type=bool):
38 self.tool_requires("msys2/cci.latest")
39 self.win_bash = True
40
41 def source(self):
42 get(self, **self.conan_data["sources"][self.version],
43 destination=self.source_folder, strip_root=True)
44
45 def generate(self):
46 env = VirtualBuildEnv(self)
47 env.generate()
48
49 tc = AutotoolsToolchain(self)
50 if is_msvc(self):
51 tc.extra_cflags.append("-FS")
52 # Avoid a `Assertion Failed Dialog Box` during configure with build_type=Debug
53 # Visual Studio does not support the %n format flag:
54 # https://docs.microsoft.com/en-us/cpp/c-runtime-library/format-specification-syntax-printf-and-wprintf-functions
55 # Because the %n format is inherently insecure, it is disabled by default. If %n is encountered in a format string,
56 # the invalid parameter handler is invoked, as described in Parameter Validation. To enable %n support, see _set_printf_count_output.
57 tc.configure_args.extend([
58 "gl_cv_func_printf_directive_n=no",
59 "gl_cv_func_snprintf_directive_n=no",
60 "gl_cv_func_snprintf_directive_n=no",
61 ])
62 if self.settings.build_type in ("Debug", "RelWithDebInfo"):
63 tc.extra_ldflags.append("-PDB")
64 elif self.settings.compiler == "clang":
65 if Version(self.version) < "1.4.19":
66 tc.extra_cflags.extend([
67 "-rtlib=compiler-rt",
68 "-Wno-unused-command-line-argument",
69 ])
70 if self.settings.os == "Windows":
71 tc.configure_args.append("ac_cv_func__set_invalid_parameter_handler=yes")
72 env = tc.environment()
73 # help2man trick
74 env.prepend_path("PATH", self.source_folder)
75 # handle msvc
76 if is_msvc(self):
77 ar_wrapper = unix_path(self, os.path.join(self.source_folder, "build-aux", "ar-lib"))
78 env.define("CC", "cl -nologo")
79 env.define("CXX", "cl -nologo")
80 env.define("AR", f"{ar_wrapper} lib")
81 env.define("LD", "link")
82 env.define("NM", "dumpbin -symbols")
83 env.define("OBJDUMP", ":")
84 env.define("RANLIB", ":")
85 env.define("STRIP", ":")
86 tc.generate(env)
87
88 def _patch_sources(self):
89 apply_conandata_patches(self)
90 # dummy file for configure
91 help2man = os.path.join(self.source_folder, "help2man")
92 save(self, help2man, "#!/usr/bin/env bash\n:")
93 if os.name == "posix":
94 os.chmod(help2man, os.stat(help2man).st_mode | 0o111)
95
96 def build(self):
97 self._patch_sources()
98 autotools = Autotools(self)
99 autotools.configure()
100 autotools.make()
101
102 def package(self):
103 copy(self, "COPYING", src=self.source_folder, dst=os.path.join(self.package_folder, "licenses"))
104 autotools = Autotools(self)
105 # TODO: replace by autotools.install() once https://github.com/conan-io/conan/issues/12153 fixed
106 autotools.install(args=[f"DESTDIR={unix_path(self, self.package_folder)}"])
107 rmdir(self, os.path.join(self.package_folder, "share"))
108
109 def package_info(self):
110 self.cpp_info.libdirs = []
111 self.cpp_info.includedirs = []
112
113 # M4 environment variable is used by a lot of scripts as a way to override a hard-coded embedded m4 path
114 bin_ext = ".exe" if self.settings.os == "Windows" else ""
115 m4_bin = os.path.join(self.package_folder, "bin", f"m4{bin_ext}").replace("\\", "/")
116 self.runenv_info.define_path("M4", m4_bin)
117 self.buildenv_info.define_path("M4", m4_bin)
118
119 # TODO: to remove in conan v2
120 bin_path = os.path.join(self.package_folder, "bin")
121 self.output.info(f"Appending PATH environment variable: {bin_path}")
122 self.env_info.PATH.append(bin_path)
123 self.env_info.M4 = m4_bin
124
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/recipes/m4/all/conanfile.py b/recipes/m4/all/conanfile.py
--- a/recipes/m4/all/conanfile.py
+++ b/recipes/m4/all/conanfile.py
@@ -6,12 +6,14 @@
from conan.tools.microsoft import is_msvc, unix_path
from conan.tools.scm import Version
import os
+import shutil
-required_conan_version = ">=1.52.0"
+required_conan_version = ">=1.55.0"
class M4Conan(ConanFile):
name = "m4"
+ package_type = "application"
description = "GNU M4 is an implementation of the traditional Unix macro processor"
topics = ("macro", "preprocessor")
homepage = "https://www.gnu.org/software/m4/"
@@ -34,9 +36,9 @@
def build_requirements(self):
if self._settings_build.os == "Windows":
- if not self.conf.get("tools.microsoft.bash:path", default=False, check_type=bool):
- self.tool_requires("msys2/cci.latest")
self.win_bash = True
+ if not self.conf.get("tools.microsoft.bash:path", check_type=str):
+ self.tool_requires("msys2/cci.latest")
def source(self):
get(self, **self.conan_data["sources"][self.version],
@@ -87,11 +89,12 @@
def _patch_sources(self):
apply_conandata_patches(self)
- # dummy file for configure
- help2man = os.path.join(self.source_folder, "help2man")
- save(self, help2man, "#!/usr/bin/env bash\n:")
- if os.name == "posix":
- os.chmod(help2man, os.stat(help2man).st_mode | 0o111)
+ if shutil.which("help2man") == None:
+ # dummy file for configure
+ help2man = os.path.join(self.source_folder, "help2man")
+ save(self, help2man, "#!/usr/bin/env bash\n:")
+ if os.name == "posix":
+ os.chmod(help2man, os.stat(help2man).st_mode | 0o111)
def build(self):
self._patch_sources()
@@ -102,8 +105,7 @@
def package(self):
copy(self, "COPYING", src=self.source_folder, dst=os.path.join(self.package_folder, "licenses"))
autotools = Autotools(self)
- # TODO: replace by autotools.install() once https://github.com/conan-io/conan/issues/12153 fixed
- autotools.install(args=[f"DESTDIR={unix_path(self, self.package_folder)}"])
+ autotools.install()
rmdir(self, os.path.join(self.package_folder, "share"))
def package_info(self):
|
{"golden_diff": "diff --git a/recipes/m4/all/conanfile.py b/recipes/m4/all/conanfile.py\n--- a/recipes/m4/all/conanfile.py\n+++ b/recipes/m4/all/conanfile.py\n@@ -6,12 +6,14 @@\n from conan.tools.microsoft import is_msvc, unix_path\n from conan.tools.scm import Version\n import os\n+import shutil\n \n-required_conan_version = \">=1.52.0\"\n+required_conan_version = \">=1.55.0\"\n \n \n class M4Conan(ConanFile):\n name = \"m4\"\n+ package_type = \"application\"\n description = \"GNU M4 is an implementation of the traditional Unix macro processor\"\n topics = (\"macro\", \"preprocessor\")\n homepage = \"https://www.gnu.org/software/m4/\"\n@@ -34,9 +36,9 @@\n \n def build_requirements(self):\n if self._settings_build.os == \"Windows\":\n- if not self.conf.get(\"tools.microsoft.bash:path\", default=False, check_type=bool):\n- self.tool_requires(\"msys2/cci.latest\")\n self.win_bash = True\n+ if not self.conf.get(\"tools.microsoft.bash:path\", check_type=str):\n+ self.tool_requires(\"msys2/cci.latest\")\n \n def source(self):\n get(self, **self.conan_data[\"sources\"][self.version],\n@@ -87,11 +89,12 @@\n \n def _patch_sources(self):\n apply_conandata_patches(self)\n- # dummy file for configure\n- help2man = os.path.join(self.source_folder, \"help2man\")\n- save(self, help2man, \"#!/usr/bin/env bash\\n:\")\n- if os.name == \"posix\":\n- os.chmod(help2man, os.stat(help2man).st_mode | 0o111)\n+ if shutil.which(\"help2man\") == None:\n+ # dummy file for configure\n+ help2man = os.path.join(self.source_folder, \"help2man\")\n+ save(self, help2man, \"#!/usr/bin/env bash\\n:\")\n+ if os.name == \"posix\":\n+ os.chmod(help2man, os.stat(help2man).st_mode | 0o111)\n \n def build(self):\n self._patch_sources()\n@@ -102,8 +105,7 @@\n def package(self):\n copy(self, \"COPYING\", src=self.source_folder, dst=os.path.join(self.package_folder, \"licenses\"))\n autotools = Autotools(self)\n- # TODO: replace by autotools.install() once https://github.com/conan-io/conan/issues/12153 fixed\n- autotools.install(args=[f\"DESTDIR={unix_path(self, self.package_folder)}\"])\n+ autotools.install()\n rmdir(self, os.path.join(self.package_folder, \"share\"))\n \n def package_info(self):\n", "issue": "[package] m4/1.4.19: Fails test_package with latest Conan 2.0\n### Description\n\nTrying to build with the latest version of the CCI m4 recipe results in the following error when using Conan 2\r\n\r\n> -------- Installing (downloading, building) binaries... --------\r\n> cmake/3.24.2: Already installed!\r\n> m4/1.4.19: Already installed!\r\n> m4/1.4.19: Appending PATH environment variable: /home/marc/.conan2/p/4c23d7e6a6e4b9b7/p/bin\r\n> WARN: The use of 'env_info' is deprecated in Conan 2.0 and will be removed in Conan 2.X. Please, update your recipes unless you are maintaining compatibility with Conan 1.X\r\n> ERROR: m4/1.4.19: 'NoneType' object has no attribute 'append'. No default values are set for components. You are probably trying to manipulate a component attribute in the 'package_info' method without defining it previously\r\n> ERROR: Conan-2.0 test failed for 'm4'\n\n### Package and Environment Details\n\n* Package Name/Version: **m4/1.4.19**\r\n* Operating System+version: **Debian 10**\r\n* Compiler+version: **GCC 8**\r\n* Docker image: **N/A**\r\n* Conan version: **conan 2.0.0-dev beta5+**\r\n* Python version: **Python 3.7.3**\r\n\n\n### Conan profile\n\nProfile host:\r\n[settings]\r\narch=x86_64\r\nbuild_type=Release\r\ncompiler=gcc\r\ncompiler.libcxx=libstdc++11\r\ncompiler.version=8\r\nos=Linux\r\n[options]\r\ncmake*:bootstrap=True\r\n[tool_requires]\r\n!openssl*: cmake/3.24.2\r\n\r\nProfile build:\r\n[settings]\r\narch=x86_64\r\nbuild_type=Release\r\ncompiler=gcc\r\ncompiler.libcxx=libstdc++11\r\ncompiler.version=8\r\nos=Linux\r\n[options]\r\ncmake*:bootstrap=True\r\n[tool_requires]\r\n!openssl*: cmake/3.24.2\r\n\n\n### Steps to reproduce\n\nconan-2.0 test -pr:b tools.jinja -pr:h tools.jinja test_package m4/1.4.19\n\n### Logs\n\n<details><summary>Click to expand log</summary>\r\n\r\n```\r\nconan-2.0 test -pr:b tools.jinja -pr:h tools.jinja test_package m4/1.4.19\r\n\r\n-------- Input profiles --------\r\nProfile host:\r\n[settings]\r\narch=x86_64\r\nbuild_type=Release\r\ncompiler=gcc\r\ncompiler.libcxx=libstdc++11\r\ncompiler.version=8\r\nos=Linux\r\n[options]\r\ncmake*:bootstrap=True\r\n[tool_requires]\r\n!openssl*: cmake/3.24.2\r\n\r\nProfile build:\r\n[settings]\r\narch=x86_64\r\nbuild_type=Release\r\ncompiler=gcc\r\ncompiler.libcxx=libstdc++11\r\ncompiler.version=8\r\nos=Linux\r\n[options]\r\ncmake*:bootstrap=True\r\n[tool_requires]\r\n!openssl*: cmake/3.24.2\r\n\r\n\r\n-------- test_package: Computing dependency graph --------\r\nGraph root\r\n m4/1.4.19 (test package): /tmp/tmp.Hu84j8HryY/m4/test_package/conanfile.py\r\nBuild requirements\r\n cmake/3.24.2#623afae5289cadc0b9f11a8f43eae83b - Cache\r\n m4/1.4.19#d5e4c4ec85145f2a2bfea4bceef5e56a - Cache\r\n openssl/1.1.1s#b304462aeda9923b735e6b37368c233e - Cache\r\n\r\n-------- test_package: Computing necessary packages --------\r\nBuild requirements\r\n cmake/3.24.2#623afae5289cadc0b9f11a8f43eae83b:ccbf287e38142241463d713141c76d0c18207a9d#5e10a6d92143344f25472aa9178b24fc - Cache\r\n m4/1.4.19#d5e4c4ec85145f2a2bfea4bceef5e56a:3593751651824fb813502c69c971267624ced41a#028e06b2ec8f151ba5ee47e640cc2c5c - Cache\r\n openssl/1.1.1s#b304462aeda9923b735e6b37368c233e:896855b1e3b5961bfcc08e699116d9ed588cac00#7fbe50a5f635dbba8a47e75cf8b42165 - Skip\r\n\r\n-------- test_package: Installing packages --------\r\n\r\n-------- Installing (downloading, building) binaries... --------\r\ncmake/3.24.2: Already installed!\r\nm4/1.4.19: Already installed!\r\nm4/1.4.19: Appending PATH environment variable: /home/marc/.conan2/p/4c23d7e6a6e4b9b7/p/bin\r\nWARN: The use of 'env_info' is deprecated in Conan 2.0 and will be removed in Conan 2.X. Please, update your recipes unless you are maintaining compatibility with Conan 1.X\r\nERROR: m4/1.4.19: 'NoneType' object has no attribute 'append'. No default values are set for components. You are probably trying to manipulate a component attribute in the 'package_info' method without defining it previously\r\nERROR: Conan-2.0 test failed for 'm4'\r\n```\r\n\r\n</details>\r\n\n", "before_files": [{"content": "from conan import ConanFile\nfrom conan.tools.env import VirtualBuildEnv\nfrom conan.tools.files import apply_conandata_patches, copy, export_conandata_patches, get, rmdir, save\nfrom conan.tools.gnu import Autotools, AutotoolsToolchain\nfrom conan.tools.layout import basic_layout\nfrom conan.tools.microsoft import is_msvc, unix_path\nfrom conan.tools.scm import Version\nimport os\n\nrequired_conan_version = \">=1.52.0\"\n\n\nclass M4Conan(ConanFile):\n name = \"m4\"\n description = \"GNU M4 is an implementation of the traditional Unix macro processor\"\n topics = (\"macro\", \"preprocessor\")\n homepage = \"https://www.gnu.org/software/m4/\"\n url = \"https://github.com/conan-io/conan-center-index\"\n license = \"GPL-3.0-only\"\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n\n @property\n def _settings_build(self):\n return getattr(self, \"settings_build\", self.settings)\n\n def export_sources(self):\n export_conandata_patches(self)\n\n def layout(self):\n basic_layout(self, src_folder=\"src\")\n\n def package_id(self):\n del self.info.settings.compiler\n\n def build_requirements(self):\n if self._settings_build.os == \"Windows\":\n if not self.conf.get(\"tools.microsoft.bash:path\", default=False, check_type=bool):\n self.tool_requires(\"msys2/cci.latest\")\n self.win_bash = True\n\n def source(self):\n get(self, **self.conan_data[\"sources\"][self.version],\n destination=self.source_folder, strip_root=True)\n\n def generate(self):\n env = VirtualBuildEnv(self)\n env.generate()\n\n tc = AutotoolsToolchain(self)\n if is_msvc(self):\n tc.extra_cflags.append(\"-FS\")\n # Avoid a `Assertion Failed Dialog Box` during configure with build_type=Debug\n # Visual Studio does not support the %n format flag:\n # https://docs.microsoft.com/en-us/cpp/c-runtime-library/format-specification-syntax-printf-and-wprintf-functions\n # Because the %n format is inherently insecure, it is disabled by default. If %n is encountered in a format string,\n # the invalid parameter handler is invoked, as described in Parameter Validation. To enable %n support, see _set_printf_count_output.\n tc.configure_args.extend([\n \"gl_cv_func_printf_directive_n=no\",\n \"gl_cv_func_snprintf_directive_n=no\",\n \"gl_cv_func_snprintf_directive_n=no\",\n ])\n if self.settings.build_type in (\"Debug\", \"RelWithDebInfo\"):\n tc.extra_ldflags.append(\"-PDB\")\n elif self.settings.compiler == \"clang\":\n if Version(self.version) < \"1.4.19\":\n tc.extra_cflags.extend([\n \"-rtlib=compiler-rt\",\n \"-Wno-unused-command-line-argument\",\n ])\n if self.settings.os == \"Windows\":\n tc.configure_args.append(\"ac_cv_func__set_invalid_parameter_handler=yes\")\n env = tc.environment()\n # help2man trick\n env.prepend_path(\"PATH\", self.source_folder)\n # handle msvc\n if is_msvc(self):\n ar_wrapper = unix_path(self, os.path.join(self.source_folder, \"build-aux\", \"ar-lib\"))\n env.define(\"CC\", \"cl -nologo\")\n env.define(\"CXX\", \"cl -nologo\")\n env.define(\"AR\", f\"{ar_wrapper} lib\")\n env.define(\"LD\", \"link\")\n env.define(\"NM\", \"dumpbin -symbols\")\n env.define(\"OBJDUMP\", \":\")\n env.define(\"RANLIB\", \":\")\n env.define(\"STRIP\", \":\")\n tc.generate(env)\n\n def _patch_sources(self):\n apply_conandata_patches(self)\n # dummy file for configure\n help2man = os.path.join(self.source_folder, \"help2man\")\n save(self, help2man, \"#!/usr/bin/env bash\\n:\")\n if os.name == \"posix\":\n os.chmod(help2man, os.stat(help2man).st_mode | 0o111)\n\n def build(self):\n self._patch_sources()\n autotools = Autotools(self)\n autotools.configure()\n autotools.make()\n\n def package(self):\n copy(self, \"COPYING\", src=self.source_folder, dst=os.path.join(self.package_folder, \"licenses\"))\n autotools = Autotools(self)\n # TODO: replace by autotools.install() once https://github.com/conan-io/conan/issues/12153 fixed\n autotools.install(args=[f\"DESTDIR={unix_path(self, self.package_folder)}\"])\n rmdir(self, os.path.join(self.package_folder, \"share\"))\n\n def package_info(self):\n self.cpp_info.libdirs = []\n self.cpp_info.includedirs = []\n\n # M4 environment variable is used by a lot of scripts as a way to override a hard-coded embedded m4 path\n bin_ext = \".exe\" if self.settings.os == \"Windows\" else \"\"\n m4_bin = os.path.join(self.package_folder, \"bin\", f\"m4{bin_ext}\").replace(\"\\\\\", \"/\")\n self.runenv_info.define_path(\"M4\", m4_bin)\n self.buildenv_info.define_path(\"M4\", m4_bin)\n\n # TODO: to remove in conan v2\n bin_path = os.path.join(self.package_folder, \"bin\")\n self.output.info(f\"Appending PATH environment variable: {bin_path}\")\n self.env_info.PATH.append(bin_path)\n self.env_info.M4 = m4_bin\n", "path": "recipes/m4/all/conanfile.py"}], "after_files": [{"content": "from conan import ConanFile\nfrom conan.tools.env import VirtualBuildEnv\nfrom conan.tools.files import apply_conandata_patches, copy, export_conandata_patches, get, rmdir, save\nfrom conan.tools.gnu import Autotools, AutotoolsToolchain\nfrom conan.tools.layout import basic_layout\nfrom conan.tools.microsoft import is_msvc, unix_path\nfrom conan.tools.scm import Version\nimport os\nimport shutil\n\nrequired_conan_version = \">=1.55.0\"\n\n\nclass M4Conan(ConanFile):\n name = \"m4\"\n package_type = \"application\"\n description = \"GNU M4 is an implementation of the traditional Unix macro processor\"\n topics = (\"macro\", \"preprocessor\")\n homepage = \"https://www.gnu.org/software/m4/\"\n url = \"https://github.com/conan-io/conan-center-index\"\n license = \"GPL-3.0-only\"\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n\n @property\n def _settings_build(self):\n return getattr(self, \"settings_build\", self.settings)\n\n def export_sources(self):\n export_conandata_patches(self)\n\n def layout(self):\n basic_layout(self, src_folder=\"src\")\n\n def package_id(self):\n del self.info.settings.compiler\n\n def build_requirements(self):\n if self._settings_build.os == \"Windows\":\n self.win_bash = True\n if not self.conf.get(\"tools.microsoft.bash:path\", check_type=str):\n self.tool_requires(\"msys2/cci.latest\")\n\n def source(self):\n get(self, **self.conan_data[\"sources\"][self.version],\n destination=self.source_folder, strip_root=True)\n\n def generate(self):\n env = VirtualBuildEnv(self)\n env.generate()\n\n tc = AutotoolsToolchain(self)\n if is_msvc(self):\n tc.extra_cflags.append(\"-FS\")\n # Avoid a `Assertion Failed Dialog Box` during configure with build_type=Debug\n # Visual Studio does not support the %n format flag:\n # https://docs.microsoft.com/en-us/cpp/c-runtime-library/format-specification-syntax-printf-and-wprintf-functions\n # Because the %n format is inherently insecure, it is disabled by default. If %n is encountered in a format string,\n # the invalid parameter handler is invoked, as described in Parameter Validation. To enable %n support, see _set_printf_count_output.\n tc.configure_args.extend([\n \"gl_cv_func_printf_directive_n=no\",\n \"gl_cv_func_snprintf_directive_n=no\",\n \"gl_cv_func_snprintf_directive_n=no\",\n ])\n if self.settings.build_type in (\"Debug\", \"RelWithDebInfo\"):\n tc.extra_ldflags.append(\"-PDB\")\n elif self.settings.compiler == \"clang\":\n if Version(self.version) < \"1.4.19\":\n tc.extra_cflags.extend([\n \"-rtlib=compiler-rt\",\n \"-Wno-unused-command-line-argument\",\n ])\n if self.settings.os == \"Windows\":\n tc.configure_args.append(\"ac_cv_func__set_invalid_parameter_handler=yes\")\n env = tc.environment()\n # help2man trick\n env.prepend_path(\"PATH\", self.source_folder)\n # handle msvc\n if is_msvc(self):\n ar_wrapper = unix_path(self, os.path.join(self.source_folder, \"build-aux\", \"ar-lib\"))\n env.define(\"CC\", \"cl -nologo\")\n env.define(\"CXX\", \"cl -nologo\")\n env.define(\"AR\", f\"{ar_wrapper} lib\")\n env.define(\"LD\", \"link\")\n env.define(\"NM\", \"dumpbin -symbols\")\n env.define(\"OBJDUMP\", \":\")\n env.define(\"RANLIB\", \":\")\n env.define(\"STRIP\", \":\")\n tc.generate(env)\n\n def _patch_sources(self):\n apply_conandata_patches(self)\n if shutil.which(\"help2man\") == None:\n # dummy file for configure\n help2man = os.path.join(self.source_folder, \"help2man\")\n save(self, help2man, \"#!/usr/bin/env bash\\n:\")\n if os.name == \"posix\":\n os.chmod(help2man, os.stat(help2man).st_mode | 0o111)\n\n def build(self):\n self._patch_sources()\n autotools = Autotools(self)\n autotools.configure()\n autotools.make()\n\n def package(self):\n copy(self, \"COPYING\", src=self.source_folder, dst=os.path.join(self.package_folder, \"licenses\"))\n autotools = Autotools(self)\n autotools.install()\n rmdir(self, os.path.join(self.package_folder, \"share\"))\n\n def package_info(self):\n self.cpp_info.libdirs = []\n self.cpp_info.includedirs = []\n\n # M4 environment variable is used by a lot of scripts as a way to override a hard-coded embedded m4 path\n bin_ext = \".exe\" if self.settings.os == \"Windows\" else \"\"\n m4_bin = os.path.join(self.package_folder, \"bin\", f\"m4{bin_ext}\").replace(\"\\\\\", \"/\")\n self.runenv_info.define_path(\"M4\", m4_bin)\n self.buildenv_info.define_path(\"M4\", m4_bin)\n\n # TODO: to remove in conan v2\n bin_path = os.path.join(self.package_folder, \"bin\")\n self.output.info(f\"Appending PATH environment variable: {bin_path}\")\n self.env_info.PATH.append(bin_path)\n self.env_info.M4 = m4_bin\n", "path": "recipes/m4/all/conanfile.py"}]}
| 3,191 | 652 |
gh_patches_debug_38598
|
rasdani/github-patches
|
git_diff
|
apache__airflow-32382
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add DagProcessor status to health endpoint.
### Description
Add DagProcessor status including latest heartbeat to health endpoint similar to Triggerer status added recently. Related PRs.
https://github.com/apache/airflow/pull/31529
https://github.com/apache/airflow/pull/27755
### Use case/motivation
It helps in dag processor monitoring
### Related issues
_No response_
### Are you willing to submit a PR?
- [X] Yes I am willing to submit a PR!
### Code of Conduct
- [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `airflow/api_connexion/schemas/health_schema.py`
Content:
```
1 # Licensed to the Apache Software Foundation (ASF) under one
2 # or more contributor license agreements. See the NOTICE file
3 # distributed with this work for additional information
4 # regarding copyright ownership. The ASF licenses this file
5 # to you under the Apache License, Version 2.0 (the
6 # "License"); you may not use this file except in compliance
7 # with the License. You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing,
12 # software distributed under the License is distributed on an
13 # "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
14 # KIND, either express or implied. See the License for the
15 # specific language governing permissions and limitations
16 # under the License.
17 from __future__ import annotations
18
19 from marshmallow import Schema, fields
20
21
22 class BaseInfoSchema(Schema):
23 """Base status field for metadatabase and scheduler."""
24
25 status = fields.String(dump_only=True)
26
27
28 class MetaDatabaseInfoSchema(BaseInfoSchema):
29 """Schema for Metadatabase info."""
30
31
32 class SchedulerInfoSchema(BaseInfoSchema):
33 """Schema for Scheduler info."""
34
35 latest_scheduler_heartbeat = fields.String(dump_only=True)
36
37
38 class TriggererInfoSchema(BaseInfoSchema):
39 """Schema for Triggerer info."""
40
41 latest_triggerer_heartbeat = fields.String(dump_only=True)
42
43
44 class HealthInfoSchema(Schema):
45 """Schema for the Health endpoint."""
46
47 metadatabase = fields.Nested(MetaDatabaseInfoSchema)
48 scheduler = fields.Nested(SchedulerInfoSchema)
49 triggerer = fields.Nested(TriggererInfoSchema)
50
51
52 health_schema = HealthInfoSchema()
53
```
Path: `airflow/api/common/airflow_health.py`
Content:
```
1 # Licensed to the Apache Software Foundation (ASF) under one
2 # or more contributor license agreements. See the NOTICE file
3 # distributed with this work for additional information
4 # regarding copyright ownership. The ASF licenses this file
5 # to you under the Apache License, Version 2.0 (the
6 # "License"); you may not use this file except in compliance
7 # with the License. You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing,
12 # software distributed under the License is distributed on an
13 # "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
14 # KIND, either express or implied. See the License for the
15 # specific language governing permissions and limitations
16 # under the License.
17 from __future__ import annotations
18
19 from typing import Any
20
21 from airflow.jobs.scheduler_job_runner import SchedulerJobRunner
22 from airflow.jobs.triggerer_job_runner import TriggererJobRunner
23
24 HEALTHY = "healthy"
25 UNHEALTHY = "unhealthy"
26
27
28 def get_airflow_health() -> dict[str, Any]:
29 """Get the health for Airflow metadatabase, scheduler and triggerer."""
30 metadatabase_status = HEALTHY
31 latest_scheduler_heartbeat = None
32 latest_triggerer_heartbeat = None
33 scheduler_status = UNHEALTHY
34 triggerer_status: str | None = UNHEALTHY
35
36 try:
37 latest_scheduler_job = SchedulerJobRunner.most_recent_job()
38
39 if latest_scheduler_job:
40 latest_scheduler_heartbeat = latest_scheduler_job.latest_heartbeat.isoformat()
41 if latest_scheduler_job.is_alive():
42 scheduler_status = HEALTHY
43 except Exception:
44 metadatabase_status = UNHEALTHY
45
46 try:
47 latest_triggerer_job = TriggererJobRunner.most_recent_job()
48
49 if latest_triggerer_job:
50 latest_triggerer_heartbeat = latest_triggerer_job.latest_heartbeat.isoformat()
51 if latest_triggerer_job.is_alive():
52 triggerer_status = HEALTHY
53 else:
54 triggerer_status = None
55 except Exception:
56 metadatabase_status = UNHEALTHY
57
58 airflow_health_status = {
59 "metadatabase": {"status": metadatabase_status},
60 "scheduler": {
61 "status": scheduler_status,
62 "latest_scheduler_heartbeat": latest_scheduler_heartbeat,
63 },
64 "triggerer": {
65 "status": triggerer_status,
66 "latest_triggerer_heartbeat": latest_triggerer_heartbeat,
67 },
68 }
69
70 return airflow_health_status
71
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/airflow/api/common/airflow_health.py b/airflow/api/common/airflow_health.py
--- a/airflow/api/common/airflow_health.py
+++ b/airflow/api/common/airflow_health.py
@@ -18,6 +18,7 @@
from typing import Any
+from airflow.jobs.dag_processor_job_runner import DagProcessorJobRunner
from airflow.jobs.scheduler_job_runner import SchedulerJobRunner
from airflow.jobs.triggerer_job_runner import TriggererJobRunner
@@ -30,8 +31,10 @@
metadatabase_status = HEALTHY
latest_scheduler_heartbeat = None
latest_triggerer_heartbeat = None
+ latest_dag_processor_heartbeat = None
scheduler_status = UNHEALTHY
triggerer_status: str | None = UNHEALTHY
+ dag_processor_status: str | None = UNHEALTHY
try:
latest_scheduler_job = SchedulerJobRunner.most_recent_job()
@@ -55,6 +58,18 @@
except Exception:
metadatabase_status = UNHEALTHY
+ try:
+ latest_dag_processor_job = DagProcessorJobRunner.most_recent_job()
+
+ if latest_dag_processor_job:
+ latest_dag_processor_heartbeat = latest_dag_processor_job.latest_heartbeat.isoformat()
+ if latest_dag_processor_job.is_alive():
+ dag_processor_status = HEALTHY
+ else:
+ dag_processor_status = None
+ except Exception:
+ metadatabase_status = UNHEALTHY
+
airflow_health_status = {
"metadatabase": {"status": metadatabase_status},
"scheduler": {
@@ -65,6 +80,10 @@
"status": triggerer_status,
"latest_triggerer_heartbeat": latest_triggerer_heartbeat,
},
+ "dag_processor": {
+ "status": dag_processor_status,
+ "latest_dag_processor_heartbeat": latest_dag_processor_heartbeat,
+ },
}
return airflow_health_status
diff --git a/airflow/api_connexion/schemas/health_schema.py b/airflow/api_connexion/schemas/health_schema.py
--- a/airflow/api_connexion/schemas/health_schema.py
+++ b/airflow/api_connexion/schemas/health_schema.py
@@ -41,12 +41,19 @@
latest_triggerer_heartbeat = fields.String(dump_only=True)
+class DagProcessorInfoSchema(BaseInfoSchema):
+ """Schema for DagProcessor info."""
+
+ latest_dag_processor_heartbeat = fields.String(dump_only=True)
+
+
class HealthInfoSchema(Schema):
"""Schema for the Health endpoint."""
metadatabase = fields.Nested(MetaDatabaseInfoSchema)
scheduler = fields.Nested(SchedulerInfoSchema)
triggerer = fields.Nested(TriggererInfoSchema)
+ dag_processor = fields.Nested(DagProcessorInfoSchema)
health_schema = HealthInfoSchema()
|
{"golden_diff": "diff --git a/airflow/api/common/airflow_health.py b/airflow/api/common/airflow_health.py\n--- a/airflow/api/common/airflow_health.py\n+++ b/airflow/api/common/airflow_health.py\n@@ -18,6 +18,7 @@\n \n from typing import Any\n \n+from airflow.jobs.dag_processor_job_runner import DagProcessorJobRunner\n from airflow.jobs.scheduler_job_runner import SchedulerJobRunner\n from airflow.jobs.triggerer_job_runner import TriggererJobRunner\n \n@@ -30,8 +31,10 @@\n metadatabase_status = HEALTHY\n latest_scheduler_heartbeat = None\n latest_triggerer_heartbeat = None\n+ latest_dag_processor_heartbeat = None\n scheduler_status = UNHEALTHY\n triggerer_status: str | None = UNHEALTHY\n+ dag_processor_status: str | None = UNHEALTHY\n \n try:\n latest_scheduler_job = SchedulerJobRunner.most_recent_job()\n@@ -55,6 +58,18 @@\n except Exception:\n metadatabase_status = UNHEALTHY\n \n+ try:\n+ latest_dag_processor_job = DagProcessorJobRunner.most_recent_job()\n+\n+ if latest_dag_processor_job:\n+ latest_dag_processor_heartbeat = latest_dag_processor_job.latest_heartbeat.isoformat()\n+ if latest_dag_processor_job.is_alive():\n+ dag_processor_status = HEALTHY\n+ else:\n+ dag_processor_status = None\n+ except Exception:\n+ metadatabase_status = UNHEALTHY\n+\n airflow_health_status = {\n \"metadatabase\": {\"status\": metadatabase_status},\n \"scheduler\": {\n@@ -65,6 +80,10 @@\n \"status\": triggerer_status,\n \"latest_triggerer_heartbeat\": latest_triggerer_heartbeat,\n },\n+ \"dag_processor\": {\n+ \"status\": dag_processor_status,\n+ \"latest_dag_processor_heartbeat\": latest_dag_processor_heartbeat,\n+ },\n }\n \n return airflow_health_status\ndiff --git a/airflow/api_connexion/schemas/health_schema.py b/airflow/api_connexion/schemas/health_schema.py\n--- a/airflow/api_connexion/schemas/health_schema.py\n+++ b/airflow/api_connexion/schemas/health_schema.py\n@@ -41,12 +41,19 @@\n latest_triggerer_heartbeat = fields.String(dump_only=True)\n \n \n+class DagProcessorInfoSchema(BaseInfoSchema):\n+ \"\"\"Schema for DagProcessor info.\"\"\"\n+\n+ latest_dag_processor_heartbeat = fields.String(dump_only=True)\n+\n+\n class HealthInfoSchema(Schema):\n \"\"\"Schema for the Health endpoint.\"\"\"\n \n metadatabase = fields.Nested(MetaDatabaseInfoSchema)\n scheduler = fields.Nested(SchedulerInfoSchema)\n triggerer = fields.Nested(TriggererInfoSchema)\n+ dag_processor = fields.Nested(DagProcessorInfoSchema)\n \n \n health_schema = HealthInfoSchema()\n", "issue": "Add DagProcessor status to health endpoint.\n### Description\n\nAdd DagProcessor status including latest heartbeat to health endpoint similar to Triggerer status added recently. Related PRs.\r\n\r\nhttps://github.com/apache/airflow/pull/31529\r\nhttps://github.com/apache/airflow/pull/27755\n\n### Use case/motivation\n\nIt helps in dag processor monitoring \n\n### Related issues\n\n_No response_\n\n### Are you willing to submit a PR?\n\n- [X] Yes I am willing to submit a PR!\n\n### Code of Conduct\n\n- [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md)\n\n", "before_files": [{"content": "# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\nfrom __future__ import annotations\n\nfrom marshmallow import Schema, fields\n\n\nclass BaseInfoSchema(Schema):\n \"\"\"Base status field for metadatabase and scheduler.\"\"\"\n\n status = fields.String(dump_only=True)\n\n\nclass MetaDatabaseInfoSchema(BaseInfoSchema):\n \"\"\"Schema for Metadatabase info.\"\"\"\n\n\nclass SchedulerInfoSchema(BaseInfoSchema):\n \"\"\"Schema for Scheduler info.\"\"\"\n\n latest_scheduler_heartbeat = fields.String(dump_only=True)\n\n\nclass TriggererInfoSchema(BaseInfoSchema):\n \"\"\"Schema for Triggerer info.\"\"\"\n\n latest_triggerer_heartbeat = fields.String(dump_only=True)\n\n\nclass HealthInfoSchema(Schema):\n \"\"\"Schema for the Health endpoint.\"\"\"\n\n metadatabase = fields.Nested(MetaDatabaseInfoSchema)\n scheduler = fields.Nested(SchedulerInfoSchema)\n triggerer = fields.Nested(TriggererInfoSchema)\n\n\nhealth_schema = HealthInfoSchema()\n", "path": "airflow/api_connexion/schemas/health_schema.py"}, {"content": "# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\nfrom __future__ import annotations\n\nfrom typing import Any\n\nfrom airflow.jobs.scheduler_job_runner import SchedulerJobRunner\nfrom airflow.jobs.triggerer_job_runner import TriggererJobRunner\n\nHEALTHY = \"healthy\"\nUNHEALTHY = \"unhealthy\"\n\n\ndef get_airflow_health() -> dict[str, Any]:\n \"\"\"Get the health for Airflow metadatabase, scheduler and triggerer.\"\"\"\n metadatabase_status = HEALTHY\n latest_scheduler_heartbeat = None\n latest_triggerer_heartbeat = None\n scheduler_status = UNHEALTHY\n triggerer_status: str | None = UNHEALTHY\n\n try:\n latest_scheduler_job = SchedulerJobRunner.most_recent_job()\n\n if latest_scheduler_job:\n latest_scheduler_heartbeat = latest_scheduler_job.latest_heartbeat.isoformat()\n if latest_scheduler_job.is_alive():\n scheduler_status = HEALTHY\n except Exception:\n metadatabase_status = UNHEALTHY\n\n try:\n latest_triggerer_job = TriggererJobRunner.most_recent_job()\n\n if latest_triggerer_job:\n latest_triggerer_heartbeat = latest_triggerer_job.latest_heartbeat.isoformat()\n if latest_triggerer_job.is_alive():\n triggerer_status = HEALTHY\n else:\n triggerer_status = None\n except Exception:\n metadatabase_status = UNHEALTHY\n\n airflow_health_status = {\n \"metadatabase\": {\"status\": metadatabase_status},\n \"scheduler\": {\n \"status\": scheduler_status,\n \"latest_scheduler_heartbeat\": latest_scheduler_heartbeat,\n },\n \"triggerer\": {\n \"status\": triggerer_status,\n \"latest_triggerer_heartbeat\": latest_triggerer_heartbeat,\n },\n }\n\n return airflow_health_status\n", "path": "airflow/api/common/airflow_health.py"}], "after_files": [{"content": "# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\nfrom __future__ import annotations\n\nfrom marshmallow import Schema, fields\n\n\nclass BaseInfoSchema(Schema):\n \"\"\"Base status field for metadatabase and scheduler.\"\"\"\n\n status = fields.String(dump_only=True)\n\n\nclass MetaDatabaseInfoSchema(BaseInfoSchema):\n \"\"\"Schema for Metadatabase info.\"\"\"\n\n\nclass SchedulerInfoSchema(BaseInfoSchema):\n \"\"\"Schema for Scheduler info.\"\"\"\n\n latest_scheduler_heartbeat = fields.String(dump_only=True)\n\n\nclass TriggererInfoSchema(BaseInfoSchema):\n \"\"\"Schema for Triggerer info.\"\"\"\n\n latest_triggerer_heartbeat = fields.String(dump_only=True)\n\n\nclass DagProcessorInfoSchema(BaseInfoSchema):\n \"\"\"Schema for DagProcessor info.\"\"\"\n\n latest_dag_processor_heartbeat = fields.String(dump_only=True)\n\n\nclass HealthInfoSchema(Schema):\n \"\"\"Schema for the Health endpoint.\"\"\"\n\n metadatabase = fields.Nested(MetaDatabaseInfoSchema)\n scheduler = fields.Nested(SchedulerInfoSchema)\n triggerer = fields.Nested(TriggererInfoSchema)\n dag_processor = fields.Nested(DagProcessorInfoSchema)\n\n\nhealth_schema = HealthInfoSchema()\n", "path": "airflow/api_connexion/schemas/health_schema.py"}, {"content": "# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\nfrom __future__ import annotations\n\nfrom typing import Any\n\nfrom airflow.jobs.dag_processor_job_runner import DagProcessorJobRunner\nfrom airflow.jobs.scheduler_job_runner import SchedulerJobRunner\nfrom airflow.jobs.triggerer_job_runner import TriggererJobRunner\n\nHEALTHY = \"healthy\"\nUNHEALTHY = \"unhealthy\"\n\n\ndef get_airflow_health() -> dict[str, Any]:\n \"\"\"Get the health for Airflow metadatabase, scheduler and triggerer.\"\"\"\n metadatabase_status = HEALTHY\n latest_scheduler_heartbeat = None\n latest_triggerer_heartbeat = None\n latest_dag_processor_heartbeat = None\n scheduler_status = UNHEALTHY\n triggerer_status: str | None = UNHEALTHY\n dag_processor_status: str | None = UNHEALTHY\n\n try:\n latest_scheduler_job = SchedulerJobRunner.most_recent_job()\n\n if latest_scheduler_job:\n latest_scheduler_heartbeat = latest_scheduler_job.latest_heartbeat.isoformat()\n if latest_scheduler_job.is_alive():\n scheduler_status = HEALTHY\n except Exception:\n metadatabase_status = UNHEALTHY\n\n try:\n latest_triggerer_job = TriggererJobRunner.most_recent_job()\n\n if latest_triggerer_job:\n latest_triggerer_heartbeat = latest_triggerer_job.latest_heartbeat.isoformat()\n if latest_triggerer_job.is_alive():\n triggerer_status = HEALTHY\n else:\n triggerer_status = None\n except Exception:\n metadatabase_status = UNHEALTHY\n\n try:\n latest_dag_processor_job = DagProcessorJobRunner.most_recent_job()\n\n if latest_dag_processor_job:\n latest_dag_processor_heartbeat = latest_dag_processor_job.latest_heartbeat.isoformat()\n if latest_dag_processor_job.is_alive():\n dag_processor_status = HEALTHY\n else:\n dag_processor_status = None\n except Exception:\n metadatabase_status = UNHEALTHY\n\n airflow_health_status = {\n \"metadatabase\": {\"status\": metadatabase_status},\n \"scheduler\": {\n \"status\": scheduler_status,\n \"latest_scheduler_heartbeat\": latest_scheduler_heartbeat,\n },\n \"triggerer\": {\n \"status\": triggerer_status,\n \"latest_triggerer_heartbeat\": latest_triggerer_heartbeat,\n },\n \"dag_processor\": {\n \"status\": dag_processor_status,\n \"latest_dag_processor_heartbeat\": latest_dag_processor_heartbeat,\n },\n }\n\n return airflow_health_status\n", "path": "airflow/api/common/airflow_health.py"}]}
| 1,584 | 652 |
gh_patches_debug_31339
|
rasdani/github-patches
|
git_diff
|
pwndbg__pwndbg-1853
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Better exception handling for unmet dependencies
Some of our users update Pwndbg only by `git pull`ing the newest version and not re-running `setup.sh`. If that happens and when we updated our dependencies recently, the user may end up with broken Pwndbg such as (likely) happened in https://github.com/pwndbg/pwndbg/issues/1790.
We should do the two following things:
1) When we detect/handle an exception in the [`pwndbg/exception.py:handle` function]( https://github.com/pwndbg/pwndbg/blob/de4acb2f40da3b0c97353a8b680ffa6440346f7b/pwndbg/exception.py#L61-L96), we should check the installed dependencies versions against the required ones and if they do not match, we should inform the user to update them.
2) We may want to display installed dependencies versions within the `bugreport` command output?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pwndbg/exception.py`
Content:
```
1 from __future__ import annotations
2
3 import functools
4 import sys
5 import traceback
6
7 import gdb
8
9 import pwndbg.lib.cache
10 import pwndbg.lib.stdio
11 from pwndbg.color import message
12 from pwndbg.gdblib import config
13
14 with pwndbg.lib.stdio.stdio:
15 try:
16 import ipdb as pdb
17 except ImportError:
18 import pdb
19 try:
20 from rich.console import Console
21
22 _rich_console = Console()
23 except ImportError:
24 _rich_console = None
25
26 verbose = config.add_param(
27 "exception-verbose",
28 False,
29 "whether to print a full stacktrace for exceptions raised in Pwndbg commands",
30 )
31 debug = config.add_param(
32 "exception-debugger", False, "whether to debug exceptions raised in Pwndbg commands"
33 )
34
35
36 @pwndbg.lib.cache.cache_until("forever")
37 def inform_report_issue(exception_msg) -> None:
38 """
39 Informs user that he can report an issue.
40 The use of caching makes it reporting only once for a given exception message.
41 """
42 print(
43 message.notice(
44 "If that is an issue, you can report it on https://github.com/pwndbg/pwndbg/issues\n"
45 "(Please don't forget to search if it hasn't been reported before)\n"
46 "To generate the report and open a browser, you may run "
47 )
48 + message.hint("`bugreport --run-browser`")
49 + message.notice("\nPS: Pull requests are welcome")
50 )
51
52
53 def inform_verbose_and_debug() -> None:
54 print(
55 message.notice("For more info invoke `")
56 + message.hint("set exception-verbose on")
57 + message.notice("` and rerun the command\nor debug it by yourself with `")
58 + message.hint("set exception-debugger on")
59 + message.notice("`")
60 )
61
62
63 def handle(name="Error"):
64 """Displays an exception to the user, optionally displaying a full traceback
65 and spawning an interactive post-moretem debugger.
66
67 Notes:
68 - ``set exception-verbose on`` enables stack traces.
69 - ``set exception-debugger on`` enables the post-mortem debugger.
70 """
71
72 # This is for unit tests so they fail on exceptions instead of displaying them.
73 if getattr(sys, "_pwndbg_unittest_run", False) is True:
74 E, V, T = sys.exc_info()
75 e = E(V)
76 e.__traceback__ = T
77 raise e
78
79 # Display the error
80 if debug or verbose:
81 exception_msg = traceback.format_exc()
82 if _rich_console:
83 _rich_console.print_exception()
84 else:
85 print(exception_msg)
86 inform_report_issue(exception_msg)
87
88 else:
89 exc_type, exc_value, exc_traceback = sys.exc_info()
90
91 print(message.error(f"Exception occurred: {name}: {exc_value} ({exc_type})"))
92
93 inform_verbose_and_debug()
94
95 # Break into the interactive debugger
96 if debug:
97 with pwndbg.lib.stdio.stdio:
98 pdb.post_mortem()
99
100
101 @functools.wraps(pdb.set_trace)
102 def set_trace() -> None:
103 """Enable sane debugging in Pwndbg by switching to the "real" stdio."""
104 debugger = pdb.Pdb(
105 stdin=sys.__stdin__, stdout=sys.__stdout__, skip=["pwndbg.lib.stdio", "pwndbg.exception"]
106 )
107 debugger.set_trace()
108
109
110 pdb.set_trace = set_trace
111
112
113 @config.trigger(verbose, debug)
114 def update() -> None:
115 if verbose or debug:
116 command = "set python print-stack full"
117 else:
118 command = "set python print-stack message"
119
120 gdb.execute(command, from_tty=True, to_string=True)
121
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pwndbg/exception.py b/pwndbg/exception.py
--- a/pwndbg/exception.py
+++ b/pwndbg/exception.py
@@ -1,10 +1,12 @@
from __future__ import annotations
import functools
+import os
import sys
import traceback
import gdb
+import pkg_resources
import pwndbg.lib.cache
import pwndbg.lib.stdio
@@ -33,6 +35,41 @@
)
+def inform_unmet_dependencies(errors) -> None:
+ """
+ Informs user about unmet dependencies
+ """
+ msg = message.error("You appear to have unmet Pwndbg dependencies.\n")
+ for e in errors:
+ if isinstance(e, pkg_resources.DistributionNotFound):
+ msg += message.notice(f"- required {e.args[0]}, but not installed\n")
+ else:
+ msg += message.notice(f"- required {e.args[1]}, installed: {e.args[0]}\n")
+ msg += message.notice("Consider running: ")
+ msg += message.hint("`setup.sh` ")
+ msg += message.notice("from Pwndbg project directory.\n")
+ print(msg)
+
+
[email protected]_until("forever")
+def check_dependencies():
+ """
+ Checks if there are any unmet dependencies in requirements.txt
+ """
+ project_path = os.path.dirname(os.path.abspath(__file__))
+ requirements_path = os.path.join(project_path, os.pardir, "requirements.txt")
+ with open(requirements_path, "r") as f:
+ errors = []
+ for line in f.readlines():
+ try:
+ pkg_resources.require(line)
+ except (pkg_resources.VersionConflict, pkg_resources.DistributionNotFound) as e:
+ errors.append(e)
+
+ if errors:
+ inform_unmet_dependencies(errors)
+
+
@pwndbg.lib.cache.cache_until("forever")
def inform_report_issue(exception_msg) -> None:
"""
@@ -76,6 +113,9 @@
e.__traceback__ = T
raise e
+ # Check dependencies against requirements.txt and warn user
+ check_dependencies()
+
# Display the error
if debug or verbose:
exception_msg = traceback.format_exc()
|
{"golden_diff": "diff --git a/pwndbg/exception.py b/pwndbg/exception.py\n--- a/pwndbg/exception.py\n+++ b/pwndbg/exception.py\n@@ -1,10 +1,12 @@\n from __future__ import annotations\n \n import functools\n+import os\n import sys\n import traceback\n \n import gdb\n+import pkg_resources\n \n import pwndbg.lib.cache\n import pwndbg.lib.stdio\n@@ -33,6 +35,41 @@\n )\n \n \n+def inform_unmet_dependencies(errors) -> None:\n+ \"\"\"\n+ Informs user about unmet dependencies\n+ \"\"\"\n+ msg = message.error(\"You appear to have unmet Pwndbg dependencies.\\n\")\n+ for e in errors:\n+ if isinstance(e, pkg_resources.DistributionNotFound):\n+ msg += message.notice(f\"- required {e.args[0]}, but not installed\\n\")\n+ else:\n+ msg += message.notice(f\"- required {e.args[1]}, installed: {e.args[0]}\\n\")\n+ msg += message.notice(\"Consider running: \")\n+ msg += message.hint(\"`setup.sh` \")\n+ msg += message.notice(\"from Pwndbg project directory.\\n\")\n+ print(msg)\n+\n+\[email protected]_until(\"forever\")\n+def check_dependencies():\n+ \"\"\"\n+ Checks if there are any unmet dependencies in requirements.txt\n+ \"\"\"\n+ project_path = os.path.dirname(os.path.abspath(__file__))\n+ requirements_path = os.path.join(project_path, os.pardir, \"requirements.txt\")\n+ with open(requirements_path, \"r\") as f:\n+ errors = []\n+ for line in f.readlines():\n+ try:\n+ pkg_resources.require(line)\n+ except (pkg_resources.VersionConflict, pkg_resources.DistributionNotFound) as e:\n+ errors.append(e)\n+\n+ if errors:\n+ inform_unmet_dependencies(errors)\n+\n+\n @pwndbg.lib.cache.cache_until(\"forever\")\n def inform_report_issue(exception_msg) -> None:\n \"\"\"\n@@ -76,6 +113,9 @@\n e.__traceback__ = T\n raise e\n \n+ # Check dependencies against requirements.txt and warn user\n+ check_dependencies()\n+\n # Display the error\n if debug or verbose:\n exception_msg = traceback.format_exc()\n", "issue": "Better exception handling for unmet dependencies\nSome of our users update Pwndbg only by `git pull`ing the newest version and not re-running `setup.sh`. If that happens and when we updated our dependencies recently, the user may end up with broken Pwndbg such as (likely) happened in https://github.com/pwndbg/pwndbg/issues/1790.\r\n\r\nWe should do the two following things:\r\n1) When we detect/handle an exception in the [`pwndbg/exception.py:handle` function]( https://github.com/pwndbg/pwndbg/blob/de4acb2f40da3b0c97353a8b680ffa6440346f7b/pwndbg/exception.py#L61-L96), we should check the installed dependencies versions against the required ones and if they do not match, we should inform the user to update them.\r\n2) We may want to display installed dependencies versions within the `bugreport` command output? \n", "before_files": [{"content": "from __future__ import annotations\n\nimport functools\nimport sys\nimport traceback\n\nimport gdb\n\nimport pwndbg.lib.cache\nimport pwndbg.lib.stdio\nfrom pwndbg.color import message\nfrom pwndbg.gdblib import config\n\nwith pwndbg.lib.stdio.stdio:\n try:\n import ipdb as pdb\n except ImportError:\n import pdb\n try:\n from rich.console import Console\n\n _rich_console = Console()\n except ImportError:\n _rich_console = None\n\nverbose = config.add_param(\n \"exception-verbose\",\n False,\n \"whether to print a full stacktrace for exceptions raised in Pwndbg commands\",\n)\ndebug = config.add_param(\n \"exception-debugger\", False, \"whether to debug exceptions raised in Pwndbg commands\"\n)\n\n\[email protected]_until(\"forever\")\ndef inform_report_issue(exception_msg) -> None:\n \"\"\"\n Informs user that he can report an issue.\n The use of caching makes it reporting only once for a given exception message.\n \"\"\"\n print(\n message.notice(\n \"If that is an issue, you can report it on https://github.com/pwndbg/pwndbg/issues\\n\"\n \"(Please don't forget to search if it hasn't been reported before)\\n\"\n \"To generate the report and open a browser, you may run \"\n )\n + message.hint(\"`bugreport --run-browser`\")\n + message.notice(\"\\nPS: Pull requests are welcome\")\n )\n\n\ndef inform_verbose_and_debug() -> None:\n print(\n message.notice(\"For more info invoke `\")\n + message.hint(\"set exception-verbose on\")\n + message.notice(\"` and rerun the command\\nor debug it by yourself with `\")\n + message.hint(\"set exception-debugger on\")\n + message.notice(\"`\")\n )\n\n\ndef handle(name=\"Error\"):\n \"\"\"Displays an exception to the user, optionally displaying a full traceback\n and spawning an interactive post-moretem debugger.\n\n Notes:\n - ``set exception-verbose on`` enables stack traces.\n - ``set exception-debugger on`` enables the post-mortem debugger.\n \"\"\"\n\n # This is for unit tests so they fail on exceptions instead of displaying them.\n if getattr(sys, \"_pwndbg_unittest_run\", False) is True:\n E, V, T = sys.exc_info()\n e = E(V)\n e.__traceback__ = T\n raise e\n\n # Display the error\n if debug or verbose:\n exception_msg = traceback.format_exc()\n if _rich_console:\n _rich_console.print_exception()\n else:\n print(exception_msg)\n inform_report_issue(exception_msg)\n\n else:\n exc_type, exc_value, exc_traceback = sys.exc_info()\n\n print(message.error(f\"Exception occurred: {name}: {exc_value} ({exc_type})\"))\n\n inform_verbose_and_debug()\n\n # Break into the interactive debugger\n if debug:\n with pwndbg.lib.stdio.stdio:\n pdb.post_mortem()\n\n\[email protected](pdb.set_trace)\ndef set_trace() -> None:\n \"\"\"Enable sane debugging in Pwndbg by switching to the \"real\" stdio.\"\"\"\n debugger = pdb.Pdb(\n stdin=sys.__stdin__, stdout=sys.__stdout__, skip=[\"pwndbg.lib.stdio\", \"pwndbg.exception\"]\n )\n debugger.set_trace()\n\n\npdb.set_trace = set_trace\n\n\[email protected](verbose, debug)\ndef update() -> None:\n if verbose or debug:\n command = \"set python print-stack full\"\n else:\n command = \"set python print-stack message\"\n\n gdb.execute(command, from_tty=True, to_string=True)\n", "path": "pwndbg/exception.py"}], "after_files": [{"content": "from __future__ import annotations\n\nimport functools\nimport os\nimport sys\nimport traceback\n\nimport gdb\nimport pkg_resources\n\nimport pwndbg.lib.cache\nimport pwndbg.lib.stdio\nfrom pwndbg.color import message\nfrom pwndbg.gdblib import config\n\nwith pwndbg.lib.stdio.stdio:\n try:\n import ipdb as pdb\n except ImportError:\n import pdb\n try:\n from rich.console import Console\n\n _rich_console = Console()\n except ImportError:\n _rich_console = None\n\nverbose = config.add_param(\n \"exception-verbose\",\n False,\n \"whether to print a full stacktrace for exceptions raised in Pwndbg commands\",\n)\ndebug = config.add_param(\n \"exception-debugger\", False, \"whether to debug exceptions raised in Pwndbg commands\"\n)\n\n\ndef inform_unmet_dependencies(errors) -> None:\n \"\"\"\n Informs user about unmet dependencies\n \"\"\"\n msg = message.error(\"You appear to have unmet Pwndbg dependencies.\\n\")\n for e in errors:\n if isinstance(e, pkg_resources.DistributionNotFound):\n msg += message.notice(f\"- required {e.args[0]}, but not installed\\n\")\n else:\n msg += message.notice(f\"- required {e.args[1]}, installed: {e.args[0]}\\n\")\n msg += message.notice(\"Consider running: \")\n msg += message.hint(\"`setup.sh` \")\n msg += message.notice(\"from Pwndbg project directory.\\n\")\n print(msg)\n\n\[email protected]_until(\"forever\")\ndef check_dependencies():\n \"\"\"\n Checks if there are any unmet dependencies in requirements.txt\n \"\"\"\n project_path = os.path.dirname(os.path.abspath(__file__))\n requirements_path = os.path.join(project_path, os.pardir, \"requirements.txt\")\n with open(requirements_path, \"r\") as f:\n errors = []\n for line in f.readlines():\n try:\n pkg_resources.require(line)\n except (pkg_resources.VersionConflict, pkg_resources.DistributionNotFound) as e:\n errors.append(e)\n\n if errors:\n inform_unmet_dependencies(errors)\n\n\[email protected]_until(\"forever\")\ndef inform_report_issue(exception_msg) -> None:\n \"\"\"\n Informs user that he can report an issue.\n The use of caching makes it reporting only once for a given exception message.\n \"\"\"\n print(\n message.notice(\n \"If that is an issue, you can report it on https://github.com/pwndbg/pwndbg/issues\\n\"\n \"(Please don't forget to search if it hasn't been reported before)\\n\"\n \"To generate the report and open a browser, you may run \"\n )\n + message.hint(\"`bugreport --run-browser`\")\n + message.notice(\"\\nPS: Pull requests are welcome\")\n )\n\n\ndef inform_verbose_and_debug() -> None:\n print(\n message.notice(\"For more info invoke `\")\n + message.hint(\"set exception-verbose on\")\n + message.notice(\"` and rerun the command\\nor debug it by yourself with `\")\n + message.hint(\"set exception-debugger on\")\n + message.notice(\"`\")\n )\n\n\ndef handle(name=\"Error\"):\n \"\"\"Displays an exception to the user, optionally displaying a full traceback\n and spawning an interactive post-moretem debugger.\n\n Notes:\n - ``set exception-verbose on`` enables stack traces.\n - ``set exception-debugger on`` enables the post-mortem debugger.\n \"\"\"\n\n # This is for unit tests so they fail on exceptions instead of displaying them.\n if getattr(sys, \"_pwndbg_unittest_run\", False) is True:\n E, V, T = sys.exc_info()\n e = E(V)\n e.__traceback__ = T\n raise e\n\n # Check dependencies against requirements.txt and warn user\n check_dependencies()\n\n # Display the error\n if debug or verbose:\n exception_msg = traceback.format_exc()\n if _rich_console:\n _rich_console.print_exception()\n else:\n print(exception_msg)\n inform_report_issue(exception_msg)\n\n else:\n exc_type, exc_value, exc_traceback = sys.exc_info()\n\n print(message.error(f\"Exception occurred: {name}: {exc_value} ({exc_type})\"))\n\n inform_verbose_and_debug()\n\n # Break into the interactive debugger\n if debug:\n with pwndbg.lib.stdio.stdio:\n pdb.post_mortem()\n\n\[email protected](pdb.set_trace)\ndef set_trace() -> None:\n \"\"\"Enable sane debugging in Pwndbg by switching to the \"real\" stdio.\"\"\"\n debugger = pdb.Pdb(\n stdin=sys.__stdin__, stdout=sys.__stdout__, skip=[\"pwndbg.lib.stdio\", \"pwndbg.exception\"]\n )\n debugger.set_trace()\n\n\npdb.set_trace = set_trace\n\n\[email protected](verbose, debug)\ndef update() -> None:\n if verbose or debug:\n command = \"set python print-stack full\"\n else:\n command = \"set python print-stack message\"\n\n gdb.execute(command, from_tty=True, to_string=True)\n", "path": "pwndbg/exception.py"}]}
| 1,541 | 506 |
gh_patches_debug_19367
|
rasdani/github-patches
|
git_diff
|
pypa__pip-2028
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Use of uninitialised variable in pip/commands/list.py
The BestVersionAlreadyInstalled case of find_packages_latests_versions() does not set the variable remote_version_parsed, thus it could be used uninitialised.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pip/commands/list.py`
Content:
```
1 from __future__ import absolute_import
2
3 import logging
4 import warnings
5
6 from pip.basecommand import Command
7 from pip.exceptions import DistributionNotFound, BestVersionAlreadyInstalled
8 from pip.index import PackageFinder
9 from pip.req import InstallRequirement
10 from pip.utils import get_installed_distributions, dist_is_editable
11 from pip.utils.deprecation import RemovedInPip17Warning
12 from pip.cmdoptions import make_option_group, index_group
13
14
15 logger = logging.getLogger(__name__)
16
17
18 class ListCommand(Command):
19 """
20 List installed packages, including editables.
21
22 Packages are listed in a case-insensitive sorted order.
23 """
24 name = 'list'
25 usage = """
26 %prog [options]"""
27 summary = 'List installed packages.'
28
29 def __init__(self, *args, **kw):
30 super(ListCommand, self).__init__(*args, **kw)
31
32 cmd_opts = self.cmd_opts
33
34 cmd_opts.add_option(
35 '-o', '--outdated',
36 action='store_true',
37 default=False,
38 help='List outdated packages (excluding editables)')
39 cmd_opts.add_option(
40 '-u', '--uptodate',
41 action='store_true',
42 default=False,
43 help='List uptodate packages (excluding editables)')
44 cmd_opts.add_option(
45 '-e', '--editable',
46 action='store_true',
47 default=False,
48 help='List editable projects.')
49 cmd_opts.add_option(
50 '-l', '--local',
51 action='store_true',
52 default=False,
53 help=('If in a virtualenv that has global access, do not list '
54 'globally-installed packages.'),
55 )
56
57 cmd_opts.add_option(
58 '--pre',
59 action='store_true',
60 default=False,
61 help=("Include pre-release and development versions. By default, "
62 "pip only finds stable versions."),
63 )
64
65 index_opts = make_option_group(index_group, self.parser)
66
67 self.parser.insert_option_group(0, index_opts)
68 self.parser.insert_option_group(0, cmd_opts)
69
70 def _build_package_finder(self, options, index_urls, session):
71 """
72 Create a package finder appropriate to this list command.
73 """
74 return PackageFinder(
75 find_links=options.find_links,
76 index_urls=index_urls,
77 allow_external=options.allow_external,
78 allow_unverified=options.allow_unverified,
79 allow_all_external=options.allow_all_external,
80 allow_all_prereleases=options.pre,
81 process_dependency_links=options.process_dependency_links,
82 session=session,
83 )
84
85 def run(self, options, args):
86 if options.outdated:
87 self.run_outdated(options)
88 elif options.uptodate:
89 self.run_uptodate(options)
90 elif options.editable:
91 self.run_editables(options)
92 else:
93 self.run_listing(options)
94
95 def run_outdated(self, options):
96 for dist, remote_version_raw, remote_version_parsed in \
97 self.find_packages_latests_versions(options):
98 if remote_version_parsed > dist.parsed_version:
99 logger.info(
100 '%s (Current: %s Latest: %s)',
101 dist.project_name, dist.version, remote_version_raw,
102 )
103
104 def find_packages_latests_versions(self, options):
105 index_urls = [options.index_url] + options.extra_index_urls
106 if options.no_index:
107 logger.info('Ignoring indexes: %s', ','.join(index_urls))
108 index_urls = []
109
110 if options.use_mirrors:
111 warnings.warn(
112 "--use-mirrors has been deprecated and will be removed in the "
113 "future. Explicit uses of --index-url and/or --extra-index-url"
114 " is suggested.",
115 RemovedInPip17Warning,
116 )
117
118 if options.mirrors:
119 warnings.warn(
120 "--mirrors has been deprecated and will be removed in the "
121 "future. Explicit uses of --index-url and/or --extra-index-url"
122 " is suggested.",
123 RemovedInPip17Warning,
124 )
125 index_urls += options.mirrors
126
127 dependency_links = []
128 for dist in get_installed_distributions(local_only=options.local):
129 if dist.has_metadata('dependency_links.txt'):
130 dependency_links.extend(
131 dist.get_metadata_lines('dependency_links.txt'),
132 )
133
134 with self._build_session(options) as session:
135 finder = self._build_package_finder(options, index_urls, session)
136 finder.add_dependency_links(dependency_links)
137
138 installed_packages = get_installed_distributions(
139 local_only=options.local,
140 include_editables=False,
141 )
142 for dist in installed_packages:
143 req = InstallRequirement.from_line(dist.key, None)
144 try:
145 link = finder.find_requirement(req, True)
146
147 # If link is None, means installed version is most
148 # up-to-date
149 if link is None:
150 continue
151 except DistributionNotFound:
152 continue
153 except BestVersionAlreadyInstalled:
154 remote_version = req.installed_version
155 else:
156 # It might be a good idea that link or finder had a public
157 # method that returned version
158 remote_version = finder._link_package_versions(
159 link, req.name
160 )[0]
161 remote_version_raw = remote_version[2]
162 remote_version_parsed = remote_version[0]
163 yield dist, remote_version_raw, remote_version_parsed
164
165 def run_listing(self, options):
166 installed_packages = get_installed_distributions(
167 local_only=options.local,
168 )
169 self.output_package_listing(installed_packages)
170
171 def run_editables(self, options):
172 installed_packages = get_installed_distributions(
173 local_only=options.local,
174 editables_only=True,
175 )
176 self.output_package_listing(installed_packages)
177
178 def output_package_listing(self, installed_packages):
179 installed_packages = sorted(
180 installed_packages,
181 key=lambda dist: dist.project_name.lower(),
182 )
183 for dist in installed_packages:
184 if dist_is_editable(dist):
185 line = '%s (%s, %s)' % (
186 dist.project_name,
187 dist.version,
188 dist.location,
189 )
190 else:
191 line = '%s (%s)' % (dist.project_name, dist.version)
192 logger.info(line)
193
194 def run_uptodate(self, options):
195 uptodate = []
196 for dist, remote_version_raw, remote_version_parsed in \
197 self.find_packages_latests_versions(options):
198 if dist.parsed_version == remote_version_parsed:
199 uptodate.append(dist)
200 self.output_package_listing(uptodate)
201
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pip/commands/list.py b/pip/commands/list.py
--- a/pip/commands/list.py
+++ b/pip/commands/list.py
@@ -4,7 +4,7 @@
import warnings
from pip.basecommand import Command
-from pip.exceptions import DistributionNotFound, BestVersionAlreadyInstalled
+from pip.exceptions import DistributionNotFound
from pip.index import PackageFinder
from pip.req import InstallRequirement
from pip.utils import get_installed_distributions, dist_is_editable
@@ -150,8 +150,6 @@
continue
except DistributionNotFound:
continue
- except BestVersionAlreadyInstalled:
- remote_version = req.installed_version
else:
# It might be a good idea that link or finder had a public
# method that returned version
|
{"golden_diff": "diff --git a/pip/commands/list.py b/pip/commands/list.py\n--- a/pip/commands/list.py\n+++ b/pip/commands/list.py\n@@ -4,7 +4,7 @@\n import warnings\n \n from pip.basecommand import Command\n-from pip.exceptions import DistributionNotFound, BestVersionAlreadyInstalled\n+from pip.exceptions import DistributionNotFound\n from pip.index import PackageFinder\n from pip.req import InstallRequirement\n from pip.utils import get_installed_distributions, dist_is_editable\n@@ -150,8 +150,6 @@\n continue\n except DistributionNotFound:\n continue\n- except BestVersionAlreadyInstalled:\n- remote_version = req.installed_version\n else:\n # It might be a good idea that link or finder had a public\n # method that returned version\n", "issue": "Use of uninitialised variable in pip/commands/list.py\nThe BestVersionAlreadyInstalled case of find_packages_latests_versions() does not set the variable remote_version_parsed, thus it could be used uninitialised.\n\n", "before_files": [{"content": "from __future__ import absolute_import\n\nimport logging\nimport warnings\n\nfrom pip.basecommand import Command\nfrom pip.exceptions import DistributionNotFound, BestVersionAlreadyInstalled\nfrom pip.index import PackageFinder\nfrom pip.req import InstallRequirement\nfrom pip.utils import get_installed_distributions, dist_is_editable\nfrom pip.utils.deprecation import RemovedInPip17Warning\nfrom pip.cmdoptions import make_option_group, index_group\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass ListCommand(Command):\n \"\"\"\n List installed packages, including editables.\n\n Packages are listed in a case-insensitive sorted order.\n \"\"\"\n name = 'list'\n usage = \"\"\"\n %prog [options]\"\"\"\n summary = 'List installed packages.'\n\n def __init__(self, *args, **kw):\n super(ListCommand, self).__init__(*args, **kw)\n\n cmd_opts = self.cmd_opts\n\n cmd_opts.add_option(\n '-o', '--outdated',\n action='store_true',\n default=False,\n help='List outdated packages (excluding editables)')\n cmd_opts.add_option(\n '-u', '--uptodate',\n action='store_true',\n default=False,\n help='List uptodate packages (excluding editables)')\n cmd_opts.add_option(\n '-e', '--editable',\n action='store_true',\n default=False,\n help='List editable projects.')\n cmd_opts.add_option(\n '-l', '--local',\n action='store_true',\n default=False,\n help=('If in a virtualenv that has global access, do not list '\n 'globally-installed packages.'),\n )\n\n cmd_opts.add_option(\n '--pre',\n action='store_true',\n default=False,\n help=(\"Include pre-release and development versions. By default, \"\n \"pip only finds stable versions.\"),\n )\n\n index_opts = make_option_group(index_group, self.parser)\n\n self.parser.insert_option_group(0, index_opts)\n self.parser.insert_option_group(0, cmd_opts)\n\n def _build_package_finder(self, options, index_urls, session):\n \"\"\"\n Create a package finder appropriate to this list command.\n \"\"\"\n return PackageFinder(\n find_links=options.find_links,\n index_urls=index_urls,\n allow_external=options.allow_external,\n allow_unverified=options.allow_unverified,\n allow_all_external=options.allow_all_external,\n allow_all_prereleases=options.pre,\n process_dependency_links=options.process_dependency_links,\n session=session,\n )\n\n def run(self, options, args):\n if options.outdated:\n self.run_outdated(options)\n elif options.uptodate:\n self.run_uptodate(options)\n elif options.editable:\n self.run_editables(options)\n else:\n self.run_listing(options)\n\n def run_outdated(self, options):\n for dist, remote_version_raw, remote_version_parsed in \\\n self.find_packages_latests_versions(options):\n if remote_version_parsed > dist.parsed_version:\n logger.info(\n '%s (Current: %s Latest: %s)',\n dist.project_name, dist.version, remote_version_raw,\n )\n\n def find_packages_latests_versions(self, options):\n index_urls = [options.index_url] + options.extra_index_urls\n if options.no_index:\n logger.info('Ignoring indexes: %s', ','.join(index_urls))\n index_urls = []\n\n if options.use_mirrors:\n warnings.warn(\n \"--use-mirrors has been deprecated and will be removed in the \"\n \"future. Explicit uses of --index-url and/or --extra-index-url\"\n \" is suggested.\",\n RemovedInPip17Warning,\n )\n\n if options.mirrors:\n warnings.warn(\n \"--mirrors has been deprecated and will be removed in the \"\n \"future. Explicit uses of --index-url and/or --extra-index-url\"\n \" is suggested.\",\n RemovedInPip17Warning,\n )\n index_urls += options.mirrors\n\n dependency_links = []\n for dist in get_installed_distributions(local_only=options.local):\n if dist.has_metadata('dependency_links.txt'):\n dependency_links.extend(\n dist.get_metadata_lines('dependency_links.txt'),\n )\n\n with self._build_session(options) as session:\n finder = self._build_package_finder(options, index_urls, session)\n finder.add_dependency_links(dependency_links)\n\n installed_packages = get_installed_distributions(\n local_only=options.local,\n include_editables=False,\n )\n for dist in installed_packages:\n req = InstallRequirement.from_line(dist.key, None)\n try:\n link = finder.find_requirement(req, True)\n\n # If link is None, means installed version is most\n # up-to-date\n if link is None:\n continue\n except DistributionNotFound:\n continue\n except BestVersionAlreadyInstalled:\n remote_version = req.installed_version\n else:\n # It might be a good idea that link or finder had a public\n # method that returned version\n remote_version = finder._link_package_versions(\n link, req.name\n )[0]\n remote_version_raw = remote_version[2]\n remote_version_parsed = remote_version[0]\n yield dist, remote_version_raw, remote_version_parsed\n\n def run_listing(self, options):\n installed_packages = get_installed_distributions(\n local_only=options.local,\n )\n self.output_package_listing(installed_packages)\n\n def run_editables(self, options):\n installed_packages = get_installed_distributions(\n local_only=options.local,\n editables_only=True,\n )\n self.output_package_listing(installed_packages)\n\n def output_package_listing(self, installed_packages):\n installed_packages = sorted(\n installed_packages,\n key=lambda dist: dist.project_name.lower(),\n )\n for dist in installed_packages:\n if dist_is_editable(dist):\n line = '%s (%s, %s)' % (\n dist.project_name,\n dist.version,\n dist.location,\n )\n else:\n line = '%s (%s)' % (dist.project_name, dist.version)\n logger.info(line)\n\n def run_uptodate(self, options):\n uptodate = []\n for dist, remote_version_raw, remote_version_parsed in \\\n self.find_packages_latests_versions(options):\n if dist.parsed_version == remote_version_parsed:\n uptodate.append(dist)\n self.output_package_listing(uptodate)\n", "path": "pip/commands/list.py"}], "after_files": [{"content": "from __future__ import absolute_import\n\nimport logging\nimport warnings\n\nfrom pip.basecommand import Command\nfrom pip.exceptions import DistributionNotFound\nfrom pip.index import PackageFinder\nfrom pip.req import InstallRequirement\nfrom pip.utils import get_installed_distributions, dist_is_editable\nfrom pip.utils.deprecation import RemovedInPip17Warning\nfrom pip.cmdoptions import make_option_group, index_group\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass ListCommand(Command):\n \"\"\"\n List installed packages, including editables.\n\n Packages are listed in a case-insensitive sorted order.\n \"\"\"\n name = 'list'\n usage = \"\"\"\n %prog [options]\"\"\"\n summary = 'List installed packages.'\n\n def __init__(self, *args, **kw):\n super(ListCommand, self).__init__(*args, **kw)\n\n cmd_opts = self.cmd_opts\n\n cmd_opts.add_option(\n '-o', '--outdated',\n action='store_true',\n default=False,\n help='List outdated packages (excluding editables)')\n cmd_opts.add_option(\n '-u', '--uptodate',\n action='store_true',\n default=False,\n help='List uptodate packages (excluding editables)')\n cmd_opts.add_option(\n '-e', '--editable',\n action='store_true',\n default=False,\n help='List editable projects.')\n cmd_opts.add_option(\n '-l', '--local',\n action='store_true',\n default=False,\n help=('If in a virtualenv that has global access, do not list '\n 'globally-installed packages.'),\n )\n\n cmd_opts.add_option(\n '--pre',\n action='store_true',\n default=False,\n help=(\"Include pre-release and development versions. By default, \"\n \"pip only finds stable versions.\"),\n )\n\n index_opts = make_option_group(index_group, self.parser)\n\n self.parser.insert_option_group(0, index_opts)\n self.parser.insert_option_group(0, cmd_opts)\n\n def _build_package_finder(self, options, index_urls, session):\n \"\"\"\n Create a package finder appropriate to this list command.\n \"\"\"\n return PackageFinder(\n find_links=options.find_links,\n index_urls=index_urls,\n allow_external=options.allow_external,\n allow_unverified=options.allow_unverified,\n allow_all_external=options.allow_all_external,\n allow_all_prereleases=options.pre,\n process_dependency_links=options.process_dependency_links,\n session=session,\n )\n\n def run(self, options, args):\n if options.outdated:\n self.run_outdated(options)\n elif options.uptodate:\n self.run_uptodate(options)\n elif options.editable:\n self.run_editables(options)\n else:\n self.run_listing(options)\n\n def run_outdated(self, options):\n for dist, remote_version_raw, remote_version_parsed in \\\n self.find_packages_latests_versions(options):\n if remote_version_parsed > dist.parsed_version:\n logger.info(\n '%s (Current: %s Latest: %s)',\n dist.project_name, dist.version, remote_version_raw,\n )\n\n def find_packages_latests_versions(self, options):\n index_urls = [options.index_url] + options.extra_index_urls\n if options.no_index:\n logger.info('Ignoring indexes: %s', ','.join(index_urls))\n index_urls = []\n\n if options.use_mirrors:\n warnings.warn(\n \"--use-mirrors has been deprecated and will be removed in the \"\n \"future. Explicit uses of --index-url and/or --extra-index-url\"\n \" is suggested.\",\n RemovedInPip17Warning,\n )\n\n if options.mirrors:\n warnings.warn(\n \"--mirrors has been deprecated and will be removed in the \"\n \"future. Explicit uses of --index-url and/or --extra-index-url\"\n \" is suggested.\",\n RemovedInPip17Warning,\n )\n index_urls += options.mirrors\n\n dependency_links = []\n for dist in get_installed_distributions(local_only=options.local):\n if dist.has_metadata('dependency_links.txt'):\n dependency_links.extend(\n dist.get_metadata_lines('dependency_links.txt'),\n )\n\n with self._build_session(options) as session:\n finder = self._build_package_finder(options, index_urls, session)\n finder.add_dependency_links(dependency_links)\n\n installed_packages = get_installed_distributions(\n local_only=options.local,\n include_editables=False,\n )\n for dist in installed_packages:\n req = InstallRequirement.from_line(dist.key, None)\n try:\n link = finder.find_requirement(req, True)\n\n # If link is None, means installed version is most\n # up-to-date\n if link is None:\n continue\n except DistributionNotFound:\n continue\n else:\n # It might be a good idea that link or finder had a public\n # method that returned version\n remote_version = finder._link_package_versions(\n link, req.name\n )[0]\n remote_version_raw = remote_version[2]\n remote_version_parsed = remote_version[0]\n yield dist, remote_version_raw, remote_version_parsed\n\n def run_listing(self, options):\n installed_packages = get_installed_distributions(\n local_only=options.local,\n )\n self.output_package_listing(installed_packages)\n\n def run_editables(self, options):\n installed_packages = get_installed_distributions(\n local_only=options.local,\n editables_only=True,\n )\n self.output_package_listing(installed_packages)\n\n def output_package_listing(self, installed_packages):\n installed_packages = sorted(\n installed_packages,\n key=lambda dist: dist.project_name.lower(),\n )\n for dist in installed_packages:\n if dist_is_editable(dist):\n line = '%s (%s, %s)' % (\n dist.project_name,\n dist.version,\n dist.location,\n )\n else:\n line = '%s (%s)' % (dist.project_name, dist.version)\n logger.info(line)\n\n def run_uptodate(self, options):\n uptodate = []\n for dist, remote_version_raw, remote_version_parsed in \\\n self.find_packages_latests_versions(options):\n if dist.parsed_version == remote_version_parsed:\n uptodate.append(dist)\n self.output_package_listing(uptodate)\n", "path": "pip/commands/list.py"}]}
| 2,154 | 173 |
gh_patches_debug_13721
|
rasdani/github-patches
|
git_diff
|
mdn__kuma-6226
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
SSR Sentry error reporting
At the time of writing, 7 times this has happened:
```
HTTPError: 500 Server Error: Internal Server Error for url: http://ssr/ssr/SPA
File "django/core/handlers/exception.py", line 41, in inner
response = get_response(request)
File "django/core/handlers/base.py", line 187, in _get_response
response = self.process_exception_by_middleware(e, request)
File "django/core/handlers/base.py", line 185, in _get_response
response = wrapped_callback(request, *callback_args, **callback_kwargs)
File "newrelic/hooks/framework_django.py", line 544, in wrapper
return wrapped(*args, **kwargs)
File "django/views/decorators/cache.py", line 57, in _wrapped_view_func
response = view_func(request, *args, **kwargs)
File "django/views/decorators/http.py", line 40, in inner
return func(request, *args, **kwargs)
File "ratelimit/decorators.py", line 30, in _wrapped
return fn(*args, **kw)
File "kuma/search/views.py", line 34, in search
return render(request, 'search/react.html', context)
File "django/shortcuts.py", line 30, in render
content = loader.render_to_string(template_name, context, request, using=using)
File "django/template/loader.py", line 68, in render_to_string
return template.render(context, request)
File "django_jinja/backend.py", line 106, in render
return mark_safe(self.template.render(context))
File "newrelic/api/function_trace.py", line 121, in dynamic_wrapper
return wrapped(*args, **kwargs)
File "jinja2/environment.py", line 1008, in render
return self.environment.handle_exception(exc_info, True)
File "jinja2/environment.py", line 780, in handle_exception
reraise(exc_type, exc_value, tb)
File "/app/kuma/search/jinja2/search/react.html", line 3, in top-level template code
{% set query = request.GET.get('q') %}
File "/app/jinja2/react_base.html", line 103, in top-level template code
{% block document_head %}{% endblock %}
File "/app/kuma/search/jinja2/search/react.html", line 20, in block "document_head"
results)|safe }}
File "kuma/wiki/templatetags/ssr.py", line 50, in render_react
return server_side_render(component_name, data)
File "kuma/wiki/templatetags/ssr.py", line 133, in server_side_render
response.raise_for_status()
File "requests/models.py", line 940, in raise_for_status
raise HTTPError(http_error_msg, response=self)
```
https://sentry.prod.mozaws.net/operations/mdn-prod/issues/6448273/?query=is:unresolved
It's "fine". The SSR service is bound to be imperfect. What's worrying is that there are no Node errors in Sentry. It's just too unlikely that there have been no exceptions in the SSR Node service.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kuma/wiki/templatetags/ssr.py`
Content:
```
1
2
3 import json
4 import os
5 from functools import lru_cache
6
7 import requests
8 import requests.exceptions
9 from django.conf import settings
10 from django_jinja import library
11
12
13 @lru_cache()
14 def get_localization_data(locale):
15 """
16 Read the frontend string catalog for the specified locale, parse
17 it as JSON, and return the resulting dict. The returned values
18 are cached so that we don't have to read files all the time.
19 """
20 path = os.path.join(settings.BASE_DIR,
21 'static', 'jsi18n',
22 locale, 'react.json')
23 with open(path, 'r') as f:
24 return json.load(f)
25
26
27 @library.global_function
28 def render_react(component_name, locale, url, document_data, ssr=True):
29 """
30 Render a script tag to define the data and any other HTML tags needed
31 to enable the display of a React-based UI. By default, this does
32 server side rendering, falling back to client-side rendering if
33 the SSR attempt fails. Pass False as the second argument to do
34 client-side rendering unconditionally.
35
36 Note that we are not defining a generic Jinja template tag here.
37 The code in this file is specific to Kuma's React-based UI.
38 """
39 localization_data = get_localization_data(locale)
40
41 data = {
42 'locale': locale,
43 'stringCatalog': localization_data['catalog'],
44 'pluralExpression': localization_data['plural'],
45 'url': url,
46 'documentData': document_data,
47 }
48
49 if ssr:
50 return server_side_render(component_name, data)
51 else:
52 return client_side_render(component_name, data)
53
54
55 def _render(component_name, html, script, needs_serialization=False):
56 """A utility function used by both client side and server side rendering.
57 Returns a string that includes the specified HTML and a serialized
58 form of the state dict, in the format expected by the client-side code
59 in kuma/javascript/src/index.jsx.
60 """
61 if needs_serialization:
62 assert isinstance(script, dict), type(script)
63 script = json.dumps(script).replace('</', '<\\/')
64 else:
65 script = 'JSON.parse({})'.format(script)
66
67 return (
68 '<div id="react-container" data-component-name="{}">{}</div>\n'
69 '<script>window._react_data = {};</script>\n'
70 ).format(component_name, html, script)
71
72
73 def client_side_render(component_name, data):
74 """
75 Output an empty <div> and a script with complete state so that
76 the UI can be rendered on the client-side.
77 """
78 return _render(component_name, '', data, needs_serialization=True)
79
80
81 def server_side_render(component_name, data):
82 """
83 Pre-render the React UI to HTML and output it in a <div>, and then
84 also pass the necessary serialized state in a <script> so that
85 React on the client side can sync itself with the pre-rendred HTML.
86
87 If any exceptions are thrown during the server-side rendering, we
88 fall back to client-side rendering instead.
89 """
90 url = '{}/{}'.format(settings.SSR_URL, component_name)
91 timeout = settings.SSR_TIMEOUT
92 # Try server side rendering
93 try:
94 # POST the document data as JSON to the SSR server and we
95 # should get HTML text (encoded as plain text) in the body
96 # of the response
97 response = requests.post(url,
98 headers={'Content-Type': 'application/json'},
99 data=json.dumps(data).encode('utf8'),
100 timeout=timeout)
101
102 # Even though we've got fully rendered HTML now, we still need to
103 # send the document data along with it so that React can sync its
104 # state on the client side with what is in the HTML. When rendering
105 # a document page, the data includes long strings of HTML that
106 # we can get away without duplicating. So as an optimization when
107 # component_name is "document", we're going to make a copy of the
108 # data (because the original belongs to our caller) and delete those
109 # strings from the copy.
110 #
111 # WARNING: This optimization can save 20kb in data transfer
112 # for typical pages, but it requires us to be very careful on
113 # the frontend. If any components render conditionally based on
114 # the state of bodyHTML, tocHTML or quickLinkHTML, then they will
115 # render differently on the client than during SSR, and the hydrate
116 # will not just work cleanly, and those components will re-render
117 # with empty strings. This has already caused Bug 1558308, and
118 # I've commented it out because the benefit in file size doesn't
119 # seem worth the risk of client-side bugs.
120 #
121 # As an alternative, it ought to be possible to extract the HTML
122 # strings from the SSR'ed document and rebuild the document object
123 # on the client right before we call hydrate(). So if you uncomment
124 # the lines below, you should also edit kuma/javascript/src/index.jsx
125 # to extract the HTML from the document as well.
126 #
127 # if component_name == 'document':
128 # data = data.copy()
129 # data['documentData'] = data['documentData'].copy()
130 # data['documentData'].update(bodyHTML='',
131 # tocHTML='',
132 # quickLinksHTML='')
133 response.raise_for_status()
134 result = response.json()
135 return _render(component_name, result['html'], result['script'])
136
137 except requests.exceptions.ConnectionError:
138 print("Connection error contacting SSR server.")
139 print("Falling back to client side rendering.")
140 return client_side_render(component_name, data)
141 except requests.exceptions.ReadTimeout:
142 print("Timeout contacting SSR server.")
143 print("Falling back to client side rendering.")
144 return client_side_render(component_name, data)
145
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kuma/wiki/templatetags/ssr.py b/kuma/wiki/templatetags/ssr.py
--- a/kuma/wiki/templatetags/ssr.py
+++ b/kuma/wiki/templatetags/ssr.py
@@ -134,11 +134,7 @@
result = response.json()
return _render(component_name, result['html'], result['script'])
- except requests.exceptions.ConnectionError:
- print("Connection error contacting SSR server.")
- print("Falling back to client side rendering.")
- return client_side_render(component_name, data)
- except requests.exceptions.ReadTimeout:
- print("Timeout contacting SSR server.")
+ except requests.exceptions.RequestException as exception:
+ print(f"{exception.__class__} error contacting SSR server.")
print("Falling back to client side rendering.")
return client_side_render(component_name, data)
|
{"golden_diff": "diff --git a/kuma/wiki/templatetags/ssr.py b/kuma/wiki/templatetags/ssr.py\n--- a/kuma/wiki/templatetags/ssr.py\n+++ b/kuma/wiki/templatetags/ssr.py\n@@ -134,11 +134,7 @@\n result = response.json()\n return _render(component_name, result['html'], result['script'])\n \n- except requests.exceptions.ConnectionError:\n- print(\"Connection error contacting SSR server.\")\n- print(\"Falling back to client side rendering.\")\n- return client_side_render(component_name, data)\n- except requests.exceptions.ReadTimeout:\n- print(\"Timeout contacting SSR server.\")\n+ except requests.exceptions.RequestException as exception:\n+ print(f\"{exception.__class__} error contacting SSR server.\")\n print(\"Falling back to client side rendering.\")\n return client_side_render(component_name, data)\n", "issue": "SSR Sentry error reporting\nAt the time of writing, 7 times this has happened:\r\n```\r\nHTTPError: 500 Server Error: Internal Server Error for url: http://ssr/ssr/SPA\r\n File \"django/core/handlers/exception.py\", line 41, in inner\r\n response = get_response(request)\r\n File \"django/core/handlers/base.py\", line 187, in _get_response\r\n response = self.process_exception_by_middleware(e, request)\r\n File \"django/core/handlers/base.py\", line 185, in _get_response\r\n response = wrapped_callback(request, *callback_args, **callback_kwargs)\r\n File \"newrelic/hooks/framework_django.py\", line 544, in wrapper\r\n return wrapped(*args, **kwargs)\r\n File \"django/views/decorators/cache.py\", line 57, in _wrapped_view_func\r\n response = view_func(request, *args, **kwargs)\r\n File \"django/views/decorators/http.py\", line 40, in inner\r\n return func(request, *args, **kwargs)\r\n File \"ratelimit/decorators.py\", line 30, in _wrapped\r\n return fn(*args, **kw)\r\n File \"kuma/search/views.py\", line 34, in search\r\n return render(request, 'search/react.html', context)\r\n File \"django/shortcuts.py\", line 30, in render\r\n content = loader.render_to_string(template_name, context, request, using=using)\r\n File \"django/template/loader.py\", line 68, in render_to_string\r\n return template.render(context, request)\r\n File \"django_jinja/backend.py\", line 106, in render\r\n return mark_safe(self.template.render(context))\r\n File \"newrelic/api/function_trace.py\", line 121, in dynamic_wrapper\r\n return wrapped(*args, **kwargs)\r\n File \"jinja2/environment.py\", line 1008, in render\r\n return self.environment.handle_exception(exc_info, True)\r\n File \"jinja2/environment.py\", line 780, in handle_exception\r\n reraise(exc_type, exc_value, tb)\r\n File \"/app/kuma/search/jinja2/search/react.html\", line 3, in top-level template code\r\n {% set query = request.GET.get('q') %}\r\n File \"/app/jinja2/react_base.html\", line 103, in top-level template code\r\n {% block document_head %}{% endblock %}\r\n File \"/app/kuma/search/jinja2/search/react.html\", line 20, in block \"document_head\"\r\n results)|safe }}\r\n File \"kuma/wiki/templatetags/ssr.py\", line 50, in render_react\r\n return server_side_render(component_name, data)\r\n File \"kuma/wiki/templatetags/ssr.py\", line 133, in server_side_render\r\n response.raise_for_status()\r\n File \"requests/models.py\", line 940, in raise_for_status\r\n raise HTTPError(http_error_msg, response=self)\r\n```\r\nhttps://sentry.prod.mozaws.net/operations/mdn-prod/issues/6448273/?query=is:unresolved\r\n\r\nIt's \"fine\". The SSR service is bound to be imperfect. What's worrying is that there are no Node errors in Sentry. It's just too unlikely that there have been no exceptions in the SSR Node service. \n", "before_files": [{"content": "\n\nimport json\nimport os\nfrom functools import lru_cache\n\nimport requests\nimport requests.exceptions\nfrom django.conf import settings\nfrom django_jinja import library\n\n\n@lru_cache()\ndef get_localization_data(locale):\n \"\"\"\n Read the frontend string catalog for the specified locale, parse\n it as JSON, and return the resulting dict. The returned values\n are cached so that we don't have to read files all the time.\n \"\"\"\n path = os.path.join(settings.BASE_DIR,\n 'static', 'jsi18n',\n locale, 'react.json')\n with open(path, 'r') as f:\n return json.load(f)\n\n\[email protected]_function\ndef render_react(component_name, locale, url, document_data, ssr=True):\n \"\"\"\n Render a script tag to define the data and any other HTML tags needed\n to enable the display of a React-based UI. By default, this does\n server side rendering, falling back to client-side rendering if\n the SSR attempt fails. Pass False as the second argument to do\n client-side rendering unconditionally.\n\n Note that we are not defining a generic Jinja template tag here.\n The code in this file is specific to Kuma's React-based UI.\n \"\"\"\n localization_data = get_localization_data(locale)\n\n data = {\n 'locale': locale,\n 'stringCatalog': localization_data['catalog'],\n 'pluralExpression': localization_data['plural'],\n 'url': url,\n 'documentData': document_data,\n }\n\n if ssr:\n return server_side_render(component_name, data)\n else:\n return client_side_render(component_name, data)\n\n\ndef _render(component_name, html, script, needs_serialization=False):\n \"\"\"A utility function used by both client side and server side rendering.\n Returns a string that includes the specified HTML and a serialized\n form of the state dict, in the format expected by the client-side code\n in kuma/javascript/src/index.jsx.\n \"\"\"\n if needs_serialization:\n assert isinstance(script, dict), type(script)\n script = json.dumps(script).replace('</', '<\\\\/')\n else:\n script = 'JSON.parse({})'.format(script)\n\n return (\n '<div id=\"react-container\" data-component-name=\"{}\">{}</div>\\n'\n '<script>window._react_data = {};</script>\\n'\n ).format(component_name, html, script)\n\n\ndef client_side_render(component_name, data):\n \"\"\"\n Output an empty <div> and a script with complete state so that\n the UI can be rendered on the client-side.\n \"\"\"\n return _render(component_name, '', data, needs_serialization=True)\n\n\ndef server_side_render(component_name, data):\n \"\"\"\n Pre-render the React UI to HTML and output it in a <div>, and then\n also pass the necessary serialized state in a <script> so that\n React on the client side can sync itself with the pre-rendred HTML.\n\n If any exceptions are thrown during the server-side rendering, we\n fall back to client-side rendering instead.\n \"\"\"\n url = '{}/{}'.format(settings.SSR_URL, component_name)\n timeout = settings.SSR_TIMEOUT\n # Try server side rendering\n try:\n # POST the document data as JSON to the SSR server and we\n # should get HTML text (encoded as plain text) in the body\n # of the response\n response = requests.post(url,\n headers={'Content-Type': 'application/json'},\n data=json.dumps(data).encode('utf8'),\n timeout=timeout)\n\n # Even though we've got fully rendered HTML now, we still need to\n # send the document data along with it so that React can sync its\n # state on the client side with what is in the HTML. When rendering\n # a document page, the data includes long strings of HTML that\n # we can get away without duplicating. So as an optimization when\n # component_name is \"document\", we're going to make a copy of the\n # data (because the original belongs to our caller) and delete those\n # strings from the copy.\n #\n # WARNING: This optimization can save 20kb in data transfer\n # for typical pages, but it requires us to be very careful on\n # the frontend. If any components render conditionally based on\n # the state of bodyHTML, tocHTML or quickLinkHTML, then they will\n # render differently on the client than during SSR, and the hydrate\n # will not just work cleanly, and those components will re-render\n # with empty strings. This has already caused Bug 1558308, and\n # I've commented it out because the benefit in file size doesn't\n # seem worth the risk of client-side bugs.\n #\n # As an alternative, it ought to be possible to extract the HTML\n # strings from the SSR'ed document and rebuild the document object\n # on the client right before we call hydrate(). So if you uncomment\n # the lines below, you should also edit kuma/javascript/src/index.jsx\n # to extract the HTML from the document as well.\n #\n # if component_name == 'document':\n # data = data.copy()\n # data['documentData'] = data['documentData'].copy()\n # data['documentData'].update(bodyHTML='',\n # tocHTML='',\n # quickLinksHTML='')\n response.raise_for_status()\n result = response.json()\n return _render(component_name, result['html'], result['script'])\n\n except requests.exceptions.ConnectionError:\n print(\"Connection error contacting SSR server.\")\n print(\"Falling back to client side rendering.\")\n return client_side_render(component_name, data)\n except requests.exceptions.ReadTimeout:\n print(\"Timeout contacting SSR server.\")\n print(\"Falling back to client side rendering.\")\n return client_side_render(component_name, data)\n", "path": "kuma/wiki/templatetags/ssr.py"}], "after_files": [{"content": "\n\nimport json\nimport os\nfrom functools import lru_cache\n\nimport requests\nimport requests.exceptions\nfrom django.conf import settings\nfrom django_jinja import library\n\n\n@lru_cache()\ndef get_localization_data(locale):\n \"\"\"\n Read the frontend string catalog for the specified locale, parse\n it as JSON, and return the resulting dict. The returned values\n are cached so that we don't have to read files all the time.\n \"\"\"\n path = os.path.join(settings.BASE_DIR,\n 'static', 'jsi18n',\n locale, 'react.json')\n with open(path, 'r') as f:\n return json.load(f)\n\n\[email protected]_function\ndef render_react(component_name, locale, url, document_data, ssr=True):\n \"\"\"\n Render a script tag to define the data and any other HTML tags needed\n to enable the display of a React-based UI. By default, this does\n server side rendering, falling back to client-side rendering if\n the SSR attempt fails. Pass False as the second argument to do\n client-side rendering unconditionally.\n\n Note that we are not defining a generic Jinja template tag here.\n The code in this file is specific to Kuma's React-based UI.\n \"\"\"\n localization_data = get_localization_data(locale)\n\n data = {\n 'locale': locale,\n 'stringCatalog': localization_data['catalog'],\n 'pluralExpression': localization_data['plural'],\n 'url': url,\n 'documentData': document_data,\n }\n\n if ssr:\n return server_side_render(component_name, data)\n else:\n return client_side_render(component_name, data)\n\n\ndef _render(component_name, html, script, needs_serialization=False):\n \"\"\"A utility function used by both client side and server side rendering.\n Returns a string that includes the specified HTML and a serialized\n form of the state dict, in the format expected by the client-side code\n in kuma/javascript/src/index.jsx.\n \"\"\"\n if needs_serialization:\n assert isinstance(script, dict), type(script)\n script = json.dumps(script).replace('</', '<\\\\/')\n else:\n script = 'JSON.parse({})'.format(script)\n\n return (\n '<div id=\"react-container\" data-component-name=\"{}\">{}</div>\\n'\n '<script>window._react_data = {};</script>\\n'\n ).format(component_name, html, script)\n\n\ndef client_side_render(component_name, data):\n \"\"\"\n Output an empty <div> and a script with complete state so that\n the UI can be rendered on the client-side.\n \"\"\"\n return _render(component_name, '', data, needs_serialization=True)\n\n\ndef server_side_render(component_name, data):\n \"\"\"\n Pre-render the React UI to HTML and output it in a <div>, and then\n also pass the necessary serialized state in a <script> so that\n React on the client side can sync itself with the pre-rendred HTML.\n\n If any exceptions are thrown during the server-side rendering, we\n fall back to client-side rendering instead.\n \"\"\"\n url = '{}/{}'.format(settings.SSR_URL, component_name)\n timeout = settings.SSR_TIMEOUT\n # Try server side rendering\n try:\n # POST the document data as JSON to the SSR server and we\n # should get HTML text (encoded as plain text) in the body\n # of the response\n response = requests.post(url,\n headers={'Content-Type': 'application/json'},\n data=json.dumps(data).encode('utf8'),\n timeout=timeout)\n\n # Even though we've got fully rendered HTML now, we still need to\n # send the document data along with it so that React can sync its\n # state on the client side with what is in the HTML. When rendering\n # a document page, the data includes long strings of HTML that\n # we can get away without duplicating. So as an optimization when\n # component_name is \"document\", we're going to make a copy of the\n # data (because the original belongs to our caller) and delete those\n # strings from the copy.\n #\n # WARNING: This optimization can save 20kb in data transfer\n # for typical pages, but it requires us to be very careful on\n # the frontend. If any components render conditionally based on\n # the state of bodyHTML, tocHTML or quickLinkHTML, then they will\n # render differently on the client than during SSR, and the hydrate\n # will not just work cleanly, and those components will re-render\n # with empty strings. This has already caused Bug 1558308, and\n # I've commented it out because the benefit in file size doesn't\n # seem worth the risk of client-side bugs.\n #\n # As an alternative, it ought to be possible to extract the HTML\n # strings from the SSR'ed document and rebuild the document object\n # on the client right before we call hydrate(). So if you uncomment\n # the lines below, you should also edit kuma/javascript/src/index.jsx\n # to extract the HTML from the document as well.\n #\n # if component_name == 'document':\n # data = data.copy()\n # data['documentData'] = data['documentData'].copy()\n # data['documentData'].update(bodyHTML='',\n # tocHTML='',\n # quickLinksHTML='')\n response.raise_for_status()\n result = response.json()\n return _render(component_name, result['html'], result['script'])\n\n except requests.exceptions.RequestException as exception:\n print(f\"{exception.__class__} error contacting SSR server.\")\n print(\"Falling back to client side rendering.\")\n return client_side_render(component_name, data)\n", "path": "kuma/wiki/templatetags/ssr.py"}]}
| 2,627 | 197 |
gh_patches_debug_42461
|
rasdani/github-patches
|
git_diff
|
python-gitlab__python-gitlab-2773
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ProjectMergeRequestApprovalRule.save() throws 404
## Description of the problem, including code/CLI snippet
`gl.project.get(proj_id).merge_requests.get(mr_iid).approval_rules.get(rule_id).save()`
This example is an MVP example; actually making changes to the rule object before calling `.save()` doesn't change the behaviour
## Expected Behavior
The function should succeed silently, returning `None`
## Actual Behavior
`gitlab.exceptions.GitlabUpdateError: 404: 404 Not found` is thrown. Trying it with debug mode on, it appears as though the root cause of the issue is that when the CLI invokes `/projects/:id/merge_requests/:merge_request_iid/approval_rules/:approval_rule_id` in the API, `:id` (i.e. project ID) is passed where the URL expects `:approval_rule_id`, as can be seen from this debug output (anonymized to remove sensitive information)
```
>>> rule.save()
DEBUG:urllib3.connectionpool:Resetting dropped connection: mygitlab.example.com
send: b'PUT /api/v4/projects/93/merge_requests/1/approval_rules/93 HTTP/1.1\r\nHost: mygitlab.example.com\r\nUser-Agent: python-gitlab/3.14.0\r\nAccept-Encoding: gzip, deflate\r\nAccept: */*\r\nConnection: keep-alive\r\nPRIVATE-TOKEN: TOKEN\r\nContent-type: application/json\r\nContent-Length: 768\r\n\r\n'
send: b'{"id": "93", "merge_request_iid": "1", "approval_rule_id": 89, "name": "testrule", "approvals_required": 1, "users": ["{\\"id\\": 168, \\"username\\": \\"myusername\\", \\"name\\": \\"My Name\\", \\"state\\": \\"active\\", \\"avatar_url\\": \\"https://secure.gravatar.com/avatar/8306d9f17d1c91970c2447b61c7a9f29?s=80&d=identicon\\", \\"web_url\\": \\"https://mygitlab.example.com/myusername\\", \\"created_at\\": \\"2023-03-29T14:30:13.371Z\\", \\"bio\\": \\"\\", \\"location\\": null, \\"public_email\\": null, \\"skype\\": \\"\\", \\"linkedin\\": \\"\\", \\"twitter\\": \\"\\", \\"website_url\\": \\"\\", \\"organization\\": null, \\"job_title\\": \\"\\", \\"pronouns\\": null, \\"bot\\": false, \\"work_information\\": null, \\"followers\\": 0, \\"following\\": 0, \\"is_followed\\": false, \\"local_time\\": null}"]}'
reply: 'HTTP/1.1 404 Not Found\r\n'
```
## Specifications
- python-gitlab version: 3.14.0
- API version you are using (v3/v4): v4
- Gitlab server version (or gitlab.com): 15.7.2-ee
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `gitlab/v4/objects/merge_request_approvals.py`
Content:
```
1 from typing import Any, cast, Dict, List, Optional, TYPE_CHECKING, Union
2
3 from gitlab import exceptions as exc
4 from gitlab.base import RESTManager, RESTObject
5 from gitlab.mixins import (
6 CreateMixin,
7 CRUDMixin,
8 DeleteMixin,
9 GetWithoutIdMixin,
10 ListMixin,
11 ObjectDeleteMixin,
12 SaveMixin,
13 UpdateMethod,
14 UpdateMixin,
15 )
16 from gitlab.types import RequiredOptional
17
18 __all__ = [
19 "ProjectApproval",
20 "ProjectApprovalManager",
21 "ProjectApprovalRule",
22 "ProjectApprovalRuleManager",
23 "ProjectMergeRequestApproval",
24 "ProjectMergeRequestApprovalManager",
25 "ProjectMergeRequestApprovalRule",
26 "ProjectMergeRequestApprovalRuleManager",
27 "ProjectMergeRequestApprovalState",
28 "ProjectMergeRequestApprovalStateManager",
29 ]
30
31
32 class ProjectApproval(SaveMixin, RESTObject):
33 _id_attr = None
34
35
36 class ProjectApprovalManager(GetWithoutIdMixin, UpdateMixin, RESTManager):
37 _path = "/projects/{project_id}/approvals"
38 _obj_cls = ProjectApproval
39 _from_parent_attrs = {"project_id": "id"}
40 _update_attrs = RequiredOptional(
41 optional=(
42 "approvals_before_merge",
43 "reset_approvals_on_push",
44 "disable_overriding_approvers_per_merge_request",
45 "merge_requests_author_approval",
46 "merge_requests_disable_committers_approval",
47 ),
48 )
49 _update_method = UpdateMethod.POST
50
51 def get(self, **kwargs: Any) -> ProjectApproval:
52 return cast(ProjectApproval, super().get(**kwargs))
53
54
55 class ProjectApprovalRule(SaveMixin, ObjectDeleteMixin, RESTObject):
56 _id_attr = "id"
57
58
59 class ProjectApprovalRuleManager(
60 ListMixin, CreateMixin, UpdateMixin, DeleteMixin, RESTManager
61 ):
62 _path = "/projects/{project_id}/approval_rules"
63 _obj_cls = ProjectApprovalRule
64 _from_parent_attrs = {"project_id": "id"}
65 _create_attrs = RequiredOptional(
66 required=("name", "approvals_required"),
67 optional=("user_ids", "group_ids", "protected_branch_ids", "usernames"),
68 )
69
70
71 class ProjectMergeRequestApproval(SaveMixin, RESTObject):
72 _id_attr = None
73
74
75 class ProjectMergeRequestApprovalManager(GetWithoutIdMixin, UpdateMixin, RESTManager):
76 _path = "/projects/{project_id}/merge_requests/{mr_iid}/approvals"
77 _obj_cls = ProjectMergeRequestApproval
78 _from_parent_attrs = {"project_id": "project_id", "mr_iid": "iid"}
79 _update_attrs = RequiredOptional(required=("approvals_required",))
80 _update_method = UpdateMethod.POST
81
82 def get(self, **kwargs: Any) -> ProjectMergeRequestApproval:
83 return cast(ProjectMergeRequestApproval, super().get(**kwargs))
84
85 @exc.on_http_error(exc.GitlabUpdateError)
86 def set_approvers(
87 self,
88 approvals_required: int,
89 approver_ids: Optional[List[int]] = None,
90 approver_group_ids: Optional[List[int]] = None,
91 approval_rule_name: str = "name",
92 **kwargs: Any,
93 ) -> RESTObject:
94 """Change MR-level allowed approvers and approver groups.
95
96 Args:
97 approvals_required: The number of required approvals for this rule
98 approver_ids: User IDs that can approve MRs
99 approver_group_ids: Group IDs whose members can approve MRs
100
101 Raises:
102 GitlabAuthenticationError: If authentication is not correct
103 GitlabUpdateError: If the server failed to perform the request
104 """
105 approver_ids = approver_ids or []
106 approver_group_ids = approver_group_ids or []
107
108 data = {
109 "name": approval_rule_name,
110 "approvals_required": approvals_required,
111 "rule_type": "regular",
112 "user_ids": approver_ids,
113 "group_ids": approver_group_ids,
114 }
115 if TYPE_CHECKING:
116 assert self._parent is not None
117 approval_rules: ProjectMergeRequestApprovalRuleManager = (
118 self._parent.approval_rules
119 )
120 # update any existing approval rule matching the name
121 existing_approval_rules = approval_rules.list()
122 for ar in existing_approval_rules:
123 if ar.name == approval_rule_name:
124 ar.user_ids = data["user_ids"]
125 ar.approvals_required = data["approvals_required"]
126 ar.group_ids = data["group_ids"]
127 ar.save()
128 return ar
129 # if there was no rule matching the rule name, create a new one
130 return approval_rules.create(data=data, **kwargs)
131
132
133 class ProjectMergeRequestApprovalRule(SaveMixin, ObjectDeleteMixin, RESTObject):
134 _repr_attr = "name"
135 id: int
136 approval_rule_id: int
137 merge_request_iid: int
138
139 @exc.on_http_error(exc.GitlabUpdateError)
140 def save(self, **kwargs: Any) -> None:
141 """Save the changes made to the object to the server.
142
143 The object is updated to match what the server returns.
144
145 Args:
146 **kwargs: Extra options to send to the server (e.g. sudo)
147
148 Raise:
149 GitlabAuthenticationError: If authentication is not correct
150 GitlabUpdateError: If the server cannot perform the request
151 """
152 # There is a mismatch between the name of our id attribute and the put
153 # REST API name for the project_id, so we override it here.
154 self.approval_rule_id = self.id
155 self.merge_request_iid = self._parent_attrs["mr_iid"]
156 self.id = self._parent_attrs["project_id"]
157 # save will update self.id with the result from the server, so no need
158 # to overwrite with what it was before we overwrote it.
159 SaveMixin.save(self, **kwargs)
160
161
162 class ProjectMergeRequestApprovalRuleManager(CRUDMixin, RESTManager):
163 _path = "/projects/{project_id}/merge_requests/{mr_iid}/approval_rules"
164 _obj_cls = ProjectMergeRequestApprovalRule
165 _from_parent_attrs = {"project_id": "project_id", "mr_iid": "iid"}
166 _update_attrs = RequiredOptional(
167 required=(
168 "id",
169 "merge_request_iid",
170 "approval_rule_id",
171 "name",
172 "approvals_required",
173 ),
174 optional=("user_ids", "group_ids"),
175 )
176 # Important: When approval_project_rule_id is set, the name, users and
177 # groups of project-level rule will be copied. The approvals_required
178 # specified will be used.
179 _create_attrs = RequiredOptional(
180 required=("id", "merge_request_iid", "name", "approvals_required"),
181 optional=("approval_project_rule_id", "user_ids", "group_ids"),
182 )
183
184 def get(
185 self, id: Union[str, int], lazy: bool = False, **kwargs: Any
186 ) -> ProjectMergeRequestApprovalRule:
187 return cast(
188 ProjectMergeRequestApprovalRule, super().get(id=id, lazy=lazy, **kwargs)
189 )
190
191 def create(
192 self, data: Optional[Dict[str, Any]] = None, **kwargs: Any
193 ) -> RESTObject:
194 """Create a new object.
195
196 Args:
197 data: Parameters to send to the server to create the
198 resource
199 **kwargs: Extra options to send to the server (e.g. sudo or
200 'ref_name', 'stage', 'name', 'all')
201
202 Raises:
203 GitlabAuthenticationError: If authentication is not correct
204 GitlabCreateError: If the server cannot perform the request
205
206 Returns:
207 A new instance of the manage object class build with
208 the data sent by the server
209 """
210 if TYPE_CHECKING:
211 assert data is not None
212 new_data = data.copy()
213 new_data["id"] = self._from_parent_attrs["project_id"]
214 new_data["merge_request_iid"] = self._from_parent_attrs["mr_iid"]
215 return CreateMixin.create(self, new_data, **kwargs)
216
217
218 class ProjectMergeRequestApprovalState(RESTObject):
219 pass
220
221
222 class ProjectMergeRequestApprovalStateManager(GetWithoutIdMixin, RESTManager):
223 _path = "/projects/{project_id}/merge_requests/{mr_iid}/approval_state"
224 _obj_cls = ProjectMergeRequestApprovalState
225 _from_parent_attrs = {"project_id": "project_id", "mr_iid": "iid"}
226
227 def get(self, **kwargs: Any) -> ProjectMergeRequestApprovalState:
228 return cast(ProjectMergeRequestApprovalState, super().get(**kwargs))
229
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/gitlab/v4/objects/merge_request_approvals.py b/gitlab/v4/objects/merge_request_approvals.py
--- a/gitlab/v4/objects/merge_request_approvals.py
+++ b/gitlab/v4/objects/merge_request_approvals.py
@@ -1,4 +1,4 @@
-from typing import Any, cast, Dict, List, Optional, TYPE_CHECKING, Union
+from typing import Any, cast, List, Optional, TYPE_CHECKING, Union
from gitlab import exceptions as exc
from gitlab.base import RESTManager, RESTObject
@@ -132,42 +132,16 @@
class ProjectMergeRequestApprovalRule(SaveMixin, ObjectDeleteMixin, RESTObject):
_repr_attr = "name"
- id: int
- approval_rule_id: int
- merge_request_iid: int
-
- @exc.on_http_error(exc.GitlabUpdateError)
- def save(self, **kwargs: Any) -> None:
- """Save the changes made to the object to the server.
-
- The object is updated to match what the server returns.
-
- Args:
- **kwargs: Extra options to send to the server (e.g. sudo)
-
- Raise:
- GitlabAuthenticationError: If authentication is not correct
- GitlabUpdateError: If the server cannot perform the request
- """
- # There is a mismatch between the name of our id attribute and the put
- # REST API name for the project_id, so we override it here.
- self.approval_rule_id = self.id
- self.merge_request_iid = self._parent_attrs["mr_iid"]
- self.id = self._parent_attrs["project_id"]
- # save will update self.id with the result from the server, so no need
- # to overwrite with what it was before we overwrote it.
- SaveMixin.save(self, **kwargs)
class ProjectMergeRequestApprovalRuleManager(CRUDMixin, RESTManager):
- _path = "/projects/{project_id}/merge_requests/{mr_iid}/approval_rules"
+ _path = "/projects/{project_id}/merge_requests/{merge_request_iid}/approval_rules"
_obj_cls = ProjectMergeRequestApprovalRule
- _from_parent_attrs = {"project_id": "project_id", "mr_iid": "iid"}
+ _from_parent_attrs = {"project_id": "project_id", "merge_request_iid": "iid"}
_update_attrs = RequiredOptional(
required=(
"id",
"merge_request_iid",
- "approval_rule_id",
"name",
"approvals_required",
),
@@ -177,7 +151,7 @@
# groups of project-level rule will be copied. The approvals_required
# specified will be used.
_create_attrs = RequiredOptional(
- required=("id", "merge_request_iid", "name", "approvals_required"),
+ required=("name", "approvals_required"),
optional=("approval_project_rule_id", "user_ids", "group_ids"),
)
@@ -188,32 +162,6 @@
ProjectMergeRequestApprovalRule, super().get(id=id, lazy=lazy, **kwargs)
)
- def create(
- self, data: Optional[Dict[str, Any]] = None, **kwargs: Any
- ) -> RESTObject:
- """Create a new object.
-
- Args:
- data: Parameters to send to the server to create the
- resource
- **kwargs: Extra options to send to the server (e.g. sudo or
- 'ref_name', 'stage', 'name', 'all')
-
- Raises:
- GitlabAuthenticationError: If authentication is not correct
- GitlabCreateError: If the server cannot perform the request
-
- Returns:
- A new instance of the manage object class build with
- the data sent by the server
- """
- if TYPE_CHECKING:
- assert data is not None
- new_data = data.copy()
- new_data["id"] = self._from_parent_attrs["project_id"]
- new_data["merge_request_iid"] = self._from_parent_attrs["mr_iid"]
- return CreateMixin.create(self, new_data, **kwargs)
-
class ProjectMergeRequestApprovalState(RESTObject):
pass
|
{"golden_diff": "diff --git a/gitlab/v4/objects/merge_request_approvals.py b/gitlab/v4/objects/merge_request_approvals.py\n--- a/gitlab/v4/objects/merge_request_approvals.py\n+++ b/gitlab/v4/objects/merge_request_approvals.py\n@@ -1,4 +1,4 @@\n-from typing import Any, cast, Dict, List, Optional, TYPE_CHECKING, Union\n+from typing import Any, cast, List, Optional, TYPE_CHECKING, Union\n \n from gitlab import exceptions as exc\n from gitlab.base import RESTManager, RESTObject\n@@ -132,42 +132,16 @@\n \n class ProjectMergeRequestApprovalRule(SaveMixin, ObjectDeleteMixin, RESTObject):\n _repr_attr = \"name\"\n- id: int\n- approval_rule_id: int\n- merge_request_iid: int\n-\n- @exc.on_http_error(exc.GitlabUpdateError)\n- def save(self, **kwargs: Any) -> None:\n- \"\"\"Save the changes made to the object to the server.\n-\n- The object is updated to match what the server returns.\n-\n- Args:\n- **kwargs: Extra options to send to the server (e.g. sudo)\n-\n- Raise:\n- GitlabAuthenticationError: If authentication is not correct\n- GitlabUpdateError: If the server cannot perform the request\n- \"\"\"\n- # There is a mismatch between the name of our id attribute and the put\n- # REST API name for the project_id, so we override it here.\n- self.approval_rule_id = self.id\n- self.merge_request_iid = self._parent_attrs[\"mr_iid\"]\n- self.id = self._parent_attrs[\"project_id\"]\n- # save will update self.id with the result from the server, so no need\n- # to overwrite with what it was before we overwrote it.\n- SaveMixin.save(self, **kwargs)\n \n \n class ProjectMergeRequestApprovalRuleManager(CRUDMixin, RESTManager):\n- _path = \"/projects/{project_id}/merge_requests/{mr_iid}/approval_rules\"\n+ _path = \"/projects/{project_id}/merge_requests/{merge_request_iid}/approval_rules\"\n _obj_cls = ProjectMergeRequestApprovalRule\n- _from_parent_attrs = {\"project_id\": \"project_id\", \"mr_iid\": \"iid\"}\n+ _from_parent_attrs = {\"project_id\": \"project_id\", \"merge_request_iid\": \"iid\"}\n _update_attrs = RequiredOptional(\n required=(\n \"id\",\n \"merge_request_iid\",\n- \"approval_rule_id\",\n \"name\",\n \"approvals_required\",\n ),\n@@ -177,7 +151,7 @@\n # groups of project-level rule will be copied. The approvals_required\n # specified will be used.\n _create_attrs = RequiredOptional(\n- required=(\"id\", \"merge_request_iid\", \"name\", \"approvals_required\"),\n+ required=(\"name\", \"approvals_required\"),\n optional=(\"approval_project_rule_id\", \"user_ids\", \"group_ids\"),\n )\n \n@@ -188,32 +162,6 @@\n ProjectMergeRequestApprovalRule, super().get(id=id, lazy=lazy, **kwargs)\n )\n \n- def create(\n- self, data: Optional[Dict[str, Any]] = None, **kwargs: Any\n- ) -> RESTObject:\n- \"\"\"Create a new object.\n-\n- Args:\n- data: Parameters to send to the server to create the\n- resource\n- **kwargs: Extra options to send to the server (e.g. sudo or\n- 'ref_name', 'stage', 'name', 'all')\n-\n- Raises:\n- GitlabAuthenticationError: If authentication is not correct\n- GitlabCreateError: If the server cannot perform the request\n-\n- Returns:\n- A new instance of the manage object class build with\n- the data sent by the server\n- \"\"\"\n- if TYPE_CHECKING:\n- assert data is not None\n- new_data = data.copy()\n- new_data[\"id\"] = self._from_parent_attrs[\"project_id\"]\n- new_data[\"merge_request_iid\"] = self._from_parent_attrs[\"mr_iid\"]\n- return CreateMixin.create(self, new_data, **kwargs)\n-\n \n class ProjectMergeRequestApprovalState(RESTObject):\n pass\n", "issue": "ProjectMergeRequestApprovalRule.save() throws 404\n## Description of the problem, including code/CLI snippet\r\n`gl.project.get(proj_id).merge_requests.get(mr_iid).approval_rules.get(rule_id).save()`\r\n\r\nThis example is an MVP example; actually making changes to the rule object before calling `.save()` doesn't change the behaviour\r\n\r\n## Expected Behavior\r\nThe function should succeed silently, returning `None`\r\n\r\n## Actual Behavior\r\n`gitlab.exceptions.GitlabUpdateError: 404: 404 Not found` is thrown. Trying it with debug mode on, it appears as though the root cause of the issue is that when the CLI invokes `/projects/:id/merge_requests/:merge_request_iid/approval_rules/:approval_rule_id` in the API, `:id` (i.e. project ID) is passed where the URL expects `:approval_rule_id`, as can be seen from this debug output (anonymized to remove sensitive information)\r\n\r\n```\r\n>>> rule.save()\r\nDEBUG:urllib3.connectionpool:Resetting dropped connection: mygitlab.example.com\r\nsend: b'PUT /api/v4/projects/93/merge_requests/1/approval_rules/93 HTTP/1.1\\r\\nHost: mygitlab.example.com\\r\\nUser-Agent: python-gitlab/3.14.0\\r\\nAccept-Encoding: gzip, deflate\\r\\nAccept: */*\\r\\nConnection: keep-alive\\r\\nPRIVATE-TOKEN: TOKEN\\r\\nContent-type: application/json\\r\\nContent-Length: 768\\r\\n\\r\\n'\r\nsend: b'{\"id\": \"93\", \"merge_request_iid\": \"1\", \"approval_rule_id\": 89, \"name\": \"testrule\", \"approvals_required\": 1, \"users\": [\"{\\\\\"id\\\\\": 168, \\\\\"username\\\\\": \\\\\"myusername\\\\\", \\\\\"name\\\\\": \\\\\"My Name\\\\\", \\\\\"state\\\\\": \\\\\"active\\\\\", \\\\\"avatar_url\\\\\": \\\\\"https://secure.gravatar.com/avatar/8306d9f17d1c91970c2447b61c7a9f29?s=80&d=identicon\\\\\", \\\\\"web_url\\\\\": \\\\\"https://mygitlab.example.com/myusername\\\\\", \\\\\"created_at\\\\\": \\\\\"2023-03-29T14:30:13.371Z\\\\\", \\\\\"bio\\\\\": \\\\\"\\\\\", \\\\\"location\\\\\": null, \\\\\"public_email\\\\\": null, \\\\\"skype\\\\\": \\\\\"\\\\\", \\\\\"linkedin\\\\\": \\\\\"\\\\\", \\\\\"twitter\\\\\": \\\\\"\\\\\", \\\\\"website_url\\\\\": \\\\\"\\\\\", \\\\\"organization\\\\\": null, \\\\\"job_title\\\\\": \\\\\"\\\\\", \\\\\"pronouns\\\\\": null, \\\\\"bot\\\\\": false, \\\\\"work_information\\\\\": null, \\\\\"followers\\\\\": 0, \\\\\"following\\\\\": 0, \\\\\"is_followed\\\\\": false, \\\\\"local_time\\\\\": null}\"]}'\r\nreply: 'HTTP/1.1 404 Not Found\\r\\n'\r\n```\r\n\r\n## Specifications\r\n\r\n - python-gitlab version: 3.14.0\r\n - API version you are using (v3/v4): v4\r\n - Gitlab server version (or gitlab.com): 15.7.2-ee\r\n\n", "before_files": [{"content": "from typing import Any, cast, Dict, List, Optional, TYPE_CHECKING, Union\n\nfrom gitlab import exceptions as exc\nfrom gitlab.base import RESTManager, RESTObject\nfrom gitlab.mixins import (\n CreateMixin,\n CRUDMixin,\n DeleteMixin,\n GetWithoutIdMixin,\n ListMixin,\n ObjectDeleteMixin,\n SaveMixin,\n UpdateMethod,\n UpdateMixin,\n)\nfrom gitlab.types import RequiredOptional\n\n__all__ = [\n \"ProjectApproval\",\n \"ProjectApprovalManager\",\n \"ProjectApprovalRule\",\n \"ProjectApprovalRuleManager\",\n \"ProjectMergeRequestApproval\",\n \"ProjectMergeRequestApprovalManager\",\n \"ProjectMergeRequestApprovalRule\",\n \"ProjectMergeRequestApprovalRuleManager\",\n \"ProjectMergeRequestApprovalState\",\n \"ProjectMergeRequestApprovalStateManager\",\n]\n\n\nclass ProjectApproval(SaveMixin, RESTObject):\n _id_attr = None\n\n\nclass ProjectApprovalManager(GetWithoutIdMixin, UpdateMixin, RESTManager):\n _path = \"/projects/{project_id}/approvals\"\n _obj_cls = ProjectApproval\n _from_parent_attrs = {\"project_id\": \"id\"}\n _update_attrs = RequiredOptional(\n optional=(\n \"approvals_before_merge\",\n \"reset_approvals_on_push\",\n \"disable_overriding_approvers_per_merge_request\",\n \"merge_requests_author_approval\",\n \"merge_requests_disable_committers_approval\",\n ),\n )\n _update_method = UpdateMethod.POST\n\n def get(self, **kwargs: Any) -> ProjectApproval:\n return cast(ProjectApproval, super().get(**kwargs))\n\n\nclass ProjectApprovalRule(SaveMixin, ObjectDeleteMixin, RESTObject):\n _id_attr = \"id\"\n\n\nclass ProjectApprovalRuleManager(\n ListMixin, CreateMixin, UpdateMixin, DeleteMixin, RESTManager\n):\n _path = \"/projects/{project_id}/approval_rules\"\n _obj_cls = ProjectApprovalRule\n _from_parent_attrs = {\"project_id\": \"id\"}\n _create_attrs = RequiredOptional(\n required=(\"name\", \"approvals_required\"),\n optional=(\"user_ids\", \"group_ids\", \"protected_branch_ids\", \"usernames\"),\n )\n\n\nclass ProjectMergeRequestApproval(SaveMixin, RESTObject):\n _id_attr = None\n\n\nclass ProjectMergeRequestApprovalManager(GetWithoutIdMixin, UpdateMixin, RESTManager):\n _path = \"/projects/{project_id}/merge_requests/{mr_iid}/approvals\"\n _obj_cls = ProjectMergeRequestApproval\n _from_parent_attrs = {\"project_id\": \"project_id\", \"mr_iid\": \"iid\"}\n _update_attrs = RequiredOptional(required=(\"approvals_required\",))\n _update_method = UpdateMethod.POST\n\n def get(self, **kwargs: Any) -> ProjectMergeRequestApproval:\n return cast(ProjectMergeRequestApproval, super().get(**kwargs))\n\n @exc.on_http_error(exc.GitlabUpdateError)\n def set_approvers(\n self,\n approvals_required: int,\n approver_ids: Optional[List[int]] = None,\n approver_group_ids: Optional[List[int]] = None,\n approval_rule_name: str = \"name\",\n **kwargs: Any,\n ) -> RESTObject:\n \"\"\"Change MR-level allowed approvers and approver groups.\n\n Args:\n approvals_required: The number of required approvals for this rule\n approver_ids: User IDs that can approve MRs\n approver_group_ids: Group IDs whose members can approve MRs\n\n Raises:\n GitlabAuthenticationError: If authentication is not correct\n GitlabUpdateError: If the server failed to perform the request\n \"\"\"\n approver_ids = approver_ids or []\n approver_group_ids = approver_group_ids or []\n\n data = {\n \"name\": approval_rule_name,\n \"approvals_required\": approvals_required,\n \"rule_type\": \"regular\",\n \"user_ids\": approver_ids,\n \"group_ids\": approver_group_ids,\n }\n if TYPE_CHECKING:\n assert self._parent is not None\n approval_rules: ProjectMergeRequestApprovalRuleManager = (\n self._parent.approval_rules\n )\n # update any existing approval rule matching the name\n existing_approval_rules = approval_rules.list()\n for ar in existing_approval_rules:\n if ar.name == approval_rule_name:\n ar.user_ids = data[\"user_ids\"]\n ar.approvals_required = data[\"approvals_required\"]\n ar.group_ids = data[\"group_ids\"]\n ar.save()\n return ar\n # if there was no rule matching the rule name, create a new one\n return approval_rules.create(data=data, **kwargs)\n\n\nclass ProjectMergeRequestApprovalRule(SaveMixin, ObjectDeleteMixin, RESTObject):\n _repr_attr = \"name\"\n id: int\n approval_rule_id: int\n merge_request_iid: int\n\n @exc.on_http_error(exc.GitlabUpdateError)\n def save(self, **kwargs: Any) -> None:\n \"\"\"Save the changes made to the object to the server.\n\n The object is updated to match what the server returns.\n\n Args:\n **kwargs: Extra options to send to the server (e.g. sudo)\n\n Raise:\n GitlabAuthenticationError: If authentication is not correct\n GitlabUpdateError: If the server cannot perform the request\n \"\"\"\n # There is a mismatch between the name of our id attribute and the put\n # REST API name for the project_id, so we override it here.\n self.approval_rule_id = self.id\n self.merge_request_iid = self._parent_attrs[\"mr_iid\"]\n self.id = self._parent_attrs[\"project_id\"]\n # save will update self.id with the result from the server, so no need\n # to overwrite with what it was before we overwrote it.\n SaveMixin.save(self, **kwargs)\n\n\nclass ProjectMergeRequestApprovalRuleManager(CRUDMixin, RESTManager):\n _path = \"/projects/{project_id}/merge_requests/{mr_iid}/approval_rules\"\n _obj_cls = ProjectMergeRequestApprovalRule\n _from_parent_attrs = {\"project_id\": \"project_id\", \"mr_iid\": \"iid\"}\n _update_attrs = RequiredOptional(\n required=(\n \"id\",\n \"merge_request_iid\",\n \"approval_rule_id\",\n \"name\",\n \"approvals_required\",\n ),\n optional=(\"user_ids\", \"group_ids\"),\n )\n # Important: When approval_project_rule_id is set, the name, users and\n # groups of project-level rule will be copied. The approvals_required\n # specified will be used.\n _create_attrs = RequiredOptional(\n required=(\"id\", \"merge_request_iid\", \"name\", \"approvals_required\"),\n optional=(\"approval_project_rule_id\", \"user_ids\", \"group_ids\"),\n )\n\n def get(\n self, id: Union[str, int], lazy: bool = False, **kwargs: Any\n ) -> ProjectMergeRequestApprovalRule:\n return cast(\n ProjectMergeRequestApprovalRule, super().get(id=id, lazy=lazy, **kwargs)\n )\n\n def create(\n self, data: Optional[Dict[str, Any]] = None, **kwargs: Any\n ) -> RESTObject:\n \"\"\"Create a new object.\n\n Args:\n data: Parameters to send to the server to create the\n resource\n **kwargs: Extra options to send to the server (e.g. sudo or\n 'ref_name', 'stage', 'name', 'all')\n\n Raises:\n GitlabAuthenticationError: If authentication is not correct\n GitlabCreateError: If the server cannot perform the request\n\n Returns:\n A new instance of the manage object class build with\n the data sent by the server\n \"\"\"\n if TYPE_CHECKING:\n assert data is not None\n new_data = data.copy()\n new_data[\"id\"] = self._from_parent_attrs[\"project_id\"]\n new_data[\"merge_request_iid\"] = self._from_parent_attrs[\"mr_iid\"]\n return CreateMixin.create(self, new_data, **kwargs)\n\n\nclass ProjectMergeRequestApprovalState(RESTObject):\n pass\n\n\nclass ProjectMergeRequestApprovalStateManager(GetWithoutIdMixin, RESTManager):\n _path = \"/projects/{project_id}/merge_requests/{mr_iid}/approval_state\"\n _obj_cls = ProjectMergeRequestApprovalState\n _from_parent_attrs = {\"project_id\": \"project_id\", \"mr_iid\": \"iid\"}\n\n def get(self, **kwargs: Any) -> ProjectMergeRequestApprovalState:\n return cast(ProjectMergeRequestApprovalState, super().get(**kwargs))\n", "path": "gitlab/v4/objects/merge_request_approvals.py"}], "after_files": [{"content": "from typing import Any, cast, List, Optional, TYPE_CHECKING, Union\n\nfrom gitlab import exceptions as exc\nfrom gitlab.base import RESTManager, RESTObject\nfrom gitlab.mixins import (\n CreateMixin,\n CRUDMixin,\n DeleteMixin,\n GetWithoutIdMixin,\n ListMixin,\n ObjectDeleteMixin,\n SaveMixin,\n UpdateMethod,\n UpdateMixin,\n)\nfrom gitlab.types import RequiredOptional\n\n__all__ = [\n \"ProjectApproval\",\n \"ProjectApprovalManager\",\n \"ProjectApprovalRule\",\n \"ProjectApprovalRuleManager\",\n \"ProjectMergeRequestApproval\",\n \"ProjectMergeRequestApprovalManager\",\n \"ProjectMergeRequestApprovalRule\",\n \"ProjectMergeRequestApprovalRuleManager\",\n \"ProjectMergeRequestApprovalState\",\n \"ProjectMergeRequestApprovalStateManager\",\n]\n\n\nclass ProjectApproval(SaveMixin, RESTObject):\n _id_attr = None\n\n\nclass ProjectApprovalManager(GetWithoutIdMixin, UpdateMixin, RESTManager):\n _path = \"/projects/{project_id}/approvals\"\n _obj_cls = ProjectApproval\n _from_parent_attrs = {\"project_id\": \"id\"}\n _update_attrs = RequiredOptional(\n optional=(\n \"approvals_before_merge\",\n \"reset_approvals_on_push\",\n \"disable_overriding_approvers_per_merge_request\",\n \"merge_requests_author_approval\",\n \"merge_requests_disable_committers_approval\",\n ),\n )\n _update_method = UpdateMethod.POST\n\n def get(self, **kwargs: Any) -> ProjectApproval:\n return cast(ProjectApproval, super().get(**kwargs))\n\n\nclass ProjectApprovalRule(SaveMixin, ObjectDeleteMixin, RESTObject):\n _id_attr = \"id\"\n\n\nclass ProjectApprovalRuleManager(\n ListMixin, CreateMixin, UpdateMixin, DeleteMixin, RESTManager\n):\n _path = \"/projects/{project_id}/approval_rules\"\n _obj_cls = ProjectApprovalRule\n _from_parent_attrs = {\"project_id\": \"id\"}\n _create_attrs = RequiredOptional(\n required=(\"name\", \"approvals_required\"),\n optional=(\"user_ids\", \"group_ids\", \"protected_branch_ids\", \"usernames\"),\n )\n\n\nclass ProjectMergeRequestApproval(SaveMixin, RESTObject):\n _id_attr = None\n\n\nclass ProjectMergeRequestApprovalManager(GetWithoutIdMixin, UpdateMixin, RESTManager):\n _path = \"/projects/{project_id}/merge_requests/{mr_iid}/approvals\"\n _obj_cls = ProjectMergeRequestApproval\n _from_parent_attrs = {\"project_id\": \"project_id\", \"mr_iid\": \"iid\"}\n _update_attrs = RequiredOptional(required=(\"approvals_required\",))\n _update_method = UpdateMethod.POST\n\n def get(self, **kwargs: Any) -> ProjectMergeRequestApproval:\n return cast(ProjectMergeRequestApproval, super().get(**kwargs))\n\n @exc.on_http_error(exc.GitlabUpdateError)\n def set_approvers(\n self,\n approvals_required: int,\n approver_ids: Optional[List[int]] = None,\n approver_group_ids: Optional[List[int]] = None,\n approval_rule_name: str = \"name\",\n **kwargs: Any,\n ) -> RESTObject:\n \"\"\"Change MR-level allowed approvers and approver groups.\n\n Args:\n approvals_required: The number of required approvals for this rule\n approver_ids: User IDs that can approve MRs\n approver_group_ids: Group IDs whose members can approve MRs\n\n Raises:\n GitlabAuthenticationError: If authentication is not correct\n GitlabUpdateError: If the server failed to perform the request\n \"\"\"\n approver_ids = approver_ids or []\n approver_group_ids = approver_group_ids or []\n\n data = {\n \"name\": approval_rule_name,\n \"approvals_required\": approvals_required,\n \"rule_type\": \"regular\",\n \"user_ids\": approver_ids,\n \"group_ids\": approver_group_ids,\n }\n if TYPE_CHECKING:\n assert self._parent is not None\n approval_rules: ProjectMergeRequestApprovalRuleManager = (\n self._parent.approval_rules\n )\n # update any existing approval rule matching the name\n existing_approval_rules = approval_rules.list()\n for ar in existing_approval_rules:\n if ar.name == approval_rule_name:\n ar.user_ids = data[\"user_ids\"]\n ar.approvals_required = data[\"approvals_required\"]\n ar.group_ids = data[\"group_ids\"]\n ar.save()\n return ar\n # if there was no rule matching the rule name, create a new one\n return approval_rules.create(data=data, **kwargs)\n\n\nclass ProjectMergeRequestApprovalRule(SaveMixin, ObjectDeleteMixin, RESTObject):\n _repr_attr = \"name\"\n\n\nclass ProjectMergeRequestApprovalRuleManager(CRUDMixin, RESTManager):\n _path = \"/projects/{project_id}/merge_requests/{merge_request_iid}/approval_rules\"\n _obj_cls = ProjectMergeRequestApprovalRule\n _from_parent_attrs = {\"project_id\": \"project_id\", \"merge_request_iid\": \"iid\"}\n _update_attrs = RequiredOptional(\n required=(\n \"id\",\n \"merge_request_iid\",\n \"name\",\n \"approvals_required\",\n ),\n optional=(\"user_ids\", \"group_ids\"),\n )\n # Important: When approval_project_rule_id is set, the name, users and\n # groups of project-level rule will be copied. The approvals_required\n # specified will be used.\n _create_attrs = RequiredOptional(\n required=(\"name\", \"approvals_required\"),\n optional=(\"approval_project_rule_id\", \"user_ids\", \"group_ids\"),\n )\n\n def get(\n self, id: Union[str, int], lazy: bool = False, **kwargs: Any\n ) -> ProjectMergeRequestApprovalRule:\n return cast(\n ProjectMergeRequestApprovalRule, super().get(id=id, lazy=lazy, **kwargs)\n )\n\n\nclass ProjectMergeRequestApprovalState(RESTObject):\n pass\n\n\nclass ProjectMergeRequestApprovalStateManager(GetWithoutIdMixin, RESTManager):\n _path = \"/projects/{project_id}/merge_requests/{mr_iid}/approval_state\"\n _obj_cls = ProjectMergeRequestApprovalState\n _from_parent_attrs = {\"project_id\": \"project_id\", \"mr_iid\": \"iid\"}\n\n def get(self, **kwargs: Any) -> ProjectMergeRequestApprovalState:\n return cast(ProjectMergeRequestApprovalState, super().get(**kwargs))\n", "path": "gitlab/v4/objects/merge_request_approvals.py"}]}
| 3,451 | 970 |
gh_patches_debug_5461
|
rasdani/github-patches
|
git_diff
|
pyodide__pyodide-2913
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
https://pyodide.org/en/latest/console.html doesn't show latest `main` version
## 🐛 Bug
The https://pyodide.org/en/latest/console.html console is stuck at `v0.21.0a3`. I believe this is because the version wasn't bumped to the next 'dev' version after the `v0.21.0a3` release, so somebody probably needs to run
```
./tools/bump_version.py --new-version 0.21.0.dev0
```
Without `dev` in the version, the documentation's console uses the release:
https://github.com/pyodide/pyodide/blob/7231cab3ffc83f6221fafb7458f9b223d2a7c759/docs/conf.py#L20-L23
### To Reproduce
Go to https://pyodide.org/en/latest/console.html and load a package added since v0.21.0a3, e.g., `import rebound`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/conf.py`
Content:
```
1 # Configuration file for the Sphinx documentation builder.
2
3 # -- Path setup --------------------------------------------------------------
4
5 import atexit
6 import os
7 import shutil
8 import subprocess
9 import sys
10 from pathlib import Path
11 from typing import Any
12 from unittest import mock
13
14 # -- Project information -----------------------------------------------------
15
16 project = "Pyodide"
17 copyright = "2019-2022, Pyodide contributors and Mozilla"
18 pyodide_version = "0.21.0a3"
19
20 if ".dev" in pyodide_version:
21 CDN_URL = "https://cdn.jsdelivr.net/pyodide/dev/full/"
22 else:
23 CDN_URL = f"https://cdn.jsdelivr.net/pyodide/v{pyodide_version}/full/"
24
25 # -- General configuration ---------------------------------------------------
26
27 # If your documentation needs a minimal Sphinx version, state it here.
28 #
29 # needs_sphinx = '1.0'
30
31 extensions = [
32 "sphinx.ext.autodoc",
33 "sphinx.ext.autosummary",
34 "sphinxcontrib.napoleon",
35 "myst_parser",
36 "sphinx_js",
37 "autodocsumm",
38 "sphinx_panels",
39 "sphinx_pyodide",
40 "sphinx_argparse_cli",
41 "versionwarning.extension",
42 "sphinx_issues",
43 ]
44
45 myst_enable_extensions = ["substitution"]
46
47 js_language = "typescript"
48 jsdoc_config_path = "../src/js/tsconfig.json"
49 root_for_relative_js_paths = "../src/"
50 issues_github_path = "pyodide/pyodide"
51
52 versionwarning_messages = {
53 "latest": (
54 "This is the development version of the documentation. "
55 'See <a href="https://pyodide.org/">here</a> for latest stable '
56 "documentation. Please do not use Pyodide with non "
57 "versioned (`dev`) URLs from the CDN for deployed applications!"
58 )
59 }
60 versionwarning_body_selector = "#main-content > div"
61
62 autosummary_generate = True
63 autodoc_default_flags = ["members", "inherited-members"]
64
65 # Add modules to be mocked.
66 mock_modules = ["ruamel.yaml", "tomli"]
67
68 # Add any paths that contain templates here, relative to this directory.
69 templates_path = ["_templates"]
70
71 # The suffix(es) of source filenames.
72 source_suffix = [".rst", ".md"]
73
74 # The master toctree document.
75 master_doc = "index"
76
77 # The language for content autogenerated by Sphinx.
78 language = None
79
80 # List of patterns, relative to source directory, that match files and
81 # directories to ignore when looking for source files.
82 exclude_patterns = ["_build", "Thumbs.db", ".DS_Store", "README.md"]
83
84 # The name of the Pygments (syntax highlighting) style to use.
85 pygments_style = None
86
87 # -- Options for HTML output -------------------------------------------------
88
89 # The theme to use for HTML and HTML Help pages. See the documentation for
90 # a list of builtin themes.
91 #
92 html_theme = "sphinx_book_theme"
93 html_logo = "_static/img/pyodide-logo.png"
94
95 # theme-specific options
96 html_theme_options: dict[str, Any] = {}
97
98 # paths that contain custom static files (such as style sheets)
99 html_static_path = ["_static"]
100
101
102 html_css_files = [
103 "css/pyodide.css",
104 ]
105
106 # Custom sidebar templates, must be a dictionary that maps document names
107 # to template names.
108 # html_sidebars = {}
109
110 # -- Options for HTMLHelp output ---------------------------------------------
111
112 # Output file base name for HTML help builder.
113 htmlhelp_basename = "Pyodidedoc"
114
115 # A list of files that should not be packed into the epub file.
116 epub_exclude_files = ["search.html"]
117
118
119 def delete_attrs(cls):
120 for name in dir(cls):
121 if not name.startswith("_"):
122 try:
123 delattr(cls, name)
124 except Exception:
125 pass
126
127
128 # Try not to cause side effects if we are imported incidentally.
129
130 try:
131 import sphinx
132
133 IN_SPHINX = hasattr(sphinx, "application")
134 except ImportError:
135 IN_SPHINX = False
136
137 IN_READTHEDOCS = "READTHEDOCS" in os.environ
138
139 if IN_READTHEDOCS:
140 env = {"PYODIDE_BASE_URL": CDN_URL}
141 os.makedirs("_build/html", exist_ok=True)
142 res = subprocess.check_output(
143 ["make", "-C", "..", "docs/_build/html/console.html"],
144 env=env,
145 stderr=subprocess.STDOUT,
146 encoding="utf-8",
147 )
148 print(res)
149
150 if IN_SPHINX:
151 # Compatibility shims. sphinx-js and sphinxcontrib-napoleon have not been updated for Python 3.10
152 import collections
153 from typing import Callable, Mapping
154
155 collections.Mapping = Mapping # type: ignore[attr-defined]
156 collections.Callable = Callable # type: ignore[attr-defined]
157
158 base_dir = Path(__file__).resolve().parent.parent
159 path_dirs = [
160 str(base_dir),
161 str(base_dir / "pyodide-build"),
162 str(base_dir / "docs/sphinx_pyodide"),
163 str(base_dir / "src/py"),
164 str(base_dir / "packages/micropip/src"),
165 ]
166 sys.path = path_dirs + sys.path
167
168 import micropip # noqa: F401
169 import pyodide
170
171 # We hacked it so that autodoc will look for submodules, but only if we import
172 # them here. TODO: look these up in the source directory?
173 import pyodide.code
174 import pyodide.console
175 import pyodide.ffi.wrappers
176 import pyodide.http
177 import pyodide.webloop
178
179 # The full version, including alpha/beta/rc tags.
180 release = version = pyodide.__version__
181 html_title = f"Version {version}"
182
183 shutil.copy("../src/core/pyproxy.ts", "../src/js/pyproxy.gen.ts")
184 shutil.copy("../src/core/error_handling.ts", "../src/js/error_handling.gen.ts")
185 js_source_path = [str(x) for x in Path("../src/js").glob("*.ts")]
186
187 def remove_pyproxy_gen_ts():
188 Path("../src/js/pyproxy.gen.ts").unlink(missing_ok=True)
189
190 atexit.register(remove_pyproxy_gen_ts)
191
192 os.environ["PATH"] += f':{str(Path("../src/js/node_modules/.bin").resolve())}'
193 print(os.environ["PATH"])
194 if IN_READTHEDOCS:
195 subprocess.run(["npm", "ci"], cwd="../src/js")
196 elif not shutil.which("typedoc"):
197 raise Exception(
198 "Before building the Pyodide docs you must run 'npm install' in 'src/js'."
199 )
200
201 # Prevent API docs for webloop methods: they are the same as for base event loop
202 # and it clutters api docs too much
203 delete_attrs(pyodide.webloop.WebLoop)
204 delete_attrs(pyodide.webloop.WebLoopPolicy)
205 delete_attrs(pyodide.console.PyodideConsole)
206
207 for module in mock_modules:
208 sys.modules[module] = mock.Mock()
209
210
211 # https://github.com/sphinx-doc/sphinx/issues/4054
212 def globalReplace(app, docname, source):
213 result = source[0]
214 for key in app.config.global_replacements:
215 result = result.replace(key, app.config.global_replacements[key])
216 source[0] = result
217
218
219 global_replacements = {"{{PYODIDE_CDN_URL}}": CDN_URL}
220
221
222 def setup(app):
223 app.add_config_value("global_replacements", {}, True)
224 app.connect("source-read", globalReplace)
225
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -17,7 +17,7 @@
copyright = "2019-2022, Pyodide contributors and Mozilla"
pyodide_version = "0.21.0a3"
-if ".dev" in pyodide_version:
+if ".dev" in pyodide_version or os.environ.get("READTHEDOCS_VERSION") == "latest":
CDN_URL = "https://cdn.jsdelivr.net/pyodide/dev/full/"
else:
CDN_URL = f"https://cdn.jsdelivr.net/pyodide/v{pyodide_version}/full/"
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -17,7 +17,7 @@\n copyright = \"2019-2022, Pyodide contributors and Mozilla\"\n pyodide_version = \"0.21.0a3\"\n \n-if \".dev\" in pyodide_version:\n+if \".dev\" in pyodide_version or os.environ.get(\"READTHEDOCS_VERSION\") == \"latest\":\n CDN_URL = \"https://cdn.jsdelivr.net/pyodide/dev/full/\"\n else:\n CDN_URL = f\"https://cdn.jsdelivr.net/pyodide/v{pyodide_version}/full/\"\n", "issue": "https://pyodide.org/en/latest/console.html doesn't show latest `main` version\n## \ud83d\udc1b Bug\r\n\r\nThe https://pyodide.org/en/latest/console.html console is stuck at `v0.21.0a3`. I believe this is because the version wasn't bumped to the next 'dev' version after the `v0.21.0a3` release, so somebody probably needs to run\r\n```\r\n./tools/bump_version.py --new-version 0.21.0.dev0\r\n\r\n```\r\nWithout `dev` in the version, the documentation's console uses the release:\r\nhttps://github.com/pyodide/pyodide/blob/7231cab3ffc83f6221fafb7458f9b223d2a7c759/docs/conf.py#L20-L23\r\n\r\n### To Reproduce\r\n\r\nGo to https://pyodide.org/en/latest/console.html and load a package added since v0.21.0a3, e.g., `import rebound`\r\n\r\n\n", "before_files": [{"content": "# Configuration file for the Sphinx documentation builder.\n\n# -- Path setup --------------------------------------------------------------\n\nimport atexit\nimport os\nimport shutil\nimport subprocess\nimport sys\nfrom pathlib import Path\nfrom typing import Any\nfrom unittest import mock\n\n# -- Project information -----------------------------------------------------\n\nproject = \"Pyodide\"\ncopyright = \"2019-2022, Pyodide contributors and Mozilla\"\npyodide_version = \"0.21.0a3\"\n\nif \".dev\" in pyodide_version:\n CDN_URL = \"https://cdn.jsdelivr.net/pyodide/dev/full/\"\nelse:\n CDN_URL = f\"https://cdn.jsdelivr.net/pyodide/v{pyodide_version}/full/\"\n\n# -- General configuration ---------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\n# needs_sphinx = '1.0'\n\nextensions = [\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.autosummary\",\n \"sphinxcontrib.napoleon\",\n \"myst_parser\",\n \"sphinx_js\",\n \"autodocsumm\",\n \"sphinx_panels\",\n \"sphinx_pyodide\",\n \"sphinx_argparse_cli\",\n \"versionwarning.extension\",\n \"sphinx_issues\",\n]\n\nmyst_enable_extensions = [\"substitution\"]\n\njs_language = \"typescript\"\njsdoc_config_path = \"../src/js/tsconfig.json\"\nroot_for_relative_js_paths = \"../src/\"\nissues_github_path = \"pyodide/pyodide\"\n\nversionwarning_messages = {\n \"latest\": (\n \"This is the development version of the documentation. \"\n 'See <a href=\"https://pyodide.org/\">here</a> for latest stable '\n \"documentation. Please do not use Pyodide with non \"\n \"versioned (`dev`) URLs from the CDN for deployed applications!\"\n )\n}\nversionwarning_body_selector = \"#main-content > div\"\n\nautosummary_generate = True\nautodoc_default_flags = [\"members\", \"inherited-members\"]\n\n# Add modules to be mocked.\nmock_modules = [\"ruamel.yaml\", \"tomli\"]\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = [\"_templates\"]\n\n# The suffix(es) of source filenames.\nsource_suffix = [\".rst\", \".md\"]\n\n# The master toctree document.\nmaster_doc = \"index\"\n\n# The language for content autogenerated by Sphinx.\nlanguage = None\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\nexclude_patterns = [\"_build\", \"Thumbs.db\", \".DS_Store\", \"README.md\"]\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = None\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nhtml_theme = \"sphinx_book_theme\"\nhtml_logo = \"_static/img/pyodide-logo.png\"\n\n# theme-specific options\nhtml_theme_options: dict[str, Any] = {}\n\n# paths that contain custom static files (such as style sheets)\nhtml_static_path = [\"_static\"]\n\n\nhtml_css_files = [\n \"css/pyodide.css\",\n]\n\n# Custom sidebar templates, must be a dictionary that maps document names\n# to template names.\n# html_sidebars = {}\n\n# -- Options for HTMLHelp output ---------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = \"Pyodidedoc\"\n\n# A list of files that should not be packed into the epub file.\nepub_exclude_files = [\"search.html\"]\n\n\ndef delete_attrs(cls):\n for name in dir(cls):\n if not name.startswith(\"_\"):\n try:\n delattr(cls, name)\n except Exception:\n pass\n\n\n# Try not to cause side effects if we are imported incidentally.\n\ntry:\n import sphinx\n\n IN_SPHINX = hasattr(sphinx, \"application\")\nexcept ImportError:\n IN_SPHINX = False\n\nIN_READTHEDOCS = \"READTHEDOCS\" in os.environ\n\nif IN_READTHEDOCS:\n env = {\"PYODIDE_BASE_URL\": CDN_URL}\n os.makedirs(\"_build/html\", exist_ok=True)\n res = subprocess.check_output(\n [\"make\", \"-C\", \"..\", \"docs/_build/html/console.html\"],\n env=env,\n stderr=subprocess.STDOUT,\n encoding=\"utf-8\",\n )\n print(res)\n\nif IN_SPHINX:\n # Compatibility shims. sphinx-js and sphinxcontrib-napoleon have not been updated for Python 3.10\n import collections\n from typing import Callable, Mapping\n\n collections.Mapping = Mapping # type: ignore[attr-defined]\n collections.Callable = Callable # type: ignore[attr-defined]\n\n base_dir = Path(__file__).resolve().parent.parent\n path_dirs = [\n str(base_dir),\n str(base_dir / \"pyodide-build\"),\n str(base_dir / \"docs/sphinx_pyodide\"),\n str(base_dir / \"src/py\"),\n str(base_dir / \"packages/micropip/src\"),\n ]\n sys.path = path_dirs + sys.path\n\n import micropip # noqa: F401\n import pyodide\n\n # We hacked it so that autodoc will look for submodules, but only if we import\n # them here. TODO: look these up in the source directory?\n import pyodide.code\n import pyodide.console\n import pyodide.ffi.wrappers\n import pyodide.http\n import pyodide.webloop\n\n # The full version, including alpha/beta/rc tags.\n release = version = pyodide.__version__\n html_title = f\"Version {version}\"\n\n shutil.copy(\"../src/core/pyproxy.ts\", \"../src/js/pyproxy.gen.ts\")\n shutil.copy(\"../src/core/error_handling.ts\", \"../src/js/error_handling.gen.ts\")\n js_source_path = [str(x) for x in Path(\"../src/js\").glob(\"*.ts\")]\n\n def remove_pyproxy_gen_ts():\n Path(\"../src/js/pyproxy.gen.ts\").unlink(missing_ok=True)\n\n atexit.register(remove_pyproxy_gen_ts)\n\n os.environ[\"PATH\"] += f':{str(Path(\"../src/js/node_modules/.bin\").resolve())}'\n print(os.environ[\"PATH\"])\n if IN_READTHEDOCS:\n subprocess.run([\"npm\", \"ci\"], cwd=\"../src/js\")\n elif not shutil.which(\"typedoc\"):\n raise Exception(\n \"Before building the Pyodide docs you must run 'npm install' in 'src/js'.\"\n )\n\n # Prevent API docs for webloop methods: they are the same as for base event loop\n # and it clutters api docs too much\n delete_attrs(pyodide.webloop.WebLoop)\n delete_attrs(pyodide.webloop.WebLoopPolicy)\n delete_attrs(pyodide.console.PyodideConsole)\n\n for module in mock_modules:\n sys.modules[module] = mock.Mock()\n\n\n# https://github.com/sphinx-doc/sphinx/issues/4054\ndef globalReplace(app, docname, source):\n result = source[0]\n for key in app.config.global_replacements:\n result = result.replace(key, app.config.global_replacements[key])\n source[0] = result\n\n\nglobal_replacements = {\"{{PYODIDE_CDN_URL}}\": CDN_URL}\n\n\ndef setup(app):\n app.add_config_value(\"global_replacements\", {}, True)\n app.connect(\"source-read\", globalReplace)\n", "path": "docs/conf.py"}], "after_files": [{"content": "# Configuration file for the Sphinx documentation builder.\n\n# -- Path setup --------------------------------------------------------------\n\nimport atexit\nimport os\nimport shutil\nimport subprocess\nimport sys\nfrom pathlib import Path\nfrom typing import Any\nfrom unittest import mock\n\n# -- Project information -----------------------------------------------------\n\nproject = \"Pyodide\"\ncopyright = \"2019-2022, Pyodide contributors and Mozilla\"\npyodide_version = \"0.21.0a3\"\n\nif \".dev\" in pyodide_version or os.environ.get(\"READTHEDOCS_VERSION\") == \"latest\":\n CDN_URL = \"https://cdn.jsdelivr.net/pyodide/dev/full/\"\nelse:\n CDN_URL = f\"https://cdn.jsdelivr.net/pyodide/v{pyodide_version}/full/\"\n\n# -- General configuration ---------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\n# needs_sphinx = '1.0'\n\nextensions = [\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.autosummary\",\n \"sphinxcontrib.napoleon\",\n \"myst_parser\",\n \"sphinx_js\",\n \"autodocsumm\",\n \"sphinx_panels\",\n \"sphinx_pyodide\",\n \"sphinx_argparse_cli\",\n \"versionwarning.extension\",\n \"sphinx_issues\",\n]\n\nmyst_enable_extensions = [\"substitution\"]\n\njs_language = \"typescript\"\njsdoc_config_path = \"../src/js/tsconfig.json\"\nroot_for_relative_js_paths = \"../src/\"\nissues_github_path = \"pyodide/pyodide\"\n\nversionwarning_messages = {\n \"latest\": (\n \"This is the development version of the documentation. \"\n 'See <a href=\"https://pyodide.org/\">here</a> for latest stable '\n \"documentation. Please do not use Pyodide with non \"\n \"versioned (`dev`) URLs from the CDN for deployed applications!\"\n )\n}\nversionwarning_body_selector = \"#main-content > div\"\n\nautosummary_generate = True\nautodoc_default_flags = [\"members\", \"inherited-members\"]\n\n# Add modules to be mocked.\nmock_modules = [\"ruamel.yaml\", \"tomli\"]\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = [\"_templates\"]\n\n# The suffix(es) of source filenames.\nsource_suffix = [\".rst\", \".md\"]\n\n# The master toctree document.\nmaster_doc = \"index\"\n\n# The language for content autogenerated by Sphinx.\nlanguage = None\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\nexclude_patterns = [\"_build\", \"Thumbs.db\", \".DS_Store\", \"README.md\"]\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = None\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nhtml_theme = \"sphinx_book_theme\"\nhtml_logo = \"_static/img/pyodide-logo.png\"\n\n# theme-specific options\nhtml_theme_options: dict[str, Any] = {}\n\n# paths that contain custom static files (such as style sheets)\nhtml_static_path = [\"_static\"]\n\n\nhtml_css_files = [\n \"css/pyodide.css\",\n]\n\n# Custom sidebar templates, must be a dictionary that maps document names\n# to template names.\n# html_sidebars = {}\n\n# -- Options for HTMLHelp output ---------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = \"Pyodidedoc\"\n\n# A list of files that should not be packed into the epub file.\nepub_exclude_files = [\"search.html\"]\n\n\ndef delete_attrs(cls):\n for name in dir(cls):\n if not name.startswith(\"_\"):\n try:\n delattr(cls, name)\n except Exception:\n pass\n\n\n# Try not to cause side effects if we are imported incidentally.\n\ntry:\n import sphinx\n\n IN_SPHINX = hasattr(sphinx, \"application\")\nexcept ImportError:\n IN_SPHINX = False\n\nIN_READTHEDOCS = \"READTHEDOCS\" in os.environ\n\nif IN_READTHEDOCS:\n env = {\"PYODIDE_BASE_URL\": CDN_URL}\n os.makedirs(\"_build/html\", exist_ok=True)\n res = subprocess.check_output(\n [\"make\", \"-C\", \"..\", \"docs/_build/html/console.html\"],\n env=env,\n stderr=subprocess.STDOUT,\n encoding=\"utf-8\",\n )\n print(res)\n\nif IN_SPHINX:\n # Compatibility shims. sphinx-js and sphinxcontrib-napoleon have not been updated for Python 3.10\n import collections\n from typing import Callable, Mapping\n\n collections.Mapping = Mapping # type: ignore[attr-defined]\n collections.Callable = Callable # type: ignore[attr-defined]\n\n base_dir = Path(__file__).resolve().parent.parent\n path_dirs = [\n str(base_dir),\n str(base_dir / \"pyodide-build\"),\n str(base_dir / \"docs/sphinx_pyodide\"),\n str(base_dir / \"src/py\"),\n str(base_dir / \"packages/micropip/src\"),\n ]\n sys.path = path_dirs + sys.path\n\n import micropip # noqa: F401\n import pyodide\n\n # We hacked it so that autodoc will look for submodules, but only if we import\n # them here. TODO: look these up in the source directory?\n import pyodide.code\n import pyodide.console\n import pyodide.ffi.wrappers\n import pyodide.http\n import pyodide.webloop\n\n # The full version, including alpha/beta/rc tags.\n release = version = pyodide.__version__\n html_title = f\"Version {version}\"\n\n shutil.copy(\"../src/core/pyproxy.ts\", \"../src/js/pyproxy.gen.ts\")\n shutil.copy(\"../src/core/error_handling.ts\", \"../src/js/error_handling.gen.ts\")\n js_source_path = [str(x) for x in Path(\"../src/js\").glob(\"*.ts\")]\n\n def remove_pyproxy_gen_ts():\n Path(\"../src/js/pyproxy.gen.ts\").unlink(missing_ok=True)\n\n atexit.register(remove_pyproxy_gen_ts)\n\n os.environ[\"PATH\"] += f':{str(Path(\"../src/js/node_modules/.bin\").resolve())}'\n print(os.environ[\"PATH\"])\n if IN_READTHEDOCS:\n subprocess.run([\"npm\", \"ci\"], cwd=\"../src/js\")\n elif not shutil.which(\"typedoc\"):\n raise Exception(\n \"Before building the Pyodide docs you must run 'npm install' in 'src/js'.\"\n )\n\n # Prevent API docs for webloop methods: they are the same as for base event loop\n # and it clutters api docs too much\n delete_attrs(pyodide.webloop.WebLoop)\n delete_attrs(pyodide.webloop.WebLoopPolicy)\n delete_attrs(pyodide.console.PyodideConsole)\n\n for module in mock_modules:\n sys.modules[module] = mock.Mock()\n\n\n# https://github.com/sphinx-doc/sphinx/issues/4054\ndef globalReplace(app, docname, source):\n result = source[0]\n for key in app.config.global_replacements:\n result = result.replace(key, app.config.global_replacements[key])\n source[0] = result\n\n\nglobal_replacements = {\"{{PYODIDE_CDN_URL}}\": CDN_URL}\n\n\ndef setup(app):\n app.add_config_value(\"global_replacements\", {}, True)\n app.connect(\"source-read\", globalReplace)\n", "path": "docs/conf.py"}]}
| 2,702 | 148 |
gh_patches_debug_41319
|
rasdani/github-patches
|
git_diff
|
pytorch__ignite-1328
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Update SSIM metric
## 🚀 Feature
Current implementation of [SSIM](https://github.com/pytorch/ignite/blob/master/ignite/metrics/ssim.py) does not use torch tensor as internal storage and hasn't device in the constructor. Following #1238 we expect all metrics to have a similar structure.
@n2cholas , could you please work on that ?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ignite/metrics/ssim.py`
Content:
```
1 from typing import Callable, Sequence, Union
2
3 import torch
4 import torch.nn.functional as F
5
6 from ignite.exceptions import NotComputableError
7 from ignite.metrics.metric import Metric, reinit__is_reduced, sync_all_reduce
8
9 __all__ = ["SSIM"]
10
11
12 class SSIM(Metric):
13 """
14 Computes Structual Similarity Index Measure
15
16 Args:
17 data_range (int or float): Range of the image. Typically, ``1.0`` or ``255``.
18 kernel_size (int or list or tuple of int): Size of the kernel. Default: (11, 11)
19 sigma (float or list or tuple of float): Standard deviation of the gaussian kernel.
20 Argument is used if ``gaussian=True``. Default: (1.5, 1.5)
21 k1 (float): Parameter of SSIM. Default: 0.01
22 k2 (float): Parameter of SSIM. Default: 0.03
23 gaussian (bool): ``True`` to use gaussian kernel, ``False`` to use uniform kernel
24 output_transform (callable, optional): A callable that is used to transform the
25 :class:`~ignite.engine.engine.Engine`'s ``process_function``'s output into the
26 form expected by the metric.
27
28 Example:
29
30 To use with ``Engine`` and ``process_function``, simply attach the metric instance to the engine.
31 The output of the engine's ``process_function`` needs to be in the format of
32 ``(y_pred, y)`` or ``{'y_pred': y_pred, 'y': y, ...}``.
33
34 ``y_pred`` and ``y`` can be un-normalized or normalized image tensors. Depending on that, the user might need
35 to adjust ``data_range``. ``y_pred`` and ``y`` should have the same shape.
36
37 .. code-block:: python
38
39 def process_function(engine, batch):
40 # ...
41 return y_pred, y
42 engine = Engine(process_function)
43 metric = SSIM(data_range=1.0)
44 metric.attach(engine, "ssim")
45 """
46
47 def __init__(
48 self,
49 data_range: Union[int, float],
50 kernel_size: Union[int, Sequence[int]] = (11, 11),
51 sigma: Union[float, Sequence[float]] = (1.5, 1.5),
52 k1: float = 0.01,
53 k2: float = 0.03,
54 gaussian: bool = True,
55 output_transform: Callable = lambda x: x,
56 ):
57 if isinstance(kernel_size, int):
58 self.kernel_size = [kernel_size, kernel_size]
59 elif isinstance(kernel_size, Sequence):
60 self.kernel_size = kernel_size
61 else:
62 raise ValueError("Argument kernel_size should be either int or a sequence of int.")
63
64 if isinstance(sigma, float):
65 self.sigma = [sigma, sigma]
66 elif isinstance(sigma, Sequence):
67 self.sigma = sigma
68 else:
69 raise ValueError("Argument sigma should be either float or a sequence of float.")
70
71 if any(x % 2 == 0 or x <= 0 for x in self.kernel_size):
72 raise ValueError("Expected kernel_size to have odd positive number. Got {}.".format(kernel_size))
73
74 if any(y <= 0 for y in self.sigma):
75 raise ValueError("Expected sigma to have positive number. Got {}.".format(sigma))
76
77 self.gaussian = gaussian
78 self.c1 = (k1 * data_range) ** 2
79 self.c2 = (k2 * data_range) ** 2
80 self.pad_h = (self.kernel_size[0] - 1) // 2
81 self.pad_w = (self.kernel_size[1] - 1) // 2
82 self._kernel = self._gaussian_or_uniform_kernel(kernel_size=self.kernel_size, sigma=self.sigma)
83 super(SSIM, self).__init__(output_transform=output_transform)
84
85 @reinit__is_reduced
86 def reset(self) -> None:
87 self._sum_of_batchwise_ssim = 0.0
88 self._num_examples = 0
89 self._kernel = self._gaussian_or_uniform_kernel(kernel_size=self.kernel_size, sigma=self.sigma)
90
91 def _uniform(self, kernel_size):
92 max, min = 2.5, -2.5
93 kernel = torch.arange(start=(1 - kernel_size) / 2, end=(1 + kernel_size) / 2, step=1, dtype=torch.float32)
94 for i, j in enumerate(kernel):
95 if min <= j <= max:
96 kernel[i] = 1 / (max - min)
97 else:
98 kernel[i] = 0
99
100 return kernel.unsqueeze(dim=0) # (1, kernel_size)
101
102 def _gaussian(self, kernel_size, sigma):
103 kernel = torch.arange(start=(1 - kernel_size) / 2, end=(1 + kernel_size) / 2, step=1, dtype=torch.float32)
104 gauss = torch.exp(-kernel.pow(2) / (2 * pow(sigma, 2)))
105 return (gauss / gauss.sum()).unsqueeze(dim=0) # (1, kernel_size)
106
107 def _gaussian_or_uniform_kernel(self, kernel_size, sigma):
108 if self.gaussian:
109 kernel_x = self._gaussian(kernel_size[0], sigma[0])
110 kernel_y = self._gaussian(kernel_size[1], sigma[1])
111 else:
112 kernel_x = self._uniform(kernel_size[0])
113 kernel_y = self._uniform(kernel_size[1])
114
115 return torch.matmul(kernel_x.t(), kernel_y) # (kernel_size, 1) * (1, kernel_size)
116
117 @reinit__is_reduced
118 def update(self, output: Sequence[torch.Tensor]) -> None:
119 y_pred, y = output[0].detach(), output[1].detach()
120
121 if y_pred.dtype != y.dtype:
122 raise TypeError(
123 "Expected y_pred and y to have the same data type. Got y_pred: {} and y: {}.".format(
124 y_pred.dtype, y.dtype
125 )
126 )
127
128 if y_pred.shape != y.shape:
129 raise ValueError(
130 "Expected y_pred and y to have the same shape. Got y_pred: {} and y: {}.".format(y_pred.shape, y.shape)
131 )
132
133 if len(y_pred.shape) != 4 or len(y.shape) != 4:
134 raise ValueError(
135 "Expected y_pred and y to have BxCxHxW shape. Got y_pred: {} and y: {}.".format(y_pred.shape, y.shape)
136 )
137
138 channel = y_pred.size(1)
139 if len(self._kernel.shape) < 4:
140 self._kernel = self._kernel.expand(channel, 1, -1, -1).to(device=y_pred.device)
141
142 y_pred = F.pad(y_pred, (self.pad_w, self.pad_w, self.pad_h, self.pad_h), mode="reflect")
143 y = F.pad(y, (self.pad_w, self.pad_w, self.pad_h, self.pad_h), mode="reflect")
144
145 input_list = torch.cat([y_pred, y, y_pred * y_pred, y * y, y_pred * y])
146 outputs = F.conv2d(input_list, self._kernel, groups=channel)
147
148 output_list = [outputs[x * y_pred.size(0) : (x + 1) * y_pred.size(0)] for x in range(len(outputs))]
149
150 mu_pred_sq = output_list[0].pow(2)
151 mu_target_sq = output_list[1].pow(2)
152 mu_pred_target = output_list[0] * output_list[1]
153
154 sigma_pred_sq = output_list[2] - mu_pred_sq
155 sigma_target_sq = output_list[3] - mu_target_sq
156 sigma_pred_target = output_list[4] - mu_pred_target
157
158 a1 = 2 * mu_pred_target + self.c1
159 a2 = 2 * sigma_pred_target + self.c2
160 b1 = mu_pred_sq + mu_target_sq + self.c1
161 b2 = sigma_pred_sq + sigma_target_sq + self.c2
162
163 ssim_idx = (a1 * a2) / (b1 * b2)
164 self._sum_of_batchwise_ssim += torch.mean(ssim_idx, (1, 2, 3), dtype=torch.float64)
165 self._num_examples += y.shape[0]
166
167 @sync_all_reduce("_sum_of_batchwise_ssim", "_num_examples")
168 def compute(self) -> torch.Tensor:
169 if self._num_examples == 0:
170 raise NotComputableError("SSIM must have at least one example before it can be computed.")
171 return torch.sum(self._sum_of_batchwise_ssim / self._num_examples)
172
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ignite/metrics/ssim.py b/ignite/metrics/ssim.py
--- a/ignite/metrics/ssim.py
+++ b/ignite/metrics/ssim.py
@@ -53,6 +53,7 @@
k2: float = 0.03,
gaussian: bool = True,
output_transform: Callable = lambda x: x,
+ device: Union[str, torch.device] = torch.device("cpu"),
):
if isinstance(kernel_size, int):
self.kernel_size = [kernel_size, kernel_size]
@@ -74,23 +75,24 @@
if any(y <= 0 for y in self.sigma):
raise ValueError("Expected sigma to have positive number. Got {}.".format(sigma))
+ super(SSIM, self).__init__(output_transform=output_transform, device=device)
self.gaussian = gaussian
self.c1 = (k1 * data_range) ** 2
self.c2 = (k2 * data_range) ** 2
self.pad_h = (self.kernel_size[0] - 1) // 2
self.pad_w = (self.kernel_size[1] - 1) // 2
self._kernel = self._gaussian_or_uniform_kernel(kernel_size=self.kernel_size, sigma=self.sigma)
- super(SSIM, self).__init__(output_transform=output_transform)
@reinit__is_reduced
def reset(self) -> None:
- self._sum_of_batchwise_ssim = 0.0
+ self._sum_of_batchwise_ssim = 0.0 # Not a tensor because batch size is not known in advance.
self._num_examples = 0
self._kernel = self._gaussian_or_uniform_kernel(kernel_size=self.kernel_size, sigma=self.sigma)
def _uniform(self, kernel_size):
max, min = 2.5, -2.5
- kernel = torch.arange(start=(1 - kernel_size) / 2, end=(1 + kernel_size) / 2, step=1, dtype=torch.float32)
+ ksize_half = (kernel_size - 1) * 0.5
+ kernel = torch.linspace(-ksize_half, ksize_half, steps=kernel_size, device=self._device)
for i, j in enumerate(kernel):
if min <= j <= max:
kernel[i] = 1 / (max - min)
@@ -100,8 +102,9 @@
return kernel.unsqueeze(dim=0) # (1, kernel_size)
def _gaussian(self, kernel_size, sigma):
- kernel = torch.arange(start=(1 - kernel_size) / 2, end=(1 + kernel_size) / 2, step=1, dtype=torch.float32)
- gauss = torch.exp(-kernel.pow(2) / (2 * pow(sigma, 2)))
+ ksize_half = (kernel_size - 1) * 0.5
+ kernel = torch.linspace(-ksize_half, ksize_half, steps=kernel_size, device=self._device)
+ gauss = torch.exp(-0.5 * (kernel / sigma).pow(2))
return (gauss / gauss.sum()).unsqueeze(dim=0) # (1, kernel_size)
def _gaussian_or_uniform_kernel(self, kernel_size, sigma):
@@ -161,7 +164,7 @@
b2 = sigma_pred_sq + sigma_target_sq + self.c2
ssim_idx = (a1 * a2) / (b1 * b2)
- self._sum_of_batchwise_ssim += torch.mean(ssim_idx, (1, 2, 3), dtype=torch.float64)
+ self._sum_of_batchwise_ssim += torch.mean(ssim_idx, (1, 2, 3), dtype=torch.float64).to(self._device)
self._num_examples += y.shape[0]
@sync_all_reduce("_sum_of_batchwise_ssim", "_num_examples")
|
{"golden_diff": "diff --git a/ignite/metrics/ssim.py b/ignite/metrics/ssim.py\n--- a/ignite/metrics/ssim.py\n+++ b/ignite/metrics/ssim.py\n@@ -53,6 +53,7 @@\n k2: float = 0.03,\n gaussian: bool = True,\n output_transform: Callable = lambda x: x,\n+ device: Union[str, torch.device] = torch.device(\"cpu\"),\n ):\n if isinstance(kernel_size, int):\n self.kernel_size = [kernel_size, kernel_size]\n@@ -74,23 +75,24 @@\n if any(y <= 0 for y in self.sigma):\n raise ValueError(\"Expected sigma to have positive number. Got {}.\".format(sigma))\n \n+ super(SSIM, self).__init__(output_transform=output_transform, device=device)\n self.gaussian = gaussian\n self.c1 = (k1 * data_range) ** 2\n self.c2 = (k2 * data_range) ** 2\n self.pad_h = (self.kernel_size[0] - 1) // 2\n self.pad_w = (self.kernel_size[1] - 1) // 2\n self._kernel = self._gaussian_or_uniform_kernel(kernel_size=self.kernel_size, sigma=self.sigma)\n- super(SSIM, self).__init__(output_transform=output_transform)\n \n @reinit__is_reduced\n def reset(self) -> None:\n- self._sum_of_batchwise_ssim = 0.0\n+ self._sum_of_batchwise_ssim = 0.0 # Not a tensor because batch size is not known in advance.\n self._num_examples = 0\n self._kernel = self._gaussian_or_uniform_kernel(kernel_size=self.kernel_size, sigma=self.sigma)\n \n def _uniform(self, kernel_size):\n max, min = 2.5, -2.5\n- kernel = torch.arange(start=(1 - kernel_size) / 2, end=(1 + kernel_size) / 2, step=1, dtype=torch.float32)\n+ ksize_half = (kernel_size - 1) * 0.5\n+ kernel = torch.linspace(-ksize_half, ksize_half, steps=kernel_size, device=self._device)\n for i, j in enumerate(kernel):\n if min <= j <= max:\n kernel[i] = 1 / (max - min)\n@@ -100,8 +102,9 @@\n return kernel.unsqueeze(dim=0) # (1, kernel_size)\n \n def _gaussian(self, kernel_size, sigma):\n- kernel = torch.arange(start=(1 - kernel_size) / 2, end=(1 + kernel_size) / 2, step=1, dtype=torch.float32)\n- gauss = torch.exp(-kernel.pow(2) / (2 * pow(sigma, 2)))\n+ ksize_half = (kernel_size - 1) * 0.5\n+ kernel = torch.linspace(-ksize_half, ksize_half, steps=kernel_size, device=self._device)\n+ gauss = torch.exp(-0.5 * (kernel / sigma).pow(2))\n return (gauss / gauss.sum()).unsqueeze(dim=0) # (1, kernel_size)\n \n def _gaussian_or_uniform_kernel(self, kernel_size, sigma):\n@@ -161,7 +164,7 @@\n b2 = sigma_pred_sq + sigma_target_sq + self.c2\n \n ssim_idx = (a1 * a2) / (b1 * b2)\n- self._sum_of_batchwise_ssim += torch.mean(ssim_idx, (1, 2, 3), dtype=torch.float64)\n+ self._sum_of_batchwise_ssim += torch.mean(ssim_idx, (1, 2, 3), dtype=torch.float64).to(self._device)\n self._num_examples += y.shape[0]\n \n @sync_all_reduce(\"_sum_of_batchwise_ssim\", \"_num_examples\")\n", "issue": "Update SSIM metric\n## \ud83d\ude80 Feature\r\n\r\nCurrent implementation of [SSIM](https://github.com/pytorch/ignite/blob/master/ignite/metrics/ssim.py) does not use torch tensor as internal storage and hasn't device in the constructor. Following #1238 we expect all metrics to have a similar structure.\r\n\r\n@n2cholas , could you please work on that ?\n", "before_files": [{"content": "from typing import Callable, Sequence, Union\n\nimport torch\nimport torch.nn.functional as F\n\nfrom ignite.exceptions import NotComputableError\nfrom ignite.metrics.metric import Metric, reinit__is_reduced, sync_all_reduce\n\n__all__ = [\"SSIM\"]\n\n\nclass SSIM(Metric):\n \"\"\"\n Computes Structual Similarity Index Measure\n\n Args:\n data_range (int or float): Range of the image. Typically, ``1.0`` or ``255``.\n kernel_size (int or list or tuple of int): Size of the kernel. Default: (11, 11)\n sigma (float or list or tuple of float): Standard deviation of the gaussian kernel.\n Argument is used if ``gaussian=True``. Default: (1.5, 1.5)\n k1 (float): Parameter of SSIM. Default: 0.01\n k2 (float): Parameter of SSIM. Default: 0.03\n gaussian (bool): ``True`` to use gaussian kernel, ``False`` to use uniform kernel\n output_transform (callable, optional): A callable that is used to transform the\n :class:`~ignite.engine.engine.Engine`'s ``process_function``'s output into the\n form expected by the metric.\n\n Example:\n\n To use with ``Engine`` and ``process_function``, simply attach the metric instance to the engine.\n The output of the engine's ``process_function`` needs to be in the format of\n ``(y_pred, y)`` or ``{'y_pred': y_pred, 'y': y, ...}``.\n\n ``y_pred`` and ``y`` can be un-normalized or normalized image tensors. Depending on that, the user might need\n to adjust ``data_range``. ``y_pred`` and ``y`` should have the same shape.\n\n .. code-block:: python\n\n def process_function(engine, batch):\n # ...\n return y_pred, y\n engine = Engine(process_function)\n metric = SSIM(data_range=1.0)\n metric.attach(engine, \"ssim\")\n \"\"\"\n\n def __init__(\n self,\n data_range: Union[int, float],\n kernel_size: Union[int, Sequence[int]] = (11, 11),\n sigma: Union[float, Sequence[float]] = (1.5, 1.5),\n k1: float = 0.01,\n k2: float = 0.03,\n gaussian: bool = True,\n output_transform: Callable = lambda x: x,\n ):\n if isinstance(kernel_size, int):\n self.kernel_size = [kernel_size, kernel_size]\n elif isinstance(kernel_size, Sequence):\n self.kernel_size = kernel_size\n else:\n raise ValueError(\"Argument kernel_size should be either int or a sequence of int.\")\n\n if isinstance(sigma, float):\n self.sigma = [sigma, sigma]\n elif isinstance(sigma, Sequence):\n self.sigma = sigma\n else:\n raise ValueError(\"Argument sigma should be either float or a sequence of float.\")\n\n if any(x % 2 == 0 or x <= 0 for x in self.kernel_size):\n raise ValueError(\"Expected kernel_size to have odd positive number. Got {}.\".format(kernel_size))\n\n if any(y <= 0 for y in self.sigma):\n raise ValueError(\"Expected sigma to have positive number. Got {}.\".format(sigma))\n\n self.gaussian = gaussian\n self.c1 = (k1 * data_range) ** 2\n self.c2 = (k2 * data_range) ** 2\n self.pad_h = (self.kernel_size[0] - 1) // 2\n self.pad_w = (self.kernel_size[1] - 1) // 2\n self._kernel = self._gaussian_or_uniform_kernel(kernel_size=self.kernel_size, sigma=self.sigma)\n super(SSIM, self).__init__(output_transform=output_transform)\n\n @reinit__is_reduced\n def reset(self) -> None:\n self._sum_of_batchwise_ssim = 0.0\n self._num_examples = 0\n self._kernel = self._gaussian_or_uniform_kernel(kernel_size=self.kernel_size, sigma=self.sigma)\n\n def _uniform(self, kernel_size):\n max, min = 2.5, -2.5\n kernel = torch.arange(start=(1 - kernel_size) / 2, end=(1 + kernel_size) / 2, step=1, dtype=torch.float32)\n for i, j in enumerate(kernel):\n if min <= j <= max:\n kernel[i] = 1 / (max - min)\n else:\n kernel[i] = 0\n\n return kernel.unsqueeze(dim=0) # (1, kernel_size)\n\n def _gaussian(self, kernel_size, sigma):\n kernel = torch.arange(start=(1 - kernel_size) / 2, end=(1 + kernel_size) / 2, step=1, dtype=torch.float32)\n gauss = torch.exp(-kernel.pow(2) / (2 * pow(sigma, 2)))\n return (gauss / gauss.sum()).unsqueeze(dim=0) # (1, kernel_size)\n\n def _gaussian_or_uniform_kernel(self, kernel_size, sigma):\n if self.gaussian:\n kernel_x = self._gaussian(kernel_size[0], sigma[0])\n kernel_y = self._gaussian(kernel_size[1], sigma[1])\n else:\n kernel_x = self._uniform(kernel_size[0])\n kernel_y = self._uniform(kernel_size[1])\n\n return torch.matmul(kernel_x.t(), kernel_y) # (kernel_size, 1) * (1, kernel_size)\n\n @reinit__is_reduced\n def update(self, output: Sequence[torch.Tensor]) -> None:\n y_pred, y = output[0].detach(), output[1].detach()\n\n if y_pred.dtype != y.dtype:\n raise TypeError(\n \"Expected y_pred and y to have the same data type. Got y_pred: {} and y: {}.\".format(\n y_pred.dtype, y.dtype\n )\n )\n\n if y_pred.shape != y.shape:\n raise ValueError(\n \"Expected y_pred and y to have the same shape. Got y_pred: {} and y: {}.\".format(y_pred.shape, y.shape)\n )\n\n if len(y_pred.shape) != 4 or len(y.shape) != 4:\n raise ValueError(\n \"Expected y_pred and y to have BxCxHxW shape. Got y_pred: {} and y: {}.\".format(y_pred.shape, y.shape)\n )\n\n channel = y_pred.size(1)\n if len(self._kernel.shape) < 4:\n self._kernel = self._kernel.expand(channel, 1, -1, -1).to(device=y_pred.device)\n\n y_pred = F.pad(y_pred, (self.pad_w, self.pad_w, self.pad_h, self.pad_h), mode=\"reflect\")\n y = F.pad(y, (self.pad_w, self.pad_w, self.pad_h, self.pad_h), mode=\"reflect\")\n\n input_list = torch.cat([y_pred, y, y_pred * y_pred, y * y, y_pred * y])\n outputs = F.conv2d(input_list, self._kernel, groups=channel)\n\n output_list = [outputs[x * y_pred.size(0) : (x + 1) * y_pred.size(0)] for x in range(len(outputs))]\n\n mu_pred_sq = output_list[0].pow(2)\n mu_target_sq = output_list[1].pow(2)\n mu_pred_target = output_list[0] * output_list[1]\n\n sigma_pred_sq = output_list[2] - mu_pred_sq\n sigma_target_sq = output_list[3] - mu_target_sq\n sigma_pred_target = output_list[4] - mu_pred_target\n\n a1 = 2 * mu_pred_target + self.c1\n a2 = 2 * sigma_pred_target + self.c2\n b1 = mu_pred_sq + mu_target_sq + self.c1\n b2 = sigma_pred_sq + sigma_target_sq + self.c2\n\n ssim_idx = (a1 * a2) / (b1 * b2)\n self._sum_of_batchwise_ssim += torch.mean(ssim_idx, (1, 2, 3), dtype=torch.float64)\n self._num_examples += y.shape[0]\n\n @sync_all_reduce(\"_sum_of_batchwise_ssim\", \"_num_examples\")\n def compute(self) -> torch.Tensor:\n if self._num_examples == 0:\n raise NotComputableError(\"SSIM must have at least one example before it can be computed.\")\n return torch.sum(self._sum_of_batchwise_ssim / self._num_examples)\n", "path": "ignite/metrics/ssim.py"}], "after_files": [{"content": "from typing import Callable, Sequence, Union\n\nimport torch\nimport torch.nn.functional as F\n\nfrom ignite.exceptions import NotComputableError\nfrom ignite.metrics.metric import Metric, reinit__is_reduced, sync_all_reduce\n\n__all__ = [\"SSIM\"]\n\n\nclass SSIM(Metric):\n \"\"\"\n Computes Structual Similarity Index Measure\n\n Args:\n data_range (int or float): Range of the image. Typically, ``1.0`` or ``255``.\n kernel_size (int or list or tuple of int): Size of the kernel. Default: (11, 11)\n sigma (float or list or tuple of float): Standard deviation of the gaussian kernel.\n Argument is used if ``gaussian=True``. Default: (1.5, 1.5)\n k1 (float): Parameter of SSIM. Default: 0.01\n k2 (float): Parameter of SSIM. Default: 0.03\n gaussian (bool): ``True`` to use gaussian kernel, ``False`` to use uniform kernel\n output_transform (callable, optional): A callable that is used to transform the\n :class:`~ignite.engine.engine.Engine`'s ``process_function``'s output into the\n form expected by the metric.\n\n Example:\n\n To use with ``Engine`` and ``process_function``, simply attach the metric instance to the engine.\n The output of the engine's ``process_function`` needs to be in the format of\n ``(y_pred, y)`` or ``{'y_pred': y_pred, 'y': y, ...}``.\n\n ``y_pred`` and ``y`` can be un-normalized or normalized image tensors. Depending on that, the user might need\n to adjust ``data_range``. ``y_pred`` and ``y`` should have the same shape.\n\n .. code-block:: python\n\n def process_function(engine, batch):\n # ...\n return y_pred, y\n engine = Engine(process_function)\n metric = SSIM(data_range=1.0)\n metric.attach(engine, \"ssim\")\n \"\"\"\n\n def __init__(\n self,\n data_range: Union[int, float],\n kernel_size: Union[int, Sequence[int]] = (11, 11),\n sigma: Union[float, Sequence[float]] = (1.5, 1.5),\n k1: float = 0.01,\n k2: float = 0.03,\n gaussian: bool = True,\n output_transform: Callable = lambda x: x,\n device: Union[str, torch.device] = torch.device(\"cpu\"),\n ):\n if isinstance(kernel_size, int):\n self.kernel_size = [kernel_size, kernel_size]\n elif isinstance(kernel_size, Sequence):\n self.kernel_size = kernel_size\n else:\n raise ValueError(\"Argument kernel_size should be either int or a sequence of int.\")\n\n if isinstance(sigma, float):\n self.sigma = [sigma, sigma]\n elif isinstance(sigma, Sequence):\n self.sigma = sigma\n else:\n raise ValueError(\"Argument sigma should be either float or a sequence of float.\")\n\n if any(x % 2 == 0 or x <= 0 for x in self.kernel_size):\n raise ValueError(\"Expected kernel_size to have odd positive number. Got {}.\".format(kernel_size))\n\n if any(y <= 0 for y in self.sigma):\n raise ValueError(\"Expected sigma to have positive number. Got {}.\".format(sigma))\n\n super(SSIM, self).__init__(output_transform=output_transform, device=device)\n self.gaussian = gaussian\n self.c1 = (k1 * data_range) ** 2\n self.c2 = (k2 * data_range) ** 2\n self.pad_h = (self.kernel_size[0] - 1) // 2\n self.pad_w = (self.kernel_size[1] - 1) // 2\n self._kernel = self._gaussian_or_uniform_kernel(kernel_size=self.kernel_size, sigma=self.sigma)\n\n @reinit__is_reduced\n def reset(self) -> None:\n self._sum_of_batchwise_ssim = 0.0 # Not a tensor because batch size is not known in advance.\n self._num_examples = 0\n self._kernel = self._gaussian_or_uniform_kernel(kernel_size=self.kernel_size, sigma=self.sigma)\n\n def _uniform(self, kernel_size):\n max, min = 2.5, -2.5\n ksize_half = (kernel_size - 1) * 0.5\n kernel = torch.linspace(-ksize_half, ksize_half, steps=kernel_size, device=self._device)\n for i, j in enumerate(kernel):\n if min <= j <= max:\n kernel[i] = 1 / (max - min)\n else:\n kernel[i] = 0\n\n return kernel.unsqueeze(dim=0) # (1, kernel_size)\n\n def _gaussian(self, kernel_size, sigma):\n ksize_half = (kernel_size - 1) * 0.5\n kernel = torch.linspace(-ksize_half, ksize_half, steps=kernel_size, device=self._device)\n gauss = torch.exp(-0.5 * (kernel / sigma).pow(2))\n return (gauss / gauss.sum()).unsqueeze(dim=0) # (1, kernel_size)\n\n def _gaussian_or_uniform_kernel(self, kernel_size, sigma):\n if self.gaussian:\n kernel_x = self._gaussian(kernel_size[0], sigma[0])\n kernel_y = self._gaussian(kernel_size[1], sigma[1])\n else:\n kernel_x = self._uniform(kernel_size[0])\n kernel_y = self._uniform(kernel_size[1])\n\n return torch.matmul(kernel_x.t(), kernel_y) # (kernel_size, 1) * (1, kernel_size)\n\n @reinit__is_reduced\n def update(self, output: Sequence[torch.Tensor]) -> None:\n y_pred, y = output[0].detach(), output[1].detach()\n\n if y_pred.dtype != y.dtype:\n raise TypeError(\n \"Expected y_pred and y to have the same data type. Got y_pred: {} and y: {}.\".format(\n y_pred.dtype, y.dtype\n )\n )\n\n if y_pred.shape != y.shape:\n raise ValueError(\n \"Expected y_pred and y to have the same shape. Got y_pred: {} and y: {}.\".format(y_pred.shape, y.shape)\n )\n\n if len(y_pred.shape) != 4 or len(y.shape) != 4:\n raise ValueError(\n \"Expected y_pred and y to have BxCxHxW shape. Got y_pred: {} and y: {}.\".format(y_pred.shape, y.shape)\n )\n\n channel = y_pred.size(1)\n if len(self._kernel.shape) < 4:\n self._kernel = self._kernel.expand(channel, 1, -1, -1).to(device=y_pred.device)\n\n y_pred = F.pad(y_pred, (self.pad_w, self.pad_w, self.pad_h, self.pad_h), mode=\"reflect\")\n y = F.pad(y, (self.pad_w, self.pad_w, self.pad_h, self.pad_h), mode=\"reflect\")\n\n input_list = torch.cat([y_pred, y, y_pred * y_pred, y * y, y_pred * y])\n outputs = F.conv2d(input_list, self._kernel, groups=channel)\n\n output_list = [outputs[x * y_pred.size(0) : (x + 1) * y_pred.size(0)] for x in range(len(outputs))]\n\n mu_pred_sq = output_list[0].pow(2)\n mu_target_sq = output_list[1].pow(2)\n mu_pred_target = output_list[0] * output_list[1]\n\n sigma_pred_sq = output_list[2] - mu_pred_sq\n sigma_target_sq = output_list[3] - mu_target_sq\n sigma_pred_target = output_list[4] - mu_pred_target\n\n a1 = 2 * mu_pred_target + self.c1\n a2 = 2 * sigma_pred_target + self.c2\n b1 = mu_pred_sq + mu_target_sq + self.c1\n b2 = sigma_pred_sq + sigma_target_sq + self.c2\n\n ssim_idx = (a1 * a2) / (b1 * b2)\n self._sum_of_batchwise_ssim += torch.mean(ssim_idx, (1, 2, 3), dtype=torch.float64).to(self._device)\n self._num_examples += y.shape[0]\n\n @sync_all_reduce(\"_sum_of_batchwise_ssim\", \"_num_examples\")\n def compute(self) -> torch.Tensor:\n if self._num_examples == 0:\n raise NotComputableError(\"SSIM must have at least one example before it can be computed.\")\n return torch.sum(self._sum_of_batchwise_ssim / self._num_examples)\n", "path": "ignite/metrics/ssim.py"}]}
| 2,675 | 883 |
gh_patches_debug_18840
|
rasdani/github-patches
|
git_diff
|
pyro-ppl__numpyro-1325
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
compat module: compat.infer.MCMC broken
Calling
```python
compat.infer.MCMC(kernel, num_warmup=100, num_samples=1000)
```
throws an error since no kwargs are handed to `mcmc.MCMC`. Also, shouldnt the correct `compat` call be
```python
compat.infer.MCMC(kernel, warmup_steps=100, num_samples=1000)
```
Thanks :)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `numpyro/compat/infer.py`
Content:
```
1 # Copyright Contributors to the Pyro project.
2 # SPDX-License-Identifier: Apache-2.0
3
4 import math
5
6 from jax import jit
7
8 import numpyro
9 from numpyro.compat.pyro import get_param_store
10 from numpyro.infer import elbo, hmc, mcmc, svi
11
12
13 class HMC(hmc.HMC):
14 def __init__(
15 self,
16 model=None,
17 potential_fn=None,
18 step_size=1,
19 adapt_step_size=True,
20 adapt_mass_matrix=True,
21 full_mass=False,
22 use_multinomial_sampling=True,
23 transforms=None,
24 max_plate_nesting=None,
25 jit_compile=False,
26 jit_options=None,
27 ignore_jit_warnings=False,
28 trajectory_length=2 * math.pi,
29 target_accept_prob=0.8,
30 ):
31 super(HMC, self).__init__(
32 model=model,
33 potential_fn=potential_fn,
34 step_size=step_size,
35 adapt_step_size=adapt_step_size,
36 adapt_mass_matrix=adapt_mass_matrix,
37 dense_mass=full_mass,
38 target_accept_prob=target_accept_prob,
39 trajectory_length=trajectory_length,
40 )
41
42
43 class NUTS(hmc.NUTS):
44 def __init__(
45 self,
46 model=None,
47 potential_fn=None,
48 step_size=1,
49 adapt_step_size=True,
50 adapt_mass_matrix=True,
51 full_mass=False,
52 use_multinomial_sampling=True,
53 transforms=None,
54 max_plate_nesting=None,
55 jit_compile=False,
56 jit_options=None,
57 ignore_jit_warnings=False,
58 trajectory_length=2 * math.pi,
59 target_accept_prob=0.8,
60 max_tree_depth=10,
61 ):
62 if potential_fn is not None:
63 raise ValueError(
64 "Only `model` argument is supported in generic module;"
65 " `potential_fn` is not supported."
66 )
67 super(NUTS, self).__init__(
68 model=model,
69 potential_fn=potential_fn,
70 step_size=step_size,
71 adapt_step_size=adapt_step_size,
72 adapt_mass_matrix=adapt_mass_matrix,
73 dense_mass=full_mass,
74 target_accept_prob=target_accept_prob,
75 trajectory_length=trajectory_length,
76 max_tree_depth=max_tree_depth,
77 )
78
79
80 class MCMC(object):
81 def __init__(
82 self,
83 kernel,
84 num_samples,
85 num_warmup=None,
86 initial_params=None,
87 num_chains=1,
88 hook_fn=None,
89 mp_context=None,
90 disable_progbar=False,
91 disable_validation=True,
92 transforms=None,
93 ):
94 if num_warmup is None:
95 num_warmup = num_samples
96 self._initial_params = initial_params
97 self._mcmc = mcmc.MCMC(
98 kernel,
99 num_warmup,
100 num_samples,
101 num_chains=num_chains,
102 progress_bar=(not disable_progbar),
103 )
104
105 def run(self, *args, rng_key=None, **kwargs):
106 if rng_key is None:
107 rng_key = numpyro.prng_key()
108 self._mcmc.run(rng_key, *args, init_params=self._initial_params, **kwargs)
109
110 def get_samples(self, num_samples=None, group_by_chain=False):
111 if num_samples is not None:
112 raise ValueError("`num_samples` arg unsupported in NumPyro.")
113 return self._mcmc.get_samples(group_by_chain=group_by_chain)
114
115 def summary(self, prob=0.9):
116 self._mcmc.print_summary()
117
118
119 class SVI(svi.SVI):
120 def __init__(
121 self,
122 model,
123 guide,
124 optim,
125 loss,
126 loss_and_grads=None,
127 num_samples=10,
128 num_steps=0,
129 **kwargs
130 ):
131 super(SVI, self).__init__(model=model, guide=guide, optim=optim, loss=loss)
132 self.svi_state = None
133
134 def evaluate_loss(self, *args, **kwargs):
135 return self.evaluate(self.svi_state, *args, **kwargs)
136
137 def step(self, *args, rng_key=None, **kwargs):
138 if self.svi_state is None:
139 if rng_key is None:
140 rng_key = numpyro.prng_key()
141 self.svi_state = self.init(rng_key, *args, **kwargs)
142 try:
143 self.svi_state, loss = jit(self.update)(self.svi_state, *args, **kwargs)
144 except TypeError as e:
145 if "not a valid JAX type" in str(e):
146 raise TypeError(
147 "NumPyro backend requires args, kwargs to be arrays or tuples, "
148 "dicts of arrays."
149 ) from e
150 else:
151 raise e
152 params = jit(super(SVI, self).get_params)(self.svi_state)
153 get_param_store().update(params)
154 return loss
155
156 def get_params(self):
157 return super(SVI, self).get_params(self.svi_state)
158
159
160 class Trace_ELBO(elbo.Trace_ELBO):
161 def __init__(
162 self,
163 num_particles=1,
164 max_plate_nesting=float("inf"),
165 max_iarange_nesting=None, # DEPRECATED
166 vectorize_particles=False,
167 strict_enumeration_warning=True,
168 ignore_jit_warnings=False,
169 jit_options=None,
170 retain_graph=None,
171 tail_adaptive_beta=-1.0,
172 ):
173 super(Trace_ELBO, self).__init__(num_particles=num_particles)
174
175
176 # JIT is enabled by default
177 JitTrace_ELBO = Trace_ELBO
178
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/numpyro/compat/infer.py b/numpyro/compat/infer.py
--- a/numpyro/compat/infer.py
+++ b/numpyro/compat/infer.py
@@ -82,7 +82,7 @@
self,
kernel,
num_samples,
- num_warmup=None,
+ warmup_steps=None,
initial_params=None,
num_chains=1,
hook_fn=None,
@@ -91,13 +91,13 @@
disable_validation=True,
transforms=None,
):
- if num_warmup is None:
- num_warmup = num_samples
+ if warmup_steps is None:
+ warmup_steps = num_samples
self._initial_params = initial_params
self._mcmc = mcmc.MCMC(
kernel,
- num_warmup,
- num_samples,
+ num_warmup=warmup_steps,
+ num_samples=num_samples,
num_chains=num_chains,
progress_bar=(not disable_progbar),
)
|
{"golden_diff": "diff --git a/numpyro/compat/infer.py b/numpyro/compat/infer.py\n--- a/numpyro/compat/infer.py\n+++ b/numpyro/compat/infer.py\n@@ -82,7 +82,7 @@\n self,\n kernel,\n num_samples,\n- num_warmup=None,\n+ warmup_steps=None,\n initial_params=None,\n num_chains=1,\n hook_fn=None,\n@@ -91,13 +91,13 @@\n disable_validation=True,\n transforms=None,\n ):\n- if num_warmup is None:\n- num_warmup = num_samples\n+ if warmup_steps is None:\n+ warmup_steps = num_samples\n self._initial_params = initial_params\n self._mcmc = mcmc.MCMC(\n kernel,\n- num_warmup,\n- num_samples,\n+ num_warmup=warmup_steps,\n+ num_samples=num_samples,\n num_chains=num_chains,\n progress_bar=(not disable_progbar),\n )\n", "issue": "compat module: compat.infer.MCMC broken\nCalling\r\n```python\r\ncompat.infer.MCMC(kernel, num_warmup=100, num_samples=1000)\r\n```\r\nthrows an error since no kwargs are handed to `mcmc.MCMC`. Also, shouldnt the correct `compat` call be\r\n```python\r\ncompat.infer.MCMC(kernel, warmup_steps=100, num_samples=1000)\r\n```\r\nThanks :)\n", "before_files": [{"content": "# Copyright Contributors to the Pyro project.\n# SPDX-License-Identifier: Apache-2.0\n\nimport math\n\nfrom jax import jit\n\nimport numpyro\nfrom numpyro.compat.pyro import get_param_store\nfrom numpyro.infer import elbo, hmc, mcmc, svi\n\n\nclass HMC(hmc.HMC):\n def __init__(\n self,\n model=None,\n potential_fn=None,\n step_size=1,\n adapt_step_size=True,\n adapt_mass_matrix=True,\n full_mass=False,\n use_multinomial_sampling=True,\n transforms=None,\n max_plate_nesting=None,\n jit_compile=False,\n jit_options=None,\n ignore_jit_warnings=False,\n trajectory_length=2 * math.pi,\n target_accept_prob=0.8,\n ):\n super(HMC, self).__init__(\n model=model,\n potential_fn=potential_fn,\n step_size=step_size,\n adapt_step_size=adapt_step_size,\n adapt_mass_matrix=adapt_mass_matrix,\n dense_mass=full_mass,\n target_accept_prob=target_accept_prob,\n trajectory_length=trajectory_length,\n )\n\n\nclass NUTS(hmc.NUTS):\n def __init__(\n self,\n model=None,\n potential_fn=None,\n step_size=1,\n adapt_step_size=True,\n adapt_mass_matrix=True,\n full_mass=False,\n use_multinomial_sampling=True,\n transforms=None,\n max_plate_nesting=None,\n jit_compile=False,\n jit_options=None,\n ignore_jit_warnings=False,\n trajectory_length=2 * math.pi,\n target_accept_prob=0.8,\n max_tree_depth=10,\n ):\n if potential_fn is not None:\n raise ValueError(\n \"Only `model` argument is supported in generic module;\"\n \" `potential_fn` is not supported.\"\n )\n super(NUTS, self).__init__(\n model=model,\n potential_fn=potential_fn,\n step_size=step_size,\n adapt_step_size=adapt_step_size,\n adapt_mass_matrix=adapt_mass_matrix,\n dense_mass=full_mass,\n target_accept_prob=target_accept_prob,\n trajectory_length=trajectory_length,\n max_tree_depth=max_tree_depth,\n )\n\n\nclass MCMC(object):\n def __init__(\n self,\n kernel,\n num_samples,\n num_warmup=None,\n initial_params=None,\n num_chains=1,\n hook_fn=None,\n mp_context=None,\n disable_progbar=False,\n disable_validation=True,\n transforms=None,\n ):\n if num_warmup is None:\n num_warmup = num_samples\n self._initial_params = initial_params\n self._mcmc = mcmc.MCMC(\n kernel,\n num_warmup,\n num_samples,\n num_chains=num_chains,\n progress_bar=(not disable_progbar),\n )\n\n def run(self, *args, rng_key=None, **kwargs):\n if rng_key is None:\n rng_key = numpyro.prng_key()\n self._mcmc.run(rng_key, *args, init_params=self._initial_params, **kwargs)\n\n def get_samples(self, num_samples=None, group_by_chain=False):\n if num_samples is not None:\n raise ValueError(\"`num_samples` arg unsupported in NumPyro.\")\n return self._mcmc.get_samples(group_by_chain=group_by_chain)\n\n def summary(self, prob=0.9):\n self._mcmc.print_summary()\n\n\nclass SVI(svi.SVI):\n def __init__(\n self,\n model,\n guide,\n optim,\n loss,\n loss_and_grads=None,\n num_samples=10,\n num_steps=0,\n **kwargs\n ):\n super(SVI, self).__init__(model=model, guide=guide, optim=optim, loss=loss)\n self.svi_state = None\n\n def evaluate_loss(self, *args, **kwargs):\n return self.evaluate(self.svi_state, *args, **kwargs)\n\n def step(self, *args, rng_key=None, **kwargs):\n if self.svi_state is None:\n if rng_key is None:\n rng_key = numpyro.prng_key()\n self.svi_state = self.init(rng_key, *args, **kwargs)\n try:\n self.svi_state, loss = jit(self.update)(self.svi_state, *args, **kwargs)\n except TypeError as e:\n if \"not a valid JAX type\" in str(e):\n raise TypeError(\n \"NumPyro backend requires args, kwargs to be arrays or tuples, \"\n \"dicts of arrays.\"\n ) from e\n else:\n raise e\n params = jit(super(SVI, self).get_params)(self.svi_state)\n get_param_store().update(params)\n return loss\n\n def get_params(self):\n return super(SVI, self).get_params(self.svi_state)\n\n\nclass Trace_ELBO(elbo.Trace_ELBO):\n def __init__(\n self,\n num_particles=1,\n max_plate_nesting=float(\"inf\"),\n max_iarange_nesting=None, # DEPRECATED\n vectorize_particles=False,\n strict_enumeration_warning=True,\n ignore_jit_warnings=False,\n jit_options=None,\n retain_graph=None,\n tail_adaptive_beta=-1.0,\n ):\n super(Trace_ELBO, self).__init__(num_particles=num_particles)\n\n\n# JIT is enabled by default\nJitTrace_ELBO = Trace_ELBO\n", "path": "numpyro/compat/infer.py"}], "after_files": [{"content": "# Copyright Contributors to the Pyro project.\n# SPDX-License-Identifier: Apache-2.0\n\nimport math\n\nfrom jax import jit\n\nimport numpyro\nfrom numpyro.compat.pyro import get_param_store\nfrom numpyro.infer import elbo, hmc, mcmc, svi\n\n\nclass HMC(hmc.HMC):\n def __init__(\n self,\n model=None,\n potential_fn=None,\n step_size=1,\n adapt_step_size=True,\n adapt_mass_matrix=True,\n full_mass=False,\n use_multinomial_sampling=True,\n transforms=None,\n max_plate_nesting=None,\n jit_compile=False,\n jit_options=None,\n ignore_jit_warnings=False,\n trajectory_length=2 * math.pi,\n target_accept_prob=0.8,\n ):\n super(HMC, self).__init__(\n model=model,\n potential_fn=potential_fn,\n step_size=step_size,\n adapt_step_size=adapt_step_size,\n adapt_mass_matrix=adapt_mass_matrix,\n dense_mass=full_mass,\n target_accept_prob=target_accept_prob,\n trajectory_length=trajectory_length,\n )\n\n\nclass NUTS(hmc.NUTS):\n def __init__(\n self,\n model=None,\n potential_fn=None,\n step_size=1,\n adapt_step_size=True,\n adapt_mass_matrix=True,\n full_mass=False,\n use_multinomial_sampling=True,\n transforms=None,\n max_plate_nesting=None,\n jit_compile=False,\n jit_options=None,\n ignore_jit_warnings=False,\n trajectory_length=2 * math.pi,\n target_accept_prob=0.8,\n max_tree_depth=10,\n ):\n if potential_fn is not None:\n raise ValueError(\n \"Only `model` argument is supported in generic module;\"\n \" `potential_fn` is not supported.\"\n )\n super(NUTS, self).__init__(\n model=model,\n potential_fn=potential_fn,\n step_size=step_size,\n adapt_step_size=adapt_step_size,\n adapt_mass_matrix=adapt_mass_matrix,\n dense_mass=full_mass,\n target_accept_prob=target_accept_prob,\n trajectory_length=trajectory_length,\n max_tree_depth=max_tree_depth,\n )\n\n\nclass MCMC(object):\n def __init__(\n self,\n kernel,\n num_samples,\n warmup_steps=None,\n initial_params=None,\n num_chains=1,\n hook_fn=None,\n mp_context=None,\n disable_progbar=False,\n disable_validation=True,\n transforms=None,\n ):\n if warmup_steps is None:\n warmup_steps = num_samples\n self._initial_params = initial_params\n self._mcmc = mcmc.MCMC(\n kernel,\n num_warmup=warmup_steps,\n num_samples=num_samples,\n num_chains=num_chains,\n progress_bar=(not disable_progbar),\n )\n\n def run(self, *args, rng_key=None, **kwargs):\n if rng_key is None:\n rng_key = numpyro.prng_key()\n self._mcmc.run(rng_key, *args, init_params=self._initial_params, **kwargs)\n\n def get_samples(self, num_samples=None, group_by_chain=False):\n if num_samples is not None:\n raise ValueError(\"`num_samples` arg unsupported in NumPyro.\")\n return self._mcmc.get_samples(group_by_chain=group_by_chain)\n\n def summary(self, prob=0.9):\n self._mcmc.print_summary()\n\n\nclass SVI(svi.SVI):\n def __init__(\n self,\n model,\n guide,\n optim,\n loss,\n loss_and_grads=None,\n num_samples=10,\n num_steps=0,\n **kwargs\n ):\n super(SVI, self).__init__(model=model, guide=guide, optim=optim, loss=loss)\n self.svi_state = None\n\n def evaluate_loss(self, *args, **kwargs):\n return self.evaluate(self.svi_state, *args, **kwargs)\n\n def step(self, *args, rng_key=None, **kwargs):\n if self.svi_state is None:\n if rng_key is None:\n rng_key = numpyro.prng_key()\n self.svi_state = self.init(rng_key, *args, **kwargs)\n try:\n self.svi_state, loss = jit(self.update)(self.svi_state, *args, **kwargs)\n except TypeError as e:\n if \"not a valid JAX type\" in str(e):\n raise TypeError(\n \"NumPyro backend requires args, kwargs to be arrays or tuples, \"\n \"dicts of arrays.\"\n ) from e\n else:\n raise e\n params = jit(super(SVI, self).get_params)(self.svi_state)\n get_param_store().update(params)\n return loss\n\n def get_params(self):\n return super(SVI, self).get_params(self.svi_state)\n\n\nclass Trace_ELBO(elbo.Trace_ELBO):\n def __init__(\n self,\n num_particles=1,\n max_plate_nesting=float(\"inf\"),\n max_iarange_nesting=None, # DEPRECATED\n vectorize_particles=False,\n strict_enumeration_warning=True,\n ignore_jit_warnings=False,\n jit_options=None,\n retain_graph=None,\n tail_adaptive_beta=-1.0,\n ):\n super(Trace_ELBO, self).__init__(num_particles=num_particles)\n\n\n# JIT is enabled by default\nJitTrace_ELBO = Trace_ELBO\n", "path": "numpyro/compat/infer.py"}]}
| 1,971 | 234 |
gh_patches_debug_8297
|
rasdani/github-patches
|
git_diff
|
acl-org__acl-anthology-2133
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Correction to Anthology ID 2022.clpsych-1.9
Metadata correction:
author’s name is listed as Aren, but should be Areán (as shown in the pdf)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bin/add_revision.py`
Content:
```
1 #! /usr/bin/env python3
2 # -*- coding: utf-8 -*-
3 #
4 # Copyright 2019 Matt Post <[email protected]>
5 #
6 # Licensed under the Apache License, Version 2.0 (the "License");
7 # you may not use this file except in compliance with the License.
8 # You may obtain a copy of the License at
9 #
10 # http://www.apache.org/licenses/LICENSE-2.0
11 #
12 # Unless required by applicable law or agreed to in writing, software
13 # distributed under the License is distributed on an "AS IS" BASIS,
14 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
15 # See the License for the specific language governing permissions and
16 # limitations under the License.
17
18 """
19 Used to add revisions to the Anthology.
20 Assumes all files have a base format like ANTHOLOGY_ROOT/P/P18/P18-1234.pdf format.
21 The revision process is as follows.
22
23 - The original paper is named as above.
24 - When a first revision is created, the original paper is archived to PYY-XXXXv1.pdf.
25 - The new revision is copied to PYY-XXXXvN, where N is the next revision ID (usually 2).
26 The new revision is also copied to PYY-XXXX.pdf.
27 This causes it to be returned by the anthology when the base paper format is queried.
28
29 Usage:
30
31 add_revision.py [-e] paper_id URL_OR_PATH.pdf "Short explanation".
32
33 `-e` denotes erratum instead of revision.
34 By default, a dry run happens.
35 When you are ready, add `--do`.
36 """
37
38 import argparse
39 import filetype
40 import os
41 import shutil
42 import ssl
43 import sys
44 import tempfile
45
46 from anthology.utils import (
47 deconstruct_anthology_id,
48 make_simple_element,
49 indent,
50 compute_hash_from_file,
51 infer_url,
52 is_newstyle_id,
53 retrieve_url,
54 get_pdf_dir,
55 get_xml_file,
56 )
57 from anthology.data import (
58 PDF_LOCATION_TEMPLATE,
59 ANTHOLOGY_FILE_DIR,
60 )
61
62 import lxml.etree as ET
63 import urllib.request
64
65 from datetime import datetime
66
67
68 def validate_file_type(path):
69 """Ensure downloaded file mime type matches its extension (e.g., PDF)"""
70 detected = filetype.guess(path)
71 if detected is None or not detected.mime.endswith(detected.extension):
72 mime_type = 'UNKNOWN' if detected is None else detected.mime
73 print(
74 f"FATAL: file {path} has MIME type {mime_type}",
75 file=sys.stderr,
76 )
77 sys.exit(1)
78
79
80 def add_revision(
81 anth_id, pdf_path, explanation, change_type="revision", dry_run=True, date=None
82 ):
83 """
84 Takes an Anthology ID. It then adds a revision to the Anthology XML,
85 updating and writing the XML file, and copies the PDFs into place.
86 For PDFs, the revised PDF is saved to {anth_id}.pdf and {anth_id}v{version}.pdf.
87 For the first revision, we first copy {anth_id}.pdf to {anth_id}v1.pdf.
88 """
89 if date is None:
90 now = datetime.now()
91 date = f"{now.year}-{now.month:02d}-{now.day:02d}"
92
93 def maybe_copy(file_from, file_to):
94 if not dry_run:
95 print("-> Copying from {} -> {}".format(file_from, file_to), file=sys.stderr)
96 shutil.copy(file_from, file_to)
97 os.chmod(file_to, 0o644)
98 else:
99 print(
100 "-> DRY RUN: Copying from {} -> {}".format(file_from, file_to),
101 file=sys.stderr,
102 )
103
104 # The new version
105 revno = None
106
107 change_letter = "e" if change_type == "erratum" else "v"
108
109 checksum = compute_hash_from_file(pdf_path)
110
111 # Files for old-style IDs are stored under anthology-files/pdf/P/P19/*
112 # Files for new-style IDs are stored under anthology-files/pdf/2020.acl/*
113 output_dir = get_pdf_dir(anth_id)
114
115 # Make sure directory exists
116 if not os.path.exists(output_dir):
117 print(f"-> Creating directory {output_dir}", file=sys.stderr)
118 os.makedirs(output_dir)
119
120 canonical_path = os.path.join(output_dir, f"{anth_id}.pdf")
121
122 # Update XML
123 xml_file = get_xml_file(anth_id)
124 collection_id, volume_id, paper_id = deconstruct_anthology_id(anth_id)
125 tree = ET.parse(xml_file)
126 if paper_id == "0":
127 paper = tree.getroot().find(f"./volume[@id='{volume_id}']/frontmatter")
128 else:
129 paper = tree.getroot().find(
130 f"./volume[@id='{volume_id}']/paper[@id='{paper_id}']"
131 )
132 if paper is not None:
133 revisions = paper.findall(change_type)
134 revno = 1 if change_type == "erratum" else 2
135 for revision in revisions:
136 revno = int(revision.attrib["id"]) + 1
137
138 if not dry_run:
139 # Update the URL hash on the <url> tag
140 url = paper.find("./url")
141 if url is not None:
142 url.attrib["hash"] = checksum
143
144 if change_type == "revision" and revno == 2:
145 if paper.find("./url") is not None:
146 current_version_url = infer_url(paper.find("./url").text) + ".pdf"
147
148 # Download original file
149 # There are no versioned files the first time around, so create the first one
150 # (essentially backing up the original version)
151 revised_file_v1_path = os.path.join(
152 output_dir, f"{anth_id}{change_letter}1.pdf"
153 )
154
155 retrieve_url(current_version_url, revised_file_v1_path)
156 validate_file_type(revised_file_v1_path)
157
158 old_checksum = compute_hash_from_file(revised_file_v1_path)
159
160 # First revision requires making the original version explicit
161 revision = make_simple_element(
162 change_type,
163 None,
164 attrib={
165 "id": "1",
166 "href": f"{anth_id}{change_letter}1",
167 "hash": old_checksum,
168 },
169 parent=paper,
170 )
171
172 revision = make_simple_element(
173 change_type,
174 explanation,
175 attrib={
176 "id": str(revno),
177 "href": f"{anth_id}{change_letter}{revno}",
178 "hash": checksum,
179 "date": date,
180 },
181 parent=paper,
182 )
183 indent(tree.getroot())
184
185 tree.write(xml_file, encoding="UTF-8", xml_declaration=True)
186 print(
187 f'-> Added {change_type} node "{revision.text}" to XML', file=sys.stderr
188 )
189
190 else:
191 print(
192 f"-> FATAL: paper ID {anth_id} not found in the Anthology",
193 file=sys.stderr,
194 )
195 sys.exit(1)
196
197 revised_file_versioned_path = os.path.join(
198 output_dir, f"{anth_id}{change_letter}{revno}.pdf"
199 )
200
201 # Copy the file to the versioned path
202 maybe_copy(pdf_path, revised_file_versioned_path)
203
204 # Copy it over the canonical path
205 if change_type == "revision":
206 maybe_copy(pdf_path, canonical_path)
207
208
209 def main(args):
210 change_type = "erratum" if args.erratum else "revision"
211
212 print(f"Processing {change_type} to {args.anthology_id}...")
213
214 # TODO: make sure path exists, or download URL to temp file
215 if args.path.startswith("http"):
216 _, input_file_path = tempfile.mkstemp()
217 retrieve_url(args.path, input_file_path)
218 else:
219 input_file_path = args.path
220
221 validate_file_type(input_file_path)
222
223 add_revision(
224 args.anthology_id,
225 input_file_path,
226 args.explanation,
227 change_type=change_type,
228 dry_run=args.dry_run,
229 )
230
231 if args.path.startswith("http"):
232 os.remove(input_file_path)
233
234
235 if __name__ == "__main__":
236 parser = argparse.ArgumentParser()
237 parser.add_argument(
238 "anthology_id", help="The Anthology paper ID to revise (e.g., P18-1001)"
239 )
240 parser.add_argument(
241 "path", type=str, help="Path to the revised paper ID (can be URL)"
242 )
243 parser.add_argument("explanation", help="Brief description of the changes.")
244 parser.add_argument(
245 "--erratum",
246 "-e",
247 action="store_true",
248 help="This is an erratum instead of a revision.",
249 )
250 now = datetime.now()
251 today = f"{now.year}-{now.month:02d}-{now.day:02d}"
252 parser.add_argument(
253 "--date",
254 "-d",
255 type=str,
256 default=today,
257 help="The date of the revision (ISO 8601 format)",
258 )
259 parser.add_argument(
260 "--dry-run", "-n", action="store_true", default=False, help="Just a dry run."
261 )
262 args = parser.parse_args()
263
264 main(args)
265
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/bin/add_revision.py b/bin/add_revision.py
--- a/bin/add_revision.py
+++ b/bin/add_revision.py
@@ -137,9 +137,10 @@
if not dry_run:
# Update the URL hash on the <url> tag
- url = paper.find("./url")
- if url is not None:
- url.attrib["hash"] = checksum
+ if change_type != "erratum":
+ url = paper.find("./url")
+ if url is not None:
+ url.attrib["hash"] = checksum
if change_type == "revision" and revno == 2:
if paper.find("./url") is not None:
|
{"golden_diff": "diff --git a/bin/add_revision.py b/bin/add_revision.py\n--- a/bin/add_revision.py\n+++ b/bin/add_revision.py\n@@ -137,9 +137,10 @@\n \n if not dry_run:\n # Update the URL hash on the <url> tag\n- url = paper.find(\"./url\")\n- if url is not None:\n- url.attrib[\"hash\"] = checksum\n+ if change_type != \"erratum\":\n+ url = paper.find(\"./url\")\n+ if url is not None:\n+ url.attrib[\"hash\"] = checksum\n \n if change_type == \"revision\" and revno == 2:\n if paper.find(\"./url\") is not None:\n", "issue": "Correction to Anthology ID 2022.clpsych-1.9\nMetadata correction:\r\nauthor\u2019s name is listed as Aren, but should be Are\u00e1n (as shown in the pdf)\n", "before_files": [{"content": "#! /usr/bin/env python3\n# -*- coding: utf-8 -*-\n#\n# Copyright 2019 Matt Post <[email protected]>\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nUsed to add revisions to the Anthology.\nAssumes all files have a base format like ANTHOLOGY_ROOT/P/P18/P18-1234.pdf format.\nThe revision process is as follows.\n\n- The original paper is named as above.\n- When a first revision is created, the original paper is archived to PYY-XXXXv1.pdf.\n- The new revision is copied to PYY-XXXXvN, where N is the next revision ID (usually 2).\n The new revision is also copied to PYY-XXXX.pdf.\n This causes it to be returned by the anthology when the base paper format is queried.\n\nUsage:\n\n add_revision.py [-e] paper_id URL_OR_PATH.pdf \"Short explanation\".\n\n`-e` denotes erratum instead of revision.\nBy default, a dry run happens.\nWhen you are ready, add `--do`.\n\"\"\"\n\nimport argparse\nimport filetype\nimport os\nimport shutil\nimport ssl\nimport sys\nimport tempfile\n\nfrom anthology.utils import (\n deconstruct_anthology_id,\n make_simple_element,\n indent,\n compute_hash_from_file,\n infer_url,\n is_newstyle_id,\n retrieve_url,\n get_pdf_dir,\n get_xml_file,\n)\nfrom anthology.data import (\n PDF_LOCATION_TEMPLATE,\n ANTHOLOGY_FILE_DIR,\n)\n\nimport lxml.etree as ET\nimport urllib.request\n\nfrom datetime import datetime\n\n\ndef validate_file_type(path):\n \"\"\"Ensure downloaded file mime type matches its extension (e.g., PDF)\"\"\"\n detected = filetype.guess(path)\n if detected is None or not detected.mime.endswith(detected.extension):\n mime_type = 'UNKNOWN' if detected is None else detected.mime\n print(\n f\"FATAL: file {path} has MIME type {mime_type}\",\n file=sys.stderr,\n )\n sys.exit(1)\n\n\ndef add_revision(\n anth_id, pdf_path, explanation, change_type=\"revision\", dry_run=True, date=None\n):\n \"\"\"\n Takes an Anthology ID. It then adds a revision to the Anthology XML,\n updating and writing the XML file, and copies the PDFs into place.\n For PDFs, the revised PDF is saved to {anth_id}.pdf and {anth_id}v{version}.pdf.\n For the first revision, we first copy {anth_id}.pdf to {anth_id}v1.pdf.\n \"\"\"\n if date is None:\n now = datetime.now()\n date = f\"{now.year}-{now.month:02d}-{now.day:02d}\"\n\n def maybe_copy(file_from, file_to):\n if not dry_run:\n print(\"-> Copying from {} -> {}\".format(file_from, file_to), file=sys.stderr)\n shutil.copy(file_from, file_to)\n os.chmod(file_to, 0o644)\n else:\n print(\n \"-> DRY RUN: Copying from {} -> {}\".format(file_from, file_to),\n file=sys.stderr,\n )\n\n # The new version\n revno = None\n\n change_letter = \"e\" if change_type == \"erratum\" else \"v\"\n\n checksum = compute_hash_from_file(pdf_path)\n\n # Files for old-style IDs are stored under anthology-files/pdf/P/P19/*\n # Files for new-style IDs are stored under anthology-files/pdf/2020.acl/*\n output_dir = get_pdf_dir(anth_id)\n\n # Make sure directory exists\n if not os.path.exists(output_dir):\n print(f\"-> Creating directory {output_dir}\", file=sys.stderr)\n os.makedirs(output_dir)\n\n canonical_path = os.path.join(output_dir, f\"{anth_id}.pdf\")\n\n # Update XML\n xml_file = get_xml_file(anth_id)\n collection_id, volume_id, paper_id = deconstruct_anthology_id(anth_id)\n tree = ET.parse(xml_file)\n if paper_id == \"0\":\n paper = tree.getroot().find(f\"./volume[@id='{volume_id}']/frontmatter\")\n else:\n paper = tree.getroot().find(\n f\"./volume[@id='{volume_id}']/paper[@id='{paper_id}']\"\n )\n if paper is not None:\n revisions = paper.findall(change_type)\n revno = 1 if change_type == \"erratum\" else 2\n for revision in revisions:\n revno = int(revision.attrib[\"id\"]) + 1\n\n if not dry_run:\n # Update the URL hash on the <url> tag\n url = paper.find(\"./url\")\n if url is not None:\n url.attrib[\"hash\"] = checksum\n\n if change_type == \"revision\" and revno == 2:\n if paper.find(\"./url\") is not None:\n current_version_url = infer_url(paper.find(\"./url\").text) + \".pdf\"\n\n # Download original file\n # There are no versioned files the first time around, so create the first one\n # (essentially backing up the original version)\n revised_file_v1_path = os.path.join(\n output_dir, f\"{anth_id}{change_letter}1.pdf\"\n )\n\n retrieve_url(current_version_url, revised_file_v1_path)\n validate_file_type(revised_file_v1_path)\n\n old_checksum = compute_hash_from_file(revised_file_v1_path)\n\n # First revision requires making the original version explicit\n revision = make_simple_element(\n change_type,\n None,\n attrib={\n \"id\": \"1\",\n \"href\": f\"{anth_id}{change_letter}1\",\n \"hash\": old_checksum,\n },\n parent=paper,\n )\n\n revision = make_simple_element(\n change_type,\n explanation,\n attrib={\n \"id\": str(revno),\n \"href\": f\"{anth_id}{change_letter}{revno}\",\n \"hash\": checksum,\n \"date\": date,\n },\n parent=paper,\n )\n indent(tree.getroot())\n\n tree.write(xml_file, encoding=\"UTF-8\", xml_declaration=True)\n print(\n f'-> Added {change_type} node \"{revision.text}\" to XML', file=sys.stderr\n )\n\n else:\n print(\n f\"-> FATAL: paper ID {anth_id} not found in the Anthology\",\n file=sys.stderr,\n )\n sys.exit(1)\n\n revised_file_versioned_path = os.path.join(\n output_dir, f\"{anth_id}{change_letter}{revno}.pdf\"\n )\n\n # Copy the file to the versioned path\n maybe_copy(pdf_path, revised_file_versioned_path)\n\n # Copy it over the canonical path\n if change_type == \"revision\":\n maybe_copy(pdf_path, canonical_path)\n\n\ndef main(args):\n change_type = \"erratum\" if args.erratum else \"revision\"\n\n print(f\"Processing {change_type} to {args.anthology_id}...\")\n\n # TODO: make sure path exists, or download URL to temp file\n if args.path.startswith(\"http\"):\n _, input_file_path = tempfile.mkstemp()\n retrieve_url(args.path, input_file_path)\n else:\n input_file_path = args.path\n\n validate_file_type(input_file_path)\n\n add_revision(\n args.anthology_id,\n input_file_path,\n args.explanation,\n change_type=change_type,\n dry_run=args.dry_run,\n )\n\n if args.path.startswith(\"http\"):\n os.remove(input_file_path)\n\n\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser()\n parser.add_argument(\n \"anthology_id\", help=\"The Anthology paper ID to revise (e.g., P18-1001)\"\n )\n parser.add_argument(\n \"path\", type=str, help=\"Path to the revised paper ID (can be URL)\"\n )\n parser.add_argument(\"explanation\", help=\"Brief description of the changes.\")\n parser.add_argument(\n \"--erratum\",\n \"-e\",\n action=\"store_true\",\n help=\"This is an erratum instead of a revision.\",\n )\n now = datetime.now()\n today = f\"{now.year}-{now.month:02d}-{now.day:02d}\"\n parser.add_argument(\n \"--date\",\n \"-d\",\n type=str,\n default=today,\n help=\"The date of the revision (ISO 8601 format)\",\n )\n parser.add_argument(\n \"--dry-run\", \"-n\", action=\"store_true\", default=False, help=\"Just a dry run.\"\n )\n args = parser.parse_args()\n\n main(args)\n", "path": "bin/add_revision.py"}], "after_files": [{"content": "#! /usr/bin/env python3\n# -*- coding: utf-8 -*-\n#\n# Copyright 2019 Matt Post <[email protected]>\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nUsed to add revisions to the Anthology.\nAssumes all files have a base format like ANTHOLOGY_ROOT/P/P18/P18-1234.pdf format.\nThe revision process is as follows.\n\n- The original paper is named as above.\n- When a first revision is created, the original paper is archived to PYY-XXXXv1.pdf.\n- The new revision is copied to PYY-XXXXvN, where N is the next revision ID (usually 2).\n The new revision is also copied to PYY-XXXX.pdf.\n This causes it to be returned by the anthology when the base paper format is queried.\n\nUsage:\n\n add_revision.py [-e] paper_id URL_OR_PATH.pdf \"Short explanation\".\n\n`-e` denotes erratum instead of revision.\nBy default, a dry run happens.\nWhen you are ready, add `--do`.\n\"\"\"\n\nimport argparse\nimport filetype\nimport os\nimport shutil\nimport ssl\nimport sys\nimport tempfile\n\nfrom anthology.utils import (\n deconstruct_anthology_id,\n make_simple_element,\n indent,\n compute_hash_from_file,\n infer_url,\n is_newstyle_id,\n retrieve_url,\n get_pdf_dir,\n get_xml_file,\n)\nfrom anthology.data import (\n PDF_LOCATION_TEMPLATE,\n ANTHOLOGY_FILE_DIR,\n)\n\nimport lxml.etree as ET\nimport urllib.request\n\nfrom datetime import datetime\n\n\ndef validate_file_type(path):\n \"\"\"Ensure downloaded file mime type matches its extension (e.g., PDF)\"\"\"\n detected = filetype.guess(path)\n if detected is None or not detected.mime.endswith(detected.extension):\n mime_type = 'UNKNOWN' if detected is None else detected.mime\n print(\n f\"FATAL: file {path} has MIME type {mime_type}\",\n file=sys.stderr,\n )\n sys.exit(1)\n\n\ndef add_revision(\n anth_id, pdf_path, explanation, change_type=\"revision\", dry_run=True, date=None\n):\n \"\"\"\n Takes an Anthology ID. It then adds a revision to the Anthology XML,\n updating and writing the XML file, and copies the PDFs into place.\n For PDFs, the revised PDF is saved to {anth_id}.pdf and {anth_id}v{version}.pdf.\n For the first revision, we first copy {anth_id}.pdf to {anth_id}v1.pdf.\n \"\"\"\n if date is None:\n now = datetime.now()\n date = f\"{now.year}-{now.month:02d}-{now.day:02d}\"\n\n def maybe_copy(file_from, file_to):\n if not dry_run:\n print(\"-> Copying from {} -> {}\".format(file_from, file_to), file=sys.stderr)\n shutil.copy(file_from, file_to)\n os.chmod(file_to, 0o644)\n else:\n print(\n \"-> DRY RUN: Copying from {} -> {}\".format(file_from, file_to),\n file=sys.stderr,\n )\n\n # The new version\n revno = None\n\n change_letter = \"e\" if change_type == \"erratum\" else \"v\"\n\n checksum = compute_hash_from_file(pdf_path)\n\n # Files for old-style IDs are stored under anthology-files/pdf/P/P19/*\n # Files for new-style IDs are stored under anthology-files/pdf/2020.acl/*\n output_dir = get_pdf_dir(anth_id)\n\n # Make sure directory exists\n if not os.path.exists(output_dir):\n print(f\"-> Creating directory {output_dir}\", file=sys.stderr)\n os.makedirs(output_dir)\n\n canonical_path = os.path.join(output_dir, f\"{anth_id}.pdf\")\n\n # Update XML\n xml_file = get_xml_file(anth_id)\n collection_id, volume_id, paper_id = deconstruct_anthology_id(anth_id)\n tree = ET.parse(xml_file)\n if paper_id == \"0\":\n paper = tree.getroot().find(f\"./volume[@id='{volume_id}']/frontmatter\")\n else:\n paper = tree.getroot().find(\n f\"./volume[@id='{volume_id}']/paper[@id='{paper_id}']\"\n )\n if paper is not None:\n revisions = paper.findall(change_type)\n revno = 1 if change_type == \"erratum\" else 2\n for revision in revisions:\n revno = int(revision.attrib[\"id\"]) + 1\n\n if not dry_run:\n # Update the URL hash on the <url> tag\n if change_type != \"erratum\":\n url = paper.find(\"./url\")\n if url is not None:\n url.attrib[\"hash\"] = checksum\n\n if change_type == \"revision\" and revno == 2:\n if paper.find(\"./url\") is not None:\n current_version_url = infer_url(paper.find(\"./url\").text) + \".pdf\"\n\n # Download original file\n # There are no versioned files the first time around, so create the first one\n # (essentially backing up the original version)\n revised_file_v1_path = os.path.join(\n output_dir, f\"{anth_id}{change_letter}1.pdf\"\n )\n\n retrieve_url(current_version_url, revised_file_v1_path)\n validate_file_type(revised_file_v1_path)\n\n old_checksum = compute_hash_from_file(revised_file_v1_path)\n\n # First revision requires making the original version explicit\n revision = make_simple_element(\n change_type,\n None,\n attrib={\n \"id\": \"1\",\n \"href\": f\"{anth_id}{change_letter}1\",\n \"hash\": old_checksum,\n },\n parent=paper,\n )\n\n revision = make_simple_element(\n change_type,\n explanation,\n attrib={\n \"id\": str(revno),\n \"href\": f\"{anth_id}{change_letter}{revno}\",\n \"hash\": checksum,\n \"date\": date,\n },\n parent=paper,\n )\n indent(tree.getroot())\n\n tree.write(xml_file, encoding=\"UTF-8\", xml_declaration=True)\n print(\n f'-> Added {change_type} node \"{revision.text}\" to XML', file=sys.stderr\n )\n\n else:\n print(\n f\"-> FATAL: paper ID {anth_id} not found in the Anthology\",\n file=sys.stderr,\n )\n sys.exit(1)\n\n revised_file_versioned_path = os.path.join(\n output_dir, f\"{anth_id}{change_letter}{revno}.pdf\"\n )\n\n # Copy the file to the versioned path\n maybe_copy(pdf_path, revised_file_versioned_path)\n\n # Copy it over the canonical path\n if change_type == \"revision\":\n maybe_copy(pdf_path, canonical_path)\n\n\ndef main(args):\n change_type = \"erratum\" if args.erratum else \"revision\"\n\n print(f\"Processing {change_type} to {args.anthology_id}...\")\n\n # TODO: make sure path exists, or download URL to temp file\n if args.path.startswith(\"http\"):\n _, input_file_path = tempfile.mkstemp()\n retrieve_url(args.path, input_file_path)\n else:\n input_file_path = args.path\n\n validate_file_type(input_file_path)\n\n add_revision(\n args.anthology_id,\n input_file_path,\n args.explanation,\n change_type=change_type,\n dry_run=args.dry_run,\n )\n\n if args.path.startswith(\"http\"):\n os.remove(input_file_path)\n\n\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser()\n parser.add_argument(\n \"anthology_id\", help=\"The Anthology paper ID to revise (e.g., P18-1001)\"\n )\n parser.add_argument(\n \"path\", type=str, help=\"Path to the revised paper ID (can be URL)\"\n )\n parser.add_argument(\"explanation\", help=\"Brief description of the changes.\")\n parser.add_argument(\n \"--erratum\",\n \"-e\",\n action=\"store_true\",\n help=\"This is an erratum instead of a revision.\",\n )\n now = datetime.now()\n today = f\"{now.year}-{now.month:02d}-{now.day:02d}\"\n parser.add_argument(\n \"--date\",\n \"-d\",\n type=str,\n default=today,\n help=\"The date of the revision (ISO 8601 format)\",\n )\n parser.add_argument(\n \"--dry-run\", \"-n\", action=\"store_true\", default=False, help=\"Just a dry run.\"\n )\n args = parser.parse_args()\n\n main(args)\n", "path": "bin/add_revision.py"}]}
| 2,987 | 153 |
gh_patches_debug_4953
|
rasdani/github-patches
|
git_diff
|
getnikola__nikola-2998
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Theme meta file ignored_assets key should ignore whitespace
### Environment (if reporting a bug)
**Python Version:**
3.5.4
**Nikola Version:**
8.0.0dev HEAD
**Operating System:**
gentoo GNU/Linux
### Description:
Current behaviour: The ignored_assets key in theme meta files takes a comma-separated list of filenames, that must not contain leading or trailing whitespace because it's considered to be part of the filename.
Expected behaviour: The comma-separated list may contain the usual amount of whitespace: foo, bar, baz, etc
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nikola/plugins/task/copy_assets.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # Copyright © 2012-2018 Roberto Alsina and others.
4
5 # Permission is hereby granted, free of charge, to any
6 # person obtaining a copy of this software and associated
7 # documentation files (the "Software"), to deal in the
8 # Software without restriction, including without limitation
9 # the rights to use, copy, modify, merge, publish,
10 # distribute, sublicense, and/or sell copies of the
11 # Software, and to permit persons to whom the Software is
12 # furnished to do so, subject to the following conditions:
13 #
14 # The above copyright notice and this permission notice
15 # shall be included in all copies or substantial portions of
16 # the Software.
17 #
18 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY
19 # KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE
20 # WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR
21 # PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS
22 # OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR
23 # OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
24 # OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
25 # SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
26
27 """Copy theme assets into output."""
28
29
30 import io
31 import os
32
33 from nikola.plugin_categories import Task
34 from nikola import utils
35
36
37 class CopyAssets(Task):
38 """Copy theme assets into output."""
39
40 name = "copy_assets"
41
42 def gen_tasks(self):
43 """Create tasks to copy the assets of the whole theme chain.
44
45 If a file is present on two themes, use the version
46 from the "youngest" theme.
47 """
48 kw = {
49 "themes": self.site.THEMES,
50 "translations": self.site.translations,
51 "files_folders": self.site.config['FILES_FOLDERS'],
52 "output_folder": self.site.config['OUTPUT_FOLDER'],
53 "filters": self.site.config['FILTERS'],
54 "code_color_scheme": self.site.config['CODE_COLOR_SCHEME'],
55 "code.css_selectors": ['pre.code', '.highlight pre'],
56 "code.css_head": '/* code.css file generated by Nikola */\n',
57 "code.css_close": "\ntable.codetable { width: 100%;} td.linenos {text-align: right; width: 4em;}\n",
58 }
59 tasks = {}
60 code_css_path = os.path.join(kw['output_folder'], 'assets', 'css', 'code.css')
61 code_css_input = utils.get_asset_path('assets/css/code.css',
62 themes=kw['themes'],
63 files_folders=kw['files_folders'], output_dir=None)
64 yield self.group_task()
65
66 main_theme = utils.get_theme_path(kw['themes'][0])
67 theme_ini = utils.parse_theme_meta(main_theme)
68 if theme_ini:
69 ignored_assets = theme_ini.get("Nikola", "ignored_assets", fallback='').split(',')
70 else:
71 ignored_assets = []
72
73 for theme_name in kw['themes']:
74 src = os.path.join(utils.get_theme_path(theme_name), 'assets')
75 dst = os.path.join(kw['output_folder'], 'assets')
76 for task in utils.copy_tree(src, dst):
77 asset_name = os.path.relpath(task['name'], dst)
78 if task['name'] in tasks or asset_name in ignored_assets:
79 continue
80 tasks[task['name']] = task
81 task['uptodate'] = [utils.config_changed(kw, 'nikola.plugins.task.copy_assets')]
82 task['basename'] = self.name
83 if code_css_input:
84 if 'file_dep' not in task:
85 task['file_dep'] = []
86 task['file_dep'].append(code_css_input)
87 yield utils.apply_filters(task, kw['filters'])
88
89 # Check whether or not there is a code.css file around.
90 if not code_css_input and kw['code_color_scheme']:
91 def create_code_css():
92 from pygments.formatters import get_formatter_by_name
93 formatter = get_formatter_by_name('html', style=kw["code_color_scheme"])
94 utils.makedirs(os.path.dirname(code_css_path))
95 with io.open(code_css_path, 'w+', encoding='utf8') as outf:
96 outf.write(kw["code.css_head"])
97 outf.write(formatter.get_style_defs(kw["code.css_selectors"]))
98 outf.write(kw["code.css_close"])
99
100 if os.path.exists(code_css_path):
101 with io.open(code_css_path, 'r', encoding='utf-8') as fh:
102 testcontents = fh.read(len(kw["code.css_head"])) == kw["code.css_head"]
103 else:
104 testcontents = False
105
106 task = {
107 'basename': self.name,
108 'name': code_css_path,
109 'targets': [code_css_path],
110 'uptodate': [utils.config_changed(kw, 'nikola.plugins.task.copy_assets'), testcontents],
111 'actions': [(create_code_css, [])],
112 'clean': True,
113 }
114 yield utils.apply_filters(task, kw['filters'])
115
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nikola/plugins/task/copy_assets.py b/nikola/plugins/task/copy_assets.py
--- a/nikola/plugins/task/copy_assets.py
+++ b/nikola/plugins/task/copy_assets.py
@@ -67,6 +67,7 @@
theme_ini = utils.parse_theme_meta(main_theme)
if theme_ini:
ignored_assets = theme_ini.get("Nikola", "ignored_assets", fallback='').split(',')
+ ignored_assets = [asset_name.strip() for asset_name in ignored_assets]
else:
ignored_assets = []
|
{"golden_diff": "diff --git a/nikola/plugins/task/copy_assets.py b/nikola/plugins/task/copy_assets.py\n--- a/nikola/plugins/task/copy_assets.py\n+++ b/nikola/plugins/task/copy_assets.py\n@@ -67,6 +67,7 @@\n theme_ini = utils.parse_theme_meta(main_theme)\n if theme_ini:\n ignored_assets = theme_ini.get(\"Nikola\", \"ignored_assets\", fallback='').split(',')\n+ ignored_assets = [asset_name.strip() for asset_name in ignored_assets]\n else:\n ignored_assets = []\n", "issue": "Theme meta file ignored_assets key should ignore whitespace\n### Environment (if reporting a bug)\r\n\r\n**Python Version:**\r\n3.5.4\r\n**Nikola Version:**\r\n8.0.0dev HEAD\r\n**Operating System:**\r\ngentoo GNU/Linux\r\n### Description:\r\nCurrent behaviour: The ignored_assets key in theme meta files takes a comma-separated list of filenames, that must not contain leading or trailing whitespace because it's considered to be part of the filename.\r\n\r\nExpected behaviour: The comma-separated list may contain the usual amount of whitespace: foo, bar, baz, etc\r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright \u00a9 2012-2018 Roberto Alsina and others.\n\n# Permission is hereby granted, free of charge, to any\n# person obtaining a copy of this software and associated\n# documentation files (the \"Software\"), to deal in the\n# Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the\n# Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice\n# shall be included in all copies or substantial portions of\n# the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY\n# KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE\n# WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR\n# PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS\n# OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\n# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR\n# OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\n\"\"\"Copy theme assets into output.\"\"\"\n\n\nimport io\nimport os\n\nfrom nikola.plugin_categories import Task\nfrom nikola import utils\n\n\nclass CopyAssets(Task):\n \"\"\"Copy theme assets into output.\"\"\"\n\n name = \"copy_assets\"\n\n def gen_tasks(self):\n \"\"\"Create tasks to copy the assets of the whole theme chain.\n\n If a file is present on two themes, use the version\n from the \"youngest\" theme.\n \"\"\"\n kw = {\n \"themes\": self.site.THEMES,\n \"translations\": self.site.translations,\n \"files_folders\": self.site.config['FILES_FOLDERS'],\n \"output_folder\": self.site.config['OUTPUT_FOLDER'],\n \"filters\": self.site.config['FILTERS'],\n \"code_color_scheme\": self.site.config['CODE_COLOR_SCHEME'],\n \"code.css_selectors\": ['pre.code', '.highlight pre'],\n \"code.css_head\": '/* code.css file generated by Nikola */\\n',\n \"code.css_close\": \"\\ntable.codetable { width: 100%;} td.linenos {text-align: right; width: 4em;}\\n\",\n }\n tasks = {}\n code_css_path = os.path.join(kw['output_folder'], 'assets', 'css', 'code.css')\n code_css_input = utils.get_asset_path('assets/css/code.css',\n themes=kw['themes'],\n files_folders=kw['files_folders'], output_dir=None)\n yield self.group_task()\n\n main_theme = utils.get_theme_path(kw['themes'][0])\n theme_ini = utils.parse_theme_meta(main_theme)\n if theme_ini:\n ignored_assets = theme_ini.get(\"Nikola\", \"ignored_assets\", fallback='').split(',')\n else:\n ignored_assets = []\n\n for theme_name in kw['themes']:\n src = os.path.join(utils.get_theme_path(theme_name), 'assets')\n dst = os.path.join(kw['output_folder'], 'assets')\n for task in utils.copy_tree(src, dst):\n asset_name = os.path.relpath(task['name'], dst)\n if task['name'] in tasks or asset_name in ignored_assets:\n continue\n tasks[task['name']] = task\n task['uptodate'] = [utils.config_changed(kw, 'nikola.plugins.task.copy_assets')]\n task['basename'] = self.name\n if code_css_input:\n if 'file_dep' not in task:\n task['file_dep'] = []\n task['file_dep'].append(code_css_input)\n yield utils.apply_filters(task, kw['filters'])\n\n # Check whether or not there is a code.css file around.\n if not code_css_input and kw['code_color_scheme']:\n def create_code_css():\n from pygments.formatters import get_formatter_by_name\n formatter = get_formatter_by_name('html', style=kw[\"code_color_scheme\"])\n utils.makedirs(os.path.dirname(code_css_path))\n with io.open(code_css_path, 'w+', encoding='utf8') as outf:\n outf.write(kw[\"code.css_head\"])\n outf.write(formatter.get_style_defs(kw[\"code.css_selectors\"]))\n outf.write(kw[\"code.css_close\"])\n\n if os.path.exists(code_css_path):\n with io.open(code_css_path, 'r', encoding='utf-8') as fh:\n testcontents = fh.read(len(kw[\"code.css_head\"])) == kw[\"code.css_head\"]\n else:\n testcontents = False\n\n task = {\n 'basename': self.name,\n 'name': code_css_path,\n 'targets': [code_css_path],\n 'uptodate': [utils.config_changed(kw, 'nikola.plugins.task.copy_assets'), testcontents],\n 'actions': [(create_code_css, [])],\n 'clean': True,\n }\n yield utils.apply_filters(task, kw['filters'])\n", "path": "nikola/plugins/task/copy_assets.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright \u00a9 2012-2018 Roberto Alsina and others.\n\n# Permission is hereby granted, free of charge, to any\n# person obtaining a copy of this software and associated\n# documentation files (the \"Software\"), to deal in the\n# Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the\n# Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice\n# shall be included in all copies or substantial portions of\n# the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY\n# KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE\n# WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR\n# PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS\n# OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\n# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR\n# OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\n\"\"\"Copy theme assets into output.\"\"\"\n\n\nimport io\nimport os\n\nfrom nikola.plugin_categories import Task\nfrom nikola import utils\n\n\nclass CopyAssets(Task):\n \"\"\"Copy theme assets into output.\"\"\"\n\n name = \"copy_assets\"\n\n def gen_tasks(self):\n \"\"\"Create tasks to copy the assets of the whole theme chain.\n\n If a file is present on two themes, use the version\n from the \"youngest\" theme.\n \"\"\"\n kw = {\n \"themes\": self.site.THEMES,\n \"translations\": self.site.translations,\n \"files_folders\": self.site.config['FILES_FOLDERS'],\n \"output_folder\": self.site.config['OUTPUT_FOLDER'],\n \"filters\": self.site.config['FILTERS'],\n \"code_color_scheme\": self.site.config['CODE_COLOR_SCHEME'],\n \"code.css_selectors\": ['pre.code', '.highlight pre'],\n \"code.css_head\": '/* code.css file generated by Nikola */\\n',\n \"code.css_close\": \"\\ntable.codetable { width: 100%;} td.linenos {text-align: right; width: 4em;}\\n\",\n }\n tasks = {}\n code_css_path = os.path.join(kw['output_folder'], 'assets', 'css', 'code.css')\n code_css_input = utils.get_asset_path('assets/css/code.css',\n themes=kw['themes'],\n files_folders=kw['files_folders'], output_dir=None)\n yield self.group_task()\n\n main_theme = utils.get_theme_path(kw['themes'][0])\n theme_ini = utils.parse_theme_meta(main_theme)\n if theme_ini:\n ignored_assets = theme_ini.get(\"Nikola\", \"ignored_assets\", fallback='').split(',')\n ignored_assets = [asset_name.strip() for asset_name in ignored_assets]\n else:\n ignored_assets = []\n\n for theme_name in kw['themes']:\n src = os.path.join(utils.get_theme_path(theme_name), 'assets')\n dst = os.path.join(kw['output_folder'], 'assets')\n for task in utils.copy_tree(src, dst):\n asset_name = os.path.relpath(task['name'], dst)\n if task['name'] in tasks or asset_name in ignored_assets:\n continue\n tasks[task['name']] = task\n task['uptodate'] = [utils.config_changed(kw, 'nikola.plugins.task.copy_assets')]\n task['basename'] = self.name\n if code_css_input:\n if 'file_dep' not in task:\n task['file_dep'] = []\n task['file_dep'].append(code_css_input)\n yield utils.apply_filters(task, kw['filters'])\n\n # Check whether or not there is a code.css file around.\n if not code_css_input and kw['code_color_scheme']:\n def create_code_css():\n from pygments.formatters import get_formatter_by_name\n formatter = get_formatter_by_name('html', style=kw[\"code_color_scheme\"])\n utils.makedirs(os.path.dirname(code_css_path))\n with io.open(code_css_path, 'w+', encoding='utf8') as outf:\n outf.write(kw[\"code.css_head\"])\n outf.write(formatter.get_style_defs(kw[\"code.css_selectors\"]))\n outf.write(kw[\"code.css_close\"])\n\n if os.path.exists(code_css_path):\n with io.open(code_css_path, 'r', encoding='utf-8') as fh:\n testcontents = fh.read(len(kw[\"code.css_head\"])) == kw[\"code.css_head\"]\n else:\n testcontents = False\n\n task = {\n 'basename': self.name,\n 'name': code_css_path,\n 'targets': [code_css_path],\n 'uptodate': [utils.config_changed(kw, 'nikola.plugins.task.copy_assets'), testcontents],\n 'actions': [(create_code_css, [])],\n 'clean': True,\n }\n yield utils.apply_filters(task, kw['filters'])\n", "path": "nikola/plugins/task/copy_assets.py"}]}
| 1,697 | 122 |
gh_patches_debug_18140
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-2408
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
OTLP Exporter: Add support for Gauge point types
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/_metric_exporter/__init__.py`
Content:
```
1 # Copyright The OpenTelemetry Authors
2 # Licensed under the Apache License, Version 2.0 (the "License");
3 # you may not use this file except in compliance with the License.
4 # You may obtain a copy of the License at
5 #
6 # http://www.apache.org/licenses/LICENSE-2.0
7 #
8 # Unless required by applicable law or agreed to in writing, software
9 # distributed under the License is distributed on an "AS IS" BASIS,
10 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
11 # See the License for the specific language governing permissions and
12 # limitations under the License.
13
14 import logging
15 from os import environ
16 from typing import Optional, Sequence
17 from grpc import ChannelCredentials, Compression
18 from opentelemetry.exporter.otlp.proto.grpc.exporter import (
19 OTLPExporterMixin,
20 get_resource_data,
21 )
22 from opentelemetry.proto.collector.metrics.v1.metrics_service_pb2 import (
23 ExportMetricsServiceRequest,
24 )
25 from opentelemetry.proto.collector.metrics.v1.metrics_service_pb2_grpc import (
26 MetricsServiceStub,
27 )
28 from opentelemetry.proto.common.v1.common_pb2 import InstrumentationLibrary
29 from opentelemetry.proto.metrics.v1 import metrics_pb2 as pb2
30 from opentelemetry.sdk.environment_variables import (
31 OTEL_EXPORTER_OTLP_METRICS_INSECURE,
32 )
33 from opentelemetry.sdk._metrics.point import (
34 Gauge,
35 Histogram,
36 Metric,
37 Sum,
38 )
39
40 from opentelemetry.sdk._metrics.export import (
41 MetricExporter,
42 MetricExportResult,
43 )
44
45 logger = logging.getLogger(__name__)
46
47
48 class OTLPMetricExporter(
49 MetricExporter,
50 OTLPExporterMixin[Metric, ExportMetricsServiceRequest, MetricExportResult],
51 ):
52 _result = MetricExportResult
53 _stub = MetricsServiceStub
54
55 def __init__(
56 self,
57 endpoint: Optional[str] = None,
58 insecure: Optional[bool] = None,
59 credentials: Optional[ChannelCredentials] = None,
60 headers: Optional[Sequence] = None,
61 timeout: Optional[int] = None,
62 compression: Optional[Compression] = None,
63 ):
64
65 if insecure is None:
66 insecure = environ.get(OTEL_EXPORTER_OTLP_METRICS_INSECURE)
67 if insecure is not None:
68 insecure = insecure.lower() == "true"
69
70 super().__init__(
71 **{
72 "endpoint": endpoint,
73 "insecure": insecure,
74 "credentials": credentials,
75 "headers": headers,
76 "timeout": timeout,
77 "compression": compression,
78 }
79 )
80
81 def _translate_data(
82 self, data: Sequence[Metric]
83 ) -> ExportMetricsServiceRequest:
84 sdk_resource_instrumentation_library_metrics = {}
85
86 for metric in data:
87 resource = metric.resource
88 instrumentation_library_map = (
89 sdk_resource_instrumentation_library_metrics.get(resource, {})
90 )
91 if not instrumentation_library_map:
92 sdk_resource_instrumentation_library_metrics[
93 resource
94 ] = instrumentation_library_map
95
96 instrumentation_library_metrics = instrumentation_library_map.get(
97 metric.instrumentation_info
98 )
99
100 if not instrumentation_library_metrics:
101 if metric.instrumentation_info is not None:
102 instrumentation_library_map[
103 metric.instrumentation_info
104 ] = pb2.InstrumentationLibraryMetrics(
105 instrumentation_library=InstrumentationLibrary(
106 name=metric.instrumentation_info.name,
107 version=metric.instrumentation_info.version,
108 )
109 )
110 else:
111 instrumentation_library_map[
112 metric.instrumentation_info
113 ] = pb2.InstrumentationLibraryMetrics()
114
115 instrumentation_library_metrics = instrumentation_library_map.get(
116 metric.instrumentation_info
117 )
118
119 pbmetric = pb2.Metric(
120 name=metric.name,
121 description=metric.description,
122 unit=metric.unit,
123 )
124 if isinstance(metric.point, Gauge):
125 # TODO: implement gauge
126 pbmetric.gauge = pb2.Gauge(
127 data_points=[],
128 )
129 elif isinstance(metric.point, Histogram):
130 # TODO: implement histogram
131 pbmetric.histogram = pb2.Histogram(
132 data_points=[],
133 )
134 elif isinstance(metric.point, Sum):
135 pt = pb2.NumberDataPoint(
136 attributes=self._translate_attributes(metric.attributes),
137 start_time_unix_nano=metric.point.start_time_unix_nano,
138 time_unix_nano=metric.point.time_unix_nano,
139 )
140 if isinstance(metric.point.value, int):
141 pt.as_int = metric.point.value
142 else:
143 pt.as_double = metric.point.value
144 # note that because sum is a message type, the fields must be
145 # set individually rather than instantiating a pb2.Sum and setting
146 # it once
147 pbmetric.sum.aggregation_temporality = (
148 metric.point.aggregation_temporality
149 )
150 pbmetric.sum.is_monotonic = metric.point.is_monotonic
151 pbmetric.sum.data_points.append(pt)
152 else:
153 logger.warn("unsupported datapoint type %s", metric.point)
154 continue
155
156 instrumentation_library_metrics.metrics.append(
157 pbmetric,
158 )
159 return ExportMetricsServiceRequest(
160 resource_metrics=get_resource_data(
161 sdk_resource_instrumentation_library_metrics,
162 pb2.ResourceMetrics,
163 "metrics",
164 )
165 )
166
167 def export(self, metrics: Sequence[Metric]) -> MetricExportResult:
168 return self._export(metrics)
169
170 def shutdown(self):
171 pass
172
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/_metric_exporter/__init__.py b/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/_metric_exporter/__init__.py
--- a/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/_metric_exporter/__init__.py
+++ b/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/_metric_exporter/__init__.py
@@ -122,10 +122,15 @@
unit=metric.unit,
)
if isinstance(metric.point, Gauge):
- # TODO: implement gauge
- pbmetric.gauge = pb2.Gauge(
- data_points=[],
+ pt = pb2.NumberDataPoint(
+ attributes=self._translate_attributes(metric.attributes),
+ time_unix_nano=metric.point.time_unix_nano,
)
+ if isinstance(metric.point.value, int):
+ pt.as_int = metric.point.value
+ else:
+ pt.as_double = metric.point.value
+ pbmetric.gauge.data_points.append(pt)
elif isinstance(metric.point, Histogram):
# TODO: implement histogram
pbmetric.histogram = pb2.Histogram(
|
{"golden_diff": "diff --git a/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/_metric_exporter/__init__.py b/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/_metric_exporter/__init__.py\n--- a/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/_metric_exporter/__init__.py\n+++ b/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/_metric_exporter/__init__.py\n@@ -122,10 +122,15 @@\n unit=metric.unit,\n )\n if isinstance(metric.point, Gauge):\n- # TODO: implement gauge\n- pbmetric.gauge = pb2.Gauge(\n- data_points=[],\n+ pt = pb2.NumberDataPoint(\n+ attributes=self._translate_attributes(metric.attributes),\n+ time_unix_nano=metric.point.time_unix_nano,\n )\n+ if isinstance(metric.point.value, int):\n+ pt.as_int = metric.point.value\n+ else:\n+ pt.as_double = metric.point.value\n+ pbmetric.gauge.data_points.append(pt)\n elif isinstance(metric.point, Histogram):\n # TODO: implement histogram\n pbmetric.histogram = pb2.Histogram(\n", "issue": "OTLP Exporter: Add support for Gauge point types\n\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport logging\nfrom os import environ\nfrom typing import Optional, Sequence\nfrom grpc import ChannelCredentials, Compression\nfrom opentelemetry.exporter.otlp.proto.grpc.exporter import (\n OTLPExporterMixin,\n get_resource_data,\n)\nfrom opentelemetry.proto.collector.metrics.v1.metrics_service_pb2 import (\n ExportMetricsServiceRequest,\n)\nfrom opentelemetry.proto.collector.metrics.v1.metrics_service_pb2_grpc import (\n MetricsServiceStub,\n)\nfrom opentelemetry.proto.common.v1.common_pb2 import InstrumentationLibrary\nfrom opentelemetry.proto.metrics.v1 import metrics_pb2 as pb2\nfrom opentelemetry.sdk.environment_variables import (\n OTEL_EXPORTER_OTLP_METRICS_INSECURE,\n)\nfrom opentelemetry.sdk._metrics.point import (\n Gauge,\n Histogram,\n Metric,\n Sum,\n)\n\nfrom opentelemetry.sdk._metrics.export import (\n MetricExporter,\n MetricExportResult,\n)\n\nlogger = logging.getLogger(__name__)\n\n\nclass OTLPMetricExporter(\n MetricExporter,\n OTLPExporterMixin[Metric, ExportMetricsServiceRequest, MetricExportResult],\n):\n _result = MetricExportResult\n _stub = MetricsServiceStub\n\n def __init__(\n self,\n endpoint: Optional[str] = None,\n insecure: Optional[bool] = None,\n credentials: Optional[ChannelCredentials] = None,\n headers: Optional[Sequence] = None,\n timeout: Optional[int] = None,\n compression: Optional[Compression] = None,\n ):\n\n if insecure is None:\n insecure = environ.get(OTEL_EXPORTER_OTLP_METRICS_INSECURE)\n if insecure is not None:\n insecure = insecure.lower() == \"true\"\n\n super().__init__(\n **{\n \"endpoint\": endpoint,\n \"insecure\": insecure,\n \"credentials\": credentials,\n \"headers\": headers,\n \"timeout\": timeout,\n \"compression\": compression,\n }\n )\n\n def _translate_data(\n self, data: Sequence[Metric]\n ) -> ExportMetricsServiceRequest:\n sdk_resource_instrumentation_library_metrics = {}\n\n for metric in data:\n resource = metric.resource\n instrumentation_library_map = (\n sdk_resource_instrumentation_library_metrics.get(resource, {})\n )\n if not instrumentation_library_map:\n sdk_resource_instrumentation_library_metrics[\n resource\n ] = instrumentation_library_map\n\n instrumentation_library_metrics = instrumentation_library_map.get(\n metric.instrumentation_info\n )\n\n if not instrumentation_library_metrics:\n if metric.instrumentation_info is not None:\n instrumentation_library_map[\n metric.instrumentation_info\n ] = pb2.InstrumentationLibraryMetrics(\n instrumentation_library=InstrumentationLibrary(\n name=metric.instrumentation_info.name,\n version=metric.instrumentation_info.version,\n )\n )\n else:\n instrumentation_library_map[\n metric.instrumentation_info\n ] = pb2.InstrumentationLibraryMetrics()\n\n instrumentation_library_metrics = instrumentation_library_map.get(\n metric.instrumentation_info\n )\n\n pbmetric = pb2.Metric(\n name=metric.name,\n description=metric.description,\n unit=metric.unit,\n )\n if isinstance(metric.point, Gauge):\n # TODO: implement gauge\n pbmetric.gauge = pb2.Gauge(\n data_points=[],\n )\n elif isinstance(metric.point, Histogram):\n # TODO: implement histogram\n pbmetric.histogram = pb2.Histogram(\n data_points=[],\n )\n elif isinstance(metric.point, Sum):\n pt = pb2.NumberDataPoint(\n attributes=self._translate_attributes(metric.attributes),\n start_time_unix_nano=metric.point.start_time_unix_nano,\n time_unix_nano=metric.point.time_unix_nano,\n )\n if isinstance(metric.point.value, int):\n pt.as_int = metric.point.value\n else:\n pt.as_double = metric.point.value\n # note that because sum is a message type, the fields must be\n # set individually rather than instantiating a pb2.Sum and setting\n # it once\n pbmetric.sum.aggregation_temporality = (\n metric.point.aggregation_temporality\n )\n pbmetric.sum.is_monotonic = metric.point.is_monotonic\n pbmetric.sum.data_points.append(pt)\n else:\n logger.warn(\"unsupported datapoint type %s\", metric.point)\n continue\n\n instrumentation_library_metrics.metrics.append(\n pbmetric,\n )\n return ExportMetricsServiceRequest(\n resource_metrics=get_resource_data(\n sdk_resource_instrumentation_library_metrics,\n pb2.ResourceMetrics,\n \"metrics\",\n )\n )\n\n def export(self, metrics: Sequence[Metric]) -> MetricExportResult:\n return self._export(metrics)\n\n def shutdown(self):\n pass\n", "path": "exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/_metric_exporter/__init__.py"}], "after_files": [{"content": "# Copyright The OpenTelemetry Authors\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport logging\nfrom os import environ\nfrom typing import Optional, Sequence\nfrom grpc import ChannelCredentials, Compression\nfrom opentelemetry.exporter.otlp.proto.grpc.exporter import (\n OTLPExporterMixin,\n get_resource_data,\n)\nfrom opentelemetry.proto.collector.metrics.v1.metrics_service_pb2 import (\n ExportMetricsServiceRequest,\n)\nfrom opentelemetry.proto.collector.metrics.v1.metrics_service_pb2_grpc import (\n MetricsServiceStub,\n)\nfrom opentelemetry.proto.common.v1.common_pb2 import InstrumentationLibrary\nfrom opentelemetry.proto.metrics.v1 import metrics_pb2 as pb2\nfrom opentelemetry.sdk.environment_variables import (\n OTEL_EXPORTER_OTLP_METRICS_INSECURE,\n)\nfrom opentelemetry.sdk._metrics.point import (\n Gauge,\n Histogram,\n Metric,\n Sum,\n)\n\nfrom opentelemetry.sdk._metrics.export import (\n MetricExporter,\n MetricExportResult,\n)\n\nlogger = logging.getLogger(__name__)\n\n\nclass OTLPMetricExporter(\n MetricExporter,\n OTLPExporterMixin[Metric, ExportMetricsServiceRequest, MetricExportResult],\n):\n _result = MetricExportResult\n _stub = MetricsServiceStub\n\n def __init__(\n self,\n endpoint: Optional[str] = None,\n insecure: Optional[bool] = None,\n credentials: Optional[ChannelCredentials] = None,\n headers: Optional[Sequence] = None,\n timeout: Optional[int] = None,\n compression: Optional[Compression] = None,\n ):\n\n if insecure is None:\n insecure = environ.get(OTEL_EXPORTER_OTLP_METRICS_INSECURE)\n if insecure is not None:\n insecure = insecure.lower() == \"true\"\n\n super().__init__(\n **{\n \"endpoint\": endpoint,\n \"insecure\": insecure,\n \"credentials\": credentials,\n \"headers\": headers,\n \"timeout\": timeout,\n \"compression\": compression,\n }\n )\n\n def _translate_data(\n self, data: Sequence[Metric]\n ) -> ExportMetricsServiceRequest:\n sdk_resource_instrumentation_library_metrics = {}\n\n for metric in data:\n resource = metric.resource\n instrumentation_library_map = (\n sdk_resource_instrumentation_library_metrics.get(resource, {})\n )\n if not instrumentation_library_map:\n sdk_resource_instrumentation_library_metrics[\n resource\n ] = instrumentation_library_map\n\n instrumentation_library_metrics = instrumentation_library_map.get(\n metric.instrumentation_info\n )\n\n if not instrumentation_library_metrics:\n if metric.instrumentation_info is not None:\n instrumentation_library_map[\n metric.instrumentation_info\n ] = pb2.InstrumentationLibraryMetrics(\n instrumentation_library=InstrumentationLibrary(\n name=metric.instrumentation_info.name,\n version=metric.instrumentation_info.version,\n )\n )\n else:\n instrumentation_library_map[\n metric.instrumentation_info\n ] = pb2.InstrumentationLibraryMetrics()\n\n instrumentation_library_metrics = instrumentation_library_map.get(\n metric.instrumentation_info\n )\n\n pbmetric = pb2.Metric(\n name=metric.name,\n description=metric.description,\n unit=metric.unit,\n )\n if isinstance(metric.point, Gauge):\n pt = pb2.NumberDataPoint(\n attributes=self._translate_attributes(metric.attributes),\n time_unix_nano=metric.point.time_unix_nano,\n )\n if isinstance(metric.point.value, int):\n pt.as_int = metric.point.value\n else:\n pt.as_double = metric.point.value\n pbmetric.gauge.data_points.append(pt)\n elif isinstance(metric.point, Histogram):\n # TODO: implement histogram\n pbmetric.histogram = pb2.Histogram(\n data_points=[],\n )\n elif isinstance(metric.point, Sum):\n pt = pb2.NumberDataPoint(\n attributes=self._translate_attributes(metric.attributes),\n start_time_unix_nano=metric.point.start_time_unix_nano,\n time_unix_nano=metric.point.time_unix_nano,\n )\n if isinstance(metric.point.value, int):\n pt.as_int = metric.point.value\n else:\n pt.as_double = metric.point.value\n # note that because sum is a message type, the fields must be\n # set individually rather than instantiating a pb2.Sum and setting\n # it once\n pbmetric.sum.aggregation_temporality = (\n metric.point.aggregation_temporality\n )\n pbmetric.sum.is_monotonic = metric.point.is_monotonic\n pbmetric.sum.data_points.append(pt)\n else:\n logger.warn(\"unsupported datapoint type %s\", metric.point)\n continue\n\n instrumentation_library_metrics.metrics.append(\n pbmetric,\n )\n return ExportMetricsServiceRequest(\n resource_metrics=get_resource_data(\n sdk_resource_instrumentation_library_metrics,\n pb2.ResourceMetrics,\n \"metrics\",\n )\n )\n\n def export(self, metrics: Sequence[Metric]) -> MetricExportResult:\n return self._export(metrics)\n\n def shutdown(self):\n pass\n", "path": "exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc/_metric_exporter/__init__.py"}]}
| 1,841 | 308 |
gh_patches_debug_30133
|
rasdani/github-patches
|
git_diff
|
napari__napari-1788
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Text in welcome visual is too dark on non-macOS platforms
## 🐛 Bug
The welcome text is almost unreadable on Windows or Linux:


It's fine on mac:
<img width="1200" alt="Screen-Shot-2020-10-27-at-7 12 45-PM" src="https://user-images.githubusercontent.com/492549/97384494-e7e49880-1923-11eb-9286-90f141bd0827.png">
@sofroniewn noted that he had to make the text darker for it to appear normal on mac. It appears that this is due to some bug in macOS graphics — the workaround should be applied only on mac.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `napari/_vispy/vispy_welcome_visual.py`
Content:
```
1 from os.path import dirname, join
2
3 import numpy as np
4 import scipy.ndimage as ndi
5 from imageio import imread
6 from vispy.scene.visuals import Text
7 from vispy.visuals.transforms import STTransform
8
9 from ..utils.misc import str_to_rgb
10 from ..utils.theme import darken, lighten
11 from .image import Image as ImageNode
12
13
14 class VispyWelcomeVisual:
15 """Welcome to napari visual.
16 """
17
18 def __init__(self, viewer, parent=None, order=0):
19
20 self._viewer = viewer
21
22 # Load logo and make grayscale
23 logopath = join(dirname(__file__), '..', 'resources', 'logo.png')
24 logo = imread(logopath)
25 self._logo_raw = logo
26 self._logo_border = np.all(logo[..., :3] == [38, 40, 61], axis=2)
27 self._logo = np.zeros(logo.shape)
28
29 self.node = ImageNode(parent=parent)
30 self.node.order = order
31
32 self.node.cmap = 'grays'
33 self.node.transform = STTransform()
34
35 self.text_node = Text(
36 pos=[0, 0], parent=parent, method='gpu', bold=False
37 )
38 self.text_node.order = order
39 self.text_node.transform = STTransform()
40 self.text_node.anchors = ('left', 'center')
41 self.text_node.text = (
42 'to add data:\n'
43 ' - drag and drop file(s) here\n'
44 ' - select File > Open from the menu\n'
45 ' - call a viewer.add_* method'
46 )
47 self.text_node.color = np.divide(
48 str_to_rgb(darken(self._viewer.palette['foreground'], 30)), 255
49 )
50
51 self._on_palette_change(None)
52 self._on_visible_change(None)
53 self._on_canvas_change(None)
54
55 def _on_palette_change(self, event):
56 """Change colors of the logo and text."""
57 if (
58 np.mean(str_to_rgb(self._viewer.palette['background'])[:3])
59 < 255 / 2
60 ):
61 foreground_color = np.divide(
62 str_to_rgb(darken(self._viewer.palette['foreground'], 50)), 255
63 )
64 background_color = np.divide(
65 str_to_rgb(darken(self._viewer.palette['background'], 70)), 255
66 )
67 # Note this unsual scaling is done to preserve color balance on
68 # rendering by VisPy, which appears to be off when opacity < 1
69 text_color = np.multiply(foreground_color, [0.4, 0.65, 0.9])
70 else:
71 foreground_color = np.divide(
72 str_to_rgb(lighten(self._viewer.palette['foreground'], 30)),
73 255,
74 )
75 background_color = np.divide(
76 str_to_rgb(lighten(self._viewer.palette['background'], 30)),
77 255,
78 )
79 text_color = np.divide(
80 str_to_rgb(darken(self._viewer.palette['background'], 60)), 255
81 )
82
83 new_logo = np.zeros(self._logo_raw.shape)
84 new_logo[self._logo_border, :3] = foreground_color
85 new_logo[np.invert(self._logo_border), :3] = background_color
86 new_logo[..., -1] = self._logo_raw[..., -1] * 0.7
87
88 # Do a convolution to smooth any pixelation
89 kernel = np.array([[0, 0.5, 0], [0.5, 1, 0.5], [0, 0.5, 0]])
90 kernel = np.expand_dims(kernel / np.sum(kernel), axis=2)
91 new_logo = ndi.convolve(new_logo, kernel)
92
93 self._logo = new_logo
94 self.node.set_data(self._logo)
95 # Having opacity < 1 improves blending but throws color balance
96 # off which needs to be adjusted if desired
97 self.text_node.color = list(text_color) + [0.7]
98
99 def _on_visible_change(self, event):
100 """Change visibiliy of axes."""
101 visible = len(self._viewer.layers) == 0
102 self.node.visible = visible
103 self.text_node.visible = visible
104
105 def _on_canvas_change(self, event):
106 """Change visibiliy of axes."""
107 if self.node.canvas is not None:
108 center = np.divide(self.node.canvas.size, 2)
109 else:
110 center = np.array([256, 256])
111
112 # Calculate some good default positions for the logo and text
113 center_logo = [
114 center[0] - center[1] / 2.4,
115 2 / 3 * center[1] - center[1] / 3,
116 ]
117 self.node.transform.translate = [center_logo[0], center_logo[1], 0, 0]
118 self.node.transform.scale = [
119 center[1] / 1.2 / self._logo.shape[0],
120 center[1] / 1.2 / self._logo.shape[0],
121 0,
122 0,
123 ]
124
125 self.text_node.font_size = center[1] / 24
126 self.text_node.transform.translate = [
127 center[0] - center[1] / 2.4,
128 1.45 * center[1],
129 0,
130 0,
131 ]
132
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/napari/_vispy/vispy_welcome_visual.py b/napari/_vispy/vispy_welcome_visual.py
--- a/napari/_vispy/vispy_welcome_visual.py
+++ b/napari/_vispy/vispy_welcome_visual.py
@@ -1,3 +1,4 @@
+import sys
from os.path import dirname, join
import numpy as np
@@ -64,9 +65,17 @@
background_color = np.divide(
str_to_rgb(darken(self._viewer.palette['background'], 70)), 255
)
- # Note this unsual scaling is done to preserve color balance on
- # rendering by VisPy, which appears to be off when opacity < 1
- text_color = np.multiply(foreground_color, [0.4, 0.65, 0.9])
+ text_color = foreground_color
+ if sys.platform == 'darwin':
+ # Note this unsual scaling is done to preserve color balance on
+ # rendering by VisPy, which appears to be off when opacity < 1.
+ # It only needs to be done on a mac, where we need opacity < 1
+ # to achieve good blending.
+ text_color = np.multiply(text_color, [0.4, 0.65, 0.9])
+ text_color = list(text_color) + [0.7]
+ else:
+ text_color = list(text_color) + [1]
+
else:
foreground_color = np.divide(
str_to_rgb(lighten(self._viewer.palette['foreground'], 30)),
@@ -92,9 +101,8 @@
self._logo = new_logo
self.node.set_data(self._logo)
- # Having opacity < 1 improves blending but throws color balance
- # off which needs to be adjusted if desired
- self.text_node.color = list(text_color) + [0.7]
+
+ self.text_node.color = text_color
def _on_visible_change(self, event):
"""Change visibiliy of axes."""
|
{"golden_diff": "diff --git a/napari/_vispy/vispy_welcome_visual.py b/napari/_vispy/vispy_welcome_visual.py\n--- a/napari/_vispy/vispy_welcome_visual.py\n+++ b/napari/_vispy/vispy_welcome_visual.py\n@@ -1,3 +1,4 @@\n+import sys\n from os.path import dirname, join\n \n import numpy as np\n@@ -64,9 +65,17 @@\n background_color = np.divide(\n str_to_rgb(darken(self._viewer.palette['background'], 70)), 255\n )\n- # Note this unsual scaling is done to preserve color balance on\n- # rendering by VisPy, which appears to be off when opacity < 1\n- text_color = np.multiply(foreground_color, [0.4, 0.65, 0.9])\n+ text_color = foreground_color\n+ if sys.platform == 'darwin':\n+ # Note this unsual scaling is done to preserve color balance on\n+ # rendering by VisPy, which appears to be off when opacity < 1.\n+ # It only needs to be done on a mac, where we need opacity < 1\n+ # to achieve good blending.\n+ text_color = np.multiply(text_color, [0.4, 0.65, 0.9])\n+ text_color = list(text_color) + [0.7]\n+ else:\n+ text_color = list(text_color) + [1]\n+\n else:\n foreground_color = np.divide(\n str_to_rgb(lighten(self._viewer.palette['foreground'], 30)),\n@@ -92,9 +101,8 @@\n \n self._logo = new_logo\n self.node.set_data(self._logo)\n- # Having opacity < 1 improves blending but throws color balance\n- # off which needs to be adjusted if desired\n- self.text_node.color = list(text_color) + [0.7]\n+\n+ self.text_node.color = text_color\n \n def _on_visible_change(self, event):\n \"\"\"Change visibiliy of axes.\"\"\"\n", "issue": "Text in welcome visual is too dark on non-macOS platforms\n## \ud83d\udc1b Bug\r\n\r\nThe welcome text is almost unreadable on Windows or Linux:\r\n\r\n\r\n\r\n\r\n\r\nIt's fine on mac:\r\n\r\n<img width=\"1200\" alt=\"Screen-Shot-2020-10-27-at-7 12 45-PM\" src=\"https://user-images.githubusercontent.com/492549/97384494-e7e49880-1923-11eb-9286-90f141bd0827.png\">\r\n\r\n@sofroniewn noted that he had to make the text darker for it to appear normal on mac. It appears that this is due to some bug in macOS graphics \u2014 the workaround should be applied only on mac.\n", "before_files": [{"content": "from os.path import dirname, join\n\nimport numpy as np\nimport scipy.ndimage as ndi\nfrom imageio import imread\nfrom vispy.scene.visuals import Text\nfrom vispy.visuals.transforms import STTransform\n\nfrom ..utils.misc import str_to_rgb\nfrom ..utils.theme import darken, lighten\nfrom .image import Image as ImageNode\n\n\nclass VispyWelcomeVisual:\n \"\"\"Welcome to napari visual.\n \"\"\"\n\n def __init__(self, viewer, parent=None, order=0):\n\n self._viewer = viewer\n\n # Load logo and make grayscale\n logopath = join(dirname(__file__), '..', 'resources', 'logo.png')\n logo = imread(logopath)\n self._logo_raw = logo\n self._logo_border = np.all(logo[..., :3] == [38, 40, 61], axis=2)\n self._logo = np.zeros(logo.shape)\n\n self.node = ImageNode(parent=parent)\n self.node.order = order\n\n self.node.cmap = 'grays'\n self.node.transform = STTransform()\n\n self.text_node = Text(\n pos=[0, 0], parent=parent, method='gpu', bold=False\n )\n self.text_node.order = order\n self.text_node.transform = STTransform()\n self.text_node.anchors = ('left', 'center')\n self.text_node.text = (\n 'to add data:\\n'\n ' - drag and drop file(s) here\\n'\n ' - select File > Open from the menu\\n'\n ' - call a viewer.add_* method'\n )\n self.text_node.color = np.divide(\n str_to_rgb(darken(self._viewer.palette['foreground'], 30)), 255\n )\n\n self._on_palette_change(None)\n self._on_visible_change(None)\n self._on_canvas_change(None)\n\n def _on_palette_change(self, event):\n \"\"\"Change colors of the logo and text.\"\"\"\n if (\n np.mean(str_to_rgb(self._viewer.palette['background'])[:3])\n < 255 / 2\n ):\n foreground_color = np.divide(\n str_to_rgb(darken(self._viewer.palette['foreground'], 50)), 255\n )\n background_color = np.divide(\n str_to_rgb(darken(self._viewer.palette['background'], 70)), 255\n )\n # Note this unsual scaling is done to preserve color balance on\n # rendering by VisPy, which appears to be off when opacity < 1\n text_color = np.multiply(foreground_color, [0.4, 0.65, 0.9])\n else:\n foreground_color = np.divide(\n str_to_rgb(lighten(self._viewer.palette['foreground'], 30)),\n 255,\n )\n background_color = np.divide(\n str_to_rgb(lighten(self._viewer.palette['background'], 30)),\n 255,\n )\n text_color = np.divide(\n str_to_rgb(darken(self._viewer.palette['background'], 60)), 255\n )\n\n new_logo = np.zeros(self._logo_raw.shape)\n new_logo[self._logo_border, :3] = foreground_color\n new_logo[np.invert(self._logo_border), :3] = background_color\n new_logo[..., -1] = self._logo_raw[..., -1] * 0.7\n\n # Do a convolution to smooth any pixelation\n kernel = np.array([[0, 0.5, 0], [0.5, 1, 0.5], [0, 0.5, 0]])\n kernel = np.expand_dims(kernel / np.sum(kernel), axis=2)\n new_logo = ndi.convolve(new_logo, kernel)\n\n self._logo = new_logo\n self.node.set_data(self._logo)\n # Having opacity < 1 improves blending but throws color balance\n # off which needs to be adjusted if desired\n self.text_node.color = list(text_color) + [0.7]\n\n def _on_visible_change(self, event):\n \"\"\"Change visibiliy of axes.\"\"\"\n visible = len(self._viewer.layers) == 0\n self.node.visible = visible\n self.text_node.visible = visible\n\n def _on_canvas_change(self, event):\n \"\"\"Change visibiliy of axes.\"\"\"\n if self.node.canvas is not None:\n center = np.divide(self.node.canvas.size, 2)\n else:\n center = np.array([256, 256])\n\n # Calculate some good default positions for the logo and text\n center_logo = [\n center[0] - center[1] / 2.4,\n 2 / 3 * center[1] - center[1] / 3,\n ]\n self.node.transform.translate = [center_logo[0], center_logo[1], 0, 0]\n self.node.transform.scale = [\n center[1] / 1.2 / self._logo.shape[0],\n center[1] / 1.2 / self._logo.shape[0],\n 0,\n 0,\n ]\n\n self.text_node.font_size = center[1] / 24\n self.text_node.transform.translate = [\n center[0] - center[1] / 2.4,\n 1.45 * center[1],\n 0,\n 0,\n ]\n", "path": "napari/_vispy/vispy_welcome_visual.py"}], "after_files": [{"content": "import sys\nfrom os.path import dirname, join\n\nimport numpy as np\nimport scipy.ndimage as ndi\nfrom imageio import imread\nfrom vispy.scene.visuals import Text\nfrom vispy.visuals.transforms import STTransform\n\nfrom ..utils.misc import str_to_rgb\nfrom ..utils.theme import darken, lighten\nfrom .image import Image as ImageNode\n\n\nclass VispyWelcomeVisual:\n \"\"\"Welcome to napari visual.\n \"\"\"\n\n def __init__(self, viewer, parent=None, order=0):\n\n self._viewer = viewer\n\n # Load logo and make grayscale\n logopath = join(dirname(__file__), '..', 'resources', 'logo.png')\n logo = imread(logopath)\n self._logo_raw = logo\n self._logo_border = np.all(logo[..., :3] == [38, 40, 61], axis=2)\n self._logo = np.zeros(logo.shape)\n\n self.node = ImageNode(parent=parent)\n self.node.order = order\n\n self.node.cmap = 'grays'\n self.node.transform = STTransform()\n\n self.text_node = Text(\n pos=[0, 0], parent=parent, method='gpu', bold=False\n )\n self.text_node.order = order\n self.text_node.transform = STTransform()\n self.text_node.anchors = ('left', 'center')\n self.text_node.text = (\n 'to add data:\\n'\n ' - drag and drop file(s) here\\n'\n ' - select File > Open from the menu\\n'\n ' - call a viewer.add_* method'\n )\n self.text_node.color = np.divide(\n str_to_rgb(darken(self._viewer.palette['foreground'], 30)), 255\n )\n\n self._on_palette_change(None)\n self._on_visible_change(None)\n self._on_canvas_change(None)\n\n def _on_palette_change(self, event):\n \"\"\"Change colors of the logo and text.\"\"\"\n if (\n np.mean(str_to_rgb(self._viewer.palette['background'])[:3])\n < 255 / 2\n ):\n foreground_color = np.divide(\n str_to_rgb(darken(self._viewer.palette['foreground'], 50)), 255\n )\n background_color = np.divide(\n str_to_rgb(darken(self._viewer.palette['background'], 70)), 255\n )\n text_color = foreground_color\n if sys.platform == 'darwin':\n # Note this unsual scaling is done to preserve color balance on\n # rendering by VisPy, which appears to be off when opacity < 1.\n # It only needs to be done on a mac, where we need opacity < 1\n # to achieve good blending.\n text_color = np.multiply(text_color, [0.4, 0.65, 0.9])\n text_color = list(text_color) + [0.7]\n else:\n text_color = list(text_color) + [1]\n\n else:\n foreground_color = np.divide(\n str_to_rgb(lighten(self._viewer.palette['foreground'], 30)),\n 255,\n )\n background_color = np.divide(\n str_to_rgb(lighten(self._viewer.palette['background'], 30)),\n 255,\n )\n text_color = np.divide(\n str_to_rgb(darken(self._viewer.palette['background'], 60)), 255\n )\n\n new_logo = np.zeros(self._logo_raw.shape)\n new_logo[self._logo_border, :3] = foreground_color\n new_logo[np.invert(self._logo_border), :3] = background_color\n new_logo[..., -1] = self._logo_raw[..., -1] * 0.7\n\n # Do a convolution to smooth any pixelation\n kernel = np.array([[0, 0.5, 0], [0.5, 1, 0.5], [0, 0.5, 0]])\n kernel = np.expand_dims(kernel / np.sum(kernel), axis=2)\n new_logo = ndi.convolve(new_logo, kernel)\n\n self._logo = new_logo\n self.node.set_data(self._logo)\n\n self.text_node.color = text_color\n\n def _on_visible_change(self, event):\n \"\"\"Change visibiliy of axes.\"\"\"\n visible = len(self._viewer.layers) == 0\n self.node.visible = visible\n self.text_node.visible = visible\n\n def _on_canvas_change(self, event):\n \"\"\"Change visibiliy of axes.\"\"\"\n if self.node.canvas is not None:\n center = np.divide(self.node.canvas.size, 2)\n else:\n center = np.array([256, 256])\n\n # Calculate some good default positions for the logo and text\n center_logo = [\n center[0] - center[1] / 2.4,\n 2 / 3 * center[1] - center[1] / 3,\n ]\n self.node.transform.translate = [center_logo[0], center_logo[1], 0, 0]\n self.node.transform.scale = [\n center[1] / 1.2 / self._logo.shape[0],\n center[1] / 1.2 / self._logo.shape[0],\n 0,\n 0,\n ]\n\n self.text_node.font_size = center[1] / 24\n self.text_node.transform.translate = [\n center[0] - center[1] / 2.4,\n 1.45 * center[1],\n 0,\n 0,\n ]\n", "path": "napari/_vispy/vispy_welcome_visual.py"}]}
| 2,074 | 471 |
gh_patches_debug_45587
|
rasdani/github-patches
|
git_diff
|
saleor__saleor-11760
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
add API version to update_payment_method parameters
In the `update_payment_method` function in `payment/gateways/stripe/stripe_api` there should be a `STRIPE_API_VERSION` passed in `stripe.PaymentMethod.modify`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `saleor/payment/gateways/stripe/stripe_api.py`
Content:
```
1 import logging
2 from contextlib import contextmanager
3 from decimal import Decimal
4 from typing import Dict, List, Optional, Tuple
5 from urllib.parse import urljoin
6
7 import stripe
8 from django.contrib.sites.models import Site
9 from django.urls import reverse
10 from stripe.error import AuthenticationError, InvalidRequestError, StripeError
11 from stripe.stripe_object import StripeObject
12
13 from ....core.tracing import opentracing_trace
14 from ....core.utils import build_absolute_uri
15 from ...interface import PaymentMethodInfo
16 from ...utils import price_to_minor_unit
17 from .consts import (
18 AUTOMATIC_CAPTURE_METHOD,
19 MANUAL_CAPTURE_METHOD,
20 METADATA_IDENTIFIER,
21 PLUGIN_ID,
22 STRIPE_API_VERSION,
23 WEBHOOK_EVENTS,
24 WEBHOOK_PATH,
25 )
26
27 logger = logging.getLogger(__name__)
28
29
30 @contextmanager
31 def stripe_opentracing_trace(span_name):
32 with opentracing_trace(
33 span_name=span_name, component_name="payment", service_name="stripe"
34 ):
35 yield
36
37
38 def is_secret_api_key_valid(api_key: str):
39 """Call api to check if api_key is a correct key."""
40 try:
41 with stripe_opentracing_trace("stripe.WebhookEndpoint.list"):
42 stripe.WebhookEndpoint.list(api_key, stripe_version=STRIPE_API_VERSION)
43 return True
44 except AuthenticationError:
45 return False
46
47
48 def _extra_log_data(error: StripeError, payment_intent_id: Optional[str] = None):
49 data = {
50 "error_message": error.user_message,
51 "http_status": error.http_status,
52 "code": error.code,
53 }
54 if payment_intent_id is not None:
55 data["payment_intent_id"] = payment_intent_id
56 return data
57
58
59 def subscribe_webhook(api_key: str, channel_slug: str) -> Optional[StripeObject]:
60 domain = Site.objects.get_current().domain
61 api_path = reverse(
62 "plugins-per-channel",
63 kwargs={"plugin_id": PLUGIN_ID, "channel_slug": channel_slug},
64 )
65
66 base_url = build_absolute_uri(api_path)
67 webhook_url = urljoin(base_url, WEBHOOK_PATH)
68
69 with stripe_opentracing_trace("stripe.WebhookEndpoint.create"):
70 try:
71 return stripe.WebhookEndpoint.create(
72 api_key=api_key,
73 url=webhook_url,
74 enabled_events=WEBHOOK_EVENTS,
75 metadata={METADATA_IDENTIFIER: domain},
76 stripe_version=STRIPE_API_VERSION,
77 )
78 except StripeError as error:
79 logger.warning(
80 "Failed to create Stripe webhook",
81 extra=_extra_log_data(error),
82 )
83 return None
84
85
86 def delete_webhook(api_key: str, webhook_id: str):
87 try:
88 with stripe_opentracing_trace("stripe.WebhookEndpoint.delete"):
89 stripe.WebhookEndpoint.delete(
90 webhook_id,
91 api_key=api_key,
92 stripe_version=STRIPE_API_VERSION,
93 )
94 except InvalidRequestError:
95 # webhook doesn't exist
96 pass
97
98
99 def get_or_create_customer(
100 api_key: str,
101 customer_id: Optional[str] = None,
102 customer_email: Optional[str] = None,
103 ) -> Optional[StripeObject]:
104 try:
105 if customer_id:
106 with stripe_opentracing_trace("stripe.Customer.retrieve"):
107 return stripe.Customer.retrieve(
108 customer_id,
109 api_key=api_key,
110 stripe_version=STRIPE_API_VERSION,
111 )
112 with stripe_opentracing_trace("stripe.Customer.create"):
113 return stripe.Customer.create(
114 api_key=api_key, email=customer_email, stripe_version=STRIPE_API_VERSION
115 )
116 except StripeError as error:
117 logger.warning(
118 "Failed to get/create Stripe customer",
119 extra=_extra_log_data(error),
120 )
121 return None
122
123
124 def create_payment_intent(
125 api_key: str,
126 amount: Decimal,
127 currency: str,
128 auto_capture: bool = True,
129 customer: Optional[StripeObject] = None,
130 payment_method_id: Optional[str] = None,
131 metadata: Optional[dict] = None,
132 setup_future_usage: Optional[str] = None,
133 off_session: Optional[bool] = None,
134 payment_method_types: Optional[List[str]] = None,
135 customer_email: Optional[str] = None,
136 ) -> Tuple[Optional[StripeObject], Optional[StripeError]]:
137
138 capture_method = AUTOMATIC_CAPTURE_METHOD if auto_capture else MANUAL_CAPTURE_METHOD
139 additional_params = {}
140
141 if customer:
142 additional_params["customer"] = customer
143
144 if payment_method_id and customer:
145 additional_params["payment_method"] = payment_method_id
146
147 additional_params["off_session"] = off_session if off_session else False
148 if off_session:
149 additional_params["confirm"] = True
150
151 if setup_future_usage in ["on_session", "off_session"] and not payment_method_id:
152 additional_params["setup_future_usage"] = setup_future_usage
153
154 if metadata:
155 additional_params["metadata"] = metadata
156
157 if payment_method_types and isinstance(payment_method_types, list):
158 additional_params["payment_method_types"] = payment_method_types
159
160 if customer_email:
161 additional_params["receipt_email"] = customer_email
162
163 try:
164 with stripe_opentracing_trace("stripe.PaymentIntent.create"):
165 intent = stripe.PaymentIntent.create(
166 api_key=api_key,
167 amount=price_to_minor_unit(amount, currency),
168 currency=currency,
169 capture_method=capture_method,
170 stripe_version=STRIPE_API_VERSION,
171 **additional_params,
172 )
173 return intent, None
174 except StripeError as error:
175 logger.warning(
176 "Failed to create Stripe payment intent", extra=_extra_log_data(error)
177 )
178 return None, error
179
180
181 def update_payment_method(
182 api_key: str,
183 payment_method_id: str,
184 metadata: Dict[str, str],
185 ):
186 with stripe_opentracing_trace("stripe.PaymentMethod.modify"):
187 try:
188 stripe.PaymentMethod.modify(
189 payment_method_id,
190 api_key=api_key,
191 metadata=metadata,
192 )
193 except StripeError as error:
194 logger.warning(
195 "Failed to assign channel slug to payment method",
196 extra=_extra_log_data(error),
197 )
198
199
200 def list_customer_payment_methods(
201 api_key: str, customer_id: str
202 ) -> Tuple[Optional[StripeObject], Optional[StripeError]]:
203 try:
204 with stripe_opentracing_trace("stripe.PaymentMethod.list"):
205 payment_methods = stripe.PaymentMethod.list(
206 api_key=api_key,
207 customer=customer_id,
208 stripe_version=STRIPE_API_VERSION,
209 type="card", # we support only cards for now
210 )
211 return payment_methods, None
212 except StripeError as error:
213 return None, error
214
215
216 def retrieve_payment_intent(
217 api_key: str, payment_intent_id: str
218 ) -> Tuple[Optional[StripeObject], Optional[StripeError]]:
219 try:
220 with stripe_opentracing_trace("stripe.PaymentIntent.retrieve"):
221 payment_intent = stripe.PaymentIntent.retrieve(
222 payment_intent_id,
223 api_key=api_key,
224 stripe_version=STRIPE_API_VERSION,
225 )
226 return payment_intent, None
227 except StripeError as error:
228 logger.warning(
229 "Unable to retrieve a payment intent",
230 extra=_extra_log_data(error),
231 )
232 return None, error
233
234
235 def capture_payment_intent(
236 api_key: str, payment_intent_id: str, amount_to_capture: int
237 ) -> Tuple[Optional[StripeObject], Optional[StripeError]]:
238 try:
239 with stripe_opentracing_trace("stripe.PaymentIntent.capture"):
240 payment_intent = stripe.PaymentIntent.capture(
241 payment_intent_id,
242 amount_to_capture=amount_to_capture,
243 api_key=api_key,
244 stripe_version=STRIPE_API_VERSION,
245 )
246 return payment_intent, None
247 except StripeError as error:
248 logger.warning(
249 "Unable to capture a payment intent",
250 extra=_extra_log_data(error),
251 )
252 return None, error
253
254
255 def refund_payment_intent(
256 api_key: str, payment_intent_id: str, amount_to_refund: int
257 ) -> Tuple[Optional[StripeObject], Optional[StripeError]]:
258 try:
259 with stripe_opentracing_trace("stripe.Refund.create"):
260 refund = stripe.Refund.create(
261 payment_intent=payment_intent_id,
262 amount=amount_to_refund,
263 api_key=api_key,
264 stripe_version=STRIPE_API_VERSION,
265 )
266 return refund, None
267 except StripeError as error:
268 logger.warning(
269 "Unable to refund a payment intent",
270 extra=_extra_log_data(error),
271 )
272 return None, error
273
274
275 def cancel_payment_intent(
276 api_key: str, payment_intent_id: str
277 ) -> Tuple[Optional[StripeObject], Optional[StripeError]]:
278 try:
279 with stripe_opentracing_trace("stripe.PaymentIntent.cancel"):
280 payment_intent = stripe.PaymentIntent.cancel(
281 payment_intent_id,
282 api_key=api_key,
283 stripe_version=STRIPE_API_VERSION,
284 )
285 return payment_intent, None
286 except StripeError as error:
287 logger.warning(
288 "Unable to cancel a payment intent",
289 extra=_extra_log_data(error),
290 )
291
292 return None, error
293
294
295 def construct_stripe_event(
296 api_key: str, payload: bytes, sig_header: str, endpoint_secret: str
297 ) -> StripeObject:
298 with stripe_opentracing_trace("stripe.Webhook.construct_event"):
299 return stripe.Webhook.construct_event(
300 payload, sig_header, endpoint_secret, api_key=api_key
301 )
302
303
304 def get_payment_method_details(
305 payment_intent: StripeObject,
306 ) -> Optional[PaymentMethodInfo]:
307 charges = payment_intent.get("charges", None)
308 payment_method_info = None
309 if charges:
310 charges_data = charges.get("data", [])
311 if not charges_data:
312 return None
313 charge_data = charges_data[-1]
314 payment_method_details = charge_data.get("payment_method_details", {})
315
316 if payment_method_details.get("type") == "card":
317 card_details = payment_method_details.get("card", {})
318 exp_year = card_details.get("exp_year", "")
319 exp_year = int(exp_year) if exp_year else None
320 exp_month = card_details.get("exp_month", "")
321 exp_month = int(exp_month) if exp_month else None
322 payment_method_info = PaymentMethodInfo(
323 last_4=card_details.get("last4", ""),
324 exp_year=exp_year,
325 exp_month=exp_month,
326 brand=card_details.get("brand", ""),
327 type="card",
328 )
329 return payment_method_info
330
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/saleor/payment/gateways/stripe/stripe_api.py b/saleor/payment/gateways/stripe/stripe_api.py
--- a/saleor/payment/gateways/stripe/stripe_api.py
+++ b/saleor/payment/gateways/stripe/stripe_api.py
@@ -27,6 +27,9 @@
logger = logging.getLogger(__name__)
+stripe.api_version = STRIPE_API_VERSION
+
+
@contextmanager
def stripe_opentracing_trace(span_name):
with opentracing_trace(
@@ -39,7 +42,7 @@
"""Call api to check if api_key is a correct key."""
try:
with stripe_opentracing_trace("stripe.WebhookEndpoint.list"):
- stripe.WebhookEndpoint.list(api_key, stripe_version=STRIPE_API_VERSION)
+ stripe.WebhookEndpoint.list(api_key)
return True
except AuthenticationError:
return False
@@ -73,7 +76,6 @@
url=webhook_url,
enabled_events=WEBHOOK_EVENTS,
metadata={METADATA_IDENTIFIER: domain},
- stripe_version=STRIPE_API_VERSION,
)
except StripeError as error:
logger.warning(
@@ -89,7 +91,6 @@
stripe.WebhookEndpoint.delete(
webhook_id,
api_key=api_key,
- stripe_version=STRIPE_API_VERSION,
)
except InvalidRequestError:
# webhook doesn't exist
@@ -107,11 +108,11 @@
return stripe.Customer.retrieve(
customer_id,
api_key=api_key,
- stripe_version=STRIPE_API_VERSION,
)
with stripe_opentracing_trace("stripe.Customer.create"):
return stripe.Customer.create(
- api_key=api_key, email=customer_email, stripe_version=STRIPE_API_VERSION
+ api_key=api_key,
+ email=customer_email,
)
except StripeError as error:
logger.warning(
@@ -167,7 +168,6 @@
amount=price_to_minor_unit(amount, currency),
currency=currency,
capture_method=capture_method,
- stripe_version=STRIPE_API_VERSION,
**additional_params,
)
return intent, None
@@ -205,7 +205,6 @@
payment_methods = stripe.PaymentMethod.list(
api_key=api_key,
customer=customer_id,
- stripe_version=STRIPE_API_VERSION,
type="card", # we support only cards for now
)
return payment_methods, None
@@ -221,7 +220,6 @@
payment_intent = stripe.PaymentIntent.retrieve(
payment_intent_id,
api_key=api_key,
- stripe_version=STRIPE_API_VERSION,
)
return payment_intent, None
except StripeError as error:
@@ -241,7 +239,6 @@
payment_intent_id,
amount_to_capture=amount_to_capture,
api_key=api_key,
- stripe_version=STRIPE_API_VERSION,
)
return payment_intent, None
except StripeError as error:
@@ -261,7 +258,6 @@
payment_intent=payment_intent_id,
amount=amount_to_refund,
api_key=api_key,
- stripe_version=STRIPE_API_VERSION,
)
return refund, None
except StripeError as error:
@@ -280,7 +276,6 @@
payment_intent = stripe.PaymentIntent.cancel(
payment_intent_id,
api_key=api_key,
- stripe_version=STRIPE_API_VERSION,
)
return payment_intent, None
except StripeError as error:
|
{"golden_diff": "diff --git a/saleor/payment/gateways/stripe/stripe_api.py b/saleor/payment/gateways/stripe/stripe_api.py\n--- a/saleor/payment/gateways/stripe/stripe_api.py\n+++ b/saleor/payment/gateways/stripe/stripe_api.py\n@@ -27,6 +27,9 @@\n logger = logging.getLogger(__name__)\n \n \n+stripe.api_version = STRIPE_API_VERSION\n+\n+\n @contextmanager\n def stripe_opentracing_trace(span_name):\n with opentracing_trace(\n@@ -39,7 +42,7 @@\n \"\"\"Call api to check if api_key is a correct key.\"\"\"\n try:\n with stripe_opentracing_trace(\"stripe.WebhookEndpoint.list\"):\n- stripe.WebhookEndpoint.list(api_key, stripe_version=STRIPE_API_VERSION)\n+ stripe.WebhookEndpoint.list(api_key)\n return True\n except AuthenticationError:\n return False\n@@ -73,7 +76,6 @@\n url=webhook_url,\n enabled_events=WEBHOOK_EVENTS,\n metadata={METADATA_IDENTIFIER: domain},\n- stripe_version=STRIPE_API_VERSION,\n )\n except StripeError as error:\n logger.warning(\n@@ -89,7 +91,6 @@\n stripe.WebhookEndpoint.delete(\n webhook_id,\n api_key=api_key,\n- stripe_version=STRIPE_API_VERSION,\n )\n except InvalidRequestError:\n # webhook doesn't exist\n@@ -107,11 +108,11 @@\n return stripe.Customer.retrieve(\n customer_id,\n api_key=api_key,\n- stripe_version=STRIPE_API_VERSION,\n )\n with stripe_opentracing_trace(\"stripe.Customer.create\"):\n return stripe.Customer.create(\n- api_key=api_key, email=customer_email, stripe_version=STRIPE_API_VERSION\n+ api_key=api_key,\n+ email=customer_email,\n )\n except StripeError as error:\n logger.warning(\n@@ -167,7 +168,6 @@\n amount=price_to_minor_unit(amount, currency),\n currency=currency,\n capture_method=capture_method,\n- stripe_version=STRIPE_API_VERSION,\n **additional_params,\n )\n return intent, None\n@@ -205,7 +205,6 @@\n payment_methods = stripe.PaymentMethod.list(\n api_key=api_key,\n customer=customer_id,\n- stripe_version=STRIPE_API_VERSION,\n type=\"card\", # we support only cards for now\n )\n return payment_methods, None\n@@ -221,7 +220,6 @@\n payment_intent = stripe.PaymentIntent.retrieve(\n payment_intent_id,\n api_key=api_key,\n- stripe_version=STRIPE_API_VERSION,\n )\n return payment_intent, None\n except StripeError as error:\n@@ -241,7 +239,6 @@\n payment_intent_id,\n amount_to_capture=amount_to_capture,\n api_key=api_key,\n- stripe_version=STRIPE_API_VERSION,\n )\n return payment_intent, None\n except StripeError as error:\n@@ -261,7 +258,6 @@\n payment_intent=payment_intent_id,\n amount=amount_to_refund,\n api_key=api_key,\n- stripe_version=STRIPE_API_VERSION,\n )\n return refund, None\n except StripeError as error:\n@@ -280,7 +276,6 @@\n payment_intent = stripe.PaymentIntent.cancel(\n payment_intent_id,\n api_key=api_key,\n- stripe_version=STRIPE_API_VERSION,\n )\n return payment_intent, None\n except StripeError as error:\n", "issue": "add API version to update_payment_method parameters\nIn the `update_payment_method` function in `payment/gateways/stripe/stripe_api` there should be a `STRIPE_API_VERSION` passed in `stripe.PaymentMethod.modify`\n", "before_files": [{"content": "import logging\nfrom contextlib import contextmanager\nfrom decimal import Decimal\nfrom typing import Dict, List, Optional, Tuple\nfrom urllib.parse import urljoin\n\nimport stripe\nfrom django.contrib.sites.models import Site\nfrom django.urls import reverse\nfrom stripe.error import AuthenticationError, InvalidRequestError, StripeError\nfrom stripe.stripe_object import StripeObject\n\nfrom ....core.tracing import opentracing_trace\nfrom ....core.utils import build_absolute_uri\nfrom ...interface import PaymentMethodInfo\nfrom ...utils import price_to_minor_unit\nfrom .consts import (\n AUTOMATIC_CAPTURE_METHOD,\n MANUAL_CAPTURE_METHOD,\n METADATA_IDENTIFIER,\n PLUGIN_ID,\n STRIPE_API_VERSION,\n WEBHOOK_EVENTS,\n WEBHOOK_PATH,\n)\n\nlogger = logging.getLogger(__name__)\n\n\n@contextmanager\ndef stripe_opentracing_trace(span_name):\n with opentracing_trace(\n span_name=span_name, component_name=\"payment\", service_name=\"stripe\"\n ):\n yield\n\n\ndef is_secret_api_key_valid(api_key: str):\n \"\"\"Call api to check if api_key is a correct key.\"\"\"\n try:\n with stripe_opentracing_trace(\"stripe.WebhookEndpoint.list\"):\n stripe.WebhookEndpoint.list(api_key, stripe_version=STRIPE_API_VERSION)\n return True\n except AuthenticationError:\n return False\n\n\ndef _extra_log_data(error: StripeError, payment_intent_id: Optional[str] = None):\n data = {\n \"error_message\": error.user_message,\n \"http_status\": error.http_status,\n \"code\": error.code,\n }\n if payment_intent_id is not None:\n data[\"payment_intent_id\"] = payment_intent_id\n return data\n\n\ndef subscribe_webhook(api_key: str, channel_slug: str) -> Optional[StripeObject]:\n domain = Site.objects.get_current().domain\n api_path = reverse(\n \"plugins-per-channel\",\n kwargs={\"plugin_id\": PLUGIN_ID, \"channel_slug\": channel_slug},\n )\n\n base_url = build_absolute_uri(api_path)\n webhook_url = urljoin(base_url, WEBHOOK_PATH)\n\n with stripe_opentracing_trace(\"stripe.WebhookEndpoint.create\"):\n try:\n return stripe.WebhookEndpoint.create(\n api_key=api_key,\n url=webhook_url,\n enabled_events=WEBHOOK_EVENTS,\n metadata={METADATA_IDENTIFIER: domain},\n stripe_version=STRIPE_API_VERSION,\n )\n except StripeError as error:\n logger.warning(\n \"Failed to create Stripe webhook\",\n extra=_extra_log_data(error),\n )\n return None\n\n\ndef delete_webhook(api_key: str, webhook_id: str):\n try:\n with stripe_opentracing_trace(\"stripe.WebhookEndpoint.delete\"):\n stripe.WebhookEndpoint.delete(\n webhook_id,\n api_key=api_key,\n stripe_version=STRIPE_API_VERSION,\n )\n except InvalidRequestError:\n # webhook doesn't exist\n pass\n\n\ndef get_or_create_customer(\n api_key: str,\n customer_id: Optional[str] = None,\n customer_email: Optional[str] = None,\n) -> Optional[StripeObject]:\n try:\n if customer_id:\n with stripe_opentracing_trace(\"stripe.Customer.retrieve\"):\n return stripe.Customer.retrieve(\n customer_id,\n api_key=api_key,\n stripe_version=STRIPE_API_VERSION,\n )\n with stripe_opentracing_trace(\"stripe.Customer.create\"):\n return stripe.Customer.create(\n api_key=api_key, email=customer_email, stripe_version=STRIPE_API_VERSION\n )\n except StripeError as error:\n logger.warning(\n \"Failed to get/create Stripe customer\",\n extra=_extra_log_data(error),\n )\n return None\n\n\ndef create_payment_intent(\n api_key: str,\n amount: Decimal,\n currency: str,\n auto_capture: bool = True,\n customer: Optional[StripeObject] = None,\n payment_method_id: Optional[str] = None,\n metadata: Optional[dict] = None,\n setup_future_usage: Optional[str] = None,\n off_session: Optional[bool] = None,\n payment_method_types: Optional[List[str]] = None,\n customer_email: Optional[str] = None,\n) -> Tuple[Optional[StripeObject], Optional[StripeError]]:\n\n capture_method = AUTOMATIC_CAPTURE_METHOD if auto_capture else MANUAL_CAPTURE_METHOD\n additional_params = {}\n\n if customer:\n additional_params[\"customer\"] = customer\n\n if payment_method_id and customer:\n additional_params[\"payment_method\"] = payment_method_id\n\n additional_params[\"off_session\"] = off_session if off_session else False\n if off_session:\n additional_params[\"confirm\"] = True\n\n if setup_future_usage in [\"on_session\", \"off_session\"] and not payment_method_id:\n additional_params[\"setup_future_usage\"] = setup_future_usage\n\n if metadata:\n additional_params[\"metadata\"] = metadata\n\n if payment_method_types and isinstance(payment_method_types, list):\n additional_params[\"payment_method_types\"] = payment_method_types\n\n if customer_email:\n additional_params[\"receipt_email\"] = customer_email\n\n try:\n with stripe_opentracing_trace(\"stripe.PaymentIntent.create\"):\n intent = stripe.PaymentIntent.create(\n api_key=api_key,\n amount=price_to_minor_unit(amount, currency),\n currency=currency,\n capture_method=capture_method,\n stripe_version=STRIPE_API_VERSION,\n **additional_params,\n )\n return intent, None\n except StripeError as error:\n logger.warning(\n \"Failed to create Stripe payment intent\", extra=_extra_log_data(error)\n )\n return None, error\n\n\ndef update_payment_method(\n api_key: str,\n payment_method_id: str,\n metadata: Dict[str, str],\n):\n with stripe_opentracing_trace(\"stripe.PaymentMethod.modify\"):\n try:\n stripe.PaymentMethod.modify(\n payment_method_id,\n api_key=api_key,\n metadata=metadata,\n )\n except StripeError as error:\n logger.warning(\n \"Failed to assign channel slug to payment method\",\n extra=_extra_log_data(error),\n )\n\n\ndef list_customer_payment_methods(\n api_key: str, customer_id: str\n) -> Tuple[Optional[StripeObject], Optional[StripeError]]:\n try:\n with stripe_opentracing_trace(\"stripe.PaymentMethod.list\"):\n payment_methods = stripe.PaymentMethod.list(\n api_key=api_key,\n customer=customer_id,\n stripe_version=STRIPE_API_VERSION,\n type=\"card\", # we support only cards for now\n )\n return payment_methods, None\n except StripeError as error:\n return None, error\n\n\ndef retrieve_payment_intent(\n api_key: str, payment_intent_id: str\n) -> Tuple[Optional[StripeObject], Optional[StripeError]]:\n try:\n with stripe_opentracing_trace(\"stripe.PaymentIntent.retrieve\"):\n payment_intent = stripe.PaymentIntent.retrieve(\n payment_intent_id,\n api_key=api_key,\n stripe_version=STRIPE_API_VERSION,\n )\n return payment_intent, None\n except StripeError as error:\n logger.warning(\n \"Unable to retrieve a payment intent\",\n extra=_extra_log_data(error),\n )\n return None, error\n\n\ndef capture_payment_intent(\n api_key: str, payment_intent_id: str, amount_to_capture: int\n) -> Tuple[Optional[StripeObject], Optional[StripeError]]:\n try:\n with stripe_opentracing_trace(\"stripe.PaymentIntent.capture\"):\n payment_intent = stripe.PaymentIntent.capture(\n payment_intent_id,\n amount_to_capture=amount_to_capture,\n api_key=api_key,\n stripe_version=STRIPE_API_VERSION,\n )\n return payment_intent, None\n except StripeError as error:\n logger.warning(\n \"Unable to capture a payment intent\",\n extra=_extra_log_data(error),\n )\n return None, error\n\n\ndef refund_payment_intent(\n api_key: str, payment_intent_id: str, amount_to_refund: int\n) -> Tuple[Optional[StripeObject], Optional[StripeError]]:\n try:\n with stripe_opentracing_trace(\"stripe.Refund.create\"):\n refund = stripe.Refund.create(\n payment_intent=payment_intent_id,\n amount=amount_to_refund,\n api_key=api_key,\n stripe_version=STRIPE_API_VERSION,\n )\n return refund, None\n except StripeError as error:\n logger.warning(\n \"Unable to refund a payment intent\",\n extra=_extra_log_data(error),\n )\n return None, error\n\n\ndef cancel_payment_intent(\n api_key: str, payment_intent_id: str\n) -> Tuple[Optional[StripeObject], Optional[StripeError]]:\n try:\n with stripe_opentracing_trace(\"stripe.PaymentIntent.cancel\"):\n payment_intent = stripe.PaymentIntent.cancel(\n payment_intent_id,\n api_key=api_key,\n stripe_version=STRIPE_API_VERSION,\n )\n return payment_intent, None\n except StripeError as error:\n logger.warning(\n \"Unable to cancel a payment intent\",\n extra=_extra_log_data(error),\n )\n\n return None, error\n\n\ndef construct_stripe_event(\n api_key: str, payload: bytes, sig_header: str, endpoint_secret: str\n) -> StripeObject:\n with stripe_opentracing_trace(\"stripe.Webhook.construct_event\"):\n return stripe.Webhook.construct_event(\n payload, sig_header, endpoint_secret, api_key=api_key\n )\n\n\ndef get_payment_method_details(\n payment_intent: StripeObject,\n) -> Optional[PaymentMethodInfo]:\n charges = payment_intent.get(\"charges\", None)\n payment_method_info = None\n if charges:\n charges_data = charges.get(\"data\", [])\n if not charges_data:\n return None\n charge_data = charges_data[-1]\n payment_method_details = charge_data.get(\"payment_method_details\", {})\n\n if payment_method_details.get(\"type\") == \"card\":\n card_details = payment_method_details.get(\"card\", {})\n exp_year = card_details.get(\"exp_year\", \"\")\n exp_year = int(exp_year) if exp_year else None\n exp_month = card_details.get(\"exp_month\", \"\")\n exp_month = int(exp_month) if exp_month else None\n payment_method_info = PaymentMethodInfo(\n last_4=card_details.get(\"last4\", \"\"),\n exp_year=exp_year,\n exp_month=exp_month,\n brand=card_details.get(\"brand\", \"\"),\n type=\"card\",\n )\n return payment_method_info\n", "path": "saleor/payment/gateways/stripe/stripe_api.py"}], "after_files": [{"content": "import logging\nfrom contextlib import contextmanager\nfrom decimal import Decimal\nfrom typing import Dict, List, Optional, Tuple\nfrom urllib.parse import urljoin\n\nimport stripe\nfrom django.contrib.sites.models import Site\nfrom django.urls import reverse\nfrom stripe.error import AuthenticationError, InvalidRequestError, StripeError\nfrom stripe.stripe_object import StripeObject\n\nfrom ....core.tracing import opentracing_trace\nfrom ....core.utils import build_absolute_uri\nfrom ...interface import PaymentMethodInfo\nfrom ...utils import price_to_minor_unit\nfrom .consts import (\n AUTOMATIC_CAPTURE_METHOD,\n MANUAL_CAPTURE_METHOD,\n METADATA_IDENTIFIER,\n PLUGIN_ID,\n STRIPE_API_VERSION,\n WEBHOOK_EVENTS,\n WEBHOOK_PATH,\n)\n\nlogger = logging.getLogger(__name__)\n\n\nstripe.api_version = STRIPE_API_VERSION\n\n\n@contextmanager\ndef stripe_opentracing_trace(span_name):\n with opentracing_trace(\n span_name=span_name, component_name=\"payment\", service_name=\"stripe\"\n ):\n yield\n\n\ndef is_secret_api_key_valid(api_key: str):\n \"\"\"Call api to check if api_key is a correct key.\"\"\"\n try:\n with stripe_opentracing_trace(\"stripe.WebhookEndpoint.list\"):\n stripe.WebhookEndpoint.list(api_key)\n return True\n except AuthenticationError:\n return False\n\n\ndef _extra_log_data(error: StripeError, payment_intent_id: Optional[str] = None):\n data = {\n \"error_message\": error.user_message,\n \"http_status\": error.http_status,\n \"code\": error.code,\n }\n if payment_intent_id is not None:\n data[\"payment_intent_id\"] = payment_intent_id\n return data\n\n\ndef subscribe_webhook(api_key: str, channel_slug: str) -> Optional[StripeObject]:\n domain = Site.objects.get_current().domain\n api_path = reverse(\n \"plugins-per-channel\",\n kwargs={\"plugin_id\": PLUGIN_ID, \"channel_slug\": channel_slug},\n )\n\n base_url = build_absolute_uri(api_path)\n webhook_url = urljoin(base_url, WEBHOOK_PATH)\n\n with stripe_opentracing_trace(\"stripe.WebhookEndpoint.create\"):\n try:\n return stripe.WebhookEndpoint.create(\n api_key=api_key,\n url=webhook_url,\n enabled_events=WEBHOOK_EVENTS,\n metadata={METADATA_IDENTIFIER: domain},\n )\n except StripeError as error:\n logger.warning(\n \"Failed to create Stripe webhook\",\n extra=_extra_log_data(error),\n )\n return None\n\n\ndef delete_webhook(api_key: str, webhook_id: str):\n try:\n with stripe_opentracing_trace(\"stripe.WebhookEndpoint.delete\"):\n stripe.WebhookEndpoint.delete(\n webhook_id,\n api_key=api_key,\n )\n except InvalidRequestError:\n # webhook doesn't exist\n pass\n\n\ndef get_or_create_customer(\n api_key: str,\n customer_id: Optional[str] = None,\n customer_email: Optional[str] = None,\n) -> Optional[StripeObject]:\n try:\n if customer_id:\n with stripe_opentracing_trace(\"stripe.Customer.retrieve\"):\n return stripe.Customer.retrieve(\n customer_id,\n api_key=api_key,\n )\n with stripe_opentracing_trace(\"stripe.Customer.create\"):\n return stripe.Customer.create(\n api_key=api_key,\n email=customer_email,\n )\n except StripeError as error:\n logger.warning(\n \"Failed to get/create Stripe customer\",\n extra=_extra_log_data(error),\n )\n return None\n\n\ndef create_payment_intent(\n api_key: str,\n amount: Decimal,\n currency: str,\n auto_capture: bool = True,\n customer: Optional[StripeObject] = None,\n payment_method_id: Optional[str] = None,\n metadata: Optional[dict] = None,\n setup_future_usage: Optional[str] = None,\n off_session: Optional[bool] = None,\n payment_method_types: Optional[List[str]] = None,\n customer_email: Optional[str] = None,\n) -> Tuple[Optional[StripeObject], Optional[StripeError]]:\n\n capture_method = AUTOMATIC_CAPTURE_METHOD if auto_capture else MANUAL_CAPTURE_METHOD\n additional_params = {}\n\n if customer:\n additional_params[\"customer\"] = customer\n\n if payment_method_id and customer:\n additional_params[\"payment_method\"] = payment_method_id\n\n additional_params[\"off_session\"] = off_session if off_session else False\n if off_session:\n additional_params[\"confirm\"] = True\n\n if setup_future_usage in [\"on_session\", \"off_session\"] and not payment_method_id:\n additional_params[\"setup_future_usage\"] = setup_future_usage\n\n if metadata:\n additional_params[\"metadata\"] = metadata\n\n if payment_method_types and isinstance(payment_method_types, list):\n additional_params[\"payment_method_types\"] = payment_method_types\n\n if customer_email:\n additional_params[\"receipt_email\"] = customer_email\n\n try:\n with stripe_opentracing_trace(\"stripe.PaymentIntent.create\"):\n intent = stripe.PaymentIntent.create(\n api_key=api_key,\n amount=price_to_minor_unit(amount, currency),\n currency=currency,\n capture_method=capture_method,\n **additional_params,\n )\n return intent, None\n except StripeError as error:\n logger.warning(\n \"Failed to create Stripe payment intent\", extra=_extra_log_data(error)\n )\n return None, error\n\n\ndef update_payment_method(\n api_key: str,\n payment_method_id: str,\n metadata: Dict[str, str],\n):\n with stripe_opentracing_trace(\"stripe.PaymentMethod.modify\"):\n try:\n stripe.PaymentMethod.modify(\n payment_method_id,\n api_key=api_key,\n metadata=metadata,\n )\n except StripeError as error:\n logger.warning(\n \"Failed to assign channel slug to payment method\",\n extra=_extra_log_data(error),\n )\n\n\ndef list_customer_payment_methods(\n api_key: str, customer_id: str\n) -> Tuple[Optional[StripeObject], Optional[StripeError]]:\n try:\n with stripe_opentracing_trace(\"stripe.PaymentMethod.list\"):\n payment_methods = stripe.PaymentMethod.list(\n api_key=api_key,\n customer=customer_id,\n type=\"card\", # we support only cards for now\n )\n return payment_methods, None\n except StripeError as error:\n return None, error\n\n\ndef retrieve_payment_intent(\n api_key: str, payment_intent_id: str\n) -> Tuple[Optional[StripeObject], Optional[StripeError]]:\n try:\n with stripe_opentracing_trace(\"stripe.PaymentIntent.retrieve\"):\n payment_intent = stripe.PaymentIntent.retrieve(\n payment_intent_id,\n api_key=api_key,\n )\n return payment_intent, None\n except StripeError as error:\n logger.warning(\n \"Unable to retrieve a payment intent\",\n extra=_extra_log_data(error),\n )\n return None, error\n\n\ndef capture_payment_intent(\n api_key: str, payment_intent_id: str, amount_to_capture: int\n) -> Tuple[Optional[StripeObject], Optional[StripeError]]:\n try:\n with stripe_opentracing_trace(\"stripe.PaymentIntent.capture\"):\n payment_intent = stripe.PaymentIntent.capture(\n payment_intent_id,\n amount_to_capture=amount_to_capture,\n api_key=api_key,\n )\n return payment_intent, None\n except StripeError as error:\n logger.warning(\n \"Unable to capture a payment intent\",\n extra=_extra_log_data(error),\n )\n return None, error\n\n\ndef refund_payment_intent(\n api_key: str, payment_intent_id: str, amount_to_refund: int\n) -> Tuple[Optional[StripeObject], Optional[StripeError]]:\n try:\n with stripe_opentracing_trace(\"stripe.Refund.create\"):\n refund = stripe.Refund.create(\n payment_intent=payment_intent_id,\n amount=amount_to_refund,\n api_key=api_key,\n )\n return refund, None\n except StripeError as error:\n logger.warning(\n \"Unable to refund a payment intent\",\n extra=_extra_log_data(error),\n )\n return None, error\n\n\ndef cancel_payment_intent(\n api_key: str, payment_intent_id: str\n) -> Tuple[Optional[StripeObject], Optional[StripeError]]:\n try:\n with stripe_opentracing_trace(\"stripe.PaymentIntent.cancel\"):\n payment_intent = stripe.PaymentIntent.cancel(\n payment_intent_id,\n api_key=api_key,\n )\n return payment_intent, None\n except StripeError as error:\n logger.warning(\n \"Unable to cancel a payment intent\",\n extra=_extra_log_data(error),\n )\n\n return None, error\n\n\ndef construct_stripe_event(\n api_key: str, payload: bytes, sig_header: str, endpoint_secret: str\n) -> StripeObject:\n with stripe_opentracing_trace(\"stripe.Webhook.construct_event\"):\n return stripe.Webhook.construct_event(\n payload, sig_header, endpoint_secret, api_key=api_key\n )\n\n\ndef get_payment_method_details(\n payment_intent: StripeObject,\n) -> Optional[PaymentMethodInfo]:\n charges = payment_intent.get(\"charges\", None)\n payment_method_info = None\n if charges:\n charges_data = charges.get(\"data\", [])\n if not charges_data:\n return None\n charge_data = charges_data[-1]\n payment_method_details = charge_data.get(\"payment_method_details\", {})\n\n if payment_method_details.get(\"type\") == \"card\":\n card_details = payment_method_details.get(\"card\", {})\n exp_year = card_details.get(\"exp_year\", \"\")\n exp_year = int(exp_year) if exp_year else None\n exp_month = card_details.get(\"exp_month\", \"\")\n exp_month = int(exp_month) if exp_month else None\n payment_method_info = PaymentMethodInfo(\n last_4=card_details.get(\"last4\", \"\"),\n exp_year=exp_year,\n exp_month=exp_month,\n brand=card_details.get(\"brand\", \"\"),\n type=\"card\",\n )\n return payment_method_info\n", "path": "saleor/payment/gateways/stripe/stripe_api.py"}]}
| 3,448 | 812 |
gh_patches_debug_2760
|
rasdani/github-patches
|
git_diff
|
getredash__redash-464
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Error running query: datetime.time(13, 52, 27) is not JSON serializable
My table schema:
``` sql
CREATE TABLE F_entrances (
id SERIAL PRIMARY KEY,
timeOfEntrance time,
customerId int REFERENCES D_customers
);
```
(and yes, I committed the horrible sin of camel_case vs underScore. I'll be fixing that soonish)
The query
``` sql
SELECT
timeofentrance
FROM F_entrances
```
Gives me the error `Error running query: datetime.time(13, 52, 27) is not JSON serializable`. I worked around it with `to_char` but this seems to be a problem at the [Python layer](http://stackoverflow.com/a/11875813/1216976).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `redash/utils.py`
Content:
```
1 import cStringIO
2 import csv
3 import codecs
4 import decimal
5 import datetime
6 import json
7 import re
8 import hashlib
9 import sqlparse
10 import pytz
11
12 COMMENTS_REGEX = re.compile("/\*.*?\*/")
13
14
15 class SQLMetaData(object):
16 TABLE_SELECTION_KEYWORDS = ('FROM', 'JOIN', 'LEFT JOIN', 'FULL JOIN', 'RIGHT JOIN', 'CROSS JOIN', 'INNER JOIN',
17 'OUTER JOIN', 'LEFT OUTER JOIN', 'RIGHT OUTER JOIN', 'FULL OUTER JOIN')
18
19 def __init__(self, sql):
20 self.sql = sql
21 self.parsed_sql = sqlparse.parse(self.sql)
22
23 self.has_ddl_statements = self._find_ddl_statements()
24 self.has_non_select_dml_statements = self._find_dml_statements()
25 self.used_tables = self._find_tables()
26
27 def _find_ddl_statements(self):
28 for statement in self.parsed_sql:
29 if len([x for x in statement.flatten() if x.ttype == sqlparse.tokens.DDL]):
30 return True
31
32 return False
33
34 def _find_tables(self):
35 tables = set()
36 for statement in self.parsed_sql:
37 tables.update(self.extract_table_names(statement.tokens))
38
39 return tables
40
41 def extract_table_names(self, tokens):
42 tables = set()
43 tokens = [t for t in tokens if t.ttype not in (sqlparse.tokens.Whitespace, sqlparse.tokens.Newline)]
44
45 for i in range(len(tokens)):
46 if tokens[i].is_group():
47 tables.update(self.extract_table_names(tokens[i].tokens))
48 else:
49 if tokens[i].ttype == sqlparse.tokens.Keyword and tokens[i].normalized in self.TABLE_SELECTION_KEYWORDS:
50 if isinstance(tokens[i + 1], sqlparse.sql.Identifier):
51 tables.add(tokens[i + 1].value)
52
53 if isinstance(tokens[i + 1], sqlparse.sql.IdentifierList):
54 tables.update(set([t.value for t in tokens[i+1].get_identifiers()]))
55 return tables
56
57 def _find_dml_statements(self):
58 for statement in self.parsed_sql:
59 for token in statement.flatten():
60 if token.ttype == sqlparse.tokens.DML and token.normalized != 'SELECT':
61 return True
62
63 return False
64
65
66 def utcnow():
67 """Return datetime.now value with timezone specified.
68
69 Without the timezone data, when the timestamp stored to the database it gets the current timezone of the server,
70 which leads to errors in calculations.
71 """
72 return datetime.datetime.now(pytz.utc)
73
74 def slugify(s):
75 return re.sub('[^a-z0-9_\-]+', '-', s.lower())
76
77
78 def gen_query_hash(sql):
79 """Returns hash of the given query after stripping all comments, line breaks and multiple
80 spaces, and lower casing all text.
81
82 TODO: possible issue - the following queries will get the same id:
83 1. SELECT 1 FROM table WHERE column='Value';
84 2. SELECT 1 FROM table where column='value';
85 """
86 sql = COMMENTS_REGEX.sub("", sql)
87 sql = "".join(sql.split()).lower()
88 return hashlib.md5(sql.encode('utf-8')).hexdigest()
89
90
91 class JSONEncoder(json.JSONEncoder):
92 """Custom JSON encoding class, to handle Decimal and datetime.date instances.
93 """
94 def default(self, o):
95 if isinstance(o, decimal.Decimal):
96 return float(o)
97
98 if isinstance(o, datetime.date):
99 return o.isoformat()
100
101 super(JSONEncoder, self).default(o)
102
103
104 def json_dumps(data):
105 return json.dumps(data, cls=JSONEncoder)
106
107
108 class UnicodeWriter:
109 """
110 A CSV writer which will write rows to CSV file "f",
111 which is encoded in the given encoding.
112 """
113 def __init__(self, f, dialect=csv.excel, encoding="utf-8", **kwds):
114 # Redirect output to a queue
115 self.queue = cStringIO.StringIO()
116 self.writer = csv.writer(self.queue, dialect=dialect, **kwds)
117 self.stream = f
118 self.encoder = codecs.getincrementalencoder(encoding)()
119
120 def _encode_utf8(self, val):
121 if isinstance(val, (unicode, str)):
122 return val.encode('utf-8')
123
124 return val
125
126 def writerow(self, row):
127 self.writer.writerow([self._encode_utf8(s) for s in row])
128 # Fetch UTF-8 output from the queue ...
129 data = self.queue.getvalue()
130 data = data.decode("utf-8")
131 # ... and reencode it into the target encoding
132 data = self.encoder.encode(data)
133 # write to the target stream
134 self.stream.write(data)
135 # empty queue
136 self.queue.truncate(0)
137
138 def writerows(self, rows):
139 for row in rows:
140 self.writerow(row)
141
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/redash/utils.py b/redash/utils.py
--- a/redash/utils.py
+++ b/redash/utils.py
@@ -95,7 +95,7 @@
if isinstance(o, decimal.Decimal):
return float(o)
- if isinstance(o, datetime.date):
+ if isinstance(o, (datetime.date, datetime.time, datetime.timedelta)):
return o.isoformat()
super(JSONEncoder, self).default(o)
|
{"golden_diff": "diff --git a/redash/utils.py b/redash/utils.py\n--- a/redash/utils.py\n+++ b/redash/utils.py\n@@ -95,7 +95,7 @@\n if isinstance(o, decimal.Decimal):\n return float(o)\n \n- if isinstance(o, datetime.date):\n+ if isinstance(o, (datetime.date, datetime.time, datetime.timedelta)):\n return o.isoformat()\n \n super(JSONEncoder, self).default(o)\n", "issue": "Error running query: datetime.time(13, 52, 27) is not JSON serializable\nMy table schema:\n\n``` sql\nCREATE TABLE F_entrances (\n id SERIAL PRIMARY KEY,\n timeOfEntrance time,\n customerId int REFERENCES D_customers\n);\n```\n\n(and yes, I committed the horrible sin of camel_case vs underScore. I'll be fixing that soonish)\n\nThe query\n\n``` sql\nSELECT\ntimeofentrance\nFROM F_entrances\n```\n\nGives me the error `Error running query: datetime.time(13, 52, 27) is not JSON serializable`. I worked around it with `to_char` but this seems to be a problem at the [Python layer](http://stackoverflow.com/a/11875813/1216976).\n\n", "before_files": [{"content": "import cStringIO\nimport csv\nimport codecs\nimport decimal\nimport datetime\nimport json\nimport re\nimport hashlib\nimport sqlparse\nimport pytz\n\nCOMMENTS_REGEX = re.compile(\"/\\*.*?\\*/\")\n\n\nclass SQLMetaData(object):\n TABLE_SELECTION_KEYWORDS = ('FROM', 'JOIN', 'LEFT JOIN', 'FULL JOIN', 'RIGHT JOIN', 'CROSS JOIN', 'INNER JOIN',\n 'OUTER JOIN', 'LEFT OUTER JOIN', 'RIGHT OUTER JOIN', 'FULL OUTER JOIN')\n\n def __init__(self, sql):\n self.sql = sql\n self.parsed_sql = sqlparse.parse(self.sql)\n\n self.has_ddl_statements = self._find_ddl_statements()\n self.has_non_select_dml_statements = self._find_dml_statements()\n self.used_tables = self._find_tables()\n\n def _find_ddl_statements(self):\n for statement in self.parsed_sql:\n if len([x for x in statement.flatten() if x.ttype == sqlparse.tokens.DDL]):\n return True\n\n return False\n\n def _find_tables(self):\n tables = set()\n for statement in self.parsed_sql:\n tables.update(self.extract_table_names(statement.tokens))\n\n return tables\n\n def extract_table_names(self, tokens):\n tables = set()\n tokens = [t for t in tokens if t.ttype not in (sqlparse.tokens.Whitespace, sqlparse.tokens.Newline)]\n\n for i in range(len(tokens)):\n if tokens[i].is_group():\n tables.update(self.extract_table_names(tokens[i].tokens))\n else:\n if tokens[i].ttype == sqlparse.tokens.Keyword and tokens[i].normalized in self.TABLE_SELECTION_KEYWORDS:\n if isinstance(tokens[i + 1], sqlparse.sql.Identifier):\n tables.add(tokens[i + 1].value)\n\n if isinstance(tokens[i + 1], sqlparse.sql.IdentifierList):\n tables.update(set([t.value for t in tokens[i+1].get_identifiers()]))\n return tables\n\n def _find_dml_statements(self):\n for statement in self.parsed_sql:\n for token in statement.flatten():\n if token.ttype == sqlparse.tokens.DML and token.normalized != 'SELECT':\n return True\n\n return False\n\n\ndef utcnow():\n \"\"\"Return datetime.now value with timezone specified.\n\n Without the timezone data, when the timestamp stored to the database it gets the current timezone of the server,\n which leads to errors in calculations.\n \"\"\"\n return datetime.datetime.now(pytz.utc)\n\ndef slugify(s):\n return re.sub('[^a-z0-9_\\-]+', '-', s.lower())\n\n\ndef gen_query_hash(sql):\n \"\"\"Returns hash of the given query after stripping all comments, line breaks and multiple\n spaces, and lower casing all text.\n\n TODO: possible issue - the following queries will get the same id:\n 1. SELECT 1 FROM table WHERE column='Value';\n 2. SELECT 1 FROM table where column='value';\n \"\"\"\n sql = COMMENTS_REGEX.sub(\"\", sql)\n sql = \"\".join(sql.split()).lower()\n return hashlib.md5(sql.encode('utf-8')).hexdigest()\n\n\nclass JSONEncoder(json.JSONEncoder):\n \"\"\"Custom JSON encoding class, to handle Decimal and datetime.date instances.\n \"\"\"\n def default(self, o):\n if isinstance(o, decimal.Decimal):\n return float(o)\n\n if isinstance(o, datetime.date):\n return o.isoformat()\n \n super(JSONEncoder, self).default(o)\n\n\ndef json_dumps(data):\n return json.dumps(data, cls=JSONEncoder)\n\n\nclass UnicodeWriter:\n \"\"\"\n A CSV writer which will write rows to CSV file \"f\",\n which is encoded in the given encoding.\n \"\"\"\n def __init__(self, f, dialect=csv.excel, encoding=\"utf-8\", **kwds):\n # Redirect output to a queue\n self.queue = cStringIO.StringIO()\n self.writer = csv.writer(self.queue, dialect=dialect, **kwds)\n self.stream = f\n self.encoder = codecs.getincrementalencoder(encoding)()\n\n def _encode_utf8(self, val):\n if isinstance(val, (unicode, str)):\n return val.encode('utf-8')\n\n return val\n\n def writerow(self, row):\n self.writer.writerow([self._encode_utf8(s) for s in row])\n # Fetch UTF-8 output from the queue ...\n data = self.queue.getvalue()\n data = data.decode(\"utf-8\")\n # ... and reencode it into the target encoding\n data = self.encoder.encode(data)\n # write to the target stream\n self.stream.write(data)\n # empty queue\n self.queue.truncate(0)\n\n def writerows(self, rows):\n for row in rows:\n self.writerow(row)\n", "path": "redash/utils.py"}], "after_files": [{"content": "import cStringIO\nimport csv\nimport codecs\nimport decimal\nimport datetime\nimport json\nimport re\nimport hashlib\nimport sqlparse\nimport pytz\n\nCOMMENTS_REGEX = re.compile(\"/\\*.*?\\*/\")\n\n\nclass SQLMetaData(object):\n TABLE_SELECTION_KEYWORDS = ('FROM', 'JOIN', 'LEFT JOIN', 'FULL JOIN', 'RIGHT JOIN', 'CROSS JOIN', 'INNER JOIN',\n 'OUTER JOIN', 'LEFT OUTER JOIN', 'RIGHT OUTER JOIN', 'FULL OUTER JOIN')\n\n def __init__(self, sql):\n self.sql = sql\n self.parsed_sql = sqlparse.parse(self.sql)\n\n self.has_ddl_statements = self._find_ddl_statements()\n self.has_non_select_dml_statements = self._find_dml_statements()\n self.used_tables = self._find_tables()\n\n def _find_ddl_statements(self):\n for statement in self.parsed_sql:\n if len([x for x in statement.flatten() if x.ttype == sqlparse.tokens.DDL]):\n return True\n\n return False\n\n def _find_tables(self):\n tables = set()\n for statement in self.parsed_sql:\n tables.update(self.extract_table_names(statement.tokens))\n\n return tables\n\n def extract_table_names(self, tokens):\n tables = set()\n tokens = [t for t in tokens if t.ttype not in (sqlparse.tokens.Whitespace, sqlparse.tokens.Newline)]\n\n for i in range(len(tokens)):\n if tokens[i].is_group():\n tables.update(self.extract_table_names(tokens[i].tokens))\n else:\n if tokens[i].ttype == sqlparse.tokens.Keyword and tokens[i].normalized in self.TABLE_SELECTION_KEYWORDS:\n if isinstance(tokens[i + 1], sqlparse.sql.Identifier):\n tables.add(tokens[i + 1].value)\n\n if isinstance(tokens[i + 1], sqlparse.sql.IdentifierList):\n tables.update(set([t.value for t in tokens[i+1].get_identifiers()]))\n return tables\n\n def _find_dml_statements(self):\n for statement in self.parsed_sql:\n for token in statement.flatten():\n if token.ttype == sqlparse.tokens.DML and token.normalized != 'SELECT':\n return True\n\n return False\n\n\ndef utcnow():\n \"\"\"Return datetime.now value with timezone specified.\n\n Without the timezone data, when the timestamp stored to the database it gets the current timezone of the server,\n which leads to errors in calculations.\n \"\"\"\n return datetime.datetime.now(pytz.utc)\n\ndef slugify(s):\n return re.sub('[^a-z0-9_\\-]+', '-', s.lower())\n\n\ndef gen_query_hash(sql):\n \"\"\"Returns hash of the given query after stripping all comments, line breaks and multiple\n spaces, and lower casing all text.\n\n TODO: possible issue - the following queries will get the same id:\n 1. SELECT 1 FROM table WHERE column='Value';\n 2. SELECT 1 FROM table where column='value';\n \"\"\"\n sql = COMMENTS_REGEX.sub(\"\", sql)\n sql = \"\".join(sql.split()).lower()\n return hashlib.md5(sql.encode('utf-8')).hexdigest()\n\n\nclass JSONEncoder(json.JSONEncoder):\n \"\"\"Custom JSON encoding class, to handle Decimal and datetime.date instances.\n \"\"\"\n def default(self, o):\n if isinstance(o, decimal.Decimal):\n return float(o)\n\n if isinstance(o, (datetime.date, datetime.time, datetime.timedelta)):\n return o.isoformat()\n \n super(JSONEncoder, self).default(o)\n\n\ndef json_dumps(data):\n return json.dumps(data, cls=JSONEncoder)\n\n\nclass UnicodeWriter:\n \"\"\"\n A CSV writer which will write rows to CSV file \"f\",\n which is encoded in the given encoding.\n \"\"\"\n def __init__(self, f, dialect=csv.excel, encoding=\"utf-8\", **kwds):\n # Redirect output to a queue\n self.queue = cStringIO.StringIO()\n self.writer = csv.writer(self.queue, dialect=dialect, **kwds)\n self.stream = f\n self.encoder = codecs.getincrementalencoder(encoding)()\n\n def _encode_utf8(self, val):\n if isinstance(val, (unicode, str)):\n return val.encode('utf-8')\n\n return val\n\n def writerow(self, row):\n self.writer.writerow([self._encode_utf8(s) for s in row])\n # Fetch UTF-8 output from the queue ...\n data = self.queue.getvalue()\n data = data.decode(\"utf-8\")\n # ... and reencode it into the target encoding\n data = self.encoder.encode(data)\n # write to the target stream\n self.stream.write(data)\n # empty queue\n self.queue.truncate(0)\n\n def writerows(self, rows):\n for row in rows:\n self.writerow(row)\n", "path": "redash/utils.py"}]}
| 1,799 | 96 |
gh_patches_debug_1663
|
rasdani/github-patches
|
git_diff
|
Textualize__rich-211
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[BUG] Deprecation warning due to invalid escape sequences
**Describe the bug**
Deprecation warnings are raised due to invalid escape sequences. This can be fixed by using raw strings or escaping the literals. pyupgrade also helps in automatic conversion : https://github.com/asottile/pyupgrade/
**To Reproduce**
```
./tests/test_markup.py:26: DeprecationWarning: invalid escape sequence \[
assert escape("foo[bar]") == "foo\[bar]"
./tests/test_markup.py:30: DeprecationWarning: invalid escape sequence \[
result = list(_parse("[foo]hello[/foo][bar]world[/]\[escaped]"))
./rich/markup.py:50: DeprecationWarning: invalid escape sequence \[
return markup.replace("[", "\[")
```
**Platform**
What platform (Win/Linux/Mac) are you running on? What terminal software are you using. Which version of Rich?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `rich/markup.py`
Content:
```
1 import re
2 from typing import Iterable, List, NamedTuple, Optional, Tuple, Union
3
4 from .errors import MarkupError
5 from .style import Style
6 from .text import Span, Text
7 from ._emoji_replace import _emoji_replace
8
9
10 RE_TAGS = re.compile(
11 r"""
12 (\\\[)|
13 \[([a-z#\/].*?)\]
14 """,
15 re.VERBOSE,
16 )
17
18
19 class Tag(NamedTuple):
20 """A tag in console markup."""
21
22 name: str
23 """The tag name. e.g. 'bold'."""
24 parameters: Optional[str]
25 """Any additional parameters after the name."""
26
27 def __str__(self) -> str:
28 return (
29 self.name if self.parameters is None else f"{self.name} {self.parameters}"
30 )
31
32 @property
33 def markup(self) -> str:
34 return (
35 f"[{self.name}]"
36 if self.parameters is None
37 else f"[{self.name}={self.parameters}]"
38 )
39
40
41 def escape(markup: str) -> str:
42 """Escapes text so that it won't be interpreted as markup.
43
44 Args:
45 markup (str): Content to be inserted in to markup.
46
47 Returns:
48 str: Markup with square brackets escaped.
49 """
50 return markup.replace("[", "\[")
51
52
53 def _parse(markup: str) -> Iterable[Tuple[int, Optional[str], Optional[Tag]]]:
54 """Parse markup in to an iterable of tuples of (position, text, tag).
55
56 Args:
57 markup (str): A string containing console markup
58
59 """
60 position = 0
61 for match in RE_TAGS.finditer(markup):
62 (escape_open, tag_text) = match.groups()
63 start, end = match.span()
64 if start > position:
65 yield start, markup[position:start], None
66 if escape_open:
67 yield start, "[", None
68 else:
69 text, equals, parameters = tag_text.partition("=")
70 if equals:
71 yield start, None, Tag(text, parameters)
72 else:
73 yield start, None, Tag(tag_text.strip(), None)
74 position = end
75 if position < len(markup):
76 yield position, markup[position:], None
77
78
79 def render(markup: str, style: Union[str, Style] = "", emoji: bool = True) -> Text:
80 """Render console markup in to a Text instance.
81
82 Args:
83 markup (str): A string containing console markup.
84 emoji (bool, optional): Also render emoji code. Defaults to True.
85
86 Raises:
87 MarkupError: If there is a syntax error in the markup.
88
89 Returns:
90 Text: A test instance.
91 """
92 emoji_replace = _emoji_replace
93 if "[" not in markup:
94 return Text(emoji_replace(markup) if emoji else markup, style=style)
95 text = Text(style=style)
96 append = text.append
97 normalize = Style.normalize
98
99 style_stack: List[Tuple[int, Tag]] = []
100 pop = style_stack.pop
101
102 spans: List[Span] = []
103 append_span = spans.append
104
105 _Span = Span
106
107 def pop_style(style_name: str) -> Tuple[int, Tag]:
108 """Pop tag matching given style name."""
109 for index, (_, tag) in enumerate(reversed(style_stack), 1):
110 if tag.name == style_name:
111 return pop(-index)
112 raise KeyError(style_name)
113
114 for position, plain_text, tag in _parse(markup):
115 if plain_text is not None:
116 append(emoji_replace(plain_text) if emoji else plain_text)
117 elif tag is not None:
118 if tag.name.startswith("/"): # Closing tag
119 style_name = tag.name[1:].strip()
120 if style_name: # explicit close
121 style_name = normalize(style_name)
122 try:
123 start, open_tag = pop_style(style_name)
124 except KeyError:
125 raise MarkupError(
126 f"closing tag '{tag.markup}' at position {position} doesn't match any open tag"
127 )
128 else: # implicit close
129 try:
130 start, open_tag = pop()
131 except IndexError:
132 raise MarkupError(
133 f"closing tag '[/]' at position {position} has nothing to close"
134 )
135
136 append_span(_Span(start, len(text), str(open_tag)))
137 else: # Opening tag
138 normalized_tag = Tag(normalize(tag.name), tag.parameters)
139 style_stack.append((len(text), normalized_tag))
140
141 text_length = len(text)
142 while style_stack:
143 start, tag = style_stack.pop()
144 append_span(_Span(start, text_length, str(tag)))
145
146 text.spans = sorted(spans)
147 return text
148
149
150 if __name__ == "__main__": # pragma: no cover
151 # from rich import print
152 from rich.console import Console
153 from rich.text import Text
154
155 console = Console(highlight=False)
156
157 # t = Text.from_markup('Hello [link="https://www.willmcgugan.com"]W[b]o[/b]rld[/]!')
158 # print(repr(t._spans))
159
160 console.print("Hello [1], [1,2,3] ['hello']")
161 console.print("foo")
162 console.print("Hello [link=https://www.willmcgugan.com]W[b]o[/b]rld[/]!")
163
164 # console.print("[bold]1 [not bold]2[/] 3[/]")
165
166 # console.print("[green]XXX[blue]XXX[/]XXX[/]")
167
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/rich/markup.py b/rich/markup.py
--- a/rich/markup.py
+++ b/rich/markup.py
@@ -47,7 +47,7 @@
Returns:
str: Markup with square brackets escaped.
"""
- return markup.replace("[", "\[")
+ return markup.replace("[", r"\[")
def _parse(markup: str) -> Iterable[Tuple[int, Optional[str], Optional[Tag]]]:
|
{"golden_diff": "diff --git a/rich/markup.py b/rich/markup.py\n--- a/rich/markup.py\n+++ b/rich/markup.py\n@@ -47,7 +47,7 @@\n Returns:\n str: Markup with square brackets escaped.\n \"\"\"\n- return markup.replace(\"[\", \"\\[\")\n+ return markup.replace(\"[\", r\"\\[\")\n \n \n def _parse(markup: str) -> Iterable[Tuple[int, Optional[str], Optional[Tag]]]:\n", "issue": "[BUG] Deprecation warning due to invalid escape sequences\n**Describe the bug**\r\n\r\nDeprecation warnings are raised due to invalid escape sequences. This can be fixed by using raw strings or escaping the literals. pyupgrade also helps in automatic conversion : https://github.com/asottile/pyupgrade/\r\n\r\n**To Reproduce**\r\n\r\n```\r\n./tests/test_markup.py:26: DeprecationWarning: invalid escape sequence \\[\r\n assert escape(\"foo[bar]\") == \"foo\\[bar]\"\r\n./tests/test_markup.py:30: DeprecationWarning: invalid escape sequence \\[\r\n result = list(_parse(\"[foo]hello[/foo][bar]world[/]\\[escaped]\"))\r\n./rich/markup.py:50: DeprecationWarning: invalid escape sequence \\[\r\n return markup.replace(\"[\", \"\\[\")\r\n```\r\n\r\n**Platform**\r\nWhat platform (Win/Linux/Mac) are you running on? What terminal software are you using. Which version of Rich?\r\n\n", "before_files": [{"content": "import re\nfrom typing import Iterable, List, NamedTuple, Optional, Tuple, Union\n\nfrom .errors import MarkupError\nfrom .style import Style\nfrom .text import Span, Text\nfrom ._emoji_replace import _emoji_replace\n\n\nRE_TAGS = re.compile(\n r\"\"\"\n(\\\\\\[)|\n\\[([a-z#\\/].*?)\\]\n\"\"\",\n re.VERBOSE,\n)\n\n\nclass Tag(NamedTuple):\n \"\"\"A tag in console markup.\"\"\"\n\n name: str\n \"\"\"The tag name. e.g. 'bold'.\"\"\"\n parameters: Optional[str]\n \"\"\"Any additional parameters after the name.\"\"\"\n\n def __str__(self) -> str:\n return (\n self.name if self.parameters is None else f\"{self.name} {self.parameters}\"\n )\n\n @property\n def markup(self) -> str:\n return (\n f\"[{self.name}]\"\n if self.parameters is None\n else f\"[{self.name}={self.parameters}]\"\n )\n\n\ndef escape(markup: str) -> str:\n \"\"\"Escapes text so that it won't be interpreted as markup. \n\n Args:\n markup (str): Content to be inserted in to markup.\n\n Returns:\n str: Markup with square brackets escaped.\n \"\"\"\n return markup.replace(\"[\", \"\\[\")\n\n\ndef _parse(markup: str) -> Iterable[Tuple[int, Optional[str], Optional[Tag]]]:\n \"\"\"Parse markup in to an iterable of tuples of (position, text, tag).\n \n Args:\n markup (str): A string containing console markup\n \n \"\"\"\n position = 0\n for match in RE_TAGS.finditer(markup):\n (escape_open, tag_text) = match.groups()\n start, end = match.span()\n if start > position:\n yield start, markup[position:start], None\n if escape_open:\n yield start, \"[\", None\n else:\n text, equals, parameters = tag_text.partition(\"=\")\n if equals:\n yield start, None, Tag(text, parameters)\n else:\n yield start, None, Tag(tag_text.strip(), None)\n position = end\n if position < len(markup):\n yield position, markup[position:], None\n\n\ndef render(markup: str, style: Union[str, Style] = \"\", emoji: bool = True) -> Text:\n \"\"\"Render console markup in to a Text instance.\n\n Args:\n markup (str): A string containing console markup.\n emoji (bool, optional): Also render emoji code. Defaults to True.\n \n Raises:\n MarkupError: If there is a syntax error in the markup.\n \n Returns:\n Text: A test instance.\n \"\"\"\n emoji_replace = _emoji_replace\n if \"[\" not in markup:\n return Text(emoji_replace(markup) if emoji else markup, style=style)\n text = Text(style=style)\n append = text.append\n normalize = Style.normalize\n\n style_stack: List[Tuple[int, Tag]] = []\n pop = style_stack.pop\n\n spans: List[Span] = []\n append_span = spans.append\n\n _Span = Span\n\n def pop_style(style_name: str) -> Tuple[int, Tag]:\n \"\"\"Pop tag matching given style name.\"\"\"\n for index, (_, tag) in enumerate(reversed(style_stack), 1):\n if tag.name == style_name:\n return pop(-index)\n raise KeyError(style_name)\n\n for position, plain_text, tag in _parse(markup):\n if plain_text is not None:\n append(emoji_replace(plain_text) if emoji else plain_text)\n elif tag is not None:\n if tag.name.startswith(\"/\"): # Closing tag\n style_name = tag.name[1:].strip()\n if style_name: # explicit close\n style_name = normalize(style_name)\n try:\n start, open_tag = pop_style(style_name)\n except KeyError:\n raise MarkupError(\n f\"closing tag '{tag.markup}' at position {position} doesn't match any open tag\"\n )\n else: # implicit close\n try:\n start, open_tag = pop()\n except IndexError:\n raise MarkupError(\n f\"closing tag '[/]' at position {position} has nothing to close\"\n )\n\n append_span(_Span(start, len(text), str(open_tag)))\n else: # Opening tag\n normalized_tag = Tag(normalize(tag.name), tag.parameters)\n style_stack.append((len(text), normalized_tag))\n\n text_length = len(text)\n while style_stack:\n start, tag = style_stack.pop()\n append_span(_Span(start, text_length, str(tag)))\n\n text.spans = sorted(spans)\n return text\n\n\nif __name__ == \"__main__\": # pragma: no cover\n # from rich import print\n from rich.console import Console\n from rich.text import Text\n\n console = Console(highlight=False)\n\n # t = Text.from_markup('Hello [link=\"https://www.willmcgugan.com\"]W[b]o[/b]rld[/]!')\n # print(repr(t._spans))\n\n console.print(\"Hello [1], [1,2,3] ['hello']\")\n console.print(\"foo\")\n console.print(\"Hello [link=https://www.willmcgugan.com]W[b]o[/b]rld[/]!\")\n\n # console.print(\"[bold]1 [not bold]2[/] 3[/]\")\n\n # console.print(\"[green]XXX[blue]XXX[/]XXX[/]\")\n", "path": "rich/markup.py"}], "after_files": [{"content": "import re\nfrom typing import Iterable, List, NamedTuple, Optional, Tuple, Union\n\nfrom .errors import MarkupError\nfrom .style import Style\nfrom .text import Span, Text\nfrom ._emoji_replace import _emoji_replace\n\n\nRE_TAGS = re.compile(\n r\"\"\"\n(\\\\\\[)|\n\\[([a-z#\\/].*?)\\]\n\"\"\",\n re.VERBOSE,\n)\n\n\nclass Tag(NamedTuple):\n \"\"\"A tag in console markup.\"\"\"\n\n name: str\n \"\"\"The tag name. e.g. 'bold'.\"\"\"\n parameters: Optional[str]\n \"\"\"Any additional parameters after the name.\"\"\"\n\n def __str__(self) -> str:\n return (\n self.name if self.parameters is None else f\"{self.name} {self.parameters}\"\n )\n\n @property\n def markup(self) -> str:\n return (\n f\"[{self.name}]\"\n if self.parameters is None\n else f\"[{self.name}={self.parameters}]\"\n )\n\n\ndef escape(markup: str) -> str:\n \"\"\"Escapes text so that it won't be interpreted as markup. \n\n Args:\n markup (str): Content to be inserted in to markup.\n\n Returns:\n str: Markup with square brackets escaped.\n \"\"\"\n return markup.replace(\"[\", r\"\\[\")\n\n\ndef _parse(markup: str) -> Iterable[Tuple[int, Optional[str], Optional[Tag]]]:\n \"\"\"Parse markup in to an iterable of tuples of (position, text, tag).\n \n Args:\n markup (str): A string containing console markup\n \n \"\"\"\n position = 0\n for match in RE_TAGS.finditer(markup):\n (escape_open, tag_text) = match.groups()\n start, end = match.span()\n if start > position:\n yield start, markup[position:start], None\n if escape_open:\n yield start, \"[\", None\n else:\n text, equals, parameters = tag_text.partition(\"=\")\n if equals:\n yield start, None, Tag(text, parameters)\n else:\n yield start, None, Tag(tag_text.strip(), None)\n position = end\n if position < len(markup):\n yield position, markup[position:], None\n\n\ndef render(markup: str, style: Union[str, Style] = \"\", emoji: bool = True) -> Text:\n \"\"\"Render console markup in to a Text instance.\n\n Args:\n markup (str): A string containing console markup.\n emoji (bool, optional): Also render emoji code. Defaults to True.\n \n Raises:\n MarkupError: If there is a syntax error in the markup.\n \n Returns:\n Text: A test instance.\n \"\"\"\n emoji_replace = _emoji_replace\n if \"[\" not in markup:\n return Text(emoji_replace(markup) if emoji else markup, style=style)\n text = Text(style=style)\n append = text.append\n normalize = Style.normalize\n\n style_stack: List[Tuple[int, Tag]] = []\n pop = style_stack.pop\n\n spans: List[Span] = []\n append_span = spans.append\n\n _Span = Span\n\n def pop_style(style_name: str) -> Tuple[int, Tag]:\n \"\"\"Pop tag matching given style name.\"\"\"\n for index, (_, tag) in enumerate(reversed(style_stack), 1):\n if tag.name == style_name:\n return pop(-index)\n raise KeyError(style_name)\n\n for position, plain_text, tag in _parse(markup):\n if plain_text is not None:\n append(emoji_replace(plain_text) if emoji else plain_text)\n elif tag is not None:\n if tag.name.startswith(\"/\"): # Closing tag\n style_name = tag.name[1:].strip()\n if style_name: # explicit close\n style_name = normalize(style_name)\n try:\n start, open_tag = pop_style(style_name)\n except KeyError:\n raise MarkupError(\n f\"closing tag '{tag.markup}' at position {position} doesn't match any open tag\"\n )\n else: # implicit close\n try:\n start, open_tag = pop()\n except IndexError:\n raise MarkupError(\n f\"closing tag '[/]' at position {position} has nothing to close\"\n )\n\n append_span(_Span(start, len(text), str(open_tag)))\n else: # Opening tag\n normalized_tag = Tag(normalize(tag.name), tag.parameters)\n style_stack.append((len(text), normalized_tag))\n\n text_length = len(text)\n while style_stack:\n start, tag = style_stack.pop()\n append_span(_Span(start, text_length, str(tag)))\n\n text.spans = sorted(spans)\n return text\n\n\nif __name__ == \"__main__\": # pragma: no cover\n # from rich import print\n from rich.console import Console\n from rich.text import Text\n\n console = Console(highlight=False)\n\n # t = Text.from_markup('Hello [link=\"https://www.willmcgugan.com\"]W[b]o[/b]rld[/]!')\n # print(repr(t._spans))\n\n console.print(\"Hello [1], [1,2,3] ['hello']\")\n console.print(\"foo\")\n console.print(\"Hello [link=https://www.willmcgugan.com]W[b]o[/b]rld[/]!\")\n\n # console.print(\"[bold]1 [not bold]2[/] 3[/]\")\n\n # console.print(\"[green]XXX[blue]XXX[/]XXX[/]\")\n", "path": "rich/markup.py"}]}
| 2,062 | 102 |
gh_patches_debug_7666
|
rasdani/github-patches
|
git_diff
|
tensorflow__addons-2204
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Drop Python3.5 Support
Per SIG Build, python3.5 will not be supported in TF2.4 since it has reached end of life. We should align.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # Copyright 2019 The TensorFlow Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ==============================================================================
15 """TensorFlow Addons.
16
17 TensorFlow Addons is a repository of contributions that conform to well-
18 established API patterns, but implement new functionality not available
19 in core TensorFlow. TensorFlow natively supports a large number of
20 operators, layers, metrics, losses, and optimizers. However, in a fast
21 moving field like ML, there are many interesting new developments that
22 cannot be integrated into core TensorFlow (because their broad
23 applicability is not yet clear, or it is mostly used by a smaller subset
24 of the community).
25 """
26
27 import os
28 from pathlib import Path
29 import sys
30
31 from datetime import datetime
32 from setuptools import find_packages
33 from setuptools import setup
34 from setuptools.dist import Distribution
35 from setuptools import Extension
36
37 DOCLINES = __doc__.split("\n")
38
39
40 def get_last_commit_time() -> str:
41 string_time = os.getenv("NIGHTLY_TIME").replace('"', "")
42 return datetime.strptime(string_time, "%Y-%m-%dT%H:%M:%SZ").strftime("%Y%m%d%H%M%S")
43
44
45 def get_project_name_version():
46 # Version
47 version = {}
48 base_dir = os.path.dirname(os.path.abspath(__file__))
49 with open(os.path.join(base_dir, "tensorflow_addons", "version.py")) as fp:
50 exec(fp.read(), version)
51
52 project_name = "tensorflow-addons"
53 if "--nightly" in sys.argv:
54 project_name = "tfa-nightly"
55 version["__version__"] += get_last_commit_time()
56 sys.argv.remove("--nightly")
57
58 return project_name, version
59
60
61 def get_ext_modules():
62 ext_modules = []
63 if "--platlib-patch" in sys.argv:
64 if sys.platform.startswith("linux"):
65 # Manylinux2010 requires a patch for platlib
66 ext_modules = [Extension("_foo", ["stub.cc"])]
67 sys.argv.remove("--platlib-patch")
68 return ext_modules
69
70
71 class BinaryDistribution(Distribution):
72 """This class is needed in order to create OS specific wheels."""
73
74 def has_ext_modules(self):
75 return True
76
77
78 project_name, version = get_project_name_version()
79 min_tf_version = version["MIN_TF_VERSION"]
80 max_tf_version = version["MAX_TF_VERSION"]
81 setup(
82 name=project_name,
83 version=version["__version__"],
84 description=DOCLINES[0],
85 long_description="\n".join(DOCLINES[2:]),
86 author="Google Inc.",
87 author_email="[email protected]",
88 packages=find_packages(),
89 ext_modules=get_ext_modules(),
90 install_requires=Path("requirements.txt").read_text().splitlines(),
91 extras_require={
92 "tensorflow": ["tensorflow>={},<{}".format(min_tf_version, max_tf_version)],
93 "tensorflow-gpu": [
94 "tensorflow-gpu>={},<{}".format(min_tf_version, max_tf_version)
95 ],
96 "tensorflow-cpu": [
97 "tensorflow-cpu>={},<{}".format(min_tf_version, max_tf_version)
98 ],
99 },
100 include_package_data=True,
101 zip_safe=False,
102 distclass=BinaryDistribution,
103 classifiers=[
104 "Development Status :: 4 - Beta",
105 "Intended Audience :: Developers",
106 "Intended Audience :: Education",
107 "Intended Audience :: Science/Research",
108 "License :: OSI Approved :: Apache Software License",
109 "Programming Language :: Python :: 3",
110 "Programming Language :: Python :: 3.5",
111 "Programming Language :: Python :: 3.6",
112 "Programming Language :: Python :: 3.7",
113 "Programming Language :: Python :: 3.8",
114 "Topic :: Scientific/Engineering :: Mathematics",
115 "Topic :: Software Development :: Libraries :: Python Modules",
116 "Topic :: Software Development :: Libraries",
117 ],
118 license="Apache 2.0",
119 keywords="tensorflow addons machine learning",
120 )
121
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -107,7 +107,6 @@
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
- "Programming Language :: Python :: 3.5",
"Programming Language :: Python :: 3.6",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -107,7 +107,6 @@\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Programming Language :: Python :: 3\",\n- \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n", "issue": "Drop Python3.5 Support\nPer SIG Build, python3.5 will not be supported in TF2.4 since it has reached end of life. We should align.\n", "before_files": [{"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"TensorFlow Addons.\n\nTensorFlow Addons is a repository of contributions that conform to well-\nestablished API patterns, but implement new functionality not available\nin core TensorFlow. TensorFlow natively supports a large number of\noperators, layers, metrics, losses, and optimizers. However, in a fast\nmoving field like ML, there are many interesting new developments that\ncannot be integrated into core TensorFlow (because their broad\napplicability is not yet clear, or it is mostly used by a smaller subset\nof the community).\n\"\"\"\n\nimport os\nfrom pathlib import Path\nimport sys\n\nfrom datetime import datetime\nfrom setuptools import find_packages\nfrom setuptools import setup\nfrom setuptools.dist import Distribution\nfrom setuptools import Extension\n\nDOCLINES = __doc__.split(\"\\n\")\n\n\ndef get_last_commit_time() -> str:\n string_time = os.getenv(\"NIGHTLY_TIME\").replace('\"', \"\")\n return datetime.strptime(string_time, \"%Y-%m-%dT%H:%M:%SZ\").strftime(\"%Y%m%d%H%M%S\")\n\n\ndef get_project_name_version():\n # Version\n version = {}\n base_dir = os.path.dirname(os.path.abspath(__file__))\n with open(os.path.join(base_dir, \"tensorflow_addons\", \"version.py\")) as fp:\n exec(fp.read(), version)\n\n project_name = \"tensorflow-addons\"\n if \"--nightly\" in sys.argv:\n project_name = \"tfa-nightly\"\n version[\"__version__\"] += get_last_commit_time()\n sys.argv.remove(\"--nightly\")\n\n return project_name, version\n\n\ndef get_ext_modules():\n ext_modules = []\n if \"--platlib-patch\" in sys.argv:\n if sys.platform.startswith(\"linux\"):\n # Manylinux2010 requires a patch for platlib\n ext_modules = [Extension(\"_foo\", [\"stub.cc\"])]\n sys.argv.remove(\"--platlib-patch\")\n return ext_modules\n\n\nclass BinaryDistribution(Distribution):\n \"\"\"This class is needed in order to create OS specific wheels.\"\"\"\n\n def has_ext_modules(self):\n return True\n\n\nproject_name, version = get_project_name_version()\nmin_tf_version = version[\"MIN_TF_VERSION\"]\nmax_tf_version = version[\"MAX_TF_VERSION\"]\nsetup(\n name=project_name,\n version=version[\"__version__\"],\n description=DOCLINES[0],\n long_description=\"\\n\".join(DOCLINES[2:]),\n author=\"Google Inc.\",\n author_email=\"[email protected]\",\n packages=find_packages(),\n ext_modules=get_ext_modules(),\n install_requires=Path(\"requirements.txt\").read_text().splitlines(),\n extras_require={\n \"tensorflow\": [\"tensorflow>={},<{}\".format(min_tf_version, max_tf_version)],\n \"tensorflow-gpu\": [\n \"tensorflow-gpu>={},<{}\".format(min_tf_version, max_tf_version)\n ],\n \"tensorflow-cpu\": [\n \"tensorflow-cpu>={},<{}\".format(min_tf_version, max_tf_version)\n ],\n },\n include_package_data=True,\n zip_safe=False,\n distclass=BinaryDistribution,\n classifiers=[\n \"Development Status :: 4 - Beta\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Topic :: Scientific/Engineering :: Mathematics\",\n \"Topic :: Software Development :: Libraries :: Python Modules\",\n \"Topic :: Software Development :: Libraries\",\n ],\n license=\"Apache 2.0\",\n keywords=\"tensorflow addons machine learning\",\n)\n", "path": "setup.py"}], "after_files": [{"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"TensorFlow Addons.\n\nTensorFlow Addons is a repository of contributions that conform to well-\nestablished API patterns, but implement new functionality not available\nin core TensorFlow. TensorFlow natively supports a large number of\noperators, layers, metrics, losses, and optimizers. However, in a fast\nmoving field like ML, there are many interesting new developments that\ncannot be integrated into core TensorFlow (because their broad\napplicability is not yet clear, or it is mostly used by a smaller subset\nof the community).\n\"\"\"\n\nimport os\nfrom pathlib import Path\nimport sys\n\nfrom datetime import datetime\nfrom setuptools import find_packages\nfrom setuptools import setup\nfrom setuptools.dist import Distribution\nfrom setuptools import Extension\n\nDOCLINES = __doc__.split(\"\\n\")\n\n\ndef get_last_commit_time() -> str:\n string_time = os.getenv(\"NIGHTLY_TIME\").replace('\"', \"\")\n return datetime.strptime(string_time, \"%Y-%m-%dT%H:%M:%SZ\").strftime(\"%Y%m%d%H%M%S\")\n\n\ndef get_project_name_version():\n # Version\n version = {}\n base_dir = os.path.dirname(os.path.abspath(__file__))\n with open(os.path.join(base_dir, \"tensorflow_addons\", \"version.py\")) as fp:\n exec(fp.read(), version)\n\n project_name = \"tensorflow-addons\"\n if \"--nightly\" in sys.argv:\n project_name = \"tfa-nightly\"\n version[\"__version__\"] += get_last_commit_time()\n sys.argv.remove(\"--nightly\")\n\n return project_name, version\n\n\ndef get_ext_modules():\n ext_modules = []\n if \"--platlib-patch\" in sys.argv:\n if sys.platform.startswith(\"linux\"):\n # Manylinux2010 requires a patch for platlib\n ext_modules = [Extension(\"_foo\", [\"stub.cc\"])]\n sys.argv.remove(\"--platlib-patch\")\n return ext_modules\n\n\nclass BinaryDistribution(Distribution):\n \"\"\"This class is needed in order to create OS specific wheels.\"\"\"\n\n def has_ext_modules(self):\n return True\n\n\nproject_name, version = get_project_name_version()\nmin_tf_version = version[\"MIN_TF_VERSION\"]\nmax_tf_version = version[\"MAX_TF_VERSION\"]\nsetup(\n name=project_name,\n version=version[\"__version__\"],\n description=DOCLINES[0],\n long_description=\"\\n\".join(DOCLINES[2:]),\n author=\"Google Inc.\",\n author_email=\"[email protected]\",\n packages=find_packages(),\n ext_modules=get_ext_modules(),\n install_requires=Path(\"requirements.txt\").read_text().splitlines(),\n extras_require={\n \"tensorflow\": [\"tensorflow>={},<{}\".format(min_tf_version, max_tf_version)],\n \"tensorflow-gpu\": [\n \"tensorflow-gpu>={},<{}\".format(min_tf_version, max_tf_version)\n ],\n \"tensorflow-cpu\": [\n \"tensorflow-cpu>={},<{}\".format(min_tf_version, max_tf_version)\n ],\n },\n include_package_data=True,\n zip_safe=False,\n distclass=BinaryDistribution,\n classifiers=[\n \"Development Status :: 4 - Beta\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Topic :: Scientific/Engineering :: Mathematics\",\n \"Topic :: Software Development :: Libraries :: Python Modules\",\n \"Topic :: Software Development :: Libraries\",\n ],\n license=\"Apache 2.0\",\n keywords=\"tensorflow addons machine learning\",\n)\n", "path": "setup.py"}]}
| 1,498 | 114 |
gh_patches_debug_3093
|
rasdani/github-patches
|
git_diff
|
googleapis__python-bigquery-135
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
A new release of rsa dependency breaks Python 2.7 tests
Recent `rsa` releases are not compatible with Python 2.7 anymore, the last compatible version is 4.0. We need to bound its version in order to preserve Python 2.7 compatibility.
> Major changes in 4.1
Version 4.0 was the last version to support Python 2 and 3.4. Version 4.1 is compatible with Python 3.5+ only.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # Copyright 2018 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import io
16 import os
17
18 import setuptools
19
20
21 # Package metadata.
22
23 name = "google-cloud-bigquery"
24 description = "Google BigQuery API client library"
25 version = "1.25.0"
26 # Should be one of:
27 # 'Development Status :: 3 - Alpha'
28 # 'Development Status :: 4 - Beta'
29 # 'Development Status :: 5 - Production/Stable'
30 release_status = "Development Status :: 5 - Production/Stable"
31 dependencies = [
32 'enum34; python_version < "3.4"',
33 "google-auth >= 1.9.0, < 2.0dev",
34 "google-api-core >= 1.15.0, < 2.0dev",
35 "google-cloud-core >= 1.1.0, < 2.0dev",
36 "google-resumable-media >= 0.5.0, < 0.6dev",
37 "protobuf >= 3.6.0",
38 "six >=1.13.0,< 2.0.0dev",
39 ]
40 extras = {
41 "bqstorage": [
42 "google-cloud-bigquery-storage >= 1.0.0, <2.0.0dev",
43 # Due to an issue in pip's dependency resolver, the `grpc` extra is not
44 # installed, even though `google-cloud-bigquery-storage` specifies it
45 # as `google-api-core[grpc]`. We thus need to explicitly specify it here.
46 # See: https://github.com/googleapis/python-bigquery/issues/83
47 "grpcio >= 1.8.2, < 2.0dev",
48 "pyarrow>=0.16.0, < 2.0dev",
49 ],
50 "pandas": ["pandas>=0.17.1"],
51 # Exclude PyArrow dependency from Windows Python 2.7.
52 'pyarrow: platform_system != "Windows" or python_version >= "3.4"': [
53 # Bad Linux release for 0.14.0.
54 # https://issues.apache.org/jira/browse/ARROW-5868
55 "pyarrow>=0.4.1, != 0.14.0"
56 ],
57 "tqdm": ["tqdm >= 4.0.0, <5.0.0dev"],
58 "fastparquet": [
59 "fastparquet",
60 "python-snappy",
61 # llvmlite >= 0.32.0 cannot be installed on Python 3.5 and below
62 # (building the wheel fails), thus needs to be restricted.
63 # See: https://github.com/googleapis/python-bigquery/issues/78
64 "llvmlite <= 0.31.0",
65 ],
66 }
67
68 all_extras = []
69
70 for extra in extras:
71 if extra == "fastparquet":
72 # Skip fastparquet from "all" because it is redundant with pyarrow and
73 # creates a dependency on pre-release versions of numpy. See:
74 # https://github.com/googleapis/google-cloud-python/issues/8549
75 continue
76 all_extras.extend(extras[extra])
77
78 extras["all"] = all_extras
79
80 # Setup boilerplate below this line.
81
82 package_root = os.path.abspath(os.path.dirname(__file__))
83
84 readme_filename = os.path.join(package_root, "README.rst")
85 with io.open(readme_filename, encoding="utf-8") as readme_file:
86 readme = readme_file.read()
87
88 # Only include packages under the 'google' namespace. Do not include tests,
89 # benchmarks, etc.
90 packages = [
91 package for package in setuptools.find_packages() if package.startswith("google")
92 ]
93
94 # Determine which namespaces are needed.
95 namespaces = ["google"]
96 if "google.cloud" in packages:
97 namespaces.append("google.cloud")
98
99
100 setuptools.setup(
101 name=name,
102 version=version,
103 description=description,
104 long_description=readme,
105 author="Google LLC",
106 author_email="[email protected]",
107 license="Apache 2.0",
108 url="https://github.com/googleapis/python-bigquery",
109 classifiers=[
110 release_status,
111 "Intended Audience :: Developers",
112 "License :: OSI Approved :: Apache Software License",
113 "Programming Language :: Python",
114 "Programming Language :: Python :: 2",
115 "Programming Language :: Python :: 2.7",
116 "Programming Language :: Python :: 3",
117 "Programming Language :: Python :: 3.5",
118 "Programming Language :: Python :: 3.6",
119 "Programming Language :: Python :: 3.7",
120 "Programming Language :: Python :: 3.8",
121 "Operating System :: OS Independent",
122 "Topic :: Internet",
123 ],
124 platforms="Posix; MacOS X; Windows",
125 packages=packages,
126 namespace_packages=namespaces,
127 install_requires=dependencies,
128 extras_require=extras,
129 python_requires=">=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*",
130 include_package_data=True,
131 zip_safe=False,
132 )
133
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -36,6 +36,10 @@
"google-resumable-media >= 0.5.0, < 0.6dev",
"protobuf >= 3.6.0",
"six >=1.13.0,< 2.0.0dev",
+ # rsa >= 4.1 is not compatible with Python 2
+ # https://github.com/sybrenstuvel/python-rsa/issues/152
+ 'rsa <4.1; python_version < "3"',
+ 'rsa >=3.1.4, <5; python_version >= "3"',
]
extras = {
"bqstorage": [
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -36,6 +36,10 @@\n \"google-resumable-media >= 0.5.0, < 0.6dev\",\n \"protobuf >= 3.6.0\",\n \"six >=1.13.0,< 2.0.0dev\",\n+ # rsa >= 4.1 is not compatible with Python 2\n+ # https://github.com/sybrenstuvel/python-rsa/issues/152\n+ 'rsa <4.1; python_version < \"3\"',\n+ 'rsa >=3.1.4, <5; python_version >= \"3\"',\n ]\n extras = {\n \"bqstorage\": [\n", "issue": "A new release of rsa dependency breaks Python 2.7 tests\nRecent `rsa` releases are not compatible with Python 2.7 anymore, the last compatible version is 4.0. We need to bound its version in order to preserve Python 2.7 compatibility.\r\n\r\n> Major changes in 4.1\r\nVersion 4.0 was the last version to support Python 2 and 3.4. Version 4.1 is compatible with Python 3.5+ only.\n", "before_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport io\nimport os\n\nimport setuptools\n\n\n# Package metadata.\n\nname = \"google-cloud-bigquery\"\ndescription = \"Google BigQuery API client library\"\nversion = \"1.25.0\"\n# Should be one of:\n# 'Development Status :: 3 - Alpha'\n# 'Development Status :: 4 - Beta'\n# 'Development Status :: 5 - Production/Stable'\nrelease_status = \"Development Status :: 5 - Production/Stable\"\ndependencies = [\n 'enum34; python_version < \"3.4\"',\n \"google-auth >= 1.9.0, < 2.0dev\",\n \"google-api-core >= 1.15.0, < 2.0dev\",\n \"google-cloud-core >= 1.1.0, < 2.0dev\",\n \"google-resumable-media >= 0.5.0, < 0.6dev\",\n \"protobuf >= 3.6.0\",\n \"six >=1.13.0,< 2.0.0dev\",\n]\nextras = {\n \"bqstorage\": [\n \"google-cloud-bigquery-storage >= 1.0.0, <2.0.0dev\",\n # Due to an issue in pip's dependency resolver, the `grpc` extra is not\n # installed, even though `google-cloud-bigquery-storage` specifies it\n # as `google-api-core[grpc]`. We thus need to explicitly specify it here.\n # See: https://github.com/googleapis/python-bigquery/issues/83\n \"grpcio >= 1.8.2, < 2.0dev\",\n \"pyarrow>=0.16.0, < 2.0dev\",\n ],\n \"pandas\": [\"pandas>=0.17.1\"],\n # Exclude PyArrow dependency from Windows Python 2.7.\n 'pyarrow: platform_system != \"Windows\" or python_version >= \"3.4\"': [\n # Bad Linux release for 0.14.0.\n # https://issues.apache.org/jira/browse/ARROW-5868\n \"pyarrow>=0.4.1, != 0.14.0\"\n ],\n \"tqdm\": [\"tqdm >= 4.0.0, <5.0.0dev\"],\n \"fastparquet\": [\n \"fastparquet\",\n \"python-snappy\",\n # llvmlite >= 0.32.0 cannot be installed on Python 3.5 and below\n # (building the wheel fails), thus needs to be restricted.\n # See: https://github.com/googleapis/python-bigquery/issues/78\n \"llvmlite <= 0.31.0\",\n ],\n}\n\nall_extras = []\n\nfor extra in extras:\n if extra == \"fastparquet\":\n # Skip fastparquet from \"all\" because it is redundant with pyarrow and\n # creates a dependency on pre-release versions of numpy. See:\n # https://github.com/googleapis/google-cloud-python/issues/8549\n continue\n all_extras.extend(extras[extra])\n\nextras[\"all\"] = all_extras\n\n# Setup boilerplate below this line.\n\npackage_root = os.path.abspath(os.path.dirname(__file__))\n\nreadme_filename = os.path.join(package_root, \"README.rst\")\nwith io.open(readme_filename, encoding=\"utf-8\") as readme_file:\n readme = readme_file.read()\n\n# Only include packages under the 'google' namespace. Do not include tests,\n# benchmarks, etc.\npackages = [\n package for package in setuptools.find_packages() if package.startswith(\"google\")\n]\n\n# Determine which namespaces are needed.\nnamespaces = [\"google\"]\nif \"google.cloud\" in packages:\n namespaces.append(\"google.cloud\")\n\n\nsetuptools.setup(\n name=name,\n version=version,\n description=description,\n long_description=readme,\n author=\"Google LLC\",\n author_email=\"[email protected]\",\n license=\"Apache 2.0\",\n url=\"https://github.com/googleapis/python-bigquery\",\n classifiers=[\n release_status,\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Operating System :: OS Independent\",\n \"Topic :: Internet\",\n ],\n platforms=\"Posix; MacOS X; Windows\",\n packages=packages,\n namespace_packages=namespaces,\n install_requires=dependencies,\n extras_require=extras,\n python_requires=\">=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*\",\n include_package_data=True,\n zip_safe=False,\n)\n", "path": "setup.py"}], "after_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport io\nimport os\n\nimport setuptools\n\n\n# Package metadata.\n\nname = \"google-cloud-bigquery\"\ndescription = \"Google BigQuery API client library\"\nversion = \"1.25.0\"\n# Should be one of:\n# 'Development Status :: 3 - Alpha'\n# 'Development Status :: 4 - Beta'\n# 'Development Status :: 5 - Production/Stable'\nrelease_status = \"Development Status :: 5 - Production/Stable\"\ndependencies = [\n 'enum34; python_version < \"3.4\"',\n \"google-auth >= 1.9.0, < 2.0dev\",\n \"google-api-core >= 1.15.0, < 2.0dev\",\n \"google-cloud-core >= 1.1.0, < 2.0dev\",\n \"google-resumable-media >= 0.5.0, < 0.6dev\",\n \"protobuf >= 3.6.0\",\n \"six >=1.13.0,< 2.0.0dev\",\n # rsa >= 4.1 is not compatible with Python 2\n # https://github.com/sybrenstuvel/python-rsa/issues/152\n 'rsa <4.1; python_version < \"3\"',\n 'rsa >=3.1.4, <5; python_version >= \"3\"',\n]\nextras = {\n \"bqstorage\": [\n \"google-cloud-bigquery-storage >= 1.0.0, <2.0.0dev\",\n # Due to an issue in pip's dependency resolver, the `grpc` extra is not\n # installed, even though `google-cloud-bigquery-storage` specifies it\n # as `google-api-core[grpc]`. We thus need to explicitly specify it here.\n # See: https://github.com/googleapis/python-bigquery/issues/83\n \"grpcio >= 1.8.2, < 2.0dev\",\n \"pyarrow>=0.16.0, < 2.0dev\",\n ],\n \"pandas\": [\"pandas>=0.17.1\"],\n # Exclude PyArrow dependency from Windows Python 2.7.\n 'pyarrow: platform_system != \"Windows\" or python_version >= \"3.4\"': [\n # Bad Linux release for 0.14.0.\n # https://issues.apache.org/jira/browse/ARROW-5868\n \"pyarrow>=0.4.1, != 0.14.0\"\n ],\n \"tqdm\": [\"tqdm >= 4.0.0, <5.0.0dev\"],\n \"fastparquet\": [\n \"fastparquet\",\n \"python-snappy\",\n # llvmlite >= 0.32.0 cannot be installed on Python 3.5 and below\n # (building the wheel fails), thus needs to be restricted.\n # See: https://github.com/googleapis/python-bigquery/issues/78\n \"llvmlite <= 0.31.0\",\n ],\n}\n\nall_extras = []\n\nfor extra in extras:\n if extra == \"fastparquet\":\n # Skip fastparquet from \"all\" because it is redundant with pyarrow and\n # creates a dependency on pre-release versions of numpy. See:\n # https://github.com/googleapis/google-cloud-python/issues/8549\n continue\n all_extras.extend(extras[extra])\n\nextras[\"all\"] = all_extras\n\n# Setup boilerplate below this line.\n\npackage_root = os.path.abspath(os.path.dirname(__file__))\n\nreadme_filename = os.path.join(package_root, \"README.rst\")\nwith io.open(readme_filename, encoding=\"utf-8\") as readme_file:\n readme = readme_file.read()\n\n# Only include packages under the 'google' namespace. Do not include tests,\n# benchmarks, etc.\npackages = [\n package for package in setuptools.find_packages() if package.startswith(\"google\")\n]\n\n# Determine which namespaces are needed.\nnamespaces = [\"google\"]\nif \"google.cloud\" in packages:\n namespaces.append(\"google.cloud\")\n\n\nsetuptools.setup(\n name=name,\n version=version,\n description=description,\n long_description=readme,\n author=\"Google LLC\",\n author_email=\"[email protected]\",\n license=\"Apache 2.0\",\n url=\"https://github.com/googleapis/python-bigquery\",\n classifiers=[\n release_status,\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Operating System :: OS Independent\",\n \"Topic :: Internet\",\n ],\n platforms=\"Posix; MacOS X; Windows\",\n packages=packages,\n namespace_packages=namespaces,\n install_requires=dependencies,\n extras_require=extras,\n python_requires=\">=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*\",\n include_package_data=True,\n zip_safe=False,\n)\n", "path": "setup.py"}]}
| 1,877 | 169 |
gh_patches_debug_40943
|
rasdani/github-patches
|
git_diff
|
ARM-DOE__ACT-728
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Sunset Stamen maps in GeoDisplay and potentially replace
Stamen is transitioning their maps to stadia at the end of October 2023. ACT will need to deprecate that feature in GeoDisplay and potentially look for replacements.
https://github.com/SciTools/cartopy/pull/2266
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `act/plotting/geodisplay.py`
Content:
```
1 """
2 Stores the class for GeographicPlotDisplay.
3
4 """
5
6 import matplotlib
7 import matplotlib.pyplot as plt
8 import numpy as np
9 import pandas as pd
10
11 from .plot import Display
12
13 try:
14 import cartopy.crs as ccrs
15 import cartopy.feature as cfeature
16 from cartopy.io.img_tiles import Stamen
17
18 CARTOPY_AVAILABLE = True
19 except ImportError:
20 CARTOPY_AVAILABLE = False
21
22
23 class GeographicPlotDisplay(Display):
24 """
25 A class for making geographic tracer plot of aircraft, ship or other moving
26 platform plot.
27
28 This is inherited from the :func:`act.plotting.Display`
29 class and has therefore has the same attributes as that class.
30 See :func:`act.plotting.Display`
31 for more information. There are no additional attributes or parameters
32 to this class.
33
34 In order to create geographic plots, ACT needs the Cartopy package to be
35 installed on your system. More information about
36 Cartopy go here:https://scitools.org.uk/cartopy/docs/latest/ .
37
38 """
39
40 def __init__(self, ds, ds_name=None, **kwargs):
41 if not CARTOPY_AVAILABLE:
42 raise ImportError(
43 'Cartopy needs to be installed on your ' 'system to make geographic display plots.'
44 )
45 super().__init__(ds, ds_name, **kwargs)
46 if self.fig is None:
47 self.fig = plt.figure(**kwargs)
48
49 def geoplot(
50 self,
51 data_field=None,
52 lat_field='lat',
53 lon_field='lon',
54 dsname=None,
55 cbar_label=None,
56 title=None,
57 projection=None,
58 plot_buffer=0.08,
59 stamen='terrain-background',
60 tile=8,
61 cartopy_feature=None,
62 cmap='rainbow',
63 text=None,
64 gridlines=True,
65 **kwargs,
66 ):
67 """
68 Creates a latitude and longitude plot of a time series data set with
69 data values indicated by color and described with a colorbar.
70 Latitude values must be in degree north (-90 to 90) and
71 longitude must be in degree east (-180 to 180).
72
73 Parameters
74 ----------
75 data_field : str
76 Name of data field in the dataset to plot.
77 lat_field : str
78 Name of latitude field in the dataset to use.
79 lon_field : str
80 Name of longitude field in the dataset to use.
81 dsname : str or None
82 The name of the datastream to plot. Set to None to make ACT
83 attempt to automatically determine this.
84 cbar_label : str
85 Label to use with colorbar. If set to None will attempt
86 to create label from long_name and units.
87 title : str
88 Plot title.
89 projection : cartopy.crs object
90 Project to use on plot. See
91 https://scitools.org.uk/cartopy/docs/latest/reference/projections.html?highlight=projections
92 plot_buffer : float
93 Buffer to add around data on plot in lat and lon dimension.
94 stamen : str
95 Dataset to use for background image. Set to None to not use
96 background image.
97 tile : int
98 Tile zoom to use with background image. Higer number indicates
99 more resolution. A value of 8 is typical for a normal sonde plot.
100 cartopy_feature : list of str or str
101 Cartopy feature to add to plot.
102 cmap : str
103 Color map to use for colorbar.
104 text : dictionary
105 Dictionary of {text:[lon,lat]} to add to plot. Can have more
106 than one set of text to add.
107 gridlines : boolean
108 Use latitude and longitude gridlines.
109 **kwargs : keyword arguments
110 Any other keyword arguments that will be passed
111 into :func:`matplotlib.pyplot.scatter` when the figure
112 is made. See the matplotlib documentation for further details
113 on what keyword arguments are available.
114
115 """
116 if dsname is None and len(self._ds.keys()) > 1:
117 raise ValueError(
118 'You must choose a datastream when there are 2 '
119 'or more datasets in the GeographicPlotDisplay '
120 'object.'
121 )
122 elif dsname is None:
123 dsname = list(self._ds.keys())[0]
124
125 if data_field is None:
126 raise ValueError('You must enter the name of the data ' 'to be plotted.')
127
128 if projection is None:
129 if CARTOPY_AVAILABLE:
130 projection = ccrs.PlateCarree()
131
132 # Extract data from the dataset
133 try:
134 lat = self._ds[dsname][lat_field].values
135 except KeyError:
136 raise ValueError(
137 (
138 'You will need to provide the name of the '
139 "field if not '{}' to use for latitude "
140 'data.'
141 ).format(lat_field)
142 )
143 try:
144 lon = self._ds[dsname][lon_field].values
145 except KeyError:
146 raise ValueError(
147 (
148 'You will need to provide the name of the '
149 "field if not '{}' to use for longitude "
150 'data.'
151 ).format(lon_field)
152 )
153
154 # Set up metadata information for display on plot
155 if cbar_label is None:
156 try:
157 cbar_label = (
158 self._ds[dsname][data_field].attrs['long_name']
159 + ' ('
160 + self._ds[dsname][data_field].attrs['units']
161 + ')'
162 )
163 except KeyError:
164 cbar_label = data_field
165
166 lat_limits = [np.nanmin(lat), np.nanmax(lat)]
167 lon_limits = [np.nanmin(lon), np.nanmax(lon)]
168 box_size = np.max([np.abs(np.diff(lat_limits)), np.abs(np.diff(lon_limits))])
169 bx_buf = box_size * plot_buffer
170
171 lat_center = np.sum(lat_limits) / 2.0
172 lon_center = np.sum(lon_limits) / 2.0
173
174 lat_limits = [
175 lat_center - box_size / 2.0 - bx_buf,
176 lat_center + box_size / 2.0 + bx_buf,
177 ]
178 lon_limits = [
179 lon_center - box_size / 2.0 - bx_buf,
180 lon_center + box_size / 2.0 + bx_buf,
181 ]
182
183 data = self._ds[dsname][data_field].values
184
185 # Create base plot projection
186 ax = plt.axes(projection=projection)
187 plt.subplots_adjust(left=0.01, right=0.99, bottom=0.05, top=0.93)
188 ax.set_extent([lon_limits[0], lon_limits[1], lat_limits[0], lat_limits[1]], crs=projection)
189
190 if title is None:
191 try:
192 dim = list(self._ds[dsname][data_field].dims)
193 ts = pd.to_datetime(str(self._ds[dsname][dim[0]].values[0]))
194 date = ts.strftime('%Y-%m-%d')
195 time_str = ts.strftime('%H:%M:%S')
196 plt.title(' '.join([dsname, 'at', date, time_str]))
197 except NameError:
198 plt.title(dsname)
199 else:
200 plt.title(title)
201
202 if stamen:
203 tiler = Stamen(stamen)
204 ax.add_image(tiler, tile)
205
206 colorbar_map = None
207 if cmap is not None:
208 colorbar_map = matplotlib.colormaps.get_cmap(cmap)
209 sc = ax.scatter(lon, lat, c=data, cmap=colorbar_map, **kwargs)
210 cbar = plt.colorbar(sc)
211 cbar.ax.set_ylabel(cbar_label)
212 if cartopy_feature is not None:
213 if isinstance(cartopy_feature, str):
214 cartopy_feature = [cartopy_feature]
215 cartopy_feature = [ii.upper() for ii in cartopy_feature]
216 if 'STATES' in cartopy_feature:
217 ax.add_feature(cfeature.STATES.with_scale('10m'))
218 if 'LAND' in cartopy_feature:
219 ax.add_feature(cfeature.LAND)
220 if 'OCEAN' in cartopy_feature:
221 ax.add_feature(cfeature.OCEAN)
222 if 'COASTLINE' in cartopy_feature:
223 ax.add_feature(cfeature.COASTLINE)
224 if 'BORDERS' in cartopy_feature:
225 ax.add_feature(cfeature.BORDERS, linestyle=':')
226 if 'LAKES' in cartopy_feature:
227 ax.add_feature(cfeature.LAKES, alpha=0.5)
228 if 'RIVERS' in cartopy_feature:
229 ax.add_feature(cfeature.RIVERS)
230 if text is not None:
231 for label, location in text.items():
232 ax.plot(location[0], location[1], marker='*', color='black')
233 ax.text(location[0], location[1], label, color='black')
234
235 if gridlines:
236 if projection == ccrs.PlateCarree() or projection == ccrs.Mercator:
237 gl = ax.gridlines(
238 crs=projection,
239 draw_labels=True,
240 linewidth=1,
241 color='gray',
242 alpha=0.5,
243 linestyle='--',
244 )
245 gl.top_labels = False
246 gl.left_labels = True
247 gl.bottom_labels = True
248 gl.right_labels = False
249 gl.xlabel_style = {'size': 6, 'color': 'gray'}
250 gl.ylabel_style = {'size': 6, 'color': 'gray'}
251 else:
252 # Labels are only currently supported for PlateCarree and Mercator
253 gl = ax.gridlines(
254 draw_labels=False,
255 linewidth=1,
256 color='gray',
257 alpha=0.5,
258 linestyle='--',
259 )
260
261 return ax
262
```
Path: `examples/plotting/plot_aaf_track.py`
Content:
```
1 """
2 Plot ARM AAF Flight Path
3 --------------------------------
4
5 Plot the ARM AAF flight path using the GeographicPlotDisplay
6
7 Author: Joe O'Brien
8
9 """
10 import matplotlib.pyplot as plt
11
12 import act
13 from act.io.icartt import read_icartt
14
15 # Call the read_icartt function, which supports input
16 # for ICARTT (v2.0) formatted files.
17 # Example file is ARM Aerial Facility Navigation Data
18 ds = read_icartt(act.tests.EXAMPLE_AAF_ICARTT)
19
20 # Use GeographicPlotDisplay for referencing.
21 # NOTE: Cartopy is needed!
22 display = act.plotting.GeographicPlotDisplay(ds, figsize=(12, 10))
23
24 # Plot the ARM AAF flight track with respect to Pressure Altitude
25 display.geoplot('press_alt', lat_field='lat', lon_field='lon', stamen=None)
26
27 # Display the plot
28 plt.show()
29
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/act/plotting/geodisplay.py b/act/plotting/geodisplay.py
--- a/act/plotting/geodisplay.py
+++ b/act/plotting/geodisplay.py
@@ -3,6 +3,8 @@
"""
+import warnings
+
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
@@ -13,7 +15,7 @@
try:
import cartopy.crs as ccrs
import cartopy.feature as cfeature
- from cartopy.io.img_tiles import Stamen
+ from cartopy.io import img_tiles
CARTOPY_AVAILABLE = True
except ImportError:
@@ -56,8 +58,10 @@
title=None,
projection=None,
plot_buffer=0.08,
- stamen='terrain-background',
+ img_tile=None,
+ img_tile_args={},
tile=8,
+ stamen='terrain-background',
cartopy_feature=None,
cmap='rainbow',
text=None,
@@ -91,11 +95,18 @@
https://scitools.org.uk/cartopy/docs/latest/reference/projections.html?highlight=projections
plot_buffer : float
Buffer to add around data on plot in lat and lon dimension.
- stamen : str
- Dataset to use for background image. Set to None to not use
- background image.
+ img_tile : str
+ Image to use for the plot background. Set to None to not use
+ background image. For all image background types, see:
+ https://scitools.org.uk/cartopy/docs/v0.16/cartopy/io/img_tiles.html
+ Default is None.
+ img_tile_args : dict
+ Keyword arguments for the chosen img_tile. These arguments can be
+ found for the corresponding img_tile here:
+ https://scitools.org.uk/cartopy/docs/v0.16/cartopy/io/img_tiles.html
+ Default is an empty dictionary.
tile : int
- Tile zoom to use with background image. Higer number indicates
+ Tile zoom to use with background image. Higher number indicates
more resolution. A value of 8 is typical for a normal sonde plot.
cartopy_feature : list of str or str
Cartopy feature to add to plot.
@@ -199,9 +210,16 @@
else:
plt.title(title)
- if stamen:
- tiler = Stamen(stamen)
+ if stamen and img_tile is None:
+ tiler = img_tiles.Stamen(stamen)
ax.add_image(tiler, tile)
+ warnings.warn(
+ "Stamen is deprecated in Cartopy and in future versions of ACT, "
+ "please use img_tile to specify the image background. ")
+ else:
+ if img_tile is not None:
+ tiler = getattr(img_tiles, img_tile)(**img_tile_args)
+ ax.add_image(tiler, tile)
colorbar_map = None
if cmap is not None:
diff --git a/examples/plotting/plot_aaf_track.py b/examples/plotting/plot_aaf_track.py
--- a/examples/plotting/plot_aaf_track.py
+++ b/examples/plotting/plot_aaf_track.py
@@ -22,7 +22,7 @@
display = act.plotting.GeographicPlotDisplay(ds, figsize=(12, 10))
# Plot the ARM AAF flight track with respect to Pressure Altitude
-display.geoplot('press_alt', lat_field='lat', lon_field='lon', stamen=None)
+display.geoplot('press_alt', lat_field='lat', lon_field='lon')
# Display the plot
plt.show()
|
{"golden_diff": "diff --git a/act/plotting/geodisplay.py b/act/plotting/geodisplay.py\n--- a/act/plotting/geodisplay.py\n+++ b/act/plotting/geodisplay.py\n@@ -3,6 +3,8 @@\n \n \"\"\"\n \n+import warnings\n+\n import matplotlib\n import matplotlib.pyplot as plt\n import numpy as np\n@@ -13,7 +15,7 @@\n try:\n import cartopy.crs as ccrs\n import cartopy.feature as cfeature\n- from cartopy.io.img_tiles import Stamen\n+ from cartopy.io import img_tiles\n \n CARTOPY_AVAILABLE = True\n except ImportError:\n@@ -56,8 +58,10 @@\n title=None,\n projection=None,\n plot_buffer=0.08,\n- stamen='terrain-background',\n+ img_tile=None,\n+ img_tile_args={},\n tile=8,\n+ stamen='terrain-background',\n cartopy_feature=None,\n cmap='rainbow',\n text=None,\n@@ -91,11 +95,18 @@\n https://scitools.org.uk/cartopy/docs/latest/reference/projections.html?highlight=projections\n plot_buffer : float\n Buffer to add around data on plot in lat and lon dimension.\n- stamen : str\n- Dataset to use for background image. Set to None to not use\n- background image.\n+ img_tile : str\n+ Image to use for the plot background. Set to None to not use\n+ background image. For all image background types, see:\n+ https://scitools.org.uk/cartopy/docs/v0.16/cartopy/io/img_tiles.html\n+ Default is None.\n+ img_tile_args : dict\n+ Keyword arguments for the chosen img_tile. These arguments can be\n+ found for the corresponding img_tile here:\n+ https://scitools.org.uk/cartopy/docs/v0.16/cartopy/io/img_tiles.html\n+ Default is an empty dictionary.\n tile : int\n- Tile zoom to use with background image. Higer number indicates\n+ Tile zoom to use with background image. Higher number indicates\n more resolution. A value of 8 is typical for a normal sonde plot.\n cartopy_feature : list of str or str\n Cartopy feature to add to plot.\n@@ -199,9 +210,16 @@\n else:\n plt.title(title)\n \n- if stamen:\n- tiler = Stamen(stamen)\n+ if stamen and img_tile is None:\n+ tiler = img_tiles.Stamen(stamen)\n ax.add_image(tiler, tile)\n+ warnings.warn(\n+ \"Stamen is deprecated in Cartopy and in future versions of ACT, \"\n+ \"please use img_tile to specify the image background. \")\n+ else:\n+ if img_tile is not None:\n+ tiler = getattr(img_tiles, img_tile)(**img_tile_args)\n+ ax.add_image(tiler, tile)\n \n colorbar_map = None\n if cmap is not None:\ndiff --git a/examples/plotting/plot_aaf_track.py b/examples/plotting/plot_aaf_track.py\n--- a/examples/plotting/plot_aaf_track.py\n+++ b/examples/plotting/plot_aaf_track.py\n@@ -22,7 +22,7 @@\n display = act.plotting.GeographicPlotDisplay(ds, figsize=(12, 10))\n \n # Plot the ARM AAF flight track with respect to Pressure Altitude\n-display.geoplot('press_alt', lat_field='lat', lon_field='lon', stamen=None)\n+display.geoplot('press_alt', lat_field='lat', lon_field='lon')\n \n # Display the plot\n plt.show()\n", "issue": "Sunset Stamen maps in GeoDisplay and potentially replace\nStamen is transitioning their maps to stadia at the end of October 2023. ACT will need to deprecate that feature in GeoDisplay and potentially look for replacements.\r\n\r\nhttps://github.com/SciTools/cartopy/pull/2266 \n", "before_files": [{"content": "\"\"\"\nStores the class for GeographicPlotDisplay.\n\n\"\"\"\n\nimport matplotlib\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport pandas as pd\n\nfrom .plot import Display\n\ntry:\n import cartopy.crs as ccrs\n import cartopy.feature as cfeature\n from cartopy.io.img_tiles import Stamen\n\n CARTOPY_AVAILABLE = True\nexcept ImportError:\n CARTOPY_AVAILABLE = False\n\n\nclass GeographicPlotDisplay(Display):\n \"\"\"\n A class for making geographic tracer plot of aircraft, ship or other moving\n platform plot.\n\n This is inherited from the :func:`act.plotting.Display`\n class and has therefore has the same attributes as that class.\n See :func:`act.plotting.Display`\n for more information. There are no additional attributes or parameters\n to this class.\n\n In order to create geographic plots, ACT needs the Cartopy package to be\n installed on your system. More information about\n Cartopy go here:https://scitools.org.uk/cartopy/docs/latest/ .\n\n \"\"\"\n\n def __init__(self, ds, ds_name=None, **kwargs):\n if not CARTOPY_AVAILABLE:\n raise ImportError(\n 'Cartopy needs to be installed on your ' 'system to make geographic display plots.'\n )\n super().__init__(ds, ds_name, **kwargs)\n if self.fig is None:\n self.fig = plt.figure(**kwargs)\n\n def geoplot(\n self,\n data_field=None,\n lat_field='lat',\n lon_field='lon',\n dsname=None,\n cbar_label=None,\n title=None,\n projection=None,\n plot_buffer=0.08,\n stamen='terrain-background',\n tile=8,\n cartopy_feature=None,\n cmap='rainbow',\n text=None,\n gridlines=True,\n **kwargs,\n ):\n \"\"\"\n Creates a latitude and longitude plot of a time series data set with\n data values indicated by color and described with a colorbar.\n Latitude values must be in degree north (-90 to 90) and\n longitude must be in degree east (-180 to 180).\n\n Parameters\n ----------\n data_field : str\n Name of data field in the dataset to plot.\n lat_field : str\n Name of latitude field in the dataset to use.\n lon_field : str\n Name of longitude field in the dataset to use.\n dsname : str or None\n The name of the datastream to plot. Set to None to make ACT\n attempt to automatically determine this.\n cbar_label : str\n Label to use with colorbar. If set to None will attempt\n to create label from long_name and units.\n title : str\n Plot title.\n projection : cartopy.crs object\n Project to use on plot. See\n https://scitools.org.uk/cartopy/docs/latest/reference/projections.html?highlight=projections\n plot_buffer : float\n Buffer to add around data on plot in lat and lon dimension.\n stamen : str\n Dataset to use for background image. Set to None to not use\n background image.\n tile : int\n Tile zoom to use with background image. Higer number indicates\n more resolution. A value of 8 is typical for a normal sonde plot.\n cartopy_feature : list of str or str\n Cartopy feature to add to plot.\n cmap : str\n Color map to use for colorbar.\n text : dictionary\n Dictionary of {text:[lon,lat]} to add to plot. Can have more\n than one set of text to add.\n gridlines : boolean\n Use latitude and longitude gridlines.\n **kwargs : keyword arguments\n Any other keyword arguments that will be passed\n into :func:`matplotlib.pyplot.scatter` when the figure\n is made. See the matplotlib documentation for further details\n on what keyword arguments are available.\n\n \"\"\"\n if dsname is None and len(self._ds.keys()) > 1:\n raise ValueError(\n 'You must choose a datastream when there are 2 '\n 'or more datasets in the GeographicPlotDisplay '\n 'object.'\n )\n elif dsname is None:\n dsname = list(self._ds.keys())[0]\n\n if data_field is None:\n raise ValueError('You must enter the name of the data ' 'to be plotted.')\n\n if projection is None:\n if CARTOPY_AVAILABLE:\n projection = ccrs.PlateCarree()\n\n # Extract data from the dataset\n try:\n lat = self._ds[dsname][lat_field].values\n except KeyError:\n raise ValueError(\n (\n 'You will need to provide the name of the '\n \"field if not '{}' to use for latitude \"\n 'data.'\n ).format(lat_field)\n )\n try:\n lon = self._ds[dsname][lon_field].values\n except KeyError:\n raise ValueError(\n (\n 'You will need to provide the name of the '\n \"field if not '{}' to use for longitude \"\n 'data.'\n ).format(lon_field)\n )\n\n # Set up metadata information for display on plot\n if cbar_label is None:\n try:\n cbar_label = (\n self._ds[dsname][data_field].attrs['long_name']\n + ' ('\n + self._ds[dsname][data_field].attrs['units']\n + ')'\n )\n except KeyError:\n cbar_label = data_field\n\n lat_limits = [np.nanmin(lat), np.nanmax(lat)]\n lon_limits = [np.nanmin(lon), np.nanmax(lon)]\n box_size = np.max([np.abs(np.diff(lat_limits)), np.abs(np.diff(lon_limits))])\n bx_buf = box_size * plot_buffer\n\n lat_center = np.sum(lat_limits) / 2.0\n lon_center = np.sum(lon_limits) / 2.0\n\n lat_limits = [\n lat_center - box_size / 2.0 - bx_buf,\n lat_center + box_size / 2.0 + bx_buf,\n ]\n lon_limits = [\n lon_center - box_size / 2.0 - bx_buf,\n lon_center + box_size / 2.0 + bx_buf,\n ]\n\n data = self._ds[dsname][data_field].values\n\n # Create base plot projection\n ax = plt.axes(projection=projection)\n plt.subplots_adjust(left=0.01, right=0.99, bottom=0.05, top=0.93)\n ax.set_extent([lon_limits[0], lon_limits[1], lat_limits[0], lat_limits[1]], crs=projection)\n\n if title is None:\n try:\n dim = list(self._ds[dsname][data_field].dims)\n ts = pd.to_datetime(str(self._ds[dsname][dim[0]].values[0]))\n date = ts.strftime('%Y-%m-%d')\n time_str = ts.strftime('%H:%M:%S')\n plt.title(' '.join([dsname, 'at', date, time_str]))\n except NameError:\n plt.title(dsname)\n else:\n plt.title(title)\n\n if stamen:\n tiler = Stamen(stamen)\n ax.add_image(tiler, tile)\n\n colorbar_map = None\n if cmap is not None:\n colorbar_map = matplotlib.colormaps.get_cmap(cmap)\n sc = ax.scatter(lon, lat, c=data, cmap=colorbar_map, **kwargs)\n cbar = plt.colorbar(sc)\n cbar.ax.set_ylabel(cbar_label)\n if cartopy_feature is not None:\n if isinstance(cartopy_feature, str):\n cartopy_feature = [cartopy_feature]\n cartopy_feature = [ii.upper() for ii in cartopy_feature]\n if 'STATES' in cartopy_feature:\n ax.add_feature(cfeature.STATES.with_scale('10m'))\n if 'LAND' in cartopy_feature:\n ax.add_feature(cfeature.LAND)\n if 'OCEAN' in cartopy_feature:\n ax.add_feature(cfeature.OCEAN)\n if 'COASTLINE' in cartopy_feature:\n ax.add_feature(cfeature.COASTLINE)\n if 'BORDERS' in cartopy_feature:\n ax.add_feature(cfeature.BORDERS, linestyle=':')\n if 'LAKES' in cartopy_feature:\n ax.add_feature(cfeature.LAKES, alpha=0.5)\n if 'RIVERS' in cartopy_feature:\n ax.add_feature(cfeature.RIVERS)\n if text is not None:\n for label, location in text.items():\n ax.plot(location[0], location[1], marker='*', color='black')\n ax.text(location[0], location[1], label, color='black')\n\n if gridlines:\n if projection == ccrs.PlateCarree() or projection == ccrs.Mercator:\n gl = ax.gridlines(\n crs=projection,\n draw_labels=True,\n linewidth=1,\n color='gray',\n alpha=0.5,\n linestyle='--',\n )\n gl.top_labels = False\n gl.left_labels = True\n gl.bottom_labels = True\n gl.right_labels = False\n gl.xlabel_style = {'size': 6, 'color': 'gray'}\n gl.ylabel_style = {'size': 6, 'color': 'gray'}\n else:\n # Labels are only currently supported for PlateCarree and Mercator\n gl = ax.gridlines(\n draw_labels=False,\n linewidth=1,\n color='gray',\n alpha=0.5,\n linestyle='--',\n )\n\n return ax\n", "path": "act/plotting/geodisplay.py"}, {"content": "\"\"\"\nPlot ARM AAF Flight Path\n--------------------------------\n\nPlot the ARM AAF flight path using the GeographicPlotDisplay\n\nAuthor: Joe O'Brien\n\n\"\"\"\nimport matplotlib.pyplot as plt\n\nimport act\nfrom act.io.icartt import read_icartt\n\n# Call the read_icartt function, which supports input\n# for ICARTT (v2.0) formatted files.\n# Example file is ARM Aerial Facility Navigation Data\nds = read_icartt(act.tests.EXAMPLE_AAF_ICARTT)\n\n# Use GeographicPlotDisplay for referencing.\n# NOTE: Cartopy is needed!\ndisplay = act.plotting.GeographicPlotDisplay(ds, figsize=(12, 10))\n\n# Plot the ARM AAF flight track with respect to Pressure Altitude\ndisplay.geoplot('press_alt', lat_field='lat', lon_field='lon', stamen=None)\n\n# Display the plot\nplt.show()\n", "path": "examples/plotting/plot_aaf_track.py"}], "after_files": [{"content": "\"\"\"\nStores the class for GeographicPlotDisplay.\n\n\"\"\"\n\nimport warnings\n\nimport matplotlib\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport pandas as pd\n\nfrom .plot import Display\n\ntry:\n import cartopy.crs as ccrs\n import cartopy.feature as cfeature\n from cartopy.io import img_tiles\n\n CARTOPY_AVAILABLE = True\nexcept ImportError:\n CARTOPY_AVAILABLE = False\n\n\nclass GeographicPlotDisplay(Display):\n \"\"\"\n A class for making geographic tracer plot of aircraft, ship or other moving\n platform plot.\n\n This is inherited from the :func:`act.plotting.Display`\n class and has therefore has the same attributes as that class.\n See :func:`act.plotting.Display`\n for more information. There are no additional attributes or parameters\n to this class.\n\n In order to create geographic plots, ACT needs the Cartopy package to be\n installed on your system. More information about\n Cartopy go here:https://scitools.org.uk/cartopy/docs/latest/ .\n\n \"\"\"\n\n def __init__(self, ds, ds_name=None, **kwargs):\n if not CARTOPY_AVAILABLE:\n raise ImportError(\n 'Cartopy needs to be installed on your ' 'system to make geographic display plots.'\n )\n super().__init__(ds, ds_name, **kwargs)\n if self.fig is None:\n self.fig = plt.figure(**kwargs)\n\n def geoplot(\n self,\n data_field=None,\n lat_field='lat',\n lon_field='lon',\n dsname=None,\n cbar_label=None,\n title=None,\n projection=None,\n plot_buffer=0.08,\n img_tile=None,\n img_tile_args={},\n tile=8,\n stamen='terrain-background',\n cartopy_feature=None,\n cmap='rainbow',\n text=None,\n gridlines=True,\n **kwargs,\n ):\n \"\"\"\n Creates a latitude and longitude plot of a time series data set with\n data values indicated by color and described with a colorbar.\n Latitude values must be in degree north (-90 to 90) and\n longitude must be in degree east (-180 to 180).\n\n Parameters\n ----------\n data_field : str\n Name of data field in the dataset to plot.\n lat_field : str\n Name of latitude field in the dataset to use.\n lon_field : str\n Name of longitude field in the dataset to use.\n dsname : str or None\n The name of the datastream to plot. Set to None to make ACT\n attempt to automatically determine this.\n cbar_label : str\n Label to use with colorbar. If set to None will attempt\n to create label from long_name and units.\n title : str\n Plot title.\n projection : cartopy.crs object\n Project to use on plot. See\n https://scitools.org.uk/cartopy/docs/latest/reference/projections.html?highlight=projections\n plot_buffer : float\n Buffer to add around data on plot in lat and lon dimension.\n img_tile : str\n Image to use for the plot background. Set to None to not use\n background image. For all image background types, see:\n https://scitools.org.uk/cartopy/docs/v0.16/cartopy/io/img_tiles.html\n Default is None.\n img_tile_args : dict\n Keyword arguments for the chosen img_tile. These arguments can be\n found for the corresponding img_tile here:\n https://scitools.org.uk/cartopy/docs/v0.16/cartopy/io/img_tiles.html\n Default is an empty dictionary.\n tile : int\n Tile zoom to use with background image. Higher number indicates\n more resolution. A value of 8 is typical for a normal sonde plot.\n cartopy_feature : list of str or str\n Cartopy feature to add to plot.\n cmap : str\n Color map to use for colorbar.\n text : dictionary\n Dictionary of {text:[lon,lat]} to add to plot. Can have more\n than one set of text to add.\n gridlines : boolean\n Use latitude and longitude gridlines.\n **kwargs : keyword arguments\n Any other keyword arguments that will be passed\n into :func:`matplotlib.pyplot.scatter` when the figure\n is made. See the matplotlib documentation for further details\n on what keyword arguments are available.\n\n \"\"\"\n if dsname is None and len(self._ds.keys()) > 1:\n raise ValueError(\n 'You must choose a datastream when there are 2 '\n 'or more datasets in the GeographicPlotDisplay '\n 'object.'\n )\n elif dsname is None:\n dsname = list(self._ds.keys())[0]\n\n if data_field is None:\n raise ValueError('You must enter the name of the data ' 'to be plotted.')\n\n if projection is None:\n if CARTOPY_AVAILABLE:\n projection = ccrs.PlateCarree()\n\n # Extract data from the dataset\n try:\n lat = self._ds[dsname][lat_field].values\n except KeyError:\n raise ValueError(\n (\n 'You will need to provide the name of the '\n \"field if not '{}' to use for latitude \"\n 'data.'\n ).format(lat_field)\n )\n try:\n lon = self._ds[dsname][lon_field].values\n except KeyError:\n raise ValueError(\n (\n 'You will need to provide the name of the '\n \"field if not '{}' to use for longitude \"\n 'data.'\n ).format(lon_field)\n )\n\n # Set up metadata information for display on plot\n if cbar_label is None:\n try:\n cbar_label = (\n self._ds[dsname][data_field].attrs['long_name']\n + ' ('\n + self._ds[dsname][data_field].attrs['units']\n + ')'\n )\n except KeyError:\n cbar_label = data_field\n\n lat_limits = [np.nanmin(lat), np.nanmax(lat)]\n lon_limits = [np.nanmin(lon), np.nanmax(lon)]\n box_size = np.max([np.abs(np.diff(lat_limits)), np.abs(np.diff(lon_limits))])\n bx_buf = box_size * plot_buffer\n\n lat_center = np.sum(lat_limits) / 2.0\n lon_center = np.sum(lon_limits) / 2.0\n\n lat_limits = [\n lat_center - box_size / 2.0 - bx_buf,\n lat_center + box_size / 2.0 + bx_buf,\n ]\n lon_limits = [\n lon_center - box_size / 2.0 - bx_buf,\n lon_center + box_size / 2.0 + bx_buf,\n ]\n\n data = self._ds[dsname][data_field].values\n\n # Create base plot projection\n ax = plt.axes(projection=projection)\n plt.subplots_adjust(left=0.01, right=0.99, bottom=0.05, top=0.93)\n ax.set_extent([lon_limits[0], lon_limits[1], lat_limits[0], lat_limits[1]], crs=projection)\n\n if title is None:\n try:\n dim = list(self._ds[dsname][data_field].dims)\n ts = pd.to_datetime(str(self._ds[dsname][dim[0]].values[0]))\n date = ts.strftime('%Y-%m-%d')\n time_str = ts.strftime('%H:%M:%S')\n plt.title(' '.join([dsname, 'at', date, time_str]))\n except NameError:\n plt.title(dsname)\n else:\n plt.title(title)\n\n if stamen and img_tile is None:\n tiler = img_tiles.Stamen(stamen)\n ax.add_image(tiler, tile)\n warnings.warn(\n \"Stamen is deprecated in Cartopy and in future versions of ACT, \"\n \"please use img_tile to specify the image background. \")\n else:\n if img_tile is not None:\n tiler = getattr(img_tiles, img_tile)(**img_tile_args)\n ax.add_image(tiler, tile)\n\n colorbar_map = None\n if cmap is not None:\n colorbar_map = matplotlib.colormaps.get_cmap(cmap)\n sc = ax.scatter(lon, lat, c=data, cmap=colorbar_map, **kwargs)\n cbar = plt.colorbar(sc)\n cbar.ax.set_ylabel(cbar_label)\n if cartopy_feature is not None:\n if isinstance(cartopy_feature, str):\n cartopy_feature = [cartopy_feature]\n cartopy_feature = [ii.upper() for ii in cartopy_feature]\n if 'STATES' in cartopy_feature:\n ax.add_feature(cfeature.STATES.with_scale('10m'))\n if 'LAND' in cartopy_feature:\n ax.add_feature(cfeature.LAND)\n if 'OCEAN' in cartopy_feature:\n ax.add_feature(cfeature.OCEAN)\n if 'COASTLINE' in cartopy_feature:\n ax.add_feature(cfeature.COASTLINE)\n if 'BORDERS' in cartopy_feature:\n ax.add_feature(cfeature.BORDERS, linestyle=':')\n if 'LAKES' in cartopy_feature:\n ax.add_feature(cfeature.LAKES, alpha=0.5)\n if 'RIVERS' in cartopy_feature:\n ax.add_feature(cfeature.RIVERS)\n if text is not None:\n for label, location in text.items():\n ax.plot(location[0], location[1], marker='*', color='black')\n ax.text(location[0], location[1], label, color='black')\n\n if gridlines:\n if projection == ccrs.PlateCarree() or projection == ccrs.Mercator:\n gl = ax.gridlines(\n crs=projection,\n draw_labels=True,\n linewidth=1,\n color='gray',\n alpha=0.5,\n linestyle='--',\n )\n gl.top_labels = False\n gl.left_labels = True\n gl.bottom_labels = True\n gl.right_labels = False\n gl.xlabel_style = {'size': 6, 'color': 'gray'}\n gl.ylabel_style = {'size': 6, 'color': 'gray'}\n else:\n # Labels are only currently supported for PlateCarree and Mercator\n gl = ax.gridlines(\n draw_labels=False,\n linewidth=1,\n color='gray',\n alpha=0.5,\n linestyle='--',\n )\n\n return ax\n", "path": "act/plotting/geodisplay.py"}, {"content": "\"\"\"\nPlot ARM AAF Flight Path\n--------------------------------\n\nPlot the ARM AAF flight path using the GeographicPlotDisplay\n\nAuthor: Joe O'Brien\n\n\"\"\"\nimport matplotlib.pyplot as plt\n\nimport act\nfrom act.io.icartt import read_icartt\n\n# Call the read_icartt function, which supports input\n# for ICARTT (v2.0) formatted files.\n# Example file is ARM Aerial Facility Navigation Data\nds = read_icartt(act.tests.EXAMPLE_AAF_ICARTT)\n\n# Use GeographicPlotDisplay for referencing.\n# NOTE: Cartopy is needed!\ndisplay = act.plotting.GeographicPlotDisplay(ds, figsize=(12, 10))\n\n# Plot the ARM AAF flight track with respect to Pressure Altitude\ndisplay.geoplot('press_alt', lat_field='lat', lon_field='lon')\n\n# Display the plot\nplt.show()\n", "path": "examples/plotting/plot_aaf_track.py"}]}
| 3,375 | 828 |
gh_patches_debug_54533
|
rasdani/github-patches
|
git_diff
|
dbt-labs__dbt-core-7566
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[CT-2552] Pin protobuf to greater than 4.0
Some users were seeing an error:
> ImportError: cannot import name 'builder' from 'google.protobuf.internal'.
The generated types_pb2.py file was built with protobuf 4 and requires protobuf 4 in order to import "builder".
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `core/setup.py`
Content:
```
1 #!/usr/bin/env python
2 import os
3 import sys
4
5 if sys.version_info < (3, 7, 2):
6 print("Error: dbt does not support this version of Python.")
7 print("Please upgrade to Python 3.7.2 or higher.")
8 sys.exit(1)
9
10
11 from setuptools import setup
12
13 try:
14 from setuptools import find_namespace_packages
15 except ImportError:
16 # the user has a downlevel version of setuptools.
17 print("Error: dbt requires setuptools v40.1.0 or higher.")
18 print('Please upgrade setuptools with "pip install --upgrade setuptools" ' "and try again")
19 sys.exit(1)
20
21
22 this_directory = os.path.abspath(os.path.dirname(__file__))
23 with open(os.path.join(this_directory, "README.md")) as f:
24 long_description = f.read()
25
26
27 package_name = "dbt-core"
28 package_version = "1.6.0a1"
29 description = """With dbt, data analysts and engineers can build analytics \
30 the way engineers build applications."""
31
32
33 setup(
34 name=package_name,
35 version=package_version,
36 description=description,
37 long_description=long_description,
38 long_description_content_type="text/markdown",
39 author="dbt Labs",
40 author_email="[email protected]",
41 url="https://github.com/dbt-labs/dbt-core",
42 packages=find_namespace_packages(include=["dbt", "dbt.*"]),
43 include_package_data=True,
44 test_suite="test",
45 entry_points={
46 "console_scripts": ["dbt = dbt.cli.main:cli"],
47 },
48 install_requires=[
49 "Jinja2==3.1.2",
50 "agate>=1.6,<1.7.1",
51 "click>=7.0,<9",
52 "colorama>=0.3.9,<0.4.7",
53 "hologram>=0.0.14,<=0.0.16",
54 "isodate>=0.6,<0.7",
55 "logbook>=1.5,<1.6",
56 "mashumaro[msgpack]==3.6",
57 "minimal-snowplow-tracker==0.0.2",
58 "networkx>=2.3,<2.8.1;python_version<'3.8'",
59 "networkx>=2.3,<3;python_version>='3.8'",
60 "packaging>20.9",
61 "sqlparse>=0.2.3,<0.4.4",
62 "dbt-extractor~=0.4.1",
63 "typing-extensions>=3.7.4",
64 "werkzeug>=1,<3",
65 "pathspec>=0.9,<0.12",
66 "protobuf>=3.18.3",
67 "pytz>=2015.7",
68 # the following are all to match snowflake-connector-python
69 "requests<3.0.0",
70 "idna>=2.5,<4",
71 "cffi>=1.9,<2.0.0",
72 "pyyaml>=6.0",
73 ],
74 zip_safe=False,
75 classifiers=[
76 "Development Status :: 5 - Production/Stable",
77 "License :: OSI Approved :: Apache Software License",
78 "Operating System :: Microsoft :: Windows",
79 "Operating System :: MacOS :: MacOS X",
80 "Operating System :: POSIX :: Linux",
81 "Programming Language :: Python :: 3.7",
82 "Programming Language :: Python :: 3.8",
83 "Programming Language :: Python :: 3.9",
84 "Programming Language :: Python :: 3.10",
85 "Programming Language :: Python :: 3.11",
86 ],
87 python_requires=">=3.7.2",
88 )
89
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/core/setup.py b/core/setup.py
--- a/core/setup.py
+++ b/core/setup.py
@@ -63,7 +63,7 @@
"typing-extensions>=3.7.4",
"werkzeug>=1,<3",
"pathspec>=0.9,<0.12",
- "protobuf>=3.18.3",
+ "protobuf>=4.0.0",
"pytz>=2015.7",
# the following are all to match snowflake-connector-python
"requests<3.0.0",
|
{"golden_diff": "diff --git a/core/setup.py b/core/setup.py\n--- a/core/setup.py\n+++ b/core/setup.py\n@@ -63,7 +63,7 @@\n \"typing-extensions>=3.7.4\",\n \"werkzeug>=1,<3\",\n \"pathspec>=0.9,<0.12\",\n- \"protobuf>=3.18.3\",\n+ \"protobuf>=4.0.0\",\n \"pytz>=2015.7\",\n # the following are all to match snowflake-connector-python\n \"requests<3.0.0\",\n", "issue": "[CT-2552] Pin protobuf to greater than 4.0\nSome users were seeing an error:\r\n\r\n> ImportError: cannot import name 'builder' from 'google.protobuf.internal'.\r\nThe generated types_pb2.py file was built with protobuf 4 and requires protobuf 4 in order to import \"builder\".\n", "before_files": [{"content": "#!/usr/bin/env python\nimport os\nimport sys\n\nif sys.version_info < (3, 7, 2):\n print(\"Error: dbt does not support this version of Python.\")\n print(\"Please upgrade to Python 3.7.2 or higher.\")\n sys.exit(1)\n\n\nfrom setuptools import setup\n\ntry:\n from setuptools import find_namespace_packages\nexcept ImportError:\n # the user has a downlevel version of setuptools.\n print(\"Error: dbt requires setuptools v40.1.0 or higher.\")\n print('Please upgrade setuptools with \"pip install --upgrade setuptools\" ' \"and try again\")\n sys.exit(1)\n\n\nthis_directory = os.path.abspath(os.path.dirname(__file__))\nwith open(os.path.join(this_directory, \"README.md\")) as f:\n long_description = f.read()\n\n\npackage_name = \"dbt-core\"\npackage_version = \"1.6.0a1\"\ndescription = \"\"\"With dbt, data analysts and engineers can build analytics \\\nthe way engineers build applications.\"\"\"\n\n\nsetup(\n name=package_name,\n version=package_version,\n description=description,\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n author=\"dbt Labs\",\n author_email=\"[email protected]\",\n url=\"https://github.com/dbt-labs/dbt-core\",\n packages=find_namespace_packages(include=[\"dbt\", \"dbt.*\"]),\n include_package_data=True,\n test_suite=\"test\",\n entry_points={\n \"console_scripts\": [\"dbt = dbt.cli.main:cli\"],\n },\n install_requires=[\n \"Jinja2==3.1.2\",\n \"agate>=1.6,<1.7.1\",\n \"click>=7.0,<9\",\n \"colorama>=0.3.9,<0.4.7\",\n \"hologram>=0.0.14,<=0.0.16\",\n \"isodate>=0.6,<0.7\",\n \"logbook>=1.5,<1.6\",\n \"mashumaro[msgpack]==3.6\",\n \"minimal-snowplow-tracker==0.0.2\",\n \"networkx>=2.3,<2.8.1;python_version<'3.8'\",\n \"networkx>=2.3,<3;python_version>='3.8'\",\n \"packaging>20.9\",\n \"sqlparse>=0.2.3,<0.4.4\",\n \"dbt-extractor~=0.4.1\",\n \"typing-extensions>=3.7.4\",\n \"werkzeug>=1,<3\",\n \"pathspec>=0.9,<0.12\",\n \"protobuf>=3.18.3\",\n \"pytz>=2015.7\",\n # the following are all to match snowflake-connector-python\n \"requests<3.0.0\",\n \"idna>=2.5,<4\",\n \"cffi>=1.9,<2.0.0\",\n \"pyyaml>=6.0\",\n ],\n zip_safe=False,\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: Microsoft :: Windows\",\n \"Operating System :: MacOS :: MacOS X\",\n \"Operating System :: POSIX :: Linux\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Programming Language :: Python :: 3.11\",\n ],\n python_requires=\">=3.7.2\",\n)\n", "path": "core/setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\nimport os\nimport sys\n\nif sys.version_info < (3, 7, 2):\n print(\"Error: dbt does not support this version of Python.\")\n print(\"Please upgrade to Python 3.7.2 or higher.\")\n sys.exit(1)\n\n\nfrom setuptools import setup\n\ntry:\n from setuptools import find_namespace_packages\nexcept ImportError:\n # the user has a downlevel version of setuptools.\n print(\"Error: dbt requires setuptools v40.1.0 or higher.\")\n print('Please upgrade setuptools with \"pip install --upgrade setuptools\" ' \"and try again\")\n sys.exit(1)\n\n\nthis_directory = os.path.abspath(os.path.dirname(__file__))\nwith open(os.path.join(this_directory, \"README.md\")) as f:\n long_description = f.read()\n\n\npackage_name = \"dbt-core\"\npackage_version = \"1.6.0a1\"\ndescription = \"\"\"With dbt, data analysts and engineers can build analytics \\\nthe way engineers build applications.\"\"\"\n\n\nsetup(\n name=package_name,\n version=package_version,\n description=description,\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n author=\"dbt Labs\",\n author_email=\"[email protected]\",\n url=\"https://github.com/dbt-labs/dbt-core\",\n packages=find_namespace_packages(include=[\"dbt\", \"dbt.*\"]),\n include_package_data=True,\n test_suite=\"test\",\n entry_points={\n \"console_scripts\": [\"dbt = dbt.cli.main:cli\"],\n },\n install_requires=[\n \"Jinja2==3.1.2\",\n \"agate>=1.6,<1.7.1\",\n \"click>=7.0,<9\",\n \"colorama>=0.3.9,<0.4.7\",\n \"hologram>=0.0.14,<=0.0.16\",\n \"isodate>=0.6,<0.7\",\n \"logbook>=1.5,<1.6\",\n \"mashumaro[msgpack]==3.6\",\n \"minimal-snowplow-tracker==0.0.2\",\n \"networkx>=2.3,<2.8.1;python_version<'3.8'\",\n \"networkx>=2.3,<3;python_version>='3.8'\",\n \"packaging>20.9\",\n \"sqlparse>=0.2.3,<0.4.4\",\n \"dbt-extractor~=0.4.1\",\n \"typing-extensions>=3.7.4\",\n \"werkzeug>=1,<3\",\n \"pathspec>=0.9,<0.12\",\n \"protobuf>=4.0.0\",\n \"pytz>=2015.7\",\n # the following are all to match snowflake-connector-python\n \"requests<3.0.0\",\n \"idna>=2.5,<4\",\n \"cffi>=1.9,<2.0.0\",\n \"pyyaml>=6.0\",\n ],\n zip_safe=False,\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: Microsoft :: Windows\",\n \"Operating System :: MacOS :: MacOS X\",\n \"Operating System :: POSIX :: Linux\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Programming Language :: Python :: 3.11\",\n ],\n python_requires=\">=3.7.2\",\n)\n", "path": "core/setup.py"}]}
| 1,302 | 130 |
gh_patches_debug_4049
|
rasdani/github-patches
|
git_diff
|
strawberry-graphql__strawberry-1811
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Decimal scalars aren't serialized as strings when passed as numbers
When using the `Decimal` scalar, if the value passed in is a floating point number, the value isn't serialized as a string, but as if it were still the floating point number which causes precision issues as can be seen in the working example below.
[Working example](https://la4de.github.io/strawberry-playground/#UEsDBAoAAAAAAFaAjFQgaUU4EgAAABIAAAAQAAAAcmVxdWlyZW1lbnRzLnR4dHN0cmF3YmVycnktZ3JhcGhxbFBLAwQKAAAAAABWgIxUj3TlatIAAADSAAAACQAAAHNjaGVtYS5weWltcG9ydCBzdHJhd2JlcnJ5CmZyb20gZGVjaW1hbCBpbXBvcnQgRGVjaW1hbAoKQHN0cmF3YmVycnkudHlwZQpjbGFzcyBRdWVyeToKICAgIEBzdHJhd2JlcnJ5LmZpZWxkCiAgICBkZWYgZGVjaW1hbChzZWxmLCB2YWx1ZTogRGVjaW1hbCkgLT4gRGVjaW1hbDoKICAgICAgICByZXR1cm4gdmFsdWUKCnNjaGVtYSA9IHN0cmF3YmVycnkuU2NoZW1hKHF1ZXJ5PVF1ZXJ5KVBLAwQKAAAAAABWgIxUERrh0UMAAABDAAAACQAAAHF1ZXJ5LmdxbHsKICBkZWNpbWFsKHZhbHVlOiAzLjE0KQogIGFub3RoZXJEZWNpbWFsOiBkZWNpbWFsKHZhbHVlOiAiMy4xNCIpCn1QSwMECgAAAAAAVoCMVKi7vnMDAAAAAwAAAA4AAAB2YXJpYWJsZXMuanNvbnsKfVBLAQIUAAoAAAAAAFaAjFQgaUU4EgAAABIAAAAQAAAAAAAAAAAAAAAAAAAAAAByZXF1aXJlbWVudHMudHh0UEsBAhQACgAAAAAAVoCMVI905WrSAAAA0gAAAAkAAAAAAAAAAAAAAAAAQAAAAHNjaGVtYS5weVBLAQIUAAoAAAAAAFaAjFQRGuHRQwAAAEMAAAAJAAAAAAAAAAAAAAAAADkBAABxdWVyeS5ncWxQSwECFAAKAAAAAABWgIxUqLu+cwMAAAADAAAADgAAAAAAAAAAAAAAAACjAQAAdmFyaWFibGVzLmpzb25QSwUGAAAAAAQABADoAAAA0gEAAAAA)
Actual output - `"3.140000000000000124344978758017532527446746826171875"`
Expected output - `"3.14"`
As text:
```
@strawberry.type
class DecimalResponse:
value: Decimal
@strawberry.field
def decimals(
dec_value: Decimal,
) -> DecimalResponse:
return DecimalResponse(value=dec_value)
```
```
mutation decimals($dec_value: Decimal!) {
decimals(
decValue: $dec_value
) {
... on DecimalResponse {
value
}
}
}
{
"dec_value": 3.14
}
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `strawberry/schema/types/base_scalars.py`
Content:
```
1 import datetime
2 import decimal
3 import uuid
4 from operator import methodcaller
5 from typing import Callable
6
7 import dateutil.parser
8
9 from graphql import GraphQLError
10
11 from strawberry.custom_scalar import scalar
12
13
14 def wrap_parser(parser: Callable, type_: str) -> Callable:
15 def inner(value: str):
16 try:
17 return parser(value)
18 except ValueError as e:
19 raise GraphQLError(f'Value cannot represent a {type_}: "{value}". {e}')
20
21 return inner
22
23
24 def parse_decimal(value: str) -> decimal.Decimal:
25 try:
26 return decimal.Decimal(value)
27 except decimal.DecimalException:
28 raise GraphQLError(f'Value cannot represent a Decimal: "{value}".')
29
30
31 isoformat = methodcaller("isoformat")
32
33
34 Date = scalar(
35 datetime.date,
36 name="Date",
37 description="Date (isoformat)",
38 serialize=isoformat,
39 parse_value=wrap_parser(datetime.date.fromisoformat, "Date"),
40 )
41 DateTime = scalar(
42 datetime.datetime,
43 name="DateTime",
44 description="Date with time (isoformat)",
45 serialize=isoformat,
46 parse_value=wrap_parser(dateutil.parser.isoparse, "DateTime"),
47 )
48 Time = scalar(
49 datetime.time,
50 name="Time",
51 description="Time (isoformat)",
52 serialize=isoformat,
53 parse_value=wrap_parser(datetime.time.fromisoformat, "Time"),
54 )
55
56 Decimal = scalar(
57 decimal.Decimal,
58 name="Decimal",
59 description="Decimal (fixed-point)",
60 serialize=str,
61 parse_value=parse_decimal,
62 )
63
64 UUID = scalar(
65 uuid.UUID,
66 name="UUID",
67 serialize=str,
68 parse_value=wrap_parser(uuid.UUID, "UUID"),
69 )
70
71
72 def _verify_void(x) -> None:
73 if x is not None:
74 raise ValueError(f"Expected 'None', got '{x}'")
75
76
77 Void = scalar(
78 type(None),
79 name="Void",
80 serialize=_verify_void,
81 parse_value=_verify_void,
82 description="Represents NULL values",
83 )
84
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/strawberry/schema/types/base_scalars.py b/strawberry/schema/types/base_scalars.py
--- a/strawberry/schema/types/base_scalars.py
+++ b/strawberry/schema/types/base_scalars.py
@@ -21,9 +21,9 @@
return inner
-def parse_decimal(value: str) -> decimal.Decimal:
+def parse_decimal(value: object) -> decimal.Decimal:
try:
- return decimal.Decimal(value)
+ return decimal.Decimal(str(value))
except decimal.DecimalException:
raise GraphQLError(f'Value cannot represent a Decimal: "{value}".')
|
{"golden_diff": "diff --git a/strawberry/schema/types/base_scalars.py b/strawberry/schema/types/base_scalars.py\n--- a/strawberry/schema/types/base_scalars.py\n+++ b/strawberry/schema/types/base_scalars.py\n@@ -21,9 +21,9 @@\n return inner\n \n \n-def parse_decimal(value: str) -> decimal.Decimal:\n+def parse_decimal(value: object) -> decimal.Decimal:\n try:\n- return decimal.Decimal(value)\n+ return decimal.Decimal(str(value))\n except decimal.DecimalException:\n raise GraphQLError(f'Value cannot represent a Decimal: \"{value}\".')\n", "issue": "Decimal scalars aren't serialized as strings when passed as numbers\nWhen using the `Decimal` scalar, if the value passed in is a floating point number, the value isn't serialized as a string, but as if it were still the floating point number which causes precision issues as can be seen in the working example below.\r\n\r\n\r\n[Working example](https://la4de.github.io/strawberry-playground/#UEsDBAoAAAAAAFaAjFQgaUU4EgAAABIAAAAQAAAAcmVxdWlyZW1lbnRzLnR4dHN0cmF3YmVycnktZ3JhcGhxbFBLAwQKAAAAAABWgIxUj3TlatIAAADSAAAACQAAAHNjaGVtYS5weWltcG9ydCBzdHJhd2JlcnJ5CmZyb20gZGVjaW1hbCBpbXBvcnQgRGVjaW1hbAoKQHN0cmF3YmVycnkudHlwZQpjbGFzcyBRdWVyeToKICAgIEBzdHJhd2JlcnJ5LmZpZWxkCiAgICBkZWYgZGVjaW1hbChzZWxmLCB2YWx1ZTogRGVjaW1hbCkgLT4gRGVjaW1hbDoKICAgICAgICByZXR1cm4gdmFsdWUKCnNjaGVtYSA9IHN0cmF3YmVycnkuU2NoZW1hKHF1ZXJ5PVF1ZXJ5KVBLAwQKAAAAAABWgIxUERrh0UMAAABDAAAACQAAAHF1ZXJ5LmdxbHsKICBkZWNpbWFsKHZhbHVlOiAzLjE0KQogIGFub3RoZXJEZWNpbWFsOiBkZWNpbWFsKHZhbHVlOiAiMy4xNCIpCn1QSwMECgAAAAAAVoCMVKi7vnMDAAAAAwAAAA4AAAB2YXJpYWJsZXMuanNvbnsKfVBLAQIUAAoAAAAAAFaAjFQgaUU4EgAAABIAAAAQAAAAAAAAAAAAAAAAAAAAAAByZXF1aXJlbWVudHMudHh0UEsBAhQACgAAAAAAVoCMVI905WrSAAAA0gAAAAkAAAAAAAAAAAAAAAAAQAAAAHNjaGVtYS5weVBLAQIUAAoAAAAAAFaAjFQRGuHRQwAAAEMAAAAJAAAAAAAAAAAAAAAAADkBAABxdWVyeS5ncWxQSwECFAAKAAAAAABWgIxUqLu+cwMAAAADAAAADgAAAAAAAAAAAAAAAACjAQAAdmFyaWFibGVzLmpzb25QSwUGAAAAAAQABADoAAAA0gEAAAAA)\r\n\r\nActual output - `\"3.140000000000000124344978758017532527446746826171875\"`\r\nExpected output - `\"3.14\"`\r\n\r\nAs text:\r\n\r\n```\r\[email protected]\r\nclass DecimalResponse:\r\n value: Decimal\r\n\r\n\r\[email protected]\r\ndef decimals(\r\n dec_value: Decimal,\r\n) -> DecimalResponse:\r\n return DecimalResponse(value=dec_value)\r\n ```\r\n```\r\nmutation decimals($dec_value: Decimal!) {\r\n decimals(\r\n decValue: $dec_value\r\n ) {\r\n ... on DecimalResponse {\r\n value\r\n }\r\n }\r\n}\r\n{\r\n \"dec_value\": 3.14\r\n}\r\n```\r\n\n", "before_files": [{"content": "import datetime\nimport decimal\nimport uuid\nfrom operator import methodcaller\nfrom typing import Callable\n\nimport dateutil.parser\n\nfrom graphql import GraphQLError\n\nfrom strawberry.custom_scalar import scalar\n\n\ndef wrap_parser(parser: Callable, type_: str) -> Callable:\n def inner(value: str):\n try:\n return parser(value)\n except ValueError as e:\n raise GraphQLError(f'Value cannot represent a {type_}: \"{value}\". {e}')\n\n return inner\n\n\ndef parse_decimal(value: str) -> decimal.Decimal:\n try:\n return decimal.Decimal(value)\n except decimal.DecimalException:\n raise GraphQLError(f'Value cannot represent a Decimal: \"{value}\".')\n\n\nisoformat = methodcaller(\"isoformat\")\n\n\nDate = scalar(\n datetime.date,\n name=\"Date\",\n description=\"Date (isoformat)\",\n serialize=isoformat,\n parse_value=wrap_parser(datetime.date.fromisoformat, \"Date\"),\n)\nDateTime = scalar(\n datetime.datetime,\n name=\"DateTime\",\n description=\"Date with time (isoformat)\",\n serialize=isoformat,\n parse_value=wrap_parser(dateutil.parser.isoparse, \"DateTime\"),\n)\nTime = scalar(\n datetime.time,\n name=\"Time\",\n description=\"Time (isoformat)\",\n serialize=isoformat,\n parse_value=wrap_parser(datetime.time.fromisoformat, \"Time\"),\n)\n\nDecimal = scalar(\n decimal.Decimal,\n name=\"Decimal\",\n description=\"Decimal (fixed-point)\",\n serialize=str,\n parse_value=parse_decimal,\n)\n\nUUID = scalar(\n uuid.UUID,\n name=\"UUID\",\n serialize=str,\n parse_value=wrap_parser(uuid.UUID, \"UUID\"),\n)\n\n\ndef _verify_void(x) -> None:\n if x is not None:\n raise ValueError(f\"Expected 'None', got '{x}'\")\n\n\nVoid = scalar(\n type(None),\n name=\"Void\",\n serialize=_verify_void,\n parse_value=_verify_void,\n description=\"Represents NULL values\",\n)\n", "path": "strawberry/schema/types/base_scalars.py"}], "after_files": [{"content": "import datetime\nimport decimal\nimport uuid\nfrom operator import methodcaller\nfrom typing import Callable\n\nimport dateutil.parser\n\nfrom graphql import GraphQLError\n\nfrom strawberry.custom_scalar import scalar\n\n\ndef wrap_parser(parser: Callable, type_: str) -> Callable:\n def inner(value: str):\n try:\n return parser(value)\n except ValueError as e:\n raise GraphQLError(f'Value cannot represent a {type_}: \"{value}\". {e}')\n\n return inner\n\n\ndef parse_decimal(value: object) -> decimal.Decimal:\n try:\n return decimal.Decimal(str(value))\n except decimal.DecimalException:\n raise GraphQLError(f'Value cannot represent a Decimal: \"{value}\".')\n\n\nisoformat = methodcaller(\"isoformat\")\n\n\nDate = scalar(\n datetime.date,\n name=\"Date\",\n description=\"Date (isoformat)\",\n serialize=isoformat,\n parse_value=wrap_parser(datetime.date.fromisoformat, \"Date\"),\n)\nDateTime = scalar(\n datetime.datetime,\n name=\"DateTime\",\n description=\"Date with time (isoformat)\",\n serialize=isoformat,\n parse_value=wrap_parser(dateutil.parser.isoparse, \"DateTime\"),\n)\nTime = scalar(\n datetime.time,\n name=\"Time\",\n description=\"Time (isoformat)\",\n serialize=isoformat,\n parse_value=wrap_parser(datetime.time.fromisoformat, \"Time\"),\n)\n\nDecimal = scalar(\n decimal.Decimal,\n name=\"Decimal\",\n description=\"Decimal (fixed-point)\",\n serialize=str,\n parse_value=parse_decimal,\n)\n\nUUID = scalar(\n uuid.UUID,\n name=\"UUID\",\n serialize=str,\n parse_value=wrap_parser(uuid.UUID, \"UUID\"),\n)\n\n\ndef _verify_void(x) -> None:\n if x is not None:\n raise ValueError(f\"Expected 'None', got '{x}'\")\n\n\nVoid = scalar(\n type(None),\n name=\"Void\",\n serialize=_verify_void,\n parse_value=_verify_void,\n description=\"Represents NULL values\",\n)\n", "path": "strawberry/schema/types/base_scalars.py"}]}
| 1,686 | 133 |
gh_patches_debug_6817
|
rasdani/github-patches
|
git_diff
|
SeldonIO__MLServer-866
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add more debugging information
I am running a custom Python model in MLServer, and it fails with an error. The error itself is not interesting, what's important is that MLServer gives very little helpful information to debug it.
After sending a request with grpcurl here is the entire response:
````
ERROR:
Code: Unknown
Message: Unexpected <class 'TypeError'>: list indices must be integers or slices, not str
````
No stack trace, no line numbers or class names. The only thing that appears in the logs is
> scv2-mlserver-1 | 2022-10-19 09:10:44,218 [mlserver.grpc] INFO - /inference.GRPCInferenceService/ModelInfer
Would be great if MLServer propagated more debugging info to the response message and to the log.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mlserver/grpc/utils.py`
Content:
```
1 import grpc
2
3 from typing import Callable, Dict, Tuple
4 from fastapi import status
5
6 from grpc import ServicerContext
7
8 from .logging import logger
9 from ..errors import MLServerError
10
11
12 STATUS_CODE_MAPPING = {
13 status.HTTP_400_BAD_REQUEST: grpc.StatusCode.INVALID_ARGUMENT,
14 status.HTTP_404_NOT_FOUND: grpc.StatusCode.NOT_FOUND,
15 status.HTTP_422_UNPROCESSABLE_ENTITY: grpc.StatusCode.FAILED_PRECONDITION,
16 status.HTTP_500_INTERNAL_SERVER_ERROR: grpc.StatusCode.INTERNAL,
17 }
18
19
20 def to_headers(context: ServicerContext) -> Dict[str, str]:
21 metadata = context.invocation_metadata()
22 if hasattr(context, "trailing_metadata"):
23 # NOTE: Older versions of `grpcio` (e.g. `grpcio==1.34.0`) don't expose
24 # access to the trailing metadata on the service side
25 metadata += context.trailing_metadata()
26 headers = {}
27 for metadatum in metadata:
28 headers[metadatum.key] = metadatum.value
29
30 return headers
31
32
33 def to_metadata(headers: Dict[str, str]) -> Tuple[Tuple[str, str], ...]:
34 return tuple((key.lower(), value) for key, value in headers.items())
35
36
37 def _grpc_status_code(err: MLServerError):
38 return STATUS_CODE_MAPPING.get(err.status_code, grpc.StatusCode.UNKNOWN)
39
40
41 def handle_mlserver_error(f: Callable):
42 async def _inner(self, request, context):
43 try:
44 return await f(self, request, context)
45 except MLServerError as err:
46 logger.error(err)
47 await context.abort(code=_grpc_status_code(err), details=str(err))
48
49 return _inner
50
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mlserver/grpc/utils.py b/mlserver/grpc/utils.py
--- a/mlserver/grpc/utils.py
+++ b/mlserver/grpc/utils.py
@@ -43,7 +43,10 @@
try:
return await f(self, request, context)
except MLServerError as err:
- logger.error(err)
+ logger.exception(err)
await context.abort(code=_grpc_status_code(err), details=str(err))
+ except Exception as err:
+ logger.exception(err)
+ await context.abort(code=grpc.StatusCode.INTERNAL, details=str(err))
return _inner
|
{"golden_diff": "diff --git a/mlserver/grpc/utils.py b/mlserver/grpc/utils.py\n--- a/mlserver/grpc/utils.py\n+++ b/mlserver/grpc/utils.py\n@@ -43,7 +43,10 @@\n try:\n return await f(self, request, context)\n except MLServerError as err:\n- logger.error(err)\n+ logger.exception(err)\n await context.abort(code=_grpc_status_code(err), details=str(err))\n+ except Exception as err:\n+ logger.exception(err)\n+ await context.abort(code=grpc.StatusCode.INTERNAL, details=str(err))\n \n return _inner\n", "issue": "Add more debugging information\nI am running a custom Python model in MLServer, and it fails with an error. The error itself is not interesting, what's important is that MLServer gives very little helpful information to debug it.\r\n\r\nAfter sending a request with grpcurl here is the entire response:\r\n````\r\nERROR:\r\n Code: Unknown\r\n Message: Unexpected <class 'TypeError'>: list indices must be integers or slices, not str\r\n````\r\nNo stack trace, no line numbers or class names. The only thing that appears in the logs is\r\n> scv2-mlserver-1 | 2022-10-19 09:10:44,218 [mlserver.grpc] INFO - /inference.GRPCInferenceService/ModelInfer\r\n\r\nWould be great if MLServer propagated more debugging info to the response message and to the log.\n", "before_files": [{"content": "import grpc\n\nfrom typing import Callable, Dict, Tuple\nfrom fastapi import status\n\nfrom grpc import ServicerContext\n\nfrom .logging import logger\nfrom ..errors import MLServerError\n\n\nSTATUS_CODE_MAPPING = {\n status.HTTP_400_BAD_REQUEST: grpc.StatusCode.INVALID_ARGUMENT,\n status.HTTP_404_NOT_FOUND: grpc.StatusCode.NOT_FOUND,\n status.HTTP_422_UNPROCESSABLE_ENTITY: grpc.StatusCode.FAILED_PRECONDITION,\n status.HTTP_500_INTERNAL_SERVER_ERROR: grpc.StatusCode.INTERNAL,\n}\n\n\ndef to_headers(context: ServicerContext) -> Dict[str, str]:\n metadata = context.invocation_metadata()\n if hasattr(context, \"trailing_metadata\"):\n # NOTE: Older versions of `grpcio` (e.g. `grpcio==1.34.0`) don't expose\n # access to the trailing metadata on the service side\n metadata += context.trailing_metadata()\n headers = {}\n for metadatum in metadata:\n headers[metadatum.key] = metadatum.value\n\n return headers\n\n\ndef to_metadata(headers: Dict[str, str]) -> Tuple[Tuple[str, str], ...]:\n return tuple((key.lower(), value) for key, value in headers.items())\n\n\ndef _grpc_status_code(err: MLServerError):\n return STATUS_CODE_MAPPING.get(err.status_code, grpc.StatusCode.UNKNOWN)\n\n\ndef handle_mlserver_error(f: Callable):\n async def _inner(self, request, context):\n try:\n return await f(self, request, context)\n except MLServerError as err:\n logger.error(err)\n await context.abort(code=_grpc_status_code(err), details=str(err))\n\n return _inner\n", "path": "mlserver/grpc/utils.py"}], "after_files": [{"content": "import grpc\n\nfrom typing import Callable, Dict, Tuple\nfrom fastapi import status\n\nfrom grpc import ServicerContext\n\nfrom .logging import logger\nfrom ..errors import MLServerError\n\n\nSTATUS_CODE_MAPPING = {\n status.HTTP_400_BAD_REQUEST: grpc.StatusCode.INVALID_ARGUMENT,\n status.HTTP_404_NOT_FOUND: grpc.StatusCode.NOT_FOUND,\n status.HTTP_422_UNPROCESSABLE_ENTITY: grpc.StatusCode.FAILED_PRECONDITION,\n status.HTTP_500_INTERNAL_SERVER_ERROR: grpc.StatusCode.INTERNAL,\n}\n\n\ndef to_headers(context: ServicerContext) -> Dict[str, str]:\n metadata = context.invocation_metadata()\n if hasattr(context, \"trailing_metadata\"):\n # NOTE: Older versions of `grpcio` (e.g. `grpcio==1.34.0`) don't expose\n # access to the trailing metadata on the service side\n metadata += context.trailing_metadata()\n headers = {}\n for metadatum in metadata:\n headers[metadatum.key] = metadatum.value\n\n return headers\n\n\ndef to_metadata(headers: Dict[str, str]) -> Tuple[Tuple[str, str], ...]:\n return tuple((key.lower(), value) for key, value in headers.items())\n\n\ndef _grpc_status_code(err: MLServerError):\n return STATUS_CODE_MAPPING.get(err.status_code, grpc.StatusCode.UNKNOWN)\n\n\ndef handle_mlserver_error(f: Callable):\n async def _inner(self, request, context):\n try:\n return await f(self, request, context)\n except MLServerError as err:\n logger.exception(err)\n await context.abort(code=_grpc_status_code(err), details=str(err))\n except Exception as err:\n logger.exception(err)\n await context.abort(code=grpc.StatusCode.INTERNAL, details=str(err))\n\n return _inner\n", "path": "mlserver/grpc/utils.py"}]}
| 900 | 126 |
gh_patches_debug_39788
|
rasdani/github-patches
|
git_diff
|
cupy__cupy-2145
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Use `ReductionKernel` in k-means example
The k-mean example uses `ElementwiseKernel` as an example of a custom kernel, but its algorithm is essentially reduction rather than mapping. It would be better to use `ReductionKernel` in the k-means example and to provide another example that uses `ElementwiseKernel`.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/kmeans/kmeans.py`
Content:
```
1 import argparse
2 import contextlib
3 import time
4
5 import matplotlib.pyplot as plt
6 import numpy as np
7 import six
8
9 import cupy
10
11
12 @contextlib.contextmanager
13 def timer(message):
14 cupy.cuda.Stream.null.synchronize()
15 start = time.time()
16 yield
17 cupy.cuda.Stream.null.synchronize()
18 end = time.time()
19 print('%s: %f sec' % (message, end - start))
20
21
22 _fit_calc_distances = cupy.ElementwiseKernel(
23 'S data, raw S centers, int32 n_clusters, int32 dim', 'raw S dist',
24 '''
25 for (int j = 0; j < n_clusters; j++){
26 int cent_ind[] = {j, i % dim};
27 int dist_ind[] = {i / dim, j};
28 double diff = centers[cent_ind] - data;
29 atomicAdd(&dist[dist_ind], diff * diff);
30 }
31 ''',
32 'calc_distances'
33 )
34 _fit_calc_center = cupy.ElementwiseKernel(
35 'S data, T label, int32 dim', 'raw S centers, raw S group',
36 '''
37 int cent_ind[] = {label, i % dim};
38 atomicAdd(¢ers[cent_ind], data);
39 atomicAdd(&group[label], 1);
40 ''',
41 'calc_center'
42 )
43
44
45 def fit(X, n_clusters, max_iter, use_custom_kernel):
46 assert X.ndim == 2
47 xp = cupy.get_array_module(X)
48 pred = xp.zeros(len(X), dtype=np.int32)
49 initial_indexes = np.random.choice(len(X), n_clusters,
50 replace=False).astype(np.int32)
51 centers = X[initial_indexes]
52 data_num = X.shape[0]
53 data_dim = X.shape[1]
54
55 for _ in six.moves.range(max_iter):
56 # calculate distances and label
57 if not use_custom_kernel or xp == np:
58 distances = xp.linalg.norm(X[:, None, :] - centers[None, :, :],
59 axis=2)
60 else:
61 distances = xp.zeros((data_num, n_clusters), dtype=np.float32)
62 _fit_calc_distances(X, centers, n_clusters, data_dim, distances)
63
64 new_pred = xp.argmin(distances, axis=1).astype(np.int32)
65 if xp.all(new_pred == pred):
66 break
67 pred = new_pred
68
69 # calculate centers
70 if not use_custom_kernel or xp == np:
71 centers = xp.stack([X[pred == i].mean(axis=0)
72 for i in six.moves.range(n_clusters)])
73 else:
74 centers = xp.zeros((n_clusters, data_dim),
75 dtype=np.float32)
76 group = xp.zeros(n_clusters, dtype=np.float32)
77 label = pred[:, None]
78 _fit_calc_center(X, label, data_dim, centers, group)
79 group /= data_dim
80 centers /= group[:, None]
81
82 return centers, pred
83
84
85 def draw(X, n_clusters, centers, pred, output):
86 xp = cupy.get_array_module(X)
87 for i in six.moves.range(n_clusters):
88 labels = X[pred == i]
89 if xp == cupy:
90 labels = labels.get()
91 plt.scatter(labels[:, 0], labels[:, 1], c=np.random.rand(3))
92 if xp == cupy:
93 centers = centers.get()
94 plt.scatter(centers[:, 0], centers[:, 1], s=120, marker='s',
95 facecolors='y', edgecolors='k')
96 plt.savefig(output)
97
98
99 def run(gpuid, n_clusters, num, max_iter, use_custom_kernel, output):
100 samples = np.random.randn(num, 2).astype(np.float32)
101 X_train = np.r_[samples + 1, samples - 1]
102 repeat = 1
103
104 with timer(' CPU '):
105 for i in range(repeat):
106 centers, pred = fit(X_train, n_clusters, max_iter,
107 use_custom_kernel)
108
109 with cupy.cuda.Device(gpuid):
110 X_train = cupy.asarray(X_train)
111 with timer(' GPU '):
112 for i in range(repeat):
113 centers, pred = fit(X_train, n_clusters, max_iter,
114 use_custom_kernel)
115 if output is not None:
116 index = np.random.choice(10000000, 300, replace=False)
117 draw(X_train[index], n_clusters, centers, pred[index], output)
118
119
120 if __name__ == '__main__':
121 parser = argparse.ArgumentParser()
122 parser.add_argument('--gpu-id', '-g', default=0, type=int,
123 help='ID of GPU.')
124 parser.add_argument('--n-clusters', '-n', default=2, type=int,
125 help='number of clusters')
126 parser.add_argument('--num', default=5000000, type=int,
127 help='number of samples')
128 parser.add_argument('--max-iter', '-m', default=10, type=int,
129 help='number of iterations')
130 parser.add_argument('--use-custom-kernel', action='store_true',
131 default=False, help='use Elementwise kernel')
132 parser.add_argument('--output-image', '-o', default=None, type=str,
133 help='output image file name')
134 args = parser.parse_args()
135 run(args.gpu_id, args.n_clusters, args.num, args.max_iter,
136 args.use_custom_kernel, args.output_image)
137
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/kmeans/kmeans.py b/examples/kmeans/kmeans.py
--- a/examples/kmeans/kmeans.py
+++ b/examples/kmeans/kmeans.py
@@ -19,26 +19,22 @@
print('%s: %f sec' % (message, end - start))
-_fit_calc_distances = cupy.ElementwiseKernel(
- 'S data, raw S centers, int32 n_clusters, int32 dim', 'raw S dist',
- '''
- for (int j = 0; j < n_clusters; j++){
- int cent_ind[] = {j, i % dim};
- int dist_ind[] = {i / dim, j};
- double diff = centers[cent_ind] - data;
- atomicAdd(&dist[dist_ind], diff * diff);
- }
- ''',
- 'calc_distances'
+var_kernel = cupy.ElementwiseKernel(
+ 'T x0, T x1, T c0, T c1', 'T out',
+ 'out = (x0 - c0) * (x0 - c0) + (x1 - c1) * (x1 - c1)',
+ 'var_kernel'
)
-_fit_calc_center = cupy.ElementwiseKernel(
- 'S data, T label, int32 dim', 'raw S centers, raw S group',
- '''
- int cent_ind[] = {label, i % dim};
- atomicAdd(¢ers[cent_ind], data);
- atomicAdd(&group[label], 1);
- ''',
- 'calc_center'
+sum_kernel = cupy.ReductionKernel(
+ 'T x, S mask', 'T out',
+ 'mask ? x : 0',
+ 'a + b', 'out = a', '0',
+ 'sum_kernel'
+)
+count_kernel = cupy.ReductionKernel(
+ 'T mask', 'float32 out',
+ 'mask ? 1.0 : 0.0',
+ 'a + b', 'out = a', '0.0',
+ 'count_kernel'
)
@@ -49,8 +45,6 @@
initial_indexes = np.random.choice(len(X), n_clusters,
replace=False).astype(np.int32)
centers = X[initial_indexes]
- data_num = X.shape[0]
- data_dim = X.shape[1]
for _ in six.moves.range(max_iter):
# calculate distances and label
@@ -58,8 +52,8 @@
distances = xp.linalg.norm(X[:, None, :] - centers[None, :, :],
axis=2)
else:
- distances = xp.zeros((data_num, n_clusters), dtype=np.float32)
- _fit_calc_distances(X, centers, n_clusters, data_dim, distances)
+ distances = var_kernel(X[:, None, 0], X[:, None, 1],
+ centers[None, :, 1], centers[None, :, 0])
new_pred = xp.argmin(distances, axis=1).astype(np.int32)
if xp.all(new_pred == pred):
@@ -67,17 +61,16 @@
pred = new_pred
# calculate centers
+ i = xp.arange(n_clusters)
+ mask = pred == i[:, None]
if not use_custom_kernel or xp == np:
- centers = xp.stack([X[pred == i].mean(axis=0)
- for i in six.moves.range(n_clusters)])
+ sums = xp.where(mask[:, :, None], X, 0).sum(axis=1)
+ counts = xp.count_nonzero(mask, axis=1)
+ centers = sums / counts
else:
- centers = xp.zeros((n_clusters, data_dim),
- dtype=np.float32)
- group = xp.zeros(n_clusters, dtype=np.float32)
- label = pred[:, None]
- _fit_calc_center(X, label, data_dim, centers, group)
- group /= data_dim
- centers /= group[:, None]
+ sums = sum_kernel(X, mask[:, :, None], axis=1)
+ counts = count_kernel(mask, axis=1)
+ centers = sums / counts
return centers, pred
|
{"golden_diff": "diff --git a/examples/kmeans/kmeans.py b/examples/kmeans/kmeans.py\n--- a/examples/kmeans/kmeans.py\n+++ b/examples/kmeans/kmeans.py\n@@ -19,26 +19,22 @@\n print('%s: %f sec' % (message, end - start))\n \n \n-_fit_calc_distances = cupy.ElementwiseKernel(\n- 'S data, raw S centers, int32 n_clusters, int32 dim', 'raw S dist',\n- '''\n- for (int j = 0; j < n_clusters; j++){\n- int cent_ind[] = {j, i % dim};\n- int dist_ind[] = {i / dim, j};\n- double diff = centers[cent_ind] - data;\n- atomicAdd(&dist[dist_ind], diff * diff);\n- }\n- ''',\n- 'calc_distances'\n+var_kernel = cupy.ElementwiseKernel(\n+ 'T x0, T x1, T c0, T c1', 'T out',\n+ 'out = (x0 - c0) * (x0 - c0) + (x1 - c1) * (x1 - c1)',\n+ 'var_kernel'\n )\n-_fit_calc_center = cupy.ElementwiseKernel(\n- 'S data, T label, int32 dim', 'raw S centers, raw S group',\n- '''\n- int cent_ind[] = {label, i % dim};\n- atomicAdd(¢ers[cent_ind], data);\n- atomicAdd(&group[label], 1);\n- ''',\n- 'calc_center'\n+sum_kernel = cupy.ReductionKernel(\n+ 'T x, S mask', 'T out',\n+ 'mask ? x : 0',\n+ 'a + b', 'out = a', '0',\n+ 'sum_kernel'\n+)\n+count_kernel = cupy.ReductionKernel(\n+ 'T mask', 'float32 out',\n+ 'mask ? 1.0 : 0.0',\n+ 'a + b', 'out = a', '0.0',\n+ 'count_kernel'\n )\n \n \n@@ -49,8 +45,6 @@\n initial_indexes = np.random.choice(len(X), n_clusters,\n replace=False).astype(np.int32)\n centers = X[initial_indexes]\n- data_num = X.shape[0]\n- data_dim = X.shape[1]\n \n for _ in six.moves.range(max_iter):\n # calculate distances and label\n@@ -58,8 +52,8 @@\n distances = xp.linalg.norm(X[:, None, :] - centers[None, :, :],\n axis=2)\n else:\n- distances = xp.zeros((data_num, n_clusters), dtype=np.float32)\n- _fit_calc_distances(X, centers, n_clusters, data_dim, distances)\n+ distances = var_kernel(X[:, None, 0], X[:, None, 1],\n+ centers[None, :, 1], centers[None, :, 0])\n \n new_pred = xp.argmin(distances, axis=1).astype(np.int32)\n if xp.all(new_pred == pred):\n@@ -67,17 +61,16 @@\n pred = new_pred\n \n # calculate centers\n+ i = xp.arange(n_clusters)\n+ mask = pred == i[:, None]\n if not use_custom_kernel or xp == np:\n- centers = xp.stack([X[pred == i].mean(axis=0)\n- for i in six.moves.range(n_clusters)])\n+ sums = xp.where(mask[:, :, None], X, 0).sum(axis=1)\n+ counts = xp.count_nonzero(mask, axis=1)\n+ centers = sums / counts\n else:\n- centers = xp.zeros((n_clusters, data_dim),\n- dtype=np.float32)\n- group = xp.zeros(n_clusters, dtype=np.float32)\n- label = pred[:, None]\n- _fit_calc_center(X, label, data_dim, centers, group)\n- group /= data_dim\n- centers /= group[:, None]\n+ sums = sum_kernel(X, mask[:, :, None], axis=1)\n+ counts = count_kernel(mask, axis=1)\n+ centers = sums / counts\n \n return centers, pred\n", "issue": "Use `ReductionKernel` in k-means example\nThe k-mean example uses `ElementwiseKernel` as an example of a custom kernel, but its algorithm is essentially reduction rather than mapping. It would be better to use `ReductionKernel` in the k-means example and to provide another example that uses `ElementwiseKernel`.\n", "before_files": [{"content": "import argparse\nimport contextlib\nimport time\n\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport six\n\nimport cupy\n\n\[email protected]\ndef timer(message):\n cupy.cuda.Stream.null.synchronize()\n start = time.time()\n yield\n cupy.cuda.Stream.null.synchronize()\n end = time.time()\n print('%s: %f sec' % (message, end - start))\n\n\n_fit_calc_distances = cupy.ElementwiseKernel(\n 'S data, raw S centers, int32 n_clusters, int32 dim', 'raw S dist',\n '''\n for (int j = 0; j < n_clusters; j++){\n int cent_ind[] = {j, i % dim};\n int dist_ind[] = {i / dim, j};\n double diff = centers[cent_ind] - data;\n atomicAdd(&dist[dist_ind], diff * diff);\n }\n ''',\n 'calc_distances'\n)\n_fit_calc_center = cupy.ElementwiseKernel(\n 'S data, T label, int32 dim', 'raw S centers, raw S group',\n '''\n int cent_ind[] = {label, i % dim};\n atomicAdd(¢ers[cent_ind], data);\n atomicAdd(&group[label], 1);\n ''',\n 'calc_center'\n)\n\n\ndef fit(X, n_clusters, max_iter, use_custom_kernel):\n assert X.ndim == 2\n xp = cupy.get_array_module(X)\n pred = xp.zeros(len(X), dtype=np.int32)\n initial_indexes = np.random.choice(len(X), n_clusters,\n replace=False).astype(np.int32)\n centers = X[initial_indexes]\n data_num = X.shape[0]\n data_dim = X.shape[1]\n\n for _ in six.moves.range(max_iter):\n # calculate distances and label\n if not use_custom_kernel or xp == np:\n distances = xp.linalg.norm(X[:, None, :] - centers[None, :, :],\n axis=2)\n else:\n distances = xp.zeros((data_num, n_clusters), dtype=np.float32)\n _fit_calc_distances(X, centers, n_clusters, data_dim, distances)\n\n new_pred = xp.argmin(distances, axis=1).astype(np.int32)\n if xp.all(new_pred == pred):\n break\n pred = new_pred\n\n # calculate centers\n if not use_custom_kernel or xp == np:\n centers = xp.stack([X[pred == i].mean(axis=0)\n for i in six.moves.range(n_clusters)])\n else:\n centers = xp.zeros((n_clusters, data_dim),\n dtype=np.float32)\n group = xp.zeros(n_clusters, dtype=np.float32)\n label = pred[:, None]\n _fit_calc_center(X, label, data_dim, centers, group)\n group /= data_dim\n centers /= group[:, None]\n\n return centers, pred\n\n\ndef draw(X, n_clusters, centers, pred, output):\n xp = cupy.get_array_module(X)\n for i in six.moves.range(n_clusters):\n labels = X[pred == i]\n if xp == cupy:\n labels = labels.get()\n plt.scatter(labels[:, 0], labels[:, 1], c=np.random.rand(3))\n if xp == cupy:\n centers = centers.get()\n plt.scatter(centers[:, 0], centers[:, 1], s=120, marker='s',\n facecolors='y', edgecolors='k')\n plt.savefig(output)\n\n\ndef run(gpuid, n_clusters, num, max_iter, use_custom_kernel, output):\n samples = np.random.randn(num, 2).astype(np.float32)\n X_train = np.r_[samples + 1, samples - 1]\n repeat = 1\n\n with timer(' CPU '):\n for i in range(repeat):\n centers, pred = fit(X_train, n_clusters, max_iter,\n use_custom_kernel)\n\n with cupy.cuda.Device(gpuid):\n X_train = cupy.asarray(X_train)\n with timer(' GPU '):\n for i in range(repeat):\n centers, pred = fit(X_train, n_clusters, max_iter,\n use_custom_kernel)\n if output is not None:\n index = np.random.choice(10000000, 300, replace=False)\n draw(X_train[index], n_clusters, centers, pred[index], output)\n\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser()\n parser.add_argument('--gpu-id', '-g', default=0, type=int,\n help='ID of GPU.')\n parser.add_argument('--n-clusters', '-n', default=2, type=int,\n help='number of clusters')\n parser.add_argument('--num', default=5000000, type=int,\n help='number of samples')\n parser.add_argument('--max-iter', '-m', default=10, type=int,\n help='number of iterations')\n parser.add_argument('--use-custom-kernel', action='store_true',\n default=False, help='use Elementwise kernel')\n parser.add_argument('--output-image', '-o', default=None, type=str,\n help='output image file name')\n args = parser.parse_args()\n run(args.gpu_id, args.n_clusters, args.num, args.max_iter,\n args.use_custom_kernel, args.output_image)\n", "path": "examples/kmeans/kmeans.py"}], "after_files": [{"content": "import argparse\nimport contextlib\nimport time\n\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport six\n\nimport cupy\n\n\[email protected]\ndef timer(message):\n cupy.cuda.Stream.null.synchronize()\n start = time.time()\n yield\n cupy.cuda.Stream.null.synchronize()\n end = time.time()\n print('%s: %f sec' % (message, end - start))\n\n\nvar_kernel = cupy.ElementwiseKernel(\n 'T x0, T x1, T c0, T c1', 'T out',\n 'out = (x0 - c0) * (x0 - c0) + (x1 - c1) * (x1 - c1)',\n 'var_kernel'\n)\nsum_kernel = cupy.ReductionKernel(\n 'T x, S mask', 'T out',\n 'mask ? x : 0',\n 'a + b', 'out = a', '0',\n 'sum_kernel'\n)\ncount_kernel = cupy.ReductionKernel(\n 'T mask', 'float32 out',\n 'mask ? 1.0 : 0.0',\n 'a + b', 'out = a', '0.0',\n 'count_kernel'\n)\n\n\ndef fit(X, n_clusters, max_iter, use_custom_kernel):\n assert X.ndim == 2\n xp = cupy.get_array_module(X)\n pred = xp.zeros(len(X), dtype=np.int32)\n initial_indexes = np.random.choice(len(X), n_clusters,\n replace=False).astype(np.int32)\n centers = X[initial_indexes]\n\n for _ in six.moves.range(max_iter):\n # calculate distances and label\n if not use_custom_kernel or xp == np:\n distances = xp.linalg.norm(X[:, None, :] - centers[None, :, :],\n axis=2)\n else:\n distances = var_kernel(X[:, None, 0], X[:, None, 1],\n centers[None, :, 1], centers[None, :, 0])\n\n new_pred = xp.argmin(distances, axis=1).astype(np.int32)\n if xp.all(new_pred == pred):\n break\n pred = new_pred\n\n # calculate centers\n i = xp.arange(n_clusters)\n mask = pred == i[:, None]\n if not use_custom_kernel or xp == np:\n sums = xp.where(mask[:, :, None], X, 0).sum(axis=1)\n counts = xp.count_nonzero(mask, axis=1)\n centers = sums / counts\n else:\n sums = sum_kernel(X, mask[:, :, None], axis=1)\n counts = count_kernel(mask, axis=1)\n centers = sums / counts\n\n return centers, pred\n\n\ndef draw(X, n_clusters, centers, pred, output):\n xp = cupy.get_array_module(X)\n for i in six.moves.range(n_clusters):\n labels = X[pred == i]\n if xp == cupy:\n labels = labels.get()\n plt.scatter(labels[:, 0], labels[:, 1], c=np.random.rand(3))\n if xp == cupy:\n centers = centers.get()\n plt.scatter(centers[:, 0], centers[:, 1], s=120, marker='s',\n facecolors='y', edgecolors='k')\n plt.savefig(output)\n\n\ndef run(gpuid, n_clusters, num, max_iter, use_custom_kernel, output):\n samples = np.random.randn(num, 2).astype(np.float32)\n X_train = np.r_[samples + 1, samples - 1]\n repeat = 1\n\n with timer(' CPU '):\n for i in range(repeat):\n centers, pred = fit(X_train, n_clusters, max_iter,\n use_custom_kernel)\n\n with cupy.cuda.Device(gpuid):\n X_train = cupy.asarray(X_train)\n with timer(' GPU '):\n for i in range(repeat):\n centers, pred = fit(X_train, n_clusters, max_iter,\n use_custom_kernel)\n if output is not None:\n index = np.random.choice(10000000, 300, replace=False)\n draw(X_train[index], n_clusters, centers, pred[index], output)\n\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser()\n parser.add_argument('--gpu-id', '-g', default=0, type=int,\n help='ID of GPU.')\n parser.add_argument('--n-clusters', '-n', default=2, type=int,\n help='number of clusters')\n parser.add_argument('--num', default=5000000, type=int,\n help='number of samples')\n parser.add_argument('--max-iter', '-m', default=10, type=int,\n help='number of iterations')\n parser.add_argument('--use-custom-kernel', action='store_true',\n default=False, help='use Elementwise kernel')\n parser.add_argument('--output-image', '-o', default=None, type=str,\n help='output image file name')\n args = parser.parse_args()\n run(args.gpu_id, args.n_clusters, args.num, args.max_iter,\n args.use_custom_kernel, args.output_image)\n", "path": "examples/kmeans/kmeans.py"}]}
| 1,806 | 946 |
gh_patches_debug_38523
|
rasdani/github-patches
|
git_diff
|
ietf-tools__datatracker-5167
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
/sync/discrepancies is missing `.distinct()`
At the moment in the second table:

Likely this will not show the same when viewed shortly after now, as I expect the state to be reconciled quickly.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ietf/sync/discrepancies.py`
Content:
```
1 from django.db import models
2 from ietf.doc.models import Document, State
3
4 def find_discrepancies():
5 res = []
6
7 title = "Internet-Drafts that have been sent to the RFC Editor but do not have an RFC Editor state"
8
9 docs = Document.objects.filter(states__in=list(State.objects.filter(used=True, type="draft-iesg", slug__in=("ann", "rfcqueue")))).exclude(states__in=list(State.objects.filter(used=True, type="draft-rfceditor")))
10
11 res.append((title, docs))
12
13 title = "Internet-Drafts that have the IANA Action state \"In Progress\" but do not have a \"IANA\" RFC-Editor state/tag"
14
15 docs = Document.objects.filter(states__in=list(State.objects.filter(used=True, type="draft-iana-action", slug__in=("inprog",)))).exclude(tags="iana").exclude(states__in=list(State.objects.filter(used=True, type="draft-rfceditor", slug="iana")))
16
17 res.append((title, docs))
18
19 title = "Internet-Drafts that have the IANA Action state \"Waiting on RFC Editor\" or \"RFC-Ed-Ack\" but are in the RFC Editor state \"IANA\"/tagged with \"IANA\""
20
21 docs = Document.objects.filter(states__in=list(State.objects.filter(used=True, type="draft-iana-action", slug__in=("waitrfc", "rfcedack")))).filter(models.Q(tags="iana") | models.Q(states__in=list(State.objects.filter(used=True, type="draft-rfceditor", slug="iana"))))
22
23 res.append((title, docs))
24
25 title = "Internet-Drafts that have a state other than \"RFC Ed Queue\", \"RFC Published\" or \"Sent to the RFC Editor\" and have an RFC Editor or IANA Action state"
26
27 docs = Document.objects.exclude(states__in=list(State.objects.filter(used=True, type="draft-iesg", slug__in=("rfcqueue", "pub"))) + list(State.objects.filter(used=True, type__in=("draft-stream-iab", "draft-stream-ise", "draft-stream-irtf"), slug="rfc-edit"))).filter(states__in=list(State.objects.filter(used=True, type__in=("draft-iana-action", "draft-rfceditor"))))
28
29 res.append((title, docs))
30
31 for _, docs in res:
32 for d in docs:
33 d.iesg_state = d.get_state("draft-iesg")
34 d.rfc_state = d.get_state("draft-rfceditor")
35 d.iana_action_state = d.get_state("draft-iana-action")
36
37 return res
38
39
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ietf/sync/discrepancies.py b/ietf/sync/discrepancies.py
--- a/ietf/sync/discrepancies.py
+++ b/ietf/sync/discrepancies.py
@@ -6,25 +6,25 @@
title = "Internet-Drafts that have been sent to the RFC Editor but do not have an RFC Editor state"
- docs = Document.objects.filter(states__in=list(State.objects.filter(used=True, type="draft-iesg", slug__in=("ann", "rfcqueue")))).exclude(states__in=list(State.objects.filter(used=True, type="draft-rfceditor")))
+ docs = Document.objects.filter(states__in=list(State.objects.filter(used=True, type="draft-iesg", slug__in=("ann", "rfcqueue")))).exclude(states__in=list(State.objects.filter(used=True, type="draft-rfceditor"))).distinct()
res.append((title, docs))
title = "Internet-Drafts that have the IANA Action state \"In Progress\" but do not have a \"IANA\" RFC-Editor state/tag"
- docs = Document.objects.filter(states__in=list(State.objects.filter(used=True, type="draft-iana-action", slug__in=("inprog",)))).exclude(tags="iana").exclude(states__in=list(State.objects.filter(used=True, type="draft-rfceditor", slug="iana")))
+ docs = Document.objects.filter(states__in=list(State.objects.filter(used=True, type="draft-iana-action", slug__in=("inprog",)))).exclude(tags="iana").exclude(states__in=list(State.objects.filter(used=True, type="draft-rfceditor", slug="iana"))).distinct()
res.append((title, docs))
title = "Internet-Drafts that have the IANA Action state \"Waiting on RFC Editor\" or \"RFC-Ed-Ack\" but are in the RFC Editor state \"IANA\"/tagged with \"IANA\""
- docs = Document.objects.filter(states__in=list(State.objects.filter(used=True, type="draft-iana-action", slug__in=("waitrfc", "rfcedack")))).filter(models.Q(tags="iana") | models.Q(states__in=list(State.objects.filter(used=True, type="draft-rfceditor", slug="iana"))))
+ docs = Document.objects.filter(states__in=list(State.objects.filter(used=True, type="draft-iana-action", slug__in=("waitrfc", "rfcedack")))).filter(models.Q(tags="iana") | models.Q(states__in=list(State.objects.filter(used=True, type="draft-rfceditor", slug="iana")))).distinct()
res.append((title, docs))
title = "Internet-Drafts that have a state other than \"RFC Ed Queue\", \"RFC Published\" or \"Sent to the RFC Editor\" and have an RFC Editor or IANA Action state"
- docs = Document.objects.exclude(states__in=list(State.objects.filter(used=True, type="draft-iesg", slug__in=("rfcqueue", "pub"))) + list(State.objects.filter(used=True, type__in=("draft-stream-iab", "draft-stream-ise", "draft-stream-irtf"), slug="rfc-edit"))).filter(states__in=list(State.objects.filter(used=True, type__in=("draft-iana-action", "draft-rfceditor"))))
+ docs = Document.objects.exclude(states__in=list(State.objects.filter(used=True, type="draft-iesg", slug__in=("rfcqueue", "pub"))) + list(State.objects.filter(used=True, type__in=("draft-stream-iab", "draft-stream-ise", "draft-stream-irtf"), slug="rfc-edit"))).filter(states__in=list(State.objects.filter(used=True, type__in=("draft-iana-action", "draft-rfceditor")))).distinct()
res.append((title, docs))
|
{"golden_diff": "diff --git a/ietf/sync/discrepancies.py b/ietf/sync/discrepancies.py\n--- a/ietf/sync/discrepancies.py\n+++ b/ietf/sync/discrepancies.py\n@@ -6,25 +6,25 @@\n \n title = \"Internet-Drafts that have been sent to the RFC Editor but do not have an RFC Editor state\"\n \n- docs = Document.objects.filter(states__in=list(State.objects.filter(used=True, type=\"draft-iesg\", slug__in=(\"ann\", \"rfcqueue\")))).exclude(states__in=list(State.objects.filter(used=True, type=\"draft-rfceditor\")))\n+ docs = Document.objects.filter(states__in=list(State.objects.filter(used=True, type=\"draft-iesg\", slug__in=(\"ann\", \"rfcqueue\")))).exclude(states__in=list(State.objects.filter(used=True, type=\"draft-rfceditor\"))).distinct()\n \n res.append((title, docs))\n \n title = \"Internet-Drafts that have the IANA Action state \\\"In Progress\\\" but do not have a \\\"IANA\\\" RFC-Editor state/tag\"\n \n- docs = Document.objects.filter(states__in=list(State.objects.filter(used=True, type=\"draft-iana-action\", slug__in=(\"inprog\",)))).exclude(tags=\"iana\").exclude(states__in=list(State.objects.filter(used=True, type=\"draft-rfceditor\", slug=\"iana\")))\n+ docs = Document.objects.filter(states__in=list(State.objects.filter(used=True, type=\"draft-iana-action\", slug__in=(\"inprog\",)))).exclude(tags=\"iana\").exclude(states__in=list(State.objects.filter(used=True, type=\"draft-rfceditor\", slug=\"iana\"))).distinct()\n \n res.append((title, docs))\n \n title = \"Internet-Drafts that have the IANA Action state \\\"Waiting on RFC Editor\\\" or \\\"RFC-Ed-Ack\\\" but are in the RFC Editor state \\\"IANA\\\"/tagged with \\\"IANA\\\"\"\n \n- docs = Document.objects.filter(states__in=list(State.objects.filter(used=True, type=\"draft-iana-action\", slug__in=(\"waitrfc\", \"rfcedack\")))).filter(models.Q(tags=\"iana\") | models.Q(states__in=list(State.objects.filter(used=True, type=\"draft-rfceditor\", slug=\"iana\"))))\n+ docs = Document.objects.filter(states__in=list(State.objects.filter(used=True, type=\"draft-iana-action\", slug__in=(\"waitrfc\", \"rfcedack\")))).filter(models.Q(tags=\"iana\") | models.Q(states__in=list(State.objects.filter(used=True, type=\"draft-rfceditor\", slug=\"iana\")))).distinct()\n \n res.append((title, docs))\n \n title = \"Internet-Drafts that have a state other than \\\"RFC Ed Queue\\\", \\\"RFC Published\\\" or \\\"Sent to the RFC Editor\\\" and have an RFC Editor or IANA Action state\"\n \n- docs = Document.objects.exclude(states__in=list(State.objects.filter(used=True, type=\"draft-iesg\", slug__in=(\"rfcqueue\", \"pub\"))) + list(State.objects.filter(used=True, type__in=(\"draft-stream-iab\", \"draft-stream-ise\", \"draft-stream-irtf\"), slug=\"rfc-edit\"))).filter(states__in=list(State.objects.filter(used=True, type__in=(\"draft-iana-action\", \"draft-rfceditor\"))))\n+ docs = Document.objects.exclude(states__in=list(State.objects.filter(used=True, type=\"draft-iesg\", slug__in=(\"rfcqueue\", \"pub\"))) + list(State.objects.filter(used=True, type__in=(\"draft-stream-iab\", \"draft-stream-ise\", \"draft-stream-irtf\"), slug=\"rfc-edit\"))).filter(states__in=list(State.objects.filter(used=True, type__in=(\"draft-iana-action\", \"draft-rfceditor\")))).distinct()\n \n res.append((title, docs))\n", "issue": "/sync/discrepancies is missing `.distinct()`\nAt the moment in the second table:\r\n\r\nLikely this will not show the same when viewed shortly after now, as I expect the state to be reconciled quickly.\n", "before_files": [{"content": "from django.db import models\nfrom ietf.doc.models import Document, State\n\ndef find_discrepancies():\n res = []\n\n title = \"Internet-Drafts that have been sent to the RFC Editor but do not have an RFC Editor state\"\n\n docs = Document.objects.filter(states__in=list(State.objects.filter(used=True, type=\"draft-iesg\", slug__in=(\"ann\", \"rfcqueue\")))).exclude(states__in=list(State.objects.filter(used=True, type=\"draft-rfceditor\")))\n\n res.append((title, docs))\n\n title = \"Internet-Drafts that have the IANA Action state \\\"In Progress\\\" but do not have a \\\"IANA\\\" RFC-Editor state/tag\"\n\n docs = Document.objects.filter(states__in=list(State.objects.filter(used=True, type=\"draft-iana-action\", slug__in=(\"inprog\",)))).exclude(tags=\"iana\").exclude(states__in=list(State.objects.filter(used=True, type=\"draft-rfceditor\", slug=\"iana\")))\n\n res.append((title, docs))\n\n title = \"Internet-Drafts that have the IANA Action state \\\"Waiting on RFC Editor\\\" or \\\"RFC-Ed-Ack\\\" but are in the RFC Editor state \\\"IANA\\\"/tagged with \\\"IANA\\\"\"\n\n docs = Document.objects.filter(states__in=list(State.objects.filter(used=True, type=\"draft-iana-action\", slug__in=(\"waitrfc\", \"rfcedack\")))).filter(models.Q(tags=\"iana\") | models.Q(states__in=list(State.objects.filter(used=True, type=\"draft-rfceditor\", slug=\"iana\"))))\n\n res.append((title, docs))\n\n title = \"Internet-Drafts that have a state other than \\\"RFC Ed Queue\\\", \\\"RFC Published\\\" or \\\"Sent to the RFC Editor\\\" and have an RFC Editor or IANA Action state\"\n\n docs = Document.objects.exclude(states__in=list(State.objects.filter(used=True, type=\"draft-iesg\", slug__in=(\"rfcqueue\", \"pub\"))) + list(State.objects.filter(used=True, type__in=(\"draft-stream-iab\", \"draft-stream-ise\", \"draft-stream-irtf\"), slug=\"rfc-edit\"))).filter(states__in=list(State.objects.filter(used=True, type__in=(\"draft-iana-action\", \"draft-rfceditor\"))))\n\n res.append((title, docs))\n\n for _, docs in res:\n for d in docs:\n d.iesg_state = d.get_state(\"draft-iesg\")\n d.rfc_state = d.get_state(\"draft-rfceditor\")\n d.iana_action_state = d.get_state(\"draft-iana-action\")\n\n return res\n\n", "path": "ietf/sync/discrepancies.py"}], "after_files": [{"content": "from django.db import models\nfrom ietf.doc.models import Document, State\n\ndef find_discrepancies():\n res = []\n\n title = \"Internet-Drafts that have been sent to the RFC Editor but do not have an RFC Editor state\"\n\n docs = Document.objects.filter(states__in=list(State.objects.filter(used=True, type=\"draft-iesg\", slug__in=(\"ann\", \"rfcqueue\")))).exclude(states__in=list(State.objects.filter(used=True, type=\"draft-rfceditor\"))).distinct()\n\n res.append((title, docs))\n\n title = \"Internet-Drafts that have the IANA Action state \\\"In Progress\\\" but do not have a \\\"IANA\\\" RFC-Editor state/tag\"\n\n docs = Document.objects.filter(states__in=list(State.objects.filter(used=True, type=\"draft-iana-action\", slug__in=(\"inprog\",)))).exclude(tags=\"iana\").exclude(states__in=list(State.objects.filter(used=True, type=\"draft-rfceditor\", slug=\"iana\"))).distinct()\n\n res.append((title, docs))\n\n title = \"Internet-Drafts that have the IANA Action state \\\"Waiting on RFC Editor\\\" or \\\"RFC-Ed-Ack\\\" but are in the RFC Editor state \\\"IANA\\\"/tagged with \\\"IANA\\\"\"\n\n docs = Document.objects.filter(states__in=list(State.objects.filter(used=True, type=\"draft-iana-action\", slug__in=(\"waitrfc\", \"rfcedack\")))).filter(models.Q(tags=\"iana\") | models.Q(states__in=list(State.objects.filter(used=True, type=\"draft-rfceditor\", slug=\"iana\")))).distinct()\n\n res.append((title, docs))\n\n title = \"Internet-Drafts that have a state other than \\\"RFC Ed Queue\\\", \\\"RFC Published\\\" or \\\"Sent to the RFC Editor\\\" and have an RFC Editor or IANA Action state\"\n\n docs = Document.objects.exclude(states__in=list(State.objects.filter(used=True, type=\"draft-iesg\", slug__in=(\"rfcqueue\", \"pub\"))) + list(State.objects.filter(used=True, type__in=(\"draft-stream-iab\", \"draft-stream-ise\", \"draft-stream-irtf\"), slug=\"rfc-edit\"))).filter(states__in=list(State.objects.filter(used=True, type__in=(\"draft-iana-action\", \"draft-rfceditor\")))).distinct()\n\n res.append((title, docs))\n\n for _, docs in res:\n for d in docs:\n d.iesg_state = d.get_state(\"draft-iesg\")\n d.rfc_state = d.get_state(\"draft-rfceditor\")\n d.iana_action_state = d.get_state(\"draft-iana-action\")\n\n return res\n\n", "path": "ietf/sync/discrepancies.py"}]}
| 1,017 | 854 |
gh_patches_debug_9564
|
rasdani/github-patches
|
git_diff
|
watchdogpolska__small_eod-494
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
udostępnienie id w API dla tags i documentType
Id dla tags i documetType, jest niezbędne dla zbudowania listy tych elementów w reakcie.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `backend-project/small_eod/letters/serializers.py`
Content:
```
1 from uuid import uuid4
2 from django.conf import settings
3 from rest_framework import serializers
4 from .models import Letter, DocumentType
5 from ..generic.serializers import UserLogModelSerializer
6 from ..cases.models import Case
7 from ..institutions.models import Institution
8 from ..channels.models import Channel
9 from ..files.apps import minio_app
10 from ..files.serializers import FileSerializer
11
12
13 class DocumentTypeSerializer(serializers.ModelSerializer):
14 class Meta:
15 model = DocumentType
16 fields = ["name"]
17
18
19 class LetterSerializer(UserLogModelSerializer):
20 document_type = serializers.PrimaryKeyRelatedField(
21 many=False, default=None, queryset=DocumentType.objects.all()
22 )
23 case = serializers.PrimaryKeyRelatedField(
24 many=False, default=None, queryset=Case.objects.all()
25 )
26 institution = serializers.PrimaryKeyRelatedField(
27 many=False, default=None, queryset=Institution.objects.all()
28 )
29 channel = serializers.PrimaryKeyRelatedField(
30 many=False, default=None, queryset=Channel.objects.all()
31 )
32 attachments = FileSerializer(many=True, read_only=True)
33
34 class Meta:
35 model = Letter
36 fields = [
37 "id",
38 "direction",
39 "channel",
40 "final",
41 "date",
42 "reference_number",
43 "institution",
44 "case",
45 "attachments",
46 "ordering",
47 "comment",
48 "excerpt",
49 "document_type",
50 "created_on",
51 "created_by",
52 "modified_on",
53 "modified_by",
54 ]
55
56 def create(self, validated_data):
57 channel = validated_data.pop("channel")
58 document_type = validated_data.pop("document_type")
59 institution = validated_data.pop("institution")
60 case = validated_data.pop("case")
61
62 letter = super().create(validated_data)
63 letter.channel = channel
64 letter.document_type = document_type
65 letter.institution = institution
66 letter.case = case
67 letter.save()
68 return letter
69
70 def update(self, instance, validated_data):
71 """
72 nested - variable storing representations of the nested objects
73 of LetterSerializer (Channel, Address and DocumentType).
74 Iterating over those 3 and updating fields of the related objects,
75 using key-value pairs from PATCH request.
76 """
77 nested = []
78 for nested_object in nested:
79 for attr, value in nested_object["data"].items():
80 setattr(nested_object["instance"], attr, value)
81 nested_object["instance"].save()
82 return super().update(instance, validated_data)
83
84
85 class SignRequestSerializer(serializers.Serializer):
86 name = serializers.CharField(max_length=200)
87 method = serializers.CharField(read_only=True)
88 url = serializers.CharField(read_only=True)
89 formData = serializers.DictField(read_only=True, child=serializers.CharField())
90 path = serializers.CharField(read_only=True)
91
92 def create(self, validated_data):
93 path = f'{uuid4()}/{validated_data["name"]}'
94 url, form_data = minio_app.presigned_post_form_data(settings.MINIO_BUCKET, path)
95 return {
96 "name": validated_data["name"],
97 "method": "POST",
98 "url": url,
99 "formData": form_data,
100 "path": path,
101 }
102
```
Path: `backend-project/small_eod/tags/serializers.py`
Content:
```
1 from rest_framework import serializers
2 from .models import Tag
3
4
5 class TagSerializer(serializers.ModelSerializer):
6 class Meta:
7 model = Tag
8 fields = [
9 "name",
10 ]
11
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/backend-project/small_eod/letters/serializers.py b/backend-project/small_eod/letters/serializers.py
--- a/backend-project/small_eod/letters/serializers.py
+++ b/backend-project/small_eod/letters/serializers.py
@@ -13,7 +13,7 @@
class DocumentTypeSerializer(serializers.ModelSerializer):
class Meta:
model = DocumentType
- fields = ["name"]
+ fields = ["id", "name"]
class LetterSerializer(UserLogModelSerializer):
diff --git a/backend-project/small_eod/tags/serializers.py b/backend-project/small_eod/tags/serializers.py
--- a/backend-project/small_eod/tags/serializers.py
+++ b/backend-project/small_eod/tags/serializers.py
@@ -6,5 +6,6 @@
class Meta:
model = Tag
fields = [
+ "id",
"name",
]
|
{"golden_diff": "diff --git a/backend-project/small_eod/letters/serializers.py b/backend-project/small_eod/letters/serializers.py\n--- a/backend-project/small_eod/letters/serializers.py\n+++ b/backend-project/small_eod/letters/serializers.py\n@@ -13,7 +13,7 @@\n class DocumentTypeSerializer(serializers.ModelSerializer):\n class Meta:\n model = DocumentType\n- fields = [\"name\"]\n+ fields = [\"id\", \"name\"]\n \n \n class LetterSerializer(UserLogModelSerializer):\ndiff --git a/backend-project/small_eod/tags/serializers.py b/backend-project/small_eod/tags/serializers.py\n--- a/backend-project/small_eod/tags/serializers.py\n+++ b/backend-project/small_eod/tags/serializers.py\n@@ -6,5 +6,6 @@\n class Meta:\n model = Tag\n fields = [\n+ \"id\",\n \"name\",\n ]\n", "issue": "udost\u0119pnienie id w API dla tags i documentType \nId dla tags i documetType, jest niezb\u0119dne dla zbudowania listy tych element\u00f3w w reakcie. \n", "before_files": [{"content": "from uuid import uuid4\nfrom django.conf import settings\nfrom rest_framework import serializers\nfrom .models import Letter, DocumentType\nfrom ..generic.serializers import UserLogModelSerializer\nfrom ..cases.models import Case\nfrom ..institutions.models import Institution\nfrom ..channels.models import Channel\nfrom ..files.apps import minio_app\nfrom ..files.serializers import FileSerializer\n\n\nclass DocumentTypeSerializer(serializers.ModelSerializer):\n class Meta:\n model = DocumentType\n fields = [\"name\"]\n\n\nclass LetterSerializer(UserLogModelSerializer):\n document_type = serializers.PrimaryKeyRelatedField(\n many=False, default=None, queryset=DocumentType.objects.all()\n )\n case = serializers.PrimaryKeyRelatedField(\n many=False, default=None, queryset=Case.objects.all()\n )\n institution = serializers.PrimaryKeyRelatedField(\n many=False, default=None, queryset=Institution.objects.all()\n )\n channel = serializers.PrimaryKeyRelatedField(\n many=False, default=None, queryset=Channel.objects.all()\n )\n attachments = FileSerializer(many=True, read_only=True)\n\n class Meta:\n model = Letter\n fields = [\n \"id\",\n \"direction\",\n \"channel\",\n \"final\",\n \"date\",\n \"reference_number\",\n \"institution\",\n \"case\",\n \"attachments\",\n \"ordering\",\n \"comment\",\n \"excerpt\",\n \"document_type\",\n \"created_on\",\n \"created_by\",\n \"modified_on\",\n \"modified_by\",\n ]\n\n def create(self, validated_data):\n channel = validated_data.pop(\"channel\")\n document_type = validated_data.pop(\"document_type\")\n institution = validated_data.pop(\"institution\")\n case = validated_data.pop(\"case\")\n\n letter = super().create(validated_data)\n letter.channel = channel\n letter.document_type = document_type\n letter.institution = institution\n letter.case = case\n letter.save()\n return letter\n\n def update(self, instance, validated_data):\n \"\"\"\n nested - variable storing representations of the nested objects\n of LetterSerializer (Channel, Address and DocumentType).\n Iterating over those 3 and updating fields of the related objects,\n using key-value pairs from PATCH request.\n \"\"\"\n nested = []\n for nested_object in nested:\n for attr, value in nested_object[\"data\"].items():\n setattr(nested_object[\"instance\"], attr, value)\n nested_object[\"instance\"].save()\n return super().update(instance, validated_data)\n\n\nclass SignRequestSerializer(serializers.Serializer):\n name = serializers.CharField(max_length=200)\n method = serializers.CharField(read_only=True)\n url = serializers.CharField(read_only=True)\n formData = serializers.DictField(read_only=True, child=serializers.CharField())\n path = serializers.CharField(read_only=True)\n\n def create(self, validated_data):\n path = f'{uuid4()}/{validated_data[\"name\"]}'\n url, form_data = minio_app.presigned_post_form_data(settings.MINIO_BUCKET, path)\n return {\n \"name\": validated_data[\"name\"],\n \"method\": \"POST\",\n \"url\": url,\n \"formData\": form_data,\n \"path\": path,\n }\n", "path": "backend-project/small_eod/letters/serializers.py"}, {"content": "from rest_framework import serializers\nfrom .models import Tag\n\n\nclass TagSerializer(serializers.ModelSerializer):\n class Meta:\n model = Tag\n fields = [\n \"name\",\n ]\n", "path": "backend-project/small_eod/tags/serializers.py"}], "after_files": [{"content": "from uuid import uuid4\nfrom django.conf import settings\nfrom rest_framework import serializers\nfrom .models import Letter, DocumentType\nfrom ..generic.serializers import UserLogModelSerializer\nfrom ..cases.models import Case\nfrom ..institutions.models import Institution\nfrom ..channels.models import Channel\nfrom ..files.apps import minio_app\nfrom ..files.serializers import FileSerializer\n\n\nclass DocumentTypeSerializer(serializers.ModelSerializer):\n class Meta:\n model = DocumentType\n fields = [\"id\", \"name\"]\n\n\nclass LetterSerializer(UserLogModelSerializer):\n document_type = serializers.PrimaryKeyRelatedField(\n many=False, default=None, queryset=DocumentType.objects.all()\n )\n case = serializers.PrimaryKeyRelatedField(\n many=False, default=None, queryset=Case.objects.all()\n )\n institution = serializers.PrimaryKeyRelatedField(\n many=False, default=None, queryset=Institution.objects.all()\n )\n channel = serializers.PrimaryKeyRelatedField(\n many=False, default=None, queryset=Channel.objects.all()\n )\n attachments = FileSerializer(many=True, read_only=True)\n\n class Meta:\n model = Letter\n fields = [\n \"id\",\n \"direction\",\n \"channel\",\n \"final\",\n \"date\",\n \"reference_number\",\n \"institution\",\n \"case\",\n \"attachments\",\n \"ordering\",\n \"comment\",\n \"excerpt\",\n \"document_type\",\n \"created_on\",\n \"created_by\",\n \"modified_on\",\n \"modified_by\",\n ]\n\n def create(self, validated_data):\n channel = validated_data.pop(\"channel\")\n document_type = validated_data.pop(\"document_type\")\n institution = validated_data.pop(\"institution\")\n case = validated_data.pop(\"case\")\n\n letter = super().create(validated_data)\n letter.channel = channel\n letter.document_type = document_type\n letter.institution = institution\n letter.case = case\n letter.save()\n return letter\n\n def update(self, instance, validated_data):\n \"\"\"\n nested - variable storing representations of the nested objects\n of LetterSerializer (Channel, Address and DocumentType).\n Iterating over those 3 and updating fields of the related objects,\n using key-value pairs from PATCH request.\n \"\"\"\n nested = []\n for nested_object in nested:\n for attr, value in nested_object[\"data\"].items():\n setattr(nested_object[\"instance\"], attr, value)\n nested_object[\"instance\"].save()\n return super().update(instance, validated_data)\n\n\nclass SignRequestSerializer(serializers.Serializer):\n name = serializers.CharField(max_length=200)\n method = serializers.CharField(read_only=True)\n url = serializers.CharField(read_only=True)\n formData = serializers.DictField(read_only=True, child=serializers.CharField())\n path = serializers.CharField(read_only=True)\n\n def create(self, validated_data):\n path = f'{uuid4()}/{validated_data[\"name\"]}'\n url, form_data = minio_app.presigned_post_form_data(settings.MINIO_BUCKET, path)\n return {\n \"name\": validated_data[\"name\"],\n \"method\": \"POST\",\n \"url\": url,\n \"formData\": form_data,\n \"path\": path,\n }\n", "path": "backend-project/small_eod/letters/serializers.py"}, {"content": "from rest_framework import serializers\nfrom .models import Tag\n\n\nclass TagSerializer(serializers.ModelSerializer):\n class Meta:\n model = Tag\n fields = [\n \"id\",\n \"name\",\n ]\n", "path": "backend-project/small_eod/tags/serializers.py"}]}
| 1,248 | 197 |
gh_patches_debug_19197
|
rasdani/github-patches
|
git_diff
|
enthought__chaco-717
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Remove "PopupablePlot"
`PopupablePlot` was introduced in the commit https://github.com/enthought/chaco/commit/4af154cec6f678862ba7e695ae62d681312b50e8#diff-c93657842da48caff25acdb9de9f919f9c04b5301d0fafc28598c9fdeee829f8 but it is not clear why it exists or who uses it.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `chaco/ui/popupable_plot.py`
Content:
```
1 # Enthought library imports
2 from traits.api import List
3 from chaco.plot import Plot
4 from chaco.plot_containers import VPlotContainer
5 from chaco.tools.pan_tool import PanTool
6 from chaco.tools.zoom_tool import ZoomTool
7 from chaco.ui.plot_window import PlotWindow
8
9 from traitsui.wx.constants import WindowColor
10
11
12 class PopupablePlot(Plot):
13 """A Plot class that pops up in a new window on double click"""
14
15 # FIXME: It would be nice to queue up other types of commands and settings
16 command_queue = List()
17
18 def normal_left_dclick(self, event):
19 plot = Plot(self.data)
20 for data, kw in self.command_queue:
21 plot.plot(data, **kw)
22 plot.title = self.title
23
24 plot.title = self.title
25 container = VPlotContainer(bgcolor=WindowColor)
26 container.add(plot)
27 plot.tools.append(PanTool(plot))
28 plot.overlays.append(ZoomTool(plot))
29 window = PlotWindow(plot=container)
30 window.edit_traits(kind="live", parent=event.window.control)
31
32 def plot(self, data, **kw):
33 """Queue up the plot commands"""
34 self.command_queue.append((data, kw))
35 super().plot(data, **kw)
36
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/chaco/ui/popupable_plot.py b/chaco/ui/popupable_plot.py
deleted file mode 100644
--- a/chaco/ui/popupable_plot.py
+++ /dev/null
@@ -1,35 +0,0 @@
-# Enthought library imports
-from traits.api import List
-from chaco.plot import Plot
-from chaco.plot_containers import VPlotContainer
-from chaco.tools.pan_tool import PanTool
-from chaco.tools.zoom_tool import ZoomTool
-from chaco.ui.plot_window import PlotWindow
-
-from traitsui.wx.constants import WindowColor
-
-
-class PopupablePlot(Plot):
- """A Plot class that pops up in a new window on double click"""
-
- # FIXME: It would be nice to queue up other types of commands and settings
- command_queue = List()
-
- def normal_left_dclick(self, event):
- plot = Plot(self.data)
- for data, kw in self.command_queue:
- plot.plot(data, **kw)
- plot.title = self.title
-
- plot.title = self.title
- container = VPlotContainer(bgcolor=WindowColor)
- container.add(plot)
- plot.tools.append(PanTool(plot))
- plot.overlays.append(ZoomTool(plot))
- window = PlotWindow(plot=container)
- window.edit_traits(kind="live", parent=event.window.control)
-
- def plot(self, data, **kw):
- """Queue up the plot commands"""
- self.command_queue.append((data, kw))
- super().plot(data, **kw)
|
{"golden_diff": "diff --git a/chaco/ui/popupable_plot.py b/chaco/ui/popupable_plot.py\ndeleted file mode 100644\n--- a/chaco/ui/popupable_plot.py\n+++ /dev/null\n@@ -1,35 +0,0 @@\n-# Enthought library imports\n-from traits.api import List\n-from chaco.plot import Plot\n-from chaco.plot_containers import VPlotContainer\n-from chaco.tools.pan_tool import PanTool\n-from chaco.tools.zoom_tool import ZoomTool\n-from chaco.ui.plot_window import PlotWindow\n-\n-from traitsui.wx.constants import WindowColor\n-\n-\n-class PopupablePlot(Plot):\n- \"\"\"A Plot class that pops up in a new window on double click\"\"\"\n-\n- # FIXME: It would be nice to queue up other types of commands and settings\n- command_queue = List()\n-\n- def normal_left_dclick(self, event):\n- plot = Plot(self.data)\n- for data, kw in self.command_queue:\n- plot.plot(data, **kw)\n- plot.title = self.title\n-\n- plot.title = self.title\n- container = VPlotContainer(bgcolor=WindowColor)\n- container.add(plot)\n- plot.tools.append(PanTool(plot))\n- plot.overlays.append(ZoomTool(plot))\n- window = PlotWindow(plot=container)\n- window.edit_traits(kind=\"live\", parent=event.window.control)\n-\n- def plot(self, data, **kw):\n- \"\"\"Queue up the plot commands\"\"\"\n- self.command_queue.append((data, kw))\n- super().plot(data, **kw)\n", "issue": "Remove \"PopupablePlot\"\n`PopupablePlot` was introduced in the commit https://github.com/enthought/chaco/commit/4af154cec6f678862ba7e695ae62d681312b50e8#diff-c93657842da48caff25acdb9de9f919f9c04b5301d0fafc28598c9fdeee829f8 but it is not clear why it exists or who uses it.\n", "before_files": [{"content": "# Enthought library imports\nfrom traits.api import List\nfrom chaco.plot import Plot\nfrom chaco.plot_containers import VPlotContainer\nfrom chaco.tools.pan_tool import PanTool\nfrom chaco.tools.zoom_tool import ZoomTool\nfrom chaco.ui.plot_window import PlotWindow\n\nfrom traitsui.wx.constants import WindowColor\n\n\nclass PopupablePlot(Plot):\n \"\"\"A Plot class that pops up in a new window on double click\"\"\"\n\n # FIXME: It would be nice to queue up other types of commands and settings\n command_queue = List()\n\n def normal_left_dclick(self, event):\n plot = Plot(self.data)\n for data, kw in self.command_queue:\n plot.plot(data, **kw)\n plot.title = self.title\n\n plot.title = self.title\n container = VPlotContainer(bgcolor=WindowColor)\n container.add(plot)\n plot.tools.append(PanTool(plot))\n plot.overlays.append(ZoomTool(plot))\n window = PlotWindow(plot=container)\n window.edit_traits(kind=\"live\", parent=event.window.control)\n\n def plot(self, data, **kw):\n \"\"\"Queue up the plot commands\"\"\"\n self.command_queue.append((data, kw))\n super().plot(data, **kw)\n", "path": "chaco/ui/popupable_plot.py"}], "after_files": [{"content": null, "path": "chaco/ui/popupable_plot.py"}]}
| 723 | 347 |
gh_patches_debug_31794
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-2552
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
image scanning does not cleanup the twistcli binary
```
~ checkov --bc-api-key REDACTED --dockerfile-path Dockerfile --docker-image checkov_scan_me --repo-id tkishel/example
<SNIP>
More details: https://www.bridgecrew.cloud/projects?repository=tkishel73_tkishel/example&branch=bc-bdfab20_master&runId=latest
```
```
~ git status
On branch main
Your branch is up to date with 'origin/main'.
Untracked files:
(use "git add <file>..." to include in what will be committed)
twistcli
no changes added to commit (use "git add" and/or "git commit -a")
```
Some usage of `twistcli` includes a `cleanup_scan()` or (misspelled) `cleanup_twictcli()` method, but they do not appear to be called:
https://github.com/bridgecrewio/checkov/blob/master/checkov/sca_image/runner.py
https://github.com/bridgecrewio/checkov/blob/master/checkov/sca_package/scanner.py
https://github.com/bridgecrewio/checkov/blob/master/checkov/common/bridgecrew/vulnerability_scanning/image_scanner.py
So, it may be valuable to add something like this, after all possible uses of `twistcli` have executed ...
```
def __exit__(self, t, v, tr):
self.cleanup_scan()
````
... especially to execute that cleanup after an exception exit.
An argument could also be made to instead download and cache the `twistcli` binary outside of the current directory.
And, it may be valuable to consolidate the various duplicate methods that interact with the `twistcli` binary in the above files.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `checkov/sca_package/runner.py`
Content:
```
1 import logging
2 import os
3 from pathlib import Path
4 from typing import Optional, List, Tuple, Set, Union, Sequence, Dict, Any
5
6 from checkov.common.bridgecrew.platform_integration import bc_integration
7 from checkov.common.models.enums import CheckResult
8 from checkov.common.output.report import Report, CheckType
9 from checkov.common.runners.base_runner import BaseRunner, ignored_directories, strtobool
10 from checkov.runner_filter import RunnerFilter
11 from checkov.sca_package.output import create_report_record
12 from checkov.sca_package.scanner import Scanner
13
14 SUPPORTED_PACKAGE_FILES = {
15 "bower.json",
16 "build.gradle",
17 "build.gradle.kts",
18 "go.sum",
19 "gradle.properties",
20 "METADATA",
21 "npm-shrinkwrap.json",
22 "package.json",
23 "package-lock.json",
24 "pom.xml",
25 "requirements.txt",
26 }
27
28 class Runner(BaseRunner):
29 check_type = CheckType.SCA_PACKAGE
30
31 def __init__(self):
32 self._check_class: Optional[str] = None
33 self._code_repo_path: Optional[Path] = None
34
35 def prepare_and_scan(
36 self,
37 root_folder: Union[str, Path],
38 files: Optional[List[str]] = None,
39 runner_filter: RunnerFilter = RunnerFilter(),
40 exclude_package_json: bool = True,
41 cleanup_twictcli: bool = True,
42 ) -> "Optional[Sequence[Dict[str, Any]]]":
43
44 if not strtobool(os.getenv("ENABLE_SCA_PACKAGE_SCAN", "False")):
45 return None
46
47 # skip complete run, if flag '--check' was used without a CVE check ID
48 if runner_filter.checks and all(not check.startswith("CKV_CVE") for check in runner_filter.checks):
49 return None
50
51 if not bc_integration.bc_api_key:
52 logging.info("The --bc-api-key flag needs to be set to run SCA package scanning")
53 return None
54
55 logging.info("SCA package scanning searching for scannable files")
56
57 self._code_repo_path = Path(root_folder)
58
59 excluded_paths = {*ignored_directories}
60 if runner_filter.excluded_paths:
61 excluded_paths.update(runner_filter.excluded_paths)
62
63 input_output_paths = self.find_scannable_files(
64 root_path=self._code_repo_path,
65 files=files,
66 excluded_paths=excluded_paths,
67 exclude_package_json=exclude_package_json
68 )
69 if not input_output_paths:
70 # no packages found
71 return None
72
73 logging.info(f"SCA package scanning will scan {len(input_output_paths)} files")
74
75 scanner = Scanner()
76 self._check_class = f"{scanner.__module__}.{scanner.__class__.__qualname__}"
77 scan_results = scanner.scan(input_output_paths, cleanup_twictcli)
78
79 logging.info(f"SCA package scanning successfully scanned {len(scan_results)} files")
80 return scan_results
81
82 def run(
83 self,
84 root_folder: Union[str, Path],
85 external_checks_dir: Optional[List[str]] = None,
86 files: Optional[List[str]] = None,
87 runner_filter: RunnerFilter = RunnerFilter(),
88 collect_skip_comments: bool = True,
89 ) -> Report:
90 report = Report(self.check_type)
91
92 scan_results = self.prepare_and_scan(root_folder, files, runner_filter)
93 if scan_results is None:
94 return report
95
96 for result in scan_results:
97 package_file_path = Path(result["repository"])
98 try:
99 package_file_path = package_file_path.relative_to(self._code_repo_path)
100 except ValueError:
101 # Path.is_relative_to() was implemented in Python 3.9
102 pass
103
104 vulnerabilities = result.get("vulnerabilities") or []
105
106 rootless_file_path = str(package_file_path).replace(package_file_path.anchor, "", 1)
107 self.parse_vulns_to_records(report, result, rootless_file_path, runner_filter, vulnerabilities)
108
109 return report
110
111 def parse_vulns_to_records(self, report, result, rootless_file_path, runner_filter, vulnerabilities,
112 file_abs_path=''):
113 for vulnerability in vulnerabilities:
114 record = create_report_record(
115 rootless_file_path=rootless_file_path,
116 file_abs_path=file_abs_path or result.get("repository"),
117 check_class=self._check_class,
118 vulnerability_details=vulnerability,
119 runner_filter=runner_filter
120 )
121 if not runner_filter.should_run_check(check_id=record.check_id, bc_check_id=record.bc_check_id,
122 severity=record.severity):
123 if runner_filter.checks:
124 continue
125 else:
126 record.check_result = {
127 "result": CheckResult.SKIPPED,
128 "suppress_comment": f"{vulnerability['id']} is skipped"
129 }
130
131 report.add_resource(record.resource)
132 report.add_record(record)
133
134 def find_scannable_files(
135 self, root_path: Path, files: Optional[List[str]], excluded_paths: Set[str], exclude_package_json: bool = True
136 ) -> Set[Tuple[Path, Path]]:
137 input_paths = {
138 file_path
139 for file_path in root_path.glob("**/*")
140 if file_path.name in SUPPORTED_PACKAGE_FILES and not any(p in file_path.parts for p in excluded_paths)
141 }
142
143 package_lock_parent_paths = set()
144 if exclude_package_json:
145 # filter out package.json, if package-lock.json exists
146 package_lock_parent_paths = {
147 file_path.parent for file_path in input_paths if file_path.name == "package-lock.json"
148 }
149
150 input_output_paths = {
151 (file_path, file_path.parent / f"{file_path.stem}_result.json")
152 for file_path in input_paths
153 if file_path.name != "package.json" or file_path.parent not in package_lock_parent_paths
154 }
155
156 for file in files or []:
157 file_path = Path(file)
158 if not file_path.exists():
159 logging.warning(f"File {file_path} doesn't exist")
160 continue
161
162 input_output_paths.add((file_path, file_path.parent / f"{file_path.stem}_result.json"))
163
164 return input_output_paths
165
```
Path: `checkov/sca_image/runner.py`
Content:
```
1 import asyncio
2 import json
3 import logging
4 import os.path
5 from pathlib import Path
6 from typing import Optional, List, Union, Dict, Any
7
8 from checkov.common.bridgecrew.platform_integration import bc_integration
9 from checkov.common.bridgecrew.vulnerability_scanning.image_scanner import image_scanner, TWISTCLI_FILE_NAME
10 from checkov.common.bridgecrew.vulnerability_scanning.integrations.docker_image_scanning import \
11 docker_image_scanning_integration
12 from checkov.common.output.report import Report, CheckType
13 from checkov.runner_filter import RunnerFilter
14 from checkov.sca_package.runner import Runner as PackageRunner
15
16
17 class Runner(PackageRunner):
18 check_type = CheckType.SCA_IMAGE
19
20 def __init__(self) -> None:
21 self._check_class: Optional[str] = None
22 self._code_repo_path: Optional[Path] = None
23 self._check_class = f"{image_scanner.__module__}.{image_scanner.__class__.__qualname__}"
24 self.raw_report: Optional[Dict[str, Any]] = None
25
26 def scan(
27 self,
28 image_id: str,
29 dockerfile_path: str,
30 runner_filter: RunnerFilter = RunnerFilter(),
31 ) -> Optional[Dict[str, Any]]:
32
33 # skip complete run, if flag '--check' was used without a CVE check ID
34 if runner_filter.checks and all(not check.startswith("CKV_CVE") for check in runner_filter.checks):
35 return None
36
37 if not bc_integration.bc_api_key:
38 logging.info("The --bc-api-key flag needs to be set to run SCA package scanning")
39 return None
40
41 logging.info(f"SCA image scanning is scanning the image {image_id}")
42 image_scanner.setup_scan(image_id, dockerfile_path, skip_extract_image_name=False)
43 scan_result = asyncio.run(self.execute_scan(image_id, Path('results.json')))
44 logging.info(f"SCA image scanning successfully scanned the image {image_id}")
45 return scan_result
46
47 @staticmethod
48 async def execute_scan(
49 image_id: str,
50 output_path: Path,
51 ) -> Dict[str, Any]:
52 command = f"./{TWISTCLI_FILE_NAME} images scan --address {docker_image_scanning_integration.get_proxy_address()} --token {docker_image_scanning_integration.get_bc_api_key()} --details --output-file \"{output_path}\" {image_id}"
53 process = await asyncio.create_subprocess_shell(
54 command, stdout=asyncio.subprocess.PIPE, stderr=asyncio.subprocess.PIPE
55 )
56
57 stdout, stderr = await process.communicate()
58
59 # log output for debugging
60 logging.debug(stdout.decode())
61
62 exit_code = await process.wait()
63
64 if exit_code:
65 logging.error(stderr.decode())
66 return {}
67
68 # read and delete the report file
69 scan_result: Dict[str, Any] = json.loads(output_path.read_text())
70 output_path.unlink()
71
72 return scan_result
73
74 def run(
75 self,
76 root_folder: Union[str, Path],
77 external_checks_dir: Optional[List[str]] = None,
78 files: Optional[List[str]] = None,
79 runner_filter: RunnerFilter = RunnerFilter(),
80 collect_skip_comments: bool = True,
81 **kwargs: str
82 ) -> Report:
83 report = Report(self.check_type)
84
85 dockerfile_path = kwargs['dockerfile_path']
86 image_id = kwargs['image_id']
87 scan_result = self.scan(image_id, dockerfile_path, runner_filter)
88 if scan_result is None:
89 return report
90 self.raw_report = scan_result
91 result = scan_result.get('results', [{}])[0]
92
93 vulnerabilities = result.get("vulnerabilities") or []
94 self.parse_vulns_to_records(report, result, f"{dockerfile_path} ({image_id})", runner_filter, vulnerabilities,
95 file_abs_path=os.path.abspath(dockerfile_path))
96
97 return report
98
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/checkov/sca_image/runner.py b/checkov/sca_image/runner.py
--- a/checkov/sca_image/runner.py
+++ b/checkov/sca_image/runner.py
@@ -40,9 +40,14 @@
logging.info(f"SCA image scanning is scanning the image {image_id}")
image_scanner.setup_scan(image_id, dockerfile_path, skip_extract_image_name=False)
- scan_result = asyncio.run(self.execute_scan(image_id, Path('results.json')))
- logging.info(f"SCA image scanning successfully scanned the image {image_id}")
- return scan_result
+ try:
+ scan_result = asyncio.run(self.execute_scan(image_id, Path('results.json')))
+ logging.info(f"SCA image scanning successfully scanned the image {image_id}")
+ image_scanner.cleanup_scan()
+ return scan_result
+ except Exception as err:
+ image_scanner.cleanup_scan()
+ raise err
@staticmethod
async def execute_scan(
diff --git a/checkov/sca_package/runner.py b/checkov/sca_package/runner.py
--- a/checkov/sca_package/runner.py
+++ b/checkov/sca_package/runner.py
@@ -38,7 +38,7 @@
files: Optional[List[str]] = None,
runner_filter: RunnerFilter = RunnerFilter(),
exclude_package_json: bool = True,
- cleanup_twictcli: bool = True,
+ cleanup_twistcli: bool = True,
) -> "Optional[Sequence[Dict[str, Any]]]":
if not strtobool(os.getenv("ENABLE_SCA_PACKAGE_SCAN", "False")):
@@ -74,7 +74,7 @@
scanner = Scanner()
self._check_class = f"{scanner.__module__}.{scanner.__class__.__qualname__}"
- scan_results = scanner.scan(input_output_paths, cleanup_twictcli)
+ scan_results = scanner.scan(input_output_paths, cleanup_twistcli)
logging.info(f"SCA package scanning successfully scanned {len(scan_results)} files")
return scan_results
|
{"golden_diff": "diff --git a/checkov/sca_image/runner.py b/checkov/sca_image/runner.py\n--- a/checkov/sca_image/runner.py\n+++ b/checkov/sca_image/runner.py\n@@ -40,9 +40,14 @@\n \n logging.info(f\"SCA image scanning is scanning the image {image_id}\")\n image_scanner.setup_scan(image_id, dockerfile_path, skip_extract_image_name=False)\n- scan_result = asyncio.run(self.execute_scan(image_id, Path('results.json')))\n- logging.info(f\"SCA image scanning successfully scanned the image {image_id}\")\n- return scan_result\n+ try:\n+ scan_result = asyncio.run(self.execute_scan(image_id, Path('results.json')))\n+ logging.info(f\"SCA image scanning successfully scanned the image {image_id}\")\n+ image_scanner.cleanup_scan()\n+ return scan_result\n+ except Exception as err:\n+ image_scanner.cleanup_scan()\n+ raise err\n \n @staticmethod\n async def execute_scan(\ndiff --git a/checkov/sca_package/runner.py b/checkov/sca_package/runner.py\n--- a/checkov/sca_package/runner.py\n+++ b/checkov/sca_package/runner.py\n@@ -38,7 +38,7 @@\n files: Optional[List[str]] = None,\n runner_filter: RunnerFilter = RunnerFilter(),\n exclude_package_json: bool = True,\n- cleanup_twictcli: bool = True,\n+ cleanup_twistcli: bool = True,\n ) -> \"Optional[Sequence[Dict[str, Any]]]\":\n \n if not strtobool(os.getenv(\"ENABLE_SCA_PACKAGE_SCAN\", \"False\")):\n@@ -74,7 +74,7 @@\n \n scanner = Scanner()\n self._check_class = f\"{scanner.__module__}.{scanner.__class__.__qualname__}\"\n- scan_results = scanner.scan(input_output_paths, cleanup_twictcli)\n+ scan_results = scanner.scan(input_output_paths, cleanup_twistcli)\n \n logging.info(f\"SCA package scanning successfully scanned {len(scan_results)} files\")\n return scan_results\n", "issue": "image scanning does not cleanup the twistcli binary\n```\r\n~ checkov --bc-api-key REDACTED --dockerfile-path Dockerfile --docker-image checkov_scan_me --repo-id tkishel/example\r\n\r\n<SNIP>\r\n\r\nMore details: https://www.bridgecrew.cloud/projects?repository=tkishel73_tkishel/example&branch=bc-bdfab20_master&runId=latest\r\n```\r\n\r\n```\r\n~ git status\r\nOn branch main\r\nYour branch is up to date with 'origin/main'.\r\n\r\nUntracked files:\r\n (use \"git add <file>...\" to include in what will be committed)\r\n\ttwistcli\r\n\r\nno changes added to commit (use \"git add\" and/or \"git commit -a\")\r\n```\r\n\r\nSome usage of `twistcli` includes a `cleanup_scan()` or (misspelled) `cleanup_twictcli()` method, but they do not appear to be called:\r\n\r\nhttps://github.com/bridgecrewio/checkov/blob/master/checkov/sca_image/runner.py\r\n\r\nhttps://github.com/bridgecrewio/checkov/blob/master/checkov/sca_package/scanner.py\r\n\r\nhttps://github.com/bridgecrewio/checkov/blob/master/checkov/common/bridgecrew/vulnerability_scanning/image_scanner.py\r\n\r\nSo, it may be valuable to add something like this, after all possible uses of `twistcli` have executed ...\r\n\r\n```\r\ndef __exit__(self, t, v, tr):\r\n self.cleanup_scan()\r\n````\r\n\r\n... especially to execute that cleanup after an exception exit.\r\n\r\nAn argument could also be made to instead download and cache the `twistcli` binary outside of the current directory.\r\n\r\nAnd, it may be valuable to consolidate the various duplicate methods that interact with the `twistcli` binary in the above files.\n", "before_files": [{"content": "import logging\nimport os\nfrom pathlib import Path\nfrom typing import Optional, List, Tuple, Set, Union, Sequence, Dict, Any\n\nfrom checkov.common.bridgecrew.platform_integration import bc_integration\nfrom checkov.common.models.enums import CheckResult\nfrom checkov.common.output.report import Report, CheckType\nfrom checkov.common.runners.base_runner import BaseRunner, ignored_directories, strtobool\nfrom checkov.runner_filter import RunnerFilter\nfrom checkov.sca_package.output import create_report_record\nfrom checkov.sca_package.scanner import Scanner\n\nSUPPORTED_PACKAGE_FILES = {\n \"bower.json\",\n \"build.gradle\",\n \"build.gradle.kts\",\n \"go.sum\",\n \"gradle.properties\",\n \"METADATA\",\n \"npm-shrinkwrap.json\",\n \"package.json\",\n \"package-lock.json\",\n \"pom.xml\",\n \"requirements.txt\",\n}\n\nclass Runner(BaseRunner):\n check_type = CheckType.SCA_PACKAGE\n\n def __init__(self):\n self._check_class: Optional[str] = None\n self._code_repo_path: Optional[Path] = None\n\n def prepare_and_scan(\n self,\n root_folder: Union[str, Path],\n files: Optional[List[str]] = None,\n runner_filter: RunnerFilter = RunnerFilter(),\n exclude_package_json: bool = True,\n cleanup_twictcli: bool = True,\n ) -> \"Optional[Sequence[Dict[str, Any]]]\":\n\n if not strtobool(os.getenv(\"ENABLE_SCA_PACKAGE_SCAN\", \"False\")):\n return None\n\n # skip complete run, if flag '--check' was used without a CVE check ID\n if runner_filter.checks and all(not check.startswith(\"CKV_CVE\") for check in runner_filter.checks):\n return None\n\n if not bc_integration.bc_api_key:\n logging.info(\"The --bc-api-key flag needs to be set to run SCA package scanning\")\n return None\n\n logging.info(\"SCA package scanning searching for scannable files\")\n\n self._code_repo_path = Path(root_folder)\n\n excluded_paths = {*ignored_directories}\n if runner_filter.excluded_paths:\n excluded_paths.update(runner_filter.excluded_paths)\n\n input_output_paths = self.find_scannable_files(\n root_path=self._code_repo_path,\n files=files,\n excluded_paths=excluded_paths,\n exclude_package_json=exclude_package_json\n )\n if not input_output_paths:\n # no packages found\n return None\n\n logging.info(f\"SCA package scanning will scan {len(input_output_paths)} files\")\n\n scanner = Scanner()\n self._check_class = f\"{scanner.__module__}.{scanner.__class__.__qualname__}\"\n scan_results = scanner.scan(input_output_paths, cleanup_twictcli)\n\n logging.info(f\"SCA package scanning successfully scanned {len(scan_results)} files\")\n return scan_results\n\n def run(\n self,\n root_folder: Union[str, Path],\n external_checks_dir: Optional[List[str]] = None,\n files: Optional[List[str]] = None,\n runner_filter: RunnerFilter = RunnerFilter(),\n collect_skip_comments: bool = True,\n ) -> Report:\n report = Report(self.check_type)\n\n scan_results = self.prepare_and_scan(root_folder, files, runner_filter)\n if scan_results is None:\n return report\n\n for result in scan_results:\n package_file_path = Path(result[\"repository\"])\n try:\n package_file_path = package_file_path.relative_to(self._code_repo_path)\n except ValueError:\n # Path.is_relative_to() was implemented in Python 3.9\n pass\n\n vulnerabilities = result.get(\"vulnerabilities\") or []\n\n rootless_file_path = str(package_file_path).replace(package_file_path.anchor, \"\", 1)\n self.parse_vulns_to_records(report, result, rootless_file_path, runner_filter, vulnerabilities)\n\n return report\n\n def parse_vulns_to_records(self, report, result, rootless_file_path, runner_filter, vulnerabilities,\n file_abs_path=''):\n for vulnerability in vulnerabilities:\n record = create_report_record(\n rootless_file_path=rootless_file_path,\n file_abs_path=file_abs_path or result.get(\"repository\"),\n check_class=self._check_class,\n vulnerability_details=vulnerability,\n runner_filter=runner_filter\n )\n if not runner_filter.should_run_check(check_id=record.check_id, bc_check_id=record.bc_check_id,\n severity=record.severity):\n if runner_filter.checks:\n continue\n else:\n record.check_result = {\n \"result\": CheckResult.SKIPPED,\n \"suppress_comment\": f\"{vulnerability['id']} is skipped\"\n }\n\n report.add_resource(record.resource)\n report.add_record(record)\n\n def find_scannable_files(\n self, root_path: Path, files: Optional[List[str]], excluded_paths: Set[str], exclude_package_json: bool = True\n ) -> Set[Tuple[Path, Path]]:\n input_paths = {\n file_path\n for file_path in root_path.glob(\"**/*\")\n if file_path.name in SUPPORTED_PACKAGE_FILES and not any(p in file_path.parts for p in excluded_paths)\n }\n\n package_lock_parent_paths = set()\n if exclude_package_json:\n # filter out package.json, if package-lock.json exists\n package_lock_parent_paths = {\n file_path.parent for file_path in input_paths if file_path.name == \"package-lock.json\"\n }\n\n input_output_paths = {\n (file_path, file_path.parent / f\"{file_path.stem}_result.json\")\n for file_path in input_paths\n if file_path.name != \"package.json\" or file_path.parent not in package_lock_parent_paths\n }\n\n for file in files or []:\n file_path = Path(file)\n if not file_path.exists():\n logging.warning(f\"File {file_path} doesn't exist\")\n continue\n\n input_output_paths.add((file_path, file_path.parent / f\"{file_path.stem}_result.json\"))\n\n return input_output_paths\n", "path": "checkov/sca_package/runner.py"}, {"content": "import asyncio\nimport json\nimport logging\nimport os.path\nfrom pathlib import Path\nfrom typing import Optional, List, Union, Dict, Any\n\nfrom checkov.common.bridgecrew.platform_integration import bc_integration\nfrom checkov.common.bridgecrew.vulnerability_scanning.image_scanner import image_scanner, TWISTCLI_FILE_NAME\nfrom checkov.common.bridgecrew.vulnerability_scanning.integrations.docker_image_scanning import \\\n docker_image_scanning_integration\nfrom checkov.common.output.report import Report, CheckType\nfrom checkov.runner_filter import RunnerFilter\nfrom checkov.sca_package.runner import Runner as PackageRunner\n\n\nclass Runner(PackageRunner):\n check_type = CheckType.SCA_IMAGE\n\n def __init__(self) -> None:\n self._check_class: Optional[str] = None\n self._code_repo_path: Optional[Path] = None\n self._check_class = f\"{image_scanner.__module__}.{image_scanner.__class__.__qualname__}\"\n self.raw_report: Optional[Dict[str, Any]] = None\n\n def scan(\n self,\n image_id: str,\n dockerfile_path: str,\n runner_filter: RunnerFilter = RunnerFilter(),\n ) -> Optional[Dict[str, Any]]:\n\n # skip complete run, if flag '--check' was used without a CVE check ID\n if runner_filter.checks and all(not check.startswith(\"CKV_CVE\") for check in runner_filter.checks):\n return None\n\n if not bc_integration.bc_api_key:\n logging.info(\"The --bc-api-key flag needs to be set to run SCA package scanning\")\n return None\n\n logging.info(f\"SCA image scanning is scanning the image {image_id}\")\n image_scanner.setup_scan(image_id, dockerfile_path, skip_extract_image_name=False)\n scan_result = asyncio.run(self.execute_scan(image_id, Path('results.json')))\n logging.info(f\"SCA image scanning successfully scanned the image {image_id}\")\n return scan_result\n\n @staticmethod\n async def execute_scan(\n image_id: str,\n output_path: Path,\n ) -> Dict[str, Any]:\n command = f\"./{TWISTCLI_FILE_NAME} images scan --address {docker_image_scanning_integration.get_proxy_address()} --token {docker_image_scanning_integration.get_bc_api_key()} --details --output-file \\\"{output_path}\\\" {image_id}\"\n process = await asyncio.create_subprocess_shell(\n command, stdout=asyncio.subprocess.PIPE, stderr=asyncio.subprocess.PIPE\n )\n\n stdout, stderr = await process.communicate()\n\n # log output for debugging\n logging.debug(stdout.decode())\n\n exit_code = await process.wait()\n\n if exit_code:\n logging.error(stderr.decode())\n return {}\n\n # read and delete the report file\n scan_result: Dict[str, Any] = json.loads(output_path.read_text())\n output_path.unlink()\n\n return scan_result\n\n def run(\n self,\n root_folder: Union[str, Path],\n external_checks_dir: Optional[List[str]] = None,\n files: Optional[List[str]] = None,\n runner_filter: RunnerFilter = RunnerFilter(),\n collect_skip_comments: bool = True,\n **kwargs: str\n ) -> Report:\n report = Report(self.check_type)\n\n dockerfile_path = kwargs['dockerfile_path']\n image_id = kwargs['image_id']\n scan_result = self.scan(image_id, dockerfile_path, runner_filter)\n if scan_result is None:\n return report\n self.raw_report = scan_result\n result = scan_result.get('results', [{}])[0]\n\n vulnerabilities = result.get(\"vulnerabilities\") or []\n self.parse_vulns_to_records(report, result, f\"{dockerfile_path} ({image_id})\", runner_filter, vulnerabilities,\n file_abs_path=os.path.abspath(dockerfile_path))\n\n return report\n", "path": "checkov/sca_image/runner.py"}], "after_files": [{"content": "import logging\nimport os\nfrom pathlib import Path\nfrom typing import Optional, List, Tuple, Set, Union, Sequence, Dict, Any\n\nfrom checkov.common.bridgecrew.platform_integration import bc_integration\nfrom checkov.common.models.enums import CheckResult\nfrom checkov.common.output.report import Report, CheckType\nfrom checkov.common.runners.base_runner import BaseRunner, ignored_directories, strtobool\nfrom checkov.runner_filter import RunnerFilter\nfrom checkov.sca_package.output import create_report_record\nfrom checkov.sca_package.scanner import Scanner\n\nSUPPORTED_PACKAGE_FILES = {\n \"bower.json\",\n \"build.gradle\",\n \"build.gradle.kts\",\n \"go.sum\",\n \"gradle.properties\",\n \"METADATA\",\n \"npm-shrinkwrap.json\",\n \"package.json\",\n \"package-lock.json\",\n \"pom.xml\",\n \"requirements.txt\",\n}\n\nclass Runner(BaseRunner):\n check_type = CheckType.SCA_PACKAGE\n\n def __init__(self):\n self._check_class: Optional[str] = None\n self._code_repo_path: Optional[Path] = None\n\n def prepare_and_scan(\n self,\n root_folder: Union[str, Path],\n files: Optional[List[str]] = None,\n runner_filter: RunnerFilter = RunnerFilter(),\n exclude_package_json: bool = True,\n cleanup_twistcli: bool = True,\n ) -> \"Optional[Sequence[Dict[str, Any]]]\":\n\n if not strtobool(os.getenv(\"ENABLE_SCA_PACKAGE_SCAN\", \"False\")):\n return None\n\n # skip complete run, if flag '--check' was used without a CVE check ID\n if runner_filter.checks and all(not check.startswith(\"CKV_CVE\") for check in runner_filter.checks):\n return None\n\n if not bc_integration.bc_api_key:\n logging.info(\"The --bc-api-key flag needs to be set to run SCA package scanning\")\n return None\n\n logging.info(\"SCA package scanning searching for scannable files\")\n\n self._code_repo_path = Path(root_folder)\n\n excluded_paths = {*ignored_directories}\n if runner_filter.excluded_paths:\n excluded_paths.update(runner_filter.excluded_paths)\n\n input_output_paths = self.find_scannable_files(\n root_path=self._code_repo_path,\n files=files,\n excluded_paths=excluded_paths,\n exclude_package_json=exclude_package_json\n )\n if not input_output_paths:\n # no packages found\n return None\n\n logging.info(f\"SCA package scanning will scan {len(input_output_paths)} files\")\n\n scanner = Scanner()\n self._check_class = f\"{scanner.__module__}.{scanner.__class__.__qualname__}\"\n scan_results = scanner.scan(input_output_paths, cleanup_twistcli)\n\n logging.info(f\"SCA package scanning successfully scanned {len(scan_results)} files\")\n return scan_results\n\n def run(\n self,\n root_folder: Union[str, Path],\n external_checks_dir: Optional[List[str]] = None,\n files: Optional[List[str]] = None,\n runner_filter: RunnerFilter = RunnerFilter(),\n collect_skip_comments: bool = True,\n ) -> Report:\n report = Report(self.check_type)\n\n scan_results = self.prepare_and_scan(root_folder, files, runner_filter)\n if scan_results is None:\n return report\n\n for result in scan_results:\n package_file_path = Path(result[\"repository\"])\n try:\n package_file_path = package_file_path.relative_to(self._code_repo_path)\n except ValueError:\n # Path.is_relative_to() was implemented in Python 3.9\n pass\n\n vulnerabilities = result.get(\"vulnerabilities\") or []\n\n rootless_file_path = str(package_file_path).replace(package_file_path.anchor, \"\", 1)\n self.parse_vulns_to_records(report, result, rootless_file_path, runner_filter, vulnerabilities)\n\n return report\n\n def parse_vulns_to_records(self, report, result, rootless_file_path, runner_filter, vulnerabilities,\n file_abs_path=''):\n for vulnerability in vulnerabilities:\n record = create_report_record(\n rootless_file_path=rootless_file_path,\n file_abs_path=file_abs_path or result.get(\"repository\"),\n check_class=self._check_class,\n vulnerability_details=vulnerability,\n runner_filter=runner_filter\n )\n if not runner_filter.should_run_check(check_id=record.check_id, bc_check_id=record.bc_check_id,\n severity=record.severity):\n if runner_filter.checks:\n continue\n else:\n record.check_result = {\n \"result\": CheckResult.SKIPPED,\n \"suppress_comment\": f\"{vulnerability['id']} is skipped\"\n }\n\n report.add_resource(record.resource)\n report.add_record(record)\n\n def find_scannable_files(\n self, root_path: Path, files: Optional[List[str]], excluded_paths: Set[str], exclude_package_json: bool = True\n ) -> Set[Tuple[Path, Path]]:\n input_paths = {\n file_path\n for file_path in root_path.glob(\"**/*\")\n if file_path.name in SUPPORTED_PACKAGE_FILES and not any(p in file_path.parts for p in excluded_paths)\n }\n\n package_lock_parent_paths = set()\n if exclude_package_json:\n # filter out package.json, if package-lock.json exists\n package_lock_parent_paths = {\n file_path.parent for file_path in input_paths if file_path.name == \"package-lock.json\"\n }\n\n input_output_paths = {\n (file_path, file_path.parent / f\"{file_path.stem}_result.json\")\n for file_path in input_paths\n if file_path.name != \"package.json\" or file_path.parent not in package_lock_parent_paths\n }\n\n for file in files or []:\n file_path = Path(file)\n if not file_path.exists():\n logging.warning(f\"File {file_path} doesn't exist\")\n continue\n\n input_output_paths.add((file_path, file_path.parent / f\"{file_path.stem}_result.json\"))\n\n return input_output_paths\n", "path": "checkov/sca_package/runner.py"}, {"content": "import asyncio\nimport json\nimport logging\nimport os.path\nfrom pathlib import Path\nfrom typing import Optional, List, Union, Dict, Any\n\nfrom checkov.common.bridgecrew.platform_integration import bc_integration\nfrom checkov.common.bridgecrew.vulnerability_scanning.image_scanner import image_scanner, TWISTCLI_FILE_NAME\nfrom checkov.common.bridgecrew.vulnerability_scanning.integrations.docker_image_scanning import \\\n docker_image_scanning_integration\nfrom checkov.common.output.report import Report, CheckType\nfrom checkov.runner_filter import RunnerFilter\nfrom checkov.sca_package.runner import Runner as PackageRunner\n\n\nclass Runner(PackageRunner):\n check_type = CheckType.SCA_IMAGE\n\n def __init__(self) -> None:\n self._check_class: Optional[str] = None\n self._code_repo_path: Optional[Path] = None\n self._check_class = f\"{image_scanner.__module__}.{image_scanner.__class__.__qualname__}\"\n self.raw_report: Optional[Dict[str, Any]] = None\n\n def scan(\n self,\n image_id: str,\n dockerfile_path: str,\n runner_filter: RunnerFilter = RunnerFilter(),\n ) -> Optional[Dict[str, Any]]:\n\n # skip complete run, if flag '--check' was used without a CVE check ID\n if runner_filter.checks and all(not check.startswith(\"CKV_CVE\") for check in runner_filter.checks):\n return None\n\n if not bc_integration.bc_api_key:\n logging.info(\"The --bc-api-key flag needs to be set to run SCA package scanning\")\n return None\n\n logging.info(f\"SCA image scanning is scanning the image {image_id}\")\n image_scanner.setup_scan(image_id, dockerfile_path, skip_extract_image_name=False)\n try:\n scan_result = asyncio.run(self.execute_scan(image_id, Path('results.json')))\n logging.info(f\"SCA image scanning successfully scanned the image {image_id}\")\n image_scanner.cleanup_scan()\n return scan_result\n except Exception as err:\n image_scanner.cleanup_scan()\n raise err\n\n @staticmethod\n async def execute_scan(\n image_id: str,\n output_path: Path,\n ) -> Dict[str, Any]:\n command = f\"./{TWISTCLI_FILE_NAME} images scan --address {docker_image_scanning_integration.get_proxy_address()} --token {docker_image_scanning_integration.get_bc_api_key()} --details --output-file \\\"{output_path}\\\" {image_id}\"\n process = await asyncio.create_subprocess_shell(\n command, stdout=asyncio.subprocess.PIPE, stderr=asyncio.subprocess.PIPE\n )\n\n stdout, stderr = await process.communicate()\n\n # log output for debugging\n logging.debug(stdout.decode())\n\n exit_code = await process.wait()\n\n if exit_code:\n logging.error(stderr.decode())\n return {}\n\n # read and delete the report file\n scan_result: Dict[str, Any] = json.loads(output_path.read_text())\n output_path.unlink()\n\n return scan_result\n\n def run(\n self,\n root_folder: Union[str, Path],\n external_checks_dir: Optional[List[str]] = None,\n files: Optional[List[str]] = None,\n runner_filter: RunnerFilter = RunnerFilter(),\n collect_skip_comments: bool = True,\n **kwargs: str\n ) -> Report:\n report = Report(self.check_type)\n\n dockerfile_path = kwargs['dockerfile_path']\n image_id = kwargs['image_id']\n scan_result = self.scan(image_id, dockerfile_path, runner_filter)\n if scan_result is None:\n return report\n self.raw_report = scan_result\n result = scan_result.get('results', [{}])[0]\n\n vulnerabilities = result.get(\"vulnerabilities\") or []\n self.parse_vulns_to_records(report, result, f\"{dockerfile_path} ({image_id})\", runner_filter, vulnerabilities,\n file_abs_path=os.path.abspath(dockerfile_path))\n\n return report\n", "path": "checkov/sca_image/runner.py"}]}
| 3,362 | 457 |
gh_patches_debug_3353
|
rasdani/github-patches
|
git_diff
|
TabbycatDebate__tabbycat-1092
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Team partial check-in indicator doesn't work with 2+ speaker-teams
The team's partial check-in indicator (where the box on the 'check-ins' page has green and grey stripes) displays when only 1 speaker in a team is checked-in, but then turns grey again when more than 1 speaker is checked-in but the entire team is not checked-in.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `tabbycat/checkins/views.py`
Content:
```
1 import json
2
3 from asgiref.sync import async_to_sync
4 from channels.layers import get_channel_layer
5 from django.contrib import messages
6 from django.core.exceptions import ObjectDoesNotExist
7 from django.views.generic.base import TemplateView
8 from django.template.response import TemplateResponse
9 from django.utils.translation import gettext as _
10
11 from actionlog.mixins import LogActionMixin
12 from actionlog.models import ActionLogEntry
13 from options.utils import use_team_code_names
14 from participants.models import Person, Speaker
15 from utils.misc import reverse_tournament
16 from utils.mixins import AdministratorMixin, AssistantMixin
17 from utils.views import PostOnlyRedirectView
18 from tournaments.mixins import PublicTournamentPageMixin, TournamentMixin
19
20 from .consumers import CheckInEventConsumer
21 from .models import PersonIdentifier, VenueIdentifier
22 from .utils import create_identifiers, get_unexpired_checkins
23
24
25 class CheckInPreScanView(TournamentMixin, TemplateView):
26 template_name = 'checkin_scan.html'
27 page_title = _('Scan Identifiers')
28 page_emoji = '📷'
29
30 def get_context_data(self, **kwargs):
31 kwargs["scan_url"] = self.tournament.slug + '/checkins/'
32 return super().get_context_data(**kwargs)
33
34
35 class AdminCheckInPreScanView(AdministratorMixin, CheckInPreScanView):
36 scan_view = 'admin-checkin-scan'
37
38
39 class AssistantCheckInPreScanView(AssistantMixin, CheckInPreScanView):
40 scan_view = 'assistant-checkin-scan'
41
42
43 class BaseCheckInStatusView(TournamentMixin, TemplateView):
44 template_name = 'checkin_status.html'
45 scan_view = False
46 for_admin = True
47
48 def get_context_data(self, **kwargs):
49 events = get_unexpired_checkins(self.tournament, self.window_preference)
50 kwargs["events"] = json.dumps([e.serialize() for e in events])
51 if self.scan_view:
52 kwargs["scan_url"] = self.tournament.slug + '/checkins/'
53 kwargs["for_admin"] = self.for_admin
54 return super().get_context_data(**kwargs)
55
56
57 class CheckInPeopleStatusView(BaseCheckInStatusView):
58 page_emoji = '⌚️'
59 page_title = _("People's Check-In Statuses")
60 window_preference = 'checkin_window_people'
61
62 def get_context_data(self, **kwargs):
63
64 team_codes = use_team_code_names(self.tournament, admin=self.for_admin)
65 kwargs["team_codes"] = json.dumps(team_codes)
66
67 adjudicators = []
68 for adj in self.tournament.relevant_adjudicators.all().select_related('institution', 'checkin_identifier'):
69 try:
70 code = adj.checkin_identifier.barcode
71 except ObjectDoesNotExist:
72 code = None
73
74 adjudicators.append({
75 'id': adj.id, 'name': adj.name, 'type': 'Adjudicator',
76 'identifier': [code], 'locked': False, 'independent': adj.independent,
77 'institution': adj.institution.serialize if adj.institution else None,
78 })
79 kwargs["adjudicators"] = json.dumps(adjudicators)
80
81 speakers = []
82 for speaker in Speaker.objects.filter(team__tournament=self.tournament).select_related('team', 'team__institution', 'checkin_identifier'):
83 try:
84 code = speaker.checkin_identifier.barcode
85 except ObjectDoesNotExist:
86 code = None
87
88 speakers.append({
89 'id': speaker.id, 'name': speaker.name, 'type': 'Speaker',
90 'identifier': [code], 'locked': False,
91 'team': speaker.team.code_name if team_codes else speaker.team.short_name,
92 'institution': speaker.team.institution.serialize if speaker.team.institution else None,
93 })
94 kwargs["speakers"] = json.dumps(speakers)
95
96 return super().get_context_data(**kwargs)
97
98
99 class AdminCheckInPeopleStatusView(AdministratorMixin, CheckInPeopleStatusView):
100 scan_view = 'admin-checkin-scan'
101
102
103 class AssistantCheckInPeopleStatusView(AssistantMixin, CheckInPeopleStatusView):
104 scan_view = 'assistant-checkin-scan'
105
106
107 class PublicCheckInPeopleStatusView(PublicTournamentPageMixin, CheckInPeopleStatusView):
108 for_admin = False
109 public_page_preference = 'public_checkins'
110
111
112 class CheckInVenuesStatusView(BaseCheckInStatusView):
113 page_emoji = '👜'
114 page_title = _("Venue's Check-In Statuses")
115 window_preference = 'checkin_window_venues'
116
117 def get_context_data(self, **kwargs):
118 venues = []
119 for venue in self.tournament.relevant_venues.select_related('checkin_identifier').prefetch_related('venuecategory_set').all():
120 item = venue.serialize()
121 item['locked'] = False
122 try:
123 item['identifier'] = [venue.checkin_identifier.barcode]
124 except ObjectDoesNotExist:
125 item['identifier'] = [None]
126 venues.append(item)
127 kwargs["venues"] = json.dumps(venues)
128 kwargs["team_codes"] = json.dumps(False)
129
130 return super().get_context_data(**kwargs)
131
132
133 class AdminCheckInVenuesStatusView(AdministratorMixin, CheckInVenuesStatusView):
134 scan_view = 'admin-checkin-scan'
135
136
137 class AssistantCheckInVenuesStatusView(AssistantMixin, CheckInVenuesStatusView):
138 scan_view = 'assistant-checkin-scan'
139
140
141 class SegregatedCheckinsMixin(TournamentMixin):
142
143 def t_speakers(self):
144 return Speaker.objects.filter(
145 team__tournament=self.tournament).values_list(
146 'person_ptr_id', flat=True)
147
148 def speakers_with_barcodes(self):
149 identifiers = PersonIdentifier.objects.all()
150 return identifiers.filter(person_id__in=self.t_speakers())
151
152 def t_adjs(self):
153 return self.tournament.adjudicator_set.values_list(
154 'person_ptr_id', flat=True)
155
156 def adjs_with_barcodes(self):
157 identifiers = PersonIdentifier.objects.all()
158 return identifiers.filter(person_id__in=self.t_adjs())
159
160
161 class CheckInIdentifiersView(SegregatedCheckinsMixin, TemplateView):
162 template_name = 'checkin_ids.html'
163 page_title = _('Make Identifiers')
164 page_emoji = '📛'
165
166 def get_context_data(self, **kwargs):
167 t = self.tournament
168 kwargs["check_in_info"] = {
169 "speakers": {
170 "title": _("Speakers"),
171 "total": self.t_speakers().count(),
172 "in": self.speakers_with_barcodes().count()
173 },
174 "adjudicators": {
175 "title": _("Adjudicators"),
176 "total": self.t_adjs().count(),
177 "in": self.adjs_with_barcodes().count()
178 },
179 "venues": {
180 "title": _("Venues"),
181 "total": t.venue_set.count(),
182 "in": VenueIdentifier.objects.filter(venue__tournament=t).count(),
183 }
184 }
185 return super().get_context_data(**kwargs)
186
187
188 class AdminCheckInIdentifiersView(AdministratorMixin, CheckInIdentifiersView):
189 pass
190
191
192 class AssistantCheckInIdentifiersView(AssistantMixin, CheckInIdentifiersView):
193 pass
194
195
196 class AdminCheckInGenerateView(AdministratorMixin, LogActionMixin,
197 TournamentMixin, PostOnlyRedirectView):
198
199 def get_action_log_type(self):
200 if self.kwargs["kind"] == "speakers":
201 return ActionLogEntry.ACTION_TYPE_CHECKIN_SPEAK_GENERATE
202 elif self.kwargs["kind"] == "adjudicators":
203 return ActionLogEntry.ACTION_TYPE_CHECKIN_ADJ_GENERATE
204 elif self.kwargs["kind"] == "venues":
205 return ActionLogEntry.ACTION_TYPE_CHECKIN_VENUES_GENERATE
206
207 # Providing tournament_slug_url_kwarg isn't working for some reason; so use:
208 def get_redirect_url(self, *args, **kwargs):
209 return reverse_tournament('admin-checkin-identifiers', self.tournament)
210
211 def post(self, request, *args, **kwargs):
212 t = self.tournament
213
214 if self.kwargs["kind"] == "speakers":
215 create_identifiers(PersonIdentifier, Speaker.objects.filter(team__tournament=t))
216 elif self.kwargs["kind"] == "adjudicators":
217 create_identifiers(PersonIdentifier, t.adjudicator_set.all())
218 elif self.kwargs["kind"] == "venues":
219 create_identifiers(VenueIdentifier, t.venue_set.all())
220
221 messages.success(request, _("Generated identifiers for %s" % self.kwargs["kind"]))
222 self.log_action() # Need to call explicitly
223 return super().post(request, *args, **kwargs)
224
225
226 class CheckInPrintablesView(SegregatedCheckinsMixin, TemplateView):
227 template_name = 'checkin_printables.html'
228 page_title = _('Identifiers')
229 page_emoji = '📛'
230
231 def get_context_data(self, **kwargs):
232 if self.kwargs["kind"] == "speakers":
233 kwargs["identifiers"] = self.speakers_with_barcodes().order_by('person__name')
234 elif self.kwargs["kind"] == "adjudicators":
235 kwargs["identifiers"] = self.adjs_with_barcodes().order_by('person__name')
236 elif self.kwargs["kind"] == "venues":
237 venues = self.tournament.relevant_venues
238 kwargs["identifiers"] = VenueIdentifier.objects.filter(venue__in=venues)
239
240 return super().get_context_data(**kwargs)
241
242
243 class AdminCheckInPrintablesView(AdministratorMixin, CheckInPrintablesView):
244 pass
245
246
247 class AssistantCheckInPrintablesView(AssistantMixin, CheckInPrintablesView):
248 pass
249
250
251 class ParticipantCheckinView(PublicTournamentPageMixin, PostOnlyRedirectView):
252
253 public_page_preference = 'public_checkins_submit'
254
255 def post(self, request, *args, **kwargs):
256 t = self.tournament
257
258 action = request.POST['action']
259
260 try:
261 person = Person.objects.get(url_key=kwargs['url_key'])
262 identifier = PersonIdentifier.objects.get(person=person)
263 except ObjectDoesNotExist:
264 messages.error(self.request, _("Could not check you in as you do not have an identifying code — your tab director may need to make you an identifier."))
265 return super().post(request, *args, **kwargs)
266
267 checkins = get_unexpired_checkins(t, 'checkin_window_people')
268 existing_checkin = checkins.filter(identifier=identifier)
269 if action == 'revoke':
270 if existing_checkin.exists():
271 messages.success(self.request, _("You have revoked your check-in."))
272 else:
273 messages.error(self.request, _("Whoops! Looks like your check-in was already revoked."))
274 elif action == 'checkin':
275 if existing_checkin.exists():
276 messages.error(self.request, _("Whoops! Looks like you're already checked in."))
277 else:
278 messages.success(self.request, _("You are now checked in."))
279 else:
280 return TemplateResponse(request=self.request, template='400.html', status=400)
281
282 group_name = CheckInEventConsumer.group_prefix + "_" + t.slug
283
284 # Override permissions check - no user but authenticated through URL
285 async_to_sync(get_channel_layer().group_send)(
286 group_name, {
287 'type': 'broadcast_checkin',
288 'content': {
289 'barcodes': [identifier.barcode],
290 'status': action == 'checkin',
291 'type': 'people',
292 'component_id': None
293 }
294 }
295 )
296
297 return super().post(request, *args, **kwargs)
298
299 def get_redirect_url(self, *args, **kwargs):
300 return reverse_tournament('privateurls-person-index', self.tournament, kwargs={'url_key': kwargs['url_key']})
301
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/tabbycat/checkins/views.py b/tabbycat/checkins/views.py
--- a/tabbycat/checkins/views.py
+++ b/tabbycat/checkins/views.py
@@ -51,6 +51,7 @@
if self.scan_view:
kwargs["scan_url"] = self.tournament.slug + '/checkins/'
kwargs["for_admin"] = self.for_admin
+ kwargs["team_size"] = self.tournament.pref('substantive_speakers')
return super().get_context_data(**kwargs)
|
{"golden_diff": "diff --git a/tabbycat/checkins/views.py b/tabbycat/checkins/views.py\n--- a/tabbycat/checkins/views.py\n+++ b/tabbycat/checkins/views.py\n@@ -51,6 +51,7 @@\n if self.scan_view:\n kwargs[\"scan_url\"] = self.tournament.slug + '/checkins/'\n kwargs[\"for_admin\"] = self.for_admin\n+ kwargs[\"team_size\"] = self.tournament.pref('substantive_speakers')\n return super().get_context_data(**kwargs)\n", "issue": "Team partial check-in indicator doesn't work with 2+ speaker-teams\nThe team's partial check-in indicator (where the box on the 'check-ins' page has green and grey stripes) displays when only 1 speaker in a team is checked-in, but then turns grey again when more than 1 speaker is checked-in but the entire team is not checked-in.\n", "before_files": [{"content": "import json\n\nfrom asgiref.sync import async_to_sync\nfrom channels.layers import get_channel_layer\nfrom django.contrib import messages\nfrom django.core.exceptions import ObjectDoesNotExist\nfrom django.views.generic.base import TemplateView\nfrom django.template.response import TemplateResponse\nfrom django.utils.translation import gettext as _\n\nfrom actionlog.mixins import LogActionMixin\nfrom actionlog.models import ActionLogEntry\nfrom options.utils import use_team_code_names\nfrom participants.models import Person, Speaker\nfrom utils.misc import reverse_tournament\nfrom utils.mixins import AdministratorMixin, AssistantMixin\nfrom utils.views import PostOnlyRedirectView\nfrom tournaments.mixins import PublicTournamentPageMixin, TournamentMixin\n\nfrom .consumers import CheckInEventConsumer\nfrom .models import PersonIdentifier, VenueIdentifier\nfrom .utils import create_identifiers, get_unexpired_checkins\n\n\nclass CheckInPreScanView(TournamentMixin, TemplateView):\n template_name = 'checkin_scan.html'\n page_title = _('Scan Identifiers')\n page_emoji = '\ud83d\udcf7'\n\n def get_context_data(self, **kwargs):\n kwargs[\"scan_url\"] = self.tournament.slug + '/checkins/'\n return super().get_context_data(**kwargs)\n\n\nclass AdminCheckInPreScanView(AdministratorMixin, CheckInPreScanView):\n scan_view = 'admin-checkin-scan'\n\n\nclass AssistantCheckInPreScanView(AssistantMixin, CheckInPreScanView):\n scan_view = 'assistant-checkin-scan'\n\n\nclass BaseCheckInStatusView(TournamentMixin, TemplateView):\n template_name = 'checkin_status.html'\n scan_view = False\n for_admin = True\n\n def get_context_data(self, **kwargs):\n events = get_unexpired_checkins(self.tournament, self.window_preference)\n kwargs[\"events\"] = json.dumps([e.serialize() for e in events])\n if self.scan_view:\n kwargs[\"scan_url\"] = self.tournament.slug + '/checkins/'\n kwargs[\"for_admin\"] = self.for_admin\n return super().get_context_data(**kwargs)\n\n\nclass CheckInPeopleStatusView(BaseCheckInStatusView):\n page_emoji = '\u231a\ufe0f'\n page_title = _(\"People's Check-In Statuses\")\n window_preference = 'checkin_window_people'\n\n def get_context_data(self, **kwargs):\n\n team_codes = use_team_code_names(self.tournament, admin=self.for_admin)\n kwargs[\"team_codes\"] = json.dumps(team_codes)\n\n adjudicators = []\n for adj in self.tournament.relevant_adjudicators.all().select_related('institution', 'checkin_identifier'):\n try:\n code = adj.checkin_identifier.barcode\n except ObjectDoesNotExist:\n code = None\n\n adjudicators.append({\n 'id': adj.id, 'name': adj.name, 'type': 'Adjudicator',\n 'identifier': [code], 'locked': False, 'independent': adj.independent,\n 'institution': adj.institution.serialize if adj.institution else None,\n })\n kwargs[\"adjudicators\"] = json.dumps(adjudicators)\n\n speakers = []\n for speaker in Speaker.objects.filter(team__tournament=self.tournament).select_related('team', 'team__institution', 'checkin_identifier'):\n try:\n code = speaker.checkin_identifier.barcode\n except ObjectDoesNotExist:\n code = None\n\n speakers.append({\n 'id': speaker.id, 'name': speaker.name, 'type': 'Speaker',\n 'identifier': [code], 'locked': False,\n 'team': speaker.team.code_name if team_codes else speaker.team.short_name,\n 'institution': speaker.team.institution.serialize if speaker.team.institution else None,\n })\n kwargs[\"speakers\"] = json.dumps(speakers)\n\n return super().get_context_data(**kwargs)\n\n\nclass AdminCheckInPeopleStatusView(AdministratorMixin, CheckInPeopleStatusView):\n scan_view = 'admin-checkin-scan'\n\n\nclass AssistantCheckInPeopleStatusView(AssistantMixin, CheckInPeopleStatusView):\n scan_view = 'assistant-checkin-scan'\n\n\nclass PublicCheckInPeopleStatusView(PublicTournamentPageMixin, CheckInPeopleStatusView):\n for_admin = False\n public_page_preference = 'public_checkins'\n\n\nclass CheckInVenuesStatusView(BaseCheckInStatusView):\n page_emoji = '\ud83d\udc5c'\n page_title = _(\"Venue's Check-In Statuses\")\n window_preference = 'checkin_window_venues'\n\n def get_context_data(self, **kwargs):\n venues = []\n for venue in self.tournament.relevant_venues.select_related('checkin_identifier').prefetch_related('venuecategory_set').all():\n item = venue.serialize()\n item['locked'] = False\n try:\n item['identifier'] = [venue.checkin_identifier.barcode]\n except ObjectDoesNotExist:\n item['identifier'] = [None]\n venues.append(item)\n kwargs[\"venues\"] = json.dumps(venues)\n kwargs[\"team_codes\"] = json.dumps(False)\n\n return super().get_context_data(**kwargs)\n\n\nclass AdminCheckInVenuesStatusView(AdministratorMixin, CheckInVenuesStatusView):\n scan_view = 'admin-checkin-scan'\n\n\nclass AssistantCheckInVenuesStatusView(AssistantMixin, CheckInVenuesStatusView):\n scan_view = 'assistant-checkin-scan'\n\n\nclass SegregatedCheckinsMixin(TournamentMixin):\n\n def t_speakers(self):\n return Speaker.objects.filter(\n team__tournament=self.tournament).values_list(\n 'person_ptr_id', flat=True)\n\n def speakers_with_barcodes(self):\n identifiers = PersonIdentifier.objects.all()\n return identifiers.filter(person_id__in=self.t_speakers())\n\n def t_adjs(self):\n return self.tournament.adjudicator_set.values_list(\n 'person_ptr_id', flat=True)\n\n def adjs_with_barcodes(self):\n identifiers = PersonIdentifier.objects.all()\n return identifiers.filter(person_id__in=self.t_adjs())\n\n\nclass CheckInIdentifiersView(SegregatedCheckinsMixin, TemplateView):\n template_name = 'checkin_ids.html'\n page_title = _('Make Identifiers')\n page_emoji = '\ud83d\udcdb'\n\n def get_context_data(self, **kwargs):\n t = self.tournament\n kwargs[\"check_in_info\"] = {\n \"speakers\": {\n \"title\": _(\"Speakers\"),\n \"total\": self.t_speakers().count(),\n \"in\": self.speakers_with_barcodes().count()\n },\n \"adjudicators\": {\n \"title\": _(\"Adjudicators\"),\n \"total\": self.t_adjs().count(),\n \"in\": self.adjs_with_barcodes().count()\n },\n \"venues\": {\n \"title\": _(\"Venues\"),\n \"total\": t.venue_set.count(),\n \"in\": VenueIdentifier.objects.filter(venue__tournament=t).count(),\n }\n }\n return super().get_context_data(**kwargs)\n\n\nclass AdminCheckInIdentifiersView(AdministratorMixin, CheckInIdentifiersView):\n pass\n\n\nclass AssistantCheckInIdentifiersView(AssistantMixin, CheckInIdentifiersView):\n pass\n\n\nclass AdminCheckInGenerateView(AdministratorMixin, LogActionMixin,\n TournamentMixin, PostOnlyRedirectView):\n\n def get_action_log_type(self):\n if self.kwargs[\"kind\"] == \"speakers\":\n return ActionLogEntry.ACTION_TYPE_CHECKIN_SPEAK_GENERATE\n elif self.kwargs[\"kind\"] == \"adjudicators\":\n return ActionLogEntry.ACTION_TYPE_CHECKIN_ADJ_GENERATE\n elif self.kwargs[\"kind\"] == \"venues\":\n return ActionLogEntry.ACTION_TYPE_CHECKIN_VENUES_GENERATE\n\n # Providing tournament_slug_url_kwarg isn't working for some reason; so use:\n def get_redirect_url(self, *args, **kwargs):\n return reverse_tournament('admin-checkin-identifiers', self.tournament)\n\n def post(self, request, *args, **kwargs):\n t = self.tournament\n\n if self.kwargs[\"kind\"] == \"speakers\":\n create_identifiers(PersonIdentifier, Speaker.objects.filter(team__tournament=t))\n elif self.kwargs[\"kind\"] == \"adjudicators\":\n create_identifiers(PersonIdentifier, t.adjudicator_set.all())\n elif self.kwargs[\"kind\"] == \"venues\":\n create_identifiers(VenueIdentifier, t.venue_set.all())\n\n messages.success(request, _(\"Generated identifiers for %s\" % self.kwargs[\"kind\"]))\n self.log_action() # Need to call explicitly\n return super().post(request, *args, **kwargs)\n\n\nclass CheckInPrintablesView(SegregatedCheckinsMixin, TemplateView):\n template_name = 'checkin_printables.html'\n page_title = _('Identifiers')\n page_emoji = '\ud83d\udcdb'\n\n def get_context_data(self, **kwargs):\n if self.kwargs[\"kind\"] == \"speakers\":\n kwargs[\"identifiers\"] = self.speakers_with_barcodes().order_by('person__name')\n elif self.kwargs[\"kind\"] == \"adjudicators\":\n kwargs[\"identifiers\"] = self.adjs_with_barcodes().order_by('person__name')\n elif self.kwargs[\"kind\"] == \"venues\":\n venues = self.tournament.relevant_venues\n kwargs[\"identifiers\"] = VenueIdentifier.objects.filter(venue__in=venues)\n\n return super().get_context_data(**kwargs)\n\n\nclass AdminCheckInPrintablesView(AdministratorMixin, CheckInPrintablesView):\n pass\n\n\nclass AssistantCheckInPrintablesView(AssistantMixin, CheckInPrintablesView):\n pass\n\n\nclass ParticipantCheckinView(PublicTournamentPageMixin, PostOnlyRedirectView):\n\n public_page_preference = 'public_checkins_submit'\n\n def post(self, request, *args, **kwargs):\n t = self.tournament\n\n action = request.POST['action']\n\n try:\n person = Person.objects.get(url_key=kwargs['url_key'])\n identifier = PersonIdentifier.objects.get(person=person)\n except ObjectDoesNotExist:\n messages.error(self.request, _(\"Could not check you in as you do not have an identifying code \u2014 your tab director may need to make you an identifier.\"))\n return super().post(request, *args, **kwargs)\n\n checkins = get_unexpired_checkins(t, 'checkin_window_people')\n existing_checkin = checkins.filter(identifier=identifier)\n if action == 'revoke':\n if existing_checkin.exists():\n messages.success(self.request, _(\"You have revoked your check-in.\"))\n else:\n messages.error(self.request, _(\"Whoops! Looks like your check-in was already revoked.\"))\n elif action == 'checkin':\n if existing_checkin.exists():\n messages.error(self.request, _(\"Whoops! Looks like you're already checked in.\"))\n else:\n messages.success(self.request, _(\"You are now checked in.\"))\n else:\n return TemplateResponse(request=self.request, template='400.html', status=400)\n\n group_name = CheckInEventConsumer.group_prefix + \"_\" + t.slug\n\n # Override permissions check - no user but authenticated through URL\n async_to_sync(get_channel_layer().group_send)(\n group_name, {\n 'type': 'broadcast_checkin',\n 'content': {\n 'barcodes': [identifier.barcode],\n 'status': action == 'checkin',\n 'type': 'people',\n 'component_id': None\n }\n }\n )\n\n return super().post(request, *args, **kwargs)\n\n def get_redirect_url(self, *args, **kwargs):\n return reverse_tournament('privateurls-person-index', self.tournament, kwargs={'url_key': kwargs['url_key']})\n", "path": "tabbycat/checkins/views.py"}], "after_files": [{"content": "import json\n\nfrom asgiref.sync import async_to_sync\nfrom channels.layers import get_channel_layer\nfrom django.contrib import messages\nfrom django.core.exceptions import ObjectDoesNotExist\nfrom django.views.generic.base import TemplateView\nfrom django.template.response import TemplateResponse\nfrom django.utils.translation import gettext as _\n\nfrom actionlog.mixins import LogActionMixin\nfrom actionlog.models import ActionLogEntry\nfrom options.utils import use_team_code_names\nfrom participants.models import Person, Speaker\nfrom utils.misc import reverse_tournament\nfrom utils.mixins import AdministratorMixin, AssistantMixin\nfrom utils.views import PostOnlyRedirectView\nfrom tournaments.mixins import PublicTournamentPageMixin, TournamentMixin\n\nfrom .consumers import CheckInEventConsumer\nfrom .models import PersonIdentifier, VenueIdentifier\nfrom .utils import create_identifiers, get_unexpired_checkins\n\n\nclass CheckInPreScanView(TournamentMixin, TemplateView):\n template_name = 'checkin_scan.html'\n page_title = _('Scan Identifiers')\n page_emoji = '\ud83d\udcf7'\n\n def get_context_data(self, **kwargs):\n kwargs[\"scan_url\"] = self.tournament.slug + '/checkins/'\n return super().get_context_data(**kwargs)\n\n\nclass AdminCheckInPreScanView(AdministratorMixin, CheckInPreScanView):\n scan_view = 'admin-checkin-scan'\n\n\nclass AssistantCheckInPreScanView(AssistantMixin, CheckInPreScanView):\n scan_view = 'assistant-checkin-scan'\n\n\nclass BaseCheckInStatusView(TournamentMixin, TemplateView):\n template_name = 'checkin_status.html'\n scan_view = False\n for_admin = True\n\n def get_context_data(self, **kwargs):\n events = get_unexpired_checkins(self.tournament, self.window_preference)\n kwargs[\"events\"] = json.dumps([e.serialize() for e in events])\n if self.scan_view:\n kwargs[\"scan_url\"] = self.tournament.slug + '/checkins/'\n kwargs[\"for_admin\"] = self.for_admin\n kwargs[\"team_size\"] = self.tournament.pref('substantive_speakers')\n return super().get_context_data(**kwargs)\n\n\nclass CheckInPeopleStatusView(BaseCheckInStatusView):\n page_emoji = '\u231a\ufe0f'\n page_title = _(\"People's Check-In Statuses\")\n window_preference = 'checkin_window_people'\n\n def get_context_data(self, **kwargs):\n\n team_codes = use_team_code_names(self.tournament, admin=self.for_admin)\n kwargs[\"team_codes\"] = json.dumps(team_codes)\n\n adjudicators = []\n for adj in self.tournament.relevant_adjudicators.all().select_related('institution', 'checkin_identifier'):\n try:\n code = adj.checkin_identifier.barcode\n except ObjectDoesNotExist:\n code = None\n\n adjudicators.append({\n 'id': adj.id, 'name': adj.name, 'type': 'Adjudicator',\n 'identifier': [code], 'locked': False, 'independent': adj.independent,\n 'institution': adj.institution.serialize if adj.institution else None,\n })\n kwargs[\"adjudicators\"] = json.dumps(adjudicators)\n\n speakers = []\n for speaker in Speaker.objects.filter(team__tournament=self.tournament).select_related('team', 'team__institution', 'checkin_identifier'):\n try:\n code = speaker.checkin_identifier.barcode\n except ObjectDoesNotExist:\n code = None\n\n speakers.append({\n 'id': speaker.id, 'name': speaker.name, 'type': 'Speaker',\n 'identifier': [code], 'locked': False,\n 'team': speaker.team.code_name if team_codes else speaker.team.short_name,\n 'institution': speaker.team.institution.serialize if speaker.team.institution else None,\n })\n kwargs[\"speakers\"] = json.dumps(speakers)\n\n return super().get_context_data(**kwargs)\n\n\nclass AdminCheckInPeopleStatusView(AdministratorMixin, CheckInPeopleStatusView):\n scan_view = 'admin-checkin-scan'\n\n\nclass AssistantCheckInPeopleStatusView(AssistantMixin, CheckInPeopleStatusView):\n scan_view = 'assistant-checkin-scan'\n\n\nclass PublicCheckInPeopleStatusView(PublicTournamentPageMixin, CheckInPeopleStatusView):\n for_admin = False\n public_page_preference = 'public_checkins'\n\n\nclass CheckInVenuesStatusView(BaseCheckInStatusView):\n page_emoji = '\ud83d\udc5c'\n page_title = _(\"Venue's Check-In Statuses\")\n window_preference = 'checkin_window_venues'\n\n def get_context_data(self, **kwargs):\n venues = []\n for venue in self.tournament.relevant_venues.select_related('checkin_identifier').prefetch_related('venuecategory_set').all():\n item = venue.serialize()\n item['locked'] = False\n try:\n item['identifier'] = [venue.checkin_identifier.barcode]\n except ObjectDoesNotExist:\n item['identifier'] = [None]\n venues.append(item)\n kwargs[\"venues\"] = json.dumps(venues)\n kwargs[\"team_codes\"] = json.dumps(False)\n\n return super().get_context_data(**kwargs)\n\n\nclass AdminCheckInVenuesStatusView(AdministratorMixin, CheckInVenuesStatusView):\n scan_view = 'admin-checkin-scan'\n\n\nclass AssistantCheckInVenuesStatusView(AssistantMixin, CheckInVenuesStatusView):\n scan_view = 'assistant-checkin-scan'\n\n\nclass SegregatedCheckinsMixin(TournamentMixin):\n\n def t_speakers(self):\n return Speaker.objects.filter(\n team__tournament=self.tournament).values_list(\n 'person_ptr_id', flat=True)\n\n def speakers_with_barcodes(self):\n identifiers = PersonIdentifier.objects.all()\n return identifiers.filter(person_id__in=self.t_speakers())\n\n def t_adjs(self):\n return self.tournament.adjudicator_set.values_list(\n 'person_ptr_id', flat=True)\n\n def adjs_with_barcodes(self):\n identifiers = PersonIdentifier.objects.all()\n return identifiers.filter(person_id__in=self.t_adjs())\n\n\nclass CheckInIdentifiersView(SegregatedCheckinsMixin, TemplateView):\n template_name = 'checkin_ids.html'\n page_title = _('Make Identifiers')\n page_emoji = '\ud83d\udcdb'\n\n def get_context_data(self, **kwargs):\n t = self.tournament\n kwargs[\"check_in_info\"] = {\n \"speakers\": {\n \"title\": _(\"Speakers\"),\n \"total\": self.t_speakers().count(),\n \"in\": self.speakers_with_barcodes().count()\n },\n \"adjudicators\": {\n \"title\": _(\"Adjudicators\"),\n \"total\": self.t_adjs().count(),\n \"in\": self.adjs_with_barcodes().count()\n },\n \"venues\": {\n \"title\": _(\"Venues\"),\n \"total\": t.venue_set.count(),\n \"in\": VenueIdentifier.objects.filter(venue__tournament=t).count(),\n }\n }\n return super().get_context_data(**kwargs)\n\n\nclass AdminCheckInIdentifiersView(AdministratorMixin, CheckInIdentifiersView):\n pass\n\n\nclass AssistantCheckInIdentifiersView(AssistantMixin, CheckInIdentifiersView):\n pass\n\n\nclass AdminCheckInGenerateView(AdministratorMixin, LogActionMixin,\n TournamentMixin, PostOnlyRedirectView):\n\n def get_action_log_type(self):\n if self.kwargs[\"kind\"] == \"speakers\":\n return ActionLogEntry.ACTION_TYPE_CHECKIN_SPEAK_GENERATE\n elif self.kwargs[\"kind\"] == \"adjudicators\":\n return ActionLogEntry.ACTION_TYPE_CHECKIN_ADJ_GENERATE\n elif self.kwargs[\"kind\"] == \"venues\":\n return ActionLogEntry.ACTION_TYPE_CHECKIN_VENUES_GENERATE\n\n # Providing tournament_slug_url_kwarg isn't working for some reason; so use:\n def get_redirect_url(self, *args, **kwargs):\n return reverse_tournament('admin-checkin-identifiers', self.tournament)\n\n def post(self, request, *args, **kwargs):\n t = self.tournament\n\n if self.kwargs[\"kind\"] == \"speakers\":\n create_identifiers(PersonIdentifier, Speaker.objects.filter(team__tournament=t))\n elif self.kwargs[\"kind\"] == \"adjudicators\":\n create_identifiers(PersonIdentifier, t.adjudicator_set.all())\n elif self.kwargs[\"kind\"] == \"venues\":\n create_identifiers(VenueIdentifier, t.venue_set.all())\n\n messages.success(request, _(\"Generated identifiers for %s\" % self.kwargs[\"kind\"]))\n self.log_action() # Need to call explicitly\n return super().post(request, *args, **kwargs)\n\n\nclass CheckInPrintablesView(SegregatedCheckinsMixin, TemplateView):\n template_name = 'checkin_printables.html'\n page_title = _('Identifiers')\n page_emoji = '\ud83d\udcdb'\n\n def get_context_data(self, **kwargs):\n if self.kwargs[\"kind\"] == \"speakers\":\n kwargs[\"identifiers\"] = self.speakers_with_barcodes().order_by('person__name')\n elif self.kwargs[\"kind\"] == \"adjudicators\":\n kwargs[\"identifiers\"] = self.adjs_with_barcodes().order_by('person__name')\n elif self.kwargs[\"kind\"] == \"venues\":\n venues = self.tournament.relevant_venues\n kwargs[\"identifiers\"] = VenueIdentifier.objects.filter(venue__in=venues)\n\n return super().get_context_data(**kwargs)\n\n\nclass AdminCheckInPrintablesView(AdministratorMixin, CheckInPrintablesView):\n pass\n\n\nclass AssistantCheckInPrintablesView(AssistantMixin, CheckInPrintablesView):\n pass\n\n\nclass ParticipantCheckinView(PublicTournamentPageMixin, PostOnlyRedirectView):\n\n public_page_preference = 'public_checkins_submit'\n\n def post(self, request, *args, **kwargs):\n t = self.tournament\n\n action = request.POST['action']\n\n try:\n person = Person.objects.get(url_key=kwargs['url_key'])\n identifier = PersonIdentifier.objects.get(person=person)\n except ObjectDoesNotExist:\n messages.error(self.request, _(\"Could not check you in as you do not have an identifying code \u2014 your tab director may need to make you an identifier.\"))\n return super().post(request, *args, **kwargs)\n\n checkins = get_unexpired_checkins(t, 'checkin_window_people')\n existing_checkin = checkins.filter(identifier=identifier)\n if action == 'revoke':\n if existing_checkin.exists():\n messages.success(self.request, _(\"You have revoked your check-in.\"))\n else:\n messages.error(self.request, _(\"Whoops! Looks like your check-in was already revoked.\"))\n elif action == 'checkin':\n if existing_checkin.exists():\n messages.error(self.request, _(\"Whoops! Looks like you're already checked in.\"))\n else:\n messages.success(self.request, _(\"You are now checked in.\"))\n else:\n return TemplateResponse(request=self.request, template='400.html', status=400)\n\n group_name = CheckInEventConsumer.group_prefix + \"_\" + t.slug\n\n # Override permissions check - no user but authenticated through URL\n async_to_sync(get_channel_layer().group_send)(\n group_name, {\n 'type': 'broadcast_checkin',\n 'content': {\n 'barcodes': [identifier.barcode],\n 'status': action == 'checkin',\n 'type': 'people',\n 'component_id': None\n }\n }\n )\n\n return super().post(request, *args, **kwargs)\n\n def get_redirect_url(self, *args, **kwargs):\n return reverse_tournament('privateurls-person-index', self.tournament, kwargs={'url_key': kwargs['url_key']})\n", "path": "tabbycat/checkins/views.py"}]}
| 3,669 | 115 |
gh_patches_debug_37597
|
rasdani/github-patches
|
git_diff
|
streamlit__streamlit-3548
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
File uploader does not return multiple files
From: https://discuss.streamlit.io/t/issue-with-file-uploader-and-streamlit-version-0-84-0/14812
---
Hi everyone,
I'm new here. First of all thank you really much for your great work in this forum. It helped me out multiple times. But now I encountered an issue where I couldn't find a thread on, yet.
With the latest version (0.84.0) I'm experiencing a problem with the file_uploader widget.
In the prior version (0.82.0) it was very handy, for my case, to select one file after another and drag&drop it to the widget. With the latest version this doesn't seems possible anymore. When one or more files were uploaded the next file/s draged and droped to the widget are not accessible, even though these files appear in the interactive list below the widget.
I want to use st.session_state is the app I'm working on and for that reason the version 0.84.0 is necessary to my understanding.
In order for you to reproduce the situation I made up this example:
```
import streamlit as st
uploaded_files = st.file_uploader('Select files',type=['txt'],accept_multiple_files=True)
file_lst = [uploaded_file.name for uploaded_file in uploaded_files]
st.write(file_lst)
```
Assuming I want to upload the two files test1.txt and test2.txt one after another. For the first file (test1.txt) the behavior is as expected and equivalent for both versions:

Then later I want to upload another file in this case test2.txt.
The expected behavior can be seen with version 0.82.0. Both files are shown in the interactive list below the widget as well as in the written file_lst.

With version 0.84.0 only the interactive list below the widget shows both files. The written file_lst shows only test1.txt.
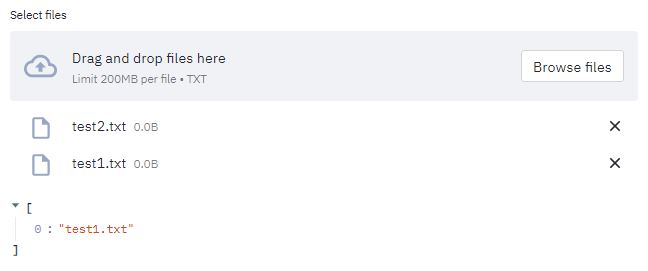
Anyone had a similar issue? I apologize, if the solution is obvious, but I got stuck with it and can't figure out, how to solve the issue.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lib/streamlit/elements/file_uploader.py`
Content:
```
1 # Copyright 2018-2021 Streamlit Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from typing import cast, List, Optional, Union
16
17 import streamlit
18 from streamlit import config
19 from streamlit.logger import get_logger
20 from streamlit.proto.FileUploader_pb2 import FileUploader as FileUploaderProto
21 from streamlit.report_thread import get_report_ctx
22 from streamlit.state.widgets import register_widget, NoValue
23 from .form import current_form_id
24 from ..proto.Common_pb2 import SInt64Array
25 from ..uploaded_file_manager import UploadedFile, UploadedFileRec
26 from .utils import check_callback_rules, check_session_state_rules
27
28 LOGGER = get_logger(__name__)
29
30
31 class FileUploaderMixin:
32 def file_uploader(
33 self,
34 label,
35 type=None,
36 accept_multiple_files=False,
37 key=None,
38 help=None,
39 on_change=None,
40 args=None,
41 kwargs=None,
42 ):
43 """Display a file uploader widget.
44 By default, uploaded files are limited to 200MB. You can configure
45 this using the `server.maxUploadSize` config option.
46
47 Parameters
48 ----------
49 label : str
50 A short label explaining to the user what this file uploader is for.
51
52 type : str or list of str or None
53 Array of allowed extensions. ['png', 'jpg']
54 The default is None, which means all extensions are allowed.
55
56 accept_multiple_files : bool
57 If True, allows the user to upload multiple files at the same time,
58 in which case the return value will be a list of files.
59 Default: False
60
61 key : str
62 An optional string to use as the unique key for the widget.
63 If this is omitted, a key will be generated for the widget
64 based on its content. Multiple widgets of the same type may
65 not share the same key.
66
67 help : str
68 A tooltip that gets displayed next to the file uploader.
69
70 on_change : callable
71 An optional callback invoked when this file_uploader's value
72 changes.
73
74 args : tuple
75 An optional tuple of args to pass to the callback.
76
77 kwargs : dict
78 An optional dict of kwargs to pass to the callback.
79
80 Returns
81 -------
82 None or UploadedFile or list of UploadedFile
83 - If accept_multiple_files is False, returns either None or
84 an UploadedFile object.
85 - If accept_multiple_files is True, returns a list with the
86 uploaded files as UploadedFile objects. If no files were
87 uploaded, returns an empty list.
88
89 The UploadedFile class is a subclass of BytesIO, and therefore
90 it is "file-like". This means you can pass them anywhere where
91 a file is expected.
92
93 Examples
94 --------
95 Insert a file uploader that accepts a single file at a time:
96
97 >>> uploaded_file = st.file_uploader("Choose a file")
98 >>> if uploaded_file is not None:
99 ... # To read file as bytes:
100 ... bytes_data = uploaded_file.getvalue()
101 ... st.write(bytes_data)
102 >>>
103 ... # To convert to a string based IO:
104 ... stringio = StringIO(uploaded_file.getvalue().decode("utf-8"))
105 ... st.write(stringio)
106 >>>
107 ... # To read file as string:
108 ... string_data = stringio.read()
109 ... st.write(string_data)
110 >>>
111 ... # Can be used wherever a "file-like" object is accepted:
112 ... dataframe = pd.read_csv(uploaded_file)
113 ... st.write(dataframe)
114
115 Insert a file uploader that accepts multiple files at a time:
116
117 >>> uploaded_files = st.file_uploader("Choose a CSV file", accept_multiple_files=True)
118 >>> for uploaded_file in uploaded_files:
119 ... bytes_data = uploaded_file.read()
120 ... st.write("filename:", uploaded_file.name)
121 ... st.write(bytes_data)
122 """
123 check_callback_rules(self.dg, on_change)
124 check_session_state_rules(default_value=None, key=key, writes_allowed=False)
125
126 if type:
127 if isinstance(type, str):
128 type = [type]
129
130 # May need a regex or a library to validate file types are valid
131 # extensions.
132 type = [
133 file_type if file_type[0] == "." else f".{file_type}"
134 for file_type in type
135 ]
136
137 file_uploader_proto = FileUploaderProto()
138 file_uploader_proto.label = label
139 file_uploader_proto.type[:] = type if type is not None else []
140 file_uploader_proto.max_upload_size_mb = config.get_option(
141 "server.maxUploadSize"
142 )
143 file_uploader_proto.multiple_files = accept_multiple_files
144 file_uploader_proto.form_id = current_form_id(self.dg)
145 if help is not None:
146 file_uploader_proto.help = help
147
148 def deserialize_file_uploader(
149 ui_value: List[int], widget_id: str
150 ) -> Optional[Union[List[UploadedFile], UploadedFile]]:
151 file_recs = self._get_file_recs(widget_id, ui_value)
152 if len(file_recs) == 0:
153 return_value: Optional[Union[List[UploadedFile], UploadedFile]] = (
154 [] if accept_multiple_files else None
155 )
156 else:
157 files = [UploadedFile(rec) for rec in file_recs]
158 return_value = files if accept_multiple_files else files[0]
159 return return_value
160
161 def serialize_file_uploader(
162 files: Optional[Union[List[UploadedFile], UploadedFile]]
163 ) -> List[int]:
164 if not files:
165 return []
166 if isinstance(files, list):
167 ids = [f.id for f in files]
168 else:
169 ids = [files.id]
170 ctx = get_report_ctx()
171 if ctx is None:
172 return []
173 max_id = ctx.uploaded_file_mgr._file_id_counter
174 return [max_id] + ids
175
176 # FileUploader's widget value is a list of file IDs
177 # representing the current set of files that this uploader should
178 # know about.
179 widget_value, _ = register_widget(
180 "file_uploader",
181 file_uploader_proto,
182 user_key=key,
183 on_change_handler=on_change,
184 args=args,
185 kwargs=kwargs,
186 deserializer=deserialize_file_uploader,
187 serializer=serialize_file_uploader,
188 )
189
190 self.dg._enqueue("file_uploader", file_uploader_proto)
191 return widget_value
192
193 @staticmethod
194 def _get_file_recs(
195 widget_id: str, widget_value: Optional[List[int]]
196 ) -> List[UploadedFileRec]:
197 if widget_value is None:
198 return []
199
200 ctx = get_report_ctx()
201 if ctx is None:
202 return []
203
204 if len(widget_value) == 0:
205 # Sanity check
206 LOGGER.warning(
207 "Got an empty FileUploader widget_value. (We expect a list with at least one value in it.)"
208 )
209 return []
210
211 # The first number in the widget_value list is 'newestServerFileId'
212 newest_file_id = widget_value[0]
213 active_file_ids = list(widget_value[1:])
214
215 # Grab the files that correspond to our active file IDs.
216 file_recs = ctx.uploaded_file_mgr.get_files(
217 session_id=ctx.session_id,
218 widget_id=widget_id,
219 file_ids=active_file_ids,
220 )
221
222 # Garbage collect "orphaned" files.
223 ctx.uploaded_file_mgr.remove_orphaned_files(
224 session_id=ctx.session_id,
225 widget_id=widget_id,
226 newest_file_id=newest_file_id,
227 active_file_ids=active_file_ids,
228 )
229
230 return file_recs
231
232 @property
233 def dg(self) -> "streamlit.delta_generator.DeltaGenerator":
234 """Get our DeltaGenerator."""
235 return cast("streamlit.delta_generator.DeltaGenerator", self)
236
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lib/streamlit/elements/file_uploader.py b/lib/streamlit/elements/file_uploader.py
--- a/lib/streamlit/elements/file_uploader.py
+++ b/lib/streamlit/elements/file_uploader.py
@@ -167,10 +167,15 @@
ids = [f.id for f in files]
else:
ids = [files.id]
+
ctx = get_report_ctx()
if ctx is None:
return []
- max_id = ctx.uploaded_file_mgr._file_id_counter
+
+ # ctx.uploaded_file_mgr._file_id_counter stores the id to use for
+ # the next uploaded file, so the current highest file id is the
+ # counter minus 1.
+ max_id = ctx.uploaded_file_mgr._file_id_counter - 1
return [max_id] + ids
# FileUploader's widget value is a list of file IDs
@@ -187,6 +192,22 @@
serializer=serialize_file_uploader,
)
+ ctx = get_report_ctx()
+ if ctx is not None and widget_value:
+ serialized = serialize_file_uploader(widget_value)
+
+ # The first number in the serialized widget_value list is the id
+ # of the most recently uploaded file.
+ newest_file_id = serialized[0]
+ active_file_ids = list(serialized[1:])
+
+ ctx.uploaded_file_mgr.remove_orphaned_files(
+ session_id=ctx.session_id,
+ widget_id=file_uploader_proto.id,
+ newest_file_id=newest_file_id,
+ active_file_ids=active_file_ids,
+ )
+
self.dg._enqueue("file_uploader", file_uploader_proto)
return widget_value
@@ -208,27 +229,15 @@
)
return []
- # The first number in the widget_value list is 'newestServerFileId'
- newest_file_id = widget_value[0]
active_file_ids = list(widget_value[1:])
# Grab the files that correspond to our active file IDs.
- file_recs = ctx.uploaded_file_mgr.get_files(
+ return ctx.uploaded_file_mgr.get_files(
session_id=ctx.session_id,
widget_id=widget_id,
file_ids=active_file_ids,
)
- # Garbage collect "orphaned" files.
- ctx.uploaded_file_mgr.remove_orphaned_files(
- session_id=ctx.session_id,
- widget_id=widget_id,
- newest_file_id=newest_file_id,
- active_file_ids=active_file_ids,
- )
-
- return file_recs
-
@property
def dg(self) -> "streamlit.delta_generator.DeltaGenerator":
"""Get our DeltaGenerator."""
|
{"golden_diff": "diff --git a/lib/streamlit/elements/file_uploader.py b/lib/streamlit/elements/file_uploader.py\n--- a/lib/streamlit/elements/file_uploader.py\n+++ b/lib/streamlit/elements/file_uploader.py\n@@ -167,10 +167,15 @@\n ids = [f.id for f in files]\n else:\n ids = [files.id]\n+\n ctx = get_report_ctx()\n if ctx is None:\n return []\n- max_id = ctx.uploaded_file_mgr._file_id_counter\n+\n+ # ctx.uploaded_file_mgr._file_id_counter stores the id to use for\n+ # the next uploaded file, so the current highest file id is the\n+ # counter minus 1.\n+ max_id = ctx.uploaded_file_mgr._file_id_counter - 1\n return [max_id] + ids\n \n # FileUploader's widget value is a list of file IDs\n@@ -187,6 +192,22 @@\n serializer=serialize_file_uploader,\n )\n \n+ ctx = get_report_ctx()\n+ if ctx is not None and widget_value:\n+ serialized = serialize_file_uploader(widget_value)\n+\n+ # The first number in the serialized widget_value list is the id\n+ # of the most recently uploaded file.\n+ newest_file_id = serialized[0]\n+ active_file_ids = list(serialized[1:])\n+\n+ ctx.uploaded_file_mgr.remove_orphaned_files(\n+ session_id=ctx.session_id,\n+ widget_id=file_uploader_proto.id,\n+ newest_file_id=newest_file_id,\n+ active_file_ids=active_file_ids,\n+ )\n+\n self.dg._enqueue(\"file_uploader\", file_uploader_proto)\n return widget_value\n \n@@ -208,27 +229,15 @@\n )\n return []\n \n- # The first number in the widget_value list is 'newestServerFileId'\n- newest_file_id = widget_value[0]\n active_file_ids = list(widget_value[1:])\n \n # Grab the files that correspond to our active file IDs.\n- file_recs = ctx.uploaded_file_mgr.get_files(\n+ return ctx.uploaded_file_mgr.get_files(\n session_id=ctx.session_id,\n widget_id=widget_id,\n file_ids=active_file_ids,\n )\n \n- # Garbage collect \"orphaned\" files.\n- ctx.uploaded_file_mgr.remove_orphaned_files(\n- session_id=ctx.session_id,\n- widget_id=widget_id,\n- newest_file_id=newest_file_id,\n- active_file_ids=active_file_ids,\n- )\n-\n- return file_recs\n-\n @property\n def dg(self) -> \"streamlit.delta_generator.DeltaGenerator\":\n \"\"\"Get our DeltaGenerator.\"\"\"\n", "issue": "File uploader does not return multiple files\nFrom: https://discuss.streamlit.io/t/issue-with-file-uploader-and-streamlit-version-0-84-0/14812\r\n\r\n---\r\n\r\nHi everyone,\r\n\r\nI'm new here. First of all thank you really much for your great work in this forum. It helped me out multiple times. But now I encountered an issue where I couldn't find a thread on, yet.\r\n\r\nWith the latest version (0.84.0) I'm experiencing a problem with the file_uploader widget.\r\n\r\nIn the prior version (0.82.0) it was very handy, for my case, to select one file after another and drag&drop it to the widget. With the latest version this doesn't seems possible anymore. When one or more files were uploaded the next file/s draged and droped to the widget are not accessible, even though these files appear in the interactive list below the widget. \r\nI want to use st.session_state is the app I'm working on and for that reason the version 0.84.0 is necessary to my understanding.\r\n\r\nIn order for you to reproduce the situation I made up this example:\r\n\r\n```\r\nimport streamlit as st\r\n\r\nuploaded_files = st.file_uploader('Select files',type=['txt'],accept_multiple_files=True)\r\nfile_lst = [uploaded_file.name for uploaded_file in uploaded_files]\r\nst.write(file_lst)\r\n```\r\n\r\nAssuming I want to upload the two files test1.txt and test2.txt one after another. For the first file (test1.txt) the behavior is as expected and equivalent for both versions:\r\n\r\n\r\n\r\nThen later I want to upload another file in this case test2.txt. \r\nThe expected behavior can be seen with version 0.82.0. Both files are shown in the interactive list below the widget as well as in the written file_lst.\r\n\r\n\r\n\r\nWith version 0.84.0 only the interactive list below the widget shows both files. The written file_lst shows only test1.txt.\r\n\r\n\r\n\r\nAnyone had a similar issue? I apologize, if the solution is obvious, but I got stuck with it and can't figure out, how to solve the issue.\n", "before_files": [{"content": "# Copyright 2018-2021 Streamlit Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom typing import cast, List, Optional, Union\n\nimport streamlit\nfrom streamlit import config\nfrom streamlit.logger import get_logger\nfrom streamlit.proto.FileUploader_pb2 import FileUploader as FileUploaderProto\nfrom streamlit.report_thread import get_report_ctx\nfrom streamlit.state.widgets import register_widget, NoValue\nfrom .form import current_form_id\nfrom ..proto.Common_pb2 import SInt64Array\nfrom ..uploaded_file_manager import UploadedFile, UploadedFileRec\nfrom .utils import check_callback_rules, check_session_state_rules\n\nLOGGER = get_logger(__name__)\n\n\nclass FileUploaderMixin:\n def file_uploader(\n self,\n label,\n type=None,\n accept_multiple_files=False,\n key=None,\n help=None,\n on_change=None,\n args=None,\n kwargs=None,\n ):\n \"\"\"Display a file uploader widget.\n By default, uploaded files are limited to 200MB. You can configure\n this using the `server.maxUploadSize` config option.\n\n Parameters\n ----------\n label : str\n A short label explaining to the user what this file uploader is for.\n\n type : str or list of str or None\n Array of allowed extensions. ['png', 'jpg']\n The default is None, which means all extensions are allowed.\n\n accept_multiple_files : bool\n If True, allows the user to upload multiple files at the same time,\n in which case the return value will be a list of files.\n Default: False\n\n key : str\n An optional string to use as the unique key for the widget.\n If this is omitted, a key will be generated for the widget\n based on its content. Multiple widgets of the same type may\n not share the same key.\n\n help : str\n A tooltip that gets displayed next to the file uploader.\n\n on_change : callable\n An optional callback invoked when this file_uploader's value\n changes.\n\n args : tuple\n An optional tuple of args to pass to the callback.\n\n kwargs : dict\n An optional dict of kwargs to pass to the callback.\n\n Returns\n -------\n None or UploadedFile or list of UploadedFile\n - If accept_multiple_files is False, returns either None or\n an UploadedFile object.\n - If accept_multiple_files is True, returns a list with the\n uploaded files as UploadedFile objects. If no files were\n uploaded, returns an empty list.\n\n The UploadedFile class is a subclass of BytesIO, and therefore\n it is \"file-like\". This means you can pass them anywhere where\n a file is expected.\n\n Examples\n --------\n Insert a file uploader that accepts a single file at a time:\n\n >>> uploaded_file = st.file_uploader(\"Choose a file\")\n >>> if uploaded_file is not None:\n ... # To read file as bytes:\n ... bytes_data = uploaded_file.getvalue()\n ... st.write(bytes_data)\n >>>\n ... # To convert to a string based IO:\n ... stringio = StringIO(uploaded_file.getvalue().decode(\"utf-8\"))\n ... st.write(stringio)\n >>>\n ... # To read file as string:\n ... string_data = stringio.read()\n ... st.write(string_data)\n >>>\n ... # Can be used wherever a \"file-like\" object is accepted:\n ... dataframe = pd.read_csv(uploaded_file)\n ... st.write(dataframe)\n\n Insert a file uploader that accepts multiple files at a time:\n\n >>> uploaded_files = st.file_uploader(\"Choose a CSV file\", accept_multiple_files=True)\n >>> for uploaded_file in uploaded_files:\n ... bytes_data = uploaded_file.read()\n ... st.write(\"filename:\", uploaded_file.name)\n ... st.write(bytes_data)\n \"\"\"\n check_callback_rules(self.dg, on_change)\n check_session_state_rules(default_value=None, key=key, writes_allowed=False)\n\n if type:\n if isinstance(type, str):\n type = [type]\n\n # May need a regex or a library to validate file types are valid\n # extensions.\n type = [\n file_type if file_type[0] == \".\" else f\".{file_type}\"\n for file_type in type\n ]\n\n file_uploader_proto = FileUploaderProto()\n file_uploader_proto.label = label\n file_uploader_proto.type[:] = type if type is not None else []\n file_uploader_proto.max_upload_size_mb = config.get_option(\n \"server.maxUploadSize\"\n )\n file_uploader_proto.multiple_files = accept_multiple_files\n file_uploader_proto.form_id = current_form_id(self.dg)\n if help is not None:\n file_uploader_proto.help = help\n\n def deserialize_file_uploader(\n ui_value: List[int], widget_id: str\n ) -> Optional[Union[List[UploadedFile], UploadedFile]]:\n file_recs = self._get_file_recs(widget_id, ui_value)\n if len(file_recs) == 0:\n return_value: Optional[Union[List[UploadedFile], UploadedFile]] = (\n [] if accept_multiple_files else None\n )\n else:\n files = [UploadedFile(rec) for rec in file_recs]\n return_value = files if accept_multiple_files else files[0]\n return return_value\n\n def serialize_file_uploader(\n files: Optional[Union[List[UploadedFile], UploadedFile]]\n ) -> List[int]:\n if not files:\n return []\n if isinstance(files, list):\n ids = [f.id for f in files]\n else:\n ids = [files.id]\n ctx = get_report_ctx()\n if ctx is None:\n return []\n max_id = ctx.uploaded_file_mgr._file_id_counter\n return [max_id] + ids\n\n # FileUploader's widget value is a list of file IDs\n # representing the current set of files that this uploader should\n # know about.\n widget_value, _ = register_widget(\n \"file_uploader\",\n file_uploader_proto,\n user_key=key,\n on_change_handler=on_change,\n args=args,\n kwargs=kwargs,\n deserializer=deserialize_file_uploader,\n serializer=serialize_file_uploader,\n )\n\n self.dg._enqueue(\"file_uploader\", file_uploader_proto)\n return widget_value\n\n @staticmethod\n def _get_file_recs(\n widget_id: str, widget_value: Optional[List[int]]\n ) -> List[UploadedFileRec]:\n if widget_value is None:\n return []\n\n ctx = get_report_ctx()\n if ctx is None:\n return []\n\n if len(widget_value) == 0:\n # Sanity check\n LOGGER.warning(\n \"Got an empty FileUploader widget_value. (We expect a list with at least one value in it.)\"\n )\n return []\n\n # The first number in the widget_value list is 'newestServerFileId'\n newest_file_id = widget_value[0]\n active_file_ids = list(widget_value[1:])\n\n # Grab the files that correspond to our active file IDs.\n file_recs = ctx.uploaded_file_mgr.get_files(\n session_id=ctx.session_id,\n widget_id=widget_id,\n file_ids=active_file_ids,\n )\n\n # Garbage collect \"orphaned\" files.\n ctx.uploaded_file_mgr.remove_orphaned_files(\n session_id=ctx.session_id,\n widget_id=widget_id,\n newest_file_id=newest_file_id,\n active_file_ids=active_file_ids,\n )\n\n return file_recs\n\n @property\n def dg(self) -> \"streamlit.delta_generator.DeltaGenerator\":\n \"\"\"Get our DeltaGenerator.\"\"\"\n return cast(\"streamlit.delta_generator.DeltaGenerator\", self)\n", "path": "lib/streamlit/elements/file_uploader.py"}], "after_files": [{"content": "# Copyright 2018-2021 Streamlit Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom typing import cast, List, Optional, Union\n\nimport streamlit\nfrom streamlit import config\nfrom streamlit.logger import get_logger\nfrom streamlit.proto.FileUploader_pb2 import FileUploader as FileUploaderProto\nfrom streamlit.report_thread import get_report_ctx\nfrom streamlit.state.widgets import register_widget, NoValue\nfrom .form import current_form_id\nfrom ..proto.Common_pb2 import SInt64Array\nfrom ..uploaded_file_manager import UploadedFile, UploadedFileRec\nfrom .utils import check_callback_rules, check_session_state_rules\n\nLOGGER = get_logger(__name__)\n\n\nclass FileUploaderMixin:\n def file_uploader(\n self,\n label,\n type=None,\n accept_multiple_files=False,\n key=None,\n help=None,\n on_change=None,\n args=None,\n kwargs=None,\n ):\n \"\"\"Display a file uploader widget.\n By default, uploaded files are limited to 200MB. You can configure\n this using the `server.maxUploadSize` config option.\n\n Parameters\n ----------\n label : str\n A short label explaining to the user what this file uploader is for.\n\n type : str or list of str or None\n Array of allowed extensions. ['png', 'jpg']\n The default is None, which means all extensions are allowed.\n\n accept_multiple_files : bool\n If True, allows the user to upload multiple files at the same time,\n in which case the return value will be a list of files.\n Default: False\n\n key : str\n An optional string to use as the unique key for the widget.\n If this is omitted, a key will be generated for the widget\n based on its content. Multiple widgets of the same type may\n not share the same key.\n\n help : str\n A tooltip that gets displayed next to the file uploader.\n\n on_change : callable\n An optional callback invoked when this file_uploader's value\n changes.\n\n args : tuple\n An optional tuple of args to pass to the callback.\n\n kwargs : dict\n An optional dict of kwargs to pass to the callback.\n\n Returns\n -------\n None or UploadedFile or list of UploadedFile\n - If accept_multiple_files is False, returns either None or\n an UploadedFile object.\n - If accept_multiple_files is True, returns a list with the\n uploaded files as UploadedFile objects. If no files were\n uploaded, returns an empty list.\n\n The UploadedFile class is a subclass of BytesIO, and therefore\n it is \"file-like\". This means you can pass them anywhere where\n a file is expected.\n\n Examples\n --------\n Insert a file uploader that accepts a single file at a time:\n\n >>> uploaded_file = st.file_uploader(\"Choose a file\")\n >>> if uploaded_file is not None:\n ... # To read file as bytes:\n ... bytes_data = uploaded_file.getvalue()\n ... st.write(bytes_data)\n >>>\n ... # To convert to a string based IO:\n ... stringio = StringIO(uploaded_file.getvalue().decode(\"utf-8\"))\n ... st.write(stringio)\n >>>\n ... # To read file as string:\n ... string_data = stringio.read()\n ... st.write(string_data)\n >>>\n ... # Can be used wherever a \"file-like\" object is accepted:\n ... dataframe = pd.read_csv(uploaded_file)\n ... st.write(dataframe)\n\n Insert a file uploader that accepts multiple files at a time:\n\n >>> uploaded_files = st.file_uploader(\"Choose a CSV file\", accept_multiple_files=True)\n >>> for uploaded_file in uploaded_files:\n ... bytes_data = uploaded_file.read()\n ... st.write(\"filename:\", uploaded_file.name)\n ... st.write(bytes_data)\n \"\"\"\n check_callback_rules(self.dg, on_change)\n check_session_state_rules(default_value=None, key=key, writes_allowed=False)\n\n if type:\n if isinstance(type, str):\n type = [type]\n\n # May need a regex or a library to validate file types are valid\n # extensions.\n type = [\n file_type if file_type[0] == \".\" else f\".{file_type}\"\n for file_type in type\n ]\n\n file_uploader_proto = FileUploaderProto()\n file_uploader_proto.label = label\n file_uploader_proto.type[:] = type if type is not None else []\n file_uploader_proto.max_upload_size_mb = config.get_option(\n \"server.maxUploadSize\"\n )\n file_uploader_proto.multiple_files = accept_multiple_files\n file_uploader_proto.form_id = current_form_id(self.dg)\n if help is not None:\n file_uploader_proto.help = help\n\n def deserialize_file_uploader(\n ui_value: List[int], widget_id: str\n ) -> Optional[Union[List[UploadedFile], UploadedFile]]:\n file_recs = self._get_file_recs(widget_id, ui_value)\n if len(file_recs) == 0:\n return_value: Optional[Union[List[UploadedFile], UploadedFile]] = (\n [] if accept_multiple_files else None\n )\n else:\n files = [UploadedFile(rec) for rec in file_recs]\n return_value = files if accept_multiple_files else files[0]\n return return_value\n\n def serialize_file_uploader(\n files: Optional[Union[List[UploadedFile], UploadedFile]]\n ) -> List[int]:\n if not files:\n return []\n if isinstance(files, list):\n ids = [f.id for f in files]\n else:\n ids = [files.id]\n\n ctx = get_report_ctx()\n if ctx is None:\n return []\n\n # ctx.uploaded_file_mgr._file_id_counter stores the id to use for\n # the next uploaded file, so the current highest file id is the\n # counter minus 1.\n max_id = ctx.uploaded_file_mgr._file_id_counter - 1\n return [max_id] + ids\n\n # FileUploader's widget value is a list of file IDs\n # representing the current set of files that this uploader should\n # know about.\n widget_value, _ = register_widget(\n \"file_uploader\",\n file_uploader_proto,\n user_key=key,\n on_change_handler=on_change,\n args=args,\n kwargs=kwargs,\n deserializer=deserialize_file_uploader,\n serializer=serialize_file_uploader,\n )\n\n ctx = get_report_ctx()\n if ctx is not None and widget_value:\n serialized = serialize_file_uploader(widget_value)\n\n # The first number in the serialized widget_value list is the id\n # of the most recently uploaded file.\n newest_file_id = serialized[0]\n active_file_ids = list(serialized[1:])\n\n ctx.uploaded_file_mgr.remove_orphaned_files(\n session_id=ctx.session_id,\n widget_id=file_uploader_proto.id,\n newest_file_id=newest_file_id,\n active_file_ids=active_file_ids,\n )\n\n self.dg._enqueue(\"file_uploader\", file_uploader_proto)\n return widget_value\n\n @staticmethod\n def _get_file_recs(\n widget_id: str, widget_value: Optional[List[int]]\n ) -> List[UploadedFileRec]:\n if widget_value is None:\n return []\n\n ctx = get_report_ctx()\n if ctx is None:\n return []\n\n if len(widget_value) == 0:\n # Sanity check\n LOGGER.warning(\n \"Got an empty FileUploader widget_value. (We expect a list with at least one value in it.)\"\n )\n return []\n\n active_file_ids = list(widget_value[1:])\n\n # Grab the files that correspond to our active file IDs.\n return ctx.uploaded_file_mgr.get_files(\n session_id=ctx.session_id,\n widget_id=widget_id,\n file_ids=active_file_ids,\n )\n\n @property\n def dg(self) -> \"streamlit.delta_generator.DeltaGenerator\":\n \"\"\"Get our DeltaGenerator.\"\"\"\n return cast(\"streamlit.delta_generator.DeltaGenerator\", self)\n", "path": "lib/streamlit/elements/file_uploader.py"}]}
| 3,413 | 615 |
gh_patches_debug_3516
|
rasdani/github-patches
|
git_diff
|
getmoto__moto-2446
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
STS: Invalid xmlns in response from STS
I got error below, when trying to AssumeRole by AWS SDK (for PHP).
```
Error parsing XML: xmlns: 'https:\/\/sts.amazonaws.com\/doc\/ 2011-06-15\/' is not a valid URI
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `moto/sts/responses.py`
Content:
```
1 from __future__ import unicode_literals
2
3 from moto.core.responses import BaseResponse
4 from moto.iam.models import ACCOUNT_ID
5 from moto.iam import iam_backend
6 from .exceptions import STSValidationError
7 from .models import sts_backend
8
9 MAX_FEDERATION_TOKEN_POLICY_LENGTH = 2048
10
11
12 class TokenResponse(BaseResponse):
13
14 def get_session_token(self):
15 duration = int(self.querystring.get('DurationSeconds', [43200])[0])
16 token = sts_backend.get_session_token(duration=duration)
17 template = self.response_template(GET_SESSION_TOKEN_RESPONSE)
18 return template.render(token=token)
19
20 def get_federation_token(self):
21 duration = int(self.querystring.get('DurationSeconds', [43200])[0])
22 policy = self.querystring.get('Policy', [None])[0]
23
24 if policy is not None and len(policy) > MAX_FEDERATION_TOKEN_POLICY_LENGTH:
25 raise STSValidationError(
26 "1 validation error detected: Value "
27 "'{\"Version\": \"2012-10-17\", \"Statement\": [...]}' "
28 "at 'policy' failed to satisfy constraint: Member must have length less than or "
29 " equal to %s" % MAX_FEDERATION_TOKEN_POLICY_LENGTH
30 )
31
32 name = self.querystring.get('Name')[0]
33 token = sts_backend.get_federation_token(
34 duration=duration, name=name, policy=policy)
35 template = self.response_template(GET_FEDERATION_TOKEN_RESPONSE)
36 return template.render(token=token, account_id=ACCOUNT_ID)
37
38 def assume_role(self):
39 role_session_name = self.querystring.get('RoleSessionName')[0]
40 role_arn = self.querystring.get('RoleArn')[0]
41
42 policy = self.querystring.get('Policy', [None])[0]
43 duration = int(self.querystring.get('DurationSeconds', [3600])[0])
44 external_id = self.querystring.get('ExternalId', [None])[0]
45
46 role = sts_backend.assume_role(
47 role_session_name=role_session_name,
48 role_arn=role_arn,
49 policy=policy,
50 duration=duration,
51 external_id=external_id,
52 )
53 template = self.response_template(ASSUME_ROLE_RESPONSE)
54 return template.render(role=role)
55
56 def assume_role_with_web_identity(self):
57 role_session_name = self.querystring.get('RoleSessionName')[0]
58 role_arn = self.querystring.get('RoleArn')[0]
59
60 policy = self.querystring.get('Policy', [None])[0]
61 duration = int(self.querystring.get('DurationSeconds', [3600])[0])
62 external_id = self.querystring.get('ExternalId', [None])[0]
63
64 role = sts_backend.assume_role_with_web_identity(
65 role_session_name=role_session_name,
66 role_arn=role_arn,
67 policy=policy,
68 duration=duration,
69 external_id=external_id,
70 )
71 template = self.response_template(ASSUME_ROLE_WITH_WEB_IDENTITY_RESPONSE)
72 return template.render(role=role)
73
74 def get_caller_identity(self):
75 template = self.response_template(GET_CALLER_IDENTITY_RESPONSE)
76
77 # Default values in case the request does not use valid credentials generated by moto
78 user_id = "AKIAIOSFODNN7EXAMPLE"
79 arn = "arn:aws:sts::{account_id}:user/moto".format(account_id=ACCOUNT_ID)
80
81 access_key_id = self.get_current_user()
82 assumed_role = sts_backend.get_assumed_role_from_access_key(access_key_id)
83 if assumed_role:
84 user_id = assumed_role.user_id
85 arn = assumed_role.arn
86
87 user = iam_backend.get_user_from_access_key_id(access_key_id)
88 if user:
89 user_id = user.id
90 arn = user.arn
91
92 return template.render(account_id=ACCOUNT_ID, user_id=user_id, arn=arn)
93
94
95 GET_SESSION_TOKEN_RESPONSE = """<GetSessionTokenResponse xmlns="https://sts.amazonaws.com/doc/2011-06-15/">
96 <GetSessionTokenResult>
97 <Credentials>
98 <SessionToken>AQoEXAMPLEH4aoAH0gNCAPyJxz4BlCFFxWNE1OPTgk5TthT+FvwqnKwRcOIfrRh3c/LTo6UDdyJwOOvEVPvLXCrrrUtdnniCEXAMPLE/IvU1dYUg2RVAJBanLiHb4IgRmpRV3zrkuWJOgQs8IZZaIv2BXIa2R4OlgkBN9bkUDNCJiBeb/AXlzBBko7b15fjrBs2+cTQtpZ3CYWFXG8C5zqx37wnOE49mRl/+OtkIKGO7fAE</SessionToken>
99 <SecretAccessKey>wJalrXUtnFEMI/K7MDENG/bPxRfiCYzEXAMPLEKEY</SecretAccessKey>
100 <Expiration>{{ token.expiration_ISO8601 }}</Expiration>
101 <AccessKeyId>AKIAIOSFODNN7EXAMPLE</AccessKeyId>
102 </Credentials>
103 </GetSessionTokenResult>
104 <ResponseMetadata>
105 <RequestId>58c5dbae-abef-11e0-8cfe-09039844ac7d</RequestId>
106 </ResponseMetadata>
107 </GetSessionTokenResponse>"""
108
109
110 GET_FEDERATION_TOKEN_RESPONSE = """<GetFederationTokenResponse xmlns="https://sts.amazonaws.com/doc/
111 2011-06-15/">
112 <GetFederationTokenResult>
113 <Credentials>
114 <SessionToken>AQoDYXdzEPT//////////wEXAMPLEtc764bNrC9SAPBSM22wDOk4x4HIZ8j4FZTwdQWLWsKWHGBuFqwAeMicRXmxfpSPfIeoIYRqTflfKD8YUuwthAx7mSEI/qkPpKPi/kMcGdQrmGdeehM4IC1NtBmUpp2wUE8phUZampKsburEDy0KPkyQDYwT7WZ0wq5VSXDvp75YU9HFvlRd8Tx6q6fE8YQcHNVXAkiY9q6d+xo0rKwT38xVqr7ZD0u0iPPkUL64lIZbqBAz+scqKmlzm8FDrypNC9Yjc8fPOLn9FX9KSYvKTr4rvx3iSIlTJabIQwj2ICCR/oLxBA==</SessionToken>
115 <SecretAccessKey>wJalrXUtnFEMI/K7MDENG/bPxRfiCYzEXAMPLEKEY</SecretAccessKey>
116 <Expiration>{{ token.expiration_ISO8601 }}</Expiration>
117 <AccessKeyId>AKIAIOSFODNN7EXAMPLE</AccessKeyId>
118 </Credentials>
119 <FederatedUser>
120 <Arn>arn:aws:sts::{{ account_id }}:federated-user/{{ token.name }}</Arn>
121 <FederatedUserId>{{ account_id }}:{{ token.name }}</FederatedUserId>
122 </FederatedUser>
123 <PackedPolicySize>6</PackedPolicySize>
124 </GetFederationTokenResult>
125 <ResponseMetadata>
126 <RequestId>c6104cbe-af31-11e0-8154-cbc7ccf896c7</RequestId>
127 </ResponseMetadata>
128 </GetFederationTokenResponse>"""
129
130
131 ASSUME_ROLE_RESPONSE = """<AssumeRoleResponse xmlns="https://sts.amazonaws.com/doc/
132 2011-06-15/">
133 <AssumeRoleResult>
134 <Credentials>
135 <SessionToken>{{ role.session_token }}</SessionToken>
136 <SecretAccessKey>{{ role.secret_access_key }}</SecretAccessKey>
137 <Expiration>{{ role.expiration_ISO8601 }}</Expiration>
138 <AccessKeyId>{{ role.access_key_id }}</AccessKeyId>
139 </Credentials>
140 <AssumedRoleUser>
141 <Arn>{{ role.arn }}</Arn>
142 <AssumedRoleId>{{ role.user_id }}</AssumedRoleId>
143 </AssumedRoleUser>
144 <PackedPolicySize>6</PackedPolicySize>
145 </AssumeRoleResult>
146 <ResponseMetadata>
147 <RequestId>c6104cbe-af31-11e0-8154-cbc7ccf896c7</RequestId>
148 </ResponseMetadata>
149 </AssumeRoleResponse>"""
150
151
152 ASSUME_ROLE_WITH_WEB_IDENTITY_RESPONSE = """<AssumeRoleWithWebIdentityResponse xmlns="https://sts.amazonaws.com/doc/2011-06-15/">
153 <AssumeRoleWithWebIdentityResult>
154 <Credentials>
155 <SessionToken>{{ role.session_token }}</SessionToken>
156 <SecretAccessKey>{{ role.secret_access_key }}</SecretAccessKey>
157 <Expiration>{{ role.expiration_ISO8601 }}</Expiration>
158 <AccessKeyId>{{ role.access_key_id }}</AccessKeyId>
159 </Credentials>
160 <AssumedRoleUser>
161 <Arn>{{ role.arn }}</Arn>
162 <AssumedRoleId>ARO123EXAMPLE123:{{ role.session_name }}</AssumedRoleId>
163 </AssumedRoleUser>
164 <PackedPolicySize>6</PackedPolicySize>
165 </AssumeRoleWithWebIdentityResult>
166 <ResponseMetadata>
167 <RequestId>c6104cbe-af31-11e0-8154-cbc7ccf896c7</RequestId>
168 </ResponseMetadata>
169 </AssumeRoleWithWebIdentityResponse>"""
170
171
172 GET_CALLER_IDENTITY_RESPONSE = """<GetCallerIdentityResponse xmlns="https://sts.amazonaws.com/doc/2011-06-15/">
173 <GetCallerIdentityResult>
174 <Arn>{{ arn }}</Arn>
175 <UserId>{{ user_id }}</UserId>
176 <Account>{{ account_id }}</Account>
177 </GetCallerIdentityResult>
178 <ResponseMetadata>
179 <RequestId>c6104cbe-af31-11e0-8154-cbc7ccf896c7</RequestId>
180 </ResponseMetadata>
181 </GetCallerIdentityResponse>
182 """
183
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/moto/sts/responses.py b/moto/sts/responses.py
--- a/moto/sts/responses.py
+++ b/moto/sts/responses.py
@@ -128,8 +128,7 @@
</GetFederationTokenResponse>"""
-ASSUME_ROLE_RESPONSE = """<AssumeRoleResponse xmlns="https://sts.amazonaws.com/doc/
-2011-06-15/">
+ASSUME_ROLE_RESPONSE = """<AssumeRoleResponse xmlns="https://sts.amazonaws.com/doc/2011-06-15/">
<AssumeRoleResult>
<Credentials>
<SessionToken>{{ role.session_token }}</SessionToken>
|
{"golden_diff": "diff --git a/moto/sts/responses.py b/moto/sts/responses.py\n--- a/moto/sts/responses.py\n+++ b/moto/sts/responses.py\n@@ -128,8 +128,7 @@\n </GetFederationTokenResponse>\"\"\"\n \n \n-ASSUME_ROLE_RESPONSE = \"\"\"<AssumeRoleResponse xmlns=\"https://sts.amazonaws.com/doc/\n-2011-06-15/\">\n+ASSUME_ROLE_RESPONSE = \"\"\"<AssumeRoleResponse xmlns=\"https://sts.amazonaws.com/doc/2011-06-15/\">\n <AssumeRoleResult>\n <Credentials>\n <SessionToken>{{ role.session_token }}</SessionToken>\n", "issue": "STS: Invalid xmlns in response from STS\nI got error below, when trying to AssumeRole by AWS SDK (for PHP).\r\n```\r\nError parsing XML: xmlns: 'https:\\/\\/sts.amazonaws.com\\/doc\\/ 2011-06-15\\/' is not a valid URI\r\n```\r\n\n", "before_files": [{"content": "from __future__ import unicode_literals\n\nfrom moto.core.responses import BaseResponse\nfrom moto.iam.models import ACCOUNT_ID\nfrom moto.iam import iam_backend\nfrom .exceptions import STSValidationError\nfrom .models import sts_backend\n\nMAX_FEDERATION_TOKEN_POLICY_LENGTH = 2048\n\n\nclass TokenResponse(BaseResponse):\n\n def get_session_token(self):\n duration = int(self.querystring.get('DurationSeconds', [43200])[0])\n token = sts_backend.get_session_token(duration=duration)\n template = self.response_template(GET_SESSION_TOKEN_RESPONSE)\n return template.render(token=token)\n\n def get_federation_token(self):\n duration = int(self.querystring.get('DurationSeconds', [43200])[0])\n policy = self.querystring.get('Policy', [None])[0]\n\n if policy is not None and len(policy) > MAX_FEDERATION_TOKEN_POLICY_LENGTH:\n raise STSValidationError(\n \"1 validation error detected: Value \"\n \"'{\\\"Version\\\": \\\"2012-10-17\\\", \\\"Statement\\\": [...]}' \"\n \"at 'policy' failed to satisfy constraint: Member must have length less than or \"\n \" equal to %s\" % MAX_FEDERATION_TOKEN_POLICY_LENGTH\n )\n\n name = self.querystring.get('Name')[0]\n token = sts_backend.get_federation_token(\n duration=duration, name=name, policy=policy)\n template = self.response_template(GET_FEDERATION_TOKEN_RESPONSE)\n return template.render(token=token, account_id=ACCOUNT_ID)\n\n def assume_role(self):\n role_session_name = self.querystring.get('RoleSessionName')[0]\n role_arn = self.querystring.get('RoleArn')[0]\n\n policy = self.querystring.get('Policy', [None])[0]\n duration = int(self.querystring.get('DurationSeconds', [3600])[0])\n external_id = self.querystring.get('ExternalId', [None])[0]\n\n role = sts_backend.assume_role(\n role_session_name=role_session_name,\n role_arn=role_arn,\n policy=policy,\n duration=duration,\n external_id=external_id,\n )\n template = self.response_template(ASSUME_ROLE_RESPONSE)\n return template.render(role=role)\n\n def assume_role_with_web_identity(self):\n role_session_name = self.querystring.get('RoleSessionName')[0]\n role_arn = self.querystring.get('RoleArn')[0]\n\n policy = self.querystring.get('Policy', [None])[0]\n duration = int(self.querystring.get('DurationSeconds', [3600])[0])\n external_id = self.querystring.get('ExternalId', [None])[0]\n\n role = sts_backend.assume_role_with_web_identity(\n role_session_name=role_session_name,\n role_arn=role_arn,\n policy=policy,\n duration=duration,\n external_id=external_id,\n )\n template = self.response_template(ASSUME_ROLE_WITH_WEB_IDENTITY_RESPONSE)\n return template.render(role=role)\n\n def get_caller_identity(self):\n template = self.response_template(GET_CALLER_IDENTITY_RESPONSE)\n\n # Default values in case the request does not use valid credentials generated by moto\n user_id = \"AKIAIOSFODNN7EXAMPLE\"\n arn = \"arn:aws:sts::{account_id}:user/moto\".format(account_id=ACCOUNT_ID)\n\n access_key_id = self.get_current_user()\n assumed_role = sts_backend.get_assumed_role_from_access_key(access_key_id)\n if assumed_role:\n user_id = assumed_role.user_id\n arn = assumed_role.arn\n\n user = iam_backend.get_user_from_access_key_id(access_key_id)\n if user:\n user_id = user.id\n arn = user.arn\n\n return template.render(account_id=ACCOUNT_ID, user_id=user_id, arn=arn)\n\n\nGET_SESSION_TOKEN_RESPONSE = \"\"\"<GetSessionTokenResponse xmlns=\"https://sts.amazonaws.com/doc/2011-06-15/\">\n <GetSessionTokenResult>\n <Credentials>\n <SessionToken>AQoEXAMPLEH4aoAH0gNCAPyJxz4BlCFFxWNE1OPTgk5TthT+FvwqnKwRcOIfrRh3c/LTo6UDdyJwOOvEVPvLXCrrrUtdnniCEXAMPLE/IvU1dYUg2RVAJBanLiHb4IgRmpRV3zrkuWJOgQs8IZZaIv2BXIa2R4OlgkBN9bkUDNCJiBeb/AXlzBBko7b15fjrBs2+cTQtpZ3CYWFXG8C5zqx37wnOE49mRl/+OtkIKGO7fAE</SessionToken>\n <SecretAccessKey>wJalrXUtnFEMI/K7MDENG/bPxRfiCYzEXAMPLEKEY</SecretAccessKey>\n <Expiration>{{ token.expiration_ISO8601 }}</Expiration>\n <AccessKeyId>AKIAIOSFODNN7EXAMPLE</AccessKeyId>\n </Credentials>\n </GetSessionTokenResult>\n <ResponseMetadata>\n <RequestId>58c5dbae-abef-11e0-8cfe-09039844ac7d</RequestId>\n </ResponseMetadata>\n</GetSessionTokenResponse>\"\"\"\n\n\nGET_FEDERATION_TOKEN_RESPONSE = \"\"\"<GetFederationTokenResponse xmlns=\"https://sts.amazonaws.com/doc/\n2011-06-15/\">\n <GetFederationTokenResult>\n <Credentials>\n <SessionToken>AQoDYXdzEPT//////////wEXAMPLEtc764bNrC9SAPBSM22wDOk4x4HIZ8j4FZTwdQWLWsKWHGBuFqwAeMicRXmxfpSPfIeoIYRqTflfKD8YUuwthAx7mSEI/qkPpKPi/kMcGdQrmGdeehM4IC1NtBmUpp2wUE8phUZampKsburEDy0KPkyQDYwT7WZ0wq5VSXDvp75YU9HFvlRd8Tx6q6fE8YQcHNVXAkiY9q6d+xo0rKwT38xVqr7ZD0u0iPPkUL64lIZbqBAz+scqKmlzm8FDrypNC9Yjc8fPOLn9FX9KSYvKTr4rvx3iSIlTJabIQwj2ICCR/oLxBA==</SessionToken>\n <SecretAccessKey>wJalrXUtnFEMI/K7MDENG/bPxRfiCYzEXAMPLEKEY</SecretAccessKey>\n <Expiration>{{ token.expiration_ISO8601 }}</Expiration>\n <AccessKeyId>AKIAIOSFODNN7EXAMPLE</AccessKeyId>\n </Credentials>\n <FederatedUser>\n <Arn>arn:aws:sts::{{ account_id }}:federated-user/{{ token.name }}</Arn>\n <FederatedUserId>{{ account_id }}:{{ token.name }}</FederatedUserId>\n </FederatedUser>\n <PackedPolicySize>6</PackedPolicySize>\n </GetFederationTokenResult>\n <ResponseMetadata>\n <RequestId>c6104cbe-af31-11e0-8154-cbc7ccf896c7</RequestId>\n </ResponseMetadata>\n</GetFederationTokenResponse>\"\"\"\n\n\nASSUME_ROLE_RESPONSE = \"\"\"<AssumeRoleResponse xmlns=\"https://sts.amazonaws.com/doc/\n2011-06-15/\">\n <AssumeRoleResult>\n <Credentials>\n <SessionToken>{{ role.session_token }}</SessionToken>\n <SecretAccessKey>{{ role.secret_access_key }}</SecretAccessKey>\n <Expiration>{{ role.expiration_ISO8601 }}</Expiration>\n <AccessKeyId>{{ role.access_key_id }}</AccessKeyId>\n </Credentials>\n <AssumedRoleUser>\n <Arn>{{ role.arn }}</Arn>\n <AssumedRoleId>{{ role.user_id }}</AssumedRoleId>\n </AssumedRoleUser>\n <PackedPolicySize>6</PackedPolicySize>\n </AssumeRoleResult>\n <ResponseMetadata>\n <RequestId>c6104cbe-af31-11e0-8154-cbc7ccf896c7</RequestId>\n </ResponseMetadata>\n</AssumeRoleResponse>\"\"\"\n\n\nASSUME_ROLE_WITH_WEB_IDENTITY_RESPONSE = \"\"\"<AssumeRoleWithWebIdentityResponse xmlns=\"https://sts.amazonaws.com/doc/2011-06-15/\">\n <AssumeRoleWithWebIdentityResult>\n <Credentials>\n <SessionToken>{{ role.session_token }}</SessionToken>\n <SecretAccessKey>{{ role.secret_access_key }}</SecretAccessKey>\n <Expiration>{{ role.expiration_ISO8601 }}</Expiration>\n <AccessKeyId>{{ role.access_key_id }}</AccessKeyId>\n </Credentials>\n <AssumedRoleUser>\n <Arn>{{ role.arn }}</Arn>\n <AssumedRoleId>ARO123EXAMPLE123:{{ role.session_name }}</AssumedRoleId>\n </AssumedRoleUser>\n <PackedPolicySize>6</PackedPolicySize>\n </AssumeRoleWithWebIdentityResult>\n <ResponseMetadata>\n <RequestId>c6104cbe-af31-11e0-8154-cbc7ccf896c7</RequestId>\n </ResponseMetadata>\n</AssumeRoleWithWebIdentityResponse>\"\"\"\n\n\nGET_CALLER_IDENTITY_RESPONSE = \"\"\"<GetCallerIdentityResponse xmlns=\"https://sts.amazonaws.com/doc/2011-06-15/\">\n <GetCallerIdentityResult>\n <Arn>{{ arn }}</Arn>\n <UserId>{{ user_id }}</UserId>\n <Account>{{ account_id }}</Account>\n </GetCallerIdentityResult>\n <ResponseMetadata>\n <RequestId>c6104cbe-af31-11e0-8154-cbc7ccf896c7</RequestId>\n </ResponseMetadata>\n</GetCallerIdentityResponse>\n\"\"\"\n", "path": "moto/sts/responses.py"}], "after_files": [{"content": "from __future__ import unicode_literals\n\nfrom moto.core.responses import BaseResponse\nfrom moto.iam.models import ACCOUNT_ID\nfrom moto.iam import iam_backend\nfrom .exceptions import STSValidationError\nfrom .models import sts_backend\n\nMAX_FEDERATION_TOKEN_POLICY_LENGTH = 2048\n\n\nclass TokenResponse(BaseResponse):\n\n def get_session_token(self):\n duration = int(self.querystring.get('DurationSeconds', [43200])[0])\n token = sts_backend.get_session_token(duration=duration)\n template = self.response_template(GET_SESSION_TOKEN_RESPONSE)\n return template.render(token=token)\n\n def get_federation_token(self):\n duration = int(self.querystring.get('DurationSeconds', [43200])[0])\n policy = self.querystring.get('Policy', [None])[0]\n\n if policy is not None and len(policy) > MAX_FEDERATION_TOKEN_POLICY_LENGTH:\n raise STSValidationError(\n \"1 validation error detected: Value \"\n \"'{\\\"Version\\\": \\\"2012-10-17\\\", \\\"Statement\\\": [...]}' \"\n \"at 'policy' failed to satisfy constraint: Member must have length less than or \"\n \" equal to %s\" % MAX_FEDERATION_TOKEN_POLICY_LENGTH\n )\n\n name = self.querystring.get('Name')[0]\n token = sts_backend.get_federation_token(\n duration=duration, name=name, policy=policy)\n template = self.response_template(GET_FEDERATION_TOKEN_RESPONSE)\n return template.render(token=token, account_id=ACCOUNT_ID)\n\n def assume_role(self):\n role_session_name = self.querystring.get('RoleSessionName')[0]\n role_arn = self.querystring.get('RoleArn')[0]\n\n policy = self.querystring.get('Policy', [None])[0]\n duration = int(self.querystring.get('DurationSeconds', [3600])[0])\n external_id = self.querystring.get('ExternalId', [None])[0]\n\n role = sts_backend.assume_role(\n role_session_name=role_session_name,\n role_arn=role_arn,\n policy=policy,\n duration=duration,\n external_id=external_id,\n )\n template = self.response_template(ASSUME_ROLE_RESPONSE)\n return template.render(role=role)\n\n def assume_role_with_web_identity(self):\n role_session_name = self.querystring.get('RoleSessionName')[0]\n role_arn = self.querystring.get('RoleArn')[0]\n\n policy = self.querystring.get('Policy', [None])[0]\n duration = int(self.querystring.get('DurationSeconds', [3600])[0])\n external_id = self.querystring.get('ExternalId', [None])[0]\n\n role = sts_backend.assume_role_with_web_identity(\n role_session_name=role_session_name,\n role_arn=role_arn,\n policy=policy,\n duration=duration,\n external_id=external_id,\n )\n template = self.response_template(ASSUME_ROLE_WITH_WEB_IDENTITY_RESPONSE)\n return template.render(role=role)\n\n def get_caller_identity(self):\n template = self.response_template(GET_CALLER_IDENTITY_RESPONSE)\n\n # Default values in case the request does not use valid credentials generated by moto\n user_id = \"AKIAIOSFODNN7EXAMPLE\"\n arn = \"arn:aws:sts::{account_id}:user/moto\".format(account_id=ACCOUNT_ID)\n\n access_key_id = self.get_current_user()\n assumed_role = sts_backend.get_assumed_role_from_access_key(access_key_id)\n if assumed_role:\n user_id = assumed_role.user_id\n arn = assumed_role.arn\n\n user = iam_backend.get_user_from_access_key_id(access_key_id)\n if user:\n user_id = user.id\n arn = user.arn\n\n return template.render(account_id=ACCOUNT_ID, user_id=user_id, arn=arn)\n\n\nGET_SESSION_TOKEN_RESPONSE = \"\"\"<GetSessionTokenResponse xmlns=\"https://sts.amazonaws.com/doc/2011-06-15/\">\n <GetSessionTokenResult>\n <Credentials>\n <SessionToken>AQoEXAMPLEH4aoAH0gNCAPyJxz4BlCFFxWNE1OPTgk5TthT+FvwqnKwRcOIfrRh3c/LTo6UDdyJwOOvEVPvLXCrrrUtdnniCEXAMPLE/IvU1dYUg2RVAJBanLiHb4IgRmpRV3zrkuWJOgQs8IZZaIv2BXIa2R4OlgkBN9bkUDNCJiBeb/AXlzBBko7b15fjrBs2+cTQtpZ3CYWFXG8C5zqx37wnOE49mRl/+OtkIKGO7fAE</SessionToken>\n <SecretAccessKey>wJalrXUtnFEMI/K7MDENG/bPxRfiCYzEXAMPLEKEY</SecretAccessKey>\n <Expiration>{{ token.expiration_ISO8601 }}</Expiration>\n <AccessKeyId>AKIAIOSFODNN7EXAMPLE</AccessKeyId>\n </Credentials>\n </GetSessionTokenResult>\n <ResponseMetadata>\n <RequestId>58c5dbae-abef-11e0-8cfe-09039844ac7d</RequestId>\n </ResponseMetadata>\n</GetSessionTokenResponse>\"\"\"\n\n\nGET_FEDERATION_TOKEN_RESPONSE = \"\"\"<GetFederationTokenResponse xmlns=\"https://sts.amazonaws.com/doc/\n2011-06-15/\">\n <GetFederationTokenResult>\n <Credentials>\n <SessionToken>AQoDYXdzEPT//////////wEXAMPLEtc764bNrC9SAPBSM22wDOk4x4HIZ8j4FZTwdQWLWsKWHGBuFqwAeMicRXmxfpSPfIeoIYRqTflfKD8YUuwthAx7mSEI/qkPpKPi/kMcGdQrmGdeehM4IC1NtBmUpp2wUE8phUZampKsburEDy0KPkyQDYwT7WZ0wq5VSXDvp75YU9HFvlRd8Tx6q6fE8YQcHNVXAkiY9q6d+xo0rKwT38xVqr7ZD0u0iPPkUL64lIZbqBAz+scqKmlzm8FDrypNC9Yjc8fPOLn9FX9KSYvKTr4rvx3iSIlTJabIQwj2ICCR/oLxBA==</SessionToken>\n <SecretAccessKey>wJalrXUtnFEMI/K7MDENG/bPxRfiCYzEXAMPLEKEY</SecretAccessKey>\n <Expiration>{{ token.expiration_ISO8601 }}</Expiration>\n <AccessKeyId>AKIAIOSFODNN7EXAMPLE</AccessKeyId>\n </Credentials>\n <FederatedUser>\n <Arn>arn:aws:sts::{{ account_id }}:federated-user/{{ token.name }}</Arn>\n <FederatedUserId>{{ account_id }}:{{ token.name }}</FederatedUserId>\n </FederatedUser>\n <PackedPolicySize>6</PackedPolicySize>\n </GetFederationTokenResult>\n <ResponseMetadata>\n <RequestId>c6104cbe-af31-11e0-8154-cbc7ccf896c7</RequestId>\n </ResponseMetadata>\n</GetFederationTokenResponse>\"\"\"\n\n\nASSUME_ROLE_RESPONSE = \"\"\"<AssumeRoleResponse xmlns=\"https://sts.amazonaws.com/doc/2011-06-15/\">\n <AssumeRoleResult>\n <Credentials>\n <SessionToken>{{ role.session_token }}</SessionToken>\n <SecretAccessKey>{{ role.secret_access_key }}</SecretAccessKey>\n <Expiration>{{ role.expiration_ISO8601 }}</Expiration>\n <AccessKeyId>{{ role.access_key_id }}</AccessKeyId>\n </Credentials>\n <AssumedRoleUser>\n <Arn>{{ role.arn }}</Arn>\n <AssumedRoleId>{{ role.user_id }}</AssumedRoleId>\n </AssumedRoleUser>\n <PackedPolicySize>6</PackedPolicySize>\n </AssumeRoleResult>\n <ResponseMetadata>\n <RequestId>c6104cbe-af31-11e0-8154-cbc7ccf896c7</RequestId>\n </ResponseMetadata>\n</AssumeRoleResponse>\"\"\"\n\n\nASSUME_ROLE_WITH_WEB_IDENTITY_RESPONSE = \"\"\"<AssumeRoleWithWebIdentityResponse xmlns=\"https://sts.amazonaws.com/doc/2011-06-15/\">\n <AssumeRoleWithWebIdentityResult>\n <Credentials>\n <SessionToken>{{ role.session_token }}</SessionToken>\n <SecretAccessKey>{{ role.secret_access_key }}</SecretAccessKey>\n <Expiration>{{ role.expiration_ISO8601 }}</Expiration>\n <AccessKeyId>{{ role.access_key_id }}</AccessKeyId>\n </Credentials>\n <AssumedRoleUser>\n <Arn>{{ role.arn }}</Arn>\n <AssumedRoleId>ARO123EXAMPLE123:{{ role.session_name }}</AssumedRoleId>\n </AssumedRoleUser>\n <PackedPolicySize>6</PackedPolicySize>\n </AssumeRoleWithWebIdentityResult>\n <ResponseMetadata>\n <RequestId>c6104cbe-af31-11e0-8154-cbc7ccf896c7</RequestId>\n </ResponseMetadata>\n</AssumeRoleWithWebIdentityResponse>\"\"\"\n\n\nGET_CALLER_IDENTITY_RESPONSE = \"\"\"<GetCallerIdentityResponse xmlns=\"https://sts.amazonaws.com/doc/2011-06-15/\">\n <GetCallerIdentityResult>\n <Arn>{{ arn }}</Arn>\n <UserId>{{ user_id }}</UserId>\n <Account>{{ account_id }}</Account>\n </GetCallerIdentityResult>\n <ResponseMetadata>\n <RequestId>c6104cbe-af31-11e0-8154-cbc7ccf896c7</RequestId>\n </ResponseMetadata>\n</GetCallerIdentityResponse>\n\"\"\"\n", "path": "moto/sts/responses.py"}]}
| 3,059 | 153 |
gh_patches_debug_42444
|
rasdani/github-patches
|
git_diff
|
geopandas__geopandas-1160
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Lazy Loading Dataframes
There have been times when I wanted to use geopandas to get an idea of what was in a large file. But, it took a long time to load it in. So, I used `fiona` instead. Are there any plans (or desires) to do lazy loading of the geopandas data?
This is library I recently saw is related:
https://vaex.readthedocs.io/en/latest/index.html
https://github.com/vaexio/vaex
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `geopandas/io/file.py`
Content:
```
1 from distutils.version import LooseVersion
2
3 import numpy as np
4 import pandas as pd
5
6 import fiona
7
8 from geopandas import GeoDataFrame, GeoSeries
9
10 try:
11 from fiona import Env as fiona_env
12 except ImportError:
13 from fiona import drivers as fiona_env
14 # Adapted from pandas.io.common
15 from urllib.request import urlopen as _urlopen
16 from urllib.parse import urlparse as parse_url
17 from urllib.parse import uses_relative, uses_netloc, uses_params
18
19
20 _FIONA18 = LooseVersion(fiona.__version__) >= LooseVersion("1.8")
21 _VALID_URLS = set(uses_relative + uses_netloc + uses_params)
22 _VALID_URLS.discard("")
23
24
25 def _is_url(url):
26 """Check to see if *url* has a valid protocol."""
27 try:
28 return parse_url(url).scheme in _VALID_URLS
29 except Exception:
30 return False
31
32
33 def read_file(filename, bbox=None, **kwargs):
34 """
35 Returns a GeoDataFrame from a file or URL.
36
37 Parameters
38 ----------
39 filename: str
40 Either the absolute or relative path to the file or URL to
41 be opened.
42 bbox : tuple | GeoDataFrame or GeoSeries, default None
43 Filter features by given bounding box, GeoSeries, or GeoDataFrame.
44 CRS mis-matches are resolved if given a GeoSeries or GeoDataFrame.
45 **kwargs:
46 Keyword args to be passed to the `open` or `BytesCollection` method
47 in the fiona library when opening the file. For more information on
48 possible keywords, type:
49 ``import fiona; help(fiona.open)``
50
51 Examples
52 --------
53 >>> df = geopandas.read_file("nybb.shp")
54
55 Returns
56 -------
57 geodataframe : GeoDataFrame
58
59 Notes
60 -----
61 The format drivers will attempt to detect the encoding of your data, but
62 may fail. In this case, the proper encoding can be specified explicitly
63 by using the encoding keyword parameter, e.g. ``encoding='utf-8'``.
64 """
65 if _is_url(filename):
66 req = _urlopen(filename)
67 path_or_bytes = req.read()
68 reader = fiona.BytesCollection
69 else:
70 path_or_bytes = filename
71 reader = fiona.open
72
73 with fiona_env():
74 with reader(path_or_bytes, **kwargs) as features:
75
76 # In a future Fiona release the crs attribute of features will
77 # no longer be a dict, but will behave like a dict. So this should
78 # be forwards compatible
79 crs = (
80 features.crs["init"]
81 if features.crs and "init" in features.crs
82 else features.crs_wkt
83 )
84
85 if bbox is not None:
86 if isinstance(bbox, GeoDataFrame) or isinstance(bbox, GeoSeries):
87 bbox = tuple(bbox.to_crs(crs).total_bounds)
88 assert len(bbox) == 4
89 f_filt = features.filter(bbox=bbox)
90 else:
91 f_filt = features
92
93 columns = list(features.meta["schema"]["properties"]) + ["geometry"]
94 gdf = GeoDataFrame.from_features(f_filt, crs=crs, columns=columns)
95
96 return gdf
97
98
99 def to_file(df, filename, driver="ESRI Shapefile", schema=None, index=None, **kwargs):
100 """
101 Write this GeoDataFrame to an OGR data source
102
103 A dictionary of supported OGR providers is available via:
104 >>> import fiona
105 >>> fiona.supported_drivers
106
107 Parameters
108 ----------
109 df : GeoDataFrame to be written
110 filename : string
111 File path or file handle to write to.
112 driver : string, default 'ESRI Shapefile'
113 The OGR format driver used to write the vector file.
114 schema : dict, default None
115 If specified, the schema dictionary is passed to Fiona to
116 better control how the file is written. If None, GeoPandas
117 will determine the schema based on each column's dtype
118 index : bool, default None
119 If True, write index into one or more columns (for MultiIndex).
120 Default None writes the index into one or more columns only if
121 the index is named, is a MultiIndex, or has a non-integer data
122 type. If False, no index is written.
123
124 .. versionadded:: 0.7
125 Previously the index was not written.
126
127 The *kwargs* are passed to fiona.open and can be used to write
128 to multi-layer data, store data within archives (zip files), etc.
129 The path may specify a fiona VSI scheme.
130
131 Notes
132 -----
133 The format drivers will attempt to detect the encoding of your data, but
134 may fail. In this case, the proper encoding can be specified explicitly
135 by using the encoding keyword parameter, e.g. ``encoding='utf-8'``.
136 """
137 if index is None:
138 # Determine if index attribute(s) should be saved to file
139 index = list(df.index.names) != [None] or type(df.index) not in (
140 pd.RangeIndex,
141 pd.Int64Index,
142 )
143 if index:
144 df = df.reset_index(drop=False)
145 if schema is None:
146 schema = infer_schema(df)
147 with fiona_env():
148 crs_wkt = None
149 try:
150 gdal_version = fiona.env.get_gdal_release_name()
151 except AttributeError:
152 gdal_version = "2.0.0" # just assume it is not the latest
153 if LooseVersion(gdal_version) >= LooseVersion("3.0.0") and df.crs:
154 crs_wkt = df.crs.to_wkt()
155 elif df.crs:
156 crs_wkt = df.crs.to_wkt("WKT1_GDAL")
157 with fiona.open(
158 filename, "w", driver=driver, crs_wkt=crs_wkt, schema=schema, **kwargs
159 ) as colxn:
160 colxn.writerecords(df.iterfeatures())
161
162
163 def infer_schema(df):
164 from collections import OrderedDict
165
166 # TODO: test pandas string type and boolean type once released
167 types = {"Int64": "int", "string": "str", "boolean": "bool"}
168
169 def convert_type(column, in_type):
170 if in_type == object:
171 return "str"
172 if in_type.name.startswith("datetime64"):
173 # numpy datetime type regardless of frequency
174 return "datetime"
175 if str(in_type) in types:
176 out_type = types[str(in_type)]
177 else:
178 out_type = type(np.zeros(1, in_type).item()).__name__
179 if out_type == "long":
180 out_type = "int"
181 if not _FIONA18 and out_type == "bool":
182 raise ValueError(
183 'column "{}" is boolean type, '.format(column)
184 + "which is unsupported in file writing with fiona "
185 "< 1.8. Consider casting the column to int type."
186 )
187 return out_type
188
189 properties = OrderedDict(
190 [
191 (col, convert_type(col, _type))
192 for col, _type in zip(df.columns, df.dtypes)
193 if col != df._geometry_column_name
194 ]
195 )
196
197 if df.empty:
198 raise ValueError("Cannot write empty DataFrame to file.")
199
200 # Since https://github.com/Toblerity/Fiona/issues/446 resolution,
201 # Fiona allows a list of geometry types
202 geom_types = _geometry_types(df)
203
204 schema = {"geometry": geom_types, "properties": properties}
205
206 return schema
207
208
209 def _geometry_types(df):
210 """
211 Determine the geometry types in the GeoDataFrame for the schema.
212 """
213 if _FIONA18:
214 # Starting from Fiona 1.8, schema submitted to fiona to write a gdf
215 # can have mixed geometries:
216 # - 3D and 2D shapes can coexist in inferred schema
217 # - Shape and MultiShape types can (and must) coexist in inferred
218 # schema
219 geom_types_2D = df[~df.geometry.has_z].geometry.geom_type.unique()
220 geom_types_2D = [gtype for gtype in geom_types_2D if gtype is not None]
221 geom_types_3D = df[df.geometry.has_z].geometry.geom_type.unique()
222 geom_types_3D = ["3D " + gtype for gtype in geom_types_3D if gtype is not None]
223 geom_types = geom_types_3D + geom_types_2D
224
225 else:
226 # Before Fiona 1.8, schema submitted to write a gdf should have
227 # one single geometry type whenever possible:
228 # - 3D and 2D shapes cannot coexist in inferred schema
229 # - Shape and MultiShape can not coexist in inferred schema
230 geom_types = _geometry_types_back_compat(df)
231
232 if len(geom_types) == 0:
233 # Default geometry type supported by Fiona
234 # (Since https://github.com/Toblerity/Fiona/issues/446 resolution)
235 return "Unknown"
236
237 if len(geom_types) == 1:
238 geom_types = geom_types[0]
239
240 return geom_types
241
242
243 def _geometry_types_back_compat(df):
244 """
245 for backward compatibility with Fiona<1.8 only
246 """
247 unique_geom_types = df.geometry.geom_type.unique()
248 unique_geom_types = [gtype for gtype in unique_geom_types if gtype is not None]
249
250 # merge single and Multi types (eg Polygon and MultiPolygon)
251 unique_geom_types = [
252 gtype
253 for gtype in unique_geom_types
254 if not gtype.startswith("Multi") or gtype[5:] not in unique_geom_types
255 ]
256
257 if df.geometry.has_z.any():
258 # declare all geometries as 3D geometries
259 unique_geom_types = ["3D " + type for type in unique_geom_types]
260 # by default, all geometries are 2D geometries
261
262 return unique_geom_types
263
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/geopandas/io/file.py b/geopandas/io/file.py
--- a/geopandas/io/file.py
+++ b/geopandas/io/file.py
@@ -4,17 +4,21 @@
import pandas as pd
import fiona
-
-from geopandas import GeoDataFrame, GeoSeries
+from shapely.geometry import mapping
+from shapely.geometry.base import BaseGeometry
try:
from fiona import Env as fiona_env
except ImportError:
from fiona import drivers as fiona_env
+
+from geopandas import GeoDataFrame, GeoSeries
+
+
# Adapted from pandas.io.common
from urllib.request import urlopen as _urlopen
from urllib.parse import urlparse as parse_url
-from urllib.parse import uses_relative, uses_netloc, uses_params
+from urllib.parse import uses_netloc, uses_params, uses_relative
_FIONA18 = LooseVersion(fiona.__version__) >= LooseVersion("1.8")
@@ -30,18 +34,29 @@
return False
-def read_file(filename, bbox=None, **kwargs):
+def read_file(filename, bbox=None, mask=None, rows=None, **kwargs):
"""
Returns a GeoDataFrame from a file or URL.
+ .. versionadded:: 0.7.0 mask, rows
+
Parameters
----------
filename: str
Either the absolute or relative path to the file or URL to
be opened.
- bbox : tuple | GeoDataFrame or GeoSeries, default None
- Filter features by given bounding box, GeoSeries, or GeoDataFrame.
+ bbox: tuple | GeoDataFrame or GeoSeries | shapely Geometry, default None
+ Filter features by given bounding box, GeoSeries, GeoDataFrame or a
+ shapely geometry. CRS mis-matches are resolved if given a GeoSeries
+ or GeoDataFrame. Cannot be used with mask.
+ mask: dict | GeoDataFrame or GeoSeries | shapely Geometry, default None
+ Filter for features that intersect with the given dict-like geojson
+ geometry, GeoSeries, GeoDataFrame or shapely geometry.
CRS mis-matches are resolved if given a GeoSeries or GeoDataFrame.
+ Cannot be used with bbox.
+ rows: int or slice, default None
+ Load in specific rows by passing an integer (first `n` rows) or a
+ slice() object.
**kwargs:
Keyword args to be passed to the `open` or `BytesCollection` method
in the fiona library when opening the file. For more information on
@@ -54,7 +69,7 @@
Returns
-------
- geodataframe : GeoDataFrame
+ :obj:`geopandas.GeoDataFrame`
Notes
-----
@@ -82,11 +97,29 @@
else features.crs_wkt
)
+ # handle loading the bounding box
if bbox is not None:
- if isinstance(bbox, GeoDataFrame) or isinstance(bbox, GeoSeries):
+ if isinstance(bbox, (GeoDataFrame, GeoSeries)):
bbox = tuple(bbox.to_crs(crs).total_bounds)
+ elif isinstance(bbox, BaseGeometry):
+ bbox = bbox.bounds
assert len(bbox) == 4
- f_filt = features.filter(bbox=bbox)
+ # handle loading the mask
+ elif isinstance(mask, (GeoDataFrame, GeoSeries)):
+ mask = mapping(mask.to_crs(crs).unary_union)
+ elif isinstance(mask, BaseGeometry):
+ mask = mapping(mask)
+ # setup the data loading filter
+ if rows is not None:
+ if isinstance(rows, int):
+ rows = slice(rows)
+ elif not isinstance(rows, slice):
+ raise TypeError("'rows' must be an integer or a slice.")
+ f_filt = features.filter(
+ rows.start, rows.stop, rows.step, bbox=bbox, mask=mask
+ )
+ elif any((bbox, mask)):
+ f_filt = features.filter(bbox=bbox, mask=mask)
else:
f_filt = features
|
{"golden_diff": "diff --git a/geopandas/io/file.py b/geopandas/io/file.py\n--- a/geopandas/io/file.py\n+++ b/geopandas/io/file.py\n@@ -4,17 +4,21 @@\n import pandas as pd\n \n import fiona\n-\n-from geopandas import GeoDataFrame, GeoSeries\n+from shapely.geometry import mapping\n+from shapely.geometry.base import BaseGeometry\n \n try:\n from fiona import Env as fiona_env\n except ImportError:\n from fiona import drivers as fiona_env\n+\n+from geopandas import GeoDataFrame, GeoSeries\n+\n+\n # Adapted from pandas.io.common\n from urllib.request import urlopen as _urlopen\n from urllib.parse import urlparse as parse_url\n-from urllib.parse import uses_relative, uses_netloc, uses_params\n+from urllib.parse import uses_netloc, uses_params, uses_relative\n \n \n _FIONA18 = LooseVersion(fiona.__version__) >= LooseVersion(\"1.8\")\n@@ -30,18 +34,29 @@\n return False\n \n \n-def read_file(filename, bbox=None, **kwargs):\n+def read_file(filename, bbox=None, mask=None, rows=None, **kwargs):\n \"\"\"\n Returns a GeoDataFrame from a file or URL.\n \n+ .. versionadded:: 0.7.0 mask, rows\n+\n Parameters\n ----------\n filename: str\n Either the absolute or relative path to the file or URL to\n be opened.\n- bbox : tuple | GeoDataFrame or GeoSeries, default None\n- Filter features by given bounding box, GeoSeries, or GeoDataFrame.\n+ bbox: tuple | GeoDataFrame or GeoSeries | shapely Geometry, default None\n+ Filter features by given bounding box, GeoSeries, GeoDataFrame or a\n+ shapely geometry. CRS mis-matches are resolved if given a GeoSeries\n+ or GeoDataFrame. Cannot be used with mask.\n+ mask: dict | GeoDataFrame or GeoSeries | shapely Geometry, default None\n+ Filter for features that intersect with the given dict-like geojson\n+ geometry, GeoSeries, GeoDataFrame or shapely geometry.\n CRS mis-matches are resolved if given a GeoSeries or GeoDataFrame.\n+ Cannot be used with bbox.\n+ rows: int or slice, default None\n+ Load in specific rows by passing an integer (first `n` rows) or a\n+ slice() object.\n **kwargs:\n Keyword args to be passed to the `open` or `BytesCollection` method\n in the fiona library when opening the file. For more information on\n@@ -54,7 +69,7 @@\n \n Returns\n -------\n- geodataframe : GeoDataFrame\n+ :obj:`geopandas.GeoDataFrame`\n \n Notes\n -----\n@@ -82,11 +97,29 @@\n else features.crs_wkt\n )\n \n+ # handle loading the bounding box\n if bbox is not None:\n- if isinstance(bbox, GeoDataFrame) or isinstance(bbox, GeoSeries):\n+ if isinstance(bbox, (GeoDataFrame, GeoSeries)):\n bbox = tuple(bbox.to_crs(crs).total_bounds)\n+ elif isinstance(bbox, BaseGeometry):\n+ bbox = bbox.bounds\n assert len(bbox) == 4\n- f_filt = features.filter(bbox=bbox)\n+ # handle loading the mask\n+ elif isinstance(mask, (GeoDataFrame, GeoSeries)):\n+ mask = mapping(mask.to_crs(crs).unary_union)\n+ elif isinstance(mask, BaseGeometry):\n+ mask = mapping(mask)\n+ # setup the data loading filter\n+ if rows is not None:\n+ if isinstance(rows, int):\n+ rows = slice(rows)\n+ elif not isinstance(rows, slice):\n+ raise TypeError(\"'rows' must be an integer or a slice.\")\n+ f_filt = features.filter(\n+ rows.start, rows.stop, rows.step, bbox=bbox, mask=mask\n+ )\n+ elif any((bbox, mask)):\n+ f_filt = features.filter(bbox=bbox, mask=mask)\n else:\n f_filt = features\n", "issue": "Lazy Loading Dataframes\nThere have been times when I wanted to use geopandas to get an idea of what was in a large file. But, it took a long time to load it in. So, I used `fiona` instead. Are there any plans (or desires) to do lazy loading of the geopandas data?\r\n\r\nThis is library I recently saw is related:\r\nhttps://vaex.readthedocs.io/en/latest/index.html\r\nhttps://github.com/vaexio/vaex\n", "before_files": [{"content": "from distutils.version import LooseVersion\n\nimport numpy as np\nimport pandas as pd\n\nimport fiona\n\nfrom geopandas import GeoDataFrame, GeoSeries\n\ntry:\n from fiona import Env as fiona_env\nexcept ImportError:\n from fiona import drivers as fiona_env\n# Adapted from pandas.io.common\nfrom urllib.request import urlopen as _urlopen\nfrom urllib.parse import urlparse as parse_url\nfrom urllib.parse import uses_relative, uses_netloc, uses_params\n\n\n_FIONA18 = LooseVersion(fiona.__version__) >= LooseVersion(\"1.8\")\n_VALID_URLS = set(uses_relative + uses_netloc + uses_params)\n_VALID_URLS.discard(\"\")\n\n\ndef _is_url(url):\n \"\"\"Check to see if *url* has a valid protocol.\"\"\"\n try:\n return parse_url(url).scheme in _VALID_URLS\n except Exception:\n return False\n\n\ndef read_file(filename, bbox=None, **kwargs):\n \"\"\"\n Returns a GeoDataFrame from a file or URL.\n\n Parameters\n ----------\n filename: str\n Either the absolute or relative path to the file or URL to\n be opened.\n bbox : tuple | GeoDataFrame or GeoSeries, default None\n Filter features by given bounding box, GeoSeries, or GeoDataFrame.\n CRS mis-matches are resolved if given a GeoSeries or GeoDataFrame.\n **kwargs:\n Keyword args to be passed to the `open` or `BytesCollection` method\n in the fiona library when opening the file. For more information on\n possible keywords, type:\n ``import fiona; help(fiona.open)``\n\n Examples\n --------\n >>> df = geopandas.read_file(\"nybb.shp\")\n\n Returns\n -------\n geodataframe : GeoDataFrame\n\n Notes\n -----\n The format drivers will attempt to detect the encoding of your data, but\n may fail. In this case, the proper encoding can be specified explicitly\n by using the encoding keyword parameter, e.g. ``encoding='utf-8'``.\n \"\"\"\n if _is_url(filename):\n req = _urlopen(filename)\n path_or_bytes = req.read()\n reader = fiona.BytesCollection\n else:\n path_or_bytes = filename\n reader = fiona.open\n\n with fiona_env():\n with reader(path_or_bytes, **kwargs) as features:\n\n # In a future Fiona release the crs attribute of features will\n # no longer be a dict, but will behave like a dict. So this should\n # be forwards compatible\n crs = (\n features.crs[\"init\"]\n if features.crs and \"init\" in features.crs\n else features.crs_wkt\n )\n\n if bbox is not None:\n if isinstance(bbox, GeoDataFrame) or isinstance(bbox, GeoSeries):\n bbox = tuple(bbox.to_crs(crs).total_bounds)\n assert len(bbox) == 4\n f_filt = features.filter(bbox=bbox)\n else:\n f_filt = features\n\n columns = list(features.meta[\"schema\"][\"properties\"]) + [\"geometry\"]\n gdf = GeoDataFrame.from_features(f_filt, crs=crs, columns=columns)\n\n return gdf\n\n\ndef to_file(df, filename, driver=\"ESRI Shapefile\", schema=None, index=None, **kwargs):\n \"\"\"\n Write this GeoDataFrame to an OGR data source\n\n A dictionary of supported OGR providers is available via:\n >>> import fiona\n >>> fiona.supported_drivers\n\n Parameters\n ----------\n df : GeoDataFrame to be written\n filename : string\n File path or file handle to write to.\n driver : string, default 'ESRI Shapefile'\n The OGR format driver used to write the vector file.\n schema : dict, default None\n If specified, the schema dictionary is passed to Fiona to\n better control how the file is written. If None, GeoPandas\n will determine the schema based on each column's dtype\n index : bool, default None\n If True, write index into one or more columns (for MultiIndex).\n Default None writes the index into one or more columns only if\n the index is named, is a MultiIndex, or has a non-integer data\n type. If False, no index is written.\n\n .. versionadded:: 0.7\n Previously the index was not written.\n\n The *kwargs* are passed to fiona.open and can be used to write\n to multi-layer data, store data within archives (zip files), etc.\n The path may specify a fiona VSI scheme.\n\n Notes\n -----\n The format drivers will attempt to detect the encoding of your data, but\n may fail. In this case, the proper encoding can be specified explicitly\n by using the encoding keyword parameter, e.g. ``encoding='utf-8'``.\n \"\"\"\n if index is None:\n # Determine if index attribute(s) should be saved to file\n index = list(df.index.names) != [None] or type(df.index) not in (\n pd.RangeIndex,\n pd.Int64Index,\n )\n if index:\n df = df.reset_index(drop=False)\n if schema is None:\n schema = infer_schema(df)\n with fiona_env():\n crs_wkt = None\n try:\n gdal_version = fiona.env.get_gdal_release_name()\n except AttributeError:\n gdal_version = \"2.0.0\" # just assume it is not the latest\n if LooseVersion(gdal_version) >= LooseVersion(\"3.0.0\") and df.crs:\n crs_wkt = df.crs.to_wkt()\n elif df.crs:\n crs_wkt = df.crs.to_wkt(\"WKT1_GDAL\")\n with fiona.open(\n filename, \"w\", driver=driver, crs_wkt=crs_wkt, schema=schema, **kwargs\n ) as colxn:\n colxn.writerecords(df.iterfeatures())\n\n\ndef infer_schema(df):\n from collections import OrderedDict\n\n # TODO: test pandas string type and boolean type once released\n types = {\"Int64\": \"int\", \"string\": \"str\", \"boolean\": \"bool\"}\n\n def convert_type(column, in_type):\n if in_type == object:\n return \"str\"\n if in_type.name.startswith(\"datetime64\"):\n # numpy datetime type regardless of frequency\n return \"datetime\"\n if str(in_type) in types:\n out_type = types[str(in_type)]\n else:\n out_type = type(np.zeros(1, in_type).item()).__name__\n if out_type == \"long\":\n out_type = \"int\"\n if not _FIONA18 and out_type == \"bool\":\n raise ValueError(\n 'column \"{}\" is boolean type, '.format(column)\n + \"which is unsupported in file writing with fiona \"\n \"< 1.8. Consider casting the column to int type.\"\n )\n return out_type\n\n properties = OrderedDict(\n [\n (col, convert_type(col, _type))\n for col, _type in zip(df.columns, df.dtypes)\n if col != df._geometry_column_name\n ]\n )\n\n if df.empty:\n raise ValueError(\"Cannot write empty DataFrame to file.\")\n\n # Since https://github.com/Toblerity/Fiona/issues/446 resolution,\n # Fiona allows a list of geometry types\n geom_types = _geometry_types(df)\n\n schema = {\"geometry\": geom_types, \"properties\": properties}\n\n return schema\n\n\ndef _geometry_types(df):\n \"\"\"\n Determine the geometry types in the GeoDataFrame for the schema.\n \"\"\"\n if _FIONA18:\n # Starting from Fiona 1.8, schema submitted to fiona to write a gdf\n # can have mixed geometries:\n # - 3D and 2D shapes can coexist in inferred schema\n # - Shape and MultiShape types can (and must) coexist in inferred\n # schema\n geom_types_2D = df[~df.geometry.has_z].geometry.geom_type.unique()\n geom_types_2D = [gtype for gtype in geom_types_2D if gtype is not None]\n geom_types_3D = df[df.geometry.has_z].geometry.geom_type.unique()\n geom_types_3D = [\"3D \" + gtype for gtype in geom_types_3D if gtype is not None]\n geom_types = geom_types_3D + geom_types_2D\n\n else:\n # Before Fiona 1.8, schema submitted to write a gdf should have\n # one single geometry type whenever possible:\n # - 3D and 2D shapes cannot coexist in inferred schema\n # - Shape and MultiShape can not coexist in inferred schema\n geom_types = _geometry_types_back_compat(df)\n\n if len(geom_types) == 0:\n # Default geometry type supported by Fiona\n # (Since https://github.com/Toblerity/Fiona/issues/446 resolution)\n return \"Unknown\"\n\n if len(geom_types) == 1:\n geom_types = geom_types[0]\n\n return geom_types\n\n\ndef _geometry_types_back_compat(df):\n \"\"\"\n for backward compatibility with Fiona<1.8 only\n \"\"\"\n unique_geom_types = df.geometry.geom_type.unique()\n unique_geom_types = [gtype for gtype in unique_geom_types if gtype is not None]\n\n # merge single and Multi types (eg Polygon and MultiPolygon)\n unique_geom_types = [\n gtype\n for gtype in unique_geom_types\n if not gtype.startswith(\"Multi\") or gtype[5:] not in unique_geom_types\n ]\n\n if df.geometry.has_z.any():\n # declare all geometries as 3D geometries\n unique_geom_types = [\"3D \" + type for type in unique_geom_types]\n # by default, all geometries are 2D geometries\n\n return unique_geom_types\n", "path": "geopandas/io/file.py"}], "after_files": [{"content": "from distutils.version import LooseVersion\n\nimport numpy as np\nimport pandas as pd\n\nimport fiona\nfrom shapely.geometry import mapping\nfrom shapely.geometry.base import BaseGeometry\n\ntry:\n from fiona import Env as fiona_env\nexcept ImportError:\n from fiona import drivers as fiona_env\n\nfrom geopandas import GeoDataFrame, GeoSeries\n\n\n# Adapted from pandas.io.common\nfrom urllib.request import urlopen as _urlopen\nfrom urllib.parse import urlparse as parse_url\nfrom urllib.parse import uses_netloc, uses_params, uses_relative\n\n\n_FIONA18 = LooseVersion(fiona.__version__) >= LooseVersion(\"1.8\")\n_VALID_URLS = set(uses_relative + uses_netloc + uses_params)\n_VALID_URLS.discard(\"\")\n\n\ndef _is_url(url):\n \"\"\"Check to see if *url* has a valid protocol.\"\"\"\n try:\n return parse_url(url).scheme in _VALID_URLS\n except Exception:\n return False\n\n\ndef read_file(filename, bbox=None, mask=None, rows=None, **kwargs):\n \"\"\"\n Returns a GeoDataFrame from a file or URL.\n\n .. versionadded:: 0.7.0 mask, rows\n\n Parameters\n ----------\n filename: str\n Either the absolute or relative path to the file or URL to\n be opened.\n bbox: tuple | GeoDataFrame or GeoSeries | shapely Geometry, default None\n Filter features by given bounding box, GeoSeries, GeoDataFrame or a\n shapely geometry. CRS mis-matches are resolved if given a GeoSeries\n or GeoDataFrame. Cannot be used with mask.\n mask: dict | GeoDataFrame or GeoSeries | shapely Geometry, default None\n Filter for features that intersect with the given dict-like geojson\n geometry, GeoSeries, GeoDataFrame or shapely geometry.\n CRS mis-matches are resolved if given a GeoSeries or GeoDataFrame.\n Cannot be used with bbox.\n rows: int or slice, default None\n Load in specific rows by passing an integer (first `n` rows) or a\n slice() object.\n **kwargs:\n Keyword args to be passed to the `open` or `BytesCollection` method\n in the fiona library when opening the file. For more information on\n possible keywords, type:\n ``import fiona; help(fiona.open)``\n\n Examples\n --------\n >>> df = geopandas.read_file(\"nybb.shp\")\n\n Returns\n -------\n :obj:`geopandas.GeoDataFrame`\n\n Notes\n -----\n The format drivers will attempt to detect the encoding of your data, but\n may fail. In this case, the proper encoding can be specified explicitly\n by using the encoding keyword parameter, e.g. ``encoding='utf-8'``.\n \"\"\"\n if _is_url(filename):\n req = _urlopen(filename)\n path_or_bytes = req.read()\n reader = fiona.BytesCollection\n else:\n path_or_bytes = filename\n reader = fiona.open\n\n with fiona_env():\n with reader(path_or_bytes, **kwargs) as features:\n\n # In a future Fiona release the crs attribute of features will\n # no longer be a dict, but will behave like a dict. So this should\n # be forwards compatible\n crs = (\n features.crs[\"init\"]\n if features.crs and \"init\" in features.crs\n else features.crs_wkt\n )\n\n # handle loading the bounding box\n if bbox is not None:\n if isinstance(bbox, (GeoDataFrame, GeoSeries)):\n bbox = tuple(bbox.to_crs(crs).total_bounds)\n elif isinstance(bbox, BaseGeometry):\n bbox = bbox.bounds\n assert len(bbox) == 4\n # handle loading the mask\n elif isinstance(mask, (GeoDataFrame, GeoSeries)):\n mask = mapping(mask.to_crs(crs).unary_union)\n elif isinstance(mask, BaseGeometry):\n mask = mapping(mask)\n # setup the data loading filter\n if rows is not None:\n if isinstance(rows, int):\n rows = slice(rows)\n elif not isinstance(rows, slice):\n raise TypeError(\"'rows' must be an integer or a slice.\")\n f_filt = features.filter(\n rows.start, rows.stop, rows.step, bbox=bbox, mask=mask\n )\n elif any((bbox, mask)):\n f_filt = features.filter(bbox=bbox, mask=mask)\n else:\n f_filt = features\n\n columns = list(features.meta[\"schema\"][\"properties\"]) + [\"geometry\"]\n gdf = GeoDataFrame.from_features(f_filt, crs=crs, columns=columns)\n\n return gdf\n\n\ndef to_file(df, filename, driver=\"ESRI Shapefile\", schema=None, index=None, **kwargs):\n \"\"\"\n Write this GeoDataFrame to an OGR data source\n\n A dictionary of supported OGR providers is available via:\n >>> import fiona\n >>> fiona.supported_drivers\n\n Parameters\n ----------\n df : GeoDataFrame to be written\n filename : string\n File path or file handle to write to.\n driver : string, default 'ESRI Shapefile'\n The OGR format driver used to write the vector file.\n schema : dict, default None\n If specified, the schema dictionary is passed to Fiona to\n better control how the file is written. If None, GeoPandas\n will determine the schema based on each column's dtype\n index : bool, default None\n If True, write index into one or more columns (for MultiIndex).\n Default None writes the index into one or more columns only if\n the index is named, is a MultiIndex, or has a non-integer data\n type. If False, no index is written.\n\n .. versionadded:: 0.7\n Previously the index was not written.\n\n The *kwargs* are passed to fiona.open and can be used to write\n to multi-layer data, store data within archives (zip files), etc.\n The path may specify a fiona VSI scheme.\n\n Notes\n -----\n The format drivers will attempt to detect the encoding of your data, but\n may fail. In this case, the proper encoding can be specified explicitly\n by using the encoding keyword parameter, e.g. ``encoding='utf-8'``.\n \"\"\"\n if index is None:\n # Determine if index attribute(s) should be saved to file\n index = list(df.index.names) != [None] or type(df.index) not in (\n pd.RangeIndex,\n pd.Int64Index,\n )\n if index:\n df = df.reset_index(drop=False)\n if schema is None:\n schema = infer_schema(df)\n with fiona_env():\n crs_wkt = None\n try:\n gdal_version = fiona.env.get_gdal_release_name()\n except AttributeError:\n gdal_version = \"2.0.0\" # just assume it is not the latest\n if LooseVersion(gdal_version) >= LooseVersion(\"3.0.0\") and df.crs:\n crs_wkt = df.crs.to_wkt()\n elif df.crs:\n crs_wkt = df.crs.to_wkt(\"WKT1_GDAL\")\n with fiona.open(\n filename, \"w\", driver=driver, crs_wkt=crs_wkt, schema=schema, **kwargs\n ) as colxn:\n colxn.writerecords(df.iterfeatures())\n\n\ndef infer_schema(df):\n from collections import OrderedDict\n\n # TODO: test pandas string type and boolean type once released\n types = {\"Int64\": \"int\", \"string\": \"str\", \"boolean\": \"bool\"}\n\n def convert_type(column, in_type):\n if in_type == object:\n return \"str\"\n if in_type.name.startswith(\"datetime64\"):\n # numpy datetime type regardless of frequency\n return \"datetime\"\n if str(in_type) in types:\n out_type = types[str(in_type)]\n else:\n out_type = type(np.zeros(1, in_type).item()).__name__\n if out_type == \"long\":\n out_type = \"int\"\n if not _FIONA18 and out_type == \"bool\":\n raise ValueError(\n 'column \"{}\" is boolean type, '.format(column)\n + \"which is unsupported in file writing with fiona \"\n \"< 1.8. Consider casting the column to int type.\"\n )\n return out_type\n\n properties = OrderedDict(\n [\n (col, convert_type(col, _type))\n for col, _type in zip(df.columns, df.dtypes)\n if col != df._geometry_column_name\n ]\n )\n\n if df.empty:\n raise ValueError(\"Cannot write empty DataFrame to file.\")\n\n # Since https://github.com/Toblerity/Fiona/issues/446 resolution,\n # Fiona allows a list of geometry types\n geom_types = _geometry_types(df)\n\n schema = {\"geometry\": geom_types, \"properties\": properties}\n\n return schema\n\n\ndef _geometry_types(df):\n \"\"\"\n Determine the geometry types in the GeoDataFrame for the schema.\n \"\"\"\n if _FIONA18:\n # Starting from Fiona 1.8, schema submitted to fiona to write a gdf\n # can have mixed geometries:\n # - 3D and 2D shapes can coexist in inferred schema\n # - Shape and MultiShape types can (and must) coexist in inferred\n # schema\n geom_types_2D = df[~df.geometry.has_z].geometry.geom_type.unique()\n geom_types_2D = [gtype for gtype in geom_types_2D if gtype is not None]\n geom_types_3D = df[df.geometry.has_z].geometry.geom_type.unique()\n geom_types_3D = [\"3D \" + gtype for gtype in geom_types_3D if gtype is not None]\n geom_types = geom_types_3D + geom_types_2D\n\n else:\n # Before Fiona 1.8, schema submitted to write a gdf should have\n # one single geometry type whenever possible:\n # - 3D and 2D shapes cannot coexist in inferred schema\n # - Shape and MultiShape can not coexist in inferred schema\n geom_types = _geometry_types_back_compat(df)\n\n if len(geom_types) == 0:\n # Default geometry type supported by Fiona\n # (Since https://github.com/Toblerity/Fiona/issues/446 resolution)\n return \"Unknown\"\n\n if len(geom_types) == 1:\n geom_types = geom_types[0]\n\n return geom_types\n\n\ndef _geometry_types_back_compat(df):\n \"\"\"\n for backward compatibility with Fiona<1.8 only\n \"\"\"\n unique_geom_types = df.geometry.geom_type.unique()\n unique_geom_types = [gtype for gtype in unique_geom_types if gtype is not None]\n\n # merge single and Multi types (eg Polygon and MultiPolygon)\n unique_geom_types = [\n gtype\n for gtype in unique_geom_types\n if not gtype.startswith(\"Multi\") or gtype[5:] not in unique_geom_types\n ]\n\n if df.geometry.has_z.any():\n # declare all geometries as 3D geometries\n unique_geom_types = [\"3D \" + type for type in unique_geom_types]\n # by default, all geometries are 2D geometries\n\n return unique_geom_types\n", "path": "geopandas/io/file.py"}]}
| 3,250 | 903 |
gh_patches_debug_32143
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-321
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
crashing on GCP EGRESS firewall rule which doesn't have allow field defined
**Describe the bug**
Checkov crashing on GCP EGRESS firewall rule which doesn't have allow field defined. Tf version 0.12.26 Google provider version: 3.23
**To Reproduce**
Steps to reproduce the behavior:
1. Resource defined as
```
resource "google_compute_firewall" "default_deny_egress" {
name = "deny-all-egress-all"
description = "Prevent all egress traffic by default"
disabled = true
network = google_compute_network.vpc_network.name
enable_logging = true
priority = 65534
direction = "EGRESS"
destination_ranges = ["0.0.0.0/0"]
deny { protocol = "all" }
}
```
2. Run cli command : checkov -d folder
3. See error
```
ERROR:checkov.terraform.checks.resource.gcp.GoogleComputeFirewallUnrestrictedIngress3389:Failed to run check: Ensure Google compute firewall ingress does not allow unrestricted rdp access for configuration: {'name': ['${var.env}-deny-all-egress-all'], 'description': ['Prevent all egress traffic by default'], 'disabled': [True], 'network': ['${google_compute_network.vpc_network.name}'], 'enable_logging': [True], 'priority': [65534], 'direction': ['EGRESS'], 'destination_ranges': [['0.0.0.0/0']], 'deny': [{'protocol': {'all': {}}}]} at file: /../../modules/network/firewalls.tf
Traceback (most recent call last):
File "/Users/jakub/Development/GIT_REPO/tfenv/bin/checkov", line 5, in <module>
run()
File "/Users/jakub/Development/GIT_REPO/tfenv/lib/python3.7/site-packages/checkov/main.py", line 76, in run
files=file)
File "/Users/jakub/Development/GIT_REPO/tfenv/lib/python3.7/site-packages/checkov/common/runners/runner_registry.py", line 26, in run
runner_filter=self.runner_filter)
File "/Users/jakub/Development/GIT_REPO/tfenv/lib/python3.7/site-packages/checkov/terraform/runner.py", line 50, in run
self.check_tf_definition(report, root_folder, runner_filter)
File "/Users/jakub/Development/GIT_REPO/tfenv/lib/python3.7/site-packages/checkov/terraform/runner.py", line 91, in check_tf_definition
block_type, runner_filter)
File "/Users/jakub/Development/GIT_REPO/tfenv/lib/python3.7/site-packages/checkov/terraform/runner.py", line 113, in run_block
results = registry.scan(scanned_file, entity, skipped_checks, runner_filter)
File "/Users/jakub/Development/GIT_REPO/tfenv/lib/python3.7/site-packages/checkov/common/checks/base_check_registry.py", line 64, in scan
result = self.run_check(check, entity_configuration, entity_name, entity_type, scanned_file, skip_info)
File "/Users/jakub/Development/GIT_REPO/tfenv/lib/python3.7/site-packages/checkov/common/checks/base_check_registry.py", line 71, in run_check
entity_name=entity_name, entity_type=entity_type, skip_info=skip_info)
File "/Users/jakub/Development/GIT_REPO/tfenv/lib/python3.7/site-packages/checkov/common/checks/base_check.py", line 44, in run
raise e
File "/Users/jakub/Development/GIT_REPO/tfenv/lib/python3.7/site-packages/checkov/common/checks/base_check.py", line 33, in run
check_result['result'] = self.scan_entity_conf(entity_configuration)
File "/Users/jakub/Development/GIT_REPO/tfenv/lib/python3.7/site-packages/checkov/terraform/checks/resource/base_resource_check.py", line 20, in scan_entity_conf
return self.scan_resource_conf(conf)
File "/Users/jakub/Development/GIT_REPO/tfenv/lib/python3.7/site-packages/checkov/terraform/checks/resource/gcp/**GoogleComputeFirewallUnrestrictedIngress3389.py**", line 22, in scan_resource_conf
allow_blocks = conf['allow']
KeyError: 'allow'
```
**Expected behavior**
Not to crash when resource has valid specification
**Screenshots**
If applicable, add screenshots to help explain your problem.
**Desktop (please complete the following information):**
- OS: Mac OS
- Checkov Version: 1.0.346
**Additional context**
Add any other context about the problem here (e.g. code snippets).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `checkov/terraform/checks/resource/gcp/GoogleComputeFirewallUnrestrictedIngress22.py`
Content:
```
1 from checkov.common.models.enums import CheckResult, CheckCategories
2 from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck
3
4 PORT = '22'
5
6
7 class GoogleComputeFirewallUnrestrictedIngress22(BaseResourceCheck):
8 def __init__(self):
9 name = "Ensure Google compute firewall ingress does not allow unrestricted ssh access"
10 id = "CKV_GCP_2"
11 supported_resources = ['google_compute_firewall']
12 categories = [CheckCategories.NETWORKING]
13 super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
14
15 def scan_resource_conf(self, conf):
16 """
17 Looks for password configuration at google_compute_firewall:
18 https://www.terraform.io/docs/providers/google/r/compute_firewall.html
19 :param conf: azure_instance configuration
20 :return: <CheckResult>
21 """
22 allow_blocks = conf['allow']
23 for block in allow_blocks:
24 if 'ports' in block.keys():
25 if PORT in block['ports'][0]:
26 if 'source_ranges' in conf.keys():
27 source_ranges = conf['source_ranges'][0]
28 if "0.0.0.0/0" in source_ranges:
29 return CheckResult.FAILED
30 return CheckResult.PASSED
31
32
33 check = GoogleComputeFirewallUnrestrictedIngress22()
34
```
Path: `checkov/terraform/checks/resource/gcp/GoogleComputeFirewallUnrestrictedIngress3389.py`
Content:
```
1 from checkov.common.models.enums import CheckResult, CheckCategories
2 from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck
3
4 PORT = '3389'
5
6
7 class GoogleComputeFirewallUnrestrictedIngress3389(BaseResourceCheck):
8 def __init__(self):
9 name = "Ensure Google compute firewall ingress does not allow unrestricted rdp access"
10 id = "CKV_GCP_3"
11 supported_resources = ['google_compute_firewall']
12 categories = [CheckCategories.NETWORKING]
13 super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
14
15 def scan_resource_conf(self, conf):
16 """
17 Looks for password configuration at google_compute_firewall:
18 https://www.terraform.io/docs/providers/google/r/compute_firewall.html
19 :param conf: azure_instance configuration
20 :return: <CheckResult>
21 """
22 allow_blocks = conf['allow']
23 for block in allow_blocks:
24 if 'ports' in block.keys():
25 if PORT in block['ports'][0]:
26 if 'source_ranges' in conf.keys():
27 source_ranges = conf['source_ranges'][0]
28 if "0.0.0.0/0" in source_ranges:
29 return CheckResult.FAILED
30 return CheckResult.PASSED
31
32
33 check = GoogleComputeFirewallUnrestrictedIngress3389()
34
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/checkov/terraform/checks/resource/gcp/GoogleComputeFirewallUnrestrictedIngress22.py b/checkov/terraform/checks/resource/gcp/GoogleComputeFirewallUnrestrictedIngress22.py
--- a/checkov/terraform/checks/resource/gcp/GoogleComputeFirewallUnrestrictedIngress22.py
+++ b/checkov/terraform/checks/resource/gcp/GoogleComputeFirewallUnrestrictedIngress22.py
@@ -19,14 +19,15 @@
:param conf: azure_instance configuration
:return: <CheckResult>
"""
- allow_blocks = conf['allow']
- for block in allow_blocks:
- if 'ports' in block.keys():
- if PORT in block['ports'][0]:
- if 'source_ranges' in conf.keys():
- source_ranges = conf['source_ranges'][0]
- if "0.0.0.0/0" in source_ranges:
- return CheckResult.FAILED
+ if 'allow' in conf:
+ allow_blocks = conf['allow']
+ for block in allow_blocks:
+ if 'ports' in block.keys():
+ if PORT in block['ports'][0]:
+ if 'source_ranges' in conf.keys():
+ source_ranges = conf['source_ranges'][0]
+ if "0.0.0.0/0" in source_ranges:
+ return CheckResult.FAILED
return CheckResult.PASSED
diff --git a/checkov/terraform/checks/resource/gcp/GoogleComputeFirewallUnrestrictedIngress3389.py b/checkov/terraform/checks/resource/gcp/GoogleComputeFirewallUnrestrictedIngress3389.py
--- a/checkov/terraform/checks/resource/gcp/GoogleComputeFirewallUnrestrictedIngress3389.py
+++ b/checkov/terraform/checks/resource/gcp/GoogleComputeFirewallUnrestrictedIngress3389.py
@@ -19,14 +19,15 @@
:param conf: azure_instance configuration
:return: <CheckResult>
"""
- allow_blocks = conf['allow']
- for block in allow_blocks:
- if 'ports' in block.keys():
- if PORT in block['ports'][0]:
- if 'source_ranges' in conf.keys():
- source_ranges = conf['source_ranges'][0]
- if "0.0.0.0/0" in source_ranges:
- return CheckResult.FAILED
+ if 'allow' in conf:
+ allow_blocks = conf['allow']
+ for block in allow_blocks:
+ if 'ports' in block.keys():
+ if PORT in block['ports'][0]:
+ if 'source_ranges' in conf.keys():
+ source_ranges = conf['source_ranges'][0]
+ if "0.0.0.0/0" in source_ranges:
+ return CheckResult.FAILED
return CheckResult.PASSED
|
{"golden_diff": "diff --git a/checkov/terraform/checks/resource/gcp/GoogleComputeFirewallUnrestrictedIngress22.py b/checkov/terraform/checks/resource/gcp/GoogleComputeFirewallUnrestrictedIngress22.py\n--- a/checkov/terraform/checks/resource/gcp/GoogleComputeFirewallUnrestrictedIngress22.py\n+++ b/checkov/terraform/checks/resource/gcp/GoogleComputeFirewallUnrestrictedIngress22.py\n@@ -19,14 +19,15 @@\n :param conf: azure_instance configuration\n :return: <CheckResult>\n \"\"\"\n- allow_blocks = conf['allow']\n- for block in allow_blocks:\n- if 'ports' in block.keys():\n- if PORT in block['ports'][0]:\n- if 'source_ranges' in conf.keys():\n- source_ranges = conf['source_ranges'][0]\n- if \"0.0.0.0/0\" in source_ranges:\n- return CheckResult.FAILED\n+ if 'allow' in conf:\n+ allow_blocks = conf['allow']\n+ for block in allow_blocks:\n+ if 'ports' in block.keys():\n+ if PORT in block['ports'][0]:\n+ if 'source_ranges' in conf.keys():\n+ source_ranges = conf['source_ranges'][0]\n+ if \"0.0.0.0/0\" in source_ranges:\n+ return CheckResult.FAILED\n return CheckResult.PASSED\n \n \ndiff --git a/checkov/terraform/checks/resource/gcp/GoogleComputeFirewallUnrestrictedIngress3389.py b/checkov/terraform/checks/resource/gcp/GoogleComputeFirewallUnrestrictedIngress3389.py\n--- a/checkov/terraform/checks/resource/gcp/GoogleComputeFirewallUnrestrictedIngress3389.py\n+++ b/checkov/terraform/checks/resource/gcp/GoogleComputeFirewallUnrestrictedIngress3389.py\n@@ -19,14 +19,15 @@\n :param conf: azure_instance configuration\n :return: <CheckResult>\n \"\"\"\n- allow_blocks = conf['allow']\n- for block in allow_blocks:\n- if 'ports' in block.keys():\n- if PORT in block['ports'][0]:\n- if 'source_ranges' in conf.keys():\n- source_ranges = conf['source_ranges'][0]\n- if \"0.0.0.0/0\" in source_ranges:\n- return CheckResult.FAILED\n+ if 'allow' in conf:\n+ allow_blocks = conf['allow']\n+ for block in allow_blocks:\n+ if 'ports' in block.keys():\n+ if PORT in block['ports'][0]:\n+ if 'source_ranges' in conf.keys():\n+ source_ranges = conf['source_ranges'][0]\n+ if \"0.0.0.0/0\" in source_ranges:\n+ return CheckResult.FAILED\n return CheckResult.PASSED\n", "issue": "crashing on GCP EGRESS firewall rule which doesn't have allow field defined\n**Describe the bug**\r\nCheckov crashing on GCP EGRESS firewall rule which doesn't have allow field defined. Tf version 0.12.26 Google provider version: 3.23\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Resource defined as \r\n```\r\nresource \"google_compute_firewall\" \"default_deny_egress\" {\r\n name = \"deny-all-egress-all\"\r\n description = \"Prevent all egress traffic by default\"\r\n disabled = true\r\n\r\n network = google_compute_network.vpc_network.name\r\n enable_logging = true\r\n\r\n priority = 65534\r\n direction = \"EGRESS\"\r\n destination_ranges = [\"0.0.0.0/0\"]\r\n deny { protocol = \"all\" }\r\n}\r\n```\r\n2. Run cli command : checkov -d folder\r\n3. See error\r\n```\r\nERROR:checkov.terraform.checks.resource.gcp.GoogleComputeFirewallUnrestrictedIngress3389:Failed to run check: Ensure Google compute firewall ingress does not allow unrestricted rdp access for configuration: {'name': ['${var.env}-deny-all-egress-all'], 'description': ['Prevent all egress traffic by default'], 'disabled': [True], 'network': ['${google_compute_network.vpc_network.name}'], 'enable_logging': [True], 'priority': [65534], 'direction': ['EGRESS'], 'destination_ranges': [['0.0.0.0/0']], 'deny': [{'protocol': {'all': {}}}]} at file: /../../modules/network/firewalls.tf\r\nTraceback (most recent call last):\r\n File \"/Users/jakub/Development/GIT_REPO/tfenv/bin/checkov\", line 5, in <module>\r\n run()\r\n File \"/Users/jakub/Development/GIT_REPO/tfenv/lib/python3.7/site-packages/checkov/main.py\", line 76, in run\r\n files=file)\r\n File \"/Users/jakub/Development/GIT_REPO/tfenv/lib/python3.7/site-packages/checkov/common/runners/runner_registry.py\", line 26, in run\r\n runner_filter=self.runner_filter)\r\n File \"/Users/jakub/Development/GIT_REPO/tfenv/lib/python3.7/site-packages/checkov/terraform/runner.py\", line 50, in run\r\n self.check_tf_definition(report, root_folder, runner_filter)\r\n File \"/Users/jakub/Development/GIT_REPO/tfenv/lib/python3.7/site-packages/checkov/terraform/runner.py\", line 91, in check_tf_definition\r\n block_type, runner_filter)\r\n File \"/Users/jakub/Development/GIT_REPO/tfenv/lib/python3.7/site-packages/checkov/terraform/runner.py\", line 113, in run_block\r\n results = registry.scan(scanned_file, entity, skipped_checks, runner_filter)\r\n File \"/Users/jakub/Development/GIT_REPO/tfenv/lib/python3.7/site-packages/checkov/common/checks/base_check_registry.py\", line 64, in scan\r\n result = self.run_check(check, entity_configuration, entity_name, entity_type, scanned_file, skip_info)\r\n File \"/Users/jakub/Development/GIT_REPO/tfenv/lib/python3.7/site-packages/checkov/common/checks/base_check_registry.py\", line 71, in run_check\r\n entity_name=entity_name, entity_type=entity_type, skip_info=skip_info)\r\n File \"/Users/jakub/Development/GIT_REPO/tfenv/lib/python3.7/site-packages/checkov/common/checks/base_check.py\", line 44, in run\r\n raise e\r\n File \"/Users/jakub/Development/GIT_REPO/tfenv/lib/python3.7/site-packages/checkov/common/checks/base_check.py\", line 33, in run\r\n check_result['result'] = self.scan_entity_conf(entity_configuration)\r\n File \"/Users/jakub/Development/GIT_REPO/tfenv/lib/python3.7/site-packages/checkov/terraform/checks/resource/base_resource_check.py\", line 20, in scan_entity_conf\r\n return self.scan_resource_conf(conf)\r\n File \"/Users/jakub/Development/GIT_REPO/tfenv/lib/python3.7/site-packages/checkov/terraform/checks/resource/gcp/**GoogleComputeFirewallUnrestrictedIngress3389.py**\", line 22, in scan_resource_conf\r\n allow_blocks = conf['allow']\r\nKeyError: 'allow'\r\n```\r\n\r\n**Expected behavior**\r\nNot to crash when resource has valid specification\r\n\r\n**Screenshots**\r\nIf applicable, add screenshots to help explain your problem.\r\n\r\n**Desktop (please complete the following information):**\r\n - OS: Mac OS\r\n - Checkov Version: 1.0.346\r\n\r\n**Additional context**\r\nAdd any other context about the problem here (e.g. code snippets).\r\n\n", "before_files": [{"content": "from checkov.common.models.enums import CheckResult, CheckCategories\nfrom checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\n\nPORT = '22'\n\n\nclass GoogleComputeFirewallUnrestrictedIngress22(BaseResourceCheck):\n def __init__(self):\n name = \"Ensure Google compute firewall ingress does not allow unrestricted ssh access\"\n id = \"CKV_GCP_2\"\n supported_resources = ['google_compute_firewall']\n categories = [CheckCategories.NETWORKING]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def scan_resource_conf(self, conf):\n \"\"\"\n Looks for password configuration at google_compute_firewall:\n https://www.terraform.io/docs/providers/google/r/compute_firewall.html\n :param conf: azure_instance configuration\n :return: <CheckResult>\n \"\"\"\n allow_blocks = conf['allow']\n for block in allow_blocks:\n if 'ports' in block.keys():\n if PORT in block['ports'][0]:\n if 'source_ranges' in conf.keys():\n source_ranges = conf['source_ranges'][0]\n if \"0.0.0.0/0\" in source_ranges:\n return CheckResult.FAILED\n return CheckResult.PASSED\n\n\ncheck = GoogleComputeFirewallUnrestrictedIngress22()\n", "path": "checkov/terraform/checks/resource/gcp/GoogleComputeFirewallUnrestrictedIngress22.py"}, {"content": "from checkov.common.models.enums import CheckResult, CheckCategories\nfrom checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\n\nPORT = '3389'\n\n\nclass GoogleComputeFirewallUnrestrictedIngress3389(BaseResourceCheck):\n def __init__(self):\n name = \"Ensure Google compute firewall ingress does not allow unrestricted rdp access\"\n id = \"CKV_GCP_3\"\n supported_resources = ['google_compute_firewall']\n categories = [CheckCategories.NETWORKING]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def scan_resource_conf(self, conf):\n \"\"\"\n Looks for password configuration at google_compute_firewall:\n https://www.terraform.io/docs/providers/google/r/compute_firewall.html\n :param conf: azure_instance configuration\n :return: <CheckResult>\n \"\"\"\n allow_blocks = conf['allow']\n for block in allow_blocks:\n if 'ports' in block.keys():\n if PORT in block['ports'][0]:\n if 'source_ranges' in conf.keys():\n source_ranges = conf['source_ranges'][0]\n if \"0.0.0.0/0\" in source_ranges:\n return CheckResult.FAILED\n return CheckResult.PASSED\n\n\ncheck = GoogleComputeFirewallUnrestrictedIngress3389()\n", "path": "checkov/terraform/checks/resource/gcp/GoogleComputeFirewallUnrestrictedIngress3389.py"}], "after_files": [{"content": "from checkov.common.models.enums import CheckResult, CheckCategories\nfrom checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\n\nPORT = '22'\n\n\nclass GoogleComputeFirewallUnrestrictedIngress22(BaseResourceCheck):\n def __init__(self):\n name = \"Ensure Google compute firewall ingress does not allow unrestricted ssh access\"\n id = \"CKV_GCP_2\"\n supported_resources = ['google_compute_firewall']\n categories = [CheckCategories.NETWORKING]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def scan_resource_conf(self, conf):\n \"\"\"\n Looks for password configuration at google_compute_firewall:\n https://www.terraform.io/docs/providers/google/r/compute_firewall.html\n :param conf: azure_instance configuration\n :return: <CheckResult>\n \"\"\"\n if 'allow' in conf:\n allow_blocks = conf['allow']\n for block in allow_blocks:\n if 'ports' in block.keys():\n if PORT in block['ports'][0]:\n if 'source_ranges' in conf.keys():\n source_ranges = conf['source_ranges'][0]\n if \"0.0.0.0/0\" in source_ranges:\n return CheckResult.FAILED\n return CheckResult.PASSED\n\n\ncheck = GoogleComputeFirewallUnrestrictedIngress22()\n", "path": "checkov/terraform/checks/resource/gcp/GoogleComputeFirewallUnrestrictedIngress22.py"}, {"content": "from checkov.common.models.enums import CheckResult, CheckCategories\nfrom checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\n\nPORT = '3389'\n\n\nclass GoogleComputeFirewallUnrestrictedIngress3389(BaseResourceCheck):\n def __init__(self):\n name = \"Ensure Google compute firewall ingress does not allow unrestricted rdp access\"\n id = \"CKV_GCP_3\"\n supported_resources = ['google_compute_firewall']\n categories = [CheckCategories.NETWORKING]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def scan_resource_conf(self, conf):\n \"\"\"\n Looks for password configuration at google_compute_firewall:\n https://www.terraform.io/docs/providers/google/r/compute_firewall.html\n :param conf: azure_instance configuration\n :return: <CheckResult>\n \"\"\"\n if 'allow' in conf:\n allow_blocks = conf['allow']\n for block in allow_blocks:\n if 'ports' in block.keys():\n if PORT in block['ports'][0]:\n if 'source_ranges' in conf.keys():\n source_ranges = conf['source_ranges'][0]\n if \"0.0.0.0/0\" in source_ranges:\n return CheckResult.FAILED\n return CheckResult.PASSED\n\n\ncheck = GoogleComputeFirewallUnrestrictedIngress3389()\n", "path": "checkov/terraform/checks/resource/gcp/GoogleComputeFirewallUnrestrictedIngress3389.py"}]}
| 2,077 | 653 |
gh_patches_debug_12556
|
rasdani/github-patches
|
git_diff
|
DDMAL__CantusDB-726
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Ensure that dummy users (i.e. old indexers) can't log in.
Currently, on NewCantus we have created dummy users for people who had an Indexer object but no User account on OldCantus. These dummy users have randomly generated email addresses and no passwords, the rationale being that a user with no password will not be able to log in.
A comment on [this stackoverflow topic](https://stackoverflow.com/questions/35690022/django-create-new-user-without-password) suggests that this is not strictly the case. It would probably be safer to set these dummy users to have [has_useable_password = False](https://docs.djangoproject.com/en/4.2/ref/contrib/auth/#django.contrib.auth.models.User.has_usable_password) if it is not already set up this way.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `django/cantusdb_project/main_app/management/commands/sync_indexers.py`
Content:
```
1 from django.core.management.base import BaseCommand
2 from django.contrib.auth import get_user_model
3 import requests, json
4 from faker import Faker
5
6 INDEXER_ID_FILE = "indexer_list.txt"
7
8
9 def get_id_list(file_path):
10 indexer_list = []
11 file = open(file_path, "r")
12 for line in file:
13 line = line.strip("\n")
14 indexer_list.append(line)
15 file.close()
16 return indexer_list
17
18
19 def get_new_indexer(indexer_id):
20 # use json-export to get indexer information
21 url = f"http://cantus.uwaterloo.ca/json-node/{indexer_id}"
22 response = requests.get(url)
23 json_response = json.loads(response.content)
24 if json_response["field_first_name"]:
25 first_name = json_response["field_first_name"]["und"][0]["value"]
26 else:
27 first_name = None
28 if json_response["field_family_name"]:
29 family_name = json_response["field_family_name"]["und"][0]["value"]
30 else:
31 family_name = None
32 if json_response["field_indexer_institution"]:
33 institution = json_response["field_indexer_institution"]["und"][0]["value"]
34 else:
35 institution = None
36 if json_response["field_indexer_city"]:
37 city = json_response["field_indexer_city"]["und"][0]["value"]
38 else:
39 city = None
40 if json_response["field_indexer_country"]:
41 country = json_response["field_indexer_country"]["und"][0]["value"]
42 else:
43 country = None
44
45 # check whether the current indexer has a user entry of the same name
46 indexer_full_name = f"{first_name} {family_name}"
47 print(f"{indexer_id} {indexer_full_name}")
48 homonymous_users = get_user_model().objects.filter(
49 full_name__iexact=indexer_full_name
50 )
51 # if the indexer also exists as a user
52 if homonymous_users:
53 assert homonymous_users.count() == 1
54 homonymous_user = homonymous_users.get()
55 print(f"homonymous: {homonymous_user.full_name}")
56 # keep the user as it is (merge the indexer into existing user)
57 # and store the ID of its indexer object
58 homonymous_user.old_indexer_id = indexer_id
59 homonymous_user.is_indexer = True
60 homonymous_user.save()
61 # if the indexer doesn't exist as a user
62 else:
63 faker = Faker()
64 # create a new user with the indexer information
65 get_user_model().objects.create(
66 institution=institution,
67 city=city,
68 country=country,
69 full_name=indexer_full_name,
70 # assign random email to dummy users
71 email=f"{faker.lexify('????????')}@fakeemail.com",
72 # leave the password empty for dummy users
73 # the password can't be empty in login form, so they can't log in
74 password="",
75 old_indexer_id=indexer_id,
76 is_indexer=True,
77 )
78
79
80 class Command(BaseCommand):
81 def add_arguments(self, parser):
82 pass
83
84 def handle(self, *args, **options):
85 indexer_list = get_id_list(INDEXER_ID_FILE)
86 for id in indexer_list:
87 get_new_indexer(id)
88
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/django/cantusdb_project/main_app/management/commands/sync_indexers.py b/django/cantusdb_project/main_app/management/commands/sync_indexers.py
--- a/django/cantusdb_project/main_app/management/commands/sync_indexers.py
+++ b/django/cantusdb_project/main_app/management/commands/sync_indexers.py
@@ -69,12 +69,9 @@
full_name=indexer_full_name,
# assign random email to dummy users
email=f"{faker.lexify('????????')}@fakeemail.com",
- # leave the password empty for dummy users
- # the password can't be empty in login form, so they can't log in
- password="",
old_indexer_id=indexer_id,
is_indexer=True,
- )
+ ).set_unusable_password() # Set unusable password so the user can't log in or access reset password page
class Command(BaseCommand):
|
{"golden_diff": "diff --git a/django/cantusdb_project/main_app/management/commands/sync_indexers.py b/django/cantusdb_project/main_app/management/commands/sync_indexers.py\n--- a/django/cantusdb_project/main_app/management/commands/sync_indexers.py\n+++ b/django/cantusdb_project/main_app/management/commands/sync_indexers.py\n@@ -69,12 +69,9 @@\n full_name=indexer_full_name,\n # assign random email to dummy users\n email=f\"{faker.lexify('????????')}@fakeemail.com\",\n- # leave the password empty for dummy users\n- # the password can't be empty in login form, so they can't log in\n- password=\"\",\n old_indexer_id=indexer_id,\n is_indexer=True,\n- )\n+ ).set_unusable_password() # Set unusable password so the user can't log in or access reset password page\n \n \n class Command(BaseCommand):\n", "issue": "Ensure that dummy users (i.e. old indexers) can't log in.\nCurrently, on NewCantus we have created dummy users for people who had an Indexer object but no User account on OldCantus. These dummy users have randomly generated email addresses and no passwords, the rationale being that a user with no password will not be able to log in.\r\n\r\nA comment on [this stackoverflow topic](https://stackoverflow.com/questions/35690022/django-create-new-user-without-password) suggests that this is not strictly the case. It would probably be safer to set these dummy users to have [has_useable_password = False](https://docs.djangoproject.com/en/4.2/ref/contrib/auth/#django.contrib.auth.models.User.has_usable_password) if it is not already set up this way.\n", "before_files": [{"content": "from django.core.management.base import BaseCommand\nfrom django.contrib.auth import get_user_model\nimport requests, json\nfrom faker import Faker\n\nINDEXER_ID_FILE = \"indexer_list.txt\"\n\n\ndef get_id_list(file_path):\n indexer_list = []\n file = open(file_path, \"r\")\n for line in file:\n line = line.strip(\"\\n\")\n indexer_list.append(line)\n file.close()\n return indexer_list\n\n\ndef get_new_indexer(indexer_id):\n # use json-export to get indexer information\n url = f\"http://cantus.uwaterloo.ca/json-node/{indexer_id}\"\n response = requests.get(url)\n json_response = json.loads(response.content)\n if json_response[\"field_first_name\"]:\n first_name = json_response[\"field_first_name\"][\"und\"][0][\"value\"]\n else:\n first_name = None\n if json_response[\"field_family_name\"]:\n family_name = json_response[\"field_family_name\"][\"und\"][0][\"value\"]\n else:\n family_name = None\n if json_response[\"field_indexer_institution\"]:\n institution = json_response[\"field_indexer_institution\"][\"und\"][0][\"value\"]\n else:\n institution = None\n if json_response[\"field_indexer_city\"]:\n city = json_response[\"field_indexer_city\"][\"und\"][0][\"value\"]\n else:\n city = None\n if json_response[\"field_indexer_country\"]:\n country = json_response[\"field_indexer_country\"][\"und\"][0][\"value\"]\n else:\n country = None\n\n # check whether the current indexer has a user entry of the same name\n indexer_full_name = f\"{first_name} {family_name}\"\n print(f\"{indexer_id} {indexer_full_name}\")\n homonymous_users = get_user_model().objects.filter(\n full_name__iexact=indexer_full_name\n )\n # if the indexer also exists as a user\n if homonymous_users:\n assert homonymous_users.count() == 1\n homonymous_user = homonymous_users.get()\n print(f\"homonymous: {homonymous_user.full_name}\")\n # keep the user as it is (merge the indexer into existing user)\n # and store the ID of its indexer object\n homonymous_user.old_indexer_id = indexer_id\n homonymous_user.is_indexer = True\n homonymous_user.save()\n # if the indexer doesn't exist as a user\n else:\n faker = Faker()\n # create a new user with the indexer information\n get_user_model().objects.create(\n institution=institution,\n city=city,\n country=country,\n full_name=indexer_full_name,\n # assign random email to dummy users\n email=f\"{faker.lexify('????????')}@fakeemail.com\",\n # leave the password empty for dummy users\n # the password can't be empty in login form, so they can't log in\n password=\"\",\n old_indexer_id=indexer_id,\n is_indexer=True,\n )\n\n\nclass Command(BaseCommand):\n def add_arguments(self, parser):\n pass\n\n def handle(self, *args, **options):\n indexer_list = get_id_list(INDEXER_ID_FILE)\n for id in indexer_list:\n get_new_indexer(id)\n", "path": "django/cantusdb_project/main_app/management/commands/sync_indexers.py"}], "after_files": [{"content": "from django.core.management.base import BaseCommand\nfrom django.contrib.auth import get_user_model\nimport requests, json\nfrom faker import Faker\n\nINDEXER_ID_FILE = \"indexer_list.txt\"\n\n\ndef get_id_list(file_path):\n indexer_list = []\n file = open(file_path, \"r\")\n for line in file:\n line = line.strip(\"\\n\")\n indexer_list.append(line)\n file.close()\n return indexer_list\n\n\ndef get_new_indexer(indexer_id):\n # use json-export to get indexer information\n url = f\"http://cantus.uwaterloo.ca/json-node/{indexer_id}\"\n response = requests.get(url)\n json_response = json.loads(response.content)\n if json_response[\"field_first_name\"]:\n first_name = json_response[\"field_first_name\"][\"und\"][0][\"value\"]\n else:\n first_name = None\n if json_response[\"field_family_name\"]:\n family_name = json_response[\"field_family_name\"][\"und\"][0][\"value\"]\n else:\n family_name = None\n if json_response[\"field_indexer_institution\"]:\n institution = json_response[\"field_indexer_institution\"][\"und\"][0][\"value\"]\n else:\n institution = None\n if json_response[\"field_indexer_city\"]:\n city = json_response[\"field_indexer_city\"][\"und\"][0][\"value\"]\n else:\n city = None\n if json_response[\"field_indexer_country\"]:\n country = json_response[\"field_indexer_country\"][\"und\"][0][\"value\"]\n else:\n country = None\n\n # check whether the current indexer has a user entry of the same name\n indexer_full_name = f\"{first_name} {family_name}\"\n print(f\"{indexer_id} {indexer_full_name}\")\n homonymous_users = get_user_model().objects.filter(\n full_name__iexact=indexer_full_name\n )\n # if the indexer also exists as a user\n if homonymous_users:\n assert homonymous_users.count() == 1\n homonymous_user = homonymous_users.get()\n print(f\"homonymous: {homonymous_user.full_name}\")\n # keep the user as it is (merge the indexer into existing user)\n # and store the ID of its indexer object\n homonymous_user.old_indexer_id = indexer_id\n homonymous_user.is_indexer = True\n homonymous_user.save()\n # if the indexer doesn't exist as a user\n else:\n faker = Faker()\n # create a new user with the indexer information\n get_user_model().objects.create(\n institution=institution,\n city=city,\n country=country,\n full_name=indexer_full_name,\n # assign random email to dummy users\n email=f\"{faker.lexify('????????')}@fakeemail.com\",\n old_indexer_id=indexer_id,\n is_indexer=True,\n ).set_unusable_password() # Set unusable password so the user can't log in or access reset password page\n\n\nclass Command(BaseCommand):\n def add_arguments(self, parser):\n pass\n\n def handle(self, *args, **options):\n indexer_list = get_id_list(INDEXER_ID_FILE)\n for id in indexer_list:\n get_new_indexer(id)\n", "path": "django/cantusdb_project/main_app/management/commands/sync_indexers.py"}]}
| 1,307 | 217 |
gh_patches_debug_26635
|
rasdani/github-patches
|
git_diff
|
rasterio__rasterio-1344
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Replace 'src.set_*()' methods with getter/setter properties
Like `src.colorinterp() -> src.colorinterp` in https://github.com/mapbox/rasterio/pull/1134. A quick search shows these:
```
$ git grep "def set_"
rasterio/_env.pyx:cpdef set_gdal_config(key, val, normalize=True):
rasterio/_io.pyx: def set_crs(self, crs):
rasterio/_io.pyx: def set_nodatavals(self, vals):
rasterio/_io.pyx: def set_description(self, bidx, value):
rasterio/_io.pyx: def set_units(self, bidx, value):
rasterio/_io.pyx: def set_gcps(self, gcps, crs=None):
```
Looks like `src.gcps` might be a bit harder.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `rasterio/rio/edit_info.py`
Content:
```
1 """Fetch and edit raster dataset metadata from the command line."""
2
3
4 from collections import OrderedDict
5 import json
6 import warnings
7
8 import click
9
10 import rasterio
11 import rasterio.crs
12 from rasterio.crs import CRS
13 from rasterio.enums import ColorInterp
14 from rasterio.errors import CRSError
15 from rasterio.rio import options
16 from rasterio.transform import guard_transform
17
18
19 # Handlers for info module options.
20
21
22 def all_handler(ctx, param, value):
23 """Get tags from a template file or command line."""
24 if ctx.obj and ctx.obj.get('like') and value is not None:
25 ctx.obj['all_like'] = value
26 value = ctx.obj.get('like')
27 return value
28
29
30 def crs_handler(ctx, param, value):
31 """Get crs value from a template file or command line."""
32 retval = options.from_like_context(ctx, param, value)
33 if retval is None and value:
34 try:
35 retval = json.loads(value)
36 except ValueError:
37 retval = value
38 try:
39 if isinstance(retval, dict):
40 retval = CRS(retval)
41 else:
42 retval = CRS.from_string(retval)
43 except CRSError:
44 raise click.BadParameter(
45 "'%s' is not a recognized CRS." % retval,
46 param=param, param_hint='crs')
47 return retval
48
49
50 def tags_handler(ctx, param, value):
51 """Get tags from a template file or command line."""
52 retval = options.from_like_context(ctx, param, value)
53 if retval is None and value:
54 try:
55 retval = dict(p.split('=') for p in value)
56 except:
57 raise click.BadParameter(
58 "'%s' contains a malformed tag." % value,
59 param=param, param_hint='transform')
60 return retval
61
62
63 def transform_handler(ctx, param, value):
64 """Get transform value from a template file or command line."""
65 retval = options.from_like_context(ctx, param, value)
66 if retval is None and value:
67 try:
68 value = json.loads(value)
69 except ValueError:
70 pass
71 try:
72 retval = guard_transform(value)
73 except:
74 raise click.BadParameter(
75 "'%s' is not recognized as an Affine array." % value,
76 param=param, param_hint='transform')
77 return retval
78
79
80 def colorinterp_handler(ctx, param, value):
81
82 """Validate a string like ``red,green,blue,alpha`` and convert to
83 a tuple. Also handle ``RGB`` and ``RGBA``.
84 """
85
86 if value is None:
87 return value
88 # Using '--like'
89 elif value.lower() == 'like':
90 return options.from_like_context(ctx, param, value)
91 elif value.lower() == 'rgb':
92 return ColorInterp.red, ColorInterp.green, ColorInterp.blue
93 elif value.lower() == 'rgba':
94 return ColorInterp.red, ColorInterp.green, ColorInterp.blue, ColorInterp.alpha
95 else:
96 colorinterp = tuple(value.split(','))
97 for ci in colorinterp:
98 if ci not in ColorInterp.__members__:
99 raise click.BadParameter(
100 "color interpretation '{ci}' is invalid. Must be one of: "
101 "{valid}".format(
102 ci=ci, valid=', '.join(ColorInterp.__members__)))
103 return tuple(ColorInterp[ci] for ci in colorinterp)
104
105
106 @click.command('edit-info', short_help="Edit dataset metadata.")
107 @options.file_in_arg
108 @options.bidx_opt
109 @options.edit_nodata_opt
110 @click.option('--unset-nodata', default=False, is_flag=True,
111 help="Unset the dataset's nodata value.")
112 @click.option('--crs', callback=crs_handler, default=None,
113 help="New coordinate reference system")
114 @click.option('--unset-crs', default=False, is_flag=True,
115 help="Unset the dataset's CRS value.")
116 @click.option('--transform', callback=transform_handler,
117 help="New affine transform matrix")
118 @click.option('--units', help="Edit units of a band (requires --bidx)")
119 @click.option('--description',
120 help="Edit description of a band (requires --bidx)")
121 @click.option('--tag', 'tags', callback=tags_handler, multiple=True,
122 metavar='KEY=VAL', help="New tag.")
123 @click.option('--all', 'allmd', callback=all_handler, flag_value='like',
124 is_eager=True, default=False,
125 help="Copy all metadata items from the template file.")
126 @click.option(
127 '--colorinterp', callback=colorinterp_handler,
128 metavar="name[,name,...]|RGB|RGBA|like",
129 help="Set color interpretation for all bands like 'red,green,blue,alpha'. "
130 "Can also use 'RGBA' as shorthand for 'red,green,blue,alpha' and "
131 "'RGB' for the same sans alpha band. Use 'like' to inherit color "
132 "interpretation from '--like'.")
133 @options.like_opt
134 @click.pass_context
135 def edit(ctx, input, bidx, nodata, unset_nodata, crs, unset_crs, transform,
136 units, description, tags, allmd, like, colorinterp):
137 """Edit a dataset's metadata: coordinate reference system, affine
138 transformation matrix, nodata value, and tags.
139
140 The coordinate reference system may be either a PROJ.4 or EPSG:nnnn
141 string,
142
143 --crs 'EPSG:4326'
144
145 or a JSON text-encoded PROJ.4 object.
146
147 --crs '{"proj": "utm", "zone": 18, ...}'
148
149 Transforms are JSON-encoded Affine objects like:
150
151 --transform '[300.038, 0.0, 101985.0, 0.0, -300.042, 2826915.0]'
152
153 Prior to Rasterio 1.0 GDAL geotransforms were supported for --transform,
154 but are no longer supported.
155
156 Metadata items may also be read from an existing dataset using a
157 combination of the --like option with at least one of --all,
158 `--crs like`, `--nodata like`, and `--transform like`.
159
160 rio edit-info example.tif --like template.tif --all
161
162 To get just the transform from the template:
163
164 rio edit-info example.tif --like template.tif --transform like
165
166 """
167 import numpy as np
168
169 def in_dtype_range(value, dtype):
170 kind = np.dtype(dtype).kind
171 if kind == 'f' and np.isnan(value):
172 return True
173 infos = {'c': np.finfo, 'f': np.finfo, 'i': np.iinfo,
174 'u': np.iinfo}
175 rng = infos[kind](dtype)
176 return rng.min <= value <= rng.max
177
178 # If '--all' is given before '--like' on the commandline then 'allmd'
179 # is the string 'like'. This is caused by '--like' not having an
180 # opportunity to populate metadata before '--all' is evaluated.
181 if allmd == 'like':
182 allmd = ctx.obj['like']
183
184 with ctx.obj['env'], rasterio.open(input, 'r+') as dst:
185
186 if allmd:
187 nodata = allmd['nodata']
188 crs = allmd['crs']
189 transform = allmd['transform']
190 tags = allmd['tags']
191 colorinterp = allmd['colorinterp']
192
193 if unset_nodata and nodata is not options.IgnoreOption:
194 raise click.BadParameter(
195 "--unset-nodata and --nodata cannot be used together.")
196
197 if unset_crs and crs:
198 raise click.BadParameter(
199 "--unset-crs and --crs cannot be used together.")
200
201 if unset_nodata:
202 # Setting nodata to None will raise NotImplementedError
203 # if GDALDeleteRasterNoDataValue() isn't present in the
204 # GDAL library.
205 try:
206 dst.nodata = None
207 except NotImplementedError as exc: # pragma: no cover
208 raise click.ClickException(str(exc))
209
210 elif nodata is not options.IgnoreOption:
211 dtype = dst.dtypes[0]
212 if nodata is not None and not in_dtype_range(nodata, dtype):
213 raise click.BadParameter(
214 "outside the range of the file's "
215 "data type (%s)." % dtype,
216 param=nodata, param_hint='nodata')
217 dst.nodata = nodata
218
219 if unset_crs:
220 dst.crs = None # CRS()
221 elif crs:
222 dst.crs = crs
223
224 if transform:
225 dst.transform = transform
226
227 if tags:
228 dst.update_tags(**tags)
229
230 if units:
231 dst.set_units(bidx, units)
232
233 if description:
234 dst.set_description(bidx, description)
235
236 if colorinterp:
237 if like and len(colorinterp) != dst.count:
238 raise click.ClickException(
239 "When using '--like' for color interpretation the "
240 "template and target images must have the same number "
241 "of bands. Found {template} color interpretations for "
242 "template image and {target} bands in target "
243 "image.".format(
244 template=len(colorinterp),
245 target=dst.count))
246 try:
247 dst.colorinterp = colorinterp
248 except ValueError as e:
249 raise click.ClickException(str(e))
250
251 # Post check - ensure that crs was unset properly
252 if unset_crs:
253 with ctx.obj['env'], rasterio.open(input, 'r') as src:
254 if src.crs:
255 warnings.warn(
256 'CRS was not unset. Availability of his functionality '
257 'differs depending on GDAL version and driver')
258
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/rasterio/rio/edit_info.py b/rasterio/rio/edit_info.py
--- a/rasterio/rio/edit_info.py
+++ b/rasterio/rio/edit_info.py
@@ -53,7 +53,7 @@
if retval is None and value:
try:
retval = dict(p.split('=') for p in value)
- except:
+ except Exception:
raise click.BadParameter(
"'%s' contains a malformed tag." % value,
param=param, param_hint='transform')
@@ -70,7 +70,7 @@
pass
try:
retval = guard_transform(value)
- except:
+ except Exception:
raise click.BadParameter(
"'%s' is not recognized as an Affine array." % value,
param=param, param_hint='transform')
@@ -228,10 +228,10 @@
dst.update_tags(**tags)
if units:
- dst.set_units(bidx, units)
+ dst.set_band_unit(bidx, units)
if description:
- dst.set_description(bidx, description)
+ dst.set_band_description(bidx, description)
if colorinterp:
if like and len(colorinterp) != dst.count:
|
{"golden_diff": "diff --git a/rasterio/rio/edit_info.py b/rasterio/rio/edit_info.py\n--- a/rasterio/rio/edit_info.py\n+++ b/rasterio/rio/edit_info.py\n@@ -53,7 +53,7 @@\n if retval is None and value:\n try:\n retval = dict(p.split('=') for p in value)\n- except:\n+ except Exception:\n raise click.BadParameter(\n \"'%s' contains a malformed tag.\" % value,\n param=param, param_hint='transform')\n@@ -70,7 +70,7 @@\n pass\n try:\n retval = guard_transform(value)\n- except:\n+ except Exception:\n raise click.BadParameter(\n \"'%s' is not recognized as an Affine array.\" % value,\n param=param, param_hint='transform')\n@@ -228,10 +228,10 @@\n dst.update_tags(**tags)\n \n if units:\n- dst.set_units(bidx, units)\n+ dst.set_band_unit(bidx, units)\n \n if description:\n- dst.set_description(bidx, description)\n+ dst.set_band_description(bidx, description)\n \n if colorinterp:\n if like and len(colorinterp) != dst.count:\n", "issue": "Replace 'src.set_*()' methods with getter/setter properties\nLike `src.colorinterp() -> src.colorinterp` in https://github.com/mapbox/rasterio/pull/1134. A quick search shows these:\r\n\r\n```\r\n$ git grep \"def set_\"\r\nrasterio/_env.pyx:cpdef set_gdal_config(key, val, normalize=True):\r\nrasterio/_io.pyx: def set_crs(self, crs):\r\nrasterio/_io.pyx: def set_nodatavals(self, vals):\r\nrasterio/_io.pyx: def set_description(self, bidx, value):\r\nrasterio/_io.pyx: def set_units(self, bidx, value):\r\nrasterio/_io.pyx: def set_gcps(self, gcps, crs=None):\r\n```\r\n\r\nLooks like `src.gcps` might be a bit harder.\n", "before_files": [{"content": "\"\"\"Fetch and edit raster dataset metadata from the command line.\"\"\"\n\n\nfrom collections import OrderedDict\nimport json\nimport warnings\n\nimport click\n\nimport rasterio\nimport rasterio.crs\nfrom rasterio.crs import CRS\nfrom rasterio.enums import ColorInterp\nfrom rasterio.errors import CRSError\nfrom rasterio.rio import options\nfrom rasterio.transform import guard_transform\n\n\n# Handlers for info module options.\n\n\ndef all_handler(ctx, param, value):\n \"\"\"Get tags from a template file or command line.\"\"\"\n if ctx.obj and ctx.obj.get('like') and value is not None:\n ctx.obj['all_like'] = value\n value = ctx.obj.get('like')\n return value\n\n\ndef crs_handler(ctx, param, value):\n \"\"\"Get crs value from a template file or command line.\"\"\"\n retval = options.from_like_context(ctx, param, value)\n if retval is None and value:\n try:\n retval = json.loads(value)\n except ValueError:\n retval = value\n try:\n if isinstance(retval, dict):\n retval = CRS(retval)\n else:\n retval = CRS.from_string(retval)\n except CRSError:\n raise click.BadParameter(\n \"'%s' is not a recognized CRS.\" % retval,\n param=param, param_hint='crs')\n return retval\n\n\ndef tags_handler(ctx, param, value):\n \"\"\"Get tags from a template file or command line.\"\"\"\n retval = options.from_like_context(ctx, param, value)\n if retval is None and value:\n try:\n retval = dict(p.split('=') for p in value)\n except:\n raise click.BadParameter(\n \"'%s' contains a malformed tag.\" % value,\n param=param, param_hint='transform')\n return retval\n\n\ndef transform_handler(ctx, param, value):\n \"\"\"Get transform value from a template file or command line.\"\"\"\n retval = options.from_like_context(ctx, param, value)\n if retval is None and value:\n try:\n value = json.loads(value)\n except ValueError:\n pass\n try:\n retval = guard_transform(value)\n except:\n raise click.BadParameter(\n \"'%s' is not recognized as an Affine array.\" % value,\n param=param, param_hint='transform')\n return retval\n\n\ndef colorinterp_handler(ctx, param, value):\n\n \"\"\"Validate a string like ``red,green,blue,alpha`` and convert to\n a tuple. Also handle ``RGB`` and ``RGBA``.\n \"\"\"\n\n if value is None:\n return value\n # Using '--like'\n elif value.lower() == 'like':\n return options.from_like_context(ctx, param, value)\n elif value.lower() == 'rgb':\n return ColorInterp.red, ColorInterp.green, ColorInterp.blue\n elif value.lower() == 'rgba':\n return ColorInterp.red, ColorInterp.green, ColorInterp.blue, ColorInterp.alpha\n else:\n colorinterp = tuple(value.split(','))\n for ci in colorinterp:\n if ci not in ColorInterp.__members__:\n raise click.BadParameter(\n \"color interpretation '{ci}' is invalid. Must be one of: \"\n \"{valid}\".format(\n ci=ci, valid=', '.join(ColorInterp.__members__)))\n return tuple(ColorInterp[ci] for ci in colorinterp)\n\n\[email protected]('edit-info', short_help=\"Edit dataset metadata.\")\[email protected]_in_arg\[email protected]_opt\[email protected]_nodata_opt\[email protected]('--unset-nodata', default=False, is_flag=True,\n help=\"Unset the dataset's nodata value.\")\[email protected]('--crs', callback=crs_handler, default=None,\n help=\"New coordinate reference system\")\[email protected]('--unset-crs', default=False, is_flag=True,\n help=\"Unset the dataset's CRS value.\")\[email protected]('--transform', callback=transform_handler,\n help=\"New affine transform matrix\")\[email protected]('--units', help=\"Edit units of a band (requires --bidx)\")\[email protected]('--description',\n help=\"Edit description of a band (requires --bidx)\")\[email protected]('--tag', 'tags', callback=tags_handler, multiple=True,\n metavar='KEY=VAL', help=\"New tag.\")\[email protected]('--all', 'allmd', callback=all_handler, flag_value='like',\n is_eager=True, default=False,\n help=\"Copy all metadata items from the template file.\")\[email protected](\n '--colorinterp', callback=colorinterp_handler,\n metavar=\"name[,name,...]|RGB|RGBA|like\",\n help=\"Set color interpretation for all bands like 'red,green,blue,alpha'. \"\n \"Can also use 'RGBA' as shorthand for 'red,green,blue,alpha' and \"\n \"'RGB' for the same sans alpha band. Use 'like' to inherit color \"\n \"interpretation from '--like'.\")\[email protected]_opt\[email protected]_context\ndef edit(ctx, input, bidx, nodata, unset_nodata, crs, unset_crs, transform,\n units, description, tags, allmd, like, colorinterp):\n \"\"\"Edit a dataset's metadata: coordinate reference system, affine\n transformation matrix, nodata value, and tags.\n\n The coordinate reference system may be either a PROJ.4 or EPSG:nnnn\n string,\n\n --crs 'EPSG:4326'\n\n or a JSON text-encoded PROJ.4 object.\n\n --crs '{\"proj\": \"utm\", \"zone\": 18, ...}'\n\n Transforms are JSON-encoded Affine objects like:\n\n --transform '[300.038, 0.0, 101985.0, 0.0, -300.042, 2826915.0]'\n\n Prior to Rasterio 1.0 GDAL geotransforms were supported for --transform,\n but are no longer supported.\n\n Metadata items may also be read from an existing dataset using a\n combination of the --like option with at least one of --all,\n `--crs like`, `--nodata like`, and `--transform like`.\n\n rio edit-info example.tif --like template.tif --all\n\n To get just the transform from the template:\n\n rio edit-info example.tif --like template.tif --transform like\n\n \"\"\"\n import numpy as np\n\n def in_dtype_range(value, dtype):\n kind = np.dtype(dtype).kind\n if kind == 'f' and np.isnan(value):\n return True\n infos = {'c': np.finfo, 'f': np.finfo, 'i': np.iinfo,\n 'u': np.iinfo}\n rng = infos[kind](dtype)\n return rng.min <= value <= rng.max\n\n # If '--all' is given before '--like' on the commandline then 'allmd'\n # is the string 'like'. This is caused by '--like' not having an\n # opportunity to populate metadata before '--all' is evaluated.\n if allmd == 'like':\n allmd = ctx.obj['like']\n\n with ctx.obj['env'], rasterio.open(input, 'r+') as dst:\n\n if allmd:\n nodata = allmd['nodata']\n crs = allmd['crs']\n transform = allmd['transform']\n tags = allmd['tags']\n colorinterp = allmd['colorinterp']\n\n if unset_nodata and nodata is not options.IgnoreOption:\n raise click.BadParameter(\n \"--unset-nodata and --nodata cannot be used together.\")\n\n if unset_crs and crs:\n raise click.BadParameter(\n \"--unset-crs and --crs cannot be used together.\")\n\n if unset_nodata:\n # Setting nodata to None will raise NotImplementedError\n # if GDALDeleteRasterNoDataValue() isn't present in the\n # GDAL library.\n try:\n dst.nodata = None\n except NotImplementedError as exc: # pragma: no cover\n raise click.ClickException(str(exc))\n\n elif nodata is not options.IgnoreOption:\n dtype = dst.dtypes[0]\n if nodata is not None and not in_dtype_range(nodata, dtype):\n raise click.BadParameter(\n \"outside the range of the file's \"\n \"data type (%s).\" % dtype,\n param=nodata, param_hint='nodata')\n dst.nodata = nodata\n\n if unset_crs:\n dst.crs = None # CRS()\n elif crs:\n dst.crs = crs\n\n if transform:\n dst.transform = transform\n\n if tags:\n dst.update_tags(**tags)\n\n if units:\n dst.set_units(bidx, units)\n\n if description:\n dst.set_description(bidx, description)\n\n if colorinterp:\n if like and len(colorinterp) != dst.count:\n raise click.ClickException(\n \"When using '--like' for color interpretation the \"\n \"template and target images must have the same number \"\n \"of bands. Found {template} color interpretations for \"\n \"template image and {target} bands in target \"\n \"image.\".format(\n template=len(colorinterp),\n target=dst.count))\n try:\n dst.colorinterp = colorinterp\n except ValueError as e:\n raise click.ClickException(str(e))\n\n # Post check - ensure that crs was unset properly\n if unset_crs:\n with ctx.obj['env'], rasterio.open(input, 'r') as src:\n if src.crs:\n warnings.warn(\n 'CRS was not unset. Availability of his functionality '\n 'differs depending on GDAL version and driver')\n", "path": "rasterio/rio/edit_info.py"}], "after_files": [{"content": "\"\"\"Fetch and edit raster dataset metadata from the command line.\"\"\"\n\n\nfrom collections import OrderedDict\nimport json\nimport warnings\n\nimport click\n\nimport rasterio\nimport rasterio.crs\nfrom rasterio.crs import CRS\nfrom rasterio.enums import ColorInterp\nfrom rasterio.errors import CRSError\nfrom rasterio.rio import options\nfrom rasterio.transform import guard_transform\n\n\n# Handlers for info module options.\n\n\ndef all_handler(ctx, param, value):\n \"\"\"Get tags from a template file or command line.\"\"\"\n if ctx.obj and ctx.obj.get('like') and value is not None:\n ctx.obj['all_like'] = value\n value = ctx.obj.get('like')\n return value\n\n\ndef crs_handler(ctx, param, value):\n \"\"\"Get crs value from a template file or command line.\"\"\"\n retval = options.from_like_context(ctx, param, value)\n if retval is None and value:\n try:\n retval = json.loads(value)\n except ValueError:\n retval = value\n try:\n if isinstance(retval, dict):\n retval = CRS(retval)\n else:\n retval = CRS.from_string(retval)\n except CRSError:\n raise click.BadParameter(\n \"'%s' is not a recognized CRS.\" % retval,\n param=param, param_hint='crs')\n return retval\n\n\ndef tags_handler(ctx, param, value):\n \"\"\"Get tags from a template file or command line.\"\"\"\n retval = options.from_like_context(ctx, param, value)\n if retval is None and value:\n try:\n retval = dict(p.split('=') for p in value)\n except Exception:\n raise click.BadParameter(\n \"'%s' contains a malformed tag.\" % value,\n param=param, param_hint='transform')\n return retval\n\n\ndef transform_handler(ctx, param, value):\n \"\"\"Get transform value from a template file or command line.\"\"\"\n retval = options.from_like_context(ctx, param, value)\n if retval is None and value:\n try:\n value = json.loads(value)\n except ValueError:\n pass\n try:\n retval = guard_transform(value)\n except Exception:\n raise click.BadParameter(\n \"'%s' is not recognized as an Affine array.\" % value,\n param=param, param_hint='transform')\n return retval\n\n\ndef colorinterp_handler(ctx, param, value):\n\n \"\"\"Validate a string like ``red,green,blue,alpha`` and convert to\n a tuple. Also handle ``RGB`` and ``RGBA``.\n \"\"\"\n\n if value is None:\n return value\n # Using '--like'\n elif value.lower() == 'like':\n return options.from_like_context(ctx, param, value)\n elif value.lower() == 'rgb':\n return ColorInterp.red, ColorInterp.green, ColorInterp.blue\n elif value.lower() == 'rgba':\n return ColorInterp.red, ColorInterp.green, ColorInterp.blue, ColorInterp.alpha\n else:\n colorinterp = tuple(value.split(','))\n for ci in colorinterp:\n if ci not in ColorInterp.__members__:\n raise click.BadParameter(\n \"color interpretation '{ci}' is invalid. Must be one of: \"\n \"{valid}\".format(\n ci=ci, valid=', '.join(ColorInterp.__members__)))\n return tuple(ColorInterp[ci] for ci in colorinterp)\n\n\[email protected]('edit-info', short_help=\"Edit dataset metadata.\")\[email protected]_in_arg\[email protected]_opt\[email protected]_nodata_opt\[email protected]('--unset-nodata', default=False, is_flag=True,\n help=\"Unset the dataset's nodata value.\")\[email protected]('--crs', callback=crs_handler, default=None,\n help=\"New coordinate reference system\")\[email protected]('--unset-crs', default=False, is_flag=True,\n help=\"Unset the dataset's CRS value.\")\[email protected]('--transform', callback=transform_handler,\n help=\"New affine transform matrix\")\[email protected]('--units', help=\"Edit units of a band (requires --bidx)\")\[email protected]('--description',\n help=\"Edit description of a band (requires --bidx)\")\[email protected]('--tag', 'tags', callback=tags_handler, multiple=True,\n metavar='KEY=VAL', help=\"New tag.\")\[email protected]('--all', 'allmd', callback=all_handler, flag_value='like',\n is_eager=True, default=False,\n help=\"Copy all metadata items from the template file.\")\[email protected](\n '--colorinterp', callback=colorinterp_handler,\n metavar=\"name[,name,...]|RGB|RGBA|like\",\n help=\"Set color interpretation for all bands like 'red,green,blue,alpha'. \"\n \"Can also use 'RGBA' as shorthand for 'red,green,blue,alpha' and \"\n \"'RGB' for the same sans alpha band. Use 'like' to inherit color \"\n \"interpretation from '--like'.\")\[email protected]_opt\[email protected]_context\ndef edit(ctx, input, bidx, nodata, unset_nodata, crs, unset_crs, transform,\n units, description, tags, allmd, like, colorinterp):\n \"\"\"Edit a dataset's metadata: coordinate reference system, affine\n transformation matrix, nodata value, and tags.\n\n The coordinate reference system may be either a PROJ.4 or EPSG:nnnn\n string,\n\n --crs 'EPSG:4326'\n\n or a JSON text-encoded PROJ.4 object.\n\n --crs '{\"proj\": \"utm\", \"zone\": 18, ...}'\n\n Transforms are JSON-encoded Affine objects like:\n\n --transform '[300.038, 0.0, 101985.0, 0.0, -300.042, 2826915.0]'\n\n Prior to Rasterio 1.0 GDAL geotransforms were supported for --transform,\n but are no longer supported.\n\n Metadata items may also be read from an existing dataset using a\n combination of the --like option with at least one of --all,\n `--crs like`, `--nodata like`, and `--transform like`.\n\n rio edit-info example.tif --like template.tif --all\n\n To get just the transform from the template:\n\n rio edit-info example.tif --like template.tif --transform like\n\n \"\"\"\n import numpy as np\n\n def in_dtype_range(value, dtype):\n kind = np.dtype(dtype).kind\n if kind == 'f' and np.isnan(value):\n return True\n infos = {'c': np.finfo, 'f': np.finfo, 'i': np.iinfo,\n 'u': np.iinfo}\n rng = infos[kind](dtype)\n return rng.min <= value <= rng.max\n\n # If '--all' is given before '--like' on the commandline then 'allmd'\n # is the string 'like'. This is caused by '--like' not having an\n # opportunity to populate metadata before '--all' is evaluated.\n if allmd == 'like':\n allmd = ctx.obj['like']\n\n with ctx.obj['env'], rasterio.open(input, 'r+') as dst:\n\n if allmd:\n nodata = allmd['nodata']\n crs = allmd['crs']\n transform = allmd['transform']\n tags = allmd['tags']\n colorinterp = allmd['colorinterp']\n\n if unset_nodata and nodata is not options.IgnoreOption:\n raise click.BadParameter(\n \"--unset-nodata and --nodata cannot be used together.\")\n\n if unset_crs and crs:\n raise click.BadParameter(\n \"--unset-crs and --crs cannot be used together.\")\n\n if unset_nodata:\n # Setting nodata to None will raise NotImplementedError\n # if GDALDeleteRasterNoDataValue() isn't present in the\n # GDAL library.\n try:\n dst.nodata = None\n except NotImplementedError as exc: # pragma: no cover\n raise click.ClickException(str(exc))\n\n elif nodata is not options.IgnoreOption:\n dtype = dst.dtypes[0]\n if nodata is not None and not in_dtype_range(nodata, dtype):\n raise click.BadParameter(\n \"outside the range of the file's \"\n \"data type (%s).\" % dtype,\n param=nodata, param_hint='nodata')\n dst.nodata = nodata\n\n if unset_crs:\n dst.crs = None # CRS()\n elif crs:\n dst.crs = crs\n\n if transform:\n dst.transform = transform\n\n if tags:\n dst.update_tags(**tags)\n\n if units:\n dst.set_band_unit(bidx, units)\n\n if description:\n dst.set_band_description(bidx, description)\n\n if colorinterp:\n if like and len(colorinterp) != dst.count:\n raise click.ClickException(\n \"When using '--like' for color interpretation the \"\n \"template and target images must have the same number \"\n \"of bands. Found {template} color interpretations for \"\n \"template image and {target} bands in target \"\n \"image.\".format(\n template=len(colorinterp),\n target=dst.count))\n try:\n dst.colorinterp = colorinterp\n except ValueError as e:\n raise click.ClickException(str(e))\n\n # Post check - ensure that crs was unset properly\n if unset_crs:\n with ctx.obj['env'], rasterio.open(input, 'r') as src:\n if src.crs:\n warnings.warn(\n 'CRS was not unset. Availability of his functionality '\n 'differs depending on GDAL version and driver')\n", "path": "rasterio/rio/edit_info.py"}]}
| 3,243 | 278 |
gh_patches_debug_25374
|
rasdani/github-patches
|
git_diff
|
MycroftAI__mycroft-core-168
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
custom skills
Currently there is no architecture to create a 3rd party skill
- User dir `~/.mycroft/third_party_skills`
- `mycroft/third_party_skills`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mycroft/skills/main.py`
Content:
```
1 # Copyright 2016 Mycroft AI, Inc.
2 #
3 # This file is part of Mycroft Core.
4 #
5 # Mycroft Core is free software: you can redistribute it and/or modify
6 # it under the terms of the GNU General Public License as published by
7 # the Free Software Foundation, either version 3 of the License, or
8 # (at your option) any later version.
9 #
10 # Mycroft Core is distributed in the hope that it will be useful,
11 # but WITHOUT ANY WARRANTY; without even the implied warranty of
12 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
13 # GNU General Public License for more details.
14 #
15 # You should have received a copy of the GNU General Public License
16 # along with Mycroft Core. If not, see <http://www.gnu.org/licenses/>.
17
18
19 import json
20
21 from mycroft.messagebus.client.ws import WebsocketClient
22 from mycroft.skills.core import load_skills
23 from mycroft.util.log import getLogger
24 logger = getLogger("Skills")
25
26 __author__ = 'seanfitz'
27
28 client = None
29
30
31 def load_skills_callback():
32 global client
33 load_skills(client)
34
35
36 def connect():
37 global client
38 client.run_forever()
39
40
41 def main():
42 global client
43 client = WebsocketClient()
44
45 def echo(message):
46 try:
47 _message = json.loads(message)
48
49 if _message.get("message_type") == "registration":
50 # do not log tokens from registration messages
51 _message["metadata"]["token"] = None
52 message = json.dumps(_message)
53 except:
54 pass
55 logger.debug(message)
56
57 client.on('message', echo)
58 client.once('open', load_skills_callback)
59 client.run_forever()
60
61
62 if __name__ == "__main__":
63 main()
64
```
Path: `mycroft/skills/core.py`
Content:
```
1 # Copyright 2016 Mycroft AI, Inc.
2 #
3 # This file is part of Mycroft Core.
4 #
5 # Mycroft Core is free software: you can redistribute it and/or modify
6 # it under the terms of the GNU General Public License as published by
7 # the Free Software Foundation, either version 3 of the License, or
8 # (at your option) any later version.
9 #
10 # Mycroft Core is distributed in the hope that it will be useful,
11 # but WITHOUT ANY WARRANTY; without even the implied warranty of
12 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
13 # GNU General Public License for more details.
14 #
15 # You should have received a copy of the GNU General Public License
16 # along with Mycroft Core. If not, see <http://www.gnu.org/licenses/>.
17
18
19 import imp
20 import time
21
22 import abc
23 import os.path
24 import re
25 from adapt.intent import Intent
26 from os.path import join, dirname, splitext, isdir
27
28 from mycroft.client.enclosure.api import EnclosureAPI
29 from mycroft.configuration import ConfigurationManager
30 from mycroft.dialog import DialogLoader
31 from mycroft.filesystem import FileSystemAccess
32 from mycroft.messagebus.message import Message
33 from mycroft.util.log import getLogger
34
35 __author__ = 'seanfitz'
36
37 PRIMARY_SKILLS = ['intent', 'wake']
38 BLACKLISTED_SKILLS = ["send_sms"]
39 SKILLS_BASEDIR = dirname(__file__)
40
41 MainModule = '__init__'
42
43 logger = getLogger(__name__)
44
45
46 def load_vocab_from_file(path, vocab_type, emitter):
47 with open(path, 'r') as voc_file:
48 for line in voc_file.readlines():
49 parts = line.strip().split("|")
50 entity = parts[0]
51
52 emitter.emit(
53 Message("register_vocab",
54 metadata={'start': entity, 'end': vocab_type}))
55 for alias in parts[1:]:
56 emitter.emit(
57 Message("register_vocab",
58 metadata={'start': alias, 'end': vocab_type,
59 'alias_of': entity}))
60
61
62 def load_vocabulary(basedir, emitter):
63 for vocab_type in os.listdir(basedir):
64 load_vocab_from_file(
65 join(basedir, vocab_type), splitext(vocab_type)[0], emitter)
66
67
68 def create_intent_envelope(intent):
69 return Message(None, metadata=intent.__dict__, context={})
70
71
72 def open_intent_envelope(message):
73 intent_dict = message.metadata
74 return Intent(intent_dict.get('name'),
75 intent_dict.get('requires'),
76 intent_dict.get('at_least_one'),
77 intent_dict.get('optional'))
78
79
80 def load_skill(skill_descriptor, emitter):
81 try:
82 skill_module = imp.load_module(
83 skill_descriptor["name"] + MainModule, *skill_descriptor["info"])
84 if (hasattr(skill_module, 'create_skill') and
85 callable(skill_module.create_skill)):
86 # v2 skills framework
87 skill = skill_module.create_skill()
88 skill.bind(emitter)
89 skill.initialize()
90 return skill
91 else:
92 logger.warn(
93 "Module %s does not appear to be skill" % (
94 skill_descriptor["name"]))
95 except:
96 logger.error(
97 "Failed to load skill: " + skill_descriptor["name"], exc_info=True)
98 return None
99
100
101 def get_skills(skills_folder):
102 skills = []
103 possible_skills = os.listdir(skills_folder)
104 for i in possible_skills:
105 location = join(skills_folder, i)
106 if (not isdir(location) or
107 not MainModule + ".py" in os.listdir(location)):
108 continue
109
110 skills.append(create_skill_descriptor(location))
111 skills = sorted(skills, key=lambda p: p.get('name'))
112 return skills
113
114
115 def create_skill_descriptor(skill_folder):
116 info = imp.find_module(MainModule, [skill_folder])
117 return {"name": os.path.basename(skill_folder), "info": info}
118
119
120 def load_skills(emitter, skills_root=SKILLS_BASEDIR):
121 skills = get_skills(skills_root)
122 for skill in skills:
123 if skill['name'] in PRIMARY_SKILLS:
124 load_skill(skill, emitter)
125
126 for skill in skills:
127 if (skill['name'] not in PRIMARY_SKILLS and
128 skill['name'] not in BLACKLISTED_SKILLS):
129 load_skill(skill, emitter)
130
131
132 class MycroftSkill(object):
133 """
134 Abstract base class which provides common behaviour and parameters to all
135 Skills implementation.
136 """
137
138 def __init__(self, name, emitter=None):
139 self.name = name
140 self.bind(emitter)
141 config = ConfigurationManager.get()
142 self.config = config.get(name)
143 self.config_core = config.get('core')
144 self.dialog_renderer = None
145 self.file_system = FileSystemAccess(join('skills', name))
146 self.registered_intents = []
147
148 @property
149 def location(self):
150 return self.config_core.get('location')
151
152 @property
153 def lang(self):
154 return self.config_core.get('lang')
155
156 def bind(self, emitter):
157 if emitter:
158 self.emitter = emitter
159 self.enclosure = EnclosureAPI(emitter)
160 self.__register_stop()
161
162 def __register_stop(self):
163 self.stop_time = time.time()
164 self.stop_threshold = self.config_core.get('stop_threshold')
165 self.emitter.on('mycroft.stop', self.__handle_stop)
166
167 def detach(self):
168 for name in self.registered_intents:
169 self.emitter.emit(
170 Message("detach_intent", metadata={"intent_name": name}))
171
172 def initialize(self):
173 """
174 Initialization function to be implemented by all Skills.
175
176 Usually used to create intents rules and register them.
177 """
178 raise Exception("Initialize not implemented for skill: " + self.name)
179
180 def register_intent(self, intent_parser, handler):
181 intent_message = create_intent_envelope(intent_parser)
182 intent_message.message_type = "register_intent"
183 self.emitter.emit(intent_message)
184 self.registered_intents.append(intent_parser.name)
185
186 def receive_handler(message):
187 try:
188 handler(message)
189 except:
190 # TODO: Localize
191 self.speak(
192 "An error occurred while processing a request in " +
193 self.name)
194 logger.error(
195 "An error occurred while processing a request in " +
196 self.name, exc_info=True)
197
198 self.emitter.on(intent_parser.name, receive_handler)
199
200 def register_vocabulary(self, entity, entity_type):
201 self.emitter.emit(
202 Message('register_vocab',
203 metadata={'start': entity, 'end': entity_type}))
204
205 def register_regex(self, regex_str):
206 re.compile(regex_str) # validate regex
207 self.emitter.emit(
208 Message('register_vocab', metadata={'regex': regex_str}))
209
210 def speak(self, utterance):
211 self.emitter.emit(Message("speak", metadata={'utterance': utterance}))
212
213 def speak_dialog(self, key, data={}):
214 self.speak(self.dialog_renderer.render(key, data))
215
216 def init_dialog(self, root_directory):
217 self.dialog_renderer = DialogLoader().load(
218 join(root_directory, 'dialog', self.lang))
219
220 def load_data_files(self, root_directory):
221 self.init_dialog(root_directory)
222 self.load_vocab_files(join(root_directory, 'vocab', self.lang))
223
224 def load_vocab_files(self, vocab_dir):
225 load_vocabulary(vocab_dir, self.emitter)
226
227 def __handle_stop(self, event):
228 self.stop_time = time.time()
229 self.stop()
230
231 @abc.abstractmethod
232 def stop(self):
233 pass
234
235 def is_stop(self):
236 passed_time = time.time() - self.stop_time
237 return passed_time < self.stop_threshold
238
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mycroft/skills/core.py b/mycroft/skills/core.py
--- a/mycroft/skills/core.py
+++ b/mycroft/skills/core.py
@@ -37,6 +37,7 @@
PRIMARY_SKILLS = ['intent', 'wake']
BLACKLISTED_SKILLS = ["send_sms"]
SKILLS_BASEDIR = dirname(__file__)
+THIRD_PARTY_SKILLS_DIR = "/opt/mycroft/third_party"
MainModule = '__init__'
diff --git a/mycroft/skills/main.py b/mycroft/skills/main.py
--- a/mycroft/skills/main.py
+++ b/mycroft/skills/main.py
@@ -17,9 +17,11 @@
import json
+from os.path import join, expanduser, exists
+from mycroft.configuration import ConfigurationManager
from mycroft.messagebus.client.ws import WebsocketClient
-from mycroft.skills.core import load_skills
+from mycroft.skills.core import load_skills, THIRD_PARTY_SKILLS_DIR
from mycroft.util.log import getLogger
logger = getLogger("Skills")
@@ -31,6 +33,20 @@
def load_skills_callback():
global client
load_skills(client)
+ config = ConfigurationManager.get()
+ config_core = config.get("core")
+
+ try:
+ ini_third_party_skills_dir = expanduser(
+ config_core.get("third_party_skills_dir"))
+ except AttributeError as e:
+ logger.warning(e.message)
+
+ if exists(THIRD_PARTY_SKILLS_DIR):
+ load_skills(client, THIRD_PARTY_SKILLS_DIR)
+
+ if ini_third_party_skills_dir and exists(ini_third_party_skills_dir):
+ load_skills(client, ini_third_party_skills_dir)
def connect():
|
{"golden_diff": "diff --git a/mycroft/skills/core.py b/mycroft/skills/core.py\n--- a/mycroft/skills/core.py\n+++ b/mycroft/skills/core.py\n@@ -37,6 +37,7 @@\n PRIMARY_SKILLS = ['intent', 'wake']\n BLACKLISTED_SKILLS = [\"send_sms\"]\n SKILLS_BASEDIR = dirname(__file__)\n+THIRD_PARTY_SKILLS_DIR = \"/opt/mycroft/third_party\"\n \n MainModule = '__init__'\n \ndiff --git a/mycroft/skills/main.py b/mycroft/skills/main.py\n--- a/mycroft/skills/main.py\n+++ b/mycroft/skills/main.py\n@@ -17,9 +17,11 @@\n \n \n import json\n+from os.path import join, expanduser, exists\n \n+from mycroft.configuration import ConfigurationManager\n from mycroft.messagebus.client.ws import WebsocketClient\n-from mycroft.skills.core import load_skills\n+from mycroft.skills.core import load_skills, THIRD_PARTY_SKILLS_DIR\n from mycroft.util.log import getLogger\n logger = getLogger(\"Skills\")\n \n@@ -31,6 +33,20 @@\n def load_skills_callback():\n global client\n load_skills(client)\n+ config = ConfigurationManager.get()\n+ config_core = config.get(\"core\")\n+\n+ try:\n+ ini_third_party_skills_dir = expanduser(\n+ config_core.get(\"third_party_skills_dir\"))\n+ except AttributeError as e:\n+ logger.warning(e.message)\n+\n+ if exists(THIRD_PARTY_SKILLS_DIR):\n+ load_skills(client, THIRD_PARTY_SKILLS_DIR)\n+\n+ if ini_third_party_skills_dir and exists(ini_third_party_skills_dir):\n+ load_skills(client, ini_third_party_skills_dir)\n \n \n def connect():\n", "issue": "custom skills\nCurrently there is no architecture to create a 3rd party skill\n- User dir `~/.mycroft/third_party_skills`\n- `mycroft/third_party_skills`\n\n", "before_files": [{"content": "# Copyright 2016 Mycroft AI, Inc.\n#\n# This file is part of Mycroft Core.\n#\n# Mycroft Core is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Mycroft Core is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Mycroft Core. If not, see <http://www.gnu.org/licenses/>.\n\n\nimport json\n\nfrom mycroft.messagebus.client.ws import WebsocketClient\nfrom mycroft.skills.core import load_skills\nfrom mycroft.util.log import getLogger\nlogger = getLogger(\"Skills\")\n\n__author__ = 'seanfitz'\n\nclient = None\n\n\ndef load_skills_callback():\n global client\n load_skills(client)\n\n\ndef connect():\n global client\n client.run_forever()\n\n\ndef main():\n global client\n client = WebsocketClient()\n\n def echo(message):\n try:\n _message = json.loads(message)\n\n if _message.get(\"message_type\") == \"registration\":\n # do not log tokens from registration messages\n _message[\"metadata\"][\"token\"] = None\n message = json.dumps(_message)\n except:\n pass\n logger.debug(message)\n\n client.on('message', echo)\n client.once('open', load_skills_callback)\n client.run_forever()\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "mycroft/skills/main.py"}, {"content": "# Copyright 2016 Mycroft AI, Inc.\n#\n# This file is part of Mycroft Core.\n#\n# Mycroft Core is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Mycroft Core is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Mycroft Core. If not, see <http://www.gnu.org/licenses/>.\n\n\nimport imp\nimport time\n\nimport abc\nimport os.path\nimport re\nfrom adapt.intent import Intent\nfrom os.path import join, dirname, splitext, isdir\n\nfrom mycroft.client.enclosure.api import EnclosureAPI\nfrom mycroft.configuration import ConfigurationManager\nfrom mycroft.dialog import DialogLoader\nfrom mycroft.filesystem import FileSystemAccess\nfrom mycroft.messagebus.message import Message\nfrom mycroft.util.log import getLogger\n\n__author__ = 'seanfitz'\n\nPRIMARY_SKILLS = ['intent', 'wake']\nBLACKLISTED_SKILLS = [\"send_sms\"]\nSKILLS_BASEDIR = dirname(__file__)\n\nMainModule = '__init__'\n\nlogger = getLogger(__name__)\n\n\ndef load_vocab_from_file(path, vocab_type, emitter):\n with open(path, 'r') as voc_file:\n for line in voc_file.readlines():\n parts = line.strip().split(\"|\")\n entity = parts[0]\n\n emitter.emit(\n Message(\"register_vocab\",\n metadata={'start': entity, 'end': vocab_type}))\n for alias in parts[1:]:\n emitter.emit(\n Message(\"register_vocab\",\n metadata={'start': alias, 'end': vocab_type,\n 'alias_of': entity}))\n\n\ndef load_vocabulary(basedir, emitter):\n for vocab_type in os.listdir(basedir):\n load_vocab_from_file(\n join(basedir, vocab_type), splitext(vocab_type)[0], emitter)\n\n\ndef create_intent_envelope(intent):\n return Message(None, metadata=intent.__dict__, context={})\n\n\ndef open_intent_envelope(message):\n intent_dict = message.metadata\n return Intent(intent_dict.get('name'),\n intent_dict.get('requires'),\n intent_dict.get('at_least_one'),\n intent_dict.get('optional'))\n\n\ndef load_skill(skill_descriptor, emitter):\n try:\n skill_module = imp.load_module(\n skill_descriptor[\"name\"] + MainModule, *skill_descriptor[\"info\"])\n if (hasattr(skill_module, 'create_skill') and\n callable(skill_module.create_skill)):\n # v2 skills framework\n skill = skill_module.create_skill()\n skill.bind(emitter)\n skill.initialize()\n return skill\n else:\n logger.warn(\n \"Module %s does not appear to be skill\" % (\n skill_descriptor[\"name\"]))\n except:\n logger.error(\n \"Failed to load skill: \" + skill_descriptor[\"name\"], exc_info=True)\n return None\n\n\ndef get_skills(skills_folder):\n skills = []\n possible_skills = os.listdir(skills_folder)\n for i in possible_skills:\n location = join(skills_folder, i)\n if (not isdir(location) or\n not MainModule + \".py\" in os.listdir(location)):\n continue\n\n skills.append(create_skill_descriptor(location))\n skills = sorted(skills, key=lambda p: p.get('name'))\n return skills\n\n\ndef create_skill_descriptor(skill_folder):\n info = imp.find_module(MainModule, [skill_folder])\n return {\"name\": os.path.basename(skill_folder), \"info\": info}\n\n\ndef load_skills(emitter, skills_root=SKILLS_BASEDIR):\n skills = get_skills(skills_root)\n for skill in skills:\n if skill['name'] in PRIMARY_SKILLS:\n load_skill(skill, emitter)\n\n for skill in skills:\n if (skill['name'] not in PRIMARY_SKILLS and\n skill['name'] not in BLACKLISTED_SKILLS):\n load_skill(skill, emitter)\n\n\nclass MycroftSkill(object):\n \"\"\"\n Abstract base class which provides common behaviour and parameters to all\n Skills implementation.\n \"\"\"\n\n def __init__(self, name, emitter=None):\n self.name = name\n self.bind(emitter)\n config = ConfigurationManager.get()\n self.config = config.get(name)\n self.config_core = config.get('core')\n self.dialog_renderer = None\n self.file_system = FileSystemAccess(join('skills', name))\n self.registered_intents = []\n\n @property\n def location(self):\n return self.config_core.get('location')\n\n @property\n def lang(self):\n return self.config_core.get('lang')\n\n def bind(self, emitter):\n if emitter:\n self.emitter = emitter\n self.enclosure = EnclosureAPI(emitter)\n self.__register_stop()\n\n def __register_stop(self):\n self.stop_time = time.time()\n self.stop_threshold = self.config_core.get('stop_threshold')\n self.emitter.on('mycroft.stop', self.__handle_stop)\n\n def detach(self):\n for name in self.registered_intents:\n self.emitter.emit(\n Message(\"detach_intent\", metadata={\"intent_name\": name}))\n\n def initialize(self):\n \"\"\"\n Initialization function to be implemented by all Skills.\n\n Usually used to create intents rules and register them.\n \"\"\"\n raise Exception(\"Initialize not implemented for skill: \" + self.name)\n\n def register_intent(self, intent_parser, handler):\n intent_message = create_intent_envelope(intent_parser)\n intent_message.message_type = \"register_intent\"\n self.emitter.emit(intent_message)\n self.registered_intents.append(intent_parser.name)\n\n def receive_handler(message):\n try:\n handler(message)\n except:\n # TODO: Localize\n self.speak(\n \"An error occurred while processing a request in \" +\n self.name)\n logger.error(\n \"An error occurred while processing a request in \" +\n self.name, exc_info=True)\n\n self.emitter.on(intent_parser.name, receive_handler)\n\n def register_vocabulary(self, entity, entity_type):\n self.emitter.emit(\n Message('register_vocab',\n metadata={'start': entity, 'end': entity_type}))\n\n def register_regex(self, regex_str):\n re.compile(regex_str) # validate regex\n self.emitter.emit(\n Message('register_vocab', metadata={'regex': regex_str}))\n\n def speak(self, utterance):\n self.emitter.emit(Message(\"speak\", metadata={'utterance': utterance}))\n\n def speak_dialog(self, key, data={}):\n self.speak(self.dialog_renderer.render(key, data))\n\n def init_dialog(self, root_directory):\n self.dialog_renderer = DialogLoader().load(\n join(root_directory, 'dialog', self.lang))\n\n def load_data_files(self, root_directory):\n self.init_dialog(root_directory)\n self.load_vocab_files(join(root_directory, 'vocab', self.lang))\n\n def load_vocab_files(self, vocab_dir):\n load_vocabulary(vocab_dir, self.emitter)\n\n def __handle_stop(self, event):\n self.stop_time = time.time()\n self.stop()\n\n @abc.abstractmethod\n def stop(self):\n pass\n\n def is_stop(self):\n passed_time = time.time() - self.stop_time\n return passed_time < self.stop_threshold\n", "path": "mycroft/skills/core.py"}], "after_files": [{"content": "# Copyright 2016 Mycroft AI, Inc.\n#\n# This file is part of Mycroft Core.\n#\n# Mycroft Core is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Mycroft Core is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Mycroft Core. If not, see <http://www.gnu.org/licenses/>.\n\n\nimport json\nfrom os.path import join, expanduser, exists\n\nfrom mycroft.configuration import ConfigurationManager\nfrom mycroft.messagebus.client.ws import WebsocketClient\nfrom mycroft.skills.core import load_skills, THIRD_PARTY_SKILLS_DIR\nfrom mycroft.util.log import getLogger\nlogger = getLogger(\"Skills\")\n\n__author__ = 'seanfitz'\n\nclient = None\n\n\ndef load_skills_callback():\n global client\n load_skills(client)\n config = ConfigurationManager.get()\n config_core = config.get(\"core\")\n\n try:\n ini_third_party_skills_dir = expanduser(\n config_core.get(\"third_party_skills_dir\"))\n except AttributeError as e:\n logger.warning(e.message)\n\n if exists(THIRD_PARTY_SKILLS_DIR):\n load_skills(client, THIRD_PARTY_SKILLS_DIR)\n\n if ini_third_party_skills_dir and exists(ini_third_party_skills_dir):\n load_skills(client, ini_third_party_skills_dir)\n\n\ndef connect():\n global client\n client.run_forever()\n\n\ndef main():\n global client\n client = WebsocketClient()\n\n def echo(message):\n try:\n _message = json.loads(message)\n\n if _message.get(\"message_type\") == \"registration\":\n # do not log tokens from registration messages\n _message[\"metadata\"][\"token\"] = None\n message = json.dumps(_message)\n except:\n pass\n logger.debug(message)\n\n client.on('message', echo)\n client.once('open', load_skills_callback)\n client.run_forever()\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "mycroft/skills/main.py"}, {"content": "# Copyright 2016 Mycroft AI, Inc.\n#\n# This file is part of Mycroft Core.\n#\n# Mycroft Core is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Mycroft Core is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Mycroft Core. If not, see <http://www.gnu.org/licenses/>.\n\n\nimport imp\nimport time\n\nimport abc\nimport os.path\nimport re\nfrom adapt.intent import Intent\nfrom os.path import join, dirname, splitext, isdir\n\nfrom mycroft.client.enclosure.api import EnclosureAPI\nfrom mycroft.configuration import ConfigurationManager\nfrom mycroft.dialog import DialogLoader\nfrom mycroft.filesystem import FileSystemAccess\nfrom mycroft.messagebus.message import Message\nfrom mycroft.util.log import getLogger\n\n__author__ = 'seanfitz'\n\nPRIMARY_SKILLS = ['intent', 'wake']\nBLACKLISTED_SKILLS = [\"send_sms\"]\nSKILLS_BASEDIR = dirname(__file__)\nTHIRD_PARTY_SKILLS_DIR = \"/opt/mycroft/third_party\"\n\nMainModule = '__init__'\n\nlogger = getLogger(__name__)\n\n\ndef load_vocab_from_file(path, vocab_type, emitter):\n with open(path, 'r') as voc_file:\n for line in voc_file.readlines():\n parts = line.strip().split(\"|\")\n entity = parts[0]\n\n emitter.emit(\n Message(\"register_vocab\",\n metadata={'start': entity, 'end': vocab_type}))\n for alias in parts[1:]:\n emitter.emit(\n Message(\"register_vocab\",\n metadata={'start': alias, 'end': vocab_type,\n 'alias_of': entity}))\n\n\ndef load_vocabulary(basedir, emitter):\n for vocab_type in os.listdir(basedir):\n load_vocab_from_file(\n join(basedir, vocab_type), splitext(vocab_type)[0], emitter)\n\n\ndef create_intent_envelope(intent):\n return Message(None, metadata=intent.__dict__, context={})\n\n\ndef open_intent_envelope(message):\n intent_dict = message.metadata\n return Intent(intent_dict.get('name'),\n intent_dict.get('requires'),\n intent_dict.get('at_least_one'),\n intent_dict.get('optional'))\n\n\ndef load_skill(skill_descriptor, emitter):\n try:\n skill_module = imp.load_module(\n skill_descriptor[\"name\"] + MainModule, *skill_descriptor[\"info\"])\n if (hasattr(skill_module, 'create_skill') and\n callable(skill_module.create_skill)):\n # v2 skills framework\n skill = skill_module.create_skill()\n skill.bind(emitter)\n skill.initialize()\n return skill\n else:\n logger.warn(\n \"Module %s does not appear to be skill\" % (\n skill_descriptor[\"name\"]))\n except:\n logger.error(\n \"Failed to load skill: \" + skill_descriptor[\"name\"], exc_info=True)\n return None\n\n\ndef get_skills(skills_folder):\n skills = []\n possible_skills = os.listdir(skills_folder)\n for i in possible_skills:\n location = join(skills_folder, i)\n if (not isdir(location) or\n not MainModule + \".py\" in os.listdir(location)):\n continue\n\n skills.append(create_skill_descriptor(location))\n skills = sorted(skills, key=lambda p: p.get('name'))\n return skills\n\n\ndef create_skill_descriptor(skill_folder):\n info = imp.find_module(MainModule, [skill_folder])\n return {\"name\": os.path.basename(skill_folder), \"info\": info}\n\n\ndef load_skills(emitter, skills_root=SKILLS_BASEDIR):\n skills = get_skills(skills_root)\n for skill in skills:\n if skill['name'] in PRIMARY_SKILLS:\n load_skill(skill, emitter)\n\n for skill in skills:\n if (skill['name'] not in PRIMARY_SKILLS and\n skill['name'] not in BLACKLISTED_SKILLS):\n load_skill(skill, emitter)\n\n\nclass MycroftSkill(object):\n \"\"\"\n Abstract base class which provides common behaviour and parameters to all\n Skills implementation.\n \"\"\"\n\n def __init__(self, name, emitter=None):\n self.name = name\n self.bind(emitter)\n config = ConfigurationManager.get()\n self.config = config.get(name)\n self.config_core = config.get('core')\n self.dialog_renderer = None\n self.file_system = FileSystemAccess(join('skills', name))\n self.registered_intents = []\n\n @property\n def location(self):\n return self.config_core.get('location')\n\n @property\n def lang(self):\n return self.config_core.get('lang')\n\n def bind(self, emitter):\n if emitter:\n self.emitter = emitter\n self.enclosure = EnclosureAPI(emitter)\n self.__register_stop()\n\n def __register_stop(self):\n self.stop_time = time.time()\n self.stop_threshold = self.config_core.get('stop_threshold')\n self.emitter.on('mycroft.stop', self.__handle_stop)\n\n def detach(self):\n for name in self.registered_intents:\n self.emitter.emit(\n Message(\"detach_intent\", metadata={\"intent_name\": name}))\n\n def initialize(self):\n \"\"\"\n Initialization function to be implemented by all Skills.\n\n Usually used to create intents rules and register them.\n \"\"\"\n raise Exception(\"Initialize not implemented for skill: \" + self.name)\n\n def register_intent(self, intent_parser, handler):\n intent_message = create_intent_envelope(intent_parser)\n intent_message.message_type = \"register_intent\"\n self.emitter.emit(intent_message)\n self.registered_intents.append(intent_parser.name)\n\n def receive_handler(message):\n try:\n handler(message)\n except:\n # TODO: Localize\n self.speak(\n \"An error occurred while processing a request in \" +\n self.name)\n logger.error(\n \"An error occurred while processing a request in \" +\n self.name, exc_info=True)\n\n self.emitter.on(intent_parser.name, receive_handler)\n\n def register_vocabulary(self, entity, entity_type):\n self.emitter.emit(\n Message('register_vocab',\n metadata={'start': entity, 'end': entity_type}))\n\n def register_regex(self, regex_str):\n re.compile(regex_str) # validate regex\n self.emitter.emit(\n Message('register_vocab', metadata={'regex': regex_str}))\n\n def speak(self, utterance):\n self.emitter.emit(Message(\"speak\", metadata={'utterance': utterance}))\n\n def speak_dialog(self, key, data={}):\n self.speak(self.dialog_renderer.render(key, data))\n\n def init_dialog(self, root_directory):\n self.dialog_renderer = DialogLoader().load(\n join(root_directory, 'dialog', self.lang))\n\n def load_data_files(self, root_directory):\n self.init_dialog(root_directory)\n self.load_vocab_files(join(root_directory, 'vocab', self.lang))\n\n def load_vocab_files(self, vocab_dir):\n load_vocabulary(vocab_dir, self.emitter)\n\n def __handle_stop(self, event):\n self.stop_time = time.time()\n self.stop()\n\n @abc.abstractmethod\n def stop(self):\n pass\n\n def is_stop(self):\n passed_time = time.time() - self.stop_time\n return passed_time < self.stop_threshold\n", "path": "mycroft/skills/core.py"}]}
| 3,058 | 375 |
gh_patches_debug_36620
|
rasdani/github-patches
|
git_diff
|
qutebrowser__qutebrowser-425
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Make /foo a normal command
Searching on a page should be a normal command, with `/foo` just being an "alias".
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `qutebrowser/commands/runners.py`
Content:
```
1 # vim: ft=python fileencoding=utf-8 sts=4 sw=4 et:
2
3 # Copyright 2014 Florian Bruhin (The Compiler) <[email protected]>
4 #
5 # This file is part of qutebrowser.
6 #
7 # qutebrowser is free software: you can redistribute it and/or modify
8 # it under the terms of the GNU General Public License as published by
9 # the Free Software Foundation, either version 3 of the License, or
10 # (at your option) any later version.
11 #
12 # qutebrowser is distributed in the hope that it will be useful,
13 # but WITHOUT ANY WARRANTY; without even the implied warranty of
14 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
15 # GNU General Public License for more details.
16 #
17 # You should have received a copy of the GNU General Public License
18 # along with qutebrowser. If not, see <http://www.gnu.org/licenses/>.
19
20 """Module containing command managers (SearchRunner and CommandRunner)."""
21
22 import re
23
24 from PyQt5.QtCore import pyqtSlot, pyqtSignal, QObject, QUrl
25 from PyQt5.QtWebKitWidgets import QWebPage
26
27 from qutebrowser.config import config, configexc
28 from qutebrowser.commands import cmdexc, cmdutils
29 from qutebrowser.utils import message, log, utils, objreg
30 from qutebrowser.misc import split
31
32
33 def replace_variables(win_id, arglist):
34 """Utility function to replace variables like {url} in a list of args."""
35 args = []
36 tabbed_browser = objreg.get('tabbed-browser', scope='window',
37 window=win_id)
38 for arg in arglist:
39 if arg == '{url}':
40 # Note we have to do this in here as the user gets an error message
41 # by current_url if no URL is open yet.
42 url = tabbed_browser.current_url().toString(QUrl.FullyEncoded |
43 QUrl.RemovePassword)
44 args.append(url)
45 else:
46 args.append(arg)
47 return args
48
49
50 class SearchRunner(QObject):
51
52 """Run searches on webpages.
53
54 Attributes:
55 _text: The text from the last search.
56 _flags: The flags from the last search.
57
58 Signals:
59 do_search: Emitted when a search should be started.
60 arg 1: Search string.
61 arg 2: Flags to use.
62 """
63
64 do_search = pyqtSignal(str, 'QWebPage::FindFlags')
65
66 def __init__(self, parent=None):
67 super().__init__(parent)
68 self._text = None
69 self._flags = 0
70
71 def __repr__(self):
72 return utils.get_repr(self, text=self._text, flags=self._flags)
73
74 def _search(self, text, rev=False):
75 """Search for a text on the current page.
76
77 Args:
78 text: The text to search for.
79 rev: Search direction, True if reverse, else False.
80 """
81 if self._text is not None and self._text != text:
82 # We first clear the marked text, then the highlights
83 self.do_search.emit('', 0)
84 self.do_search.emit('', QWebPage.HighlightAllOccurrences)
85 self._text = text
86 self._flags = 0
87 ignore_case = config.get('general', 'ignore-case')
88 if ignore_case == 'smart':
89 if not text.islower():
90 self._flags |= QWebPage.FindCaseSensitively
91 elif not ignore_case:
92 self._flags |= QWebPage.FindCaseSensitively
93 if config.get('general', 'wrap-search'):
94 self._flags |= QWebPage.FindWrapsAroundDocument
95 if rev:
96 self._flags |= QWebPage.FindBackward
97 # We actually search *twice* - once to highlight everything, then again
98 # to get a mark so we can navigate.
99 self.do_search.emit(self._text, self._flags)
100 self.do_search.emit(self._text, self._flags |
101 QWebPage.HighlightAllOccurrences)
102
103 @pyqtSlot(str)
104 def search(self, text):
105 """Search for a text on a website.
106
107 Args:
108 text: The text to search for.
109 """
110 self._search(text)
111
112 @pyqtSlot(str)
113 def search_rev(self, text):
114 """Search for a text on a website in reverse direction.
115
116 Args:
117 text: The text to search for.
118 """
119 self._search(text, rev=True)
120
121 @cmdutils.register(instance='search-runner', hide=True, scope='window')
122 def search_next(self, count: {'special': 'count'}=1):
123 """Continue the search to the ([count]th) next term.
124
125 Args:
126 count: How many elements to ignore.
127 """
128 if self._text is not None:
129 for _ in range(count):
130 self.do_search.emit(self._text, self._flags)
131
132 @cmdutils.register(instance='search-runner', hide=True, scope='window')
133 def search_prev(self, count: {'special': 'count'}=1):
134 """Continue the search to the ([count]th) previous term.
135
136 Args:
137 count: How many elements to ignore.
138 """
139 if self._text is None:
140 return
141 # The int() here serves as a QFlags constructor to create a copy of the
142 # QFlags instance rather as a reference. I don't know why it works this
143 # way, but it does.
144 flags = int(self._flags)
145 if flags & QWebPage.FindBackward:
146 flags &= ~QWebPage.FindBackward
147 else:
148 flags |= QWebPage.FindBackward
149 for _ in range(count):
150 self.do_search.emit(self._text, flags)
151
152
153 class CommandRunner(QObject):
154
155 """Parse and run qutebrowser commandline commands.
156
157 Attributes:
158 _cmd: The command which was parsed.
159 _args: The arguments which were parsed.
160 _win_id: The window this CommandRunner is associated with.
161 """
162
163 def __init__(self, win_id, parent=None):
164 super().__init__(parent)
165 self._cmd = None
166 self._args = []
167 self._win_id = win_id
168
169 def _get_alias(self, text):
170 """Get an alias from the config.
171
172 Args:
173 text: The text to parse.
174
175 Return:
176 None if no alias was found.
177 The new command string if an alias was found.
178 """
179 parts = text.strip().split(maxsplit=1)
180 try:
181 alias = config.get('aliases', parts[0])
182 except (configexc.NoOptionError, configexc.NoSectionError):
183 return None
184 try:
185 new_cmd = '{} {}'.format(alias, parts[1])
186 except IndexError:
187 new_cmd = alias
188 if text.endswith(' '):
189 new_cmd += ' '
190 return new_cmd
191
192 def parse(self, text, aliases=True, fallback=False, keep=False):
193 """Split the commandline text into command and arguments.
194
195 Args:
196 text: Text to parse.
197 aliases: Whether to handle aliases.
198 fallback: Whether to do a fallback splitting when the command was
199 unknown.
200 keep: Whether to keep special chars and whitespace
201
202 Return:
203 A split string commandline, e.g ['open', 'www.google.com']
204 """
205 cmdstr, sep, argstr = text.partition(' ')
206 if not cmdstr and not fallback:
207 raise cmdexc.NoSuchCommandError("No command given")
208 if aliases:
209 new_cmd = self._get_alias(text)
210 if new_cmd is not None:
211 log.commands.debug("Re-parsing with '{}'.".format(new_cmd))
212 return self.parse(new_cmd, aliases=False, fallback=fallback,
213 keep=keep)
214 try:
215 self._cmd = cmdutils.cmd_dict[cmdstr]
216 except KeyError:
217 if fallback and keep:
218 cmdstr, sep, argstr = text.partition(' ')
219 return [cmdstr, sep] + argstr.split()
220 elif fallback:
221 return text.split()
222 else:
223 raise cmdexc.NoSuchCommandError(
224 '{}: no such command'.format(cmdstr))
225 self._split_args(argstr, keep)
226 retargs = self._args[:]
227 if keep and retargs:
228 return [cmdstr, sep + retargs[0]] + retargs[1:]
229 elif keep:
230 return [cmdstr, sep]
231 else:
232 return [cmdstr] + retargs
233
234 def _split_args(self, argstr, keep):
235 """Split the arguments from an arg string.
236
237 Args:
238 argstr: An argument string.
239 keep: Whether to keep special chars and whitespace
240
241 Return:
242 A list containing the splitted strings.
243 """
244 if not argstr:
245 self._args = []
246 elif self._cmd.maxsplit is None:
247 self._args = split.split(argstr, keep=keep)
248 else:
249 # If split=False, we still want to split the flags, but not
250 # everything after that.
251 # We first split the arg string and check the index of the first
252 # non-flag args, then we re-split again properly.
253 # example:
254 #
255 # input: "--foo -v bar baz"
256 # first split: ['--foo', '-v', 'bar', 'baz']
257 # 0 1 2 3
258 # second split: ['--foo', '-v', 'bar baz']
259 # (maxsplit=2)
260 split_args = split.simple_split(argstr, keep=keep)
261 flag_arg_count = 0
262 for i, arg in enumerate(split_args):
263 arg = arg.strip()
264 if arg.startswith('-'):
265 if arg.lstrip('-') in self._cmd.flags_with_args:
266 flag_arg_count += 1
267 else:
268 self._args = []
269 maxsplit = i + self._cmd.maxsplit + flag_arg_count
270 args = split.simple_split(argstr, keep=keep,
271 maxsplit=maxsplit)
272 for s in args:
273 # remove quotes and replace \" by "
274 s = re.sub(r"""(^|[^\\])["']""", r'\1', s)
275 s = re.sub(r"""\\(["'])""", r'\1', s)
276 self._args.append(s)
277 break
278 else:
279 # If there are only flags, we got it right on the first try
280 # already.
281 self._args = split_args
282
283 def run(self, text, count=None):
284 """Parse a command from a line of text and run it.
285
286 Args:
287 text: The text to parse.
288 count: The count to pass to the command.
289 """
290 if ';;' in text:
291 for sub in text.split(';;'):
292 self.run(sub, count)
293 return
294 self.parse(text)
295 args = replace_variables(self._win_id, self._args)
296 if count is not None:
297 self._cmd.run(self._win_id, args, count=count)
298 else:
299 self._cmd.run(self._win_id, args)
300
301 @pyqtSlot(str, int)
302 def run_safely(self, text, count=None):
303 """Run a command and display exceptions in the statusbar."""
304 try:
305 self.run(text, count)
306 except (cmdexc.CommandMetaError, cmdexc.CommandError) as e:
307 message.error(self._win_id, e, immediately=True)
308
309 @pyqtSlot(str, int)
310 def run_safely_init(self, text, count=None):
311 """Run a command and display exceptions in the statusbar.
312
313 Contrary to run_safely, error messages are queued so this is more
314 suitable to use while initializing."""
315 try:
316 self.run(text, count)
317 except (cmdexc.CommandMetaError, cmdexc.CommandError) as e:
318 message.error(self._win_id, e)
319
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/qutebrowser/commands/runners.py b/qutebrowser/commands/runners.py
--- a/qutebrowser/commands/runners.py
+++ b/qutebrowser/commands/runners.py
@@ -71,12 +71,14 @@
def __repr__(self):
return utils.get_repr(self, text=self._text, flags=self._flags)
- def _search(self, text, rev=False):
+ @pyqtSlot(str)
+ @cmdutils.register(instance='search-runner', scope='window', maxsplit=0)
+ def search(self, text, reverse=False):
"""Search for a text on the current page.
Args:
text: The text to search for.
- rev: Search direction, True if reverse, else False.
+ reverse: Reverse search direction.
"""
if self._text is not None and self._text != text:
# We first clear the marked text, then the highlights
@@ -92,7 +94,7 @@
self._flags |= QWebPage.FindCaseSensitively
if config.get('general', 'wrap-search'):
self._flags |= QWebPage.FindWrapsAroundDocument
- if rev:
+ if reverse:
self._flags |= QWebPage.FindBackward
# We actually search *twice* - once to highlight everything, then again
# to get a mark so we can navigate.
@@ -100,15 +102,6 @@
self.do_search.emit(self._text, self._flags |
QWebPage.HighlightAllOccurrences)
- @pyqtSlot(str)
- def search(self, text):
- """Search for a text on a website.
-
- Args:
- text: The text to search for.
- """
- self._search(text)
-
@pyqtSlot(str)
def search_rev(self, text):
"""Search for a text on a website in reverse direction.
@@ -116,7 +109,7 @@
Args:
text: The text to search for.
"""
- self._search(text, rev=True)
+ self.search(text, reverse=True)
@cmdutils.register(instance='search-runner', hide=True, scope='window')
def search_next(self, count: {'special': 'count'}=1):
|
{"golden_diff": "diff --git a/qutebrowser/commands/runners.py b/qutebrowser/commands/runners.py\n--- a/qutebrowser/commands/runners.py\n+++ b/qutebrowser/commands/runners.py\n@@ -71,12 +71,14 @@\n def __repr__(self):\n return utils.get_repr(self, text=self._text, flags=self._flags)\n \n- def _search(self, text, rev=False):\n+ @pyqtSlot(str)\n+ @cmdutils.register(instance='search-runner', scope='window', maxsplit=0)\n+ def search(self, text, reverse=False):\n \"\"\"Search for a text on the current page.\n \n Args:\n text: The text to search for.\n- rev: Search direction, True if reverse, else False.\n+ reverse: Reverse search direction.\n \"\"\"\n if self._text is not None and self._text != text:\n # We first clear the marked text, then the highlights\n@@ -92,7 +94,7 @@\n self._flags |= QWebPage.FindCaseSensitively\n if config.get('general', 'wrap-search'):\n self._flags |= QWebPage.FindWrapsAroundDocument\n- if rev:\n+ if reverse:\n self._flags |= QWebPage.FindBackward\n # We actually search *twice* - once to highlight everything, then again\n # to get a mark so we can navigate.\n@@ -100,15 +102,6 @@\n self.do_search.emit(self._text, self._flags |\n QWebPage.HighlightAllOccurrences)\n \n- @pyqtSlot(str)\n- def search(self, text):\n- \"\"\"Search for a text on a website.\n-\n- Args:\n- text: The text to search for.\n- \"\"\"\n- self._search(text)\n-\n @pyqtSlot(str)\n def search_rev(self, text):\n \"\"\"Search for a text on a website in reverse direction.\n@@ -116,7 +109,7 @@\n Args:\n text: The text to search for.\n \"\"\"\n- self._search(text, rev=True)\n+ self.search(text, reverse=True)\n \n @cmdutils.register(instance='search-runner', hide=True, scope='window')\n def search_next(self, count: {'special': 'count'}=1):\n", "issue": "Make /foo a normal command\nSearching on a page should be a normal command, with `/foo` just being an \"alias\".\n\n", "before_files": [{"content": "# vim: ft=python fileencoding=utf-8 sts=4 sw=4 et:\n\n# Copyright 2014 Florian Bruhin (The Compiler) <[email protected]>\n#\n# This file is part of qutebrowser.\n#\n# qutebrowser is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# qutebrowser is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with qutebrowser. If not, see <http://www.gnu.org/licenses/>.\n\n\"\"\"Module containing command managers (SearchRunner and CommandRunner).\"\"\"\n\nimport re\n\nfrom PyQt5.QtCore import pyqtSlot, pyqtSignal, QObject, QUrl\nfrom PyQt5.QtWebKitWidgets import QWebPage\n\nfrom qutebrowser.config import config, configexc\nfrom qutebrowser.commands import cmdexc, cmdutils\nfrom qutebrowser.utils import message, log, utils, objreg\nfrom qutebrowser.misc import split\n\n\ndef replace_variables(win_id, arglist):\n \"\"\"Utility function to replace variables like {url} in a list of args.\"\"\"\n args = []\n tabbed_browser = objreg.get('tabbed-browser', scope='window',\n window=win_id)\n for arg in arglist:\n if arg == '{url}':\n # Note we have to do this in here as the user gets an error message\n # by current_url if no URL is open yet.\n url = tabbed_browser.current_url().toString(QUrl.FullyEncoded |\n QUrl.RemovePassword)\n args.append(url)\n else:\n args.append(arg)\n return args\n\n\nclass SearchRunner(QObject):\n\n \"\"\"Run searches on webpages.\n\n Attributes:\n _text: The text from the last search.\n _flags: The flags from the last search.\n\n Signals:\n do_search: Emitted when a search should be started.\n arg 1: Search string.\n arg 2: Flags to use.\n \"\"\"\n\n do_search = pyqtSignal(str, 'QWebPage::FindFlags')\n\n def __init__(self, parent=None):\n super().__init__(parent)\n self._text = None\n self._flags = 0\n\n def __repr__(self):\n return utils.get_repr(self, text=self._text, flags=self._flags)\n\n def _search(self, text, rev=False):\n \"\"\"Search for a text on the current page.\n\n Args:\n text: The text to search for.\n rev: Search direction, True if reverse, else False.\n \"\"\"\n if self._text is not None and self._text != text:\n # We first clear the marked text, then the highlights\n self.do_search.emit('', 0)\n self.do_search.emit('', QWebPage.HighlightAllOccurrences)\n self._text = text\n self._flags = 0\n ignore_case = config.get('general', 'ignore-case')\n if ignore_case == 'smart':\n if not text.islower():\n self._flags |= QWebPage.FindCaseSensitively\n elif not ignore_case:\n self._flags |= QWebPage.FindCaseSensitively\n if config.get('general', 'wrap-search'):\n self._flags |= QWebPage.FindWrapsAroundDocument\n if rev:\n self._flags |= QWebPage.FindBackward\n # We actually search *twice* - once to highlight everything, then again\n # to get a mark so we can navigate.\n self.do_search.emit(self._text, self._flags)\n self.do_search.emit(self._text, self._flags |\n QWebPage.HighlightAllOccurrences)\n\n @pyqtSlot(str)\n def search(self, text):\n \"\"\"Search for a text on a website.\n\n Args:\n text: The text to search for.\n \"\"\"\n self._search(text)\n\n @pyqtSlot(str)\n def search_rev(self, text):\n \"\"\"Search for a text on a website in reverse direction.\n\n Args:\n text: The text to search for.\n \"\"\"\n self._search(text, rev=True)\n\n @cmdutils.register(instance='search-runner', hide=True, scope='window')\n def search_next(self, count: {'special': 'count'}=1):\n \"\"\"Continue the search to the ([count]th) next term.\n\n Args:\n count: How many elements to ignore.\n \"\"\"\n if self._text is not None:\n for _ in range(count):\n self.do_search.emit(self._text, self._flags)\n\n @cmdutils.register(instance='search-runner', hide=True, scope='window')\n def search_prev(self, count: {'special': 'count'}=1):\n \"\"\"Continue the search to the ([count]th) previous term.\n\n Args:\n count: How many elements to ignore.\n \"\"\"\n if self._text is None:\n return\n # The int() here serves as a QFlags constructor to create a copy of the\n # QFlags instance rather as a reference. I don't know why it works this\n # way, but it does.\n flags = int(self._flags)\n if flags & QWebPage.FindBackward:\n flags &= ~QWebPage.FindBackward\n else:\n flags |= QWebPage.FindBackward\n for _ in range(count):\n self.do_search.emit(self._text, flags)\n\n\nclass CommandRunner(QObject):\n\n \"\"\"Parse and run qutebrowser commandline commands.\n\n Attributes:\n _cmd: The command which was parsed.\n _args: The arguments which were parsed.\n _win_id: The window this CommandRunner is associated with.\n \"\"\"\n\n def __init__(self, win_id, parent=None):\n super().__init__(parent)\n self._cmd = None\n self._args = []\n self._win_id = win_id\n\n def _get_alias(self, text):\n \"\"\"Get an alias from the config.\n\n Args:\n text: The text to parse.\n\n Return:\n None if no alias was found.\n The new command string if an alias was found.\n \"\"\"\n parts = text.strip().split(maxsplit=1)\n try:\n alias = config.get('aliases', parts[0])\n except (configexc.NoOptionError, configexc.NoSectionError):\n return None\n try:\n new_cmd = '{} {}'.format(alias, parts[1])\n except IndexError:\n new_cmd = alias\n if text.endswith(' '):\n new_cmd += ' '\n return new_cmd\n\n def parse(self, text, aliases=True, fallback=False, keep=False):\n \"\"\"Split the commandline text into command and arguments.\n\n Args:\n text: Text to parse.\n aliases: Whether to handle aliases.\n fallback: Whether to do a fallback splitting when the command was\n unknown.\n keep: Whether to keep special chars and whitespace\n\n Return:\n A split string commandline, e.g ['open', 'www.google.com']\n \"\"\"\n cmdstr, sep, argstr = text.partition(' ')\n if not cmdstr and not fallback:\n raise cmdexc.NoSuchCommandError(\"No command given\")\n if aliases:\n new_cmd = self._get_alias(text)\n if new_cmd is not None:\n log.commands.debug(\"Re-parsing with '{}'.\".format(new_cmd))\n return self.parse(new_cmd, aliases=False, fallback=fallback,\n keep=keep)\n try:\n self._cmd = cmdutils.cmd_dict[cmdstr]\n except KeyError:\n if fallback and keep:\n cmdstr, sep, argstr = text.partition(' ')\n return [cmdstr, sep] + argstr.split()\n elif fallback:\n return text.split()\n else:\n raise cmdexc.NoSuchCommandError(\n '{}: no such command'.format(cmdstr))\n self._split_args(argstr, keep)\n retargs = self._args[:]\n if keep and retargs:\n return [cmdstr, sep + retargs[0]] + retargs[1:]\n elif keep:\n return [cmdstr, sep]\n else:\n return [cmdstr] + retargs\n\n def _split_args(self, argstr, keep):\n \"\"\"Split the arguments from an arg string.\n\n Args:\n argstr: An argument string.\n keep: Whether to keep special chars and whitespace\n\n Return:\n A list containing the splitted strings.\n \"\"\"\n if not argstr:\n self._args = []\n elif self._cmd.maxsplit is None:\n self._args = split.split(argstr, keep=keep)\n else:\n # If split=False, we still want to split the flags, but not\n # everything after that.\n # We first split the arg string and check the index of the first\n # non-flag args, then we re-split again properly.\n # example:\n #\n # input: \"--foo -v bar baz\"\n # first split: ['--foo', '-v', 'bar', 'baz']\n # 0 1 2 3\n # second split: ['--foo', '-v', 'bar baz']\n # (maxsplit=2)\n split_args = split.simple_split(argstr, keep=keep)\n flag_arg_count = 0\n for i, arg in enumerate(split_args):\n arg = arg.strip()\n if arg.startswith('-'):\n if arg.lstrip('-') in self._cmd.flags_with_args:\n flag_arg_count += 1\n else:\n self._args = []\n maxsplit = i + self._cmd.maxsplit + flag_arg_count\n args = split.simple_split(argstr, keep=keep,\n maxsplit=maxsplit)\n for s in args:\n # remove quotes and replace \\\" by \"\n s = re.sub(r\"\"\"(^|[^\\\\])[\"']\"\"\", r'\\1', s)\n s = re.sub(r\"\"\"\\\\([\"'])\"\"\", r'\\1', s)\n self._args.append(s)\n break\n else:\n # If there are only flags, we got it right on the first try\n # already.\n self._args = split_args\n\n def run(self, text, count=None):\n \"\"\"Parse a command from a line of text and run it.\n\n Args:\n text: The text to parse.\n count: The count to pass to the command.\n \"\"\"\n if ';;' in text:\n for sub in text.split(';;'):\n self.run(sub, count)\n return\n self.parse(text)\n args = replace_variables(self._win_id, self._args)\n if count is not None:\n self._cmd.run(self._win_id, args, count=count)\n else:\n self._cmd.run(self._win_id, args)\n\n @pyqtSlot(str, int)\n def run_safely(self, text, count=None):\n \"\"\"Run a command and display exceptions in the statusbar.\"\"\"\n try:\n self.run(text, count)\n except (cmdexc.CommandMetaError, cmdexc.CommandError) as e:\n message.error(self._win_id, e, immediately=True)\n\n @pyqtSlot(str, int)\n def run_safely_init(self, text, count=None):\n \"\"\"Run a command and display exceptions in the statusbar.\n\n Contrary to run_safely, error messages are queued so this is more\n suitable to use while initializing.\"\"\"\n try:\n self.run(text, count)\n except (cmdexc.CommandMetaError, cmdexc.CommandError) as e:\n message.error(self._win_id, e)\n", "path": "qutebrowser/commands/runners.py"}], "after_files": [{"content": "# vim: ft=python fileencoding=utf-8 sts=4 sw=4 et:\n\n# Copyright 2014 Florian Bruhin (The Compiler) <[email protected]>\n#\n# This file is part of qutebrowser.\n#\n# qutebrowser is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# qutebrowser is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with qutebrowser. If not, see <http://www.gnu.org/licenses/>.\n\n\"\"\"Module containing command managers (SearchRunner and CommandRunner).\"\"\"\n\nimport re\n\nfrom PyQt5.QtCore import pyqtSlot, pyqtSignal, QObject, QUrl\nfrom PyQt5.QtWebKitWidgets import QWebPage\n\nfrom qutebrowser.config import config, configexc\nfrom qutebrowser.commands import cmdexc, cmdutils\nfrom qutebrowser.utils import message, log, utils, objreg\nfrom qutebrowser.misc import split\n\n\ndef replace_variables(win_id, arglist):\n \"\"\"Utility function to replace variables like {url} in a list of args.\"\"\"\n args = []\n tabbed_browser = objreg.get('tabbed-browser', scope='window',\n window=win_id)\n for arg in arglist:\n if arg == '{url}':\n # Note we have to do this in here as the user gets an error message\n # by current_url if no URL is open yet.\n url = tabbed_browser.current_url().toString(QUrl.FullyEncoded |\n QUrl.RemovePassword)\n args.append(url)\n else:\n args.append(arg)\n return args\n\n\nclass SearchRunner(QObject):\n\n \"\"\"Run searches on webpages.\n\n Attributes:\n _text: The text from the last search.\n _flags: The flags from the last search.\n\n Signals:\n do_search: Emitted when a search should be started.\n arg 1: Search string.\n arg 2: Flags to use.\n \"\"\"\n\n do_search = pyqtSignal(str, 'QWebPage::FindFlags')\n\n def __init__(self, parent=None):\n super().__init__(parent)\n self._text = None\n self._flags = 0\n\n def __repr__(self):\n return utils.get_repr(self, text=self._text, flags=self._flags)\n\n @pyqtSlot(str)\n @cmdutils.register(instance='search-runner', scope='window', maxsplit=0)\n def search(self, text, reverse=False):\n \"\"\"Search for a text on the current page.\n\n Args:\n text: The text to search for.\n reverse: Reverse search direction.\n \"\"\"\n if self._text is not None and self._text != text:\n # We first clear the marked text, then the highlights\n self.do_search.emit('', 0)\n self.do_search.emit('', QWebPage.HighlightAllOccurrences)\n self._text = text\n self._flags = 0\n ignore_case = config.get('general', 'ignore-case')\n if ignore_case == 'smart':\n if not text.islower():\n self._flags |= QWebPage.FindCaseSensitively\n elif not ignore_case:\n self._flags |= QWebPage.FindCaseSensitively\n if config.get('general', 'wrap-search'):\n self._flags |= QWebPage.FindWrapsAroundDocument\n if reverse:\n self._flags |= QWebPage.FindBackward\n # We actually search *twice* - once to highlight everything, then again\n # to get a mark so we can navigate.\n self.do_search.emit(self._text, self._flags)\n self.do_search.emit(self._text, self._flags |\n QWebPage.HighlightAllOccurrences)\n\n @pyqtSlot(str)\n def search_rev(self, text):\n \"\"\"Search for a text on a website in reverse direction.\n\n Args:\n text: The text to search for.\n \"\"\"\n self.search(text, reverse=True)\n\n @cmdutils.register(instance='search-runner', hide=True, scope='window')\n def search_next(self, count: {'special': 'count'}=1):\n \"\"\"Continue the search to the ([count]th) next term.\n\n Args:\n count: How many elements to ignore.\n \"\"\"\n if self._text is not None:\n for _ in range(count):\n self.do_search.emit(self._text, self._flags)\n\n @cmdutils.register(instance='search-runner', hide=True, scope='window')\n def search_prev(self, count: {'special': 'count'}=1):\n \"\"\"Continue the search to the ([count]th) previous term.\n\n Args:\n count: How many elements to ignore.\n \"\"\"\n if self._text is None:\n return\n # The int() here serves as a QFlags constructor to create a copy of the\n # QFlags instance rather as a reference. I don't know why it works this\n # way, but it does.\n flags = int(self._flags)\n if flags & QWebPage.FindBackward:\n flags &= ~QWebPage.FindBackward\n else:\n flags |= QWebPage.FindBackward\n for _ in range(count):\n self.do_search.emit(self._text, flags)\n\n\nclass CommandRunner(QObject):\n\n \"\"\"Parse and run qutebrowser commandline commands.\n\n Attributes:\n _cmd: The command which was parsed.\n _args: The arguments which were parsed.\n _win_id: The window this CommandRunner is associated with.\n \"\"\"\n\n def __init__(self, win_id, parent=None):\n super().__init__(parent)\n self._cmd = None\n self._args = []\n self._win_id = win_id\n\n def _get_alias(self, text):\n \"\"\"Get an alias from the config.\n\n Args:\n text: The text to parse.\n\n Return:\n None if no alias was found.\n The new command string if an alias was found.\n \"\"\"\n parts = text.strip().split(maxsplit=1)\n try:\n alias = config.get('aliases', parts[0])\n except (configexc.NoOptionError, configexc.NoSectionError):\n return None\n try:\n new_cmd = '{} {}'.format(alias, parts[1])\n except IndexError:\n new_cmd = alias\n if text.endswith(' '):\n new_cmd += ' '\n return new_cmd\n\n def parse(self, text, aliases=True, fallback=False, keep=False):\n \"\"\"Split the commandline text into command and arguments.\n\n Args:\n text: Text to parse.\n aliases: Whether to handle aliases.\n fallback: Whether to do a fallback splitting when the command was\n unknown.\n keep: Whether to keep special chars and whitespace\n\n Return:\n A split string commandline, e.g ['open', 'www.google.com']\n \"\"\"\n cmdstr, sep, argstr = text.partition(' ')\n if not cmdstr and not fallback:\n raise cmdexc.NoSuchCommandError(\"No command given\")\n if aliases:\n new_cmd = self._get_alias(text)\n if new_cmd is not None:\n log.commands.debug(\"Re-parsing with '{}'.\".format(new_cmd))\n return self.parse(new_cmd, aliases=False, fallback=fallback,\n keep=keep)\n try:\n self._cmd = cmdutils.cmd_dict[cmdstr]\n except KeyError:\n if fallback and keep:\n cmdstr, sep, argstr = text.partition(' ')\n return [cmdstr, sep] + argstr.split()\n elif fallback:\n return text.split()\n else:\n raise cmdexc.NoSuchCommandError(\n '{}: no such command'.format(cmdstr))\n self._split_args(argstr, keep)\n retargs = self._args[:]\n if keep and retargs:\n return [cmdstr, sep + retargs[0]] + retargs[1:]\n elif keep:\n return [cmdstr, sep]\n else:\n return [cmdstr] + retargs\n\n def _split_args(self, argstr, keep):\n \"\"\"Split the arguments from an arg string.\n\n Args:\n argstr: An argument string.\n keep: Whether to keep special chars and whitespace\n\n Return:\n A list containing the splitted strings.\n \"\"\"\n if not argstr:\n self._args = []\n elif self._cmd.maxsplit is None:\n self._args = split.split(argstr, keep=keep)\n else:\n # If split=False, we still want to split the flags, but not\n # everything after that.\n # We first split the arg string and check the index of the first\n # non-flag args, then we re-split again properly.\n # example:\n #\n # input: \"--foo -v bar baz\"\n # first split: ['--foo', '-v', 'bar', 'baz']\n # 0 1 2 3\n # second split: ['--foo', '-v', 'bar baz']\n # (maxsplit=2)\n split_args = split.simple_split(argstr, keep=keep)\n flag_arg_count = 0\n for i, arg in enumerate(split_args):\n arg = arg.strip()\n if arg.startswith('-'):\n if arg.lstrip('-') in self._cmd.flags_with_args:\n flag_arg_count += 1\n else:\n self._args = []\n maxsplit = i + self._cmd.maxsplit + flag_arg_count\n args = split.simple_split(argstr, keep=keep,\n maxsplit=maxsplit)\n for s in args:\n # remove quotes and replace \\\" by \"\n s = re.sub(r\"\"\"(^|[^\\\\])[\"']\"\"\", r'\\1', s)\n s = re.sub(r\"\"\"\\\\([\"'])\"\"\", r'\\1', s)\n self._args.append(s)\n break\n else:\n # If there are only flags, we got it right on the first try\n # already.\n self._args = split_args\n\n def run(self, text, count=None):\n \"\"\"Parse a command from a line of text and run it.\n\n Args:\n text: The text to parse.\n count: The count to pass to the command.\n \"\"\"\n if ';;' in text:\n for sub in text.split(';;'):\n self.run(sub, count)\n return\n self.parse(text)\n args = replace_variables(self._win_id, self._args)\n if count is not None:\n self._cmd.run(self._win_id, args, count=count)\n else:\n self._cmd.run(self._win_id, args)\n\n @pyqtSlot(str, int)\n def run_safely(self, text, count=None):\n \"\"\"Run a command and display exceptions in the statusbar.\"\"\"\n try:\n self.run(text, count)\n except (cmdexc.CommandMetaError, cmdexc.CommandError) as e:\n message.error(self._win_id, e, immediately=True)\n\n @pyqtSlot(str, int)\n def run_safely_init(self, text, count=None):\n \"\"\"Run a command and display exceptions in the statusbar.\n\n Contrary to run_safely, error messages are queued so this is more\n suitable to use while initializing.\"\"\"\n try:\n self.run(text, count)\n except (cmdexc.CommandMetaError, cmdexc.CommandError) as e:\n message.error(self._win_id, e)\n", "path": "qutebrowser/commands/runners.py"}]}
| 3,717 | 513 |
gh_patches_debug_15156
|
rasdani/github-patches
|
git_diff
|
unionai-oss__pandera-1588
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Custom DTypes With Polars
**Describe the bug**
A clear and concise description of what the bug is.
- [x] I have checked that this issue has not already been reported.
- [x] I have confirmed this bug exists on the latest version of pandera.
- [ ] (optional) I have confirmed this bug exists on the master branch of pandera.
I'm not sure if this is a bug, intentional or just missing documentation.
#### Code Sample, a copy-pastable example
```python
from pandera import dtypes
from pandera.engines import numpy_engine, pandas_engine
from pandera.typing import Series, Bool
from pandas.api.types import infer_dtype
import pandas as pd
import pandera as pa_core
@numpy_engine.Engine.register_dtype
@dtypes.immutable
class LiteralFloat(numpy_engine.Float64):
def coerce(self, series: Series) -> Series[Bool]:
"""If comes across a string, coerce it to a float. If it fails, return NaN."""
if "string" in infer_dtype(series):
series = series.apply(
lambda x: str.replace(x, ",", "") if isinstance(x, str) else x
)
return pd.to_numeric(series, errors="coerce")
class Schema(pa_core.SchemaModel):
state: str
price: Series[LiteralFloat]
class Config:
strict = "filter"
coerce = True
df = pd.DataFrame(
{
"state": ["FL", "FL", "FL", "CA", "CA", "CA"],
"price": ["8,000", "12.0", "10.0", "16.0", "20.0", "18.0"],
}
)
Schema.validate(df)
```
With the pandas API this was possible - you could write some custom dtypes that perform some basic data cleaning. For example, in our case we had a `YesNoBool` that coerces -> "yes" / "no" to booleans. This was handy since we deal with hundreds of these columns and it's a pain to write transformation logic for each one.
The documentation is pretty vague on this (not sure if this is an anti-pattern) but this was my best attempt on porting the code to polars.
```python
import pandera.polars as pa
import polars as pl
from pandera.engines import polars_engine
from pandera import dtypes
from pandera.typing import Series
@polars_engine.Engine.register_dtype
@dtypes.immutable
class LiteralFloat(pl.Float64):
def coerce(self, series):
"""If comes across a string, remove commas and coerce it to a float. If it fails, return NaN."""
series = series.str.replace(",", "").cast(pl.Float64, strict=False)
return series
class Schema(pa.DataFrameModel):
city: str
price: Series[LiteralFloat] = pa.Field(coerce=True)
class Config:
strict = "filter"
coerce = True
dl = pl.from_pandas(df)
Schema.validate(dl)
```
```
>>> SchemaInitError: Invalid annotation 'price: pandera.typing.pandas.Series[__main__.LiteralFloat]'
```
Is this intentional?
#### Desktop (please complete the following information):
- OS: Apple Silicon
- Version:
```
pandera==0.19.0b1
polars==0.20.21
pandas==2.2.2
```
#### Screenshots
None
#### Additional context
I'll be glad to open a PR to update the docs if this is just a docs issue.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pandera/api/polars/model.py`
Content:
```
1 """Class-based api for polars models."""
2
3 from typing import (
4 Any,
5 Dict,
6 List,
7 Tuple,
8 Type,
9 )
10
11 import pandas as pd
12 import polars as pl
13 from pandera.api.checks import Check
14 from pandera.api.dataframe.model import (
15 DataFrameModel as _DataFrameModel,
16 get_dtype_kwargs,
17 )
18 from pandera.api.dataframe.model_components import FieldInfo
19 from pandera.api.polars.container import DataFrameSchema
20 from pandera.api.polars.components import Column
21 from pandera.api.polars.model_config import BaseConfig
22 from pandera.errors import SchemaInitError
23 from pandera.typing import AnnotationInfo
24
25
26 class DataFrameModel(_DataFrameModel[pl.LazyFrame, DataFrameSchema]):
27 """Model of a polars :class:`~pandera.api.pandas.container.DataFrameSchema`.
28
29 See the :ref:`User Guide <dataframe-models>` for more.
30 """
31
32 Config: Type[BaseConfig] = BaseConfig
33
34 @classmethod
35 def build_schema_(cls, **kwargs):
36 return DataFrameSchema(
37 cls._build_columns(cls.__fields__, cls.__checks__),
38 checks=cls.__root_checks__,
39 **kwargs,
40 )
41
42 @classmethod
43 def _build_columns( # pylint:disable=too-many-locals
44 cls,
45 fields: Dict[str, Tuple[AnnotationInfo, FieldInfo]],
46 checks: Dict[str, List[Check]],
47 ) -> Dict[str, Column]:
48
49 columns: Dict[str, Column] = {}
50 for field_name, (annotation, field) in fields.items():
51 field_checks = checks.get(field_name, [])
52 field_name = field.name
53 check_name = getattr(field, "check_name", None)
54
55 if annotation.metadata:
56 if field.dtype_kwargs:
57 raise TypeError(
58 "Cannot specify redundant 'dtype_kwargs' "
59 + f"for {annotation.raw_annotation}."
60 + "\n Usage Tip: Drop 'typing.Annotated'."
61 )
62 dtype_kwargs = get_dtype_kwargs(annotation)
63 dtype = annotation.arg(**dtype_kwargs) # type: ignore
64 elif annotation.default_dtype:
65 dtype = annotation.default_dtype
66 else:
67 dtype = annotation.arg
68
69 dtype = None if dtype is Any else dtype
70
71 if annotation.origin is None or isinstance(
72 annotation.origin, pl.datatypes.DataTypeClass
73 ):
74 if check_name is False:
75 raise SchemaInitError(
76 f"'check_name' is not supported for {field_name}."
77 )
78
79 column_kwargs = (
80 field.column_properties(
81 dtype,
82 required=not annotation.optional,
83 checks=field_checks,
84 name=field_name,
85 )
86 if field
87 else {}
88 )
89 columns[field_name] = Column(**column_kwargs)
90
91 else:
92 raise SchemaInitError(
93 f"Invalid annotation '{field_name}: "
94 f"{annotation.raw_annotation}'"
95 )
96
97 return columns
98
99 @classmethod
100 def to_json_schema(cls):
101 """Serialize schema metadata into json-schema format.
102
103 :param dataframe_schema: schema to write to json-schema format.
104
105 .. note::
106
107 This function is currently does not fully specify a pandera schema,
108 and is primarily used internally to render OpenAPI docs via the
109 FastAPI integration.
110 """
111 schema = cls.to_schema()
112 empty = pd.DataFrame(columns=schema.columns.keys()).astype(
113 {k: v.type for k, v in schema.dtypes.items()}
114 )
115 table_schema = pd.io.json.build_table_schema(empty)
116
117 def _field_json_schema(field):
118 return {
119 "type": "array",
120 "items": {"type": field["type"]},
121 }
122
123 return {
124 "title": schema.name or "pandera.DataFrameSchema",
125 "type": "object",
126 "properties": {
127 field["name"]: _field_json_schema(field)
128 for field in table_schema["fields"]
129 },
130 }
131
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pandera/api/polars/model.py b/pandera/api/polars/model.py
--- a/pandera/api/polars/model.py
+++ b/pandera/api/polars/model.py
@@ -89,9 +89,19 @@
columns[field_name] = Column(**column_kwargs)
else:
+ origin_name = (
+ f"{annotation.origin.__module__}."
+ f"{annotation.origin.__name__}"
+ )
+ msg = (
+ " Series[TYPE] annotations are not supported for polars. "
+ "Use the bare TYPE directly"
+ if origin_name == "pandera.typing.pandas.Series"
+ else ""
+ )
raise SchemaInitError(
f"Invalid annotation '{field_name}: "
- f"{annotation.raw_annotation}'"
+ f"{annotation.raw_annotation}'.{msg}"
)
return columns
|
{"golden_diff": "diff --git a/pandera/api/polars/model.py b/pandera/api/polars/model.py\n--- a/pandera/api/polars/model.py\n+++ b/pandera/api/polars/model.py\n@@ -89,9 +89,19 @@\n columns[field_name] = Column(**column_kwargs)\n \n else:\n+ origin_name = (\n+ f\"{annotation.origin.__module__}.\"\n+ f\"{annotation.origin.__name__}\"\n+ )\n+ msg = (\n+ \" Series[TYPE] annotations are not supported for polars. \"\n+ \"Use the bare TYPE directly\"\n+ if origin_name == \"pandera.typing.pandas.Series\"\n+ else \"\"\n+ )\n raise SchemaInitError(\n f\"Invalid annotation '{field_name}: \"\n- f\"{annotation.raw_annotation}'\"\n+ f\"{annotation.raw_annotation}'.{msg}\"\n )\n \n return columns\n", "issue": "Custom DTypes With Polars\n**Describe the bug**\r\nA clear and concise description of what the bug is.\r\n\r\n- [x] I have checked that this issue has not already been reported.\r\n- [x] I have confirmed this bug exists on the latest version of pandera.\r\n- [ ] (optional) I have confirmed this bug exists on the master branch of pandera.\r\n\r\nI'm not sure if this is a bug, intentional or just missing documentation.\r\n\r\n#### Code Sample, a copy-pastable example\r\n\r\n```python\r\nfrom pandera import dtypes\r\nfrom pandera.engines import numpy_engine, pandas_engine\r\nfrom pandera.typing import Series, Bool\r\nfrom pandas.api.types import infer_dtype\r\nimport pandas as pd\r\nimport pandera as pa_core\r\n\r\n\r\n@numpy_engine.Engine.register_dtype\r\[email protected]\r\nclass LiteralFloat(numpy_engine.Float64):\r\n def coerce(self, series: Series) -> Series[Bool]:\r\n \"\"\"If comes across a string, coerce it to a float. If it fails, return NaN.\"\"\"\r\n if \"string\" in infer_dtype(series):\r\n series = series.apply(\r\n lambda x: str.replace(x, \",\", \"\") if isinstance(x, str) else x\r\n )\r\n\r\n return pd.to_numeric(series, errors=\"coerce\")\r\n\r\n\r\nclass Schema(pa_core.SchemaModel):\r\n state: str\r\n price: Series[LiteralFloat]\r\n\r\n class Config:\r\n strict = \"filter\"\r\n coerce = True\r\n\r\n\r\ndf = pd.DataFrame(\r\n {\r\n \"state\": [\"FL\", \"FL\", \"FL\", \"CA\", \"CA\", \"CA\"],\r\n \"price\": [\"8,000\", \"12.0\", \"10.0\", \"16.0\", \"20.0\", \"18.0\"],\r\n }\r\n)\r\n\r\nSchema.validate(df)\r\n```\r\n\r\nWith the pandas API this was possible - you could write some custom dtypes that perform some basic data cleaning. For example, in our case we had a `YesNoBool` that coerces -> \"yes\" / \"no\" to booleans. This was handy since we deal with hundreds of these columns and it's a pain to write transformation logic for each one.\r\n\r\nThe documentation is pretty vague on this (not sure if this is an anti-pattern) but this was my best attempt on porting the code to polars.\r\n\r\n```python\r\nimport pandera.polars as pa\r\nimport polars as pl\r\nfrom pandera.engines import polars_engine\r\nfrom pandera import dtypes\r\nfrom pandera.typing import Series\r\n\r\n\r\n@polars_engine.Engine.register_dtype\r\[email protected]\r\nclass LiteralFloat(pl.Float64):\r\n def coerce(self, series):\r\n \"\"\"If comes across a string, remove commas and coerce it to a float. If it fails, return NaN.\"\"\"\r\n series = series.str.replace(\",\", \"\").cast(pl.Float64, strict=False)\r\n return series\r\n\r\n\r\nclass Schema(pa.DataFrameModel):\r\n city: str\r\n price: Series[LiteralFloat] = pa.Field(coerce=True)\r\n\r\n class Config:\r\n strict = \"filter\"\r\n coerce = True\r\n\r\n\r\ndl = pl.from_pandas(df)\r\nSchema.validate(dl)\r\n```\r\n\r\n```\r\n>>> SchemaInitError: Invalid annotation 'price: pandera.typing.pandas.Series[__main__.LiteralFloat]'\r\n```\r\n\r\nIs this intentional?\r\n\r\n#### Desktop (please complete the following information):\r\n\r\n - OS: Apple Silicon\r\n - Version:\r\n ```\r\npandera==0.19.0b1\r\npolars==0.20.21\r\npandas==2.2.2\r\n```\r\n\r\n#### Screenshots\r\nNone\r\n\r\n#### Additional context\r\nI'll be glad to open a PR to update the docs if this is just a docs issue.\r\n\n", "before_files": [{"content": "\"\"\"Class-based api for polars models.\"\"\"\n\nfrom typing import (\n Any,\n Dict,\n List,\n Tuple,\n Type,\n)\n\nimport pandas as pd\nimport polars as pl\nfrom pandera.api.checks import Check\nfrom pandera.api.dataframe.model import (\n DataFrameModel as _DataFrameModel,\n get_dtype_kwargs,\n)\nfrom pandera.api.dataframe.model_components import FieldInfo\nfrom pandera.api.polars.container import DataFrameSchema\nfrom pandera.api.polars.components import Column\nfrom pandera.api.polars.model_config import BaseConfig\nfrom pandera.errors import SchemaInitError\nfrom pandera.typing import AnnotationInfo\n\n\nclass DataFrameModel(_DataFrameModel[pl.LazyFrame, DataFrameSchema]):\n \"\"\"Model of a polars :class:`~pandera.api.pandas.container.DataFrameSchema`.\n\n See the :ref:`User Guide <dataframe-models>` for more.\n \"\"\"\n\n Config: Type[BaseConfig] = BaseConfig\n\n @classmethod\n def build_schema_(cls, **kwargs):\n return DataFrameSchema(\n cls._build_columns(cls.__fields__, cls.__checks__),\n checks=cls.__root_checks__,\n **kwargs,\n )\n\n @classmethod\n def _build_columns( # pylint:disable=too-many-locals\n cls,\n fields: Dict[str, Tuple[AnnotationInfo, FieldInfo]],\n checks: Dict[str, List[Check]],\n ) -> Dict[str, Column]:\n\n columns: Dict[str, Column] = {}\n for field_name, (annotation, field) in fields.items():\n field_checks = checks.get(field_name, [])\n field_name = field.name\n check_name = getattr(field, \"check_name\", None)\n\n if annotation.metadata:\n if field.dtype_kwargs:\n raise TypeError(\n \"Cannot specify redundant 'dtype_kwargs' \"\n + f\"for {annotation.raw_annotation}.\"\n + \"\\n Usage Tip: Drop 'typing.Annotated'.\"\n )\n dtype_kwargs = get_dtype_kwargs(annotation)\n dtype = annotation.arg(**dtype_kwargs) # type: ignore\n elif annotation.default_dtype:\n dtype = annotation.default_dtype\n else:\n dtype = annotation.arg\n\n dtype = None if dtype is Any else dtype\n\n if annotation.origin is None or isinstance(\n annotation.origin, pl.datatypes.DataTypeClass\n ):\n if check_name is False:\n raise SchemaInitError(\n f\"'check_name' is not supported for {field_name}.\"\n )\n\n column_kwargs = (\n field.column_properties(\n dtype,\n required=not annotation.optional,\n checks=field_checks,\n name=field_name,\n )\n if field\n else {}\n )\n columns[field_name] = Column(**column_kwargs)\n\n else:\n raise SchemaInitError(\n f\"Invalid annotation '{field_name}: \"\n f\"{annotation.raw_annotation}'\"\n )\n\n return columns\n\n @classmethod\n def to_json_schema(cls):\n \"\"\"Serialize schema metadata into json-schema format.\n\n :param dataframe_schema: schema to write to json-schema format.\n\n .. note::\n\n This function is currently does not fully specify a pandera schema,\n and is primarily used internally to render OpenAPI docs via the\n FastAPI integration.\n \"\"\"\n schema = cls.to_schema()\n empty = pd.DataFrame(columns=schema.columns.keys()).astype(\n {k: v.type for k, v in schema.dtypes.items()}\n )\n table_schema = pd.io.json.build_table_schema(empty)\n\n def _field_json_schema(field):\n return {\n \"type\": \"array\",\n \"items\": {\"type\": field[\"type\"]},\n }\n\n return {\n \"title\": schema.name or \"pandera.DataFrameSchema\",\n \"type\": \"object\",\n \"properties\": {\n field[\"name\"]: _field_json_schema(field)\n for field in table_schema[\"fields\"]\n },\n }\n", "path": "pandera/api/polars/model.py"}], "after_files": [{"content": "\"\"\"Class-based api for polars models.\"\"\"\n\nfrom typing import (\n Any,\n Dict,\n List,\n Tuple,\n Type,\n)\n\nimport pandas as pd\nimport polars as pl\nfrom pandera.api.checks import Check\nfrom pandera.api.dataframe.model import (\n DataFrameModel as _DataFrameModel,\n get_dtype_kwargs,\n)\nfrom pandera.api.dataframe.model_components import FieldInfo\nfrom pandera.api.polars.container import DataFrameSchema\nfrom pandera.api.polars.components import Column\nfrom pandera.api.polars.model_config import BaseConfig\nfrom pandera.errors import SchemaInitError\nfrom pandera.typing import AnnotationInfo\n\n\nclass DataFrameModel(_DataFrameModel[pl.LazyFrame, DataFrameSchema]):\n \"\"\"Model of a polars :class:`~pandera.api.pandas.container.DataFrameSchema`.\n\n See the :ref:`User Guide <dataframe-models>` for more.\n \"\"\"\n\n Config: Type[BaseConfig] = BaseConfig\n\n @classmethod\n def build_schema_(cls, **kwargs):\n return DataFrameSchema(\n cls._build_columns(cls.__fields__, cls.__checks__),\n checks=cls.__root_checks__,\n **kwargs,\n )\n\n @classmethod\n def _build_columns( # pylint:disable=too-many-locals\n cls,\n fields: Dict[str, Tuple[AnnotationInfo, FieldInfo]],\n checks: Dict[str, List[Check]],\n ) -> Dict[str, Column]:\n\n columns: Dict[str, Column] = {}\n for field_name, (annotation, field) in fields.items():\n field_checks = checks.get(field_name, [])\n field_name = field.name\n check_name = getattr(field, \"check_name\", None)\n\n if annotation.metadata:\n if field.dtype_kwargs:\n raise TypeError(\n \"Cannot specify redundant 'dtype_kwargs' \"\n + f\"for {annotation.raw_annotation}.\"\n + \"\\n Usage Tip: Drop 'typing.Annotated'.\"\n )\n dtype_kwargs = get_dtype_kwargs(annotation)\n dtype = annotation.arg(**dtype_kwargs) # type: ignore\n elif annotation.default_dtype:\n dtype = annotation.default_dtype\n else:\n dtype = annotation.arg\n\n dtype = None if dtype is Any else dtype\n\n if annotation.origin is None or isinstance(\n annotation.origin, pl.datatypes.DataTypeClass\n ):\n if check_name is False:\n raise SchemaInitError(\n f\"'check_name' is not supported for {field_name}.\"\n )\n\n column_kwargs = (\n field.column_properties(\n dtype,\n required=not annotation.optional,\n checks=field_checks,\n name=field_name,\n )\n if field\n else {}\n )\n columns[field_name] = Column(**column_kwargs)\n\n else:\n origin_name = (\n f\"{annotation.origin.__module__}.\"\n f\"{annotation.origin.__name__}\"\n )\n msg = (\n \" Series[TYPE] annotations are not supported for polars. \"\n \"Use the bare TYPE directly\"\n if origin_name == \"pandera.typing.pandas.Series\"\n else \"\"\n )\n raise SchemaInitError(\n f\"Invalid annotation '{field_name}: \"\n f\"{annotation.raw_annotation}'.{msg}\"\n )\n\n return columns\n\n @classmethod\n def to_json_schema(cls):\n \"\"\"Serialize schema metadata into json-schema format.\n\n :param dataframe_schema: schema to write to json-schema format.\n\n .. note::\n\n This function is currently does not fully specify a pandera schema,\n and is primarily used internally to render OpenAPI docs via the\n FastAPI integration.\n \"\"\"\n schema = cls.to_schema()\n empty = pd.DataFrame(columns=schema.columns.keys()).astype(\n {k: v.type for k, v in schema.dtypes.items()}\n )\n table_schema = pd.io.json.build_table_schema(empty)\n\n def _field_json_schema(field):\n return {\n \"type\": \"array\",\n \"items\": {\"type\": field[\"type\"]},\n }\n\n return {\n \"title\": schema.name or \"pandera.DataFrameSchema\",\n \"type\": \"object\",\n \"properties\": {\n field[\"name\"]: _field_json_schema(field)\n for field in table_schema[\"fields\"]\n },\n }\n", "path": "pandera/api/polars/model.py"}]}
| 2,158 | 198 |
gh_patches_debug_5627
|
rasdani/github-patches
|
git_diff
|
nf-core__tools-2075
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Lint linter config for Python < 3.6 and issue warning if Actions are using Python 3.6 and older
### Description of the bug
```
Run nf-core -l lint_log.txt lint --dir ${GITHUB_WORKSPACE} --markdown lint_results.md
```
```python
Traceback (most recent call last):
File "/opt/hostedtoolcache/Python/3.6.15/x64/bin/nf-core", line 5, in <module>
from nf_core.__main__ import run_nf_core
File "/opt/hostedtoolcache/Python/3.6.15/x64/lib/python3.6/site-packages/nf_core/__main__.py", line 19, in <module>
import nf_core.lint
File "/opt/hostedtoolcache/Python/3.6.15/x64/lib/python3.6/site-packages/nf_core/lint/__init__.py", line 23, in <module>
import nf_core.modules.lint
File "/opt/hostedtoolcache/Python/3.6.15/x64/lib/python3.6/site-packages/nf_core/modules/__init__.py", line 1, in <module>
from .bump_versions import ModuleVersionBumper
File "/opt/hostedtoolcache/Python/3.6.15/x64/lib/python3.6/site-packages/nf_core/modules/bump_versions.py", line 24, in <module>
from .modules_command import ModuleCommand
File "/opt/hostedtoolcache/Python/3.6.15/x64/lib/python3.6/site-packages/nf_core/modules/modules_command.py", line [11](https://github.com/nf-core/scrnaseq/actions/runs/3188310073/jobs/5200822519#step:6:12), in <module>
from .modules_json import ModulesJson
File "/opt/hostedtoolcache/Python/3.6.[15](https://github.com/nf-core/scrnaseq/actions/runs/3188310073/jobs/5200822519#step:6:16)/x64/lib/python3.6/site-packages/nf_core/modules/modules_json.py", line 15, in <module>
import nf_core.modules.modules_repo
File "/opt/hostedtoolcache/Python/3.6.15/x64/lib/python3.6/site-packages/nf_core/modules/modules_repo.py", line 5, in <module>
from importlib.resources import path
ModuleNotFoundError: No module named 'importlib.resources'
```
```
Error: Process completed with exit code 1.
```
### Command used and terminal output
```console
https://github.com/nf-core/scrnaseq/actions/runs/3188310073/jobs/5200822519
```
### System information
GHA
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2
3 from setuptools import find_packages, setup
4
5 version = "2.7dev"
6
7 with open("README.md") as f:
8 readme = f.read()
9
10 with open("requirements.txt") as f:
11 required = f.read().splitlines()
12
13 setup(
14 name="nf-core",
15 version=version,
16 description="Helper tools for use with nf-core Nextflow pipelines.",
17 long_description=readme,
18 long_description_content_type="text/markdown",
19 keywords=[
20 "nf-core",
21 "nextflow",
22 "bioinformatics",
23 "workflow",
24 "pipeline",
25 "biology",
26 "sequencing",
27 "NGS",
28 "next generation sequencing",
29 ],
30 author="Phil Ewels",
31 author_email="[email protected]",
32 url="https://github.com/nf-core/tools",
33 license="MIT",
34 entry_points={
35 "console_scripts": ["nf-core=nf_core.__main__:run_nf_core"],
36 "refgenie.hooks.post_update": ["nf-core-refgenie=nf_core.refgenie:update_config"],
37 },
38 install_requires=required,
39 packages=find_packages(exclude=("docs")),
40 include_package_data=True,
41 zip_safe=False,
42 )
43
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -35,6 +35,7 @@
"console_scripts": ["nf-core=nf_core.__main__:run_nf_core"],
"refgenie.hooks.post_update": ["nf-core-refgenie=nf_core.refgenie:update_config"],
},
+ python_requires=">=3.7, <4",
install_requires=required,
packages=find_packages(exclude=("docs")),
include_package_data=True,
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -35,6 +35,7 @@\n \"console_scripts\": [\"nf-core=nf_core.__main__:run_nf_core\"],\n \"refgenie.hooks.post_update\": [\"nf-core-refgenie=nf_core.refgenie:update_config\"],\n },\n+ python_requires=\">=3.7, <4\",\n install_requires=required,\n packages=find_packages(exclude=(\"docs\")),\n include_package_data=True,\n", "issue": "Lint linter config for Python < 3.6 and issue warning if Actions are using Python 3.6 and older\n### Description of the bug\r\n\r\n```\r\nRun nf-core -l lint_log.txt lint --dir ${GITHUB_WORKSPACE} --markdown lint_results.md\r\n```\r\n```python\r\nTraceback (most recent call last):\r\n File \"/opt/hostedtoolcache/Python/3.6.15/x64/bin/nf-core\", line 5, in <module>\r\n from nf_core.__main__ import run_nf_core\r\n File \"/opt/hostedtoolcache/Python/3.6.15/x64/lib/python3.6/site-packages/nf_core/__main__.py\", line 19, in <module>\r\n import nf_core.lint\r\n File \"/opt/hostedtoolcache/Python/3.6.15/x64/lib/python3.6/site-packages/nf_core/lint/__init__.py\", line 23, in <module>\r\n import nf_core.modules.lint\r\n File \"/opt/hostedtoolcache/Python/3.6.15/x64/lib/python3.6/site-packages/nf_core/modules/__init__.py\", line 1, in <module>\r\n from .bump_versions import ModuleVersionBumper\r\n File \"/opt/hostedtoolcache/Python/3.6.15/x64/lib/python3.6/site-packages/nf_core/modules/bump_versions.py\", line 24, in <module>\r\n from .modules_command import ModuleCommand\r\n File \"/opt/hostedtoolcache/Python/3.6.15/x64/lib/python3.6/site-packages/nf_core/modules/modules_command.py\", line [11](https://github.com/nf-core/scrnaseq/actions/runs/3188310073/jobs/5200822519#step:6:12), in <module>\r\n from .modules_json import ModulesJson\r\n File \"/opt/hostedtoolcache/Python/3.6.[15](https://github.com/nf-core/scrnaseq/actions/runs/3188310073/jobs/5200822519#step:6:16)/x64/lib/python3.6/site-packages/nf_core/modules/modules_json.py\", line 15, in <module>\r\n import nf_core.modules.modules_repo\r\n File \"/opt/hostedtoolcache/Python/3.6.15/x64/lib/python3.6/site-packages/nf_core/modules/modules_repo.py\", line 5, in <module>\r\n from importlib.resources import path\r\nModuleNotFoundError: No module named 'importlib.resources'\r\n```\r\n```\r\nError: Process completed with exit code 1.\r\n```\r\n\r\n### Command used and terminal output\r\n\r\n```console\r\nhttps://github.com/nf-core/scrnaseq/actions/runs/3188310073/jobs/5200822519\r\n```\r\n\r\n\r\n### System information\r\n\r\nGHA\n", "before_files": [{"content": "#!/usr/bin/env python\n\nfrom setuptools import find_packages, setup\n\nversion = \"2.7dev\"\n\nwith open(\"README.md\") as f:\n readme = f.read()\n\nwith open(\"requirements.txt\") as f:\n required = f.read().splitlines()\n\nsetup(\n name=\"nf-core\",\n version=version,\n description=\"Helper tools for use with nf-core Nextflow pipelines.\",\n long_description=readme,\n long_description_content_type=\"text/markdown\",\n keywords=[\n \"nf-core\",\n \"nextflow\",\n \"bioinformatics\",\n \"workflow\",\n \"pipeline\",\n \"biology\",\n \"sequencing\",\n \"NGS\",\n \"next generation sequencing\",\n ],\n author=\"Phil Ewels\",\n author_email=\"[email protected]\",\n url=\"https://github.com/nf-core/tools\",\n license=\"MIT\",\n entry_points={\n \"console_scripts\": [\"nf-core=nf_core.__main__:run_nf_core\"],\n \"refgenie.hooks.post_update\": [\"nf-core-refgenie=nf_core.refgenie:update_config\"],\n },\n install_requires=required,\n packages=find_packages(exclude=(\"docs\")),\n include_package_data=True,\n zip_safe=False,\n)\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\n\nfrom setuptools import find_packages, setup\n\nversion = \"2.7dev\"\n\nwith open(\"README.md\") as f:\n readme = f.read()\n\nwith open(\"requirements.txt\") as f:\n required = f.read().splitlines()\n\nsetup(\n name=\"nf-core\",\n version=version,\n description=\"Helper tools for use with nf-core Nextflow pipelines.\",\n long_description=readme,\n long_description_content_type=\"text/markdown\",\n keywords=[\n \"nf-core\",\n \"nextflow\",\n \"bioinformatics\",\n \"workflow\",\n \"pipeline\",\n \"biology\",\n \"sequencing\",\n \"NGS\",\n \"next generation sequencing\",\n ],\n author=\"Phil Ewels\",\n author_email=\"[email protected]\",\n url=\"https://github.com/nf-core/tools\",\n license=\"MIT\",\n entry_points={\n \"console_scripts\": [\"nf-core=nf_core.__main__:run_nf_core\"],\n \"refgenie.hooks.post_update\": [\"nf-core-refgenie=nf_core.refgenie:update_config\"],\n },\n python_requires=\">=3.7, <4\",\n install_requires=required,\n packages=find_packages(exclude=(\"docs\")),\n include_package_data=True,\n zip_safe=False,\n)\n", "path": "setup.py"}]}
| 1,269 | 111 |
gh_patches_debug_21694
|
rasdani/github-patches
|
git_diff
|
plone__Products.CMFPlone-3586
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Site title entered in the @@plone-addsite form is not set as site title
Plone site title is set in the @@site-controlpanel form and saved in the registry. But the @@plone-addsite form gets the site title from the user and saves it as a Zope property in the portal object.
Related to https://github.com/plone/plone.app.layout/issues/317
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `Products/CMFPlone/factory.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 from logging import getLogger
3 from plone.registry.interfaces import IRegistry
4 from Products.CMFPlone import PloneMessageFactory as _
5 from Products.CMFPlone.events import SiteManagerCreatedEvent
6 from Products.CMFPlone.interfaces import INonInstallable
7 from Products.CMFPlone.Portal import PloneSite
8 from Products.GenericSetup.tool import SetupTool
9 from Products.statusmessages.interfaces import IStatusMessage
10 from zope.component import queryUtility
11 from zope.component.hooks import setSite
12 from zope.event import notify
13 from zope.interface import implementer
14
15 _TOOL_ID = 'portal_setup'
16 _DEFAULT_PROFILE = 'Products.CMFPlone:plone'
17 _TYPES_PROFILE = 'plone.app.contenttypes:default'
18 _CONTENT_PROFILE = 'plone.app.contenttypes:plone-content'
19
20 # A little hint for PloneTestCase
21 _IMREALLYPLONE5 = True
22
23 # Marker hints for code that needs to know the major Plone version
24 # Works the same way than zcml condition hints so it contains the current and the
25 # last ones
26 PLONE52MARKER = True
27
28 logger = getLogger('Plone')
29
30
31 @implementer(INonInstallable)
32 class NonInstallable(object):
33
34 def getNonInstallableProducts(self):
35 return [
36 'Archetypes', 'Products.Archetypes',
37 'CMFDefault', 'Products.CMFDefault',
38 'CMFPlone', 'Products.CMFPlone', 'Products.CMFPlone.migrations',
39 'CMFTopic', 'Products.CMFTopic',
40 'CMFUid', 'Products.CMFUid',
41 'DCWorkflow', 'Products.DCWorkflow',
42 'PasswordResetTool', 'Products.PasswordResetTool',
43 'PlonePAS', 'Products.PlonePAS',
44 'wicked.at',
45 'PloneLanguageTool', 'Products.PloneLanguageTool',
46 'CMFFormController', 'Products.CMFFormController',
47 'MimetypesRegistry', 'Products.MimetypesRegistry',
48 'PortalTransforms', 'Products.PortalTransforms',
49 'CMFDiffTool', 'Products.CMFDiffTool',
50 'CMFEditions', 'Products.CMFEditions',
51 'Products.NuPlone',
52 'borg.localrole',
53 'plone.app.blob',
54 'plone.app.caching',
55 'plone.app.collection',
56 'plone.app.dexterity',
57 'plone.app.discussion',
58 'plone.app.event',
59 'plone.app.imaging',
60 'plone.app.intid',
61 'plone.app.linkintegrity',
62 'plone.app.querystring',
63 'plone.app.registry',
64 'plone.app.referenceablebehavior',
65 'plone.app.relationfield',
66 'plone.app.theming',
67 'plone.app.users',
68 'plone.app.widgets',
69 'plone.app.z3cform',
70 'plone.formwidget.recurrence',
71 'plone.keyring',
72 'plone.outputfilters',
73 'plone.portlet.static',
74 'plone.portlet.collection',
75 'plone.protect',
76 'plone.resource',
77 'plonetheme.barceloneta',
78 ]
79
80 def getNonInstallableProfiles(self):
81 return [_DEFAULT_PROFILE,
82 _CONTENT_PROFILE,
83 u'Products.Archetypes:Archetypes',
84 u'Products.ATContentTypes:default',
85 u'Products.CMFDiffTool:CMFDiffTool',
86 u'Products.CMFEditions:CMFEditions',
87 u'Products.CMFFormController:CMFFormController',
88 u'Products.CMFPlone:dependencies',
89 u'Products.CMFPlone:testfixture',
90 u'Products.CMFQuickInstallerTool:CMFQuickInstallerTool',
91 u'Products.NuPlone:uninstall',
92 u'Products.MimetypesRegistry:MimetypesRegistry',
93 u'Products.PasswordResetTool:PasswordResetTool',
94 u'Products.PortalTransforms:PortalTransforms',
95 u'Products.PloneLanguageTool:PloneLanguageTool',
96 u'Products.PlonePAS:PlonePAS',
97 u'borg.localrole:default',
98 u'plone.browserlayer:default',
99 u'plone.keyring:default',
100 u'plone.outputfilters:default',
101 u'plone.portlet.static:default',
102 u'plone.portlet.collection:default',
103 u'plone.protect:default',
104 u'plone.app.blob:default',
105 u'plone.app.blob:file-replacement',
106 u'plone.app.blob:image-replacement',
107 u'plone.app.blob:sample-type',
108 u'plone.app.collection:default',
109 u'plone.app.contenttypes:default',
110 u'plone.app.dexterity:default',
111 u'plone.app.discussion:default',
112 u'plone.app.event:default',
113 u'plone.app.imaging:default',
114 u'plone.app.linkintegrity:default',
115 u'plone.app.registry:default',
116 u'plone.app.relationfield:default',
117 u'plone.app.theming:default',
118 u'plone.app.users:default',
119 u'plone.app.versioningbehavior:default',
120 u'plone.app.z3cform:default',
121 u'plone.formwidget.recurrence:default',
122 u'plone.resource:default',
123 ]
124
125
126 def zmi_constructor(context):
127 """This is a dummy constructor for the ZMI."""
128 url = context.DestinationURL()
129 request = context.REQUEST
130 return request.response.redirect(url + '/@@plone-addsite?site_id=Plone')
131
132
133 def addPloneSite(context, site_id, title='Plone site', description='',
134 profile_id=_DEFAULT_PROFILE,
135 content_profile_id=_CONTENT_PROFILE, snapshot=False,
136 extension_ids=(), setup_content=True,
137 default_language='en', portal_timezone='UTC'):
138 """Add a PloneSite to the context."""
139 context._setObject(site_id, PloneSite(site_id))
140 site = context._getOb(site_id)
141 site.setLanguage(default_language)
142 # Set the accepted language for the rest of the request. This makes sure
143 # the front-page text gets the correct translation also when your browser
144 # prefers non-English and you choose English as language for the Plone
145 # Site.
146 request = context.REQUEST
147 request['HTTP_ACCEPT_LANGUAGE'] = default_language
148
149 site[_TOOL_ID] = SetupTool(_TOOL_ID)
150 setup_tool = site[_TOOL_ID]
151
152 notify(SiteManagerCreatedEvent(site))
153 setSite(site)
154
155 setup_tool.setBaselineContext('profile-%s' % profile_id)
156 setup_tool.runAllImportStepsFromProfile('profile-%s' % profile_id)
157
158 reg = queryUtility(IRegistry, context=site)
159 reg['plone.portal_timezone'] = portal_timezone
160 reg['plone.available_timezones'] = [portal_timezone]
161 reg['plone.default_language'] = default_language
162 reg['plone.available_languages'] = [default_language]
163
164 # Install default content types profile if user do not select "example content"
165 # during site creation.
166 content_types_profile = content_profile_id if setup_content else _TYPES_PROFILE
167
168 setup_tool.runAllImportStepsFromProfile('profile-{0}'.format(content_types_profile))
169
170 props = dict(
171 title=title,
172 description=description,
173 )
174 # Do this before applying extension profiles, so the settings from a
175 # properties.xml file are applied and not overwritten by this
176 site.manage_changeProperties(**props)
177
178 for extension_id in extension_ids:
179 try:
180 setup_tool.runAllImportStepsFromProfile(
181 'profile-%s' % extension_id)
182 except Exception as msg:
183 IStatusMessage(request).add(_(
184 'Could not install ${profile_id}: ${error_msg}! '
185 'Please try to install it manually using the "Addons" '
186 'controlpanel and report any issues to the '
187 'addon maintainers.',
188 mapping={
189 'profile_id': extension_id,
190 'error_msg': msg.args,
191 }),
192 type='error')
193 logger.exception(
194 'Error while installing addon {}. '
195 'See traceback below for details.'.format(extension_id))
196
197 if snapshot is True:
198 setup_tool.createSnapshot('initial_configuration')
199
200 return site
201
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/Products/CMFPlone/factory.py b/Products/CMFPlone/factory.py
--- a/Products/CMFPlone/factory.py
+++ b/Products/CMFPlone/factory.py
@@ -5,6 +5,7 @@
from Products.CMFPlone.events import SiteManagerCreatedEvent
from Products.CMFPlone.interfaces import INonInstallable
from Products.CMFPlone.Portal import PloneSite
+from Products.CMFPlone.utils import safe_unicode
from Products.GenericSetup.tool import SetupTool
from Products.statusmessages.interfaces import IStatusMessage
from zope.component import queryUtility
@@ -160,6 +161,7 @@
reg['plone.available_timezones'] = [portal_timezone]
reg['plone.default_language'] = default_language
reg['plone.available_languages'] = [default_language]
+ reg['plone.site_title'] = safe_unicode(title)
# Install default content types profile if user do not select "example content"
# during site creation.
|
{"golden_diff": "diff --git a/Products/CMFPlone/factory.py b/Products/CMFPlone/factory.py\n--- a/Products/CMFPlone/factory.py\n+++ b/Products/CMFPlone/factory.py\n@@ -5,6 +5,7 @@\n from Products.CMFPlone.events import SiteManagerCreatedEvent\n from Products.CMFPlone.interfaces import INonInstallable\n from Products.CMFPlone.Portal import PloneSite\n+from Products.CMFPlone.utils import safe_unicode\n from Products.GenericSetup.tool import SetupTool\n from Products.statusmessages.interfaces import IStatusMessage\n from zope.component import queryUtility\n@@ -160,6 +161,7 @@\n reg['plone.available_timezones'] = [portal_timezone]\n reg['plone.default_language'] = default_language\n reg['plone.available_languages'] = [default_language]\n+ reg['plone.site_title'] = safe_unicode(title)\n \n # Install default content types profile if user do not select \"example content\"\n # during site creation.\n", "issue": "Site title entered in the @@plone-addsite form is not set as site title\nPlone site title is set in the @@site-controlpanel form and saved in the registry. But the @@plone-addsite form gets the site title from the user and saves it as a Zope property in the portal object.\r\n\r\n\r\nRelated to https://github.com/plone/plone.app.layout/issues/317\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom logging import getLogger\nfrom plone.registry.interfaces import IRegistry\nfrom Products.CMFPlone import PloneMessageFactory as _\nfrom Products.CMFPlone.events import SiteManagerCreatedEvent\nfrom Products.CMFPlone.interfaces import INonInstallable\nfrom Products.CMFPlone.Portal import PloneSite\nfrom Products.GenericSetup.tool import SetupTool\nfrom Products.statusmessages.interfaces import IStatusMessage\nfrom zope.component import queryUtility\nfrom zope.component.hooks import setSite\nfrom zope.event import notify\nfrom zope.interface import implementer\n\n_TOOL_ID = 'portal_setup'\n_DEFAULT_PROFILE = 'Products.CMFPlone:plone'\n_TYPES_PROFILE = 'plone.app.contenttypes:default'\n_CONTENT_PROFILE = 'plone.app.contenttypes:plone-content'\n\n# A little hint for PloneTestCase\n_IMREALLYPLONE5 = True\n\n# Marker hints for code that needs to know the major Plone version\n# Works the same way than zcml condition hints so it contains the current and the\n# last ones\nPLONE52MARKER = True\n\nlogger = getLogger('Plone')\n\n\n@implementer(INonInstallable)\nclass NonInstallable(object):\n\n def getNonInstallableProducts(self):\n return [\n 'Archetypes', 'Products.Archetypes',\n 'CMFDefault', 'Products.CMFDefault',\n 'CMFPlone', 'Products.CMFPlone', 'Products.CMFPlone.migrations',\n 'CMFTopic', 'Products.CMFTopic',\n 'CMFUid', 'Products.CMFUid',\n 'DCWorkflow', 'Products.DCWorkflow',\n 'PasswordResetTool', 'Products.PasswordResetTool',\n 'PlonePAS', 'Products.PlonePAS',\n 'wicked.at',\n 'PloneLanguageTool', 'Products.PloneLanguageTool',\n 'CMFFormController', 'Products.CMFFormController',\n 'MimetypesRegistry', 'Products.MimetypesRegistry',\n 'PortalTransforms', 'Products.PortalTransforms',\n 'CMFDiffTool', 'Products.CMFDiffTool',\n 'CMFEditions', 'Products.CMFEditions',\n 'Products.NuPlone',\n 'borg.localrole',\n 'plone.app.blob',\n 'plone.app.caching',\n 'plone.app.collection',\n 'plone.app.dexterity',\n 'plone.app.discussion',\n 'plone.app.event',\n 'plone.app.imaging',\n 'plone.app.intid',\n 'plone.app.linkintegrity',\n 'plone.app.querystring',\n 'plone.app.registry',\n 'plone.app.referenceablebehavior',\n 'plone.app.relationfield',\n 'plone.app.theming',\n 'plone.app.users',\n 'plone.app.widgets',\n 'plone.app.z3cform',\n 'plone.formwidget.recurrence',\n 'plone.keyring',\n 'plone.outputfilters',\n 'plone.portlet.static',\n 'plone.portlet.collection',\n 'plone.protect',\n 'plone.resource',\n 'plonetheme.barceloneta',\n ]\n\n def getNonInstallableProfiles(self):\n return [_DEFAULT_PROFILE,\n _CONTENT_PROFILE,\n u'Products.Archetypes:Archetypes',\n u'Products.ATContentTypes:default',\n u'Products.CMFDiffTool:CMFDiffTool',\n u'Products.CMFEditions:CMFEditions',\n u'Products.CMFFormController:CMFFormController',\n u'Products.CMFPlone:dependencies',\n u'Products.CMFPlone:testfixture',\n u'Products.CMFQuickInstallerTool:CMFQuickInstallerTool',\n u'Products.NuPlone:uninstall',\n u'Products.MimetypesRegistry:MimetypesRegistry',\n u'Products.PasswordResetTool:PasswordResetTool',\n u'Products.PortalTransforms:PortalTransforms',\n u'Products.PloneLanguageTool:PloneLanguageTool',\n u'Products.PlonePAS:PlonePAS',\n u'borg.localrole:default',\n u'plone.browserlayer:default',\n u'plone.keyring:default',\n u'plone.outputfilters:default',\n u'plone.portlet.static:default',\n u'plone.portlet.collection:default',\n u'plone.protect:default',\n u'plone.app.blob:default',\n u'plone.app.blob:file-replacement',\n u'plone.app.blob:image-replacement',\n u'plone.app.blob:sample-type',\n u'plone.app.collection:default',\n u'plone.app.contenttypes:default',\n u'plone.app.dexterity:default',\n u'plone.app.discussion:default',\n u'plone.app.event:default',\n u'plone.app.imaging:default',\n u'plone.app.linkintegrity:default',\n u'plone.app.registry:default',\n u'plone.app.relationfield:default',\n u'plone.app.theming:default',\n u'plone.app.users:default',\n u'plone.app.versioningbehavior:default',\n u'plone.app.z3cform:default',\n u'plone.formwidget.recurrence:default',\n u'plone.resource:default',\n ]\n\n\ndef zmi_constructor(context):\n \"\"\"This is a dummy constructor for the ZMI.\"\"\"\n url = context.DestinationURL()\n request = context.REQUEST\n return request.response.redirect(url + '/@@plone-addsite?site_id=Plone')\n\n\ndef addPloneSite(context, site_id, title='Plone site', description='',\n profile_id=_DEFAULT_PROFILE,\n content_profile_id=_CONTENT_PROFILE, snapshot=False,\n extension_ids=(), setup_content=True,\n default_language='en', portal_timezone='UTC'):\n \"\"\"Add a PloneSite to the context.\"\"\"\n context._setObject(site_id, PloneSite(site_id))\n site = context._getOb(site_id)\n site.setLanguage(default_language)\n # Set the accepted language for the rest of the request. This makes sure\n # the front-page text gets the correct translation also when your browser\n # prefers non-English and you choose English as language for the Plone\n # Site.\n request = context.REQUEST\n request['HTTP_ACCEPT_LANGUAGE'] = default_language\n\n site[_TOOL_ID] = SetupTool(_TOOL_ID)\n setup_tool = site[_TOOL_ID]\n\n notify(SiteManagerCreatedEvent(site))\n setSite(site)\n\n setup_tool.setBaselineContext('profile-%s' % profile_id)\n setup_tool.runAllImportStepsFromProfile('profile-%s' % profile_id)\n\n reg = queryUtility(IRegistry, context=site)\n reg['plone.portal_timezone'] = portal_timezone\n reg['plone.available_timezones'] = [portal_timezone]\n reg['plone.default_language'] = default_language\n reg['plone.available_languages'] = [default_language]\n\n # Install default content types profile if user do not select \"example content\"\n # during site creation.\n content_types_profile = content_profile_id if setup_content else _TYPES_PROFILE\n\n setup_tool.runAllImportStepsFromProfile('profile-{0}'.format(content_types_profile))\n\n props = dict(\n title=title,\n description=description,\n )\n # Do this before applying extension profiles, so the settings from a\n # properties.xml file are applied and not overwritten by this\n site.manage_changeProperties(**props)\n\n for extension_id in extension_ids:\n try:\n setup_tool.runAllImportStepsFromProfile(\n 'profile-%s' % extension_id)\n except Exception as msg:\n IStatusMessage(request).add(_(\n 'Could not install ${profile_id}: ${error_msg}! '\n 'Please try to install it manually using the \"Addons\" '\n 'controlpanel and report any issues to the '\n 'addon maintainers.',\n mapping={\n 'profile_id': extension_id,\n 'error_msg': msg.args,\n }),\n type='error')\n logger.exception(\n 'Error while installing addon {}. '\n 'See traceback below for details.'.format(extension_id))\n\n if snapshot is True:\n setup_tool.createSnapshot('initial_configuration')\n\n return site\n", "path": "Products/CMFPlone/factory.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\nfrom logging import getLogger\nfrom plone.registry.interfaces import IRegistry\nfrom Products.CMFPlone import PloneMessageFactory as _\nfrom Products.CMFPlone.events import SiteManagerCreatedEvent\nfrom Products.CMFPlone.interfaces import INonInstallable\nfrom Products.CMFPlone.Portal import PloneSite\nfrom Products.CMFPlone.utils import safe_unicode\nfrom Products.GenericSetup.tool import SetupTool\nfrom Products.statusmessages.interfaces import IStatusMessage\nfrom zope.component import queryUtility\nfrom zope.component.hooks import setSite\nfrom zope.event import notify\nfrom zope.interface import implementer\n\n_TOOL_ID = 'portal_setup'\n_DEFAULT_PROFILE = 'Products.CMFPlone:plone'\n_TYPES_PROFILE = 'plone.app.contenttypes:default'\n_CONTENT_PROFILE = 'plone.app.contenttypes:plone-content'\n\n# A little hint for PloneTestCase\n_IMREALLYPLONE5 = True\n\n# Marker hints for code that needs to know the major Plone version\n# Works the same way than zcml condition hints so it contains the current and the\n# last ones\nPLONE52MARKER = True\n\nlogger = getLogger('Plone')\n\n\n@implementer(INonInstallable)\nclass NonInstallable(object):\n\n def getNonInstallableProducts(self):\n return [\n 'Archetypes', 'Products.Archetypes',\n 'CMFDefault', 'Products.CMFDefault',\n 'CMFPlone', 'Products.CMFPlone', 'Products.CMFPlone.migrations',\n 'CMFTopic', 'Products.CMFTopic',\n 'CMFUid', 'Products.CMFUid',\n 'DCWorkflow', 'Products.DCWorkflow',\n 'PasswordResetTool', 'Products.PasswordResetTool',\n 'PlonePAS', 'Products.PlonePAS',\n 'wicked.at',\n 'PloneLanguageTool', 'Products.PloneLanguageTool',\n 'CMFFormController', 'Products.CMFFormController',\n 'MimetypesRegistry', 'Products.MimetypesRegistry',\n 'PortalTransforms', 'Products.PortalTransforms',\n 'CMFDiffTool', 'Products.CMFDiffTool',\n 'CMFEditions', 'Products.CMFEditions',\n 'Products.NuPlone',\n 'borg.localrole',\n 'plone.app.blob',\n 'plone.app.caching',\n 'plone.app.collection',\n 'plone.app.dexterity',\n 'plone.app.discussion',\n 'plone.app.event',\n 'plone.app.imaging',\n 'plone.app.intid',\n 'plone.app.linkintegrity',\n 'plone.app.querystring',\n 'plone.app.registry',\n 'plone.app.referenceablebehavior',\n 'plone.app.relationfield',\n 'plone.app.theming',\n 'plone.app.users',\n 'plone.app.widgets',\n 'plone.app.z3cform',\n 'plone.formwidget.recurrence',\n 'plone.keyring',\n 'plone.outputfilters',\n 'plone.portlet.static',\n 'plone.portlet.collection',\n 'plone.protect',\n 'plone.resource',\n 'plonetheme.barceloneta',\n ]\n\n def getNonInstallableProfiles(self):\n return [_DEFAULT_PROFILE,\n _CONTENT_PROFILE,\n u'Products.Archetypes:Archetypes',\n u'Products.ATContentTypes:default',\n u'Products.CMFDiffTool:CMFDiffTool',\n u'Products.CMFEditions:CMFEditions',\n u'Products.CMFFormController:CMFFormController',\n u'Products.CMFPlone:dependencies',\n u'Products.CMFPlone:testfixture',\n u'Products.CMFQuickInstallerTool:CMFQuickInstallerTool',\n u'Products.NuPlone:uninstall',\n u'Products.MimetypesRegistry:MimetypesRegistry',\n u'Products.PasswordResetTool:PasswordResetTool',\n u'Products.PortalTransforms:PortalTransforms',\n u'Products.PloneLanguageTool:PloneLanguageTool',\n u'Products.PlonePAS:PlonePAS',\n u'borg.localrole:default',\n u'plone.browserlayer:default',\n u'plone.keyring:default',\n u'plone.outputfilters:default',\n u'plone.portlet.static:default',\n u'plone.portlet.collection:default',\n u'plone.protect:default',\n u'plone.app.blob:default',\n u'plone.app.blob:file-replacement',\n u'plone.app.blob:image-replacement',\n u'plone.app.blob:sample-type',\n u'plone.app.collection:default',\n u'plone.app.contenttypes:default',\n u'plone.app.dexterity:default',\n u'plone.app.discussion:default',\n u'plone.app.event:default',\n u'plone.app.imaging:default',\n u'plone.app.linkintegrity:default',\n u'plone.app.registry:default',\n u'plone.app.relationfield:default',\n u'plone.app.theming:default',\n u'plone.app.users:default',\n u'plone.app.versioningbehavior:default',\n u'plone.app.z3cform:default',\n u'plone.formwidget.recurrence:default',\n u'plone.resource:default',\n ]\n\n\ndef zmi_constructor(context):\n \"\"\"This is a dummy constructor for the ZMI.\"\"\"\n url = context.DestinationURL()\n request = context.REQUEST\n return request.response.redirect(url + '/@@plone-addsite?site_id=Plone')\n\n\ndef addPloneSite(context, site_id, title='Plone site', description='',\n profile_id=_DEFAULT_PROFILE,\n content_profile_id=_CONTENT_PROFILE, snapshot=False,\n extension_ids=(), setup_content=True,\n default_language='en', portal_timezone='UTC'):\n \"\"\"Add a PloneSite to the context.\"\"\"\n context._setObject(site_id, PloneSite(site_id))\n site = context._getOb(site_id)\n site.setLanguage(default_language)\n # Set the accepted language for the rest of the request. This makes sure\n # the front-page text gets the correct translation also when your browser\n # prefers non-English and you choose English as language for the Plone\n # Site.\n request = context.REQUEST\n request['HTTP_ACCEPT_LANGUAGE'] = default_language\n\n site[_TOOL_ID] = SetupTool(_TOOL_ID)\n setup_tool = site[_TOOL_ID]\n\n notify(SiteManagerCreatedEvent(site))\n setSite(site)\n\n setup_tool.setBaselineContext('profile-%s' % profile_id)\n setup_tool.runAllImportStepsFromProfile('profile-%s' % profile_id)\n\n reg = queryUtility(IRegistry, context=site)\n reg['plone.portal_timezone'] = portal_timezone\n reg['plone.available_timezones'] = [portal_timezone]\n reg['plone.default_language'] = default_language\n reg['plone.available_languages'] = [default_language]\n reg['plone.site_title'] = safe_unicode(title)\n\n # Install default content types profile if user do not select \"example content\"\n # during site creation.\n content_types_profile = content_profile_id if setup_content else _TYPES_PROFILE\n\n setup_tool.runAllImportStepsFromProfile('profile-{0}'.format(content_types_profile))\n\n props = dict(\n title=title,\n description=description,\n )\n # Do this before applying extension profiles, so the settings from a\n # properties.xml file are applied and not overwritten by this\n site.manage_changeProperties(**props)\n\n for extension_id in extension_ids:\n try:\n setup_tool.runAllImportStepsFromProfile(\n 'profile-%s' % extension_id)\n except Exception as msg:\n IStatusMessage(request).add(_(\n 'Could not install ${profile_id}: ${error_msg}! '\n 'Please try to install it manually using the \"Addons\" '\n 'controlpanel and report any issues to the '\n 'addon maintainers.',\n mapping={\n 'profile_id': extension_id,\n 'error_msg': msg.args,\n }),\n type='error')\n logger.exception(\n 'Error while installing addon {}. '\n 'See traceback below for details.'.format(extension_id))\n\n if snapshot is True:\n setup_tool.createSnapshot('initial_configuration')\n\n return site\n", "path": "Products/CMFPlone/factory.py"}]}
| 2,666 | 230 |
gh_patches_debug_9252
|
rasdani/github-patches
|
git_diff
|
HypothesisWorks__hypothesis-2889
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Improve handling of self-referential strategies
As mentioned in #2783, the following strategy is not explicitly forbidden but fails with an `AssertionError`:
```python
from hypothesis import strategies as st
SELF_REF = st.recursive(
st.deferred(lambda: SELF_REF | st.booleans()),
lambda s: st.lists(s, min_size=1)
)
```
There is an alternative strategy that produces the same data, but doesn't fail the same way:
```python
SELF_REF = st.recursive(
st.booleans(),
lambda s: st.lists(s, min_size=1)
)
```
I am not sure if all self-referential strategies can be rewritten like this, but probably we can either explicitly forbid such strategies or revisit our drawing approach for them.
Here is my reasoning from #2783
> As far as I see, the cap is needed to prevent the drawing from this strategy & generating a certain maximum amount of leaves. However, assuming a single thread (more on the multi-threaded behavior in the next section) and such a self-referential strategy, I am not sure if capping is needed as it is - we can just apply it once on the first capped usage and make all subsequent calls no-op (e.g., just yield without modifying marked). Then we still have the marker set only once on the very first RecursiveStrategy.do_draw call, and it will be monotonically decreasing. Therefore, we'll have the max size properly maintained, and there will be no oversized subtrees because, at some point, LimitReached will occur.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `hypothesis-python/src/hypothesis/strategies/_internal/recursive.py`
Content:
```
1 # This file is part of Hypothesis, which may be found at
2 # https://github.com/HypothesisWorks/hypothesis/
3 #
4 # Most of this work is copyright (C) 2013-2021 David R. MacIver
5 # ([email protected]), but it contains contributions by others. See
6 # CONTRIBUTING.rst for a full list of people who may hold copyright, and
7 # consult the git log if you need to determine who owns an individual
8 # contribution.
9 #
10 # This Source Code Form is subject to the terms of the Mozilla Public License,
11 # v. 2.0. If a copy of the MPL was not distributed with this file, You can
12 # obtain one at https://mozilla.org/MPL/2.0/.
13 #
14 # END HEADER
15
16 import threading
17 from contextlib import contextmanager
18
19 from hypothesis.internal.lazyformat import lazyformat
20 from hypothesis.internal.reflection import get_pretty_function_description
21 from hypothesis.strategies._internal.strategies import (
22 OneOfStrategy,
23 SearchStrategy,
24 check_strategy,
25 )
26
27
28 class LimitReached(BaseException):
29 pass
30
31
32 class LimitedStrategy(SearchStrategy):
33 def __init__(self, strategy):
34 super().__init__()
35 self.base_strategy = strategy
36 self._threadlocal = threading.local()
37
38 @property
39 def marker(self):
40 return getattr(self._threadlocal, "marker", 0)
41
42 @marker.setter
43 def marker(self, value):
44 self._threadlocal.marker = value
45
46 @property
47 def currently_capped(self):
48 return getattr(self._threadlocal, "currently_capped", False)
49
50 @currently_capped.setter
51 def currently_capped(self, value):
52 self._threadlocal.currently_capped = value
53
54 def __repr__(self):
55 return f"LimitedStrategy({self.base_strategy!r})"
56
57 def do_validate(self):
58 self.base_strategy.validate()
59
60 def do_draw(self, data):
61 assert self.currently_capped
62 if self.marker <= 0:
63 raise LimitReached()
64 self.marker -= 1
65 return data.draw(self.base_strategy)
66
67 @contextmanager
68 def capped(self, max_templates):
69 assert not self.currently_capped
70 try:
71 self.currently_capped = True
72 self.marker = max_templates
73 yield
74 finally:
75 self.currently_capped = False
76
77
78 class RecursiveStrategy(SearchStrategy):
79 def __init__(self, base, extend, max_leaves):
80 self.max_leaves = max_leaves
81 self.base = base
82 self.limited_base = LimitedStrategy(base)
83 self.extend = extend
84
85 strategies = [self.limited_base, self.extend(self.limited_base)]
86 while 2 ** (len(strategies) - 1) <= max_leaves:
87 strategies.append(extend(OneOfStrategy(tuple(strategies))))
88 self.strategy = OneOfStrategy(strategies)
89
90 def __repr__(self):
91 if not hasattr(self, "_cached_repr"):
92 self._cached_repr = "recursive(%r, %s, max_leaves=%d)" % (
93 self.base,
94 get_pretty_function_description(self.extend),
95 self.max_leaves,
96 )
97 return self._cached_repr
98
99 def do_validate(self):
100 check_strategy(self.base, "base")
101 extended = self.extend(self.limited_base)
102 check_strategy(extended, f"extend({self.limited_base!r})")
103 self.limited_base.validate()
104 extended.validate()
105
106 def do_draw(self, data):
107 count = 0
108 while True:
109 try:
110 with self.limited_base.capped(self.max_leaves):
111 return data.draw(self.strategy)
112 except LimitReached:
113 # Workaround for possible coverage bug - this branch is definitely
114 # covered but for some reason is showing up as not covered.
115 if count == 0: # pragma: no branch
116 data.note_event(
117 lazyformat(
118 "Draw for %r exceeded max_leaves and had to be retried",
119 self,
120 )
121 )
122 count += 1
123
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/hypothesis-python/src/hypothesis/strategies/_internal/recursive.py b/hypothesis-python/src/hypothesis/strategies/_internal/recursive.py
--- a/hypothesis-python/src/hypothesis/strategies/_internal/recursive.py
+++ b/hypothesis-python/src/hypothesis/strategies/_internal/recursive.py
@@ -66,13 +66,13 @@
@contextmanager
def capped(self, max_templates):
- assert not self.currently_capped
try:
+ was_capped = self.currently_capped
self.currently_capped = True
self.marker = max_templates
yield
finally:
- self.currently_capped = False
+ self.currently_capped = was_capped
class RecursiveStrategy(SearchStrategy):
|
{"golden_diff": "diff --git a/hypothesis-python/src/hypothesis/strategies/_internal/recursive.py b/hypothesis-python/src/hypothesis/strategies/_internal/recursive.py\n--- a/hypothesis-python/src/hypothesis/strategies/_internal/recursive.py\n+++ b/hypothesis-python/src/hypothesis/strategies/_internal/recursive.py\n@@ -66,13 +66,13 @@\n \n @contextmanager\n def capped(self, max_templates):\n- assert not self.currently_capped\n try:\n+ was_capped = self.currently_capped\n self.currently_capped = True\n self.marker = max_templates\n yield\n finally:\n- self.currently_capped = False\n+ self.currently_capped = was_capped\n \n \n class RecursiveStrategy(SearchStrategy):\n", "issue": "Improve handling of self-referential strategies\nAs mentioned in #2783, the following strategy is not explicitly forbidden but fails with an `AssertionError`:\r\n\r\n```python\r\nfrom hypothesis import strategies as st\r\n\r\nSELF_REF = st.recursive(\r\n st.deferred(lambda: SELF_REF | st.booleans()),\r\n lambda s: st.lists(s, min_size=1)\r\n)\r\n```\r\n\r\nThere is an alternative strategy that produces the same data, but doesn't fail the same way:\r\n\r\n```python\r\nSELF_REF = st.recursive(\r\n st.booleans(),\r\n lambda s: st.lists(s, min_size=1)\r\n)\r\n```\r\n\r\nI am not sure if all self-referential strategies can be rewritten like this, but probably we can either explicitly forbid such strategies or revisit our drawing approach for them.\r\n\r\nHere is my reasoning from #2783 \r\n\r\n> As far as I see, the cap is needed to prevent the drawing from this strategy & generating a certain maximum amount of leaves. However, assuming a single thread (more on the multi-threaded behavior in the next section) and such a self-referential strategy, I am not sure if capping is needed as it is - we can just apply it once on the first capped usage and make all subsequent calls no-op (e.g., just yield without modifying marked). Then we still have the marker set only once on the very first RecursiveStrategy.do_draw call, and it will be monotonically decreasing. Therefore, we'll have the max size properly maintained, and there will be no oversized subtrees because, at some point, LimitReached will occur.\r\n\r\n\n", "before_files": [{"content": "# This file is part of Hypothesis, which may be found at\n# https://github.com/HypothesisWorks/hypothesis/\n#\n# Most of this work is copyright (C) 2013-2021 David R. MacIver\n# ([email protected]), but it contains contributions by others. See\n# CONTRIBUTING.rst for a full list of people who may hold copyright, and\n# consult the git log if you need to determine who owns an individual\n# contribution.\n#\n# This Source Code Form is subject to the terms of the Mozilla Public License,\n# v. 2.0. If a copy of the MPL was not distributed with this file, You can\n# obtain one at https://mozilla.org/MPL/2.0/.\n#\n# END HEADER\n\nimport threading\nfrom contextlib import contextmanager\n\nfrom hypothesis.internal.lazyformat import lazyformat\nfrom hypothesis.internal.reflection import get_pretty_function_description\nfrom hypothesis.strategies._internal.strategies import (\n OneOfStrategy,\n SearchStrategy,\n check_strategy,\n)\n\n\nclass LimitReached(BaseException):\n pass\n\n\nclass LimitedStrategy(SearchStrategy):\n def __init__(self, strategy):\n super().__init__()\n self.base_strategy = strategy\n self._threadlocal = threading.local()\n\n @property\n def marker(self):\n return getattr(self._threadlocal, \"marker\", 0)\n\n @marker.setter\n def marker(self, value):\n self._threadlocal.marker = value\n\n @property\n def currently_capped(self):\n return getattr(self._threadlocal, \"currently_capped\", False)\n\n @currently_capped.setter\n def currently_capped(self, value):\n self._threadlocal.currently_capped = value\n\n def __repr__(self):\n return f\"LimitedStrategy({self.base_strategy!r})\"\n\n def do_validate(self):\n self.base_strategy.validate()\n\n def do_draw(self, data):\n assert self.currently_capped\n if self.marker <= 0:\n raise LimitReached()\n self.marker -= 1\n return data.draw(self.base_strategy)\n\n @contextmanager\n def capped(self, max_templates):\n assert not self.currently_capped\n try:\n self.currently_capped = True\n self.marker = max_templates\n yield\n finally:\n self.currently_capped = False\n\n\nclass RecursiveStrategy(SearchStrategy):\n def __init__(self, base, extend, max_leaves):\n self.max_leaves = max_leaves\n self.base = base\n self.limited_base = LimitedStrategy(base)\n self.extend = extend\n\n strategies = [self.limited_base, self.extend(self.limited_base)]\n while 2 ** (len(strategies) - 1) <= max_leaves:\n strategies.append(extend(OneOfStrategy(tuple(strategies))))\n self.strategy = OneOfStrategy(strategies)\n\n def __repr__(self):\n if not hasattr(self, \"_cached_repr\"):\n self._cached_repr = \"recursive(%r, %s, max_leaves=%d)\" % (\n self.base,\n get_pretty_function_description(self.extend),\n self.max_leaves,\n )\n return self._cached_repr\n\n def do_validate(self):\n check_strategy(self.base, \"base\")\n extended = self.extend(self.limited_base)\n check_strategy(extended, f\"extend({self.limited_base!r})\")\n self.limited_base.validate()\n extended.validate()\n\n def do_draw(self, data):\n count = 0\n while True:\n try:\n with self.limited_base.capped(self.max_leaves):\n return data.draw(self.strategy)\n except LimitReached:\n # Workaround for possible coverage bug - this branch is definitely\n # covered but for some reason is showing up as not covered.\n if count == 0: # pragma: no branch\n data.note_event(\n lazyformat(\n \"Draw for %r exceeded max_leaves and had to be retried\",\n self,\n )\n )\n count += 1\n", "path": "hypothesis-python/src/hypothesis/strategies/_internal/recursive.py"}], "after_files": [{"content": "# This file is part of Hypothesis, which may be found at\n# https://github.com/HypothesisWorks/hypothesis/\n#\n# Most of this work is copyright (C) 2013-2021 David R. MacIver\n# ([email protected]), but it contains contributions by others. See\n# CONTRIBUTING.rst for a full list of people who may hold copyright, and\n# consult the git log if you need to determine who owns an individual\n# contribution.\n#\n# This Source Code Form is subject to the terms of the Mozilla Public License,\n# v. 2.0. If a copy of the MPL was not distributed with this file, You can\n# obtain one at https://mozilla.org/MPL/2.0/.\n#\n# END HEADER\n\nimport threading\nfrom contextlib import contextmanager\n\nfrom hypothesis.internal.lazyformat import lazyformat\nfrom hypothesis.internal.reflection import get_pretty_function_description\nfrom hypothesis.strategies._internal.strategies import (\n OneOfStrategy,\n SearchStrategy,\n check_strategy,\n)\n\n\nclass LimitReached(BaseException):\n pass\n\n\nclass LimitedStrategy(SearchStrategy):\n def __init__(self, strategy):\n super().__init__()\n self.base_strategy = strategy\n self._threadlocal = threading.local()\n\n @property\n def marker(self):\n return getattr(self._threadlocal, \"marker\", 0)\n\n @marker.setter\n def marker(self, value):\n self._threadlocal.marker = value\n\n @property\n def currently_capped(self):\n return getattr(self._threadlocal, \"currently_capped\", False)\n\n @currently_capped.setter\n def currently_capped(self, value):\n self._threadlocal.currently_capped = value\n\n def __repr__(self):\n return f\"LimitedStrategy({self.base_strategy!r})\"\n\n def do_validate(self):\n self.base_strategy.validate()\n\n def do_draw(self, data):\n assert self.currently_capped\n if self.marker <= 0:\n raise LimitReached()\n self.marker -= 1\n return data.draw(self.base_strategy)\n\n @contextmanager\n def capped(self, max_templates):\n try:\n was_capped = self.currently_capped\n self.currently_capped = True\n self.marker = max_templates\n yield\n finally:\n self.currently_capped = was_capped\n\n\nclass RecursiveStrategy(SearchStrategy):\n def __init__(self, base, extend, max_leaves):\n self.max_leaves = max_leaves\n self.base = base\n self.limited_base = LimitedStrategy(base)\n self.extend = extend\n\n strategies = [self.limited_base, self.extend(self.limited_base)]\n while 2 ** (len(strategies) - 1) <= max_leaves:\n strategies.append(extend(OneOfStrategy(tuple(strategies))))\n self.strategy = OneOfStrategy(strategies)\n\n def __repr__(self):\n if not hasattr(self, \"_cached_repr\"):\n self._cached_repr = \"recursive(%r, %s, max_leaves=%d)\" % (\n self.base,\n get_pretty_function_description(self.extend),\n self.max_leaves,\n )\n return self._cached_repr\n\n def do_validate(self):\n check_strategy(self.base, \"base\")\n extended = self.extend(self.limited_base)\n check_strategy(extended, f\"extend({self.limited_base!r})\")\n self.limited_base.validate()\n extended.validate()\n\n def do_draw(self, data):\n count = 0\n while True:\n try:\n with self.limited_base.capped(self.max_leaves):\n return data.draw(self.strategy)\n except LimitReached:\n # Workaround for possible coverage bug - this branch is definitely\n # covered but for some reason is showing up as not covered.\n if count == 0: # pragma: no branch\n data.note_event(\n lazyformat(\n \"Draw for %r exceeded max_leaves and had to be retried\",\n self,\n )\n )\n count += 1\n", "path": "hypothesis-python/src/hypothesis/strategies/_internal/recursive.py"}]}
| 1,745 | 180 |
gh_patches_debug_3958
|
rasdani/github-patches
|
git_diff
|
pre-commit__pre-commit-472
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Can't use ruby hooks with "BUNDLE_DISABLE_SHARED_GEMS: true" in .bundle/config
I have a repo with a `.bundle/config` file with these contents:
```yaml
BUNDLE_DISABLE_SHARED_GEMS: true
BUNDLE_PATH: vendor/gem
```
And a `Gemfile` with these contents:
```ruby
gem 'lol_hai'
```
I can't use any Ruby hooks in this repo; I get an error like this:
```
/nail/home/ckuehl/.pre-commit/repobarlh9c4/rbenv-1.9.3-p551/versions/1.9.3-p551/lib/ruby/site_ruby/1.9.1/rubygems/dependency.rb:315:in `to_specs': Could not find '__fake_gem' (>= 0) among 0 total gem(s) (Gem::LoadError)
Checked in 'GEM_PATH=/nail/tmp/tmp.jPQDWVcTGz/pre-commit-bug/vendor/gem/ruby/1.9.1', execute `gem env` for more information
from /nail/home/ckuehl/.pre-commit/repobarlh9c4/rbenv-1.9.3-p551/versions/1.9.3-p551/lib/ruby/site_ruby/1.9.1/rubygems/dependency.rb:324:in `to_spec'
from /nail/home/ckuehl/.pre-commit/repobarlh9c4/rbenv-1.9.3-p551/versions/1.9.3-p551/lib/ruby/site_ruby/1.9.1/rubygems/core_ext/kernel_gem.rb:58:in `gem'
from /nail/home/ckuehl/.pre-commit/repobarlh9c4/rbenv-1.9.3-p551/gems/bin/puppet-validate:22:in `<main>'
from /nail/home/ckuehl/.pre-commit/repobarlh9c4/rbenv-1.9.3-p551/gems/bin/ruby_executable_hooks:15:in `eval'
from /nail/home/ckuehl/.pre-commit/repobarlh9c4/rbenv-1.9.3-p551/gems/bin/ruby_executable_hooks:15:in `<main>'
```
Interesting bit is: `GEM_PATH=/nail/tmp/tmp.jPQDWVcTGz/pre-commit-bug/vendor/gem/ruby/1.9.1`
That doesn't look right (it's a path in my project).
Here's a failing test:
```patch
commit 260f981ae8cdf1c6b1f796dda5cf56811ed237d3 (HEAD -> gemfile-in-root, origin/gemfile-in-root)
Author: Chris Kuehl <[email protected]>
AuthorDate: Mon Jan 23 19:39:47 2017 -0800
Commit: Chris Kuehl <[email protected]>
CommitDate: Mon Jan 23 19:59:28 2017 -0800
Add failing test for BUNDLE_DISABLE_SHARED_GEMS
diff --git a/tests/repository_test.py b/tests/repository_test.py
index b7ce8dd..203852c 100644
--- a/tests/repository_test.py
+++ b/tests/repository_test.py
@@ -207,6 +207,30 @@ def test_run_versioned_ruby_hook(tempdir_factory, store):
)
+@skipif_slowtests_false
+@xfailif_windows_no_ruby
[email protected]
+def test_run_ruby_hook_with_disable_shared_gems(
+ tempdir_factory,
+ store,
+ tmpdir,
+):
+ """Make sure a Gemfile in the project doesn't interfere."""
+ tmpdir.join('Gemfile').write('gem "lol_hai"')
+ tmpdir.join('.bundle').mkdir()
+ tmpdir.join('.bundle', 'config').write(
+ 'BUNDLE_DISABLE_SHARED_GEMS: true\n'
+ 'BUNDLE_PATH: vendor/gem\n'
+ )
+ with cwd(tmpdir.strpath):
+ _test_hook_repo(
+ tempdir_factory, store, 'ruby_versioned_hooks_repo',
+ 'ruby_hook',
+ ['/dev/null'],
+ b'2.1.5\nHello world from a ruby hook\n',
+ )
+
+
@pytest.mark.integration
def test_system_hook_with_spaces(tempdir_factory, store):
_test_hook_repo(
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pre_commit/languages/ruby.py`
Content:
```
1 from __future__ import unicode_literals
2
3 import contextlib
4 import io
5 import os.path
6 import shutil
7 import tarfile
8
9 from pre_commit.envcontext import envcontext
10 from pre_commit.envcontext import Var
11 from pre_commit.languages import helpers
12 from pre_commit.util import CalledProcessError
13 from pre_commit.util import clean_path_on_failure
14 from pre_commit.util import resource_filename
15 from pre_commit.xargs import xargs
16
17
18 ENVIRONMENT_DIR = 'rbenv'
19
20
21 def get_env_patch(venv, language_version): # pragma: windows no cover
22 patches = (
23 ('GEM_HOME', os.path.join(venv, 'gems')),
24 ('RBENV_ROOT', venv),
25 ('PATH', (
26 os.path.join(venv, 'gems', 'bin'), os.pathsep,
27 os.path.join(venv, 'shims'), os.pathsep,
28 os.path.join(venv, 'bin'), os.pathsep, Var('PATH'),
29 )),
30 )
31 if language_version != 'default':
32 patches += (('RBENV_VERSION', language_version),)
33 return patches
34
35
36 @contextlib.contextmanager
37 def in_env(repo_cmd_runner, language_version): # pragma: windows no cover
38 envdir = repo_cmd_runner.path(
39 helpers.environment_dir(ENVIRONMENT_DIR, language_version),
40 )
41 with envcontext(get_env_patch(envdir, language_version)):
42 yield
43
44
45 def _install_rbenv(
46 repo_cmd_runner, version='default',
47 ): # pragma: windows no cover
48 directory = helpers.environment_dir(ENVIRONMENT_DIR, version)
49
50 with tarfile.open(resource_filename('rbenv.tar.gz')) as tf:
51 tf.extractall(repo_cmd_runner.path('.'))
52 shutil.move(
53 repo_cmd_runner.path('rbenv'), repo_cmd_runner.path(directory),
54 )
55
56 # Only install ruby-build if the version is specified
57 if version != 'default':
58 # ruby-download
59 with tarfile.open(resource_filename('ruby-download.tar.gz')) as tf:
60 tf.extractall(repo_cmd_runner.path(directory, 'plugins'))
61
62 # ruby-build
63 with tarfile.open(resource_filename('ruby-build.tar.gz')) as tf:
64 tf.extractall(repo_cmd_runner.path(directory, 'plugins'))
65
66 activate_path = repo_cmd_runner.path(directory, 'bin', 'activate')
67 with io.open(activate_path, 'w') as activate_file:
68 # This is similar to how you would install rbenv to your home directory
69 # However we do a couple things to make the executables exposed and
70 # configure it to work in our directory.
71 # We also modify the PS1 variable for manual debugging sake.
72 activate_file.write(
73 '#!/usr/bin/env bash\n'
74 "export RBENV_ROOT='{directory}'\n"
75 'export PATH="$RBENV_ROOT/bin:$PATH"\n'
76 'eval "$(rbenv init -)"\n'
77 'export PS1="(rbenv)$PS1"\n'
78 # This lets us install gems in an isolated and repeatable
79 # directory
80 "export GEM_HOME='{directory}/gems'\n"
81 'export PATH="$GEM_HOME/bin:$PATH"\n'
82 '\n'.format(directory=repo_cmd_runner.path(directory))
83 )
84
85 # If we aren't using the system ruby, add a version here
86 if version != 'default':
87 activate_file.write('export RBENV_VERSION="{}"\n'.format(version))
88
89
90 def _install_ruby(runner, version): # pragma: windows no cover
91 try:
92 helpers.run_setup_cmd(runner, ('rbenv', 'download', version))
93 except CalledProcessError: # pragma: no cover (usually find with download)
94 # Failed to download from mirror for some reason, build it instead
95 helpers.run_setup_cmd(runner, ('rbenv', 'install', version))
96
97
98 def install_environment(
99 repo_cmd_runner,
100 version='default',
101 additional_dependencies=(),
102 ): # pragma: windows no cover
103 additional_dependencies = tuple(additional_dependencies)
104 directory = helpers.environment_dir(ENVIRONMENT_DIR, version)
105 with clean_path_on_failure(repo_cmd_runner.path(directory)):
106 # TODO: this currently will fail if there's no version specified and
107 # there's no system ruby installed. Is this ok?
108 _install_rbenv(repo_cmd_runner, version=version)
109 with in_env(repo_cmd_runner, version):
110 # Need to call this before installing so rbenv's directories are
111 # set up
112 helpers.run_setup_cmd(repo_cmd_runner, ('rbenv', 'init', '-'))
113 if version != 'default':
114 _install_ruby(repo_cmd_runner, version)
115 # Need to call this after installing to set up the shims
116 helpers.run_setup_cmd(repo_cmd_runner, ('rbenv', 'rehash'))
117 helpers.run_setup_cmd(
118 repo_cmd_runner,
119 ('gem', 'build') + repo_cmd_runner.star('.gemspec'),
120 )
121 helpers.run_setup_cmd(
122 repo_cmd_runner,
123 (
124 ('gem', 'install', '--no-ri', '--no-rdoc') +
125 repo_cmd_runner.star('.gem') + additional_dependencies
126 ),
127 )
128
129
130 def run_hook(repo_cmd_runner, hook, file_args): # pragma: windows no cover
131 with in_env(repo_cmd_runner, hook['language_version']):
132 return xargs(helpers.to_cmd(hook), file_args)
133
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pre_commit/languages/ruby.py b/pre_commit/languages/ruby.py
--- a/pre_commit/languages/ruby.py
+++ b/pre_commit/languages/ruby.py
@@ -22,6 +22,7 @@
patches = (
('GEM_HOME', os.path.join(venv, 'gems')),
('RBENV_ROOT', venv),
+ ('BUNDLE_IGNORE_CONFIG', '1'),
('PATH', (
os.path.join(venv, 'gems', 'bin'), os.pathsep,
os.path.join(venv, 'shims'), os.pathsep,
|
{"golden_diff": "diff --git a/pre_commit/languages/ruby.py b/pre_commit/languages/ruby.py\n--- a/pre_commit/languages/ruby.py\n+++ b/pre_commit/languages/ruby.py\n@@ -22,6 +22,7 @@\n patches = (\n ('GEM_HOME', os.path.join(venv, 'gems')),\n ('RBENV_ROOT', venv),\n+ ('BUNDLE_IGNORE_CONFIG', '1'),\n ('PATH', (\n os.path.join(venv, 'gems', 'bin'), os.pathsep,\n os.path.join(venv, 'shims'), os.pathsep,\n", "issue": "Can't use ruby hooks with \"BUNDLE_DISABLE_SHARED_GEMS: true\" in .bundle/config\nI have a repo with a `.bundle/config` file with these contents:\r\n```yaml\r\nBUNDLE_DISABLE_SHARED_GEMS: true\r\nBUNDLE_PATH: vendor/gem\r\n```\r\n\r\nAnd a `Gemfile` with these contents:\r\n```ruby\r\ngem 'lol_hai'\r\n```\r\n\r\nI can't use any Ruby hooks in this repo; I get an error like this:\r\n\r\n```\r\n/nail/home/ckuehl/.pre-commit/repobarlh9c4/rbenv-1.9.3-p551/versions/1.9.3-p551/lib/ruby/site_ruby/1.9.1/rubygems/dependency.rb:315:in `to_specs': Could not find '__fake_gem' (>= 0) among 0 total gem(s) (Gem::LoadError)\r\nChecked in 'GEM_PATH=/nail/tmp/tmp.jPQDWVcTGz/pre-commit-bug/vendor/gem/ruby/1.9.1', execute `gem env` for more information\r\n from /nail/home/ckuehl/.pre-commit/repobarlh9c4/rbenv-1.9.3-p551/versions/1.9.3-p551/lib/ruby/site_ruby/1.9.1/rubygems/dependency.rb:324:in `to_spec'\r\n from /nail/home/ckuehl/.pre-commit/repobarlh9c4/rbenv-1.9.3-p551/versions/1.9.3-p551/lib/ruby/site_ruby/1.9.1/rubygems/core_ext/kernel_gem.rb:58:in `gem'\r\n from /nail/home/ckuehl/.pre-commit/repobarlh9c4/rbenv-1.9.3-p551/gems/bin/puppet-validate:22:in `<main>'\r\n from /nail/home/ckuehl/.pre-commit/repobarlh9c4/rbenv-1.9.3-p551/gems/bin/ruby_executable_hooks:15:in `eval'\r\n from /nail/home/ckuehl/.pre-commit/repobarlh9c4/rbenv-1.9.3-p551/gems/bin/ruby_executable_hooks:15:in `<main>'\r\n```\r\n\r\nInteresting bit is: `GEM_PATH=/nail/tmp/tmp.jPQDWVcTGz/pre-commit-bug/vendor/gem/ruby/1.9.1`\r\n\r\nThat doesn't look right (it's a path in my project).\r\n\r\n\r\nHere's a failing test:\r\n\r\n```patch\r\ncommit 260f981ae8cdf1c6b1f796dda5cf56811ed237d3 (HEAD -> gemfile-in-root, origin/gemfile-in-root)\r\nAuthor: Chris Kuehl <[email protected]>\r\nAuthorDate: Mon Jan 23 19:39:47 2017 -0800\r\nCommit: Chris Kuehl <[email protected]>\r\nCommitDate: Mon Jan 23 19:59:28 2017 -0800\r\n\r\n Add failing test for BUNDLE_DISABLE_SHARED_GEMS\r\n\r\ndiff --git a/tests/repository_test.py b/tests/repository_test.py\r\nindex b7ce8dd..203852c 100644\r\n--- a/tests/repository_test.py\r\n+++ b/tests/repository_test.py\r\n@@ -207,6 +207,30 @@ def test_run_versioned_ruby_hook(tempdir_factory, store):\r\n )\r\n \r\n \r\n+@skipif_slowtests_false\r\n+@xfailif_windows_no_ruby\r\[email protected]\r\n+def test_run_ruby_hook_with_disable_shared_gems(\r\n+ tempdir_factory,\r\n+ store,\r\n+ tmpdir,\r\n+):\r\n+ \"\"\"Make sure a Gemfile in the project doesn't interfere.\"\"\"\r\n+ tmpdir.join('Gemfile').write('gem \"lol_hai\"')\r\n+ tmpdir.join('.bundle').mkdir()\r\n+ tmpdir.join('.bundle', 'config').write(\r\n+ 'BUNDLE_DISABLE_SHARED_GEMS: true\\n'\r\n+ 'BUNDLE_PATH: vendor/gem\\n'\r\n+ )\r\n+ with cwd(tmpdir.strpath):\r\n+ _test_hook_repo(\r\n+ tempdir_factory, store, 'ruby_versioned_hooks_repo',\r\n+ 'ruby_hook',\r\n+ ['/dev/null'],\r\n+ b'2.1.5\\nHello world from a ruby hook\\n',\r\n+ )\r\n+\r\n+\r\n @pytest.mark.integration\r\n def test_system_hook_with_spaces(tempdir_factory, store):\r\n _test_hook_repo(\r\n```\n", "before_files": [{"content": "from __future__ import unicode_literals\n\nimport contextlib\nimport io\nimport os.path\nimport shutil\nimport tarfile\n\nfrom pre_commit.envcontext import envcontext\nfrom pre_commit.envcontext import Var\nfrom pre_commit.languages import helpers\nfrom pre_commit.util import CalledProcessError\nfrom pre_commit.util import clean_path_on_failure\nfrom pre_commit.util import resource_filename\nfrom pre_commit.xargs import xargs\n\n\nENVIRONMENT_DIR = 'rbenv'\n\n\ndef get_env_patch(venv, language_version): # pragma: windows no cover\n patches = (\n ('GEM_HOME', os.path.join(venv, 'gems')),\n ('RBENV_ROOT', venv),\n ('PATH', (\n os.path.join(venv, 'gems', 'bin'), os.pathsep,\n os.path.join(venv, 'shims'), os.pathsep,\n os.path.join(venv, 'bin'), os.pathsep, Var('PATH'),\n )),\n )\n if language_version != 'default':\n patches += (('RBENV_VERSION', language_version),)\n return patches\n\n\[email protected]\ndef in_env(repo_cmd_runner, language_version): # pragma: windows no cover\n envdir = repo_cmd_runner.path(\n helpers.environment_dir(ENVIRONMENT_DIR, language_version),\n )\n with envcontext(get_env_patch(envdir, language_version)):\n yield\n\n\ndef _install_rbenv(\n repo_cmd_runner, version='default',\n): # pragma: windows no cover\n directory = helpers.environment_dir(ENVIRONMENT_DIR, version)\n\n with tarfile.open(resource_filename('rbenv.tar.gz')) as tf:\n tf.extractall(repo_cmd_runner.path('.'))\n shutil.move(\n repo_cmd_runner.path('rbenv'), repo_cmd_runner.path(directory),\n )\n\n # Only install ruby-build if the version is specified\n if version != 'default':\n # ruby-download\n with tarfile.open(resource_filename('ruby-download.tar.gz')) as tf:\n tf.extractall(repo_cmd_runner.path(directory, 'plugins'))\n\n # ruby-build\n with tarfile.open(resource_filename('ruby-build.tar.gz')) as tf:\n tf.extractall(repo_cmd_runner.path(directory, 'plugins'))\n\n activate_path = repo_cmd_runner.path(directory, 'bin', 'activate')\n with io.open(activate_path, 'w') as activate_file:\n # This is similar to how you would install rbenv to your home directory\n # However we do a couple things to make the executables exposed and\n # configure it to work in our directory.\n # We also modify the PS1 variable for manual debugging sake.\n activate_file.write(\n '#!/usr/bin/env bash\\n'\n \"export RBENV_ROOT='{directory}'\\n\"\n 'export PATH=\"$RBENV_ROOT/bin:$PATH\"\\n'\n 'eval \"$(rbenv init -)\"\\n'\n 'export PS1=\"(rbenv)$PS1\"\\n'\n # This lets us install gems in an isolated and repeatable\n # directory\n \"export GEM_HOME='{directory}/gems'\\n\"\n 'export PATH=\"$GEM_HOME/bin:$PATH\"\\n'\n '\\n'.format(directory=repo_cmd_runner.path(directory))\n )\n\n # If we aren't using the system ruby, add a version here\n if version != 'default':\n activate_file.write('export RBENV_VERSION=\"{}\"\\n'.format(version))\n\n\ndef _install_ruby(runner, version): # pragma: windows no cover\n try:\n helpers.run_setup_cmd(runner, ('rbenv', 'download', version))\n except CalledProcessError: # pragma: no cover (usually find with download)\n # Failed to download from mirror for some reason, build it instead\n helpers.run_setup_cmd(runner, ('rbenv', 'install', version))\n\n\ndef install_environment(\n repo_cmd_runner,\n version='default',\n additional_dependencies=(),\n): # pragma: windows no cover\n additional_dependencies = tuple(additional_dependencies)\n directory = helpers.environment_dir(ENVIRONMENT_DIR, version)\n with clean_path_on_failure(repo_cmd_runner.path(directory)):\n # TODO: this currently will fail if there's no version specified and\n # there's no system ruby installed. Is this ok?\n _install_rbenv(repo_cmd_runner, version=version)\n with in_env(repo_cmd_runner, version):\n # Need to call this before installing so rbenv's directories are\n # set up\n helpers.run_setup_cmd(repo_cmd_runner, ('rbenv', 'init', '-'))\n if version != 'default':\n _install_ruby(repo_cmd_runner, version)\n # Need to call this after installing to set up the shims\n helpers.run_setup_cmd(repo_cmd_runner, ('rbenv', 'rehash'))\n helpers.run_setup_cmd(\n repo_cmd_runner,\n ('gem', 'build') + repo_cmd_runner.star('.gemspec'),\n )\n helpers.run_setup_cmd(\n repo_cmd_runner,\n (\n ('gem', 'install', '--no-ri', '--no-rdoc') +\n repo_cmd_runner.star('.gem') + additional_dependencies\n ),\n )\n\n\ndef run_hook(repo_cmd_runner, hook, file_args): # pragma: windows no cover\n with in_env(repo_cmd_runner, hook['language_version']):\n return xargs(helpers.to_cmd(hook), file_args)\n", "path": "pre_commit/languages/ruby.py"}], "after_files": [{"content": "from __future__ import unicode_literals\n\nimport contextlib\nimport io\nimport os.path\nimport shutil\nimport tarfile\n\nfrom pre_commit.envcontext import envcontext\nfrom pre_commit.envcontext import Var\nfrom pre_commit.languages import helpers\nfrom pre_commit.util import CalledProcessError\nfrom pre_commit.util import clean_path_on_failure\nfrom pre_commit.util import resource_filename\nfrom pre_commit.xargs import xargs\n\n\nENVIRONMENT_DIR = 'rbenv'\n\n\ndef get_env_patch(venv, language_version): # pragma: windows no cover\n patches = (\n ('GEM_HOME', os.path.join(venv, 'gems')),\n ('RBENV_ROOT', venv),\n ('BUNDLE_IGNORE_CONFIG', '1'),\n ('PATH', (\n os.path.join(venv, 'gems', 'bin'), os.pathsep,\n os.path.join(venv, 'shims'), os.pathsep,\n os.path.join(venv, 'bin'), os.pathsep, Var('PATH'),\n )),\n )\n if language_version != 'default':\n patches += (('RBENV_VERSION', language_version),)\n return patches\n\n\[email protected]\ndef in_env(repo_cmd_runner, language_version): # pragma: windows no cover\n envdir = repo_cmd_runner.path(\n helpers.environment_dir(ENVIRONMENT_DIR, language_version),\n )\n with envcontext(get_env_patch(envdir, language_version)):\n yield\n\n\ndef _install_rbenv(\n repo_cmd_runner, version='default',\n): # pragma: windows no cover\n directory = helpers.environment_dir(ENVIRONMENT_DIR, version)\n\n with tarfile.open(resource_filename('rbenv.tar.gz')) as tf:\n tf.extractall(repo_cmd_runner.path('.'))\n shutil.move(\n repo_cmd_runner.path('rbenv'), repo_cmd_runner.path(directory),\n )\n\n # Only install ruby-build if the version is specified\n if version != 'default':\n # ruby-download\n with tarfile.open(resource_filename('ruby-download.tar.gz')) as tf:\n tf.extractall(repo_cmd_runner.path(directory, 'plugins'))\n\n # ruby-build\n with tarfile.open(resource_filename('ruby-build.tar.gz')) as tf:\n tf.extractall(repo_cmd_runner.path(directory, 'plugins'))\n\n activate_path = repo_cmd_runner.path(directory, 'bin', 'activate')\n with io.open(activate_path, 'w') as activate_file:\n # This is similar to how you would install rbenv to your home directory\n # However we do a couple things to make the executables exposed and\n # configure it to work in our directory.\n # We also modify the PS1 variable for manual debugging sake.\n activate_file.write(\n '#!/usr/bin/env bash\\n'\n \"export RBENV_ROOT='{directory}'\\n\"\n 'export PATH=\"$RBENV_ROOT/bin:$PATH\"\\n'\n 'eval \"$(rbenv init -)\"\\n'\n 'export PS1=\"(rbenv)$PS1\"\\n'\n # This lets us install gems in an isolated and repeatable\n # directory\n \"export GEM_HOME='{directory}/gems'\\n\"\n 'export PATH=\"$GEM_HOME/bin:$PATH\"\\n'\n '\\n'.format(directory=repo_cmd_runner.path(directory))\n )\n\n # If we aren't using the system ruby, add a version here\n if version != 'default':\n activate_file.write('export RBENV_VERSION=\"{}\"\\n'.format(version))\n\n\ndef _install_ruby(runner, version): # pragma: windows no cover\n try:\n helpers.run_setup_cmd(runner, ('rbenv', 'download', version))\n except CalledProcessError: # pragma: no cover (usually find with download)\n # Failed to download from mirror for some reason, build it instead\n helpers.run_setup_cmd(runner, ('rbenv', 'install', version))\n\n\ndef install_environment(\n repo_cmd_runner,\n version='default',\n additional_dependencies=(),\n): # pragma: windows no cover\n additional_dependencies = tuple(additional_dependencies)\n directory = helpers.environment_dir(ENVIRONMENT_DIR, version)\n with clean_path_on_failure(repo_cmd_runner.path(directory)):\n # TODO: this currently will fail if there's no version specified and\n # there's no system ruby installed. Is this ok?\n _install_rbenv(repo_cmd_runner, version=version)\n with in_env(repo_cmd_runner, version):\n # Need to call this before installing so rbenv's directories are\n # set up\n helpers.run_setup_cmd(repo_cmd_runner, ('rbenv', 'init', '-'))\n if version != 'default':\n _install_ruby(repo_cmd_runner, version)\n # Need to call this after installing to set up the shims\n helpers.run_setup_cmd(repo_cmd_runner, ('rbenv', 'rehash'))\n helpers.run_setup_cmd(\n repo_cmd_runner,\n ('gem', 'build') + repo_cmd_runner.star('.gemspec'),\n )\n helpers.run_setup_cmd(\n repo_cmd_runner,\n (\n ('gem', 'install', '--no-ri', '--no-rdoc') +\n repo_cmd_runner.star('.gem') + additional_dependencies\n ),\n )\n\n\ndef run_hook(repo_cmd_runner, hook, file_args): # pragma: windows no cover\n with in_env(repo_cmd_runner, hook['language_version']):\n return xargs(helpers.to_cmd(hook), file_args)\n", "path": "pre_commit/languages/ruby.py"}]}
| 2,763 | 131 |
gh_patches_debug_6900
|
rasdani/github-patches
|
git_diff
|
Flexget__Flexget-2761
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
base64 issues with python 3.9
I just updated my install of python and something seams to have changed with base64
```
python -V
Python 3.9.0
```
Logs :
```
$ flexget
2020-10-18 13:00:03 CRITICAL plugin Exception while loading plugin flexget.plugins.input.apple_trailers
Traceback (most recent call last):
File "/home/striker/.local/bin/flexget", line 8, in <module>
sys.exit(main())
| | -> <function main at 0x7f2b3ee7d160>
| -> <built-in function exit>
-> <module 'sys' (built-in)>
File "/home/striker/.local/lib/python3.9/site-packages/flexget/__init__.py", line 43, in main
manager.start()
| -> <function Manager.start at 0x7f2b3d118280>
-> <flexget.manager.Manager object at 0x7f2b3d0fdc10>
File "/home/striker/.local/lib/python3.9/site-packages/flexget/manager.py", line 371, in start
self.initialize()
| -> <function Manager.initialize at 0x7f2b3d118040>
-> <flexget.manager.Manager object at 0x7f2b3d0fdc10>
File "/home/striker/.local/lib/python3.9/site-packages/flexget/manager.py", line 211, in initialize
plugin.load_plugins(
| -> <function load_plugins at 0x7f2b3d428c10>
-> <module 'flexget.plugin' from '/home/striker/.local/lib/python3.9/site-packages/flexget/plugin.py'>
File "/home/striker/.local/lib/python3.9/site-packages/flexget/plugin.py", line 555, in load_plugins
_load_plugins_from_dirs(extra_plugins)
| -> ['/home/striker/.config/flexget/plugins', '/home/striker/.local/lib/python3.9/site-packages/flexget/plugins']
-> <function _load_plugins_from_dirs at 0x7f2b3d428a60>
File "/home/striker/.local/lib/python3.9/site-packages/flexget/plugin.py", line 473, in _load_plugins_from_dirs
_import_plugin(module_name, plugin_path)
| | -> PosixPath('/home/striker/.local/lib/python3.9/site-packages/flexget/plugins/input/apple_trailers.py')
| -> 'flexget.plugins.input.apple_trailers'
-> <function _import_plugin at 0x7f2b3d4289d0>
> File "/home/striker/.local/lib/python3.9/site-packages/flexget/plugin.py", line 424, in _import_plugin
import_module(module_name)
| -> 'flexget.plugins.input.apple_trailers'
-> <function import_module at 0x7f2b3ef898b0>
File "/usr/lib/python3.9/importlib/__init__.py", line 127, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
| | | | | -> 0
| | | | -> None
| | | -> 0
| | -> 'flexget.plugins.input.apple_trailers'
| -> <function _gcd_import at 0x7f2b3f0c1310>
-> <module 'importlib._bootstrap' (frozen)>
File "<frozen importlib._bootstrap>", line 1030, in _gcd_import
File "<frozen importlib._bootstrap>", line 1007, in _find_and_load
File "<frozen importlib._bootstrap>", line 986, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 680, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 790, in exec_module
File "<frozen importlib._bootstrap>", line 228, in _call_with_frames_removed
File "/home/striker/.local/lib/python3.9/site-packages/flexget/plugins/input/apple_trailers.py", line 3, in <module>
import feedparser
File "/home/striker/.local/lib/python3.9/site-packages/feedparser.py", line 93, in <module>
_base64decode = getattr(base64, 'decodebytes', base64.decodestring)
| -> <module 'base64' from '/usr/lib/python3.9/base64.py'>
-> <module 'base64' from '/usr/lib/python3.9/base64.py'>
AttributeError: module 'base64' has no attribute 'decodestring'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 import sys
2 from pathlib import Path
3 from typing import List
4
5 from setuptools import find_packages, setup
6
7 long_description = Path('README.rst').read_text()
8
9 # Populates __version__ without importing the package
10 __version__ = None
11 with open('flexget/_version.py', encoding='utf-8') as ver_file:
12 exec(ver_file.read()) # pylint: disable=W0122
13 if not __version__:
14 print('Could not find __version__ from flexget/_version.py')
15 sys.exit(1)
16
17
18 def load_requirements(filename: str) -> List[str]:
19 return [
20 line.strip()
21 for line in Path(filename).read_text().splitlines()
22 if not line.startswith('#')
23 ]
24
25
26 setup(
27 name='FlexGet',
28 version=__version__,
29 description='FlexGet is a program aimed to automate downloading or processing content (torrents, podcasts, etc.) '
30 'from different sources like RSS-feeds, html-pages, various sites and more.',
31 long_description=long_description,
32 long_description_content_type='text/x-rst',
33 author='Marko Koivusalo',
34 author_email='[email protected]',
35 license='MIT',
36 url='https://flexget.com',
37 project_urls={
38 'Repository': 'https://github.com/Flexget/Flexget',
39 'Issue Tracker': 'https://github.com/Flexget/Flexget/issues',
40 'Forum': 'https://discuss.flexget.com',
41 },
42 packages=find_packages(exclude=['flexget.tests']),
43 include_package_data=True,
44 zip_safe=False,
45 install_requires=load_requirements('requirements.txt'),
46 tests_require=['pytest'],
47 extras_require={'dev': load_requirements('dev-requirements.txt')},
48 entry_points={
49 'console_scripts': ['flexget = flexget:main'],
50 'gui_scripts': [
51 'flexget-headless = flexget:main'
52 ], # This is useful on Windows to avoid a cmd popup
53 },
54 python_requires='>=3.6',
55 classifiers=[
56 "Development Status :: 5 - Production/Stable",
57 "License :: OSI Approved :: MIT License",
58 "Operating System :: OS Independent",
59 "Programming Language :: Python",
60 "Programming Language :: Python :: 3.6",
61 "Programming Language :: Python :: 3.7",
62 "Programming Language :: Python :: 3.8",
63 "Programming Language :: Python :: Implementation :: CPython",
64 "Programming Language :: Python :: Implementation :: PyPy",
65 ],
66 )
67
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -60,6 +60,7 @@
"Programming Language :: Python :: 3.6",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
+ "Programming Language :: Python :: 3.9",
"Programming Language :: Python :: Implementation :: CPython",
"Programming Language :: Python :: Implementation :: PyPy",
],
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -60,6 +60,7 @@\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n+ \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n ],\n", "issue": "base64 issues with python 3.9\nI just updated my install of python and something seams to have changed with base64\r\n```\r\npython -V\r\nPython 3.9.0\r\n```\r\n\r\nLogs :\r\n```\r\n$ flexget\r\n2020-10-18 13:00:03 CRITICAL plugin Exception while loading plugin flexget.plugins.input.apple_trailers\r\nTraceback (most recent call last):\r\n File \"/home/striker/.local/bin/flexget\", line 8, in <module>\r\n sys.exit(main())\r\n | | -> <function main at 0x7f2b3ee7d160>\r\n | -> <built-in function exit>\r\n -> <module 'sys' (built-in)>\r\n File \"/home/striker/.local/lib/python3.9/site-packages/flexget/__init__.py\", line 43, in main\r\n manager.start()\r\n | -> <function Manager.start at 0x7f2b3d118280>\r\n -> <flexget.manager.Manager object at 0x7f2b3d0fdc10>\r\n File \"/home/striker/.local/lib/python3.9/site-packages/flexget/manager.py\", line 371, in start\r\n self.initialize()\r\n | -> <function Manager.initialize at 0x7f2b3d118040>\r\n -> <flexget.manager.Manager object at 0x7f2b3d0fdc10>\r\n File \"/home/striker/.local/lib/python3.9/site-packages/flexget/manager.py\", line 211, in initialize\r\n plugin.load_plugins(\r\n | -> <function load_plugins at 0x7f2b3d428c10>\r\n -> <module 'flexget.plugin' from '/home/striker/.local/lib/python3.9/site-packages/flexget/plugin.py'>\r\n File \"/home/striker/.local/lib/python3.9/site-packages/flexget/plugin.py\", line 555, in load_plugins\r\n _load_plugins_from_dirs(extra_plugins)\r\n | -> ['/home/striker/.config/flexget/plugins', '/home/striker/.local/lib/python3.9/site-packages/flexget/plugins']\r\n -> <function _load_plugins_from_dirs at 0x7f2b3d428a60>\r\n File \"/home/striker/.local/lib/python3.9/site-packages/flexget/plugin.py\", line 473, in _load_plugins_from_dirs\r\n _import_plugin(module_name, plugin_path)\r\n | | -> PosixPath('/home/striker/.local/lib/python3.9/site-packages/flexget/plugins/input/apple_trailers.py')\r\n | -> 'flexget.plugins.input.apple_trailers'\r\n -> <function _import_plugin at 0x7f2b3d4289d0>\r\n> File \"/home/striker/.local/lib/python3.9/site-packages/flexget/plugin.py\", line 424, in _import_plugin\r\n import_module(module_name)\r\n | -> 'flexget.plugins.input.apple_trailers'\r\n -> <function import_module at 0x7f2b3ef898b0>\r\n File \"/usr/lib/python3.9/importlib/__init__.py\", line 127, in import_module\r\n return _bootstrap._gcd_import(name[level:], package, level)\r\n | | | | | -> 0\r\n | | | | -> None\r\n | | | -> 0\r\n | | -> 'flexget.plugins.input.apple_trailers'\r\n | -> <function _gcd_import at 0x7f2b3f0c1310>\r\n -> <module 'importlib._bootstrap' (frozen)>\r\n File \"<frozen importlib._bootstrap>\", line 1030, in _gcd_import\r\n File \"<frozen importlib._bootstrap>\", line 1007, in _find_and_load\r\n File \"<frozen importlib._bootstrap>\", line 986, in _find_and_load_unlocked\r\n File \"<frozen importlib._bootstrap>\", line 680, in _load_unlocked\r\n File \"<frozen importlib._bootstrap_external>\", line 790, in exec_module\r\n File \"<frozen importlib._bootstrap>\", line 228, in _call_with_frames_removed\r\n File \"/home/striker/.local/lib/python3.9/site-packages/flexget/plugins/input/apple_trailers.py\", line 3, in <module>\r\n import feedparser\r\n File \"/home/striker/.local/lib/python3.9/site-packages/feedparser.py\", line 93, in <module>\r\n _base64decode = getattr(base64, 'decodebytes', base64.decodestring)\r\n | -> <module 'base64' from '/usr/lib/python3.9/base64.py'>\r\n -> <module 'base64' from '/usr/lib/python3.9/base64.py'>\r\n\r\nAttributeError: module 'base64' has no attribute 'decodestring'\r\n```\n", "before_files": [{"content": "import sys\nfrom pathlib import Path\nfrom typing import List\n\nfrom setuptools import find_packages, setup\n\nlong_description = Path('README.rst').read_text()\n\n# Populates __version__ without importing the package\n__version__ = None\nwith open('flexget/_version.py', encoding='utf-8') as ver_file:\n exec(ver_file.read()) # pylint: disable=W0122\nif not __version__:\n print('Could not find __version__ from flexget/_version.py')\n sys.exit(1)\n\n\ndef load_requirements(filename: str) -> List[str]:\n return [\n line.strip()\n for line in Path(filename).read_text().splitlines()\n if not line.startswith('#')\n ]\n\n\nsetup(\n name='FlexGet',\n version=__version__,\n description='FlexGet is a program aimed to automate downloading or processing content (torrents, podcasts, etc.) '\n 'from different sources like RSS-feeds, html-pages, various sites and more.',\n long_description=long_description,\n long_description_content_type='text/x-rst',\n author='Marko Koivusalo',\n author_email='[email protected]',\n license='MIT',\n url='https://flexget.com',\n project_urls={\n 'Repository': 'https://github.com/Flexget/Flexget',\n 'Issue Tracker': 'https://github.com/Flexget/Flexget/issues',\n 'Forum': 'https://discuss.flexget.com',\n },\n packages=find_packages(exclude=['flexget.tests']),\n include_package_data=True,\n zip_safe=False,\n install_requires=load_requirements('requirements.txt'),\n tests_require=['pytest'],\n extras_require={'dev': load_requirements('dev-requirements.txt')},\n entry_points={\n 'console_scripts': ['flexget = flexget:main'],\n 'gui_scripts': [\n 'flexget-headless = flexget:main'\n ], # This is useful on Windows to avoid a cmd popup\n },\n python_requires='>=3.6',\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"License :: OSI Approved :: MIT License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n ],\n)\n", "path": "setup.py"}], "after_files": [{"content": "import sys\nfrom pathlib import Path\nfrom typing import List\n\nfrom setuptools import find_packages, setup\n\nlong_description = Path('README.rst').read_text()\n\n# Populates __version__ without importing the package\n__version__ = None\nwith open('flexget/_version.py', encoding='utf-8') as ver_file:\n exec(ver_file.read()) # pylint: disable=W0122\nif not __version__:\n print('Could not find __version__ from flexget/_version.py')\n sys.exit(1)\n\n\ndef load_requirements(filename: str) -> List[str]:\n return [\n line.strip()\n for line in Path(filename).read_text().splitlines()\n if not line.startswith('#')\n ]\n\n\nsetup(\n name='FlexGet',\n version=__version__,\n description='FlexGet is a program aimed to automate downloading or processing content (torrents, podcasts, etc.) '\n 'from different sources like RSS-feeds, html-pages, various sites and more.',\n long_description=long_description,\n long_description_content_type='text/x-rst',\n author='Marko Koivusalo',\n author_email='[email protected]',\n license='MIT',\n url='https://flexget.com',\n project_urls={\n 'Repository': 'https://github.com/Flexget/Flexget',\n 'Issue Tracker': 'https://github.com/Flexget/Flexget/issues',\n 'Forum': 'https://discuss.flexget.com',\n },\n packages=find_packages(exclude=['flexget.tests']),\n include_package_data=True,\n zip_safe=False,\n install_requires=load_requirements('requirements.txt'),\n tests_require=['pytest'],\n extras_require={'dev': load_requirements('dev-requirements.txt')},\n entry_points={\n 'console_scripts': ['flexget = flexget:main'],\n 'gui_scripts': [\n 'flexget-headless = flexget:main'\n ], # This is useful on Windows to avoid a cmd popup\n },\n python_requires='>=3.6',\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"License :: OSI Approved :: MIT License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n ],\n)\n", "path": "setup.py"}]}
| 2,077 | 107 |
gh_patches_debug_65637
|
rasdani/github-patches
|
git_diff
|
saulpw__visidata-2036
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug: cannot read .vds with expression column
**Small description**
Visidata cannot read back sheet(s) it saved as `.vds` if they contain an
expression column.
"KeyError: 'ExprColumn'" shows as error, resulting in a partial read.
**Expected result**
It should be able to read those files.
**Actual result with ~~screenshot~~ stacktrace**
```
Traceback (most recent call last):
File "/nix/store/z4xjb4j8i73894r2wqjvlnps9j60rjr0-visidata-2.11/lib/python3.10/site-packages/visidata/threads.py", line 198, in _toplevelTryFunc
t.status = func(*args, **kwargs)
File "/nix/store/z4xjb4j8i73894r2wqjvlnps9j60rjr0-visidata-2.11/lib/python3.10/site-packages/visidata/pyobj.py", line 26, in reload
for r in self.iterload():
File "/nix/store/z4xjb4j8i73894r2wqjvlnps9j60rjr0-visidata-2.11/lib/python3.10/site-packages/visidata/loaders/vds.py", line 76, in iterload
c = globals()[classname](d.pop('name'), sheet=self)
KeyError: 'ExprColumn'
```
**Steps to reproduce with sample data and a .vd**
Create and save some test sheet with an expr column with this `cmdlog.vdj`:
```
#!vd -p
{"col": "", "row": "", "longname": "open-new", "input": "", "keystrokes": "Shift+A", "comment": "Open new empty sheet"}
{"sheet": "unnamed", "col": "A", "row": "", "longname": "type-int", "input": "", "keystrokes": "#", "comment": "set type of current column to int"}
{"sheet": "unnamed", "col": "", "row": "", "longname": "add-row", "input": "", "keystrokes": "a", "comment": "append a blank row"}
{"sheet": "unnamed", "col": "A", "row": "0", "longname": "edit-cell", "input": "2", "keystrokes": "e", "comment": "edit contents of current cell"}
{"sheet": "unnamed", "col": "A", "row": "", "longname": "addcol-expr", "input": "A*2", "keystrokes": "=", "comment": "create new column from Python expression, with column names as variables"}
{"sheet": "unnamed", "col": "", "row": "", "longname": "save-sheet", "input": "sheet.vds", "keystrokes": "Ctrl+S", "comment": "save current sheet to filename in format determined by extension (default .tsv)"}
```
This produces `sheet.vds` as follows, which seems valid:
```
#{"name": "unnamed"}
#{"name": "A", "width": 4, "height": 1, "expr": null, "keycol": 0, "formatter": "", "fmtstr": "", "voffset": 0, "hoffset": 0, "aggstr": "", "type": "int", "col": "Column"}
#{"name": "A*2", "width": 5, "height": 1, "expr": "A*2", "keycol": 0, "formatter": "", "fmtstr": "", "voffset": 0, "hoffset": 0, "aggstr": "", "type": "", "col": "ExprColumn"}
{"A": 2, "A*2": 4}
```
Quit visidata and open that file again with `vd sheet.vds`,
and observe the loading error.
**Additional context**
- visidata v2.11
- python 3.10.12
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `visidata/loaders/vds.py`
Content:
```
1 'Custom VisiData save format'
2
3 import json
4
5 from visidata import VisiData, JsonSheet, Progress, IndexSheet, SettableColumn, ItemColumn
6
7
8 NL='\n'
9
10 @VisiData.api
11 def open_vds(vd, p):
12 return VdsIndexSheet(p.name, source=p)
13
14
15 @VisiData.api
16 def save_vds(vd, p, *sheets):
17 'Save in custom VisiData format, preserving columns and their attributes.'
18
19 with p.open(mode='w', encoding='utf-8') as fp:
20 for vs in sheets:
21 # class and attrs for vs
22 d = { 'name': vs.name, }
23 fp.write('#'+json.dumps(d)+NL)
24
25 # class and attrs for each column in vs
26 for col in vs.visibleCols:
27 d = col.__getstate__()
28 if isinstance(col, SettableColumn):
29 d['col'] = 'Column'
30 else:
31 d['col'] = type(col).__name__
32 fp.write('#'+json.dumps(d)+NL)
33
34 with Progress(gerund='saving'):
35 for row in vs.iterdispvals(*vs.visibleCols, format=False):
36 d = {col.name:val for col, val in row.items()}
37 fp.write(json.dumps(d, default=str)+NL)
38
39
40 class VdsIndexSheet(IndexSheet):
41 def iterload(self):
42 vs = None
43 with self.source.open(encoding='utf-8') as fp:
44 line = fp.readline()
45 while line:
46 if line.startswith('#{'):
47 d = json.loads(line[1:])
48 if 'col' not in d:
49 vs = VdsSheet(d.pop('name'), columns=[], source=self.source, source_fpos=fp.tell())
50 yield vs
51 line = fp.readline()
52
53
54 class VdsSheet(JsonSheet):
55 def newRow(self):
56 return {} # rowdef: dict
57
58 def iterload(self):
59 self.colnames = {}
60 self.columns = []
61
62 with self.source.open(encoding='utf-8') as fp:
63 fp.seek(self.source_fpos)
64
65 # consume all metadata, create columns
66 line = fp.readline()
67 while line and line.startswith('#{'):
68 d = json.loads(line[1:])
69 if 'col' not in d:
70 raise Exception(d)
71 classname = d.pop('col')
72 if classname == 'Column':
73 classname = 'ItemColumn'
74 d['expr'] = d['name']
75
76 c = globals()[classname](d.pop('name'), sheet=self)
77 self.addColumn(c)
78 self.colnames[c.name] = c
79 for k, v in d.items():
80 setattr(c, k, v)
81
82 line = fp.readline()
83
84 while line and not line.startswith('#{'):
85 d = json.loads(line)
86 yield d
87 line = fp.readline()
88
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/visidata/loaders/vds.py b/visidata/loaders/vds.py
--- a/visidata/loaders/vds.py
+++ b/visidata/loaders/vds.py
@@ -2,7 +2,7 @@
import json
-from visidata import VisiData, JsonSheet, Progress, IndexSheet, SettableColumn, ItemColumn
+from visidata import VisiData, JsonSheet, Progress, IndexSheet, SettableColumn, ItemColumn, ExprColumn
NL='\n'
|
{"golden_diff": "diff --git a/visidata/loaders/vds.py b/visidata/loaders/vds.py\n--- a/visidata/loaders/vds.py\n+++ b/visidata/loaders/vds.py\n@@ -2,7 +2,7 @@\n \n import json\n \n-from visidata import VisiData, JsonSheet, Progress, IndexSheet, SettableColumn, ItemColumn\n+from visidata import VisiData, JsonSheet, Progress, IndexSheet, SettableColumn, ItemColumn, ExprColumn\n \n \n NL='\\n'\n", "issue": "Bug: cannot read .vds with expression column\n**Small description**\n\nVisidata cannot read back sheet(s) it saved as `.vds` if they contain an\nexpression column.\n\n\"KeyError: 'ExprColumn'\" shows as error, resulting in a partial read.\n\n\n**Expected result**\n\nIt should be able to read those files.\n\n\n**Actual result with ~~screenshot~~ stacktrace**\n\n```\nTraceback (most recent call last):\n File \"/nix/store/z4xjb4j8i73894r2wqjvlnps9j60rjr0-visidata-2.11/lib/python3.10/site-packages/visidata/threads.py\", line 198, in _toplevelTryFunc\n t.status = func(*args, **kwargs)\n File \"/nix/store/z4xjb4j8i73894r2wqjvlnps9j60rjr0-visidata-2.11/lib/python3.10/site-packages/visidata/pyobj.py\", line 26, in reload\n for r in self.iterload():\n File \"/nix/store/z4xjb4j8i73894r2wqjvlnps9j60rjr0-visidata-2.11/lib/python3.10/site-packages/visidata/loaders/vds.py\", line 76, in iterload\n c = globals()[classname](d.pop('name'), sheet=self)\nKeyError: 'ExprColumn'\n```\n\n\n**Steps to reproduce with sample data and a .vd**\n\nCreate and save some test sheet with an expr column with this `cmdlog.vdj`:\n\n```\n#!vd -p\n{\"col\": \"\", \"row\": \"\", \"longname\": \"open-new\", \"input\": \"\", \"keystrokes\": \"Shift+A\", \"comment\": \"Open new empty sheet\"}\n{\"sheet\": \"unnamed\", \"col\": \"A\", \"row\": \"\", \"longname\": \"type-int\", \"input\": \"\", \"keystrokes\": \"#\", \"comment\": \"set type of current column to int\"}\n{\"sheet\": \"unnamed\", \"col\": \"\", \"row\": \"\", \"longname\": \"add-row\", \"input\": \"\", \"keystrokes\": \"a\", \"comment\": \"append a blank row\"}\n{\"sheet\": \"unnamed\", \"col\": \"A\", \"row\": \"0\", \"longname\": \"edit-cell\", \"input\": \"2\", \"keystrokes\": \"e\", \"comment\": \"edit contents of current cell\"}\n{\"sheet\": \"unnamed\", \"col\": \"A\", \"row\": \"\", \"longname\": \"addcol-expr\", \"input\": \"A*2\", \"keystrokes\": \"=\", \"comment\": \"create new column from Python expression, with column names as variables\"}\n{\"sheet\": \"unnamed\", \"col\": \"\", \"row\": \"\", \"longname\": \"save-sheet\", \"input\": \"sheet.vds\", \"keystrokes\": \"Ctrl+S\", \"comment\": \"save current sheet to filename in format determined by extension (default .tsv)\"}\n```\n\nThis produces `sheet.vds` as follows, which seems valid:\n\n```\n#{\"name\": \"unnamed\"}\n#{\"name\": \"A\", \"width\": 4, \"height\": 1, \"expr\": null, \"keycol\": 0, \"formatter\": \"\", \"fmtstr\": \"\", \"voffset\": 0, \"hoffset\": 0, \"aggstr\": \"\", \"type\": \"int\", \"col\": \"Column\"}\n#{\"name\": \"A*2\", \"width\": 5, \"height\": 1, \"expr\": \"A*2\", \"keycol\": 0, \"formatter\": \"\", \"fmtstr\": \"\", \"voffset\": 0, \"hoffset\": 0, \"aggstr\": \"\", \"type\": \"\", \"col\": \"ExprColumn\"}\n{\"A\": 2, \"A*2\": 4}\n```\n\nQuit visidata and open that file again with `vd sheet.vds`,\nand observe the loading error.\n\n\n**Additional context**\n\n- visidata v2.11\n- python 3.10.12\n\n", "before_files": [{"content": "'Custom VisiData save format'\n\nimport json\n\nfrom visidata import VisiData, JsonSheet, Progress, IndexSheet, SettableColumn, ItemColumn\n\n\nNL='\\n'\n\[email protected]\ndef open_vds(vd, p):\n return VdsIndexSheet(p.name, source=p)\n\n\[email protected]\ndef save_vds(vd, p, *sheets):\n 'Save in custom VisiData format, preserving columns and their attributes.'\n\n with p.open(mode='w', encoding='utf-8') as fp:\n for vs in sheets:\n # class and attrs for vs\n d = { 'name': vs.name, }\n fp.write('#'+json.dumps(d)+NL)\n\n # class and attrs for each column in vs\n for col in vs.visibleCols:\n d = col.__getstate__()\n if isinstance(col, SettableColumn):\n d['col'] = 'Column'\n else:\n d['col'] = type(col).__name__\n fp.write('#'+json.dumps(d)+NL)\n\n with Progress(gerund='saving'):\n for row in vs.iterdispvals(*vs.visibleCols, format=False):\n d = {col.name:val for col, val in row.items()}\n fp.write(json.dumps(d, default=str)+NL)\n\n\nclass VdsIndexSheet(IndexSheet):\n def iterload(self):\n vs = None\n with self.source.open(encoding='utf-8') as fp:\n line = fp.readline()\n while line:\n if line.startswith('#{'):\n d = json.loads(line[1:])\n if 'col' not in d:\n vs = VdsSheet(d.pop('name'), columns=[], source=self.source, source_fpos=fp.tell())\n yield vs\n line = fp.readline()\n\n\nclass VdsSheet(JsonSheet):\n def newRow(self):\n return {} # rowdef: dict\n\n def iterload(self):\n self.colnames = {}\n self.columns = []\n\n with self.source.open(encoding='utf-8') as fp:\n fp.seek(self.source_fpos)\n\n # consume all metadata, create columns\n line = fp.readline()\n while line and line.startswith('#{'):\n d = json.loads(line[1:])\n if 'col' not in d:\n raise Exception(d)\n classname = d.pop('col')\n if classname == 'Column':\n classname = 'ItemColumn'\n d['expr'] = d['name']\n\n c = globals()[classname](d.pop('name'), sheet=self)\n self.addColumn(c)\n self.colnames[c.name] = c\n for k, v in d.items():\n setattr(c, k, v)\n\n line = fp.readline()\n\n while line and not line.startswith('#{'):\n d = json.loads(line)\n yield d\n line = fp.readline()\n", "path": "visidata/loaders/vds.py"}], "after_files": [{"content": "'Custom VisiData save format'\n\nimport json\n\nfrom visidata import VisiData, JsonSheet, Progress, IndexSheet, SettableColumn, ItemColumn, ExprColumn\n\n\nNL='\\n'\n\[email protected]\ndef open_vds(vd, p):\n return VdsIndexSheet(p.name, source=p)\n\n\[email protected]\ndef save_vds(vd, p, *sheets):\n 'Save in custom VisiData format, preserving columns and their attributes.'\n\n with p.open(mode='w', encoding='utf-8') as fp:\n for vs in sheets:\n # class and attrs for vs\n d = { 'name': vs.name, }\n fp.write('#'+json.dumps(d)+NL)\n\n # class and attrs for each column in vs\n for col in vs.visibleCols:\n d = col.__getstate__()\n if isinstance(col, SettableColumn):\n d['col'] = 'Column'\n else:\n d['col'] = type(col).__name__\n fp.write('#'+json.dumps(d)+NL)\n\n with Progress(gerund='saving'):\n for row in vs.iterdispvals(*vs.visibleCols, format=False):\n d = {col.name:val for col, val in row.items()}\n fp.write(json.dumps(d, default=str)+NL)\n\n\nclass VdsIndexSheet(IndexSheet):\n def iterload(self):\n vs = None\n with self.source.open(encoding='utf-8') as fp:\n line = fp.readline()\n while line:\n if line.startswith('#{'):\n d = json.loads(line[1:])\n if 'col' not in d:\n vs = VdsSheet(d.pop('name'), columns=[], source=self.source, source_fpos=fp.tell())\n yield vs\n line = fp.readline()\n\n\nclass VdsSheet(JsonSheet):\n def newRow(self):\n return {} # rowdef: dict\n\n def iterload(self):\n self.colnames = {}\n self.columns = []\n\n with self.source.open(encoding='utf-8') as fp:\n fp.seek(self.source_fpos)\n\n # consume all metadata, create columns\n line = fp.readline()\n while line and line.startswith('#{'):\n d = json.loads(line[1:])\n if 'col' not in d:\n raise Exception(d)\n classname = d.pop('col')\n if classname == 'Column':\n classname = 'ItemColumn'\n d['expr'] = d['name']\n\n c = globals()[classname](d.pop('name'), sheet=self)\n self.addColumn(c)\n self.colnames[c.name] = c\n for k, v in d.items():\n setattr(c, k, v)\n\n line = fp.readline()\n\n while line and not line.startswith('#{'):\n d = json.loads(line)\n yield d\n line = fp.readline()\n", "path": "visidata/loaders/vds.py"}]}
| 1,949 | 113 |
gh_patches_debug_7921
|
rasdani/github-patches
|
git_diff
|
OpenMined__PySyft-5330
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Check and Fix notebook / jupyter client warning on Colab
## Description
This needs to be checked on Colab, since it seems colab has its own outdated versions of notebook and jupyter-client as well.
https://github.com/OpenMined/PySyft/issues/4915
## Definition of Done
Fix for Colab if possible.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/syft/core/common/environment.py`
Content:
```
1 # stdlib
2 import sys
3
4 # checks if we are in a python repl or python -i script.py
5 is_interactive = bool(getattr(sys, "ps1", sys.flags.interactive))
6
7 # checks if we are in jupyter
8 is_jupyter = True
9
10 try:
11 get_ipython() # type: ignore
12 # third party
13 import notebook
14 from packaging import version
15
16 NOTEBOOK_VERSION = version.parse(notebook.__version__.split("+")[0])
17 if NOTEBOOK_VERSION < version.parse("6.0.0"):
18 raise Exception(
19 "Your Jupyter Notebook is too old. Please upgrade to version 6 or higher."
20 )
21 except NameError:
22 is_jupyter = False
23
24 __all__ = ["is_interactive", "is_jupyter"]
25
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/syft/core/common/environment.py b/src/syft/core/common/environment.py
--- a/src/syft/core/common/environment.py
+++ b/src/syft/core/common/environment.py
@@ -14,7 +14,8 @@
from packaging import version
NOTEBOOK_VERSION = version.parse(notebook.__version__.split("+")[0])
- if NOTEBOOK_VERSION < version.parse("6.0.0"):
+ if NOTEBOOK_VERSION < version.parse("6.0.0") and "google.colab" not in sys.modules:
+ # google.colab check to fix issue #5315
raise Exception(
"Your Jupyter Notebook is too old. Please upgrade to version 6 or higher."
)
|
{"golden_diff": "diff --git a/src/syft/core/common/environment.py b/src/syft/core/common/environment.py\n--- a/src/syft/core/common/environment.py\n+++ b/src/syft/core/common/environment.py\n@@ -14,7 +14,8 @@\n from packaging import version\n \n NOTEBOOK_VERSION = version.parse(notebook.__version__.split(\"+\")[0])\n- if NOTEBOOK_VERSION < version.parse(\"6.0.0\"):\n+ if NOTEBOOK_VERSION < version.parse(\"6.0.0\") and \"google.colab\" not in sys.modules:\n+ # google.colab check to fix issue #5315\n raise Exception(\n \"Your Jupyter Notebook is too old. Please upgrade to version 6 or higher.\"\n )\n", "issue": "Check and Fix notebook / jupyter client warning on Colab\n## Description\r\nThis needs to be checked on Colab, since it seems colab has its own outdated versions of notebook and jupyter-client as well.\r\nhttps://github.com/OpenMined/PySyft/issues/4915\r\n\r\n## Definition of Done\r\nFix for Colab if possible.\n", "before_files": [{"content": "# stdlib\nimport sys\n\n# checks if we are in a python repl or python -i script.py\nis_interactive = bool(getattr(sys, \"ps1\", sys.flags.interactive))\n\n# checks if we are in jupyter\nis_jupyter = True\n\ntry:\n get_ipython() # type: ignore\n # third party\n import notebook\n from packaging import version\n\n NOTEBOOK_VERSION = version.parse(notebook.__version__.split(\"+\")[0])\n if NOTEBOOK_VERSION < version.parse(\"6.0.0\"):\n raise Exception(\n \"Your Jupyter Notebook is too old. Please upgrade to version 6 or higher.\"\n )\nexcept NameError:\n is_jupyter = False\n\n__all__ = [\"is_interactive\", \"is_jupyter\"]\n", "path": "src/syft/core/common/environment.py"}], "after_files": [{"content": "# stdlib\nimport sys\n\n# checks if we are in a python repl or python -i script.py\nis_interactive = bool(getattr(sys, \"ps1\", sys.flags.interactive))\n\n# checks if we are in jupyter\nis_jupyter = True\n\ntry:\n get_ipython() # type: ignore\n # third party\n import notebook\n from packaging import version\n\n NOTEBOOK_VERSION = version.parse(notebook.__version__.split(\"+\")[0])\n if NOTEBOOK_VERSION < version.parse(\"6.0.0\") and \"google.colab\" not in sys.modules:\n # google.colab check to fix issue #5315\n raise Exception(\n \"Your Jupyter Notebook is too old. Please upgrade to version 6 or higher.\"\n )\nexcept NameError:\n is_jupyter = False\n\n__all__ = [\"is_interactive\", \"is_jupyter\"]\n", "path": "src/syft/core/common/environment.py"}]}
| 548 | 163 |
gh_patches_debug_35215
|
rasdani/github-patches
|
git_diff
|
cal-itp__benefits-1804
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Adjust handling of enrollment when customer already exists in group
Our payment processor uses a `500` error response to indicate that a customer is already enrolled in a group.
This is not an actual problem for Benefits, so we have [code that handles the response](https://github.com/cal-itp/benefits/blob/dev/benefits/enrollment/api.py#L82) and returns a success to the user.
The error handling is brittle, relying to some degree on the returned error message. This message has now changed, thus our handling is broken.
## To Reproduce
Steps to reproduce the behavior:
1. Go to test
2. Verify as a senior with SacRT
3. Enroll a card
4. Do 2-3 again with the same card --> BOOM
## Expected behavior
Attempting to re-enroll with the same card should not cause an error for the end user.
## Additional context
New error message from the logs looks like:
```log
Customer xxxx already exists in group yyyy
```
The old one looked more like:
```
Duplicate customer xxxxx...
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `benefits/enrollment/api.py`
Content:
```
1 """
2 The enrollment application: Benefits Enrollment API implementation.
3 """
4 import logging
5 from tempfile import NamedTemporaryFile
6 import time
7
8 from django.conf import settings
9 import requests
10
11
12 logger = logging.getLogger(__name__)
13
14
15 class ApiError(Exception):
16 """Error calling the enrollment APIs."""
17
18 pass
19
20
21 class AccessTokenResponse:
22 """Benefits Enrollment API Access Token response."""
23
24 def __init__(self, response):
25 logger.info("Read access token from response")
26
27 try:
28 payload = response.json()
29 except ValueError:
30 raise ApiError("Invalid response format")
31
32 self.access_token = payload.get("access_token")
33 self.token_type = payload.get("token_type")
34 self.expires_in = payload.get("expires_in")
35 if self.expires_in is not None:
36 logger.debug("Access token has expiry")
37 self.expiry = time.time() + self.expires_in
38 else:
39 logger.debug("Access token has no expiry")
40 self.expiry = None
41
42 logger.info("Access token successfully read from response")
43
44
45 class CustomerResponse:
46 """Benefits Enrollment Customer API response."""
47
48 def __init__(self, response):
49 logger.info("Read customer details from response")
50
51 try:
52 payload = response.json()
53 self.id = payload["id"]
54 except (KeyError, ValueError):
55 raise ApiError("Invalid response format")
56
57 if self.id is None:
58 raise ApiError("Invalid response format")
59
60 self.is_registered = str(payload.get("is_registered", "false")).lower() == "true"
61
62 logger.info("Customer details successfully read from response")
63
64
65 class GroupResponse:
66 """Benefits Enrollment Customer Group API response."""
67
68 def __init__(self, response, requested_id, payload=None):
69 if payload is None:
70 try:
71 payload = response.json()
72 except ValueError:
73 raise ApiError("Invalid response format")
74 else:
75 try:
76 # Group API uses an error response (500) to indicate that the customer already exists in the group (!!!)
77 # The error message should contain the customer ID we sent via payload and start with "Duplicate"
78 error = response.json()["errors"][0]
79 customer_id = payload[0]
80 detail = error["detail"]
81
82 failure = (
83 customer_id is None
84 or detail is None
85 or customer_id not in detail
86 or customer_id in detail
87 and not detail.startswith("Duplicate")
88 )
89
90 if failure:
91 raise ApiError("Invalid response format")
92 except (KeyError, ValueError):
93 raise ApiError("Invalid response format")
94
95 self.customer_ids = list(payload)
96 self.updated_customer_id = self.customer_ids[0] if len(self.customer_ids) == 1 else None
97 self.success = requested_id == self.updated_customer_id
98 self.message = "Updated customer_id does not match enrolled customer_id" if not self.success else ""
99
100
101 class Client:
102 """Benefits Enrollment API client."""
103
104 def __init__(self, agency):
105 logger.debug("Initialize Benefits Enrollment API Client")
106
107 if agency is None:
108 raise ValueError("agency")
109 if agency.payment_processor is None:
110 raise ValueError("agency.payment_processor")
111
112 self.agency = agency
113 self.payment_processor = agency.payment_processor
114 self.headers = {"Accept": "application/json", "Content-type": "application/json"}
115
116 def _headers(self, headers=None):
117 h = dict(self.headers)
118 if headers:
119 h.update(headers)
120 return h
121
122 def _make_url(self, *parts):
123 return "/".join((self.payment_processor.api_base_url, self.agency.merchant_id, *parts))
124
125 def _get(self, url, payload, headers=None):
126 h = self._headers(headers)
127 return self._cert_request(
128 lambda verify, cert: requests.get(
129 url,
130 headers=h,
131 params=payload,
132 verify=verify,
133 cert=cert,
134 timeout=settings.REQUESTS_TIMEOUT,
135 )
136 )
137
138 def _patch(self, url, payload, headers=None):
139 h = self._headers(headers)
140 return self._cert_request(
141 lambda verify, cert: requests.patch(
142 url,
143 headers=h,
144 json=payload,
145 verify=verify,
146 cert=cert,
147 timeout=settings.REQUESTS_TIMEOUT,
148 )
149 )
150
151 def _post(self, url, payload, headers=None):
152 h = self._headers(headers)
153 return self._cert_request(
154 lambda verify, cert: requests.post(
155 url,
156 headers=h,
157 json=payload,
158 verify=verify,
159 cert=cert,
160 timeout=settings.REQUESTS_TIMEOUT,
161 )
162 )
163
164 def _cert_request(self, request_func):
165 """
166 Creates named (on-disk) temp files for client cert auth.
167 * request_func: curried callable from `requests` library (e.g. `requests.get`).
168 """
169 # requests library reads temp files from file path
170 # The "with" context destroys temp files when response comes back
171 with NamedTemporaryFile("w+") as cert, NamedTemporaryFile("w+") as key, NamedTemporaryFile("w+") as ca:
172 # write client cert data to temp files
173 # resetting so they can be read again by requests
174 cert.write(self.payment_processor.client_cert.data)
175 cert.seek(0)
176
177 key.write(self.payment_processor.client_cert_private_key.data)
178 key.seek(0)
179
180 ca.write(self.payment_processor.client_cert_root_ca.data)
181 ca.seek(0)
182
183 # request using temp file paths
184 return request_func(verify=ca.name, cert=(cert.name, key.name))
185
186 def _get_customer(self, token):
187 """Get a customer record from Payment Processor's system"""
188 logger.info("Check for existing customer record")
189
190 if token is None:
191 raise ValueError("token")
192
193 url = self._make_url(self.payment_processor.customers_endpoint)
194 payload = {"token": token}
195
196 try:
197 r = self._get(url, payload)
198 r.raise_for_status()
199
200 logger.debug("Customer record exists")
201 customer = CustomerResponse(r)
202 if customer.is_registered:
203 logger.debug("Customer is registered, skip update")
204 return customer
205 else:
206 logger.debug("Customer is not registered, update")
207 return self._update_customer(customer.id)
208
209 except requests.ConnectionError:
210 raise ApiError("Connection to enrollment server failed")
211 except requests.Timeout:
212 raise ApiError("Connection to enrollment server timed out")
213 except requests.TooManyRedirects:
214 raise ApiError("Too many redirects to enrollment server")
215 except requests.HTTPError as e:
216 raise ApiError(e)
217
218 def _update_customer(self, customer_id):
219 """Update a customer using their unique info."""
220 logger.info("Update existing customer record")
221
222 if customer_id is None:
223 raise ValueError("customer_id")
224
225 url = self._make_url(self.payment_processor.customer_endpoint, customer_id)
226 payload = {"is_registered": True, "id": customer_id}
227
228 r = self._patch(url, payload)
229 r.raise_for_status()
230
231 return CustomerResponse(r)
232
233 def access_token(self):
234 """Obtain an access token to use for integrating with other APIs."""
235 logger.info("Get new access token")
236
237 url = self._make_url(self.payment_processor.api_access_token_endpoint)
238 payload = {self.payment_processor.api_access_token_request_key: self.payment_processor.api_access_token_request_val}
239
240 try:
241 r = self._post(url, payload)
242 r.raise_for_status()
243 except requests.ConnectionError:
244 raise ApiError("Connection to enrollment server failed")
245 except requests.Timeout:
246 raise ApiError("Connection to enrollment server timed out")
247 except requests.TooManyRedirects:
248 raise ApiError("Too many redirects to enrollment server")
249 except requests.HTTPError as e:
250 raise ApiError(e)
251
252 return AccessTokenResponse(r)
253
254 def enroll(self, customer_token, group_id):
255 """Enroll a customer in a product group using the token that represents that customer."""
256 logger.info("Enroll customer in product group")
257
258 if customer_token is None:
259 raise ValueError("customer_token")
260 if group_id is None:
261 raise ValueError("group_id")
262
263 customer = self._get_customer(customer_token)
264 url = self._make_url(self.payment_processor.group_endpoint, group_id)
265 payload = [customer.id]
266
267 try:
268 r = self._patch(url, payload)
269
270 if r.status_code in (200, 201):
271 logger.info("Customer enrolled in group")
272 return GroupResponse(r, customer.id)
273 elif r.status_code == 500:
274 logger.info("Customer already exists in group")
275 return GroupResponse(r, customer.id, payload=payload)
276 else:
277 r.raise_for_status()
278 except requests.ConnectionError:
279 raise ApiError("Connection to enrollment server failed")
280 except requests.Timeout:
281 raise ApiError("Connection to enrollment server timed out")
282 except requests.TooManyRedirects:
283 raise ApiError("Too many redirects to enrollment server")
284 except requests.HTTPError as e:
285 raise ApiError(e)
286
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/benefits/enrollment/api.py b/benefits/enrollment/api.py
--- a/benefits/enrollment/api.py
+++ b/benefits/enrollment/api.py
@@ -65,7 +65,7 @@
class GroupResponse:
"""Benefits Enrollment Customer Group API response."""
- def __init__(self, response, requested_id, payload=None):
+ def __init__(self, response, requested_id, group_id, payload=None):
if payload is None:
try:
payload = response.json()
@@ -74,18 +74,12 @@
else:
try:
# Group API uses an error response (500) to indicate that the customer already exists in the group (!!!)
- # The error message should contain the customer ID we sent via payload and start with "Duplicate"
+ # The error message should contain the customer ID and group ID we sent via payload
error = response.json()["errors"][0]
customer_id = payload[0]
detail = error["detail"]
- failure = (
- customer_id is None
- or detail is None
- or customer_id not in detail
- or customer_id in detail
- and not detail.startswith("Duplicate")
- )
+ failure = customer_id is None or detail is None or not (customer_id in detail and group_id in detail)
if failure:
raise ApiError("Invalid response format")
@@ -269,10 +263,10 @@
if r.status_code in (200, 201):
logger.info("Customer enrolled in group")
- return GroupResponse(r, customer.id)
+ return GroupResponse(r, customer.id, group_id)
elif r.status_code == 500:
logger.info("Customer already exists in group")
- return GroupResponse(r, customer.id, payload=payload)
+ return GroupResponse(r, customer.id, group_id, payload=payload)
else:
r.raise_for_status()
except requests.ConnectionError:
|
{"golden_diff": "diff --git a/benefits/enrollment/api.py b/benefits/enrollment/api.py\n--- a/benefits/enrollment/api.py\n+++ b/benefits/enrollment/api.py\n@@ -65,7 +65,7 @@\n class GroupResponse:\n \"\"\"Benefits Enrollment Customer Group API response.\"\"\"\n \n- def __init__(self, response, requested_id, payload=None):\n+ def __init__(self, response, requested_id, group_id, payload=None):\n if payload is None:\n try:\n payload = response.json()\n@@ -74,18 +74,12 @@\n else:\n try:\n # Group API uses an error response (500) to indicate that the customer already exists in the group (!!!)\n- # The error message should contain the customer ID we sent via payload and start with \"Duplicate\"\n+ # The error message should contain the customer ID and group ID we sent via payload\n error = response.json()[\"errors\"][0]\n customer_id = payload[0]\n detail = error[\"detail\"]\n \n- failure = (\n- customer_id is None\n- or detail is None\n- or customer_id not in detail\n- or customer_id in detail\n- and not detail.startswith(\"Duplicate\")\n- )\n+ failure = customer_id is None or detail is None or not (customer_id in detail and group_id in detail)\n \n if failure:\n raise ApiError(\"Invalid response format\")\n@@ -269,10 +263,10 @@\n \n if r.status_code in (200, 201):\n logger.info(\"Customer enrolled in group\")\n- return GroupResponse(r, customer.id)\n+ return GroupResponse(r, customer.id, group_id)\n elif r.status_code == 500:\n logger.info(\"Customer already exists in group\")\n- return GroupResponse(r, customer.id, payload=payload)\n+ return GroupResponse(r, customer.id, group_id, payload=payload)\n else:\n r.raise_for_status()\n except requests.ConnectionError:\n", "issue": "Adjust handling of enrollment when customer already exists in group\nOur payment processor uses a `500` error response to indicate that a customer is already enrolled in a group.\r\n\r\nThis is not an actual problem for Benefits, so we have [code that handles the response](https://github.com/cal-itp/benefits/blob/dev/benefits/enrollment/api.py#L82) and returns a success to the user.\r\n\r\nThe error handling is brittle, relying to some degree on the returned error message. This message has now changed, thus our handling is broken.\r\n\r\n## To Reproduce\r\n\r\nSteps to reproduce the behavior:\r\n\r\n1. Go to test\r\n2. Verify as a senior with SacRT\r\n3. Enroll a card\r\n4. Do 2-3 again with the same card --> BOOM\r\n\r\n## Expected behavior\r\n\r\nAttempting to re-enroll with the same card should not cause an error for the end user.\r\n\r\n## Additional context\r\n\r\nNew error message from the logs looks like:\r\n\r\n```log\r\nCustomer xxxx already exists in group yyyy\r\n```\r\n\r\nThe old one looked more like:\r\n\r\n```\r\nDuplicate customer xxxxx...\r\n```\r\n\r\n\n", "before_files": [{"content": "\"\"\"\nThe enrollment application: Benefits Enrollment API implementation.\n\"\"\"\nimport logging\nfrom tempfile import NamedTemporaryFile\nimport time\n\nfrom django.conf import settings\nimport requests\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass ApiError(Exception):\n \"\"\"Error calling the enrollment APIs.\"\"\"\n\n pass\n\n\nclass AccessTokenResponse:\n \"\"\"Benefits Enrollment API Access Token response.\"\"\"\n\n def __init__(self, response):\n logger.info(\"Read access token from response\")\n\n try:\n payload = response.json()\n except ValueError:\n raise ApiError(\"Invalid response format\")\n\n self.access_token = payload.get(\"access_token\")\n self.token_type = payload.get(\"token_type\")\n self.expires_in = payload.get(\"expires_in\")\n if self.expires_in is not None:\n logger.debug(\"Access token has expiry\")\n self.expiry = time.time() + self.expires_in\n else:\n logger.debug(\"Access token has no expiry\")\n self.expiry = None\n\n logger.info(\"Access token successfully read from response\")\n\n\nclass CustomerResponse:\n \"\"\"Benefits Enrollment Customer API response.\"\"\"\n\n def __init__(self, response):\n logger.info(\"Read customer details from response\")\n\n try:\n payload = response.json()\n self.id = payload[\"id\"]\n except (KeyError, ValueError):\n raise ApiError(\"Invalid response format\")\n\n if self.id is None:\n raise ApiError(\"Invalid response format\")\n\n self.is_registered = str(payload.get(\"is_registered\", \"false\")).lower() == \"true\"\n\n logger.info(\"Customer details successfully read from response\")\n\n\nclass GroupResponse:\n \"\"\"Benefits Enrollment Customer Group API response.\"\"\"\n\n def __init__(self, response, requested_id, payload=None):\n if payload is None:\n try:\n payload = response.json()\n except ValueError:\n raise ApiError(\"Invalid response format\")\n else:\n try:\n # Group API uses an error response (500) to indicate that the customer already exists in the group (!!!)\n # The error message should contain the customer ID we sent via payload and start with \"Duplicate\"\n error = response.json()[\"errors\"][0]\n customer_id = payload[0]\n detail = error[\"detail\"]\n\n failure = (\n customer_id is None\n or detail is None\n or customer_id not in detail\n or customer_id in detail\n and not detail.startswith(\"Duplicate\")\n )\n\n if failure:\n raise ApiError(\"Invalid response format\")\n except (KeyError, ValueError):\n raise ApiError(\"Invalid response format\")\n\n self.customer_ids = list(payload)\n self.updated_customer_id = self.customer_ids[0] if len(self.customer_ids) == 1 else None\n self.success = requested_id == self.updated_customer_id\n self.message = \"Updated customer_id does not match enrolled customer_id\" if not self.success else \"\"\n\n\nclass Client:\n \"\"\"Benefits Enrollment API client.\"\"\"\n\n def __init__(self, agency):\n logger.debug(\"Initialize Benefits Enrollment API Client\")\n\n if agency is None:\n raise ValueError(\"agency\")\n if agency.payment_processor is None:\n raise ValueError(\"agency.payment_processor\")\n\n self.agency = agency\n self.payment_processor = agency.payment_processor\n self.headers = {\"Accept\": \"application/json\", \"Content-type\": \"application/json\"}\n\n def _headers(self, headers=None):\n h = dict(self.headers)\n if headers:\n h.update(headers)\n return h\n\n def _make_url(self, *parts):\n return \"/\".join((self.payment_processor.api_base_url, self.agency.merchant_id, *parts))\n\n def _get(self, url, payload, headers=None):\n h = self._headers(headers)\n return self._cert_request(\n lambda verify, cert: requests.get(\n url,\n headers=h,\n params=payload,\n verify=verify,\n cert=cert,\n timeout=settings.REQUESTS_TIMEOUT,\n )\n )\n\n def _patch(self, url, payload, headers=None):\n h = self._headers(headers)\n return self._cert_request(\n lambda verify, cert: requests.patch(\n url,\n headers=h,\n json=payload,\n verify=verify,\n cert=cert,\n timeout=settings.REQUESTS_TIMEOUT,\n )\n )\n\n def _post(self, url, payload, headers=None):\n h = self._headers(headers)\n return self._cert_request(\n lambda verify, cert: requests.post(\n url,\n headers=h,\n json=payload,\n verify=verify,\n cert=cert,\n timeout=settings.REQUESTS_TIMEOUT,\n )\n )\n\n def _cert_request(self, request_func):\n \"\"\"\n Creates named (on-disk) temp files for client cert auth.\n * request_func: curried callable from `requests` library (e.g. `requests.get`).\n \"\"\"\n # requests library reads temp files from file path\n # The \"with\" context destroys temp files when response comes back\n with NamedTemporaryFile(\"w+\") as cert, NamedTemporaryFile(\"w+\") as key, NamedTemporaryFile(\"w+\") as ca:\n # write client cert data to temp files\n # resetting so they can be read again by requests\n cert.write(self.payment_processor.client_cert.data)\n cert.seek(0)\n\n key.write(self.payment_processor.client_cert_private_key.data)\n key.seek(0)\n\n ca.write(self.payment_processor.client_cert_root_ca.data)\n ca.seek(0)\n\n # request using temp file paths\n return request_func(verify=ca.name, cert=(cert.name, key.name))\n\n def _get_customer(self, token):\n \"\"\"Get a customer record from Payment Processor's system\"\"\"\n logger.info(\"Check for existing customer record\")\n\n if token is None:\n raise ValueError(\"token\")\n\n url = self._make_url(self.payment_processor.customers_endpoint)\n payload = {\"token\": token}\n\n try:\n r = self._get(url, payload)\n r.raise_for_status()\n\n logger.debug(\"Customer record exists\")\n customer = CustomerResponse(r)\n if customer.is_registered:\n logger.debug(\"Customer is registered, skip update\")\n return customer\n else:\n logger.debug(\"Customer is not registered, update\")\n return self._update_customer(customer.id)\n\n except requests.ConnectionError:\n raise ApiError(\"Connection to enrollment server failed\")\n except requests.Timeout:\n raise ApiError(\"Connection to enrollment server timed out\")\n except requests.TooManyRedirects:\n raise ApiError(\"Too many redirects to enrollment server\")\n except requests.HTTPError as e:\n raise ApiError(e)\n\n def _update_customer(self, customer_id):\n \"\"\"Update a customer using their unique info.\"\"\"\n logger.info(\"Update existing customer record\")\n\n if customer_id is None:\n raise ValueError(\"customer_id\")\n\n url = self._make_url(self.payment_processor.customer_endpoint, customer_id)\n payload = {\"is_registered\": True, \"id\": customer_id}\n\n r = self._patch(url, payload)\n r.raise_for_status()\n\n return CustomerResponse(r)\n\n def access_token(self):\n \"\"\"Obtain an access token to use for integrating with other APIs.\"\"\"\n logger.info(\"Get new access token\")\n\n url = self._make_url(self.payment_processor.api_access_token_endpoint)\n payload = {self.payment_processor.api_access_token_request_key: self.payment_processor.api_access_token_request_val}\n\n try:\n r = self._post(url, payload)\n r.raise_for_status()\n except requests.ConnectionError:\n raise ApiError(\"Connection to enrollment server failed\")\n except requests.Timeout:\n raise ApiError(\"Connection to enrollment server timed out\")\n except requests.TooManyRedirects:\n raise ApiError(\"Too many redirects to enrollment server\")\n except requests.HTTPError as e:\n raise ApiError(e)\n\n return AccessTokenResponse(r)\n\n def enroll(self, customer_token, group_id):\n \"\"\"Enroll a customer in a product group using the token that represents that customer.\"\"\"\n logger.info(\"Enroll customer in product group\")\n\n if customer_token is None:\n raise ValueError(\"customer_token\")\n if group_id is None:\n raise ValueError(\"group_id\")\n\n customer = self._get_customer(customer_token)\n url = self._make_url(self.payment_processor.group_endpoint, group_id)\n payload = [customer.id]\n\n try:\n r = self._patch(url, payload)\n\n if r.status_code in (200, 201):\n logger.info(\"Customer enrolled in group\")\n return GroupResponse(r, customer.id)\n elif r.status_code == 500:\n logger.info(\"Customer already exists in group\")\n return GroupResponse(r, customer.id, payload=payload)\n else:\n r.raise_for_status()\n except requests.ConnectionError:\n raise ApiError(\"Connection to enrollment server failed\")\n except requests.Timeout:\n raise ApiError(\"Connection to enrollment server timed out\")\n except requests.TooManyRedirects:\n raise ApiError(\"Too many redirects to enrollment server\")\n except requests.HTTPError as e:\n raise ApiError(e)\n", "path": "benefits/enrollment/api.py"}], "after_files": [{"content": "\"\"\"\nThe enrollment application: Benefits Enrollment API implementation.\n\"\"\"\nimport logging\nfrom tempfile import NamedTemporaryFile\nimport time\n\nfrom django.conf import settings\nimport requests\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass ApiError(Exception):\n \"\"\"Error calling the enrollment APIs.\"\"\"\n\n pass\n\n\nclass AccessTokenResponse:\n \"\"\"Benefits Enrollment API Access Token response.\"\"\"\n\n def __init__(self, response):\n logger.info(\"Read access token from response\")\n\n try:\n payload = response.json()\n except ValueError:\n raise ApiError(\"Invalid response format\")\n\n self.access_token = payload.get(\"access_token\")\n self.token_type = payload.get(\"token_type\")\n self.expires_in = payload.get(\"expires_in\")\n if self.expires_in is not None:\n logger.debug(\"Access token has expiry\")\n self.expiry = time.time() + self.expires_in\n else:\n logger.debug(\"Access token has no expiry\")\n self.expiry = None\n\n logger.info(\"Access token successfully read from response\")\n\n\nclass CustomerResponse:\n \"\"\"Benefits Enrollment Customer API response.\"\"\"\n\n def __init__(self, response):\n logger.info(\"Read customer details from response\")\n\n try:\n payload = response.json()\n self.id = payload[\"id\"]\n except (KeyError, ValueError):\n raise ApiError(\"Invalid response format\")\n\n if self.id is None:\n raise ApiError(\"Invalid response format\")\n\n self.is_registered = str(payload.get(\"is_registered\", \"false\")).lower() == \"true\"\n\n logger.info(\"Customer details successfully read from response\")\n\n\nclass GroupResponse:\n \"\"\"Benefits Enrollment Customer Group API response.\"\"\"\n\n def __init__(self, response, requested_id, group_id, payload=None):\n if payload is None:\n try:\n payload = response.json()\n except ValueError:\n raise ApiError(\"Invalid response format\")\n else:\n try:\n # Group API uses an error response (500) to indicate that the customer already exists in the group (!!!)\n # The error message should contain the customer ID and group ID we sent via payload\n error = response.json()[\"errors\"][0]\n customer_id = payload[0]\n detail = error[\"detail\"]\n\n failure = customer_id is None or detail is None or not (customer_id in detail and group_id in detail)\n\n if failure:\n raise ApiError(\"Invalid response format\")\n except (KeyError, ValueError):\n raise ApiError(\"Invalid response format\")\n\n self.customer_ids = list(payload)\n self.updated_customer_id = self.customer_ids[0] if len(self.customer_ids) == 1 else None\n self.success = requested_id == self.updated_customer_id\n self.message = \"Updated customer_id does not match enrolled customer_id\" if not self.success else \"\"\n\n\nclass Client:\n \"\"\"Benefits Enrollment API client.\"\"\"\n\n def __init__(self, agency):\n logger.debug(\"Initialize Benefits Enrollment API Client\")\n\n if agency is None:\n raise ValueError(\"agency\")\n if agency.payment_processor is None:\n raise ValueError(\"agency.payment_processor\")\n\n self.agency = agency\n self.payment_processor = agency.payment_processor\n self.headers = {\"Accept\": \"application/json\", \"Content-type\": \"application/json\"}\n\n def _headers(self, headers=None):\n h = dict(self.headers)\n if headers:\n h.update(headers)\n return h\n\n def _make_url(self, *parts):\n return \"/\".join((self.payment_processor.api_base_url, self.agency.merchant_id, *parts))\n\n def _get(self, url, payload, headers=None):\n h = self._headers(headers)\n return self._cert_request(\n lambda verify, cert: requests.get(\n url,\n headers=h,\n params=payload,\n verify=verify,\n cert=cert,\n timeout=settings.REQUESTS_TIMEOUT,\n )\n )\n\n def _patch(self, url, payload, headers=None):\n h = self._headers(headers)\n return self._cert_request(\n lambda verify, cert: requests.patch(\n url,\n headers=h,\n json=payload,\n verify=verify,\n cert=cert,\n timeout=settings.REQUESTS_TIMEOUT,\n )\n )\n\n def _post(self, url, payload, headers=None):\n h = self._headers(headers)\n return self._cert_request(\n lambda verify, cert: requests.post(\n url,\n headers=h,\n json=payload,\n verify=verify,\n cert=cert,\n timeout=settings.REQUESTS_TIMEOUT,\n )\n )\n\n def _cert_request(self, request_func):\n \"\"\"\n Creates named (on-disk) temp files for client cert auth.\n * request_func: curried callable from `requests` library (e.g. `requests.get`).\n \"\"\"\n # requests library reads temp files from file path\n # The \"with\" context destroys temp files when response comes back\n with NamedTemporaryFile(\"w+\") as cert, NamedTemporaryFile(\"w+\") as key, NamedTemporaryFile(\"w+\") as ca:\n # write client cert data to temp files\n # resetting so they can be read again by requests\n cert.write(self.payment_processor.client_cert.data)\n cert.seek(0)\n\n key.write(self.payment_processor.client_cert_private_key.data)\n key.seek(0)\n\n ca.write(self.payment_processor.client_cert_root_ca.data)\n ca.seek(0)\n\n # request using temp file paths\n return request_func(verify=ca.name, cert=(cert.name, key.name))\n\n def _get_customer(self, token):\n \"\"\"Get a customer record from Payment Processor's system\"\"\"\n logger.info(\"Check for existing customer record\")\n\n if token is None:\n raise ValueError(\"token\")\n\n url = self._make_url(self.payment_processor.customers_endpoint)\n payload = {\"token\": token}\n\n try:\n r = self._get(url, payload)\n r.raise_for_status()\n\n logger.debug(\"Customer record exists\")\n customer = CustomerResponse(r)\n if customer.is_registered:\n logger.debug(\"Customer is registered, skip update\")\n return customer\n else:\n logger.debug(\"Customer is not registered, update\")\n return self._update_customer(customer.id)\n\n except requests.ConnectionError:\n raise ApiError(\"Connection to enrollment server failed\")\n except requests.Timeout:\n raise ApiError(\"Connection to enrollment server timed out\")\n except requests.TooManyRedirects:\n raise ApiError(\"Too many redirects to enrollment server\")\n except requests.HTTPError as e:\n raise ApiError(e)\n\n def _update_customer(self, customer_id):\n \"\"\"Update a customer using their unique info.\"\"\"\n logger.info(\"Update existing customer record\")\n\n if customer_id is None:\n raise ValueError(\"customer_id\")\n\n url = self._make_url(self.payment_processor.customer_endpoint, customer_id)\n payload = {\"is_registered\": True, \"id\": customer_id}\n\n r = self._patch(url, payload)\n r.raise_for_status()\n\n return CustomerResponse(r)\n\n def access_token(self):\n \"\"\"Obtain an access token to use for integrating with other APIs.\"\"\"\n logger.info(\"Get new access token\")\n\n url = self._make_url(self.payment_processor.api_access_token_endpoint)\n payload = {self.payment_processor.api_access_token_request_key: self.payment_processor.api_access_token_request_val}\n\n try:\n r = self._post(url, payload)\n r.raise_for_status()\n except requests.ConnectionError:\n raise ApiError(\"Connection to enrollment server failed\")\n except requests.Timeout:\n raise ApiError(\"Connection to enrollment server timed out\")\n except requests.TooManyRedirects:\n raise ApiError(\"Too many redirects to enrollment server\")\n except requests.HTTPError as e:\n raise ApiError(e)\n\n return AccessTokenResponse(r)\n\n def enroll(self, customer_token, group_id):\n \"\"\"Enroll a customer in a product group using the token that represents that customer.\"\"\"\n logger.info(\"Enroll customer in product group\")\n\n if customer_token is None:\n raise ValueError(\"customer_token\")\n if group_id is None:\n raise ValueError(\"group_id\")\n\n customer = self._get_customer(customer_token)\n url = self._make_url(self.payment_processor.group_endpoint, group_id)\n payload = [customer.id]\n\n try:\n r = self._patch(url, payload)\n\n if r.status_code in (200, 201):\n logger.info(\"Customer enrolled in group\")\n return GroupResponse(r, customer.id, group_id)\n elif r.status_code == 500:\n logger.info(\"Customer already exists in group\")\n return GroupResponse(r, customer.id, group_id, payload=payload)\n else:\n r.raise_for_status()\n except requests.ConnectionError:\n raise ApiError(\"Connection to enrollment server failed\")\n except requests.Timeout:\n raise ApiError(\"Connection to enrollment server timed out\")\n except requests.TooManyRedirects:\n raise ApiError(\"Too many redirects to enrollment server\")\n except requests.HTTPError as e:\n raise ApiError(e)\n", "path": "benefits/enrollment/api.py"}]}
| 3,185 | 446 |
gh_patches_debug_38678
|
rasdani/github-patches
|
git_diff
|
getnikola__nikola-3130
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Templating in charts - Feature
Regarding the chart directive https://www.getnikola.com/handbook.html#chart
Can we use templates with the charts?
So data could be stored as csv or json and not manually written?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nikola/plugins/compile/rest/chart.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # Copyright © 2012-2018 Roberto Alsina and others.
4
5 # Permission is hereby granted, free of charge, to any
6 # person obtaining a copy of this software and associated
7 # documentation files (the "Software"), to deal in the
8 # Software without restriction, including without limitation
9 # the rights to use, copy, modify, merge, publish,
10 # distribute, sublicense, and/or sell copies of the
11 # Software, and to permit persons to whom the Software is
12 # furnished to do so, subject to the following conditions:
13 #
14 # The above copyright notice and this permission notice
15 # shall be included in all copies or substantial portions of
16 # the Software.
17 #
18 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY
19 # KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE
20 # WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR
21 # PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS
22 # OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR
23 # OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
24 # OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
25 # SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
26 """Chart directive for reSTructuredText."""
27
28 from docutils import nodes
29 from docutils.parsers.rst import Directive, directives
30
31 try:
32 import pygal
33 except ImportError:
34 pygal = None # NOQA
35
36 from nikola.plugin_categories import RestExtension
37
38 _site = None
39
40
41 class Plugin(RestExtension):
42 """Plugin for chart role."""
43
44 name = "rest_chart"
45
46 def set_site(self, site):
47 """Set Nikola site."""
48 global _site
49 _site = self.site = site
50 directives.register_directive('chart', Chart)
51 return super(Plugin, self).set_site(site)
52
53
54 class Chart(Directive):
55 """reStructuredText extension for inserting charts as SVG.
56
57 Usage:
58 .. chart:: Bar
59 :title: 'Browser usage evolution (in %)'
60 :x_labels: ["2002", "2003", "2004", "2005", "2006", "2007"]
61
62 'Firefox', [None, None, 0, 16.6, 25, 31]
63 'Chrome', [None, None, None, None, None, None]
64 'IE', [85.8, 84.6, 84.7, 74.5, 66, 58.6]
65 'Others', [14.2, 15.4, 15.3, 8.9, 9, 10.4]
66 """
67
68 has_content = True
69 required_arguments = 1
70 option_spec = {
71 "box_mode": directives.unchanged,
72 "classes": directives.unchanged,
73 "css": directives.unchanged,
74 "defs": directives.unchanged,
75 "disable_xml_declaration": directives.unchanged,
76 "dots_size": directives.unchanged,
77 "dynamic_print_values": directives.unchanged,
78 "explicit_size": directives.unchanged,
79 "fill": directives.unchanged,
80 "force_uri_protocol": directives.unchanged,
81 "half_pie": directives.unchanged,
82 "height": directives.unchanged,
83 "human_readable": directives.unchanged,
84 "include_x_axis": directives.unchanged,
85 "inner_radius": directives.unchanged,
86 "interpolate": directives.unchanged,
87 "interpolation_parameters": directives.unchanged,
88 "interpolation_precision": directives.unchanged,
89 "inverse_y_axis": directives.unchanged,
90 "js": directives.unchanged,
91 "legend_at_bottom": directives.unchanged,
92 "legend_at_bottom_columns": directives.unchanged,
93 "legend_box_size": directives.unchanged,
94 "logarithmic": directives.unchanged,
95 "margin": directives.unchanged,
96 "margin_bottom": directives.unchanged,
97 "margin_left": directives.unchanged,
98 "margin_right": directives.unchanged,
99 "margin_top": directives.unchanged,
100 "max_scale": directives.unchanged,
101 "min_scale": directives.unchanged,
102 "missing_value_fill_truncation": directives.unchanged,
103 "no_data_text": directives.unchanged,
104 "no_prefix": directives.unchanged,
105 "order_min": directives.unchanged,
106 "pretty_print": directives.unchanged,
107 "print_labels": directives.unchanged,
108 "print_values": directives.unchanged,
109 "print_values_position": directives.unchanged,
110 "print_zeroes": directives.unchanged,
111 "range": directives.unchanged,
112 "rounded_bars": directives.unchanged,
113 "secondary_range": directives.unchanged,
114 "show_dots": directives.unchanged,
115 "show_legend": directives.unchanged,
116 "show_minor_x_labels": directives.unchanged,
117 "show_minor_y_labels": directives.unchanged,
118 "show_only_major_dots": directives.unchanged,
119 "show_x_guides": directives.unchanged,
120 "show_x_labels": directives.unchanged,
121 "show_y_guides": directives.unchanged,
122 "show_y_labels": directives.unchanged,
123 "spacing": directives.unchanged,
124 "stack_from_top": directives.unchanged,
125 "strict": directives.unchanged,
126 "stroke": directives.unchanged,
127 "stroke_style": directives.unchanged,
128 "style": directives.unchanged,
129 "title": directives.unchanged,
130 "tooltip_border_radius": directives.unchanged,
131 "truncate_label": directives.unchanged,
132 "truncate_legend": directives.unchanged,
133 "value_formatter": directives.unchanged,
134 "width": directives.unchanged,
135 "x_label_rotation": directives.unchanged,
136 "x_labels": directives.unchanged,
137 "x_labels_major": directives.unchanged,
138 "x_labels_major_count": directives.unchanged,
139 "x_labels_major_every": directives.unchanged,
140 "x_title": directives.unchanged,
141 "x_value_formatter": directives.unchanged,
142 "xrange": directives.unchanged,
143 "y_label_rotation": directives.unchanged,
144 "y_labels": directives.unchanged,
145 "y_labels_major": directives.unchanged,
146 "y_labels_major_count": directives.unchanged,
147 "y_labels_major_every": directives.unchanged,
148 "y_title": directives.unchanged,
149 "zero": directives.unchanged,
150 }
151
152 def run(self):
153 """Run the directive."""
154 self.options['site'] = None
155 html = _site.plugin_manager.getPluginByName(
156 'chart', 'ShortcodePlugin').plugin_object.handler(
157 self.arguments[0],
158 data='\n'.join(self.content),
159 **self.options)
160 return [nodes.raw('', html, format='html')]
161
```
Path: `nikola/plugins/shortcode/chart.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # Copyright © 2012-2018 Roberto Alsina and others.
4
5 # Permission is hereby granted, free of charge, to any
6 # person obtaining a copy of this software and associated
7 # documentation files (the "Software"), to deal in the
8 # Software without restriction, including without limitation
9 # the rights to use, copy, modify, merge, publish,
10 # distribute, sublicense, and/or sell copies of the
11 # Software, and to permit persons to whom the Software is
12 # furnished to do so, subject to the following conditions:
13 #
14 # The above copyright notice and this permission notice
15 # shall be included in all copies or substantial portions of
16 # the Software.
17 #
18 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY
19 # KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE
20 # WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR
21 # PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS
22 # OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR
23 # OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
24 # OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
25 # SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
26 """Chart shortcode."""
27
28 from ast import literal_eval
29
30 try:
31 import pygal
32 except ImportError:
33 pygal = None # NOQA
34
35 from nikola.plugin_categories import ShortcodePlugin
36 from nikola.utils import req_missing
37
38 _site = None
39
40
41 class ChartShortcode(ShortcodePlugin):
42 """Plugin for chart shortcode."""
43
44 name = "chart"
45
46 def handler(self, chart_type, **_options):
47 """Generate chart using Pygal."""
48 if pygal is None:
49 msg = req_missing(
50 ['pygal'], 'use the Chart directive', optional=True)
51 return '<div class="text-error">{0}</div>'.format(msg)
52 options = {}
53 data = _options.pop('data')
54 _options.pop('post', None)
55 _options.pop('site')
56 if 'style' in _options:
57 style_name = _options.pop('style')
58 else:
59 style_name = 'BlueStyle'
60 if '(' in style_name: # Parametric style
61 style = eval('pygal.style.' + style_name)
62 else:
63 style = getattr(pygal.style, style_name)
64 for k, v in _options.items():
65 try:
66 options[k] = literal_eval(v)
67 except Exception:
68 options[k] = v
69 chart = pygal
70 for o in chart_type.split('.'):
71 chart = getattr(chart, o)
72 chart = chart(style=style)
73 if _site and _site.invariant:
74 chart.no_prefix = True
75 chart.config(**options)
76 for line in data.splitlines():
77 line = line.strip()
78 if line:
79 label, series = literal_eval('({0})'.format(line))
80 chart.add(label, series)
81 return chart.render().decode('utf8')
82
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nikola/plugins/compile/rest/chart.py b/nikola/plugins/compile/rest/chart.py
--- a/nikola/plugins/compile/rest/chart.py
+++ b/nikola/plugins/compile/rest/chart.py
@@ -72,6 +72,7 @@
"classes": directives.unchanged,
"css": directives.unchanged,
"defs": directives.unchanged,
+ "data_file": directives.unchanged,
"disable_xml_declaration": directives.unchanged,
"dots_size": directives.unchanged,
"dynamic_print_values": directives.unchanged,
diff --git a/nikola/plugins/shortcode/chart.py b/nikola/plugins/shortcode/chart.py
--- a/nikola/plugins/shortcode/chart.py
+++ b/nikola/plugins/shortcode/chart.py
@@ -33,7 +33,7 @@
pygal = None # NOQA
from nikola.plugin_categories import ShortcodePlugin
-from nikola.utils import req_missing
+from nikola.utils import req_missing, load_data
_site = None
@@ -50,18 +50,30 @@
['pygal'], 'use the Chart directive', optional=True)
return '<div class="text-error">{0}</div>'.format(msg)
options = {}
- data = _options.pop('data')
+ chart_data = []
_options.pop('post', None)
_options.pop('site')
- if 'style' in _options:
- style_name = _options.pop('style')
- else:
- style_name = 'BlueStyle'
+ data = _options.pop('data')
+
+ for line in data.splitlines():
+ line = line.strip()
+ if line:
+ chart_data.append(literal_eval('({0})'.format(line)))
+ if 'data_file' in _options:
+ options = load_data(_options['data_file'])
+ _options.pop('data_file')
+ if not chart_data: # If there is data in the document, it wins
+ for k, v in options.pop('data', {}).items():
+ chart_data.append((k, v))
+
+ options.update(_options)
+
+ style_name = options.pop('style', 'BlueStyle')
if '(' in style_name: # Parametric style
style = eval('pygal.style.' + style_name)
else:
style = getattr(pygal.style, style_name)
- for k, v in _options.items():
+ for k, v in options.items():
try:
options[k] = literal_eval(v)
except Exception:
@@ -73,9 +85,6 @@
if _site and _site.invariant:
chart.no_prefix = True
chart.config(**options)
- for line in data.splitlines():
- line = line.strip()
- if line:
- label, series = literal_eval('({0})'.format(line))
- chart.add(label, series)
+ for label, series in chart_data:
+ chart.add(label, series)
return chart.render().decode('utf8')
|
{"golden_diff": "diff --git a/nikola/plugins/compile/rest/chart.py b/nikola/plugins/compile/rest/chart.py\n--- a/nikola/plugins/compile/rest/chart.py\n+++ b/nikola/plugins/compile/rest/chart.py\n@@ -72,6 +72,7 @@\n \"classes\": directives.unchanged,\n \"css\": directives.unchanged,\n \"defs\": directives.unchanged,\n+ \"data_file\": directives.unchanged,\n \"disable_xml_declaration\": directives.unchanged,\n \"dots_size\": directives.unchanged,\n \"dynamic_print_values\": directives.unchanged,\ndiff --git a/nikola/plugins/shortcode/chart.py b/nikola/plugins/shortcode/chart.py\n--- a/nikola/plugins/shortcode/chart.py\n+++ b/nikola/plugins/shortcode/chart.py\n@@ -33,7 +33,7 @@\n pygal = None # NOQA\n \n from nikola.plugin_categories import ShortcodePlugin\n-from nikola.utils import req_missing\n+from nikola.utils import req_missing, load_data\n \n _site = None\n \n@@ -50,18 +50,30 @@\n ['pygal'], 'use the Chart directive', optional=True)\n return '<div class=\"text-error\">{0}</div>'.format(msg)\n options = {}\n- data = _options.pop('data')\n+ chart_data = []\n _options.pop('post', None)\n _options.pop('site')\n- if 'style' in _options:\n- style_name = _options.pop('style')\n- else:\n- style_name = 'BlueStyle'\n+ data = _options.pop('data')\n+\n+ for line in data.splitlines():\n+ line = line.strip()\n+ if line:\n+ chart_data.append(literal_eval('({0})'.format(line)))\n+ if 'data_file' in _options:\n+ options = load_data(_options['data_file'])\n+ _options.pop('data_file')\n+ if not chart_data: # If there is data in the document, it wins\n+ for k, v in options.pop('data', {}).items():\n+ chart_data.append((k, v))\n+\n+ options.update(_options)\n+\n+ style_name = options.pop('style', 'BlueStyle')\n if '(' in style_name: # Parametric style\n style = eval('pygal.style.' + style_name)\n else:\n style = getattr(pygal.style, style_name)\n- for k, v in _options.items():\n+ for k, v in options.items():\n try:\n options[k] = literal_eval(v)\n except Exception:\n@@ -73,9 +85,6 @@\n if _site and _site.invariant:\n chart.no_prefix = True\n chart.config(**options)\n- for line in data.splitlines():\n- line = line.strip()\n- if line:\n- label, series = literal_eval('({0})'.format(line))\n- chart.add(label, series)\n+ for label, series in chart_data:\n+ chart.add(label, series)\n return chart.render().decode('utf8')\n", "issue": "Templating in charts - Feature\nRegarding the chart directive https://www.getnikola.com/handbook.html#chart\r\n\r\nCan we use templates with the charts?\r\n\r\nSo data could be stored as csv or json and not manually written?\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright \u00a9 2012-2018 Roberto Alsina and others.\n\n# Permission is hereby granted, free of charge, to any\n# person obtaining a copy of this software and associated\n# documentation files (the \"Software\"), to deal in the\n# Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the\n# Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice\n# shall be included in all copies or substantial portions of\n# the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY\n# KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE\n# WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR\n# PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS\n# OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\n# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR\n# OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\"\"\"Chart directive for reSTructuredText.\"\"\"\n\nfrom docutils import nodes\nfrom docutils.parsers.rst import Directive, directives\n\ntry:\n import pygal\nexcept ImportError:\n pygal = None # NOQA\n\nfrom nikola.plugin_categories import RestExtension\n\n_site = None\n\n\nclass Plugin(RestExtension):\n \"\"\"Plugin for chart role.\"\"\"\n\n name = \"rest_chart\"\n\n def set_site(self, site):\n \"\"\"Set Nikola site.\"\"\"\n global _site\n _site = self.site = site\n directives.register_directive('chart', Chart)\n return super(Plugin, self).set_site(site)\n\n\nclass Chart(Directive):\n \"\"\"reStructuredText extension for inserting charts as SVG.\n\n Usage:\n .. chart:: Bar\n :title: 'Browser usage evolution (in %)'\n :x_labels: [\"2002\", \"2003\", \"2004\", \"2005\", \"2006\", \"2007\"]\n\n 'Firefox', [None, None, 0, 16.6, 25, 31]\n 'Chrome', [None, None, None, None, None, None]\n 'IE', [85.8, 84.6, 84.7, 74.5, 66, 58.6]\n 'Others', [14.2, 15.4, 15.3, 8.9, 9, 10.4]\n \"\"\"\n\n has_content = True\n required_arguments = 1\n option_spec = {\n \"box_mode\": directives.unchanged,\n \"classes\": directives.unchanged,\n \"css\": directives.unchanged,\n \"defs\": directives.unchanged,\n \"disable_xml_declaration\": directives.unchanged,\n \"dots_size\": directives.unchanged,\n \"dynamic_print_values\": directives.unchanged,\n \"explicit_size\": directives.unchanged,\n \"fill\": directives.unchanged,\n \"force_uri_protocol\": directives.unchanged,\n \"half_pie\": directives.unchanged,\n \"height\": directives.unchanged,\n \"human_readable\": directives.unchanged,\n \"include_x_axis\": directives.unchanged,\n \"inner_radius\": directives.unchanged,\n \"interpolate\": directives.unchanged,\n \"interpolation_parameters\": directives.unchanged,\n \"interpolation_precision\": directives.unchanged,\n \"inverse_y_axis\": directives.unchanged,\n \"js\": directives.unchanged,\n \"legend_at_bottom\": directives.unchanged,\n \"legend_at_bottom_columns\": directives.unchanged,\n \"legend_box_size\": directives.unchanged,\n \"logarithmic\": directives.unchanged,\n \"margin\": directives.unchanged,\n \"margin_bottom\": directives.unchanged,\n \"margin_left\": directives.unchanged,\n \"margin_right\": directives.unchanged,\n \"margin_top\": directives.unchanged,\n \"max_scale\": directives.unchanged,\n \"min_scale\": directives.unchanged,\n \"missing_value_fill_truncation\": directives.unchanged,\n \"no_data_text\": directives.unchanged,\n \"no_prefix\": directives.unchanged,\n \"order_min\": directives.unchanged,\n \"pretty_print\": directives.unchanged,\n \"print_labels\": directives.unchanged,\n \"print_values\": directives.unchanged,\n \"print_values_position\": directives.unchanged,\n \"print_zeroes\": directives.unchanged,\n \"range\": directives.unchanged,\n \"rounded_bars\": directives.unchanged,\n \"secondary_range\": directives.unchanged,\n \"show_dots\": directives.unchanged,\n \"show_legend\": directives.unchanged,\n \"show_minor_x_labels\": directives.unchanged,\n \"show_minor_y_labels\": directives.unchanged,\n \"show_only_major_dots\": directives.unchanged,\n \"show_x_guides\": directives.unchanged,\n \"show_x_labels\": directives.unchanged,\n \"show_y_guides\": directives.unchanged,\n \"show_y_labels\": directives.unchanged,\n \"spacing\": directives.unchanged,\n \"stack_from_top\": directives.unchanged,\n \"strict\": directives.unchanged,\n \"stroke\": directives.unchanged,\n \"stroke_style\": directives.unchanged,\n \"style\": directives.unchanged,\n \"title\": directives.unchanged,\n \"tooltip_border_radius\": directives.unchanged,\n \"truncate_label\": directives.unchanged,\n \"truncate_legend\": directives.unchanged,\n \"value_formatter\": directives.unchanged,\n \"width\": directives.unchanged,\n \"x_label_rotation\": directives.unchanged,\n \"x_labels\": directives.unchanged,\n \"x_labels_major\": directives.unchanged,\n \"x_labels_major_count\": directives.unchanged,\n \"x_labels_major_every\": directives.unchanged,\n \"x_title\": directives.unchanged,\n \"x_value_formatter\": directives.unchanged,\n \"xrange\": directives.unchanged,\n \"y_label_rotation\": directives.unchanged,\n \"y_labels\": directives.unchanged,\n \"y_labels_major\": directives.unchanged,\n \"y_labels_major_count\": directives.unchanged,\n \"y_labels_major_every\": directives.unchanged,\n \"y_title\": directives.unchanged,\n \"zero\": directives.unchanged,\n }\n\n def run(self):\n \"\"\"Run the directive.\"\"\"\n self.options['site'] = None\n html = _site.plugin_manager.getPluginByName(\n 'chart', 'ShortcodePlugin').plugin_object.handler(\n self.arguments[0],\n data='\\n'.join(self.content),\n **self.options)\n return [nodes.raw('', html, format='html')]\n", "path": "nikola/plugins/compile/rest/chart.py"}, {"content": "# -*- coding: utf-8 -*-\n\n# Copyright \u00a9 2012-2018 Roberto Alsina and others.\n\n# Permission is hereby granted, free of charge, to any\n# person obtaining a copy of this software and associated\n# documentation files (the \"Software\"), to deal in the\n# Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the\n# Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice\n# shall be included in all copies or substantial portions of\n# the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY\n# KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE\n# WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR\n# PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS\n# OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\n# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR\n# OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\"\"\"Chart shortcode.\"\"\"\n\nfrom ast import literal_eval\n\ntry:\n import pygal\nexcept ImportError:\n pygal = None # NOQA\n\nfrom nikola.plugin_categories import ShortcodePlugin\nfrom nikola.utils import req_missing\n\n_site = None\n\n\nclass ChartShortcode(ShortcodePlugin):\n \"\"\"Plugin for chart shortcode.\"\"\"\n\n name = \"chart\"\n\n def handler(self, chart_type, **_options):\n \"\"\"Generate chart using Pygal.\"\"\"\n if pygal is None:\n msg = req_missing(\n ['pygal'], 'use the Chart directive', optional=True)\n return '<div class=\"text-error\">{0}</div>'.format(msg)\n options = {}\n data = _options.pop('data')\n _options.pop('post', None)\n _options.pop('site')\n if 'style' in _options:\n style_name = _options.pop('style')\n else:\n style_name = 'BlueStyle'\n if '(' in style_name: # Parametric style\n style = eval('pygal.style.' + style_name)\n else:\n style = getattr(pygal.style, style_name)\n for k, v in _options.items():\n try:\n options[k] = literal_eval(v)\n except Exception:\n options[k] = v\n chart = pygal\n for o in chart_type.split('.'):\n chart = getattr(chart, o)\n chart = chart(style=style)\n if _site and _site.invariant:\n chart.no_prefix = True\n chart.config(**options)\n for line in data.splitlines():\n line = line.strip()\n if line:\n label, series = literal_eval('({0})'.format(line))\n chart.add(label, series)\n return chart.render().decode('utf8')\n", "path": "nikola/plugins/shortcode/chart.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright \u00a9 2012-2018 Roberto Alsina and others.\n\n# Permission is hereby granted, free of charge, to any\n# person obtaining a copy of this software and associated\n# documentation files (the \"Software\"), to deal in the\n# Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the\n# Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice\n# shall be included in all copies or substantial portions of\n# the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY\n# KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE\n# WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR\n# PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS\n# OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\n# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR\n# OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\"\"\"Chart directive for reSTructuredText.\"\"\"\n\nfrom docutils import nodes\nfrom docutils.parsers.rst import Directive, directives\n\ntry:\n import pygal\nexcept ImportError:\n pygal = None # NOQA\n\nfrom nikola.plugin_categories import RestExtension\n\n_site = None\n\n\nclass Plugin(RestExtension):\n \"\"\"Plugin for chart role.\"\"\"\n\n name = \"rest_chart\"\n\n def set_site(self, site):\n \"\"\"Set Nikola site.\"\"\"\n global _site\n _site = self.site = site\n directives.register_directive('chart', Chart)\n return super(Plugin, self).set_site(site)\n\n\nclass Chart(Directive):\n \"\"\"reStructuredText extension for inserting charts as SVG.\n\n Usage:\n .. chart:: Bar\n :title: 'Browser usage evolution (in %)'\n :x_labels: [\"2002\", \"2003\", \"2004\", \"2005\", \"2006\", \"2007\"]\n\n 'Firefox', [None, None, 0, 16.6, 25, 31]\n 'Chrome', [None, None, None, None, None, None]\n 'IE', [85.8, 84.6, 84.7, 74.5, 66, 58.6]\n 'Others', [14.2, 15.4, 15.3, 8.9, 9, 10.4]\n \"\"\"\n\n has_content = True\n required_arguments = 1\n option_spec = {\n \"box_mode\": directives.unchanged,\n \"classes\": directives.unchanged,\n \"css\": directives.unchanged,\n \"defs\": directives.unchanged,\n \"data_file\": directives.unchanged,\n \"disable_xml_declaration\": directives.unchanged,\n \"dots_size\": directives.unchanged,\n \"dynamic_print_values\": directives.unchanged,\n \"explicit_size\": directives.unchanged,\n \"fill\": directives.unchanged,\n \"force_uri_protocol\": directives.unchanged,\n \"half_pie\": directives.unchanged,\n \"height\": directives.unchanged,\n \"human_readable\": directives.unchanged,\n \"include_x_axis\": directives.unchanged,\n \"inner_radius\": directives.unchanged,\n \"interpolate\": directives.unchanged,\n \"interpolation_parameters\": directives.unchanged,\n \"interpolation_precision\": directives.unchanged,\n \"inverse_y_axis\": directives.unchanged,\n \"js\": directives.unchanged,\n \"legend_at_bottom\": directives.unchanged,\n \"legend_at_bottom_columns\": directives.unchanged,\n \"legend_box_size\": directives.unchanged,\n \"logarithmic\": directives.unchanged,\n \"margin\": directives.unchanged,\n \"margin_bottom\": directives.unchanged,\n \"margin_left\": directives.unchanged,\n \"margin_right\": directives.unchanged,\n \"margin_top\": directives.unchanged,\n \"max_scale\": directives.unchanged,\n \"min_scale\": directives.unchanged,\n \"missing_value_fill_truncation\": directives.unchanged,\n \"no_data_text\": directives.unchanged,\n \"no_prefix\": directives.unchanged,\n \"order_min\": directives.unchanged,\n \"pretty_print\": directives.unchanged,\n \"print_labels\": directives.unchanged,\n \"print_values\": directives.unchanged,\n \"print_values_position\": directives.unchanged,\n \"print_zeroes\": directives.unchanged,\n \"range\": directives.unchanged,\n \"rounded_bars\": directives.unchanged,\n \"secondary_range\": directives.unchanged,\n \"show_dots\": directives.unchanged,\n \"show_legend\": directives.unchanged,\n \"show_minor_x_labels\": directives.unchanged,\n \"show_minor_y_labels\": directives.unchanged,\n \"show_only_major_dots\": directives.unchanged,\n \"show_x_guides\": directives.unchanged,\n \"show_x_labels\": directives.unchanged,\n \"show_y_guides\": directives.unchanged,\n \"show_y_labels\": directives.unchanged,\n \"spacing\": directives.unchanged,\n \"stack_from_top\": directives.unchanged,\n \"strict\": directives.unchanged,\n \"stroke\": directives.unchanged,\n \"stroke_style\": directives.unchanged,\n \"style\": directives.unchanged,\n \"title\": directives.unchanged,\n \"tooltip_border_radius\": directives.unchanged,\n \"truncate_label\": directives.unchanged,\n \"truncate_legend\": directives.unchanged,\n \"value_formatter\": directives.unchanged,\n \"width\": directives.unchanged,\n \"x_label_rotation\": directives.unchanged,\n \"x_labels\": directives.unchanged,\n \"x_labels_major\": directives.unchanged,\n \"x_labels_major_count\": directives.unchanged,\n \"x_labels_major_every\": directives.unchanged,\n \"x_title\": directives.unchanged,\n \"x_value_formatter\": directives.unchanged,\n \"xrange\": directives.unchanged,\n \"y_label_rotation\": directives.unchanged,\n \"y_labels\": directives.unchanged,\n \"y_labels_major\": directives.unchanged,\n \"y_labels_major_count\": directives.unchanged,\n \"y_labels_major_every\": directives.unchanged,\n \"y_title\": directives.unchanged,\n \"zero\": directives.unchanged,\n }\n\n def run(self):\n \"\"\"Run the directive.\"\"\"\n self.options['site'] = None\n html = _site.plugin_manager.getPluginByName(\n 'chart', 'ShortcodePlugin').plugin_object.handler(\n self.arguments[0],\n data='\\n'.join(self.content),\n **self.options)\n return [nodes.raw('', html, format='html')]\n", "path": "nikola/plugins/compile/rest/chart.py"}, {"content": "# -*- coding: utf-8 -*-\n\n# Copyright \u00a9 2012-2018 Roberto Alsina and others.\n\n# Permission is hereby granted, free of charge, to any\n# person obtaining a copy of this software and associated\n# documentation files (the \"Software\"), to deal in the\n# Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the\n# Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice\n# shall be included in all copies or substantial portions of\n# the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY\n# KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE\n# WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR\n# PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS\n# OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\n# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR\n# OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\"\"\"Chart shortcode.\"\"\"\n\nfrom ast import literal_eval\n\ntry:\n import pygal\nexcept ImportError:\n pygal = None # NOQA\n\nfrom nikola.plugin_categories import ShortcodePlugin\nfrom nikola.utils import req_missing, load_data\n\n_site = None\n\n\nclass ChartShortcode(ShortcodePlugin):\n \"\"\"Plugin for chart shortcode.\"\"\"\n\n name = \"chart\"\n\n def handler(self, chart_type, **_options):\n \"\"\"Generate chart using Pygal.\"\"\"\n if pygal is None:\n msg = req_missing(\n ['pygal'], 'use the Chart directive', optional=True)\n return '<div class=\"text-error\">{0}</div>'.format(msg)\n options = {}\n chart_data = []\n _options.pop('post', None)\n _options.pop('site')\n data = _options.pop('data')\n\n for line in data.splitlines():\n line = line.strip()\n if line:\n chart_data.append(literal_eval('({0})'.format(line)))\n if 'data_file' in _options:\n options = load_data(_options['data_file'])\n _options.pop('data_file')\n if not chart_data: # If there is data in the document, it wins\n for k, v in options.pop('data', {}).items():\n chart_data.append((k, v))\n\n options.update(_options)\n\n style_name = options.pop('style', 'BlueStyle')\n if '(' in style_name: # Parametric style\n style = eval('pygal.style.' + style_name)\n else:\n style = getattr(pygal.style, style_name)\n for k, v in options.items():\n try:\n options[k] = literal_eval(v)\n except Exception:\n options[k] = v\n chart = pygal\n for o in chart_type.split('.'):\n chart = getattr(chart, o)\n chart = chart(style=style)\n if _site and _site.invariant:\n chart.no_prefix = True\n chart.config(**options)\n for label, series in chart_data:\n chart.add(label, series)\n return chart.render().decode('utf8')\n", "path": "nikola/plugins/shortcode/chart.py"}]}
| 3,026 | 678 |
gh_patches_debug_26175
|
rasdani/github-patches
|
git_diff
|
open-mmlab__mmaction2-693
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Wrong Value for flow normalization
`img_norm_cfg` should be `dict(mean=[128, 128], std=[128,128])`, not imagenet one.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `configs/recognition/tsn/tsn_r50_320p_1x1x8_110e_kinetics400_flow.py`
Content:
```
1 _base_ = ['../../_base_/models/tsn_r50.py', '../../_base_/default_runtime.py']
2
3 # dataset settings
4 dataset_type = 'RawframeDataset'
5 data_root = 'data/kinetics400/rawframes_train_320p'
6 data_root_val = 'data/kinetics400/rawframes_val_320p'
7 ann_file_train = 'data/kinetics400/kinetics400_flow_train_list_320p.txt'
8 ann_file_val = 'data/kinetics400/kinetics400_flow_val_list_320p.txt'
9 ann_file_test = 'data/kinetics400/kinetics400_flow_val_list_320p.txt'
10 img_norm_cfg = dict(
11 mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_bgr=False)
12 train_pipeline = [
13 dict(type='SampleFrames', clip_len=5, frame_interval=1, num_clips=8),
14 dict(type='RawFrameDecode'),
15 dict(type='Resize', scale=(-1, 256)),
16 dict(type='RandomResizedCrop'),
17 dict(type='Resize', scale=(224, 224), keep_ratio=False),
18 dict(type='Flip', flip_ratio=0.5),
19 dict(type='Normalize', **img_norm_cfg),
20 dict(type='FormatShape', input_format='NCHW_Flow'),
21 dict(type='Collect', keys=['imgs', 'label'], meta_keys=[]),
22 dict(type='ToTensor', keys=['imgs', 'label'])
23 ]
24 val_pipeline = [
25 dict(
26 type='SampleFrames',
27 clip_len=5,
28 frame_interval=1,
29 num_clips=8,
30 test_mode=True),
31 dict(type='RawFrameDecode'),
32 dict(type='Resize', scale=(-1, 256)),
33 dict(type='CenterCrop', crop_size=224),
34 dict(type='Flip', flip_ratio=0),
35 dict(type='Normalize', **img_norm_cfg),
36 dict(type='FormatShape', input_format='NCHW_Flow'),
37 dict(type='Collect', keys=['imgs', 'label'], meta_keys=[]),
38 dict(type='ToTensor', keys=['imgs'])
39 ]
40 test_pipeline = [
41 dict(
42 type='SampleFrames',
43 clip_len=5,
44 frame_interval=1,
45 num_clips=25,
46 test_mode=True),
47 dict(type='RawFrameDecode'),
48 dict(type='Resize', scale=(-1, 256)),
49 dict(type='TenCrop', crop_size=224),
50 dict(type='Flip', flip_ratio=0),
51 dict(type='Normalize', **img_norm_cfg),
52 dict(type='FormatShape', input_format='NCHW_Flow'),
53 dict(type='Collect', keys=['imgs', 'label'], meta_keys=[]),
54 dict(type='ToTensor', keys=['imgs'])
55 ]
56 data = dict(
57 videos_per_gpu=12,
58 workers_per_gpu=4,
59 train=dict(
60 type=dataset_type,
61 ann_file=ann_file_train,
62 data_prefix=data_root,
63 filename_tmpl='{}_{:05d}.jpg',
64 modality='Flow',
65 pipeline=train_pipeline),
66 val=dict(
67 type=dataset_type,
68 ann_file=ann_file_val,
69 data_prefix=data_root_val,
70 filename_tmpl='{}_{:05d}.jpg',
71 modality='Flow',
72 pipeline=val_pipeline),
73 test=dict(
74 type=dataset_type,
75 ann_file=ann_file_test,
76 data_prefix=data_root_val,
77 filename_tmpl='{}_{:05d}.jpg',
78 modality='Flow',
79 pipeline=test_pipeline))
80 evaluation = dict(
81 interval=5, metrics=['top_k_accuracy', 'mean_class_accuracy'])
82
83 # optimizer
84 optimizer = dict(
85 type='SGD', lr=0.001875, momentum=0.9,
86 weight_decay=0.0001) # this lr is used for 8 gpus
87 optimizer_config = dict(grad_clip=dict(max_norm=40, norm_type=2))
88 # learning policy
89 lr_config = dict(policy='step', step=[70, 100])
90 total_epochs = 110
91
92 # runtime settings
93 checkpoint_config = dict(interval=5)
94 work_dir = './work_dirs/tsn_r50_320p_1x1x8_110e_kinetics400_flow/'
95
```
Path: `configs/recognition/tsn/tsn_r50_320p_1x1x3_110e_kinetics400_flow.py`
Content:
```
1 _base_ = ['../../_base_/models/tsn_r50.py', '../../_base_/default_runtime.py']
2
3 # dataset settings
4 dataset_type = 'RawframeDataset'
5 data_root = 'data/kinetics400/rawframes_train_320p'
6 data_root_val = 'data/kinetics400/rawframes_val_320p'
7 ann_file_train = 'data/kinetics400/kinetics_flow_train_list.txt'
8 ann_file_val = 'data/kinetics400/kinetics_flow_val_list.txt'
9 ann_file_test = 'data/kinetics400/kinetics_flow_val_list.txt'
10 img_norm_cfg = dict(
11 mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_bgr=False)
12 train_pipeline = [
13 dict(type='SampleFrames', clip_len=5, frame_interval=1, num_clips=3),
14 dict(type='RawFrameDecode'),
15 dict(type='Resize', scale=(-1, 256)),
16 dict(type='RandomResizedCrop'),
17 dict(type='Resize', scale=(224, 224), keep_ratio=False),
18 dict(type='Flip', flip_ratio=0.5),
19 dict(type='Normalize', **img_norm_cfg),
20 dict(type='FormatShape', input_format='NCHW_Flow'),
21 dict(type='Collect', keys=['imgs', 'label'], meta_keys=[]),
22 dict(type='ToTensor', keys=['imgs', 'label'])
23 ]
24 val_pipeline = [
25 dict(
26 type='SampleFrames',
27 clip_len=5,
28 frame_interval=1,
29 num_clips=3,
30 test_mode=True),
31 dict(type='RawFrameDecode'),
32 dict(type='Resize', scale=(-1, 256)),
33 dict(type='CenterCrop', crop_size=224),
34 dict(type='Flip', flip_ratio=0),
35 dict(type='Normalize', **img_norm_cfg),
36 dict(type='FormatShape', input_format='NCHW_Flow'),
37 dict(type='Collect', keys=['imgs', 'label'], meta_keys=[]),
38 dict(type='ToTensor', keys=['imgs'])
39 ]
40 test_pipeline = [
41 dict(
42 type='SampleFrames',
43 clip_len=5,
44 frame_interval=1,
45 num_clips=25,
46 test_mode=True),
47 dict(type='RawFrameDecode'),
48 dict(type='Resize', scale=(-1, 256)),
49 dict(type='TenCrop', crop_size=224),
50 dict(type='Flip', flip_ratio=0),
51 dict(type='Normalize', **img_norm_cfg),
52 dict(type='FormatShape', input_format='NCHW_Flow'),
53 dict(type='Collect', keys=['imgs', 'label'], meta_keys=[]),
54 dict(type='ToTensor', keys=['imgs'])
55 ]
56 data = dict(
57 videos_per_gpu=32,
58 workers_per_gpu=4,
59 train=dict(
60 type=dataset_type,
61 ann_file=ann_file_train,
62 data_prefix=data_root,
63 filename_tmpl='{}_{:05d}.jpg',
64 modality='Flow',
65 pipeline=train_pipeline),
66 val=dict(
67 type=dataset_type,
68 ann_file=ann_file_val,
69 data_prefix=data_root_val,
70 filename_tmpl='{}_{:05d}.jpg',
71 modality='Flow',
72 pipeline=val_pipeline),
73 test=dict(
74 type=dataset_type,
75 ann_file=ann_file_test,
76 data_prefix=data_root_val,
77 filename_tmpl='{}_{:05d}.jpg',
78 modality='Flow',
79 pipeline=test_pipeline))
80 evaluation = dict(
81 interval=5, metrics=['top_k_accuracy', 'mean_class_accuracy'])
82
83 # optimizer
84 optimizer = dict(
85 type='SGD', lr=0.005, momentum=0.9,
86 weight_decay=0.0001) # this lr is used for 8 gpus
87 optimizer_config = dict(grad_clip=dict(max_norm=40, norm_type=2))
88 # learning policy
89 lr_config = dict(policy='step', step=[70, 100])
90 total_epochs = 110
91
92 # runtime settings
93 checkpoint_config = dict(interval=5)
94 work_dir = './work_dirs/tsn_r50_320p_1x1x3_110e_kinetics400_flow/'
95
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/configs/recognition/tsn/tsn_r50_320p_1x1x3_110e_kinetics400_flow.py b/configs/recognition/tsn/tsn_r50_320p_1x1x3_110e_kinetics400_flow.py
--- a/configs/recognition/tsn/tsn_r50_320p_1x1x3_110e_kinetics400_flow.py
+++ b/configs/recognition/tsn/tsn_r50_320p_1x1x3_110e_kinetics400_flow.py
@@ -7,8 +7,7 @@
ann_file_train = 'data/kinetics400/kinetics_flow_train_list.txt'
ann_file_val = 'data/kinetics400/kinetics_flow_val_list.txt'
ann_file_test = 'data/kinetics400/kinetics_flow_val_list.txt'
-img_norm_cfg = dict(
- mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_bgr=False)
+img_norm_cfg = dict(mean=[128, 128], std=[128, 128])
train_pipeline = [
dict(type='SampleFrames', clip_len=5, frame_interval=1, num_clips=3),
dict(type='RawFrameDecode'),
diff --git a/configs/recognition/tsn/tsn_r50_320p_1x1x8_110e_kinetics400_flow.py b/configs/recognition/tsn/tsn_r50_320p_1x1x8_110e_kinetics400_flow.py
--- a/configs/recognition/tsn/tsn_r50_320p_1x1x8_110e_kinetics400_flow.py
+++ b/configs/recognition/tsn/tsn_r50_320p_1x1x8_110e_kinetics400_flow.py
@@ -7,8 +7,7 @@
ann_file_train = 'data/kinetics400/kinetics400_flow_train_list_320p.txt'
ann_file_val = 'data/kinetics400/kinetics400_flow_val_list_320p.txt'
ann_file_test = 'data/kinetics400/kinetics400_flow_val_list_320p.txt'
-img_norm_cfg = dict(
- mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_bgr=False)
+img_norm_cfg = dict(mean=[128, 128], std=[128, 128])
train_pipeline = [
dict(type='SampleFrames', clip_len=5, frame_interval=1, num_clips=8),
dict(type='RawFrameDecode'),
|
{"golden_diff": "diff --git a/configs/recognition/tsn/tsn_r50_320p_1x1x3_110e_kinetics400_flow.py b/configs/recognition/tsn/tsn_r50_320p_1x1x3_110e_kinetics400_flow.py\n--- a/configs/recognition/tsn/tsn_r50_320p_1x1x3_110e_kinetics400_flow.py\n+++ b/configs/recognition/tsn/tsn_r50_320p_1x1x3_110e_kinetics400_flow.py\n@@ -7,8 +7,7 @@\n ann_file_train = 'data/kinetics400/kinetics_flow_train_list.txt'\n ann_file_val = 'data/kinetics400/kinetics_flow_val_list.txt'\n ann_file_test = 'data/kinetics400/kinetics_flow_val_list.txt'\n-img_norm_cfg = dict(\n- mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_bgr=False)\n+img_norm_cfg = dict(mean=[128, 128], std=[128, 128])\n train_pipeline = [\n dict(type='SampleFrames', clip_len=5, frame_interval=1, num_clips=3),\n dict(type='RawFrameDecode'),\ndiff --git a/configs/recognition/tsn/tsn_r50_320p_1x1x8_110e_kinetics400_flow.py b/configs/recognition/tsn/tsn_r50_320p_1x1x8_110e_kinetics400_flow.py\n--- a/configs/recognition/tsn/tsn_r50_320p_1x1x8_110e_kinetics400_flow.py\n+++ b/configs/recognition/tsn/tsn_r50_320p_1x1x8_110e_kinetics400_flow.py\n@@ -7,8 +7,7 @@\n ann_file_train = 'data/kinetics400/kinetics400_flow_train_list_320p.txt'\n ann_file_val = 'data/kinetics400/kinetics400_flow_val_list_320p.txt'\n ann_file_test = 'data/kinetics400/kinetics400_flow_val_list_320p.txt'\n-img_norm_cfg = dict(\n- mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_bgr=False)\n+img_norm_cfg = dict(mean=[128, 128], std=[128, 128])\n train_pipeline = [\n dict(type='SampleFrames', clip_len=5, frame_interval=1, num_clips=8),\n dict(type='RawFrameDecode'),\n", "issue": "Wrong Value for flow normalization\n`img_norm_cfg` should be `dict(mean=[128, 128], std=[128,128])`, not imagenet one.\n", "before_files": [{"content": "_base_ = ['../../_base_/models/tsn_r50.py', '../../_base_/default_runtime.py']\n\n# dataset settings\ndataset_type = 'RawframeDataset'\ndata_root = 'data/kinetics400/rawframes_train_320p'\ndata_root_val = 'data/kinetics400/rawframes_val_320p'\nann_file_train = 'data/kinetics400/kinetics400_flow_train_list_320p.txt'\nann_file_val = 'data/kinetics400/kinetics400_flow_val_list_320p.txt'\nann_file_test = 'data/kinetics400/kinetics400_flow_val_list_320p.txt'\nimg_norm_cfg = dict(\n mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_bgr=False)\ntrain_pipeline = [\n dict(type='SampleFrames', clip_len=5, frame_interval=1, num_clips=8),\n dict(type='RawFrameDecode'),\n dict(type='Resize', scale=(-1, 256)),\n dict(type='RandomResizedCrop'),\n dict(type='Resize', scale=(224, 224), keep_ratio=False),\n dict(type='Flip', flip_ratio=0.5),\n dict(type='Normalize', **img_norm_cfg),\n dict(type='FormatShape', input_format='NCHW_Flow'),\n dict(type='Collect', keys=['imgs', 'label'], meta_keys=[]),\n dict(type='ToTensor', keys=['imgs', 'label'])\n]\nval_pipeline = [\n dict(\n type='SampleFrames',\n clip_len=5,\n frame_interval=1,\n num_clips=8,\n test_mode=True),\n dict(type='RawFrameDecode'),\n dict(type='Resize', scale=(-1, 256)),\n dict(type='CenterCrop', crop_size=224),\n dict(type='Flip', flip_ratio=0),\n dict(type='Normalize', **img_norm_cfg),\n dict(type='FormatShape', input_format='NCHW_Flow'),\n dict(type='Collect', keys=['imgs', 'label'], meta_keys=[]),\n dict(type='ToTensor', keys=['imgs'])\n]\ntest_pipeline = [\n dict(\n type='SampleFrames',\n clip_len=5,\n frame_interval=1,\n num_clips=25,\n test_mode=True),\n dict(type='RawFrameDecode'),\n dict(type='Resize', scale=(-1, 256)),\n dict(type='TenCrop', crop_size=224),\n dict(type='Flip', flip_ratio=0),\n dict(type='Normalize', **img_norm_cfg),\n dict(type='FormatShape', input_format='NCHW_Flow'),\n dict(type='Collect', keys=['imgs', 'label'], meta_keys=[]),\n dict(type='ToTensor', keys=['imgs'])\n]\ndata = dict(\n videos_per_gpu=12,\n workers_per_gpu=4,\n train=dict(\n type=dataset_type,\n ann_file=ann_file_train,\n data_prefix=data_root,\n filename_tmpl='{}_{:05d}.jpg',\n modality='Flow',\n pipeline=train_pipeline),\n val=dict(\n type=dataset_type,\n ann_file=ann_file_val,\n data_prefix=data_root_val,\n filename_tmpl='{}_{:05d}.jpg',\n modality='Flow',\n pipeline=val_pipeline),\n test=dict(\n type=dataset_type,\n ann_file=ann_file_test,\n data_prefix=data_root_val,\n filename_tmpl='{}_{:05d}.jpg',\n modality='Flow',\n pipeline=test_pipeline))\nevaluation = dict(\n interval=5, metrics=['top_k_accuracy', 'mean_class_accuracy'])\n\n# optimizer\noptimizer = dict(\n type='SGD', lr=0.001875, momentum=0.9,\n weight_decay=0.0001) # this lr is used for 8 gpus\noptimizer_config = dict(grad_clip=dict(max_norm=40, norm_type=2))\n# learning policy\nlr_config = dict(policy='step', step=[70, 100])\ntotal_epochs = 110\n\n# runtime settings\ncheckpoint_config = dict(interval=5)\nwork_dir = './work_dirs/tsn_r50_320p_1x1x8_110e_kinetics400_flow/'\n", "path": "configs/recognition/tsn/tsn_r50_320p_1x1x8_110e_kinetics400_flow.py"}, {"content": "_base_ = ['../../_base_/models/tsn_r50.py', '../../_base_/default_runtime.py']\n\n# dataset settings\ndataset_type = 'RawframeDataset'\ndata_root = 'data/kinetics400/rawframes_train_320p'\ndata_root_val = 'data/kinetics400/rawframes_val_320p'\nann_file_train = 'data/kinetics400/kinetics_flow_train_list.txt'\nann_file_val = 'data/kinetics400/kinetics_flow_val_list.txt'\nann_file_test = 'data/kinetics400/kinetics_flow_val_list.txt'\nimg_norm_cfg = dict(\n mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_bgr=False)\ntrain_pipeline = [\n dict(type='SampleFrames', clip_len=5, frame_interval=1, num_clips=3),\n dict(type='RawFrameDecode'),\n dict(type='Resize', scale=(-1, 256)),\n dict(type='RandomResizedCrop'),\n dict(type='Resize', scale=(224, 224), keep_ratio=False),\n dict(type='Flip', flip_ratio=0.5),\n dict(type='Normalize', **img_norm_cfg),\n dict(type='FormatShape', input_format='NCHW_Flow'),\n dict(type='Collect', keys=['imgs', 'label'], meta_keys=[]),\n dict(type='ToTensor', keys=['imgs', 'label'])\n]\nval_pipeline = [\n dict(\n type='SampleFrames',\n clip_len=5,\n frame_interval=1,\n num_clips=3,\n test_mode=True),\n dict(type='RawFrameDecode'),\n dict(type='Resize', scale=(-1, 256)),\n dict(type='CenterCrop', crop_size=224),\n dict(type='Flip', flip_ratio=0),\n dict(type='Normalize', **img_norm_cfg),\n dict(type='FormatShape', input_format='NCHW_Flow'),\n dict(type='Collect', keys=['imgs', 'label'], meta_keys=[]),\n dict(type='ToTensor', keys=['imgs'])\n]\ntest_pipeline = [\n dict(\n type='SampleFrames',\n clip_len=5,\n frame_interval=1,\n num_clips=25,\n test_mode=True),\n dict(type='RawFrameDecode'),\n dict(type='Resize', scale=(-1, 256)),\n dict(type='TenCrop', crop_size=224),\n dict(type='Flip', flip_ratio=0),\n dict(type='Normalize', **img_norm_cfg),\n dict(type='FormatShape', input_format='NCHW_Flow'),\n dict(type='Collect', keys=['imgs', 'label'], meta_keys=[]),\n dict(type='ToTensor', keys=['imgs'])\n]\ndata = dict(\n videos_per_gpu=32,\n workers_per_gpu=4,\n train=dict(\n type=dataset_type,\n ann_file=ann_file_train,\n data_prefix=data_root,\n filename_tmpl='{}_{:05d}.jpg',\n modality='Flow',\n pipeline=train_pipeline),\n val=dict(\n type=dataset_type,\n ann_file=ann_file_val,\n data_prefix=data_root_val,\n filename_tmpl='{}_{:05d}.jpg',\n modality='Flow',\n pipeline=val_pipeline),\n test=dict(\n type=dataset_type,\n ann_file=ann_file_test,\n data_prefix=data_root_val,\n filename_tmpl='{}_{:05d}.jpg',\n modality='Flow',\n pipeline=test_pipeline))\nevaluation = dict(\n interval=5, metrics=['top_k_accuracy', 'mean_class_accuracy'])\n\n# optimizer\noptimizer = dict(\n type='SGD', lr=0.005, momentum=0.9,\n weight_decay=0.0001) # this lr is used for 8 gpus\noptimizer_config = dict(grad_clip=dict(max_norm=40, norm_type=2))\n# learning policy\nlr_config = dict(policy='step', step=[70, 100])\ntotal_epochs = 110\n\n# runtime settings\ncheckpoint_config = dict(interval=5)\nwork_dir = './work_dirs/tsn_r50_320p_1x1x3_110e_kinetics400_flow/'\n", "path": "configs/recognition/tsn/tsn_r50_320p_1x1x3_110e_kinetics400_flow.py"}], "after_files": [{"content": "_base_ = ['../../_base_/models/tsn_r50.py', '../../_base_/default_runtime.py']\n\n# dataset settings\ndataset_type = 'RawframeDataset'\ndata_root = 'data/kinetics400/rawframes_train_320p'\ndata_root_val = 'data/kinetics400/rawframes_val_320p'\nann_file_train = 'data/kinetics400/kinetics400_flow_train_list_320p.txt'\nann_file_val = 'data/kinetics400/kinetics400_flow_val_list_320p.txt'\nann_file_test = 'data/kinetics400/kinetics400_flow_val_list_320p.txt'\nimg_norm_cfg = dict(mean=[128, 128], std=[128, 128])\ntrain_pipeline = [\n dict(type='SampleFrames', clip_len=5, frame_interval=1, num_clips=8),\n dict(type='RawFrameDecode'),\n dict(type='Resize', scale=(-1, 256)),\n dict(type='RandomResizedCrop'),\n dict(type='Resize', scale=(224, 224), keep_ratio=False),\n dict(type='Flip', flip_ratio=0.5),\n dict(type='Normalize', **img_norm_cfg),\n dict(type='FormatShape', input_format='NCHW_Flow'),\n dict(type='Collect', keys=['imgs', 'label'], meta_keys=[]),\n dict(type='ToTensor', keys=['imgs', 'label'])\n]\nval_pipeline = [\n dict(\n type='SampleFrames',\n clip_len=5,\n frame_interval=1,\n num_clips=8,\n test_mode=True),\n dict(type='RawFrameDecode'),\n dict(type='Resize', scale=(-1, 256)),\n dict(type='CenterCrop', crop_size=224),\n dict(type='Flip', flip_ratio=0),\n dict(type='Normalize', **img_norm_cfg),\n dict(type='FormatShape', input_format='NCHW_Flow'),\n dict(type='Collect', keys=['imgs', 'label'], meta_keys=[]),\n dict(type='ToTensor', keys=['imgs'])\n]\ntest_pipeline = [\n dict(\n type='SampleFrames',\n clip_len=5,\n frame_interval=1,\n num_clips=25,\n test_mode=True),\n dict(type='RawFrameDecode'),\n dict(type='Resize', scale=(-1, 256)),\n dict(type='TenCrop', crop_size=224),\n dict(type='Flip', flip_ratio=0),\n dict(type='Normalize', **img_norm_cfg),\n dict(type='FormatShape', input_format='NCHW_Flow'),\n dict(type='Collect', keys=['imgs', 'label'], meta_keys=[]),\n dict(type='ToTensor', keys=['imgs'])\n]\ndata = dict(\n videos_per_gpu=12,\n workers_per_gpu=4,\n train=dict(\n type=dataset_type,\n ann_file=ann_file_train,\n data_prefix=data_root,\n filename_tmpl='{}_{:05d}.jpg',\n modality='Flow',\n pipeline=train_pipeline),\n val=dict(\n type=dataset_type,\n ann_file=ann_file_val,\n data_prefix=data_root_val,\n filename_tmpl='{}_{:05d}.jpg',\n modality='Flow',\n pipeline=val_pipeline),\n test=dict(\n type=dataset_type,\n ann_file=ann_file_test,\n data_prefix=data_root_val,\n filename_tmpl='{}_{:05d}.jpg',\n modality='Flow',\n pipeline=test_pipeline))\nevaluation = dict(\n interval=5, metrics=['top_k_accuracy', 'mean_class_accuracy'])\n\n# optimizer\noptimizer = dict(\n type='SGD', lr=0.001875, momentum=0.9,\n weight_decay=0.0001) # this lr is used for 8 gpus\noptimizer_config = dict(grad_clip=dict(max_norm=40, norm_type=2))\n# learning policy\nlr_config = dict(policy='step', step=[70, 100])\ntotal_epochs = 110\n\n# runtime settings\ncheckpoint_config = dict(interval=5)\nwork_dir = './work_dirs/tsn_r50_320p_1x1x8_110e_kinetics400_flow/'\n", "path": "configs/recognition/tsn/tsn_r50_320p_1x1x8_110e_kinetics400_flow.py"}, {"content": "_base_ = ['../../_base_/models/tsn_r50.py', '../../_base_/default_runtime.py']\n\n# dataset settings\ndataset_type = 'RawframeDataset'\ndata_root = 'data/kinetics400/rawframes_train_320p'\ndata_root_val = 'data/kinetics400/rawframes_val_320p'\nann_file_train = 'data/kinetics400/kinetics_flow_train_list.txt'\nann_file_val = 'data/kinetics400/kinetics_flow_val_list.txt'\nann_file_test = 'data/kinetics400/kinetics_flow_val_list.txt'\nimg_norm_cfg = dict(mean=[128, 128], std=[128, 128])\ntrain_pipeline = [\n dict(type='SampleFrames', clip_len=5, frame_interval=1, num_clips=3),\n dict(type='RawFrameDecode'),\n dict(type='Resize', scale=(-1, 256)),\n dict(type='RandomResizedCrop'),\n dict(type='Resize', scale=(224, 224), keep_ratio=False),\n dict(type='Flip', flip_ratio=0.5),\n dict(type='Normalize', **img_norm_cfg),\n dict(type='FormatShape', input_format='NCHW_Flow'),\n dict(type='Collect', keys=['imgs', 'label'], meta_keys=[]),\n dict(type='ToTensor', keys=['imgs', 'label'])\n]\nval_pipeline = [\n dict(\n type='SampleFrames',\n clip_len=5,\n frame_interval=1,\n num_clips=3,\n test_mode=True),\n dict(type='RawFrameDecode'),\n dict(type='Resize', scale=(-1, 256)),\n dict(type='CenterCrop', crop_size=224),\n dict(type='Flip', flip_ratio=0),\n dict(type='Normalize', **img_norm_cfg),\n dict(type='FormatShape', input_format='NCHW_Flow'),\n dict(type='Collect', keys=['imgs', 'label'], meta_keys=[]),\n dict(type='ToTensor', keys=['imgs'])\n]\ntest_pipeline = [\n dict(\n type='SampleFrames',\n clip_len=5,\n frame_interval=1,\n num_clips=25,\n test_mode=True),\n dict(type='RawFrameDecode'),\n dict(type='Resize', scale=(-1, 256)),\n dict(type='TenCrop', crop_size=224),\n dict(type='Flip', flip_ratio=0),\n dict(type='Normalize', **img_norm_cfg),\n dict(type='FormatShape', input_format='NCHW_Flow'),\n dict(type='Collect', keys=['imgs', 'label'], meta_keys=[]),\n dict(type='ToTensor', keys=['imgs'])\n]\ndata = dict(\n videos_per_gpu=32,\n workers_per_gpu=4,\n train=dict(\n type=dataset_type,\n ann_file=ann_file_train,\n data_prefix=data_root,\n filename_tmpl='{}_{:05d}.jpg',\n modality='Flow',\n pipeline=train_pipeline),\n val=dict(\n type=dataset_type,\n ann_file=ann_file_val,\n data_prefix=data_root_val,\n filename_tmpl='{}_{:05d}.jpg',\n modality='Flow',\n pipeline=val_pipeline),\n test=dict(\n type=dataset_type,\n ann_file=ann_file_test,\n data_prefix=data_root_val,\n filename_tmpl='{}_{:05d}.jpg',\n modality='Flow',\n pipeline=test_pipeline))\nevaluation = dict(\n interval=5, metrics=['top_k_accuracy', 'mean_class_accuracy'])\n\n# optimizer\noptimizer = dict(\n type='SGD', lr=0.005, momentum=0.9,\n weight_decay=0.0001) # this lr is used for 8 gpus\noptimizer_config = dict(grad_clip=dict(max_norm=40, norm_type=2))\n# learning policy\nlr_config = dict(policy='step', step=[70, 100])\ntotal_epochs = 110\n\n# runtime settings\ncheckpoint_config = dict(interval=5)\nwork_dir = './work_dirs/tsn_r50_320p_1x1x3_110e_kinetics400_flow/'\n", "path": "configs/recognition/tsn/tsn_r50_320p_1x1x3_110e_kinetics400_flow.py"}]}
| 2,706 | 720 |
gh_patches_debug_42569
|
rasdani/github-patches
|
git_diff
|
NVIDIA-Merlin__NVTabular-1262
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[FEA] Create a padding option in the ListSlice Op
The right padding option is required
- to create fixed length lists generated from ETL workflow (see ([example nb](https://github.com/NVIDIA-Merlin/Transformers4Rec/blob/main/examples/getting-started-session-based/01-ETL-with-NVTabular.ipynb)).
- to be able to serve a seq-to-seq model (ex. session-based model) to TIS with proper reshaped tensors and get the proper reshaped outputs.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nvtabular/ops/list_slice.py`
Content:
```
1 #
2 # Copyright (c) 2021, NVIDIA CORPORATION.
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15 #
16 import numba.cuda
17 import numpy as np
18
19 try:
20 import cupy as cp
21 except ImportError:
22 cp = None
23
24 from nvtabular.dispatch import DataFrameType, _build_cudf_list_column, _is_cpu_object, annotate
25
26 from ..tags import Tags
27 from .operator import ColumnSelector, Operator
28
29
30 class ListSlice(Operator):
31 """Slices a list column
32
33 This operator provides the ability to slice list column by row. For example, to truncate a
34 list column to only include the first 10 elements per row::
35
36 truncated = column_names >> ops.ListSlice(10)
37
38 Take the first 10 items, ignoring the first element::
39
40 truncated = column_names >> ops.ListSlice(1, 11)
41
42 Take the last 10 items from each row::
43
44 truncated = column_names >> ops.ListSlice(-10)
45 """
46
47 def __init__(self, start, end=None):
48 super().__init__()
49 self.start = start
50 self.end = end
51
52 if self.start > 0 and self.end is None:
53 self.end = self.start
54 self.start = 0
55
56 if self.end is None:
57 self.end = np.iinfo(np.int64).max
58
59 @annotate("ListSlice_op", color="darkgreen", domain="nvt_python")
60 def transform(self, col_selector: ColumnSelector, df: DataFrameType) -> DataFrameType:
61 on_cpu = _is_cpu_object(df)
62 ret = type(df)()
63 for col in col_selector.names:
64 # handle CPU via normal python slicing (not very efficient)
65 if on_cpu:
66 ret[col] = [row[self.start : self.end] for row in df[col]]
67 else:
68 # figure out the size of each row from the list offsets
69 c = df[col]._column
70 offsets = c.offsets.values
71 elements = c.elements.values
72
73 # figure out the size of each row after slicing start/end
74 new_offsets = cp.zeros(offsets.size, dtype=offsets.dtype)
75 threads = 32
76 blocks = (offsets.size + threads - 1) // threads
77
78 # calculate new row offsets after slicing
79 _calculate_row_sizes[blocks, threads](self.start, self.end, offsets, new_offsets)
80 new_offsets = cp.cumsum(new_offsets).astype(offsets.dtype)
81
82 # create a new array for the sliced elements
83 new_elements = cp.zeros(new_offsets[-1].item(), dtype=elements.dtype)
84 if new_elements.size:
85 _slice_rows[blocks, threads](
86 self.start, offsets, elements, new_offsets, new_elements
87 )
88
89 # build up a list column with the sliced values
90 ret[col] = _build_cudf_list_column(new_elements, new_offsets)
91
92 return ret
93
94 def output_tags(self):
95 return [Tags.LIST]
96
97 transform.__doc__ = Operator.transform.__doc__
98
99
100 @numba.cuda.jit
101 def _calculate_row_sizes(start, end, offsets, row_sizes):
102 """given a slice (start/end) and existing offsets indicating row lengths, this
103 calculates the size for each new row after slicing"""
104 rowid = numba.cuda.grid(1)
105 if rowid < offsets.size - 1:
106 original_row_size = offsets[rowid + 1] - offsets[rowid]
107
108 # handle negative slicing appropriately
109 if start < 0:
110 start = original_row_size + start
111 if end < 0:
112 end = original_row_size + end
113
114 # clamp start/end to be in (0, original_row_size)
115 start = min(max(0, start), original_row_size)
116 end = min(max(0, end), original_row_size)
117
118 row_sizes[rowid + 1] = end - start
119
120
121 @numba.cuda.jit
122 def _slice_rows(start, offsets, elements, new_offsets, new_elements):
123 """slices rows of a list column. requires the 'new_offsets' to
124 be previously calculated (meaning that we don't need the 'end' slice index
125 since that's baked into the new_offsets"""
126 rowid = numba.cuda.grid(1)
127 if rowid < (new_offsets.size - 1):
128 if start >= 0:
129 offset = offsets[rowid] + start
130 else:
131 offset = offsets[rowid + 1] + start
132 if offset < offsets[rowid]:
133 offset = offsets[rowid]
134
135 for new_offset in range(new_offsets[rowid], new_offsets[rowid + 1]):
136 new_elements[new_offset] = elements[offset]
137 offset += 1
138
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nvtabular/ops/list_slice.py b/nvtabular/ops/list_slice.py
--- a/nvtabular/ops/list_slice.py
+++ b/nvtabular/ops/list_slice.py
@@ -44,10 +44,12 @@
truncated = column_names >> ops.ListSlice(-10)
"""
- def __init__(self, start, end=None):
+ def __init__(self, start, end=None, pad=False, pad_value=0.0):
super().__init__()
self.start = start
self.end = end
+ self.pad = pad
+ self.pad_value = pad_value
if self.start > 0 and self.end is None:
self.end = self.start
@@ -60,27 +62,47 @@
def transform(self, col_selector: ColumnSelector, df: DataFrameType) -> DataFrameType:
on_cpu = _is_cpu_object(df)
ret = type(df)()
+
+ max_elements = self.end - self.start
+
for col in col_selector.names:
# handle CPU via normal python slicing (not very efficient)
if on_cpu:
- ret[col] = [row[self.start : self.end] for row in df[col]]
+ values = [row[self.start : self.end] for row in df[col]]
+
+ # pad out to so each row has max_elements if askeed
+ if self.pad:
+ for v in values:
+ if len(v) < max_elements:
+ v.extend([self.pad_value] * (max_elements - len(v)))
+
+ ret[col] = values
else:
# figure out the size of each row from the list offsets
c = df[col]._column
offsets = c.offsets.values
elements = c.elements.values
- # figure out the size of each row after slicing start/end
- new_offsets = cp.zeros(offsets.size, dtype=offsets.dtype)
threads = 32
blocks = (offsets.size + threads - 1) // threads
- # calculate new row offsets after slicing
- _calculate_row_sizes[blocks, threads](self.start, self.end, offsets, new_offsets)
- new_offsets = cp.cumsum(new_offsets).astype(offsets.dtype)
+ if self.pad:
+ new_offsets = cp.arange(offsets.size, dtype=offsets.dtype) * max_elements
+
+ else:
+ # figure out the size of each row after slicing start/end
+ new_offsets = cp.zeros(offsets.size, dtype=offsets.dtype)
+
+ # calculate new row offsets after slicing
+ _calculate_row_sizes[blocks, threads](
+ self.start, self.end, offsets, new_offsets
+ )
+ new_offsets = cp.cumsum(new_offsets).astype(offsets.dtype)
# create a new array for the sliced elements
- new_elements = cp.zeros(new_offsets[-1].item(), dtype=elements.dtype)
+ new_elements = cp.full(
+ new_offsets[-1].item(), fill_value=self.pad_value, dtype=elements.dtype
+ )
if new_elements.size:
_slice_rows[blocks, threads](
self.start, offsets, elements, new_offsets, new_elements
@@ -132,6 +154,15 @@
if offset < offsets[rowid]:
offset = offsets[rowid]
- for new_offset in range(new_offsets[rowid], new_offsets[rowid + 1]):
+ new_start = new_offsets[rowid]
+ new_end = new_offsets[rowid + 1]
+
+ # if we are padding (more new offsets than old olffsets) - don't keep on iterating past
+ # the end
+ offset_delta = (new_end - new_start) - (offsets[rowid + 1] - offset)
+ if offset_delta > 0:
+ new_end -= offset_delta
+
+ for new_offset in range(new_start, new_end):
new_elements[new_offset] = elements[offset]
offset += 1
|
{"golden_diff": "diff --git a/nvtabular/ops/list_slice.py b/nvtabular/ops/list_slice.py\n--- a/nvtabular/ops/list_slice.py\n+++ b/nvtabular/ops/list_slice.py\n@@ -44,10 +44,12 @@\n truncated = column_names >> ops.ListSlice(-10)\n \"\"\"\n \n- def __init__(self, start, end=None):\n+ def __init__(self, start, end=None, pad=False, pad_value=0.0):\n super().__init__()\n self.start = start\n self.end = end\n+ self.pad = pad\n+ self.pad_value = pad_value\n \n if self.start > 0 and self.end is None:\n self.end = self.start\n@@ -60,27 +62,47 @@\n def transform(self, col_selector: ColumnSelector, df: DataFrameType) -> DataFrameType:\n on_cpu = _is_cpu_object(df)\n ret = type(df)()\n+\n+ max_elements = self.end - self.start\n+\n for col in col_selector.names:\n # handle CPU via normal python slicing (not very efficient)\n if on_cpu:\n- ret[col] = [row[self.start : self.end] for row in df[col]]\n+ values = [row[self.start : self.end] for row in df[col]]\n+\n+ # pad out to so each row has max_elements if askeed\n+ if self.pad:\n+ for v in values:\n+ if len(v) < max_elements:\n+ v.extend([self.pad_value] * (max_elements - len(v)))\n+\n+ ret[col] = values\n else:\n # figure out the size of each row from the list offsets\n c = df[col]._column\n offsets = c.offsets.values\n elements = c.elements.values\n \n- # figure out the size of each row after slicing start/end\n- new_offsets = cp.zeros(offsets.size, dtype=offsets.dtype)\n threads = 32\n blocks = (offsets.size + threads - 1) // threads\n \n- # calculate new row offsets after slicing\n- _calculate_row_sizes[blocks, threads](self.start, self.end, offsets, new_offsets)\n- new_offsets = cp.cumsum(new_offsets).astype(offsets.dtype)\n+ if self.pad:\n+ new_offsets = cp.arange(offsets.size, dtype=offsets.dtype) * max_elements\n+\n+ else:\n+ # figure out the size of each row after slicing start/end\n+ new_offsets = cp.zeros(offsets.size, dtype=offsets.dtype)\n+\n+ # calculate new row offsets after slicing\n+ _calculate_row_sizes[blocks, threads](\n+ self.start, self.end, offsets, new_offsets\n+ )\n+ new_offsets = cp.cumsum(new_offsets).astype(offsets.dtype)\n \n # create a new array for the sliced elements\n- new_elements = cp.zeros(new_offsets[-1].item(), dtype=elements.dtype)\n+ new_elements = cp.full(\n+ new_offsets[-1].item(), fill_value=self.pad_value, dtype=elements.dtype\n+ )\n if new_elements.size:\n _slice_rows[blocks, threads](\n self.start, offsets, elements, new_offsets, new_elements\n@@ -132,6 +154,15 @@\n if offset < offsets[rowid]:\n offset = offsets[rowid]\n \n- for new_offset in range(new_offsets[rowid], new_offsets[rowid + 1]):\n+ new_start = new_offsets[rowid]\n+ new_end = new_offsets[rowid + 1]\n+\n+ # if we are padding (more new offsets than old olffsets) - don't keep on iterating past\n+ # the end\n+ offset_delta = (new_end - new_start) - (offsets[rowid + 1] - offset)\n+ if offset_delta > 0:\n+ new_end -= offset_delta\n+\n+ for new_offset in range(new_start, new_end):\n new_elements[new_offset] = elements[offset]\n offset += 1\n", "issue": "[FEA] Create a padding option in the ListSlice Op\nThe right padding option is required\r\n- to create fixed length lists generated from ETL workflow (see ([example nb](https://github.com/NVIDIA-Merlin/Transformers4Rec/blob/main/examples/getting-started-session-based/01-ETL-with-NVTabular.ipynb)). \r\n- to be able to serve a seq-to-seq model (ex. session-based model) to TIS with proper reshaped tensors and get the proper reshaped outputs.\r\n\r\n\n", "before_files": [{"content": "#\n# Copyright (c) 2021, NVIDIA CORPORATION.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\nimport numba.cuda\nimport numpy as np\n\ntry:\n import cupy as cp\nexcept ImportError:\n cp = None\n\nfrom nvtabular.dispatch import DataFrameType, _build_cudf_list_column, _is_cpu_object, annotate\n\nfrom ..tags import Tags\nfrom .operator import ColumnSelector, Operator\n\n\nclass ListSlice(Operator):\n \"\"\"Slices a list column\n\n This operator provides the ability to slice list column by row. For example, to truncate a\n list column to only include the first 10 elements per row::\n\n truncated = column_names >> ops.ListSlice(10)\n\n Take the first 10 items, ignoring the first element::\n\n truncated = column_names >> ops.ListSlice(1, 11)\n\n Take the last 10 items from each row::\n\n truncated = column_names >> ops.ListSlice(-10)\n \"\"\"\n\n def __init__(self, start, end=None):\n super().__init__()\n self.start = start\n self.end = end\n\n if self.start > 0 and self.end is None:\n self.end = self.start\n self.start = 0\n\n if self.end is None:\n self.end = np.iinfo(np.int64).max\n\n @annotate(\"ListSlice_op\", color=\"darkgreen\", domain=\"nvt_python\")\n def transform(self, col_selector: ColumnSelector, df: DataFrameType) -> DataFrameType:\n on_cpu = _is_cpu_object(df)\n ret = type(df)()\n for col in col_selector.names:\n # handle CPU via normal python slicing (not very efficient)\n if on_cpu:\n ret[col] = [row[self.start : self.end] for row in df[col]]\n else:\n # figure out the size of each row from the list offsets\n c = df[col]._column\n offsets = c.offsets.values\n elements = c.elements.values\n\n # figure out the size of each row after slicing start/end\n new_offsets = cp.zeros(offsets.size, dtype=offsets.dtype)\n threads = 32\n blocks = (offsets.size + threads - 1) // threads\n\n # calculate new row offsets after slicing\n _calculate_row_sizes[blocks, threads](self.start, self.end, offsets, new_offsets)\n new_offsets = cp.cumsum(new_offsets).astype(offsets.dtype)\n\n # create a new array for the sliced elements\n new_elements = cp.zeros(new_offsets[-1].item(), dtype=elements.dtype)\n if new_elements.size:\n _slice_rows[blocks, threads](\n self.start, offsets, elements, new_offsets, new_elements\n )\n\n # build up a list column with the sliced values\n ret[col] = _build_cudf_list_column(new_elements, new_offsets)\n\n return ret\n\n def output_tags(self):\n return [Tags.LIST]\n\n transform.__doc__ = Operator.transform.__doc__\n\n\[email protected]\ndef _calculate_row_sizes(start, end, offsets, row_sizes):\n \"\"\"given a slice (start/end) and existing offsets indicating row lengths, this\n calculates the size for each new row after slicing\"\"\"\n rowid = numba.cuda.grid(1)\n if rowid < offsets.size - 1:\n original_row_size = offsets[rowid + 1] - offsets[rowid]\n\n # handle negative slicing appropriately\n if start < 0:\n start = original_row_size + start\n if end < 0:\n end = original_row_size + end\n\n # clamp start/end to be in (0, original_row_size)\n start = min(max(0, start), original_row_size)\n end = min(max(0, end), original_row_size)\n\n row_sizes[rowid + 1] = end - start\n\n\[email protected]\ndef _slice_rows(start, offsets, elements, new_offsets, new_elements):\n \"\"\"slices rows of a list column. requires the 'new_offsets' to\n be previously calculated (meaning that we don't need the 'end' slice index\n since that's baked into the new_offsets\"\"\"\n rowid = numba.cuda.grid(1)\n if rowid < (new_offsets.size - 1):\n if start >= 0:\n offset = offsets[rowid] + start\n else:\n offset = offsets[rowid + 1] + start\n if offset < offsets[rowid]:\n offset = offsets[rowid]\n\n for new_offset in range(new_offsets[rowid], new_offsets[rowid + 1]):\n new_elements[new_offset] = elements[offset]\n offset += 1\n", "path": "nvtabular/ops/list_slice.py"}], "after_files": [{"content": "#\n# Copyright (c) 2021, NVIDIA CORPORATION.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\nimport numba.cuda\nimport numpy as np\n\ntry:\n import cupy as cp\nexcept ImportError:\n cp = None\n\nfrom nvtabular.dispatch import DataFrameType, _build_cudf_list_column, _is_cpu_object, annotate\n\nfrom ..tags import Tags\nfrom .operator import ColumnSelector, Operator\n\n\nclass ListSlice(Operator):\n \"\"\"Slices a list column\n\n This operator provides the ability to slice list column by row. For example, to truncate a\n list column to only include the first 10 elements per row::\n\n truncated = column_names >> ops.ListSlice(10)\n\n Take the first 10 items, ignoring the first element::\n\n truncated = column_names >> ops.ListSlice(1, 11)\n\n Take the last 10 items from each row::\n\n truncated = column_names >> ops.ListSlice(-10)\n \"\"\"\n\n def __init__(self, start, end=None, pad=False, pad_value=0.0):\n super().__init__()\n self.start = start\n self.end = end\n self.pad = pad\n self.pad_value = pad_value\n\n if self.start > 0 and self.end is None:\n self.end = self.start\n self.start = 0\n\n if self.end is None:\n self.end = np.iinfo(np.int64).max\n\n @annotate(\"ListSlice_op\", color=\"darkgreen\", domain=\"nvt_python\")\n def transform(self, col_selector: ColumnSelector, df: DataFrameType) -> DataFrameType:\n on_cpu = _is_cpu_object(df)\n ret = type(df)()\n\n max_elements = self.end - self.start\n\n for col in col_selector.names:\n # handle CPU via normal python slicing (not very efficient)\n if on_cpu:\n values = [row[self.start : self.end] for row in df[col]]\n\n # pad out to so each row has max_elements if askeed\n if self.pad:\n for v in values:\n if len(v) < max_elements:\n v.extend([self.pad_value] * (max_elements - len(v)))\n\n ret[col] = values\n else:\n # figure out the size of each row from the list offsets\n c = df[col]._column\n offsets = c.offsets.values\n elements = c.elements.values\n\n threads = 32\n blocks = (offsets.size + threads - 1) // threads\n\n if self.pad:\n new_offsets = cp.arange(offsets.size, dtype=offsets.dtype) * max_elements\n\n else:\n # figure out the size of each row after slicing start/end\n new_offsets = cp.zeros(offsets.size, dtype=offsets.dtype)\n\n # calculate new row offsets after slicing\n _calculate_row_sizes[blocks, threads](\n self.start, self.end, offsets, new_offsets\n )\n new_offsets = cp.cumsum(new_offsets).astype(offsets.dtype)\n\n # create a new array for the sliced elements\n new_elements = cp.full(\n new_offsets[-1].item(), fill_value=self.pad_value, dtype=elements.dtype\n )\n if new_elements.size:\n _slice_rows[blocks, threads](\n self.start, offsets, elements, new_offsets, new_elements\n )\n\n # build up a list column with the sliced values\n ret[col] = _build_cudf_list_column(new_elements, new_offsets)\n\n return ret\n\n def output_tags(self):\n return [Tags.LIST]\n\n transform.__doc__ = Operator.transform.__doc__\n\n\[email protected]\ndef _calculate_row_sizes(start, end, offsets, row_sizes):\n \"\"\"given a slice (start/end) and existing offsets indicating row lengths, this\n calculates the size for each new row after slicing\"\"\"\n rowid = numba.cuda.grid(1)\n if rowid < offsets.size - 1:\n original_row_size = offsets[rowid + 1] - offsets[rowid]\n\n # handle negative slicing appropriately\n if start < 0:\n start = original_row_size + start\n if end < 0:\n end = original_row_size + end\n\n # clamp start/end to be in (0, original_row_size)\n start = min(max(0, start), original_row_size)\n end = min(max(0, end), original_row_size)\n\n row_sizes[rowid + 1] = end - start\n\n\[email protected]\ndef _slice_rows(start, offsets, elements, new_offsets, new_elements):\n \"\"\"slices rows of a list column. requires the 'new_offsets' to\n be previously calculated (meaning that we don't need the 'end' slice index\n since that's baked into the new_offsets\"\"\"\n rowid = numba.cuda.grid(1)\n if rowid < (new_offsets.size - 1):\n if start >= 0:\n offset = offsets[rowid] + start\n else:\n offset = offsets[rowid + 1] + start\n if offset < offsets[rowid]:\n offset = offsets[rowid]\n\n new_start = new_offsets[rowid]\n new_end = new_offsets[rowid + 1]\n\n # if we are padding (more new offsets than old olffsets) - don't keep on iterating past\n # the end\n offset_delta = (new_end - new_start) - (offsets[rowid + 1] - offset)\n if offset_delta > 0:\n new_end -= offset_delta\n\n for new_offset in range(new_start, new_end):\n new_elements[new_offset] = elements[offset]\n offset += 1\n", "path": "nvtabular/ops/list_slice.py"}]}
| 1,829 | 892 |
gh_patches_debug_20343
|
rasdani/github-patches
|
git_diff
|
huggingface__transformers-12424
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
HfArgumentParser defaults booleans to on
## Environment info
- `transformers` version: 4.9.0.dev0 (initially discovered on 4.8.1)
- Platform: macOS-11.4-x86_64-i386-64bit
- Python version: 3.9.5
- PyTorch version (GPU?): not installed (NA)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
### Who can help
@sgugger
## Information
HfArgumentParser when used on a dataclass with a bool field with no default turns the bool on unless it's supplied with `--<field_name> False` or similar "false-y" value. I would expect that as the field has no default it should be false unless `--<field_name>` or `--<field_name> True` is supplied. This is a behaviour change from `v3.0.0` where the booleans are parsed correctly as we're looking at upgrading and this issue hit us.
## To reproduce
Steps to reproduce the behavior:
1. Define a dataclass with a boolean field
2. Supply a list of arguments which does not include that field name
3. The field is turned on.
Appending this snippet to the bottom of [`test_basic` at line 110](https://github.com/huggingface/transformers/blob/master/tests/test_hf_argparser.py#L110) in `test_hf_argparser.py` fails the test.
```python
args = ["--foo", "1", "--baz", "quux", "--bar", "0.5"]
example, = parser.parse_args_into_dataclasses(args, look_for_args_file=False)
self.assertFalse(example.flag)
```
Extending `args` with `["--flag","False"]` recovers the expected behaviour.
## Expected behavior
The boolean should be set to false if the argument is not passed in.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/transformers/hf_argparser.py`
Content:
```
1 # Copyright 2020 The HuggingFace Team. All rights reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import dataclasses
16 import json
17 import re
18 import sys
19 from argparse import ArgumentParser, ArgumentTypeError
20 from enum import Enum
21 from pathlib import Path
22 from typing import Any, Iterable, List, NewType, Optional, Tuple, Union
23
24
25 DataClass = NewType("DataClass", Any)
26 DataClassType = NewType("DataClassType", Any)
27
28
29 # From https://stackoverflow.com/questions/15008758/parsing-boolean-values-with-argparse
30 def string_to_bool(v):
31 if isinstance(v, bool):
32 return v
33 if v.lower() in ("yes", "true", "t", "y", "1"):
34 return True
35 elif v.lower() in ("no", "false", "f", "n", "0"):
36 return False
37 else:
38 raise ArgumentTypeError(
39 f"Truthy value expected: got {v} but expected one of yes/no, true/false, t/f, y/n, 1/0 (case insensitive)."
40 )
41
42
43 class HfArgumentParser(ArgumentParser):
44 """
45 This subclass of `argparse.ArgumentParser` uses type hints on dataclasses to generate arguments.
46
47 The class is designed to play well with the native argparse. In particular, you can add more (non-dataclass backed)
48 arguments to the parser after initialization and you'll get the output back after parsing as an additional
49 namespace. Optional: To create sub argument groups use the `_argument_group_name` attribute in the dataclass.
50 """
51
52 dataclass_types: Iterable[DataClassType]
53
54 def __init__(self, dataclass_types: Union[DataClassType, Iterable[DataClassType]], **kwargs):
55 """
56 Args:
57 dataclass_types:
58 Dataclass type, or list of dataclass types for which we will "fill" instances with the parsed args.
59 kwargs:
60 (Optional) Passed to `argparse.ArgumentParser()` in the regular way.
61 """
62 super().__init__(**kwargs)
63 if dataclasses.is_dataclass(dataclass_types):
64 dataclass_types = [dataclass_types]
65 self.dataclass_types = dataclass_types
66 for dtype in self.dataclass_types:
67 self._add_dataclass_arguments(dtype)
68
69 def _add_dataclass_arguments(self, dtype: DataClassType):
70 if hasattr(dtype, "_argument_group_name"):
71 parser = self.add_argument_group(dtype._argument_group_name)
72 else:
73 parser = self
74 for field in dataclasses.fields(dtype):
75 if not field.init:
76 continue
77 field_name = f"--{field.name}"
78 kwargs = field.metadata.copy()
79 # field.metadata is not used at all by Data Classes,
80 # it is provided as a third-party extension mechanism.
81 if isinstance(field.type, str):
82 raise ImportError(
83 "This implementation is not compatible with Postponed Evaluation of Annotations (PEP 563),"
84 "which can be opted in from Python 3.7 with `from __future__ import annotations`."
85 "We will add compatibility when Python 3.9 is released."
86 )
87 typestring = str(field.type)
88 for prim_type in (int, float, str):
89 for collection in (List,):
90 if (
91 typestring == f"typing.Union[{collection[prim_type]}, NoneType]"
92 or typestring == f"typing.Optional[{collection[prim_type]}]"
93 ):
94 field.type = collection[prim_type]
95 if (
96 typestring == f"typing.Union[{prim_type.__name__}, NoneType]"
97 or typestring == f"typing.Optional[{prim_type.__name__}]"
98 ):
99 field.type = prim_type
100
101 if isinstance(field.type, type) and issubclass(field.type, Enum):
102 kwargs["choices"] = [x.value for x in field.type]
103 kwargs["type"] = type(kwargs["choices"][0])
104 if field.default is not dataclasses.MISSING:
105 kwargs["default"] = field.default
106 else:
107 kwargs["required"] = True
108 elif field.type is bool or field.type == Optional[bool]:
109 if field.default is True:
110 parser.add_argument(f"--no_{field.name}", action="store_false", dest=field.name, **kwargs)
111
112 # Hack because type=bool in argparse does not behave as we want.
113 kwargs["type"] = string_to_bool
114 if field.type is bool or (field.default is not None and field.default is not dataclasses.MISSING):
115 # Default value is True if we have no default when of type bool.
116 default = True if field.default is dataclasses.MISSING else field.default
117 # This is the value that will get picked if we don't include --field_name in any way
118 kwargs["default"] = default
119 # This tells argparse we accept 0 or 1 value after --field_name
120 kwargs["nargs"] = "?"
121 # This is the value that will get picked if we do --field_name (without value)
122 kwargs["const"] = True
123 elif (
124 hasattr(field.type, "__origin__") and re.search(r"^typing\.List\[(.*)\]$", str(field.type)) is not None
125 ):
126 kwargs["nargs"] = "+"
127 kwargs["type"] = field.type.__args__[0]
128 assert all(
129 x == kwargs["type"] for x in field.type.__args__
130 ), f"{field.name} cannot be a List of mixed types"
131 if field.default_factory is not dataclasses.MISSING:
132 kwargs["default"] = field.default_factory()
133 elif field.default is dataclasses.MISSING:
134 kwargs["required"] = True
135 else:
136 kwargs["type"] = field.type
137 if field.default is not dataclasses.MISSING:
138 kwargs["default"] = field.default
139 elif field.default_factory is not dataclasses.MISSING:
140 kwargs["default"] = field.default_factory()
141 else:
142 kwargs["required"] = True
143 parser.add_argument(field_name, **kwargs)
144
145 def parse_args_into_dataclasses(
146 self, args=None, return_remaining_strings=False, look_for_args_file=True, args_filename=None
147 ) -> Tuple[DataClass, ...]:
148 """
149 Parse command-line args into instances of the specified dataclass types.
150
151 This relies on argparse's `ArgumentParser.parse_known_args`. See the doc at:
152 docs.python.org/3.7/library/argparse.html#argparse.ArgumentParser.parse_args
153
154 Args:
155 args:
156 List of strings to parse. The default is taken from sys.argv. (same as argparse.ArgumentParser)
157 return_remaining_strings:
158 If true, also return a list of remaining argument strings.
159 look_for_args_file:
160 If true, will look for a ".args" file with the same base name as the entry point script for this
161 process, and will append its potential content to the command line args.
162 args_filename:
163 If not None, will uses this file instead of the ".args" file specified in the previous argument.
164
165 Returns:
166 Tuple consisting of:
167
168 - the dataclass instances in the same order as they were passed to the initializer.abspath
169 - if applicable, an additional namespace for more (non-dataclass backed) arguments added to the parser
170 after initialization.
171 - The potential list of remaining argument strings. (same as argparse.ArgumentParser.parse_known_args)
172 """
173 if args_filename or (look_for_args_file and len(sys.argv)):
174 if args_filename:
175 args_file = Path(args_filename)
176 else:
177 args_file = Path(sys.argv[0]).with_suffix(".args")
178
179 if args_file.exists():
180 fargs = args_file.read_text().split()
181 args = fargs + args if args is not None else fargs + sys.argv[1:]
182 # in case of duplicate arguments the first one has precedence
183 # so we append rather than prepend.
184 namespace, remaining_args = self.parse_known_args(args=args)
185 outputs = []
186 for dtype in self.dataclass_types:
187 keys = {f.name for f in dataclasses.fields(dtype) if f.init}
188 inputs = {k: v for k, v in vars(namespace).items() if k in keys}
189 for k in keys:
190 delattr(namespace, k)
191 obj = dtype(**inputs)
192 outputs.append(obj)
193 if len(namespace.__dict__) > 0:
194 # additional namespace.
195 outputs.append(namespace)
196 if return_remaining_strings:
197 return (*outputs, remaining_args)
198 else:
199 if remaining_args:
200 raise ValueError(f"Some specified arguments are not used by the HfArgumentParser: {remaining_args}")
201
202 return (*outputs,)
203
204 def parse_json_file(self, json_file: str) -> Tuple[DataClass, ...]:
205 """
206 Alternative helper method that does not use `argparse` at all, instead loading a json file and populating the
207 dataclass types.
208 """
209 data = json.loads(Path(json_file).read_text())
210 outputs = []
211 for dtype in self.dataclass_types:
212 keys = {f.name for f in dataclasses.fields(dtype) if f.init}
213 inputs = {k: v for k, v in data.items() if k in keys}
214 obj = dtype(**inputs)
215 outputs.append(obj)
216 return (*outputs,)
217
218 def parse_dict(self, args: dict) -> Tuple[DataClass, ...]:
219 """
220 Alternative helper method that does not use `argparse` at all, instead uses a dict and populating the dataclass
221 types.
222 """
223 outputs = []
224 for dtype in self.dataclass_types:
225 keys = {f.name for f in dataclasses.fields(dtype) if f.init}
226 inputs = {k: v for k, v in args.items() if k in keys}
227 obj = dtype(**inputs)
228 outputs.append(obj)
229 return (*outputs,)
230
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/transformers/hf_argparser.py b/src/transformers/hf_argparser.py
--- a/src/transformers/hf_argparser.py
+++ b/src/transformers/hf_argparser.py
@@ -112,8 +112,8 @@
# Hack because type=bool in argparse does not behave as we want.
kwargs["type"] = string_to_bool
if field.type is bool or (field.default is not None and field.default is not dataclasses.MISSING):
- # Default value is True if we have no default when of type bool.
- default = True if field.default is dataclasses.MISSING else field.default
+ # Default value is False if we have no default when of type bool.
+ default = False if field.default is dataclasses.MISSING else field.default
# This is the value that will get picked if we don't include --field_name in any way
kwargs["default"] = default
# This tells argparse we accept 0 or 1 value after --field_name
|
{"golden_diff": "diff --git a/src/transformers/hf_argparser.py b/src/transformers/hf_argparser.py\n--- a/src/transformers/hf_argparser.py\n+++ b/src/transformers/hf_argparser.py\n@@ -112,8 +112,8 @@\n # Hack because type=bool in argparse does not behave as we want.\n kwargs[\"type\"] = string_to_bool\n if field.type is bool or (field.default is not None and field.default is not dataclasses.MISSING):\n- # Default value is True if we have no default when of type bool.\n- default = True if field.default is dataclasses.MISSING else field.default\n+ # Default value is False if we have no default when of type bool.\n+ default = False if field.default is dataclasses.MISSING else field.default\n # This is the value that will get picked if we don't include --field_name in any way\n kwargs[\"default\"] = default\n # This tells argparse we accept 0 or 1 value after --field_name\n", "issue": "HfArgumentParser defaults booleans to on\n## Environment info\r\n- `transformers` version: 4.9.0.dev0 (initially discovered on 4.8.1)\r\n- Platform: macOS-11.4-x86_64-i386-64bit\r\n- Python version: 3.9.5\r\n- PyTorch version (GPU?): not installed (NA)\r\n- Tensorflow version (GPU?): not installed (NA)\r\n- Flax version (CPU?/GPU?/TPU?): not installed (NA)\r\n- Jax version: not installed\r\n- JaxLib version: not installed\r\n\r\n### Who can help\r\n@sgugger\r\n\r\n## Information\r\n\r\nHfArgumentParser when used on a dataclass with a bool field with no default turns the bool on unless it's supplied with `--<field_name> False` or similar \"false-y\" value. I would expect that as the field has no default it should be false unless `--<field_name>` or `--<field_name> True` is supplied. This is a behaviour change from `v3.0.0` where the booleans are parsed correctly as we're looking at upgrading and this issue hit us.\r\n\r\n## To reproduce\r\n\r\nSteps to reproduce the behavior:\r\n\r\n1. Define a dataclass with a boolean field\r\n2. Supply a list of arguments which does not include that field name\r\n3. The field is turned on.\r\n\r\nAppending this snippet to the bottom of [`test_basic` at line 110](https://github.com/huggingface/transformers/blob/master/tests/test_hf_argparser.py#L110) in `test_hf_argparser.py` fails the test.\r\n\r\n```python\r\n\r\n args = [\"--foo\", \"1\", \"--baz\", \"quux\", \"--bar\", \"0.5\"]\r\n\r\n example, = parser.parse_args_into_dataclasses(args, look_for_args_file=False)\r\n\r\n self.assertFalse(example.flag)\r\n```\r\n\r\nExtending `args` with `[\"--flag\",\"False\"]` recovers the expected behaviour.\r\n\r\n## Expected behavior\r\n\r\nThe boolean should be set to false if the argument is not passed in.\n", "before_files": [{"content": "# Copyright 2020 The HuggingFace Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport dataclasses\nimport json\nimport re\nimport sys\nfrom argparse import ArgumentParser, ArgumentTypeError\nfrom enum import Enum\nfrom pathlib import Path\nfrom typing import Any, Iterable, List, NewType, Optional, Tuple, Union\n\n\nDataClass = NewType(\"DataClass\", Any)\nDataClassType = NewType(\"DataClassType\", Any)\n\n\n# From https://stackoverflow.com/questions/15008758/parsing-boolean-values-with-argparse\ndef string_to_bool(v):\n if isinstance(v, bool):\n return v\n if v.lower() in (\"yes\", \"true\", \"t\", \"y\", \"1\"):\n return True\n elif v.lower() in (\"no\", \"false\", \"f\", \"n\", \"0\"):\n return False\n else:\n raise ArgumentTypeError(\n f\"Truthy value expected: got {v} but expected one of yes/no, true/false, t/f, y/n, 1/0 (case insensitive).\"\n )\n\n\nclass HfArgumentParser(ArgumentParser):\n \"\"\"\n This subclass of `argparse.ArgumentParser` uses type hints on dataclasses to generate arguments.\n\n The class is designed to play well with the native argparse. In particular, you can add more (non-dataclass backed)\n arguments to the parser after initialization and you'll get the output back after parsing as an additional\n namespace. Optional: To create sub argument groups use the `_argument_group_name` attribute in the dataclass.\n \"\"\"\n\n dataclass_types: Iterable[DataClassType]\n\n def __init__(self, dataclass_types: Union[DataClassType, Iterable[DataClassType]], **kwargs):\n \"\"\"\n Args:\n dataclass_types:\n Dataclass type, or list of dataclass types for which we will \"fill\" instances with the parsed args.\n kwargs:\n (Optional) Passed to `argparse.ArgumentParser()` in the regular way.\n \"\"\"\n super().__init__(**kwargs)\n if dataclasses.is_dataclass(dataclass_types):\n dataclass_types = [dataclass_types]\n self.dataclass_types = dataclass_types\n for dtype in self.dataclass_types:\n self._add_dataclass_arguments(dtype)\n\n def _add_dataclass_arguments(self, dtype: DataClassType):\n if hasattr(dtype, \"_argument_group_name\"):\n parser = self.add_argument_group(dtype._argument_group_name)\n else:\n parser = self\n for field in dataclasses.fields(dtype):\n if not field.init:\n continue\n field_name = f\"--{field.name}\"\n kwargs = field.metadata.copy()\n # field.metadata is not used at all by Data Classes,\n # it is provided as a third-party extension mechanism.\n if isinstance(field.type, str):\n raise ImportError(\n \"This implementation is not compatible with Postponed Evaluation of Annotations (PEP 563),\"\n \"which can be opted in from Python 3.7 with `from __future__ import annotations`.\"\n \"We will add compatibility when Python 3.9 is released.\"\n )\n typestring = str(field.type)\n for prim_type in (int, float, str):\n for collection in (List,):\n if (\n typestring == f\"typing.Union[{collection[prim_type]}, NoneType]\"\n or typestring == f\"typing.Optional[{collection[prim_type]}]\"\n ):\n field.type = collection[prim_type]\n if (\n typestring == f\"typing.Union[{prim_type.__name__}, NoneType]\"\n or typestring == f\"typing.Optional[{prim_type.__name__}]\"\n ):\n field.type = prim_type\n\n if isinstance(field.type, type) and issubclass(field.type, Enum):\n kwargs[\"choices\"] = [x.value for x in field.type]\n kwargs[\"type\"] = type(kwargs[\"choices\"][0])\n if field.default is not dataclasses.MISSING:\n kwargs[\"default\"] = field.default\n else:\n kwargs[\"required\"] = True\n elif field.type is bool or field.type == Optional[bool]:\n if field.default is True:\n parser.add_argument(f\"--no_{field.name}\", action=\"store_false\", dest=field.name, **kwargs)\n\n # Hack because type=bool in argparse does not behave as we want.\n kwargs[\"type\"] = string_to_bool\n if field.type is bool or (field.default is not None and field.default is not dataclasses.MISSING):\n # Default value is True if we have no default when of type bool.\n default = True if field.default is dataclasses.MISSING else field.default\n # This is the value that will get picked if we don't include --field_name in any way\n kwargs[\"default\"] = default\n # This tells argparse we accept 0 or 1 value after --field_name\n kwargs[\"nargs\"] = \"?\"\n # This is the value that will get picked if we do --field_name (without value)\n kwargs[\"const\"] = True\n elif (\n hasattr(field.type, \"__origin__\") and re.search(r\"^typing\\.List\\[(.*)\\]$\", str(field.type)) is not None\n ):\n kwargs[\"nargs\"] = \"+\"\n kwargs[\"type\"] = field.type.__args__[0]\n assert all(\n x == kwargs[\"type\"] for x in field.type.__args__\n ), f\"{field.name} cannot be a List of mixed types\"\n if field.default_factory is not dataclasses.MISSING:\n kwargs[\"default\"] = field.default_factory()\n elif field.default is dataclasses.MISSING:\n kwargs[\"required\"] = True\n else:\n kwargs[\"type\"] = field.type\n if field.default is not dataclasses.MISSING:\n kwargs[\"default\"] = field.default\n elif field.default_factory is not dataclasses.MISSING:\n kwargs[\"default\"] = field.default_factory()\n else:\n kwargs[\"required\"] = True\n parser.add_argument(field_name, **kwargs)\n\n def parse_args_into_dataclasses(\n self, args=None, return_remaining_strings=False, look_for_args_file=True, args_filename=None\n ) -> Tuple[DataClass, ...]:\n \"\"\"\n Parse command-line args into instances of the specified dataclass types.\n\n This relies on argparse's `ArgumentParser.parse_known_args`. See the doc at:\n docs.python.org/3.7/library/argparse.html#argparse.ArgumentParser.parse_args\n\n Args:\n args:\n List of strings to parse. The default is taken from sys.argv. (same as argparse.ArgumentParser)\n return_remaining_strings:\n If true, also return a list of remaining argument strings.\n look_for_args_file:\n If true, will look for a \".args\" file with the same base name as the entry point script for this\n process, and will append its potential content to the command line args.\n args_filename:\n If not None, will uses this file instead of the \".args\" file specified in the previous argument.\n\n Returns:\n Tuple consisting of:\n\n - the dataclass instances in the same order as they were passed to the initializer.abspath\n - if applicable, an additional namespace for more (non-dataclass backed) arguments added to the parser\n after initialization.\n - The potential list of remaining argument strings. (same as argparse.ArgumentParser.parse_known_args)\n \"\"\"\n if args_filename or (look_for_args_file and len(sys.argv)):\n if args_filename:\n args_file = Path(args_filename)\n else:\n args_file = Path(sys.argv[0]).with_suffix(\".args\")\n\n if args_file.exists():\n fargs = args_file.read_text().split()\n args = fargs + args if args is not None else fargs + sys.argv[1:]\n # in case of duplicate arguments the first one has precedence\n # so we append rather than prepend.\n namespace, remaining_args = self.parse_known_args(args=args)\n outputs = []\n for dtype in self.dataclass_types:\n keys = {f.name for f in dataclasses.fields(dtype) if f.init}\n inputs = {k: v for k, v in vars(namespace).items() if k in keys}\n for k in keys:\n delattr(namespace, k)\n obj = dtype(**inputs)\n outputs.append(obj)\n if len(namespace.__dict__) > 0:\n # additional namespace.\n outputs.append(namespace)\n if return_remaining_strings:\n return (*outputs, remaining_args)\n else:\n if remaining_args:\n raise ValueError(f\"Some specified arguments are not used by the HfArgumentParser: {remaining_args}\")\n\n return (*outputs,)\n\n def parse_json_file(self, json_file: str) -> Tuple[DataClass, ...]:\n \"\"\"\n Alternative helper method that does not use `argparse` at all, instead loading a json file and populating the\n dataclass types.\n \"\"\"\n data = json.loads(Path(json_file).read_text())\n outputs = []\n for dtype in self.dataclass_types:\n keys = {f.name for f in dataclasses.fields(dtype) if f.init}\n inputs = {k: v for k, v in data.items() if k in keys}\n obj = dtype(**inputs)\n outputs.append(obj)\n return (*outputs,)\n\n def parse_dict(self, args: dict) -> Tuple[DataClass, ...]:\n \"\"\"\n Alternative helper method that does not use `argparse` at all, instead uses a dict and populating the dataclass\n types.\n \"\"\"\n outputs = []\n for dtype in self.dataclass_types:\n keys = {f.name for f in dataclasses.fields(dtype) if f.init}\n inputs = {k: v for k, v in args.items() if k in keys}\n obj = dtype(**inputs)\n outputs.append(obj)\n return (*outputs,)\n", "path": "src/transformers/hf_argparser.py"}], "after_files": [{"content": "# Copyright 2020 The HuggingFace Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport dataclasses\nimport json\nimport re\nimport sys\nfrom argparse import ArgumentParser, ArgumentTypeError\nfrom enum import Enum\nfrom pathlib import Path\nfrom typing import Any, Iterable, List, NewType, Optional, Tuple, Union\n\n\nDataClass = NewType(\"DataClass\", Any)\nDataClassType = NewType(\"DataClassType\", Any)\n\n\n# From https://stackoverflow.com/questions/15008758/parsing-boolean-values-with-argparse\ndef string_to_bool(v):\n if isinstance(v, bool):\n return v\n if v.lower() in (\"yes\", \"true\", \"t\", \"y\", \"1\"):\n return True\n elif v.lower() in (\"no\", \"false\", \"f\", \"n\", \"0\"):\n return False\n else:\n raise ArgumentTypeError(\n f\"Truthy value expected: got {v} but expected one of yes/no, true/false, t/f, y/n, 1/0 (case insensitive).\"\n )\n\n\nclass HfArgumentParser(ArgumentParser):\n \"\"\"\n This subclass of `argparse.ArgumentParser` uses type hints on dataclasses to generate arguments.\n\n The class is designed to play well with the native argparse. In particular, you can add more (non-dataclass backed)\n arguments to the parser after initialization and you'll get the output back after parsing as an additional\n namespace. Optional: To create sub argument groups use the `_argument_group_name` attribute in the dataclass.\n \"\"\"\n\n dataclass_types: Iterable[DataClassType]\n\n def __init__(self, dataclass_types: Union[DataClassType, Iterable[DataClassType]], **kwargs):\n \"\"\"\n Args:\n dataclass_types:\n Dataclass type, or list of dataclass types for which we will \"fill\" instances with the parsed args.\n kwargs:\n (Optional) Passed to `argparse.ArgumentParser()` in the regular way.\n \"\"\"\n super().__init__(**kwargs)\n if dataclasses.is_dataclass(dataclass_types):\n dataclass_types = [dataclass_types]\n self.dataclass_types = dataclass_types\n for dtype in self.dataclass_types:\n self._add_dataclass_arguments(dtype)\n\n def _add_dataclass_arguments(self, dtype: DataClassType):\n if hasattr(dtype, \"_argument_group_name\"):\n parser = self.add_argument_group(dtype._argument_group_name)\n else:\n parser = self\n for field in dataclasses.fields(dtype):\n if not field.init:\n continue\n field_name = f\"--{field.name}\"\n kwargs = field.metadata.copy()\n # field.metadata is not used at all by Data Classes,\n # it is provided as a third-party extension mechanism.\n if isinstance(field.type, str):\n raise ImportError(\n \"This implementation is not compatible with Postponed Evaluation of Annotations (PEP 563),\"\n \"which can be opted in from Python 3.7 with `from __future__ import annotations`.\"\n \"We will add compatibility when Python 3.9 is released.\"\n )\n typestring = str(field.type)\n for prim_type in (int, float, str):\n for collection in (List,):\n if (\n typestring == f\"typing.Union[{collection[prim_type]}, NoneType]\"\n or typestring == f\"typing.Optional[{collection[prim_type]}]\"\n ):\n field.type = collection[prim_type]\n if (\n typestring == f\"typing.Union[{prim_type.__name__}, NoneType]\"\n or typestring == f\"typing.Optional[{prim_type.__name__}]\"\n ):\n field.type = prim_type\n\n if isinstance(field.type, type) and issubclass(field.type, Enum):\n kwargs[\"choices\"] = [x.value for x in field.type]\n kwargs[\"type\"] = type(kwargs[\"choices\"][0])\n if field.default is not dataclasses.MISSING:\n kwargs[\"default\"] = field.default\n else:\n kwargs[\"required\"] = True\n elif field.type is bool or field.type == Optional[bool]:\n if field.default is True:\n parser.add_argument(f\"--no_{field.name}\", action=\"store_false\", dest=field.name, **kwargs)\n\n # Hack because type=bool in argparse does not behave as we want.\n kwargs[\"type\"] = string_to_bool\n if field.type is bool or (field.default is not None and field.default is not dataclasses.MISSING):\n # Default value is False if we have no default when of type bool.\n default = False if field.default is dataclasses.MISSING else field.default\n # This is the value that will get picked if we don't include --field_name in any way\n kwargs[\"default\"] = default\n # This tells argparse we accept 0 or 1 value after --field_name\n kwargs[\"nargs\"] = \"?\"\n # This is the value that will get picked if we do --field_name (without value)\n kwargs[\"const\"] = True\n elif (\n hasattr(field.type, \"__origin__\") and re.search(r\"^typing\\.List\\[(.*)\\]$\", str(field.type)) is not None\n ):\n kwargs[\"nargs\"] = \"+\"\n kwargs[\"type\"] = field.type.__args__[0]\n assert all(\n x == kwargs[\"type\"] for x in field.type.__args__\n ), f\"{field.name} cannot be a List of mixed types\"\n if field.default_factory is not dataclasses.MISSING:\n kwargs[\"default\"] = field.default_factory()\n elif field.default is dataclasses.MISSING:\n kwargs[\"required\"] = True\n else:\n kwargs[\"type\"] = field.type\n if field.default is not dataclasses.MISSING:\n kwargs[\"default\"] = field.default\n elif field.default_factory is not dataclasses.MISSING:\n kwargs[\"default\"] = field.default_factory()\n else:\n kwargs[\"required\"] = True\n parser.add_argument(field_name, **kwargs)\n\n def parse_args_into_dataclasses(\n self, args=None, return_remaining_strings=False, look_for_args_file=True, args_filename=None\n ) -> Tuple[DataClass, ...]:\n \"\"\"\n Parse command-line args into instances of the specified dataclass types.\n\n This relies on argparse's `ArgumentParser.parse_known_args`. See the doc at:\n docs.python.org/3.7/library/argparse.html#argparse.ArgumentParser.parse_args\n\n Args:\n args:\n List of strings to parse. The default is taken from sys.argv. (same as argparse.ArgumentParser)\n return_remaining_strings:\n If true, also return a list of remaining argument strings.\n look_for_args_file:\n If true, will look for a \".args\" file with the same base name as the entry point script for this\n process, and will append its potential content to the command line args.\n args_filename:\n If not None, will uses this file instead of the \".args\" file specified in the previous argument.\n\n Returns:\n Tuple consisting of:\n\n - the dataclass instances in the same order as they were passed to the initializer.abspath\n - if applicable, an additional namespace for more (non-dataclass backed) arguments added to the parser\n after initialization.\n - The potential list of remaining argument strings. (same as argparse.ArgumentParser.parse_known_args)\n \"\"\"\n if args_filename or (look_for_args_file and len(sys.argv)):\n if args_filename:\n args_file = Path(args_filename)\n else:\n args_file = Path(sys.argv[0]).with_suffix(\".args\")\n\n if args_file.exists():\n fargs = args_file.read_text().split()\n args = fargs + args if args is not None else fargs + sys.argv[1:]\n # in case of duplicate arguments the first one has precedence\n # so we append rather than prepend.\n namespace, remaining_args = self.parse_known_args(args=args)\n outputs = []\n for dtype in self.dataclass_types:\n keys = {f.name for f in dataclasses.fields(dtype) if f.init}\n inputs = {k: v for k, v in vars(namespace).items() if k in keys}\n for k in keys:\n delattr(namespace, k)\n obj = dtype(**inputs)\n outputs.append(obj)\n if len(namespace.__dict__) > 0:\n # additional namespace.\n outputs.append(namespace)\n if return_remaining_strings:\n return (*outputs, remaining_args)\n else:\n if remaining_args:\n raise ValueError(f\"Some specified arguments are not used by the HfArgumentParser: {remaining_args}\")\n\n return (*outputs,)\n\n def parse_json_file(self, json_file: str) -> Tuple[DataClass, ...]:\n \"\"\"\n Alternative helper method that does not use `argparse` at all, instead loading a json file and populating the\n dataclass types.\n \"\"\"\n data = json.loads(Path(json_file).read_text())\n outputs = []\n for dtype in self.dataclass_types:\n keys = {f.name for f in dataclasses.fields(dtype) if f.init}\n inputs = {k: v for k, v in data.items() if k in keys}\n obj = dtype(**inputs)\n outputs.append(obj)\n return (*outputs,)\n\n def parse_dict(self, args: dict) -> Tuple[DataClass, ...]:\n \"\"\"\n Alternative helper method that does not use `argparse` at all, instead uses a dict and populating the dataclass\n types.\n \"\"\"\n outputs = []\n for dtype in self.dataclass_types:\n keys = {f.name for f in dataclasses.fields(dtype) if f.init}\n inputs = {k: v for k, v in args.items() if k in keys}\n obj = dtype(**inputs)\n outputs.append(obj)\n return (*outputs,)\n", "path": "src/transformers/hf_argparser.py"}]}
| 3,527 | 229 |
gh_patches_debug_2135
|
rasdani/github-patches
|
git_diff
|
chainer__chainer-258
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Shape of output value of `concat` is list in GPU
`cuda.empty([1])` makes a `GPUArray` with `list` shape. It causes a type invalid error.
https://github.com/pfnet/chainer/blob/master/chainer/functions/concat.py#L69
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `chainer/functions/concat.py`
Content:
```
1 import numpy
2
3 from chainer import cuda
4 from chainer import function
5 from chainer.utils import type_check
6
7 _args = 'const float* x, float* y, int cdimx, int cdimy, int rdim, int coffset'
8 _preamble = '''
9 #define COPY(statement) \
10 int l = i / (rdim * cdimx); \
11 int c = i / rdim % cdimx + coffset; \
12 int r = i % rdim; \
13 int idx = r + rdim * (c + cdimy * l); \
14 statement;
15 '''
16
17
18 class Concat(function.Function):
19
20 """Concatenate multiple tensors towards specified axis."""
21
22 # concat along the channel dimension by default
23 def __init__(self, axis=1):
24 self.axis = axis
25
26 def check_type_forward(self, in_types):
27 type_check.expect(in_types.size() > 0)
28 type_check.expect(in_types[0].ndim >
29 type_check.Variable(self.axis, 'axis'))
30
31 ndim = in_types[0].ndim.eval()
32 for i in range(1, in_types.size().eval()):
33 type_check.expect(
34 in_types[0].dtype == in_types[i].dtype,
35 in_types[0].ndim == in_types[i].ndim,
36 )
37 for d in range(0, ndim):
38 if d == self.axis:
39 continue
40 type_check.expect(in_types[0].shape[d] == in_types[i].shape[d])
41
42 def check_type_backward(self, in_types, out_types):
43 type_check.expect(
44 in_types.size() > 0,
45 out_types.size() == 1,
46 )
47 y_type, = out_types
48
49 type_check.expect(y_type.dtype == in_types[0].dtype)
50 ndim = in_types[0].ndim.eval()
51 concat_size = sum(typ.shape[self.axis] for typ in in_types)
52 type_check.expect(concat_size == y_type.shape[self.axis])
53
54 for d in range(0, ndim):
55 if d == self.axis:
56 continue
57 type_check.expect(y_type.shape[d] == in_types[0].shape[d])
58
59 def forward_cpu(self, xs):
60 return numpy.concatenate(xs, axis=self.axis),
61
62 def forward_gpu(self, xs):
63 # TODO(beam2d): Unify the process into a single kernel.
64 shape = list(xs[0].shape)
65 for x in xs[1:]:
66 shape[self.axis] += x.shape[self.axis]
67 self.shape = shape
68
69 y = cuda.empty(shape, dtype=xs[0].dtype)
70 self.cdimy = y.shape[self.axis]
71 self.rdim = numpy.prod(shape[self.axis + 1:], dtype=int)
72
73 coffset = 0
74 kernel = cuda.elementwise(
75 _args, 'COPY(y[idx] = x[i])', 'concat_fwd', preamble=_preamble)
76 for x in xs:
77 cdimx = x.shape[self.axis]
78 kernel(x, y, cdimx, self.cdimy, self.rdim, coffset)
79 coffset += cdimx
80
81 return y,
82
83 def backward_cpu(self, xs, gy):
84 sizes = numpy.array([x.shape[self.axis] for x in xs[:-1]]).cumsum()
85 return numpy.split(gy[0], sizes, axis=self.axis)
86
87 def backward_gpu(self, xs, gy):
88 gxs = tuple(cuda.empty_like(x) for x in xs)
89
90 coffset = 0
91 kernel = cuda.elementwise(
92 _args, 'COPY(x[i] = y[idx])', 'concat_bwd', preamble=_preamble)
93 for gx in gxs:
94 cdimx = gx.shape[self.axis]
95 kernel(gx, gy[0], cdimx, self.cdimy, self.rdim, coffset)
96 coffset += cdimx
97
98 return gxs
99
100
101 def concat(xs, axis=1):
102 """Concatenates given variables along an axis.
103
104 Args:
105 xs (tuple of Variables): Variables to be concatenated.
106 axis (int): Axis that the input arrays are concatenated along.
107
108 Returns:
109 ~chainer.Variable: Output variable.
110
111 """
112 return Concat(axis=axis)(*xs)
113
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/chainer/functions/concat.py b/chainer/functions/concat.py
--- a/chainer/functions/concat.py
+++ b/chainer/functions/concat.py
@@ -64,6 +64,7 @@
shape = list(xs[0].shape)
for x in xs[1:]:
shape[self.axis] += x.shape[self.axis]
+ shape = tuple(shape)
self.shape = shape
y = cuda.empty(shape, dtype=xs[0].dtype)
|
{"golden_diff": "diff --git a/chainer/functions/concat.py b/chainer/functions/concat.py\n--- a/chainer/functions/concat.py\n+++ b/chainer/functions/concat.py\n@@ -64,6 +64,7 @@\n shape = list(xs[0].shape)\n for x in xs[1:]:\n shape[self.axis] += x.shape[self.axis]\n+ shape = tuple(shape)\n self.shape = shape\n \n y = cuda.empty(shape, dtype=xs[0].dtype)\n", "issue": "Shape of output value of `concat` is list in GPU\n`cuda.empty([1])` makes a `GPUArray` with `list` shape. It causes a type invalid error.\n\nhttps://github.com/pfnet/chainer/blob/master/chainer/functions/concat.py#L69\n\n", "before_files": [{"content": "import numpy\n\nfrom chainer import cuda\nfrom chainer import function\nfrom chainer.utils import type_check\n\n_args = 'const float* x, float* y, int cdimx, int cdimy, int rdim, int coffset'\n_preamble = '''\n#define COPY(statement) \\\n int l = i / (rdim * cdimx); \\\n int c = i / rdim % cdimx + coffset; \\\n int r = i % rdim; \\\n int idx = r + rdim * (c + cdimy * l); \\\n statement;\n'''\n\n\nclass Concat(function.Function):\n\n \"\"\"Concatenate multiple tensors towards specified axis.\"\"\"\n\n # concat along the channel dimension by default\n def __init__(self, axis=1):\n self.axis = axis\n\n def check_type_forward(self, in_types):\n type_check.expect(in_types.size() > 0)\n type_check.expect(in_types[0].ndim >\n type_check.Variable(self.axis, 'axis'))\n\n ndim = in_types[0].ndim.eval()\n for i in range(1, in_types.size().eval()):\n type_check.expect(\n in_types[0].dtype == in_types[i].dtype,\n in_types[0].ndim == in_types[i].ndim,\n )\n for d in range(0, ndim):\n if d == self.axis:\n continue\n type_check.expect(in_types[0].shape[d] == in_types[i].shape[d])\n\n def check_type_backward(self, in_types, out_types):\n type_check.expect(\n in_types.size() > 0,\n out_types.size() == 1,\n )\n y_type, = out_types\n\n type_check.expect(y_type.dtype == in_types[0].dtype)\n ndim = in_types[0].ndim.eval()\n concat_size = sum(typ.shape[self.axis] for typ in in_types)\n type_check.expect(concat_size == y_type.shape[self.axis])\n\n for d in range(0, ndim):\n if d == self.axis:\n continue\n type_check.expect(y_type.shape[d] == in_types[0].shape[d])\n\n def forward_cpu(self, xs):\n return numpy.concatenate(xs, axis=self.axis),\n\n def forward_gpu(self, xs):\n # TODO(beam2d): Unify the process into a single kernel.\n shape = list(xs[0].shape)\n for x in xs[1:]:\n shape[self.axis] += x.shape[self.axis]\n self.shape = shape\n\n y = cuda.empty(shape, dtype=xs[0].dtype)\n self.cdimy = y.shape[self.axis]\n self.rdim = numpy.prod(shape[self.axis + 1:], dtype=int)\n\n coffset = 0\n kernel = cuda.elementwise(\n _args, 'COPY(y[idx] = x[i])', 'concat_fwd', preamble=_preamble)\n for x in xs:\n cdimx = x.shape[self.axis]\n kernel(x, y, cdimx, self.cdimy, self.rdim, coffset)\n coffset += cdimx\n\n return y,\n\n def backward_cpu(self, xs, gy):\n sizes = numpy.array([x.shape[self.axis] for x in xs[:-1]]).cumsum()\n return numpy.split(gy[0], sizes, axis=self.axis)\n\n def backward_gpu(self, xs, gy):\n gxs = tuple(cuda.empty_like(x) for x in xs)\n\n coffset = 0\n kernel = cuda.elementwise(\n _args, 'COPY(x[i] = y[idx])', 'concat_bwd', preamble=_preamble)\n for gx in gxs:\n cdimx = gx.shape[self.axis]\n kernel(gx, gy[0], cdimx, self.cdimy, self.rdim, coffset)\n coffset += cdimx\n\n return gxs\n\n\ndef concat(xs, axis=1):\n \"\"\"Concatenates given variables along an axis.\n\n Args:\n xs (tuple of Variables): Variables to be concatenated.\n axis (int): Axis that the input arrays are concatenated along.\n\n Returns:\n ~chainer.Variable: Output variable.\n\n \"\"\"\n return Concat(axis=axis)(*xs)\n", "path": "chainer/functions/concat.py"}], "after_files": [{"content": "import numpy\n\nfrom chainer import cuda\nfrom chainer import function\nfrom chainer.utils import type_check\n\n_args = 'const float* x, float* y, int cdimx, int cdimy, int rdim, int coffset'\n_preamble = '''\n#define COPY(statement) \\\n int l = i / (rdim * cdimx); \\\n int c = i / rdim % cdimx + coffset; \\\n int r = i % rdim; \\\n int idx = r + rdim * (c + cdimy * l); \\\n statement;\n'''\n\n\nclass Concat(function.Function):\n\n \"\"\"Concatenate multiple tensors towards specified axis.\"\"\"\n\n # concat along the channel dimension by default\n def __init__(self, axis=1):\n self.axis = axis\n\n def check_type_forward(self, in_types):\n type_check.expect(in_types.size() > 0)\n type_check.expect(in_types[0].ndim >\n type_check.Variable(self.axis, 'axis'))\n\n ndim = in_types[0].ndim.eval()\n for i in range(1, in_types.size().eval()):\n type_check.expect(\n in_types[0].dtype == in_types[i].dtype,\n in_types[0].ndim == in_types[i].ndim,\n )\n for d in range(0, ndim):\n if d == self.axis:\n continue\n type_check.expect(in_types[0].shape[d] == in_types[i].shape[d])\n\n def check_type_backward(self, in_types, out_types):\n type_check.expect(\n in_types.size() > 0,\n out_types.size() == 1,\n )\n y_type, = out_types\n\n type_check.expect(y_type.dtype == in_types[0].dtype)\n ndim = in_types[0].ndim.eval()\n concat_size = sum(typ.shape[self.axis] for typ in in_types)\n type_check.expect(concat_size == y_type.shape[self.axis])\n\n for d in range(0, ndim):\n if d == self.axis:\n continue\n type_check.expect(y_type.shape[d] == in_types[0].shape[d])\n\n def forward_cpu(self, xs):\n return numpy.concatenate(xs, axis=self.axis),\n\n def forward_gpu(self, xs):\n # TODO(beam2d): Unify the process into a single kernel.\n shape = list(xs[0].shape)\n for x in xs[1:]:\n shape[self.axis] += x.shape[self.axis]\n shape = tuple(shape)\n self.shape = shape\n\n y = cuda.empty(shape, dtype=xs[0].dtype)\n self.cdimy = y.shape[self.axis]\n self.rdim = numpy.prod(shape[self.axis + 1:], dtype=int)\n\n coffset = 0\n kernel = cuda.elementwise(\n _args, 'COPY(y[idx] = x[i])', 'concat_fwd', preamble=_preamble)\n for x in xs:\n cdimx = x.shape[self.axis]\n kernel(x, y, cdimx, self.cdimy, self.rdim, coffset)\n coffset += cdimx\n\n return y,\n\n def backward_cpu(self, xs, gy):\n sizes = numpy.array([x.shape[self.axis] for x in xs[:-1]]).cumsum()\n return numpy.split(gy[0], sizes, axis=self.axis)\n\n def backward_gpu(self, xs, gy):\n gxs = tuple(cuda.empty_like(x) for x in xs)\n\n coffset = 0\n kernel = cuda.elementwise(\n _args, 'COPY(x[i] = y[idx])', 'concat_bwd', preamble=_preamble)\n for gx in gxs:\n cdimx = gx.shape[self.axis]\n kernel(gx, gy[0], cdimx, self.cdimy, self.rdim, coffset)\n coffset += cdimx\n\n return gxs\n\n\ndef concat(xs, axis=1):\n \"\"\"Concatenates given variables along an axis.\n\n Args:\n xs (tuple of Variables): Variables to be concatenated.\n axis (int): Axis that the input arrays are concatenated along.\n\n Returns:\n ~chainer.Variable: Output variable.\n\n \"\"\"\n return Concat(axis=axis)(*xs)\n", "path": "chainer/functions/concat.py"}]}
| 1,491 | 105 |
gh_patches_debug_38697
|
rasdani/github-patches
|
git_diff
|
facebookresearch__hydra-605
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Feature Request] Allow Initialize to take a module
# 🚀 Feature Request
Allow hydra.experimental.initialize to take a calling module
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `hydra/experimental/compose.py`
Content:
```
1 # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
2 from typing import List, Optional
3
4 from omegaconf import DictConfig, open_dict
5
6 from hydra._internal.hydra import Hydra
7 from hydra._internal.utils import detect_calling_file_or_module_from_stack_frame
8 from hydra.core.global_hydra import GlobalHydra
9
10
11 def initialize(
12 config_dir: Optional[str] = None,
13 strict: Optional[bool] = None,
14 caller_stack_depth: int = 1,
15 ) -> None:
16 """
17 :param config_dir: config directory relative to the calling script
18 :param strict:
19 :param caller_stack_depth:
20 :return:
21 """
22 calling_file, calling_module = detect_calling_file_or_module_from_stack_frame(
23 caller_stack_depth + 1
24 )
25 Hydra.create_main_hydra_file_or_module(
26 calling_file, calling_module, config_dir, strict
27 )
28
29
30 def compose(
31 config_name: Optional[str] = None,
32 overrides: List[str] = [],
33 strict: Optional[bool] = None,
34 ) -> DictConfig:
35 """
36 :param config_name: optional config name to load
37 :param overrides: list of overrides for config file
38 :param strict: optionally override the default strict mode
39 :return: the composed config
40 """
41 assert (
42 GlobalHydra().is_initialized()
43 ), "GlobalHydra is not initialized, use @hydra.main() or call hydra.experimental.initialize() first"
44
45 gh = GlobalHydra.instance()
46 assert gh.hydra is not None
47 cfg = gh.hydra.compose_config(
48 config_name=config_name, overrides=overrides, strict=strict
49 )
50 assert isinstance(cfg, DictConfig)
51
52 if "hydra" in cfg:
53 with open_dict(cfg):
54 del cfg["hydra"]
55 return cfg
56
```
Path: `examples/advanced/ad_hoc_composition/hydra_compose_example.py`
Content:
```
1 # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
2 from hydra.experimental import compose, initialize
3
4 if __name__ == "__main__":
5 # initialize the Hydra subsystem.
6 # This is needed for apps that cannot have a standard @hydra.main() entry point
7 initialize(config_dir="conf", strict=True)
8
9 cfg = compose("config.yaml", overrides=["db=mysql", "db.user=${env:USER}"])
10 print(cfg.pretty(resolve=True))
11
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/advanced/ad_hoc_composition/hydra_compose_example.py b/examples/advanced/ad_hoc_composition/hydra_compose_example.py
--- a/examples/advanced/ad_hoc_composition/hydra_compose_example.py
+++ b/examples/advanced/ad_hoc_composition/hydra_compose_example.py
@@ -4,7 +4,7 @@
if __name__ == "__main__":
# initialize the Hydra subsystem.
# This is needed for apps that cannot have a standard @hydra.main() entry point
- initialize(config_dir="conf", strict=True)
+ initialize(config_path="conf", strict=True)
cfg = compose("config.yaml", overrides=["db=mysql", "db.user=${env:USER}"])
print(cfg.pretty(resolve=True))
diff --git a/hydra/experimental/compose.py b/hydra/experimental/compose.py
--- a/hydra/experimental/compose.py
+++ b/hydra/experimental/compose.py
@@ -9,31 +9,58 @@
def initialize(
- config_dir: Optional[str] = None,
+ config_path: Optional[str] = None,
strict: Optional[bool] = None,
caller_stack_depth: int = 1,
) -> None:
"""
- :param config_dir: config directory relative to the calling script
- :param strict:
- :param caller_stack_depth:
- :return:
+ Initialize automatically detect the calling file or module.
+ config_path is relative to the detected calling for or module.
+
+ :param config_path: A directory relative to the declaring python file or module
+ :param strict: (Deprecated), will be removed in the next major version
+ :param caller_stack_depth: stack depth of module the config_path is relative to
"""
calling_file, calling_module = detect_calling_file_or_module_from_stack_frame(
caller_stack_depth + 1
)
Hydra.create_main_hydra_file_or_module(
- calling_file, calling_module, config_dir, strict
+ calling_file, calling_module, config_path, strict
)
+def initialize_with_file(
+ calling_file: Optional[str], config_path: Optional[str] = None
+) -> None:
+ """
+ Initialize Hydra and add the config_path to the search path.
+ The config path is relative to the calling_file.
+ :param calling_file : The file to make the config_path relative to
+ :param config_path : The config path
+ """
+ Hydra.create_main_hydra_file_or_module(calling_file, None, config_path, None)
+
+
+def initialize_with_module(
+ calling_module: Optional[str], config_path: Optional[str] = None
+) -> None:
+ """
+ Initialize Hydra and add the config_path to the search path.
+ The config path is relative to the calling_module.
+ :param calling_module : The module to make the config_path relative to
+ :param config_path : The config path
+ """
+
+ Hydra.create_main_hydra_file_or_module(None, calling_module, config_path, None)
+
+
def compose(
config_name: Optional[str] = None,
overrides: List[str] = [],
strict: Optional[bool] = None,
) -> DictConfig:
"""
- :param config_name: optional config name to load
+ :param config_name: the name of the config (usually the file name without the .yaml extension)
:param overrides: list of overrides for config file
:param strict: optionally override the default strict mode
:return: the composed config
|
{"golden_diff": "diff --git a/examples/advanced/ad_hoc_composition/hydra_compose_example.py b/examples/advanced/ad_hoc_composition/hydra_compose_example.py\n--- a/examples/advanced/ad_hoc_composition/hydra_compose_example.py\n+++ b/examples/advanced/ad_hoc_composition/hydra_compose_example.py\n@@ -4,7 +4,7 @@\n if __name__ == \"__main__\":\n # initialize the Hydra subsystem.\n # This is needed for apps that cannot have a standard @hydra.main() entry point\n- initialize(config_dir=\"conf\", strict=True)\n+ initialize(config_path=\"conf\", strict=True)\n \n cfg = compose(\"config.yaml\", overrides=[\"db=mysql\", \"db.user=${env:USER}\"])\n print(cfg.pretty(resolve=True))\ndiff --git a/hydra/experimental/compose.py b/hydra/experimental/compose.py\n--- a/hydra/experimental/compose.py\n+++ b/hydra/experimental/compose.py\n@@ -9,31 +9,58 @@\n \n \n def initialize(\n- config_dir: Optional[str] = None,\n+ config_path: Optional[str] = None,\n strict: Optional[bool] = None,\n caller_stack_depth: int = 1,\n ) -> None:\n \"\"\"\n- :param config_dir: config directory relative to the calling script\n- :param strict:\n- :param caller_stack_depth:\n- :return:\n+ Initialize automatically detect the calling file or module.\n+ config_path is relative to the detected calling for or module.\n+\n+ :param config_path: A directory relative to the declaring python file or module\n+ :param strict: (Deprecated), will be removed in the next major version\n+ :param caller_stack_depth: stack depth of module the config_path is relative to\n \"\"\"\n calling_file, calling_module = detect_calling_file_or_module_from_stack_frame(\n caller_stack_depth + 1\n )\n Hydra.create_main_hydra_file_or_module(\n- calling_file, calling_module, config_dir, strict\n+ calling_file, calling_module, config_path, strict\n )\n \n \n+def initialize_with_file(\n+ calling_file: Optional[str], config_path: Optional[str] = None\n+) -> None:\n+ \"\"\"\n+ Initialize Hydra and add the config_path to the search path.\n+ The config path is relative to the calling_file.\n+ :param calling_file : The file to make the config_path relative to\n+ :param config_path : The config path\n+ \"\"\"\n+ Hydra.create_main_hydra_file_or_module(calling_file, None, config_path, None)\n+\n+\n+def initialize_with_module(\n+ calling_module: Optional[str], config_path: Optional[str] = None\n+) -> None:\n+ \"\"\"\n+ Initialize Hydra and add the config_path to the search path.\n+ The config path is relative to the calling_module.\n+ :param calling_module : The module to make the config_path relative to\n+ :param config_path : The config path\n+ \"\"\"\n+\n+ Hydra.create_main_hydra_file_or_module(None, calling_module, config_path, None)\n+\n+\n def compose(\n config_name: Optional[str] = None,\n overrides: List[str] = [],\n strict: Optional[bool] = None,\n ) -> DictConfig:\n \"\"\"\n- :param config_name: optional config name to load\n+ :param config_name: the name of the config (usually the file name without the .yaml extension)\n :param overrides: list of overrides for config file\n :param strict: optionally override the default strict mode\n :return: the composed config\n", "issue": "[Feature Request] Allow Initialize to take a module\n# \ud83d\ude80 Feature Request\r\n\r\nAllow hydra.experimental.initialize to take a calling module\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\nfrom typing import List, Optional\n\nfrom omegaconf import DictConfig, open_dict\n\nfrom hydra._internal.hydra import Hydra\nfrom hydra._internal.utils import detect_calling_file_or_module_from_stack_frame\nfrom hydra.core.global_hydra import GlobalHydra\n\n\ndef initialize(\n config_dir: Optional[str] = None,\n strict: Optional[bool] = None,\n caller_stack_depth: int = 1,\n) -> None:\n \"\"\"\n :param config_dir: config directory relative to the calling script\n :param strict:\n :param caller_stack_depth:\n :return:\n \"\"\"\n calling_file, calling_module = detect_calling_file_or_module_from_stack_frame(\n caller_stack_depth + 1\n )\n Hydra.create_main_hydra_file_or_module(\n calling_file, calling_module, config_dir, strict\n )\n\n\ndef compose(\n config_name: Optional[str] = None,\n overrides: List[str] = [],\n strict: Optional[bool] = None,\n) -> DictConfig:\n \"\"\"\n :param config_name: optional config name to load\n :param overrides: list of overrides for config file\n :param strict: optionally override the default strict mode\n :return: the composed config\n \"\"\"\n assert (\n GlobalHydra().is_initialized()\n ), \"GlobalHydra is not initialized, use @hydra.main() or call hydra.experimental.initialize() first\"\n\n gh = GlobalHydra.instance()\n assert gh.hydra is not None\n cfg = gh.hydra.compose_config(\n config_name=config_name, overrides=overrides, strict=strict\n )\n assert isinstance(cfg, DictConfig)\n\n if \"hydra\" in cfg:\n with open_dict(cfg):\n del cfg[\"hydra\"]\n return cfg\n", "path": "hydra/experimental/compose.py"}, {"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\nfrom hydra.experimental import compose, initialize\n\nif __name__ == \"__main__\":\n # initialize the Hydra subsystem.\n # This is needed for apps that cannot have a standard @hydra.main() entry point\n initialize(config_dir=\"conf\", strict=True)\n\n cfg = compose(\"config.yaml\", overrides=[\"db=mysql\", \"db.user=${env:USER}\"])\n print(cfg.pretty(resolve=True))\n", "path": "examples/advanced/ad_hoc_composition/hydra_compose_example.py"}], "after_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\nfrom typing import List, Optional\n\nfrom omegaconf import DictConfig, open_dict\n\nfrom hydra._internal.hydra import Hydra\nfrom hydra._internal.utils import detect_calling_file_or_module_from_stack_frame\nfrom hydra.core.global_hydra import GlobalHydra\n\n\ndef initialize(\n config_path: Optional[str] = None,\n strict: Optional[bool] = None,\n caller_stack_depth: int = 1,\n) -> None:\n \"\"\"\n Initialize automatically detect the calling file or module.\n config_path is relative to the detected calling for or module.\n\n :param config_path: A directory relative to the declaring python file or module\n :param strict: (Deprecated), will be removed in the next major version\n :param caller_stack_depth: stack depth of module the config_path is relative to\n \"\"\"\n calling_file, calling_module = detect_calling_file_or_module_from_stack_frame(\n caller_stack_depth + 1\n )\n Hydra.create_main_hydra_file_or_module(\n calling_file, calling_module, config_path, strict\n )\n\n\ndef initialize_with_file(\n calling_file: Optional[str], config_path: Optional[str] = None\n) -> None:\n \"\"\"\n Initialize Hydra and add the config_path to the search path.\n The config path is relative to the calling_file.\n :param calling_file : The file to make the config_path relative to\n :param config_path : The config path\n \"\"\"\n Hydra.create_main_hydra_file_or_module(calling_file, None, config_path, None)\n\n\ndef initialize_with_module(\n calling_module: Optional[str], config_path: Optional[str] = None\n) -> None:\n \"\"\"\n Initialize Hydra and add the config_path to the search path.\n The config path is relative to the calling_module.\n :param calling_module : The module to make the config_path relative to\n :param config_path : The config path\n \"\"\"\n\n Hydra.create_main_hydra_file_or_module(None, calling_module, config_path, None)\n\n\ndef compose(\n config_name: Optional[str] = None,\n overrides: List[str] = [],\n strict: Optional[bool] = None,\n) -> DictConfig:\n \"\"\"\n :param config_name: the name of the config (usually the file name without the .yaml extension)\n :param overrides: list of overrides for config file\n :param strict: optionally override the default strict mode\n :return: the composed config\n \"\"\"\n assert (\n GlobalHydra().is_initialized()\n ), \"GlobalHydra is not initialized, use @hydra.main() or call hydra.experimental.initialize() first\"\n\n gh = GlobalHydra.instance()\n assert gh.hydra is not None\n cfg = gh.hydra.compose_config(\n config_name=config_name, overrides=overrides, strict=strict\n )\n assert isinstance(cfg, DictConfig)\n\n if \"hydra\" in cfg:\n with open_dict(cfg):\n del cfg[\"hydra\"]\n return cfg\n", "path": "hydra/experimental/compose.py"}, {"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\nfrom hydra.experimental import compose, initialize\n\nif __name__ == \"__main__\":\n # initialize the Hydra subsystem.\n # This is needed for apps that cannot have a standard @hydra.main() entry point\n initialize(config_path=\"conf\", strict=True)\n\n cfg = compose(\"config.yaml\", overrides=[\"db=mysql\", \"db.user=${env:USER}\"])\n print(cfg.pretty(resolve=True))\n", "path": "examples/advanced/ad_hoc_composition/hydra_compose_example.py"}]}
| 935 | 789 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.